Embed Size (px)
Citation preview


Simplifying Big Data Integration

Goals of the Modern Data Architecture
• Centralize all your data
• Turn raw data into insights
•Maintain governance, compliance and security standards
• Eliminate complexities within IT

Global Leader in Big Iron to Big Data Solutions
4Syncsort Confidential and Proprietary - do not copy or distribute
Deep engineering and go-to-market relationships with strategic partners in Big Iron and Big Data ecosystems
Marquee global customer base of leaders and emerging businesses across all major industries
PEARL RIVER, NY
SINGAPORE
JAPAN
Trusted Industry Leadership Providing world-class data management software to large enterprises for nearly 50 years with a focus on customer value and unparalleled support
Lower Cost, Higher PerformanceOur fast, efficient software helps power business and operational analytics while optimizing resource utilization to dramatically reduce the cost of managing mainframe and legacy systems
Connecting Big Iron To Big Data Our solutions address the complex set of requirements for delivering rich data from mainframe and legacy sources to Big Data environments

Our Strategy: Simplify Big Data Integration
• Deploy on premise or in the cloud
• Choose among multiple execution frameworks – Hadoop, Spark, Linux, Unix, Windows
• Integrate streaming and batch data with a single data pipeline for innovative applications, like IoT
• Future-proof applications to avoid re-writing jobs in order to take advantage of innovations in new execution frameworks
• Access and integrate ALL enterprise data sources – including mainframe – for advanced analytics

Simplify Big Data Integration with Syncsort
6Syncsort Confidential and Proprietary - do not copy or distribute
Access Integrate Comply Simplify
Get best in class data ingestion capabilities for Hadoop. Mainframes, RDBMS, MPP, JSON, Parquet, Avro, ORC, NoSQL, Kafka and more.
Single interface for streaming and batch processes. Single data pipeline for all enterprise data, batch or streaming.
Secure data access, data governance and lineage. Seamless integration with Kerberos, Apache Ranger, Apache Ambari, Cloudera Manager, Cloudera Navigator and Sentry.
Design once, deploy anywhere & insulate your organization from rapidly changing eco-system. Future proof your applications for new compute frameworks, on premise or in the cloud.


Polling Question
What stage of Hadoop implementation is your organization in?
– Researching/Evaluating
– Proof of Concept/Pilot
– In production
– None of the above

About the Survey – Who Responded
270+ IT decision makers
36% with revenue of $1B+
Financial Services
22%
Insurance7%
Data Services5%
Government7%
Healthcare10%
Non-profit3%
Retail8%
Software/SaaS5%
Telco8%
Information Technology
16%
Travel/Hospitality3%
Other6%
INDUSTRY
BI/Data Analyst12%
CIO/CTO/COO7%
Data Architect18%
Data Scientist9%
Developer17%
Other IT Exec5%
IT Manager21%
Other 11%
ROLE

Compute Frameworks and Cloud Deployment
Multiple frameworks are the norm – 54% use more than one framework
Migration away from MapReduce, toward Spark
More organizations are deploying on premises – but almost a third have a hybrid deployment
62%
40%
15%
11%
30%
10%
2%
4%
38%
52%
24%
13% 4%
8%
22%
6%

Polling Question
Do you plan on changing execution frameworks in the next 12 months?
– Yes
– No
– I don’t know

Data Sources
Traditional data sources are most popular for filling the data lake
Newer sources like streaming data and NoSQL databases on the rise
Even more pronounced for Financial Services & Insurance:
– 2x more likely to ingest MF data
– 20% more likely to pull data from RDBMS

Mainframe & Hadoop
71% of the Fortune 500 relies on mainframe data to conduct 30 billion business transactions a day
– 96 of the world’s top 100 banks
– 9 out of the world’s 10 largest insurance companies
– 23 out of the top 25 U.S. retailers
New solutions make it easier to take advantage of this critical data with Hadoop
HOW VALUABLE IS BEING ABLE TO
ACCESS/INTEGRATE MAINFRAME DATA
INTO HADOOP?
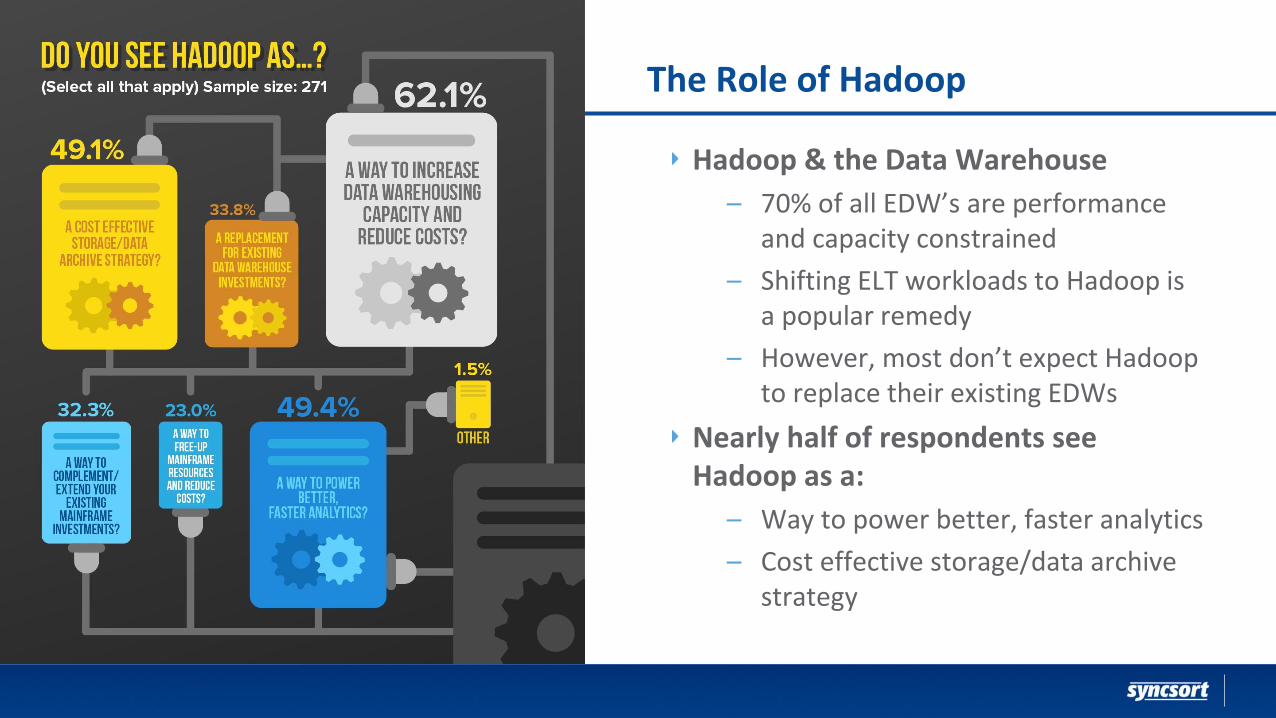
The Role of Hadoop
Hadoop & the Data Warehouse
– 70% of all EDW’s are performance and capacity constrained
– Shifting ELT workloads to Hadoop is a popular remedy
– However, most don’t expect Hadoop to replace their existing EDWs
Nearly half of respondents see Hadoop as a:
– Way to power better, faster analytics
– Cost effective storage/data archive strategy

Top Use Cases for Hadoop

Polling Question
What are the top use cases for Hadoop in your organization?
– Active archive
– Advanced/predictive analytics
– Data discover/visualization
– ETL
– Clickstream/social media data analysis
– Internet of Things
– EDW/Mainframe offload
– Operational analytics
– Real-time analytics

Significant Business Benefits Expected

Polling Question
What is the #1 challenge/barrier for implementing Hadoop in your organization?
– Lack of skills/staffing
– Cost
– Connectivity to existing data sources/apps
– Rapid change in tools/technology
– Difficulty moving data in/out of Hadoop
– Uncertainty

Top 3 Challenges/Barriers to Hadoop Adoption
Skills/Staffing:– 58% of respondents ranked it as a
significant challenge
– Top challenge reported for the 3rd
year in a row
Rapid Change:– 53% of respondents ranked it as a
significant challenge
– Difficulty keeping up with evolving compute frameworks and Hadoop-related tools
Connectivity:– 48% of respondents ranked it as a
significant challenge
1 2 3

What’s coming in 2017
1
2
3
4
5
Success begets success
Big Data insights will take their seat in the boardroom
Data governance grows in importance
Tools will become more flexible to adapt to changing
and hybrid environments
Organizations will seek simplicity to sustain & scale early
success

Thank You