Embed Size (px)
Citation preview

Распределенные вычисления на
JavaScript!Viktor Turskyi
CTO at WebbyLab
Webcamp 2015

Бизнес задача
Обработка большого массива (миллиарды записей) данных с соц. сетей.

Примера анализа
Расчет упоминаемости групп ключевых слов.
Источник данных - Twitter Public Stream API
Объем данных: +15ГБ ежедневно (5ТБ в год)

Примеры запроса
“#nike” против “#adidas”“#nike & nba” против “#adidas & nba”“(спорт|турнир) & -футбол” “волки & косметичка”

MapReduce или как это делают в Google
MapReduce — модель распределённых вычислений, представленная компанией Google, используемая для параллельных вычислений над очень большими, несколько петабайт, наборами данных в компьютерных кластерах. (Wikipedia)
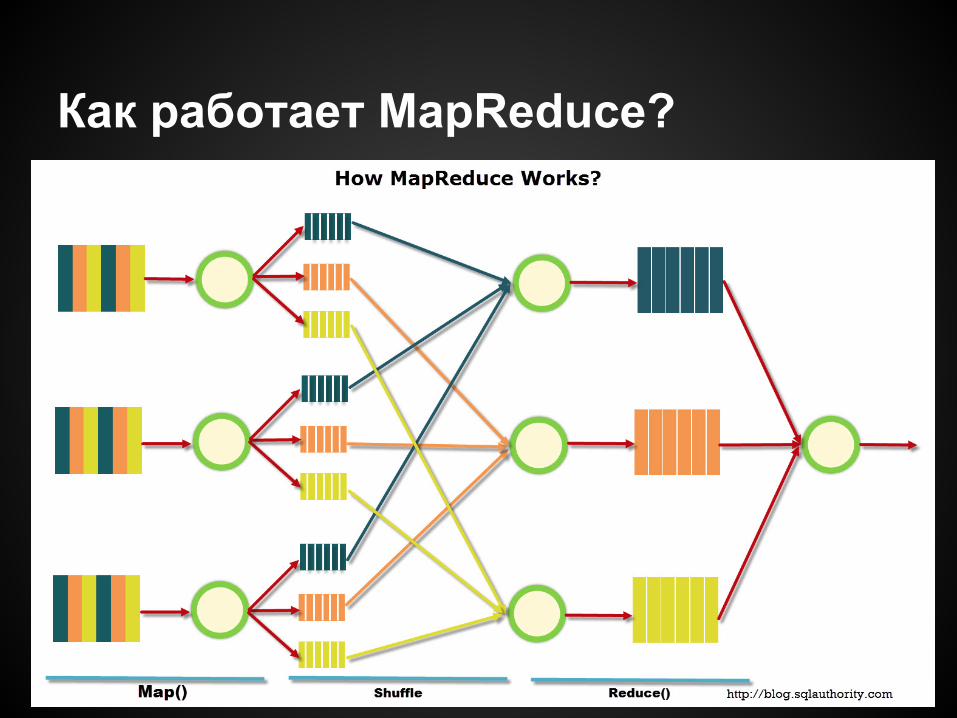
Как работает MapReduce?

Фазы mapreduce
map: mapper(line) -> (k1, v1)
shuffle: сортировка по k1
reduce: reducer(k1, [v1, v2, v3])

Подсчет слов (“hello world” из мира MR)
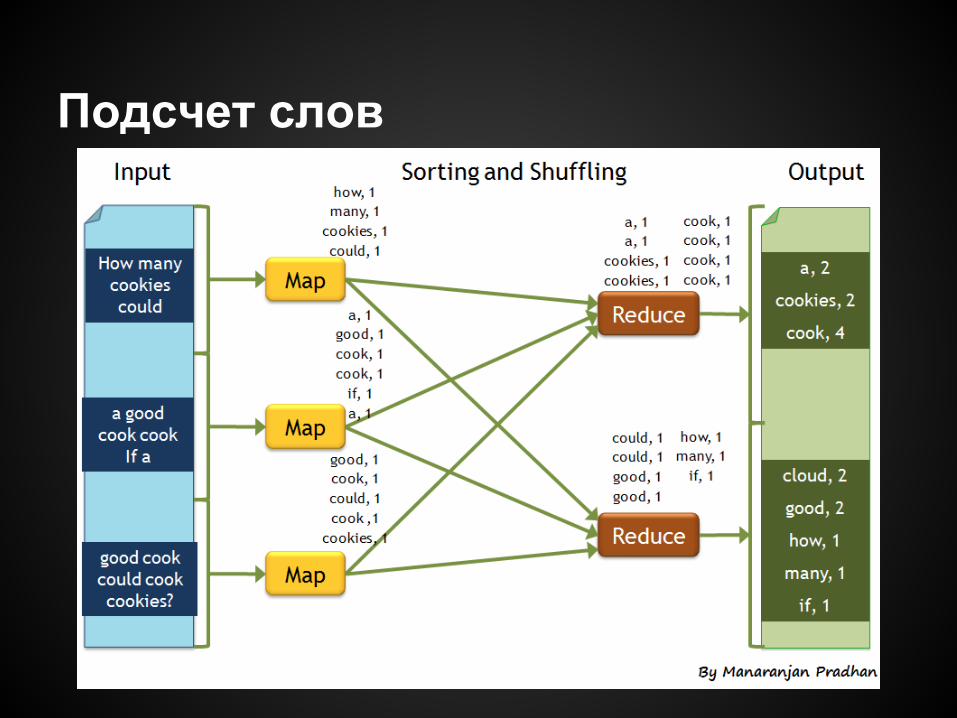
Подсчет слов

Когда Джефф Дин не может заснуть, он мап-редьюсит овечек

Экосистема Hadoop
Google MapReduce -> Hadoop Mapreduce
Google File System -> HDFS
Google BigTable -> Hbase

Как использовать JS c Hadoop (hadoop streaming)

Подсчет слов на hadoop streaming

Тестируем локально
cat data | ./mapper.js | sort -k1,1 | ./reducer.js

Boilerplate for Hadoop tasks
https://github.com/koorchik/node-hadoop-boilerplate

От “hello world” к реальной задаче
Задача: сравнение упоминаемости групп ключевых слов.
Вход: данные с твиттера
Выход: график упоминаемости групп ключевых слов по дням
Время обработки: до 10 секунд
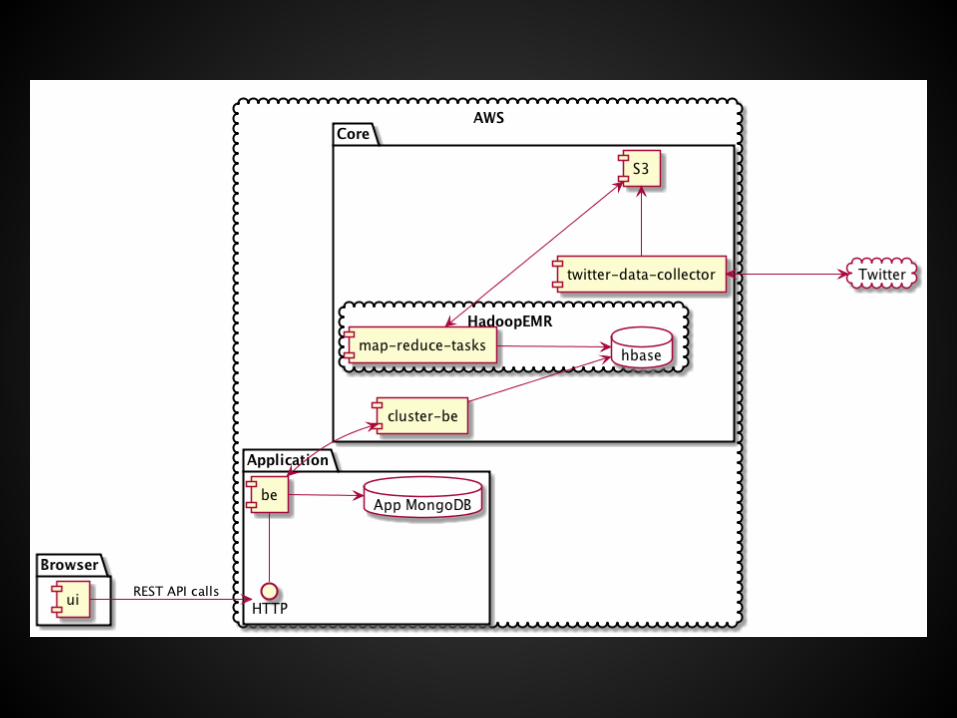
Общая архитектура

Режим работы
1) Запись и хранение данных на S32) Ежедневный пересчет (transient cluster)3) Дополнительный кластер для hbase
(хранит индексы и результаты вычислений).
4) Оплата только за используемые ресурсы
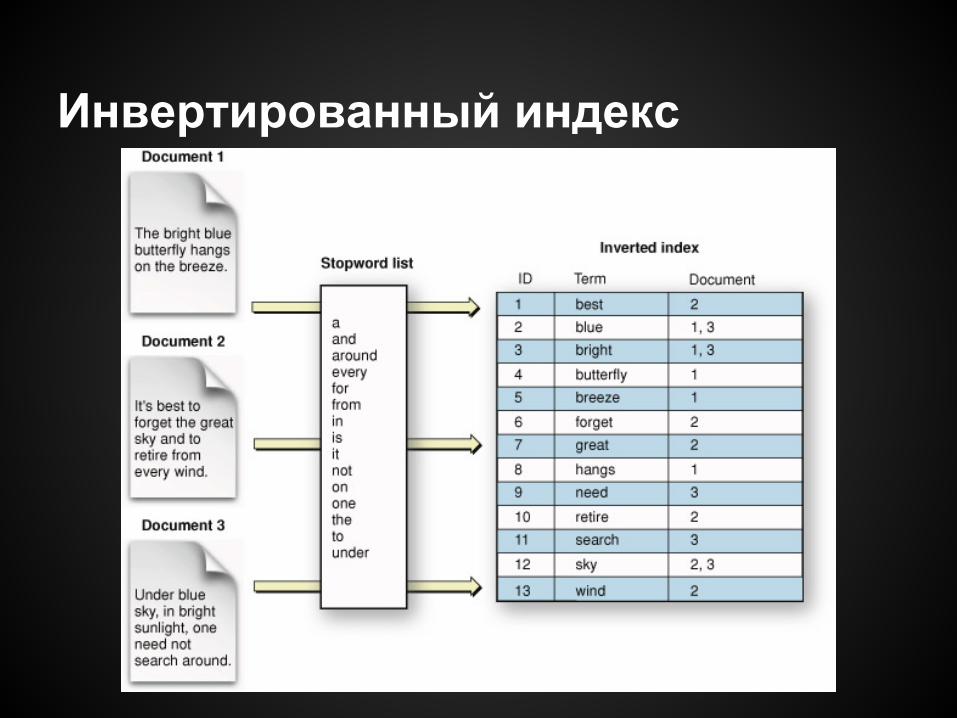
Инвертированный индекс
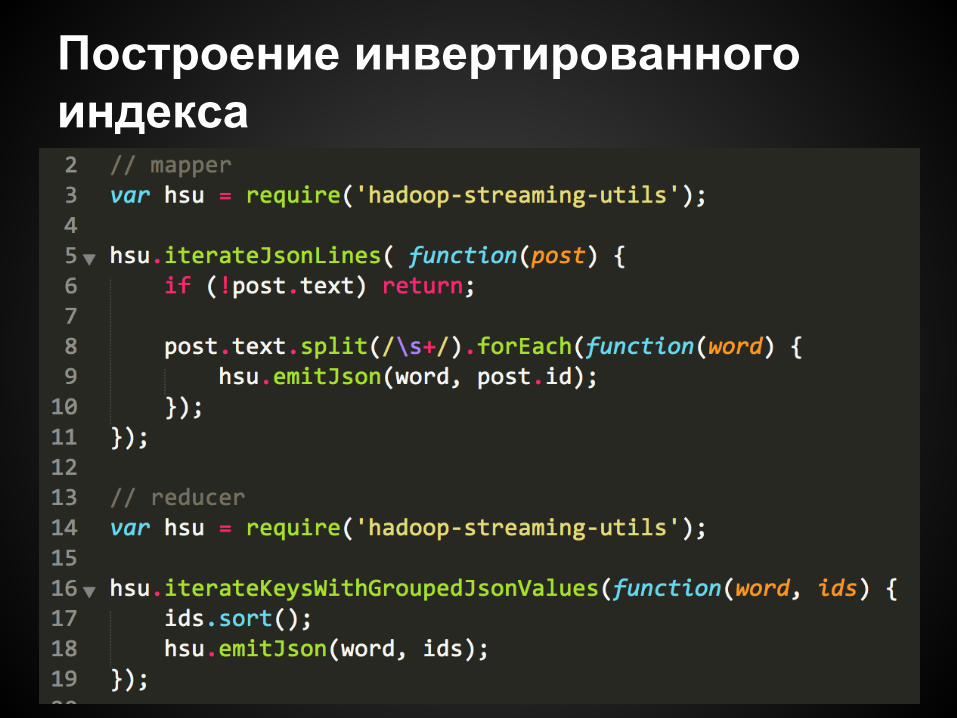
Построение инвертированного индекса

Проблемы
Установка зависимостей на кластерСклонения слов (стеминг, лематизация)Асинхронность маппераСтоп-словаТокенизация (ссылки, хеш-теги, юзернеймы)Компрессия индексаВычисление пересечений в индексеРанжирование документовОбработка словосочетаний

Создаем кластер на AWS EMR (демо)
1) Установка NodeJS на кластер2) Работа с зависимостями

Асинхронность & mystem

Живая демонстрация

Ссылки
Hadoop streaming utils for NodeJS https://www.npmjs.com/package/hadoop-streaming-utils
Node Hadoop boilerplate https://github.com/koorchik/node-hadoop-boilerplate
NodeJS Mystem3 - https://www.npmjs.com/package/mystem3
MapReduce: Simplified Data Processing on Large Clusters http://research.google.com/archive/mapreduce.html
Amazon Elastic MapReduce http://aws.amazon.com/elasticmapreduce/

Viktor [email protected]
https://twitter.com/koorchikhttps://github.com/koorchik
WebbyLabhttp://webbylab.com





























