Embed Size (px)
Citation preview

11
High Availability in the Cloud – Architecting Best Practices
Watch the video of this webinar
May 6, 2011

22
Your Panel Today
Presenting:• Michael Crandell, CEO Twitter: @michaelcrandell• Josep Blanquer, Sr. Systems Architect• Brian Adler, Professional Services Architect
Q&A:• Jason Altobelli, Account Manager
Please use the questions window to ask questions anytime!

33
Agenda
• Design for Failure• What happened in the AWS Outage• RightScale’s experience• Infrastructure abstraction and automation as building blocks
for highly available applications• Architectural options to protect against cloud failures• Conclusions / Q&A
Please use the questions window to ask questions anytime!

44
Terminology• Fault Tolerance
• Fault tolerance leverages redundancy and replication to enable systems to continue operating properly if one or more components fails
• High Availability• Fault Tolerant systems are measured by their Availability in terms of
planned and unplanned service outages for end users• 99% Availability = 3.65 days of downtime per year• 99.5% Availability = 1.83 days of downtime per year• 99.9% Availability = 8.76 hours of downtime per year• 99.99% Availability = 53 minutes of downtime per year• 99.999% Availability = 5.26 minutes of downtime per year
• Disaster Recovery• The process, policies and procedures related to restoring critical systems
after a catastrophic event

55
Design for Failure• Large scale failures in the cloud are rare but happen• Application owners are ultimately responsible for
availability and recoverability• Balance cost and complexity of HA efforts against
risk you’re willing to bear• Fortunately, cloud infrastructure has made DR and HA
remarkably affordable versus past options• Multi-server• Multi-AZ• Multi-region• Multi-cloud
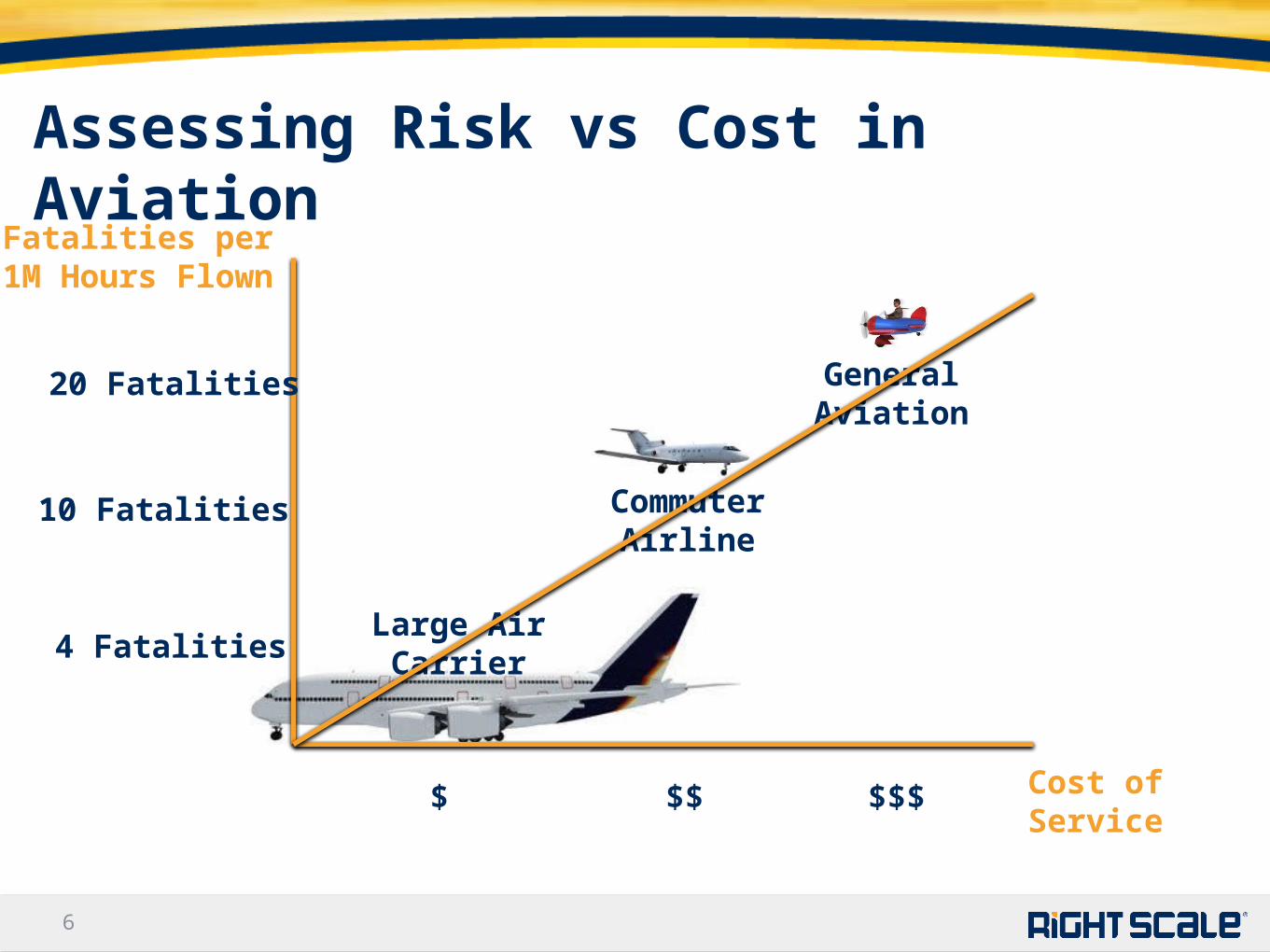
66
Assessing Risk vs Cost in Aviation
Large AirCarrier
CommuterAirline
GeneralAviation
Fatalities per 1M Hours Flown
20 Fatalities
10 Fatalities
4 Fatalities
$ $$ $$$ Cost of Service

77
What Happened in the April 21 AWS Outage?
• Triggered by operator error during a router upgrade which funneled high-volume network traffic into a low-bandwidth control network used by EBS
• Flooding of the control network caused a large number of EBS servers to be effectively isolated from one another, which broke volume replication, and caused these servers to start re-replicating the data to fresh servers
• This large-scale re-replication storm in turn had two effects:• It failed in many cases causing the volumes to go offline for manual intervention• It flooded the EBS control plane with re-replication events that affected its operation
across the entire us-east region
• Steps taken by AWS:• Stopping the re-replication attempts to quiesce the system and prevent new
volumes from being drawn into the outage• Isolated the affected availability zone from the EBS control plane to restore normal
operation in other zones• AWS started to recover volumes
• 12:30PM – All but about 2.2% of volumes in the affected AZ were restored

88
RightScale’s Experience• ~2am – Monitoring server disks started to die like flies
• Tried replacing them with fresh EBS drives – Failed• Tried re-launching them with fresh EBS drives in different Zones - Failed
• ~3am – Realized EBS wasn’t going to be fixed anytime soon: Plan B time!• Revamped our monitoring ServerTemplate to use ephemeral volumes instead of EBS• Our architecture for monitoring data continually backs up and pulls data on demand from S3
• ~3:20am – Started re-launching affected monitoring servers• Over the next several hours, ~15% of monitoring servers failed and were easily re-launched
• ~7am – Amazon announces EBS volume creation is fixed in other zones • ~11am – EBS disk failures hit our master database
• Chose one of our slaves (from our zone 1d) to be promoted • In a few minutes we had the new master up and running • It took a while to achieve needed performance due to its cold working set

99
Agenda
• Design for Failure• What happened in the AWS Outage• RightScale’s experience• Infrastructure abstraction and automation as building
blocks for highly available applications• Architectural options to protect against cloud failures• Conclusions / Q&A
Please use the questions window to ask questions anytime!

1010
What do we mean by Cloud?
• A cloud is a physical data center entity behind an API endpoint
• What do you mean by that?• Amazon Web Services is not a cloud• EC2 is not a cloud• Eucalyptus, Cloud.com are not clouds• EC2 East, EC2 AsiaPacific, my private cloud… are clouds• An availability zone is not a cloud, it’s part of one• Think of a cloud as a “resource pool” accessed via API

1111
Overcoming Multi-Cloud Pain Points• APIs differ
• Different sets of resources• Different formats, encodings and versions
• Abstractions and features differ• Network architectures differ: VLANs, security groups, NAT, IPs, ACLs, …• Storage architectures differ: local/attachable disks, backup, snapshots, …• Hypervisors, machine images…cost models, billing, reporting…etc.
• They are truly different beasts, with different semantics
• So make sure you:• Design using generic concepts yet deploy using cloud specifics• Have tools that translate your concepts to cloud-specific ones• Think of how to share resources across clouds (i.e. data sharing)
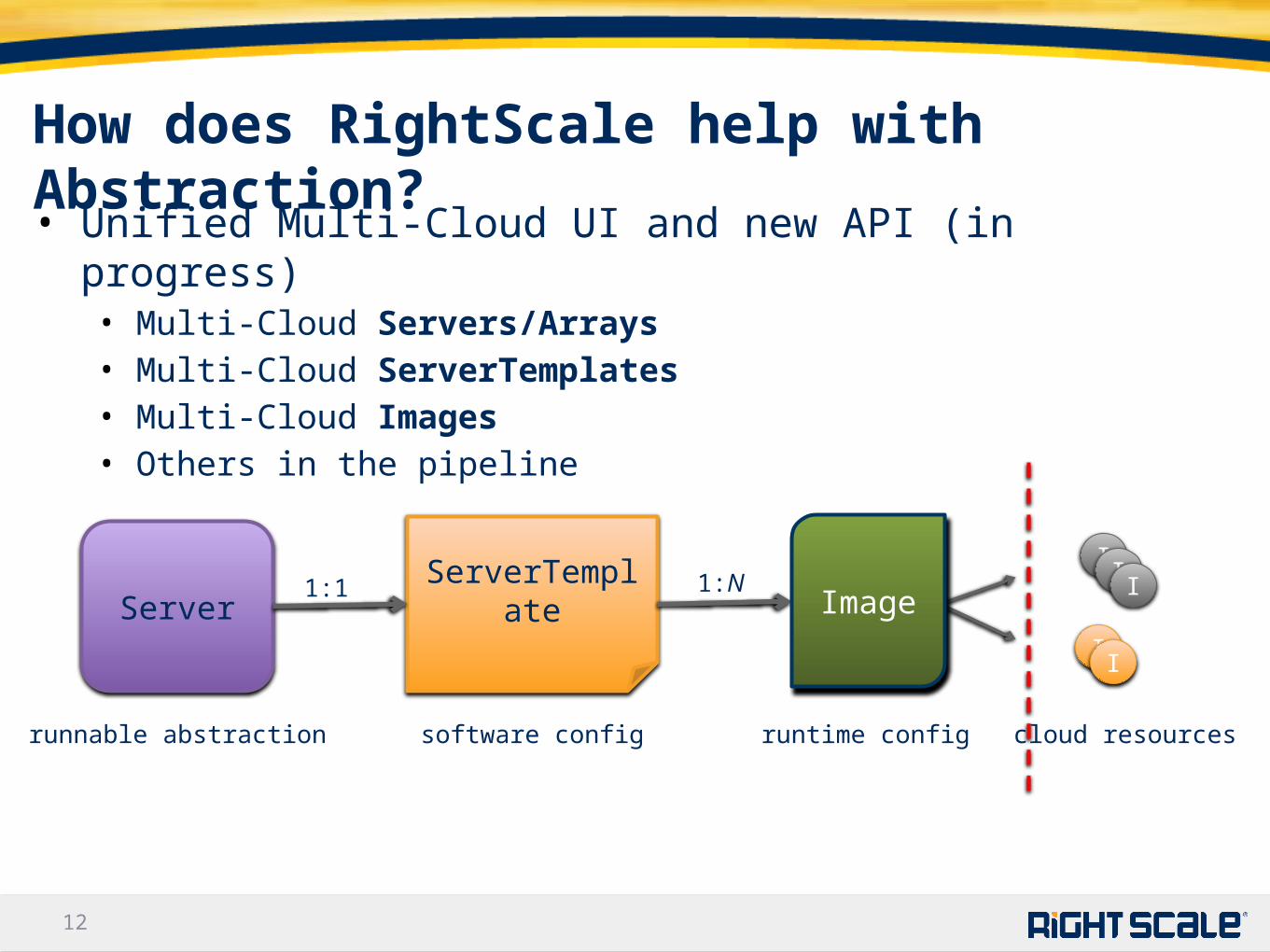
1212
How does RightScale help with Abstraction?
• Unified Multi-Cloud UI and new API (in progress)• Multi-Cloud Servers/Arrays• Multi-Cloud ServerTemplates• Multi-Cloud Images• Others in the pipeline
Server
runnable abstraction
ServerTemplate
software config runtime config
1:1 1:NI
II
II
cloud resources
Image

1313
Infrastructure Abstraction & Automation as Building Blocks of Highly Available Applications
• Multi-Cloud Dashboard, Architecture & Application Portability • Single pane of glass through UI and API• Allows simplified deployments across multiple regions/clouds
• Automated Deployments (Provisioning and Configuration Mgmt)• Reproducible Configurations with Change Control - Avoids manual configuration errors• Cost effective – Pay as you go for backup. It’s easy and inexpensive to test fault tolerance.
• Advanced Server and Deployment Monitoring • Custom monitoring dashboard, custom graphing, cluster graphing
• Automated Scaling and Operations• Easy to scale up/down, replace failed/unhealthy instances,
backup data, replicate data, etc
• Library of Cloud Optimized Solution Stacks• RightImages, RightScripts, and ServerTemplates

1414
Agenda
• Design for Failure• What happened in the AWS Outage• RightScale’s experience• Infrastructure abstraction and automation as building blocks
for highly available applications• Architectural options to protect against cloud failures• Conclusions / Q&A
Please use the questions window to ask questions anytime!

1515
HA/DR Checklist for Risk Mitigation
Determine who owns the architecture, DR process and testing. Develop expertise in house and / or get outside help. Conduct a risk assessment for each application. Specify your target Recovery Time Objective
and Recovery Point Objective. Design for failure starting with application architecture. Implement HA best practices balancing cost, complexity and risk.
Automate infrastructure for consistency and reliability. Abstract applications for flexibility and portability.
Document operational processes and automations. Test the failover... then test it again. Release the Chaos Monkey.

1616
Application Architecture Deployment Options
• Storage Options• Local storage, EBS, S3, CloudFiles, Gluster, etc.
• DNS Configuration Options• DNS APIs for dynamic configuration (Route53, DynDNS, DNS Made Easy)
• Load Balancing Options• HA Proxy or AWS ELB to distribute traffic across multiple instances / AZs
• Server Array Options• Create scalable tiers for web and application servers
• Database Options• MySQL (EBS with snapshots to S3 or Local Disk with LVM snapshots)
• Database Manager Features (Automated snapshots, replication, slave promotion, striping)
• AWS RDS• Database Sharding• NoSQL Databases

1717
General HA Best Practices
Avoid single points of failure Always place one of each component (load balancers,
app servers, databases) in at least two AZs Maintain sufficient capacity to absorb AZ / cloud failures Replicate data across AZs and backup or replicate across
clouds/regions for failover Setup monitoring, alerts and operations to identify and
automate problem resolution or failover process Design stateless applications for resilience to reboot / relaunch

1818
Multi-AZ Example
Snapshot EBS volume for backups so the database can
be readily recovered within the region.
Consider local storage for additional slave database to remove dependency on EBS
(Use LVM to snapshot backups)
Place Slave databases in one or more AZs for failover.
Consider distributed NoSQL databases with the same distribution considerations. Spread primary and replica nodes across multiple AZs. Place as many as you need
for required resiliency.
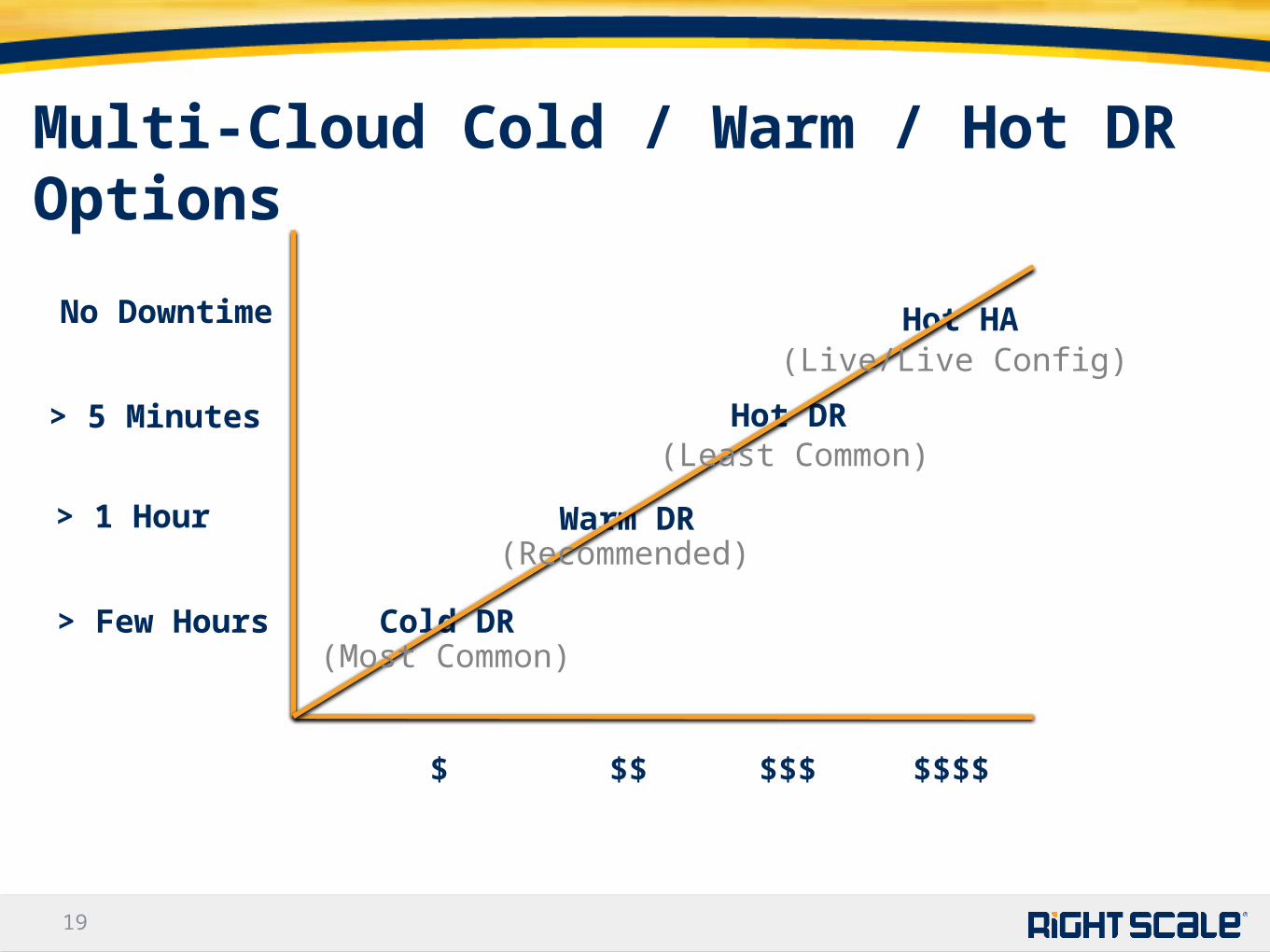
1919
Multi-Cloud Cold / Warm / Hot DR Options
Cold DR
Warm DR
Hot DR
Hot HANo Downtime
> 5 Minutes
> 1 Hour
> Few Hours
$ $$ $$$ $$$$
(Most Common)
(Recommended)
(Least Common)
(Live/Live Config)
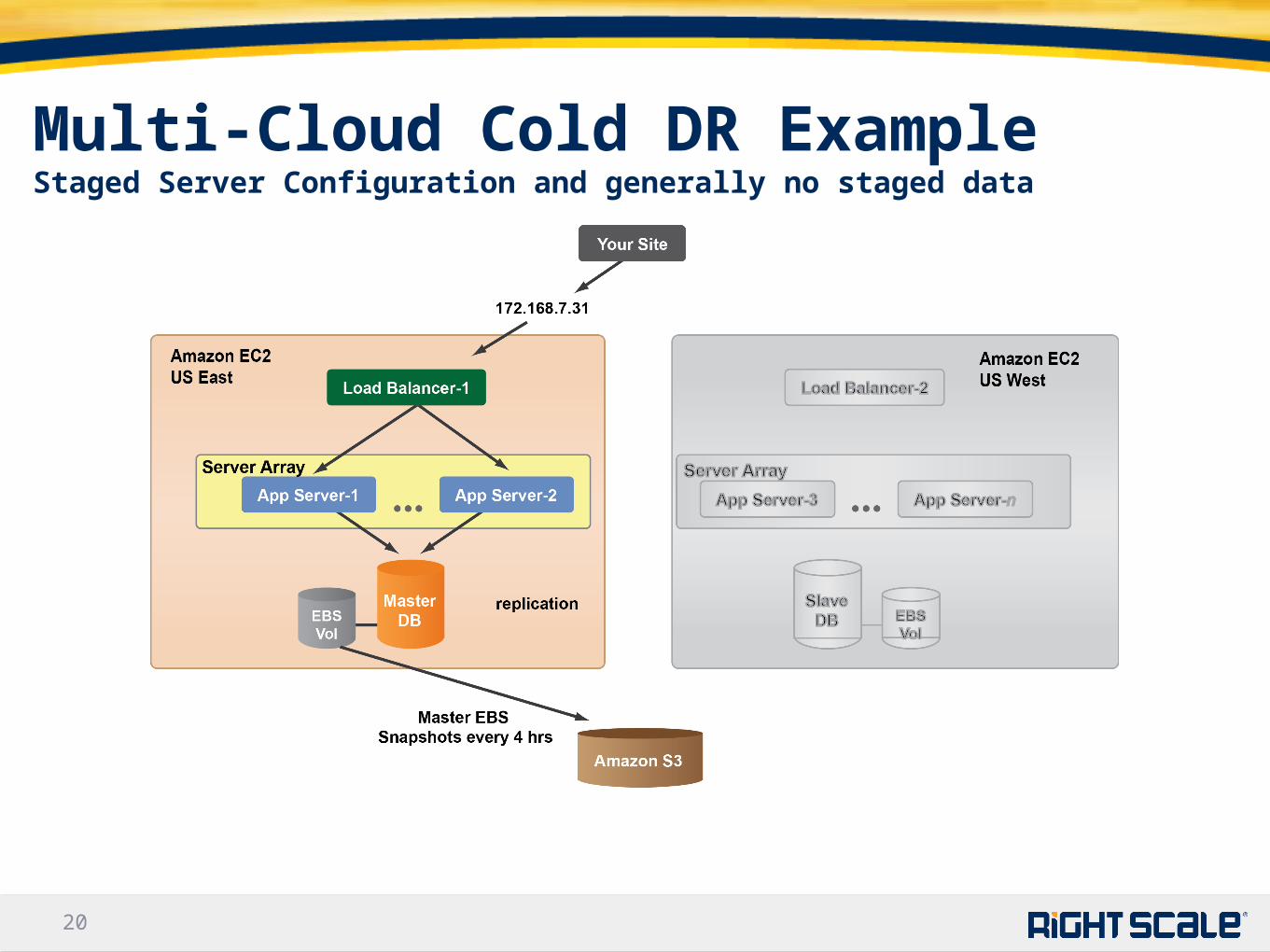
2020
Multi-Cloud Cold DR ExampleStaged Server Configuration and generally no staged data
2121
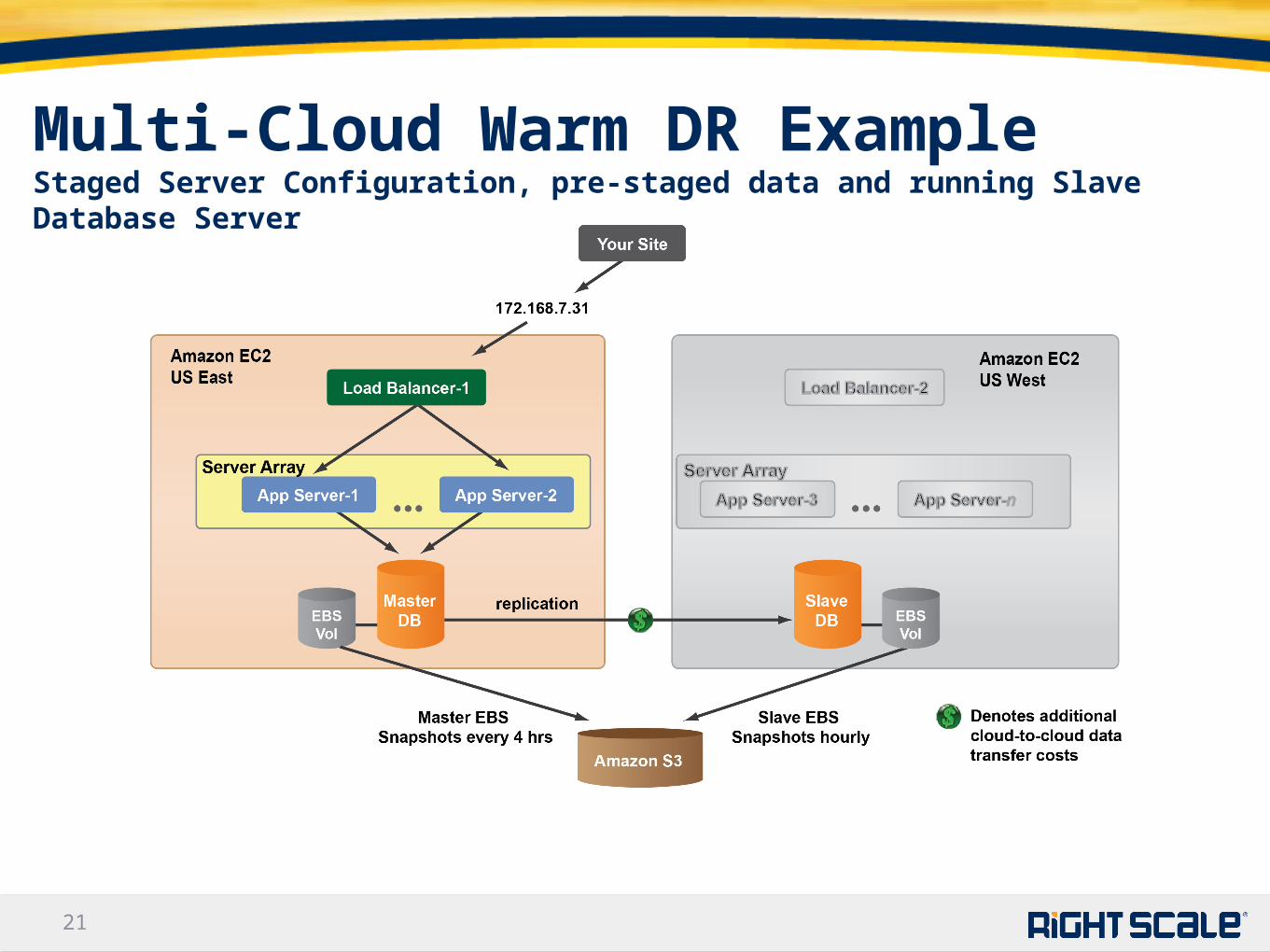
Multi-Cloud Warm DR ExampleStaged Server Configuration, pre-staged data and running Slave Database Server
2222
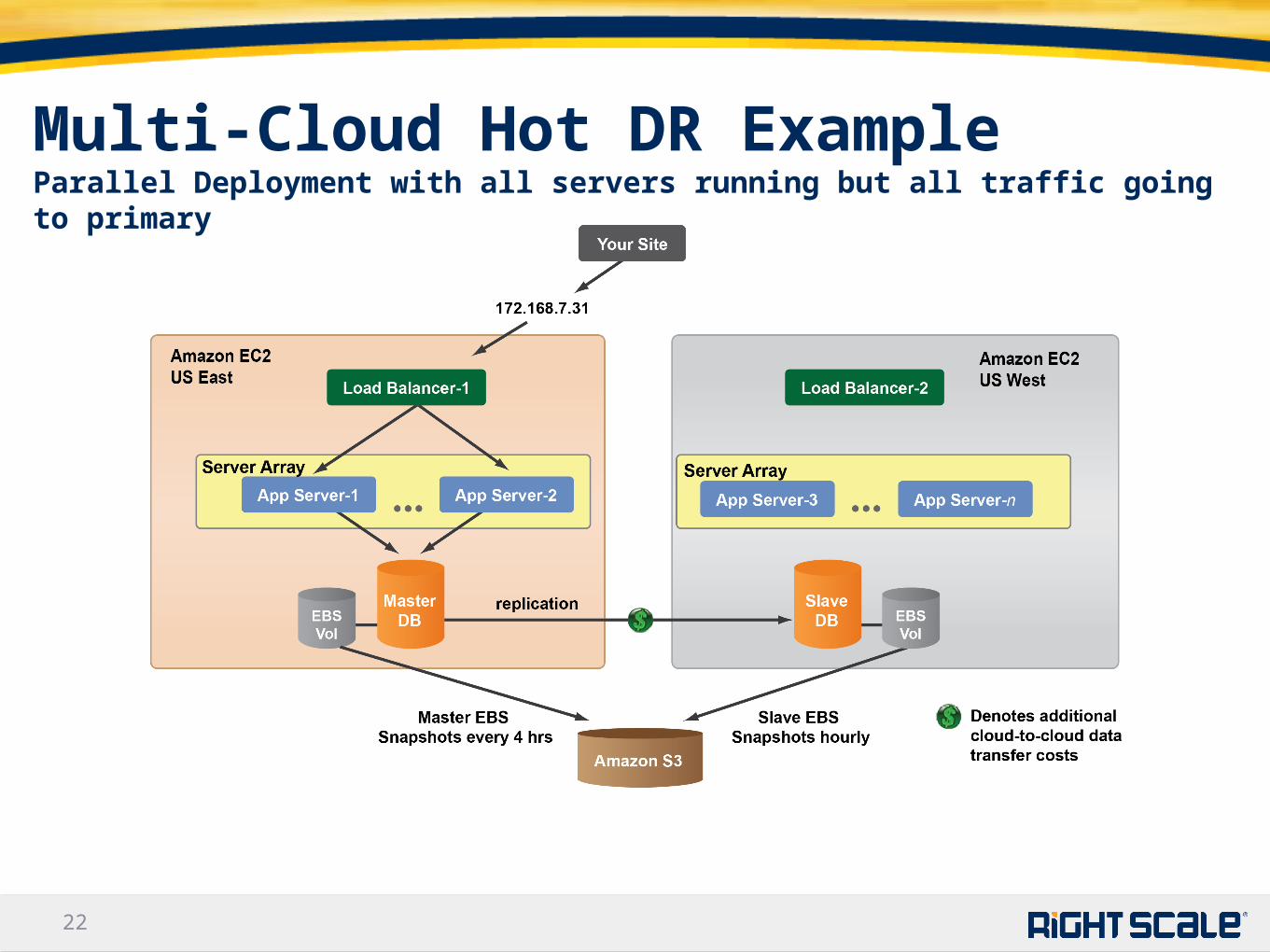
Multi-Cloud Hot DR ExampleParallel Deployment with all servers running but all traffic going to primary
2323
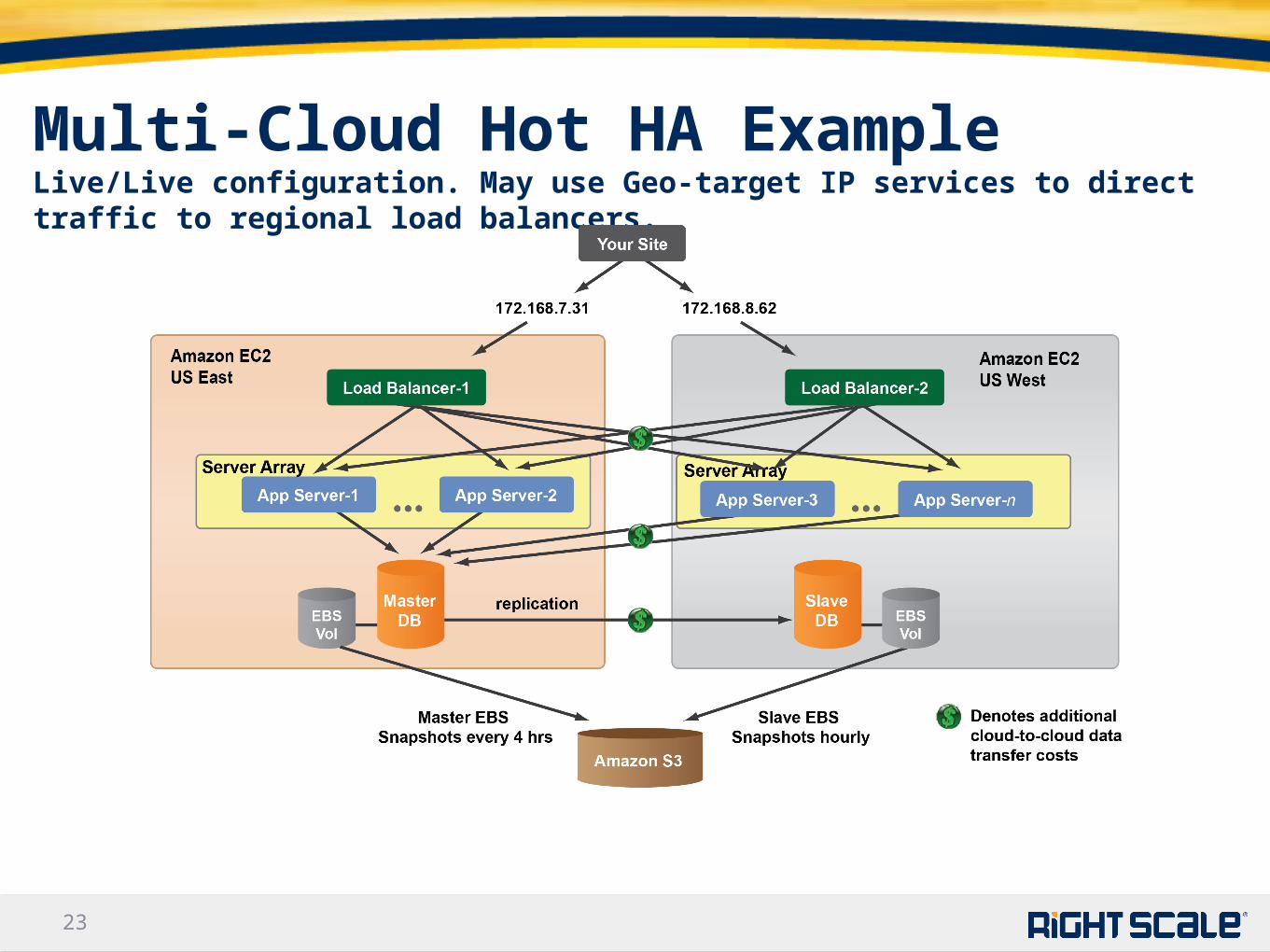
Multi-Cloud Hot HA ExampleLive/Live configuration. May use Geo-target IP services to direct traffic to regional load balancers.
2424
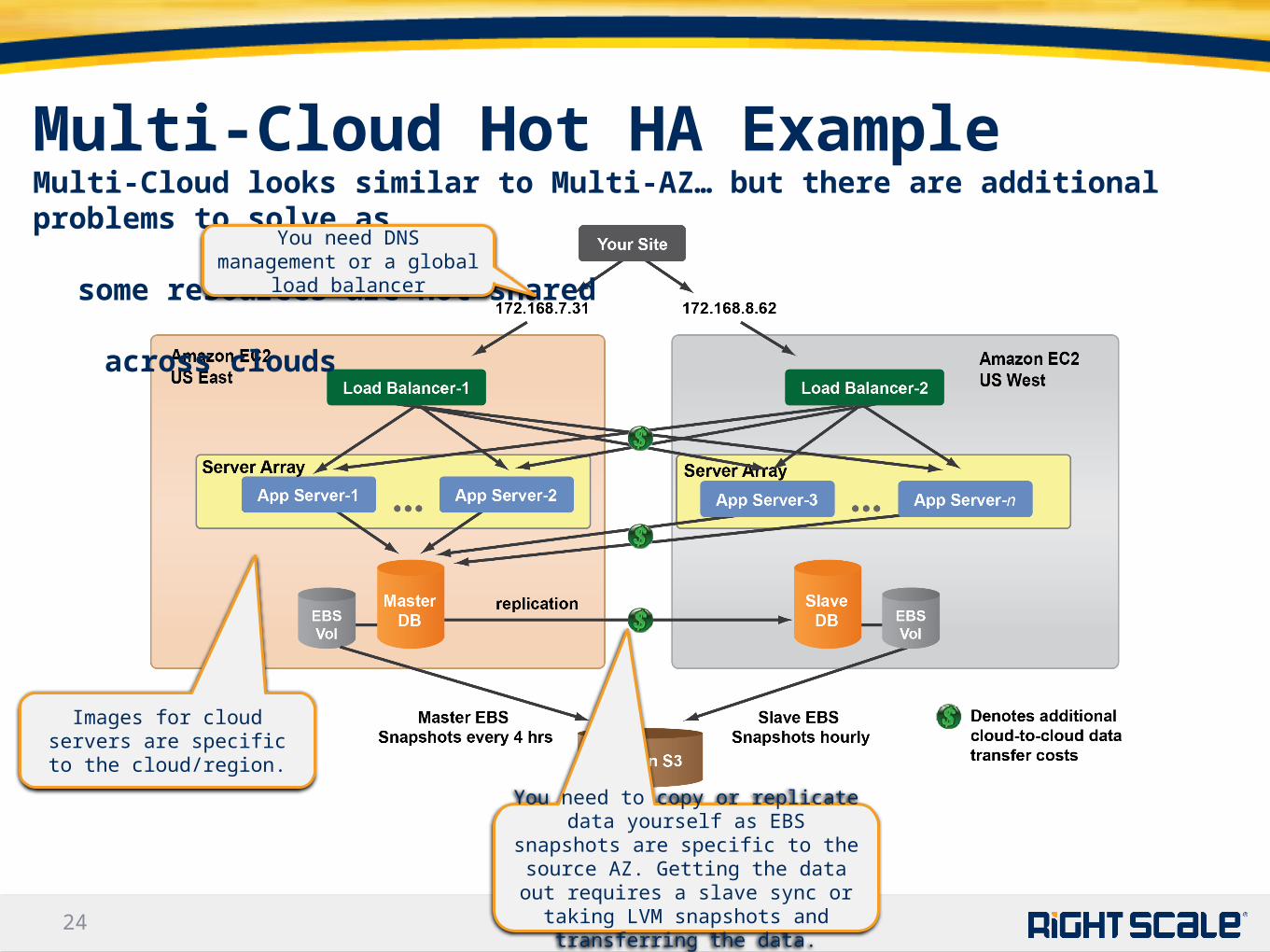
Multi-Cloud Hot HA ExampleMulti-Cloud looks similar to Multi-AZ… but there are additional problems to solve as some resources are not shared
across clouds
You need DNS management or a global load balancer
You need to copy or replicate data yourself as EBS snapshots are specific to the source AZ. Getting the data out requires a slave sync or taking LVM snapshots and transferring the data.
Images for cloud servers are specific to the cloud/region.

2525
So What’s Best?• Design for failure• No one size fits all solution
• Every application/components has its own architecture• Tradeoffs between levels of resiliency and cost
• The options available in the cloud today are unprecedented• Capabilities for global redundancy• Time to access• Investment required
• Follow our High Availability Checklist!

2626
Become a RightScale customer in May and receive:
Free High Availability Assessment
Free Design/Architecture Recommendations
Half Off Onboarding Fee
Ready to get started?
Contact us at [email protected] or (866) 720-0208
Learn More –
RightScale Free Edition White Paper Library Webinar Library RightScale.com/free Rightscale.com/whitepapers RightScale.com/webinars
RightScale User Conference – June 8 in NYC! Register here: www.rightscale.com/conference
Special Offer – High Availability Assessment &Design Recommendations

2727
Thank You!





























