Embed Size (px)
Citation preview

How to Leverage Spark and
NoSQL for Data Driven
ApplicationsWill Gardella, Product Manager
Michael Nitschinger, Senior Software Engineer

Agenda
NoSQL and Spark Use Cases
What is Spark?
What is Couchbase Server?
Why Spark and Couchbase?
Couchbase Spark Connector
Demo

©2016 Couchbase Inc. 3
NoSQL + Spark
Use Cases

©2016 Couchbase Inc. 4
Where does big data come from?
MobileWeb/Cloud Internet of Things
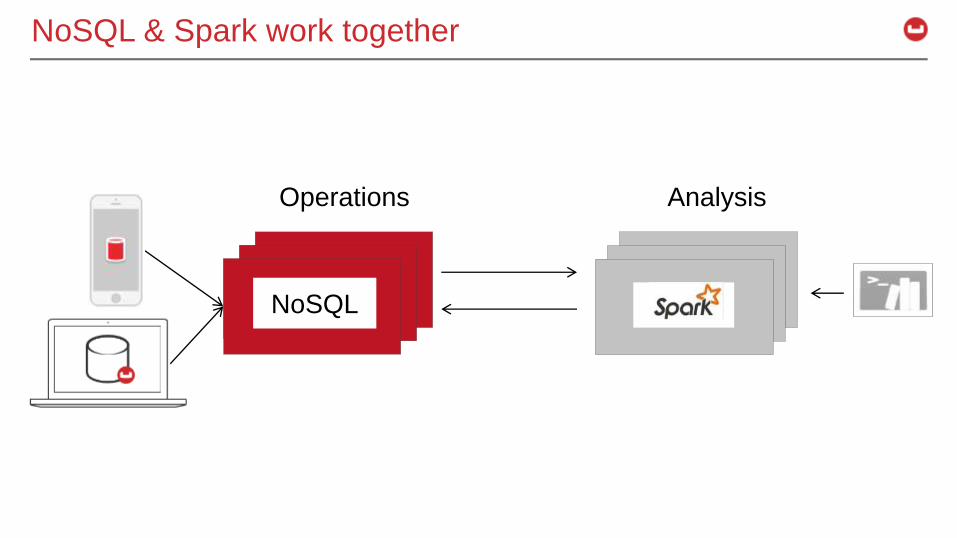
NoSQL & Spark work together
Operations Analysis
NoSQL

NoSQL + Spark use cases
Operations Analysis
NoSQL
Recommendations
Next gen data warehousing
Predictive analytics
Fraud detection
Catalog
Customer 360 + IOT
Personalization
Mobile applications

©2016 Couchbase Inc. 7
Big Data at a glance
Couchbase Spark Hadoop
Use cases• Operational
• Web / Mobile
• Analytics
• Machine
Learning
• Analytics
• Machine
Learning
Processing mode• Online
• Ad Hoc
• Ad Hoc • Batch• Streaming (+/-)
• Batch
• Ad Hoc (+/-)
Low latency = < 1ms ops Seconds Minutes
Performance Highly predictable Variable Variable
Users are
typically…
Millions of
customers
100’s of analysts or
data scientists
100’s of analysts or
data scientists
Memory-centric Memory-centric Disk-centric
Big data = 10s of Terabytes Petabytes Petabytes
ANALYTICALOPERATIONAL
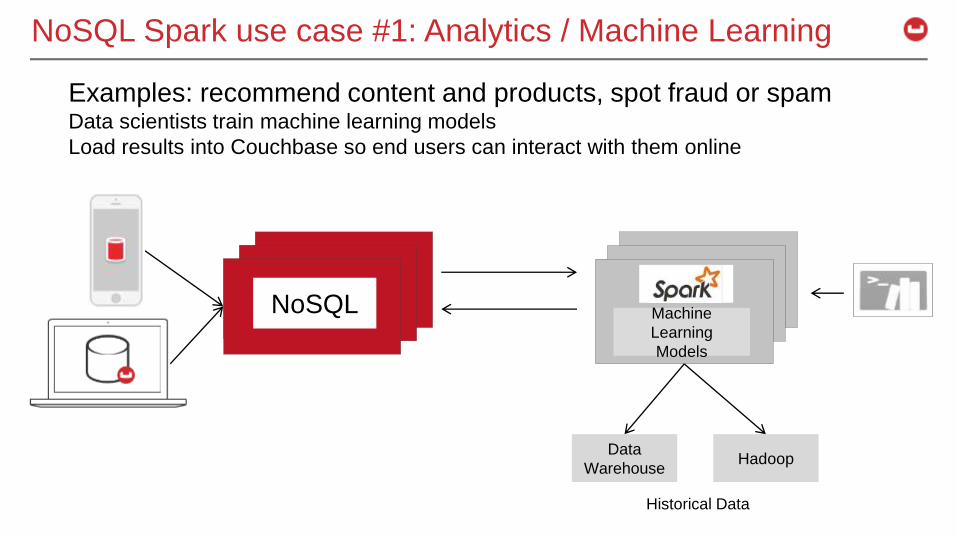
NoSQL Spark use case #1: Analytics / Machine Learning
Hadoop
Examples: recommend content and products, spot fraud or spamData scientists train machine learning models
Load results into Couchbase so end users can interact with them online
Machine
Learning
Models
Data
Warehouse
Historical Data
NoSQL

NoSQL to Operationalize Spark
Model
NoSQL
Training Data
(Observations)
Serving
Predictions

Why NoSQL with Spark?
RDBMS Challenges NoSQL Strengths
Scaling Hard Easy
Sharding & replication Manual Automatic
XDCR, geo distro, disaster
recoveryDifficult, expensive Easy, performant
Performance Add cache Integrated cache
Agility Schema migrations Flexible data model
Upgrades & maintenance Downtime Online
Cost $$$ $

Spark connects to everything…
DCP
KV
N1QL
Views
Adapted from: Databricks – Not Your Father’s Database https://www.brighttalk.com/webcast/12891/196891
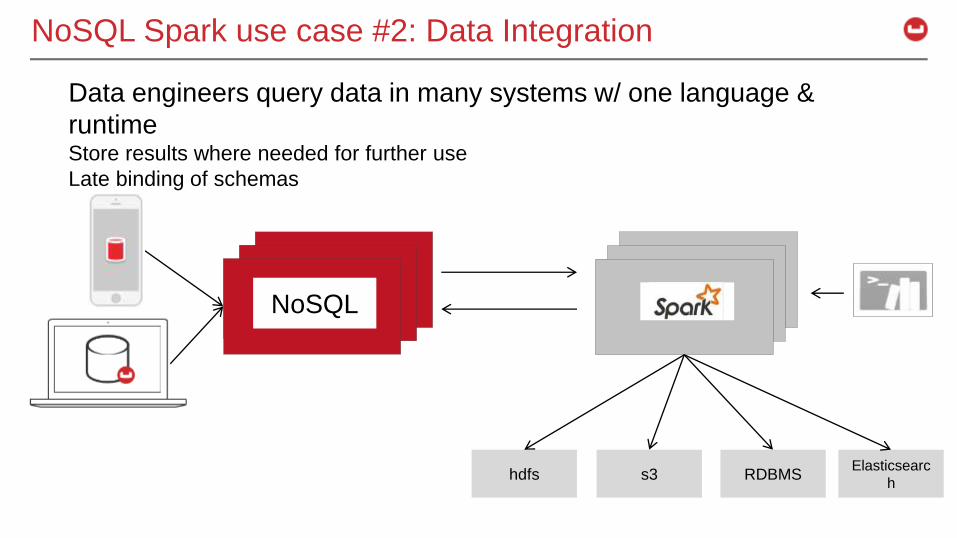
NoSQL Spark use case #2: Data Integration
RDBMSs3hdfs
Data engineers query data in many systems w/ one language &
runtimeStore results where needed for further use
Late binding of schemas
Elasticsearc
h
NoSQL

©2016 Couchbase Inc. 13
Spark

Spark is…
A compute engine for Hadoop & other platforms
Fast
100x better than MR when in-memory, 10x on disk
Sophisticated
Powerful primitives – not just MR
Advanced algorithms, graph, machine learning
Developer Convenience
Interactive shell
Well designed APIs in Java, Scala, Python, R
Supports SQL, DataFrames, and many other formats
Batch & Streaming

©2016 Couchbase Inc. 15
Couchbase

©2016 Couchbase Inc. 16
Who is Couchbase?
Couchbase is the company behind Couchbase Server & Couchbase Mobile
• Open source JSON database
• Founded 2010
• 400+ enterprise customers
globally
Some of our customers:
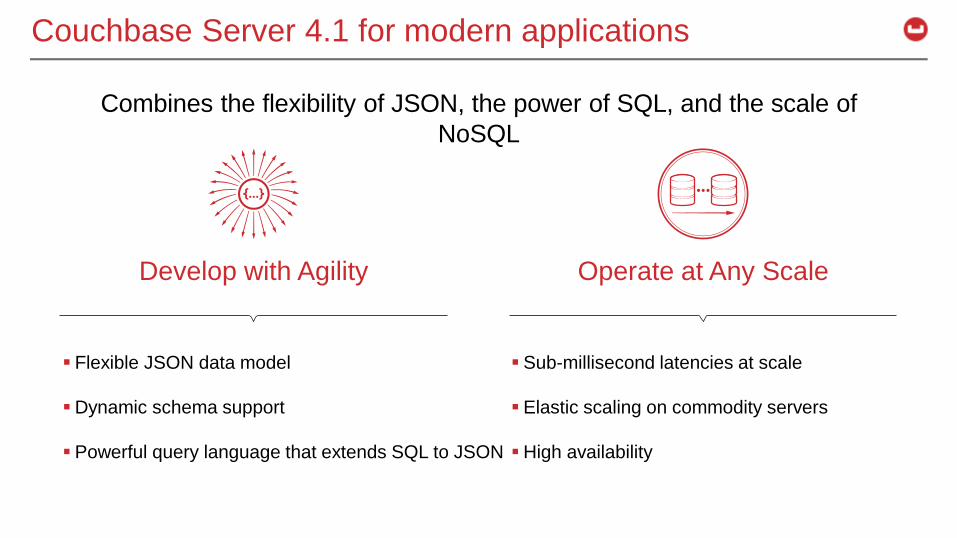
Couchbase Server 4.1 for modern applications
Combines the flexibility of JSON, the power of SQL, and the scale of
NoSQL
Develop with Agility Operate at Any Scale
Flexible JSON data model
Dynamic schema support
Powerful query language that extends SQL to JSON
Sub-millisecond latencies at scale
Elastic scaling on commodity servers
High availability

Why Couchbase for NoSQL applications w/ Spark?
Fast Memory-centric
Integrated cache
Data location awareness
Implicit batching from the SDK with async & flat-map
Developer Convenience Native SDKs
Automatic cluster management
Code your app without references to infrastructure
Sophisticated Query using SQL for JSON (N1QL)
Supports JOINs

©2016 Couchbase Inc. 19
Couchbase Spark Connector

Enter Spark
Fast and general engine for big data processing with libraries for
advanced analytics
Spark Core:
Task scheduling
Memory management
Fault recovery
Interacting with storage systems

RDDs – Resilient Distributed Datasets
The basic underlying idea of Spark
Resilient
Immutable data structures
Can be recomputed / restarted
Distributed
Separate development from operation / deployment
Execution
Types of operations
Lazy Transformations: RDD input, return new RDD
Map, filter, flatMap, groupByKey, reduceByKey, aggregateByKey, pipe, coalesce
Actions: evaluates RDD, returns a value
Reduce, collect, count, first, take, countByKey, foreach

DataFrames (SparkSQL)
Distributed collection of data organized in named columns
DataFrame = “RDD + Schema”
Perform SQL Queries on
top of your data
Optimization possibilities
inside Spark
(Catalyst, Tungsten)
From https://databricks.com/blog/2015/02/17/introducing-dataframes-in-spark-for-large-scale-data-science.html

Datasets
DataFrames with type-safety
Initial support in Spark 1.6, extended in 2.0
Higher performance & less memory usage
Encoding/Decoding for semi-structured data
https://databricks.com/blog/2016/01/04/introducing-apache-spark-datasets.html
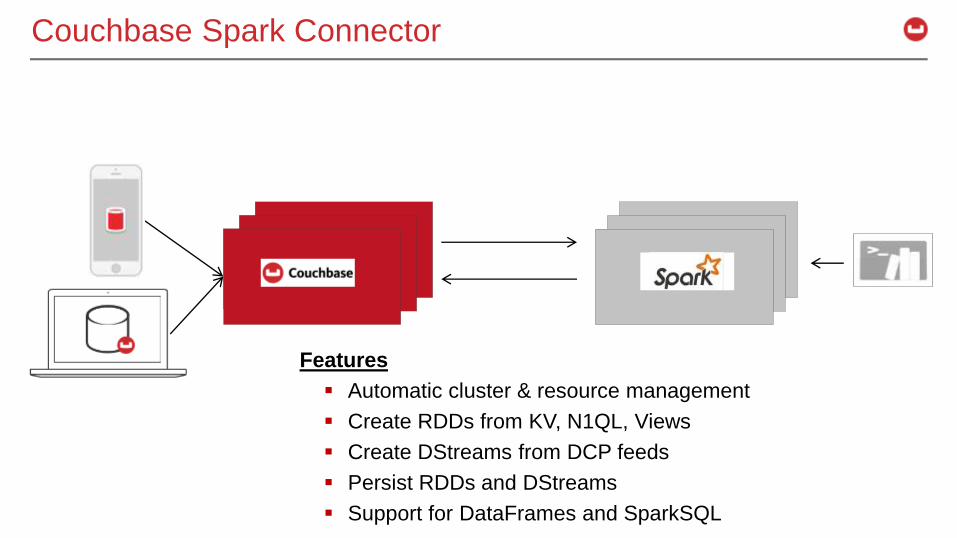
Couchbase Spark Connector
Features
Automatic cluster & resource management
Create RDDs from KV, N1QL, Views
Create DStreams from DCP feeds
Persist RDDs and DStreams
Support for DataFrames and SparkSQL
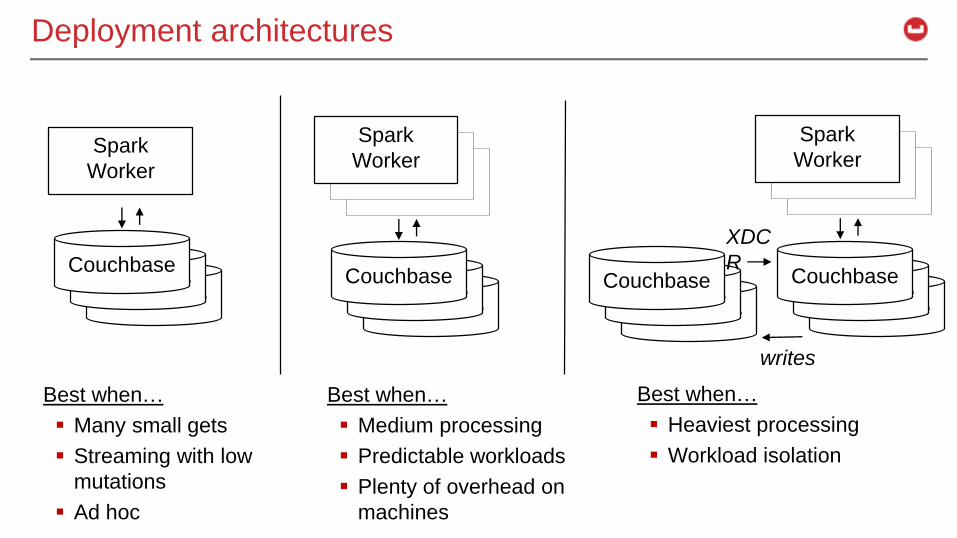
Deployment architectures
Couchbase
Spark
Worker
CouchbaseCouchbase
Best when…
Many small gets
Streaming with low
mutations
Ad hoc
Couchbase
Data NodeData NodeSpark
Worker
CouchbaseCouchbase
Best when…
Medium processing
Predictable workloads
Plenty of overhead on
machines
CouchbaseCouchbase
Couchbase
CouchbaseCouchbase
Couchbase
Data NodeData NodeSpark
Worker
XDC
R
Best when…
Heaviest processing
Workload isolation
writes

Connection management

Connection management

Creating RDDs

Persisting RDDs

RDD N1QL Query

Spark SQL - Schema

Spark SQL – DataFrame Query

Demo of Dataset (Spark 1.6)

Demo of Dataset (Spark 1.6)

Demo of Dataset (Spark 1.6)

Spark Streaming with DCP

Couchbase Spark Connector 1.2
Upcoming Release (planned) : 1.2
• Spark 1.6 Support, including Datasets
• Full DCP flow control support
• Enhanced Java APIs
• Bug fixes
37

Get Started – Couchbase & Spark
http://www.couchbase.com/bigdata
Couchbase Spark Connector
https://github.com/couchbase/couchbase-spark-
connector
Sample App - Market Basket Analysis (Avalon)
https://github.com/Avalon-Consulting-LLC/couchbase-
spark-mba
38





























