Embed Size (px)
Citation preview
1
Hadoop user group Italy
HUG Italy
Milan, 30 September 2014
Monica Franceschini Big Data Architect

2
Hadoop Summit
Hadoop Summit San Jose

3
Hadoop Summit San Jose

4
Hadoop Summit Hortonworks 2 days course

5
Hadoop Summit - YARN

6
Hadoop Summit - YARN

7
Hadoop Summit - YARN
+

8
Hadoop Summit - YARN

9
Hadoop Summit - YARN

10
Hadoop Summit - YARN

11
Hadoop Summit – SQL on Hadoop
“Things are different here in the Valley,” Gartner analyst Merv Adrian quipped during his keynote Tuesday. “Where else, when you put out a release 2.0 of something, do you begin to refer to 1.0 as ‘traditional?'”
TRADITIONAL HADOOP

12
Hadoop Summit – SQL on Hadoop
Gartner survey among existing Hadoop users
● 53 percent are doing interactive SQL● 18 percent are running database
management systems● 14 percent are doing stream processing● 9 percent are running search● 6 percent are running graph application
MapReduce

13
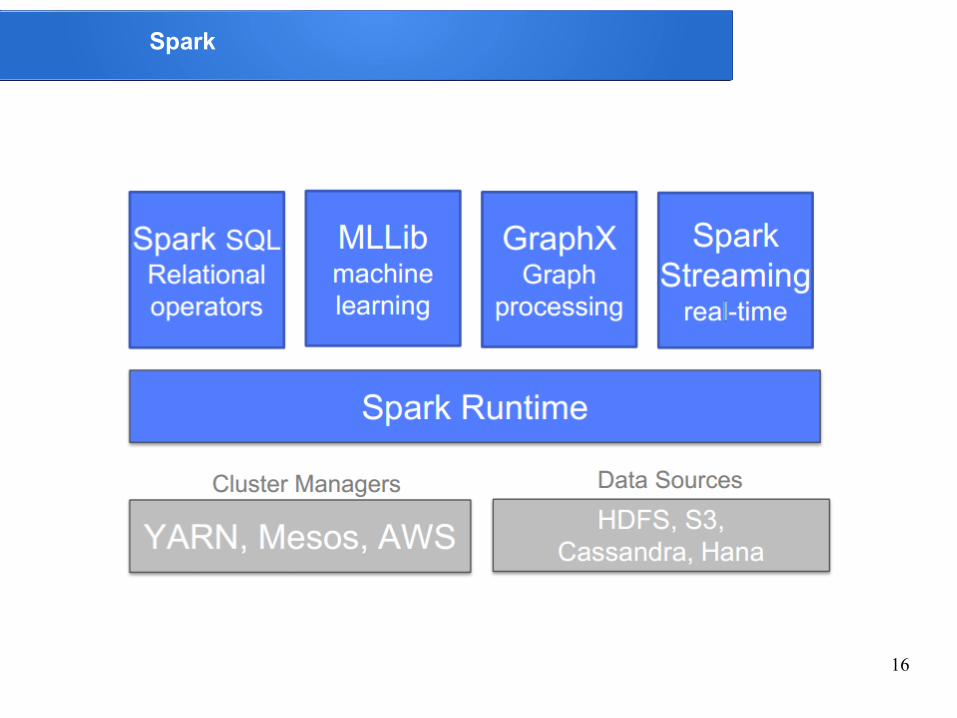
Spark
Spark: Real-time queries and analytics for big data!
Spark è un sistema di cluster computing open source che mira a garantire data analytics veloci - sia veloce a essere eseguiti che veloci da programmare.
Per eseguire i programmi più velocemente, Spark fornisce primitive per in-memory cluster computing: il job può caricare i dati in memoria e interrogarli ripetutamente molto più rapidamente rispetto ai sistemi basati su disco come Hadoop MapReduce.

14
Spark

15
Spark
Velocità: Spark consente ad applicazioni che girano su cluster Hadoop di essere fino a 100 volte più veloci nelle operazioni in memoria, e 10 volte più veloci, anche quando si eseguono su disco.
Facilità di utilizzo: Spark consente di scrivere rapidamente applicazioni in Java, Scala, o Python. Viene fornito con un set integrato di oltre 80 operatori di alto livello. E lo si può utilizzare in modo interattivo per interrogare i dati da shell.
Analisi sofisticate: Oltre alle semplici operazioni di "map" e "reduce", Spark supporta query SQL, streaming di dati e analisi complesse quali machine learning e algoritmi su grafi out-of-the-box. Inoltre, gli utenti possono combinare tutte queste funzionalità senza soluzione di continuità in un unico flusso di lavoro.
16
Spark

17
Spark

18
Spark
Spark Summit 2013

19
Spark
Spark Summit 2013
20
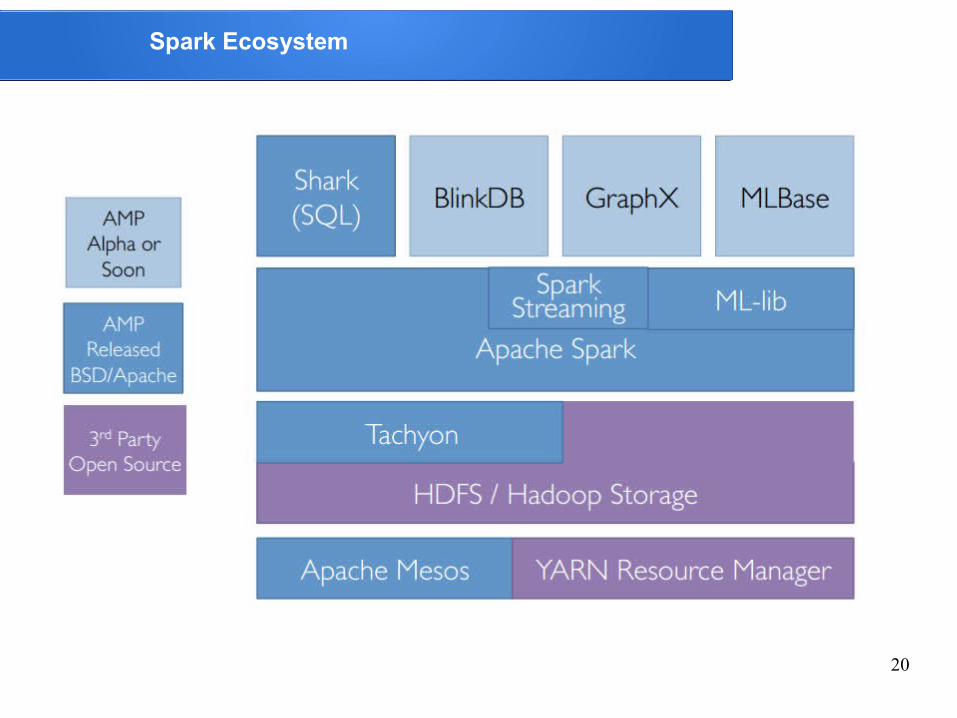
Spark Ecosystem

21
Spark
I. science ... Spark API & MLlib ease development of ML algorithmsII.speed ... Spark reduces latency of model training via in-memory RDD etcIII.scale ... YARN brings Hadoop datasets & servers at scientists’ fingertips

26
Why Spark?

27
Spark SQL
Spark SQL unifies access to structured data.
Spark SQL consente di effettuare interrogazioni SQL su dati strutturati, sotto forma di distributed dataset (RDD) in Spark, mediante le sue APIs in Python, Scala e Java. L'oggetto SchemaRDDs fornisce un'unica interfaccia per lavorare con efficientemente con tabelle Apache Hive, parquet files e JSON files.Spark SQL riutilizza sia il frontend che il metastore di Hive.

28
Spark SQL

29
BlinkDB
BlinkDB: Queries with Bounded Errors and Bounded Response Times on Very Large Data.BlinkDB is a massively parallel, approximate query engine for running interactive SQL queries on large volumes of data. It allows users to trade-off query accuracy for response time, enabling interactive queries over massive data by running queries on data samples and presenting results annotated with meaningful error bars.
Two key ideas: (1) An adaptive optimization framework that builds and maintains a set of multi-dimensional samples from original data over time, and (2) A dynamic sample selection strategy that selects an appropriately sized sample based on a query’s accuracy and/or response time requirements.
http://blinkdb.org/

30
Securing Hadoop
XA Secure
Apache Knox






























