Embed Size (px)
Citation preview

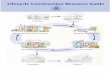
LIFECYCLEINCIDENTLIFECYCLEINCIDENT
It’s more than just ACKing

The ITIL calls it the Incident Lifecycle. Others know it as the process through which you go about solving IT issues in real-time, as they happen. You might call it a long night without sleep.
Whatever terms are used, following an alert from once it comes in to seeing it through to resolution can be along process. Fortunately, with the right tools, surviving this challenge can be made all the less daunting.
When you break it down into its parts, fighting the good fight becomes simply a matter of choosing a solution that works with each part.
INC
IDEN
T LI
FEC
YCLE

01 02 03 04 05 06
INC
IDEN
T LI
FEC
YCLE
ALERTING
in
vestigation Re
solution
TR I A GE
Ident if icat
ion
documenta
t ion

01ALERTINGALERTING
“I received notification that a critical alert has come in.” +
+ +
If you break down a typical “incident resolution” into phases, you see that, generally, the smallest portion of time is spent “being alerted to the problem”. On average, our VictorOps data shows that only 5% of the total TTR has anything to do with alerting or escalation of problems. There are incidents where a team member does not respond but this is generally more about the team member than the platform finding him or her.
Historically, the alerting phase was a longer portion of TTR back when teams actually carried “pagers”, as those systems were quite slow. Now that team members have smart phones, human behavior has changed to be more “always-on” and engaged with that device. Alerting has come along for the ride of WAN, LAN and SMS data.
Nonetheless, the truth of the matter is a perfect “zero time” alerting platform that could find people instantly can only really effect average TTR by a very small percentage, even in the best case scenario.
Push, SMS and phone notifications (with customizable ring tones) will make sure that no one misses an alert.
Additionally, rich alerts provide context around the incident and baked in solutions make the on-call person’s job easier.
What part does VictorOps play?
INC
IDEN
T LI
FEC
YCLE

TRIAGETRIAGE“I know there’s a problem but I have no idea who or what is affected.”
This is the phase of the incident lifecycle that can cause the most stress. For someone new to the on-call process, finding out what exactly is wrong by picking up the phone to call someone that may or may not be awake and may or may not have the right answer is anxiety-inducing…but even more so if the incident happens at 3am.
Based on our internal customer data, 18% of the TTR is simply getting an initial person (or subsequent team member) up to speed with what is happening. This information is rarely contained completely in the alert metadata, but rather requires seeing other markers in the system as well.
We call this situational awareness, and having situational awareness in the platform can have a big impact on TTR. The faster you can get the right eyes on the problem, the faster you can solve the problem.
The incident timeline provides a single view of all activities surrounding the incident, including alerts, paging, chat messages and the ability to reroute the alert to a different person or team.
Also, with intelligent routing that can send an alert to the person who knows how to fix the problem, triage becomes less stressful.
What part does VictorOps play? +
+
+
INC
IDEN
T LI
FEC
YCLE
02

The majority of TTR, a full 40%, falls into what we call the Investigation Phase of Incident Resolution. Investigation requires the on-call person to play the part of detective by following up on possible leads while ruling out the usual suspects.
This phase includes logging into the system, tailing logs, consulting performance monitoring tools, etc. It also involves consulting internal documentation resources such as wikis or ticketing systems. Anyone can triage but it takes a higher level of advanced thinking to figure out that one thing that’s broken and may be causing everything else to break.
If triage has been successful, the on-call engineer has already figured out who else needs to be involved in this phase. Getting other people involved early means that they can help look at the series of events and possibly recognize a pattern you may have missed.
Our timeline allows for easy collaboration. You can chat, send private messages or mention an entire team in a question posted to the timeline.
Annotations attached to alerts can provide much-needed direction as to how the problem was solved last time or who to contact to find an answer.
INVESTIGATIONINVESTIGATION“I need help digging into the issue.”
+
+
+
What part does VictorOps play?
INC
IDEN
T LI
FEC
YCLE
03

IDENTIFICATIONIDENTIFICATIONOnce you know what the problem is, you just need to find the answer. This is much easier said than done. Depending on what your company’s documentation is like, getting your hands on updated protocol might just be the hardest part of solving the problem. Remediation docs may be stored in an internal wiki, a spreadsheet, or in some cases, someone’s head.
Today’s systems are so complex and ever-changing that they require new ways of maintaining them. Add to that fact that many teams now have a varied group of individuals taking part in the on-call rotation – meaning that if a database team member is handling the alert, they need to know how to solve for problems outside of their domain expertise.
Imagine if every alert automatically surfaced contextual information and suggested solutions to resolve the problem. Knowing exactly how to solve the problem is one surefire way of reducing TTR. Having real-time remediation data right where you need it, right when you need it.
The ability to annotate alerts with links to internal runbooks, graphs and notes about how the problem was solved means that the on-call person can actually solve the problem much faster.
Knowing that the solution will be easy to find is a major game changer when it comes to making on-call suck less.
What part does VictorOps play?
+
+
+
“Everything will be better if I fix this one thing.”
INC
IDEN
T LI
FEC
YCLE
04

“I’m fixing it.”
RESOLUTIONRESOLUTION
What part does VictorOps play?
10% of TTR falls into a category called Problem Resolution. This is represented by team members performing system actionsto fix the problem that started the incident. It unfortunately also means waiting for systems to recover and verify that the root cause was found, often extending team involvement longer than desired.
The Problem Resolution phase is perhaps the largest potential lever in a true collaborative system. To reduce TTR in the Resolution phase, you need a feature set that self-documents what teams do to solve the problem. This is, in a sense, the heart of collaboration: the ability to not only reduce TTR during the current resolution cycle, but also capture that knowledge to pay it forward next time.
Fix the one thing. Watch the other things get better. Update documentation so you can easily fix that one thing again in the future.
With bidirectional integrations with HipChat and Slack, it’s easy to collaborate and manage many aspects of your infrastructure from the comfort of your firefighting chat room.
+
+
INC
IDEN
T LI
FEC
YCLE
05

DOCUMENTATIONDOCUMENTATION
What part does VictorOps play?
“I don’t want to have to deal with that again.”
After an incident is resolved, on-call best practices mandate that a post-mortem, or retrospective, take place. An accurate, comprehensive post-mortem is an essential tool for communicating with internal and external stakeholders. But more importantly, it helps prepare, and ideally prevent, similar incidents from occurring again.
The ideal report would pull together everything that happened during the entire incident lifecycle, with a single authoritative clock that gives context to the event and includes all relevant communications. That report would also be customizable - allowing you to edit out unimportant details and add notes where applicable – and provide a high-level snapshot of exactly what the incident entailed.
Want to know even more about your on-call process? Add reporting around incident frequency, incident metrics and user metrics and you have a much larger picture of what’s working with your alerting and what’s not.
Our reporting gives you the ability to improve your process around incident resolution and helps to facilitate documentation cleanup by letting you make notes about the accuracy/helpfulness of annotated alerts while in the moment.
+
INC
IDEN
T LI
FEC
YCLE
06 +

LIFECYCLEINCIDENTLIFECYCLEINCIDENTIt’s more than just ACKing