Embed Size (px)
Citation preview

Instrumentation and Telemetryガイダンス
株式会社gloops
大和屋貴仁(@t_yamatoya)
第5回クラウドデザインパターン勉強会

大和屋貴仁 2
2011年から4年間、MVPアワードを受賞
SQL Azureの分野で2年、Windwos Azureの分野で2年
Microsoft MVP
ソーシャルゲームのインフラ担当2012年間から3年間ソーシャルゲームのインフラ担当
月間150億PV、同時接続数8万人

イベント紹介 3

http://r.jazug.jp/event/goazure/

用語の定義 5
Instrumentation
Telemetry
計測
カスタムの監視およびデバッグ情報を生成する診断機能
遠隔測定
計測によって収集されたリモート情報の収集プロセス
計測する情報の種類 6
1 2 3 4
運用上のイベントログ
ECサイトの場合
発注毎の発注番号と価格を記録

計測する情報の種類 7
1 2 3 4
実行時のイベントログ
使用されたデータストアの記録アクセスにかかった応答時間の記録
※資格情報などの機密情報は記録しない

計測する情報の種類 8
1 2 3 4
実行時のエラーログ
発生したエラーを特定するための情報注文操作に失敗した時の顧客IDなど警告やエラーのイベントメッセージ
計測する情報の種類 9
1 2 3 4
性能情報
パフォーマンスカウンターの値CPU負荷、NW使用量、注文数、平均応答時間

計測レベルの変更 10
オンデマンドでレベルを変更できるようにする
アプリケーションの構成で切り替える
アプリケーションの再起動不要で、いつでも収集レベルを変更できるようにする
負荷やコストを減らせる
障害発生時に収集する情報は普段は収集しないストレージのコストやトランザクションを減らせる
エラー復旧シナリオ 11
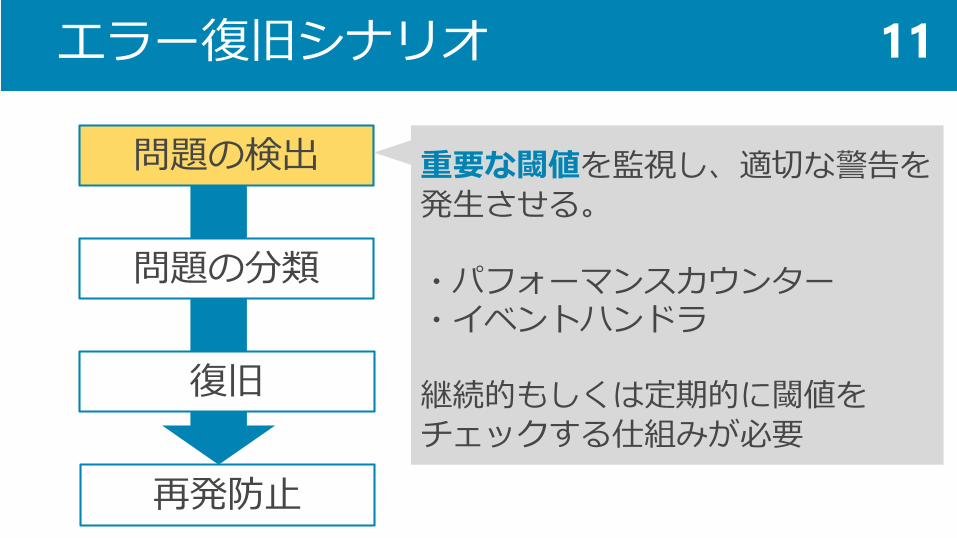
問題の検出
問題の分類
復旧
再発防止
重要な閾値を監視し、適切な警告を発生させる。
・パフォーマンスカウンター・イベントハンドラ
継続的もしくは定期的に閾値をチェックする仕組みが必要

エラー復旧シナリオ 12
問題の検出
問題の分類
復旧
再発防止
自動的に解消される問題か手動介入が必要な問題かを分類する
自動的に解消される問題データベース接続の問題
手動介入が必要な問題コーディングエラーや構成設定誤り
エラー復旧シナリオ 13
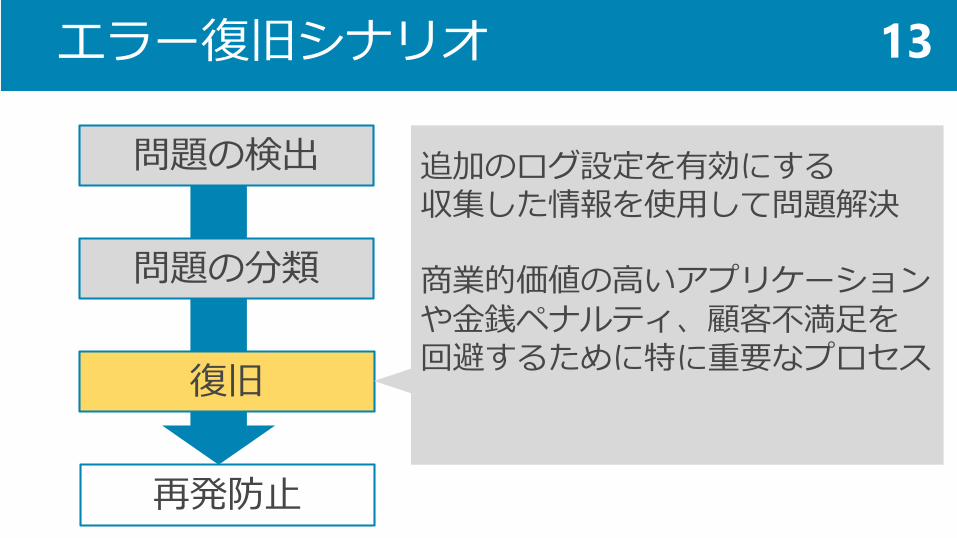
問題の検出
問題の分類
復旧
再発防止
追加のログ設定を有効にする収集した情報を使用して問題解決
商業的価値の高いアプリケーションや金銭ペナルティ、顧客不満足を回避するために特に重要なプロセス

エラー復旧シナリオ 14
問題の検出
問題の分類
復旧
再発防止
根本原因分析の実施本来の原因と問題に内在する性質を特定し、再発可能性を無くす
継続発生するパターンと傾向特定特定コンポーネントへの負荷無効なデータの受信etc

収集が必要な情報 15
インフラストラクチャに関するデータ
CPU負荷、I/O負荷、メモリ使用量
アプリケーションに関するデータ
データベース応答時間、例外、カスタムパフォーマンスビジネストランザクション数、サービスの応答時間KPIに関するデータ

セマンティックロギング 16
構造化、型付されたログを収集する
自動システムによって、イベントに関する重要な情報を発見しやすくなる
項目名 データ型
アイテム数 int型
合計 Decimal型
顧客ID Long型
配送先都市名 String型

ETW(Event Tracing for Windows) 17
イベントエントリに構造化されたペイロードを格納できる
ロギングフレームワークの使用を検討する
Microsoft patterns & practicesの
Semantic Logging Application Block
ディスクファイルやWindowsイベントログなどにログを出力できる

遠隔測定 18
計測により生成された情報を収集するプロセス
非同期処理
キューとリスナーに基づいた非同期テクニックを使用しアプリケーションへの影響を最小限にする
情報の表示
データパイプラインに取り込み、分析しやすい形式で格納傾向発見、使用方法、性能情報、エラー発見・特定に使用

計測・遠隔測定の検討事項 19
収集する情報の選定とレベル分けをする
性能測定、可用性監視、障害特定に必要な情報の選定
必要な情報を収集できていない場合、メンテナンスやトラブルシューティングが難しくなる
ロギング構成の変更方法
アプリケーションの再起動無しでロギング構成を変更できるようにする

計測・遠隔測定の検討事項 20
使用するタイミングと参照する人の選定
開発中にも計測・遠隔測定システムを利用する
システムが正常に動作していることを確認する
テストバージョン、ステージングバージョンの両方に
遠隔測定を適用する
開発チームも使用する問題の迅速解決、コードの質改善のためにリアルタイム、概要、蛍光表示ビューを用意する

計測・遠隔測定の検討事項 21
複数のチャネルを用意する
運用上重要な情報を収集する専用チャネル
運用データよりも重要なレベルの監視と警告を受信
誤警報やノイズを最小限に抑えるように調整する

計測・遠隔測定の検討事項 22
例外情報をすべて収集する
現在の例外メッセージだけでなく、
例外が内包している内部例外の情報も含めて収集する

計測・遠隔測定の検討事項 23
外部サービスへの呼び出しをログに記録する
コンテキストの情報、呼び出し先、呼び出し方法、
タイミング情報、結果(成功・失敗・リトライ数)
についての情報を記録する

計測・遠隔測定の検討事項 24
新しい問題や進行中の問題を検出する
一時的な障害とフェールオーバーの詳細を記録する
リトライ回数、ブレーカーの状態変更、
インスタンスのフェールオーバー

計測・遠隔測定の検討事項 25
保存するデータを分類する
分析とリアルタイム監視の簡素化により、
デバッグと障害の特定に役立つ
ビジネス機能の計測から生じるデータ、
パフォーマンスカウンターから生じるデータを
分けて抽出できる

計測・遠隔測定の検討事項 26
データ収集・格納メカニズムをスケーラブルにする
アプリケーションとサービスのインスタンス数の
スケールに合わせて、生成するログも多くなる
監視とログデータ収集のために
別々のストレージアカウントを使用する

計測・遠隔測定の検討事項 27
データストアを集約させるか分散させるか
複数のデータセンターにアプリケーションが
配置されている場合、ログを1つのデータセンターに
集約させるか、それぞれで保持するか
データを渡すコストと集約させることのメリット比較

計測・遠隔測定の検討事項 28
非同期またはキューを使用する
アプリケーションへの負荷をおさえる
診断システムを圧倒しないようチェネルを分ける

計測・遠隔測定の検討事項 29
データの損失を防ぐためにリトライ処理をくみこむ
一時的なエラーが発生する場合がある接続を
リトライする処理を組み込む
リトライ回数を記録し、一定回数失敗した場合は
プロセスを中止する
リトライロジックが、一時的なエラーから復旧しつつある
システムを過負荷にしないようリトライ間隔を変える

計測・遠隔測定の検討事項 30
データ項目を定期的に収集する
ホスティング環境で提供されていない場合は、
パフォーマンスカウンターを定期的に収集する
スケジューラーを実装する
エラーの急増がデータの大量挿入を誘発しないようにする

計測・遠隔測定の検討事項 31
古くなった情報の削除
古くなった情報を削除する方法を用意する
スケジュール対応か、バージョンアップ時に手動削除
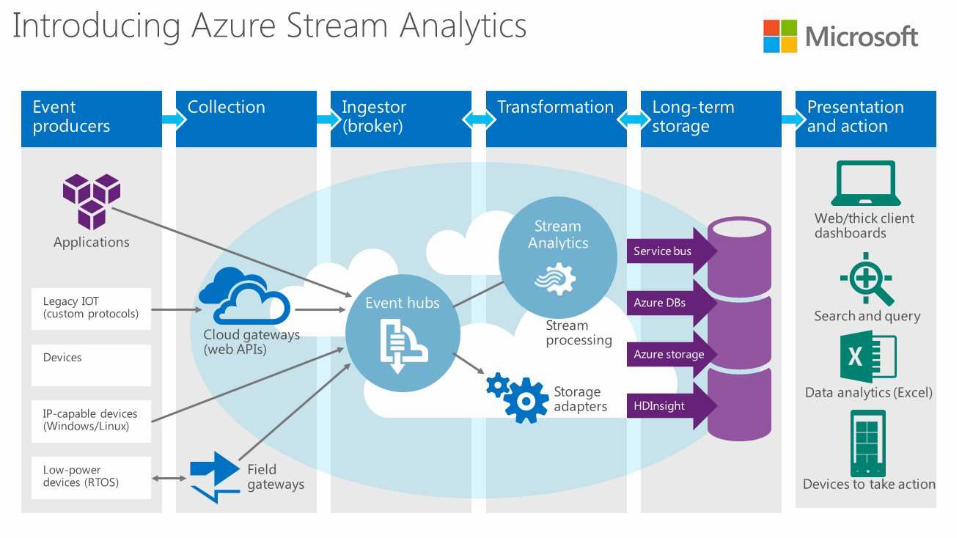
32
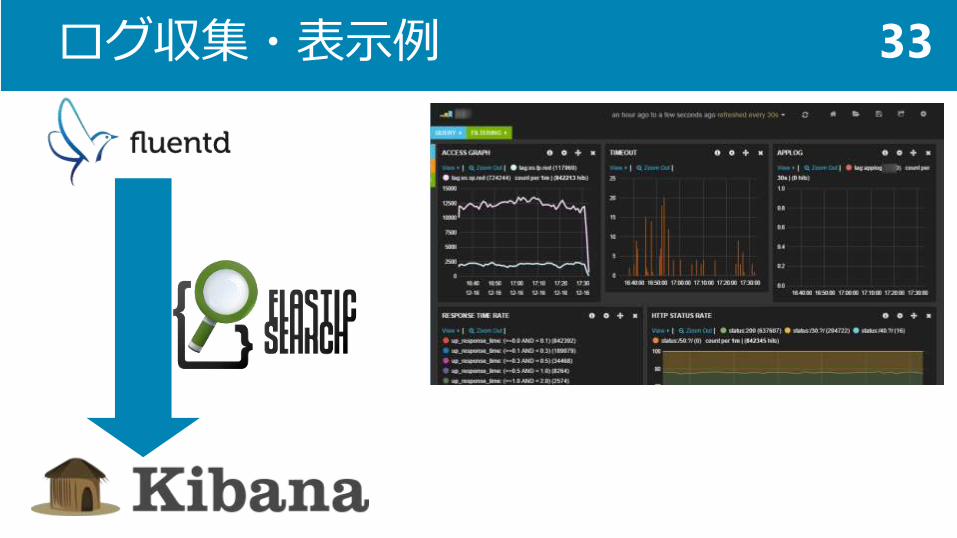
ログ収集・表示例 33





























