Embed Size (px)
Citation preview

LLVM最適化のこつ
x86/x64最適化勉強会7
サイボウズ・ラボ 光成滋生

楽してARM向け最適化をしたい
ターゲットは簡単な固定サイズの多倍長演算
固定素数𝑝に対する𝑥 ± 𝑦 mod 𝑝とか𝑥𝑦 mod 𝑝とか
期待
x86/x64向け最適なコードを生成できるようにすればARM向けもよいコードが出力されるのでは?
一つのLLVMコード→x64/x86/arm/arm64...なら最高!
いろいろやってみた
目的
2/27

LLVMとは
仮想環境上の最適化支援コンパイラ基盤
LLVMアセンブラ
型安全、任意個のレジスタ、SSAベースのアセンブラ
http://llvm.org/docs/LangRef.html
仮想環境上のオブジェクトを生成
それから更にターゲットCPU向けアセンブラを生成
LLVM入門(2年前の自分の資料)
http://www.slideshare.net/herumi/llvm-17911004
LLVMの復習
3/27

CのコードをLLVMアセンブラで出力
clang -S -c -O3 -emit-llvm t.cでt.llを生成
defineで関数の定義:"@名前"が関数名
i32, i64, i128などが整数:"%名前"が変数名
ほぼ全ての命令に型がつく:ex. add i32, ret i32
整数の足し算関数
define i32 @add(i32 %x, i32 %y) { %ret = add i32 %x, %y ret i32 %ret }
uint32_t add(uint32_t x, uint32_t y) { return x + y; }
4/27

llc t.llでx64コードに
-march=x86でx86コードに変換
-march=arm, -march=aarch64なども
VC向け出力が見当たらない→llc.exeなら可能
ターゲットCPUへの変換
add: movl 4(%esp), %eax addl 8(%esp), %eax retl
add: leal (%rdi, %rsi), %eax ; x = %rdi, y = %rsi retq
add: r0, r0, r1 mov pc, lr
5/27

Cによるコード
add128の実装
void add128(uint64_t *z, const uint64_t *x, const uint64_t *y) { uint64_t x0 = x[0]; uint64_t z0 = x0 + y[0]; pz[0] = z0; uint64_t x1 = px[1]; uint64_t y1 = py[1]; if (z0 >= x0) { // 繰り上がり無し pz[1] = x1 + y1; } else { pz[1] = x1 + y1 + 1; // 繰り上がりあり } }
6/27
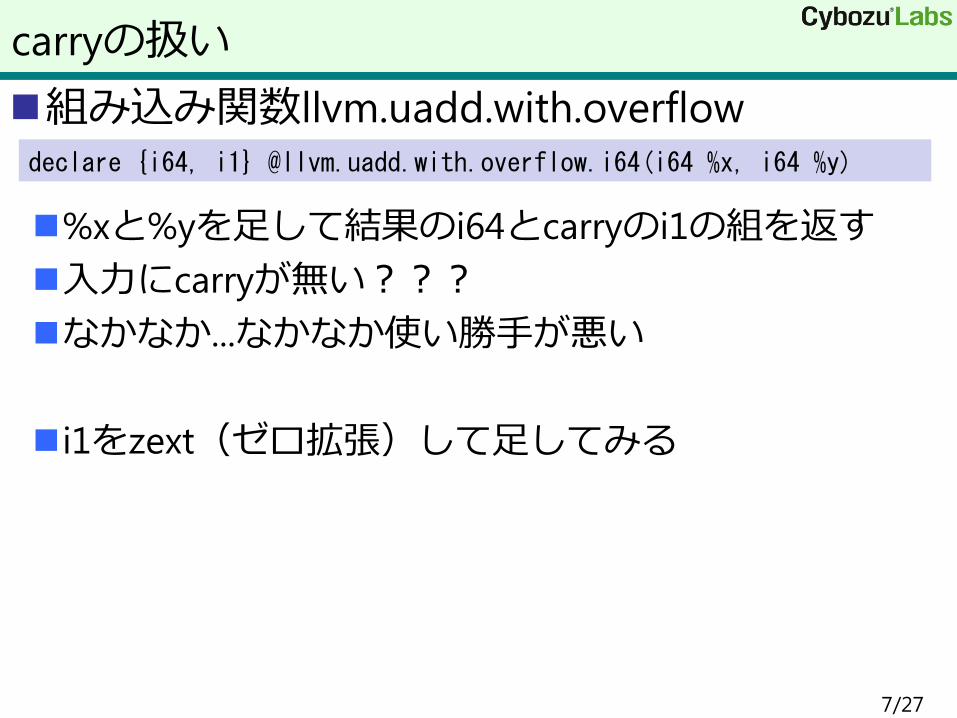
組み込み関数llvm.uadd.with.overflow
%xと%yを足して結果のi64とcarryのi1の組を返す
入力にcarryが無い???
なかなか...なかなか使い勝手が悪い
i1をzext(ゼロ拡張)して足してみる
carryの扱い
declare {i64, i1} @llvm.uadd.with.overflow.i64(i64 %x, i64 %y)
7/27
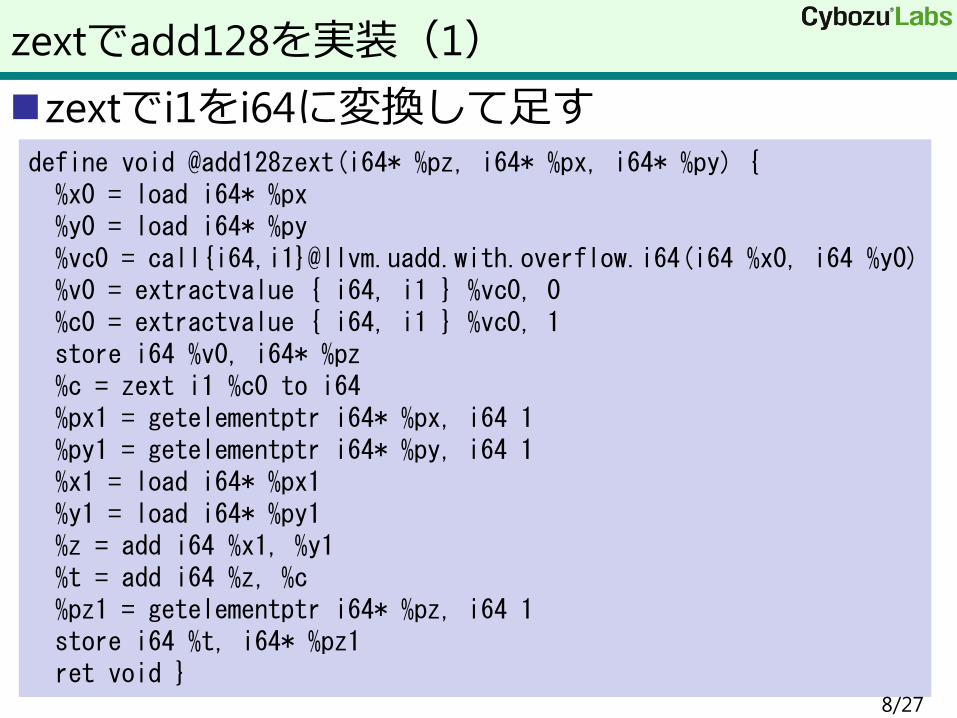
zextでi1をi64に変換して足す
zextでadd128を実装(1)
define void @add128zext(i64* %pz, i64* %px, i64* %py) { %x0 = load i64* %px %y0 = load i64* %py %vc0 = call{i64,i1}@llvm.uadd.with.overflow.i64(i64 %x0, i64 %y0) %v0 = extractvalue { i64, i1 } %vc0, 0 %c0 = extractvalue { i64, i1 } %vc0, 1 store i64 %v0, i64* %pz %c = zext i1 %c0 to i64 %px1 = getelementptr i64* %px, i64 1 %py1 = getelementptr i64* %py, i64 1 %x1 = load i64* %px1 %y1 = load i64* %py1 %z = add i64 %x1, %y1 %t = add i64 %z, %c %pz1 = getelementptr i64* %pz, i64 1 store i64 %t, i64* %pz1 ret void }
8/27

zextでi1をi64に変換して足す
carryを先に足してみる
zextでadd128を実装(2)
add128zext: mov rax, qword ptr [rsi] ; rax = x[0] mov r8, qword ptr [rdx] ; r8 = y[0] lea rcx, qword ptr [rax + r8] ; z0 = x[0] + y[0] mov qword ptr [rdi], rcx ; z[0] = z0 mov rcx, qword ptr [rdx + 8] ; rcx = x[1] add rcx, qword ptr [rsi + 8] ; rcx = y[1] add rax, r8 ; え、もう一度足すの adc rcx, 0 mov qword ptr [rdi + 8], rcx ret
%z = add i64 %x1, %y1 %t = add i64 %z, %c
%z = add i64 %x1, %c %t = add i64 %z, %y1
9/27

うーむ微妙
zextでadd128を実装(3)
add128zext2: mov rax, qword ptr [rsi] ; rax = x[0] add rax, qword ptr [rdx] ; rax += x[0] + y[0] mov qword ptr [rdi], rax ; z[0] = x[0] + y[0] sbb rax, rax ; rax = carry ? -1 : 0 and rax, 1 ; rax = carry ? 1 : 0 add rax, qword ptr [rsi + 8] ; rax = x[1] + carry add rax, qword ptr [rdx + 8] ; rax += y[1] mov qword ptr [rdi + 8], rax ; z[1] = rax ret
10/27

select i1 flag, v1, v2 ; (flag ? v1 : v0)
zextと同じ結果
まあそうかも
LLVMでの正解は
selectを使ってみる
%z = add i64, %x1, %y1 %t0 = select i1 %c0, i64 1, i64 0 %t1 = add i64 %z, %t0
11/27

整数型のサイズに制約が無い
その出力(x64とaarch64)
i128を使う
define void @add128(i128* %pz, i128* %px, i128* %py) { %x = load i128* %px %y = load i128* %py %z = add i128 %x, %y store i128 %z, i128* %pz ret void }
mov rax, [rdx] mov rcx, [rdx + 8] add rax, [rsi] adc rcx, [rsi + 8] mov [rdi + 8], rcx mov [rdi], rax ret
ldp x8, x9, [x1] ldp x10, x11, [x2] adds x8, x8, x10 adcs x9, x9, x11 stp x8, x9, [x0] ret
12/27
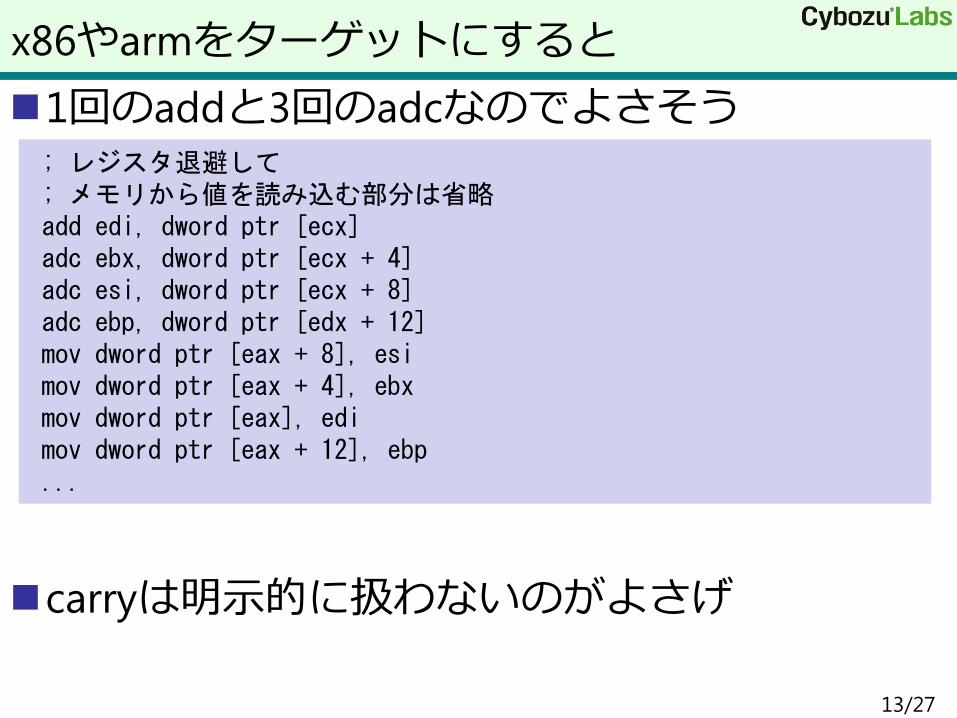
1回のaddと3回のadcなのでよさそう
carryは明示的に扱わないのがよさげ
x86やarmをターゲットにすると
; レジスタ退避して ; メモリから値を読み込む部分は省略 add edi, dword ptr [ecx] adc ebx, dword ptr [ecx + 4] adc esi, dword ptr [ecx + 8] adc ebp, dword ptr [edx + 12] mov dword ptr [eax + 8], esi mov dword ptr [eax + 4], ebx mov dword ptr [eax], edi mov dword ptr [eax + 12], ebp ...
13/27

uint8_t _addcarry_u64(CF, x, y, *out)がある
こっちのほうがいい
Visual Studioのintrinsic
#include <intrin.h> void add128(uint64_t* z, const uint64_t* x, const uint64_t* y) { uint8_t c = _addcarry_u64(0, x[0], y[0], &z[0]); _addcarry_u64(c, x[1], y[1], &z[1]); }
mov rax, [rdx] add rax, [r8] mov [rcx], rax mov rax, [rdx+8] adc rax, [r8+8] mov [rcx+8], rax ret
14/27

Cの擬似コード
比較と引き算は同じ処理
結果を捨てるか捨てないかの差
とりあえず引いて負なら(carryが立てば)捨てる
addModの実装
void addMod(INT *z, const INT *x, const INT *y, const INT *p) { INT t = *x + y if (t >= *p) t -= *p *z = t }
void addMod(INT *z, const INT *x, const INT *y, const INT *p) { INT t0 = *x + y (t1, CF) = t0 - *p *z = CF ? t0 : t1 }
15/27

こんな感じ(N=128, NP=192とか)
LLVMでの実装
declare {iNP, i1 } @llvm.usub.with.overflow.iNP(iNP, iNP) define void @addMod(iN* %pz, iN* %px, iN* %py, iN* %pp) { %x = load iN* %px %y = load iN* %py %p = load iN* %pp %x1 = zext iN %x to iNP %y1 = zext iN %y to iNP %p1 = zext iN %p to iNP %t = add iNP %x1, %y1 ; t = x + y %vc = call{iNP,i1} @llvm.usub.with.overflow.iNP(iNP %t, iNP %p1) %v = extractvalue { iNP, i1 } %vc, 0 ; v = x + y - p %c = extractvalue { iNP, i1 } %vc, 1 %z = select i1 %c, iNP %t, iNP %v ; z = CF ? t : v %z1 = trunc iNP %z to iN store iN %z1, iN* %pz ret void
16/27

まあまあ? mov r9, qword ptr [rdx] mov r10, qword ptr [rdx + 8] add r9, qword ptr [rsi] adc r10, qword ptr [rsi + 8] sbb rsi, rsi and rsi, 1 ; [rsi:r10:r9] = x + y xor r8d, r8d mov rax, r9 sub rax, qword ptr [rcx] mov rdx, r10 sbb rdx, qword ptr [rcx + 8] ; [rdx:rax] = x + y - p sbb rsi, 0 sbb r8, 0 cmovne rdx, r10 cmovne rax, r9 mov qword ptr [rdi + 8], rdx mov qword ptr [rdi], rax
これが無駄
ここはよい
17/27

usbのcarryとi1の冗長性が無駄なのか
いまいち... 模索中
usubを使わない
%t0 = add iNP %x1, %y1 ; x + y %t1 = sub iNP %t0, %p1 ; x + y - p %t2 = lshr iNP %t1, N ; 右シフトして上位ビット %t3 = trunc iNP %t2 to i1 ; を取り出して %t4 = select i1 %t3, iNP %t0, iNP %t1 ; 選択
; [r9:r8] = x + y sub rax, [rcx] mov rdx, r9 sbb rdx, [rcx + 8] ; [rdx:eax] = x + y - p sbb rsi, 0 ; 不要 and esi, 1 ; 不要 cmovne rax, r8 test sil, sil ; 不要 cmovne rdx, r9 ; z = [rdx:rax]
18/27

N bit x N bit → 2N bit みたいなの
出力が2倍になるのでzext N to 2Nしてからmulしよう
乗算は
define void @mul128(i256* %pz, i128* %px, i128* %py) { %x = load i128* %px %y = load i128* %py %x1 = zext i128 %x to i256 %y1 = zext i128 %y to i256 %z = mul i256 %x1, %y1 store i256 %z, i256* %pz ret void }
19/27

Segmentation fault
nativeに命令を持ってないと駄目のようだ
出力結果
0 libLLVM-3.5.so.1 0x00007fa53e015cd2 llvm::sys::PrintStackTrace(_IO_FILE*) + 34 1 libLLVM-3.5.so.1 0x00007fa53e015ac4 2 libc.so.6 0x00007fa53c85ad40 3 libc.so.6 0x00007fa53c8acaea strlen + 42 4 libLLVM-3.5.so.1 0x00007fa53df39d3c llvm::SelectionDAG::getExternalSymbol(char const*, llvm::EVT) + 44 5 libLLVM-3.5.so.1 0x00007fa53dfa1b78 llvm::TargetLowering::makeLibCall(llvm::SelectionDAG&, llvm::RTLIB::Libcall, llvm::EVT, llvm::SDValue const*, unsigned int, bool, llvm::SDLoc, bool, bool) const + 552 6 libLLVM-3.5.so.1 0x00007fa53ded57f0 7 libLLVM-3.5.so.1 0x00007fa53dedd0cb 8 libLLVM-3.5.so.1 0x00007fa53deea61e 9 libLLVM-3.5.so.1 0x00007fa53deeacdf llvm::SelectionDAG::LegalizeTypes() + 943 10 libLLVM-3.5.so.1 0x00007fa53df8c154 llvm::SelectionDAGISel::CodeGenAndEmitDAG() + 164 11 libLLVM-3.5.so.1 0x00007fa53df8f242 llvm::SelectionDAGISel::SelectAllBasicBlocks(llvm::Function const&) + 1154 12 libLLVM-3.5.so.1 0x00007fa53df90551 llvm::SelectionDAGISel::runOnMachineFunction(llvm::MachineFunction&) + 929 13 libLLVM-3.5.so.1 0x00007fa53e18e238 14 libLLVM-3.5.so.1 0x00007fa53d92fbb7 llvm::FPPassManager::runOnFunction(llvm::Function&) + 471 15 libLLVM-3.5.so.1 0x00007fa53d92ff3b llvm::FPPassManager::runOnModule(llvm::Module&) + 43 16 libLLVM-3.5.so.1 0x00007fa53d930215 llvm::legacy::PassManagerImpl::run(llvm::Module&) + 693 17 llc-3.5 0x0000000000412962 18 llc-3.5 0x000000000040d0f0 main + 368 19 libc.so.6 0x00007fa53c845ec5 __libc_start_main + 245 20 llc-3.5 0x000000000040d149 Stack dump: 0. Program arguments: llc-3.5 uint.ll 1. Running pass 'Function Pass Manager' on module 'uint.ll'. 2. Running pass 'X86 DAG->DAG Instruction Selection' on function '@mul128' Segmentation fault
20/27

N bit x 64 bit → N + 64bit
64bit x 64bit → 128bitを作ってそれを組み合わせる
このコードはちゃんとコンパイルできる
変数の上位bitが0であることを知っている
-mattr=bmi2つきで実行するとHaswellの命令を使う
まず64bit倍するのを作る
define i128 @mul64x64(i64 %x, i64 %y) { %x0 = zext i64 %x to i128 %y0 = zext i64 %y to i128 %z = mul i128 %x0, %y0 ret i128 %z }
mul64x64: mov rdx, rsi mulx rdx, rax, rdi ret
21/27
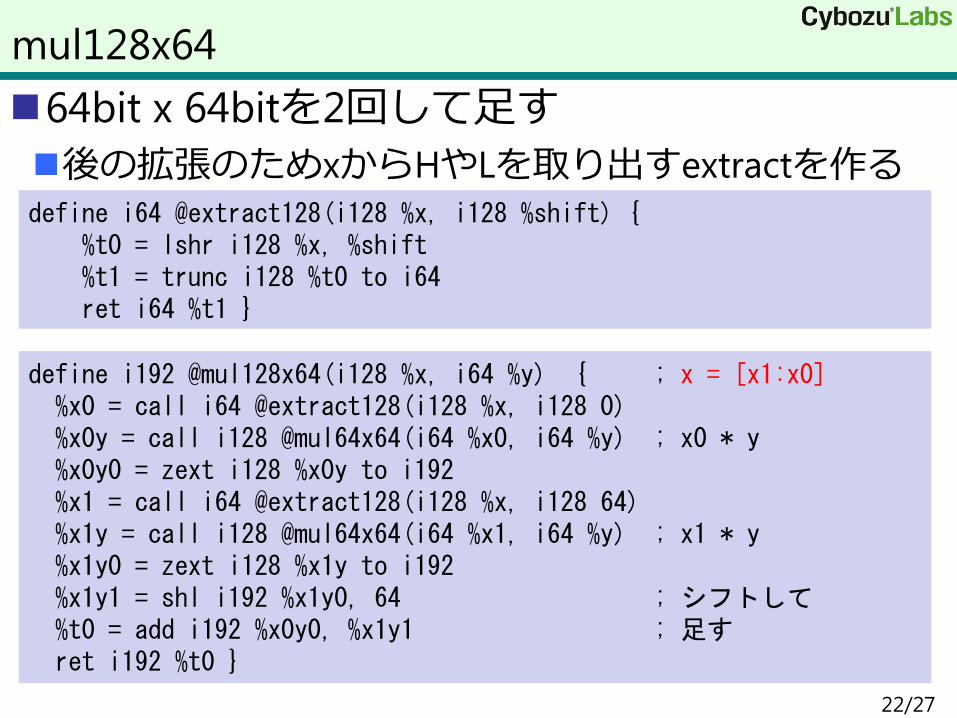
64bit x 64bitを2回して足す
後の拡張のためxからHやLを取り出すextractを作る
mul128x64
define i192 @mul128x64(i128 %x, i64 %y) { ; x = [x1:x0] %x0 = call i64 @extract128(i128 %x, i128 0) %x0y = call i128 @mul64x64(i64 %x0, i64 %y) ; x0 * y %x0y0 = zext i128 %x0y to i192 %x1 = call i64 @extract128(i128 %x, i128 64) %x1y = call i128 @mul64x64(i64 %x1, i64 %y) ; x1 * y %x1y0 = zext i128 %x1y to i192 %x1y1 = shl i192 %x1y0, 64 ; シフトして %t0 = add i192 %x0y0, %x1y1 ; 足す ret i192 %t0 }
define i64 @extract128(i128 %x, i128 %shift) { %t0 = lshr i128 %x, %shift %t1 = trunc i128 %t0 to i64 ret i64 %t1 }
22/27

mul128x64を2回呼び出して加算
そんなに細かく関数に分けて大丈夫か
問題ない
最適化 + ターゲットに変換
乗算4回、加算7回の最適なコードを出力
mul128x128
opt -O3 –o - | llc –O3 -
mulx r9, r10, r8 mov rdx, rbx mov rdx, rax mulx rbx, rdx, r11 mulx rsi, rax, r11 add rdx, r8 add rax, r9 adc rbx, 0 adc rsi, 0 add rcx, rax mov qword ptr [rdi], r10 adc rdx, rsi mov rdx, rbx adc rbx, 0 mulx r8, rcx, r8
23/27

64bit x 64bit→128bitが無いため
先に32bit x 32bit→64bitでラッパーを作る?
そうするとトータルの加算回数が増えてしまう
4N x 2Nの場合
"4N x N ; 4回" x 2回. 5N + 5Nで5回の計13回
2Nずつすると"2N x 2N ; 7回" x 2回. 後4回の計18回
32bit用の乗算コードが必要
64bitと32bitの2種類用意する必要がある
テンプレートのコードから両方を自動生成するはめに
当初の野望
LLVM一つでx86/x64/arm/arm64全部
現実:32bitと64bit必要
32bitだとやはりSEGV
24/27
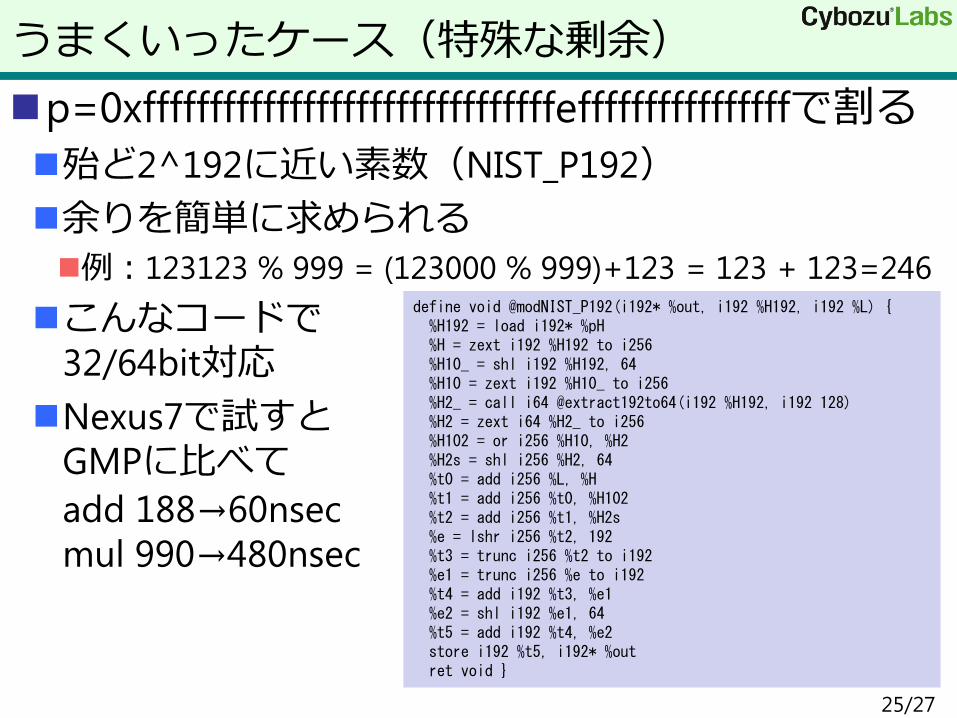
p=0xfffffffffffffffffffffffffffffffeffffffffffffffffで割る
殆ど2^192に近い素数(NIST_P192)
余りを簡単に求められる
例:123123 % 999 = (123000 % 999)+123 = 123 + 123=246
こんなコードで
32/64bit対応
Nexus7で試すと
GMPに比べて
add 188→60nsec
mul 990→480nsec
うまくいったケース(特殊な剰余)
define void @modNIST_P192(i192* %out, i192 %H192, i192 %L) { %H192 = load i192* %pH %H = zext i192 %H192 to i256 %H10_ = shl i192 %H192, 64 %H10 = zext i192 %H10_ to i256 %H2_ = call i64 @extract192to64(i192 %H192, i192 128) %H2 = zext i64 %H2_ to i256 %H102 = or i256 %H10, %H2 %H2s = shl i256 %H2, 64 %t0 = add i256 %L, %H %t1 = add i256 %t0, %H102 %t2 = add i256 %t1, %H2s %e = lshr i256 %t2, 192 %t3 = trunc i256 %t2 to i192 %e1 = trunc i256 %e to i192 %t4 = add i192 %t3, %e1 %e2 = shl i192 %e1, 64 %t5 = add i192 %t4, %e2 store i192 %t5, i192* %out ret void }
25/27

i192などの変数のどの部分が0かを
きちんと追跡している
シフトしなくていい部分は一切しない
メモリアクセスも追跡している
先ほどのmul128x128でpx = pyとして最適化すると
乗算回数が3回に減る
読み込み先と書き込み先が同じ可能性を考慮
noaliasをつけるか、値が確定したものは早い段階で
メモリに書き落とすとテンポラリが減る
例:乗算の途中結果
所感
26/27

最適化はかなり頑張ってる
レジスタサイズの制約が無いように見えて
実は結構きつい
乗算をするとき。加減算のみならほぼ大丈夫
ただし書き下せればかなりよいコード生成
フラグの扱いがやや難
3/16加筆(Windows呼び出し規約に従う方法)
https://github.com/CRogers/LLVM-Windows-Binaries
llc.exeで-march=x86-64 -x86-asm-syntax=intel
まとめ
27/27