Embed Size (px)
Citation preview

O C T O B E R 1 1 -‐ 1 4 , 2 0 1 6 • B O S T O N , M A

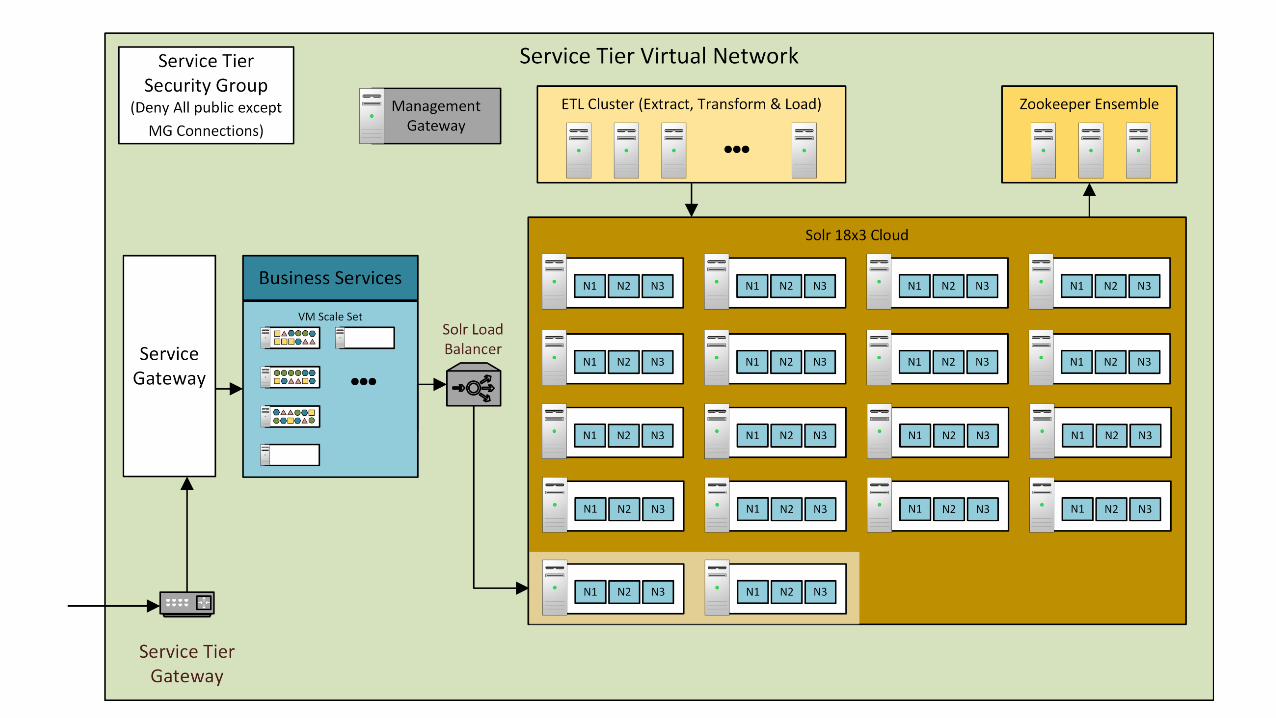
Loading 350M documents into a large Solr cluster
…in 8 hours or less

About me
• Dion Olsthoorn • Senior SoAware Engineer at Wolters Kluwer
• Wolters Kluwer • InformaJon, SoAware and Services • 19,000 employees, revenue €3.7 billion (2014)
• Ovid • World’s leading online Search/Delivery Pla[orm for Medical Research • > 350M documents in our index, from 100+ content sources • > 600K searches a day

About this talk
• “Loading 350M documents into a large Solr cluster in 8 hours or less” • Why within 8 hours?
1. Indexing of yearly content reloads from content suppliers 2. Full reindex (different analyzers, etc.) between content updates
• 350M docs / 8 hrs ≈ 12K docs / second • Yes, we did it! Using an cloud pla[orm for preprocessing. • Can you do it? It depends… • What you will get out of this: Speed up the loading of content into your Solr cloud


Indexing Solr XML
• We ! xml files • post.jar – the obvious “out-‐of-‐the-‐box” choice • We found out we were overloading our Solr cluster!
…&update.distrib=TOLEADER
…
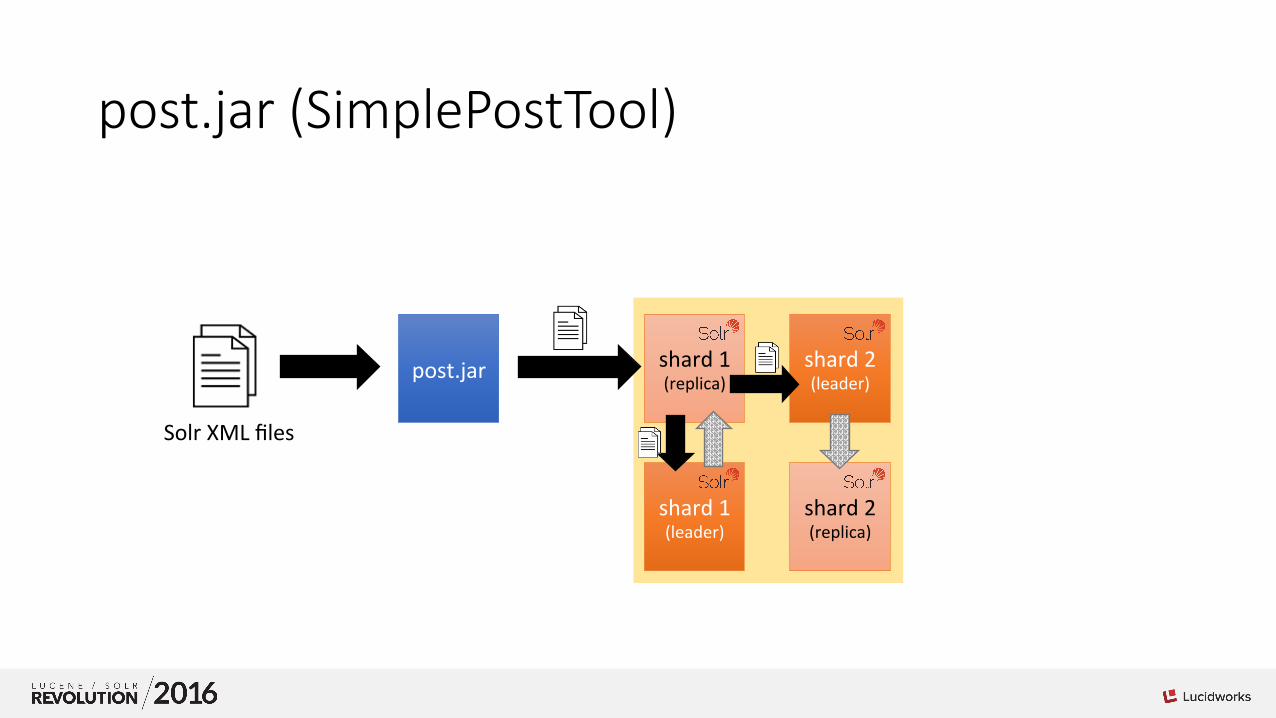
post.jar (SimplePostTool)
post.jar
shard 1 (leader)
shard 1 (replica)
shard 2 (replica)
shard 2 (leader)
Solr XML files
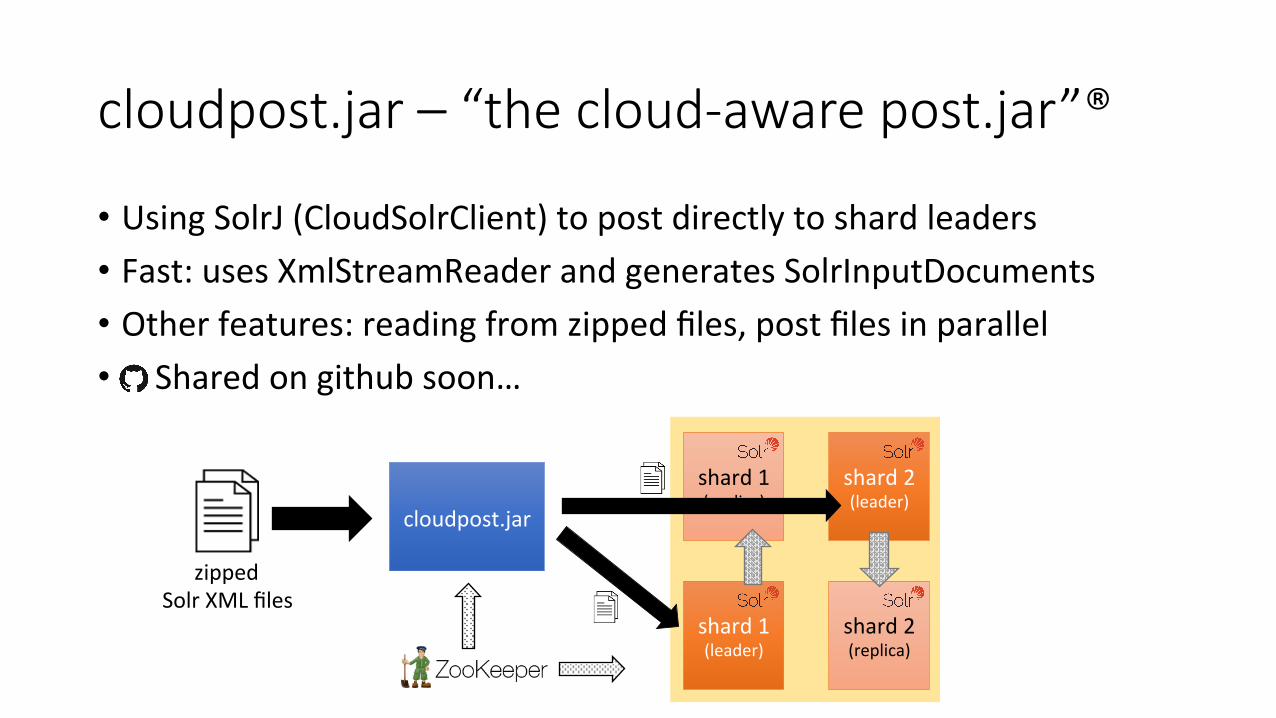
cloudpost.jar – “the cloud-‐aware post.jar”®
• Using SolrJ (CloudSolrClient) to post directly to shard leaders • Fast: uses XmlStreamReader and generates SolrInputDocuments • Other features: reading from zipped files, post files in parallel • Shared on github soon…
cloudpost.jar
shard 1 (leader)
shard 1 (replica)
shard 2 (replica)
shard 2 (leader)
zipped Solr XML files
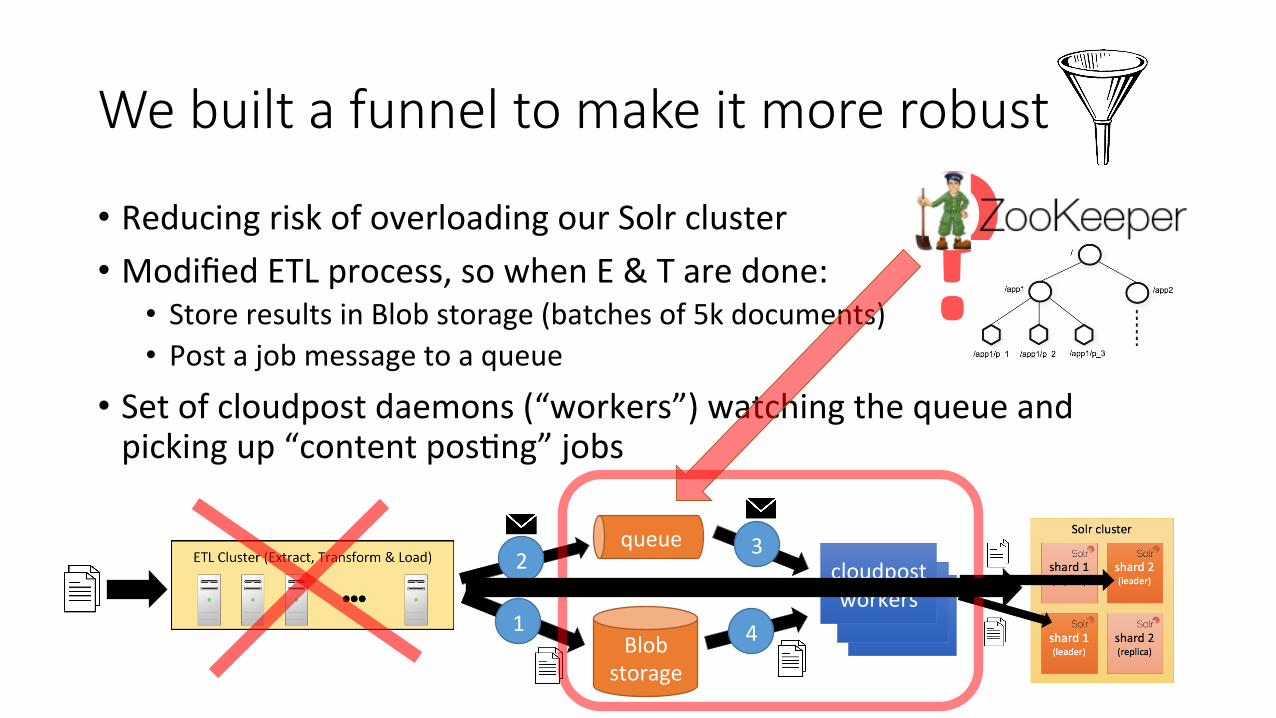
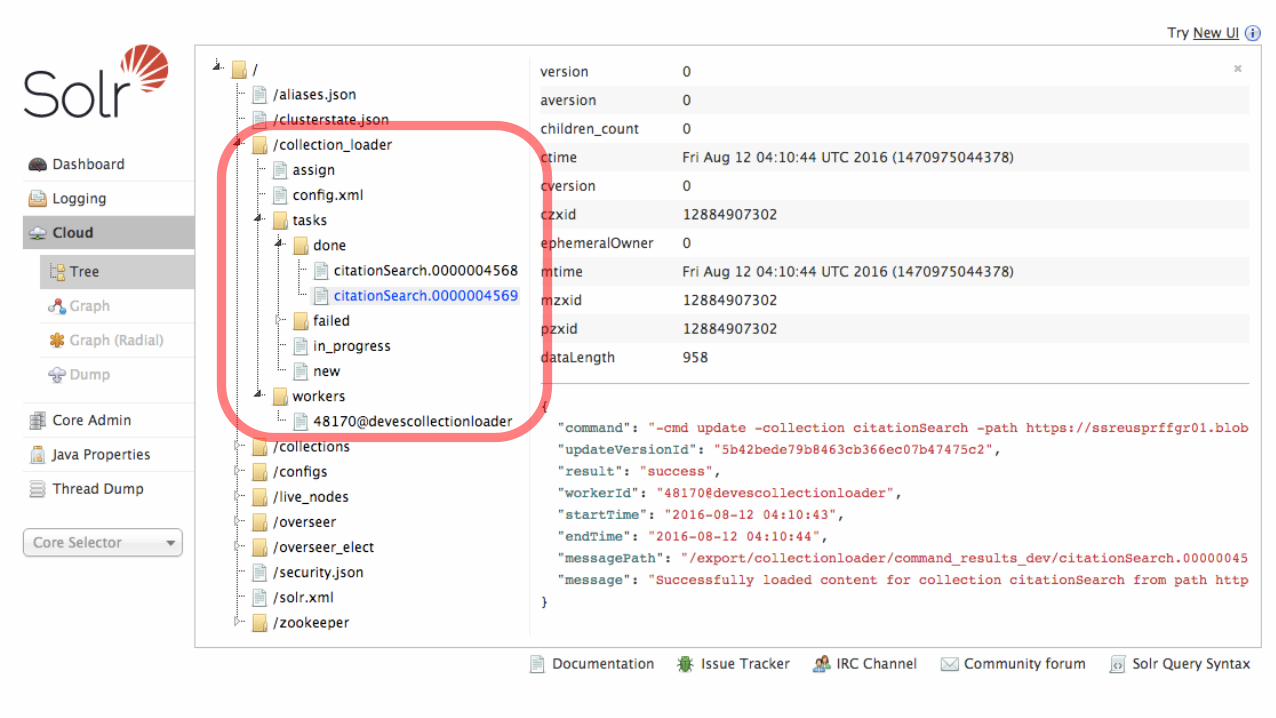
We built a funnel to make it more robust
• Reducing risk of overloading our Solr cluster • Modified ETL process, so when E & T are done:
• Store results in Blob storage (batches of 5k documents) • Post a job message to a queue
• Set of cloudpost daemons (“workers”) watching the queue and picking up “content posJng” jobs
Blob storage
queue
1
2
worker worker cloudpost workers
3
4
?
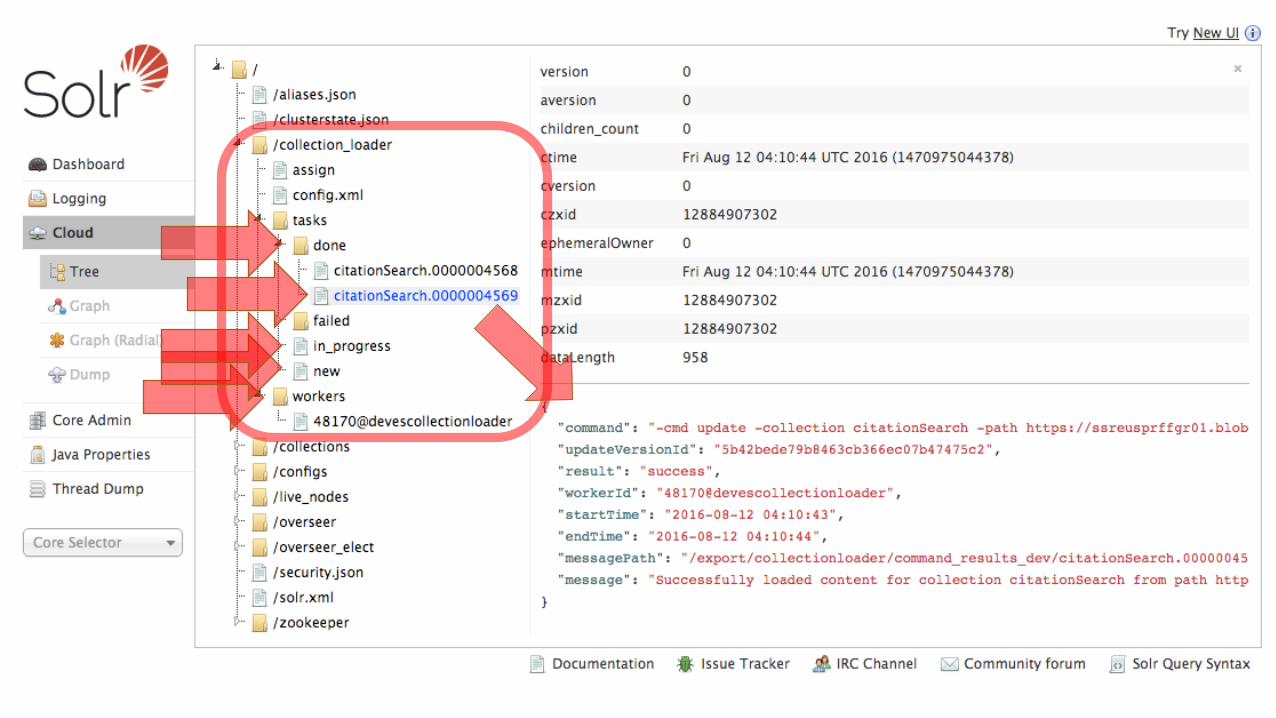

What finally worked best for us…
Two soluJons: 1. For iniJal loads of a content set (> 1M records)
• Index on (isolated) environment using the same #shards (no replicas!) • Backup & Restore shard-‐indexes to producJon Solr cluster
2. For daily “small” updates • Index on producJon • Single commit (to minimize reopening of IndexSearcher)

Conclusion & Takeaways
• Do all content pre-‐processing outside Solr. Use the power of a cloud pla[orm! • Use a queuing system to prevent overfeeding Solr • Use SolrJ when posJng content to SolrCloud à Got Solr XML files? Use our cloudpost.jar J • Got a lot of content to index on a live Solr cluster? à Index on a isolated environment (idenJcal #shards, no replica’s) à Backup each shard and restore (Solr 6.1 has SolrCloud backup!)

Q & A
• More quesJons? à [email protected] • CloudPost.jar à …soon • ZooKeeper Master-‐Worker example à github.com/fpj/zookeeper-‐book-‐example • Wolters Kluwer à www.wolterskluwer.com