Embed Size (px)
DESCRIPTION
An introduction to performing natural language processing (NLP) tasks in Ruby. Video is here: https://skillsmatter.com/skillscasts/4883-how-to-parse-go#video
Citation preview

How to parse ‘go’Natural Language Processing in Ruby
Tom Cartwright @tomcartwrightuk
!keepmebooked
giveaiddirect.com

Python, surely? Yes. The NLTK is awesome.
But you have a Ruby-based app.


Extracting meaning from !human input
Summarisation Extracting entities Tagging text Sentiment analysis Filtering text

document sentence word example
From document level!!
!
!
!
to word level

Chunking & segmenting
document sentence word example
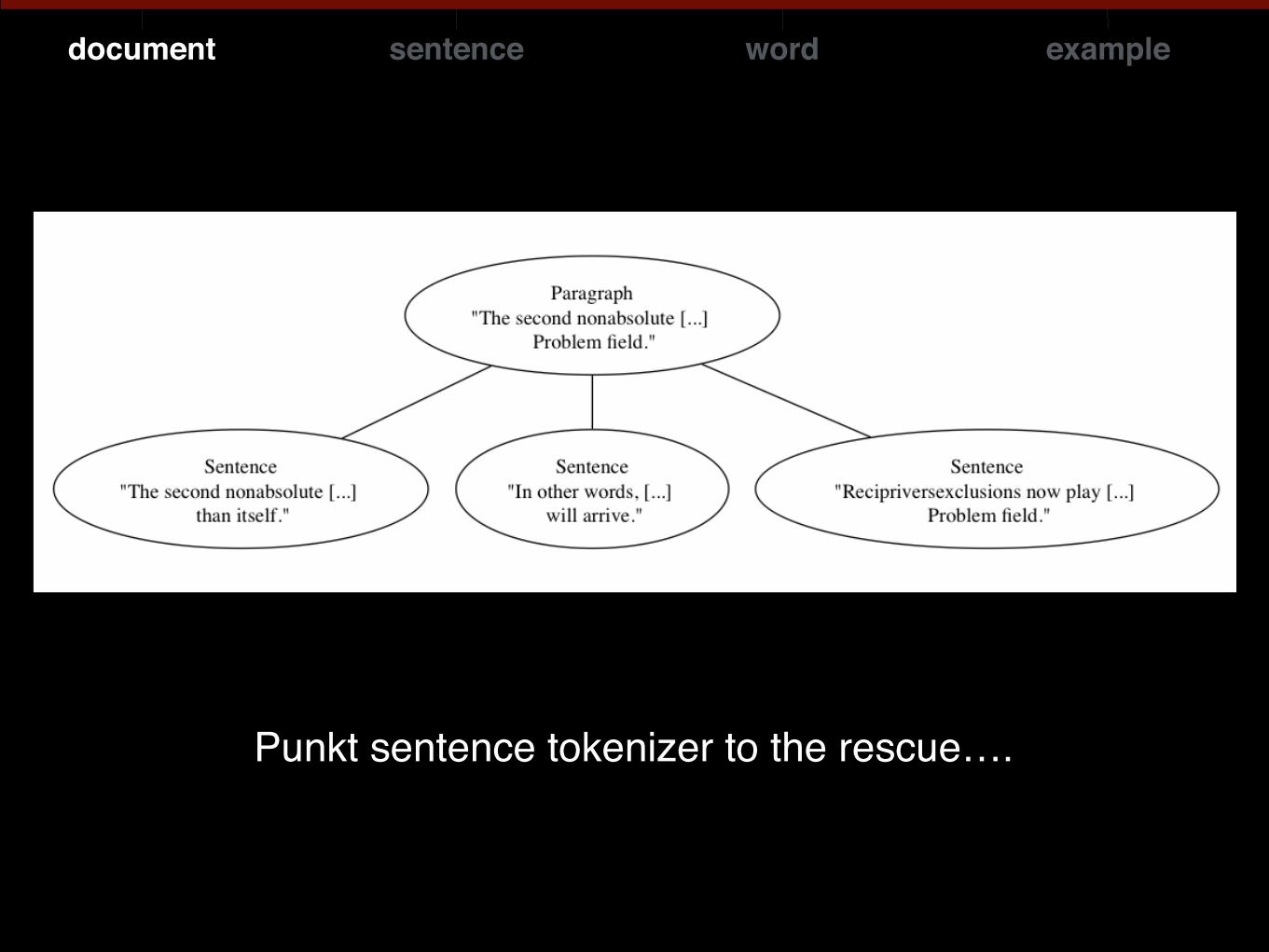
Breaking text into paragraphs, sentences and other zones
Start with a document/some text:
“The second nonabsolute number is the given time of arrival, which is now known to be one of those most bizarre of mathematical concepts, a recipriversexclusion, a number whose existence can only be defined as being anything other than itself…..”
document sentence word example
Punkt sentence tokenizer to the rescue….

tokenizer = Punkt::SentenceTokenizer.new(!
"The second nonabsolute number is the given time
of arrival...")!
!
result = !
tokenizer.sentences_from_text(text,!
:output => :sentences_text)!
!!!
document sentence word example

Training
trainer = Punkt::Trainer.new()!trainer.train(bistromatic_text)
document sentence word example

TokenisingBreaking text into words, phrases and symbols.
“Time is an illusion. Lunchtime doubly so.”.split(“ “)!!#=> !![“Time", “is", “an", “illusion.”, “Lunchtime", “doubly", “so.”]!
document sentence word example

class Tokenizer FS = Regexp.new(‘[[:blank:]]+') PAIR_PRE = ['(', '{', '['] SIMPLE_POST = ['!', '?', ',', ':', ';', '.'] PAIR_POST = [')', '}', ']'] PRE_N_POST = ['"', “'"] …
Regexes and rules Tokenizer gem
document sentence word example
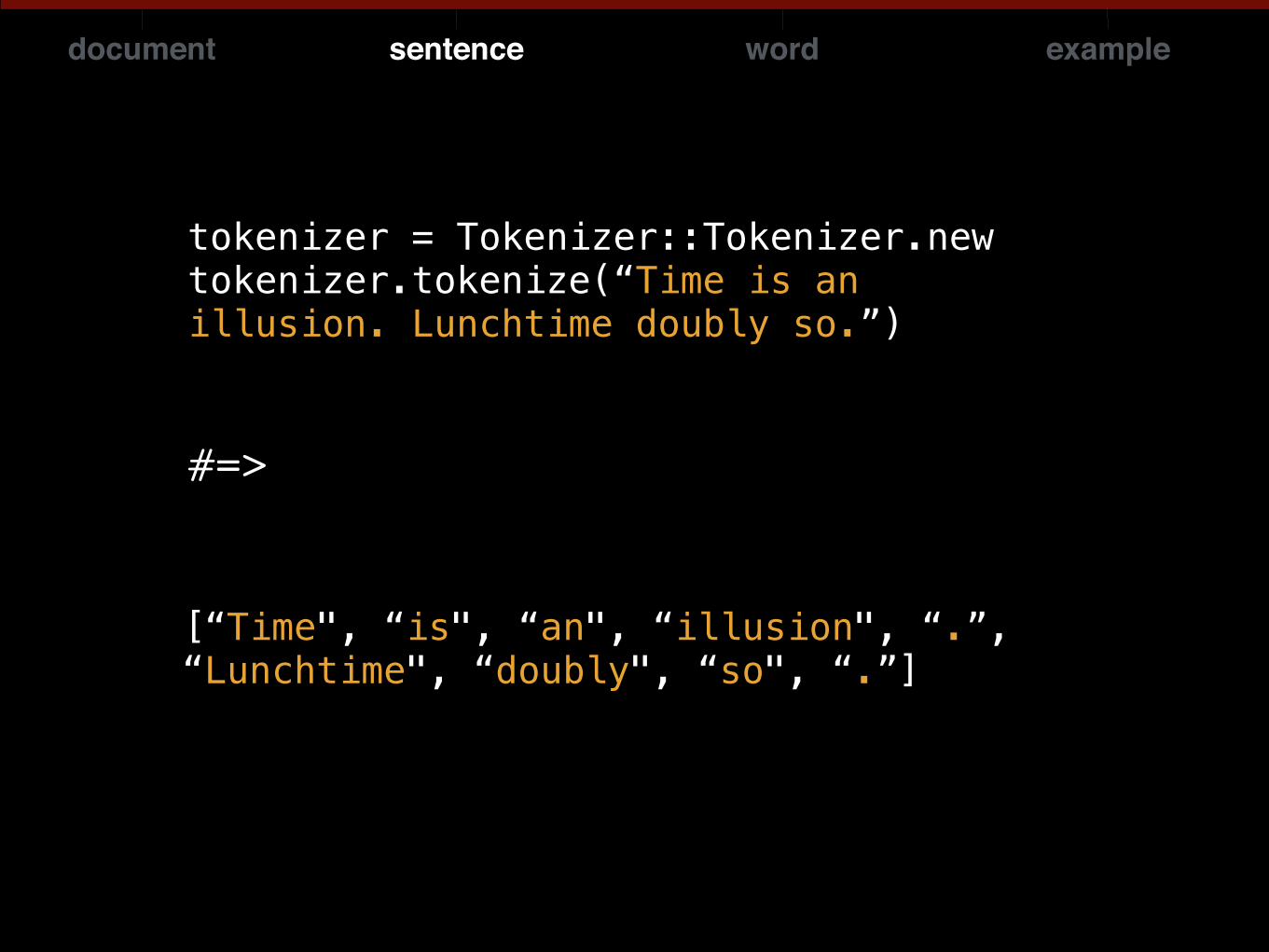
tokenizer = Tokenizer::Tokenizer.new tokenizer.tokenize(“Time is an illusion. Lunchtime doubly so.”)
#=>
document sentence word example
[“Time", “is", “an", “illusion", “.”, “Lunchtime", “doubly", “so", “.”]

StemmingJogging => Jog
“jogging”.gsub(/.ing/, “”) !#=> “jog"!!
“bring”.gsub(/.ing/, “”) !#=> “b"
document sentence word example

stemmer = Lingua::Stemmer.new(:language => "en") stemmer.stem("programming") #=> program stemmer.stem("vimming") #=> vim
1. Ruby-Stemmer ⇒ multi-language porter stemmer 2. Text ⇒ porter stemmer
document sentence word example

CC ⇒ conjunction ⇒ and, but DET ⇒ determiner ⇒ this, some IN ⇒ preposition / conjunction ⇒ above, about JJ ⇒ adjective ⇒ orange, tiny NNP ⇒ proper noun ⇒ Camden Pale Ale
Parts-of-speech tagging
document sentence word example

!Regex tagger
/*.ing/ ⇒ VBG /*.ed/ ⇒ VBD
!Lookup on words
E.g. calculating : { VBG: 6 }
orange: { JJ: 2, NN: 5 }
A couple of methods!
document sentence word example

A tale of two taggers
rb-brill-tagger
• Probabilistic (uses look up table prev. slide)
• Brown corpus trained • Pure ruby
• Rule based • C extensions
EngTagger
document sentence word example

Treat gemBundles many of the gems shown
Wraps them in a DSL
stemming; tokenising; chunking; serialising; tagging; text extraction from pdfs and html;
s = sentence(“A really good sentence.”) s.do(:chunk, :segment, :tokenize, :parse)
document sentence word example

LRUG Sentiments
{NN}A tag ⇒
Pass in regex => /({JJ}|{JJS})({NNS}|{NNP})/
And some tagged tokens
#=> [(Word @tag="JJ", @text="jolly"),!(Word @tag="NN", @text="face")]

1.0 ! epic!1.0 good!0.21875 chance!0.21875 brisk!-1.0 slanderous!-1.0 piteous
Sentimental value

Results!!!
• dedicated servers!• pdfs!• Surrey
• Ruby!• Practical Object-
Oriented Design in Ruby!
• Doctors!• Lrug!• recruiters (!)
• unsolicited phone calls from r********s!
• clients!• Paypal!• XML!• geeks

GemsText - Paul Battley’s box of tricks Treat Tokenizer Punkt segmenter Chronic - for extracting dates

Other things you can do/I didn’t talk about
Calculate text edit distance Extract entities using the Stanford libraries via the RJB !Extract topic words (LDA) !Keyword extraction - TfIdf !Jruby

Thank you for processing. Questions?
@tomcartwrightuk
Thanks to Tim Cowlishaw and the HT dev team for specialised rubber duck support





























