Embed Size (px)
Citation preview

1 © Cloudera, Inc. All rights reserved.
Parallel SQL and Analy.cs with Solr Yonik Seeley Cloudera

2 © Cloudera, Inc. All rights reserved.
My Background
• Creator of Solr • Cloudera Engineer • LucidWorks Co-‐Founder • Lucene/Solr commiFer, PMC member • Apache SoJware FoundaLon member • M.S. in Computer Science, Stanford

3 © Cloudera, Inc. All rights reserved.
What is Apache Solr
• Search server • like a database, but different indexing technology (Apache Lucene) • opLmized for interacLve results
• Columns (aka docValues) for fast scans • HighlighLng • FaceLng (category counts) • SpaLal search • Powers search for the leading Hadoop Big Data vendors
4 © Cloudera, Inc. All rights reserved.
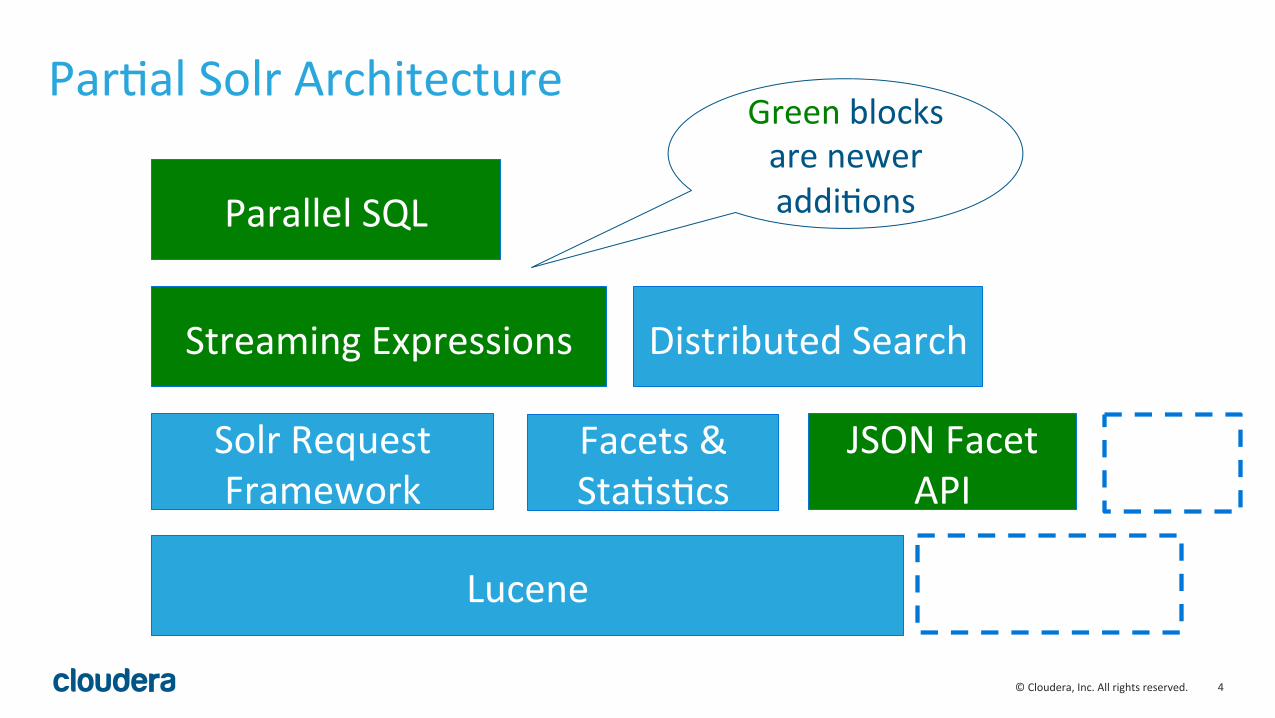
ParLal Solr Architecture
Lucene
Streaming Expressions
Parallel SQL
Distributed Search
Facets & StaLsLcs
Solr Request Framework
JSON Facet API
Green blocks are newer addiLons

5 © Cloudera, Inc. All rights reserved.
Different ways to calculate things in Solr
• Faceted search v1 / stats module facet=true&facet.field=color&facet.limit=5
• JSON Facet API (faceted search v2) {colors:{type:terms, field:color, limit:5}} • Streaming expressions rollup(search(techproducts,q="*:*",fl="id,color", sort="color asc"), over="color", count(*)) • Parallel SQL select count(*) from techproducts where _text_='(*:*)' group
by color"

6 © Cloudera, Inc. All rights reserved.
JSON Facet API
7 © Cloudera, Inc. All rights reserved.
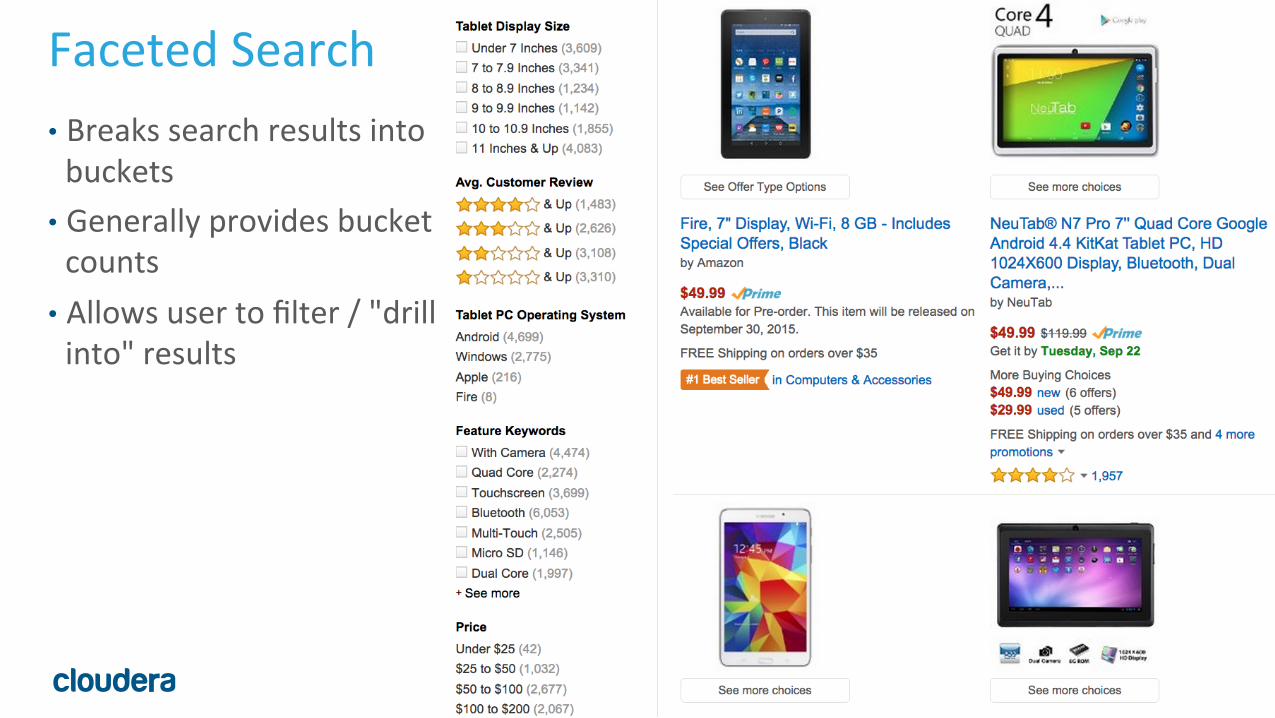
Faceted Search • Breaks search results into buckets • Generally provides bucket counts • Allows user to filter / "drill into" results
8 © Cloudera, Inc. All rights reserved.
FaceLng
Search
StaLsLcs
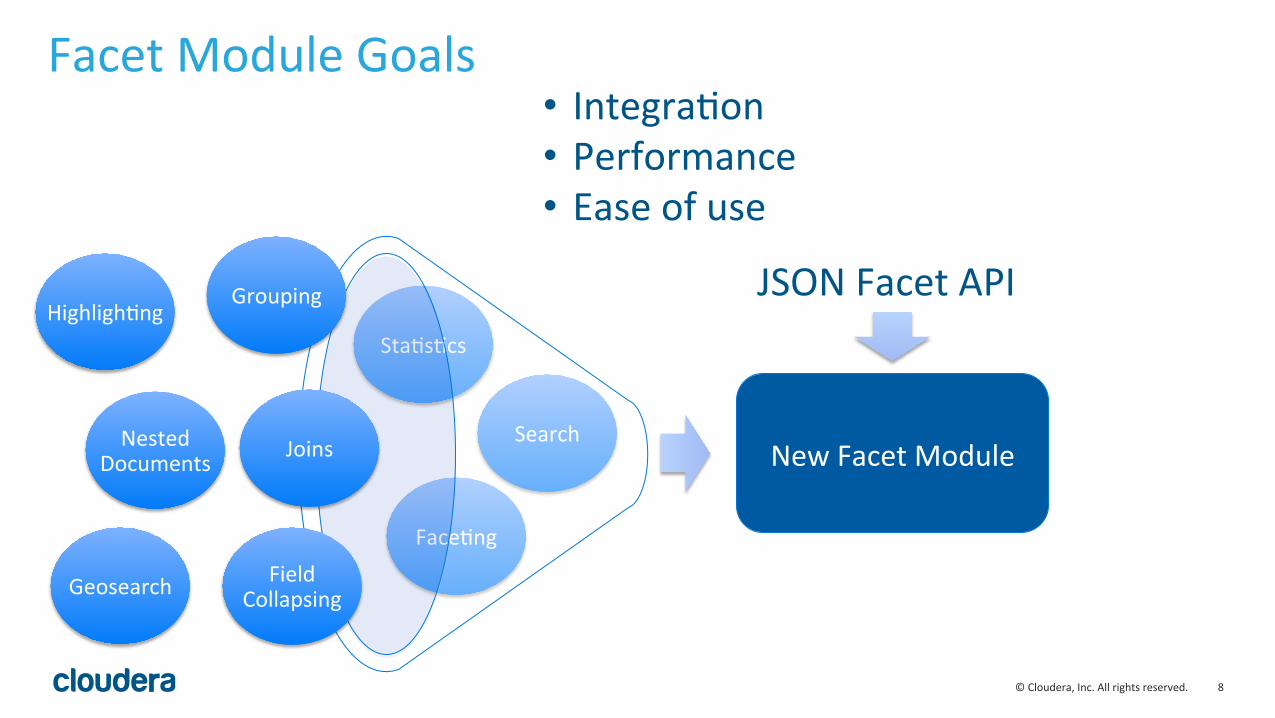
Facet Module Goals
Search
Joins
Grouping
Field Collapsing
New Facet Module
JSON Facet API
• IntegraLon • Performance • Ease of use
HighlighLng
Nested Documents
Geosearch

9 © Cloudera, Inc. All rights reserved.
Simple JSON Facet request and response
curl http://localhost:8983/solr/query -‐d ' q=widgets& json.facet= { x : "avg(price)" , y : "unique(brand)" } '
[…] "facets" : { "count" : 314, "x" : 102.5, "y" : 28 }
root domain defined by docs matching the query count of docs in the bucket

10 © Cloudera, Inc. All rights reserved.
Terms facet example
json.facet={ shoes : { type : terms, field : shoe_style, sort : {x : desc}, facet : { x : "avg(price)", y : "unique(brand)" } } }
"facets": { "count" : 472, "shoes": { "buckets" : [ { "val" : "Hiking", "count" : 34, "x" : 135.25, "y" : 17, }, { "val" : "Running", "count" : 45, "x" : 110.75, "y" : 24, },
Calculated per-‐bucket
Sort by any stat!

11 © Cloudera, Inc. All rights reserved.
Sub-‐facet example
json.facet={ shoes:{ type : terms, field : shoe_style, sort : {x : desc}, facet : { x : "avg(price)", y : "unique(brand)", colors : { type : terms, field : color } } } }
"facets": { "count" : 472, "shoes": { "buckets" : [ { "val" : "Hiking", "count" : 34, "x" : 135.25, "y" : 17, "colors" : { "buckets" : [ { "val" : "brown", "count" : 12 }, { "val" : "black", "count" : 10 }, […] ] } // end of colors sub-‐facet }, // end of Hiking bucket { "val" : "Running", "count" : 45, "x" : 110.75, "y" : 24, "colors" : { "buckets" : […]

12 © Cloudera, Inc. All rights reserved.
Facet Types • Terms Facet • Creates new domains (facet buckets) based on values in a field
• Range Facet • Creates mulLple buckets based on date ranges or numeric ranges
• Query Facet • Creates a single bucket of documents that match any given query
• Unlimited nesLng: Any facet types may have any number of sub-‐facets • MulL-‐select faceLng (filter exclusion) • Nested documents (block join)

13 © Cloudera, Inc. All rights reserved.
Streaming Expressions

14 © Cloudera, Inc. All rights reserved.
Solr Streaming Expressions
• Generic plalorm for distributed computaLon • The basis for implemenLng distributed parallel SQL • relaLonal operaLons on streams
• Works across enLre result sets (or subsets) • normal search operaLons are designed for fast top-‐N operaLons
• Map-‐reduce like "shuffle" parLLons result sets for greater scalability • Worker nodes can be allocated from a collecLon for parallelism • Incorporates streams from non-‐Solr systems

15 © Cloudera, Inc. All rights reserved.
search() expression
$ curl hFp://localhost:8983/solr/techproducts/stream -‐d 'expr=search(techproducts, q="*:*", fl="id,price,score", sort="id asc")' {"result-‐set":{"docs":[ {"score":1.0,"id":"0579B002","price":179.99}, {"score":1.0,"id":"100-‐435805","price":649.99}, {"score":1.0,"id":"3007WFP","price":2199.0}, {"score":1.0,"id":"VDBDB1A16"}, {"score":1.0,"id":"VS1GB400C3","price":74.99}, {"EOF":true,"RESPONSE_TIME":6}]}}
resulLng tuple stream
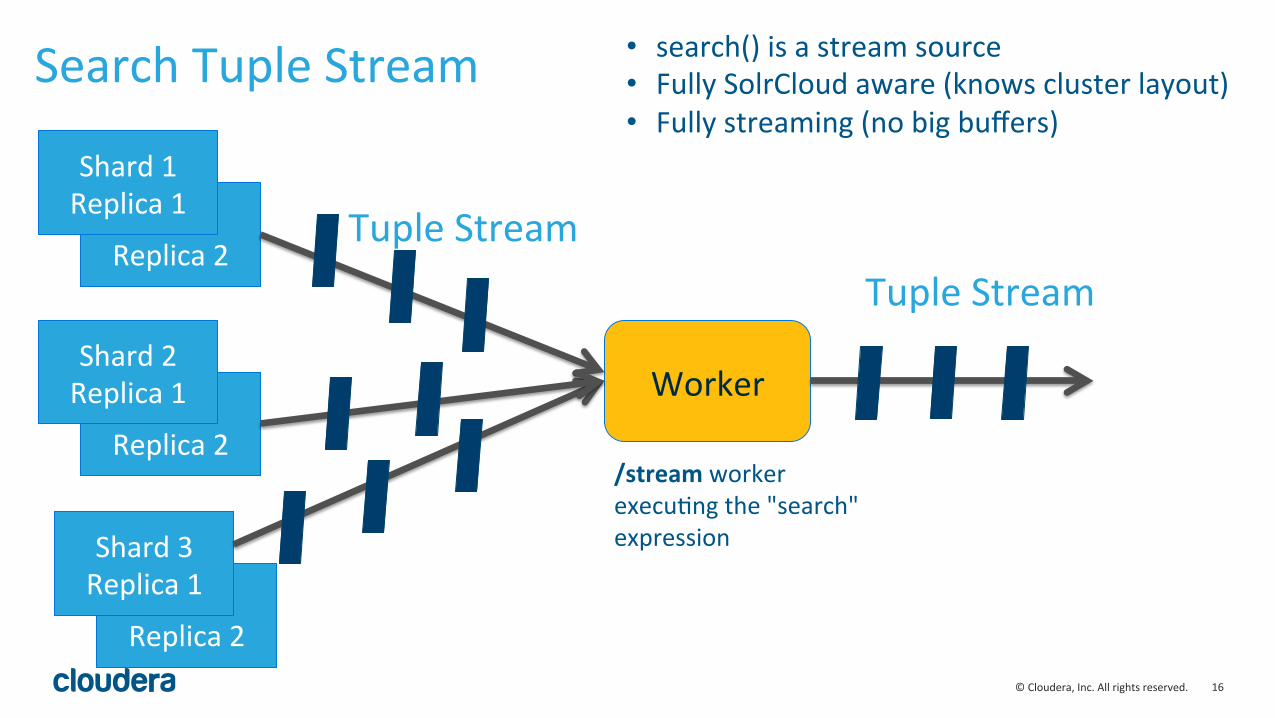
16 © Cloudera, Inc. All rights reserved.
Search Tuple Stream
Shard 1 Replica 2
Shard 1 Replica 1
Shard 1 Replica 2
Shard 2 Replica 1
Shard 1 Replica 2
Shard 3 Replica 1
Worker
Tuple Stream Tuple Stream
/stream worker execuLng the "search" expression
• search() is a stream source • Fully SolrCloud aware (knows cluster layout) • Fully streaming (no big buffers)

17 © Cloudera, Inc. All rights reserved.
search expression args
search( // parses to CloudSolrStream java class techproducts, // name of the collecLon to search zkHost="localhost:9983", // (opt) zookeeper address of collecLon to search qt="/select", // (opt) the request handler to use (/export is also available) rows=1000000, // (opt) number of rows to retrieve q=*:*, // query to match returned documents fl="id,price,score", // which fields to return sort="id asc, price desc", // how to sort the results
aliases="id=myid,price=myprice" // (opt) renames output fields )

18 © Cloudera, Inc. All rights reserved.
rollup() expression
• Groups tuples by common field values • Emits rollup value along with metrics • Closest equivalent to face.ng
rollup( search(collecLon1, qt="/export" q="*:*", fl="id,manu,price", sort="manu asc"), over="manu"), count(*), max(price) )
metrics
{"result-‐set":{"docs":[ {"manu":"apple","count(*)":1.0}, {"manu":"asus","count(*)":1.0}, {"manu":"aL","count(*)":1.0}, {"manu":"belkin","count(*)":2.0}, {"manu":"canon","count(*)":2.0}, {"manu":"corsair","count(*)":3.0}, [...]
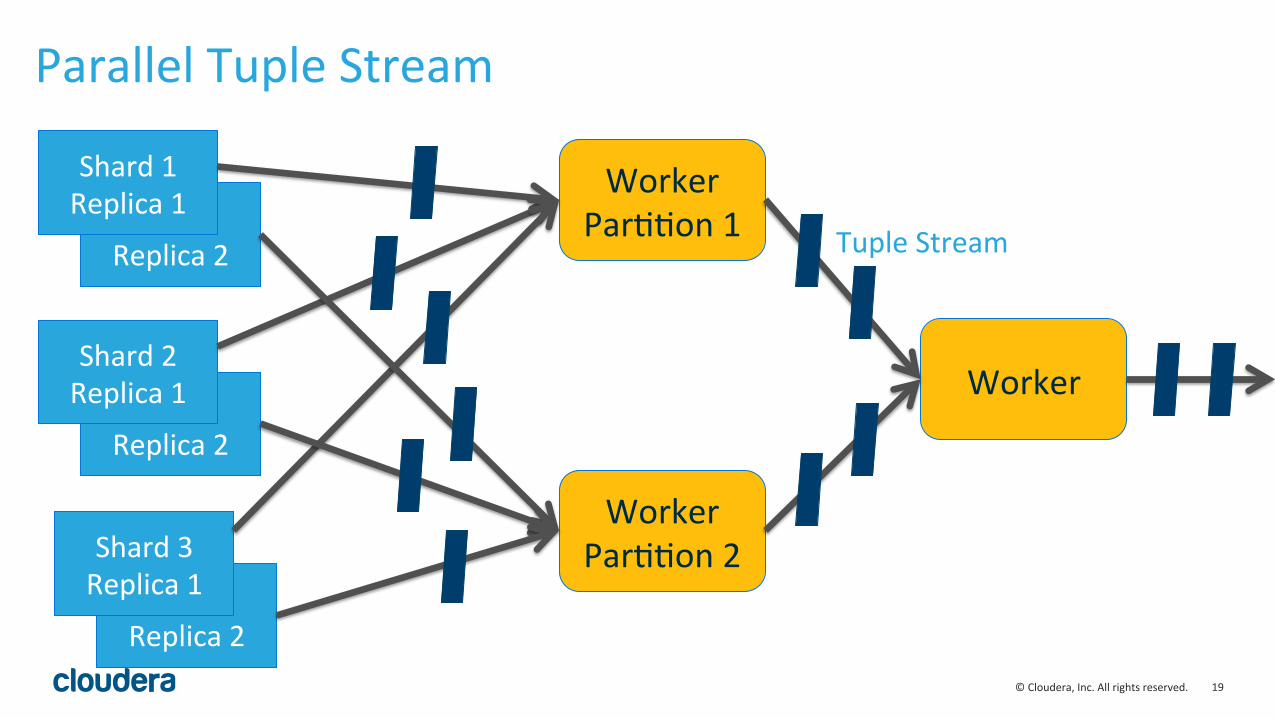
19 © Cloudera, Inc. All rights reserved.
Parallel Tuple Stream
Shard 1 Replica 2
Shard 1 Replica 1
Shard 1 Replica 2
Shard 2 Replica 1
Shard 1 Replica 2
Shard 3 Replica 1
Worker ParLLon 1
Worker ParLLon 2
Worker
Tuple Stream

20 © Cloudera, Inc. All rights reserved.
Streaming Expressions – parallel
• Wraps a stream and sends to N worker nodes • The first parameter is the collec.on to use for the intermediate worker nodes • par..onKeys must be provided to underlying workers • usually makes sense to par..on by what you are grouping on
• inner and outer sorts should match
parallel(collecLon1, rollup( search(techproducts, q="*:*", fl="id,manu,price", sort="manu asc", parLLonKeys="manu"), over="manu asc"), workers=2, zkHost="localhost:9983", sort="manu asc")

21 © Cloudera, Inc. All rights reserved.
Distributed Joins!
innerJoin( search(people, q=*:*, fl="personId,name", sort="personId asc"), search(pets, q=type:cat, fl="personId,petName", sort="personId asc"), on="personId" ) Also: leJOuterJoin, hashJoin, outerHashJoin,

22 © Cloudera, Inc. All rights reserved.
More stream decorators
• complement – emits tuples from A which do not exist in B • intersect – emits tuples from A whish do exist in B • merge • reduce • sort • top – reorders the stream and returns the top N tuples • unique – emits only the first tuple for each value • select – select, rename, or give default values to fields in a tuple hFps://cwiki.apache.org/confluence/display/solr/Streaming+Expressions
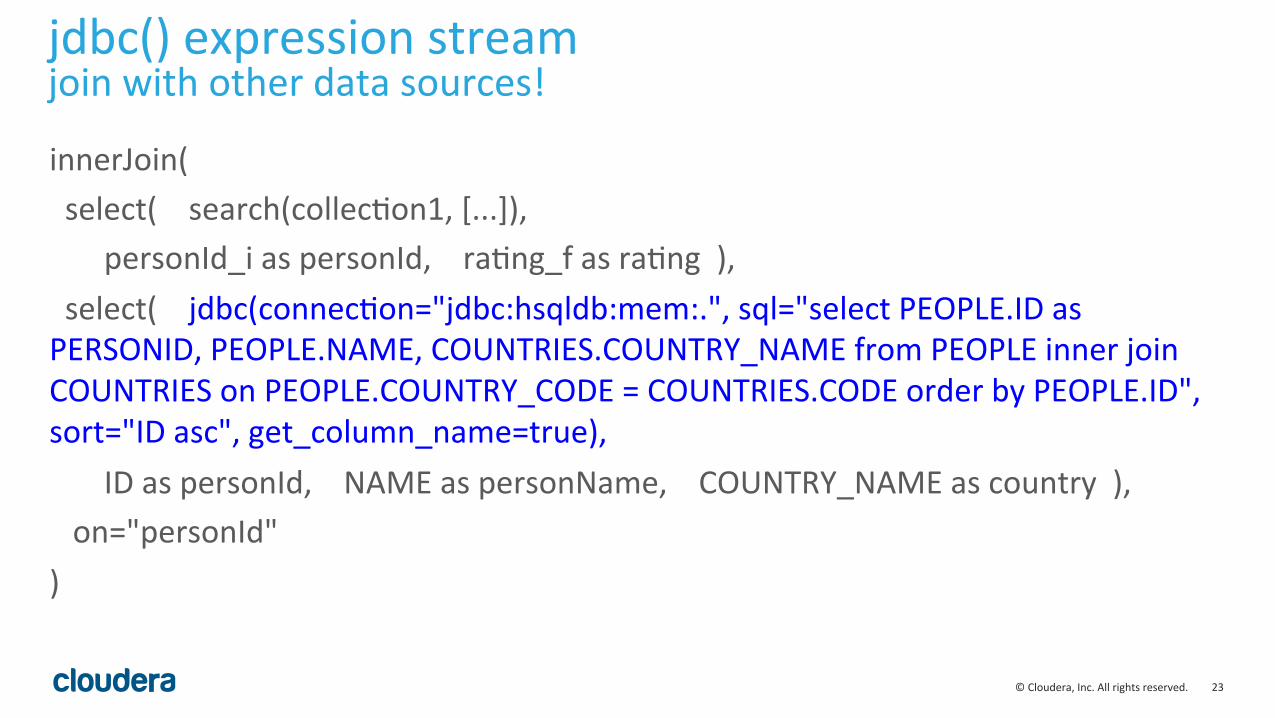
23 © Cloudera, Inc. All rights reserved.
jdbc() expression stream join with other data sources!
innerJoin( select( search(collecLon1, [...]), personId_i as personId, raLng_f as raLng ), select( jdbc(connecLon="jdbc:hsqldb:mem:.", sql="select PEOPLE.ID as PERSONID, PEOPLE.NAME, COUNTRIES.COUNTRY_NAME from PEOPLE inner join COUNTRIES on PEOPLE.COUNTRY_CODE = COUNTRIES.CODE order by PEOPLE.ID", sort="ID asc", get_column_name=true), ID as personId, NAME as personName, COUNTRY_NAME as country ), on="personId" )

24 © Cloudera, Inc. All rights reserved.
Parallel SQL

25 © Cloudera, Inc. All rights reserved.
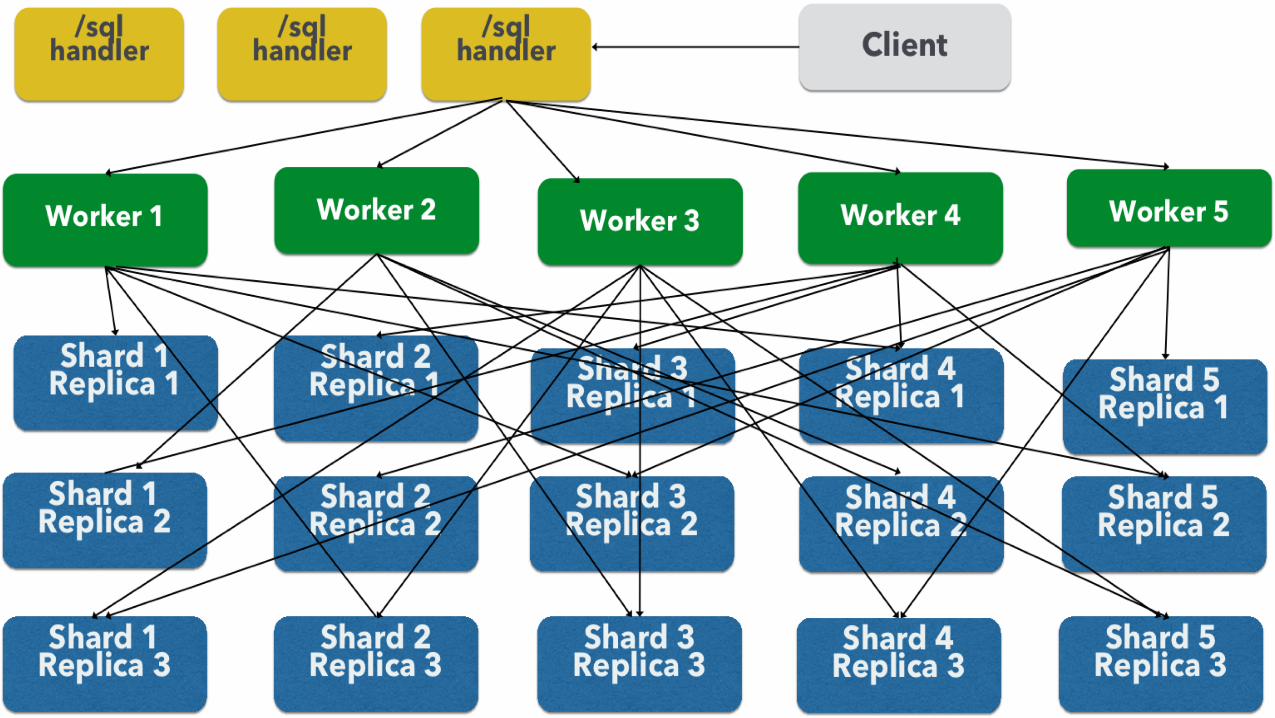
/sql Handler
Why SQL? • External integraLons • Higher level language – says what we want, not how to get it • SQL has made a comeback along with big data, more ubiquitous than ever
• /sql REST endpoint by default on all solr nodes • Translates SQL -‐> parallel streaming expressions • SQL tables map to SolrCloud collecLons • Currently uses Presto SQL parser • Switch to Apache Calcite parser in the works
26 © Cloudera, Inc. All rights reserved.
27 © Cloudera, Inc. All rights reserved.
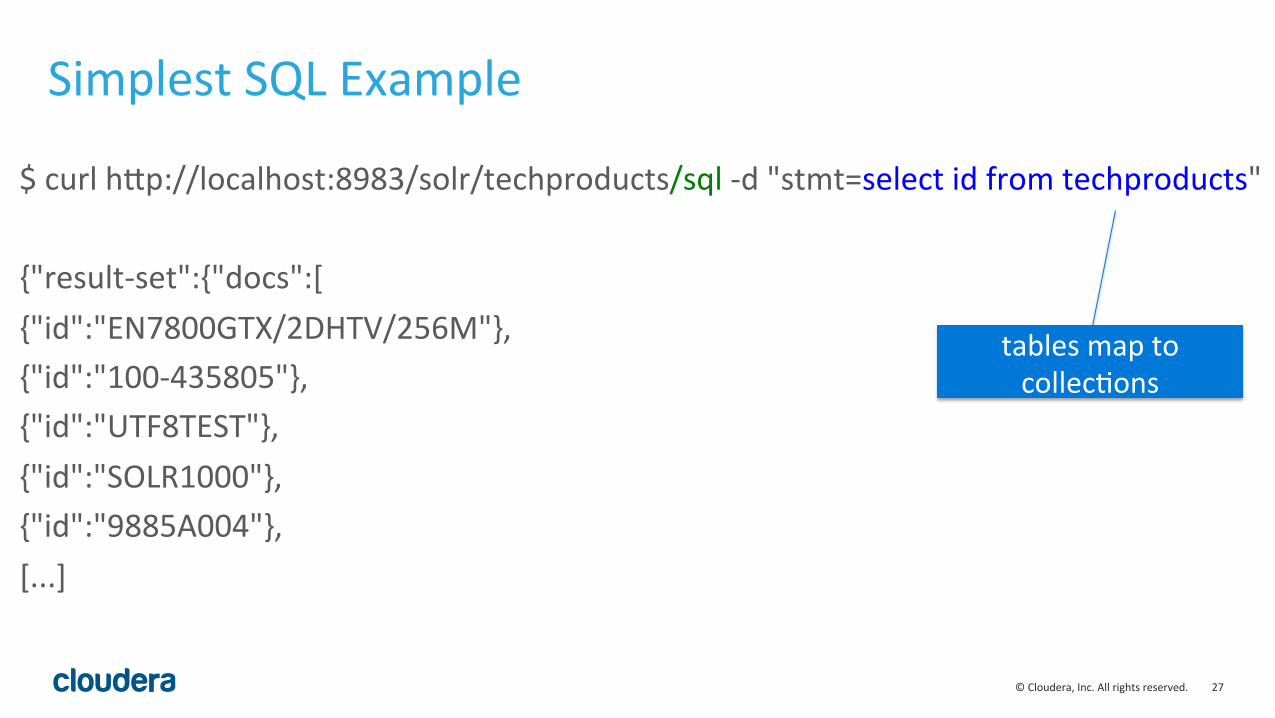
Simplest SQL Example
$ curl hFp://localhost:8983/solr/techproducts/sql -‐d "stmt=select id from techproducts" {"result-‐set":{"docs":[ {"id":"EN7800GTX/2DHTV/256M"}, {"id":"100-‐435805"}, {"id":"UTF8TEST"}, {"id":"SOLR1000"}, {"id":"9885A004"}, [...]
tables map to collecLons

28 © Cloudera, Inc. All rights reserved.
SQL handler HTTP parameters
curl hFp://localhost:8983/solr/techproducts/sql -‐d ' &stmt=<sql_statement> &numWorkers=4 // currently used by GROUP BY and DISTINCT (via parallel stream) &workerCollecLon=collecLon1 // where to create intermediate workers &workerZkhost=localhost:9983 // cluster (zookeeper ensemble) address &aggregaLonMode=map_reduce | facet

29 © Cloudera, Inc. All rights reserved.
The WHERE clause
• WHERE clauses are all pushed down to the search layer select id where popularity=10 // simple match on numeric field "popularity" where popularity='[5 TO 10]' // solr range query (note the quotes) where name='hard drive' // phrase query on the "name" field where name='((memory retail) AND popularity:[5 TO 10])' // arbitrary solr query where name='(memory retail)' AND popularity='[5 TO 10]' // boolean logic

30 © Cloudera, Inc. All rights reserved.
Ordering and LimiLng
select id,score from techproducts where text='(memory hard drive)' ORDER BY popularity desc // default order is score desc for limited queries LIMIT 100 • Limited queries use /select handler • Unlimited queries use /export handler • fields selected need to be docValues • fields in "order by" need to be docValues • no "score" field allowed

31 © Cloudera, Inc. All rights reserved.
More SQL examples
select disLnct fieldA as fa, fieldB as � from tableA order by fa desc, � desc // simple stats select count(fieldA) as count, sum(fieldB) as sum from tableA where fieldC = 'Hello' select fieldA, fieldB, count(*), sum(fieldC), avg(fieldY) from tableA where fieldC = 'term1 term2' group by fieldA, fieldB having ((sum(fieldC) > 1000) AND (avg(fieldY) <= 10)) order by sum(fieldC) asc
32 © Cloudera, Inc. All rights reserved.
Solr JDBC Driver
33 © Cloudera, Inc. All rights reserved.
Solr JDBC driver works with Apache Zeppelin

34 © Cloudera, Inc. All rights reserved.
Graph Traversal
35 © Cloudera, Inc. All rights reserved.
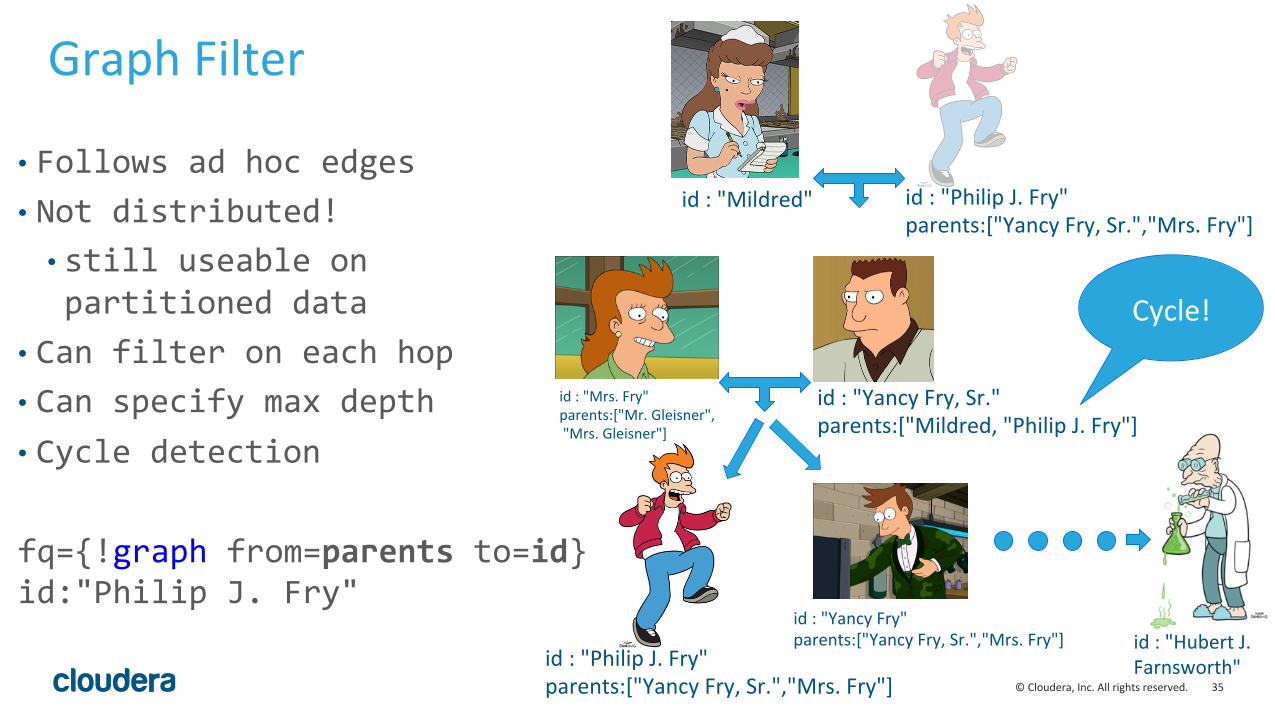
Graph Filter
• Follows ad hoc edges • Not distributed! • still useable on partitioned data
• Can filter on each hop • Can specify max depth • Cycle detection fq={!graph from=parents to=id}id:"Philip J. Fry"
id : "Philip J. Fry" parents:["Yancy Fry, Sr.","Mrs. Fry"]
id : "Yancy Fry" parents:["Yancy Fry, Sr.","Mrs. Fry"]
id : "Yancy Fry, Sr." parents:["Mildred, "Philip J. Fry"]
id : "Mrs. Fry" parents:["Mr. Gleisner", "Mrs. Gleisner"]
id : "Mildred"
id : "Hubert J. Farnsworth"
id : "Philip J. Fry" parents:["Yancy Fry, Sr.","Mrs. Fry"]
Cycle!

36 © Cloudera, Inc. All rights reserved.
Graph streaming expressions
• Breadth-‐first graph traversals • Fully integrated with streaming, fully distributed • Traverse across collecLons as well as shards • Compute aggregaLons curl http://localhost:8983/solr/emails/stream –d ' expr=gatherNodes(emails, walk="[email protected]‐>from", gather="to") '

37 © Cloudera, Inc. All rights reserved.
Graph streaming expressions example • Index some books in one collecLon
curl http://localhost:8983/solr/books/update -‐H 'Content-‐type:text/csv' -‐d ' id,cat,pubyear_i,title,author,series_s,sequence_i book1,fantasy,2000,A Storm of Swords,George R.R. Martin,A Song of Ice and Fire,3 book2,fantasy,2005,A Feast for Crows,George R.R. Martin,A Song of Ice and Fire,4 book3,fantasy,2011,A Dance with Dragons,George R.R. Martin,A Song of Ice and Fire,5 book4,sci-‐fi,1987,Consider Phlebas,Iain M. Banks,The Culture,1 book5,sci-‐fi,1988,The Player of Games,Iain M. Banks,The Culture,2 book6,sci-‐fi,1990,Use of Weapons,Iain M. Banks,The Culture,3 book7,fantasy,1984,Shadows Linger,Glen Cook,The Black Company,2 book8,fantasy,1984,The White Rose,Glen Cook,The Black Company,3 book9,fantasy,1989,Shadow Games,Glen Cook,The Black Company,4 book10,sci-‐fi,2001,Gridlinked,Neal Asher,Ian Cormac,1 book11,sci-‐fi,2003,The Line of Polity,Neal Asher,Ian Cormac,2 book12,sci-‐fi,2005,Brass Man,Neal Asher,Ian Cormac,3 '

38 © Cloudera, Inc. All rights reserved.
Graph streaming expressions example • Index some book reviews into another collecLon
curl http://localhost:8983/solr/reviews/update-‐H 'Content-‐type:text/csv' -‐d ' id,book_s,user_s,rating_i,review_t book1_r1,book1,Yonik,5,awesome book! book1_r2,book1,Aarav,2,too bloody book1_r3,book1,Haruka,5,awesome world building book2_r1,book2,Yonik,5,another great one book2_r2,book2,Maria,5,wow! book4_r1,book4,Yonik,2,i am lying... actually liked it book4_r2,book4,Aarav,5,Loved it book7_r1,book7,Yonik,4,read back in college but it was good book10_r1,book10,Maria,5,I want a gridlink! book11_r1,book11,Maria,1,Blech book11_r2,book11,Aarav,4,is this the first book? book12_r1,book12,Yonik,5,Mr. Crane is scary... '
1. Find books I like 2. Find who else rated those books highly 3. Find other books they rated highly 4. Profit!

39 © Cloudera, Inc. All rights reserved.
1. Search expression to find my high raLngs URL="http://localhost:8983/solr/reviews/stream" # Use search expression to find reviews that I have the book a "5" curl $URL -‐d 'expr=search(reviews, q="user_s:Yonik AND rating_i:5", fl="id,book_s,user_s,rating_i", sort="user_s asc")'
{"result-‐set":{"docs":[ {"raLng_i":5,"id":"book2_r1","user_s":"Yonik","book_s":"book2"}, {"raLng_i":5,"id":"book1_r1","user_s":"Yonik","book_s":"book1"}, {"raLng_i":5,"id":"book12_r1","user_s":"Yonik","book_s":"book12"}, {"EOF":true,"RESPONSE_TIME":4}]}}

40 © Cloudera, Inc. All rights reserved.
2. gatherNodes expression to find users curl $URL -‐d 'expr=gatherNodes(reviews, search(reviews, q="user_s:Yonik AND rating_i:5", fl="book_s,user_s,rating_i",sort="user_s asc"), walk="book_s-‐>book_s", gather="user_s", fq="rating_i:[4 TO *] -‐user_s:Yonik", trackTraversal=true )'
{"result-‐set":{"docs":[ {"node":"Haruka","collecLon":"reviews","field":"user_s","ancestors":["book1"],"level":1}, {"node":"Maria","collecLon":"reviews","field":"user_s","ancestors":["book2"],"level":1}, {"EOF":true,"RESPONSE_TIME":22}]}}
"gather" values

41 © Cloudera, Inc. All rights reserved.
3. gatherNodes to find high raLngs by those users curl $URL -‐d 'expr=gatherNodes(reviews, gatherNodes(reviews, search(reviews,q="user_s:Yonik AND rating_i:5",fl="id,book_s,user_s,rating_i",sort="user_s asc"), walk="book_s-‐>book_s", gather="user_s",fq="rating_i:[4 TO *] -‐user_s:Yonik"), walk="node-‐>user_s", gather="book_s", fq="rating_i:[4 TO *]", avg(rating_i), trackTraversal=true)' {"result-‐set":{"docs":[ {"node":"book10","avg(raLng_i)":5.0,"field":"book_s","level":2,"collecLon":"reviews","ancestors":["Maria"]}, {"EOF":true,"RESPONSE_TIME":65}]}}

42 © Cloudera, Inc. All rights reserved.
Retrieving complete traversal curl $URL -‐d 'expr=gatherNodes(reviews, [...], scaFer="branches,leaves")' {"result-‐set":{"docs":[ {"node":"book12","collecLon":"reviews","field":"book_s","level":0}, {"node":"book1","collecLon":"reviews","field":"book_s","level":0}, {"node":"book2","collecLon":"reviews","field":"book_s","level":0}, {"node":"Haruka","collecLon":"reviews","field":"user_s","level":1}, {"node":"Maria","collecLon":"reviews","field":"user_s","level":1}, {"node":"book10","avg(raLng_i)":5.0,"field":"book_s","level":2, "collecLon":"reviews","ancestors":["Maria"]}, {"EOF":true,"RESPONSE_TIME":111}]}}
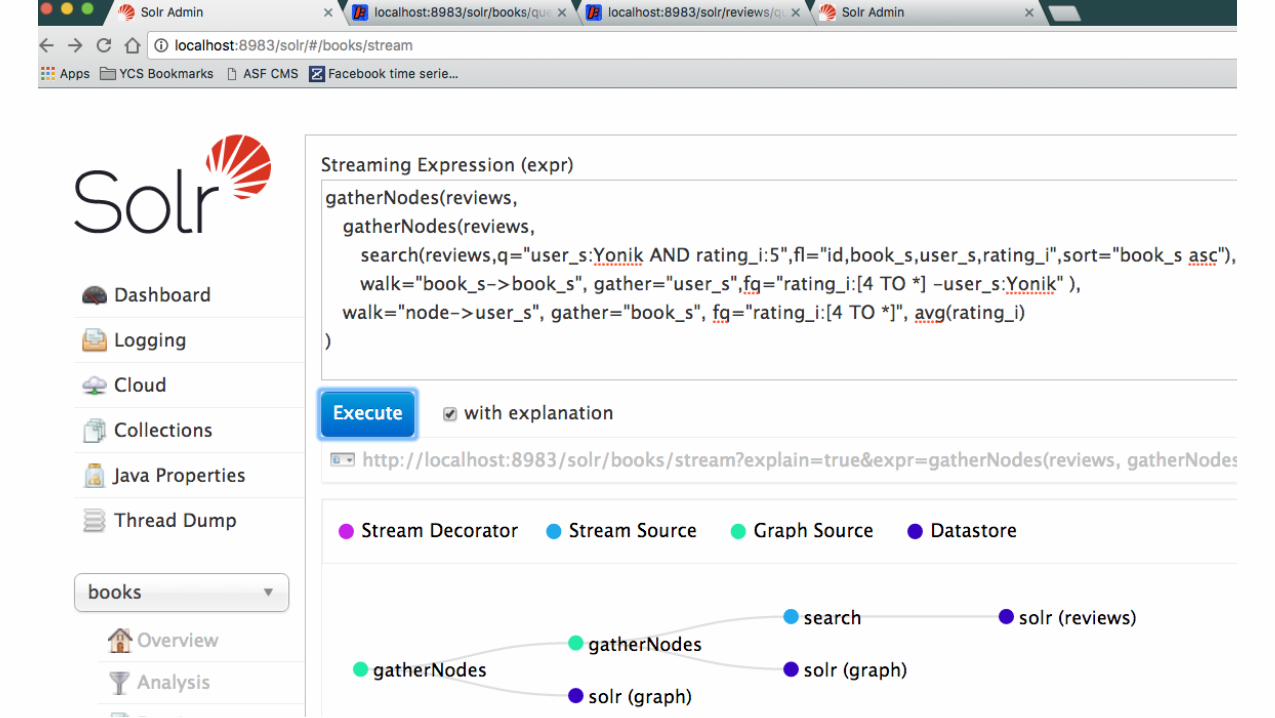
43 © Cloudera, Inc. All rights reserved.
Solr admin stream view

44 © Cloudera, Inc. All rights reserved.
More graph expressions
• shortestPath • Finds the shortest path between "from" and "to"
• scoreNodes : l-‐idf inspired scoring • wraps a gatherNodes expression that finds the co-‐occurrence count • l factor – the co-‐occurrence count • idf factor – boosts nodes that are rarer overall
45 © Cloudera, Inc. All rights reserved.
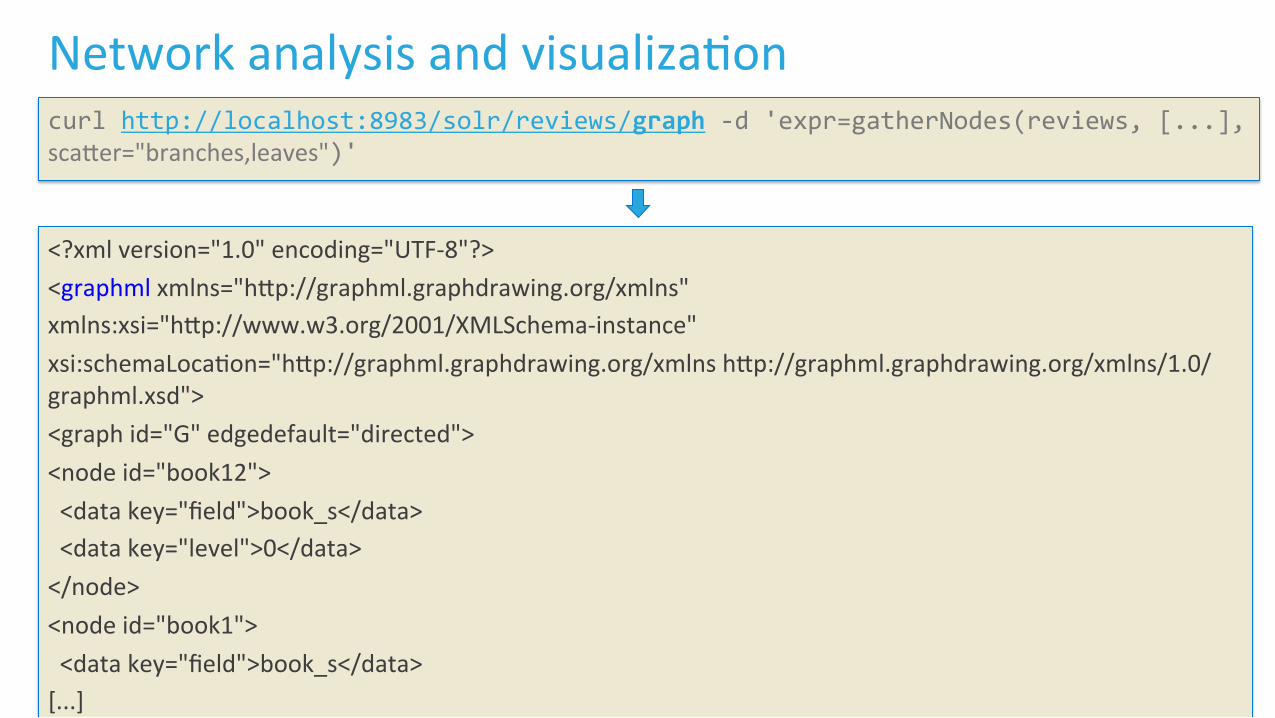
Network analysis and visualizaLon curl http://localhost:8983/solr/reviews/graph -‐d 'expr=gatherNodes(reviews, [...], scaFer="branches,leaves")' <?xml version="1.0" encoding="UTF-‐8"?> <graphml xmlns="hFp://graphml.graphdrawing.org/xmlns" xmlns:xsi="hFp://www.w3.org/2001/XMLSchema-‐instance" xsi:schemaLocaLon="hFp://graphml.graphdrawing.org/xmlns hFp://graphml.graphdrawing.org/xmlns/1.0/graphml.xsd"> <graph id="G" edgedefault="directed"> <node id="book12"> <data key="field">book_s</data> <data key="level">0</data> </node> <node id="book1"> <data key="field">book_s</data> [...]
46 © Cloudera, Inc. All rights reserved.

47 © Cloudera, Inc. All rights reserved.
Streaming Expressions vs JSON Facets

48 © Cloudera, Inc. All rights reserved.
JSON Facet API • More focused on web-‐scale interacLve responses • Tighter integraLon • ULlizes exisLng distributed search framework / just another search component • single request-‐response top-‐N, grouping, highlighLng, faceLng, etc. • block join / nested document support
• More expressive?
Streaming Expressions • More general purpose, larger scope • wrap streams within streams to do preFy much anything • not Led to documents (analyLcs across joins w/ external DBs) • update streams, machine learning streams, etc.
• Exact results (e.g. cardinality) • distributed joins, graph • Increasingly will use JSON Facet API to push work to leaves












![Yonik Seeley [email protected] 29 June 2006 Dublin, Ireland](https://img.pdfslide.net/doc/110x75/61fb6d9b2e268c58cd5e0d37/yonik-seeley-emailprotected-29-june-2006-dublin-ireland.jpg)