Embed Size (px)
Citation preview

PostgreSQLエンジニアにとってのデータ分析プロジェクト:テクノロジーとその実践
ナガヤス サトシ@snaga
~ Dive Into Data ~
第6回 関西DB勉強会

アナリティクスをPostgreSQLで始めるべき10の理由

アジェンダ• データ収集 / データベース連携• データウェアハウス・データマート構築• クエリ作成 / SQLの機能• パフォーマンス• In-Database処理

データ収集データベース連携Foreign Data Wrapper
Unlogged Table
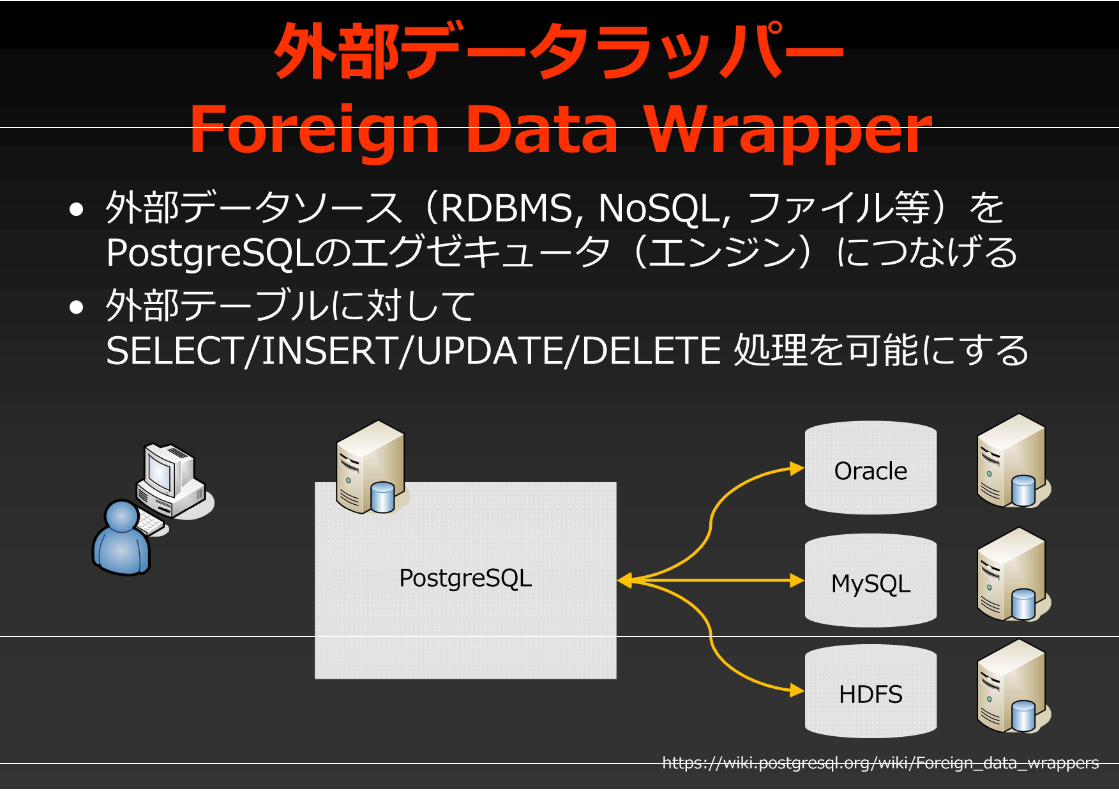
外部データラッパーForeign Data Wrapper
• 外部データソース(RDBMS, NoSQL, ファイル等)をPostgreSQLのエグゼキュータ(エンジン)につなげる
• 外部テーブルに対してSELECT/INSERT/UPDATE/DELETE 処理を可能にする
PostgreSQL
Oracle
MySQL
HDFS
https://wiki.postgresql.org/wiki/Foreign_data_wrappers

データベースリンクDatabase Link
• リモートのデータベースに対して「アドホックな」クエリを実行可能
• dblink_plus では、PostgreSQLに加えて Oracle / MySQL / SQLite に対しても接続可能
PostgreSQL
Oracle
MySQL
https://www.postgresql.jp/document/9.6/html/contrib-dblink-function.htmlhttp://interdbconnect.sourceforge.net/index.html

非ロギングテーブルUnlogged Tables
• トランザクションログを生成しない• 高いローディング(INSERT)パフォーマンス• クラッシュリカバリの際に TRUNCATE される
http://pgsnaga.blogspot.jp/2011/10/data-loading-into-unlogged-tables-and.html

データウェアハウスデータマート構築
Materialized ViewsTransactional DDLs
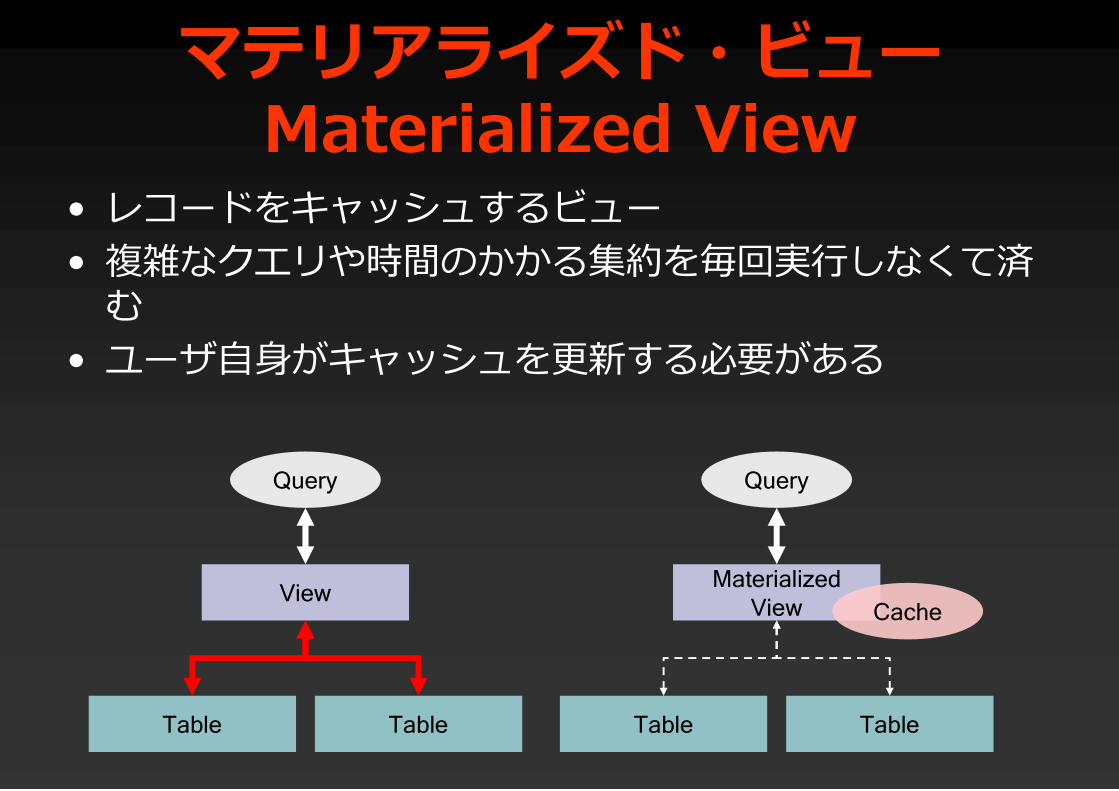
マテリアライズド・ビューMaterialized View
• レコードをキャッシュするビュー• 複雑なクエリや時間のかかる集約を毎回実行しなくて済
む• ユーザ自身がキャッシュを更新する必要がある
Table
View
Table Table
MaterializedView
Table
Query Query
Cache

トランザクショナルなDDLTransactional DDLs
• PostgreSQLではほとんどのDDL処理がトランザクション内で実行可能
• オンラインであってもスキーマの変更をアトミック(COMMIT/ROLLBACK)に行える
• トランザクショナルなDDLは、DBAがスキーマを保守するのをより容易にする

クエリの作成 / SQLの機能
Rich SQL featuresCompatibility with SQL standard

クエリの作成 / SQLの機能Writing Queries / SQL Features
• 豊富なSQLの機能– サブクエリ– WITH句 (Common Table Expressions, CTEs)– 多数の集約関数– ウィンドウ関数
• JSONデータのサポート
• SQL標準への準拠、互換性

WITH句WITH clause
• そのクエリのための一時テーブルを定義する• サブクエリ内で2回以上参照する場合には、パフ
ォーマンスが良くなる• 「サブクエリのサブクエリ(の…)」をしなくて
済むので、クエリがシンプルになるWITH foo AS (
SELECT ... FROM ... GROUP BY ...)SELECT ... FROM foo WHERE ...
UNION ALLSELECT ... FROM foo WHERE ...;
https://www.postgresql.org/docs/9.5/static/queries-with.html

多数の集約関数Many Aggregations
• 9.4で追加–percentile_cont()–percentile_disc()–mode()– rank()–dense_rank()–percent_rank()– cume_dist()
• 9.5で追加– ROLLUP()– CUBE()– GROUPING SETS()
https://www.postgresql.org/docs/9.5/static/functions-aggregate.html
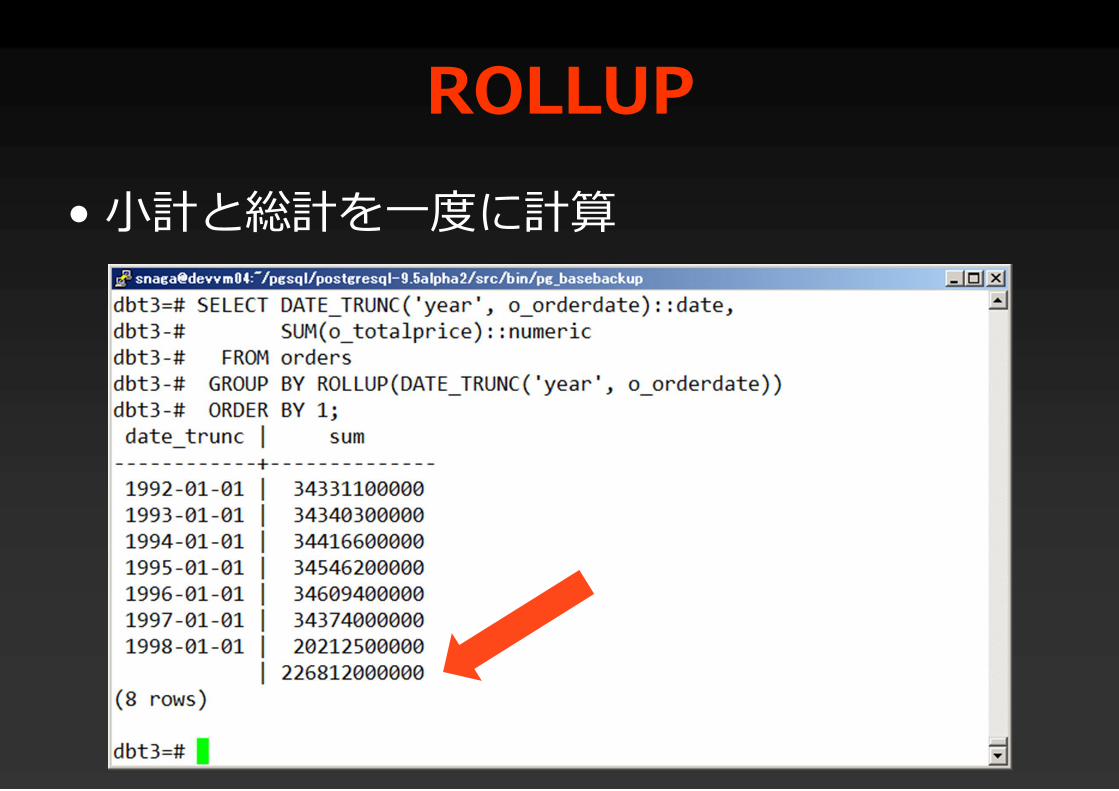
ROLLUP• 小計と総計を一度に計算
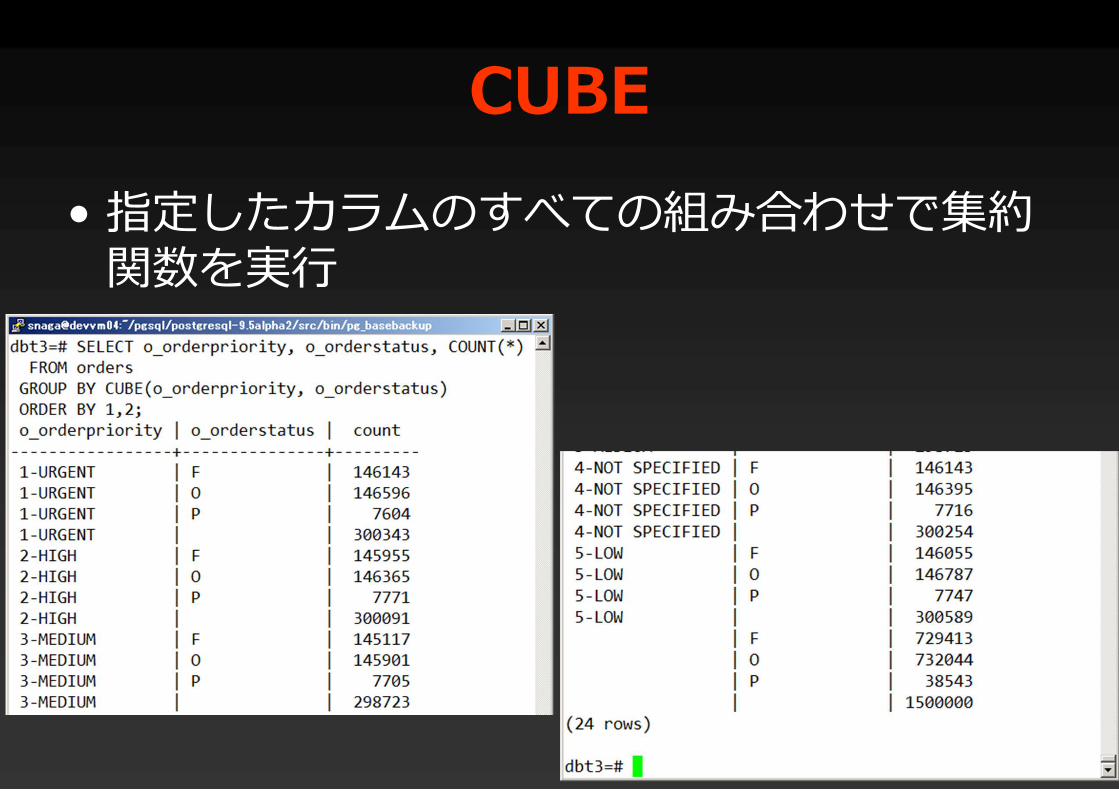
CUBE• 指定したカラムのすべての組み合わせで集約
関数を実行
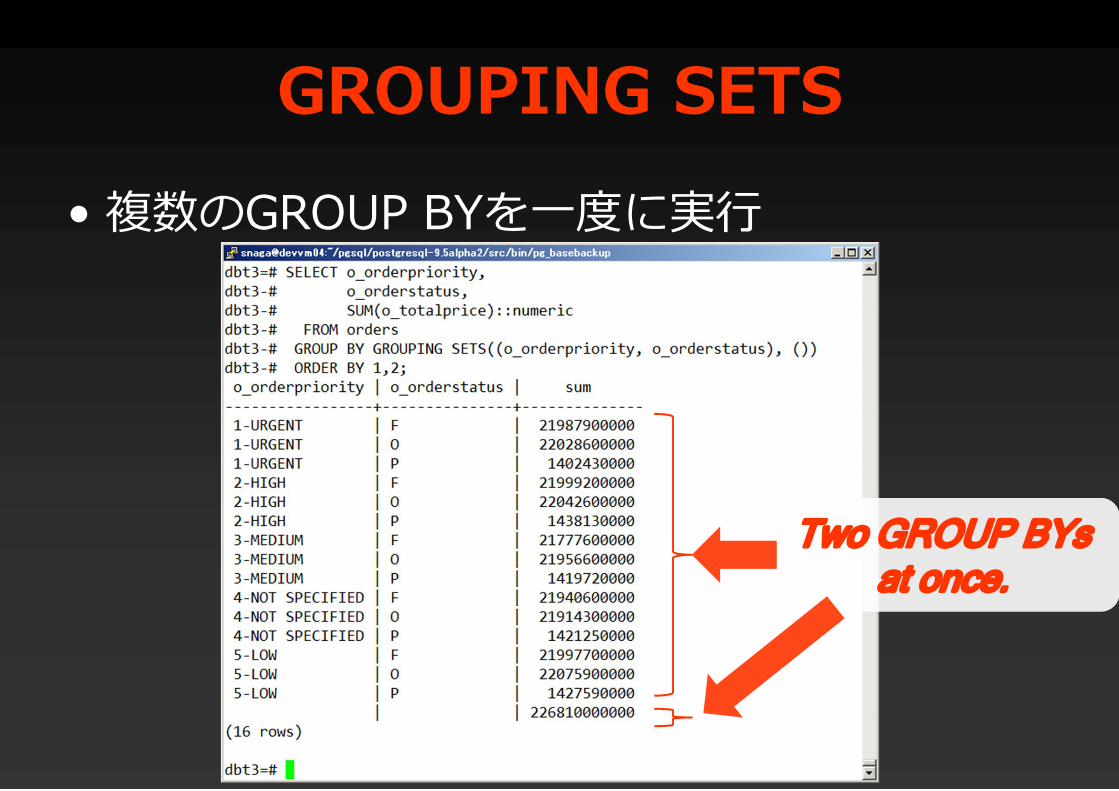
GROUPING SETS• 複数のGROUP BYを一度に実行
Two GROUP BYsat once.

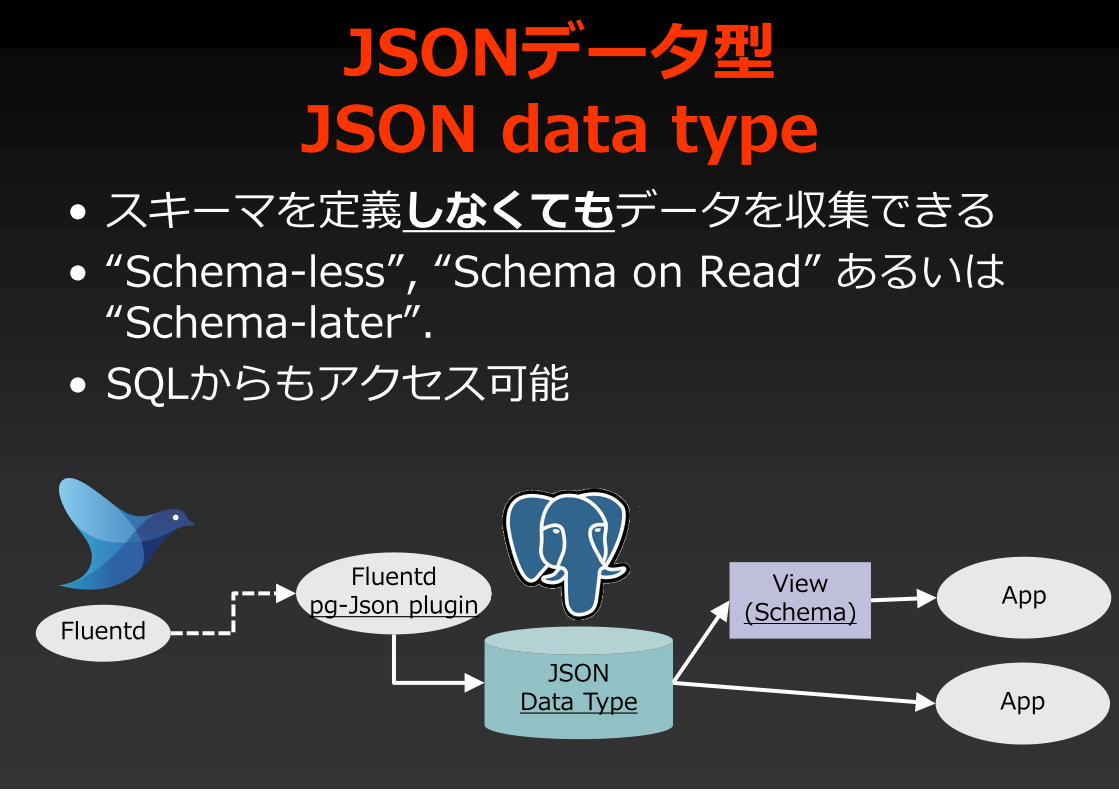
JSONデータ型JSON data type
testdb=# create table t1 ( j jsonb );CREATE TABLEtestdb=# insert into t1 values ('{ "key1": "value1", "key2": "value2" }');INSERT 0 1testdb=# select * from t1;
j--------------------------------------{"key1": "value1", "key2": "value2"}(1 row)
testdb=# select j->>'key2' key2 from t1;key2
--------value2(1 row)

JSONデータ型JSON data type
testdb=# select n_nationkey,n_name from nation where n_nationkey = 12;n_nationkey | n_name-------------+---------------------------
12 | JAPAN(1 row)
testdb=# select jsonb_build_object('n_nationkey', n_nationkey, 'n_name', n_name) from nation where n_nationkey = 12;
jsonb_build_object------------------------------------------------------------{"n_name": "JAPAN ", "n_nationkey": 12}(1 row)

Operator Description9.4-> Get an element by key as a JSON object->> Get an element by key as a text object#> Get an element by path as a JSON object#>> Get an element by path as a text object<@, @> Evaluate whether a JSON object contains a key/value pair? Evaluate whether a JSON object contains a key or a value?| Evaluate whether a JSON object contains ANY of keys or values
?& Evaluate whether a JSON object contains ALL of keys or values
9.5|| Insert or Update an element to a JSON object- Delete an element by key from a JSON object#- Delete an element by path from a JSON object
http://www.postgresql.org/docs/9.5/static/functions-json.html
JSONデータ型JSON data type
• スキーマを定義しなくてもデータを収集できる• “Schema-less”, “Schema on Read” あるいは
“Schema-later”.• SQLからもアクセス可能
JSONData Type
Fluentdpg-Json plugin
View(Schema) App
App
Fluentd

パフォーマンス3 types of Join
Full text search (n-gram)Table Partition
BRIN IndexTable Sample
Parallel Queries

3種類のJOIN3 types of Join
• Nested Loop (NL) Join– インデックスのあるテーブルの少数のレコードを結合
する場合にはパフォーマンスが良い
• Merge Join
• Hash Join– 大規模なテーブルで大量のレコードを結合する場合に
はNL結合よりもパフォーマンスが良い

全文検索(n-gram)Full-text search (n-gram)
• テキストを「N文字」のトークンに分割してインデックスを作成する– Pg_trgm: Tri-gram (3文字)– Pg_bigm: Bi-gram (2文字)
• CJKには多くの2文字単語があるので、Tri-gramよりBi-gramの方が使いやすい– CJK: 中国語・日本語・韓国語
Pg_trgm: https://www.postgresql.org/docs/9.5/static/pgtrgm.htmlPg_bigm: http://pgbigm.osdn.jp/index_en.html

Pg_bigmパフォーマンスPg_bigm performance
• Wikipediaタイトルデータ (2,789,266レコード)– https://dumps.wikimedia.org/zhwiki/20160601/– zhwiki-20160601-pages-articles-multistream-index.txt.bz2zhwikidb=> select * from zhwiki_index where title like '%香港%';
id1 | id2 | title----------+-------+----------------------------------------
5693863 | 2087 | 香港特別行政區基本法第二十三條11393231 | 4323 | 香港特别行政区12830042 | 5085 | 香港大学列表14349335 | 6088 | 香港行政区划14349335 | 6090 | 香港行政區劃14349335 | 6091 | 香港十八区14349335 | 6092 | 香港十八區16084672 | 7168 | 香港兒童文學作家18110426 | 8206 | 北區 (香港)18110426 | 8236 | 東區 (香港)19537078 | 9528 | 香港專業教育學院19537078 | 9567 | 香港中文大學
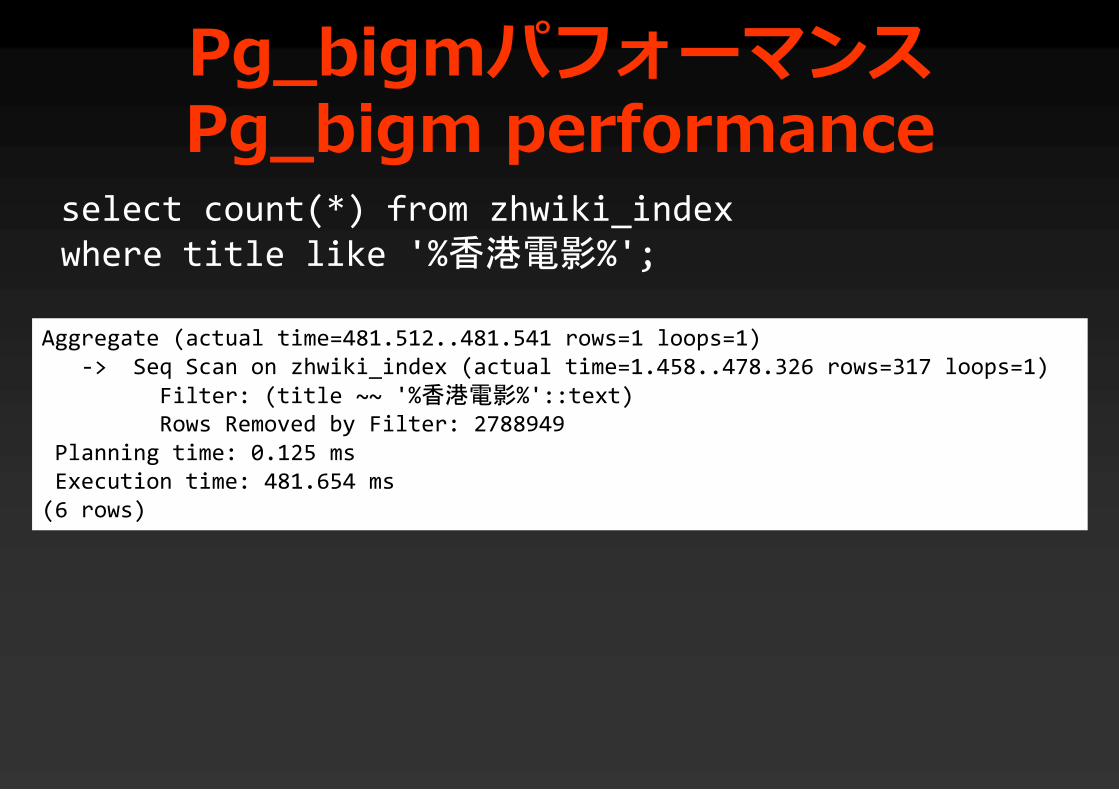
Pg_bigmパフォーマンスPg_bigm performance
Aggregate (actual time=481.512..481.541 rows=1 loops=1)-> Seq Scan on zhwiki_index (actual time=1.458..478.326 rows=317 loops=1)
Filter: (title ~~ '%香港電影%'::text)Rows Removed by Filter: 2788949
Planning time: 0.125 msExecution time: 481.654 ms
(6 rows)
select count(*) from zhwiki_indexwhere title like '%香港電影%';

Pg_bigmパフォーマンスPg_bigm performance
Aggregate (actual time=1.790..1.792 rows=1 loops=1)-> Bitmap Heap Scan on zhwiki_index (actual time=0.299..1.225 rows=317
loops=1)Recheck Cond: (title ~~ '%香港電影%'::text)Rows Removed by Index Recheck: 1Heap Blocks: exact=191-> Bitmap Index Scan on zhwiki_index_title_idx (actual
time=0.258..0.258 rows=318 loops=1)Index Cond: (title ~~ '%香港電影%'::text)
Planning time: 0.103 msExecution time: 1.833 ms
(9 rows)
select count(*) from zhwiki_indexwhere title like '%香港電影%';
481.6ms → 1.8ms.通常のLIKEに比べて200倍高速化

テーブルパーティションTable Partition
• 範囲またはリストによるテーブルパーティショニング– “Constraint Exclusion”
• 不要なパーティションをスキャンしない– 制約の内容によって判断される
• 大規模なテーブルにおいて、「降るテーブルスキャン」を避けることができる
https://www.postgresql.org/docs/9.5/static/ddl-partitioning.html
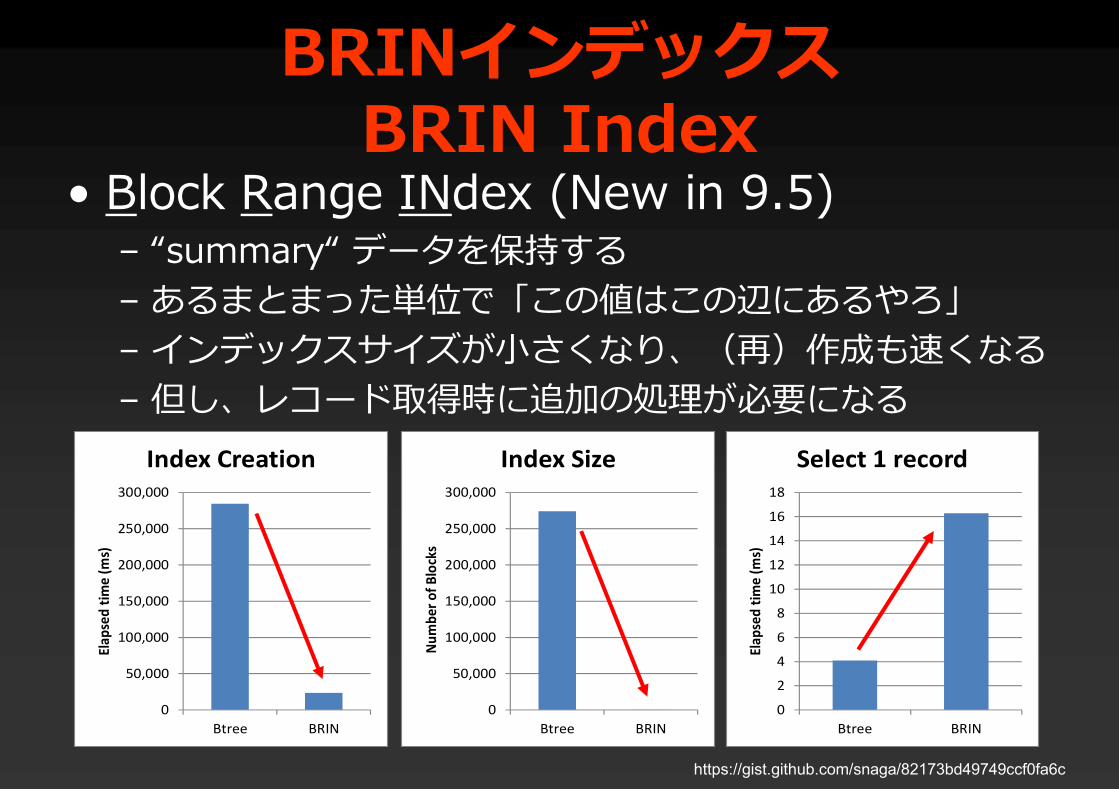
BRINインデックスBRIN Index
• Block Range INdex (New in 9.5)– “summary“ データを保持する– あるまとまった単位で「この値はこの辺にあるやろ」– インデックスサイズが小さくなり、(再)作成も速くなる– 但し、レコード取得時に追加の処理が必要になる
0
50,000
100,000
150,000
200,000
250,000
300,000
Btree BRIN
Elap
sed
time
(ms)
Index Creation
0
50,000
100,000
150,000
200,000
250,000
300,000
Btree BRIN
Num
ber o
f Blo
cks
Index Size
0
2
4
6
8
10
12
14
16
18
Btree BRIN
Elap
sed
time
(ms)
Select 1 record
https://gist.github.com/snaga/82173bd49749ccf0fa6c

BRINインデックスBRIN Index
• BRINインデックスの構造
Table File
Block Range 1 (128 Blocks)
Block Range 2
Block Range 3BlockRange
Min. Value Max. Value
1 1992-01-02 1992-01-282 1992-01-27 1992-02-083 1992-02-08 1992-02-16… … …
“Block Range” と呼ばれる塊の単位で、min/maxの値を保持する
(date型のカラムの場合)
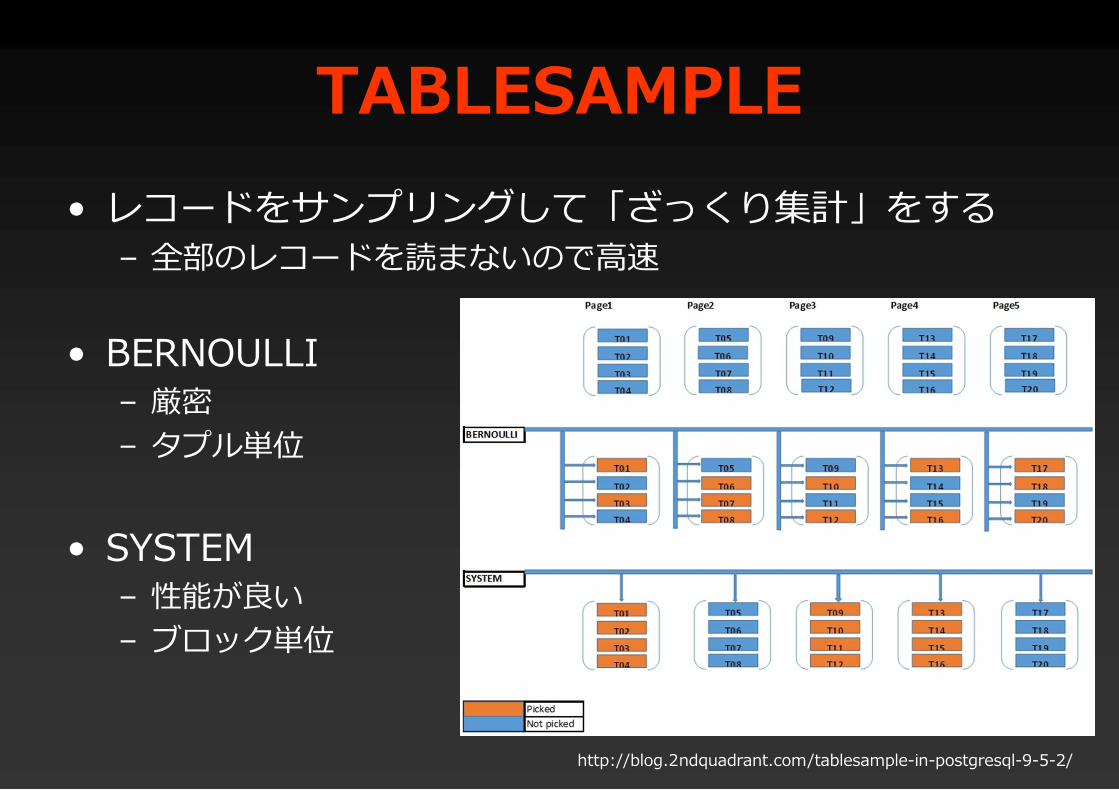
TABLESAMPLE• レコードをサンプリングして「ざっくり集計」をする
– 全部のレコードを読まないので高速
• BERNOULLI– 厳密– タプル単位
• SYSTEM– 性能が良い– ブロック単位
http://blog.2ndquadrant.com/tablesample-in-postgresql-9-5-2/

TABLESAMPLE• 合計金額の平均値を計算してみる
– 本当の値とざっくりの値(2種類)

TABLESAMPLETABLESAMPLE無し
1,787ms
SYSTEMサンプリング22ms
BERNOULLIサンプリング405ms
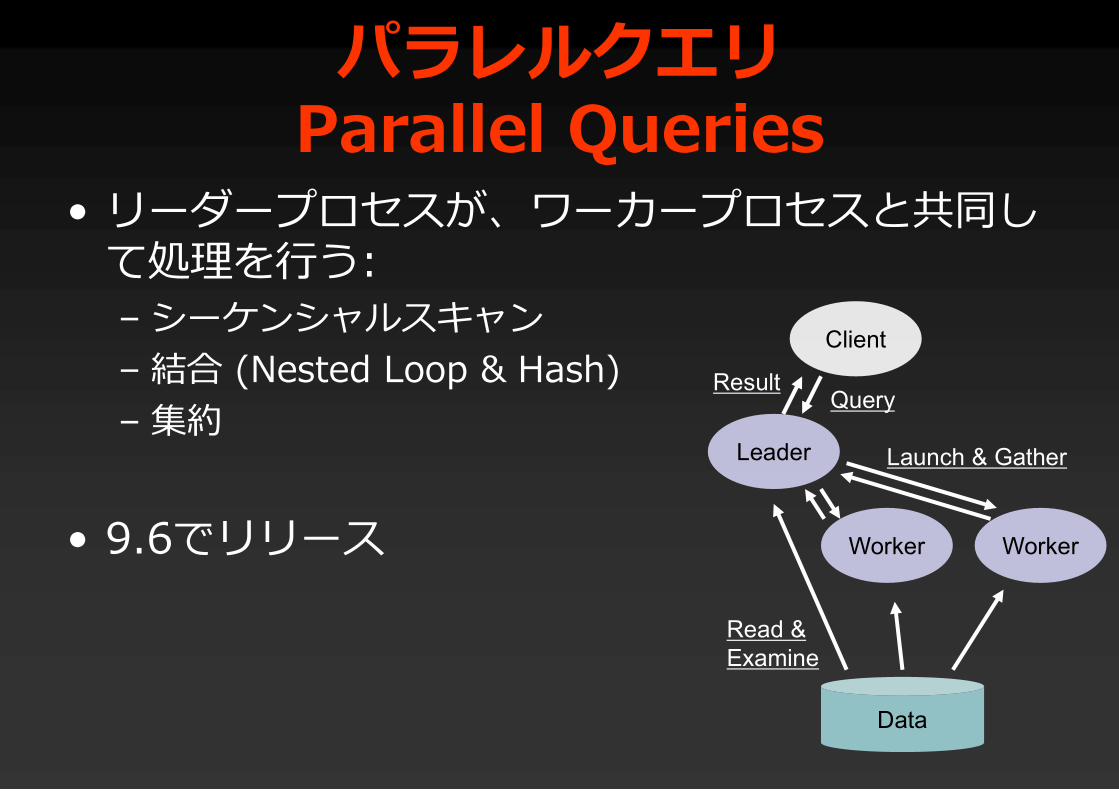
パラレルクエリParallel Queries
• リーダープロセスが、ワーカープロセスと共同して処理を行う:– シーケンシャルスキャン– 結合 (Nested Loop & Hash)– 集約
• 9.6でリリース
Leader
Worker Worker
Client
Data
Read &Examine
QueryResult
Launch & Gather
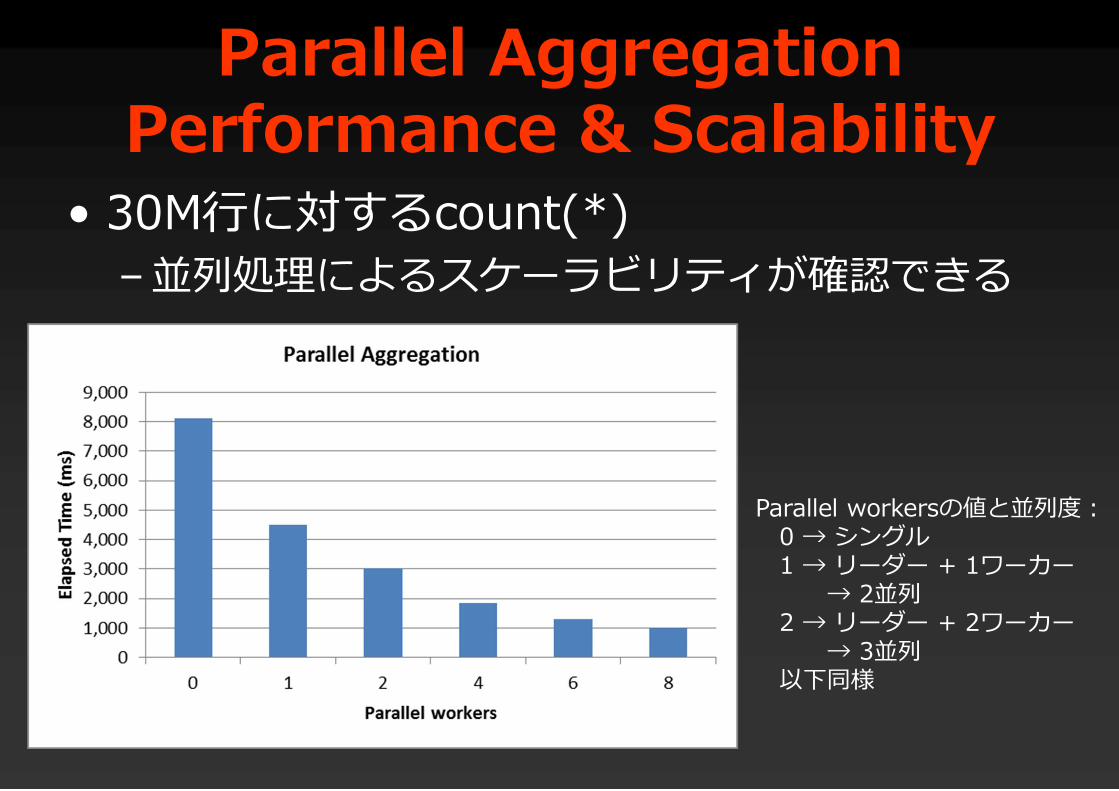
Parallel Aggregation Performance & Scalability
• 30M行に対するcount(*)– 並列処理によるスケーラビリティが確認できる
Parallel workersの値と並列度:0 → シングル1 → リーダー + 1ワーカー
→ 2並列2 → リーダー + 2ワーカー
→ 3並列以下同様

In-Database処理
User Defined FunctionsApache MADlib

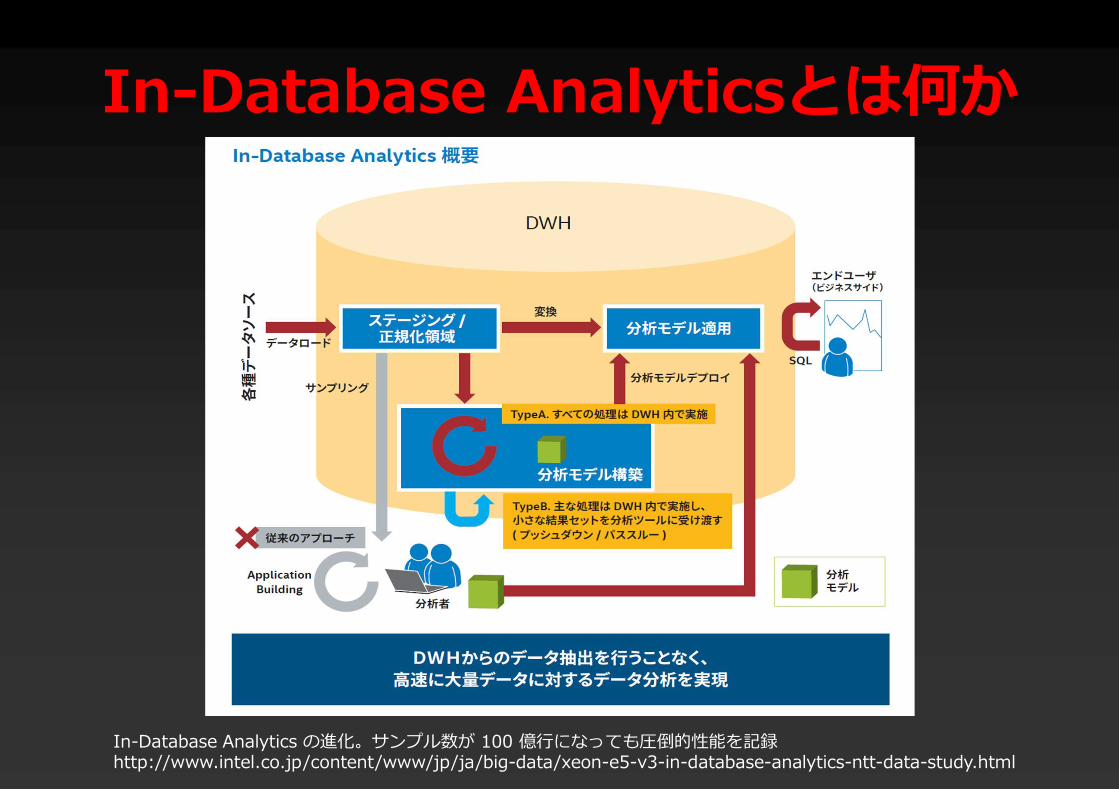
In-Database分析In-Database Analytics
• In-Database分析とは?–サーバからデータを取り出さずにアナリティク
スの処理を実行する
• In-Database分析の優位性–“ビッグデータ” をサーバ・クライアント間で移
動させずに済む–クライアントPCと比べると高いパフォーマンス
のハードウェアリソースを使える (CPU, メモリ, ストレージ)
In-Database Analyticsとは何か
In-Database Analytics の進化。サンプル数が 100 億行になっても圧倒的性能を記録http://www.intel.co.jp/content/www/jp/ja/big-data/xeon-e5-v3-in-database-analytics-ntt-data-study.html

In-Database分析In-Database Analytics
• ユーザ定義関数による実装–PL/Python, PL/R, PL/v8, ... あるいは C 言語.–(ほぼ)あらゆるロジックをデータベース内で
実行できる
• Apache MADlib–機械学習ライブラリ for PostgreSQL

In-Databaseのパフォーマンス
• In-DatabaseとOut-of-Databaseで約70倍の差– 500次元の空間ベクトル、10,000レコードのコサイン
類似度を計算
コサイン類似度に基づくソート処理の実装方法とその性能比較http://pgsqldeepdive.blogspot.jp/2017/01/consine-similarity-performance.html

ユーザ定義関数 by PythonUDF by Python
CREATE OR REPLACE FUNCTION dumpenv(OUT text, OUT text)RETURNS SETOF record
AS $$import osfor e in os.environ:
plpy.notice(str(e) + ": " + os.environ[e])yield(e, os.environ[e])
$$ LANGUAGE plpythonu;

ユーザ定義関数 by PythonUDF by Python
CREATE OR REPLACE FUNCTION dumpenv(OUT text, OUT text)RETURNS SETOF record
AS $$import osfor e in os.environ:
plpy.notice(str(e) + ": " + os.environ[e])yield(e, os.environ[e])
$$ LANGUAGE plpythonu;
testdb=# select * from dumpenv() order by 1 limit 10;column1 | column2
--------------------+-----------------------G_BROKEN_FILENAMES | 1HISTCONTROL | ignoredupsHISTSIZE | 1000HOME | /home/snagaHOSTNAME | localhost.localdomainLANG | ja_JP.UTF-8LC_COLLATE | CLC_CTYPE | CLC_MESSAGES | CLC_MONETARY | C(10 rows)

pgRoutingとは
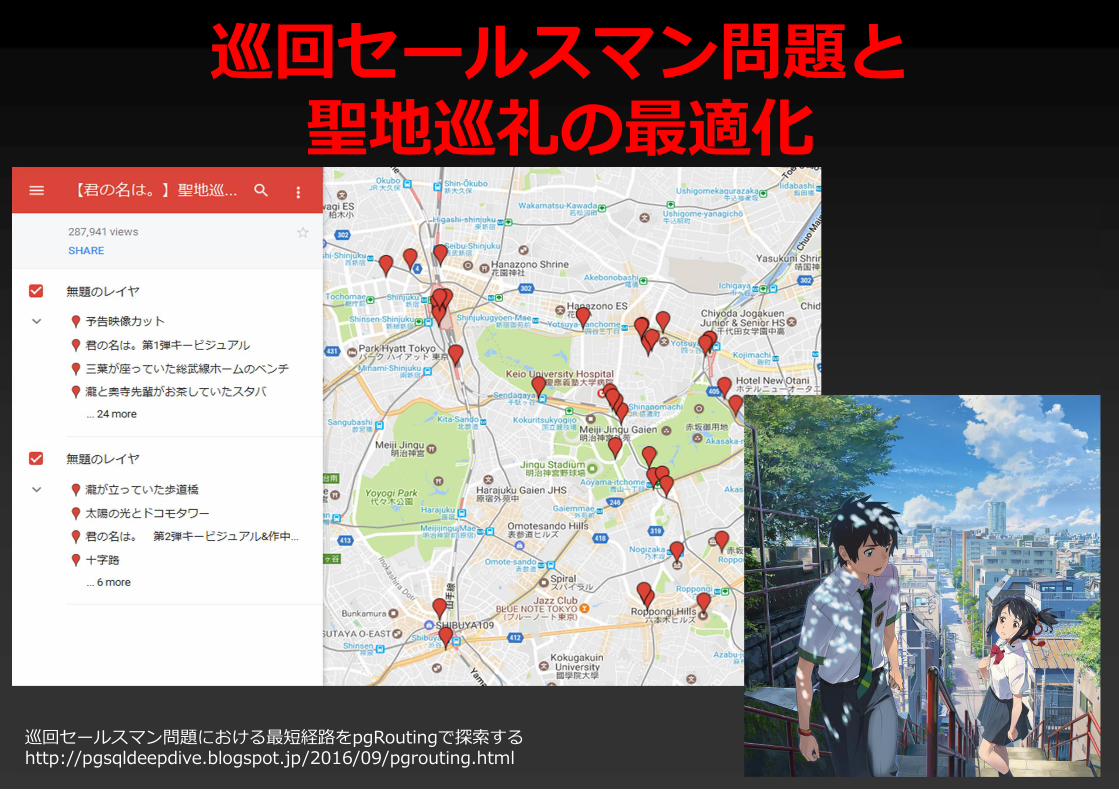
巡回セールスマン問題と聖地巡礼の最適化
巡回セールスマン問題における最短経路をpgRoutingで探索するhttp://pgsqldeepdive.blogspot.jp/2016/09/pgrouting.html
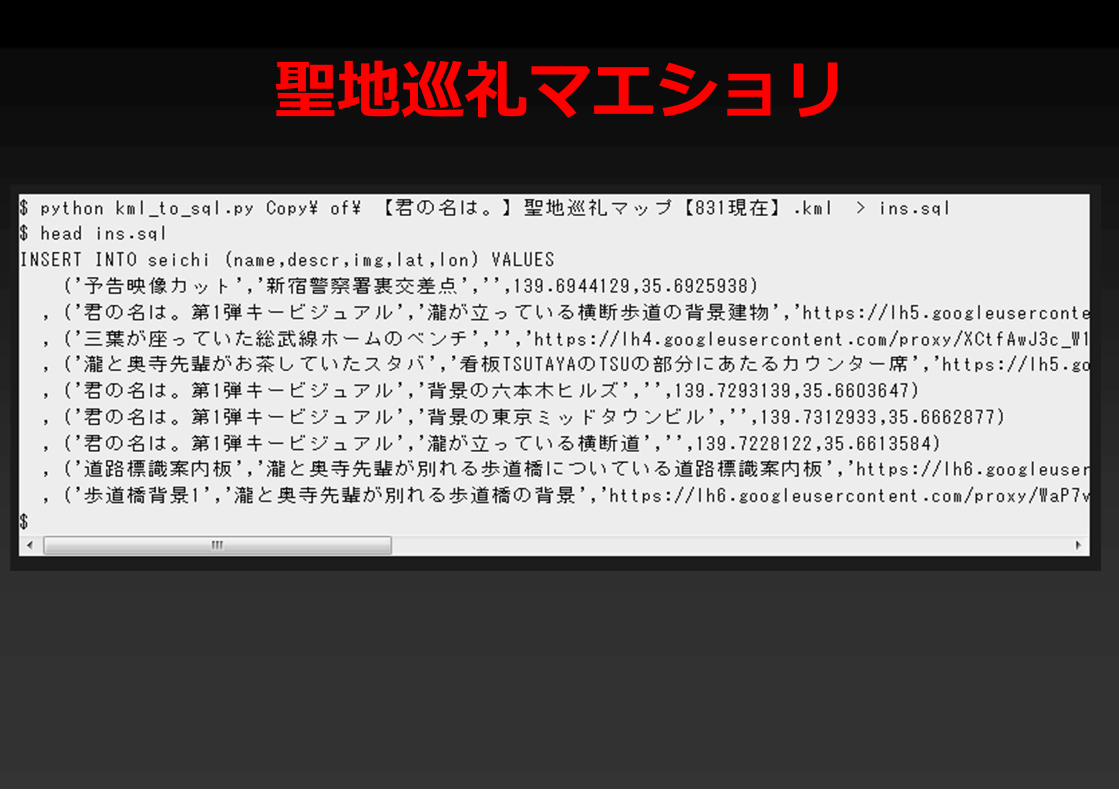
聖地巡礼マエショリ
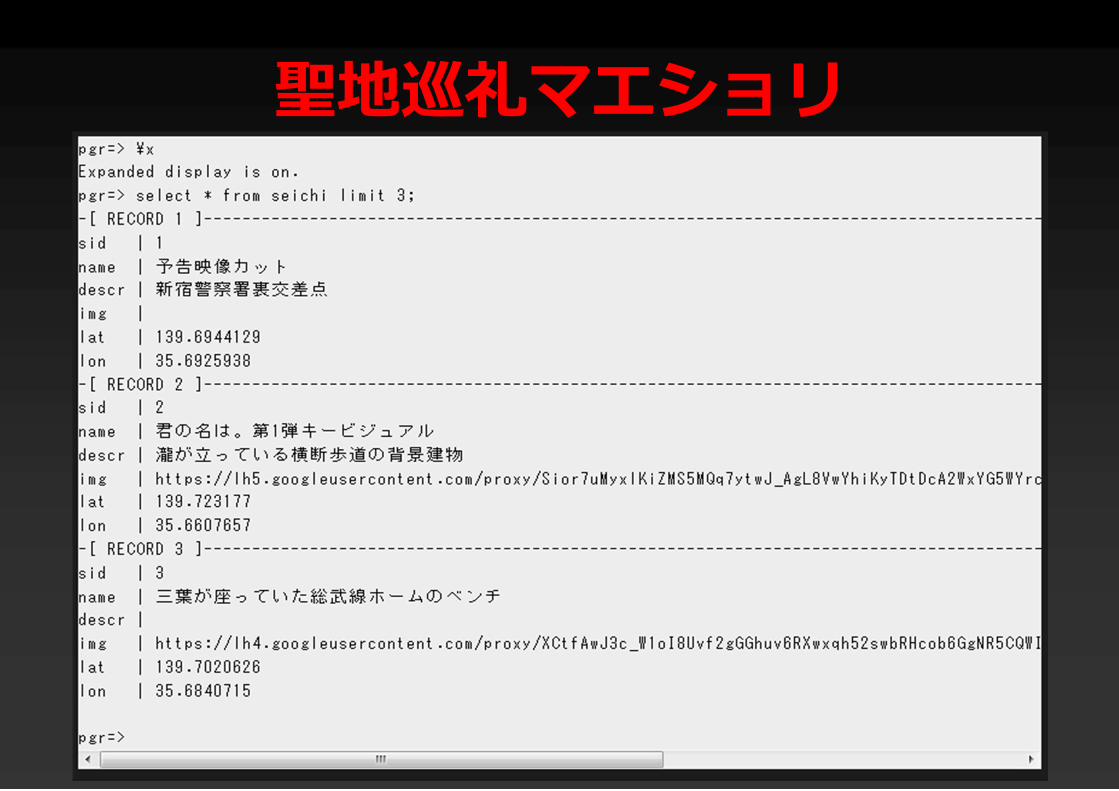
聖地巡礼マエショリ
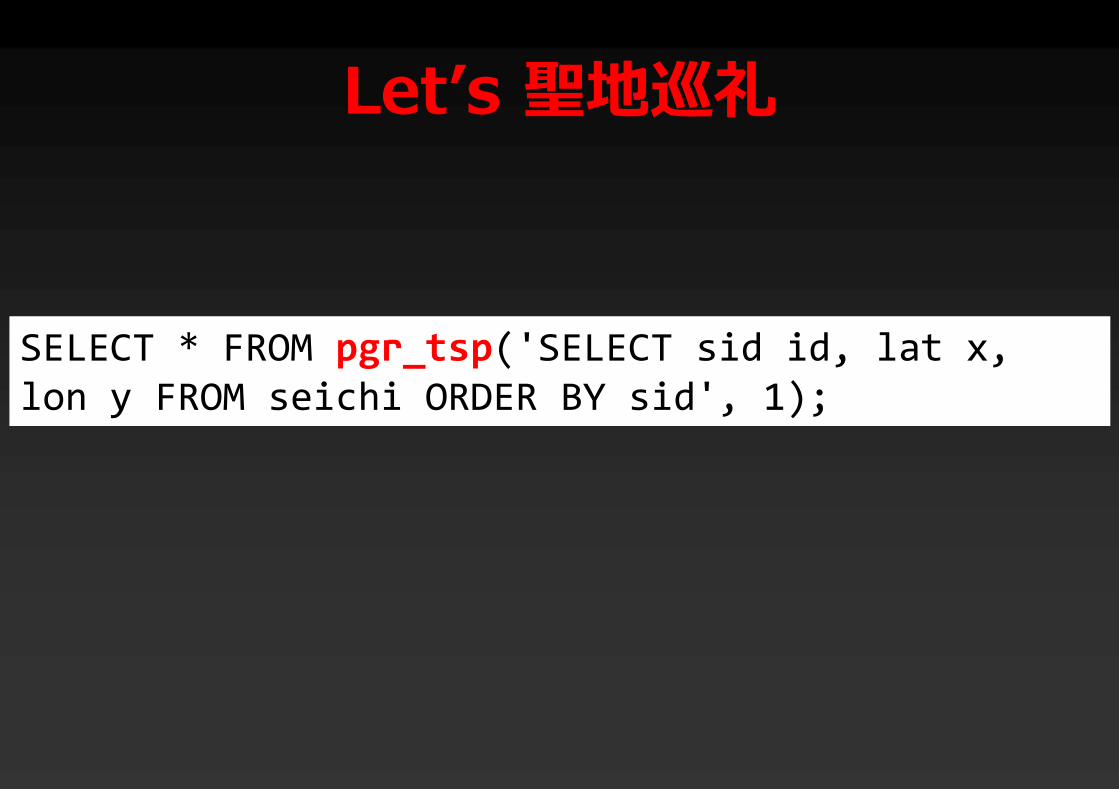
Let’s 聖地巡礼
SELECT * FROM pgr_tsp('SELECT sid id, lat x, lon y FROM seichi ORDER BY sid', 1);
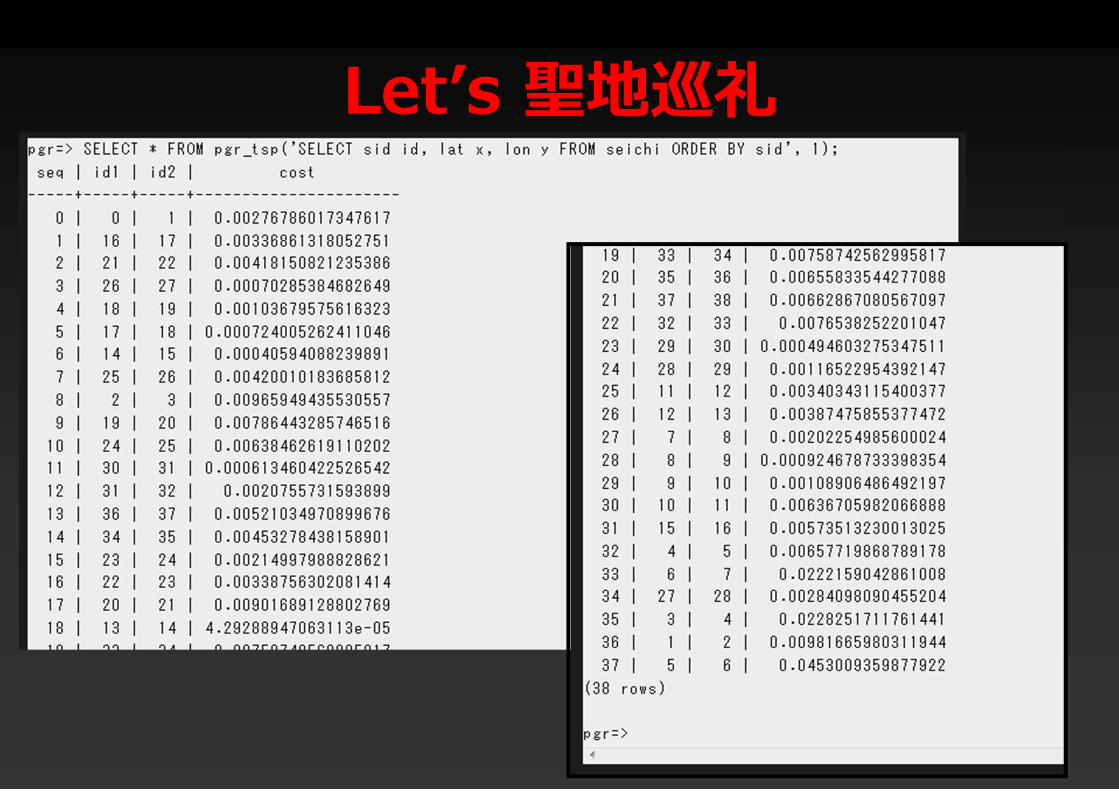
Let’s 聖地巡礼

Let’s 聖地巡礼
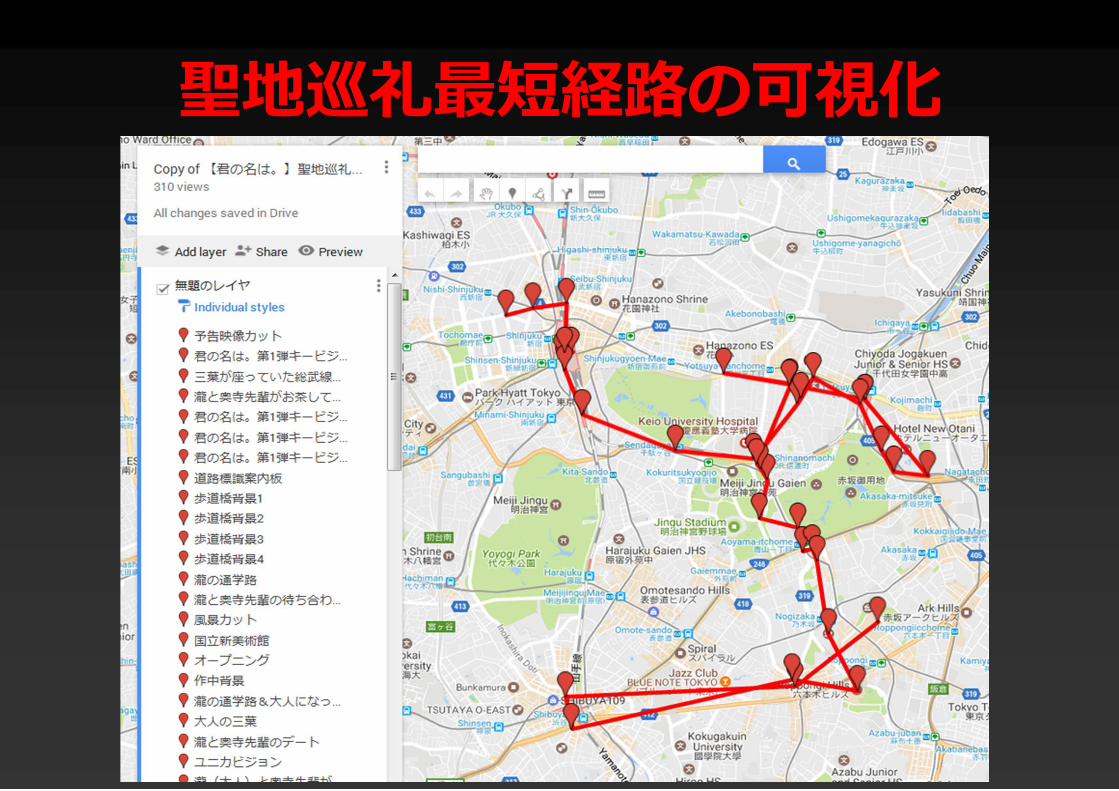
聖地巡礼最短経路の可視化

Apache MADlib• オープンソース機械学習ライブラリ
– PostgreSQL, Greenplum Database, Apache HAWQの内部で実行できる
– さまざまな機械学習アルゴリズムをサポート
http://madlib.incubator.apache.org/

ユースケース
Apache MADlib (Incubating) User Survey Results Oct 2016http://madlib.incubator.apache.org/community-artifacts/Apache-MADlib-user-survey-results-Oct-2016.pdf

機能
MADlib: Distributed In-Database Machine Learning for Fun and Profithttps://archive.fosdem.org/2016/schedule/event/hpc_bigdata_madlib/

その他
Strict type checking and constraints.
Industry Standard Interface (for BI tools)

その他Others
• 厳密な型のチェックと制約–“Garbage in, garbage out.” を避ける
• 業界標準のインターフェース (主にBIツール)–ODBC, JDBC

サマリSummary
• PostgreSQLはデータ分析のプロジェクトに役立つ機能を既に多く備えています。– 特に開発生産性やパフォーマンスという観点で
• さらに “BigData” な機能が将来のリリースで実現される予定です– パラレルクエリはその中でも非常に大きい価値
• データ分析のプロジェクトをPostgreSQLで始めて、ぜひコミュニティに参加してください!– PostgreSQL 10 beta4 になっています!






















![グーグル アナリティクスによる アクセス解析 「基 …...グーグル アナリティクスによる アクセス解析 「基本操作ガイド」 [基本編] スマート](https://img.pdfslide.net/doc/110x75/5fdece14a62012092355fa1e/ff-fff-e-oe-ff.jpg)






