Embed Size (px)
Citation preview




Our current investment status is…
Our annual revenue is… Our product range comprises of…
Our countries of operation are…
What now?
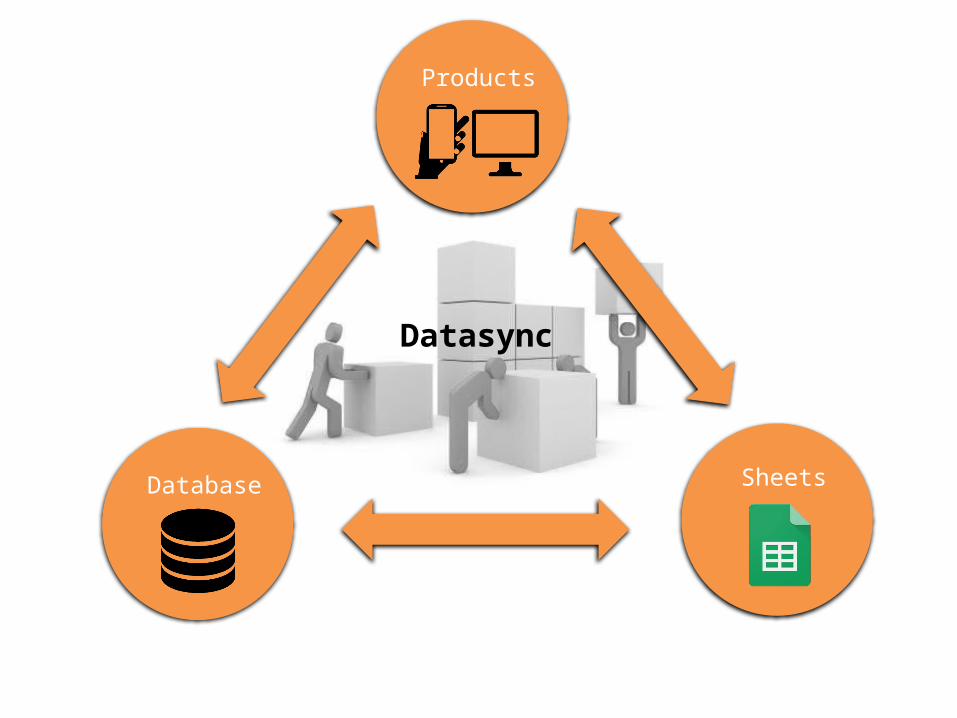
Datasync
Database Sheets
Products

>>> print(agenda) 2-way sync
Datasync in-action Building blocks of
Datasync
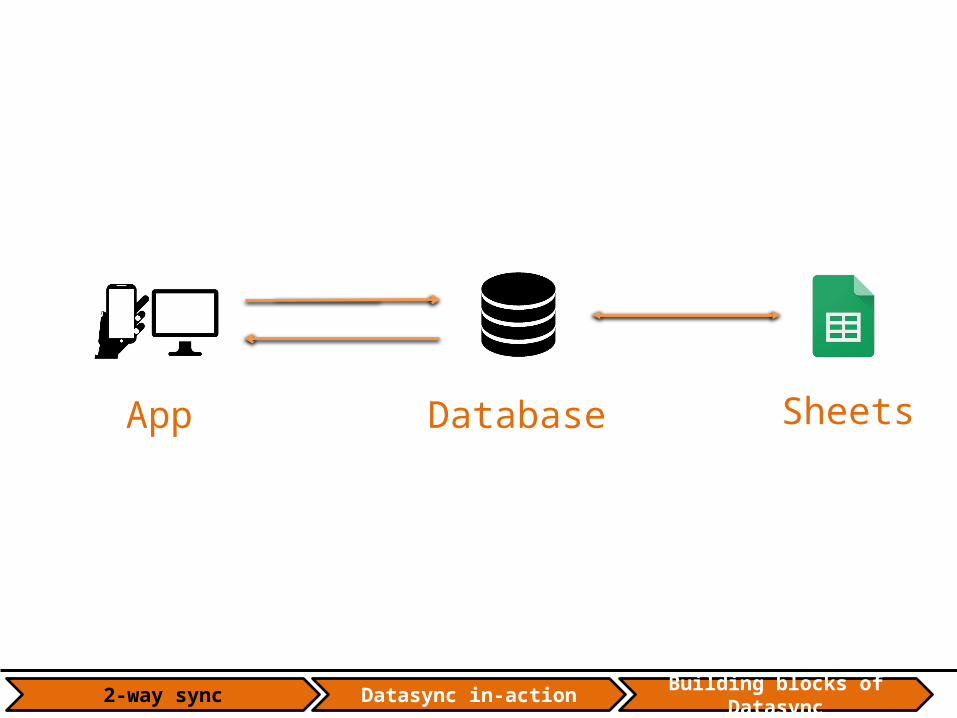
Building blocks of Datasync2-way sync Datasync in-action
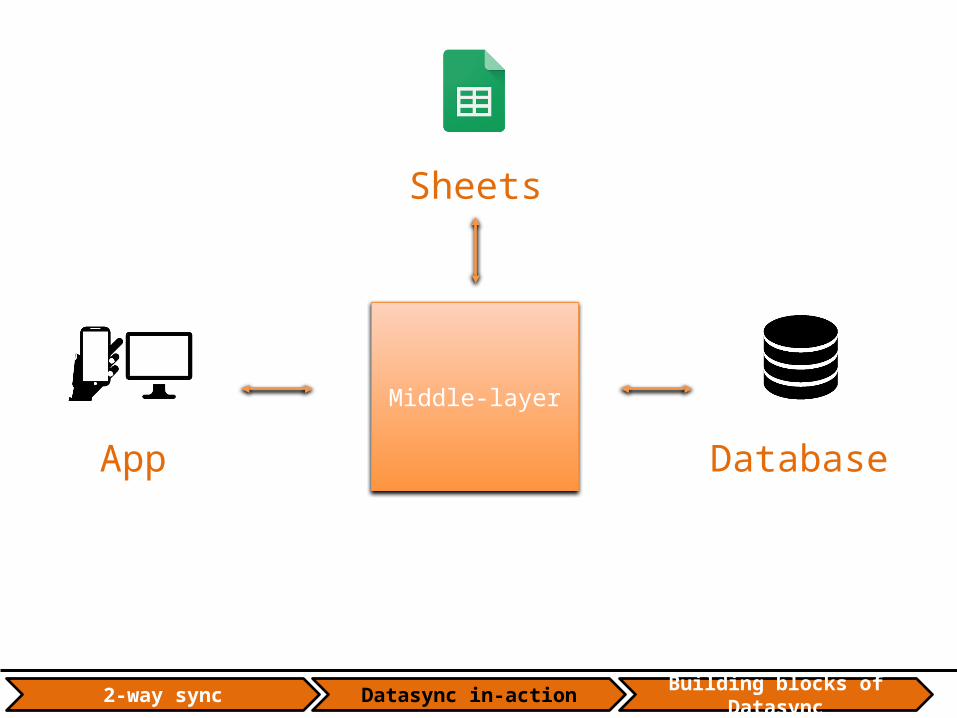
App Database Sheets
Building blocks of DatasyncDatasync in-action2-way sync
App Database
Sheets
Middle-layer

Datasync in-action Building blocks of Datasync2-way sync
Initiate google sheets serviceimport httplib2from apiclient import discoveryfrom oauth2client import toolsfrom oauth2client.client import Credentials def init_service(): credentials = #retrieve from database credentials = Credentials.new_from_json(credentials) http = build_service(credentials) discoveryUrl = ('https://sheets.googleapis.com/$discovery/rest?' 'version=v4') service = discovery.build('sheets', 'v4', http=http, discoveryServiceUrl=discoveryUrl) return service def build_service(credentials): http = httplib2.Http() http = credentials.authorize(http) return http
Datasync in-action Building blocks of Datasync2-way sync
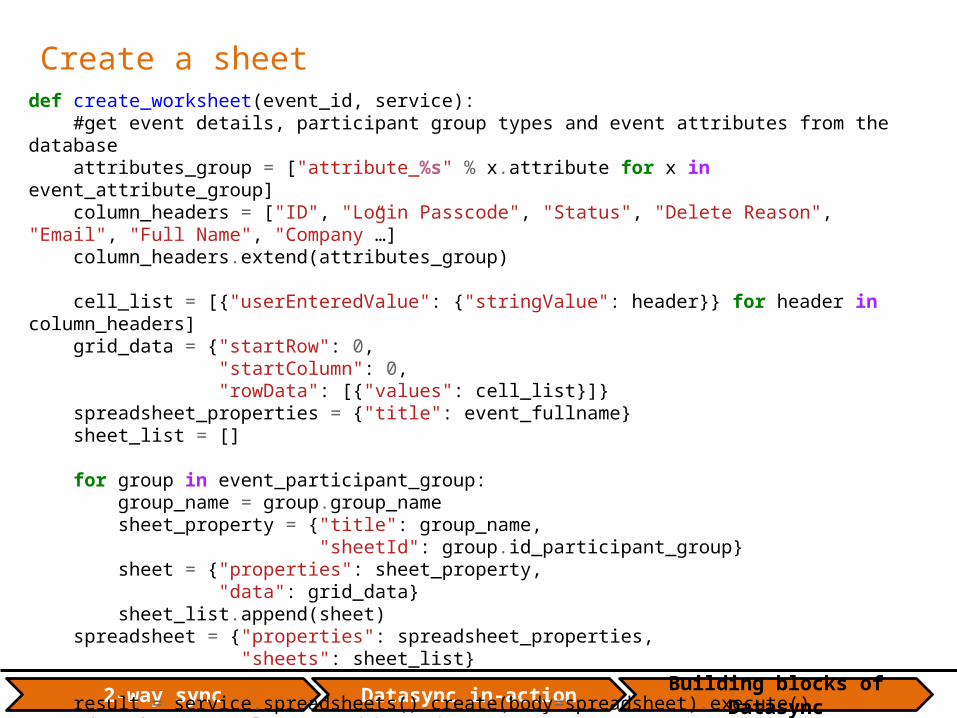
Create a sheetdef create_worksheet(event_id, service): #get event details, participant group types and event attributes from the database attributes_group = ["attribute_%s" % x.attribute for x in event_attribute_group] column_headers = ["ID", "Login Passcode", "Status", "Delete Reason", "Email", "Full Name", "Company”…] column_headers.extend(attributes_group)
cell_list = [{"userEnteredValue": {"stringValue": header}} for header in column_headers] grid_data = {"startRow": 0, "startColumn": 0, "rowData": [{"values": cell_list}]} spreadsheet_properties = {"title": event_fullname} sheet_list = [] for group in event_participant_group: group_name = group.group_name sheet_property = {"title": group_name, "sheetId": group.id_participant_group} sheet = {"properties": sheet_property, "data": grid_data} sheet_list.append(sheet) spreadsheet = {"properties": spreadsheet_properties, "sheets": sheet_list} result = service.spreadsheets().create(body=spreadsheet).execute() gdocs_key = result['spreadsheetId'] return gdocs_key
Datasync in-action Building blocks of Datasync2-way sync
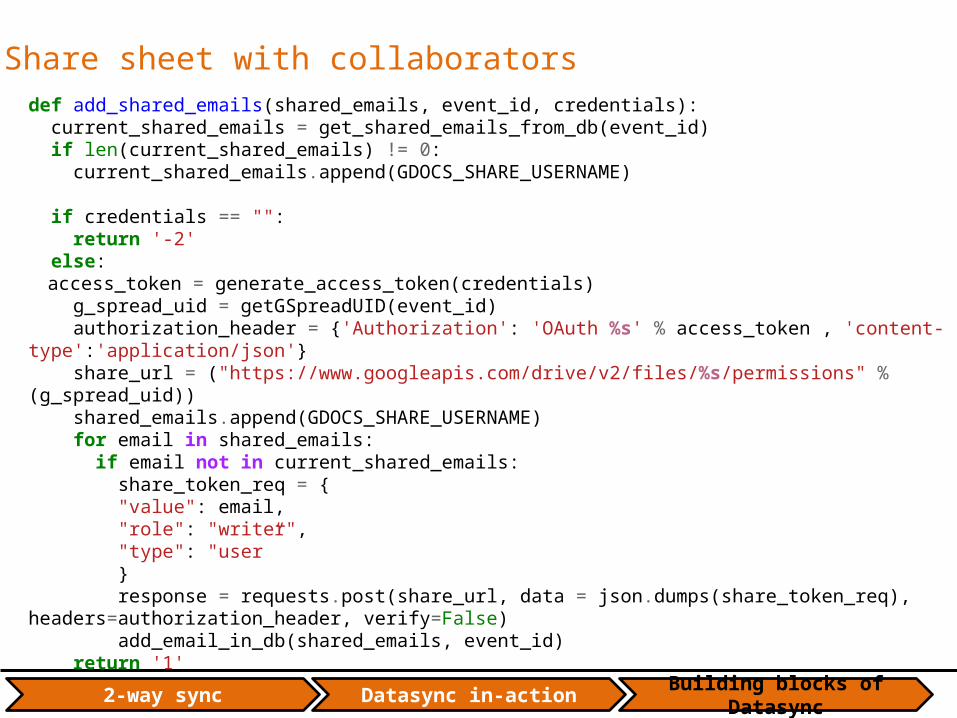
Share sheet with collaboratorsdef add_shared_emails(shared_emails, event_id, credentials): current_shared_emails = get_shared_emails_from_db(event_id) if len(current_shared_emails) != 0: current_shared_emails.append(GDOCS_SHARE_USERNAME)
if credentials == "": return '-2' else: access_token = generate_access_token(credentials) g_spread_uid = getGSpreadUID(event_id) authorization_header = {'Authorization': 'OAuth %s' % access_token , 'content-type':'application/json'} share_url = ("https://www.googleapis.com/drive/v2/files/%s/permissions" % (g_spread_uid)) shared_emails.append(GDOCS_SHARE_USERNAME) for email in shared_emails: if email not in current_shared_emails: share_token_req = { "value": email, "role": "writer", "type": "user” } response = requests.post(share_url, data = json.dumps(share_token_req), headers=authorization_header, verify=False) add_email_in_db(shared_emails, event_id) return '1'

Datasync in-action Building blocks of Datasync2-way sync
Wrappers for read/write to sheetsdef get_sheets_properties(service, spreadsheet_id): response = service.spreadsheets().get( spreadsheetId=spreadsheet_id).execute() return response
def batch_get_cells(service, spreadsheet_id, cell_ranges, dimension=None): response = service.spreadsheets().values().batchGet( spreadsheetId=spreadsheet_id, ranges=cell_ranges, majorDimension=dimension).execute() values = response.get('valueRanges') return values
def batch_update_cells(service, spreadsheet_id, cell_range, values, dimension=None, option="USER_ENTERED"):request = { "valueInputOption": option, "data" : [{ "range": cell_range, "majorDimension": dimension, "values": values, }] } try: service.spreadsheets().values().batchUpdate( spreadsheetId=spreadsheet_id, body=request).execute() except: print 'ERROR: Failed to update cells!'

Datasync in-action Building blocks of Datasync2-way sync
Sync endpoint and main classapi.add_resource(DataSync, '/sync/<int:event_id>/<int:start_row>/<int:end_row>/<int:id_participant_group>')
class DataSync(restful.Resource): def get(self, event_id, start_row, end_row, id_participant_group): nosql_table = Table('process_status', connection=dynamoconn) while True: try: file_statistic = datasync.sync_spreadsheet(event_id, start_row, end_row, id_participant_group) except (CannotSendRequest, ResponseNotReady) as e: if not nosql_table.has_item(EVENT_ID=str(event_id)): start_row = 0 else: item = nosql_table.get_item(EVENT_ID=str(event_id)) datasync_json = json.loads(item["DATASYNC_JSON"]) print datasync_json start_row = int(datasync_json["start_row"]) except Exception, e:
report_dictionary = {'status': 'error', 'data': 'data:{"error", "reason": "sync spreadsheet"}\n\n'} create_or_update_ds(event_id, nosql_table, report_dictionary) return else: break
Datasync in-action Building blocks of Datasync2-way sync
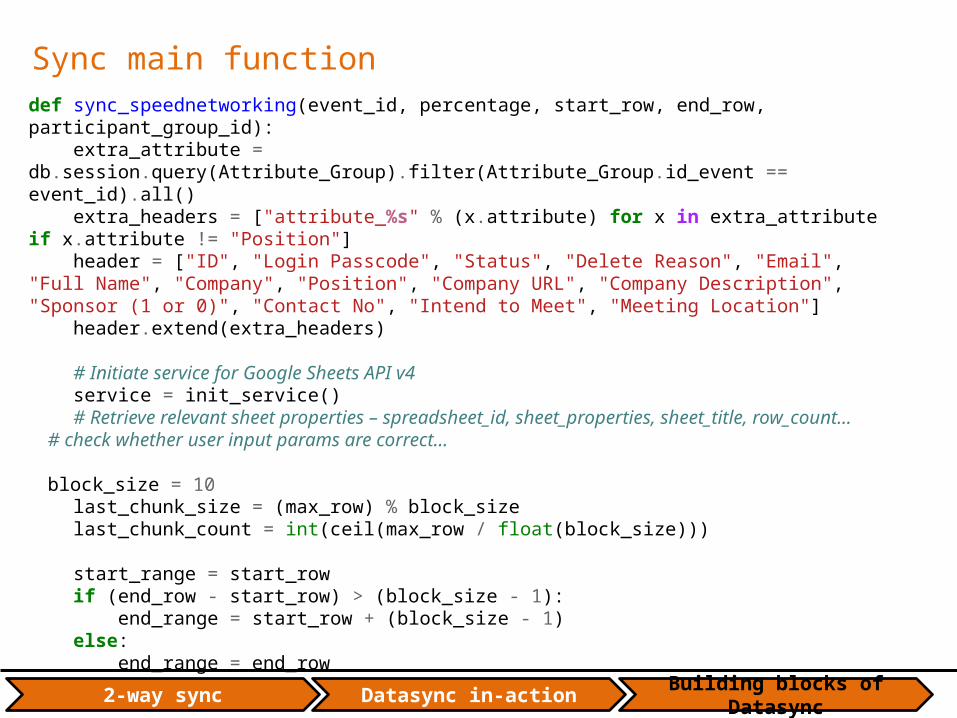
Sync main functiondef sync_speednetworking(event_id, percentage, start_row, end_row, participant_group_id): extra_attribute = db.session.query(Attribute_Group).filter(Attribute_Group.id_event == event_id).all() extra_headers = ["attribute_%s" % (x.attribute) for x in extra_attribute if x.attribute != "Position"] header = ["ID", "Login Passcode", "Status", "Delete Reason", "Email", "Full Name", "Company", "Position", "Company URL", "Company Description", "Sponsor (1 or 0)", "Contact No", "Intend to Meet", "Meeting Location"] header.extend(extra_headers) # Initiate service for Google Sheets API v4 service = init_service() # Retrieve relevant sheet properties – spreadsheet_id, sheet_properties, sheet_title, row_count… # check whether user input params are correct… block_size = 10 last_chunk_size = (max_row) % block_size last_chunk_count = int(ceil(max_row / float(block_size))) start_range = start_row if (end_row - start_row) > (block_size - 1): end_range = start_row + (block_size - 1) else: end_range = end_row
Datasync in-action Building blocks of Datasync2-way sync
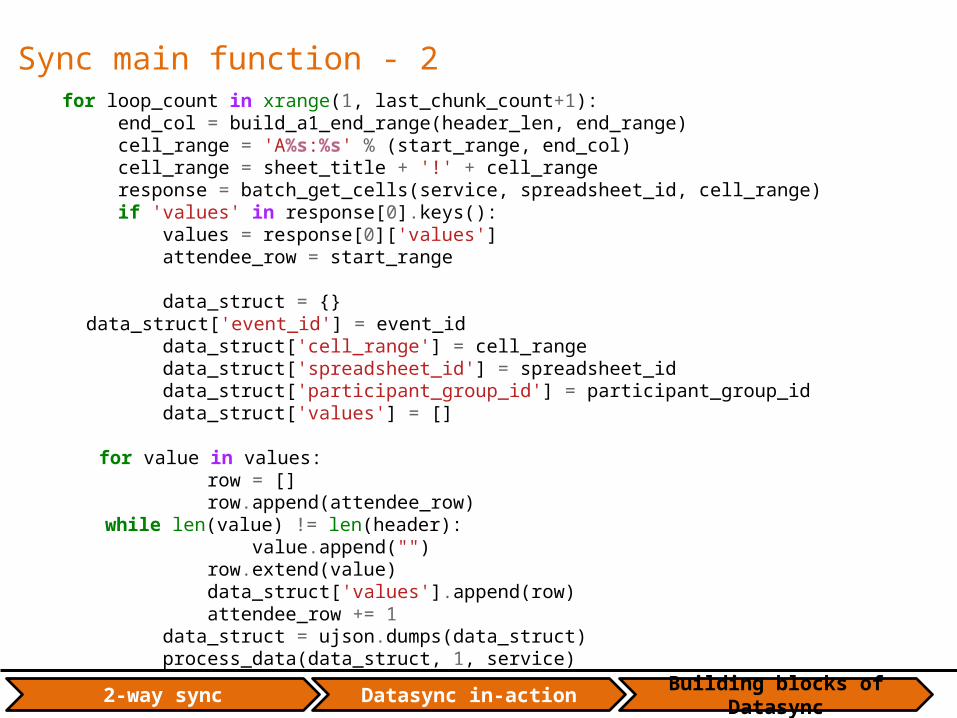
Sync main function - 2 for loop_count in xrange(1, last_chunk_count+1): end_col = build_a1_end_range(header_len, end_range) cell_range = 'A%s:%s' % (start_range, end_col) cell_range = sheet_title + '!' + cell_range response = batch_get_cells(service, spreadsheet_id, cell_range) if 'values' in response[0].keys(): values = response[0]['values'] attendee_row = start_range data_struct = {} data_struct['event_id'] = event_id data_struct['cell_range'] = cell_range data_struct['spreadsheet_id'] = spreadsheet_id data_struct['participant_group_id'] = participant_group_id data_struct['values'] = []
for value in values: row = [] row.append(attendee_row) while len(value) != len(header): value.append("") row.extend(value) data_struct['values'].append(row) attendee_row += 1 data_struct = ujson.dumps(data_struct) process_data(data_struct, 1, service)
Datasync in-action Building blocks of Datasync2-way sync
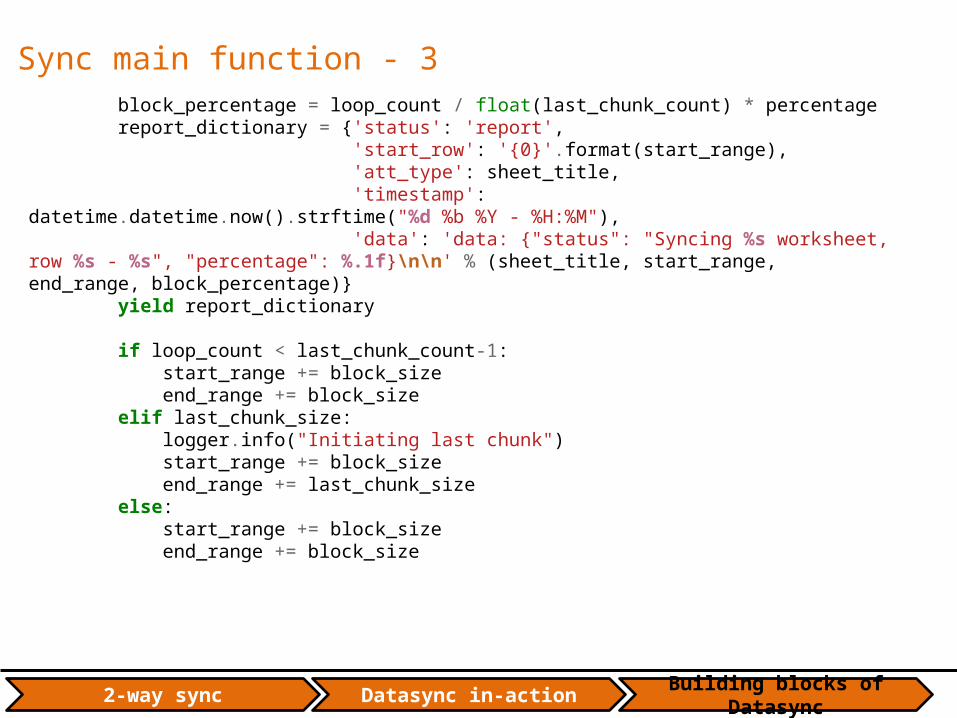
Sync main function - 3 block_percentage = loop_count / float(last_chunk_count) * percentage report_dictionary = {'status': 'report', 'start_row': '{0}'.format(start_range), 'att_type': sheet_title, 'timestamp': datetime.datetime.now().strftime("%d %b %Y - %H:%M"), 'data': 'data: {"status": "Syncing %s worksheet, row %s - %s", "percentage": %.1f}\n\n' % (sheet_title, start_range, end_range, block_percentage)} yield report_dictionary if loop_count < last_chunk_count-1: start_range += block_size end_range += block_size elif last_chunk_size: logger.info("Initiating last chunk") start_range += block_size end_range += last_chunk_size else: start_range += block_size end_range += block_size
Datasync in-action Building blocks of Datasync2-way sync
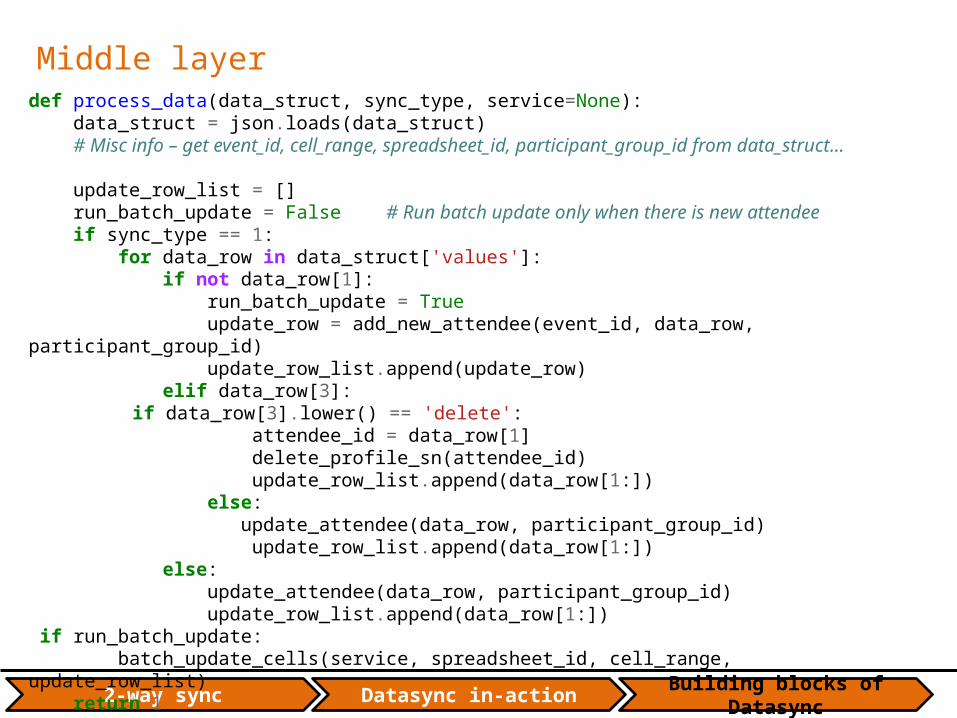
Middle layerdef process_data(data_struct, sync_type, service=None): data_struct = json.loads(data_struct) # Misc info – get event_id, cell_range, spreadsheet_id, participant_group_id from data_struct… update_row_list = [] run_batch_update = False # Run batch update only when there is new attendee if sync_type == 1: for data_row in data_struct['values']: if not data_row[1]: run_batch_update = True update_row = add_new_attendee(event_id, data_row, participant_group_id) update_row_list.append(update_row) elif data_row[3]:
if data_row[3].lower() == 'delete': attendee_id = data_row[1] delete_profile_sn(attendee_id) update_row_list.append(data_row[1:]) else: update_attendee(data_row, participant_group_id) update_row_list.append(data_row[1:]) else: update_attendee(data_row, participant_group_id) update_row_list.append(data_row[1:]) if run_batch_update: batch_update_cells(service, spreadsheet_id, cell_range, update_row_list) return 1

Datasync in-action Building blocks of Datasync2-way sync
SSE with DynamoDB
def create_or_update_ds(event_id, table, report_dictionary):event_id = str(event_id) dumped_json = ujson.dumps(report_dictionary) if table.has_item(EVENT_ID=event_id): item = table.get_item(EVENT_ID=event_id) item["DATASYNC_JSON"] = dumped_json item.save(overwrite=True) else: table.put_item({"EVENT_ID":str(event_id), "DATASYNC_JSON": dumped_json, "EMAILSENDER_JSON":"", "CRM_JSON":""})
Dynamo
DATASYNC BACKENDSENSE

>>> print(conclusion) Let data work for you
Internal data management and analysis Building external tools

Enterprises have historically spent far too little time thinking about what data they should be collecting and how they should be collecting it. Instead of spear fishing, they’ve taken to trawling the data ocean, collecting untold amounts of junk without any forethought or structure. Deferring these hard decisions has resulted in data science teams in large enterprises spending the majority of their time cleaning, processing and structuring data with manual and semi-automated methods.
Enterprises Don’t Have Big Data, They Just Have Bad Data– Jeremy Levy, Techcrunch

Questions






























