Embed Size (px)
Citation preview

Cassandra et Sparkpour gérer la musique On-line
16 Juin 2015 @ Paris
Hammed RAMDANIArchitecte SI 3.0 et [email protected]+33 6 80 22 20 70

2
Appelez-moi Hammed ;-)
(Sidi Mo)Hammed Ramdani
@smramdani
• Consultant chez
• Architecte SI 3.0 et BigData
• Trained Pig & Hive developer
• Coach Agile
• Innovation Games trained facilitator
• Speaker

3
Dream BIG and make IT happen !
PALO IT est un cabinet de conseil en stratégie d’innovation et réalisation numérique. Notre approche : Insuffler un esprit de Start-up; Identifier les technologies et les usages créateurs de nouveaux business
models; Accélérer votre Go-To-Market par l’adoption d’une organisation Lean &
Agile.
Créée en 2009, PALO IT regroupe une communauté de 160 talents de plus de 20 nationalités, passionnés par l’Agilité et l’Open Source.
PALO IT est une société apprenante et audacieuse qui se distingue par sa forte culture Projet. L’esprit entrepreneurial, le fun, le partage de connaissances, le sens client et la simplicité constituent ses valeurs centrales.

4
PALO IT en quelques chiffres
160collaborateurs
40grands comptes
+50%croissance organique/an
5bureaux

Cassandra et Sparkpour que vive la
musique On-line !
Un projet en cours …

6
…
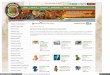
Nos clients …
7
Notre vrai client
… Client
Collecte des droits musicaux
Redistribution
DSP« Digital Service Providers »
Créateurs etayants droits
8
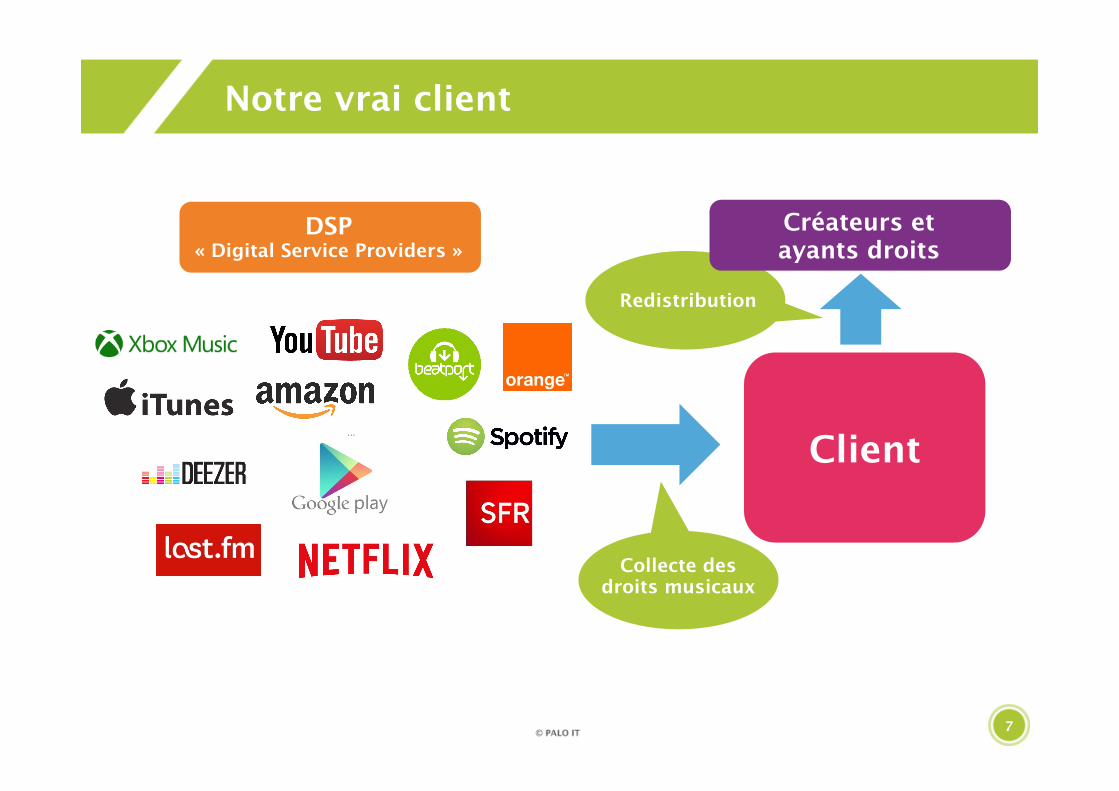
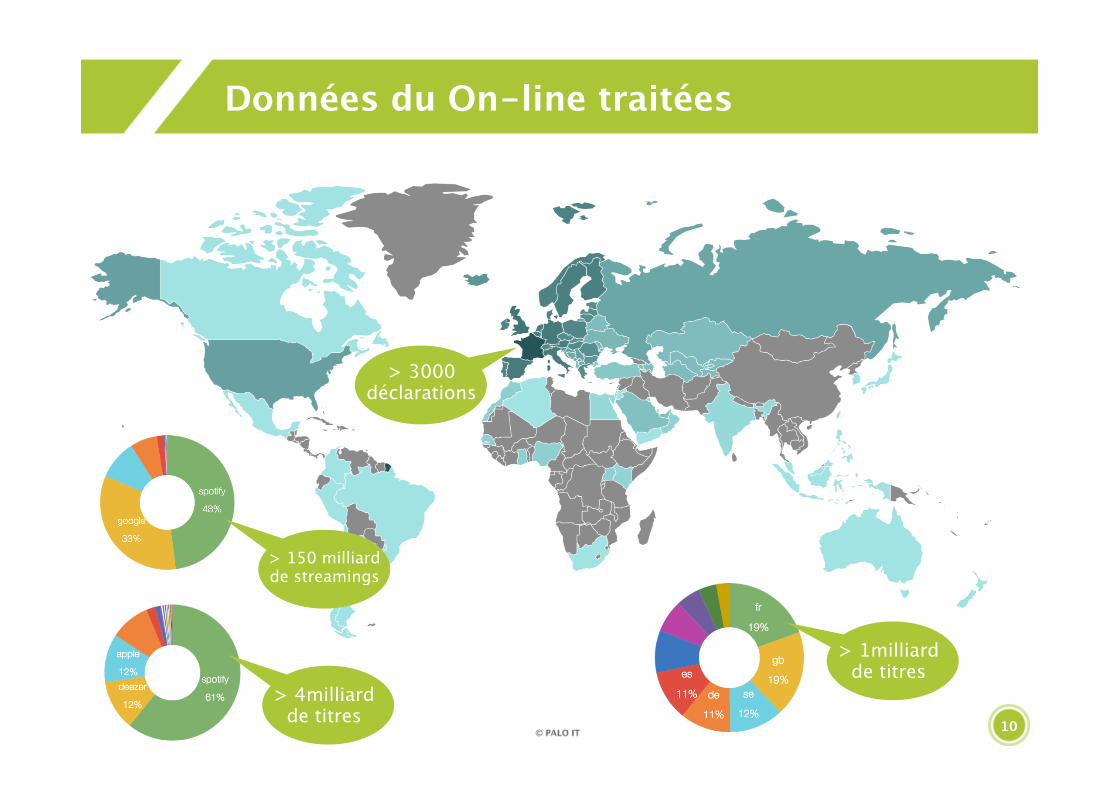
Données du On-line traitées
> 3000déclarations
9
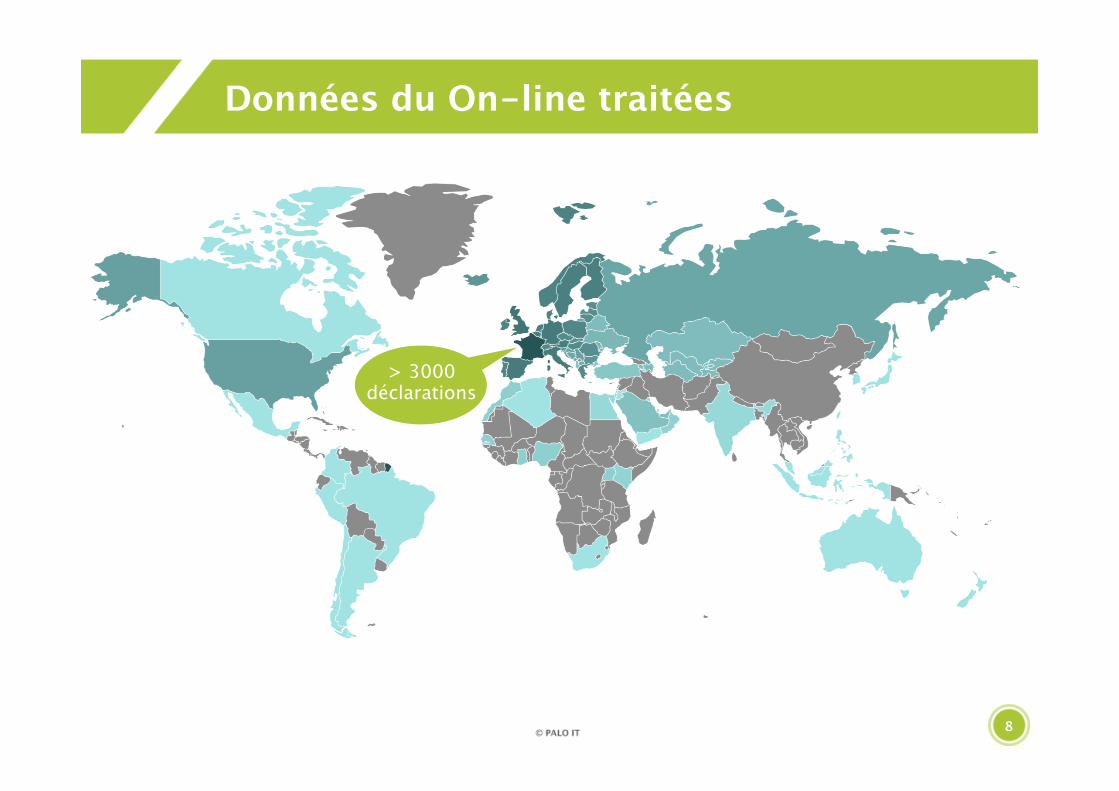
Données du On-line traitées
> 3000déclarations
> 1milliard de titres
10
Données du On-line traitées
> 3000déclarations
> 1milliard de titres
> 4milliard de titres
> 150 milliard de streamings

11
Pas seulement le On-line !
…
Client
Collecte des droits musicaux
Redistribution
DSP« Digital Service Providers »
Créateurs etayants droits
Média et supports traditionnels
12
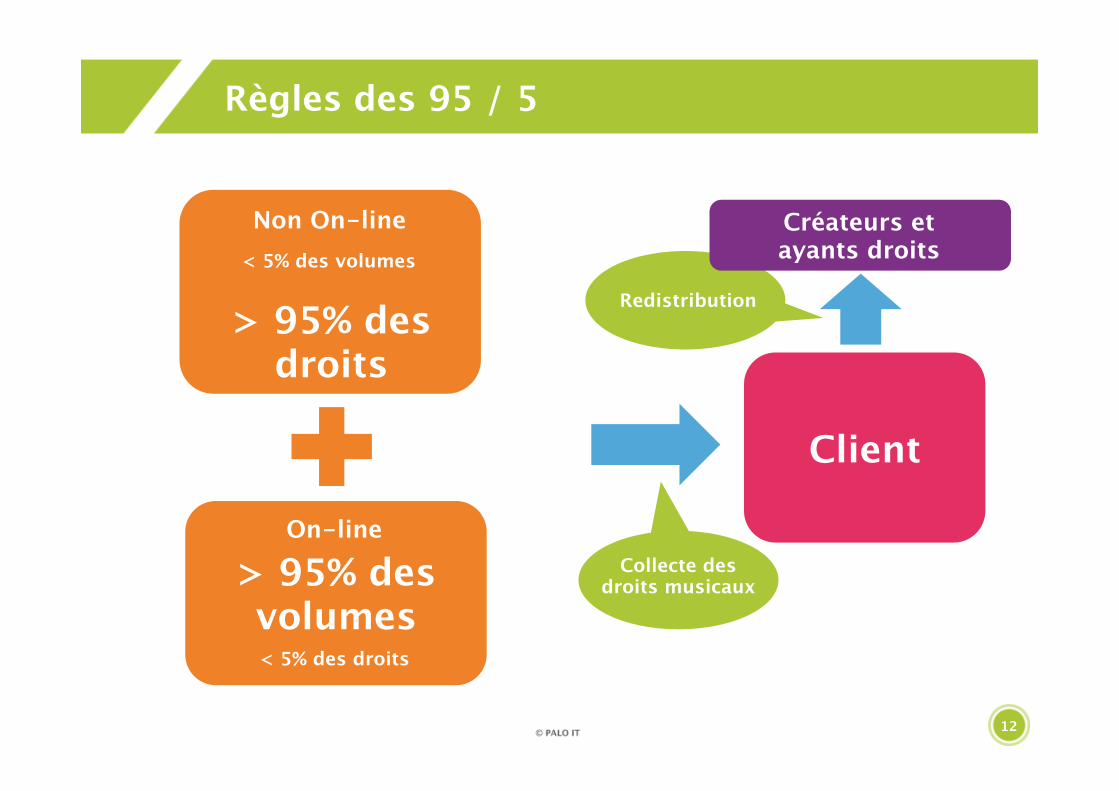
Règles des 95 / 5
Client
Collecte des droits musicaux
Redistribution
On-line
Créateurs etayants droits
Non On-line
< 5% des droits
> 95% des droits
< 5% des volumes
> 95% des volumes

13
Marché en évolution
Client
Collecte des droits musicaux
Redistribution
On-line
Créateurs etayants droits
Non On-line
< 5% des droits
> 95% des droits
< 5% des volumes
> 95% des volumes
14
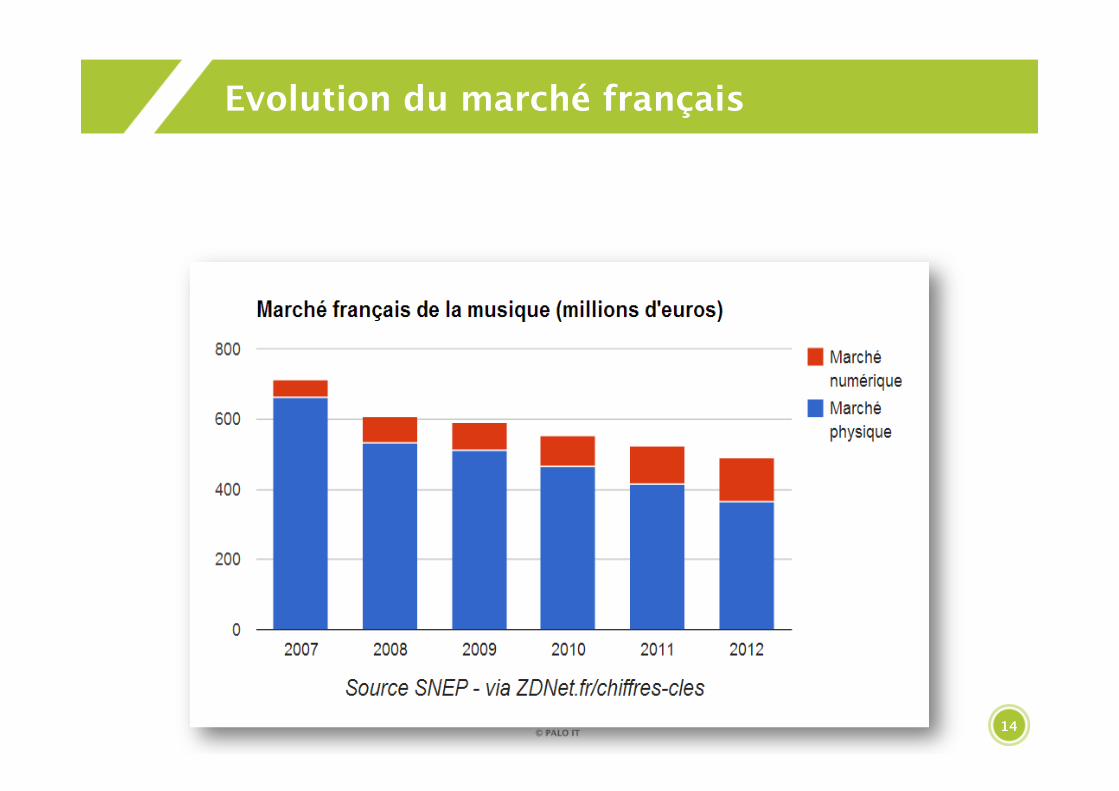
Evolution du marché français

15
Téléchargement vs Streaming

16
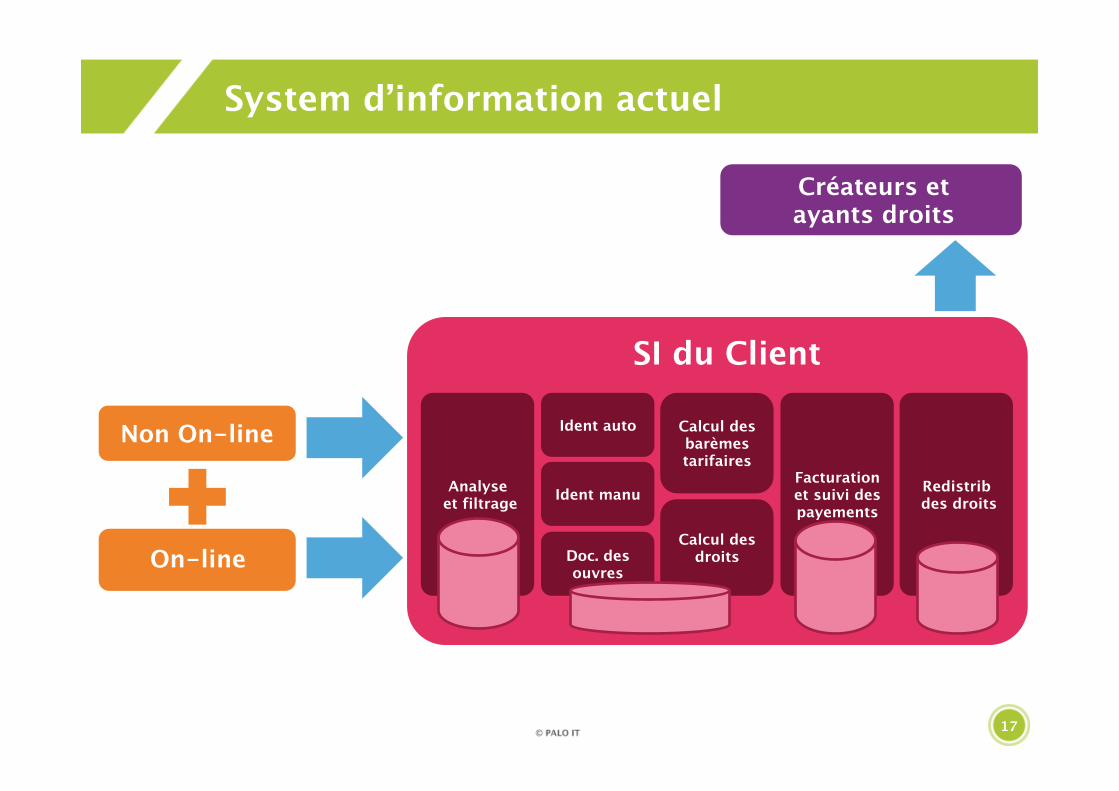
System d’information actuel
Non On-line
Créateurs etayants droits
On-line
SI du Client
Analyse et filtrage
Ident auto Calcul des barèmes tarifaires
Ident manu
Doc. des ouvres
Calcul des droits
Facturation et suivi des payements
Redistrib des droits
17
System d’information actuel
Créateurs etayants droits
SI du Client
Analyse et filtrage
Ident auto Calcul des barèmes tarifaires
Ident manu
Doc. des ouvres
Calcul des droits
Facturation et suivi des payements
Redistrib des droits
Non On-line
On-line

18
System d’information actuel
Créateurs etayants droits
SI du Client
Analyse et filtrage
Ident auto Calcul des barèmes tarifaires
Ident manu
Doc. des ouvres
Calcul des droits
Facturation et suivi des payements
Redistrib des droits
Non On-line
On-line

19
System d’information actuel
Redistribution
Créateurs etayants droits
SI du Client
Analyse et filtrage
Ident auto Calcul des barèmes tarifaires
Ident manu
Doc. des ouvres
Calcul des droits
Facturation et suivi des payements
Redistrib des droits
IHM IHM IHM IHM IHM
Non On-line
On-line
20
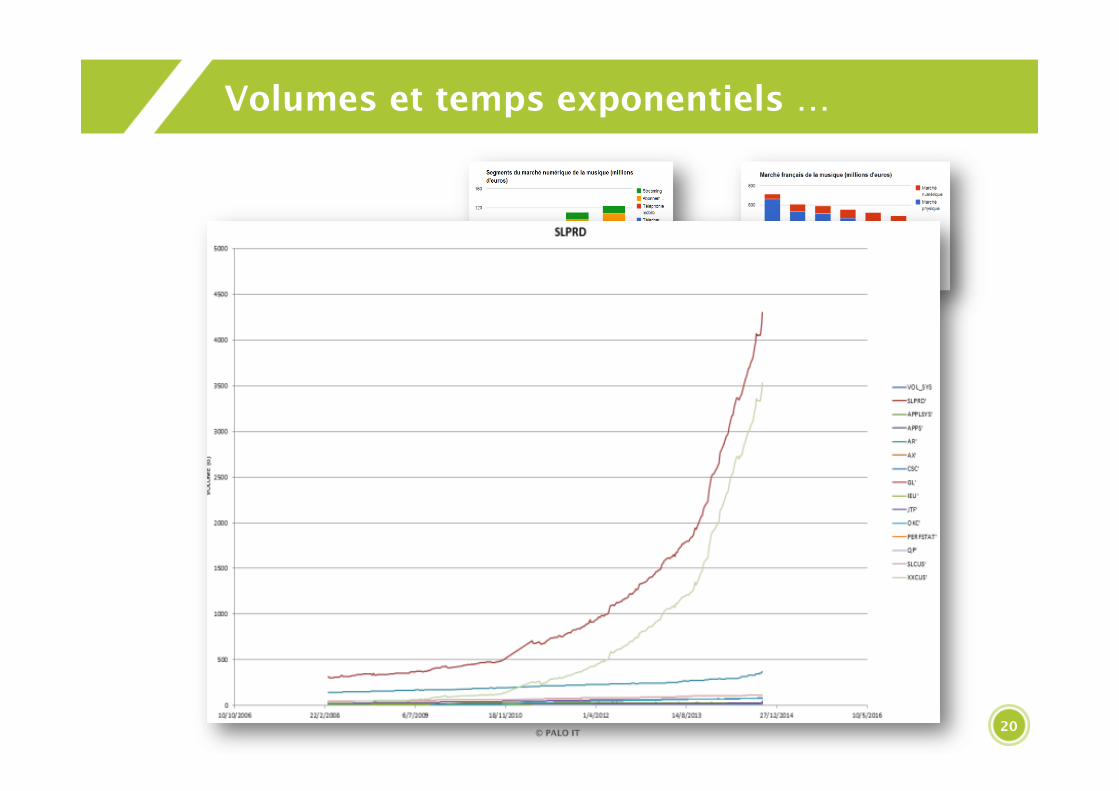
Volumes et temps exponentiels …
21
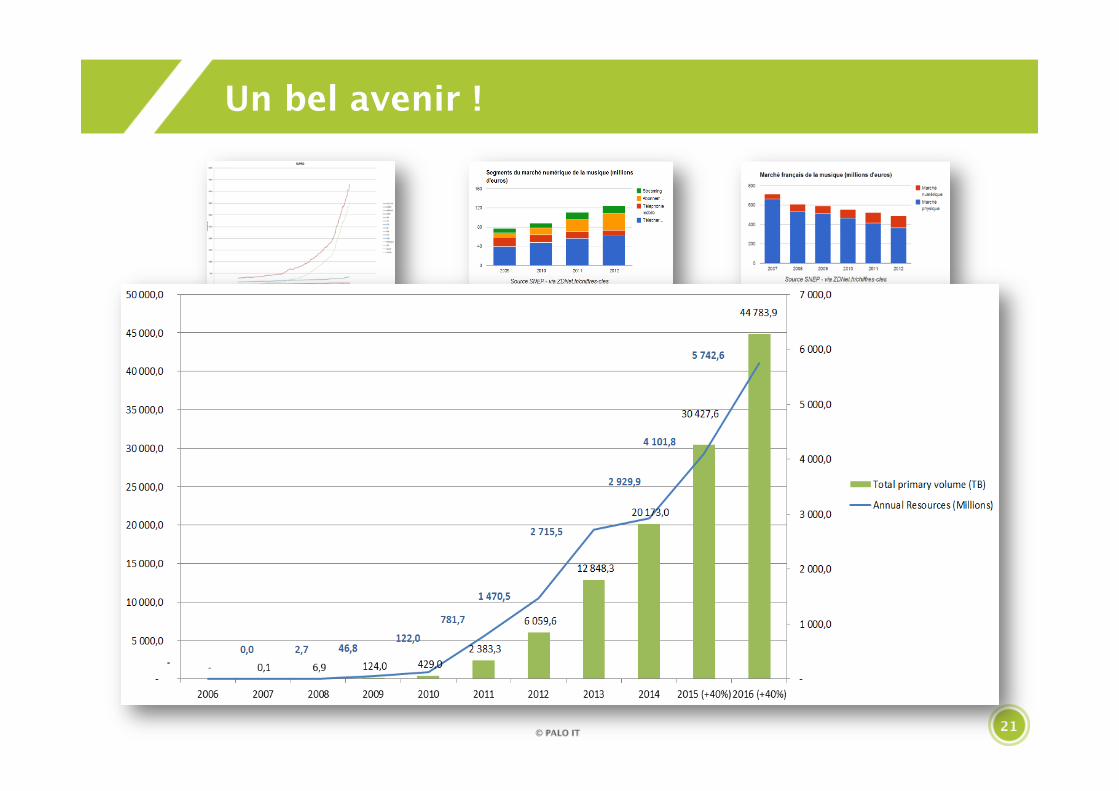
Un bel avenir !

22
Solution
Créateurs etayants droits
SI du Client
Analyse et filtrage
Ident auto Calcul des barèmes tarifaires
Ident manu
Doc. des ouvres
Calcul des droits
Facturation et suivi des payements
Redistrib des droitsNon On-line
On-line
Vision 360° Dashboards Search & analytics
Process mgmt
Nouvservices
Gisement BigData
Process Workflow en Streaming

23
BigData, Streaming et Cloud
Créateurs etayants droits
SI du Client
Analyse et filtrage
Ident auto Calcul des barèmes tarifaires
Ident manu
Doc. des ouvres
Calcul des droits
Facturation et suivi des payements
Redistrib des droitsNon On-line
On-line
Vision 360° Dashboards Search & analytics
Process mgmt
Nouvservices
Gisement BigData
S1 S2 S3 S4 SX SY SZ
24
WebBack-end
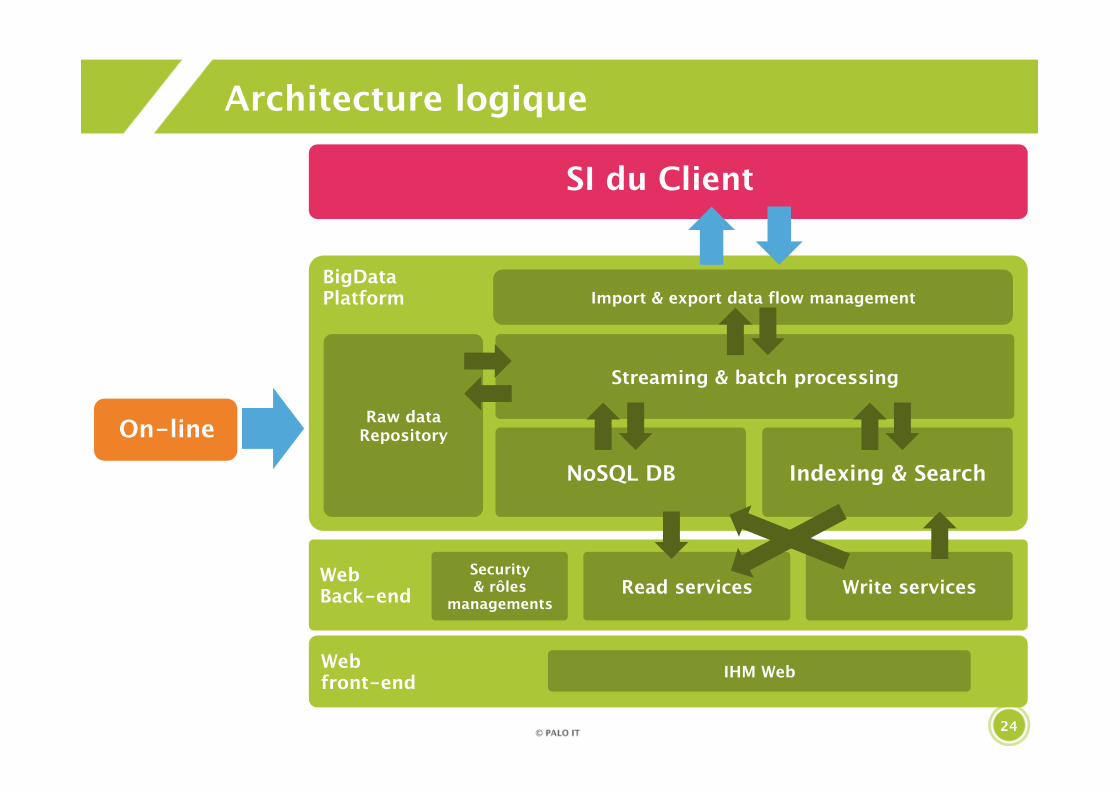
Architecture logique
SI du Client
On-line
BigDataPlatform
Web front-end IHM Web
Import & export data flow management
Read services Write servicesSecurity& rôles
managements
Streaming & batch processing
Indexing & Search
Raw dataRepository
NoSQL DB
25
WebBack-end
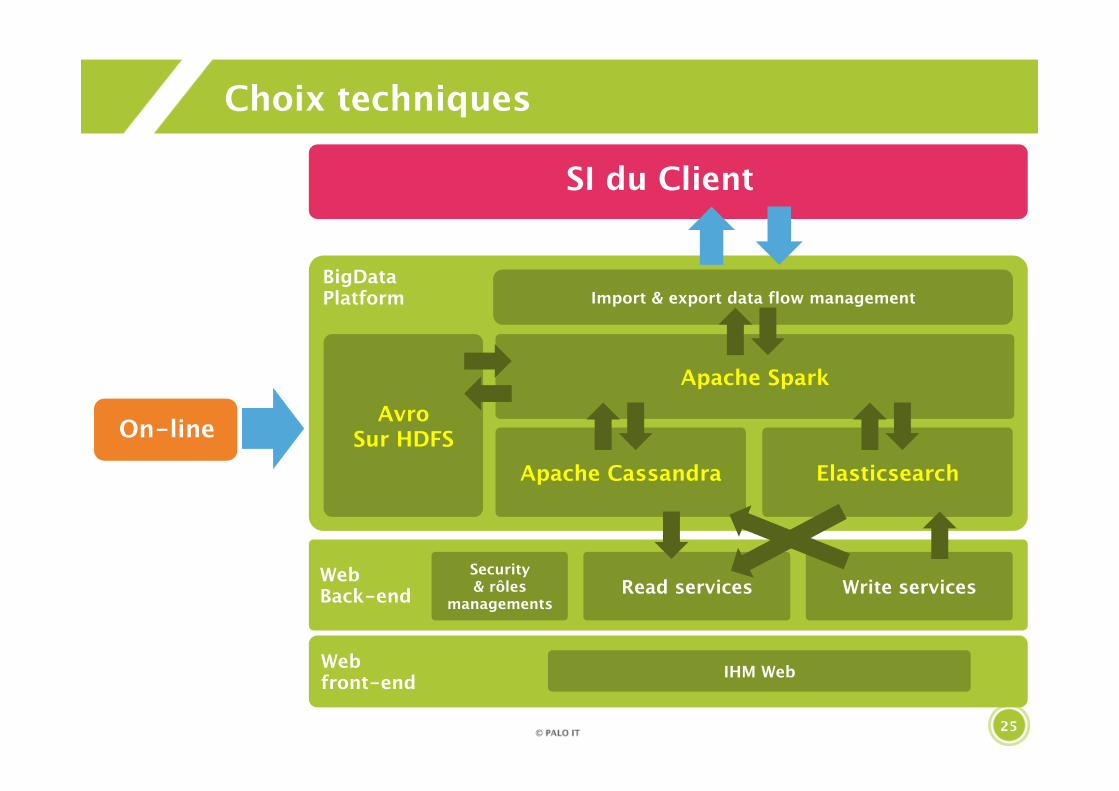
Choix techniques
SI du Client
On-line
BigDataPlatform
Web front-end IHM Web
Import & export data flow management
Read services Write servicesSecurity& rôles
managements
Apache Spark
Elasticsearch
Avro Sur HDFS
Apache Cassandra

26
• Scalabilité linéaire
• Haute dispos + Distribuée + Consistance « tunable » (CAP : 2,5/3 ;-)
• Gestion de gros volumes (> 10To)
• Faible latence en lecture et en écriture (~<10ms)
• BD NoSQL mature avec des utilisateurs de référence (eBay, Apple, etc.)
• Outillée pour les clusters de production (Rack + DC management, etc)
• Modèle de données riche + langage CQL
• Projet Open sources Apache
• Support et formation assurés par DataStax
Le choix Cassandra

27
Limites à prendre en compte :
• Pas de select … where (non clé) (opérateur <> =) (group by) (order by)
• Pas de count(…)
• Pas de jointures
• Pas de contraintes d’intégrité
• Pas de transactions : sauf if (not) exists
• Pas de « Proc Stock »
• Indexes secondaires à utiliser avec « grande » modération
Le choix Cassandra
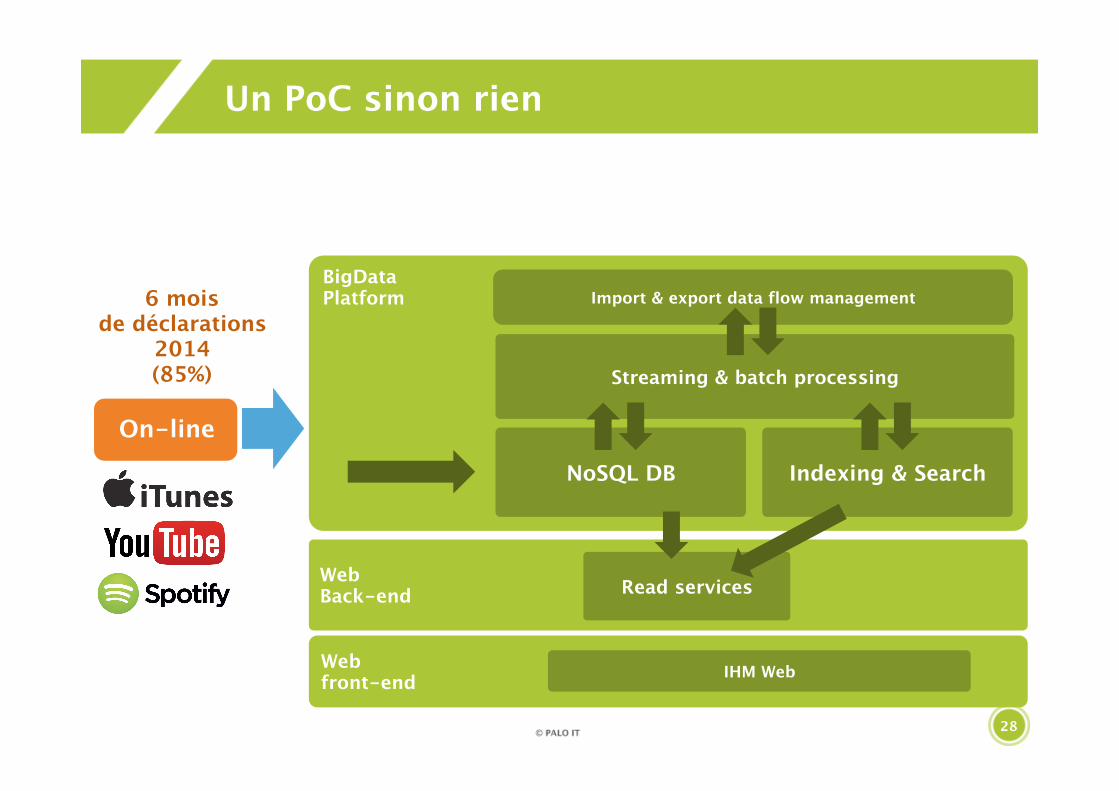
28
Un PoC sinon rien
WebBack-end
On-line
BigDataPlatform
Web front-end IHM Web
Import & export data flow management
Read services
Streaming & batch processing
Indexing & SearchNoSQL DB
6 mois de déclarations
2014(85%)

29
Infrastructure du PoC
Hadoop Cluster
CassandraNode 3
CassandraNode 5
CassandraNode 4
CassandraNode 6
Hadoop SparkNode 1
ESNode 1
ESNode 2
Web App+ Monitoring
Node 2
Frontend Applications & Monitoring
ESNode 8
Elasticsearch Cluster
CassandraNode 9
CassandraNode 10
ESNode 7
HadoopSparkNode 2
1CPU-8Cores32GB RAM2 x 3TB HD
OVH Cloude Plateforme : 10 x Nodes
NoSQL DB

30
PoC Agile

31
Planning du PoC
2014 2015
Sprints November December January W44 W45 W46 W47 W48 W49 W50 W51 W52 W1 W2 W3 W4 W5 W6 W7
Sprint #1
Sprint #2
Sprint #3
Sprint #4
Sprint #5 Sprint #6
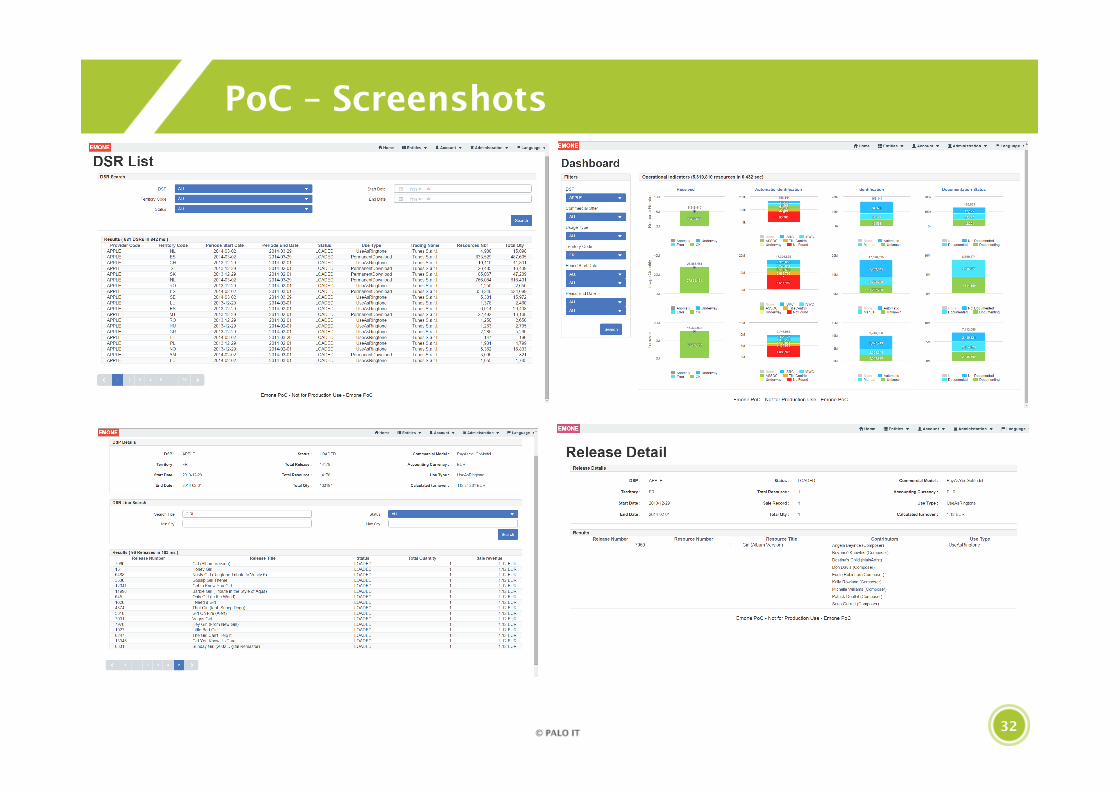
32
PoC – Screenshots
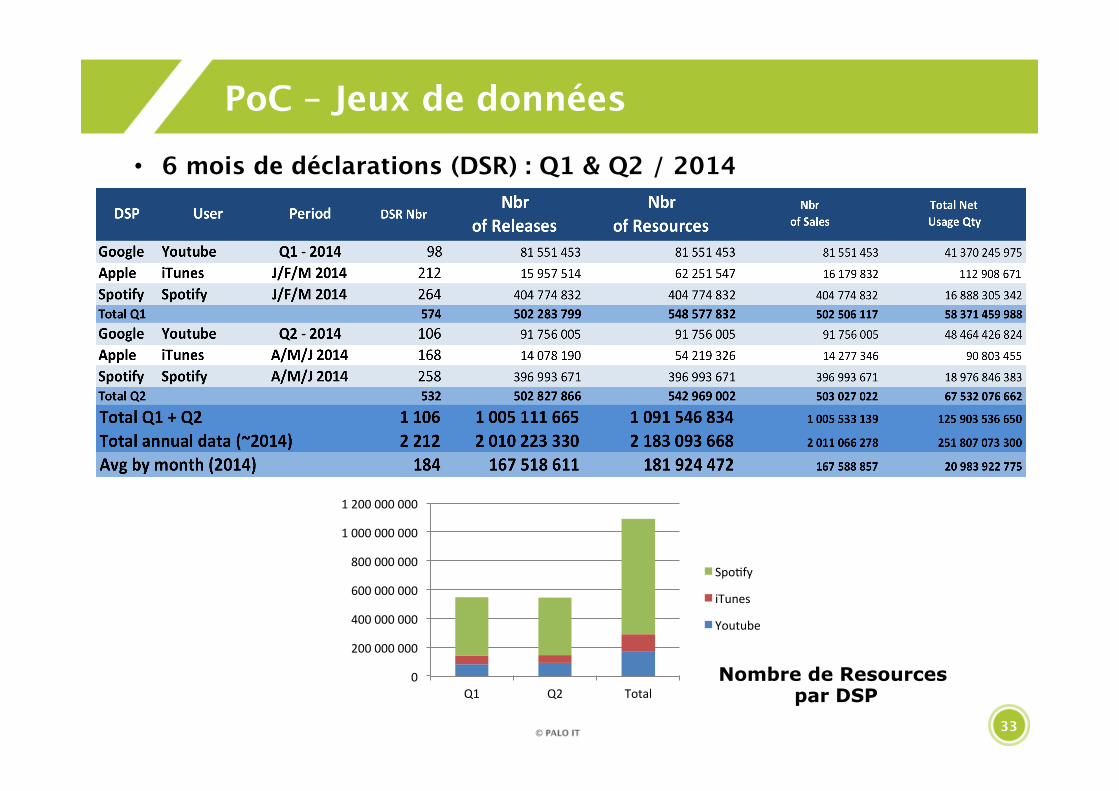
33
PoC – Jeux de données
• 6 mois de déclarations (DSR) : Q1 & Q2 / 2014
0
200 000 000
400 000 000
600 000 000
800 000 000
1 000 000 000
1 200 000 000
Q1 Q2 Total
Spo4fy
iTunes
Youtube
Nombre de Resources par DSP

34
PoC – Modèle de données
NoSQL Data Model Cassandra
DSP
DSR
Release
Resource
DSR
Release
Sale Resource
Search & Analytics Elasticsearch
Sale
DSR By Status
Resource By Status
Resource Data
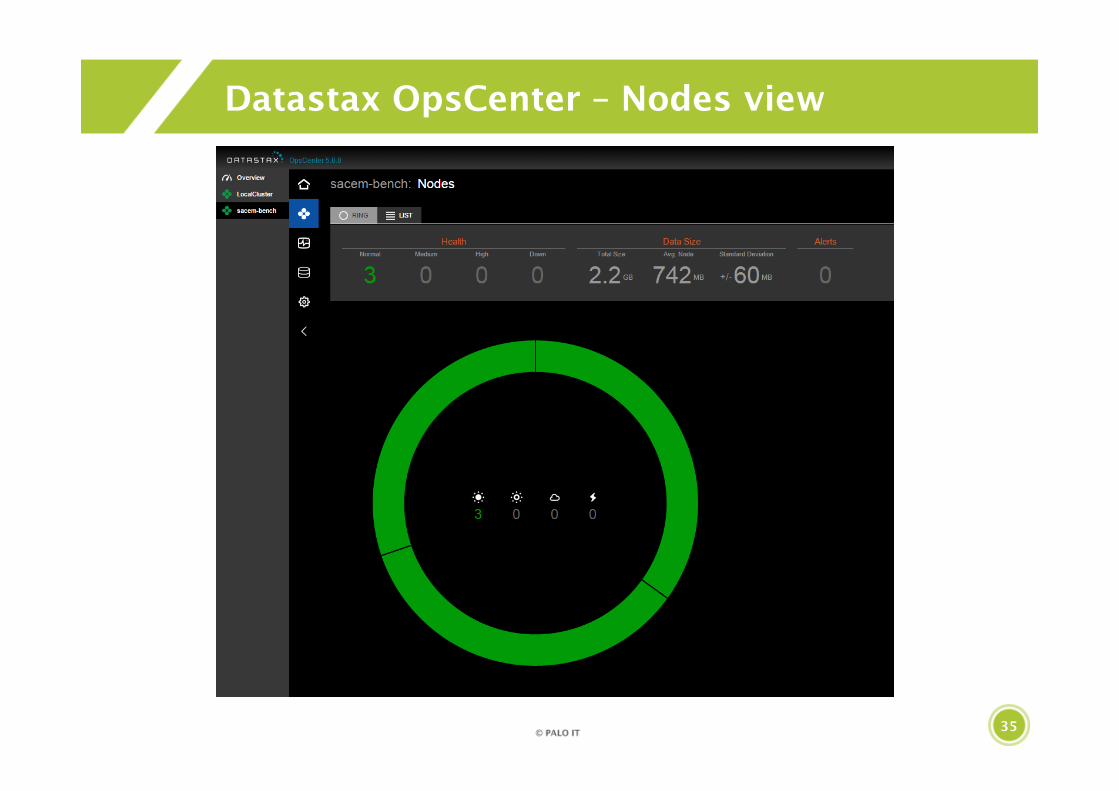
35
Datastax OpsCenter – Nodes view
36
Datastax OpsCenter - Dashboard

37
PoC – Mesures
• Benchmark du temps de chargement Cassandra
0,00
1,00
2,00
3,00
4,00
5,00
6,00
7,00
8,00
3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32
Loading forcast with a month* of DSR
13 nodes needed to load 1 month of DSR in 2 days
*1 month of DSR = 450 000 000 of resources

38
PoC – Mesures
• Benchmark du temps de chargement Cassandra Avec disques SATA 2 x 3To en RAID0 Node inserts / sec 156 Cluster size (nodes) 3 4 5 6 7 8 9 10 Cluster resources / h 1 684 800 2 246 400 2 808 000 3 369 600 3 931 200 4 492 800 5 054 400 5 616 000 Cluster resources / day 40 435 200 53 913 600 67 392 000 80 870 400 94 348 800 107 827 200 121 305 600 134 784 000
Cassandra cluster size 6 Nodes (servers) Resources / h 3 369 600 res/h Resources / day 80 870 400 res/day Total resources in 2014 ~ 3 000 Millions Resources by month in 2014 ~ 250 Millions Total month DSR loading Qme 3,09 Days Total month DSR loading Qme 74,19 h

39
PoC concluant, mais…Quelques enseignements :• A haut débit, les inserts de grands enregistrements « dé-normalisés » sont à proscrire• Les updates fréquents de grands enregistrements sont interdits ! • Limitations fortes sur les IO disques (sur les machines utilisées)• Enlever le RAID1 ;-)• Le tuning VM est crucial (MAX_HEAP_SIZE, HEAP_NEWSIZE, etc) *• D’autres Params peuvent aider (CONCURRENT_READS, CONCURRENT_WRITES,
MEMTABLE_TOTAL_SPACE) *• Pénalisation des serveurs Cassandra lors des compactions• Les écritures en batch n’améliorent pas la situation, au contraire 8-(• Les écritures asynchrones, pas mieux !• Sur un système aux limites, contrôler le débit en amont !• Envisager les disques SSD
(*) Merci Duy Hai et Datastax

40
Et la suite
• Test avec disques SSD très concluants
• Re-modélisation :• Dé-normalisation à bon escient
• Garder les tables petites
• Séparation des données « statiques » des données « dynamiques »
• Gestion de tables par « Status » avec bucketing si nécessaire
• Encore plus d’intégration entre Spark et Cassandra :• Connecteur Cassandra Spark amélioré
• Fonctions de partitionnement pour co-localisation les traitements

41
Mesures SATA vs SSD
• Nouveaux benchmarks du temps de chargement Cassandra
Amélioration x ~50
Avec disques SATA 2 x 3To en RAID0 Node inserts / sec 156 Cluster size (nodes) 3 4 5 6 7 8 9 10 Cluster resources / h 1 684 800 2 246 400 2 808 000 3 369 600 3 931 200 4 492 800 5 054 400 5 616 000 Cluster resources / day 40 435 200 53 913 600 67 392 000 80 870 400 94 348 800 107 827 200 121 305 600 134 784 000
Cassandra cluster size 6 Nodes (servers) Resources / h 3 369 600 res/h Resources / day 80 870 400 res/day Total resources in 2014 ~ 3 000 Millions Resources by month in 2014 ~ 250 Millions Total month DSR loading Qme 3,09 Days Total month DSR loading Qme 74,19 h
Avec disques SSD 4 x 800Go (1 SSD pour les CommitLogs + 3 SSD pour les SSTables) Node inserts / sec 7 407 47 x SATA Cluster size (nodes) 3 4 5 6 7 8 9 10 Cluster resources / h 80 000 000 106 666 667 133 333 333 160 000 000 186 666 667 213 333 333 240 000 000 266 666 667 Cluster resources / day 1 920 000 000 2 560 000 000 3 200 000 000 3 840 000 000 4 480 000 000 5 120 000 000 5 760 000 000 6 400 000 000
Cassandra cluster size 6 Nodes (servers) Resources / h 160 000 000 res/h Resources / day 3 840 000 000 res/day Total resources in 2014 ~ 3 000 Millions Resources by month in 2014 ~ 250 Millions Total month DSR loading Qme 0,07 Days Total month DSR loading Qme 1,56 h Total month DSR loading Qme 93,75 min
0
100000000
200000000
300000000
3 4 5 6 7 8 9 10
SATA disks (Res/h)
SSD disks (Res/h)

42
Modèle de données cible …

43
Merci pour votre attention !