Embed Size (px)
Citation preview

Hadoop use case: A scalable vertical search engine
Iván de Prado Alonso, Datasalt Co-founder Twitter: @ivanprado

Content
§ The problem § The obvious solution § When the obvious solution fails… § … Hadoop comes to the rescue § Advantages & disadvantages § Improvements
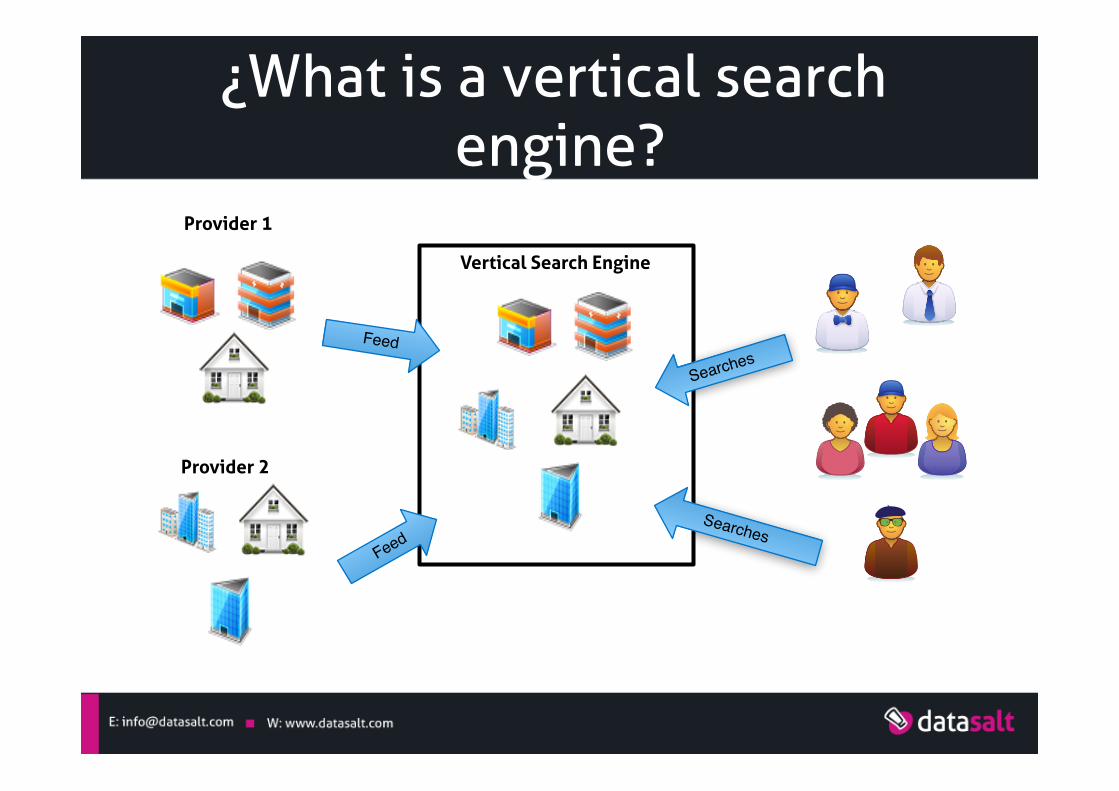
¿What is a vertical search engine?
Vertical Search Engine
Provider 1
Provider 2
Feed
Feed
Searches
Searches

Some of them
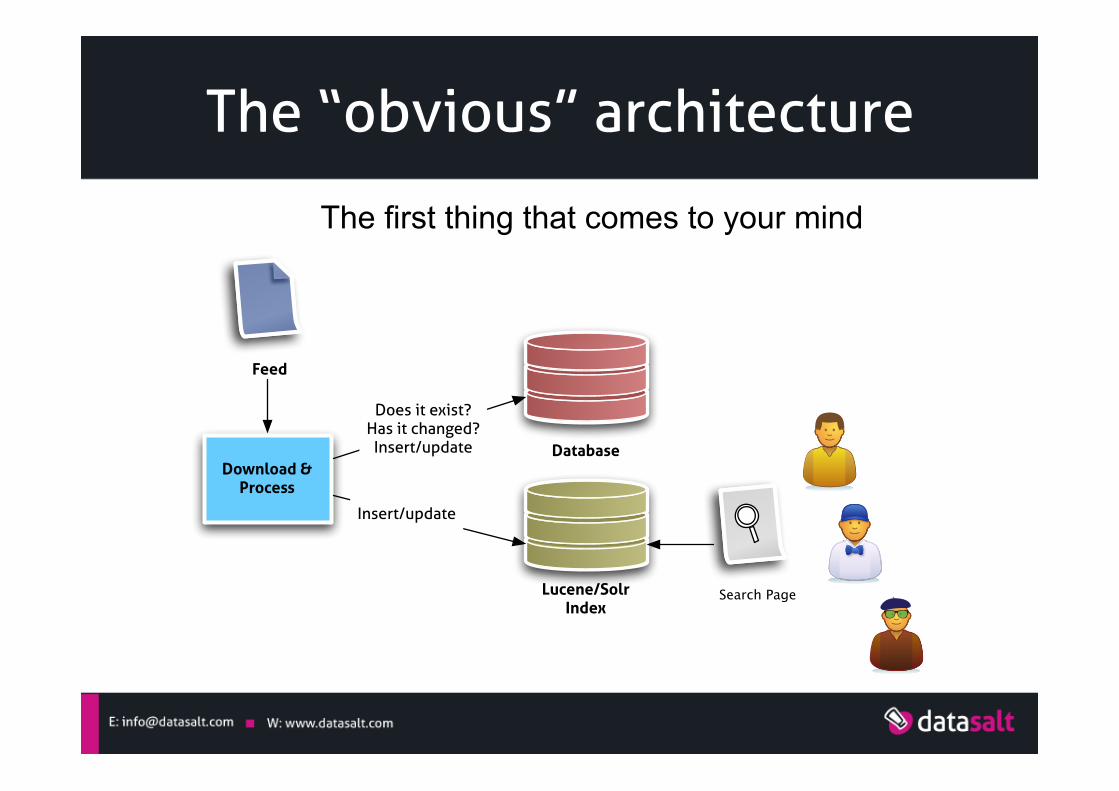
The “obvious” architecture
The first thing that comes to your mind
Database
Feed
Lucene/SolrIndex
Search Page
Download & Process
Does it exist?Has it changed?Insert/update
Insert/update

How it works
§ Feed download § For every register in the feed
• Check for existence in the DB • If it exists and has changed, update
ª The DB ª The Index
• If it doesn’t exist, insert into ª The DB ª The Index

How it works (II)
§ The Database is used for • Checking for register existence (avoiding
duplicates) • Managing the data with SQL facility
§ Lucene/Solr is used for • Quick searches • Searching by structured fields • Free-text searches • Faceting

But if things go well...…
Feed
Feed
Feed
Feed
Feed
Feed
Feed
Feed Feed
Feed
Feed
Feed
FeedFeed
Feed
Feed
Feed
FeedFeed
Feed
Feed
Feed
Feed
Feed
Feed
Feed
Feed
Feed
Feed
Feed
FeedFeed
Feed
Feed
Feed

Huge jam!

“Swiss army knife of the 21st century”
Media Guardian Innovation Awards
http://www.guardian.co.uk/technology/2011/mar/25/media-guardian-innovation-awards-apache-hadoop

Hadoop
“The Apache Hadoop software library is a
framework that allows for the distributed processing
of large data sets across clusters of computers using
a simple programming model”
From Hadoop homepage

File System
§ Distributed File System (HDFS) • Cluster of nodes exposing their storage
capacity • Big blocks: 64 Mb • Fault tolerant (replication) • Big files storage

MapReduce
§ Two functions (Map y Reduce) • Map(k, v) : [z,w]* • Reduce(z, w*) : [u, v]*
§ Example: word count • Map([document, null]) -> [word, 1]* • Reduce(word, 1*) -> [word, total]
§ MapReduce & SQL • SELECT word, count(*) GROUP BY word
§ Distributed execution on a cluster § Horizontal scalability

Ok, that’s cool, but… ¿How does it solve my problem?

Because…
§ Hadoop is not a Database § Hadoop “apparently” only
processes data § Hadoop does not allow “lookups”
Hadoop is a paradigm shift difficult to assimilate
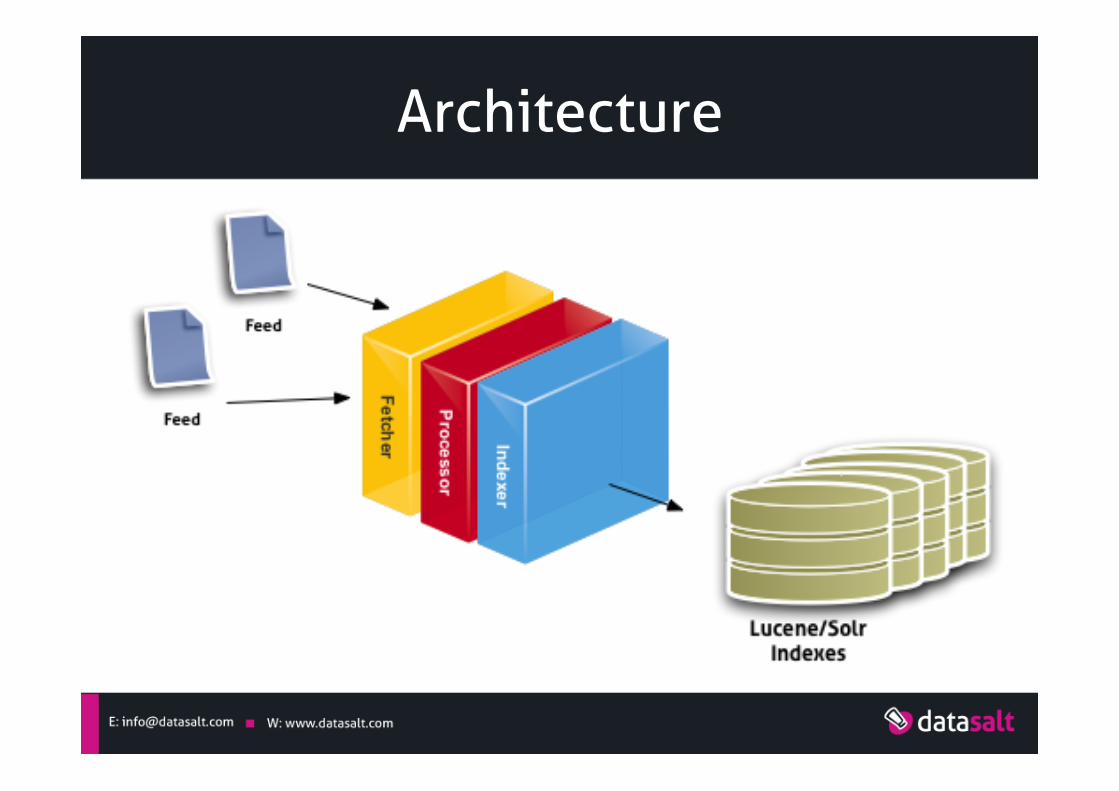
Architecture

Philosophy
§ Always reprocess everything. ¡EVERYTHING! § ¿Why?
• More bug tolerant • More flexible • More efficient. E.g.:
ª With a 7200 RPM HD – Random IOPS – 100 – Sequencial Read/Write – 40 MB/s – Hypothesis: 5 Kb register size
ª … it is faster to rewrite all data than to perform random updates when more than 1.25% of the registers has changed.
– 1 GB, 200.000 registers » Sequential writing: 25 sg » Random writing: 33 min!
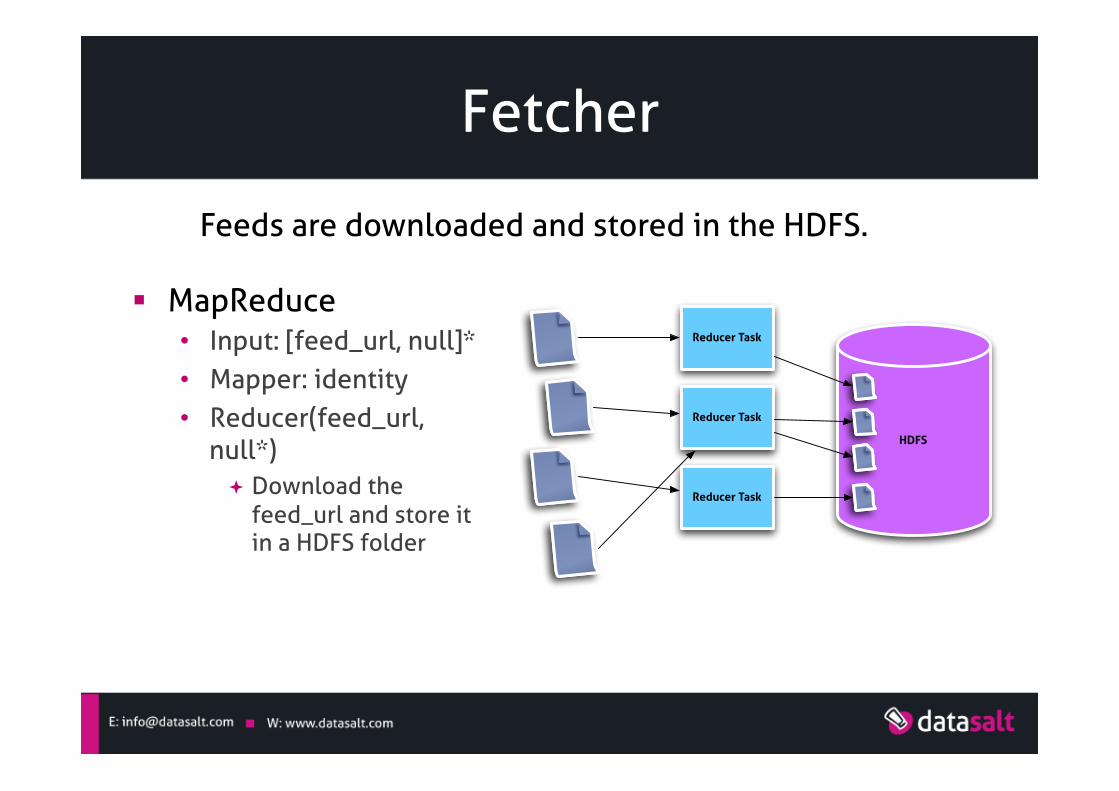
Fetcher
§ MapReduce • Input: [feed_url, null]* • Mapper: identity • Reducer(feed_url,
null*) ª Download the
feed_url and store it in a HDFS folder
Feeds are downloaded and stored in the HDFS.
Reducer Task
Reducer Task
Reducer Task
HDFS

Processor
§ MapReduce • Input: [feed_path, null]* • Map(feed_path, null) : [id, documents]*
ª The feed is parsed and converted into documents
• Reducer(id, [document]*): [id, document] ª Receives a list of documents and keeps the most
recent one (deduplication) ª A unique and global identifier is required
(idProvider + idInternal)
• Output: [id, document]*
Feeds are parsed, converted into documents and deduplicated

Processor (II)
§ Possible problem: • Very large feeds
ª Does not scale, as one task will deal with the full feed.
§ Solution • Write a custom InputFormat that divides
the feed in smaller pieces.

Serialization
§ Writables • Native Hadoop Serialization • Low level API • Basic types: IntWritable, Text, etc.
§ Others • Thrift, Avro, Protostuff • Backwards compatibility
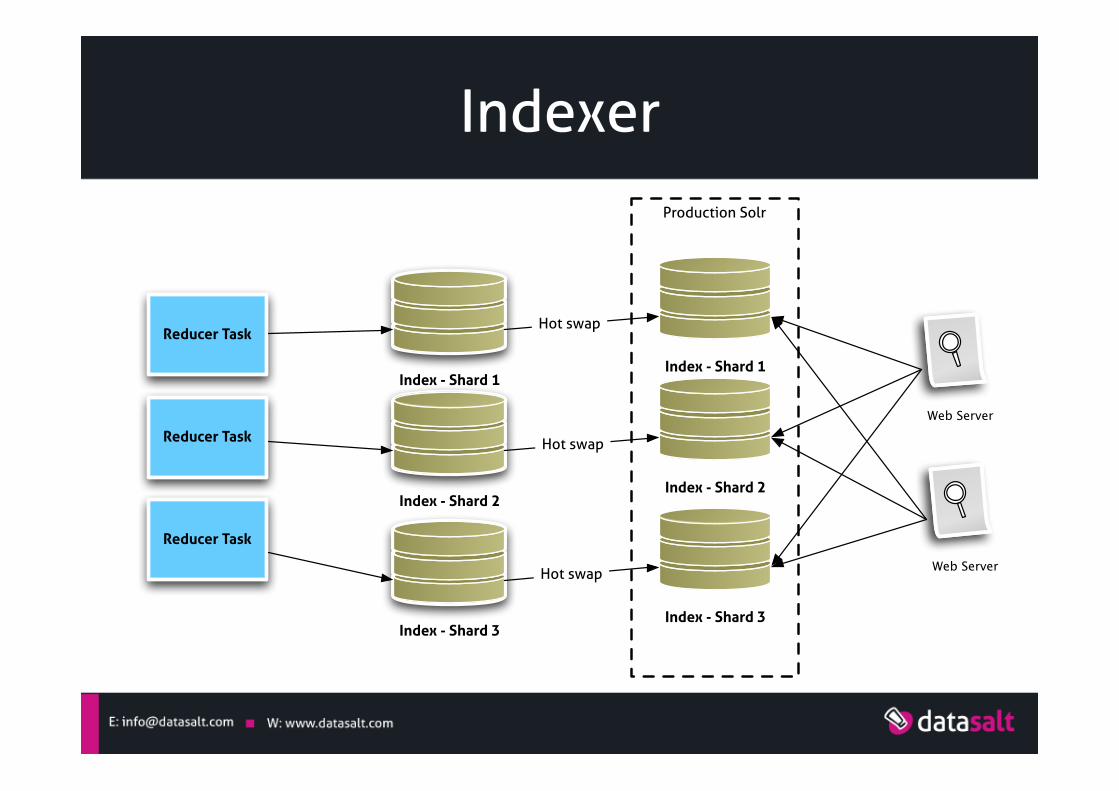
Indexer Production Solr
Reducer Task
Reducer Task
Reducer Task
Index - Shard 1
Index - Shard 2
Index - Shard 3
Index - Shard 1
Index - Shard 2
Index - Shard 3
Hot swap
Hot swap
Hot swap
Web Server
Web Server

Indexer (II)
§ SOLR-1301 • https://issues.apache.org/jira/browse/SOLR-1301 • SolrOutputFormat • 1 index per reducer • A custom Partitioner can be used to control where to
place each document § Another option
• Writing your own indexation code ª By creating a custom output format ª By Indexing at the reducer level. In each reduce call:
– Open an index – Write all incoming registers – Close the index

Search & Partitioning
§ Different partitioning schemas • Horizontal
ª Each search involves all shards
• Vertical: by ad type, country, etc. ª Searches can be restricted to the involved shard
§ Solr for index serving. Possibilities: ª Non federated Solr
– Only for vertical partitioning ª Distributed Solr ª Solr Cloud
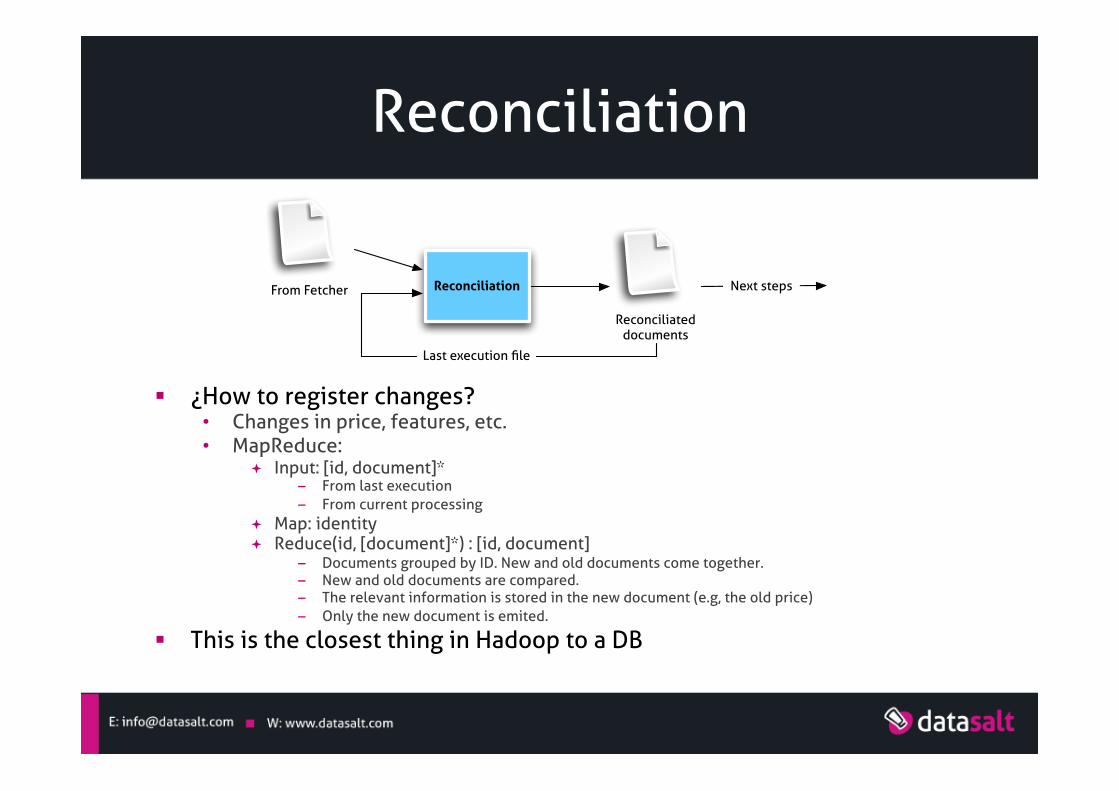
Reconciliation
§ ¿How to register changes? • Changes in price, features, etc. • MapReduce:
ª Input: [id, document]* – From last execution – From current processing
ª Map: identity ª Reduce(id, [document]*) : [id, document]
– Documents grouped by ID. New and old documents come together. – New and old documents are compared. – The relevant information is stored in the new document (e.g, the old price) – Only the new document is emited.
§ This is the closest thing in Hadoop to a DB
From Fetcher Reconciliation
Reconciliateddocuments
Last execution !le
Next steps

Advantages of the architecture
§ Horizontal Scalability • If properly programmed
§ High tolerance to failures and bugs • Always everything is reprocessed
§ Flexible • It is easy to do big changes
§ High decoupling • Indexes are the unique interaction between the
back-end and the front-end • Web servers can keep running even if the back-
end is broken.

Disadvantages
§ Batch processing • No real-time or “near” real-time • Update cycles of hours
§ Completely different programming paradigm • High learning curve

Improvements
§ System for images § Fuzzy duplicates detection § Plasam:
• Mixing this architecture with a by-pass system that provides near real time updates to the FE indexes ª Implementing a by-pass to the Solrs ª System for ensuring data consistency
– Without back jumps in time
• That combines the advantages of the proposed architecture but with near real time
• Datasalt has a prototype ready






























