Embed Size (px)
Citation preview

Spark Pipelines in the Cloud with Alluxio
Gene Pang, Alluxio, Inc. Spark Summit EU - October 2017

About Me
• Gene Pang
• Software engineer @ Alluxio, Inc.
• Alluxio open source PMC member
• Ph.D. from AMPLab @ UC Berkeley
• Worked at Google before UC Berkeley
• Twitter: @unityxx
• Github: @gpang
©2017 Alluxio, Inc. All Rights Reserved 2

Outline
©2017 Alluxio, Inc. All Rights Reserved 3
1
2
3
Alluxio Overview
Data Pipelines
Experiments

History of Alluxio
Started at UC Berkeley AMPLab In Summer 2012
• Originally named as Tachyon
• Rebranded to Alluxio in early 2016
Open Sourced in 2013
• Apache License 2.0
• Latest Release: Alluxio 1.6.0
©2017 Alluxio, Inc. All Rights Reserved 4
5©2017 Alluxio, Inc. All Rights Reserved
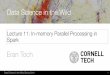
Alluxio: Unify Data at Memory Speed
Namespace Unification
Architecture Flexibility
IO Performance
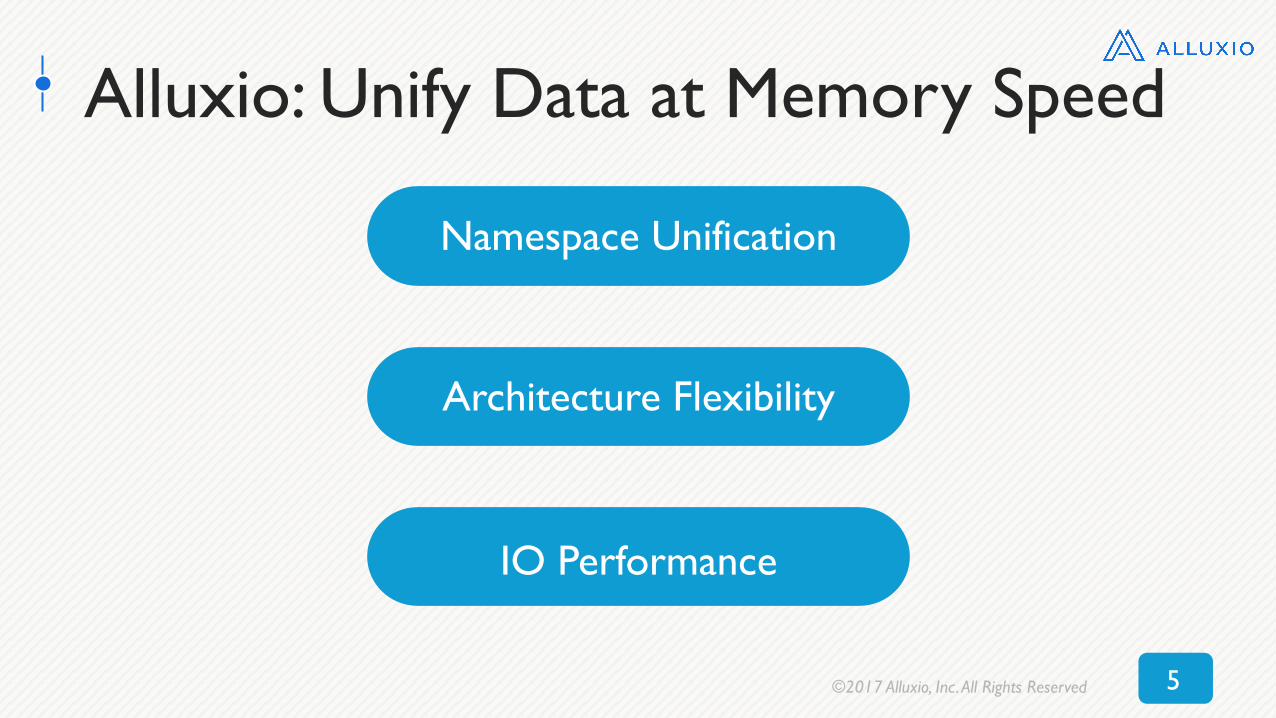
Data Ecosystem with Alluxio
• Apps only talk to Alluxio
• Simple Add/Remove
• No App Changes
• In-Memory Performance
Native File System Hadoop Compatible File System
Native Key-Value Interface
Fuse Compatible File System
HDFS Interface Amazon S3 Interface Swift Interface GlusterFS Interface
©2017 Alluxio, Inc. All Rights Reserved 6
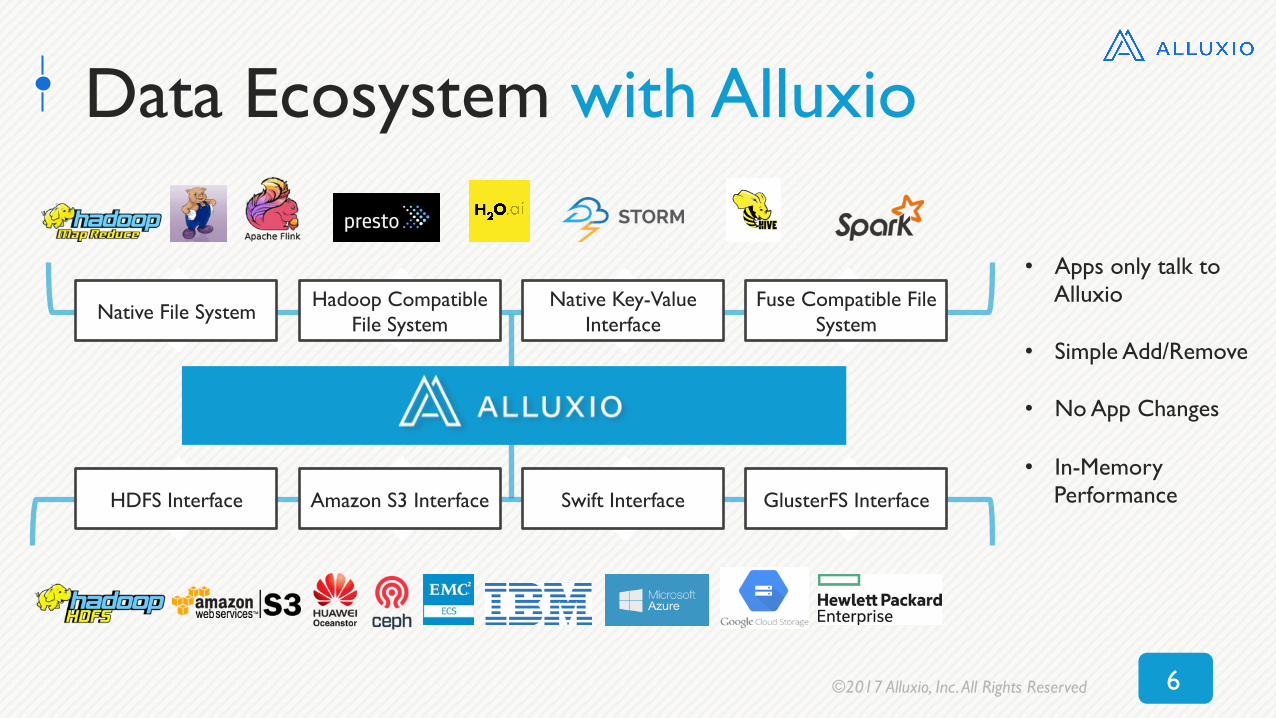
Next Gen Analytics with Alluxio
Native File System Hadoop Compatible File System
Native Key-Value Interface
Fuse Compatible File System
HDFS Interface Amazon S3 Interface Swift Interface GlusterFS Interface
Apps, Data & Storage at Memory Speed
ü Big Data/IoT ü AI/ML ü Deep Learning ü Cloud Migration ü Multi Platform ü Autonomous
©2017 Alluxio, Inc. All Rights Reserved 7
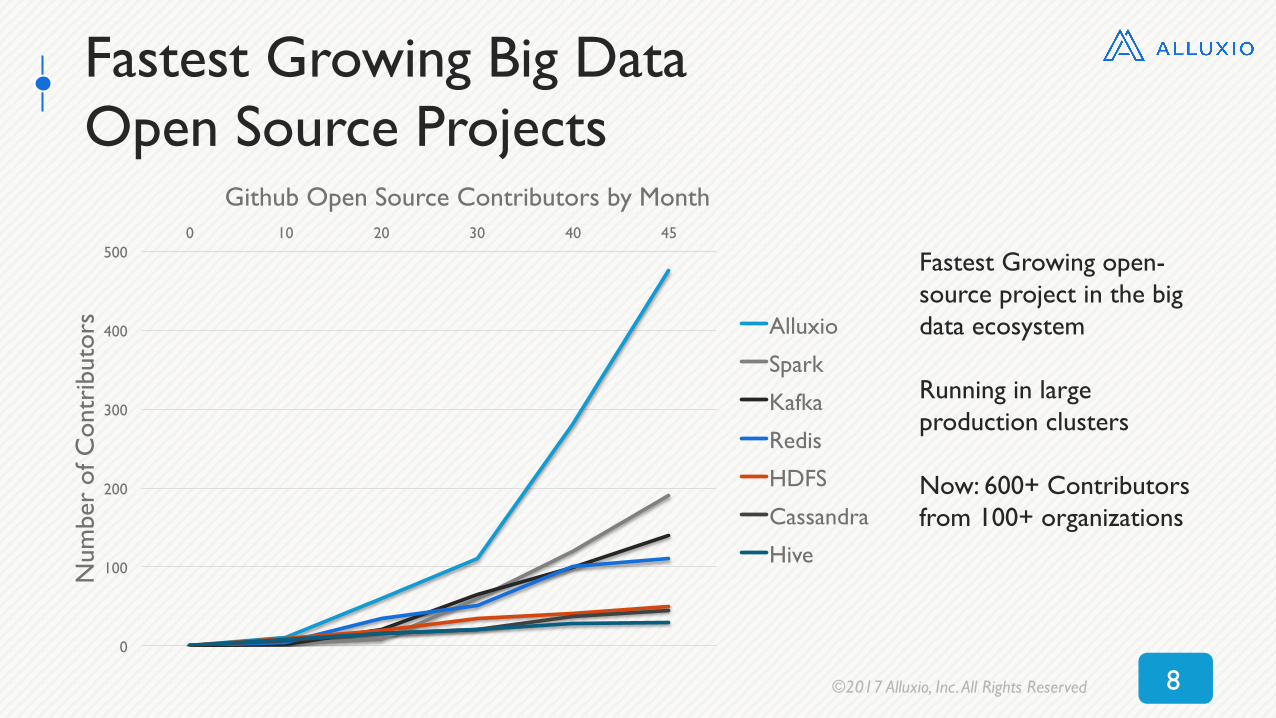
Fastest Growing Big Data Open Source Projects
Fastest Growing open-source project in the big data ecosystem
Running in large production clusters
Now: 600+ Contributors from 100+ organizations
0
100
200
300
400
500 0 10 20 30 40 45
Num
ber
of C
ontr
ibut
ors
Github Open Source Contributors by Month
Alluxio
Spark
Kafka
Redis
HDFS
Cassandra
Hive
©2017 Alluxio, Inc. All Rights Reserved 8

Outline
©2017 Alluxio, Inc. All Rights Reserved 9
1
2
3
Alluxio Overview
Data Pipelines
Experiments
1 0©2017 Alluxio, Inc. All Rights Reserved
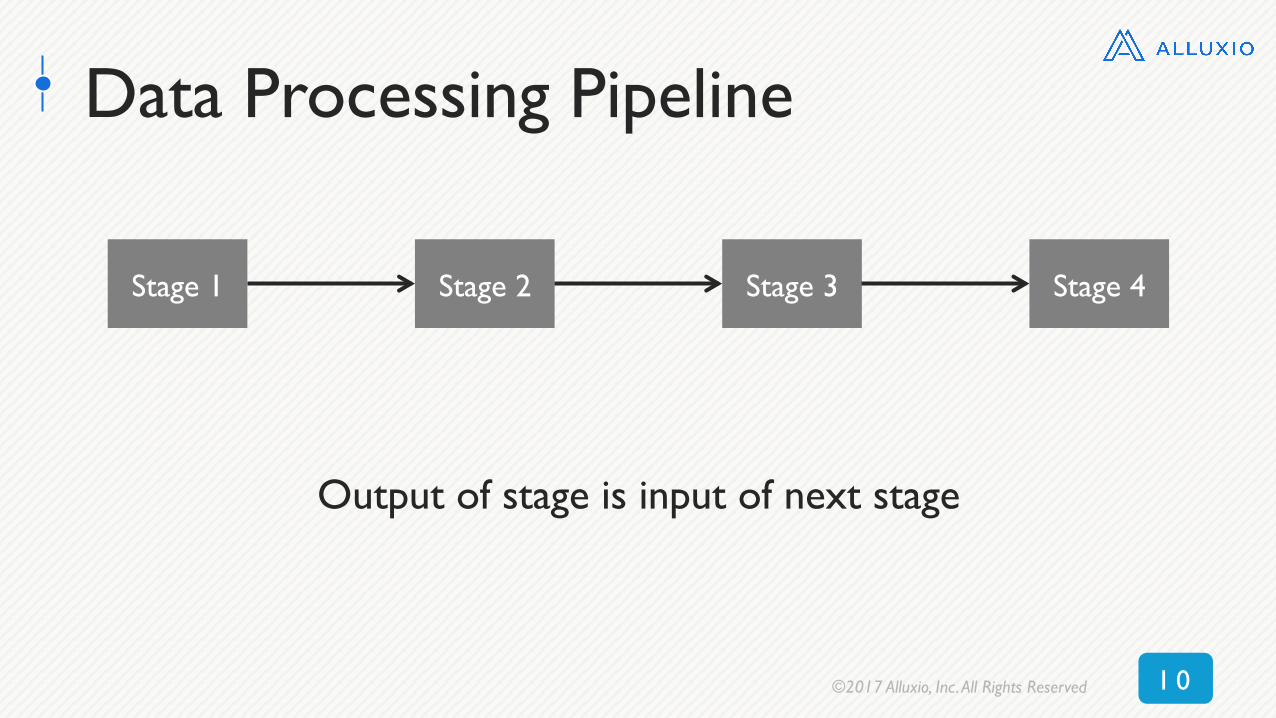
Data Processing Pipeline
Stage 1 Stage 2 Stage 3 Stage 4
Output of stage is input of next stage
1 1©2017 Alluxio, Inc. All Rights Reserved
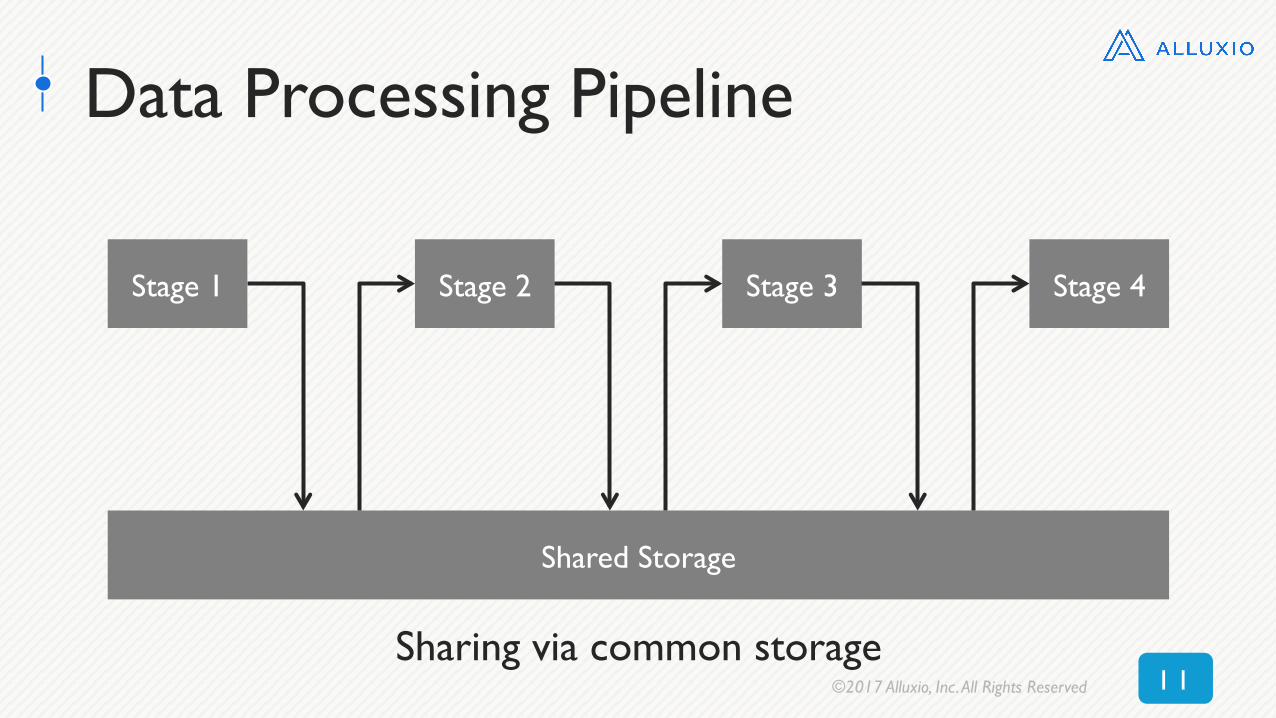
Data Processing Pipeline
Sharing via common storage
Shared Storage
Stage 1 Stage 2 Stage 3 Stage 4

1 2©2017 Alluxio, Inc. All Rights Reserved
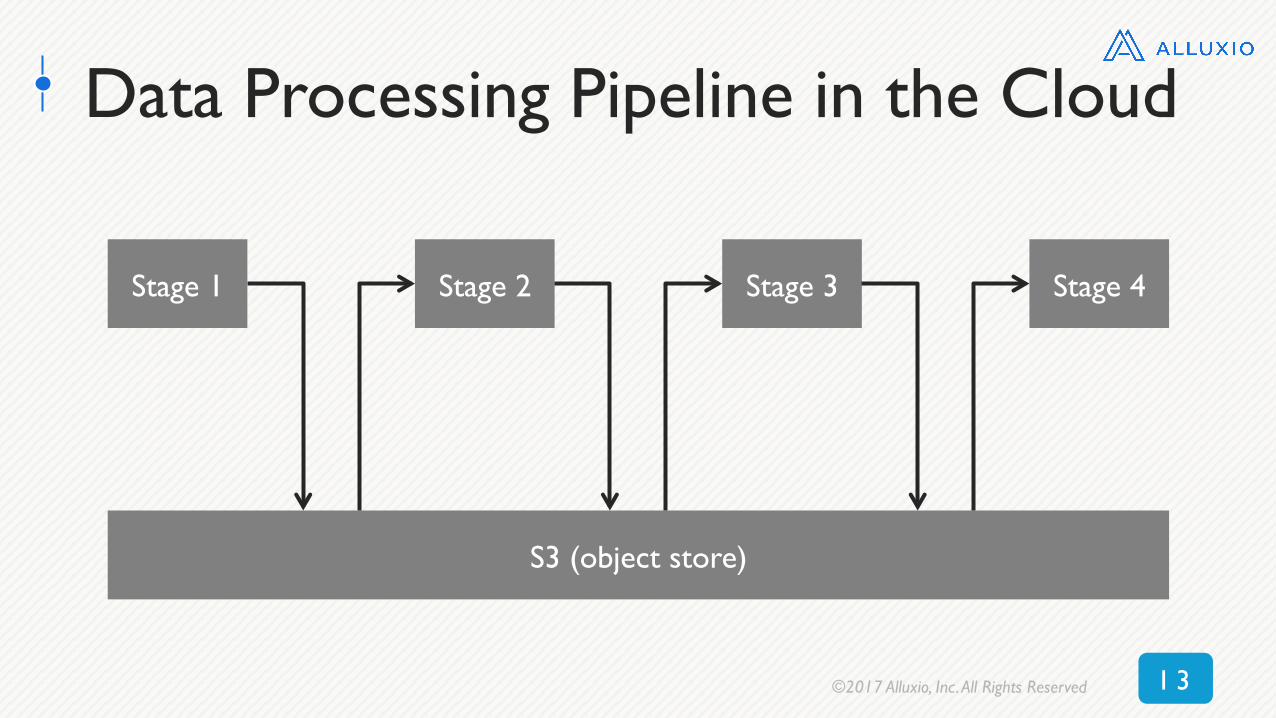
What aboutpipelines in the cloud?
1 3©2017 Alluxio, Inc. All Rights Reserved
Data Processing Pipeline in the Cloud
S3 (object store)
Stage 1 Stage 2 Stage 3 Stage 4

1 4©2017 Alluxio, Inc. All Rights Reserved
Sharing data via cloud storage slows down performance
1 5©2017 Alluxio, Inc. All Rights Reserved
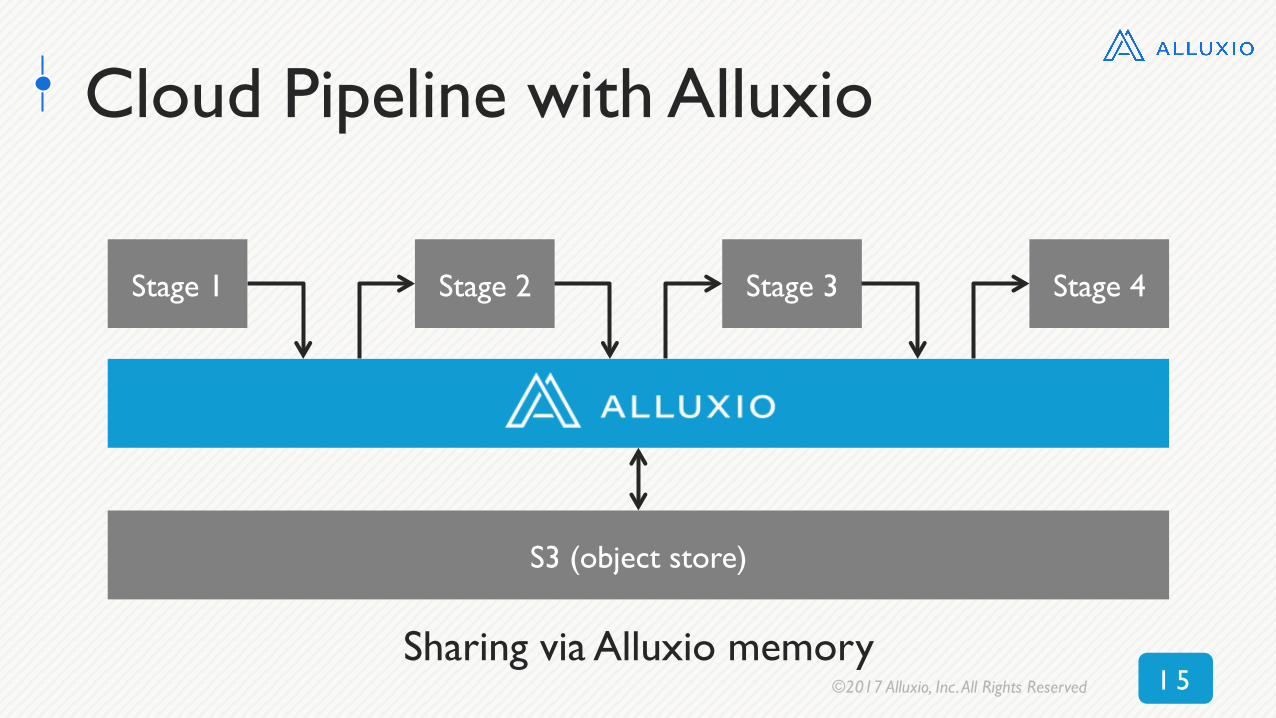
Cloud Pipeline with Alluxio
Sharing via Alluxio memory
S3 (object store)
Stage 1 Stage 2 Stage 3 Stage 4

Sharing Data in the Cloud
Previous stage writes output to storage
Next stage reads input from storage
…
©2017 Alluxio, Inc. All Rights Reserved 1 6

Sharing Data in the Cloud with Alluxio
Previous stage writes output to storage memory
Next stage reads input from storage memory
…
©2017 Alluxio, Inc. All Rights Reserved 1 7
1 8©2017 Alluxio, Inc. All Rights Reserved
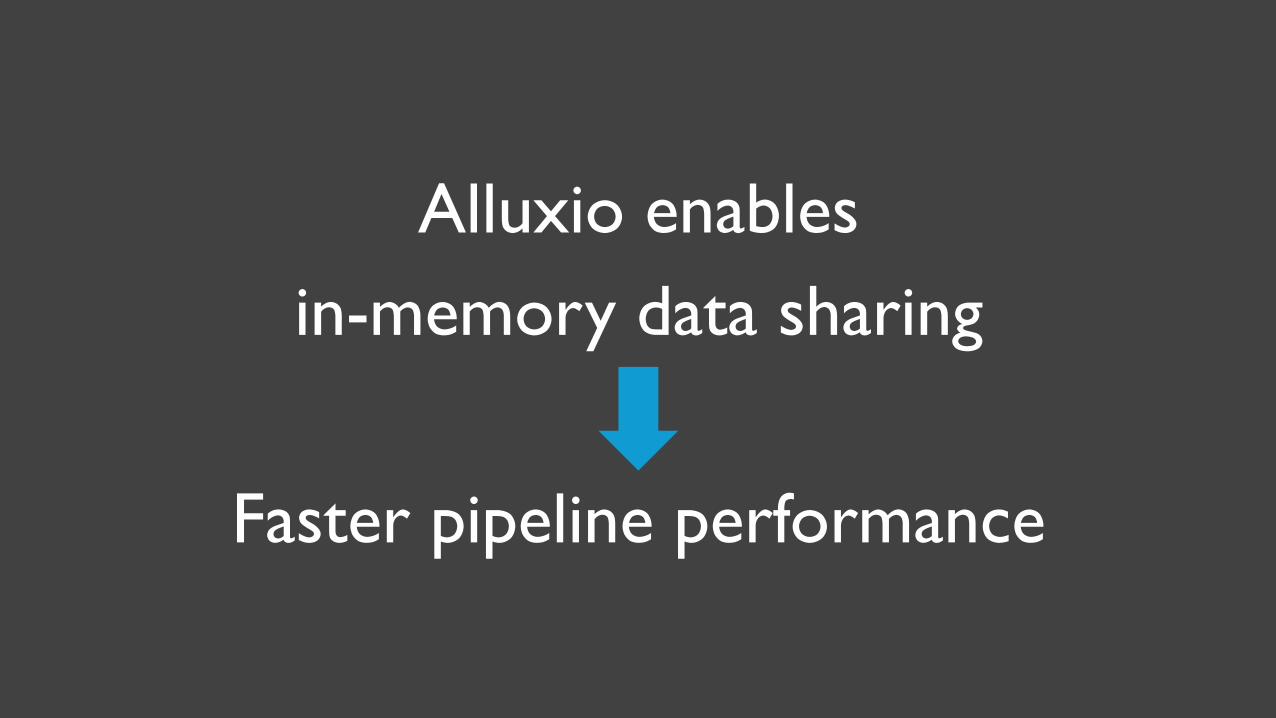
Alluxio enablesin-memory data sharing
Faster pipeline performance

Alluxio – Fast Durable Writes
Improves write performance, without sacrificing fault tolerance
©2017 Alluxio, Inc. All Rights Reserved 1 9

Alluxio – Fast Durable Writes
Synchronously write to replicas in Alluxio memory
Asynchronously write to underlying storage
©2017 Alluxio, Inc. All Rights Reserved 2 0
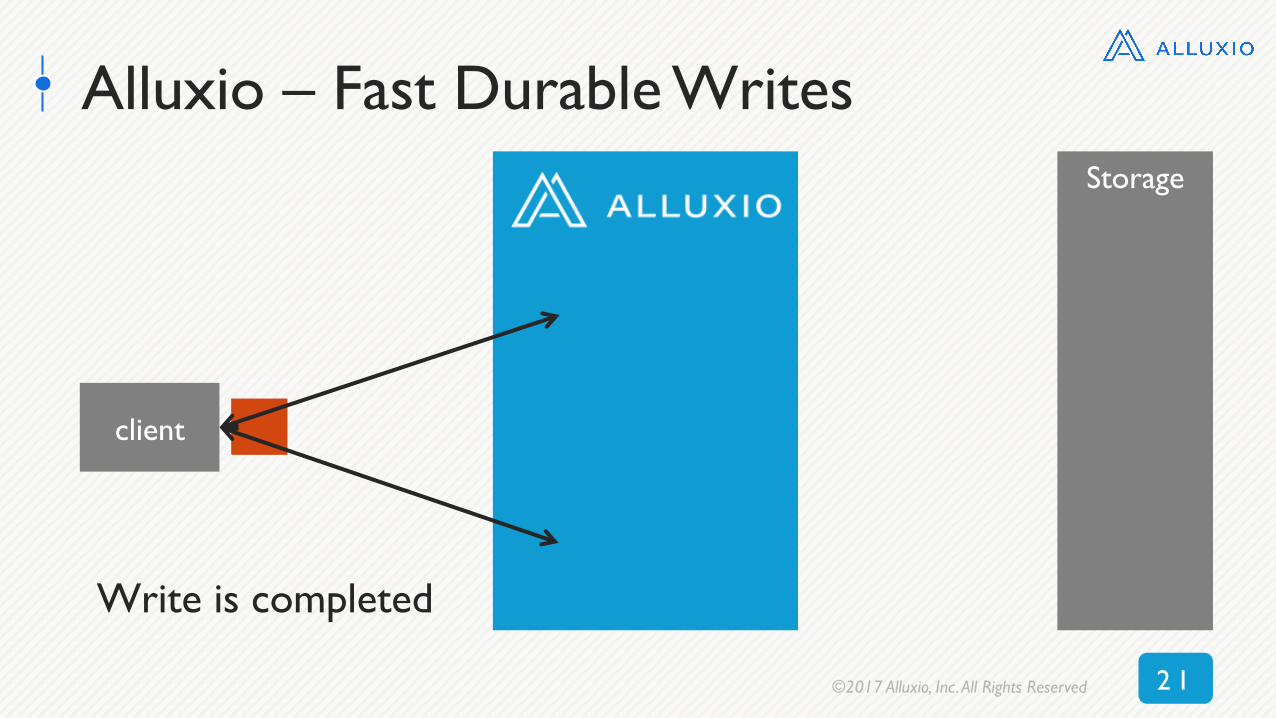
Alluxio – Fast Durable Writes
©2017 Alluxio, Inc. All Rights Reserved 2 1
client
Storage
Write is completed
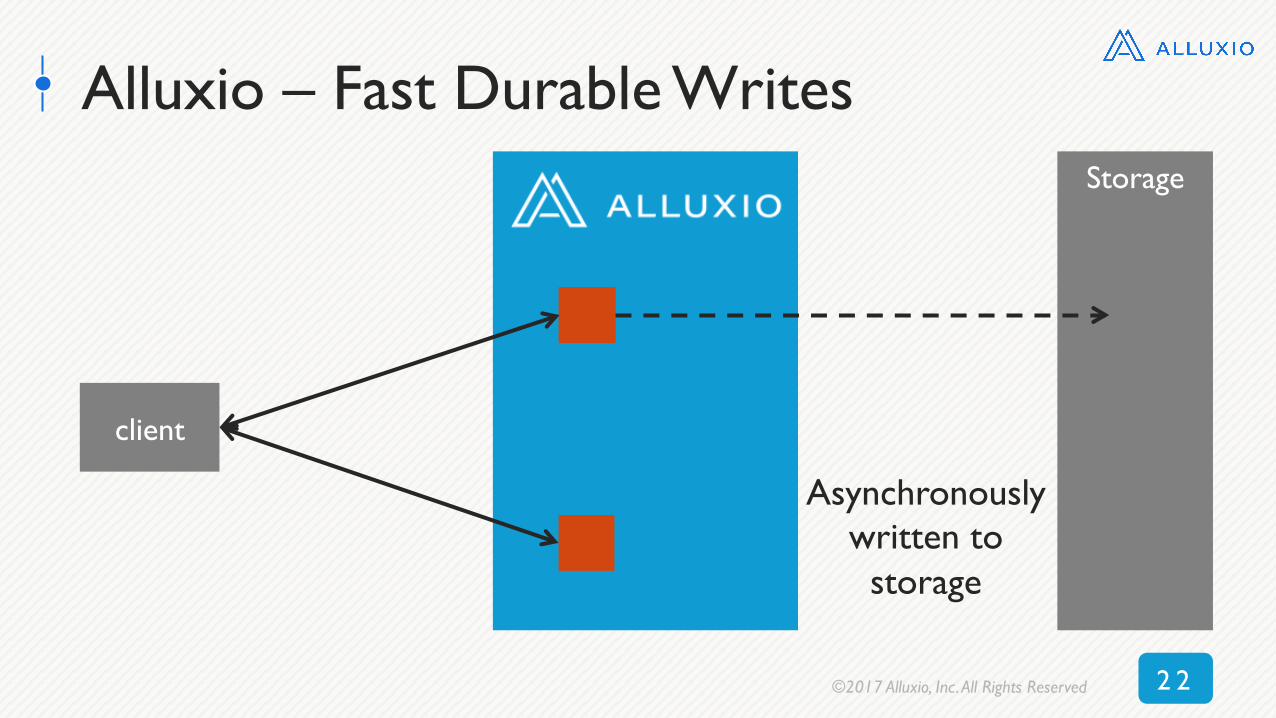
Alluxio – Fast Durable Writes
©2017 Alluxio, Inc. All Rights Reserved 2 2
client
Storage
Asynchronously written to
storage

Outline
©2017 Alluxio, Inc. All Rights Reserved 2 3
1
2
3
Alluxio Overview
Data Pipelines
Experiments
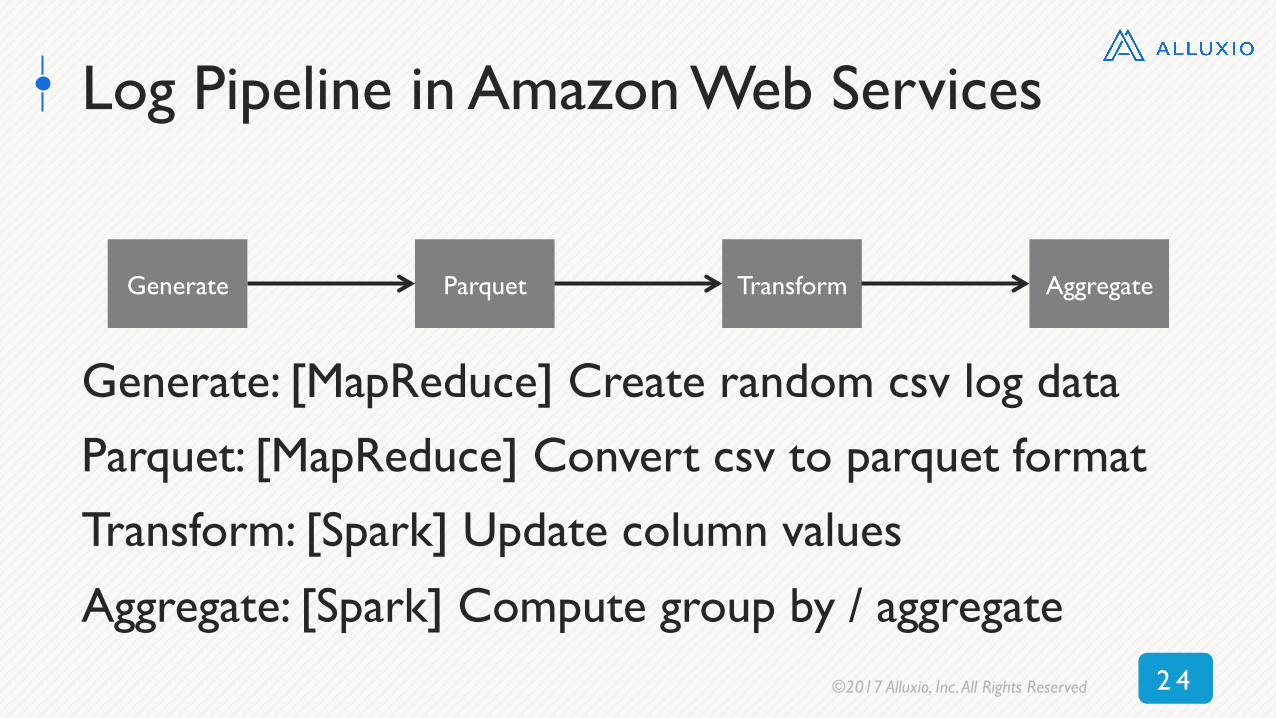
Log Pipeline in Amazon Web Services
©2017 Alluxio, Inc. All Rights Reserved 2 4
Generate Parquet Transform Aggregate
Generate: [MapReduce] Create random csv log data
Parquet: [MapReduce] Convert csv to parquet format
Transform: [Spark] Update column values
Aggregate: [Spark] Compute group by / aggregate

Log Pipeline Environment
• r4.2xlarge instances (61 GB ram, 8 CPUs) • 1 master, 3 workers
• Apache Spark 2.2.0 • Apache Hadoop 2.7.2 • Alluxio 1.6.0 • Generate 12 GB of logs • Compare AWS S3 vs Alluxio w/ Fast Durable Writes
©2017 Alluxio, Inc. All Rights Reserved 2 5
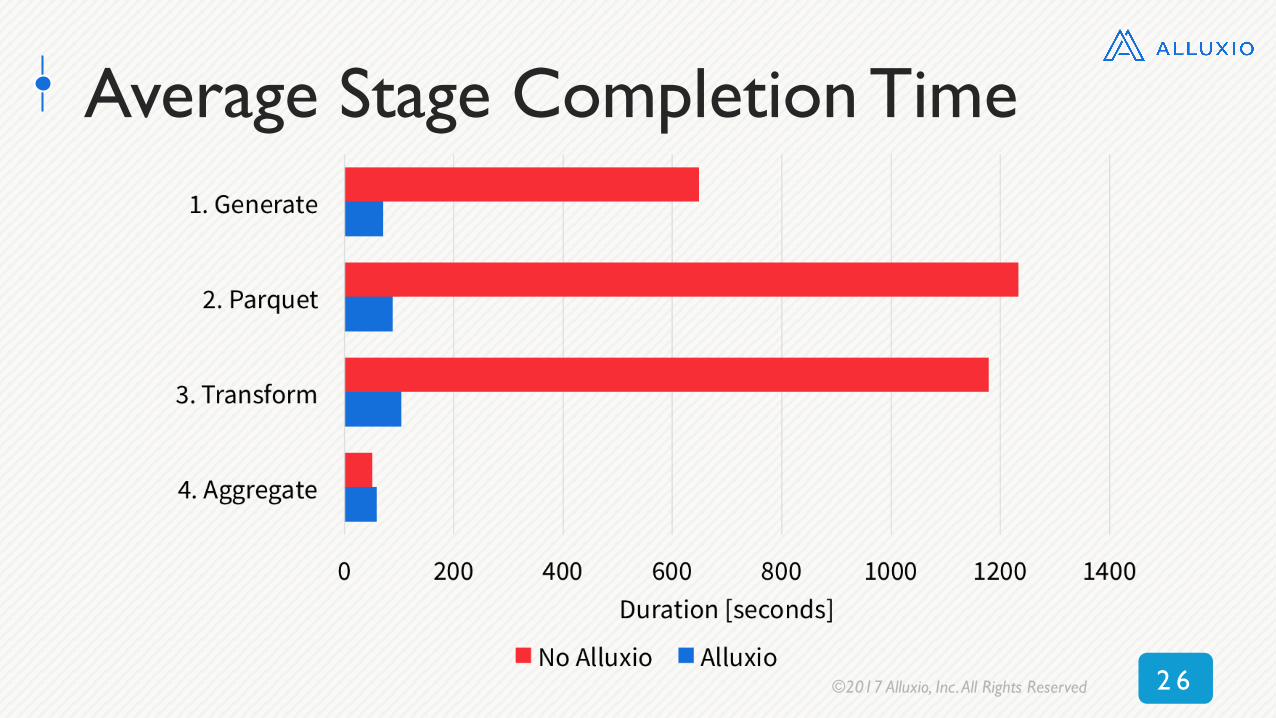
2 6©2017 Alluxio, Inc. All Rights Reserved
Average Stage Completion Time
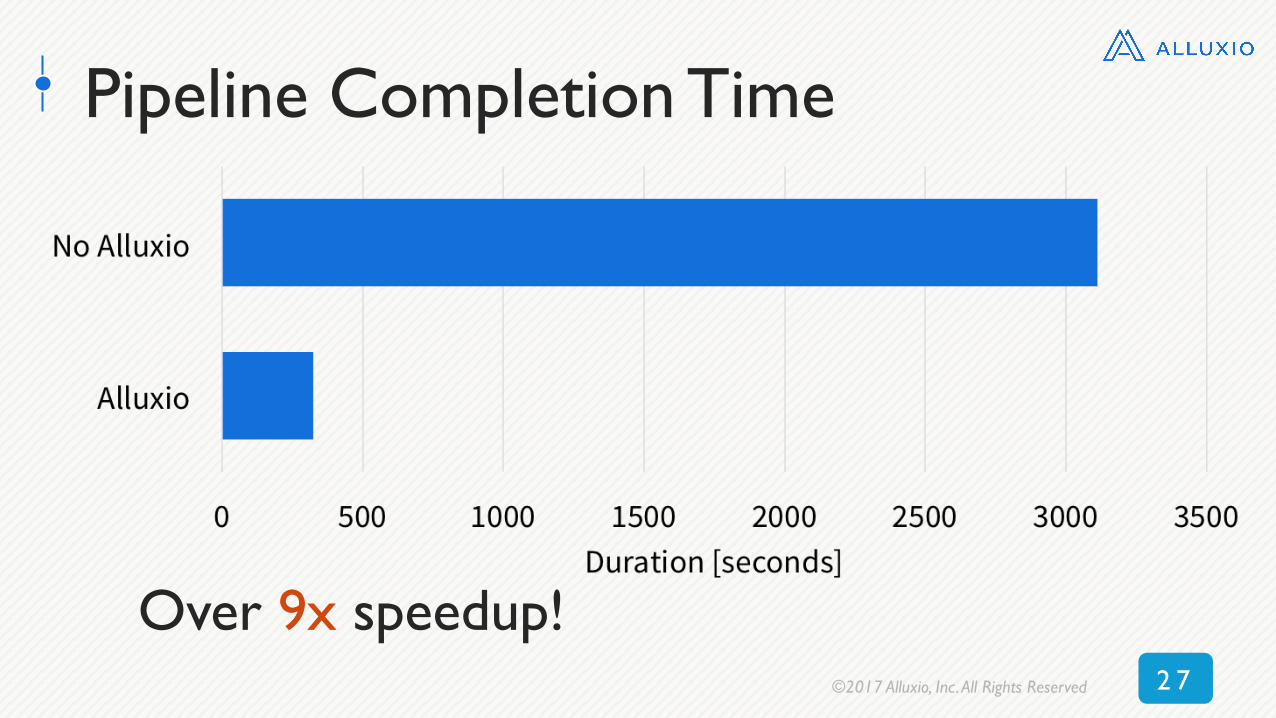
2 7©2017 Alluxio, Inc. All Rights Reserved
Pipeline Completion Time
Over 9x speedup!

Alluxio and Pipelines in the Cloud
Alluxio enables in-memory sharing for data pipelines in the cloud Alluxio’s Fast Durable Write feature increases performance without sacrificing fault tolerance
©2017 Alluxio, Inc. All Rights Reserved 2 8

Thank you!
Gene Pang [email protected] Twitter: @unityxx
Twi$er.com/alluxio
Linkedin.com/alluxio
Website www.alluxio.com
E-mail [email protected]
@
Social Media
á
�
©2017 Alluxio, Inc. All Rights Reserved 2 9