Embed Size (px)
Citation preview

How to build a successful Data Warehouse on Hadoop
Simon Harris, Senior Performance Architect, Big Data. IBM.貝嶋創 , Technical Sales, BigData, IBM
2
どの Hadoop 上の SQL ソリューションを使うべきか ???• ベンダーロックインの有無
既存 DB 、 DWH からのポーティング• データの移動• ワークロードの移動 (SQL)
Hadoop 上の WareHouse を実運用環境へ• パフォーマンス、拡張性、ワークロードマネージャー• セルフチューニング• エンタープライズレベルセキュリティ
DWH から Hadoop へのコネクティビティ• Federation• Spark exploitation
さらなる価値の創造
Agenda

3
お客様からのコメント …
Hive で十分間に合ってます!!
もしくは
Hive でも良いのですが、 BI ・レポーティングが簡単にできるものはないですか?
Hive/MapReduce への同時接続数が増えワークロードが増加すると問題が置きます . この状況でクエリの遅延がないようにできませんか?
増え続けるワークロードに対して現在持っている Hadoop を増強し続けるつもりです.ただし、無制限な増強を回避する方法はないでしょう
か?
変えたいことは色々ありますが,どこから始めればよいでしょうか?

4
Hadoop 上の SQL エンジンの多数の選択肢 – 何を選択するか ?? SQL エンジンは多数発表されており、信じられないペースで成熟して
います !
SQL on Hadoop はローコストで,簡単にスケールアウトできます .
ただし、すべてのエンジンは長所・短所があります,何を選択すればよいでしょうか?
IBM Big SQL SQL
5
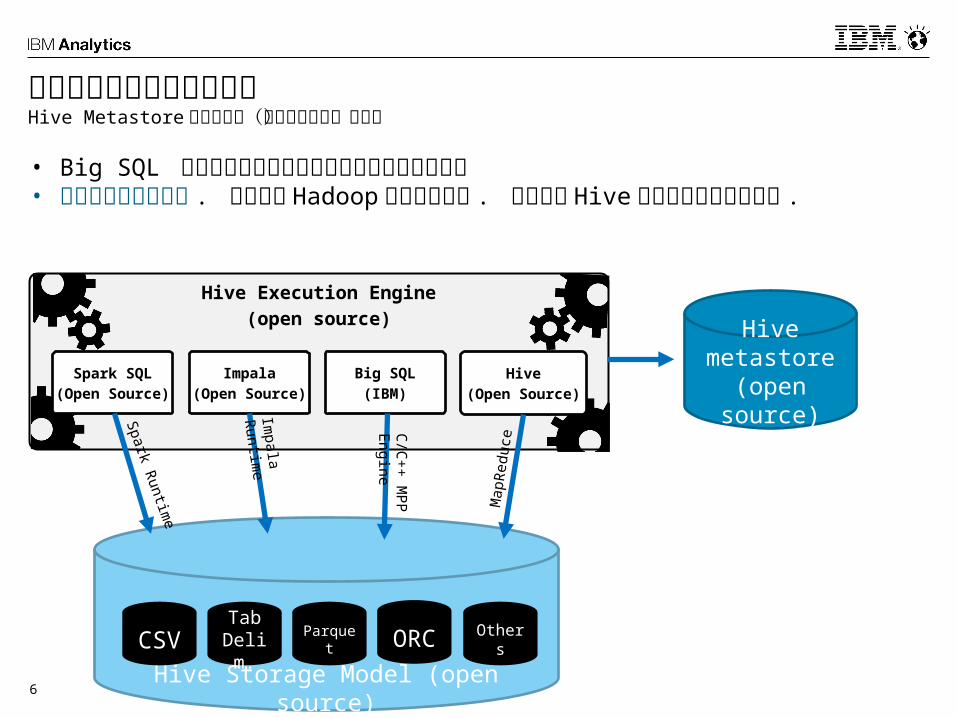
Hive Execution Engine(open source)
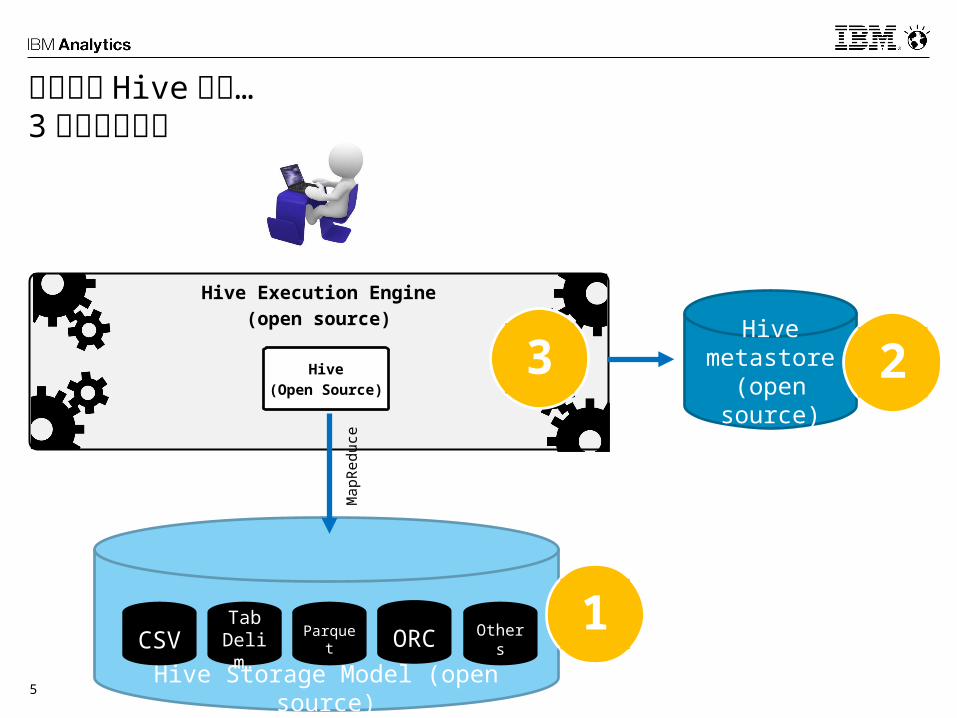
そもそも Hive とは…3 つの構成要素
Hive(Open Source)
Hive Storage Model (open source)
Hive metastore
(open source)
Map
Redu
ce
CSVTab
Delim.
Parquet ORC Others
1
23
6
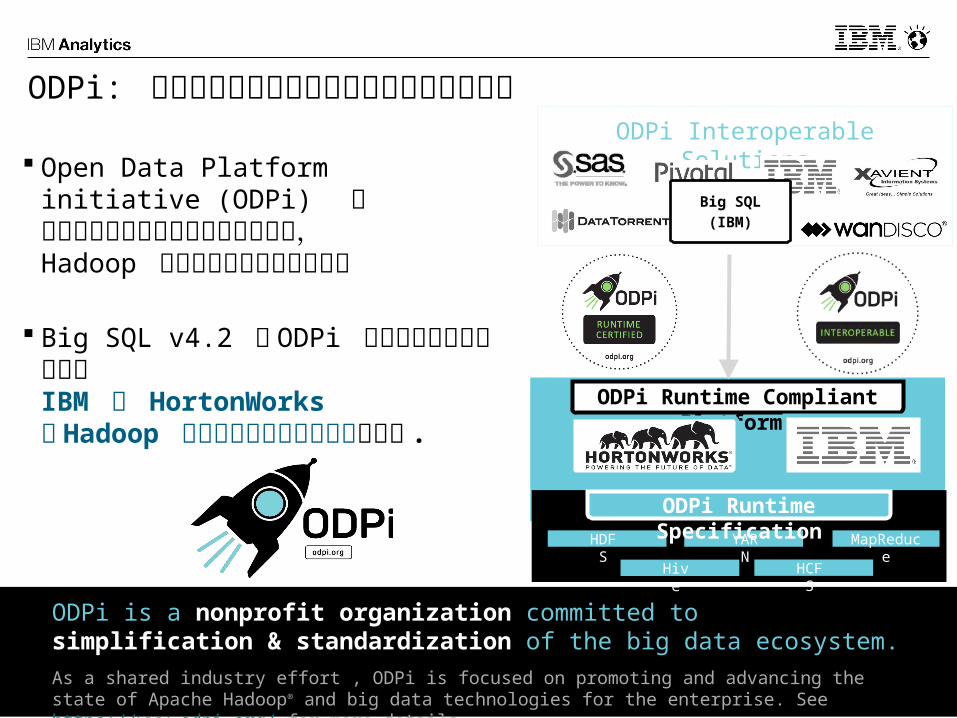
Hive Execution Engine(open source)
実行エンジンは変換が可能Hive Metastore とファイル(フォーマット)を活用
Big SQL(IBM)
Hive(Open Source)
Hive Storage Model (open source)
Hive metastore
(open source)C/C++
MPP
Engine
MapR
educ
e
Spark SQL(Open Source)
Impala(Open Source)
Impala Runtim
e
Spark Runtime
CSVTab
Delim.
Parquet ORC Others
• Big SQL は他のオープンソースエンジンと同様の構成• ロックインしません . データは Hadoop が管理します . いつでも Hive 環
境に戻ることが可能 .
7
ODPi Interoperable Solutions
ODPi is a nonprofit organization committed to simplification & standardization of the big data ecosystem.As a shared industry effort , ODPi is focused on promoting and advancing the state of Apache Hadoop® and big data technologies for the enterprise. See https://www.odpi.org/ for more details.
7
Open Data Platform initiative (ODPi) はディストリビューションの標準化と,Hadoop エコシステムの発展を促進
Big SQL v4.2 は ODPi での運用が可能であり,IBM と HortonWorks の Hadoop ディストリビューションで動作 .
ODPi: ディストリビューション間での相互運用性
ODPi Runtime Compliant Platforms
ODPi Runtime SpecificationHDFS YARN MapReduce
Hive HCFS
Big SQL(IBM)

8
どの Hadoop 上の SQL ソリューションを使うべきか ???• ベンダーロックインの有無
既存 DB 、 DWH からのポーティング• データの移動• ワークロードの移動 (SQL)
Hadoop 上の WareHouse を実運用環境へ• パフォーマンス、拡張性、ワークロードマネージャー• セルフチューニング• エンタープライズレベルセキュリティ
DWH から Hadoop へのコネクティビティ• Federation• Spark exploitation
さらなる価値の創造
Agenda
9
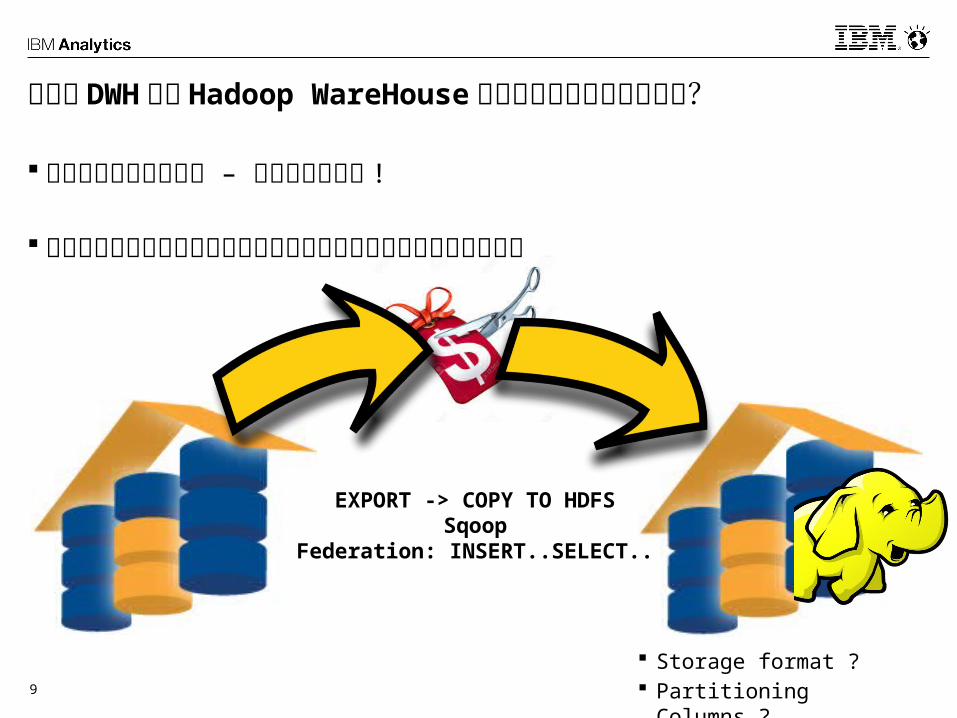
既存の DWH から Hadoop WareHouse へどのように移動するのか? データ移動はシンプル – 問題は時間だけ !
データ移動に関するツールやテクニックはすでに広く知られている
$$$ $
EXPORT -> COPY TO HDFSSqoop
Federation: INSERT..SELECT..
Storage format ? Partitioning
Columns ?
10
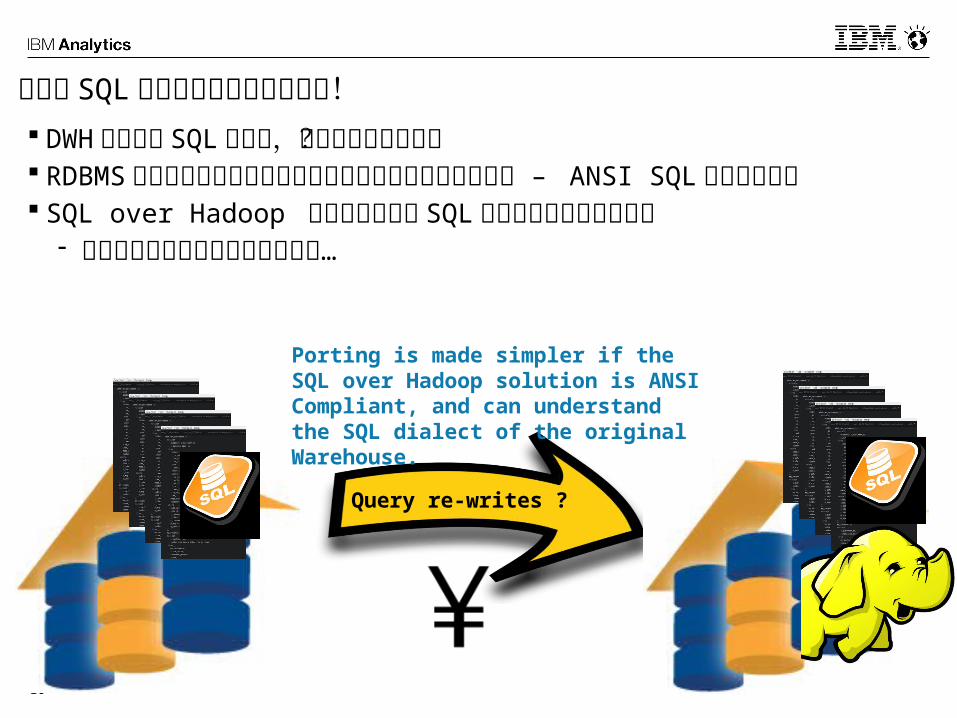
問題は SQL アプリケーションの移動! DWH は複雑な SQL を実行,移植ができるのか? RDBMS のベンダーはそれぞれ独自の構文や関数を持っている – ANSI
SQL 準拠に加えて SQL over Hadoop ベンダーによる SQL スタンダード対応は途上
- 急速に改善されては来ていますが…
Query re-writes ?
Porting is made simpler if the SQL over Hadoop solution is ANSI Compliant, and can understand the SQL dialect of the original Warehouse.
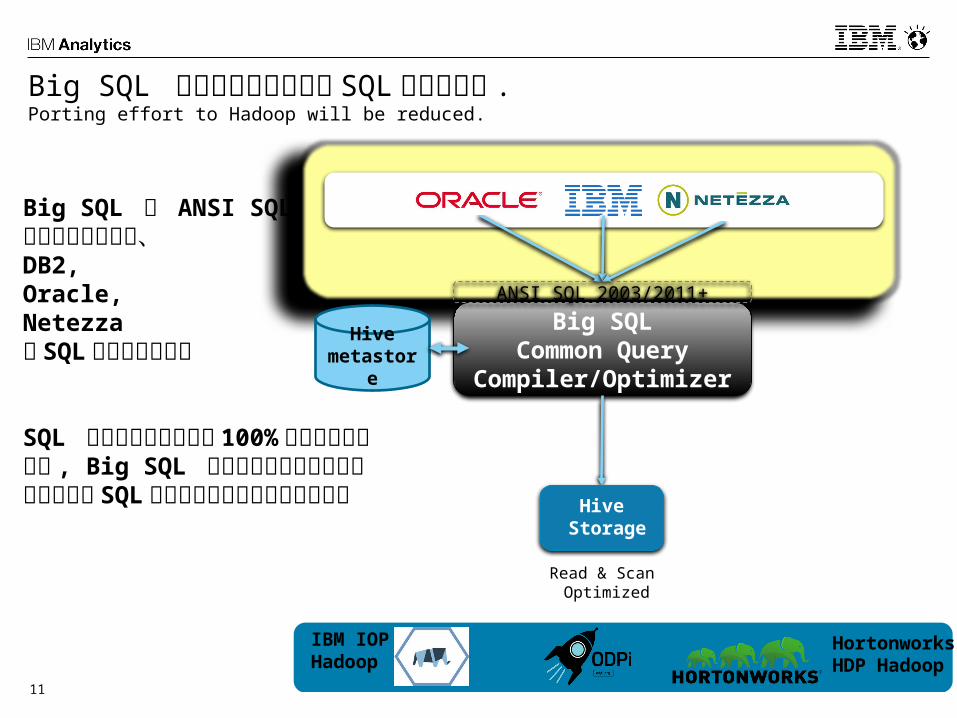
11
Big SQL は様々なベンダーの SQL を実行可能 .Porting effort to Hadoop will be reduced.
Big SQL は ANSI SQL対応だけではなく、DB2, Oracle,Netezza の SQL を実行可能です
SQL コンパチビリティは100% ではありませんが , Big SQL は複数のベンダーで実装されている SQL のポーティングを容易にします
Big SQLCommon Query
Compiler/Optimizer
Read & Scan Optimized
IBM IOP Hadoop
Hortonworks HDP Hadoop
ANSI SQL 2003/2011+
Hive Storage
Hive metastore

12
SQL on Hadoop ソリューションのチャレンジ
ポーティングにも以下の考慮点がある :- スケジュール- チューニング( SQL リライト)- アーキテクチャの違い(データ構造)
Hadoop のアーキテクチャは従来のデータウェアハウスの機能との間にはチャレンジあり- すべてはトレードオフ ! - Hadoop により DWH で直面してきた問題の解決も可能- リレーショナルデータだけではないデータ処理

13
どの Hadoop 上の SQL ソリューションを使うべきか ???• ベンダーロックインの有無
既存 DB 、 DWH からのポーティング• データの移動• ワークロードの移動 (SQL)
Hadoop 上の WareHouse を実運用環境へ• パフォーマンス、拡張性、ワークロードマネージャー• セルフチューニング• エンタープライズレベルセキュリティ
DWH から Hadoop へのコネクティビティ• Federation• Spark exploitation
さらなる価値の創造
Agenda

14
パフォーマンスとスケーラビリティWhy do they matter so much in SQL over Hadoop !
Hadoop の SQL ソリューションは既存の RDBMS より遅い- 2x – 10x slower
重要な機能の欠如 – キャッシュ / インデックス / データ配置 etc….
未成熟 - オプティマイザやワークロードマネージャ- これらは RDBMs が長年取り組んできた分野
RDBMs の特徴的な機能 :- カラムナストレージ- インメモリ DB- データ圧縮
このギャップを埋めるには時間が必要
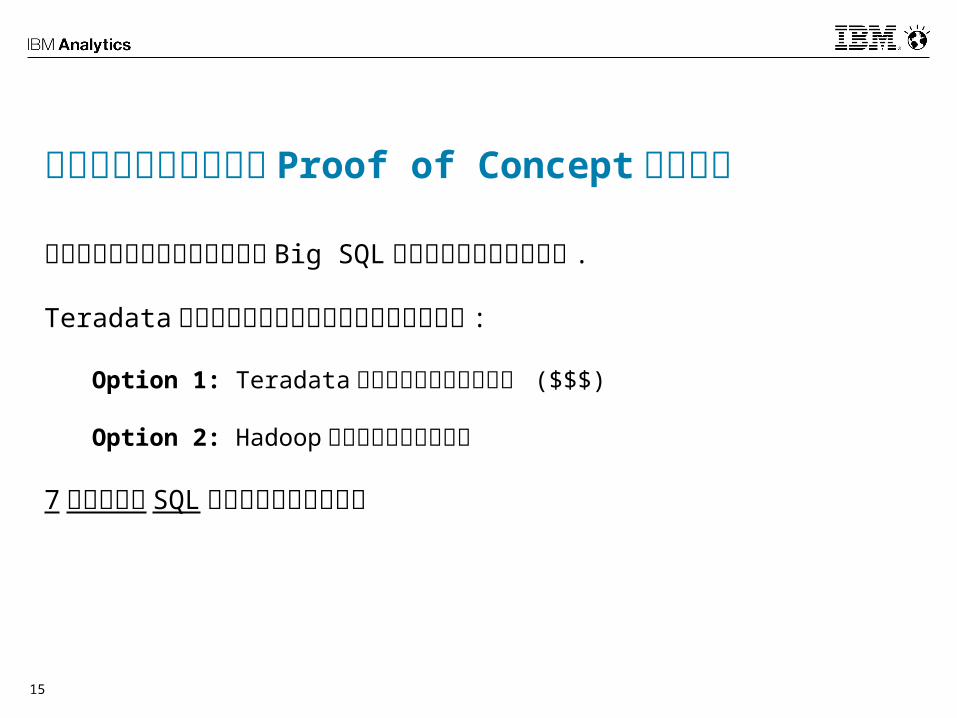
15
北米のテレコム会社の Proof of Concept 実施結果
以下のチャートはお客様により Big SQL を評価した際の結果です .
Teradata のデータ増加に対して対応が必要な状況 :
Option 1: Teradata の容量をアップして対応 ($$$)
Option 2: Hadoop へのオフロードを実施
7 つの複雑な SQL を選択して評価を実施
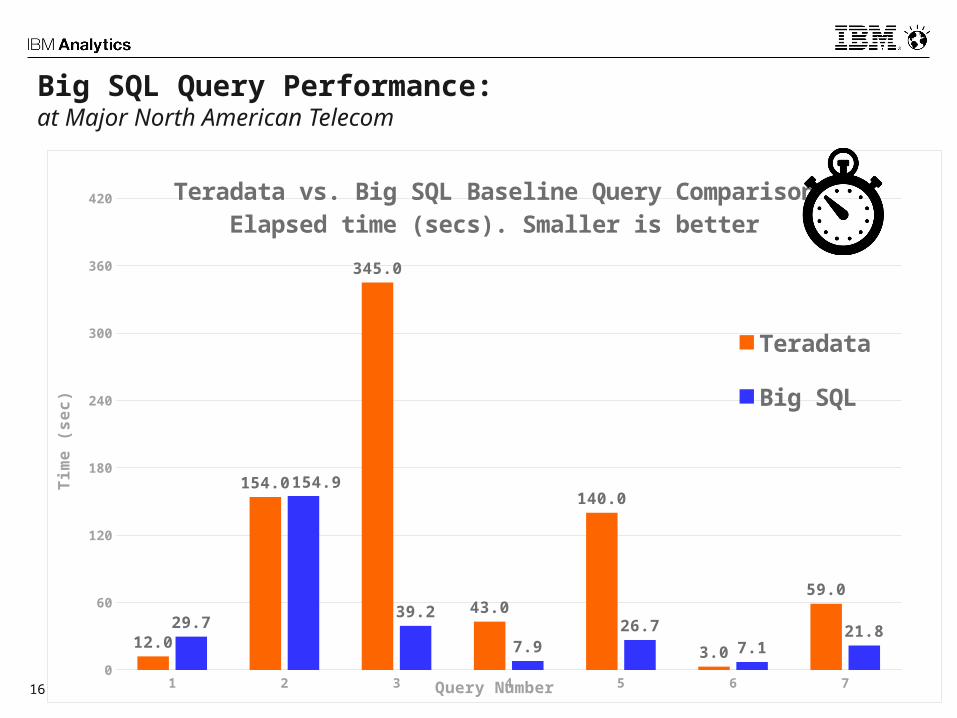
16 1 2 3 4 5 6 70
60
120
180
240
300
360
420
12.0
154.0
345.0
43.0
140.0
3.0
59.0
29.7
154.9
39.2
7.926.7
7.121.8
Teradata vs. Big SQL Baseline Query ComparisonElapsed time (secs). Smaller is better
Teradata
Big SQL
Query Number
Tim
e (s
ec)
Big SQL Query Performance:at Major North American Telecom
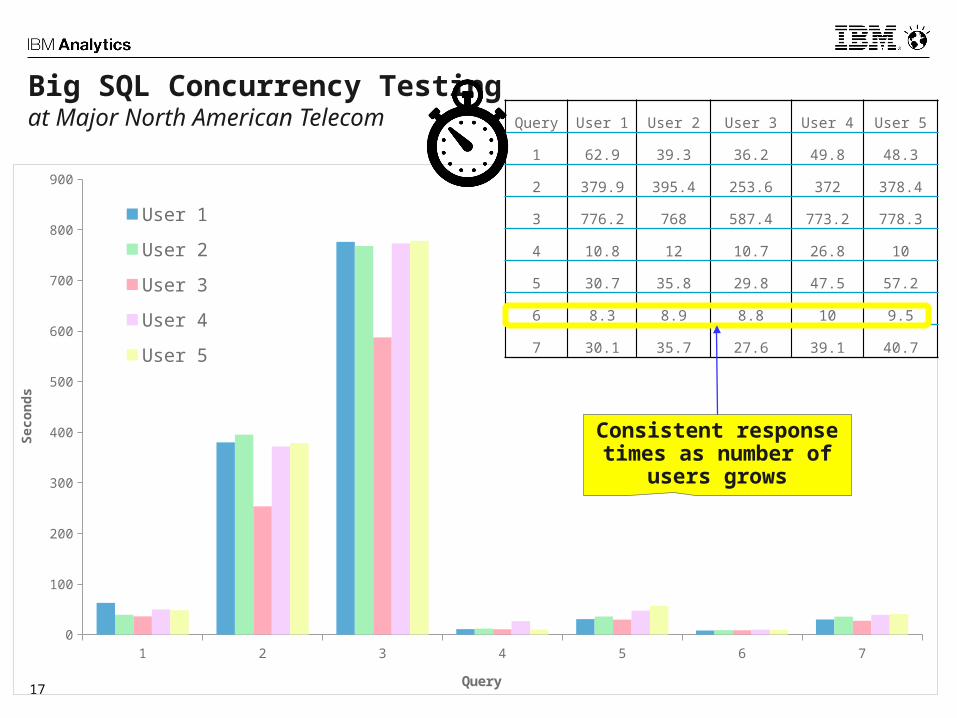
17
Big SQL Concurrency Testingat Major North American Telecom
1 2 3 4 5 6 70
100
200
300
400
500
600
700
800
900
User 1User 2User 3User 4User 5
Query
Seco
nds
Query User 1 User 2 User 3 User 4 User 5
1 62.9 39.3 36.2 49.8 48.3
2 379.9 395.4 253.6 372 378.4
3 776.2 768 587.4 773.2 778.3
4 10.8 12 10.7 26.8 10
5 30.7 35.8 29.8 47.5 57.2
6 8.3 8.9 8.8 10 9.5
7 30.1 35.7 27.6 39.1 40.7
Consistent response times as number of
users grows
18
0 20 40 60 80 100 120050
100150200250
Number of Users vs. Throughput
Number of Users
Thro
ughp
ut (
Que
ries
/Hou
r)
0 20 40 60 80 100 12002,0004,0006,0008,000
10,00012,00014,000
Number of Users vs. Test Time
Number of Users
Test
Tim
e (s
ec)
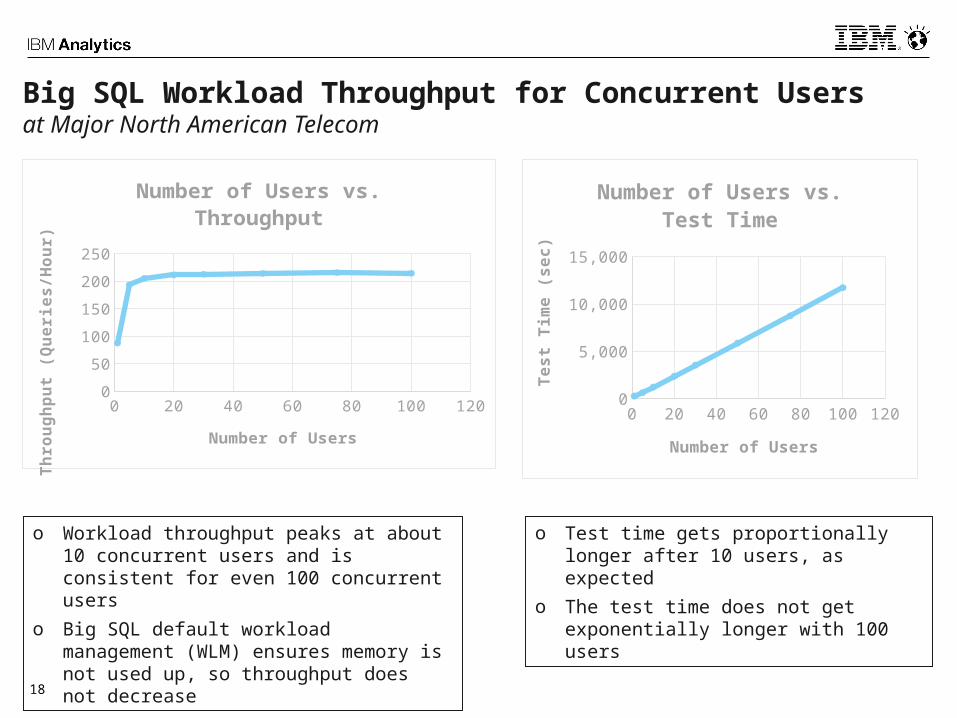
o Workload throughput peaks at about 10 concurrent users and is consistent for even 100 concurrent users
o Big SQL default workload management (WLM) ensures memory is not used up, so throughput does not decrease
o Test time gets proportionally longer after 10 users, as expected
o The test time does not get exponentially longer with 100 users
Big SQL Workload Throughput for Concurrent Usersat Major North American Telecom

19
チューニング !
Readers
Sorting
Filesystem
Database
Hadoop のチューニングは熟練者であっても大変
Hadoop 上のジョブを考慮した数百にのぼるパラメータの最適値を決定- さらに個々のクエリについてのチューニングも必要
Big SQL は Self Tuning Memory Manager (STMM) による自動チューニング- メモリ割り当てをモニターして自動でメモリ割り当て- BigSQL Consumer へのメモリの自動再割り当て
20
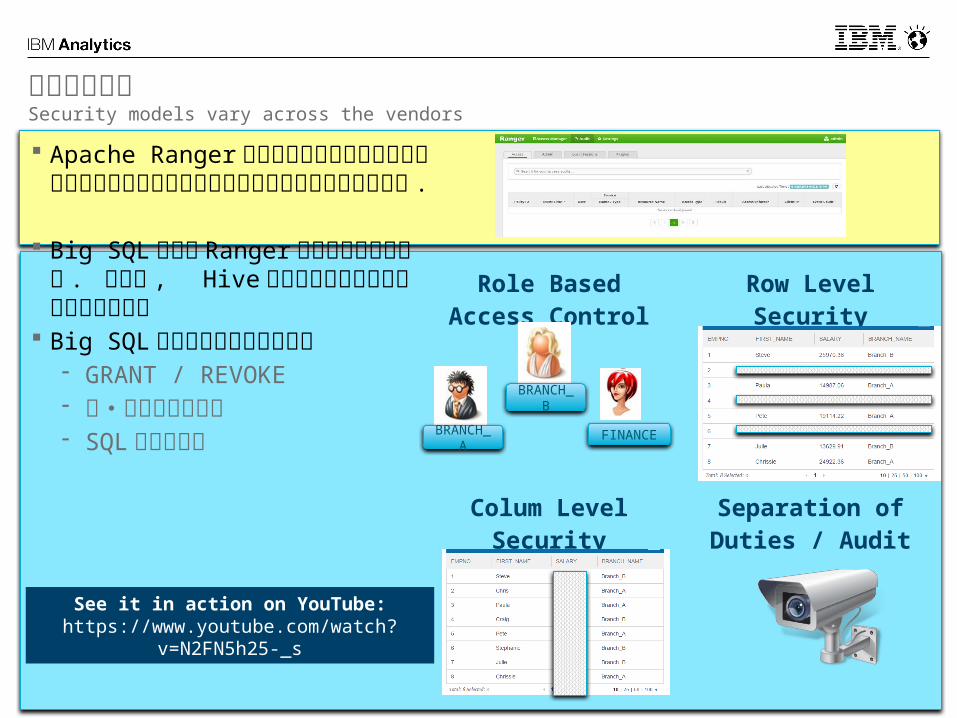
Role Based Access Control
Row Level Security
Colum Level Security
Separation of Duties / Audit
Apache Ranger は中央集約型のアクセスコントロールやログ取得を行うセキュリティフレームワーク .
Big SQL は現状 Ranger とは連携していない . ただし , Hive ではできないセキュリティ機能を提供
Big SQL の提供するセキュリティ- GRANT / REVOKE- 列・行レベルマスク- SQL による設定
セキュリティSecurity models vary across the vendors
BRANCH_A
BRANCH_B
FINANCE
See it in action on YouTube:https://www.youtube.com/watch?
v=N2FN5h25-_s

21
どの Hadoop 上の SQL ソリューションを使うべきか ???• ベンダーロックインの有無
既存 DB 、 DWH からのポーティング• データの移動• ワークロードの移動 (SQL)
Hadoop 上の WareHouse を実運用環境へ• パフォーマンス、拡張性、ワークロードマネージャー• セルフチューニング• エンタープライズレベルセキュリティ
DWH から Hadoop へのコネクティビティ• Federation• Spark exploitation
さらなる価値の創造
Agenda
22
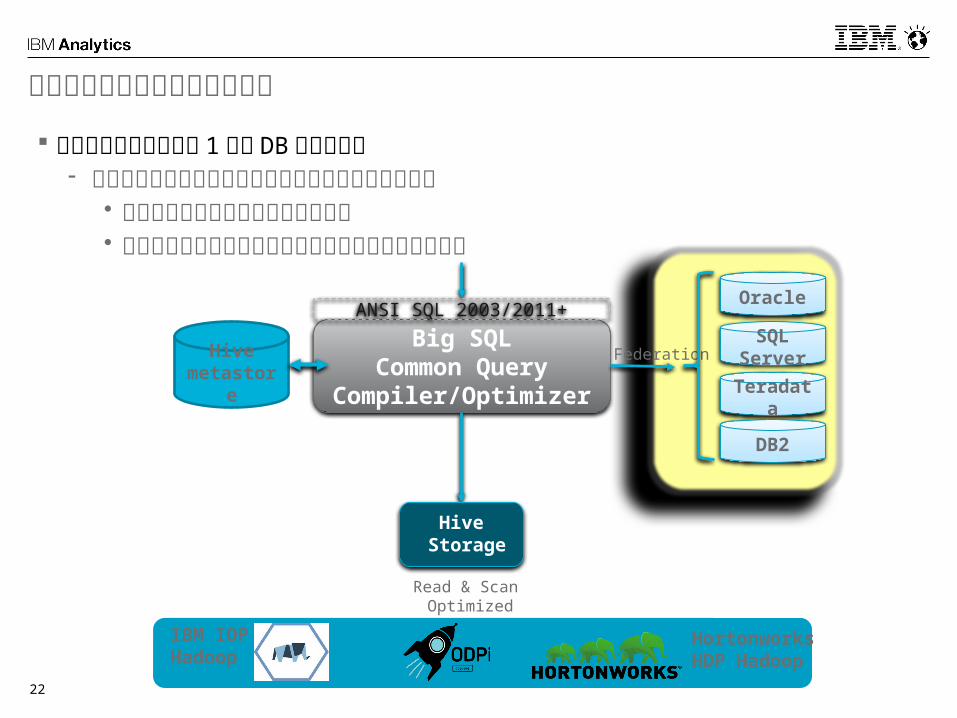
データベースフェデレーション
データウェアハウスは 1 つの DB に限らない- 様々なデータソースに分散しているデータにアクセス
• 他システムのデータへのアクセスし• ソースデータを持っているシステムからデータを取得
Big SQLCommon Query
Compiler/Optimizer
Read & Scan Optimized
Federation
Oracle
SQL Server
Teradata
DB2
IBM IOP Hadoop
Hortonworks HDP Hadoop
ANSI SQL 2003/2011+
Hive Storage
Hive metastore
23
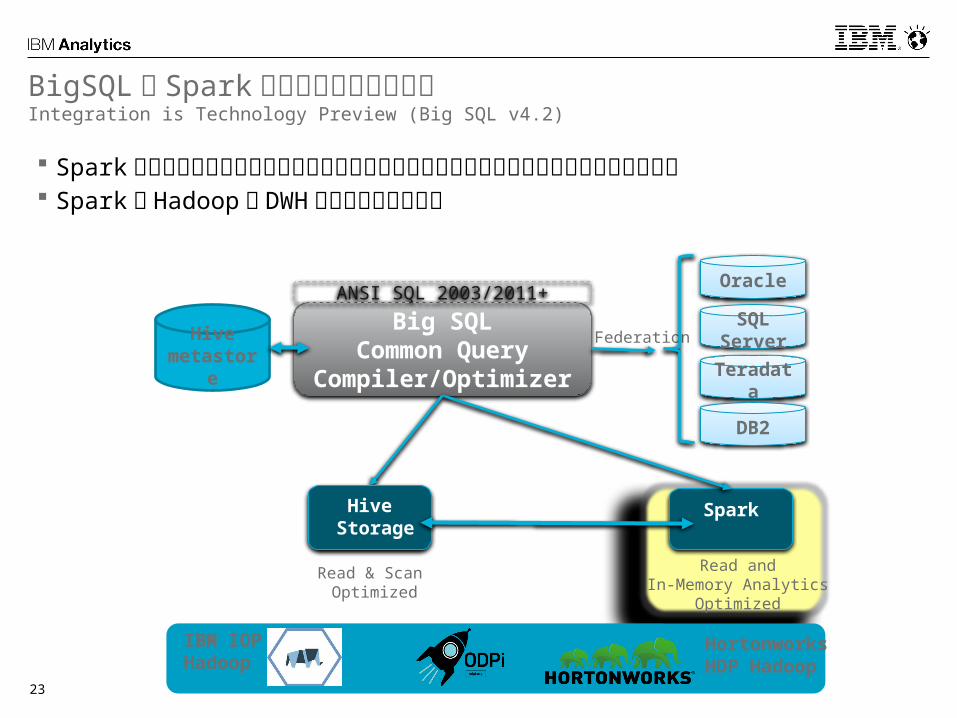
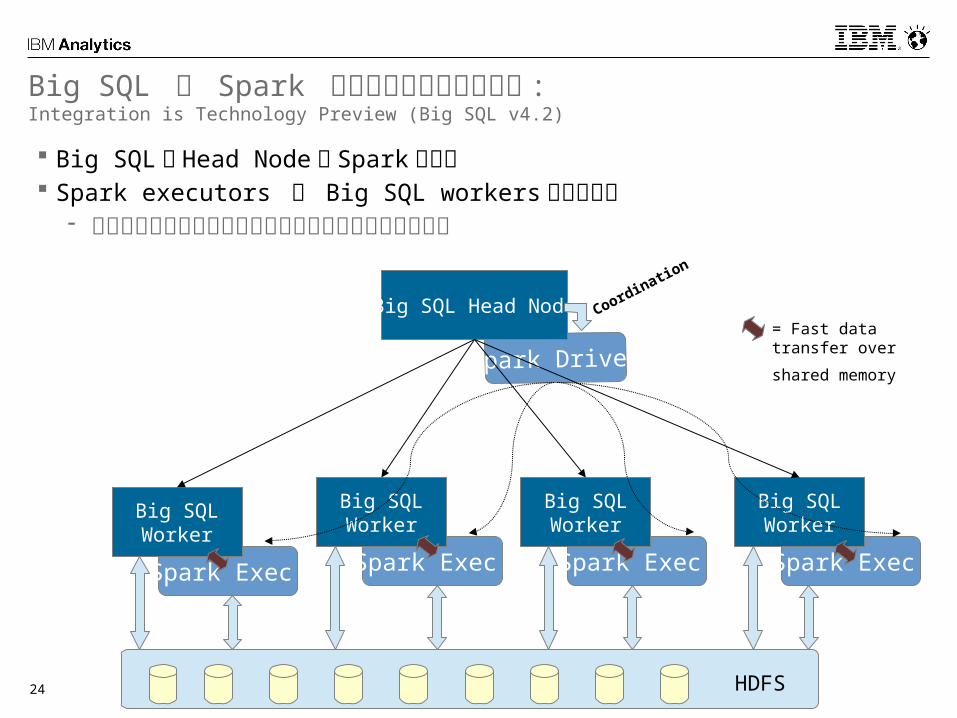
BigSQL と Spark のインテグレーションIntegration is Technology Preview (Big SQL v4.2)
Big SQLCommon Query
Compiler/Optimizer
Spark
Read & Scan Optimized
Read andIn-Memory Analytics
Optimized
Federation
Oracle
SQL Server
Teradata
DB2
IBM IOP Hadoop
Hortonworks HDP Hadoop
ANSI SQL 2003/2011+
Hive Storage
Hive metastore
Spark はデータアナリストやデータサイエンティストが利用するインメモリアーキテクチャ
Spark と Hadoop の DWH との相互利用は重要
24 HDFS
Spark Driver
Big SQL Head Node
Spark Exec.
Big SQLWorker
Spark Exec.
Big SQLWorker
Spark Exec.
Big SQLWorker
Spark Exec.
Big SQLWorker
Coordination
= Fast data transfer over
shared memory
Big SQL は Spark インメモリ実行エンジン :Integration is Technology Preview (Big SQL v4.2)
Big SQL の Head Node が Spark を起動 Spark executors が Big SQL workers と協調動作
- それぞれの実行プロセスが共有メモリを通じて協調動作

25
どの Hadoop 上の SQL ソリューションを使うべきか ???• ベンダーロックインの有無
既存 DB 、 DWH からのポーティング• データの移動• ワークロードの移動 (SQL)
Hadoop 上の WareHouse を実運用環境へ• パフォーマンス、拡張性、ワークロードマネージャー• セルフチューニング• エンタープライズレベルセキュリティ
DWH から Hadoop へのコネクティビティ• Federation• Spark exploitation
さらなる価値の創造
Agenda
26
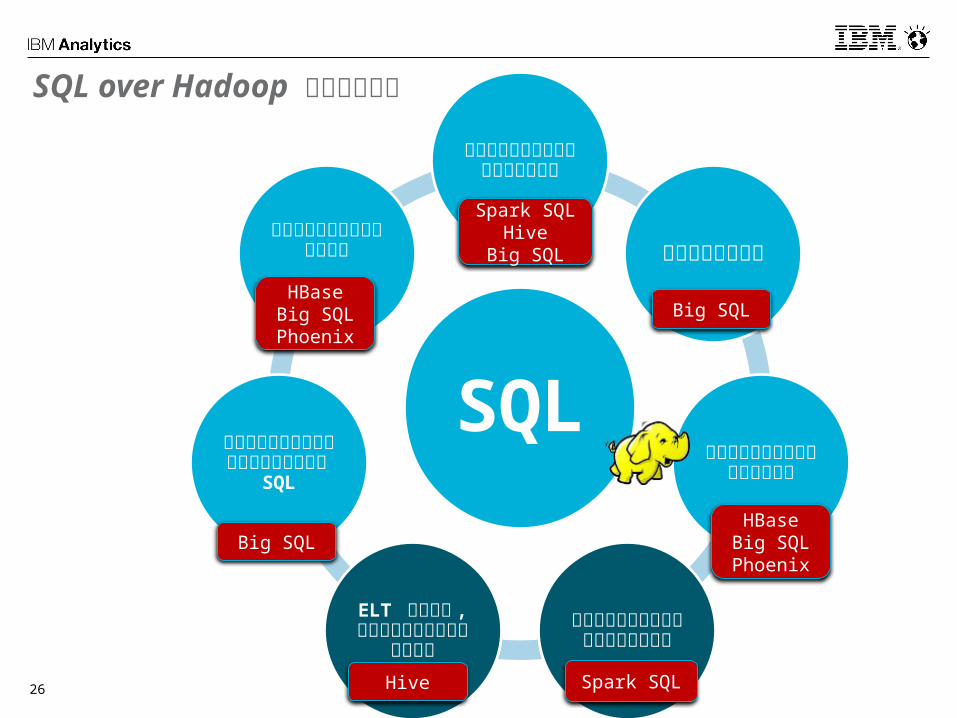
SQL
分析のためのアドホックなデータ整形
フェデレーション
キーバリューの高速なデー
タストア
少数ユーザーによるアドホックなクエ
リ
ELT や単純で , 巨大な
データを処理するクエリ
多数のユーザーが接続する環境での複
雑な SQL
オペレーショナルデータス
トア
Big SQL
Hive Spark SQL
Big SQLHBase
Big SQLPhoenix
Spark SQLHive
Big SQL
HBaseBig SQLPhoenix
SQL over Hadoop ユースケース

27
Operational Data Stores は Analytics の組織において重要
Hadoop 上で Update や Delete を実行するのは難しい
HBase は Hadoop のベースコンポーネントの一つであり、キーバリュー型- ODS としての利用は可能だが SQL の実行はできない
Apache Phoenix は SQL インターフェースを提供- Non-ANSI SQL- セキュリティモデルとユーザー認証- Hive とHBaseには別の Connection が必要- Hive と HBase のテーブルの join は現在開発中. No
ETA.
OLTP
Warehouse
ODS
Operational Data Store (ODS) on Hadoop
28
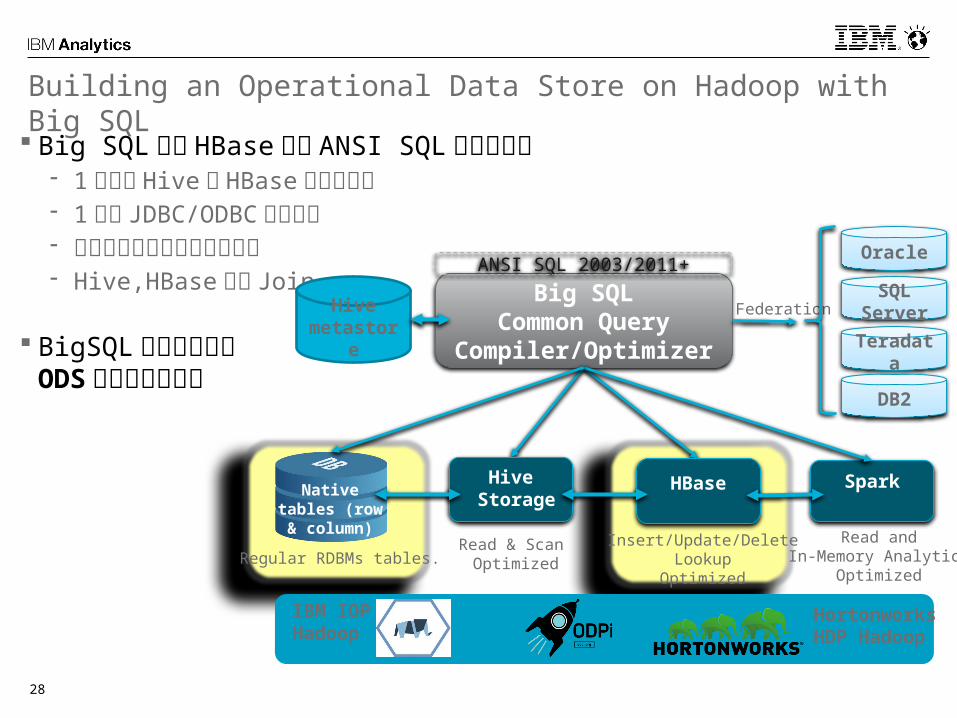
Building an Operational Data Store on Hadoop with Big SQL Big SQL なら HBase でも ANSI SQL を利用可能
- 1 接続で Hive と HBase にアクセス- 1 つの JDBC/ODBC ドライバ- 統合されたセキュリティ機能- Hive,HBase 間の Join
BigSQL のテーブルをODS として利用可能
Big SQLCommon Query
Compiler/Optimizer
Spark
Read & Scan Optimized
Insert/Update/DeleteLookup
Optimized
Read andIn-Memory Analytics
Optimized
Federation
Oracle
SQL Server
Teradata
DB2
IBM IOP Hadoop
Hortonworks HDP Hadoop
Nativetables (row &
column)
ANSI SQL 2003/2011+
HBaseHive Storage
Hive metastore
Regular RDBMs tables.
29
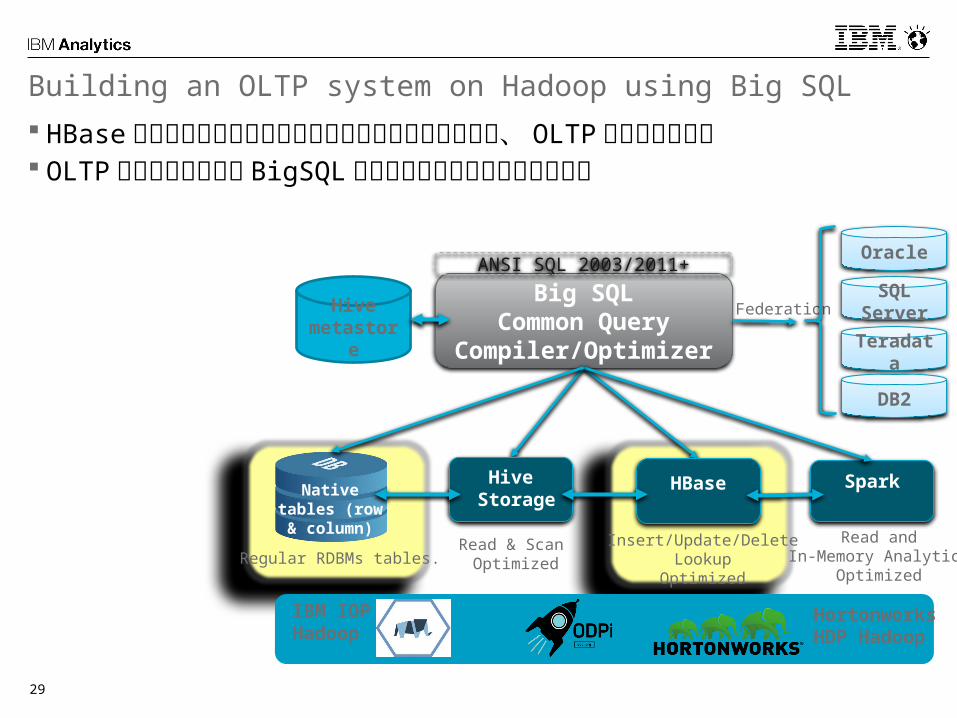
Building an OLTP system on Hadoop using Big SQL HBase は小範囲のルックアップや更新処理には優れるため、 OLTP 的
な利用も可能 OLTP ワークロードには BigSQL ・ローカルテーブルの利用も可能
Big SQLCommon Query
Compiler/Optimizer
Spark
Read & Scan Optimized
Insert/Update/DeleteLookup
Optimized
Read andIn-Memory Analytics
Optimized
Federation
Oracle
SQL Server
Teradata
DB2
IBM IOP Hadoop
Hortonworks HDP Hadoop
Nativetables (row &
column)
ANSI SQL 2003/2011+
HBaseHive Storage
Hive metastore
Regular RDBMs tables.
30
サマリ : Hadoop の Data Warehouse
ベンダーロックインは避ける – Hive metastore とストレージモデルを共用
ワークロードの移動・移行はできるだけシンプルに
RDBMS で利用していた機能に関しても考慮 ( Grant など)
他のデータソースへの接続を考慮
Spark との利用を考慮
SQL on Hadoop を積極的に使いましょう – 単なる DWH よりも多くの処理が可能で
す
31
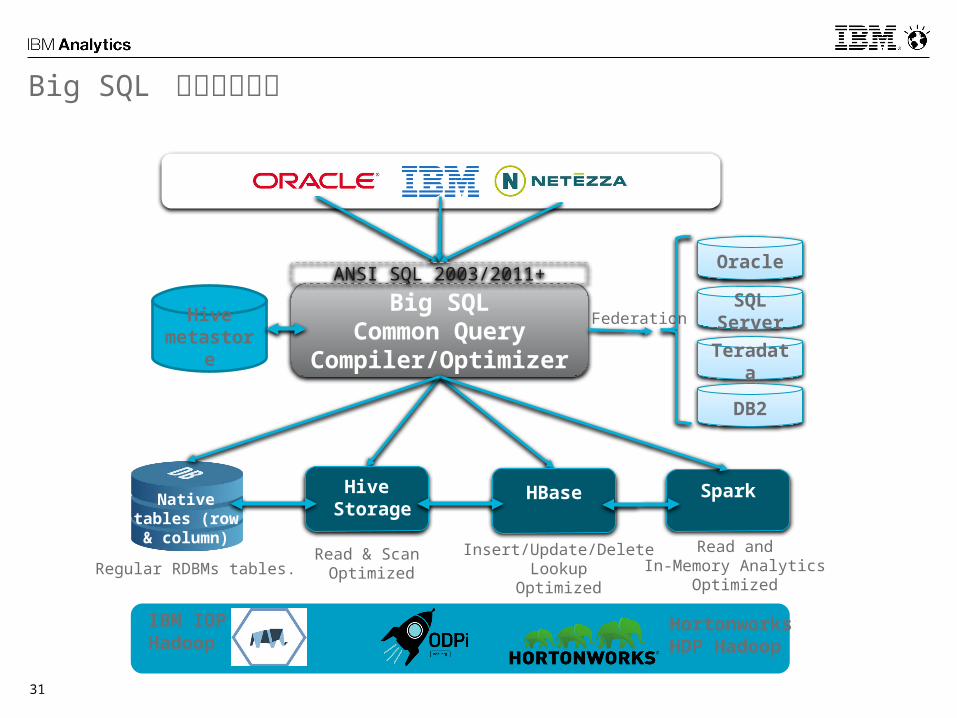
Big SQL エコシステム
Big SQLCommon Query
Compiler/Optimizer
Spark
Read & Scan Optimized
Insert/Update/DeleteLookup
Optimized
Read andIn-Memory Analytics
Optimized
Federation
Oracle
SQL Server
Teradata
DB2
IBM IOP Hadoop
Hortonworks HDP Hadoop
Nativetables (row &
column)
ANSI SQL 2003/2011+
HBaseHive Storage
Hive metastore
Regular RDBMs tables.