Embed Size (px)
Citation preview

Session 27 : Privacy II
担当:川本淳平(京都大学)
Session 27 : Privacy II 担当:川本(京大)1
【 VLDB2009 勉強会】

Anonymization of Set-Valued Data via Top-Down, Local Generalization (He and Naughton)
Set-valued Dataに対する匿名性 組合せに対する匿名性 Aliceが {Wine, Diapers, Brush}を購入 攻撃者がAliceの購入商品を知っていると
T2 = Aliceと特定可能
Session 27 : Privacy II 担当:川本(京大)2
T1: {Beer, Diapers}T2: {Wine, Diapers, Brush}T3: {Beer, Wine, Brush}
トランザクション DB Alice の購入商品と一致

Anonymization of Set-Valued Data via Top-Down, Local Generalization (He and Naughton)
Terrovitisらの km-anonymity サイズ m の集合に対しそれぞれ k 個以上あることを保証
下のDBは 22-anonymityになっている(どのペアも2個以上ある)
Session 27 : Privacy II 担当:川本(京大)3
T1: {Beer, Diapers}T2: {Wine, Diapers, Brush}T3: {Beer, Wine, Brush}T4: {Beer, Wine, Diapers, Brush}
トランザクション DBどっちが Alice か分からな
い

Anonymization of Set-Valued Data via Top-Down, Local Generalization (He and Naughton)
km-anonymityの問題点 攻撃者がさらに知識を持っている場合防ぎきれない 例えばAliceがビールを飲まないと知っていれば
T2 = Aliceと特定可能
Session 27 : Privacy II 担当:川本(京大)4
T1: {Beer, Diapers}T2: {Wine, Diapers, Brush}T3: {Beer, Wine, Brush}T4: {Beer, Wine, Diapers, Brush}
トランザクション DBやっぱり T2 = Alice と
特定可能

Anonymization of Set-Valued Data via Top-Down, Local Generalization (He and Naughton)
km-anonymityの問題点 攻撃者がさらに知識を持っている場合防ぎきれない 例えばAliceがビールを飲まないと知っていれば
T2 = Aliceと特定可能
Session 27 : Privacy II 担当:川本(京大)5
サイズ m に限定せずあらゆるサイズの集合に対しそれぞれ k 個以上の存在を保証すべき : k-
anonymity

PB
PAB
PA
→ {A}
→ {A}
→ {B}
→ {B}
→ {A, B}
→ {A, B}
→ {A, B}
Pa1a2B
Pb1b2
Pa1a2
Pa1
Anonymization of Set-Valued Data via Top-Down, Local Generalization (He and Naughton)
Session 27 : Privacy II 担当:川本(京大)6
T1: {a1}
T2: {a1, a2}
T3: {b1,b2}
T4: {b1, b2}
T5: {a1, a2, b2}
T6: {a1, a2, b2}
T7: {a1, a2, b1, b2}
一般化とパーティション分割を用いたアルゴリズム
ALL
A B
a1 a2 b1 b2
一般化階層構造
例:下記の 7 トランザクションを 2-anonymity を満たすよう変換
A B
a1 a2
→ {a1}
→ {a1, a2}
b1 b2
→ {b1, b2}
→ {b1, b2}
{Pa1B, Pa2B, Pa1a2B} と分ける
か{PAb1, PAb2, PAb1b2} と分ける
か
1. 一般化改装構造をもとにパーティションに分割する2. 各パーティションが k-anonymity を満足すれば再帰的に分割 k-anonymity を満足しなければロールバック
パーティションの分け方は情報量のロスが少なくなるように選定 ( 計算式は略 )
→ {a1, a2, b2}
→ {a1, a2, b2}
→ {a1, a2, b1, b2}

Anonymization of Set-Valued Data via Top-Down, Local Generalization (He and Naughton)
実験 データセットとして実トランザクションDB(BMS-POSなど)を使用
km-anonymity保証するアルゴリズム(AA)と計算速度を比較
k = 10, mはトランザクション中最大の集合要素数とした
結果 どのデータセットでも提案手法の方が速い
Session 27 : Privacy II 担当:川本(京大)7

K-Automorphism: A General Framework For Privacy Preserving Network Publication (Zou, Chen, and Özsu)
プライバシに配慮したネットワーク公開 データマイニング用にソーシャルネットワークを公開 公開前にプライベート情報を取り除く必要がある 名前などを取り除くだけでは不十分
本稿は Identity disclosure 問題を対象とする ある人がネットワークのどの頂点に対応するか漏洩する
問題 「友達が何人いるか」といった部分グラフからの漏洩な
ど 既存研究の問題点
1種類の攻撃にしか対応していない 乱数を用いているため解析結果が異なる 動的な匿名化に対応していない
Session 27 : Privacy II 担当:川本(京大)8
唯一 4 本の枝を持つノード

K-Automorphism すべてのノードに対して自身と同じ構造のノードが k 以
上存在 グラフ構造によるノード特定を防ぐ
例: 4本の枝を持つノードが k 個以上になる
K-Match(KM) アルゴリズム k 個のパーティションに分割 それぞれのパーティションが同型になるように調整 パーティションを跨ぐ枝のコピー
P12 P22
K-Automorphism: A General Framework For Privacy Preserving Network Publication (Zou, Chen, and Özsu)
Session 27 : Privacy II 担当:川本(京大)9
2-Automorphism の例
k=2 の例

K-Automorphism: A General Framework For Privacy Preserving Network Publication (Zou, Chen, and Özsu)
実験 既存手法とSub-graph攻撃に対する耐性を比較
ある部分グラフがネットワークのどこに位置するのか調べる攻撃 与えられた部分グラフにマッチするネットワーク上の部分グラフ数を計測
データセットはPrefuseグラフ,共著グラフや人工生成グラフなど
提案手法の k は10とした
結果 調べる部分グラフのサイズが小
どの手法も複数の部分グラフがマッチ
調べる部分グラフのサイズが大 既存手法では特定される 提案手法では必ず10個以上マッチ
Session 27 : Privacy II 担当:川本(京大)10
マッチする部分グラフは1 つ

Distribution-based Microdata Anonymization (Koudas, Srivastava, Yu, Zhang)
分布ベースのプライバシモデル ある分布に従うようにデータを匿名化(l-diversity, t-closeness)
匿名化後にも合計が計算できるように 既存研究の問題
条件を満足するグループ化が常に可能とは限らない 出力をコントロールできない
期待していたグループになっているとは限らない
目的 希望する属性値でグループ化 秘匿したい属性の属性値を希望の分布に従わせる
Session 27 : Privacy II 担当:川本(京大)11
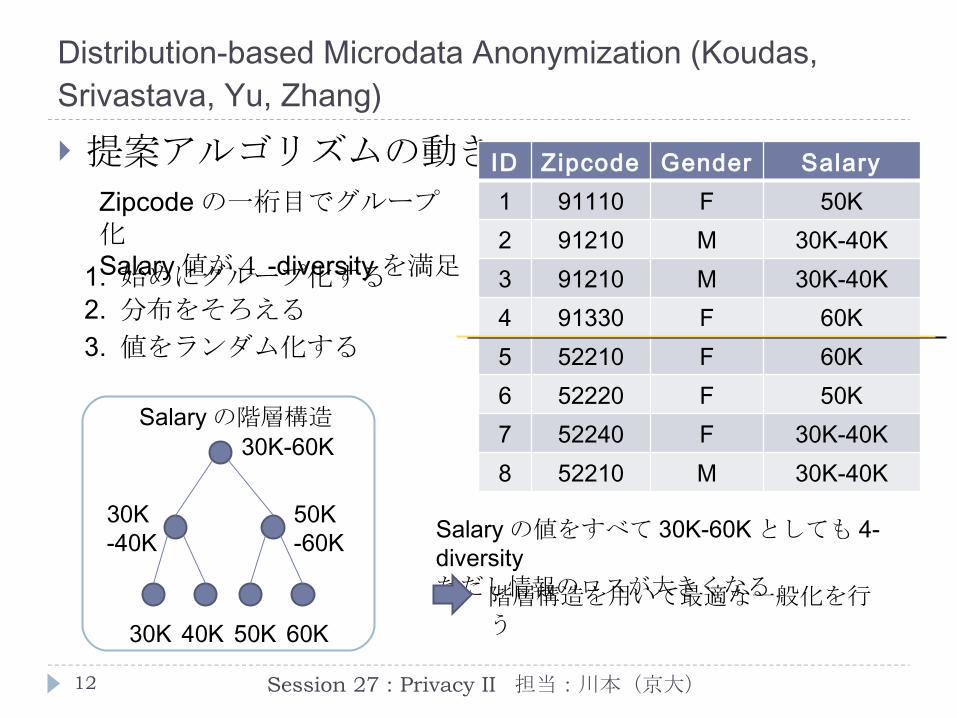
提案アルゴリズムの動き
Distribution-based Microdata Anonymization (Koudas, Srivastava, Yu, Zhang)
Session 27 : Privacy II 担当:川本(京大)12
ID Zipcode Gender Salary1 91110 F 30K2 91210 M 50K3 91210 M 60K4 91330 F 30K5 52210 F 40K6 52220 F 40K7 52240 F 60K8 52210 M 50K
Zipcode の一桁目でグループ化Salary値が4 -diversity を満足
30K 40K 50K 60K
30K-40K
50K-60K
30K-60KSalary の階層構造
2. 分布をそろえる
3. 値をランダム化する
1. 始めにグループ化する
ID Zipcode Gender Salary1 91110 F 30K-40K2 91210 M 50K3 91210 M 60K4 91330 F 30K-40K5 52210 F 30K-40K6 52220 F 30K-40K7 52240 F 60K8 52210 M 50K
ID Zipcode Gender Salary1 91110 F 50K2 91210 M 30K-40K3 91210 M 30K-40K4 91330 F 60K5 52210 F 60K6 52220 F 50K7 52240 F 30K-40K8 52210 M 30K-40K
Salary の値をすべて 30K-60K としても 4-diversityただし情報のロスが大きくなる階層構造を用いて最適な一般化を行
う

Distribution-based Microdata Anonymization (Koudas, Srivastava, Yu, Zhang)
偽のタプルを追加する改良
Session 27 : Privacy II 担当:川本(京大)13
ID Zipcode
Salary1 91210 40K
2 91220 30K3 91220 50K
ID Zipcode
Salary1 91210 30K-40K2 91220 30K-60K3 91220 50K-60K
ID Zipcode
Salary1 91210 40K
2 91220 30K3 91220 50K
60K
通常
偽タプルの追加
通常の方法だと平均が正しく計算できない
偽タプルを追加することで解決する

Distribution-based Microdata Anonymization (Koudas, Srivastava, Yu, Zhang) 実験
データセットは UCI Adult Database 指定した分布と匿名化されたデータの分布を比較
Session 27 : Privacy II 担当:川本(京大)14