Embed Size (px)
Citation preview

Copyright©2016 NTT corp. All Rights Reserved.
What’s new in Hadoop Common and HDFS@Hadoop Summit Tokyo 2016
Tsuyoshi OzawaNTT Software Innovation Center
2016/10/26

2Copyright©2016 NTT corp. All Rights Reserved.
• Tsuyoshi Ozawa• Research & Engineer @ NTTTwitter: @oza_x86_64
• Apache Hadoop Committer and PMC• Introduction to Hadoop 2nd Edition(Japanese)” Chapter
22(YARN)• Online article: gihyo.jp “Why and How does Hadoop work?”
About me

3Copyright©2016 NTT corp. All Rights Reserved.
• What’s new in Hadoop 3 Common and HDFS?
• Build• Compiling source code with JDK 8
• Common• Better Library Management
• Client-Side Class path Isolation• Dependency Upgrade
• Support for Azure Data Lake Storage• Shell script rewrite • metrics2 sink plugin for Apache Kafka HADOOP-10949
• HDFS• Erasure Coding Phase 1 HADOOP-11264
• MR, YARN -> Junping will talk!
Agenda

Copyright©2016 NTT corp. All Rights Reserved.
Build

5Copyright©2016 NTT corp. All Rights Reserved.
• We upgraded minimum JDK to JDK8• HADOOP-11858
• Oracle JDK 7 is EoL at April 2015!!• Moving forward to use new features of JDK8
• Hadoop 2.6.x• JDK 6, 7, 8 or later
• Hadoop 2.7.x/2.8.x/2.9.x• JDK 7, 8 or later
• Hadoop 3.0.x• JDK 8 or later
Apache Hadoop 3.0.0 run on JDK 8 or later

Copyright©2016 NTT corp. All Rights Reserved.
Common

7Copyright©2016 NTT corp. All Rights Reserved.
• Jersey: 1.9 to 1.19• the root element whose content is empty collection is changed
from null to empty object({}). • grizzly-http-servlet: 2.1.2 to 2.2.21• Guice: 3.0 to 4.0• cglib: 2.2 to 3.2.0• asm: 3.2 to 5.0.4
Dependency Upgrade
8Copyright©2016 NTT corp. All Rights Reserved.
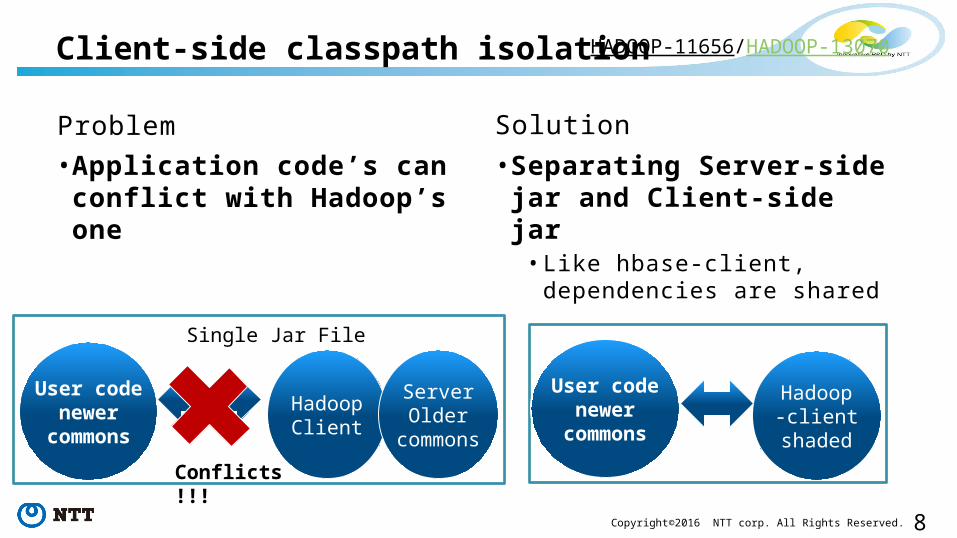
Client-side classpath isolation
Problem• Application code’s can conflict with Hadoop’s one
Solution• Separating Server-side jar and Client-side jar
• Like hbase-client, dependencies are shared
HADOOP-11656/HADOOP-13070
HadoopClient
ServerOlder
commons
User codenewer
commons
Single Jar File
Conflicts!!!
Hadoop-clientshaded
User codenewer
commons

9Copyright©2016 NTT corp. All Rights Reserved.
• FileSystem API supports various storages• HDFS• Amazon S3• Azure Blob Storage• OpenStack Swift
• 3.0.0 supports Azure Data Lake Storage officially
Support for Microsoft Azure Data Lake filesystem connector
Support for Microsoft Azure Data Lake filesystem connector
Support for Microsoft Azure Data Lake filesystem connector
Support for Azure Data Lake Storage
10Copyright©2016 NTT corp. All Rights Reserved.
• CLI are renewed!• To fix bugs (e.g. HADOOP_CONF_DIR is honored sometimes)• To introduce new features
E.g.• To launch daemons,
Use {hadoop,yarn,hdfs} --daemon command instead of {hadoop,yarn,hdfs}-daemons.sh
• To print various environment variables, java options, classpath, etc “{hadoop,yarn,hdfs} --debug” option is supported
• Please check documents• https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoo
p-common/CommandsManual.html• https://issues.apache.org/jira/browse/HADOOP-9902
Shell script rewrite
11Copyright©2016 NTT corp. All Rights Reserved.
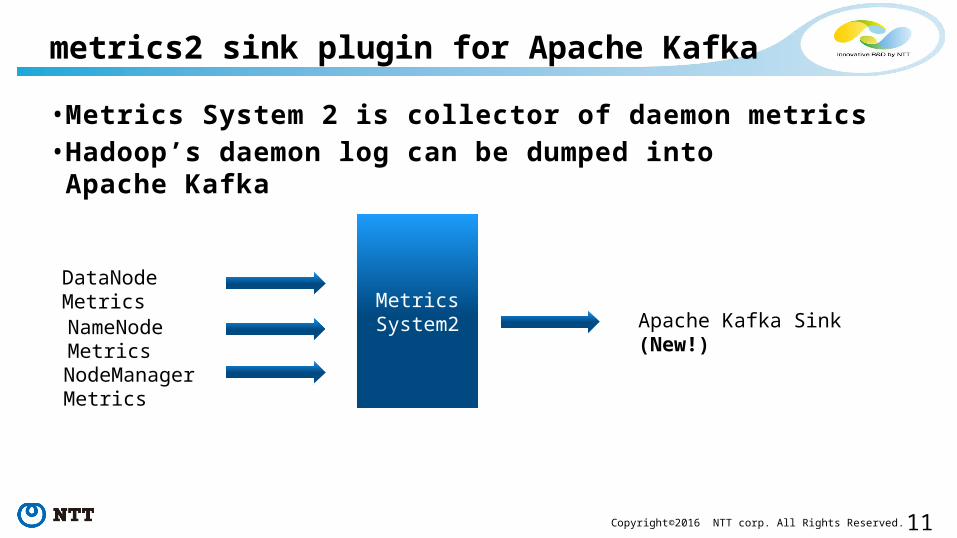
• Metrics System 2 is collector of daemon metrics• Hadoop’s daemon log can be dumped into Apache Kafka
metrics2 sink plugin for Apache Kafka
MetricsSystem2
DataNodeMetricsNameNodeMetricsNodeManagerMetrics
Apache Kafka Sink(New!)

Copyright©2016 NTT corp. All Rights Reserved.
HDFSNamenodeMulti Standby
13Copyright©2016 NTT corp. All Rights Reserved.
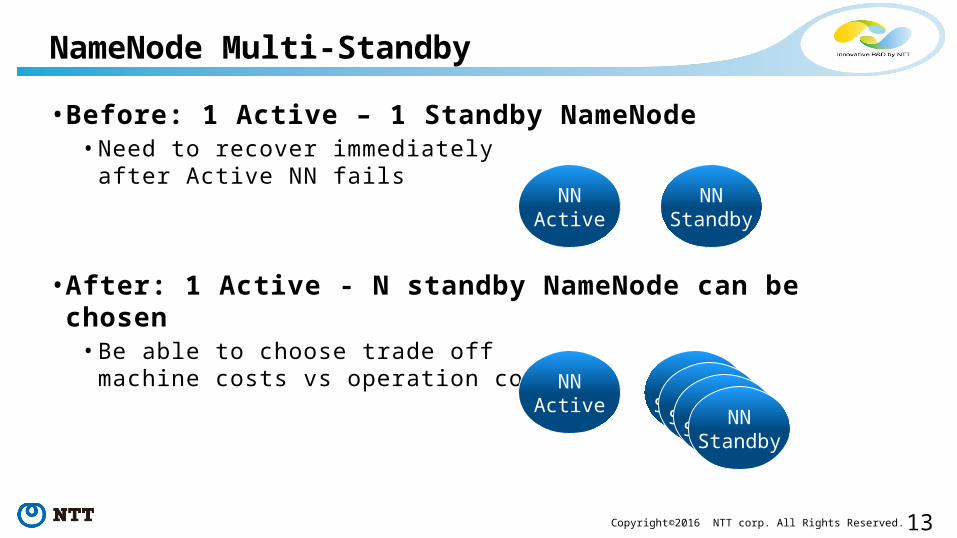
• Before: 1 Active – 1 Standby NameNode• Need to recover immediately
after Active NN fails
• After: 1 Active - N standby NameNode can be chosen
• Be able to choose trade off machine costs vs operation costs
NameNode Multi-Standby
NNActive
NNStandby
NNActive
NNStandbyNN
StandbyNNStandbyNN
Standby

Copyright©2016 NTT corp. All Rights Reserved.
HDFSErasure Coding
15Copyright©2016 NTT corp. All Rights Reserved.
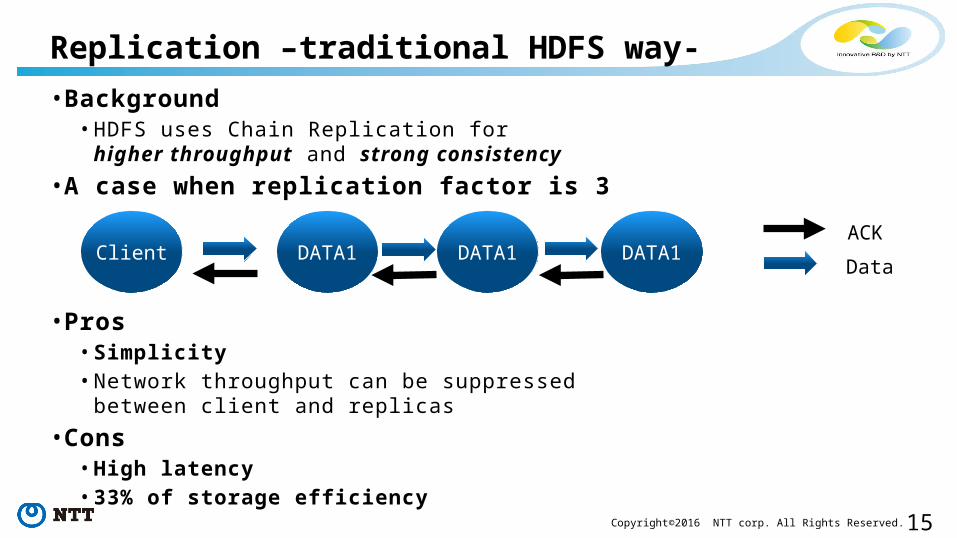
• Background• HDFS uses Chain Replication for
higher throughput and strong consistency• A case when replication factor is 3
• Pros• Simplicity• Network throughput can be suppressed
between client and replicas• Cons
• High latency• 33% of storage efficiency
Replication –traditional HDFS way-
DATA1 DATA1 DATA1ClientACKData

16Copyright©2016 NTT corp. All Rights Reserved.
• Erasure Coding is another way to save storagewith fault tolerance
• Used in RAID 5/6• Using “parity” instead of “copy” to recover
• Reed-Solomon coding is used• If data is lost, recover is done with inverse matrix
Erasure Coding
1 0 0 0
0 1 0 0
0 0 1 0
0 0 0 1× ¿
Parity Bits
Data Bits
FAST ’09: 7th, A Performance Evaluation and Examination of Open-Source Erasure Coding Libraries For Storage
Storing thesevaluesinstead of only storingdata!
4 bits data – 2 bits parity read Solomon

17Copyright©2016 NTT corp. All Rights Reserved.
• Erasure coding is flexible: tuning of data bits and parity bits can be done
• 6 data-bits, 3 parity-bits
• 3 replication vs (6, 3)-read Solomon
Effect of Erasure Coding
3-replication (6, 3) Reed-SolomonMaximum fault Tolerance 2 3Disk usage(N byte of data) 3N 1.5N
HDFS Erasure Coding Design Document: https://issues.apache.org/jira/secure/attachment/12697210/HDFSErasureCodingDesign-20150206.pdf
18Copyright©2016 NTT corp. All Rights Reserved.
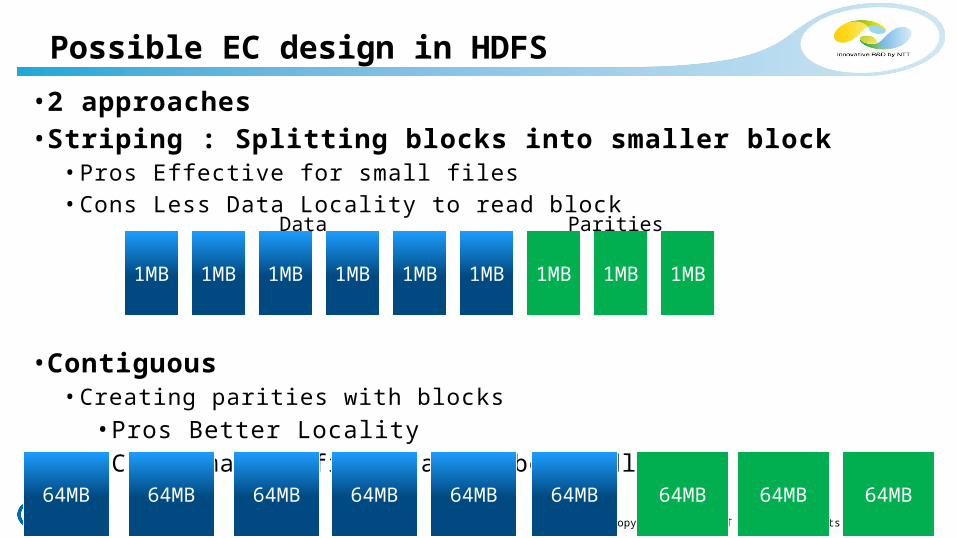
• 2 approaches• Striping : Splitting blocks into smaller block
• Pros Effective for small files• Cons Less Data Locality to read block
• Contiguous • Creating parities with blocks
• Pros Better Locality• Cons Smaller files cannot be handled
Possible EC design in HDFS
1MB 1MB 1MB 1MB 1MB 1MB 1MB 1MB 1MB
ParitiesData
64MB 64MB 64MB 64MB 64MB 64MB 64MB 64MB 64MB
19Copyright©2016 NTT corp. All Rights Reserved.
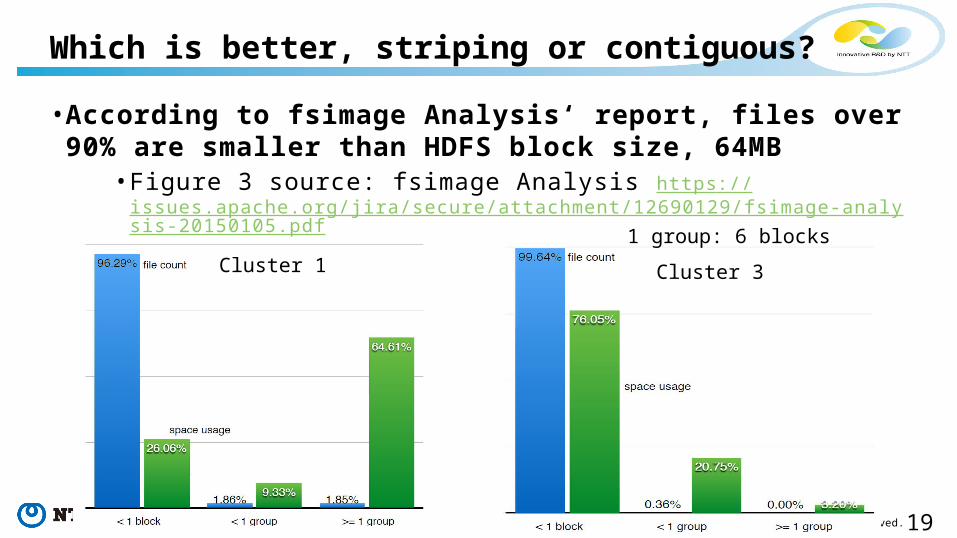
• According to fsimage Analysis‘ report, files over 90% are smaller than HDFS block size, 64MB
• Figure 3 source: fsimage Analysis https://issues.apache.org/jira/secure/attachment/12690129/fsimage-analysis-20150105.pdf
Which is better, striping or contiguous?
1 group: 6 blocksCluster 3Cluster 1
20Copyright©2016 NTT corp. All Rights Reserved.
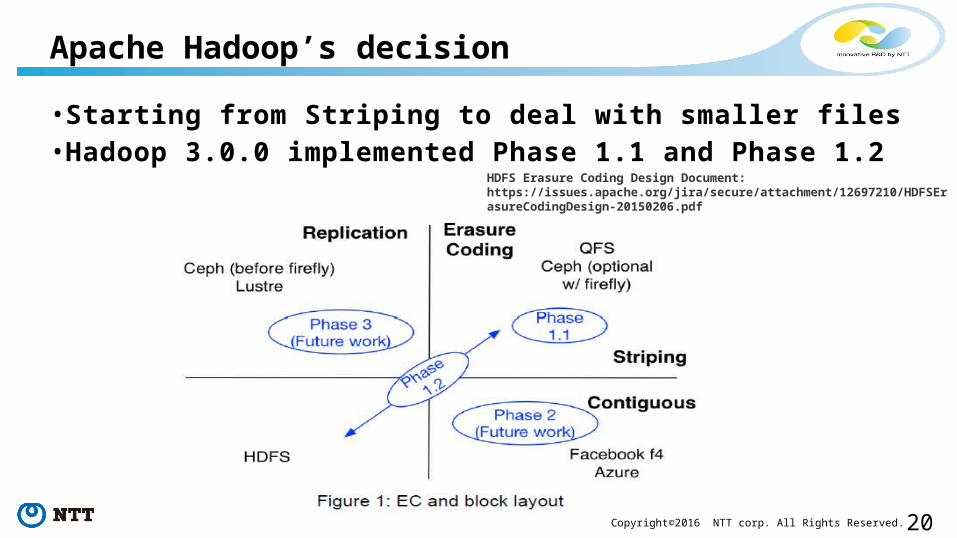
• Starting from Striping to deal with smaller files• Hadoop 3.0.0 implemented Phase 1.1 and Phase 1.2
Apache Hadoop’s decision
HDFS Erasure Coding Design Document: https://issues.apache.org/jira/secure/attachment/12697210/HDFSErasureCodingDesign-20150206.pdf
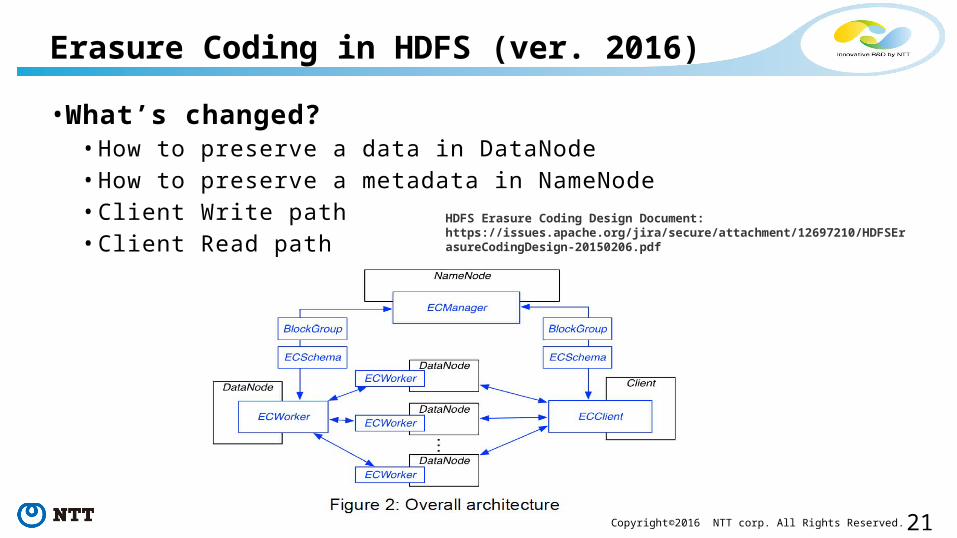
21Copyright©2016 NTT corp. All Rights Reserved.
• What’s changed?• How to preserve a data in DataNode• How to preserve a metadata in NameNode• Client Write path• Client Read path
Erasure Coding in HDFS (ver. 2016)
HDFS Erasure Coding Design Document: https://issues.apache.org/jira/secure/attachment/12697210/HDFSErasureCodingDesign-20150206.pdf
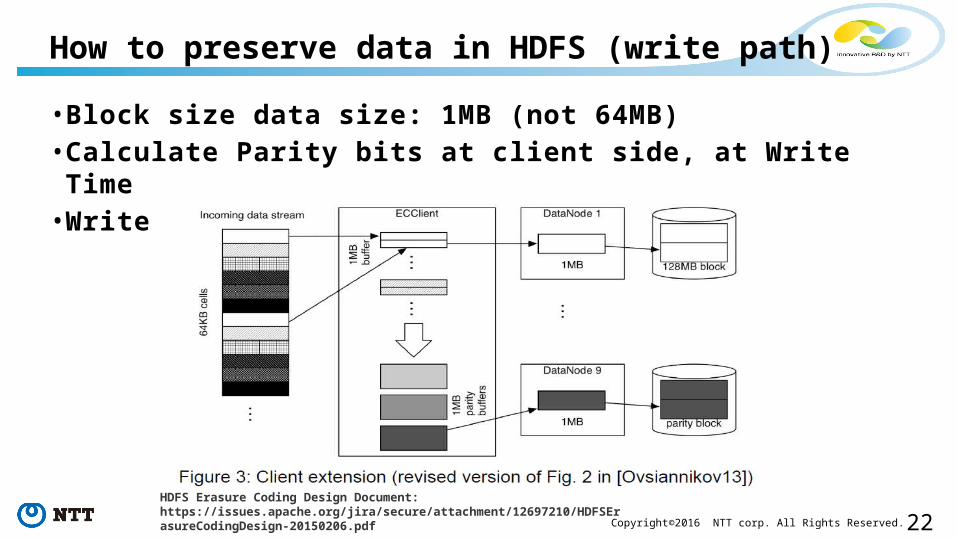
22Copyright©2016 NTT corp. All Rights Reserved.
• Block size data size: 1MB (not 64MB)• Calculate Parity bits at client side, at Write Time• Write in parallel (not chain replication)
How to preserve data in HDFS (write path)
HDFS Erasure Coding Design Document: https://issues.apache.org/jira/secure/attachment/12697210/HDFSErasureCodingDesign-20150206.pdf
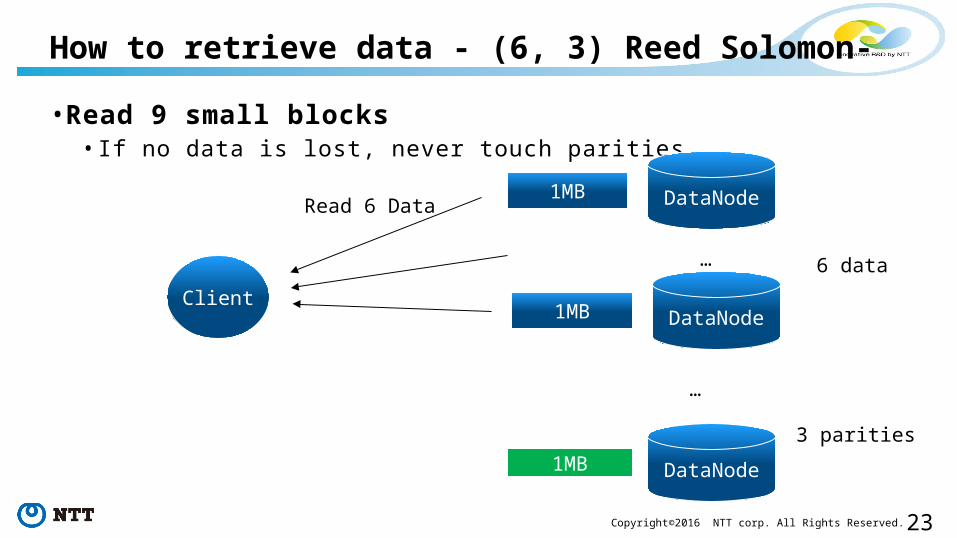
23Copyright©2016 NTT corp. All Rights Reserved.
• Read 9 small blocks• If no data is lost, never touch parities
How to retrieve data - (6, 3) Reed Solomon-
DataNode
DataNode1MB
1MB
ClientDataNode1MB
6 data
3 parities
…
…
Read 6 Data

24Copyright©2016 NTT corp. All Rights Reserved.
• Pros• Low latency because of parallel write/read• Good for small-size files
• Cons• Require high network bandwidth between client-server
Network traffic
Workload 3-replication (6, 3) Reed-SolomonRead 1 block 1 LN 1/6 LN + 5/6 RRWrite 1LN + 1LR + 1RR 1/6 LN + 1/6 LR + 7/6 RR
LN: Local NodeLR: Local RackRR: Remote Rack

25Copyright©2016 NTT corp. All Rights Reserved.
• Write path/Read path are changed!• How much network traffic?• How many small files?
• If network traffic is very high, replication seems to be preferred
• If there are cold data and most of them are small, EC is good option
Operation Points

26Copyright©2016 NTT corp. All Rights Reserved.
• Build• Upgrade minimum JDK to JDK 8
• Commons• Be careful about Dependency Management of your project
if you write hand-coded MapReduce• Shell script rewrite make operation easy• Kafka Metrics2 Sink• New FileSystem backend: Azure Data Lake
• HDFS• Multiple Standby NameNode make operation flexible• Erasure Coding
• Efficient disk usage than replication• Every know-how will be changed!
Summary

27Copyright©2016 NTT corp. All Rights Reserved.
• Kai Zheng slide is good for a reference• http://www.slideshare.net/HadoopSummit/debunking-the-myths-
of-hdfs-erasure-coding-performance• HDFS Erasure Coding Design Document
• https://issues.apache.org/jira/secure/attachment/12697210/HDFSErasureCodingDesign-20150206.pdf
• Fsimage Analysis• https://
issues.apache.org/jira/secure/attachment/12690129/fsimage-analysis-20150105.pdf
• Hadoop 3.0.0-alpha RELEASE Note• http://
hadoop.apache.org/docs/r3.0.0-alpha1/hadoop-project-dist/hadoop-common/release/3.0.0-alpha1/CHANGES.3.0.0-alpha1.html
References

28Copyright©2016 NTT corp. All Rights Reserved.
• Thanks all users, contributors, committers, and PMC of Apache Hadoop!
• Especially, Andrew Wang had great effort to release3.0.0-alpha!
• Thanks Kota Tsuyuzaki, a OpenStack Swift developer, for reviewing my EC related slides!
Acknowledgement





























