Embed Size (px)
Citation preview

HUAWEI TECHNOLOGIES CO., LTD.
www.huawei.com
Huawei Confidential
Security Level:
47pt
30pt
反白
:
FrutigerNext LT Medium
: Arial
47pt
黑体
28pt
反白
细黑体
August, 2016
Weidong Han <[email protected]>
Wei Yang <[email protected]>
Zhichao Huang <[email protected]>
>
Xen Scalability Analysis

HUAWEI TECHNOLOGIES CO., LTD. Huawei Confidential
35pt
32pt
) :18pt
Page 2
Agenda
Current Status
Issues & Proposals
Summary

HUAWEI TECHNOLOGIES CO., LTD. Huawei Confidential
35pt
32pt
) :18pt
Page 3
What’s Scalability
Scalability is the capability of a system, network, or process to
handle a growing amount of work, or its potential to be enlarged in
order to accommodate that growth [wikipedia]
We care about below dimensions of scalability on a single server
Horizontal scaling: more VMs , more users
Vertical scaling: larger VM
Source https://en.wikipedia.org/wiki/Scalability

HUAWEI TECHNOLOGIES CO., LTD. Huawei Confidential
35pt
32pt
) :18pt
Page 4
Current Status: Xen Max Limits
Xen 4.7
Host Limits (x86)
Up to 4095 physical CPUs
Up to 16TB physical memory
HVM Guest Limits (x86)
Up to 512 virtual CPUs
Up to 1TB virtual memory

HUAWEI TECHNOLOGIES CO., LTD. Huawei Confidential
35pt
32pt
) :18pt
Page 5
Current Status: Scale to Thousands of VMs
3000 VMs were experimented successfully
Improving Scalability of Xen: the 3,000 domains experiment
(https://events.linuxfoundation.org/images/stories/slides/lfcs2013_liu.pdf
)

HUAWEI TECHNOLOGIES CO., LTD. Huawei Confidential
35pt
32pt
) :18pt
Page 6
Scalability was improved a lot in upstream
Grant table
Split grant table lock into maptrack lock and grant table lock
per-vCPU maptrack free lists
Read-write lock
Per-active entry lock
Persistent grants for virtual block scalability
Avoid grant operations and TLB flushes
Event channel
Extend event channel limit: up to 131072
per-event channel lock for sending events
Scheduler
node-affinity for vCPU load balance
P2M
Use unlocked p2m lookups in hvmemul_rep_movs
defer the invalidation until the p2m lock is released

HUAWEI TECHNOLOGIES CO., LTD. Huawei Confidential
35pt
32pt
) :18pt
Page 7
Agenda
Current Status
Bottleneck & Proposals
Summary

HUAWEI TECHNOLOGIES CO., LTD. Huawei Confidential
35pt
32pt
) :18pt
Page 8
More Cores are Integrated
More and more cores are integrated into a CPU. There are hundreds of cores in 8P servers. It requires better many core scalability.

HUAWEI TECHNOLOGIES CO., LTD. Huawei Confidential
35pt
32pt
) :18pt
Page 9
Bottleneck 1: ticket spinlock is non-scalable
Xen uses ticket spinlock by default
Ticket spinlock is fair, FIFO
But, it’s non-scalable for many core
Spin on global shared variable
Expensive cache entries invalidation

HUAWEI TECHNOLOGIES CO., LTD. Huawei Confidential
35pt
32pt
) :18pt
Page 10
Proposal: scalable lock
MCS lock is scalable
Spin on local variable
Generate a constant number of cache misses per acquisition, avoid the
performance collapse with many cores.

HUAWEI TECHNOLOGIES CO., LTD. Huawei Confidential
35pt
32pt
) :18pt
Page 11
Bottleneck 2: call lock
Call lock is global lock, used in on_selected_cpus to protect
IPIs on targeted CPUs
Bottleneck case
Frequent EPT entry changes invalidate EPT on related
PCPUs
ept_sync_domain -> on_selected_cpus
heavy contention of call lock
HUAWEI TECHNOLOGIES CO., LTD. Huawei Confidential
35pt
32pt
) :18pt
Page 12
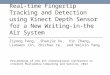
Proposal: scalable lock and finer-grain lock
Replace ticket lock with MCS lock for call lock
Change global lock to per-cpu lock
Hold a per-cpu lock of each target CPU, instead of a global lock
(call lock)
Then do IPIs: smp_send_call_function_mask(&call_data.selected);
1
2
3
N
…
It locks all even though the IPI
target CPUs are only CPU 1 and 2
src
1
2
3
N
…
src
It only locks IPI target CPUs (1 and 2),
other CPUs are still available for IPI

HUAWEI TECHNOLOGIES CO., LTD. Huawei Confidential
35pt
32pt
) :18pt
Page 13
Evaluation Environment and Method
Hardware
8 sockets, 96 cores, 192 threads
2TB RAM
Host
Xen 4.7.0
Dom0: SLES 11SP3
VM
Win 7 64bits
40GB RAM
64 vCPUs
Test case
Launch 8 VMs with POD in parallel, it will result in lots of EPT changes due to
Windows OS will zero pages during booting, then scan and recycle zero pages
when VM memory usage beyonds reserved threshold.
HUAWEI TECHNOLOGIES CO., LTD. Huawei Confidential
35pt
32pt
) :18pt
Page 14
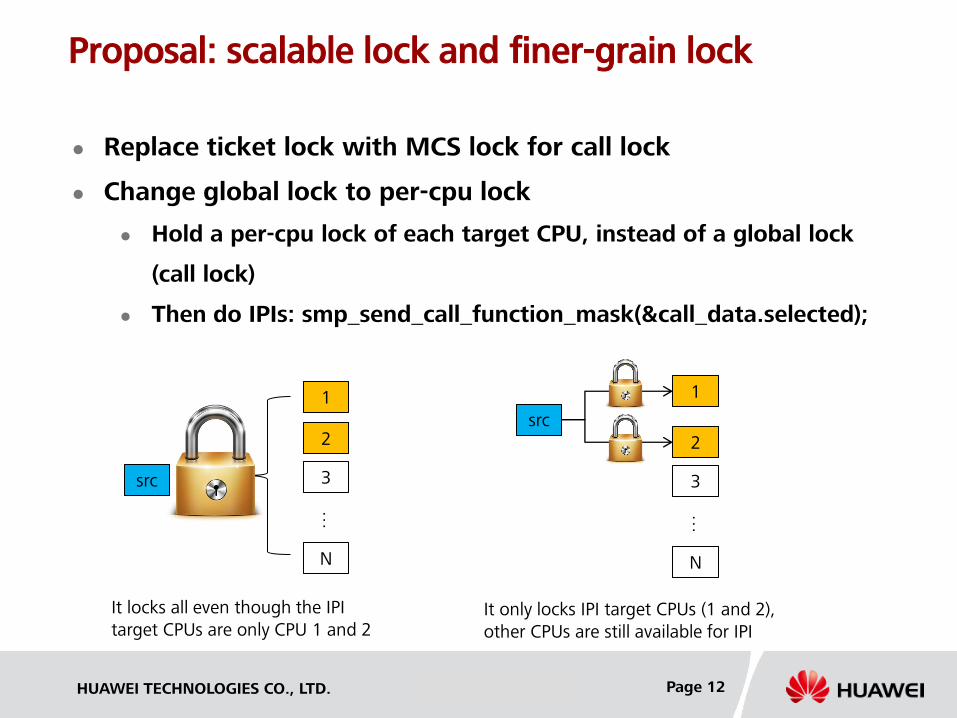
Evaluation Results
0
10000
20000
30000
40000
50000
60000
70000
1
12
23
34
45
56
67
78
89
10
0
11
1
12
2
13
3
14
4
15
5
16
6
17
7
18
8
19
9
21
0
22
1
23
2
24
3
25
4
26
5
27
6
28
7
29
8
30
9
32
0
33
1
34
2
35
3
36
4
37
5
38
6
39
7
40
8
41
9
43
0
44
1
45
2
46
3
47
4
48
5
49
6
50
7
51
8
52
9
54
0
55
1
56
2
57
3
58
4
59
5
Number of Lock Wait
Xen 4.7 Xen 4.7 with Optimization
0
2000000
4000000
6000000
8000000
10000000
1
12
23
34
45
56
67
78
89
10
0
11
1
12
2
13
3
14
4
15
5
16
6
17
7
18
8
19
9
21
0
22
1
23
2
24
3
25
4
26
5
27
6
28
7
29
8
30
9
32
0
33
1
34
2
35
3
36
4
37
5
38
6
39
7
40
8
41
9
43
0
44
1
45
2
46
3
47
4
48
5
49
6
50
7
51
8
52
9
54
0
55
1
56
2
57
3
58
4
59
5
Avg Consuming of Each Lock Wait (ns)
Xen 4.7 Xen 4.7 with Optimization
With the optimization, the number of lock wait and each wait consuming are both reduced significantly

HUAWEI TECHNOLOGIES CO., LTD. Huawei Confidential
35pt
32pt
) :18pt
Page 15
Bottleneck 3: vCPU load balance in credit scheduler
vCPU load balance
If the next highest priority local runnable vCPU has already eaten
through its credits, look on other PCPUs to see if we have more urgent
work
Select non-idling CPUs
Try to acquire the schedule lock of a non-idling CPU
Then try to steal a task from this non-idling CPU
If stealing not succeed, go to next non-idling CPU
The bottleneck analysis
In many core case, there will be lots of non-idling CPUs, it’s a big waste
if it often acquired the schedule lock but failed to steal a task.

HUAWEI TECHNOLOGIES CO., LTD. Huawei Confidential
35pt
32pt
) :18pt
Page 16
Proposal: Add a check before acquiring schedule
lock
Add a check for each non-idling CPU before acquiring
schedule lock
Add a bitmap of each PCPU, record what PCPUs its runq vCPUs can run
(vCPU may be pinned on some PCPUs)
If this CPU (which wants to steal task from other CPUs) is not in the
bitmap of a non-idling CPU, that means it cannot steal a task from this
non-idling CPU. Save the cost of acquiring schedule lock.

HUAWEI TECHNOLOGIES CO., LTD. Huawei Confidential
35pt
32pt
) :18pt
Page 17
Evaluation Environment
Hardware
8 socket, 96 cores, 192 threads
2TB RAM
Host
Xen 4.7.0
Dom0: SLES 11SP3
VM
Win 7 64bits
40GB RAM
24 vCPUs
Test case
1:1 pin vCPU to PCPU, and run NotMyFault in VM
HUAWEI TECHNOLOGIES CO., LTD. Huawei Confidential
35pt
32pt
) :18pt
Page 18
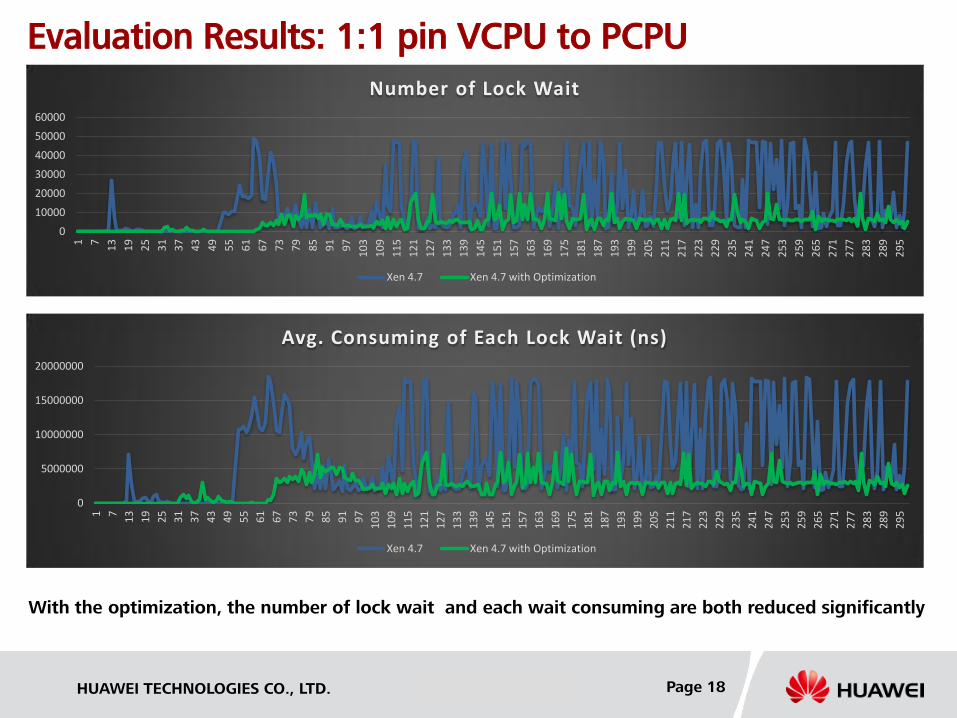
Evaluation Results: 1:1 pin VCPU to PCPU
0
10000
20000
30000
40000
50000
60000
1
7
13
19
25
31
37
43
49
55
61
67
73
79
85
91
97
10
3
10
9
11
5
12
1
12
7
13
3
13
9
14
5
15
1
15
7
16
3
16
9
17
5
18
1
18
7
19
3
19
9
20
5
21
1
21
7
22
3
22
9
23
5
24
1
24
7
25
3
25
9
26
5
27
1
27
7
28
3
28
9
29
5
Number of Lock Wait
Xen 4.7 Xen 4.7 with Optimization
0
5000000
10000000
15000000
20000000
1
7
13
19
25
31
37
43
49
55
61
67
73
79
85
91
97
10
3
10
9
11
5
12
1
12
7
13
3
13
9
14
5
15
1
15
7
16
3
16
9
17
5
18
1
18
7
19
3
19
9
20
5
21
1
21
7
22
3
22
9
23
5
24
1
24
7
25
3
25
9
26
5
27
1
27
7
28
3
28
9
29
5
Avg. Consuming of Each Lock Wait (ns)
Xen 4.7 Xen 4.7 with Optimization
With the optimization, the number of lock wait and each wait consuming are both reduced significantly

HUAWEI TECHNOLOGIES CO., LTD. Huawei Confidential
35pt
32pt
) :18pt
Page 19
Summary
Some scalability bottlenecks and proposals
Future work
Virtualization scalability benchmark
Scenarios
Measurement
Huge VM (vcpu > 128, memory > 1TB) support

Thank you www.huawei.com