Embed Size (px)
Citation preview

第1章 確率に関するベイズの定理
基礎からのベイズ統計学 輪読会 第一回資料 2015/11/17 @kenmatsu4

こちらの本、
「基礎からのベイズ統計学」(豊田秀樹) の 輪読会資料です!

MASAKARI Come On! щ(゜ロ゜щ)みんなで勉強しましょう
https://twitter.com/_inundata/status/616658949761302528

自己紹介: @kenmatsu4・Facebookページ https://www.facebook.com/matsukenbook ・Twitterアカウント @kenmatsu4 ・Qiitaでブログを書いています(統計、機械学習、Python等) http://qiita.com/kenmatsu4 (3900 contributionを超えました!)
・趣味 - バンドでベースを弾いたりしています。 - 主に東南アジアへバックパック旅行に行ったりします (カンボジア、ミャンマー、バングラデシュ、新疆ウイグル自治区 etc) 旅行の写真 : http://matsu-ken.jimdo.com
Twitterアイコン
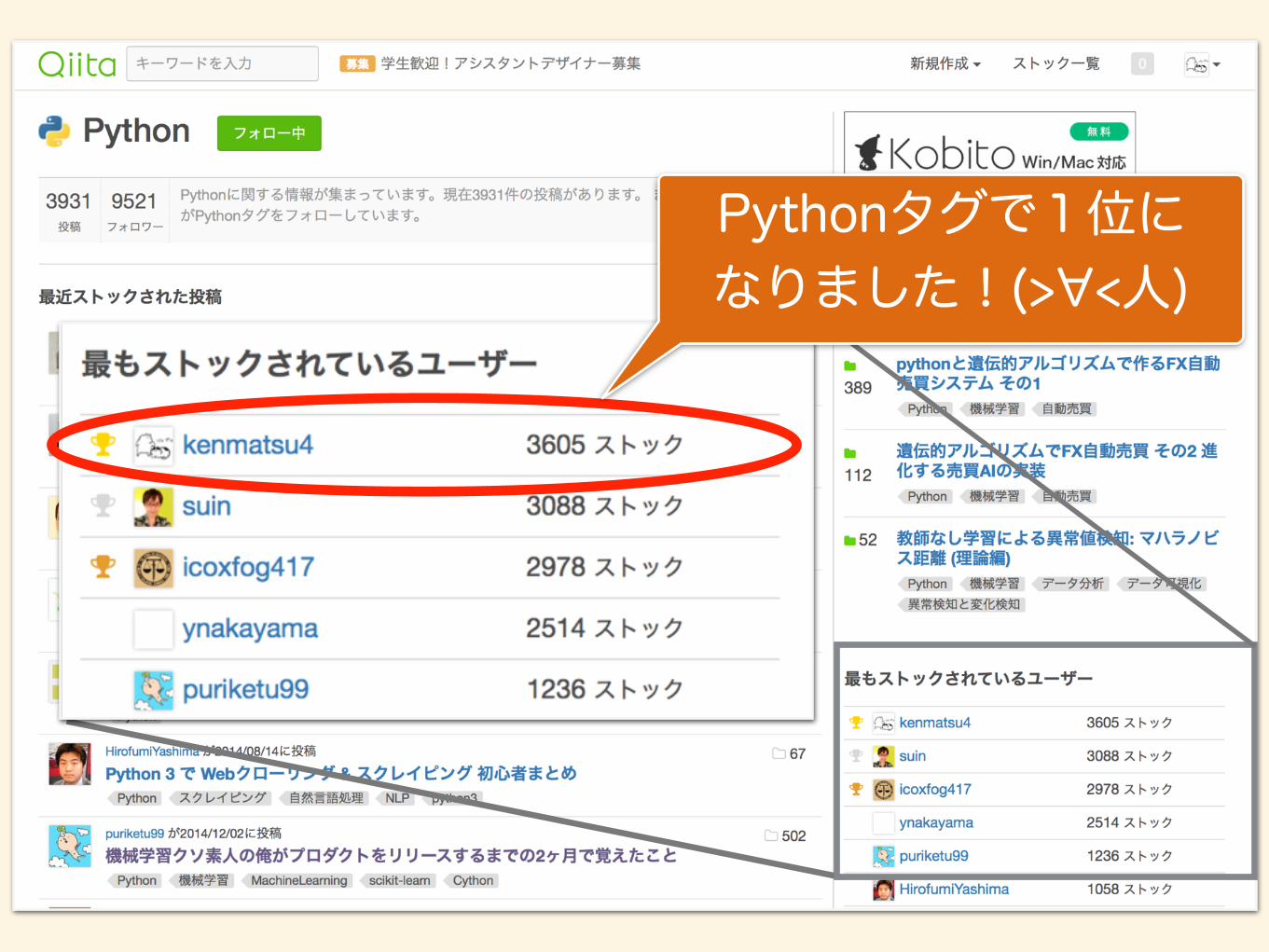
Pythonタグで1位に なりました!(>∀<人)

1.1 ベイズ統計学小史

ベイズ統計学小史
https://ja.wikipedia.org/wiki/トーマス・ベイズトーマス・ベイズらしき肖像画
ベイズ統計学(Bayesian Statistics)は、 ベイズの定理
p(A|B) =p(B|A)p(A)
p(B)
に基づき展開される。この定理は牧師であるトーマス・ ベイズにより、1740年頃に発見 され、1763年 プライスによって 世に公開された。

ベイズ統計学小史
https://ja.wikipedia.org/wiki/ピエール=シモン・ラプラスピエール=シモン・ラプラス
さらに、ラプラスが独自にこの定理を再発見し、 近代数学にふさわしい形式にまとめた。
しかし、実用的な形式にはならず、 理論的な論文が多く、一般に使われる ようにはならなかった。

1.2 導入

・客観確率 … 伝統的な統計学で用いられる確率 ・主観確率 … ベイズ統計学で用いられる確率
導入
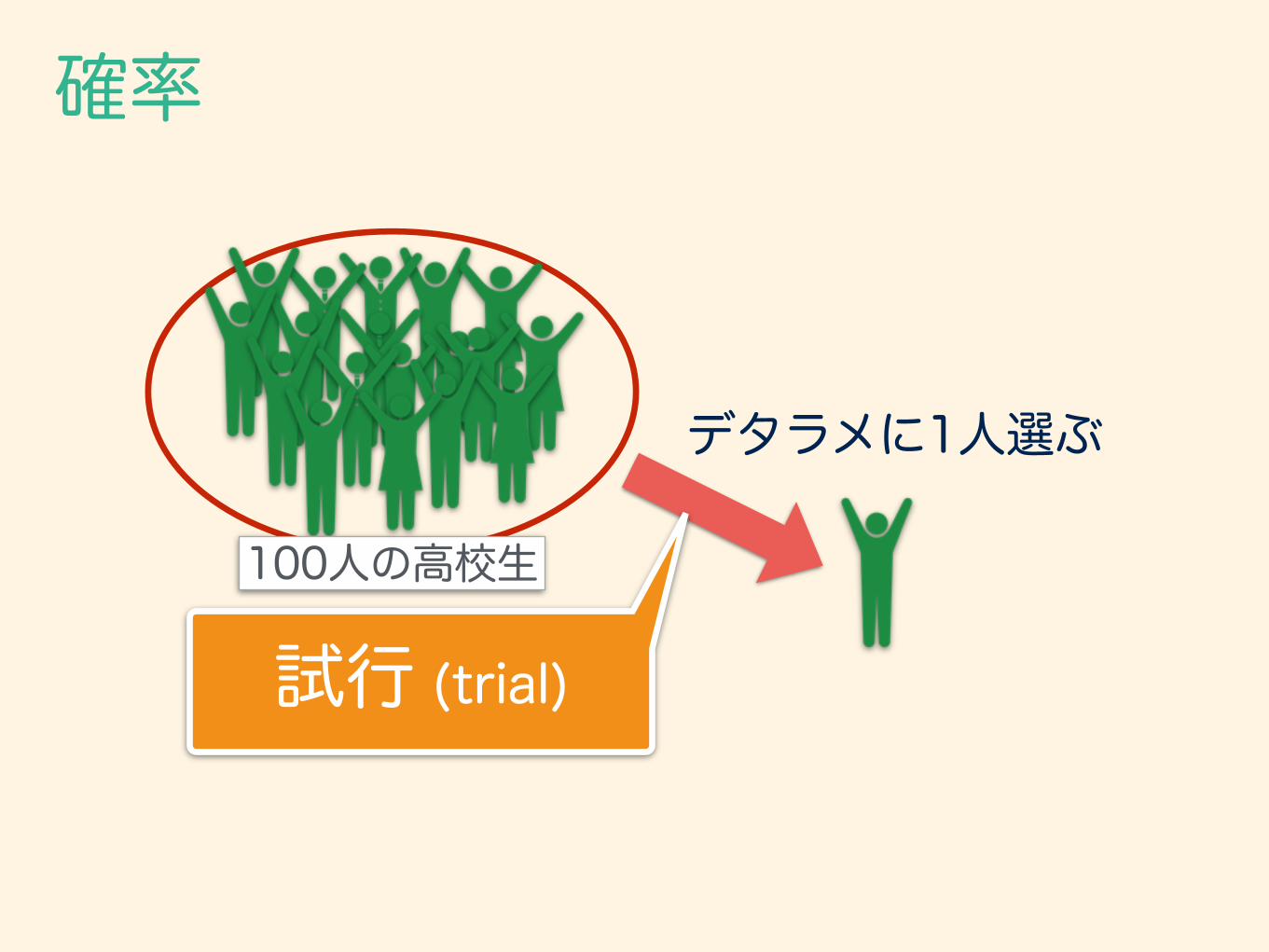
まずは異論の少ない客観確率 から説明を行う。
確率
100人の高校生
デタラメに1人選ぶ
試行 (trial)
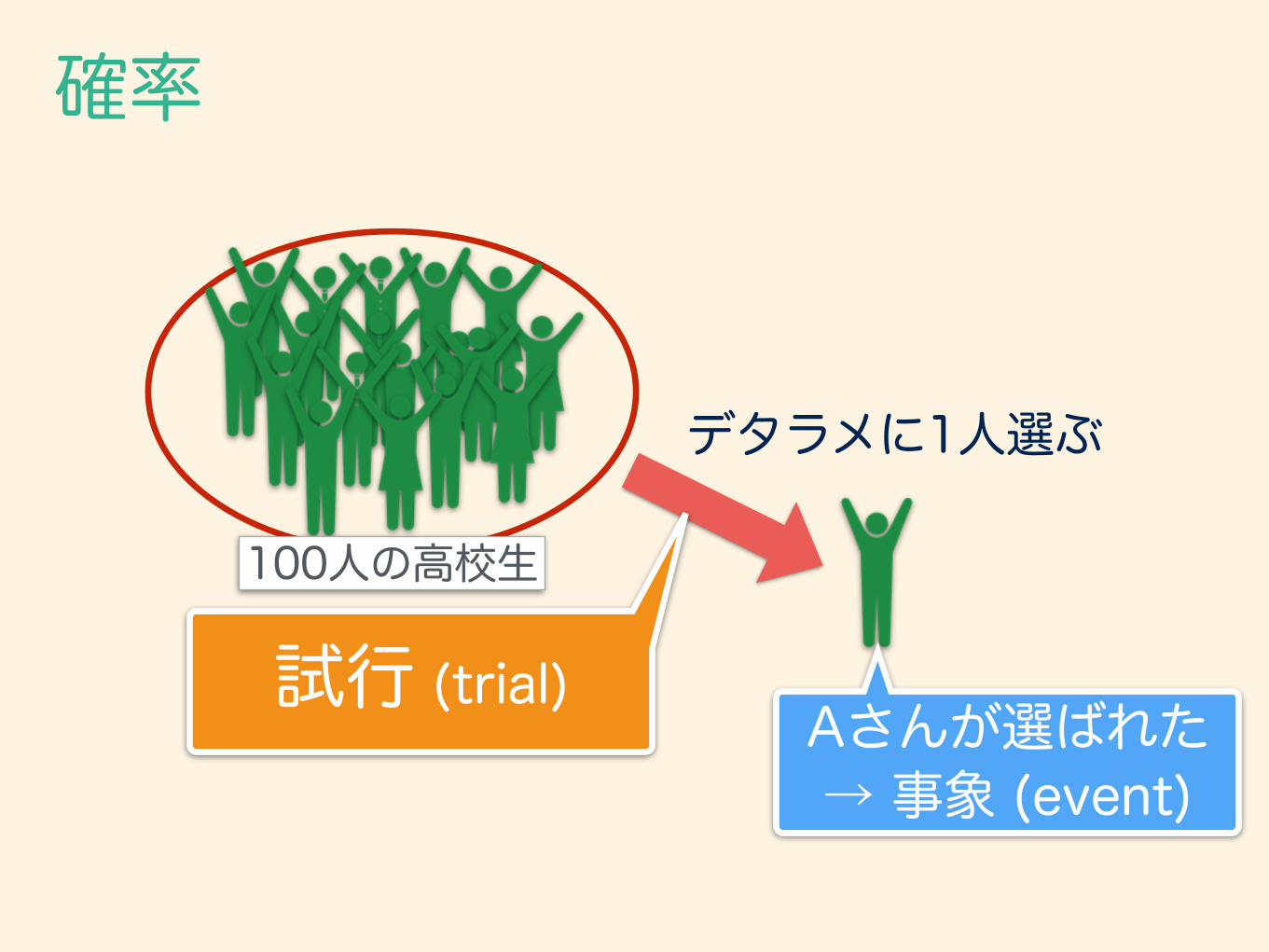
確率
100人の高校生
デタラメに1人選ぶ
試行 (trial)Aさんが選ばれた → 事象 (event)

・施行 (trial) … 偶然によて決まる観測・実験のこと ・事象 (event) … 施行の結果起こりうる状態 ・標本空間 (sample space) … 起こりうるすべての状態の集合 ・根元事象 (fundamental event) … それ以上分割できない事象
確率:各種用語の定義

確率:確率の定義
N(A) = 事象Aに含まれる根元事象の数事象の数を数える関数 N(・) を
のように定義すると、確率は
標本空間
p(A) =N(A)
N(sample space)
と定義できる。

確率:例
p(woman) =
40
100
= 0.4
いま、女性が40人、男性が60人、計100人とすると、ランダムに1人選んだ時に女性が選ばれる確率は、
となる。
赤が女性、青が男性、計100人
N(標本空間) = 100 N(woman) = 40
女性p(woman) =
40
100
= 0.4
標本空間
woman
man
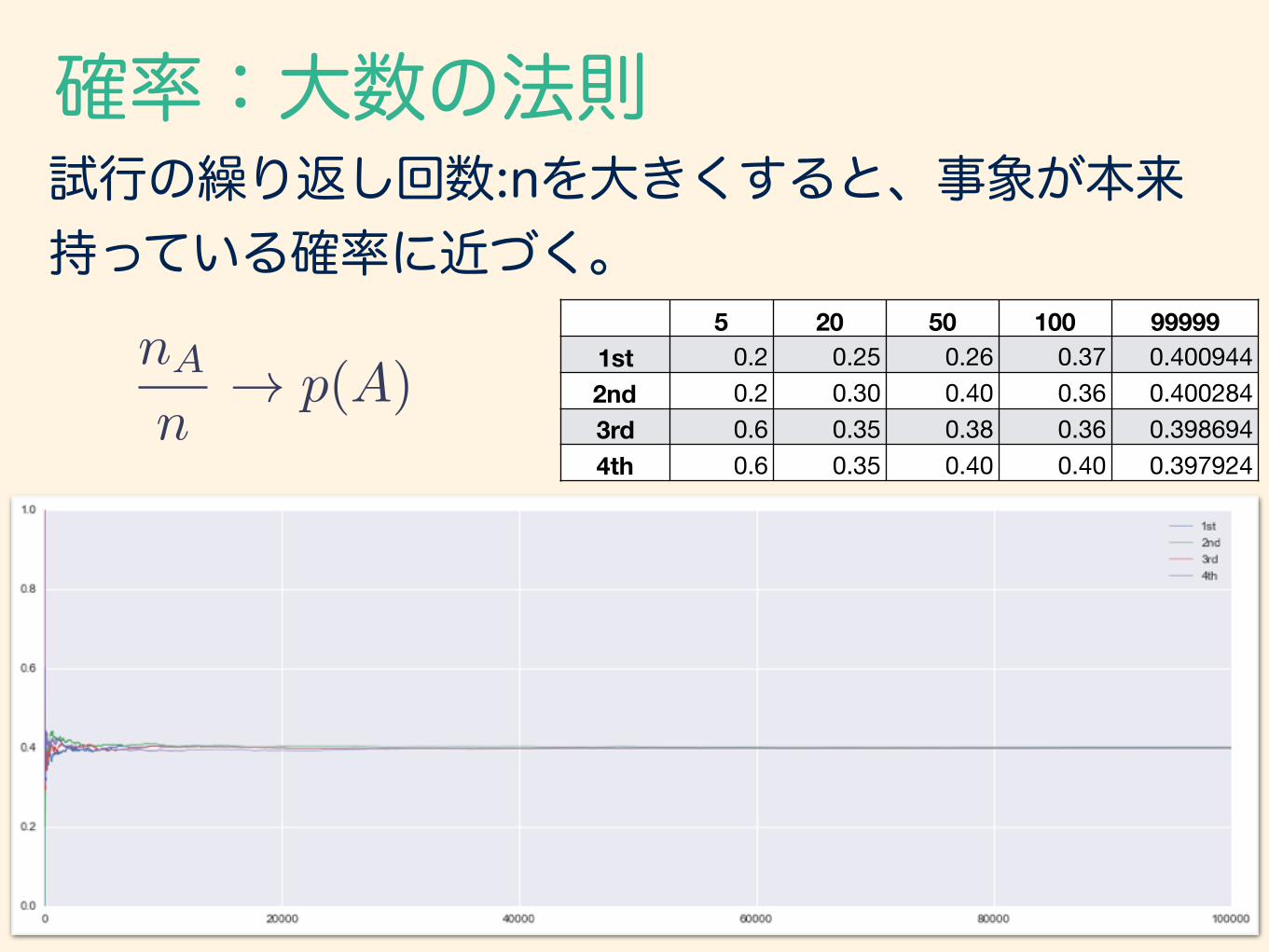
確率:大数の法則
5 20 50 100 999991st 0.2 0.25 0.26 0.37 0.4009442nd 0.2 0.30 0.40 0.36 0.4002843rd 0.6 0.35 0.38 0.36 0.3986944th 0.6 0.35 0.40 0.40 0.397924
試行の繰り返し回数:nを大きくすると、事象が本来持っている確率に近づく。
nA
n! p(A)
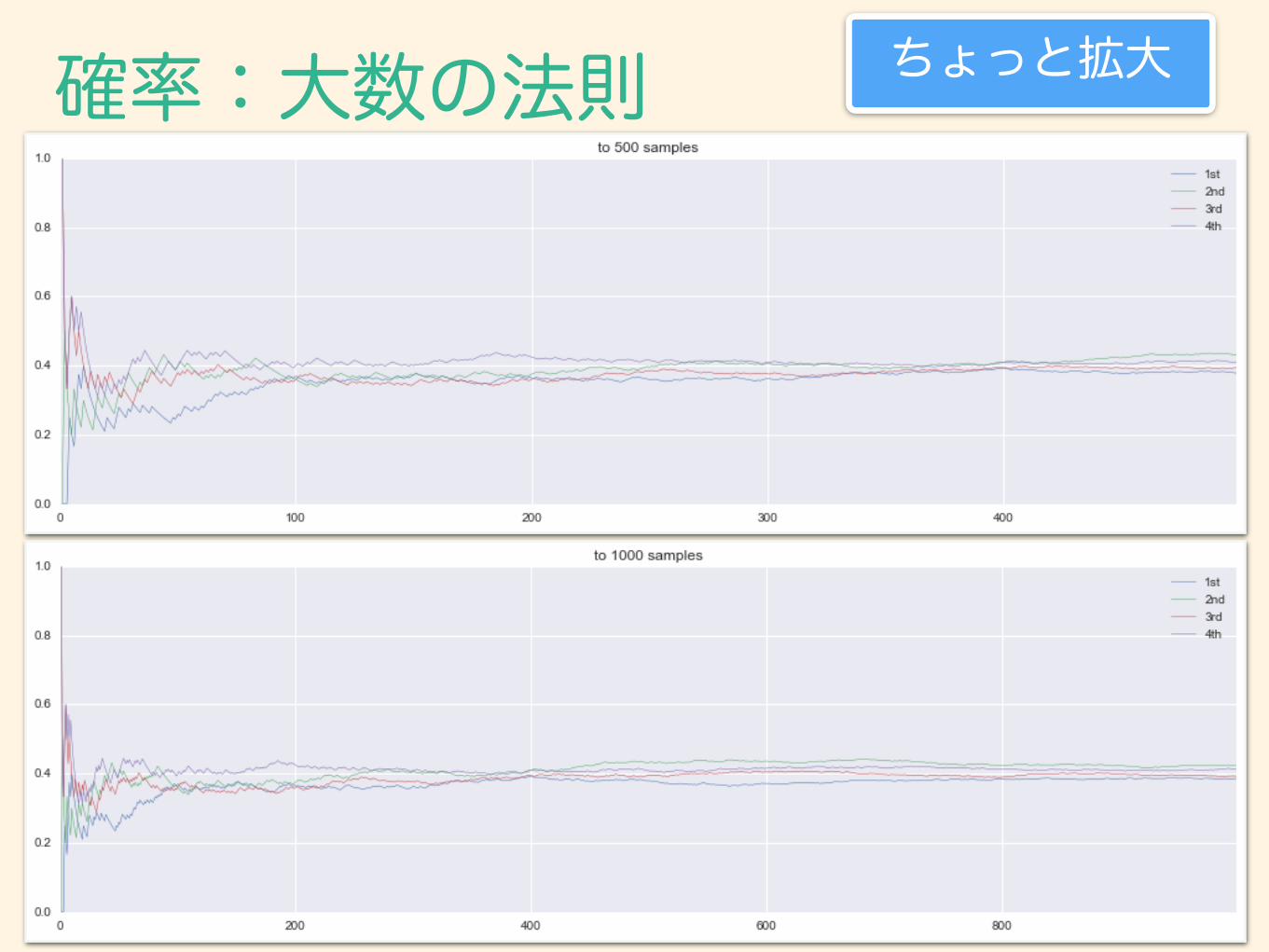
確率:大数の法則 ちょっと拡大
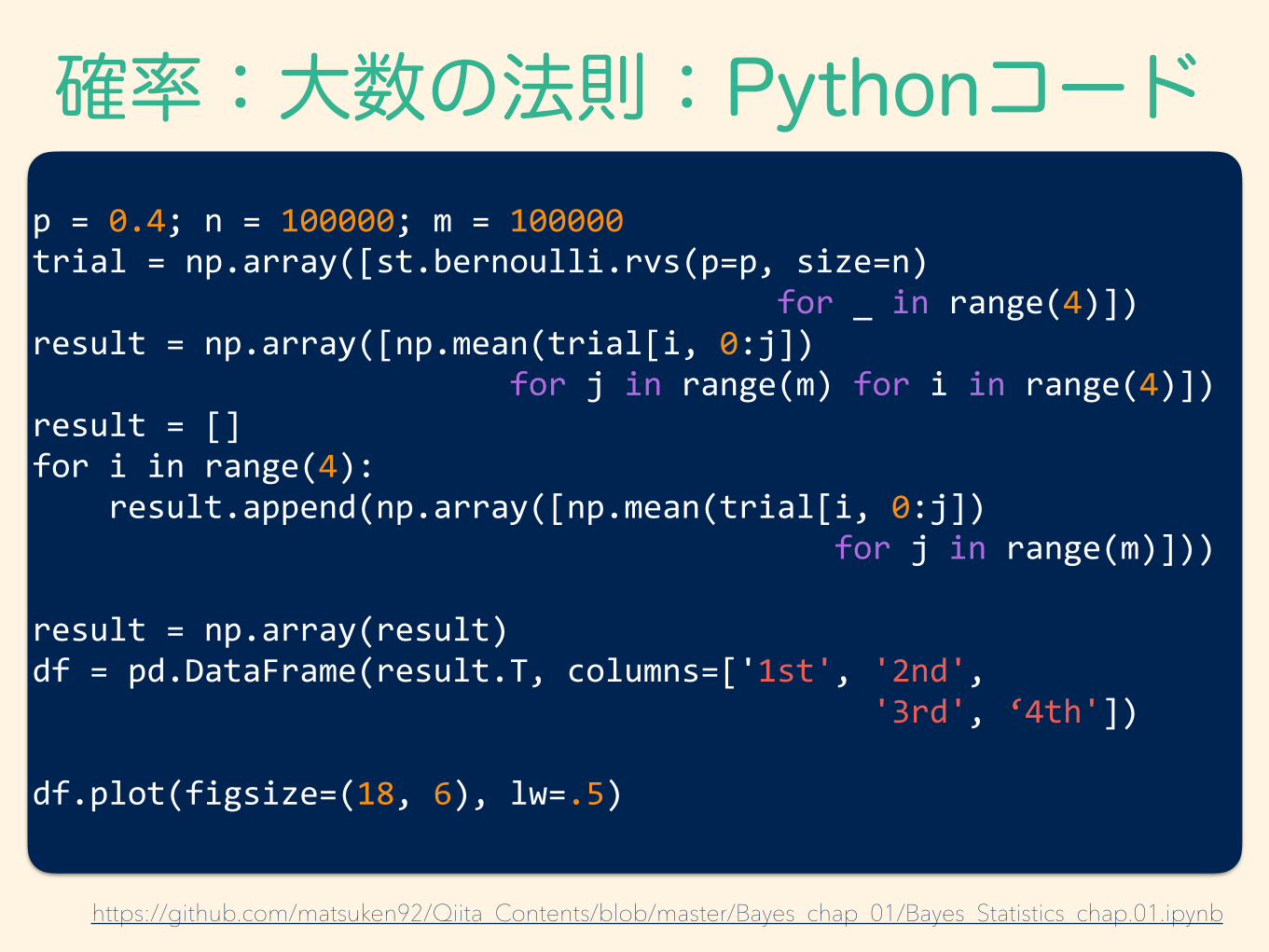
確率:大数の法則:Pythonコードp = 0.4; n = 100000; m = 100000 trial = np.array([st.bernoulli.rvs(p=p, size=n) for _ in range(4)]) result = np.array([np.mean(trial[i, 0:j]) for j in range(m) for i in range(4)]) result = [] for i in range(4): result.append(np.array([np.mean(trial[i, 0:j]) for j in range(m)]))
result = np.array(result) df = pd.DataFrame(result.T, columns=['1st', '2nd', '3rd', ‘4th'])
df.plot(figsize=(18, 6), lw=.5)
https://github.com/matsuken92/Qiita_Contents/blob/master/Bayes_chap_01/Bayes_Statistics_chap.01.ipynb

分割
A1
A2
A1, A2, · · · , Ai, · · · , Aa
a個の事象の組、
が、互いに共通の根元事象を含まず、同時に標本空間を表現しているとする。
aX
i=1
p(Ai) = 1
標本空間がa個に分割されている時、その確率の総和は1となる。
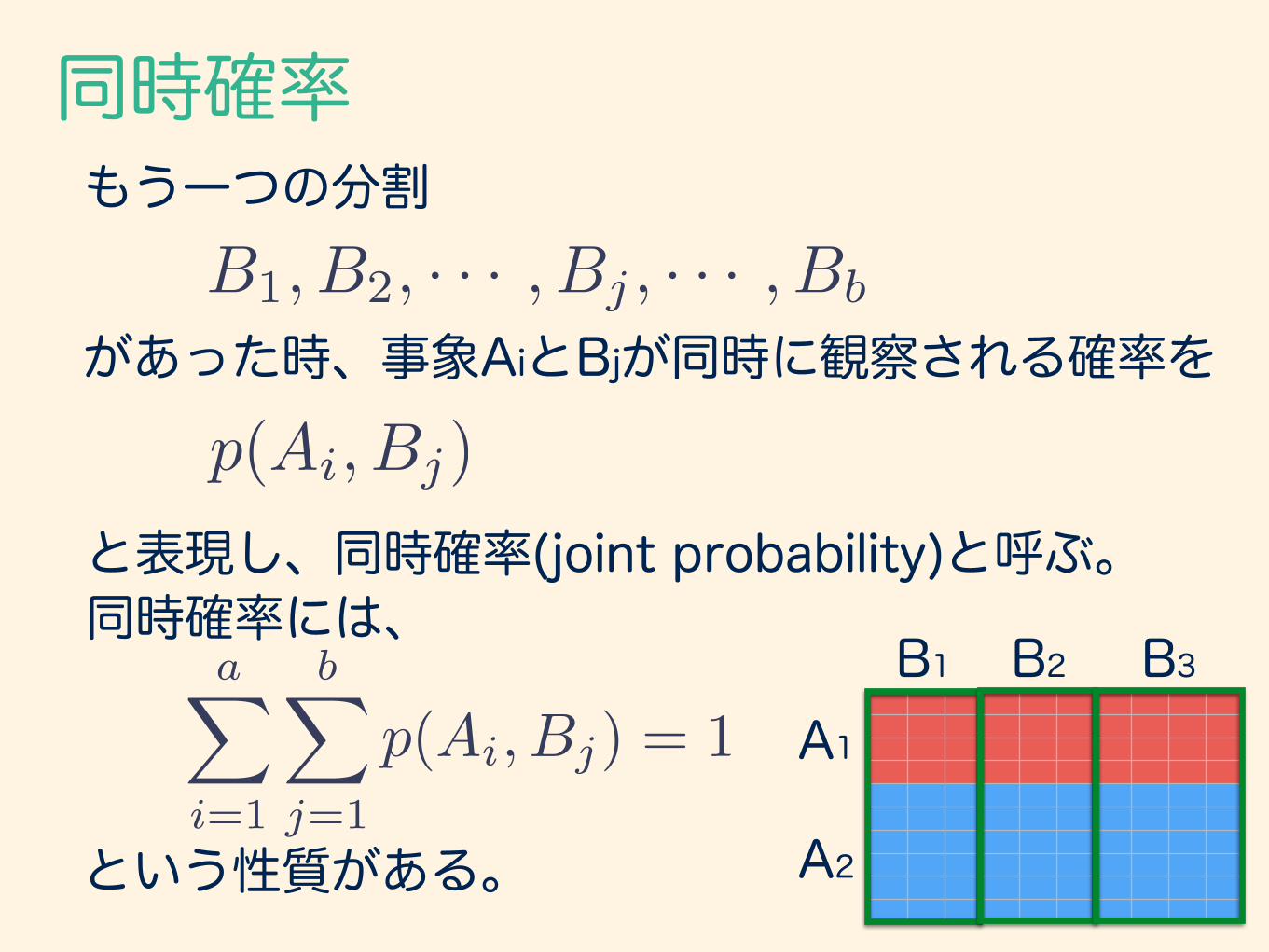
同時確率もう一つの分割
があった時、事象AiとBjが同時に観察される確率をp(Ai, Bj)
と表現し、同時確率(joint probability)と呼ぶ。 同時確率には、
という性質がある。
aX
i=1
bX
j=1
p(Ai, Bj) = 1
B1, B2, · · · , Bj , · · · , Bb
A1
A2
B1 B2 B3

性別での分割 に加え、学年での分割を とすると、表1.2のような分割表が 得られる。
同時確率:例
1年生 2年生 3年生合計
女性 15 12 13 40
男性 22 20 18 60
合計 37 32 31 100
B1 B2 B3
A2
A1
B1, B2, B3
A1, A2
このとき、3年生男子が選ばれる確率は、p(A2, B3) = 0.18
となる。表1.2 生徒の人数の内訳

同時確率:例
1年生 2年生 3年生合計
女性 C1: 7 C2: 8
C1: 5 C2: 7
C1: 6 C2: 7 40
男性 C1: 10 C2: 12
C1: 11 C2: 9
C1: 10 C2: 8 60
合計 37 32 31 100
表1.2 生徒の人数の内訳
B1 B2 B3
A2
A1
さらに、3つ目の分割、 を考える。 c=2で、きょうだいの有無を表すとするとこれも分割になる。 このときも、Ai, Bj, Ckに関して
が成りたつ。
aX
i=1
bX
j=1
cX
k=1
p(Ai, Bj , Ck) = 1
C1, C2, · · · , Ck, · · · , Cc

周辺確率
1年生 2年生 3年生合計
女性 15 12 13 40
男性 22 20 18 60
合計 37 32 31 100
B1 B2 B3
A2
A1
aX
i=1
p(Ai, Bj) = p(Bj)bX
j=1
p(Ai, Bj) = p(Ai)
1つの分割に対して足し上げをすると、残りの分割の確率となる
2X
i=1
p(Ai, B1) = p(A1, B1) + p(A2, B1) = p(B1)0.12 0.20 0.32

周辺確率
aX
i=1
p(Ai, Bj , Ck) = p(Bj , Ck)
aX
i=1
bX
j=1
p(Ai, Bj , Ck) = p(Ck)
3つ目の分割Ckに関して考えると、下記のような公式が導かれる。
1年生 2年生 3年生合計
女性 15 12 13 40
男性 22 20 18 60
合計 37 32 31 100
B1 B2 B3
A2
A1

条件付き確率選ばれた生徒が女性であるとわかっている ↑ 事前情報あり
1年生 2年生 3年生合計
女性 0.15 0.12 0.13 0.40
男性 0.22 0.20 0.18 0.60
合計 0.37 0.32 0.31 1.00
B1 B2 B3
A2
A1
その条件のもとで、その生徒が2年生である確率は?
女性は40人なので、その中の12人なので、 12/40 = 0.3 or 0.12/0.40 = 0.3
同時確率を周辺確率で割って求めている。
確率で表し直した表

条件付き確率一般にAiが観察されたという条件の下で、Bjが観察される確率は、
1年生 2年生 3年生合計
女性 0.15 0.12 0.13 0.40
男性 0.22 0.20 0.18 0.60
合計 0.37 0.32 0.31 1.00
B1 B2 B3
A2
A1
確率で表し直した表
p(Bj |Ai) =p(Ai, Bj)
p(Ai)
で、計算される。これを条件付き確率という。

条件付き確率分割Ckも含めて考えると、
p(Bj , Ck|Ai) =p(Ai, Bj , Ck)
p(Ai)
や、
p(Ck|Ai, Bj) =p(Ai, Bj , Ck)
p(Ai, bj)
などが導かれる。
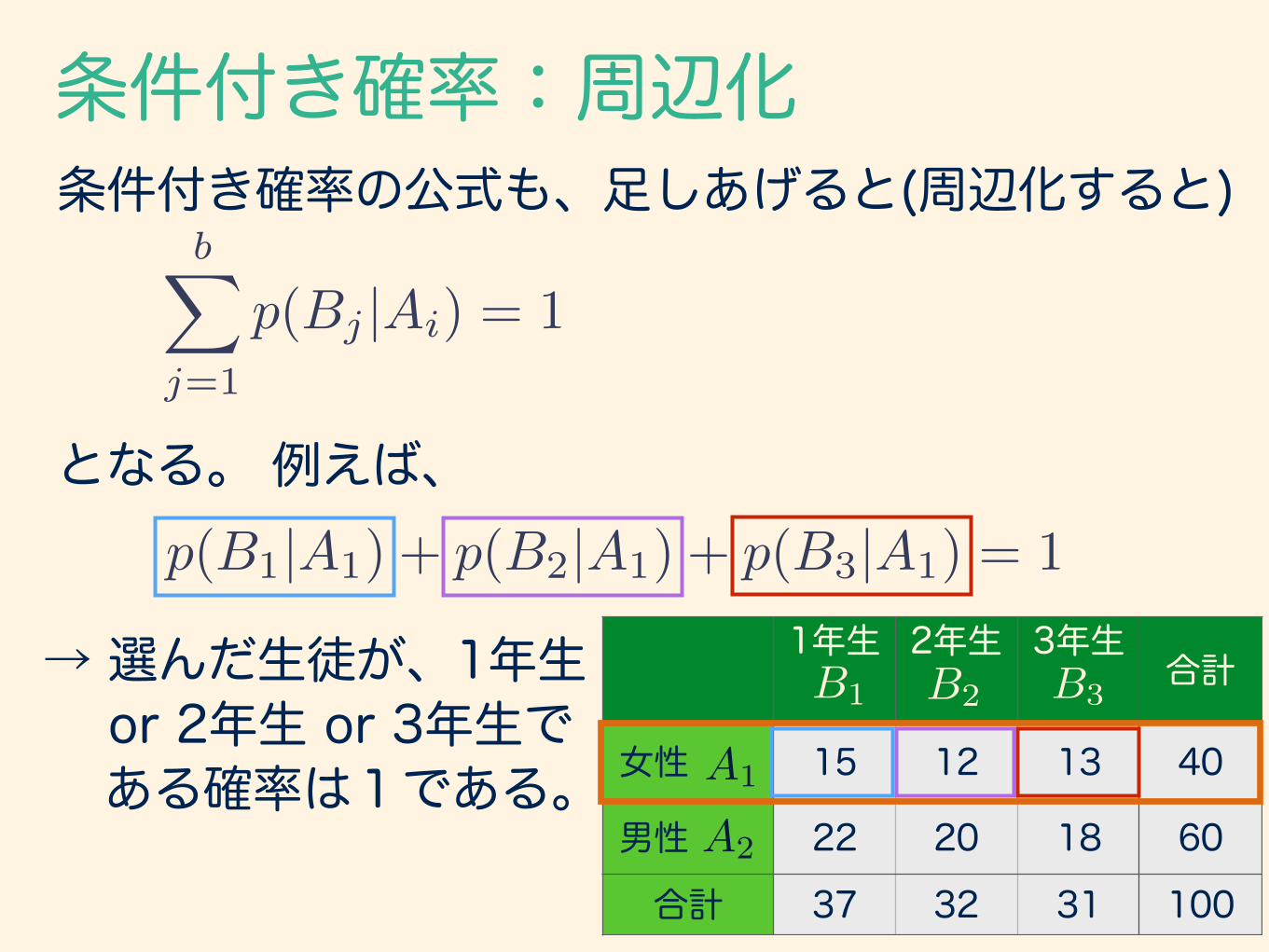
条件付き確率:周辺化条件付き確率の公式も、足しあげると(周辺化すると)
bX
j=1
p(Bj |Ai) = 1
となる。 例えば、p(B1|A1) + p(B2|A1) + p(B3|A1) = 1
→ 選んだ生徒が、1年生 or 2年生 or 3年生で ある確率は1である。
1年生 2年生 3年生合計
女性 15 12 13 40
男性 22 20 18 60
合計 37 32 31 100
B1 B2 B3
A2
A1

条件付き確率:周辺化その他、
cX
k=1
p(Bj , Ck|Ai) = p(Bj |Ai)
cX
k=1
p(Ck|Ai, Bj) = 1
も、成り立つ。
1年生 2年生 3年生合計
女性 C1: 7 C2: 8
C1: 5 C2: 7
C1: 6 C2: 7 40
男性 C1: 10 C2: 12
C1: 11 C2: 9
C1: 10 C2: 8 60
合計 37 32 31 100
B1 B2 B3
A2
A1 15 12 13

乗法定理条件付き確率の式、
p(Bj |Ai) =p(Ai, Bj)
p(Ai)
の右辺の分母を移行すると、
p(Ai, Bj) = p(Bj |Ai)p(Ai)
が成り立つ。これを乗法定理という。
Aiが起きたAiが起きたという条件で Bjが起きた

全確率の公式
1年生 2年生 3年生合計
女性 15 12 13 40
男性 22 20 18 60
合計 37 32 31 100
B1 B2 B3
A2
A1
乗法定理と周辺化により下記が成り立つ。
p(Bj) =aX
i=1
p(Bj , Ai)
=aX
i=1
p(Bj |Ai)p(Ai)
重要!
= 12/40 x 40/100 + 20/60 x 60/100= 12/100 + 20/100 = 32/100
j=2の例)

1.3 ベイズの定理

ベイズの定理
p(Ai, Bj) = p(Bj |Ai)p(Ai)
乗法定理に対称性があるので、下記の2つはどちらも成り立つ。
p(Ai, Bj) = p(Ai|Bj)p(Bj)
よって2つの式をつないで で割ることで
が得られる。これが確率に関するベイズの定理。
p(Ai|Bj) =p(Bj |Ai)p(Ai)
p(Bj)
p(Ai, Bj) = p(Ai|Bj)p(Bj)
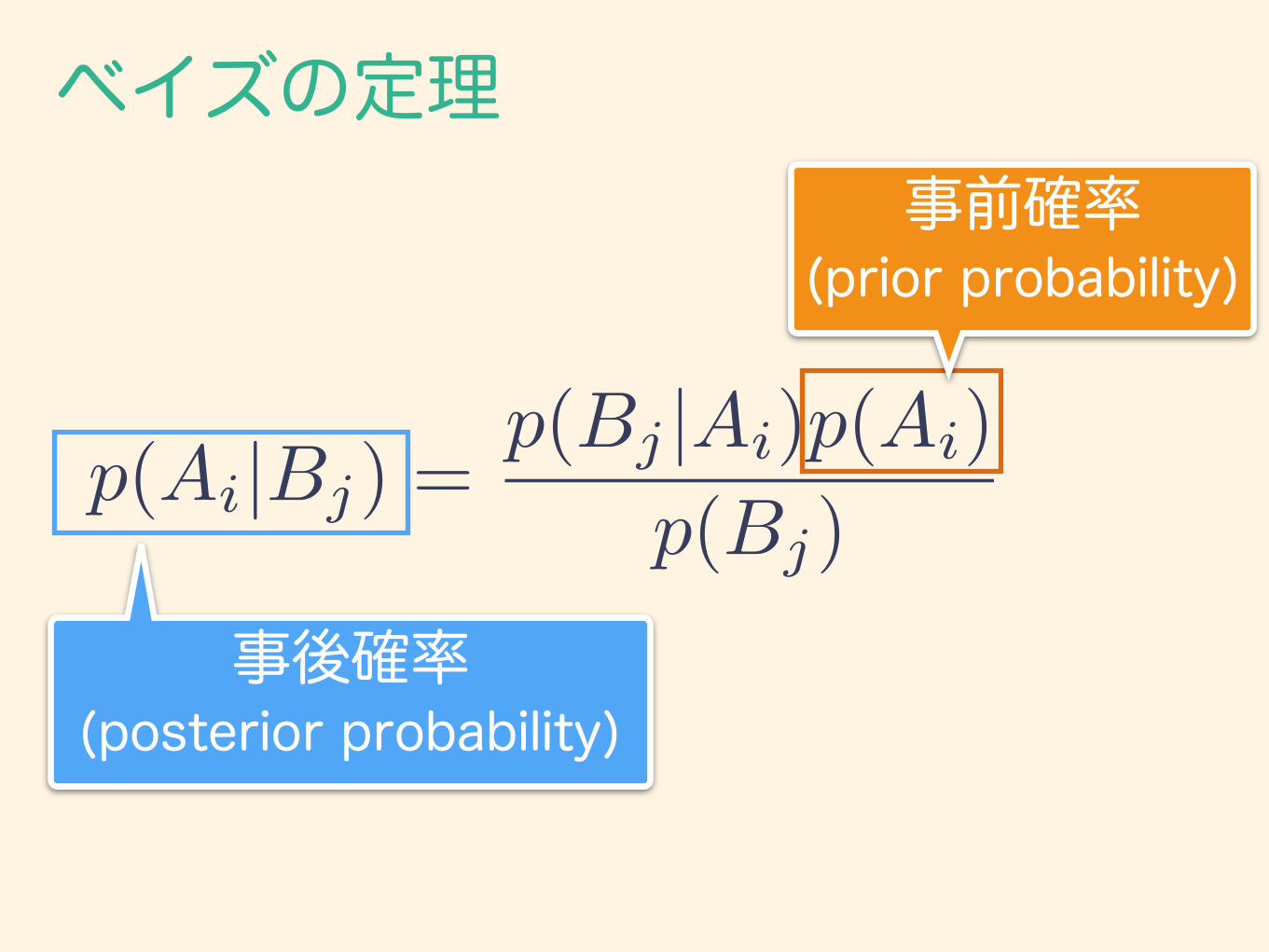
ベイズの定理
p(Ai|Bj) =p(Bj |Ai)p(Ai)
p(Bj)
事前確率 (prior probability)
事後確率 (posterior probability)

ベイズの定理右辺の分母に全確率の公式を代入して、
p(Ai|Bj) =p(Bj |Ai)p(Ai)Pai=1 p(Bj |Ai)p(Ai)
という表現もある。
p(Bj) =aX
i=1
p(Bj , Ai)=aX
i=1
p(Bj |Ai)p(Ai)
全確率の公式

ベイズの定理:検診問題ある国で病気Aは、1万人あたり40人の割合でかかっていることが知られている。病気Aに罹っている人が検診Bを受けると8割の確率で陽性となる。 健常な人が検診Bを受けると9割の確率で陰性となる 検診Bによって陽性と判定された場合、その受信者が病気Aにかかっている確率はどれくらいか?
つまりp(A1|B1)
を計算する問題。
陽性 陰性計
病気である 4/1000 * 0.8
4/1000 * 0.2 4/1000
病気でない 996/1000 * 0.1
996/1000 * 0.9 996/1000
B1 B2
A2
A1
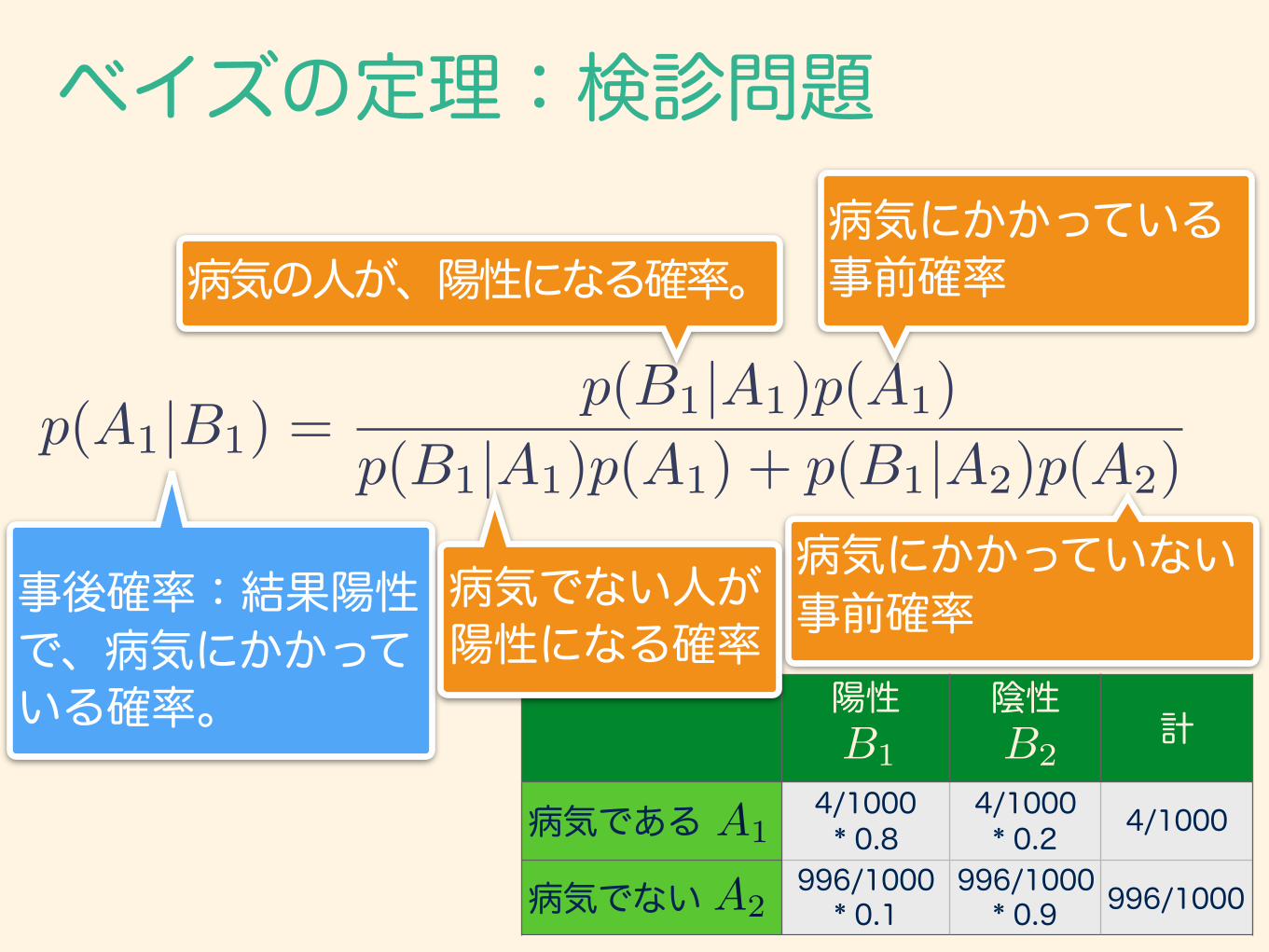
ベイズの定理:検診問題
p(A1|B1) =p(B1|A1)p(A1)
p(B1|A1)p(A1) + p(B1|A2)p(A2)
陽性 陰性計
病気である 4/1000 * 0.8
4/1000 * 0.2 4/1000
病気でない 996/1000 * 0.1
996/1000 * 0.9 996/1000
B1 B2
A2
A1
病気の人が、陽性になる確率。
事後確率:結果陽性で、病気にかかっている確率。
病気にかかっている事前確率
病気にかかっていない事前確率病気でない人が
陽性になる確率

ベイズの定理:検診問題
p(A1|B1) =p(B1|A1)p(A1)
p(B1|A1)p(A1) + p(B1|A2)p(A2)
ベイズの定理で表すと、
陽性 陰性計
病気である 4/1000 * 0.8
4/1000 * 0.2 4/1000
病気でない 996/1000 * 0.1
996/1000 * 0.9 996/1000
B1 B2
A2
A1
=0.8⇥ 0.004
0.8⇥ 0.004 + 0.1⇥ 0.996⇡ 0.0311
よって、陽性判定で病気の確率は 3% !!!

逆確率検診問題では
・病気A … 原因 ・検診B … 結果
であった。通常の条件付き確率はp(結果 | 原因)
のように、時間の流れにあった形で利用される。 しかし、ベイズの定理では、時間の流れが逆である
時間の流れ
p(原因 | 結果)のような「原因の確率」を論じる。
このような事後確率のことを「逆確率」という

独立p(Ai|Bj) = p(Ai|Bk) (全てのi, j, kに対して)
Bの観察結果によって、Aの確率が影響を受けない。
この時「AとBは互いに独立である」という
例) 性別 Aと、学年 Bは独立ではない。 → 何故ならば2年生であるとわかっている場合の 女性である確率と、3年生である場合のそれと で、確率が異なるから。
例) サイコロAとサイコロBの出目は独立。 → 1つ目のサイコロの目は次の目に影響しない

独立 : 重要な性質p(Ai|Bj) = p(Ai|Bk)
⇔p(Ai, Bj)
p(Bj)=
p(Ai, Bk)
p(Bk)
⇔添え字 k で足しあげる
p(Ai, Bj)bX
k=1
p(Bk) = p(Bj)bX
k=1
p(Ai, Bk)
p(Ai, Bj)p(Bk) = p(Bj)p(Ai, Bk)
= 1 = p(Ai)
(Bはjでもkでも同じ確率)

独立 : 重要な性質
p(Ai, Bj)bX
k=1
p(Bk) = p(Bj)bX
k=1
p(Ai, Bk)
= 1 = p(Ai)
⇔ p(Ai, Bj) = p(Ai)p(Bj)
つまり、AとBが独立である場合には、 「同時確率が、個々の確率の積で表現される」

独立 : 重要な性質例:2つのサイコロAとBの出た目が2と3だった場合
1
36= p(A2, B3) = p(A2)p(B3) =
1
6⇥ 1
6
例:3つのサイコロA, B, Cを振る。Aが6だった時、 BとCの出目として2と3が出た場合
1
36= p(B2, C3|A6) = p(B2|A6)p(C3|A6) =
1
6⇥ 1
6コレの扱いは次ページ

独立 : 重要な性質
p(Ai, Bj) = p(Ai|Bj)p(Bj)
Ai, Bj が独立である時
⇔ p(Ai)p(Bj) = p(Ai|Bj)p(Bj)
p(Ai) = p(Ai|Bj)⇔
であるので、
p(B2|A6) = p(B2)
も、A6の影響を受けない形になる。
p(Ai, Bj) = p(Ai)p(Bj)
p(Ai, Bj) = p(Ai)p(Bj)

ベイズ更新
送られたEメールが
・迷惑メール A1
・迷惑メールでない A2
の確率に着目する。メールの特徴 B に基づいてAの事後確率を調べる。
ベイズ流!!!

ベイズ更新ここでさらに、追加的なメールの特徴 C (Bとは独立した情報)が得られた時、事後確率はどのように変化するか?
条件付き確率より、
p(A,B,C) = p(A|B,C)p(B,C)
が成り立ちますが、同時に
p(A,B,C) = p(B,C|A)p(A)
も、成り立っています。

ベイズ更新前ページの2式の右辺が等しいのでつなげると、
p(A|B,C)p(B,C) = p(B,C|A)p(A)
⇔ p(A|B,C) =p(B,C|A)p(A)
p(B,C)
BとCは独立なので、
p(A|B,C) =p(B,C|A)p(A)
p(B,C)p(A|B,C) =
p(B,C|A)p(A)
p(B,C)p(A|B,C) =
p(B,C|A)p(A)
p(B,C)p(A|B,C) =
p(B,C|A)p(A)
p(B,C)
p(B|A)p(C|A)p(A)
p(B), p(C)p(A|B,C) =
p(B,C|A)p(A)
p(B,C)p(A|B,C) =
p(B,C|A)p(A)
p(B,C)p(A|B,C) =
p(B,C|A)p(A)
p(B,C)p(A|B,C) =
p(B,C|A)p(A)
p(B,C)p(A|B,C) =
p(B,C|A)p(A)
p(B,C)
p(B|A)p(C|A)p(A)
p(B), p(C)
p(B|A)p(C|A)p(A)
p(B)p(C)
p(B|A)p(C|A)p(A)
p(B), p(C)p(A|B,C) =
p(B,C|A)p(A)
p(B,C)p(B|A)p(C|A)p(A)
p(B), p(C)p(A|B,C) =
p(B,C|A)p(A)
p(B,C)
p(B|A)p(C|A)p(A)
p(B)p(C)

p(A|B,C) =p(B,C|A)p(A)
p(B,C)
p(B|A)p(C|A)p(A)
p(B), p(C)p(B|A)p(C|A)p(A)
p(B), p(C)p(A|B,C) =
p(B,C|A)p(A)
p(B,C)p(B|A)p(C|A)p(A)
p(B), p(C)p(A|B,C) =
p(B,C|A)p(A)
p(B,C)
p(B|A)p(C|A)p(A)
p(B)p(C)
ベイズ更新p(A|B)
p(A|B) = p(A)⇤ として、これを情報Cに対する事前分布である、という見方をすると
=p(C|A)p(A)⇤
p(C)
情報Bが与えられた時のAの事後確率を、新たなAの事前確率としてベイズの定理を新情報Cに独立に適用している。これをベイズ更新という。
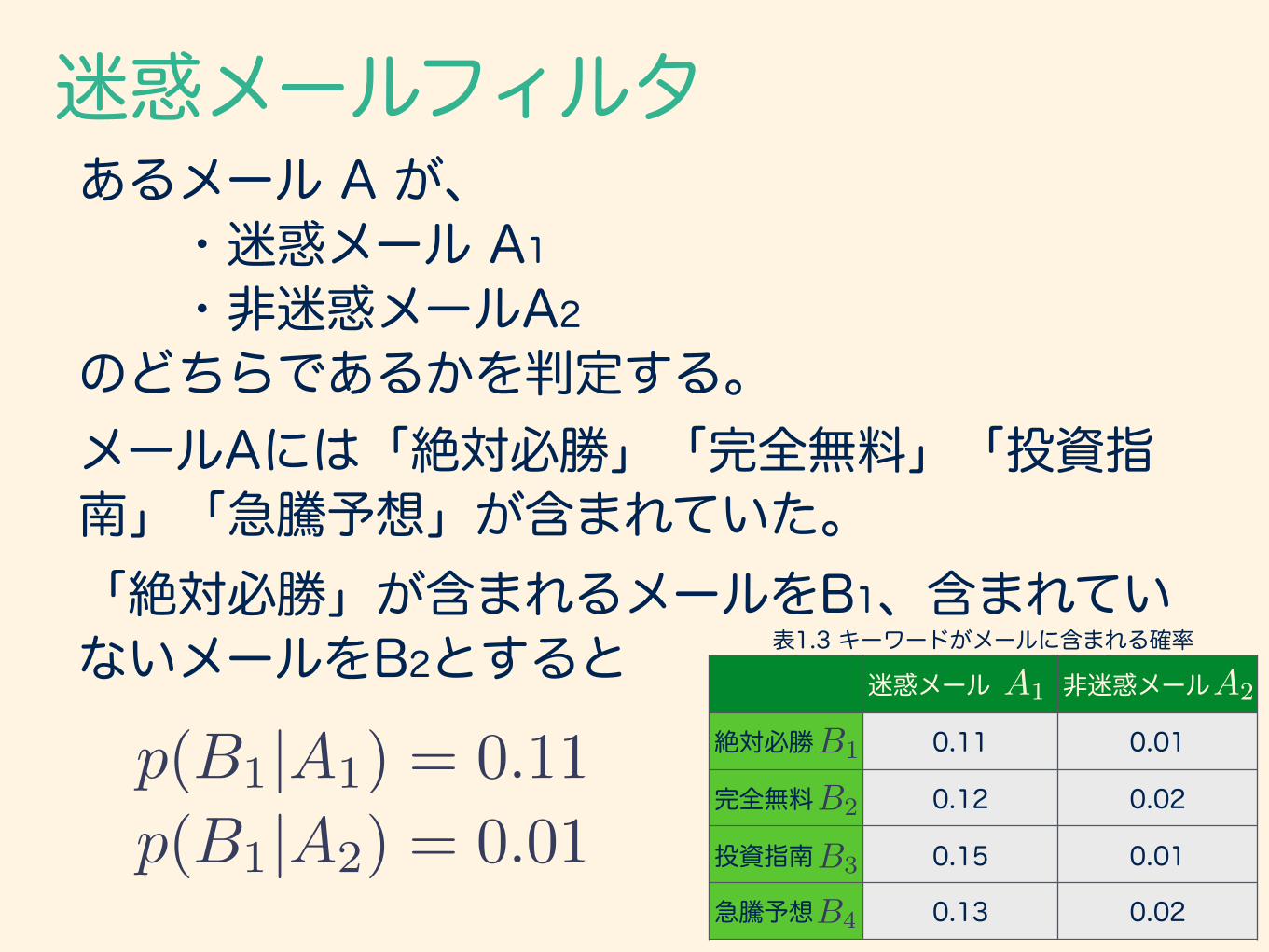
迷惑メールフィルタあるメール A が、 ・迷惑メール A1 ・非迷惑メールA2 のどちらであるかを判定する。メールAには「絶対必勝」「完全無料」「投資指南」「急騰予想」が含まれていた。「絶対必勝」が含まれるメールをB1、含まれていないメールをB2とすると
p(B1|A1) = 0.11p(B1|A2) = 0.01
迷惑メール 非迷惑メール
絶対必勝 0.11 0.01
完全無料 0.12 0.02
投資指南 0.15 0.01
急騰予想 0.13 0.02
表1.3 キーワードがメールに含まれる確率
A1 A2
B1
B2
B3
B4

迷惑メールフィルタまた、ある地域で交わされている メールのうち6割が迷惑メールであると分かっている。
つまり、 p(A1) = 0.6このとき、「絶対必勝」が含まれるメールが迷惑メールである確率は、
p(A1|B1) =p(B1|A1)p(A1)Pai=1 p(B1|Ai)p(Ai)
0.9429 =0.11⇥ 0.60
0.11⇥ 0.60 + 0.01⇥ (1� 0.06)

迷惑メールフィルタ
0.9429 =0.11⇥ 0.60
0.11⇥ 0.60 + 0.01⇥ (1� 0.06)さらに「完全無料」がメールにあったと判明
0.9429p(A|B,C) =
p(B,C|A)p(A)
p(B,C)0.9900 = 0.12⇥0.9429
0.12⇥0.9429
+ 0.01⇥ (1� )0.9900p(A|B,C) =
p(B,C|A)p(A)
p(B,C)= 0.15⇥
0.15⇥0.9900
+0.02⇥ (1� )
0.99000.9993
さらに「投資指南」がメールにあったと判明
さらに「急騰予想」がメールにあったと判明
p(A|B,C) =p(B,C|A)p(A)
p(B,C)= 0.99930.13⇥
0.99930.13⇥ 0.9993+0.02⇥ (1� )0.9999
0.9429

迷惑メールフィルタ
0.9429 =0.11⇥ 0.60
0.11⇥ 0.60 + 0.01⇥ (1� 0.06)さらに「完全無料」がメールにあったと判明
0.9429p(A|B,C) =
p(B,C|A)p(A)
p(B,C)0.9900 = 0.12⇥0.9429
0.12⇥0.9429
+ 0.01⇥ (1� )0.9900p(A|B,C) =
p(B,C|A)p(A)
p(B,C)= 0.15⇥
0.15⇥0.9900
+0.02⇥ (1� )
0.99000.9993
さらに「投資指南」がメールにあったと判明
さらに「急騰予想」がメールにあったと判明
p(A|B,C) =p(B,C|A)p(A)
p(B,C)= 0.99930.13⇥
0.99930.13⇥ 0.9993+0.02⇥ (1� )0.9999
0.9429
4回のベイズ更新で、迷惑メールではない という確率が1万分の一以下!
ただし、「絶対必勝」「完全無料」等の単語が含まれるか 否かの確率は互いに独立ではないことに注意。 しかし、近似ではあるが、実践には十分使える

1.4 主観確率

主観確率
逆確率の理論(ベイズ統計学)は、 完全に葬り去らなければならない
R.A.フィッシャーhttps://ja.wikipedia.org/wiki/ロナルド・フィッシャー
ベイズ統計学は、フィッシャーに「完全に葬り去らなければならない」とまで言われた。しかし、本章までの使い方は統計学全体で認められている。
しかし、主観確率という概念が入ってくると話が違う。

客観確率による事前確率観測上の根拠が前もって存在する ような場合を除くと、逆確率の方法 では、既知の標本が取り出された
母集団に関するする推論を、確率的に 表現することはできないのである。
R.A.フィッシャー
フィッシャーも、「観測上の根拠が前もって 存在する場合は否定していない!
前述の検診の例は、病気にかかっている確率も、有病者が陽性になる確率もデータに基づいて計算されている。 なので、ここまでは異論がない!

一期一会な事象
ベイズ統計学が疑念の目を向けられるのは、 事前確率に主観確率を用いるから!
主観確率 (subjective probability) とは?
ある事象が生じる確からしさの程度を、 0~1の間で表現した、個人的信念。

一期一会な事象例: 天気予報における 「降水確率30%」
客観確率これまで降水確率 30% が発表された 多数の日を集めて、それらを観察すると
10日のうち平均的に3日は雨が降っていた。
主観確率
まさに今日、雨が降る確率が 30% その確からしさは10本中3本あたりが入っている くじと私にとっては全く同じです。仮に賭けを
するならどちらでも構いません。
客観確率で表現できる事象は主観確率で 表現できるが、逆は必ずしも成り立たない。

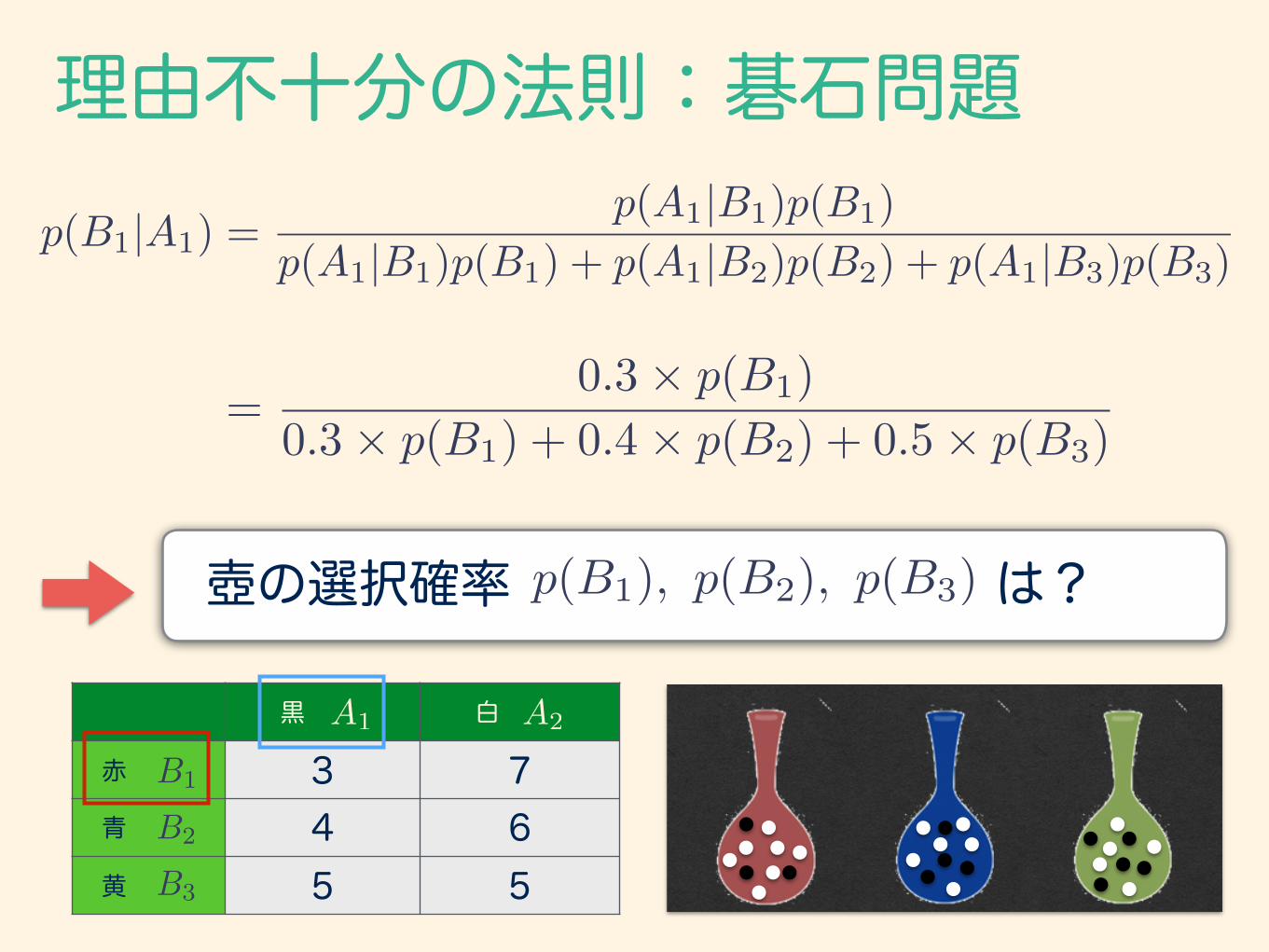
理由不十分の法則:碁石問題真っ暗な部屋に同じ形の3つの壺、赤い壺、青い壺、緑の壺が置いてあります。壺の中には、形・大きさ・手触り・重さの全く等しい碁石が、それぞれ10個入っています。そのうち黒い碁石は、それぞれ3個・4個・5個です。手探りで1つの壺を選び、その壺から碁石を1つ取り出しました。明るい部屋に移動して碁石の色を確認すると黒でした。選んだ壺が赤い壺であった確率は?
は?
理由不十分の法則:碁石問題
黒 白
赤 3 7 青 4 6 黄 5 5
A1 A2
B1
B2
B3
p(B1|A1) =p(A1|B1)p(B1)
p(A1|B1)p(B1) + p(A1|B2)p(B2) + p(A1|B3)p(B3)
=0.3⇥ p(B1)
0.3⇥ p(B1) + 0.4⇥ p(B2) + 0.5⇥ p(B3)
p(B1), p(B2), p(B3)壺の選択確率

理由不十分の法則:碁石問題繰り返し実験ができないケースのため、主観的な確率を 割り当てるしかない。
「理由不十分の法則」を適用する。
事象の発生原因がわからず、どれかを重視する 根拠が全くない場合、事象の発生確率を
全て同じとする。 黒 白
赤 3 7 青 4 6 黄 5 5
A1 A2
B1
B2
B3
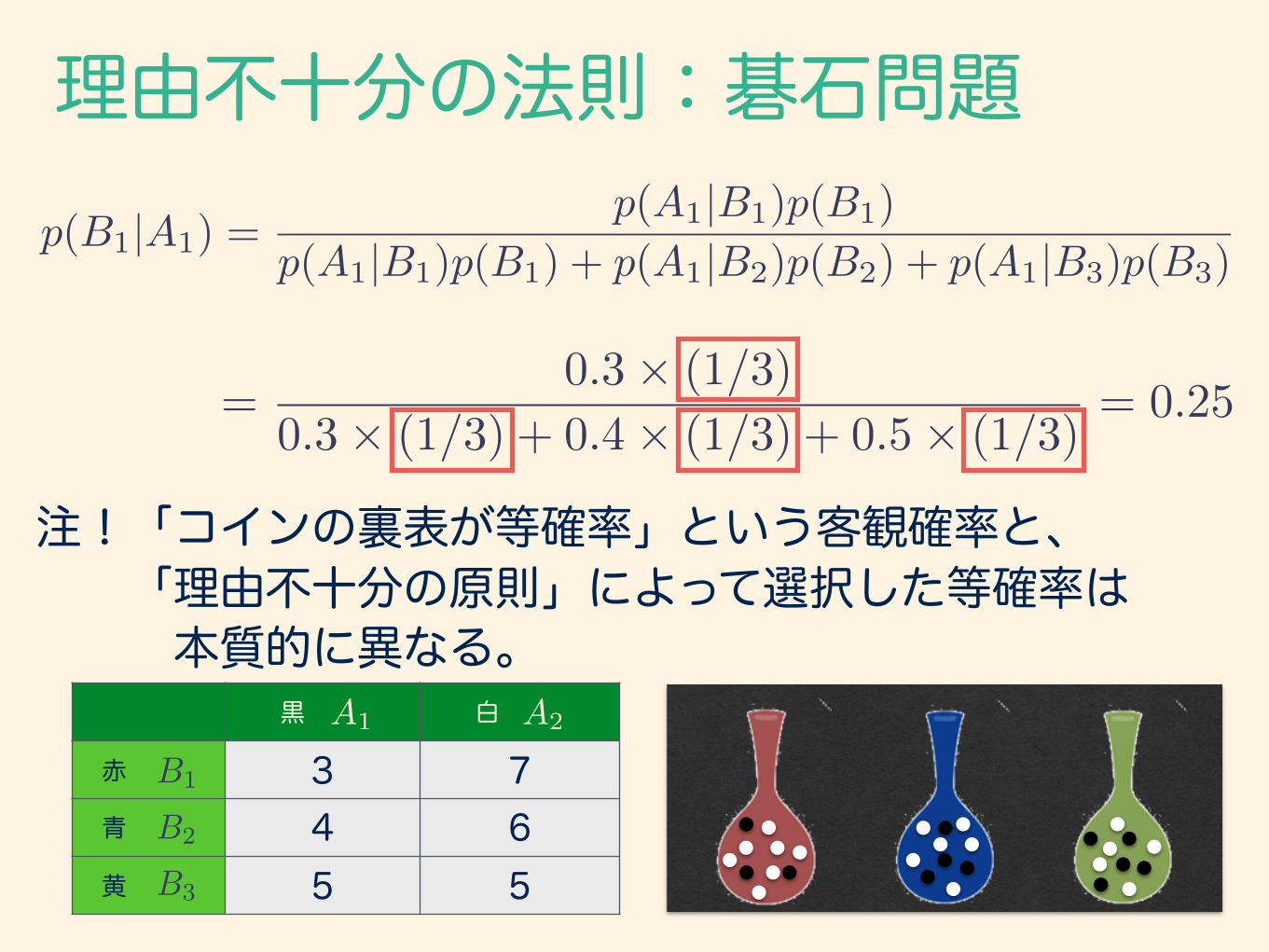
理由不十分の法則:碁石問題
黒 白
赤 3 7 青 4 6 黄 5 5
A1 A2
B1
B2
B3
p(B1|A1) =p(A1|B1)p(B1)
p(A1|B1)p(B1) + p(A1|B2)p(B2) + p(A1|B3)p(B3)
=0.3⇥ (1/3)
0.3⇥ (1/3) + 0.4⇥ (1/3) + 0.5⇥ (1/3)= 0.25
注!「コインの裏表が等確率」という客観確率と、 「理由不十分の原則」によって選択した等確率は 本質的に異なる。

理由不十分の法則:血液鑑定問題
東京で殺人事件が発生した。現場に残された犯人の血液を鑑定したところ、この町に住むA氏の血液と特徴が一致した。それは10万人に1人という高い一致率。他には 証拠は全くない。 この時A氏が犯人である確率は?
p(A|B,C) =p(B,C|A)p(A)
p(B,C)=p(犯人|一致)
p(一致|犯人) p(犯人)p(一致|犯人でない) p(犯人でない)+p(一致|犯人) p(犯人)
もう少しシリアスな例

p(犯人|一致)
p(一致|犯人) = 1 p(一致|犯人でない) = 1/10000 p(犯人でない) = 1 - p(犯人)
理由不十分の法則:血液鑑定問題
なので、p(犯人)の関数で表すことができる。
=
p(A|B,C) =p(B,C|A)p(A)
p(B,C)p(犯人)
(1/10000)(1 - p(犯人)+p(犯人)=
f( p(犯人) )
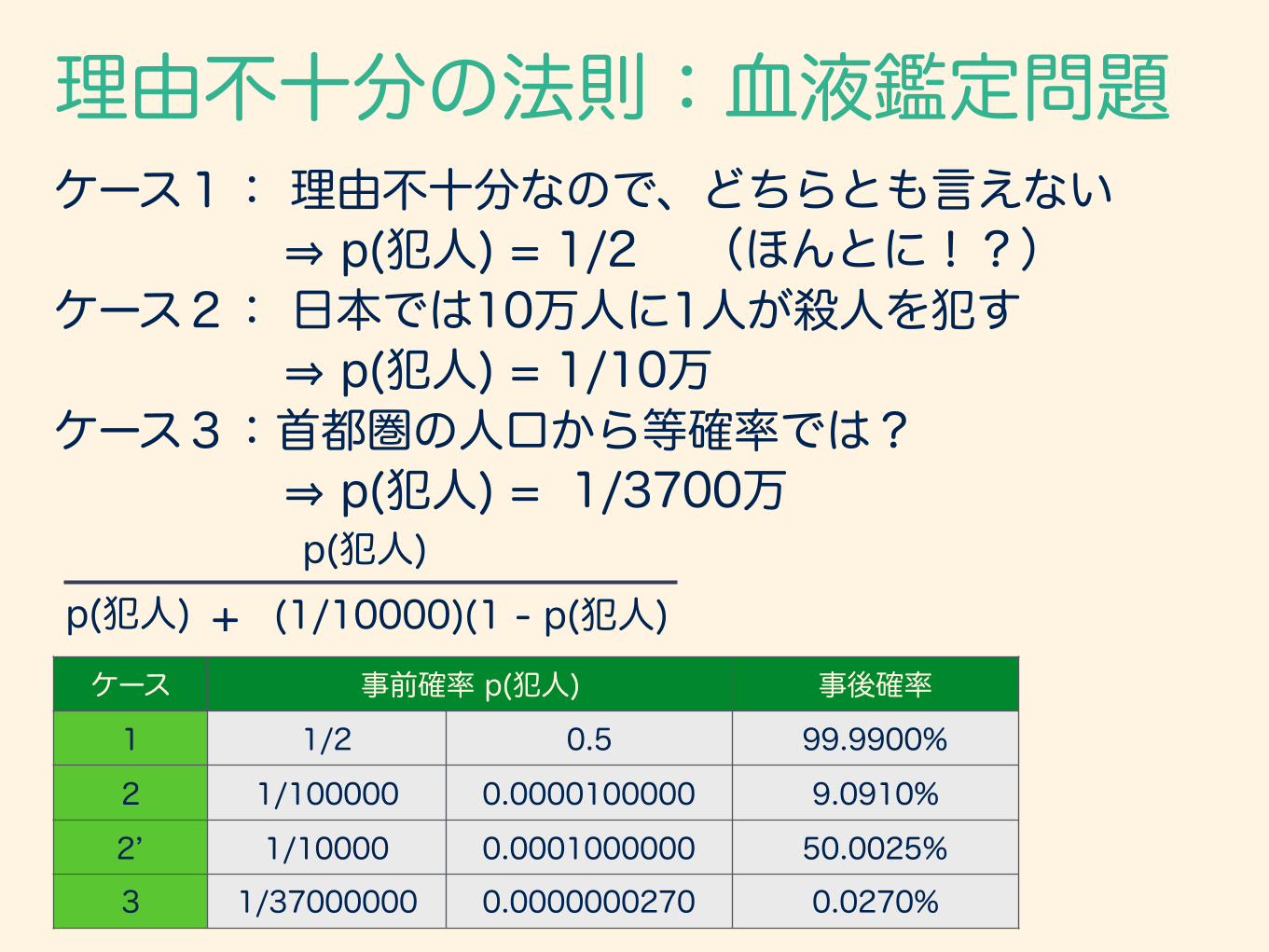
ケース 事前確率 p(犯人) 事後確率1 1/2 0.5 99.9900%2 1/100000 0.0000100000 9.0910%2’ 1/10000 0.0001000000 50.0025%3 1/37000000 0.0000000270 0.0270%
p(A|B,C) =p(B,C|A)p(A)
p(B,C)p(犯人)
(1/10000)(1 - p(犯人)+p(犯人)
理由不十分の法則:血液鑑定問題ケース1: 理由不十分なので、どちらとも言えない ⇒ p(犯人) = 1/2 (ほんとに!?) ケース2: 日本では10万人に1人が殺人を犯す ⇒ p(犯人) = 1/10万 ケース3:首都圏の人口から等確率では? ⇒ p(犯人) = 1/3700万

ケース 事前確率 p(犯人) 事後確率1 1/2 0.5 99.9900%2 1/100000 0.0000100000 9.0910%2’ 1/10000 0.0001000000 50.0025%3 1/37000000 0.0000000270 0.0270%
p(A|B,C) =p(B,C|A)p(A)
p(B,C)p(犯人)
(1/10000)(1 - p(犯人)+p(犯人)
理由不十分の法則:血液鑑定問題ケース1: 理由不十分なので、どちらとも言えない ⇒ p(犯人) = 1/2 (ほんとに!?) ケース2: 日本では10万人に1人が殺人を犯す ⇒ p(犯人) = 1/10万 ケース3:首都圏の人口から等確率では? ⇒ p(犯人) = 1/3700万主観確率による事前確率を使い、事前確率を変えると、なんでもありで、どんな結果でも
出せてしまう!
結果が恣意的になりそうな時には ベイズの定理による分析を控えるべき!

事前確率を圧倒するデータ前述のように、恣意的に確率を操作できてしまうと、分析として利用できない。
データの量を増やして、事前確率の影響を事実上ないものにしてしまえば良い。
レオナルド・ジミー・サベッジ
p(A|B,C,D, · · · , H) =p(B,C,D, · · · , H|A)p(A)
p(B,C,D, · · · , H)
客観的データを増やす! p(A)の影響が小さくなる
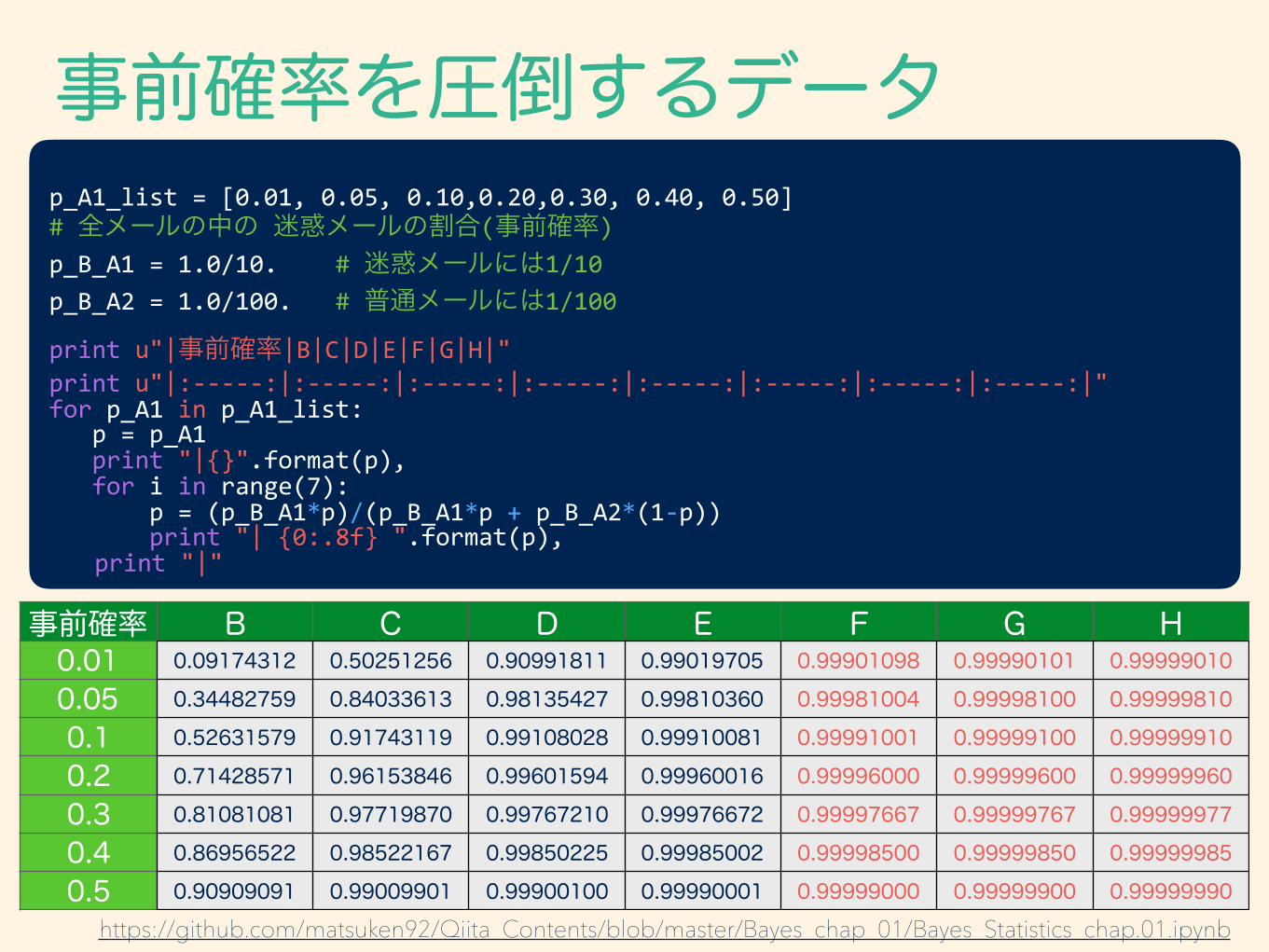
事前確率 B C D E F G H0.01 0.09174312 0.50251256 0.90991811 0.99019705 0.99901098 0.99990101 0.99999010
0.05 0.34482759 0.84033613 0.98135427 0.99810360 0.99981004 0.99998100 0.99999810
0.1 0.52631579 0.91743119 0.99108028 0.99910081 0.99991001 0.99999100 0.99999910
0.2 0.71428571 0.96153846 0.99601594 0.99960016 0.99996000 0.99999600 0.99999960
0.3 0.81081081 0.97719870 0.99767210 0.99976672 0.99997667 0.99999767 0.99999977
0.4 0.86956522 0.98522167 0.99850225 0.99985002 0.99998500 0.99999850 0.99999985
0.5 0.90909091 0.99009901 0.99900100 0.99990001 0.99999000 0.99999900 0.99999990
事前確率を圧倒するデータ p_A1_list = [0.01, 0.05, 0.10,0.20,0.30, 0.40, 0.50] # 全メールの中の 迷惑メールの割合(事前確率) p_B_A1 = 1.0/10. # 迷惑メールには1/10 p_B_A2 = 1.0/100. # 普通メールには1/100
print u"|事前確率|B|C|D|E|F|G|H|" print u"|:-‐-‐-‐-‐-‐:|:-‐-‐-‐-‐-‐:|:-‐-‐-‐-‐-‐:|:-‐-‐-‐-‐-‐:|:-‐-‐-‐-‐-‐:|:-‐-‐-‐-‐-‐:|:-‐-‐-‐-‐-‐:|:-‐-‐-‐-‐-‐:|" for p_A1 in p_A1_list: p = p_A1 print "|{}".format(p), for i in range(7): p = (p_B_A1*p)/(p_B_A1*p + p_B_A2*(1-‐p)) print "| {0:.8f} ".format(p), print "|"
https://github.com/matsuken92/Qiita_Contents/blob/master/Bayes_chap_01/Bayes_Statistics_chap.01.ipynb

p_A1_list = [0.01, 0.05, 0.10,0.20,0.30, 0.40, 0.50] # 全メールの中の 迷惑メールの割合(事前確率) p_B_A1 = 1.0/10. # 迷惑メールには1/10 p_B_A2 = 1.0/100. # 普通メールには1/100
print u"|事前確率|B|C|D|E|F|G|H|" print u"|:-‐-‐-‐-‐-‐:|:-‐-‐-‐-‐-‐:|:-‐-‐-‐-‐-‐:|:-‐-‐-‐-‐-‐:|:-‐-‐-‐-‐-‐:|:-‐-‐-‐-‐-‐:|:-‐-‐-‐-‐-‐:|:-‐-‐-‐-‐-‐:|" for p_A1 in p_A1_list: p = p_A1 print "|{}".format(p), for i in range(7): p = (p_B_A1*p)/(p_B_A1*p + p_B_A2*(1-‐p)) print "| {0:.8f} ".format(p), print "|"
事前確率 B C D E F G H0.01 0.09174312 0.50251256 0.90991811 0.99019705 0.99901098 0.99990101 0.99999010
0.05 0.34482759 0.84033613 0.98135427 0.99810360 0.99981004 0.99998100 0.99999810
0.1 0.52631579 0.91743119 0.99108028 0.99910081 0.99991001 0.99999100 0.99999910
0.2 0.71428571 0.96153846 0.99601594 0.99960016 0.99996000 0.99999600 0.99999960
0.3 0.81081081 0.97719870 0.99767210 0.99976672 0.99997667 0.99999767 0.99999977
0.4 0.86956522 0.98522167 0.99850225 0.99985002 0.99998500 0.99999850 0.99999985
0.5 0.90909091 0.99009901 0.99900100 0.99990001 0.99999000 0.99999900 0.99999990
事前確率を圧倒するデータ
この例の場合、 迷惑メールに多い単語が7つくらいあると 事前確率の影響はほとんどなくなる!
しかし、大量のデータがある場合も 事前確率の主観性・恣意性に関する
警戒は怠ってはならない!

私的分析と公的分析・私的分析 (private analysis) … 事後確率の計算を分析者とその仲間で 自らのために行う分析 例:軍関連(暗号解読、砲術)→結果が良ければ 主観的でも構わない
・公的分析 (public analysis) … 事後確率の計算を論文や報告書、著作を 通じてその知見を社会に還元するための分析 例:科学論文など → 分析者の主観で結論が 変わると困る。

ベイズの定理の第3の使用法1:事前確率 : 客観確率 条件付き確率 : 客観確率
検診問題の例。使い方に異議なし。
2:事前確率 : 客観確率 条件付き確率 : 主観確率
碁石問題など。主観確率の恣意性に注意して私的or公的分析かに気をつけて使用
3:事前確率 : 主観確率 条件付き確率 : 主観確率
3囚人問題の例。データ分析に使用してはならない!

3囚人問題ある監獄に、罪状が似ている3人の死刑因A, B, Cがぞれぞれ独房に入れられている。3人まとめて処刑の予定が、1人が恩赦隣釈放され、残り2人が処刑されることになった。誰が恩赦になるか知っている看守に「私は助かるか?」と聞いても看守は答えない。そこで、Aは「BとCのうち少なくとも1人は処刑されるのは確実だから、2人の中で処刑される1人の名前を教えてくれないか」と頼むと、看守は「Bは処刑される」と答えた。 Aは「これで自分が助かる確率が1/3から1/2に増えた」と喜んだ。実際、この答えを聞いた後のAの釈放される確率はどれくらいか?
B or C?
A B C
B!

も同じく、理由不十分の 原則より、1/2ずつとする。
とする。また、Bが恩赦になった時に、処刑されることはないので、
3囚人問題 釈放 処刑囚人A Aa Ab
囚人B Ba Bb
囚人C Ca Cb
主役: 囚人A 処刑が判明: 囚人B
各事象
p(Aa|Bd) =p(Bd|Aa)p(Aa)
p(Bd|Aa)p(Aa) + p(Bd|Ba)p(Ba) + p(Bd|Ca)p(Ca)
p(Aa) = p(Ba) = p(Ca) = 1/3理由不十分の原則より
p(Bd|Ba) = 0
p(Bd|Aa) = p(Cd|Aa) = 1/2
p(Bd|Ca) = 1Cが恩赦となれば、AとBは処刑となるので、
主観!
主観!

3囚人問題p(Aa|Bd) =
p(Bd|Aa)p(Aa)
p(Bd|Aa)p(Aa) + p(Bd|Ba)p(Ba) + p(Bd|Ca)p(Ca)
p(Aa) = p(Ba) = p(Ca) = 1/3
p(Bd|Ba) = 0
p(Bd|Aa) = p(Cd|Aa) = 1/2
p(Bd|Ca) = 1
以上より、
p(Aa|Bd) =1/2⇥ 1/3
1/2⇥ 1/3 + 0⇥ 1/3 + 1⇥ 1/3
= 0.5

3囚人問題p(Aa|Bd) =
p(Bd|Aa)p(Aa)
p(Bd|Aa)p(Aa) + p(Bd|Ba)p(Ba) + p(Bd|Ca)p(Ca)
p(Aa) = p(Ba) = p(Ca) = 1/3
p(Bd|Ba) = 0
p(Bd|Aa) = p(Cd|Aa) = 1/2
p(Bd|Ca) = 1
以上より、
p(Aa|Bd) =1/2⇥ 1/3
1/2⇥ 1/3 + 0⇥ 1/3 + 1⇥ 1/3
= 0.5
事前確率:主観確率
条件付き確率:主観確率
第3の使用法! 主観確率同士の積なので危険!

参考
・グラフや計算をしたPythonコード (Github) https://github.com/matsuken92/Qiita_Contents/blob/master/Bayes_chap_01/Bayes_Statistics_chap.01.ipynb
・基礎からのベイズ統計学 (豊田 秀樹) http://www.asakura.co.jp/books/isbn/978-4-254-12212-1/