Embed Size (px)
Citation preview

MLaPP Ch.5ベイズ統計学Bayes statistics
1/73

Baysian Statistics
アウトライン
1. イントロダクション2. 事後分布の要約3. ベイズ的モデル選択4. 事前分布5. 階層ベイズ6. 経験ベイズ7. ベイズ的決定理論
2/73

Baysian Statistics Introduction
Subsection 1
Introduction
3/73

Baysian Statistics Introduction
ベイズ統計とは
▶ 観測したデータ以外のあらゆる量が確率変数であるとみなす統計学
▶ データを⽣成した分布の平均や分散など(※データそのものの平均や分散ではありません)
▶ 未知の量 θ に関するすべての情報は事後分布 p (θ|D) に集約される
4/73

Baysian Statistics Summarizing posterior distribution
Subsection 2
Summarizing posterior distribution
5/73

Baysian Statistics Summarizing posterior distribution
事後分布の要約
▶ θの事後分布 p (θ|D) を要約した簡単な量によって未知の量θを表してやる
▶ 結果の直感的な理解・可視化▶ 計算上の利点
6/73

Baysian Statistics Summarizing posterior distribution
1. MAP推定2. 信⽤区間
7/73

Baysian Statistics Summarizing posterior distribution
点推定 (point estimate)θの事後分布 p (θ|D) をある定数θによって表して計算
▶ 平均 (mean)
θ = E [θ] =
ˆθp (θ|D)dθ
▶ 中央値 (median) (θが1次元なら)
θ s.t. P(θ ≤ θ|D
)= P
(θ > θ|D
)= 0.5
▶ 最頻値 (mode) → MAP推定で求めてるのはこれ
θ = argmaxθ
p (θ|D)
8/73

Baysian Statistics Summarizing posterior distribution
MAP推定の問題点
1. 推定の不安定さが評価できない(他の点推定にもあてはまる)
2. 過学習しやすい3. 最頻値は分布の要約に適さないことがある4. パラメータ変換に対して不変でない
▶ ただしどの点推定量が良いかは考えてる問題に依存→ 詳しくは後ででてくる決定理論で
9/73
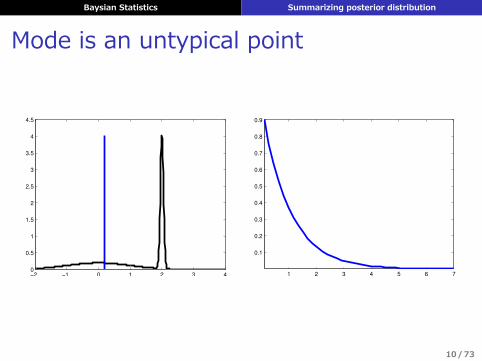
Baysian Statistics Summarizing posterior distribution
Mode is an untypical point
−2 −1 0 1 2 3 40
0.5
1
1.5
2
2.5
3
3.5
4
4.5
1 2 3 4 5 6 7
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
10/73
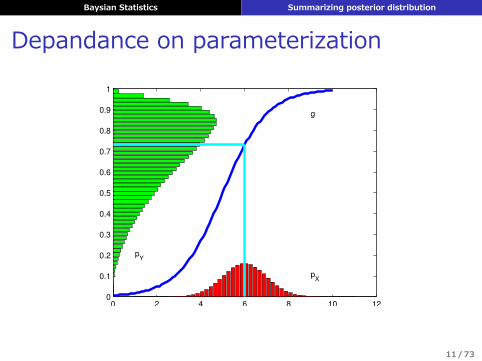
Baysian Statistics Summarizing posterior distribution
Depandance on parameterization
0 2 4 6 8 10 120
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
pX
pY
g
11/73

Baysian Statistics Summarizing posterior distribution
信⽤区間 (credible interval)
Definitionθ の 100 (1− α)% 信⽤区間 Cα (D) = (ℓ,u) とは
P (ℓ ≤ θ ≤ u|D) = 1− α
を満たす区間のこと
▶ ⼀意には決まらない▶ Central interval, HDP region などが使われる
▶ 信頼区間 (confidence interval) とは別物
12/73
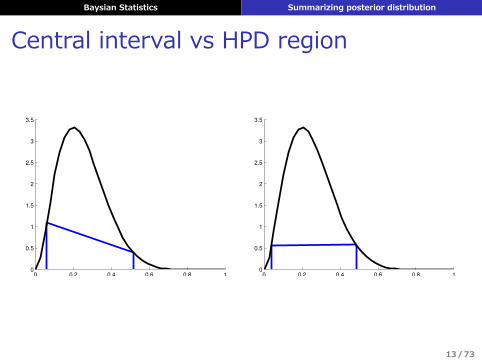
Baysian Statistics Summarizing posterior distribution
Central interval vs HPD region
0 0.2 0.4 0.6 0.8 10
0.5
1
1.5
2
2.5
3
3.5
0 0.2 0.4 0.6 0.8 10
0.5
1
1.5
2
2.5
3
3.5
13/73
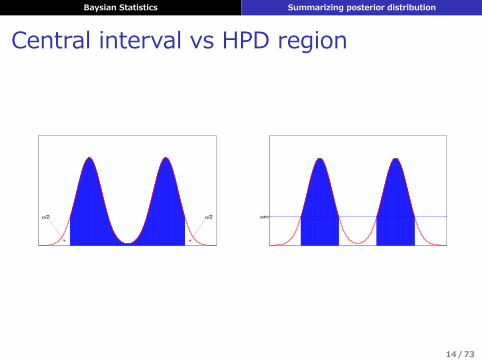
Baysian Statistics Summarizing posterior distribution
Central interval vs HPD region
α/2 α/2 pMIN
14/73

Baysian Statistics Summarizing posterior distribution
例: Amazonでお買い物
▶ 2つの商品を⽐較して良い⽅を買いたい▶ 商品1は良い評価が90,悪い評価が10▶ 商品2は良い評価が2,悪い評価が0
それぞれの商品の良さ θ1, θ2(0 ≤ θi ≤ 1) を確率分布で表してやり θ1 > θ2 になる確率を求める
15/73

Baysian Statistics Summarizing posterior distribution
例: Amazonでお買い物
▶ 2つの商品を⽐較して良い⽅を買いたい▶ 商品1は良い評価が90,悪い評価が10▶ 商品2は良い評価が2,悪い評価が0
それぞれの商品の良さ θ1, θ2(0 ≤ θi ≤ 1) を確率分布で表してやり θ1 > θ2 になる確率を求める
15/73

Baysian Statistics Summarizing posterior distribution
確率モデルで定式化
▶ θ1, θ2 の事前分布 θ1, θ2 ∼ Beta (1, 1)▶ 良い評価の数を Bin (N, θi) でモデリング
▶ 事後分布は
p (θ1|D1) = Beta (91, 11)p (θ2|D2) = Beta (3, 1)
▶ δ = θ1 − θ2 とし p (δ|D) を数値積分で評価
16/73

Baysian Statistics Summarizing posterior distribution
確率モデルで定式化
▶ θ1, θ2 の事前分布 θ1, θ2 ∼ Beta (1, 1)▶ 良い評価の数を Bin (N, θi) でモデリング
▶ 事後分布は
p (θ1|D1) = Beta (91, 11)p (θ2|D2) = Beta (3, 1)
▶ δ = θ1 − θ2 とし p (δ|D) を数値積分で評価
16/73
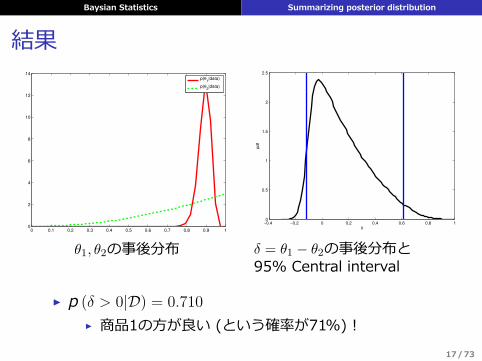
Baysian Statistics Summarizing posterior distribution
結果
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
2
4
6
8
10
12
14
p(θ
1|data)
p(θ2|data)
θ1, θ2の事後分布
−0.4 −0.2 0 0.2 0.4 0.6 0.8 10
0.5
1
1.5
2
2.5
δ
pd
fδ = θ1 − θ2の事後分布と95% Central interval
▶ p (δ > 0|D) = 0.710
▶ 商品1の⽅が良い (という確率が71%) !17/73

Baysian Statistics Bayesian model selection
Subsection 3
Bayesian model selection
18/73

Baysian Statistics Bayesian model selection
モデル選択 (model selection)
▶ 複雑度の違う複数のモデルの中から最良のモデルを1つ選びたい
▶ 多項式フィッティングの多項式の次数▶ 正則化パラメータの⼤きさ▶ k最近傍法の近傍の数
19/73

Baysian Statistics Bayesian model selection
ベイズ的モデル選択
▶ モデル m の事後分布 p (m|D) を求めて最頻値のモデルを選択
p (m|D) =p (D|m)p (m)∑m∈M p (m,D)
▶ M: すべてのモデルを含む集合▶ p (D|m): モデル m の周辺尤度
(marginal likelihood)
▶ モデルの事前分布が⼀様 (p (m) ∝ 1) なら周辺尤度が最⼤のモデル argmax
m∈Mp (D|m) を選択
20/73

Baysian Statistics Bayesian model selection
周辺尤度 (marginal likelihood)
Definitionモデル m の周辺尤度 (marginal likelihood)またはエビデンス p (D|m)
p (D|m) =
ˆp (D|θ)p (θ|m)dθ
▶ p (D|θ): モデル m に対する θ の尤度▶ p (θ|m): モデル m に対する θ の事前分布
21/73

Baysian Statistics Bayesian model selection
1. ベイズ的オッカムの剃⼑2. ベイズ因⼦3. ジェフリーズ-リンドレーのパラドックス
22/73

Baysian Statistics Bayesian model selection
ベイズ的オッカムの剃⼑
▶ オッカムの剃⼑ (Occamʼs razor)▶ 同じ現象を適切に説明する仮説が複数あるときはその中で最も簡単なものを採⽤するべきである
▶ 周辺尤度最⼤化で⾃動的に簡単なモデルが選ばれる▶ モデルが有限個でなく連続値の複雑度パラメータで表されている場合であっても周辺尤度最⼤化により複雑度パラメータを決められる (経験ベイズ)
23/73

Baysian Statistics Bayesian model selection
Chain rule による解釈
p (D) = p (y1)p (y2|y1)p (y3|y1:2) . . .p (yN|y1:N−1)
24/73
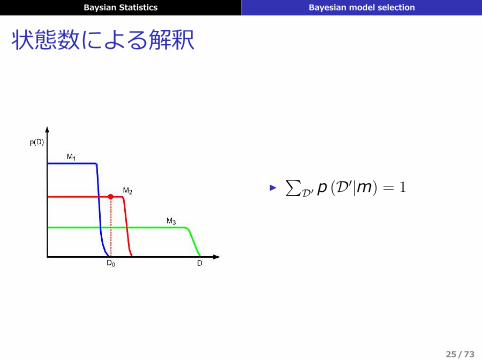
Baysian Statistics Bayesian model selection
状態数による解釈
▶∑
D′ p (D′|m) = 1
25/73
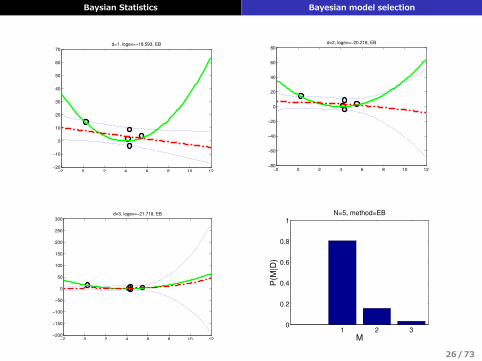
Baysian Statistics Bayesian model selection
−2 0 2 4 6 8 10 12−20
−10
0
10
20
30
40
50
60
70d=1, logev=−18.593, EB
−2 0 2 4 6 8 10 12−200
−150
−100
−50
0
50
100
150
200
250
300d=3, logev=−21.718, EB
−2 0 2 4 6 8 10 12−80
−60
−40
−20
0
20
40
60
80d=2, logev=−20.218, EB
1 2 30
0.2
0.4
0.6
0.8
1
M
P(M
|D)
N=5, method=EB
26/73
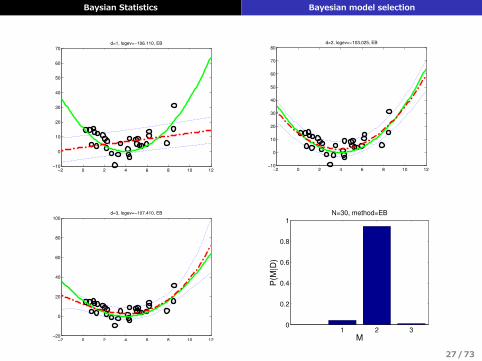
Baysian Statistics Bayesian model selection
−2 0 2 4 6 8 10 12−10
0
10
20
30
40
50
60
70d=1, logev=−106.110, EB
−2 0 2 4 6 8 10 12−20
0
20
40
60
80
100d=3, logev=−107.410, EB
−2 0 2 4 6 8 10 12−10
0
10
20
30
40
50
60
70
80d=2, logev=−103.025, EB
1 2 30
0.2
0.4
0.6
0.8
1
M
P(M
|D)
N=30, method=EB
27/73

Baysian Statistics Bayesian model selection
周辺尤度の計算
▶ 共役事前分布を使うと簡単
p (D) =ZNZ0Zℓ
▶ ZN: 事後分布 p (θ|D) の正則化項▶ Z0: 事前分布p (θ) の正則化項▶ Zℓ: 尤度p (D|θ) の定数項
28/73

Baysian Statistics Bayesian model selection
周辺尤度の計算例
▶ ベータ-⼆項モデル
p (D) =
(NN1
) B (a+ N1,b+N2)
B (a,b)
▶ ディリクレ-多項モデル
p (D) =Γ (
∑k αk)
Γ (N+∑
k αk)
∏k
Γ (Nk + αk)
Γ (αk)
29/73

Baysian Statistics Bayesian model selection
▶ ガウス-ガウス-ウィシャートモデル
p (D) =1
πND/2
(κ0
κN
)D/2 |S0|ν0/2
|SN|νN/2ΓD (νN/2)
ΓD (ν0/2)
▶ 分布とか記号の定義は4.6.3.2節で
30/73

Baysian Statistics Bayesian model selection
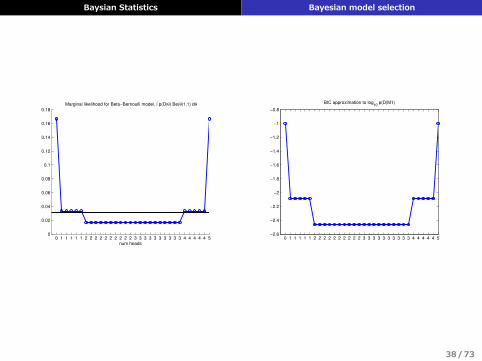
周辺尤度の近似式Definitionモデルのベイズ情報量規準(BIC; Bayes information criterion)
BIC ≜ logp(D|θ
)−dof
(θ)
2logN ≈ logp (D)
▶ θ: モデルのパラメータθの最尤推定量▶ dof
(θ): モデルの⾃由度 (≈パラメータ空間の次元)
▶ BICの最⼩化は最⼩記述⻑ (MDL; minimumdescription length) の最⼩化と等価
31/73

Baysian Statistics Bayesian model selection
BICの例
▶ 線形回帰モデル p (y|x, θ) = N(wTx, σ2
)の最⼤尤度
logp(D|θ
)= −N
2log
(2πσ2
)− N
2
▶ よってBICは (定数項を除いて)
BIC = −N2log
(2πσ2
)− D
2logN
▶ D: モデルに含まれる変数の数
▶ BICが最⼩になる変数集合を選べばよい
32/73

Baysian Statistics Bayesian model selection
⾚池情報量規準
Definitionモデルの⾚池情報量規準(AIC; Akaike information criterion)
AIC (m,D) ≜ logp(D|θ
)− dof (m)
▶ 予測精度の観点から有⽤
33/73

Baysian Statistics Bayesian model selection
事前分布の影響▶ 周辺尤度は事前分布の違いに影響される
▶ ⼀⽅で事後分布はあまり影響されない
▶ 事前分布のハイパーパラメータも確率変数としてハイパーパラメータの事後分布についても周辺化
p (D|m) =
ˆ ˆp (D|θ)p (θ|α,m)p (α|m)dθdα
▶ α: θの事前分布 p (θ|m) のハイパーパラメータ▶ p (α|m): ハイパーパラメータの事前分布
▶ ↑の代わりに周辺尤度の最⼤化によってαを決めると計算が楽 (経験ベイズ(11枚ぶり2回⽬))
34/73

Baysian Statistics Bayesian model selection
ベイズ因⼦ (Bayes factor)Definition帰無仮説 M0 対⽴仮説 M1 に対して,ベイズ因⼦はその周辺尤度の⽐
BF1,0 ≜p (D|M1)
p (D|M0)=p (M1|D)
p (M0|D)/p (M1)
p (M0)
▶ BF1,0 > 1 なら対⽴仮説を⽀持し,BF1,0 < 1 なら帰無仮説を⽀持
▶ ベイズ因⼦の⼤きさでどのくらい信⽤できるかを評価もできる
▶ 頻度でいうところのp値みたいな
35/73

Baysian Statistics Bayesian model selection
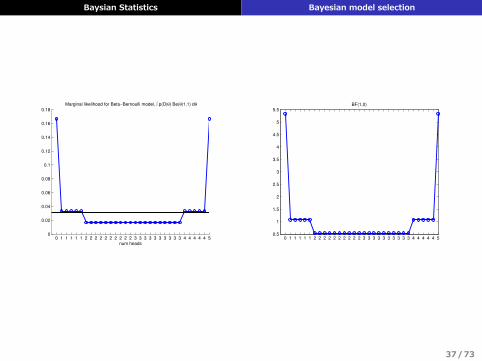
例: コイン投げ
▶ コインが公平かどうかを知りたい▶ M0: コインが公平 p(D|M0) =
(12
)N▶ M1: 公平でないp (D|M1) =
´ 1
0p (D|θ)p (θ)dθ = B(α1+N1,α0+N0)
B(α1,α0)
▶ M1はベータ-ベルヌーイモデル
36/73
Baysian Statistics Bayesian model selection
0 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 3 3 3 3 3 3 3 3 3 3 4 4 4 4 4 50
0.02
0.04
0.06
0.08
0.1
0.12
0.14
0.16
0.18
num heads
Marginal likelihood for Beta−Bernoulli model, ∫ p(D|θ) Be(θ|1,1) dθ
0 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 3 3 3 3 3 3 3 3 3 3 4 4 4 4 4 50.5
1
1.5
2
2.5
3
3.5
4
4.5
5
5.5BF(1,0)
37/73
Baysian Statistics Bayesian model selection
0 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 3 3 3 3 3 3 3 3 3 3 4 4 4 4 4 50
0.02
0.04
0.06
0.08
0.1
0.12
0.14
0.16
0.18
num heads
Marginal likelihood for Beta−Bernoulli model, ∫ p(D|θ) Be(θ|1,1) dθ
0 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 3 3 3 3 3 3 3 3 3 3 4 4 4 4 4 5−2.6
−2.4
−2.2
−2
−1.8
−1.6
−1.4
−1.2
−1
−0.8
BIC approximation to log10
p(D|M1)
38/73

Baysian Statistics Bayesian model selection
ジェフリーズ-リンドレーのパラドックス
▶ 各モデルのθの事前分布として変則事前分布 (または変則でなくても極端に広がった分布) を使うと常にシンプルなモデルが選ばれてしまう
▶ ベイズ的モデル選択と仮説検定で結論の⾷い違い▶ M0 : θ ∈ {0} vs M1 : θ ∈ R\ {0} とか
▶ 変則事前分布 (improper prior) は積分しても1にならない事前分布
▶ たとえば θ ∈ (−∞,∞) ならp (θ) ∝ 定数 ⇒
´p (θ)dθ → ∞
39/73

Baysian Statistics Prior
Subsection 4
Prior
40/73

Baysian Statistics Prior
事前分布
▶ だれ⼀⼈として⽩紙状態 (tabula rasa) ではない▶ あらゆる推論は世界についての仮定の下で⾏われる
▶ とはいえ事前分布の選び⽅の影響が少ない⽅がうれしいこともある
41/73

Baysian Statistics Prior
事前分布
▶ だれ⼀⼈として⽩紙状態 (tabula rasa) ではない▶ あらゆる推論は世界についての仮定の下で⾏われる
▶ とはいえ事前分布の選び⽅の影響が少ない⽅がうれしいこともある
41/73

Baysian Statistics Prior
1. 無情報事前分布2. ジェフリーズ事前分布3. 頑健な事前分布4. 事前分布の混合分布
42/73

Baysian Statistics Prior
無情報事前分布 (uninformative prior)
▶ θについて何も知らない場合に使われる▶ “Let the data speak for itself.”
▶ ⼀⼝に無情報と⾔っても⾊々ある▶ ベルヌーイ分布 Ber (x|θ) (コイン投げ) なら...
▶ ⼀様事前分布: θ ∼ Beta (1, 1) ∝ 定数▶ ホールデン事前分布:
θ ∼ limc→0 Beta (c, c) = Beta (0, 0)→ 事後分布の期待値が N1/N
▶ ジェフリーズ事前分布: θ ∼ Beta(12 ,
12
)
43/73

Baysian Statistics Prior
ジェフリーズ事前分布 (Jeffreys prior)
▶ フッシャー情報量の平⽅根に⽐例する事前分布
pϕ (ϕ) ∝ (I (ϕ))1/2
I (ϕ) ≜ −E
[(d logp (X|ϕ)dϕ
)2]1/2
▶ パラメータ変換に対する不変性
θ = h (ϕ),pθ (θ) : Jeffreys ⇒ pϕ (ϕ)
∣∣∣∣dϕdθ∣∣∣∣ : Jeffreys
44/73

Baysian Statistics Prior
頑健な事前分布 (Robust prior)
▶ 結果に過度の影響を与えない事前分布▶ 典型的には裾の重い (heavy tail) 分布
Exampleガウス分布 N (θ, 1) の平均θのRobust prior
▶ p (θ ≤ −1) = p (−1 < θ ≤ 0)= p (0 < θ ≤ 1) = p (1 < θ) = 0.25
▶ なめらかで単峰→ θ ∼ N (θ|0, 2.192)とすれば上の条件をみたす 他にはコーシー分布 θ ∼ T (θ|0, 1, 1) も
45/73

Baysian Statistics Prior
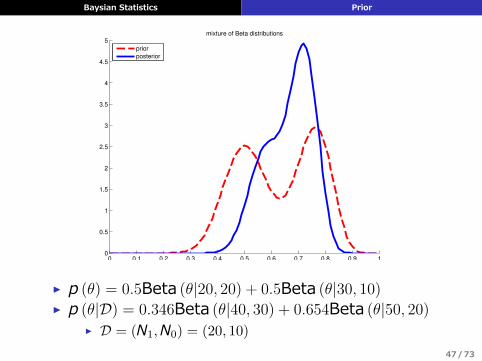
共役事前分布の混合分布
▶ 共役事前分布の混合分布は共役事前分布になる▶ 計算が楽
▶ ex) ベルヌーイ分布 Ber (x|θ) (コイン投げ)▶ p (θ) = 0.5Beta (θ|20, 20) + 0.5Beta (θ|30, 10)
▶ (公平なコインが多めに⼊った袋 (第1項) と表のでやすいコインが多めに⼊った袋 (第2項) から無作為にコインを選ぶイメージ(頻度的表現))
46/73
Baysian Statistics Prior
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5mixture of Beta distributions
prior
posterior
▶ p (θ) = 0.5Beta (θ|20, 20) + 0.5Beta (θ|30, 10)▶ p (θ|D) = 0.346Beta (θ|40, 30) + 0.654Beta (θ|50, 20)
▶ D = (N1,N0) = (20, 10)
47/73

Baysian Statistics Prior
事後分布の計算
1. 各混合要素の事後分布は普通の共役事前分布と同じ2. 混合⽐の事後分布は
p (Z = k|D) =p (Z = k)p (D|Z = k)∑k′ p (Z = k′)p (D|Z = k′)
▶ p (Z = k): k番⽬の混合要素の混合⽐の事前分布▶ p (D|Z = k): k番⽬の混合要素についての周辺尤度´
p (D|θ)p (θ|Z = k)dθ
48/73

Baysian Statistics Prior
例: DNA塩基配列▶ DNA塩基配列の各位置について
1. ほぼどの塩基かが決まっている (A or T or C or G)2. どの塩基かがランダム
▶ 1の位置と対応する塩基が知りたい▶ 多項-ディリクレモデルで混合分布を事前分布に
▶ 混合要素は
p (θ|Zt = 0) = Dir (θ| (1, 1, 1, 1))
p (θ|Zt = 1) =1
4Dir (θ| (10, 1, 1, 1)) + · · ·
+1
4Dir (θ| (1, 1, 1, 10))
▶ 事後分布の Zt = 1 の混合⽐が⼤きい位置をみる49/73

Baysian Statistics Hierarchical Bayes
Subsection 5
Hierarchical Bayes
50/73

Baysian Statistics Hierarchical Bayes
階層ベイズモデル
▶ 事前分布のハイパーパラメータにさらに事前分布を導⼊したモデル
p (η, θ|D) ∝ p (D|θ)p (θ|η)p (η)
▶ グラフィカルモデル (→Ch.10) でかくと
η → θ → D
51/73

Baysian Statistics Hierarchical Bayes
例: がんでの死亡率
▶ 街ごとのがんでの死亡率を推定▶ 各街の死亡率θiの事前分布をBeta (a,b)▶ ハイパーパラメータ η = (a,b) の事前分布を p (η)
52/73

Baysian Statistics Empirical Bayes
Subsection 6
Empirical Bayes
53/73

Baysian Statistics Empirical Bayes
経験ベイズ法 (EB; empirical Bayes)▶ 階層モデルのハイパーパラメータの事後分布を点推定で近似
p (η|D) =
ˆp (η, θ|D)dθ
≈ δη (η)
▶ η = argmaxp (η|D)
▶ η の事前分布を⼀様とする (⇒ p (η|D) ∝ p (D|η)) とη = argmaxp (D|η)
= argmax[ˆ
p (D|θ)p (θ|η)dθ]
▶ 第2種の最尤推定 (type-II maximum likelihood)とも呼ぶ (周辺尤度を最⼤化している)
54/73

Baysian Statistics Empirical Bayes
Bayesian check!
Method DefinitionMaximum likelihood θ = argmax
θp (D|θ)
MAP estimation θ = argmaxθ
p (D|θ)p (θ)
ML-II (EB) η = argmaxη
´p (D|θ)p (θ|η)dθ = argmax
ηp (D|η)
MAP-II η = argmaxη
´p (D|θ)p (θ|η)p (η)dθ = argmax
ηp (D|η)p (η)
Full Bayes p (θ, η|D) ∝ p (D|θ)p (θ|η)p (η)
55/73

Baysian Statistics Bayesian decision theory
Subsection 7
Bayesian decision theory
56/73

Baysian Statistics Bayesian decision theory
ベイズ的決定理論
▶ 得られた信念から実際の⾏動を決めたい▶ 「⾃然とのゲーム」として定式化
▶ ⾃分の⾏動によって相⼿の⾏動が変わらないゲーム
57/73

Baysian Statistics Bayesian decision theory
▶ y ∈ Y: ⾃然が選ぶ状態・パラメータ・ラベル▶ x ∈ X : y から⽣成された観測▶ a ∈ A: 選ぶ⾏動 (A を⾏動空間と呼ぶ)▶ L (y,a): 状態 y に対して⾏動 a を選んだ時の損失
▶ U (y,a) = −L (y,a) を効⽤関数とも
▶ δ : X → A : 観測から⾏動を決める決定⼿順
58/73

Baysian Statistics Bayesian decision theory
▶ 期待効⽤最⼤化原理(maximum expected utility principle)
δ (x) = argmaxa∈A
E [U (y,a)]
= argmina∈A
E [L (y,a)]
▶ 事後期待損失 (posterior expected loss)
ρ (a|x) ≜ Ep(y|x) [L (y,a)] =∑yL (y,a)p (y|x)
▶ ベイズ推定量 (Bayes estimator)またはベイズ決定則 (Bayes decision rule)
δ (x) = argmina∈A
ρ (a|x)
59/73

Baysian Statistics Bayesian decision theory
1. よくある損失関数に対するベイズ推定量2. 偽陽性と偽陰性のトレードオフ3. その他の話題
60/73

Baysian Statistics Bayesian decision theory
0− 1 lossのベイズ推定量
▶ L (y,a) = I (y = a) ={0 if a = y1 if a = y
▶ 分類問題で使う
▶ 事後期待損失は
ρ (a|x) = p (a = y|x) = 1− p (y|x)
▶ ベイズ推定量は事後分布の最頻値 (→MAP推定)
y∗ (x) = argmaxy∈Y
p (y|x)
61/73
Baysian Statistics Bayesian decision theory
� �
���
���
���������
�������� ����������
������ �����
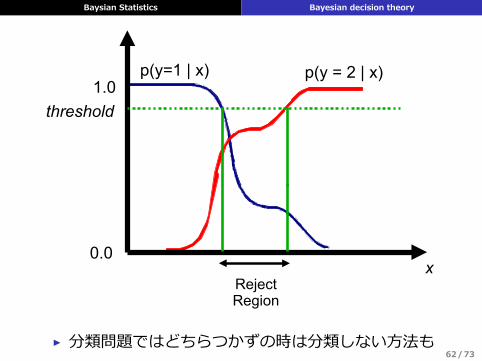
▶ 分類問題ではどちらつかずの時は分類しない⽅法も62/73

Baysian Statistics Bayesian decision theory
⼆乗損失のベイズ推定量▶ L (y,a) = (y− a)2
▶ 回帰問題で使う
▶ 事後期待損失は
ρ (a|x) = E[(y− a)2 |x
]= E
[y2|a
]− 2aE [y|x] + a2
▶ ベイズ推定量は事後分布の平均
y = E [y|x] =ˆyp (y|x)dy
▶ 最⼩平均⼆乗誤差推定 (minimum mean squarederror; MMSE) とよぶ
63/73

Baysian Statistics Bayesian decision theory
絶対損失のベイズ推定量
▶ L (y,a) = |y− a|▶ これも回帰問題で使う▶ 2乗損失より外れ値に頑健
▶ ベイズ推定量は事後分布の中央値つまり下式を満たす a
P (y < a|x) = P (y ≥ a|x) = 0.5
64/73

Baysian Statistics Bayesian decision theory
教師あり学習真の値yに対する予測y′についての cost function ℓ (y,y′)が与えられたとき,汎化誤差 (generalization error)
L (θ, δ) ≜ E(x,y)∼p(x,y|θ) [ℓ (y, δ (x))]=
∑x
∑yL (y, δ (x))p (x,y|θ)
の事後期待損失
ρ (δ|D) =
ˆp (θ|D)L (θ, δ)dθ
を最⼩化する決定⼿順 δ : X → Y を求める
65/73

Baysian Statistics Bayesian decision theory
偽陽性と偽陰性のトレードオフ
▶ 2値の決定問題▶ 仮説検定・2クラス分類・物体検出など
▶ 2種類の過誤▶ 偽陽性 (false positive) : y = 0 を y = 1 と推定▶ 偽陰性 (false negative) : y = 1 を y = 0 と推定
▶ 0-1損失ではこれらの誤差を同等に扱ってしまう
66/73

Baysian Statistics Bayesian decision theory
y = 1 y = 0y = 1 0 LFNy = 0 LFP 0
loss matrix
▶ LFN: 偽陰性の損失 LFP: 偽陽性の損失▶ もしLFN,LFPが与えられれば事後期待損失は
ρ(y = 0|x
)= LFNp (y = 1|x)
ρ(y = 1|x
)= LFNp (y = 0|x)
となり p (y = 1|x) /p (y = 0|x) の閾値τを決められる▶ ROC曲線を使うと閾値を定めない (LFN, LFPが与えられない) 場合にも議論できる
67/73

Baysian Statistics Bayesian decision theory
1. ROC曲線2. Precision recall curves3. F-score4. Falsediscovery rates
68/73
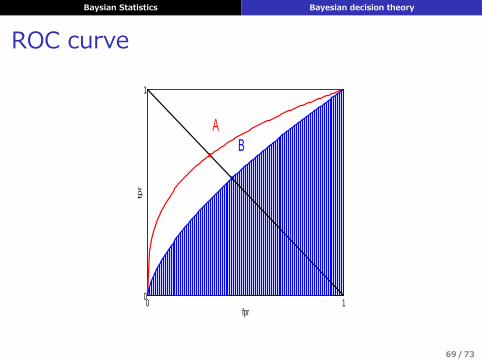
Baysian Statistics Bayesian decision theory
ROC curve
0 10
1
fpr
tpr
AB
69/73
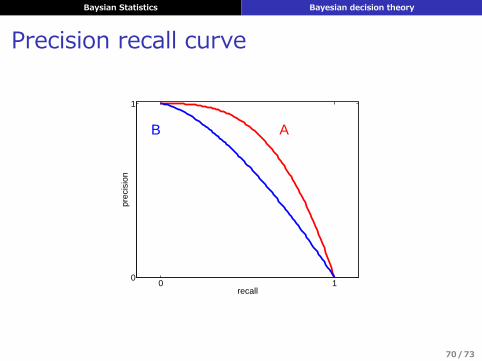
Baysian Statistics Bayesian decision theory
Precision recall curve
0 10
1
recall
prec
isio
nAB
70/73

Baysian Statistics Bayesian decision theory
F-score
▶ 適合度と再現率の調和平均
F1 ≜2
1/P+ 1/R =2PRR+ P
71/73

Baysian Statistics Bayesian decision theory
False discovery rates
▶
FD (τ,D) ≜∑
(1− pi) I (pi > τ)
FDR (τ,D) ≜ FD (τ,D) /N (τ,D)
▶ N (τ,D) =∑
I (pi > τ)
72/73

Baysian Statistics Bayesian decision theory
その他の話題
▶ Contextual bandits▶ Utility theory▶ Sequential decision theory
▶ 強化学習 (reinforcement learning) の問題
73/73




![R-stat-intro 20.ppt [互換モード] - nfunao.web.fc2.comnfunao.web.fc2.com/files/R-intro/R-stat-intro_20.pdf · とWi BUGSWinBUGS R で統計解析入門 (20) ベイズ統計「超」入門](https://img.pdfslide.net/doc/110x75/5d67a5f988c993306c8b8d16/r-stat-intro-20ppt-wi-bugswinbugs-r-.jpg)
























