Embed Size (px)
Citation preview

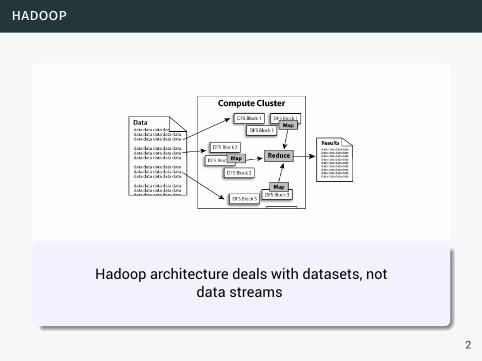
data streams
Big Data & Real Time1
hadoop
Hadoop architecture deals with datasets, notdata streams
2

apache s4
Apache S4
3
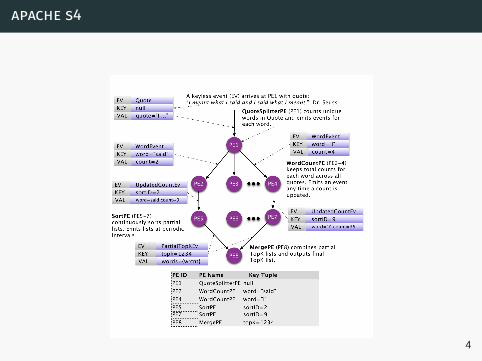
apache s4
4
apache storm
Storm from Twitter
5
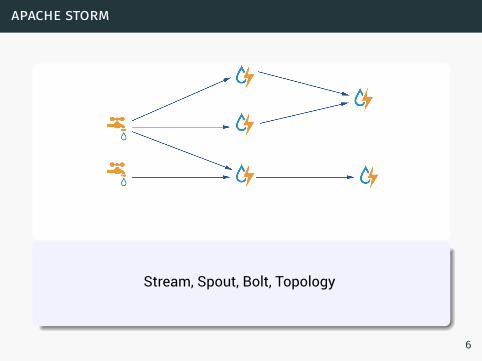
apache storm
Stream, Spout, Bolt, Topology
6
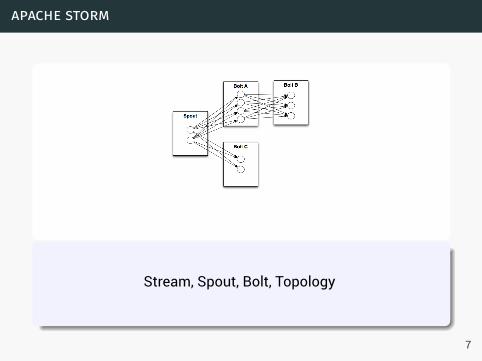
apache storm
Stream, Spout, Bolt, Topology
7

apache storm
Storm characteristics for real-time data processing workloads:
1 Fast2 Scalable3 Fault-tolerant4 Reliable5 Easy to operate
8
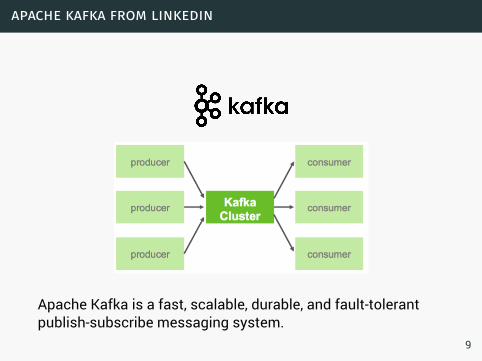
apache kafka from linkedin
Apache Kafka is a fast, scalable, durable, and fault-tolerantpublish-subscribe messaging system.
9
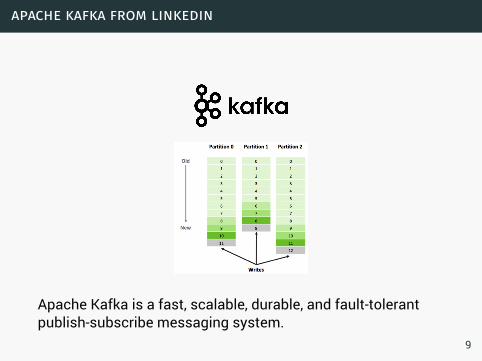
apache kafka from linkedin
Apache Kafka is a fast, scalable, durable, and fault-tolerantpublish-subscribe messaging system.
9

apache samza from linkedin
Storm and Samza are fairly similar. Both systems provide:
1 a partitioned stream model,2 a distributed execution environment,3 an API for stream processing,4 fault tolerance,5 Kafka integration
10
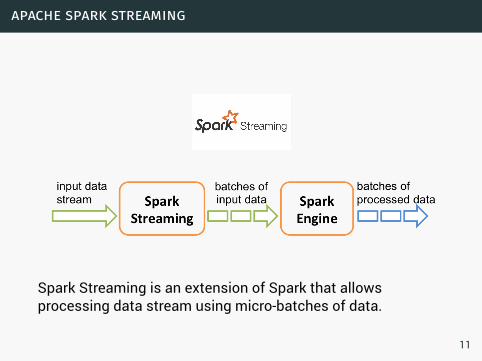
apache spark streaming
Spark Streaming is an extension of Spark that allowsprocessing data stream using micro-batches of data.
11

apache flink motivation

apache flink motivation
1 Real time computation: streaming computation2 Fast, as there is not need to write to disk3 Easy to write code
13

real time computation: streaming computation
MapReduce Limitations
ExampleHow compute in real time (latency less than 1 second):
1 predictions2 frequent items as Twitter hashtags3 sentiment analysis
14

easy to write code
case class Word (word : Str ing , frequency : I n t )
DataSet API (batch):
va l l i n es : DataSet [ S t r ing ] = env . readTextF i le ( . . . )
l i n es . flatMap { l i n e => l i n e . s p l i t ( ” ” ).map(word => Word (word , 1 ) ) }
. groupBy ( ” word ” ) . sum( ” frequency ” )
. p r i n t ( )
15

easy to write code
case class Word (word : Str ing , frequency : I n t )
DataSet API (batch):
va l l i n es : DataSet [ S t r ing ] = env . readTextF i le ( . . . )
l i n es . flatMap { l i n e => l i n e . s p l i t ( ” ” ).map(word => Word (word , 1 ) ) }
. groupBy ( ” word ” ) . sum( ” frequency ” )
. p r i n t ( )
DataStream API (streaming):
va l l i n es : DataStream [ St r ing ] = env . fromSocketStream ( . . . )
l i n es . flatMap { l i n e => l i n e . s p l i t ( ” ” ).map(word => Word (word , 1 ) ) }
. window ( Time . of ( 5 ,SECONDS ) ) . every ( Time . of ( 1 ,SECONDS) )
. groupBy ( ” word ” ) . sum( ” frequency ” )
. p r i n t ( )16
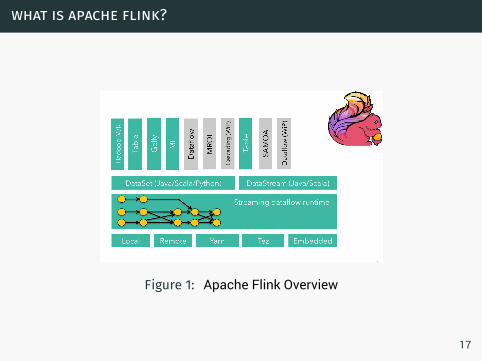
what is apache flink?
Figure 1: Apache Flink Overview
17

batch and streaming engines
Figure 2: Batch, streaming and hybrid data processing engines.
18

batch comparison
Figure 3: Comparison between Hadoop, Spark And Flink.
19
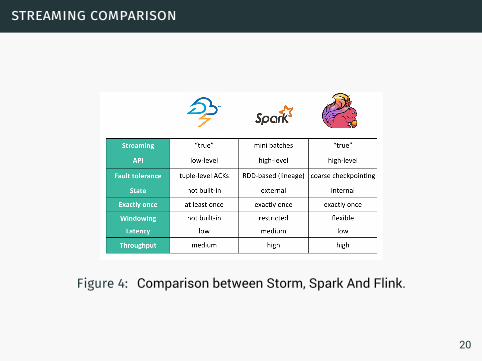
streaming comparison
Figure 4: Comparison between Storm, Spark And Flink.
20

scala language
• What is Scala?• object oriented• functional
• How is Scala?• Scala is compatible• Scala is concise• Scala is high-level• Scala is statically typed
21

short course on scala
• Easy to use: includes an interpreter• Variables:
• val: immutable (preferable)• var: mutable
• Scala treats everything as objects with methods• Scala has first-class functions• Functions:
def max( x : In t , y : I n t ) : I n t = {i f ( x > y ) x
e lse y}
def max2( x : In t , y : I n t ) = i f ( x > y ) x e lse y
22

short course on scala
• Functional:args . foreach ( ( arg : S t r ing ) => p r i n t l n ( arg ) )args . foreach ( arg => p r i n t l n ( arg ) )args . foreach ( p r i n t l n )
• Imperative:fo r ( arg <− args ) p r i n t l n ( arg )
• Scala achieves a conceptual simplicity by treatingeverything, from arrays to expressions, as objects withmethods.( 1 ) . + ( 2 )
g ree tSt r ings (0 ) = ” Hel lo ”g ree tSt r ings . update (0 , ” Hel lo ” )va l numNames2 = Array . apply ( ” zero ” , ” one ” , ” two ” )23

short course on scala
• Array: mutable sequence of objects that share the same type• List: immutable sequence of objects that share the sametype
• Tuple: immutable sequence of objects that does not sharethe same type
va l pa i r = (99 , ” Luf tba l lons ” )p r i n t l n ( pa i r . _1 )p r i n t l n ( pa i r . _2 )
24

short course on scala
• Sets and mapsvar j e tSe t = Set ( ” Boeing ” , ” Airbus ” )j e tSe t += ” Lear ”p r i n t l n ( j e tSe t . contains ( ” Cessna ” ) )
import scala . co l l e c t i on . mutable .Mapva l treasureMap = Map[ Int , S t r ing ] ( )treasureMap += (1 −> ”Go to is land . ” )treasureMap += (2 −> ” Find big X on ground . ” )treasureMap += (3 −> ” Dig . ” )p r i n t l n ( treasureMap ( 2 ) )
25

short course on scala
• Functional style• Does not contain any vardef pr in tArgs ( args : Array [ S t r ing ] ) : Uni t = {
var i = 0whi le ( i < args . length ) {
p r i n t l n ( args ( i ) )i += 1
}}
def pr in tArgs ( args : Array [ S t r ing ] ) : Uni t = {fo r ( arg <− args )
p r i n t l n ( arg )}
def pr in tArgs ( args : Array [ S t r ing ] ) : Uni t = {args . foreach ( p r i n t l n )
}
def formatArgs ( args : Array [ S t r ing ] ) = args . mkString ( ” \ n ” )p r i n t l n ( formatArgs ( args ) ) 26

short course on scala
• Prefer vals, immutable objects, and methods without sideeffects.
• Use vars, mutable objects, and methods with side effectswhen you have a specific need and justification for them.
• In a Scala program, a semicolon at the end of a statement isusually optional.
• A singleton object definition looks like a class definition,except instead of the keyword class you use the keywordobject .
• Scala provides a trait, scala.Application:object FallWinterSpringSummer extends App l icat ion {
fo r ( season <− L i s t ( ” f a l l ” , ” winter ” , ” spr ing ” ) )p r i n t l n ( season + ” : ”+ ca lcu la te ( season ) )
}
27

short course on scala
• Scala has first-class functions: you can write downfunctions as unnamed literals and then pass them around asvalues.
( x : I n t ) => x + 1
• Short forms of function literalssomeNumbers . f i l t e r ( ( x : I n t ) => x > 0)someNumbers . f i l t e r ( ( x ) => x > 0)someNumbers . f i l t e r ( x => x > 0)someNumbers . f i l t e r ( _ > 0)
someNumbers . foreach ( x => p r i n t l n ( x ) )someNumbers . foreach ( p r i n t l n _ )
28

short course on scala
• Zipping lists: zip and unzip• The zip operation takes two lists and forms a list of pairs:• A useful special case is to zip a list with its index. This is donemost efficiently with the zipWithIndex method,
• Mapping over lists: map , flatMap and foreach• Filtering lists: filter , partition , find , takeWhile , dropWhile ,and span
• Folding lists: /: and : or foldLeft and foldRight.
( z / : L i s t ( a , b , c ) ) ( op )
equals
op ( op ( op ( z , a ) , b ) , c )
• Sorting lists: sortWith
29

apache flink architecture
references
Apache Flink Documentation
http://dataartisans.github.io/flink-training/ 31
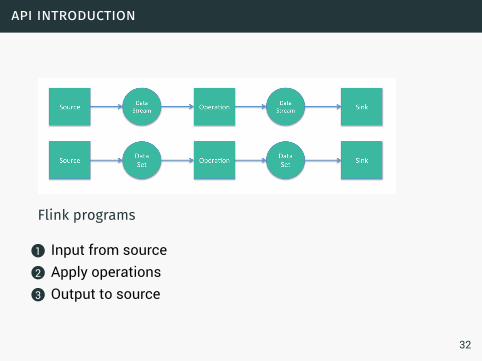
api introduction
Flink programs
1 Input from source2 Apply operations3 Output to source
32
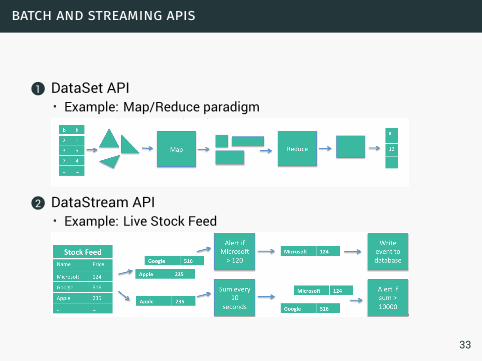
batch and streaming apis
1 DataSet API• Example: Map/Reduce paradigm
2 DataStream API• Example: Live Stock Feed
33

streaming and batch comparison
34
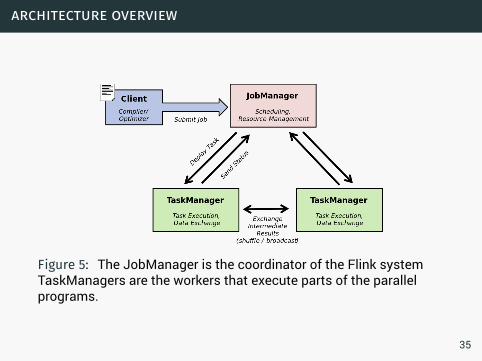
architecture overview
Figure 5: The JobManager is the coordinator of the Flink systemTaskManagers are the workers that execute parts of the parallelprograms.
35
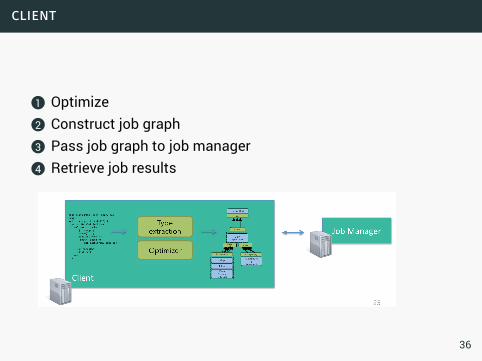
client
1 Optimize2 Construct job graph3 Pass job graph to job manager4 Retrieve job results
36
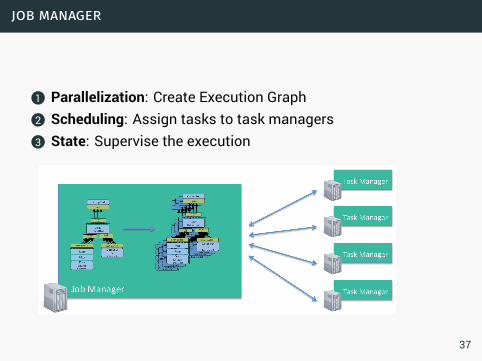
job manager
1 Parallelization: Create Execution Graph2 Scheduling: Assign tasks to task managers3 State: Supervise the execution
37
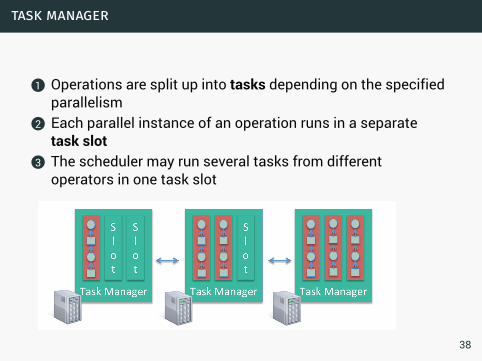
task manager
1 Operations are split up into tasks depending on the specifiedparallelism
2 Each parallel instance of an operation runs in a separatetask slot
3 The scheduler may run several tasks from differentoperators in one task slot
38
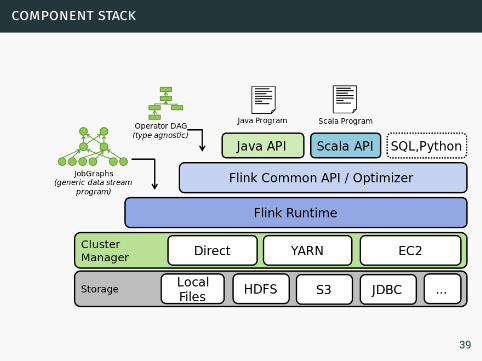
component stack
39

component stack
1 API layer: implements multiple APIs that create operatorDAGs for their programs. Each API needs to provide utilities(serializers, comparators) that describe the interactionbetween its data types and the runtime.
2 Optimizer and common api layer: takes programs in the formof operator DAGs. The operators are specific (e.g., Map,Join, Filter, Reduce, …), but are data type agnostic.
3 Runtime layer: receives a program in the form of aJobGraph. A JobGraph is a generic parallel data flow witharbitrary tasks that consume and produce data streams.
40
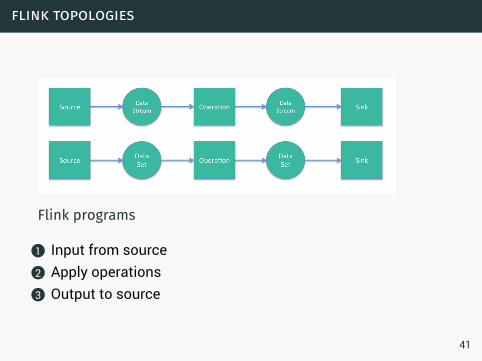
flink topologies
Flink programs
1 Input from source2 Apply operations3 Output to source
41

sources (selection)
• Collection-based• fromCollection• fromElements
• File-based• TextInputFormat• CsvInputFormat
• Other• SocketInputFormat• KafkaInputFormat• Databases
42
sinks (selection)
• File-based• TextOutputFormat• CsvOutputFormat• PrintOutput
• Others• SocketOutputFormat• KafkaOutputFormat• Databases
43

apache flink algorithns

flink skeleton program
1 Obtain an ExecutionEnvironment,2 Load/create the initial data,3 Specify transformations on this data,4 Specify where to put the results of your computations,5 Trigger the program execution
45

java wordcount example
publ ic class WordCountExample {pub l ic s t a t i c void main ( St r ing [ ] args ) throws Exception {
f i n a l ExecutionEnvironment env =ExecutionEnvironment . getExecutionEnvironment ( ) ;
DataSet <Str ing > tex t = env . fromElements (”Who’ s there ? ” ,” I th ink I hear them . Stand , ho ! Who’ s there ? ” ) ;
DataSet <Tuple2 <Str ing , Integer >> wordCounts = tex t. flatMap (new L i n eSp l i t t e r ( ) ). groupBy (0 ).sum( 1 ) ;
wordCounts . p r i n t ( ) ;}
. . . .}
46

java wordcount example
publ ic class WordCountExample {pub l ic s t a t i c void main ( St r ing [ ] args ) throws Exception {
. . . .}
pub l ic s t a t i c class L i n eSp l i t t e r implementsFlatMapFunction <Str ing , Tuple2 <Str ing , Integer >> {@Overridepub l ic void flatMap ( St r ing l i ne , Co l lec to r <Tuple2 <Str ing ,
Integer >> out ) {fo r ( S t r ing word : l i n e . s p l i t ( ” ” ) ) {
out . co l l e c t (new Tuple2 <Str ing , Integer >(word , 1 ) ) ;}
}}
}
47

scala wordcount example
import org . apache . f l i n k . api . scala . _
object WordCount {def main ( args : Array [ S t r ing ] ) {
va l env = ExecutionEnvironment . getExecutionEnvironmentva l t ex t = env . fromElements (
”Who’ s there ? ” ,” I th ink I hear them . Stand , ho ! Who’ s there ? ” )
va l counts = tex t . flatMap{ _ . toLowerCase . s p l i t ( ” \ \W+” ) f i l t e r { _ . nonEmpty } }
.map { ( _ , 1) }
. groupBy (0 )
.sum(1 )
counts . p r i n t ( )}
} 48

java 8 wordcount example
publ ic class WordCountExample {pub l ic s t a t i c void main ( St r ing [ ] args ) throws Exception {
f i n a l ExecutionEnvironment env =ExecutionEnvironment . getExecutionEnvironment ( ) ;
DataSet <Str ing > tex t = env . fromElements (”Who’ s there ?”” I th ink I hear them . Stand , ho ! Who’ s there ? ” ) ;
t ex t .map( l i n e −> l i n e . s p l i t ( ” ” ) ). f latMap ( ( S t r ing [ ] wordArray ,
Co l lec to r <Tuple2 <Str ing , Integer >> out )−> Arrays . stream ( wordArray )
. forEach ( t −> out . co l l e c t (new Tuple2 < >( t , 1 ) ) ))
. groupBy (0 )
.sum(1 )
. p r i n t ( ) ;}
} 49

data streams algorithns

flink skeleton program
1 Obtain an StreamExecutionEnvironment,2 Load/create the initial data,3 Specify transformations on this data,4 Specify where to put the results of your computations,5 Trigger the program execution
51

java wordcount example
pub l ic class StreamingWordCount {
pub l ic s t a t i c void main ( St r ing [ ] args ) {
StreamExecutionEnvironment env =StreamExecutionEnvironment . getExecutionEnvironment ( ) ;
DataStream<Tuple2 <Str ing , Integer >> dataStream = env. socketTextStream ( ” loca lhost ” , 9999). flatMap (new Sp l i t t e r ( ) ). groupBy (0 ).sum( 1 ) ;
dataStream . p r i n t ( ) ;
env . execute ( ” Socket Stream WordCount ” ) ;}
. . . .}
52

java wordcount example
pub l ic class StreamingWordCount {pub l ic s t a t i c void main ( St r ing [ ] args ) throws Exception {
. . . .}
pub l ic s t a t i c class S p l i t t e r implementsFlatMapFunction <Str ing , Tuple2 <Str ing , Integer >> {
@Overridepub l ic void flatMap ( St r ing sentence ,
Co l lec to r <Tuple2 <Str ing , Integer >> out ) throws Exception {fo r ( S t r ing word : sentence . s p l i t ( ” ” ) ) {
out . co l l e c t (new Tuple2 <Str ing , Integer >(word , 1 ) ) ;}
}}
}
53

scala wordcount example
object WordCount {def main ( args : Array [ S t r ing ] ) {
va l env = StreamExecutionEnvironment . getExecutionEnvironmentva l t ex t = env . socketTextStream ( ” loca lhost ” , 9999)
va l counts = tex t . flatMap { _ . toLowerCase . s p l i t ( ” \ \W+” )f i l t e r { _ . nonEmpty } }
.map { ( _ , 1) }
. groupBy (0 )
.sum(1 )
counts . p r i n t
env . execute ( ” Scala Socket Stream WordCount ” )}
}
54

obtain an streamexecutionenvironment
The StreamExecutionEnvironment is the basis for all Flink programs.
StreamExecutionEnvironment . getExecutionEnvironmentStreamExecutionEnvironment . createLocalEnvironment ( pa ra l l e l i sm )StreamExecutionEnvironment . createRemoteEnvironment ( host : Str ing ,
port : St r ing , pa ra l l e l i sm : Int , j a r F i l e s : S t r ing * )
env . socketTextStream ( host , port )env . fromElements ( elements . . . )env . addSource ( sourceFunction )
55

specify transformations on this data
• Map• FlatMap• Filter• Reduce• Fold• Union
56

3) specify transformations on this data
MapTakes one element and produces one element.
data .map { x => x . t o I n t }
57

3) specify transformations on this data
FlatMapTakes one element and produces zero, one, or more elements.
data . flatMap { s t r => s t r . s p l i t ( ” ” ) }
58

3) specify transformations on this data
FilterEvaluates a boolean function for each element and retainsthose for which the function returns true.
data . f i l t e r { _ > 1000 }
59

3) specify transformations on this data
ReduceCombines a group of elements into a single element byrepeatedly combining two elements into one. Reduce may beapplied on a full data set, or on a grouped data set.
data . reduce { _ + _ }
60

3) specify transformations on this data
UnionProduces the union of two data sets.
data . union ( data2 )
61

window operators
The user has different ways of using the result of a windowoperation:
• windowedDataStream.flatten() - streams the resultselement wise and returns a DataStream<T> where T is thetype of the underlying windowed stream
• windowedDataStream.getDiscretizedStream() -returns a DataStream<StreamWindow<T» for applyingsome advanced logic on the stream windows itself.
• Calling any window transformation further transforms thewindows, while preserving the windowing logic
dataStream .window ( Time . of ( 5 , TimeUnit .SECONDS) ). every ( Time . of ( 1 , TimeUnit .SECONDS ) ) ;
dataStream .window ( Count . of (100) ). every ( Time . of ( 1 , TimeUnit .MINUTES ) ) ;
6 62

gelly: flink graph api
• Gelly is a Java Graph API for Flink.• In Gelly, graphs can be transformed and modified usinghigh-level functions similar to the ones provided by thebatch processing API.
• In Gelly, a Graph is represented by a DataSet of vertices anda DataSet of edges.
• The Graph nodes are represented by the Vertex type. AVertex is defined by a unique ID and a value.
// create a new ver tex with a Long ID and a St r ing valueVertex <Long , Str ing > v = new Vertex <Long , Str ing >(1L , ” foo ” ) ;
/ / create a new ver tex with a Long ID and no valueVertex <Long , NullValue > v =
new Vertex <Long , Nul lValue >(1L , Nul lValue . getInstance ( ) ) ;
63

gelly: flink graph api
• The graph edges are represented by the Edge type.• An Edge is defined by a source ID (the ID of the sourceVertex), a target ID (the ID of the target Vertex) and anoptional value.
• The source and target IDs should be of the same type as theVertex IDs. Edges with no value have a NullValue value type.
Edge<Long , Double > e = new Edge<Long , Double >(1L , 2L , 0 . 5 ) ;
/ / reverse the source and ta rge t of t h i s edgeEdge<Long , Double > reversed = e . reverse ( ) ;
Double weight = e . getValue ( ) ; / / weight = 0.5
64

table api - relational queries
• Flink provides an API that allows specifying operationsusing SQL-like expressions.
• Instead of manipulating DataSet or DataStream you workwith Table on which relational operations can be performed.
import org . apache . f l i n k . api . scala . _import org . apache . f l i n k . api . scala . tab le . _
case class WC(word : Str ing , count : I n t )va l input = env . fromElements (WC( ” he l l o ” , 1 ) ,
WC( ” he l l o ” , 1 ) , WC( ” ciao ” , 1 ) )va l expr = input . toTableva l r e su l t = expr . groupBy ( ’ word )
. se lec t ( ’ word , ’ count .sum as ’ count ) . toDataSet [WC]
65