Embed Size (px)
Citation preview

AS
Ya
b
a
ARRAA
KFSVS
1
pthucd[otrptsow
h1
Applied Soft Computing 36 (2015) 392–407
Contents lists available at ScienceDirect
Applied Soft Computing
j ourna l ho me page: www.elsev ier .com/ locate /asoc
n improved focused crawler based on Semantic Similarity Vectorpace Model
ajun Dua,∗, Wenjun Liub, Xianjing Lvb, Guoli Pengb
School of Computer and Software Engineering, Xihua University, Chengdu 610039, ChinaXihua University Library, Chengdu 610039, China
r t i c l e i n f o
rticle history:eceived 17 February 2014eceived in revised form 27 March 2015ccepted 15 July 2015vailable online 1 August 2015
eywords:ocused crawleremantic similaritySMSRM
a b s t r a c t
A focused crawler is topic-specific and aims selectively to collect web pages that are relevant to agiven topic from the Internet. In many studies, the Vector Space Model (VSM) and Semantic SimilarityRetrieval Model (SSRM) take advantage of cosine similarity and semantic similarity to compute similari-ties between web pages and the given topic. However, if there are no common terms between a web pageand the given topic, the VSM will not obtain the proper topical similarity of the web page. In addition, if allof the terms between them are synonyms, then the SSRM will also not obtain the proper topical similar-ity. To address these problems, this paper proposes an improved retrieval model, the Semantic SimilarityVector Space Model (SSVSM), which integrates the TF*IDF values of the terms and the semantic similar-ities among the terms to construct topic and document semantic vectors that are mapped to the samedouble-term set, and computes the cosine similarities between these semantic vectors as topic-relevant
similarities of documents, including the full texts and anchor texts of unvisited hyperlinks. Next, theproposed model predicts the priorities of the unvisited hyperlinks by integrating the full text and anchortext topic-relevant similarities. The experimental results demonstrate that this approach improves theperformance of the focused crawlers and outperforms other focused crawlers based on Breadth-First,VSM and SSRM. In conclusion, this method is significant and effective for focused crawlers.© 2015 Elsevier B.V. All rights reserved.
. Introduction
Web crawlers are programs that collect information from webages on the World Wide Web (WWW). In the crawling process,he web crawlers first traverse the seed URLs, and then, parse theyperlinks in the newly downloaded web pages, add them to annvisited list, select a URL from the unvisited list to traverse, andontinue the above operations repeatedly. Web crawlers can beivided into general-purpose and special-purpose web crawlers1–3]. General-purpose web crawlers retrieve enormous numbersf web pages in all fields from the huge Internet. To find and storehese web pages, general-purpose web crawlers must have longunning times and immense hard-disk space. However, special-urpose web crawlers acquire many web pages that are relevanto a given topic. Compared with general-purpose web crawlers,
pecial-purpose web crawlers obviously need a smaller amountf runtime and hardware resources. With the sharp growth ofeb pages in the WWW, special-purpose web crawlers, known as∗ Corresponding author.E-mail address: [email protected] (Y. Du).
ttp://dx.doi.org/10.1016/j.asoc.2015.07.026568-4946/© 2015 Elsevier B.V. All rights reserved.
focused crawlers, have become increasingly important in gather-ing information from web pages for finite resources and in bettersatisfying the needs of the topic search for the large variety of userinterests [4–6].
The most critical task of the focused crawler is selecting theURLs. All of the new URLs are extracted from downloaded webpages and are consecutively traversed by the focused crawlers. Theselection of URLs ensures that the crawler acquires more web pagesthat are relevant to a special topic [7–10]. The selected URLs areclassified into two types: the seed URLs from the Internet and theupdated URLs from the unvisited list [11]. The seed URLs that arerelated to a given topic can be selected from the gathered results[12], which are retrieved by inputting topic queries to the generalsearch engine. Moreover, the focused crawler itself can also obtainthe seed URLs by providing topic keywords to the focused crawler[13]. The updated URLs are selected from the unvisited list, wherethe URLs are ranked in descending order based on the weights thatare relevant to the given topic. In [14–16], the texts of retrieved
web pages were employed to assign topic-relevant priorities torank the unvisited hyperlinks, and each priority for a hyperlink wascomputed by averaging the concept values of the web pages thatcontain the hyperlink.
Compu
cre[aptTettttbmtItibcuMwiita
taa
(
(
Y. Du et al. / Applied Soft
Most focused crawlers take advantage of the web page text toalculate the topic-relevant similarities for unvisited hyperlinks toank them. First, focused crawlers must determine the text type ofach unvisited hyperlink to compute their traversed priorities. In17–19], the documents of the hyperlinks consist of the full textsnd anchor texts of the web pages. Specifically, the downloadedriorities for the hyperlinks are computed by linearly integratinghe correlations between the full texts, anchor texts and given topic.he correlations are calculated based on information retrieval mod-ls such as the Vector Space Model (VSM) [20]. The VSM buildshe document vector and query vector that are composed by usinghe Term Frequency Inverse Document Frequency (TF*IDF) of theerms. The web page must have common terms with the topico compute its topical similarity. Otherwise, there is no similarityetween the web page and the topic. Classic information retrievalodels, such as the VSM, achieve topic-relevant degrees based on
he terms that are common between the documents and the topic.f there are not any of the same terms between a document andhe topic, the document will be topic-irrelevant. However, two lex-cally different terms does not mean that they must be irrelevantecause they might be semantically similar [21]. Consequently, thelassic methods are not able to collect conceptually similar doc-ments. To solve the problem, the Semantic Similarity Retrieveodel (SSRM) was proposed to cause focused crawlers to retrieveeb pages that have semantically similar terms [22,23]. The SSRM
ndicates that the document correlation is computed by multiply-ng the term frequencies and the semantic similarity of the twoerms, summing these product values and finally normalizing theccumulated value.
These focused crawlers can reliably predict the priorities of all ofhe unvisited hyperlinks to rank those hyperlinks. However, therere several problems that are challenges to these focused crawlers,s follows:
1) Certain focused crawlers cannot take semantic similarity intoconsideration. For the focused crawlers that are based on theVSM, there must be common terms between the documents ofthe hyperlinks and the given topic by using the cosine simi-larity to compute the topical similarities of the documents, topredict the priorities of the hyperlinks. In other words, if thereare no common terms between a document of a hyperlink andthe given topic, then the topical similarity of the document iszero, i.e., the document is irrelevant to the given topic. How-ever, in the VSM, a document of a hyperlink and the given topiccould have similar semantic terms and even the same semanticterms. Then, although there are no common terms between thedocument and the given topic, the topical similarity of the doc-ument is still equal to zero based on the VSM. In fact, due to theexisting similar semantic terms, the document should be rele-vant to the given topic. Therefore, the VSM cannot combine thesemantic similarity, and the focused crawlers based on it mightnot retrieve semantically similar web pages from the Internet.
2) A number of focused crawlers cannot take the cosine similarityinto consideration. For a focused crawler based on the SSRM,although there are no common terms between the documentsof the hyperlinks and the given topic, the topical similarities ofthe documents can be computed by using the semantic simi-larity and will not be equal to zero, as it would be for a focusedcrawler based on the VSM. However, in the two term sets of adocument of a hyperlink and the given topic, all of the terms inthe two sets can be synonyms, and all of the semantic similari-ties between the two arbitrary terms are equal to the identical
value of one. Then, even though the term frequencies of the doc-ument are largely different from the term frequencies for thegiven topic, the topical similarity of the document becomes oneby using the SSRM. In fact, due to the existing, largely differentting 36 (2015) 392–407 393
term frequencies between the document and the given topic,the topical similarity of the document cannot be equal to one.In contrast, the VSM can obtain the proper value. Therefore, theSSRM cannot combine the cosine similarity, and the focusedcrawlers based on it could incorrectly gather web pages.
To solve these problems, this paper proposes an improvedapproach, the Semantic Similarity Vector Space Model (SSVSM).This model combines cosine similarity and semantic similarityand uses the full text and anchor text of a hyperlink as its docu-ments. The SSVSM first computes the TF*IDF values of the termsand semantic similarities among the terms, and these terms areextracted from the full texts, anchor texts and given topic. Specif-ically, the semantic similarities between the terms are calculatedbased on the ontology and the relationships in that ontology. Inthe experiment, the WordNet ontology was selected to computethe semantic similarities between the terms because it is the mostpopular natural language ontology. Then, the SSVSM establishes thedocument and topic semantic vectors, mapped to the same double-term set for each unvisited hyperlink. In addition, the documentsemantic vectors for each unvisited hyperlink include two full textand anchor text semantic vectors. Simultaneously, the SSVSM com-putes the cosine similarity between the full text and topic semanticvectors as the full text topic-relevant similarity and the cosinesimilarity between the anchor text and topic semantic vectors asthe anchor text topic-relevant similarity for each unvisited hyper-link. Finally, the priority of each unvisited hyperlink is computedby linearly integrating its full text and anchor text topic-relevantsimilarities. The SSVSM can more accurately predict the prioritiesof an unvisited hyperlink that are related to the given topic andguide a focused crawler to continuously download a larger quan-tity of higher quality topic-relevant web pages from the Internet.The experimental results demonstrate that the proposed methodimproves the performance of the focused crawlers and outperformsthe Breadth-First Crawler, VSM Crawler and SSRM Crawler. In con-clusion, the SSVSM method is significant and effective for focusedcrawlers.
The contributions of this paper are as follows:
(1) The SSVSM is proposed. It integrates the cosine similarity andthe semantic similarity to predict the priorities of the unvisitedhyperlinks. Additionally, relevant definitions are given in thispaper, and they primarily include the definitions of the termspace, term vector, semantic space and semantic vector.
(2) Four focused crawlers based on Breadth-First, VSM, SSRM andSSVSM have been implemented and evaluated. The perfor-mance of the four focused crawlers was evaluated by using theharvest rate, average similarity, the average error.
The remainder of this paper is constructed as follows: Section2 introduces two typical focused crawlers and related advancedtechniques. In Section 3, the improved focused crawler based onthe SSVSM is proposed, and the experimental results are analyzedin Section 4. Finally, Section 5 presents the conclusions and outlinesfurther research.
2. Related works
Focused crawlers must predict the priorities for unvisited hyper-links, to guide themselves to retrieve web pages that are related to a
given topic from the Internet. The priorities for the unvisited hyper-links are affected by two main factors, including topical similaritiesof the full texts and the anchor texts of those hyperlinks [12,17]. Inother words, these priorities are computed by linearly integrating
3 Compu
th
P
wasstlah
tptTmItaTcIgt
2
pstttbta
S
wotnTa
w
wrofiaw
2
pt
94 Y. Du et al. / Applied Soft
he topical similarities of the full texts and the anchor texts of theyperlinks. The formula is expressed as follows:
riority(l) = 12
· 1N
N∑p=1
Sim(fp, t) + 12
· Sim(al, t) (1)
here Priority(l) is the priority of the unvisited hyperlink l (1 ≤ l ≤ L),nd L is the number of unvisited hyperlinks; Sim(fp, t) is theimilarity between the topic t and the full text fp, which corre-ponds to web page p including the unvisited hyperlink l; N ishe number of retrieved web pages including the unvisited hyper-ink l; Sim(al, t) is the similarity between the topic t and thenchor text al corresponding to anchor texts including the unvisitedyperlink l.
In the above formula, the topical similarities of both types ofexts of the unvisited hyperlinks must be computed to obtain theriorities for these hyperlinks for focused crawlers. Consider twoypical focused crawlers: the VSM Crawler and the SSRM Crawler.he VSM Crawler computes the cosine similarity between the docu-ent and the topic vectors as the topical similarity of the document.
n contrast, the SSRM Crawler computes the topical similarity ofhe document by normalizing the sum value that is obtained byccumulating the products between semantic similarities and theF*IDF values of the terms. Based on the two models, there are twoorresponding focused crawlers: VSM Crawlers and SSRM Crawlers.n addition, there are many advanced methods that are used touide the focused crawlers to retrieve more topical web pages fromhe Internet.
.1. VSM Crawler
The VSM Crawler takes advantage of the cosine similarity toredict priorities for the hyperlinks. It must compute the topicalimilarities of the documents, including the full texts and anchorexts of the hyperlinks. In the VSM Crawler, the document andopic vectors are first constructed based on the TF*IDF values ofhe terms from the document and topic. Then, the cosine similarityetween the document and the topic vectors is computed as theopical similarity of the document [20]. The formula is representeds follows:
im(d, t) = → d · → t
|→ d| · |→ t| =∑n
i=1wdiwti√∑ni=1w2
di
√∑nj=1w2
tj
(2)
here → d is the term vector of the document d that is the full textr anchor text; → t is the term vector of the topic t; wdi, wti arehe TF*IDF weights that correspond to the same term i; and n is theumber of common terms between the document d and the topic t.he TF*IDF weights of the terms for the document d are computeds follows:
di = tfi · idfi = fifmax
· logN
Ni(3)
here wdi is the TF*IDF weight of term i in document d; tfi, idfi are,espectively, the term frequency and inverse document frequencyf term i in document d; fi is the frequency of term i in document d;
max is the maximum frequency of all of the terms in document d; Ns the total number of documents in all of the retrieved web pages;nd Ni is the number of documents including term i. The TF*IDFeights of the terms for topic t are also calculated based on Eq. (3).
.2. SSRM Crawler
The SSRM Crawler takes advantage of the semantic similarity toredict the priorities for the hyperlinks. It also must compute theopical similarities of the documents including the full texts and
ting 36 (2015) 392–407
anchor texts of the hyperlinks. In the SSRM Crawler, the seman-tic similarities between the terms are first computed based on theontology. In addition, the TF*IDF values of the terms in the docu-ment and the topic are also computed based on formula (3). Then,the topical similarity of the document is computed by normaliz-ing the sum value that is obtained by accumulating the productsbetween semantic similarities and the TF*IDF values of the terms[22,23]. The formula is represented as follows:
Sim(d, t) =∑n
i=1
∑mj=1Semijwdiwtj∑n
i=1
∑mj=1wdiwtj
(4)
where wdi, wtj are, respectively, the TF*IDF weights that correspondto term i of document d and term j of topic t; n, m are, respectively,the numbers of the terms of document d and topic t; and Semij isthe semantic similarity between term i and term j.
In the formula (4), the semantic similarity between the termsdepends mainly on their relationships in the ontology. Specifically,the WordNet ontology was selected to compute the semantic sim-ilarities between the terms in the experiment. In WordNet, thenouns, verbs, adjectives, and adverbs are organized into synonymsets (synsets), and each synset represents a distinct underlying lex-icalized concept [24,25]. Given two arbitrary terms w1 and w2, thesemantic similarity between the two terms can be computed bymeans of the semantic hierarchy of the words in WordNet. Thesemantic similarity of w1 and w2 should be influenced by similarand different features of two terms [26–28]. The more common fea-tures that the two terms have, the higher the semantic similarityof w1 and w2. Wu and Palmer proposed a method for calculatingthe semantic similarity between terms in some different ontologies[29]. The formula is shown as follows:
Sem(C1, C2) = 2Depth(C3)Path(C1, C3) + Path(C2, C3) + 2Depth(C3)
(5)
where C1, C2 are two concepts, which correspond to the two termsw1 and w2, respectively; Sem(C1, C2) is the semantic similaritybetween concepts C1 and C2; C3 is the lowest shared concept ofC1 and C2; Path(C1, C3) is the number of nodes on the path from C1to C3; Path(C2, C3) is the number of nodes on the path from C2 toC3; and Depth(C3) is the number of nodes on the path from C3 tothe root node in some different ontology.
2.3. Advanced methods
Recently, many advanced methods for computing the semanticsimilarities between the terms have arisen, such as Formal ConceptAnalysis, Multidimensional Scaling and Emergent Self Organiz-ing Maps. Formal Concept Analysis (FCA) is a novel method thatis applied in data representation and analysis [30]. FCA consid-ers objects to be an extension of a formal concept and considersattributes to be the intension of the formal concept. FCA hierar-chically organizes all of the formal concepts to construct a conceptlattice that is actually a directed, acyclic graph. MultidimensionalScaling (MDS) is also applied to achieve data analysis to explore thesimilarity and dissimilarity of data [31]. MDS considers objects tobe points in a multidimensional space. The points that correspondto similar objects are closer in the space than dissimilar objects. Theinvestigator attempts to make sense of the derived object config-uration by identifying meaningful regions and/or directions in thespace. Emergent Self Organizing Maps (ESOM) is a valuable datamining tool for examining unstructured texts [32]. ESOM possesses
a very large number of neurons to represent the data clusters com-pared with traditional SOM. ESOM uses a non-linear mapping ofa high-dimensional data space to enrich the feature set, discovernew knowledge and improve the classification accuracy.
Compu
tietasbstbteb
3V
hcsSmsaiftataitlavatachcc
3
hrfhwtrt
sasccoa
Y. Du et al. / Applied Soft
The FCA is focused on the following: FCA computes seman-ic similarities between terms by using extension similarities andntension similarities of formal concepts [16]. FCA first considersach term to be an object, and considers different semantics ofhis term to be attributes. Next, these terms and their semanticsre used to construct different formal concepts and a corre-ponding concept lattice. Additionally, the extension similarityetween the formal concepts is computed based on the relation-hips between the extensions of the concepts in the ontology, whilehe intension similarity is computed based on the relationshipsetween the intension of the concepts in the concept lattice. Finally,he semantic similarity between two terms is computed by lin-arly integrating the extension similarity and intension similarityetween two concepts.
. Improved focused crawler based on Semantic Similarityector Space Model
In this section, the prediction of the priorities for unvisitedyperlinks by the SSVSM, as a guide for the improved focusedrawler to retrieve topic-relevant web pages, is discussed. Fig. 1hows the flowchart for an improved focused crawler based onSVSM. The flowchart for this focused crawler is divided into threeain modules, as follows: acquiring term weights and semantic
imilarity matrixes, computing topical similarities of the full textsnd anchor texts based on SSVSM and designing priorities for unvis-ted hyperlinks. First, this focused crawler parses the hyperlinksrom the crawled web pages in a web page database, and placeshese hyperlinks in the unvisited list. Correspondingly, the full textsnd anchor texts of each unvisited hyperlink are extracted fromhe web pages. Then, the term weights of these text segmentsre acquired based on the TF*IDF formula, and semantic similar-ty matrixes between the terms of these texts and the terms of theopic are calculated based on formula (5). Second, the topical simi-arities of the full texts and anchor texts of the unvisited hyperlinksre computed based on the SSVSM. The SSVSM constructs semanticectors that are mapped to the same semantic space for the topicnd the above two text segments. The cosine similarity between theopic and the semantic vectors of each text segment is computeds the topic-relevant similarity of the text. Finally, the two topi-al similarities of the full texts and anchor texts of each unvisitedyperlink are linearly integrated as the priority of the hyperlink. Toontinue downloading web pages from the Internet, this focusedrawler selects unvisited hyperlinks that have higher priorities.
.1. Term weights and semantic similarity matrixes
Terms are extracted from the given topic and documents of theyperlinks to predict the priority of an unvisited hyperlink that iselated to a given topic. Documents of hyperlinks include many dif-erent text segments. In this paper, the documents of the unvisitedyperlinks are classified into full texts and anchor texts from theeb pages. More importantly, the full text terms and anchor text
erms are considered to be text terms of hyperlinks to more accu-ately predict their priorities for the hyperlinks that are related tohe given topic.
This procedure primarily computes the term weights andemantic similarity matrixes for the given topic, full texts andnchor texts. The given topic can be manually provided with aet of topic-relevant web pages. The full text is derived from the
ontents of the retrieved web pages. In contrast, the anchor textould come from various retrieved web pages, and the descriptionf a hyperlink in a single web page is usually very short. Therefore,ll of the descriptions of the hyperlink are wholly integrated as theting 36 (2015) 392–407 395
anchor text. For computing the term weights, there are two majorcomponents, as follows:
(1) Pre-processing the given topic, full texts and anchor texts. Thiscomponent includes term stopping and term stemming. Theterm stopping module removes the most common words, suchas ‘the’, ‘of’, and ‘for’, which contribute little to the topics of theweb pages. The term stemming function groups words that arederived from the same stem, base, or root form [33]. For exam-ple, the ‘tree’, ‘trees’ and ‘treeing’ can be organized as ‘tree’. Afterthis pre-processing, many topic terms and text terms from thegiven topic, full texts and anchor texts can be easily extracted.
(2) Calculating the term weights for the given topic, full texts andanchor texts. The term weights can quantitatively express thewhole document with long characters. The term weights arecommonly computed based on formula (3).
The semantic similarity between two arbitrary terms can becomputed by employing their relationships in the ontology. In thissection, the semantic similarities between the topic terms and textterms are computed based on formula (5). Specifically, the textterms are classified into full text terms and anchor text terms. Cor-respondingly, the semantic similarities between the topic and textterms form two different matrixes, including the full text–topicmatrix and the anchor text–topic matrix. In addition, the text termsrepresent the rows of the matrixes, while the topic terms repre-sent the columns of the matrixes. These two semantic similaritymatrixes are described in detail as follows:
term1 of topic t term2 of topic t · · · termm of topic t
term1 of fp Semp11 Semp
12 · · · Semp1m
term2 of fp Semp21 Semp
22 · · · Semp2m
......
... · · ·...
termn of fp Sempn1 Semp
n2 · · · Sempnm
(6)
term1 of topic t term2 of topic t · · · termm of topic t
term1 of al Seml11 Seml
12 · · · Seml1m
term2 of al Seml22 Seml
22 · · · Seml2m
......
... · · ·...
termr of al Semlr1 Seml
r2 · · · Semlrm
(7)
where fp, al, t (1 ≤ p ≤ P, 1 ≤ l ≤ L) are, respectively, the full text ofthe retrieved web page p, the anchor text of the unvisited hyper-link l and the given topic; P, L are, respectively, the total numbersof the retrieved web pages and the unvisited hyperlinks; termi of fp,termk of al, termj of topic t (1 ≤ i ≤ n, 1 ≤ k ≤ r, 1 ≤ j ≤ m) are, respec-tively, the term i of the full text fp, the term k of the anchor textal and the term j of the topic t; Semp
ijis the semantic similarity
between termi of fp and termj of topic t; Semlkj
is the semantic similar-ity between termk of al and termj of topic t; m, n, r are, respectively,the number of topic terms, the number of full text terms of theretrieved web page p and the number of anchor text terms of theunvisited hyperlink l.
3.2. Semantic Similarity Vector Space Model
In this module, the Semantic Similarity Vector Space Model(SSVSM) is described in detail. The SSVSM can detect similarities

396 Y. Du et al. / Applied Soft Computing 36 (2015) 392–407
The improv ed fo cused crawler b ased on SSVS M
Retrieved web
pages da taba se
Parsing the hyperl ink s
from craw led web
pages
Calculatin g ancho r
text term weig hts of
an unvis ite d hy perli nk
Computin g an cho r
text rel evanc e of the
unvisite d hyperlink
by using the
SSVSM
Selecting the
hyperl ink s that
have hig her
relevance degree s
in th e unvisite d list
to down load th e
web page s
Ranking the
hyperl ink s in
the unvi sited
list
Putt ing the hyperl ink s
into the unvi sited li st
Topic te rm
weights
Calculatin g ter m
weights of a
retrieved web pa ge
Computing full text
relevan ce of th e
retrieve d web page
by us ing th e
SSVSM
Desig ning pr iorit y sco res f or all of the
unvis ite d hyp erli nks
The semantic
matrix of fu ll
text
The semantic
matrix of
anchor te xt
World Wide
Web (WWW)
oved f
bIlvud
D
T
wil
DT
T
wt
Fig. 1. The flowchart of the impr
etween semantically but not necessarily lexically similar terms.t must build semantic vectors in the semantic space. In the fol-owing, the term space, term vector, semantic space and semanticector definitions are given to enable the SSVSM to be more easilynderstood. The four definitions of the above list are, respectively,escribed as follows:
efinition 1. The term space is defined as the single-term set:
Space = {termi|termi ∈ Lex, 1 ≤ i ≤ |Lex|} (8)
here Lex is the lexicon, i.e., the word library, termi is the term in the lexicon; and |Lex| is the number of terms or words in theexicon.
efinition 2. The term vector corresponds to the term spaceSpace and is defined as follows:
Vector = (val1, val2, . . ., val|Lex|) (9)
here valk (1 ≤ k ≤ |Lex|) is the value that corresponds to the single-erm termk in the term space TSpace, and |TVector| = |TSpace| = |Lex|.
ocused crawler based on SSVSM.
Definition 3. The semantic space is defined as the double-termset, as follows:
SSpace = {dbtl|dbtl = (termi, termj), termi, termj ∈ Lex,1 ≤ i, j ≤ |Lex|, 1 ≤ l ≤ |Lex|2} (10)
where Lex is the same lexicon as in formula (8); termi, termj are,respectively, term i and term j in the lexicon; dbtl is the double-term that corresponds to termi and termj in the double-term set;and |Lex| is also the number of terms or words in the lexicon.
Definition 4. The semantic vector corresponds to the semanticspace SSpace and is defined as follows:
SVector = (val1, val2, . . ., val|Lex|2 ) (11)
where valk (1 ≤ k ≤ |Lex|2) is the value that corresponds tothe double-term dbtk in the semantic space SSpace, and
|SVector| = |SSpace| = |Lex|2.The SSVSM takes advantage of the cosine similarity and seman-tic similarity to compute the topic-relevant similarities of thedocuments. This approach first establishes semantic vectors for the

Compu
gbttttvtv
3
sasetovTtt
owm
D
wTii
pvf
wwtnt→t
tsdf
wD(
Y. Du et al. / Applied Soft
iven topic and documents of the hyperlinks in the semantic spacey using term semantic similarities. Specifically, the documents ofhe hyperlinks include their full texts and anchor texts; thereforehe document semantic vector refers to the full text semantic vec-or or the anchor text semantic vector. Next, the SSVSM considershe cosine similarities between the document and topic semanticectors to be the topical similarities of the documents. In the sequel,he SSVSM is decomposed into two steps: establishing the semanticectors and calculating the topical similarities.
.2.1. Establishing semantic vectorsThe document and topic semantic vectors are established in the
emantic space SSpace. The values of the two semantic vectors arecquired by using the TF*IDF weights of the terms and the semanticimilarities between the terms. For the document semantic vector,ach value that maps each double-term is computed by multiplyinghe TF*IDF weight of the document term and the semantic similarityf the two terms. In contrast, for the topic semantic vector, eachalue that maps each double-term is computed by multiplying theF*IDF weight of the topic term and the semantic similarity of thewo terms. The concrete process for establishing the document andopic semantic vectors is described in the sequel.
The TF*IDF weights of the terms in a document dk (a full textr an anchor text) can be computed by using formula (3). Theseeights comprise the term vector → dk that represents the docu-ent dk. The expressions are shown as follows:
TSk = {term1, term2, . . ., termn},→ dk = (wk1, wk2, . . ., wkn, 0, 0, . . ., 0) (12)
here DTSk is the set of terms in document dk; wki (1 ≤ i ≤ n) is theF*IDF weight of term i in document dk; n is the number of termsn document dk; and the number of zero values in the vector → dk
s |Lex| − n.The TF*IDF weights of the terms in the topic t can also be com-
uted based on formula (3). These weights comprise the termector → t, which represents the topic t. The expressions are theollowings:
TTS = {term1, term2, . . ., termm},→ t = (wt1, wt2, . . ., wtm, 0, 0, . . ., 0)
(13)
here TTS is the set of terms in topic t; wtj (1 ≤ j ≤ m) is the TF*IDFeight of term j in topic t; m is the number of terms in topic t; and
he number of zero values in vector → t is |Lex| − m. Typically, theumber of nonzero values in the topic vector → t is not necessarilyhe same as the number of nonzero values in the document vector
dk. In addition, there are not necessarily common terms betweenhe document term set DTSk and the topic term set TTS.
The semantic similarities between the document terms andopic terms can be generated based on formula (5). Corre-pondingly, the semantic similarity matrix between the terms ofocument dk and the terms of topic t can be obtained similarly toormulas (6) or (7). This matrix is displayed as follows:
term1 term2 · · · termm
term1 Semk11 Semk
12 · · · Semk1m
term2 Semk21 Semk
22 · · · Semk2m
......
... · · ·...
term Semk Semk · · · Semk
(14)
n n1 n2 nm
here termi, termj (1 ≤ i ≤ n, 1 ≤ j ≤ m) are, respectively, term i inTSk shown in formula (12) and term j in TTS, shown in formula
13); Semkij
is the semantic similarity between termi in document dk
ting 36 (2015) 392–407 397
and termj in topic t; and n, m are, respectively, shown in formulas(12) and (13).
The two semantic vectors of document dk and topic t are estab-lished based on the term vector → dk of document dk, the termvector → t of topic t and the semantic similarity matrix shown informula (14). The document and topic semantic vectors are listedas follows:
→ DSVk = (→ dsv1, → dsv2, . . ., → dsvn, → 0)→ dsvi = (dval(i−1)∗m+1, dval(i−1)∗m+2, . . ., dvali∗m)
→ TSVk = (→ tsv1, → tsv2, . . ., → tsvn, → 0)→ tsvi = (tval(i−1)∗m+1, tval(i−1)∗m+2, . . ., tvali∗m)
dbTSk = {dbtr |dbtr = (termp, termq),termp ∈ DTSk, termq ∈ TTS, 1 ≤ p ≤ n, 1 ≤ q ≤ m}
dval(i−1)∗m+j = wki ∗ Semkij
tval(i−1)∗m+j = wtj ∗ Semkij
(1 ≤ i ≤ n, 1 ≤ j ≤ m)
→ 0 = (0, 0, . . ., 0)1×(|Lex|2−m∗n)
(15)
where → DSVk, → TSVk are the semantic vectors mapped to thesemantic space SSpace shown in formula (10), respectively, for doc-ument dk and topic t; DTSk, TTS are, respectively, shown in formulas(12) and (13); dbTSk is the double-term set between DTSk and TTS;termi is term i in DTSk, dbTSki is the double-term set between termiin document dk and all of the terms of the topic t; and both → dsvi
and → tsvi correspond to the double-term set dbTSk. Here, → 0 isthe zero vector mapped to the double-term set SSpace − dbTSk, i.e.,these double-terms do not belong to the dbTSk, and the dimensionof → 0 is equal to |Lex|2 − m * n. Additionally n, m are respectivelyshown in formulas (12) and (13); both dval(i−1)∗m+j and tval(i−1)∗m+j
are values that are mapped to the double-term dbtr = (termi, termj)for document dk and topic t, and termj is term j in TTS; wki, wtj are,respectively, shown in formulas (12) and (13), and Semk
ijis shown
in formula (14).A simple example is given in Fig. 2 to establish the semantic
vectors for the SSVSM. Topic t has three terms, and documentsd1 and d2 have three terms and two terms, respectively. The twosemantic similarity matrix dimensions for documents d1, d2 andtopic t are, respectively, 3 × 3 and 2 × 3. There are only 9 double-terms between the terms of document d1 and the terms of topict, and only 6 double-terms between the terms of document d2and the terms of topic t. However, there are |Lex|2 double-termsin the semantic space SSpace, and there are, respectively, |Lex|2 − 9double-terms that do not exist in the double-term set between theterms of document d1 and the terms of topic t, and in addition,|Lex|2 − 6 double-terms do not exist in the double-term set betweenthe terms of document d2 and the terms of topic t. All of the valuescorresponding to these double-terms are regarded as 0. In Fig. 2,the semantic similarity vector → DSV2 for document d2 is equal to(1.128, 0.901, 1.449, 0.535, 0.385, 0.602, 0, 0, . . ., 0)1×|Lex|2 .
3.2.2. Calculating the topical similaritiesThe topical similarities between the documents and the given
topic are computed based on semantic vectors. Traditionally, thesimilarity between the document and the given topic can be com-puted based on the VSM only if they have many common terms, i.e.,the VSM does not consider the semantic similarity. In addition, thetopical similarities of documents can be computed only if the termsbetween the documents and the given topic are not all synonyms,i.e., the SSRM does not take the cosine similarity into consideration.In contrast to the SSVSM, the topical similarities of the documents
are computed by using the cosine similarity between the docu-ment and topic semantic vectors, which is acquired by applyingthe semantic similarities of the terms. The topical similarity of thedocument dk is calculated based on the cosine similarity between
398 Y. Du et al. / Applied Soft Computing 36 (2015) 392–407
vecto
ttf
S
wt
Fig. 2. A simple example of semantic
he document semantic vector → DSVk and the topic semantic vec-or → TSVk, as shown in formula (15). The standard formula is asollows:
im(dk, t) = → DSVk · → TSVk
|→ DSVk| · |→ TSVk|
=∑n
i=1
∑mj=1wkiwtj
(Semk
ij
)2
√∑ni=1
(w2
ki
∑mj=1
(Semk
ij
)2)√∑n
i=1
∑mj=1w2
tj
(Semk
ij
)2
(16)
here Sim(dk, t) is the topical similarity of the document dk; andhe other symbols correspond to formulas (12)–(15).
rs for two documents and the topic.
The term vectors and semantic vectors in Fig. 2 are simply plot-ted in the three-dimensional coordinate system shown in Fig. 3.Both DTS1 and TTSin Fig. 2 are projected into three double-terms.From Fig. 2, the projection values of the document vector → d1and the topic vector → t are, respectively, (1.493, 1.182, 0.485) and(0.119, 0.106, 0.096) and are mapped to the term subspace in theterm coordinate system. In addition, the projection values of thedocument semantic vector → DSV1 and the topic semantic vector→ TSV1 are, respectively, (0.83, 0.448, 0.933) and (0.066, 0.032,0.06) and are mapped to the semantic subspace in the seman-tic coordinate system. For the semantic space SSpace, → DSV1and → TSV1 are, respectively, (0.83, 0.448, 0.933, 0.739, 0.394,
0.844, 0.243, 0.162, 0.243, 0, 0, . . ., 0)1×|Lex|2 and (0.066, 0.032,0.06, 0.074, 0.035, 0.069, 0.06, 0.035, 0.048, 0, 0, . . ., 0)1×|Lex|2 .Based on formula (16), the topical similarity of document d1 iscalculated as follows: Sim(d1, t) = → DSV1 · → TSV1 = 0.964.
Y. Du et al. / Applied Soft Computing 36 (2015) 392–407 399
ed to
cdgbtai
3
dtafohmaThthi
P
whb
Fig. 3. The coordinate system mapp
The SSVSM properly combines the semantic similarity andosine similarity to compute the topical similarities of theocuments. Specifically, the documents of the hyperlinks are cate-orized as full texts and anchor texts. Correspondingly, the SSVSMuilds semantic vectors for the given topic, and full texts and anchorexts based on formula (15). The topical similarities of the full textsnd anchor texts are, respectively, computed by using formula (16)n the SSVSM.
.3. Priority of the unvisited hyperlinks
The topic-relevant priorities of each unvisited hyperlink areetermined by the topical similarities of the anchor texts and fullexts. The similarities between the given topic and the documentsre directly computed based on the SSVSM. There can be many dif-erent web pages that contain the same hyperlink, and the contentf each web page is considered to be one full text. Therefore, eachyperlink can have many different full texts. Additionally, there areany different descriptions for the hyperlink in the web pages, and
ll of these descriptions are wholly integrated as the anchor text.herefore, each hyperlink has only one anchor text. For an unvisitedyperlink, the topical similarities of the full texts and one anchorext are linearly combined as a topic-relevant priority score of theyperlink to rank the URLs in the unvisited list. The integrated rule
s as follows:
riority(h) = � · 1N
N∑p=1
Sim(fp, t) + (1 − �) · Sim(ah, t) (17)
here Priority(h) is the priority value of the unvisited hyperlink (1 ≤ h ≤ H); H is the number of unvisited hyperlinks; N is the num-er of retrieved web pages, which contain the unvisited hyperlink
subspaces of the TSpace and SSpace.
h; Sim(fp, t), which can be calculated by using formula (16), is thetopical similarity of the full text that corresponds to the retrievedweb page p including the unvisited hyperlink h; Sim(ah, t), whichcan be computed by using the same formula (16), is the topicalsimilarity of the anchor text of the unvisited hyperlink h; and �(0 < � < 1) is a balance factor to adjust the weights of the topicalsimilarities of the full texts and anchor texts.
It is important for focused crawlers to sort the unvisited hyper-links based on the priority scores of those hyperlinks. For focusedcrawlers, the crawled web page is first stored in the web pagedatabase and, then, is parsed to extract new hyperlinks that areplaced into the unvisited list. Next, the topical priorities of thesenew hyperlinks are predicted based on the SSVSM. Specifically,the SSVSM takes advantage of the cosine similarity and semanticsimilarity to compute the topical similarities of the documents ofthe hyperlinks. Finally, focused crawlers continuously select betterhyperlinks that have higher priorities to download web pages fromthe Internet. Therefore, the focused crawler based on the SSVSMacquires a greater quantity and higher quality of sets of web pageswith respect to the given topic.
4. Experiments
An experiment was designed to indicate that the proposedSSVSM approach can improve the performance of the focusedcrawlers. In this experiment, four focused crawlers were con-structed based on Breadth-First, VSM, SSRM and SSVSM, and theywere called Breadth-First Crawler, VSM Crawler, SSRM Crawler
and SSVSM Crawler, respectively. In addition, SSRM Crawler andSSVSM Crawler used the WordNet ontology to compute seman-tic similarities between two arbitrary terms in this experiment. Allof the focused crawlers were given the same topics, as follows:
400 Y. Du et al. / Applied Soft Compu
Table 1The seed URLs for 10 different topics.
Topic Seed URLs
1. Football http://en.wikipedia.org/wiki/Footballhttp://espn.go.com/college-footballhttp://collegefootball.ap.org
2. Knowledge Mapping http://en.wikipedia.org/wiki/Knowledge mappinghttp://www.knowledge-mapping.comhttp://pmtips.net/knowledge-mapping
3. Robot Army http://en.wikipedia.org/wiki/Military robothttp://angryrobotbooks.com/robot-armyhttp://robotarmy.com
4. Smart Phone http://en.wikipedia.org/wiki/Smartphonehttp://cell-phones.toptenreviews.com/smartphoneshttp://reviews.cnet.com/smartphone-reviews
5. Mobile Games http://www.gamesgames.com/mobile-games.htmlhttp://www.ea.com/mobilehttp://www.tomasha.com/mobile-games
6. Tennis http://sports.yahoo.comhttp://espn.go.comhttp://msn.foxsports.com
7. Cloud Computing http://www.informationweek.comhttp://www.forbes.com/sites/lisaarthurhttp://www.oracle.com/us/technologies
8. Aircraft Carrier http://www.navy.comhttp://en.wikipedia.org/wiki/Navyhttp://www.navysports.com
9. Tablet Computer http://en.wikipedia.org/wiki/Computerhttp://www.newegg.comhttp://www.apple.com
“““wfrawf
4
swtwttoscTwt
bvprot
10. Web Games http://www.games.comhttp://games.msn.comhttp://games.yahoo.com
Football”, “Knowledge Mapping”, “Robot Army”, “Smart Phone”,Mobile Games”, “Tennis”, “Cloud Computing”, “Aircraft Carrier”,Tablet Computer”, and “Web Games”. In the experiment, topicaleb pages and seed URLs were considered to be input information
or the four focused crawlers. At the same time, the experimentalesults for these focused crawlers included harvest rates, aver-ge similarities, and average errors. Then, the experimental resultsere analyzed and discussed to evaluate the performance of the
our focused crawlers.
.1. Experimental setup
The required information contains the topical web pages and theeed URLs for the above 10 topics in the experiment. The topicaleb pages for each topic accurately describe the corresponding
opic. In this experiment, the topical web pages for all of the topicsere given by the users, and the number of those web pages for each
opic was set to 20. Seed URLs for each topic were provided to starthe four focused crawlers. In this experiment, the seed URLs for allf the topics were also given by the users, and the seed URLs werehown in Table 1 for each topic. Specifically, the 10 topics werelassified into two categories based on the seed URLs in Table 1.he first category was the first 5 topics to which the seed URLsere directly relevant. Correspondingly, the second category was
he last five topics, to which the seed URLs were indirectly relevant.The performance of the four focused crawlers can be evaluated
y the harvest rate, average similarity and average error. The har-est rate (HR) is equal to the ratio of the number of retrieved web
ages relevant to the given topic over the total number of all of theetrieved web pages [34]. For the harvest rate, a predefined thresh-ld is given to judge whether each retrieved web page is relevant tohe given topic; i.e., if the topical similarity of a retrieved web pageting 36 (2015) 392–407
is higher than the predefined threshold, then the retrieved webpage is judged to be the topical web page. The average similarity(AS) is equal to the arithmetic mean of the similarities of the topi-cal web pages for all of the retrieved web pages. The average error(AE) is equal to the arithmetic mean of the absolute values of thedifferences between the topical priorities and the topical similari-ties for all of the retrieved web pages. The three evaluation indexesare expressed as follows:
HR = n
N, AS = 1
n
n∑i=1
Ri Ri ≥ th, AE = 1N
N∑j=1
|Rj − Pj|
(1 ≤ i ≤ n, 1 ≤ j ≤ N) (18)
where HR is the harvest rate; th is the predefined threshold for thetopical similarity; n is the number of topical web pages, for which allof the topical similarities are higher than the predefined thresholdth; N is the total number of retrieved web pages; AS is the averagesimilarity of the topical web pages; Ri is the topical similarity oftopical web page i; AE is the average error of all of the retrievedweb pages; and Pj, Rj are, respectively, the topical priority and thetopical similarity of the retrieved web page j. The topical similarityof each retrieved web page for all of the four focused crawlers isacquired based on the cosine similarity. Specifically, because eachtopic has 20 different topical web pages, correspondingly, there are20 topical similarities for each retrieved web page for each topic.Then, the maximum of all 20 topical similarities is considered tobe the topical similarity of the retrieved web page. In contrast, thetopical priority of each retrieved web page is calculated based onformula (17).
4.2. Experimental results
The experimental results were analyzed to evaluate the fourfocused crawlers including the Breadth-First Crawler, the VSMCrawler, the SSRM Crawler and the SSVSM Crawler. In this experi-ment, the predefined threshold was set to 0.7 in formula (18), andthis value reflects that focused crawlers must have a strong abilityto retrieve topic-relevant web pages [31]. In addition, the balancefactor was set to 0.5 in formula (17), and this value indicates thatthe contribution of similarities of full texts to the topical prioritiesis the same as the contribution of the similarities of anchortexts [17]. The experimental results are three evaluation indexesincluding the harvest rates, average similarities and average errors.Specifically, because the Breadth-First Crawler directly selects theunvisited hyperlinks to download the corresponding web pageswithout computing their topical priorities, there were no averageerrors in the experimental results for the Breadth-First Crawler.In Tables 2–4, the experimental results change as the number ofretrieved web pages changes. In Table 5, the experimental resultsare three evaluation indexes, which correspond to 5000 retrievedweb pages. The number of retrieved web pages starts with 100and increases in steps of 100. In addition, each focused crawlercontinuously downloads web pages for each topic until the numberof retrieved web pages reaches 5000 in this experiment.
The experimental results are divided into four groups, basedon the above topic categories. The first group contains the experi-mental results for topics 1–5 with the seed URLs directly relevantto them. The second group contains the experimental results ontopics 6–10 with the seed URLs indirectly relevant to them. Thethird group contains experimental results for all of the topics 1–10.The fourth group contains the experimental results for 10 different
topics, which correspond to 5000 retrieved web pages. The exper-imental results include the harvest rates (HR), average similarities(AS) and average errors (AE) of different numbers of retrieved webpages for different focused crawlers. The index HR evaluates the
Y. Du et al. / Applied Soft Computing 36 (2015) 392–407 401
Table 2The average results including HR, AS and AE for the first group.
Num ofretrieved webpages
Breadth-First Crawler SSRM Crawler VSM Crawler SSVSM Crawler
HR AS HR AS AE HR AS AE HR AS AE
100 0.290 0.822 0.370 0.869 0.449 0.460 0.899 0.270 0.530 0.861 0.158200 0.440 0.768 0.310 0.863 0.448 0.490 0.885 0.257 0.545 0.890 0.191300 0.417 0.792 0.343 0.896 0.461 0.530 0.898 0.262 0.623 0.910 0.214400 0.390 0.780 0.365 0.915 0.471 0.465 0.897 0.303 0.655 0.913 0.240500 0.368 0.784 0.346 0.915 0.466 0.470 0.906 0.305 0.674 0.923 0.267600 0.317 0.786 0.328 0.916 0.466 0.558 0.926 0.257 0.728 0.934 0.303700 0.291 0.783 0.316 0.917 0.467 0.561 0.931 0.252 0.767 0.941 0.328800 0.276 0.790 0.310 0.918 0.468 0.504 0.930 0.280 0.774 0.945 0.338900 0.280 0.785 0.306 0.916 0.471 0.478 0.925 0.294 0.742 0.941 0.331
1000 0.260 0.786 0.296 0.914 0.468 0.475 0.922 0.297 0.735 0.939 0.3351500 0.200 0.782 0.261 0.909 0.466 0.429 0.926 0.316 0.534 0.927 0.2902000 0.174 0.781 0.272 0.912 0.491 0.390 0.909 0.332 0.414 0.922 0.2772500 0.142 0.778 0.269 0.921 0.475 0.386 0.912 0.327 0.339 0.919 0.2653000 0.167 0.784 0.310 0.932 0.479 0.329 0.910 0.352 0.431 0.929 0.2763500 0.142 0.781 0.296 0.931 0.465 0.285 0.909 0.380 0.512 0.941 0.3064000 0.124 0.781 0.296 0.931 0.462 0.256 0.906 0.404 0.573 0.948 0.3294500 0.110 0.777 0.306 0.929 0.465 0.235 0.903 0.417 0.572 0.948 0.3255000 0.102 0.777 0.303 0.928 0.463 0.216 0.901 0.426 0.578 0.934 0.321
Table 3The average results including HR, AS and AE for the second group.
Num ofretrieved webpages
Breadth-First Crawler SSRM Crawler VSM Crawler SSVSM Crawler
HR AR HR AR AE HR AR AE HR AR AE
100 0.130 0.776 0.160 0.836 0.398 0.210 0.825 0.438 0.420 0.797 0.165200 0.070 0.775 0.165 0.827 0.422 0.420 0.835 0.373 0.505 0.800 0.231300 0.050 0.776 0.180 0.827 0.431 0.323 0.831 0.409 0.377 0.803 0.220400 0.045 0.771 0.175 0.820 0.437 0.415 0.828 0.370 0.295 0.825 0.234500 0.070 0.771 0.186 0.821 0.451 0.392 0.826 0.379 0.242 0.825 0.237600 0.128 0.784 0.205 0.823 0.462 0.367 0.824 0.373 0.232 0.828 0.232700 0.113 0.784 0.197 0.820 0.435 0.396 0.822 0.357 0.260 0.831 0.220800 0.103 0.783 0.189 0.820 0.422 0.444 0.822 0.345 0.294 0.829 0.222900 0.121 0.783 0.183 0.820 0.411 0.483 0.820 0.335 0.319 0.828 0.223
1000 0.146 0.782 0.262 0.819 0.433 0.512 0.818 0.327 0.308 0.827 0.2171500 0.131 0.778 0.212 0.815 0.400 0.432 0.816 0.369 0.337 0.827 0.2232000 0.119 0.775 0.195 0.813 0.391 0.348 0.817 0.400 0.456 0.827 0.2582500 0.110 0.780 0.194 0.813 0.393 0.294 0.816 0.416 0.376 0.823 0.2363000 0.101 0.776 0.182 0.812 0.394 0.268 0.815 0.424 0.318 0.820 0.2263500 0.094 0.776 0.175 0.810 0.397 0.236 0.813 0.435 0.281 0.818 0.2224000 0.088 0.774 0.167 0.810 0.399 0.214 0.813 0.445 0.247 0.817 0.2204500 0.084 0.774 0.156 0.809 0.401 0.197 0.812 0.447 0.225 0.815 0.2215000 0.077 0.774 0.154 0.808 0.405 0.180 0.811 0.451 0.208 0.816 0.225
Table 4The averaged results including HR, AS and AE for the third group.
Num ofretrieved webpages
Breadth-First Crawler SSRM Crawler VSM Crawler SSVSM Crawler
HR AR HR AR AE HR AR AE HR AR AE
100 0.210 0.799 0.270 0.852 0.423 0.340 0.862 0.354 0.480 0.829 0.161200 0.255 0.772 0.240 0.845 0.435 0.455 0.860 0.315 0.525 0.845 0.211300 0.233 0.784 0.263 0.862 0.446 0.427 0.865 0.336 0.500 0.857 0.217400 0.218 0.775 0.270 0.868 0.454 0.440 0.862 0.336 0.475 0.869 0.237500 0.220 0.778 0.266 0.868 0.459 0.432 0.866 0.342 0.458 0.874 0.252600 0.223 0.785 0.267 0.869 0.464 0.463 0.875 0.315 0.480 0.881 0.267700 0.203 0.783 0.257 0.869 0.451 0.479 0.877 0.305 0.514 0.886 0.274800 0.190 0.787 0.250 0.869 0.445 0.474 0.876 0.313 0.534 0.887 0.280900 0.201 0.784 0.244 0.868 0.441 0.481 0.873 0.315 0.531 0.885 0.277
1000 0.203 0.784 0.279 0.866 0.450 0.494 0.870 0.312 0.522 0.883 0.2761500 0.165 0.780 0.237 0.862 0.433 0.431 0.871 0.342 0.435 0.877 0.2562000 0.146 0.778 0.234 0.863 0.441 0.369 0.863 0.366 0.435 0.875 0.2682500 0.126 0.779 0.232 0.867 0.434 0.340 0.864 0.371 0.358 0.871 0.2513000 0.134 0.780 0.246 0.872 0.437 0.299 0.863 0.388 0.375 0.875 0.2513500 0.118 0.778 0.235 0.871 0.431 0.261 0.861 0.408 0.397 0.880 0.2644000 0.106 0.778 0.232 0.870 0.430 0.235 0.860 0.424 0.410 0.883 0.2744500 0.097 0.776 0.231 0.869 0.433 0.216 0.857 0.432 0.399 0.882 0.2735000 0.090 0.775 0.228 0.868 0.434 0.198 0.856 0.439 0.393 0.875 0.273

402 Y. Du et al. / Applied Soft Computing 36 (2015) 392–407
Table 5The HR, AS and AE for the fourth group at the point that corresponds to 5000 retrieved web pages.
Topics Breadth-First Crawler SSRM Crawler VSM Crawler SSVSM Crawler
HR AR HR AR AE HR AR AE HR AR AE
Football 0.105 0.778 0.299 0.924 0.456 0.215 0.902 0.428 0.578 0.933 0.321Knowledge Mapping 0.096 0.780 0.301 0.925 0.460 0.221 0.906 0.432 0.582 0.937 0.328Robot Army 0.090 0.782 0.307 0.932 0.468 0.213 0.895 0.422 0.584 0.942 0.324Smart Phone 0.108 0.774 0.310 0.936 0.473 0.209 0.896 0.418 0.575 0.931 0.317Mobile Games 0.112 0.769 0.296 0.921 0.458 0.223 0.904 0.430 0.569 0.925 0.313Tennis 0.085 0.774 0.154 0.807 0.405 0.181 0.811 0.452 0.204 0.816 0.225Cloud Computing 0.070 0.770 0.151 0.805 0.403 0.188 0.814 0.459 0.212 0.818 0.232Aircraft Carrier 0.072 0.767 0.158 0.811 0.410 0.175 0.807 0.443 0.216 0.824 0.228Tablet Computer 0.074 0.781 0.161 0.813 0.408 0.173 0.802 0.447 0.206 0.812 0.218Web Games 0.084 0.776 0.144 0.806 0.397 0.184 0.819 0.456 0.202 0.808 0.220
acces
4
taaicHT
tvfbttrfCc
chvctCaiCCvoptc
cvstIV
bility of the focused crawlers to collect large quantities of topi-al web pages. The index AS evaluates the ability of the focusedrawlers to collect high quality topical web pages. The index AEvaluates the ability of focused crawlers to predict accurate topicalimilarities of unvisited hyperlinks.
.2.1. First groupThe first group is composed of experimental results on the first 5
opics for each focused crawler. Table 2 displays excerpts from theverage results for the first 5 topics. Specifically, the average resultsre computed by averaging the harvest rates (HR), average similar-ties (AS) and average errors (AE) of topics 1–5 for each focusedrawler. In other words, the averaged results include the averageR, average AS and average AE for each focused crawler shown inable 2.
Figs. 4–6 are drawn based on Table 2. Fig. 4 is drawn by usinghe HR values of four focused crawlers in Table 2. In Fig. 4, the HRalues of the SSVSM Crawler are higher than those of the other threeocused crawlers for most of the retrieved web pages. Fig. 5 is drawny using the AS values of four focused crawlers in Table 2. In Fig. 5,he HS values of the Breadth-First Crawler are obviously lower thanhose of the other three focused crawlers for all of the numbers ofetrieved web pages. Fig. 6 is drawn by using the AE values of theour focused crawlers in Table 2. In Fig. 6, the AE values of the SSRMrawler are obviously higher than those of the other two focusedrawlers for all of the numbers of retrieved web pages.
Fig. 4 shows a comparison of the harvest rates for the fourrawlers for the first group. In Fig. 4, the SSVSM Crawler has veryigh harvest rates in the previous stage and in later stage. The har-est rates of the SSVSM Crawler are higher than the other threerawlers for most numbers of retrieved web pages. In addition,he harvest rates of the Breadth-First Crawler, VSM Crawler, SSRMrawler and SSVSM Crawler are, respectively, 0.102, 0.216, 0.303,nd 0.578 at the point that correspond to 5000 retrieved web pagesn Fig. 4. These values show that the harvest rate of the SSVSMrawler is 5.7, 2.7, 1.9 times as large as those of the Breadth-Firstrawler, VSM Crawler and SSRM Crawler, respectively. The har-est rate for the retrieved topical web pages indicates the abilityf the crawler to retrieve the relative quantities of topical webages. Therefore, the figure indicates that the SSVSM Crawler hashe ability to collect more topical web pages than the other threerawlers.
Fig. 5 shows a comparison of the average similarities for the fourrawlers for the first group. In Fig. 5, the SSVSM Crawler maintainsery high average similarities during the entire stage. The average
imilarities for the SSVSM Crawler are higher than those of the otherhree crawlers for most of the numbers of retrieved web pages.n addition, the average similarities for the Breadth-First Crawler,SM Crawler, SSRM Crawler and SSVSM Crawler are, respectively,0.777, 0.901, 0.928 and 0.934, at the point that correspond to 5000retrieved web pages in Fig. 5. These values show that the averagesimilarity of the SSVSM Crawler is increased by 20.2%, 3.7% and0.65% compared with the Breadth-First Crawler, VSM Crawler andSSRM Crawler, respectively. The average similarity for the retrievedtopical web pages indicates the ability of the crawler to retrievehigh quality topical web pages. Therefore, the figure indicates thatthe SSVSM Crawler has the ability to collect higher quality topicalweb pages compared with the other three crawlers.
Fig. 6 shows a comparison of the average errors for threecrawlers for the first group. In Fig. 6, the SSVSM Crawler maintainsvery low average errors in the middle stage and later stage. Theaverage errors for the SSVSM Crawler are obviously lower than forthe other two crawlers for most numbers of retrieved web pages. Inaddition, the average errors of the VSM Crawler, SSRM Crawler andSSVSM Crawler are, respectively, 0.426, 0.463 and 0.321 at the pointthat corresponds to 5000 retrieved web pages in Fig. 6. These valuesshow that the average error of the SSVSM Crawler is decreased by24.7% and 30.7% compared to the VSM Crawler and SSRM Crawler.The average errors indicate the ability of the crawler to predict thetopical similarities of unvisited hyperlinks. Therefore, the figureindicates that the SSVSM Crawler has the ability to predict moreaccurate topical similarities of unvisited hyperlinks than the othertwo crawlers.
4.2.2. Second groupThe second group is composed of experimental results from the
last 5 topics for each focused crawler. Table 3 also displays excerptsfrom the averaged results for the last 5 topics. Specifically, the aver-aged results are computed by the averaging harvest rates (HR),average similarities (AS) and average errors (AE) of topics 6–10 foreach focused crawler. In other words, the averaged results includethe average HR, average AS and average AE for each focused crawlershown in Table 3.
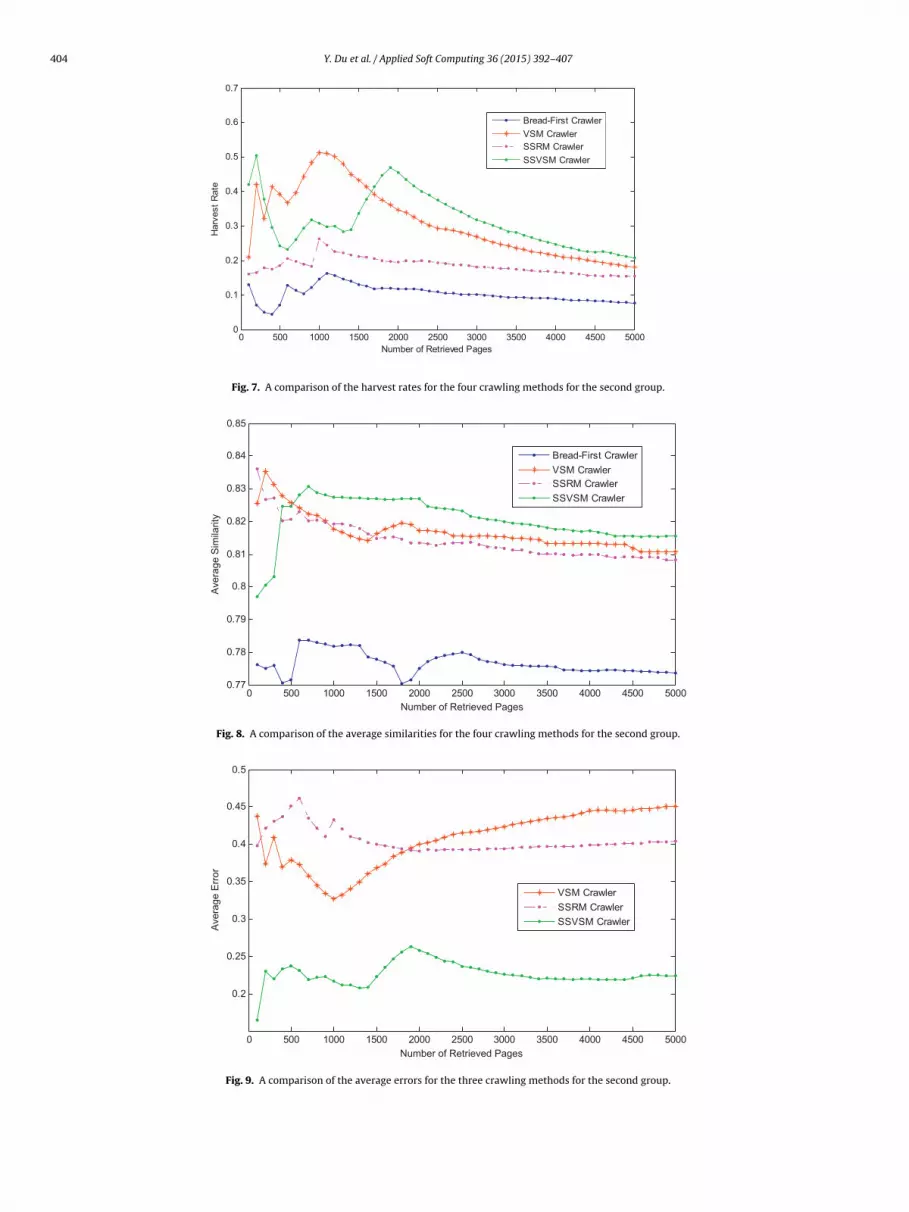
Figs. 7–9 are drawn based on Table 3. Fig. 7 is drawn by usingthe HR values of the four focused crawlers in Table 3. In Fig. 7, theHR values of the Breadth-First Crawler are lower than those of theother three focused crawlers for all of the numbers of the retrievedweb pages. Fig. 8 is drawn by using the AS values of the four focusedcrawlers in Table 3. In Fig. 8, the HS values of the SSVSM Crawlerare higher than those of the other three focused crawlers for mostof the numbers of retrieved web pages. Fig. 9 is drawn by using theAE values of the four focused crawlers in Table 3. In Fig. 9, the AEvalues of the SSVSM Crawler are obviously lower than those of theother two focused crawlers for all of the numbers of retrieved web
pages.Fig. 7 shows a comparison of the harvest rates for four crawlersfor the second group. In Fig. 7, the SSVSM Crawler has a very highharvest rate in the middle stage and later stage. The harvest rates of

Y. Du et al. / Applied Soft Computing 36 (2015) 392–407 403
0 500 10 00 15 00 2000 250 0 3000 3500 400 0 450 0 50 000.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
Number of Retrieved Pages
Har
vest
Rat
e
Bread-First CrawlerVSM CrawlerSSRM CrawlerSSVSM Crawler
Fig. 4. A comparison of the harvest rates for four crawling methods for the first group.
0 500 10 00 15 00 2000 250 0 3000 3500 400 0 450 0 50 000.76
0.78
0.8
0.82
0.84
0.86
0.88
0.9
0.92
0.94
0.96
Numbe r of Retrieved Pag es
Ave
rage
Sim
ilarit
y
Bread-First CrawlerVSM CrawlerSSRM CrawlerSSVSM Crawler
Fig. 5. A comparison of the average similarities for four crawling methods for the first group.
0 500 10 00 15 00 2000 250 0 3000 3500 400 0 450 0 50 00
0.2
0.25
0.3
0.35
0.4
0.45
0.5
0.55
Numbe r of Retrieved Pag es
Ave
rage
Erro
r
VSM Cra wlerSSRM CrawlerSSVSM Cra wler
Fig. 6. A comparison of the average errors for three crawling methods for the first group.
404 Y. Du et al. / Applied Soft Computing 36 (2015) 392–407
0 500 1000 1500 2000 2500 3000 3500 4000 4500 50000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
Numbe r of Retrieved Pag es
Har
vest
Rat
e
Brea d-First CrawlerVSM CrawlerSSRM CrawlerSSVSM Crawler
Fig. 7. A comparison of the harvest rates for the four crawling methods for the second group.
0 500 1000 1500 2000 2500 3000 3500 4000 4500 50000.77
0.78
0.79
0.8
0.81
0.82
0.83
0.84
0.85
Number of Retrieved Pages
Ave
rage
Sim
ilarit
y
Bread-First Cra wlerVSM CrawlerSSRM CrawlerSSVSM Crawler
Fig. 8. A comparison of the average similarities for the four crawling methods for the second group.
0 500 10 00 15 00 2000 250 0 3000 3500 400 0 450 0 50 00
0.2
0.25
0.3
0.35
0.4
0.45
0.5
Number of Retrieved Pages
Ave
rage
Err
or
VSM CrawlerSSRM Cra wlerSSVSM Crawler
Fig. 9. A comparison of the average errors for the three crawling methods for the second group.

Compu
tfvaaTiVit
ctstwFrst5CSw
cteoIatTdChu
4
ofrsfat
uFtbooopcaf
chrfva
Y. Du et al. / Applied Soft
he SSVSM Crawler are higher than those of the other three crawlersor most of the numbers of retrieved web pages. In addition, the har-est rates of the Breadth-First Crawler, VSM Crawler, SSRM Crawlernd SSVSM Crawler are, respectively, 0.077, 0.180, 0.154, and 0.208,t the point that corresponds to 5000 retrieved web pages in Fig. 7.hese values indicate that the harvest rate of the SSVSM Crawlers 2.7, 1.2, 1.4 times as large as those of the Breadth-First Crawler,SM Crawler and SSRM Crawler, respectively. Therefore, the figure
ndicates that the SSVSM Crawler has the ability to collect moreopical web pages than the other three crawlers.
Fig. 8 shows a comparison of the average similarities for the fourrawlers for the second group. In Fig. 8, the SSVSM Crawler main-ains very high average similarities in the middle stage and latertage. The average similarities of the SSVSM Crawler are higherhan the other three crawlers for most of the numbers of retrievedeb pages. In addition, the average similarities of the Breadth-
irst Crawler, VSM Crawler, SSRM Crawler and SSVSM Crawler are,espectively, 0.774, 0.811, 0.808 and 0.816 at the point that corre-ponds to 5000 retrieved web pages in Fig. 8. These values show thathe average similarity of the SSVSM Crawler shows an increase of.4%, 0.62% and 0.99% compared to the Breadth-First Crawler, VSMrawler and SSRM Crawler. Therefore, the figure indicates that theSVSM Crawler has the ability to collect greater qualities of topicaleb pages than the other three crawlers.
Fig. 9 shows a comparison of the average errors for the threerawlers for the second group. In Fig. 9, the SSVSM Crawler main-ains very low average errors during the entire stage. The averagerrors for the SSVSM Crawler are obviously lower than those for thether two crawlers for most of the numbers of retrieved web pages.n addition, the average errors of the VSM Crawler, SSRM Crawlernd SSVSM Crawler are, respectively, 0.451, 0.405 and 0.225, athe point that corresponds to 5000 retrieved web pages in Fig. 9.hese values show that the average error of the SSVSM Crawler isecreased by 50.1% and 44.4% to the VSM Crawler and the SSRMrawler. Therefore, the figure indicates that the SSVSM Crawleras the ability to predict more accurate topical similarities for thenvisited hyperlinks than the other two crawlers.
.2.3. Third groupThe third group is composed of the experimental results for all
f the topics for each focused crawler. Table 4 also displays excerptsrom the averaged results for all 10 topics. Specifically, the averagedesults are computed by averaging the harvest rates (HR), averageimilarities (AS) and average errors (AE) for all 1–10 topics for eachocused crawler. In other words, the averaged results include theverage HR, average AS and average AE for each focused crawlerhat is shown in Table 4.
Figs. 10–12 are drawn based on Table 4. Fig. 10 is drawn bysing the HR values of the four focused crawlers in Table 4. Inig. 10, the HR values of the SSVSM Crawler are obviously higherhan those of the other three focused crawlers for all of the num-ers of retrieved web pages. Fig. 11 is drawn by using the AS valuesf the four focused crawlers in Table 4. In Fig. 11, the HS valuesf the Breadth-First Crawler are obviously lower than those of thether three focused crawlers for all of the numbers of retrieved webages. Fig. 12 is drawn by using the AE values of the four focusedrawlers in Table 4. In Fig. 12, the AE values of the SSVSM Crawlerre obviously lower than those of the other two focused crawlersor all of the numbers of retrieved web pages.
Fig. 10 shows a comparison of the harvest rates for the fourrawlers for the third group. In Fig. 10, the SSVSM Crawler has veryigh harvest rates in the middle stage and later stage. The harvest
ates of the SSVSM Crawler are higher than the other three crawlersor most of the numbers of retrieved web pages. In addition, the har-est rates of the Breadth-First Crawler, VSM Crawler, SSRM Crawlernd SSVSM Crawler are, respectively, 0.090, 0.198, 0.228, and 0.393,ting 36 (2015) 392–407 405
at the point that corresponds to the 5000 retrieved web pagesin Fig. 10. These values show that the harvest rate of the SSVSMCrawler is 4.4, 2.0, 1.7 times as large as those of the Breadth-FirstCrawler, VSM Crawler and SSRM Crawler, respectively. Therefore,the figure indicates that the SSVSM Crawler has the ability to collectmore topical web pages than the other three crawlers.
Fig. 11 shows a comparison of the average similarities for thefour crawlers for the first group. In Fig. 11, the SSVSM Crawlermaintains very high average similarities during the entire stage.The average similarities of the SSVSM Crawler are higher thanfor the other three crawlers for most of the numbers of retrievedweb pages. In addition, the average similarities of the Breadth-First Crawler, VSM Crawler, SSRM Crawler and SSVSM Crawler are,respectively, 0.775, 0.856, 0.868 and 0.875, at the point that cor-responds to the 5000 retrieved web pages in Fig. 11. These valuesshow that the average similarity of the SSVSM Crawler is increasedby 12.9%, 2.2% and 0.81% compared to the Breadth-First Crawler,VSM Crawler and SSRM Crawler, respectively. Therefore, the figureindicates that the SSVSM Crawler has the ability to collect greaterqualities of topical web pages than the other three crawlers.
Fig. 12 shows a comparison of the average errors for the threecrawlers for the first group. In Fig. 12, the SSVSM Crawler main-tains very low average errors in during the entire stage. The averageerrors of the SSVSM Crawler are obviously lower than the othertwo crawlers for most of the numbers of retrieved web pages. Inaddition, the average errors of the VSM Crawler, SSRM Crawlerand SSVSM Crawler are, respectively, 0.439, 0.434 and 0.273, at thepoint that corresponds to the 5000 retrieved web pages in Fig. 12.These values show that the average error of the SSVSM Crawleris decreased by 37.8% and 37.1% compared to the VSM Crawlerand SSRM Crawler. Therefore, the figure indicates that the SSVSMCrawler has the ability to predict more accurate topical similaritiesof unvisited hyperlinks than the other two crawlers.
4.2.4. Fourth groupThe fourth group is composed of the experimental results of
10 different topics for each focused crawler at the point that cor-responds to the 5000 retrieved web pages. Table 5 displays theharvest rates (HR), average similarities (AS) and average errors (AE)of 10 different topics for each focused crawler at the point thatcorresponds to the 5000 retrieved web pages.
Table 5 displays a comparison of three evaluation indexes forthe four crawlers for the fourth group. In Table 5, the harvest ratesof the SSVSM Crawler are obviously higher than for the other threecrawlers for all of the 10 different topics. In Table 5, the averagesimilarities of the SSVSM Crawler are higher than those of the otherthree crawlers for most of the numbers of the 10 different topics.In Table 5, the SSVSM Crawler, compared with the SSRM Crawlerand VSM Crawler, maintains obviously lower average error ratesfor all of the 10 different topics. Therefore, these indexes indicatethat the SSVSM Crawler has the ability to retrieve a large quantityand better quality of web pages.
It can be concluded that the SSVSM Crawler has a higher perfor-mance than the other three focused crawlers. For the four groups,the SSVSM Crawler has the ability to retrieve greater quantitiesof topical web pages than the other three crawlers. Moreover, theSSVSM Crawler has the ability to retrieve greater qualities of topi-cal web pages than the other three crawlers. In addition, the SSVSMCrawler has the ability to predict more accurate topical priorities ofhyperlinks than the VSM Crawler and SSRM Crawler. Specifically,the harvest rates in the first group are obviously higher than in the
second group, because the seed URLs in the first group are morerelevant to the corresponding topics than in the second group. Inshort, the SSVSM, by integrating the cosine similarity and semanticsimilarity, improves the performance of the focused crawlers.
406 Y. Du et al. / Applied Soft Computing 36 (2015) 392–407
0 500 1000 1500 2000 2500 3000 3500 4000 4500 50000.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0.5
0.55
Number of Retrieved Pages
Har
vest
Rat
e
Bread-First Cra wlerVSM CrawlerSSRM Cra wlerSSVSM Crawler
Fig. 10. A comparison of the harvest rates for the four crawling methods for the third group.
0 500 10 00 15 00 2000 250 0 3000 3500 400 0 450 0 50 000.76
0.78
0.8
0.82
0.84
0.86
0.88
0.9
Numbe r of Retrieved Pag es
Ave
rage
Sim
ilarit
y
Bread-First CrawlerVSM CrawlerSSRM Cra wlerSSVSM Crawler
Fig. 11. A comparison of the average similarities for the four crawling methods for the third group.
0 500 10 00 15 00 2000 250 0 3000 3500 400 0 450 0 50 00
0.2
0.25
0.3
0.35
0.4
0.45
0.5
Number of Retrieved Pages
Ave
rage
Err
or
VSM CrawlerSSRM Cra wlerSSVSM Crawler
Fig. 12. A comparison of the average errors for the three crawling methods for the third group.

Compu
5
fsaTttatcsulttcaa
mtmoIc
A
eWm
R
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[33] C.J.V. Rijsbergen, S.E. Robertson, M.F. Porter, New Models in Probabilistic Infor-mation Retrieval, Computer Laboratory, University of Cambridge, London,
Y. Du et al. / Applied Soft
. Conclusions and future work
The SSVSM is proposed to improve the performance of theocused crawlers. This model combines the cosine similarity andemantic similarity, and takes the full texts and anchor texts of
hyperlink as its two documents. This model first computes theF*IDF values of the terms and the semantic similarities among theerms, and these terms are extracted from the full texts, anchorexts and the given topic. Next, this model establishes documentnd topic semantic vectors that are mapped to the same double-erm set for each unvisited hyperlink. Simultaneously, the SSVSMomputes the cosine similarities between the document and topicemantic vectors as topic-relevant similarities for documents ofnvisited hyperlinks. Finally, the priority of each unvisited hyper-
ink is computed by linearly integrating its full text and anchor textopic-relevant similarities. The experimental results demonstratehat the proposed method improves the performance of focusedrawlers and outperforms the Breadth-First Crawler, VSM Crawlernd SSRM Crawler. In conclusion, the SSVSM method is significantnd effective for focused crawlers.
In the future, deeper and broader research is necessary. Theore accurate semantic similarity methods between two arbitrary
erms should be investigated based on the ontology. Moreover, aore appropriate balance factor should be determined and can be
btained based on an intelligent, rather than an artificial method.n addition, the hyperlink structure of the hyperlinks can also beonsidered to predict the priorities of the unvisited hyperlinks.
cknowledgments
This research work was supported by the National Natural Sci-nce Foundation of China (Grant Nos. 61271413 and 61472329).e especially thank to Prof. Xiaofei He at zhejiang university forany helpful comments and suggestions.
eferences
[1] D. Hati, A. Kumar, Improved focused crawling approach for retrieving relevantpages based on block partitioning, in: The Proceeding of the 2010 2nd Inter-national Conference on Education Technology and Computer, vol. 3, 2010, pp.3269–3273.
[2] T. Peng, L. Liu, Focused crawling enhanced by CBP–SLC, Knowl. Based Syst. 51(2013) 15–26.
[3] P. Bedi, A. Thukral, H. Banati, Focused crawling of tagged web resources usingontology, Comput. Electr. Eng. 39 (2) (2013) 613–628.
[4] Y.J. Du, Y.F. Hai, et al., An approach for selecting seed URLs of focused crawlerbased on user-interest ontology, Appl. Soft Comput. 14 (2014) 663–676.
[5] M. Kumar, R. Vig, Learnable focused meta crawling through Web, ProcediaTechnol. 6 (2012) 606–611.
[6] Y. Uemura, T. Itokawa, et al., An effectively focused crawling system, Stud.Comput. Intell. 2012 (376) (2012) 61–76.
[7] M. Diligenti, F.M. Coetzee, et al., Focused crawling using context graphs, in: TheProceeding of the 26th International Conference on Very Large Database, 2000,pp. 527–534.
[8] C.C. Hsua, F. Wub, Focused crawling on the web with the measurements of therelevancy context graph, Inf. Syst. 4–5 (31) (2006) 232–246.
[
ting 36 (2015) 392–407 407
[9] Y.J. Du, Z.B. Dong, Focused web crawling strategy based on concept contextgraph, J. Comput. Inf. Syst. 5 (3) (2009) 1097–1105.
10] F.A. Abkenari, A. Selamat, An architecture for a focused trend parallel webcrawler with the application of clickstream analysis, Inf. Sci. 184 (1) (2012)266–281.
11] H.X. Zhang, J. Lu, SCTWC: an online semi-supervised clustering approach totopical web crawlers, Appl. Soft Comput. 10 (2010) 490–495.
12] A. Patel, N. Schmidt, Application of structured document parsing to focusedweb crawling, Comput. Stand. Interfaces 33 (2011) 325–331.
13] S. Mukherjea, Organizing focused web information, in: The Proceeding of the11th ACM Conference on Hypertext and Hypermedia, San Antonio, 2000, pp.133–141.
14] Z.J. Liu, Y.J. Du, Y. Zhao, Focused crawler based on domain ontology and FCA, J.Inf. Comput. Sci. 8 (10) (2011) 1909–1917.
15] Q.Q. Peng, Y.J. Du, Focused crawling on the web with concept context graphbased on FCA, in: The Proceeding of the Management and Service Science, 2009,pp. 1–4.
16] Y.J. Du, Y.F. Hai, Semantic ranking of web pages based on formal concept anal-ysis, J. Syst. Softw. 86 (1) (2013) 187–197.
17] S. Batsakis, E.G.M. Petrakis, E. Milios, Improving the performance of focusedweb crawlers, Data Knowl. Eng. 68 (2009) 1001–1013.
18] F. Menczer, G. Pant, P. Srinivasan, Topical web crawlers: evaluating adaptivealgorithms, ACM Trans. Internet Technol. 4 (4) (2004) 378–419.
19] S. Chakrabarti, M.V.D. Berg, B. Dom, Focused crawling: a new approachfor topic specific resource discovery, Comput. Netw. 11–16 (31) (1999)1623–1640.
20] G. Salton, A. Wong, C.S. Yang, A vector space model for automatic indexing,Commun. ACM 18 (11) (1975) 613–620.
21] Y.J. Du, Q.Q. Pen, Zhaoqiu Gao, A topic-specific crawling strategy based onsemantics similarity, Data Knowl. Eng. 88 (2013) 75–93.
22] G. Varelas, E. Voutsakis, et al., Semantic similarity methods in wordnet and theirapplication to information retrieval on the web, in: Seventh ACM InternationalWorkshop on Web Information and Data Management, Bremen, Germany,2005.
23] A. Hliaoutakis, G. Varelas, et al., Information retrieval by semantic similarity,Int. J. Semant. Web Inf. Syst. 3 (3) (2006) 55–73.
24] M.M. Stark, R.F. Riesenfeld, Wordnet: an electronic lexical database, in: TheProceeding of the 11th Eurographics Workshop on Rendering, 1998.
25] A. Solé-Ribalta, D. Sánchez, et al., Towards the estimation of feature-basedsemantic similarity using multiple ontologies, Knowl. Based Syst. 55 (2014)101–113.
26] Y. Li, Z.A. Bandar, D. McLean, An approach for measuring semantic similaritybetween words using multiple information sources, IEEE Trans. Knowl. DataEng. 15 (4) (2003) 871–882.
27] D. Sánchez, M. Batet, A semantic similarity method based on informationcontent exploiting multiple ontologies, Expert Syst. Appl. 40 (4) (2013)1393–1399.
28] R. Richardson, A. Smeaton, J. Murphy, Using wordnet as a knowledge base formeasuring semantic similarity between words, in: The Proceeding of the AICSConference, 1994.
29] Z. Wu, M. Palmer, Verb semantics and lexical selection, in: The Proceeding ofthe 32nd Annual Meeting on Association for Computational Linguistics, 1994,pp. 133–138.
30] F. Skopljanac-Macina, B. Blaskovic, Formal concept analysis – overview andapplications, Procedia Eng. 69 (2014) 1258–1267.
31] Z. Zhang, Y. Takane, Multidimensional Scaling, third ed., International Encyclo-pedia of Education, 2010, pp. 304–311.
32] J. Poelmansa, M.M. Van Hulle, et al., Text mining with emergent self organiz-ing maps and multi-dimensional scaling: a comparative study on domesticviolence, Appl. Soft Comput. 11 (4) (2011) 3870–3876.
1980.34] W.J. Liu, Y.J. Du, A novel focused crawler based on cell-like membrane comput-
ing optimization algorithm, Neurocomputing 123 (2014) 266–280.





























