Embed Size (px)
Citation preview

ANALISIS DE REGRESION LINEAL
La Regresión lineal se refiere a la predicción del valor de una variablea partir de una o más variables. En ocasiones se denomina a la variabledependiente (y) variable de respuesta y a la variable independiente (x)variable de predicción.En muchos problemas hay dos o más variables inherentemente relacionadas,y es necesario explorar la naturaleza de esta relación. El análisis deregresión puede emplearse por ejemplo para construir un modelo queexprese el rendimiento como una función de la temperatura. Este modelopuede utilizarse luego para predecir el rendimiento en un niveldeterminado de temperatura. También puede emplearse con propósitos deoptimización o control del proceso.Comenzaremos con el caso más sencillo, la predicción de una variable (y) apartir de otra variable (x).
REGRESIÓN LINEAL SIMPLE: Para las situaciones siguientes establezca cual es la variable dependiente y cual es la independiente.
a) Un actuario quiere predecir el monto del seguro de vida alcanzado porlos maestros a partir de sus salarios mensuales.Solución: la variable dependiente o de respuesta, es el monto delseguro de vida alcanzado por un maestro, y la variable independiente ovariable de predicción es el salario anual del docente.
b) El gerente de un restaurante quiere estimar el número de clientes quepuede esperar cierta noche a partir del número de reservaciones paracenar recibidas hasta las 5:00 PMSolución: El número de clientes es la variable de respuesta, el númerode reservaciones es la variable independiente.
Supuestos para el modelo de regresión lineal1
1. Para cada valor de x, la variable aleatoria se distribuyenormalmente.
2. Para cada valor de x, la media o valor esperado de es 0; esto es,.
3. Para cada valor de x, la varianza de es la constante (llamadavarianza del error).
4. Los valores del término de error son independientes.5. Para un valor fijo de x, la distribución muestral de y es normal,
porque sus valores dependen de los de .
Página 1
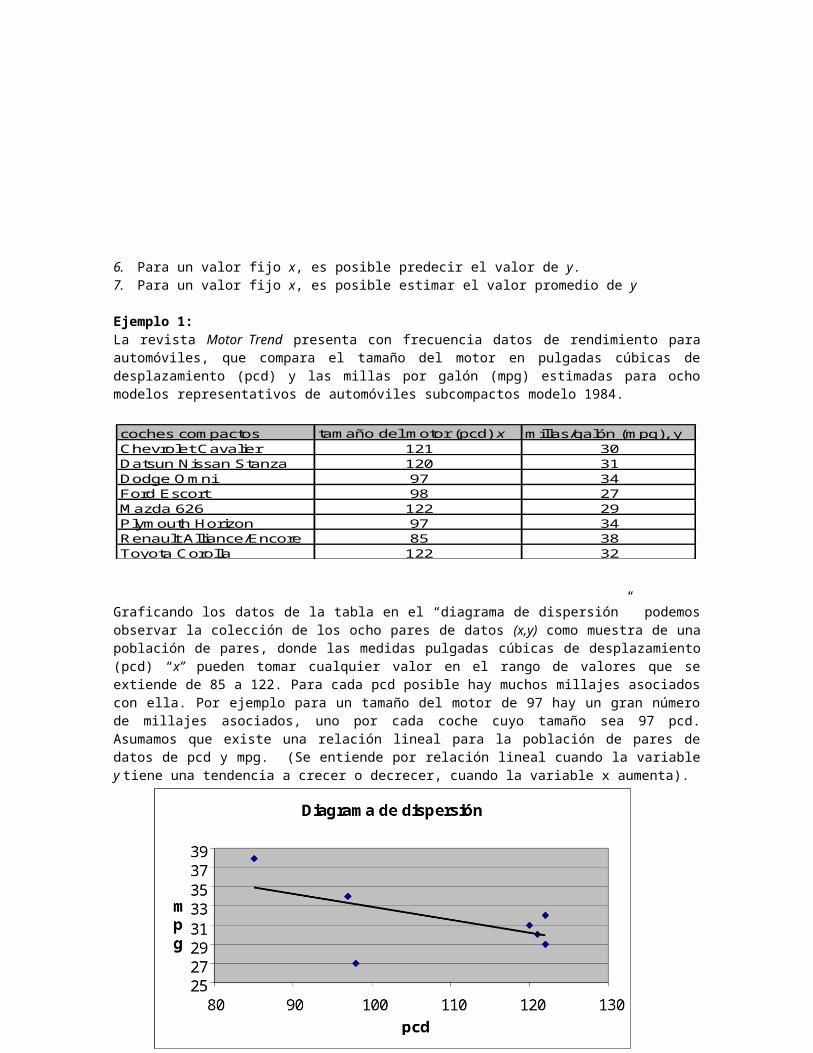
6. Para un valor fijo x, es posible predecir el valor de y.7. Para un valor fijo x, es posible estimar el valor promedio de y
Ejemplo 1:La revista Motor Trend presenta con frecuencia datos de rendimiento paraautomóviles, que compara el tamaño del motor en pulgadas cúbicas dedesplazamiento (pcd) y las millas por galón (mpg) estimadas para ochomodelos representativos de automóviles subcompactos modelo 1984.
Graficando los datos de la tabla en el “diagrama de dispersión” podemosobservar la colección de los ocho pares de datos (x,y) como muestra de unapoblación de pares, donde las medidas pulgadas cúbicas de desplazamiento(pcd) “x” pueden tomar cualquier valor en el rango de valores que seextiende de 85 a 122. Para cada pcd posible hay muchos millajes asociadoscon ella. Por ejemplo para un tamaño del motor de 97 hay un gran númerode millajes asociados, uno por cada coche cuyo tamaño sea 97 pcd.Asumamos que existe una relación lineal para la población de pares dedatos de pcd y mpg. (Se entiende por relación lineal cuando la variabley tiene una tendencia a crecer o decrecer, cuando la variable x aumenta).
Página 2
coches com pactos tam año del m otor (pcd) x m illas/galón (m pg), yChevrolet Cavalier 121 30Datsun Nissan Stanza 120 31Dodge O m ni 97 34Ford Escort 98 27M azda 626 122 29Plym outh Horizon 97 34Renault Alliance/Encore 85 38Toyota Corolla 122 32

Usamos el modelo probabilístico siguiente para explicar el comportamientode los millajes para las ocho medidas de tamaño de motor, este se llamamodelo de regresión lineal, y expresa la relación lineal entre tamaño demotor (x) y millas por galón (y).
Modelo de regresión lineal
Donde y = variable dependiente
ordenada al origen = pendiente
x = variable independiente = Error aleatorio
La expresión se denomina componente determinística del modelode regresión lineal. La muestra de pares de datos se usará para estimarlos parámetros de la componente determinística. La diferencia principal entre un modelo pobabilístico y unodeterminístico es la inclusión de un término de error aleatorio en elmodelo probabilístico. En el ejemplo los diferentes rendimientos paraun mismo tamaño de motor se atribuyen al término de error en el modelo deregresión.
Cálculo de la ecuación de regresión: También es llamada ecuación de predicción de mínimos cuadrados. La ecuación de regresión estimada es:
Donde:Valor predicho de para un valor particular de x.
b0 = Estimador puntual de .(ordenada al origen)
Página 3

b1= Estimador puntual de (pendiente)
Para el cálculo de b0 y b1 se utilizamos las siguientes fórmulas:
Donde:SS = suma de cuadradosb1 = pendienteb0 = ordenada al origenn = número de pares de datos
En la tabla incluimos las sumatorias que utilizaremos para el cálculo de las fórmulas.
Calculando b0 y b1 tenemos:SSx = 1575.50SSy = 82.88SSxy = -212.25b1 = -0.13472b0 = 46.39099La ecuación de predicción de mínimos cuadrados es:
Página 4
coches com pactos tam año del m otor (pcd) x m illas/galón (m pg), y x 2 y 2 xyChevrolet Cavalier 121 30 14641 900 3630Datsun Nissan Stanza 120 31 14400 961 3720Dodge Om ni 97 34 9409 1156 3298Ford Escort 98 27 9604 729 2646M azda 626 122 29 14884 841 3538Plym outh Horizon 97 34 9409 1156 3298Renault Alliance/Encore 85 38 7225 1444 3230Toyota Corolla 122 32 14884 1024 3904SUM AS 862 255 94456 8211 27264M edia 107.75 31.875
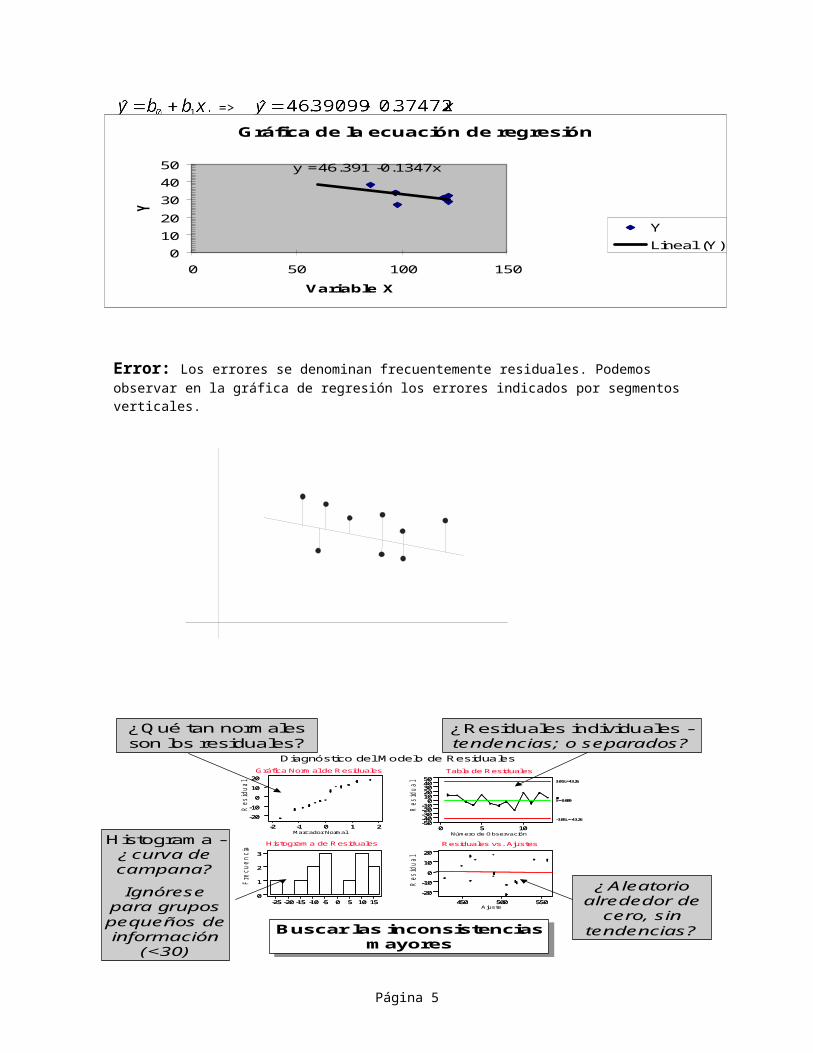
=>
Error: Los errores se denominan frecuentemente residuales. Podemos observar en la gráfica de regresión los errores indicados por segmentos verticales.
Página 5
Gráfica de la ecuación de regresión
y =46.391 -0.1347x
01020304050
0 50 100 150Variable X
Y
YLineal (Y)
¿Qué tan norm ales son los residuales?
¿Residuales individuales -tendencias; o separados?
Histogram a -¿ curva de campana?Ignórese
para grupos pequeños de información
(<30)
¿ Aleatorio alrededor de
cero, sin tendencias?Buscar las inconsistencias
m ayoresBuscar las inconsistencias
m ayores
Diagnóstico del M odelo de ResidualesGráfica Norm al de Residuales Tabla de Residuales
Histogram a de Residuales Residuales vs. Ajustes
Marcador Normal Número de Observación
Ajuste
Frec
uenc
ia
151050-5-10-15-20-25
3
2
1
0
1050
50403020100
-10-20-30-40-50
X=0.000
3.0SL=43.26
-3.0SL=-43.26
550500450
2010
0-10-20
210-1-2
20100
-10-20
151050-5-10-15-20-25
3
2
1
0
1050
50403020100
-10-20-30-40-50
X=0.000
3.0SL=43.26
-3.0SL=-43.26
550500450
2010
0-10-20
210-1-2
20100
-10-20
Resi
dual
Resi
dual
Resi
dual

Al usar el criterio de mínimos cuadrados para obtener la recta que mejorse ajuste a nuestros datos, podemos obtener el valor mínimo para la sumade cuadrados del error (SSE)
A la varianza de los errores e se le llama varianza residual siendodenotada por , se encuentra dividiendo SSE entre n-2
La raíz cuadrada positiva de la varianza residual se llama error estándarde estimación y se denota por Se.
Aplicando las fórmulas en obtenemos la suma de cuadrados del error, la varianza residual y el error estándar de la estimación:
SSE = 82.88-(-0.13472)(-212.25) =54.2849
Se = 3.007
Ejemplo 2: Una firma de renta de coches recabó los datos adjuntos sobrelos costos de mantenimiento y, y las millas recorridas x para siete de susautomóviles.
Encuentre:
a) Una estimación puntual para .b) Una estimación puntual para c) Una estimación puntual para la varianza del error .d) Una estimación puntual para el costo promedio del mantenimiento de
un coche con 36,000 millas recorridas.
Página 7
Autom óvil M illas recorridas x Costos de m anteni-en m iles m iento y (dólares)
A 55 299B 27 160C 36 215D 42 255E 65 350F 48 275G 29 207
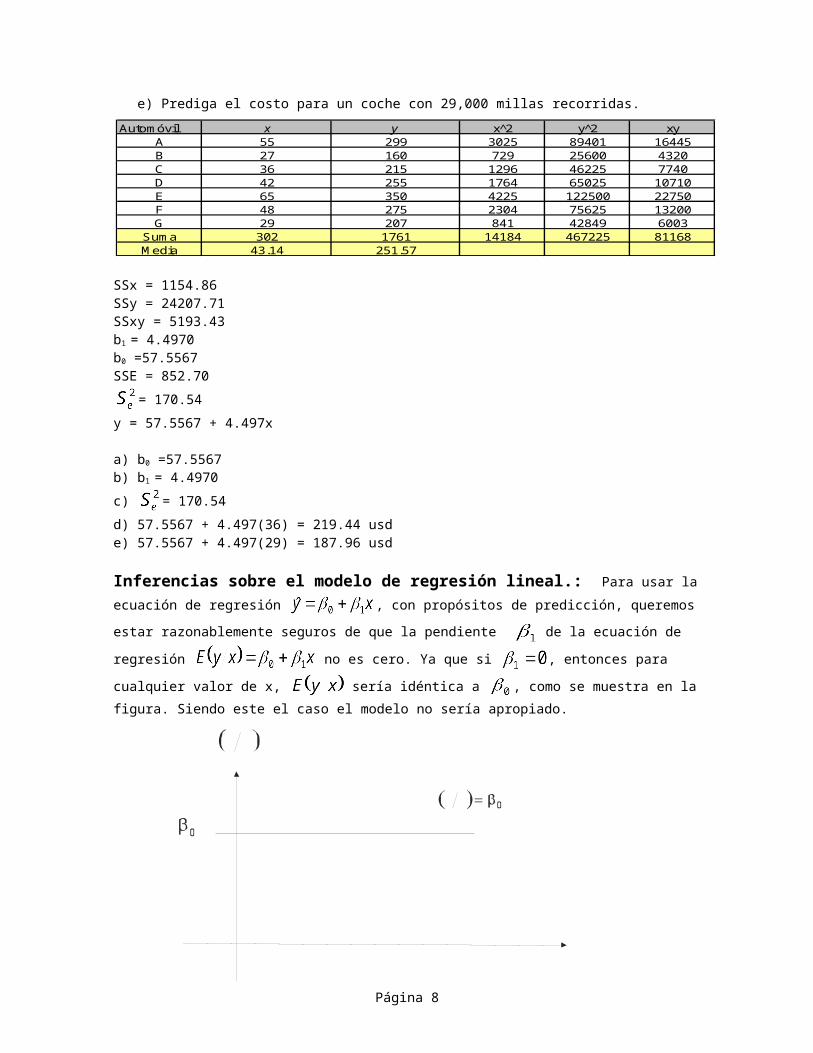
e) Prediga el costo para un coche con 29,000 millas recorridas.
SSx = 1154.86SSy = 24207.71SSxy = 5193.43b1 = 4.4970b0 =57.5567SSE = 852.70
= 170.54y = 57.5567 + 4.497x
a) b0 =57.5567b) b1 = 4.4970c) = 170.54d) 57.5567 + 4.497(36) = 219.44 usde) 57.5567 + 4.497(29) = 187.96 usd
Inferencias sobre el modelo de regresión lineal.: Para usar laecuación de regresión , con propósitos de predicción, queremosestar razonablemente seguros de que la pendiente de la ecuación de
regresión no es cero. Ya que si , entonces para
cualquier valor de x, sería idéntica a , como se muestra en lafigura. Siendo este el caso el modelo no sería apropiado.
Página 8
Autom óvil x y x 2 y 2 xyA 55 299 3025 89401 16445B 27 160 729 25600 4320C 36 215 1296 46225 7740D 42 255 1764 65025 10710E 65 350 4225 122500 22750F 48 275 2304 75625 13200G 29 207 841 42849 6003
Sum a 302 1761 14184 467225 81168M edia 43.14 251.57

Con el propósito de determinar si la pendiente de la regresión poblacional es diferente de cero, separemos SSy en dos componentes, SSE ySSR.Tenemos la siguiente relación:SSy = SSE + SSR
Donde:SSE = Suma de cuadrados del errorSSR = Suma de cuadrados de la regresión
SSE = SSy-b1SSxy
SSR = b1SSy
Prueba de hipótesis utilizando la distribución FSi fuera cierta , el estadístico F serviría como estadístico de prueba: F está definido como:
Con gl = (1,n-2), se puede usar el estadístico F para determinar si es diferente de cero. Si la pendiente de la ecuación de regresión poblacional es diferente de cero, entonces la ecuación se puede usar con propósitos de predicción.
Ejemplo 3: Para los datos del ejemplo 1 haga una prueba para determinar si , usando
En el ejemplo 1 y 2 obtuvimos los siguientes valores:SSxy = -212.25b1 = -0.13472
La suma de cuadrados para la regresión SSR se calcula mediante:SSR = b1SSxy = (-212.25)(-0.1347) =28.5901
Hallamos el estadístico de prueba F:
Página 9

=
Se encuentra el valor crítico F0.05(1,6) = 5.99. Como F = 3.16<5.99, no rechazamos . Concluimos que la ecuación
no debe usarse con propósitos de predicción, y notenemos evidencia que apoye que el modelo lineal es correcto para nuestros datos.
Prueba de hipótesis utilizando la distribución t Otra manera de realizar la prueba de hipótesis es usando la distribución t.
El estadístico de prueba es:
, donde gl = n-2
Ejemplo 4: Usando los datos del ejemplo 1, haga una prueba para determinar si usando la prueba de t y .
=
Los valores críticos para gl = 6 son . Como –t.025 < t no rechazamos . Por tanto no tenemos evidencia que sugiera que el modelo lineal es apropiado para nuestros datos.
Análisis de correlación: Establece si existe una relación entre las variables y responde a la pregunta,”¿Qué tan evidente es esta relación?".La correlación es una prueba fácil y rápida para eliminar factores que noinfluyen en la predicción, para una respuesta dada. Coeficiente de Correlación de Pearson Es una medida de la fuerza de la relación lineal entre dos variables x
y y. Es un número entre -1 y 1
Página 10

Un valor positivo indica que cuando una variable aumenta, la otravariable aumenta
Un valor negativo indica que cuando una variable aumenta, la otradisminuye
Si las dos variables no están relacionadas, el coeficiente decorrelación se aproxima a 0.
El coeficiente de correlación r se calcula mediante la siguiente fórmula:
Página 11
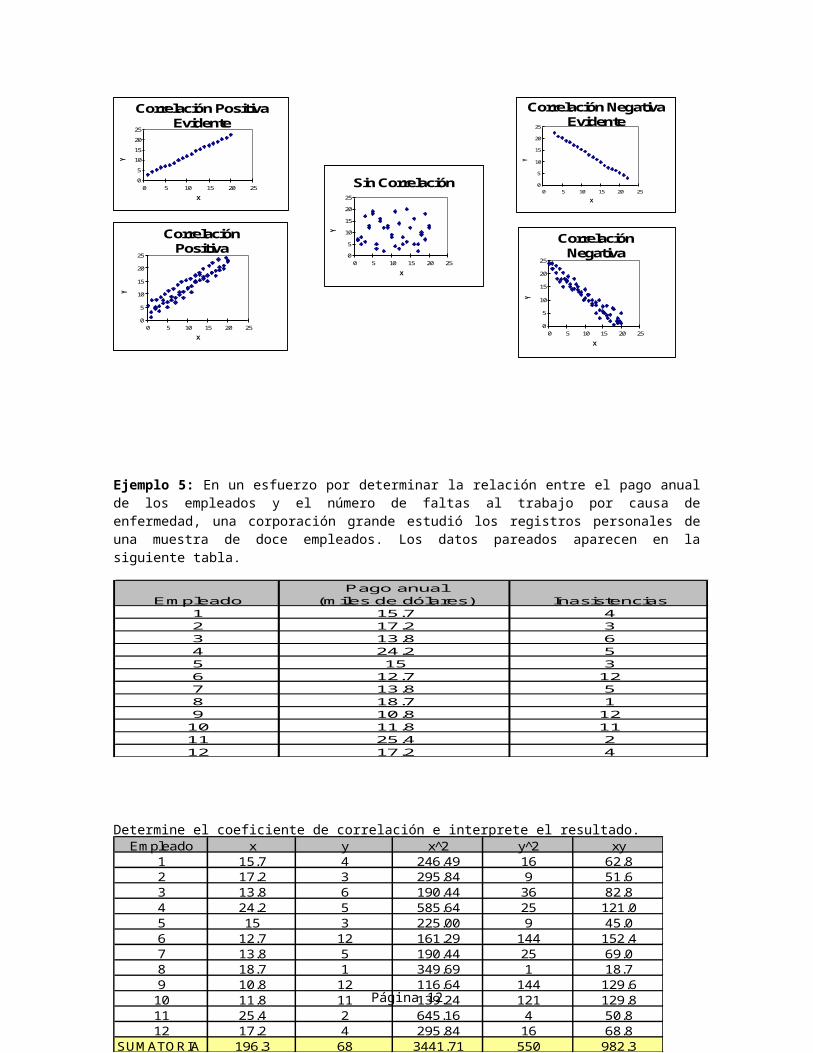
Ejemplo 5: En un esfuerzo por determinar la relación entre el pago anualde los empleados y el número de faltas al trabajo por causa deenfermedad, una corporación grande estudió los registros personales deuna muestra de doce empleados. Los datos pareados aparecen en lasiguiente tabla.
Determine el coeficiente de correlación e interprete el resultado.
Página 12
Pago anualEm pleado (m iles de dólares) Inasistencias
1 15.7 42 17.2 33 13.8 64 24.2 55 15 36 12.7 127 13.8 58 18.7 19 10.8 1210 11.8 1111 25.4 212 17.2 4
Em pleado x y x 2 y 2 xy1 15.7 4 246.49 16 62.82 17.2 3 295.84 9 51.63 13.8 6 190.44 36 82.84 24.2 5 585.64 25 121.05 15 3 225.00 9 45.06 12.7 12 161.29 144 152.47 13.8 5 190.44 25 69.08 18.7 1 349.69 1 18.79 10.8 12 116.64 144 129.610 11.8 11 139.24 121 129.811 25.4 2 645.16 4 50.812 17.2 4 295.84 16 68.8
SUM ATORIA 196.3 68 3441.71 550 982.3
Correlación PositivaEvidente
0510152025
0 5 10 15 20 25X
YCorrelación Negativa
Evidente
0
5
10
15
20
25
0 5 10 15 20 25X
Y
CorrelaciónPositiva
0
5
10
15
20
25
0 5 10 15 20 25X
Y
CorrelaciónNegativa
0
5
10
15
20
25
0 5 10 15 20 25X
Y
Sin Correlación
10
15
20
25
5 10 15 20 25X
Y
0
5
0
Correlación PositivaEvidente
0510152025
0 5 10 15 20 25X
YCorrelación Negativa
Evidente
0
5
10
15
20
25
0 5 10 15 20 25X
Y
CorrelaciónPositiva
0
5
10
15
20
25
0 5 10 15 20 25X
Y
CorrelaciónNegativa
0
5
10
15
20
25
0 5 10 15 20 25X
Y
Sin Correlación
10
15
20
25
5 10 15 20 25X
Y
0
5
0
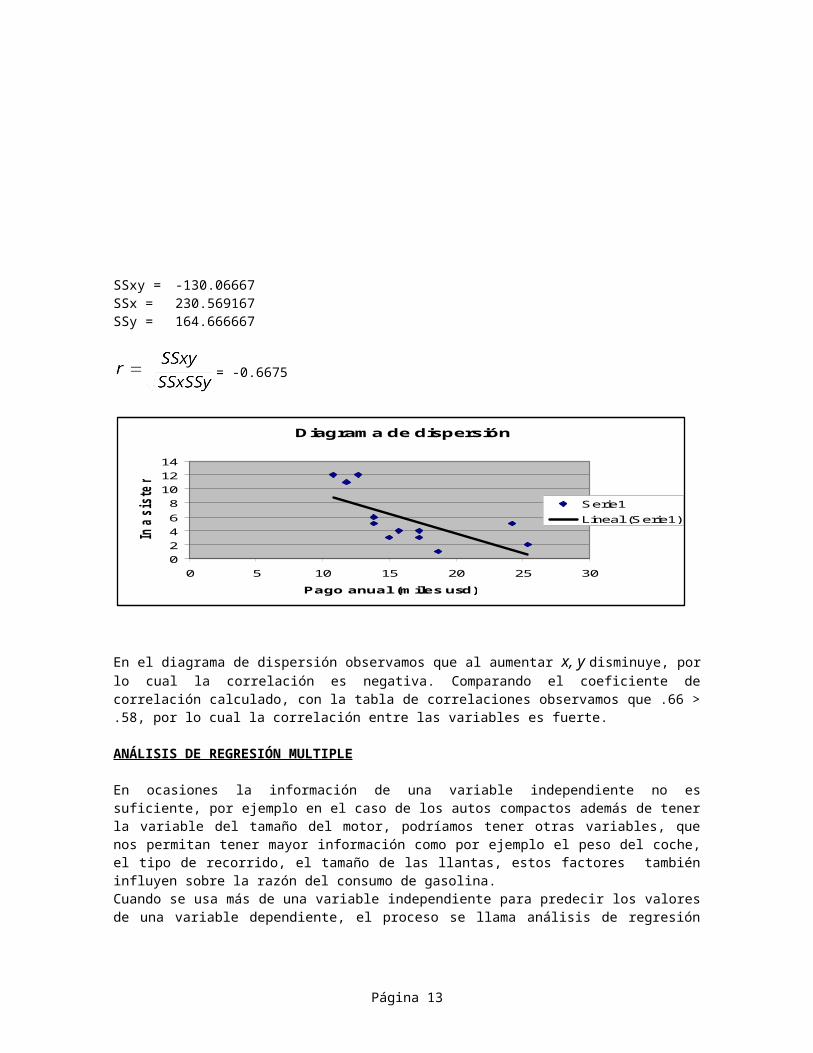
SSxy = -130.06667SSx = 230.569167SSy = 164.666667
= -0.6675
En el diagrama de dispersión observamos que al aumentar x, y disminuye, porlo cual la correlación es negativa. Comparando el coeficiente decorrelación calculado, con la tabla de correlaciones observamos que .66 >.58, por lo cual la correlación entre las variables es fuerte.
ANÁLISIS DE REGRESIÓN MULTIPLE
En ocasiones la información de una variable independiente no essuficiente, por ejemplo en el caso de los autos compactos además de tenerla variable del tamaño del motor, podríamos tener otras variables, quenos permitan tener mayor información como por ejemplo el peso del coche,el tipo de recorrido, el tamaño de las llantas, estos factores tambiéninfluyen sobre la razón del consumo de gasolina.Cuando se usa más de una variable independiente para predecir los valoresde una variable dependiente, el proceso se llama análisis de regresión
Página 13
Diagram a de dispersión
02468101214
0 5 10 15 20 25 30Pago anual (m iles usd)
Inas
isten
cias
Serie1Lineal (Serie1)

múltiple, incluye el uso de ecuaciones lineales y no lineales, en esteestudio nos ocuparemos de las ecuaciones de regresión lineales.
Ejemplo 6 Muchos programas de estudios premédicos usan los promedios delas calificaciones del MCAT de los estudiantes egresados como unindicador de la calidad de sus programas. Las variables que se sabeinfluencian esos promedios del MCAT(y) son: la combinación de lascalificaciones del SAT en matemáticas y en oratoria (x1) y el GPA (x2) delos prospectos a médicos. La tabla muestra las medidas de x1, x2 y y de seisestudiantes que han cursado un programa de premedicina y que hanpresentado el MCAT
Con esta información podemos encontrar una ecuación lineal que nospermita predecir el promedio de calificaciones del MCAT para unestudiante si se conocen su GPA y su calificación combinada del SAT.La ecuación lineal para los datos del ejemplo tiene la forma
Es posible encontrar los valores de b0, b1, y b2 usandoel método de mínimos cuadrados, al igual que en el método de regresiónlineal simple. El método en este caso requiere resolver tres ecuacioneslineales con tres incógnitas, estas ecuaciones, conocidas como ecuacionesnormales, son:
La siguiente tabla organiza los cálculos para obtener las ecuaciones:
Página 14
Calificación Calificación pro-Estudiante SAT (X1) G PA (X2) m edio del M CAT (Y)
1 1200 3.8 12.42 1350 3.4 13.33 1000 2.9 9.24 1250 3.3 10.65 1425 3.9 13.26 1340 3.1 11.2
X1 X2 Y X1 2 X2 2 X1X2 X1Y X2Y1200 3.8 12.4 1440000 14.44 4560 14880 47.121350 3.4 13.3 1822500 11.56 4590 17955 45.221000 2.9 9.2 1000000 8.41 2900 9200 26.681250 3.3 10.6 1562500 10.89 4125 13250 34.981425 3.9 13.2 2030625 15.21 5557.5 18810 51.481340 3.1 11.2 1795600 9.61 4154 15008 34.727565 20.4 69.9 9651225 70.12 25886.5 89103 240.2

Las ecuaciones normales para este ejemplo son:
Resolviendo el sistema de ecuaciones lineales obtenemos: b0 = -2.537, b1=0.005425, b2 = 2.161.
La ecuación de regresión es:
Suma de cuadrados: La suma total de cuadrados SST, se descompone en doscomponentes: suma de cuadrados para la regresión, y suma de cuadrados delerror.
SST = SSR + SSE La suma de cuadrados para la regresión es aquella parte de la suma totalde cuadrados que se atribuye a las variables independientes. Mientras quela suma de cuadrados del error es aquella porción de la suma de cuadradostotal y que no se debe a las variables independientes, por ello se llamasuma de cuadrados del error.
Grados de libertad para la regresión:
donde: k = número de variables independientes
Cálculo de cuadrados medios:
Página 15

Donde:MSR= Cuadrado medio de la regresiónMSE= Cuadrado medio del error.
Prueba de hipótesis: Para determinar si el modelo lineal describe adecuadamente los datos, se usa la prueba F. Para los datos del ejemplo las hipótesis son:
El valor del estadístico F se encuentra dividiendo MSR entre MSE.
Buscando el valor crítico para =7.71.Como 7.71 > 7.20 no podemos rechazar H0, lo cual nos indica que podría serarriesgado utilizar la ecuación de regresión con propósitos predictivos.
Coeficiente de determinación múltiple
Utilizando los datos del ejemplo:
Esto significa que aproximadamente el 83% de la variación en el promediode las calificaciones se atribuye a la variación de las variablesindependientes y solamente el 17% de la variación de la variabledependiente no se atribuye a eso.
Página 16





























