Embed Size (px)
Citation preview

APRENDIZADO DA COORDENAÇÃO DE COMPORTAMENTOSPRIMITIVOS PARA ROBÔS MÓVEIS
Antonio Henrique Pinto Selvatici∗[email protected]
Anna Helena Reali Costa∗
∗Laboratório de Técnicas Inteligentes – LTIEscola Politécnica da Universidade de São Paulo – EPUSP
Av. Prof. Luciano Gualberto, trav.3, n.158Cidade Universitária – 05508-900
São Paulo-SP, Brasil
ABSTRACT
In most real world applications, mobile robots should per-form their tasks in previously unknown environments. Thus,a mobile robot architecture capable of adaptation is very suit-able. This work presents an adaptive architecture for mobilerobots, AAREACT, which has the ability of learning howto coordinate primitive behaviors codified by the PotentialFields method by using Reinforcement Learning. The pro-posed architecture’s performance is compared to that showedby an architecture that performs a fixed coordination of itsbehaviors, and shows a better performance for different en-vironments. Experiments were performed in the robot Pi-oneer’s simulator, from ActivMedia Robotics R©. The ob-tained results also suggest that AAREACT has good adap-tation skills for specific environment and task.
KEYWORDS: Mobile robotics, control architecture, reactivebehaviors, reinforcement learning.
ARTIGO CONVIDADO:Versão completa e revisada de artigo apresentado no SBAI-2005Artigo submetido em 01/06/20061a. Revisão em 22/08/2006Aceito sob recomendação do Editor ConvidadoProf. Osvaldo Ronald Saavedra Mendez
RESUMO
Para ter uma aplicação real, um robô móvel deve poder de-sempenhar sua tarefa em ambientes desconhecidos. Uma ar-quitetura para robôs móveis que se adapte ao meio em que orobô se encontra é então desejável. Este trabalho apresentauma arquitetura adaptativa para robôs móveis, de nome AA-REACT, que aprende como coordenar comportamentos pri-mitivos codificados por Campos Potenciais através de Apren-dizado por Reforço. A atuação da arquitetura proposta, apósuma fase de aprendizado inicial, é comparada com a apresen-tada por uma arquitetura com coordenação fixa dos compor-tamentos, demonstrando melhor desempenho para diversosambientes. Os experimentos foram realizados no simuladordo robô Pioneer, da ActivMedia Robotics R©. Os resultadosexperimentais obtidos neste trabalho apontam também a altacapacidade de adaptação da arquitetura AAREACT para umambiente e tarefa especificos.
PALAVRAS-CHAVE : Robótica móvel, arquitetura de con-trole, comportamentos reativos, aprendizado por reforço.
1 INTRODUÇÃO
Define-se um robô móvel inteligente como um agente inte-ligente, artificial, autônomo, com capacidade de locomoção,imerso no mundo físico real. Agente inteligente por decidirde forma racional; artificial por ser máquina e não uma enti-dade criada pela natureza; autônomo por ser capaz de decidir
Revista Controle & Automação/Vol.18 no.2/Abril, Maio e Junho 2007 173

por si só, de se auto-governar, de atuar no ambiente de formapropositada, não passiva, de se adaptar a mudanças ocorri-das, no ambiente ou em si próprio, e continuar a atingir suasmetas; com capacidade de locomoção por poder se mover noambiente. (Ribeiro et al., 2001; Murphy, 2000).
A execução da tarefa atribuída a um robô móvel inteligente,ou simplesmente robô móvel, inclui necessariamente a sualocomoção de forma autônoma até localidades no espaço di-ferentes de sua posição inicial. É de interesse que essa loco-moção possa ser feita em ambientes não estruturados, ondehá, possivelmente, a presença de objetos obstruindo e difi-cultando a navegação. Por isso um robô móvel deve estarbem adaptado ao seu ambiente para que obtenha sucesso nocumprimento de sua tarefa. Em muitas situações, é necessá-rio que ele possa se adaptar a novas condições, o que requerque seu sistema de controle tenha a capacidade de aprendi-zado. Ele pode, assim, observar e criticar sua própria atua-ção, julgando-a segundo alguma medida de utilidade, e ajus-tar seus parâmetros no intuito de melhorá-la. Russel andNorvig (2003) apresentam a idéia do agente aprendiz, cujaarquitetura incorpora um agente não aprendiz, que tem seusparâmetros modificados por um elemento de aprendizado.
Devido à natureza autônoma dos robôs móveis, é mais in-teressante que o aprendizado a ser executado por eles nãoseja supervisionado. Dessa forma, o robô aprende sem a ne-cessidade de um tutor, podendo adaptar-se automaticamentea mudanças no ambiente. Aprendizado por Reforço (AR)(Kaelbling et al., 1996) mostra-se assim bastante promissorpara a utilização em arquiteturas de robôs móveis. De fato,AR é um dos tipos de aprendizado mais largamente utiliza-dos em sistemas robóticos para a adaptação do sistema decontrole (Arkin, 1998).
Este trabalho propõe uma arquitetura para robôs móveis, denome AAREACT, inspirada na idéia do agente aprendiz. Elautiliza como base uma arquitetura baseada em comportamen-tos reativos codificados por campos potenciais, de nome RE-ACT. Uma camada de aprendizado por reforço baseado emmódulos (Kalmár et al., 1998), que constitui o elemento deaprendizado, supervisiona o desempenho do robô e ajusta acontribuição de cada comportamento na sua atuação final.
Neste trabalho, a seção 2 contextualiza a arquitetura pro-posta, relacionando-a com outros trabalhos. A seção 3 apre-senta os conceitos fundamentais do aprendizado que foi em-pregado na arquitetura. A seção 4 descreve como é a plata-forma robótica adotada neste trabalho. Então, a seção 5 des-creve a arquitetura REACT, que serve de base para a arquite-tura proposta, e a seção 6 descreve os incrementos realizadosna arquitetura original de modo a dotá-la da capacidade deaprendizado. Os resultados obtidos com a arquitetura AA-REACT são discutidos na seção 7. Finalmente, a seção 8
traz as conclusões deste trabalho, bem como sugestões paratrabalhos futuros.
2 TRABALHOS CORRELATOS
REACT é uma arquitetura reativa aplicada à navegação derobôs móveis, projetada com base em comportamentos pri-mitivos coordenados de forma cooperativa (Selvatici andCosta, 2004; Pacheco and Costa, 2002). Dessa forma, asações comandadas por cada comportamento contribuem nageração da ação final. Os comportamentos são codificadoscom o método dos Campos Potenciais, gerando forças, queincindem sobre o robô, baseadas em alguma função poten-cial que associa cargas repulsivas aos obstáculos detectadose cargas atrativas à posição objetivo (Arkin, 1998). Assim,a REACT é de simples implementação e demanda pouco es-forço computacional, sendo muito adequada para o controledo robô em tempo real. Uma vez que a codificação dos com-portamentos é contínua, o movimento do robô é mais suave,apresentando poucas frenagens ou guinadas bruscas. Alémdisso, devido à alta modularidade da abordagem comporta-mental, é relativamente fácil dotar o robô de outras capacida-des, bastando, para isso, acrescentar novos comportamentos.
Apesar da REACT funcionar bem para diversos ambientes,ela possui os problemas intrínsecos das arquiteturas que uti-lizam o método de Campos Potenciais. A literatura tradi-cionalmente aponta duas principais falhas nessas arquitetu-ras (Koren and Borenstein, 1991). A primeira é a possibi-lidade da existência de mínimos locais do campo potencialgerado pelos comportamentos, configurando regiões de atra-ção indevidas para onde o robô pode se dirigir e permane-cer. A outra falha é a forte oscilação na trajetória apresen-tada pelo robô quando passa dentro de corredores estreitos,devido à rápida alternância de direção do campo força resul-tante experimentada pelo robô. Esse efeito é em parte atenu-ado pelo comportamento moveAhead na arquitetura REACT.Esses problemas ocorrem porque o campo gerado pelos com-portamentos nessas arquiteturas é fixo. Desse modo, caso ocampo resultante possua regiões de atração diferentes do ob-jetivo ou ainda regiões de oscilação, nada impede o robô deentrar nessas regiões.
Borenstein and Koren (1990) propuseram uma arquiteturapara navegação de robôs móveis em ambientes com obstá-culos baseada na análise do mapa do ambiente, representadopor uma grade de ocupação (Elfes, 1989). O vetor de mo-vimento é determinado a partir de um histograma polar devalores de ocupação, de forma que sempre aponta para a di-reção com o melhor compromisso entre baixa probabilidadede obstáculos e alto alinhamento com a direção do alvo. Noentanto, devido à falta de modularidade dessa arquitetura, elafoge da abordagem comportamental, o que torna difícil adap-tar capacidades adicionais ao robô, além do desvio de obstá-
174 Revista Controle & Automação/Vol.18 no.2/Abril, Maio e Junho 2007

culos e do movimento em direção ao objetivo.
Para manter a abordagem comportamental e aproveitar asvantagens do método de campos potenciais, Ranganathanand Koenig (2003) propuseram o acréscimo de uma camadade planejamento e seqüenciamento de comportamentos deforma a coordená-los de forma mais eficiente. Ela funcionacomo supervisora da arquitetura: quando é detectada umasituação em que o robô não consegue sair de uma regiãode atração indevida, a camada de planejamento e seqüen-ciamento determina uma posição alvo intermediária, que seencontre no caminho até o objetivo final, e a informa ao com-portamento de ir até o alvo, move-to-goal. Assim fica carac-terizada uma mudança no valor de um parâmetro desse com-portamento através de planejamento na tentativa de adaptar aarquitetura às condições ambientais.
Kalmár et al. (1998) também utilizaram uma arquiteturacomportamental que executa planejamento e seqüencia-mento sobre os comportamentos. Uma função de seleção uti-liza aprendizado por reforço baseado em módulos na escolhado comportamento mais adequado para cada possível situa-ção encontrada pelo robô, configurando, assim, uma coorde-nação competitiva dos comportamentos, ou seja, apenas umdeles está ativo cada vez. Os comportamentos são definidosatravés de uma decomposição da tarefa que o robô deve exe-cutar em sub-tarefas mais simples, de forma que cada com-portamento é projetado para executar uma determinada sub-tarefa. A vantagem dessa arquitetura é que o aprendizadobaseia-se na própria experiência do robô, o que caracterizaum maior grau de autonomia.
A arquitetura aprendiz proposta neste trabalho também em-prega AR para coordenar comportamentos primitivos. Deforma semelhante a Kalmár et al. (1998), a AAREACT pro-cura fazer com que a coordenação dos comportamentos seadapte às situações encontradas pelo robô. Uma camada deaprendizado atua sobre parâmetros que influenciam a coorde-nação dos comportamentos com base no conhecimento ad-quirido pela experiência do robô. Vale ressaltar que, nestetrabalho, utiliza-se uma coordenação cooperativa de compor-tamentos, na qual mais de um comportamento contribui paraa atuação final do robô, de forma a guiá-lo entre os obstáculosaté chegar a uma posição alvo. Uma vez que a participaçãode cada comportamento muda conforme a situação do am-biente, o campo potencial gerado não é mais fixo, evitandosituações de mínimos locais permanentes ou que levariam atrajetórias oscilantes.
3 APRENDIZADO POR REFORÇO
AR permite que um agente aprenda uma política de atua-ção na base de interações do tipo tentativa e erro com umambiente dinâmico (Kaelbling et al., 1996). Para ambientes
estacionários, a teoria de processos markovianos de decisão— em inglês, Markov Decision Processes, ou MDPs — ga-rante um tratamento matemático adequado. De fato, a maiorparte dos trabalhos em AR baseiam-se em MDPs, emboraos conceitos envolvidos possam ser aplicados de forma maisgenérica (Monteiro, 2002).
3.1 Processos markovianos de decisão(MDPs)
Processos markovianos de decisão são processos a tempodiscreto onde um agente deve decidir que ação tomar dadoque o ambiente se encontra no estado s e satisfaz a condiçãode Markov. A condição de Markov diz que o estado correntedo ambiente resume o passado de forma compacta, de modoque estados futuros não dependem de estados anteriores casose conheça o estado corrente. Isto é, pode-se predizer qualserá o próximo estado dado o estado corrente e a ação a sertomada (Sutton and Barto, 1998).
Formalmente, um MDP consiste de:
• um conjunto discreto de Ns estados do ambienteS = {s1, s2, . . . , sNs
};
• um conjunto discreto de Na possíveis açõesA = {a1, a2, . . . , aNa
};
• uma função de probabilidade de transição P (s′|s, a),que determina a probabilidade de se ir para o estado s′
dado que se está no estado s e é tomada a ação a;
• funções de reforço associadas à ação a tomada no es-tado s, r(s, a) ∈ R, onde R é um conjunto de funçõesr : S × A →
�que podem não ser deterministas.
Uma política π, em um MDP, é aquela que relaciona um es-tado a uma ação a ser tomada. Diz-se que π∗ é a políticaótima quando ela garante a maior soma dos reforços a longoprazo, representada por um modelo de otimalidade para aatuação do agente. Uma possibilidade é o modelo de ho-rizonte infinito com desconto, que leva em consideração arecompensa a longo prazo, mas as recompensas que são re-cebidas no futuro são descontadas de acordo com um fatorde desconto γ, com 0 < γ < 1:
RT = E
[∞∑
t=0
γtr(st, at)
∣∣∣∣∣ π]
. (1)
Este é o modelo utilizado na maior parte dos trabalhos emMDP, e que embasa os algoritmos mais conhecidos de AR.Uma vez escolhido esse modelo de otimalidade, pode-se de-
Revista Controle & Automação/Vol.18 no.2/Abril, Maio e Junho 2007 175

finir um valor ótimo para a atuação do agente como sendo:
V ∗ = maxπ
E
[∞∑
t=0
γtr(st, at)
∣∣∣∣∣ π]
. (2)
Esse valor ótimo só depende do estado corrente e, para cadaestado, pode ser definido como a solução do sistema de equa-ções recursivas
V ∗(si) = maxa
(r(si, a) + γ
∑s′∈S
P (s′|si, a)V ∗(s′)
)
= maxa
Q∗(si, a), i = 1, 2, . . . , Ns,
(3)onde Q∗(s, a) é o reforço total esperado caso se tome a açãoa no estado s e depois se siga agindo otimamente. Isso sig-nifica que o valor de um estado s é dado pela recompensainstantânea esperada mais o valor esperado para o próximoestado, descontado de γ, quando se usa a melhor ação dispo-nível. Dada a função valor V ∗(s), a política ótima é aquelaque garante (3), ou seja,
π∗(s) = argmaxa
Q∗(s, a). (4)
A função Q∗(s, a) também pode ser definida de forma recur-siva como
Q∗(si, a) = r(si, a) + γ∑s′∈S
P (s′|si, a)maxa′
Q∗(s′, a′).
(5)
3.2 Algoritmo SARSA
De modo geral, o papel dos algoritmos de AR é construir,de modo iterativo e através de interações com o ambiente,uma função Q(s, a), inspirada na definição de Q∗(s, a) dadaem (5). Q(s, a) é uma medida de utilidade de se escolher aação a dado que o ambiente se encontra no estado s. Comoo espaço de estados e ações é finito e enumerável, essa fun-ção é guardada em uma tabela, geralmente denominada ta-bela Q. Assumindo-se certas condições, e após um grandenúmero de interações, esses algoritmos aproximam Q∗(s, a)por Q(s, a), encontrando a política ótima através de (4).
Neste trabalho, optou-se por usar o algoritmo SARSA (Suttonand Barto, 1998). Quando o agente se encontra no estado s
e executa a ação a, obtém como resposta do ambiente um re-forço r e um novo estado s′. Uma vez nesse novo estado s′, oagente deve escolher uma nova ação a′. Assim, a partir dessaquíntupla <s, a, r, s′, a′>, tem-se a regra de aprendizado doalgoritmo:
Q(s, a) := Q(s, a) + α(r + γQ(s′, a′) − Q(s, a)), (6)
onde r ∈�
é o sinal de reforço, α ∈ ]0, 1[ é a taxa de apren-dizado e γ é a taxa de desconto, sendo α e γ parâmetros deprojeto. O algoritmo SARSA utiliza (6) para construir a ta-bela Q ao longo das iterações do agente com seu ambiente.
No entanto, (6) não fornece meios para determinar a açãoseguinte a ser executada, o que depende da estratégia de atu-ação escolhida. Caso se confie no resultado do aprendizadoobtido até então, pode-se adotar uma estratégia gulosa —greedy, em inglês — que escolhe sempre a ação com maiorvalor de utilidade Q para o estado em que o agente se en-contra. Caso contrário, pode-se adotar alguma estratégia queexplore mais o espaço de ações, na tentativa de se aceleraro aprendizado. Note-se, porém, que no caso do algoritmoSARSA, uma condição para garantir a convergência para apolítica ótima é que a estratégia de atuação convirja para aestratégia gulosa, pois, assim, (6) torna-se
Q(s, a) := Q(s, a) + α(r + γ maxa′∈A
{Q(s′, a′)} − Q(s, a)),
(7)permitindo a aplicação da prova de convergência dada em(Mitchell, 1997).
3.3 AR baseado em módulos
Para a resolução de um problema através dos algoritmos deAR mais conhecidos, e em especial, do SARSA, é necessárioque ele seja antes modelado nos termos de um MDP. Assim,o desempenho do algoritmo de AR depende de como são de-finidos os espaços de estados e ações do agente. Em muitoscasos, definir esses conjuntos do modo mais direto implicana inviabilidade do uso dos algoritmos de AR, pois, além donúmero muito elevado de estados e ações, os estados pode-riam não ser precisamente observados pelo agente.
Uma alternativa para a definição dos conjuntos de estadose ações é utilizar o conhecimento qualitativo a priori so-bre a tarefa do agente de modo a decompô-la em sub-tarefasa serem executadas por controladores previamente projeta-dos, também chamados de macro-ações. Nessa abordagem,o conhecimento a priori também é usado para determinarque atributos do ambiente correspondem a condições de ope-ração para as macro-ações. Desse modo, AR baseado emmódulos consiste no aprendizado de uma função de seleçãodas macro-ações a partir da situação de presença ou ausên-cia dos atributos previamente definidos do ambiente (Kalmáret al., 1998).
Atributos
Pode acontecer que as variáveis de estado envolvidas no pro-blema sejam contínuas e ilimitadas, como em muitos pro-blemas do mundo real. Além do mais, nesses problemas émuito comum que o estado do sistema não possa ser determi-
176 Revista Controle & Automação/Vol.18 no.2/Abril, Maio e Junho 2007

nado precisamente. No caso de robôs móveis, em especial,as variáveis de estado envolvidas diretamente no problemada navegação até um determinado objetivo correspondem àpostura (posição e orientação do robô no ambiente) e as lei-turas dos sensores. Modelar os estados desse problema atra-vés de uma discretização simples de suas variáveis de estadonem sempre e possível, pois essas variáveis podem não sertodas mensuráveis com a precisão necessária. E quando issoé possível, há o inconveniente da necessidade de se definir agranularidade do modelo. Para isso, deve-se levar em conta ocompromisso entre desempenho do algoritmo e a qualidadedo resultado. Uma discretização muito fina das variáveis deestado resultaria em um grande número de estados, o queacarretaria em um tempo muito grande de processamento, oumesmo à não convergência do algoritmo de AR. Em contra-partida, uma discretização grosseira pode resultar em umapolítica pouco útil para o problema em questão. Além domais, caso o ambiente em que está inserido o robô for sufici-entemente grande e com muitos obstáculos, torna-se impro-vável obter uma granularidade do modelo capaz de levar aum resultado satisfatório.
Uma alternativa para a modelagem feita diretamente a partirdos dados dos sensores é a utilização de atributos, que sãofunções de observação do estado do sistema. Quando bemprojetados, definir o estado do sistema através de atributospode resolver o problema de dimensionalidade alta e dificul-dade na observação (Kalmár et al., 1998).
Módulos
Da mesma forma, as possíveis ações de um robô móvel for-mam um espaço contínuo, apresentando as mesmas dificul-dades para sua modelagem. Uma alternativa bem conhecidaé o emprego das macro-ações, que podem ser entendidascomo controladores projetados para solucionar um problemaespecífico, geralmente de baixa complexidade. Tendo-se emconta um modelo qualitativo do problema, é possível dividi-lo em sub-problemas suficientemente simples de tal formaque seja possível projetar uma macro-ação que o solucione.A ativação de uma macro-ação depende de uma determinadacondição de operação. A cada par formado por uma macro-ação e sua respectiva condição de operação denomina-se mó-dulo (Kalmár et al., 1998).
O emprego de atributos para modelar os estados do ambi-ente e de macro-ações para definir as possíveis ações doagente torna conveniente atrelar as condições de operaçãodas macro-ações aos atributos. Definidos assim, os atribu-tos passam a informar sobre a presença das várias condiçõesde operação no ambiente através de um valor booleano, o queos caracteriza como atributos binários. Diz-se, então, que umatributo binário está ativo caso a respectiva condição de ope-ração esteja presente no ambiente, e inativo caso contrário.
Então, o estado do ambiente é dado por um vetor de atri-butos, que indica a ativação ou inatividade de cada atributobinário predefinido.
Esse modo de definição dos atributos fornece um meio muitoapropriado de se marcar o tempo. Em vez de utilizar um reló-gio independente do processo, convém coincidir os instantesde transição de estados com os eventos de ativação ou desati-vação dos atributos. Dessa forma, os instantes de transição deestados, que medem a duração do MDP, ficam desacopladosdo tempo real de duração dos estados, o que é mais interes-sante quando as sub-tarefas possuem naturalmente diferentestempos de execução.
Dependendo de como foram projetados os módulos, podeocorrer que mais de uma condição de operação ocorra aomesmo tempo. Nesse caso, o papel do algoritmo de AR édeterminar uma função de seleção que escolhe a macro-açãomais adequada para cada estado do ambiente, definido pelovetor de atributos. Embora seja possível projetar condiçõesde operação auto-excludentes, resultando em uma funçãode seleção predefinida, resultados obtidos por Kalmár et al.(1998), estendidos por Colombini and Ribeiro (2005), mos-tram que o uso de funções de seleção aprendidas apresentammelhor desempenho, uma vez que podem captar caracterís-ticas do domínio de aplicação que passariam despercebidaspelo projetista humano. Kalmár et al. (1998) apontam aindaduas precauções que devem ser tomadas na aplicação de ARpara a seleção das macro-ações. A primeira delas é a necessi-dade de que o tempo de duração de um estado seja sempre fi-nito. Isso pode ser facilmente conseguido impondo-se restri-ções na política do agente, de forma a garantir que, qualquerque seja o estado, sempre será escolhida uma macro-ação queleve a uma mudança de estado em tempo finito. Outra pre-caução é que sempre haja pelo menos um caminho possívelno espaço de estados até algum estado objetivo, independen-temente do estado corrente.
4 ROBÔ UTILIZADO
A arquitetura proposta neste trabalho considera que o robômóvel utilizado é terrestre e move-se sobre um solo plano.Além disso, seus sensores devem permitir que ele possa selocalizar através de odometria e ainda detectar os obstáculosà sua frente por meio de um anel frontal de sonares.
O modelo de robô utilizado neste trabalho é o Pioneer 2-DX,da ActivMedia Robotics R©, ilustrado na figura 1. Ele pos-sui um corpo de alumínio com 44cm de comprimento, 38cmde largura e 22cm altura, pesando 9kg e suportando 23kg decarga adicional. A direção é diferencial, sendo que as duasrodas principais possuem 19cm de diâmetro e 5cm de lar-gura. Uma roda castor, localizada na parte traseira do robô,dá estabilidade à plataforma. O robô pode chegar a uma ve-
Revista Controle & Automação/Vol.18 no.2/Abril, Maio e Junho 2007 177

Figura 1: Foto frontal do robô Pioneer 2-DX.
locidade de translação máxima de 1,6m/s, e sua velocidadede rotação pode alcançar 230o/s.
4.1 Sensores do Pioneer 2-DX
Os sensores do Pioneer a serem considerados neste trabalhosão os sonares e os encoders, utilizados para medir os deslo-camentos das rodas. Dessa forma, esses sensores fornecem alocalização do robô por odometria. Esse tipo de localizaçãofoi adotado neste trabalho, apesar de apresentar erro acumu-lativo. Os encoders possuem 500 marcas, podendo, dessaforma, detectar deslocamentos nas rodas de até 0,72o.
Os sonares do robô trabalham a uma freqüência de 25Hz, eestão distribuídos em forma de anel na parte frontal do robô.Os seis sonares mais à frente estão uniformemente distribuí-dos em um ângulo de 90o, de forma que as direções de emis-são do ultrassom variam 15oentre cada sonar. Além desses,há um sonar lateral em cada lado, e suas direções de atuaçãoformam ângulos retos com o eixo longitudinal do robô.
4.2 Simulador do Pioneer-2DX
Os experimentos deste trabalho foram realizados no simula-dor do robô Pioneer 2-DX, distribuído conjuntamente como software de comunicação com o robô. A simulação dasleituras dos sensores, incluindo os erros, é bem realista, deforma que o simulador pôde ser utilizado sem prejuízo paraa validade dos resultados.
5 ARQUITETURA REACT
A arquitetura REACT é baseada em comportamentos mode-lados por Motor-Schemas (Arkin, 1998). Um Motor-Schemapermite, essencialmente, a definição e implementação de umcomportamento em dois módulos principais: o módulo de
percepção, que é responsável por extrair dos estímulos sen-soriais as informações relevantes para o comportamento emquestão, e o módulo de codificação do comportamento que,alimentado pelo módulo de percepção, executa o mapea-mento dos estímulos sensoriais nas respostas motoras. Os pa-râmetros que definem uma ação — que corresponde à saídade cada Motor-Schema — são a magnitude e a direção domovimento. Estes parâmetros são representados por um ve-tor, e correspondem, respectivamente, à velocidade e à ro-tação que o robô deve executar, segundo o comportamentoem questão. A coordenação dos comportamentos é feita demodo cooperativo: as contribuições de cada comportamentosão somadas, de maneira que o problema da coordenação seresume a dimensionar corretamente as saídas dos diferentescomportamentos de forma que a sua soma resulte no com-portamento global desejado para o robô.
5.1 Comportamentos da REACT
Os comportamentos utilizados na arquitetura REACT são:
Comportamento avoidCollision: este comportamento tempor objetivo evitar colisões em relação a múltiplos obstácu-los. O módulo de percepção interpreta as leituras dos sonaresde modo a identificar os obstáculos presentes no ambiente. Omódulo de codificação da ação constrói o campo potencial docomportamento associando cargas repulsivas aos obstáculos.A direção da força é definida como radial aos obstáculos. Amagnitude é determinada por uma função de decaimento quedepende apenas da distância do robô ao obstáculo. Destemodo, o módulo de codificação deste comportamento é com-posto pelas equações
V (d) =
{VAC e
−d+S
T para d > S
VAC para d ≤ S
φ = π − φrobô-obstáculo
(8)
onde V é a magnitude do comportamento (velocidade), d éa distância do centro de massa do robô ao obstáculo, VAC
é a velocidade máxima do comportamento, S é o standoffdo robô (distância abaixo da qual a magnitude do compor-tamento satura em seu valor máximo), T é a constante deescala da curva de decaimento, φ é a direção do vetor resul-tante do comportamento e φrobô-obstáculo é a direção definidapela reta que une o obstáculo ao centro de massa do robô.
Comportamento moveToGoal: este comportamento tem oobjetivo de atrair o robô para um determinado ponto no am-biente. A posição inicial do alvo no sistema global de coorde-nadas é informada ao sistema por meio de um agente externo.A posição atual do robô, estimada pelo módulo de percepção,baseia-se na informação dos odômetros. O módulo de codi-ficação determina a direção do movimento como sendo igualà direção dada pela reta que une os pontos que definem asposições do robô e do alvo (φrobô-alvo). A magnitude apre-
178 Revista Controle & Automação/Vol.18 no.2/Abril, Maio e Junho 2007

senta valor constante (VMTG), de modo que a codificação docomportamento é dada por
V = VMTG
φ = φrobô-alvo.(9)
Comportamento moveAhead: este faz com que o robô sem-pre tenha uma forte tendência de continuar na direção em quese encontra no momento. O comportamento moveAhead nãopossui módulo de percepção e o seu módulo de codificaçãoé elementar, retornando um campo de magnitude constante(VMA) e direção sempre igual à do próprio robô naquele ins-tante (φrobô):
V = VMA
φ = φrobô.(10)
5.2 Ponderação dos comportamentos naREACT
Na arquitetura REACT original, todos comportamentos sãoigualmente considerados para o cálculo da ação do robô.As magnitudes dos comportamentos (VAC , VMA e VMTG)são fixas e foram determinadas experimentalmente para ummodelo específico de robô, de forma que seu desempe-nho fosse satisfatório para diversos ambientes (Pacheco andCosta, 2002). No entanto, um melhor desempenho poderiaser alcançado caso essas magnitudes pudessem variar depen-dendo da situação do ambiente encontrada pelo robô. Issopode ser feito multiplicando a saída de cada comportamentopor um determinado peso que dependa do estado do ambi-ente, ponderando assim a participação dos comportamentosde acordo com a conveniência.
Dessa forma, um conjunto de três pesos, wAC , wMTG ewMA, que ponderam, respectivamente, as saídas de avoid-Collision, moveToGoal e moveAhead, define também umcontrolador para o robô. Pode-se, então, dispor de váriosconjuntos de pesos, projetados a priori, obtendo-se, assim,diversos controladores diferentes. Conseqüentemente, torna-se possível inserir na arquitetura uma camada de aprendi-zado com o objetivo de escolher o melhor controlador paraa situação em que o ambiente se encontra. Caso seja defi-nido um conjunto discreto de possíveis situações, a camadade aprendizado deve então aprender uma política associandocada possível situação a um determinado controlador, cená-rio muito conveniente para a utilização de AR.
6 ARQUITETURA AAREACT
A arquitetura AAREACT, acrônimo para Adaptação Auto-mática da REACT, consiste de uma camada de aprendizadopor reforço baseado em módulos que supervisiona a atua-ção do robô e modifica os pesos que multiplicam as saídas
dos comportamentos (Selvatici, 2005), conforme mostra a fi-gura 2.
avoidCollision
moveToGoal
moveAhead
sonares
MTG
AC
MA
w
w
w
Percepção
Percepção
Ação
Ação
odômetros
REACT
ΣAtuadores
Camada de Aprendizado
Elemento deaprendizado
AR
Escolha de umconjunto de pesos
s
r
supervisão
Cálculo dos reforços
crítico
estado Observação do
Posição do alvo
Ação
Figura 2: Diagrama de blocos da arquitetura AAREACT
A camada de aprendizado da AAREACT, através do compo-nente de supervisão, percebe o estado s do ambiente dadopor atributos binários calculados a partir dos dados dos sen-sores do robô (sonares e odômetros). Além disso, através docomponente crítico, define reforços r que dependem da atu-ação do robô. Então o elemento de aprendizado, que im-plementa o algoritmo SARSA, determina a política de atua-ção adequada àquele estado, π(s), correspondendo a um con-junto de pesos para os comportamentos da arquitetura.
6.1 A modelagem do problema
A tarefa principal que deve ser executada pelo robô móvelé a navegação até um determinado ponto objetivo no ambi-ente, com o desvio de obstáculos. Possíveis sub-tarefas rela-cionadas com a tarefa principal são a ultrapassagem de cadaobstáculo que se encontra no caminho até o alvo. Cada ultra-passagem pode, ainda, se subdividir em etapas, nas quais apercepção do obstáculo pelo robô vai se modificando. Consi-derando os comportamentos da REACT, descritos na seção 5,supõe-se que há uma melhor combinação desses comporta-mentos para cada etapa do desvio de um obstáculo, represen-tada por um conjunto de pesos que multiplicam as saídas doscomportamentos. Dessa forma, um conjunto de pesos podeser definido como uma macro-ação, cuja condição de opera-ção é dada pela percepção do robô com relação ao alvo e aos
Revista Controle & Automação/Vol.18 no.2/Abril, Maio e Junho 2007 179

obstáculos.
Note-se que, no trabalho de Kalmár et al. (1998), cadamacro-ação corresponde a um determinado comportamento.De fato, no campo da robótica móvel, essa correspondên-cia é bastante natural (Colombini and Ribeiro, 2005), umavez que é comum definir cada comportamento em vista daexecução de uma tarefa específica dentre aquelas que o robôdeve realizar. No entanto, neste trabalho, cada macro-açãocorresponde a uma combinação de comportamentos, e não aum comportamento isolado, caracterizando uma abordagemessencialmente diferente.
6.2 A definição dos atributos
Os atributos definidos procuram fornecer informação sufici-ente para refletir a percepção do robô com relação aos obs-táculos próximos e ao alvo. Cada atributo, quando ativo deforma isolada, leva naturalmente a uma combinação proposi-tada dos comportamentos, representada por um conjunto depesos. A relação entre um atributo e seu respectivo conjuntode pesos correlato estão apresentados na seção 6.3.
Os atributos definidos neste trabalho são:
FreeTarget: este atributo está ativo quando o robô detectaque não há obstáculos entre ele e o alvo, ou ainda queos obstáculos na direção do alvo estão muito distantes.Um obstáculo distante é caracterizado por uma leiturade sonar superior a um limiar Lfar, definido arbitraria-mente.
BackTarget: a ativação deste atributo se dá quando o alvo seencontra atrás do robô, de forma que os sonares, dispos-tos em um anel na parte frontal do robô, não conseguemdetectar se há algum impedimento entre ele e o alvo.
SideObstacle: este atributo é ativado quando um dos sona-res laterais do robô detecta a presença de um obstáculopróximo, o que equivale a uma leitura de sonar infe-rior a um limiar Lnear , definido arbitrariamente, comLnear < Lfar.
DiagonalObstacle: este atributo é ativado quando um dossonares das diagonais anteriores do robô detecta a pre-sença de um obstáculo próximo, com leitura de distân-cia inferior a Lnear .
MiddleObstacle: o que determina a ativação deste atributoé a detecção de algum obstáculo a uma distância médiado robô, caracterizada por uma leitura de qualquer sonarentre os limiares Lnear e Lfar. A presença isolada desteatributo configura uma situação confortável, onde nãohá perigo iminente de obstáculo.
NarrowPath: este atributo está ativo quando ambos os so-nares laterais do robô detectam a presença de um obs-táculo próximo, caracterizando a passagem do robô porum corredor estreito. Quando este atributo está ativo,os demais descritos anteriormente (FreeTarget, Back-Target, SideObstacle, DiagonalObstacle e MiddleObs-tacle) são ignorados, uma vez que a navegação em umcorredor estreito é uma situação especial na qual não sedeve preocupar com a posição do alvo ou a presença dosobstáculos fora do corredor.
FrontalObstacle: este atributo está ativo quando um dos so-nares frontais do robô detecta a presença de um obs-táculo próximo, a uma distância menor do que Lnear,caracterizando um perigo iminente de colisão. Quandoeste atributo é ativado, todos os demais são ignorados,já que a reação mais prudente do robô é se afastar desseobstáculo e não se preocupar com o alvo ou com obstá-culos mais distantes.
A figura 3 ilustra a definição de cada atributo em termos dadistribuição espacial dos obstáculos e do alvo em torno dorobô. O estado do ambiente é caracterizado pelo vetor deatributos que indica quais estão ativos e quais estão inati-vos. Uma mudança de estado ocorre quando há a ativaçãode um ou mais atributos antes inativos, ou ainda quando umou mais atributos deixam de estar ativos. A princípio, dado onúmero de atributos definidos, pode-se pensar que o númerode estados possíveis é 27 = 128. No entanto, o modo comoestão definidos os atributos resulta em que vários sejam mu-tuamente exclusivos, reduzindo drasticamente o tamanho doespaço de estados. Uma análise dos atributos definidos mos-tra que há apenas 24 estados possíveis para o ambiente.
6.3 Definição dos conjuntos de pesos
A elaboração dos pesos é baseada na idéia de se atrelar umcontrolador a cada atributo definido. Quando o estado doambiente for definido pela ativação isolada de um único atri-buto, o conjunto de pesos escolhido é aquele atrelado ao atri-buto em questão. Nos demais estados, nos quais há mais deum atributo ativo, o módulo de AR deve decidir o melhorconjunto de pesos dentre aqueles relacionados na tabela 1.O modo como foram definidos os atributos garante que nãohá a possibilidade de todos os atributos estarem desativadossimultaneamente.
Ao atributo FreeTarget foi atrelado o conjunto de pesos 1,que ativa apenas o comportamento moveToGoal. Já ao atri-buto BackTarget foi atrelado o conjunto de pesos 2, que, alémdo moveToGoal, ativa também o comportamento avoidColli-sion como uma forma de prevenção contra colisões com ob-jetos não detectados. Possíveis obstáculos posicionados atrásdo robô não podem ser percebidos previamente pela falta de
180 Revista Controle & Automação/Vol.18 no.2/Abril, Maio e Junho 2007

Figura 3: Ilustração de como foram definidos os atributos. O robô está representado pelo círculo central, sendo que osegmento de reta em seu interior define a direção do movimento. A cruz representa o alvo até onde o robô deve se locomover,e os retângulos representam os obstáculos detectados pelos sonares. As circunferências de linha pontilhada representam asdistâncias Lnear e Lfar, sendo que Lnear é a circunferência mais próxima do robô.
sonares traseiros, de forma que se o giro do robô em direçãoao alvo for muito rápido, sem haver tempo para a mudançade estados, e, com isso, mudança no conjunto de pesos es-colhidos, o comportamento avoidCollision evitará a colisão.No caso de SideObstacle, além do comportamento de andarpara frente, é interessante haver uma participação de avoid-Collision para que haja um afastamento gradual do obstáculolateral. Já o atributo DiagonalObstacle requer uma participa-ção maior do comportamento avoidCollision, pois o risco decolisão é maior. Como a ativação isolada do atributo Mid-dleObstacle indica que não há perigo de colisão iminente,o conjunto de pesos atrelado determina o grau de participa-ção dos comportamentos igual à utilizada, de forma fixa, naarquitetura REACT. O atributo FrontalObstacle, que repre-senta perigo de colisão iminente, requer a ativação máximado comportamento avoidCollision, mais uma pequena parti-cipação de moveAhead para evitar movimentos muitos brus-cos do robô. A ativação do atributo NarrowPath indica umasituação semelhante à ativação isolada de SideObstacle.
Nota-se que o conjunto de pesos 8 não está atrelado a ne-nhum atributo do ambiente. Ele foi elaborado de modo a serbastante diferente dos demais definidos até então: além dele,
apenas o conjunto 5 conjuga os três comportamentos simul-taneamente, mas cada um desses conjuntos de pesos enfatizacomportamentos diferentes. Dessa forma, o conjunto de pe-sos 8 está presente entre as possíveis ações do módulo de ARcomo uma opção a mais a ser explorada no caso de mais deum atributo estar presente ao mesmo tempo.
Tabela 1: Relação entre os atributos definidos e o conjuntode pesos dos comportamentos associados a cada um.
Índice Atributo Conjunto de pesos associado{wMA; wMTG; wAC}
1 FreeTarget {0,0 ; 1,0 ; 0,0}2 BackTarget {0,0 ; 1,0 ; 1,0}3 SideObstacle {1,0 ; 0,0 ; 0,3}4 DiagonalObstacle {1,0 ; 0,0 ; 1,0}5 MiddleObstacle {0,6 ; 0,4 ; 1,0}6 NarrowPath {1,0 ; 0,0 ; 0,3}7 FrontalObstacle {0,3 ; 0,0 ; 1,0}8 — {0,5 ; 1,0 ; 0,7}
Revista Controle & Automação/Vol.18 no.2/Abril, Maio e Junho 2007 181

6.4 Modelo da função de reforço
Em AR, reforços positivos são utilizados para premiar situ-ações desejáveis para o agente, podendo-se aplicar tambémpenalidades para situações indesejáveis. O objetivo primáriodo robô é chegar à posição alvo. Dessa forma, a camada deaprendizado recebe um grande reforço positivo quando issoocorre, definido por rgoal.
No entanto, é desejável também que o robô apresente umbom desempenho na sua atuação, o que é difícil de expressarquantitativamente. Neste trabalho, tentou-se modelar essedesempenho através de dois parâmetros: a velocidade mé-dia desenvolvida e a velocidade média de aproximação doalvo. Assim, recompensas proporcionais a essas medidas dedesempenho são fornecidas à camada de aprendizado sem-pre que é percebida uma mudança na situação do ambiente,caracterizando um reforço intermediário, recebido antes documprimento da tarefa especificada. Reforços intermediá-rios são importantes para acelerar o aprendizado, no entanto,esses reforços devem ter valores inferiores àquele recebidoquando o robô atinge o alvo. O reforço intermediário rece-bido é dado por
rint = K1vm + K2va, (11)
onde:
• K1 e K2 são ganhos arbitrariamente definidos;
• vm é a velocidade média desenvolvida pelo robô duranteo tempo em que o ambiente se encontra num determi-nado estado ou situação;
• va é a velocidade média de aproximação do alvo pelorobô durante o tempo de duração de uma situação, dadapela diferença entre as distâncias inicial e final do alvo,dividida pelo tempo de permanência na situação.
A formulação acima permite valores positivos e negativospara rint. O valor desse reforço intermediário é saturado em±r̄, para garantir que será sempre menor do que rgoal.
7 EXPERIMENTOS COM A AAREACT
No início do aprendizado, não se conhece uma política ade-quada para a escolha dos conjuntos de pesos, de modo que éesperada uma atuação ruim do robô em qualquer ambiente.A única política predefinida é a que relaciona a ativação deum único atributo do ambiente com o respectivo conjunto depesos; esta porém é fixa e não é influenciada pelo resultadodo aprendizado. Por isso, decidiu-se dividir o aprendizadoda arquitetura em duas fases. Na primeira fase, denominadade aprendizado inicial, o módulo de AR ainda não tem uma
boa estimativa das utilidades Q(s, a), e adota uma estraté-gia ε-gulosa (Sutton and Barto, 1998), que, ou escolhe umaação aleatória, com probabilidade ε, ou escolhe a ação commaior utilidade, com probabilidade 1− ε. Nessa fase é espe-rada uma atuação ruim para o robô, que, inicialmente, deveapresentar até mesmo um comportamento errante. Com isso,espera-se que ele experimente as várias situações diferentese aprenda a lidar com elas, resultando assim em uma políticainicial satisfatória, válida para qualquer ambiente, definida apartir da tabela Q obtida.
Na segunda fase, utiliza-se o conhecimento adquirido noaprendizado inicial, de forma que já é esperado um desem-penho razoável do robô em qualquer ambiente que venha aatuar. Nessa fase, o módulo de AR não mais explora os possí-veis conjuntos de pesos, e passa a adotar a estratégia gulosa,visando apenas a obter um bom desempenho. No entanto,vale ressaltar que o aprendizado por reforço continua ativo.Os experimentos que avaliam o desempenho da arquiteturaAAREACT são realizados nessa fase.
7.1 Aprendizado inicial
Como o conhecimento adquirido pela AAREACT se estendea diversos ambientes, é interessante aproveitar o aprendizadoinicial para treinar o robô em um ambiente que apresente di-versas situações possíveis a serem exploradas. Foi elaboradoum cenário onde o robô é obrigado a passar por vários ti-pos de configurações de obstáculos para atingir seu objetivo.Esse cenário é constituído de uma sala retangular, onde fo-ram definidas quatro posições alvo de modo a ficarem próxi-mas das quinas da sala, conforme mostra a figura 4. O robôfoi então comandado a procurar um alvo por vez, de modoa garantir que, ao percorrer os quatro alvos consecutivos, orobô circunde a sala.
Na implementação da arquitetura AAREACT, os seguintesparâmetros foram utilizados:
• Parâmetros dos comportamentos
– Stand off : S = 40cm
– Constante de decaimento: T = 15cm
– Velocidade moveAhead: VMA = 15, 0cm/s
– Velocidade avoidCollision: VAC = 15, 0cm/s
– Velocidade moveToGoal: VMTG = 15, 0cm/s
• Parâmetros dos atributos
– Limiar de detecção de obstáculo próximo:Lnear = 50cm
– Limiar de detecção de obstáculo distante: Lfar =200cm
182 Revista Controle & Automação/Vol.18 no.2/Abril, Maio e Junho 2007
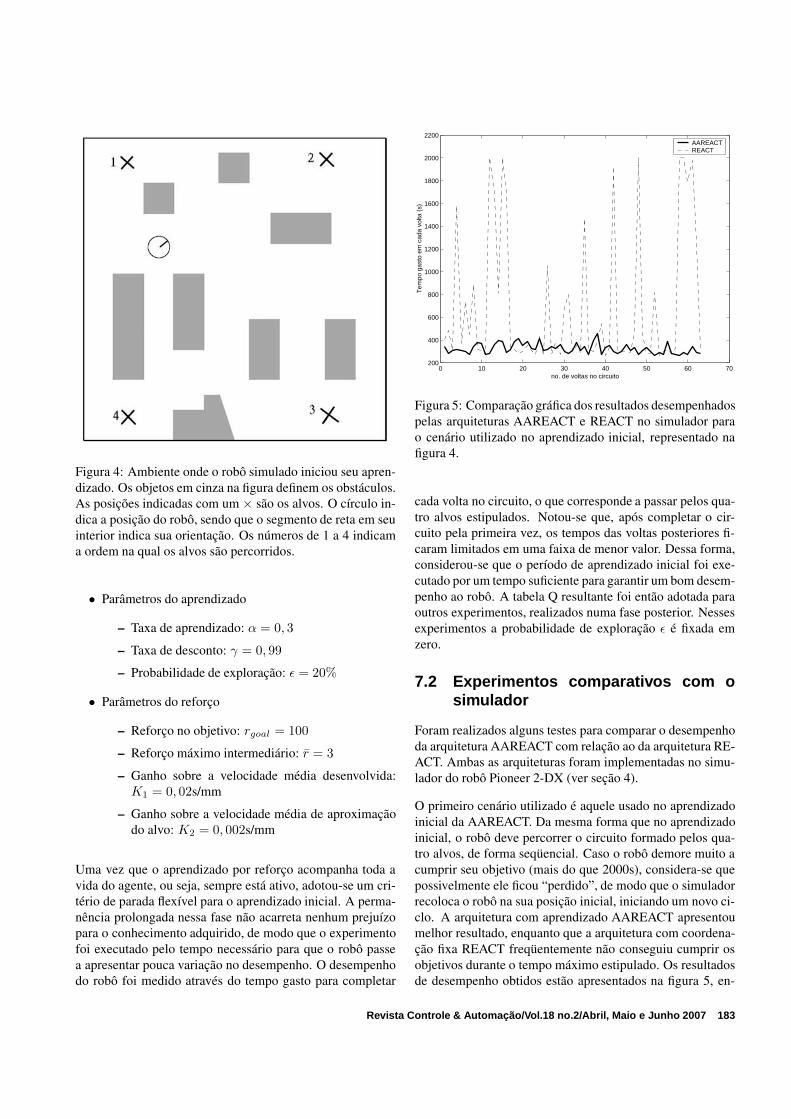
Figura 4: Ambiente onde o robô simulado iniciou seu apren-dizado. Os objetos em cinza na figura definem os obstáculos.As posições indicadas com um × são os alvos. O círculo in-dica a posição do robô, sendo que o segmento de reta em seuinterior indica sua orientação. Os números de 1 a 4 indicama ordem na qual os alvos são percorridos.
• Parâmetros do aprendizado
– Taxa de aprendizado: α = 0, 3
– Taxa de desconto: γ = 0, 99
– Probabilidade de exploração: ε = 20%
• Parâmetros do reforço
– Reforço no objetivo: rgoal = 100
– Reforço máximo intermediário: r̄ = 3
– Ganho sobre a velocidade média desenvolvida:K1 = 0, 02s/mm
– Ganho sobre a velocidade média de aproximaçãodo alvo: K2 = 0, 002s/mm
Uma vez que o aprendizado por reforço acompanha toda avida do agente, ou seja, sempre está ativo, adotou-se um cri-tério de parada flexível para o aprendizado inicial. A perma-nência prolongada nessa fase não acarreta nenhum prejuízopara o conhecimento adquirido, de modo que o experimentofoi executado pelo tempo necessário para que o robô passea apresentar pouca variação no desempenho. O desempenhodo robô foi medido através do tempo gasto para completar
0 10 20 30 40 50 60 70200
400
600
800
1000
1200
1400
1600
1800
2000
2200
no. de voltas no circuito
Tem
po g
asto
em
cad
a vo
lta (
s)
AAREACTREACT
Figura 5: Comparação gráfica dos resultados desempenhadospelas arquiteturas AAREACT e REACT no simulador parao cenário utilizado no aprendizado inicial, representado nafigura 4.
cada volta no circuito, o que corresponde a passar pelos qua-tro alvos estipulados. Notou-se que, após completar o cir-cuito pela primeira vez, os tempos das voltas posteriores fi-caram limitados em uma faixa de menor valor. Dessa forma,considerou-se que o período de aprendizado inicial foi exe-cutado por um tempo suficiente para garantir um bom desem-penho ao robô. A tabela Q resultante foi então adotada paraoutros experimentos, realizados numa fase posterior. Nessesexperimentos a probabilidade de exploração ε é fixada emzero.
7.2 Experimentos comparativos com osimulador
Foram realizados alguns testes para comparar o desempenhoda arquitetura AAREACT com relação ao da arquitetura RE-ACT. Ambas as arquiteturas foram implementadas no simu-lador do robô Pioneer 2-DX (ver seção 4).
O primeiro cenário utilizado é aquele usado no aprendizadoinicial da AAREACT. Da mesma forma que no aprendizadoinicial, o robô deve percorrer o circuito formado pelos qua-tro alvos, de forma seqüencial. Caso o robô demore muito acumprir seu objetivo (mais do que 2000s), considera-se quepossivelmente ele ficou “perdido”, de modo que o simuladorrecoloca o robô na sua posição inicial, iniciando um novo ci-clo. A arquitetura com aprendizado AAREACT apresentoumelhor resultado, enquanto que a arquitetura com coordena-ção fixa REACT freqüentemente não conseguiu cumprir osobjetivos durante o tempo máximo estipulado. Os resultadosde desempenho obtidos estão apresentados na figura 5, en-
Revista Controle & Automação/Vol.18 no.2/Abril, Maio e Junho 2007 183

Figura 6: Comparação entre trajetórias típicas apresentadaspelas arquiteturas REACT e AAREACT nos experimentosrealizados no simulador, com o cenário do aprendizado ini-cial. As setas indicam o sentido do movimento do robô.
quanto que a figura 6 compara trajetórias típicas obtidas comas arquiteturas REACT e AAREACT. As trajetórias foramobtidas através do modelo de odometria com erro apresen-tado pelo simulador do robô Pioneer. Dessa forma, as tra-jetórias marcadas indicam apenas um caminho aproximado.As regiões onde as trajetórias se sobrepõem aos obstáculossão conseqüência desse erro de odometria. As oscilações nascurvas de desempenho da figura 5 devem-se ao fato de que,mesmo para uma determinada arquitetura, os trajetos percor-ridos são diferentes a cada volta no cenário, uma vez que ossensores e atuadores são ruidosos. Observa-se uma grandevariação no desempenho da arquitetura REACT neste cená-rio, de forma que ela apresenta bons resultados (tempo gastomenor do que 400s) apenas esporadicamente. Enquanto isso,a AAREACT se mostra mais constante, sendo que, na grandemaioria dos casos, ela apresenta um resultado muito melhordo que a REACT.
Em outro experimento, foi utilizado um segundo cenário,mostrado na figura 7. Nesse cenário há dois alvos que sealternam, de modo que o robô deve percorrer um circuito deida e volta entre eles.
No entanto, observou-se que nesse cenário, a arquiteturaaprendiz apresentou desempenho muito melhor, já que, en-quanto a arquitetura REACT se mostrou incapaz de, muitasvezes, cumprir o objetivo, a arquitetura AAREACT iniciou
Figura 7: Ambiente da segunda experiência no simulador.Os alvos estão indicados com um ×.
sua atuação com um desempenho satisfatório, e, à medidaem que se adaptava ao ambiente específico, melhorava seudesempenho de modo visível, como mostra a figura 8. Noentanto, a fase de adaptação é caracterizada por uma grandeoscilação na curva de desempenho, resultando nos “picos”observados no gráfico referente à AAREACT até a 24a volta.
0 5 10 15 20 25 30 35 400
500
1000
1500
2000
2500
No. de voltas
Tem
po g
asto
em
cad
a vo
lta (
s)
REACTAAREACT
Figura 8: Comparação gráfica dos resultados entre os desem-penhos das arquiteturas AAREACT e REACT no segundocenário do simulador.
8 CONCLUSÃO
Foi apresentada uma arquitetura adaptativa para robôs mó-veis baseada em comportamentos reativos e com capacidadede aprendizado. Os resultados obtidos com a arquitetura AA-REACT demonstram que a adaptação da influência de cada
184 Revista Controle & Automação/Vol.18 no.2/Abril, Maio e Junho 2007

comportamento na atuação do robô de acordo com a situa-ção encontrada de fato melhora o seu desempenho, quandocomparado com o obtido pela ponderação fixa dos comporta-mentos na coordenação cooperativa dos mesmos, conformeimplementada na REACT. Alguns experimentos mostraram,inclusive, que a arquitetura adaptativa é capaz de fazer o robôatingir seu objetivo em alguns ambientes nos quais a arqui-tetura REACT dificilmente tem sucesso. O aprendizado daAAREACT procura ajustar a atuação do robô a uma situa-ção percebida localmente. Assim, ela não foi projetada parase adaptar a um ambiente específico, mas seu aprendizadoé orientado de forma a ajustar a atuação do robô de modoa se comportar bem nas várias configurações possíveis doambiente. Por isso, o resultado do aprendizado inicial, reali-zado em um ambiente específico, é utilizado pela arquiteturaem todos os outros ambientes, onde o aprendizado continuaa ser realizado, de forma incremental. Mesmo que o robôopere sempre em um ambiente específico e se especializenele, a transição para outro ambiente ocorre facilmente, umavez que o aprendizado evolui naturalmente.
No entanto, não é possível concluir que o conjunto de atribu-tos e de pesos, e a função reforço utilizados são realmente osque proporcionam melhor resultado para o aprendizado. Éimportante ressaltar, porém, que a tarefa para qual foi proje-tada a arquitetura é bastante genérica no âmbito de robóticamóvel, de forma que a investigação a respeito do refinamentodos atributos, pesos e reforços definidos podem consistir emuma contribuição importante. Por isso, como trabalho futuro,sugere-se a realização de estudos comparativos entre possí-veis atributos e reforços, além da determinação de atributoseficientes baseados em outros tipos de sensores utilizados nodesvio de obstáculos de robôs móveis.
AGRADECIMENTO
Antonio Henrique P. Selvatici agradece o apoio dado pelaFundação de Amparo à Pesquisa do Estado de São Paulo —FAPESP, através do processo no. 02/11792-0, e pelo Con-selho Nacional de Desenvolvimento Científico e Tecnoló-gico — CNPq, através do processo número 1408682005-4.Este trabalho teve apoio parcial do projeto MultiBot CA-PES/GRICES, proc. n. 099/03.
REFERÊNCIAS
Arkin, R. C. (1998). Behavior-Based Robotics, The MITPress, Cambridge, MA.
Borenstein, J. and Koren, Y. (1990). Real-time obstacle avoi-dance for fast mobile robots in cluttered environments,Proceedings of the 1990 IEEE Conference on Roboticsand Automation, Vol. 1, pp. 572–577.
Colombini, E. L. and Ribeiro, C. H. (2005). An analy-sis of feature-based and state-based representations formodule-based learning in mobile robots, Proceedingsof the 5th International Conference on Hibrid Intelli-gent Systems, IEEE Computer Society, Rio de Janeiro,Brasil, pp. 163–168.
Elfes, A. (1989). Occupancy Grids: A Probabilistic Fra-mework for Robot Perception and Navigation, PhD the-sis, Department of Electical and Computer Enginee-ring, Carnegie Mellon University.
Kaelbling, L. P., Littman, M. L. and Moore, A. (1996). Rein-forcement learning: A survey, Journal of Artificial In-telligence Research 4: 237–285.
Kalmár, Z., Szepesvári, C. and Lörincz, A. (1998). Module-based reinforcement learning: Experiments with a realrobot, Machine Learning 31: 55–85.
Koren, Y. and Borenstein, J. (1991). Potential field methodsand their inherent limitations for mobile robot naviga-tion, Proceedings of the IEEE Conference on Robo-tics and Automation, Sacramento, California, pp. 1398–1404.
Mitchell, T. (1997). Machine Learning, McGraw-Hill, Bos-ton, MA.
Monteiro, S. T. (2002). Estudo de desempenho de agorit-mos de aprendizagem sob condições de ambigüidadesensorial, Master’s thesis, Instituto Tecnológico de Ae-ronáutica, São José dos Campos, Brasil.
Murphy, R. (2000). Introduction to AI Robotics, The MITPress, Cambridge, MA.
Pacheco, R. N. and Costa, A. H. R. (2002). Navegação derobôs móveis utilizando o método de campos potenci-ais, in M. T. S. Sakude and C. de A. Castro Cesar (eds),Workshop de Computação – WORKCOMP’2002, Ins-tituto Tecnológico de Aeronáutica, São José dos Cam-pos, SP, pp. 125–130.
Ranganathan, A. and Koenig, S. (2003). A reactive robot ar-chitecture with planning on demand, Proceedings of theIEEE/RSJ Int. Conf. on Intelligent Robots and Systems,Vol. 2, Las Vegas, Califórnia, pp. 1462–1468.
Ribeiro, C. H. C., Costa, A. H. R. and Romero, R. A. F.(2001). Robôs móveis inteligentes: princípios e técni-cas, in A. T. Martins and D. L. Borges (eds), I Jornadade Atualização em Inteligência Artificial - JAIA. Anaisdo XXI Congresso da Sociedade Brasileira de Compu-tação, Vol. 3, SBC, Fortaleza, CE, pp. 257–306.
Revista Controle & Automação/Vol.18 no.2/Abril, Maio e Junho 2007 185

Russel, S. and Norvig, P. (2003). Artificial Intelligence: AModern Approach, 2nd edn, Prentice Hall, Upper Sad-dle River, New Jersey.
Selvatici, A. H. P. (2005). AAREACT: Uma arquitetura com-portamental adaptativa para robôs móveis que integravisão, sonares e odometria, Master’s thesis, Escola Po-litécnica da Universidade de São Paulo, São Paulo, Bra-sil.
Selvatici, A. H. P. and Costa, A. H. R. (2004). Combinaçãode sensores através da cooperação de comportamentosprimitivos, Anais do XV Congresso Brasileiro de Auto-mática CBA’2004, Gramado, RS.
Sutton, R. S. and Barto, A. G. (1998). Reinforcement Lear-ning: An Introduction, MIT Press, Massachussets, MA.
186 Revista Controle & Automação/Vol.18 no.2/Abril, Maio e Junho 2007






















