Embed Size (px)
Citation preview

Dc
AGa
b
a
ARR1AA
KRLCIU
1
tisnattmtth
1
ib
(
h1
Journal of Computational Science 12 (2016) 83–94
Contents lists available at ScienceDirect
Journal of Computational Science
journa l h om epage: www.elsev ier .com/ locate / jocs
esign of a recommender system based on users’ behavior andollaborative location and tracking
lberto Huertas Celdrána,∗, Manuel Gil Péreza, Félix J. García Clementeb,regorio Martínez Péreza
Departamento de Ingeniería de la Información y las Comunicaciones, University of Murcia, 30100 Murcia, SpainDepartamento de Ingeniería y Tecnología de Computadores, University of Murcia, 30100 Murcia, Spain
r t i c l e i n f o
rticle history:eceived 7 October 2015eceived in revised form9 November 2015ccepted 27 November 2015vailable online 10 December 2015
a b s t r a c t
During the last years, mobile devices allow incorporating users’ location and movements into recommen-dations to potentially suggest most valuable information. In this context, this paper presents a hybridrecommender algorithm that combines users’ location and preferences and the content of the itemslocated close to such users. This algorithm also includes a way of providing implicit ratings consider-ing the users’ movements after receiving recommendations, aimed at measuring the users’ interest for
eywords:ecommenderocation-basedollaborative
mplicit ratings
the recommended items. Conducted experiments measure the effectiveness and the efficiency of ourrecommender algorithm, as well as the impact of implicit ratings.
© 2015 Elsevier B.V. All rights reserved.
sers’ behavior
. Introduction
The increasing volume of information received by people inheir daily lives usually presents the challenge of deciding whatnformation is useful for them, and which does not. Recommenderystems are tools that can be used to suggest items that mayot have been found by users themselves [1]. In this context, thedvent of mobile devices has allowed the use of location informa-ion to provide context-aware recommendations by consideringhe distance between users and items, as well as their subsequent
ovements. The ability to combine users’ location and movements,ogether with other aspects like users’ preferences, items’ proper-ies, or users’ ratings provides more valuable information that canelp to suggest more accurate items of potential interest to users.
.1. Motivation
Designing a recommender system with the previous aspectss a complex task, as it should need to combine a large num-er of parameters, such as the ones defined in collaborative (CF)
∗ Corresponding author.E-mail addresses: [email protected] (A.H. Celdrán), [email protected]
M.G. Pérez), [email protected] (F.J. García Clemente), [email protected] (G.M. Pérez).
ttp://dx.doi.org/10.1016/j.jocs.2015.11.010877-7503/© 2015 Elsevier B.V. All rights reserved.
[2], content-based (CBF) [3], and context-aware (CAF) [4] filteringtechniques. First, the user-based CF methods recommend items bytaking into account the feedback (ratings) of users with similar pre-ferences to the target user. Secondly, the CBF approaches operatewith the similarity of the items, so similar items to the ones liked bythe target user are recommended. Finally, the location-based CAFapproaches use the location of users to recommend items close tothem. These techniques present certain challenges that have to beaddressed adequately; namely:
• How to find similar users so as to consider their ratings whengenerating new recommendations in the CF models.
• How to create users’ profiles and classify items in the CBFapproaches.
• How to use the location and the tracking of users in the location-based CAF approaches, also taking into account the environmentinformation where the elements (users and items) are.
These techniques also present additional drawbacks [5], suchas sparsity and cold-start in the CF approaches, the need of humanknowledge to classify items and users considering different aspects
(e.g. establishing the relationship between the items’ informationand the likes of users) in the CBF approaches, and the use of com-plex systems to represent and model the users’ context in theCAF approaches. Although current hybrid recommenders combine
84 A.H. Celdrán et al. / Journal of Computational Science 12 (2016) 83–94
Table 1Comparative of recommender systems.
Recommenders
Information [10] [11] [12] [14] [15] [16] [17] [18] Ours
Items’ properties√ √
CBF Users’ preferences√
Users’ profile√
Ratings√ √ √ √ √
CF Tracking√
Users’ preferences√ √
Location√ √ √ √ √ √
Direction√
CAF Time√ √ √ √
Social relationships√ √
Physical conditions√ √ √
Budget
Preference
Age
Gender
Profession
Abilityinherits
TimeStamp
Tracking
hasPreference isPreferenceOf
ion
isRelatedTo
Recommendation Rating
Expiration hasItemRatinghasExpiration
DatehasDateRating
hasDateRecommendation
Item
Property
User
hasUserRating
hasItemisItemOf
Elementinherits inherits
ServicehasRecommendationisRecommendationOf
hasRecommendedItem
VisitedPlace
Duration
hasTimeStamp
hasDurationPath
isSpaceOf hasSpace
isPathOfhasPath
inherits
SpaceLocation
inherits
hasVisitedPlace
isVisitedPlaceOf
Thing
hasElementisLocated
mme
sdrsmnbi
1
tSbuooo(wotcfab
Preferences Recommendat
Fig. 1. The reco
ome of the previous approaches in order to minimize the previousrawbacks and provide most valuable items [6], more work is stillequired. Moreover, rating is another major aspect in recommenderystems. Most existing solutions only rely on users to rate recom-endations, although it is proved that a large number of users do
ot usually spend time rating items. We believe that ratings shoulde mostly generated by recommenders automatically, as indicated
n [7,8].
.2. Our contribution
In order to conduct the tasks mentioned earlier, we propose inhis paper a hybrid recommender with an implicit rating support.pecifically, our recommender algorithm ranks the suggested itemsy considering ratings given by our rating procedure for similarsers to the target one (CF approach). We think that the ratingsf users similar to the target are useful in order to offer new rec-mmendations to him/her. In this sense, similar users are foundut combining their implicit ratings about items, their preferenceslikes, gender, budget, etc.), and their tracking in the environmenthere they are. The majority of the collaborative filtering solutions
nly use the ratings of users to measure their similarity, but we alsohink that in location-based solutions the users’ tracking should be
onsidered to know the places most visited by users and, there-ore, their likes and preferences. Furthermore, items’ propertiesre used by our recommender algorithm to measure the similarityetween items, with which we can suggest new items with similarhasProperty
nder ontology.
properties (type, price, etc.) to the items usually liked by the targetuser (CBF approach). Finally, the context-aware information relatedto the location and description of elements close to the users, aswell as their relevance and meaning (CAF approach), is used by ourrecommender to rank and filter items. The information managedby the combination of these approaches allows us to provide accu-rate recommendations and decrease problems like cold-start andsparsity [9].
Regarding the way of generating implicit ratings automati-cally, we propose a novel rating procedure that takes into accountthe users’ movements after receiving the recommendations (userbehavior-aware approach). It considers the time and the locationsof users and items in order to measure the users’ interest for therecommended items to provide a rating score. An example of usingtime to measure the interest is when the time since a user receives arecommendation until he/she reaches the item gets shorter, the rat-ing for the item gets greater. Note that the implicit rating procedureproposed here may be adopted in any other location-based recom-mender algorithm. Furthermore, our recommender algorithm andrating procedure are configurable through parameters, allowingbeing adapted to different environments.
1.3. Paper organization
The remainder of the paper is structured as follows. Section 2discusses the main related work regarding other recommender sys-tems. Section 3 presents our solution, where the ontology managed

A.H. Celdrán et al. / Journal of Computational Science 12 (2016) 83–94 85
Get target user's preferences and item's properties
Compute the similarity between users and items
Compute the similarity between items
Compute user's similarity with others regarding the item
Compute the user's final score regarding the item
Compute the distance between users and the item
Obtain the users' tracking (movements)
Rank above results to compute item’s recommendation
Add the item to the recommend list
sort and return the list of recommended items
No
|common preferences/properties|=0Yes
for each of the available items
target user, available items, other previous users
3.2.1
3.2.2
3.2.3
3.2.4
3.2.5
3.2.6
3.2.7
Section
// Filter undesired items
// Ratings from similar users
Lines in Listing 1
4, [7-9]
4, 10
11
8
9
16
3, 17, 18
19
20
4, 5, [12-15]
(1)
(2)
(8)
(9)
(10)
(11)
(6) & (7)
Equation Result
iIV
,t iPPV
,t iDV
,t iTV
,t iFV
,t iUV
CBF CF location-based CAFApproach:
Fig. 2. Design flowchart of the recommender system.
of the
baSocw
2
r
Listing 1. Pseudo-code
y the recommender is described in Section 3.1. The recommenderlgorithm and the rating procedure are thoroughly explained inections 3.2, 3.3, respectively. Section 4 shows the deploymentf our recommender system and reports some experimental out-omes to analyze its performance. Finally, conclusions and futureorks are drawn in Section 5.
. Related work
Traditional recommender systems were initially focused onecommending items but only considering their preferences. These
recommender function.
systems were based on the CF or the CBF models [2,3]. First, theCBF approach classified items according to their content and theusers’ preferences, but classifying items is a hard task that usuallyrequires human knowledge. Secondly, the CF models surfaced toovercome this drawback, considering stereotype-based models toestablish the similarity between users. So, the CF models targeted torecommend items that people with similar preferences had liked.
Nowadays, we consider that it is not enough to just use the CBFand the CF models to give recommendations. The location and theinformation regarding the environment, where users and items are,are also useful to recommend appropriate items. A depth study on

86 A.H. Celdrán et al. / Journal of Computa
Table 2Parameters to calculate the precision, recall, and F-measure.
Parameters in
Eq. (6) Eq. (11)
Users’ similarity by using ̨ � ε ω �
P only Pearson coefficient 0 1 0 0 1
PPPearson (P) 0.5 0.5 0 0 1
Preferences
PPSSPearson + Preferences (PP) 0.5 0.5 0.25 0.25 0.5
Similarity between items• Similarity between users and items
A
riwcmieiruot
tlcsdacCttrpsettimftcgtgt
strst
throughout this section.
pproach: CBF and CF.
ecommender systems argued the importance of the context-awarenformation to recommendations, where a number of solutions
ere analyzed [4]. For example, Mak et al. [10] suggested moviesonsidering techniques of text categorization to learn from theovie synopses. In that sense, to get recommendations, the user
s asked to rate a minimum number of movies into different cat-gories. Umyarov and Tuzhilin [11] incorporated external ratingsnto the recommender process, and demonstrated that this helpedecommender systems to provide more accurate estimations ofnknown ratings. Yang et al. [12] proposed a distance-based rec-mmender system, considering the location of users and items, andhe content of the latter to suggest items related to users’ needs.
Despite the advances of the above solutions, the context-awareechniques had limitations for not considering the ratings of simi-ar users or the items’ content. Although the CF and the CBF modelsonsidered these aspects, they had other problems like data spar-ity, cold-start, or scalability [9]. Due to this, hybrid solutions wereefined [13]. Oku et al. [14] proposed a way to include new context-ware information in the CF recommender algorithm, such as time,ompanion, and weather by using a multidimensional approach.hen presented in [15] a context-aware and CF recommender sys-em that predicted the users’ preferences in different contexts byaking past experiences of like-minded users. Chen defined theequirements of the context-aware information into a CF model androposed a solution combining the two. Cantador et al. [16] pre-ented an ontology-based context-aware CF solution where theyvaluated and combined two models: the first one consideringhe users’ preferences, interests, and profiles to rank items; andhe second one reordering items according to the context-awarenformation. LARS [17] was another CF and location-aware recom-
ender system supporting three classes of ratings: spatial ratingsor non-spatial items, non-spatial ratings for spatial items, and spa-ial ratings for spatial items. The CF approach was used by LARS toonsider the rating of users located in the same region of the tar-et user. Dao et al. [18] proposed a CF approach that consideredhe location, time, and needs of the users to recommend items by aenetic algorithm. They defined discrete contexts, and applied con-ext similarity to create a context-aware recommendation model.
Despite the progress of the previous works, more work istill required to improve key aspects like combining the informa-ion of each one of the previous approaches to provide accurate
ecommendations; reducing problems such as cold-start, spar-ity, complexity, and scalability; and supporting implicit ratingshat consider the users’ location and the context information.tional Science 12 (2016) 83–94
Furthermore, the previous works only relied on users to rate recom-mendations, thereby shortening the capacity to quickly convergeunder any new situation. In this sense, our solution faces this lim-itation by automatically rating the recommended items accordingto the users’ movements after receiving these recommendations.Finally, although users’ privacy is an important issue in recom-mender systems, we do not address it here as it should be mostlycovered by the architecture in which the recommender algorithmoperates. Several solutions, such as [19–21], present different waysto preserve users’ privacy, which can integrate our solution toprovide recommendations in a privacy-preserving way. A compar-ison between the recommender we propose here and the mainrelated works introduced throughout this section is illustrated inTable 1.
3. Recommendations and ratings
We present in this section how our recommender combinesthe CF approach, considering the ratings from similar users; theCBF approach, taking into account the items’ properties; and thecontext-aware information regarding the users’ and items’ loca-tion to offer recommendations. We also present a location-basedalgorithm to rate the recommended items automatically, consid-ering the users’ movements after receiving recommendations (i.e.,user behavior-aware approach).
3.1. How to model the information
We use semantic web techniques to model the information ofour recommender system [22], which provides a common approacheasing the tasks of representing, processing, and sharing informa-tion between independent systems. In this context, we present theRecommender ontology as an extension to the PRECISE ontologyproposed in [21], and accessible on-line in [23]. The Recommenderontology shapes the information of four related topics: recommen-dation, preference, location, and tracking. Fig. 1 shows the mostimportant elements that compose these topics.
The top-level class of the recommendation topic is Recom-mendation. These recommendations are provided to Users aboutseveral Items belonging to certain Services. They are received at aDate with a duration defined by Expiration. Recommended itemscan be classified by using the Property class, and are rated throughthe Rating class that stores the value and Date of each rating. Userscan define their preferences regarding types of items in which theyare interested to receive recommendations. The Preference classbelongs to the preference topic with five predefined subclasses:Age, Gender, Profession, Budget, and Ability. Finally, the Recom-mender ontology is based on the work proposed in [24] to modelthe tracking and location topics, where users’ tracking is shapedby the Path class. Each path can have several Visited Places, whereeach place is given by a Timestamp, a Duration, and a Space class.The ontology can be extended to work in other scenarios. An exam-ple on a realistic scenario and the complete ontology is provided in[25].
3.2. Recommender algorithm
The flowchart for showing how our recommender systemoperates to suggest items located at the users’ environment isdepicted in Fig. 2. The right hand side of this flowchart is includ-ing the references on which section the corresponding step of therecommender is defined. Further information will be also provided
In order to perform each of the steps of Fig. 2, we define therecommender function whose pseudo-code is shown in Listing 1.This function returns a list of recommended items in accordance

A.H. Celdrán et al. / Journal of Computational Science 12 (2016) 83–94 87
Fig. 3. Precision of the recommender for two numbers of similar users.
Fig. 4. Recall of the recommender for two numbers of similar users.
nder
wiTa
pArur(3turtb
3
c
Fig. 5. F-measure of the recomme
ith the parameters received: the target user, the list of availabletems, and the list of users who have used the system previously.he effectiveness of some of the equations and metrics proposedre analyzed in Section 4.1.
The recommender function first filters items by comparing theirroperties with the users’ preferences (lines 4 and from 7 to 9).fter that, it measures the similarity between items (line 11), theatings of similar users (lines from 12 to 16), the distance betweensers and items (lines 17 and 18), and the users’ movements toank the items (line 19); and finally provides the recommendationslines from 20 to 25). Note that the first lines in Listing 1 (from
to 5) could be inserted into the loop, but they are outside dueo performance matters. Furthermore, some information such assers’ paths or ratings are not contained in the parameters of theecommender function, because there are some other defined func-ions that retrieve this information from the users’ data. We explainelow in detail all this process.
.2.1. Filtering undesired itemsThe content of items is an important aspect to decide if a spe-
ific item can be or not of interest by a given user. We consider
for two numbers of similar users.
undesired items (from the perspective of the target user) if they donot have at least one property in common with the target user’s pre-ferences. Thus, our algorithm filters in this step the items that do notaccomplish this condition. Items’ properties and users’ preferencesare used to decide whether users U = {u1, u2, . . ., um} are interestedor not in one or more items of the set I = {i1, i2, . . ., in}, where m isthe number of users and n the number of items. In this context, thecommonPreferencesProperties function (line 8 in Listing 1) comparesthe preferences Pt = {p1, p2, . . ., po} of user t (line 4), where o is thenumber of preferences of user t, with the properties Pri = {pr1, pr2,. . ., prp} of item i (line 7), where p is the number of properties ofthe i-th item. After comparing both sets, the function returns thenumber of common preferences/properties (cpprnt,i), whereas if nocommon preferences/properties exist, the item is filtered.
3.2.2. Computing similarity between users and itemsWe measure the similarity between the target user and each
item by comparing his/her preferences with the item’s properties.Our algorithm considers that properties common to many items areless important than others specific to a few of them. Besides, it alsotakes into account the number of preferences and properties. For
88 A.H. Celdrán et al. / Journal of Computational Science 12 (2016) 83–94
Table 3Parameters used in the second experiment to measure the effectiveness of therecommender.
Second experiment on Eq. (7)
Parameter Domain Description
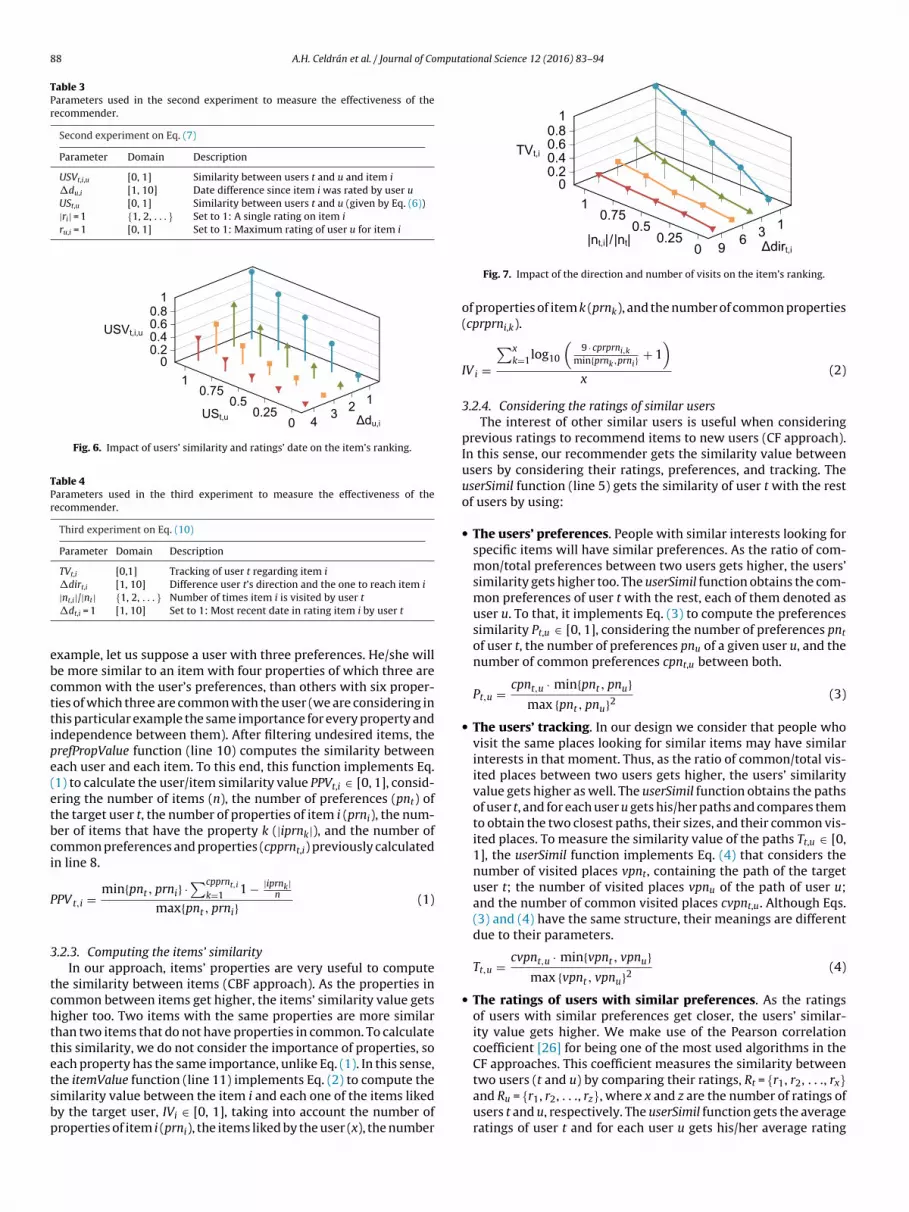
USVt,i,u [0, 1] Similarity between users t and u and item i�du,i [1, 10] Date difference since item i was rated by user uUSt,u [0, 1] Similarity between users t and u (given by Eq. (6))|ri| = 1 {1, 2, . . . } Set to 1: A single rating on item iru,i = 1 [0, 1] Set to 1: Maximum rating of user u for item i
Fig. 6. Impact of users’ similarity and ratings’ date on the item’s ranking.
Table 4Parameters used in the third experiment to measure the effectiveness of therecommender.
Third experiment on Eq. (10)
Parameter Domain Description
TVt,i [0,1] Tracking of user t regarding item i�dirt,i [1, 10] Difference user t’s direction and the one to reach item i
ebcttipe(etbci
P
3
tchttetsbp
|nt,i|/|nt| {1, 2, . . . } Number of times item i is visited by user t�dt,i = 1 [1, 10] Set to 1: Most recent date in rating item i by user t
xample, let us suppose a user with three preferences. He/she wille more similar to an item with four properties of which three areommon with the user’s preferences, than others with six proper-ies of which three are common with the user (we are considering inhis particular example the same importance for every property andndependence between them). After filtering undesired items, therefPropValue function (line 10) computes the similarity betweenach user and each item. To this end, this function implements Eq.1) to calculate the user/item similarity value PPVt,i ∈ [0, 1], consid-ring the number of items (n), the number of preferences (pnt) ofhe target user t, the number of properties of item i (prni), the num-er of items that have the property k (|iprnk|), and the number ofommon preferences and properties (cpprnt,i) previously calculatedn line 8.
PVt,i = min{pnt, prni} ·∑cpprnt,i
k=1 1 − |iprnk |n
max{pnt, prni}(1)
.2.3. Computing the items’ similarityIn our approach, items’ properties are very useful to compute
he similarity between items (CBF approach). As the properties inommon between items get higher, the items’ similarity value getsigher too. Two items with the same properties are more similarhan two items that do not have properties in common. To calculatehis similarity, we do not consider the importance of properties, soach property has the same importance, unlike Eq. (1). In this sense,
he itemValue function (line 11) implements Eq. (2) to compute theimilarity value between the item i and each one of the items likedy the target user, IVi ∈ [0, 1], taking into account the number ofroperties of item i (prni), the items liked by the user (x), the numberFig. 7. Impact of the direction and number of visits on the item’s ranking.
of properties of item k (prnk), and the number of common properties(cprprni,k).
IV i =∑x
k=1log10
(9 · cprprni,k
min{prnk,prni} + 1)
x(2)
3.2.4. Considering the ratings of similar usersThe interest of other similar users is useful when considering
previous ratings to recommend items to new users (CF approach).In this sense, our recommender gets the similarity value betweenusers by considering their ratings, preferences, and tracking. TheuserSimil function (line 5) gets the similarity of user t with the restof users by using:
• The users’ preferences. People with similar interests looking forspecific items will have similar preferences. As the ratio of com-mon/total preferences between two users gets higher, the users’similarity gets higher too. The userSimil function obtains the com-mon preferences of user t with the rest, each of them denoted asuser u. To that, it implements Eq. (3) to compute the preferencessimilarity Pt,u ∈ [0, 1], considering the number of preferences pnt
of user t, the number of preferences pnu of a given user u, and thenumber of common preferences cpnt,u between both.
Pt,u = cpnt,u · min{pnt, pnu}max {pnt, pnu}2
(3)
• The users’ tracking. In our design we consider that people whovisit the same places looking for similar items may have similarinterests in that moment. Thus, as the ratio of common/total vis-ited places between two users gets higher, the users’ similarityvalue gets higher as well. The userSimil function obtains the pathsof user t, and for each user u gets his/her paths and compares themto obtain the two closest paths, their sizes, and their common vis-ited places. To measure the similarity value of the paths Tt,u ∈ [0,1], the userSimil function implements Eq. (4) that considers thenumber of visited places vpnt, containing the path of the targetuser t; the number of visited places vpnu of the path of user u;and the number of common visited places cvpnt,u. Although Eqs.(3) and (4) have the same structure, their meanings are differentdue to their parameters.
Tt,u = cvpnt,u · min{vpnt, vpnu}max {vpnt, vpnu}2
(4)
• The ratings of users with similar preferences. As the ratingsof users with similar preferences get closer, the users’ similar-ity value gets higher. We make use of the Pearson correlationcoefficient [26] for being one of the most used algorithms in theCF approaches. This coefficient measures the similarity between
two users (t and u) by comparing their ratings, Rt = {r1, r2, . . ., rx}and Ru = {r1, r2, . . ., rz}, where x and z are the number of ratings ofusers t and u, respectively. The userSimil function gets the averageratings of user t and for each user u gets his/her average rating
A.H. Celdrán et al. / Journal of Computational Science 12 (2016) 83–94 89
s on t
edefgTU˛tirswtcpo
U
lciistiuurtb1to
Fig. 8. Impact of response and visiting time
as well as the rating for each item. With this information, thisfunction implements Eq. (5) to compute the rating importanceRt,u ∈ [−1, 1], considering the ratings (rt,i) of user t for item i, theratings of user u for item i (ru,i), and the average rating of both (rt
and ru).
Rt,u =∑
i(rt,i − r̄t) · (ru,i − r̄u)√∑i(rt,i − r̄t)
2 ·√∑
i(ru,i − r̄u)2(5)
Finally, we have to combine the three previous aspects to gen-rate the users’ similarity value. In that sense, we allow users toecide the relevance of each factor in the final similarity value. Forxample, a user could not be interested in considering his/her pre-erences to calculate his/her similarity with other users, or couldive more importance to his/her ratings than his/her visited places.he userSimil function computes the final users’ similarity valueSt,u ∈ [0, 1] following Eq. (6), where ˛, ˇ, and � ∈ [0, 1], with
+ ̌ + � = 1, are the weights set by an administrator to indicatehe importance of Pt,u, Tt,u, and Rt,u, respectively. It is worth not-ng that the function userSimil computes the similarity level beforeeceiving recommendations, in order to avoid performance andcalability problems. While the administrators set these weightsith default values, our recommender also allows users to establish
heir values ( ̨ + ̌ + �) according to their own preferences. Specifi-ally, ̨ indicates the weight that the similarity between the user’sreferences will have in the final value for USt,u, ̌ the importancef the visited places, and � the importance of ratings.
St,u = ̨ · Pt,u + ̌ · Tt,u + � · Rt,u + 12
(6)
The next step consists on deciding how to combine the simi-arity value of user t with the rest of users, denoted as USt,u andomputed as given by Eq. (6), with the users’ ratings. Thus, if item
was rated recently, the importance of the rating is higher thanf the rating is old. Besides, if the item has been rated by a user ueveral times, the importance of the rating for any user u is higherhan if it has just been rated once. The userRatings function (line 14)mplements Eq. (7) to compute the similarity between users t and
and item i, USVt,i,u ∈ [0, 1]. This uses the similarity between t and (USt,u), the rating of u for item i (ru,i), the number of ratings of uegarding i (|ru,i|), the number of times that i has been rated (|ri|),he relevance of the ratio between |ru,i| and |ri|, and the difference
etween the current date and when item i was rated (�du,i ∈ [1,0]). In this equation, note that ru,i corresponds to the final ratinghat was computed by our recommender with respect to the previ-us interactions performed by user u with item i. This final rating ishe item’s rating (y-axis is this final rating).
subsequently defined in Section 3.3.5 and computed by using Eq.(17).
USVt,i,u = USt,u · ru,i
�du,i− 0.5 ·
(1 − |ru,i|
|ri|)
(7)
Finally, the recommender function invokes the userValue func-tion (line 16) with the ratings of the similar users for item i. Thisfunction implements Eq. (8), which uses the aggregation function(denoted as ⊕) to combine the previous information and provide afinal value to item i for user t: UVt,i ∈ [0, 1].
UVt,i = ⊕mu=1USVt,i,u (8)
3.2.5. Considering the location of users and itemsThe location is a key factor to measure the importance of items
for users (location-based CAF approach), as items closest to thetarget user are more relevant than the ones far away. In order tomeasure distances, we use the Manhattan distance rather than oth-ers, such as the Euclidean distance, due to it is not always possibleto go straight from one place to another. The recommender func-tion gets the location of user t (line 3) and item i (line 17), and theManhattan distance between the two most distant points in thespace. With them, the distanceValue function (line 18) computesthe importance of this distance DVt,i ∈ [0, 1] through Eq. (9), whichtakes the Manhattan distance between user t and item i in an y-dimension space and the distance of the two most distant points inthe space (d).
DVt,i = 1 −∑y
z=1(lt − li)
d(9)
3.2.6. Considering the users’ trackingThe places visited by users are very important to know their
interests, as items in places frequently visited, and those locatedin the same direction in which the user is moving, are usuallymore important than others (location-based CAF approach). In thiscontext, the getTimesPlaces function (line 19) gets the number oftimes that user t has visited the same location where item i is(|nt,i|); the getTimesMostVisitedPlace function returns the numberof times that user t has been in his/her most visited place (|nt|),with |nt,i| ≤ |nt|; and the getDiffDirection function gets the differencebetween the user’s direction and the required direction to achieveitem i (�dirt,i ∈ [1, 10], where 1 means that the user is going straightto the item and 10 is the opposite direction). Finally, the getDiffDatefunction returns the difference between the current date and thedate when the user visited item i last time (�dt,i ∈ [1, 10], where
1 means that the item was recently rated and 10 the opposite). Eq.(10) is used in the trackingValue function (line 19) to compute theuser’s tracking, denoted as TVt,i ∈ [0, 1]. Eq. (10) considers that asthe number of times that user t has visited item i gets higher, and
90 A.H. Celdrán et al. / Journal of Computational Science 12 (2016) 83–94
e on th
tl
T
3
gtepehbfϕitωt
F
3
tufat
3
rigltoiroFltt
Fig. 9. Impact of the assiduity and distanc
he difference between the user’s direction and the spent time getsower, the tracking score gets higher.
Vt,i =|nt,i ||nt |
�dirt,i · �dt,i(10)
.2.7. Ranking items to generate recommendationsThe final step consists on combining the previous parameters to
enerate the value that ranks the items and which will be suggestedo the user in the recommendation. In this sense, and as indicatedarlier, we allow users to establish the level of importance of eacharameter depending on their interest. If a user wants that the clos-st items have more relevance in the recommendation than the rest,e/she can indicate it. The relevance of item i for user t is computedy the finalV function (line 20), which implements Eq. (11). Thisunction considers all the previous aspects, but weighted by ε, ω, �,, � ∈ [0, 1] (with ε + ω + � + ϕ + � = 1) to establish their importance
n the final value of FVt,i ∈ [0, 1]. Specifically, ε indicates the weighthat the similarity between users and items has in the final value,
the weight of the items’ similarity, � the ratings of similar userso the target, ϕ the distance, and � the tracking.
Vt,i = ε · PPVt,i + ω · IV i + � · UVt,i + ϕ · DVt,i + � · TVt,i (11)
.3. Rating algorithm
Our recommender algorithm supports implicit rating based onhe users’ tracking after receiving recommendations to measure thesers’ interest for the recommended items. To this end, the ratingunction automatically rates the recommended items by using thespects described below. The effectiveness of the proposed equa-ions is measured in 4.2.
.3.1. The response timeThe time since a user receives a recommendation until he/she
eaches the places where the items are is a potential measure on thenterest of this particular user on such items. As the response timeets shorter, the rating for the item gets greater. As we know theocation of the user and the items, we can estimate the time neededo reach the item, so we compare it with the spent time in order tobtain the user’s interest. If the time difference is small, the user’snterest is greater than if the difference is large. To this end, theating function gets the date (time) when the user received the rec-mmendation, as well as computing the location at that moment.
or each item, the function compares if user t was in the item’socation. If so, Eq. (12) computes the rating for each item accordingo the response time RRt,i ∈ [0, 1], where ett,i is the estimated timeo go from the location of user t to the one of item i, considering thee item’s rating (y-axis is this final rating).
distance between the user and the item and the spent time by usert to go to item i (stt,i), with ett,i ≤ stt,i.
RRt,i = e−(
stt,iett,i
−1
)(12)
3.3.2. The visiting timeThe time spent by a user at the places in which recommended
items are located indicates the potential importance of the itemsfor the user. So, as the visiting time gets longer, the rating for theitem gets greater. Moreover, we consider that if the visiting timeis the same for the first and the last recommended items, the rat-ing for the latter ones should be bigger than for the former ones.In this sense, the rating function gets the time that user t stayedat the environment (composed of places, people, items, and theirproperties) during his/her session and the time stayed at the itemi’s location. With these data and the ranking of item i, Eq. (13) auto-matically computes the rating for item i by considering the visitingtime VRt,i ∈ [0, 1], where vtt,i is the visiting time of user t for item i,tt the total time spent by t in the environment, and pt,i the positionof the recommended item i in the list of recommended items.
VRt,i = 1 − e−(
vtt,itt
· pt,i
)(13)
3.3.3. AssiduityThe number of times that a user visits the places where items
are is important to know their relevance for the user. For example,users interested in buying an item first usually visit the stores forcomparing prices, and after knowing which is the cheapest one theywill come back to the chosen store to buy it. Thus, as the assiduitygets bigger, the rating for the item gets greater. To this end, Eq.(14) is used by the rating function to compute the assiduity ratingARt,i ∈ [0, 1], considering for that the number of times that the itemi’s location is visited by user t (at,i).
ARt,i = 1 − e−at,i (14)
3.3.4. The distanceThe distance between the user and the visited items is important
to rate them, as the distance gets longer, the rating for items getsgreater. Eq. (15) computes this distance rating DRt,i ∈ [0, 1] throughthe Manhattan distance between the location of user t and item iin a y dimension space, where d is the distance between the mostdistant points.
DRt,i = 1 − e−∑y
z=1(lt−li)
2
d (15)
3.3.5. The previous ratings
The new rating of user t for item i is computed by consideringthe response time, the visiting time, the assiduity, and the distancein between them. Eq. (16) computes the new item rating scoreNRt,i ∈ [0, 1], considering the previous aspects that are weighted

mputa
uSrdttp
N
so1tit
F
4
truTpmottfac
4
n
4
pttSamp
P
toum
R
m
F
A.H. Celdrán et al. / Journal of Co
sing the parameters: , , �, � ∈ [0, 1] (with + + � + � = 1).pecifically, indicates the weight of the response time in the newating, the impact of the visiting time, � the assiduity, and � theistance. These parameters should be set by the administrators ofhe recommender system depending on the environment wherehe recommender is being implemented, their preferences and thearticular business model of the location they are managing.
Rt,i = · RRt,i + · VRt,i + � · ARt,i + � · DRt,i (16)
The last step in the rating function according to our design con-ists on integrating the new rating of item i with the previous ratingf user t. To this end, Eq. (17) computes this final rating FRt,i ∈ [0,], taking into account the difference between the current time andhe time at which item i was rated (�tt,i), the number of ratings thattem i has (|rnt,i|), the previous rating of user t for item i (rt,i), andhe new rating of user t for item i (NRt,i).
Rt,i = · rt,i − · NRt,i + 1, with = 0.5
e
�tt,i|rnt,i |
(17)
. Experimental results
We analyze in this section the impact of some of the parametershat comprise the equations of our recommender algorithm andating procedure, as well as the importance of their correct config-ration, through conducting experimental tests with a prototype.his implements our hybrid recommender system to validate itsroper functioning and measure its efficiency and scalability. Toanage the information used by our solution, the Recommender
ntology is defined with OWL 2, which was generated with the Pro-égé tool. The Jena API is used to generate ontological models withhe information shaped in the ontology, and the Pellet reasoneror inferring new knowledge. Finally, queries defined in SPARQLre applied to the inferred model generated by Pellet to get theorresponding result and generate the final recommendation.
.1. Effectiveness of the recommender
We conducted three experiments for measuring the effective-ess of our recommender.
.1.1. First experiment: precision, recall, and F-measure metricsTo estimate the prediction accuracy of recommender systems,
recision and recall metrics are the best in top-N recommenda-ion [27]. In this sense, Eq. (18) computes the precision, such ashe proportion of recommended items that users actually liked.pecifically, n is the amount of items which the target user likesnd appears in the recommendation, and TopN is the first n recom-ended items. This measure should be as high as possible for good
erformance.
recision = n
TopN(18)
On the other hand, the recall score is computed in Eq. (19) ashe average proportion of all relevant items included in the rec-mmended items. MT is the number of items liked by the targetser (these items can belong to the recommendation or not). Thiseasure is also as high as possible for good performance.
ecall = n
MT(19)
Finally, the F-measure is computed in Eq. (20) as the harmonicean of precision and recall metrics.
-measure = 2 · Precision · RecallPrecision + Recall
(20)
tional Science 12 (2016) 83–94 91
In order to measure the effectiveness of our recommender sys-tem we use the MovieLens 100k data set. This data set contains100,000 ratings with 943 persons and 1682 movies. Each personhas rated at least 20 movies, each movie can be categorized into19 different genres, and the density of the user-item matrix is 6.3%.Despite MovieLens does not contain location information, we havechosen this one because, to the best of our knowledge, there isnot a data set which contains users’ preferences, items’ proper-ties, users’ tracking, and items’ location. Furthermore, MovieLensis one of the most used data set by the related works, where sev-eral examples of MovieLens can be found in [28,29], for example. Inorder to show how the location features impact the recommendereffectiveness, Zhen et al. demonstrated in [30] that recommendersystems affected by users’ locations significantly enhance the effec-tiveness and precision. Moreover, we conduct the third experiment,in Section 4.1.3, to show how the users’ tracking impact the rec-ommended items.
To evaluate the precision, recall, and F-measure of our recom-mender we use the parameters shown in Table 2, and set the user’spreference considering the genre of the most watched movies bythat user. Furthermore, since our algorithm uses a CF approach,combined with CBF and CAF, we calculate the efficiency of our rec-ommender taking into account two different sets of similar users(K = 10 and K = 100).
Fig. 3 shows the precision of the methods depicted in Table 2,varying the number of recommended items, in which y-axis cor-responds to the precision values and x-axis varies depending onthe TopN recommended items. In this figure, we can see that theprecision of PP and PPSS is better than the precision of P, obtainingthe best values for recommendations composed of 2 items (0.74for K = 10 and 0.78 for K = 100). In addition, we also can see thatincreasing the number of similar users, for example from K = 10 inFig. 3a to K = 100 in Fig. 3b, the precision of the recommendationimproves.
On the other hand, Figs. 4 and 5 show the recall and F-measure,respectively, of the algorithms depicted in Table 2. In these figuresthe y-axis corresponds to the recall and F-measure values and x-axis varies depending on the TopN recommended items. As shownin both figures, the values of PP and PPSS significantly improves theones obtained by P. Specifically, the PPSS algorithm improves theresults when increase the TopN value.
In conclusion, in this section we have demonstrated a significantimprovement on the precision, recall, and F-measure metrics of ourproposal (PP and PPSS) in comparison with the Pearson correlationcoefficient (P).
4.1.2. Second experiment: influence of the similar users’ ratings torank items
As a second experiment, we show how the ratings of similarusers are considered to rank items depending on the similaritybetween users (USt,u) and the date of the ratings (�du,i). Table 3shows the parameters used in conducting this experiment.
The results of this experiment are depicted in Fig. 6, in which theprevious two parameters (similarity between users and date of theratings) are plots of the y and x axis, respectively. We used Eq. (7)to this end, where |ri| and ru,i were set to 1 for seeing more clearlythe impact of other parameters in the final value of USVt,i,u, such asUSt,u and �du,i. Then, when users u and t are very similar (close to1), and the rating of u for item i is recent (�du,i tending to 1), theimpact of this rating is bigger than when the similarity is close to 0and the rating is older (close to 4).
4.1.3. Third experiment: how the users’ tracking affects to theitems’ ranking
The third experiment shows how the user’s tracking affects tothe item’s ranking depending on the number of times that he/she

9 mputational Science 12 (2016) 83–94
vtt
rt
at
4
iipFcthN
I
t(ApbiI
iCtP
oietAdb
tutb(
4
pq
((
(
iRs
Table 5Number of individuals and statements per population.
Population 0 1 2 3
Individuals 30,000 60,000 90,000 120,000Users 2100 4200 6300 8400Items 4500 9000 13,500 18,000Statements 313,841 627,682 941,523 1,255,364
2 A.H. Celdrán et al. / Journal of Co
isits the item and the difference between the user’s direction andhe one required to reach it. Table 4 shows the parameters used inhis experiment.
Specifically, we used Eq. (10), considering �dt,i = 1, whoseesults are depicted in Fig. 7. As seen, when item i is located inhe same direction in which user t is moving (�dirt,i tending to 1),
nd the number of times that a user t visits item i is greater (|nt,i ||nt |
ending to 1), the impact of the tracking value is bigger.
.2. Effectiveness of the implicit ratings
We want now to check how the item’s rating varies when mod-fying the parameters managed by our rating procedure, as definedn Section 3.3. To this end, we conducted an experiment per eacharameter: response time, visiting time, assiduity, and distance.igs. 8 and 9 show the results for each experiment, where y-axisorresponds to the final rating score and x-axis varies depending onhe experiment. It is worth noting that each experiment also showsow the corresponding parameter impacts in the new rating scoreRt,i.
First, Fig. 8a shows how the response time affects to the rating.n this sense, we vary the response time (
stt,iett,i
) in Eq. (12). To do
hat, we used Eq. (16) with the following values: = = � = � = 0.25equal weight for the four parameters) and VRt,i = ARt,i = SDRt,i = 0.63.s shown, when the response time is close to 0, the impact of thisarameter on the rating is bigger than when the response time isigger. Secondly, Fig. 8b shows how the visiting time affects the
tem’s rating, considering the position where it was recommended.n this sense, the visiting time (
vtt,itt
) is modified in Eq. (13).In our solution, the impact of the visiting time is bigger depend-
ng on the position of the item in the recommendation list.onsidering the same visiting time, the item recommended in Posi-ion 10 will have a greater rating than the one recommended inosition 1.
The next experiment, shown in Fig. 9a, checks how the numberf times that a user visits an item (assiduity) affects the item’s rat-ng. To this end, the assiduity value at,i is modified in Eq. (14). Thisxperiment shows that as the number of times that a user visitshe item increase (at,i tending to 4), its rating gets greater value.nd, finally, the last experiment depicted in Fig. 9b shows how theistance between the user and the item affects to the item’s rating,eing the distance modified in Eq. (15).
As a main conclusion of this section, we have demonstratedhat our recommender provides accurate ratings by considering thesers’ similarity and tracking. Furthermore, we have demonstratedhat the visiting and spend time, the assiduity, and the distanceetween users and items are useful parameters to generate impliciti.e., automatic) ratings.
.3. Efficiency of the recommender
We present here some experiments to measure the through-ut and scalability of our prototype. They deal with the followinguestions:
a) Is the computing time of reasoning acceptable?b) How it scales with different amount of individuals (i.e., users,
items, recommendations, ratings, etc.)?c) How the recommendation and rating times vary when consid-
ering the previous premises?
As experimental setting, the conducted tests were carried outn a dedicated PC with an Intel Core i7-3770 3.40 GHz, 16 GB ofAM, and an Ubuntu 12.04 LTS as operative system. The resultshown below were obtained by executing the tests 100 times and
Fig. 10. Recommendation time variation for different populations.
computing their arithmetic mean. In order to answer questions (a)and (b), we measured the Recommender ontology’s performanceby making several executions with different complexity. This com-plexity depends mainly on the statements hold in the knowledgebase, and which are determined by the number of individuals andthe ontology’s complexity. The individuals contained in the ontol-ogy are referred as population. For the experiments, the populationwas randomly generated but taking into account realistic percent-ages of the elements. For example,
• Users are the 7% of the individuals;• Preferences the 8%;• Spaces the 50%;• Items the 15%;• Recommendations, Ratings, and items’ Properties are the 15%;
and• others like Paths and VisitedPlaces, the 5%.
To measure the scalability of the reasoner, in order to answerquestion (b), we defined an initial population of 30,000 individ-uals with 2100 users, where they (the individuals) are increased by30,000 in each step. Table 5 shows the relationships between theindividuals and the statements generated by the reasoner, whichindicates the complexity of our ontology. As observed, the numberof statements obtained after the reasoning process is proportionallyincreased according to the number of individuals. Fig. 10 depictsthe time in milliseconds (ms) used by the reasoner to validate theontology, considering different populations. Furthermore, we usedthe recommender function (defined in Section 3.2) and the rat-ing function (defined in Section 3.3) to answer question (c), whoseresults are shown in Fig. 10.
Our recommender supports a large number of individualswithin a balanced reasoning, recommendation, and rating times.The linearity property of the reasoner time allows us to deducethat a better computer system setting would get lower reasoningtimes. Regarding the recommendation time, we can observe that itis influenced by the population; as more statements in the knowl-edge base, the complexity to provide a recommendation is higher.Finally, the rating time is constant for every population as the num-
ber of recommended items does not vary with the number of usersor items.As a main conclusion of this section, we have shown thatthe reasoner and recommendation times are influenced by the

mputa
prtbui
5
taetttdbdtet
muo(eta
A
wtawSDw(G0
R
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
A.H. Celdrán et al. / Journal of Co
opulation size. When the individuals are linearly increased, theeasoning time also increases linearly, and the recommendationime increases quadratically. In that sense, our solution offers aetter performance in environments with a moderate number ofsers (between 2000 and 6000). On the other hand, the rating time
s constant for different number of individuals.
. Conclusion and future work
We have presented in this paper a hybrid recommender systemhat combines content-based, collaborative filtering, and context-ware approaches to recommend items located at the users’nvironment. It takes into account the context-aware information;he similarity between users-items, users-users, and items-items;he ratings of similar users; the location of users and items; andhe users’ tracking to automatically provide accurate recommen-ations. Our solution also provides implicit location-based ratingsy considering the users’ movements after receiving recommen-ations. To perform the previous tasks, our solution manageshe information by using semantic web techniques. Finally, somexperiments have demonstrated the usefulness and efficiency ofhe proposed solution.
As next steps of research, we plan to improve our recom-ender algorithm incorporating other aspects to measure the
sers’ similarity, such as the distance between the users’ pathsr the relationships between preferences (users) and propertiesitems). Furthermore, we plan to deploy our solution in a realnvironment, where users can probe it and provide their satisfac-ion level. Finally, the privacy of the recommender and its users isnother interesting future work.
cknowledgements
This work has been supported by a Séneca Foundation grantithin the Human Resources Researching Training Program 2014,
he European Commission Horizon 2020 Programme under grantgreement number H2020-ICT-2014-2/671672 – SELFNET (Frame-ork for Self-Organized Network Management in Virtualized and
oftware Defined Networks), the Spanish MICINN (project DHARMA,ynamic Heterogeneous Threats Risk Management and Assessment,ith code TIN2014-59023-C2-1-R), and the European Commission
FEDER/ERDF). Thanks also to the Funding Program for Researchroups of Excellence granted by the Séneca Foundation with code4552/GERM/06.
eferences
[1] F. Ricci, L. Rokach, B. Shapira, Introduction to recommender systemshandbook, in: Recommender Systems Handbook, Springer, US, 2011, pp. 1–35.
[2] J.B. Schafer, D. Frankowski, J. Herlocker, S. Sen, Collaborative filteringrecommender systems, in: Adaptive Web, Springer, Berlin, Heidelberg, 2007,pp. 291–324.
[3] P. Lops, M. de Gemmis, G. Semeraro, Content-based recommender systems:State of the art and trends, in: Recommender Systems Handbook, Springer,US, 2011, pp. 73–105.
[4] G. Adomavicius, A. Tuzhilin, Context-aware recommender systems, in:Recommender Systems Handbook, Springer, US, 2011, pp. 217–253.
[5] J.P. Lucas, S. Segrera, M.N. Moreno, Making use of associative classifiers inorder to alleviate typical drawbacks in recommender systems, Expert Syst.Appl. 39 (1) (2012) 1273–1283.
[6] J. Bobadilla, F. Ortega, A. Hernando, A. Gutiérrez, Recommender systemssurvey, Knowl. Based Syst. 46 (2013) 109–132.
[7] T.Q. Lee, Y. Park, Y.-T. Park, An empirical study on effectiveness of temporal
information as implicit ratings, Expert Syst. Appl. 36 (2009)1315–1321.[8] L. Lerche, D. Jannach, Using graded implicit feedback for Bayesianpersonalized ranking, in: Proceedings of the 8th ACM Conference onRecommender Systems, 2014, pp. 353–356.
tional Science 12 (2016) 83–94 93
[9] G. Guo, J. Zhang, D. Thalmann, Merging trust in collaborative filtering toalleviate data sparsity and cold start, Knowl. Based Syst. 57 (2014)57–68.
10] H. Mak, I. Koprinska, J. Poon, INTIMATE: A web-based movie recommenderusing text categorization, in: Proceedings of the 2003 IEEE/WIC InternationalConference on Web Intelligence, 2003, pp. 602–605.
11] A. Umyarov, A. Tuzhilin, Using external aggregate ratings for improvingindividual recommendations, ACM Trans. Web 5 (1) (2011) 3:1–3:40.
12] W.-S. Yang, H.-C. Cheng, J.-B. Dia, A location-aware recommender system formobile shopping environments, Expert Syst. Appl. 34 (1) (2008) 437–445.
13] R. Burke, Hybrid recommender systems: survey and experiments, UserModel. User Adapt. Interact. 12 (4) (2002) 331–370.
14] K. Oku, S. Nakajima, J. Miyazaki, S. Uemura, Context-aware SVM forcontext-dependent information recommendation, in: Proceedings of the 7thInternational Conference on Mobile Data Management, 2006, p. 109.
15] A. Chen, Context-aware collaborative filtering system: predicting the user’spreference in the ubiquitous computing environment, in: Location andContext-Awareness, Springer, Berlin, Heidelberg, 2005, pp. 244–253.
16] I. Cantador, A. Bellogin, P. Castells, Ontology-based personalised andcontext-aware recommendations of news items, in: Proceedings of the 2008IEEE/WIC/ACM International Conference on Web Intelligence and IntelligentAgent Technology, 2008, pp. 562–565.
17] J.J. Levandoski, M. Sarwat, A. Eldawy, M.F. Mokbel, LARS: a location-awarerecommender system, in: Proceedings 28th International Conference on DataEngineering, 2012, pp. 450–461.
18] T.H. Dao, S.R. Jeong, A. Hyunchul, A novel recommendation model oflocation-based advertising: Context-aware collaborative filtering using GAapproach, Expert Syst. Appl. 39 (3) (2012) 3731–3739.
19] R. Cissée, S. Albayrak, An agent-based approach for privacy-preservingrecommender systems, in: Proceedings of the 6th International JointConference on Autonomous Agents and Multiagent Systems, 2007, pp.182:1–182:8.
20] R. Shokri, P. Pedarsani, G. Theodorakopoulos, J.-P. Hubaux, Preserving privacyin collaborative filtering through distributed aggregation of offline profiles,in: Proceedings of the 3rd ACM Conference on Recommender Systems, 2009,pp. 157–164.
21] A. Huertas Celdrán, M. Gil Pérez, F.J. García Clemente, G. Martínez Pérez,PRECISE: privacy-aware recommender based on context information forcloud service environments, IEEE Commun. Mag. 52 (8) (2014) 90–96.
22] T. Berners-Lee, J. Hendler, O. Lassila, The semantic web, Sci. Am. 284 (5)(2001) 34–43.
23] University of Murcia, Complete definition of the PRECISE ontologies, Availablefrom: http://reclamo.inf.um.es/precise.
24] V. Tsetsos, C. Anagnostopoulos, P. Kikiras, S. Hadjiefthymiades, Semanticallyenriched navigation for indoor environments, Int. J. Web Grid Serv. 2 (4)(2006) 453–478.
25] University of Murcia, Complete definition of the Recommender ontology,Available from: http://dharma.inf.um.es/recommender.
26] Y. Koren, R. Bell, Advances in collaborative filtering, in: RecommenderSystems Handbook, Springer, US, 2011, pp. 145–186.
27] P. Cremonesi, Y. Koren, R. Turrin, Performance of recommender algorithms onTop-n recommendation tasks, in: Proceedings of the 4th ACM Conference onRecommender Systems, 2010, pp. 39–46.
28] G. Guo, J. Zhang, N. Yorke-Smith, A novel Bayesian similarity measure forrecommender systems, in: Proceedings of the 23rd International JointConference on Artificial Intelligence, 2013, pp. 2619–2625.
29] H. Liu, Z. Hu, A. Mian, H. Tian, X. Zhu, A new user similarity model to improvethe accuracy of collaborative filtering, Knowl. Based Syst. 56 (2014) 156–166.
30] Y. Zheng, X. Xie, Learning travel recommendations from user-generated GPStraces, ACM Trans. Intell. Syst. Technol. 2 (1) (2011) 2:1–2:29.
Alberto Huertas Celdrán is Research Associate in theDepartment of Information and Communication Engi-neering of the University of Murcia, Murcia, Spain. Hisscientific interests include security, semantic technology,and policy-based context-aware systems. He received anM.Sc. in Computer Science from the University of Murcia.
Manuel Gil Pérez is Research Associate in the Departmentof Information and Communication Engineering of theUniversity of Murcia, Murcia, Spain. His scientific activityis mainly devoted to security infrastructures, trust man-agement, and intrusion detection systems. He received anM.Sc. in Computer Science from the University of Murcia.

9 mputa
4 A.H. Celdrán et al. / Journal of CoFélix J. García Clemente is Associate Professor ofComputer Networks in the Department of Computer Engi-
neering of the University of Murcia, Murcia, Spain. Hisresearch interests include security and management ofdistributed communication networks. He received M.Sc.and Ph.D. degrees in Computer Science from the Univer-sity of Murcia.tional Science 12 (2016) 83–94
Gregorio Martínez Pérez is Full Professor in the Depart-ment of Information and Communication Engineering
of the University of Murcia, Murcia, Spain. His researchinterests include security and management of distributedcommunication networks. He received M.Sc. and Ph.D.degrees in Computer Science from the University ofMurcia.




























