Embed Size (px)
Citation preview

“01-fm-i-iv-9780444537263” — 2010/11/29 — 21:08 — page ii — #2

“01-fm-i-iv-9780444537263” — 2010/11/29 — 21:08 — page i — #1
Handbook of Logic and Language

“01-fm-i-iv-9780444537263” — 2010/11/29 — 21:08 — page ii — #2
This page intentionally left blank

“01-fm-i-iv-9780444537263” — 2010/11/29 — 21:08 — page iii — #3
Handbook of Logic andLanguage
Second Edition
Johan van BenthemAlice ter Meulen
AMSTERDAM • BOSTON • HEIDELBERG • LONDON • NEW YORK • OXFORDPARIS • SAN DIEGO • SAN FRANCISCO • SINGAPORE • SYDNEY • TOKYO

“01-fm-i-iv-9780444537263” — 2010/11/29 — 21:08 — page iv — #4
Elsevier32 Jamestown Road London NW1 7BY30 Corporate Drive, Suite 400, Burlington, MA 01803, USA
First edition 2011
Copyright c! 2011 Elsevier B.V. All rights reserved
No part of this publication may be reproduced or transmitted in any form or by any means, electronic ormechanical, including photocopying, recording, or any information storage and retrieval system, withoutpermission in writing from the publisher. Details on how to seek permission, further information about thePublisher’s permissions policies and our arrangement with organizations such as the Copyright ClearanceCenter and the Copyright Licensing Agency, can be found at our website: www.elsevier.com/permissions
This book and the individual contributions contained in it are protected under copyright by the Publisher(other than as may be noted herein).
NoticesKnowledge and best practice in this field are constantly changing. As new research and experiencebroaden our understanding, changes in research methods, professional practices, or medical treatment maybecome necessary.
Practitioners and researchers must always rely on their own experience and knowledge in evaluating andusing any information, methods, compounds, or experiments described herein. In using such informationor methods they should be mindful of their own safety and the safety of others, including parties for whomthey have a professional responsibility.
To the fullest extent of the law, neither the Publisher nor the authors, contributors, or editors, assume anyliability for any injury and/or damage to persons or property as a matter of products liability, negligence orotherwise, or from any use or operation of any methods, products, instructions, or ideas contained in thematerial herein.
British Library Cataloguing in Publication DataA catalogue record for this book is available from the British Library
Library of Congress Cataloging-in-Publication DataA catalog record for this book is available from the Library of Congress
ISBN: 978-0-444-53726-3
For information on all Elsevier publicationsvisit our website at www.elsevierdirect.com
Typeset by: diacriTech, India
This book has been manufactured using Print On Demand technology. Each copy is produced to order andis limited to black ink. The online version of this book will show color figures where appropriate.

“02-toc-v-x-9780444537263” — 2010/11/29 — 21:08 — page v — #1
Contents
Preface xiii
List of Contributors xv
Part 1 Frameworks 1
1 Montague Grammar 3Barbara H. Partee, with Herman L.W. Hendriks1.1 Introduction 31.2 Montague Grammar in Historical Context 41.3 The Theory and the Substance 141.4 The Montagovian Revolution: Impact on Linguistics and
Philosophy, Further Developments. Montague’s Legacy 52
2 Categorial Type Logics 95Michael MoortgatPart I. Excerpts from the 1997 Chapter 952.1 Introduction: Grammatical Reasoning 952.2 Linguistic Inference: the Lambek Systems 1002.3 The Syntax-Semantics Interface: Proofs and Readings 1152.4 Grammatical Composition: Multimodal Systems 126Part II. Update 2009 1462.5 1997–2009: A Road Map 1462.6 Four Views on Compositionality 1482.7 Proof Nets and Processing 1622.8 Recognizing Capacity, Complexity 1662.9 Related Approaches 1692.10 Concluding Remarks 171
3 Discourse Representation in Context 181Jan van Eijck and Hans Kamp3.1 Overview 1813.2 Interpretation of Text in Context 1823.3 The Problem of Anaphoric Linking in Context 1833.4 Basic Ideas of Discourse Representation 1853.5 Discourse Representation Structures 1923.6 The Static and Dynamic Meaning of Representation Structures 1963.7 Sequential Composition of Representation Structures 200

“02-toc-v-x-9780444537263” — 2010/11/29 — 21:08 — page vi — #2
vi Contents
3.8 Strategies for Merging Representation Structures 2063.9 Disjoint Merge and Memory Management 2133.10 Constructing DRSs for Natural Language Fragments 2173.11 The Proper Treatment of Quantification in DRT 2243.12 Representing Tense and Aspect in Texts 2283.13 Extensions and Variations 2363.14 Addendum to the Second Edition 238A Simplified Representation of Contexts 238B Pronouns and Anaphoric Reference 243C Once More: DRSs for Natural Language Fragments 244D Salience Updating as Context Manipulation 245E Further Reading 247
4 Situation Theory 253Jeremy Seligman and Lawrence S. Moss4.1 Introduction 2534.2 The Structure of Information 2544.3 A Theory of Structural Relations 2714.4 Truth and Circumstance 2934.5 Guide to the Literature 321
5 Situations, Constraints and Channels (Update of Chapter 4) 329Edwin Mares, Jeremy Seligman, Greg Restall5.1 From Situation Semantics to Situation Theory 3295.2 Early Channel Theory 3305.3 Situated Inference 3335.4 Modern Channel Theory 335
6 GB Theory: An Introduction 345James Higginbotham6.1 Phrase Structure 3466.2 Limitations of Phrase-Structure Description 3516.3 D-Structure and S-Structure 3576.4 Logical Form 3656.5 Formal Development and Applications 3686.6 Beyond GB: Checking and Copying 3826.7 Minimalism and Derivational and Non-Derivational Syntax 388
7 After Government and Binding Theory (Update of Chapter 6) 395Edward P. Stabler7.1 Theoretical Developments 3957.2 Algebraic Analyses 4007.3 Logical and Categorial Analyses 4067.4 The Future 409

“02-toc-v-x-9780444537263” — 2010/11/29 — 21:08 — page vii — #3
Contents vii
8 Game-Theoretical Semantics 415Jaakko Hintikka and Gabriel Sandu8.1 Formal Languages 4158.2 Natural Languages 4338.3 A Survey of Games in Logic and in Language Theory 453
Note on Recent Developments 461
9 Game-Theoretical Pragmatics (Update of Chapter 8) 467Gerhard Jäger9.1 Introduction 4679.2 Signaling Games 4689.3 Rational Communication 4719.4 Information States and Message Costs 4799.5 Connection to Optimality Theory 4859.6 Conclusion 488
Part 2 General Topics 493
10 Compositionality 495Theo M.V. Janssen, with Barbara H. Partee10.1 The Principle of Compositionality of Meaning 49510.2 Illustrations of Compositionality 49710.3 Towards Formalization 50210.4 Examples of Non-Compositional Semantics 50610.5 Logic as Auxiliary Language 51010.6 Alledged Counterexamples to Compositionality 51310.7 Fundamental Arguments Against Compositionality 51710.8 A Mathematical Model of Compositionality 52310.9 The Formal Power of Compositionality 52910.10 Other Applications of Compositionality 53510.11 Conclusion and Further References 537A Appendix: Related Principles 538B Appendix: Genitives – A Case Study (by B. Partee) 541
11 Types 555Raymond Turner11.1 Categories, Functions and Types 55511.2 The Typed Lambda Calculus 55711.3 Higher-Order Logic 57511.4 Universal Types and Nominalization 58411.5 Constructive Type Theories 59411.6 Types in Semantics, Logic and Computation 602

“02-toc-v-x-9780444537263” — 2010/11/29 — 21:08 — page viii — #4
viii Contents
12 Dynamics 607Reinhard Muskens, Johan van Benthem, Albert Visser12.0 Introduction 60712.1 Some Specific Dynamic Systems 61012.2 Logical Observations 635
13 Dynamic Epistemic Logic (Update of Chapter 12) 671Barteld Kooi13.1 Introduction 67113.2 An Example Scenario 67213.3 A History of DEL 67413.4 DEL and Language 681
14 Partiality 691Jens Erik Fenstad14.0 Introduction 69114.1 Sources of Partiality 69114.2 Partiality and Models for Linguistic Structure 70314.3 Partiality and the Structure of Knowledge 708
15 Formal Learning Theory 725Daniel Osherson, Dick de Jongh, Eric Martin and Scott Weinstein15.1 Introduction 72515.2 Identification 72715.3 Remarks About the Identification Paradigm 72915.4 More Refined Paradigms 73215.5 The Need for Complementary Approaches 74015.6 Ontology and Basic Concepts 74215.7 First Paradigm: Absolute Solvability 74515.8 Second Paradigm: Probabilistic Solvability 74715.9 Third Paradigm: Solvability with Specified Probability 74915.10 Empirical Evaluation 75115.11 Concluding Remarks 75215.12 Appendix: Proofs 752
16 Computational Language Learning (Update of Chapter 15) 765Menno van Zaanen, Collin de la Higuera16.1 Introduction 76516.2 Settings 76616.3 Paradigms 77516.4 Conclusion 777
17 Non-monotonicity in Linguistics 781Richmond H. Thomason17.1 Non-monotonicity and Linguistic Theory 78117.2 Overview of Nonmonotonic Reasoning 784

“02-toc-v-x-9780444537263” — 2010/11/29 — 21:08 — page ix — #5
Contents ix
17.3 Non-monotonicity and Feature Structures 80417.4 Applications in Phonology 81017.5 Applications in Morphology 81317.6 Syntax 82217.7 Applications in Semantics 82217.8 Applications in Discourse 825
18 Non-Monotonic Reasoning in Interpretation (Update of Chapter 17) 839Robert van Rooij, Katrin Schulz18.1 Introduction 83918.2 Implicatures as Non-Monotonic Inferences 83918.3 More on Non-Monotonic Reasoning and Linguistics 84818.4 Conclusions 853
Part 3 Descriptive Topics 857
19 Generalized Quantifiers in Linguistics and Logic 859Edward L. Keenan, Dag Westerståhl19.1 Introduction 85919.2 Generalized Quantifiers in Natural Language: Interpretations
of Noun Phrases and Determiners 86119.3 Polyadic Quantification 887
20 On the Learnability of Quantifiers (Update of Chapter 19) 911Robin Clark20.1 Some Computational Properties of Determiners 91220.2 The Learnability of First-Order Determiners 91620.3 Higher-Order Determiners 920
21 Temporality 925Mark Steedman21.1 A Case-study in Knowledge Representation 92521.2 Temporal Ontology 92721.3 Temporal Relations 93321.4 Temporal Reference 95721.5 Conclusion 96221.6 Further Reading 962
22 Tense, Aspect, and Temporal Representation (Update of Chapter 21) 971Henk Verkuyl22.1 Introduction 97122.2 Issues of Aspectuality 97122.3 Tense 97922.4 Preparing for Discourse 98422.5 Conclusion 985

“02-toc-v-x-9780444537263” — 2010/11/29 — 21:08 — page x — #6
x Contents
23 Plurals and Collectives 989Jan Tore Lønning23.1 Introduction 98923.2 Setting the Stage 99023.3 Higher-Order Approaches 99623.4 First-Order Approaches 100723.5 Reading Plural NPs 102023.6 Non-Denotational Approaches 102623.7 Further Directions 1029
24 Plural Discourse Reference (Update of Chapter 23) 1035Adrian Brasoveanu24.1 Plural Reference and Plural Discourse Reference 103524.2 Multiple Interdependent Anaphora 103624.3 Ontology and Logic 104324.4 Compositionality 104924.5 Conclusion 1055
25 Questions 1059Jeroen Groenendijk, Martin Stokhof25.1 Preliminary 105925.2 Setting the Stage 106025.3 The Pragmatic Approach 106325.4 The Semantic Approach 107925.5 Logical and Computational Theories 110225.6 Linguistic Theories 1108
26 Questions: Logic and Interactions (Update of Chapter 25) 1133Jonathan Ginzburg26.1 Overview 113326.2 The Ontology and Logic of Questions 113326.3 Questions in Interaction 113826.4 Other Question-Related Work 114326.5 Conclusions 1143

“03-pref-xi-xiv-9780444537263” — 2010/11/29 — 21:08 — page xi — #1
Preface
When it first appeared in 1997, the Handbook of Logic and Language documented sev-eral decades of research at the interface of logic and linguistics, showing how a sub-stantial body of insights and techniques had developed about natural language throughcooperation, and sometimes competition, between various approaches. Its statementstill stands, so, given its continued success, the first edition of the Handbook willremain available in new forms of electronic access. But in our rapidly evolving field,we decided in 2007 that an additional updated edition would be warranted. Besidesapproaching many original authors for chapter updates, we also solicited supplemen-tary texts from other, often younger authors to highlight important new developments.Responses have been very encouraging and constructive, and before you lies the resultof three years of pleasant cooperative work. Although this second edition involvesboth revised chapters from the first edition and new pieces, it retains the overall struc-ture of the original Handbook enriched with many new topics.
Part I, Frameworks, presents chapters on classical Montague Grammar, Categorialtype-logical grammars, Government-Binding theory, Discourse representation theory,Situation theory, and Game theory. They represent currently prevalent approaches tonatural language, created often by combining insights from linguistics, philosophy,and logic. One striking feature here is the convergence of approaches, as valuableinsights were sifted from more polemical salvos in the course of time. For instance,core concepts on minimality or economy of derivation turn out to ‘click’ betweencategorial type-logical grammars and government-binding grammars. Furthermore,in the thirteen years since the first edition of the Handbook of Logic and Languageappeared, some other trends have stabilized across frameworks. First is the importantrole of information as a unifying phenomenon in language and communication, bothin its structure and the mechanisms that make it flow. The chapters on situation theoryand discourse representation amply demonstrate this. Information flows through activemechanisms, with computation as a prime paradigm. Many other chapters show thisinfluence, not just as a concern with ‘implementation’, but as a source of fundamentalconcepts about what language is, what it does and how it functions. Secondly, anotherfundamental theme has been gaining prominence through the past decade. Informationflow in natural language naturally involves the interaction of many agents: speakers,hearers, writers, readers, and their public or private sources. It is this irreducibly multi-agent interaction that determines how language functions in communication, evolu-tion and action generally. Our updated chapter on game-theoretical semantics reflectsthis trend, establishing significant links to game theory and refining the traditionalborders between semantics and pragmatics.

“03-pref-xi-xiv-9780444537263” — 2010/11/29 — 21:08 — page xii — #2
xii Preface
Part II, General Themes, contains chapters on traditional topics of Composition-ality, Types and Partiality, and new developments in Dynamics semantics and logics,Formal learning theory, and Non-monotonic interpretation and reasoning. The chap-ter on compositionality describes what still is a major methodology for analysis anddesign of the syntax-semantics interface in logic, linguistics and computer science.There has been much renewed attention to the scope of this method in the recent lit-erature, especially in the setting of information and games, so it is as alive as ever.The chapters on types and partiality have been reprinted from Lola I, since they stillrepresent major themes in studying the structure of information. The other three chap-ters in Part 2 represent a new trend that has become more conspicuous over the pastdecade. Information is produced and received by agents, and hence agency is comingto the fore as a new unifying theme. We cannot just look at the structure of language,without thinking about the processes that it is used for. But even one step further, weneed to look at the agents that engage in such activities, what they do and why. This isinvestigated in the updated chapter on dynamics, where semantics of natural languageinterfaces with recent logics of informational acts of observation and communication.It is also reflected in the updated chapter on learning, an agent-oriented activity fromthe start, allowing for many policies. The theme also resurfaces in the chapter on non-monotonicity, since this is all about common sense reasoning, strategies of conveyinginformation, and in the end, not just monotonic information update, but also beliefrevision. The theme of information-driven agency has brought the logical study oflanguage in closer contact with disciplines such as computer science, artificial intelli-gence, cognitive science, game theory, and eventually, the behavioral sciences.
Finally, Part III, Special Topics collects chapters on the perennial topics of Quan-tifiers, Plurals and collectives, Temporality, and Questions. These major parts oflanguage demonstrate the more tangible forms of these influences. The quantifierschapter has been updated with computational perspectives, including different notionsof computational complexity of various linguistic expressions. The chapter on pluralsand collectives has been updated with recent developments, where the semantics ofcollective expressions meets with current logics of dependence, a crucial foundationalnotion in recent logical studies of information and interaction. The chapter on tem-porality now includes new procedural perspectives on how temporal representationand reasoning take place, its linguistic variability and composition from lexicon todiscourse. And finally, the chapter on questions has been updated to a much broaderperspective on the fundamental role of questions in setting issues in context and direct-ing information flow effectively.
One word of explanation may be needed here. As the Table of Contents shows, wehave arranged the material of LOLA II as follows. The chapters come in a sequencewhere newly commissioned texts are marked as updates of the chapters that are theircompanion from the first edition. As to the latter, all included chapters have all beenrevised: sometimes just lightly, sometimes drastically, as the topic required.
We hope that the material presented here gives a fair overview of the lively currentcontacts between logic and language, and the new interdisciplinary alignments aroundthese. We do not pretend, as we never did, to claim exhaustive coverage, however. Inparticular, we see some major challenges at our horizon that have not been included

“03-pref-xi-xiv-9780444537263” — 2010/11/29 — 21:08 — page xiii — #3
Preface xiii
in this second edition. One is a dramatic change in the nature of the empirical evi-dence that fuels logical theory about natural language. In bygone ages, it consistedof the intuitions of competent language users about valid inferences or ambiguities ofexpressions, if truth be told: usually professional academics, serving dually as theorydesigners and judges of its validity. But over the past decades, even logicians havecome to realize that their homespun intuitions pale in significance compared to realdata about the actual use of language by a large community or developmental pro-cesses of language acquisition. Hence corpus-based methods have gained popularityin linguistics and gradually also in logic – and a lot of novel challenges result regard-ing their interface with abstract modeling methods. Some interesting hybrids of logi-cal and corpus-based approaches have been developed, such as ‘data-oriented parsing’combining logical rules with memory storage of experience with language use. Yet,nothing like a conclusive perspective has emerged. Taking this trend further, the top-ics in this Handbook all impinge on cognitive science, and the experimental realitiesabout language and reasoning studied by cognitive psychologists, and nowadays also,neuroscientists. Again, we have decided to leave these fascinating developments outof the second edition of the Handbook, as being one bridge too far. Finally, in termsof methods, the traditional mixture of insights from linguistics, logic, discrete mathe-matics, and computer science that fueled the interface of logic and language now feelsincreasing pressure from probabilistic methods. Logicians may long have thought thatthese were just unprincipled ways of smoothening the interface with reality, but it isbecoming clear that probability may lie at the heart of understanding the foundationsof information, interaction, and cognitive understanding of what language really is.Again, interesting new links between logic and probability are emerging these days,but we have drawn the line well short of them.
Summarizing, the methods and modus operandi in this second edition of theHandbook of Logic and Language finds itself in a much larger, if perhaps less cozy,scientific environment these days. It meets with other explanatory perspectives andexperimental methods, and its true value remains to be ascertained in historical per-spective. The editors feel that this will lead to highly interesting mixtures of logicand probability, normative and descriptive perspectives, and hybrids between natu-ral language and designed languages and procedures. Logical methods and ideas willno doubt have a role to play in this new constellation, since they are already makinginroads even into neuroscience. But we also feel that producing a next edition LOLAIII of this Handbook is safely entrusted to a new generation of authors and editors,perhaps in another ten years.
Finally, it is time to acknowledge our debts. We thank all authors involved in thisnew edition for their enthusiastic response and generous cooperation. We also thankour publishers at Elsevier, and especially Lauren Schulz and Lisa Tickner for workingwith us toward a new edition on Science Direct to reach a new audience. We also thankEline van der Ploeg1 and especially Jakub Szymanik for their efficient assistance inmaking LOLA II happen.
1 The editors acknowledge with gratitude the support of this project at the NIAS (Netherlands Institute ofAdvanced Studies).

“03-pref-xi-xiv-9780444537263” — 2010/11/29 — 21:08 — page xiv — #4
This page intentionally left blank

“04-loc-xv-xxii-9780444537263” — 2010/11/29 — 21:08 — page xv — #1
List of Contributors
Johan van Benthem is University Professor of Logic, University of Amsterdam, andHenry Waldgrave Stuart Professor of Philosophy, Stanford University. His researchinterests include logical dynamics of information and agency, game theory, and cog-nitive science.
Address: ILLC, Universiteit van Amsterdam, P.O. Box 94242, 1090 GE Amsterdam,The Netherlands.E-mail: [email protected]
Adrian Brasoveanu is Assistant Professor at the Department of Linguistics, UC SantaCruz. His research interests include anaphora and quantification, integrating differentsemantic and pragmatic frameworks, and cross-linguistic semantics and syntax.
Address: Department of Linguistics, University of California at Santa Cruz, CA950641077, USA.E-mail: [email protected]
Robin Clark is Assistant Professor at the Department of Linguistics, University ofPennsylvania, Philadelphia. He is concerned with game-theoretic approaches to mean-ing, neuroscience of number sense and quantification, proof theory, and languagelearnability.
Address: Department of Linguistics, University of Pennsylvania, Philadelphia, PA19104-305, USA.E-mail: [email protected]
Jan van Eijck is Senior Researcher at the Centre for Mathematics and Computer Sci-ence in Amsterdam and Professor of Computational Linguistics at the Utrecht Insti-tute of Linguistics OTS. His research concerns dynamic semantics, social software,and computational linguistics.
Address: Centrum voor Wiskunde en Informatica, P.O. Box 94079, 1090 GB Amster-dam, The Netherlands.E-mail: [email protected]
Jens Erik Fenstad is Professor Emeritus of Logic at the University of Oslo. Hisresearch concerns computability theory, non-standard analysis, foundations of cog-nition, and the semantics of natural language systems.

“04-loc-xv-xxii-9780444537263” — 2010/11/29 — 21:08 — page xvi — #2
xvi List of Contributors
Address: University of Oslo, Institute of Mathematics, P.O. Box 1053 Blindern,N-0316 Oslo, Norway.E-mail: [email protected]
Jonathan Ginzburg is Professor at the UFR d’Etudes Anglophones, Université Paris-Diderot. He has been working on interaction in dialogue, semantics of natural lan-guage, and language acquisition.
Address: UFR d’Etudes Anglophones, Université Paris-Diderot, 10 rue Charles V,750004 Paris, France.E-mail: [email protected]
Jeroen Groenendijk is Professor of Philosophy of Language at the University ofAmsterdam. His research interests concern logic, linguistics and philosophy of lan-guage, in particular the semantics and pragmatics of questions and answers, and dyna-mic semantics.
Address: Faculteit der Geesteswetenschappen, ILLC, Universiteit van Amsterdam,P.O. Box 94242 1090, GE Amsterdam, The Netherlands.E-mail: [email protected]
Herman L.W. Hendriks is Docent at the Research Institute for Language and Speechat Utrecht University. His current research addresses the relationship between ‘natu-ralist’ theories of meaning and the theory of evolution.
Address: OTS, Utrecht University, Trans 10, 3512 JK Utrecht, The Netherlands.E-mail: [email protected]
James Higginbotham is Distinguished Professor of Philosophy and Linguistics andLinda MacDonald Hilf Chair in Philosophy at the University of Southern California.His research includes philosophical logic and philosophy of language, and theoreticallinguistics, especially syntax and semantics.
Address: University of Southern California, School of Philosophy, 3709 TrousdaleParkway, Los Angeles, CA 90089-0451, USA.E-mail: [email protected]
Collin de la Higuera is a member of the Laboratoire d’Informatique at Nantes Uni-versity in Nantes. His current research interests revolve around different aspects ofgrammatical inference and learning models in general.
Address: Laboratoire LINA UMR CNRS 6241, UFR de Sciences et Techniques, 2 ruede la Houssiniêre, BP 92208, 44322 Nantes Cedex 03, France.E-mail: [email protected]
Jaakko Hintikka is Professor of Philosophy at Boston University. His research con-cerns mathematical and philosophical logic, language theory, epistemology and phi-losophy of science, philosophy of mathematics, and history of philosophy.

“04-loc-xv-xxii-9780444537263” — 2010/11/29 — 21:08 — page xvii — #3
List of Contributors xvii
Address: Department of Philosophy, 745 Commonwealth Avenue, Boston, MA 02215,USA.E-mail: [email protected]
Gerhard Jäger is Professor of General Linguistics at the University of Tübingen. Hiscurrent favorite research area is using game-theoretical methods in the semantics andpragmatics of natural language, including their connections to cognitive science.
Address: University of Tübingen, Department of Linguistics, Wilhelmstraße 19,72074 Tübingen, Germany.E-mail: [email protected]
Theo M.V. Janssen is Assistant Professor of Computer Science at the Universityof Amsterdam. His research interests are on the interface of natural language, logic,and computer science, in particular, compositionality, game-theoretical semantics, andapplications of universal algebra in natural language syntax and semantics.
Address: ILLC Universiteit van Amsterdam, P.O. Box 94242, 1090 GE Amsterdam,The Netherlands.E-mail: [email protected]
Dick de Jongh is Emeritus Professor of Mathematical Logic and Foundations ofMathematics at the University of Amsterdam. His research includes intuitionisticlogic, modal logic, formalized arithmetic, learning theory, and recently also logicsof preference and belief.
Address: FNWI, ILLC, Universiteit van Amsterdam, P.O. Box 94242, 1090 GE Ams-terdam, The Netherlands.E-mail: [email protected]
Hans Kamp is Emeritus Professor of Logic and Philosophy of Language at the Uni-versity of Stuttgart and Visiting Professor at the University of Texas at Austin. Hisresearch interests include mathematical and philosophical logic; philosophy of lan-guage; semantics and pragmatics of natural language, and computational linguistics.
Address: Department of Linguistics, The University of Texas at Austin, Calhoun Hall405, 1 University Station B5100, Austin, TX 78712-0198, USA.E-mail: [email protected]
Universität Stuttgart, Institut für Maschinelle Sprachverarbeitung, Formale Logik undSprachphilosophie, Azenbergstraße 12, D-70174 Stuttgart, Germany.E-mail: [email protected]
Edward L. Keenan is Distinguished Professor of Linguistics in the Department ofLinguistics, University of California, Los Angeles. His scientific contributions touchon natural logic, algebraic semantics for generalized quantifier theory, Malagasyand Austronesian Languages, language typology, historical English, and theoreticalsyntax.

“04-loc-xv-xxii-9780444537263” — 2010/11/29 — 21:08 — page xviii — #4
xviii List of Contributors
Address: UCLA, Department of Linguistics, 405 Hilgard Ave., Los Angeles, CA90095-1543, USA.E-mail: [email protected]
Barteld Kooi is Assistant Professor of Theoretical Philosophy at the University ofGroningen. He is a logician studying systems describing multi-agent social interac-tions, like Dynamic Epistemic Logic and related formalisms, and their connectionswith probability.
Address: Faculty of Philosophy, University of Groningen, Oude Boteringestraat 52,9712 GL Groningen, The Netherlands.E-mail: [email protected]
Jan Tore Lønning is Professor of Linguistics at the University of Oslo. He has mainlyworked on the semantics and logic of noun phrases: plurals, mass terms and quan-tification. Currently, he is also pursuing the relation between formal semantics andcomputational linguistics.
Address: Department of Informatics, P.O. Box 1080 Blindern, N-0316 Oslo, Norway.E-mail: [email protected]
Edwin Mares is Professor at the Department of Philosophy, Victoria University ofWellington. He is concerned both with philosophical and formal aspects of relevantlogic, foundations of information, and the logic of belief revision.
Address: Department of Philosophy, Victoria University of Wellington, P.O. Box 600,Wellington, New Zealand.E-mail: [email protected]
Eric Martin is Senior Lecturer in the School of Computer Science and Engineering atthe University of New South Wales. His main interests are in the logical foundationsof Artificial Intelligence: in particular, parametric logic.
Address: Department of Artificial Intelligence, School of Computer Science and Engi-neering, University of New South Wales, UNSW SYDNEY NSW 2052, Australia.E-mail: [email protected]
Alice G. B. ter Meulen is a faculty member at the Department of Linguistics, Univer-sity of Geneva. Her research interests focus on the logical aspects of natural languageinterpretation, especially on temporal reasoning with aspectual information.
Address: Dept. de Linguistique, Faculté des Lettres, Université de Genève, 2 rue deCandolle, 1211 Genève 4, Suisse.E-mail: [email protected]
Michael Moortgat is Professor of Computational Linguistics at Utrecht University,Utrecht Institute for Linguistics OTS. His research interests include categorial gram-mar, the logic of grammar architectures, and applications of proof theoretic techniquesin natural language processing and understanding.

“04-loc-xv-xxii-9780444537263” — 2010/11/29 — 21:08 — page xix — #5
List of Contributors xix
Address: Utrecht Institute of Linguistics, Trans 10, 3512 JK Utrecht.E-mail: [email protected]
Lawrence S. Moss is Professor of Mathematics and Computer Science at Indiana Uni-versity. His research concerns many areas of pure and applied logic close to computerscience and linguistics, as well as non-well-founded sets, co-algebra, modal logic, andgraph theory.
Address: Department of Mathematics, Indiana University, 831 East Third Street,Bloomington, IN 47405-7106, USA.E-mail: [email protected]
Reinhard Muskens is Associate Professor of Logic and Language at Tilburg Uni-versity. His main interest is in the logic and semantics of natural language, includingthe foundations of the theory of meaning, computational semantics, and translationalmethods.
Address: Tilburg Universiteit, Department of Philosophy, P.O. Box 90153, 5000 LETilburg, The Netherlands.E-mail: [email protected]
Daniel Osherson is Professor of Psychology at Princeton University. His research isconcerned with brain loci of rational thought, formal models of learning and scientificdiscovery, human judgment of uncertainty, and psychological structure of concepts.
Address: Princeton University, Department of Psychology, Green Hall, Princeton,NJ 08544, USA.E-mail: [email protected]
Barbara H. Partee is Distinguished University Professor Emerita of Linguistics andPhilosophy, University of Massachusetts at Amherst. Her research interests focus onsemantics, including its foundations and its relation to syntax and to pragmatics, tologic and the philosophy of language, and to cognitive and representational theoriesof language.
Address: Department of Linguistics, University of Massachusetts, Amherst, MA01003-7130, USA.E-mail: [email protected]
Greg Restall is Professor at the Department of Philosophy, University of Melbourne.His research interests centre on the intersection of logic with philosophy, with topicsincluding substructural logics, paradox and truth, realism, and logical pluralism.
Address: Department of Philosophy, School of Philosophy, Anthropology and SocialInquiry, The University of Melbourne, Old Quad, Parkville, Victoria 3010, Australia.E-mail: [email protected]
Robert van Rooij is Assistant Professor at the Institute of Logic, Language and Com-putation of the University of Amsterdam. His research interests include the formal

“04-loc-xv-xxii-9780444537263” — 2010/11/29 — 21:08 — page xx — #6
xx List of Contributors
semantics and pragmatics of natural language, with topics such as questions, exhaus-tive interpretation, and others connecting to logic, evolutionary game theory, andcognitive science.
Address: Faculteit der Geesteswetenschappen, ILLC, Universiteit van Amsterdam,P.O. Box 94242, 1090 GE Amsterdam, The Netherlands.E-mail: [email protected]
Katrin Schulz is Assistant Professor at the Institute of Logic, Language and Compu-tation, University of Amsterdam. Her research focuses on topics in formal semanticsand pragmatics of natural language, often crossing the borderline to philosophy oflanguage and logic.
Address: Faculteit der Geesteswetenschappen, ILLC, Universiteit van Amsterdam,P.O. Box 94242, 1090 GE Amsterdam, The Netherlands.E-mail: [email protected]
Jeremy Seligman is Professor at the Department of Philosophy, The University ofAuckland. He has published on the philosophy of computation, hybrid logic, informa-tion flow and channel theory, theories of truth, situation theory, and tense and aspect.
Address: Department of Philosophy, The University of Auckland, Private Bag 92019,Auckland 1142, New Zealand.E-mail: [email protected]
Edward P. Stabler is Professor of Linguistics at the University of California at LosAngeles. He has worked mainly in syntactic typology and in formal semantics fornatural language, his primary research interest. Here the emphasis in the past ten yearshas been on generalized quantifier theory, Boolean semantics, and recently also modeltheory.
Address: UCLA, Department of Linguistics, 3125 Campbell Hall, Los Angeles, CA90095-1543, USA.E-mail: [email protected]
Gabriel Sandu is Professor of Philosophy at the University of Helsinki. His mainfields of interest are theories of truth, philosophy of mathematics, game-theoreticsemantics for natural language, independence-friendly logic, and logic and gametheory.
Address: Department of Philosophy, History and Culture, PB 24 (Unioninkatu 40 A,6th floor), 00014 University of Helsinki, Finland.E-mail: [email protected]
Mark Steedman is Professor of Cognitive Science in the School of Informatics at theEdinburgh University. His research interests cover a wide range of issues in linguistics(including grammar and temporality), computational linguistics, artificial intelligence,computer science, and cognitive science.

“04-loc-xv-xxii-9780444537263” — 2010/11/29 — 21:08 — page xxi — #7
List of Contributors xxi
Address: School of Informatics, University of Edinburgh, Informatics Forum 415, 10Crichton Street, Edinburgh, EH8 9AB, Scotland, UK.E-mail: [email protected]
Martin Stokhof is a Professor of Philosophy at the University of Amsterdam. He isworking on dynamic semantic, questions, and the philosophy of language.
Address: Faculteit der Geesteswetenschappen, ILLC, Universiteit van Amsterdam,Room NO 2.15, Nieuwe Doelenstraat 15, 1012 CP Amsterdam.E-mail: [email protected]
Richmond H. Thomason is Professor of Philosophy at the University of Michigan,departments of Philosophy, Linguistics, and Electrical Engineering and ComputerScience. He is a logician with long-term research interests in philosophical logic,philosophy of language, natural language semantics and pragmatics, knowledge rep-resentation, default reasoning in Artificial Intelligence, and computational linguistics.
Address: Department of Philosophy, University of Michigan, Ann Arbor, MI 48109-1003, USA.E-mail: [email protected]
Raymond Turner is Professor of Computer Science at the University of Essex, UK.His research interests include logic and natural language, logic and computation,philosophical logic, and philosophy of mathematics and computer science.
Address: University of Essex, Department of Computer Science, Wivenhoe Park,Colchester, CO4 35Q, UK.E-mail: [email protected]
Henk Verkuyl is a Professor Emeritus at the Department of Linguistics, UtrechtInstitute for Linguistics OTS, Utrecht University. He is interested in the interface oflogic and language. In particular, he has been studying temporal structures in naturallanguage.
Address: De Lairessestraat 163HS, 1075 HK Amsterdam, The Netherlands.E-mail: [email protected]
Albert Visser is Professor of Philosophy at the University of Utrecht. His researchcenters on logic and arithmetic, modal and intuitionistic logic, dynamic semantics,and topics in the philosophy of language.
Address: Heidelberglaan 6–8, room 166, 3584 CS Utrecht, The Netherlands.E-mail: [email protected]
Scott Weinstein is Professor of Philosophy at the University of Pennsylvania.His research interests include computational learning theory, and applications oflogic in computer science, especially descriptive complexity theory and finite modeltheory.

“04-loc-xv-xxii-9780444537263” — 2010/11/29 — 21:08 — page xxii — #8
xxii List of Contributors
Address: Department of Philosophy, Logan Hall, Room 433, University of Pennsyl-vania, Philadelphia, Pennsylvania 19104-6304, USA.E-mail: [email protected]
Dag Westerståhl is Professor of Philosophy at Gothenburg University. His main areaof research has been model theory and formal semantics for natural language, espe-cially theory of generalized quantifiers, but recently also issues of compositionalityand logicality.
Address: University of Gothenburg, Department of Philosophy, Linguistics, andTheory of Science, Box 200, 405 30, Gothenburg, Sweden.E-mail: [email protected]
Menno van Zaanen is an Assistant Professor at the Tilburg Center for Cognition andCommunication, Tilburg University. His research interests are symbolic and statisticalmachine learning and statistical natural language processing.
Address: Tilburg Centre for Cognition and Communication, Department of Communi-cation and Information Sciences, Faculty of Humanities, Tilburg University, P.O. Box90153, NL-5000 LE Tilburg, The Netherlands.E-mail: [email protected]

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 1 — #1
Part 1
Frameworks

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 2 — #2
This page intentionally left blankThis page intentionally left blank

“05-ch01-0001-0094-9780444537263” — 2010/11/30 — 3:44 — page 3 — #3
1 Montague GrammarBarbara H. Partee!, with Herman L.W. Hendriks†
!Department of Linguistics, University of Massachusetts, Amherst,MA 01003-7130, USA, E-mail: [email protected]
†OTS, Utrecht University, Trans 10, 3512 JK Utrecht, The Netherlands,E-mail: [email protected]
Commentator: T. Janssen
1.1 Introduction
“Montague grammar” is a term that was first applied soon after the untimely deathof Richard Montague (September 20, 1930 – March 7, 1971) to an approach to thesyntax and semantics of natural languages based on Montague’s last three papers(Montague, 1970b,c, 1973). The term may be taken in a narrower or a broader sense,since continuing research has led to a variety of work that can be considered to involveeither “developments of” or “departures from” Montague’s original theory and prac-tice. In its narrower sense, “Montague grammar”, or “MG”, means Montague’s theoryand those extensions and applications of it which remain consistent with most of theprinciples of that theory. But the boundaries are vague and if taken somewhat morebroadly, as the present author (who I believe coined the term) is inclined to do, theterm extends to a family of principles and practices which still constitute a large partof the common basis for the field of formal semantics.1
The term has never been restricted to Montague’s work alone and it should notbe, given that Montague was not single-handedly responsible for all of the ideas thatwere articulated in his papers; others such as David Lewis, Terry Parsons and MaxCresswell were contemporary contributors to more or less the same enterprise, as willbe noted below. But Montague’s work was particularly influential, in part because ofthe fact that the three papers just cited give a remarkably clear, concise, and completestatement of a powerful general theory, a good indication of a range of alternative more
1 The term “formal semantics” has become the dominant name for the field, but is sometimes considered anunfortunate choice, insofar as the “formalist” tradition in logic and mathematics (associated with Hilbert)is a tradition that eschews model-theoretic semantics and pursues a purely syntactic and proof-theoreticapproach. “Formal” semantics, like “formal” philosophy as Montague practiced it, is to be understood ascontrasted with “informal”. Other terms that are broadly applied to Montague grammar and its relativesare “model-theoretic semantics”, “truth-conditional semantics”, “logical semantics”, “logical grammar”.
Handbook of Logic and Language. DOI: 10.1016/B978-0-444-53726-3.00001-3c" 2011 Elsevier B.V. All rights reserved.

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 4 — #4
4 Handbook of Logic and Language
particular theories and formal tools and three different “fragments” of English thatillustrate both the general theory and some of the choices that are available within it.
The plan of this article is to highlight the historical development of Montaguegrammar as both narrowly and broadly construed, with particular attention to the keyideas that led Montague’s work to have such a great impact on subsequent devel-opments. Section 1.2 outlines the historical context of Montague’s work, describingearlier traditions in semantics in logic and philosophy that laid some of the founda-tions for Montague’s work and the contrasting traditions in linguistics, against whichMontague’s work represented a fundamental and controversial change. Section 1.3provides a selective overview of the basic principles and methodology of Montaguegrammar as laid out in “Universal Grammar” (Montague, 1970c) and some of thehighlights of Montague’s best-known and most influential paper, “The Proper Treat-ment of Quantification in Ordinary English” (“PTQ”; Montague, 1973), with briefremarks about Montague’s two other fragments (Montague, 1970b,c). In the final sec-tion of the paper we discuss the influence of Montague’s work and Montague grammaron subsequent developments and theoretical innovations in linguistics and philosophy,illustrate the evolution from “Montague grammar” to a more heterogeneous but inter-related family of theoretical approaches by tracing progress in several key problemareas and venture an assessment of some of the main achievements and controversiesthat make up Montague’s legacy.
1.2 Montague Grammar in Historical Context
It is important to look at the historical context in which Montague grammar devel-oped, since the history of Montague grammar is also the history of the emergence ofa new interdisciplinary field, formal semantics. One might reasonably speak of theMontagovian revolution in semantics as a landmark in the development of linguisticscomparable to the Chomskyan revolution in generative grammar. The potential forfruitful interaction among linguists, philosophers and logicians had already existedfor some time before Montague’s work and some cross-fertilization had already takenplace, but not until Montague made his foundational contributions was there a satis-factory systematic and comprehensive framework that could support the explosion offruitful research on natural language semantics and the syntax-semantics interface thathas occurred since the publication of his seminal papers.
1.2.1 Earlier Traditions in Semantics
Contemporary formal semantics has roots in several disciplines, most importantlylogic, philosophy, and linguistics. The central figure in its recent history was RichardMontague, a logician and philosopher whose seminal works in this area date fromthe late 1960s and the beginning of the 1970s. But Montague’s work did not occurin a vacuum, and the development of “Montague grammar” and of formal seman-tics more generally, has involved contributions from many sources before, during and

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 5 — #5
Montague Grammar 5
after Montague’s work, sometimes in separate historical strands and sometimes in theform of fruitful interdisciplinary collaboration among linguists, philosophers, logi-cians, and others, the fruits of which are evident in many of the other chapters in thisHandbook.
At the time of Montague’s work, semantics had been a lively and controversial fieldof research for centuries and radically different approaches to it could be found acrossvarious disciplines. One source of deep differences was (and still is) the selection ofthe object of study: there are at least as many different kinds of “central questions”as there are ways in which issues involving meaning may be relevant to a given dis-cipline. Desiderata for a theory of meaning come out quite differently if one focuseson language and thought, or on language and communication, on language and truth,or on language “structure” per se. Here we will restrict our attention to the differenttraditions that fed into Montague grammar, principally logic, “formal philosophy”,and generative grammar. The psychologism prevalent in much of linguistics and fun-damental to the Chomskyan research program, contrasts with the anti-psychologismexplicitly argued by Frege (1892) and prevalent in the traditions of philosophical logicand model theory from which Montague’s work arose. This is bound to lead not onlyto differences in the nature of the questions being asked (although both are concernedwith structure and the relation between form and meaning) but also to serious differ-ences about the terms in which answers might be framed.
A more accidental but no less profound source of differences is the researchmethodology prevalent in the field within which one approaches questions of seman-tics. Thus Katz and J.A. Fodor (1963) in the early years of generative linguistics con-centrated first on “semantic features”, using methodology influenced by phonology tostudy questions of meaning and structure. Where the logician Quine would say: “Logicchases truth up the tree of grammar” (1970, p. 35), Katz and Fodor were equally seek-ing a compositional account of how the meanings of sentences were determined fromthe meanings of the smallest parts and the syntactic derivation of the whole from thoseparts, but they conceived of semantic projection rules chasing “features”, not truth, upthe tree of grammar, analyzing meanings as representable in terms of complexes offeatures rather than in terms of truth conditions. This was the practice David Lewiswas deploring on the first page of his 1970 paper “General Semantics”:
But we can know the Markerese translation of an English sentence without know-ing the first thing about the meaning of the English sentence: namely, the conditionsunder which it would be true. Semantics with no treatment of truth conditions is notsemantics. Translation into Markerese is at best a substitute for real semantics, rely-ing either on our tacit competence (at some future date) as speakers of Markerese oron our ability to do real semantics at least for the one language Markerese.
I believe linguists did presuppose tacit competence in Markerese and moreovertook it to represent a hypothesis about a universal and innate representation, what Jerry(J.A.) Fodor later dubbed the Language of Thought (e.g., Fodor, 1975), and thereforenot in need of further interpretation (see Jackendoff, 1996, for a contemporary defense

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 6 — #6
6 Handbook of Logic and Language
of a similar view). The problems that resulted and still result, however, from makingup names for operators like “CAUSE” or features like “AGENT” without addressingthe formidable problems of defining what they might mean, are evident whenever onelooks at disputes that involve the “same” operators as conceived by different linguistsor in the analysis of different languages or even different constructions in the samelanguage.
To a philosopher like Vermazen (1967) or Lewis (1970), the language of “mark-erese” looked empty. To the generative linguist, the concern with truth seemed puz-zling: the concern was with mental representation, because semantics was part of thelanguage faculty, the explication of which was the linguist’s central concern. The inter-pretation of (the innate) semantic primitives would be in terms of concepts and thestudy of details of such interpretation might relate to semantics in something like theway phonetics relates to phonology, involving an interface at which linguistic andnon-linguistic (but still psychological) factors might intermingle. “Actual” truth wastaken to be irrelevant to semantics and the richer conception behind the notion of truthconditions and entailment relations did not come to be widely appreciated within lin-guistics for some time. Linguists in the 1960s and early 1970s sought accounts ofsynonymy, antonymy, anomaly and ambiguity, structural notions that concerned suchthings as how many meanings a given sentence had and which meanings were sharedby which sentences. These were kinds of questions which largely concerned samenessand difference of meaning and ways in which meanings are structured and thereforemight be fruitfully addressed in terms of representations. Linguistic studies of lexi-cal meaning were sometimes concerned with paraphrase and metonymy, but this didnot generalize to any systematic attention to inference or entailment. The increasinginfluence of truth-conditional semantics on linguistics therefore led to a concomitantgradual shift in the nature of the questions linguists might ask about meanings and notonly to a change in the arsenal of tools available for digging out answers.
The truth-conditional tradition in semantics has its source in the work of thoselogicians and philosophers of language who viewed semantics as the study of therelation between language on the one hand and whatever language is about on theother, some domain of interpretation which might be the real world or a part of it,or a hypothesized model of it, or some constructed model in the case of an artificiallanguage. Such philosophers and logicians, at least since Frege, have tended stronglyto view semantics non-psychologistically, making a distinction between language andour knowledge of it and generally taking such notions as reference, truth conditionsand entailment relations as principal data a semantic description has to get right toreach even minimal standards of adequacy.
Before Montague, most logicians and most linguists (with important exceptionssuch as Reichenbach, 1947) had been agreed, for different reasons, that the apparatusdeveloped by logicians for the syntax and semantics of formal languages was inappli-cable to the analysis of natural languages. Logicians considered natural languages toounsystematic, too full of vagueness, ambiguity and irrelevant syntactic idiosyncraciesto be amenable to formalization. Logicians also took to heart the warning of Tarski(1944) that natural languages contain their own truth predicate and his argument thatsuch languages could not be consistently formalized.

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 7 — #7
Montague Grammar 7
Those linguists who took note of logicians’ formalizations of the syntax and seman-tics of formal languages tended to reject the logicians’ approach for either or both oftwo reasons: (i) because the formal languages invented and studied by the logiciansappeared to be structurally so different from any natural language as to fall outsidethe bounds of the class of possible human languages and hence to be irrelevant to lin-guistics,2 and (ii) because logicians generally eschewed the concern for psychologicalreality which is so important to most linguists; not only is this difference noticeable inwhat the notion of “possible language” means to a logician vs. a linguist, but it leadsto opposite answers to the basic question of whether truth conditions and entailmentrelations are central to, or on the contrary irrelevant to, linguistics, given that speakersof a natural language do not always (in fact cannot always) have reliable intuitionsabout them.
1.2.2 Developments that made Montague Grammar Possible
1.2.2.1 The Rise of Model-Theoretic Semantics in Philosophy and Logic
Within philosophical logic, the foundational work of Frege, Carnap and Tarski led toa flowering in the middle third of this century of work on modal logic and on tenselogic, on conditionals, on referential opacity, and on the analysis of other philosophi-cally interesting natural language phenomena. The competition among different modallogics characterized by different axiom systems had led some philosophers like Quineto reject modal and intensional notions as incurably unclear; but the field was revo-lutionized when Kripke (1959), Kanger (1957a,b), and Hintikka (1962) first provideda model-theoretic semantics for modal logic, a possible-worlds semantics with differ-ences in accessibility relations among worlds serving as the principal parameters dis-tinguishing among different modal logics. Then necessity could be analyzed as truth inall accessible possible worlds and different sorts of accessibility relations (e.g., sym-metrical or not, reflexive or not) could be plausibly correlated with different sorts ofnecessity (logical, deontic, epistemic, etc.), replacing arguments about which is the“right” modal logic with productive investigations of different modal logics and theirapplications. Carnap (1947) had earlier done something similar but not identical inanalyzing (logically) necessary truth as truth in all models, but Kripke argued for theimportance of distinguishing between possible models of a language (the basis for thesemantical definition of entailment) and possible worlds (possible states of affairs, dif-ferent ways things might be or might have been) as elements that should be includedwithin a given model to be used in giving a model-theoretic semantics for modalnotions.3
2 See the rebuff by Chomsky (1955) of the exhortation to collaboration made by Bar-Hillel (1954).3 Quine was evidently not satisfied by these advances; Quine (1970) expresses as much aversion to inten-
sions as Quine (1960, 1961), although possible-worlds semanticists generally considered it one of theirmajor accomplishments to have satisfactorily answered the important concerns Quine had raised concer-ning quantifying into modal contexts.

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 8 — #8
8 Handbook of Logic and Language
The distinction between models and worlds is an important one for the seman-tics of all intensional constructions, but one that is still not always clearly appreci-ated; see discussion in Gamut, 1991, Volume II, Chapter 2. Part of the difficulty forstudents who come to semantics from linguistics rather than from logic is that logi-cians are accustomed to the freedom of designing formal languages with uninterpretednon-logical vocabulary; the stipulation of alternative models then provides alternativepossible interpretations for a given language. Linguists, on the other hand, tend topresuppose that they are studying natural languages as independently existing empir-ical phenomena and the notion of alternative model-theoretic interpretations for oneand the same language is therefore an unfamiliar and unnatural one. For that matter,the early philosophical literature did not always distinguish between Carnapian statedescriptions as alternative interpretations for the non-logical vocabulary and as alter-native ways the facts might have been. (The distinction between moments or intervalsof time and models is intuitively much clearer and invites no such confusion, so it canbe helpful to point out to students the analogy between the role of times as elements ofmodels of tensed languages and the role of possible worlds as elements of models ofmodal languages, an analogy noted below as one of Montague’s contributions to thefield.)
The resulting extension of model-theoretic techniques into the realm of modal logicled to a great expansion of work in logic and the philosophy of language on quanti-fied modal logic, tense logic, the logic of indexicals and demonstratives, studies ofadjectives and adverbs, propositional attitude verbs, conditional sentences and inten-sionality more generally. With few exceptions, most of this work followed the earliertradition of not formalizing the relation between the natural language constructionsbeing studied and their logico-semantic analyses: the philosopher-analyst served as abilingual speaker of both English and the formal language used for analysis; only theformal language would be provided with a model-theoretic semantics. Much insightinto the semantic content of natural language expressions was achieved in these stud-ies, but relatively little progress was made on systematically relating semantic contentto syntactic structure. For those natural language constructions where the semanticallyrelevant syntactic structure was not perfectly straightforward (which were many), thestrategy was “regimentation”: the invention and analysis of formal languages whichcontained syntactically “transparent” analogs of the constructions of interest, lan-guages which met the logician’s criterion for being “logically perfect” – unambiguousand describable with a unique semantic interpretation rule for each syntactic formationrule.
These developments went along with the rise of the tradition of “logical syntax”,or “logical grammar” and the logicians’ clean conception, going back to Peirce andMorris and Carnap, of the division of labor among syntax (well-formedness rules),semantics (compositional rules for specifying the truth-theoretic or model-theoreticinterpretation of well-formed expressions) and pragmatics (rules or principles relatingto the use of expressions in context). This tradition is nicely encapsulated in DonaldKalish’s article “Semantics” in the Encyclopedia of Philosophy (1967). But althoughmuch work in that tradition is inspired by and concerned with issues in the semantics

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 9 — #9
Montague Grammar 9
of ordinary language, relatively few attempts were made before Montague’s work toapply the logicians’ techniques directly and systematically to the grammatical analysisof natural language.
1.2.2.2 The Chomskyan Revolution
In the meantime, the Chomskyan revolution in linguistics, commencing with the pub-lication of Chomsky (1957) and in full swing by the mid-1960s, had led to what Bach(1989) has dubbed “Chomsky’s Thesis”, namely the thesis that English (and othernatural languages) could be described on the syntactic level as a formal system. (Bachcontrasts this with “Montague’s Thesis”, the thesis that English can be described asan interpreted formal system.) The previously prevalent view that natural languageswere too unsystematic to be amenable to formal analysis came to be seen as a mat-ter of not looking below the surface, not appreciating that the apparently bewilderingcomplexity that meets the eye can be the result of the interaction of a complex but notunsystematic set of rules or principles.
Chomsky redefined the central task of linguistics as the explanation of the possibil-ity of language acquisition by the child; as Davidson (1967) also emphasized, the factthat natural languages are infinite but learnable provides one of the most straightfor-ward arguments for the thesis that they must be finitely characterizable. The form ofthat finite characterization, whether by something like a phrase structure or transfor-mational grammar, a recursive definition, a set of simultaneously satisfied constraints,or something else and with exactly what aspects are universal and what aspects aresubject to cross-linguistic variation, is the central subject matter of syntactic theoryand subject to a great deal of ongoing debate and research.
The explosion of work in generative syntax starting in the late 1950s graduallygave rise to interest by linguists in issues of semantics, often driven by problems insyntax. A brief sketch of the situation in semantics within linguistics at the time thatMontague’s work began to be known to linguists is found in Section 1.2.4 below.
1.2.3 Montague and the Idea of “English as a Formal Language”
Montague was himself an important contributor to the developments in philosophicallogic, as well as to areas of mathematical logic such as axiomatic set theory and gene-ralized recursion theory. Montague had been a student of Tarski at UC Berkeley andas a faculty member at UCLA was a teacher and then a colleague of David Kaplan,co-authored a logic textbook with his colleague Donald Kalish and was an active partof a strong logic group spanning the departments of Philosophy and Mathematics.
Montague did not work single-handedly or in a vacuum: his students included HansKamp, Daniel Gallin, Nino Cocchiarella, Frank Vlach, Michael Bennett and HarryDeutsch; and his co-authors included Donald Kalish, Leon Henkin, Alfred Tarski,Robert Vaught, David Kaplan and Rolf Eberle. All of his papers on the development ofpragmatics, intensional logic and his theory of grammar, however, are singly authored;but they include numerous acknowledgements to suggestions from others, especiallyHans Kamp, David Kaplan, David Lewis and Dan Gallin; also Dana Scott, Rudolph

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 10 — #10
10 Handbook of Logic and Language
Carnap, Alonzo Church, Yehoshua Bar-Hillel, Charles Chastain, Terence Parsons, theauthor and others.
Montague did important work on intensional logic, including the unification oftense logic and modal logic and more generally the unification of “formal pragmat-ics” with intensional logic (Montague, 1968, 1970a). This was accomplished in partby treating both worlds and times as components of “indices” and intensions as func-tions from indices (not just possible worlds) to extensions. He also generalized theintensional notions of property, proposition, individual concept, etc., into a fully typedintensional logic, extending the work of Carnap (1947), Church (1951) and Kaplan(1964), putting together the function-argument structure common to type theoriessince Russell with the treatment of intensions as functions to extensions.4
Although linguists have focused on Montague’s last three papers and it is thosethat most directly set the framework for formal semantics, a considerable amount ofMontague’s earlier work was on areas of philosophical logic of direct relevance to issuesin semantics and on the logico-philosophical analysis of various concepts that havetraditionally been of concern in the philosophy of language: the logic of knowledge andbelief, the interpretation of embedded that-clauses, syntactic vs. semantic analysis ofmodal operators, the analysis of events as properties of moments of time and the analysisof obligations and other “philosophical entities” (discussed in Montague, 1969).
It was reportedly5 the experience of co-authoring Kalish and Montague (1964), alogic textbook, that gave Montague the idea that English should after all be amenableto the same kind of formal treatment as the formal languages of logic. Kalish andMontague took pains to give students explicit guidance in the process of translationfrom English to first-order logic: rather than the usual informal explanations and exam-ples, they produced an algorithm for step-by-step conversion of sentences of (a subsetof) English into formulas of first-order logic. Montague reportedly then reasoned thatif translation from English into logic could be formalized, it must also be possibleto formalize the syntax and semantics of English directly, without proceeding via anintermediate logical language. This led to the provocatively titled paper “English asa Formal Language” (EFL; Montague, 1970b), which contains the first statement ofwhat Bach (1989) dubbed “Montague’s Thesis”, that English can be described as aninterpreted formal system: EFL begins with the famous sentence “I reject the con-tention that an important theoretical difference exists between formal and natural lan-guages” (Montague, 1974, p. 188). As noted by Bach, the term “theoretical” here mustbe understood from a logician’s perspective and not from a linguist’s. What Mon-tague was denying was the logicians’ and philosophers’ common belief that naturallanguages were not directly amenable to formalization. What he was proposing, in
4 The variant type system Ty2 of Gallin (1975) is a possibly more perspicuous version of Montague’s typedintensional logic, especially with respect to explicitly showing the ubiquity of function-argument structurein the analysis of intensions. See Turner’s “Type Theory” chapter in this Handbook for fuller discussionof type theories; particular issues will be mentioned at various points below.
5 I recall learning this from one of Montague’s UCLA colleagues or former students, but I no longer recallwho: probably David Lewis or David Kaplan or Michael Bennett or Hans Kamp, but my misty memorymakes a proper acknowledgement impossible.

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 11 — #11
Montague Grammar 11
this paper and even more systematically in another work (Montague, 1970c), was aframework for describing syntax and semantics and the relation between them that heconsidered compatible with existing practice for formal languages (in the tradition of“logical grammar” mentioned earlier) and an improvement on existing practice for thedescription of natural language.
Montague was aware of Chomsky’s innovations in syntax but was puzzled andsomewhat put off by the generative grammarians’ practice of studying syntax withoutsimultaneous attention to semantics. (See footnote 13 below for an excerpt from one ofMontague’s notorious footnotes offering his unsympathetic opinion of the Chomskyanenterprise.) While Montague’s broad conception of “universal grammar” was closer tothe notion of “logically possible grammar” than to the Chomskyan notion of universalgrammar, which is tied to the aim of demarcating the humanly possible languages as asubset of the logically possible ones, linguists such as the present author argued that alinguistic conception of universal grammar could in principle be identified with a con-strained subtheory of Montague’s theory, the linguist’s task being to identify furtherconstraints on the syntactic and semantic rules and on the nature of the correspon-dence between them (Partee, 1976b, 1979a). Chomsky himself remained skeptical.6
The central properties of Montague’s framework are the subject of Section 1.3 and theimpact of his work is discussed in Section 1.4.
1.2.4 Semantics in Linguistics before Montague and the Introductionof Montague’s Work into Linguistics
Semantics in linguistics before the Chomskyan revolution, like semantics in parts ofanthropology and psychology, was largely concerned with the decompositional analy-sis of lexical meaning. A central goal in such approaches to lexical semantics was andstill is to identify semantic “distinctive features” or semantic “atoms” which combineto form lexical meanings, with heated but seemingly endless debates about whethertotal decomposability into such atoms is possible at all and about the universality ornon-universality of the “semantic primitives” of natural languages. (A problem forsuch debates has been the difficulty of finding common starting points on which bothsides might agree and the concomitant difficulty of identifying what kinds of empiricalevidence could be brought to bear on the question.)
The increasingly dominant impact of syntax on the whole field soon led to focus onquestions such as the relation between syntactic and semantic ambiguity, the issue ofwhether transformations preserve meaning and other such structural questions whichcan be explored relatively independently of the issue of “what meanings are”; semanticrepresentations were often modeled on syntactic tree structures (sometimes influencedby the syntax of some logic) and in some theories were (and are) taken to be identical
6 There were no immediate reactions to Montague’s work by Chomsky in print, but one can see a consistentline from Chomsky (1955) to the anti-compositionality arguments of Chomsky (1975); Chomsky mayalso have shared the general “East Coast” skepticism to possible-worlds semantics and intensional logicarticulated by Quine and others.

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 12 — #12
12 Handbook of Logic and Language
with some level of syntactic structures (e.g., the underlying structures of GenerativeSemantics or the level of Logical Form of GB syntax).
In the first years of generative grammar, as noted above, the key semantic propertiesof sentences were taken to be ambiguity, anomaly, and synonymy, analyzed in termsof how many readings a given sentence has and which sentences share which readings(Katz and J.A. Fodor, 1963; Chomsky, 1965).
The impact of philosophy and logic on semantics in linguistic work of the 1950sand 1960s was limited; many linguists knew some first-order logic, aspects of whichbegan to be borrowed into linguists’ “semantic representations” and there was grad-ually increasing awareness of the work of some philosophers of language.7 WhileChomsky alternated between general skepticism about the possibility of puttingsemantics on a rigorous footing and tentative endorsement of attempts by J.A. Fodor,Katz and Postal to map syntactic structures from one or more levels in some composi-tional way onto semantic representations, generative semanticists in the late 1960sand early 1970s in particular started giving serious attention to issues of “logicalform” in relation to grammar and to propose ever more abstract underlying repre-sentations intended to serve simultaneously as unambiguous semantic representationsand as input to the transformational mapping from meaning to surface form (see, forinstance, Bach, 1968; Fillmore, 1968; Karttunen, 1969; Lakoff, 1968, 1971, 1972). Butlinguists’ semantic representations were generally not suggested to be in need of fur-ther interpretation and truth conditions and entailment relations were never explicitlymentioned as an object of study in the indigenously linguistic traditions that existedbefore formal semantics came into linguistics in the 1970s.
By the late 1960s, linguists were intensely debating the question of what level orlevels of syntactic representation should provide the input to semantic interpretation.The generative semanticists had rejected the idea that syntax should be studied inde-pendently of semantics and had moved almost to an opposite extreme which, to someresearchers, appeared to give too little weight to syntactic evidence and too muchweight to raw intuitions about underlying semantic structure, possibly influenced bythe structure of first-order logic. Interpretive semantics, under the lead of Chomskyand Jackendoff, maintained the principle of the autonomy of syntax both in terms ofgrammatical description (syntax can be described without appeal to semantic notions)and in terms of argumentation (the choice among competing syntactic analyses can bemade independently of evidence from semantics) and explored hypotheses about thesyntactic input to semantics that ranged from surface structure only to multiple inputsfrom multiple syntactic levels.
Montague was doing his work on natural language at the height of the “linguisticwars” between generative and interpretive semantics (see J.D. Fodor, 1980; Harris,
7 See for instance the references to Lewis (1968) in Lakoff (1968), to Geach (1962) in Karttunen (1969), toDonnellan (1966) in Partee (1970a) and the evidence of awareness of logical and philosophical concernsin Keenan (1971a,b), Karttunen (1971), McCawley (1971), and Bach (1968), and the volume by Davidsonand Harman (1972), in part a proceedings from one of the earliest linguistics and philosophy conferences(in 1969), one to which Montague was not invited.

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 13 — #13
Montague Grammar 13
1993; Newmeyer, 1980), though Montague and the semanticists in linguistics had noawareness of one another. (Montague was aware of Chomsky’s work and respectedits aim for rigor but was skeptical about the fruitfulness of studying syntax in isola-tion from semantics (see footnote 13 below).) As argued in Partee (1973b, 1975), oneof the potential attractions of Montague’s work for linguistics was that it offered aninterestingly different view of the relation between syntax and semantics that mightbe able to accommodate the best aspects of both of the warring approaches. The PTQinstantiation of Montague’s algebraic theory illustrates what Bach (1976) christenedthe “rule-by-rule” approach to the syntax-semantics correspondence: syntactic rulesput expressions (or expressions-cum-structures, see Partee, 1975) together to formmore complex expressions and corresponding semantic rules interpret the whole as afunction of the interpretations of the corresponding parts. This is quite different fromboth generative and interpretive semantics, which were framed in terms of the prevail-ing conception of syntactic derivations from some kind of phrase-structure-generatedunderlying structures via transformations to surface structures, with the debate cen-tered on which level(s) of syntactic representations provided the basis for semanticinterpretation. The closest linguistic analog to Montague’s rule-by-rule approach wasin Katz and J.A. Fodor’s (1963) proposal for compositional interpretation of Chom-sky’s T-markers (deep structure P-markers plus transformational history), but thatapproach was abandoned as too unrestrictive once Katz and Postal (1964) had intro-duced the hypothesis that transformations might be meaning-preserving, a hypothesisthat in a sense defines generative semantics. Interpretive semantics did not go backto the derivational T-marker correspondence of early Katz and Fodor,8 but, rather,focused on the level of surface structure and the question of what other levels ofsyntactic representation might have to feed into semantic interpretation (Jackendoff,1972).
The earliest introduction of Montague’s work to linguists came via Partee (1973a,b,1975) and Thomason (1974),9 where it was argued that Montague’s work might allowthe syntactic structures generated to be relatively conservative (“syntactically moti-vated”) and with relatively minimal departure from direct generation of surface struc-ture, while offering a principled way to address the semantic concerns such as scopeambiguity that motivated some of the best work in generative semantics.
While “Montague grammar” was undoubtedly the principal vehicle by which theinfluence of model-theoretic semantics came into linguistics, there were other moreor less connected lines of similar research which contributed to the ensuing coop-erative linguistics-philosophy enterprise. The work of David Lewis is important in
8 See Bach’s (1976; 1979b) reexamination of generalized transformations in this context.9 The author sat in on some of Montague’s seminars at UCLA along with David Lewis, who was very
helpful in interpreting Montague to her, as was David Kaplan over the next several years. The 1970two-part workshop at which Montague presented PTQ in September and at which Partee (1973a) waspresented as commentary in December took place only months before Montague’s untimely death. Parteeand Thomason discussed potential linguistic applications of Montague grammar with each other and withother philosophers of language at an institute in philosophy of language and linguistics organized byDavidson and Harman at the University of California, Irvine in the summer of 1971.

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 14 — #14
14 Handbook of Logic and Language
this regard, both because Lewis, who knew the work of Chomsky and other linguistsquite well, was an important influence on Montague’s own work via conversations andhis participation in Montague’s seminars and because Lewis (1968, 1969, 1970) pre-sented many of the same kinds of ideas in a form much more accessible to linguists.Cresswell (1973) was another related work, a book-length treatment of a similar sem-antic program, with a great deal of valuable discussion of both foundational issues andmany specific grammatical constructions. Also Parsons (1972), Keenan (1971a,b) andThomason and Stalnaker (1973) were early and active contributors to linguistics-logic-philosophy exchanges. The 1973 conference at Cambridge University which led to thecollection Keenan (ed.) (1975) was the first international meeting devoted to formalsemantics and the 1977 conference at SUNY Albany which led to the collection Davisand Mithun (eds) (1979) was the first international formal semantics conference in theUSA. By the time of the latter conference, Montague grammar had become the dom-inant if not exclusive reference point for cooperative work by linguists, philosophersand logicians working on the formal semantics of natural language.
1.3 The Theory and the Substance
The paper of Montague that had the most impact on linguists and on the subsequentdevelopment of formal semantics in general, was PTQ (Montague, 1973): 24 pageslong, but densely packed. To many, “Montague Grammar” has probably meant whatMontague did in the fragment in PTQ and the extensions of PTQ by subsequent lin-guists and philosophers with greater and lesser innovations, but it is the broader alge-braic framework of “UG” (“Universal Grammar”; Montague, 1970c) that constitutesMontague’s theory of grammar. We therefore begin this section with a discussionof the basic principles laid out in UG, concentrating on the implications of treatingsyntax and semantics as algebras and compositionality as the requirement of a homo-morphism between them. In Section 1.3.2 we take up issues of model theory andthe difference between direct model-theoretic interpretation and indirect interpreta-tion via translation into an intermediate language such as the language of Montague’sintensional logic (IL). Section 1.3.3 concerns issues of type theory, intensionality andchoices of model structures. All of the issues discussed in these first three sections rep-resent perspectives on semantics that were generally unknown to linguists (and even tomany philosophers) before Montague’s work but have become central to the founda-tions of contemporary formal semantics. In Section 1.3.4 we turn to the classic paperPTQ, focusing discussion on features of Montague’s analysis that were particularlynovel, either absolutely or for most working linguists, and which had a major impacton later work in the field. Finally, in Section 1.3.5, we include some brief notes on thefragments contained in Montague’s two 1970 papers, EFL and UG, since a comparisonof Montague’s three fragments can be very helpful for distinguishing between generalrequirements of Montague’s theoretical framework and particular choices made byMontague in PTQ and also because those often-neglected papers contain a number ofideas and analyses that are not duplicated in PTQ.

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 15 — #15
Montague Grammar 15
1.3.1 Universal Grammar: Syntax as Algebra, Semantics as Algebra,Compositionality as Homomorphism
Montague’s paper “Universal Grammar” (UG; Montague, 1970c) contains the mostgeneral statement of Montague’s formal framework for the description of language.10
The central idea is that anything that should count as a grammar should be able to becast in the following form: the syntax is an algebra, the semantics is an algebra andthere is a homomorphism mapping elements of the syntactic algebra onto elements ofthe semantic algebra.
The algebraic perspective is a generalization of the logician’s approach to gram-mar in terms of recursive definitions. It is also a perspective which linguists shouldin principle find congenial, since it focuses on the structure of the syntax and of thesemantics and of the relation between them, remaining quite neutral about the particu-lars of content, ontological commitment, epistemological grounding, etc. In principleit is a perspective that is entirely neutral with respect to whether grammars are in thehead or are Platonic abstract entities, or other such foundational questions which maydivide theorists who can nevertheless engage fruitfully in arguments about the syntaxand semantics of various constructions.11 The algebraic perspective therefore offers agood common ground, at least in principle, for logicians, linguists and philosophers oflanguage and this aspect of Montague’s contribution has indeed been valuable, eventhough relatively few researchers present analyses in explicitly algebraic form.
The syntactic algebra contains elements (expressions) and operations which applyto tuples of expressions to yield other expressions; the language, in the simplest case,is the set of all expressions which can be formed by starting from some basic expres-sions (the generators of the algebra) and applying operations in all possible ways; thatis, it is the closure of the generator set under the operations of the algebra. The seman-tic algebra is similarly conceived. The homomorphism requirement is the composi-tionality requirement (more below); the fact that it is a homomorphism requirementand not an isomorphism requirement means that distinct syntactic expressions mayhave the same meaning, but each syntactic expression must have only one meaning.The requirement is thus that there be a many-one relationship between expressionsand meanings and not a requirement of a one-one relationship, although the compo-sitionality requirement has sometimes mistakenly been described this way (e.g., inPartee, 1973b). A brief pedagogical introduction to the algebraic formulation of theUG framework can be found in Partee, Ter Meulen and Wall (1990); more can befound in the three references cited in footnote 10.
10 Three good references include Ladusaw (1979), an early expository introduction for linguists; Link(1979), an introductory text in German which is particularly rich in showing how various familiar frag-ments would look when spelled out in the algebraic terms of UG; and Janssen (1986a,b), in English,which includes a good discussion of exactly what the UG framework amounts to, what compositionalitymeans in the theory of UG and what sorts of analyses the UG framework permits and excludes.
11 When I once mentioned to Montague the linguist’s preferred conception of universal grammar as thecharacterization of all and only possible human languages, his reaction was to express surprise that lin-guists should wish to disqualify themselves on principle from being the relevant scientists to call on ifsome extraterrestrial beings turn out to have some kind of language.

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 16 — #16
16 Handbook of Logic and Language
This very general definition leaves a great deal of freedom as to what sorts of thingsthe elements and the operations of these algebras are. As for the syntactic algebra, inthe case of a typical logical language the elements can be the well-formed expres-sions, but in the case of a natural language, ambiguity makes that impossible, sincethe homomorphism requirement means that each element of the syntactic algebra mustbe mapped onto a unique element of the semantic algebra12 (the shorthand terminol-ogy for this is that the syntax must provide a “disambiguated language”). In the PTQgrammar for a fragment of English, the syntax is not explicitly presented as an alge-bra, but could be transformed into one; the elements of the syntactic algebra couldnot be the expressions, since many are ambiguous, but could be the analysis trees(Partee, 1973b). Montague allows for the grammar to include an “ambiguating rela-tion” mapping elements of the syntactic algebra onto the actual (“surface”) expressionsof the language; as McCawley (1979) notes, if it were the case that a generative seman-tics deep structure were the right level to interpret compositionally, the entire trans-formational component mapping deep structures onto surface structures (plus a tree-wipeout rule to yield surface strings) could be the description of such an ambiguatingrelation.
The relation between a linguist’s syntactic component and syntax as an algebra isnot always easy to see and it can be non-trivial to determine whether and how a givensyntax can be presented as an algebra, and more particularly, as an algebra homomor-phic to a corresponding semantic algebra. The core issue is compositionality, since forMontague, the central function of syntax is not simply to generate the well-formedexpressions of a language but to do so in such a way as to provide the necessary struc-tural basis for their semantic interpretation.13 Some kinds of non-transformationalgrammars such as Generalized Phrase Structure Grammar (Gazdar, Klein, Pullum andSag, 1985), Head-Driven Phrase Structure Grammar (Pollard and Sag, 1987, 1994),
12 Actually, there is a way of respecting the homomorphism requirement while working with semanticallyambiguous expressions. It is standard in mathematics to turn a (one-many) relation into a function bymaking it a set-valued function. This method is employed, for instance, by Cooper (1975), who takes“sets of (standard) meanings” as the semantic objects, mapping each (possibly ambiguous) linguisticexpression onto the semantic object which consists of all of its possible meanings; not all kinds of ambi-guity are amenable in a natural way to this kind of treatment, but Cooper’s device of “quantifier storage”for handling scope ambiguities for which there is no independent evidence of syntactic ambiguities isone of the serious options in this domain. The same general strategy for working directly with ambigu-ous expressions is employed by Hendriks (1988, 1993) to deal with the multiplicity of readings madeavailable by type-lifting principles and in Rosetta (1994) to turn translations from English into Dutch andSpanish into functions. Thanks to Theo Janssen for pointing out to me the general principle behind allthese cases.
13 “It appears to me that the syntactical analyses of particular fragmentary languages that have been sug-gested by transformational grammarians, even if successful in correctly characterizing the declarativesentences of those languages, will prove to lack semantic relevance; and I fail to see any great interest insyntax except as a preliminary to semantics.” (From the notorious footnote 2 of UG, p. 223 in Montague,1974.) Footnote 2, which goes on to criticize other aspects of “existing syntactical efforts by Chomskyand his associates”, was not designed to endear Montague to generative linguists, although in the begin-ning of the paper he does present himself as agreeing more with Chomsky than with many philosophersabout the goals of formal theories of syntax and semantics.

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 17 — #17
Montague Grammar 17
and the various categorial grammar frameworks (see Chapter 2 on Categorial TypeLogics in this Handbook) are among the clearest examples of “linguists’ grammars”that are more or less consistent with the requirements of Montague’s UG. A simplecontext-free grammar is the most straightforward kind of grammar to convert to anequivalent algebra, since its surface phrase structure trees are isomorphic to its deriva-tion trees.
The choice for the semantic elements is totally free, as long as they make up analgebra, i.e. as long as there is a well-defined set of elements and well-defined opera-tions that have elements of the algebra as operands and values. The semantic elements,or “semantic values” as they are often called, could be taken to be the model-theoreticconstructs of possible-worlds semantics as in Montague’s fragments of English andmost “classical” formal semantics, or the file change potentials of Heim (1982), orthe game strategies of game-theoretical semantics, or the simple extensional domainsof first-order logic, or hypothesized psychological concepts, or expressions in a “lan-guage of thought”, or bundles of features, or anything else; what is constrained is notthe “substance” of the semantics but some properties of its structure and of its relationto syntactic structure.
While there is no direct constraint on the kinds of things that make up the elementsof a semantic algebra, there is nevertheless a further requirement that relates to truthconditions. An important guiding principle of the UG framework and at the heart ofMontague’s semantics, inherited from the traditions of logic and model theory andtransmitted as one of the defining principles of formal semantics, is the principle thattruth conditions and entailment relations are the basic semantic data, the phenomenathat have to be accounted for to reach a minimal level of adequacy. Although UG givesa very unconstrained specification of the notion of a semantic algebra, under the head-ing “Theory of Meaning”, it also provides, under the heading “Theory of Reference”,a specification of the notion of a “Fregean interpretation”; a semantic algebra cannotform part of a Fregean interpretation unless it can be connected to an assignment oftruth conditions in a specified way. An algebra whose elements were expressions in a“language of thought” would probably not directly be construable as properly semanticin that stronger sense and would probably fit better into the category of “intermediatelanguage” in the sense of Section 1.3.2 below. The same is undoubtedly true a for-tiori of a linguistic representational level such as the level of “LF” in a contemporaryChomskyan framework.
It is the homomorphism requirement, which is in effect the compositionalityrequirement, that provides one of the most important constraints on UG in Mon-tague’s sense and it is therefore appropriate that compositionality is frequently atthe heart of controversies concerning formal semantics, including internal theoreticalcontroversies concerning the appropriate formulation of the requirement and its impli-cations for theories of formal semantics, external controversies concerning whethernatural languages are best described or even reasonably described as compositionaland “applications” controversies concerning whether a given analysis is or is notcompositional (often a debate concerning whether a somewhat informally presentedanalysis could be given a compositional formulation).

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 18 — #18
18 Handbook of Logic and Language
The compositionality requirement, sometimes called Frege’s principle (see Janssen,1986a, for discussion) can be stated in plain language as follows:
The Principle of Compositionality:The meaning of a complex expression is a function of the meaningsof its parts and of the way they are syntactically combined.
Construed broadly and vaguely enough, the principle has sometimes seemeduncontroversial,14 but Montague’s precise version of it places strong constraints onadmissible systems of syntax and semantics. As the wording given above suggests,the exact import of the compositionality principle depends on how one makes precisethe notions of meaning, of part and of syntactic combination, as well as on the classof functions permitted to instantiate the “is a function of” requirement.
In the specification of formal languages, the compositionality principle is generallysatisfied in the following way: the syntax is given by a recursive specification, startingwith a stipulation of basic expressions of given categories and with recursive rules ofthe following sort:
Syntactic Rule n:If ! is a well-formed expression of category A and " is a well-formedexpression of category B, then # is a well-formed expression ofcategory C, where # = Fi(!, ").
In such a rule, Fi is a syntactic operation; it may be as simple as concatenationor, as far as the requirements of UG are concerned, arbitrarily complex and not evennecessarily computable. It is the job of a linguistic theory of syntax to put furtherrequirements on the nature of syntactic categories and syntactic operations.
The semantics is then given by a parallel recursive specification, including a stipu-lation of the semantic values for the basic expressions and for each syntactic rule n asingle semantic rule of the following form:
Semantic Rule n:If ! is interpreted as !! and " is interpreted as " !, then # isinterpreted as # !, where # ! = Gk(!
!, " !).
In such a rule, Gk is a semantic operation; in typical examples it may be somethinglike function-argument application, set intersection, or function composition, thoughthat too is totally unconstrained by the theory of UG; it is up to a linguistic theory ofsemantics to specify the available semantic operations and any formal or substantiveconstraints on which semantic operations are used in the interpretation of which syn-tactic constructions.
14 But in fact even the most general form of the compositionality principle has been controversial; seediscussion in Chapter 10 on Compositionality.

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 19 — #19
Montague Grammar 19
This way of implementing the compositionality requirement in terms of correspon-ding recursive rule specifications of syntax and semantics has been dubbed by Bach(1976) the requirement of “rule-by-rule interpretation” and it is the form in whichMontague grammars are most commonly instantiated.
When the systems of rules that make up the syntax and the semantics are recastas algebras, the requirement of rule-by-rule correspondence becomes the requirementof homomorphism. As the schematic illustration of the rule-by-rule correspondencerequirement above illustrates, the homomorphism requirement applies at the level ofrules, or derivation trees, not at the level of the particular syntactic or semantic opera-tions employed in the rules. This is frequently a point of confusion for novices, under-standably, since the operations of the syntactic algebra are the rules or constructionsof the syntax and not what are normally referred to (including in the preceding para-graphs) as syntactic operations. But it is clear that while there may be a uniform com-positional interpretation of the Subject-Predicate combining rule (that’s a non-trivialchallenge already!), there could not be not expected to be a uniform semantic interpre-tation of a syntactic operation such as concatenation, a syntactic operation which maybe common to many rules. And of course it can make a big difference to the possibil-ity of meeting the homomorphism requirement whether the elements of the syntacticalgebra are taken to be strings, bracketed strings, labeled bracketed strings, or someother kind of abstract structures and what kinds of syntactic operations are allowed inthe syntactic rules.
For a fuller discussion of the compositionality requirement, its various formula-tions, its place in various theories of formal syntax and semantics in addition toclassical Montague grammar and discussion of its status as a methodological or anempirical principle, see Chapter 10 on Compositionality in this Handbook. With res-pect to the last point, most formal semanticists have come to agree with the claimsof Gamut (1991) and Janssen (1986a) that the principle is so deeply constitutive ofMontague grammar and most of its close relatives that it must be considered to bea methodological principle: there is no way to test it without testing an entire theoryin which it is embedded. So the claim that natural languages have a compositionalsemantics amounts to a claim that natural languages can be fruitfully described with atheory that includes compositionality as one of its principles. (In this respect debatesabout compositionality are analogous to debates between transformational and non-transformational grammars, for instance; it is not that they can’t be debated or thatempirical evidence is not relevant, it is just that it is whole theories that must be eval-uated.)
Some discussion of “external” controversies surrounding the Principle of Com-positionality and initial skepticism among linguists, is found in Section 1.4.1. Someof the “internal” controversies will be touched on in various sections below in thecontext of discussions of specific constructions and of the development of various“post-Montague” theories.
Very few linguists and not very many philosophers or logicians have wrestled withthe technically difficult presentation of Montague’s theory as presented in “UG”; theauthor has made a few forays into the ring, but does not claim to have mastered it,

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 20 — #20
20 Handbook of Logic and Language
relying for difficult points on the colleagues whose works are cited above.15 Never-theless, the basic ideas of the algebraic approach and the homomorphism require-ment are not difficult to grasp and can be a very useful way to look at grammar.Partly similar approaches to looking at syntactic structure in terms of algebras, orderivational history, or analysis trees, or “constructions”, can be found in the concep-tion of T-markers noted in Section 1.2.4 above and at various points in the work ofZellig Harris, Hugh Matthews, Sebastian Shaumjan, Pavel Tichý and Prague schoolcolleagues such as Pavel Materna and Petr Sgall and very clearly in the theory ofTree-Adjoining Grammars (TAGs) of Joshi and his colleagues (Joshi, 1985; Joshi,Vijay-Shanker and Weir, 1991), where the difference between the derivation tree andthe derived constituent structure tree is especially vivid. It is a conception that maybe natural not only from a formal language point of view, but also from a typologicalperspective, since languages may often be fruitfully compared at the level of construc-tions, or rules in Montague’s sense, in cases where the input and output categories fora family of counterpart constructions are the same and the semantic interpretationof these constructions in different languages is the same or similar, but the syntacticoperations involved are different. For instance, “Yes-No questions” may be a com-mon construction to find cross-linguistically but may be realized by the addition of amorpheme in one language, by reduplication of a specified part in another, by a rear-rangement of word order in another, by application of a certain intonational contourin another, or by a composition of two or more such operations. Rosetta (1994), des-cribed briefly below in Section 1.3.4.7, discusses and demonstrates the fruitfulness ofmaking explicit cross-linguistic correspondences at the level of derivation trees as partof a project of compositional translation.
1.3.2 Model Theory; Direct and Indirect Interpretation
“Universal Grammar” presents formal frameworks for both “direct” and “indirect”semantic interpretation, differing with respect to whether an “intermediate language”(such as the language of Montague’s Intensional Logic) is employed or whether thelanguage in question is given a direct model-theoretic interpretation. Relevant notionsof compositionality are defined for each.
Direct interpretation is what was described in the preceding section, involving thehomomorphic mapping of a syntactic algebra onto a semantic algebra. The semanticalgebra in the normal case is a model-theoretic structure, containing domains with atyped structure. For each syntactic category, there must be a domain of possible inter-pretations for expressions of that category and the relation of syntactic categories tothese semantic types must also be a homomorphism. For a simple formal language likethe language of first-order logic, the semantic domains may consist just of a domain
15 For that reason and also for the sake of brevity, the discussion of UG presented here is somewhat over-simplified. Issues left aside include the role of polynomials in stating the homomorphism requirementprecisely, the distinctions among models, model structures and interpretations and of course all of theexact definitions.

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 21 — #21
Montague Grammar 21
of entities, a domain of truth values and domains of sets of n-tuples of entities servingas the domains of possible interpretations of n-place predicates. In EFL, the only frag-ment in which Montague gave a direct model-theoretic interpretation of English, twobasic semantic categories are used: a set of possible individuals as the domain of possi-ble denotations of “name phrases”, and a domain of sets of possible worlds, or proposi-tions, as the domain for possible denotation of formulas; each of the other six semanticcategories used for EFL is defined as the set of functions from an n-tuple (for a cer-tain n) of particular semantic categories to a particular semantic category. (Examplesof direct interpretation can also be found in the work of Cresswell, Von Stechow andKratzer.)
Direct interpretation compositionally determines truth conditions for the expres-sions of the category “sentence” or “formula” and hence also determines entailmentrelations among the sentences or formulas of a given language. Indirect interpretationproceeds via translation into an intermediate language, as in Montague’s grammars forfragments of English in UG and PTQ, where the intermediate language is a version ofhis Intensional Logic.
For “indirect” semantic interpretation, the notion of compositional translation isdefined; as expected, this involves a requirement of homomorphism between two syn-tactic algebras, one for the source language and one for the target language, the inter-mediate language. The intermediate language must then be interpreted by means ofa homomorphism from its own syntactic algebra to a semantic algebra in the ear-lier sense. Translation is iterable and any number of intermediate languages could beinvoked, as long as the last in the chain is given a Fregean interpretation. (See theapplication of this idea in Rosetta, 1994, where, since the goal is actually translationfrom one natural language to another, the step of providing a Fregean interpretation isnot included.)
When both the translation into an intermediate language and the semantic interpre-tation of that intermediate language are compositional, the intermediate language is inprinciple dispensable, since the composition of those two homomorphisms amountsto a direct compositional interpretation of the original language.
There may be various reasons for providing a semantics for a natural language viatranslation into an intermediate language. Montague viewed the use of an intermediatelanguage as motivated by increased perspicuity in presentation and by the expectation(which has been amply realized in practice) that a sufficiently well-designed languagesuch as his Intensional Logic with a known semantics could provide a convenienttool for giving the semantics of various fragments of various natural languages. Lin-guists with a Chomskyan background tend to be interested in the psychological realityof some level of “semantic representation” and hope to find evidence for or againstthe existence of some intermediate level and to discover its syntactic properties if itexists. Not surprisingly, direct empirical evidence for or against such levels is hard tofind and the positing of an intermediate level is therefore another good candidate fora methodological principle rather than an empirical hypothesis. Linguists who workwith a level of “LF” do not usually reach that level via a compositional translationfrom a disambiguated syntax, so the linguist’s LF is not an intermediate language in

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 22 — #22
22 Handbook of Logic and Language
the sense of UG.16 Evidence for an intermediate language in the sense of UG wouldbe particularly hard to find in any straightforward way, given that compositionalityrequirements force the intermediate language to be dispensable in principle.
1.3.3 Type Theory and Intensionality
Montague’s general framework leaves wide latitude for choices at many points,including in particular many choices about the nature of the model structures whichmake up the semantic algebras. The choices involved in the semantic algebras areof two main sorts: structural and ontological. The structural choices involve the typetheory and the choices of semantic operations; the ontological choices concern prin-cipally the nature of the basic elements, such as a domain of entities or of possibleentities, a domain of moments or intervals of time, a domain of truth values, a domainof possible worlds, etc.
Certain choices made by Montague have become conventionally associated withMontague grammar but are not essential to Montague’s theory. The possible-worldsanalysis of intensionality, for instance, while not essential to the algebraic conceptionof grammar presented in UG, was central to much of Montague’s work, not only inhis three “grammar” papers, and in practice is often regarded as if it were an inherentaspect of Montague grammar. Only in more recent times has there been a critical massof researchers with enough background in both linguistics and model theory to beginto evaluate alternative choices in ways that are responsive to both linguistic and formalconcerns.17
In this section we note some of the particular choices made by Montague in therealm of semantic structures that seem particularly interesting in hindsight, includingthe selection of model structures and their basic elements and issues of type theory,particularly Montague’s use of functional types, which led to the heavy use of thelambda calculus in MG.
Montague did not present exactly the same type theory in all of his work, but thedifferent systems are similar. What all type theories have in common is some selectionof primitive types, some means for defining non-primitive types and a model-theoreticinterpretation of the basic types and of the defined types.
16 Applications of formal semantics to theories including a Chomskyan level of LF usually take the languageof LF as the language to be semantically interpreted; the LF language itself can be given a straightforwardcontext-free grammar and can then be compositionally provided with a model-theoretic interpretation.Whether the rest of the syntax that pairs possible LFs with possible surface forms or phonological formscan be construed as a complex instantiation of Montague’s “ambiguating relation” is an open questionwhich to my knowledge is unexplored.
17 In the early years of Montague grammar when linguists like the author were asked questions like “whydo you used a typed rather than an untyped lambda calculus?”, we did not have the training to answerand were completely dependent on choices made by our logician friends, who in turn were motivatedby considerations that rested on a deep knowledge of logic but a shallow knowledge of linguistics. It isclearly important to localize at least some interdisciplinary competence inside single heads, as happensmore frequently for these fields now.

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 23 — #23
Montague Grammar 23
Montague usually took as his primitive types the two types e and t, and his definedtypes always included some kinds of functional types and sometimes included a par-ticular device for forming intensional types. The interpretation of the two basic typeswas different in different papers and even so did not exhaust the range of choiceswhich could be made. Correspondence between Montague and Dana Scott18 includesdiscussion of whether the domain corresponding to the type e should be a single world-independent domain of “possible individuals” (intuitively, the collection of all of theindividuals that exist in any world), or whether there should be a domain of indi-viduals assigned to each possible world; that issue was a matter of lively debate inthe development of quantified modal logic (see Chellas, 1980; Gamut, 1991; Hughesand Cresswell, 1968, Volume II, Chapter 3). Montague’s eventual choice of workingwith a single domain of world-independent individuals seems to have been motivatedin part by his desire to treat verbs such as worship, remember and seek as simpletransitive verbs and names as rigid designators; he did not want to have to syntac-tically decompose sentences such as Jones worships Zeus or Smith still remem-bers Einstein with analyses involving embedded propositions with embedded modaloperators and descriptions in place of the names.19 But while most formal semanti-cists have followed Montague’s practice of working with a single domain of world-independent individuals, the issues here remain difficult and complexly interwoven,including issues concerning existence and the interpretation of the existential opera-tor, differences between verbs like worship and verbs like seek (Bennett, 1974), thesemantics of proper names, and the ontological status of “situations”.20
The interpretation of the other basic type, t, is subject to well-known variation.In the systems of PTQ and UG, the associated domain is simply the two-element setconsisting of the truth values 0 and 1; all intensional types are complex types of theform "s, a# for some type a. In the system of EFL, the universes of possible denotationscorresponding to the two basic semantic categories are the set of possible individualsand the set of functions from possible worlds to truth values, or propositions. In theEFL system, as in Cresswell’s lambda-categorial languages (Cresswell, 1973; and laterworks), the basic type t is interpreted as the type of propositions, which for Montagueare again identified with functions from possible worlds to truth values.
It is frequently noted that the Boolean structure evident from the cross-categorialgenerality of and, or and not is good evidence that whatever the interpretation of type
18 Part of Scott’s side of that correspondence was presented in published form in Scott (1970); see alsoHintikka (1970).
19 But see Montague’s footnote 8 in PTQ for a careful statement of division of labor between semanticalanalysis and philosophical argumentation: “If there are individuals that are only possible but not actual,A [i.e. the domain corresponding to the type e] is to contain them; but this is an issue on which it would beunethical for me as a logician (or linguist or grammarian or semanticist, for that matter) to take a stand”.
20 The widespread adoption of Montague’s practice has not been the result of much explicit argument.Explicit argument on the side of adopting Lewis’s counterpart theory and combining it with a theory ofsituations as parts of worlds can be found in Kratzer (1989) and the debates between Lewis (1973) andKripke (1972), among others, concerning Lewis’s counterpart theory with its world-bound individuals.There are also very interesting ontological issues that arise in applications of possible-worlds semanticsin the field of poetics and the semantics of fictional language; see Parsons (1980), Pavel (1986).

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 24 — #24
24 Handbook of Logic and Language
t is, it should form a Boolean structure and that, furthermore, the types of many othermajor syntactic categories should systematically reflect a similar Boolean structure(see Keenan and Faltz, 1985; Partee and Rooth, 1983). Both of Montague’s choices,the set {0, 1} and the set of functions from possible worlds to truth values, can beinterpreted as Boolean algebras and the same holds for various other candidate inter-pretations for type t such as the set of sets of assignments (taking as the interpretationof a given formula the set of assignments that satisfy it). It is because of the needfor Boolean structure that it is problematical to try to work with sets of truth valuesconstrued as real or rational numbers in the interval [0, 1] (as has been proposed insome approaches to “fuzzy logic”), but there are other ways to structure analogs of“intermediate truth values” that do respect Boolean structure by working with “logicalspaces” to which linear values can derivatively be assigned as measures (see Kampand Partee, 1995).
For a natural language, the family of syntactic categories and corresponding seman-tic domains may be so rich that it is simplest to define an infinite system of domainsrecursively via a type theory and then only use the ones that are actually neededin a given fragment of grammar. In EFL, eight semantic domains were individuallydefined, although there was clearly a pattern evident, which was generalized in thesystems of UG and PTQ. In UG and PTQ, Montague had two type-forming rules: arule which would produce a functional type "a, b# from any two types a and b, withdenotations as functions from type a to type b; and a rule which would produce anintensional type "s, a# from any type a, with denotations as functions from possibleworlds (or more generally, indices, which might be worlds, times, world-time pairs,or other choices in a given interpretation) to denotations of type a. Both of these com-plex types are functional types; the only difference is that the type s has no independentexistence. Possible worlds are taken to be ingredients of model structures and tools forthe definition of intensionality, but never themselves a domain of possible interpreta-tions for any category of expressions.
An alternative closely related but interestingly different type structure is Gallin’sTy2: it differs from the type structure of Montague’s intensional logic in taking e, tand s as basic types and having the formation of functional types "a, b# as the uniformmeans of forming complex types. A brief introduction into Ty2 can be found in Gamut(1991, Volume II, Chapter 5); the original reference is Gallin (1975). Ty2 is used inmany of Groenendijk and Stokhof’s papers and is discussed in Janssen (1986a). Seealso Zimmermann (1989) for an embedding of Ty2 into Montague’s IL.
At the time of Montague’s work, the use of type theory in the structuring of seman-tic domains was basically unknown in linguistics and not widespread within the phi-losophy of language, in part because of the dominance of first-order logic and modestextensions of it; a rich type theory is unnecessary if one is only working with asmall number of types. Model theory and possible-worlds semantics were sometimescalled “West Coast semantics”, centered as they were in California institutions whereTarski and his students and colleagues (and Carnap in the later part of his career)were located, and that enterprise was looked upon with considerable skepticism byQuine and much of the “East Coast establishment”. As a result of unfamiliarity with

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 25 — #25
Montague Grammar 25
type theory, few early Montague grammarians were in a position to consider propos-als for alternative type theories. Eventually variety in type theories became one ofthe dimensions in which theories might differ. Alternative modes of semantic com-bination such as function composition and corresponding enrichment of type struc-ture, came to play a greater role as semanticists learned to appreciate the work thata powerful type theory could do; these developments will be touched on briefly inSection 1.4.4.
One important and lasting feature of Montague’s type theory, one which hasbecome so thoroughly absorbed into linguistics that its novelty in the early 1970s iseasily forgotten, is the idea of seeing function-argument structure as the basic semanticglue by which meanings are combined. What did linguists think before that? In earlywork such as Katz and J.A. Fodor (1963) or Katz and Postal (1964) one sees attemptsto represent meanings by means of bundles of features and meaning combinationsas the manipulations of such feature bundles; there were obvious problems with anysemantic combinations that didn’t amount to predicate-conjunction. Later logically-oriented linguists working on semantics invoked representations that looked more orless like first-order logic augmented by various “operators” (this was equally true forgenerative and interpretive semantics) and more generally the practice of linguistsdealt in “semantic representations” without explicit attention to the interpretation ofthose representations. Therefore the issue of how semantic interpretations of parts arecombined to make semantic interpretations of wholes did not really arise, since thesemantic representations were not formally different in kind from syntactic represen-tations.
The impact of seeing semantic interpretation as involving a great deal of function-argument structure (something also emphasized early by Lewis, Cresswell and Parsonsand traceable to the work of Frege, Tarski and Carnap) was felt in linguistics moststrongly in terms of its effect on the analysis of particular linguistic constructions,about which more will be said below. For example, the idea of an “intensional transi-tive verb” like Montague’s treatment of seek had apparently not occurred to linguistsor philosophers before: referential opacity was diagnosed as resulting from embeddingunder some sentential operator and to make the opacity of a verb like seek explicitrequired engaging in lexical decomposition (as suggested, for instance, in Quine,1960) to make the opacity-producing operator overt (see Partee, 1974, for a discus-sion of the contrasting approaches). Similarly, linguists had never thought to analyzeadjectives as functions applying to nouns. “Normal” adjectives were all assumed tooriginate as predicates and get to prenominal position via relative clause reduction(Bach, 1968, went so far as to get nouns into their head positions via relative clausereduction as well, thereby providing a clausal structure that could contain temporaloperators in order to account for temporal ambiguity in superficially tenseless expres-sions like the president) and linguists who noticed the non-predicate-like behavior ofadjectives like former and alleged also noted the existence of cognate adverbs whichwere taken to be their sources through syntactically complex derivational relations (orequally complex derivations in an interpretivist treatment, where the “more logical”representation was derived, not underlying).

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 26 — #26
26 Handbook of Logic and Language
Function-argument structure and a rich type theory go naturally together in thetreatment of natural language, given the fairly rich array of kinds of constituentsthat natural languages contain. Even if Chierchia (1984a) is correct in hypothesiz-ing that the productive categories, those which have corresponding wh-words and/orpro-forms and are not limited to a small finite set of exemplars (criteria which maynot always exactly agree, but are a good start), are never higher than second-order intheir types, that is still a much richer type structure than was found in classical predi-cate logic, which has so little diversity of types (sentence, entity and n-place first-orderpredicates) as to leave linguists who employed it unaware of types at all and to make itunderstandable why explicit semantics before Montague grammar seemed to requireso much lexical decomposition. (See Dowty, 1979, for illuminating discussion by agenerative semanticist who became a leading Montague grammarian.)
1.3.4 The Method of FragmentsEach of Montague’s three “grammar” papers contains a “fragment”. The term wasintroduced in EFL, where it is used four times in the second paragraph, which begins(Montague, 1974, p. 188):
In the present paper I shall accordingly present a precise treatment, culminating in atheory of truth, of a formal language that I believe may be reasonably regarded as afragment of ordinary English.
The “method of fragments” was a feature of Montague’s work which was novelto linguists and became quite influential methodologically as one of the hallmarks ofMontague grammar; “fragment” has become almost a technical term of formal seman-tics. What is meant is simply writing a complete syntax and semantics for a specifi-able subset (“fragment”) of a language, rather than, say, writing rules for the syntaxand semantics of relative clauses or some other construction of interest while makingimplicit assumptions about the grammar of the rest of the language. Linguists havetraditionally given small (but interesting) fragments of analyses of various aspects ofcomplete natural languages; Montague gave complete analyses of small (but interest-ing) fragments of natural languages.21
In this section we turn to the fragment of PTQ. Features of PTQ that will be dis-cussed include the use of a version of categorial grammar in the syntax, the use ofthe lambda calculus, the interpretation of NPs as generalized quantifiers, the treat-ment of bound variable anaphora and scope phenomena and the role of analysis treesin capturing the relevant notion of “logical form”. Discussion will be brief and will
21 There has not been much explicit discussion of pro’s and con’s of the method of fragments in theoreticallinguistics and the methodological gap is in principle even wider now that some theories don’t believein rules at all. In practice the gap is not always unbridgeable, since, e.g., principles for interpreting LFtree structures can be comparable to descriptions of rules of a Montague grammar whose analysis treesthose LFs resemble. To quote from Partee (1979a), “I would not recommend that one always work withthe constraint of full explicitness. But I feel strongly that it is important to do so periodically, becauseotherwise it is extremely easy to think that you have a solution to a problem when in fact you don’t”.

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 27 — #27
Montague Grammar 27
not recapitulate the content of PTQ; pedagogical introductions and fuller discussionsare readily available elsewhere, for example, Partee (1973b, 1975), Thomason (1974),Dowty, Wall and Peters (1981), Link (1979), Gamut (1991); see Zimmermann (1981)for an insightful review of three German Montague grammar textbooks including Link(1979). The topics have been chosen for their importance to the subsequent devel-opment of the field of semantics and theories of the syntax-semantic interface. Thediscussion is partly from the perspective of the historical context in which PTQ madeits first impact on linguistics. It is also partly retrospective, since it is impossible todiscuss PTQ in the 1990s without thinking simultaneously about its impact on sub-sequent developments and about which of its features have had the most long-lastingsignificance.
1.3.4.1 Function-Argument Structure, Category-Type Correspondences,Modified Categorial Grammar and the Lambda Calculus
One of the noteworthy features of PTQ was the systematic correspondence betweensyntactic categories and semantic types. As in his other fragments, Montague usedfunction-argument application as the most basic “semantic glue”, employing it in theinterpretation of virtually all basic grammatical relations (often composed with theoperation of intensionalizing the argument). And as other philosophers and logicianssuch as Bar-Hillel, Curry, Lambek and David Lewis had realized, if there is to be asystematic correspondence between syntactic categories and semantic types and thenon-basic semantic types are all constructed as functional types, then categorial gram-mar offers a good way to make the correspondence between syntax and semanticsexplicit in the very names of the syntactic categories. In PTQ it is not the case thatall of the non-basic semantic types are functional types, because there are also theintensional types "s, a#; but it is the case that all of the non-basic syntactic types areinterpreted as functional types (see below), so a variant of the basic category-typecorrespondence of categorial grammar could be used in PTQ.
Strict classical categorial grammars use concatenation as the only syntactic opera-tion and are equivalent to context-free grammars. Montague used the system of cate-gories of categorial grammar and made a uniform category-type correspondence as incategorial grammar (with the addition of intensionalizing the type of the argument),but did not limit the syntactic operations to concatenation. If one works with a classi-cal categorial grammar, the analysis tree which shows the rule-by-rule structure of aderivation is isomorphic to the surface syntactic structure of the generated expression;in PTQ, these structures are generally not isomorphic and it is the analysis tree whichdisplays the semantically relevant syntactic structure.
An appreciation of the importance of function-argument structure, gained throughexperience with MG and related work, has helped linguists understand much moreof the original motivation of categorial grammar, a formalism which had been dis-missed by linguists as soon as it was proven to be equivalent in generative powerto context-free phrase structure grammar. But since one of its central features isthe way its category names encode an intimate correspondence between syntactic

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 28 — #28
28 Handbook of Logic and Language
category and semantic type, categorial grammars are attractive from the point of viewof compositionality. This had been pointed out by Lyons (1968) and Lewis (1970);Montague, as noted, used a modified categorial grammar for PTQ, and Cresswell(1973) used what he christened a lambda-categorial grammar. The problem of the(supposed) non-context-freeness of English and the context-freeness of standard cat-egorial grammar was addressed in three different ways by those four authors. Lyonsand Lewis added a (meaning-preserving) transformational component to a categorialbase. Montague used categorial grammar nomenclature to establish the homomor-phic category-type correspondence among generated expressions but allowed syn-tactic operations much more powerful than concatenation for putting expressionstogether (as with the Quantifying In rule and the relative clause rule mentioned inSection 1.3.4.1 below,22 but the core “rules of functional application” did just useconcatenation plus bits of morphology). Cresswell added free permutations to his cat-egorial grammar, thereby generating a superset of English, with disclaimers aboutsyntactic adequacy and suggestions about possible filters that might be added. (Seealso Chapter 2 on Categorial Type Logics in this Handbook.)
It was noted in Section 1.3.3 that the basic semantic types used in PTQ were e and t.The basic syntactic categories used in PTQ were also called e and t, with t the categoryof formulas (sentences) and e a “phantom” category that would have been the categoryof proper names and pronouns if all term phrases were not uniformly analyzed asgeneralized quantifiers (Section 1.3.4.2). The rest of the syntactic categories were allof the form A/B or A//B (an arbitrary distinction designed simply to distinguishsyntactic categories that had the same semantic type), with corresponding semantictype ""s, $ (B)#, $ (A)# (where $ is the type-assignment function): the type of functionsfrom intensions of things of the type of Bs to things of the type of As.
Montague did not require every word and morpheme to be assigned to a syntacticcategory and semantic type. Words and morphemes could also be introduced as partof the effect of applying a syntactic rule, in which case they were not assigned anysyntactic category, semantic type, or isolable meaning. Such expressions are called“syncategorematic”; relatively uncontroversial examples include the to of infinitivesand the that of sentential complements. Montague treated most of the logical vocab-ulary of English syncategorematically, including not only the conjunctions and andor, but also the determiners every, a/an and the, each of which was introduced bya single syntactic rule which applied to a common noun phrase and yielded a termphrase. Subsequent work in Montague grammar quickly introduced the category ofdeterminer phrases, replacing Montague’s syncategorematic treatment of determinerswith a categorematic one.
The PTQ type assignment was uniform, elegant and interestingly encoded the gen-eralization that all function-argument-interpreted constructions included intensional
22 Janssen (1986a) shows that with the unrestricted power Montague allows for his syntactic rules, everyrecursively enumerable language can be generated and compositionally associated with any desiredmeaning assignment, i.e. that in the absence of any constraints on the power of syntactic rules, composi-tionality by itself does not formally limit the class of grammars in any serious way. See also Chapter 10on “Compositionality” in this Handbook.

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 29 — #29
Montague Grammar 29
examples, examples where the argument had to be interpreted as intensional (of whichthe seek case is an example for the verb-object construction; see Section 1.4.4.3 belowfor discussion of the “generalize to the worst case” strategy which dictated that thewhole construction should therefore be treated as intensional). Nevertheless it becamecontroversial whether the use Montague made of it for the treatment of nouns likeprice and temperature and intransitive verbs like rise and change was appropriate.Bennett (1974) therefore took as basic syntactic categories t, CN and IV, with the types"e, t# assigned to both of the latter;23 for the remainder of the syntactic categories,Montague’s categorial schema was used, resulting in types for the remaining cate-gories that are identical to Montague’s except that the “Bennett types” have simply ewherever Montague’s original types have "s, e#, the type of individual concepts. (Seediscussion in Dowty, Wall and Peters, 1981, of the “temperature puzzle” and Mon-tague’s solution using individual concepts in PTQ. Dowty, Wall and Peters adoptedthe Bennett types, from which point they became widespread, but see Janssen, 1984,for further discussion of the usefulness of individual concepts.)
A natural concomitant of the rich type structure of PTQ and the centrality of func-tional types in the PTQ analysis of English was the important use of the lambda cal-culus as a part of Montague’s intensional logic, IL, the intermediate language usedin the interpretation of PTQ. The lambda calculus gives one very good way to pro-vide compositional names for functions and is therefore an important tool for makingcompositionality realizable. (If one uses direct rather than indirect interpretation, thenwhere PTQ translates some grammatical construction as a lambda expression, directinterpretation will refer to “that function f such that . . .”, as one sees in the work ofCresswell and others, as well as in the fragment in EFL (Montague, 1970b).)
As illustrated in Gallin (1975), following Henkin (1963), it is possible to let abstrac-tion, application and identity be the only primitive logical operators in a typed logiclike Montague’s IL and define both the propositional connectives and the existentialand universal quantifiers in terms of these operators; it is not possible to take one ofthe quantifiers as primitive and define the lambda operators. So the lambda operatorsare more basic than the quantifiers, undoubtedly another reason for their importancein the development of Montague grammar and formal semantics more generally.
The lambda calculus embedded in the intensional logic used for PTQ is designedfor unary functions only; the functional types in PTQ are all unary functions and theanalysis trees are all strictly binary branching (where branching at all). This is one ofthe choices in type structure that could have been different and it is a constraint that isnot observed in all extensions of MG, although in subsequent years arguments in favorof binary branching structures have been made in a number of contexts.
The lambda vied with the unicorn as the “emblem” of Montague grammar, andboth became famous among semanticists because of PTQ.24 At the time of PTQ, thelambda calculus was virtually unknown among linguists and it is still not included in
23 In PTQ these were categories t//e and t/e, respectively, with type ""s, e#, t#.24 The unicorn is from Montague’s example sentence John seeks a unicorn, used to illustrate his treatment
of intensional transitive verbs; Bob Rodman chose the unicorn to illustrate the cover of the first collec-tion of papers on Montague Grammar, and Rodman (ed.) (1972) and Partee continued the tradition withthe cover of Partee (ed.) (1976a).

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 30 — #30
30 Handbook of Logic and Language
most introductory logic courses, although by now an elementary exposition of lambdaabstraction and lambda conversion can be found in many introductions to semanticsor to logic for linguists (see Cresswell, 1973; Dowty, Wall and Peters, 1981; Gamut,1991; Link, 1979; Partee, 1973b, 1975; Partee, Ter Meulen and Wall, 1990; and otherintroductions to formal semantics).
It is of interest to recall briefly some of the principal uses for lambdas in PTQwhich were excitingly innovative at the time; many of them have become more or lessstandard in the meantime or laid the groundwork for later analyses to be mentioned inlater sections.
(i) Conjunction. Montague showed in PTQ how the lambda calculus could be usedto specify meanings for constituent conjunction as in (1) and (2) below which met theprincipal desiderata of both the generative and the interpretive semanticists.
(1) John and Bill love Mary.
(2) John walks and talks.
The PTQ interpretation for the conjoined T phrase25 in (1) is as in (3); the conjoinedIVP in (2) is interpreted as in (4), where John! stands for the translation of John, etc.
(3) %P[John!(P) $ Bill!(P)].
(4) %x[walk!(x) $ talk!(x)].
As an interpretivist would wish, Montague’s syntax generated the sentencesdirectly in their surface form without a need for syntactic “conjunction reduction”from full conjoined sentences. As a generative semanticist would wish, Montague’ssemantic rules for constituent conjunction related the meanings clearly to the mean-ings of conjoined sentences. Empirically, Montague’s proposal made, for the mostpart, correct predictions about the relative scopes of the connectives in conjoinedconstituents relative to one another and relative to quantifiers, negation and opacity-producing predicates that appeared in the sentence and did so more straightforwardlythan any proposals then available in either generative or interpretive semantics, offer-ing an elegant solution to the kinds of problems debated in Partee (1970b) and Lakoff(1970), for example. PTQ did overgenerate in that there was no implementation ofRoss’s Coordinate Structure Constraint in the “Quantifying In rules”; see Rodman(1976) for an extension that implemented such a constraint uniformly for both wh-movement rules and for quantifying in.
The analysis of constituent conjunction in PTQ has been extended and generalizedin various ways since PTQ and it has been noted that it is not always the only interpre-tation available (see Krifka, 1990, for an analysis of “part-whole” based interpretationsof John and Mary, red and white, sing and dance, etc.), but the basic analysis hasproved very robust and has become standard. Later authors noted that the treatmentof constituent conjunction in PTQ could be generalized into a schema and eventually
25 Actually, PTQ gave rules of disjunction with or for sentences, T phrases and IVPs, but rules of conjunc-tion with and only for sentences and IVPs, in order to avoid having to introduce plurals.

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 31 — #31
Montague Grammar 31
argued for a cross-categorial treatment of and and or (and possibly not) that wouldmake the explicit lambda formulas unnecessary; but the types needed in order to makea generalized cross-categorial and and or possible were not available directly in PTQ;cross-categorial and in PTQ terms would have to be an abbreviation for a recursivelydefinable infinite family of meanings of an infinite family of types. (See Gazdar, 1980;Keenan and Faltz, 1985; Partee and Rooth, 1983; von Stechow, 1974).
(ii) Relative clauses. As noted in Partee (1973a), the semantics of relative clauses,which is expressed by means of lambdas in PTQ, is not original with Montague; it canbe found earlier in Quine (1960), where it is expressed in terms of simple set abstrac-tion (equivalent to lambda abstraction when the “source” expression is of type t). Thecentral idea is that relative clauses denote predicates formed from open sentences byabstracting on the relativized position. What was novel about the analysis at the timewas not the use of lambdas per se but the insistence that restrictive relative clausesmust be formed from open sentences and not from closed sentences. The Quine–Montague analysis, once it was acknowledged as the only way to interpret relativeclauses compositionally, helped to bring about a shift in the way underlying structurewas conceived and opened the way to the presence of variable-like elements in syn-tactic structures in many frameworks, whether expressed as the Montagovian hei, byallowing variables like xi in syntax, or with GB elements like traces, PRO and pro.Most of what had standardly been analyzed via some sort of deletion under identityin transformational grammar, including relative clause formation and “Equi-NP Dele-tion” in controlled infinitival constructions (with force, persuade, promise, etc.), wassubsequently argued to semantically require that some relevant syntactic “part” of orinput to the construction must be an “open” expression containing something inter-preted as a free variable.
The Quine–Montague analysis of relative clauses has not been entirely uncon-troversial, although its basic idea is now widely accepted. One ongoing issue hasconcerned the distinction between restrictive and non-restrictive relative clauses andhow to analyze both kinds if the distinction between them is not always grammati-cized (see Rodman, 1976; von Stechow, 1980) and whether restrictive relative clausesmust be combined with CNPs or whether they can be combined with full T phrases(Bach and Cooper, 1978; Janssen, 1981; von Stechow, 1980).
(iii) The interpretation of noun phrases as generalized quantifiers and the treatmentof scope by “Quantifying In”. The interpretation of NPs (Ts) as generalized quantifiersis the subject of Section 1.3.4.2 below and “Quantifying In” will be discussed alongwith the interpretation of bound variable anaphora in Section 1.3.4.3. In the presentconnection there are several relevant points to note about the importance of the lamb-das in those analyses. In the first place, the NP interpretations are second order: sets ofproperties of individual concepts; the many puzzles resolved by that analysis providedthe first really vivid evidence for linguists of the value of going beyond the more famil-iar territory of first-order logic. All NP interpretations begin with a lambda (althoughhere too, since the “body” of the expression is of type t, that lambda is just a setabstractor). And in the compositional interpretation of NPs of any complexity, additi-onal lambdas turn up repeatedly; they can be seen in PTQ in the rule that combines a

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 32 — #32
32 Handbook of Logic and Language
relative clause with its head and in the conjoined and disjoined NPs discussed above;and lambdas that are not just set abstractors arise in the categorematic treatment ofthe three PTQ determiners (as in Dowty, Wall and Peters, 1981; Gamut, 1991) whichMontague introduced syncategorematically.
Another important role for lambda abstraction in this area was its use in the inter-pretation of the Quantifying In rule. As with the relative clause rule, an importantinnovation (from a linguist’s perspective) in Montague’s Quantifying In rule was itscrucial use of an open sentence as one constituent in a syntactic formation rule; therule takes a term phrase and a sentence to make a sentence, but will apply vacuouslyunless the sentence contains a free variable (a hen in PTQ). The partial analysis treein (5) illustrates the use of the rule.
(5) John seeks a unicorn, 10, 0/ \
a unicorn, 2 John seeks him0, 4
In the interpretation of the resulting sentence, in which the NP is substituted forthe target free variable pronoun, the variable x0 gets bound. By what? Not directlyby the quantificational NP, as had been posited in the otherwise analogous propos-als for “Quantifier Lowering” in generative semantics or in early versions of “Quan-tifier Raising” in later GB work by May and others; rather, by a lambda operatorthat is added as part of the interpretation of the rule. The NP a unicorn denotes aset of properties and must take a property expression as its argument. The semanticinterpretation of Quantifying In involves the application of lambda abstraction to theopen sentence (abstracting on the variable x0) and applying an intension operator tothat to form the property of being an x0 such that John seeks x0; the NP interpreta-tion is then applied to that property, exactly as the interpretation of an NP subjectis applied to the property which is the interpretation of the (intension of the) verbphrase.
1.3.4.2 NPs as Generalized Quantifiers
As noted in the previous section, a major legacy of PTQ has been the very impor-tant and influential analysis of noun phrases as denoting generalized quantifiers.26
Part of the appeal of this analysis for linguists was that it allowed one to be explicitabout the important semantic differences among NPs headed by different determin-ers, as in generative semantics treatments, while having a single semantic constituentcorresponding to the syntactic NP constituent, unlike the distribution of pieces ofNP-meanings all over the tree as required by the first-order-logic-like analyses lin-guists had been trying to work with (because linguists generally knew nothing abouttype theory, certainly nothing about generalized quantifiers). Dependence on first-order logic had made it impossible for linguists to imagine giving an explicit semantic
26 Although it was principally through PTQ that this analysis became influential in linguistics, this may beone of the ideas that Montague got from David Lewis, since it also appears in Lewis (1970), embeddedin a theory which combined a categorial grammar phrase structure with a transformational component.

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 33 — #33
Montague Grammar 33
interpretation for the or a/an or every or no that didn’t require a great deal of struc-tural decomposition into formulas with quantifiers and connectives, more or less thetranslations one finds in logic textbooks. The generative semanticists embraced suchstructures and made underlying structure look more like first-order logic, while theChomskyites rejected such aspects of meaning as not belonging to any linguistic leveland gave no explicit account of them at all. One can speculate that the rift might neverhave grown so large if linguists had known about generalized quantifiers earlier; theproductive teamwork of Barwise and Cooper (1981) is a beautiful early example ofhow formal properties and linguistic constraints and explanations can be fruitfullyexplored in tandem with the combined insights and methdologies of model theory andlinguistics, and generalized quantifiers have continued to be a fertile domain for furtherlinguistically insightful work exploiting formal tools (see Chapter 19 on GeneralizedQuantifiers by Keenan and Westerståhl in this Handbook).
A second important aspect of NP interpretation in PTQ is the handling of scopevia differences in analysis trees. The treatment (and sometimes even the existence) ofthe scope ambiguity of (6) was a matter of considerable controversy in the interpre-tive/generative semantics debates. PTQ used a “Quantifying In” rule which resulted ina single syntactic tree structure for (6) but two different analysis trees,27 an importantillustration of the “rule-by-rule” approach.
(6) A unicorn eats every fish.
McCawley (1981) points out the similarity between Montague’s Quantifying Inrules and the generative semantics rule of Quantifier Lowering and there are indeedimportant similarities between what one might look at as a command relation in aMontagovian analysis tree and a command relation in a generative semantics under-lying structure or a GB LF. The differences in conception are nevertheless interestingand important, with Montague’s approach more like some structuralists’ “item-and-process” (vs. “item-and-arrangement”) grammars or like Zellig Harris’s underappreci-ated algebraic work (e.g., Harris, 1968) which also treats structural similarity betweenlanguages in terms of derivational history rather than in terms of geometrical configu-rations at selected levels of representation. Montague’s Quantifying In rule was in factoutside the bounds of what linguists would have called a single rule at the time, sinceit simultaneously substituted a full NP for one occurrence of a given variable/pronoun(hei) and pronouns of appropriate gender, case and number for all other occurrencesof that same variable.
The proper treatment of scope ambiguity and the binding of pronouns is of coursea continuing area of controversy with profound implications for the nature of thesyntactic and semantic components of grammar and their interface and there is fur-ther discussion in Section 1.4 below.
27 The generation of a syntactic tree structure assumes Partee’s (1973b) amendment to the effect that thesyntactic rules generate trees rather than strings. In fact, PTQ assigns not just two different analysis treesto (6) but infinitely many; see discussion in Section 1.3.4.5 below.

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 34 — #34
34 Handbook of Logic and Language
1.3.4.3 Bound Variable Anaphora
It is quite remarkable what a great role the analysis of anaphora and puzzles involv-ing pronouns have played in arguments for choosing among theories of syntax andsemantics over the last thirty-some years, before MG, in arguing for and against MG,post-MG and still now. Quantification and anaphora were very tightly connected inMontague grammar; that was not a consequence of Montague’s general theory asspelled out in UG, but nevertheless was closely associated with MG as a result ofthe legacy of PTQ.
In PTQ, the only pronouns explicitly treated were pronouns interpreted as boundvariables; but every pronoun that might possibly be treated as a bound variable wasso treated. One of the important insights that was gained from PTQ was that the pos-sibility of interpreting a pronoun as a bound variable did not depend directly on thesemantic properties of its antecedent NP, but rather on the construction by which itwas introduced. With all NPs analyzed as generalized quantifiers, any NP could binda bound-variable pronoun, including proper names or even other pronouns, since thebinding is not actually by the NP itself, but by the lambda abstractor introduced in theQuantifying In rule, as noted in Section 1.3.4.1. This insight had a major impact onsubsequent analyses of “strict-identity” and “sloppy-identity” puzzles in the interpre-tation of ellipsis in sentences like (7), discussed in Section 1.4.3 below.
(7) Sam gave some fish to his dog and Sally did too.
There are four rules in PTQ which effect the binding of pronouns: the three Quan-tifying In rules and the relative clause rule. In order for an NP to “bind” a pronoun, theNP has to be introduced via a Quantifying In rule, which as noted earlier introduces alambda operator with scope over the expression being quantified into. And the relativeclause rule also causes the relative pronoun and any further coindexed pronouns to bebound by a lambda operator.
The fact that PTQ treats only bound-variable uses of pronouns leads to a respect inwhich some “filtering” may be needed in the PTQ syntax. Subscripted pronouns hei,interpreted as free variables, are freely generated in NP positions; rules which havethe semantic effect of binding them also have the syntactic effect of replacing themby non-subscripted pronouns of appropriate gender. Semantically this corresponds toFrege’s insight that the recursive formation rules for generating closed quantified sen-tences need to work with open formulas as parts in order to support a compositionalinterpretation; the basic semantic valuation for formulas has to be truth relative to anassignment rather than truth simpliciter. But if the output of the grammar is to consistonly of the closed sentences, then one must filter out of the final output any “sen-tences” that still contain free variables. The PTQ grammar does generate “sentences”that contain subscripted pronouns; semantically these are interpreted as open formulasrather than closed sentences. They may have different truth values relative to differentassignments of variables, which is a useful property for their role as parts in the genera-tion of other sentences, but it leads to an artificial treatment of assignment-independenttruth, i.e. truth with respect to model, world and time, since in the system of PTQ, a

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 35 — #35
Montague Grammar 35
formula is true with respect to a model, world and time if and only if it is true at thatmodel, world and time with respect to every variable assignment. Thus a sentence con-taining a subscripted pronoun which happens to be true on some assignments and falseon others is classified as false simpliciter, a counter-intuitive result. Montague saidnothing explicit about these cases in PTQ; there have been two common proposals forhow to view them. One possibility is simply to filter them out on the grounds that thesubscripted pronouns are not really part of English but are just auxiliary expressionsthat are used in the derivation of real English expressions. The other possibility, andone which is explicitly worked out by Montague in UG, is to enrich the semantics intoa formal pragmatic framework in which one treats subscripted pronouns that remainat the end of a derivation as demonstrative pronouns, letting “contexts of use” includeassignments to variables. (In UG Montague had a slightly more intricate treatment ofpronouns and their indices, treating the indices as basic entity-type expressions andintroducing the pronouns syncategorematically, and using his “ambiguating relation”to delete “free” indices from the surface forms of the generated language.)
It was noted above that PTQ has three Quantifying In rules. These apply to quantifi-cation into sentences, IV-phrases (VPs) and CN-phrases. The idea that quantificationcould have scope other than sentence-size was also novel to linguists and is part of thepackage of ideas and techniques that opened up new debates about the division of laborbetween syntax and semantics and led over the course of a few years from the ideaof constraining the role of transformations in a compositional theory to the possibilitythat a more adequate semantic component might make it possible to eliminate trans-formations altogether from the syntactic component. In an early and influential paper,Dowty (1978) showed that lexically governed transformations could be more appro-priately replaced by lexical rules in a Montague grammar. Gazdar (1982) took thefurther step of arguing for the elimination of transformations altogether. Like cross-categorial conjunction and disjunction, cross-categorial Quantifying In rules helpedto eliminate some of the earlier arguments for deriving infinitival complements fromfull sentences. Example (8) below, from Karttunen (1968), who attributes it to Baker(1966), presented one of the puzzles that Montague addressed in PTQ: how to accountfor the fact that there can be an anaphoric connection between it and a fish even whena fish is given a de dicto reading. Without a Quantifying In rule that can apply tothe VP catch him0 and eat him0, one would either have to derive that VP from afull conjoined sentence (which would then also necessitate a conjunction-reductiontransformation) or else quantify in at the top sentence level, deriving only a de re or“specific” reading.
(8) John wants to catch a fish and eat it.
The systematic similarity between quantification with sentence scope and quantifi-cation with VP scope is seen in the similarity of the translation rules and in the result-ing patterns of logical entailment in those cases where there are relevant entailments.And as later noted in Partee and Rooth (1983), the three Quantifying In rules spelledout explicitly in PTQ can be seen as three instances of a recursively specificiablecross-categorial schema in which sentence-scope quantification may be taken as basic

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 36 — #36
36 Handbook of Logic and Language
and the other rules are predictable from the semantic types of the categories beingquantified into.28
Can all pronouns be treated as bound variables? That was a question which lin-guists were already debating at the time Montague was working (Karttunen, 1969;Partee, 1970a). But given the method of fragments, Montague did not have to addressit in PTQ and he did not make any such claim. Among the problematic cases for auniform treatment of pronouns as bound variables, some of which will be mentionedin Section 1.4.3 and later, are demonstrative and indexical uses of pronouns, “dis-course” pronouns with explicit or implicit antecedents in other sentences, “donkey”pronouns and Karttunen’s “paycheck” pronouns. An elegant treatment of demonstra-tives and indexicals was given in Bennett (1978); this work was not quickly integratedwith work on pronouns as bound variables and fully unified approaches are only morerecently being pursued. One important matter which Montague ignored in PTQ is thedistinction between reflexive and non-reflexive pronouns; there is a footnote aboutthat in EFL,29 but in PTQ Montague simply used non-reflexive forms of pronouns inall cases, even where a reflexive form is obligatory.
A final note about the semantics of bound variable anaphora in PTQ: the interpre-tation of variables in PTQ is accomplished through the use of variable assignments gwhich are manipulated in basically the same way as in the classical model – theoreticsemantics of quantification that goes back to Tarski. The variables that correspondto bound-variable pronouns are variables over a single world-independent and time-independent domain of individuals and the manipulation of the assignments g is com-pletely insulated from the manipulation of world and time indices. The result is that inPTQ, pronouns are treated as “rigid” with respect to modal and temporal dimensionsand so are the variables that correspond to positions that NPs are quantified into. Thistreatment represents a certain view about the semantics of quantified modal statementsin ordinary English that has served well at least as a very good first approximation, butwhich may not adequately cover all pronoun occurrences. Janssen (1984) advocatesthe use of variables over individual concepts to account for cases where a bound pro-noun has an index-dependent, non-rigid interpretation, as in example (9) below. Otherproposals have suggested treatments of some pronouns as disguised definite descrip-tions or as “Skolem functions”, or as ranging over “guises”.
28 The reason for the presence of an explicit rule quantifying into CNs in PTQ is not clear; there wouldbe a clearer need for such a rule in a fragment including expressions like every search for a man withred hair or most pictures of two horses, in which the head noun creates an opaque context for itscomplement much like an intensional transitive verb and for which one can distinguish three readings, inone of which the NP in the prepositional phrase has wider scope than the head noun but narrower scopethan the top determiner. EFL included the expression brother of v0 as a basic common noun phrase andthe CN-quantification rule in PTQ may simply be a carry-over from EFL. Partee (1975) discusses somepossible uses for the rule in PTQ in cases of an NP containing multiple relative clauses, citing an examplefrom Joan Bresnan (p.c.): Every girl who attended a women’s college who made a large donation toit was included in the list.
29 See Bach and Partee (1980) for a treatment which builds on the idea in Montague’s footnote 12 to EFL.

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 37 — #37
Montague Grammar 37
(9) This year the president is a Democrat, but next year he willbe a Republican.
The legacy of PTQ in its treatment of pronouns as bound variables bound by lambdaoperators introduced either in a Quantifying In rule or in the relative clause formationrule has been profound; even though other treatments of many pronouns have beenand continue to be proposed, the PTQ treatment has the status of a kind of “standard”,at least with respect to the semantics. Syntactically, the PTQ treatment is not com-pletely elegant and this is one domain in which the grammar does not generate surfacestructures directly. Some suggested alternatives will be discussed further below.
1.3.4.4 Scope and Intensionality
Scope is not a notion that is explicitly defined in PTQ and I will not try to define ithere; other than in the context of a specific formal language it seems not to be a per-fectly simple or straightforward matter. Scope would be easier to define in IL thandirectly in the English fragment of PTQ and it may not even always make completesense to try to define scope in a uniform way for natural language constructions if theyare not all uniformly interpreted, e.g., as always involving function-argument applica-tion. The common sense notion that if A is in the scope of B, then the interpretationof A may depend on that of B but not vice versa, may be correct as far as it goes.But the same natural language construction may be subject to competing analyses ofwhich part is the function and which the argument, as, for example, in the case of thesubject-predicate rule for which most analyses had traditionally treated the subject asan argument of the predicate but Montague treated the subject as the functor and thepredicate as its argument, and therefore one cannot derive an unequivocal assignmentof relative scopes to parts of an expression on the basis of such a notion in the absenceof a specific formal analysis.
But as a fair approximation for PTQ one might venture the following. Given an ana-lysis tree of an expression generated by PTQ, “higher in the tree” (assuming that treesare drawn with the root at the top) normally corresponds to “wider scope”. Slightlymore precisely, it probably makes sense to say that any expression interpreted as afunction has scope over all parts of the expression interpreted as its argument. Forthe rules that involve the syncategorematic introduction of negation, auxiliary verbsexpressing tense and aspect, and and or and the determiners every, a/an, and the, it isclearly in each case the syncategorematically introduced element that has scope overthe other elements introduced in the same rule. This still does not cover every rule inPTQ; for instance, in the rule that combines a CNP with a relative clause, neither hasscope over the other: the rule introduces a lambda abstractor which has scope over aconjunction which in turn has scope over both the CNP and the relative clause. And italso does not say anything directly about the sense in which the determiner in a subjectNP has scope over the whole VP, since the determiner is the functor element in the NPinterpretation and the VP is in turn the argument of the subject NP.
One of the consequences of the rich intensional type theory of Montague’s IL andhis exploitation of it in PTQ, is that matters of scope and scope ambiguities permeate

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 38 — #38
38 Handbook of Logic and Language
the fragment. If one asks which are the scope-taking elements in PTQ, the answer is,“Almost all of them”. Noun phrases, treated as generalized quantifiers, may take otherexpressions in their scope and may occur within the scope of other expressions. Theusual sentential operators such as modals and tenses, negation and sentential adverbslike necessarily take scope in familiar ways even though some of them are introducedsyncategorematically. But there are many other intensional constructions in whichrelative scope is also a significant phenomenon. Verbs like believe and assert takescope over their sentential complement; verbs like try to and wish to take scope overtheir infinitival complement; and intensional transitive verbs like seek and conceivetake scope over their direct object. (In all of these cases, a given NP may “escape”out of the scope of a given scope-taking element if it is quantified in from a position“above” that element in the analysis tree, i.e. if it is introduced into the expressionafter the given scope-taking element has already been incorporated into the expres-sion.) In fact, given Montague’s uniform analysis, all transitive verbs take scope overtheir direct object; it only happens that in the case of the relation between an exten-sional transitive verb like eat and its object, the semantics of the verb (as constrainedby a meaning postulate, see below) renders the issue of scope semantically inert. Thatis, whereas a sentence like (5) above, repeated below as (10), has different truth con-ditions depending on whether the NP object is generated in situ or quantified in, asentence like (11) has the same truth conditions on either derivation.
(10) John seeks a unicorn.
(11) John eats a fish.
Other scope-taking elements in PTQ include the intransitive verbs rise and change,which Montague included in PTQ in order to treat the “temperature puzzle” illustratedby the invalid inference in (12) below,30 whose invalidity needs to be explained.
(12) (a) The temperature rises.(b) The temperature is ninety.(c) Therefore, ninety rises. [invalid]
But how can the intransitive verb be scope-taking if the generalized quantifier sub-ject always has scope over the VP? This example illustrates the difficulty of talk-ing unambiguously about the scopes of parts of natural language expressions. Thegeneralized quantifier does indeed take scope over the intransitive verb, but its mean-ing is such that the verb takes scope over an individual concept expression that is“inside” the meaning of the generalized quantifier. The unreduced translation of (12c),ninety!($rise!), is as in (12c!); but (12c!) is logically equivalent to the reduced trans-lation (12c!!).
30 Note that Montague treated simple present tense forms of verbs such as rises as having the kinds ofmeanings that often have to be conveyed in English with the use of a progressive form. This was areasonable simplification, given that most Indo-European languages do use the simple present tense formswith such meaning.

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 39 — #39
Montague Grammar 39
(12) (c!) [%P[[%P]($n)]]($rise!).
(c!!) rise!($n).
The scope-taking elements in PTQ include not only quantifiers, sentential(extended to be cross-categorial) operators of various sorts, and all the verbs, but alsoverb-phrase adverbs such as voluntarily and prepositions such as about. And in EFLMontague had also included prenominal adjectives like alleged, with scope over theCN phrase they combine with. (Scope arguments involving intensional adjectives likealleged and former were Montague’s principal argument against the then-prevailinglinguistic preference for deriving all prenominal adjectives from predicative ones, anearly and strong instance of the use of the compositionality principle to choose bet-ween competing syntactic analyses.) In fact, given that in PTQ the sets of basic expres-sions of the two primitive categories e and t are empty, it follows that all of the basiclexical expressions of PTQ are of functional types and hence are the kinds of expres-sions that may in principle take scope over other expressions.
An intensional construction is one in which the determination of the extension ofthe whole depends not simply on the extensions of the parts but on the intension ofat least one of the parts. Montague found instances of intensionality in virtually allof the basic grammatical relations of English and therefore constructed PTQ so thatintensionality became the general case. For every syntactic category B/A or B//A, thecorresponding semantic type $ (A/B) or $ (A//B) is not simply the type of functionsfrom $ (A) to $ (B) but rather the type of functions from the intensional type "s, $ (A)#to $ (B). Montague’s use of his richly typed intensional logic contrasted sharply withmore familiar analyses of intensionality which analyzed all intensional constructionsas underlyingly sentential, involving some propositional operator or some predicateor relation that took a whole proposition as its argument. The arguments for suchdecompositional analyses, e.g., decomposing sentence (5), John seeks a unicorn, intosomething like “John endeavors that he find a unicorn” (Quine, 1960) had been largelysemantic, often crucially resting on the assumption that intensionality must involvesome sentence-scope operator or relation and many of those arguments dissolved oncea richer semantics was available.
The treatment of seeks as a basic transitive verb (interpreted as applying tothe intension of a generalized quantifier), for example, was a major innovation inMontague and sentence (5) became one of the most famous examples from PTQ, epit-omizing the potential Montague offered for treating something very close to surfacesyntax as an optimal “logical form” and changing the methodology of semantics cor-respondingly. Instead of doing semantics by transforming natural language syntacticstructures into structures dictated by some particular logical Procrustean bed, the taskbecame one of identifying the right kind of logic and the right kind of semantic inter-pretations to be able to make sense of natural language syntax as it actually occurs.In this respect Montague grammar was in principle quite close in spirit to generativegrammar; the syntax should be autonomously describable and the semantics shouldprovide an interpretation of a given syntactic structure. The only respect in which thesyntax is not autonomous in a Montague grammar, as noted earlier, is argumentation

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 40 — #40
40 Handbook of Logic and Language
concerning the basis for choosing between alternative syntactic hypotheses, which inMontague grammar may include arguments from semantics and compositionality.
If Montague treated all basic grammatical relations as intensional in principle, howdid he handle the extensional cases? By means of what have come to be called mean-ing postulates (after Carnap, 1952), restrictions on the interpretations of intensionallogic which would be “reasonable candidates for interpretations of English” (Mon-tague, 1974, p. 263). In choosing semantic types corresponding to syntactic categories,Montague followed the strategy of “generalizing to the worst case”, with meaning pos-tulates then guaranteeing that the “simpler” cases are indeed simpler. So, for exam-ple, the meaning postulate for the extensional transitive verbs find, lose, eat, love,date says that although their direct object is semantically an intension of a generalizedquantifier and their subject an individual concept, they are in a well-defined sense equi-valent to a relation between two entities. There are also meaning postulates guarantee-ing the extensionality of the subject position of all PTQ verbs except rise and change,the extensionality of the preposition in, the rigidity of proper names, the constancy ofthe individual concepts in the extension of nouns other than price and temperature,and the truth-conditional equivalence of seek and try to find. Meaning postulates arein principle an important means for specifying linguistically significant aspects of themeanings of lexical items in a theory like Montague’s in which lexical items are mostlytreated as primitives rather than provided with explicit model-theoretic interpretationsor “decomposed” into “semantic primitives”. On the other hand, in the absence ofa substantive theory constraining the class of possible meaning postulates, meaningpostulates may sometimes be regarded as stipulating aspects of meanings of expres-sions without explaining them. For a linguist, meaning postulates might be thought ofas supplying explicit model-theoretic content to “semantic features” which might belisted in lexical entries and it is an empirical question which semantic properties of agiven lexical item should be so captured and included in the lexicon.
Montague unified tense logic and modal logic in a way which makes matters ofscope with respect to intensionality very similar structurally to matters of quantifierscope. Tense and modal operators are interpreted as involving quantification overtimes and worlds and the “up” operator which yields an expression whose extensionis the intension of the operand expression is semantically equivalent to a lambdaabstractor over the world-time index. These structural parallels among intensionaloperators and quantification with NPs are somewhat more perspicuous in Gallin’sTy2 than in Montague’s IL.
1.3.4.5 Disambiguated Language. Analysis Trees as Logical Form
In Section 1.3.1 above it was noted that Montague’s general theory as spelled out inMontague (1970c) requires that the syntax provide a disambiguated language, sincethe homomorphism that maps the syntactic algebra onto the semantic algebra mustbe a (single-valued) function. It was noted there that this means that the elementsof the syntactic algebra for PTQ cannot simply be the expressions generated by thegiven rules, since these are in many cases ambiguous. Nor can they be the constituent

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 41 — #41
Montague Grammar 41
structures of the derived expressions (not explicitly given in PTQ, but they could andprobably should be added; see Partee, 1973b), since an ambiguous sentence like (6),repeated here as (13), is not ambiguous with respect to its resulting constituent struc-ture, a simplified representation of which is given in (14).
(13) A unicorn eats every fish.
(14)
DET|a
CNP|
|
unicorn
NP!!
!! ""S
IVP| ""
TVP|
eats
NP| ""
DET|
CNP
every|
fish
A novelty of PTQ with respect to most then-existing linguistic frameworks and afeature still not always fully understood, is that syntactic disambiguation is by meansof a difference in the order of putting the parts together, a difference captured by“analysis trees” or “derivation trees”. Two analysis trees for (13) are given belowin (15).31
(15) (a) a unicorn eats every fish, 4/ \
a unicorn, 2 eat every fish, 5| / \
unicorn eat every fish, 0|
fish
(b) a unicorn eats every fish, 10, 0/ \
every fish, 0 a unicorn eats him0, 4| / \
fish a unicorn, 2 eat him0, 5| / \
unicorn eat he0
31 There are actually infinitely many different analysis trees for (13), because of the free choice of variablesin the positions to be quantified into and also because of the possibility of quantifying one variable infor another. But even if we regard analysis trees differing in only those ways as equivalent, there arestill seven distinct equivalence classes of analysis trees for (13): Each NP can be generated in situ orquantified in; and the direct object NP can be quantified in with either S scope or VP scope. Whenboth NPs are quantified in with S scope, they can be quantified in in either order. The reasonablenessof such apparent overgeneration of syntactic analysis trees is discussed in various overview articles andtextbooks, including Thomason (1974) and Dowty, Wall and Peters (1981, pp. 209–210). In the case ofsentence (13), there are just two non-equivalent readings and I have selected the simplest analysis treesfrom among the several possible for each reading.

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 42 — #42
42 Handbook of Logic and Language
The analysis trees show the semantically relevant syntactic structure; the pairingof syntactic derivation rules with rules of translation into IL provides the basis for thehomomorphic mapping from the PTQ syntax of English into (the polynomial closureof) the PTQ syntactic algebra for IL; and IL has its own pairing of syntactic andsemantic rules leading to a homomorphic mapping onto the model-theoretic semanticalgebra. The actual elements of the syntactic algebra for the English syntax of PTQshould therefore be taken to be the analysis trees. And each of the “syntactic rules”of PTQ provides an operation in the syntactic algebra, operating on one or two inputanalysis trees and yielding an analysis tree as result. (PTQ actually contains an infiniteset of rules, finitely specified, since each of the three Quantifying In rules, as well asthe relative clause rule, is actually a rule schema.)
The analysis trees are therefore the best candidates for a level of “logical form”, ifby “logical form” one means a structural representation of an expression from whichits meaning is transparently derivable. While a translation of an expression into thelogical language IL might also be taken as a candidate for a “logical form” for theexpression, there are two arguments against that choice: (i) given that the IL expres-sion obtained directly by the translation rules is usually reducible to a sequence of pro-gressively simpler logically equivalent expressions, differing significantly from oneanother in their form, a given expression on a given derivation would either have amultiplicity of logical forms, or some (non-obvious) means would have to be foundto designate one of those many equivalent expressions as “the” logical form of theexpression; and (ii) IL is a dispensable convenience (“probably more perspicuous”,Montague, 1974, p. 256) with no serious theoretical status in PTQ; it is the analysistrees and the model-theoretic interpretations that are essential to the syntax and seman-tics respectively (see further discussion in Gamut, 1991, Volume II, Section 6.5).
The issue of “logical form” is related to the issue of ambiguity. How many waysambiguous is sentence (13) in PTQ and how many distinct logical forms does it have?If one asks the ambiguity question about (13) in PTQ, the usual answer is “two”,since all of the different possible syntactic derivations lead to one of two distinct truthconditions, i.e. one of two distinct model-theoretic objects. However, if one asks aboutlogical forms, it seems that the only systematic answers are either “infinitely many”or “seven” (see footnote 31 above.) And on reflection, it would not be indefensibleto say that sentence (13) is seven-ways structurally ambiguous in PTQ; it followsfrom the semantics of the particular lexical items chosen that those seven distinctstructures collapse into two distinct truth conditions. Among sentences with the samestructure, example (16) is truth-conditionally unambiguous, while example (17) has 3truth-conditionally distinct readings.
(16) John loves Mary.
(17) Every man seeks a unicorn.
There is no sentence without further scope-bearing elements that has more thanthree truth-conditionally distinct readings. The distinction between VP-scope andS-scope for the direct object becomes crucial in the presence of additional VP-scope

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 43 — #43
Montague Grammar 43
operators such as a VP-adverb or a verb taking an infinitival complement, as inexample (8) in Section 1.3.4.3 and the distinction between in situ generation of thesubject and quantifying it in becomes crucial only if either the object is quantified inor there is some additional S-scope element such as tense or negation in the sentence:an example such as Every man will seek a unicorn, with the addition of future tense,has seven non-equivalent readings. So one might want to argue that the sentences(13), (16) and (17) should have just three logical forms, which leads to a problem withtaking the analysis trees as the level of logical form: which three and is there even any“formal” algorithm for determining how many logical forms a given expression has?However, all of the differences in the seven different derivation trees have semanticsignificance in other examples, as noted, so it seems reasonable to say that all of sen-tences (13), (16) and (17) are seven ways structurally ambiguous in PTQ and all haveseven logical forms.32 The notion of structural ambiguity without truth-conditionaldifference is not without precedent; it applies to any simple sentence containing twouniversal or two existential quantifiers, where most analyses will necessarily providea scope ambiguity which will happen to be semantically neutralized, as well as to theaccidental neutralization of truth-conditional difference in sentence (18), an examplein which we still strongly “feel” the ambiguity and have to “work” to compute thetruth-conditional equivalence.33
(18) They are visiting relatives.
It should be noted, with respect to the questions raised about trying to pin down anotion of “logical form” that would have the properties that people seem to expect of it,that perhaps any lexical element whose interpretation is completely spelled out in thegrammar, as that of be is in PTQ (see Section 1.3.4.6 below), should be considered apart of the logical form of any expression in which it occurs. Thus while two sentencesthat are alike except for a different choice of transitive verb, eat vs. lose, for instance,will be said to have the same logical form and only a lexical difference, it is not clearthat the same would or should be said about two sentences differing with respect toeat vs. be. (But then it may have been a mistake to classify be as a transitive verbin the first place.) A similar issue arises with respect to the determiners, the adverbnecessarily, etc. But we will not pursue the issue of logical form further here; our aimhas been more to raise warning flags about the non-obviousness of the notion than totry to elucidate it and it is not a notion that Montague ever discussed explicitly, to thebest of this author’s knowledge.
32 Tichý (1988) takes the fundamental semantic values of expressions to be not their intensions but “con-structions” and a Tichý version of PTQ would accordingly treat all of these sentences as having sevendistinct semantic interpretations, collapsing into a smaller number of readings only at the level of inten-sions. The same is presumably true for virtually any “structured meanings” approach and a similar ideacan be traced back to Carnap’s notion of “intensional isomorphism” (Carnap, 1947).
33 I learned this example from Emmon Bach, who learned it from Janet (J.D.) Fodor; I don’t know where itoriginated.

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 44 — #44
44 Handbook of Logic and Language
1.3.4.6 Other Choices made in Design of PTQ
There are other specific choices made by Montague in constructing PTQ whichdeserve mention but do not fit under the general headings above. A few of them willbe discussed briefly here.
As discussed by Thomason (1974), one important property of PTQ and of Mon-tague’s theory more generally is the separation of the lexicon from the grammar. Whilea linguistically more sophisticated treatment would have to pay more systematic atten-tion to morphology, the central point is that whatever are taken to be the smallestsemantically contentful units, whether words or morphemes, are treated as primitiveswith respect to the grammar. The only aspect of lexical meaning that is obligatorilyincluded in giving a grammar in accordance with UG is that each basic expressionmust be assigned a specific semantic type; and the semantic types must in turn behomomorphically related to the syntactic categories: expressions assigned to the samesyntactic category should be assigned the same semantic type. The meanings of somebasic expressions may be further constrained by meaning postulates and for words ormorphemes considered to have “logical” rather than “empirical” meanings, the mean-ings may be completely spelled out in the grammar, but in general lexical meaningsare left unspecified. As Thomason puts it, Montague considered the syntax, seman-tics and (formal) pragmatics of natural language to be branches of mathematics, butlexicography to be an empirical discipline.34
In the framework of Montague grammar, as in most frameworks, the line betweenlexicon and grammar may be debated. In PTQ, there are a fixed number of syntac-tic categories and the “lexicon” consists of the basic expressions of those categories.Elements which are not members of any category but are introduced syntactegore-matically by the operation of some syntactic rule include the determiners every, a,the, the conjunctions and, or, the negative particle not, the auxiliary verbs will, have.While these elements are not themselves assigned meanings, the syntactic rules inwhich they occur are given semantic interpretations in which it is in fact quite clearwhat the semantic contributions of those elements is and in the textbook (Dowty, Walland Peters, 1981) there are exercises which consist of giving alternative grammarsin which such elements are treated either categorematically or syncategorematically.Of the mentioned elements, the determiners undoubtedly have the strongest claim tobelonging to a syntactic category, since the class of determiner phrases may not be aclosed class and it certainly contains non-basic elements such as almost every, at mostfive. Most formal semantic textbooks in fact follow Thomason (1976) and Dowty, Walland Peters (1981) in recasting PTQ to include a category T/CN, i.e. DET.
34 It is of course also an empirical matter to determine which particular syntax and semantic correspondsto the language of a particular speech community; this is discussed very clearly in Lewis (1969, 1975b).Montague, like others in the tradition of logic and model theory, saw the study of language and grammaras analogous to the study of geometry, separating the study of the platonic objects and their formaldescription from the study of the epistemological relation of humans to particular such abstract objects(including any questions of the “psychological reality” of any given formal description of the objects).

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 45 — #45
Montague Grammar 45
One “logical” element which is treated categorematically in PTQ is be, which isanalyzed as a transitive verb, but one whose semantics is completely spelled out. Mon-tague gave a clever analysis of the semantics of be, given in two forms below as (19),which enabled him to give the correct semantics for both (20) and (21) without hav-ing to distinguish a “be of identity” from a “be of predication”. The advantages anddisadvantages of Montague’s treatment of be, and a suggested alternative in which themeaning of English be is basically “Predicate!”, as in (22), and Montague’s (19) isreconstrued as a type-shifting operation that provides predicate meanings for full termphrases, are discussed in Partee (1987).
(19) (a) PTQ: be! = %Q%x
".
(b) Equivalently: be! = %Q%x[${x} &% Q].
(20) Cicero is Tully.
(21) John is a man.
(22) Alternative: be! = %P%x[[%P](x)].
It is interesting to see what Montague did about one clear difference betweenEnglish and the formal languages of logic. In any logic, the sentential operators likenegation and the tense and modal operators are all recursive and there is no limit to thenumber of them that may be prefixed to a given sentence. In English, however, suchelements are mainly limited to one per clause: this is certainly true of the tense-aspect-modal elements like will, have + ' en and true (with certain caveats) of negation.In his earlier fragment in EFL, the trick Montague used for limiting negation to oneoccurrence per sentence was to “regiment” English into a form closer to a real his-torically earlier form, putting the not at the end of the sentence and limiting the ruleto applying to sentences that do not already end with not. This was an expedient thatmade the fragment less like real English but allowed for a simple rule that had a sen-tence as its input and a sentence as its output, so that the corresponding semantic rulecould just apply the usual logical negation operator to the corresponding proposition.
In PTQ, Montague chose a different solution for negation and his two auxiliaryverbs. Instead of introducing them in “sentence-to-sentence” rules, he introduced themin a set of six rules all of which took as input a subject NP and a VP and gave astheir outputs the six sentence forms “present affirmative”, “present negative”, “futureaffirmative”, etc. Most linguists did not and do not regard this as an optimal solution tothe problem of “sentence-scope operators” which do not apply recursively in naturallanguages; see Carlson (1983) for further discussion.
1.3.4.7 PTQ in Retrospect
The discussion of PTQ above is already partly retrospective; in this short section wewill focus more directly on two kinds of issues that are illuminated by the perspec-tive of hindsight: (i) how some of the PTQ rules might be derivable from more gen-eral principles and how others might be modified, generalized, or questioned; and (ii)issues relating to Montague’s type theory.

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 46 — #46
46 Handbook of Logic and Language
To a linguist, Montague’s syntax in many points seemed somewhat primitive andhighly unconstrained and stipulative. PTQ did, however, lead to the revival of catego-rial grammar that had been urged in the work of Lyons (1968) and Lewis (1970) andto an investigation of various versions of it and was also one important catalyst forthe reintroduction of serious interest in “monostratal”, or non-transformational, gram-mars, since it pointed the way to a conception of grammar in which more of the workof explaining relatedness between different expressions could be accomplished by thesemantics.35 And some other points of PTQ syntax were noted above to have had con-tinuing influence: the idea that restrictive relative clauses should modify CNPs and notNPs, the idea that underlying structures should include “open” sentences containing(expressions to be interpreted as) free variables and most importantly the idea that it isthe derivation tree, or analysis tree, that is the crucial semantically relevant syntacticstructure rather than any level or levels of phrase structure.
One weakness of the PTQ syntax is that the grammar generates strings rather thanbracketed strings or constituent structure trees and the syntactic operations are definedon strings. About the only place where this leads to an actual error in PTQ is in theinteraction of subject-verb agreement with verb phrase conjunction rules, as notedin Partee (1973b). But most subsequent researchers have made the “friendly amend-ment” of having the rules generate bracketed strings or trees as a matter of courseand Montague grammar is taught that way in Dowty, Wall and Peters (1981). (Gamut,1991, follows Montague in generating strings; the authors discuss the need for identi-fying the “main verb(s)” of a verb phrase in stating subject-verb agreement, but theydo not define the notion “main verb” explicitly and it seems clear that doing so for afragment that contains ambiguous strings like try to walk and find a fish will requireeither bracketing or reference to derivational history.)
More generally, linguists have from the start wanted to think about the syntacticrules of PTQ in terms of a theory of natural language syntax. As noted earlier, Mon-tague put no constraints on the syntactic operations that could be used in a syntacticrule, not even a constraint of computability. A linguist wants a theory of syntax tospecify the class of possible syntactic operations and to clarify what is universal andwhat is the minimum that must be stipulated in the grammar of a particular language.And many of Montague’s syntactic rules combine syntactic concatenation with somemorphological operations such as case-marking and agreement; some modularizationof syntax proper and morphology is adopted in virtually all linguistically more sophis-ticated versions of Montague grammar. (But the notion of a “construction”, whichmay involve function composition of several operations, may be a useful one, as notedabove in Section 1.3.1.)
A linguist also wants a theory of syntax and semantics to specify whatever empiri-cal generalizations there might be about the relation between the form of a given syn-tactic rule and the form of the corresponding semantic interpretation rule (see Janssen,1981; Partee, 1976b, 1979a; for some early suggestions in this direction). Thus, for
35 Gazdar (1982), who made one of the earliest of several kinds of proposals for a non-transformationalphrase structure grammar in the 1970s and 1980s, used a semantics explicitly modeled on that of PTQ.

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 47 — #47
Montague Grammar 47
example, it is probably no accident that PTQ’s “Rules of Functional Application”cover virtually all of the basic grammatical relations instantiated in PTQ; one mighthypothesize that the interpretation of all “X-bar” structures is by functional applica-tion: lexical heads applying to their subcategorized arguments, modifiers to their mod-ifiees and specifiers to specifiees. Some directions in which linguistic theorizing hasgone in this respect include the idea of “type-driven translation” (Klein and Sag, 1985)and the idea of “type shifting”, discussed in Section 1.4.4.3 below, and the search for“natural functions” discussed in Partee (1987) as an alternative to Montague’s strategyof always “generalizing to the worst case”.
The rules in PTQ for conjunction and disjunction and the rules for quantifying in,are in retrospect just particular instances of cross-categorial schemas which call for“recursive types” and a recursive definition of both the syntactic and semantic rules;see Partee and Rooth (1983).
The rules for quantifying in and for the handling of pronominal anaphora are ruleswhich work remarkably well as far as they go (although Montague made no attemptto capture “island constraints” or the distinction between reflexive and non-reflexivepronouns), but that is certainly one area in which there have been many other pro-posals before, simultaneously and since. Some discussion of alternatives is found inSections 1.4.2 and 1.4.3.
Certain constructions which had been used in the transformational grammar lit-erature to argue for the need for transformations and for their cyclic ordering weremissing from the PTQ fragment and it was not obvious how to add them; in particu-lar, there was no treatment of passive sentences, of existential there sentences, or of“raising” constructions with seem, appear, etc., although examples of the latter werementioned in PTQ as a kind of sentence which could be accommodated directly inthe UG fragment but would have to be treated “indirectly as paraphrases” (perhapsvia transformations?) in PTQ. Explorations of extensions of PTQ to include such con-structions included attempts to synthesize Montague grammar with transformationalgrammar (Bach, 1976, 1979b; Bennett, 1974; Partee, 1973b, 1975); further reflectionson how best to constrain transformations to make them consistent with the require-ments of compositionality led to proposals for eliminating them entirely, as discussedabove in Section 1.3.4.3.
In contrast to approaches which have concentrated on minimizing or eliminatingtransformations, one noteworthy large-scale research effort, directed at the linguisticaspects of machine translation, has found that the factoring out of meaning-preservingtransformations from the meaning-relevant construction rules of a grammar can be ofgreat advantage in designing a compositional translation procedure. Rosetta (1994)describes the results of a seven-year project for translating among English, Dutchand Spanish; the system uses an interlingua which consists of semantic deriva-tion trees and the grammars for the individual languages are of a form inspiredby and very close to Montague grammar, with departures designed in part to cap-ture linguistic generalizations within the individual languages and at the same timeto make the transfer between languages as simple and systematic as possible. Byseparating the translation-relevant rules from the purely syntactic (and in general

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 48 — #48
48 Handbook of Logic and Language
more language-specific) transformations, it proved feasible to make the grammars ofthe different languages isomorphic (in a precisely defined sense) with respect to thetranslation-relevant rules without having to complicate the grammars artificially. Thetranslation-relevant rules in a number of cases introduce abstract elements which serveas triggers for transformations, a practice that recalls the work of Katz and Katz andPostal (1964), where the hypothesis that transformations should preserve meaning wasfirst argued; the success of the Rosetta project suggests that that practice merits contin-ued exploration in the context of Montague grammar (as was suggested by McCawley,1979), as a competitor to the strategy of trying to generate and interpret surface struc-tures as directly as possible.
In general, there has been much more lasting attachment to the principle of compo-sitionality and to many aspects of Montague’s semantics than to the manner in whichMontague presented his syntax or to the particulars of his syntactic rules, althoughMontague’s syntax was certainly of interest and has also influenced later develop-ments in many ways.
1.3.5 The Other Two Fragments: Brief Notes
While a number of the ideas instantiated in PTQ, and particularly a great deal of thebackground of Montague’s intensional logic IL, are developed in Montague’s earlierpapers (1959–1969), the two 1970 papers EFL and UG, corresponding to lectures andseminars given in 1966–1968 and 1969–1970 respectively, provide the most imme-diate background for PTQ, which was presented as a lecture in late 1970. EFL isparticularly rich in discussion of particular grammatical constructions, sources andattributions for ideas about the handling of various phenomena, and informal descrip-tions of alternative ways things might be done or ways one might eliminate cer-tain oversimplifications. Both papers contain discussion that is relevant to a fullerunderstanding of some of the choices made in PTQ, discussion which is mostly notrepeated in PTQ and it is therefore rewarding to read even just the prose parts of bothpapers.
EFL contains a fragment of English with a direct model-theoretic interpretation.In UG, in order to demonstrate the applicability of the general theory presented there(see Section 1.3.1 above) to both formal and natural languages, Montague presents thesyntax and semantics of his intensional logic and the syntax and compositional trans-lation into intensional logic of a fragment of English (plus meaning postulates cuttingdown the class of “logically possible models” for the fragment to a class of “stronglylogically possible models”), thus illustrating the method of indirect interpretation alsoused in PTQ. In UG as in PTQ he emphasizes that the interpretation of English couldhave been done directly and that proceeding by way of translation into intensionallogic is simply for the sake of greater perspicuity.
The fragments of EFL and UG contain many of the same parts of English that aretreated in PTQ, with some differences of detail in the treatment in some points and withcertain differences in the handling of the relation between extensions and intensions.EFL and UG both contain adjectives, absent from PTQ; they are less comprehensive

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 49 — #49
Montague Grammar 49
than PTQ only in lacking infinitival complements, tenses other than the present and thenouns and verbs of the “temperature puzzle”. EFL lacks intensional transitive verbslike seeks and non-intersective adjectives like alleged, former, but these are includedin the UG fragment.
Besides using the method of direct interpretation, EFL also eliminates the distinc-tion between extension and intension by treating sentences as denoting propositionsand setting everything else up accordingly (verbs as denoting relations-in-intension,etc.). In UG, the distinction between sense and reference is reintroduced, as well asa further distinction between senses (functions from possible worlds or world-timepairs) and meanings, which serve as interpretations of expressions and are analyzedas functions from not only worlds or world-time pairs but also contexts of use (rele-vant for indexicals and other context-dependent expressions); Montague’s meaningsare thus similar in some respects to Kaplan’s characters (Kaplan, 1979). For a discus-sion of the interdefinability of various ways of instantiating or eliminating the sense-reference distinction, see Lewis (1974). Montague intended for EFL to have a Part IIwhich would include indexical expressions, among other extensions; that was neverwritten, but many of Montague’s ideas about the treatment of indexicals can be foundin his papers on formal pragmatics and in UG, whose fragment includes “free variablepronouns” interpreted as demonstratives.
The treatment of anaphora, while semantically basically the same in EFL, UG andPTQ, is syntactically different in the three fragments; in all three, some kind of indexedvariables are used in order to support a compositional interpretation, departing to thisextent from the direct generation of surface expressions of English. In EFL, the cat-egory of “basic name phrases” contains both ordinary proper nouns of English andindividual variables v0, . . . , vn, . . . , and the rules of quantification and relative clauseformation replace occurrences of the relevant variables by anaphoric expressions ofthe form that N, where N is the head common noun of the quantified-in noun phraseand the head noun of the common noun phrase to which the relative clause is beingattached, respectively. (Bound variable uses of the determiner that are in fact possiblein English, although this analysis of Montague’s has not been much followed up on.)Thus EFL contains derivations like those partially sketched in (23) and (24).
(23) every tall man in Amsterdam loves a woman such thatthat woman loves that man, 9
/ | \v0 loves a woman such that v0 every tall man in
that woman loves v0 Amsterdam
(24) every man loves that man, 9/ | \
v0 loves v0 v0 every man
As remarked earlier, Montague included a footnote in EFL about the fact that (24)would be more naturally expressed as “every man loves himself”, with interestingideas about how a reflexive rule might be formulated. But in fact in EFL there are

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 50 — #50
50 Handbook of Logic and Language
no pronouns generated at all, either reflexive or plain; the “bound-variable” anaphoricexpressions are all of the form that N.
In UG, the set of “basic individual expressions” no longer contains proper nouns,which are elevated to the status of “basic singular terms” and given intensional gene-ralized quantifier interpretations as in PTQ, except for the addition of the intensionoperator and the omission of individual concepts. The set of basic individual expres-sions (which ends up being the set of all individual expressions; there are no non-basicones) consists of the set of symbols v2n+1 for n a natural number. There is a syntacticrule that then says that if ! is an individual expression, then he ! is a term; com-pound expressions like he v2n+1 play the role in UG of subscripted pronouns likehen in PTQ, with the pronoun part serving as the locus of case marking and the vari-able part keeping the expressions disambiguated. The interpretation of that syntacticrule gives a term of the form he v2n+1 the intensional generalized quantifier meaning$%P[[%P](v2n+1)], the intensional variant of the PTQ meaning of hen (modulo indi-vidual concepts). The variables stay in the expressions throughout a derivation, unlikethe indices on the pronouns in PTQ and are eliminated at the very end as part of theoperation of an “ambiguating” relation that also deletes certain parentheses that areintroduced in the syntactic rules of UG.
The use of parentheses in UG is interesting; UG introduces certain marked paren-theses in the course of the syntactic rules which serve the function served by introduc-ing bracketing and defining the syntactic rules to operate on bracketed strings insteadof strings. Montague in UG introduces such parentheses as parts of strings only wherethey are specifically needed and defines the rules on strings, referring to the parenthe-ses where necessary. The definition of the main verb of a verb phrase is a recursivedefinition given as part of the grammar and involving such parenthesization and theagreement rules in UG correspondingly point the way to Montague’s likely intendedsolution of the problem with the agreement rules of PTQ noted in Section 1.3.4.7.
It was noted earlier that lambda abstraction is a more basic variable-binding devicethan quantification. It is noteworthy in this respect that in UG, there is no quanti-fying in rule; the effects of PTQ’s and EFL’s quantifying in rules, including bound-variable anaphora and variations in quantifier scope, are all accomplished with thehelp of such that relative clauses and the “empty” noun entity. The proposition exp-ressed by (25) in PTQ is expressed by (26) in UG ((26)a is generated and transformedby the ambiguating relation to (26)b) and corresponding to the ambiguous sentence(27) in PTQ are the two unambiguous sentences (28)a and (28)b in UG.36 In UG thesuch (v2n+1) that construction is analyzed as expressing predicate abstraction and thesemantic interpretation associated with quantifying in in PTQ and EFL is more trans-parently expressed in UG by an English construction which, while stilted, is interest-ingly close in its surface syntax to the “logical form” displayed by the analysis trees of
36 The example given in UG is Jones seeks a horse such that it speaks; unicorns make their first appea-rance in the examples of PTQ. But the lexicon of UG is open-ended, so the proper and common nouns ofthe explicit fragment of PTQ are also implicitly included in the fragment of UG.

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 51 — #51
Montague Grammar 51
EFL or PTQ. The PTQ and EFL fragments, especially PTQ, associate what is basicallythe same semantic analysis with a more natural English syntax.
(25) Every man loves a woman such that she loves him.
(26) (a) Every man is a(n) entity such v1 that it v1 lovesa woman such v3 that she v3 loves it v1.
(b) Every man is a(n) entity such that it loves awoman that she loves it.
(27) John seeks a unicorn.
(28) (a) John seeks a unicorn.(b) A unicorn is a(n) entity such that John seeks it.
The rule that forms such that relative clauses is the only variable binding rule in thegrammar,37 and it leaves the indexed pronoun expressions ungendered; it is the rulethat combines those relative clauses with a common noun phrase that adjusts the gen-der of the relevant pronouns to correspond to the gender of the head noun of thecommon noun phrase. (And when that head noun is entity, the corresponding pro-nouns become it, which accounts for part of the stiltedness of (26).) Thomason (1976)made a related and even richer use of (sentential) “abstracts” in his early extension ofMontague grammar.
One of the progressions that one sees in the three fragments is a drive toward find-ing general patterns in the syntactic and semantic rules and the relation between them.One instance of this is the gradual emptying out of the syntactic category of entity-expressions: in EFL that category included both proper names and variables; in UG,it still contained variables, but the proper names were put in the category of basicterms and the generated “pronoun plus variable” complexes were also in the categoryof terms. In PTQ, there are no longer “variables” per se in the syntax, but indexedpronouns and these and the proper names are both in the category of basic terms.All terms and term phrases in PTQ belong to a single syntactic category and all areinterpreted uniformly as generalized quantifiers. (The present move toward type multi-plicity and type shifting may be seen in part as a way of reconciling the different moti-vations that may lie behind the different treatments in the three fragments, one beingthe wish to treat each kind of expression in the simplest way possible and anotherbeing the desire for uniformity of category-type correspondence without unnecessarymultiplication of categories.)
Another interesting feature of the EFL and UG fragments is the treatment of adjec-tives. Montague followed ideas of Parsons and Kamp in interpreting adjectives as
37 In EFL, Montague discusses the complications that would be involved in writing a rule for relativeclauses headed simply by the complementizer that, with deletion of the appropriate variable inside theclause and pronominalization of subsequent ones; he notes some of the “island restrictions” that wouldhave to be dealt with in such a rule and for that reason sticks to the syntactically simpler such that rulein all three fragments. See Rodman (1976) for the earliest Montague grammar of relative clauses withthat and which.

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 52 — #52
52 Handbook of Logic and Language
functions from properties to properties. In EFL he discussed the possibility of separat-ing out subclasses of intersective and subsective adjectives but preferred for the sakeof conceptual simplicity to keep a single class of adjectives. He did suggest the pos-sibility of adding “postulates” to identify those subclasses, suggesting that a sentencemight be called analytic with respect to a given analysis if it is a logical consequenceof such postulates and noting that for some purposes we might be more concernedwith analyticity than with logical truth. On the Parsons–Kamp–Montague treatmentof adjectives, it is adnominal adjectives that are basic. In EFL, Montague also gen-erated such adjectives in predicate position after be and there interpreted them as ifthey occurred in a full indefinite term phrase an Adj entity. (In UG, he omitted thatadditional rule; it was one of the few examples of the use of an interpretive analog of“abstract syntax” in Montague’s work as opposed to a more direct interpretation of theactual surface forms.) In EFL, he remarked on the parallels between adjectival mod-ification and adverbial modification; adverbial modification is included in both EFLand PTQ.
Some of the other interesting features of EFL and UG were noted in earlier sections:the “regimentation” of English negation in EFL (Section 1.3.4.6), the rich footnoteconcerning reflexive pronouns in the same paper (Section 1.3.4.3), the interpretationof “free variable pronouns” as demonstratives in UG (Section 1.3.4.3).
It was noted in Section 1.3.4.7 that work in the Montague tradition has been muchmore diverse in the degree to which it is influenced by Montague’s syntax than inits continuity with Montague’s semantics. Here we can add that the three fragments ofEFL, UG and PTQ are themselves more diverse in their syntax than in their semantics.But all are compositional and the differences are interesting in illustrating some of thechoices that may be made with respect to analyses of a given phenomenon within theoverall theoretical framework of Montague’s Universal Grammar.
1.4 The Montagovian Revolution: Impact on Linguistics andPhilosophy, Further Developments. Montague’s Legacy
In this section, we focus on a few selected topics to illustrate the impact Montague’swork has had on linguistics and the philosophy of language and the progressive evo-lution of Montague grammar and formal semantics over the last 25 years, includinga few of the main revisions that have largely supplanted aspects of Montague’s the-ory. The topics that have been selected center around the domains of quantification,anaphora and type theory. The discussion is brief, with pointers to several other chap-ters in this Handbook which treat some of these topics in greater detail. As in thecase of the Chomskyan revolution in syntax, the Montagovian revolution in semanticshas had as its most lasting effect an exciting raising of expectations of what is pos-sible, grounded on the foundations of a methodology, some powerful new tools andtechniques, and some useful criteria for success. The richness of Montague’s legacycan be seen not only in those specifics of Montague’s theory or in specific aspects ofhis grammar fragments that have survived the test of time but also in the ease with

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 53 — #53
Montague Grammar 53
which later researchers have been able to propose and debate alternative analyses andtheoretical innovations within a common core of largely shared goals and standardsfor evaluating progress.
1.4.1 The Montagovian Revolution. Initial Impact
In the characterization of Bach (1989), the Chomskyan revolution had at its core thethesis that a natural language can be described as a formal system. Montague’s rev-olutionary contribution was the thesis that a natural language can be described as aninterpreted formal system, a thesis about which there had been skepticism from lin-guists and logicians alike (see Section 1.2.1) before Montague’s demonstration of whatcould be accomplished with the skillful use of sophisticated tools.
The principal initial hurdles that had to be overcome in introducing Montague’sideas to the linguistics community were the historical skepticism just noted and thefact that on first exposure to Montague’s work, many linguists were daunted by theheavy formalism and the high-powered typed intensional logic used by Montague;the reaction has been caricatured by the epithet “English as a Foreign Language”38
applied to Montague’s analysis of natural language. For some linguists, Montaguegrammar was simply somewhat unapproachable, since working with it required facil-ity with logical tools that were previously unfamiliar. And among philosophers, therewere many who followed Quine and Davidson in skepticism about possible-worldssemantics and about Montague’s approach to intensionality. But among linguists andmany philosophers of language, the central question was whether the theory’s fruit-fulness was worth the effort it took to learn it and for a critical mass of linguists andphilosophers the answer was affirmative and within the decade of the 1970s Mon-tague’s semantics became a dominant (although by no means universally accepted)approach to semantics.
By the middle of the 1970s, Montague grammar and related work in formal seman-tics was flourishing as a cooperative linguistics-and-philosophy enterprise in partsof the USA, the Netherlands, Germany, Scandinavia, and New Zealand. (By thelate 1970s it was no longer possible to keep track.) The first published collection,Partee (ed.) (1976a), contained contributions by Lewis, Partee, Thomason, Bennett,Rodman, Delacruz, Dowty, Hamblin, Cresswell, Siegel and Cooper and Parsons; thefirst issue of Linguistics and Philosophy contained Karttunen (1977) as its first arti-cle; the biennial Amsterdam Colloquia, still a major forum for new results in formalsemantics, started up in the mid-1970s and opened its doors to scholars from outsideEurope by the late 1970s. Other conferences and workshops on or including Mon-tague grammar were held in various places in the USA and Europe from the mid-1970s onward.
Acceptance of Montague grammar was by no means universal, however; there wasconsiderable skepticism among some linguists about compositionality and the appli-cability to natural language of truth-conditional model-theoretic tools (see Chomsky,1975, for an important and influential example). And some philosophers have always
38 The phrase was coined, I believe, by Emmon Bach, to use with students in sympathy with the formidablehurdle that the study of Montague grammar often seemed to present.

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 54 — #54
54 Handbook of Logic and Language
considered Montague’s intensional logic insufficiently intentional, given that all logi-cally equivalent expressions are treated as semantically identical. Other linguists andphilosophers had other reasons for pursuing different approaches, as always.
As time and theories have progressed, it is increasingly difficult to distinguish bet-ween theories that might be considered modified versions of Montague grammar, theo-ries developed explicitly to provide alternatives to some aspect of Montague grammarand theories whose principal origins are different but which show the influence ofsome aspects of Montague grammar. The pedigrees are in any case not of substantiveimportance; the problem only arises when trying to decide what belongs in an articleon “Montague grammar”.
With respect to the dauntingness of Montague’s formal tools, the main “antidote”,besides good textbooks and added training in logic, has been the gradual progress infinding formal tools that are more and more closely adapted to the needs of naturallanguage semantics, so that it is gradually less necessary to couch explanations of thesemantics in terms of logics not well suited for that purpose. It will probably take moregenerations, however, before we have formal tools to work with which have both allof the advantages of explicitness and nice formal properties of logics like Montague’sintensional logic and a very close and perspicuous relationship to the structures that arefound in natural languages. And it will take even longer before any such formal toolsgain the degree of familiarity and apparent “naturalness” now enjoyed by first-orderlogic.
1.4.2 Quantification
There are two convergent reasons for starting with a discussion of some of the salientpoints about analyses of quantificational phenomena since PTQ. One is that Montague,by his title, chose that as the most salient feature of the PTQ fragment; the other isthat it has been an extremely fertile and richly cultivated area of semantic research inthe last 25 years, involving productive interaction across the contributing disciplines.The discussion that follows will omit many specifics; see Chapter 19 on GeneralizedQuantifiers in this Handbook by Keenan and Westerståhl, or a textbook such as Gamut(1991).
1.4.2.1 Generalized Quantifiers
Montague’s analysis of noun phrases as denoting generalized quantifiers was novel tolinguists, but it was already a topic of research among logicians, who had long beenaware that some kinds of quantificational expressions, like most books, are not first-order representable (see Barwise and Cooper, 1981) but can be satisfactorily analyzedas generalized quantifiers: the determiner most can be treated as a relation betweentwo sets, or, equivalently, as a function mapping a set onto a set of sets. When thelinguist Robin Cooper met the logician Jon Barwise at the University of Wisconsinin the late 1970s, a productive collaboration resulted which led to the now-classicpaper of Barwise and Cooper (Ibid. 1981). Another fruitful collaboration that beganat about the same time was that between the linguist Ed Keenan and the logician

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 55 — #55
Montague Grammar 55
Jonathan Stavi, leading to another highly influential paper, by Keenan and Stavi (1986)(versions of which circulated several years earlier).
Barwise and Cooper started from Montague’s analysis of NPs as generalized quan-tifiers, recast it in more directly model-theoretic terms and greatly expanded the rangeof determiners considered. One of their most important and influential contributionswas the identification of a number of model-theoretic properties that could be usedto classify determiners and NPs in ways that correlated interestingly with linguisticgeneralizations concerning the identified subclasses of determiners and NPs. Severalof the particular properties that they isolated, including conservativity, monotonicityand the weak-strong distinction, continue to play a central role in the developmentof explanatory theories of the syntactic and semantic behavior of NPs and determin-ers. Even more important was the example they set of how one might search for lin-guistically significant model-theoretic properties of the interpretations of expressions,properties that might not have any direct representation in either “logical forms” or in“formal” properties of the expressions in some logic such as IL that might be used inan intermediate representation.
Barwise and Cooper suggested some properties that might be shared by all naturallanguage determiners, though not by all logically possible meanings of the semantictype of determiners. The best-known of these is what is now called Conservativity,what Barwise and Cooper called the “lives-on” property. The statement that all naturallanguage determiners live on their common noun set, or are conservative in their firstargument, is formally captured by (29) and illustrated by the necessary truth of (30).
(29) A determiner meaning D lives on its first argument iffor all sets A, B, it holds that D(A)(B) if D(A)(A ( B).
(30) At most three horses are black if and only ifat most three horses are horses that are black.
Barwise and Cooper also identified the properties “weak” and “strong” (see Chap-ter 19 on Generalized Quantifiers) and showed their correlation with the classes ofNPs subject to various “indefiniteness effects” and “definiteness effects”, for some ofwhich they were able to give a semantic account of the effects as well. Others sincethen have continued to explore alternative approaches to these and related propertiesand alternative analyses of the constructions in question, since this is an area wherethere are many significant linguistic phenomena to be explained and not all appear to besensitive to exactly the same properties or to be analyzable by exactly the same means.
One interesting family of properties studied by Barwise and Cooper and furtherexplored by subsequent scholars are the monotonicity properties, intimately related tothe property of “downward-entailingness” identified by Ladusaw (1979) in what wasprobably the first clear example of a place where the model theory could do someexplanatory work that could not be duplicated by logical forms or properties of logicalformulas.
A function classified as downward-entailing by Ladusaw, given a suitable definitionof a partial ordering “)” applicable to its domain and range, is a function f such

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 56 — #56
56 Handbook of Logic and Language
that f (y) ) f (x) whenever x ) y. Ladusaw showed that given the structure of thefunctional types of PTQ-like fragments, one can recursively define a partial orderfor most of the used types starting from the assumption that 0 (false) is less than 1(true); the partial order’s “)” corresponds to “*” on all the types whose domain aresets. And given those formal tools, Ladusaw was able to argue that the possibilityof occurrence of negative polarity items like any, ever, at all is best explained insemantic terms: negative polarity items can occur within the arguments of downward-entailing (monotone decreasing) functions, an insight which had been suggested inearlier work of Fauconnier (1975a,b); see Chapter 19 for further details.
Ladusaw’s work was followed by a very interesting debate between Ladusaw andLinebarger, with Linebarger defending a syntactic account based on the triggering itembeing a C-commanding negative operator (Ladusaw, 1980, 1983; Linebarger, 1980,1987). The debate illustrated the difficulty of settling arguments between a syntacticand a semantic account of a given phenomenon in any straightforwardly empiricalway; it also illustrated both the advantages and the pitfalls of the method of frag-ments. Each account handled some of the same central cases adequately; each accounthad trouble with some kinds of “peripheral” cases; but the two accounts differed inother cases, handling different examples directly and requiring pragmatic augmenta-tion for an account of some cases (different ones on the two approaches). But in anycase, formal semanticists would agree that Ladusaw’s work on polarity sensitivity asa semantic property was important and ground-breaking research which has servedas a model for much that followed. Barwise and Cooper’s investigation of mono-tonicity properties of determiners and NPs was a further development of the samesort.
Another major model-theoretic advance in the semantics of noun phrases and deter-miners came from the work of Godehard Link (1983), discussed in part in Chapter 23“Plurals and Collectivies” in this Handbook. Link proposed a treatment of the seman-tics of mass and plural nouns whose principal innovations rest on enriching the struc-ture of the model by treating the domain of entities as a set endowed with a partic-ular algebraic structure. In the model Link proposes, the domain of entities is not anunstructured set but contains subdomains which have the algebraic structure of semi-lattices. A distinction is made between atomic and non-atomic semilattices. Intuitively,atomic lattices have smallest discrete elements (their atoms), while non-atomic ones(really “not necessarily atomic”) may not.
These atomic and non-atomic join semilattice structures, when used to providestructures for the domains of count and mass nouns respectively, give an excellentbasis for showing both what properties mass and plural nouns share and how massand count nouns differ, as well as for formally elucidating the parallelism between themass/count distinction and the process/event distinction (Bach, 1986b). Some briefintroductions to the main ideas can be found in (Bach, 1986b; Partee, 1992, 1993),and in Landman’s contribution to Lappin (ed.) (1996); for more complete expositions,see Link (1983), Landman (1989a,b, 1991).
A chief pay-off is that these lattice structures also make it possible to give a uni-fied interpretation for those determiners (and other expressions) that are insensitive to

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 57 — #57
Montague Grammar 57
atomicity, i.e. which can be used with what is intuitively a common interpretation formass and count domains, such as the, all, some and no. The, for instance, can be ele-gantly and simply defined as a “supremum” operation that can be applied uniformly toatomic and non-atomic structures and to singular or plural entities within the atomicstructures. “Count-only” determiners such as three and every have interpretations thatinherently require an atomic semilattice structure.
Link’s work, like that of Heim (discussed in the next subsection), adds support forthe idea that the definite article is not primarily quantificational, contrary to Russelland contrary to Montague. Link’s uniform analysis of the treats it as a supremum oper-ator in the subsemilattice denoted by the common noun phrase it applies to; the seman-tic value of the result is an entity, not a generalized quantifier. Of course the resultingentity can always be “lifted” to the type of generalized quantifiers by the same meansused for proper names and pronouns in PTQ, but the basic semantics of the definitedeterminer on Link’s analysis is that it forms an individual-denoting expression ratherthan a quantifier phrase.
One of the most important features of this analysis is that the mass lattice struc-ture emerges as unequivocally more general than the count noun structure, i.e. as theunmarked case. The domains of mass noun interpretations are simply join semilat-tices, unspecified as to atomicity. Atomic join semilattices are characterized as thesame structures but with an added requirement, hence clearly a marked case. Thismeans that languages without the mass/count distinction are describable as if all theirnouns are mass nouns; we need not seek some alternative structure that is neutral bet-ween mass and count, since mass itself turns out to be the neutral case (see also Stein,1981).
While some of these innovations naturally depart in various ways from Montague’swork, they can all be seen as exploiting the possibility of finding model-theoreticbases for linguistic generalizations, removing some of the explanatory load from thesyntactic component and showing that semantics is more than a matter of finding asymbolic “logical form”. Link’s work in particular shows the potential importanceof uncovering further algebraic structure within the domains corresponding to simpletypes, an important step in the further integration of lexical semantic investigationsinto formal semantics, an enterprise which began with the work of Dowty (1979).
1.4.2.2 Kamp–Heim and Non-Uniform Treatment of NPs
The work of Kamp and Heim beginning in the early 1980s was one of the major devel-opments in the semantics of noun phrases, quantification and anaphora, and, moregenerally, influenced the shift from a “static” to a “dynamic” conception of meaning,discussed further in Sections 1.4.3 and 1.4.5 below. For substantive detail, see Heim(1982), Kamp (1981), Kamp and Reyle (1993) and Chapter 3 on Discourse Represen-tation in Context in this Handbook by Kamp and Van Eijck. Here we briefly underlinesome of the principal issues raised by their innovations in the context of Montaguegrammar, particularly their challenge to Montague’s uniform interpretation of NPs asgeneralized quantifiers.

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 58 — #58
58 Handbook of Logic and Language
Kamp (1981) and Heim (1982) offered solutions to classic problems involvingindefinite noun phrases and anaphora in multi-sentence discourses and in the famous“donkey-sentences” of Geach (1962) like (31) and (32).
(31) Every farmer who owns a donkey beats it.
(32) If a farmer owns a donkey, he beats it.
On their theories, indefinite (and in Heim’s theory also definite) noun phrasesare interpreted as variables (in the relevant argument position) plus open sentences,rather than as quantifier phrases. The puzzle about why an indefinite NP seems to beinterpreted as existential in simple sentences but universal in the antecedents of con-ditionals stops being localized on the noun phrase itself; its apparently varying inter-pretations are explained in terms of the larger properties of the structures in which itoccurs, which contribute explicit or implicit unselective binders that bind everythingthey find free within their scope.
Both Kamp and Heim make a major distinction between quantificational and non-quantificational NPs and the semantics they give to NPs varies with the internal struc-ture of the NP. It is not straightforward to say what type is assigned to an indefiniteNP on their approaches, given that the NP makes several separate contributions to thesemantic interpretation of the larger expression in which it occurs. But in any case, thesemantics of indefinites, definites, pronouns and names is on their analysis fundamen-tally different from the semantics of the “genuinely quantificational” NPs, representedin their original fragments by NPs headed by the determiner every.
A related innovation of Kamp’s and Heim’s work is their systematization of thesimilarities between adverbs of quantification and determiner quantifiers, starting fromthe classic paper of Lewis (1975a) on adverbs of quantification as unselective binders.While not uncontroversial, their proposals opened up a rich line of research on quan-tificational structures of different kinds that has broadened into interesting typologicalresearch (see Section 1.4.6 below).
Both the diversification of NP semantics and the unification of some kinds of deter-miner quantification with adverbial quantification represented an important challengeto Montague’s uniformity of assignment of semantic types to syntactic categories andin Kamp’s presentation of DRT, even an apparent challenge to compositionality. Wereturn to these issues in Section 1.4.4.3 in our discussion of type flexibility. We willalso briefly discuss the claim that Kamp’s Discourse Representation Theory is insuffi-ciently compositional, a concern which formed part of the motivation for the theory of“Dynamic Montague Grammar”, developed by Groenendijk and Stokhof (1990, 1991)and extended by colleagues in Amsterdam and elsewhere (see especially Chapter 12on Dynamics in this Handbook).
1.4.2.3 Quantifier Scope Ambiguity
The analysis of quantifier scope ambiguity has been a perennial source of controversy.The heart of the problem is that in English and many other languages, sentences like(13), A unicorn eats every fish, which are ambiguous only with respect to quantifier

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 59 — #59
Montague Grammar 59
scope, do not show any independent evidence of being syntactically ambiguous. Theneed to consider them syntactically ambiguous is purely a theoretical consequenceof the acceptance of two assumptions: (i) the principle that semantic ambiguity mustalways be a result of lexical ambiguity or syntactic ambiguity (or both); and (ii) theassumption that quantifier scope ambiguity is an instance of semantic ambiguity thatmust be captured in a linguistic analysis.
Each of these principles is widely although not universally accepted. The principlestated in (i) is accepted by many theories and certainly must hold in any theory thataccepts the principle of compositionality and therefore in most variants of Montaguegrammar. The assumption in (ii) contrasts with views which suggest that quantifierscope “ambiguity” is, rather, an instance of unspecificity, and that sentences with such“ambiguities” are to be given a single meaning which only in a given context of usemay be further “specified”; but for theories which take truth conditions as an essentialingredient of linguistic meaning, it has proved very difficult to find an appropriatetruth-conditional content which might be a plausible candidate for the “scope-neutral”content of such a sentence.
It therefore seems that any linguistic theory that includes a compositional truth-conditional semantics must analyze sentences like (13) as syntactically ambiguous.But there is tension from the fact that a sentence like (13) does not show any obvi-ous signs of syntactic ambiguity, so a theoretical framework which wants to have anexplanatorily as well as descriptively adequate syntax will prefer to regard (13) as syn-tactically unambiguous even at the cost of giving up or weakening compositionality.And even if one accepts the consequence that (13) must be syntactically ambiguous,there seems to be little syntactic evidence bearing on the question of what the natureof that ambiguity is, which is undoubtedly part of the reason why there have been andcontinue to be such a variety of proposals for dealing with them.
Some kinds of theories have proposed multiple levels of syntax, such that (13) hasonly a single syntactic structure on some levels (e.g., surface structure) and distinctstructures on another, semantically relevant, level (e.g., “deep structure” on some the-ories, “logical form” on others). Thus May (1977, 1985) introduced Quantifier Rais-ing, approximately the mirror image of the generative semantics rule of QuantifierLowering, for deriving different logical forms from surface structures, but then madethe startling proposal that (c-command at) the level of logical form does not in factdisambiguate quantifier scope.39
For Montague grammar, however, the principle of compositionality dictates that inall cases where a non-lexical ambiguity is found that cannot be traced to independentlymotivated differences of syntactic structure, there must nevertheless be two differentsyntactic derivations, two different routes of constructing one and the same expression(or surface syntactic structure, if one generates trees rather than strings). Montague,as described above, introduced Quantifying In rules for creating these derivational
39 Thereby abandoning the otherwise respected principle that the input to semantic interpretation must bea disambiguated syntax and that whatever “logical form” may mean, being truth-conditionally disam-biguated is part of it. (See the discussion in Chierchia, 1993.)

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 60 — #60
60 Handbook of Logic and Language
ambiguities. It was noted above that such Quantifying In rules, which simultaneouslysubstitute a full NP and pronouns of appropriate case and gender for respective occur-rences of a given syntactic variable hen, are in fact outside the bounds of what linguistswould have called a single rule at the time. They are, moreover, the only rules in PTQwhich give rise to syntactic derivations that do not respect the “intuitive” syntacticconstituent structure and hence assign counterintuitive part/whole structures. The lackof “independent syntactic motivation” for Montague’s Quantifying In rules has meantthat even those linguists most sympathetic to many aspects of Montague’s programhave continued to explore alternative treatments of quantifier scope ambiguities, start-ing from the earliest days of Montague grammar.
Cooper (1975, 1983) invented the alternative of “Cooper storage” as a means toavoid even a derivational ambiguity in a sentence such as (13), for which there isarguably no independent syntactic motivation for positing ambiguity. In the processof bottom-up compositional interpretation, whenever an NP is encountered, there isthe option of either interpreting it in situ or of putting the NP meaning together witha chosen index into “storage” and putting the meaning of a correspondingly indexedpronoun into the interpretation in place of the given NP’s meaning. The stored NPmeaning is then “retrieved” into the sentence interpretation at any of the positionsthat correspond to possible scopes, i.e. any of the domains of Montague’s Quantify-ing In rules; the stored index determines which variable is to be abstracted on in theaccompanying lambda abstraction on the meaning with which the retrieved NP mean-ing is to be combined. (As noted in Section 1.3.1, this weakening of compositionalityby permitting one syntactic structure to yield multiple meanings is only formal. Theapproach can be seen as compositional by taking the mapping from syntax to seman-tics to be a set-valued function.)
Scope ambiguity was the clearest phenomenon for which GPSG (“generalizedphrase structure grammar”; see Gazdar, Klein, Pullum and Sag, 1985) had to choosebetween abandoning context-freeness or weakening compositionality; the latter optionwas chosen in quietly presupposing Cooper storage for quantifier scope. Cooper’smechanism of semantically storing quantifiers (and pronouns) avoids the “unintu-itive” syntactic aspects of Montague’s Quantifying In, but accomplishes this at theexpense of complicating the semantic component. Weighing the additional complex-ities of semantic interpretation against the simpler ambiguous syntax in his treatmentof scope ambiguities, Cooper concludes: “What seems unappetizing about this systemis not that we map into sets of meanings but that we have to map into sets of sequencesof sequences of meanings” (Cooper, 1975, p. 160).
The “flexible Montague grammar” of Hendriks (1988, 1993) shares with Cooper’ssystem the avoidance of a syntactic Quantifying In rule. It also represents quan-tifier (and coordination) scope ambiguities without syntactic repercussions such as“artificial” alternative ways of construction, but accounts for them by flexible typeassignment, which affects the relationship between syntax and semantics: syntacticobjects are associated with sets of systematically related interpretations of differ-ent types (see also Section 1.4.4.3 below). The flexible grammar can be shown tobe fully compositional (i.e. in the single-valued sense), provided that its semantic

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 61 — #61
Montague Grammar 61
“type-shifting” interpretation derivations are recast as unary syntactic/semantic rules.Since, moreover, all its syntactic operations respect the “intuitive” syntactic structure,so that constituent expressions are always real parts, the grammar also observes whatPartee (1979b) called the “well-formedness constraint”, i.e. the “most intuitive inter-pretation of the principle of compositionality, which says that the parts of a compoundexpression have to be visible parts of the compound expression” (Janssen, 1986a,pp. 65–66).
Other proposals for dealing with quantifier scope can be found in contemporaryliterature. Some scholars (see Szabolcsi (ed.) (1997)) are putting more emphasis onthe investigation of the semantics of individual determiners and noun phrases andthe separate ingredients that go into the interpretation of quantificational expressions,such as distributivity and specificity or the lack of it. Some “classic” cases of scopeambiguity are being suggested not to involve scope ambiguity but other phenomena(e.g., see Kratzer, 1995b), and the study of the interaction of scope phenomena withtopic-focus articulation and word-order phenomena in various languages is bringingnew perspectives to bear on old problems.
Quantification and matters of scope have been and undoubtedly will continue tobe an important arena for exploring consequences of rules and representations andthe connections among them, as are the equally varied and controversial proposalsconcerning the syntax and semantics of pronouns and other “bindable” expressions.40
These are areas in which the division of labor between syntax and semantics and eventhe question of whether that is a simple dichotomy, is particularly non-obvious.41
The integration of psycholinguistics and formal semantics requires some resolu-tion of the problem of combinatorial explosion that comes with the disambiguationof such pervasive ambiguities as scope ambiguities; see Johnson-Laird (1983), J.D.Fodor (1982). It is hard to imagine all the ways in which recent linguistic historymight be different if quantifier scope did not have to be worried about at all, but aslong as systematic truth-conditional differences are regarded as semantic differences,quantifier scope possibilities must be accounted for.
1.4.3 Anaphora
Montague in PTQ treated only bound variable anaphora; in his earlier work develop-ing pragmatics and intensional logic he treated indexical pronouns like I and demon-stratives like he, this, that. At the time of Montague’s work, linguists were already
40 Linguists not bound by a commitment to making truth conditions and entailment relations central tosemantic adequacy criteria have the possibility of not representing scope as a linguistic ambiguity at all.This was a possibility sometimes entertained in Chomsky’s earlier work, allowed for in current Pragueschool work such as Hajičová and Sgall (1987), explored in the context of parsing by Hindle and Rooth(1993) and in the context of Discourse Representation Theory by Reyle (1993); see also Poesio (1991,1994).
41 See, for instance, the “indexing mechanism” proposed by Williams (1988) as an alternative to QuantifierRaising and the similar indexing mechanism elaborated by Cooper and Parsons (1976); the status of an“indexed tree” with respect to syntax “or” semantics is not straightforward.

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 62 — #62
62 Handbook of Logic and Language
engaged in debates concerning how many and what kinds of uses of pronouns neededto be distinguished and to what extent these different uses could be unified or atleast systematized. Karttunen (1969) considered the question of whether all non-demonstrative pronouns could be analyzed as bound variables and came up with someproblematic examples that are still being debated, such as the “paycheck pronoun” itin (33).
(33) The man who gave his paycheck to his wife was wiser thanthe man who gave it to his mistress.
Partee (1970a) also explored the problem of trying to find a unified analysis of pro-nouns, with particular attention to cases that seem to require some kind of “pronounof laziness”,42 and to the problems raised by indefinite antecedents in particular. Otherauthors began to explore the possibility of pronouns sometimes being interpreted as“Skolem functions” with a hidden dependence on some non-overt variable as a possi-ble solution to the paycheck pronouns and some other problematic cases.
As mentioned in Section 1.3.4.3 above, the insight that any NP, including a propername, could be the antecedent of a bound-variable pronoun has had a major impacton subsequent discussions of the “strict”/“sloppy” identity puzzles in VP ellipsis insentences like (7), repeated below.
(34) Sam gave some fish to his dog and Sally did too.
What had originally been seen as syntactic deletion of a VP under “sloppy” identityconditions (deleting gave some fish to her dog under “identity” with gave some fishto his dog) came to be seen instead as strict semantic identity of properties involvinglambda binding of corresponding variables: %x[x gave some fish to x’s dog]. Thedifference between a proper name and a quantifier phrase like every man could thenbe argued to be that while both could be “antecedents” of bound variable pronouns(actually bound by a lambda operator), a proper name could also be “coreferential”with a non-bound-variable pronoun, while such coreference is not possible between aquantifier like every man and a singular pronoun like he.
The famous “donkey sentences” of Geach (1962), mentioned in Section 1.4.2.2above and repeated below, were already beginning to receive some attention aroundthe time of Montague’s work, but it was not until after the importance of paying closeattention to compositionality became more widely recognized by linguists that the realchallenge of the donkey sentences was fully appreciated.
(35) Every farmer who owns a donkey beats it.
(36) If a farmer owns a donkey, he beats it.
42 The use of this term is not fully standardized; Partee (1970a) took the term from Geach (1962), but Geach(p.c.) took issue with Partee’s usage of the term, arguing that in his original sense, there was never anyshift of reference between the pronoun and its antecedent. Subsequent authors often use the term for anyuse of a pronoun which seems to be tantamount to a disguised definite description, which is closer toPartee’s use than to the original Geach use.

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 63 — #63
Montague Grammar 63
The importance of donkey pronouns in the contemporary history of formal seman-tics could probably not have been predicted 25 years ago. The analysis of donkey-sentences and related problems remains at the time of writing this article a locus ofintense unresolved arguments, arguments very important to competing views aboutissues of “logical form”, compositionality, dynamics, the dispensability of intermedi-ate levels of representation and other such key issues about the nature of semanticsand its relation to syntax and to pragmatics.
In the following subsections, we mention briefly a small selection of the manyissues and developments in the analysis of anaphora that have played an importantrole in the development of Montague grammar and “post-Montague grammar” overthe last 25 years.
1.4.3.1 Binding by Lambda Operators
One issue, some of whose consequences were realized early, although it has rarelyhad “center stage” in discussions of anaphora, is the fact that on Montague’s analysisin all three of his fragments of English, the binding of bound-variable pronouns isdone not by the quantifier directly, but by the lambda operator that binds the “scope”expression that the quantifier applies to, as in the schematic translation (38) of (25),repeated here as (37), where not only the she in the relative clause but also the himwhose antecedent is every man is bound by a lambda operator. It is true that after sim-plification steps, one may end up with a corresponding variable bound by a quantifier,as in (39), but (i) that is not true of the direct translation; and (ii) in a fragment withnon-first-order generalized quantifiers like most women, there would not be any suchreduction to a formula containing a first-order quantifier, so the variable correspondingto the pronoun would never be directly bound by a quantifier, but only by the lambda.
(37) Every man loves a woman such that she loves him.
(38) every!($man!)#$%x1
!love!($a!($%x3[woman!(x3) $ love!
*(x3, x1)]))(x1)"$
.
(39) +u!man!
*(u) , -v[woman!*(v) $ love!
*(v, u) $ love!*(u, v)]
".
Recall the rather stilted structure (26)a, repeated here as (40), generated by the UGfragment before the disambiguating relation removes the variables.
(40) Every man is a(n) entity such v1 that it v1 loves a womansuch v3 that she v3 loves it v1.
The indirect relation between the actual binding of the pronoun and the assignmentof a gender to the pronoun on the basis of the gender of its “antecedent” in the case ofa Quantifying In rule and on the basis of the head noun of the relative clause contain-ing the pronoun in the case of the relative clause rule creates both opportunities andproblems.
One positive effect of lambda binding is that it allows us to see “sloppy identity”,so called because of the apparently imperfect identity of love her mother and lovehis mother in the putative “VP-deletion” derivation of a sentence like (41), as strict

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 64 — #64
64 Handbook of Logic and Language
semantic identity. There is no inherent gender in the property representable by thelambda expression in (42).
(41) Mary loves her mother and John does too.
(42) %x[love(x, x’s mother)].
The challenge is to figure out from this perspective what the right account of pro-noun gender is, both in languages like English and in languages with “grammaticalgender”. See Dowty and Jacobson (1989) for relevant discussion. Montague’s PTQrules may seem clumsy and ad hoc with respect to the assignment of gender to pro-nouns, but they opened up new possibilities that linguists had not considered; the rela-tionships among control, agreement and anaphora are currently under active explo-ration in many frameworks.
1.4.3.2 Evans and E-Type Pronouns
Montague in PTQ allowed quantification into coordinate structures with the possibilityof an NP in one conjunct binding a pronoun in another conjunct, as in example (43),discussed earlier as (8), and as in example (44).
(43) John wants to catch a fish and eat it.
(44) Mary catches a fish and John eats it.
The semantic interpretation of (44) given by the Quantifying In rule is that there isat least one fish which Mary catches and John eats. Evans (1980) argued that this givesthe wrong truth conditions for (44), that (44) implies that Mary caught just one fish (inthe relevant context) and John ate the fish that Mary caught. Intuitions are even clearerwith Evans’s plural examples such as (45), which do clearly seem to imply that all ofJones’s sheep were vaccinated, not just that there are some sheep owned by Jones thatwere vaccinated by Smith.
(45) Jones owns some sheep and Smith vaccinated them.
Evans therefore argued for an interpretation of the pronouns in these sentences thatamounts to a definite description interpretation, the description to be systematicallyderived from the clause in which the antecedent occurs; (44) would then be interpretedin the same way as (46).
(46) Mary catches a fish and John eats the fish that Mary catches.
Evans called these pronouns “E-type” pronouns,43 and versions of this kind ofanalysis continue to resurface as live candidates for some pronoun interpretations (e.g.,see Heim, 1990). The problem is always to figure out which pronouns can/must havesuch an analysis and how the appropriate interpretation, or possible interpretations,
43 It is not known, at least to this author and her colleagues, why he chose that term, but presumably not for“Evans”.

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 65 — #65
Montague Grammar 65
can be compositionally determined, or by what principles the right choice(s) might benarrowed down if the choice is grammatically non-deterministic.
1.4.3.3 Cooper Pronouns
Cooper (1979) offered a theory of pronominal anaphora which was a Montague-grammar-oriented version of a theory combining Montague’s treatment of bound vari-ables with a generalization of theories like Evans’s and other proposals for “pronounsas disguised definite descriptions”, but which differed from most proposals of the lat-ter type in relying on contextual/pragmatic rather than syntactic or explicit semanticprinciples for identifying the content of the “description”-type pronouns. Cooper’sproposal was that a possible pronoun meaning was any meaning of the type of gene-ralized quantifiers and of the form shown in the metalinguistic expression (47) belowwith the restriction that & be a property-denoting expression containing only freevariables and parentheses.
(47) %K-x!+y[[%& ](y) . y = x] $ K(x)
".
Constraints on the possibilities on a given occasion of use of a given sentence areunderstood to be governed by the kinds of considerations that arise from the situationof speaker and hearer. We illustrate this idea briefly below.
Note first that Montague’s pronoun meanings in PTQ are an instance of theseCooper pronouns. Their meanings are all of the form (48):
(48) %P[[%P](xi)].
(And if one follows the UG suggestion of allowing contexts of utterance to con-tain variable assignments, these same pronoun meanings can serve for bound-variablepronouns and pronouns whose referents are salient in the speech context.)
For a donkey pronoun or a paycheck pronoun, Cooper does not reconstruct pronounmeanings that are explicit descriptions like “the donkey hei owns” or “hisi paycheck”,but does provide pronoun meanings that are like those except for having free propertyor relation variables that are to be filled in contextually with salient properties andrelations. A “paycheck pronoun” (see (33) above), for instance, is represented as in(49), where the relevant value of R would be “is the paycheck of” and the pronounmight be expected to be so understood if that relation were sufficiently salient to thehearer.
(49) %K-x!+y[[R(u)](y) . y = x] $ K(x)
".
The inclusion in the formula of u, a free variable that will be bound by the secondoccurrence of the man, is what lets this pronoun meaning be “functional”, with itsvalue dependent on the value of another bound variable in the sentence. Thus Cooperpronouns also subsume the idea of “Skolem-function pronouns”.
Cooper pronouns offer a nice generalization of a number of proposals; but withoutmore elaboration and auxiliary principles, the theory is too unrestrictive and allows too

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 66 — #66
66 Handbook of Logic and Language
much. However, the continuing difficulty of devising an explicit theory which gener-ates all and only the possible readings of pronouns leaves this approach an importantlive option.
1.4.3.4 Discourse Referents and Kamp–Heim Theories
As noted in Section 1.4.2.2, the interaction of indefinite noun phrases and anaphoraraised the hardest puzzles about indefinites and some of the hardest puzzles aboutanaphora. The problem of donkey-sentences became particularly acute and well-defined in the context of PTQ, which did so many things nicely but did not offer atreatment of donkey-sentences and in the context of compositionality concerns moregenerally, which set high standards for the properties a genuine solution should have.(The best discussion of the problem and the inadequacy of previous approaches isfound in the first chapter of Heim, 1982.)
The other major puzzle, also well-described in Heim (1982), is the problem of“discourse anaphora”, anaphora across sentences and the behavior of indefinite NPsin that phenomenon.
Kamp’s and Heim’s theories addressed both problems by offering a formalizationof Karttunen’s insight that indefinite NPs “introduce new discourse referents” in theprocess of interpreting a text and pronouns and definite NPs “refer to old discoursereferents”; and that the “life span” of a discourse referent introduced by a given indef-inite NP is determined by where in the structure the introducing NP occurs. The for-malization of these insights required a shift from the usual “static” truth-conditionalconception of meaning to a more dynamic conception.
Heim (1982) draws on the work of Stalnaker (1974, 1978), who characterized thefunction of assertion as the updating of the “common ground” of the participants ina conversation. Heim generalizes this conception and speaks of meaning as context-change potential; she shows how ordinary truth conditions can be defined in termsof context-change potential but not vice versa. Heim enriched the notion of commonground to include discourse referents as well as propositional information and Heim,Kamp and others since have enriched it further to serve as the locus of a variety ofcontext-properties which show similarities in their formal behavior to the behavior ofindefinites and anaphora.
Heim’s and Kamp’s theories are not formally identical and their worked-out frag-ments did not have exactly the same empirical coverage. Heim (1982) presented twoalternative formalizations of her ideas: one, the Chapter II theory, with various kindsof explicit indexing carried out in the construction of “logical forms” and a rather stan-dard semantic interpretation component applying to the output; the other, the ChapterIII theory, involving a more basic semantic innovation, treating meaning as “context-change potential” and using the metaphor of “files”, “file cards” and “file change” todescribe the parts of the model structure and their formal manipulation in the processof interpretation. This second theory of Heim often goes by the name of File ChangeSemantics. See Heim (1982), which by now is probably even more crucial as requiredreading for students of formal semantics than PTQ.

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 67 — #67
Montague Grammar 67
Kamp’s theory, Discourse Representation in Context, described in Chapter 3 of thisHandbook, makes use of a novel “box language” (which can be converted to a linearrepresentation if desired; see Zeevat, 1989; Chierchia, 1995) of Discourse Representa-tions and Discourse Representation Structures; the semantics is presented in terms ofrecursive conditions of embeddability of such structures in a model. The details of theoriginal presentation of Kamp’s theory make it not obvious whether the theory is com-positional; Zeevat (1989) explicitly provides a compositional version of the theory.Heim’s theory is clearly compositional to begin with. The later versions of Kamp’swork, including Kamp and Reyle (1993), again raise questions of compositionalitywhich are not explicitly addressed. See the discussion and debate in Groenendijk andStokhof (1991) and Kamp (1990).
1.4.3.5 Nominal and Temporal Anaphora
Another area that has been a rich one in the development of Montague grammar andformal semantics is the area of tense and aspect and temporal adverbials. This area,like many, is being almost entirely neglected in this article, but here we include a fewwords in connection with quantification and anaphora, partly in order to mention theimpact Montague’s contributions have had on more recent developments and partlybecause so much recent work has been concerned with the similarities and differencesbetween entity-oriented language and event-oriented language, and this has been amajor enrichment of the long history of work on anaphora and quantification.
The existence of parallels between expressions of quantification and anaphora inthe noun phrase domain and in the temporal domain has long been recognized; enti-ties, times and places and to some extent manners and degrees show similarities inhaving special wh-words, quantifier words like everyone, everything, always, every-where and corresponding expressions with some-, any-, no-, deictic and demon-strative expressions, and anaphoric expressions. In pre-Montague days, linguistscould only try to capture these similarities on some level of syntax or in first-orderterms, invoking the existence of variables over times, places, degrees, etc. (e.g., seePartee, 1973c).
Montague’s unification of modal and tense logic and the indirect parallels betweentheir quantificational interpretation in the model theory and their non-quantificational“operator” treatment in the object language, opened up a richer array of ways to see thesimilarities and differences between quantificational and anaphoric phenomena in theNP domain and partly similar phenomena in the domain of tense, aspect and tempo-ral adverbials. The work of Dowty (1979, 1982), Bach (1980, 1981, 1986b), Hinrichs(1981, 1985, 1986), Krifka (1986, 1987), Partee (1984) and others built in increasinglyrich ways on the model-theoretic perspective common to all of Montague grammar,on the integration of nominal and adverbial quantification offered by the Kamp–Heimperspective and on the richer algebraic structure imposed first on the domain of enti-ties and then in a similar way on the domain of events on the basis of the work ofLink (1983) as extended by Bach (1986b). The exploration of the similarities anddifferences between nominal and temporal quantification and nominal and temporal

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 68 — #68
68 Handbook of Logic and Language
anaphora, and the mutual influences between aspectual properties of verb phrases andsentences (in a variety of languages) and quantificational properties of noun phrases,is a rich and growing area of research. See also the discussion in Chapter 22 on Tenseand Aspect in this Handbook.
1.4.3.6 Reflexives, 0-Pronouns and Ellipsis, Control, Traces
Most early work on anaphora in Montague grammar and much of the continuing workon anaphora in formal semantics more generally has focused on the properties of ordi-nary personal pronouns in English and related languages. There has, however, beenincreasing attention to questions concerning the variety of kinds of anaphoric ele-ments that exist in English and in other languages and to the “anaphoric nature” of ele-ments besides pronouns, elements ranging from “pro-forms” in other categories (then,there, such, one, etc.) to presuppositions, context-dependent words like local, enemy(Mitchell, 1986; Partee, 1989b) and focus-sensitive constructions (Rooth, 1992a; vonFintel, 1994).
Bach and Partee (1980) offered an account of the distribution of reflexive and non-reflexive pronouns in terms of a Montague Grammar making use of Cooper storage(Section 1.4.2.3) and following up on the idea of the importance of “co-argumentsof the verb” discussed in Montague’s footnote about reflexives in EFL; in their frag-ment, they built in a structural similarity between reflexivization and control phenom-ena, extending proposals that had been made by Bach (1979a). There is much currentwork and much current debate on the analysis of reflexive pronouns, both in formalsemantics and in GB syntax and in approaches which blend the two; see, for instance,Reinhart and Reuland (1993).
Heim (1982) gave a unified account of the semantics of various elements that sheincluded in the level of LF of GB theory, including ordinary pronouns, traces of NPmovement and indices on NPs and on common nouns and relative pronouns.
With respect to the interpretation of ordinary pronouns, besides the continuingdebates about the proper analysis of donkey pronouns and about the existence andnature of “functional” readings of some pronouns, both described above, there is alsoincreasing attention to issues in the interpretation of plural pronouns, which raise abroader range of problems than singular pronouns because of the associated family ofissues that arise in the interpretation of plural NPs more generally (see Kadmon, 1987,1990; Kamp and Reyle, 1993; Landman, 1989a,b; Schwarzschild, 1992, for a sampleof relevant issues).
Other scholars have debated the semantic status of “zero pronouns” and “pro-drop”phenomena in various languages, tending toward the (still not completely clear) gen-eralization that zero forms of pronouns are more likely to be obligatorily interpreted asbound variables than phonologically non-empty forms of pronouns. Debates concer-ning the semantics of various empty or abstract pronominal elements are intimatelyconnected with debates concerning whether infinitival complements are to be ana-lyzed as full sentences at some level of structure. Montague in PTQ showed that formany purposes a VP could simply be generated as a VP and Partee (1973b) showed

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 69 — #69
Montague Grammar 69
how a “Derived Verb Phrase Rule” deriving a VP from an open sentence (with a freevariable subject) could obviate the need for transformations like “Equi-NP Deletion”;subsequent work has gone back and forth with much debate on the question of whethersome or all infinitival VPs still need to be analyzed as deriving from sentences on somelevel. See especially Chierchia (1984a,b) for a defense of “VPs as VPs” and Chierchiaand Jacobson (1986) for an argument that certain kinds of “Raising” constructions dohave sentential sources for infinitival VPs.
The important domain of VP-anaphora (including so-called “VP-Deletion”) inter-acts crucially with quantification and NP-anaphora and has also been the locus ofmuch debate, particularly between approaches which analyze VP-deletion as involv-ing identity of logical form and approaches which invoke identity of appropriatemodel-theoretic semantic objects. See, for a sample, Williams (1977), Sag (1976),Partee and Bach (1981), Rooth (1992b), Kratzer (1991).
Among approaches to VP-anaphora, the interesting new perspective of Dalrymple,Shieber and Pereira (1991) deserves mention: they propose to treat many kinds ofanaphora as involving “solving for a missing variable”. In particular, their approachis novel in providing for the ambiguity between strict- and sloppy-identity readingsof (7), repeated here as (50), without requiring that the first clause, (51), be analyzedas itself ambiguous as between a bound-variable and a coreferential reading of thepronoun.
(50) Sam gave some fish to his dog and Sally did too.
(51) Sam gave some fish to his dog.
Whether the approach of Dalrymple, Shieber and Pereira can be expressed in amanner compatible with compositionality is an open question, but the proposal isattractive enough in many respects for its theoretical consequences to deserve seri-ous attention.
1.4.3.7 Combinators and Variable-Free Syntax
One novel development in the area of anaphora is the reinvigoration of the possibilitythat natural language pronouns might be analyzed in terms of “combinators” of combi-natory logic in the context of an extended categorial grammar treatment of the syntaxunderlying a compositional semantics; see Szabolcsi (1987), (Jacobson, 1992, 1994,1996), Dowty (1992). A “combinator” analysis of pronouns had been proposed in var-ious forms at various times for reflexive pronouns, especially for languages in whichreflexivization takes the form of a clitic on a verb rather than looking structurally likea normal NP: it is then natural to see the reflexive pronoun as a functor that appliesto an n-place verb and identifies two of its arguments to yield an (n ' 1)-place verb.Combinators were also heavily used in the unpublished but widely known semanticsfor a large fragment of English of Parsons (1972), but then were not reintroduced intoformal semantics until the resurgence of categorial grammar in the 1980s (Bach, 1984;Zwarts, 1986; Oehrle, Bach and Wheeler (eds), 1988).

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 70 — #70
70 Handbook of Logic and Language
The recent work on pronouns as combinators raises the possibility of a “variable-free syntax” and the possibility of giving a compositional analysis of natural languageswithout requiring indices or variables as part of the natural language, hence the possi-bility of respecting what Partee (1979b) called the “well-formedness constraint” to agreater extent than previously imagined by most investigators. Advances in this direc-tion are always welcome as support for the hypothesis that natural languages “weartheir logical forms on their sleeve”, i.e. that the actual syntactic structures of natu-ral languages are well-designed vehicles for expressing their semantic content. (Thishypothesis corresponds to a methodological principle: whenever the interpretation of acertain construction seems to require some transformation of the independently moti-vated syntactic structure into some differently structured “logical form”, keep lookingfor different ways of assigning meanings to the parts or different semantic operationsfor putting meanings together in hopes of finding a way of interpreting the given syn-tactic structure more directly.)
1.4.4 Type Theory, Ontology, Theoretical Foundations
In this section we briefly review a few of the developments and controversial issuesthat have emerged in extensions of and reactions to Montague’s work that bear onsome of the more general features of Montague’s framework. Many of these concernthe choice of type theory and the generalizations concerning the type structure of nat-ural languages. Some concern such foundational questions as the choice between settheory and some version of property theory at the very foundations of the formal sys-tem and the perennial issue of the epistemological relation of the language user to thelanguage and to its grammar.
1.4.4.1 Basic Ontology, Basic Types, Philosophical Underpinnings
It was noted above in Section 1.3.3 that various cross-categorial constructions seem torequire that however one interprets the domain corresponding to the type of sentences,that domain should form a Boolean algebra (or some relevantly similar structure: per-haps lattices or semilattices would suffice; and it is also possible to work with a domainthat is not itself a Boolean algebra but has a Boolean algebra lurking somewhere withinit, e.g., a domain of functions whose range (codomain) is such an algebra). There area variety of possible choices that can be and have been made for the model-theoreticdomain corresponding to the basic type t in a Montague semantics. On the extensionalside, the simplest choice is the two-element set of truth values; this is the domain cor-responding to extensions of expressions of type t in PTQ. Another extensional choiceis the set of sets of assignment functions: the extension of an expression of type twould then be the set of all assignments that satisfy it. (Such a choice relates to earlierwork on the semantics of variables and variable-binding operators that interprets themin terms of cylindric algebras; see Janssen, 1986a.) There also exist various proposalsfor countenancing domains of more than two “truth values”, although there are dis-putes over whether those values should be called truth values; in any case, whether

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 71 — #71
Montague Grammar 71
entertained in the context of considerations of presuppositionality or in the context ofconsiderations of vagueness or “fuzziness”, or in other contexts, it makes a big dif-ference whether the domain in question is “Boolean-valued” or not; as long as it is,the extensions to cross-categorial versions of conjunction, quantification, etc. can becarried out straightforwardly by the kinds of pointwise lifting techniques described byGazdar (1980), Partee and Rooth (1983), etc. and the arguments of Keenan and Faltz(1985) for seeing pervasive Boolean structure in natural language can be respected.44
It is equally common to take the extension of sentences to be an “intensional object”such as a proposition.45 Montague in EFL, as noted earlier, took the extensions of sen-tences to be propositions, analyzed as functions from possible worlds to truth valuesand Cresswell did similarly (Cresswell, 1973) (which also contains more explicit dis-cussion of underlying ontological issues than is found in Montague’s papers). It wasalso noted by Montague and others that one can generalize that notion and analyzepropositions as functions from some richer “indices” that include not only possibleworlds but times and perhaps other parameters of evaluation.
In early situation semantics as developed by Barwise and Perry, the basic semantictype of sentences was defined in terms of situations and/or “situation types”. Barwise(1981) and Barwise and Perry (1983) argued that the use of possible worlds in tradi-tional theories of meaning leads to a notion of intension that is too coarse-grained foradequately representing the meanings of sentences reporting propositional attitudesand neutral perceptions. For example, the sentences (52) and (53) are wrongly pre-dicted to express the same proposition.
(52) Mary sees John walk.
(53) Mary sees John walk and Bill talk or not talk.
Accordingly, Barwise and Perry replace the concept of a possible world with that ofa situation in their own theory of situation semantics. Barwise and Perry’s challenge topossible world semantics is taken up by Muskens (1989), who shows that Montaguegrammar can be specified in terms of a relational formulation of the theory of typesas given in Orey (1959) and that, moreover, this relational theory can serve as thebasis of a partialization (i.e. technically, a four-valued generalization) which yieldspartially specified possible situations instead of completely defined possible worlds.
44 For explicit arguments against the idea of letting “truth values” be elements of some linear scale such asreal numbers in the interval [0, 1] as proposed in classic versions of fuzzy logic, see Kamp and Partee(1995).
45 This is not a contradiction, although on some sloppy uses of the vocabulary of intensionality, includingby the present author, it might seem to be. When we spoke above of verbs like seek taking intensions asarguments, that was an oversimplified way of speaking; the potential for confusion comes from the factthat in Montague’s intensional logic, the extension of an expression of the form $! is the same as theintension of the expression ! and it is common but sloppy practice to call $! itself (both the expressionand its interpretation) “the intension of !”. Speaking more accurately takes a lot more words and thereis no standardized non-sloppy shorthand terminology. But it is reasonable to call the PTQ extension ofexpressions of type "s, t# “intensional objects” and to use that term for any model-theoretic object whichconsists of a function from possible worlds to something.

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 72 — #72
72 Handbook of Logic and Language
The ensuing finer-grained notion of entailment can be put to use in an adequate accountof the semantic phenomena brought up by Barwise and Perry.
The ontological status of Barwise and Perry’s notion of situations and situationtypes became a matter of some controversy, especially with respect to those authors’avoidance of possible worlds or possible situations. Subsequent work by Kratzer andby some of her students has developed the possibility of letting situations, construedas parts of worlds, function both as individuals (analogous to events, playing a directrole in the interpretation of event nominals, for instance) and as “world-like” in thatpropositions are reinterpreted as sets of possible situations and expressions are eval-uated at situations rather than at world-time pairs (e.g., see Berman, 1987; Kratzer,1989, 1995a; Portner, 1992; Zucchi, 1989). The rich research opened up by this devel-opment may shed light not only on the linguistic constructions under study but onproperties of cognitive structurings of ontological domains which play a central rolein human thought and language.
Attention to demonstratives, indexicals and other aspects of context has ledresearchers to at least two different strategies of enrichment of the type structure.One strategy, illustrated in Lewis (1970), is to enrich the “indices” to include notonly possible worlds and times, but a speaker, a place of utterance and other contex-tual elements; Cresswell (1973) argues that there is no finite limit to the number ofsuch elements that might be needed and so something like a single “context property”should be posited for that role. The other strategy, illustrated in Kaplan (1979) anddeveloped as an extension of Montague grammar by Bennett (1978) (foreshadowedin Montague’s UG and with similar proposals further developed in Stalnaker (1974,1978)), is to distinguish “character” from “content”, character capturing what differ-ent occurrences of a sentence like I am here share in common and “content” beingthe proposition (the intensional object) expressed by a given use of such a sentencein a given context. Characters are thus analyzed as functions from possible contextsof use to contents, which themselves are functions from indices of evaluation (e.g.,world-time pairs) to truth values. See Lewis (1974) for further discussion of variouspermutations of such choices.
There are doubtless other choices possible for the basic semantic type of sentences;a rich variety of kinds of choices can be found in the literature on the formal seman-tics of programming languages, where special purposes may dictate specific sorts ofsemantic values and the commonalities of structural or algebraic properties acrossdifferent choices become even more apparent. The type structure underlying various“dynamic” approaches is not reflected in the brief set of alternatives surveyed above,nor are the possibilities offered by replacing the background set theory by propertytheory (see Section 1.4.4.2 below).
Montague worked in a tradition in which linguistic objects were abstract objectsand the basic conception was Platonistic, following Frege. As noted earlier, the ques-tion of “psychological reality” was not central in that tradition, particularly if for-mal languages and natural languages were being subsumed under a single largercategory, as in Montague’s work. The most explicit statement of the relation of alanguage to its users on such a conception is probably that found in the work of

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 73 — #73
Montague Grammar 73
David Lewis (1969, 1975b), where a clear distinction is drawn between the inves-tigation of a language as an abstract object and the investigation of the nature of theconventions of language users that form the basis for a claim that a particular languageis the language of a given person or a given language community.
Nevertheless, it is of course to be expected that other researchers sympathetic tomany of the goals and methods of Montague grammar or related work in formalsemantics might prefer to investigate different kinds of foundations and that in somecases this might lead to differences in semantic analysis. One good example is theData Semantics of Frank Veltman (Veltman, 1981, 1985a,b) or its successor theoryUpdate Semantics (Veltman, 1990), in which the epistemological relation of a speakerto her language and to her constantly changing “information state” is central. Thechange in philosophical underpinnings leads to changes in the semantics of modalverbs, of negation and of various other constructions. Ramifications for the interpreta-tion of noun phrases as “partial objects” are explored in Landman (1986). The dynamicapproach of Groenendijk and Stokhof (1990, 1991) draws together some of the moti-vations for Heim’s and Kamp’s “meanings as context-change potential” and Veltman’sepistemological perspective.
Linguists in the generative grammar tradition following the seminal work ofChomsky (1957, 1965) generally share his concern with locating grammars in theheads of language users; some of the difficulties of combining such a view witha possible-worlds semantics like Montague’s are explored in Partee (1979c, 1980,1982), with some summary of the issues and of varieties of views about the natureof semantics in Partee (1989a). The viability of such an integration is challenged inSchiffer (1987), to which Partee (1988) is a disagreeing reply. See also Soames (1987).The nature of intensionality is a constant issue in such discussions.
1.4.4.2 Property Theory vs. Set Theory as Metalevel Theoretical Basis
Some philosophers still seriously defend the claim that intensions (truth conditions)adequately individuate propositions; most philosophers and linguists reject the ideathat any two logically equivalent sentences express the same proposition, at least ifpropositions are to be, among other things, the objects of the propositional attitudes.Montague acknowledged the initially counterintuitive nature of that consequence ofhis treatment of belief as a relation between persons and propositions and the givenanalysis of propositions. In EFL he characterizes it as a conclusion he believes weshould accept, pointing to discussion in Montague (1970a). Some of the most thought-ful defenses of a truth-conditional notion of proposition can be found in the work ofStalnaker (see Stalnaker, 1976, 1984).
One foundational development which could have a profound impact on this peren-nial problem and on the analysis of intensionality is the recent working out of severalversions of property theory as candidate replacements for set theory in the foundationsof formal semantics. The principal difference between all versions of set theory andall versions of property theory is the presence vs. absence of the axiom of extension-ality. That axiom of set theory says that any two sets that contain exactly the same

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 74 — #74
74 Handbook of Logic and Language
members are the same set. The absence of such an axiom in property theory allowsdistinct properties to apply to exactly the same individuals.
When set theory is given a foundational role in the reconstruction of mathematicsand logic, as has been standard since the Principia (Russell and Whitehead, 1913), theaxiom of extensionality has many repercussions. One result of extensionality is thatwhen functions are reconstructed in set-theoretic terms, any two functions that haveexactly the same set of input-output pairs (the same graph) are the same function. Itmay be argued that this is not a property of the working mathematician’s notion offunction; Moschovakis (1985) explores the possibility of a suitably intensional notionof function somewhere between the extensional standard notion and the very procedu-ral notion of algorithm. In any case, with the standard extensional notion of function inthe foundations that Montague (following common practice in logic and model theory)worked with, it followed that if propositions are analyzed as functions from possibleworlds to truth values, then any two truth-conditionally equivalent propositions areanalyzed as the same proposition.
But if one could replace set theory by a suitable property theory in the foundations(for various proposals, see Bealer, 1982; Chierchia and Turner, 1988; Cocchiarella,1985; Jubien, 1985; Turner, 1987, 1989), then functions could be reconstructed as aspecies of relations-in-intension rather than as relations-in-extension, and propositionscould be analyzed as functions from possible worlds to truth values without treatingas identical all functions that happen to give the same values. That is, the analysis ofpropositions as functions from possible worlds (or possible situations) to truth valuesis not necessarily the culprit in giving us an insufficiently intensional notion of propo-sition; the fault may lie in the overly extensional notion of function we have beenworking with.
Other suggested solutions to the problem of an insufficient notion of intensionalityhave mostly involved trying to find ways to make meanings more “fine-grained”, usu-ally by adding some element of syntactic part-whole analysis to the truth-conditionalcontent as standardly characterized. See the “constructions” of Tichý (1988), the“structured meanings” of David Lewis (1970) and the further development of thestructured meanings approach of Cresswell and von Stechow (1982), von Stechow(1984), Cresswell (1985), among others. Other approaches treat propositional attitudesmore like quotational contexts, sensitive to the linguistic form as well as the semanticcontent of their argument expressions. But the issues are large and have philosophicalas well as semantic consequences and there is not space for a serious discussion ofthem here.
The possibility of a shift from set theory to property theory could have conse-quences for other parts of the semantics as well as for the basic analysis of inten-sionality. Chierchia (1982, 1985) and Chierchia and Turner (1988) explore the use ofproperty theory in the analysis of nominalizations, exploiting the fact that propertiesmay hold of themselves without the problem of paradox. There are a number of placeswhere the imposition of a rigid type theory causes problems for the analysis of naturallanguage, including the necessity to assign possibly infinitely many different types toa single expression like “has a property” (see Parsons, 1979).

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 75 — #75
Montague Grammar 75
1.4.4.3 Type Shifting, Coercion, Flexibility
The type theory which Montague used in his intensional logic and indirectly or directlyin the semantics of all three fragments was not an essential consequence of his generaltheory in Universal Grammar. Having some type theory is essential to that theory, butthe range of kinds of type theories that are compatible with the principal constraints ofMontague grammar has not been explored nearly as far as it could be. For that matter,the general theory permits having a trivial type theory with only one type.
Imposing a strong type theory on a semantics offers both advantages and disad-vantages as a working methodology. Advantages include the explicitness of checkingwell-formedness of function-argument structure; without the discipline of type theory,it is easy to write down expressions that turn out to be difficult to interpret coherently.Type theory can also offer interesting perspectives on the correspondence betweensyntax and semantics, as witnessed in the renewal of active research in categorialgrammar, a framework which takes type theory into its syntax even more systemat-ically than Montague did in PTQ, where the syntactic categories are inspired by thework of Ajdukiewicz (1935), but the syntactic rules are much less constrained than inany systematic version of categorial grammar. Disadvantages come from the apparentgreat flexibility of natural language expressions to occur in a variety of types. Moregenerally, it is not yet clear that natural languages really are as strongly typed as astrict type theory like Montague’s would require. But as with other strong constraintsof Montague’s, trying to work within them is probably the best way to find out whetherthey are in the end reasonable or not.
Thus we saw above that in choosing semantic types corresponding to syntactic cate-gories, Montague required that every category be associated with a single type, so thatthe interpretation of an expression of a category is always of the unique type assignedto that category. As a consequence, a strategy of “generalizing to the worst case”must be adopted: all expressions of a certain syntactic category have to be uniformlyassigned an interpretation of the most complex type needed for some expression inthat category and meaning postulates are necessary for guaranteeing that the “sim-pler” cases are indeed simpler. The latter means that this rigid category-type assign-ment entails a possible distortion of the semantics – a distortion which, as Bach (1980)argues, had not yet reached its full extent with PTQ. In itself, such a complication isnot necessarily a defect, provided that it serves the empirical adequacy of the theory.But there is some evidence that Montague’s strategy of generalizing to the worst casecannot be pursued successfully.
This has been claimed by, among others, Partee and Rooth (1983), whose startingpoint is a generalized, cross-categorial semantics for coordination by means of andand or (due to Gazdar, 1980; Keenan and Faltz, 1985; von Stechow, 1974), whichis based on the set of “conjoinable types”, i.e. the smallest set that contains the typeof truth values as well as all types of functions from entities of some type to entitiesof a conjoinable type.46 In consideration of the interpretation of sentences involving
46 Note that the domain of the type of truth values constitutes a Boolean algebra. Hence all conjoinabletypes have domains that are Boolean algebras (cf. Keenan and Faltz, 1985).

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 76 — #76
76 Handbook of Logic and Language
the coordination of extensional and intensional transitive and intransitive verbs, Par-tee and Rooth conclude that Montague’s strategy should be given up. Instead, theyenter each expression lexically in its minimal type and let type-shifting rules furnisha higher-type homonym for lower-type expressions. In addition, a coercion princi-ple ensures that all expressions are interpreted at the lowest type possible, invokinghigher-type homonyms only when needed for type coherence: “try simplest typesfirst”. This is a reversal of Montague’s strategy in the sense that the generalizationis to the “best case” on the lexical level. Moreover, although there is still a “worstcase” (most general case) in this set-up, one does not uniformly generalize to it, onaccount of the coercion principle.
The purpose of the coercion principle is the prevention of undesired readings, but,as Partee and Rooth note, it also precludes a use of type-shifting rules for the represen-tation of ambiguities. They discuss an interesting example: the so-called de dicto widescope-or reading of sentence (54), which is suggested by the continuation “. . . but Idon’t know which” and which is not accounted for in the PTQ fragment.47
(54) The department is looking for a phonologist or a phonetician.
Groenendijk and Stokhof (1984, 1989) argue that type-shifting rules are useful inthe semantic description of various constructions involving interrogatives. They showthat an extension of Partee and Rooth’s rules to other categories allows for a represen-tation of desired readings, and, furthermore, that certain intuitive entailments between(coordinated) interrogatives48 can only be accounted for if it is assumed that a type-shifting rule admits of interpretations of interrogatives in higher types than their basictype. On the other hand, the basic type is needed as well, viz., for entailments betweenatomic interrogatives. Accordingly, Groenendijk and Stokhof liberalize interpretationof syntactic structures to a relation: coercion is replaced by the principle “anythinggoes that fits”.
In order to be able to account for ambiguities by means of type-shifting rules,this principle of the survival of the fitting is also adopted in the fully explicit frag-ment of “flexible Montague grammar” of Hendriks (1988, 1993), where Montague’sstrategy of generalizing to the worst case fails, though for a different reason thanin the grammar of Partee and Rooth. It fails, not because the worst case cannotalways be generalized to, but simply because there is no such case. Expressions areassigned interpretation sets consisting of basic interpretations plus derived interpreta-tions. Every lexical expression is assigned a “best case” basic interpretation of the min-imal type available for that particular expression and generalized syntactic/semanticrules permit the compounding of all “mutually fitting” interpretations of constituentparts into basic translations of compound expressions. The derived interpretations
47 A sketch of an alternative treatment of wide scope-or along the lines of Kamp (1981) and Heim (1982,1983) is given in Rooth and Partee (1982).
48 Using a generalized notion of entailment according to which an interrogative A entails an interrogative Bjust in case every complete and true answer to A is a complete and true answer to B, so that a conjunctionentails its conjuncts and a disjunction is entailed by its disjuncts.

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 77 — #77
Montague Grammar 77
are obtained by closing the set of basic interpretations under the generalized type-shifting rules of value raising, argument raising and argument lowering. The recursivenature of these rules precludes the existence of “worst case” interpretations. De dictowide scope-or readings of increasingly complex sentences are adduced as evidence indefense of this feature. As noted, the type-shifting rules of Partee and Rooth (1983)can be used to represent some of these readings. In addition, the generalized rulesare argued to yield a general account of natural language scope ambiguities that arisein the presence of quantifying and coordinating expressions: the fragment representscoordination scope ambiguities beyond the reach of the original rules, and also thequantifier scope ambiguities and de dicto/de re ambiguities that gave rise to the ruleof Quantifying In, as well as their mutual interactions.
Flexible type-assignment has been argued to lead to a more adequate division oflabor between the syntactic and the semantic component, in that it eliminates theneed for the arguably unintuitive syntactic and semantic devices of Quantifying Inand Cooper storage for the representation of scope ambiguities. The representation ofanaphoric pronouns, the second aspect of Quantifying In (and of Cooper storage), isalso addressed by a flexible set-up: a flexible grammar which handles both anaphoraand scope ambiguities is obtained by adding the generalized type-shifting mecha-nism to – a “best case” version of – the “dynamic Montague grammar” (DMG) ofGroenendijk and Stokhof (1990). An interesting contribution in this respect is Dekker(1990, 1993). Focusing on the notion of negation in a dynamic Montague grammar,Dekker concludes that sentences should be assigned interpretations of a higher typethan the type of sets of propositions, the type assigned to sentence interpretations inDMG. This claim is substantiated in the guise of a structural, conservative modifi-cation of DMG into the system DMG(2), where sentences are interpreted as gene-ralized quantifiers over propositions. Dekker shows that the DMG(2)-style dynamicinterpretations of expressions can actually be obtained in a systematic way from sim-ple static interpretations, viz., by employing the generalized type-shifting system offlexible Montague grammar. The resulting flexible dynamic Montague grammar isshown to apply to an interesting range of examples that exhibit puzzling and complexanaphoric dependencies.
Partee (1987) employs type-shifting principles in an attempt to resolve the apparentconflict between Montague’s uniform treatment of NPs as generalized quantifiers andapproaches such as those of Kamp (1981) and Heim (1982, 1983), which distinguishamong referring, predicative and quantificational NPs. In addition, it is shown thatthe availability of language-specific and universal type-shifting principles suggests anew perspective on the copula be and the determiners a and the, that may offer somehelp in explaining why certain semantic “functors” may be encoded either lexically orgrammatically, or may not be explicitly marked at all in different natural languages. Inthis perspective, the meaning of English be is basically “Predicate!”, as in (22) above,and Montague’s meaning can be reconstructed as the result of subjecting this basicmeaning to a type-shifting operation that provides predicate meanings for full termphrases. Type-shifting principles are also invoked cross-linguistically in the semantictheory of Bittner (1994). Some versions of categorial grammar make very heavy use

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 78 — #78
78 Handbook of Logic and Language
of type-shifting operations in interesting explanations of subtle linguistic phenomenain terms of the possibilities allowed (see Chapter 2 on Categorial Type Logics in thisHandbook).
Does formal semantics necessarily require attention to type theory? Not intrinsi-cally, since one could have a trivial type theory with only one type. But most work sofar has worked within some well-defined type theory and the results have been fruitful.It seems more likely that future work will see the enrichment of type theory and/or theaddition of more attention to possibly cross-classifying sortal distinctions in additionto type distinctions, rather than the abandonment of type theory. See Chapters 2 and11 on Categorial Type Logics and Types for more on these topics.
1.4.5 Context Dependence and Context Change
As noted in Sections 1.4.2.2, 1.4.3.4 and 1.4.4.1 above, one of the major changes sinceMontague’s work has been increased integration of context dependence and context-change potential into semantics. Montague helped to lay the foundations for thesedevelopments in his own work on formal pragmatics, which were further advanced byDavid Kaplan’s seminal work on demonstratives, developed in a Montague grammarframework by Bennett (1978), and by Stalnaker’s work on many issues at the bor-derline of semantics and pragmatics. The term “pragmatics” is becoming increasinglydifficult to define as a consequence, since it had its origins as part of a partition ofsemiotics into syntax, semantics and pragmatics, and the line between the latter two isshifting in ways that make earlier definitions obsolete and new ones not yet stable.
From this perspective the Kamp–Heim theories brought with them important fun-damental innovations, most centrally in the intimate integration of context dependenceand context change in the recursive semantics of natural language. A related importantinnovation was Heim’s successful formal integration of Stalnaker’s (1978) context-change analysis of assertion with Karttunen’s (1975) discourse-referent analysis ofindefinite NPs.
Kamp’s and Heim’s work has led to a great deal of further research, applying itto other phenomena, extending and refining it in various directions and challengingit (see Chapter 3). Heim herself has been one of the challengers, arguing for arevival of a modified version of Evans’s (1980) “E-type pronouns” in Heim (1990),discussed further in Section 1.4.3 above. One line of research concerns the interactionof quantification and context-dependence, starting from the observation of Mitchell(1986) that open-class context-dependent predicates such as local and enemy behavelike bound variables in that they can anchor not only to utterance contexts and con-structed discourse contexts but also to “quantified contexts” as discussed in Partee(1989b).
There is still a need for a great deal more research on the linguistically significantstructuring of various aspects of “context”, and on the relationships among contextsof different sorts: the context of the speech act, narrative context in both fiction andordinary dialog and the very local context of a word within larger phrases. Here toothere is a great deal of insightful work in other traditions that needs to be integrated

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 79 — #79
Montague Grammar 79
with the approaches of formal semantics. What aspects of context should be reflectedin the type structure of natural languages, if meanings are to be functions from con-texts to contexts, is a major theoretical open issue, with ramifications for questions of“modularity” in the realm of semantics and pragmatics.
1.4.6 Typology and Natural Language Metaphysics
Early work on Montague grammar focused largely on English. As with other kinds oflinguistic research, attention to typologically diverse languages, now that it has gottenwell underway, has been of great mutual benefit for the understanding of the semanticsof those languages and for the development of semantic theory.
Montague himself speculated about the potential benefit for typological studies ofa powerful formal semantic theory. Here is what he said on August 26, 1967:49
Perhaps the most important applications of a formal treatment [of natural languagealong Montague’s lines, that is – Th. E. Z.] will occur in the realm of prehistory.Indeed, certain pairs of natural languages, hitherto, on the basis of relatively super-ficial criteria, considered unrelated, appear now to exhibit identical idiosyncrasiesin very basic formal features; it would be difficult to account for these similaritiesexcept on the hypothesis of a common origin or very early, as yet unsuspected, histor-ical interaction.
But that speculation (“wild” speculation, some would undoubtedly say) was neverfollowed up on, as far as we know.
More seriously: given that Montague grammar offers semantic tools that in manycases remove the need for “abstract syntax”, it offers the potential for describing eachlanguage more “on its own terms” than do theories that posit a more nearly universallevel of semantic representation and a more indirect relation between syntactic struc-tures and semantic representations, e.g., via a transformational mapping. It thus hasbecome an interesting and important enterprise to figure out such things as the seman-tics of noun phrases in languages which lack articles; the semantics of tense and aspectin languages which mark more or fewer or very different distinctions from English;the difference, if any, between the semantics (and pragmatics) of focus in languageswhich mark focus principally by word order, languages which mark it by intonationalprominence and languages which mark it with a specific syntactic position.
An early effort in this direction was the work of Stein (1981) on the semanticsof Thai noun phrases. Thai is a classifier language that does not grammatically distin-guish count/mass or singular/plural. Most of the earlier philosophical treatments of thesemantics of mass nouns had presupposed that count nouns are more basic and betterunderstood; this may have been yet another legacy of the virtually universal adoptionof set theory (rather than some mereological system) as a metalanguage. It provedvery difficult to construct on such a basis a semantics for Thai that faithfully reflec-ted the lack of a count/mass distinction and made that seem “natural”. Only after the
49 Thanks to Ede Zimmermann for this quotation from Staal (ed.) (1969).

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 80 — #80
80 Handbook of Logic and Language
introduction of Link’s algebraic structuring of the entity domain (Link, 1983) did itbecome straightforward to view “mass” as the unmarked member of the mass/countopposition (see Section 1.4.2.1 above).
Such work falls in the realm of what Bach (1986a) called “natural languagemetaphysics”, characterizing a linguistic concern which may or may not be distinctfrom metaphysics as a field of philosophy: that is a controversy among philosophersthemselves (see Peregrin, 1995). Metaphysics is concerned with what there is and thestructure of what there is; natural language metaphysics, Bach proposes, is concernednot with those questions in their pure form, but with the question of what metaphysicalassumptions, if any, are presupposed by the semantics of natural languages (individu-ally and universally). In the domain of time, one can ask whether a tense and aspectsystem requires any assumptions about whether time is discrete or continuous, whetherinstants, intervals, or events are basic, whether the same “time line” must exist in everypossible world, etc.
Link’s work opened up interesting avenues of research in this area, suggesting theexploration of algebraically characterizable structures in various domains, structuresthat might differ from language to language. Bach (1986b) extended Link’s algebra ofmass and count domains to an algebra of processes and events and others have begunto explore how the relation between the semantics of noun phrases and the semanticsof verb phrases and event expressions might be interestingly and differently connectedin different languages (see Filip, 1992, 1993; Krifka, 1986, 1987).
Not surprisingly, since quantification has been the object of so much attention byformal semanticists, typological perspectives have become important in recent work.Bach, Kratzer and Partee (1989) hypothesized that adverbial quantification might bemore widespread linguistically than the familiar noun phrase quantification of Englishdescribed in PTQ; that hypothesis was confirmed first by Jelinek (1995), who showedthat Straits Salish does not have noun phrases that are analyzed as generalized quan-tifiers. That and further typological issues are explored and richly illustrated in thecollection Bach, Jelinek, Kratzer and Partee (1995).
Thematic roles and the structuring of lexical domains into semantic subclasses ofvarious kinds is another area that is growing in importance and one where there isinteresting potential for contact and mutual enrichment between formal semantics andother theories which have devoted much more attention to the structuring of lexicalmeanings (see Chierchia, 1984a; Dowty, 1979; Partee, 1995).
1.4.7 The Naturalization of Formal Semantics and Montague’s Legacy
As formal semantics has come to be integrated more centrally into linguistic theory,especially in the United States, there has been a strong push to “naturalize” formalsemantics (Partee, 1992). Whereas in the beginning, linguists were largely “con-sumers” of theories and formal tools developed by logicians and philosophers, nowthere is a much more symmetrical relationship, with linguists contributing activelyto the specification of the properties an adequate theory of natural language semanticsmust have and to the development of such theories. These developments are beginning

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 81 — #81
Montague Grammar 81
to have repercussions back into philosophy and logic and potentially on the design ofartificial languages for computational purposes, as evidenced in diverse ways in thearticles of this Handbook.
Within and around the field of formal semantics, there is currently a great deal ofdiversity, as the foregoing discussion and other articles in this Handbook makes clear.At the same time, there is a sense of community among researchers working on formalsemantics in different ways and from different disciplinary perspectives. Part of whatmakes discussion and debate possible and fruitful across considerable diversity is theexistence of a common reference point, Montague Grammar, serving as a backgroundand baseline for much of the work that has followed. No one of its properties is univer-sally accepted by people who would be willing to identify themselves as doing formalsemantics or model-theoretic semantics or “post-Montague” semantics, but there is ashared sense that Montague’s work represented a fundamental advance, opening upnew possibilities and setting new standards for the analysis of the semantics of nat-ural languages, for linguistics as well as for philosophy. Montague’s legacy enduresin the continuing centrality of his theoretical contributions and the influence of hisparticular proposals about the semantics of natural language and probably even morestrongly in harder-to-define ways that may be considered methodological, as reflec-ted above in the discussion of compositionality, as well as in the mutual influences oflinguists, philosophers and logicians on each other’s thinking about semantics. Whilefew would claim that the analysis of truth conditions (or context-change potential)exhausts the study of meaning, or that the tools of formal semantics can solve allof the linguistically interesting problems in semantics, the fruitfulness of research inMontague grammar and related theories has shown convincingly that this domain is arobust one and that the kind of approach which Montague illustrated so masterfully inhis work has not come close to exhausting its potential usefulness for understandingnatural language semantics and its relation to syntax.
Acknowledgments
There are several people whose help was crucial in the writing of this chapter, and to whom Iam immensely grateful.
Theo Janssen was both an inspiration and a source of help of many kinds from the earli-est conception of this project to its completion. Theo’s own writings on Montague grammar,both technical and pedagogical, were among my principal starting points. And Theo, alongwith Alice ter Meulen, was persistent in encouraging me to keep trying to find time towrite the chapter long after several initial deadlines had passed, encouragement that kept mefrom giving up on the project altogether. And when I was finally able to get down to thewriting, in two major episodes separated by almost a year, Theo was always ready to pro-vide helpful references, discuss questions, and read drafts and offer comments. Theo’s verythoughtful and detailed comments on the penultimate draft were the principal basis for thefinal revisions. And not least, Theo’s enthusiastic reaction to the first draft was one of thebiggest emotional supports that kept me going through times when I feared I would neverfinish.

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 82 — #82
82 Handbook of Logic and Language
Emmon Bach read more successive drafts of this chapter than anyone else, and made manysuggestions, from global organizational strategy to detailed comments on specific points, whichled to a great many improvements and often helped me see the forest when I was in danger ofbeing overwhelmed by the trees. I was fortunate to have the benefit of his excellent judgmentabout both the subject matter and how to write about it.
I also want to use this occasion to thank Herman Hendriks and comment on our non-standardsemi-co-author status. It should be clear that I (BHP) am the principal author, responsible forchoice and organization of content and for most of the writing; and wherever there is a detectable“authorial voice”, it is mine. On the other hand, Herman’s help was crucial and substantial. Hedid the writing of substantial parts of two subsections, 4.2.3. and 4.4.3; and he did a great dealof work, often at short notice and under great time pressure, with things that were crucial forpulling the chapter into final shape – not only did he catch and correct a number of potentialerrors in content and infelicities in expression, but he did all the work of putting the manuscriptinto LATEX, including getting the formulas, the example numberings and the footnotes straight.He also did a very large amount of work on the bibliography, and provided other help at varioustimes with reference searches, cross-references to other chapters, and proofreading. I suggested,and the editors of the volume agreed, that Herman deserved more than a mention in the acknowl-edgements, but that he was not a co-author in the standard sense. So we have appropriated the“with” that one sometimes finds, for instance, in a book written by a rock star “with” the helpof a real writer. We don’t pretend to be a rock star or a real writer respectively, but that “with”trick seems to fit here too.
Another crucial figure in the passage from possibility to actuality of this chapter was Aliceter Meulen. Alice was the one who really refused to give up on this chapter, and she has masteredthe art of constructive nagging. She was always patient but persistent, ready with great positivefeedback at any signs of life, and most importantly, constantly involved in the substance of thework. Alice and Johan van Benthem together did an excellent job of keeping authors informedabout the potential relationships among the various chapters as the authors and commentatorswent through the many stages of planning and writing and commenting and revising. Alice wasthe shepherd for this chapter, and she made invaluable comments and suggestions at every stagefrom conception to final draft, and helped to coordinate communication with Herman and Theoas well. She is responsible for many improvements in the chapter as well as for making surethat we actually completed it.
All of the above helped to provide references when I needed help, which was often, sincemost of the writing was done while on sabbatical in northern British Columbia, away fromany major research university or university library. For additional help in tracking down refe-rences, I am very grateful to Ede Zimmermann, Reinhard Muskens, Terry Parsons, and NinoCocchiarella.
All of the many colleagues and students who were thanked in my earlier writings on Mon-tague Grammar starting in the early 1970s should be thanked here too; they are too many tolist, but they all helped to shape my understanding of Montague’s work and of its potentialusefulness for thinking about linguistic problems.
A few sections of this chapter overlap in content with some sections of the chapter “Thedevelopment of formal semantics in linguistic theory”, in Shalom Lappin (ed.), The Hand-book of Contemporary Semantic Theory, Blackwell Handbooks in Linguistics Series, Black-well, Oxford (1996), pp. 11–38.
Time to work was made available by a research leave from my department in the Fall of1994 and a sabbatical leave from the University of Massachusetts in the Spring of 1995. For the

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 83 — #83
Montague Grammar 83
most pleasant imaginable working environment as well as for his specific contributions to thechapter I am grateful to Emmon Bach, with thanks for inviting me to come with him to northernBritish Columbia, where the first substantial drafts were completed in the Fall 1994 semester,and the first near-complete draft was finished in the summer of 1995.
References
Ajdukiewicz, K., 1935. Die syntaktische Konnexität, Stud. Philos. 1, 1–27. Translated asSyntactic connexion, Polish Logic, McCall, S. (Ed.), 1967. Clarendon Press, Oxford,pp. 207–231.
Bach, E., 1968. Nouns and noun phrases, in: Bach, E., Harms, R.T. (Eds.), Universals inLinguistic Theory. Holt, Rinehart and Winston, New York, pp. 91–124.
Bach, E., 1976. An extension of classical transformational grammar, in: Saenz, R. (Ed.),Problems of Linguistic Metatheory, Proceedings of the 1976 Conference, Michigan StateUniversity, Michigan, MI, pp. 183–224.
Bach, E., 1979a. Control in Montague grammar. Ling. Inq. 10, 515–531.Bach, E., 1979b. Montague grammar and classical transformational grammar, in: Davis, S.,
Mithun, M. (Eds.), Linguistics, Philosophy, and Montague grammar. University of TexasPress, Austin, TX.
Bach, E., 1980. Tenses and aspects as functions on verb-phrases, in: Rohrer, C. (Ed.), Time,Tense and Quantifiers, Max Niemeyer, Tübingen, pp. 19–37.
Bach, E., 1981. On time, tense and aspect: an essay in English metaphysics, in: Cole, P. (Ed.),Radical Pragmatics. Academic Press, New York, pp. 62–81.
Bach, E., 1984. Some generalizations of categorial grammars, in: Landman, F., Veltman, F.(Eds.), Varieties of Formal Semantics. Foris, Dordrecht, pp. 1–24.
Bach, E., 1986a. Natural language metaphysics, in: Marcus, R.B., Dorn, G.J.W., Weingartner, P.(Eds.), Logic, Methodology and Philosophy of Science VII. North-Holland, Amsterdam,pp. 573–595.
Bach, E., 1986b. The algebra of events. Ling. Philos. 9, 5–15.Bach, E., 1989. Informal Lectures on Formal Semantics. State University of New York Press,
Albany, NY.Bach, E., Cooper, R., 1978. The NP-S analysis of relative clauses and compositional semantics,
Ling. Philos. 2, 145–150.Bach, E., Jelinek, E., Kratzer, A., Partee, B.H. (Eds.), 1995. Quantification in Natural
Languages. Kluwer, Dordrecht.Bach, E., Kratzer, A., Partee, B.H. (Eds.), 1989. Papers in Quantification: Report to NSF.
Linguistics Department, University of Massachusetts, Amherst, MA.Bach, E., Partee, B.H., 1980. Anaphora and semantic structure, in: Kreiman, J., Ojeda, A. (Eds.),
Papers from the Parasession on Pronouns and Anaphora. Chicago Linguistic Society,Chicago, IL, pp. 1–28.
Baker, C.L., 1966. Definiteness and Indefiniteness in English. Unpublished Master’s Thesis,University of Illinois, Chicago, IL.
Bar-Hillel, Y., 1954. Logical syntax and semantics. Language 30, 230–237.Barwise, J., 1981. Scenes and other situations. J. Philos. 78, 369–397.Barwise, J., Cooper, R., 1981. Generalized quantifiers and natural language. Ling. Philos. 4,
159–219.

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 84 — #84
84 Handbook of Logic and Language
Barwise, J., Perry, J., 1983. Situations and Attitudes. MIT Press, Cambridge, MA.Bealer, G., 1982. Quality and Concept. Clarendon Press, Oxford.Bennett, M., 1974. Some Extensions of a Montague Fragment of English. PhD Dissertation,
University of California at Los Angeles, Indiana University Linguistics Club, Blooming-ton, IN.
Bennett, M., 1978. Demonstratives and indexicals in Montague grammar. Synthese 39, 1–80.Berman, S., 1987. Situation-based semantics for adverbs of quantification, in: University of
Massachusetts Occasional Papers in Linguistics 1. University of Massachusetts, UmassGraduate Linguistics Students Association, Amherst, MA, 45–68.
Bittner, M., 1994. Cross-linguistic semantics. Ling. Philos. 17, 53–108.Carlson, G.N., 1983. Marking constituents, in: Heny, F., Richards, B. (Eds.), Linguistic Cate-
gories: Auxiliaries and Related Puzzles, vol. I: Categories. Reidel, Dordrecht.Carnap, R., 1947. Meaning and Necessity. A Study in Semantics and Modal Logic. Chicago
University Press, Chicago, IL.Carnap, R., 1952. Meaning postulates. Philos. Stud. 3, 65–73.Chellas, B., 1980. Modal Logic: An Introduction. Cambridge University Press, Cambridge, MA.Chierchia, G., 1982. Nominalization and Montague grammar. Ling. Philos. 5, 303–354.Chierchia, G., 1984a. Topics in the Syntax and Semantics of Infinitives and Gerunds. PhD Dis-
sertation, University of Massachusetts, Amherst, MA.Chierchia, G., 1984b. Anaphoric properties of infinitives and gerunds, in: Cobler, M., Mackaye,
S., Wescoat, M. (Eds.), Proceedings of the West Coast Conference on Formal Linguisticsvol. 3. Stanford Linguistics Association, Stanford University, Stanford, CA, pp. 28–39.
Chierchia, G., 1985. Formal semantics and the grammar of predication. Ling. Inq. 16, 417–443.Chierchia, G., 1993. Questions with quantifiers. Nat. Lang. Semant. 1, 181–234.Chierchia, G., 1995. Dynamics of Meaning. Anaphora, Presupposition and the Theory of Gram-
mar. University of Chicago Press, Chicago, IL and London.Chierchia, G., Jacobson, P., 1986. Local and long distance control, in: Berman, S., Choe, J.,
McConough, J. (Eds.), Papers from the Sixteenth Annual Meeting of the North EasternLinguistic Society. University of Massachusetts, Umass Graduate Linguistics StudentsAssociation, Amherst, MA.
Chierchia, G., Turner, R., 1988. Semantics and property theory. Ling. Philos. 11, 261–302.Chomsky, N., 1955. Logical syntax and semantics: their linguistic relevance. Language 31,
36–45.Chomsky, N., 1957. Syntactic Structures. Mouton, The Hague.Chomsky, N., 1965. Aspects of the Theory of Syntax. MIT Press, Cambridge, MA.Chomsky, N., 1975. Questions of form and interpretation. Ling. Anal. 1, 75–109. Also:
Austerlitz, R. (Ed.), The Scope of American Linguistics, Peter de Ridder Press, Lisse,pp. 159–196.
Church, A., 1951. A formulation of the logic of sense and denotation, in: Henle, P., Kallen,H., Langer, S. (Eds.), Structure, Method and Meaning: Essays in Honor of H.M. Sheffer.Liberal Arts Press, New York, pp. 3–24.
Cocchiarella, N. 1981. Richard Montague and the logical analysis of language, in: Fløistad,G. (Ed.), Contemporary Philosophy: A New Survey, vol. 2. Philosophy of Lan-guage/Philosophical Logic, Martinus Nijhoff, The Hague, pp. 113–155.
Cocchiarella, N., 1985. Frege’s double correlation thesis and Quine’s set-theories NF and ML.J. Philos. Logic 14, 1–39.

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 85 — #85
Montague Grammar 85
Cooper, R., 1975. Montague’s Semantic Theory and Transformational Syntax. PhD Disser-tation, University of Massachusetts, Umass Graduate Linguistics Students Association,Amherst, MA.
Cooper, R., 1979. The interpretation of pronouns, in: Heny, F., Schnelle, H. (Eds.), Syntax andSemantics 10. Selections from the Third Groningen Round Table. Academic Press, NewYork, pp. 61–92.
Cooper, R., 1983. Quantification and Syntactic Theory. Reidel, Dordrecht.Cooper, R., Parsons, T., 1976. Montague grammar, generative semantics and interpretive seman-
tics, in: Partee, B.H. (Ed.), Montague Grammar, Academic Press, New York, pp. 311–362.Cresswell, M.J., 1973. Logics and Languages. Methuen, London.Cresswell, M.J., 1985. Structured Meanings. MIT Press, Cambridge, MA.Cresswell, M.J., von Stechow, A., 1982. De re belief generalized. Ling. Philos. 5, 503–535.Dalrymple, M., Shieber, S.M., Pereira, F.C.N., 1991. Ellipsis and higher-order unification. Ling.
Philos. 14, 399–452.Davidson, D., 1967. The logical form of action sentences, in: Rescher, N. (Ed.), The Logic of
Decision and Action, University of Pittsburgh Press, Pittsburgh, pp. 81–95.Davidson, D., Harman, G.F. (Eds.), 1972. Semantics of Natural Language. Reidel, Dordrecht.Davis, S., Mithun, M. (Eds.), 1979. Linguistics, Philosophy and Montague Grammar. University
of Texas Press, Austin, TX.Dekker, P., 1990. The scope of negation in discourse. Towards a flexible dynamic Montague
grammar, in: Groenendijk, J., Stokhof, M., Beaver, D. (Eds.), Quantification and AnaphoraI. Esprit Basic Research Project 3175, Dynamic Interpretation of Natural Language,Dyana Deliverable R2.2A, pp. 79–134.
Dekker, P., 1993. Transsentential Meditations. Ups and Downs in Dynamic Semantics. PhDDissertation, ILLC Dissertation Series, University of Amsterdam.
Donnellan, K., 1966. Reference and definite descriptions. Philos. Rev. 75, 281–304.Dowty, D., 1978. Governed transformations as lexical rules in a Montague grammar. Ling. Inq.
9, 393–426.Dowty, D., 1979. Word Meaning and Montague Grammar. Reidel, Dordrecht.Dowty, D., 1982. Tenses, time adverbials and compositional semantic theory. Ling. Philos. 5,
23–55.Dowty, D., 1992. Variable-free syntax, variable-binding syntax, the natural deduction Lambek
calculus and the crossover constraint, in: Proceedings of the 11th Meeting of the WestCoast Conference on Formal Linguistics. CSLI Lecture Notes, Stanford, CA, pp. 161–176.
Dowty, D., Jacobson, P., 1989. Agreement as a semantic phenomenon, in: Powers, J., de Jong,K. (Eds.), Proceedings of the Fifth Eastern States Conference on Linguistics. Ohio StateUniversity, Columbus, OH, pp. 95–101.
Dowty, D., Wall, R., Peters, S., 1981. Introduction to Montague Semantics. Reidel, Dordrecht.Evans, G., 1980. Pronouns. Ling. Inq. 11, 337–362.Fauconnier, G., 1975a. Pragmatic scales and logical structure. Ling. Inq. 6, 353–375.Fauconnier, G.. 1975b. Polarity and the scale principle, in: Glossman, R.E., San, L.J., Vance,
T.J. (Eds.), Papers from the Eleventh Meeting of the Chicago Linguistic Society. ChicagoLinguistics Society, University of Chicago, Chicago, IL.
Feferman, A.B., Feferman, S., 2004. Alfred Tarski: Life and Logic. Cambridge University Press,MA, Cambridge.

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 86 — #86
86 Handbook of Logic and Language
Filip, H., 1992. Aspect and interpretation of nominal arguments, in: Canakis, C.P., Chan, G.P.,Denton, J.M. (Eds.), Proceedings of the Twenty-Eighth Meeting of the Chicago LinguisticSociety. The University of Chicago, Chicago, IL, pp. 139–158.
Filip, H., 1993. Aspect, Situation Types and Nominal Reference. Unpublished PhD Dissertation,University of California, Berkeley, CA.
Fillmore, C., 1968. The case for case, in: Bach, E., Harms, R. (Eds.), Universals in LinguisticTheory. Holt, Rinehart and Winston, New York, pp. 1–88.
Fodor, J.A., 1975. The Language of Thought. Thomas Y. Crowell, New York.Fodor, J.D., 1980. Semantics: Theories of Meaning in Generative Grammar. Harvard University
Press, Cambridge, MA.Fodor, J.D., 1982. The mental representation of quantifiers, in: Peters, S., Saarinen, E. (Eds.),
Processes, Beliefs and Questions. Reidel, Dordrecht, 129–164.Frege, G., 1892. Über Sinn und Bedeutung. Z. Philos. Philosoph. Kritik 100, 25–50. [Translated
as 1952. On sense and reference, Geach, P.T., Black, M. (Eds.), Translations from thePhilosophical Writings of Gottlob Frege. Blackwell, Oxford, pp. 56–78.]
Gallin, D., 1975. Intensional and Higher-Order Modal Logic. North-Holland, Amsterdam.Gamut, L.T.F., 1991. Logic, Language and Meaning, vol. I: Introduction to Logic, vol. II: Inten-
sional Logic and Logical Grammar. University of Chicago Press, Chicago and London.Gazdar, G., 1980. A cross-categorial semantics for coordination. Ling. Philos. 3, 407–410.Gazdar, G., 1982. Phrase structure grammar, in: Jacobson, P., Pullum, G. (Eds.), The Nature of
Syntactic Representation. Reidel, Dordrecht, pp. 131–186.Gazdar, G., Klein, E., Pullum, G.K., Sag, I.A., 1985. Generalized Phrase Structure Grammar.
Basil Blackwell, Oxford; and Harvard University Press, Cambridge, MA.Geach, P.T., 1962. Reference and Generality: An Examination of Some Medieval and Modern
Theories. Cornell University Press, Ithaca, NY.Groenendijk, J., Stokhof, M., 1984. Studies on the Semantics of Questions and the Pragmatics
of Answers. PhD Dissertation, University of Amsterdam, the Netherlands.Groenendijk, J., Stokhof, M., 1989. Type-shifting rules and the semantics of interrogatives,
in: Chierchia, G., Partee, B., Turner, R. (Eds.), Properties, Types and Meaning, vol. II:Semantic Issues. Kluwer, Dordrecht, pp. 21–68.
Groenendijk, J., Stokhof, M., 1990. Dynamic Montague grammar, in: Kálmán, L., Pólos, L.(Eds.), Papers from the Second Symposium on Logic and Language. Akademiai Kiado,Budapest, pp. 3–48.
Groenendijk, J., Stokhof, M., 1991. Dynamic predicate logic. Ling. Philos. 14, 39–100.Hajičová, E., Sgall, P., 1987. The ordering principle. J. Pragmat. 11, 435–454.Halvorsen, P.-K., Ladusaw, W.A., 1979. Montague’s “Universal Grammar”. An introduction for
the linguist. Ling. Philos. 3, 185–223.Harris, R.A., 1993. The Linguistic Wars. Oxford University Press, New York and Oxford.Harris, Z.S., 1968. The Mathematics of Language. Reidel, Dordrecht.Heim, I., 1982. The Semantics of Definite and Indefinite Noun Phrases. PhD Dissertation,
University of Massachusetts, Umass Graduate Linguistics Students Association, Amherst,MA.
Heim, I., 1983. File change semantics and the familiarity theory of definiteness, in: Bäuerle,R., Schwarze, C., von Stechow, A. (Eds.), Meaning, Use and Interpretation of Language.Walter de Gruyter, Berlin, pp. 164–189.
Heim, I., 1990. E-type pronouns and donkey anaphora. Ling. Philos. 13, 137–177.Heim, I., Kratzer, A., 1998. Semantics in Generative Grammar. Blackwell, Oxford.

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 87 — #87
Montague Grammar 87
Hendriks, H., 1988. Type change in semantics: the scope of quantification and coordination,in: Klein, E., van Benthem, J. (Eds.), Categories, Polymorphism and Unification. Centrefor Cognitive Science and Amsterdam: ITLI, University of Amsterdam, the Netherlands,pp. 96–119.
Hendriks, H., 1993. Studied Flexibility. Categories and Types in Syntax and Semantics. PhDDissertation, ILLC Dissertation Series, University of Amsterdam, the Netherlands.
Henkin, L., 1963. A theory of propositional types. Fund. Math. 52, 323–344.Hindle, D., Rooth, M., 1993. Structural ambiguity and lexical relations. Comput. Ling. 19,
103–120.Hinrichs, E., 1981. Temporale Anaphora im Englischen. Thesis, University of Tübingen,
Deutschland.Hinrichs, E., 1985. A Compositional Semantics for Aktionsarten and NP Reference in English.
PhD Dissertation, Ohio State University, Columbus, OH.Hinrichs, E., 1986. Temporal anaphora in discourses of English. Ling. Philos. 9, 63–82.Hintikka, K.J.J., 1962. Knowledge and Belief. Cornell University Press, Ithaca, NY.Hintikka, K.J.J., 1970. The semantics of modal notions. Synthese 21, 408–424. Reprinted:
Davidson, D., Harman, G.F. (Eds.), 1972; and (slightly revised) Hintikka, K.J.J.,1975. The Intentions of Intentionality and Other New Models for Modalities. Reidel,Dordrecht.
Hughes, G., Cresswell, M., 1968. An Introduction to Modal Logic. Methuen, London.Jackendoff, R., 1972. Semantic Interpretation in Generative Grammar. MIT Press, Cambridge,
MA.Jackendoff, R., 1996. Semantics and cognition, in: Lappin, S. (Ed.), The Handbook of Contem-
porary Semantic Theory, Blackwell, Oxford, pp. 539–559.Jacobson, P., 1992. Bach–Peters sentences in a variable-free semantics, in: Dekker, P.,
Stokhof, M. (Eds.), Proceedings of the Eighth Amsterdam Colloquium. Institute for Logic,Language and Computation, University of Amsterdam, the Netherlands, pp. 283–302.
Jacobson, P., 1994. i-within-i effects in a variable-free semantics and a categorial syntax, in:Dekker, P., Stokhof, M. (Eds.), Proceedings of the Ninth Amsterdam Colloquium. Insti-tute for Logic, Language and Computation, University of Amsterdam, the Netherlands,pp. 349–368.
Jacobson, P., 1996. The locality of interpretation: the case of binding and coordination,in: Hamm, F., von Stechow, A. (Eds.), Proceedings of the Blaubeuren Symposium onRecent Developments in Natural Language Semantics. University of Tübingen, Tübingen,pp. 111–135.
Janssen, T.M.V., 1981. Compositional semantics and relative clause formation in Montaguegrammar, in: Groenendijk, J., Janssen, T., Stokhof, M. (Eds.), Formal Methods in the Studyof Language. Mathematisch Centrum, Amsterdam, pp. 445–481.
Janssen, T.M.V., 1984. Individual concepts are useful, in: Landman, F., Veltman, F. (Eds.), Vari-eties of Formal Semantics, Foris, Dordrecht, pp. 171–192.
Janssen, T.M.V., 1986a. Foundations and Applications of Montague Grammar, part 1: Founda-tions, Logic, Computer Science. CWI Tracts no. 19, Centre for Mathematics and ComputerScience, Amsterdam.
Janssen, T.M.V., 1986b. Foundations and Applications of Montague Grammar, part 2: Appli-cations to Natural Language. CWI Tracts no. 28, Centre for Mathematics and ComputerScience, Amsterdam.
Jelinek, E., 1995. Quantification in straits salish, in: Bach, E., Jelinek, E., Kratzer, A., Partee,B.H. (Eds.), Quantification in Natural Languages. Kluwer, Dordrecht, pp. 487–540.

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 88 — #88
88 Handbook of Logic and Language
Johnson-Laird, P.N., 1983. Mental Models: Towards a Cognitive Science of Language, Infer-ence and Consciousness. Harvard University Press, Cambridge, MA.
Joshi, A., 1985. How much context-sensitivity is necessary for characterizing structural descrip-tions – tree adjoining grammars, in: Dowty, D., Karttunen, L., Zwicky, A. (Eds.), Natu-ral Language Processing. Theoretical, Computational and Psychological Perspectives.Cambridge University Press, Cambridge, MA, pp. 206–250.
Joshi, A., Vijay-Shanker, K., Weir, D., 1991. The convergence of mildly context-sensitive for-malisms, in: Sells, P., Shieber, S., Wasow, T. (Eds.), Processing of Linguistic Structure.MIT Press, Cambridge, MA, pp. 31–81.
Jubien, M., 1985. First-order Property Theory. Manuscript, University of Massachusetts,Amherst, MA.
Kadmon, N., 1987. On Unique and Non-Unique Reference and Asymmetric Quantification.PhD Dissertation, University of Massachusetts, Umass Graduate Linguistics StudentsAssociation, Amherst, MA.
Kadmon, N., 1990. Uniqueness. Ling. Philos. 13, 273–324.Kalish, D., 1967. Semantics, in: Edwards, P. (Ed.), Encyclopedia of Philosophy, Macmillan,
New York, pp. 348–358.Kalish, D., Montague, R., 1964. Logic: Techniques of Formal Reasoning. Harcourt, Brace,
Jovanovich, New York.Kamp, H., 1981. A theory of truth and semantic representation, in: Groenendijk, J., Janssen, T.,
Stokhof, M. (Eds.), Formal Methods in the Study of Language: Proceedings of the ThirdAmsterdam Colloquium. Mathematisch Centrum, Amsterdam. Reprinted: Groenendijk, J.,Janssen, T.M.V., Stokhof, M. (Eds.), 1984. Truth, Interpretation and Information: SelectedPapers from the Third Amsterdam Colloquium. Foris, Dordrecht, pp. 1–42.
Kamp, H., 1990. Uniqueness presuppositions and plural anaphora in DTT and DRT, in:Groenendijk, J., Stokhof, M., Beaver, D. (Eds.), Quantification and Anaphora I. EspritBasic Research Project 3175, Dynamic Interpretation of Natural Language, Dyana Deliv-erable R2.2A, pp. 177–190.
Kamp, H., Partee, B.H., 1995. Property theory and compositionality. Cognition 57, 129–191.Kamp, H., Reyle, U., 1993. From Discourse to Logic. Kluwer, Dordrecht.Kanger, S., 1957a. The morning star paradox. Theoria 23, 1–11.Kanger, S., 1957b. A note on quantification and modalities. Theoria 23, 133–134.Kaplan, D., 1964. Foundations of Intensional Logic. PhD Dissertation, University of California,
Los Angeles, CA.Kaplan, D., 1979. On the logic of demonstratives, in: French, P., Uehling, Th., Wettstein, H.
(Eds.), Contemporary Perspectives in the Philosophy of Language. University of Min-nesota Press, Minneapolis, MN, pp. 401–412.
Karttunen, L., 1968. What Do Referential Indices Refer to? The Rand Corporation, SantaMonica, CA.
Karttunen, L., 1969. Pronouns and variables, in: Binnick, R. et al., (Eds.), Papers from the FifthRegional Meeting of the Chicago Linguistic Society. University of Chicago, Chicago, IL.Linguistics Department, pp. 108–115.
Karttunen, L., 1971. Implicative verbs. Language 47, 340–358.Karttunen, L., 1975. Discourse Referents, in: McCawley, J. (Ed.), Syntax and Semantics vol. 7.
Academic Press, New York, pp. 363–385.Karttunen, L., 1977. Syntax and semantics of questions. Ling. Philos. 1, 3–44.Katz, J.J., Fodor, J.A., 1963. The structure of a semantic theory. Language 39, 170–210.

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 89 — #89
Montague Grammar 89
Katz, J.J., Postal, P.M., 1964. An Integrated Theory of Linguistic Descriptions. MIT Press,Cambridge, MA.
Keenan, E.L., 1971a. Names, quantifiers and a solution to the sloppy identity problem. PapersLing. 42.
Keenan, E.L., 1971b. Quantifier structures in English. Found. Lang. 7, 225–284.Keenan, E.L. (Ed.) 1975. Formal Semantics of Natural Language. Cambridge University Press,
Cambridge, MA.Keenan, E.L., Faltz, L., 1985. Boolean Semantics for Natural Language. Reidel, Dordrecht.Keenan, E.L., Stavi, J., 1986. A semantic characterization of natural language determiners. Ling.
Philos. 9, 253–326.Klein, E., Sag, I., 1985. Type-driven translation. Ling. Philos. 8, 163–201.Kratzer, A., 1989. An investigation of the lumps of thought. Ling. Philos. 12, 607–653.Kratzer, A., 1991. The representation of focus, in: von Stechow, A., Wunderlich, D. (Eds.),
Semantics: An International Handbook of Contemporary Research. Walter de Gruyter,Berlin, pp. 825–834.
Kratzer, A., 1995a. Stage-level and individual-level predicates, in: Carlson, G.N., Pelletier, F.J.(Eds.), The Generic Book, University of Chicago Press, Chicago, pp. 125–175.
Kratzer, A., 1995b. Pseudoscope. Manuscript, Amherst, MA.Krifka, M., 1986. Nominalreferenz und Zeitkonstitution. Zur Semantik von Massentermen, Plu-
raltermen und Aspektklassen. PhD Dissertation, University of Munich. Published in 1989,Wilhelm Fink, Munich.
Krifka, M., 1987. Nominal reference and temporal constitution: towards a semantics of quantity,in: Groenendijk, J., Stokhof, M., Veltman, F. (Eds.), Proceedings of the Sixth AmsterdamColloquium. Institute of linguistics, Logic and Information, University of Amsterdam, theNetherlands, pp. 153–173.
Krifka, M., 1990. Boolean and non-boolean And, in: Kalman, L., Polos, L. (Eds.), Papers fromthe Second Symposium on Logic and Language. Akademiai Kiado, Budapest, pp. 161–187.
Kripke, S., 1959. A completeness theorem in modal logic. J. Symb. Logic 24, 1–14.Kripke, S., 1972. Naming and necessity, in: Davidson, D., Harman, G.H. (Eds.), Semantics of
Natural Language. Reidel, Dordrech, pp. 253–355, 763–769.Ladusaw, G., 1979. Polarity Sensitivity as Inherent Scope Relations. PhD Dissertation, Univer-
sity of Texas, Austin, TX, Indiana University Linguistics Club, Bloomington, IN.Ladusaw, G., 1980. On the notion “affective” in the analysis of negative polarity items. J. Ling.
Res. 2, 1–16.Ladusaw, G., 1983. Logical form and conditions on grammaticality. Ling. Philos. 6, 373–392.Lakoff, G., 1968. Pronouns and Reference, Parts I and II. Indiana University Linguistics Club,
Bloomington, IN.Lakoff, G., 1970. Repartee. Found. Lang. 6, 389–422.Lakoff, G., 1971. On generative semantics, in: Steinberg, D., Jakobovits, L. (Eds.), Semantics.
An Interdisciplinary Reader in Philosophy, Linguistics and Psychology. Cambridge Uni-versity Press, Cambridge, MA, pp. 232–296.
Lakoff, G., 1972. Linguistics and Natural Logic, in: Davidson, D., Harman, G. (Eds.), Semanticsof Natural Language, Reidel, Dordrecht, pp. 545–665.
Landman, F., 1986. Towards a Theory of Information: The Status of Partial Objects in Seman-tics. PhD Dissertation, University of Amsterdam, Foris, Dordrecht.
Landman, F., 1989a. Groups I. Ling. Philos. 12, 559–605.

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 90 — #90
90 Handbook of Logic and Language
Landman, F., 1989b. Groups II. Ling. Philos. 12, 724–744.Landman, F., 1991. Structures for Semantics. Kluwer, Dordrecht.Lappin, S. (Ed.), 1996. The Handbook of Contemporary Semantic Theory. Blackwell,
Dordrecht.Lewis, D., 1968. Counterpart theory and quantified modal logic. J. Philos. 65, 113–126.Lewis, D., 1969. Convention: A Philosophical Study. Harvard University Press, Cambridge,
MA.Lewis, D., 1970. General semantics. Synthese 22, 18–67. Reprinted: Davidson, D., Harman G.
(Eds.), 1972, 169–218.Lewis, D., 1973. Counterfactuals. Basil Blackwell, Oxford.Lewis, D., 1974. Tensions, in: Munitz, M., Unger, P. (Eds.), Semantics and Philosophy. New
York University Press, New York.Lewis, D., 1975a. Adverbs of quantification, in: Keenan, E.L. (Ed.), Formal Semantics of
Natural Language. Cambridge University Press, Cambridge, MA, pp. 3–15.Lewis, D., 1975b. Languages and language, in: Gunderson, K. (Ed.), Language, Mind and
Knowledge. University of Minnesota Press, Minneapolis, MN, pp. 3–35.Linebarger, M., 1980. The Grammar of Negative Polarity. PhD Dissertation, MIT press, Cam-
bridge, MA.Linebarger, M., 1987. Negative polarity and grammatical representation. Ling. Philos. 10,
325–387.Link, G., 1979. Montague-Grammatik. Die Logische Grundlagen. Wilhelm Fink Verlag,
Munich.Link, G., 1983. The logical analysis of plurals and mass terms: a lattice-theoretic approach, in:
Bäuerle, R., Schwarze, C., von Stechow, A. (Eds.), Meaning, Use and Interpretation ofLanguage. Walter de Gruyter, Berlin, pp. 302–323.
Lyons, J., 1968. Introduction to Theoretical Linguistics. Cambridge University Press, Cam-bridge, MA.
May, R., 1977. The Grammar of Quantification. PhD Dissertation, MIT press, Cambridge, MA.May, R., 1985. Logical Form: Its Structure and Derivation. MIT Press, Cambridge, MA.McCawley, J.D., 1971. Where do noun phrases come from?, in: Steinberg, D., Jakobovits, L.
(Eds.), Semantics. An Interdisciplinary Reader in Philosophy. Linguistics and Psychology.Cambridge University Press, Cambridge, MA, pp. 217–231.
McCawley, J.D., 1979. Helpful hints to the ordinary working Montague grammarian, in: Davis,S., Mithun, M. (Eds.), Linguistic, Philosophy, and Montague grammar, University of TexasPress, Austin, TX, pp. 103–125.
McCawley, J.D., 1981. Everything that Linguists Have Always Wanted to Know About Logicbut were Ashamed to Ask, University of Chicago Press, Chicago, IL.
Mitchell, J., 1986. The Formal Semantics of Point of View. PhD Dissertation, University ofMassachusetts, UMass Graduate Linguistics Students Association, Amherst, MA.
Montague, R., 1968. Pragmatics, in: Klibansky, R. (Ed.), Contemporary Philosophy: A Survey.La Nuova Italia Editrice, Florence, pp. 102–122. Reprinted: Montague 1974, pp. 95–118.
Montague, R., 1969. On the nature of certain philosophical entities. The Monist 53, 159–194.Reprinted: Montague 1974, 148–187.
Montague, R., 1970a. Pragmatics and intensional logic. Synthese 22, 68–94. Reprinted: Mon-tague 1974, 119–147.
Montague, R., 1970b. English as a formal language, in: Visentini, B. et al., (Eds.), Linguagginella Società e nella Tecnica, Edizioni di Communità, Milan, pp. 189–224. Reprinted:Montague 1974, pp. 188–221.

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 91 — #91
Montague Grammar 91
Montague, R., 1970c. Universal grammar. Theoria 36, 373–398. Reprinted: Montague 1974,222–246.
Montague, R., 1973. The proper treatment of quantification in ordinary English, in: Hintikka,K.J.J., Moravcsik, J.M.E., Suppes, P. (Eds.), Approaches to Natural Language. Proceed-ings of the 1970 Stanford Workshop on Grammar and Semantics, Reidel, Dordrecht,pp. 221–242. Reprinted: Montague, 1974, pp. 247–270.
Montague, R., 1974. Formal Philosophy: Selected Papers of Richard Montague, edited and withan introduction by Richmond Thomason. Yale University Press, New Haven, CT.
Moschovakis, Y., 1985, Unpublished lecture notes, CSLI-ASL Summer School on Logic, Lan-guage and Information, Stanford, CA.
Muskens, R., 1989. Meaning and Partiality. PhD Dissertation, University of Amsterdam, theNetherlands.
Newmeyer, F.J., 1980. Linguistic Theory in America. Academic Press, New York.Oehrle, R., Bach, E., Wheeler, D. (Eds.), 1988. Categorial Grammars and Natural Language
Structures. Reidel, Dordrecht.Orey, S., 1959. Model theory for the higher-order predicate calculus. Trans. Amer. Math. Soc.
92, 72–84.Parsons, T., 1972. An Outline of a Semantics for English. Manuscript, Amherst, MA.Parsons, T., 1979. Type theory and ordinary language, in: Davis, S., Mithun, M. (Eds.), Linguis-
tic, Philosophy, and Montague grammar. University of Texas Press, Austin, 127–151.Parsons, T., 1980. Nonexistent Objects. Yale University Press, New Haven, CT.Partee, B.H., 1970a. Opacity, coreference and pronouns. Synthese 21, 359–385.Partee, B.H., 1970b. Negation, conjunction and quantifiers: syntax vs. semantics. Found. Lang.
6, 153–165.Partee, B.H., 1973a. Comments on Montague’s paper, in: Hintikka, K.J.J., Moravcsik, J.M.E.,
Suppes, P. (Eds.), Approaches to Natural Language. Reidel, Dordrecht, pp. 243–258.Partee, B.H., 1973b. Some transformational extensions of Montague grammar. J. Philos. Logic
2, 509–534. Reprinted: Partee, B.H.(Ed.), 1976a, 51–76.Partee, B.H., 1973c. Some structural analogies between tenses and pronouns in English. J. Phi-
los. 70, 601–609.Partee, B.H., 1974. Opacity and scope, in: Munitz, M., Unger, P. (Eds.), Semantics and Philos-
ophy, New York University Press, New York, pp. 81–101.Partee, B.H., 1975. Montague grammar and transformational grammar. Ling. Inq. 6, 203–300.Partee, B.H. (Ed.) 1976a. Montague Grammar. Academic Press, New York.Partee, B.H., 1976b. Semantics and syntax: The search for constraints, in: Rameh, C. (Ed.),
Georgetown University Roundtable on Languages and Linguistics. Georgetown UniversitySchool of Languages and Linguistics, New York, NY, pp. 99–110.
Partee, B.H., 1979a. Constraining Montague grammar: a framework and a fragment, in: Davis,S., Mithun, M. (Eds.), Linguistics, Philosophy and Montague, University of Texas Press,Austin, pp. 51–101.
Partee, B., 1979b. Montague grammar and the well-formedness constraint, in: Heny, F.,Schnelle, H. (Eds.), Syntax and Semantics 10. Selections from the Third Groningen RoundTable. Academic Press, New York, pp. 275–313.
Partee, B., 1979c. Semantics – mathematics or psychology?, in: Bäuerle, R., Egli, U.,von Stechow, A. (Eds.), Semantics from Different Points of View. Springer, Berlin,pp. 1–14.
Partee, B., 1980. Montague grammar, mental representation and reality, in: Ohman, S., Kanger,S. (Eds.), Philosophy and Grammar, Reidel, Dordrecht, pp. 59–78. Reprinted: French, P.

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 92 — #92
92 Handbook of Logic and Language
et al. (Eds.), 1979. Contemporary Perspectives in the Philosophy of Language. Universityof Minnesota Press, Minneapolis, MN .
Partee, B., 1982. Belief sentences and the limits of semantics, in: Peters, S., Saarinen, E. (Eds.),Processes, Beliefs and Questions. Reidel, Dordrecht, pp. 87–106.
Partee, B., 1984. Nominal and temporal anaphora. Ling. Philos. 7, 243–286.Partee, B., 1987. Noun phrase interpretation and type-shifting principles, in: Groenendijk, J., de
Jongh, D., Stokhof, M. (Eds.), Studies in Discourse Representation Theory and the Theoryof Generalized Quantifiers, Foris, Dordrecht, pp. 115–144.
Partee, B., 1988. Semantic facts and psychological facts. Mind Lang. 3, 43–52.Partee, B., 1989a. Possible worlds in model-theoretic semantics: A linguistic perspective, in:
Allen, S. (Ed.), Possible Worlds in Humanities, Arts and Sciences: Proceedings of NobelSymposium 65. Walter de Gruyter, Berlin and New York, pp. 93–123.
Partee, B., 1989b. Binding implicit variables in quantified contexts, in: Wiltshire, C., Music, B.,Graczyk, R. (Eds.), Papers from CLS 25. Chicago Linguistic Society, Chicago, IL,pp. 342–365.
Partee, B., 1992. Naturalizing formal semantics, in: Proceedings of the XVth World Congressof Linguists: Texts of Plenary Sessions. Laval University, Quebec, pp. 62–76.
Partee, B., 1993. Semantic structures and semantic properties, in: Reuland, E., Abraham, W.,(Eds.), Knowledge and Language, vol. II: Lexical and Conceptual Structure. Kluwer, Dor-drecht, pp. 7–29.
Partee, B., 1995. Lexical semantics and compositionality, in: Osherson, D. (Ed.), Invitationto Cognitive Science, Second edition: Gleitman, L., Liberman M. (Eds.), 1995. Part I:Language. MIT Press, Cambridge, MA.
Partee, B.H., 2001. Montague grammar, in: Smelser, N.J., Baltes, P.B. (Eds.), InternationalEncyclopedia of the Social and Behavioral Sciences. Elsevier, Amsterdam and New York.
Partee, B.H., 2004. Reflections of a formal semanticist, in: Partee, B.H. (Ed.), Compositionalityin Formal Semantics: Selected Papers. Blackwell Publishing, Oxford, pp. 1–25.
Partee, B.H., 2006. Richard Montague (1930–1971), in: Brown, K. (Ed.), Encyclopedia of Lan-guage and Linguistics, Second ed., vol. 8. Elsevier, Oxford, pp. 255–257.
Partee, B.H., 2010. Montague grammar, in: Hogan, P.C. (Ed.), The Cambridge Encyclopedia ofthe Language Sciences. Cambridge University Press, Cambridge.
Partee, B., Bach, E., 1981. Quantification, pronouns and VP anaphora, in: Groenendijk, J.,Janssen, T., Stokhof, M. (Eds.), Formal Methods in the Study of Language: Proceedings ofthe Third Amsterdam Colloquium. Mathematisch Centrum, Amsterdam. Reprinted: Groe-nendijk, J., Janssen, T., Stokhof M. (Eds.) 1984. Truth, Information and Interpretation:Selected Papers from the Third Amsterdam Colloquium. Foris, Dordrecht, pp. 99–130.
Partee, B.H., Ter Meulen, A., Wall, R.E., 1990. Mathematical Methods in Linguistics. Kluwer,Dordrecht.
Partee, B.H., Rooth, M., 1983. Generalized Conjunction and Type Ambiguity, in: Bäuerle,R., Schwarze, C., von Stechow, A. (Eds.), Meaning, Use and Interpretation of Language.Walter de Gruyter, Berlin, pp. 361–383.
Pavel, T.G., 1986. Fictional Worlds. Harvard University Press, Cambridge, MA.Peregrin, J., 1995. Doing Worlds and Words. Kluwer, Dordrecht.Poesio, M., 1991. Relational semantics and scope ambiguity, in: Barwise, J., Gawron, J.M.,
Plotkin, G., Tutiya, S. (Eds.), Situation Theory and Its Applications vol. 2. CSLI,Stanford, CA, pp. 469–497.
Poesio, M., 1994. Discourse Interpretation and The Scope of Operators. PhD Dissertation,University of Rochester, New York, NY.

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 93 — #93
Montague Grammar 93
Pollard, C., Sag, I.A., 1987. Information-Based Syntax and Semantics, vol. 1: Fundamentals.CSLI Lecture Notes, Stanford, CA.
Pollard, C., Sag, I.A., 1994. Head-Driven Phrase Structure Grammar. Center for the Study ofLanguage and Information, Stanford, CA; and University of Chicago Press, Chicago, ILand London.
Portner, P., 1992. Situation Theory and the Semantics of Propositional Expressions. PhD Dis-sertation, University of Massachusetts, Amherst, MA.
Portner, P., Partee, B.H. (Eds.) 2002. Formal Semantics: The Essential Readings. BlackwellPublishers, Oxford.
Quine, W.V.O., 1960. Word and Object. MIT Press, Cambridge, MA.Quine, W.V.O., 1961. From a Logical Point of View. MIT Press, Cambridge, MA.Quine, W.V.O., 1970. Philosophy of Logic. Prentice-Hall, Englewood Cliffs, NJ.Reichenbach, H., 1947. Elements of Symbolic Logic. Macmillan, New York.Reinhart, T., Reuland, E., 1993. Reflexivity. Ling. Inq. 24, 657–720.Reyle, U., 1993. Dealing with ambiguities by underspecification: construction, representation
and deduction. J. Semant. 10, 123–179.Rodman, R. (Ed.) 1972. Papers in Montague grammar. Occasional Papers in Linguistics, Lin-
guistics Department, UCLA, Los Angeles, CA.Rodman, R., 1976. Scope phenomena, “movement transformations” and relative clauses, Mon-
tague grammar, in: Partee, B.H. (Ed.), Academic Press, New York, pp. 165–176.Rooth, M., 1992a. A theory of focus interpretation. Nat. Lang. Semant. 1, 75–116.Rooth, M., 1992b. Ellipsis Redundancy and Reduction Redundancy. Manuscript, University of
Stuttgart, Stuttgart, Deutschland.Rooth, M., Partee, B., 1982. Conjunction, type ambiguity and wide scope “or”, in: Flickinger,
D., Macken, M., Wiegand, N. (Eds.), Proceedings of the 1982 West Coast Conference onFormal Linguistics. Stanford Linguistics Department, Stanford, CA.
Rosetta, M.T., 1994. Compositional Translation. Kluwer, Dordrecht.Russell, B., Whitehead, A., 1913. Principia Mathematica. Cambridge University Press, Cam-
bridge, MA.Sag, I.A., 1976. Deletion and Logical Form. PhD Dissertation, MIT, Cambridge, MA.Schiffer, S., 1987. Remnants of Meaning. MIT Press, Cambridge, MA.Schwarzschild, R., 1992. Types of plural individuals. Ling. Philos. 15, 641–675.Scott, D., 1970. Advice on modal logic, in: Lambert, K. (Ed.), Philosophical Problems in Logic.
Reidel, Dordrecht, pp. 143–173.Soames, S., 1987. Semantics and semantic competence, in: Schiffer, S., Steele, S. (Eds.),
Thought and Language: Second Arizona Colloquium in Cognitive Science. University ofArizona Press, Tucson, AZ.
Staal, J.F. (Ed.), 1969. Formal logic and natural languages: a symposium. Found. Lang. 5,256–284.
Stalnaker, R., 1974. Pragmatic presuppositions, in: Munitz, M., Unger, P. (Eds.), Semantics andPhilosophy. New York University Press, New York, pp. 197–214.
Stalnaker, R., 1976. Propositions, in: Mackay, A., Merrill, D. (Eds.), Issues in the Philosophy ofLanguage. Yale University Press, New Haven, CT, pp. 79–91.
Stalnaker, R., 1978. Assertion, in: Cole, P. (Ed.), Syntax and Semantics, vol. 9: Pragmatics.Academic Press, New York, pp. 315–332.
Stalnaker, R., 1984. Inquiry. MIT Press, Cambridge, MA.Stein, M., 1981. Quantification in Thai. PhD Dissertation, University of Massachusetts, Umass
Graduate Linguistics Students Association, Amherst, MA.

“05-ch01-0001-0094-9780444537263” — 2010/11/29 — 21:08 — page 94 — #94
94 Handbook of Logic and Language
Szabolcsi, A., 1987. Bound variables in syntax (are there any?), in: Groenendijk, J., Stokhof,M., Veltman, F. (Eds.), Proceedings of the Sixth Amsterdam Colloquium, University ofAmsterdam, the Netherlands, pp. 331–351.
Szabolcsi, A. (Ed.), 1997. Ways of Scope Taking. Kluwer, Dordrecht.Tarski, A., 1944. The semantic conception of truth and the foundations of semantics. Philos.
Phenomenolog. Res. 4, 341–375.Thomason, R., 1974. Introduction, in: Thomason, R., Montague, R. (Ed.), Yale University Press,
New Haven, pp. 1–69.Thomason, R., 1976. Some extensions of Montague grammar, in: Partee, B.H. (Ed.), Montague
grammar. Academic Press, New York, pp. 77–118.Thomason, R., Stalnaker, R., 1973. A semantic theory of adverbs. Ling. Inq. 4, 195–220.Tichý, P., 1988. The Foundations of Frege’s Logic. Walter de Gruyter, Berlin.Turner, R., 1987. A theory of properties. J. Symb. Logic 52, 63–86.Turner, R., 1989. Two issues in the foundations of semantic theory, in: Chierchia, G., Partee, B.,
Turner, R. (Eds.), Properties, Types and Meaning vol. 1. Kluwer, Dordrecht, pp. 63–84.Veltman, F., 1981. Data semantics, in: Groenendijk, J., Formal Methods in the Study of
Language: Proceedings of the Third Amsterdam Colloquium. Mathematisch Centrum,Amsterdam. Reprinted: Janssen, T., Stokhof, M. (Eds.), 1984. Truth, Information andInterpretation: Selected Papers from the Third Amsterdam Colloquium. Foris, Dordrecht,pp. 43–63.
Veltman, F., 1985a. Logics for Conditionals. PhD Dissertation, University of Amsterdam, theNetherlands.
Veltman, F., 1985b. Data semantics and the pragmatics of indicative conditionals, in: Traugott,E. et al. (Eds.), On Conditionals. Cambridge University Press, Cambridge, MA, pp. 147–168.
Veltman, F., 1990. Defaults in update semantics, in: Kamp, H. (Ed.), Conditionals, Defaults, andBelief Revision. Dyana Deliverable R2.5.A, Edinburgh. To appear in J. Philos. Logic.
Vermazen, B., 1967. Review of Katz, J.J., Postal, P., 1964, An Integrated Theory of LinguisticDescriptions and Katz, J.J., 1966, The Philosophy of Language, Synthese 17, 350–365.
von Fintel, K., 1994. Restrictions on Quantifier Domains. PhD Dissertation, University of Mas-sachusetts, Umass Graduate Linguistics Students Association, Amherst, MA.
von Stechow, A., 1974, ' ' % kontextfreie Sprachen: Ein Beitrag zu einer natürlichen formalenSemantik. Ling. Ber. 34, 1–34.
von Stechow, A., 1980. Modification of noun phrases: a challenge for compositional semantics.Theor. Ling. 7, 57–110.
von Stechow, A., 1984. Structured propositions and essential indexicals, in: Landman, F., Velt-man, F. (Eds.), Varieties of Formal Semantics. Foris, Dordrecht, pp. 385–403.
Williams, E., 1977. Discourse and logical form. Ling. Inq. 8, 101–139.Williams, E., 1988. Is LF distinct from S-structure? a reply to May. Ling. Inq. 19, 135–146.Zeevat, H., 1989. A compositional approach to discourse representation theory. Ling. Philos.
12, 95–131.Zimmermann, T.E., 1981. Einführungen in die Montague-Grammatik. Ling. Ber. 75, 26–40.Zimmermann, T.E., 1989. Intensional logic and two-sorted type theory. J. Symb. Logic 54,
65–77.Zucchi, A., 1989. The Language of Propositions and Events: Issues in the Syntax and Semantics
of Nominalization. PhD Dissertation, University of Massachusetts, Amherst, MA.Zwarts, F., 1986. Categoriale Grammatica En Algebraı̈sche Semantiek. PhD Dissertation,
Groningen University, the Netherlands.

“06-ch02-0095-0180-9780444537263” — 2010/11/30 — 3:53 — page 95 — #1
2 Categorial Type LogicsMichael MoortgatUtrecht Institute of Linguistics, Trans 10,3512 JK Utrecht, E-mail: [email protected]
This chapter consists of two parts. Part I reprints four sections of the chapter onCategorial Type Logics from the 1997 edition of this Handbook. Part II is an update,reviewing developments in the period 1997–2009. The excerpt of Part I retains thecore materials of the 1997 chapter: the discussion of the “classical” Lambek systems,the Curry-Howard perspective on the syntax-semantics interface, and the develop-ment of multimodal architectures. Because of space limitations, three sections fromthe original chapter are omitted here. The first of these, “Reasoning about multipletype assignments”, dealt with first-order predicational types and second-order poly-morphic type schemata, and with additive and Boolean type constructors. For newresults in this area, we refer the reader to Buszkowski and Farulewski (2009) andBuszkowski (2010). The 1997 section “Hybrid architectures” discussed the integra-tion of categorial and unification grammars. This was an active area of research in thatperiod, but there have been no follow-up results in more recent years. The third sec-tion left out, “Categorial parsing as deduction”, dealt with proofs nets and processing.An up-to-date treatment of these topics can be found in the Update.
Readers who want to further explore the material covered here can turn to somerecent book-length studies. Restall’s “Introduction to Substructural Logics” (Restall,2000) will help to situate categorial grammars within the broader setting of resource-sensitive styles of reasoning. Resource-sensitivity in the categorial treatment of bind-ing and anaphora is the theme of the anthology (Kruijff and Oehrle, 2003). The bookincludes useful notes on the historical background of the idea. Jäger’s monograph“Anaphora and Type Logical Grammar” (Jäger, 2005) includes a self-contained intro-duction to typelogical grammar. Finally, there is Morrill’s monograph on categorialgrammar (Morrill, 2010).
Part I. Excerpts from the 1997 Chapter
2.1 Introduction: Grammatical Reasoning
Les quantités du langage et leurs rapports sont regulièrement exprimables dansleur nature fondamentale, par des formules mathématiques. . . . L’expression simple
Handbook of Logic and Language. DOI: 10.1016/B978-0-444-53726-3.00002-5c! 2011 Elsevier B.V. All rights reserved.

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 96 — #2
96 Handbook of Logic and Language
[of linguistic concepts] sera algébrique ou elle ne sera pas. . . . On aboutit à desthéorèmes qu’il faut démontrer.
Ferdinand de Saussure1
The central objective of the type-logical approach is to develop a uniform deductiveaccount of the composition of form and meaning in natural language: formal grammaris presented as a logic—a system for reasoning about structured linguistic resources.In the sections that follow, the model-theoretic and proof-theoretic aspects of this pro-gram will be executed in technical detail. First, we introduce the central concept of“grammatical composition” in an informal way. It will be useful to distinguish twoaspects of the composition relation: a fixed logical component, and a variable struc-tural component. We discuss these in turn.
Grammatical composition: Logic. The categorial perspective on the form-meaningarticulation in natural language is based on a distinction, which can be traced back toFrege, between “complete” and “incomplete” expressions. Such a distinction makesit possible to drastically simplify the traditional Aristotelian theory of categories (ortypes): one can reserve atomic category names for the complete expressions, and forthe categorization of the incomplete expressions one inductively defines an infinitesupply of category names out of the atomic types and a small number of type-formingconnectives.
For the categorization of incomplete expressions, Ajdukiewicz in his seminal(Ajdukiewicz, 1935) used a fractional notation A
B , inspired by Husserl’s “Bedeu-tungskategorien” and Russell’s “Theory of Types”. The fractional notation immedi-ately suggests the basic combination schema via an analogy with multiplication: A
B ! Byields A. Bar-Hillel (1964) refined the impractical fractional notation by splitting upAB into a division from the left B\A and a division from the right A/B, in order todiscriminate between incomplete expressions that will produce an expression of typeA when composed with an arbitrary expression of type B to the left, and to the right,respectively.
It will be helpful for what follows to take a logical (rather than arithmetical)perspective on the category formulas, and read A/B, B\A as directionally-sensitive“implications”—implications with respect to structural composition of linguisticmaterial, rather than logical conjunction of propositions. Let us write ! " A for thebasic judgement of the grammar logic: the judgement that the structured configurationof linguistic expressions ! can be categorized as a well-formed expression of type A.The inference pattern (2.1) tells us how to arrive at a grammaticality judgement forthe composite structure !,# from judgements for the parts ! and #—it tells us howwe can use the implications / and \ in grammatical reasoning. Where the premises
1 N10 and N13a in R. Godel Les sources manuscrites du CLG de F. de Saussure, Genève, 1957. Quotedwithout reference by Roman Jakobson in his introduction in Jakobson (1961).

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 97 — #3
Categorial Type Logics 97
are immediate, the basic law of grammatical composition takes the form of a ModusPonens inference: A/B, B " A and B, B\A " A.
from ! " A/B and # " B, infer !,# " A(2.1)
from ! " B and # " B\A, infer !,# " A
In the example (2.2), one finds a little piece of grammatical reasoning leading fromlexical categorizations to the conclusion that “Kazimierz talks to the mathematician”is a well-formed sentence. In this example, sentences s, (proper) noun phrases np,common nouns n, and prepositional phrases pp are taken to be “complete expressions”,whereas the verb “talk”, the determiner “the” and the preposition “to” are categorizedas incomplete with respect to these complete phrases. The sequence of Modus Ponensinference steps is displayed in the so-called Natural Deduction format, with labels[/E], [\E] for the “elimination” of the implication connectives.
Kazimierznp
talks((np\s)/pp)
to(pp/np)
the(np/n)
mathematiciann
np/E
pp/E
(np\s)/E
s \E
(2.2)
The inferences of (2.1) build more complex structural configurations out of theirparts by using the grammatical implications. What about looking at grammaticalstructure from the opposite perspective? In other words: given information about thecategorization of a composite structure, what conclusions could we draw about thecategorization of its parts? Suppose we want to find out whether a structure ! canbe appropriately categorized as A/B. Given the interpretation we had in mind for theimplication /, such a conclusion would be justified if we could show that ! in con-struction with an arbitrary expression of type B can be categorized as an expression oftype A. Similarly, from the grammaticality judgement that B in construction with ! isof type A, we can conclude that ! itself is of type B\A. The inference patterns (2.3),introduced in Lambek (1958), tell us how to prove formulas A/B or B\A, just as the(2.1) inferences told us how to use these implications.
from !, B " A, infer ! " A/B from B, ! " A, infer ! " B\A (2.3)
In order to see where this type of “deconstructive” reasoning comes into play, considerthe relative clause example “the mathematician whom Kazimierz talks to”. There isone new lexical item in this example: the relative pronoun whom. This item is catego-rized as incomplete: on the right, it wants to enter into composition with the relative

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 98 — #4
98 Handbook of Logic and Language
clause body—an expression which we would like to assign to the category s/np.
the(np/n)
mathematiciann
whom((n\n)/(s/np))
Kazimierznp
talks((np\s)/pp)
to(pp/np) np
pp/E
(np\s)/E
s\E
(s/np)/I
(n\n)/E
n\E
np /E
(2.4)
In order to show that “Kazimierz talks to” is indeed of type s/np, we make a hypo-thetical assumption, and suppose we have an arbitrary np expression. With the aidof this hypothetical assumption, we derive s for “Kazimierz talks to np”, using thefamiliar Modus Ponens steps of inference. At the point where we have derived s, wewithdraw the hypothetical np assumption, and conclude that “Kazimierz talks to” canbe categorized as s/np. This step is labeled [/I], for the “introduction” of the implica-tion connective, and the withdrawn assumption is marked by overlining.
The relation between the wh pronoun and the hypothetical np position which it pre-empts is often described metaphorically in terms of “movement”. Notice that in ourdeductive setting we achieve the effects of “movement” without adding anything tothe theory of grammatical composition: there is no need for abstract syntactic place-holders (such as the “empty” trace categories of Chomskyan syntax, or the hei syntac-tic variables of Montague’s PTQ), or for extra combination schemata beyond ModusPonens. The similarity between the Natural Deduction graphs and phrase structuretrees, in other words, is misleading: what we have represented graphically are thesteps in a deductive process—not to be confused with the construction of a synt-actic tree.
In the above, we have talked about the form dimension of grammatical compo-sition: about putting together linguistic resources into well-formed structural config-urations. But a key point of the categorial approach is that one can simultaneouslyconsider the types/categories, and hence grammatical composition, in the meaningdimension. From the semantic perspective, one fixes the kind of meaning objects onewants for the basic types that categorize complete expressions, and then interpretsobjects of types A/B, B\A as functions from B type objects to A type objects. Struc-tural composition by means of Modus Ponens can then be naturally correlated withfunctional application, and Hypothetical Reasoning with functional abstraction in thesemantic dimension. Composition of linguistic form and meaning composition thusbecome aspects of one and the same process of grammatical inference.

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 99 — #5
Categorial Type Logics 99
Grammatical composition: Structure. An aspect we have ignored so far in ourdiscussion of the Modus Ponens and Hypothetical Reasoning inferences is the man-agement of the linguistic resources—the manipulations we allow ourselves in usinglinguistic assumptions. Some aspects of resource management are explicitly encodedin the logical vocabulary—the distinction between the “implications” / and \, forexample, captures the fact that grammatical inference is sensitive to the linear orderof the resources. But other equally important aspects of resource management haveremained implicit. In the relative clause example, we inferred ! " A/B from !, B " A.In withdrawing the hypothetical B assumption, we didn’t take into account the hierar-chical embedding of the B resource: we ignored its vertical nesting in the configura-tion of assumptions. Resource management, in other words, was implicitly taken to beassociative: different hierarchical groupings over the same linear ordering of assump-tions were considered as indistinguishable for the purposes of grammatical inference.On closer inspection, the implicit claim that restructuring of resources would notaffect derivability (grammatical well-formedness) might be justified in some cases,whereas in other cases a more fine-grained notion of grammatical consequence mightbe appropriate. Similarly, the sensitivity to linear order, which restricts hypotheticalreasoning to the withdrawal of a peripheral assumption, might be too strong in somecases. Compare (2.4) with the variant “whom Kazimierz talked to yesterday”, whereone would like to withdraw a hypothetical np assumption from the non-peripheralposition “Kazimierz talked to np yesterday”. Switching to a commutative resourcemanagement regime would be too drastic—we would not be able anymore to deduc-tively distinguish between the well-formed relative clause and its ill-formed permu-tations. In cases like this, one would like the grammar logic to provide facilitiesfor controlled modulation of the management of linguistic resources, rather than toimplement this in a global fashion as a hard-wired component of the type-formingconnectives.
A Brief History of Types. The above discussion recapitulates the crucial phases in thehistorical development of the field. The Modus Ponens type of reasoning, with itsfunctional application interpretation, provided the original motivation for the devel-opment of categorial grammar in Ajdukiewicz (1935). The insight that Modus Ponensand Hypothetical Reasoning are two inseparable aspects of the interpretation of the“logical constants” /, \ is the key contribution of Lambek’s work in the late 1950s.Lambek (1958, 1961) shows that attempts to generalize Modus Ponens in terms ofextra rule schemata, such as Type Lifting or Functional Composition, are in factweak approximations of Hypothetical Reasoning: viewing the type-forming opera-tors as logical connectives, such schemata are reduced to theorems, given appropriateresource management choices. In retrospect, one can see that the core components ofthe type-logical architecture were worked out in 1958. But it took a quarter of a centurybefore Lambek’s work had a clear impact on the linguistic community. Contributionssuch as (Geach 1972; Lewis 1972; Lyons 1968) are continuations of the rule-basedAjdukiewicz/Bar-Hillel tradition. Ironically, when linguists developed a renewed

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 100 — #6
100 Handbook of Logic and Language
interest in categorial grammar in the early 1980s, they did not adopt Lambek’s deduc-tive view on grammatical composition, but fell back on an essentially rule-basedapproach. The framework of Combinatory Categorial Grammar (CCG, Steedman,1988) epitomizes the rule-based generalized categorial architecture. In this frame-work, laws of type change and type combination are presented as theoretical primitives(“combinators”) as a matter of methodological principle. For a good tutorial introduc-tion to CCG, and a comparison with the deductive approach, we refer the reader toSteedman (1993).
The 1985 Tucson conference on Categorial Grammar brought together the adher-ents of the rule-based and the deductive traditions. In the proceedings of that con-ference, Categorial Grammars and Natural Language Structures (Oehrle, Bach andWheeler, 1988) one finds a comprehensive picture of the varieties of categorialresearch in the 1980s.
Lambek originally presented his type logic as a calculus of syntactic types. Seman-tic interpretation of categorial deductions along the lines of the Curry-Howard corre-spondence was put on the categorial agenda in van Benthem (1983). This contributionmade it clear how the categorial type logics realize Montague’s Universal Grammarprogram—in fact, how they improve on Montague’s own execution of that programin offering an integrated account of the composition of linguistic meaning and form.Montague’s adoption of a categorial syntax does not go far beyond notation: he wasnot interested in offering a principled theory of allowable “syntactic operations” goingwith the category formalism.
The introduction of Linear Logic in (Girard, 1987) created a wave of research in thegeneral landscape of “substructural” logics: logics where structural rules of resourcemanagement are controlled rather than globally available. The importance of the dis-tinction between the logical and the structural aspects of grammatical composition is atheme that directly derives from this research. The analysis of the linguistic ramifica-tions of this distinction has guided the development of the present-day “multimodal”type-logical architecture discussed in the pages that follow.
2.2 Linguistic Inference: the Lambek Systems
In the following sections we present the basic model-theory and proof-theory forthe logical constants /, •, \, the so-called multiplicative connectives. On the model-theoretic level, we introduce abstract mathematical structures that capture the relevantaspects of grammatical composition. On the proof-theoretic level, we want to knowhow to perform valid inferences on the basis of the interpreted type language. Weare not interested in syntax as the manipulation of meaningless symbols: we wantthe grammatical proof-theory to be sound and complete with respect to the abstractmodels of grammatical composition.
We proceed in two stages. In the present section, we develop a landscape of sim-ple Lambek systems. Simple Lambek systems are obtained by taking the logic of

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 101 — #7
Categorial Type Logics 101
residuation for a family of multiplicative connectives /, •, \, together with a packageof structural postulates characterizing the resource management properties of the •connective. As resource management options, we consider Associativity and Commu-tativity. Different choices for these options yield the type logics known as NL, L, NLP,LP. Each of these systems has its virtues in linguistic analysis. But none of them inisolation provides a basis for a realistic theory of grammar. Mixed architectures, whichovercome the limitations of the simple systems, are the subject of Section 2.4.
2.2.1 Modeling Grammatical Composition
Consider the language F of category formulae of a simple Lambek system. F isobtained by closing a set A of atomic formulae (or: basic types, prime formulae,e.g., s, np, n, . . .) under binary connectives (or: type forming operators) /, •, \. Wehave already seen the connectives /, \ at work in our informal introduction. The •connective will make it possible to explicitly refer to composed structures—in theintroduction we informally used a comma for this purpose.
F ::= A|F/F |F • F |F\F (2.5)
In this chapter we explore a broad landscape of categorial type logics. On thesemantic level, we are interested in a uniform model theory that naturally accom-modates the subtle variations in categorial inference we want to study. A suitablelevel of abstraction can be obtained by viewing the categorial connectives as modaloperators, and interpreting the type formulae in the powerset algebra of Kripke-stylerelational structures. The frame-based semantics for categorial logics is developed inDošen (1992). As will become clear later on, it extends smoothly to the generalizedand mixed architectures that form the core of this chapter. The “modal” semantics alsooffers a suitable basis for comparison of the categorial systems with the feature-basedgrammar architectures studied in Chapter 8.
A modal frame, in general, is a set of “worlds” W together with an n + 1-ary“accessibility relation” R for the n-ary modal operators. In the case of the binary cat-egorial connectives, we interpret with respect to ternary relational structures and con-sider frames $W, R3%. The domain W is to be thought of here as the set of linguisticresources (or: signs, form-meaning complexes of linguistic information). The ternaryaccessibility relation R models the core notion of grammatical composition. We obtaina model by adding a valuation v assigning subsets v(p) of W to prime formulae p andsatisfying the clauses of Definition 2.2.1 for compound formulae.
Definition 2.2.1. Frame semantics: interpretation of compound formulae.
v(A • B) = {x |&y&z[Rxyz & y ' v(A) & z ' v(B)]}v(C/B) = {y |(x(z[(Rxyz & z ' v(B)) ) x ' v(C)]}v(A\C) = {z |(x(y[(Rxyz & y ' v(A)) ) x ' v(C)]}

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 102 — #8
102 Handbook of Logic and Language
Notice that the categorial vocabulary is highly restricted in its expressivity. In contrastwith standard Modal Logic, where the modal operators interact with the usual Booleanconnectives, the formula language of the type logics we are considering here is purelymodal.
We are interested in characterizing a relation of derivability between formulae suchthat A * B is provable iff v(A) + v(B) for all valuations v over ternary frames. Con-sider the deductive system NL, given by the basic properties of the derivability rela-tion refl and trans, together with the so-called residuation laws res establishingthe relation between • and the two implications /, \ with respect to derivability.Proposition 2.2.1 states the essential soundness and completeness result with res-pect to the frame semantics. (We write “L " A * B” for “A * B is provable inlogic L”).
Definition 2.2.2. The pure logic of residuation NL (Lambek, 1961).
(refl) A * A (trans) from A * B and B * C, infer A * C
(res) A * C/B iff A • B * C iff B * A\C
Proposition 2.2.1. (Došen, 1992). NL " A * B iff v(A) + v(B) for every valuationv on every ternary frame.
The proof of the ()) soundness part is by induction on the length of the deriva-tion of A * B. For the (,) completeness direction, one uses a simple canonicalmodel, which effectively falsifies non-theorems. To show that the canonical model isadequate, one proves a Truth Lemma to the effect that, for any formula ",MK, A |=" iff NL " A * ". Due to the Truth Lemma we have that if NL ! A * B, thenA ' vK(A) but A /' vK(B), so vK(A) " vK(B).
Definition 2.2.3. Define the canonical model as MK = $WK, R3K, vK%, where
(i) WK is the set of formulae F(ii) R3
K(A, B, C) iff NL " A * B • C(iii) A ' vK(p) iff NL " A * p
Structural Postulates, Constraints on Frames. In Section 2.1, we gave a deconstruc-tion of the notion of grammatical composition into a fixed “logical” component and avariable “structural” component. The pure logic of residuation NL captures the fixedlogical component: the completeness result of Proposition 2.2.1 puts no interpretiveconstraints whatsoever on the grammatical composition relation. Let us turn now tothe resource management component.
Starting from NL one can unfold a landscape of categorial type logics by grad-ually relaxing structure sensitivity in a number of linguistically relevant dimen-sions. Consider the dimensions of linear precedence (order sensitivity) and immediate

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 103 — #9
Categorial Type Logics 103
dominance (constituent sensitivity). Adding structural postulates licensing associativeor commutative resource management (or both) to the pure logic of residuation, oneobtains the systems L, NLP, and LP. In order to maintain completeness in the pres-ence of these structural postulates, one has to impose restrictions on the interpretationof the grammatical composition relation R3. Below we give the postulates of Associa-tivity and Commutativity with the corresponding frame constraints. The completenessresult of Proposition 2.2.1 is then extended to the stronger logics by restricting theattention to the relevant classes of frames.
Definition 2.2.4. Structural postulates and their frame conditions ((x, y, z, u ' W).
(ass) (A • B) • C - A • (B • C) &t.Rtxy & Rutz . &v.Rvyz & Ruxv
(comm) A • B * B • A Rxyz . Rxzy
Proposition 2.2.2. (Došen, 1992). L, NLP, LP " A * B iff v(A) + v(B) for everyvaluation v on every ternary frame satisfying (ass), (comm), (ass) + (comm), respec-tively.
Correspondence Theory. In the remainder of this chapter, we consider more dimen-sions of linguistic structuring than those affected by the Associativity and Commu-tativity postulates. In Kurtonina (1995) it is shown that one can use the tools ofmodal Correspondence Theory (van Benthem, 1984) to generalize the completenessresults discussed above to these other dimensions. A useful class of structural postu-lates with pleasant completeness properties is characterized in Definition 2.2.5. Theframe conditions for structural postulates of the required weak Sahlqvist form canbe effectively computed using the Sahlqvist–van Benthem algorithm as discussed inKurtonina (1995).
Definition 2.2.5. Weak Sahlqvist Axioms. A weak Sahlqvist axiom is an arrow ofthe form " * # where " is a pure product formula, associated in any order, withoutrepetition of proposition letters, and # is a pure product formula containing at leastone •, all of whose atoms occur in ".
Proposition 2.2.3. Sahlqvist Completeness (Kurtonina, 1995). If P is a weakSahlqvist axiom, then (i) NL + P is frame complete for the first-order frame condi-tion corresponding to P, and (ii) L+ P has a canonical model whenever L does.
Specialized Semantics. As remarked above, the choice for the modal frame semanticsis motivated by the desire to have a uniform interpretation for the extended and mixedcategorial architectures that form the core of this chapter. Grammatical composition ismodeled in an abstract way, as a relation between grammatical processes. There is notrace, in this view, of what one could call “syntactic representationalism”. As a matterof fact, the relational view on composition does not even require that for resources

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 104 — #10
104 Handbook of Logic and Language
y, z ' W there will always be a resource x such that Rxyz (Existence), or if such an xexists, that it be unique (Uniqueness).
For many individual systems in the categorial hierarchy, completeness results havebeen obtained for more concrete models. The “dynamic” interpretation of Lambek cal-culus interprets formulae with respect to pairs of points—transitions between infor-mation states. The • connective, in this setting, is seen as relational composition. InAndréka and Mikulás (1994), L is shown to be complete for this interpretation. Ingroupoid semantics, one considers structures $W, ·%, which can be seen as specializa-tions of the composition relation R3: one now reads Rxyz as x = y · z, where “·” isan arbitrary binary operation. Formulae are interpreted in the powerset algebra overthese structures, with the simplified interpretation clauses of (2.6) for the connectives,because the properties of “·” now guarantee Existence and Uniqueness.
v(A • B) = {x · y | x ' v(A) & y ' v(B)}v(C/B) = {x | (y ' v(B) x · y ' v(C)} (2.6)
v(A\C) = {y | (x ' v(A) x · y ' v(C)}
In the groupoid setting, options for resource management can be realized byattributing associativity and/or commutativity properties to the groupoid operation.Notice that the groupoid models are inappropriate if one wants to consider “one-directional” structural postulates (e.g., one half of the Associativity postulate, A • (B •C) * (A • B) • C, allowing restructuring of left-branching structures), unless one iswilling to reintroduce abstractness in the form of a partial order on the resources W.See Buszkowski (1986); Došen (1992) and Chapter 12 for discussion.
Even more concrete are the language models or free semigroup semantics for L.In the language models, one takes W as V+ (non-empty strings over the vocabulary)and · as string concatenation. This type of semantics turns out to be too specializedfor our purposes: whereas Pentus (1995), with a quite intricate proof, has been ableto establish completeness of L with respect to the free semigroup models, there is anincompleteness result for NL with respect to the corresponding free non-associativestructures, viz. finite tree models.
General Models versus Specific Grammars. In the discussion so far we have studiedtype-logical derivability in completely general terms, abstracting away from language-specific grammar specifications. Let us see then how we can relativize the generalnotions so as to take actual grammar specification into account. In accordance with thecategorial tenet of radical lexicalism, we assume that the grammar for a language L isgiven by the conjunction of the general type logic L with a language-specific lexiconlex(L). The lexicon itself is characterized in terms of a type assignment function f :VL * P(F), stipulating the primitive association of lexical resources VL with theirtypes. (We assume that for all lexical resources x ' VL, the sets f (x) are finite. Inthe so-called rigid categorial grammars, one further restricts the values of f to besingletons.)

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 105 — #11
Categorial Type Logics 105
For a general model M = $W, R3, v% to qualify as appropriate for lex(L), weassume VL + W, and we require the valuation v to be compatible with lexical typeassignment, in the sense that, for all x ' VL, A ' f (x) implies x ' v(A). Given this,we will say that the grammar assigns type B to a non-empty string of lexical resourcesx1, . . . , xn ' V+
L , provided there are lexical type specifications Ai ' f (xi) such that wecan deduce B from /(A1, . . . , An) in the general type logic L. By /(A1, . . . , An) wemean any of the possible products of the formulas A1, . . . , An, in that order.
Categorical Combinators and CCG. To round off the discussion of the axiomatic pre-sentation, we present the logics NL, L, NLP, LP with a proof term annotation, fol-lowing Lambek (1988). The proof terms—categorical combinators—are motivated byLambek’s original category-theoretic interpretation of the type logics. The category-theoretic connection is not further explored here, but the combinator proof terms willbe used in later sections as compact notation for complete deductions.
Definition 2.2.6. Combinator proof terms (Lambek, 1988). Deductions of the formf : A * B, where f is a process for deducing B from A.
1A : A * Af : A * B g : B * C
g / f : A * C
f : A • B * C$A,B,C( f ) : A * C/B
f : A • B * C%A,B,C( f ) : B * A\C
g : A * C/B
$01A,B,C(g) : A • B * C
g : B * A\C
% 01A,B,C(g) : A • B * C
&A,B,C : A • (B • C) - (A • B) • C : &01A,B,C
'A,B : A • B * B • A
Example 2.2.1. Combinator proof terms for rightward functional application, and forleftward type lifting. (We omit the type subscripts where they are clear from context.)In the derivation of lifting, we write RA for $01(1A/B).
1A/B : A/B * A/B$01(1A/B) : A/B • B * A
RA : A/B • B * A% (RA) : B * (A/B)\A
This presentation makes obvious a variety of methods for creating fragments (sub-systems) and extensions: restrict or extend the formula language; remove or add infer-ence rules; remove or add structural postulates. The Ajdukiewicz/Bar-Hillel system(Ajdukiewicz, 1935; Bar-Hillel, 1964) appears in this guise as a subsystem lackingthe hypothetical reasoning rules $ and % and the permutation rule ' , but implicitlycountenancing associativity. A more complex example is the rule-based approach of

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 106 — #12
106 Handbook of Logic and Language
Combinatory Categorial Grammar (CCG, Steedman, 1993) where a finite collectionof unary type transitions and binary type combinations (such as Lifting, Application)are postulated as primitive rule schemata. Within the CCG framework, CombinatoryLogic (Curry and Feys, 1958) is put forward as the general theory for the class of gram-matical operations natural languages draw upon. Combinatory Logic in itself, beingequivalent with the full Lambda Calculus in its expressivity, is not very informativeas to the fine-structure of grammatical inference. A decomposition of the CCG com-binators in their logical and structural parts uncovers the hidden assumptions aboutgrammatical resource management and makes it possible to situate the CCG systemswithin a more articulate landscape of grammatical inference. Comparing the CCGframework with the type-logical approach studied here, one should realize that CCGsystems are, by necessity, only approximations of logics such as L, LP. These logicshave been shown to be not finitely axiomatizable (see Zielonka, 1989 and Chapter 12),which means that no finite set of combinators in combination with Modus Ponens canequal their deductive strength.
2.2.2 Gentzen Calculus, Cut Elimination and Decidability
The axiomatic presentation is the proper vehicle for model-theoretic investigationof the logics we have considered: it closely follows the semantics, thus providing asuitable basis for “easy” completeness results. But proof-theoretically the axiomaticpresentation has a serious drawback: it does not offer an appropriate basis for proofsearch. The problematic rule of inference is trans, which is used to compose typetransitions A * B and B * C into a transition A * C. A type transition A * C, inthe presence of trans, could be effected with the aid of a formula B of which one findsno trace in the conclusion of the trans inference. Since there is an infinity of candi-date formulae B, exhaustive traversal of the search space for the auxiliary B formulain a trans inference is not an option.
For proof-theoretic investigation of the categorial type logics, one introduces aGentzen presentation which is shown to be equivalent to the axiomatic presentation.The main result for the Gentzen calculus (the Hauptsatz of Gentzen, 1934) then statesthat the counterpart of the trans rule, the Cut inference, can be eliminated from thelogic without affecting the set of derivable theorems. An immediate corollary of thisCut Elimination Theorem is the subformula property which limits proof search to thesubformulae of the theorem one wants to derive. In the absence of resource-affectingstructural rules, decidability follows. The essential results for L have been establishedin Lambek (1958). They have been extended to the full landscape of type logics inKandulski (1988a) and Došen (1988/1989).
In the axiomatic presentation, we considered derivability as a relation between for-mulae, i.e. we considered arrows A * B with A, B ' F . In the Gentzen presen-tation, the derivability relation is stated to hold between a term S (the antecedent)and a type formula (the succedent). A Gentzen term is a structured configuration offormulae—a structured database, in the terminology of Gabbay (1996). The term lan-guage is defined inductively as S ::= F |(S,S). The binary structural connective (·, ·)

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 107 — #13
Categorial Type Logics 107
in the term language tells you how structured databases (1 and (2 have been puttogether into a structured database ((1, (2). The structural connective mimics thelogical connective • in the type language. A sequent is a pair (!, A) with ! ' S andA ' F , written as ! ) A.
To establish the equivalence between the two presentations, we define the formulatranslation (/ of a structured database (:((1, (2)
/ = (/1 • (/
2, and A/ = A, forA ' F .
Proposition 2.2.4. (Lambek, 1958). For every arrow f : A * B there is a Gentzenproof of A ) B, and for every proof of a sequent ! ) B there is an arrow f : !/ * B.
Definition 2.2.7. NL: Gentzen presentation. Sequents S ) F where S ::=F |(S,S). We write ![(] for a term ! containing a distinguished occurrence of thesubterm (. (The distinguished occurrences in premise and conclusion of an inferencerule are supposed to occupy the same position within !.)
[Ax]A ) A
( ) A ![A] ) C![(] ) C
[Cut]
[/R](!, B) ) A! ) A/B
( ) B ![A] ) C![(A/B, ()] ) C
[/L]
[\R](B, !) ) A! ) B\A
( ) B ![A] ) C![((, B\A)] ) C
[\L]
[•L]![(A, B)] ) C![A • B] ) C
! ) A ( ) B(!, () ) A • B
[•R]
As was the case for the axiomatic presentation of Definition 2.2.2, the Gentzenarchitecture of Definition 2.2.7 consists of three components: (i) [Ax] and [Cut] cap-ture the basic properties of the derivability relation “)”: reflexivity and contextual-ized transitivity for the Cut rule; (ii) each connective comes with two logical rules: arule of use introducing the connective to the left of “)” and a rule of proof introduc-ing it on the right of “)”; and finally (iii) there is a block of structural rules, emptyin the case of NL, with different packages of structural rules resulting in systems withdifferent resource management properties. (We should note here that sometimes theCut rule is counted among the structural rules. We will reserve the term “structuralrule” for the Gentzen counterpart of the structural postulates governing the resourcemanagement properties of the composition operation.)
Structural Rules. Structural postulates, in the axiomatic presentation, have been pre-sented as transitions A * B where A and B are constructed out of formula vari-ables p1, . . . ,pn and the logical connective •. For corresponding structure variables(1, . . . ,(n and the structural connective (·, ·), define the structural equivalent ) (A)
of a formula A : ) (pi) = (i, ) (A • B) = () (A), ) (B)). The transformation of

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 108 — #14
108 Handbook of Logic and Language
structural postulates into Gentzen rules allowing Cut Elimination is then straightfor-ward: a postulate A * B translates as the Gentzen rule (2.7):
![) (B)] ) C![) (A)] ) C
(2.7)
To obtain the logics L, NLP, LP from NL, one thus adds the structural rules ofAssociativity and/or Permutation. Such additions result in less fine-grained notionsof linguistic inference, where structural discrimination with respect to the dimensionsof dominance and/or precedence is lost, as discussed above. (The double line in [A]stands for a two-way inference.)
![((2, (1)] ) A![((1, (2)] ) A
[P]![(((1, (2), (3)] ) A
![((1, ((2, (3))] ) A[A] (2.8)
Sugaring. For the logics L and LP where • is associative, resp. associative and com-mutative, explicit application of the structural rules is generally compiled away bymeans of syntactic sugaring of the sequent language. Antecendent terms then take theform of sequences of formulae A1, . . . , An where the comma is now of variable arity,rather than a binary connective. Reading these antecedents as sequences, one avoidsexplicit reference to the Associativity rule; reading them as multisets, one also makesPermutation implicit.
Definition 2.2.8. Sugared Gentzen presentation: implicit structural rules. SequentsS ) F where S ::= F |F,S. L: implicit Associativity, interpreting S as a sequence.LP: implicit Associativity + Permutation, interpreting S as a multiset. (The contextvariables !, !1 can be empty.)
[Ax]A ) A
( ) A !, A, !1 ) C!, (,!1 ) C
[Cut]
[/R](, B ) A( ) A/B
( ) B !, A, !1 ) C!, A/B, (,!1 ) C
[/L]
[\R]B, ( ) A
( ) B \A( ) B !, A, !1 ) C
!, (, B\A, ! ) C[\L]
[•L]!, A, B, !1 ) C!, A • B, !1 ) C
( ) A (1 ) B(, (1 ) A • B
[•R]
Cut Elimination and Decidability. A categorial version of Gentzen’s Hauptsatz is thecore of Lambek (1958), who proves Cut Elimination for L, on the basis of the “sug-ared” presentation introduced in Definition 2.2.8. In Došen (1988/1989) the result is

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 109 — #15
Categorial Type Logics 109
extended to the full landscape of categorial logics, using the structured term represen-tation of antecedent databases, and explicit structural rules. It is important to carefullydistinguish between an admissible rule of inference versus a derived one. We will seeexamples of derived rules of inference in Proposition 2.2.6: as the name indicates, onecan deduce the derived inference rules using the basic logical rules for the connectives.The Cut rule cannot be so derived—it does not mention any logical connectives, butis admissible in the sense that it does not increase the set of theorems that can alreadybe derived using just the logical rules of inference.
Proposition 2.2.5. Cut Elimination (Došen, 1988/1989; Lambek, 1958). The Cut ruleis admissible in NL, L, NLP, LP: every theorem has a cut-free proof.
Below we present the general strategy for the cut elimination transformation, so thatthe reader can check how the various extensions of the type-logical vocabulary wewill consider in the remainder of this chapter can be accommodated under the generalcases of the elimination schema.
Cut Elimination Algorithm. The proof of the admissibility of the Cut rule is a con-structive algorithm for a stepwise transformation of a derivation involving Cut infer-ences into a Cut-free derivation. Eliminability of the Cut rule is proved by inductionon the complexity d of Cut inferences, measured in the number of connective occur-rences. For the Cut rule of Definition 2.2.8, we have the following schema, with Cutcomplexity d defined as d(Cut) = d(() + d(!) + d(!1) + d(A) + d(B).
( ) A !, A, !1 ) B!, (,!1 ) B
Cut (2.9)
The targets for the elimination algorithm are instances of Cut which have them-selves been derived without using the Cut rule. It is shown that in the derivation inquestion such a Cut inference can be replaced by one or two Cuts of lower degree.One repeats the process until all Cuts have been removed. The following main casescan be distinguished.
Case 1 The base case of the recursion: one of the Cut premises is an Axiom. Inthis case the other premise is identical to the conclusion, and the application ofCut can be pruned.
Case 2 Permutation conversions. In these cases, the active formula in the left orright premise of Cut is not the Cut formula. One shows that the logical ruleintroducing the main connective of the active formula and the Cut rule can bepermuted, pushing the Cut inference upwards, with a decrease in degree becausea connective is now introduced lower in the proof. (Explicit structural rules forthe structured antecedent representation assimilate to this case: the Cut rule ispermuted upwards over the structural rule.)
Case 3 Principal Cuts. The active formula in the left and right premise of Cut makeup the Cut formula A. Here one reduces the degree by splitting the Cut formulaup into its two immediate subformulae, and applying Cuts on these.

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 110 — #16
110 Handbook of Logic and Language
Example 2.2.2. Case 2. The active formula in the left Cut premise is A1/A11. The Cutrule is moved upwards, permuting with the [/L] logical inference.
(11 ) A11 (, A1, (1 ) A
(, A1/A11, (11, (1 ) A/L
!, A, !1 ) B
!, (, A1/A11, (11, (1, !1 ) BCut !
(11 ) A11(, A1, (1 ) A !, A, !1 ) B
!, (, A1, (1, !1 ) BCut
!, (, A1/A11, (11, (1, !1 ) B/L
Example 2.2.3. Case 3. Principal Cut on A1/A11. The Cut inference is replaced by twoCuts, on the subformulae A1 and A11.
(, A11 ) A1
( ) A1/A11 /R(1 ) A11 !, A1, !1 ) B
!, A1/A11, (1, !1 ) B/L
!, (,(1, !1 ) BCut !
(1 ) A11(, A11, ) A !, A1, !1 ) B
!, (, A11, !1 ) BCut
!, (,(1, !1 ) BCut
Decidability, Subformula Property. In the case of NL, L, NLP, LP, the Cut Elimina-tion theorem immediately gives a decision procedure for theoremhood. One searchesfor a cut-free proof in a backward chaining manner, working from conclusion topremises. Every logical rule of inference removes a connective, breaking the selectedactive formula up into its immediate subformulae. The number of connectives of thegoal sequent is finite. Exhaustive traversal of the finite cut-free search space will eitherproduce a proof (a derivation tree the leaves of which are all instances of the Axiomschema), or it will fail to do so.
The important point about Cut Elimination and decidability is not so much to avoidthe Cut rule altogether, but to restrict the attention to “safe” cuts—instances of theCut rule that do not affect the finiteness of the search space. The astute reader willhave noticed that the left rules for the implications A\B (B/A) are in fact compiled Cutinferences on the basis of the subtypes A, B and Modus Ponens. These compiled Cutsare innocent: they preserve the complexity-decreasing property of the inference ruleswhich guarantees decidability. The compilation of [\L] can be found below.
( ) BB ) B A ) A
B, B\A ) A\L
(, B\A ) A[Cut]
!, A, !1 ) C!, (, B\A, !1 ) C
[Cut] !( ) B !, A, !1 ) C
!, (, B\A, *1 ) C\L
(2.10)Natural Deduction. As a final item on the list of presentation formats for categorialderivations, Definition 2.2.9 gives the official definition of the Natural Deduction for-mat used in Section 2.1. This style of presentation has Elimination rules and Introduc-tion rules for the logical connectives: the Cut rule is not a part of the Natural Deductionformat.
For the equivalence of the sequent and natural deduction styles the reader can turnto Girard, Taylor and Lafont (1989), where one finds explicit mappings relating thetwo presentations. The mapping from Gentzen proofs to natural deductions is many-to-one—there may be a number of Gentzen derivations for one and the same naturaldeduction. In this sense, natural deduction captures the “essence” of a proof better thana Gentzen derivation, which allows irrelevant permutation alternatives in deriving atheorem. We will be in a better position to assess this spurious type of non-determinism

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 111 — #17
Categorial Type Logics 111
of the sequent calculus after discussing the Curry–Howard interpretation of categorialdeductions, which gives a precise answer to the question as to which derivations are“essentially the same”. See Definition 2.3.4.
Definition 2.2.9. Natural deduction. Sequent-style presentation. Notation: ! " A fora deduction of the formula A from a configuration of undischarged assumptions !.Elimination/Introduction rules for NL. Structural rules as in (2.8).
A " A
[/I](!, B) " A! " A/B
! " A/B ( " B(!, () " A
[/E]
[\I](B, !) " A! " B\A
! " B ( " B\A(!, () " A
[\E]
[•I]! " A ( " B(!, () " A • B
( " A • B ![(A, B)] " C![(] " C
[•E]
2.2.3 Discussion: Options for Resource Management
In the previous sections, we have introduced the technical apparatus that is needed fora proper appreciation of the logics NL, L, NLP, LP. Let us turn now to the linguisticmotivation for the different resource management regimes these logics represent. Inorder to compare the strengths and weaknesses of these individual systems, Propo-sition 2.2.6 gives a useful inventory of characteristic theorems and derived rules ofinference for the logics in question. We leave their proof to the reader, who can testtheir understanding of the axiomatic and Gentzen presentations in deriving them.
Proposition 2.2.6. Characteristic theorems and derived inference rules for NL(1–6); L (7–11), plus (1–6); NLP (12–14), plus (1–6); LP (15), plus (1–14).
1. Application: A/B • B * A, B • B\A * A2. Co-application: A * (A • B)/B, A * B\(B • A)
3. Monotonicity •: if A * B and C * D, then A •C * B • D4. Isotonicity ·/C, C\·: if A * B, then A/C * B/C and C\A * C\B5. Antitonicity C/·, ·\C: if A * B, then C/B * C/A and B\C * A\C6. Lifting: A * B/(A\B), A * (B/A)\B7. Geach (main functor): A/B * (A/C)/(B/C), B\A * (C\B)\(C\A)
8. Geach (secondary functor): B/C * (A/B)\(A/C), C\B * (C\A)/(B\A)
9. Composition: A/B • B/C * A/C, C\B • B\A * C\A10. Restructuring: (A\B)/C - A\(B/C)
11. (De)Currying: A/(B • C) - (A/C)/B, (A • B)\C - B\(A\C)
12. Permutation: if A * B\C then B * A\C13. Exchange: A/B - B\A14. Preposing/Postposing: A * B/(B/A), A * (A\B)\B15. Mixed Composition: A/B • C\B * C\A, B/C • B\A * A/C

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 112 — #18
112 Handbook of Logic and Language
Items (1) to (6) are valid in the most discriminating logic NL. As shown in Došen(1988/1989), the combination of (1)–(5) provides an alternative way of characterizing(•, /) and (•, \) as residuated pairs, i.e. one can replace the RES inferences of Defi-nition 2.2.2 by (1) 0(5). The reader with a background in category theory recognizesthe adjointness (1–2) and functoriality (3–5) laws. Lifting is the closest one can get to(2) in “product-free” type languages, i.e. type languages where the role of the prod-uct operator (generally left implicit) is restricted to glue together purely implicationaltypes on the left-hand side of the arrow. Items (7) to (11) mark the transition to L: theirderivation involves the structural postulate of associativity for •. Rule (12) is charac-teristic for systems with a commutative •, NLP and LP. From (12) one immediatelyderives the collapse of the implications /and \, (13). As a result of this collapse, onegets variants of the earlier theorems obtained by substituting subtypes of the form A/Bby B\A or vice versa. Examples are (14), an NLP variant of Lifting, or (15), an LPvariant of Composition.
The Pure Logic of Residuation. Let us look first at the most discriminating logic inthe landscape, NL. In the absence of structural postulates for •, grammatical infer-ence is fully sensitive to both the horizontal and the vertical dimensions of linguisticstructure: linear ordering and hierarchical grouping. As in classical Ajdukiewicz stylecategorial grammar, Application is the basic reduction law for this system. But thecapacity for hypothetical reasoning already greatly increases the inferential strengthof NL in comparison with the pure application fragment. The principles of ArgumentLowering (e.g. (s/(np\s))\s * np\s) and Value Raising (e.g. np/n * (s/(np\s))/n),introduced as primitive postulates in Partee and Rooth (1983), turn out to be gene-rally valid type change schemata, derivable from the combination of Lifting and theIsotonicity/Antitonicity laws for the implications. These type-changing laws play animportant role in the semantic investigation of categorial type systems, as we will seein Section 2.3. On a more general level, it is pointed out in Lambek (1988) that Liftingis a closure operation, as it obeys the defining principles (11). (We write AB for eitherB/(A\B) or (B/A)\B).
A * AB (AB)B * AB from A * C, infer AB * CB (2.11)
Associativity and Flexible Constituency. An essential limitation of the pure residuationlogic is its rigid concept of constituency—a property which NL shares with conven-tional phrase structure grammars. The revival of interest in categorial grammar wasinspired in the first place by a more fiexible notion of constituent structure, depend-ing on L theorems such as the Geach laws, Functional Composition, or its recursivegeneralization. These Geach and Composition principles are formulated as implica-tional laws, but with the interpretation of the type-logical connectives we have beenassuming, the implicational laws and the product versions of the structural postulatesare interderivable.
Example 2.2.4. Deriving (one half of) Associativity from (one directional instan-tiation of) Geach. (We write b for the left-division variant of principle (7) in

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 113 — #19
Categorial Type Logics 113
Proposition 2.2.6, and use X as an abbreviation for A • ((A\(A • B)) • ((A • B)\((A •B) • C))).)
b : A\B * (C\A)\(C\B)
% 01(b) : C\A • A\B * C\B(†)% 01(% 01(b)) : C • (C\A • A\B) * B
(2) : B * A\(A • B) (2) : C * (A • B)\((A • B) • C)
A * A (3) : B • C * (A\(A • B)) • ((A • B)\((A • B) • C))
(3) : A • (B • C) * X (†) : X * (A • B) • CA • (B • C) * (A • B) • C
Associative resource management makes the grammar logic insensitive to hierar-chical constituent structure: derivability of a sequent ! ) A is preserved under arbit-rary rebracketings of the antecedent assumptions !, a property which is referred to asthe structural completeness of L (Buszkowski, 1988). The free availability of restruc-turing makes it possible to give alternative constituent analyses for expressions thatwould count as structurally unambiguous under rigid constituency assumptions, suchas embodied by NL.
Example 2.2.5. Restructuring: subject-(verb-object) versus (subject-verb)-object ana-lysis. Derivation in CCG tree format, in terms of the combinators Lifting, Compo-sition, and Application. One can see the CCG trees as concise representations ofcombinator proofs in the sense of Definition 2.2.6, given as compositions of “primi-tive” CCG arrows.
Mary
Marynp
cooked(np\s)/np
the beansnp
np\sapp
nps/(np\s)
liftcooked
(np\s)/nps/np
compthe beans
npapp app
s s
Coordination phenomena provide crucial motivation for associative resource man-agement and the non-standard constituent analyses that come with it (cf. Dowty, 1988;Steedman, 1985; Zwarts, 1986) for the original argumentation. On the assumption thatcoordination joins expressions of like category, theories of rigid constituency run intoproblems with cases of so-called non-constituent coordination, such as the Right NodeRaising example below. With an associative theory of grammatical composition, non-constituent coordination can be reduced to standard coordination of phrases of liketype. As will become clear in Section 2.3, the interpretation produced for the s/npinstantiation of the coordination type is the appropriate one for a theory of generalizedconjoinability such as Keenan and Faltz (1985); Partee and Rooth (1983).

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 114 — #20
114 Handbook of Logic and Language
Example 2.2.6. Conjunction of non-constituents. Natural Deduction format.Polymorphic type schema for “and”.
hatesloves Ferdinand ((np\s)/np) np /E
Kazimierznp
((np\s)/np) np(np\s)
/Eand
(X.(X\X)/Xnp (np\s)
s\E
\E (E /Is (((s/np)\(s/np))/(s/np)) (s/np)/I /E
(s/np) ((s/np)\(s/np)) Gottlob\E(s/np) np /E
s
Other types of argumentation for fiexible constituency have been based on pro-cessing considerations (an associative regime can produce an incremental left-to-rightanalysis of a sentence cf. Ades and Steedman, 1982), or intonational structure (dis-tinct prosodic phrasing realizing alternative information packaging for the same truthconditional content, cf. Steedman, 1991).
Unfortunately, the strength of L is at the same time its weakness. Associativeresource management globally destroys discrimination for constituency, not just whereone would like to see a relaxation of structure sensitivity. Standard constituent anal-yses provide the proper basis for the characterization of domains of locality: in anassociative setting, the constituent information is lost. As examples of the resultingovergeneration one can cite violations of the Coordinate Structure Constraint such as(2.12). The type assignment (n\n)/(s/np) to the relative pronoun requires Gottlobadmired Kazimierz and Jim detested’ to be of type s/np. With an instantiation (s\s)/sfor the conjunction, and an associative regime of composition, there is nothing thatcan stop the derivation of (2.12), as pointed out in Steedman (1993), where this typeof example is traced back to Lambek (1961).
2(the mathematician) whom Gottlob admired Kazimierz and Jim detested(2.12)
Discontinuous Dependencies and Restricted Commutativity. The discussion aboveshows that L is too strong in that it fully ignores constituent information. But at thesame time, the order sensitivity of this logic makes it too weak to handle discontinuousdependencies. A case in point are the crossed dependencies of the Dutch verb cluster.In the example below, the verb raising trigger “wil” has to combine with the infinitival“voeren” before the latter (a transitive verb) combines with its direct object.
Example 2.2.7. Dutch verb clusters via Mixed Composition. (We write iv for infini-tival verb phrases, vp for tensed ones.)
(dat Marie) de nijlpaarden (np) wil (vp/iv) voeren (np\iv)“(that Mary) the hippos wants feed” (= that M. wants to feed the hippos)vp/iv, np\iv ) np\vp (Mixed Composition)
A/B * (C\A)/(C\B) (Mixed Geach, schematically)

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 115 — #21
Categorial Type Logics 115
In order to form the cluster “wil voeren” in such a way that it “inherits” the argu-ments of the embedded infinitive, composition laws (or their Geach generalizations)have been proposed (Moortgat, 1988; Steedman, 1984) that would combine functorswith conflicting directionality requirements, so-called Mixed Composition. Clearly,with these laws, one goes beyond the inferential capacity of L. As the reader cancheck with the aid of Example 2.2.4, the product counterpart of the mixed Geach tran-sition of Example 2.2.7 is A• (B•C) * B• (A•C), which together with Associativityintroduces a contextualized form of Commutativity. The permutation side effects ofMixed Composition cause a damaging loss of control over the grammatical resources.Not surprisingly, then, the introduction of such combination schemata went hand inhand with the formulation of extralogical control principles. A more attractive alter-native will be presented in Example 2.4.1.
Conclusion. Let us summarize this discussion. The individual simple Lambek systemseach have their merits and their limitations when it comes to grammatical analysis. Asa grammar writer, one would like to exploit the inferential capacities of a combinationof different systems. Importing theorems from a system with more relaxed resourcemanagement into a logic with a higher degree of structural discrimination is not aviable strategy: it globally affects sensitivity for the relevant structural parameter ofthe more discriminating logic. In Section 2.6.1 we will develop a logical frameworksupporting a truly “mixed” style of categorial inference. Structural collapse is avoidedby moving to a multimodal architecture which is better adapted to deal with the fine-structure of grammatical composition. But first we discuss an aspect of grammaticalinference which is of crucial importance for the categorial architecture but which hasbeen ignored so far: the syntax-semantics interface.
2.3 The Syntax-Semantics Interface: Proofs and Readings
Categorial type logics offer a highly transparent view on the relation between formand meaning: semantic interpretation can be read off directly from the proof whichestablishes the well-formedness (derivability) of an expression. The principle of com-positionality (see Chapters 1 and 10) is realized in a particularly stringent, purelydeductive form, leaving no room for rule-to-rule stipulated meaning assignment.
In Section 2.1 we noticed that the categorial program ultimately has its ancestry inRussell’s theory of types. In the original “Polish” version of the program, categorialtypes were viewed simultaneously in the syntactic and in the semantic dimension.This unified perspective was lost in subsequent work: Lambek developed catego-rial calculi as theories of syntactic types, and Curry advocated the application of hissemantic types of functionality in natural language analysis—a development whichled up to Montague’s use of type theory. The divergence can be traced back to Jakob-son (1961), where Curry (1961) in fact criticizes Lambek (1961) for introducingthe structural dimension of grammatical composition in his category concept. Thesedivergent lines of research were brought together again in van Benthem (1983), who

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 116 — #22
116 Handbook of Logic and Language
established the connection between Lambek’s categorial framework and the Curry–Howard “formulas-as-types” program.
In the logical setting, the Curry–Howard program takes the form of an isomor-phism between (Natural Deduction) proofs in the Positive Intuitionistic PropositionalLogic and terms of the + calculus. In the categorial application, one is interested inthe Curry–Howard mapping as a correspondence rather than an isomorphism, in thesense that derivations for the various categorial logics are all associated with LP termrecipes. The system LP, in this sense, plays the role of a general semantic compositionlanguage which abstracts away from syntactic fine-structure. As we have seen in Sec-tion 2.2, the form dimension of grammatical composition can be profitably studied inthe context of the frame semantics for the type formulae: on that level, the structuralpostulates regulating sub-LP resource management naturally find their interpretationin terms of frame constraints.
The emphasis in this section is on the limited semantic expressivity of the catego-rial languages. With respect to the original intuitionistic terms, the LP fragment obeyslinearity constraints refiecting the resource sensitivity of the categorial logic; movingon to more discriminating systems, the set of derivable readings further decreases.The price one pays for obtaining more fine-grained syntactic discrimination may bethe loss of readings one would like to retain from a purely semantic point of view.This tension has played an important role in the development of the field. To regainlost readings one can enrich the logical vocabulary, and introduce more delicate typeconstructors compatible with both the structural and the semantic aspects of gram-matical composition. And one can exploit the division of labor between lexical andderivational semantics. We discuss this theme in Section 2.3.2. In Section 2.3.1 wefirst introduce the necessary technical material, basing the exposition on van Benthem(1991,1995); Hendriks (1993); Wansing (1992b). Our treatment of term assignmentfocuses on the Gentzen presentation of the categorial calculi. For a parallel treatmentin terms of Natural Deduction, the reader can turn to Chapter 12.
2.3.1 Term Assignment for Categorial Deductions
We start our discussion of semantic term assignment with the system at the top of thecategorial hierarchy—the system LP. Instead of sequents A1, . . . , An ) B we nowconsider annotated sequents x1 : A1, . . . , xn : An ) t : B where the type formulae aredecorated with terms—distinct xi for the assumptions and a term t constructed outof these xi, in ways to be made precise below, for the goal. On the intuitive level,a derivation for an annotated sequent will represent the computation of a denotationrecipe t of type B with input parameters xi of type Ai. Let us specify the syntax andsemantics of the language of type formulae and term labels, and define the systematicassociation of the term labeling with the unfolding of a sequent derivation.
In the case of LP, we are considering a type language with formulaeF ::= A|F *F |F / F (the two implications collapse in the presence of Permutation). The choiceof primitive types A will depend on the application. A common choice would bee (the type of individual objects) and t (the type of truth values). In Section 2.3.2,

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 117 — #23
Categorial Type Logics 117
we will encounter more elaborate inventories for the “dynamic” approach to naturallanguage semantics. For semantic interpretation of the type language, we considerframes F = {DA}A'F based on some non-empty set E, the domain of discourse. Suchframes consist of a family of semantic domains, one for each type A ' F , such that
DA/B = DA ! DB (Cartesian product) DA*B = DDAB (Function space)
(2.13)
For the primitive types we can fix De = E and Dt = {0, 1} (the set of truth values).We need a representation language to refer to the objects in our semantic structures.
The language of the typed lambda calculus (with its familiar interpretation with respectto standard models) will serve this purpose.
Definition 2.3.1. Syntax of typed lambda terms. Let VA be the set of variables oftype A. The set * of typed + terms is {T A}A'F , where for all A, B ' F :
T A ::= VA|T B*A(T B)|(T A/B)0|(T B/A)1
T A*B ::= +VAT B T A/B ::= $T A, T B%We now have all the ingredients for presenting term assignment to LP sequent
proofs. We proceed in two stages: first we present the algorithm for decorating LPderivations with intuitionistic term labeling. For Intuitionistic Logic, there is a per-fect correspondence between (Natural Deduction) proofs and * terms. But not everyintuitionistic theorem is LP derivable. In the second stage, then, we identify a sub-language *(LP) of terms which effectively correspond to the resource-sensitive LPderivations.
Definition 2.3.2. Term assignment for LP. Notation: x, y, z for variables; t, u, v forarbitrary terms; u[t/x] for the substitution of term t for variable x in term u. In sequentsx1 : A1, . . . , xn : An ) t : B, the antecedent xi are distinct. For the implication *,the rule of use corresponds to functional application, the rule of proof to functionalabstraction (+ binding). For /, the rule of proof corresponds to pairing, the rule of useto projection. The Cut rule corresponds to substitution.
x : A ) x : A(Ax)
! ) t : A x : A, ( ) u : B!, ( ) u[t/x] : B
(Cut)
!, x : A, y : B, ( ) t : C!, y : B, x : A, ( ) t : C
(P)
( ) t : A !, x : B ) u : C!, (, y : A * B ) u[y(t)/x] : C
(* L)!, x : A ) t : B
! ) +x.t : A * B(* R)
! ) t : A ( ) u : B!, ( ) $t, u% : A / B
(/R)!, x : A, y : B ) t : C
!, z : A / B ) t[(z)0/x, (z)1/y] : C(/L)

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 118 — #24
118 Handbook of Logic and Language
Unlike intuitionistic resource management, where the structural rules of Contrac-tion and Weakening are freely available, the LP regime requires every resource in aproof to be used exactly once. For the implicational fragment, Proposition 2.3.1 indi-cates how the resource sensitivity of LP translates into the syntactic properties of itsproof terms, as specified in Definition 2.3.32
Definition 2.3.3. Let *(LP) be the largest ! + * such that
(i) each subterm of t ' ! contains a free variable(ii) no subterm of t ' ! contains more than one free occurrence of the same variable
(iii) each occurrence of the + abstractor in t ' ! binds a variable within its scope
Proposition 2.3.1. (Buszkowski, 1987; van Benthem, 1987; Wansing, 1992b). Corre-spondence between LP proofs and *(LP) terms. Given an LP derivation of a sequent) = A1, . . . , An ) B one can find a construction tB ' *(LP) of ) , and conversely(where a term tB ' *(LP) is called a construction of a sequent A1, . . . , An ) B iff thas exactly the free variable occurrences xA1
1 , . . . , xAnn .)
Identifying Proofs. So far we have been concerned with individual terms, not withrelations of equivalence and reducibility between terms. Given the standard interpre-tation of the * term language, the equations (E1) to (E4) of Definition 2.3.4 representsemantic equivalences of certain terms. Read from left (redex) to right (contractum),these equivalences can be seen as valid term reductions. From the Gentzen proof-theoretic perspective, it is natural to look for the operations on proofs that correspondto these term reductions.
Definition 2.3.4. Term equations and their proof-theoretic reflexes (Lambek, 1993;Wansing, 1992b). (E1) and (E3) correspond to $ reduction, (E2) and (E4) to , reduc-tion for function and product types, respectively.
(E1) (+xA.t B)u = t[u/x] principal Cut on A * B(E2) +xA.(tx)B = t non-atomic axiom A * B(E3) ($t A, uB%)0 = t ($t, u%)1 = u principal Cut on A / B(E4) $(t A/B)0, (t A/B)1%% = t non-atomic axiom A / B
The terms for Cut-free proofs are in $-normal form: the principal Cut Elimina-tion step replaces a redex by its contractum. Proofs restricted to atomic axioms yield,-expanded terms. Such proofs can always be simplified by substituting complexaxioms for their unfoldings, yielding ,-normal proof terms. The search space for Cut-free proofs is finite. Exhaustive Cut-free search produces the finite number of LP
2 For the product, one needs an auxiliary notion specifying what it means for the variables associated withthe use of / to be used “exactly once”, cf. Roorda (1991). In Linear Logic, alternative term assignmentfor the product is available in terms of a construct which directly captures the resource sensitivity of theproof regime: let s be x / y in t. See Troelstra (1992).

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 119 — #25
Categorial Type Logics 119
readings, thus providing a proof-theoretic perspective on the Finite Reading Propertyfor LP established in van Benthem (1983).
Example 2.3.1. Principal Cut: $-conversion. Input:
!, x : B ) t : A! ) +x.t : A/B
[R/](1 ) u : B (, z : A, (11 ) v : C(, y : A/B, (1, (11 ) v[y(u)/z] : C
[L/]
(, !,(1, (11 ) v[y(u)/z][+x.t/y] : C[Cut]
Output:
(1 ) u : B !, x : B ) t : A [Cut]!, (1 ) t[u/x] : A (, z : A, (11 ) v : C
(, !,(1, (11 ) v[t[u/x]/z] : C[Cut]
Example 2.3.2. Complex axioms: ,-conversion.
x : B ) x : B y : A ) y : A [L/]v : A/B, x : B ) y[v(x)/y] : Av : A/B ) +x.y[v(x)/y] : A/B
[R/] !.
v : A/B ) v : A/B[Ax]
Term Assignment for Syntactically more Discriminating Systems. In moving to thesyntactically more discriminating inhabitants of the categorial landscape, we have twooptions for setting up the term assignment. The primary interest of the working lin-guist is not so much in the two-way correspondence between terms and proofs, butrather in the one-way computation of a meaning recipe as an automatic spin-off ofproof search. From this perspective, one can be perfectly happy with LP term deco-ration also for the logics with a more developed structure-sensitivity. One relies hereon a healthy division of labor between the syntactic and semantic dimensions of thelinguistic resources. The role of the uniform *(LP) term labeling is to capture thecomposition of signs qua semantic objects. Linguistic composition in the form dimen-sion is captured in the term structure over antecedent assumptions. As the commondenominator of the various calculi in the categorial hierarchy, LP can play the roleof a generalpurpose language of semantic composition. (In LFG, LP functions in asimilar way as the semantic glue language, cf. Dalrymple et al., 1995.)
In order to accommodate the dualism between syntactic and semantic types, wedefine a mapping t :F *F 1 from syntactic to semantic types, which interprets com-plex types’ modulo directionality.
t(A/B) = t(B\A) = t(B) * t(A), t(A • B) = t(A) / t(B) (2.14)
The primitive type inventory is a second source of divergence: categorizing signs intheir syntactic and semantic dimensions may lead to different choices of atomic types.

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 120 — #26
120 Handbook of Logic and Language
(For example, both common nouns (n) and verb phrases (np\s) may be mapped to thesemantic type e * t of properties.)
Definition 2.3.5. Term assignment for “sublinear” calculi NL, L, NLP using *(LP)
as the language of semantic composition. Structural rules, if any, are neutral with res-pect to term assignment: they manipulate formulae with their associated term labels.
[Ax]x : A ) x : A
( ) u : A ![x : A] ) t : C![(] ) t[u/x] : C
[Cut]
[/R](!, x : B) ) t : A! ) +x.t : A/B
( ) t : B ![x : A] ) u : C![(y : A/B, ()] ) u[y(t))/x] : C
[/L]
[\R](x : B, !) ) t : A! ) +x.t : B\A
( ) t : B ![x : A] ) u : C![((, y : B\A)] ) u[y(t)/x] : C
[\L]
[•L]![(x : A, y : B)] ) t : C
![z : A • B] ) t[(z)0/x, (z)1/y] : C! ) t : A ( ) u : B(!, () ) $t, u% : A • B
[•R]
The alternative for the dualistic view is to equip the various inhabitants of the cate-gorial landscape with more structured semantic term languages which directly reflectthe syntactic resource management regime of the logics in question. In Buszkowski(1987); Wansing (1992b); Hepple (1994) one finds a term language which distin-guishes left- and right-oriented forms of abstraction +l, +r and application. Theseallow for a refinement of the term restrictions characterizing the *(L) fragment andthe two-way correspondence between term constructions and proofs: in the case of Lthe left (right) abstractors bind the leftmost (rightmost) free variable in their scope. Ina similar vein, one could look for a structural characterization of the non-associativityof NL.
As long as the interpretation of the types is given in terms of function spaces andCartesian products, the distinctions between left/right abstraction/application remainpurely syntactic. For a more ambitious programme, see Abrusci (1996), who proposesa refinement of the notion “meaning of proofs” in the context of a generalization of thecoherence semantics for Linear Logic. One considers bimodules on coherent spacesand refines the class of linear functions into left-linear and right-linear functions. Inter-preting A on the coherent space X and B on the coherent space Y, DA\B (resp. DB/A)is the coherent space of all the left-linear (resp. right-linear) functions from X to Y .
Natural Deduction. For the display of sample derivations in the following section, wewill continue to use the handy natural deduction format, which is presented below inits term-annotated form.
Definition 2.3.6. Term assignment: (sequent-style) Natural Deduction. Notation:! " t : A for a deduction of the formula A decorated with term t from a structuredconfiguration of undischarged term-decorated assumptions !.

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 121 — #27
Categorial Type Logics 121
x : A " x : A
[/I](!, x : B) " t : A! " +x.t : A/B
! " t : A/B ( " u : B(!, () " t(u) : A
[/E]
[\I](x : B, !) " t : A! " +x.t : B\A
! " u : B ( " t : B\A(!, () " t(u) : A
[\E]
[•I]! " t : A ( " u : B(!, () " $t, u% : A • B
( " u : A • B ![(x : A, y : B)] " t : C![(] " t[(u)0/x, (u)1/y] : C
[•E]
2.3.2 Natural Language Interpretation: The Deductive View
For an assessment of categorial type logics in the context of Montague’s UniversalGrammar program, it is instructive to compare the type-logical deductive view on thecomposition of linguistic meaning with the standard Montagovian rule-to-rule philo-sophy as discussed in Chapter 1. The rule-to-rule view on the syntax-semantics inter-face characterizes syntax in terms of a collection of syntactic rules (or rule schemata);for every syntactic rule, there is a corresponding semantic rule, specifying how themeaning of the whole is put together in terms of the meaning of the parts and the waythey are put together. Apart from the homomorphism requirement for the syntacticand semantic algebras, compositionality, in its rule-to-rule implementation, does notimpose any principled restrictions on exactly what operations in the semantic algebraone wants to line up with the syntactic algebra: the correlation between syntactic andsemantic rules/operations can be entirely stipulative.
The type logical approach, as we have seen in Section 2.2 eliminates “syntax”as a component of primitive rules. Instead of syntactic rules, one finds theorems—deductive consequences derived from the interpretation of the type-constructors. Inthe absence of syntactic rules, there can be no rule-to-rule stipulated assignment ofmeaning to derivations: rather, every theorem has to derive its meaning from its proof,again purely in terms of the semantic action of the type-constructors under the Curry–Howard correspondence.
Example 2.3.3. Argument lowering (Partee and Rooth, 1983): the lexical type assign-ment for the verb “needs”, (np\s)/((s/np)\s), can be lowered to (np\s)/np. As dis-cussed in Section 2.2, the principle is generally valid in the pure residuation logic NL.
needsneeds : (np\s)/((s/np)\s)
x1 : s/np x0 : npx1(x0) : s
/E
+x1.x1(x0) : (s/np)\s\I
needs(+x1.x1(x0)) : np\s+x0.needs(+x1.x1(x0)) : (np\s)/np
/I/E
Derivational Ambiguity: Proofs and Readings. The rule-to-rule implementation ofcompositionality requires there to be a unique meaning assignment for every syntactic

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 122 — #28
122 Handbook of Logic and Language
rule. If one would like to associate different semantic effects with what looks like oneand the same syntactic rule, one has to introduce diacritics in the syntax in order tokeep the homomorphism requirement intact. In contrast, for the type-logical approachmeaning resides in the proof, not in the type-change theorem that labels the conclusionof a proof. Different ways of proving one and the same goal sequent may, or may not,result in different readings.
Example 2.3.4. As an example of derivational ambiguity, we consider the type-shifting principle known as Argument Raising (Partee and Rooth, 1983). The deriva-tions below represent two semantically distinct L proofs of the theorem (np\s)/np )((s/(np\s))\s)/((s/np)\s), turning a simple first-order transitive verb into a third-order functor taking second-order generalized quantifier type arguments, encoding thesubject wide scope reading (†) and object wide scope (‡) reading, respectively.
tvtv : (np\s)/np x1 : np
tv(x1) : np\s/E
x0 : np \E
(†)
tv(x1)(x0) : s+x1.tv(x1)(x0) : s/np
/Ix2 : (s/np)\s
x2(+x1.tv(x1)(x0)) : s+x0.x2(+x1.tv(x1)(x0)) : np\s
\I\E
x3 : s/(np\s)/E
x3(+x0.x2(+x1.tv(x1)(x0))) : s+x3.x3(+x0.x2(+x1.tv(x1)(x0))) : (s/(np\s))\s
\I
+x2+x3.x3(+x0.x2(+x1.tv(x1)(x0))) : ((s/(np\s))\s)/((s/np)\s)/I
tvtv : (np\s)/np x1 : np
tv(x1) : np\s/E
x0 : np \Etv(x1)(x0) : s
+x0.tv(x1)(x0) : np/s/I
x2 : s/(np\s)(‡) /E
x2(+x0.tv(x1)(x0)) : s+x1.x2(+x0.tv(x1)(x0)) : s/np
/Ix3 : (s/np)\s
x3(+x1.x2(+x0.tv(x1)(x0))) : s+x2.x3(+x1.x2(+x0.tv(x1)(x0))) : (s/(np\s))\s
\I
+x3+x2.x3(+x1.x2(+x0.tv(x1)(x0))) : ((s/(np\s))\s)/((s/np)\s)/I
\E
Lexical Versus Derivational Semantics. The derivational semantics of a sequent ! )t : A gives a meaning recipe t in terms of free variables xi for the antecedent assump-tions Ai in !, the “parameters” of the recipe. In the actual computation of the mean-ing of a natural language expression, we substitute the lexical meanings of the words

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 123 — #29
Categorial Type Logics 123
constituting the expression for these variables. For the logically more exciting part ofthe vocabulary, this will involve the substitution of a compound + term representingthe lexical meaning for a parameter in the proof term. The strict division of labor bet-ween the role assigned to derivational and lexical semantics realizes a fully modularimplementation of compositionality, which has a number of pleasant consequences:on the level of individual lexical items, lexical semantics can overcome the expressivelimitations of the resource-conscious derivational component; on a more global level,one can interface the neutral derivational semantics with one’s favorite semantic the-ory via an appropriate category-to-type mapping and lexical meaning assignment. Weillustrate these two aspects in turn.
Non-Linear Meaning Recipes. We saw that the resource-sensitive LP terms have theproperty that every assumption is used exactly once: the lambda operator binds exactlyone variable occurrence. Natural language semantics, in a variety of constructions,requires the identification of variables. Assigning multiple-bind terms to the rele-vant classes of lexical items one can realize variable-sharing while maintaining theresource-sensitivity of derivational semantics.
Example 2.3.5. “Everyone loves himself”. Proof term and substitution of lexicalrecipes. (Notice that reductions after lexical substitution can destructively affect theproof term, in the sense that the original proof term becomes irrecoverable after the“lexical” $ conversions.)
himself((np\s)/np)\(np\s) := +x+y.x(y)(y)
everyones/(np\s) := +x(y(person (y) ) x(y))
everyoneeveryone : s/(np\s)
x0 : np
x1 : np
lovesloves : (np\s)/np x2 : np
loves(x2) : np\s/E
loves(x2)(x1) : s\E
+x1.loves(x2)(x1) : np\s\I
+x2+x1.loves(x2)(x1) : (np\s)/np/I
himselfhimself : ((np\s)/np)\(np\s)
himself(+x2+x1.loves(x2)(x1)) : np\s\E
himself(+x2+x1.loves(x2)(x1))(x0)) : s\E
+x0.himself(+x2+x1.loves(x2)(x1))(x0)) : np\s\I
everyone(+x0.himself(+x2+x1.loves(x2)(x1))(x0)) : s/E
everyone(+x0.himself(+x2+x1.loves(x2)(x1))(x0)) *$ (y.person(y) ) love(y)(y)
Derivational Semantics: Portability. The proof terms associated with categorialderivations relate structural composition in a systematic way to the composition ofmeaning. The derivational semantics is fully neutral with respect to the particular “the-ory of natural language semantics” one wants to plug in: an attractive design propertyof the type-logical architecture when it comes to portability. An illustration can befound in Muskens (1994), who proposes a type-logical emulation of Discourse Rep-resentation in Context (cf. Chapter 3) driven by a categorial proof engine.

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 124 — #30
124 Handbook of Logic and Language
Discussion: Quantifier Scope Ambiguities
We close this section with a discussion of scope ambiguities involving generalizedquantifier expressions: these phenomena nicely illustrate the tension between the com-position of form and meaning, and the different strategies for resolving these tensions.
Consider generalized quantifier expressions like “someone”, “everybody”. Fromthe perspective of LP, we can study their semantic contribution via a standard Fregeantype assignment (e * t) * t, with lexical recipes +x.&y[x(y)], +x.(y[x(y)]. The LPnotion of derivability, of course, is too crude to offer a unified deductive accountof semantics in conjunction with syntax. Suppose we want to refine the LP type(e * t) * t to take syntactic fine-structure into account. Within L, one can find twodirectional realizations compatible with the fact that generalized quantifiers occupythe positions of ordinary (proper noun) noun phrases: s/(np\s) and (s/np)\s. Butimposing order sensitivity in the type-assignment already causes the loss of scopereadings one wants to preserve. Compare “peripheral” versus “medial” occurrencesof generalized quantifiers. Given a “direct object” assignment (s/np)\s to “someone”,both the (a) and (a1) readings are L-derivable. Given a “subject” assignment s/(np\s)the (b) reading is not derivable: in L one only derives the narrow scope reading (b1).
(a) Suzy thinks Mary loves someone ! someone(+x.thinks(loves(x)(m))(s))
(a1) ! thinks(someone(+x.loves(x)(m)))(s)
(b) Suzy thinks someone loves Mary ! someone(+x.thinks(loves(m)(x))(s))
(b1) ! thinks(someone(+x.loves(m)(x)))(s)(2.15)
The diagnosis of the problem is easy in the light of Section 2.2: the (b) reading wouldrequire the generalized quantifier expression to enter into structural composition witha discontinuous configuration of resources: such syntactic behavior is beyond theexpressivity of the (N)L connectives:
Suzy thinks someone loves Mary
We compare two strategies to resolve this problem: (i) in the rule-based approach, onepostulates type-change axiom schemata to regain the lost readings; (ii) in the deductiveapproach, one enriches the vocabulary of connectives with logical constants such thatthese axiom schemata become derivable theorems. Flexible Montague Grammar Hen-driks (1993), and the closely related polymorphic approach of Emms (1993) are rep-resentatives of (i). The deductive alternative has been developed in Moortgat (1996a);Morrill (1995a); Carpenter (1996).
Flexible Montague Grammar. Hendriks’ proposal is formulated as a flexible version ofMontague Grammar (FMG). For an assessment in the Montagovian context we referto Chapter 1. Our objective here is to give a type-logical reconstruction of the essen-tial ideas. Syntactically, FMG is restricted to combine phrases by means of function

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 125 — #31
Categorial Type Logics 125
application rule schemata. In order to accommodate quantificational scope ambigu-ities, the category-to-type mapping is relaxed to a relation rather than a function: agiven syntactic type is associated with a set of semantic types. The semantic typesare not unrelated: from a generator type an infinite number of semantic types (and theassociated meaning recipes) are derived via the type-shifting rule schemata of ValueRaising (VR), Argument Lowering (AL), and Argument Raising (AR).
Let us identify the pure application syntax of FMG as NL, and try to pinpointexactly where the type-shifting schemata give a surplus inferential capacity. As wehave seen in Section 2.2, Value Raising and Argument Lowering are universally validalready in the pure residuation logic NL: they reflect the monotonicity properties of theimplicational type constructors. Argument Raising, as a semantic type-shifting rule, isschematically characterized in (2.16) (where 3A * B abbreviates A1 *. . . An * B,and similiarly for 3x).
(AR)3A * B * 3C * D ) 3A * ((B * D) * D) * 3C * D(2.16)
t ) +3x3A+w(B*D)*D+3y3C.w(+zB.t(3x)(z)(3y))
Directional realizations of this schema are not generally valid. We saw two specialcases in our Example 3.11: these happened to be derivable, in the associative setting ofL, for generalized quantifiers occupying peripheral positions in their scopal domain.But what we would like to have in full generality is the possibility of having a gene-ralized quantifier phrase at any np position, exerting its binding force at any s level ofembedding.
As an illustration for the FMG type-shifting approach, take the sentence “Kaz-imierz thinks someone left”. In (2.17) we list the necessary steps producing the widescope reading for “someone”. We give both the semantic shifts—abbreviating A * Bas (AB)—and their directional counterpart. The (AR) transition for “left”, with thegeneralized quantifier variable x1 in head position, is the critical one that cannot beobtained as a pure NL proof term. Combining the words (in their shifted types) bymeans of functional application produces the desired reading.
thinks (np\s)/s ) (np\s)/((s/s)\s) left np\s ) np\((s/s)\s)(t(et)) )AR ((tt)t)(et) (et) )VR (e((tt)t)thinks ) +x2+x0.x2(+x1. left ) +x1+x0.x0(left(x1)) (= left’)
thinks(x1)(x0))
np\((s/s)\s) ) (s/(np\s))\((s/s)\s)(e((tt)t) )AR ((et)t)((tt)t)left’ ) +x2+x0.x2(+x1.x0(left(x1)))
(2.17)
A Connective for Binding. The deductive alternative is to investigate the theoreticalspace provided by the Lambek landscape in order to identify within this space a logicalconstant which renders the critical AR cases (the cases beyond the reach of (N)L)derivable.

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 126 — #32
126 Handbook of Logic and Language
Definition 2.3.7. In situ binding q(A, B, C) (Moortgat, 1996a). Use of a formulaq(A, B, C) binds a variable x of type A, where the resource A is substituted for (takesthe place of) q(A, B, C) in the binding domain B. Using q(A, B, C) turns the bindingdomain B into C. In the generalized quantifier case we have typing q(np, s, s) whereit happens that B = C = s. For the semantic term decoration of the rule of use [qL],assume t(q(A, B, C)) = (t(A) * t(B)) * t(C).
([x : A] ) t : B ![y : C] ) u : D![([z : q(A, B, C)]] ) u[z(+x.t)/y] : D
(qL)
Example 2.3.7. Direct cut-free proof search for “Kazimierz thinks someone left”, withwide scope “someone”. (Compare: the FMG strategy of (2.17).)
np ) np s ) snp, np\s ) s
(\L)np ) np s ) s
np, np\s ) s(\L)
np, (np\s)/s, x : np , np\s ) u : s(\L)
y : s ) y : s
np, (np\s)/s, someone:q(np, s, s) , np\s ) y[someone(+x.u)/y] : s(qL)
u = thinks(left(x))(k), y[someone(+x.u)/y] = someone(+x.thinks(left(x))(k))
Carpenter (1994, 1996) offers an in-depth discussion of the empirical range of thebinding connective as compared with competing approaches to quantification, and anextension with a treatment of plurals. Notice finally the different “heuristic” quali-ties of the connective-based and the rule-based type-shifting alternatives. The type-shifting approach is specifically designed to handle the semantics of quantificationalphenomena and obtain minimal type assignment. The deductive approach introducesa connective, i.e. a fully general operation on types that cannot have a construction-specific limited range of application. Support for the generality of a connective for insitu binding can be found in the analyses of Pied-Piping (Morrill, 1995a), or more . . .
than comparative subdeletion (Hendriks, 1995).We close this discussion with some open questions. With the [qL] inference, we
have given a rule of use—what about the rule of proof for the in situ binder? Also, theq connective was presented as a primitive connective, whereas the term assignmentz(+x.t) shows the interaction of two implications—could we decompose the q connec-tive into more elementary logical constants? In the context of the simple type logics weare discussing here, these questions must remain unanswered. In Section 2.6.1, multi-modal type logics will be introduced which provide the tools to tackle these issues ina principled way.
2.4 Grammatical Composition: Multimodal Systems
In the present section we generalize the multiplicative vocabulary in a number of direc-tions. The generalizations do not affect the overall model-theoretic or proof-theoretic

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 127 — #33
Categorial Type Logics 127
properties of the categorial architecture in any essential sense. But they increase thelinguistic sophistication in such a way that the limitations of the simple systems dis-cussed in Section 2.2.3 are overcome.
In Section 2.6.1, simple type logics are put together into a mixed, multimodalsystem where distinct notions of grammatical composition coexist and communicate.The multimodal style of reasoning was developed in the work of Oehrle, Morrill,Hepple and the author (cf. Hepple, 1994; Moortgat and Morrill, 1991; Moortgat andOehrle, 1993, 1994). This development reintroduces in the type-logical discussionthe theme of the “multi-dimensionality” of grammatical composition that had beendealt with on a more philosophical level in earlier work such as Oehrle (1988) andBach (1984). Another antecedent is Dowty (1996), who distinguishes compositionmodes with different degrees of coherence.
In Section 2.4.2, the binary vocabulary is extended with a language of unary multi-plicatives. The unary connectives play the role of control devices, with respect to boththe static aspects of linguistic structure, and the dynamic aspects of putting this struc-ture together. Unary operations entered the type-logical discussion in Morrill (1990a),who provides an analysis of semantic domains of intensionality in terms of a " opera-tor. The unary vocabulary soon found a variety of applications, including the syntacticdomain modalities of Hepple (1990a), the “structural modalities” of Barry, Hepple,Leslie and Morrill (1991), and the “bracket” operators of Morrill (1995a). Our treat-ment below systematizes and refines these earlier proposals.
As indicated in Section 2.1, the developments to be discussed here represent thecategorial digestion of a number of themes in the field of Linear Logic and relatedsubstructural systems, and of Gabbay’s general program for combining logics. Thecollection Substructural Logics of Došen and Schröder-Heister (1993) and Gabbay(1996) offers useful background reading for these lines of research.
2.4.1 Mixed Inference: The Modes of Composition
In Section 2.2 the type-forming connectives /, •, \ were interpreted in terms of a sin-gle notion of linguistic composition. In moving to a multimodal architecture the objec-tive is to combine the virtues of the individual logics we have discussed so far, andto exploit new forms of grammatical inference arising from their communication. Inmerging different logics into a mixed system, we have to take care that their individ-ual resource management properties are left intact. This can be done by relativizinglinguistic composition to specific resource management modes. But also, we want theinferential capacity of the combined logic to be more than the sum of the parts. Theextra expressivity comes from interaction postulates that hold when different modesare in construction with one another. The interaction postulates can apply in full gen-erality, or can themselves be intrinsically controlled by exploiting mode distinctions,or by composition of modes.
On the syntactic level, the category formulae for the multimodal language aredefined inductively on the basis of a set of category atomsA and a set of indices I. We

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 128 — #34
128 Handbook of Logic and Language
refer to the i ' I as composition modes, or modes for short.
F ::= A |F/iF |F •i F |F\iF (2.18)
The interpretation for the mixed language is a straightforward generalization of thesemantics for the simple systems. Rather than interpret the multiplicatives in termsof one privileged notion of linguistic composition, we put together different forms oflinguistic composition and interpret in multimodal frames $W, {R3
i }i'I%. The valuationv respects the structure of the complex formulae in the familiar way, interpreting eachof the modes i ' I in terms of its own composition relation Ri. The basic residuationlaws (2.19) are relativized with respect to the composition modes.
Definition 2.4.1. Interpretation in multimodal frames $W, {R3i }i'I%.
v(A •i B) = {x |&y&z[Rixyz & y ' v(A) & z ' v(B)]}v(C/iB) = {y |(x(z[(Rixyz & z ' v(B)) ) x ' v(C)]}v(A\iC) = {z |(x(y[(Rixyz & y ' v(A)) ) x ' v(C)]}
A * C/iB iff A •i B * C iff B * A\iC (2.19)
In sequent presentation, each residuated family of multiplicatives {/i, •i, \i} has amatching structural connective (·, ·)i. Logical rules insist that use and proof of con-nectives respect the resource management modes. The explicit construction of theantecedent database in terms of structural connectives derives directly from Belnap’s(1982) work on Display Logic, where it serves the same purpose as it does here, viz.to combine logics with different resource management regimes. In Kracht (1996);Wansing (1994) one finds recent applications in the context of modal logic. Morerecently, the same idea has been introduced in Linear Logic in Girard (1993).
Definition 2.4.2. Multimodal Gentzen calculus: logical rules. Structure terms S ::=F |(S,S)i.
[R/i](!, B)i ) A! ) A/iB
! ) B ([A] ) C([(A/iB, !)i] ) C
[L/i]
[R\i](B, !)i ) A! ) B\iA
! ) B ([A] ) C([(!, B\iA)i] ) C
[L\i]
[L•i]![(A, B)i] ) C![A •i B] ) C
! ) A ( ) B(!, ()i ) A •i B
[R•i]
Notice that the mode specification can keep apart distinct forms of grammaticalcomposition even if they have the same resource management properties. The depen-dency calculus of Moortgat and Morrill (1991) provides an example. By splitting up

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 129 — #35
Categorial Type Logics 129
the product • in a left-headed •l and a right-headed •r, these authors introduce adimension of dependency structure next to the dimensions of precedence and dom-inance. The dependency products could both be non-associative operators; still, withthe mode specification we would be able to distinguish left-headed structures fromright-headed ones. Linguistic motivation for the dependency dimension can be foundin Barry (1991) and Barry and Pickering (1990).
In addition to the residuation inferences (the fixed “logical” component for allmodes), we can now have mode-specific structural options. For a commutative modec, for example, we would have the structural postulates (structural rules, in the Gentzenstyle) below, together with the matching frame constraint for the composition relationinterpreting •c: ((x, y, z ' W)Rcxyz ) Rcxzy.
A •c B - B •c A![((2, (1)
c] ) A![((1, (2)c] ) A
[P] (2.20)
It is straightforward to extend the completeness results of Section 2.2 to the mul-timodal architecture, cf. Kurtonina (1995) for discussion. Semantic annotation of themultimodal derivations with + term meaning recipes is implemented in exactly thesame way as for the unimodal systems.
Multimodal Communication. What we have done so far is simply put together the indi-vidual systems discussed before in isolation. This is enough to gain combined accessto the inferential capacities of the component logics, and one avoids the unpleasantcollapse into the least discriminating logic that results from putting together theoremsfrom different simple logics without taking into account the mode distinctions, cf. ourdiscussion in Section 2.2. But as things are, the borders between the constituting log-ics in our multimodal setting are still hermetically closed. Communication betweencomposition relations Ri and Rj can be established in two ways.
Inclusion Postulates. Postulates A •i B * A •j B, with corresponding frame con-ditions ((xyz ' W)Rixyz ) Rjxyz, impose a “specificity” order on compositionmodes i, j.
Interaction Postulates. Postulates “mixing” distinct modes i, j allow for thestatement of distributivity principles regulating the communication between com-position modes Ri, Rj. One obtains constrained multimodal forms of the resourcemanagement postulates of Section 2.2.
Inclusion Principles. One can develop different perspectives on inclusion principlesdepending on the interpretation one has in mind for the ordering of the compositionrelations Ri, Rj involved. A natural candidate would be an ordering in terms of theinformation they provide about the structure of the linguistic resources. From thisperspective, the non-commutative product • would count as more informative thanthe commutative product •c, since the former but not the latter is sensitive to thelinear order of the resources. In terms of frame conditions, one imposes the constraint

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 130 — #36
130 Handbook of Logic and Language
R•xyz ) Rcxyz, corresponding to the postulate A • B * A •c B. This perspective istaken in general terms in Moortgat and Oehrle (1993), where two products •i and •jare related by an inclusion principle A•i B * A•j B if the latter has greater freedom ofresource management than the former. The opposite view is taken in Hepple (1995),where one finds a systematic reversal of the derivability arrows in the inclusion princi-ples, e.g., A •c B * A • B. In Kurtonina (1995) it is shown that from the framesemantics point of view the two perspectives can be equally well accommodated: theyrefiect the choice for a “conjunctive” versus “disjunctive” reading of the commutativeproduct.
Interaction Principles. Among the multimodal interaction principles, we distinguishcases of weak and strong distributivity. The weak distributivity principles do notaffect the multiplicity of the linguistic resources. They allow for the realization ofmixed associativity or commutativity laws as the multimodal counterparts of theunimodal versions discussed above. Interaction principles of the strong distributiv-ity type duplicate resources, thus giving access to mode-restricted forms of Con-traction.
Weak Distributivity. Consider first interaction of the weak distributivity type.Definition 2.4.3 states principles of mixed associativity and commutativity. Instead ofthe global associativity and commutativity options characterizing L, NLP, LP, theseprinciples realize constrained forms of associativity/commutativity, restricted to thesituation where modes i and j are in construction. (Symmetric duals can be addedwith the i mode distributing from the right, and one can split up the two-directionalinferences in their one-directional components, if so required.)
Definition 2.4.3. Mixed Associativity (MA), Mixed Commutativity (MP). Structuralpostulates, frame constraints, Gentzen rules.
MP : A •i (B •j C) - B •j (A •i C) &t(Riuxt & Rjtyz) . &t1(Rjuyt1 & Rit1xz)MA : A •i (B •j C) - (A •i B) •j C &t(Riuxt & Rjtyz) . &t1(Rjut1z & Rit1xy)
![((2, ((1, (3)i) j] ) A
![((1, ((2, (3) j)i] ) A[MP]
![(((1, (2)i, (3)
j] ) A
![((1, ((2, (3) j)i] ) A[MA]
For linguistic application of these general postulates, we turn to discontinuous depen-dencies. In the work of authors such as Bach (1984); Pollard (1984); Jakobson (1987),it has been argued that the discontinuous mode of combination (“wrapping”) shouldbe treated as a grammatical operation sui generis, rather than simulated in terms of theregular “concatenation” mode. In the type-logical setting one can adopt this emanci-pated position with respect to wrapping operations, and formulate the logic of discon-tinuity in terms of multimodal interaction principles. Consider the Dutch Verb Raisingconstruction. In Example 2.2.7 we saw that a unimodal “Mixed Composition” lawcauses permutation disturbances in an otherwise order-sensitive grammar logic. With

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 131 — #37
Categorial Type Logics 131
the aid of the MP/MA interaction principles, one obtains the multimodal version ofExample 2.4.1.
Example 2.4.1. Mixed Composition/Geach as a multimodal theorem (Moortgatand Oehrle, 1994). The MP interaction principle relates the head adjunction mode•h, which provides typing for the verb-raising triggers, and the dependency mode•r, which characterizes the head-final basic clausal structure of Dutch. (Compare(vp/hiv, np\riv)h ) np\rvp with Example 2.2.7.)
C ) C B ) B(C, C\rB)r ) B
\rLA ) A
/hL(A/hB, (C, C\rB)r)h ) A(C, (A/hB, C\rB)h)r ) A
MP\rR
(A/hB, C\rB)h ) C\rAA/hB ) (C\rA)/h(C\rB)
/hR
Notice that the order sensitivity of the individual modes •r and •h is respected: thevalid forms of mixed composition form a subset of the composition laws derivablewithin unimodal LP. The principles of Directional Consistency and Directional Inher-itance, introduced as theoretical primitives in the rule-based setting of CCG, can beseen here to follow automatically from the individual resource management proper-ties of the modes involved and the distributivity principle governing their communi-cation. Example 2.4.1 shows that it is possible to derive head adjunction. In order toforce the formation of the verb cluster, the type language has to be further refined. SeeMoortgat and Oehrle (1994) for discussion, and Section 2.4.2 for the required logicalvocabulary.
For a second illustration, we take up the discussion of in situ binding of Sec-tion 2.3. It is shown in Morrill (1994a) that the connective q(A, B, C) can be definedin a multimodal system with three communicating modes: a (associative regime), n(non-associative regime), and w (wrapping). The crucial interaction principle is givenin (2.21). The deconstruction of Example 2.4.2 partially answers the question raisedin Section 2.3: for a default associative regime, it shows how one can define an in situbinding operator as (s/wnp)\ws. Associativity here is essential for obtaining access toarbitrary infixation points for the wrapping expression.
(WN) : (A •a B) •a C - (A •n C) •w B![(((1, (3)
n, (2)w] ) A
![(((1, (2)a, (3)a] ) A[WN]
(2.21)
Example 2.4.2. Multimodal deconstruction of q(A, B, C) as (B/wA)\wC. On the leftis the [qL] rule of Definition 2.3.7. On the right is the “partial execution” compilation

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 132 — #38
132 Handbook of Logic and Language
in terms of interaction principle (2.21):
((, (A, (1)a)a ) B(((, (1)n, A)w ) B
WN/wR
((, (1)n ) B/wA ![C] ) D![(((, (1)n, (B/wA)\wC)w] ) D
\wLW N
([x : A] ) t : B ![y : C] ) u : D![([z : q(A, B, C)]] ) u[z(+x.t)/y] : D
(qL)![(((, (B/wA)\wC)a, (1)a] ) D![(((, q(A, B, C))a, (1)a] ) D
(def)
Interaction Principles: Strong Distributivity. As remarked above, the weak distribu-tivity principles MP, MA keep us within the family of resource neutral logics: theydo not affect the multiplicity of the resources in a configuration. Strong distribu-tivity principles are not resource neutral: they duplicate resources. As an example,consider the interaction principle of Mixed Contraction in Definition 2.4.4, whichstrongly distributes mode j over mode i thus copying a C datum. Rather than intro-ducing global Contraction, this interaction principle allows for a constrained form ofcopying, restricted to the case where modes i and j are in construction.
Definition 2.4.4. Restricted Contraction. Structural postulate, Gentzen rule, frameconstraint.
MC : (A •i B) •j C * (A •j C) •i (B •j C)![(((1, (3)
j, ((2, (3)j)i] ) A
![(((1, (2)i, (3) j] ) AMC
(Ritxy & Rjutz) ) &t1&t11(Rjt1xz & Rjt11yz & Riut1t11)
It has been argued that grammatical inference requires restricted access to Con-traction for the analysis of the so-called parasitic gap constructions in (2.22) below.In this construction, one would like the abstractor associated with the wh element tobind multiple occurrences of the same variable, for the interpretation of the structuralpositions indicated by the underscores. Such multiple binding is beyond the scope ofoccurrence-sensitive logics we have considered so far. In the framework of CCG, para-sitic gaps are handled by means of the combinator S which is introduced as a primitivefor this purpose, cf. Szabolcsi (1987), Steedman (1987).
S:A/C, (A\B)/C ) B/C Which books did John (file— without reading—)(2.22)
In a multimodal framework, a mode-restricted form of the S combinator can bederived from the strong distributivity principle discussed above. In the Gentzen proofbelow, we give the relevant instance for the derivation of the example sentence (instan-tiate A/jC as vp/jnp for file, and (A\iB)/jC as (vp\ivp/jnp for without reading). Modej here would be the default mode by which the transitive verbs file and read consumetheir direct objects; the combination of the vp adjunct without reading— with the vp

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 133 — #39
Categorial Type Logics 133
it modifies is given in terms of mode i, the “parasitic” mode which licenses the sec-ondary gap depending on the primary one, the argument of file.
Example 2.4.3. Deriving the combinator S as a multimodal theorem.
&c((A/jC, C)j, (A\iB)/jC, C)j)i ) B
((A/jC, (A\iB)/jC)i, C)j ) B(A/jC, (A\iB)/jC)i ) B/jC
/jR
MC
2.4.2 Grammatical Composition: Unary Operations
The language of binary multiplicative connectives is designed to talk about forms oflinguistic composition where two resources are put together. It is not difficult to seehow one could generalize the type language to n-ary multiplicatives, and interpretfamilies of n-ary residuated connectives with respect to a composition relation of arityn + 1, in the setting of frame semantics. Writing f•(A1, . . . , An) for an n-ary productand f i
*(A1, . . . , An) for the i-th place residual, the basic residuation laws take the formshown in (2.23). For arities 2 4 n, an n-ary product connective would be interpretedwith respect to a form of grammatical composition relating n “component” resourcesto their “fusion”. Such generalizations have been studied in a logical setting in Dunn(1993), and in the context of categorial grammar logics in Buszkowski (1984) andMoortgat and Oehrle (1993).
f•(A1, . . . , An) * B iff Ai * f i*(A1, . . . , Ai01, B, Ai+1, . . . , An) (2.23)
In this section we present the logic of unary residuated operations in the categorialtype language. The need for unary complementation of the familiar binary vocabu-lary has long been felt: for arguments see Bach (1988), or Schmerling (1983), whorelates the discussion to the “item-and-arrangement” versus “item-and-process” viewson structuring linguistic resources. As remarked above, unary connectives were intro-duced in the type-logical discussion around 1990 in Morrill (1990a), and in subsequentwork of a number of Edinburgh researchers. A representative collection of papers canbe found in Barry and Morrill (1990).
Our aim in this section is to systematize this area of research by developing a gen-eral framework that will naturally accommodate the various proposals for unary oper-ators while at the same time providing more fine-grained notions of resource control.We extend the language of binary multiplicatives with a pair of unary residual oper-ators #, ". Parallel to our treatment of the binary multiplicatives in Section 2.2, westart from the most discriminating system, i.e. the pure logic of residuation for #, ".By gradually adding structural postulates, we obtain versions of these unary opera-tors with a coarser resource management regime. We develop the model-theoretic andproof-theoretic technicalities in Section 2.4.2.1, drawing heavily on Moortgat (1996b).

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 134 — #40
134 Handbook of Logic and Language
In Section 2.4.2.2, we discuss the linguistic motivation for the various resource man-agement options. Finally, in Section 2.4.2.3, we present a general theory of structuralcontrol in terms of embedding theorems connecting resource management regimes.
2.4.2.1 Unary Connectives: Logic and Structure
Consider first the pure logic of residuation for a pair of unary type-forming operators#, ".
Definition 2.4.5. Unary multiplicative connectives: the pure logic of residuation.Interpretation clauses. Residuation laws. Note that the interpretation of # and "“moves” in opposite directions along the R2 accessibility relation. (To emphasize thefact that these categorial modalities are inverse duals, we use the lozenge and boxsymbols, rather than diamond and box, which would suggest regular duals.)
v(#A) = {x|&y(Rxy 5 y ' v(A)}v("A) = {x|(y(Ryx ) y ' v(A)}
#A * B iff A * "B
Completeness. The completeness result of Proposition 2.2.1 for the binary multi-plicative language extends unproblematically to the language enriched with #, ".We interpret now with respect to mixed frames, where a binary and a ternary com-position relation live together, and consider models M = $W, R2, R3, v%. In theformula-based canonical model construction of Definition 2.2.4, one defines R2(A, B)
iff " A * #B. The Truth Lemma has to be checked for the new compound formulae#A, "A. The direction that requires a little thinking is dealt with below.
(#) Assume A ' v(#B). We have to show " A * #B. A ' v(#B) implies &A1 such that R2AA1
and A1 ' v(B). By induction hypothesis, " A1 * B. By Isotonicity for # (cf. (26) below)this implies " #A1 * #B. We have " A * #A1 by (Def R2) in the canonical frame. ByTransitivity, " A * #B.
(") Assume A ' v("B). We have to show " A * "B. A ' v("B) implies that (A1 suchthat R2A1A we have A1 ' v(B). Let A1 be #A. R2A1A holds in the canonical frame since" #A * #A. By induction hypothesis we have " A1 * B, i.e. " #A * B. By Residuationthis gives " A * "B.
Figure 2.1 may clarify the relation between the unary and the binary residuatedpairs of connectives. Notice that if one were interpreting R2 as temporal priority, #and " would be interpreted as past possibility and future necessity, respectively. Butin the grammatical application, R2 just like R3 is to be interpreted in terms of structuralcomposition. Where a ternary configuration (xyz) ' R3 abstractly represents puttingtogether the components y and z into a structured configuration x in the manner indi-cated by R3, a binary configuration (xy) ' R2 can be seen as the construction of thesign x out of a single structural component y in terms of the building instructionsreferred to by R2.

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 135 — #41
Categorial Type Logics 135
Figure 2.1 Kripke graphs: binary and unary multiplicatives.
In our discussion of the binary vocabulary in Section 2.2, we pointed out that onecan characterize /, • , \ as a residuated family either in terms of the basic law res ofDefinition 2.2.2, or in terms of the (Co-)Application and Monotonicity laws of Propo-sition 2.2.6. Similarly, for the unary connectives, we have the equivalent Lambek-styleand Došen-style axiomatizations of Definition 2.4.6.
Definition 2.4.6. Unary connectives: alternative combinator presentations. (†)
Lambek-style in terms of Residuation. (‡) Došen-style in terms of compositions#", "#, and Isotonicity.
(†)f : #A * B
µ( f ) : A * "Bg : A * "B
µ01(g) : #A * B
(‡) unit! : #"A * Aco-unit! : A * "#A
f : A * B( f )/ : #A * #B
f : A * B
( f )! : "A * "B
We take the Lambek-style presentation as our starting point here, and show for theextended system how from the residuation inferences µ, µ01 we obtain the alternativeaxiomatization in terms of Isotonicity and the inequalities for the compositions #"and "# (Term decoration for the right column left to the reader.)
1"A : "A * "Aµ01(1"A) : #"A * A
#A * #AA * "#A
(2.24)
f : A * B
1"B : #B * #Bµ(1"B) : B * "#B
µ(1"B) / f : A * "#Bµ01(µ(1"B)) / f ) : #A * #B
"A * "A#"A * A A * B
#"A * B"A * "B
(2.25)
Gentzen Calculus. Following the agenda set out in Section 2.2 for the binary connec-tives, we introduce Gentzen sequent rules for the connectives #, ". Corresponding

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 136 — #42
136 Handbook of Logic and Language
to the formula language F of (2.26) we have a language of Gentzen terms S forstructured configurations of formulae. Gentzenization for the extended type languagerequires an n-ary structural operator for every family of n-ary logical operators: binary(·, ·) for the family /, • , \, and unary (·)" for the family #, ".
F ::= A|F/F |F • F |F\F |#F |"F S ::= F |(S,S)|(S)" (2.26)
Definition 2.4.7. Unary connectives: Gentzen rules. Belnap-style antecedent punc-tuation, with unary structural connective (·)" matching the unary logical con-nective #.
! ) A(!)" ) #A
#R![(A)"] ) B![#A] ) B
#L
(!)" ) A! ) "A
"R![A] ) B
![("A)"] ) B"L
As shown in Moortgat (1996b), the Gentzen presentation is equivalent to theaxiomatization of Definition 2.4.6, and it allows Cut Elimination with its pleasantcorollaries: decidability and the subformula property.
Unary Connectives: Structural Postulates. Completeness for the pure logic of resid-uation for the unary family #, " does not depend on semantic restrictions on the R2
composition relation. In addition to the fixed “logical” part of the #, " connectives,we can consider various structural resource management options for the unary family#, " and its binary accessibility relation R2, and for the mixed R2, R3 system.
The structural postulates in Definition 2.4.8 constrain R2 to be transitive (4), orreflexive (T). Communication between R2 and R3 can be established via the “percola-tion” principles K(1, 2). The strong distributivity postulate K distributes unary # overboth components of a binary •. The more constrained weak distributivity postulatesK1, K2 make # select the left or right subtype of a product. The combination of theoptions KT4 gives an S4 modality with the logical rules of use and proof of the LinearLogic exponential “!”.
Observe that the postulates have the required Weak Sahlqvist form for the extendedcompleteness result of Proposition 2.2.7. In Moortgat (1996b), the Cut Eliminationresult for the pure residuation logic of Definition 2.4.7 is extended to cover the struc-tural options of Definition 2.4.8. In a multimodal setting, one can further enhance thelinguistic expressivity by combining different composition modes R2
j for #j, "j in onelogic. The multimodal generalization is completely standard.
Definition 2.4.8. Unary connectives: resource management options. Structural pos-tulates, frame constraints, Gentzen rules. (For " duals of these postulates: replace #

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 137 — #43
Categorial Type Logics 137
by " and reverse the arrow.)
4 : ##A * #A (Rxy & Ryz) ) Rxz
T : A * #A Rxx
K1 : #(A • B) * #A • B (Rwx & Rxyz) ) &y1(Ry1y & Rwy1z)
K2 : #(A • B) * A • #B (Rwx & Rxyz) ) &z1(Rz1z & Rwyz1)
K : #(A • B) * #A • #B (Rwx & Rxyz) ) &y1&z1(Ry1y & Rz1z & Rwy1z1)
![(()"] ) A![((()")"] ) A
4![(()"] ) A
![(] ) AT
![(((1)", (2)] ) A
![(((1, (2))"] ) AK1
![(((1)", ((2)
")] ) A![(((1, (2))"] ) A
K![((1, ((2)
")] ) A![(((1, (2))"] ) A
K2
S4: Compilation of Structural Rules. We saw in Definition 2.2.8 that in the presence ofAssociativity for •, we have a sugared Gentzen presentation where the structural ruleis compiled away, and the binary sequent punctuation (·, ·) omitted. Analogously, for" with the combination KT4 (i.e. S4), we have a sugared version of the Gentzen rules,where the KT4 structural rules are compiled away, so that the unary (·)" punctuationcan be omitted. In the sugared version, we recognize the rules of use and proof for thedomain modalities of Morrill (1990a) and Hepple (1990a).
Definition 2.4.9. Sugared presentation of KT4 modalities: compiling out the (·)"structural punctuation. We write "!, (")"!, ("")"! for a term ! of which the(pre)terminal subterms are all of the form "A, ("A)", (""A)", respectively. The4(Cut) step is a series of replacements (read bottom-up) of terminal "A by ""A viaCuts depending on 4.
![A] ) B![("A)6] ) B
"LT
!["A] ) B ! ![A] ) B!["A] ) B
"L(S4)
"! ) A("")6! ) A
"L4(Cut)
(")6! ) AK
("!)6 ) A"! ) "A
"R ! "! ) A"! ) "A
"R(S4)
Situating Unary Operators. The above analysis of the unary vocabulary in its logicaland structural components provides us with a tool to evaluate existing proposals forunary operators. In doing so, we follow the methodological “minimality” principleadopted above in the discussion of the binary vocabulary, i.e. we try to pinpoint exactly

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 138 — #44
138 Handbook of Logic and Language
which assumptions about the composition relation are necessary to achieve a certaingrammatical effect.
At one end of the spectrum, the proposals that come closest to the pure logic ofresiduation for #, " are the “bracket” operators of Morrill (1994a, 1995a). On thesemantic level, the bracket operators are given an algebraic interpretation which, in thecontext of frame semantics, would amount to a functionality requirement for the acces-sibility relation R2. The linguistic applications of the bracket operators as markers oflocality domains can be recast straightforwardly in terms of the more discriminatingpure residuation logic for #, " for which a sound and complete logic is available,imposing no functionality constraints on R2.
At the other end of the spectrum, we find the domain modalities of Morrill (1990a);Hepple (1990a), universal " operators which assume the full set of postulates KT4,i.e. S4. Adding modally controlled structural rules, we obtain the structural modalitiesof Barry, Hepple, Leslie and Morrill (1991); Morrill (1994a). Like the exponentialsof Linear Logic, the structural modalities license controlled access to resource man-agement options that are not freely available. Unfortunately, it is shown in Versmissen(1993) that the S4 logical rules are incomplete with respect to the intended subalgebrasemantics for these connectives. Again, we can scrutinize the S4 assumptions, and seewhether a more delicate resource management regime can achieve the same effects.
In the framework presented here, where we consider a residuated pair of modal-ities #, " rather than a single S4 universal modality, we can simulate the T and 4postulates proof-theoretically, without making Reflexivity or Transitivity assumptionsabout the R2 composition relation. With the translation of Definition 2.4.10 the imagesof the T and 4 postulates for a S4 " become valid type transitions in the pure residua-tion system for #, ", as the reader can check. For modally controlled structural rules,Definition 2.4.11 gives restricted versions of the global rules keyed to # contexts; forcommunication between the unary and binary multiplicatives, one can rely on the Kdistributivity principles.
Definition 2.4.10. Simulating T and 4 via compilation: translate S4 " by #" in thepure residuation logic.
T : "A * A ! #"A * A4 : "A * ""A ! #"A * #"#"A
Definition 2.4.11. Modally restricted structural options: Commutativity (P"), Asso-ciativity (A"). Structural postulates, Gentzen rules. The side condition (†) requiresone of the Ai ((i) to be of the form #A ((()").
(P") : #A • B * B • #A (A") : (A1 • A2) • A3 - A1 • (A2 • A3)(†)
![(((2)", (1)] ) A
![((1, ((2)")] ) A
(P") (†)![(((1, (2), (3)] ) A
![((1, ((2, (3))] ) A(A")

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 139 — #45
Categorial Type Logics 139
Term Assignment: Unary Connectives. To close this section, we present the termassignment for the unary connectives in an abstract format, with constructor/destructoroperations in the term language matching rules of use and proof.
Definition 2.4.12. Syntax of typed lambda terms: clauses for #, ". Destructors 7·and 8·, corresponding to rules of use for # and ". Constructors 9· and 5·, for rules ofproof. Compare Definition 2.3.1 for the binary vocabulary.
MA ::= . . . |7(M"A)|8(M!A) M"A ::=9 (MA) M!A ::= 5(MA)
Definition 2.4.13. Term assignment. The #, " cases.
! ) t : A(!)" ) 9t : #A
#R![(y : A)"] ) t : B
![x : #A] ) t[7x/y] : B#L
(!)" ) t : A! ) 5t : "A
"R![y : A] ) t : B
![(x : "A)"] ) t[8x/y] : B"L
Definition 2.4.14. Term equations and their Gentzen proof-theoretic reflexes. Com-pare the binary case in Definition 2.3.4.
7(9t) = t ! principal cut on #A 8(5t) = t ! principal cut on "A9(7t) = t ! non-atomic axiom #A 5(8t) = t ! non-atomic axiom "A
Concrete realizations of the abstract term assignment schema will depend on the appli-cation. For an example, we refer to the type-logical implementation of Montague-styleintensional semantics driven from an S4 universal modality in Morrill (1990a). Let uswrite the “intensionality” type-forming operator as "1. We interpret formulas "1A asfunctions from indices to the denotata of formulas A. Term assignment for the rulesof use and proof for "1 can then be given in terms of Montague’s “cup” and “cap”operations, respectively. Cf. Chapter 1.
"1! ) t : A"1! ) 5t : "1A
"1R!, x : A, !1 ) t : B
!, y : "1A, !1 ) t[8y/x] : B"1L (2.27)
For another application, we refer to the work on information packaging in Hen-driks (1999), where the term assignment for # realizes the prosodic and pragmaticstructuring of the text in terms of stress and given/new distinctions.
2.4.2.2 Applications: Imposing Constraints, Structural Relaxation
One can develop two perspectives on controlling resource management, dependingon the direction of communication. On the one hand, one would like to have control

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 140 — #46
140 Handbook of Logic and Language
devices to license limited access to a more liberal resource management regime fromwithin a system with a higher sense of structural discrimination. On the other hand,one would like to impose constraints on resource management in systems where suchconstraints are lacking by default.
Licensing Structural Relaxation. For the licensing type of communication, considertype assignment r/(s/np) to relative pronouns like that in the sentences below.
(the book) that Kazimierz wrote(the book) that Kazimierz wrote yesterday
L " r/(s/np), np, (np\s)/np ) rL ! r/(s/np), np, (np\s)/np, s\s ) r
NL ! (r/(s/np), (np, (np\s)/np)) ) r
(2.28)
Suppose first we are dealing with the associative regime of L. The first example isderivable, the second is not because the hypothetical np assumption in the subderiva-tion “Kazimierz wrote yesterday np” is not in the required position adjacent to the verb“wrote”. We can refine the assignment to the relative pronoun to r/(s/!cnp), where!cnp is a noun phrase resource which has access to Permutation in virtue of its modaldecoration. Similarly, if we change the default regime to NL, the first example alreadyfails on the assignment r/(s/np) with the indicated constituent bracketing: althoughthe hypothetical np in the subcomputation “((Kazimierz wrote) np)” finds itself in theright position with respect to linear order requirements, it cannot satisfy the directobject role for “wrote” being outside the clausal boundaries. A refined assignmentr/(s/!anp) here could license the marked !anp a controlled access to the structuralrule of Associativity which is absent in the NL default regime.
As remarked above, cases like these have been handled in terms of S4-style struc-tural modalities in Barry and Morrill (1990); Morrill (1994a). In (2.29), we illus-trate the deconstruction of ! as #" with the derivation of controlled rebracketingwithin NL.
&c(np, (tv, np)) ) s
(np, (tv, ("anp):)) ) s"L
((np, tv), ("anp):) ) s A:
((np, tv), #a"anp) ) s#L
(np, tv) ) s/#a"anp/R
(2.29)
Imposing Structural Constraints. For the other direction of communication, we returnto the violations of the Coordinate Structure Constraint, discussed in Section 2.2 inconnection with the overgeneration of L. Consider the relative clauses of Example2.4.4. With the instantiation X = s/np for the polymorphic conjunction particle, wecan derive the (a) example. But, given Associativity and an instantiation X = s, noth-ing blocks the derivation of the ungrammatical (b) example.

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 141 — #47
Categorial Type Logics 141
Example 2.4.4. Lexical projection of island constraints—Morrill (1994a, 1995a).
a. (the logician) whom Gottlob admired and Kazimierzdetested
L " r/(s/np), np, tv, (X\X)/X, np, tv ) r (X = s/np)
L# " r/(s/np), (np, tv, (X\"X)/X, np, tv)" ) r
b. 2(the logician) whom Gottlob admired Jim and Kazimierzdetested
L " r/(s/np), np, tv, np, (X\X)/X, np, tv ) r (X = s)
L# ! r/(s/np), (np, tv, np, (X\"X)/X, np, tv)" ) r
In Morrill (1994a, 1995a) it is shown that the coordinate structure domain can belexically projected from a modal refinement of the assignment to “and”: (X\"X)/X.(We recast the analysis in terms of the pure residuation logic for #, ".) The refinedassignment allows the conjunction to combine with the left and right conjuncts in theassociative mode. The resulting coordinate structure is of type "X. To eliminate the" connective, we have to close off the coordinate structure with # (or the correspon-ding structural operator (·)" in the Gentzen presentation)—recall the basic reduction#"X * X. The Across-the-Board case of extraction (4.18a) works out fine; the islandviolation (4.18b) fails because the hypothetical gap np assumption finds itself outsidethe scope of the (·)" operator.
In Versmissen (1996), this use of modal decoration is generalized into a type-logicalformulation of the theory of word-order domains of Reape (1989). The control opera-tors #, " provide a fully general vocabulary for projection and erasure of domains oflocality, according to the following scheme distinguishing the antecedent (resource)versus succedent (goal) effects of #, " decoration.
Resource Goal
# domain-erasure domain-projection
" domain-projection domain-erasure
(2.30)
Modalities as Domains of Locality. In Morrill (1990a), locality domains, in the sense ofsemantic intensionality, are characterized in terms of a uniform S4 modal decorationfor the resources that make up a domain, cf. (2.27). Hepple (1990a), dropping thesemantic component of this proposal, uses this modal decoration to capture syntacticboundary effects. These applications are instructive because they crucially rely onthe rule of proof for the S4 universal modality: as we have seen in Definition 2.4.9,this rule insists that all assumptions on which a boxed formula depends are boxedthemselves.
Consider the constraint of clause-boundedness that governs the use of theEnglish reflexive pronouns. In Example 2.3.5 we discussed an L type-assignment

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 142 — #48
142 Handbook of Logic and Language
((np\s)/np)\(np\s) for “himself” with meaning recipe +x+y.x(y)(y). Within L, (a),(b) and (c) are all derivable: this system, because of the global availability of asso-ciativity, cannot discriminate between a lexical or complex clause-internal expressionof type ((np\s)/np) and a complex expression of that type which has been composedacross clausal boundaries.
a. David admires himself L " (np\s)/np ) (np\s)/np
b. David cares for himself L " (np\s)/pp, pp/np ) (np\s)/np
c. *David thinks Emmy admires himself L " (np\s)/s, np,
(np\s)/np ) (np\s)/np(2.31)
Within L + ", appropriate modalization provides lexical control to make (a) and(b) derivable while ruling out (c). In moving from L to L+" lexical type assignments,one prefixes the original L lexical assignments with a " operator, and further deco-rates with a " every argument subtype B that constitutes a locality domain. The effectof such modalization for the lexical resources of (2.31c) is shown in Example 2.4.5.
Example 2.4.5. Blocking locality violations via S4 " decoration (Hepple, 1990a;Morrill, 1990a). The assignment to the verb “think” marks its clausal complementas a locality domain. The derivation for the non-local reading (2.31c) fails, becausethe hypothetical direct object np assumption is not decorated with ", blocking appli-cation of the ["R] inference, which requires all the antecedent assumptions on whichit depends to be modally marked.
FAIL"np, "((np\s)/np), np ) "s
&cnp, np\s ) s
np, (np\s)/"s),"np, "((np\s)/np), np ) s/L
np, "((np\s)/"s),"np, "((np\s)/np), np ) s "L
"((np\s)/"s),"np, "((np\s)/np) ) (np\s)/np/R, \R
&cnp, np\s ) s
"np, np\s ) s "L
"np,"((np\s)/"s),"np, "((np\s)/np), ((np\s)/np)\(np\s) ) s\L
"np, "((np\s)/"s),"np,"((np\s)/np),"((np\s)/np)\(np\s) ) s "L
"np, "((np\s)/"s),"np, "((np\s)/np),"((np\s)/np)\(np\s) ) "s "R
2David thinks Emmy loves himself
A more elaborate account of syntactic island constraints is offered in Hepple (1990a,1992) in terms of a polymodal system with domain modalities {"j}j'J . The domainmodalities have an order defined on them, which allows for the characterizationof syntactic boundaries of different strength. Island constraints are lexically con-trolled through the interplay of type-assignment to complement taking functors and“extractable” elements. Take a relative pronoun with type "((n\n)/(s/"inp)) and averb subcategorizing for a clausal complement, "((np\s)/"js). The relative pronounwill be extractable from the "js embedded clause provided "i ; "j. We have pre-sented the analysis of locality domains in terms of the original S4 decoration ofHepple

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 143 — #49
Categorial Type Logics 143
(1990a). Decomposing the S4 account into its structural components, we see that thechecking of uniform antecedent " marking is taken care of by the K distributivity prin-ciple of Definition 2.4.8. In fact, with a slightly adapted modalization strategy whichdecorates the assignment to “think” with the minimal box modality, one can recastthe above analysis in terms of K and the #, " residuation logic, as the reader cancheck. The same combination of res#, "+K lies at the basis of an analysis of Frenchclitic pronouns in Kraak (1998), and of the type-logical account of Linear Precedenceconstraints in Versmissen (1996).
2.4.2.3 Resource Control: Faithful Embeddings
In Section 2.4.2.2 we have presented analyses of a number of linguistic phenomenawhich rely on modally decorated type-assignments to obtain structural relaxation, or toimpose structural constraints. These applications suggest a more fundamental logicalquestion: can one provide a general theory of resource control in terms of the unaryvocabulary? The embedding theorems of Kurtonina and Moortgat (1997) answer thisquestion in the affirmative: they show that the #, " connectives provide a theory ofsystematic communication between the type logics of Figure 2.2. Below, we discussthe strategies for modal decoration realizing the embeddings, and reflect on generallogical and linguistic aspects of this approach.
Figure 2.2 displays the resource logics one obtains in terms of the structural para-meters of precedence (word-order), dominance (constituent structure) and depen-dency. The systems occupying the upper plane of Figure 2.2 were the subject ofSection 2.2. As we have seen in our discussion of Definition 2.4.2, each of these sys-tems has a dependency variant, where the product is split up into a left-headed •- anda right-headed •r version.
LP
L
DL
DNL
DNLP
NLP DLP
NL
Figure 2.2 Resource-sensitive logics: precedence, dominance, dependency.

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 144 — #50
144 Handbook of Logic and Language
Consider a pair of logics L0, L1 where L0 is a “southern” neighbor of L1. Let uswrite L# for the system L extended with the unary operators #, " with their minimalresiduation logic. For the 12 edges of the cube of Figure 2.2, one can define embeddingtranslations (·). : F(L0) <* F(L1#) which impose the structural discrimination ofL0 in L1 with its more liberal resource management, and (·)/ : F(L1) <* F(L0#)
which license relaxation of structure sensitivity in L0 in such a way that one fullyrecovers the flexibility of the coarser L1. The embedding translations decorate criticalsubformulae in the target logic with the operators #, ". The translations are definedon the product • of the source logic: their action on the implicational formulas is fullydetermined by the residuation laws. For the ·. type of embedding, the modal decorationhas the effect of blocking a structural rule that would be applicable otherwise. For the·/ direction, the modal decoration gives access to a controlled version of a structuralrule which is unavailable in its “global” (non-decorated) version.
We illustrate the two-way structural control with the pair NL and L. Let us subscriptthe connectives in NL with 0 and those of L with 1. The embedding translations ·. and·/ are given in Definition 2.4.15. For the two directions of communication, the samedecoration schema can be used.
Definition 2.4.15. Embedding translations ·. : F(NL) <* F(L#), and ·/ : F(L) <*F(L#).
p. = p p/ = p(A •0 B). = #(A. •1 B.) (A •1 B)/ = #(A/ •0 B/)
(A/0B). = "A./1B. (A/1B)/ = "A//0B/
(B\0A). = B.\1"A. (B\1A)/ = B/\0"A/
The L system has an associative resource management which is insensitive to con-stituent bracketing. Extending L with the operators #, " we can recover control overassociativity in the sense of Proposition 2.4.1. A conjecture of embedding on the basisof ·. can be found in Morrill (1994b).
Proposition 2.4.1. Dominance structure: recovering control (Kurtonina and Moort-gat, 1997).
NL " A * B iff L# " A. * B.
Consider next the other direction of communication: suppose one wants to obtain thestructural flexibility of L within the system NL with its rigid constituent sensitivity.This time, one achieves the desired embedding result by means of the embeddingtranslation ·/ of Definition 2.4.15 together with a modally controlled version of thestructural rule of Associativity, relativized to the critical # decoration.
Definition 2.4.16. Associativity. Global version (A) and its image under (·)/, (A").
L1 : A •1 (B •1 C) - (A •1 B) •1 C (A)
L0 : #(A •0 #(B •0 C)) - #(#(A •0 B) •0 C) (A")

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 145 — #51
Categorial Type Logics 145
Proposition 2.4.2. Dominance structure: licensing relaxation (Kurtonina and Moort-gat, 1997).
L " A * B iff NL# + A" " A/ * B/
The derivations of Example 2.4.6 illustrate the complementary strategies with theGeach rule, the characteristic theorem which differentiates L from NL. On the left,we try to derive the ·. translation of the Geach rule in L#. The resource managementregime is associative—still the derivation fails because of the structural (·)" decora-tion which makes the C resource inaccessible for the functor "B/1C. On the right onefinds a successful derivation of the ·/ translation in NL#. Although the resource man-agement regime in this case does not allow free rebracketing, the # decoration givesaccess to the modal version of the structural rule.
Example 2.4.6. Imposing structural control versus relaxing structure sensitivity.
FAIL(((("A/1B, "B/1C)1):, C)1): ) "A
"R
((("A/1B, "B/1C)1):, C)1 ) "A"R
(("A/1B, "B/1C)1): ) "A/1C/1R
("A/1B, "B/1C)1 ) "("A/1C)"R
"A/1B ) "("A/1C)/1("B/1C)/1R
C ) CB ) B
("B): ) B"L
(("B/0C, C)0): ) B/0L A ) A
("A): ) A"L
(("A/0B, (("B/0C, C)0):)0): ) A/0L
(((("A/0B, "B/0C)0):, C)0): ) AA:
((("A/0B, "B/0C)0):, C)0 ) "A"R
(("A/0B, "B/0C)0): ) "A/0C/0R
("A/0B, "B/0C)0 ) "("A/0C)"R
"A/0B ) "("A/0C)/0("B/0C)/0R
L# ! (A/0B). ) ((A/0C)/0(B/0C)). NL#+ (A") " (A/1B)/ ) ((A/1C)/1(B/1C))/
Discussion. With respect to the theme of resource control it is instructive to contrastLinear Logic with the grammar logics discussed here. The theory of communicationpresented above uses the standard logical technique of embeddings. In Linear Logic,the unary “exponentials” are designed to recover the expressivity of the structuralrules of Contraction and Weakening in a controlled way. The modalities that achievethe desired embedding are governed by an S4-like regime. The “sublinear” grammarlogics exhibit a higher degree of structural organization. These more discriminatinglogics suggest more delicate instruments for obtaining structural control: as we haveseen, the pure residuation logic for #, " does not depend on specific assumptionsabout the grammatical composition relation R2, but it is expressive enough to obtainfull control over grammatical resource management.3 A second difference with theLinear Logic approach is the bi-directionality of the proposed communication: fromthe grammatical point of view, imposing structural constraints and licensing structuralrelaxation are equally significant forms of resource control.
3 It is interesting to note that for reasons different from ours, and for different types of models, a numberof proposals in the field of Linear Logic have argued for a decomposition of the exponentials into moreelementary operators (cf. Bucalo, 1994; Girard, 1995a, 1998).

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 146 — #52
146 Handbook of Logic and Language
On the level of actual grammar development, the embedding results provide a solu-tion to the problem of “mode proliferation” inherent in the multimodal approach ofSection 2.6.1. The multimodal style of grammatical reasoning relies heavily on a(potentially unmanageable) inventory of primitive composition modes •i. The con-trol operators #, " make it possible to reanalyze the various •i as defined connectives,in terms of a familiar • and modal decoration. The dependency connectives •-, •r, forexample, can be introduced as synthetic operators with definitions (#0) •0, and 0•(#0), respectively, with # marking the head component. This perspective suggests aglobal division of labor between “syntax” and “semantics”, with LP playing the roleof the default semantic composition language, and the pure residuation logic NL thedefault language of structural composition. The intermediate territory can be navigatedby means of the modal control operators.
Part II. Update 2009
2.5 1997–2009: A Road Map
The following sections trace the development of the field of categorial type logics overa period of a dozen years (1997–2009). The aim of this introduction is to provide thereader with a travel guide. To put the developments in perspective, we sketch howthey deal with the conflicting demands of form and meaning at the syntax-semanticsinterface.
The Standard SystemsFor the familiar Lambek systems NL, L and LP, a compositional interpretation, asdiscussed in the 1997 chapter, takes the form of a mapping between a syntactic sourcecalculus and a semantic target calculus. The mapping is a homomorphism, in the senseof Montague’s Universal Grammar program.
(N)L{n,np,s}/,\
(·)10000000000000* LP{e,t}*
syntactic calculus homomorphism semantic calculus(2.32)
To keep the picture simple, we limit our attention here to the implicational fragments.The source calculus has a directional type system; the inventory of basic types is moti-vated by considerations of syntactic distribution. The target calculus, LP aka multi-plicative intuitionistic linear logic, has basic types motivated by the modeltheoreticinterpretation one has in mind, and complex types formed by means of the linearimplication. Derivations in the source and target systems stand in Curry–Howard cor-respondence with a term calculus—the linear lambda calculus in the case of LP, withapplication and abstraction mirroring the * Elimination and Introduction rules. Forthe syntactic systems (N)L, a directional version of linear lambda calculus is appro-priate, distinguishing left and right abstraction, and left and right application, as inWansing (1992). Surface forms are then directly read off the directional proof terms,

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 147 — #53
Categorial Type Logics 147
yielding a string of free variable occurrences in the case of L, and a bracketed stringin the case of NL.
The mapping (·)1 relating source and target calculi respects the types and opera-tions. For atomic source types, one stipulates an interpretation in the target type sys-tem, for example np1 = e, s1 = t, n1 = e * t; for complex types, the directionalimplications of the source calculus are identified in the interpreting semantic calculus.Identification of the directional source constructs also holds for the operations (i.e. therules of inference). Writing x̃ for the target variable of type A1 corresponding to sourcevariable x of type A, (M ‘ N) for the image of the / Elimination rule, M of type B/A,and (N ’ M) for \ Elimination, M of type A\B, we then have
(A\B)1 = (B/A)1 = A1 * B1 ;(+rx.M)1 = (+lx.M)1 = +x̃.M1 ; (M ‘ N)1 = (N ’ M)1 = (M1N1)
The LP target terms that can be reached as the (·)1 image of derivations in the syn-tactic source calculi form a strict inclusion hierarchy (*NL)1 = (*L)1 = *LP: as oneimposes tighter constraints on the syntax, a growing number of desirable recipes forsemantic composition are lost in translation. These losses are severe, as the follow-ing examples show. The transformations of lifting and argument lowering are validthroughout the hierarchy. But function composition +x.(f (g x)) is lost in NL, andonly available in a restricted form in L. In Combinatory Categorial Grammar, functioncomposition is an essential ingredient in the analysis of long-distance dependencies,bridging the gap between an extracted element and the hypothetical position of itstrace. A transformation of argument lifting, taking a function f of type A * (B * C)
to +w.+z.(w +y.(( f y) z)) of type ((A * C) * C) * (B * C) is available in LP, butin none of the syntactic calculi. But such a transformation is a vital component of theanalysis of scope ambiguities in Hendriks (1993). In general, the compositional inter-pretation of discontinuous dependencies, either overt (displacement) or covert (scopeconstrual), is problematic for the “classical” Lambek calculi.
Extended Type-Logical GrammarsThe approaches discussed in Section 2.6 each have their own way of resolving thistension between semantic expressivity and syntactic discrimination. In the multimodalsystems of Section 2.6.1 and the discontinuous calculi of Section 2.6.2, the efforts areconcentrated on the source calculus, whereas the mapping (·)1 itself is left unchanged.In addition to the Lambek slashes \, /, these systems have operations for extraction,infixation, wrapping, and so on. In the mapping to the semantic target calculus, allthese operations are identified, and interpreted in terms of the linear implication. Lostsemantic expressivity in this case is recovered by introducing greater agility in thesource calculi.
The continuation-based approaches of Section 2.6.3 and Section 2.6.4 put morestructure in the mapping that connects the source and target calculi by introducing thecontext as an explicit parameter in the computation of meanings. In the semantic targetcalculus, a function, instead of simply returning a value for a given argument, now

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 148 — #54
148 Handbook of Logic and Language
passes on that value to a function representing the future of the computation. The richerinterpretation creates a choice as to the evaluation order of continuized interpretations.Depending on that choice, a single source derivation can be associated with differentinterpretations. The symmetric calculus discussed in Section 2.6.4 already introducesthe distinction between values and evaluation contexts at the level of the syntacticsource calculus: the \, / implications for the composition of values are complementedwith dual co-implications >, ! for the composition of continuations; a set of lineardistributivity principles makes it possible to interleave these two views on the linguisticresources, and to recover semantic expressivity within a tightly constrained syntax.
Structure of the UpdateWe review four current views on the syntax-semantics interface in Section 2.6. Forreadability, we try to keep references in the text to a minimum, collecting further read-ing suggestions at the end of a section where appropriate. Proof nets and processing forthe categorial landscape as a whole are discussed in Section 2.7. Issues of generativecapacity and computational complexity are the subject of Section 2.8. In Section 2.9,we briefly compare categorial type logics with Pregroup Grammars and Abstract Cat-egorial Grammars.
2.6 Four Views on Compositionality
2.6.1 Multimodal Systems
The emergence of the multimodal architecture was the main topic of the chapter onCategorial Type Logics in the first edition of this Handbook. We can suffice here withhighlighting some lines of convergence with Generative Grammar and CombinatoryCategorial Grammar that have come to the fore in subsequent research.
Recall the key ingredients of the approach. Instead of committing oneself to a par-ticular calculus in the categorial landscape, the syntactic source calculus of multi-modal type-logical grammar (MMTLG) combines different families of compositionoperations in one logic. For the individual composition operations, one sticks to ahighly constrained resource management regime—the pure residuation logic, ideally.The extra expressivity of MMTLG resides completely in the principles that governthe interaction between the composition operations. Interaction can be lexically con-trolled by structural modalities, the unary operations #, ", possibly relativized withrespect to particular composition modes.
In the initial phase of exploration of MMTLG, the structural rules responsible forthe interaction between composition modes were seen as an open-ended set. This lib-eral attitude towards structural rules is incompatible with the generative position thatthe properties of structural reasoning (“Move”) are fixed by Universal Grammar. Italso undermines an attractive design principle of classical categorial grammar: theequation that identifies the grammar for a particular language with its lexicon. With anopen-ended structural rule set, acquiring a grammar would involve solving the lexicalequations and the structural equations of the language under consideration. The origi-

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 149 — #55
Categorial Type Logics 149
nal position of strong lexicalism is reinstalled in MMTLG in Vermaat (2006). Basedon a cross-linguistic study of questions formation, she comes to the conclusion that whextraction can universally be accounted for in terms of the postulates below, togetherwith a left-right symmetric set, where the # marked formula starts out at the left edge.These postulates, then, are thought of as fixed by UG. Languages can differ only as aresult of how their lexica provide access to them.
(P1) (A ? B) ? #C * A ? (B ? #C)
(P2) (A ? B) ? #C * (A ? #C) ? B (2.33)
In combination with a type assignment (n\n)/(s/#"np) to a relative pronoun,(P1), (P2) make the right branches of structural configurations accessible for gapintroduction. The symmetric set of postulates, together with a relative pronoun type(n\n)/(#"np\s), licenses gap introduction on left branches. The notion of “accessi-bility” of the gap (the #"np hypothesis) correlates well with the classical work ofKeenan and Comrie (1977): it sets apart “structurally free” subject relativization, andlines up constraints on the accessibility of non-subject gaps with the typological dis-tinction between head-initial and head-final languages.
The way in which the # operation controls movement, and has to be canceledultimately by a matching " for the derivation to be successful, is highly reminiscent ofthe use of licensor-licensee features in Minimalist Grammar: see Stabler (Chapter 7)for agreements and disagreements. Apart from their use as controllers of structuralreasoning, the unary modalities provide facilities for subtyping via the derivabilitypatterns #"A * A * "#A. An illustration of the use of these patterns (and a similarset for a Galois connected pair of unary operations) is the analysis of quantifier scopeand negative polarity licensing in Hungarian in Bernardi and Szabolcsi (2008). Modaldecorations naturally accommodate the partial ordering of syntactic categories that isat the basis of these phenomena. Such partial orders are problematic for minimalisttheories of syntax where the ordering of “functional heads” is held to be total.
In Baldridge (2002) and Kruijff and Baldridge (2003) the typelogical techniqueof multimodal control is imported into Combinatory Categorial Grammar (CCG): byrelativizing the combinator schemas to composition modes, extra-logical side condi-tions on their applicability can be avoided. This transfer of ideas has led to a rap-prochement between the TLG and CCG schools. The picture that emerges from Hoytand Baldridge (2008) has MMTLG as the underlying general logic which one uses toestablish the validity of CCG combinatory schemata; the particular choice of combi-nators thus definable is then motivated by considerations of computational efficiency(polynomial parsability) or properties of human language processing (incrementality).
2.6.2 The Logic of Discontinuity
The discontinuous Lambek calculi that have been developed by Morrill andco-workers (Morrill, 2002; Morrill et al., 2007, 2009) are extensions of the associativeLambek calculus L. We saw that L is the logic of strings composed by concatenation.

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 150 — #56
150 Handbook of Logic and Language
The discontinuous calculi enrich the ontology with a notion of split strings: expres-sions consisting of detached parts, as in the idiom “take—to task”. To build the phrase“take someone to task”, one wraps the discontinuous expression around its object. Inthis particular example, there is a single point of discontinuity, but it is easy to think ofcases with more than one split point. This naturally leads to two notions of discontinu-ous composition: a deterministic view, where wrapping targets a particular split point,and a non-deterministic view where the targeted split point is arbitrary. In the case ofexpressions with a single split point, these two notions coincide.
The vocabulary of DL (Discontinuous Lambek Calculus) consists of residuatedfamilies of unary and binary type-forming operations. For the binary case, in addi-tion to the concatenation product of L and the residual slash operations, we have adiscontinuous (wrapping) product @, with residual infixation A and extraction B oper-ations. For the deterministic interpretation, the discontinuous type-forming operationshave an indexed form Bk, @k, Ak explicitly referring to the k-th split point of theirinterpretants.
A, B ::= . . . | A @ B | A A B | B B A | 5A | 8A | #A | #01A | $A | $01A(2.34)
Also, the unary type-forming operations come in residuated pairs. The function ofthese operations, as we will see below, is to control the creation and removal of splitpoints. As in the binary case, we have non-deterministic operations (bridge 5 , split 8 )and deterministic ones (left and right injection/projection, and the indexed forms ofbridge/split 5k , 8k ).
Let us turn to the intended models for this extended vocabulary. The modelsencountered so far have been single-sorted; an innovative feature of DL is the moveto a multi-sorted interpretation. The key notion is that of a graded algebra: a freelygenerated algebra (L, +, 0, 1) where the monoid (L, +, 0) of the interpretation of Lis augmented with a distinguished generator 1, called the separator. The sort of anexpression s, ) (s), is given by the number of occurrences of the separator in it. Expres-sions of sort 0 are the familiar strings for the language models of L. Expressions ofsort n > 0 are split strings, with n marked positions where other expressions can besubstituted.
Interpretation of types is now relativized to sorted domains Li = {s | ) (s) = i} fori C 0. The type language of DL contains unary and binary type-forming operations.Frames for DL are 0-sorted structures
({Li}i'N, -1, -2, {Uk}k'N2 , +, {Wk}k'N2 , U, W)
with unary and binary operations, and binary and ternary relations. The operation+ : Li ! Lj * Li+j is the sorted version of the concatenation operation of L. Theinterpretation of the new operations and relations is given in (2.35). The operationsprovide deterministic interpretation for the type-forming operations; in the relationalcase, one obtains a non-deterministic interpretation. Compare the wrapping relation W

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 151 — #57
Categorial Type Logics 151
with the deterministic variant Wk: the latter substitutes the infix for a particular splitpoint, the former for an arbitrary one—similarly for U vs Uk, degenerate forms ofwrapping where the infix is the monoid identity.
operation/relation interpretation-1, -2 : Li * Li+1 -1(s) = 1 + s ; -2(s) = s + 1W + Li+1 ! Lj ! Li+j the smallest relation s.t. W(s1 + 1 + s3, s2, s1 + s2 + s3)
U + Li+1 ! Li the smallest relation s.t. U(s1 + 1 + s2, s1 + s2)
Wk : Li+1 ! Lj * Li+j Wk(s, t) is the result of replacing the k-th separator in s by tUk : Li+1 * Li Uk(s) is the result of replacing the k-th separator in s by 0
(2.35)
An interpretation for DL associates atomic types of sort i to subsets of Li. Inter-pretation clauses for the new complex types are standard. In the light of the illustra-tions below, we give the clauses for right edge injection/projection, non-deterministicbridge/split, and the wrapping family. The sort of the types can be readily computedfrom the sort information for the interpreting operations/relations.
[[DA]] = {-2(s)| s ' [[A]]}[[D01B]] = {s| -2(s) ' [[B]]}
[[ˆA]] = {s| &s1 ' [[A]], U(s1, s)}[[ˇB]] = {s1| (s, U(s1, s) ) s ' [[B]]} (2.36)
[[A@B]] = {s| &s1 ' [[A]] & &s2 ' [[B]], W(s1, s2, s)}[[AAC]] = {s2| (s1 ' [[A]], (s, W(s1, s2, s) ) s ' [[C]]}[[CBB]] = {s1| (s2 ' [[B]], (s, W(s1, s2, s) ) s ' [[C]]}
(2.37)
On the proof-theoretic side, decidability of DL is shown on the basis of a sequentpresentation which enjoys cut-elimination. In order to deal with the discontinuous con-structs, the sequent language is extended with a root notation, allowing reference to theconstituting components of a configuration denoting a discontinuous expression: thesecomponents are the maximal subparts not containing the separator. The resulting pre-sentation is called the hypersequent calculus for DL. Cut-free proof search proceeds inthe familiar backward chaining manner, with each inference step removing an occur-rence of a type-forming operation either from the sequent antecedent (Left rules) orfrom the succedent (Right rules). The interpretation of types is extended to sequentstructural configurations. Whether the hypersequent calculus for DL is complete withrespect to the intended interpretation remains open.
As for the syntax-semantics interface, DL follows the direct interpretation. For themapping from the syntactic source calculus DL to the semantic target calculus LP, theunary type-forming operations are considered inert: the inference rules for these con-nectives, consequently, leave no trace in the LP proof term associated with a deriva-tion in the syntactic source calculus. The continuous and discontinuous families, forthe rest, are treated exactly alike. Specifically, the infixation and extraction operationsare mapped to LP function types, like the slashes.

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 152 — #58
152 Handbook of Logic and Language
IllustrationDL has been successfully applied to a great number of discontinuous dependencies,both of the overt and of the covert type. The non-deterministic operations have beenused to model particle shift and complement alternation constructions. The determin-istic operations of sort 1 (single split point) are used in the analysis of non-peripheralextraction, discontinuous idioms, gapping and ellipsis, quantifier scope construal,reflexivization, pied-piping and the Dutch cross-serial dependencies, among others.
We illustrate the non-deterministic use of DL with English particle shift,using labeled natural deduction format to display derivations, with items Form-Meaning:Type. A verb-particle combination “call—up” is lexically typed as#01((8(np\s)) B np). Eliminating the main connective #01 creates an extra splitpoint at the right periphery. Elimination of the non-deterministic extraction operationB offers a choice as to whether wrapping will affect the first or the second split point.The first option is displayed below. The remaining separator is removed in the elimi-nation step for 8, with the continuous verb phrases “call Mary up” or “call up Mary”as the result.
called + 1 + up 0 phone : E01((8(np\s)) B np)
called + 1 + up + 1 0 phone : 8(np\s) B np EE01Mary 0 m : np
called + Mary + up + 1 0 (phone m) : 8(np\s)E B
called + Mary + up 0 (phone m) : np\s E8
(2.38)
For an example involving covert discontinuity, consider quantifier scope construal.DL provides a uniform type assignment to generalized quantifier expressions suchas “everyone”, “someone”: (s B np) A s. In the syntactic source calculus, this typeassignment allows a quantifier phrase QP to occupy any position that could be occu-pied by a regular non-quantificational noun phrase. Semantically, the image of theB Introduction rule at the level of the semantic target calculus LP binds an np typehypothesis at the position that was occupied by the QP. The image of the A Eliminationrule applies the term representing the QP meaning to this abstract. Scope ambiguitiesarise from derivational ambiguity in the source calculus DL. The derivation belowresults in a non-local (de re) reading “there is a particular x such that Mary thinksx left”. Looking upward from the conclusion, the last rule applied is A Elimination,which means the QP takes scope at the main clause level. An alternative derivation,producing the local scope reading, would have the / Elimination rule for “thinks”:(np\s)/s as the last step.
someone 0 & : (s B np) A s
. . . a 0 x : np . . .
...
mary + thinks + a + left 0 ((thinks (left x)) m) : smary + thinks + 1 + left 0 +x.((thinks (left x)) m) : s B np
B I
mary + thinks + someone + left 0 (& +x.((thinks (left x)) m)) : sA E

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 153 — #59
Categorial Type Logics 153
DiscussionThe basis for the DL extensions is the associative calculus L. As we saw above, aglobal insensitivity to phrase structure is a source of overgeneration, unless blockedby explicit island modalities. In the development of DL nothing seems to hinge onthe associativity of the base system: it would seem entirely feasible, in other words, todevelop DL as an extension of a non-associative basis. In the interpreting frames, onewould then start from a graded groupoid (rather than a monoid), i.e. a structure (L, +, 0)
with a + operation that is not required to be associative. This would obviate the needfor island modalities to block overgeneration resulting from global insensitivity tophrase structure. It would also facilitate the comparison with the continuation-basedapproaches of Section 2.6.3 and Section 2.6.4, which are grafted on non-associativesyntactic base systems. The fact that the DL framework can readily accommodate astring or tree-based point of view testifies to the versatility of the approach.
Reading SuggestionsSee Chapter 6 of the forthcoming monograph (Morrill, 2010) for a comprehensivestatement of the logic of discontinuity.
2.6.3 Continuation Passing Style Translation
The multimodal and discontinuous systems discussed above obtain semantic expres-sivity by making the combinatorics of the syntactic source calculus more flexible. Inthis section and Section 2.6.4 below, we explore an alternative, where derivations inthe syntactic source calculus are associated with a continuation passing style transla-tion (CPS) in the semantic target calculus.
In the theory of programming languages, a continuation is a representation of thecontrol state, i.e. the future of the computation to be performed. By adding the controlstate as an explicit parameter in the interpretation, it becomes possible for a programto manipulate its continuation. Expressions with a functional type A * B, insteadof being considered as procedures that simply transform an A value into a B value(as in the direct interpretation (·)1 of (2.32)) become procedures that, when presentedwith an A value, themselves return a function specifying how the computation willproceed when presented with an evaluation context for a B value. With an explicitrepresentation of the context, one can distinguish different evaluation strategies forsituations where a value and its evaluation context interact: a call-by-value regimegiving precedence to the reduction of the former, a call-by-name regime to that of thelatter.
The use of continuations in computational semantics has been pioneered byde Groote (2001b) and Barker (2002), and has since been successfully applied to pro-vide attractive analyses of a number of recalcitrant phenomena that would seem todefy a compositional treatment; see the reading suggestions at the end of this section.
IllustrationExecuting the syntax-semantics interface in continuation passing style creates newopportunities for meaning assembly. We illustrate with an example, based on Barker

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 154 — #60
154 Handbook of Logic and Language
(2004). Let us assume that the syntactic source calculus is the simplest system in thecategorial hierarchy: the Ajdukiewicz/Bar-Hillel system AB. Mapping the source cal-culus to the semantic target calculus, we parameterize all subexpressions M by a func-tion, their continuation, which provided with the value of M returns the overall resultof the expression. At the level of the target calculus LP*, we can identify this overallresult with the type of truth values t, i.e. the type assigned to complete sentences.
Let us first inspect the effect of a continuation semantics at the level of types.A source language type A is associated with a computation in the target language, i.e. afunction acting on its own continuation: A11 = (A1 * t) * t. For noun phrases np, wethus obtain the familiar lifted Montague type (e * t) * t in the target language. ButMontague’s lifting strategy is now generalized to all source types: a transitive verb(np\s)/np) is mapped to ((e * e * t) * t) * t, etc. Consider next what happensat the level of proofs. Given the above interpretation of types, the task is to find an LPproof for the (·)11 image of the \ and / elimination rules.
(A, A\B "AB B)11
(B/A, A "AB B)11
!"
# = (A1 * t) * t, ((A1 * B1) * t) * t "LP (B1 * t) * t
(2.39)
Whereas in the source calculus there is only one way of putting together an A\B(or B/A) function with its A argument, in the target calculus there is a choice as tothe evaluation order: do we want to first evaluate the (·)11 image of the argument, thenthat of the function, or the other way around? In (2.40) we write ·< for the first option,and ·> for the second. The terms (M‘N) and (N’M) are the source language directionalproof terms in Curry–Howard correspondence with the / and \ elimination rules. Inthe target language, m and n are variables of type A1 * B1 and A1 respectively; k is theresulting B1 * t continuation.
(M ‘ N)< = (N ’ M)< = +k.(N< +n.(M< +m.(k (m n))))
(N ’ M)> = (M ‘ N)> = +k.(M> +m.(N> +n.(k (m n))))(2.40)
The continuized interpretation (·)11 changes the division of labor between syntaxand semantics in interesting ways. First, note that the simple syntactic type np can beassigned both to proper names and to quantificational noun phrases such as “some-one”, “everyone”: in the target calculus, the (·)11 image of np has the appropriatesemantic type (e * t) * t. Proper names are interpreted via a recipe +k.(k c), ca non-logical constant of type np1, i.e. they simply pass their value to the continuationparameter k. The schema +k.(k c) applies to expressions with a non-logical interpreta-tion in general, so we’ll also have +k.(k loves), with loves of type ((np\s)/np)1. Butquantificational noun phrases effectively exploit the continuation parameter: they takescope over their continuation, leading to lexical recipes +k.(( +x.(k x)), +k.(& +x.(k x))for “everyone” and “someone”. The choice between the ·< and ·> evaluation strate-gies, in combination with these lexical recipes, can now result in different interpreta-tions for a single derivation in the source calculus AB, with ·< producing the surface

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 155 — #61
Categorial Type Logics 155
scope construal, and ·> the inverted scope reading for the AB derivation of “everyoneloves someone”.
(everyone ’ (loves ‘ someone))< = +k.(( +x.(& +y.(k ((loves y) x)))
(everyone ’ (loves ‘ someone))> = +k.(& +y.(( +x.(k ((loves y) x)))(2.41)
DiscussionWith respect to the syntax-semantics interface, we obtain the picture below. Each ofthe mappings ·>, ·< by itself constitutes a compositional interpretation. Having both ofthem together leads to a relational (rather than functional) view on the correspondencebetween syntax and semantics. In this respect, the architecture of (2.42) is stronglyreminiscent of the type-shifting approach in Hendriks (1993).
AB{np,s}/,\
·> !!
LP{e,t}*!!
·<(2.42)
In the case of the mappings ·< and ·>, the choice for an evaluation order is madeat the level of the target calculus LP, where the distinction between left and rightdirectional function types has already been obliterated. There is an alternative view,where the difference between \ and / also takes semantic effect. An incremental left-to-right evaluation ·lr would evaluate the argument N before the function M in theinterpretation of the \ elimination rule (N ’ M)lr, but the function M before the argu-ment N in the case of (M ‘ N)lr. These contrasting views make different predictions asto preferred scope construals for languages with different surface order realizations ofthe function-argument structure.
Reading SuggestionsThe program of continuation semantics has been presented in a number of ESSLLIcourses (Barker and Shan, 2004; Shan 2008). There is a choice of presentation formatsfor continuized grammars, either in the style of Combinatory Categorial Grammar(Barker and Shan, 2008), or in the sequent style as in Barker and Shan (2006).Recent examples of continuation-based analyses, at the sentential level, include thetreatment of in situ scope construal and wh questions of Shan and Barker (2006),where crossover and superiority violations are explained in terms of a preference ofthe human processor for a left-to-right evaluation strategy. At the discourse level,de Groote (2006) gives a type-theoretic analysis of dynamic phenomena, modelingpropositions as functions over a sentence’s left and right context (continuation).
2.6.4 Symmetric Categorial Grammar
The extensions of the Syntactic Calculus that we have studied so far all obey an “intu-itionistic” restriction: in the sequent format, we have statements A1, . . . , An " B,where the antecedent is a structured configuration of formulas (a ? tree in the

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 156 — #62
156 Handbook of Logic and Language
non-associative case, a list or a multiset in the case of L, LP), the succedent a sin-gle formula.
In a remarkable paper antedating Linear Logic by five years, Grishin (1983) pro-posed a framework for a symmetric extension of the Syntactic Calculus. Initial presen-tations of this work were Lambek (1993) and Goré (1997); the exploration of Grishin’sideas in computational linguistics started in recent years. The vocabulary of the sym-metric calculus (which we will refer to as LG for Lambek-Grishin calculus) adds aco-product F together with right and left difference operations to the familiar Lambekconnectives. For the difference operations, we pronounce A > B as “A minus B” andB ! A as “B from A”.
A, B ::= p | A ? B | B\A | A/B | A F B | A > B | B ! A (2.43)
The logic of LG is governed by an arrow reversal duality. In addition to the pre-order laws for derivability (reflexivity, transitivity) we have the principles below, to theeffect that the operations /, ?, \ form a residuated triple, and the operations !, F, >a dual residuated triple.
A * C/B iff A ? B * C iff B * A\C
B ! C * A iff C * B F A iff C > A * B(2.44)
Soundness and completeness with respect to a Kripke-style relational semantics areestablished in Kurtonina and Moortgat (2010). We saw that for this type of semanticsthe multiplicative conjunction ? is an existential modality with respect to an inter-preting ternary relation R? (“Merge”); the residual / and \ operations are the corres-ponding universal modalities. For the co-product F and its residuals, a dual situationobtains: the multiplicative disjunction F here is the universal modality with respectto the interpreting relation RF; the co-implications are the corresponding existentialmodalities.
x $ A F B iff (yz.RFxyz implies (y $ A or z $ B)
y $ C > B iff &xz.RFxyz and z G$ B and x $ Cz $ A ! C iff &xy.RFxyz and y G$ A and $ C
(2.45)
In the pure residuation logic of (2.44), there is no interaction between the the ? andthe F families. Grishin discusses two options for adding such interaction. One optionis to augment the logic of (2.44) with the inference rules in (2.46); the other option isto use the converses of these rules, switching premise and conclusion. Each of thesechoices constitutes a conservative extension of the pure residuation logic of (2.44).For their combination (with two-way inferences) this is no longer true: Bastenhof (toappear) shows that this combination introduces associativity and/or commutativity for

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 157 — #63
Categorial Type Logics 157
the individual ? and F families.
A ? B * C F DC ! A * D/B
; A ? B * C F DB ! D * A\C
; A ? B * C F DA ! D * C/B
; A ? B * C F DC ! B * A\D
(2.46)
In what follows, we focus on the type of interaction given in (2.46), because it is thistype that forms the basis for the treatments of discontinuous dependencies that havebeen proposed within LG. The many manifestations of the interaction principles areobtained by closing the premise and conclusion of (2.46) under the residuation rules of(2.44). One verifies, for example, that (2.47) are consequences, and a left-right sym-metric pair for the interaction between ! and ?. These interactions have been calledmixed associativity and commutativity principles—a misleading terminology, sincewe saw that the rules of (2.46) in fact preserve the non-associativity/commutativity ofthe pure residuation logic for ?, F. We prefer to call them linear distributivity princi-ples, following Cockett and Seely (1996).
A ? (B > C) * (A ? B) > C (A > B) ? C * (A ? C) > B (2.47)
Display Sequent Calculus, DecidabilityA decision procedure based on cut-free proof search in a sequent presentation of LGis presented in Moortgat (2009). The sequent calculus used extends the Display Logicformat for substructural logics in Goré (1997) in two respects: for the Curry–Howardinterpretation of LG derivations, an explicit mechanism for activating passive for-mulas is added; secondly, the full set of Grishin’s distributivity principles (2.46) isimplemented.
Proofs and TermsThe term calculus in Curry–Howard correspondence with LG proofs is a bilineardirectional version of the +µ$µ calculus of Herbelin (2005) and Curien and Herbelin(2000). For expository purposes, we restrict our attention to the fragment with impli-cations /, \ and co-implications !, >. We distinguish three types of expression:terms, contexts, and commands. Corresponding to these three types of expression,
we have three types of sequent: Xc" Y , X
v" A and A
e" Y . In these sequents,
X, Y are input/output structures, built out of passive formulas labeled with variablesx, . . . (input) or co-variables &, . . . (output) according to the grammar of (2.49). Asequent has at most one active formula, which is unlabeled. The active formula deter-mines the type of the proof. We write the proof term as a superscript of the turnstile.
(commands) c ::= $v | e%(terms) v ::= x | µ&.c | v > e | e ! v | +(x, $).c | +($, x).c
(contexts) e ::= & | $µx.c | v \ e | e / v |$+(x, $).c |$+($, x).c
(2.48)

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 158 — #64
158 Handbook of Logic and Language
(input structures) S• ::= Var : F | S• · ?· S• | S/ · ! · S• | S• · >· S/
(output structures) S/ ::= Covar : F | S/ · F· S/ | S• · \ · S/ | S/ · / · S•
(2.49)
A characteristic feature of Display Logic is that each logical connective has a struc-tural counterpart. Typographically, we use the same symbols for logical and structuralconnectives, marking off the structural operations by midpoints. The (dual) residua-tion laws and the distributivity principles in the display presentation then becomestructural rules: in (2.44) and (2.46), one replaces the formula variables by structurevariables, and the logical connectives by their structural counterparts. Structural rulesdo not affect the command c which labels the premise and the conclusion.
In the linear setting of LG one can think of a term of type A as a producer andof a context as a consumer of an A value. Axiomatic sequents come in two variants,depending on the point of view (producer/consumer). The Cut Rule represents thetransaction between consumer and producer. The result of a Cut is a state of equilibriumwhere the available resources (the passive input assumptions) and their consumers (thepassive output co-assumptions) are in balance. In order for the derivation to proceedfrom this state of equilibrium, one has to activate an output or an input formula,creating a surplus on the supply or on the demand side. This is the role of the focusingrules (µ) and ($µ). In the premise of these rules, the targeted formula is displayed asthe single antecedent or succedent constituent by means of the structural rules.
x : Ax" A
Xv" A A
e" Y
X$v|e%" Y
cut A&" & : A (2.50)
Xc" & : A
Xµ&.c" A
µ
x : Ac" Y
A
Hµ x.c
" y
Hµ (2.51)
The left and right introduction rules for the connectives \ and > are given below.The cases for / and ! are left-right symmetric. The two-premise rules (\L) and (>R)
start from the same premises: a term v of type A and a context e of type B. Theseresources can be combined in two ways: either one creates a context v\e of type A\B,or a term v > e of type A > B. The one-premise rules (\R) and (>L) have a commandc as premise, with passive resources x : A and $ : B. From this command, an activeoutput formula A\B or input formula A > B is created by binding the variable x andcovariable $.
Xv" A B
e" Y
A\Bv\e" X · \ · Y
\LX
v" A B
e" Y
X · >· Yv>e" A > B
> R (2.52)

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 159 — #65
Categorial Type Logics 159
Xc" x : A · \ · $ : B
X+(x,$).c
" A\B\R
x : A · >· $ : Bc" X
A > B
H+(x,$).c
" X
> L (2.53)
DecidabilityIn the display presentation of LG Cuts can be eliminated, except for Cuts with a(co)axiom premise, corresponding to commands $x | e%, $v | &%, where e (v) is not ofthe form $µy.c (µ$.c). Such Cuts have the effect of deactivating an active formula, sothat the focusing rules (µ, $µ) can be given a chance to shift the attention to another for-mula. The Cuts on a (co)axiom do not affect the subformula property, which means wehave a decision procudure by means of backward-chaining exhaustive proof search.The computation rules below are the images of the Cut elimination steps. The casesfor (/) and (!) are left-right symmetric.
(\) $+(x, $).c | v \ e% ! $v | $µx.$µ$.c | e%%(>) $v > e |$+(x, $).c% ! $µ$.$v | $µx.c% | e%(µ) $µ&.c | e% ! c[& I e]($µ) $v | $µx.c% ! c[x I v]
The Syntax-Semantics InterfaceAs we saw above, LG sequents can have multiple conclusions B1, . . . , Bm heldtogether by the multiplicative disjunction ·F·. To obtain a compositional interpretationof LG derivations in the semantic calculus LP, one proceeds in two steps. The firststep maps the derivations of the multiple conclusion syntactic source calculus LG tosingle-conclusion linear intuitionistic LP proofs by means of a double-negation trans-lation. From a formulas-as-types perspective, this mapping, J·K in the schema below,takes the form of a continuation-passing-style (CPS) translation. The CPS translationintroduces a designated type R, the type of “responses” of a computation, in the targetcalculus; continuations are functions from values into that response type. The secondstep of the interpretation process, "·# in the schema below, takes the output of theCPS translation and maps it to the familiar {e, t} based semantic calculus by identi-fying R as t, the type of truth values. For the NL subsystem of LG the compositionof the J·K and "·# mappings produces the same results as the direct interpretation (·)1.But for derivations involving the difference operations >, !, we obtain novel ways ofmeaning assembly.
NLA/,\(·)1
!!
9""
LP{e,t}*
LGA/,\,>,! J·K!! LPA7{R}
*
"·#
##

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 160 — #66
160 Handbook of Logic and Language
As we saw in Section 2.6.3, two evaluation strategies are available for the CPStranslation: call-by-value or call-by-name. Here we sketch the call-by-value transla-tion; the dual call-by-name approach is worked out in Bernardi and Moortgat (2010).For source types A, in the target language we distinguish values of type A, JAK; con-tinuations JAK * R, i.e. functions from values to the response type R; and computa-tions (JAK * R) * R, functions from continuations to R. For atomic source types,JpK = p. For complex types, we have the definitions below, abbreviating A * R asAL. The target calculus is non-directional LP: as in the case of the direct interpre-tation, the CPS translation identifies the interpretation of the directional implicationsand co-implications. A source type A\B is interpreted as a function from B continua-tions to A continuations. The interpretation of a co-implication A > B is dual: the CPStranslation identifies values of type A > B with continuations of type A\B.
JB/AK =J A\BK = JBKL * JAKL
JB ! AK =J A > BK = (JBKL * JAKL)L = JA\BKL
At the level of proofs, the CPS translation is a compositional mapping in the senseof the following invariant. An LG derivation of a term v of type B is mapped to anLP proof of a B computation from values and continuations for the input and outputliterals of the antecedent structure X. An LG derivation of a context e of type A ismapped to an LP proof of an A continuation from values and continuations for theinput and output literals of the succedent structure Y . A source language command ccorresponds to the derivation of a target language term JcK of type R from values andcontinuations for the input and output literals of X and Y .
source: LGA/,\,>,!J·K000000000000000*
CPS translationtarget: LPA7{R}
*
Xv" B
Ae" Y
Xc" Y
JX•K, JX/KL " JvK : JBKLL
JY•K, JY/KL " JeK : JAKL
JX•K, JY•K, JX/KL, JY/KL " JcK : R
At the term level, the translations below respect the invariant. Since terms aremapped to computations and contexts to continuations, the leading abstraction forthe translation of terms is over a continuation variable; in the case of contexts, theabstraction is over a variable for a value of the relevant type. We write $x ($&) for thetarget language (co)variable corresponding to source language x (&). Notice that Jv >eK = +k.(k Jv\eK) as a result of the fact that JA > BK =J A\BKL.
(terms) JxK = +k.(k$x)J+(x, $).cK =J +($, x).cK = +k.(k +$$+$x.JcK)
Jv > eK =J e ! vK = +k.(k +u.(JvK (u JeK)))Jµ&.cK = +$&.JcK
(contexts) J&K = $& (= +x.($& x))Jv\eK =J e/vK = +u.(JvK (u JeK))

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 161 — #67
Categorial Type Logics 161
J$+(x, $).cK =J$+($, x).cK = +u.(u +$$+$x.JcK)J$µx.cK = +$x.JcK
(commands) J$v | e%K = (JvK JeK)
IllustrationWe run through the two-step interpretation process with a small example from pseudo-English. Suppose, in the syntactic source calculus, we make a distinction betweentenseless and tensed clauses, with categories vp and tns respectively. A transitive verbstem, say kiss, could then be typed as (np\vp)/np: in combination with a subject and anobject, it produces a tenseless clause. Next, consider a tense operation in this language,say, past tense -ed. We would like to treat it as a function turning tenseless vp into tns.A syntactic type-assignment vp\tns would have that effect, building tns phrases with astructure ((john kiss mary) -ed). As we saw in the discussion of (2.52), in LG there isan alternative way of expressing the idea of a function turning tenseless vp into tns: theco-implication vp> tns. Consider a type-assignment (vp> tns)! tv to the combinationkiss+ed. The Grishin distributivity principles will allow the subformula vp > tns toescape from its internal position within the tenseless clause, and take scope over thecomplete vp. A shorthand derivation is given in (2.54), with silent structural stepslinking the active formulas of premises and conclusions. The crucial distributivity stepis hidden in the (!L) rule, as the reader may want to check. We transform the proofterm for this derivation (2.55) by means of the J·K and "·# translations. In (2.56),kiss+ed, john, mary are values of type JAK for source language type assignments A.The final step takes the image of the CPS translation and interprets it as an LP proofover the {e, t} basic types. For the CPS response type, we have "R# = t. For therest, "np# = e, "vp# = "tns# = t. In (2.58), the interpretation of "kiss+ed# isgiven in terms of non-logical constants kiss, past, of types e * e * t and t * t,respectively—the types that would be associated with (np\vp)/np and vp\tns underthe direct interpretation. We can evaluate (2.57) by providing the identity function forthe final continuation c of type t * t.
· np ·john" np vp
&1" · vp ·
np\vp " np · \ · vp\L · np ·
mary" np
(np\vp)/np " (np · \ · vp) · / · np/L
np · ?· ((np\vp)/np · ?· np) " vp%
tns&0" · tns ·
(np · ?· ((np\vp)/np · ?· np)) · >· tns " vp > tns>R
(vp > tns) ! ((np\vp)/np) " (np · \ · tns) · / · np!L
np%&'(john
· ?· ((vp > tns) ! ((np\vp)/np)% &' (kiss + ed
· ?· np%&'(mary
) " tns%
(2.54)
µ&0.$ kiss+ed |$+($, z).$ (µ&1.$ z | ((john \ &1) / mary) % > &0) | $ % % (2.55)

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 162 — #68
162 Handbook of Logic and Language
J(2.56)K = +$&0.(kiss+ed +$$.(+$z.($$ +h.(($z +u.((u (h $&0)) john)) mary))))(2.56)
"(2.57)# = +c.(c (past ((kiss mary) john))) (2.57)
"kiss#= +V+y.(V +c+x.(c ((kiss y) x)))
"-ed#= +c+v.(c (past v))
"kiss+ed#= +Q.((Q +u.(u "-ed#)) "kiss#)
(2.58)
DiscussionThe symmetric calculus LG has been applied to a number of discontinuous depen-dencies. Quantifier scope ambiguities are dealt with in Bernardi and Moortgat (2010);Moot (2007) presents mappings that translate the LTAG analyses of mildly context-sensitive constructions into LG grammars. Whereas the Discontinuous Calculus ofSection 2.6.2 treats extraction and the infixation phenomena in a similar fashion, thedistributivity principles (2.46) would seem to address only the latter. See Bastenhof(to appear) for a proposal to use the converses of the (2.46) distributivity principlesto handle displacement. Moortgat (2010) extends the language of LG with a Galoisconnected and a dual Galois connected pair of negations; these downward monotonicoperations bring the arrow-reversal duality that we observed at the metalevel into theobject language of LG. As for the syntax-semantics interface, the two-step interpreta-tion of LG into LP via the CPS translation reconciles semantic expressivity with thesensitivity for word order and phrase structure information one finds in NL.
Reading SuggestionsThe web page symcg.pbwiki.com of the Bernardi and Moortgat ESSLLI’07 coursecontains background materials for LG, including a (corrected) translation of Grishin’soriginal paper, which is difficult to find elsewhere.
2.7 Proof Nets and Processing
Sequent calculus identifies fewer proofs than natural deduction. This existence ofa many-to-one relation between sequent and natural deduction derivations (or thelambda terms in Curry–Howard correspondence with them) can be perceived as a flawof the sequent calculus—a problem of “spurious” ambiguity. One way of addressingthis problem is by introducing a normal form for sequent derivations. Proposals tothat effect in Hepple (1990) and Hendriks (1993) can be compared with the focusedproof search regimes developed in linear logic (Andreoli, 2001). Focused proof searchcan then be combined with standard chart-based parsing methods as in Hepple (1996,1999); Capelletti (2007).

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 163 — #69
Categorial Type Logics 163
An alternative for categorial “parsing-as-deduction” is to leave the sequent calculusfor what it is, and to switch to a proof net approach. Proof nets, originally developed inthe context of linear logic, use a representation of derivations that is inherently free of“spurious ambiguity”, i.e. the issue of irrelevant rule orderings simply doesn’t arise.
Roorda’s Nets for Lambek CalculusThe study of proof nets for the associative calculus L and the Lambek–Van Benthemsystem LP was initiated by Roorda; see his 1991 thesis and Roorda (1992). We con-sider formulas with polarities: input (“given”) polarity ·• for antecedent occurrencesof a formula, versus output (“to prove”) polarity ·/ for succedent occurrences. Onecomputes the formula decomposition tree for arbitrary formulas with the followingunfolding rules. These rules make a distinction between two types of links: ?-type(“tensor”) links corresponding to the two-premise sequent rules /L, \L, ?R, and F-type (“cotensor”/“par”) links, corresponding to the one-premise sequent rules ?L, /R,\R. The order of the subformulas in the premises of the cotensor links is reversed withrespect to their order in the conclusion.
A• B/
A/B• ? B• A/
A/B• F B/ A•
B\A• ? A/ B•
B\A/ F A• B•
A ? B• F B/ A/
A ? B/ F
(2.59)
To build a proof net for an L sequent A1, . . . , An " B one proceeds in two stages. (1)Build a candidate proof structure. A proof structure is obtained by taking the formuladecomposition trees A•
1 . . . A•nB/ (or any cyclic permutation) together with an axiom
linking. An axiom linking is a pairwise matching of leaves (literals, atomic formulas)with opposite polarities. (2) Check whether the proof structure is in fact a proof net bytesting the correctness criteria on its correction graphs. A correction graph is obtainedfrom a proof structure by removing exactly one edge from every F link. A proofstructure is a proof net iff every correction graph for it is: (i) a-cyclic and connected:the criteria for linear wellformedness, as one has them for LP; (ii) planar: no crossingaxiom links—the distinguishing criterion for non-commutative L.
The links in (2.59) are for the syntactic source calculus. It is shown in de Groote andRetoré (1996) that the lambda terms in Curry–Howard correspondence with deriva-tions in the semantic target calculus can be read off from a proof net by specifyinga set of “travel instructions” for traversing a net; these instructions then correspondstep-by-step with the construction of the associated lambda term.
Incremental ProcessingAs we saw above, the main selling point for the proof net approach is its “declara-tive” view on derivations: nets, considered statically as graphs satisfying certain cor-rectness criteria, remove spurious choices relating to the order of rule applicationsin sequent calculi. Johnson (1998) and Morrill (2000) have pointed out that an alter-native “procedural” view on the actual process of constructing a net makes perfect

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 164 — #70
164 Handbook of Logic and Language
sense as well, and offers an attractive perspective on performance phenomena. Underthis interpretation, a net is built in a left-to-right incremental fashion by establishingpossible linkings between the input/output literals of the partial proof nets associatedwith lexical items as they occur in real time. This suggests a simple complexity mea-sure on an incremental traversal, given by the number of unresolved dependenciesbetween literals. This complexity measure correlates nicely with a number of well-attested processing issues, such as the difficulty of center embedding, garden patheffects, attachment preferences, and preferred scope construals in ambiguous cons-tructions.
First-order QuantifiersThe planarity condition singles out the non-commutative proof nets for L among theLP nets. To deal with the more structured categorial calculi discussed here, the cor-rectness criteria have to be refined. One strategy of doing this is via a translation intoMILL1 (first-order multiplicative intuitionistic linear logic) where one has proof netswith extra links for existential and universal quantification over 1-st order variables.One can then use these variables in a way very similar to the use of position argumentsin the DCG grammar encoding familiar from logic programming. Moot and Piazza(2001) work out such translations for L and NL. For the concatenation operations ofL, one replaces the proposition letters (atomic formulas) by two-place terms, markingthe beginning and end of a continuous string. For non-associative NL, one adds anextra variable to keep track of the nesting depth of subformulas. For wrapping opera-tions in the simple discontinuous calculus DL (allowing a single split point), Morrilland Fadda (2008) use four-place predicates. In general, we find a correlation here bet-ween the syntactic expressivity of the calculi and the number of variables needed toencode their structural resource management.
Nets and RewritingThe multimodal and symmetric calculi of Section 2.6.1 and Section 2.6.4 pose a chal-lenge to the proof net methods as originally developed for linear logic. In these systemswe typically find one-way structural rules, such as the extraction postulates for overtdisplacement, or the Grishin distributivity laws in the case of LG: these one-way rulesnaturally suggest a notion of graph rewriting. A completely general proof net frame-work for the extended Lambek calculi has been developed by Moot and Puite (2002)and Moot (2007).
The basic building block for the Moot–Puite nets is a generalized notion of alink. A link is determined by its type (tensor or cotensor), its premises (a sequenceP1, . . . , Pn, 0 4 n), its conclusions (a sequence C1, . . . , Cm, 0 4 m), and its mainformula (which can be empty, in the case of a neutral link, or one of the Pi or Ci).We present the links for the unary and binary connectives of NL# below. Premisesare written above, conclusions below the link; tensor links are represented by opencircles, cotensor links by closed circles. Mode distinctions can be straightforwardlyadded. The links for the co-product and difference operations of LG are obtained by

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 165 — #71
Categorial Type Logics 165
turning the links for the dual product and slash operations upside down.
A / B
A / B A \ B
A \ BB
B BA
A A B A
A A
AB
A ABB
A
BA A A
A A
A
A proof structure is a set of links over a finite set of formulas such that every for-mula is at most once the premise of a link and at most once the conclusion. Formulaswhich are not the conclusion of any link are the hypotheses of the proof structures,whereas the formulas which are not the premise of any link are the conclusions. Anaxiom formula is a formula which is not the main formula of any link.
From a proof structure we obtain a more general structure, the abstract proof struc-ture, by erasing all formulas on the internal nodes. A proof net is a proof structure forwhich the abstract proof structure converts to a tensor tree—a rooted tree in the caseof the intuitionistic systems, possibly an unrooted tree in the case of symmetric LG.Proofs nets, then, are the graphs that correspond to valid derivations.
H
C
[R\] [R/][L ]C C
H H
The conversions transforming a candidate abstract proof structure into a proof netare of two kinds. The logical contractions correspond to identities A " A, for com-plex formulas A. The input configurations for the logical contractions of NL# aregiven above; the output in each case is a single point. The LG contractions for theco-product and difference operations are dual to those for product and slashes. Thestructural conversions perform an internal rewiring of a proof structure with hypothe-ses H1, . . . , Hn and conclusions C1, . . . , Cm to a structure with some permutation ofthe Hi as hypotheses and some permutation of the Ci as conclusions. Copying anddeletion, in other words, are ruled out. We give the ! distributivity laws of LG as anillustration. Because structural rules in general are not invertible, the Input!Outputorientation is important.

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 166 — #72
166 Handbook of Logic and Language
V V WW
W
WGr1 Gr2
X
Y X
XV
Y
Y
X · ! · V " Y · / · W Gr1, V · ?· W " X · F· Y Gr2) X · ! · W " V · \ · Y
IllustrationThe construction of an LG net for “John believes someone left”, under the non-localreading is presented in Figures 2.3 and 2.4. The partial proof nets for the lexical entriesare given in Figure 2.3. Figure 2.4 traces the steps rewriting the abstract proof structureto a tensor tree. The abstract proof structure (left) contains a cotensor link that has tobe contracted. The input configuration for this contraction is obtained after three stepsof structural rewriting by means of the Grishin distributivities.
2.8 Recognizing Capacity, Complexity
Stabler (Chapter 7) discusses the remarkable convergence of a variety of contem-porary grammar formalisms on “mild context-sensitivity”: in the characterization ofJoshi, Vijay-Shanker, and Weir (1991) such formalisms are more expressive thancontext-free (able to handle the Dutch crossed dependencies, for example), but strictlyweaker than context-sensitive, and they allow polynomial parsing algorithms. Wherecan we situate the type-logical systems discussed here with respect to these mildlycontext-sensitive formalisms?
The minimal system in the type-logical hierarchy NL has a polynomial recognitionproblem (see de Groote, 1999 and Capelletti, 2007 for actual parsing algorithms), but it
believes
someone
left
John
(np \ s) / s s
s
s ss ss
np
np
np \ s
s s( ) np
np
np np \ s
Figure 2.3 “John believes someone left”: lexical entries.
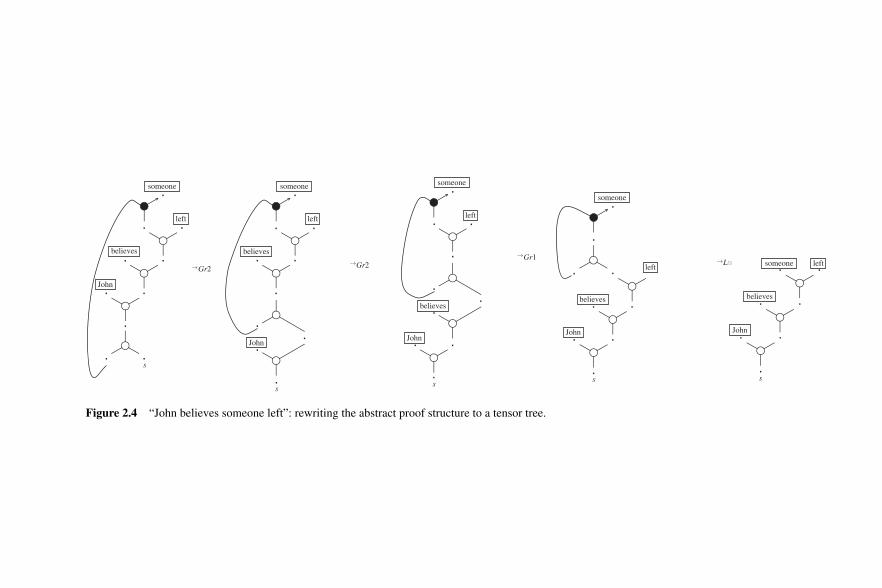
“06-ch02-0095-0180-9780444537263”—
2010/11/29—
21:15—
page167
—#73
someone
left
Gr2
believes
John
s
ss s s
someone
left
believes
John
someone
left
believes
John
someone
leftL
believes
John
someone left
believes
John
Gr2Gr1
Figure 2.4 “John believes someone left”: rewriting the abstract proof structure to a tensor tree.

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 168 — #74
168 Handbook of Logic and Language
is strictly context-free (Kandulski, 1988b). Extensions with global structural rules areunsatisfactory, both on the expressivity and on the complexity front. As for L, Pentus(1993, 2006) shows that it remains strictly context-free, whereas the addition of globalassociativity makes the derivability problem NP complete. NP completeness alreadyholds for the product-free fragment of L (Savateev, 2009). Also for LP, i.e. multi-plicative intuitionistic linear logic, we have NP completeness (Kanovich, 1994). Withregard to recognizing capacity, shows that LP recognizes all permutation closures ofcontext-free languages: a class which is too wide from the syntactic point of view.As the logic of meaning assembly, LP is a core component of the type-logical inven-tory. But as we saw in the discussion of the syntax-semantics interface, we can restrictattention to the sublanguage of LP that forms the image of derivations in syntacticcalculi making interesting claims about word order and phrase structure.
The situation of the multimodal and symmetric extensions is more intricate.Expressivity here is directly related to the kind of restrictions one imposes on struc-tural resource management. At one end of the spectrum, multimodality without struc-tural rules does not lead us beyond context-free recognition: Jäger (2003) shows thatthe pure residuation logic for n-ary families of type-forming operations stays strictlycontext-free. The extension with the dual residuated operators of LG also remainscontext-free as long as no distributivity principles are considered, see (Bastenhof,2010). If one requires structural rules to be resource-sensitive (no copying or dele-tion) and, for the unary modalities, non-expanding, one obtains the full expressivityof context-sensitive grammars, and the PSPACE complexity that goes with it (Moot,2002). If one imposes no restrictions on structural rules (specifically, if one allowscopying and deletion operations), unsurprisingly, one obtains the expressivity of unre-stricted rewriting systems (Carpenter, 1999). A controlled use of copying is used inthe analysis of anaphora resolution (Jäger, 2005).
As for the symmetric calculus with the distributivity principles of (2.46), Melissen(2009) shows that all languages which are the intersection of a context-free languageand the permutation closure of a context-free language are recognizable in LG. In thisclass, we find generalized forms of MIX, with equal multiplicity of k alphabet symbolsin any order, and counting dependencies an
1 . . . ank for any number k of alphabet sym-
bols. Patterns of this type are recognized by Range Concatenation Grammars (Boul-lier, 1999) and Global Index Grammars (Castaño, 2004); a comparison with theseformalisms then might be useful to fix the upper bound of the recognizing capacity ofLG, which is as yet unknown.
With respect to computational complexity, Moot (2008) establishes a correspon-dence between LTAG grammars on the one hand, and categorial grammars with themultimodal extraction postulates of Section 2.6.1 and a restricted set of LG gram-mars on the other. For these grammars he obtains a polynomial parsability result viaa translation into Hyperedge Replacement Grammars of rank 2. In the case of LG,the restriction requires the Galois connected >, ! operations to occur in matchingpairs in lexical type assignments. The lexicon of the generalized MIX construction ofMelissen (2009), and the type assignment used for quantifier phrases in the analysisof scope construal in Bernardi and Moortgat (2010), do not respect this restriction.

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 169 — #75
Categorial Type Logics 169
For the general case of LG with the interaction principles of (2.46), Bransen (2010)establishes NP-completeness. The position of the discontinuous calculi of Section2.6.2 in this hierarchy has to be determined: they recognize more than the context-free languages, but it is not clear whether they stay within the mildly CS family.
2.9 Related Approaches
The type-logical approaches discussed in this chapter share a number of characteristicswith related formal grammar frameworks. Throughout the text, we have commentedon the correspondences with Combinatory Categorial Grammars and MinimalistGrammars. Below we briefly comment on Pregroup Grammars and Abstract Catego-rial Grammars. It is impossible to do justice to these frameworks within the confinesof this update, but we provide pointers to relevant literature for further exploration.
Pregroup GrammarsPregroups are an algebraic version of compact bilinear logic obtained by collapsingthe tensor and cotensor operations. Pregroup grammars were introduced in Lambek(1999) and have since been used to build computational fragments for a great varietyof languages by Lambek and co-workers. A pregroup is a partially ordered monoid inwhich each element a has a left and a right adjoint, al, ar, satisfying ala * 1 * aal
and aar * 1 * ara, respectively. Type assignment takes the form of associatinga word with one or more elements from the free pregroup generated by a partiallyordered set of basic types. For the connection with categorial type formulas, one canuse the translations a/b = abl and b\a = bra. Parsing, in the pregroup setting, isextremely straightforward. Lambek (1999) proves that one only has to perform thecontractions replacing ala and ala by the multiplicative unit. This is essentially a checkfor well-bracketing—an operation that can be entrusted to a pushdown automaton. Theexpansions 1 * aal and 1 * ara are needed to prove equations like (ab)l = blal. Wehave used the latter to obtain the pregroup version of the higher-order relative pronountype (n\n)/(s/np) in the example below.
book that Carroll wrotecategorial types : n (n\n)/(s/np) np (np\s)/np
pregroup assignment : n nr n npll sl np npr s npl * n
Compact bilinear logic is not a conservative extension of the original SyntacticCalculus. Every sequent derivable in L has a translation derivable in the correspondingpregroup, but the converse is not true: the pregroup image of the types (a ? b)/c anda ? (b/c), for example, is a b cl, but these two types are not interderivable in L.
With respect to generative capacity, Buszkowski (2001) shows that the pregroupgrammars are equivalent to context-free grammars. They share, in other words, theexpressive limitations of the original categorial grammars. To overcome these lim-itations different strategies have been pursued, including lexical rules (metarules),

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 170 — #76
170 Handbook of Logic and Language
derivational constraints, controlled forms of commutativity and products of pregroups.The Studia Logica special issue (Buszkowski and Preller, 2007) and the monograph(Lambek, 2008) give a good picture of current research.
Abstract Categorial GrammarThe ACG framework (de Groote, 2001a) is a meta-theory of compositional grammararchitectures. ACGs are built on higher-order linear signatures 1 = (A, C, 2 ), whereA and C are finite sets of atomic types and constants respectively, and 2 a functionassigning each constant a linear implicative type over A. Given a source signature 1
and a target signature 11, an interpretation is a mapping form 1 to 11 given by a pairof functions: , mapping the type atoms of 1 to linear implicative types of 11 and 3
mapping the constants of 1 to well-typed linear lambda terms of 11; the interpretivefunctions are required to be such that for all constants c from 1 the typing rules of11 assign to 3(c) the type ,̂(2 (c)) where ,̂ is the (unique) homomorphic extensionof ,. Using the terminology of compiler theory, one refers to the source and targetsignatures as the abstract vocabulary and the concrete vocabulary, respectively, andto the interpretive mapping as the lexicon. An ACG is then obtained by specifying anatomic type of 1 as the distinguished type of the grammar.
In the ACG setting, one can model the syntax-semantics interface in terms of theabstract versus object vocabulary distinction. But one can also study the compositionof natural language form as an interpretive mapping, using the canonical + term encod-ings of strings and trees and operations on them. The ACG architecture is independentof the particular type system used. In de Groote, Maarek, and Yoshinaka (2007), theexpressive effects of richer vocabularies of type-constructors are investigated: linearimplication together with Cartesian and dependent products. ACG has given rise to aninteresting complexity hierarchy for rewriting grammar formalisms encoded as ACGs:context-free grammars, tree-adjoining grammars, etc. (see for example de Groote andPogodalla, 2004). Expressive power of these formalisms is measured in terms of themaximal order of the constants in the abstract vocabulary and of the object types inter-preting the atomic abstract types. The study of ACG encodings of type-logical systemsproper has started with Retoré and Salvati (2010); these authors present an ACG con-struction for product-free NL.
The ACG architecture is closely related to the compositional interpretation for cate-gorial type logics discussed in this chapter: these frameworks can both be seen asinstances of Montague’s Universal Grammar programme. A key difference relates tothe nature of the “abstract syntax”, i.e. the source calculus from which interpretationsare homomorphically derived. In the case of the standard Lambek systems and theextended systems discussed in Section 2.6 above, the abstract syntax is a directionaltype logic; in the case of ACG, one finds LP and the linear lambda calculus bothat the source and at the target end. The debate as to whether structural propertiesof language have to be accounted for at the level of the abstract syntax has a longhistory, starting with Curry (1961). The type-logical view accounts for word-orderuniversals at the level of its logical constants, i.e. the type-forming operations, and the

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 171 — #77
Categorial Type Logics 171
laws that govern them. In the ACG view, the derivation of surface form is of a non-logical nature that can be specified on a word-by-word basis. When it comes to thepractice of actual grammar writing, the ideological difference often turns out to be lesspronounced. An example is Muskens (2007), who simulates a multimodal account ofa number of Dutch word-order phenomena, starting from an LP source calculus. Themultimodal analysis controls verb placement in terms of interaction postulates, withcorresponding frame constraints in the relational models. The simulation translatesthese frame constraints into structural combinators, expressed as linear lambda terms.
2.10 Concluding Remarks
Comparing the state of the field in 1997 with the situation described in this update,one notices that certain lines of research that were in fashion then are not productiveanymore. The hybrid architectures aiming for an integration of ideas from unificationgrammars and categorial systems seem to have disappeared from the scene, for exam-ple. A marked trend, in general, is the move to leaner syntactic calculi, by exchangingstructural rules for richer algebraic models (the graded algebra of DL), or by introduc-ing more structure in the interpreting semantic calculi (the continuation-based seman-tics of Section 2.6.3 and Section 2.6.4).
It is tempting to speculate about future developments too. The intriguing openquestions at the end of Section 2.8 are likely to generate a flurry of activity on thegenerative capacity and computational complexity front. The dualities that link theevaluation strategies of the continuation-based semantics and those that are at the heartof symmetric categorial grammar invite a category theoretic analysis. Category theory,so far, has not been a prominent theme in the linguistic development of type-logicalgrammar—it certainly was one of the primary sources of inspiration for Lambek’soriginal work in this area.
References
Abrusci, M.V., 1996. Semantics of Proofs for Noncommutative Linear Logic. Preprint CILA,University of Bari.
Ades, A., Steedman, M., 1982. On the order of words. Ling., Philos. 4, 517–558.Ajdukiewicz, K., 1935. Die syntaktische Konnexität. Studia Philos. 1, 1–27. (English translation
in Storrs McCall (Ed.), Polish Logic, 1920–1939. Oxford (1967), pp. 207–231.)Andréka, H., Mikulás, S., 1994. Lambek calculus and its relational semantics: completeness
and incompleteness. J. Logic Lang. Inf. 3, 1–38.Andreoli, J., 2001. Focussing and proof construction. Ann. Pure Appl. Logic 107 (1–3),
131–163.Bach, E., 1984. Some generalizations of categorial grammar, in: Landman, F., Veltman, F.
(Eds.), Varieties of Formal Semantics. Foris, Dordrecht, pp. 1–23.Bach, E., 1988. Categorial grammars as theories of language, in: Oehrle, R.T., Bach, E.,
Wheeler, D. (Eds.), Categorial Grammars and Natural Language Structures. Reidel,Dordrecht, pp. 17–34.

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 172 — #78
172 Handbook of Logic and Language
Baldridge, J., 2002. Lexically Speciffied Derivational Control in Combinatory Categorial Gram-mar. PhD thesis, University of Edinburgh.
Bar-Hillel, Y., 1964. Language and Information. Addison-Wesley, New York.Barker, C., 2002. Continuations and the nature of quantification. Nat. Lang. Semant. 10,
211–242.Barker, C., 2004. Continuations in natural language, in: Thielecke, H. (Ed.), CW’04: Proceed-
ings of the 4th ACM SIGPLAN continuations workshop. Technical Report CSR-04-1,School of Computer Science, University of Birmingham, pp. 1–11.
Barker, C., Shan, C., 2006. Types as graphs: continuations in type logical grammar. J. LogicLang. Inf. 15 (4), 331–370.
Barker, C., Shan, C.-c., 2008. Donkey anaphora is in-scope binding. Semant. Pragmat. 1 (1),1–46.
Barry, G., 1991. Derivation and Structure in Categorial Grammar. PhD Dissertation, Edinburgh.Barry, G., Morrill, G. (Eds.), 1990. Studies in Categorial Grammar. Edinburgh Working Papers
in Cognitive Science, vo1. 5. CCS, Edinburgh.Barry, G., Hepple, M., Leslie, N., Morrill, G., 1991. Proof figures and structural operators for
categorial grammar. Proceedings of the Fifth Conference of the European Chapter of theAssociation for Computational Linguistics. Berlin.
Barry, G., Pickering, M., 1990. Dependency and constituency in categorial grammar, in:Barry, G., Morrill, G. (1990), pp. 23–45, Edinburgh.
Bastenhof, A., 2010. Tableaux for the Lambek-Grishin calculus. CoRR abs/1009.3238.Bastenhof, A., to appear. Polarized Montagovian semantics for the Lambek-Grishin calculus,
in: Proceedings 15th Conference on Formal Grammar, Copenhagen.Belnap, N.D., 1982. Display logic. J. Philos. Logic 11, 375–417.Bernardi, R., Moortgat, M., 2010. Continuation semantics for the Lambek-Grishin calculus. Inf.
Comput., 208 (5): pp. 397–416.Bernardi, R., Szabolcsi, A., 2008. Optionality, scope, and licensing: an application of partially
ordered categories. J. Logic Lang. Inf. 17 (3), 237–283.Boullier, P., 1999. Chinese numbers, MIX, scrambling, and range concatenation grammars,
in: Proceedings of the 9th EACL Conference. Association for Computational LinguisticsMorristown, NJ, USA, pp. 53–60.
Bransen, J., 2010. The Lambek-Grishin calculus is NP-complete. CoRR abs/1005.4697.Bucalo, A., 1994. Modalities in Linear Logic weaker than the exponential “of course”: algebraic
and relational semantics. J. Logic Lang. Inf. 3 (3), 211–232.Buszkowski, W., 1984. Fregean grammar and residuated semigroups, in: Wechsung, G. (Ed.),
Frege Conference 1984. Akademie-Verlag, Berlin, pp. 57–62.Buszkowski, W., 1986. Completeness results for Lambek syntactic calculus. Zeitschrift für
Mathematische Logik und Grundlagen der Mathematik, 32, 13–28.Buszkowski, W., 1987. The logic of types, in: Srzednicki, J.T. (Ed.), Initiatives in Logic. Nijhoff,
The Hague, pp. 180–206.Buszkowski, W., 1988. Generative power of categorial grammars, in; Oehrle, R.T., Bach,
E., Wheeler, D. (Eds.), Categorial Grammars and Natural Language Structures. Reidel,Dordrecht, pp. 69–94.
Buszkowski, W., 2001. Lambek grammars based on pregroups, in: de Groote, P., Morrill, G.,Retore, C. (Eds.), Logical Aspects of Computational Linguistics, vol. 2099. Lecture Notesin Artificial Intelligence, Springer, Berlin, pp. 95–109.
Buszkowski, W., 2010. Interpolation and FEP for logics of residuated algebras. Logic J. IGPL.Special issue Logic, Algebra and Truth Degrees (LATD 2008).

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 173 — #79
Categorial Type Logics 173
Buszkowski, W., Farulewski, M., 2009. Nonassociative Lambek Calculus with Additives andContext-Free Languages, in: Grumberg, O., Kaminski, M., Wintner, S. (Eds.), Languages:From formal to Natural. Essays Dedicated to Nissim Francez on the Occasion of His 65thBirthday, vol. 5533. Lecture Notes in Computer Science, Springer, pp. 45–58.
Buszkowski, W., Preller, A., 2007. Editorial introduction special issue on pregroup grammars.Studia Logica 87 (2), 139–144.
Capelletti, M., 2007. Parsing with structure-preserving categorial grammars. PhD thesis,Utrecht Institute of Linguistics OTS, Utrecht University.
Carpenter, B., 1994. Quantification and scoping: a deductive account. Proceedings 13th WestCoast Conference on Formal Linguistics. San Diego, CA.
Carpenter, B., 1996. Type-Logical Semantics. MIT Press, Cambridge, MA.Carpenter, B., 1999. The Turing-completeness of multimodal categorial grammars, in:
Gerbrandy, J., Marx, M., de Rijke, M., Venema, Y. (Eds.), JFAK. Essays Dedicated toJohan van Benthem on the Occasion of his 50th Birthday. Amsterdam University Press,Amsterdam.
Castaño, J., 2004. Global index grammars and descriptive power. J. Logic Lang. Inf. 13 (4),403–419.
Cockett, C., Seely, R.A.G., 1996. Proof theory for full intuitionistic linear logic, bilinear logicand mix categories. Theory and Applications of Categories 3, pp. 85–131.
Curien, P., Herbelin, H., 2000. Duality of computation. International Conference on FunctionalProgramming (ICFP’00), pp. 233–243. [2005: corrected version].
Curry, H.B., 1961. Some logical aspects of grammatical structure, in: Jakobson, R. (Ed.), Struc-ture of Language and its Mathematical Aspects, volume XII of Proceedings of the Sym-posia in Applied Mathematics. American Mathematical Society, pp. 56–68.
Curry, H., Feys, R., 1958. Combinatory Logic, Vol. I. Studies in Logic, North Holland,Amsterdam.
Dalrymple, M., Lamping, J., Pereira, F., Saraswat, V., 1995. Linear logic for meaning assembly,in: Morrill, G., Oehrle, R.T. (Eds.), Formal Grammar, ESSLLI Barcelona, pp. 75–93.
de Groote, P., 1999. The non-associative Lambek calculus with product in polynomial time, in:Murray, N.V. (Ed.), Automated Reasoning With Analytic Tableaux and Related Methods,vol. 1617. Lecture Notes in Artificial Intelligence, Springer, pp. 128–139.
de Groote, P., 2001a. Towards abstract categorial grammars. Proceedings of 39th Annual Meet-ing of the Association for Computational Linguistics. Toulouse, France, pp. 252–259.(Association for Computational Linguistics.)
de Groote, P., 2001b. Type raising, continuations, and classical logic, in: van Rooy, M.S.R.(Ed.), Proceedings of the Thirteenth Amsterdam Colloquium. ILLC, Universiteit vanAmsterdam, the Netherlands, pp. 97–101.
de Groote, P., 2006. Towards a Montagovian account of dynamics, Proceedings SALT 16. CLCPublications.
de Groote, P., Maarek, S., Yoshinaka, R., 2007. On two extensions of abstract categorial gram-mars, in: Dershowitz, N., Voronkov, A. (Eds.), LPAR. Lecture Notes in Computer Science,vol. 4790. Springer, pp. 273–287.
de Groote, P., Pogodalla, S., 2004. On the expressive power of abstract categorial grammars:representing context-free formalisms. J. Logic Lang. Inf. 13 (4), 421–438.
de Groote, P., Retoré, C., 1996. On the semantic readings of proof nets, in: Kruijff, G.-J.,Morrill, G., Oehrle, R.T. (Eds.), Proceedings 2nd Formal Grammar Conference. Prague,pp. 57–70.
Došen, K., 1988, 1989. Sequent systems and groupoid models. Studia Logica 47, 353–385; 48,41–65.

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 174 — #80
174 Handbook of Logic and Language
Došen, K., 1992. A brief survey of frames for the Lambek calculus. Zeitschr. f. math. Logik undGrundlagen d. Mathematik 38, 179–187.
Došen, K., Schröder-Heister, P. (Eds.), 1993. Substructural Logics. Clarendon Press. Oxford.Dowty, D., 1988. Type-raising, functional composition, and non-constituent conjunction, in:
Oehrle, R.T. et al. (Eds.), Categorial Grammar and Natural Language Structures, D. Reidel,pp. 153–197.
Dowty, D., 1996. Towards a minimalist theory of syntactic structure, in: Bunt, H., Van Horck,A. (Eds.), Discontinuous Constituency. Mouton de Gruyter, Berlin, pp. 11–62.
Dunn, M., 1993. Partial Gaggles applied to logics with restricted structural rules, in: Došen, K.,Schröder-Heister, P. (1993), Structural Logics, Oxford University Press, pp. 63–108.
Emms, M., 1993. Some applications of categorial polymorphism, in: Moortgat, M. (Ed.), Poly-morphic Treatments. Esprit BRA 6852 Dyana-2 Deliverable R1.3.A, pp. 1–52.
Gabbay, D., 1996. Labeled Deductive Systems. Oxford University Press.Geach, P., 1972. A program for syntax, in: Davidson, D., Harman, G. (Eds.), Semantics of
Natural Language, Reidel, Dordrecht, pp. 483–497. (Also in Buszkowski et al., 1988.)Gentzen, G., 1934. Untersuchungen über das logische Schliessen. Mathematische Zeitschrift 39,
176–210; 405–431.Girard, J.-Y., 1987. Linear logic. Theor. Comput. Sci. 50, 1–102.Girard, J.-Y., 1993. On the unity of logic. Ann. Pure Appl. Logic 59, 201–217.Girard, J.-Y., 1995a. Geometry of interaction III: the general case, in: Girard, J.-Y., Lafont, Y.,
Regnier, L. (Eds.), Advances in Linear Logic. Cambridge, MA, pp. 329–389.Girard, J.-Y., 1998. Light linear logic. Inf. Comput. 143: 175–204.Girard, J.-Y., Taylor, P., Lafont, Y., 1989. Proofs and Types. Cambridge Tracts in Theoretical
Computer Science 7, Cambridge, MA.Goré, R., 1997. Substructural logics on display. Logic J. IGPL 6 (3), 451–504.Grishin, V., 1983. On a generalization of the Ajdukiewicz-Lambek system, in: Mikhailov, A.
(Ed.), Studies in Nonclassical Logics and Formal Systems. Nauka, Moscow, pp. 315–334.[English translation in Abrusci, V.M., Casadio, C. (Eds.), New Perspectives in Logic andFormal Linguistics. Bulzoni, Rome, 2002.]
Hendriks, H., 1993. Studied Flexibility. Categories and Types in Syntax and Semantics. PhDDissertation, ILLC, Amsterdam.
Hendriks, H., 1999. The logic of tune. A proof-theoretic analysis of intonation, in: Lecomte,A., Lamarche, F., Perrier, G. (Eds.) Logical Aspects of Computational Linguistics. LectureNotes in Computer Science, vol. 1582, pp. 132–159. Springer, Berlin, Heidelberg.
Hendriks, P., 1995. Comparatives and Categorial Grammar. PhD Dissertation, University ofGroningen, the Netherlands.
Hepple, M., 1990a. The Grammar and Processing of Order and Dependency. PhD Dissertation,University of Edinburgh, Scotland.
Hepple, M., 1990b. Normal Form theorem proving for the Lambek calculus. COLING.pp. 173–178.
Hepple, M., 1992. Command and domain constraints in a categorial theory of binding. Proceed-ings Eighth Amsterdam Colloquium. pp. 253–270.
Hepple, M., 1994. Labelled deduction and discontinuous constituency, in: Abrusci, M., Casa-dio, C., Moortgat, M. (Eds.), Linear Logic and Lambek Calculus. Proceedings 1993Rome Workshop. Esprit BRA 6852 Dyana-2 Occasional Publications, ILLC, Amsterdam,pp. 123–150.
Hepple, M., 1995. Hybrid categorial logics. Bull. IGPL 3(2,3). Special issue on Deduction andLanguage (Ed. Kempson, R.), pp. 343–355.

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 175 — #81
Categorial Type Logics 175
Hepple, M., 1996. A compilation-chart method for linear categorial deduction. COLING.pp. 537–542.
Hepple, M., 1999. An Early-style predictive chart parsing method for Lambek grammars. Pro-ceedings of the 37th annual meeting of the Association for Computational Linguistics onComputational Linguistics, pp. 465–472. (Association for Computational Linguistics.)
Herbelin, H., 2005. C’est maintenant qu’on calcule: au cœur de la dualité. Université ParisXI.Habilitation à diriger les recherches.
Hoyt, F., Baldridge, J., 2008. A logical basis for the D combinator and normal form in CCG.Proceedings of ACL-08: HLT. Columbus, Ohio, pp. 326–334. (Association for Computa-tional Linguistics.)
Jakobson, P., 1987. Phrase structure, grammatical relations, and discontinuous constituents, in:Huck, G.J., Ojeda, A.E. (Eds.), Syntax and Semantics 20: Discontinuous Constituency.Academic Press, New York, pp. 27–69.
Jäger, G., 2003. On the generative capacity of multi-modal categorial grammars. Res. Lang.Comput. 1 (1), 105–125.
Jäger, G., 2005. Anaphora And Type Logical Grammar, vol. 24 of Trends in Logic. Springer,Dordrecht.
Jakobson, R. (Ed.), 1961. Structure of Language and Its Mathematical Aspects. Proceedingsof the 12th Symposium in Applied Mathematics. American Mathematical Society. Provi-dence, Rhode Island.
Johnson, M., 1998. Proof nets and the complexity of processing center-embedded constructions.J. Logic Lang. Inf. 7 (4), 433–447.
Joshi, A.K., Vijay-Shanker, K., Weir, D., 1991. The convergence of mildly context-sensitivegrammar formalisms, in: Sells, P., Shieber, S.M., Wasow, T. (Eds.), Foundational Issues inNatural Language Processing. Cambridge, MA, MIT Press, pp. 31–81.
Kandulski, M., 1988a. The non-associative Lambek calculus, in: Buszkowski, W., Mar-ciszewski, W., Van Benthem, J. (Eds.), Categorial Grammar. John Benjamins, Amsterdam,pp. 141–151.
Kandulski, M., 1988b. The equivalence of nonassociative Lambek categorial grammars andcontext-free grammars. Zeitschrift für mathematische Logik und Grundlagen der Mathe-matik 34, 41–52.
Kanovich, M., 1994. The complexity of Horn fragments of Linear Logic. Ann. Pure Appl. Logic69 (2-3), 195–241.
Keenan, E., Comrie, B., 1977. Noun phrase accessibility and universal grammar. Ling. Inq.63–99.
Keenan, E.L., Faltz, L., 1985. Boolean Semantics for Natural Language. Reidel, Dordrecht.Kraak, E., 1998. A deductive account of French object clitics, in: Hinrichs, E., Kathol, A.,
Nakazawa, T. (Eds.), Complex Predicates in Nonderivational Syntax. Syntax and Seman-tics vol. 30. Academic Press, pp. 166–180.
Kracht, M., 1996. Power and weakness of the modal display calculus, in: Wansing, H. (Ed.),Proof Theory of Modal Logic. Kluwer, Dordrecht, pp. 93–121.
Kruijff, G.-J., Baldridge, J., 2003. Multi-modal combinatory categorial grammar. EACL’03. Pro-ceedings of the 10th Conference of the European Chapter of the Association for Computa-tional Linguistics. Budapest, pp. 211–218.
Kruijff, G., Oehrle, R., (Eds.) 2003. Resource-Sensitivity, Binding, and Anaphora. Kluwer,Dordrecht.
Kurtonina, N., 1995. Frames and Labels. A Modal Analysis of Categorial Inference. PhDDissertation, OTS Utrecht, ILLC Amsterdam.

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 176 — #82
176 Handbook of Logic and Language
Kurtonina, N., Moortgat, M., 1997. Structural control, in: Blackburn, P., De Rijke, M. (Eds.),Specifying Syntactic Structures, CSLI Publications, Stanford, pp. 75–113.
Kurtonina, N., Moortgat, M., 2010. Relational semantics for the Lambek-Grishin calculus, in:Ebert, C., Jäger, G., Michaelis, J. (Eds.), The Mathematics of Language. Proceedings ofthe 10th and 11th Biennial Conference, Lecture Notes in Computer Science, vol. 6149.Springer, Berlin, pp. 210–222.
Lambek, J., 1958. The mathematics of sentence structure, Am. Math. Mon. 65, 154–170.Lambek, J., 1961. On the calculus of syntactic types, in: Jakobson, R. (Ed.), Structure of Lan-
guage and its Mathematical Aspects, Proceedings of the Symposia in Applied Mathematicsvol. XII, American Mathematical Society, pp. 166–178.
Lambek, J., 1988. Categorial and categorical grammar, in: Oehrle, R. et al. (Eds.), CategorialGrammars and Natural Language, D. Reidel, Dordrecht, 297–317.
Lambek, J., 1993. Logic without structural rules (Another look at Cut Elimination) in:Došen, K., Schröder-Heister, P., McGill University, Montreal, pp. 179–206.
Lambek, J., 1999. Type grammar revisited, in: Lecomte, A., Lamarche, F., Perrier, G. (Eds.),Logical Aspects of Computational Linguistics, Lecture Notes in Artificial Intelligence.vol. 1582. Springer, pp. 1–27.
Lambek, J., 2008. From Word to Sentence. A Computational Algebraic Approach to Grammar.Polimetrica, Milan.
Lecomte, A., Retoré, Ch., 1995. Pomset logic as an alternative categorial grammar, in:Morrill, G., Oehrle, R.T. (Eds.), Formal Grammar, ESSLLI Barcelona, pp. 181–196.
Lewis, D., 1972. General semantics, in: Davidson, D., Harman, G. (Eds.), Semantics of NaturalLanguage. Reidel, Dordrecht, pp. 169–218.
Lyons, J., 1968. Introduction to Theoretical Linguistics. University Press, Cambridge.Melissen, M., 2009. The generative capacity of the Lambek-Grishin Calculus: a new lower
bound, in: de Groote, P. (Ed.), Proceedings 14th Conference on Formal Grammar, LectureNotes in Computer Science, vol. 5591. Springer.
Moortgat, M., 1988. Categorial Investigations. Logical and Linguistic Aspects of the LambekCalculus, Foris, Dordrecht.
Moortgat, M., 1996. Generalized quantifiers and discontinuous type constructors, in: Bunt,H., Van Horck, A. (Eds.), Discontinuous Constituency. Mouton de Gruyter. Berlin,pp. 181–207.
Moortgat, M., 1996. Multimodal linguistic inference. Journal of Logic, Language and Informa-tion, 5(3–4): 349–385.
Moortgat, M., 2009. Symmetric categorial grammar. J. Philos. Logic 38 (6), 681–710.
Moortgat, M., 2010. Symmetric categorial grammar: residuation and Galois connections. Ling.Anal. 36 (1–4). Special issue in honor of Jim Lambek. CoRR abs/1008.0170.
Moortgat, M., Morrill, G., 1991. Heads and phrases. Type calculus for dependency and con-stituent structure. Ms OTS, Working papers, RUU, Utrecht University.
Moortgat, M., Oehrle, R.T. 1993. Logical Parameters and Linguistic Variation. Lecture Notes onCategorial Grammar. 5th European Summer School in Logic, Language and Information.Lisbon.
Moortgat, M., Oehrle, R.T. 1994. Adjacency, dependency and order, in: Dekker, P., Stokhof, M.(Eds.), Proceedings Ninth Amsterdam Colloquium. ILLC, Amsterdam, pp. 447–466.
Moot, R., 2002. Proof Nets for Linguistic Analysis. PhD thesis, Utrecht Institute of LinguisticsOTS, Utrecht University.

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 177 — #83
Categorial Type Logics 177
Moot, R., 2007. Proof nets for display logic. CoRR, abs/0711.2444.Moot, R., 2008. Lambek grammars, tree adjoining grammars and hyperedge replacement gram-
mars. Proceedings of TAG+9, The 9th International Workshop on Tree Adjoining Gram-mars and Related Formalisms. Tübingen, pp. 65–72.
Moot, R., Piazza, M., 2001. Linguistic applications of first order Intuitionistic Linear Logic. J.Logic Lang. Inf. 10 (2), 211–232.
Moot, R., Puite, Q., 2002. Proof nets for the multimodal Lambek calculus. Studia Logica 71 (3),415–442.
Morrill, G., 1990a. Intensionality and boundedness. Ling. Philos. 13, 699–726.Morrill, G., 1994a. Type Logical Grammar. Categorial Logic of Signs. Kluwer, Dordrecht.Morrill, G., 1994b. Structural facilitation and structural inhibition, in: Abrusci, M., Casadio,
Moorgat, M.(Eds.), Linear Logic and Lambek Calculus. ILLC, Amsterdam, pp. 183–210.Morrill, G., 1995a. Discontinuity in categorial grammar. Ling. Philos. 18, 175–219.Morrill, G., Fadda, M., Valentin, O., 2007. Nondeterministic discontinuous Lambek calcu-
lus. Proceedings of the Seventh International Workshop on Computational Semantics(IWCS7), Tilburg.
Morrill, G., Valentı́n, O., Fadda, M., 2009. Dutch grammar and processing: a case study inTLG, in: Bosch, P., Gabelaia, D., Lang, J. (Eds.), TbiLLC 2007, LNAI 5422. Springer,pp. 272–286.
Morrill, G., 2000. Incremental processing and acceptability. Comput. Ling. 26 (3), 319–338.Morrill, G., 2002. Towards generalised discontinuity. in: Jager, G., Monachesi, P., Penn, G.,
Wintner, S. (Eds.), Proceedings of the 7th Conference on Formal Grammar. Trento,pp. 103–111.
Morrill, G., 2010. Categorial grammar: logical syntax, semantics, and processing. OxfordUniversity Press.
Morrill, G., Fadda, M., 2008. Proof nets for basic discontinuous Lambek calculus. J. LogicComput. 18 (2), 239–256.
Muskens, R., 1994. Categorial grammar and Discourse Representation Theory.Muskens, R., 2007. Separating syntax and combinatorics in categorial grammar. Res. Lang.
Comput. 5 (3), 267–285.Oehrle, R.T., 1988. Multi-dimensional compositional functions as a basis for grammatical ana-
lysis, in: Oehrle, R., Bach, E., Wheeler, D. Categorial Grammars and Natural LanguageStructures, D. Reidel, Dordrecht, pp. 349–389.
Oehrle, R.T., Bach, E., Wheeler, D. (Eds.), 1988. Categorial Grammars and Natural LanguageStructures, Reidel, Dordrecht.
Partee, B., Rooth, M., 1983. Generalized conjunction and type ambiguity, in: Bäuerle, R.,Schwarze, Ch., von Stechow, A. (Eds.), Meaning, Use, and Interpretation of Language.De Gruyter, Berlin, pp. 361–383.
Pentus, M., 1993. Lambek grammars are context free. Proceedings of the 8th Annual IEEESymposium on Logic in Computer Science, IEEE Computer Society Press, pp. 429–433.
Pentus, M., 1995. Models for the Lambek calculus. Annals of Pure and Applied Logic 75 (1–2):179–213.
Pentus, M., 2006. Lambek calculus is NP-complete. Theor. Comput. Sci. 357, 186–201.Pollard, C., 1984. Head Grammars, Generalized Phrase Structure Grammars, and Natural Lan-
guage. PhD Dissertation, Stanford, CA.Reape, M., 1989. A logical treatment of semi-free word order and bounded discontinuous con-
stituency. Proceedings of the Fourth Conference of the European Chapter of the Associa-tion for Computational Linguistics. Manchester, pp. 103–115.

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 178 — #84
178 Handbook of Logic and Language
Restall, G., 2000. An Introduction to Substructural Logics. Routledge, London.Retoré, C., Salvati, S., 2010. A faithful representation of non-associative Lambek grammars in
Abstract Categorial Grammars. J. Logic Lang. Inf. 19 (2). Special issue on New Directionsin Type Theoretic Grammars, pp. 185–200.
Roorda, D., 1991. Resource Logics. Proof-Theoretical Investigations. PhD Dissertation,Amsterdam.
Roorda, D., 1992. Proof nets for Lambek calculus. J. Logic Comput. 2 (2), 211–231.Savateev, Y., 2009. Product-free Lambek calculus is NP-complete. Proceedings of the 2009
International Symposium on Logical Foundations of Computer Science. LNCS, vol. 1617.Springer, pp. 380–394.
Schmerling, S., 1983. A new theory of English auxiliaries, in: Heny, F., Richards, B. (Eds.),Linguistic Categories. Auxiliaries and Related Puzzles, Vol II. Reidel, Dordrecht, pp. 1–53.
Shan, C., Barker, C., 2006. Explaining crossover and superiority as left-to-right evaluation.Ling. Philos. 29 (1), 91–134.
Steedman, M., 1984. A categorial theory of intersecting dependencies in Dutch infinitival com-plements, in: De Geest, W., Putseys, Y. (Eds.), Proceedings of the International Conferenceon Complementation. Foris, Dordrecht, pp. 215–226.
Steedman, M., 1985. Dependency and coordination in the grammar of Dutch and English. Lan-guage 61, 523–568.
Steedman, M., 1987. Combinatory grammars and parasitic gaps. Nat. Lang. Ling. Theory 5,403–439.
Steedman, M., 1988. Combinators and grammars. Oehrle, R.T. et al. (1988), Categorial Gram-mars and Natural Language Structures, D. Reidel, Dordrecht, 417–442.
Steedman, M., 1991. Structure and intonation. Language 68, 260–296.Steedman, M., 1993. Categorial grammar. Tutorial overview. Lingua 90, 221–258.Szabolcsi, A., 1987. On combinatory categorial grammar. Proceedings of the Symposium on
Logic and Language, Debrečen. Budapest, pp. 151–162.Troelstra, A.S., 1992. Lectures on Linear Logic. CSLI Lecture Notes. Stanford, CA.van Benthem, J., 1983. The semantics of variety in Categorial Grammar. Report 83-29,
Simon Fraser University, Burnaby, BC, Canada. Revised version in Buszkowski,W., Marciszewski, W., Van Benthem, J. (Eds.), Categorial Grammar. John Benjamins,Amsterdam, pp. 37–55.
van Benthem, J., 1984. Correspondence theory, in: Gabbay, D., Günthner, F. (Eds.), Handbookof Philosophical Logic, vol. II. Dordrecht, pp. 167–247.
van Benthem, J., 1987. Categorial grammar and lambda calculus, in: Skordev, D. (Ed.), Mathe-matical Logic and Its Applications. Plenum, New York, pp. 39–60.
van Benthem, J., 1991, 1995. Language in Action. Categories, Lambdas, and DynamicLogic. Studies in Logic, North-Holland, Amsterdam. (Student edition: MIT Press (1995),Cambridge, MA.)
Vermaat, W., 2006. The Logic of Variation. A Cross-Linguistic Account of Wh-Question For-mation. PhD thesis, Utrecht Institute of Linguistics OTS, Utrecht University.
Versmissen, K., 1993. Categorial grammar, modalities and algebraic semantics. ProceedingsEACL93, pp. 377–383.
Versmissen, K., 1996. Grammatical Composition. Modes, Models and Modalities. PhD Disser-tation, OTS Utrecht.
Wansing, H., 1994. Sequent calculi for normal modal propositional logics. J Logic Computation4 (2): 125–142.

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 179 — #85
Categorial Type Logics 179
Wansing, H., 1992b. Formulas-as-types for a hierarchy of sublogics of intuitionistic propo-sitional logic, in: Pearce, D., Wansing, H. (Eds.), Non-classical Logics and InformationProcessing. Springer Lecture Notes in AI 619, Berlin.
Zielonka, W., 1989. A simple and general method of solving the finite axiomatizability problemsfor Lambek’s syntactic calculi. Studia Logica 48, 35–39.
Zwarts, F., 1986. Categoriale Grammatica En Algebraı̈sche Semantiek. PhD Dissertation, Uni-versity of Groningen, the Netherlands.

“06-ch02-0095-0180-9780444537263” — 2010/11/29 — 21:15 — page 180 — #86
This page intentionally left blank

“07-ch03-0181-0252-9780444537263” — 2010/11/30 — 3:44 — page 181 — #1
3 Discourse Representation in ContextJan van Eijck† and Hans Kamp!
† Centrum voor Wiskunde en Informatica,P.O. Box 94079, 1090 GB Amsterdam, The Netherlands,E-mail: [email protected]
!Department of Linguistics, The University of Texas at Austin,Calhoun Hall 405, 1 University Station B5100, Austin, TX 78712-0198, USA,E-mail: [email protected]
3.1 Overview
Discourse representation in context is the attempt to capture certain aspects of theinterpretation of natural language texts that are beyond the mere truth conditions ofthe text. Prime examples are interpretation of indefinites and pronouns in context, andinterpretation of tenses, in French and other languages.
One of the debates surrounding the advent of discourse representation theory (DRT)(Kamp, 1981) and file change semantics (FCS) (Heim, 1982) had to do with the issueof representationalism. Should we assume the representation structures to say some-thing about what goes on in the mind of the interpreter, or not? On this issue, thefollowers of the Montague tradition tend to have strongly anti-mentalist views. Seman-tics, in the Montagovian perspective, is not about what goes on in the mind, but abouthow language relates to reality.
Montague tried to settle the issue of representation languages (“logical form”) onceand for all by means of a careful demonstration that immediate interpretation of naturallanguage fragments in appropriate models, without an intervening logical form, waspossible. DRT and FSC, in their original presentations, re-introduced logical formsinto the picture. The first attempts at rational reconstruction of DRT and FCS weregeared at showing that the representation language (the boxes of DRT) could be elim-inated again. This led to the development of compositional versions of DRT such asdynamic predicate logic (DPL), and dynamic versions of Montague grammar basedon DPL. The snag was that these rational reconstructions were not quite faithful tothe original enterprise. See van Eijck and Stokhof (2006) for a detailed account of therelationship between DRT and DPL, in the context of a historical study of dynamiclogics in computer science and natural language analysis. An overview of DRT fromthe viewpoint of representationalism can be found in Kamp and Reyle (to appear).
Anti-mentalism is less fashionable nowadays. Indeed, many researchers have cometo view natural language analysis as a branch of cognitive science. But this new view
Handbook of Logic and Language. DOI: 10.1016/B978-0-444-53726-3.00003-7c" 2011 Elsevier B.V. All rights reserved.

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 182 — #2
182 Handbook of Logic and Language
creates new obligations. If one takes this connection with cognition seriously, one hasto take on the burden of showing that the building of discourse representations, as itgoes on in the theory, somehow corresponds with what goes on in the mind. It seemsfair to say that this is a challenge that has yet to be met.
This chapter is an update to our previous overview (van Eijck and Kamp, 1997).We will first introduce the purpose of the overall enterprise of discourse representation.Next, we focus on some technical issues, in order to clarify what goes on essentiallywhen text is interpreted in context.
3.2 Interpretation of Text in Context
The fundamental idea behind the theory of the semantics of coherent multi-sentencediscourse and text that is presented in this chapter—Discourse Representation Theory,or DRT for short—is that each new sentence S of a discourse is interpreted in thecontext provided by the sentences preceding it. The result of this interpretation is thatthe context is updated with the contribution made by S; often an important part of thisprocess is that anaphoric elements of S are hooked up to elements that are present inthe context. An implication of this conception of text interpretation is that one andthe same structure serves simultaneously as content and as context—as content of thesentences that have been interpreted already and as context for the sentence that isto be interpreted next. This double duty imposes special constraints on logical form,which are absent when, as in most older conceptions of semantics and pragmatics, thecontents and contexts are kept separate.
The initial problem that motivated the present theory is the interpretation of nom-inal and temporal anaphora in discourse. The key idea in the way of thinking aboutthe semantics of discourse in context exemplified in Heim (1982) and Kamp (1981) isthat each new sentence or phrase is interpreted as an addition to, or “update” of, thecontext in which it is used and that this update often involves connections betweenelements from the sentence or phrase with elements from the context.
In the approach of Kamp (1981), which we will follow more closely here than thelargely equivalent approach of Heim (1982), this idea is implemented in the form ofinterpretation rules—each associated with a particular lexical item or syntactic con-struction. When applied to a given sentence S, these rules identify the semantic contri-butions which S makes to the context C in which S is used and add these to C. In thisway C is transformed into a new context, which carries the information contributed byS as well as the information that was part of the context already. The result can thenserve as context for the interpretation of the sentence following S (in the given dis-course or text), which leads to yet another context, and so on until the entire discourseor text has been interpreted.
An important aspect of this kind of updating of contexts is the introductionof elements—so-called reference markers or discourse referents—that can serveas antecedents to anaphoric expressions in subsequent discourse. These referencemarkers play a key part in the the context structures posited by DRT, the so-calledDiscourse Representation Structures or DRSs.

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 183 — #3
Discourse Representation in Context 183
With its emphasis on representing and interpreting discourse in context, discourserepresentation theory has been instrumental in the emergence of a dynamic perspec-tive on natural language semantics, where the center of the stage, occupied so longby the concept of truth with respect to appropriate models, has been replaced by con-text change conditions, with truth conditions defined in terms of those. Thus, underthe influence of discourse representation theory, many traditional Montague gram-marians have made the switch from static to dynamic semantics (see Chapter 12 onDynamics in this Handbook). This shift has considerably enriched the enterprise offormal semantics, by bringing areas formerly belonging to informal pragmatics withinits compass.
In the next section we will first look at some examples of DRSs and at the consid-erations which have led to their specific form. After that we will look more closely atthe relationship between DRSs and the syntactic structure of sentences, discourses ortexts from which they can be derived. This will lead us naturally to the much debatedquestion whether the theory presented here is compositional. The compositionalityissue will force us to look carefully at the operations by means of which DRSs canbe put together from minimal building blocks. Next we will show, by developinga toy example, what a compositional discourse semantics for a fragment of naturallanguage may look like. This is followed by sample treatments of quantification, tenseand aspect. The chapter ends with some pointers to the literature on further extensionsof the approach and to connections with related approaches.
3.3 The Problem of Anaphoric Linking in Context
The semantic relationship between personal pronouns and their antecedents was longperceived as being of two kinds: a pronoun either functions as an individual constantcoreferential with its antecedent or it acts as a variable bound by its antecedent. How-ever, in the examples (1)–(4) below, neither of these two possibilities seems to providea correct account of how pronoun and antecedent are related.
(1) A man1 entered. He1 smiled.(2) Every man who meets a nice woman1 smiles at her1.(3) If a man1 enters, he1 smiles.(4) Hob believes a witch1 blighted his mare. Nob believes she1 killed his sow.
In these examples we have used subscripts and superscripts to coindex anaphoricpronouns and their intended antecedents.
The first option—of pronoun and antecedent being coreferential—does not workfor the simple reason that the antecedent does not refer (as there is no one particularthing that can be counted as the referent!); so a fortiori antecedent and pronoun can-not corefer (that is, refer to the same thing). The second option, the bound variableanalysis, runs into problems because the pronoun seems to be outside the scope of itsantecedent. For instance, in (1) the antecedent of the pronoun is an indefinite nounphrase occurring in the preceding sentence. In the approaches which see pronouns as

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 184 — #4
184 Handbook of Logic and Language
either coreferring terms or bound variables, indefinite NPs are viewed as existentialquantifiers whose scope does not extend beyond the sentence in which they occur. Insuch an approach there is no hope of the pronoun getting properly bound. Examples(2)–(4) present similar difficulties. Example (2) is arguably ambiguous in that a nicewoman may be construed either as having wide or as having narrow scope with res-pect to every man. If a nice woman is construed as having narrow scope, i.e. as havingits scope restricted to the relative clause, then the pronoun won’t be bound; the phrasecan bind the pronoun if it is given wide scope, as in that case its scope is the entire sen-tence, but this leads to an interpretation which, though perhaps marginally possible,is clearly not the preferred reading of (2). We find much the same problem with (3):in order that the indefinite a man bind the pronoun he, it must be construed as havingscope over the conditional as a whole, and not just over the if-clause; but again, thisyields a reading that is marginal at best, while the preferred reading is not available.
Sentences with the patterns of (2) and (3) have reached the modern semanticliterature through Geach (1980), who traces them back to the Middle Ages andbeyond. Geach’s discussion revolves around examples with donkeys, so these sen-tences became known in the literature as donkey sentences. Also due to Geach aresentences like (4), which pose a binding problem across a sentential boundary, com-plicated by the fact that antecedent and anaphoric elements occur in the scopes ofdifferent attitude predications, with distinct subjects.
Problems like the ones we encountered with (1)–(4) arise not just with pronouns.There are several other types of expressions with anaphoric uses that present essen-tially the same difficulties to the traditional ways of viewing the relationship betweennatural language and logic. First, there are other anaphoric noun phrases besides pro-nouns, viz. definite descriptions and demonstratives; and these also occur in the con-texts where the problems we have just noted arise. Moreover, as was remarked alreadymore than 20 years ago in Partee (1973), there are striking similarities in the beha-vior of anaphoric pronouns and tenses, and it turns out that the interpretation of tenseinvolves the same sort of anaphoric dependencies which (1)–(4) exhibit. More pre-cisely, the past tense is often to be understood as referring to some particular time inthe past (rather than meaning “sometime in the past”) and more often than not this par-ticular time is to be recovered from the context in which the given past tense sentenceis used.
(5) John entered the room. He switched on the light.(6) Whenever John entered the room, he switched on the light.
In (5) the switching time is understood as temporally related to the time at whichJohn entered the room (presumably the time of switching was directly after the timeof entering) and a full interpretation of (5) needs to make this explicit. A quantifica-tional sentence such as (6) suggests the same relationship between switching timesand entering times; and insofar as the tense of the main clause is to be interpreted asanaphoric to that of the whenever-clause, this anaphoric connection raises the samequestions as those of (2) and (3).

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 185 — #5
Discourse Representation in Context 185
3.4 Basic Ideas of Discourse Representation
The central concepts of DRT are best explained with reference to simple examplessuch as (1) in the previous section. The logical content of (1) appears to be that therewas some man who entered and (then) smiled. That is, the content of (1) is whatin standard predicate logic would be expressed by an existential quantification overmaterial coming in part from the first and in another part from the second sentence of(1), roughly as in (7).
(7) !x(man (x) " entered (x) " smiled (x))
As observed in the last section, according to DRT the interpretation of (1) resultsfrom a process in which an interpretation is obtained for the first sentence, which thenserves as context for the interpretation of the second sentence. The interpretation ofthe second sentence transforms this context into a new context structure, the contentof which is essentially that of (7).
The problem with (1) is that the first sentence has an existential interpretation andthus must in some way involve an existential quantifier, and that the contributionwhich the second sentence makes to the interpretation of (1) must be within the scopeof that quantifier. Given the basic tenets of DRT, this means that (i) the first sentenceof (1) must get assigned a representation, i.e. a DRS, K1 which captures the existen-tial interpretation of that sentence; and (ii) this DRS K1 must be capable of acting ascontext for the interpretation of the second sentence in such a way that this secondinterpretation process transforms it into a DRS K2 representing the truth conditionsidentified by (7). (i) entails that the reference marker introduced by the indefinite NPa man—let it be x—must get an existential interpretation within K1; and (ii) entailsthat it is nevertheless available subsequently as antecedent for the pronoun he. Finally,after x has been so exploited in the interpretation of the second sentence, it must thenreceive once more an existential interpretation within the resulting DRS K2.
Heim (1982) uses the metaphor of a filing cabinet for this process. The establishedrepresentation structure K1 is a set of file cards, and additions to the discourse effect anew structure K2, which is the result of changing the file in the light of the new infor-mation. Here is how DRT deals with these desiderata. The DRS K1 is as given in (8).
(8)
x
man xentered x
This can also be rendered in canonical set-theoretical notation, as in (9).
(9) ({x}, {man x, entered x})
Precisely how this DRS is derived from the syntactic structure of the first sen-tence of (1), and how DRS construction from sentences and texts works generally is

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 186 — #6
186 Handbook of Logic and Language
discussed in Section 3.10. For now, suffice it to note that the reference marker x getsintroduced when the NP a man is interpreted and that this interpretation also yieldsthe two conditions man(x) and entered(x), expressing that any admissible value a forx must be a man and that this man was one who entered.
A DRS like (8) can be viewed as a kind of “model” of the situation which the rep-resented discourse describes. The modeled situation contains at least one individual a,corresponding to the reference marker x, which satisfies the two conditions containedin (8), i.e. a is a man and a is someone who entered.
When a DRS is used as context in the interpretation of some sentence S, its refer-ence markers may serve as antecedents for anaphoric NPs occurring in S. In the case ofour example we have the following. (8), serving as context for the second sentenceof (1), makes x available as antecedent for the pronoun he. That is, the interpretationof he links the reference marker it introduces, y say, to the marker x for the intendedantecedent, something we express by means of the equational condition y .= x. Inaddition, the interpretation step yields, as in the case of the indefinite a man, a con-dition expressing the clausal predication which involves he as argument. Through theapplication of this principle (8) gets expanded to the DRS (10), which represents thecontent of all of (1).
(10)
x y
man xenter xy .= xsmiled y
DRS (10) models situations in which there is at least one individual that is a man, thatentered and that smiled. It is easy to see that these are precisely the situations whichsatisfy the predicate formula (7). (This claim will be made formal by the model theoryfor DRSs, to be presented in Section 3.5.)
As illustrated by the above examples (8) and (10), a DRS generally consists oftwo parts: (i) a set of reference markers, the universe of the DRS, and (ii) a set ofconditions, its condition set. There are some other general points which our exampleillustrates:
1. The reference markers in the universe of a DRS all get an existential interpretation.2. All reference markers in the universe of a context DRS are available as anaphoric
antecedents to pronouns and other anaphoric expressions that are interpreted within thiscontext.
3. The interpretation of a sentence S in the context provided by a DRS K results in a newDRS K#, which captures not only the content represented by K but also the content of S, asinterpreted with respect to K.
It should be clear that DRSs such as (8) and (10) can only represent information thathas the logical form of an existentially quantified conjunction of atomic predications.

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 187 — #7
Discourse Representation in Context 187
But there is much information that is not of this form. This is so, in particular, for theinformation expressed by (3). So the DRS for (3) will have to make use of representa-tional devices different from those that we have used up to this point.
The DRT conception of conditional information is this. The antecedent of a con-ditional describes a situation, and the conditional asserts that this situation must alsosatisfy the information specified in its consequent. When conditionals are seen fromthis perspective, it is not surprising that the interpretation of their consequents may usethe interpretations of their antecedents as contexts much in the way the interpretationof a sentence S may build upon the interpretation assigned to the sentences precedingit in the discourse to which it belongs; for the consequent extends the situation des-cription provided by the antecedent in essentially the same way in which S extends thesituation described by its predecessors.
In the case of (3) this means that the DRS (8), which represents its antecedent (seethe discussion of (1) above), can be exploited in the interpretation of the consequent,just as (8), as interpretation of the first sentence of (1), supported the interpretation ofthe second sentence of (1). To make this work out, we need a suitable representationfor the consequent. This turns out to be (11).
(11)smile x
To obtain a representation of (3), (8) and (11) must be combined in a way whichreveals the conditional connection between them. We represent this combination by adouble arrow in between the two DRSs. The result K $ K#, where K and K# are thetwo DRSs to be combined, is a DRS condition (a complex condition as opposed tothe simple DRS conditions we have encountered so far). The DRS for a conditionalsentence such as (3) will consist just of such a condition and nothing else.
Intuitively the meaning of a condition K $ K# is that a situation satisfying K alsosatisfies K#. This is indeed the semantics we adopt for such conditions (for details seeSection 3.5). Applying this to the case of (3) we get the representation (12).
(12)xman xenter x
$smile x
Conditions of the form K $ K# illustrate an important feature of DRT: The logicalrole played by a reference marker depends on the DRS-universe to which it belongs.Markers belonging to the universe of the main DRS get an existential interpretation—this is, we saw, a consequence of the principle that a DRS is true if it is possible to

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 188 — #8
188 Handbook of Logic and Language
find individuals corresponding to the reference markers in the DRS universe whichsatisfy its conditions. This principle, however, applies only to the reference markers inthe main DRS universe. The logic of reference markers in subordinate universes, suchas for instance x in (12), is determined by the principles governing the complex DRSconditions to which they belong. Thus the semantics of conditions of the form K $ K#
implies that for all individuals corresponding to reference markers in the universe ofK which satisfy the conditions of K it is the case that K# is satisfiable as well. Thusthe $-condition of (12) has the meaning that for every individual corresponding tothe marker x—that is, for every man that enters—the right hand side DRS of (12) issatisfied, i.e. that individual smiles. Reference markers in the left hand side universeof an $-condition thus get a universal, not an existential interpretation.
It is worth noting explicitly the ingredients to this solution of the semantic dilemmaposed by conditionals like (3). Crucial to the solution are:
1. the combination of the principles of DRS construction, which assign to conditional sentencessuch as (3) representations such as (12), and
2. the semantics for $-conditions that has just been described.
Like any other DRS, (12) is a pair consisting of a set of reference markers and a setof conditions. But in (12) the first of these sets is empty. In particular, the referencemarker x which does occur in (12) belongs not to the universe of the “main” DRSof (12) but to that of a subordinate DRS, which itself is a constituent of some DRScondition occurring in (12). One important difference between reference markers insuch subordinate positions and those belonging to the universe of the main DRS isthat only the latter are accessible as antecedents for anaphoric pronouns in subsequentsentences. In general, in order that a reference marker can serve as antecedent to asubsequent pronoun, it must be accessible from the position that the pronoun occupies.Compare for instance the discourses (13) and (14).
(13) A man came in. He smiled. He was holding a flower in his right hand.(14) If a man comes in, he smiles. ?He is holding a flower in his right hand.
While in (13) the second he is as unproblematic as the first he, in (14) the secondhe is hard or impossible to process. This difference is reflected by the fact that in theDRS for the first two sentences of (13) the reference marker for a man belongs to theuniverse of the main DRS and so is accessible to the pronoun of the last sentence,whereas in (14) this is not so.
The rules for processing sentences in the context of a representation structureimpose formal constraints on availability of discourse referents for anaphoric link-ing. The set of available markers consists of the markers of the current structure, plusthe markers of structures that can be reached from the current one by a series of stepsin the directions left (i.e. from the consequent of a pair K $ K# to the antecedent), andup (i.e. from a structure to an encompassing structure).
For universally quantified sentences such as (2) DRT offers an analysis that closelyresembles its treatment of conditionals. According to this analysis a universally quan-tifying NP imposes a conditional connection between its own descriptive content and

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 189 — #9
Discourse Representation in Context 189
the information expressed by the predication in which it participates as argumentphrase; and this connection is interpreted in the same way as the $-conditions thatthe theory uses to represent conditional sentences. In particular, (2) gets an analysis inwhich any individual satisfying the descriptive content man who meets a nice woman,i.e. any individual corresponding to the reference marker x in the DRS (15), satisfiesthe DRS representing the main predication of (2). According to this way of looking atquantification, the descriptive content of the quantifying phrase can be taken as pre-supposed for purposes of interpreting the predication in which the phrase partakes, justas the antecedent of a conditional can be taken as given when interpreting its conse-quent. Thus, just as we saw for the consequent of the conditional (3), the constructionof the DRS for the main predication of (2) may make use of information encoded inthe “descriptive content” DRS (15). The result is the DRS in (16).
(15)
x y
man xwoman ynice ymeet (x,y)
(16)
u
u .= ysmiles-at (x,u)
To get a representation of (2), DRSs (15) and (16) have to be combined into a singleDRS condition. It is clear that $ has the desired effect. The result is (17).
(17)
x yman xwoman ynice ymeet (x,y)
$
u
u .= ysmiles-at (x,u)
The constraints on marker accessibility are used to account for the awkwardness ofanaphoric links as in (18).
(18) *If every man1 meets a nice woman2, he1 smiles at her2.
The difference between pronominal anaphora and the variable binding we find inclassical logic is also nicely illustrated by anaphora involving the word other. Considerfor example (19).

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 190 — #10
190 Handbook of Logic and Language
(19) A man walked in. Another man followed him.
Here another man is anaphoric to a man, but the sense is that the two men shouldbe different, not that they are the same. In other words, while any phrase of the formanother CN must, just as an anaphorically used pronoun, find an antecedent in itscontext of interpretation, the semantic significance of the link is just the opposite here.The DRS for (19) is (20).
(20)
x y zman xwalk-in xy %= xman yz .= xfollow (y,z)
Note that the representation of other-anaphora always needs two reference markers,one introduced by the anaphoric NP itself and one for the antecedent; there is noquestion here of replacing the former marker by the latter (that is: eliminating the y atthe top of (20) and the inequality y %= x and replacing the other occurrences of y byx), as that would force the two men to be the same, rather than different. In this regardother-anaphora differs from pronoun anaphora, for which the substitution treatmentyields representations that are equivalent to the ones we have been constructing above.
One reason for preferring the treatment of pronoun anaphora we have adopted isthat it brings out the similarity as well as the difference between pronouns and phraseswith other: In both cases interpretation involves the choice of a suitable antecedent.But the “links” between the chosen antecedent and the marker for the anaphoric NPare different in nature: they express equality in one case, inequality in the other.
We have said something about the interpretation of three kinds of NPs: indefinitedescriptions, anaphoric pronouns and quantified NPs, and we have introduced link-ing as a central theme in DRT. More about quantification in Section 3.11. We willnow briefly turn to definite descriptions. One of the most obvious facts about them,but a fact systematically ignored or played down in the classical theories of denotingphrases (Frege, 1892; Russell, 1905; Strawson, 1950), is that, like pronouns, definitedescriptions often act as anaphoric expressions.
Indeed, there seems to be a kind of interchangeability in the use of pronouns anddescriptions, with a description taking the place of a pronoun in positions wherethe latter would create an unwanted ambiguity; thus, in discourses like (21) the useof a definite description in the second sentence serves to disambiguate the intendedanaphoric link.
(21) A man and a boy came in. The man/he(?) smiled.
Anaphoric definite descriptions are, like pronouns, linked to existing discoursereferents, and thus, like pronouns, they impose certain conditions on the context inwhich they are used: the context must contain at least one discourse referent that canserve as an antecedent. In this sense both pronouns and anaphoric definite descriptions

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 191 — #11
Discourse Representation in Context 191
may be said to carry a certain presupposition: only when the context satisfies thispresupposition is it possible to interpret the pronoun, or to interpret the descriptionanaphorically. The descriptive content then serves as information to guide theanaphora resolution process. This will permit anaphora resolution in cases like (21).
Matters are not always this simple, however. Definite descriptions have uses thatcan hardly be described as anaphoric. For instance, in (22), the description the streetis certainly not anaphoric in the strict sense of the word, for there is no antecedentpart of the given discourse which has introduced an element that the description canbe linked up with.
(22) A man was walking down the street. He was smiling.
It is argued in Heim (1982) that the use of a definite description is a means for thespeaker to convey that he takes the referent of the description to be in some sensefamiliar. The hearer who is already acquainted with the street that is intended as thereferent of the street by the speaker of (22) may be expected to interpret the descriptionas referring to this street; in such cases speaker and hearer are said to share a commonground (see for example Stalnaker, 1974) which includes the street in question, andit is this which enables the hearer to interpret the speaker’s utterance as he meantit. Such common grounds can also be represented in the form of DRSs. Thus, thecommon ground just referred to will contain, at a minimum, a component of the form(23), where we assume that the marker u in (23) is anchored to a suitable object (thestreet that speaker and hearer have in mind).
(23)
u
street u
On the assumption of such a “common ground DRS” (including a suitable anchor)it becomes possible to view the NP the street of (22) as anaphoric. Interpretation of(22) will then be relative to the context DRS (23) and the interpretation of its definitedescription will yield, by the same principle that governs the interpretation of the manin (21), a DRS like (24).
(24)
u x v ystreet uman xv .= ustreet vwas-walking-down (x,v)y .= xwas-smiling y
This way of dealing with definite descriptions such as the street in (24) may seemto restore uniformity to the analysis of definites. An important difference betweendefinite descriptions and pronouns remains, however. Definite descriptions can be

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 192 — #12
192 Handbook of Logic and Language
linked much more easily than pronouns to objects that are implicit in the commonground, but have not been explicitly introduced by earlier parts of the same discourse.
To assimilate the use of definite descriptions as unique identifiers (the use that Fregeand Russell focus on to the exclusion of all others) to the present anaphoric analysisone must allow for accommodation. When the context available to the hearer does notcontain a representation of the referent of a definite description, he may accommodatethis context so that it now does contain such a representation, and then proceed as ifthe representation had been there all along. However, under what conditions preciselyaccommodation is possible is still a largely unsolved problem.
Interesting cases where the anaphoric account and the unique identification accountof definite description have to be combined are the so-called bridging descriptions, asin (25) and (26).
(25) (Yesterday) an M.P. was killed. The murderer got away.(26) Usually when an M.P. is killed, the murderer gets away.
In (25) the murderer is naturally interpreted as referring to the murderer of the M.P.mentioned in the preceding sentence. In other words, the context provides a referentx, and the definite description is interpreted as the unique individual who murdered x.This account also works for (26), where x varies over murdered M.P.s, and the definitedescription ranges over the set of unique murderers for all those x.
We conclude with a brief remark on proper names. As has been emphasized in thephilosophical literature (see in particular Kripke, 1972) a proper name has no descrip-tive content, or at any rate its descriptive content plays no essential part in the wayit refers. One consequence of this is that a name cannot have more than one refer-ential value (a point which should not be confused with the evident fact that manynames—Fred, Fido, John Smith, Fayetteville—are in many ways ambiguous). Thismeans that a name cannot have the sort of anaphoric use which we found with themurderer in (25) and (26), and that the antecedent to which the reference marker for aname will have to be linked will always be a marker in the main universe of the con-text DRS. Logically speaking, therefore, a proper name will always have “maximallywide scope”. One might think about this process in several ways. One might assume,as in the construction rule for proper names in Kamp (1981), that the processing ofa proper name always leads to the introduction of a marker in the top DRS, even ifthe name gets processed in a subordinate DRS somewhere way down. Or one mightassume an external element in the semantics of proper names, namely the presence ofexternal anchors: reference markers that are already in place in the top box of a DRS.Any proper name, then, comes equipped with its fixed anaphoric index for linking thename to its anchor. This is the approach we will follow in Section 3.10.
3.5 Discourse Representation Structures
It is now time to turn to formal details. Let A be a set of constants, and U a set ofreference markers or discourse referents (variables, in fact). We also assume that a set

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 193 — #13
Discourse Representation in Context 193
of predicate letters with their arities is given. In the following definition, c ranges overA, v over the set U, and P over the set of predicates.
Definition 3.5.1. (DRSs; preliminary definition)
terms t ::= v | c
conditions C ::= &| Pt1 · · · tk | v .= t | v %= t | ¬D
DRSs D ::= ({v1, . . . , vn}, {C1, . . . , Cm})
Note that this definition of the representation language is provisional; it will be modi-fied in Section 3.7. We introduce the convention that
({v1, . . . , vn}, {C1, . . . , Cm}) $ D
is shorthand for
¬({v1, . . . , vn}, {C1, . . . , Cm, ¬D}).
As in the previous sections DRSs will sometimes be presented in the box notation:
DRSs D ::=
v1 · · · vnC1...
Cm
The abbreviation D1 $ D2 is rendered in box format by the agreement to write (27)as (28).
(27) ¬
v1 · · · vnC1...
Cm
¬· · ·...
(28)
v1 · · · vnC1...
Cm
$· · ·...
Conditions can be atoms, links, or complex conditions. Complex conditions are nega-tions or implications. As the implications are abbreviations for special negations, wecan assume that all complex conditions are negations.

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 194 — #14
194 Handbook of Logic and Language
An atom is the symbol & or a predicate name applied to a number of terms(constants or discourse referents), a link is an expression v .= t or v %= t, where vis a marker, and t is either a constant or a marker. The clause for complex conditionsuses recursion: a complex condition is a condition of the form ¬D, where D is a dis-course representation structure.
We will first give a static truth definition for discourse representation structures.Later on, when discussing the problem of compositionality for DRSs, we turn to acontext change formulation of those same conditions. Call a first-order model M ='M, I( (we assume the domain M is non-empty) an appropriate model for DRS D ifI maps the n-place predicate names in the atomic conditions of D to n-place relationson M, the individual constants occurring in the link conditions of D to members of M,and (here is the recursive part of the definition)M is also appropriate for the DRSs inthe complex conditions of D.
Let M = 'M, I( be an appropriate model for DRS D. An assignment s for M ='M, I( is a mapping of the set of reference markers U to elements of M. The termvaluation determined byM and s is the function VM,s defined by VM,s(t) := I(t) ift ) A and VM,s(t) := s(t) if t ) U. In the following definition we use s[X]s# for: s#
agrees with s except possibly on the values of the members of X.
Definition 3.5.2. (Assignments verifying a DRS)An assignment s verifies D = ({v1, . . . , vn}, {C1, . . . , Cm}) inM if there is an assign-ment s# with s[{v1, . . . , vn}]s# which satisfies every member of {C1, . . . , Cm} inM.
Definition 3.5.3. (Assignments satisfying a condition)
1. s always satisfies & inM.2. s satisfies P(t1, . . . , tn) inM iff 'VM,s(t1), . . . , VM,s(tn)( ) I(P).3. s satisfies v .= t inM iff s(v) = VM,s(t).4. s satisfies v %= t inM iff s(v) %= VM,s(t).5. s satisfies ¬D inM iff s does not verify D inM.
Definition 3.5.4. Structure D is true inM if there is an assignment which verifies DinM.
Note that it follows from Definition 3.5.4 that ({x}, {Pxy}) is true in M iff({x, y}, {Pxy}) is true inM. In other words: free variables are existentially quantified.
We leave it to the reader to check that the definition of verifying assignments yieldsthe following requirement for conditions of the form D1 $ D2:
! s satisfies D1 $ D2 in M, where D1 = (X, {C1, . . . , Ck}), iff every assignment s# withs[X]s# which satisfies C1, . . . , Ck inM verifies D2 inM.
These definitions are easily modified to take anchors (partial assignments of valuesto fixed referents) into account. This is done by focusing on assignments extending agiven anchor.

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 195 — #15
Discourse Representation in Context 195
It is not difficult to see that the expressive power of basic DRT is the same asthat of first-order logic. In fact, there is an easy recipe for translating representationstructures to formulae of predicate logic. Assuming that discourse referents can doduty as predicate logical variables, the atomic and link conditions of a representationstructure are atomic formulae of predicate logic. The translation function * which mapsrepresentation structures to formulae of predicate logic is defined as follows:
Definition 3.5.5. (Translation from DRT to FOL)
! For DRSs: if D = ({v1, . . . , vn}, {C1, . . . , Cm}) thenD* := !v1 · · · !vn(C*
1 " · · · " C*m).
! For atomic conditions (i.e. atoms or links): C* := C.! For negations: (¬D)* := ¬D*.
It follows from this that the translation instruction for implications becomes (assumeD1 = ({v1, . . . , vn}, {C1, . . . , Cm}))! (D1 $ D2)
* := +v1 · · · +vn((C*1 " · · · " C*
m) , D*2).
The following is now easy to show:
Proposition 3.5.1. s verifies D inM iffM, s |= D*, where |= is Tarski’s definition ofsatisfaction for first order predicate logic.
It is also not difficult to give a meaning preserving translation from first-order predi-cate logic to basic DRT. In the following definition, !• is the DRS corresponding tothe predicate logical formula !, and !•
1 and !•2 are its first and second components.
Definition 3.5.6. (Translation from FOL to DRT)
! For atomic formulas: C• := (-, C).! For conjunctions: (! " ")• := (-, {!•, "•}).! For negations: (¬!)• := (-, ¬!•).! For quantifications: (!v!)• := (!•
1 . {v}, !•2).
Proposition 3.5.2.M, s |= ! iff s verifies !• inM, where |= is Tarski’s definition ofsatisfaction for first order predicate logic.
The difference between first-order logic and basic DRT has nothing to do with expres-sive power but resides entirely in the different way in which DRT handles context.The importance of this new perspective on context and context change is illustratedby the following examples with their DRS representations.
(29) Someone did not smile. He was angry.(30) Not everyone smiled. *He was angry.

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 196 — #16
196 Handbook of Logic and Language
A suitable DRS representation (ignoring tense) for the first sentence of (29) is thefollowing.
(31)
xperson x
¬smile x
Here we see that the pronoun he in the next sentence of (29) can be resolved bylinking it to the marker x occurring in the top box. The anaphoric possibilities of (30)are different; witness its DRS representation (32).
(32) ¬ xperson x
$smile x
In this case there is no suitable marker available as an antecedent for he in the nextsentence of (30).
What we see here is that DRSs with the same truth conditions, such as (31) and (32),may nevertheless be semantically different in an extended sense. The context changepotentials of (31) and (32) are different, as the former creates a context for subsequentanaphoric links whereas the latter does not. This is as it should be, of course, as thepronoun in the second sentence of (29) can pick up the reference marker in the firstsentence, but the pronoun in the second sentence of (30) cannot. The comparison of(31) and (32) illustrates that meaning in the narrow sense of truth conditions does notexhaust the concept of meaning for DRSs. The extended sense of meaning in which(31) and (32) are different can be informally phrased as follows: (31) creates a newcontext that can furnish an antecedent for a pronoun is subsequent discourse, (32) doesnot. This is because (31) changes the context, whereas (32) does not.
3.6 The Static and Dynamic Meaning of RepresentationStructures
DRT has often been criticized for failing to be “compositional”. It is important to seewhat this criticism could mean and to distinguish between two possible ways it couldbe taken. According to the first of these DRT fails to provide a direct compositionalsemantics for the natural language fragments to which it is applied. Given the form inwhich DRT was originally presented, this charge is justifiable, or at least it was so in

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 197 — #17
Discourse Representation in Context 197
the past. We will address it in Section 3.10. In its second interpretation the criticismpertains to the formalism of DRT itself. This objection is groundless. As Definitions3.5.2 and 3.5.3 more or less directly imply, the formal language of Definition 3.5.1is as compositional as standard predicate logic. We can make the point more explicitby rephrasing Definitions 3.5.2 and 3.5.3 as a definition of the semantic values [[ ]]Mthat is assigned to each of the terms, conditions and DRSs of the DRT language by anappropriate modelM. As values for DRSs inM we use pairs 'X, F( consisting of afinite set of reference markers X / U and a set of functions F / MU , and as meaningsfor conditions we use sets of assignments.
Definition 3.6.1. (Semantics of DRSs)[[({v1, . . . , vn}, {C1, . . . , Cm})]]M := ({v1, . . . , vn}, [[C1]]M 0 · · · 0 [[Cm]]M).
Definition 3.6.2. (Semantics of conditions)
1. [[P(t1, . . . , tn)]]M := {s ) MU | 'VM,s(t1), . . . , VM,s(tn)( ) I(P)}.2. [[v .= t]]M := {s ) MU | s(v) = VM,s(t)}.3. [[v %= t]]M := {s ) MU | s(v) %= VM,s(t)}.4. [[¬D]]M := {s ) MU | for no s# ) MU : s[X]s# and s# ) F},
where (X, F) = [[D]]M.
To see the connection with the earlier definition of verification, 3.5.2, note that thefollowing proposition holds:
Proposition 3.6.1.
! s verifies D inM iff [[D]]M = 'X, F( and there is an s# ) MU with s[X]s# and s# ) F.! D is true inM iff [[D]]M = 'X, F( and F %= -.
If one asks what are the DRS components of a DRS ({v1, . . . , vn}, {C1, . . . , Cm}), thenthe answer has to be: there aren’t any. For those who do not like this answer, it turnsout to be possible to view DRSs as built from atomic building blocks which are alsoDRSs. This was first pointed out by Zeevat (1989). The DRS language is now givenin a slightly different way:
Definition 3.6.3. (Building DRSs from atomic DRSs)
1. If v is a reference marker, ({v}, -) is a DRS.2. If (-, {&}) is a DRS.3. If P is an n-ary predicate and t1, . . . , tn are terms,
then (-, {P(t1, . . . , tn)}) is a DRS.4. If v is a reference marker and t is a term, then (-, {v .= t}) is a DRS.5. If v is a reference marker and t is a term, then (-, {v %= t}) is a DRS.6. If D is a DRS, then (-, ¬D) is a DRS.7. If D = (X, C) and D# = (X#, C#) are DRSs,
then (X . X#, C . C#) is a DRS.8. Nothing else is a DRS.

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 198 — #18
198 Handbook of Logic and Language
It is clear that this defines the same DRS language. Let us use – for the constructionstep that forms negated DRSs (that is, we use 1D for (-, ¬D)) and 2 for the operationof merging the universes and the constraint sets of two DRSs (that is, if D = (X, C)
and D# = (X#, C#), then D 2 D# := (X . X#, C . C#)).Under this DRS definition, DRSs have become structurally ambiguous. DRS
({x}, {Px, Qx}), for example, has several possible construction histories:
! ({x}, -) 2 ((-, {Px}) 2 (-, {Qx})),! ({x}, -) 2 ((-, {Qx}) 2 (-, {Px})),! (({x}, -) 2 (-, {Px})) 2 (-, {Qx}),! and so on.
The DRS semantics to be given next ensures that these structural ambiguities are harm-less: the semantic operation corresponding to 2 is commutative and associative.
The following two semantic operations correspond to the syntactic operations 2, 1on DRSs (note that we overload the notation by calling the semantic operations by thesame names as their syntactic counterparts):
'X, F( 2 'Y, G( := 'X . Y, F 0 G(1'X, F( := '-, {g ) MU | ¬!f ) F with g[X] f }(
The DRS semantics now looks like this:
Definition 3.6.4.
1. [[({v}, -)]]M := ({v}, MU).2. [[(-, {&})]]M := (-, MU).3. [[(-, {Pt1, . . . , tn})]]M := (-, {f ) MU | 'VM,f (t1), . . . , VM,f (tn)( ) I(P)}).4. [[(-, {v .= t})]]M := (-, {f ) MU | f (v) = VM,f (t)}).5. [[(-, {v %= t})]]M := (-, {f ) MU | f (v) %= VM,f (t)}).6. [[1D]]M := 1[[D]]M.7. [[D 2 D#]]M := [[D]]M 2 [[D#]]M.
Clearly, this provides an elegant and compositional model-theoretic semantics forDRSs. Moreover, it is easily verified that Definition 3.6.4 is equivalent to Definitions3.6.1 and 3.6.2 in the sense that if [[D]]M = 'X, F(, then for any assignment s, s ) Fiff s verifies D inM.
The semantics considered so far defines the truth conditions of DRSs. But as wenoted at the end of Section 3.5, there is more to the meaning of a DRS than truthconditions alone. For DRSs which define the same truth conditions may still differ intheir context change potentials.
To capture differences in context change potential, and not just in truth conditions,we need a different kind of semantics, which makes use of a more finely differentiated(and thus, necessarily, of a more complex) notion of semantic value. There are severalways in which this can be achieved. The one which we follow in the next definitiondefines the semantic value of a DRS as a relation between assignments—between

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 199 — #19
Discourse Representation in Context 199
input assignments, which verify the context to which the DRS is being evaluated, andoutput assignments, which reflect the way in which the DRS modifies this context.A semantics which characterizes the meaning of an expression in terms of its con-text change potential is nowadays usually referred to as dynamic semantics, while asemantics like that of the Definitions 3.5.2 and 3.5.3 or Definitions 3.6.1 and 3.6.2,whose central concern is with conditions of truth, is called static. The first explicitformulation of a dynamic semantics in this sense can be found in Barwise (1987). Anelegant formulation is given in Groenendijk and Stokhof (1991).
Although they are quite different from a conceptual point of view, the dynamicand the static semantics for formalisms like those of DRT are nonetheless closelyconnected. Thus, if we denote the dynamic value of DRS D in model M—i.e. therelation between assignments ofM which D determines—as s[[D]]Ms# , with s the inputassignment and s# the output assignment, we have:
! If D = (X, C) then: s[[D]]Ms# iff s[X]s# and s# verifies D inM.
We can also characterize this relation directly, by a definition that is compositional in asimilar spirit as Definition 3.6.4 in that it characterizes the dynamic value of a complexDRS in terms of the dynamic values of its constituents. It will be convenient to basethis definition on a slightly different syntactic characterization of the DRS formalismthan we have used hitherto, one in which the symmetric merge of Definition 3.6.4 isreplaced by an asymmetric merge 3 defined as follows:
! If D = (X, C) and D# = (Y, C#) then D 3 D# := (X, C . C#) is a DRS.
It is clear that all DRSs can be built from atomic DRSs using—and 3 (but note that 3disregards the universe of its second argument).
The dynamic semantics is given as follows. We use s[[D]]Ms# for s, s# is aninput/output state pair for D in model M, and s[v]s# for: s and s# differ at most inthe value for v.
Definition 3.6.5.
1. s[[({v}, -)]]Ms# iff s[v]s#.
2. s[[(-, {&})]]Ms# iff s = s#.
3. s[[(-, {Pt1, . . . , tn})]]Ms# iff s = s# and 'VM,s(t1), . . . , VM,s(tn)( ) I(P).
4. s[[(-, {v .= t})]]Ms# iff s = s# and s(v) = VM,s(t).
5. s[[(-, {v %= t})]]Ms## iff s = s# and s(v) %= VM,s(t).
6. s[[1D]]Ms# iff s = s# and for no s## it is the case that s[[D]]Ms## .
7. s[[D 3 D#]]Ms# iff s[[D]]Ms# and s# [[D#]]Ms# .
The static and the dynamic semantics of DRSs are equivalent, for we have the follow-ing proposition:
Proposition 3.6.2. [[D]]M = 'X, F(, s[X]s#, s# ) F iff s[[D]]Ms#

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 200 — #20
200 Handbook of Logic and Language
Still, the relation between static and dynamic semantics that we have given here leavessomething to be desired. The composition operations for static semantics and dynamicsemantics are different. The basic reason for this is that the dynamic semantics has anotion of sequentiality built in, a notion of processing in a given order. Thereforethe commutative merge operation 2 does not quite fit the dynamic semantics: 2 iscommutative, and sequential merging of DRSs intuitively is not. The operation 3 isnot commutative, but it is unsatisfactory because it discards the dynamic effect of thesecond DRS (which is treated as if it had an empty universe).
To give a true account of the context change potential of DRSs one has to be ableto answer the question how the context change potential of a DRS D1 and that of aDRS D2 which follows it determine the context change potential of their composition.This leads directly to the question of how DRSs can be built from constituent DRSsby an operation of sequential merging.
3.7 Sequential Composition of Representation Structures
Taking unions of universes and constraint sets is a natural commutative merge oper-ation on DRSs, but it is not quite the operation on DRS meanings one would expect,given the dynamic perspective on DRS semantics. Intuitively, the process of gluing anexisting DRS representing the previous discourse to a DRS representation for the nextpiece of natural language text is a process of sequential composition, a process whichone would expect not to be commutative.
How should DRS meanings be composed sequentially? Before we address thisquestion, it is convenient to switch to a slightly modified language for DRSs. It turnsout that if one introduces a sequencing operator ; the distinction between DRSs andconditions can be dropped. This move yields the following language that we will callthe language of proto-DRSs or pDRSs.
pDRSs D ::= v | &| Pt1 · · · tn | v .= t | ¬D | (D1; D2).
In this language, a reference marker taken by itself is an atomic pDRS, and pDRSsare composed by means of ;. Thus, introductions of markers and conditions can befreely mixed. Although we drop the distinction between markers and conditions andthat between conditions and pDRSs, a pDRS of the form v will still be called a marker,and one of the form &, Pt1 · · · tn, v .= t or ¬D a condition. Thus, a pDRS is a referencemarker or an atomic condition or a negation or a ;-composition of pDRSs.
From now on, we will consider v %= t as an abbreviation of ¬v .= t, and D1 $ D2as an abbreviation of ¬(D1; ¬D2). It will turn out that the process of merging pDRSswith “;” is associative, so we will often drop parentheses where it does no harm, andwrite D1; D2; D3 for both ((D1; D2); D3) and (D1; (D2; D3)).
It is possible to give a commutative semantics for pDRSs, by using the semanticoperation—to interpret ¬, and 2 to interpret;

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 201 — #21
Discourse Representation in Context 201
Definition 3.7.1. (Commutative Semantics of pDRSs)
1. [[v]]M := '{v}, MU(.2. [[&]]M := '-, MU(.3. [[Pt1, . . . , tn]]M := '-, { f ) MU | 'VM,f (t1), . . . , VM,f (tn)( ) I(P)}(.4. [[v .= t]]M := '-, {f ) MU | f (v) = VM,f (t)}(.5. [[¬D]]M := 1[[D]]M.6. [[D; D#]]M := [[D]]M 2 [[D#]]M.
This interpretation of ; makes merging of pDRSs into a commutative operation. Tosee the effect of this, look for instance at examples (33) and (34).
(33) A man entered.(34) A boy smiled.
How should pDRSs for these examples be merged? The commutative merge thatwe just defined gives the result (35).
(35)xman xenter x
;xboy xsmile x
=
xman xenter xboy xsmile x
In the pDRT semantics the two discourse referents for a man and a a boy will befused, for according to the operation 2 the fact that a marker is mentioned more thanonce is irrelevant. This shows that (35) cannot be the right translation of the sequentialcomposition of (33) and (34).
A different approach to merging pDRSs is suggested by the fact that in a dynamicperspective merging in left to right order has a very natural relational meaning:
! s[[D1; D2]]Ms# iff there is an assignment s## with s[[D1]]Ms## and s## [[D2]]Ms# .
This semantic clause complies with the intuition that the first pDRS is interpreted inan initial context s yielding a new context s##, and this new context serves as the initialcontext for the interpretation of the second pDRS.
Once we are here a natural way to extend the dynamic approach to the full languagesuggests itself, as was noted by Groenendijk and Stokhof in (1991). Their observationis basically this. If we interpret the DRS conditions in terms of pairs of assignments,the dynamic semantic values of DRS conditions can be given in the same form as thedynamic values of DRSs.
At first sight, DRS conditions do not look like context changers. If (s, s#) is a con-text pair for a condition, then always s = s#, representing the fact that the conditiondoes not change anything. But who cares? If we allow degenerate context changers,we can drop the distinction between conditions and DRSs altogether. What is more,even the distinction between marker introductions and conditions is not essential, forthe introduction of a marker u can also be interpreted in terms of context pairs, and the

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 202 — #22
202 Handbook of Logic and Language
introduction of a list of markers can be obtained by merging the introductions of thecomponents.
These considerations yield the following relational semantics for the pDRS format(this is in fact the semantic format of the dynamic version of first-order predicate logicdefined in Groenendijk and Stokhof, 1991):
Definition 3.7.2. (Relational Semantics of pDRSs)
1. s[[v]]Ms# iff s[v]s#.
2. s[[&]]Ms# iff s = s#.
3. s[[Pt1, . . . , tn]]Ms# iff s = s# and 'VM,s(t1), . . . , VM,s(tn)( ) I(P).
4. s[[v.= t]]Ms# iff s = s# and s(v) = VM,s(t).
5. s[[¬D]]Ms# iff s = s# and for no s## it is the case that s[[D]]Ms## .
6. s[[D; D#]]Ms# iff there is an s## with s[[D]]Ms## and s## [[D#]]Ms# .
Truth is defined in terms of this, as follows.
Definition 3.7.3. (Truth in relational semantics for pDRSs.) D is true inM, givens, notationM, s |= D, iff there is an s# with s[[D]]Ms# .
Note that the difference with the previous semantics (Definition 3.7.1) resides in theinterpretation of ; and has nothing to do with with the static/dynamic opposition. Tosee that, observe that the relational semantics Definition 3.7.2 can also be given astatic formulation. For that, the only change one has to make to Definition 3.7.1 is inthe clause for D1; D2, by interpreting ; as the operation * defined as follows:
'X, F( * 'X#, F#( := 'X . X#, {f # ) F# | !f ) F f [X#] f #}(
Given this change to Definition 3.7.1, we have the following proposition:
Proposition 3.7.1.M, s |= D iff [[D]] = 'X, F( and !f ) F with s[X] f .
So we see that 3.7.2 can be given an equivalent static formulation. Conversely, it isnot hard to give a relational clause for 2:
f R 2 Sg 4$ f [R• . S•]g & g ) rng (R) 0 rng (S),
where R• = {v ) U | (f , g) ) R & f (v) %= g(v)} (and similarly for S•).According to the relational semantics of Definition 3.7.2, (36) and (37) have the
same meanings.
(36) x; y; man x; woman y; love (x,y).(37) x; man x; y; woman y; love (x,y).

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 203 — #23
Discourse Representation in Context 203
This means that we can use the same box representation (38) for both:
(38)
x yman xwoman ylove (x,y)
Unfortunately, other examples show that the box notation does not really fit therelational semantics for the pDRSs given in Definition 3.7.2. The use of collectingdiscourse referents in universes, as it is done in the box format, is that this allows oneto see the anaphoric possibilities of a representation at a glance: the discourse referentsin the top box are the markers available for subsequent anaphoric linking.
However, when the composition operation ; is interpreted as in Definition 3.7.2 (or,alternatively, as the operation *), the pDRS notation becomes capable of expressingdistinctions that cannot be captured in the box notation we have been using. Note,for instance, that the pDRSs in (39) and (40) are not equivalent with regard to thesemantics of Definition 3.7.2, although they are equivalent with regard to that givenby (the unmodified) Definitions 3.6.1 and 3.6.2.
(39) x; man x; dog y; y; woman y; love (x,y).(40) x; y; man x; dog y; woman y; love (x,y).
To take this difference into account the box representation for (39) would have to besomething like (41).
(41)x yman x woman ydog y love (x,y)
The vertical dividing line in (41) separates the occurrences of y that receive theirinterpretation from the previously given context from those that are linked to the newintroduction.
Thus we see that the relational semantics for pDRSs provides a natural notion ofsequential merging, which allows sharing of introduced markers between two DRSs.However, it distinguishes between different introductions of the same marker. Thisintroduces a problem of destructive assignment: after a new introduction of a markerv that was already present, its previous value is lost. This feature of Definition 3.7.2 isthe root cause of the mismatch between box representation and sequential presentationthat we just noted. It is also the source of the non-equivalence of the commutative andthe relational composition semantics for the pDRS format.
For a fruitful discussion of the problem of sequential merge, it is necessary to beclear about the nature of the different kinds of marker occurrences in a pDRS. In thefollowing discussion we compare the role of reference markers with that of variablesin classical logic and in programming languages. Classical logic has two kinds ofvariable occurrences: bound and free. In the dynamic logic that underlies DRT thereare three kinds of variable or marker occurrences (see Visser, 1994).

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 204 — #24
204 Handbook of Logic and Language
1. marker occurrences that get their reference fixed by the larger context,2. marker occurrences that get introduced in the current context,3. markers occurrences that get introduced in a subordinate context.
We will call the first kind fixed marker occurrences, the second kind introduced markeroccurrences, and the third kind classically bound marker occurrences. The first kindcorresponds roughly to the free variable occurrences of classical logic, and the thirdkind to the bound variable occurrences of classical logic (hence the name). The secondkind is altogether different: these are the markers that embody the context changepotential of a given pDRS.
As the distinction between these three kinds of marker occurrences is given by“dynamic” considerations, it is not surprising that there is a close connection withthe various roles that variables can play in imperative programming. Here are thecorrespondences:
1. Fixed markers correspond to variables in read memory.2. Introduced markers correspond to variables in write memory.3. Bound markers correspond to scratch memory (memory used for intermediate computations
that are not part of the output of the program under consideration).
Due to the semantic motivation for this tripartite distinction, the formal definition willdepend on the semantics for ; that we adopt. We will give the definition based on therelational semantics.
The set of discourse referents which have a fixed occurrence in a pDRS is givenby a function fix : pDRSs , PU. The set of discourse referents which are introducedin a pDRS is given by a function intro : pDRSs , PU, and the set of discoursereferents which have a classically bound occurrence in a pDRS is given by a functioncbnd : pDRSs , PU. To define these functions, we first define a function var on theatomic conditions of a DRS.
var(Pt1 · · · tn) := {ti | 1 5 i 5 n, ti ) U}
var(v .= t) :=!
{v, t} if t ) U,
{v} otherwise.
Definition 3.7.4. (fix, intro, cbnd)
! fix(v) := -, intro(v) := {v}, cbnd(v) := -.! fix(&) := -, intro(&) := -, cbnd(&) := -.! fix(Pt1 · · · tn) := var(Pt1 · · · tn), intro(Pt1 · · · tn) := -, cbnd(Pt1 · · · tn) := -.! fix(v .= t) := var(v .= t), intro(v .= t) := -, cbnd(v .= t) := -.! fix(¬D) := fix(D), intro(¬D) := -, cbnd(¬D) := intro(D) . cbnd(D).! fix(D1; D2) := fix(D1) . (fix(D2) 1 intro(D1)),
intro(D1; D2) := intro(D1) . intro(D2),cbnd(D1; D2) := cbnd(D1) . cbnd(D2).

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 205 — #25
Discourse Representation in Context 205
We will occasionally use activ(D) for the set of markers fix(D) . intro(D).The set of conditions of a pDRS is given by the function cond : pDRSs ,
P(pDRSs), which collects the conditions of D together in a set:
Definition 3.7.5. (cond)
1. cond(v) := -.2. cond(&) := {&}.3. cond(Pt1 · · · tn) := {Pt1 · · · tn}.4. cond(v .= t) := {v .= t}.5. cond(¬D) := {¬D}.6. cond(D1; D2) := cond(D1) . cond(D2).
Note that there are pDRSs D with intro(D) 0 fix(D) %= -. An example is given in (42).
(42) Px; x; Qx.
Also, there are pDRSs D where a marker is introduced more than once. An exampleis given in (43).
(43) x; Px; x; Qx
We will call a pDRS proper (or a DRS) if these situations do not occur. Thus, theset of DRSs is defined as follows:
Definition 3.7.6. (DRSs)
! If v is a marker, then v is a DRS.! & is a DRS.! If t1, . . . , tn are terms and P is an n-place predicate letter, then Pt1 · · · tn is a DRS.! If v is a marker and t is a term, then v .= t is a DRS.! If D is a DRS, then ¬D is a DRS.! If D1, D2 are DRSs, and ( fix(D1) . intro(D1)) 0 intro(D2) = -, then D1; D2 is a DRS.! Nothing else is a DRS.
Note that examples (42) and (43) are not DRSs. Indeed, we have:
Proposition 3.7.2. For every DRS D, intro(D) 0 fix(D) = -.
Proposition 3.7.2 entails that DRSs of the form D; v are equivalent to v; D. This meansthat any DRS D can be written in box format (44) without change of meaning. Indeed,we can view the box format for DRSs as an abstract version of the underlying realsyntax.
(44)
intro(D)
cond(D)

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 206 — #26
206 Handbook of Logic and Language
Note that if a DRS D has intro(D) %= - and cond(D) %= -, then D must be of theform D1; D2, where ( fix(D1) . intro(D1)) 0 intro(D2) = -. We say that D is a simplemerge of D1 and D2.
According to the DRS definition, DRSs are either of one of the forms in (45) orthey are simple merges of two DRSs (but note that taking simple merges is a partialoperation).
(45)
v
& Pt1 · · · tn v .= t ¬D
For DRSs, the truth conditions according to the commutative semantics coincide withthose according to the relational semantics:
Proposition 3.7.3. For all modelsM, all DRSs D:
if [[D]]M = 'X, F( then s[[D]]Ms# iff s[X]s# and s# ) F
3.8 Strategies for Merging Representation Structures
To get a clear perspective on the problem of merging DRSs, note that the issue doesnot even occur in an approach where a natural language discourse is processed bymeans of a DRS construction algorithm that proceeds by “deconstructing” naturallanguage sentences in the context of a given DRS, as in Kamp (1981) or Kamp andReyle (1993).
The problem emerges as soon as one modifies this architecture by switching to aset-up where representations for individual sentences are constructed first, and nextthese have to be merged in left to right order. Suppose we want to construct a DRS forthe sequential composition of S1 and S2 on the basis of a DRS D1 for S1 and a DRS D2for S2. Now it might happen that D1; D2 is not a DRS, because (fix(D1). intro(D1))0intro(D2) %= -. Our idea is to resolve this situation by applying a renaming strategy. Inthe example sentences given so far the problem has been avoided by a prudent choiceof indices, but example (46) would pose such a conflict.
(46) A man1 entered. A boy1 smiled.
The initial representation for the sequential composition of D1 and D2 can be givenby D1 • D2. The problem of sequential merge now takes the form of finding strategiesfor reducing DRS-like expressions with occurrences of • to DRSs.
Before we list of a number of options for “merge reduction”, we define a class ofreducible DRSs or RDRSs (assume D ranges over DRSs):
RDRSs R ::= D | ¬R | (R1 • R2).

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 207 — #27
Discourse Representation in Context 207
Thus, RDRSs are compositions out of DRSs by means of ¬ and •. It is useful to extendthe definitions of intro, fix and cbnd to RDRSs:
Definition 3.8.1. (fix, intro, cbnd for RDRSs)
! fix(¬R) := fix(R), intro(¬R) := -, cbnd(¬R) := intro(R) . cbnd(R).! fix(R1 • R2) := fix(R1) . ( fix(R2) 1 intro(R1)),
intro(R1 • R2) := intro(R1) . intro(R2),cbnd(R1 • R2) := cbnd(R1) . cbnd(R2).
We use • for sequential merge. The various options for how to merge DRSs all have asemantic and a syntactic side, for they must handle two questions:
1. What is the semantics of •?2. How can RDRSs be reduced to DRSs?
In order to talk about these reductions in a sensible way, we must take negative contextinto account. Here is a definition of negative contexts (D ranges over DRSs, R overRDRSs).
Negative Contexts N ::= ¬! | ¬N | (N; D) | (D; N) | (N • R) | (R • N).
Condition on (N; D): activ(N) 0 intro(D) = -. Condition on (D; N): activ(D) 0intro(N) = -, where activ(N) and intro(N) are calculated on the basis of intro(!) :=fix(!) := cbnd(!) := -.
What the definition says is that a negative context is an RDRS with one constituentRDRS immediately within the scope of a negation replaced by !. If N is a negativecontext, then N[R] is the result of substituting RDRS R for ! in N. The definition ofnegative contexts allows us to single out an arbitrary negated sub-RDRS R of a givenRDRS by writing that RDRS in the form N[R].
Contexts C ::= ! | N.
A context is either a ! or a negative context. If C is a context, then C[R] is the resultof substituting RDRS R for ! in N. Thus, if we want to say that a reduction ruleapplies to an RDRS R that may (but need not) occur immediately within the scope of anegation sign within a larger RDRS, we say that the rule applies to C[R]. If we specifya reduction rule
R =$ R#,
this is meant to be understood as licensing all reductions of the form:
C[R] 1, C[R#].
This format ensures that the rule can both apply at the top level and at a level boundedby a negation sign inside a larger RDRS.

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 208 — #28
208 Handbook of Logic and Language
We will now discuss several options for merge reduction: symmetric merge,prudent merge, destructive merge, deterministic merge with substitution, and inde-terministic merge with substitution.
Symmetric Merge Interpret • as 2 and ; as *. The reduction rules that go withthis are:
(R • v) =$ (v; R)
(R • &) =$ (R; &)
(R • Pt1, . . . , tn) =$ (R; Pt1, . . . , tn)
(R • ¬R#) =$ (R; ¬R#)
((R • v) • R#) =$ ((v; R) • R#)
((R • &) • R#) =$ ((R; &) • R#)
((R • Pt1, . . . , tn) • R#) =$ ((R; Pt1, . . . , tn) • R#)
((R • ¬R1) • R2) =$ ((R; ¬R#) • R2)
(R • (R1; R2)) =$ ((R • R1) • R2)
(R • (R1 • R2)) =$ ((R • R1) • R2)
Partial Merge Interpret • as a partial operation (see for example Muskens, 1996)while retaining * as the interpretation of ; (as we will do throughout the remainderof this section). To give the semantics, we have to take context into account. Assumethat the semantics of a DRS D is given as a triple 'X, Y, F(, where X = fix(D), Y =intro(D) and F is a set of assignments; then the following partial operation gives thesemantics of partial merge:
'X, Y, F( 6 'X#, Y #, F#( :=!
'X . X#, Y . Y #, F 0 F#( if (X . Y) 0 Y # = -,
7 otherwise.
The reduction rules that go with this: same as above, except for the following changein the rules that handle marker introductions:
(R • v) =$ (R; v) if v /) fix(R) . intro(R)
(R • v) =$ ERROR if v ) fix(R) . intro(R)
((R • v) • R#) =$ ((R; v) • R#) if v /) fix(R) . intro(R)
((R • v) • R#) =$ ERROR if v ) fix(R) . intro(R).
Prudent Merge To give the semantics of prudent merging for • (see Visser, 1994),one again has to take context fully into account.
'X, Y, F( 6 'X#, Y #, F#( := 'X . (X# 1 Y), Y . (Y # 1 X), F 0 F#(.

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 209 — #29
Discourse Representation in Context 209
Reduction rules that go with this: same as above, except for the following change inthe rules that handle marker introduction:
(R • v) =$ (R; v) if v /) fix(R) . intro(R)
(R • v) =$ R if v ) fix(R) . intro(R)
((R • v) • R#) =$ (R; v) • R#) if v /) fix(R) . intro(R)
((R • v) • R#) =$ R • R# if v ) fix(R) . intro(R).
Destructive Merge Interpret • as * (relational composition), and allow destructiveassignment. The reduction rule that goes with this is very simple: replace all occur-rences of • in one go by ;, and interpret ; as *. But of course, this reduction does notyield DRSs but only proto-DRSs.
For the next two perspectives on merging DRSs, we need to develop a bit of techniquefor handling substitution, or, more precisely, marker renamings.
Definition 3.8.2. A marker renaming is a function # : U , U, such that its domainDom(#) := {v ) U | v %= #(v)} is finite. If # is a renaming with Dom(#) ={v1, . . . , vn}, then Rng(#) := {#(v1), . . . , #(vn)}. A renaming # avoids a set X / U :8Rng(#) 0 X = -. If # is a renaming, then #1v := the renaming $ that is like # but forthe fact that $ (v) = v. If X / U then #X := {#(x) | x ) X}. A marker renaming # isinjective on X :8 |X| = |#X|.
We will refer to a renaming # with domain {v1, . . . , vn} as [#(v1)/v1, . . . , #(vn)/vn].Thus, [x/y] is the renaming # with #(u) = x if u = y and #(u) = u otherwise. Thisrenaming is of course injective on {x}, but not on {x, y}. [x/y, x/z] is a renaming whichis not injective on {y, z}. [x/y, x/z] 1 z = [x/y].
A renaming of a subset of intro(D) intuitively has as its semantic effect that thewrite memory of D gets shifted. Renaming in a dynamic system like DRT works quitedifferently from variable substitution in classical logic, because of the three kinds ofmarker occurrences that have to be taken into account: fix, intro and cbnd. In particular,a renaming of intro(D) has to satisfy the following requirements:
1. it should be injective on intro(D),2. it should avoid fix(D),3. it should leave cbnd(D) untouched.
The first two of these requirements can be imposed globally. Requirement (3) shouldbe part of the definition of the effects of renamings on (R)DRSs: we will handle it bydistinguishing between outer and inner renaming. For an outer renaming of RDRS Rwith # we employ #R, for an inner renaming #R. Inner renaming is renaming within acontext where marker introductions act as classical binders, i.e. within the scope of anoccurrence of ¬. For example, if # = [v/x, w/y], then:
#(x; ¬(y; Rxy)) = v; ¬(y; Rvy).

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 210 — #30
210 Handbook of Logic and Language
A renaming # induces functions from terms to terms as follows:
#(t) :=!
#(v) if t = v with v ) U,
t if t ) C.
A renaming #1v induces functions from terms to terms as follows:
#1v(t) :=
"#
$
#(w) if t = w %= v with w ) U,
v if t = v,t if t ) C.
The induced renaming functions from (R)DRSs to (R)DRSs are given by:
#v := #(v)
#& := &#& := &
#(Pt1 · · · tn) := P# t1 · · · # tn
#(Pt1 · · · tn) := P# t1 · · · # tn#(v .= t) := #v .= # t
#(v .= t) := #v .= # t
#(¬R) := ¬#R
#(¬R) := ¬#R
#(v; R) := #v; #R
#(v; R) := v; #1vR
#(C; R) := #C; #R, C ) {Pt1 · · · tn, v .= t, ¬R#}#(C; R) := #C; #R, C ) {Pt1 · · · tn, v .= t, ¬R#}
#((R1; R2); R3) := #(R1; (R2; R3))
#((R1; R2); R3) := #(R1; (R2; R3)),
plus rules for • exactly like those for ;.For the semantics, let us again assume that a meaning for DRS D is a triple
'X, Y, F(, where X = fix(D), Y = intro(D), and F is the set of assignments satis-fying cond(D).
Definition 3.8.3. # is a proper renaming for DRS D :8
1. Dom(#) / intro(D),2. # is injective on intro(D),3. Rng(#) 0 fix(D) = -.
Definition 3.8.4. If F / MU , #F := {g ) MU | g * # ) F}.

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 211 — #31
Discourse Representation in Context 211
For example, if F = {f ) MU | f (x) ) I(P)}, and # = [y/x], then:
[y/x]F = {g ) MU | g * [y/x](x) ) I(P)} = {g ) MU | g(y) ) I(P)}.
Proposition 3.8.1. If # is a proper renaming for D and |D|M = 'X, Y, F( then|#D|M = 'X, #Y, #F(.
The upshot of this proposition is that a proper renaming only changes the write mem-ory of a DRS.
Deterministic Merge With Substitution The sequence semantics for dynamic pred-icate logic defined in Vermeulen (1993) can be used as a semantics for a language ofunreduced DRSs:
R ::= PUSH v | &| Pt1 · · · tn | v .= t | ¬R | (R1 • R2),
where v ranges over a set U of markers without indices. The meaning of a variableintroduction v in sequence semantics is: push a new value for v on a stack of v values.Clearly, this prevents the destructive use of memory that we saw in connection withDefinition 3.7.2. Suggestive notation for this: PUSH v.
We can reduce expressions of this language to a language of proper DRSs wherethe markers are taken from the set of indexed markers U# := {ui | u ) U, i > 0}.The corresponding merge reduction rules for this use fully determined renamings, asfollows.
First we do a global renaming, by replacing every occurrence of v ) U, exceptthose immediately preceded by a PUSH, by v1 ) U#. Next, assume that we are ina situation D • PUSH v • R, where D is a DRS (no occurrences of PUSH in D, nooccurrences of • in D). Then there are two cases to consider.
It may be that vj does not occur in fix(D) . intro(D), for any index j. In that case,rewrite as follows:
(D • PUSH v) • R =$ (D; v1); R.
It may also be that vj does occur in fix(D). intro(D), for some index j. In that case, leti be sup({j ) IN | vj ) fix(D) . intro(D)}), and rewrite as follows:
(D • PUSH v) • R =$ (D; vi+1); [vi+1/vi]R.
The idea behind these instructions is that if vj does not occur in D, then v1 can safelybe introduced, and it will actively bind the occurrences of v1 which occur in openposition on the right. If vj does occur in D, then the present push should affect thev-variables with the highest index in open position on the right. This is precisely whatthe renaming [vi+1/vi] effects.
Indeterministic Merge With Substitution Indeterministic merge does involve a fam-ily 6# of merge operations, where # is a renaming that is constrained by the two DRSsD1 and D2 to be merged, in the sense that # is proper for D2 and # avoids the setintro(D1) . fix(D1). If the interpretations of D1 and D2 are given by 'X1, Y1, F1( and

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 212 — #32
212 Handbook of Logic and Language
'X2, Y2, F2(, respectively, then the interpretation of D1 •# D2 is given by:
'X1 . X2, Y1 . #Y2, F1 0 #F2(.
If # is constrained in the way stated above, this is a proper DRS denotation.The rules for indeterministic merge reduction use renamings, as follows (we use
activ(R) for intro(R) . fix(R)):
(R • v) =$
"#
$
(R; v) if v /) activ(R),
(R; w) if v ) activ(R),
w /) activ(R)
(R • &) =$ (R; &)
(R • Pt1, . . . , tn) =$ (R; Pt1, . . . , tn)
(R • ¬R#) =$ (R; ¬R#)
((R • v) • R#) =$
"#
$
((R; v); R#) if v /) activ(R),
((R; w); [w/v]R# if v ) activ(R),
w /) activ(R) . activ(R#)
((R • &) • R#) =$ ((R; &) • R#)
((R • Pt1, . . . , tn) • R#) =$ ((R; Pt1, . . . , tn) • R#)
((R • ¬R1) • R2) =$ ((R; ¬R1) • R2)
(R • (R1; R2)) =$ ((R • R1) • R2)
(R • (R1 • R2)) =$ ((R • R1) • R2)
Note that under the indeterministic merge regime, • does not get an independentsemantics, so one cannot talk about “the” meaning of D • D# anymore, only about itsmeaning modulo renaming of intro(D#). One can still prove that different reductionsof R to normal form (i.e. to proper DRSs) are always write variants of one another,i.e. R,,D and R,,D# together entail that there is some proper renaming # of D with#D = D#.
A set of RDRSs together with a set of merge reduction rules like the example setsgiven above is a so-called abstract reduction system (Klop, 1992), and the theory ofabstract reduction systems can fruitfully be applied to their study (van Eijck, 1996).What all the merge reduction rule sets above, with the exception of destructive merge,have in common is that they start out from reducible DRSs and produce proper DRSsas normal forms. They all take into account that the merge operation • should notdestroy anaphoric links. An additional feature of merge with substitution is that itpreserves anaphoric sockets, and that is what we will use in the sequel. For practicalreasons we opt for the indeterministic version, to avoid possible confusion due to theappearance of a new kind of indices (indicating stack depth).
Each RDRS or DRS has a set of anaphoric plugs and a set of anaphoric sockets. Theplugs anchor the representation structure to previous discourse or to contextually given

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 213 — #33
Discourse Representation in Context 213
antecedents. In both reduced and unreduced RDRSs, these plugs have fixed names,given by fix(R). The sockets are the anchoring ground for the next bit of discourse.In unreduced RDRSs, the sockets do not have fixed names yet, and they may not yetrepresent the full set of anaphoric possibilities of the represented discourse. During theprocess of merge reduction, the internal wiring of the representation structure gets re-shuffled and some members of intro(R) may end up with a new name, to make roomfor extra sockets. If D is a fully reduced DRS, however, the sockets have fixed names,given by intro(D) . fix(D), and this set of markers represents the full set of anaphoricpossibilities for subsequent discourse.
Here is a concrete example of how disjoint merging according to the indeterministicmerge regime works:
(47)xman xenter x
•xwoman xsmile x
,xman xenter x
; [y/x]xwoman xsmile x
=
x yman xenter xwoman ysmile y
In DRT with indeterministic merge, introduced markers are always new, so noinformation is ever destroyed, and merging of representations preserves all anaphoricpossibilities of the parts that are merged.
We now know what the basic building blocks of DRT are, namely structures asgiven in (45), and what is the glue that puts them together, namely the disjoint mergeoperation involving marker renaming. This concludes the discussion of compositional-ity for DRSs. Quite a few philosophical and technical questions concerning the naturalnotion of information ordering in DRT remain. See Visser (1994) for illumination onthese matters.
3.9 Disjoint Merge and Memory Management
Reference markers are similar to variables, but differ from them in that they are notbound by logical operators in the usual sense. In fact, reference markers behave morelike variables in programming languages than like variables in ordinary first-orderlogic (Section 3.7 above).
Anaphoric links are created by linking new reference markers to available ones.How does one discard references? By de-allocating storage space on popping out of a“subroutine”. The representation, in box format, for (3) is given in (48).
(48)xman xenter x
$smile x

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 214 — #34
214 Handbook of Logic and Language
The semantic treatment of this uses a subroutine for checking if every way of mak-ing a reference to a man who enters (where the reference is established via marker x)makes the property given by the consequent of the clause succeed. Next, the storagespace for x is de-allocated, which explains why an anaphoric link to a man in subse-quent discourse is ruled out, or at least infelicitous (see example (49)).
(49) If a man1 enters, he1 smiles. 9He1 is happy.
Thus we see that anaphoric linking is not subsumed under variable binding, or atleast not under variable binding perceived in a standard fashion, as in first-order logic.The process is much more akin to variable binding in programming, where storagespace is created and discarded dynamically, and where links to a variable remain pos-sible until the space occupied by the variable gets de-allocated to be used for some-thing else, so that further anaphoric links remain possible as long as the variable spacefor the antecedent remains accessible.
Reference markers, as we have seen, are allocated pieces of storage space for (rep-resentations of) things in the world. We can picture the building of a representationstructure as an interactive process, where we give instructions to make memory reser-vations and to provide names for the allocated chunks of memory, as in (50).
(50) new(Var)
The system responds by allocating a chunk of memory of the correct size and byreturning a name as value of Var, say u385, indicating that a piece of storage spaceis allocated and henceforth known under the name u385, where 385 presumably isthe offset from the beginning of the piece of memory where the representation underconstruction is stored. Once storage space has been allocated to a discourse referent, itis useful to know the scope of the allocation. In DRT the scope of the introduction ofa discourse referent is closed off by the closest ¬ operator (or the closest $ operator,in case $ is taken as a primitive) that has that introduction in its scope.
Of course, this interactive picture is an inside picture of what happens during therepresentation building process. We must also be able to look at the situation from theoutside, and answer the question of what happens if we assume that we have builtand stored two representation structures D1, D2 in the memory of a computer, oneafter the other. Next, we want to store them in memory simultaneously, i.e. to mergethem, where the merging has to preserve sequential order. This will in general involvechanging the names of those variables declared in the second representation that wouldotherwise overwrite the area of memory already used by the first representation.
What if some very suspicious semanticist still has qualms about disjoint mergebecause of the indeterminism of the operation? We then would have to explain tothem that the indeterminism is entirely natural, as it reflects the fact that the renamingoperation is nothing but the familiar operation of copying variable values to a different(unused) part of memory before combining two memory states (Figure 3.1). Disjoint

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 215 — #35
Discourse Representation in Context 215
+ =
Figure 3.1 Copying registers before merging memory states.
merge is indeterministic simply because any way of copying part of memory to asafe new location will do. This suggests that indeterminism is a strength rather than aweakness of the disjoint merge.
The story of a reasonable definition of merge is a story of memory management.Assuming we have an unlimited supply of memory available, we may picture the datapart of memory where the active markers of representation structure D reside as anarray a[0], . . . , a[i], . . ., where the a[i] are the cells containing the referents (point-ers to the individuals in the model under consideration). Where exactly in absolutememory representation structure D is stored is immaterial; we assume it is stored inrelative memory, that is to say, at some unknown offset m from the start of the datapart of memory. If the marker set activ(D) of structure D occupies k memory cells andis stored at offset m from the beginning of data memory, then the active markers of Drange from a[m] to a[m + k].
As soon as we are willing to keep track of where in relative memory the result ofmerging representation structures D1 and D2 is going to reside, counting from theoffset where D1 is stored, a deterministic disjoint merge is readily available, in termsof a particular renaming # determined by the memory locations. Now the story getsus down to the level of programming the bare silicon of the discourse representationmachine, so to speak. Assuming the markers activ(D1) of D1 reside in memory atu[0], . . . , u[i] (where u[0] = a[m], for some offset m), and the markers activ(D2)
of D2 reside in some scratch part of memory s[0], . . . , s[ j], then D1 and D2 can bemerged after a renaming # = [u[i+1]/s[0], . . . , u[i+ j+1]/s[j]], and activ(D1; #D2)
will reside in memory at u[0], . . . , u[i + j + 1].But once again, such a detailed description of the implementation of merge is
really unnecessary. What we will need for the next section is the assumption thatfor all R1, R2, the merge R1 • R2 is a well-defined (reducible) discourse representa-tion structure, and that the result of merging R1 and R2 is independent of the choice

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 216 — #36
216 Handbook of Logic and Language
of marker names, in the sense that the operation does not destroy anaphoric socketsdue to variable name clashes. This is precisely what we have got in the definition ofthe merge operation provided by indeterministic merge. What it all boils down to isthis. Anaphoric links are essentially arrows pointing from anaphoric expressions toantecedents (Figure 3.2). Often these links can be represented by indices, as in (51).
(51) Johni hates a manj who hates himi and another manj who does not.
The actual choice of the index numbers does not matter. What matters is the pro-perty of having the same index. In a slogan: anaphoric arrows are index pairs (i
i)modulo renamings. Of course, one might also assume that all indices have been pickedappropriately from the start, but as a general strategy this would seem quite unrealistic;and in any case the point we want to make here is that that assumption is not necessary.
While we are on the topic of memory management, we might as well mentionthat there are at least two non-equivalent ways in which storage space for referencemarkers can get allocated. In the first variant, which we have assumed until now, onallocating memory and giving it a name v, v becomes the name of the piece of memorycontaining the data (Figure 3.3).
In the second variant, v refers to the data indirectly by pointing to a piece of stor-age space containing the data. This second variant allows much greater versatility inmanipulating data structures. The name v might for instance be used to allocate andpoint to a new piece of memory, without destroying previous data (Figure 3.4). Indi-rect allocation ensures that old data are preserved in memory, although they may nolonger be accessible under the old name (Figure 3.5). The development of a pointersemantics for DRT suggests the use of pointer stacks to keep track of referents thatare contextually salient, allowing pointers to be set to nil to indicate that a referenthas drifted out of focus, and so on. For a detailed account of a pointer semantics for avariant of DRT we refer the reader to Vermeulen (1995).
John hates a man who hates him and another man who does not.
Figure 3.2 Anaphoric links are arrows.
v
data
Figure 3.3 Direct allocation of storage space to variable v.
v
data
Figure 3.4 Indirect allocation of storage space to variable v.

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 217 — #37
Discourse Representation in Context 217
v
data
Figure 3.5 Allocating new memory space to v without destroying old data.
3.10 Constructing DRSs for Natural Language Fragments
As we have seen in Section 3.6, there is one sense in which the compositionality ofDRT is unproblematic: the representation formalisms DRT proposes are as composi-tional as one could like. In fact, all semantic definitions we have considered in the lastthree sections, from Definition 3.6.1 onwards, have been essentially compositional:they either were, or else could readily be converted into, compositional definitions ofthe semantic values that expressions of these formalisms determine in a model. More-over, in the last two sections we have looked at a number of merge operations forputting two DRSs together into a single one. These operations too, we found, can begiven direct semantic interpretations which map the semantic values of the componentDRSs into the semantic value of the compound.
But what about compositionality in the second sense? Does DRT provide a wayof analyzing fragments of natural language which assigns these fragments a seman-tics that is compositional with respect to these fragments themselves, a semantics thatis compositional with respect to a natural syntax for these fragments? The originalformulation of DRT did not seem to provide such an analysis, and it was even sug-gested at the time that a compositional treatment of the natural language fragmentsthen considered would be impossible. In the meantime we have, through the dynamicreformulation of DRT discussed in Sections 3.7, 3.8 and 3.9, come to see that suchpessimism is not quite warranted: when applied judiciously, the traditional computa-tional methods familiar from Montague Grammar can be made to work so that theyassign sentences and texts from these fragments the same truth conditions as the origi-nal version of DRT. It suffices to define the building blocks of DRSs as suitably typedexpressions of a typed language. In particular, each word of the natural language frag-ment in question can be assigned an expression of the typed language as its lexicalentry, and these expressions can then be combined, by “semantic” rules correspondingto syntactic composition rules, into representations of any given sentence or text ofthe fragment; by an entirely analogous process, one can compute the semantic valueof the sentence or text directly from the semantic values of the (entries of) the wordscomposing them.
Whether the compositional approach towards DRT, which operates under muchstricter constraints than the original DRT approach (e.g., Kamp and Reyle, 1993), can

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 218 — #38
218 Handbook of Logic and Language
handle all the purposes to which DRT has been put is a question to which there is atpresent no clear answer. We turn to this question briefly at the end of this section andagain in Section 3.12.
A DRS construction algorithm for a given natural language fragment has to provideinstructions for extending a given DRS with the information contained in a sentencefrom the fragment. This entails that the processing instructions for that sentence shouldtake information from the previous representation into account. In practice, this is thelist of available referents. Assuming that the representation of the previous discourseis in reduced form, we may take it that we have a list u1, . . . , un available of referencemarkers introduced by previous discourse. Pronouns may be resolved to any memberof this list, and also to markers that get introduced by antecedents in the sentence underconsideration.
The process of anaphoric resolution on the basis of available information fromthe representation of previous discourse poses a highly non-trivial challenge, and it isquestionable if a real algorithm for this process is on the cards. The following problemis more manageable. Assuming that an anaphoric indexing for a sentence is given, andalso that a decision has been made about the relative scopes of the operators (i.e. areading of the sentence has been fixed by the sentence grammar), give an algorithm forupdating an available representation structure with the information from that sentence.In fact, as we shall see, we get a lot of this for free because of the presence of the mergeoperation •.
To illustrate the process of constructing DRSs for natural language fragments, webegin by defining a sentence grammar for a toy fragment. Basic categories are S (with-out features) for sentences, TXT (without features) for texts, and E (with features forcase, antecedent index i, anaphoric index j), for markers for individual entities. Weassume the category abbreviations given in Table 3.1. Here the feature variable tenseranges over the values Tensed and Inf, the feature variable case ranges over the valuesNom and Acc, and the index features range over the positive natural numbers. Theexample structure generated by this grammar given in Figure 3.6 illustrates how thegrammar works. Further information about the categorial format with feature unifica-tion is provided in Chapter 2 on Categorial Grammar in this Handbook and on FeatureStructures (Chapter 8, in first edition of the Handbook).
Table 3.1 Category Abbreviations fora Toy Grammar
category abbreviates
CN S/E(*,*,*)VP(*) E(Nom,*,*)\SNP(case,i,j) S/(E(case,i,j)\S)TV(tense) VP(tense)/NP(Acc,*,*)DET(i,j) NP(*,i,j)/CNAUX VP(Tensed)/VP(Inf)REL (CN\CN)/VP(Tensed)

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 219 — #39
Discourse Representation in Context 219
S
NP(*,i,j)
DET(i,j) CN
CN
CN\CN
REL VP(Tensed)
VP(Tensed)
AUX VP(Inf)
TV(Inf) NP(Acc,*,*)
Figure 3.6 Example of a possible sentence structure according to the toy grammar.
If we start out with basic types e for entities and T for state transitions (not truthvalues!), then the data given in Table 3.2 define the lexical component of a tiny frag-ment of English. Variables u, v range over type e, variables p, q over type T , variablesP, Q over type (e, T), variables P over type ((e, T), T).
We distinguish between variables of the typed logic and reference markers (i.e.variables of the dynamic representation). Markers ui are taken from a set U which weassume to be disjoint from the set Ve of variables of type e. Thus, from the perspectiveof the typed logic the reference markers behave like constants. A rather straightfor-ward definition of the interpretation of a typed expression can now be given in termsof an interpretation function I, a (typed logic) variable assignment g, and a markerassignment f . This theme is played (sometimes with minor variations) in Asher (1993),Bos et al. (1994), Kuschert (1995) and Muskens (1996).
From the point of view of the dynamic logic, reference markers are variables, tobe sure, but, as we have seen, substitution for dynamic variables is handled quitedifferently from variable substitution in static logics. Another way of expressing therelation between typed variables and reference markers is by saying that % reduc-tion (which affects typed variables) and merge reduction (which affects markers) areorthogonal: there is no interaction between the & reduction rules and the • reductionrules.
The category table in the lexicon makes clear that example sentence (52) has thestructure specified in Figure 3.6.
(52) The man who smiles does not hate Bill.
Some other sentences in the fragment are given in (53) and (54) (we use the partic-ular nouns and verbs in the table as paradigms, of course).
(53) If a man hates Bill, he does not smile.
(54) If a bishop meets another bishop, he blesses him.

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 220 — #40
220 Handbook of Logic and Language
Table 3.2 Lexical Component of the Toy Fragment for English
expression category translates to type
ai DET(i,*) &P&Q(ui • P(ui) • Q(ui)) ((e,T),((e,T),T))everyi DET(i,*) &P&Q¬((ui • P(ui)) • ¬Q(ui)) ((e,T),((e,T),T))noi DET(i,*) &P&Q¬((ui • P(ui)) • Q(ui)) ((e,T),((e,T),T))anotheri
j DET(i,j) &P&Q(ui; ui %= uj • P(ui) • Q(ui)) ((e,T),((e,T),T))thei
j DET(i,j) &P&Q(ui; ui.= uj • P(ui) • Q(ui)) ((e,T),((e,T),T))
hisij DET(i,j) &P&Q(ui; poss (uj, ui) • P(ui) • Q(ui)) ((e,T),((e,T),T))
Billi NP(*,*,i) &P(ui.= b • P(ui)) ((e,T),T)
who REL &P&Q&v(Q(v) • P(v)) ((e,T),((e,T),(e,T)))hei NP(nom,*,i) &P(P(ui)) ((e,T),T)himi NP(acc,*,i) &P(P(ui)) ((e,T),T)man CN &v(man (v)) (e,T)boy CN &v(boy (v)) (e,T)smiles VP(Tensed) &v(smile (v)) (e,T)smile VP(Inf) &v(smile (v)) (e,T)has TV(Tensed) &P&u(P&v(poss (u, v))) (((e,T),T),(e,T))have TV(Inf) &P&u(P&v(poss (u, v))) (((e,T),T),(e,T))hates TV(Tensed) &P&u(P&v(hate (u, v))) (((e,T),T),(e,T))hate TV(Inf) &P&u(P&v(hate (u, v))) (((e,T),T),(e,T))does not AUX &P&v¬P(v)) ((e,T),(e,T))if (S/S)/S &p&q(¬(p • ¬q)) (T,(T,T)). S\(TXT/S) &p&q(p • q) (T,(T,T)). TXT\(TXT/S) &p&q(p • q) (T,(T,T))
For convenience, we have assumed that the connective “.” serves as a discourseconstructor. Example (55) gives a text which is in the fragment.
(55) The man who smiles does not hate Bill. He respects Bill.
Note that • is used for merging of structures in all those cases where renaming maystill be necessary. The translations of if and every use ¬(p • ¬q) rather than p $ q toallow for the possibility of renaming during the merge of the components.
The composition of representation structures for these example sentences is a matterof routine. See Gamut (1991) for a didactic account of the general procedure, Asher(1993) and Muskens (1996) for applications in dynamic semantics, and Bouchez et al.(1993) for a description of an implementation of dynamic semantics using the technique.
As an example, let us go through the procedure of building a representation for(55). We assume the following indexing to indicate the intended anaphoric link.
(56) The [man who smiles]1 does not hate Bill. He1 respects Bill.
We also have to choose anaphoric indices for the man who smiles and Bill. Assumethese to be 2 and 3, respectively. In the table we find translation &P&Q&v(Q(v) • P(v))for who, while smiles translates as &v(smile (v)). These combine by functional appli-cation, which gives (57) (after renaming of variables for perspicuity).

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 221 — #41
Discourse Representation in Context 221
(57) &Q&v(Q(v) • &w(smile (w))(v)).
Expression (57) % reduces to (58).
(58) &Q&v(Q(v) • smile (v)).
Combining (58) with the translation of man, we get (59).
(59) &v(&w(man (w))(v) • smile (v)).
Expression (59) % reduces to (60).
(60) &v(man (v) • smile (v)).
Combining (60) with the translation of the 12 gives expression (61) as translation for
the 12 man who smiles:
(61) &Q(u1; u1.= u2 • &w(man (w) • smile (w))(u1) • Q(u1)).
Applying % reduction to expression (61) gives (62).
(62) &Q(u1; u1.= u2 • man (u1) • smile (u1) • Q(u1)).
In a similar way, we get (63) for does not hate Bill33.
(63) &u¬(u3.= b • hate (u, u3)).
Combining (62) and (63) gives the translation of the first sentence of (56):
(64) (u1; u1.= u2 • man (u1) • smile (u1); ¬(u3
.= b • hate (u1, u3))).
Merge reduction of (64) (with the identical renaming) gives:
(65) (u1; u1.= u2; man (u1); smile (u1); ¬(u3
.= b; hate (u1, u3))).
In box format:
(66)
u1u1
.= u2man u1smile u1
¬ u3.= b
hate (u1, u3)
The translation of the second sentence of (56) is (67).
(67) (u3.= b • respect (u1, u3)).
One merge reduction step, with identical renaming:
(68) (u3.= b; respect (u1, u3)).

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 222 — #42
222 Handbook of Logic and Language
The translation of discourse (56) is the result of applying the semantic operationfor text composition (the semantics for “.” in the lexicon table) to (65) and (67), inthat order:
(69) &p&q(p•q))(u1; u1.= u2; man (u1); smile (u1); ¬(u3
.= b; hate (u1, u3))) (u3.=
b; respect (u1, u3)).
Two % reductions and one further merge reduction with identical renaming givesthe following result (in box format):
(70)
u1u1
.= u2man u1smile u1
¬ u3.= b
hate (u1, u3)
u3.= b
respect (u1, u3)
The fact that no new discourse referent gets introduced for the proper name Bill isa reflection of our treatment of proper names. Here is the entry for proper names in thelexicon table again:
expression category translates to typeBilli NP(*,*,i) &P(ui
.= b • P(ui)) ((e,T),T)
Here i is the index that links the constant b for the proper name to its external anchor.Anaphoric links involving proper names are insensitive to where the name gets intro-duced, for they are interpreted as links where the anaphor and the proper name areboth anaphoric expressions with a common “externally given” antecedent.
At this point a couple of remarks are in order about the rules of index assignmentwhich are part of our present treatment. The first remark concerns the lower indices,which, we have been assuming, must be assigned not only to pronouns but in factto definite noun phrases of any kind. The requirement that every definite NP mustreceive a lower index reflects the so-called familiarity principle (see Heim, 1982),according to which a definite NP is used felicitously only when the utterance contextalready contains a reference marker for its referent, which can then serve as “anaphoricantecedent” for the NP. It is doubtful that the familiarity principle can be upheld in asrigid and comprehensive a form as this, in which it is taken to apply to every occur-rence of every type of definite noun phrase. The definite description the man whosmiles in (52) is a case in point. It would certainly be possible to use this phrasefor picking out from a given crowd the unique person smiling, pretty much as manyphilosophers, from Frege and Russell onwards, have been claiming about definitedescriptions. Such a use could easily occur in a context in which no reference marker

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 223 — #43
Discourse Representation in Context 223
for the smiling man had as yet been introduced. A treatment of definite descriptionswhich insists on the presence of antecedent reference markers for definites could stillbe saved by assuming that definite descriptions always come with a presupposition thatthe context contains such a reference marker, but that this presupposition can be easilyaccommodated when necessary. One may have one’s doubts about the plausibility ofthis rescue strategy. But even if we go along with it, we will have to reformulate oursemantics in such a way that it allows for such accommodations, and allows them tobe made at those points where human interpreters would have to make them. In otherwords, the theory will have to be restated so that it can deal with aspects of presup-position. Unfortunately, this is a matter that we cannot go into for reasons of space.For the treatment of presupposition within DRT, see the bibliographical remarks insection E at the end of this chapter.
A similar remark is in order about the lower indices of proper names such as John.Does the use of a proper name presuppose that its referent is already represented in thegiven context? Perhaps, but if so, then “context” needs to be construed in a quite lib-eral way. So, before such a treatment of proper names can be considered satisfactory,much more needs to be said about how the notion of context is to be construed—whatkinds of information may contexts include, from what kinds of contexts can theirinformation come, etc.
The second remark concerns the implicit assumption that the texts to which ourtheory is applied come fully equipped with all the necessary upper and lower indicesand that all of these have been assigned in advance. One way in which this assumptiongets us into difficulties shows up in the text (71), which has the structure indicated inFigure 3.7.
TXT
TXT/S
TXT
TXT/S
S .
S
.
S
Figure 3.7 The structure of a three sentence text in our grammar set-up.

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 224 — #44
224 Handbook of Logic and Language
(71) A man1 who mistrusted the assistant23 walked in. He1 asked for the manager24.
He2 turned out to be on holiday.
As the text structure indicates, first representations are built for the first two sen-tences and these are merged together, and only then is a representation for the thirdsentence merged with the representation of the preceding discourse. Note that in thiscase the merge of the representations of the first and the second sentence would involvea renaming of the discourse referent for the manager, to avoid a clash with the markerfor the assistant from the first sentence. This means that the anaphoric index 2 in thethird sentence is not going to pick up a reference to the manager anymore, as waspresumably intended.
The example points towards an aspect of DRT that deserves comment. DRT—thisis as true of the form in which it was originally stated as it is of the dynamic formu-lation presented here—is not a theory of anaphora resolution: the theory itself tellsus little about how to select the intended antecedent for a given anaphoric expressionfrom among a number of possible candidates. The only substantive contribution whichclassical DRT makes to the problem of anaphora resolution consists in what it has tosay about the “accessibility” of reference markers that have been introduced in onepart of a text to anaphoric expressions occurring elsewhere (see for example Kampand Reyle, 1993, Ch. 1.4); but this is only a small part of a comprehensive accountof anaphora resolution capable of predicting the intended anaphoric connections in allcases in which these are evident to a human interpreter.
Arguably this is as it should be. It would be unreasonable to demand of a theory oflinguistic semantics—and it is that which DRT originally aimed at—that it incorpo-rate a detailed account of anaphora resolution, which would have to rely on a host ofpragmatic principles as well as on an indefinite amount of world knowledge.
It seems not unreasonable, however, to demand of such a theory that it offer a suit-able interface to other (pragmatic and/or extra-linguistic) components of a compre-hensive theory of meaning which are designed to deal with anaphora resolution (seeSidner, 1979; Webber, 1979; and Chapter 10 of Alshawi, 1992) and to allow theseother components to come into action at those points when the information needed foranaphora resolution has become available and the resolution is necessary for interpre-tation to proceed. To insist that all upper and lower indexation take place in advanceof interpretation would fly in the face of this demand. For as a rule it is only throughand thus after interpretation of the earlier parts of a discourse that the correct links forsubsequent anaphoric expressions can be established.
3.11 The Proper Treatment of Quantification in DRT
As we have seen above, universal quantification can be treated in terms of D $ D#,which can in turn be taken as an abbreviation of ¬¬(D; ¬¬D#). Look again at the treat-ment of the quantifiers every and no in the fragment given above.

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 225 — #45
Discourse Representation in Context 225
expression category translates to type
everyi DET(i,*) &P&Q&c :, (ui ; Pi) $ Qi K , K , Tnoi DET(i,*) &P&Q&c :, ¬¬(ui ; Pi ; Qi) K , K , T
Working out an example like Every man walks on the basis of this gives a representa-tion that is equivalent to the following box notation:
(72)xman x $ walk x
The treatment of every creates the impression that the quantificational force residesin the dynamic implication $. Note, by the way, that all occurrences of marker x inrepresentation (72) are classically bound. The same holds for more complex exampleslike the representation for (73) in (74).
(73) Every man who meets a nice woman smiles at her.
(74)
x yman xwoman ynice ymeet(x,y)
$
zz .= ysmile-at (x,z)
Now consider sentence (75).
(75) Most men who meet a nice woman smile at her.
This sentence is true if most individuals which satisfy the descriptive content ofthe subject NP also satisfy the VP, i.e. if most men who meet a nice woman have theproperty of smiling at her. Note that assessing the truth of (75) involves two classesof men, the class of men who meet a nice woman and the class of men who meet anice woman and smile at her: the sentence is true, roughly, if the cardinality of thesecond class is more than half that of the first. Note that the truth conditions do notinvolve the comparison of two sets of pairs of individuals—they do not compare theset of pairs (a, b) such that a is a man, b a nice woman and a meets b with the set ofpairs (a, b) such that a is a man, b a nice woman, a meets b and a smiles at b. One cansee this by considering a situation in which one man meets lots of women and smilesat them all whereas the other men (say there are 20 of them) meet very few women

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 226 — #46
226 Handbook of Logic and Language
and never smile at any. With regard to such a situation intuition says that (75) is false,even though the pairs (a, b) such that a smiles at b may be a clear majority within theset of pairs (a, b) such that a is a man, b is a nice woman and a meets b.
Thus, while the treatment of universal quantification in (74) creates the impres-sion that the quantificational force resides somehow in the dynamic implication $,we cannot hope that this can be extended to non-standard quantifiers by working outspecial variants of dynamic implication. For suppose that we represent (75) as (76).
(76)
x yman xwoman ynice ymeet(x,y)
=m$
zz .= ysmile-at (x,z)
The semantics of =m$ is given by:
! s[[D1 =m$ D2]]Ms# iff s = s# and for most assignments s1 with s[[D1]]Ms1there is an assign-
ment s2 with s1 [[D2]]Ms2.
Unfortunately, this analysis gives the wrong truth conditions. In the example case, itquantifies over man–woman pairs instead of individual men. This problem (called theproportion problem in the literature) suggests that generalized quantifiers be addedexplicitly to the representation language; see Chapters 19 and 20 on Quantification inthis Handbook.
Assuming that what is true for most holds in essence also for every, the aboveconsiderations show that the roles which x and y play in (74) are not identical. The roleplayed by x, the “variable bound by the quantifier”, is special in that it is x, and only x,which determines between which sets the generalized quantifier relation expressed bythe determiner of the quantifying NP can be said to hold. A notation that singles outthe variable of quantification achieves this. These considerations lead to the followingGeneralized Quantifier notation for (74) and (76).
(77)EVERY x
yman xwoman ynice ymeet(x,y)
zz .= ysmile-at (x,z)

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 227 — #47
Discourse Representation in Context 227
(78)MOST x
yman xwoman ynice ymeet(x,y)
zz .= ysmile-at (x,z)
We can now revise the treatment of quantification in our fragment and extend thecoverage to other non-standard quantifiers such as most, at most half, at least seven,as follows. Every is the function of type K , K , t that takes two K expressions Pand Q, and an input context, c, checks whether all items satisfying
&x :, !c#|c| = i " Pi cˆx c#
also satisfy
&x :, !c##!c#|c| = i " Pi cˆx c## " Pi cˆx c## " Qic##c#,
and if so, returns c as output context (and otherwise fails). Similarly for the othergeneralized quantifiers.
Note that this interpretation also takes care of the “internal dynamics” of the quan-tification. To spell this out in terms of box satisfaction conditions we use s[x] for anassignment which differs at most from s in the value assigned to x, andM, s |= D fortruth inM, given s.
(79) s[[Qx(D1, D2)]]Ms# iff s = s# and the set of assignments s[x] for whichM, s[x] |=D1 is Q-related to the set of assignments s[x] for whichM, s[x] |= D1 ; D2.
Note the fact that the meaning of D1 figures both in the definition of the restriction setR of the quantifier and in the definition of its body set B. The reason for this is that D1may introduce referents that have to be resolved in order to get at the meaning of thebody set. In the example sentence we have to compare the set of men who meet a nicewoman with the set of men who meet a nice woman at whom they smile. Saying thatwe want to compare the set of “men who meet a nice woman” with that of “men whosmile at her” will not do, for the specification of the second set contains an unresolvedpronominal reference.
It seems intuitively clear that the pronoun her is to be interpreted as anaphoric tothe indefinite NP a woman. It is one of the central claims of DRT that this kind ofanaphoric connection is possible because the material of the quantifying sentence thatmakes up the restrictor is also, implicitly, part of the quantifier’s body. This principlealso explains why natural language quantifiers are always conservative, i.e. express

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 228 — #48
228 Handbook of Logic and Language
relations between sets with the property that for any sets A and B, A stands in therelation to B iff it stands in the relation to A 0 B. They satisfy this equation because anatural language quantification with restrictor condition P and body condition Q has alogical form to the effect that the quantifier relation holds between the extension of Pand the extension of P " Q. Conservativity is built directly into the logical form.
For the example sentence with most, (79) gives the following meaning: for mostmen who meet a nice woman it holds that they smile at at least one nice womanthat they meet. This is called the weak reading of the dynamic generalized quantifier.Note that under the semantics given above, EVERY x ((y; Rxy), Sxy) is not equivalentto (x; y; Rxy) $ Sxy. In the first expression y has existential force, in the second, yhas universal force. There is no perfect agreement among speakers whether (73) and(75) can be interpreted as having the weak reading. Some prefer the so-called strongreading:
(80) s[[Qx(D1, D2)]]Ms# iff s = s# and the set of assignments s[x] for whichM, s[x] |=D1 is Q-related to the set of assignments s[x] for which M, s[x] |= ¬¬(D1 •¬¬D2).
Under this interpretation for the quantifiers, EVERY x ((y; Rxy), Sxy) and(x; y; Rxy) $ Sxy are equivalent.
In the definition of strong readings for the quantifiers, we again use the restrictionset to resolve pronominal references in the specification of the body set, and againthe conservativity property of the generalized quantifier denotation ensures that thisdoes not change the truth conditions. In example case (78) the strong reading canbe paraphrased as: for most men who meet a nice woman it holds that they smile atall the nice women that they meet. See Chapters 19 and 20 on Quantification in thisHandbook for more information on how to choose between weak and strong readingsof dynamic quantifiers.
3.12 Representing Tense and Aspect in Texts
As mentioned in Section 3.3 above, discourse representation theory was motivatedby a desire to give a systematic account of the interpretation of unbound nominal andtemporal anaphora in context. In example (81), there is not only an intended anaphoriclink between the indefinite subject of the first sentence and the pronominal subject ofthe second, but also between the tenses of the verbs in the two sentences.
(81) A man entered the White Hart. He smiled.
The events described in example (81) are naturally understood as sequential, withthe event of entering preceding the event of smiling. Also, the past tense indicatesthat both events precede the time of speech. A plausible DRS representation for theexample that makes this temporal anaphoric link explicit is given in (82).

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 229 — #49
Discourse Representation in Context 229
(82)
u1 u2 u3 e1 e2man u1u2
.= WHenter (e1, u1, u2)t(e1) < nu3
.= u1smile (e2, u3)
t(e1) < t(e2)
t(e2) < n
In this representation we have given the verbs a Davidsonian event argument(Davidson, 1967), and we have assumed that t(e) denotes the temporal interval duringwhich the event e takes place. Also, we assume that n (“now”) refers to an intervalduring which the text is uttered (the speech interval).
As the example representation indicates, we assume an ontology of events, withtemporal intervals at which these take place. Furthermore, we assume that the setof temporal intervals is ordered by precedence < and by temporal inclusion ;. Weassume that t1 < t2 expresses that interval t1 completely precedes t2, i.e. the end oft1 is before the beginning of t2, while t1 ; t2 expresses that the beginning of t2 is notlater than the beginning of t1 and the end of t2 is not earlier than the end of t1.
It is plausible to further assume that < is irreflexive and transitive, while ; is apartial order (reflexive and transitive). Also, the following are plausible interactionprinciples:
monotonicity (x ; y " y < z " u ; z) , x < u.
convexity (x ; u " x < y " y < z " z ; u) , y ; u.
But we will not dwell on the underlying temporal ontology; for further information onthe temporal logic of intervals we refer to Chapter 21 on Temporality of this Handbookand to van Benthem (1983).
In (82) the smiling event e2 is represented as following the entering event e1. This isintuitively as it should be and has to do with the fact that in (81) the sentence reportingthe smiling event comes after the one which reports the entering event. (Note that theinterpretation given in (82) is not, or only barely, available when the sentences of (81)are reversed.) However, the order in which the sentences of a text appear is only one ofseveral factors that determine the temporal relations between the events they mention.A second factor is aspect. For instance, when we replace the non-progressive smiledin (81) by the progressive was smiling, there is a strong tendency to understand thesmiling as something that was going on while the man was entering the White Hart:the progressive of an activity verb like smile suggests, at least in narrative passagessuch as (81), simultaneity with the last mentioned event, rather than succession to it.Similarly, simultaneity rather than succession is suggested by a stative verb such aslike. Consider example (83).

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 230 — #50
230 Handbook of Logic and Language
(83) A man1 entered the White Hart2. He1 smiled. He1 liked the place2.
In this example, the man’s liking of the White Hart is not naturally interpreted ashaving been the case only after his smiling. Rather, it seems that the state of the manliking the White Hart obtained already at the time when he was smiling, and possiblyeven before he came in. Thus, the representation of (83) should be as in (84):
(84)
u1 u2 u3 u4 u5 e1 e2 e3man u1 u2
.= WHenter (e1, u1, u2) t(e1) < nsmile (e2, u3) u3
.= u1t(e1) < t(e2)
t(e2) < nu4
.= u1place (u5) u5
.= u2like (e3, u4, u5) t(e2) ; t(e3)
t(e3) < n
When we consider the question whether one should assume that the man’s liking theplace in (83) anteceded his entering the White Hart, we perceive a further factor that isimportant for the interpretation of temporal relations. In order that a text is perceived ascoherent, its successive sentences must be seen as standing in certain rhetorical rela-tions to each other (Halliday and Hassan, 1976; Mann and Thompson, 1987). One suchrelation is explanation, a relation which holds between two neighboring sentences (orsometimes larger units, consisting of several sentences) when the later sentence orsentence group provides an explanation for what is claimed by the earlier sentenceor group. Like many other rhetorical relations explanation carries certain implicationsfor temporal order. For instance, when, say, two sentences S and S# are interpreted asstanding in the explanation relation, with S# providing an explanation for what is saidin S, the event or state described by S# cannot be later than that described in S. We seethis when we look closely at (83): the man’s liking the place can either be taken as anexplanation of his smiling or as an explanation of why the man went to the White Hartin the first place. The first interpretation entails that his liking the place did not startafter his smiling, but it leaves open whether he liked the place only upon entering itor already before. According to the second interpretation the man must have liked theplace even before he went in.
We have dwelt on this dimension of the interpretation of the temporal relations in(83) to indicate how complicated the matter of interpreting temporal relations is andhow much it depends on pragmatic factors such as discourse coherence and rhetoricalrelations. Just as with pronominal anaphora, linguistic form does in general no morethan impose a frame of constraints within which the precise interpretation of temporalrelations must be decided on other grounds.
For a presentation of the semantics of temporal reference within the very limitedspace available here this poses a dilemma. On the one hand, a presentation that does

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 231 — #51
Discourse Representation in Context 231
justice to what is now known about the interactions between the different factors men-tioned above is out of the question. On the other, a general treatment of the purelygrammatical constraints on temporal reference would, in view of its inevitable lackof specificity, be rather uninformative. We have therefore chosen to concentrate on acertain small subclass of texts, in which rhetorical relations are fully determined bylinguistic form (by the order of the sentences in the text, by the tenses of the verbs andby their aspectual properties). (81) and (83) are both instances of this class.
The central idea behind the treatment we will present goes back to Reichenbach(1947). The interpretation of the tenses involves relating the event or state describedto a reference point. For instance, for unembedded cases of the simple past tense,the reference point is provided by the context in which the given past tense sentenceoccurs. In texts of the kind to which our theory is intended to apply, it is the immedi-ately preceding sentence which supplies the reference point. How the reference pointis used to temporally locate the event or state described by the sentence in questiondepends on whether the sentence has stative or non-stative aspect (or, what comesto the same in our terminology, whether what the sentence describes is a state or anevent). For past tense sentences, the difference that aspect makes is illustrated by thedistinct interpretations that are assigned to the second and the third sentence of (83)—the event described by the second sentence is interpreted as following the referencepoint by the preceding sentence, the state described by the third sentence as obtainingat the reference point provided by its predecessor. Moreover, an event sentence likethe second sentence of (83) resets the reference point it inherits from the context to theevent it itself introduces, whereas a stative sentence like the third one passes the ref-erence point on to the next sentence unchanged. (To test this, see what happens whenone adds a fourth sentence, stative or non-stative, on to (83)).
Besides playing a role in locating the described event or state in relation to thereference point, tense forms usually also have an “absolute” semantic impact in thatthey relate the described state or event to the utterance time. For instance, unembeddedoccurrences of the past tense imply that the state or event lies before the utterance timeand unembedded occurrences of the English present tense imply, with few exceptions,location at the utterance time.
For the limited domain to which our “mini theory” is meant to apply, the use andmodification of reference points can be elegantly handled along the lines proposedby Muskens (1995). As noted there, in a dynamic set-up it is natural to implementthe reference interval as a register r to which a new value gets assigned for a non-stative verb, while the value is unaffected for stative verbs. For instance, the lexicalentry for smiled specifies that the interval of the smiling event is constrained to followthe current reference interval, that the reference interval is reset to the interval of theevent, and that the event interval has to precede the interval of speech:
&v(e; smile (e, v); r < t(e); r := t(e); r < n).
Here r := t(e) is shorthand for r; r .= t(e).

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 232 — #52
232 Handbook of Logic and Language
Table 3.3 Lexical Entries for Main and Auxiliary Verbs
expression category translates to type
does not AUX &P&v¬¬(P(v); r ; n) ((e,T),(e,T))did not AUX &P&v¬¬(P(v); r < n) ((e,T),(e,T))will AUX &P&v(P(v); n < r) ((e,T),(e,T))will not AUX &P&v¬¬(P(v); n < r) ((e,T),(e,T))smiles VP(Tensed) &v(e; smile (e, v); r < t(e); r := t(e); r ; n) (e,T)smiled VP(Tensed) &v(e; smile (e, v); r < t(e); r := t(e); r < n) (e,T)smile VP(Inf) &v(e; smile (e, v); r < t(e); r := t(e)) (e,T)hates TV(Tensed) &P&u(P&v(e; hate (e, u, v); r ; t(e); r ; n)) (((e,T),T),(e,T))hated TV(Tensed) &P&u(P&v(e; hate (e, u, v); r ; t(e); r < n)) (((e,T),T),(e,T))hate TV(Inf) &P&u(P&v(e; hate (e, u, v); r ; t(e))) (((e,T),T),(e,T))likes TV(Tensed) &P&u(P&v(e; like (e, u, v); r ; t(e); r ; n)) (((e,T),T),(e,T))liked TV(Tensed) &P&u(P&v(e; like (e, u, v); r ; t(e); r < n)) (((e,T),T),(e,T))like TV(Inf) &P&u(P&v(e; like (e, u, v); r ; t(e); )) (((e,T),T),(e,T))
For verbs denoting stative events, the representation is the same, except for the factthat now the current reference interval has to be included in the event interval, and thereference interval is not reset. Here is a lexical entry for liked:
&P&u(P&v(e; like (e, u, v); r ; t(e); r < n)).
Table 3.3 gives a list of lexical entries for stative and non-stative main verbs and fortemporal auxiliary verbs.
Note that in defining disjoint merge for fragments involving the markers r and nfor the reference and the speech interval, we have to make sure that these never getrenamed. For n, we get this for free, for an inspection of the lexical entries makes clearthat n is a fixed marker of every DRS, as it never gets introduced. For r matters aredifferent: r := t(e) is shorthand for r; r .= t(e), so r does get introduced. But we do notwant r := t(e1); D1 • r := t(e2); D2 to reduce to r := t(e1); D; r# := t(e2); [r#/r]D2.To ensure that this does not happen, it is enough to exclude r from the set of referencemarkers; this guarantees that r := t(e1); D1; r := t(e2); D2 is a proper DRS if D1; D2is one, because r /) intro(r := t(e2); D2).
Let us go through the procedure of building the representation for (83), assumingthe antecedent and anaphoric indices to be as given in the example. The representationof entered the White Hart becomes (85).
(85)&P&u(P&v(e; enter (e, u, v); r < t(e); r := t(e); r < n))
(&P(u2.= WH • P(u2))).
After % reduction:
(86) &u(u2.= WH • (e; enter (e, u, u2); r < t(e); r := t(e); r < n)).
Combining with the translation of a man and reducing the result gives (87).
(87) u1 • man u1 • (u2.= WH • (e; enter (e, u1, u2); r < t(e); r := t(e); r < n)).

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 233 — #53
Discourse Representation in Context 233
Merge reduction with the identical renaming gives:
(88) u1; man u1; u2.= WH; e; enter (e, u1, u2); r < t(e); r := t(e); r < n.
Similarly, we get for he smiled, after % and merge reduction:
(89) e; smile(e, u1); r < t(e); r := t(e); r < n.
The text consisting of the first two sentences gets the following translation after %
reduction:
(90)u1; man u1; u2
.= WH; e; enter (e, u1, u2); r < t(e); r := t(e); r < n• e; smile(e, u1); r < t(e); r := t(e); r < n.
After merge reduction, this becomes:
(91)u1; man u1; u2
.= WH; e; enter (e, u1, u2); r < t(e); r := t(e); r < n;e2; smile(e2, u1); r < t(e2); r := t(e2); r < n.
The translation of the third sentence from the discourse, after % and merge reduc-tion:
(92) u3; u3.= u2; place u3; e; like(e, u1, u3); r ; t(e); r < n.
The translation of the whole example, after % and merge reduction:
(93)u1; man u1; u2
.= WH; e; enter (e, u1, u2); r < t(e); r := t(e); r < n;e2; smile(e2, u1); r < t(e2); r := t(e2); r < n;u3; u3
.= u2; place u3; e3; like(e3, u1, u3); r ; t(e3); r < n.
Evidently this treatment of temporal reference is to be seen as no more than a hintof the direction that a fully fledged account of tense and aspect for a language likeEnglish might take. One feature of our treatment that ought to be changed is the useof separate lexical entries for full forms of verbs, such as smiled and smiles. Whatone would like to have instead is specifications of the meaning and/or function ofthe different tenses, such that when these are applied to the entries for the infini-tival forms of our mini-lexicon we get the entries of the corresponding full formsas results. For instance, one might consider assigning the simple past the followingentry:
expression category translates to typeSimple Past VP(Tensed)/VP(Perf) &P&v(P(v); r < n) ((e,T),(e,T))
Indeed, applying this entry to the entries for smile and like produces the translationsthat our lexicon specifies for smiled and liked.
But here it behoves to repeat an earlier caveat. Tense forms do not always functionin the same way. In particular, embedded occurrences of tenses often behave quitedifferently than when they occur in unembedded positions. (To cite just one example,involving the simple past, recall Baker’s: “I thought you were going to say that youhad only one trick to play.” Here the past tense of had is compatible with the event in

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 234 — #54
234 Handbook of Logic and Language
question being located in the future of the utterance time.) So, if we adopt the entryjust proposed as entry for the “past tense” in general, we will have to distinguishcarefully between occurrences of the past tense in the semantic sense characterizedby this entry on the one hand and, on the other hand, arbitrary occurrences of simplepast tense morphology. But this is a distinction which requires a careful revision ofthe syntax-semantics interface used in our mini-fragment; and it is only one exampleamong many which render such a revision necessary.
Another matter which seriously complicates the treatment of temporal referenceis aspect. We already saw that the temporal relations between the states and eventsthat are mentioned by sentences in a text depend in part on the aspectual properties ofthose sentences (i.e. in our terminology, on whether what they describe is a state oran event) and that the aspectual properties of those sentences depend in their turn onthe aspectual properties of the verbs they contain. However, as noted explicitly firstin Verkuyl (1972), the aspectual properties of a sentence depend not just on its verbbut on several other factors as well. Prominent among those factors is the question ofwhether the verb has been modified by some aspectual operator, such as the Englishperfect or progressive, or aspectual control verbs such as begin, stop or go on. It isnatural to try to treat aspectual modifiers along the same lines as we have suggested forthe tenses, viz. by assigning them their own lexical entries, which then should combinesystematically with the entry of any verb to which the operators can be applied (e.g.,through functional application of the operator entry to the verb entry). But here weencounter a new difficulty, which is especially noticeable in relation to the progressive,and known in that context as the imperfective paradox. A simple-minded analysis ofthe progressive might treat it as transforming a given verb phrase (VP) into one whichdescribes a process or state holding at precisely those times that fall within the durationof any state or event described by VP. With telic verbal predicates such as cross thestreet, however, this analysis breaks down, for a sentence involving the progressive ofsuch a verb phrase can be true at times when an event described by the embedded VPdid not actually happen. For instance, The old lady was crossing the street may be truewith respect to times not included in the duration of any crossing-the-street event. Forthe lady may have changed her mind when she got halfway and turned around to thesidewalk from which she started, or she may have become a victim to the incalculablebrutalities of motorized traffic. Thus the semantic relation between progressives andtheir underlying VPs is in general an intensional rather than a purely extensional one,and a fully satisfactory analysis of this intensional relationship is still lacking.
Formulating an entry for the English perfect, which transforms a verb phrase (VP)into one which describes result states of events or states described by VP, may at firstseem less problematic: the states described by the application of the perfect hold atprecisely those times which follow a state or event of the type defined by the operand.But when one looks at the semantics of the perfect more closely, such simplicity provesillusory. It is part of the meanings of many perfects that the event of which the des-cribed state is understood to be the result did not just happen at some earlier time orother, but that it happened only recently, or that its influence is still tangible at thetime of the result state; and these additional meaning components cannot be analyzed

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 235 — #55
Discourse Representation in Context 235
in purely extensional terms any more than the relationship between progressive andnon-progressive uses of telic verb phrases.
For the perfect it is nevertheless possible to finesse the intensionality problem byassuming a relation " between events and states which holds between e and e# whene# is the result state of e. We adopt the obvious assumption that e " e# entails t(e) <
t(e#). Using ", (94) might be represented as (95).
(94) Bill has smiled.
(95)
e1 e2u .= bsmile (e1, u)e1 " e2t(e2) ; n
This does not yet constrain the effect on the wider context. The effect is roughlythis. First the current value of the reference interval is saved. Then r is reset to avalue earlier than its old value. Next the verb is evaluated with respect to the shiftedreference interval. Then the old value is restored, and finally the reference interval islocated with respect to the speech interval (Muskens, 1995).
Using o as a store for the old value of r, we get the following DRS that also takesthe external effects into account:
(96)
e1 e2 ou .= bo .= r
¬¬¬¬
rr < osmile (e1, u)e1 " e2r < t(e1)
r := t(e2)
r ; n
For a compositional account, we have to assume that we can get access to the eventparameter of a verb, so a typical entry for untensed verbs will now look like this:
expression category translates to typesmile VP(Inf) &e&v(smile (e, v); r < t(e); r := t(e)) (e,(e,T))
The entry of the perfective operator introduces two events: the verb phrase event andthe consequent state (assumeR ranges over type (e,(e, T))).
expression category translates to typePERF VP(Perf)/ &R&v(e1; e2; o := r; ((e,(e,T)),
VP(Inf) ¬¬¬¬(r; r < o;R(e1)(v); e1 " e2); (e,T))r < t(e2); r := t(e2))

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 236 — #56
236 Handbook of Logic and Language
Temporal auxiliaries will now have the effect of putting further temporal constraints,as discussed above. For instance the present tense form has of the perfect auxiliaryhave could be given the following entry:
expression category translates to typehas VP(Tensed)/VP(Perf) &P&v(P(v); r ; n) ((e,T),(e,T))
This section has presented a catalog of problems rather than a list of fully satisfactorysolutions. The emphasis on problems with the analysis of tense and aspect may haveserved to illustrate a dilemma that one faces in formal approaches to the semanticsof natural language discourse such as DRT. The dilemma is this: the more closelyone tries to stick to the ideal of strict compositionality when dealing with the man-ifold complexities of the syntax-semantics interface of natural languages, the trick-ier the analysis tends to become, especially if discourse effects are to be taken intoaccount too.
There exists a good deal of work within DRT, current as well as past, which hasbeen prepared to sacrifice certain aspects of this ideal in pursuit of a more flexiblearchitecture that can be fitted more easily to the requirements that certain linguisticphenomena seem to impose. This does not mean that this work ignores the funda-mental compositional imperative of explaining how grammars can be finitely encodedand languages can be used by beings whose knowledge of language takes this finitaryform. In particular, a good part of the work within DRT on the problems of tense andaspect has opted for such a relaxation of strict compositionality. However, experienceof the past 10 years has shown that often, once the phenomena have been properlyunderstood and have been given a systematic description using means that are notstrictly compositional, it is then possible to also find a way of accounting for thosephenomena that is strictly compositional, as well as attractive in other ways. Whetherattractive strictly compositional solutions will become available in all cases is yet tobe seen.
3.13 Extensions and Variations
An important extension of the representation language concerns the singular/pluraldistinction. Singular and plural reference markers should be distinguished, and a con-straint imposed that singular pronouns are linked to singular discourse referents, pluralpronouns to plural reference markers. Accounting for plural anaphoric possibilitiesalong these lines involves quite a lot of further work, however, as delicate issuesconcerning the formation of plurals by means of summation and abstraction, and theinterpretation of dependent plurals have to be dealt with (Kamp and Reyle, 1993,Chapter 4).
Another fruitful application area for theories about the representation of dis-course in context is the area of presupposition. Presuppositions can get canceledor weakened by an evolving context; in other words, presupposition projection is a

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 237 — #57
Discourse Representation in Context 237
dynamic phenomenon. Approaches to presupposition in connection with discourserepresentation are of two kinds. The first kind exploits the representationalism inher-ent in the framework. See, for example, van der Sandt (1992), where the presuppo-sition facts get accounted for in terms of manipulations of the representations. Thesecond kind does not assume representationalism but exploits the dynamic aspect ofthe theory by providing a partial dynamic semantics fitting the presupposition facts.See, for example, the account of the presuppositions of definite descriptions in vanEijck, 1993, which does not depend on properties of the representations, but dependsonly on the underlying “error state” semantics. Further references can be found in thechapter on Presupposition in the first edition of the Handbook.
The next extension concerns the representation of belief sentences. The Hob Nobsentence from Section 3.3 provides an example of a belief puzzle that seems amenableto solution within the present framework. A theory of representation of discourse incontext holds a particular promise for the treatment of belief because the represen-tation structures themselves could be viewed as a kind of mental representation lan-guage; thus a belief relation could typically be modeled as a relation between a subjectand a representation structure (Asher, 1986).
The plausibility of using Discourse Representation Structures to model belief andother propositional attitudes is closely connected with the existence of cognitivelyplausible inference systems for DRSs. For work on proof theories for DRSs seeSedogbo and Eytan (1988), Saurer (1993) and Kamp and Reyle (1996).
A different approach is reasoning about discourse structures with assertion logicand dynamic logic. Assume a language of quantified dynamic logic with discourserepresentation structures as program modalities 'D( and [D]. Then 'D(! and [D]! getinterpreted as follows:
! M, s |= 'D(! iff there is an s# with s[[D]]Ms# andM, s# |= !.! M, s |= [D]! iff for all s# with s[[D]]Ms# it holds thatM, s# |= !.
An axiomatization of discourse representation theory along the same lines as the cal-culus for dynamic predicate logic Groenendijk and Stokhof (1991) given in van Eijck(1994) is now readily available. Some example principles of this calculus are:
'¬¬D(! < ([D]= " !).
'D1 $ D2(! < ([D1]'D2(& " !).
'D1; D2(! < 'D1('D2(!.
For marker introduction we have:
'u(! < !u!,
or dually:
[u]! < +u!.

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 238 — #58
238 Handbook of Logic and Language
For atoms we have:
'Pt1 · · · tn(! < (Pt1 · · · tn " !),
or dually:
[Pt1 · · · tn]! < (Pt1 · · · tn , !).
The calculus nicely demonstrates the way in which discourse representation theorygives universal force to the markers introduced in the antecedent of an if–then clause.
(97) If a man greets a woman he smiles at her.
(98) (x; Mx; y; Wy; Gxy) $ Sxy.
The truth conditions of (97), represented as (98), are given by the following calcu-lation that uses the principles above.
'(x; Mx; y; Wy; Gxy) $ Sxy(&< [x; Mx; y; Wy; Gxy]'Sxy(&< [x][Mx][y][Wy][Gxy]'Sxy(&< +x([Mx][y][Wy][Gxy]'Sxy(&)
< · · ·< +x(Mx , +y(Wy , (Gxy , Sxy))).
An important new direction is the theory of Underspecified Discourse Representa-tion Structures, which allows for representations that leave certain matters undecided.Among these are scope relations between quantifiers and other scope taking opera-tors; the distinction between distributive and collective interpretations of plural NPs;different readings of certain lexical item – but the list is open-ended. This work is ofparticular interest insofar as it has succeeded in developing proof theories that operatedirectly on the underspecified representations themselves (Reyle, 1993, 1995).
3.14 Addendum to the Second Edition
A Simplified Representation of Contexts
As an extension of our treatment above we will now consider a simplified representa-tion of contexts as stacks of references to entities.
If the context has name c and length i, then the reference markers are calledc0, . . . , ci11 (or c[0], . . . , c[i 1 1], for those who prefer the programmers’ way ofreferring to array indexing). Extending a context c of length i with a “fresh” referencemarker can now consist of incrementing the length of the context to i + 1 and addingmarker ci to it. As we will show in the next section, this approach allows the formu-lation of an elegant type theoretical version of discourse representation theory, thus

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 239 — #59
Discourse Representation in Context 239
facilitating the definition of natural language fragments with a dynamic flavor in themanner of Montague grammar.
Representing discourse in context by means of context updating while puttingappropriate constraints on the evolving context can be viewed as constructing a func-tion with the following shape:
&
context
constraints:,
%
&&'
context
constraints+
context extension
constraints extension
(
))*
The compositional version of DRT presented in the fragment given in Section 3.10below works according to this pattern. It assumes that contexts are lists of refer-ence markers, together with their values, and that constraints are expressed as DRSconditions.
A simplified representation is possible by taking contexts to be lists of referencemarkers with canonical names c0, c1, . . . . If we view a context as the one-variableversion of Vermeulen’s sequence semantics (1993), then a context is just a stack ofitems:
c0 c1 c2 c3 c4 · · ·
Existential quantification now is context extension: it pushes a new item d on thecontext stack:
c0 c1 c2 c3 + d = c0 c1 c2 c3 d
We can use indices to refer to the items:
0 1 2 3 4 · · · n 1 1 nc0 c1 c2 c3 c4 · · · cn11 d
If c is a context, c[0] is its first element, and |c| is its length. So the context elementsare c[0] up to c[k] where k = |c| 1 1.
A context has the type of a list of entities. Call this type [e]. Assume c, c# are oftype [e] and that x is of type e. Then we use cˆx to denote the result of extendingcontext c with item x. Note that the type of (ˆ) is [e] , e , [e], and that cˆx is anew context with |cˆx| = |c| + 1 (the context length has increased by 1). Now we candefine dynamic existential quantification as follows:
!! := &c&c# :, !x(cˆx = c#)
Thus, the quantifier !! is interpreted as a context extender. It extends an input context cwith an element x from the domain, and creates an output context cˆx. More precisely,!x(cˆx = c#) states the conditions under which c# is an appropriate output context,given that c is the input context.

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 240 — #60
240 Handbook of Logic and Language
We see that !! has the type [e] , [e] , t. The operation !! takes a list of enti-ties c (an input context) and a second context c# (an output context), and it states theconditions under which c and c# are properly related. In DRT terms, !! expresses “takea new reference marker and extend the context with that marker”.
The type [e] , [e] , t is essentially the type of a binary relation on contexts;call such relations on contexts context transitions. In a compositional account of con-text shifting, this is the fundamental type. A DRT version of extensional Montaguegrammar can now be viewed as a lift of the type t to [e] , [e] , t.
Instead of conjunction (type t , t , t) we get sequential composition of contexts,with type ([e] , [e] , t) , ([e] , [e] , t) , [e] , [e] , t). Assume that !, "
are context transitions (i.e. !, " have type [e] , [e] , t) and that c, c# are contexts(c, c# have type [e]). Then the following operation defines context composition:
! ; " := &c&c# :, !c##(!cc## " "c##c#)
Since !, " are parameters, we can define the operation ; as:
&!&"&c&c# :, !c##(!cc## " "c##c#)
The definitions of !! and ; are the key ingredients in the definition of the semantics ofthe indefinite determiner. Note ; defines a sequential merge operation for context tran-sitions. Before we proceed, we introduce the type theoretic version of the introductionof a reference marker, by means of the following combinator u.
u = &i&c&c# :, |c| = i " !x(cˆx = c#).
Variable i ranges over natural numbers, so this defines a function of type N , [e] ,[e] , t. Writing the application ui as ui, we get from the definition of u:
ui = &c&c# :, |c| = i " !x(cˆx = c#).
This means that ui denotes the context transition that consists of selecting an inputcontext of length i and extending that context with a new element.
The entry for the indefinite noun phrase a man should express that an input contextc can be extended with a new element, that this new element has to be a man, that italso has to satisfy the body of the determiner, and that it will remain accessible forfuture reference. If we assume the context has length i, then the new element will beat position i in the new context. This gives:
a man: &Q&c :, ciMan ci
; Q i where i = |c|
But now we have to realize that the box notation is shorthand for a context transi-tion. The fine structure is given by the sequential composition of ui (the operation forselecting a context of length i and extending that context with a new element), and a

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 241 — #61
Discourse Representation in Context 241
context transition M that consists of predicating the property Man of the new elementin context.
The predication Q has to be of a type that combines with an index i to yield acontext transition. This is type N , [e] , [e] , t, the type of natural numberpointers into context transitions. We still have to abstract over the restriction of theindefinite. Let the type of the restriction be the same as that of Q (the body).
Assume P and Q are pointers into context transitions, and c is a context. Then thelexical entry for the indefinite determiner a looks like this:
&P&Q :, (ui ; Pi ; Qi). (3.1)
Abbreviating N , [e] , [e] , t as K, we can express the type of this entry asK , K , [e] , [e] , t. An indefinite determiner translates into a function thattakes a pointer into a context transition for the restriction, a pointer into a contexttransition for the body, and then yields a context transition.
What the entry for the indefinite determiner says is that the input context c haslength i, that it can be extended with a new element, and that this new element willsatisfy both P and Q, and it will remain accessible for future reference.
The final thing that is missing is the lift from unary predicates (the type of theregular denotation for entries like man) to pointers into context transitions. Here is afunction for achieving that lift:
&A&i&c&c# :, c = c# " A(ci).
This takes a unary predicate (A has type e , t) and yields a function of type K. Thenew function puts a constraint on the current context c, namely the constraint that theitem at position i in that context has to satisfy predicate A.
For the treatment of universal noun phrases like every man we need either a combi-nation of dynamic negation and sequential composition, or an operation for dynamicimplication. The way to express context negation or dynamic negation in DRT is this:
$ =
The typed logical version is the following, where ! represents the embedded rep-resentation structure.
¬¬! := &cc# :, (c = c# " ¬!c##!cc##)

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 242 — #62
242 Handbook of Logic and Language
This defines a relation between input context c and output context c# where the inputcontext equals the output context, and where there is no extension c## of context c forwhich ! holds. Abstracting from the embedded context transition, we get the followingtype logical definition for dynamic negation:
&!cc# :, (c = c# " ¬!c##!cc##)
Dynamic implication can be defined in a similar way:
! $ " := &c&c# :, (c = c# " +c2(!cc2 , !c3"c2c3).
Abstracting from the two context transitions !, " , this gives:
&!&"&c&c# :, (c = c# " +c2(!cc2 , !c3"c2c3).
Compare this with the truth definition for DRS conditions of the form
$ .
Now the lexical entry for the determiner every can be phrased in terms of dynamicimplication, as follows:
&P&Q :, ((ui ; Pi) $ Qi) (3.2)
Note that (ui ; Pi) $ Qi is a context transition, with type [e] , [e] , t. Therefore,the type of the translation of every is K , K , [e] , [e] , t.
Another way to phrase the lexical entry for the determiner every is as follows:
&P&Q&c :, (¬¬(ui ; Pi ; ¬¬Qi)).
It is left to the reader to check that this is equivalent to the definition in (3.2).With these ingredients we give a compositional treatment of the following dis-
course:
A woman entered and a woman left. (3.3)
Here are the representations for a woman, entered, and left:
a woman: &Q&c&c# :, !x(W x " Qi(cˆx)c#) where i = |c|entered: &j&c&c# :, (c = c# " E cj) where j ) |c|
left: &j&c&c# :, (c = c# " L cj) where j ) |c|
The notation j ) |c| is shorthand for j ) {0, . . . , |c| 1 1}. Note that the constraint on jis in fact a restriction on the type of j to a subset of N.

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 243 — #63
Discourse Representation in Context 243
The above entries yield the following representation for A woman entered:
&c&c# :, !x(W x " E (cˆx)[i] " cˆx = c#) (3.4)This reduces to (3.5).
&c&c# :, !x(W x " E x " cˆx = c#) (3.5)
Similarly, we get the following as representation for A woman left:
&c&c# :, !x(W x " L x " cˆx = c#) (3.6)
Combining (3.5) and (3.6) by means of and (translated as &!&" :, ! ; ") gives thefollowing representation for A woman entered and a woman left:
&c&c# :, !x(W x " E x " cˆx = c#) ; &c&c# :, !x(W x " L x " cˆx = c#)
This reduces to the following (note the renaming of variables):
&c&c1 :, !x(W x " E x " cˆx = c1) ; &c2&c# :, !y(W y " L y " c2ˆy = c#)
Applying the ; combinator and using % reduction gives:
&cc# :, !c##!x(M x " E x " cˆx = c## " !y(M y " L y " c##ˆy = c#)).
By simple equality reasoning, this reduces to:
&c&c# :, !x(W x " E x " !y(W y " L y " cˆxˆy = c#)).
So the interpretation of (3.3) sets up an appropriate context with references to twowomen, with the right constraints.
B Pronouns and Anaphoric Reference
The correct interpretation of pronouns and anaphoric definite descriptions shouldallow picking up appropriate references from the existing context.
A new customer entered the shop. He asked for the manager. (3.7)
A new customer entered the shop. The man smiled. (3.8)
On the most salient reading of (3.7), he is interpreted as an anaphoric reference toa new customer, and the manager is interpreted as the manager of the shop. On themost salient reading of (3.8), the man is interpreted as an anaphoric reference to anew customer. To pick up such references, the available context information shouldinclude gender and number, actor focus (agent of the sentence), and discourse focus(“what is talked about” in the sentence). The most important, however, is the list ofavailable referents.

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 244 — #64
244 Handbook of Logic and Language
Spelling out a full fledged anaphoric reference resolution mechanism is beyond thescope of this addendum. Instead, we will describe how anaphoric linking to a givenobject ci (or c[i] in array notation) in context c is to be implemented. So we assume thatresolution in context c has taken place, and we show that the linking to the appropriateitem gets encoded by means of an appropriate lexical item for pronouns. More inparticular:
A new customer entered the shop. He0 smiled. (3.9)
Here, the index indicates that he gets resolved to the first introduced referent in con-text, i.e. to the referent for a new customer.
The following lexical entry for indexed pronouns accomplishes that the pronounhei gets resolved to item i in context. Assume that Q has type e , [e] , [e] , t andthat c, c# have type [e]. Then the following translation for hei has type [e] , [e] , t.
hei: &Q&c&c# :, Q(ci)cc#
C Once More: DRSs for Natural Language Fragments
We can now redo the fragment from Section 3.10; the result is in Table 3.4. If we startout with basic types e for entities and t for truth values, we can define the type ofcontexts as [e] (lists of entities), that of context transitions T as [e] , [e] , t, andthat of indices into context transitions K as N , T .
In the present set-up (unlike in that of Asher, 1993; Bos et al., 1994; Kuschert,1995; Muskens, 1996), and Section 3.10, there is no need to distinguish between vari-ables of the typed logic and reference markers.
The composition of representation structures for example sentences from this frag-ment is a matter of routine. See Gamut (1991) for a didactic account of the generalprocedure, and van Eijck and Unger (2009) for a textbook treatment including animplementation of dynamic semantics using the technique.
As in the previous fragment, there is an implicit assumption that the texts to whichour theory is applied come fully equipped with all the necessary upper and lowerindices and that all of these have been assigned in advance. Again, this assumptiongets us into difficulties. Consider text (99).
(99) A mani who mistrusted the assistantjk walked in. Hei asked for the managerjm.
Hej turned out to be on holiday.
If this text is processed incrementally, first representations are built for the first twosentences and these are combined. Only then is a representation for the third sentencecombined with the representation of the preceding discourse. Note that in this case therepresentation of the second sentence puts a constraint on the context produced by thefirst sentence that cannot be fulfilled. The input context contains a representation forthe assistant, at position j, so it has length > j. The indexing for the manager wouldforce the context to have length j, which is impossible. The solution is to choose adifferent upper index for the manager, to avoid the clash.

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 245 — #65
Discourse Representation in Context 245
Table 3.4 Lexical Component of the Toy Fragment for English
expression category translates to type
ai DET(i,*) &P&Q&c :, (ui ; Pi ; Qi) K , K , Teveryi DET(i,*) &P&Q&c :, (ui ; Pi) $ Qi K , K , Tnoi DET(i,*) &P&Q&c :, ¬¬(ui ; Pi ; Qi) K , K , Tanotheri
j DET(i,j) &P&Q&c :, ui ; NEQ ij ; Pi ; Qi K , K , Twhere NEQ ij equals &c&c# :, c = c# " ci %= cj T
theij DET(i,j) &P&Q&c :, ui ; EQ ij ; Pi ; Qi K , K , T
where EQ ij equals &c&c# :, c = c# " ci = cj Thisi
j DET(i,j) &P&Q&c :, ui ; POSS ji ; Pi ; Qi K , K , Twhere POSS ji equals &c&c# :, c = c# " poss (cj, ci) T
Billi NP(*,*,i) &P :, (I b i ; Pi) K , Twhere I b i equals &c&c# :, c = c# " ci = b T
who REL &P&Q&i :, (Qi ; Pi) K , K , Khei NP(nom,*,i) &P :, Pi K , Thimi NP(acc,*,i) &P :, Pi K , Tman CN &i&c&c# :, (c = c# " man ci) Kboy CN &i&c&c# :, (c = c# " boy ci) Ksmiles VP(Tensed) &i&c&c# :, (c = c# " smile ci) Ksmile VP(Inf) &i&c&c# :, (c = c# " smile ci) Khas TV(Tensed) &P&i :, (P(&j :, (POSS i j)) (K , T) , K
where POSS i j = &c&c# :, c = c# " poss (ci, cj) Thave TV(Inf) &P&i :, (P(&j :, (POSS i j)) (K , T) , K
where POSS i j = &c&c# :, c = c# " poss (ci, cj) Thates TV(Tensed) &P&i :, (P(&j&c&c# :, (c = c# " hate (ci, cj))) (K , T) , Khate TV(Inf) &P&i :, (P(&j&c&c# :, (c = c# " hate (ci, cj))) (K , T) , Kdoes not AUX &P&i :, ¬¬Pi K , Kif (S/S)/S &p&q :, (p $ q) T , T , T. S\(TXT/S) &p&q :, (p ; q) T , T , T. TXT\(TXT/S) &p&q :, (p ; q) T , T , T
D Salience Updating as Context Manipulation
A suitable interface for anaphora resolution needs to incorporate a notion of salience,or measure of availability of referents as candidates for resolution. Surface syntacticform is an important determinant for salience; for example it is usually assumed that asubject is more salient than an object. Thus, the first choice for resolving he in (3.10)is a farmer.
A farmer hit a gentleman. He was upset. (3.10)
And the first choice for resolving he in (3.11) is a gentleman.
A gentleman was hit by a farmer. He was upset. (3.11)

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 246 — #66
246 Handbook of Logic and Language
In these two examples, a farmer and a gentleman are the two obvious candi-dates for resolving the reference of the pronoun he, because both a farmer and agentleman have been made salient by the preceding text. Consider the followingcontext:
Pedro Bernardo Don Diego
Salience update in context is a reshuffle of the order of importance of the items in acontext list. This may make Don Diego the most salient item:
Don Diego Pedro Bernardo
To allow reshuffling of a context with Don Diego in it, in such a way that we do notlose track of him, we represent contexts as lists of indexed objects, with the indicesrunning from 0 to the length of the context minus 1:
0
Don Diego1
Bernardo2
Pedro
Reshuffling this to make Pedro most salient gives:
2
Pedro0
Don Diego1
Bernardo
Note that the indices 0, . . . , n 1 1 determine a permutation of the context list. We callthese lists of indexed objects contexts under permutation.
In a context c, the entity with index i is given by c[9i].
%
'2
Pedro0
Don Diego1
Bernardo
(
* [90] = Don Diego
If c is a context under permutation, let (i)c be the result of placing the item (i, c[9i])upfront. Here is an example:
(1)
%
'2
Pedro0
Don Diego1
Bernardo
(
* =1
Bernardo2
Pedro0
Don Diego
(i)c is the result of moving the item with index i to the head position of the context list.Successive applications of this operation can generate all permutations of a context. Ifd is an object and c a context, then d : c is the result of putting item (|c|, d) at the headposition of the context list.

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 247 — #67
Discourse Representation in Context 247
Don Alejandro :
%
'2
Pedro0
Don Diego1
Bernardo
(
* =
3
Don Alejandro1
Bernardo2
Pedro0
Don Diego
The operation (:) is used for adding a new element to the context, in the most salientposition. Using this, and introducing a type p[e] for contexts under permutation, wecan give a type theoretical version of discourse representation that allows salienceupdating. Assume c, c# are variables of type p[e], and P, Q are variables of type N ,p[e] , p[e] , t. Then the new definition of context extension runs as follows:
!! := &cc# :, !x((x : c) = c#)
Here (x : c) means that x is added to the context, at the most salient position. Thelift of unary predicates to pointers into context-under-permutation transitions that isnecessary to make this work is defined as:
&A&i&c&c# :, c = c# " A(c[9i]).
The new translation of a man effects a salience reshuffle:
&Qcc# :, |c| = i " !x(Man x " Qi(x : c)c#).
The referent x for the indefinite gets put in the most salient position in the new contextby means of the operation x : c. Note that (x : c)[9i] will pick up x.
E Further Reading
Two key publications on discourse representation are Heim (1982) and Kamp (1981),which address themselves specifically to the problem of the interpretation of indefinitedescriptions and their interaction with unbound and transsentential anaphora. Tempo-ral anaphora, a kind of anaphora that is largely transsentential, is treated along the samelines in Kamp and Rohrer (1983). A systematic presentation of discourse representa-tion theory including various later developments is given in Kamp and Reyle (1993).Asher (1993) extends DRT to a more comprehensive theory, which among other thingsalso takes discourse structure and rhetorical relations into account. The connectionsbetween the principles of DRT and those of generative syntax are explored in depthin Chierchia (1995). Questions of lexical semantics from a DR-theoretical perspectiveare explored in Kamp and Rossdeutscher (1994).
A precursor paper is Karttunen (1976). Examples of related approaches to seman-tics, which have also advocated focusing on the discourse level, are Seuren’s discoursesemantics (1986), Barwise’s dynamic interpretation of anaphora (1987), and the game-theoretical school of Hintikka c.s. (Hintikka and Kulas, 1985).

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 248 — #68
248 Handbook of Logic and Language
Further references on the connection with dynamic reasoning are given inChapter 12 on Dynamics in this Handbook. Connections between discourse repre-sentation and type theory are sketched in Ahn and Kolb (1990). Connections betweendiscourse representation and game-theoretical semantics are given in van Benthemand van Eijck (1982).
The mathematics of context and context extension has developed into a topic in itsown right; see, for example, Visser and Vermeulen (1996). A version of DRT calledincremental dynamics is presented in van Eijck (2001). This framework can be viewedas the one-variable version of sequence semantics for dynamic predicate logic, as pro-posed in Vermeulen (1993). Incremental dynamics is described in terms of polymor-phic type theory in van Eijck (2001). This system makes clear how the instruction totake fresh discourse referents when needed can be made fully precise by using thestandard toolset of (polymorphic) type theory. Such a reconstruction of DRT in typetheory does justice to the incrementality and the finite state semantics of the original.The proposal for the treatment of salience in Section D of this addendum is workedout as a fragment with a mechanism for reference resolution in a textbook chapter invan Eijck and Unger (2009). This treatment should be compared with the treatmentof pronoun resolution in DRT proposed in the second volume of Blackburn and Bos(2005), as well as with the earlier proposal for pronoun resolution in DRT in Wadaand Asher (1986). Discourse semantics in the style of Kamp and Heim can be viewedas a form of continuation passing style semantics for texts. This connection is workedout further in de Groote (2007) and Barker and Shan (2008).
To change a function f of type a , b into a continuation passing style function f #
of type a , (b , c) , c, one can define f # as &x&g :, g(fx). Then f # is a functionthat first takes an x, next takes a continuation function g, then starts to compute like f ,but instead of returning the result fx, applies the function g to that result.
If we look at this more closely, we see that this can be viewed as a combination ofapplication and argument raising, as follows. Define R(x) as &g :, gx. Then f # can beredefined as &x :, R(fx). The reader who is familiar with Montague semantics has nodoubt seen this argument raising before. This is how Montague grammar deals withproper names, to assimilate them to the type of generalized quantifiers. Reynolds,in his overview of the use of continuations in computer science (1993), shows thatcontinuations were invented over and over again. We can add that the person whoreinvented them first for natural language semantics was Richard Montague.
In the case of discourse representation another kind of lifting takes place. Insteadof just interpreting a piece of discourse in context, a second context is returned thatcan be interpreted in context next, according to the recipe:
!c = &c# :, !cc#.
To define truth, one has to step out of the continuation, by means of:
T(!c) = !c#(!cc#).
Truth is a derived notion. To say that a text is true in context c boils down to thestatement that the context c can be extended to c#, all relative to some model M inwhich c is embedded.

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 23:59 — page 249 — #69
Discourse Representation in Context 249
Besides the connections with type theory and continuations, there is a link withdynamic logic and Hoare style correctness reasoning in programming. DPL, a closecousin of DRT, can be viewed as a fragment of quantified dynamic logic. For thetracing of this connection we refer to van Eijck and Stokhof (2006). For a still broaderperspective on natural language text processing as information processing we refer toKamp and Stokhof (2008), in particular Chapter 3, “Meaning in Context”.
Discourse representation theory has found its way into implementations of large-scale natural language processing systems. A prominent example of this is the aptlynamed Boxer system for building and manipulating DRT box representations of natu-ral language texts. See Curran et al. (2007).
Speaking very generally, discourse is an act of communication that establishescommon knowledge between a speaker and an audience. As the discourse processes,speaker and audience may switch roles. Beliefs are updated in the course of commu-nication, but the discourse situation also employs common knowledge and commonbelief (what the speaker knows or believes about the audience) to establish commu-nication. The update idea that announcing a proposition ! removes all worlds where! does not hold is old logical folklore; explicit statements can be found since the1970s in the works of Stalnaker, Heim, and others. The same idea also served as ahighlight in the work on epistemic logic in computer science (cf. Fagin et al., 1995).Its first implementation as a dynamic-epistemic logic is due to Plaza (1989) (see alsoGerbrandy, 1999). The public announcement update idea was generalized in Baltaget al. (1999); a streamlined version of a general logic of communication and changeis given in van Benthem et al. (2006), and a textbook treatment in van Ditmarsch etal. (2006). In the last chapter of van Eijck and Unger (2009) a textbook treatment ofpresupposition and question answering within this framework is given.
The study of social mechanisms may offer an extended agenda for natural languageanalysis, with the analysis of natural language communication in settings where some-thing more definite than just information exchange is the focus: achievement of somewell-stated goals given by specific social protocols. See Parikh (2002) and van Eijckand Verbrugge (2009).
Acknowledgments
Thanks to Johan van Benthem and Valeria de Paiva for support, hints and suggestions.
References
Ahn, R., Kolb, H.-P., 1990. Discourse representation meets constructive mathematics, in:Kalman, L., Polos, L. (Eds.), Papers from the Second Symposium on Logic and Language,Akademiai Kiadoo, Budapest, pp. 105–124.
Alshawi, H. (Ed.), 1992. The Core Language Engine. MIT Press, Cambridge, MA, London,England.
Asher, N., 1986. Belief in discourse representation theory. J. Philos. Logic 15, 127–189.Asher, N., 1993. Reference to Abstract Objects in Discourse. Kluwer, Dordrecht.

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 250 — #70
250 Handbook of Logic and Language
Baltag, A., Moss, L.S., Solecki, S., 1999. The Logic of Public Announcements, CommonKnowledge, and Private Suspicions. Technical Report SEN-R9922, CWI, Amsterdam.Many updates.
Barker, C., Shan, C.-c., 2008. Donkey anaphora is in-scope binding. Semant. Pragmat. 1 (1),1–46.
Barwise, J., 1987. Noun phrases, generalized quantifiers and anaphora, in: Gärdenfors, P. (Ed.),Generalized Quantifiers: Linguistic and Logical Approaches. Reidel, Dordrecht, pp. 1–30.
Blackburn, P., Bos, J., 2005. Representation and Inference for Natural Language; A First Coursein Computational Semantics. CSLI Lecture Notes, CSLI (Palo Alto).
Bos, J., Mastenbroek, E., McGlashan, S., Millies, S., Pinkal, M., 1994. A compositional DRS-based formalism for NLP-applications, in: Bunt, H., Muskens, R., Rentier, G. (Eds.),Proceedings of the International Workshop on Computational Linguistics. University ofTilburg, Tilburg, the Netherlands, pp. 21–31.
Bouchez, O., van Eijck, J., Istace, O., 1993. A strategy for dynamic interpretation: a frag-ment and an implementation, in: Krauwer, S., Moortgat, M., des Tombe, L. (Eds.), SixthConference of the European Chapter of the Association for Computational Linguistics—Proceedings of the Conference, ACL, Stroudsburg, USA, pp. 61–70.
Chierchia, G., 1995. The Dynamics of Meaning. The University of Chicago Press, Chicago andLondon.
Curran, J.R., Clark, S., Bos, J., 2007. Linguistically Motivated Large-Scale NLP with C&Cand Boxer, in: Proceedings of the ACL 2007 Demo and Poster Sessions, Prague, CzechRepublic, pp. 33–36.
Davidson, D., 1967. The logical form of action sentences, in: Rescher, N. (Ed.), The Logic ofDecision and Action. The University Press, Pittsburgh, pp. 81–95.
de Groote, P., 2007. Towards a Montegovian account of dynamics, in: Gibson, M., Friedman, T.,(Eds.), Proceedings Semantics and Linguistic Theory XVII. CLC Publications, Ithaca, NY[paperback].
Fagin, R., Halpern, J.Y., Moses, Y., Vardi, M.Y., 1995. Reasoning About Knowledge. MIT Press,Cambridge, MA.
Frege, G., 1892. Ueber sinn und bedeutung, in: Geach, Black (Eds.), On Sense and Reference.Translations from the Philosophical Writings of Gottlob Frege, Blackwell, Oxford (1952).
Gamut, L.T.F., 1991. Language, Logic and Meaning, part 2. Chicago University Press, Chicago.Geach, P.T., 1980. Reference and Generality: An Examination of some Medieval and Modern
Theories, third ed. Cornell University Press, Ithaca, NY, 1962.Gerbrandy, J., 1999. Bisimulations on Planet Kripke. ILLC Dissertation Series, Amsterdam.Groenendijk, J., Stokhof, M., 1991. Dynamic predicate logic. Ling. Philos. 14, 39–100.Halliday, M.A.K., Hassan, R., 1976. Cohesion in English. Longman, London.Heim, I., 1982. The Semantics of Definite and Indefinite Noun Phrases. PhD thesis, University
of Massachusetts, Amherst.Hintikka, J., Kulas, J., 1985. Anaphora and Definite Descriptions: Two Applications of Game-
Theoretical Semantics. Reidel, Dordrecht.Kamp, H., 1981. A theory of truth and semantic representation, in: Groenendijk, J., Janssen, T.,
Stokhof, M. (Eds.), Formal Methods in the Study of Language. Mathematisch Centrum,Amsterdam, pp. 277–322.
Kamp, H., Reyle, U., 1993. From Discourse to Logic. Kluwer, Dordrecht.Kamp, H., Reyle, U., 1996. A calculus for first order discourse representation structures. J.
Logic Lang. Inf. 5 (3–4), 297–348.

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 251 — #71
Discourse Representation in Context 251
Kamp, H., Reyle, U. Discourse representation theory, in: Maienborn, C., von Heusinger, K.,Partner, P. (Eds.), Handbuch Semantik. Walter de Gruyter (to appear).
Kamp, H., Rohrer, C., 1983. Tense in texts, in: Bäuerle, R., Schwarze, Chr., von Stechow, A.(Eds.), Meaning, Use and Interpretation of Language. De Gruyter, Berlin, pp. 250–269.
Kamp, H., Rossdeutscher, A., 1994. Remarks on lexical structure and DRS construction. Theor.Ling. 20 (2/3), 97–164.
Kamp, H., Stokhof, M., 2008. Information in natural language, in: van Benthem, J., Adriaans, P.(Eds.), Philosophy of Information, vol. 8. Handbook of the Philosophy of Science, NorthHolland, Elsevier, Amsterdam and Oxford, UK, pp. 49–111.
Karttunen, L., 1976. Discourse referents, in: McCawley, J. (Ed.), Syntax and Semantics 7, Aca-demic Press, Amsterdam, pp. 363–385.
Klop, J.W., 1992. Term rewriting systems, in: Abramski, S., Gabbay, D., Maibaum, T. (Eds.),Handbook of Logic in Computer Science. Oxford University Press, UK, pp. 1–116.
Kripke, S.A., 1972. Naming and necessity, in: Davidson, D., Harman, G. (Eds.), Semantics ofNatural Language. Reidel, Dordrecht, pp. 253–355.
Kuschert, S., 1995. Eine Erweiterung des &-Kaküls um Diskursrepresentationsstrukturen. Mas-ter’s thesis, Universität des Saarlandes, Deutschland.
Mann, W.C., Thompson, S.A., 1987. Rhetorical structure theory: a framework for the analysisof texts. IPRA Pap. Pragmat. 1, 1–21.
Muskens, R., 1995. Tense and the logic of change, in: Egli, U., Pause, E.P., Schwarze, Chr.,von Stechow, A., Wienold, G. (Eds.), Lexical Knowledge in the Organization of Language.W. Benjamins, John Benjamins, Amsterdam/Philadelphia, pp. 147–183.
Muskens, R., 1996. Combining montague semantics and discourse representation. Ling. Philos.19, 143–186.
Parikh, R., 2002. Social software. Synthese, 132, 187–211.Partee, B., 1973. Some structural analogies between tenses and pronouns in English. J. Philos.
70, 601–609.Plaza, J.A., 1989. Logics of public communications, in: Emrich, M.L., Pfeifer, M.S.,
Hadzikadic, M., Ras, Z.W. (Eds.), Proceedings of the 4th International Symposium onMethodologies for Intelligent Systems, pp. 201–216.
Reichenbach, H., 1947. Elements of Symbolic Logic. Macmillan, London.Reyle, U., 1993. Dealing with ambiguities by underspecification: construction, representation
and deduction. J. Semant. 10, 123–179.Reyle, U., 1995. On reasoning with ambiguities, in: Seventh Conference of the European Chap-
ter of the Association for Computational Linguistics—Proceedings of the Conference,Morgan Kaufmann, San Francisco, pp. 1–8.
Reynolds, J.C., 1993, The discoveries of continuations. Lisp Symb. Comput. 6 (3–4), 233–247.Russell, B., 1905. On denoting. Mind 14, 479–493.van der Sandt, R.A., 1992. Presupposition projection as anaphora resolution. J. Semant. 9, 333–
377. Special Issue: Presupposition, Part 2.Saurer, W., 1993. A natural deduction system of discourse representation theory. J. Philos. Logic
22 (3), 249–302.Sedogbo, C., Eytan, M., 1988. A tableau calculus for DRT. Logique et Analyse 31, 379–402.Seuren, P., 1986. Discourse Semantics. Blackwell, Oxford.Sidner, C.L., 1979. Towards a Computation Theory of Definite Anaphora Comprehension in
English Discourse. PhD thesis, MIT Press, Cambridge, MA.

“07-ch03-0181-0252-9780444537263” — 2010/11/29 — 21:08 — page 252 — #72
252 Handbook of Logic and Language
Stalnaker, R., 1974. Pragmatic presuppositions, in: Munitz, M.K., Unger, P.K. (Eds.), Semanticsand Philosophy. New York University Press, New York, NY, pp. 197–213.
Strawson, P.F., 1950. On referring. Mind 59, 320–344.van Benthem, J., 1983. The Logic of Time. Reidel, Dordrecht.van Benthem, J., van Eijck, J., 1982. The dynamics of interpretation. J. Semant. 1 (1), 3–20.van Benthem, J., van Eijck, J., Kooi, B., 2006. Logics of communication and change. Inf.
Comput. 204 (11), 1620–1662.van Ditmarsch, H.P., van der Hoek, W., Kooi, B., 2006. Dynamic Epistemic Logic, Synthese
Library, vol. 337. Springer, Dordrecht.van Eijck, J., 1993. The dynamics of description. J. Semant. 10, 239–267.van Eijck, J., 1994. Axiomatizing dynamic predicate logic with quantified dynamic logic, in:
van Eijck, J., Visser, A. (Eds.), Logic and Information Flow. MIT Press, Cambridge MA,pp. 30–48.
van Eijck, J., 1996. Merge reduction in dynamic semantics. Manuscript, CWI, Spring.van Eijck, J., 2000. The proper treatment of context in NL, in: Monachesi, P. (Ed.), Computa-
tional Linguistics in the Netherlands 1999; Selected Papers from the Tenth CLIN Meeting.Utrecht Institute of Linguistics OTS, Utrecht, pp. 41–51.
van Eijck, J., 2001. Incremental dynamics. J. Logic, Lang. Inf. 10, 319–351.van Eijck, J., Kamp, H., 1997. Representing discourse in context, in: van Benthem, J., ter
Meulen, A. (Eds.), Handbook of Logic and Language. Elsevier, Amsterdam, the Nether-lands, pp. 179–237.
van Eijck, J., Stokhof, M., 2006. The gamut of dymamic logics, in: Gabbay, D.M., Woods, J.(Eds.), The Handbook of the History of Logic, vol. 7. Logic and the Modalities in theTwentieth Century, Elsevier, pp. 499–600.
van Eijck, J., Unger, C., 2009. Computational Semantics with Functional Programming. Cam-bridge University Press, Cambridge, UK.
van Eijck, J., Verbrugge, R. (Eds.), 2009. Discourses on Social Software, Texts in Logic andGames, vol 5. Amsterdam University Press, Amsterdam.
Verkuyl, H., 1972. On the Compositional Nature of the Aspects. PhD thesis, University ofUtrecht, Utrecht.
Vermeulen, C.F.M., 1993. Sequence semantics for dynamic predicate logic. J. Logic Lang. Inf.2, 217–254.
Vermeulen, C.F.M., 1995. Merging without mystery. J. Philos. Logic 24, 405–450.Visser, A., 1994. Actions under presuppositions, in: van Eijck, J., Visser, A. (Eds.), Logic and
Information Flow. MIT Press, pp. 196–233.Visser, A., 1994. The design of dynamic discourse denotations. Lecture notes, Utrecht
University, the Netherlands.Visser, A., Vermeulen, C., 1996. Dynamic bracketing and discourse representation. Notre Dame
J. Formal Logic 37, 321–365.Wada, H., Asher, N., 1986. BUILDRS: an implementation of DR theory and LFG, in: 11th Inter-
national Conference on Computational Linguistics. Proceedings of Coling ’86. Universityof Bonn, Germany, pp. 540–545.
Webber, B., 1979. A Formal Approach to Discourse Anaphora. Garland, New York.Zeevat, H., 1989. A compositional approach to discourse representation theory. Ling. Philos.
12, 95–131.

“08-ch04-0253-0328-9780444537263” — 2010/11/30 — 3:44 — page 253 — #1
4 Situation TheoryJeremy Seligman!, Lawrence S. Moss†
!Department of Philosophy, The University of Auckland,Private Bag 92019, Auckland 1142, New Zealand,E-mail: [email protected]
†Department of Mathematics, Indiana University, 831 East Third Street,Bloomington, IN 47405-7106, USA, E-mail: [email protected]
4.1 Introduction
With the book Situations and Attitudes, Barwise and Perry (1983) initiated a programof research that has occupied a diverse group of researchers for many of the subse-quent years. The original motivation was to provide a richer, more honest semantictheory of natural languages, one that called a spade a spade, a situation a situation,and (eventually) a proposition a proposition. The emphasis was on defending a naı̈veontology containing all the entities to which linguistic expressions appear to refer.
A natural division of labor developed. Linguists were encouraged to providesemantic analyses that used whatever entities they needed, without worrying too muchabout the technical matter of how such entities should be modeled. Logicians weredriven to investigate foundational questions about the emerging ontology, with thehope of providing a unified mathematical framework in which the linguists’ workcould be interpreted. The linguistic project became known as Situation Semantics andthe logical project was called Situation Theory. Situation Theory was intended to standto Situation Semantics as Type Theory stands to Montague Grammar.
This chapter is written as a self-contained introduction to the main themes andtechnical contributions of Situation Theory. We have not attempted to give a surveyof Situation Semantics, although key references are included in the bibliography. Thisis a serious omission because many of the ideas in Situation Theory originated fromlinguistic considerations. One excuse is that neither of us is a linguist; a second is thatthe chapter is too long as it stands.
A more defensible excuse is that Situations and Attitudes was not only concernedwith semantics. The program of research it initiated has spilled into many neighboringdisciplines, such as philosophy, computer science, psychology, and even sociology.The influence of these other fields has been significant – so much so that it would bedifficult to account for the purely linguistic factors.
In writing this chapter, we aimed both to present the existing literature on thesubject and to provide a coherent statement of Situation Theory. Unfortunately,
Handbook of Logic and Language. DOI: 10.1016/B978-0-444-53726-3.00004-9c" 2011 Elsevier B.V. All rights reserved.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 254 — #2
254 Handbook of Logic and Language
these goals conflict. The literature contains many technical contributions, some quitesophisticated; but they have not yet been put together. We judged that a mere survey ofthe existing results would be of limited interest, and decided to re-present the materialin as coherent a way as possible.
In any foundational study one has to decide whether to build models or theories.The strategies are distinct if not divergent, and the ideal of a canonical theory is rarelyachieved. Most of the research on Situation Theory has been directed towards con-structing models. There are many models; they differ both on subject matter (whichparts of the theory they model) and on substance (which axioms they satisfy), and noclear consensus has emerged. The work on developing a formal theory has been evenless unified: approaches using classical logic, partial logic and even “illative logic”have been tried. The subject matter of the theories and the models do not coincidecompletely, and when they do overlap there are many differences on matters of detail.In an effort to make this chapter compatible with all this, we have adopted a fairlyabstract, loose approach. Axioms and models are discussed side by side.
In Section 4.2 we introduce the class of “simple information structures”. Structuresin this class are intended to provide a naı̈ve model of the structure of information, ascaptured by the relational structures of first-order model theory. The class is axioma-tized, and each of the axioms is discussed with a view to generalization. Many of thenovelties of Situation Theory can be seen as generalizations of this sort.
Section 4.3 introduces techniques for constructing models of the generalizationsconsidered in Section 4.2. All of the techniques may be found in the literature butwe have reorganized them into a framework called the Theory of Structural Rela-tions. This is a new approach, with which those working on Situation Theory will beunfamiliar.
In Sections 4.2 and 4.3 the reader will not meet a single situation. Section 4.4remedies the disappointment by introducing a host of ontological categories, includingfacts, restricted abstracts, situations, propositions, types, and constraints. The theory ofstructural relations is used throughout, but the focus in this section is on the motivationfor diverging opinions in Situation Theory, critical evaluation, and pointers to openproblems.
Finally, in Section 4.5 we give a brief guide to the literature on Situation Theoryand related areas of research, followed by a selective bibliography.
4.2 The Structure of Information
Situation Theory has its fair share of neologisms, the most inspired of which is surelythe term infon, coined by Keith Devlin. An infon is an item of information. The termis intended to be as neutral as possible about the form in which the information isrepresented. The common item of information separately conveyed by the statementsmade in the following little conversation is an example of an infon.
Raymond: (to Paul, displaying an omelette) I have cooked this for you.Paul: (proudly, to Delia) Raymond cooked this omelette for me.Delia: (to Albert) The chef cooked the omelette for Paul.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 255 — #3
Situation Theory 255
Of course, much more information can be gleaned about the situation from each ofthese statements, but that it is one in which the two people, Raymond and Paul, and anomelette stand in a certain relationship, that of Raymond having cooked the omelettefor Paul, is information expressed by all three. The very same information may also berepresented by other means, in a film, or a cartoon-strip, for example, or in the mindsof Raymond, Paul, Delia and even Albert.1
The first goal of this chapter is to show how information of this simple form ismodeled. To specify the structure of the infon in the example, we must say whichindividuals are involved and how they are related. We shall abbreviate “Raymond”and “Paul” to “R” and “P”, and introduce the name “O” to refer to the omelette. Weuse “cooked” to name the relation that holds between a cook, a diner and a dish justin case the the cook has cooked the dish for the diner. Let I be information that R, P,and O stand in the relation cooked. The individuals R, P, and O are called argumentsof the infon I, and the relation cooked, is called the relation of I.
By specifying the relation and arguments of I we have done a lot toward charac-terizing everything of informational significance, but not quite all. Care must be takento distinguish the information that Raymond cooked the omelette for Paul from theinformation that Paul cooked the omelette for Raymond. For this purpose, we requirethe concept of a role. In any infon involving the relation cooked there are three rolesto be filled: that of the cook, the diner and the dish. In the present case, the cook isR, the diner is P, and the dish is O; if instead Paul cooked the omelette for Raymond,then the roles of cook and diner would be reversed. We say that an individual is anargument of an infon if it fills one of the infon’s roles. The omelette O is an argumentof the infon I by virtue of filling the dish role of I’s relation cooked.
We have established that there are two basic ingredients determining the structureof I: that of cooked being the relation of I, and that of the three individuals R, P, andO filling the three roles of I, which we name cook, diner, and dish, respectively. Weintroduce the predicates “Rel” and “Arg” to denote these structural relations, writing“Rel(cooked, I)” to mean that cooked is the relation of I, and “Arg(O, dish, I)” tomean that O, the omelette, fills the dish role of our infon I.
More generally, we shall take simple infons like I to be “structured” by the tworelations, Rel and Arg. The first of these, Rel, determines the relation of the infonand the other, Arg, determines which arguments fill which roles. We define a “simpleinfon” to be anything that has a relation or an argument. Similarly, a “relation” isanything that is a relation of some infon, and a “role” is anything that is filled by anargument in some infon. In other words,
! is a (simple) infon if !r Rel(r, ! ) or !a, i Arg(a, i, ! ),r is a relation if !! Rel(r, ! ), andr is a role if !a, ! Arg(a, i, ! ).
1 The reader may think to identify this item of information with the Russellian proposition expressed by“R cooked O for P”, with the understanding that “R”, “O”, and “P” are proper names for Raymond, theomelette, and Paul, respectively. One branch of the theory follows this path (see Section 4.4) but theidentification would be premature.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 256 — #4
256 Handbook of Logic and Language
These definitions form the basis of an abstract account of the structure ofinformation that will be the focus of this section. The approach is “abstract” becausewe consider any structure in which the predicates “Rel” and “Arg” are defined to be acandidate model for the theory of information, with the derived predicates “relation”,“role” and “infon” interpreted according to the above definitions. Our strategy is toisolate axioms describing those properties of infons that have been discussed in theliterature on Situation Theory, generalizing from the properties of certain “standard”models, to be introduced shortly.
First, a short digression.
4.2.1 Relational Structures
It is a commonplace that in foundational theories one must be very careful to distin-guish between meta-language and object-language. Situation Theory is no exception,and special difficulties arise with the word “relation”. Before going further it will proveuseful to make some preliminary definitions concerning relational structures. The fol-lowing is slightly non-standard but enables us to avoid certain ambiguities with ouruse of “relation” and similar words.
A (relational) signature is a function " : S " N from a finite set S to the set Nof positive integers. The elements of S are called primitive relations and the number"(R) associated with a primitive relation R is a called its arity. A relational structureA of signature " consists of a class |A|, called the universe of A, and for each primi-tive relation R, a class [[R]]A of finite sequences of elements of |A|, each of length"(R), called the extension of R in A.2 For example, we may model the situation ofRaymond having cooked an omelette for Paul as a relational structure N1 of signature" : {cooked} " N defined by "(cooked) = 3, with universe |N1| = {R, P, O} and[[cooked]]N1 containing, at least, the sequence ROP.
In discussing relational structures, we say that A is of type [A, R"11 , . . . , R"n
n ] if Ahas universe A and primitive relations R1, . . . , Rn, with arities "1, . . . , "n respectively.For example, N1 is of type [{R, P, O}, cooked3]. The notation is stretched to pro-vide a way of saying that one relational structure extends another. If A is of type[A, R"1
1 , . . . , R"nn ] and n < m then we say that B is of type [A, R"n+1
n+1 , . . . , R"mm ] if it is
of type [A, R"11 , . . . , R"n
n , . . . , R"mm ] and [[Ri]]B = [[Ri]]A for 1 # i # n.
We use the names of the primitive relations of a structure to form sentencesabout the structure as if they were predicates in a formal language. Given elementsa1, . . . , a"i of |A|, the sentence “Ri(a1, . . . , a"i)” when used to describe the structureA, is true if and only if the finite sequence a1, . . . , a"i lies in [[Ri]]A. For example, the
2 We allow relational structures whose universe is a proper class because models of Situation Theory areoften very large. The exact meaning of the word “set” will be discussed below, but for the moment thereader may assume that we are working with any theory of sets that accounts for their mundane prop-erties, supports a distinction between “set” and “class”, and allows collections of ordinary objects to becalled “sets”.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 257 — #5
Situation Theory 257
sentence “cooked(R, P, O)” provides yet another way of saying that Raymond cookedthe omelette for Paul.
We also need to talk about specific elements of the universe of a relational structure.Given a set C, a relational structure with constants C is a relational structure A togetherwith an element [[c]]A of |A| for each c $ C.
Relational structures A and B, both of signature " : S " N and with constants C,are isomorphic if there is a bijective function f : |A| " |B| such that for each R $ Sand a1, . . . , a"(R) $ |A|,
R(a1, . . . , a"(R)) in A iff R( f (a1), . . . , f (a"(R))) in B
and for each c $ C, [[c]]B = f ([[c]]A).
4.2.2 Simple Information Structures
We are interested in relational structures in two quite different ways. First, we mayuse them to build models of a given situation. The structure N1, defined in the previ-ous section, models the situation discussed by Raymond and his friends in our initialexample. It is the sort of model that underlies standard “model-theoretic” semantics.In the manner of Tarski, we may provide a definition of truth in N1 for a language hav-ing the predicate “cooked” and perhaps the names “R”, “O”, and “P”. By virtue of thissemantic function, structures like N1 may also be thought to provide a model of theinformation conveyed in the conversation, but in this capacity they are rather limited.In constructing N1 we are forced to determine the complete extension of cooked andso include more information than was conveyed. Consider the sequence ROR. If thislies in [[cooked]]N1 then the situation modeled is one in which Raymond also cookedthe omelette for himself, and O is a two-person omelette. If, on the other hand, RORis in not in [[cooked]]N1 then Paul has the feast to himself. The necessary overdeter-mination of information is one of the deficiencies that Situation Theory is intended toovercome.
The second, more important use of relational structures is as models of frag-ments of Situation Theory itself. Our strategy is to define successive classes of rela-tional structures, that may be regarded as approximations to a suitable model for thetheory as a whole. An example of the second use is given by our first substantialdefinition.
Definition 4.2.1. A relational structure A of type [A, Rel2, Arg3] is a (simple) infor-mation structure if it satisfies the following conditions:
A1 If Rel(r, ! ) and Rel(r%, ! ) then r = r%.A2 If Arg(a, i, ! ) and Arg(b, i, ! ) then a = b.A3 No relation is a role.A4 No role is an infon.A5 No infon is a relation.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 258 — #6
258 Handbook of Logic and Language
Axioms A1 to A5 are not particularly stringent; they merely impose some disciplineon the domain. Together, they say nothing more than that the relations, roles and infonsform disjoint classes, and that infons may have at most one relation and at most oneargument filling each role.
The previously mentioned ambiguity in the word “relation” can be seen with thehelp of this definition.3 First, we use the word to talk about the relations of any rela-tional structure. For example, the theoretical predicates “Rel” and “Arg” refer tothe primitive relations of simple information structures. Relations of this kind willbe dubbed “external”. Any other relation between elements of a relational structurewhose extension is determined by our theoretical language is also called “external”.Examples include relations defined from primitive relations, such as the property ofbeing a simple infon.4
The second use of “relation” is governed by the extension of Rel in a specificinformation structure. An element r of the universe of a simple information structureA is an internal relation of A if Rel(r, ! ) for some infon ! . The ambiguity, onceunderstood, should not cause the reader any difficulty. Where necessary the sense willbe made clear using the adjectives “internal” and “external.”
Aside from illustrating ambiguities, simple information structures provide our first,crude approximation to the models of a fragment of Situation Theory. Their principaluse is to show how the two ways in which we use relational structures are related.Suppose, for example, we use the structure N1 to model the situation discussed byRaymond and his friends. There is a sense in which N1 gives us all we need to knowabout the common informational content of the three culinary pronouncements. Therelation of the infon, cooked, is included as a primitive relation of N1; the three rolesof this relation, cook, diner, and dish, are modeled by the first, second, and thirdpositions in the sequences in the extension of cooked; and the arguments – Raymond,Paul and the omelette – are also directly included in the universe of N1. The thoughtthat we have thereby obtained a simple information structure is made more precise asfollows.
Construction 4.2.1. Given a relational structure M of type [M, R"11 , . . . , R"n
n ], pos-sibly with constants, we construct an information structure SInf(M). First, let
A1 = {1} &{ R1, . . . , Rn},
A2 = {2} &!
1#i#n
{1, . . . , "i},
A3 = {'3, Ri, #( | 1 # i # n and # : {1, . . . , "i} " M}.
3 Other words we use, such as “role” and “argument”, have a similar ambiguity.4 Typically, an n-ary external relation is identified with its graph, the set, or class, of sequences x1, . . . , xn of
objects that stand in the relation. We make no such assumption here. A meta-theory in which intensionaldistinctions are made between relations – as they are in our object-theory – is quite compatible with ourapproach.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 259 — #7
Situation Theory 259
The basic idea is to model simple infons as pairs of the form 'Ri, #( in which # isa function from {1, . . . , "i} to the universe of M. But we must be careful to keeprelations, roles and infons distinct, and so we also include a numerical prefix indicatingthe sort of object modeled: 1 for relations, 2 for roles, and 3 for simple infons. Theinformation structure SInf)(M) has universe M * A1 * A2 * A3 and the extensions ofRel and Arg given by
Rel(r, ! ) iff !R, # with r = '1, R( and ! = '3, R, #(,Arg(a, i, ! ) iff !j, R, # with i = '2, j(, ! = '3, R, #(, and #( j) = a.
The constants of SInf)(M) include all the constants of M. In addition, we take eachprimitive relation R of M to be a constant denoting '1, R(. It is a simple matter tocheck that the resulting structure A satisfies axioms A1 to A5.
A minor complication arises because of the need to ensure that isomorphic rela-tional structures give rise to isomorphic information structures – we don’t want acci-dental features of the representation to encode more information than there is in theoriginal structure. We would get more if, for example, M happened to contain an ele-ment m = '1, R( in which R is one of the primitive relations of M. In the structureSInf)(M), this pair would serve both as the object m of M and as the internal relationdenoted by the constant R.
We overcome this difficulty by first making a copy of M. Let M0 be the isomor-phic copy of M in which each element m of M is replaced by the pair '0, m(, andlet SInf(M) = SInf)(M0). Unlike SInf)(M), the structure SInf(M) keeps the oldelements distinct from the newly constructed elements, and so our construction hasthe desired property of preserving isomorphism: if M1 and M2 are isomorphic, so areSInf(M1) and SInf(M2).5
For example, consider once again the model N1. The information structureSInf(N1) has individuals '0, R(, '0, P(, and '0, O(, copied from N1, a single rela-tion '1, cooked(, three roles '2, 1(, '2, 2(, and '2, 3(, and infons of the form'3, 'cooked, #((, where # is a function from {1, 2, 3} into {'0, R(, '0, P(, '0, O(}. Thestructure also has a constant cooked that denotes the internal relation '1, cooked(.The information that Raymond cooked the omelette O for Paul is modeled by the ele-ment '3, 'cooked, #(( in which # is the function with domain {1, 2, 3}, and such that#(1) = '0, R(, #(2) = '0, P(, and #(3) = '0, O(.
Information structures constructed in this way serve as the starting point in ourinvestigation into the structure of information. But we must proceed with care. Vari-ous aspects of the construction are artifacts of the set-theoretic tools used. For exam-ple, the choice of the numbers 0 to 3 as indicators of the sort of object modeled isquite arbitrary. In making theoretical claims about the properties of these structures wemust consider only the essential aspects of the construction. This is easily achieved by
5 The construction depends only on the type of the relational structure. If M1 and M2 are isomorphicrelational structures of the same type then SInf(M1) = SInf(M2).

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 260 — #8
260 Handbook of Logic and Language
widening our focus to include all structures isomorphic to one obtained by Construc-tion 4.2.1.
Definition 4.2.2. A simple information structure is standard if it is isomorphic toSInf(M) for some relational structure M.
In the remainder of Section 4.2 we shall study standard information structures insome detail. We shall see that some properties of the standard structures capture ourbasic intuitions about the structure of information, while others reflect only the lim-itations of the construction. By the end of the section we shall have a list of axiomscharacterizing the class of standard structures, and a number of alternative axiomsdesigned to overcome their limitations.6
4.2.3 Roles
Suppose N2 is a relational structure of type [N2, stir-fried2, braised2] and that Rand P are elements of M. Let #1 and #2 be functions with domain {1, 2} and such that#1(1) = R and #2(1) = P. The information structure SInf(N2) contains the simpleinfons !1 = '3, stir-fried2, #1( and !2 = '3, braised2, #2(. Thus, in SInf(N2),we have
Arg('0, R(, '2, 1(, !1) and Arg('0, P(, '2, 1(, !2).
The elements '0, R( and '0, P( have the common property of filling the role '2, 1(.What, if anything, does this signify?
In information structures obtained using Construction 4.2.1, roles are pairs of theform '2, n(, where n is a positive integer. These roles are simply indices recording therelative positions of arguments in the original relational structure, and it is difficultto see how the identity of roles – mere indices – in different infons can be givenmuch import. Yet we must not be misled by the peculiarities of the coding used in theconstruction. The statement that Raymond stir-fried the frogs’ legs and Paul braisedthe monkfish implies that both Raymond and Paul are cooks; at least, it tells us thatthey played the role of cook in the situation described. Perhaps we can regard '2, 1(as modeling this role in SInf(N2).
Whatever the merits of this suggestion, the behaviour of roles in standard informa-tion structures is severely constrained. The roles of stir-fried and braised in N2 are thesame two, '2, 1( and '2, 2(, not for culinary reasons but simply because both are binaryrelations and so we use the same numbers, 1 and 2, to index their arguments. Thisrather artificial limitation of standard structures is captured by the following ratherartificial axiom.
A6 If ! has a role that is not a role of $ , then every role of $ is a role of ! .
6 The axioms for standard information structures are labeled A1, A2, and so on. The alternatives to AxiomAn are labeled An.1, An.2, and so on. Some of the alternatives are weaker than the corresponding standardaxioms, generalizing some aspect of standard structures. Others are stronger, asserting the existence ofobjects not present in standard structures.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 261 — #9
Situation Theory 261
In effect, Axiom A6 says that the sets of roles of infons are linearly ordered byinclusion. In moving away from standard structures, this axiom is sure to be dropped.Theoretical considerations concerning roles have been studied in connection with thelinguistic concept of “thematic role” by Engdahl (1990). Another restriction obeyedby standard structures is that
A7 Each infon has only finitely many roles.
Relations with infinite arities are conceivable, and perhaps of some theoretical use,but it is important to focus on those items of information that are finitely expressible.Indeed, it has been proposed (Devlin, 1991b) that the finiteness of infons is an essentialcharacteristic. A much less reasonable restriction is that
A8 There are only finitely many relations.
This is satisfied by all standard information structures but it will be dropped whenwe generalize.
4.2.4 Identity
In all standard information structures, the following criterion of identity is satisfied.
A9 Suppose ! and $ are infons and for all r, a, and i,
1. Rel(r, ! ) iff Rel(r, $ ), and2. Arg(a, i, ! ) iff Arg(a, i, $ ).
Then ! = $ .
In many presentations of Situation Theory there is a further condition, relatingto the “polarity” of an infon. The infons expressed by “Amelia is loquacious” and“Amelia is not loquacious” are taken to be on an equal footing, instead of taking thenegative form to be a constructed from the positive by an operation of negation, as isdone in propositional logic. The infons have the same relation (being loquacious) andthe same argument (Amelia) filling the same role. They are distinguished only by theirpolarity, which can be either positive or negative.
We can incorporate this proposal into the present account in various ways. Forexample, we could introduce a new unary relation, Pos, that holds of the positiveinfons only, and axioms to give the modified identity conditions and to ensure that forevery positive infon there is a corresponding negative infon. For the moment, we shallkeep our basic definitions uncluttered by matters of polarity; but we return to the topicwhen discussing complex infons in Section 4.3.6.
Considerations of polarity aside, Axiom A9 has found widespread support, partlybecause it allows the use of a convenient functional notation. For any finite infon !
there is a relation r and a finite sequence 'i1, a1(, . . . , 'in, an( of role-argument pairs,such that Rel(r, ! ) and Arg(aj, ij, ! ) for 1 # j # n, and no other pair 'i, a( is suchthat Arg(a, i, ! ). Given Axiom A9, the identity of ! is completely determined by thisinformation, and so we may write ! unambiguously as
''r; i1 : a1, . . . , in : an((.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 262 — #10
262 Handbook of Logic and Language
The set of role-argument pairs in a basic infon is called an assignment. Althoughconfined by the linearity of text, the elements of the assignment are intended to beunordered, so that, for example, ''r; i : a, j : b(( and ''r; j : b, i : a(( denote the sameinfon – this follows from Axiom A9, of course.7
The functional notation and its variants are widely used. Indeed, it is tempting tobase the subsequent development of Situation Theory on an infon-building functionthat maps each pair consisting of a relation r and an assignment ''i1, a1(, . . . , 'in, an((to the infon ''r; i1 : a1, . . . , in : an((. A problem is that the infon-building function ispartial. Even in standard information structures, not every relation-assignment pairdetermines an infon; an infon will result only if the length of assignment is the sameas the arity of the relation.
Faced with partiality there are three natural responses. The first (Plotkin, 1990), isto have an infon-building function that is total but does not always deliver an infon.The advantage is an uncomplicated model; the disadvantage is the existence of many“pseudo-objects” in the universe of the model that fail to model anything real. Thesecond response (Barwise and Cooper, 1991; Plotkin, 1990) is to accept that the infon-building function is partial, and make do with a partial language (and logic) for des-cribing situation-theoretic objects. The third response (Muskens, 1995; Cooper, 1991;and this chapter) is to base the theory on relations instead of functions. The advantageis that we retain the services of classical logic and our models remain uncomplicated.The disadvantage is that we must abandon the functional notation, at least for theore-tical purposes.
In less formal discussions we shall still use terms of the form “''r; i : a, j : b((” withthe presupposition that there is an infon to which the term refers. When the roles areclear from the context, or are numerical indices in the canonical order (i = 1, j = 2),we use the abbreviated form “''r; a, b((”.
The identity criteria discussed above are only intended to apply to infons of thesimplest kind. Quite different criteria will be needed for complex infons, such as con-junctions and disjunctions. They will be discussed in Section 4.3.4.
4.2.5 Arguments
Standard information structures have the property that
A10 No argument is an infon, relation or role.
In other words, the information modeled is of a purely “non-reflexive” kind: noinformation about infons, relations, or roles is included. This is a severe limitationthat has motivated a number of important developments in Situation Theory.
A reason for rejecting Axiom A10 in favor of a more liberal framework is theneed to express “higher-order” information – information about infons. Ascriptions ofpropositional attitudes and conditionals are the obvious examples. For example, if !
7 The use of angle brackets in the functional notation is suggestive of the set-theoretic model of infons usedin Construction 4.2.1. It is important not to confuse the two.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 263 — #11
Situation Theory 263
is the information that Albert is replete, then the information that Delia knows thatAlbert is replete may be thought to involve some relation between Delia and ! . A firstcandidate for modeling this is an infon of the form ''knows; Delia, ! ((. Likewise,if $ is the information that Albert is snoring, then we might regard the conditional“if Albert is snoring then he is replete” as expressing the information ''if; !, $ ((.8We might also wish to model information about Situation Theory itself. For example,the information that r is the relation of ! may be modeled by an infon of the form''Rel; r, ! ((.
Recalling Construction 4.2.1, it is easy to see why Axiom A10 is satisfied. InSInf(M) all arguments of infons are of the form '0, m( but infons, relations and rolesare of the form 'i, a( for i += 0. As we have seen, these sortal restrictions are neededto ensure that the construction preserves isomorphism. They are enforced in the finalmove from SInf)(M) to SInf(M) in which a copy is made of |M|. We can obtainmodels constraining higher-order infons by dropping this step. For example, supposeM is of type [M, R1
1, R22] and M happens to contain an element ! = '3, R2, #(, in
which # is a function from {1, 2} to M. Then ! is classified as an infon because of itsset-theoretic form. But it is also an element of M and so may occur as an argument toanother infon. If % is the function with domain {1} and %(1) = ! then $ = '3, R1, %(is such a “higher-order” infon. In the functional notation, $ = ''R1; ! ((. The nearestcounterpart in SInf(M) is ''R1; '0, ! (((, which is not the same thing at all.
The method may be made more systematic by iterating the construction ofSInf)(M).
Construction 4.2.2. Given a relational structure M, we define an infinite sequenceA0, A1, A2, . . . of information structures as follows. Let A0 be M, and for each integern, let An+1 be SInf)(An). Let A be the “iterated” structure defined by taking unions:
|A| =!
n$N|An|, [[Rel]]A =
!
n$N[[Rel]]An , [[Arg]]A =
!
n$N[[Arg]]An .
It is simple to check that A is an information structure, and that it is a fixed point:SInf)(A) = A. Moreover, like Construction 4.2.1, this construction preserves iso-morphism.
As intended, Axiom A10 fails in the iterated structures. In addition to the infonsof SInf(M), the iterated structure contains infons of the forms ''Rel; r, ! (( and''Arg; a, i, ! ((. Other “higher-order” infons can be incorporated by extending the def-inition of SInf)(M) appropriately.9
8 Conditionals are reconsidered in Section 4.4.9.9 For example, in addition to A1, A2, and A3, extend the universe to include
A4 = {'4, knows, #( | # : {1, 2} " M and !x, y #(1) = '0, x(, #(2) = '3, y(} and
A5 = {'5, if, #( | # : {1, 2} " M and !x, y #(1) = '3, x(, #(2) = '3, y(}.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 264 — #12
264 Handbook of Logic and Language
4.2.6 Circularity
Despite escaping Axiom A10, the arguments of infons in iterated informationstructures are not entirely without restriction. The following axiom is satisfied by alliterated information structures, as well as by all standard ones.
A10.1 There is no infinite sequence a0, a1, a2, . . . such that, for each integer n, an+1 is anargument of an.
Axiom A10.1 is weaker than Axiom A10, which disallows even finite sequencesof nested arguments, but it is strong enough to prohibit “circular” information. Forexample, let ! be the information expressed by the following sentence: “The informa-tion expressed by this sentence is expressible in English”. A simple-minded analysisof the structure of ! is that it has a relation expressible-in-English with a single role i,and is such that Arg(!, i, ! ). In other words, ! satisfies the equation
! = ''expressible-in-English; ! ((,
and the infinite path !, !, !, . . . is forbidden by Axiom A10.1. Infons with the self-referential properties that conflict with Axiom A10.1 have been called “hyperinfons”.There are other examples.
Let $ be the information that the soufflé Paul cooked has failed to rise. If $ iscommon knowledge among Paul and Albert then they both know $ and each knowsthat the other knows $ . Moreover, each knows that the other knows that he knows $ –and so on, ad infinitum. Barwise (1987) notes that the shared information ! satisfiesthe following equation:
! = $ , ''knows, Albert, ! (( , ''knows, Paul, ! ((.
Next, suppose that being incorrect is a property of infons, and let “incorrect” namethis property. Any infon satisfying the equation
! = ''incorrect; ! ((
leads to some tricky problems for a theory of the relationship between information andtruth (to be discussed in Section 4.4). One could claim that there are no such infons,but then it would be difficult to say what information is expressed by the statementthat the information expressed by this statement is incorrect. Many similar puzzlesare discussed in Barwise and Etchemendy (1987). Koons (1990, 1992) uses a similarapproach to tackle doxastic puzzles involving self-reference.
The elucidation of the structure of hyperinfons and other “circular phenomena” isone of Situation Theory’s main achievements. It is also one of the main reasons for thepresent, relational approach. Although Axiom A10.1 is satisfied by all standard infor-mation structures, there are non-standard structures in which hyperinfons exist. This

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 265 — #13
Situation Theory 265
is easy to see: the structure A1 with just three elements {a, r, i} and with extensions[[Arg]] = {'a, i, a(} and [[Rel]] = {'r, a(} is a simple information structure in whichthe element a satisfies the equation a = ''r; a((.
When Axiom A10.1 is dropped in order to model hyperinfons, Axiom A9 isno longer sufficient to determine identity. Consider the structure A2 with universe{a, b, r, i} and extensions [[Arg]] = {'a, i, a(, 'b, i, b(} and [[Rel]] = {'r, a(, 'r, b(}.In this structure there are two infons, a and b, that satisfy the equation ! = ''r; ! ((.There is no difference in the structure of a and b, and yet they are distinct, despite thefact that Axiom A9 is satisfied. What went wrong?
The solution to this problem was a turning point in the development of Situ-ation Theory. The crucial concept of “bisimulation” first appeared in modal logicand in theoretical computer science, where it is used to define equivalence of pro-cesses. The latter led directly to Aczel (1988), where it is used to formulate the Anti-Foundation Axiom (AFA), an alternative to the Axiom of Foundation in Set Theory.The resulting theory of sets offered a rich new class of structures with which to con-struct models of circular objects, such as hyperinfons. AFA is discussed further inSection 4.3.2.
Applied to simple information structures, “bisimulation” is defined as follows.
Definition 4.2.3. Given a simple information structure A, a binary relation R on A, isa bisimulation iff for all !, $ in A, if R(!, $ ) then
1. if either ! or $ are not infons then ! = $ ,2. if ! and $ are infons then they have the same relation and roles,3. -i, a, b if Arg(a, i, ! ) and Arg(b, i, $ ) then R(a, b), and4. R($, ! ).
For any elements a, b in A, we say that a is bisimilar to b iff there is a bisimulationR such that R(a, b). It is easy to show that the relation of being bisimilar is itself abisimulation, the largest bisimulation in A.
A more general definition of bisimulation is given in Section 4.3.1, but the oneabove will do for now. It allows use to state an improved principle of identity forinfons:
A10.2 If a is bisimilar to b then a = b.
Returning to our example, we see that the structure A2 fails to satisfy Axiom A10.2because a and b are bisimilar but not identical. Axiom A10.2 is strictly stronger thanAxiom A9, but equivalent to it when restricted to the class of structures satisfyingAxiom A10.1, which includes the standard structures. At this stage it is importantto realize that we have only shown the possibility of constructing models of somehyperinfons. The question of whether all “circular phenomena” in Situation Theorycan be modeled in this way is as yet undecided. A positive answer will be given inSection 4.3.2.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 266 — #14
266 Handbook of Logic and Language
4.2.7 Appropriateness
Let’s say that an object is ordinary if it is neither a role, nor an infon, nor a relation.In standard structures, for each relation r of arity n and each sequence a1, . . . , anof ordinary objects, the infon ''r; 1 : a1, . . . , n : an(( exists. We call this property ofstandard structures “generality”. To state it precisely, we say that infons ! and $ eachwith role i are i-variants if for each role j += i and each a, Arg(a, j, ! ) iff Arg(a, j, $ ).With this terminology, the principle of generality, which is respected by all standardinformation structures, may be stated as follows.
A11 For each infon ! with role i and each ordinary object a, there is an i-variant $ of !
such that Arg(a, i, $ ).
There are reasons for thinking that Axiom A11 is both too weak and too strong. Itis too weak because it says nothing about the appropriateness of arguments that arenot ordinary. Removing the restriction to ordinary objects, we get the following:
A11.1 For each infon ! with role i and each object a, there is an i-variant $ of ! such thatArg(a, i, $ ).
Axiom A11.1 is not satisfied by standard information structures. The iterated struc-tures of Construction 4.2.2 obey a version of the axiom restricted to infons with rela-tion Rel or Arg.
Axioms A11 and A11.1 are both too strong because they do not permit sortal rest-rictions. For example, the information expressed by “Albert tasted the crème brûlée”presupposes that Albert is an agent, perhaps even that he is subject of conscious expe-rience. Good evidence for this is that “Albert did not taste the crème brûlée” has thesame presupposition; we would be surprised to the point of incomprehension if wewere told later that Albert is a Moulinex food processor. An explanation for sortalpresuppositions like these is that the argument roles of infons carry certain restrictionson what can fill them. The omelette O of our original example may be prevented fromfilling the role of cook played by Raymond by ensuring that there is no infon $ suchthat Arg(0, cook, $ ). Since there is an infon ! such that Arg(R, cook, $ ) and O is anordinary object, this is inconsistent with Axiom A11.
We say that an object a is an appropriate filler of role i just in case there is an infon! such that Arg(a, i, ! ). To allow for role-linked sortal restrictions, we may modifyAxiom A11 to get the principle of “sortal generality”:
A11.2 For each infon ! with role i and each appropriate filler a of i, there is an i-variant $
of ! such that Arg(a, i, $ ).
This is a great improvement. In effect, each role is associated with a class of appro-priate fillers, and any argument may be replaced by any object in that set. In standardinformation structures, the class of appropriate fillers for each role is just the class ofordinary objects, but other structures may have different classes for different roles.The iterated structures of Construction 4.2.2 all satisfy Axiom A11.2. There are twoclasses of fillers: roles of the original structure may be filled by any ordinary object,and roles of infons whose relation is Arg of Rel may be filled by any object at all.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 267 — #15
Situation Theory 267
A theory of appropriateness, stating in general terms which arguments may fillwhich roles, has not yet been given. Axiom A11.2 is consistent with the way roles areusually thought to restrict their fillers, but there may be restrictions on the formationof infons that are not attributable to a single role. For example, a sketch of Paul andRaymond standing side-by-side conveys the information that Paul is standing next toRaymond; we can model this with an infon of the form ''next-to; P, R((. Arguably,the infon presupposes that there are two people rather than one. We could capture thepresupposition by saying that the two roles of next-to place a joint restriction ontheir fillers, namely, that they cannot be filled by the same argument. This kind ofrestriction is not permitted by Axiom A11 or by Axiom A11.2.
4.2.8 Partiality
In standard information structures every infon has a relation and a set of roles deter-mined by that relation. This is captured by the following two axioms.
A12 For each infon ! there is a relation r such that Rel(r, ! ).A13 If Rel(r, ! ) and Rel(r, $ ) and Arg(a, i, ! ) then for some b, Arg(b, i, $ ).
One reason for dropping these axioms is to allow infons to be unsaturated. Forexample, suppose you overhear someone saying “Mary saw Elvis in Tokyo” but a dis-tracting noise prevents you from hearing the word “Elvis”. The information conveyedis unsaturated because the filler of one of the roles is missing. We may represent theunsaturated infon as ''saw; seer: Mary, location: Tokyo((, to be contrasted with theinfon
''saw; seer: Mary, seen: Elvis, location: Tokyo((,
which would have been conveyed had you heard the whole utterance. The coexistenceof these infons is forbidden by Axiom A13. Another way in which an infon can beunsaturated is by lacking a relation – consider, for example, the information conveyedif the word “saw” had been obscured. This possibility counts against Axiom A12.
In the absence of Axioms A12 and A13, it is useful to define an ordering of infonsthat captures the degree to which they are saturated.
Definition 4.2.4. Infon ! is part of infon $ , written ! . $ , if
1. for all r, if Rel(r, ! ) then Rel(r, $ ), and2. for each role i and object a, if Arg(a, i, ! ) then Arg(a, i, $ ).
An infon ! is unsaturated if there is another infon $ such that ! . $ . If there is nosuch infon, ! is saturated.
Despite the need for unsaturated infons, there is something to be said for the intui-tion that an infon should have a relation that determines its roles. We can recover theforce of this idea by restricting Axioms A12 and A13 to apply only to saturated infons.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 268 — #16
268 Handbook of Logic and Language
A13.1 Every saturated infon has a relation.A13.2 For saturated infons, ! and $ , having the same relation and for each object a and
role i, if Arg(a, i, ! ) then, for some b, Arg(b, i, $ ).
Axioms A12 and A13 follow from A13.1 and A13.2 given the additional assump-tion that every infon is saturated. In this way, we see that the standard structures are alimiting special case.
The ordering . is clearly a pre-order of infons (reflexive and transitive). In infor-mation structures satisfying Axiom A9 it is a partial order (reflexive, transitive, andantisymmetric), and in standard structures it is trivial (! . $ iff ! = $ ) because everyinfon is saturated.
In non-standard information structures, we can ensure the existence of the greatestnumber of unsaturated infons with the following axiom:
A13.3 For every set I of roles and every infon ! , there is an infon $ such that, for each rolei and object a, Arg(a, i, $ ) iff Arg(a, i, ! ) and i $ I.
Axiom A13.3 entails that if ''r; i : a, j : b(( exists then so do ''r; i : a((, ''r; j : b((and even ''r; ((. In other words, it allows every infon to be broken up into smaller parts.The issue of whether and how the parts can be recombined is separate, and requiresthe following definition.
Definition 4.2.5. Infons ! and $ are compatible if they have the same relation andfor each role i and objects a and b, if Arg(a, i, ! ) and Arg(b, i, $ ) then a = b. Theyare unifiable if they possess a least upper bound in the . ordering.10
For example, the information that Mary saw Elvis is compatible with the informa-tion that Elvis was seen in Tokyo. These two infons may be unified to produce theinformation that Mary saw Elvis in Tokyo.11 This suggests the following unificationaxiom.
A13.4 Every compatible pair of infons is unifiable.
Questions concerning the order of infons become a lot more difficult to answer ifthe arguments of infons are also partial objects. This is unavoidable when we include“higher-order” infons, as discussed in Section 4.2.5. There are a variety of ways ofextending the order between infons by taking the order of arguments into account, butnone of them is entirely satisfactory. Consider, for example, the idea that if a . a% thenthe infon ''r; i : a, j : b(( is part of the infon ''r; i : a%, j : b((. This is initially plausiblebut has unattractive consequences when applied to higher-order infons, such as thoseof the conditional form ''if; !, $ ((. If ! += ! % then we would not wish to say that''if; !, $ (( is part of ''if; ! %, $ (( even if ! . ! %. Of course, one could take this asevidence against modeling conditionals as infons of this form, instead of evidence
10 I.e. if !x such that ! . x, $ . x, and -y, if ! . y and $ . y, then x . y.11 There is no requirement that the unification of two infons is “entailed” by the infons being unified; just
that the unification of the two infons is the least infon containing them.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 269 — #17
Situation Theory 269
against the proposed order-structure. As the issue is presently unresolved, we shallstick with the “flat” order.
With discussions of unification, comparison with the literature on feature struc-tures is unavoidable. Indeed, it is easy to see how one can construct informationstructures using feature structures to model the infons. Conversely, one can use infor-mation structures to model feature structures, by identifying features with roles andvalues with arguments. The order . defined for infons is relatively uninterestingwhen applied to feature structures, precisely because it does not take into accountthe order of arguments. Rounds (1991) discusses the relationship between the twosubjects.
4.2.9 Representation Theorems
In addition to the axioms discussed above, we need one more axiom to account for thebehaviour of constants in standard information structures.
A14 Every relation but no role and no infon is denoted by a constant.
This axiom is entirely artificial, and of little consequence to the general theory.
Theorem 4.2.1. A simple information structure is standard if and only if it satisfiesAxioms A1 to A14.
Proof. We have already seen that each of these axioms is satisfied by all standardinformation structures. For the converse, let A be an information structure satisfy-ing the axioms, with constants C. We shall construct a relational structure M and anisomorphism f : |A| "| SInf(M)|.
Let R be the class of relations in A, I the class of roles, & the class of infons, andM the class of ordinary objects. By Axioms A3 to A5, these four classes are pairwisedisjoint and exhaust the universe of A.
The class R of relations is finite by Axiom A8. For each r in R, let
Ir = {i | !a, ! Rel(r, ! ) and Arg(a, i, ! )}.
We shall show that Ir is finite. For each infon ! of A, let I! = {i | !a Arg(a, i, ! )}. ByAxiom A13, for all infons ! and $ such that Rel(r, ! ) and Rel(r, $ ), I! = I$ . Thusfor each ! having relation r, Ir = I! . By Axiom A7, I! is finite for each infon ! , andso Ir is finite also.
Let S / C be the class of those constants that denote relations in A. By Axiom A14,S is the same size as R. This enables us to define a relational signature " with primitiverelations S and such that for each R% in S, "(R%) is equal to the size of I[[R%]]A . Let Mbe any relational structure with signature ", universe M, and constants C ) S, eachwith the same denotation it has in A; this is possible because these constants denoteordinary objects, by Axiom A14. We shall construct an isomorphism f from A toSInf(M).

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 270 — #18
270 Handbook of Logic and Language
First, we must enumerate the set I of roles of A. By Axioms A1 and A12, foreach infon ! of A there is a unique relation r! such that Rel(r! , ! ). By the above,I! = Ir! . But there are only a finite number of relations (Axiom A8), and so there areonly a finite number of sets of the form I! , even if the number of infons is infinite.Moreover, by Axiom A6, these sets are linearly ordered by inclusion. Consequently,there is an enumeration r1, . . . , rn of R such that Irk / Irk+1 , for for 1 # k # n ) 1.Now
I = Ir1 * · · · * Irn = Ir1 * · · · * (Irk+1 ) Irk) * · · · * (Irn ) In)1)
and so we may enumerate I by enumerating each of the sets (Irk+1 ) Irk) in order, andwithout repetition. Let i1, . . . , iN be such an enumeration. It has the property that for1 # k # n, Irk = {i1, . . . , i"(rk)}.
Next, we must consider the arguments of infons. For each infon ! , we have seenthat
I! = Ir! = {i1, . . . , i"(r! )}
and by Axiom A2, for 1 # k # n, there is a unique object ak such thatArg(ak, ik, ! ). By Axiom A10, ak is ordinary and so is in M. Define the function#! : {1, . . . , "(r! )} "{ 0} & M by #! (k) = '0, ak(.
Now we are ready to define the function f from |A| to | SInf(M)|.
f (x) =
"###$
###%
'0, x( if x is in M,
'1, x( if x is in R,
'2, k( if x is in I and ik = x,'3, 'rx, #x(( if x is in &.
This is a good definition, because every element of |A| is in exactly one of theclasses M, R, I or & , and for each x in I there is a unique k such that ik = x. To showthat f is one-one, suppose that f (x) = f (y). We can show that x = y by cases accordingto whether x and y are in M, R, I or & . The only non-trivial case is that in which xand y are infons. Then f (x) = '3, 'rx, #x(( and f (y) = '3, 'ry, #y((. Thus, rx = ry and#x = #y, and so by Axiom A9, x = y, as required.
To show that f maps onto the universe of SInf(M), consider any element ' j, x(of that universe. We need to find a y such that f (y) = ' j, x(. The only non-trivialcase is that in which j = 3. Then x = 'r, #( for some relation r and function# : {1, . . . , "(r)} " {0} & M. For 1 # k # "(r), let mk be the element of M forwhich #(k) = '0, mk(. Now, r is a relation, so there is some infon ! of A such thatRel(r, ! ). The roles of ! are those in the set I! = {i1, . . . , i"(r)} and so, applyingAxiom A11 repeatedly ("(r) times), we obtain an infon ! % such that Arg(mk, ik, ! %)for 1 # k # "(r). Spelling out the definition of #! % we see that this function is just #,so 'r! % , #! % ( =' r, #( = x, and so f (! %) = '3, 'r! % , #! % (( = '3, x(, as required.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 271 — #19
Situation Theory 271
Finally, we must show that f preserves the structure of A. This follows from thefollowing two chains of equivalences. Firstly for Rel:
Rel( f (r), f (! )) in SInf(M) iff
Rel('1, r(, '3, 'r! , #! (() in SInf(M) iff
r = r! iff
Rel(r, ! ) in A.
And then for Arg:
Arg( f (m), f (i), f (! )) in SInf(M) iff
Arg('0, m(, '2, k(, '3, 'r! , #! (() in SInf(M) and ik = i iff
#! (k) = '0, m( and ik = i iff
Arg(m, i, ! ) in A.
That f preserves the denotation of the constants in C follows from Axiom A14 and thedefinition of SInf(M). !
So much for standard information structures. We have argued that these struc-tures are too rigid to provide a comprehensive framework for modeling the struc-ture of information, even information of the simple kind we have been considering.Nonetheless, several of the axioms of standard structures lead to attractive generaliza-tions. Specifically, Axioms A10.2 and A11.2 provide a useful direction. Both will beexplored in greater depth in the next section.
4.3 A Theory of Structural Relations12
Information processed, inferred, conveyed, expressed, or otherwise represented neednot be of the simple kind considered above; it may come in larger, more complexchunks.
Logical combinations present an obvious example: we need to account for conjunc-tions, disjunctions, and perhaps negations of infons. Yet even with the first item on thelist there is a potential problem. The identity condition for well-founded simple infonswas very clear: ! and $ are identical if and only if they have the same relation andthe same arguments filling the same roles. It is much less clear what should be saidabout conjunctions. A strong condition, analogous to the one for basic infons, is that!1 , $1 is identical to !2 , $2 if and only if !1 is identical to !2 and $1 is identical to$2. The problem arises if we combine this condition with natural logically-motivated
12 In this section the theory of information structure introduced in Section 4.2 is developed in greatergenerality and depth. The reader impatient to find out about situations should jump ahead to Section 4.4.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 272 — #20
272 Handbook of Logic and Language
requirements on conjunction, such as commutativity, associativity and idempotence.For example, by idempotence, ! , $ = (! , $ ) , (! , $ ), and so, by the abovecondition, ! = ! , $ = $ .
The heart of the problem is an inherent tension in the concept of information. Onthe one hand, information is representation-independent: the same information maybe represented in many different ways. On the other hand, information is fine-grained:two pieces of information may be logically equivalent without being identical. Conse-quently, the identity conditions for information represented by complex signs must liesomewhere between those for the syntactic form of the sign and those for its semanticcontent. Striking the right balance is, in general, very difficult.
Another problem is that there has been little agreement as to which combinations ofinfons are needed. Finite conjunction and disjunction are commonly adopted; infiniteconjunctions and disjunction, quantified infons (with variable binding), various nega-tions and conditionals, have also been proposed. For applications in computer scienceother forms may be found useful. For example, it is not clear that the informationstored as a list is simply a conjunction of the items of information stored in each cell,and even if it is some kind of conjunction, it is not clear that it is the same conjunctionas expressed by an unordered set of the same items.
In view of the above, it would seem sensible to pursue a fairly open minded policyabout complex infons. The approach adopted here is intended to cover various propos-als made in the literature, as well as offering a framework in which other approachesmay be tried.
4.3.1 Extensional Structures
Our idea is to generalize the notion of bisimulation to apply in a wider context. In thesequel, we will have (relational) structures of type
[A, S1, . . . , Sm; R1, . . . , Rn].
The relations in the first group, S1, . . . , Sm, are called structural relations becausethey capture the structure of elements of the domain. A structural relation Si of arityn + 1 is to be thought of as relating a list of n objects to a single structured object. IfSi(x1, . . . , xn, y) then y is a structured object with components x1, . . . , xn, which mayor may not be structured themselves.
More generally, we say that b is a component of a in A if there is a structural relationSi of arity n+1 and elements x1, . . . , xn of A such that Si(x1, . . . , xn, a) and xj = b forsome 1 # j # n. For technical reasons, we require that the number of components ofany object is not a proper class – that is to say, the class of all components of a givenobject can be placed in one-to-one correspondence with some set. An object a is anatom of A if it has no components.
In an information structure, the only structured objects are the infons. Relations,roles and ordinary objects are all atomic, but infons have a component structure cap-tured by the relations Rel and Arg. These are the structural relations of information

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 273 — #21
Situation Theory 273
structures. Information structures have no other primitive relations, but the definedrelation . is an example of a non-structural relation – albeit one whose extension isdetermined by the structure of infons. The important distinction between Rel and Arg,on the one hand, and ., on the other, is that the identity of infons is determined by theformer by virtue of adherence to Axiom A10.2.
But now consider an arbitrary relational structure. What conditions must a rela-tion satisfy to qualify as a structural relation? Our answer is based on the followingdefinition.
Definition 4.3.1. Given a relational structure A of type [A, S1, . . . , Sm; R1, . . . , Rn],a binary relation E on A is said to be a bisimulation on A if for all a, b $ A, if E(a, b)
then the following three conditions hold:
1. if a is atomic then a = b,2. for 1 # i # m, if "i = k then, for all y1, . . . , yk such that Si(y1, . . . , yk, a), there are
z1, . . . , zk such that Si(z1, . . . , zk, b) and E(yj, zj) for 1 # j # k, and3. E(b, a).
a is bisimilar to b in A iff there is a bisimulation E of A such that E(a, b). The structureA is extensional if it has no distinct bisimilar objects; i.e. if a is bisimilar to b in Athen a = b.
In an extensional structure, the non-atomic objects are individuated according totheir structural properties alone. The extensionality condition is a form of Leibniz’sLaw: objects that are indistinguishable on the basis of their structural relationshipsare identical. The non-structural relations, R1, . . . , Rn, do not enter into the identityconditions of objects in the domain. They may be entirely determined by the structureof the objects they relate – . relation is an example of this – or they may capturegenuinely non-structural properties.
Extensional structures will be used throughout the rest of this chapter to modela variety of situation-theoretic objects. Our strategy is to define different kinds ofextensional structures to model different parts of the situation-theoretic universe, in away that allows us to re-combine the parts easily.
Definition 4.3.2. If A is an extensional structure, then, for each structural relation Sof A, let S0 be the class of those objects a such that S(x, a) in A for some sequence x(possibly empty) of elements of |A|. In other words, S0 is the projection of S along itslast co-ordinate. We call these classes the (structural) sorts of A.
Every information structure satisfying Axiom A10.2 is an extensional structurewith structural relations Rel and Arg. The standard structures and even the iteratedstructures are also well-founded, by Axiom A10.1. In a standard information structureRel0 = Arg0; and this is the class of infons, the only structured objects. In non-standard information structures, Rel0 and Arg0 may be slightly different if there areinfons with a relation but no arguments or with arguments but no relation. In any case,the class of infons is Rel0 * Arg0. The relations, roles and ordinary objects are allatoms.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 274 — #22
274 Handbook of Logic and Language
Another, familiar example of an extensional structure is the structure V of type[V, $2; ] where V is the class of all sets, and the extension of $ is the binary relationof membership. The class $0 consists of all non-empty sets. Extensionality is assuredby the set-theoretic axiom of the same name, together with the Axiom of Foundationor Anti-foundation, depending on whether V is assumed to satisfy the axioms of well-founded or anti-founded set theory.
Definition 4.3.3. An extensional structure A of of type [A, Set1, $2; ] is called a setstructure if $0/ Set0 and A satisfies the axioms of ZFC) with quantifiers restrictedto Set0.13
The ambiguity in our use of the word “set” and the predicate “$” is of the nowfamiliar kind. Internal sets are those elements of the structure in Set0, which may ormay not be (external) sets. But for any internal set a, we may define a correspondingexternal set a0 = {b | $(b, a)}.
Our third example of an extensional structure presents functions as structuredobjects whose components are their arguments and values.
Definition 4.3.4. An extensional structure A of type [A, App3, Fun1; ] is a functionstructure if App0 / Fun0 and, for all #, x, y and i in A, App(i, x, #) iff App(i, y, #),then x = y.
If # $ Fun0 then # is an (internal) function of A. We associate it with an externalfunction #0 whose domain consists of those elements i of A for which there is an xsuch that App(i, x, #). For each such i, #0(i) is the unique x such that App(i, x, #).
The extensionality requirement on function structures means that different internalfunctions represent different external functions. For if a0 = b0, then IA*{'a, b(, 'b, a(}is a bisimulation relating a and b and so a = b. If the structure is flat (i.e. if nofunction is also an argument), then extensionality is equivalent to this condition; inother structures it is a stronger condition.
4.3.2 Structural Descriptions and Anti-Foundedness
The extensionality condition ensures that our structures are not over-populated. In thissection we guard against the danger of under-population, by showing how extensionalstructures can be populated to capacity.
Every object in an extensional structure can be identified by listing its structuralrelationships with other objects. Given an extensional structure A and a “parameter”x, which may be any object and not necessarily an element of |A|, a unary structuraldescription T is a pair 'x, Tx( consisting of a set Tx of tuples of the form 'S, b1, . . . , bk(where S is a structural relation of arity k + 1 and each of b1, . . . , bk is either the
13 ZFC) is Zermelo–Frankel Set Theory with the Axiom of Choice, but without the Axiom of Foundation.See Section 4.3.2 for more details.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 275 — #23
Situation Theory 275
parameter x or an object of A. For each a in |A|, we form the set a.T of tuples ofthe form 'S, b1[x/a], . . . , bk[x/a]( for each 'S, b1, . . . , bk( in Tx, where bi[x/a] = aif bi = x and is bi otherwise. The object a satisfies the description T if for all S andb1, . . . , bk,
S(b1, . . . , bk, a) in A iff 'S, b1, . . . , bk( is in a.T.
For example, in a simple information structure A the infon ! = ''r; i : !, j : a((satisfies the description
T = 'x, {'Rel, r(, 'Arg, i, x(, 'Arg, j, a(}(
because
!.T = {'Rel, r(, 'Arg, i, ! (, 'Arg, j, a(}
and Rel(r, ! ), Arg(i, !, ! ), and Arg( j, a, ! ) hold in A; and these are all the structuralrelationships in which ! participates.
Every object satisfies some description. An object a of A satisfies the canonicaldescription 'a, Ta( where Ta is the set of tuples of the form 'S, b1, . . . , bk( such thatS(b1, . . . , bk, a) in A.14 By extensionality, no two objects satisfy the same canoni-cal description, but in most cases there many more descriptions than there are objectsdescribed. The problem of under-population is that there may be too few objects to sat-isfy the descriptions used in Situation Theory. To solve it, the definition of “structuraldescription” must be extended to cover the polyadic case.
Definition 4.3.5. Suppose A is an extensional structure. A structural description Tin A is an indexed family {Tx}x$X of sets Tx of tuples of the form 'S, b1, . . . , bk( suchthat S is a structural relation of A of arity k +1 and b1, . . . , bk are elements of |A|*X.The elements of the index set X are called parameters. Given a mapping s from X to|A| let s.T be the family of sets s.Tx of tuples of the form 'S, b1[s], . . . , bk[s]( for each'S, b1, . . . , bk( in Tx where bi[s] = s(bi) if bi is in X and is bi otherwise. The mappings satisfies T if for each x in X, s(x) satisfies the unary description 's(x), s.Tx(.
To see how this definition works, consider its application to set structures. A set asatisfies the unary description T just in case
a.T =&'$, b( | b in a0' * {'Set(}.
Now, for each set U of tuples, let U0 = {b | '$, b( is in U}. Then a satisfies T iffa0 = (a.T)0. Likewise, if T is a polyadic structural description, then a mapping s
14 Ta cannot be a proper class because we have assumed that every object has only a set-sized class ofcomponents.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 276 — #24
276 Handbook of Logic and Language
satisfies T iff s(x)0 = (s.Tx)0 for each parameter x of T . This relationship enables
us to represent a structural description in a set structure as a system of simultaneousequations. For example, the system of equations shown on the left below correspondsto the structural description shown on the right.
x = {y, z}y = 1z = {x, a}
Tx = {'$, y(, '$, z(, 'Set(},Ty = {'Set(},Tz = {'$, x(, '$, a(, 'Set(}.
A mapping s that satisfies the description on the right determines (and is determinedby) a solution to the equations. It gives us sets s(x), s(y), and s(z), such that s(x) ={s(y), s(z)}, s(y) = 1 and s(z) = {s(x), a}.
Thus, in set structures the “population density” is determined by the number ofsystems of equations that have solutions. Structural descriptions correspond to a widerrange of systems of equations than one might expect. Consider X = {x, y} and e(x) ={'x, y(}, e(y) = {x, y, 1}. This system is unlike the ones we’ve seen so far becausee(x) contains the ordered pair 'x, y(. In set theory, this pair is standardly taken tobe {{x}, {x, y}}. To solve a system involving pairs, we must add more variables toX and more equations. Here we would take X% = {x, y, z0, z1, z2} and e(x) = {z0},e(y) = {x, y, 1}, e(z0) = {z1, z2}, e(z1) = {x}, e(z2) = {x, y}. A solution to theexpanded system gives us a solution to the original system. This would be a map sdefined on X with the property that s(x) = {'s(x), s(y)(} and s(y) = {s(x), s(y), 1}.The usual models of Set Theory are rather sparse by this standard. The above system,for example, cannot be solved because any solution would conflict with the FoundationAxiom. If s is a solution, then there is an infinite descending sequence of elements:s(x) 2 s(z) 2 · · · 2 s(x) 2 s(z) 2 · · · .
Fortunately, Aczel (1988) showed that if the Foundation Axiom is dropped fromZermelo–Frankel Set Theory (ZFC), the resulting theory (ZFC)) is consistent withthe claim that every system of equations has a unique solution. That claim, calledthe Solution Lemma in Barwise and Etchemendy (1987), is equivalent to the Anti-Foundation Axiom (AFA) used by Aczel.15 Aczel proposes ZFC) plus AFA as a newtheory of sets, perhaps more suitable than ZFC when it comes to modeling the variouscircular phenomena encountered in applied logic.
Returning to the general case, we can formulate the two extremes of populationdensity by generalizing Foundation and Anti-Foundation to apply to arbitrary exten-sional structures.
15 The Anti-Foundation Axiom is defined using “decorations” of a pointed graph, rather than solutions ofequations or the satisfiers of structural descriptions. Another approach is to look at the fixed points ofmonotone operators on an upper semi-lattice. We advise the interested reader to consult Aczel (1988)and Barwise and Moss (1996) for details. Aczel discusses the application of AFA to situation theoryin Aczel (1996), and a more general framework for modeling structured objects is introduced in Aczel(1990). The approach taken here is also related to Fernando (1990).

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 277 — #25
Situation Theory 277
Definition 4.3.6. An extensional structure A is well-founded if there is no infinitesequence a1, a2, . . . of elements of A such that an+1 is a component of an for eachpositive integer n. It is anti-founded if every structural description in A is satisfied.
In particular, a set structure is well-founded if it satisfies the Foundation Axiom ofZFC and is anti-founded if it satisfies the Anti-Foundation Axiom. The well-foundedextensional structures are those with the lowest population density: only those objectsexplicitly requested by other parts of the theory are required to be present. Anti-founded structures, by contrast, are full to the brim: any object you can describe issure to be there. The next theorem shows that every extensional structure lies betweenthese two such extremes.
Theorem 4.3.1. For every extensional structure A there is a well-founded extensionalstructure Awf and an anti-founded extensional structure Aaf such that Awf is isomor-phically embedded in a A, and A is isomorphically embedded Aaf.
Proof. The existence of a well-founded part of A is easy to show. We can just restrictthe structure to those objects that are not at the start of an infinitely descending chainof components, and check that the extensionality condition still holds. For the anti-founded extension of A, we shall assume that we are working in a universe of setsthat satisfies ZFC)+AFA, and that there is a proper class of ur-elements (non-sets)available.
With each structural relation S of A, we associate an ur-element zs. We also asso-ciate an ur-element za with each atom of A. Let U be the collection of all these ur-elements. We assume that the association is one-to-one. For any set a, the “support”of a is the set of objects b0 for which there is a sequence b0 $ · · · $ bn with bn = a.We assume that no ur-elements in U occur in the support of |A|.
From Aczel (1988) and Barwise and Moss (1996) we know that every system ofequations in a model of ZFC)+AFA has a unique solution.
Definition 4.3.7. A system of equations is a function e whose domain is a set X ofur-elements with the property that for each x in X, e(x) is a set (not an ur-element).A solution to e is a function s with domain X, such that for every x in X, s(x) = {a[s] |a $ e(x)}. The square-brackets operation is defined by: (i) y[s] = s(y) for all y in X;(ii) y[s] = y for all ur-elements y not in X; and (iii) a[s] = {b[s] | b $ a} for sets b.16
Now, with each structural description T in A with parameter set XT , we associatethe function eT mapping each parameter x to the set
{'zs, b1, . . . , bk( |' S, b1, . . . , bk( $ Tx}.
16 That [s] is uniquely determined from s and these three conditions is also a consequence of AFA.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 278 — #26
278 Handbook of Logic and Language
In other words, each structural relation S is replaced by the corresponding zs. As itstands, eT is not a system of equations in the strict sense defined above because theelements of eT(x) are tuples of parameters and sets, rather than the parameters and setsthemselves. Using the method illustrated earlier, eT is easily converted into a systemof equations e%
T with parameter set X%T (containing XT ) such that a solution for e%
T is asolution for eT and vice versa.
The system e%T has a unique solution, sT . Let
B =&sT(x) | T is a structural description in A and x is in X%
T
'.
We’ll soon see how to interpret the relations of A on this set to get the desired structureAaf, but first we need a subsidiary fact about structural descriptions.
Recall that each a $ A satisfies a description Ta in one variable x. Let i : A " B begiven by i(a) = sTa(x) for a a non-atom of A, and i(a) = za if a is an atom. Then isone-to-one: if sTa(x) = sTb(x), then we could get a bisimulation relation on A relatinga and b. Since A is extensional, we would have a = b. And if a is a non-atom, theni(a) is a set, so it cannot equal i(b) = zb for b a non-atom
Now we can see how to make B into a structure Aaf of the same type as A. Let S bea structural relation. We interpret it by
S(c1, . . . , cn, c) in Aaf iff 'zS, c1, . . . , cn( $ c.
The definition of the principal descriptions Ta implies that
S(b1, . . . , bk, a) in A iff S(i(b1), . . . , i(bk), i(a)) in Aaf.
The non-structural relations extend to the image of A via the isomorphism; we’ll saythat on tuples outside the image of i, each non-structural relation is false.
At this point we have Aaf. This structure is extensional by AFA. A bisimulation ofstructures relating c and c% would give us a bisimulation of sets doing the same thing.And according to AFA, bisimilar sets are equal.
Finally, we sketch a proof that Aaf is anti-founded. Before we do this, we need torecall that for each c $ B there is a structural description Tc over the original A and aparameter x of T such that sT(x) = c. Let T % be a structural description in Aaf. Noweach Ty may contain elements c $ |Aaf|, so we replace each such c by a new ur-element(say zc) and then adjoin all of the structural descriptions Tc to T . Of course, we mustuse new parameters to do this. In this way, T % is equivalent to a structural descriptionin the original A. So by definition of Aaf, there is some a $ |Aaf| instantiating T %. !
As a corollary, we apply this result to simple information structures. Suppose Ais a simple information structure with a set R of relations, a set I of roles, and a setO of ordinary objects. A structural description of an infon in A with parameter set Xis determined by a system of equations of the form e(x) = ''r; i1 : b1, . . . , in : bn((where r $ R, ij $ I and bi $ O * X for 1 # i # n. Theorem 4.3.1 tells us that there is

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 279 — #27
Situation Theory 279
an anti-founded information structure Aaf extending A. In this structure all structuraldescriptions are satisfied and so there are solutions to the equations. In particular, allthe hyperinfons we care to define using relations R, roles I, and ordinary objects O canbe found in this structure.
4.3.3 Partiality and Order
We have seen how infons may be ordered according to their arguments and relations.In fact, the definition of . is quite general.
Definition 4.3.8. Given an extensional structure A of type
[A, S1, . . . , Sm; R1, . . . , Rn],
we define a relation . on the non-atomic elements of A as follows: a . b if for1 # i # m, and each sequence x of appropriate length, if Si(x, a) then Si(x, b).
For information structures, the definition of . agrees with our previous definition.For set structures, a . b iff a0 / b0, and for function structures, it is the usual orderon partial functions: f . g iff each i in the domain of f 0 belongs to the domain ofg0 and f 0(i) = g0(i). The relation . is a partial order on structured (non-atomic)objects.17
Other ordering of structured objects is possible and has been studied extensively.The most important of these is the “hereditary” order, which takes into account theorder of components. Roughly, an object a is a hereditary part of b if for every com-ponent a% of a there is a component b% of b such that either a% = b% or a% is a hereditarycomponent of b%. Stated thus, the definition is circular. In some cases we can overcomethe problem using an inductive layering of the domain. Say that an object is of order 0if it is atomic, and of order n + 1 if it has a component of order n but no componentsof order greater that n. This enables us to give a recursive definition of the hereditaryorder on objects of order n in terms of the hereditary order of objects of order lessthan n.
This strategy works for well-founded structures, in which every object has an order.But in structures with a “circular” component relation there are objects that do not havean order. This is a common problem in the study of circular phenomena. The solutionis as follows. First, we regard the “definition” of the order as an operation on binaryrelations. Given one binary relation R, we let R+ be defined by
R+(a, b) if for every component a% of a there is a component b% of b such that
either a% = b% or R(a%, b%).
17 It is clearly reflexive and transitive, and anti-symmetry follows from extensionality: if a . b and b . athen the union of {'a, b(, 'b, a(} and the identity relation is a bisimulation of A, and so a = b.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 280 — #28
280 Handbook of Logic and Language
Now, the operation taking R to R+ is monotone: if R / S then R+ / S+. A basicresult of the theory of order is that every monotone operation has a greatest fixedpoint. In other words, there is an R such that R+ = R and for any S such that S+ = S,
S / R. This observation enables us to define the hereditary order in the general case asfollows.
Definition 4.3.9. The hereditary order, .h, on an extensional structure A of type[A, S1, . . . , Sm; R1, . . . , Rn] is the largest binary relation between non-atomic objectsof A such that if a .h b then for 1 # i # m, if Si(x1, . . . , xk, a) then there arey1, . . . , yk such that Si(y1, . . . , yk, b) and xj .h yj for each 1 # j # k.
The hereditary order is a partial order on non-atomic objects for the same reasonthat . is. Other orders may be obtained by defining different monotone operations.
It is important to realize that both . and .h are purely structural concepts. In thecase of simple infons, if ! . $ then it is possible to go further and interpret the order interms of epistemological advantage: knowing ! is not as valuable as knowing $ . Thisinterpretation is not available in the general case. For example, in Section 4.3.4 weshow how to obtain a disjunction !1 3 !2 whose components are !1 and !2, and suchthat !1 3 !2 . !1 3 !2 3 !3. The question of how to relate the partiality of structureto logical operations is a difficult one; it is shared by those studying databases andfeature logic (Rounds, 1991).
The discussion of unification in information structures may also be generalized,although no uniform definition of compatibility is available. Instead, we may introducethe following abstract version.
Definition 4.3.10. An extensional structure A : [A, S1, . . . , Sm; R1, . . . , Rn, C2, P2]is a unification structure with order P and compatibility relation C if
1. C is symmetric and reflexive on non-atoms,2. P is a partial order of non-atoms, and3. If C(a, b) then a and b have a least upper bound in P.
For example, taking C(!, $ ) iff ! and $ are compatible simple infons, and P(!, $ )
iff ! . $ , we see that information structures obeying Axiom 13.4 are unificationstructures. For set structures, take P to be . and C to be the universal relation onSet0. Then the unification of any two sets is just their union. For function structureswith P taken to be the . order, let C( f , g) iff there is no i in the domains of both f 0
and g0 and such that f 0(i) += g0(i). The hereditary orders may also be used to defineunification structures with weaker, hereditary compatibility relations.
The converse of unification, imposed by Axiom 13.3 in the case of simple infor-mation structures, has no clear generalization to arbitrary extensional structures,but may be applied to function structures as follows. A function structure A isdownwards-complete if for each function f and each set I there is a function g suchthat for each i and a, App(i, a, g) iff App(i, a, f ) and i $ I.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 281 — #29
Situation Theory 281
4.3.4 Complex Infons
We have seen that infons, sets and functions may all be modeled using extensionalstructures. In each of these cases, the identity conditions are relatively straightfor-ward. In this section we consider structured objects with more complicated identityconditions.
Suppose we wish to have a binary operation of conjunction with the followingproperties:
(commutativity) ! , $ = $ , ! ,(associativity) ! , ($1 , $2) = (! , $1) , $2), and(idempotence) ! , ! = ! .
Suppose that we already have a stock of infons & in some information structure Afrom which to form conjunctions. Our task is to extend A with new elements andrelations designed to capture the structure of the conjunctions.
The solution is to define a new binary structural relation ConjunctOf that holdsbetween conjuncts and their conjunction. Using this relation we can define the opera-tion of conjunction: given infons ! and $ , the conjunction ! , $ is the least x in the .order such that ConjunctOf(!, x) and ConjunctOf($, x).
In other words, ! , $ is the structurally smallest conjunction containing ! and $
as conjuncts. Defined this way, conjunction is clearly commutative. Additional prop-erties of , may be imposed by careful construction of ConjunctOf. By way ofexample, we show that it is possible to extend an information structure either witha conjunction that is associative and idempotent, or with one that has neither of theseproperties.
Construction 4.3.1. Let A be an extensional structure with a class & of non-atomicobjects, which we call “infons”. We shall define an extensional structure B extendingA with new elements and a new binary structural relation ConjunctOf such that theconjunction , defined, as above, on objects in & is both associative and idempotent.Let B0 = 0 & (|A| ) &), B1 = 1 & pow(&), and for each a $ |A| let
a0 =('0, a( if a /$ &,
'1, {a}( if a $ &.
Now let B be the structure with universe B0 * B1, and with
R(a01, . . . , a0
n) in B iff R(a1, . . . , an) in A
for each primitive relation R of A and
ConjunctOf('1, x(, '1, y() iff x / y.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 282 — #30
282 Handbook of Logic and Language
The new relation ConjunctOf is treated as a structural relation of B so we mustcheck that B is extensional.18 The binary conjunction , is defined, as above, for all“infons”, which in this case refers to those objects in B1. Now for any x, y / & , it iseasily checked that '1, x( , '1, y( = '1, x * y(. Thus conjunction is both idempotentand associative in B.
Construction 4.3.2. For the second construction, let A and & be as before. Let&1 = {1} & pow({0} & &), &(n+1) = &n * {1} & pow &n, and &0 =
)'n=1 &n. Now
let B be the structure with universe &0 * {0} &| A|, and with
R('0, a1(, . . . , '0, an() in B iff R(a1, . . . , an), in A
for each primitive relation R of A, and
ConjunctOf (x, '1, y() iff x $ y.
Again we must check that B is extensional. The proof requires the notion of the “rank”of an element of |B|. An element b $ |B| is of rank 0 if b = '0, a( for some a $ |A|and is of rank n > 0 if b $ &n but b +$ &m for each m < n. We show that if a isbisimilar to b then a = b, by induction on the maximum of the ranks of a and b.19
The “infons” of B are those objects of non-zero rank together with those objects ofthe form '0, x( for which x $ & . It is easy to check that a , b = '1, {a, b}( and soconjunction is neither idempotent nor associative.
Both constructions give a commutative conjunction. In fact, commutativity fol-lows from the definition of , from ConjunctOf. To get a non-commutative
18 If a is bisimilar to b then a = 'i, a0(, b = ' j, b0( for some a0 and b0. First observe that i = j. For ifi += j, say i = 0 and j = 1, then b0 is a subset of & , and so ConjunctOf('1, 1(, b) whereas there is no xsuch that ConjunctOf(x, a), and this contradicts the assumption that a is bisimilar to b. In the case thati = j = 0, a0 is bisimilar to b0 in A, so a0 = b0 by the extensionality of A, and so a = b. And if i = j = 1then for every x $ a0, there is a b1 / b0 such that '1, {x}( is bisimilar to '1, b1(. Then for each y $ b1,'1, {y}( is bisimilar to '1, {x}( – it cannot be bisimilar to '1, 1(, the only other conjunct of '1, {x}(. Butthen either x and y are atoms of A, which is ruled out because x, y $ & , or x is bisimilar to y in A and sox = y by the extensionality of A. Thus b1 = {x} and so a0 / b0. By a symmetrical argument, it can beshown that b0 / a0, so a0 = b0 and so a = b.
19 Suppose that a is bisimilar to b. There are three cases: (i) both x and y have rank 0; (ii) one of x or y hasrank 0 and the other has rank greater than 0; and (iii) both x and y have ranks greater than 0. Case (i) isthe base of the induction. In this case, a = '0, x( and b = '0, y( for some x and y, so x is bisimilar to y inA, so x = y by the extensionality of A, and so a = b. Case (ii) is impossible. Suppose, for example, thata = '0, x( and b = '1, y(. Then either y is empty, making b an atom of B and so only bisimilar to itself,or y has an element y% and so ConjunctOf(y%, b). There is no x% such that ConjunctOf(x%, a), and so (ii)contradicts the assumption that a is bisimilar to b. Case (iii) is the inductive case. We may suppose thata = '1, x( and b = '1, y( for some x and y. Then for each x% $ x there is a y% $ y such that x% is bisimilarto y%. But the ranks of x% and y% are strictly less than those of x and y respectively, and so by the inductivehypothesis, x% = y%. Thus x / y, and by a similar argument y / x, so x = y, and so a = b.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 283 — #31
Situation Theory 283
conjunction, we would need use different structural relations. For a non-associative,non-commutative conjunction we could use two binary structural relations, say,ConjunctOf1 and ConjunctOf2, with , defined such that ConjunctOf1(!, ! , $ )
and ConjunctOf2($, ! , $ ). For an associative, non-commutative conjunction, wecould use a ternary structural relation ConjunctOf0, with integer roles, and , definedso that ConjunctOf0(i, !i, (!1 , · · · , !n)).
The goal of defining a structural notion of conjunction is to capture those proper-ties of conjunctive information that are immediately available to anyone receiving theinformation, without further reflection on the significance of the information itself. Forthis reason, conjunctive information represented in different forms may best be mod-eled by different conjunctions. For example, information about the relative heights ofIndiana’s Hoosiers may be conveyed in a list of sentences of the form “x is taller thany”, or by a team photograph. In the former case, the information conveyed may bestbe represented by a non-commutative, associative conjunction; in the latter case, acommutative, associative conjunction would be preferable.
Similar issues affect the choice of structural relations for modeling other complexinfons such as disjunctions and conditionals. Negations may be modeled as complexinfons, or as basic infons as indicated in Section 4.2.4. Constructions almost identicalto Constructions 4.3.1 and 4.3.2 may be used for disjunctions. We simply re-name“ConjunctOf” as “DisjunctOf” and “,” as “3” throughout. This further underlinesthe point that the issues are structural, not logical. Definitions of several kinds ofstructures having complex infons are given in Section 4.3.6, below.
The question of how to represent quantifiers is even more vexed (Robin Cooper,1991a; Richard Cooper, 1991b). One approach is to use infinitary conjunctions anddisjunctions. In Constructions 4.3.1 and 4.3.2 we may define an infinitary conjunc-tion: given a set X of infons, the conjunction
*X is the least x in the . order such
that ConjunctOf(!, x) for each ! $ X. This operation*
has similar properties to thecorresponding binary conjunction. In the structure defined in Construction 4.3.1 it isboth associative an idempotent, but in that of Construction 4.3.2 it is neither.
Another approach is to model a quantified infon as a pair 'Q, (x.! (, in which Q isa quantifier and (x.! is a “infon-abstract”. We shall discuss abstracts in Section 4.3.7.
4.3.5 Substitution
In any extensional structure there is a well-defined operation of substitution. The fol-lowing definition is influenced by the treatment of substitution in (Aczel, 1990) and(Aczel and Lunnon, 1991).
Definition 4.3.11. Let A be an extensional structure of type [A, S1, . . . , Sm;R1, . . . , Rn]. A function f is a substitution in A if its arguments and values are allelements of A. Given a substitution f , a binary relation E on A is an f -simulation if forall a, b $ A, if E(a, b) then b = f (a) if a is in the domain of f , and if a is not in thedomain of f then

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 284 — #32
284 Handbook of Logic and Language
1. if a is atomic then a = b,2. for 1 # i # m, if Si is of arity k then for all x1, . . . , xk such that Si(x1, . . . , xk, a), there are
y1, . . . , yk such that Si(y1, . . . , yk, b), and E(xj, yj) for 1 # j # k, and3. for 1 # i # m, if Si is of arity k then for all y1, . . . , yk such that Si(y1, . . . , yk, b), there are
x1, . . . , xk such that Si(x1, . . . , xk, a), and E(xj, yj) for 1 # j # k.
b is f -similar to a in A if there is an f -simulation E of A such that E(a, b). For agiven f and a, there need not be an element of A that is f -similar to a, but if there is onethen there is only one, by the extensionality of A. We write f .a for the unique elementf -similar to a, should it exist. An extensional structure is a substitution structure if f .aexists for every f and a.
For example, suppose that there are solutions to the equations
v = ''r; a, b((,w = ''r; b, b((,x = ''r; y, a((,y = ''r; x, b((,z = ''r; z, b((,
in an extensional information structure A. Let [a 4" b] be the function with domain{a} such that [a 4" b](a) = b, and let E be the relation with graph
{'v, w(, 'x, z(, 'y, z(, 'a, b(} * I{b,r,z},
where I{b,r,z} is the identity relation on {b, r, z}. It is easy to check that E is an [a 4" b]-simulation on A, and so [a 4" b].v = w and [a 4" b].x = [a 4" b].y = z.
Set structures are substitution structures, by the set-theoretic Axiom of Replace-ment, if they also satisfy either Foundation or Anti-Foundation. A simple informationstructure satisfying Axioms A7 (finite roles) and A10.2 (extensionality) is a substitu-tion structure if and only if it satisfies the generality principle given in Axiom A11.1.The weaker principle of sortal generality, given by Axiom A11.2, is not sufficient.Nonetheless, all extensional structures are at least partial substitution structures andwe can interpret the non-existence of f .a as the inappropriateness of the substitution ffor a.20
Next, we prove a result that shows us how to extend an arbitrary extensional struc-ture to a substitution structure.
Theorem 4.3.2. Every anti-founded extensional structure is a substitution structure.
20 An interesting, weaker, substitutional property of extensional structures is as follows: if f .a and g.a bothexist and f and g are compatible functions then (f 5 g).a also exists. This is implied by sortal generalityif the domains of f and g do not contain roles.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 285 — #33
Situation Theory 285
Proof. Suppose that A is an anti-founded extensional structure of type [A, S1, . . . , Sm;R1, . . . , Rn] and that f is a substitution in A. Let X be the set {xa : a a non-atom of A}.We consider a structural description T = {T(x)}x$X , using x as the set of parameters.
For a non-atom a, T(xa) is obtained from the canonical description Ta. For each'S, b1, . . . , bk( that holds in A, let yi = f (bi) if bi is in the domain of f and let yi = xbi
if bi is not in the domain of f . We put the corresponding tuple 'S, y1, . . . , yk( intoT(xa). This defines the structural description T .
Since A is anti-founded, let s satisfy T in A. For each a $ A, the construction hasensured that s(xa) is f -similar to a. This proves that f .a exists. !
As an immediate corollary of Theorem 4.3.2 and Theorem 4.3.1, we see that everyextensional may be extended to a substitution structure.
4.3.6 Infon Structures
We are now in a position to improve our model of infons in a way that allows forthe smooth incorporation of complex infons and a uniform treatment of abstraction(to be given in Section 4.3.7). An advantage of the models used in Section 4.2 – the“simple information structures” – is their simplicity; they have only two structuralrelations. But there are disadvantages. First, the predicate “infon”, as applied to thesestructures, is defined in a way that presupposes that infons have a simple structure.This makes the move to structures containing complex infons a bit awkward. Sec-ond, the functions associating objects to roles in the infons of a simple informationstructure are not internal functions. This complicates the treatment of substitution andabstraction.
Now that we know how to represent the structure of functions using functionstructures, we can solve this problem. The basic idea is to represent the infon ! =''r; i : a, j : b, k : c(( as a pair consisting of the relation r and an internal function #
with domain {i, j, k} and such that #0(i) = a, #0( j) = b, and #0(k) = c. The func-tion # is called the assignment of ! . We adapt the functional notation for use withassignments and write
# = [i : a, j : b, k : c] and ! = ''r; #((.
The structure of infons can now be represented using three structural relations, Rel2,Ass2 and Inf1, and one non-structural relation, Approp1. Inf(! ) iff ! is an infon;Rel(r, ! ) and Ass(#, ! ) iff ! = ''r; #((. An assignment # = [i : a, j : b, k : c] is rep-resented as an internal function, so that Fun(#) and App(i, a, #), and # is appropriateiff Approp(#).
Definition 4.3.12. A function structure of type [A, Ass2, Rel2, Inf1; Approp1] isan infon structure if it satisfies the following conditions:
1. (sorts) Ass0 / Inf0, Rel0 / Inf0, and Fun0 6 Inf0 = 1,2. (basic infons) if Rel(r, ! ) then !# Ass(#, ! ),

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 286 — #34
286 Handbook of Logic and Language
3. (appropriateness) Approp(#) iff !! Ass(#, ! ), and4. (substitution) if Ass(#, ! ) and if f is substitution such that f .# exists and Approp( f .#),
then f .! also exists.
An infon ! is basic if there is an # such that Ass(#, ! ). An infon structure is abasic-infon structure if every infon is basic. An object r is a relation if Rel(r, ! ) forsome ! ; i is a role of ! if App(i, a, #) and Ass(#, ! ) for some a; and an object isordinary if it is not an infon, a function, a role, or a relation.
Clause 3 (appropriateness) links the appropriateness of an assignment to the exis-tence of an infon with that assignment. If, for example, there is no infon in whicha fills the role i then there is no # in Fun0 such that Approp(#) and #0(i) = a.This is a generalization of the treatment of appropriateness in information structures.Clause 3.12 (substitution) ensures that the only issue governing substitution of infonsis the appropriateness of the resulting assignment. This is an abstract form of the vari-ous principles of generality discussed in Section 4.2.7. To go further, we must look atthe unification structure of appropriate assignments.
Definition 4.3.13. A unification structure is an infon unification structure if it is aninfon structure that satisfies the following conditions.
1. (Flatness) P is the “flat” order: for every x and y, P(x, y) iff x . y.2. (Function compatibility) If Fun(#1) and Fun(#2) then C(#1, #2) iff the functions #0
1 and #02
agree, that is to say for every i, a and b, if Appsl(i, a, #1) and Appsl(i, b, #2) then a = b.3. (Infon compatibility) If Ass(#1, !1), Ass(#2, !2), Rel(r1, !1), and Rel(r1, !1), then
C(!1, !2) iff r1 = r2 and C(#1, #2).4. (Unification of appropriate assignments) If C(#1, #2), Approp(#1) and Approp(#2), then
Approp(#1 5 #2).
Infon unification structures give us our best theory of appropriateness. Clause 4ensures that the appropriateness of assignments depends only on “local” issues: if#1 and #2 are compatible appropriate assignments then so is #1 5 #2; no additionalgrounds for inappropriateness can be introduced. Moreover, by clause 4 (substitution)of the definition of infon structures, substitutions that result in appropriate assignmentsmay always be used to obtain new infons.
For example, given an infon ! = ''r; #(( and an assignment # = [i : a, j : b, k : c],let f be the function with domain {a, b} such that f (a) = x and f (b) =y, and let g be the function with domain {b, c} such that g(b) = yand f (c) = z. Suppose that f .# and g.# exist and are appropriate. ThenApprop([i : x, j : y, k : c])and Approp([i : a, j : y, k : z]), and so [i : x, j : y, k : z] isan appropriate assignment (by unification of appropriate assignments) and the infonf .! = ''r; i : x, j : y, k : z(( exists (by substitution).
The implicit theory of appropriateness is still weaker than that given by the princi-ple of sortal generality, according to which appropriateness is dependent only on rest-rictions applying to individual roles. Infon unification structures may restrict relatedroles, such as those discussed in the example of next-to at the end of Section 4.2.7.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 287 — #35
Situation Theory 287
If next-to has roles nt1 and nt2, then we may deem assignments of the form[nt1 : x, nt2 : x] inappropriate, without jeopardizing the unification principle. Toobtain the principle of sortal generality we must insist that the structure is alsodownwards-complete and that appropriateness is inherited by parts: if Approp(#1)
and #2 . #1 then Approp(#2).The second feature of infon structures not present in simple information structures,
is the unary structural relation Inf. We say that ! is a basic infon if Ass(#, ! ) forsome assignment # – by clause 2 of Definition 4.3.11 (basic infons) all infons havinga relation are required to have an assignment, possibly the empty assignment [ ]. Insimple information structures, by definition of the term “infon”, all infons are basic,but in infon structures we may have non-basic infons. Of course, by extensionality andclause 1 (sorts), if there are no more structural relations in A then there is at most onenon-basic infon. If there are more structural relations, such as ConjunctOf, then wecan add the axiom that ConjunctOf0 / Inf0 without contradicting the axioms forinfon structures.
This is a good example of how the “holistic” nature of the extensionality property,which quantifies over all structural relations, allows a modular approach to the the-ory of structured objects. Another example is the treatment of polarity, discussed inSection 4.2.4. We need only add new structural relations to deal with polarity and theextensionality condition takes care of the rest.
Definition 4.3.14. An infon structure of type [A, Pos1, Neg1; ] is bi-polar if it satis-fies the following conditions:
1. ! is a basic infon iff either Pos(! ) or Neg(! ), and2. if Pos(! ) then not Neg(! ).
Infons in Pos0 are positive and those in Neg0 are negative.21
Finite conjunctions and disjunctions are introduced effortlessly, as follows:
Definition 4.3.15. An infon structure of type [A, ConjunctOf2, DisjunctOf2; ] is,3-closed if it satisfies the following conditions:
1. ConjunctOf0 / Inf0 and DisjunctOf0 / Inf0,2. if Inf(! ) and Inf($ ) then there is a .-minimal object ! , $ such that ConjunctOf(!,
! , $ ) and ConjunctOf($, ! , $ ),
3. if Inf(! ) and Inf($ ) then there is a .-minimal object ! 3 $ such that DisjunctOf(!,
! 3 $ ) and DisjunctOf($, ! 3 $ ).
21 For bi-polar infon unification structures we must modify clause 3 of the definition of infon unificationstructures to take polarity into account:
3%. If Ass(#1, !1), Ass(#2, !2), Rel(r1, !1), and Rel(r1, !1), then C(!1, !2) iff r1 = r2, C(#1, #2),and Pos(!1) 7 Pos(!2).

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 288 — #36
288 Handbook of Logic and Language
The principles of existence for infinite conjunctions and disjunctions are similar.We would like to say that for each set X of infons there is a conjunction
*X and a
disjunction+
X but this would be ambiguous. We must choose whether X is to be aninternal or an external set. Here we follow the former, more cautious approach.
Definition 4.3.16. An infon structure of type [A, Set1, $2, ConjunctOf2,
DisjunctOf2; ] is* +
-closed if it is also a set structure, and
1. ConjunctOf0 / Inf0 and DisjunctOf0 / Inf0,2. if Set(X) and Inf(! ) for each ! such that $ (!, X), then there is a .-minimal object
*X
such that ConjunctOf(!,*
X) for each ! such that $ (!, X), and3. if Set(X) and Inf(! ) for each ! such that $ (!, X), then there is a .-minimal object
+X
such that DisjunctOf(!,+
X) for each ! such that $ (!, X).
Every* +
-closed infon structure is also ,3-closed because for infons ! and $
there is an internal set X with X0 = {!, $ } and so ! , $ =*
X; and similarly fordisjunction. The precise algebraic structure of
*and
+is not determined by this
definition; they may be associative and idempotent or not – see Section 4.3.4.Negations may be modeled using a structural relation NegOf2 with the follow-
ing existence condition: if Inf(! ) then there is a unique object ¬! such thatNegOf(!, ¬! ). Another approach is to start with a bi-polar infon structure and treatNegOf2 as a non-structural relation defined as follows:
Definition 4.3.17. A bi-polar infon structure of type [A; NegOf] is a de Morgan infonstructure if it is
* +-closed and satisfies the following conditions:
1. if NegOf(!, $ ) then Inf(! ) and Inf($ ),2. if NegOf(!, $ ) and NegOf(!, $ %) then $ = $ %,3. if NegOf(!, $ ) then NegOf($, ! ),4. if Rel(r, ! ) and Arg(#, ! ) then there is an infon ¬! += ! such that NegOf(!, ¬! )
Rel(r, ¬! ) and Arg(#, ¬! ), and5. if Set(X), Set(Y) and
a. for each ! $ X0 there is a $ $ Y0 such that NegOf(!, $ ),
b. for each $ $ Y0 there is a ! $ X0 such that NegOf(!, $ ),
then NegOf(*
X,+
Y).22
A remaining question is how to distinguish between saturated and unsaturatedinfons in infon structures. In basic-infon structures, the answer is clear from the dis-cussion in Section 4.2.8: saturated basic infons are those that are maximal in the .-ordering. For complex infons, it is not so easy. In a ,3-closed infon structure, if !
and $ are distinct basic infon then ! . ! , $ and so ! is not maximal, no matter howmany roles are filled. We decide the matter as follows.
22 No mention is made of polarities here, but from the definition of bi-polar infon structures we know thatif ! is a basic infon then it is either positive or negative but not both, and from clause 4, ! += ¬! ; so if! is positive then ¬! is negative, and vice versa.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 289 — #37
Situation Theory 289
Definition 4.3.18. In an infon structure, an infon is saturated if it is the largest classS / Inf0 such that for each infon ! in S,
1. if ! is basic and ! . $ then ! = $ , and2. if ! is non-basic then every infon component of ! is also in S.
By now, the reader will have an impression of some of the possibilities for modelingbasic and complex infons using the theory of structural relations. Observers of thedevelopment of Situation Theory have been somewhat frustrated because of the lackof consensus on which structures – or even on which kinds of structures, obeyingwhich axioms – are to be chosen for the theory (see Barwise, 1989a). We will seeother reasons for diversity in Section 4.4, but the basic reason is clear from the above:logical and structural properties of infons are separate but interdependent, and strikingthe right balance is a difficult matter.
4.3.7 Abstraction
Abstraction is a natural operation in semantics. By abstracting Paul from the infor-mation ! that Raymond cooked the omelette for Paul, we obtain the property ofbeing someone for whom Raymond cooked the omelette. By abstracting both Pauland the omelette from ! , we obtain the relation that holds between x and y just incase Raymond cooked x for y. This relation and the previous property differ fromthe relations and properties we have considered so far in that they are not atomic.In this section we see how infon structures can be used to model these complexrelations.23
There are two parts to abstraction over a structural object: the object after abstrac-tion, which contains “holes” where the abstracted object used to be, and somethingindicating where the holes are, so that subsequently they may be filled in. We call thesethe “abstract” and the “pointer”, respectively.24 The relationship between abstract andpointer may be captured by a binary structural relation Abs with Abs(a, x) meaningthat x is a pointer to the abstract a.
Definition 4.3.19. An abstraction structure is an extensional structure with struc-tural relation Abs2 such that if Abs(a, x) and Abs(a%, x) then a = a%. Theobjects of sort Abs0 are called pointers. If Abs(a, x) then x is said to point to theabstract a.
23 In Situation Theory, abstraction has been treated as a structural operation, and here we shall attemptto model it using structural relations. This goes against the dominant trend in semantics, which is touse functional types in a type theory described by means of the lambda-calculus (see Chapter 11).Interestingly, Lunnon (to appear), building on the work of Aczel and Lunnon, integrates these twoapproaches.
24 Pointers are often called “indeterminates” and “parameters”; but that description of them is bad for thephilosopher’s digestion, and leaves a sour taste on the metaphysical palate.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 290 — #38
290 Handbook of Logic and Language
The objects of interest in abstraction structures are the abstracts, but they do notform a structural sort; rather, it is the pointers that are structurally determined. Theintention is that each pointer x of an abstract a is a hereditary component of a. Weobtain the results of “applying” an abstract a to some argument b by substituting b fora pointer x in a. To see how this achieves the desired effect we must consider howabstracts arise by abstraction from other objects in the domain.
Suppose, for example, that we want to abstract b from the infon ! = ''r; i : b,
j : c((. We would expect to obtain an abstract a with exactly one pointer x such thatthe result of substituting b for x in a is just ! . Furthermore, the result of substitutingb% for x in a should be the infon ''r; i : b%, j : c((, if this infon exists. This is capturedin the following definition.
Definition 4.3.20. Suppose A is an abstraction structure. Given elements a and b in|A|, an abstract (b.a is the abstraction of b from a if there is an x such that
1. [b 4" x].a = (b.a,2. Abs((b.a, x), and3. the only sort of x is Abs0.
The definite article is justified in the above definition because if Abs([b 4" x].a, x)and Abs([b 4" y].a, y) then, by extensionality, x = y. For example, if ! = ''r; i : b,
j : c(( and (b.! exists, then there is an x such that Abs(''r; i : x, j : c((, x). But sup-pose there was a y such that Abs(''r; i : y, j : c((, y). Since Abs is the only structuralrelation determining x and y, they are obviously bisimilar and so equal. A similarargument shows that (b.''r; i : b, j : c(( = (b%.''r; i : b%, j : c((, assuming that b andb% are not hereditary components of r, i, j, or c. This is the expected principle of#-equivalence.
Notice also that under similar assumptions the order of abstraction is insignificant.If, for example, b and c are both atomic then (c.(b.''r; i : b, j : c(( = (b.(c.''r; i : b,
j : c((. In both cases, the abstract obtained has two pointers, pointing to the positionspreviously occupied by b and c respectively, but there is nothing to distinguish thepointers apart from that, and so there is no trace of the order in which the abstractionwas performed. This motivates a slightly more general notion of abstraction.
Definition 4.3.21. Suppose A is an abstraction structure. Given an element a of |A|and a set B of elements of |A|, an abstract )B.a is the simultaneous abstraction of Bfrom a if there is an injective function * : B " |A| called the pointer function suchthat
1. *.a = )B.a,2. Abs(*.a, *(b)) for each b $ B, and3. for each b $ B, the only sort of *(b) is Abs0.
Despite the previous observation about commuting lambdas, one should be carefulto distinguish simultaneous abstraction from successive abstractions. When the ele-ments of B are structurally dependent, the results obtained may differ (see Aczel and

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 291 — #39
Situation Theory 291
Lunnon, 1991; Ruhrberg, 1996). For example, if ! = ''r; $1, $2((, $1 = ''s; $2, a((,and $2 = ''s; $1, b(( then
1. ($1.($2.! = ''r; ''s; x, a((, x(( with pointer x,2. ($2.($1.! = ''r; y, ''s; y, b(((( with pointer y, and3. ){$1, $2}.! = ''r; z1, z2(( with pointers z1 and z2.
Nonetheless, it is clear that simultaneous abstraction is a generalization of abstractionbecause (b.a = ){b}.a.
We have already observed that abstraction obeys an identity principle analogous to#-equivalence in the (-calculus, at least in special cases. To state the general resultobserve that if ! = ''r; b, c(( and ! % = ''r; b%, c(( and b and b% are structurally inde-pendent then [b 4" b%].! = ! % and [b% 4" b].! % = ! . These are the conditions neededto show that the two abstracts are bisimilar and so justify the claim that (b.! = (b%.! %.We state, without proof, the generalization of this result.
Theorem 4.3.3 (#-identity). If )B.a and )B%.a% exist in an abstraction structure andthere is a one-to-one correspondence f between B and B% such that f .a = a% andf )1.a% = a then )B.a = )B%.a%.
We now show that extensional structures with abstraction really exist.
Definition 4.3.22. An abstraction structure A is a Lambda structure if for everyelement a of |A| and a set B of elements of |A|, the simultaneous abstraction )B.aexists.
Theorem 4.3.4. Every extensional structure can be extended to a Lambda structure.
Proof. Given an extensional structure A, extend it trivially to an abstraction structureby adding the structural relation Abs2 with an empty extension. By Theorem 4.3.1this can be extended to an anti-founded structure B0. Throw away all pointers in thisstructure that point to more than one abstract to obtain an abstraction structure B.We show that B contains a Lambda structure extending A. Suppose a is an elementof |B| and B is a set of elements of |B|. We exhibit a structural description whosesatisfier gives the needed element (B.a. For each b $ B, let Tb = {'Abs, a(}. Let Hbe the set of hereditary components of a that are not in B, and for each c $ H, letTc be the canonical description of c in B. Now the structural description we want isT = {Tx}x$B*H . Since B is contained in an anti-founded structure, there is a functions mapping into B0 that satisfies T . But, clearly, the range of s does not contain any ofthe elements we threw away, so s maps into B. Thus for each b in B, s(b) satisfies thedescription s.Tb = {'Abs, s.a(} and so Abs(s.a, s(b)). Moreover, s(b) is only of sortAbs0, and so s.a is the required abstract )B.a. !
A short digression on the ontology of abstracts is in order. If ! is an infon withargument b then (b.! is also of sort Inf0. But, intuitively, it is a property not an infon.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 292 — #40
292 Handbook of Logic and Language
Moreover, it has a pointer as an argument, filling the role left by b, and so interferingwith whatever implicit appropriateness conditions there may have been on this role.It is therefore useful to distinguish between genuine infons and these new entities,which we may call infon abstracts. Infon abstracts are just properties (or relations ifthey have more than one pointer) and so ontologically acceptable. That is not quite theend of the matter. Consider the infon $ = ''r, ! (( and the abstract (b.$ with pointerx. The abstract (b.$ is an infon abstract, not a genuine infon. But it has an argument[b 4" x].! that is also of sort Inf0 but neither an infon abstract nor, intuitively, agenuine infon. The only reasonable position to adopt is that [b 4" x].! is a part ofan abstract. Fortunately, it is easily determined which abstract it is a part of, becausethe pointer x points to it. In this way, we may satisfy ourselves that no unexpectedontological categories have been created.25
4.3.8 Application
In the previous section we saw that an extensional structure may be extended withabstracts of the form )B.a, obtained by abstracting the elements of B from the object a.The purpose of these abstracts is to model generalizations across a class of structuredobjects. In particular, infon abstracts may be used to model properties and relations.To see how this works, we need an account of “application.”
Definition 4.3.23. Suppose A is an abstraction structure. If a is an abstract then afunction f : X " |A| is an (external) assignment for a if every x in X is a pointer of a.It is appropriate for a if f .a exists. If f is appropriate for a then the application of a tof , written a0( f ), is f .a. In this way, every abstract a is associated with a (second-order)function a0 mapping appropriate assignments to elements of |A|.
Theorem 4.3.5 (%-identity). If )B.a exists with pointer function * and f is an appro-priate assignment for )B.a then ()B.a)0( f ) = f *.a.
Proof. This follows directly from the definitions of simultaneous abstraction andapplication. !
How, then, should we incorporate complex properties and relations into infon struc-tures? The key point is that the appropriateness conditions of infons having complexrelations should be determined by those of basic infons.
Definition 4.3.24. Let A be an infon structure that is also an abstraction structure. Ahas coherent appropriateness conditions if for each infon ! = ''r; #(( in |A|, and if ris an infon abstract then #0 is an appropriate assignment for r. A is relation-closed if
25 The ontological status of “parametric objects”, which are closely related to our abstracts and their parts,is the subject of much debate. See, for example, Westerståhl (1990).

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 293 — #41
Situation Theory 293
for each infon ! and each set B of elements of A, the infon abstract )B.! exists andfor each appropriate assignment f for )B.! , there is an infon '')B.! ; #(( with #0 = f .
We state without proof the following result:
Theorem 4.3.6. Every infon structure is extendible to a relation-closed infon structure.
By way of closing this section, we note that application has only been modeledin an “external” way. We may ask what the properties of an “internal” applicationoperation should be. For more on this, see Aczel and Lunnon (1991), and Lunnon (toappear).
4.4 Truth and Circumstance
Notoriously, the word “information” is ambiguous. Traditionally, the possession ofinformation that Smith is an anarchist, like the knowledge of the same, implies thatSmith is an anarchist. With the advent of mechanisms for the gathering, storing andretrieval of large amounts of information, the word has taken on a more neutral mean-ing. According to more modern usage, to be adopted here, the information that Smithis an anarchist may be stored on a computer file in ASCII code, transmitted across theglobe, converted to speech and heard over a loudspeaker, without Smith’s ever havinghad a subversive political thought in his life.
A problem with the modern usage is that a new word is required to separate gen-uine items of information, in the traditional, truth-implying sense, from mere infons.Provisionally, we will use the adjective “factual” for this purpose. Thus, the infon''anarchist; Smith(( is factual just in case Smith is indeed an anarchist; otherwise it isnon-factual, but information nonetheless.
The present use of the word “factual” is provisional because the distinction onwhich it rests is an important contention in situation theory. No one would deny, of thestatement that Smith is an anarchist, that it is true if and only if Smith is an anarchist.It is less clear that this biconditional may be used to determine whether the correspon-ding infon is factual. To see the difficulty, let us suppose that Smith had a rebelliousyouth but has now settled down into conformist middle age. An utterance of “Smithis an anarchist” during Smith’s early period would have made a true statement, but anutterance of the same sentence today would not. On the assumption that both utter-ances express the infon ''anarchist; Smith((, we arrive at an impasse: which statementdo we use to decide whether the infon is factual?
Of course, the problem can be resolved by denying the assumption that both utter-ances express the same information. We may say that the infons expressed by thetwo utterances are distinguished by a temporal role that is filled by the time of eachutterance. Instead of one infon, we have two: ''anarchist; subject: Smith, time: Friday15th May, 1970(( and ''anarchist; subject: Smith, time: Monday 18th July, 1994((.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 294 — #42
294 Handbook of Logic and Language
The first infon is presumed to be factual, because of the truth of the statement madein 1970, and the second non-factual, because of the falsity of the statement made today.The ''anarchist; Smith(( is either excused from considerations of factuality becauseit is unsaturated, or supposed not to exist at all. We appropriate the terminology ofBarwise and Etchemendy (1987) by calling this account Russellian.
A quite different solution is to take the truth or falsity of a statement to depend onmore than just the information expressed. Following Austin (1961), two componentsof a statement are distinguished: the situation, event or state of affairs that the state-ment is about, and what is said about it. On this, the Austinian account, the differencebetween the two statements arises not because of a difference in the information theyexpress, but because different situations are described: the utterance in 1970 correctlydescribes Smith’s attitudes at that time, whereas today’s utterance falsely describeshis present state of bourgeois conformity.26 The infon ''anarchist; Smith(( is factual iftaken to be about Smith’s beliefs and actions in 1970, but not if it is taken to be abouthis current views.
Proponents of both accounts agree that the common information expressed by thetwo utterances is neither factual nor straightforwardly non-factual. They differ on thereason for this failure. According to the Russellian, the infon ''anarchist; Smith((, ifit exists at all, is merely the unsaturated common part of the distinct, saturated infonsexpressed by the two utterances. On the Austinian account, all claims to factuality ifintelligible at all are relative to the situation the information is taken to be about. Theinfon ''anarchist; Smith(( is factual if it is taken to be information about the situationdescribed by the first utterance, but not if it is taken to be about the situation describedby the second.
On matters of detail, there is room for interplay between the two positions. Forexample, the Austinian may agree that the two statements express different informa-tion by virtue of the indexical nature of tense, but still maintain that the factual statusof the information expressed is determined by the described situation. Moreover, thedebate may be conducted in different areas. Instead of focusing on tense, the Austinianmay claim an implicit relativity to a perspective from which the assessment of Smith’spolitical views is to be made – it may be Smith’s own, his fellow citizens’, “the author-ities”, or even that of the person making the statement. The Russellian account mayrespond by insisting either that the term “anarchist” is ambiguous, or that the infonexpressed has an extra role for the perspective from which the property of being ananarchist is judged.
In the next few sections we shall consider the Russellian account in more detail,before returning to the Austinian account in Section 4.4.5.
26 For Barwise and Etchemendy the terms “Russellian” and “Austinian” refer to different views aboutpropositions, but the distinction is closely related to the present one. Propositions will be discussed inSection 4.4.8. Of course, neither Russell nor Austin were concerned with information per se, but basicinfons play a very similar role in Situation Theory to the basic facts of Logical Atomism.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 295 — #43
Situation Theory 295
4.4.1 Fact Structures
From a purely technical standpoint, the Russellian account is the more straightforwardof the two. The information expressed by an unambiguous statement is modeled as asaturated infon, which may or may not be factual. If it is factual then the statement istrue; if not, it is false. Those roles of the infon that are not filled by arguments givenexplicitly by linguistic features of a statement must be determined by other features ofthe context in which the statement is made. These additional roles are called “hiddenparameters”. For example, the temporal “parameter” of the statement that Smith isan anarchist is filled by the time at which the statement is made. If there are furtherhidden parameters, such as the perspective from which this assessment is made, thenthe statement is either ambiguous or the additional role must be filled by some otheraspect of the context.
This account can be modeled using a “fact structure”, defined as follows.
Definition 4.4.1. An infon structure F of type [A; Fact] is a fact structure if for each! $ A, if Fact(! ) then ! is a saturated infon. An infon ! is a fact if Fact(! ). F istrivial if every saturated infon is a fact.
Standard fact structure may be constructed from arbitrary relational structures in astraightforward manner. If M = 'M, R1, . . . , Rn( is a relational structure and SInf(M)
is the information structure constructed from it using Construction 4.2.1, then letF(M) be the fact structure extending SInf(M) with
Fact('3, Ri, #() iff Ri(#(1), . . . ,#("i)) in M0
for each i # n and each # : {1, . . . , "i} " M. Every infon in a standard structure issaturated, so there is nothing more to check. We call F(M) the standard fact structuregenerated by M.
The main problem for the Russellian is that there are many statements that wouldnot usually be called ambiguous, but for which hidden parameters remain unfilled.These are statements that only express unsaturated information, even when all con-textual factors are considered. They are more common that one might suspect. Sup-pose that in the course of telling the story of Smith’s involvement in a riot, wesay that he panicked and ran. Superficially, the content of the statement is theinformation that Smith panicked and ran, which might be modeled by the infon''panic; Smith(( , ''run; Smith((.
This infon is unsaturated because panicking and running are events, and so occurat a particular time that has not yet been specified. Unlike in the previous example, thetense of the statement (simple past) is not sufficient to determine a saturated content.Unless there are aspects of the circumstances in which the statement is made thatprovide a way of saturating the infon, it is difficult to see how a truth-value is to bedetermined.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 296 — #44
296 Handbook of Logic and Language
There are various ways in which the missing information may be provided. Thedate of Smith’s alleged actions may be given explicitly at some earlier point in thenarrative (“On the 15th May, 1970, Smith was involved in a riot. . .”) or provided bysome other means: the date of the riot may be common knowledge, or the narratormay have special access to the facts, perhaps by being witness to the original event.
The hunt for contextual factors that determine the content of statements is ulti-mately restricted by the lack of precision in ordinary language. A threat to the Rus-sellian view is that suggestion that ordinary language is indefinitely imprecise: thereare always ways of making a given statement more precise, with successive approxi-mations to the “missing” information, and no definite level of precision beyond whichsuch improvements cannot be made.
For example, it there is no way of finding the exact date of the riot from the con-text – if for example, the context only specifies that it occurred in May, 1970 – thenwe would be forced to conclude that the statement is ambiguous. But even if the dateis supplied by context, we may still be in trouble. Supposing the date to be determinedto be 15 May, 1970, the content of the statement would be the infon
''panic; subject : Smith, date : 5/15/70(( , ''run; subject : Smith, date : 5/15/70((.
Unfortunately, this infon is still unsaturated, as we can see by supposing that Smithwas involved in two separate clashes with the police on the same day. On the firstoccasion, he bravely stood his ground; on the second he panicked and ran. The merepossibility of two clashes is sufficient to show that the infon is unsaturated and so theRussellian is left with ambiguity, even if there was only one clash.
In an effort to avoid the conclusion that there is widespread ambiguity in our useof ordinary language, we may search for more elaborate ways in which the contextfills hidden parameters. If the exact time is not supplied in the linguistic context orby common knowledge, it may be determined by a causally related chain of eventsstarting with Smith’s actions in the riot.
The danger in this move is that information expressed by a statement may beunknown, even to the person who makes the statement. The narrator may well remem-ber the day of the riot, and even whether it occurred in the morning or afternoon, butnot the exact time. If this time is to be a component of the infon expressed by thestatement then this is information that the narrator does not possess.
If, on the other hand, we are to resist the move to considering factors that go beyondthe knowledge of the narrator, there are other problems. If we take the narrator’sbeliefs to determine the temporal parameter, then falsehoods are liable to appear insurprising places. Suppose, for example, that the narrator falsely believed the incidenttook place at around noon on the 15th May, 1970; in fact, it occurred at about 11 a.m.It is awkward to maintain that this false belief, which is otherwise irrelevant to thenarrative, makes his statement that Smith panicked and ran false.
Finally, there is a problem in making the demand for ever-greater precision com-patible with our somewhat roughshod ontology of events and processes. Although wethink of the event of Smith panicking and running as having duration, it is not the sortof interval that can be measured in seconds.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 297 — #45
Situation Theory 297
We may hope that for each kind of description there is a fixed tolerance with whichinformation about the values of hidden parameters must be specified. In this way, wecould avoid the problems of requiring perfect precision. In many cases, the truth of astatement in which a time is not mentioned explicitly is fairly robust: small variationsdo not alter the truth-value. But there are circumstances in which small changes domatter – Smith’s two clashes with the police may have happened within half-an-hourof each other – and so, the precision required for the saturation of a given piece ofinformation is indefinite, depending on particular facts about the circumstances ofthe original event, and not just about the later circumstances in which the statementis made.
A way out of this web of difficulty is to embrace the conclusion that many, if notall, of the statements we make are ambiguous; or, better, to cut the link between lackof a truth-value and ambiguity. We may say that a statement is unambiguous if itexpresses a determinate item of information, even if this information is unsaturatedand the statement neither true nor false.
A quite different approach is to claim that an unsaturated infon is factual if there issome saturated fact of which it is a part. By quantifying over the possible ways of sat-urating the infon, we arrive at the rather charitable position that a statement is true justin case, in the circumstances, there is some way of construing it as expressing a sat-urated fact. This is reminiscent of Davidson’s treatment (1967) of the same problem.There are two main difficulties with this solution. Firstly, an unrestricted quantifica-tion over possible arguments is clearly too generous. If in the course of discussing theriot in 1970 we state that Smith panicked and ran, then this statement cannot be madetrue by Smith’s panicking and running last week. Thus, we must appeal to the contextagain, this time to provide suitable restrictions to the range of quantification. Secondly,the restrictions on quantifiers are often interdependent. For example, if in interpret-ing the text “Smith panicked. He ran.” we made use of the quantificational strategy,then the restrictions on the possibly ways of saturating the two unsaturated infons''panic; Smith(( and ''run; Smith(( must be related: if ''panic; Smith, time: t1, . . . ((and ''run; Smith, time: t2, . . . (( are among the permissible saturations then t1 must bebefore t2. Such technical obstacles are not insuperable (see Chapter 12) but introducecomplications that we shall not go into here.27
4.4.2 Logic in Fact Structures
In Section 4.3.4 we showed how to model compound infons using the theory ofstructural relations. There we were concerned only with the structural properties ofthose objects; now we shall examine their logical properties. For example, any rea-sonable model of conjunctive facts should satisfy the condition that Fact(! , $ )
iff Fact(! ) and Fact($ ). Certain special cases of this condition may be determined
27 The role of indexicals constituent of the content of statements is discussed in John Perry’s seminal articlePerry (1979), and something close to the Russellian approach is pursued by Perry and David Israel in aseries of papers about information beginning with Israel and Perry (1990).

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 298 — #46
298 Handbook of Logic and Language
by structural properties of conjunction. For example, in the infon structure of Con-struction 4.3.1 conjunction is idempotent, and so in any fact structure extending this,Fact(! , ! ) iff Fact(! ). But structural properties alone will not usually suffice todetermine every instance of the above condition, and so we shall need to impose addi-tional axioms.
Typically, Situation Theory uses a de Morgan infon structure F ( from Section 4.3.6)that satisfies the following conditions:
1. Fact(*
&) iff Fact(! ) for each ! $ & , and2. Fact(
+&) iff Fact(! ) for some ! $ & .
3. Fact(¬! ) iff Inf(! ) and not Fact(! ).
Let us say that a fact structure F is classical if it does satisfy the above. The logicalbehavior of abstract relations must also be considered. A fact structure that is also anabstraction structure should satisfy the
Principle of %-equivalence for Facts: if ''r, f (( is an infon whose relation r is an infon-abstract then Fact(''r, f (() iff Fact(r0( f 0)).
We could go on to define a host of different kinds of fact structures, catalogued bytheir logical properties. Such a list would be tediously long and necessarily incom-plete, and so there is no merit in producing it here. In any case, we want to addressnot just the multitude of existing logics whose compounds have the familiar syntac-tic structure of ( formal) future logics that act on more intricate structures – circularstructures, infinite structures, and anything else that can be modeled using the theoryof structural relations. Our solution is to give a general method for imposing more orless arbitrary logical structure on fact structures.
Our work is based on the notion of a consequence relation, as it is studied in philo-sophical logic. For a survey of this large field, see Makinson (1994).
Definition 4.4.2. A consequence relation 8 on a class C is a binary relation betweensubclasses of C such that + 8 , iff + % 8 ,% for every partition '+ %, ,%( of C suchthat + / + % and , / ,%.28 Given a fact structure F, a consequence relation 8 on theclass of infons in F is sound if whenever + 8 , and every infon in + is a fact thensome infon in , is a fact.
Consequence relations have the following familiar properties:
(identity) ! 8 ! ,(weakening) if + 8 , then + %, + 8 ,, ,%, and(cut) if + 8 ,, ! and !, + 8 , then + 8 ,.29
28 'X, Y( is a partition of C if X * Y = C and X 6 Y = 1.29 We use the usual abbreviations, e.g., +, ! stands for + * {! } when an argument of 8.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 299 — #47
Situation Theory 299
Moreover, if 8 is compact then these three conditions are jointly sufficient to ensurethat 8 is a consequence relation (Barwise and Seligman, 1996).30 Also note thata consequence relation is entirely determined by the class of partitions that lie init. It is easy to see that a consequence relation is sound in a fact structure just incase the partition of Inf0 into facts and non-facts does not lie in the consequencerelation.
In any de Morgan infon structure F, if 8 is a sound consequence relation on Inf0
and F is classical then 8 must satisfy the following conditions:
1.*
&, + 8 , if &, + 8 ,,2. + 8 ,,
*& if + 8 ,, ! for each ! in & ,
3. + 8 ,,+
& if + 8 ,, & ,4.
+&, + 8 , if !, + 8 , for each ! in & ,
5. +, ¬! 8 , if + 8 !, ,,6. + 8 ¬!, , if +, ! 8 ,.
The conditions are analogs of the standard inference rules of the sequent calculus for(infinitary) classical propositional logic; let us say that 8 is classical if it satisfies allthese conditions. Then it is easy to check that if F is non-trivial and has a classicalconsequence relation then F must be classical. These observations amount to the fol-lowing characterization of de Morgan fact structures: a non-trivial de Morgan factstructure is classical iff it has a sound classical consequence relation.31
In this way, the logical properties of complex infons may be investigated by study-ing their consequence relations, without explicit reference to fact structures. A multi-tude of consequence relations have already been cataloged by logicians, and so we canimport whichever logic we wish, defining the corresponding class of fact structures onwhich the consequence relation is sound.
4.4.3 Restriction
In Section 4.3.8 we saw that properties defined by means of abstraction inherit theappropriateness conditions of the infons over which they are defined. For example,the property (x.''fed; Martha, x(( of being eaten by Martha is appropriate for justthose objects a for which ''fed; Martha, a(( is an infon.
For semantics, it has proved useful to introduce a more flexible notion of abstrac-tion by which a much wider range of restrictions may be placed on appropriate assign-ments. On some semantic analyses, the information expressed by the sentence “Marthafed him” is that the referent of “him” has the property of being fed by Martha, modeledby the abstract (x.''fed; Martha, x((. But the sentence also conveys the informationthat the person fed by Martha is male. One way of incorporating this information is to
30 8 is compact if whenever + 8 , there are finite sets +0 / + and ,0 / , such that +0 8 ,0.31 Furthermore, there is a smallest classical consequence relation 8c on any de Morgan infon structure A,
and so a non-trivial fact structure F extending A is classical iff 8c is sound on F.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 300 — #48
300 Handbook of Logic and Language
maintain that the abstract is restricted so that it may only be applied to males. In otherwords, we want a property p such that ''p; a(( is
1. an infon iff a is male and ''fed;Martha, a(( is an infon,2. factual iff a is male and ''fed;Martha, a(( is factual.
In some formulations, the restriction that a be male attaches to the abstractedvariable (or “parameter”) x, and a theory of restricted parameters is developed(Fernando, 1990; Gawron and Peters, 1990a); in others, the situation-theoretic uni-verse is extended to include restricted objects quite generally: such objects areidentical to their unrestricted counterparts when the (often contingent) restricting con-dition is met, and are otherwise “undefined” or of some other ontologically inferiorstatus. Plotkin (1990) adapts Curry’s “illative” approach to logic, treating restrictionby means of a connective"whose formation rules require that the restriction be met: if! is an infon and $ is a fact then ! " $ is an infon; otherwise the expression “! " $” isnot even well-formed.
Barwise and Cooper (1993) introduce an elegant graphical notation for restrictionsand abstracts called Extended Kamp Notation, in honor of Kamp’s Discourse Repre-sentation Structures (see Chapter 3). They write situation theoretic objects as boxes. Abox directly to the right of another box acts as a restriction, and a box directly abovelists abstracted objects. For example, the restricted property p mentioned above wouldbe written as
a
''fed; Martha, a(( ''male; a((
The approach adopted here is to extend the theory of abstraction and applicationdeveloped in Sections 4.3.7 and 4.3.8.
Definition 4.4.3. A fact structure F has restricted abstraction if it is also an abstrac-tion structure and has an additional structural relation Res2, such that if Res(!, a)
then a is an abstract and for each assignment f for a, f .! is an infon. We say that a isa restricted abstract and that ! is a restriction of a. For each object a, set B of objectsin |F|, and set & of infons in |F|, an object )B[&].a is the abstraction of B from arestricted by & if there is a function * : B " |A| such that
1. Abs()B[&].a, *(b)) for each b in B,2. for each b in B, *(b) is only of sort Abs0, and3. )B[&].a satisfies the description ')B[&].a, T*.a * {'Res, *.! ( | ! $ &}(.32
F is a restricted-Lambda structure if )B[&].a exists for each a, B, and & .
32 This clause is slightly more complicated than the corresponding clause for unrestricted abstraction. Itsays that the restricted abstract )B[&].a has the component structure of *.a, together with the additionalstructural relationships Res(*.!, )B[&].a) for each ! in & .

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 301 — #49
Situation Theory 301
The above nails down the structure of restricted abstracts but we still need to sayhow they may be applied. For this the key definition is the following: an assignment ffor a is appropriate for a if f .a exists and f .! is a fact. As before, if f is appropriatefor a then the application of a to f , written a0( f ), is just f .a. F has coherent appro-priateness conditions if for each infon ! = ''r; #((, if r is a (restricted) infon abstractthen #0 is an appropriate assignment for r. F is restricted-relation-closed if for eachinfon ! , each set B of elements of A, and each set & of infons, the infon abstract)B[&].! exists and for each appropriate assignment f for )B[&].! , there is an infon'')B[&].! ; #(( for which #0 = f .
Technically there are no difficulties here. Restricted Lambda structures andrestricted-relation-closed structures may be constructed using methods similar to thoseused in Theorems 4.3.4 and 4.3.6.33
4.4.4 Internal Definability
We have already seen how an internal function f represents an external function f 0
in a function structure, and how in an abstraction structure an abstract a represents asecond-order function a0 mapping assignments to objects of the domain. In fact struc-tures, internal relations represent external relations. Suppose F is a fact structure andR is an n-ary relation on |F|. The basic idea is that an internal relation r of F repre-sents R if for each a1, . . . , an in |F|, there is a saturated infon ''r; a1, . . . , an(( in Fand R(a1, . . . , an) iff Fact(''r; a1, . . . , an((). There are, however, several complica-tions. Firstly, our use of the functional notation for infons hides an assumed correlationbetween the roles of r and the integers 1, . . . , n; this must be made explicit. Sec-ondly, the condition requires that the infon ''r; a1, . . . , an(( exists for every sequencea1, . . . , an of elements of |F|. This will rarely be satisfied because most internal rela-tions have non-trivial appropriateness conditions – it fails even in standard fact struc-tures because the relations of the underlying relational structure only take ordinaryobjects, not infons and roles, as appropriate arguments. The definition must be revisedso that the domain of each relation is restricted in some way.
Definition 4.4.4. Given a fact structure F, an n-ary external relation R on |F| is rep-resented by elements r, i1, . . . , in of |F| on the domain A / |F| if for each (external)assignment f ,
1. there is an infon ''r; #(( with #0 = f iff f : {i1, . . . , in} " A, and2. if Inf(''r; #(() then Fact(''r; f (() iff R(#0(i1), . . . ,#0(in)).
In standard fact structures, every relation r has a fixed finite arity, n say, and (bythe generality principle) the infon ''r; a1, . . . , an(( exists for each sequence a1, . . . , an
33 In the literature on Situation Theory, most authors have been concerned with objects restricted by truepropositions rather than facts. We have explained the mechanism for the latter case only because we haveyet to introduce propositions – see Section 4.4.8.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 302 — #50
302 Handbook of Logic and Language
of ordinary objects. Thus every internal relation of a standard fact structure representsan external relation on the domain of ordinary objects.
In the non-standard fact structures, internal relations may fail to be representativefor a variety of reasons: they may have infinite or variable arity; they may generateunsaturated infons; or they may have sortal – or even more complex – appropriatenessconditions. A simple generalization of the above definition handles the last of thesecases.
Definition 4.4.5. Given a fact structure F, an n-ary external relation R on |F| is rep-resented by elements r, i1, . . . , in of |F| relative to another n-ary relation D on |F| iffor each (external) assignment f ,
1. there is an infon ''r; #(( with #0 = f iff f has domain {i1, . . . , in} and D( f (i1), . . . , f (in)),and
2. if Inf(''r; #(() then Fact(''r; #(() iff R(#0(i1), . . . ,#0(in)).
In effect r is taken to represent R only in the context of D; outside of D it doesnot matter which sequences are in R, and this is captured by making the correspon-ding assignments for r inappropriate. This gives three different ways of classifying asequence a: either a is in D and R, or a is in D but not in R, or a is not in D. Cor-respondingly, there are three ways of classifying an assignment #: either ''r; #(( is afact, or ''r; #(( is not a fact, or there is no infon of the form ''r; #((.
Another approach is to say that, in general, internal relations represent partial rela-tions on |F|. A partial relation has an extension and an anti-extension that are disjointbut that need not exhaust the domain. Facts with relation r represent sequences lyingin the extension of R, and infons that are not facts represent sequences lying in theanti-extension of R.
The issue of infinite and variable arities can be handled with similar generalizationsof the meta-theoretic concept of “relation”.34 Whichever characterization of represen-tation is adopted, it is natural to ask which external relations are represented in a givenfact structure. For example, we may wonder if any of the structural relations Arg, Rel,Inf and Fact are represented.
Plotkin (1990) has various negative results. Suppose that Fact is represented by Fin a Lambda structure with classical negation. Let p be the abstract (x.¬''F; x((, whichis sure to exist in such a structure. A simple argument shows that p cannot have a fixedpoint. Suppose that ! = ¬''F; ! ((. If ! is a fact then so is ¬''F; ! (( and so ''F; ! (( isnot a fact. This contradicts the assumption that F represents Fact and so ! must not bea fact. It follows that ''F; ! (( is not a fact and so ¬''F; ! (( is a fact. But ! = ¬''F; ! ((and so we have shown that ! both is and is not a fact: a contradiction.
34 In the most general case, an internal relation may be said to represent a partial predicate of indexed sets.First specify a class I of indices. Say that an I-set is an indexed set {xj}j$J for some J / I; equivalently, itis a function with domain J. Then say that r represents the partial predicate P of I-sets if there is a one-onefunction g from I to A such that the extension (anti-extension) of P consists of those I-sets {#0(g( j))}j$J
such that ''r; #(( is a fact (infon but not a fact) and J = g)1 dom #0.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 303 — #51
Situation Theory 303
In the structures used by Plotkin, every abstract has a fixed point, and Fact cannotbe represented unless at the expense of classical logic. Plotkin uses Frege structures(Aczel, 1980), which are constructed from models of the untyped (-calculus in whichfixed-point combinators such as Y exist. Similar problems arise in structures with inter-nalized application, because they also contain fixed-point combinators. Even withoutsuch combinators fixed points will exist in any anti-founded fact structure. For exam-ple, the description 'x, ¬''r; x((( is satisfied in any such structure, and this solution isa fixed point of p.
These considerations illustrate an important trade-off in the construction of modelsfor Situation Theory. There are two ways in which we may measure the power ofour structures as modeling tools. On the one hand, we may see which operationsare possible, desiring closure under such operations as abstraction, infon-formation,and restricted abstraction. On the other hand, we may see which external entities areinternalized, which functions and relations are represented, whether application canbe internalized, and so on. We have seen in Section 4.3.2 that structures in whichmany descriptions are satisfied – in particular, anti-founded structures – are very usefulfor ensuring closure properties under structural operations. Unfortunately, the aboveresults show that if too many descriptions are satisfied then some predicates may benot be representable. The goals of structural closure and internalization are in conflict.Where the boundary lies is still far from clear.
4.4.5 Situation Structures
Sections 4.4.1 to 4.4.4 were primarily concerned with what we have called the Russel-lian approach to the relationship between information and truth. Now we turn to thealternative, Austinian approach.
Consider again the example of Smith’s involvement in a riot. The straightforwardanalysis of the statement that Smith panicked and ran is that it expresses the informa-tion ''panic; Smith(( , ''run; Smith((. The puzzle is to identify the property of thisinfon that makes the statement true. To be a fact an infon must be saturated, butthis infon is not. So, if the truth of the statement depends on its expressing a fact,the straightforward analysis cannot be correct. The Russellian solution is to claimthat the statement, if it is unambiguous, expresses a saturated infon whose additionalroles are filled by various contextually determined parameters. The task of identify-ing and cataloging the various contextual parameters is a matter for further semanticanalysis.35
In the Austinian account, the gap between information and truth is attributed to theneglect of a fundamental component of descriptive statements: the described situation.The basic idea is that a statement using sentence S involves reference to a particularsituation s, and that the truth-value of the statement depends on whether or not the S is
35 An alternative is to explain semantic relationships directly in terms of information expressed ratherthan truth. This approach is summed up nicely by Barwise’s slogan “Information conditions not truthconditions” and has become a core idea in Dynamic Semantics (see Chapter 12).

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 304 — #52
304 Handbook of Logic and Language
a correct description of s. In our example, the described situation is a particular courseof events twenty-six years ago in which Smith panicked and ran. The sentence “Smithpanicked and ran” is therefore a correct description of the described situation, and sothe statement is true.
The same sentence may be used to describe other situations. For example, laterin the narration we may be told of a second riot on the same day in which Smithparticipated but at which he stood his ground. This is obviously not correctly describedby “Smith panicked and ran”, and so a statement using this sentence to describe thelater situation would be false.
Another possibility is that the described situation is one that encompasses manydifferent events, some correctly described and others not. In this case the statementmay be genuinely ambiguous, or even unintelligible. Imagine an account of all theriotous events of 1970, including both the riot in which Smith panicked and the one inwhich he did not, and itemized by the people involved. If Smith’s entry is the singlesentence “Smith panicked and ran”, then it is difficult to assign any definite truth-value.
The different possibilities are accounted for by introducing a new predicate, “sup-ports”, to refer to the relation holding between a situation and the informationexpressed by a true statement about it. In other words, a statement expressing theinformation ! made about a situation s is true if and only if s supports ! . The straight-forward account of information is now sufficient. In our example, the statement thatSmith panicked and ran expresses the information
! = ''panic; Smith(( , ''run; Smith((
and is true because the described situation – the course of events during the first riot –supports ! . A statement made about the second riot using the same sentence expressesthe same information ! but is false because the situation to which it refers does notsupport ! .
The example shows why a simple distinction between fact and non-fact is not suf-ficient to accommodate the referential account. Two statements, one true and the otherfalse, express the same information. Clearly no property of the information expressedwill suffice to explain the difference in truth-value.
Criticism of the Austinian account has centered on two related problems. Firstly,it is difficult explain how reference to situations is achieved. Austin (1961) proposedthat a statement is related to the situation it describes by “demonstrative conventions”,which he contrasted with the “descriptive conventions” relating the statement to whatit says about the situation – the information it expresses, in our terminology. In simplepresent tense statements about one’s immediate surroundings, the relation may be akinto that relating demonstratives (“this”, “that”, etc.) to their referents; but in general, theappeal to demonstration is clearly inadequate. The problem is especially acute if thedescribed situation is temporally and spatially remote from the the person makingthe statement.
The determination of the reference of proper names is beset with similar difficul-ties, and so it is not surprising that solutions to the present problem parallel the familiar

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 305 — #53
Situation Theory 305
moves in the philosophy of language concerning singular reference. The intentions ofthe person making the statement may be involved; there may be some kind of causalrelationship between the statement and described situation; and conventions withina linguistic community may be appealed to; but, in the end, no generally satisfac-tory account has been given, and this remains a serious lacuna of the theory. Specialproblems arise in the present case because the context of a statement has consider-able importance in determining the situation to which it refers. A past tense sentence,such as the one we have been discussing, may well be referentially ambiguous whenuttered out of context, attaining a definite reference only in the context of a discourseor narrative text (see Seligman and Ter Meulen, 1995).
The first problem is compounded by the second: that it is unclear to what a state-ment refers when reference is achieved. The word “situation” is intended to be neutralbetween “event” and “state”, so that it makes sense to speak both of the situation inBosnia, meaning the war (an event or course of events), and the situation on Capi-tol Hill, meaning the state of deadlock over the budget. The theoretical uniformity ofthis terminology is bought at a price. Questions about the identity of situations appearmuch more pressing than the traditional (and equally baffling) metaphysical questionsabout the identity of material objects, persons and members of a host of other onto-logical categories.
A short, bold answer to the question of the identity of situations is that distinctsituations support different infons. Contraposing we get the
Principle of Extensionality: if for each infon ! , s supports ! iff s% supports ! , thens = s%.
If we accept this principle then we may think of situations, and model them, as struc-tured objects whose structure is determined by the infons they support. This is thebasis of a model of situations using the theory of structural relations. We introduce thestructural relations Sit1 of being a situation, and HoldsIn2, which holds between aninfon and a situation just in case the situation supports the infon.
Definition 4.4.6. An extensional structure S of type [A, HoldsIn2, Sit1; ] is a sit-uation structure if A is an infon structure and the following conditions are satisfied:
1. if HoldsIn(!, s) then Inf(! ) and Sit(s), and2. if Sit(s) then s is an ordinary object of A.
The elements of Sit0 are called situations. We say that s supports ! , written s # ! ,if HoldsIn(!, s). An ordinary object of S is an ordinary object of A that is not asituation.
The move from fact structures to situation structures is a generalization in twodirections. First, the non-relational property of being factual is replaced by the rela-tional property of holding in, or being supported by, a situation. Second, this propertymay be had by infons that are unsaturated. In other words, situations are partial in tworespects: they need not support all of the facts, and the infons they do support may beonly unsaturated parts of facts.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 306 — #54
306 Handbook of Logic and Language
Any fact structure F may be used to define a situation structure F# by adding a newelement s& for each set & of facts, and defining: HoldsIn(!, s& ) iff ! is in & . Wesay that a situation structure is standard if it is isomorphic to F#, for some standardfact structure F.
Standard situation structures depart from fact structures only in the first respect.Non-standard situation structures may be constructed by modeling situation-using setsof infons taken from an infon structure with unsaturated infons. This is a very gen-eral method if we work with a theory of sets satisfying AFA, so that no problemsare encountered with situations supporting infons about themselves. There are manyexamples, including Barwise (1987), Fernando (1990), Westerståhl (1990), Aczel(1990), Barwise and Cooper (1991). Here, as previously, we use the theory of struc-tural relations to discuss these models at general level, without going into the detailsof the constructions proposed in the literature.
4.4.6 Parts of the World
How smaller situations relate to larger situations is perhaps the most controversialissue in Situation Theory. To see why, consider the two riots, riot1 and riot2, inwhich Smith participated, and let riots be the larger situation that encompasses all ofSmith’s riotous activities that day. We have seen that the infon ! = ''panic; Smith(( issupported by riot1 but not by riot2. Indeed, riot2 supports the infon ¬! . Clearly,the larger situation riots cannot support both ! and ¬! , and so it does not supportall of the infons supported by its parts.
If these intuitions are to be accepted, it follows that the part–whole relation bet-ween situations is not correctly modeled by the .-order, obtained as an instance ofthe general theory of partiality in Section 4.3.3. According to this account, s1 . s2 iffall infons holding in s1 also hold in s2. So, if riot1 . riots and riot2 . riotsthen riots would have to support the contradictory infons ! and ¬! .
This difficulty may be resolved by supposing that riots supports the infons''panic; Smith, 10 : 15am(( and ¬''panic; Smith, 2 : 30pm((, which contain the infons! and ¬! as parts. This suggests the following definition:
Definition 4.4.7. s1 is a part of s2, written s1 $ s2, if for each infon ! , if s1 # ! thenthere is an infon $ such that s2 # $ and ! . $.
That riot1 $ riots and riot1 $ riots is consistent with the assumption thatriot1 # ! and riot1 # ¬! , and so we see that riot1 and riot2 are compatibleafter all. Note that the $-order satisfies the
Principle of Inclusion : if s1 . s2 then s1 $ s2,
but not necessarily its converse, which is equivalent to the
Principle of Persistence : if s1 $ s2 and s1 # ! then s2 # !.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 307 — #55
Situation Theory 307
In every standard situation structure, Persistence is satisfied, making $ equivalentto ., but this is only because all infons are saturated in standard structures. If weconsider situations modeled by sets of possibly unsaturated infons then Persistencemay be violated, as it is in the above example. A consequence of Extensionality andPersistence is the
Principle of Anti-symmetry : if s1 $ s2 and s2 $ s1 then s1 = s2,
which makes $ a partial order. This is a very desirable consequence because it ensuresthat the (partial) operation of joining two situations together is uniquely defined, asintuition demands it should be.
Anti-symmetry may be violated in non-standard situation structures that do notsatisfy Persistence. For example, suppose that !1 is the information that Kara is eatingand !2 is the information that Kara is eating that trout, so that !1 . !2 but !1 += !2.If s2 is the (necessarily unique) situation that supports only !2, and s1 is the situationthat supports only !1 and !2, then s1 $ s2 and s2 $ s1 but s1 += s2.
Even if one does not accept the Principle of Persistence, one might reject suchcounterexamples to Anti-symmetry as artificial. One way of ensuring that $ is apartial order without a commitment to Persistence is to argue that all situations arerelatively saturated: if s supports ! then there is no less saturated infon $ . !
that is also supported by s, although such an infon may be supported by some othersituation.
The discussion here must remain inconclusive. Definition 4.4.7 is by no meansuniversally accepted as the correct definition of the part–whole relation between sit-uations, and a number of theorists have either stuck with the .-order or taken thepart–whole relation to be a new primitive relation, not determined by the structuralproperties of situations, but perhaps constrained by one or more of the principles dis-cussed above. In what follows we shall assume that $ is used, but the questions wepose must be faced by all of the rival accounts.
Two situations are compatible if they have an upper bound in the $-ordering. Weshall consider several interpretations of compatibility below, but first some more defi-nitions. We say that a situation s is maximal if for each situation s%, if s $ s% then s = s%.A set of situations may be joined if it has a least upper bound in the $-ordering, calledthe join of S. The $-ordering in a standard situation structure is relatively simple.Every standard situation structure satisfies the following conditions:
S1 any two situations are compatible,S2 every set of pairwise-compatible situations may be joined, and soS3 every set of situations may be joined.
In standard situation structures there is a simple relation between situations andfacts: Fact(! ) iff !s.s # ! . Moreover, if the class of facts is a set, there is a uniquemaximal situation w of which every other situation is a part and so Fact(! ) iff w # ! .Non-standard situation structures are not so constrained, but to interpret them we mustbe able to make sense of incompatible situations. We shall consider two interpretations

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 308 — #56
308 Handbook of Logic and Language
of compatibility that give rise to very different ways of understanding Situation Theoryas a whole.
Compossibility InterpretationMaximal situations are completely saturated, in the sense that information about thefilling of roles in infons is specified, and there is no compatible way of adding fur-ther infons. This suggests the interpretation of maximal situations as possible worlds.Under such an interpretation we would insist that
S4 every situation is part of some maximal situation.
Consequently, compatibility becomes compossibility: two situations are compossibleiff they are part of the same possible world. Under this interpretation, one maximalsituation wa must be distinguished as the actual world, and the other incompatiblemaximal situations are ways the world might have been. There is a sharp metaphysicaldistinction between those situations that are part of wa and those that are not: theformer are actual situations; the latter are merely possible situations.
The compossibility interpretation allows one to introduce many of the tools of thetheory of possible worlds.36 For example, standard analyses of modality and condi-tionals may be given. Such analyses tend to run into difficulties because of the partial-ity of situations; we shall not go into the details here.
Relativist InterpretationIncompatible situations are regarded as embodiments of different perspectives on thesame, actual world. For example, suppose we are facing each other across the din-ner table, so that for you the salt is to the left of the pepper. The situation syou con-cerning the arrangement of objects on the table from your perspective supports theinfon ''LeftOf; salt, pepper((, whereas the situation sme from my perspective sup-ports ''LeftOf; pepper, salt((. On a relativist conception, these situations may beincompatible because they capture the structure of the world from essentially differentperspectives. No one can see the objects on the table from a perspective from whichthe salt is to the left of the pepper and the pepper is to the left of the salt.
Whether or not the situations are incompatible depends on the substantial issue asto whether the relation expressed by the phrase “to the left of” is a perspectival one ornot; and, more generally, whether there are such things as perspectival facts. Withoutprejudging the outcome of metaphysical dispute on these matters, we can see that thepresent framework is able to make the pertinent distinctions.
For example, the perspectives on either side of the dinner table may bemade compatible by appealing to a hidden parameter. If there are infons''LeftOf; salt, pepper, me(( and ''LeftOf; salt, pepper, you((, in which a rolefor an egocentric frame of reference is filled by me and you respectively, then there
36 Our construction of standard situation structures may be modified in a fairly obvious way to build stan-dard “modal” situation structures from first-order Kripke structures, by generating situations from sets ofcompossible facts.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 309 — #57
Situation Theory 309
could be a situation supporting both of these infons without conflict, and of whichsyou and sme would be parts. In this way, we can account for the fact that there aredifferent perspectives in this example (sme and syou have no upper bound in the .-ordering), while showing how the two perspectives can be reconciled using hiddenparameters.37
4.4.7 Logic in Situation Structures
The use of consequence relations to capture logical structure (Section 4.4.2) may alsobe applied to situation structures. Given a consequence relation 8 on a class C, a classX / C respects 8 if the partition 'X, C)X( is not in 8. This is a slight generalization ofsoundness: if F is a non-trivial fact structure then 8 is sound on F iff Fact0 respects 8.
The way in which a logic with consequence relation is applied to a situation struc-ture depends on selecting a class of infons to respect it. There are two obvious can-didates: the infons supported by a single situation and the infons supported by somesituation or other.
Definition 4.4.8. Let S be a situation structure and let 8 be a consequence relationon the class of infons of S. For each situation s, let Fs be the set of infons supportedby s. The relation 8 is locally sound on S if Fs respects 8, for each situation s. LetFS be the class of infons supported by some situation in S. The relation 8 is globallysound on S if FS respects 8.
S is locally/globally classical if there is a classical consequence relation that islocally/globally sound on S. From Section 4.4.2, we know that S is locally classicalif and only if it satisfies the following conditions:
1. s # *& iff s # ! for each ! $ & ,
2. s # +& iff s # ! for some ! $ & , and
3. s # ¬! iff s ! ! .
For most applications these conditions are too strong. In particular, they imply thatfor each infon ! , every situation supports either ! or ¬! , and this is quite contraryto the spirit of Situation Theory. Typically, the consequence relation chosen for localsoundness is that of a partial logic such as Kleene’s strong three-valued logic. Anotherpossibility, little studied in the literature but very appropriate to epistemological inter-pretations of Situation Theory (see Schulz, 1996), is that of taking a locally intuitionis-tic situation structure: a structure for which the consequence relation for intuitionisticlogic is locally sound. Both of these possibilities are consistent with the situation struc-ture being globally classical.
There are many other ways of evaluating a consequence relation in a situation struc-ture that are somewhere between the local and the global. For example, in order tomake sense of classical reasoning on the compossibility interpretation, we may restrict
37 For more discussion of perspectives, see Barwise (1989c) and Seligman (1990a,b).

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 310 — #58
310 Handbook of Logic and Language
the condition of local soundness to maximal situations. One could also involve the$-order in a more direct way. For example, for each situation s, let Es be the class ofinfons ! such that for each s% % s there is a s%% % s% such that s%% # ! . A situationstructure S eventually sound if Es respects 8, for each situation s in S. An attractivecombination is for a situation structure to be both locally intuitionistic and eventuallyclassical.
Space prohibits a more comprehensive treatment of logical matters, so we shallclose this section by touching on a question that brings together logical and order-theoretic considerations: how many situations are there? Logical considerations tendto restrict the number of situations, eliminating arbitrary combinations of infons thatdo not respect the local consequence relation. Consideration of the $-order has theopposite tendency: we are driven to claim the existence of the joins of existing sit-uations or of parts that support some subset of the infons supported by an existingsituation.
For example, if S is a situation structure on which 8 is locally sound, then anexample of a fairly generous existence principle compatible with logical considera-tions is the following: if & is a set of infons that respects 8 and there is a situations such that for each ! in & there is a $ supported by s for which ! . $ , then thereis a situation that supports all and only the infons in & . This principle can be used toestablish the existence of joins of compatible situations. If s1 and s2 are compatiblesituations then there is a situation s of which both are parts. Let & be the smallest setof infons satisfying the conditions of the existence principle and such that for eachinfon $ supported by either s1 or s2 there is an infon ! in & such that $ . ! . Then thejoin of s1 and s2 is the situation supporting all and only the infons in & .
4.4.8 Propositions
On the Austinian account, the truth-value of a statement is determined by whether thedescribed situation supports the information expressed. Truth is a property of state-ments but not of the information they express, which may be supported by some sit-uations and not by others. To formulate a theory of truth it is therefore necessary tointroduce a new kind of entity to which the property of being true may be predicated.Statements are the obvious choice, but statements have many contingent propertiesthat are irrelevant to their truth value, including many of the details of their produc-tion, and – most seriously – the fact that they have to be made to exist. Statements notmade do not exist and so cannot be true.
This problem is solved by introducing a new kind of abstract object: propositions.Despite its long philosophical pedigree, including an implied role as the object ofpropositional attitudes, the word “proposition” is used in Situation Theory purely asa term denoting an abstract by virtue of which a given statement has whatever truthvalue it happens to have.
The proposition associated with a given statement is its propositional content. Onthe Russellian account, this is the infon expressed by the statement – fully saturated,possibly by hidden, contextual parameters – and so a Russellian proposition is just an

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 311 — #59
Situation Theory 311
infon. On the Austinian account, the truth of a statement is determined by the situations it describes and the (possibly unsaturated) information ! it expresses. Its proposi-tional content is the Austinian proposition (s # ! ), an abstract entity that combinesthe two components in a structurally extensional manner: if (s1 # !1) = (s2 # !2)
then s1 = s2 and !1 = !2.Truth is taken primarily to be a property of propositions: a statement is true if and
only if its propositional content is true. Thus a Russellian proposition ! is true if andonly if ! is a fact. The theory of Russellian propositions is therefore just the theory offacts, and so we shall consider them no further.
An Austinian proposition (s # ! ) is true if and only if s # ! . Austinian proposi-tions were studied extensively by Barwise and Etchemendy (1987) and King (1994),and used to give an analysis of various semantic paradoxes. The Austinian propo-sition (s # ! ) is usually modeled as the ordered pair 's, ! (. It is easy to see howto characterize these models using structural relations, and so we shall skip over thedetails.
Austinian propositions are true or false absolutely but (Austinian) infons may onlybe evaluated relative to a situation. The contrast suggests an immediate generalizationof Austinian propositions to include similarly “absolute” propositions. For example,whether or not a given object ! is an infon is structurally determined and so doesnot depend on the situation in which the claim is evaluated. We introduce a newproposition (! : Inf) that is true if and only if Inf(! ). Although no typographicaldistinction is made, it is important to realize that the two occurrence of “Inf” in theprevious sentence are grammatically distinct. The latter refers to a structural (meta-theoretic) relation, whereas the former refers to a new abstract object: the type ofinfons.
Extending this idea to other structural relations, we write and (# : R) for the propo-sition that the objects in the sequence # stand in the structural relation R. The simpleAustinian proposition (s # ! ) is identified with the proposition (s, ! : HoldsIn). Thisis modeled in a situation structure extended with structural relations Seq, Type, Prop,and a non-structural relation True, having the following interpretations:
Seq(#, p) # is a sequence of objects in the basic proposition p,
Type(T, p) T is the type in the basic proposition p,
Prop(p) p is a proposition,True(p) p is true.
The key to modeling propositions and types is to observe that the axioms governingthe structure of propositions are exactly the same as those governing facts, with thefollowing relabeling of primitive relations:
Seq " Ass,Type " Rel,Prop " Inf,True " Fact.
With this in mind, we make the following definition.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 312 — #60
312 Handbook of Logic and Language
Definition 4.4.9. An extensional structure P of type
[A, Seq, Type, Prop; Approp, True]
is a proposition structure if the result of relabeling the primitive relations accordingto the above scheme is a fact structure in which each structural relation in A is repre-sented.
The requirement that each structural relation of A is represented is exactly what isneeded. For example, if A is a situation structure then it will have a binary structuralrelation HoldsIn, and so there must be a type, also denoted by “HoldsIn”, rolesHoldsIn1 and HoldsIn2, and for each situation s and infon ! , an appropriate assign-ment # such that App(HoldsIn1, !,#) and App(HoldsIn2, s, #), and a propositionp such that Seq(#, p) and Type(HoldsIn, p), and True( p) iff HoldsIn(!, s). Thisshows that P contains all the Austinian propositions.
A proposition is basic if it has a type. Compound propositions, such as conjunc-tions, disjunctions and negations may be modeled in the same way as compoundinfons. In a Lambda structure there will also be proposition-abstracts of the form (x.pfor each proposition p.38 The structure is then type-closed if for each proposition-abstract T and appropriate assignment #, there is a proposition (# : T). Moreover,when these higher-order propositions exist, they should satisfy the
Principle of %-equivalence for Propositions: if (# : T) is a proposition whose type Tis a proposition-abstract then True((# : T)) iff True(T0(#0)).
A common use of abstraction is the formation of “situation types”. A situation typeT is a type with a single argument role that forms a proposition when that argumentrole is assigned a situation. A situation s is of type T if (s : T) is a true proposition.39
In a Lambda proposition structure, we can form the situation type (x.(x # ! ) forany infon ! . %-equivalence for Propositions ensures that s is of type (x.(x # ! ) justin case s # ! . A theoretical advantage of working with situation types and complexpropositions is that it is possible to capture complex conditions on situations in away that is independent of the structure of information. For example, suppose we areworking with a model in which there is no conjunction of infons, and we need tointernalize a condition of supporting both of the infons ! and $ . This can be done withthe complex situation type (x.(x # ! ) , (x # $ ). A situation is of this type if and onlyif it supports both ! and $ .
Typically, situation theorists have proposed that the logic of propositions is clas-sical.40 This is compatible with any logic on infons, but a favorite combination is a
38 The literature has a rich variety of notations for abstraction over propositions. In addition to the notationsfor abstraction mentioned earlier, “[x|p]” is quite common.
39 We overload the notation for propositions by writing (s : T) as an abbreviation for ([i 4" s] : T) where iis the unique role of T .
40 In other words, the class of true propositions respects a classical consequence relation on the class ofpropositions.
“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 313 — #61
Situation Theory 313
classical proposition structure whose underlying situation structure locally respects apartial logic, such as Kleene’s strong three-valued logic. To see that this is a coherentcombination, note that the proposition (s # ! ) is either true or not, and so in a classicalproposition structure one of the propositions (s # ! ) or ¬(s # ! ) is true. If a situations fails to support ! then ¬(s # ! ) is true, but this does not imply that s supports ¬!
unless the underlying situation structure is locally classical.Another line of thought suggests that logical consequence is primarily a relation
between propositions; they are the bearers of truth, after all. Some models of SituationTheory take infons to be basic infons only (possibly with complex relations) and modelall logical combinations as yielding complex propositions. Whatever course is taken,the machinery of Section 4.3 can be adapted to provide the necessary structures and theapproach to logic in fact structures (Section 4.2) can be applied to yield an appropriatedefinition of consequence.
The account of propositions summarized here suggests a two-storey residence forlogical structure.
!!"!!#
!!"!!#
relations
types
propositions
infons
$$$$$$$$$$$$$$$$$$$$
On the ground floor there are infons. Basic infons are made up of assignments andrelations; compound infons are structured objects constructed from basic infons; andmore complex relations are formed from infons by abstraction.
On the upper floor there are propositions. Basic propositions are made up of assign-ments and types; compound propositions are structured objects constructed from basicpropositions; and more complex types are formed from propositions by abstraction.
The two floors may differ in matters of truth and factuality. Typically, the groundfloor is situated. An infon needs a situation to determine if it is factual or not; likewise,the extension of a relation may vary from situation to situation. The upper floor isabsolute, the lower relative. Propositions are either true or not, and types have fixedextensions. The floors are linked by the relationship between a structural relation onthe ground floor and the type that represents it on the upper floor.
Like all metaphors involving a duality, the two-storey picture raises a question ofredundancy: can we make do with just one of the two, and if so which one? It shouldbe clear that the notion of a proposition structure could serve as the basis for thewhole theory. We could re-express the theory of infons and situations using types, withaxioms involving constants referring to the internal representations of the structuralrelations Inf, Sit, and so on.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 314 — #62
314 Handbook of Logic and Language
In the other direction we have an intriguing possibility. We have already observedthat the same axioms govern infons and propositions, but so far we have regardedthem as distinct kinds. The possibility of models in which the proposition (# : t) isidentical to the infon ''t, #(( is open. In such a model, we would have to decide howthe truth of propositions is related to their support by situations. Much would dependon whether we adopt a compossibility or a relativist interpretation of compatibility. Onthe relativist interpretation, there is no privileged perspective from which to judge thetruth of perspective-independent truths, but we may require that they be recognized astrue from all perspectives. This is in conflict with the partiality of situations, but theconflict can be overcome by resorting to the notion of eventual truth, introduced inSection 4.4.7, and claiming that a proposition is true if it is eventually supported byevery situation.
On the compossibility interpretation, we could choose whether to interpret the truthof a proposition as necessary truth – truth in all possible worlds – or as truth in theactual world. As we have seen, propositions are used to capture structural relation-ships, such as Inf and Rel, but also HoldsIn. If ! is an infon and r a relation, then surelythey are necessarily so. It is less easy to evaluate the status of true Austinian propo-sitions. On the one hand, they are true solely by virtue of structural relations holdingbetween situations and the infons they support.41 On the other hand, they are respon-sible for the truth of contingent statements, like “Raymond cooked an omelette”. Thispoints at another fundamental contention. Allegiance to the the Principle of Exten-sionality suggests that a situation’s support of infons is essential: if s1 supports ! and$ but no other infons, and s2 supports only ! , then s1 must support $ , for otherwise s1would be identical to s2, by Extensionality.
This and many other important metaphysical issues raised by Situation Theory haveyet to be debated seriously. In part this is because the development of technical toolshas been slow. In a theory such as this, inconsistency lurks around every corner (asPlotkin, 1990, has shown), and it is difficult to tell if a given list of axioms is consistent.For this reason, among others, research has focused on the construction of models.
Although many models of Situation Theory have been presented, it is in the natureof model-building that all decisions be made: the result is a concrete structure thatrepresents the world in a particular way. Yet in Situation Theory, the decisions turn onsignificant philosophical issues that have yet to be considered in enough detail for usto be sure of the battle lines, let alone the outcome.
Those building models in this philosophical vacuum either have taken a particu-lar line, contested by other proponents of Situation Theory, or have steered clear ofthe more contentious issues. Barwise’s solution (1989a) was to give a list of “branchpoints” at which critical decisions must be made. It is our hope that the model-construction tools are now sufficiently well understood to allow the looser, moreabstract approach adopted in this chapter to be used to frame the important questionsand sharpen the lines of future philosophical debate.
41 They are “structurally determined” – see R.P. Cooper (1991b).

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 315 — #63
Situation Theory 315
4.4.9 Constraints and the Flow of Information
Situations are user-friendly. Unlike worlds, situations may contain a limited amountof information, an amount that a person may acquire with limited resources. But infor-mation is promiscuous. The limited information acquired in perception breeds in thefertile soil of a person’s mind, and in the cognitive organization of any other well-adapted animal or machine. Information about one’s immediate environment carriesfurther information about the more remote and hidden parts of the world. The infor-mation that the sky is darkening may be acquired by visual perception, but the furtherinformation that a storm is coming, can not. The latter is not information about theimmediate environment, and so not part of the information supported by that situa-tion. We say that a situation s carries an infon ! , written s # ! , if ! follows somehowfrom the information supported by s but is not necessarily supported by s; indeed, itmay be information about a different situation altogether.
The responsibility for this “flow of information” (Dretske, 1981) is placed on theexistence of law-like relationships between situations called “constraints”. Barwiseand Perry (1983) placed considerable importance on the role of constraints. The appealto constraints is central to the claim that Situation Theory is a viable foundation forsemantics, significantly different from Montague’s. It also lies behind the supposedaffinity between Situation Theory and Gibsonian psychology and the approach to cog-nition urged by Barwise (1986) in his debate with Fodor (1985). More recently, con-straints form an essential part of the theory of incremental information developed byIsrael and Perry (1990, 1991). And, constraints are essential to applications of Situa-tion Theory to semantics and AI, of the kind considered by Glasbey (1994, 1996) andCavedon (1995, 1996).
Despite its importance, and considerable research effort, the theory of constraintshas remained elusive. Recent developments (Barwise, 1991; Barwise and Seligman,1994, 1996; Seligman, 1991b) suggest that a quite different outlook is required, onethat has not yet been integrated with other parts of Situation Theory. For this reason,we content ourselves here with an exposition of some of the basic problems.
What are Constraints?Constraints have be categorized roughly as follows:
1. Necessary Constraints, including taxonomic relations between properties like “moles aremammals”, appropriateness conditions like “sipping involves sipping something”, incom-patibility restrictions between properties like “red things aren’t green”, or even betweenindividuals like “Kriesel is not Keisler”, and mathematical constraints like “5 + 7 = 12”;
2. Conventional Constraints, including linguistic rules, syntax and semantics, the rules ofbackgammon or the convention of driving on the right side of the road;
3. Nomic Constraints, including all laws of natures, both the commonplace – such as the lawthat unsupported coffee mugs fall to the floor, and that the radio works if you hit it – and themore esoteric laws about chemical valency or electromagnetism. Most notoriously, “smokemeans fire” expresses a nomic constraint.
4. Meta-theoretic Constraints, including all those laws that form a part of Situation Theoryitself, such as the law that if s # ! then s is a situation and ! is an infon.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 316 — #64
316 Handbook of Logic and Language
This list is haphazard, and there is little convergence on an answer to the question,“What is a constraint?” Sentences, relations, rules, and laws are all given as exam-ples. In semantics, constraints have been proposed as the referents of conditional andgeneric statements (see Barwise, 1985; Cavedon, 1995, 1996). The common thread isto be found in the epistemological role of constraints, and not their ontological status.A constraint is something that allows someone with information about one situation togain information about a possibly different situation. It is because moles are mammalsthat a photograph of Ivor the mole carries the information that Ivor is warm-blooded,at least for anyone who knows than moles are warm-blooded. Likewise, it is the lin-guistic conventions of English-speaking sailors that ensure that the sentence “Landahoy!” carries the information that land has been sighted.
To model constraints we must decide where to put them in the universe of situation-theoretic entities. The simplest approach is to take constraints to be true proposi-tions.42 Many constraints concern the dependency between types of situations, andcan be modeled by basic propositions of the form (T1, T2 : 9), abbreviated to(T1 9 T2), whose arguments T1 and T2 are situation types. If (T1 9 T2) is a con-straint (true proposition) then we say that T1 involves T2. Such constraints constrain bysatisfying the
Principle of Involvement: if s is a situation of type T1 and T1 involves T2 then there isa compatible situation of type T2.
Under the compossibility interpretation the reason for the restriction to compatiblesituations is clear: constraints only constrain situations in the same possible world. Onthe relativist interpretation, it ensures that constraints only apply within and not bet-ween irreconcilable perspectives. There may be constraints that relate different per-spectives, but they are not of the simple form considered above.
The Principle of Involvement gives a necessary but not sufficient condition forthe existence of a constraint. It is not for Situation Theory to decide what constraintsthere are in the world. Nonetheless, some sufficient conditions have been proposed,the foremost of which is the
Xerox Principle: if T1 involves T2 and T2 involves T3 then T1 involves T3.
The name is taken from Dretske’s (1981) principle about information flow. Accordingto Dretske, the transfer of information is an all-or-nothing affair with no degradation ofquality, such as one would obtain from an ideal copying machine.43 The link betweenconstraints and information flow is given by the
42 The choice is grammatically awkward because we talk of the existence of a constraint and not its truth.Other approaches include the following: constraints as facts; constraints as relations between situations,infons, or propositions; and constraints as sets of situations, worlds, infons or propositions. Some authorshave used formal expressions purporting to refer to constraints without attempting to answer the onto-logical question.
43 The Xerox Principle further constrains the distribution of information in the world: if s is of type T1 thenfrom the Principle of Involvement alone it follows that if T1 involves T2 and T2 involves T3 then there isa situation s% of type T3, but not that s% is compatible with s – this requires the Xerox Principle.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 317 — #65
Situation Theory 317
Principle of Information Flow: s carries the information that ! if s is of some type Tthat involves (x.(x # ! ).
These two Principles account for the “long range” of information flow: if s carries theinformation that ! and (x.(x # ! ) involves (x.(x # $ ) then s carries the informa-tion that $ . For this reason, the information carried by a situation may far exceed theinformation it supports.44
Other Constraints
Let us call the approach to information flow discussed above the Theory of Involve-ment. Before discussing the deficiencies of this theory, we shall consider briefly someother kinds of constraints considered in the literature.
Reflexive Constraints: The Principle of Involvement is too weak to capture theconstraints governing the informational dependencies within a situation. If aconstraint (T1 9 T2) is reflexive then every situation of type T1 is also of typeT2. For example, the analytic constraint that if something is a square then itis a rectangle, may be considered to be reflexive. In that case, any situationsupporting ''square; a(( also supports ''rectangle; a((. Reflexive constraintsmay also be used to internalize the logic of situations (Section 4.4.7). The localsoundness of a consequence relation 8 can be captured with the condition thatif + 8 , then (,+ 9 3,) is a reflexive constraint, where ,+ is the type of sit-uations supporting every infon in + and 3, is the type of situations supportingat least one infon in ,.
General Constraints: Let kiss(a, b) and touch(a, b) be the types of situationsupporting the information that a kisses b and that a touches b, respectively.Then the constraint (kiss(a, b) 9 touch(a, b)) captures the dependency bet-ween a’s kissing b and a’s touching b, but not the general relationship betweenkissing and touching. An advantage of using propositions to model constraintsis that the general constraint that kissing involves touching can be modeled asthe complex proposition -xy.(kiss(x, y) 9 touch(x, y)). The logic of propo-sitions together with the Principle of Involvement yield the desired relationshipbetween kissing and touching.
Preclusion: Informational dependencies are not always positive. The informationacquired in a given situation may rule out possibilities without indicating whichof the remaining possibilities obtains. For example, the information that Helen’sbirthday is on a weekday precludes its being on a Saturday without determiningthe day of the week on which it falls. We may model a negative constraint as aproposition of the form (T1, T2 : :), abbreviated to (T1 : T2), and reported bysaying that T1 precludes T2. The Principle of Preclusion is that if s is a situationof type T1 and T1 precludes T2 then there is no compatible situation of type T2.
44 The information carried by a situation is supported by some situation, although possibly in a more sat-urated form: if s ! ! there there is a situation s% and an infon ! % such that s " s% and ! . ! % (by thePrinciples of Involvement and Information Flow).

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 318 — #66
318 Handbook of Logic and Language
The Problem of SpecificityThe Theory of Involvement tells us that if a situation carries the information ! thenthere is a situation that supports ! , but it does not tell us which one.
On the Austinian approach to Situation Theory, the situation a statement is aboutis a very important factor in determining the truth of the statement. Comprehensionmay be severely restricted if one knows that a statement expresses the information !
without knowing which situation the statement is about. We have seen very differentstatements can be made using the sentence “Smith panicked and ran”, all of whichexpress the same information. Likewise, knowing that a situation carries an infon !
may be of little significance unless one also knows which situation supports ! . Onobserving the darkening sky, we know more than that some situation is stormy; if wedid not then this could not serve as a reason to take cover.
One approach to solving this problem is to model constraints as complex proposi-tions. We can capture the dependency between a situation s1 being of type T1 and asituation s2 being of type T2 by means of a proposition of the form (s1 # T1) " (s2 #T2), in which “"” is a binary propositional connective, modeled using structural rela-tions in the obvious way. The Principle of Involvement is replaced by the principle thatif p1 " p2 and p1 is true then so is p2; and the new Principle of Information Flowstates that a situation s carries the proposition p if there is type T such that (s : T) " p.Call the result of these modifications the Propositional Theory of Information Flow.
The Propositional Theory over-compensates for the Theory of Involvement: it istoo specific. One can understand a statement very well without knowing exactly whichsituation it is about, only that it lies within a certain range, or that it is the samesituation that was described by an earlier statement. Likewise, the darkening sky doesnot indicate exactly which situation is stormy.
The middle ground has been explored by Seligman (1990a, 1991b), Barwise(1991), and Israel and Perry (1991). Each approach involves the addition of a parame-ter to capture the dependency between specific situations. Very roughly, we supposethat some situations are connected, while others are not. Then we modify the Prin-ciple of Involvement as follows: if a situation is of type T1 and T1 involves T2 thenthere is a connected situation of type T2. Clearly, which situations are “connected”will vary greatly depending on the nature of the constraint. The connection betweenthe observed situation in which the sky is darkening and the later, stormy situation isquite different from the connection between the statement that Smith panicked and theevent of his panicking.
Another consideration that bears on this issue, and that the above accounts failto address, is the limitations on a person’s access to constraints. If every law-likeregularity in the world is a constraint, then the world is a very constrained place, andjust as “connected”. Yet a person’s information about the world at large is limited,not just by her observations but also by the constraints on which her knowledge isbased. In determining the information carried by a situation some constraints must beexcluded.
Barwise and Perry (1983) adopt the Gibsonian metaphor of attunement for thispurpose. The ability of a person (animal or machine) to extract information from the

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 319 — #67
Situation Theory 319
environment is determined by the constraints to which that person is attuned. The mereexistence of a constraint is not sufficient.
Conditional ConstraintsThe above discussion has proceeded on the assumption that constraints constrain with-out exception. This is a reasonable assumption for the necessary and meta-theoreticconstraints of our original list, and perhaps for some of the nomic constraints con-cerned with fundamental laws of nature; but for the vast majority of constraints thatunderpin a person’s beliefs and actions, the assumption is less secure. Smoke meansfire only if there are no artificial smoke generators nearby; unsupported coffee mugsfall near the surface of the Earth but not in interstellar space; and an utterance of“Land ahoy!” by a drunken sailor may not carry the information that land has beensighted.
Barwise and Perry (1983) introduced a separate category of constraint to accountfor information that flows only under special circumstances. A conditional constraintis a constraint that is guaranteed to hold only when certain background conditions aremet. For example, the background conditions of the constraint that smoke means firemust exclude those situations in which there are other sources of smoke nearby; thoseof the constraint that unsupported coffee mugs fall specify that the mug should be inthe gravitational field of the Earth.
Continuing with the strategy of modeling constraints as true propositions, wetake conditional constraints to be obtained from unconditional constraints by addinga background situation type. Conditional involvements are formed using a ternarytype 9c whose arguments are all situation types. The constraint (T1, T2, B : 9c) isabbreviated to (T1 9 T2|B), and we say that under conditions B, T1 involves T2.45
Such constraints conform to the
Principle of Conditional Involvement: if under conditions B, T1 involves T2, then foreach situation s of type B, if s is of type T1 then there is a compatible situation oftype T2.
For example, suppose that B is the type of situation in which smoke does indeed meanfire, and that smoky and firey are the types of smoky and firey situations, respectively.Then there is a conditional constraint of the form (smoky 9 firey|B). By the Prin-ciple of Conditional Involvement, if s is a situation of type B and s is of type smokythen there is a situation s% of type firey and s% is compatible with s.
The Xerox Principle must also be modified for conditional constraints. The basicidea is that it should hold under fixed background conditions, but not when backgroundconditions vary.
Conditional Xerox Principle: if T1 9 T2|B and T2 9 T3|B then T1 9 T3|B.
45 Conditional versions of reflexive constraints, general constraints and preclusions can be constructedsimilarly.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 320 — #68
320 Handbook of Logic and Language
This Principle was used by Barwise to explain the failure of inferences of the followingform: from “if - then .” and “if . then /” infer “if - then /”. The inference goesthrough only if the background conditions of the constraints denoted by each of theconditional statements are the same. Further connections between conditional logicand Situation Theory are discussed in Barwise (1985) and Cavedon (1995, 1996).
The Elusive Background ConditionThe theory of conditional constraints faces a number of difficult problems. First, it isunclear how the background condition is specified. In psychological applications ofconstraints, the basic idea is that the background conditions of constraints are thosethat hold in the “environment” of the person (animal or machine) attuned to it, butthat may fail to hold outside that environment. The background conditions are pre-conditions for the success of the organism’s behavior, and failure of a given responsemay therefore be attributed to the failure of the background conditions, rather thanto a failure of attunement per se. Unfortunately, this idea has not been successfullyincorporated into Situation Theory. In particular, the role of an “environment” as thefixer of background conditions has proved very difficult to nail down.
In semantics, the determination of background conditions is just as mysterious.One idea is that they are fixed by the described situation, either as the “environment”of that situation or as the situation itself.46 But the relationship between a statementand the situation it describes (discussed in Section 4.4.5) is far from clear, and so nosubstantial progress is made.
A second problem is with the scope of background conditions. Consider the fol-lowing example. A bathroom is wired so that a switch in the corridor outside maybe used to control the light inside. If the switch is down then the light is on, and ifthe switch is up then light is off. These conditionals may be used by a person out-side to know whether the light is on even when the door is closed. Let switch-down,switch-up, light-on, and light-off be the types of situations in which the switchand light are as indicated. The truth of the two conditional statements is attributedto the existence of constraints of the form (switch-down 9 light-on | B) and(switch-up 9 light-off | B), in which B is intended to capture the conditions underwhich the electrical circuit functions properly – no shorts, no loose wires, no blownfuses, etc.
Now suppose that Janet is outside the bathroom. The door is closed but she observesa situation s of type switch-down and infers that the light is on inside. Her conclusionthat is warranted so long as s is of type B, even if Janet does not know that it is. Itis difficult to see how the situation outside the bathroom can be of type B, a type thatensures the correct functioning of the wiring inside. A situation of type B must involvethe whole system, within and without the bathroom walls, and perhaps incorporatingcomponents even further afield, such as the fuse box and the power supply. Such asituation may be comprehensive enough to ensure the success of Janet’s inference, but
46 Barwise (1989c) takes the background condition of a constraint to be a situation instead of a type ofsituation.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 321 — #69
Situation Theory 321
it is not the situation she observes in the corridor outside the bathroom. Moreover,if the larger situation is large enough to guarantee that conditions are right, then itis difficult to see how it can fail to support the information that the light is on andthe switch is down. In that case, even if Janet were able to observe it, and so obtainthe information that the light is on, the conditional constraint would play no part in theprocess.
The problem of specificity, the need to consider connections between situations, theproblems of identifying background conditions and determining their scope, and theneed to incorporate a limitation on access suggest that there is a long way to go beforeSituation Theory is extended with a theory of constraints that satisfies the expectationsraised by Barwise and Perry (1983).
Situation Theory, in its contemporary form, provides a rich, fine-grained ontologyand the means of framing subtle questions about the the nature of truth and circum-stance that could not otherwise be put. But it is a theory of stationary objects, offrozen structure, and has proved ill-suited for accounting for the flow of information.An alternative strategy is to aim for a theory of the flow of information that is not pri-marily concerned with its structure. In different ways, this strategy has been adoptedin a number of contempory approaches, such as Dynamic Semantics (Chapter 12) andChannel Theory (Barwise and Seligman, 1994, 1996).
4.5 Guide to the Literature
The bulk of research papers in Situation Theory and Situation Semantics are containedin the collections entitled Situation Theory and its Applications, Vols I to III, publishedby CSLI. These contain selections of papers presented at a biannual conference. Thename of the conference was changed in 1994 to “Information-Theoretic Approachesto Logic, Language, and Computation”. We have listed in the references a number ofpapers from these volumes. For an introduction to Situation Semantics one could readCooper (1991). Other sources are the books by Fenstad, Halvorsen, Langholm andVan Benthem (1987) and Gawron and Peters (1990a). The latter uses technically intri-cate concepts from Situation Theory, like restricted abstraction, to propose a theory ofanaphora and quantification. In addition, Ter Meulen (1995) studies the representationof temporal information in a related framework, as does Seligman and Ter Meulen(1995). Conditionals are addressed in Barwise (1985) and Cavedon (1995, 1996).
Situation semantics has given rise to computational paradigms as well. For exam-ple, see Tin and Akman (1993) and Tin, Akman and Ersan (1995). The general the-ory has also lead to work in the social sciences; see Devlin and Rosenberg (1993)for the first paper in a series of explorations intended to give a foundation forethnomethodology.
A good introduction to Situation Theory is Devlin (1991a) and the collection ofpapers by Barwise (1989b). Key philosophical works connected with Situation The-ory are Barwise and Perry (1983) and Barwise and Etchemendy (1987). Perhaps theclosest in spirit to the approach taken here is that of Barwise and Etchemendy (1987); it

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 322 — #70
322 Handbook of Logic and Language
was the first to consider circular structures and apply them in a diagnosis of the LiarParadox. Barwise (1987) shows how to use circular structures to model commonknowledge.
The seminal work on non-well-founded sets is Aczel (1988), supplemented morerecently by Barwise and Moss (1996). The latter book has less of an emphasis on settheory, and covers many applications of bisimulations to logic and computer science.The role of bisimulation in modal logic is thoroughly explored in De Rijke (1995).
Recent work on anti-foundation has focused on sorted universes, abstraction andapplication. See, for example, Aczel and Lunnon (1991), Lunnon (to appear), andAczel (1996). The guiding idea behind these developments is that one should be able tocombine methods from set theory and the lambda calculus. The techniques developedby Aczel and Lunnon have been applied directly to Situation Theory by Barwise andCooper (1991).
The concept of information employed in Situation Theory has developed from thatused in Dretske (1981) and Barwise and Perry (1983). Israel and Perry (1990, 1991)have more to say on the subject. The importance of studying information flow hasbeen voiced by many writers (see Chapter 12) and connections to relevant logic andthe Lambek calculus have been brought out by Barwise (1993), Restall (1996) andBarwise, Gabbay and Hartonas (1994).
A recently culminating development is the theory of channels (Barwise and Selig-man, 1996). The goal of this work is a framework for understanding how informationflow results from law-like regularities in distributed systems. Key concerns are themodularity of information systems, the limitations imposed by an agent’s perspectiveand the provision for an account of error. Early papers in this direction are Seligman(1990b) and Barwise (1991).
References
Aczel, P., 1980. Frege structures and the notions of proposition, truth and set, in: Baranse,J., Keisler, H.J., Kunen, K. (Eds.), The Kleene Symposium. North-Holland, Amsterdam,pp. 31–59.
Aczel, P., 1988. Non-Well-Founded Sets. CSLI Lecture Notes no. 14. CSLI Publications,Stanford, CA.
Aczel, P., 1990. Replacement systems and the axiomatization of situation theory, in: Cooper,R., Mukai, K., Perry, J. (Eds.), Situation Theory and its Applications, vol. 1, 1–31.
Aczel, P., 1996. Generalized set theory, in: Seligman, J. Westerståhl, D. (Eds.), Logic, Languageand Computation, vol. 1. CSLI Lecture Notes Series. Center for the Study of Language andInformation, Stanford, CA.
Aczel, P., Lunnon, R., 1991. Universes and parameters, in: Barwise, J., Gawron, J.M., Plotkin,G., Tutiya, S. (Eds.), Situation Theory and its Applications, vol. 2. Center for the Study ofLanguage and Information, Stanford, CA, pp. 3–24.
Austin, J.L., 1961. Truth, Philosophical Papers, in: Urmson, J.O., Warnock, G.J. (Eds.), OxfordUniversity Press, Oxford, UK.
Barwise, J., 1985. Conditionals and Conditional Information. Technical Report, CSLI.Reprinted in Barwise, J., 1989, 97–135.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 323 — #71
Situation Theory 323
Barwise, J., 1986. Information and circumstance: a reply to Fodor, Notre Dame J. Formal Logic27 (3), 324–338.
Barwise, J., 1987. Three views of common knowledge, in: Vardi, M. (Ed.), Theoretical Aspectsof Reasoning about Knowledge, II, Morgan Kaufmann, Los Altos, CA. Reprinted withchanges as On the model theory of common knowledge, Barwise, J., 1989, pp. 201–220.
Barwise, J., 1989a. Notes on branch points in situation theory, in: Barwise, J. (Ed.), 1989b,pp. 255–276.
Barwise, J., 1989b. The Situation in Logic. CSLI Lecture Notes no. 17. CSLI Publications,Stanford, CA.
Barwise, J., 1989c. Situations, facts, and true propositions, in: Barwise, J. (Ed.), 1989b.Stanford, CA, pp. 221–254.
Barwise, J., 1991. Information Links in Domain Theory. Technical report, Indiana UniversityLogic Group. Preprint #IULG-91-7.
Barwise, J., 1993. Constraints, channels, and the flow of information, in: Aczel, P. Israel, D.Katagiri, Y. Peters, S. (Eds.), pp. 3–27.
Barwise, J., Cooper, R., 1991. Simple situation theory and its graphical representation,in: Seligman, 1991a. DYANA Deliverable R2.1.C.
Barwise, J., Cooper, R., 1993. Extended Kamp notation: A Graphical Notation for SituationTheory, in: Aczel, P. Israel, D. Katagiri, Y. Peters, S. (Eds.), Situation Theory and its Appli-cations, vol. 3. Stanford, CA, pp. 29–54.
Barwise, J., Etchemendy, J., 1987. The Liar: An Essay on Truth and Circularity. OxfordUniversity Press, New York, NY.
Barwise, J., Gabbay, D., Hartonas, C., 1994. On the Logic of Information Flow. TechnicalReport, Indiana University Logic Group.
Barwise, J., Moss, L.S., 1996. Vicious Circles: On the Mathematics of Non-WellfoundedPhenomena. CSLI Lecture Notes. CSLI Publications, Stanford, CA.
Barwise, J., Perry, J., 1983. Situations and Attitudes. MIT Press, Cambridge, MA.Barwise, J., Seligman, J., 1994. The rights and wrongs of natural regularity. Perspect. Philos.
8, 331–364.Barwise, J., Seligman, J., 1996. Information Flow: The Logic of Distributed Systems, Tracts in
Theoretical Computer Science. Cambridge University Press, Cambridge, UK.Cavedon, L., 1995. A Channel-Theoretic Approach to Conditional Reasoning. PhD thesis,
Centre for Cognitive Science, University of Edinburgh, UK.Cavedon, L., 1996. A channel-theoretic model for conditional logics, in: Seligman, J.
Westerståhl, D. (Eds.), Logic, Language and Computation, vol. 1. CSLI Lecture NotesSeries. Center for the Study of Language and Information, Stanford, CA.
Cooper, R., 1991a. Three Lectures on Situation Theoretic Grammar, in: Filgeiras, M., Damas,L., Moreira, N., Tomás, A.P. (Eds.), Natural Language Processing: EAIA 90 Pro-ceedings, Lecture Notes in Artificial Intelligence, vol. 476. Springer, New York, NY,pp. 101–140.
Cooper, R.P., 1991b. Persistence and structural determination, in: Barwise, J. Gawron, J.M.Plotkin, G. Tutiya, S. (Eds.), 1991, pp. 295–309.
Davidson, D., 1967. Truth and meaning, Synthese 17, 304–323.De Rijke, M., 1995. Modal Model Theory. Technical Report No. CS-R9517, CWI, Amsterdam.Devlin, K., 1991a. Logic and Information. Cambridge University Press, Cambridge, UK.Devlin, K., 1991b. Situations as mathematical abstractions, in: Barwise, J. Gawron, J.M.
Plotkin, G. Tutiya, S. (Eds.), 1991, pp. 25–39.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 324 — #72
324 Handbook of Logic and Language
Devlin, K., Rosenberg, D., 1993. Situation theory and cooperative action, in: Aczel, P. Israel, O.Katagiri, Y. Peters, S. (Eds.), Situation Theory and its Applications, vol. 3. CSLI, Stanford,CA, pp. 213–267.
Dretske, F., 1981. Knowledge and the Flow of Information. MIT Press, Cambridge, MA.Engdahl, E., 1990. Argument roles and anaphora, in: Cooper, R. Mukai, M. Perry, J. (Eds.),
Situation Theory and its Applications, vol. 1. CSLI, Stanford, CA, pp. 379–393.Fenstad, J.E., Halvorsen, P.-K., Langholm, T., Van Benthem, J., 1987. Situations, Language,
and Logic. Reidel, Dordrecht.Fernando, T., 1990. On the logic of situation theory, in: Cooper, R. Mukai, K. Perry, J.
(Eds.), Situation Theory and its Applications, vol. 1. CSLI Publications, Stanford, CA,pp. 97–116.
Fodor, J.D., 1985. Situations and representation. Ling. Philos. 8 (1), 13–22.Gawron, J.M., Peters, S., 1990a. Anaphora and Quantification in Situation Semantics. CSLI
Lecture Notes no. 19. CSLI Publications, Stanford, CA.Glasbey, S., 1994. Event Structure in Natural Language Discourse. PhD thesis, Centre for
Cognitive Science, University of Edinburgh, UK.Glasbey, S., 1996. Towards a channel-theoretic account of the progressive, in: Seligman, J.
Westerståhl, D. (Eds.), Logic, Language and Computation, vol. 1. CSLI Lecture NotesSeries. Center for the Study of Language and Information, Stanford, CA.
Israel, D., Perry, J., 1990. What is information? in: Hanson, P.P. (Ed.), Information, Lan-guage, and Cognition, The University of British Columbia Press, Vancouver, Canada,pp. 1–28.
Israel, D., Perry, J., 1991. Information and architecture, in: Barwise, J. Gawron, J.M. Plotkin, G.Tutiya, S. (Eds.), Situation Theory and its Applications, vol. 2. CSLI Publications, Stan-ford, CA, pp. 147–160.
King, P.J., 1994. Reconciling Austinian and Russellian accounts of the Liar paradox. J. Philos.Logic 23, 451–494.
Koons, R., 1990. Three indexical solutions to the Liar paradox, in: Cooper, R. Mukai, K.Perry, J. (Eds.), Situation Theory and its Applications. CSLI Publications, Stanford, CA,pp. 269–296.
Koons, R., 1992. Paradoxes of Belief and Strategic Rationality. Cambridge University Press,Cambridge, UK.
Makinson, D., 1994. General non-monotonic logic, in: Gabbay, D., Hogger, C., Robinson,J. (Eds.), Handbook of Logic in Artificial Intelligence and Logic Programming, vol. 3.Oxford University Press, Oxford, UK.
Muskens, R., 1995. Meaning and Partiality, Studies in Logic, Language, and Information. CSLIPublications, Stanford, CA.
Perry, J., 1979. The problem of the essential indexical. Nous 13, 3–21.Plotkin, G., 1990. An illative theory of relations, in: Cooper, R. Mukai, K. Perry, J. (Eds.),
Situation Theory and its Applications, vol. 2. CSLI Lecture Notes, CSLI Publications,Stanford, CA, pp. 133–146.
Restall, G.A., 1996. Information flow and relevant logics, in: Seligman, J. Westerståhl, D. (Eds.),Logic, Language and Computation, vol. 1. CSLI Lecture Notes Series. Center for the Studyof Language and Information, Stanford, CA.
Rounds, W.C., 1991. Situation-theoretic aspects of databases, in: Barwise, J. Gawron, J.M.Plotkin, G. Tutiya, S. (Eds.), Situation Theory and its Applications, vol. 2. CSLI Publi-cations, Stanford, CA, pp. 427–454.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 325 — #73
Situation Theory 325
Ruhrberg, P., 1996. A simultaneous abstraction calculus and theories of semantics, in: Selig-man, J. Westerståhl, D. (Eds.), Logic, Language and Computation, vol. 1. CSLI LectureNotes Series. Center for the Study of Language and Information, Stanford, CA.
Schulz, S., 1996. Minimal truth predicates and situation theory, in: Seligman, J. Westerståhl, D.(Eds.), Logic, Language and Computation, vol. 1. CSLI Lecture Notes Series. Center forthe Study of Language and Information, Stanford, CA.
Seligman, J., 1990a. Perspectives: A Relativistic Approach to the Theory of Information.PhD thesis, University of Edinburgh, UK.
Seligman, J., 1990b. Perspectives in situation theory, in: Cooper, R. Mukai, K. Perry, J. (Eds.),Situation Theory and its Applications, vol. 1. CSLI Publications, Stanford, CA, 1990,pp. 147–191.
Seligman, J., 1991b. Physical situations and information flow, in: Barwise, J. Gawron, J.M.Plotkin, G. Tutiya, S. (Eds.), Situation Theory and its Applications, vol. 2. CSLI LectureNotes, CSLI Publications, Stanford, CA, 1991, pp. 257–292.
Seligman, J., Ter Meulen, A., 1995. Dynamic aspect trees, in: Pólos, L., Masuch, M. (Eds.),Applied Logic: How, What and Why, Kluwer, Dordrecht.
Ter Meulen, A., 1995. Representing Time in Natural Language. The Dynamic Interpretation ofTense and Aspect. Bradford Books, MIT Press, Cambridge, MA.
Tin, E., Akman, V., 1993. BABY-SIT: A computational medium based on situations, in: Dekker,P., Stokhof, M. (Eds.), Proceedings of the 9th Amsterdam Colloquium. ILLC, Amsterdam.
Tin, E., Akman, V., Ersan, M., 1995. Towards situation-oriented programming languages. ACMSigplan Not. 30 (1), 27–36.
Westerståhl, D., 1990. Parametric types and propositions in first-order situation theory, in:Cooper, R. Mukai, K. Perry, J. (Eds.), Situation Theory and its Application, CSLI Pub-lications, 193–230.
Further Reading
Aczel, P., Israel, D., Katagiri, Y., Peters, S. (Eds.), 1993. Situation Theory and its Applica-tions, III, CSLI Lecture Notes no. 22. CSLI Publications, Stanford, CA.
Barwise, J., 1981. Scenes and other situations. J. Philos. 78, 369–397.Barwise, J., Etchemendy, J., 1990. Information, infons, and inference, in: Cooper, R., Mukai, K.,
Perry, J. (Eds.), Situation Theory and its Applications I, CLSI Lecture Notes. Universityof Chicago Press, Chicago, IL, pp. 33–78.
Barwise, J., Gabbay, D., Hartonas, C., 1996. Information flow and the Lambek calculus, in:Seligman, J., Westerståhl, D. (Eds.), CSLI Publications, Stanford, CA, pp. 47–62.
Barwise, J., Gawron, J.M., Plotkin, G., Tutiya, S. (Eds.), 1991. Situation Theory and its Appli-cations, II, CSLI Lecture Notes no. 26. CSLI Publications, Stanford, CA.
Barwise, J., Perry, J., 1985. Shifting situations and shaken attitudes. Ling. Philos. 8 (1),105–161.
Barwise, J., Seligman, J., 1993. Imperfect Information Flow, in: Vardi, M. (Ed.), Proceedings ofthe 8th Annual IEEE Symposium on Logic in Computer Science, IEEE Computer SocietyPress, Los Alamito, CA, pp. 252–261.
Black, A.W., 1992. A Situation Theoretic Approach to Computational Semantics. PhD thesis,Department of Artificial Intelligence, University of Edinburgh, UK.
Black, A.W., 1993. An Approach to Computational Situation Semantics. PhD thesis, Depart-ment of Artificial Intelligence, University of Edinburgh, Edinburgh, UK.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 326 — #74
326 Handbook of Logic and Language
Blackburn, P., De Rijke, M., 1996. Logical aspects of combined structures, in: Seligman, J.Westerståhl, D. (Eds.), Logic, Language and Computation, vol. 1. CSLI Lecture NotesSeries. Center for the Study of Language and Information, Stanford, CA.
Braisby, N., 1990. Situation word meaning, in: Cooper, Mukai, Perry, (Eds.), pp. 315–341.Braisby, N., Cooper, R.P., 1996. Naturalising constraints, in: Seligman, J. Westerståhl, D. (Eds.),
Logic, Language and Computation, vol. 1. CSLI Lecture Notes Series, vol. 58, pp. 91–108.Center for the Study of Language and Information, Stanford, CA.
Burke, T., 1990. Dewey on defeasibility, Cooper, R. Mukai, K. Perry, J. (Eds.), Situation Theoryand its Applications, vol. 1. CSLI Publications, Stanford, CA, pp. 233–268.
Cooper, R., 1986. Tense and discourse location in situation semantics. Ling. Philos. 9.pp. 17–36.
Cooper, R., 1992. Situation theoretic discourse representation theory, Manuscript, HCRC,Edinburgh, UK.
Cooper, R., 1993. Generalized quantifiers and resource situations, in: Aczel, P. Israel, D.Katagiri, Y. St. Peters, (Eds.), Situation Theory and its Applications, vol. 3. CSLI Lec-ture Notes, Number 37. Stanford: CSLI Publications, pp. 191–211.
Cooper, R., 1996. The attitudes in discourse representation theory and situation semantics, in:Seligman, J. Westerståhl, D. (Eds.), Logic, Language and Computation, vol. 1. CSLI Lec-ture Notes Series. Center for the Study of Language and Information, Stanford, CA.
Cooper, R., Ginzburg, J., 1996. A compositional situation semantics for attitude reports, in:Seligman, J. Westerståhl, D. (Eds.), Logic, Language and Computation, vol. 1. CSLI Lec-ture Notes Series. Center for the Study of Language and Information, Stanford, CA.
Cooper, R., Kamp, H., 1991. Negation in situation semantics and discourse representationtheory, in: Barwise, J. Gawron, J.M. Plotkin, G. Tutiya, S. (Eds.), Situation Theory andits Applications, vol. 2. CSLI Publications, Stanford, CA, pp. 311–333.
Cooper, R., Mukai, K., Perry, J. (Eds.), 1990. Situation Theory and its Applications, I, CSLILecture Notes no. 22, CSLI Publications, Stanford, CA.
Devlin, K., 1990. Infons and types in an information-based logic, in: Cooper, R. Mukai, K.Perry, J. (Eds.), Situation Theory and its Applications, vol. 1. CSLI Publications, Stanford,CA, pp. 79–95.
Fernando, T., 1991. Contributions to the Foundations of Situation Theory. PhD thesis, StanfordUniversity, Stanford, CA.
Gawron, J.M., Nerbonne, J., Peters, S., 1991. The absorption principle and E-type anaphora, in:Barwise, J. Gawron, J.M. Plotkin, G. Tutiya, S. (Eds.), Situation Theory and its Applica-tions, vol. 2. CSLI Publications, Stanford, CA, pp. 335–362.
Gawron, J.M., 1986. Situations and prepositions. Ling. Philos. 9, 327–382.Gawron, J.M., Peters, S., 1990b. Some puzzles about pronouns, in: Cooper, Mukai, Perry,
(Eds.), 1990, pp. 395–431.Georgeff, M., Morley, D., Rao, A., 1993. Situation theory and its applications, III, in: Aczel,
Israel, Katagiri, Peters, (Eds.), pp. 119–140.Ginzburg, J., 1991. Questions without answers, wh-phrases without scope: a semantics for
direct wh-questions and their responses, in: Barwise, J. Gawron, J.M. Plotkin, G. Tutiya,S. (Eds.), Situation Theory and its Applications, vol. 2. CSLI Publications, Stanford, CA,pp. 363–404.
Healey, P., Vogel, C., 1993. A situation theoretic model of dialogue, in: Jokinen, K. (Ed.), Prag-matics in Dialogue Management, Gothenburg Monographs in Linguistics.
Hintikka, J., 1983. Situations, possible worlds, and attitudes. Synthese 54, 153–162.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 327 — #75
Situation Theory 327
Katagiri, Y., 1991. Perspectivity and the Japanese reflexive ‘zibun’, in: Barwise, Gawron,Plotkin, Tutiya, (Eds.), pp. 425–447.
Katagiri, Y., 1996. A distributed system model for actions of situated agents, in: Seligman, J.Westerståhl, D. (Eds.), Logic, Language and Computation, vol. 1. CSLI Lecture NotesSeries. Center for the Study of Language and Information, Stanford, CA.
Lewis, D.K., 1979. Score keeping in a language game, in: Bauerle, R. (Ed.), Semantics fromDifferent Points of View, Springer, New York, pp. 172–187.
Lewis, D.K., 1983. General Semantics, Philosophical Papers, vol. 1, Oxford University Press,New York/Oxford, pp. 233–249.
Lewis, M., 1991. Visualization and situations, in: Barwise, J. Gawron, J.M. Plotkin, G. Tutiya, S.(Eds.), Situation Theory and its Applications, vol. 2. CSLI Publications, Stanford, CA,pp. 553–580.
Lunnon, R., 1991a. Generalised Universes. PhD thesis, Manchester University, UK.Lunnon, R., 1991b. Many sorted universes, SRD’s, and injective sums, in: Barwise, J.
Gawron, J.M. Plotkin, G. Tutiya, S. (Eds.), Situation Theory and its Applications, vol. 2.CSLI Publications, Stanford, CA, pp. 51–79.
Lunnon, R. A theory of sets and functions, J. Symb. Logic. (in press).Mori, T., Nakagawa, H., 1991. A formalization of metaphor understanding in situation seman-
tics, in: Barwise, J. Gawron, J.M. Plotkin, G. Tutiya, S. (Eds.), pp. 449–467.Nakashima, H., Suzuki, H., Halvorsen, P.-K., Peters, S., 1988. Towards a computational
interpretation of situation theory, Proceedings of the International Conference on FifthGeneration Computer Systems, Institute for New Generation Computer Technology,Tokyo, Japan, pp. 489–498.
Nakashima, H., Tutiya, S., 1991. Inferring in a situation about situations, in: Barwise, J.Gawron, J.M. Plotkin, G. Tutiya, S. (Eds.), Situation Theory and its Applications, vol. 2.CSLI Publications, Stanford, CA, pp. 215–227.
Perry, J., 1984. Contradictory situations, in: Landman, F., Veltman, F. (Eds.), Varieties of FormalSemantics: Proceedings of the 4th Amsterdam Colloquium, Groningen–Amsterdam Seriesin Semantics, Foris, Dordrecht.
Perry, J., 1986. From worlds to situations. J. Philos. Logic 15, 83–107.Perry, J., 1993. The Essential Indexical and Other Essays. Oxford University Press, New York.Perry, J., Macken, E., 1996. Interfacing situations, in: Seligman, J. Westerståhl, D. (Eds.), Logic,
Language and Computation, vol. 1. CSLI Lecture Notes Series. Center for the Study ofLanguage and Information, Stanford, CA.
Poesio, M., 1991. Relational semantics and scope ambiguity, in: Barwise, J. Gawron, J.M.Plotkin, G. Tutiya, S. (Eds.), Situation Theory and its Applications, vol. 2. CSLI Publi-cations, Stanford, CA, pp. 469–497.
Poesio, M., 1993. A situation-theoretic formalization of definite description interpretation inplan elaboration dialogues, in: Aczel, P. Israel, D. Katagiri, Y. Peters, S. (Eds.), SituationTheory and its Applications, vol. 3. CSLI, Stanford, CA, pp. 339–374.
Rounds, W.C., 1990. The complexity of paradox, in: Cooper, R. Mukai, M. Perry, J. (Eds.),Situation Theory and its Applications, vol. 1. CSLI, Stanford, CA, pp. 297–311.
Rounds, W.C., Zhang, G.-Q., 1996. Attunement to constraints in non-monotonic reasoning, in:Seligman, J. Westerståhl, D. (Eds.), Logic, Language and Computation, vol. 1. CSLI Lec-ture Notes Series. Center for the Study of Language and Information, Stanford, CA.
Schütze, H., 1991. The Prosit Language, Version 0.4. CSLI Memo, Center for the Study ofLanguage and Information, Stanford University, Stanford, CA.

“08-ch04-0253-0328-9780444537263” — 2010/11/29 — 21:08 — page 328 — #76
328 Handbook of Logic and Language
Seligman, J. (Eds.), 1991a. Partial and Dynamic Semantics III. Centre for Cognitive Science,University of Edinburgh. DYANA Deliverable R2.1.C.
Seligman, J., 1996. The logic of correct description, in: de Rijke, M. (Ed.), Advances in ModalLogic, Kluwer, Dordrecht, pp. 107–136.
Seligman, J., Westerståhl, D. (Eds.), 1996. Logic, Language and Computation. CSLI LectureNotes. CSLI Publications, Stanford, CA.
Sem, H.F., Saebo, K.J., Verne, G.B., Vestre, E.J., 1991. Parameters: dependence and absorp-tion, in: Barwise, J. Gawron, J.M. Plotkin, G. Tutiya, S. (Eds.), Situation Theory and itsApplications, vol. 2. CSLI, Stanford, CA, pp. 499–516.
Shin, S.-J., 1991. A situation-theoretic account of valid reasoning with Venn diagrams, in:Barwise, J. Gawron, J.M. Plotkin, G. Tutiya, S. (Eds.), Logic, Language and Computa-tion, vol. 1. CSLI Lecture Notes Series. Center for the Study of Language and Information,Stanford, CA.
Stalnaker, R., 1986. Possible worlds and situations. J. Philos. Logic 15, 109–123.Suzuki, H., Tutiya, S., 1991. A strictly incremental approach to Japanese grammar, in: Bar-
wise, J. Gawron, J.M. Plotkin, G. Tutiya, S. (Eds.), Situation Theory and its Applications,vol. 2. CSLI, Stanford, CA, pp. 517–532.
Tin, E., Akman, V., 1994a. Computational situation theory. ACM SIGART Bull. 5 (4), 4–17.Tin, E., Akman, V., 1994b. Situated processing of pronominal anaphora, in: Trost, H. (Ed.),
Tagungsband KONVENS ’94 Verarbeitung Natürlicher Sprache. Vienna, Austria, Infor-matik Xpress, pp. 369–378.
Tin, E., Akman, V., 1996. Information-oriented computation with BABY-SIT, in: Seligman,J. Westerståhl, D. (Eds.), Logic, Language and Computation, vol. 1. CSLI Lecture NotesSeries. Center for the Study of Language and Information, Stanford, CA.
Tojo, S., Wong, S., 1996. A legal reasoning system based on situation theory, in: Seligman,J. Westerståhl, D. (Eds.), Logic, Language and Computation, vol. 1. CSLI Lecture NotesSeries. Center for the Study of Language and Information, Stanford, CA.
Vogel, C., 1992. A situation theoretic model of inheritance reasoning, Research Conference onLogic, Language, and Information: Toward an Integrated Theory of Linguistic Processing,European Science Foundation, December, 13–17.
Zadrozny, W., 1996. From utterances to situations: parsing with constructions in small domains,in: Seligman, J. Westerståhl, D. (Eds.), Logic, Language and Computation, vol. 1. CSLILecture Notes Series. Center for the Study of Language and Information, Stanford, CA.
Zaefferer, D., 1991. Probing the iroquoian perspective: Towards a situated inquiry of linguisticrelativity, in: Barwise, Gawron, Plotkin, Tutiya, (Eds.), pp. 533–549.
Zalta, E., 1991. A theory of situations, in: Barwise, J. Gawron, J.M. Plotkin, G. Tutiya, S.(Eds.), Situation Theory and its Applications, vol. 2. CSLI Publications, Stanford, CA,pp. 81–111.

“09-ch05-0329-0344-9780444537263” — 2010/11/30 — 3:44 — page 329 — #1
5 Situations, Constraints andChannels(Update of Chapter 4)Edwin Mares!, Jeremy Seligman†, Greg Restall‡!Department of Philosophy, Victoria University of Wellington,P.O. Box 600, Wellington, New Zealand, E-mail: [email protected]
†Department of Philosophy, The University of Auckland, Private Bag92019, Auckland 1142, New Zealand, E-mail: [email protected]
‡Department of Philosophy, School of Philosophy, Anthropologyand Social Inquiry, The University of Melbourne, Old Quad,Parkville, Victoria 3010, Australia, E-mail: [email protected]
5.1 From Situation Semantics to Situation Theory
Central to the project of situation semantics was the goal of a ‘relational’ theory ofmeaning, which would explain meaning in terms of the relationship between situa-tions containing meaningful entities or actions such as utterances and situations theyare about (Barwise and Perry, 1983). The contrast is primarily with the once dominantview of Davidson, Montague, and many others following Tarski’s seminal ideas aboutsemantics, according to which the meaning of a declarative statement (at least) is to beunderstood in terms of the conditions under which it is true. There are some difficultiesin making this contrast clear. After all, truth-conditional theories of meaning typicallyalso involve a theory of reference, which is concerned specifically with the relation-ship between words and things, and the relation of reference is present in all attemptsto produce a situation-based semantics. Likewise, truth has been studied within a situ-ation theoretic framework, most notably by Barwise and Etchemendy (1987), in theirtreatment of the Liar paradox. Dressing up a truth-conditional account of meaning inthe notation of situations and infons is a futile exercise.
The important difference is in the theoretical status of semantic vocabulary. ForTarski, semantics involves a clear separation between syntax and semantics, and thisseparation has been honoured by most of his followers. By contrast, situation seman-tics aimed to do without this separation, taking reference, for example, to be a relationlike all others, and with no special theoretical status. That ‘Jon’ refers to Jon is just afact to be modelled as ""refers, ‘Jon’, Jon; 1##. A consequence of representing semanticfacts in the object language is that there is no need for a hierarchical theory of mean-ing, on which the meaning of an expression is some unitary theoretical entity, such asa truth-condition, derived from its more basic semantic properties. Instead, the manyfacets of meaning can be left unassembled and ready to be used for whatever purposeis required.
Handbook of Logic and Language. DOI: 10.1016/B978-0-444-53726-3.00005-0c$ 2011 Elsevier B.V. All rights reserved.

“09-ch05-0329-0344-9780444537263” — 2010/11/29 — 21:08 — page 330 — #2
330 Handbook of Logic and Language
As a consequence, many aspects of semantic theory that are usually treated safelyin the metalanguage need to be made explicit. For example, the relation between aconjunction ! ! " and its conjunct ! can be represented as one of ‘involvement’,so that ""involves, ! ! ", ! ; 1## is a fact of the same genus if not the same speciesas ""involves, smoke, fire; 1##. Moreover, a theory is needed to explain the way inwhich information about ‘involvement’ works. Some account must be given of whatit is for a situation to support infons of this kind. In the case of natural regularities,such as the relationship between smoke and fire, an obvious thought is that thelocalisation to a situation can accommodate the defeasible nature of the regularity.In some situations, smoke really does indicate the presence of fire, in others itdoes not. For logical laws, such as Conjunction Elimination, no such localisationis necessary, and yet to say that every situation supports the infon ""involves,! ! ", ! ; 1## conflicts with the idea that situations are informationally limited. Asituation concerning a cricket match in New Zealand may not contain any informationabout the weather in Bangkok, so it would be unfortunate if it supported the infon""involves, ""hot and humid, Bangkok; 1##, ""hot, Bangkok; 1##; 1##.
It is to deal with issues such as these that a general theory of constraints is required.Constraints, such as ‘involvement’, are relations between infons and possibly otherparts of the situation theoretic universe, that make explicit the regularities on which theflow of information depends. The replacement of truth by ‘support’ as the fundamentaltheoretical concept of situation theory succeeds in localising information but at theexpense of opening an explanatory gap: how is it that information in one situation isrelated to information in another situation?
5.2 Early Channel Theory
One approach to the flow of information stands to the ‘constraint’ view of the lastsection as an Austinian account of propositions stands to a Russellian account. It is onething to consider constraints as true propositions: generalisations or relations betweensituation types: one can go quite some way given that approach. The development ofchannel theory in the 1990s marked a new approach.
Consider this example: a student looks at her marked assignment, and the fact thatthis perceptual situation carries some information (the ‘A’ written in red ink in the topcorner of the first page) gives her the information that her tutor thought her assignmentwas a good one, that she’s passed her class, that she’s completed her degree, and thatshe’s likely to get a job. The information carried in this situation gives her informa-tion about other situations: the marking situation for one, and her future prospects, foranother. How are we to take account of this? Barwise (1993), in his paper “Constraints,Channels, and the Flow of Information” marks out a few desiderata concerning infor-mation carrying across situations.
xerox principle: If s1 : A carries the information that s2 : B and s2 : B carries theinformation that s3 : C then s1 : A carries the information that s3 : C.

“09-ch05-0329-0344-9780444537263” — 2010/11/29 — 21:08 — page 331 — #3
Situations, Constraints and Channels 331
logic as information flow: If A entails B (in some sense to be determined) thens : A carries the information that s : B.
information addition: If s1 : A carries the information that s2 : B and s1 : A$ car-ries the information that s2 : B$, then s1 : A ! A$ carries the information thats2 : B ! B$.
cases: If s1 : A carries the information that s2 : B%B$ and s2 : B carries the informa-tion that s3 : C and s2 : B$ carries the information that s3 : C then s1 : A carriesthe information that s3 : C.
In these principles, we flag the manner in which information about a situationcan carry information about some other situation. The other desirable feature is thatwe have some robust account of how information flow can be fallible. The studentseeing her ‘A’ correctly gathers the information that she has passed. However, ina perceptually indistinguishable situation, she is reading a forgery. What are we tomake of this case?
The characterising feature of channel theory is that there are objective ‘links’ bet-ween situations, which support the flow of information, just as there are objective sit-uations, which support first-order information. These links may be present or absent,distinguishing veridical information flow from cases of misinformation.
Channels are means of connection between situations. That a channel c links sand t is denoted ‘s
c&' t’. An example of a channel given by Barwise and Seligman(1994) in “The Rights and Wrongs of Natural Regularity” is the Rey Channel, linkingthermometer-reading situations with patient situations. The fact that the thermometer’smercury level has a particular height usually indicates something about the tempera-ture of a patient. The channel grounds the regularity connecting between thermometerreadings and patient temperatures.
So, if we have a situation s which includes a thermometer, and we have a ther-mometer reading A, so we have s ! A, and the channel c supports a regularity of theform A ' B (if the height is x then the temperature is y) then given that the situationt is connected to s by the channel c (s
c&' t) we can infer t ! B. In sc&' t, s is a signal
for the channel c and t is a target. A channel c supports the constraint A ' B if andonly if for each signal-target pair s and t where s
c&' t, if s ! A then t ! B.An important feature of channel theory is the presence of multiple channels, in just
the same way as multiple situations feature in situation theory. Information flows inmore than one way—it is not just a matter of physical law, or convention, or logicalentailment. The Rey channel is partly a matter of physical law, but it is also a matterof convention. Another obvious family of channels which is a mix of physical law andconvention is the doorbell. Someone pushes a button, rings the doorbell, and indicatesto us that someone is at the door. This can be analysed as a chain of channels. One fromthe bell situation to the doorbell button situation, another from the button situationto the situation out on the verandah. That is, information about the state of the bell(that it’s ringing) gives us information about the state of the button (that it’s beenpressed). Then information that the button has been pressed gives us the information

“09-ch05-0329-0344-9780444537263” — 2010/11/29 — 21:08 — page 332 — #4
332 Handbook of Logic and Language
that there’s someone on the verandah waiting to get in. These channels can be thoughtof as ‘chaining together’ to form one larger channel.
We can use these distinctions to give a taxonomy of what goes on in informationflow. And one thing which channel theory is useful for is in giving us a way to seehow different things can go wrong in our inferring about situations.
For example, suppose that the thermometer has not been near any patient, but thenurse takes a reading. If anyone infers anything about a patient’s temperature fromthe thermometer reading, they are making a mistake. In this case, the channel doesnot connect any patient situation with the thermometer situation. We say that the ther-mometer situation s is a pseudo signal for the channel c.
That this kind of error can be accommodated can help us analyse things like theproblems of counterfactuals. The conditional “If I drink a cup of tea, I feel better”is grounded by a complex (physiological, psychological and no doubt, sociological)channel which links tea drinking situations to better feeling situations. The conditionalis true. However, it is not true that if I drink a cup of tea with poison in it, I feel better.But isn’t this a counterexample to the regularity we thought we saw? It doesn’t haveto be, for a situation in which I drink tea with poison is a pseudo signal of the channelI discussed. The channel does not link all tea drinking situations with matching betterfeeling ones. It merely links “appropriate” ones.1
Now we may consider a channel-theoretic elaboration of principles of informationflow.
xerox principle: If s1 : A carries the information that s2 : B and s2 : B carries theinformation that s3 : C then s1 : A carries the information that s3 : C.
This will be met if we require for every pair of channels c1 and c2 that therebe a channel c1; c2 which composes c1 and c2, satisfying s
c1;c2&(' t iff there’s a uwhere s
c1&' u and uc2&' t. Then it is simple to show that if s
c1&' u ! A ' B andu
c2&' t ! B ' C then sc1;c2&(' u ! A ' C.
Here, c1; c2 is said to be the serial composition of c1 and c2.logic as information flow: If A entails B (in some sense to be determined) then
s : A carries the information that s : B.Here, we need only an identity channel 1, which maps each situation onto
itself. Then if A ) B is cashed out as “for each s, if s ! A then s ! B”, then Aentails B iff 1 ! A ' B.
information addition: If s1 : A carries the information that s2 : B and s1 : A$ car-ries the information that s2 : B$, then s1 : A ! A$ carries the information thats2 : B ! B$.
Here we need the parallel composition of channels. For two channels c1 andc2 we would like the parallel composition c1 * c2 to satisfy s
c1*c2&((' t iff sc1&' t
and sc2&' t. Then it is clear that if s1
c1&' s2 ! A ' B and s1c2&' s2 ! A$ ' B$
then s1c1*c2&((' s2 ! A ! A$ ' B ! B$.
1 Restall (1995) discusses the behaviour of counterfactuals in a channel-theoretic setting in “InformationFlow and Relevant Logics”.

“09-ch05-0329-0344-9780444537263” — 2010/11/29 — 21:08 — page 333 — #5
Situations, Constraints and Channels 333
cases: If s1 : A carries the information that s2 : B%B$ and s2 : B carries the informa-tion that s3 : C and s2 : B$ carries the information that s3 : C then s1 : A carriesthe information that s3 : C.
Again using parallel composition, if s1c1&' s2 ! A ' B%B$, s2
c2&' s3 ! B 'C and s2
c3&' s3 ! B$ ' C, then s1c1;(c2*c3)&((((' s3 ! A ' C.
Models in which constraints stand to channels as infons stand to situations imme-diately brought to light new connections between situation theory and other areas.Restall (1995) showed that if we identify channels with situations, then any modelof the conditions on channels is a model of Routley and Meyer’s ternary relationalsemantics for relevant logics. The channel theoretic reading for y
x&' z is another wayto conceive of the three-place relation Rxyz on points in a ternary relational model,and the clause for the relevant conditional:
x ! A ' B iff for each y, z where Rxyz if y ! A then z ! B
is merely a flattenning of the channel-theoretic account, in which channels are broughtdown to the level of situations. In this way, one is free to think of points in a modelfor relevant logic as situations.2 Situations not only are a site for the carrying of infor-mation purely about what is contained in them: they may also constrain or maintainconnections between other situations. Given this perspective, different conditions onthe three-place relation R correspond to different ways in which the topography ofthose connections are to be understood.
In a similar fashion, Barwise et al. (1996) showed that a generalisation of the Lam-bek calculus can be conceived of in a channel theoretic manner (and given a nicetwo-level cut free sequent system), in which the traditional Lambek calculus is recov-ered if the picture is flattened, and channels and situations are identified in the samemanner.3
This work on channel theory through to the mid-1990s was, it must be said, atransitional phase. A greater level of generality was reached with the publication ofBarwise and Seligman’s Information Flow: the logic of distributed systems (1997).
5.3 Situated Inference
A somewhat different way of relating relevant implication to channels is developedin the theory of situated inference in Mares (2004). This theory is a descendent ofDavid Israel and John Perry’s theory of information (1990). In the theory of situatedinference, relevant implication represents constraints, combinations of constraints, andthe logical manipulation of these constraints.
2 This is already congenial to the relevantist, for points in Routley–Meyer models may be incomplete withrespect to negation, just as situations are. Relevant models typically also allow for inconsistent points,which are perhaps a little more difficult to motivate from purely situation-theoretic considerations.
3 For more ways to interpret traditional logical structures, such as accessibility relations in a multimodalframe, see Restall (2005).

“09-ch05-0329-0344-9780444537263” — 2010/11/29 — 21:08 — page 334 — #6
334 Handbook of Logic and Language
The key distinction in this theory is between worlds and situations and the centralnotion underlying the theory of inference is that of a constraint, in the sense we havealready seen. Constraints themselves can be present as information in situations. Hereis a rather blatant example of a situated inference. Suppose that an agent is in a situa-tion in which there is the constraint that all massive bodies, heavier than air, releasednear the surface of the earth fall towards the earth. From the hypothesis of the exis-tence of an actual situation (i.e. a situation in her world) in which a massive body isreleased near the surface of the earth, she can infer that there is an actual situation inwhich that body falls towards the earth. But, like channel theory, the theory of situatedinference does not require that constraints be general in this way. They may concernparticular objects or circumstances.
The theory of situated inference deals with misinformation in a different way fromearly channel theory. In early channel theory, a situation in which there is a certainsort of information and one in which there fails to be that sort of information (butappears the same as the first situation) is explained by the presence or absence of asecond situation—a channel. In the theory of situated inference, the difference is bet-ween two situations that have different sorts of information actually available in them.This difference is not caused by a deep philosophical disagreement over the nature ofinformation. Rather, the two theories have different purposes. Early channel theory ismeant to explain information flow, whereas the theory of situated inference is meantto give a theory of deductive warrant for inferences made with partial information.But the idea that constraints be available as information to agents in situations meansthat the notion of availability used here has to be sufficiently general. We clearly donot have perceptually available to us many of the constraints that we use in infer-ring. Other sorts of reliable causal processes must be allowed to be counted as makinginformation available to us if this theory is to be viable.
In Mares (2004), the theory of situated inference is used to provide an interpretationof Alan Anderson and Nuel Belnap’s natural deduction system for relevant logic andwe use this natural deduction system here to make the theory clearer.4
At a line in a derivation in this system, we not only have a formula, but a formulasubscripted with a set of numbers. These sets, on the theory of situated inference, referto situations. Thus, for example, if we have A{1} at a line of a proof, this is to be read as‘A is satisfied by a situation s1’ or ‘s1 |= A’. So that we can see how the subscriptingmechanism works, let’s look at a proof of A ) (A ' B) ' B:
1.
2.
3.
4.
5.
!!!!!!!!!!
A{1}!!!!!!
A ' B{2}A{1}B{1,2}
(A ' B) ' B{1}
hyphyp1, reit2, 3, ' E2 ( 4, ' I
4 Situated inference is also used in Mares (2004) to give a reading of a model theory like the one discussedin the section on early channel theory in which implication is modelled using a three-place relation. Butthis interpretation is too involved to be included in the current chapter.

“09-ch05-0329-0344-9780444537263” — 2010/11/29 — 21:08 — page 335 — #7
Situations, Constraints and Channels 335
When we make a hypothesis in a proof, it takes the form of the formula hypothesizedsubscripted with a singleton of a number not used before in the proof. When we usethe rule of implication elimination (as in line 4 of this proof), the subscript of the con-clusion of the rule is the union of the subscripts of the premises. When we dischargea hypothesis (as in line 5 of this proof) we remove the number of the hypothesis fromthe subscript of the conclusion. The hypothesis’ number must be present in the lastline before the discharge in order to allow the discharge to take place. In this waywe ensure that the hypothesis is really used in the subproof, and this ensures that theresulting logic is a relevant logic. In this way we represent informational connectionsand we read A ' B as “A carries the information that B”.
A formula subscripted by a set with more than one number in it, e.g. B{1,2} fromline 4 of our derivation, is to be read as saying that on the basis of the hypotheses abouts1 and s2, we can derive that there is a situation in the same world which satisfies B.
The treatment of conjunction in the theory is also interesting. In relevant logic, thereare two types of conjunction: extension conjunction (!) and intensional conjunction or“fusion” (+). The introduction rules for the two connectives make the difference clear.From A# and B$ we may infer A + B#,$ . With regard to extensional conjunction, onthe other hand, the subscripts on two formulas must be the same before we can conjointhem: from A# and B# we may infer A ! B# . In situated terms we can explain clearlythe difference in meaning between these two connectives. If we are in a situation inwhich we have the information that (A!B) ' C, then we have warrant to infer, on thebasis of the hypothesis of an actual situation which satisfies both A and B, that thereis an actual situation which satisfies C. If, on the other hand, we have the informationthat (A + B) ' C, then we have warrant to infer, on the basis of the hypothesis of anactual situation which satisfies A and the hypothesis of an actual situation that satisfiesB, that there is an actual situation that satisfies C.
The reason for introducing fusion here is to make a point about relevant (and sit-uated) inference. The premises of a relevant inference are bound not by extensionalconjunction, but by fusion. In a situation s, the postulation of situations s1 |= A1, . . . ,sn |= An deductively warrants the postulation of sn+1 |= B if and only if s |=(A1 + · · · + An) ' B. The natural deduction rules for fusion bear out this close rela-tionship to situated inference. The introduction rule tells us that we are allowed toinfer from A# and B$ to A + B#,$ and the elimination rule tells us that we may inferfrom A + B# and A ' (B ' C)$ to C#,$ . These rules together with the rules forimplication allow us to prove the equivalence of A1 ' (A2 ' · · · (An ' B) · · · )#and (A1 + A2 + · · · + An) ' B# , which is a situated version of the deduction theorem.
This ends our discussion of situated inference. In the next section we examine amore dynamic view of the relationship between constraints and information.
5.4 Modern Channel Theory
A further development of the theory of channels introduces the distinction betweentokens and types into the model. Logical relations of entailment and contradiction are

“09-ch05-0329-0344-9780444537263” — 2010/11/29 — 21:08 — page 336 — #8
336 Handbook of Logic and Language
formal: they depend only on the form of the propositions they relate. This applies evento those entailments that depend on the meaning of non-logical words: the inferencefrom ‘Jon is taller than Jerry’ to ‘Jerry is shorter than Jon’ is a formal inference from ‘Xis taller than y’ to ‘y is taller than x’. As such, the distinction between token and type,between a specific use of these sentences and the sentence types, is irrelevant. Infor-mational dependencies between many events do not share this indifference to tokens.Whether or not an observed plume of smoke indicates the presence of a nearby firedepends a great deal on the circumstances, on the particularities of the occasion. Thisdependence on the specific circumstances can be modelled by a type. If B (for ‘back-ground condition’) is the type of situation in which smoke really does mean fire, thenwe can take the relation between smoky events and fiery events to be mediated bya channel of type B. We have seen how this idea can be developed in the previoussections. Another way is to get serious about tokens, bringing them into the modelexplicitly. This continues the situation theoretic methodology of internalising metalin-guistic concepts to advance the theory. Before we can describe the resulting modelof channels, it is therefore necessary to say something about the results of applying atype-token distinction throughout the underlying theory.
In fact, the type-token distinction is already part of situation theory in the relation-ship between situations and the set of infons they support. In early work on situationtheory, this was referred to as the distinction between real situations and abstract situ-ations. It had little effect on the development of the theory because of the principle ofextensionality, which identifies situations that support the same infons, and so ensuresthat there is only one situation of each basic type.5
5.4.1 Classifications and Local Logics
The way in which token entities (situations, events, objects or whatever) are catego-rized into types depends on the method of classification used. Different languages, forexample, give us different ways of grouping objects together. In early work on sit-uation theory, the basic divisions into objects, properties and relations, was called ascheme of individuation. This can be regarded as the result of putting the signature ofthe language into the model, with the possibility that there can be more than one. Themultiplicity of schemes allows not only for radically different ways of conceiving ofthe world by agents from different cultures (or species) but for the more mundane factthat we adapt our conceptual repertoire according to context, employing only thosedistinctions that are salient and/or useful. Seligman (1990) took the typing relationsbetween specific situation tokens (called sites) and their types as the primary objects ofstudy, called perspectives, allowing multiple typing relations to account for the pos-sibility of different schemes of individuation. In addition to classifying tokens into
5 The one situation one type rule is violated by the development of a hierarchy of complex situation types,as described in Seligman and Moss (2010), pp. 171–244, but the set of types of a situation is still fullydetermined by this one type, its principal type.

“09-ch05-0329-0344-9780444537263” — 2010/11/29 — 21:08 — page 337 — #9
Situations, Constraints and Channels 337
types, the perspectives we adopt typically impose a logical structure. If we classifyaccording to colour, for example, we allow two different objects to be classified asbeing of the same colour but disallow one object to be classified as being of two dif-ferent colours. Yet, if we use names to classify, only one object may be classified by aname but two names may be used to classify the same object. This was modelled bymeans of an involves relation and a precludes relation between types.
These ideas were developed by Barwise and Seligman (1997) into the theory oflocal logics. A classification A is simply a binary relation |=A between a set tok(A)
of tokens and a set typ(A) of types. A theory T is a set typ(T) of types together witha binary relation )T between subsets of T . When the relation )T models some con-straints on classification in A, we can understand % )T & as a prohibition on classi-fying tokens to have all the types in % and none of the types in &. For example, wecan represent a mutually exclusive and exhaustive classification using colour termsas a theory with types C = {red, yellow, green, blue} such that - ) C and #, $ ) -for each pair #, $ of distinct colour terms. Allowing the possibility that some tokensfail to be constrained, a local logic L is a classification cla(L) together with a theory"typ(L), )L# and a set NL of normal tokens such that if % )L & then there is no normaltoken of all the types in % and none of the types in &. In other words, the classificationof normal tokens is required to respect the constraints implicit in the theory.
The paradigm example of a local logic is obtained from a theory T expressed in alanguage L and a class M of models of T . The tokens are the models of L, which areclassified into types, the sentences of L, by the relation of satisfaction.6 The theory isthe consequence relation % )T & iff %, T ) & and the set of normal tokens is M.The example is atypical in having a token that is a counterexample to every inferencenot licensed by T . Local logics used to model classification by humans or other finiteagents are unlikely to have this property. For example, suppose that some primaryschool children have been asked to classify some leaves. Each child is required tothink of his or her own way of classifying. Most children use ‘colour’ as a classifyingattribute but they select different values (green, dark green, brown, yellow, etc.). Someclassify by the number of ‘points’, others use ‘rounded’ or ‘pointy’. In producing theirclassifications, the children obey various constraints, either explicitly or implicitly,some self-imposed, some deriving from language. The exclusivity of ‘pointed’ and‘rounded’ may be partly linguistic, partly a matter or conscious choice. We can modelthese constraints as a theory on the set of classificatory types they use. Occasionally,a leaf is discovered that violates some of these constraints—one that is both pointyand rounded, for example. This is classified but flagged as strange, and we model itas a token that lies outside the set of normal tokens. Moreover, unlike the local logicobtained from a formal theory, there may be invalid inferences, such as the inferencefrom being red and pointy to having three points, but without the child having found
6 Strictly speaking, either the definition of classification should permit proper classes of tokens or we shouldchoose a representative set of models, rather than the class of all models, as tokens in this classification.Nothing of present concern hangs on the difference, so we equivocate.

“09-ch05-0329-0344-9780444537263” — 2010/11/29 — 21:08 — page 338 — #10
338 Handbook of Logic and Language
Figure 5.1 A local logic for classifying leaves.
a red pointy leaf. Even if there are red pointy leaves in the token set and they all havethree points, this may be a regularity of the sample, not one that is part of the child’sclassificatory method.
A third example of a local logic, also paradigmatic, is the observed behaviour of adynamic system which at any instance occupies one of a number of distinct states. Wemodel each instance of the system as a token in the token set, which may not includetokens of all possible states but only the ones that have been observed. Our obser-vations are rarely capable of discriminating individual states, so observation typescorrespond to a limited selection of subsets of the state space.7
5.4.2 Channels Defined Algebraically
In a setting in which there are many local logics, it is important to see how they arerelated to each other, how they can be combined and modified in systematic ways.As is usual in algebra, this can be done by determining a class of transformations
7 To be a little more precise, we can derive a local logic from a probabilistic model of the behaviour of asystem with outcome set ', event set ( a ! -algebra, a probability measure µ : ' ' [0, 1], a set T oftimes at which the system is observed and a function s : T ' ' specifying the state of the system at eachtime. Instances of the system are modelled by the set T , so we can take this as the set of tokens. The setof types is (, with t |= e iff s(t) . e. The entailment relation ) can then be defined probabilistically,as % ) & iff all counterexamples have zero probability, i.e. there is no event e with µ(e) > 0 such thatboth e /
"% and ē /
"&. Aberrant behaviour of the system, perhaps due to outside influences or
initial conditions can be marked as non-normal. This example does not quite conform to the frameworkof Barwise and Seligman (1997) because of the probabilistic consequence relation, which requires theadditional work of Seligman (2009).

“09-ch05-0329-0344-9780444537263” — 2010/11/29 — 21:08 — page 339 — #11
Situations, Constraints and Channels 339
from one local logic to another. In Barwise and Seligman (1997), an infomorphism ffrom classification A to classification B is defined as a pair of contra-variant functionsf ! : typ(A) ' typ(B) and f % : tok(B) ' tok(A) which preserves the classificationrelation, in that f %(b) |=A # iff b |=B f !(#) for each token b of B and each type# of A. Some examples of transformations of classifications within this class are therestriction to a subset of tokens, the addition of new types, the splitting of a token intotwo tokens and the identification of two types which have the same tokens. In all thesecases, the infomorphism records a correlation between the two classifications that sur-vives these modifications. Infomorphisms form a Cartesian closed category and so avariety of standard algebraic operations, such as quotients, products and sums can allbe defined, giving a rich theory of what can be done when comparing different clas-sifications and constructing new classifications from old.8 All of this can be easilyextended to local logics by requiring the transformations also to preserve the theoryand set of normal tokens; such transformations are called logic-infomorphisms. Theexample of local logics constructed from theories and models provides a good illus-tration of the general idea: an infomorphism from the local logics of "T1, M1# to thatof "T2, M2# is an interpretation of theory T1 in theory T2 together with a transforma-tion of models in M2 into models in M1 that preserves the satisfaction relation in theobvious way.
In particular, the algebra of classifications provides a way of modelling relationsbetween classifications, which is exactly what is required for a theory of channels. Inany category, the concept of a binary relation between two objects, X and Y , can berepresented as a pair of transformations from a third object R to X and to Y . In thecategory of sets, R is just the set of pairs of related elements and the transformationsare the projection functions, which when a is related to b, take the pair "a, b# to a and tob, respectively. In the category of classifications, transformations are infomorphismsand so we model a channel C between classification A (the source) and classificationB (the receiver) as a pair of infomorphisms: sC from C to A and rC from C to B.The classification C is called the core of the channel. We think of a token c of C asthe specific connection within the channel that relates source token s%
C (c) to receivertoken r%
C (c).To take an example from communication theory, if messages about one system (the
source) are sent along a communication channel such as a telegraph wire to influencethe behaviour of another system (the receiver), then we can model the channel core as aclassification of token-states of the wire with infomorphisms mapping each wire tokento the corresponding token-states of the source and receiver, as shown in Figure 5.2.The source types and receiver types are also both mapped to corresponding types ofthe channel, which serves to model the way in which information flows from sourceto receiver.
8 Basic properties of the categories of classifications and local logics, together with various applications,are explored in Barwise and Seligman (1997). But Goguen (to appear) shows these to be special cases ofa much broader class of categories, which have been extensively studied in computer science.

“09-ch05-0329-0344-9780444537263” — 2010/11/29 — 21:08 — page 340 — #12
340 Handbook of Logic and Language
Figure 5.2 The telegraph channel.
Information flow along channels is modelled using local logics. Given an infomor-phism f from classification A to classification B and any local logic L ‘living’ on A(one that has A as its underlying classification), we can define the image fL of L underf , which is a local logic living on B. Likewise, any logic L$ living on B has an inverseimage f (1L$ on A.9 Local logics living on the same classification are ordered the obvi-ous (contra-variant) inclusions: L1 0 L2 iff )L1/ )L2 and NL2 / NL1 . The orderingis a complete lattice, so logics may be combined by meets and joins. In this wayinformation distributed around a network of channels may be moved from one clas-sification to another (by imaging and inverse-imaging) and combined using joins andmeets.10
Naturally, channels compose sequentially: if there is a channel C1 from A to B andanother channel C2 from B to D, they can be combined to give a channel C1; C2 from Ato D. This is just an application of the fact that the category of infomorphisms is Carte-sian closed. There is also a parallel composition C1 • C2 of channels C1 and C2 havingthe same source and receiver. To characterise these constructions precisely, we needthe concept of a refinement of one channel by another—this is just an infomorphismbetween the channel cores that commutes with the source and receiver infomorphismsof the two channels, ensuring that any information that flows in one channel also flowsin the refined channel. The two compositions C1; C2 and C1 • C2 each provide the leastrefined channel that ‘agrees’ with the component channels, in the sense of commutingwith the source and receiver infomorphisms.11
These constructions can be extended to whole networks of channels, if we gen-eralise the concept of a channel to allow multiple sources and targets. In fact, thereis no need to make a distinction between source and target, as information flows inboth directions. In general, then, a channel is modelled as a set of infomorphisms
9 More precisely, fL is the least logic on B that makes f a logic-infomorphism from L to fL, while f (1L$ isthe greatest logic on A that makes f a logic-infomorphism from f (1L$ to L$.
10 The additional structure of local logics is essential for modelling information flow across channels in aflexible way. Earlier attempts, such as Barwise (1993) and Barwise and Seligman (1994), focussed tooclosely on the relation between types. But it is logical structure—entailment, contradiction, etc.—that istransformed by infomorphisms, not propositional content. The calculus of information flow is thereforea calculus of logical structure not a calculus of propositional content.
11 One can also regard the composite channels as channels between the cores of the component channels,modelling the information flow between them.

“09-ch05-0329-0344-9780444537263” — 2010/11/29 — 21:08 — page 341 — #13
Situations, Constraints and Channels 341
with a common domain (the channel core). Each set of channels has a commonrefinement, a generalised channel with projections to all the classifications in the set,which models the common information flow in the system. Similar constructions canbe performed within the the models of constrained classification using local logics andlogic-preserving infomorphisms.
5.4.3 Connections to Modal Logic
The logic of constraints has been investigated by van Benthem in a number of dif-ferent guises (van Benthem, to appear, 2000). A simple language for reasoning aboutconstraints has atomic propositions Ts1, . . . , sn, where s1, . . . , sn are situations, fromsome set Sit, and T is an n-ary situation type, from some set Typen. To this, we addBoolean operations and a modal operator [S] for each set of situations S, with [S])meaning that ) is determined by the information shared by situations in S.12 The lan-guage allows one to state that situation s1 being of type T1 carries the information thatsituation s2 is of type T2, using the formula
[Sit](T1s1 1 T2s2)
In other words, the implication from s1 being of type T1 to s2 being of type T2 holdsin every situation. When we are restricted to a set B of situations, this is modified to
[B](T1s1 1 T2s2)
A constraint model M = "State, C, V# for this language consists of a set State (of localstates), a set C of global states, which are functions from Sit to State, and a functionV assigning an n-ary relation on State to each type in Typen. Formulas are evaluatedin a global state w as follows:
M, w |= Ts1, . . . , sn iff "w(s1), . . . , w(sn)# . V(T)
M, w |= [S]) iff M, v |= ) for all v . C such thatv(s) = w(s) for all s . S
with the standard clauses for the Boolean operators. The resulting logic is decidableand is axiomatised in van Benthem (to appear) as a polymodal S5, with additionalaxioms ([S1]) 1 [S2])) for each S2 / S1.13
12 We can ignore the distinction between situations/situation types and their names because the language hasno need for quantifiers over situations. We also place no restrictions on the size of the set of situations,although in practice it must be finite if we are to obtain a recursively enumerable language.
13 van Benthem has an additional operator U and axioms (U) 1 [S])) for each S, but U can be definedto be [Sit]. As an interesting technical aside, he also notes that constraint logic is equivalent (mutuallyembeddable) in the polyadic logic of dependency, see van Benthem (2000), in which the standard seman-tics for first-order logic is modified only by restricting the set of assignment functions to a limited set G,and then introducing a quantified formula 2x ) for each sequence x of variables, which is satisfied by anassigment g if there is an assignment g . G that is identical to g except possibly on the variables in x.

“09-ch05-0329-0344-9780444537263” — 2010/11/29 — 21:08 — page 342 — #14
342 Handbook of Logic and Language
To this simple language, the apparatus of standard epistemic logic and dynamicepistemic logic can easily be added. Given a set I of agents, we can add a modaloperator Ki representing the knowledge of agent i, for each i . I, operators [e] foreach event e in some set E, and public announcement operators [!)] for each formula). The operators Ki and [e] each require a binary relation on the set C of global statesand public announcement is defined by model restriction: M, g |= [!)]* iff M, g |= )
and M|), g |= * , where M|) is the restriction of M to those global states that satisfy) in M. The resulting logic is still decidable, as shown in van Benthem (to appear).
Logic can also be used to characterise information flow along an infomorphism.Consider the two-sorted first-order language for describing the structure of a classifi-cation with binary predicate s |= t where a is of sort tok and t is of sort typ. Now saythat formula )(a, t) implies formula *(a, t) along an infomorphism f from A to B iffor all a . tok(A) and t . typ(B),
)(a, f !t) is true in A iff *(f %a, t) is true in B
Then say that ) infomorphically entails * , if ) implies * along any infomorphism.van Benthem (2000) shows that informorphic entailment is characterised by the exis-tence of an interpolant of a special kind. A flow formula is one that has only atomicnegations, existential quantification over tokens and universal quantification overtypes, i.e. it is constructed from a |= t, 3a |= t, &, %, 2a and 4t . Flow formulasare all preserved over infomorphisms and morever the following are equivalent:
1. ) infomorphically entails *
2. there is a flow formula # such that ) ) # ) *14
This result can be extended to special classes of classifications and restrictions oninfomorphisms, and even to infinitary languages. We refer the reader to van Benthem(2000) for further details.
Finally, we note that channels can be used to model some of the operations ofinformation flow in modal logic. A model for a modal language can be regarded as aclassification M of points by formulas, and the accessibility relation ra for each modaloperator [a] determines a local logic La on M+M, such that "u, v# is normal iff ra(u, v)and "1, [a])# )a "2, )#. Given two such models M and N and their correspondinglocal logics La (on M + M) and Pa (on N + N), a channel B between M and N isa bisimulation channel if B; La and Pa; B are logical refinements of each other. Therelation that B determines between tokens of M and N, namely "+1b, +2b# for eachtoken b of B, is a bisimulation iff B is a bisimulation channel. The usual definition ofbisimulation can thus be seen as a consequence of a kind of equivalence between thetwo models when representation as channels.
It is sometimes complained that the concept of information flow modelled bychannels is too static, failing to account for changes in information that result from
14 In van Benthem (2000), these results are stated in terms of Chu-transformations, but the difference isonly one of terminology.

“09-ch05-0329-0344-9780444537263” — 2010/11/29 — 21:08 — page 343 — #15
Situations, Constraints and Channels 343
certain events, such as public announcement, which are captured very neatly in otherframeworks, such as that of dynamic epistemic logic. But the operations on modelsthat are characteristic of dynamics can also be modelled as channels. For example,the result of public announcement of ) is the restriction M|) of the model M to theextension of ). This determines a local logic on M + M|) in which "u, v# is normaliff u = v, "i, p# ) "j, p# for i = 1, 2, and "1, [!)]*# ) "2, *#. In this case, and in thebasic case of the representation of modal logics as channels, it would be nice to haveresults that characterise the constructions in purely categorical terms but that work hasnot yet been done.
References
Barwise, J. 1993. Constraints, channels and the flow of information, in: Aczel, P., Israel, D.,Katagiri, Y., Peters, S. (Eds.), Situation Theory and Its Applications, 3, number 37 in CSLILecture Notes. CSLI Publications, Stanford, CA, pp. 3–27.
Barwise, J., Etchemendy, J., 1987. The Liar: An Essay on Truth and Circularity. Oxford Uni-versity Press, New York.
Barwise, J., Gabbay, D., Hartonas, C., 1996. Information flow and the Lambek calculus, in:Seligman, J., Westerståhl, D. (Eds.), Logic, Language and Computation, ProceedingsInformation-Oriented Approaches to Logic, Language and Computation, vol. 58. CSLILecture Notes, CSLI Press, Stanford, CA, pp. 47–62.
Barwise, J., Perry, J., 1983. Situations and Attitudes. MIT Press, Cambridge, MA.Barwise, J., Etchemendy, J., 1987. The Liar: An Essay on Truth and Circularity. Oxford Uni-
versity Press, New York.Barwise, J., Seligman, J., 1994. The rights and wrongs of natural regularity. Philos. Perspect. 8,
331–364.Barwise, J., Seligman, J., 1997. Information Flow: The Logic of Distributed Systems.
Cambridge University Press, Cambridge, UK.Goguen, J., 2006. Information Integration in Institutions, in: Moss, L. (Ed.), to appear in the Jon
Barwise Memorial Volume, Indiana University Press, Bloomington, IN. cseweb.ucsd.edu/3goguen/pps/ifi04.pdf.
Israel, D., Perry, J., 1990. What is information?, in: Hanson, P. (Ed.), Information, Language,and Cognition. University of British Columbia Press, Vancouver, pp. 1–19.
Mares, E.D., 2004. Relevant Logic: A Philosophical Interpretation. Cambridge UniversityPress, Cambridge, MA.
Restall, G., 1995. Information flow and relevant logics, in: Seligman, J., Westerståhl, D. (Eds.),Logic, Language and Computation: The 1994 Moraga Proceedings. CSLI Publications,Stanford, CA, pp. 463–477.
Restall, G., 2005. Logics, situations and channels. J. Cogn. Sci. 6, 125–150. Available from:http://consequently.org/writing/channels/.
Seligman, J., 1990. Perspectives in situation theory, in: Mukai, K., Cooper, R., Perry, J.(Eds.), Situation Theory and its Applications, vol. 1. CSLI Lecture Notes, CSLI Press,Stanford, CA, pp. 147–191.
Seligman, J., 2009. Channels: from logic to probability, in: Sommaruga, G. (Ed.), Formal The-ories of Information: From Shannon to Semantic Information Theory. Springer-Verlag,Berlin and Heidelberg, LNCS 5363, pp. 193–233.

“09-ch05-0329-0344-9780444537263” — 2010/11/29 — 21:08 — page 344 — #16
344 Handbook of Logic and Language
Seligman, J., Moss, L., 2010. Situation theory, in: van Benthem, J., ter Meulen, A. (Eds.), Hand-book of Logic and Language. Elsevier BV, pp. 171–244.
van Benthem, J., 2006. Information as correlation vs. information as range, in: Moss, L. (Ed.),to appear in the Jon Barwise Memorial Volume, Indiana University Press, Bloomington,MA. www.illc.uva.nl/Publications/Research Reports/pp. 2006-07.text.pdf
van Benthem, J., 2000. Information transfer across chu spaces. Logic J. IGPL 8 (6), 719–731.

“10-ch06-0345-0394-9780444537263” — 2010/11/30 — 3:44 — page 345 — #1
6 GB Theory: An Introduction!
James HigginbothamUniversity of Southern California, School of Philosophy,3709 Trousdale Parkway, Los Angeles, CA 90089-0451, USA,E-mail: [email protected]
Commentators: M. Kracht and E. Stabler
“GB Theory” (or simply “GB”; we will use both terms) is the name commonly appliedto the syntactic framework expounded in Chomsky (1981), with which is associated alooser set of considerations of a semantic nature. This framework represents a momentin the development of linguistic theory. At the same time, it continues several linesof thought that have been conspicuous in formal syntax since the inception of thesubject in its modern form. Moreover, significant features of GB have been retained insubsequent work under the heading of “Minimalism” in the sense of Chomsky (1993,1995); we consider this latter development briefly below.
This chapter is intended for persons with various backgrounds in linguistics (oreven none at all) who are interested in becoming acquainted with the general featuresof the development and internal logic of GB and are ready to approach the subject froma somewhat abstract point of view. Hence we do not here assume prior acquaintancewith GB theory, or for that matter with syntactic theory in general; but we do expoundsome of the concepts, and the axioms governing them, that would be wanted in a fullexposition of the theory. Since the motivations both for general theoretical moves andfor their specific modes of development can best be appreciated in the light of detailedarguments involving particular examples, we have chosen to concentrate on selectedpoints rather than attempt an elementary survey. For this reason, many topics thatwould be discussed in any standard textbook (e.g., Freidin, 1992; Haegeman, 1994)are here omitted altogether. The points on which we concentrate have been chosenwith an eye to the abstract properties of the theory, which have consequences forformalization and computational implementation. Reflection on examples, the stockin trade of professionals, is essential if a feeling for syntactic inquiry is to be imparted.We therefore encourage the reader to ponder the illustrations in what follows, testingthem against his or her native language and judgments.
!This chapter would not have been possible without the assistance of my correspondents, Marcus Krachtand Edward Stabler, to whom I am much indebted both for comments and for advice on content. Errorsremain my responsibility.
Handbook of Logic and Language. DOI: 10.1016/B978-0-444-53726-3.00006-2c" 2011 Elsevier B.V. All rights reserved.

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 346 — #2
346 Handbook of Logic and Language
The extensive lore of GB contains relatively little in the nature of formalization.Although we do not attempt to fill the gap here, we have deemed it useful, especiallyin the context of this Handbook, to indicate some of the concepts and definitions thatwould form part of a formalization. The form chosen reflects to some degree the pref-erences of the present authors.1
Although the specific proposals characteristic of GB theory need not in themselvesbe seen as a part of psychological inquiry, the work of Chomsky, both early andlate, has always been advanced as a fragment of a full theory of human linguisticknowledge, or competence in the sense of Chomsky (1965). Moreover, the theory ofthe competence of mature speakers of a language is itself to be part of a larger the-ory that addresses the question how that competence was acquired. Hence, among thecriteria for the success of a full theory of syntax and interpretation is that of learnabil-ity: the theory must be such as to identify how a child can learn any language that itrecognizes as a possible human language. The aim of describing competence, and thedesideratum of learnability, often sit in the background of ongoing research, informingbut not guiding: so it will be here.
Our discussion will follow a route that is both historical and analytical: historicalin the sense that, beginning with the aspects of linguistic description first studied for-mally in the 1950s (all of them characteristic of traditional grammatical studies, thoughinformally and incompletely presented there), we proceed to the stage characteristicof GB, and thence to more recent work; analytical in the sense that the historical shiftsare also points of progressive abstraction in the theory, advanced because of genuineproblems of description or explanation within earlier stages.
6.1 Phrase Structure
To bring out the fundamental and persistent themes that mark GB theory it is useful tobegin farther back, with the explicit conception of sentence structure that is formulatedin such works as Harris (1955) and Chomsky (1955).
The dawn of syntax is marked by the realization that the structure of sentences ishierarchical; that is, that behind the linear order of words and morphemes that is vis-ible in natural languages there is another organization in terms of larger or smallerconstituents nested one within another. Suppose that parts of speech have been dis-tinguished as noun (N), verb (V), adjective (A), preposition (P), adverb (Adv), article(Art), and so forth. Then these elements may combine to make larger elements whichthemselves belong to linguistic categories. Common categorial membership is evi-denced by intersubstitutivity, so that, for example, the expressions
Londonthe woman
1 See note on the title page.

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 347 — #3
GB Theory: An Introduction 347
the old manthe proud young child
may all be called nominal, since putting any one of them in a context like
! is known to me
produces a grammatical sentence (and putting any one of them in a context like
That is known ! me
produces gibberish). In contemporary parlance such nominals are called noun phrases(NPs), on the grounds that the nominal words occurring in them are evidently whatis responsible for their nominal behavior. The nominal word (for instance child in theproud young child) is said to be the head of the construction.
As the reader may verify at leisure, what has just been said of nouns and NPsapplies equally to verbal elements. Thus
walkedis known to mewent slowly to London
are interchangeable in the context
John !
The heads are the verbs walk, be, and go, and the larger constituents are verb phrases(VPs). Prepositional phrases (PPs) are introduced similarly: they consist of a preposi-tion followed by an NP, as in
with [the proud young child]
etc. Finally, adjective phrases (APs), although most of them consist of an adjectivealone, or an adjective modified by an adverb, as in
tallvery tall
may include more material, as in comparatives
taller than John
There are also transitive adjectives, as in
proud of her sister
These admit adverbial modification, and the formation of comparatives, so that com-plex phrases like
very much prouder of her sister than of her brother
are also APs.

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 348 — #4
348 Handbook of Logic and Language
Diligent application of tests of substitutivity will produce compelling analyses ofmany complex sentences. Thus (1) may be broken down as consisting of the elementsenumerated in (2):
(1) I went to London with the proud young child;(2) The NP I; the VP went to London with the proud young child;
the V went (which carries past tense);the PP to London, consisting of the P to and the NP London;the PP with the proud young child, consisting of the P with and the NP the proudyoung child, which consists in turn of the article the and the modified noun proudyoung child, which consists in turn of a sequence of adjectives followed by ahead N.
The entire analysis may be displayed in the form of a labeled bracketing, as in (3),or in the form of a tree, as in (4), where S = Sentence:
(3) [S[NPI][VP[Vwent][PP[Pto][NPLondon]] [PP[Pwith][NP[Articlethe][N[Aproud][Ayoung] [Nchild]]]]]]
(4)
young
proud
article
the
with
NP
NP
PP
S
V
Pwent
PP
to
NA
A
NP
N
N
VP
P
child
I
London
These analyses are said to give the constituent structure of a sentence, its repre-sentation at what Chomsky (1955) called the level of phrase structure. The objectrepresented in (4) is a phrase marker; see further Section 6.5 below.
A crucial point in the development of theories of phrase structure is that phrases ofa given kind can occur within others of the same kind; it is this recursive feature of lan-guage that enables sentences of arbitrary complexity to be constructed. The realization

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 349 — #5
GB Theory: An Introduction 349
that phrase structure is recursive is very old. Thus Arnauld (1662) gives the examples(in Latin, but the point might as well have been made in English):
(5) [SThe divine law commands that [Skings are to be honored]];(6) [S[NPMen [Swho are pious]] are charitable];
remarking that in (5) the embedded element kings are to be honored is a sentenceoccurring within a sentence, and that in (6) the relative clause has all the structure ofa sentence, except that the relative pronoun who has replaced the subject.
Supposing that the sentences of human languages all admit analyses in terms ofphrase structure, how can the system that underlies a given language be made fullyexplicit? For English, we must take account of the following facts, among others:
(i) The combinations of categories that may make up a given, larger category are restricted intheir nature. For instance, nouns combine with adjectives, as in young child, but not withadverbs, as we do not have
slowly childchild slowly
as Ns; articles combine with Ns but not with Vs as we have the child but not
I the walked
Following customary practice we annotate elements that do not belong to a given categorywith an asterisk *; omission of the asterisk indicates the judgment that at least appropriatelyselected elements can belong to the category. So in general we have, for English,
"[Nadverb N][Nadjective N]"[Varticle V]
and so forth.(ii) Even when a certain combination of categories is permitted, the categories must be com-
bined in certain orders. Since we do not have *tie white as an English N, we must state thatthe tree has a linear orientation. In this respect we see at once that languages differ, sincefor instance in French we have
cravate blanche*blanche cravate
The formalization that suggests itself for expressing categorial combinations consis-tently with both (i) and (ii) is that of the inductive clause, schematically as in (7):
(7) If X1 is an A1 and · · · and Xn is an An, then:X1 · · · Xn is a C
where the Xi are variables ranging over sequences of words, and A1, . . . , An and Care categories. Such clauses enable us to say, for instance, that

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 350 — #6
350 Handbook of Logic and Language
If X is an A, and Y is an N, then XY is an N;If X is an article and Y is an N, then XY is an NP;If X is a V and Y and Z are PPs, then XYZ is a VP.
Besides inductive clauses we also require basis clauses, or assignments of primitiveexpressions to the categories to which they belong. The basis clauses underlying ourexamples could be simple lists, as in (8):
(8) child is an Nwalk is a V
and so forth. The context-free grammars of Chapter 20 of Handbook of Logic andLanguage (1997 edition) are in effect inductive definitions of categorial membership,where basis and inductive clauses are expressed by rewriting rules. Thus the rule cor-responding to (7) is (9):
(9) C # A1 · · · An.
Below we express the rules in this format.An important confirmation of the theory of phrase structure is that it yields an
account of structural ambiguity, for instance as in (10):
(10) I bought a book to read.
The ambiguity in (10) is easy to spot: it can mean either that I bought a book withthe intention of reading it, or that I bought a book that was suitable to be read. Sothe sequence a book to read is ambiguous. But no word in that sequence is ambigu-ous: such is the diagnostic for structural (rather than lexical) ambiguity. Structuralambiguities can normally be manipulated so that one or another interpretation standsout. Thus note that if we replace a book by a pronoun or title, we have only the firstinterpretation:
(11) I bought it /War and Peace to read.
Similarly, seeing that a book is the understood object of read in (10), we again haveonly this interpretation if we replace that object by a pronoun:
(12) I bought a book to read it.
Inversely, imagine A handing a book to B and saying:
(13) Here’s a book to read.
A clearly must mean that the book is for reading, a meaning corresponding to thesecond interpretation of the sequence in (10). Finally, as would be expected, (14) isungrammatical:
(14) *Here’s a book to read it.

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 351 — #7
GB Theory: An Introduction 351
Especially with the contrasts in (11)–(14) in mind, the basis of the ambiguity of(10) is explained as follows. In the first interpretation, where it is said that I boughta book with the intention of reading it, we have a construction where the infinitive toread is separated from a book, and has only the function of indicating purpose. In thesecond interpretation the infinitive functions otherwise, as a relative clause modify-ing a book. In this case a book to read is an NP. But it, or War and Peace are, likeproper names and pronouns generally, NPs that are not further modifiable; hence thefollowing infinitive can only be a purpose clause, and (11) is unambiguous. Inversely,(13) presents no agent whose purpose can be to read the book; hence the infinitive isa modifier only, and the attempt to treat it as indicating purpose, as in (14), results inungrammaticality. Combining the last two arguments, we deduce, correctly, that (15)is also ungrammatical:
(15) *Here’s it to read.
6.2 Limitations of Phrase-Structure Description
Chomsky (1955, 1957) contain a number of arguments pointing to the limitations ofphrase structure description as conceived in the last section. In this section we con-sider three such arguments, representative but by no means exhaustive. On their basisChomsky proposed a syntactic theory that is essentially derivational; that is, the phrasemarker that underlies the heard string is the last member of a sequence of computationsover phrase markers, each such computation being a grammatical transformation. Wegive the computations in question first in pre-GB and later in GB terms.
The arguments of this section leave open a number of questions about possibleelaborations of phrase structure, and to that extent leave open the question whetherthere is a conception of phrase structure that can replace transformations, thus revert-ing again to a single level of syntactic description. The question of derivational versusnon-derivational syntax will be taken up again in Section 6.7 below.
6.2.1 Easy and Eager
Against the background of the last section we may evaluate a classical discussionin Chomsky (1965), to the effect that phrase structure grammar will necessarily failto contain certain information crucial to grammaticality, and will leave some generalfeatures of languages unaccounted for. The argument takes as its point of departurethe pair of sentences (16)–(17):
(16) John is easy to please;(17) John is eager to please.
At the level of phrase structure there is no apparent distinction between these sentencessave for the choice of adjective. In each case the VP consists of a form of the verb be,

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 352 — #8
352 Handbook of Logic and Language
inflected for present tense, followed by an A, followed by a so-called infinitival V toplease, here dubbed INFV. The structure is (18):
(18) [SNP][VPV A INFV]].
However, there is an obvious distinction between (16) and (17): in (16) the subjectNP John is understood as the object of the V please, so that the sentence may beparaphrased as
It is easy for one to please John
but in (17) the subject NP is understood as the subject of please, so that the sentencemay be paraphrased as
John is eager that he, John, should please (someone).
This distinction is correlated with several syntactic differences between the adjectiveseasy and eager:
(a) easy, but not eager, admits expletive (meaningless) subject it:
It is easy to please John (expletive it);It is eager to please John (it must refer to something).
(b) eager, but not easy, admits the affix -ness, converting the A into an N, so that we have thepossessive construction
John’s eagerness to please.
However, we do not have
*John’s easiness to please.
(c) easy, but not eager, admits infinitival subjects:
To please John is easy;*To please John is eager.
It is a natural thought that these distinctions must be related to one another. Forone thing, there are a number of As that belong to the easy-class, such as tough, hard,difficult, etc., and a number that belong to the eager-class, such as anxious, ready,determined, etc. For another, we should not expect that a person who grasps Englishhas learned the facts (a)–(c) independently: the list is therefore unsatisfactory from thepoint of view of learnability. We are led, therefore, to consider the prospect of derivingall the distinctions from a common source. But no such source presents itself withinphrase structure grammar.
In Chomsky (1965) the fundamental divergence between (16) and (17) wasexplained as follows (in simplified form). With each sentence is associated a deepstructure and a surface structure. The surface structures of (16) and (17) are identical,except that (16) has the adjective easy where (17) has eager. At deep structure,

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 353 — #9
GB Theory: An Introduction 353
however, (16) is represented as in (19):
(19) It [VPis easy [one to please John]].
Two operations convert (19) into a surface structure (20):
(20) John [VPis easy [to please]]
namely:
(i) John replaces the pleonastic subject it;(ii) One becomes null.
The deep structure of (17) is (21):
(21) John [VPis eager [John to please]]
with intransitive please, and this structure is converted to (22):
(22) John [VPis eager [to please]]
by the single operation:
(iii) The second occurrence of John becomes null.
On this type of view, the distinction (or set of distinctions) between (16) and (17) isnot revealed at the level of simple phrase structure description, but rather by deepstructure representation, from which that description is derived.
The concept of a derivational syntax is thus intrinsic to the conception of gram-mar just sketched. As we will see below, the derivational histories of (16) and (17)according to GB are rather different.
6.2.2 Long-Distance Dependencies
A second type of example that argues for the necessity of departing from phrase struc-ture grammar is that of long-distance dependency. To motivate examples of this typewe first consider some simple dependencies between constituents.
(A) Feature agreement. In English, subject and verb agree visibly in number in thepresent tense; so we have a man walks (singular), but men walk (plural). Exceptionally,there is agreement in number between a V and post-verbal NP when the overt subjectis existential there, as in (23):
(23) There is a man walking/There are men walking.
Agreement is obligatory: we do not have *There are a man walking, or *There is menwalking. How can feature-agreement be expressed at the level of phrase structure?For the case of verbs and their subjects, we might try assuming complex categories,call them NP(sing) and NP(plural), V(sing) and V(plural) (though even here we aredeparting from the basic type of a phrase structure grammar, for which the categoriesdo not have a compositional structure), and introduce in place of the simple rule
If X is an NP and Y is a VP, then XY is an S

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 354 — #10
354 Handbook of Logic and Language
the pair of rules
If X is an NP(sing) and Y is a VP(sing), then XY is an S;If X is an NP(plural) and Y is a VP(plural), then XY is an S.
Since singular number is realized not on the VP but on the V this doubling-up mustextend to the rules governing VP, of which one instance would be:
If X is a V(sing) and Y is an NP, then XY is a VP(sing).
Still more special rules would be needed for the case of number-agreement betweenV and the NP following V in the context of existential there. However these rules arespecified, note that agreement is in a sense a local phenomenon. Local agreement isseen in (24), which shows the relevant parts of the phrase structure of the first sentencein (23):
(24)
NP(sing)
NP (sing)
S
V(sing)
VP(sing)
there
is a man walking
Now consider the examples (25)–(26):
(25) There seems to be *men/a man walking;(26) There seem to be men/*a man walking.
These show agreement between the argument men/a man and the V seems of the mainclause. But how are these elements able to communicate with one another? One expla-nation, practically dictated by the assumptions made above, has three parts, as follows:
(a) Expletive there shows number agreement with the post-verbal argument;(b) (25) and (26) are derived by raising there from its initial position as the subject of be to
the position of the subject of seem (where it receives nominative case from the tense on themain V);
(c) The raised element retains the features it had before movement, and they are checkedagainst the features of seem.
Thus, starting from (27), we derive (28):
(27) seem(sing) [there(sing) [to be [a man](sing) in the garden]];(28) [there(sing) seem(sing) [( ) to be [a man](sing) in the garden]];
with ‘()’ marking the place from which the expletive subject moved. The long-distanceagreement between the main V and the post-verbal NP of the embedded S is thusmediated by three more local relations, namely the two relations between there andthe postverbal NP, and the fact that there “remembers” its features when it moves.

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 355 — #11
GB Theory: An Introduction 355
(B) wh-movement. Like many other, but by no means all, languages, English hasa family of related words that serve to indicate positions of either modification orinterrogation. These are referred to appropriately as wh-expressions, since a survey ofexamples shows that there is a significant part with that pronunciation. The examplesinclude:
where, who, which, what, whether, why, ...
The contexts of interrogation are illustrated by (29), those of modification by (30):
(29) Where did Mary go?Who solved the problem?Which book did you give to John?
(30) [NPthe place [where Mary went]];[NPthe person [who solved the problem]];[NPa book [which you gave to John]].
The operation that derives an element like
which you gave to John
is crudely describable as lifting a wh-expression from the position to which it is related(in this case the object position of give), and placing it at the front of the constituentthat is to be an interrogative or a modifier: this is the operation of wh-movement. Phrasestructure rules do not countenance operations of this sort.
A survey of examples of wh-movement in English quickly reveals that the crudedescription of wh-movement would allow the generation of many sentences that arein fact not possible. Thus, where the blank ‘ ’ indicates the position from whichmovement has occurred, we cannot have any of the examples in (31):
(31) (a) *Which book did the man who likes talk to you?(b) *What did you put the spoon or on the plate?(c) *How did Mary deny [Syou fixed the car ].
(Note that the string How did Mary deny you fixed the car is grammatical with theinterpretation, “How was Mary’s denial made?” As the position of the blank withinthe sentential brackets indicates, however, the example is to be taken as, “By whatmeans x did Mary deny that you fixed the car employing method x of car-fixing?” Thequestion is then why the sentence How did Mary deny you fixed the car? fails to bestructurally ambiguous.)
The conclusion to be drawn from these reflections is that, although it is easy todescribe the basic operation of wh-movement, the conditions on well-formedness ofits output are far from trivial. Especially since Ross (1967), inquiry has attempted toformulate the conditions under which the relation between wh and the position X ofits origin is ill-formed. Any such condition is a filter !, ruling out certain otherwisepossible structures, as in (32):
(32) "[wh[...X...]] if !.

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 356 — #12
356 Handbook of Logic and Language
Local rules of agreement are likewise stateable as filters, ruling out, e.g., cases wherea subject and its verb disagree in number (and, in some languages, in other featuressuch as person and gender). Could phrase structure rules, of the simple kind thatwe have been considering, serve in principle to express some or all of the filters onwh-movement? In some cases they would. Suppose we allow the rules to “skip” an ele-ment that would otherwise be present, or to rewrite it as an “empty” element e. Thenwe might understand the first sentence in (29) (without the auxiliary) as generated inschematic form by
S(wh) # whS(e)
S(e) # NP VP(e)
VP(e) # Vegiving
[S(wh) where [S(e)[NPMary] [VP[Vgo]e]]]
where the information that the S contains a “gap” or unfilled position is passed downby features attaching to the grammatical categories. The rules introducing e wouldbe restricted in their nature so that, for instance, it would not be possible to generatethis element following the disjunction or, thus accounting for the ungrammaticality of(31b).2 On the other hand, a survey of cases reveals that the information that must bedrawn upon to decide whether an empty element in a position can or cannot be relatedto a given wh-expression is more extensive than any single, local condition will reveal.For instance, although (31c) is ungrammatical, (33), which differs only in choice ofmain V, is fully acceptable:
(33) How did Mary think [Syou fixed the car ].
6.2.3 Elements of a Transformational Grammar
Examples such as the easy-eager distinction and long-distance dependencies such aswh-movement and remote number agreement are among those that motivated the con-ceptions of grammatical transformation that are to be found, in different forms, inthe work of Harris and Chomsky in the 1950s. Summing up the lesson that theyappear to teach, one conclusion is that a grammar consists at least of the followingcomponents:
(I) A system of constituent structure;(II) Rules that allow elements to be moved from one position to another within such a
structure;
2 Proposals of this sort are (in their contemporary form at least) due to Gerald Gazdar; they still form apart of Head-Driven Phrase Structure Grammar. We do not consider any comparisons here. It should benoted, however, that developments of the alternative view involve composing categories, or combiningthem with features, and therefore constitutes a significant departure from simple phrase structure models.See further Section 6.7 below.

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 357 — #13
GB Theory: An Introduction 357
(III) Filters (including rules of agreement) on constituent structures;(IV) Principles regulating the types of rules under (II) and (III).
Let us compare the point that we have reached with the original starting point, thephrase structure grammar. Phrase structure grammars are very limited in their descrip-tive apparatus, and it is precisely this merit of theirs that allows decisive counterexam-ples either to their empirical adequacy or to their plausibility to be produced. A phrasestructure grammar has a system as in (I) above, and it is not a radical departure toadd agreement rules as in (III) so long as they are appropriately “local”. However,once we allow elements to move within a phrase structure, and allow relations that arenot local, the power of the descriptive apparatus is augmented enormously (indeed, itcan be classically demonstrated that grammatical systems that merely have a systemas in (I) and recursive relations (rules) as in II can generate any recursively enumer-able language; see Peters and Ritchie (1971)). Again, whilst the evidence for phrasestructure is quite overwhelming, it is a more complex theoretical question what rulesthere are as in (II) and (III), and still more what restrictions on them might be imposedas in (IV). For these reasons, no doubt among others, there is room for great diver-sity and development in grammatical theories that depart in any significant way fromelementary phrase structure.
6.3 D-Structure and S-Structure
In this section we consider the synthesis represented in the exposition of GB inChomsky (1981), Lectures on Government and Binding, hereafter the LGB theory,which provides a view of grammatical components answering to (I)–(IV) above.
6.3.1 Heads, Projections, and Movement
In the LGB theory, the fundamental system of constituent structure is provided bya system of lexical heads and admissible phrases of the same categories, their pro-jections. In the case of nominals, for instance, it is supposed that the head N maybe modified, perhaps more than once, producing a projection N$ (read “N-bar”). Theprojection is completed by an article (or a quantifier, such as every), so that one hasNP = N$$ with the structure
[N$$Article [N$modifier [Nhead]]].
The verbal projection is similar to the nominal, though here one must add that Vs aresorted according to the number and types of arguments that they take. The positionsof arguments and modifiers are controlled by the relation of government, a traditionalgrammatical notion that may be given a precise interpretation in terms of the hier-archical structure of phrase markers. It will suffice for our purposes to note that Vsgovern their complements (e.g., direct and indirect objects), but not their subjects, apoint to which we shall return.

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 358 — #14
358 Handbook of Logic and Language
The system of projections of heads through modifiers and completion of phrases byarticles or other expressions replaces the inductive clauses, or rewriting rules of earlierconceptions of phrase structure, in the sense that the rules are not arbitrary statementsof the form
If X is a C1 and Y is a C2, then XY is a C
but instead assume the uniform shape
If X is a Cn1 and Y is of appropriate categorial type, then XY is a Cm
1
where m = n, or m = n + 1. The levels thus constructed are normally assumed to beonly two beyond the lexical: thus N0 = N will be a nominal word, N1 = N$ will be amodified N, and N2 = N$$ the final or maximal projection of the head N.
At the level where only the inductive principles are employed in building up phrasestructures, the level of D-Structure, no syntactic movement has taken place. Thus inone of the examples under (29), repeated here as (34), we may propose a D-Structureas in (35):
(34) What did you give to John?(35) [?[you [Tense [give what to John]]]];
where Tense in this case is realized as Past, and ‘?’ is a feature in a higher positionthat indicates a question, and acts as an “attractant” for the wh-expression what. Thederived structure shows the wh-expression what moving to the front, by hypothesis infact to a designated position selected by ‘?’, and Tense, which has likewise moved,supported by the “dummy V” do. The movement creating the derived structure leavesbehind an element with no phonological content (though it may carry grammaticalfeatures) called the trace of the movement; moreover, the trace is related to the elementwhose trace it is by a relation on the derived structure. Indicating this relation bysubscripting these items with the same index, the derived structure becomes (36):
(36) [Whati [do + Tensej [you [tj [give ti [to John]]]]]].
The derived structure that is represented in the heard string of words and other mor-phemes is called S-Structure.3 As can be seen even from our simple example, thelinguistic level of S-Structure departs from traditional analysis in terms of phrasestructure in a number of ways: S-Structure representations may contain phonologi-cally empty elements; the constituents are not simply categories or morphemes butinclude sets of features; and, perhaps most significantly, there are systematic binaryrelations between constituents, and conditions governing their assignment.
In place of the single phrase markers of the simple phrase structure theory, sen-tences (and other categories) will now be associated with an ordered pair of phrase
3 This statement is not quite accurate, since there may be stylistic and other rules that rearrange elementsprior to pronunciation. These cases, which are anyway marginal for the theory, will not be consideredhere.

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 359 — #15
GB Theory: An Introduction 359
markers (", #) where " is a D-Structure and # is an S-Structure representation,# being derived from " by a sequence of grammatical transformations (the princi-ples under (II)), and with outputs subject to filters under (III).
6.3.2 Types of Transformations
In the LGB theory the permissible types of syntactic movement are only two: sub-stitution, which displaces an element to a designated position, and (left- or right-)adjunction, which inserts an element into a phrase marker above a designated posi-tion. Adjunction (here left-adjunction for illustrative purposes) of X to a position Ycreates from
. . . [Y. . . X . . .
a phrase marker
. . . [YXi [Y. . . ti . . .
The LGB theory thus places very strong constraints upon the rules as in (II) above,regulating syntactic movement. It places far weaker conditions on the filters under(III), a point to which we return in Section 6.6.2 below.
The reduction of transformation types in the manner suggested does away withmost of the transformations of earlier periods of study. A classic example is the dis-appearance of the passive transformation, proposed in different forms by both Harrisand Chomsky in early work, and relating active-passive pairs such as (37)–(38):4
(37) The boy broke the window;(38) The window was broken by the boy.
Taking the structure of the active sentence
[S[NPthe boy] [VP[Vbroke] [NPthe window]]]
as given, the passive is derived (optionally), by (a) replacing the subject NP by theobject, (b) postposing the subject, putting it as the object of the preposition by, and (c)introducing the copula bearing the tense of the active V (here, Past), and making theV a participle.
In LGB, the passive transformation cannot even be stated. The passive constructionarises instead from an (obligatory) operation of substitution, putting the object of theparticiple into the empty subject position e of a structure
[Se[VPbe [A$V + en NP]]]
4 For Harris, transformations were relations between sentences; Chomsky’s innovation was to think of themas relations between phrase markers used in the course of a derivation.

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 360 — #16
360 Handbook of Logic and Language
with or without the added PP = by NP. Thus we derive, not (38), but (39), and alsothe form without expression of an agent, (40):
(39) The window was broken t by the boy;(40) The window was broken t.
The passive construction is now seen as a special case of an operation movingan argument from one position to another, or NP-movement as it is called. Althoughwe cannot go into the details here, we can point out that this operation will also beinvolved in the so-called “raising” constructions, as in (41), and the generalized move-ment constructions, which are like the passive except that the argument that moves isnot an argument of the head whose subject it becomes, as in (42):
(41) John seems [t to be a nice fellow];(42) Many people were believed [t to have voted for the proposal].
Notice that, although the passive morphology reflected in the change from break tobroken forces movement of the argument the window to the subject position, it does notalter at all the grammatical relation between these items; we must, however, stipulatethat the passive has the property that whatever could have appeared as the subject ofthe transitive form is optionally expressible as the object of the preposition by. Thisfeature of the old passive transformation, expressed now as a reflex of a morphologicalchange, survives in the new system.
6.3.3 Empty Categories
The restrictions on transformations just outlined have gone together with a conceptionof syntactic movement, whether substitution or adjunction, as always leaving a tracet coindexed with the moved element, effectively marking the position from whichmovement took place. We shall survey some of the evidence for this point of view inSection 6.5.3 below. The introduction of unpronounced but syntactically present ele-ments such as the trace invites further reflection on the system of constituent structure,item I in our enumeration of the components of a transformational grammar.
Supposing D-Structure to be prior to all movement, we have D-Structures pairedwith S-Structures as in (43)–(44), illustrating movement from a lower to a highersubject position, and also as in (45)–(46), illustrating movement of a wh-expression:
(43) e [was seen [the boy]];(44) [the boy]i [was seen ti];(45) I know [? [you saw who]];(46) I know [whoi [you saw ti]].
One and the same expression can undergo both types of movement: thus theD-Structure (47) will yield S-Structure (48):
(47) I know [? [you think [e was seen who]]];(48) I know [whoi [you think [ti was seen ti]]].

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 361 — #17
GB Theory: An Introduction 361
The theory thus allows sequences
Moved Element . . . t1i . . . t2i . . . , . . . tni
where the position of the final trace tn was occupied by the moved element atD-Structure, and is the position that determines the grammatical function of that ele-ment (object of see in our examples). But there are also cases where an overt element,occurring in one position, is clearly related to another position that is not occupied byany phonetically realized element, and where the grammatical function of the overtelement must be located in both positions. Such cases include (49) and (50):
(49) Mary persuaded John [to go to college];(50) Bill promised [to turn in the paper on time].
In traditional terms, the indirect object John in (49) is the understood subject of theinfinitive to go to college; and the subject Bill of (50) is also the understood sub-ject of to turn in the paper on time. Now, promise is evidently a two-place predicate,selecting a subject and an object; but then the subject Bill must have been present inthe D-Structure of (50), and its S-Structure therefore does not involve movement (ofthis element). As for (49), we can verify that persuade is a three-place predicate: ifwe make the position of the clause indefinite, or existentially general, then we havesentences like (51):
(51) Mary persuaded John of something;
and expressions like (52) are nonsense, since the indirect object is missing:
(52) *Mary persuaded of something.
The position occupied by John in (49) was occupied by that expression even atD-Structure, so that we conclude in this case too that it has not undergone move-ment, and in particular has not moved from the subject position of the clause togo to college. But then, if every predicate must have its proper arguments presentat D-Structure and at S-Structure, there must at D-Structure have been somethingthat served as the subject of the infinitive, and continues at S-Structure to servethat function; at the same time, this element must be related to the overt element,for which it is understood. For (49)–(50), then, we have D- and S-Structures as in(53)–(54):
(53) Mary persuaded Johni [ei to go to college];(54) Johni promised [ei to turn in the paper on time];
with e unpronounced, but syntactically present.5
5 The above deduction depends upon the assumption that understood elements are explicitly represented ateach linguistic level; this is an informal version of the projection principle of Chomsky (1981).

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 362 — #18
362 Handbook of Logic and Language
We conclude that, alongside the trace t of movement, there must be another type ofempty category. The type is dubbed PRO in the standard literature: it is distinguishedfrom t in that it is related to another element not by movement but purely throughcoindexing. The distinction between trace and PRO is simply that whereas in relations
Ai . . . ti
the position of A is not selected by the predicate with which it occurs (but only theposition of t is, so that A appeared there at D-Structure), in relations
Ai . . . PROi
both positions are selected, by their respective predicates. It follows that PRO andtrace exclude each other: if one can occur in a given position, then the other cannot.6
The addition of PRO to the inventory of empty categories is a lexical extension ofphrase structure: PRO is a word (although not pronounced). It is an argument, but inthe cases we have discussed takes an antecedent, and is thus a kind of empty pronoun.Chomsky (1977) proposed that besides the empty argument PRO there was also anempty operator O, comparable to wh-expressions but like PRO unpronounced. Someevidence for O comes from comparative constructions in English, as in (55)–(56):
(55) Mary is taller than Susan is;(56) Seals eat more fish than penguins do.
In these constructions the final predicate is reduced to null phonological shape; butthe form of the auxiliary indicates that it is reduced from the predicate of the com-parative, the adjective tall in the case of (55), or the VP eat fish in the case of (56).Chomsky (1977) suggests that the relation between the antecedent predicate and thedeletion site is mediated by the empty operator O, which like wh-expressions hasundergone movement, so that we have at S-Structure (57) and (58):
(57) Mary is taller than [Oi [Susan is ti]];(58) Seals eat more fish than [Oi [penguins do ti]].
Part of the evidence for this view comes from dialects of English where a wh-expression may actually appear in the position of O, as in (59)–(60):
(59) Mary is taller than what Susan is;(60) Seals eat more fish than what penguins do.
6 For suppose otherwise. Then we have S-Structures as in (i) and (ii):
(i) [. . . Ai . . . P1 . . . ti . . . P2 . . .]
(ii) [. . . Ai . . . P1 . . . PROi . . . P2 . . .]
(linear order irrelevant), where P1 is the predicate hosting Ai and P2 is the predicate hosting ti or PROi. If(ii) is allowed, then Ai and PRO are independently selected by P1 and P2 respectively, or else selected indifferent positions of P1 if P1 = P2. In either case the grammatical function of Ai in (i) is not exhaustedby its role as a certain argument of P2; so if (ii) is allowed then (i) is not.

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 363 — #19
GB Theory: An Introduction 363
Application of the theory extends far beyond these cases, and in particular to the caseof easy-constructions, which we discuss immediately below. Assuming the account tothis point, we have empty categories
t, PRO, O
each with its specific properties, as additions to the lexicon.
6.3.4 Analysis of Easy Versus Eager
In light of our theoretical sketch, we return to the analysis of (16)–(17), repeatedhere:
(16) John is easy to please;(17) John is eager to please;
the D-Structure of (16) will be as in (61):
(61) [John is [easy [PRO to please O]]];
with O an empty operator, and PRO an empty pronominal. The operator, like thewh-expression of a relative clause, moves to a position external to its clause, beinginterpreted through a relation with the subject John. We thus derive (62) at S-Structure:
(62) [Johni is [easy [Oi [PRO to please ti]]]].
For (17), however, the D-Structure will be as in (63):
(63) [John is eager [PRO to please]];
with intransitive please. The subject PRO is obligatorily related to the matrix subjectJohn, so that we have just (64):
(64) [Johni is eager [PROi to please]].
Turning now to the explanation of the grammatical divergences between the structuresinto which the roots easy and eager may respectively enter, we propose:
(a) easy is a one-place predicate, whose appearance with both a subject and an object in (16)is admitted only because the subject is related to the object position of the complement, asmediated by the empty operator. Hence It is easy to please John is grammatical, with thestructure (65):
(65) [It is [easy [PRO to please John]]];
eager, however, is a two-place predicate, requiring both a subject and a complement,so that in (66) the word it will not be an expletive, and will in fact be related to PRO:
(66) [Iti is [eager [PROi to please John]]];

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 364 — #20
364 Handbook of Logic and Language
(b) The affix -ness when attached to an adjective does not disrupt the relation between theunderstood subject PRO and the subject of the underlying predicate, but in some way dis-rupts the communication between the operator O and the subject; thus we have John’seagerness to please, but not *John’s easiness to please. Compare also:
(67) the problem’s hardness;(68) *the problem’s hardness to solve;
(c) Since easy is a one-place predicate, we can have To please John is easy, just as we have(65); but not *To please John is eager, from which the subject has been omitted.
6.3.5 Long-Distance Dependencies in LGB
The representation of the long-distance dependency that consists in number agreementbetween a higher V and an NP related to an expletive there realized in the highersubject position, as in (25), repeated here, will now proceed as follows:
(25) There seems to be *men/a man walking.
First of all, there is no need to insert there at D-Structure, since its occurrence ispredictable. We may have therefore the structure (69), with e an empty element in thesubject positions of both higher and lower clauses:
(69) [e [seem [e to be [a man (sing)] in the garden]]].
Assume that there is number agreement between a man and the e of the lower clause.7
That e then moves to the position of the higher e, carrying its singular number with it,and thus imposing agreement with the tensed main V seem. It also spells out in Englishas there. The long-distance dependency between singular a man and singular seems in(25) is therefore a product of three local processes: number agreement between a manand the e of the lower clause; movement, retaining the number feature; and numberagreement between seems and the moved empty category.
The long-distance dependency exemplified by wh-movement is created by a move-ment transformation mapping D-Structure into S-Structure. Visibly, the movement isleftward. There are, however, considerations that suggest that we were right also toregard it as “upward”, or to the higher position selected by ‘?’ in (35), in a way to becharacterized more fully below. Notice that the movement of embedded e in (69) isupward, the subject of a sentence being higher in the phrase structure than the subjectof any sentence that it properly contains. Evidence that the leftward movement of whshares this property is provided by the observation that wh-movement is suppletivewith clause-introducing words of the type that Otto Jespersen called complementizers.English, for example, has relative clauses like (70) and (71), but never the likesof (72):
7 The relation between these items is a special case of a chain in the sense of Chomsky (1981); for extensivediscussion of chains of the expletive type, see particularly Safir (1985).

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 365 — #21
GB Theory: An Introduction 365
(70) the book (that) I read;(71) the book which I read;(72) *the book which that I read/the book that which I read.
The point continues to hold for embedded clauses. Thus we have embedded declara-tives, as in (73) and embedded interrogatives as in (74), but their introducing wordsmay not appear together, as in the ungrammatical (75):
(73) I know [that you read the book];(74) I know [which book you read];(75) *I know [that which book you read].
As shown especially in Bresnan (1972), these and similar facts follow at once if we butsuppose that embedded clauses are introduced by the category C = complementizer,a designated position into which a wh-expression can move; and if we assume furtherthat a wh-expression and an ordinary complementizer such as that cannot both occupythis position.8
The sense in which substitution and adjunction are always “upward” is explainedmore precisely in Section 5 below. In combination with the confinement of all syn-tactic movement to these two operations, the possibilities for syntactic movement arestill further restricted.
6.4 Logical Form
The notion of Logical Form (hereafter, LF), as proposed in Chomsky (1976) and sub-sequent work by him and many others, and incorporated as an intrinsic part of the LGBtheory, is advanced with the thought that the levels of D-Structure and S-Structure maybe insufficient for theoretical purposes. From a purely syntactic point of view there aretwo types of considerations that may support the thesis that a more abstract linguisticlevel, to which S-Structure representations constitute the input, is to be found in humanlanguage. First, there may be generalizations about given languages that are not state-able at the level of S-Structure, suggesting that a more abstract level of description iswanted. Second, the analysis of systematic similarities or differences among languages(or among dialects of given languages, or, still more finely, among styles of speech inparticular speakers) may resist classification in terms of S-Structure distinctions. Wegive examples of both types.9
8 In some languages, as in some dialects of Dutch, the latter condition does not always hold. If anything,however, this observation turns out to support Bresnan’s analysis, since the differences between thesedialects and other closely related ones is readily described, given that wh-movement (putting aside certaindetails) effectively a substitution or adjunction within a designated higher position.
9 A guiding theme of research into LF is the thought that differences among languages that would man-date different semantic algorithms are wiped out at LF, so that there is effectively a unique interfacebetween form and meaning; see Higginbotham (1985), among others. Here, however, we confine the dis-cussion to considerations of a syntactic nature only. For an overview of proposals about LF, see especiallyHuang (1995).

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 366 — #22
366 Handbook of Logic and Language
6.4.1 Negative Polarity
Considerable work has been devoted to the distribution in English and other languagesof expressions that require to be hosted by negation or another appropriate “negative”element, the so-called negative polarity items. From English an example is affordedby the word ever, as it occurs in (76):
(76) Mary didn’t ever go to France.
The meaning of ever is existential; that is, the interpretation of (76) is as in (77):10
(77) Not (for some past time $ ) Mary goes to France at $ .
In (76), the existential is understood within the scope of negation, a necessary condi-tion for the appearance of ever since scattered negations that do not take ever in theirscope do not license it:
(78) *Mary ever didn’t go to France.
Now, besides explicit negation, expressions with an appropriately “negative” meaningcan host ever:
(79) I doubt/*believe that [Mary will ever go to France];(80) Few people/*Many people thought that [Mary would ever go to France].
In these cases ever is interpreted within the scope of the negative element, doubt inthe case of (79), few people in the case of (80). Now consider (81)–(82):
(81) Fathers of few children ever go to Euro-Disney;(82) *Fathers with few children ever go to Euro-Disney;
(these are modeled after an original discussion due to Jackendoff (1972)). The negativefew children in the subject NP of (81) is taken with scope over the whole sentence, butthe same expression in (82) is interpreted within the NP; and the first but not thesecond can serve as host to the negative polarity item in the predicate.
10 An alternative hypothesis, which would suffice for (76), is that ever represents a universal quantificationtaking wider scope than the negation. But this hypothesis is refuted by the consideration of contexts‘. . . $ . . .’ where the interpretation
(For all $ ) Not . . . $ . . .
clearly fails to represent the meaning of the sentence
Not . . . ever . . .
For example, consider (i):(i) Mary is not likely ever to go to France
Evidently, (i) does not have it that(For all $ ) Not (it is likely Mary goes to France at $ )
but rather thatNot (it is likely that (for some $ ) Mary goes to France at $ )
In the text we cleave to simpler examples, for ease of exposition.

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 367 — #23
GB Theory: An Introduction 367
The distinction between (81) and (82), and the condition on the distribution of thenegative polarity item ever, is easily stated: this expression must occur within thescope of a negative element. But the condition is not represented at S-Structure, whichdoes not relevantly distinguish the grammatical (81) from the ungrammatical (82). Thehypothesis therefore suggests itself that (rather as easy and eager were distinguished atD-Structure and S-Structure, but not at the level of elementary phrase structure) thereis a level of linguistic description at which scope is marked explicitly. This level willbe distinct from S-Structure, in which such marking pays no role.11
6.4.2 Antecedent-Contained Deletion
A second notable example motivating LF is provided by the phenomenon ofantecedent-contained VP deletion, exemplified by (83):
(83) John went everywhere that Bill did !.
The position marked by ‘!’ is the site of ellipsis. Naturally, the sentence is understoodas in (84):
(84) For every place x such that Bill went to x, John went to x.
But how is this interpretation arrived at? For cases like (85), we may suggest that theantecedent VP went everywhere is simply copied into the site marked by ‘!’:
(85) John went everywhere, and then Bill did !.
But for (83) this cannot be: the ellipsis site is itself part of the VP that constitutes theantecedent. How, then, should the obvious principle governing VP-deletion, namely
Delete VP under conditions of identity with another VP
be stated in general? The evident solution, due in different forms to Sag (1976) andWilliams (1977), and recently examined at length in Fiengo and May (1994), is to pro-pose that the quantifier phrase everywhere that Bill did takes scope over the sentence,giving a structure we may represent as (86):
(86) [everywhere that Bill did !] [John went t];
with t the trace of abstract quantifier movement. At this point the antecedent of theellipsis site is went t, which does not contain it. The resulting representation, (87), iseasily understood as having the proper semantics as in (84):
(87) [everywhere that Bill did go t] [John went t].
The crucial step in this derivation is the one that leads from the S-Structure rep-resentation of (83) to (86); the latter is not an S-Structure, but an element of LF.
11 There are several ways of marking scope, which we do not distinguish here. It is sufficient for ourpurposes that there be syntactic phenomena that show the need to do so.

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 368 — #24
368 Handbook of Logic and Language
Thus the hypothesis that LF representations may be derived from S-Structure by suchoperations as indication of scope enables us to state quite generally the condition onwell-formedness of sentences with negative polarity items, and the simple operationthat restores ellipsis. At S-Structure no such simple statement is possible.12
We have considered two cases where generalizations about English, namely (i) thatnegative polarity items are licensed only within the scope of negative elements, and(ii) that VP-deletion is licensed under conditions of identity with another VP, are notstateable at S-Structure, but are stateable at a level LF, once scope has been explicitlyassigned.
It was remarked above that although English showed wh-movement, many lan-guages did not. In both Japanese and Chinese, for instance, the expressions whosemeaning corresponds to that of English wh-expressions occur in all sentences inexactly the same positions where non-wh-expressions of the same types could go. Forsuch languages, one might expect that the scopes of wh-expressions would be limitedby sense only, and not also by formal grammar. However, studies of both (very differ-ent types of) languages have shown not only that there are formal limitations, but alsothat they differ among languages. Since these differences are evidently unpredictablefrom any simple properties of S-Structures, it is natural to take them as reflectingproperties of LF.13
We thus arrive at the following picture: linguistic structures are generated initiallyfrom the lexicon, more inclusive structures being built up as they may be licensedby projection rules for modifiers and arguments. Movement (leaving trace), which isalways to higher positions, is confined to substitution and adjunction. We have thenpartial responses to the requirements of a theory with components (I)–(III) enumeratedabove. After presenting a somewhat more formal treatment, we return to the question(IV), of limiting the scope of the principles involved.
6.5 Formal Development and Applications
In this section we develop some of the elements of a formal theory of phrase markers(with reference to S-Structure, although the theory could be applied to any of thelevels discussed). Referring back to the examples given above, we see that a phrasemarker has an hierarchical structure together with a linear ordering of elements, andthat these elements carry grammatical information of various sorts. We develop thesecomponents in turn.
12 Lasnik (1993) offers a different account of antecedent-contained deletion. Lappin (1995) surveys approa-ches to this and other cases of ellipsis, in some cases placing a heavy burden on semantic principles. Allof these views, however, involve enrichment either of the syntax or of the (otherwise trivial) semanticsfor quantified sentences, and to that extent depart from the simplest assumptions.
13 Seminal work in this area includes Huang (1982) on Chinese, Nishigauchi (1990) on Japanese, andLasnik and Saito (1991) on the comparative syntax of (overt and abstract) wh-movement.

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 369 — #25
GB Theory: An Introduction 369
6.5.1 Trees, Ordering, and Labels
A tree is a partially ordered set T = (X, %) such that, for each element x ofX, {y : y % x} is well-ordered by % (in empirical linguistics one considers only finitetrees, so that linear ordering is sufficient). The elements of T are the points or nodes of(T, %). The relation % is the relation of domination. The relation of proper dominationis >, defined by
x > y iff x % y & x &= y.
A root of a tree is a point x such that x % y for every y ' T; since % is a partialordering, the root of a tree is unique if it exists. Linguistics generally considers onlytrees possessing roots, and we shall assume this restriction here. An ordered tree isa tree (T, %) together with a linear ordering O0 among the set of points that have nosuccessors; i.e. points x such that x % y implies x = y (the leaves, to continue thearboreal terminology); this ordering is projected to the relation O defined by:
O(x, y) iff for every leaf w such thatx % w and every leaf u such that y % u, O0(w, u).
If T has the property that
x " y & y " x implies O(x, y) ( O(y, x)
then T is connected, and the points of T are said to be continuous.14
The trees of linguistic theory are completed by the designation of their points asoccupied by words or other expressions, including symbols for categories, drawn fromthe theoretical vocabulary. Formally, let % be a set of labels. A relation L contained inX ) % is a labeling of T . The labels represent predicates, true of the points that theyoccupy; the exact details will depend upon what conception of labels is in force.15
14 Trees with discontinuous points have been noted as a possibility for languages with relatively free wordorder, and for languages exhibiting basic orders that would disallow the types of constituency that aregenerally attested elsewhere. A canonical example of the latter type is Irish, whose basic order is Verb-Subject-Object. If Verb and Object form a constituent VP, however, the resulting tree must either bedisconnected, or else the surface order must reflect an obligatory movement of one or more of S, V, andO. In fact there is evidence that the latter is the case (see for instance Speas (1992), which reviews workin this area): what is generated in phrase structure is in fact S-[V-O], and V subsequently moves to theleft of S, giving rise to the observed ordering. For languages of the former type, with relatively free wordorder, similar “movement” solutions have been devised. On the other hand, it has been argued that thereare exceptional constructions even in languages like English that do not in general permit discontinuousconstituents: see McCawley (1982).
15 The categorial labels, such as N, V, and their projections may be interpreted as predicates true of x ' Xmeaning “x (or the subtree with root x) is a verb”, or “...is a noun”, and so forth. The labeling L is normallyconsidered a function with respect to such labels; that is, at most one categorial label is available for agiven point. This consideration in turn can be derived if one regards categories as sets of features (moreprimitive labels), assuming that feature sets may not conflict. However, there is nothing in principle thatrules out non-functional labelings. Evidently, the choice of primitives, rather open at the present stage ofinquiry, will be crucial for the abstract theory.

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 370 — #26
370 Handbook of Logic and Language
Fully ticketed, then, a phrase marker is a structure
P = (T, O, L)
where T is a tree, O is the ordering projected from the initial ordering O0 on the leavesof T , and L is the labeling relation.
Consider in the light of these definitions the example (4), reproduced here:
(4)
young
proud
article
the
with
NP
NP
PP
S
V
Pwent
PP
to
NA
A
NP
N
N
VP
P
child
I
London
The ordering % is displayed; the ordering O0 is the order of the words as they wouldbe spoken, and it is extended to an ordering that, e.g., puts the PP to London in therelation O to the N proud young child.
We have said that labels represent predicates of points, so that if the label P attachesto point x, then P is true of x. This understanding still leaves it open what to say if apoint does not bear a certain label; here different conventions may be adopted. Ques-tions arise also about redundancy; for linguistic principles may be such as to implythat a label P must attach to a point x. (4) already contains some possible examples.Thus the label VP attaching to the predecessor of V is predictable, since V are onlyheads, and never modifiers.
Besides the many details about the nature of labels that would have to be settledin a full formalization of elementary phrase structure with labeled trees, there arisesthe question whether, besides the one-place predicates that the labels signify, there arealso two-place predicates, or linguistically significant binary relations between pointsin phrase structure. This question actually comes in two forms. First, there are relationsdefinable in tree structures (definable, that is, in terms of % and O and the resourcesof logic and set theory) and labels that may play a role; and second there may bespecifically linguistic relations not so definable that should be posited to explain thephenomena of linguistic organization. We consider these in turn.

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 371 — #27
GB Theory: An Introduction 371
6.5.2 Definable Binary Relations
A central example of a definable binary relation is that of c-command (so named byReinhart (1976), and superseding the closely related notion in construction with, dueto Edward Klima). It is defined as follows:
x c-commands y iff neither of x and y dominates the other, and the least point thatproperly dominates x and has more than one successor also dominates y.
This notion, call it CC, is (first-order) definable in terms of the primitive relation %.We define it in full by way of illustration. Put:
(i) y is a successor of x =df x > y & ¬(Ez)(x > z > y);(ii) Px is a branching point =df (Ey)(Ez)(y &= z & y and z are successors of x).
Then:(iii) CC(x, y) =df ¬(x % y) & ¬(y % x)
& (Aw) (w is a branching point & w > x # w % z).
Definability of linguistic relations of the sort discussed to this point (e.g., number-agreement) and below in this subsection is similarly straightforward.16
The c-command relation is exactly the conception of scope in standard formalizedlanguages; thus a constituent x c-commands a constituent y if and only if y is within thescope of x. To see this point, notice that the common inductive definition governingquantifiers is:
If ! is a formula and v is a variable, then
(Ev)!
is a formula. This inductive clause corresponds to the licensing of a tree
F
F
(Ev)
Q
!
in which the quantifier label Q immediately dominating ‘(Ev)’ c-commands !. Theconcept of scope has a semantic correlate, in that occurrences of a variable withinthe scope of a quantifier appearing with that variable are bound by the quantifier.
16 The definition of c-command in terms of branching points is necessitated, on a classical conception, bythe fact that an element can be simultaneously a lexical head X0 and a maximal projection X$$, so thatstructures [X$$ [X$ [X0 ]]] are possible. Where these elements are merged, and the lexical items occupyinga point X0 are part of its label, then every non-leaf is a branching point, and the extra information isnot needed. Even so, some modified command relations will attend, given X and Y, to the least subtreedominating both.

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 372 — #28
372 Handbook of Logic and Language
A point of considerable interest is that c-command, or syntactic scope, has over a widedomain the semantic effects of scope in formalized languages. The discovery that atheory of binding can be constructed along these lines is one of the chief pillars of GBtheory.
Various modifications of the fundamental c-command relation have been sug-gested for different purposes. One that we will employ below is that of m-command,defined by:
x m-commands y iff neither of x and ydominates the other, and every maximal projection thatproperly dominates x also dominates y.
The concepts of m-command and c-command are very close. If we assume that everynon-lexical node branches; that every element other than the root is properly domi-nated by a maximal projection; and that maximal projections are of level no greaterthan 2, then m-command includes c-command, and only a little bit more. The case thatwe will employ in 7.2 below uses the fact that a head X0 adjoined to a head Y0 thatc-commands it will m-command (though it will not c-command) its own trace, asin (88):
(88) [Y$$ . . . [Y$ [0YY0 + X0] . . . tX0 ]]].
Since Y is not a maximal projection, the least (and therefore every) maximal projectionproperly dominating X dominates t0X.
Aoun and Sportiche (1981) suggested that the relation of government could bedefined as mutual m-command:
x governs y iff x and y m-command each other.
On this definition, heads always govern their complements, but govern their subjectsonly if they are in the maximal projection, as shown in (89):
(89) [ZX[H$H Y]].
Here H and Y are sisters, so that H governs Y necessarily; but H governs X if and onlyif H$ is not a maximal projection. Therefore, in the familiar
[SNP[VPV NP]]
where VP is maximal, V does not govern the subject NP.17
We said above that there were two allowable movement operations, substitutionand adjunction. Suppose these operations must have the effect of putting the movedelement into a position from which it c-commands the site from which it moved. Then,besides restricting allowable movements, we imply (a) that substitution of X for Y ispossible only if Y c-commands X; and (b) that so far as the c-command requirement
17 For a systematization of various command relations see especially Barker and Pullum (1990), and furtherKracht (1993).

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 373 — #29
GB Theory: An Introduction 373
goes X may adjoin to a point Y if and only if Y dominates X. Point (a) is immediate.For (b), we observe that from a structure
. . . [Y. . . X . . .] . . .
in which Y properly dominates X, adjunction of X to Y produces
. . . [YX[Y. . . tX . . .]] . . .
so that X c-commands its trace; and that from a structure
. . . [Y. . .] . . . X . . .
where Y does not dominate X, adjunction of X to Y produces
. . . [YX[Y. . .]] . . . tX . . .
where X c-commands only material within (the old) Y, hence not the trace tX of X.Consider in this light the operation of wh-movement discussed above. In ordinary
English questions and in relative clauses the movement of some wh to the left periph-ery of the clause is obligatory: hence it is natural to regard it as a substitution operation.But then the restriction on movement imposed by the requirement that substitution beto a c-commanding position implies that the point of substitution c-commands thewh-expression, so that the input structure for the operation that produces the examplesin (29) and (30) must be as in (90):
(90)
Y
A
B
...X = wh...
with X substituting in position Y. The point B will carry the label of a clause of somesort, and it may be taken as the complement of Y, acting as the head of the construction.If so, then A is Y$, and wh-movement carries an appropriate element into the positionof a head, for reasons yet to be determined. The restrictions on movement imposedby c-command thus carry strong implications for input and derived structures undersubstitution, and the conclusion harmonizes with the idea that wh-movement is intothe position of a complementizer, as suggested above, following Bresnan.
A similar point can be made about adjunction, at least if we assume that c-commandin human languages is correlated with scope. Consider the ambiguous (91):
(91) John didn’t go out because he (John) was sick.

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 374 — #30
374 Handbook of Logic and Language
The speaker of (91) may be affirming that John didn’t go out, and stating that thereason for this was that he was sick; or may merely be denying that it was because hewas sick that John went out. The ambiguity must be structural, and is determined bywhether the subordinate clause because he was sick is outside the scope of negation,as in the first possibility, or within it, as in the second. The subordinate clause is amodifier in the broad sense; that is, the main clause John didn’t go out is completewithout it. Hence it is adjoined rather than a complement, and must in one interpreta-tion not be c-commanded, and in the other be c-commanded, by the negation not. Ifthe subordinate clause is proposed, then it may not be interpreted as within the scopeof negation:
(92) Because he was sick, John didn’t go out
an expected result, since the clause must now have adjoined to a position from whichit c-commands the main clause, and the negation in particular. On the other hand, ifwe replace the subject in (91) by a wh-expression, we can see that the pronoun in thesubordinate clause can be taken as bound to it, with either interpretation available:
(93) Who didn’t go out because he was sick?
It follows that the wh-expression c-commands the pronoun he, and therefore that inthe interpretation where x’s being sick is the reason for x’s not going out we shall havea structure as in (94):
(94) A
Y B
who B
Neg
not
D
C
because he was sick
t go out
We have seen how the definable notion of c-command can be invoked as a generalprinciple governing syntactic movement, thus partly responding to (IV) of the enumer-ation in Section 6.2 above. Our original description of the operation of wh-movementcan now be refined as (95):
(95) Move a wh-expression into an appropriate complementizer.
However, we still do not have a sufficient restriction on wh-movement: recall thatalthough all acceptable cases could be described in terms of movement to a left periph-ery (or now into the complementizer position, which in fact occurs there), not all

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 375 — #31
GB Theory: An Introduction 375
cases of such movement were acceptable. To distinguish between the acceptable andunacceptable cases a number of conditions have been proposed, of which we outlinethe best known, based on Chomsky (1973), which itself endeavored to mold as far aspossible into a single system the different constraints of Ross (1967).
Following a version of the original definition due to Chomsky (1973), say that apoint x is subjacent to a point y in a phrase marker P = (T, O, L) if y c-commandsx and the path consisting of the points in P lying between x and the least branchingpoint dominating y contains at most one point bearing some label chosen from a setB of barriers.18 Then given an interpretation of B, subjacency is definable in terms ofdomination. Suppose that
(96) If P$ is immediately derived from P by moving a constituent X from a point x toa point y, then x is subjacent to y;
and furthermore that
(97) NP and S are barriers.
Then one immediately verifies that the examples in (29) and (30) satisfy (96)–(97), butthose in (31) do not. For example, in the case of (31a), repeated here with traces andbarriers shown as (98), the position of the trace t is not subjacent to the complementizer(in fact, three barriers intervene):
(98) [[Which book] [Sdid [NPthe man who [St$ likes t]] talk to you]].
Now, it is possible to move wh-expressions over long distances, as in (99):
(99) [[Which book] [Sdid John think [SMary said [SI want[Sher to read t]]]]].
But in these cases it is supposed that the wh-expression moves step by step throughthe intervening complementizer positions, so that the structure is as in (100):
(100) [[Which book] [[Sdid John think [t[SMary said[t[SI want [t[Sher to read t]]]]]]]]];
and subjacency is preserved. No such movement is possible in (98), since (a) NPpresumably lacks a complementizer position, and (b) the relative pronoun who fillsthe complementizer position in the relative clause. Similar reasoning serves to block(31b), repeated here with barriers shown:
(31) (b) *What [Sdid you put [NPthe spoon or ] on the plate].
The subjacency condition (96), then, is a prohibition against moving an element“too far” in a single step, where, crucially, “distance” is measured not in terms of thenumber of words (which may be arbitrarily long) but rather in terms of the number
18 The terminology here is anachronistic, but seems preferable to the older term bounding nodes. For acomputational development of the theory of barriers in the contemporary sense, see Stabler (1992).

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 376 — #32
376 Handbook of Logic and Language
of phrasal points of specific types that are crossed. The ungrammaticality of (31c),repeated below, may then be owing to the fact that the wh-expression how cannotmove through an intermediate position, the C of the complement to deny:
(31) (c) *How [Sdid Mary deny [Syou fixed the car t]].
The subjacency condition is not sufficient to rule out all cases where movementis prohibited. In English in particular there is a particular case where even a “short”movement is prohibited, namely from the subject (but not the object) of a complementpreceded by the complementizer that:
(101) Who do you think [that I saw t]?(102) *Who do you think [that t saw me]?
If the complementizer is absent, then we have (103), which is fully grammatical:
(103) Who do you think [t saw me]?
The example (102) is the so-called “that-trace” effect, in the form in which it is seenin English; it is not a universal phenomenon, being absent for instance in Italian andmany other languages. Although the diagnosis of the effect is still controversial, adescriptive point to which Chomsky (1981) called attention is that it may reflect thefact that subjects alone among the arguments of a V are not governed by V.
By the definition of government in terms of mutual m-command as given above, theV see governs the object in (101), but not the subject in (102). If traces are required tobe governed, then (102) is ruled out; but so is (103), contrary to fact. However, recall-ing that wh-movement must proceed through the position C, what actually licensesWho do you think saw me? as a sentence is (104):
(104) Who [Sdo you think [t[St saw me]]]?
with an intermediate trace subjacent to Who, and incidentally a close relation betweenthis trace and the trace of the subject. We might now suppose that the presence of thecomplementizer that disrupts this relation, producing ungrammaticality.19
6.5.3 Introduced Binary Relations
We have been examining the role of linguistic relations definable in terms of the givenrelations of domination and linear ordering, assuming some stock of labels (predi-cates) of points. Relations such as c-command (and other, closely related conceptionsthat have been prominent in the literature), subjacency, government and others areused to state conditions on well-formedness. Formally, these are either filters on singlestructures or conditions on the application of grammatical transformations. Traditional
19 In LGB Chomsky suggested that the trace of wh-movement must be properly governed, where propergovernment amounted to (i) government by a lexical head (as in (101)), or (ii) antecedent governmentby a close element, as in (104). Especially in view of the cross-linguistic variability of the that-traceeffect, modifications of this proposal have been suggested; again see Lasnik and Saito (1991) for a recentcomparative analysis.

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 377 — #33
GB Theory: An Introduction 377
descriptive grammar contains many other examples of linguistic relations and condi-tions on well-formedness stateable in terms of such relations, and to the extent thatthese concepts and conditions are not superseded by the formalism of generative gram-mar we shall want to express them if possible within the apparatus given so far, andotherwise enrich the vocabulary of linguistic theory so as to accommodate them.
Consider in this regard the relation of subject to predicate. Chomsky (1965) arguedthat the notion
X is the subject of the sentence S
could be defined in terms of the properties of phrase markers, for instance by
X is the NP immediately dominated by S.
This definition is relative to a grammar G, but might hypothetically be extended to sub-jects cross-linguistically; and it can be extended to other categories than S by definingthe subject of YP as the sister of the Y$ daughter of YP. The extension allows us tosay, for instance, that in a nominalization such as (105) the phrase the Romans is thesubject of NP:
(105) [NP[the Romans’] [N$destruction of Carthage]]
a result that accords with intuitive judgment, inasmuch as the semantic relation ofthe subject phrase to the N destruction is the same as that between subject and Vin (106):
(106) The Romans destroyed Carthage.
The above definition of subject is too narrow to cover all cases, however. This point ismost easily brought out by considering the converse relation of predication. A predi-cate may be predicated of a subject that is also the subject of another constituent, orindeed of one that is the object of a constituent. An example that admits both possibili-ties is (107):
(107) Mary left John [angry].
The predicate angry may be understood as predicated of the subject Mary or the objectJohn: the choice is free. If we assume that the syntactic structure for (107) up to therelevant level of detail is just (108), then this fact is not represented:
(108) [Mary [left John angry]].
On the other hand, there are conditions that must be satisfied for a predicate to bepredicated of a given constituent. Thus in (109) we cannot take John as subject ofangry, although the meaning that would result from doing so, namely “Mary leftJohn’s mother when he, John, was angry”, is perfectly in order:
(109) Mary left John’s mother angry.
We cannot, therefore, simply omit to mention possibilities for predication in thesecases.

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 378 — #34
378 Handbook of Logic and Language
Examples like (107) contain two predicates, namely leave John, unambiguouslypredicated of the subject Mary, and angry, which may be predicated either of thesubject of the sentence or of its object. Following Rothstein (1983) we call the formerthe primary predicate, and the latter the secondary predicate of the construction. Thesubject of a primary predicate is determined by the phrase marker for the sentence inwhich it figures: it is the sister to the projection Y$ of the predicative head Y. But thesubject of a secondary predicate is not so determined, though the candidate subjects arerestricted in scope. In view of this indeterminacy Williams (1980) proposed that therelation of predication is in fact indicated in syntactic structures. This relation will notbe definable, but a new primitive, subject to conditions stated in terms of the conceptsalready available. Examples like (109), where the subject of the secondary predicateangry can be the subject or object of the sentence, but not something contained withinthese, suggest that the c-command of predicate by subject is a necessary condition forpredication. Since the subject of S and other categories c-commands the predicate, thecondition is satisfied by all cases of primary predication, so that the original definitionmay stand for this case. But even if the range of permissible subjects for a secondarypredicate is definable, secondary predication itself is not.
Besides predication, relations of co-interpretation, or anaphora in standard termi-nology, lead to an enrichment of the descriptive vocabulary for phrase markers. Ingeneral, an anaphoric relation is a relation between points in a tree that will be inter-preted as expressing dependence of the interpretation of one element upon the inter-pretation of another. We have already seen such relations in our discussion of easyversus eager, where the subject of the complement of eager, and the object of thecomplement of easy, are understood as identical with the subject of the sentence.There are many similar examples. In these cases no ambiguity is possible; but withordinary pronouns there are clear ambiguities, which there is to this point no way torepresent.
Consider in this light the possible interpretations for (93), repeated here:
(93) Who didn’t go out because he was sick?
In discussing this example above we were interested in the interpretation where thepronoun was taken as a variable bound to the wh-expression who. As we have alreadyseen, the movement of the wh-expression in (93) is taken to leave a trace coindexedwith the moved element. The coindexing represents an anaphoric relation, and it isnatural to extend the relation to include optional relations such as that between thepronoun and the wh-expression. We would then derive the representation shown in(110), where both trace and pronoun are dependent upon the quasi-quantifier who:20
(110) [Whoi] [ti didn’t go out because hei was sick].
20 The motivation given here for the explicit annotation of anaphoric relations actually reverses the histori-cal order, inasmuch as coindexing was suggested as early as Chomsky (1965) (replacing earlier “pronom-inalization” theories of anaphora), antedating by some years the trace theory of movement rules.

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 379 — #35
GB Theory: An Introduction 379
Anaphoric relations between pronouns and true quantifiers may be annotated in thesame manner, as in (111):
(111) [Every boy]i loves hisi mother.
In the context of this overview, the introduction of anaphoric relations should beseen as an essential enrichment of the theory of phrase markers, since these relationsare not definable in terms of anything antecedently given. Supposing them introduced,the question arises what conditions if any there are on their structure, as determinedby the linear or hierarchical properties of the trees in which they figure. Surveying therelations considered thus far, we see that coindexing has been licensed in the positionoccupied by X in trees such as (112):
(112)
...Wi...
Z
YXi
Further inquiry reveals that we do not in general get coindexing licensed in arbitrarystructures such as (113):
(113)
...Wi......Xi...
U
Z
Y
Moreover, it is a firm observation that subject pronominals may not be bound bythe complements of their own predicates, or any arguments contained in those com-plements. Thus contrast (114) with (115):
(114) Who [t thinks [he is a nice fellow]];(115) Who [does he think [t is a nice fellow]].
(114) can be interpreted as a general question, asking which persons x (in the relevantset) are of the opinion that x is a nice fellow. Not so (115), where the only interpretationis, for some indicated person &, the question which persons x are such that & is of theopinion that x is a nice fellow.
Suppose now that the relation of c-command governs coindexing, as suggestedmost prominently in Reinhart (1983). A signal feature of this concept is that it is com-pletely indifferent to the linear order of expressions. Think of a linearly ordered treeas if it were a mobile, with elements free to spin, altering the order of constituents.

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 380 — #36
380 Handbook of Logic and Language
A hierarchical structure such as (116) could then give rise to any of the ordersin (117):
(116) Z
X Y
W U
(117) XWU; XUW; WUX; UWX.
In (116), and likewise in all other linear arrangements, X c-commands U, but U doesnot c-command X.
Although linearity and c-command are fundamentally different notions, there isa specific case where they will coincide. Following standard terminology, say thata language is right branching if its system of phrasal projection, with hierarchicalstructure as in (116), always yields one of the orders XWU or XUW, and left branchingif it yields WUX or UWX. It is easily seen that English (and for that matter most of themore familiar European languages) are right branching. In such languages, subjectsprecede objects (modulo stylistic or “scrambling” rules), and therefore a precedingargument will normally c-command a following one.
The c-command condition on coindexing, regulating anaphoric relations, led in theLGB theory to a systematic account of anaphora in English, the binding theory asit was called there. As originally presented, the theory divided expressions accord-ing to whether or not they had a pronominal character, and whether or not they wereanaphoric. These terms overlap but do not coincide with the familiar notions of pro-nouns on the one hand, and elements that require antecedents on the other. Researchsince LGB has led to a number of modifications, both within English and cross-linguistically: we concentrate here on the abstract properties of the original theory,which it generally shares with its successors.
It is straightforward to confirm that in English the reflexive forms herself, ourselvesetc. must (apart from a few isolated locutions, not considered here) have antecedents,and that their antecedents must not only c-command but also be sufficiently “close” tothem; that ordinary pronominals her, us etc. may but need not have antecedents, andthat these, if c-commanding, cannot be too “close” to them; and, finally, that elementssuch as names, definite descriptions, quantifiers and the like, dubbed R-expressionsin LGB, cannot be related at all to elements that c-command them. Thus we havecontrasts like those in (118), (119), and (120):
(118) (a) She saw herself in the mirror(b) She saw her in the mirror (does not mean that she saw herself in the mirror)(c) She saw Mary in the mirror (does not mean that Mary saw herself in the mirror)
(119) (a) *She wants them to visit herself(b) She wants them to visit her (can mean that she is an x such that x wants them to
visit x)

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 381 — #37
GB Theory: An Introduction 381
(c) She wants them to visit Mary (cannot mean that Mary is an x such that x wants themto visit x)
(120) (a) She wants herself to visit them(b) She wants her to visit them (cannot mean that she is an x such that x wants x to visit
them)(c) She wants Mary to visit them (cannot mean that Mary is an x such that x wants x to
visit them)
(118a) shows a reflexive with a close c-commanding antecedent, the subject she; in(118b), where the reflexive is replaced with an ordinary pronominal, the pronom-inal cannot have this antecedent; and where the object of see is occupied by anR-expression, Mary, the subject and object cannot be related (as indicated by thegloss). In (119a) there is a potential c-commanding antecedent for the reflexive, thesubject she; but it is in some sense too far away; in (119b) an anaphoric relation bet-ween her and the subject is possible; but as (119c) shows the subject pronoun andan R-expression still cannot be related. Finally, (120a) shows that the antecedent ofa reflexive need not (at least on the assumption that the complement of wants is thefull infinitival clause herself to visit them) be an argument of the same predicate as thereflexive; (120b) that the complementarity between reflexives and pronominals holdsalso for this case; and (120c) that the embedded R-expression continues to resist anyrelation to the subject.
Say that X is A(rgument)-bound if it is c-commanded by and coindexed with anargument, and that it is A(rgument)-free otherwise, that an anaphor is an expressionthat is +anaphoric and !pronominal, a pronominal is !anaphoric and +pronominal,and an R-expression is !anaphoric and !pronominal. Then the general account of thedistribution above is as in (A)–(C) below (simplified from Chomsky (1981)):
(A) An anaphor is locally A-bound;(B) A pronominal is locally A-free;(C) An R-expression is A-free.21
With these points to hand, we return to the examples (114)–(115), repeated here:
(114) Who [t thinks [he is a nice fellow]];(115) Who [does he think [t is a nice fellow]].
It was remarked above that whereas (114) could be interpreted as a general question,with the pronoun he effectively functioning as a bound variable, (115) could not. For(114), we can recognize the trace t as the antecedent of the pronoun, just as the nameJohn can serve as antecedent in (121):
(121) Johni thinks [hei is a nice fellow].
21 In LGB, locality was defined in terms of minimal categories dominating the pronoun or anaphor. In therapid cross-linguistic development that followed, it was shown that if anaphoric forms were treated inthis fashion, then languages diverged in various ways, notably in virtue of admitting in many cases “long-distance” anaphora, or reflexive forms that were not locally bound. These developments, however, havenot disturbed the basic assumption that the acceptability of anaphora and antecedents for pronominalforms is in general configurationally determined.

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 382 — #38
382 Handbook of Logic and Language
For (115), we can take the step of assimilating the trace bound by an expression ofgenerality (including ordinary quantifiers and wh) to R-expressions. That will implythat the representation (122), although perfectly meaningful (and in fact meaning thesame thing as (114) with the pronoun and trace coindexed), is ungrammatical:
(122) Whoi [does hei think [ti is a nice fellow]].
In sum, the theory of anaphoric relations constitutes an intrinsic part of the theoryof linguistic structures and their interpretations, one that interacts with but is notreducible to relations definable in terms of labels and configuration.
Resuming the question of the nature of phrase markers, we now recognize struc-tures
P = (T, O, L, R1, . . . , Rn)
where T, O, and L are as above, and the Ri are linguistic relations among the points ofT , including at least the relation predicate-of and the relation antecedent-of, but per-haps involving others as well. Furthermore, we conceive the syntax of a human lan-guage to be derivational, mapping D-Structures into S-Structures via a restricted set ofgrammatical transformations, and S-Structures into LF-representations by adjunction,determining relative scope.22
6.6 Beyond GB: Checking and Copying
GB theory, with various modifications and emendations, retains several distinctivefeatures, for each of which modifications have been suggested in recent work. In thissection and the next we outline some of the points advanced in Chomsky (1993),which constitute important departures.
22 Jaakko Hintikka especially has argued that classical conceptions of relative scope are inadequate toexpress all relative binding relations in natural language, and has proposed that branching or partiallyordered quantifiers also be recognized. In the system of LF-representations, branching can be representedby allowing adjunction of two or more operators to the same position, as shown graphically in (i):(i)
S S
SO O'
...W...
where the operators O and O$ both c-command the lower S, but neither c-commands the other. If Hin-tikka’s view is correct, then LF-representations would no longer consist exclusively of trees; but thedeparture from classical assumptions would be accommodated without great disruption to the system.

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 383 — #39
GB Theory: An Introduction 383
6.6.1 Morphosyntax and Feature Checking
In the above discussion we have considered as needed, and as customary in linguistictheory, both categorial labels and other features of points in phrase markers. It is possi-ble to develop much of syntax as a theory of “communication” between such features,and we give a brief picture of the outline of such research.
The fundamental syntactic categories N, V, A, and P may be classified in terms ofthe features in the set {±N, ±V}, with
N = {+N,!V}, V = {!N,+V}, A = {+N,+V},and P = {!N,!V}.
Besides these features, we have appealed to features for person, number, and gender.Nominative and other cases are features of heads, and nominative in particular is foundin construction with tense. A label in the sense considered above may now be thoughtof as a set of features (in practice binary).
Particularly following the work of Baker (1988), Pollock (1989), and Chomsky(1986, 1993) we may regard tense or inflection INFL as itself a head, though onenot occupied by a word but rather by an affix, and take it that subjects in ordinarytensed sentences move to an external position so as to receive nominative case. Thusa sentence S may be regarded as a projection of INFL, so that we have the structure(123):
(123) INFLP
INFL'
INFL
Spec
Spec
VP
V'
V NP
where the positions marked by ‘Spec’ (“specifier”) are Spec(VP) = the underlyingposition of the subject, and Spec(IP), the position where nominative case is determinedby agreement with INFL.
Contrast (123) with the LGB structure (124):
(124) S
NP
V
INFL VP
NP

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 384 — #40
384 Handbook of Logic and Language
where in the simplest case INFL = Tense, as in examples given above. In bothaccounts the tense affix must meet up with its V somehow. But on (123) there issubstantial syntactic movement even in the simplest sentences: the subject will movefrom Spec(VP) to Spec(INFLP), and V and INFL will combine as heads in some wayto form a complex word (the present or past tense form attached to the verbal stem).
An important reason for proposing (124) as the structure for simple sentences,pointed out by Pollock (1989) following original research by Emonds (1978), is thatthe modes of combination of V and INFL seem to be different in different languages,with INFL “lowering” onto V in, e.g., English, and V “raising” to INFL in, e.g.,French. The diagnostics for the difference include the placement of ordinary adverbs,which follow the inflected V in French, but precede it in English:
(125) (a) *John kisses often Mary;(b) Jean embrasse souvent Marie;(c) John often kisses Mary;(d) *Jean souvent embrasse Marie;
(from Pollock (1989, p. 367)). Evidently, these data follow immediately if we supposethat adverbs are generated in the same positions in both languages, namely betweenINFL and V, but the combination V + INFL is realized by lowering INFL only inEnglish. Pollock extends Emonds’s proposal by “splitting” the inflectional head INFLinto Agreement (AGR) and the Tense-bearing element I, with IP a complement ofAGRP, and V in French moving through I (if it is present) to AGR, thus accountingfor the fact that V-raising is required in French also for infinitives:
(126) parler à peine l’italiento speak hardly Italian (= to hardly speak Italian).
Note that learnability considerations play a role here: the set of phrasal configurationsis given once for all, and what must be learned is just the way that morphologicalcomplexes are formed.
Chomsky (1993) suggests that the principle requiring V-raising in French involves,not the movement of an uninflected V through I so as to receive inflection, but ratherthe movement of an inflected V (bearing Tense features) to I so as to “check” thosefeatures. All features must be checked eventually, at LF. Let a feature that requiressuch checking in the overt syntax be called strong, otherwise weak. The proposal thenis that in both English and French the LF-representation for structures initially licensedby principles giving (123) is the same, with all V raising to I, but only in French is thismovement carried out so as to be audible in the heard sentence.
We may pursue this theme more fully, but now in abstraction from actual lexicalitems. In English, as we saw in connection with examples like (25) and (26) above,there is “long-distance” agreement between V (but now as mediated through I)23 andthe “real” subject, even when the element occupying the surface subject position is
23 Or, in fuller versions, through a special head for subject agreement; see Chomsky (1993). I pass over theextra complexity here, which would not affect the general point.

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 385 — #41
GB Theory: An Introduction 385
expletive there. More fully, then, we might represent one of our examples above as(127):
(127) [There (& number) [I(& number)[seems [t(& number)[to be[[a man (& number)]walking]]];
where & = +plural or !plural. The requirement for feature sharing is simply that thevalue assigned to ‘& number’ be the same for all positions. But this requirement canbe stated without mention of the specific items of vocabulary involved, so that thecondition observed in (127) might ideally be expressed as (128):
(128) Spec(IP) agrees in number with its head.
Notice, however, that agreement with a head might in principle be realized withoutsyntactic movement; i.e. without moving the entire bundle of features associated witha lexical item. Suppose, for instance, that we could detach the feature (& number) fromthe word there, and move it to Spec (IP). We would then obtain the ungrammatical(129):
(129) *Seems there to be a man walking.
That we cannot so detach features is an empirical fact, and it may be this fact, thatfeature bundles must move as wholes, that forces syntactic movement.
6.6.2 Movement and Copying
Syntactic movement is a complex operation, which may in principle be broken downinto several steps. In the theory with deep and surface structure, as in Chomsky (1965),it consisted of copying, followed by deletion of the copied element; on trace theory,the copied element is not deleted but replaced by a coindexed trace, syntactically visi-ble although not itself pronounced. Yet another alternative is to retain in full the copiedelement, requiring only that in the two sites it occupies the pieces that are syntactically(and semantically) visible are complementary. A simple motivation for the latter view(originally pursued in a somewhat different manner in Wasow (1972)) has been sug-gested for the so-called problems of reconstruction, of which we give two canonicalexamples, both involving anaphora.
“Reconstruction” is a loose term, alluding to the variety of phenomena that seem toarise from the fact that a syntactic element that has undergone movement still behaves,as a whole or in part, as if it were still visible in the site from which it moved. Con-sider (130):
(130) Which picture of herself [did John think Mary liked t].
From clause (A) of the binding theory, the reflexive should not be acceptable, sinceits only admissible antecedent, the lower-clause subject Mary, does not c-commandit following syntactic movement. However, the sentence is acceptable. The reflexiveherself is in this respect behaving as though it had not moved from its underlying

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 386 — #42
386 Handbook of Logic and Language
position, where the antecedent did indeed c-command it; it is, in other words, “recon-structed”.
Barss (1986) formulated an account of such phenomena as the acceptable anaphorain (130). The account was in terms of complex conditions on S-Structure configu-rations, so-called “chain binding”. One may suspect, however, that the complexity ofthese conditions is unilluminating, amounting to a way of somewhat artificially encod-ing the thought that it is “as if” the reflexive had not moved. Chomsky (1993) suggeststhat the “as if” formula be taken literally, in the sense that the output of movement is(131):
(131) Which picture of herself [did John think Mary liked [which picture of herself]].
We now consider two aspects of the structure: (i) its pronunciation, and (ii) its repre-sentation at LF.
(131) is pronounced such that the lower copy of the moved element is deleted. AtLF, however, there are two options, one the structure (130), where the reflexive has noc-commanding potential antecedent, and the other (132), where it does:
(132) [Which] [did John think Mary liked [t picture of herself]].
The trace in (132) is the trace of the head which only; the remainder of the NP is inplace. But now the reflexive is c-commanded by Mary, as desired.
Besides allowing otherwise impermissible cases of reflexive binding, the interpre-tation of reconstruction effects in terms of copying followed by selective deletion cancapture some cases where anaphora are not possible. Recall that the condition thatR-expressions be A-free was said to be responsible for the fact that the pronoun he,c-commanding the wh-trace t in (115), repeated here, could not be taken as bound tothe wh-expression who:
(115) Who [does he think [t is a nice fellow]].
The condition is quite general, correctly disallowing anaphora in a number of cases.But compare (133) with (134), and these with (135) and (136), respectively:
(133) Which man [do you think [he likes t]];(134) Which picture of which man [do you think [he likes t]];(135) Which man [do you think [his mother likes]];(136) Which picture of which man [do you think [his mother likes t]].
The third-person pronoun in (133) cannot be bound to which man, as expected. Butthe same is true in (134), where the pronoun c-commands, not the trace of which man,but rather the trace of the containing phrase which picture of which man; for that isthe phrase that underwent syntactic movement. That it is c-command of the site ofwh-movement by the pronoun that is playing a crucial role is seen by comparing theseexamples to (135)–(136), in each of which the relation of the pronoun to which man,although somewhat strained, is not out of the question.
Suppose now that the input structure for these binding-theoretic considerations isnot the reduced structure (134), but rather the full “copied” structure (137):

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 387 — #43
GB Theory: An Introduction 387
(137) [Which picture of which man]i [do you think [he likes [which picture of whichman]i]].
In that case, the pronoun does c-command (one copy of) which man: and this, it maybe proposed, is sufficient to block anaphora.24
It was suggested above that wh-expressions move in English, and comparableexpressions in other languages, so as to realize agreement between the site of thecomplementizer and a feature of the clause it contains, call it +WH. But it is a strik-ing fact that the movement of wh-expressions (understood now in a general sense, notconfined to English) is in many languages optional, and in others impossible. Japaneseis a case of the latter, where the expressions corresponding to English question wordsdo not undergo wh-movement at all. It has been proposed that Japanese undergoeswh-movement at an abstract level, so that at LF the structures of, say, Japaneseand English questions are effectively identical. But an alternative, first explored inWatanabe (1991), is that feature agreement comes about at LF without syntactic move-ment, either realized in the heard string, or abstract. At the abstract level a featuremight as it were break apart from the bundle within which it occurs and attach itselfto a higher position. So we might in principle have an abstract structure as in (138):
(138) [[+WH (& WH)] [. . . [& WH, ' person, $ gender, . . . ] . . . ];
where the feature (& WH) is detached from its bundle and inserted for agreementin the complementizer position. The apparent difference between English and otherlanguages showing wh-movement on the one hand and languages like Japanese on theother would now consist in the fact that in languages showing wh-movement the +WHfeature hosts full syntactic items (it is a “strong” feature, like French INFL), whereasJapanese and other languages lacking wh-movement the feature cannot do this (it is a“weak” feature, like English INFL). Thus the theory of strong and weak features canbe exploited for wh-movement as well as the V-to-I movement of the last subsection.
Pursuing other syntactic differences among languages along the lines just sketchedfor the comparative syntax of wh-movement, one might propose a syntactic theoryconsisting of the following components:
(I$) A universal system of features and their projection;(II$) For a given language, a description of those that force syntactic movement for feature
checking;(III$) Rules governing the local conditions under which agreement takes place or features are
checked;(IV$) Principles that regulate the amount of variation that human languages may permit under
(II$) and (III$).
Comparing this proposal with the research program sketched in (I)–(IV) ofSection 6.2 above, we see important difference of detail, while the outline of require-ments for obtaining an empirically adequate theory of given languages that is at the
24 This suggestion is different from the solution to (134) and like proposed in Chomsky (1993, pp. 48–49),and would require further elaboration of the structure of LF than can be provided here.

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 388 — #44
388 Handbook of Logic and Language
same time a theory of possible linguistic diversity remains the same. Ideally, thesystem of features will be small, and the conditions on feature checking reduced tohighly local configurations, perhaps to be captured by a feature logic peculiar to thedesign of human language. Thus checking in local configurations would replace theopen-ended set of filters of the LGB theory.
6.7 Minimalism and Derivational and Non-DerivationalSyntax
In Section 6.2 above we presented some of the reasons for going beyond phrase struc-ture description in an explicit syntax of English (similar arguments can be given forother languages). The type of phrase-structure descriptions considered, however, werethemselves very restricted, and as we noted in passing it is possible to elaborate thelevel of phrase structure, thereby performing directly at least some of the work doneby transformational rules.
Abstracting from the details of particular formulations, we may think of a grammaras having a generative component, consisting of the basis and inductive clauses thatbuild phrase structure, and a transformational component, involving movement anddeletion, of the types illustrated above. In the LGB theory the generative componentconsists exactly of the mechanisms yielding D-Structure configurations; the remainderof the grammar is derivational. The question arises, however, whether S-Structuresmight not be generated directly.
6.7.1 Generation of S-Structures
To appreciate the force of our question in the present context of inquiry, consider againthe pair (16)–(17), reproduced here:
(16) John is easy to please;(17) John is eager to please.
In Section 6.2 above we remarked that grammars of the type of Chomsky (1965)were intrinsically derivational, so that the distinction between (16) and (17) could notin those grammars be captured at a single, basic level of phrase structure. Now, theS-Structures of (16) and (17) in the LGB theory were (62) and (64) reproduced here:
(62) [Johni is [easy [Oi [PRO to please ti]]];(64) [Johni is [eager [PROi to please]]].
These were derived from their respective D-Structures; but since they contain (throughthe traces, empty operators and coindexing shown) the information that is wanted todistinguish (16) from (17), they are not inadequate, as surface structures lacking thesedevices were, to express the distinction between the sentences.
Consider then the possibility of generating (62) and (63) by inductive clauses.Evidently, the relevant structures can be built up if the elements that combine are

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 389 — #45
GB Theory: An Introduction 389
not merely categories but categories together with their labels; thus we might write forthe complement of easy:
If C is a complementizer with the feature + operator, andS (or IP) is a sentence, then C!S is a C$.
Especially if the outputs of the inductive clauses are subject to filters, there is noobvious bar to generating S-Structures directly in this way.
In GB, of course, there is no question of doing away with derivations altogether solong as the level LF is derived from S-Structure (and not identical to it); at the sametime, syntacticians have in general been highly conservative about the admissibility ofLF. Under Minimalism, as we saw above, a key feature of the use of LF is the capturingof reconstruction effects, a somewhat different territory from the scope-assignmentalgorithms that produced LF in the sense of Section 6.4 above; and it remains possiblethat these effects should be captured by conditions on the syntactic structures at asingle linguistic level. For these reasons, the demonstration of the derivationality ofsyntax remains controversial.
Somewhat more abstractly, the derivationality of syntax involves above all thequestion of intermediate representations and principles that apply to them; that is, torepresentations that exist en route to the final configuration and are needed for the sat-isfaction of certain principles, but are destroyed in the final output. To give the readera sample of the problems now under discussion, we consider in some detail one typeof argument for intermediate representations under Minimalism, with reference to atypical example from German.
In German yes-no questions, the V, inflected for tense, comes in first position:
(139) Kennst du das Land?Know you the land?Do you know the land?
There is strong evidence that (139) and the like involve two steps of movement, oneof the V to the position I of inflection, and the other of V + I to the complementizerposition C. V, I, and C are the heads of their respective projections, and the operation isan instance of head-to-head movement in the sense of Baker (1988) and Travis (1984).The movement is a case of adjunction, of the moved head to the head at the landingsite, so that we have, schematically:
(140) [[CX] . . . [[IY] . . . [VZ]]];
and then, successively:
(141) [[CX] . . . [[IY + Z] . . . [Vt]]];(142) [[CX[IY + Z]] . . . [[It$] . . . [Vt]]];
with t$ the trace of Y + Z, and t the trace of Z.What licenses the movement described? In earlier discussion we assumed that
movement was licensed only by c-command, but it is evident that Z does not

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 390 — #46
390 Handbook of Logic and Language
c-command its own trace, since it has adjoined to Y. But Y is a lexical head I0,whose immediate predecessor is an I1; therefore, I0 is not maximal. It follows that Zm-commands its trace, and hence that if we weaken the c-command requirement tom-command, then the movement of Z adjoining to Y is licit; similarly for the move-ment of [IY + Z] to X. Finally, in the ultimate structure (142), Z continues tom-command its trace, since the least maximal projection containing it lies outsidethe complementizer C.
Suppose now that in addition to observing m-command, head-to-head movementis required to obey a shortest move condition; i.e. each movement must be to thenearest c-commanding head, and none can be skipped.25 The shortest move conditionis satisfied in the operation that produces (141) from (140), and (142) from (141). If,however, the structure (142) were generated directly, without movement, it would beviolated: for Z has “skipped over” the intermediate position I to move up to within C.Hence, on the assumptions stated, the grammar is derivational.
The above considerations were highly theory-internal, so that derivationality wasa consequence of a number of theoretical propositions taken together. Alternativesthat suggest themselves would include abstract conceptions of linking nodes one toanother, perhaps in the manner of Head-Driven Phrase Structure Grammar.26
6.7.2 Minimalist Grammar: Induction Over Phrase Markers
Minimalism, or the Minimalist Program of Chomsky (1993) and (1995), incorporatesthe elements of feature-checking and the copy theory of movement described inSection 6.6, but remains a derivational grammar. Its specific linguistic features aredescribed in Marantz (1995), and we concentrate here on the very general, formaldescription.
Recall that in a phrase structure grammar there were basis and inductive clauseswhere the former stipulated outright that certain items belonged to certain categories(e.g., book is a Noun), and the latter allowed the construction of constituents depend-ing upon the categorial membership and linear order. Among the elaborations of thisbasic conception are (a) admitting other information than mere categorial member-ship into both basis and inductive clauses, and (b) allowing the formation of complexconstituents only in certain linguistic environments, as in context-sensitive grammars.However, one may also suggest an inductive procedure where both basis and induc-tive clauses have for their arguments whole phrase markers rather than constituentsand categories; these are generalized transformations, in the sense of Chomsky (1955,1957). On this conception, an elementary structure, say [V$ [Vread] [NPthe book]] willbe built up by pairing the phrase markers
25 This thesis is explored especially in Rizzi (1990).26 The linking established by the derivational theory of syntactic movement is more restricted than a theory
of arbitrary links of features, however: as remarked in the last section, on a derivational theory wholebundles of features are constrained to move at once.

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 391 — #47
GB Theory: An Introduction 391
NP
the
V
read book
Similarly for more complex operations; see Chomsky (1995, Chapter 4) for con-siderable detail.
The inductive procedure ultimately yields an LF-representation for the structurecomputed. But D-Structure will now have disappeared, since the whole is not presentuntil LF; and the unique significance of S-Structure disappears likewise, since thecomputation runs on unimpeded. Sentences and other linguistic objects are, however,pronounced: so at some point in the computation material is delivered to the artic-ulatory system. Chomsky dubs this point Spellout. Spellout will continue to mark atransition in the computation (for instance, lexical material may be introduced at anypoint prior to Spellout, but at no point following); but there will be no special condi-tions attaching to representations there that are not derivable from the classification offeatures, attracting movement if they are strong, and repelling it if they are weak.
Is the resulting syntax derivational or not? There will be at least two levels ofrepresentation, but one can experiment with reductions even of these; and anywaythere remains the question of intermediate representations, to which, for example, theargument from head-to-head movement of the last subsection applies, albeit highlytheory-internally.
6.7.3 Modes of Formalization
We conclude this chapter with a few remarks on the general project of formalizingGB or its descendants. The formalization of a linguistic theory requires an inven-tory of its primitives, among which we are given hierarchy, linear order, and labeling.Apart from the uncertainty about the inventory of possible labels, it was remarked inSection 6.3 above that phrase markers could, and arguably should, be enriched withbinary relations not definable in terms of hierarchy, linear order, and labeling: theseincluded at least the antecedent-anaphor relation, and the relation of predication. Thereare in fact a number of other anaphoric or quasi-anaphoric relations that have come tolight in recent years, and it is unclear at this stage of theoretical development how farthey may be assimilated and to what extent each is sui generis.27 Setting this issue toone side, we may still ask what form a formalization should take.
The question of formalization is problematic in part because the domain of syntac-tic theory is itself less than clear. Some properties especially of coordinate structuresand ellipsis may tap features of cognition that fall outside the central parts of grammat-ical competence. For example, it is no trivial problem to describe simple conjunction,
27 There is at present no single presentation of these relations, which include, for example, association ofwords such as only with a focused constituent, as in (i):
(i) We only said that John was late
in the meaning, “John is the only person x such that we said x was late”. See Rooth (1985) for aninfluential discussion.

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 392 — #48
392 Handbook of Logic and Language
and, for the natural hypothesis that only like elements may be conjoined, exemplifiedin (143)–(144), is conspicuously flouted in (145):
(143) I looked for [John and Mary];(144) I sought my glasses [in and under] the bed;(145) John is [honest and a good friend of mine].
The conjuncts in (145) are an adjective and an NP (a predicate nominative), respec-tively. Evidently, there is no way to assign a structure to the conjunction except bysomehow conjoining unlike categories. But it is not evident that the relevant notion ofa possible conjunction, in this case of predicates, is syntactic in the narrow sense.28
Wherever the line is drawn between grammatical and extra-grammatical processes,GB or Minimalist syntax may be formalized by a direct encoding of the derivationalprocess; that is, by rendering all information and definitions in the first-order languageof set theory, enriched with non-logical concepts. This course was pursued for a cru-cial part of GB in Stabler (1992) as part of the further project of providing a directcomputational implementation of the theory, an important feature when one consid-ers that syntactic theories are intricate and require long computations. Under such aformulation, however, the predictions of a theory can be accessed only by exampleand not globally, and theory comparison is correspondingly difficult. Furthermore, thequantificational complexity of any such formalization is formidable, and remains soeven where quantification is bounded (consider, for example, spelling out the condi-tions on c-command and m-command as filters using the primitive notation). Amongthe logical approaches to more tractable formalization are Rogers (1994), who uses themonadic second-order logic of n-successor functions to formalize aspects of GB. Inthis system, however, the definable languages turn out to be context-free, and the phe-nomena that have been argued to take English or other natural languages outside theclass of the context-free languages cannot be represented.29 Kracht (1995) considersinstead a dynamic modal logic over trees (phrase markers).
How much does computational tractability matter to a linguistic theory? Chomskyhimself has generally been of the opinion has its importance has not been demon-strated; after all, the theory is a theory of linguistic knowledge, not of use, and theproblems of linguistic description tend to remain where they were no matter what issaid about decidability, or real-time computability in the limit. Indeed, Minimalismincorporates a notion of “economy of derivation”, not considered here, that requirescomparison of derivations as part of the determination of the grammatical status of lin-guistic expressions (including comparison with derivations that fail on other grounds:see Marantz (1995) for examples), and this notion adds a prima facie complexity tothe computability problem. However, with a variety of avenues now being explored
28 See especially Munn (1993) for a discussion of the issues within a GB framework. Processes of ellipsisand deletion, which we considered only in the special case of VP-deletion in English in Section 6.4 above,are in fact widespread and complex. See Fiengo and May (1995) and Lappin (1995) for recent discussionof some of the options.
29 For a survey of such phenomena see Savitch, Bach, Marsh and Safran-Naveh (1987).

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 393 — #49
GB Theory: An Introduction 393
both in computational properties of grammars and empirically motivated theories oflinguistic knowledge, we cannot with security predict where convergence may occur.
References
Aoun, J., Sportiche, D., 1981. On the formal theory of government. Ling. Rev. 2, 211–236.Arnauld, A., 1662. La Logique, ou L’Art de Penser.Baker, M., 1988. Incorporation. University of Chicago Press, Chicago.Barker, C., Pullum, G., 1990. A theory of command relations. Ling. Philos. 13, 1–34.Barss, A., 1986. Chains and Anaphoric Dependence: On Reconstruction and Its Implications.
Unpublished doctoral dissertation, MIT, Cambridge, MA.Bresnan, J., 1972. Theory of Complementation in English Syntax. Unpublished doctoral disser-
tation, MIT Press, Cambridge, MA.Chomsky, N., 1955. The Logical Structure of Linguistic Theory. Mimeographed, Harvard Uni-
versity. Reprinted with additions: Plenum, New York, NY, 1975.Chomsky, N., 1957. Syntactic Structures. Mouton, The Hague.Chomsky, N., 1965. Aspects of the Theory of Syntax. MIT Press, Cambridge, MA.Chomsky, N., 1973. Conditions on transformations, in: Anderson, S., Kiparsky, P. (Eds.), A
Festschrift for Morris Halle. Holt, Rinehart & Winston, New York, pp. 232–286. Reprinted:N. Chomsky, Essays on Form and Interpretation, North-Holland, Amsterdam, 25–59.
Chomsky, N., 1976. Conditions on rules of grammar. Ling. Anal. 2, 4. Reprinted: N. Chomsky,Essays on Form and Interpretation, North-Holland, Amsterdam, 163–210.
Chomsky, N., 1977. On WH-movement, in: Culicover, P., Wasow, T., Akmajian, A. (Eds.),Formal Syntax. Academic Press, New York, pp. 71–132.
Chomsky, N., 1981. Lectures on Government and Binding. Foris, Dordrecht.Chomsky, N., 1986. Knowledge of Language. Praeger, New York.Chomsky, N., 1993. A minimalist program for linguistic theory, in: Hale, K., Keyser, S. (Eds.),
The View from Building 20: Essays in Linguistics in Honor of Sylvain Bromberger. MITPress, Cambridge, MA, pp. 1–52. Reprinted in Chomsky (1995).
Chomsky, N., 1995. The Minimalist Program. MIT Press, Cambridge, MA.Emonds, J., 1978. The verbal complex V $–V in French. Ling. Inq. 9, 151–175.Fiengo, R., May, R., 1994. Indices and Identity. MIT Press, Cambridge, MA.Fiengo, R., May, R., 1995. Anaphora and identity, in: Lappin, S. (Ed.), The Handbook of Con-
temporary Syntactic Theory. Basil Blackwell, Oxford, UK, pp. 117–144.Freidin, R., 1992. Foundations of Generative Syntax. MIT Press, Cambridge, MA.Haegeman, L., 1994. Introduction to Government and Binding Theory, second ed. Basil
Blackwell, Oxford, UK.Harris, Z., 1955. Structural Linguistics. University of Chicago Press, Chicago.Higginbotham, J., 1985. On semantics. Ling. Inq. 16, 547–593.Huang, C.-T.J., 1982. Logical form in Chinese and the Theory of Grammar. Unpublished doc-
toral dissertation, MIT, Cambridge, MA.Huang, C.-T.J., 1995. Logical form, in: Webelhuth, G. (Ed.), Government and Binding Theory
and the Minimalist Program. Basil Blackwell, Oxford, UK, pp. 125–175.Jackendoff, R., 1972. Semantic Interpretation in Generative Grammar. MIT Press, Cambridge,
MA.Kracht, M., 1993. Mathematical aspects of Command Relations, in: Proceedings of the EACL
1993, pp. 240–249.

“10-ch06-0345-0394-9780444537263” — 2010/11/29 — 21:08 — page 394 — #50
394 Handbook of Logic and Language
Kracht, M., 1995. Is there a genuine modal perspective on feature structures? Ling. Philos. 18,401–458.
Lappin, S., 1995. The interpretation of ellipsis, in: Lappin, S. (Ed.), The Handbook of Contem-porary Syntactic Theory. Basil Blackwell, Oxford, UK, pp. 145–176.
Lasnik, H., Saito, M., 1991. Move &. MIT Press, Cambridge, MA.Lasnik, H., 1993. Lectures on Minimalist Syntax. University of Connecticut Working Papers in
Linguistics, University of Connecticut, Storrs, CT.Marantz, A., 1995. The minimalist program, in: Webelhuth, G. (Ed.), Government and Binding
Theory and the Minimalist Program. Basil Blackwell, Oxford, UK, pp. 349–382.McCawley, J., 1982. Parentheticals and discontinuous constituent structure. Ling. Inq. 13,
91–106.Munn, A., 1993. Topics in the Syntax and Semantics of Coordinate Structures. Unpublished
doctoral dissertation, University of Maryland, College Park, MD.Nishigauchi, T., 1990. Quantification in the Theory of Grammar. Kluwer, Dordrecht.Peters, Jr., P.S., Ritchie, R., 1971. On restricting the base component of a transformational gram-
mar. Inform. Control 18, 483–501.Pollock, J.-Y., 1989. Verb movement, universal grammar, and the structure of IP. Ling. Inq. 20,
365–424.Reinhart, T., 1976. The Syntactic Domain of Anaphora. Unpublished doctoral dissertation, MIT
Press, Cambridge, MA.Reinhart, T., 1983. Anaphora and Semantic Interpretation. Croom Helm, London.Rizzi, L., 1990. Relativized Minimality. MIT Press, Cambridge, MA.Rogers, J., 1994. Studies in the Logic of Trees, with Applications to Grammar Formalisms.
Unpublished doctoral dissertation, University of Delaware.Rooth, M., 1985. Association with Focus. Unpublished doctoral dissertation, University of
Massachusetts, Amherst.Ross, J.R., 1967. Constraints on Variables in Syntax. Unpublished doctoral dissertation, MIT
Press, Cambridge, MA.Rothstein, S., 1983. The Syntactic Forms of Predication. Unpublished doctoral dissertation,
MIT Press, Cambridge, MA.Safir, K., 1985. Syntactic Chains. Cambridge University Press, Cambridge, MA.Sag, I., 1976. Deletion and Logical Form. Unpublished doctoral dissertation, MIT Press,
Cambridge, MA.Savitch, W., Bach, E., Marsh, W., Safran-Naveh, G. (Eds.), 1987. The Formal Complexity of
Natural Language. Kluwer, Dordrecht.Speas, M., 1992. Phrase Structure in Natural Language. Kluwer, Dordrecht.Stabler, E., 1992. The Logical Approach to Syntax. MIT Press, Cambridge, MA.Travis, L., 1984. Parameters and Effects of Word Order Variation. Unpublished doctoral disser-
tation, MIT Press, Cambridge, MA.Wasow, T., 1972. Anaphoric Relations in English. Unpublished doctoral dissertation, MIT
Press, Cambridge, MA.Watanabe, A., 1991. S-Structure movement of Wh-in-situ. MIT Press, Cambridge, MA,
manuscript.Williams, E., 1977. Discourse and logical form. Ling. Inq. 8, 101–139.Williams, E., 1980. Predication. Ling. Inq. 11, 203–238.

“11-ch07-0395-0414-9780444537263” — 2010/11/30 — 3:53 — page 395 — #1
7 After Government and BindingTheory(Update of Chapter 6)Edward P. StablerUCLA, Department of Linguistics, 3125 Campbell Hall, Los Angeles,CA 90095-1543, USA, E-mail: [email protected]
The tradition in syntax called Government and Binding (GB) theory has been trans-formed by Chomsky (1995b) and following work, with a number of rather different,sustained efforts to keep structures and mechanisms to a minimum, avoiding thenotion of ‘government’, for example, and preferring mechanisms that can be moti-vated by phonological or semantic requirements. The simpler structure of these recent‘Minimalist’ proposals has facilitated algebraic and logical studies, situating these pro-posals with respect to other traditions. Some of these developments are very brieflyreviewed here.
7.1 Theoretical Developments
As discussed in Higginbotham (1997, §3.1), GB theory provides constituent structurewith the mechanisms of X-bar theory: projecting each head of category X to an inter-mediate phrase X’ that may contain a complement phrase YP, so that X’= [X,YP],and then projecting X further to a maximal projection XP that may contain a specifierphrase ZP, so that XP = [ZP,X’]. Following Muysken (1982) and others, Chomsky(1995a, 2007) observes that this theory simply encodes the fact that certain propertiesof phrases X’ and XP are determined by the category of the head X. So rather thanpropagating a category label to each projection, it suffices to let the head itself be thelabel. In a complex containing two elements X, Y , the label can be indicated by puttingit first in an ordered pair !X, Y", commonly written in the Minimalist literature with theset-theoretic notation {X, {X, Y}}. In such a complex, we say that the element or cat-egory X ‘projects’, and that Y is ‘maximal’ in the sense that it does not project here.1
1 Obviously, if properties of X, Y determine which is the label of the complex they form, then while thenotation {X, {X, Y}} is redundant (Chomsky, 1995b; Collins, 2002, p. 243), the notation {X, Y} is inex-plicit. So it is no surprise that Chomsky (1995b, p. 246) also considers a third option, “It is natural, then,to take the label of [the complex] K [formed from ! and "] to be not ! itself, but rather H(K), a decisionthat leads to technical simplification. Assuming so, we take K = {H(K),{!, "}} where H(K) is the head of!. . . ” This introduction uses the most common, explicitly labeled set theoretic pair {X, {X, Y}}, withoutexploring the many variants of these views in the literature.
Handbook of Logic and Language. DOI: 10.1016/B978-0-444-53726-3.00007-4c# 2011 Elsevier B.V. All rights reserved.

“11-ch07-0395-0414-9780444537263” — 2010/11/29 — 21:15 — page 396 — #2
396 Handbook of Logic and Language
(The order of elements in the pair is not generally the same as the order in which theelements are pronounced, as discussed in §7.1.2 below.)
Chomsky (2007) notes that in GB theory and its immediate antecedents, a structureis built and then successively modified in “five separate cycles: X-bar theory project-ing D-structure, overt operations yielding S-structure, covert operations yielding LF,and compositional mappings to [sensory-motor] and [conceptual] interfaces.” But inrecent proposals, structure is built in a single sequence of operations, with each stepsimply extending the complexes built by earlier steps. In some proposals, certain stepsform phrases which are phases, with complements that become available for pronun-ciation and interpretation and hence unavailable for further structure-manipulation inthe syntax (Chomsky, 2004; Uriagereka, 1999). The basic structure building opera-tion, Merge, is usually described with two cases.2 External merge (EM) simply takestwo elements X, Y and pairs them to produce {X, {X, Y}}. When Y is already part ofX, another similar operation is possible, one which merges a copy of Y individuatedby reference to its position in X; this operation is a movement of Y , now more oftencalled internal merge (IM). That is, an IM step is usually regarded as producing a mul-tidominance structure. Using coindexing to indicate this multidominance, if we writeX[Yi] to indicate that X properly contains an occurrence of Yi, then IM applies toX[Yi] and Yi to produce the pair {X[Yi], {X[Yi], Yi}}.3 With this perspective on move-ment, Chomsky suggests that human languages are designed to balance two pressures,namely, to keep arguments adjacent to predicates, and to explicitly mark discourseand scopal properties. “Language seeks to satisfy the duality in the optimal way, EMserving one function and IM the other,” Chomsky (2008, pp. 140–141) says, “The cor-relation is reasonably close, and perhaps would be found to be perfect if we understoodenough.”
There are many different proposals about the conditions under which a sequence ofMerge steps yields a complete, well-formed derivation, determined in part by featuresof the lexical items, conditions on the result (interface conditions), and various kindsof least effort conditions. There are also various different proposals about how thederived expression is pronounced and interpreted, determined in part by the phoneticproperties of the lexical elements and the operations that affect them. Obviously, thereal content of each particular theory is in these details; we briefly and informallysurvey a few of them here and then mention some formal assessments.
7.1.1 Features
In GB theory, Wh-movement is triggered by a (possibly empty) complementizer witha +Wh feature (Higginbotham, 1997, §6). In Minimalism, the triggering head is often
2 Other cases of Merge have been proposed. ‘Pair Merge’ is a kind of adjunction operation (Chomsky,2004). ‘Parallel Merge’ has been proposed to handle coordination and certain other constructions (Citko,2005). And a ‘Sidewards Merge’ operation has also been proposed (Nunes, 2001). We leave these asidehere.
3 The multidominance structures usually proposed are like trees except that some elements can be immedi-ately dominated by more than one node; so they are unordered, directed, acyclic, labeled graphs. Kracht(2008) provides a careful analysis.

“11-ch07-0395-0414-9780444537263” — 2010/11/30 — 0:21 — page 397 — #3
After Government and Binding Theory 397
called a probe, the moving element is called a goal, and there are various proposalsabout the relations among the features that trigger syntactic effects. Chomsky (1995b,p. 229) begins with the assumption that features represent requirements which arechecked and deleted when the requirement is met. This first assumption is modi-fied almost immediately so that only a proper subset of the features, namely the‘formal’, ‘uninterpretable’ features, is deleted by checking operations in a success-ful derivation (Chomsky, 1995b; Collins, 1997, §4.5). Another idea is that certainfeatures, in particular the features of certain functional categories, may be initiallyunvalued, becoming valued by entering into appropriate structural configurations withother elements (Chomsky, 2008; Hiraiwa, 2005). And some recent work adopts theview that features are never deleted (Chomsky, 2007, p. 11). These issues remainunresolved.
There is also the substantive question: what are the syntactic features? Whatproperties of lexical items and of complexes is the derivation sensitive to? Someearly work in Minimalism stays close to GB theory, assuming categorial features N(noun), V (verb), A (adjective), P (preposition), T (tense), D (determiner), and soon, with additional features for agreement (often called ! features): Person, Num-ber, Gender,. . . , and for movement: Wh, Case, Focus,. . . . Recent work has anato-mized these features and provided additional structure. Analysis of traditional cate-gorial features in terms of more basic properties ±V, ±N, originally suggested in theGB era (Chomsky, 1970), has been developed further (Baker, 2003). And the featuresimplicated in overt movement of elements to phrase edges (formerly sometimes calledlicensors) seem to have distinctive syntactic and semantic properties (Boeckx, 2008b;Chomsky, 2004; Rizzi, 1997, 2004). Finally, developing earlier ideas about basicclausal requirements encoded in an ‘extended projection principle’ (Chomsky, 1981,1982), the special features triggering movement (‘EPP’) are now often distinguishedfrom the rest (Boeckx, 2008a; Chomsky, 2000b). The presence or absence of thesefeatures is similar to the ‘strong’ or ‘weak’ features of GB theories.
7.1.2 Linear Order
In GB theory, the linear order of pronounced elements in a syntactic structure is typi-cally assumed to vary from one language to another even at D-structure. For example,English grammar might include (perhaps as part of ‘Case Theory’) the stipulationthat heads precede their complements, and the stipulation that subjects precede verbphrases; these are fundamental parameters of language variation (Chomsky, 1982;Koopman, 1983; Travis, 1984, pp. 9–11, for example). Kayne (1994) takes a verydifferent approach. Greenberg (1963) observes that certain constituent orders are rare,across all languages. For example, while the neutral order subject-verb-object (SVO)is fairly common, OSV, VOS and OVS are very rare. And considering the ordersof (1) demonstrative, (2) numeral, (3) adjective, and (4) noun in noun phases, theorder 1234 is quite common, but some orders are unattested: 2134, 2143, 2413, 4213,3124, and 3142. Recent studies confirm these observations (Cinque, 2005; Hawkins,1983). Kayne proposes that some of these regularities may be due in part to a verysimple structural fact: universally, heads take complements on the right and specifiers

“11-ch07-0395-0414-9780444537263” — 2010/11/29 — 21:15 — page 398 — #4
398 Handbook of Logic and Language
on their left. If a verb underlyingly takes its object as complement on its right, andits subject as specifier on its left (Koopman and Sportiche, 1991), and if all move-ment is to specifier position, on the left, then while all orders can still be derived,some orders will require more steps in their derivation than others.4 Noting that linearorder is needed only at the PF interface, Chomsky (1995a, §4.8) also proposes adopt-ing some variant of Kayne’s (1994) proposal. With this kind of view, the parametersof word order variation in grammar are determined structurally, for example, by theproperties of (sometimes empty) functional elements in the lexicon that may triggermovements.
With Kayneian assumptions, a moved element Yi will be pronounced beforeX[Yi] in the pair {X[Yi], {X[Yi], Yi}}, at the ‘left edge’ because it is in a specifierposition. As for the lower occurrence of Yi in X[Yi], called the trace position inGB theory, usually it is not pronounced at all. But in certain cases, it seems thatthe trace is interpreted as if it were in its original position (Higginbotham, 1997,§6), and in certain ‘partial movement’ and ‘overt copying’ constructions, a movedelement (or parts of it) is apparently pronounced more than once (Bošković andNunes, 2007), as in the Vata (1a) from Koopman (1983), the Yoruba (1b) fromKobele (2006), the German (1c) from McDaniel (2004), and the Portuguese (1d) fromMartins (2007):
(1) (a) lieat
àwe
li-daeat-past
zuéyesterday
sakárice
‘We ATE rice yesterday’(b) Ri-ra
buyingadiechicken
tirel
JimoJimo
rabuy
adiechicken
‘the fact that Jimo bought chicken’(c) Wen
whomglaubtthinks
HansHans
wenwhome
JakobJakob
gesehenseen
hat?has
‘Who does Hans think Jakob saw?’(d) Sabes
know-2sgse/quewhether/that
elehe
vemcomes
àto-the
festa,party
sabesknow-2sg
‘You do know whether he is coming to the party’
There has been some controversy about whether VP ellipsis, sluicing and other con-structions also, at least sometimes, involve deletion of a full syntactic copy (Dalrym-ple, Shieber, and Pereira, 1991; Fiengo and May, 1994). Notice for example that, in atleast some English dialects, pronunciation of the parenthesized phrase is fairly naturalin (2a), to overtly express what has been ellided, while it is very unnatural with thenon-copies in (2b):
(2) (a) John went to the store, and Mary did too (go to the store)(b) John went to the store, and Mary did too (?go out, ?buy groceries).
Empirical and formal studies of these constructions are ongoing (Johnson, 2008;Kehler, 2002; Merchant, 2003).
4 This motivation for underlying SVO order is critiqued by Abels and Neeleman (2006) and Stabler (2010).

“11-ch07-0395-0414-9780444537263” — 2010/11/29 — 21:15 — page 399 — #5
After Government and Binding Theory 399
7.1.3 Least Effort and Locality for IM and Agree
In GB theory, it is assumed that maximal projections and heads can both move, subjectto certain locality conditions. Heads can only move to the ‘closest’ head position in acertain sense, and maximal projections cannot move across more than one ‘boundingnode’ or ‘barrier’. In early Minimalist proposals, there are various proposals of a sim-ilar nature: the ‘shortest move constraint’ (Chomsky, 1995b, §3.2) and the ‘minimallink condition’ (Chomsky, 1995b, §4.5), etc. More recent work introduces ‘phases’which like the ‘bounding nodes’ of GB theory provide absolute bounds of a certainsort (Chomsky, 2000a, 2001). These proposals and other alternatives are surveyedand compared to GB theory in many places (Boeckx, 2008c; Boeckx and Grohmann,2007; Bošković, 2007; Hornstein, Lasnik, and Uriagereka, 2007; Rizzi, 1997), but itremains unclear how movement should be bounded.
As noted in §7.1.1, IM is triggered by a certain kind of correspondence betweenthe features of a licensing head or ‘probe’ and an element that needs to be licensed,a goal. One idea is that a probe is a ‘functional’ element with an unvalued feature; itseeks a goal with a matching feature; the goal assigns a value to the probe; and IMoccurs if the probe has a certain additional property (e.g. an ‘EPP’ feature). It is con-ceivable that the first steps of identifying a matching pair and assigning a featurevalue could occur without movement, an operation called Agree (Chomsky, 2000a,2007, 2008). In GB theory, agreement was often supposed to be a reflex of localspecifier-head relations (Kayne, 1989; Sportiche, 1998), but many recent proposalsassume that agreement is a long-distance, movement-like relation (Chomsky, 2000b),as in the following Hindi example from Boeckx (2004) in which the matrix verb chaahagrees not with its subject but with the embedded object:
(3) Vivek-neVivek-erg
[kitaabbook.f
parh-nii]read-inf.f
chaah-iiwant-pfv.v
‘Vivek wants to read the book’
In such approaches, Agree is often assumed to have different locality conditions fromIM, attributed to the fact that it does not move any material with phonetic properties,but simply assigns values to features.
7.1.4 Head MovementIn GB theory, phrasal movement is distinguished from head movement. The twooperations seem not only to displace different kinds of elements, but they seem torespect different locality requirements (Koopman, 1983; Travis, 1984), and, unlikephrasal movement, head movement seems to have no semantic consequences. Thisperspective has been challenged on a number of fronts. Brody (2000) proposes that atleast some head movement is a reflex of syntactic structure. Chomsky suggests thatthis operation might operate at the phonetic interface, with stricter locality conditionsand no semantic effects for that reason (Boeckx and Stjepanovic, 2001; Chomsky,1995b, 2000b). But recent work suggests that head movement actually does havesemantic effects (Matushansky, 2006; Roberts, 2006). Furthermore, comparative anddiachronic studies suggest that head movement and phrasal movement are closely

“11-ch07-0395-0414-9780444537263” — 2010/11/29 — 21:15 — page 400 — #6
400 Handbook of Logic and Language
related (den Besten and Edmondson, 1983; Kroch and Santorini, 1991). Koopmanand Szabolcsi (2000) propose that many apparent head movements are really instancesof ‘remnant movement’. A remnant movement is movement of a phrase from whichsomething has already been extracted. When a phrase moves after all of its specifiersand complements (if any) have been extracted, this phrasal movement will look likehead movement, if it is appropriately bounded. In GB analyses, remnant movementwas usually blocked by some version of the Proper Binding Constraint (PBC), whichrequires that a moved phrase always c-commands its trace (Fiengo, 1977; Lasnik andSaito, 1994).5 But the PBC blocks a number of seemingly well-supported, early analy-ses in English, German, Nweh and many other languages (den Besten and Webelhuth,1990; Nkemnji, 1995):
(4) (a) [VPCriticized by his boss t1]2 John1 has never been t2.(b) [APHow likely [t1 to win]]2 is3 John1 t3 t2?(c) [VP t1 Gelesen]2
readhathas
[dasthe
Buch]1book
[keinernoone
t2].
(d) njikemhe
aAgr
kecP1
[teneg
ti akend ]jplaintains
pf tieat
tj
These and other analyses finally toppled the PBC (Abels, 2007; Müller, 1998), allow-ing new analyses like Kayne (1998, p. 134) structure (5a), and the treatment of Hun-garian verbal complexes proposed by Koopman and Szabolcsi (2000, p. 62) in (5b):
(5) (a) John [VPreads t1]2 [no novels]1 t2.(b) Nem
notakartamwanted-1sg
kezdenibegin-inf
[szétapart
szednitake-inf
t1]2 athe
[rádiót]1] t2radio-acc
With this kind of remnant movement, the empirical arguments for head movement canbe reassessed. The proper treatment of what GB theory calls head movement relationsremains an open question.
7.2 Algebraic Analyses
Although the quick survey of recent work in the previous section might seem to sug-gest that everything is in flux in Minimalist theory, the relative simplicity of recentproposals has allowed mathematical analyses that reveal a remarkable consensus, notjust among various Minimalist proposals (Thm. 7.2.2), but also between these andother grammatical traditions (Thm. 7.2.1). From this perspective, the many changesand controversies reviewed in the previous section involve matters of detail, relativelysmall adjustments in a framework that is fairly stable and fairly simple. That is, manyof the adjustments at the center of controversies now, adjustments directed towardsproviding the most insightful perspective, are not affecting the broad mathematicaland computational properties of grammar. One exception, discussed below, concernsthe fundamental properties of movement, IM.
5 This requirement is discussed, but not named, in Higginbotham (1997, §5.2).

“11-ch07-0395-0414-9780444537263” — 2010/11/29 — 21:15 — page 401 — #7
After Government and Binding Theory 401
As just reviewed, GB derivations build a basic tree (‘D-structure’) which is thenrepeatedly altered, but Minimalist proposals are much simpler. Certain operations sim-ply apply to construct complexes from lexical items. This suggests that, at least as agood first approximation, Minimalist grammars define (partial) algebras by closing afinite set of (lexical) elements with respect to a small number of (partial) structurebuilding operations (Keenan and Stabler, 2003).6
For each categorial feature N, V, A, P, . . . , let’s suppose that we have correspon-ding selection features =N, =V, =A, =P,. . . . And in addition to the ‘licensor’ fea-tures +Wh, +Case, +Focus, . . . , we have corresponding ‘licensee’ features !Wh,!Case, !Focus,. . . . Call the set of categorial, selection, licensor, and licensee featuresF. Using standard spellings of words ! to represent phonetic and semantic properties,we pair sequences " " !# of these elements with feature sequences # " F# using abinary type constructor :: for lexical items, obtaining pairs " :: #. A lexicon Lex is afinite set of string-feature sequence pairs " :: #. In derived, non-lexical expressions,sequences " " !# and features # " F# will be paired with a different constructor : toyield " : #.
We define structure building functions mapping trees to trees, so we regard Lex asproviding a stock of 1-node labelled trees, where the labels are the structured arrays" :: # of features. As mentioned above, in some of the prominent Minimalist theories,heads precede the first elements they merge with (their ‘complements’) and follow anylater elements they merge with (their ‘specifiers’). With this preliminary assumption, itis convenient to put the linear order into the syntactic trees. Nothing in the syntax willrefer to this order, so we can regard it as coming from the phonetic interface, followingstandard Minimalist proposals. So instead of building pairs {X, {X, Y}}, we will buildlabelled ordered trees with a linear order signifying the temporal sequence (to whichthe syntactic operations will never refer), and marking the head of each complex notby linear position in a pair but by labelling internal nodes with symbols > or < that‘point’ to the head. So for example, in the following tree, node 1 is the head, withcomplement 2 and specifier 3:
A tree with one node heads itself, and in any tree with more than one node, we findthe head of the tree by following the arrows from the root. The maximal projectionof any head n is the largest subtree headed by n. At the leaves, we will have pairs ofphonetic-syntactic feature sequences " :: # or " : #. When no confusion will result,we sometimes write the 1-node tree with label $ : $ simply as $.
We can now define structure building operations em and im inspired by the Mini-malist operations EM and IM. When the head of a tree is labelled " :: f # or " : f #, so
6 Compare, for example, Chomsky (2000b, pp. 100–101).

“11-ch07-0395-0414-9780444537263” — 2010/11/29 — 21:15 — page 402 — #8
402 Handbook of Logic and Language
that its syntactic features begin with feature f , we sometimes refer to that tree as t[f ]and use t to represent the result of deleting the first feature f and possibly changingthe type to :, so that the head of t is labelled " : #. Define the function em from pairsof trees to trees as follows,
em(t1[= f ], t2[ f ]) = t1 t2 if t1 has exactly 1 node
otherwise.
<
>t2 t1
Notice that em is triggered by a selection feature =f and a corresponding category f ,deleting both.
Now we define the unary function im which applies to a tree if and only if, first, itshead has first syntactic feature +f , and second, it satisfies the following simple versionof the ‘shortest move constraint’ (SMC): the tree contains at most one head with firstsyntactic feature !f . The value of the function is the result of replacing the maximalprojection of the t[!f ] subtree with the empty subtree $, and putting the correspondingsubtree t with !f deleted into specifier position. That is, letting t{t1 $% t2} be theresult of replacing t1 by t2 in t, and letting t1> be the maximal projection of the headof t1,
if (SMC) exactly one head in t1 [+ f ]has – f as its first feature.im(t1[+ f ]) = t2> t1 {t2[! f ]> ! }
>
"
So im is triggered by a licensor feature +f and a corresponding licensee feature !f ,deleting both.
Let’s call these simple grammars G = &Lex, {em, im}' MGs after the Minimalistgrammars that inspire them. Since MG generating functions em, im are fixed, eachMG is determined by its lexicon Lex. For any such grammar, let the structures S(G) bethe closure of Lex with respect to em, im. Let the completed structures be the trees inS(G) with exactly one syntactic feature, namely, the ‘start’ category at the head. Andlet the set of sentences L(G) be the phonetic yields of completed structures. For exam-ple, consider the following grammar G with eight lexical items, numbered here forconvenience:
(1) Marie::D Pierre::D (5)
(2) praises::=D =D V knows::=C =D V (6)
(3) $::=V +wh $::=V C (7)
(4) who::D !wh and::=C =C C (8)

“11-ch07-0395-0414-9780444537263” — 2010/11/29 — 21:15 — page 403 — #9
After Government and Binding Theory 403
Applying em and im to these items, we find some of the structures in S(G):
em(2,4)=(9)
em(9,1)=(10)
em(3,10)=(11)
im(11)=(12)
<
praises:=DV who:-wh
>
<
praises: V who:-wh
Marie
<
>
<
praises who:-wh
:+wh C
Marie
>
<
>
<
praises
who
:C
Marie
!!
(To reduce clutter, when a node is labelled " : $, we simply write " , and when anode is labelled $ : $ we do not write any label at all.) If C is the designated ‘start’category, then these steps show that who Marie praises is in the set of sentences L(G).We can also derive Marie praises Pierre, and Pierre knows who Marie praises, andinfinitely many other sentences. In GB theory, the tree (12) would be something likethis, co-indexing the moved element DP0 with its trace t0:
CP
DP0 C’
D’
D
who D’
D
Marie
praises t0
V DP
DP V’
C VP
MGs can define non-context-free languages. For example, letting Gxx be the gram-mar defined by the following seven-element lexicon, with start category T, Lxx ={xx| x " {a, b}#}:
a::=A +l T -l b::=B +l T -l ba::=T +r A -r b::=T +r B -r$::=T +r +l T $::T -r -l $::T
Among the derived structures in S(Gxx), we find the tree on the left below, pronouncedabab, which in GB-like notation would be as on the right:
a
a
b< >
<
<
< > <>
> >
>
b
:T
TP4 T’
TP2 BP3
AP1 B’ T TP
TP0 A’ B
bTPA
a
TP
T’
TP0 T’
T’
T a
T AP b t3
t1 t0 t2
t0
t4
T BP
T’
TP

“11-ch07-0395-0414-9780444537263” — 2010/11/29 — 21:15 — page 404 — #10
404 Handbook of Logic and Language
GB-style notation indicates the history of the derivation by co-indexing each movedelement Xi with its traces ti, making it easy to see that there are several remnantmovements in this MG derivation: there are two extractions from the moved phraseTP4, one from the moved phrase TP2, three from BP3, and so on. It is important toobserve that although this language is sometimes called a copy language, the grammardoes not use any copying operation; no operation applies to an argument to yield astructure that contains two copies of that argument.
The MGs defined here are based on the slightly more complex grammars ofStabler (1997). They have been used to capture a range of Minimalist proposals, allow-ing careful study of their formal properties.
Theorem 7.2.1 (Vijay-Shanker, Weir and Joshi, 1987; Michaelis, 1998, 2001;Harkema, 2001).
L(CF)(L(TAG) = L(CCG)(L(MG) = L(MCTAG)= L(MCFG) = L(LCFRS)(L(CS),7
where L(CF) is the set of languages defined by context-free grammars; L(TAG) isthe languages definable by tree adjoining grammars (Joshi, 1987); L(MCTAG) is thelanguages definable by set-local multiple-component tree adjoining grammars (Joshi,1987; Weir, 1988); L(CCG) is the languages definable by combinatory categorialgrammars as defined by Vijay-Shanker, Weir, and Joshi (1987); L(MG) is the languagesdefinable by MGs; L(MCFG) is the languages definable by multiple context-free gram-mars (Seki et al., 1991); L(LCFRS) is the languages definable by linear context-freerewrite systems (Weir, 1988); and, L(CS) is the languages defined by context-sensitivegrammars.
The proofs of the equations in Theorem 1 are constructive, showing how, for example,given an arbitrary MG grammar, we can construct a multiple context-free grammar(MCFG) which defines exactly the same language. The needed constructions are quitestraightforward, suggesting a similarity in their recursive mechanisms. The translationfrom MGs to the well-studied MCFG, for example, allows n step MG derivations tocorrespond to isomorphic n-step MCFG derivations.8 In fact, some of these recipesfor translating between grammars have been automated as a kind of compilation step.The MG languages are ‘mildly context sensitive’ in the sense of Joshi (1985), and theycan be recognized in polynomial time (Harkema, 2000).
7 For linguists who believe that there is a fixed, universal set of features that trigger movement in humanlanguages, it may be of interest to note that the references cited establish an infinite subhierarchy betweenL(CF) and L(MG). Let a k-MG be an MG in which there are k different features f such that +f appears inthe lexicon. Then L(0-MG) = L(CF), and for any k ) 0, and L(k-MG)(L((k + 1)-MG).
8 Given the controversies around the use of empty categories in Chomskian grammar, it is interesting tonote that while the straightforward translation of MGs to MCFGs preserves the empty categories, Sekiet al. (1991, Lemma 2.2) show how, given any MCFG, it is possible to construct an equivalent grammarwith no empty categories (except possibly the complete, empty sentence) and no rules that delete stringarguments, but this construction can increase grammar size exponentially.

“11-ch07-0395-0414-9780444537263” — 2010/11/29 — 21:15 — page 405 — #11
After Government and Binding Theory 405
The MGs defined above use structure-building rules that are rather similar tostandard Minimalist proposals, but better insight into theoretical proposals might beobtained by enriching and adjusting the simple MG with more of the mechanismsreviewed in §7.1. Many such studies have been carried out, revealing a surprisingexpressive equivalence of many ideas.
Theorem 7.2.2 (Michaelis, 2001, 2002; Kobele, 2002; Stabler, 1997, 2001, 2003,2010).
L(MG) = L(MGH) = L(MT) = L(DMG) = L(CMG) = L(PMG),
where MGH extends MG with head movement and with covert phrasal movement (QR);MT is a version of Brody’s ‘mirror theory’; DMG modifies MGs so that selection ofheads and specifiers can be on the left or on the right; CMG extends MGs by first con-flating licensors with selectors, and licensees with categories, and also allowing certainfeatures to persist when checked; and finally PMG extends MGs by designating certaincategorial features as ‘phases’ which block extraction from their complements.
The proofs of these results are again constructive, providing recipes for conversionsbetween formalisms with slightly different mechanisms.
The convergence of formalisms revealed by Theorems 1 and 2 might be taken asconfirmation of the hypothesis that human languages are MG definable, confirmingJoshi’s (1985) hypothesis that human languages are ‘mildly context sensitive’. MGvariants not conforming to this hypothesis are easily defined (Gärtner and Michaelis,2007; Kobele, 2005; Kobele and Michaelis, 2005), but, mainly, these involve theoret-ical proposals that are not well motivated.
The idea that the convergence represented by Theorems 1 and 2 supports thehypothesis that human languages are MG definable has been seriously attacked,though, as being too weak and as being too strong. Notice that these attacks concernnot just a particular Minimalist proposal or even Minimalism in general, but a widerange of proposals in various traditions of syntax.
The idea that the convergence is too weak comes mainly from the fact that, whilethe recognition problem for MG definable languages is polynomial, the ‘universalrecognition problem’ for MGs – a problem includes grammar size along with inputsize parameters – is intractable, EXP-POLY time complete (Kaji et al., 1994, 1992;Satta, 1992). So for example, if one thinks of the language learner as exploring theclass of MGs using a universal parsing strategy (possibly involving some kind ofMG compilation to obtain a feasible recognizer), then both grammar size and inputsize matter, and this intractability result suggests that some reformulation of the prob-lem may be required.9 Perhaps we should try to see human languages as falling in amore restricted class. Let a k-MG be an MG in which there are k different features
9 Cf., Barton, Berwick, and Ristad (1987, §8) on GPSG. While GPSGs define only context-free languages,recognizable in polynomial time, the universal recognition problem for GPSG is EXP-POLY time hard.

“11-ch07-0395-0414-9780444537263” — 2010/11/29 — 21:15 — page 406 — #12
406 Handbook of Logic and Language
f such that +f appears in the lexicon (see footnote 7). Then we could consider thestronger hypothesis that human languages are in L(k-MG) for some particular k, or inL(TAG).
The idea that the convergence represented by the previous Theorems is already toostrong – i.e. in spite of the convergence of independent formalisms and traditions, itis simply false that human languages are MG definable – comes from a number offronts. Various linguists have pointed out apparent regularities in human languageswhich are not definable by MG-equivalent formalisms. These include Old Georgiancase marking (Michaelis and Kracht, 1997), German scrambling (Rambow, 1994), andChinese number names (Radzinski, 1991). More central to the Minimalist program isevidence of copying in syntax, mentioned above. Intuitively, the structure-buildingrules of MGs and similar formalisms merge and rearrange substrings, but copyingrules double their arguments. Chomsky’s IM and similar proposals are explicitly andintentionally presented as copying proposals: a multidominance structure is createdby IM in which a single element (of unbounded size) may have more than one parent,allowing it to be pronounced (or partially pronounced) in more than one position. If thepronunciation of structures built by IM can involve pronouncing a complete phrase inmultiple places, as suggested in §1.2 above, this can affect the expressive power of thegrammar significantly. Kobele (2006) defines such an extension of MGs, and showsthat the definable languages fall in the class of parallel multiple context-free (PMCFG)languages, where L(MCFG)(L(PMCFG). The MG variants of Theorem 7.2.2 canall be modified in this way to allow copying in certain instances of im, producing asimilarly equivalent but now more expressive range of grammatical options, defininglanguages in L(PMCFG) with harder but still polynomial recognition problems (Sekiet al., 1991). It appears that most Minimalist syntacticians are persuaded that a stepof this kind is empirically well supported, but the question is certainly not settled.We seem to have arguments for more restrictive grammars and for less restrictivegrammars. Much current mathematical interest is focused on this problem.
7.3 Logical and Categorial Analyses
7.3.1 MSO and Tree Automata
As noted by Higginbotham (1997, §7.3), logical studies of GB theory (Kracht, 1995;Rogers, 1994, 1999) concluded that it is a context-free grammar notation, up to co-indexing of constituents. But those formalizations blocked ‘remnant movement’ withthe PBC, as discussed in §7.1.4 above. Lacking the prohibition of remnant movement,MGs define a class of languages that strictly includes the context-free languages. Thelogical connection between automata and logical definability established by Büchi(1960) and Elgot (1961), which set the stage for the extension to tree automataand Rogers’ study of GB theory, has inspired analyses of non-context-free languageclasses like this (Kobele, Retoré, and Salvati, 2007; Kolb et al., 2003; Michaelis,Mönnich, and Morawietz, 2000, 2001; Mönnich, 2007). In particular, Bloem andEngelfriet (2000) have shown how monadic second-order logic can be used to specify

“11-ch07-0395-0414-9780444537263” — 2010/11/29 — 21:15 — page 407 — #13
After Government and Binding Theory 407
an output tree as a certain kind of modification of an input tree, and such a transduceris ‘direction preserving’ if the directed edges of the input tree correspond to similarlydirected edges of the output tree. Using this notion,
Theorem 7.3.1 (Mönnich 2007). For every MG, there is a strongly equivalent direc-tion preserving tree transducer definable in monadic second-order logic.
Although trees are complicated objects and so the formal theory of tree automataremains a specialized topic, this perspective on Chomskian proposals is remarkablysimple and illuminating.
7.3.2 Type Logical Grammar
A different kind of logical perspective on Minimalist proposals is provided by mul-timodal higher-order type logic (Moortgat, 1996, §4). That system has Turing power(Carpenter, 1999; Moot, 2002) so of course it can encode any MG derivation, but aparticularly transparent representation is suggested by Vermaat (2004), with a recipefor representing any MG analysis as a type-logical proof.10 To represent trees, weuse the binary modalities •>, •<, and for each MG grammar licensee +f , we useunary modalities !f , *f to control the association of string positions related by im, asallowed by the following structural postulates (for i " {<, >}):
*f (A •>B) % *f A •>B [P1]*f A •>(B •i C) % B •i (C •<*f A) [P2]*f A •>(B •i C) % B •i (*f A •>C). [P2]
Then the four-step MG derivation of who Marie praises shown in the previous sectioncorresponds to the following proof:
who °> (C °< (Marie °> praises)) whC!who °> (C °< (Marie °> praises))"wh C!who" wh °> (C °< (Marie °> praises)) CC °< (!who" wh °> (Marie °> praises)) C
C C/ <VC °< (Marie °> (praises °< !who"wh)) C
Marie D!who"wh D
[ wh E]
[ wh I]
[P3][P2]
[P1]
[ / < E][ \ > E][ / < E]
who whDpraises (D\<V)/<D
Marie °> (praises°< !who"wh) Vpraises°< !who"wh D\ >V
10 Although multimodal type logics have Turing power, a “landscape” of grammars that includes weakersystems is presented by Moortgat (1996). And Moot (2002, §9.3) surveys complexity results for multi-modal type logics and observes (Thm. 9.16) that with only ‘non-expanding’ structural postulates, theselogics define only context-sensitive languages.

“11-ch07-0395-0414-9780444537263” — 2010/11/29 — 21:15 — page 408 — #14
408 Handbook of Logic and Language
Notice that the lexical premises are here placed at the top of the proof tree, withthe conclusion at the root on the bottom. It is easy to recognize in this proof the firstmerging of the lexical elements, followed by the movement of the wh-phrase to initialposition where the wh modality of who can ‘unlock’ the whole phrase.
Considering this representation of Minimalist derivations, Vermaat points out thatthey are unnatural in the type logical perspective in a number of fundamental respects.First, most work in categorial approaches avoids the use of empty categories as away to license type conversions, since the logic itself determines in a non-ad-hocway which type conversions are valid (Moortgat, 1996, Prop. 2.18, for example). Sec-ond, as in the earlier GB theory, in most Minimalist proposals, all the eliminationsteps are first order. That is, the type that is eliminated is always a simple category,and never a higher order type.11 Finally, and more fundamentally, movement is heretreated by the structural postulates which, under a Curry-Howard correspondence, willhave no semantic consequences. In type logical grammar, it is much more natural totreat movement as the elimination of an empty assumption, which corresponds byCurry-Howard to %-abstraction.
From the Minimalist perspective, on the other hand, the type logical analyses seemunnatural in a number of respects too. First, the use of empty categories, as for exam-ple in the case of optionally pronounced complementizers and relative pronouns, islinguistically natural (and see footnote 8). Second, while MG derivations are quitenaturally emulated in type logical grammar, a number of the easy MG extensionslook like they will be more challenging for the type logician. In particular, while it isindeed unnatural to treat movement with structural postulates lacking semantic con-sequences, the type logical alternative of treating movement as a kind of assumptiondischarge looks problematic too, particularly because of the possibility that the movedelement may be pronounced in more than one place, as discussed in §7.1.2 above. Theaddition of copying to MGs is notationally and conceptually straightforward, and canbe done in such a way that the resulting grammars are all PMCFGs with known, poly-nomial recognition methods (Kobele, 2006). It is not clear how type logical grammarshould handle this.12 More generally, while type logical grammar naturally capturesthe basic predicate argument relations of MGs, it is less clear how it will extend toagreement, case marking, and other distinctions of human languages. Finally, while
11 This assumption of GB and Minimalist theorizing is occasionally made explicit. For example, Koopmanand Sportiche (1991, p. 215) say, “No category takes as a complement a syntactic category correspon-ding to a non-saturated predicate.” Various Minimalist proposals, like the ‘parallel merge’ (Citko, 2005)mentioned in footnote 2, can be seen as ways of allowing non-first-order steps.
12 Note again that it is a simple matter to apply Vermaat’s recipe to the example derivation for abab " Lxx
in §2 above. But, in the first place, that grammar does not have copying in the sense of an operation thatdoubles the pronounced length of its arguments. And in the second place, Vermaat does not establishthat the lexical type assignments provided by her recipe define exactly the language Lxx. Similarly Shan(2005, Figure 2.30) gives a type logical grammar for Lxx, but does not establish that his grammar does, infact, define exactly Lxx. In contrast, it is relatively easy to establish that simple MGs or MCFGs for thislanguage are correct with an induction on derivation length (Cornell, 1996, for example).

“11-ch07-0395-0414-9780444537263” — 2010/11/29 — 21:15 — page 409 — #15
After Government and Binding Theory 409
the type logical framework can emulate MG derivations, no type logical characteriza-tion of the MG definable languages is known.
Given these differences, it is no surprise that various mixtures of the two tradi-tions are being explored (Amblard, 2007; Kanazawa and Salvati, 2007; Lecomte andRetoré, 1999; Retoré and Salvati, 2007; Vermaat, 2006), not so much to faithfullyrealize earlier Chomskian proposals but rather to attain an elegant and empiricallywell-supported approach.
7.4 The Future
Many developments in the Minimalist program could not be mentioned in this shortreview. Only a few of these have been carefully studied, but very many are nowwithin easy reach. The general tendency towards simpler mechanisms in Minimal-ist syntax has allowed substantial and rigorous comparisons of proposals, both withinthe Chomskian tradition and across traditions. Particularly significant is the conver-gence of Minimalist mechanisms and proposals in the tradition of tree adjoining gram-mar: Minimalist grammars (without copying) are “mildly context sensitive” in Joshi’ssense, and are naturally formalized by grammars that are very similar to other well-understood, mildly context-sensitive formalisms. It is conceivable that, with furtherresults of this sort, Minimalism will bring the rich empirical and theoretical currentsof Chomskian syntax into a more accessible form, beginning an era of more sophisti-cated language studies that transcend traditional and disciplinary boundaries.
References
Abels, K., 2007. Towards a restrictive theory of (remnant) movement: improper movement,remnant movement, and a linear asymmetry. Ling. Var. Yearb. 2007, 7, 53–120.
Abels, K., Neeleman, A., 2006. Universal 20 without the LCA. Ms., University College,London.
Amblard, M., 2007. Calculs de Représentations Sémantique et Syntaxe Générative: Les Gram-maires Minimalistes Catégorielles. PhD thesis, Université Bordeaux 1, France.
Baker, M.C., 2003. Lexical Categories: Verbs, Nouns, and Adjectives. Cambridge UniversityPress, New York.
Barton, G.E., Berwick, R.C., Ristad, E.S., 1987. Computational Complexity and Natural Lan-guage. MIT Press, Cambridge, MA.
Bloem, R., Engelfriet, J., 2000. A comparison of tree transductions defined by monadic secondorder logic and by attribute grammars. J. Comput. Syst. Sci. 61 (1), 1–50.
Boeckx, C., 2004. Long-distance agreement in Hindi: some theoretical implications. StudiaLinguistica 58, 23–36.
Boeckx, C., 2008a. Aspects of the Syntax of Agreement. Routledge, New York.Boeckx, C., 2008b. Bare Syntax. Oxford, New York.Boeckx, C., 2008c. Understanding Minimalist Syntax: Lessons from Locality in Long-Distance
Dependencies. Blackwell, Oxford.

“11-ch07-0395-0414-9780444537263” — 2010/11/29 — 21:15 — page 410 — #16
410 Handbook of Logic and Language
Boeckx, C., Grohmann, K., 2007. Putting phases in perspective. Syntax 10 (2), 204–222.Boeckx, C., Stjepanovic, S., 2001. Head-ing toward PF. Linguist. Inq. 32, 345–355.Bošković, Ž., 2007. On the locality and motivation of move and agree: an even more minimal
theory. Linguist. Inq. 38 (4), 589–644.Bošković, Ž., Nunes, J., 2007. The copy theory of movement, in: Corver, N., Nunes, J. (Eds.),
The Copy Theory of Movement. John Benjamins, Philadelphia, PA, pp. 13–74.Brody, M., 2000. Mirror theory: syntactic representation in perfect syntax. Linguist. Inq. 31,
29–56.Büchi, J.R., 1960. Weak second-order arithmetic and finite automata. Zeitschrift für mathema-
tische Logik und Grundlagen der Mathematik 6, 66–92.Carpenter, B., 1999. The Turing-completeness of multimodal categorial grammars, in: JFAK:
Essays Dedicated to Johan van Benthem on the Occasion of his 50th Birthday. Insti-tute for Logic, Language, and Computation, University of Amsterdam, Amsterdam.http://www.illc.uva.nl/j50/.
Chomsky, N., 1970. Remarks on nominalization, in: Jacobs, R.A., Rosenbaum, P.S. (Eds.),Readings in English Transformational Grammar. Ginn, Waltham, MA, pp. 184–221.Reprinted in Chomsky’s (1972) Studies on Semantics in Generative Grammar. Mouton,The Hague.
Chomsky, N., 1981. Lectures on Government and Binding. Foris, Dordrecht.Chomsky, N., 1982. Some Concepts and Consequences of the Theory of Government and Bind-
ing. MIT Press, Cambridge, MA.Chomsky, N., 1995a. Bare phrase structure, in: Webelhuth, G. (Ed.), Government and Binding
Theory and the Minimalist Program. MIT Press, Cambridge, MA, pp. 383–439.Chomsky, N., 1995b. The Minimalist Program. MIT Press, Cambridge, MA.Chomsky, N., 2000a. Minimalist inquiries: the framework, in: Martin, R., Michaels, D.,
Uriagereka, J. (Eds.), Step by Step: Essays on Minimalism in Honor of Howard Lasnik.MIT Press, Cambridge, MA, pp. 89–155.
Chomsky, N., 2000b. New Horizons in the Study of Language and Mind. Cambridge UniversityPress, New York.
Chomsky, N., 2001. Derivation by phase, in: Kenstowicz, M. (Ed.), Ken Hale: A Life in Lan-guage. MIT Press, Cambridge, MA, pp. 1–52.
Chomsky, N., 2004. Beyond explanatory adequacy, in: Belletti, A. (Ed.), Structures andBeyond: The Cartography of Syntactic Structures, vol. 3. Oxford University Press, Oxford,pp. 104–131.
Chomsky, N., 2007. Approaching UG from below, in: Sauerland, U., Gärtner, H.-M. (Eds.),Interfaces + Recursion = Language? Chomsky’s Minimalism and the View from Syntax-Semantics. Mouton de Gruyter, New York, pp. 1–30.
Chomsky, N., 2008. On phases, in: Freidin, R., Otero, C.P., Zubizarreta, M.L. (Eds.), Founda-tional Issues in Linguistic Theory: Essays in Honor of Jean-Roger Vergnaud. MIT Press,Cambridge, MA, pp. 133–166.
Cinque, G., 2005. Deriving Greenberg’s Universal 20 and its exceptions. Linguist. Inq. 36 (3),315–332.
Citko, B., 2005. On the nature of merge: external merge, internal merge, and parallel merge.Linguist. Inq. 36, 475–496.
Collins, C., 1997. Local Economy. MIT Press, Cambridge, MA.Collins, C., 2002. Eliminating labels, in: Epstein, S.D., Seeley, D. (Eds.), Derivation and Expla-
nation. Blackwell, Oxford, pp. 42–64.Cornell, T.L., 1996. A Minimalist Grammar for the Copy Language. Technical Report, Univer-
sity of Tübingen, Germany, SFB 340 Technical Report \#79.

“11-ch07-0395-0414-9780444537263” — 2010/11/29 — 21:15 — page 411 — #17
After Government and Binding Theory 411
Dalrymple, M., Shieber, S., Pereira, F., 1991. Ellipsis and higher order unification. Ling. Philos.14, 399–452.
den Besten, H., Edmondson, J.A., 1983. The verbal complex in continental West Germanic,in: Abraham, W. (Ed.), On the Formal Syntax of West Germanic. John Benjamins,Philadelphia, PA, pp. 155–216.
den Besten, H., Webelhuth, G., 1990. Stranding, in: Grewendorf, G., Sternefeld, W. (Eds.),Scrambling and Barriers. Academic Press, New York, pp. 77–92.
Elgot, C.C., 1961. Decision problems of finite automata design and related arithmetics. Trans.Am. Math. Soc. 98, 21–52.
Fiengo, R., 1977. On trace theory. Linguist. Inq. 8, 35–61.Fiengo, R., May, R., 1994. Indices and Identity. MIT Press, Cambridge, MA.Gärtner, H.-M., Michaelis, J., 2007. Some remarks on locality conditions and minimalist gram-
mars, in: Sauerland, U., Gärtner, H.-M. (Eds.), Interfaces + Recursion = Language?Chomsky’s Minimalism and the View from Syntax-Semantics. Mouton de Gruyter,New York, pp. 161–196.
Greenberg, J., 1963. Some universals of grammar with particular reference to the order ofmeaningful elements, in: Greenberg, J. (Ed.), Universals of Language: Report of a Con-ference Held at Dobbs Ferry, New York, April 13–15, 1961. MIT Press, Cambridge, MA,pp. 73–113.
Harkema, H., 2000. A recognizer for minimalist grammars. In the Sixth International Workshopon Parsing Technologies, IWPT’00.
Harkema, H., 2001. A characterization of minimalist languages, in: de Groote, P., Morrill, G.,Retoré, C. (Eds.), Logical Aspects of Computational Linguistics (Lecture Notes in Artifi-cial Intelligence, No. 2099). Springer, New York, pp. 193–211.
Hawkins, J.A., 1983. Word Order Universals. Academic Press, New York.Higginbotham, J., 1997. GB theory: an introduction, in: van Benthem, J., ter Meulen, A. (Eds.),
Handbook of Logic and Language. Elsevier, New York, pp. 311–360.Hiraiwa, K., 2005. Dimensions of Symmetry in Syntax: Agreement and Clausal Architecture.
PhD thesis, Massachusetts Institute of Technology, Cambridge, MA.Hornstein, N., Lasnik, H., Uriagereka, J., 2007. The dynamics of islands: speculations on the
locality of movement. Ling. Anal. 33, 149–175.Johnson, K., 2008. Topics in Ellipsis. Cambridge University Press, New York.Joshi, A., 1985. How much context-sensitivity is necessary for characterizing structural descrip-
tions, in: Dowty, D., Karttunen, L., Zwicky, A. (Eds.), Natural Language Processing:Theoretical, Computational and Psychological Perspectives. Cambridge University Press,New York, pp. 206–250.
Joshi, A., 1987. An introduction to tree adjoining grammars, in: Manaster-Ramer, A. (Ed.),Mathematics of Language. John Benjamins, Amsterdam, pp. 87–114.
Kaji, Y., Nakanishi, R., Seki, H., Kasami, T., 1992. The universal recognition problems formultiple context-free grammars and for linear context-free rewriting systems. IEICE Trans.Inform. Syst. E75-D (1), 78–88.
Kaji, Y., Nakanishi, R., Seki, H., Kasami, T., 1994. The computational complexity of the uni-versal recognition problem for parallel multiple context-free grammars. Comput. Intell. 10,440–452.
Kanazawa, M., Salvati, S., 2007. Generating control languages with abstract categorial gram-mars, in: Kallmeyer, L., Monachesi, P., Penn, G., Satta, G. (Eds.), Proceedings of the 12thConference on Formal Grammar (FG’07). CLSI Publications, Stanford, CA.
Kayne, R.S., 1989. Null subjects and clitic climbing, in: Jaeggli, O., Safir, K. (Eds.), The NullSubject Parameter. Kluwer, Dordrecht, pp. 239–261.

“11-ch07-0395-0414-9780444537263” — 2010/11/29 — 21:15 — page 412 — #18
412 Handbook of Logic and Language
Kayne, R.S., 1994. The Antisymmetry of Syntax. MIT Press, Cambridge, MA.Kayne, R.S., 1998. Overt vs. Covert Movement. Sytax 1, 128–191.Keenan, E.L., Stabler, E.P., 2003. Bare Grammar. CSLI Publications, Stanford, CA.Kehler, A., 2002. Coherence, Reference, and the Theory of Grammar. CSLI Publications,
Stanford, CA.Kobele, G.M., 2002. Formalizing mirror theory. Grammars 5, 177–221.Kobele, G.M., 2005. Features moving madly: a note on the complexity of an extension to MGs.
Res. Lang. Comput. 3 (4), 391–410.Kobele, G.M., 2006. Generating Copies: An Investigation into Structural Identity in Language
and Grammar. PhD thesis, UCLA.Kobele, G.M., Michaelis, J., 2005. Two type 0 variants of minimalist grammars, in: Rogers, J.
(Ed.), Proceedings of the 10th Conference on Formal Grammar and the 9th Meeting onMathematics of Language, FGMOL05. Edinburgh, Scotland, pp. 81–91.
Kobele, G.M., Retoré, C., Salvati, S., 2007. An automata-theoretic approach to minimalism,in: Rogers, J., Kepser, S. (Eds.), Model Theoretic Syntax at 10. ESSLLI’07 WorkshopProceedings, Dublin.
Kolb, H.-P., Michaelis, J., Mönnich, U., Morawietz, F., 2003. An operational and denotationalapproach to non-context-freeness. Theor. Comput. Sci. 293 (2), 261–289.
Koopman, H., 1983. The Syntax of Verbs: From Verb Movement Rules in the Kru Languagesto Universal Grammar. Foris, Dordrecht.
Koopman, H., Sportiche, D., 1991. The position of subjects. Lingua 85, 211–258. Reprintedin Dominique Sportiche, Partitions and Atoms of Clause Structure: Subjects, Agreement,Case and Clitics. Routledge, New York.
Koopman, H., Szabolcsi, A., 2000. Verbal Complexes. MIT Press, Cambridge, MA.Kracht, M., 1995. Syntactic codes and grammar refinement. J. Logic Lang. Inf. 4, 41–60.Kracht, M., 2008. On the logic of LGB-type structures, Part I: Multidominance structures,
in: Hamm, F., Kepser, S. (Eds.), Logics for Linguistic Structures. Mouton de Gruyter,New York, pp. 105–142.
Kroch, A.S., Santorini, B., 1991. The derived constituent structure of the West Germanic verb-raising construction, in: Freidin, R. (Ed.), Principles and Parameters in Comparative Gram-mar. MIT Press, Cambridge, MA, pp. 269–338.
Lasnik, H., Saito, M., 1994. Move Alpha: Conditions on Its Application and Output. MIT Press,Cambridge, MA.
Lecomte, A., Retoré, C., 1999. Towards a minimal logic for minimalist grammars, in: Kraijff,G.-J.M., Oehrle, R.T. (Eds.), Proceedings, Formal Grammar’99, Utrecht, pp. 89–92.
Martins, A.M., 2007. Double realization of verbal copies in European Portuguese emphatic affir-mation, in: Corver, N., Nunes, J. (Eds.), The Copy Theory of Movement. John Benjamins,Philadelphia, PA, pp. 77–118.
Matushansky, O., 2006. Head movement in linguistic theory. Linguist. Inq. 37 (1), 157–181.McDaniel, D., 2004. Conditions on Wh-Chains. PhD thesis, The City University of New York.Merchant, J., 2003. The Syntax of Silence. Oxford, New York.Michaelis, J., 1998. Derivational minimalism is mildly context-sensitive, in: Moortgat, M.
(Ed.), Proceedings, Logical Aspects of Computational Linguistics, LACL’98. Springer,New York, pp. 179–198.
Michaelis, J., 2001. Transforming linear context free rewriting systems into minimalist gram-mars, in: de Groote, P., Morrill, G., Retoré, C. (Eds.), Logical Aspects of ComputationalLinguistics (Lecture Notes in Artificial Intelligence, No. 2099). Springer, New York,pp. 228–244.

“11-ch07-0395-0414-9780444537263” — 2010/11/29 — 21:15 — page 413 — #19
After Government and Binding Theory 413
Michaelis, J., 2002. Notes on the complexity of complex heads in a minimalist grammar, in:Proceedings of the 6th International Workshop on Tree Adjoining Grammars and RelatedFrameworks, TAG+6, pp. 57–65.
Michaelis, J., Kracht, M., 1997. Semilinearity as a syntactic invariant, in: Retoré, C. (Ed.),Logical Aspects of Computational Linguistics (Lecture Notes in Computer Science 1328).Springer-Verlag, New York, pp. 37–40.
Michaelis, J., Mönnich, U., Morawietz, F., 2000. Algebraic description of derivational min-imalism, in: International Conference on Algebraic Methods in Language Processing,AMiLP’2000/TWLT16. University of Iowa, Iowa City, IA, pp. 125–141.
Michaelis, J., Mönnich, U., Morawietz, F., 2001. On minimalist attribute grammars and macrotree transducers, in: Rohrer, C., Rossdeutscher, A., Kamp, H. (Eds.), Linguistic Form andits Computation. CSLI Publications, Stanford, CA, pp. 287–326.
Mönnich, U., 2007. Minimalist syntax, multiple regular tree grammars, and direction preserv-ing tree transductions, in: Rogers, J., Kepser, S. (Eds.), Model Theoretic Syntax at 10.ESSLLI’07 Workshop Proceedings, Dublin.
Moortgat, M., 1996. Categorial type logics, in: van Benthem, J., ter Meulen, A. (Eds.), Hand-book of Logic and Language. Elsevier, Amsterdam, pp. 93–178.
Moot, R., 2002. Proof Nets for Linguistic Analysis. PhD thesis, Utrecht University, theNetherlands.
Müller, G., 1998. Incomplete Category Fronting. Kluwer, Boston, MA.Muysken, P., 1982. Parameterizing the notion ‘head’. J. Ling. Res. 2, 57–75.Nkemnji, M.A., 1995. Heavy Pied-Piping in Nweh. PhD thesis, University of California,
Los Angeles, CA.Nunes, J., 2001. Sideward movement. Linguist. Inq. 32, 303–344.Radzinski, D., 1991. Chinese number names, tree adjoining languages and mild context sensi-
tivity. Comput. Ling. 17, 277–300.Rambow, O., 1994. Formal and Computational Aspects of Natural Language Syntax. PhD
thesis, University of Pennsylvania, Philadelphia, PA. Computer and Information ScienceTechnical report MS-CIS-94-52 (LINC LAB 278).
Retoré, C., Salvati, S., 2007. Non-associative categorial grammars and abstract categorialgrammars, in: Muskens, R. (Ed.), Proceedings of the Workshop on New Directions inType-Theoretic Grammars (NDTTG’07). Foundation of Logic, Language and Information(FoLLI). Dublin, Ireland, pp. 51–58.
Rizzi, L., 1997. The fine structure of the left periphery, in: Haegeman, L. (Ed.), Elements ofGrammar. Kluwer, Boston, MA, pp. 281–337.
Rizzi, L., 2004. Locality and left periphery, in: Belletti, A. (Ed.), Structures and Beyond: Car-tography of Syntactic Structures, vol. 3. Oxford University Press, New York, pp. 104–131.
Roberts, I., 2006. Clitics, head movement, and incorporation. Manuscript, Downing College,University of Cambridge, UK.
Rogers, J., 1994. Unpublished doctoral dissertation. University of Delaware, Newark, DE.Rogers, J., 1999. A Descriptive Approach to Language-Theoretic Complexity. Cambridge
University Press, New York.Satta, G., 1992. Recognition of linear context-free rewriting systems, in: Proceedings of the 30th
Annual Meeting on Association for Computational Linguistics. Association for Computa-tional Linguistics, Morristown, NJ, pp. 89–95.
Seki, H., Matsumura, T., Fujii, M., Kasami, T., 1991. On multiple context-free grammars. Theor.Comput. Sci. 88, 191–229.
Shan, C.-C., 2005. Linguistic Side Effects. PhD thesis, Harvard University, Cambridge, MA.

“11-ch07-0395-0414-9780444537263” — 2010/11/29 — 21:15 — page 414 — #20
414 Handbook of Logic and Language
Sportiche, D., 1998. Movement, agreement and case, in: Sportiche, D. (Ed.), Partitions andAtoms of Clause Structure: Subjects, Agreement, Case and Clitics. Routledge, New York,pp. 88–243.
Stabler, E.P., 1997. Derivational minimalism, in: Retoré, C. (Ed.), Logical Aspects of Computa-tional Linguistics (Lecture Notes in Computer Science 1328). Springer-Verlag, New York,pp. 68–95.
Stabler, E.P., 2001. Recognizing head movement, in: de Groote, P., Morrill, G., Retoré, C. (Eds.),Logical Aspects of Computational Linguistics (Lecture Notes in Artificial Intelligence,No. 2099). Springer, New York, pp. 254–260.
Stabler, E.P., 2003. Comparing 3 perspectives on head movement, in: Mahajan, A. (Ed.), FromHead Movement and Syntactic Theory, UCLA/Potsdam Working Papers in Linguistics.UCLA, pp. 178–198.
Stabler, E.P., 2010. Computational perspectives on minimalism, in: Boeckx, C. (Ed.), OxfordHandbook of Minimalism. Oxford University Press, Oxford, pp. 616–641.
Travis, L., 1984. Parameters and Effects of Word Order Variation. PhD thesis, MassachussetsInstitute of Technology, Cambridge, MA.
Uriagereka, J., 1999. Multiple spell-out, in: Epstein, S.D., Hornstein, N. (Eds.), Working Mini-malism. MIT Press, Cambridge, MA, pp. 251–282.
Vermaat, W., 2004. The minimalist move operation in a deductive perspective. Res. Lang. Com-put. 2 (1), 69–85.
Vermaat, W., 2006. The Logic of Variation: A Cross-Linguistic Account of wh-Question For-mation. PhD thesis, Utrecht University, the Netherlands.
Vijay-Shanker, K., Weir, D., Joshi, A., 1987. Characterizing structural descriptions producedby various grammatical formalisms, in: Proceedings of the 25th Annual Meeting of theAssociation for Computational Linguistics, Stanford, CA, pp. 104–111.
Weir, D., 1988. Characterizing Mildly Context-Sensitive Grammar Formalisms. PhD thesis,University of Pennsylvania, Philadelphia, PA.

“12-ch08-0415-0466-9780444537263” — 2010/11/30 — 3:53 — page 415 — #1
8 Game-Theoretical SemanticsJaakko Hintikka! and Gabriel Sandu†
!Department of Philosophy,745 Commonwealth Avenue, Boston, MA 02215, USA,E-mail: [email protected]
†Department of Philosophy, History and Culture,PB 24 (Unioninkatu 40 A, 6th floor), 00014 University of Helsinki, Finland,E-mail: [email protected]
Commentator: W. Hodges
8.1 Formal Languages
8.1.1 Background
The leading ideas of game-theoretical semantics (GTS) can be seen best from a spe-cial case. This special case is the semantics of quantifiers. In using quantifiers and intheorizing about them, it is hard not to use game-laden terms, especially if one thinksof seeking and finding as a game. In traditional informal mathematical jargon, quanti-fiers are routinely expressed by such phrases as “given any value of x, one can find avalue of y such that”. In several natural languages, existence is expressed by phrasestranslatable as “one can find”.
As early as in C.S. Peirce, we find an explicit explanation of the meaning of quan-tifiers by reference to two-person games involving an interpreter and a respondent.(Cf. Hilpinen, 1982.) Later, mathematical logicians have spontaneously resorted togame-theoretical conceptualizations practically every time they have had to deal witha kind of logic where Tarski-type truth-definitions do not apply, including branchingquantifier languages, game quantifier languages, and infinitely deep languages. (SeeSection 3, below.) Hence a game-theoretical treatment of quantification theory (first-order logic) is more a codification of natural and time-honored ways of thinking andspeaking rather than a radical novelty.
Such a GTS for first-order languages can be implemented in a sample case as fol-lows:
We assume that we are given a first-order language L and a model M of L. M’s beinga model of L means that all the nonlogical constants of L are interpreted on M. Thisimplies that any atomic sentence or identity involving the nonlogical vocabulary of L,plus names of the individuals in the domain do(M) of M, has a definite truth-value,true or false.
Handbook of Logic and Language. DOI: 10.1016/B978-0-444-53726-3.00008-6c" 2011 Elsevier B.V. All rights reserved.

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 416 — #2
416 Handbook of Logic and Language
Consider now a sentence S of L. We define a certain two-persons semantical gameG(S; M) played with S on M. The players are called Myself (the initial verifier) andNature (the initial falsifier). When the game starts, Myself has the role of verifier andNature that of falsifier. At each stage of the game, intuitively speaking, the player whoall that time is the verifier is trying to show that the sentence considered then is trueand the falsifier is trying to show that it is false.
At each stage of a play of G(S; M), the players are considering a sentence in anextension L!{ca : a " do(M)} of L, obtained by adding the new individual constants caas names of the individuals in the domain do(M) which do not have one. The gamestarts from S and is governed by the following rules:
(R. #) G((S1 # S2); M) begins by the verifier’s choice of i = 1 or i = 2. Thegame is continued as in G(Si; M).
(R. $) G((S1 $ S2); M) begins by the falsifier’s choice of i = 1 or i = 2. Thegame is continued as in G(Si; M).
(R. %) G((%x)S0[x]; M) begins by the verifier’s choice of an individualfrom do(M). Let its name be “c”. The game is continued asin G(S0[c]; M).
(R. &) The rule for G((&x)S0[x]; M) is like (R. %), except that the falsifier makesthe choice.
(R. ¬) G(¬S0; M) is like G(S0; M), except that the roles of the two players arereversed.
(R. atom) If S is an atomic formula or an identity, the player who is then the verifierwins and that who is then the falsifier loses, if S is true in M. The playerwho is then the falsifier wins and that who is then the verifier loses if S isfalse in M.
Any play of a semantical game comes to an end after a finite number of moves, withone player winning and the other losing. The distinctive feature of GTS is the defi-nition of the central semantical notion of truth. The truth or falsity of S in M usuallycannot be seen from any one play of G(S; M). Rather, truth in M is defined by ref-erence to what the initial verifier can do in G(S; M). It refers to the strategies, in thesense of game theory, that Myself and Nature have available in G(S; M). A strategyin this sense is a rule that tells a player what to do in every conceivable situation thatmight arise in a play of the given game. More exactly, a strategy for a player m (m iseither Myself or Nature) in the game G(S; M) is a set Fm of functions fQ correspondingto different logical constants Q which can prompt a move by player m in G(S; M). Awinning strategy in a two-person zero-sum game is one which results in a win for thatplayer no matter which strategy one’s opponent uses.
The truth in M of a sentence S (M !GTS S+) can now be defined in a natural way:Definition 8.1.1. M !GTS S+ if and only if there exists a winning strategy for Myselfin G(S; M).

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 417 — #3
Game-Theoretical Semantics 417
Falsity (M !GTS S') can be defined as the dual of truth:
Definition 8.1.2. M !GTS S' if and only if there exists a winning strategy for Naturein G(S; M).
The following results are well known and will therefore be given here withoutproofs:
Theorem 8.1.3. (Assuming the axiom of choice; (Hintikka and Kulas, 1983; Hodges,1989)) For any first-order sentence S and model M, Tarski-type truth and GTS truthcoincide, i.e.
M !Tarski S if and only if M !GTS S+.
By quantifying explicitly over the functions in the set Fm we also obtain
Theorem 8.1.4. Every first-order sentence is equivalent with a second-order existen-tial (i.e. !1
1 ) sentence.
The !11 sentence S(2) equivalent with the given first-order one, say S, can be effec-
tively formed as follows:
(i) Transform S to its negation normal form Sn.(ii) For each variable x bound to an existential quantifier (%x) in Sn, replace x by f (y1, y2, . . .),
where f is a new function symbol (the Skolem function f connected with (%x)) and(&y1), (&y2), . . . are all the universal quantifiers within the scope of which (%x) occursin Sn.
(iii) Each disjunction (S1#S2) is replaced by (f (y1, y2, . . .) = 0$S1)#(f (y1, y2, . . .) (= 0$S2),where f is a new function variable and (&y1), (&y2), . . . are all the universal quantifierswithin the scope of which the disjunction occurs.
(iv) The function variables introduce in (ii)–(iii) are bound to sentence-initial existential quan-tifiers.
The equivalence of S(2) with S is a straightforward consequence of the axiom ofchoice.
We will extend the usual terminology somewhat and call all the functions intro-duced in (ii) and (iii) Skolem functions.
The argument selection for the different Skolem functions that occur in the!1
1 translation of a given first-order sentence S shows graphically the different rela-tions of dependence and independence between the corresponding quantifiers and con-nectives in S.
Later we will consider routinely first-order languages which also contain functionsymbols and which may contain an infinite number of nonlogical constants of differentkinds. The treatment outlined in this section can be extended to them without anydifficulties.

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 418 — #4
418 Handbook of Logic and Language
8.1.2 The Strategic Viewpoint
This treatment of first-order logic by means of game-theoretical concepts serves asa basis of extensions in several different directions. Some of these extensions arediscussed in the next several sections. At the same time, the treatment of first-orderlogic can serve as an illustration of the rationale of GTS.
In most approaches to language and its logic these days, language is consid-ered as a rule-governed process. The explanatory arsenal of such an approach con-sists mainly of the move-by-move rules for certain processes, for example forthe generation of well-formed sentences or rules of semantical interpretation, forinstance rules for a Tarski-type recursive determination of the truth-value of a givensentence.
In contrast, when language is considered in game-theoretical terms, it is viewedas a goal-directed process. This opens the door for conceptualizations and explana-tions which do not turn on step-by-step rules but rather on the strategies one canpursue throughout an entire process. (Indeed, the concept of strategy plays such acrucial role in game theory that it perhaps should be called strategy theory in thefirst place.) On the level of the explanation of actual linguistic phenomena, this facil-itates a wealth of new avenues of conceptualization, explanation and understanding.For instance, instead of varying the move-by-move rules of our semantical games,we could vary the sets of strategies that are open to the two players. (Cf. Section 1.9below.)
This reliance on strategies rather than move-by-move rules is in evidence in thegame-theoretical definition of truth outlined above. Thus one way in which the game-theoretical approach can be developed is in the direction of new types of explanation.(Cf. Hintikka, 1991b.)
8.1.3 The Subgame Interpretation and Conditionals
An idea which goes back to Hintikka and Carlson (1979) is to divide certain semanticalgames into subgames, each played in its own right. This idea can be used on thesentence level, especially in the treatment of conditionals (see Section 2.6 below). Itis also most useful in extending the concepts and results of GTS from the sentencelevel to discourse semantics, using the simple expedient of conceiving of discourseas a “supergame” consisting of subgames played with the successive sentences ofthe discourse. In either case, new conceptualizations are opened by the possibility ofmaking different assumptions as to what information is transferred from an earliersubgame to a later one.
In this way, practically all the concepts and results concerning sentential anaphorathat in the second part of this survey are registered on the sentential level areautomatically extended to discourse anaphora without the need of any auxiliaryassumptions.
Rules for formal conditionals will be discussed in Section 2.6 in connection withthe corresponding rules for natural-language conditionals.

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 419 — #5
Game-Theoretical Semantics 419
8.1.4 Extensions: Informational Independence
There is an important feature of the usual first-order logic which usually passesunnoticed. It is an assumption concerning the kinds of dependence and independencebetween logical constants that is allowed in logic. It is built right into the usual logicalnotation. In that notation, each quantifier is associated with a segment of the formulaas its scope. It is then required that these scopes are linearly ordered, that is, that thescopes of two different quantifiers must be either exclusive or else nested (i.e. thescope of one is included in the scope of the other).
On a closer look, alas, the requirement of (linear) ordering is seen to be unmotivatedby any deeper theoretical reasons and hence dispensable. Every single explanationoffered in introductory logic texts or anywhere else of the meaning of the notions ofscope and quantifier is applicable irrespective of the restriction. The restriction, we aretempted to say, is simply an outright mistake on Frege’s and Russell’s part.
But what happens when this arbitrary stipulation is given up? Purely notationally,the use of parentheses as scope indicators becomes awkward, for it is not easy to per-ceive at once which parenthesis is to be paired with which, even if they are indexed. Itis more convenient to introduce a special notation whose purpose is to exempt a quan-tifier (or other ingredient of a sentence) from the dependence of another one withinwhose scope it would otherwise be. For this purpose a slash notation will be usedhere. For instance, in the sentence
(4.1)!&x
"!&z
"!%y/&z
"!%u/&x
"R[x, z, y, u]
the idea is that the first existential quantifier depends on (&x) but not on (&z), whilethe second depends on (&z) but not on (&x).
An alternative notation would be to write the prefix of (4.1) in a branching form
(4.2)#
&x %y&z %u
$R[x, z, y, u]
which is taken to be equivalent with the second-order sentence
(4.3)!%f
"!%g
"!&x
"!&z
"R%x, z, f (x), g(z)
&.
The prefix of (4.2) is also known as a Henkin prefix (Henkin quantifier). It is wellknown that the logic with Henkin quantifiers is a non-axiomatizable, proper extensionof first-order logic. If ordinary (contradictory) negation is used, this logic is also non-compact.
When the linear dependence of quantifiers on each other breaks down, thenTarskian truth definitions do not help us any longer. Consider for instance (4.1). ATarskian truth definition does not work in this case, because it cannot avoid inter-preting at least one of the existential quantifiers as semantically dependent upon bothuniversal quantifiers. In contrast, a game-theoretical interpretation is readily available.We can simply associate with (4.1) a semantical game G((4.1); M) which will consistof two moves by Nature prompted by the two universal quantifiers and two movesby Myself prompted by the two existential quantifiers. The idea that the existential

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 420 — #6
420 Handbook of Logic and Language
quantifier (%y) depends only on the universal quantifier (&x) (and not on (&z)) and thequantifier (%u) depends only on the universal quantifier (&z) (and not on that (&x))can be captured in GTS by requiring that the game in question is one of imperfectinformation. In this particular case, this means that Myself, at his first move, does not“know” Nature’s second choice, and in his second move, Myself does not have accessto Nature’s first choice. We say in this case that the move prompted by (%u) is informa-tionally independent of the move prompted by (&x), and similarly for (%y) and (&z).When game-theoretical semantics is used, our notions of informational dependenceand independence thus become simply special cases of the namesake notions used inthe mathematical theory of games.
The idea of informational independence can be extended to cover, not only quanti-fiers, but all the logical constants (and even the other ingredients of a sentence). Themild-looking extension of the usual first-order notation which is proposed here canbe implemented by adding to the usual formation rules of first-order logic certain newones, to be applied after the usual formation rules. The following are examples of suchrules applied to formulas in negation normal form:
(a) If (%x) occurs within the scope of the universal quantifiers (&y1), . . . , (&yk), among others,then it may be replaced by (%x/&y1, . . . ,&yk).
(b) If # occurs within the scope of the universal quantifiers (&y1), . . . , (&yk), among others,then it may be replaced by (#/&y1, . . . ,&yk).
(c) If (&x) occurs within the scope of the existential quantifiers (%y1), . . . , (%yk), among others,then it may be replaced by (&x/%y1, . . . , %yk).
(d) If $ occurs within the scope of the universal quantifiers (%y1), . . . , (%yk), among others,then it may be replaced by ($ /%y1, . . . , %yk).
These two rules actually suffice for the simplest types of languages where informa-tional independence is allowed. When needed, analogous rules can be formulated forother kinds of independence. Any number of applications of (a)–(d) may be made toa given first-order sentence and the slash notation may be extended to formulas whichare not in negation normal form.
The game-theoretical interpretation we gave for the ordinary first-order languagescan be extended to cover also the sentences of the new language. As a matter of fact,the game rules for the new language will be the same as the old ones. The only essentialdifference between the new and the old games is thus that the former are games ofimperfect information.
The resulting logic will be called independence friendly (IF) first-order logic andthe languages associated with it IF first-order languages. These languages were intro-duced in Hintikka and Sandu (1989). The IF first-order logic is a proper extension offirst-order logic. This follows from the fact mentioned above that the Henkin quantifieris definable in this logic, i.e.
(4.4)#
&x %y&z %u
$R[x, z, y, u] )
!&x
"!&z
"!%y/&z
"!%u/&x
"R[x, z, y, u].
In fact the following holds:

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 421 — #7
Game-Theoretical Semantics 421
Theorem 8.4.1. The IF first-order logic is a nonrecursively axiomatizable but compactextension of first-order logic.
In order to prove Theorem 8.4.1 we note first that Theorem 8.1.4 extends to the IFfirst-order logic:
Theorem 8.4.2. (Hintikka, 1995; Sandu, 1991) Every IF first-order sentence is equi-valent with a !1
1 sentence.
This !11 sentence is formed in the same way as in ordinary first-order logic. (See
Section 1.1 above.)Enderton (1970) proved that every !1
1 sentence is equivalent with a first-order sen-tence prefixed by a Henkin quantifier. Since the Henkin quantifier is definable in theIF logic, it follows that the converse of Theorem 8.4.2 holds too. The equivalenceof IF first-order logic and !1
1 logic has the consequence that the we get for the for-mer all the metalogical properties of the latter: Compactness (i.e. Theorem 8.4.1), theLöwenheim–Skolem Property (cf. Ebbinghaus, Flum, and Thomas, 1984, p. 195), andthe following Separation Theorem:
Theorem 8.4.3. (Analog to Barwise, 1976) Let K1 and K2 be two disjoint nonemptyclasses of structures definable by sentences of the IF first-order language. Then thereis an elementary class K (definable by a single ordinary first-order formula) such thatK contains K1 and is disjoint from K2.
The IF languages have been introduced in Hintikka and Sandu (1989). They havesomewhat longer ancestry, however. As we saw, IF first-order logic is closely related tothe logic of partially ordered quantifiers. This study was begun by Henkin (1959), andamong its milestones are the papers by Walkoe (1970), Enderton (1970), Krynicki andLachlan (1979), Barwise (1979), Krynicki and Mostowski (1995). One novelty whichis incorporated in the IF logic is that of partially ordered connectives. Such connectivesare studied in Sandu and Väänänen (1992), and in Hella and Sandu (1995).
8.1.5 IF First-Order Logic and Partiality
In the chapter on Partiality of this handbook, we saw what are the consequences ofgiving up the assumption of complete information with respect to a model. In thatcase, truth-value gaps arise already at the level of atomic sentences, and, through theinductive clauses, they are transmitted to the more complex sentence of the languagein question.
In the case of IF first-order logic, the lack of complete information manifests itselfat the level of the interpretation of the quantificational structure of a sentence. Forthis reason, truth-value gaps arise at a complex level of quantificational structure,i.e. a level involving at least two quantifiers. An illustrative example is the sentence(&x)(%y/&x) [x = y] which fails to be true and fails to be false in any model which has

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 422 — #8
422 Handbook of Logic and Language
at least two elements. (Cf. also our discussion in Section 1.8.) At the level of atomicsentences, IF first-order logic is classical.
In the chapter on Partiality it was shown that, if the models are partial, thenthe Boolean connectives in the underlying logic satisfy the Strong-Kleene valuationschema. In addition this logic is complete and compact and has the Interpolation Pro-perty. These properties follow automatically from the encoding of partial logic intoclassical logic.
We saw in the preceding section that all these results except completeness hold forthe IF first-order logic, too. Next we will show that the Boolean connectives in IFfirst-order logic satisfy the Strong-Kleene valuation schema too. The proof of the nextproposition is straightforward:
Proposition 8.5.1. Let S be an arbitrary IF first-order sentence. Then the followingholds for any model M:
(i) M !GTS (¬S)+ iff M !GTS S'.
(ii) M !GTS (¬S)' iff M !GTS S+.
(iii) M !GTS (S # Q)+ iff M !GTS S+ or M !GTS Q+.
(iv) M !GTS (S # Q)' iff M !GTS S' and M !GTS Q'.
(v) M !GTS (S $ Q)+ iff M !GTS S+ and M !GTS Q+.
(vi) M !GTS (S $ Q)' iff M !GTS S' or M !GTS Q'.
Let us define *S*M (the truth-value of the L-sentence S in the model M) as
*S*M = 1, if M !GTS S+ (and not M !GTS S').
*S*M = 0, if M !GTS S' (and not M !GTS S+).
*S*M = ?, if not M !GTS S+ and not M !GTS S'.
*S*M = 10, if M !GTS S+ and M !GTS S'.
(*S*M = ? should be read as S is undefined in M, and *S*M = 10 should be read as Sis both true and false in M.)
It is straightforward to prove that for every IF first-order sentence S and model M,it cannot be the case that both *S*M = 1 and *S*M = 0. Thus the truth-value 10 doesnot actualize in IF first-order logic.
Using Proposition 8.5.1, it is straightforward to verify that the Boolean connectivessatisfy the Strong-Kleene valuation schema.
8.1.6 IF First-Order Logic and the Failure of Compositionality
GTS is only one of the possible semantical (model-theoretical) treatments of first-order logic. In fact, it is not the most common one. The best known interpretationof ordinary first-order logic is given by Tarski-type truth-definitions. The essentialdifference between the two is that the latter is compositional while the former is not.

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 423 — #9
Game-Theoretical Semantics 423
However, Theorem 8.1.3 showed that they are equivalent (assuming the axiom ofchoice). This result does not extend to IF first-order logic, however. Let us be morespecific about this question.
In its standard formulation, the principle of compositionality (“Frege’s Principle”)says that the meaning of a compound expression is a function of the meanings of itsconstituent parts and of the syntactic rules by which they are combined (cf. the chap-ter on compositionality in this handbook). What this comes down to in the case ofTarskian semantics is that the concepts of truth and satisfaction for a complex expres-sion are defined recursively in terms of the truth and satisfaction of certain simplerexpressions. This is also the basic reason why Tarski cannot define truth for first-ordersentences directly, but has to draw in also the notion of satisfaction. For the relevantcomponent expressions of a sentence (closed formula) are not always closed, but con-tain free variables. Since the concept of truth cannot be applied to open formulas,Tarski must resort to the concept of satisfaction.
But the principle of compositionality which is operative here presupposes a kindof semantical context-independence. If the meaning of a complex expression dependsonly on the meaning of its parts, it can never depend in its context on a still morecomprehensive expression. Thus much of the actual force of the principle of compo-sitionality lies in ruling out semantical context dependencies.
But the very idea of quantifier independence in IF logic violates the principleof compositionality. For the force of an independent quantifier (Q/Qi) depends onanother quantifier (Qi) which occurs, not within the scope of the former, but outsideits scope, in other words in the context of (Q/Qi). This clearly violates composition-ality, and it is the ultimate reason why Tarski-type truth-definitions do not work in anIF first-order logic (on the first-order level).
The impossibility of formulating Tarski-type truth-definitions for IF first-order lan-guages may not be obvious. For instance why cannot we formulate a Tarski-type truth-condition for a sentence of the form
(6.1)!&x
"!%y
"!&z
"!%w/&x
"S[x, y, z, w]
by associating with its successive component formulas those classes of assignmentswhich satisfy them in Tarski’s sense? Let us try. Assuming that the satisfaction condi-tions for S[x, y, z, w] have been determined, we must try to define the class of assign-ments which satisfy
(6.2)!%w/&x
"S[x, y, z, w].
Here the independence of the choice of w from x can perhaps be taken into account. Wecan, for instance, not just say that an assignment g0 satisfies (6.2) if and only if there isan evaluation g1 which differs from g0 only on w and which satisfies S[x, y, z, w]. Wecan add that this different value of g1 on w must be the same as soon as the values of yand z are the same. But this is not enough. We must also take into account possibledependencies of x, y, and z on each other. Neither kind of dependence or independencecan be read off (6.2), not even the first kind, for we must consider choices of values ofexistentially quantified variables to be independent of each other.

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 424 — #10
424 Handbook of Logic and Language
In Chapter 7 on Compositionality of this handbook it is proved that any languagethat can be described by finite means can be described by a compositional grammar.This raises the question of what is a compositional semantics for the IF first-orderlanguages described here.
A possible line of restoring compositionality for the IF first-order languages wouldbe to take the whole prefix of quantifiers in, for example, (6.1) as one full block, andintroduce a generalized quantifier (called the Henkin quantifier), say Hxyzw, defined by
(6.3) HxyzwS[x, y, z, w] +,!%f
"!%g
"!&x
"!&z
"S%x, f (x), z, g(z)
&.
A similar move could be done for IF first-order sentences of the form
(6.4)!&x
"!%y
"!&z
"!S0(#/&x)S1
".
Here we could restore compositionality by introducing a generalized quantifierDxyz acting on two formulas defined by
(6.5) Dxyz!S0, S1
"+,
!%f
"!%g
"!&x
"!&z
"Sg(z)
%x, f (x), z
&
where g is a function from the domain to the set {0, 1}. (Cf. Chapter 19 on GeneralizedQuantifiers.)
The resulting semantics is, however, less natural than the game-theoretical seman-tics, since it introduces an analyzable notion as a primitive. In such a case, the defini-tion of negation as role swapping loses its naturalness too.
The examples discussed here also clarify a point raised by Cresswell (1988).According to him, the advantages of GTS have the same source as those of MontagueGrammar, viz. the use of higher-order entities. Even if this were correct, it wouldnot be the whole story, since, as we saw, GTS is noncompositional while MontagueGrammar relies essentially on compositionality.
Thus the study of IF first-order logic has a general methodological moral. It sug-gests that, even if there is always some way or another of restoring compositionality,there are cases in which the noncompositional semantics is more natural and finergrained than the compositional one. To the extent that we can argue that an IF logicis a better framework of semantical representation for natural languages than ordinaryfirst-order logic, to the same extent the injunction against compositionality appliesalso to the semantical treatment of natural languages.
8.1.7 IF First-Order Logic and the Failure of the SubstitutionalAccount of Quantification
In IF first-order logic, the substitutional interpretation of quantifiers does not work.According to this interpretation, an existentially quantified sentence
(7.1)!%x
"S[x]
is true if and only if the substitution-instance S[b] of its unquantified part S[x] withrespect to some individual constant b is true. The truth of universally quantified sen-tences is defined analogously. These definitions apply only to closed sentences. If S[x]

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 425 — #11
Game-Theoretical Semantics 425
contains free individual variables other than x, S[b] is open and hence cannot be eithertrue or false. Hence the only way of basing one’s conceptions of truth on the substitu-tion idea is to use it to pare off one quantifier after another from outside in. But thisprocedure does not work in IF first-order languages. There we will eventually come toan expression of the form
(7.2)!%x/&y
"S[x]
where y does not occur in S[x]. Such an expression is not even a well-formed sen-tence of IF first-order language, and cannot be dealt with by the sole means of thesubstitution interpretation.
That this impossibility is not due to any notational peculiarity of IF logic is illus-trated by the fact that the logical rule of inference known as existential instantiationfails in IF first-order logic. Or, rather, it does not do the whole job. The usual rule ofuniversal instantiation entitles us to move from (%x)S[x] to one of its substitution-instances S[b] whenever b is a new individual constant. In IF logic, this can bestrengthened to become a noncompositional rule that entitles us to move from a sen-tence (in negation normal form) of the form
(7.3) S0%!
%x/&y1, &y2, . . ."S1
%x, y1, y2, . . .
&&
to a sentence of the form
(7.4) S0%S1
%f!z1, z2, . . .
", y1, y2, . . .
&&
where f is a new function constant and (&z1), (&z2), . . . are all the universal quantifiersother than (&y1), (&y2), . . . within the scope of which
(7.5)!%x/&y1, &y2, . . .
"S1
%x, y1, y2, . . .
&
occurs in (7.3) (= S0). Moreover, this rule must not be applied after universal instan-tiation.
The need of such a contextual rule of existential instantiation illustrates the samefailure of ordinary substitution to capture the force of informationally independentquantifiers as invalidated the substitutional interpretation of quantifiers and Tarski-type truth-definitions in IF first-order languages. In sum, the substitutional account ofquantifiers does not work for IF first-order logic. This fact is of some interest, since itarises in a logic which is purely extensional and in which, according to Kripke, thereshould not be any difference between a substitutional and a referential account. Forsuppose that we restrict our models to those in which there is a name in the object lan-guage for each individual in the domain. In one trivial sense, in such languages “quan-tification into name position is also quantification over objects of the kind named”, asDavis (1981, p. 143) puts it.
However, from the parallelism of names and individuals it simply does not followthat “there is indeed little difference between a substitutional quantifier and a referen-tial [objectual] quantifier ranging over the set of denotata”, as Kripke (1976, p. 351)claims, if this claim is extended to IF quantifiers. The hidden mistake here is to thinkof quantifiers as merely “ranging over” a set of individuals. To do so is in effect to

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 426 — #12
426 Handbook of Logic and Language
think that their semantics can be defined substitutionally. Hence Kripke’s claim (1976,p. 383) that the real dispute is over the ranges of the variables of the object languageis wrong. The real dispute is whether quantifiers should be interpreted as higher-orderpredicates or as codifying certain choice functions (Skolem functions).
8.1.8 The Nature of Negation
A pleasant feature of the GTS treatment of negation encoded in the rule (R. ¬) isits robustness. It allows us to make the same kind of distinction that was made inChapter 14 on Partiality between non-true and false. The former is the lack of a win-ning strategy for Myself, the latter is the existence of a winning strategy for Nature.Precisely, the same rule (R. ¬) can be used in ordinary first-order logic as well as inits IF variant.
Indeed, it is difficult to see how else negation could be treated game-theoretically.Furthermore, the way we defined truth and falsity preserves the usual symmetry bet-ween the two with respect to negation: S is true iff ¬S is false; S is false iff ¬S is true;S is undefined (neither true nor false) iff ¬S is undefined.
All this is so natural that it might seem trivial. On closer inspection, however, cer-tain striking consequences begin to come to light. One such striking consequence isthe failure of the law of excluded middle.
Thus the IF negation ¬ is not contradictory negation, i.e. it does not always yield,when applied to an arbitrary IF first-order sentence S, the complement of the class ofmodels in which S is true. What we have got in our logic is a much stronger negationthan contradictory negation, i.e. a dual negation, as the next theorem shows.
Definition 8.8.1. Let - be the following mapping which maps each IF first-ordersentence S into its dual S-:
S- = ¬S, S atomic;(¬S)- = S-;!(%x/&y1, . . . ,&yk)F
"- =!&x/%y1, . . . , %yk
"F-;
!(&x/%y1, . . . , %yk)F
"- =!%x/&y1, . . . ,&yk
"F-;
!F(#/&y1, . . . ,&yk)G
"- =!F-($/%y1, . . . , %yk)G-";
!F($/%y1, . . . , %yk)G
"- =!F-(#/&y1, . . . ,&yk)G-".
We call S- the dual of S. The next theorem is proved by a straightforward inductionon the length of S:
Theorem 8.8.2. For any IF first-order sentence S and model M:
M !GTS ¬S iff M !GTS S-.
Weak (contradictory) negation ¬w can be introduced in our logic in a straightfor-ward way. We first extend the IF first-order language to an extended IF first-order

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 427 — #13
Game-Theoretical Semantics 427
language (IFext first-order language) which will contain the additional logical con-stant ¬w. This is done by stipulating that for any arbitrary unextended IF first-orderformula S, ¬wS is to be an IFext formula. Thus weak negation can occur only sentenceinitially. Finally, we define:
Definition 8.8.3. For any IFext first-order sentence S and model M:
(i) M !GTS (¬wS)+ iff not M !GTS S+.
(ii) M !GTS (¬wS)' iff not M !GTS S'.
Given Definitions 1.1 and 8.3, we get:
M !GTS (¬wS)+ iff Myself does not have a winning strategy in G(S; M).
M !GTS (¬wS)' iff Nature does not have a winning strategy in G(S; M).
The presence of weak negation in our logic has the consequence of introducingthe truth-value 10 (both true and false) discussed in Section 1.5. The weak negationof sentences of the (restricted) IF first-order logic which are undefined turns out tobe both true and false (denoted by 10). More generally, for every sentences S of theextended IF first-order sentence and model M, let
(8.1) *S*M = 1, if M !GTS S+ and not M !GTS S'.
*S*M = 0, if M !GTS S' and not M !GTS S+.
*S*M = ?, if not M !GTS S+ and not M !GTS S'.
*S*M = 10, if M !GTS S+ and M !GTS S'.
Then it can be checked that the weak negation has the following truth-table:
(8.2) *S*M = 1 iff *¬wS*M = 0.
(8.3) *S*M = 0 iff *¬wS*M = 1.
(8.4) *S*M = ? iff *¬wS*M = 10.
(8.5) *S*M = 10 iff *¬wS*M = ?.
Since an IF first-order sentence S is never true and false, it follows that *¬wS*M =?is never the case.
Another consequence of the introduction of weak negation in our logic followsfrom the Separation Theorem:
Theorem 8.8.4. For any sentence S of an IF first-order language L, if ¬wS is repre-sentable in L (i.e. there is an L-sentence R such that S and R have the same models),then S is representable by an ordinary first-order sentence.

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 428 — #14
428 Handbook of Logic and Language
What Theorem 8.8.4 shows is that the only sentences of an unextended IF first-order language to have their contradictory negations expressible in the same languageare the usual first-order sentences (without slashes).
These observations put to a new light the behavior of negation in formal as well asnatural languages. What one undoubtedly would like to express in one’s favorite work-ing language is the weak (contradictory) negation obeying the principle of excludedmiddle. But for such a negation we cannot give any reasonable semantical rules, letalone any proof rules. Basically the only thing you can say of this negation is Defini-tion 8.8.1. Syntactically, weak negation can only occur sentence-initially. Game rulescan only be formulated for the strong (dual) negation which does not obey the law oftertium non datur.
In natural languages negation normally expresses weak (contradictory) negation.However, its semantical behavior can only be understood by reference to another(strong or dual) negation which usually is not explicitly expressed in language. Thisexplains why the rules for negation are as complex as they actually are in natural lan-guages. It also helps to explain a number of regularities in languages like English.They are so to speak calculated to keep weak negation sentence initial, the reasonbeing that it is interpretable only in such contexts.
In general, we can thus see that in sufficiently rich languages (natural or formal),there must be two different negations present. On the one hand, there must be thecontradictory negation there, for it is presumably what we want to express by ournegation. However, the contradictory negation cannot stand on its own feet. In orderto be able to formulate rules for dealing with negation (semantical rules, deductiverules, game rules, or what not), we must also have the strong (dual) negation present,for satisfactory rules can be formulated only for it.
This general theoretical situation is reflected by specific regularities in natural lan-guages. In Section 2.4 it will be seen that the interpretation of anaphoric pronounsrelies conceptually on what happens in a play of the semantical game in question. Butwhat has just been seen implies that sentences ¬wS with a contradictory negation ¬ware not interpreted through playing a semantical game. They say merely somethingabout the game G(S), viz. that the initial verifier does not have a winning strategyin G(S). Thus we obtain the neat prediction that (contradictory) negation is a barrier toanaphora. This regularity has been noted before, and (Heim, 1982, pp. 114–117) hasactually used its alleged inexplicability in GTS as a basis of criticizing the treatmentof anaphora in GTS.
8.1.9 Constructivism and Game Strategies
We defined truth in GTS as the existence of a winning strategy for Myself and, as wesaw, this strategy is codified by a set of functions. These functions can be assumed tobe defined on the set of natural numbers but no other restriction has been put on them.However, it might seem that the class of such functions must be restricted, for it doesnot make sense to think of any actual player as following a nonconstructive (nonre-cursive) strategy. How can I possibly follow in practice such a strategy when there

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 429 — #15
Game-Theoretical Semantics 429
is no effective way for me to find out in general what my next move will be? Hencethe basic ideas of the entire game-theoretical approach apparently motivate an impor-tant change in the semantics of first-order languages (independence-friendly or not)and in their logic. The resulting semantics is just like the ordinary game-theoreticalsemantics, except that the strategies of Myself are restricted to recursive ones. This isa perfectly well defined change. It leaves our notation completely unchanged (inde-pendently of whether the slash notation is present or not). It also leaves all the gamerules for making moves in a semantical game untouched.
The change involved in the transition to the new version of GTS is motivated by thekind of argument that appeals to constructivists and according to them ought to appealto everybody. For the basis of our argument was the requirement that the semanticalgames that are the foundations of our semantics and logic must be playable by actualhuman beings, at least in principle. The actual playability of our “language-games”is one of the most characteristic features of the thought of both Wittgenstein andDummett.
The step from ordinary GTS to the constructivistic version makes a differencealready in ordinary first-order logic. It is known that there are arithmetical sentencesthat are satisfiable in the domain of natural numbers but which do not have any recur-sive Skolem functions to satisfy them. This means that there are fewer arithmeticalsentences true in the domain of natural numbers than before. On the other side, by aresult of Vaught (1960), the set of first-order formulas valid in the class of countablemodels with constructive relations and operations is no longer effectively axiomatiz-able. There is thus an interesting interplay between the effectiveness of interpretationand the effectiveness of the resulting logic (cf. Van Benthem, 1988).
It is natural to define the falsity of a sentence in constructivistic GTS as the exis-tence of a recursive winning strategy for Nature, i.e. a recursive strategy which winsagainst any strategy of the initial verifier. If so, there will be sentences of ordinary first-order logic which are neither true nor false in suitable models. Thus constructivists arenot entirely wrong in focusing on the failure of tertium non datur as a possible symp-tom of a constructivist approach. However, as we saw, the law of excluded middle failsin perfectly classical nonconstructivist logic as soon as informational independence isallowed.
A definitive evaluation of the constructivistic version of GTS will not be attemptedhere.
8.1.10 Epistemic Logic
One of the directions in which GTS can be extended is intensional logics. Here wewill discuss the logic of knowledge as a representative special case.
The first step in the use of GTS in epistemic logic is old hat. The basic new conceptis a knows that, abbreviated by Ka. The appropriate model structure is a set of ordinarymodels (possible worlds), on which a three-place relation is defined. This relationassociates with each world M0 and each person b existing in M0 a set of worlds, theepistemic b-alternatives to M0. (The given model M0 is assumed to be always among

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 430 — #16
430 Handbook of Logic and Language
its own epistemic alternatives.) Such a structure of models might be called a modelstructure.
Then we can add the following clause to a usual Tarski-type truth-definition:
Definition 8.10.1. Let " be a model structure and M0 " ". Then KaS is true in M0if and only if for each epistemic a-alternative M1 to M0 in ", S is true in M1.
This definition reflects the intuitive idea that to know something is to be able to restrictone’s attention to a subset of all possibilities that a priori would have to be considered.From Definition 8.10.1 it is also seen that the epistemic operator Ka can be dealtwith as a universal quantifier ranging over epistemic a-alternatives. This immediatelyshows a game-theoretical treatment can be extended to epistemic logic. At each stageof the game, the players now consider some one sentence in relation to some one“world” (model). The game rules are the same, mutatis mutandis, as in first-orderlanguages, with a new one added:
(R. K) The game G(KaS; M0) begins with the choice by the falsifier of an epistemica-alternative M1 to M0. The game is then continued as in G(S; M1).
In order to analyze different kinds of knowledge statements, however, we need some-thing more. Knowing whether S1 or S2 can be analyzed as
(10.1) KS1 # KS2
and a simple knowing who (or knowing + another wh-word) as
(10.2)!%x
"KS[x].
But no similar analysis works for constructions where the choice of the operator vari-able depends on the choice of a universal quantifier, as in
(10.3) It is known whom each person admires most.
It turns out that an adequate analysis of all the different knowledge statements requiresthe notion of informational independence. Thus the logical form of (10.3) is rather
(10.4) K!&x
"!%y/K
"S[x, y].
By the same token (10.1) and (10.2) can be expressed as follows (respectively):
(10.5) K!S1(#/K)S2
",
(10.6) K!%x/K
"S[x].
The general form of a knowledge statement is
(10.7) KS
where S is a first-order statement (in negation normal form), except that a number ofexistential quantifiers (%x) have been replaced by (%x/K), and a number of disjunc-tions (S1 # S2) by (S1(#/K)S2).

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 431 — #17
Game-Theoretical Semantics 431
Indeed, the logical counterpart of the question ingredient of an indirect question innatural language can be taken to be precisely (%x/K) and (#/K).
Such an analysis of different kinds of knowledge statements can be extended to ananalysis of the main concepts relating to questions and answers.
(i) Any knowledge statement can serve as the desideratum of a direct question, i.e. as a des-cription of the cognitive state the questioner wants to achieve by his or her question. Anynumber of the expressions (%x/K) and (#/K) can be questioned in asking the question.For instance, (10.4) is the desideratum of a question of the form
(10.8) Whom does each person admire most?
(ii) If the slash expression /K is removed from the questioned ingredients, we obtain thepresupposition of the question. For instance, the presuppositions of the questions whosedesiderata are (10.4)–(10.6) are respectively
(10.9) K!&x
"!%y
"S[x, y],
(10.10) K!S1 # S2
",
(10.11) K!%x
"S[x].
(iii) A reply to a question is like the desideratum, except that each variable xi bound to a ques-tioned ingredient like
(10.12)!%xi/K
"
is replaced by
(10.13) fi!y1, y2, . . . , yj
"
where each fi is a function constant and (&y1), (&y2), . . . , (&yj) are all the universal quan-tifiers in the scope of which (10.12) occurs in (10.7). Furthermore, each questioned dis-junction
(10.14)!S1(#/K)S2
"
is replaced by
(10.15)!S1 $ fk(y1, y2, . . . , yj) = 0
"#
!S2 $ fk(y1, y2, . . . , yj) (= 0
"
where fk is a function constant and (&y1), (&y2), . . . , (&yj) are all the universal quantifierswithin the scope of which (10.14) occurs in (10.7).
(iv) The conclusiveness conditions of such a reply are the sentences
(10.16) K!&y1
"!&y2
"· · ·
!&yj
"!%x/K
"!fi(y1, y2, . . . , yj) = x
",
(10.17) K!&y1
"!&y2
"· · ·
!&yj
"!%x/K
"!fk(y1, y2, . . . , yj) = x
".
A reply plus the corresponding conclusiveness conditions logically implies the desidera-tum, which is not logically implied by the reply alone.

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 432 — #18
432 Handbook of Logic and Language
8.1.11 The Definability of Truth and its Significance
It was shown by Tarski (1956) that, given certain assumptions, truth can be definedfor a formal language only in a richer metalanguage. Tarski also argued that a com-plete and consistent notion of truth is impossible to apply to natural language (Tarski’s“colloquial language”).
Tarski’s result and his pessimistic thesis are put to a new light by IF first-order logic.Given a sentence S of an IF first-order language, one can think of its second-order (!1
1 )
translation as expressing its truth-condition. (Cf. Sections 1.1 and 1.4 above.) But the!1
1 fragment of a second-order language can be translated back into the correspondingIF first-order language.
This observation can be converted into an actual truth-definition. First, we have tobuild up a modicum of arithmetic into an IF first-order language L in order to speak ofthe syntax of L in L itself. This can be done by means of the usual strategy of Gödelnumbering. It is assumed here that this numbering is extended to the correspondingsecond-order language.
Then we can take a second-order predicate variable X and express the necessaryand sufficient conditions for its being a truth-predicate, i.e. a predicate such that thesentence X(n) is true if and only if the numeral n codifies the Gödel number of a truesentence of the language in question. This is a straightforward task for ordinary first-order language. All that needs to be done is to express the usual truth-conditions bymeans of the Gödel numbering, for instance that X applies to the Gödel number of aconjunction only if X applies to the Gödel number of both conjuncts, or that X appliesto the Gödel number of an existentially quantified sentence (%x)S[x] only if X appliesto the Gödel number of at least one formula of the form S[n], where n is a numeral.
The failure of compositionality in IF logic occasions a modification of this proce-dure. One can, for instance, do the following:
(i) Express the requirement that X applies to the Gödel number of a sentence S if and only ifX applies to the Gödel number of the Skolem normal form of S.
(ii) Express the requirement that X applies to the Gödel number of a sentence in Skolem normalform
!&x1
"!&x2
"· · ·
!&xi
"!%y1/&x11, &x12, . . .
"!%y2/&x21, &x22, . . .
"
· · ·!%yj/&xj1, &xj2, . . .
"S%x1, x2, . . . , xi, y1, y2, . . . , yj
&
(where each {xk1, xk2, . . .} . {x1, x2, . . . , xi}) only if there are functions f1, f2, . . . , fjsuch that X applies to the Gödel number of every sentence of the form S[n1, n2, . . . ,
ni, m1, m2, . . . , mj] where nk is the numeral expressing the number nk and ml the numeralexpressing the Gödel number of fl(nl1 , nl2 , . . .).
It is not hard to prove that all these requirements are expressible by !11 -formulas.
Let this conjunction be Tr[X]. Consider now the second-order formula
!%X
"!Tr[X] $ X(y)
".

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 433 — #19
Game-Theoretical Semantics 433
It is obviously a perfectly good truth-predicate in the intended sense. It is equivalent toa !1
1 -sentence. Hence it has a translation to the corresponding IF first-order language.This translation is the desired truth predicate.
It is to be noticed that we do not claim that there exists an explicit definition of atruth predicate for IF first-order logic. The truth predicate just defined captures all andonly true sentences. How it behaves with false and not true (not false) sentences is notbeing considered here.
No paradoxes arise because of the definability of truth for suitable IF first-orderlanguages in these languages themselves. You can construct a Gödel type paradoxicallooking sentence by the usual diagonal procedure and you will find that it is neithertrue nor false. And it was pointed out earlier without any fancy footwork that the lawof excluded middle fails in IF first-order logic.
The possibility of defining a truth-predicate for IF languages in the language itselfhas striking suggestions for the general methodological situation in language theory.
(i) Since informational independence occurs in natural languages (cf. Section 2.3 below), theredoes not seem to be any good reasons to doubt the possibility of applying a consistent con-cept of truth to a natural language and even to discuss that concept in the natural languageitself. There is hence no reason to exile the notion of truth from the semantical theory ofnatural languages.
(ii) All formal semantics and model theory has until now been under methodological suspicion.For what does it take to practice model theory, it may be asked. Two things are neededfor the purpose in the case of any given language: (i) a set of models and (ii) a defini-tion as to when a given sentence is true in a given model. The first requirement (i) neednot detain us here. The second purpose (ii) has to be served by a suitable truth definition.But Tarski-type truth-definitions have to be formulated in a second-order language or elseset-theoretically. In either case, the resulting theory of truth will be riddled by all the diffi-culties and uncertainties that are connected with the existence of sets and classes, completewith set-theoretical paradoxes, incompleteness of higher-order logics, difficulty of choos-ing between different set-theoretical assumptions, etc. Even though such problems do notaffect actual linguistic theorizing, they cast a dark shadow on the entire enterprise of formalsemantics methodologically and philosophically.
The possibility of self-applied truth-definitions on first-order level (viz. in IF first-order languages) removes most of these doubts. Whatever difficulties there may beabout IF first-order languages, problems of set existence, set theoretical paradoxes orproblems of infinity are not among them.
8.2 Natural Languages
8.2.1 Game Rules for Quantifier Phrases
In the tradition of generalized quantifiers started by Montague (cf. Thomason, 1974),a quantifier in English is taken to have the general structure:
(1.1) Quantifier = Determiner + Common Noun

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 434 — #20
434 Handbook of Logic and Language
where the category of determiners includes expressions such as some, every, most,etc. In what follows we will be even more liberal and take quantifier phrases to beexpressions of the following forms: some X who Y, an X who Y, every X who Y, anyX who Y , where X is a common noun and Y is a verb-phrase. Instead of who in theabove phrase-forms, we could have any other wh-word.
When who does not occupy the subject position in who Y , this sentence can bethought of as having been derived from a string of the form
Y1 – someone – Y2
by wh-movement, resulting in Y = who – Y1 – trace – Y2.Since there are no variables in natural languages, the procedure of substituting
names of individuals for bound variables is not directly applicable in them. What wecan do is to substitute proper names for such individuals for entire quantifier phrases.In addition, we stipulate that the individuals chosen in the course of a play of gameG(S; M) enter a certain choice set IS. The choice set is not constant but changes when aplay of the game progresses. The rationale of this is the presence of anaphoric expres-sions in natural language which forces us somehow to keep track of the individualswhich might be potential “heads” for those anaphors.
As before, some basic vocabulary is assumed to be given and interpreted on acertain domain. The game rules for standard quantifiers will have then the followingforms:
(R. some) If the game G(S; M) has reached an expression of the form:
Z – some X who Y – W
then the verifier may choose an individual from the appropriate domain, say b. Thegame is then continued as G(Z – b – W, b is an X and b Y; M). The individual b isadded to the choice set IS.
When Y = Y1 – trace – Y2, the penultimate clause of the output sentence will be
Y1 ' b ' Y2.
(R. every) As in the corresponding case of (R. some), except that every replaces somein (-), that b is chosen by the falsifier, and that the game is continued withG(Z – b – W, if b is an X and b Y; M). The individual b is added to the choiceset IS.
(R. an) As in the corresponding case of (R. some), except that an replaces some.
(R. any) As in the corresponding case of (R. every), except that any replaces every.
In spite of their simplicity, these rules cover nontrivial cases. For instance, (R. any)incorporates the claim that any is univocal in English, always having basically theforce of an universal quantifier. This is also the view of Quine (1960) and Lasnik(1975). In contrast, Davidson (1980) holds that any is invariably existential.

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 435 — #21
Game-Theoretical Semantics 435
The rules for conjunction (R. and) and disjunction (R. or) are the analogs of thecorresponding rules for formal languages. The rule for negation is defined in terms ofrole swapping, as in first-order logic:
(R. negation) If the game G(S; M) has reached an expression P(') which is the nega-tion in English of P, then the players exchange roles, i.e. the verifier willbecome the falsifier and vice versa. The game goes on as G(P; M).
Notice that the rule of negation is slightly different from its formal counterpart. Itis intended to cover both internal, constituent negation (do not, does not, etc.) andexternal, sentential (it is not true that, it is not the case that, etc.). This rule presupposesa theory of negation in English, which is a project of not inconsiderable difficulty.However, for our purposes in this paper, the rule (R. negation) will do.
8.2.2 The Scope of Scope
If you examine the rules for quantifier expressions sketched above, you can see thatthey differ from the corresponding rules for formal languages in an interesting way.In formal languages, the first application of the rules for semantical games is alwayscompletely determined by the scopes of the different logical constants, e.g., quantifiersor connectives. These scopes are usually indicated by parentheses (brackets). The firstrule application is always to the logical constant (or other logically active ingredient)with the widest scope. In contrast, different game rules (e.g., quantifier rules) canoften be applied to one and the same natural-language sentence, and the same rule canoften be applied to different ingredients of the same sentence. In the absence of scope-indicating parentheses, how is the order of different applications of rules determinedin natural language?
It is easily seen that the job of parentheses is done by various ordering principleswhich govern the choice of the rule to be applied and the choice of its target. (Cf. Sec-tion 2.3 below.) They are a new element in the GTS for natural languages comparedwith formal languages. In a moment, their nature will be explained more fully.
Anticipating their formulation, an interesting fact about them can be noted. Someof them depend on the syntactical structure of the sentence in question. Others dependalso on particular lexical items, e.g., on the choice between any and every. What theydo not depend on is an assignment of a segment of the sentence or the discourse underscrutiny to each quantifier or connective as its “scope”.
What this implies is that in formal languages the notion of scope does two thingsthat do not always go together in natural languages. On the one hand, the so-calledscopes indicate the relative priority of different logically active ingredients of a sen-tence. We might call this the priority scope. On the other hand, the scope of a quantifieris supposed to indicate the segment of a sentence (or discourse) where pronouns havethat particular quantifier as its head or, as the saying goes, are bound to that particularquantifier. This might be called tentatively the binding scope of the quantifier.
There is no a priori reason (or a posteriori one, either) to claim that these two kindsof scope always go together in natural language, and there are some good reasons to

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 436 — #22
436 Handbook of Logic and Language
claim that they do not go together in natural languages. Hence languages with the usualscope conventions cannot be expected to provide good models for natural languagephenomena involving both senses of scope. This is one of the reasons why formallanguages have been developed where the two scopes do not always coincide. (Cf.Chapter 3 on Discourse Representation in Context and Chapter 12 on Dynamics inthis Handbook.)
Nor is this a mere theoretical possibility. It provides an instant analysis of the sim-plest puzzle examples called donkey sentences. They are exemplified by the following:
(2.1) If Peter owns a donkey, he beats it.
The standard treatment of (2.1) makes it equivalent with
(2.2)!&x
"!!Donkey[x] $ Own [Peter, x]
"'/ Beat [Peter, x]
".
But by what rules do we get from (2.1) to (2.2)? Why does the prima facie existen-tial quantifier a (as in a donkey) suddenly assume the force of a universal quantifierin (2.2)? (For such questions and related ones, see also Chapter 3 on Discourse Rep-resentation in Context.)
The explanation is simpler if we deconstruct the notion of scope and distinguishthe priority scope [ ] from the binding scope ( ). Then (2.1) will have the translation
(2.3)!%x
"%!Donkey [x] $ Own [Peter, x]
&'/ Beat [Peter, x]
".
Since logical rules are governed by the priority scopes, (2.3) is equivalent with (2.2).Another familiar example is:
(2.4) A man walks in the park. He whistles.
On the two-scopes analysis envisaged here this sentence will translate as:
(2.5)!%x
"%!Man[x] $ Walk[x]
&$ Whistle[x]
".
In sum, the notion of scope, instead of being the simplest and unproblematic idea it isroutinely taken to be, is in reality ambiguous. It must be handled with extreme cautionwhen applied to natural language. A formal logic in which the two kinds of scope partcompany is Dynamic Predicate Logic. (See Chapter 3 on Discourse Representation inContext.)
8.2.3 Ordering Principles
In natural languages, the priority scope is handled by means of certain ordering princi-ples which govern the order of application of the rules of semantical games to differentexpressions in language or in discourse.
In formal languages, the formula reached at a given stage of a game always deter-mines what happens next. The order of application of the game rules is univocallydetermined by the syntactical structure of the sentence in question. Scope, in both ofthe two senses explained earlier, is explicitly indicated. Actually, the only orderingprinciple which is needed and which has been applied tacitly over and over again inSection 1 is:

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 437 — #23
Game-Theoretical Semantics 437
(O. LR) For any semantical game G(S; M), the game rules are applied from left toright.
In contrast, in natural languages, the order of application of different rules has so farbeen left completely open. In such languages, the concept of scope does not evenmake sense. Instead of the notion of scope, we have to deal with the notion of ruleordering, which serves many of the same purposes that scope does in formal languagesbut which is essentially different from it. Some ordering principles are in fact fairlyobvious and closely related to the phenomenon of governance studied intensively inlinguistics.
There are two kinds of ordering principles in GTS, general principles and specialones. The general principles depend only on the syntactic structure of the sentenceor sentences to whose ingredients a rule is to be applied. Special ordering principlesdepend also on the lexical items involved. The general principles are only two andextremely simple: (O. LR) mentioned above and (O. comm):
(O. comm) A game rule must not be applied to an ingredient of a lower clause if itcan be applied to an ingredient of a higher one.
(A node N1 is said to be in a higher clause than N2 if the S-node immediately domi-nating N1 also dominates N2 but not vice versa.)
(Cf. Hintikka and Kulas, 1985.)
However, (O. LR) must be restricted so as to apply only to two ingredients of oneand the same clause (i.e. ingredients governed by the same S-nodes). The generalordering principles are closely related to regularities known from the literature, suchas the conditions on the possibility of anaphora.
The special ordering principles govern the relative ordering of two particular gamerules. They overrule the general ordering principles. Here is one of them:
(O. any) (R. any) has priority over (R. negation), (R. or) and (R. conditional).
This principle assigns the right meaning to sentences like
(3.1) We haven’t got any bananas.
Here, the normal order of application of the rules would be, by virtue of (O. LR):(R. not), (R. any). However, (O. LR) is overruled in this case by (O. any) and thus(R. any) will be applied first.
Related to ordering principles there is what has been called the Well-formednessConstraint (WFC):
WFC: The output sentence of the application of a game rule to a well formed inputmust be well-formed.This constraint explains several phenomena. Among them is why certain readings ofmultiple questions are excluded in English (see Hintikka, 1976). An example is thefact that, for example, the reading of
(3.2) For whom did Mary buy what?
in which what governs For whom, is excluded (at least comparatively) in English.

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 438 — #24
438 Handbook of Logic and Language
Some ordering principles, e.g., (O. any), may be seen as directly derivablefrom WFC.
A discussion of WFC and its consequences for GTS is contained in Hand (1987).Finally, let us say something about quantifiers and informational independence in
English. There are several different types of examples of informationally independentquantifiers in English. The following are instances of sentences involving irreducibleinformational independences (i.e. having no ordinary first-order equivalent):
(3.3) Everybody has a unique hobby.
(3.4) Some official of each company knows some aide of each senator.
(3.5) Some friend of each townsman and some neighbor of each villager envy eachother.
Some of these types of examples have provoked lively discussion, especially sentencesof the form (3.5). Stenius (1976) and Boolos (1984) claim that (3.5) has a first-orderlogical form. Hintikka (1974), Barwise (1979), and Carlson and Ter Meulen (1979)argue that (3.5) is essentially branching.
We think that, as soon as we understand the underlying mechanism of these sen-tences, we understand that some such sentences are less natural than others. Sentencesof the form (3.4) have the logical form (using self-explanatory abbreviations)
(3.6) (&x)(%y)(&z)(%w/&x)!(C[x] $ S[z]) '/ (O[y, x] $ A[w, z] $ C[y, w])
"
which is equivalent with
(3.7) (%f )(%g)(&x)(&z)!(C[x]$S[z]) '/ (O[f (x), x]$A[g(z), z]$C[f (x), g(z)])
".
They are more natural the easier it is to think of familiar functions that might serve asthe truth-making values of f and g in (3.7).
8.2.4 The Treatment of Pronouns in GTS
Many linguists and logicians assimilate the typical modus operandi of anaphoric pro-nouns to that of the bound variables of quantification. For instance, Chomsky’s LFis essentially a quantificational formula. (See Chapter 6 on GB Theory.) The motiva-tion of such an approach springs from a general commitment to the principle of com-positionality. For how else can an anaphoric pronoun be handled in a compositionalsemantics if not by construing it as a bound variable? Since GTS is a noncompositionalsemantics, we are not committed to such an approach. Instead, we shall construe themin a different way.
Very briefly, the basic idea of the theory of pronouns in GTS is that a pronoun isessentially like a hidden definite description, he like the male, she like the female,etc. Moreover, these definite descriptions can be treated like Russellian ones, with onemajor exception (and some minor ones). The major one is that quantifiers employed

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 439 — #25
Game-Theoretical Semantics 439
in Russellian analysis are taken to range over not the entire universe of discourse, orsome context-independent part of it, but over the choice set IS that we described inSection 2.1. As we said there, this set is not a constant but changes in the course ofa play of a semantical game. The membership in IS is determined by the course of aplay of a semantical game G(S; M) up to the time at which the pronoun in questionis dealt with. As the first crude approximation, soon to be refined, it can be said thatIS consists of the individuals which the two players have picked out in the play of thegame G(S; M) before a rule is applied to the pronoun in question.
A sample game rule for pronouns might thus be somewhat like the following:
(R. he) When the game has reached a sentence of the form
X – he – Y,
the verifier may choose an individual, say b, from the choice set IS, to be the value ofthe pronoun he, whereupon the falsifier chooses an individual d from IS. The game isthen continued with respect to
X – b – Y, b is a male, and if d is a male then d is the same as b.
Similar rules can be formulated for the pronouns she and it as well as for pronouns inthe object position, like him, her, etc.
For illustration, let us consider the following sentence:
(4.1) I met John and gave him a letter.
The choice set formed in the course of a semantical game played with (4.1) will con-tain all the individuals chosen by the two players. At the moment (R. him) is appliedto him, an individual named by John has been already introduced in the choice setand is thus available to be picked by the the verifier as a value for him. The lastclause of the game rule for pronouns ensures that this individual is the unique onesatisfying (4.1).
This general idea leads to a number of insights, which at the same time show howit can (and must) be made more precise.
(i) This approach to pronouns is obviously quite intuitive. Why has it not been tried before?The reason why it cannot be formulated without the help of GTS is the dependence of thechoice set IS of the course taken by a play of the semantical game G(S; M) and hence onthis game. It does not depend only on the syntactical and on the semantical properties ofthe input sentence.
(ii) By the simple (and virtually inescapable) device of considering discourse as a successionof (sub)games, this theory is applicable also to discourse anaphora (cf. below). An additi-onal pragmatic feature of the situation is then that speakers often tacitly drop individualsfrom IS in the course of the discourse. In practice, the right value of a pronoun is thereforeoften the most conspicuous eligible individual rather than the unique eligible one.
(iii) The game rules for pronouns, like all other game rules, are subject to the ordering prin-ciples discussed earlier. These principles imply restrictions on the possible coreferencebetween a pronoun P and a noun phrase NP occurring in the same sentence (or discourse).

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 440 — #26
440 Handbook of Logic and Language
The value of NP can be also the value of P only if it is in IS at the time a rule is applied to P.But that is possible only if a rule has been applied to NP earlier, i.e. only if the orderingprinciples allow a rule application to NP before a rule is applied to P.
For instance, the general ordering principle (O. comm) rules out applications to a lowerclause if a rule application to a higher one is possible. This general principle, for whichone can find a great deal of evidence independently of the treatment of pronouns, impliesthe familiar exclusion of coreference of a pronoun with a potential head located in a lowerclause.
(iv) Besides individuals introduced into IS by the players’ moves, the choice set IS may con-tain individuals introduced ostensively. This explains at once why anaphoric and deicticpronouns behave (by and large) in the same way semantically. Indeed, as separate rulesare needed in GTS for deictic pronouns, merely a permission for the objects they refer toto enter the choice set IS.
(v) Another dogma that is ready to be buried is that anaphora is essentially a matter of corefer-ence. It is not. What is normally needed for an anaphoric pronoun P to be interpretable isthe presence of a suitable individual b in IS when a rule is applied to P. That individual bnormally has been introduced as a value of some NP treated earlier. But a rule applica-tion to NP can introduce b even when b is not the reference of NP. A case in point is thefollowing example:
(4.2) A couple were sitting on a bench. Suddenly he got up.
Here A couple is treated first. Whatever precisely the relevant rule is, an application intro-duces two individuals which on the most likely reading of the phrase are of different sexes.Hence by the time (R. he) is applied to he, there is in I(4.2) a unique male who thereforecan serve as the (hopefully) winning value of he. Hence (4.2) is interpretable, and receivesits normal sense in GTS. But of course, he is in no sense coreferential with A couple. In thesense illustrated by these observations, anaphora is a semantical phenomenon, not only asyntactical one.
(vi) It is not quite true that IS consists only of individuals chosen earlier in the game. In thegame rules which deal with successive subgames, it is often stipulated that a strategy func-tion used by a player in an earlier subgame is available to the other player in a later sub-game. Applied to a member of IS, such functions yield further individuals as their values.All of them must be included in IS. We can express this by saying that the “remembered”functions are included in IS and that IS must be closed with respect to functional applica-tions. These locutions are made natural by the fact that a strategy function will sometimesreduce to a constant individual. For instance, consider the following simple variant of theso-called donkey sentences
(4.3) Peter owns a donkey. He beats it.
Here in the subgame with Peter owns a donkey the winning verifying strategy reduces tothe choice of a donkey owned by Peter. This beast can serve as the value of it when (R. it)is applied to it in the second subgame.
Other cases, including more complex ones, will be treated in the next sections.(vii) In natural languages, we encounter the distinction between normal and reflexive pro-
nouns. This might seem a peculiarity of natural languages, without any deeper logicalbasis. In reality, the distinction is virtually predictable. In the logic of quantification, wehave in principle a choice between two different readings of quantifiers. The difference is

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 441 — #27
Game-Theoretical Semantics 441
especially easy to explain in GTS. When a player chooses an individual to serve as a valueof a variable of quantification, the question arises: Are the individuals chosen earlier stillavailable later on for subsequent choices by one of the players? All the traditional treat-ments of quantification theory presuppose the affirmative answer. It is said to give rise toan inclusive interpretation of quantifiers. Yet the negative answer leads to a perfectly viablealternative to a logic of quantification for which rules are easily given. They can be said tocodify an exclusive interpretation of quantifiers. The distinction is just like the contrast bet-ween draws from an urn with and without replacements in probability theory. An explicitlogical treatment of the exclusive interpretation was first presented in Hintikka (1956).
Now in natural languages a version of the exclusive interpretation is usuallyassumed. This occasions in fact a correction to rules like (R. he). The choices bythe two players in (R. he) must be restricted to a subset of the choice set IS. This sub-set is obtained by omitting from IS all individuals introduced by application of rulesto expressions which were in the same clause as the he to which we are applying therule (R. he).
But if so, we sometimes need a way of referring back to those excluded membersof the choice set. That happens in natural language by means of reflexive pronouns.A rule for one of them, e.g., (R. himself) is just like the corresponding rule for thecorresponding ordinary pronoun, (e.g., (R. he)), except that the players’ choices arenow restricted to those members of IS which were excluded in the other one.
Thus the phenomenon of reflexive pronouns becomes understandable as a conse-quence of the general laws of the logical behavior of quantifiers. For instance, we cannow put into a new theoretical perspective Chomsky’s contrast between pronominalsand anaphors. The GTS treatment also immediately yields verifiable predictions, forinstance that reflexive pronouns cannot be deictic.
There are various kinds of evidence for the idea that anaphoric pronouns are inter-preted by a game rule whose application depends on the earlier history of the game. Anespecially interesting item of evidence is the fact that ordinary contradictory negationis a barrier to anaphora. The explanation lies in the fact that a negated sentence ¬wS isnot interpretable by reference to any semantical game which would facilitate the inter-pretation of an anaphoric pronoun occurring in S. It is interpreted only by referenceto another game G(S). But unless such a game is thought of as having been actuallyplayed, there is no play context available that would make possible an application ofa rule like (R. he) or (R. she).
The theory of pronouns sketched above goes back to Hintikka and Kulas (1983,1985).
8.2.5 Comparisons with other Approaches
We will compare in this section the game-theoretical treatment of pronouns with thatoffered by other theories in this handbook. One such theory is Chomsky’s Governmentand Binding theory (GB).
The GB theory divides pronouns into
(i) Pure anaphors, that is, reflexives (himself, herself, etc.) and reciprocals (each other);

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 442 — #28
442 Handbook of Logic and Language
(ii) Pure pronominals, that is, non-reflexive pronouns (him, her, etc.) (Chomsky, 1981.)
The behaviour of these pronouns is regulated by the following binding principles:
(A) An anaphor must be bound in its minimal governing category.
(B) Pronouns are generally free in precisely those contexts in which anaphors arebound. (Chomsky, 1986.)
For the notions of binding and government category, the reader is referred to Chapter 6on GB Theory of the handbook.
Our first observation is that the binding principles (A) and (B) have a clear coun-terpart in GTS, viz. the following principles are direct consequences of the way thegame rules (R. him) and (R. himself) have been formulated:
(A-) A reflexive must be coreferential with an NP occurring in the same clause.
(B-) The values of the pronouns him and himself occurring in the same place inotherwise similar sentences must come from mutually disjoint choice sets.(Hintikka and Kulas, 1985.)
The second observation is that, although the GB theory and GTS have some struc-tural similarities as far as principles A and B are concerned, their explanatory mech-anism is completely different. The binding principles refer to such notions as govern-ment category and context, while the corresponding principles in GTS refer to suchnotions as clause and choice set. These notions mean different things in the two theo-ries. In the GB theory, they pertain to the initial syntactical structure of the sentence,while in GTS they are relative to the stage reached by the semantical game. From aGTS perspective, a GB theorist is trying to formulate all his or her rules by referenceto the initial sentence of the entire semantical game in the course of which S makes itsappearance. In contrast, a rule of GTS applies to the sentence which the players faceat the time of the rule application. This makes a difference in more complex sentenceswhere GTS and GB yield different predictions. (Cf. Hintikka and Sandu, 1991.)
Another major theory dealing with anaphora is the Discourse Representation The-ory (DRT) of Kamp (1982) and its outgrowth, Dynamic Predicate Logic (DPL), devel-oped by Groenendijk and Groenendijk and Stokhof (1991).
The basic ideas of DRT are described in Chapter 3 on Discourse Representationin Context. Essentially, the hearer of a sentence S possesses a sort of an algorithmwith the help of which he processes S so as to determine the semantical informationS conveys to him. This algorithm may be best introduced by an example. The sentence
(5.1) A farmer owns a donkey. He beats it.
is processed in DRT in the following way: the two referring expressions of the firstsentence of (5.1) are replaced by reference markers a and b; a is introduced for afarmer, and b for a donkey. Finally we write down explicitly the reference mark-ers, the expressions for which we introduced them and the result of replacing every

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 443 — #29
Game-Theoretical Semantics 443
referring expression by its reference marker. We end up with the following discourserepresentation structure:
(5.2)!a, b, farmer(a), donkey(b), owns(a, b)
".
The last three expressions are called conditions. We then go on and process the secondsentence of (5.1). This means introducing new reference markers, one for he, say c,and another one for it, say, d. Since these pronouns are interpreted anaphorically, wealso introduce the conditions c = a and d = b. Thus we end up with the representationstructure:
(5.3)!a, b, c, d, farmer(a), donkey(b), owns(a, b), c = a, d = b, beat(c, d)
".
(5.1) is true just in case there are individuals a0, b0, c0 and d0 in the “real model”corresponding to the reference markers a, b, c, and d which satisfy the conditions ofthe representation structure (5.3).
The reader might have noticed that there are some important similarities bet-ween GTS and DRT, but also some important differences. For the sake of comparison,let us give a full description of the game G associated with (5.1).
The game G is divided into two subgames G1 and G2 associated with S1 and S2,that is, with the first and the second sentence of (5.1), respectively. G1 starts with achoice of the verifier (Myself) of an individual who is given a name, say a and who isput into the choice set I(5.1). The game goes on with the sentence
(5.4) a is a farmer and a owns a donkey.
Next, in agreement with (R. and), the falsifier (Nature), chooses one of the conjuncts.If the conjunct so chosen is ‘a is a farmer’, G1 stops here. If ‘a is a farmer’ is true in themodel under consideration, then the verifier won this play of the game; otherwise thefalsifier won. If the chosen conjunct is ‘a owns a donkey’, then the verifier (Myself)chooses an individual and gives it a name, say b. b is put into the choice set I(5.1), andthe game goes on with
(5.5) a owns b and b is a donkey.
Finally, the falsifier (Nature) chooses a conjunct. In either case, the situation is analo-gous to the previous case. Only if Myself wins every possible play of the game, thatis, only if all the atomic sentences ‘a is a farmer’, ‘b is a donkey’, and ‘a owns b’ aretrue in the model, Myself wins the whole game, and then the players move to play G2.In that case Myself’s winning strategy in G1 enters the choice set I(5.1). Notice thatthis winning strategy amounts to the existence of two individuals a0 and b0 (which arethe interpretations of a and b, respectively), which are already in I(5.1), and thus itsstructure remains unchanged.
In the subgame G2 both the verifier (Myself) and the falsifier (Nature) chose indi-viduals c and d, respectively, from I(5.1), and the game goes on with
(5.6) c beats it, and c is a male, and if d is a male then d is the same as c.

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 444 — #30
444 Handbook of Logic and Language
Now there are three possible plays of the game, depending on which of the threeconjuncts Nature chooses. If the rightmost is chosen, then the game will go on with
(5.7) Either d is not a male or d is the same as c
which will prompt a move by Myself choosing one disjunct with which the gamestops.
If the middle conjunct is chosen, the game stops. If the leftmost is chosen, thesituation is similar to the case discussed above.
Notice that here too, in order for Myself to win the whole game, he will haveto win all its possible plays. This would be possible only if Myself could find twoindividuals c and e from I(5.1) so that c is the same as a, e is the same as b and ‘a beatse’ is true.
We see that the way sentences are processed and reference markers are introducedin DRT is, somehow, similar to the choices made by the two players in GTS accord-ing to the game rules described at the beginning of this section. From the perspec-tive of GTS, one can say that conceptualizations in DRT are formulated in terms ofone player’s (the text interpreter’s) choices, while in GTS, having two players, onecan bring more to the forefront the already existing resources of the well establishedmathematical and logical theory of games such as: the notions of winning strategy,information set, subgame. An important consequence of this fact is the following.
The choice set IS associated with a semantical game G(S; M) collects all the “refer-ence markers” introduced in the course of a play of G. However, in contradistinctionto DRT, IS collects more, i.e. it collects also verifying strategies. In other words, theinformation that is available in DRT from one sentence to the next one consists solelyof individuals, while in GTS this information consists essentially of verifying strate-gies. This makes a difference in certain cases, as it will be seen below.
8.2.6 Conditionals
GTS facilitates several insights into the nature of conditionals. Formal and natural-language conditionals are naturally treated together. The treatment utilizes the sub-game idea mentioned in the preceding section. Clearly, a conditional like
(6.1) If S1, then S2
asserts more than that either ¬S1 (or perhaps ¬wS1) is true or S2 is true. A condi-tional is supposed to provide a warrant for a passage from the truth of S1 to the truthof S2, that is, from a method of verifying S1 to a method of verifying S2. A way ofimplementing this idea is to introduce the following game rule for (1):
(R. cond) In G0 = G (If S1 then S2; M), the players first play G(S1; M) with theirroles reversed. If Myself wins G(S1; M), she wins G0. If Nature wins,the players move to play G(S2; M) (with their normal roles). In this sub-game, Myself has access to Nature’s strategy in G(S1; M). The player whowins G(S2; M) wins G0.

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 445 — #31
Game-Theoretical Semantics 445
The “access” mentioned here can be defined as membership of the strategy functionsNature used in G(S1; M) in the choice set of the whole game.
This rule implements the intuitions mentioned earlier in that according to it “themethod of verifying S2” (i.e. Myself’s winning strategy in G(S2; M)) depends on “themethod of verifying S1” (i.e. on Nature’s strategy in G(S1; M) which led to a win inthat game).
There are variants of this game rule depending on the information flow bet-ween G(S1; M) and G(S2; M). In the simple (R. cond), a player’s access to the otherplayer’s strategy means of course that the first player’s strategy is a function of thesecond one’s strategy. This makes it possible to express formally different game rulesfor conditionals by using a device of Gödel and writing out the strategies used in agame with a sentence as if they were arguments of the sentence. If in this notationF0 = (%f )(&h)F[f , h] and G0 = (%g)(&i)G[g, i], then the rule (R. cond) can be exp-ressed by saying that the interpretation of (F0 / G0) is
(6.2)!%#
"!%h
"!&f
"!&i
"!F[ f , h] '/ G[# (f ), i]
".
Other possible interpretations include the following
(6.3)!%$
"!%g
"!&f
"!&i
"!F[f , $(i)] '/ G[g, i]
",
(6.4)!%#
"!%$
"!&f
"!&i
"!F[f , $(i)] '/ G[# (f ), i]
",
(6.5)!%#
"!%$
"!&f
"!&i
"!F[f , $(i, f )] '/ G[# (f ), i]
".
We have formulated these rules for a formal language rather than a natural one buttheir applicability to the latter is obvious. However, in natural languages all theserules open up new possibilities of anaphoric coreference, and hence all of them makea difference. In formal languages, not all of the new rules result in an actually newinterpretation. In formal languages, an additional element is the possibility of restrict-ing the values of all higher-order quantifiers to recursive entities of the appropriatetype. With this restriction, (6.5) becomes Gödel’s interpretation of conditionals in hisfamous Dialectica paper.
Here we can indicate only some of the simplest facts about these different inter-pretations of conditionals. First, applied to natural-language conditionals, even thesimplest interpretation provides, together with the usual rules for pronouns, an expla-nation of the so-called donkey sentences, e.g.,
(6.6) If Peter owns a donkey, he beats it.
(6.7) If you give each child a gift for Christmas, some child will open it today.
The treatment of (6.6) might run as follows:The second subgame associated with he beats it is played only after Nature has veri-
fied the antecedent. Nature’s winning strategy (if any) in the game with the antecedentof (6.6) reduces to two individuals, i.e. Peter and a donkey. This winning strategy is

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 446 — #32
446 Handbook of Logic and Language
a verifying strategy and thus enters the choice set I(6.6) being available for the secondsubgame when the rules (R. he) and (R. it) are applied to the pronouns. The onlypossible values of the pronouns are the values of Peter and a donkey chosen by theinitial falsifier in the first subgame. The whole sentence (6.6) will then say that anychoices of the values of Peter and a donkey which verify the antecedent also verify theconsequent. This is obviously the right meaning.
The second example is similar to (6.6), except that the “remembered” strategy func-tion in the subgame associated with the consequent of (6.7) does not reduce to a singlevalue. Here the choice set I(6.7) will contain (a) the verifying strategy function in thesubgame associated with the antecedent of (6.7); (b) the value of some child; and(c) the individual resulting from the application of the function in (a) to the individualin (b) which will then serve as the truth-making value of it.
Second, the interpretation of natural-language conditionals varies between thetruth-functional one and (6.2)–(6.5). It is affected by the left-to-right order of theantecedent and the conditional. Among other things, this explains the semantical dif-ference between (6.6) and such examples as
(6.8) Peter will beat a donkey if he can find it.
Three, in formal languages, the new interpretations do not affect the coreference sit-uation. Hence the interpretations (6.2)–(6.5) do not necessarily yield anything new.In some cases, only the additional requirement of recursivity makes a difference.However, (6.4) yields an irreducibly branching-quantifier sentence, and (6.5) togetherwith the recursivity requirement yields Gödel’s Dialectica interpretation of condition-als. Thus Gödel’s ideas receive a natural (albeit minor) slot within the total structureof GTS.
8.2.7 Game Rules for other Expressions in English
A particularity of GTS is that almost every single lexical item occurring in a sentence Sof English prompts a move in the semantical game G(S; M). As an example of suchrules we shall give the one dealing with prepositions. In addition to lexical items, alsomorphological constructions prompt moves in semantical games. Our sample rule willdeal with possessives. However, before describing these rules, we shall treat brieflydefinite descriptions. A detailed exposition of the treatment of definite descriptions inGTS may be found in Hintikka and Kulas (1985).
The starting point of the Hintikka–Kulas theory of descriptions is Russell’s theorywhich, despite the criticisms it has encountered, remains still a natural starting pointfor any logics and semantics of definite descriptions. Roughly speaking, to say that“the F is G” (where F and G are arbitrary predicate letters) is, according to Russell, tosay three things
(7.1) There is at least one F,
(7.2) There is at most one F,

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 447 — #33
Game-Theoretical Semantics 447
(7.3) Everything that is F is G.
The uses of definite descriptions Russell had primarily in mind are those occurring incontext-independent sentences like
(7.4) The largest city in the world is Mexico City,
(7.5) The present president of France is F. Mitterand,
and not so much the anaphoric uses like
(7.6) If you are accosted by a stranger, don’t talk to the man,
(7.7) A man was seen walking down the path, but soon the man turned back,
(7.8) If Bill owns a donkey, he beats the donkey.
In such cases, the use of the anaphoric the-phrase does not require uniqueness of ref-erence in the sense of there existing only one individual of which the the-phrase istrue. Instead, such a phrase is supposed to pick up some individual which has beenintroduced earlier in discourse. The similarity with anaphoric pronouns is obvious. Infact, the meanings of (7.6)–(7.8) remain unchanged if we replace the descriptions inthem by the corresponding anaphoric pronouns. This fact by itself is enough to sug-gest what the game rule for anaphoric definite descriptions looks like: it will be almostidentical with the rule (R. him) for pronouns we described in the previous section:
(R. the) When the game has reached a sentence of the form
X – the Y – W,
the verifier may choose an individual, say b, from the choice set IS, to be the valueof the Y , whereupon the falsifier chooses an individual d from IS. The game is thencontinued with respect to
X – b – W, b is a Y, and if d is a Y then d is the same as b.
That is, like anaphoric pronouns, anaphoric descriptions turn out to be quantifiersrestricted to the choice set IS formed in the course of the play of G(S; M). And con-versely, we see now validated the statement we made at the beginning of Section 2.4to the effect that anaphoric pronouns turn out to be definite descriptions like the manor the woman restricted to the relevant choice set.
We have thus reached a unified treatment of both anaphoric pronouns and anaphor-ically used definite descriptions which puts into a new light anaphora in general.Expressions in English which apparently have nothing to do with each other turn outto have the same modus operandi. Recall, for instance, our discussion of anaphora inGB theory at the end of the previous section and the trichotomy of pronouns which isone of its by-products: (i) deictic or referential pronouns, (ii) bound anaphors (that is,pronouns which are anaphoric on NPs and which are c-commanded by them), and

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 448 — #34
448 Handbook of Logic and Language
(iii) unbound anaphors (pronouns which are anaphoric on NPs but which are notc-commanded by them) and which were assimilated by Neale to anaphoric definitedescriptions. GTS shows that both (ii) and (iii) are Russellian definite descriptions inwhich the quantifiers are restricted to the relevant choice set (as it is at the time whena rule is applied to the pronoun).
Studying the mechanism of coreference in GTS suggests the interesting predictionthat almost any expression in English which prompts a choice of an individual fromthe domain of discourse might have an anaphoric interpretation, i.e. an interpretationin which the choice in question is restricted to the relevant choice set. Indeed, thisprediction is confirmed: there are not only anaphoric pronouns and anaphorically useddefinite descriptions in English, but also anaphoric quantifiers:
(7.9) John bought three donkeys. Two donkeys died.
(7.10) Several congressmen arrived today. One was from France.
The quantifiers two donkeys and one, called choice set quantifiers, behave exactly likethe other anaphoric expressions studied so far: their values are picked up from thechoice set of the games associated with (7.9) and (7.10), respectively. In the case of,for example, (7.9) this set will contain the verifying strategy from the first subgame,i.e. three individuals which are donkeys.
We can also sketch a lexical rule pertaining to prepositions and the morphologicalrule dealing with genitives:
(R. near) If the game has reached a sentence of the form
X – near Y – Z
the verifier may choose a location, say the one named b, and the game is continuedwith respect to
X – prep + b – Z and b is near Y.
We shall not try to specify here the choice of the preposition prep. In different exam-ples, it can be in, on, at, etc.
The following can serve as an example:
(7.11) Near him, John sees a snake.
An application of (R. near) will take (7.11) to
(7.12) On the lawn, John sees a snake, and the lawn is near him.
(R. genitive) If the game has reached a sentence of the form
X – Y’s Z – W

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 449 — #35
Game-Theoretical Semantics 449
then an individual is chosen by the verifier, say b and the game is continued withrespect to
X – b – W and b is an/the Z of Y.
8.2.8 Is and Aristotelian Categories
The game rules for quantifier phrases in natural languages are worth a second and athird look. One thing that is revealed by such a re-examination are the much greaterdifferences between the logic of natural language and the usual treatments of formallogic than many linguists seem to suspect.
For one thing, ever since Frege most linguists and logicians have believed that theEnglish word is and its cognates are ambiguous between the is of identity, the is ofpredication, the is of existence, and the is of class-inclusion. That is has such differentuses is unproblematic; the question is whether these differences have to be explainedas being due to the ambiguity of a single word, rather than, for example, a difference incontext. It is of course true that the different uses of is have to be expressed differentlyin the usual first-order notation, the is of identity by =, the is of predication by fillingthe argument-place of a predicate letter by suitable singular terms, the is of existenceby the existential quantifier, and the is of class-inclusion by a general implication ofthe form (&x)(A[x] / B[x]). But the real question is how good the usual first-orderlogic is as a representation of natural language quantification.
In GTS, the Frege–Russell distinction becomes blurred and unnatural. Even moresignificantly, it is not needed in a game-theoretical approach. Examples can illustratethese facts. Consider, for instance, the sentence
(8.1) Jack is a boy who whistles.
Here is is usually taken to be the is of predication. Now an application of (R. an)takes (8.1) to a sentence of the form
(8.2) Jack is John Jr., John Jr. is a boy and John Jr. whistles.
Here the first is of (8.2) is the alter ego of the is in (8.1). But in (8.1) it is supposed tobe an is of predication while in (8.2) it plays the role of an is of identity. Alternatively,one might view the is in (8.1) as an identity. But the closely related phrase is a in (8.2)must be treated as expressing predication, on the pain of infinite regress. Thus theFrege–Russell distinction is shown to be virtually impossible to draw in GTS. This isof course not to say that a formal treatment of is as it is used in English is impossible,only that it must look quite different from traditional first-order logic.
Another difference between natural languages and formal first-order languages isthat at best natural languages can be hoped to be many-sorted first-order languages.For instance, consider the game rule (R. some) above. Since the wh-word used there iswho, the entity to be chosen as a value of a quantifier phrase must be a person. But if ithad been when, the value would have been restricted to moments (or periods) of time;

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 450 — #36
450 Handbook of Logic and Language
if where, to points (or regions of space, and so on). These alternative ranges of valuesof different quantifier phrases correspond to the different sorts of a many-sorted logic.They are thus indicated by the different question words (and some question phrases)in English.
But in some cases the entire wh-phrase may drop out. How can we then tell whichsort the players have to make their choices from? Clearly the simple predicates thatcan occur in the place of the X in (R. some) must ultimately belong likewise to thecorresponding classes. Hence we have at least a rough correspondence between fourdifferent distinctions:
(i) The largest classes that can be the value-ranges of a natural language quantifier phrases.(ii) Different question words and question phrases in English.
(iii) Different classes of unanalyzable predicates.(iv) Different means of is (occurring in the output of a quantifier rule application).
These correlated distinctions might repay a closer study. They are strongly reminiscentof Aristotelian categories. It is especially striking that Aristotle drew the distinctionbetween the different categories in four different ways closely similar to (i)–(iv). Fora further discussion of these matters, see Hintikka (1986).
8.2.9 Abstract vs. Strategic Meaning
The game-theoretical truth-definition prompts at once a fundamental distinction whichhas so far not been exploited very much in the literature. The precise formulation ofthe truth-definition (cf. above Definition 8.1.1) has to be taken seriously. The truth of agiven sentence S is defined as the existence of winning strategy for the initial verifier inthe game G(S; M). This does not imply that the verifier (or the falsifier) knows whatsuch a winning strategy looks like. The definiens is a purely existential statement.Hence, according to strictly understood GTS, when somebody asserts an interpretedfirst-order statement, he or she merely asserts that there exists in mathematicians’Platonic realm of functions a set of functions codifying a strategy for the initial verifierin G(S; M) such that it leads to a win for him (or her or it), no matter what strategy theinitial falsifier opts for. The information so conveyed is called the abstract meaning ofthe sentence in question.
Yet in an act of asserting a sentence one often conveys to the hearer more thanthis abstract meaning. One conveys also some idea of what the winning strategy issupposed to be like. Such surplus meaning is called strategic meaning. It is not somuch information about the world, as information about how a sentence can actuallybe verified.
These two kinds of meaning are both important in their basic nature. The best onecan hope for of any formal semantics to accomplish directly is a contribution to thestudy of abstract meaning. That is also what our game-theoretical rules are calculatedto do in the first place. It is possible, however, to put the apparatus of GTS to workfor the purpose of elucidating strategic meaning. An example is in fact found in thisarticle. In order to see it, consider what is meant from a game-theoretical viewpoint

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 451 — #37
Game-Theoretical Semantics 451
by saying that in the following sentence her “has its head” or “is coreferential with”Mary and that him is not coreferential with Tom but could be coreferential with Dick.
(9.1) Dick’s friend Tom saw Mary and also saw a bench between her and him.
According to the analysis sketched above, the first statement means that the individualchosen by the verifier as the value of her when (R. she) is applied is Mary, i.e. the indi-vidual introduced into I(9.1) as a value of Mary. The second statement means that Tomis not chosen as the value of him, but that Dick might be. But speaking of “choosing”refers to some play of the game, connected with and starting with (9.1). Which play?And how do we know what choices the players will in fact make? Obviously what ismeant is that the choices in question are a part of the verifier’s winning strategy. She,he or it could have made other choices without violating any rules for making movesin a semantical game. But that could have led to a loss for the verifier.
What all this amounts to is that the theory of anaphoric cross-reference is a partof the study of strategic meaning not of abstract meaning. Yet it is seen from ourexamination of anaphoric pronouns that they can be analyzed and theorized about bymeans of the very same framework as was used to define abstract meaning.
This example shows that strategic meaning is not a merely pragmatic or psycho-logical phenomenon that does not belong to the study of language, first impressionnotwithstanding.
Admittedly, other kinds of strategic meaning are more ephemeral, for instance, thecircumlocutory use of quantifier expressions like someone, or some people to refer tosomeone present, for example, in
(9.2) Some people have never learned how to behave in civilized company.
8.2.10 De dicto vs. de re Distinction
According to the GTS project, a game rule should be associated with each lexical item,not just with quantifiers, connectives and knows that. When this idea is applied suc-cessfully, the lexical item receives its semantics from the rule. What is more, its seman-tics becomes integrated into an overall theory; among other things, the new rule mustobey the same general ordering principles as other rules because its specific orderingprinciples indirectly affect the meaning of other words and because these meaning-determining game rule automatically determine the rules for anaphora involving theexpressions to be characterized. Likewise, the notion of information independence canin principle apply to any application of any rule for semantical games.
In fact, a game rule can be associated even with individual constant and predicateconstants. Given an individuate constant b, the rule in question asks the verifier toassign a member of the domain of the relevant model to b as its value. Since it must berequired that the individual chosen equals b, this rule – we shall call it (R. ind) – doesnot seem to matter for the interpretation of any sentence. In reality, the postulation ofsuch a rule makes a great deal of sense. It must be subject to the same general orderingprinciples as apply to other rules. These rules may in turn explain other phenomena,for instance, anaphora.

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 452 — #38
452 Handbook of Logic and Language
Examples are offered by pairs of sentences like
(10.1) John believes that he is clever.
(10.2) He believes that John is clever.
Because of (O. comm), in (10.1) John is treated before he. Hence John is a possiblevalue of he, making coreference possible. In (10.2) John is in a lower clause, andhence cannot be available as a value of he in virtue of (O. comm).
Likewise, the notion of independence can apply to moves made in accordance with(R. ind). Consider, for the purpose of seeing what this may entail, the following for-mulas of epistemic logic:
(10.3) KaP(b)
(10.4) KaP((b/K)).
Here (10.3) says that a knows that (it is the case that) P(b). But what does (10.4) say?In (10.4), the individual who is to serve as the value of b must be chosen independentlyof Ka, in other words, as being the same for all models compatible with what a knows.In still other words, a knows of the individual who is in fact b that that individual hasthe property P.
If you reflect on this distinction for a moment, you will see that is an instance ofwhat is meant by the difference between the de dicto and de re readings of naturallanguage sentences like
(10.5) Margaret knows that Lord Avon was indecisive.
Here what is meant may be that Margaret knows de dicto that the sentence
(10.6) Lord Avon was indecisive
is true, or that she knows of the gentleman who in fact was Lord Avon that he wasindecisive, without knowing the noble title of the gentleman in question (perhaps sheknows him only as Anthony Eden).
This explication of the famous distinction can be generalized to other cases. Inspite of its simplicity, it has some remarkable consequences. For one thing, it showsthat the de dicto vs. de re distinction is not unanalyzable, even if it is not signaledin English by any uniform syntactical device. As a consequence, the distinction doesnot involve any difference whatsoever between different kinds of knowledge. Bothkinds of knowledge have precisely the same objects, in the sense that the same entitiesare involved in the models of either kind of knowledge statement. In general, theregularities governing the de dicto vs. de re distinction are consequences of the moregeneral regularities governing informational independence.
The same distinction is found in other kinds of concepts, including functions andpredicates. For instance, there is a difference between two readings of
(10.7) Tom knows that all Dick’s friends are businessmen.

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 453 — #39
Game-Theoretical Semantics 453
It can mean either that Tom knows the truth of the generalization
(10.8)!&x
"(x is a friend of Dick / x is a businessman)
or that Tom knows of each individual who happens to be (possibly unbeknowst toTom) a friend of Dick that he is a businessman.
Likewise, our treatment of the de dicto vs. de re contrast applies mutatis mutandisto contexts other than the epistemic ones.
8.3 A Survey of Games in Logic and in Language Theory
8.3.1 Games in Logic
In order to put GTS into perspective, and for the sake of the intrinsic interest of the sub-ject, it is in order to survey the uses of game-theoretical ideas in logic and language-theory more generally.
In model theory, logicians have resorted to game-theoretical concepts whenevercompositional truth-definitions elude them. This can happen in two different ways.Either there are actual semantical context-dependencies present, or else formulas neednot be built recursively from atomic formulas, so that there are no starting points forinside-out truth-definitions.
The former predicament occurred for the first time when Henkin (1959) introducedbranching quantifiers. Predictably, he characterized the truth of branching quantifiersentences by using game-theoretical concepts.
The latter predicament occurs in the study of infinitary languages. There the syntaxof a formula need not be well-founded.
Needless to say, the natural truth-definitions for both kinds of languages are game-theoretical.
The motivation for using game-theoretical truth-definitions goes back to the workof Skolem (1920) who noticed that a sentence in prenex form, e.g., &x%y&z%wS[x, y,z, w] is true in a model M if and only if there are (Skolem) functions f and g such that&x&zS[x, f (x), z, g(x, z)] is true in M.
The connection between Skolem functions and games was made by Henkin (1959).He noticed that the truth of every sentence in prenex form in a model M can be charac-terized by a game of perfect information. The corresponding game is exactly like thesemantical games of GTS. Henkin extended the game interpretation to sentences withquantifier-prefixes of countable length and noticed that the same could be done evenfor sentences · · · %y3&y2%y1&y0R[ y0, y1, y2, y3, . . .] in which the sequence of quanti-fiers in the prefix is not well-founded. The idea of extending the game interpretationto quantifier prefixes of arbitrary infinite length led to the study of game quantifiers.A survey of these quantifiers in the context of Abstract Model Theory is contained inKolaitis (1985). (Cf. also Van Benthem, 1988; Hodges, 1985.)
In Hintikka (1974), the game interpretation of formulas was extended to formu-las which are not prenex, that is, to the truth-functional connectives exactly as it

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 454 — #40
454 Handbook of Logic and Language
is described in the first part of this chapter. As in the case of prenex formulas, thegeneralization of Hintikka’s idea to the infinitary case led to the study of non-well-founded formulas which allow arbitrary alternating infinite sequences of quantifiers,conjunctions and disjunctions. They have been proposed for the first time in Hintikkaand Rantala (1976) and thereafter studied by Joukko Väänänen and his associates, forexample, by Karttunen (1984), Hyttinen (1987) and Oikkonen (1988).
What is known as back-and-forth games were introduced by Ehrenfeucht (1961).The basic ideas of back-and-forth games nevertheless go back to Fraissé (1959), whodid not use the game terminology. These games, usually denoted by G(A, B), are usedto compare two models M and N as to elementary equivalence. Here Nature tries toshow that M and N are different (i.e. nonequivalent) and Myself tries to show that theyare the same. Every move in the game consists of Nature choosing an element fromone of the structures and Myself choosing an element from the other. Myself wins if,after a certain number of moves, the patterns of objects chosen in the two structuresform an isomorphism. Natures wins if he can choose an element which Myself cannotmatch with the elements of the other structure. Elementary equivalence between themodels is a necessary and sufficient condition for Myself winning the game G(A, B)
with countable moves. Hodges (forthcoming) contains a lively exposition of the waysin which these games can be generalized.
Another class of games used in logic deals with the construction of models. Forinstance, the Henkin-type construction of canonical models may be seen as a game ofbuilding models in which Nature formulates properties (via a language) to be realizedor “enforced” in the model, and Myself adds witnessing constants, decompositions,etc., which makes the realization of the properties possible. (Cf. Van Benthem, 1988.)
Game-theoretical truth-definitions can also be used when the concept of model isextended in certain interesting ways. A case in point is the notion of the urn modelintroduced by Rantala (1975). An urn model is like its namesake in probability theory:it can change between one’s successive choices of elements from it. Those “choices”are of course but successive moves in a semantical game. Such urn models offeramong other things a simple and natural way of reconciling a possible-worlds treat-ment of epistemic notions and the failure of “logical omniscience” (one does not knowall the logical consequences of what one knows.) (See here Hintikka, 1975.)
One of the best known uses of game-theoretical ideas is in proof theory. The moti-vation for the game-theoretical interpretation came from the work of Hintikka (1955)and Beth (1955) on Gentzen-type proofs in first-order logic.
In the game-theoretical setting, we can think of the truth-tree method of a proof asa kind of game. A nice description of such games is contained in Hodges (1985).
In such a game, Myself wants to construct a model for a sentence S and Naturetries to show that there is no such model. For instance, if S is of the form (R $ P), thenNature challenges Myself to put both R and P on the table. If Myself cannot do thishe loses the game. If S is (R # P), then Nature challenges Myself to choose either oneof the disjuncts and put it on the table. If S is %xR(x), then Nature challenges Myselfto find a name c and put R(c) on the table. If Myself can comply with all of Nature’schallenges, he wins the game. If a contradiction appears on the table, then Nature wins.

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 455 — #41
Game-Theoretical Semantics 455
These games are determinate. It is straightforward to show that Myself has a winningstrategy in the game if and only if S has a model, and Nature has a winning strategy ifand only if ¬S has a proof. Actually a winning strategy for Nature turns out to be thesame thing as a proof tableau for ¬S.
One of the interesting things about this game-theoretical setting in proof theoryis that we can put all sorts of constraints on the moves of the players. For instance,we can require that the sentences challenged by Nature cannot be any longer used inthe game, or that when challenging (R $ P), Nature decides which one of R and P isput on the table. A suitable constraint on the moves of the players yields Lorenzen’sdialogical logic.
Originally (cf. Lorenz, 1961), Lorenzen offered an interpretation of the intui-tionistic proof rules in first-order logic and in elementary arithmetic, including the usesof inductive definitions. His ideas were systematized and developed further by Lorenz(1961). The proof games they considered are identical with the ones illustrated above,except that they proceed through verbal “attacks” (Angriffe) and “defenses” (Verteidi-gungen).
Later, Lorenzen and Lorenz suggested another interpretation for closely relatedgames (Lorenz, 1968; Lorenz and Lorenzen, 1978). These games were called materialgames in contradistinction to the earlier formal games, and they were supposed toserve as the semantical basis of the ordinary (interpreted, material) truth. The factual(nonlogical) element enters into these games through the assumptions that the truth-values of atomic sentences are fixed (and decidable).
Dialog games inspired by Lorenzen’s games and closely related to them have beenconstructed and studied by E.M. Barth and her associates; e.g., see Krabbe (1982).
Lorenzen’s games have also recently inspired Blass, who presented a game seman-tics in the style of Lorenzen as an interpretation for Girard’s linear logic. Essentially, agame interpretation assigns games to propositions, and operations on games to propo-sitional connectives. The truth of a sentence in a game interpretation is defined asthe existence of a winning strategy for the “defender” in the game assigned to it bythe interpretation. Blass showed that under this interpretation, affine logic (i.e. linearlogic plus the rule of weakening) is sound and complete (with certain restrictions). (Cf.Blass, 1992; Abramsky and Jagadeesan, 1992, for an improvement and refinement ofBlass’ results.)
Recently Aarne Ranta (1994) has sought to relate Martin-Löf’s intuitionistic typetheory to GTS. He tried to show that GTS can be understood constructively by inter-preting games as propositions and winning strategies as proofs.
Occasionally, game-theoretical ideas have been used in the study of pragmatics,including conversational implicature. (See Parikh, 1992.)
8.3.2 Games in Philosophical Language Theory
In philosophy, competitive question-answer games, modeled on the Socratic methodof questioning, were cultivated in Plato’s Academy. (Cf. Ryle, 1971; Hintikka,1993a.) In the middle ages, a variety of question-answer disputation games, known

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 456 — #42
456 Handbook of Logic and Language
as obligation games, were for a long time a central part of philosophical methodology.They are dealt with in detail in Yrjönsuuri (1994).
In our century, Wittgenstein’s notion of language-game was the key concept in hislater philosophy. The game idea was first introduced by him to illustrate the claimthat language-world connections are mediated by certain human activities that aregoverned by rules just like games. Later, Wittgenstein came to assign to language-games a conceptual primacy over their rules. (See here Hintikka, 1986.)
More generally and much more loosely, analogy with games has been frequentlyemployed by philosophers to illustrate the purely formal character of logical inference.In Wittgenstein, the emphasis is not on the formal character of game rules, but on theneed for language users actually to do something.
Some philosophers have used game-theoretical concepts also in epistemology andspoken of “games of exploring the world” (Ryle). One explicit form of such games isHintikka’s interrogative games, where the factual input into an inquirer’s reasoningis conceptualized as nature’s or some other “oracle’s” answers to the inquirer’s ques-tions. (See Hintikka, 1988.) These interrogative games are logically speaking closelyrelated to Socratic games of questioning, with nature (or some other oracle) cast intothe role of the inquirer’s interlocutor. They can be used as a basis of a general logicaltheory of identification. (See Hintikka, 1991a.)
8.3.3 Differences between Different Games
Some order can be created among this multitude by distinctions between differentkinds of games. The following list of four kinds of games is not exhaustive:
(i) Games of verification and falsification.(ii) Games of formal proof.
(iii) Games of inquiry.(iv) Games of model construction.
Most of the applications of game-theoretical concepts mentioned above can easily findtheir niche in this classification.
The semantical games of GTS exemplify (i).Many other games are simply special cases of semantical games, for instance Dio-
phantine games and the games used in dealing with infinitary deep languages and withbranching quantifiers. Diophantine games are especially interesting in a general theo-retical perspective in that among them one soon runs into games in which there existswinning strategies for one of the players, but no recursive winning strategies. (Cf.Section 1.8, above, and Matiyasevich, 1993, p. 183.)
Back-and-forth games are not literally special cases of semantical games. However,they are very closely related to semantical games played with the ingredients of dis-tributive normal forms (Cf. Hintikka, 1953, 1994) called constituents. Then playing anEhrenfeucht game Gd(A, B) of length d on two models A and B is structurally relatedto playing a semantical game with a constituent of depth d. More generally, the entire

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 457 — #43
Game-Theoretical Semantics 457
back-and-forth technique can be considered as being tantamount to the technique ofconstituents and distributive normal forms.
The distinction between games of verification (i) and games of formal proof (ii) isimportant but is often overlooked. Yet the difference could not be more striking. Veri-fication games serve to define truth; proof games aim at capturing all (and only) logi-cal truths. Now truth and logical truth are categorially different. Truth presupposes afixed interpretation and is relative to a single model. Logical truth means truth on anyinterpretation (in any model). Verification games are played among the objects one’slanguage speaks of; proof games are played with pencil and paper (or on a computer).
The distinction between verification games and games of inquiry is even subtler.Games of inquiry model the ways in which sentences are actually found to be true,whereas semantical games are activities in terms of which the truth of sentences canbe defined. In games of inquiry, there is an epistemic element present; such games areattempts to come to know a truth or an answer to some question. Games of inquiryhave connections with learning theory (cf. Osherson’s article in this volume.) Theycan serve to develop a general logical theory of identification. (Cf. Hintikka, 1991a.)In contrast, in a semantical game, there may exist a winning strategy for the verifierwithout her knowing what it is or even knowing that such a strategy exists. In thissense our account of GTS differs significantly from Tennant’s (1990), who speaks allthe time about the players “possessing” strategies.
Games of model construction are becoming more and more important in logicaltheory. So far, they have not been related to language theory very closely.
Several other kinds of games used in model theory are either closely related to thesemantical games of GTS or special cases of such games, for instance the Svenoniusgames defined in Hodges (1993, p. 112.)
All these types of games must be distinguished from still others:
(v) Disputation games.(vi) Communication games.
Again there has been a great deal of confusion in the literature. Wittgenstein’slanguage-games are sometimes taken to be games of communication whose “moves”are language acts, e.g., speech acts. This is a misinterpretation, as is shown in Hin-tikka (1986). Wittgenstein’s first “calculi” were processes of verification and falsifica-tion, and even though the terms “language-game” came to cover a tremendous varietyof different uses of language, the deep point in Wittgenstein is that even descriptivemeaning is always mediated by those nonlinguistic activities he called “language-games”.
8.3.4 Interrelations between Different Kinds of Games
There is admittedly a fair amount of overlap between the different kinds ofgames (i)–(vi). For instance, dialogical games, including disputation games, caninvolve question-answer sequences, which can likewise be used to model games of

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 458 — #44
458 Handbook of Logic and Language
inquiry and even games of formal proof. It has been argued that the vagaries ofmedieval obligation-games reflect hesitation between the proof-interpretation and theinquiry-interpretation.
Likewise, and more obviously, the difficulty of understanding Lorenzen’s games isdue to the fact that they are tacitly supposed to do three different kinds of duty. Hisformal games are games of logical proof, but he claimed that the structurally simi-lar material games can be used to define truth (material truth). In reality, Lorenzen’smaterial games are not games of verification (i), but instead are very closely related toa special case of games of inquiry, viz. the case in which the only answers the inquirerhas access to are atomic. It does not seem that one and the same kind of game canserve all these three purposes.
A link between (ii) and (iv) is established by the interpretation that was proposedby Hintikka (1955) and Beth (1955) on Gentzen-type proofs in first-order logic. Suchproofs can be interpreted as frustrated attempts on the part of Myself to construct acountermodel (counter-example) to the sentence (or inference) to be proved. But then,recalling our discussion of proof games, if Myself cannot produce a model for ¬S,that is, if Myself does not have a winning strategy in the game G(¬S), then Nature hasone, and this amounts, as we saw above, to ¬ ¬S (S, in classical logic) having a proof.
Rules for such a procedure are naturally conditioned by the definitions of the truthand falsity, for the model is supposed to be one in which a certain sentence (or a set ofsentences) is true. Hence, we have here also a link with games (i).
Another connection between different kinds of games is the close connection whichexists between certain optimal strategies in games of deductive proof and optimalstrategies in certain kinds of games of empirical inquiry. (See Hintikka, 1989.)
The results of GTS help to clarify the roles of different kinds of games in languagetheory. They show that ordinary (descriptive) sentence meaning can be characterizedin terms of semantical games (games of verification and falsification). However, dif-ferent aspects of these games can all contribute to this meaning in different ways.For instance, while the difference between a universal quantifier and an existentialquantifier is based on the game rule governing each of them separately, the differencebetween the English quantifier words every and any is based on the ordering princi-ples that govern the priorities of their game rules in relation to other game rules. (Cf.Section 2.3 above.)
Normally, sentence meaning does not depend on games of inquiry. The only clear-cut exception that has come to light is the meaning of why-questions. (See hereHalonen and Hintikka, 1995.) Moreover, even though differences in the rules of for-mal proof may reflect differences between the different interpretations of a logicalconstant, there are no realistic examples where the interpretational difference can becharacterized in any informative way by reference to the rules of formal proof.
8.3.5 What is Essential about Games?
In order to sort out the variety of uses of game concepts, it is also in order to askwhat is essential about game-theoretical conceptualizations. What is essential is not

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 459 — #45
Game-Theoretical Semantics 459
the idea of competition, winning and losing. In the mathematical theory of games, onecan study games of cooperation and not only competitive games, and there are “gamesagainst nature” where one of the players has a purely reactive role. What is essen-tial is the notion of strategy. Game theory was born the moment John von Neumann(1929) formulated explicitly this notion. Hintikka (1990) has argued that the deepersignificance of game-theoretical methods in language theory lies in the paradigm theyrepresent. When they are used, language is considered a goal-directed rather than rule-governed activity. Hintikka has also repeatedly emphasized the importance of strategicrules (or principles) as distinguished from definitory rules. The latter typically specifywhich particular moves are admissible. They specify the game tree (the extensive formof the game). In contrast, strategic rules deal with better and worse ways of playingthe game (within the definitory rules). The truth-definition used in GTS is an exampleof a strategic conceptualization.
Thus the fact that Wittgensteinian language-games do not normally involve overtcompetition is no obstacle to treating them by game-theoretical means. The cru-cial question is, rather, what role is played by the notion of strategy in Wittgen-steinian language-games. The conceptual priority which Wittgenstein assigned toentire language-games vis-à-vis their rules is in keeping with an emphasis on an essen-tially strategic viewpoint. Moreover, it is important to realize what kinds of gamesWittgenstein had in mind. It turns out that during his formative period in 1929–1931,Wittgenstein was preoccupied with the activities (“games” or “calculi”) of verificationand falsification. In view of this fact, it is not unnatural to consider semantical gamesas a species of language-games in a Wittgensteinian sense.
How essential is the reliance on game-theoretical concepts in these various“games”? In many cases, as Hodges (forthcoming) points out, game-theoretical ter-minology is dispensable. One has to be careful here, however, for what is at issue isnot mere terminology. It does not normally matter, for instance, whether we speakof Skolem functions, choice functions or functions codifying winning strategies in asemantical game, or whether we speak of back-and-forth games or of distributive nor-mal forms. The interesting question is whether the structures that are characteristicallygame-theoretical are being utilized. Among them there is the notion of strategy andthe notions depending on it.
A typical notion of that kind is the idea of determinacy. This notion is applicableto two-person zero-sum games. In such games, the question arises whether one or theother of the two players has a winning strategy in a given game. If and only if that isthe case, the game is called determinate. It was seen in Section 1.8 above that the lawof excluded middle is a determinacy assumption. From the set-theoretical assumptionof determinacy (Fenstad, 1971) it is seen that determinacy assumptions can, in suitablecircumstances, be very strong indeed.
When such typically game-theoretical ideas are used, the game-theoretical inputcan be taken to be essential.
Another kind of essential reliance on game-theoretical ideas is exemplified by thefact that GTS is independent of the assumption of compositionality, whereas severaltraditional methods, such as Tarski-type truth-definition, presuppose compositionality.

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 460 — #46
460 Handbook of Logic and Language
In the light of these remarks, it can be seen that the game element in games of for-mal proof is rather thin. At most, it amounts to an emphasis on the strategic aspects oflogical proof. These strategic aspects are not very deeply connected with the questionof whether a given formula is provable at all. For the very existence of a completeproof procedure means that it suffices to consider a single procedure in order to find aproof for a given sentence, if there exists one. In other words, we do not have to con-sider all the possible plays of a given game, as we have to do if the use of the conceptof strategy is indispensable, as it is in the game-theoretical truth-definitions.
8.3.6 Games and Nonclassical Logic
These remarks can be illustrated by raising the question as to what the reasons are foropting for intuitionistic rules rather than classical ones. Some logicians, e.g., Loren-zen, have claimed that the dialogical approach naturally leads to a nonclassical logic.This is dubious. The crucial restriction which leads to intuitionistic logic in Lorenzen’sapproach is that “attacks” and “defenses” of one of the players cannot be repeated arbi-trarily, as they can be in the Lorenzenian version of classical logic (see Lorenz, 1961,Section 2.4). The motivation of that requirement is far from obvious, especially in the“material” games dealing with truth rather than provability.
By and large, nonclassical or nonclassical looking elements can enter into logicalgames in several different ways:
(i) When informational independence is allowed, the law of excluded middle fails.It is important to see that this failure of the laws of classical logic has nothing to do
with constructivistic or intuitionistic ideas. It cannot be captured by modifying classicalproof procedures, for IF first-order logic is inevitably incomplete.
(ii) Constructivistic ideas are most naturally implemented by restricting the initial verifier’sstrategies in a semantical games to recursive ones. The resulting first-order logic isinevitably incomplete, however, and hence differs from Heyting’s well-known axioma-tization of intuitionistic first-order logic.
(iii) Games of inquiry involve an epistemic element. They are games of coming to know cer-tain truths or of answering certain questions. If this epistemic element is not representedexplicitly, the resulting rules will differ from classical ones, and at least in some casesagree with intuitionistic ones.
(iv) Nonclassical game rules can be given for propositional connectives, especially for condi-tional and negation. For negation, such rules were described in Section 1.8, and for theconditional in Section 2.6.
Sometimes game-theoretical concepts are used in a nontrivial way even when noovert game-terminology is employed. Thus Dana Scott (1993) has shown that Gödel’sDialectica interpretation (1958) of first-order logic and arithmetic can be given anelegant game-theoretical formulation. This way of looking at Gödel’s interpretationhas been examined further by Hintikka (1993b). Indeed, Gödel’s interpretation turnsout to exemplify several of the uses of game-theoretical concepts mentioned in thissurvey, including the constructivistic restriction of verificatory strategies to recursiveones and the nonstandard treatment of conditionals.

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 461 — #47
Game-Theoretical Semantics 461
Note on Recent Developments
Hintikka (2010) shows how neglecting the function of quantifiers as dependence indi-cators has actually led to serious difficulties in the theory of definitions and in thefoundations of set theory. Hintikka (2009) and Hintikka and Symons (2010) consideran extension of IF logic in which, in addition to the independence of the existentialquantifiers on the universal quantifiers in the scope of which they occur, freer pat-terns of dependence and independence are allowed. The result is a general logic thatis as strong as the entire second-order logic (with standard interpretation). It allowsunrestricted use of contradictory negation. Finally, Hintikka (2009) and Hintikka andKarakadilar (2006) discuss the foundational significance of the extended IF logic inrelation to Hilbert’s Program.
References
Abramsky, S., Jagadeesan, R., 1992. Games and Full Completeness for Multiplicative LinearLogic, Technical Report DoC 92/94, Imperial College of Science, Technology andMedicine, London.
Barwise, J., 1976. Some applications of Henkin quantifiers. Israel J. Math. 25, 47–63.Barwise, J., 1979. On branching quantifiers in English. J. Philos. Logic 8, 47–80.Beth, E.W., 1955. Semantic entailment and formal derivability. Mededelingen der Koninklijke
Nederlandse Akademie van Wetenschappen, Afd. Letterkunde, n.s. 18, 309–342.Blass, A., 1992. A game semantics for linear logic. Ann. Pure Appl. Logic 56, 183–220.Boolos, G., 1984. To be is to be the value of a variable (or to be the values of some variables).
J. Philos. 10, 430–449.Carlson, L., Ter Meulen, A., 1979. Informational independence in intensional context, in:
Saarinen, E., Hilpinen, R., Niiniluoto, I., Hintikka, M.B. (Eds.), Essays in Honor ofJaakko Hintikka on the occasion of his fiftieth birthday on January 12, Reidel, Dordrecht,pp. 61–74.
Chomsky, N., 1981. Lectures on Government and Binding. Foris, Dordrecht.Chomsky, N., 1986. Knowledge of Language. Praeger, New York.Cresswell, M.J., 1988. Semantical Essays. Possible Worlds and Their Rivals. Kluwer,
Dordrecht.Davidson, D., 1980. Any as universal or existential?, in: van der Auwera, J. (Ed.), The Seman-
tics of Determiners, Croom Helm, London, pp. 11–40.Davis, M., 1981. Meaning, Quantification, Necessity. Routledge and Kegan Paul, London.Ebbinghaus, H.D., Flum, J., Thomas, W., 1984. Mathematical Logic. Springer, New York.Ehrenfeucht, A., 1961. An application of games to the completeness problem for formalized
theories. Fund. Math. 49, 129–141.Enderton, H.B., 1970. Finite partially-ordered quantifiers. Z. Math. Logik Grundlag. Math. 16,
393–397.Fenstad, J.E., 1971. The axiom of determinateness, in: Fenstad, J.E. (Ed.), Proceedings of the
Second Scandinavian Logic Symposium. North-Holland, Amsterdam, pp. 41–62.Fraissé, R., 1959. Sur l’extension aux relations de quelques proprietés des ordres. Ann. Sci.
École Norm. Sup. 71, 363–388.Groenendijk, J., Stokhof, M., 1991. Dynamic predicate logic. Ling. Philos. 14, 39–100.

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 462 — #48
462 Handbook of Logic and Language
Hand, M., 1987. Semantical games, verification procedures, and wellformedness. Philos. Stud.51, 271–284.
Heim, I.R., 1982. The Semantics of Definite and Indefinite Noun Phrases: Dissertation at theUniversity of Massachusetts, MA.
Henkin, L., 1959. Some remarks on infinitely long formulas, Infinitistic Methods, Proceedingsof the Symposium on Foundations of Mathematics, Warsaw, pp. 167–183.
Hilpinen, R., 1982. On C.S. Peirce’s theory of the proposition: Peirce as a precursor of game-theoretical semantics. Monist 62, 182–189.
Hintikka, J., 1953. Distributive normal forms in the calculus of predicates. Acta Philos. Fennica6, Societas Philosophica Fennica, Helsinki, pp. 97–104.
Hintikka, J., 1955. Form and content in quantification theory, two papers on symbolic logic.Acta Philos. Fennica 8, 7–55.
Hintikka, J., 1956. Variables, identity and impredicative definitions. J. Symb. Logic 21,225–245.
Hintikka, J., 1974. Quantifiers vs. quantification theory. Ling. Inq. 5, 153–177.Hintikka, J., 1975. Impossible possible worlds vindicated. J. Philos. Logic 4, 475–484.Hintikka, J., 1976. The semantics of questions and the questions of semantics. Acta Philos.
Fennica 28 (4), Societas Philos. Fennica, Helsinki.Hintikka, J., 1986. The varieties of being in Aristotle, in: Knuuttila, S., Hintikka, J. (Eds.), The
Logic of Being. Reidel, Dordrecht, pp. 81–114.Hintikka, J., 1988. What is the logic of experimental inquiry?. Synthese 74, 173–190.Hintikka, J., 1989. The role of logic in argumentation. Monist 72 (1), 3–24.Hintikka, J., 1990. Paradigms for language theory, in: Haaparanta, L., Kusch, M., Niinilu-
oto, I. (Eds.), Language, Knowledge, and Intentionality: Perspectives on the Philosophyof Jaakko Hintikka. Acta Philos. Fennica, vol. 49, Societas Philos. Fennica, Helsinki,pp. 181–209.
Hintikka, J., 1991a. Towards a general theory of identification, in: Fetzer, J.H., Shatz, D.,Schlesinger, G.N. (Eds.), Definitions and Definability. Kluwer, Dordrecht, pp. 161–183.
Hintikka, J., 1991b. Defining Truth, the Whole Truth and Nothing but the Truth, Reports fromthe Department of Philosophy of the University of Helsinki, No. 2.
Hintikka, J., 1993a. Gödel’s Functional Interpretation in a Wider Perspective. Kurt Gödel Soci-ety, Yearbook 1991, Vienna, pp. 5–43.
Hintikka, J., 1993b. Socratic questioning, logic and rhetoric. Rev. Internat. Philos. 47, 5–30.Hintikka, J., 1994. New Foundations for Mathematical Theories. Lecture Notes in Math. vol. 2.Hintikka, J., 1995. What is elementary logic? Independence-friendly logic as the true core area
of logic, in: Gavroglu, K., Stachel, J., Wartofsky, M.W. (Eds.), Physics, Philosophy, andthe Scientific Community, Kluwer, Dordrecht, pp. 301–326.
Hintikka, J., 2009. A proof of nominalism, Hinke, A., Leitgeb, H. (Eds.), Reduction-Abstraction-Analysis. Ontos Verlag, Frankfurt, pp. 1–13.
Hintikka, J., 2010. IF Logic, Definitions and the Vicious Circle Principle, working paper.Department of Philosophy, Boston University, MA.
Hintikka, J., Rantala, V., 1976. A new approach to infinitary languages. Ann. Math. Log. 10,95–115.
Hintikka, J., Carlson, L., 1979. Conditionals, generic quantifiers, and other applications of sub-games, in: Margalit, A. (Ed.), Meaning and Use. Reidel, Dordrecht, 57–92. (reprinted inSaarinen, 1979).
Hintikka, J., Hintikka, M.B., 1986. Investigating Wittgenstein. Basil Blackwell, Oxford.Hintikka, J., Kulas, J., 1983. The Game of Language. Reidel, Dordrecht.

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 463 — #49
Game-Theoretical Semantics 463
Hintikka, J., Kulas, J., 1985. Anaphora and Definite Descriptions. Reidel, Dordrecht.Hintikka, J., Sandu, G., 1989. Informational independence as a semantical phenomenon, in:
Fenstad, J.E., Frolov, I.T., Hilpinen, R. (Eds.), Logic, Methodology and Philosophy ofScience VIII. Elsevier, Amsterdam, pp. 571–589.
Hintikka, J., Sandu, G., 1991. On the Methodology of Liguistics. Basil Blackwell, Oxford, UK.Hintikka, J., Karakadilar, B., 2006. How to prove the consistency of arithmetic. Acta Philos.
Fennica 78, 1–15.Hintikka, J., Symons, J., 2010. Game-Theoretical Semantics as the Basis of a General Logic.
working paper, Department of Philosophy, Boston University and Department of Philoso-phy, University of Texas at El Paso, TX.
Hodges, W., 1985. Building Models by Games. Cambridge University Press, Cambridge, MA.Hodges, W., 1989. Elementary predicate logic, in: Gabbay, D., Guenther, F. (Eds.), Handbook
of Philosophical Logic I, vol. 2. Gabbay, Reidel, Dordrecht, pp. 1–131.Hyttinen, T., 1987. Games and Infinitary Languages. Doctoral Dissertation, Annales Academiae
Scientiarum Fennicae, Vol. 64, pp. 1–32.Kamp, H., 1982. A theory of truth and semantic representation, in: Groenendijk, J., Janssen,
T.M.V., Stokhof, M.B.J. (Eds.), Formal Methods in the Study of Language. MatematischCentrum, Amsterdam, pp. 277–322.
Karttunen, M., 1984. Model theory for infinitely deep languages. Ann. Acad. Sci. Fenn. ser. A I,Math. Dissertationes, 50, University of Helsinki, pp. 897–908.
Krabbe, C.W.E., 1982. Studies in Dialogical Logic, Dissertation, University of Groningen,Netherlands.
Kripke, S., 1976. Is there a problem about substitutional quantification?, in: Evans, G., McDow-ell, J. (Eds.), Truth and Meaning. Oxford University Press, UK, pp. 325–419.
Krynicki, M., Lachlan, A., 1979. On the semantics of the Henkin quantifier. J. Symb. Logic 44,184–200.
Krynicki, M., Mostowski, M., 1995. Henkin quantifiers, in: Krynicki, M., Mostowski, M.,Szczerba, L. (Eds.), Quantifiers: Logic, Models and Computation, vol. 1: Surveys. Kluwer,Dordrecht, pp. 193–262.
Lasnik, H., 1975. On the semantics of negation, in: Hockney, D.J. (Ed.), Contemporary Researchin Philosophical Logic and Linguistic Semantics. Reidel, Dordrecht, pp. 279–311.
Lorenz, K., 1961. Arithmetik und Logik als Spiele. Dissertation, University of Kiel, Deutsch-land.
Lorenz, K., 1968. Dialogspiele als semantische Grundlagen von Logikkalkülen. Arch. Math.Logik Grund. 11, 32–55, 73–100.
Lorenz, K., Lorenzen, P., 1978. Dialogische Logik. Wissenschaftliche Buchgesellschaft, Darm-stadt.
Lorenzen, P., 1961. Ein dialogisches Konstruktivitätskriterium, Infinitistic Methods. PergamonPress, Oxford, pp. 193–200.
Oikkonen, J., 1988. How to Obtain Interpolation for L%+% , Logic Colloquium ’86, in: Drake,F., Thuss, J. (Eds.), North-Holland, Amsterdam, pp. 175–208.
Parikh, P., 1992. A game-theoretic account of implicature, in: Moses, Y. (Ed.), Theoreti-cal Aspects of Reasoning about Knowledge IV. Morgan Kaufmann, Los Altos, CA,pp. 85–94.
Quine, W.V.O., 1960. Word and Object. MIT Press, Cambridge, MA.Ranta, A., 1994. Type-Theoretical Grammar. Oxford University Press, UK.Rantala, V., 1975. Urn models. J. Philos. Logic 4, 455–474.

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 464 — #50
464 Handbook of Logic and Language
Ryle, G., 1971. The Academy and Dialectic, Collected Papers, vol. 1. Hutchinson, London,pp. 89–115.
Sandu, G., 1991. Studies in Game-Theoretical Logics and Semantics. Doctoral Dissertation,Department of Philosophy, University of Helsinki, Deutschland.
Scott, D., 1993. A game-theoretical interpretation of logical formulae. Kurt Gödel Society, Year-book 1991, Vienna, 1993, pp. 47–48. (Originally written in 1968.)
Skolem, T., 1920. Logisch-kombinatorische Untersuchungen über die Erfüllbarkeit oderBeweisbarkeit mathematischer Sätze nebst einem Theoreme über dichte Mengen, Viden-skapsselskapets Skrifter, I. Matem.-naturv. Kl. I 4, 1–36.
Stenius, E., 1976. Comments on Jaakko Hintikka’s paper “Quantification vs. QuantificationTheory”. Dialectica 30, 67–88.
Tarski, A., 1956. Logic, Semantics, and Metamathematics. Clarendon Press, Oxford.Tennant, N., 1990. Natural Logic. Edinburgh University Press, UK.Thomason, R. (Ed.), 1974. Formal Philosophy: Selected Papers by Richard Montague. Yale
University Press, New Haven, CT.Van Benthem, J., 1988. Games in logic, in: Hoepelman, J. (Ed.), Representation and Reasoning.
Niemeyer Verlag, Tübingen, 3–15, pp. 165–168.Vaught, R.L., 1960. Sentences true in all constructive models. J. Symb. Logic 25, 39–53.von Neumann, J., 1929. Zur Theorie der Gesellschaftsspiele. Math. Ann. 100, 295–320.Walkoe, W., 1970. Finite partially order quantification. J. Symb. Logic 35, 535–550.Yrjönsuuri, M., 1994. Obligationes: 14th Century Logic of Disputational Duties. Societas Phi-
los. Fennica, Acta Philos. Fennica 55, Helsinki, p. 182.
Further Reading
Conway, J.H., 1976. On Numbers and Games. Academic Press, London.Halonen, I., Hintikka, J., 1955. Semantics and pragmatics for why-questions. J. Philos. 92,
636–657.Hella, L., Sandu, G., 1995. Partially ordered connectives and finite graphs, in: Mostowski, M.,
Krynicki, M., Szczerba, L. et al. (Eds.), Quantifiers, Generalizations, Extensions and Vari-ants of Elementary Logic. Kluwer, Dordrecht, pp. 79–88.
Hintikka, J., 1982. Temporal discourse and semantical games. Ling. Philos. 5, 3–22.Hintikka, J., 1986. Is scope a viable concept in semantics?, in: Marshall, F. et al. (Eds.), Pro-
ceedings of the Third Eastern State Conference in Semantics, ESCOL ’86, The Ohio StateUniversity, Columbia, pp. 259–270.
Hintikka, J., 1988. On the development of the model-theoretical tradition in logical theory.Synthese 77, 1–36.
Hintikka, J., Besim, K., 2006. How to prove the consistency of arithmetic. Acta Philos. Fennica78, 1–15.
Hodges, W., 1993. Model Theory, Cambridge University Press, Cambridge, MA.Jones, P.J., 1974. Recursive undecidability – an exposition. Am. Math. Monthly 87, 724–738.Kolaitis, PhG., 1985. Game quantification, in: Barwise, J., Feferman, S. (Eds.), Model-
Theoretical Logics, Springer, New York, pp. 365–421.Kuhn, S.T., 1989. Tense and time, in: Gabbay, D., Guenther, F. (Eds.), Handbook of Philosoph-
ical Logic IV. Reidel, Dordrecht, pp. 552–573.Lorenzen, P., 1960. Logik und Agon, Atti del XII Congresso Internationale di Filosofia, vol. 4,
Sansoni Editore, Firenze, pp. 187–194.

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 465 — #51
Game-Theoretical Semantics 465
Makkai, M., 1977. Admissible sets and infinitary logic, in: Barwise, J. (Ed.), Handbook ofMathematical Logic, North-Holland, Amsterdam, pp. 233–282.
Matiyasevich, Y.M., 1993. Hilbert’s Tenth Problem. MIT Press, Cambridge, MA.May, R., 1985. Logical Form, its Structure and Derivation. MIT Press, Cambridge, MA.Neale, S., 1990. Descriptions. MIT Press, Cambridge, MA.Rabin, O.M., 1957. Effective computability of winning strategies, in: Tucker, A.W., Wolf, P.
(Eds.), Contributions to the Theory of Games vol. III. Ann. Math. Stud. 39, 147–157.Reichenbach, H., 1947. Elements of Symbolic Logic. Macmillan, New York.Reinhart, T., 1983. Anaphora and Semantic Interpretation. Croom Helm, London.Saarinen, E. (Ed.), 1979. Game-Theoretical Semantics: Essays on Semantics by Hintikka,
Carlson, Peacocke, Rantala, and Saarinen. Reidel, Dordrecht.Sandu, G., 1993. On the logic of informational independence and its applications. J. Philos.
Logic 22, 29–60.Sandu, G., Väänänen, J., 1992. Partially ordered connectives. Z. Math. Logik Grundlag. Math.
38, 361–372.Sher, G., 1991. The Bounds of Logic: A Generalized Viewpoint. MIT Press, Cambridge, MA.Tuuri, H., 1990. Infinitary languages and Ehrenfeucht–Fraissé games. Dissertation, University
of Helsinki, Deutschland.

“12-ch08-0415-0466-9780444537263” — 2010/11/29 — 21:15 — page 466 — #52
This page intentionally left blank

“13-ch09-0467-0492-9780444537263” — 2010/11/30 — 3:44 — page 467 — #1
9 Game-Theoretical Pragmatics(Update of Chapter 8)Gerhard JägerUniversity of Tübingen, Department of Linguistics, Wilhelmstraße 19,72074 Tübingen, Germany, E-mail: [email protected]
9.1 Introduction
In his book Using Language (Clark, 1996), Herb Clark makes a distinction betweentwo approaches to the psychology of language. He favors what he calls an actionapproach to language use and distinguishes it from the more traditional productapproach. The latter line of research focuses on linguistic structures, the former onprocesses. Clark’s distinction is also useful when considering languages of logic andlogic-based approaches to natural language. While the language-as-product perspec-tive may represent the mainstream of the logic-and-language line of research, theprocedural aspects of language have been stressed over and over again by manyresearchers. (It is not a coincidence that a rather influential book on logical gram-mar, (van Benthem, 1991), is titled Language in Action.) This ranges from proof theo-retic investigations into the algorithmic aspects of reasoning via the automata-theoreticreconstruction of generation and parsing of syntactic structures to the various brandsof dynamic semantics that model the effects that the process of interpreting an expres-sion has on the agent who does the interpreting.
It is only natural to move one step further, from language-as-action to language-as-interaction. To get the full picture, the social aspects of language as a medium forcommunication have to be taken into account. If we further assume that the interact-ing agents are able to choose between different possible actions, and that they havepreferences regarding the outcome of their interaction, we are entering the realm ofgame theory.
The best worked-out implementation of such an approach is Game-theoreticsemantics in the sense of Hintikka (1973). Here the process of interpreting a syn-tactically complex sentence S is modeled as a game. One can imagine the situationas a debate where one player, the proponent, tries to convince an invisible audienceof the truth of S, while the opponent tries to disprove S. To take a simple example,consider the first-order sentence
!x"y(x = y) (9.1)
Handbook of Logic and Language. DOI: 10.1016/B978-0-444-53726-3.00009-8c# 2011 Elsevier B.V. All rights reserved.

“13-ch09-0467-0492-9780444537263” — 2010/11/29 — 21:08 — page 468 — #2
468 Handbook of Logic and Language
As S starts with a universal quantifier, the opponent is free to choose some object fromthe universe of discourse as value for the bound variable. The subsequent existentialquantifier means that the proponent can choose some object as value for y. After theplayers made their choices, the remaining atomic formula is evaluated. If it is true, theproponent wins, otherwise the opponent wins. In this particular game, it is obvious thatthe proponent has a winning strategy: always choose the same object as the opponent!Generally, if the proponent has a winning strategy for a particular model, the formulais true in this model.
Game-theoretic semantics offers an alternative to Tarskian semantics because themeaning of a complex formula is not computed in terms of the truth conditions of itscomponents, but with reference to the sub-games that correspond to these components.The rules of the game can be modified in various ways regarding the pieces of infor-mation that the players have at their disposal at the various positions within the gametree. The most important application of this approach is perhaps the game-theoreticanalysis of IF-logics (Independence friendly logics). To modify the previous exampleminimally, consider the following formula:
!x"y/{x}(x = y) (9.2)
The slash notation indicates that the choice of a value for y has to be independent ofthe value of x. Technically speaking, the proponent now has imperfect informationat the second stage of the game because she does not know which move the opponentmade in the first stage. In this particular example, this implies that neither player hasa winning strategy if the domain of discourse contains at least two elements. So theformula does not have a definite truth value.
Varying the rules of the game along these lines leads to interesting analyses ofconcepts like branching quantifiers, but also of intricate natural language phenom-ena like donkey anaphora. The interested reader is referred to Hintikka and Sandu’sChapter 8 in this handbook (Hintikka and Sandu, 1997) for an in-depth discussion.A more recent representative collection of papers about this version of game theo-retic semantics (which also contains abundant material about linguistic applications ofsignaling games) can be found in Pietarinen (2007).
9.2 Signaling Games
As was said above, Hintikka-style semantic games can be conceptualized as zero-sumgames between two players that try to win a debate (about the truth of the sentencein question) in front of an audience. This basic scenario has also been employed byseveral authors to model the act of choosing an expression. Here we enter the realmof communication and pragmatics. This language-as-a-debate model of pragmaticswas worked out in some detail by Arthur Merin (see for instance Merin, 1999a,b),building on earlier work by Ducrot (1973) and Anscombre and Ducrot (1983). Ina series of recent publications, Jacob Glazer and Ariel Rubinstein develop a theoryof the “pragmatics of debate”. They also model communication as an argumentation

“13-ch09-0467-0492-9780444537263” — 2010/11/29 — 21:08 — page 469 — #3
Game-Theoretical Pragmatics 469
game between two competing agents, trying to convince a third party (see for instanceGlazer and Rubinstein, 2004, 2005). Considering the issue from an economist’s per-spective, they are mainly interested in the issue of how the rules of the debate affectthe amount of useful information that the third party will extract from listening to sucha competitive debate.
Besides this language-as-a-debate model, there is another tradition of game-theoretic models of communication that goes back to the work of Lewis (1969). Here,communication is essentially seen as an attempt of a sender to manipulate a receiverby transmitting certain signals that might influence future decisions of the receiver. Ifwe assume that the interests of the players are common knowledge, such a manipula-tion will only be successful if the game is not zero-sum. (In a purely competitive gamelike poker, rational players are well advised not to give away any private informationby sending signals!) So in this tradition, communication is essentially seen as part ofan at least partially collaborative endeavor.
The simplest model of this kind are signaling games that were originally pro-posed by Lewis in his dissertation, and later refined (and repeatedly reinvented) byeconomists and biologists.
In a signaling game we have two players, the sender (let us call her Sally) andthe receiver (whom I will call Robin). Sally has some private information that Robinlacks. In the first stage of the game, Sally sends a message to Robin. The choice ofthe message may depend on Sally’s private information. Robin in turn chooses anaction, possibly dependent on the message that he observed. Both players have a pref-erence ordering over possible (message, action) sequences that is captured by utilityfunctions.
A strategy for Sally in such a game is a function from information states to mes-sages, while a strategy for Robin would be a function from messages to actions. Lewisfocuses on the Nash-equilibria on such games. A Nash equilibrium is a configura-tion of strategies that is self-reinforcing in the sense that no player has an incentiveto deviate from it provided he has reason to believe that everybody else is abiding byit. For instance, if it is generally believed that nodding means affirmation and shakingthe head means negation, then the best thing to do is to nod if you want to express“yes”, and to shake your head if you want to express “no”. This is an equilibrium thatworks fine in western Europe. However, the opposite convention is also an equilib-rium, as can be observed in parts of south-east Europe. There is nothing intrinsicallyaffirmative or negative in nodding or shaking one’s head.
Lewis’ main point was to demonstrate that signals may be associated with a mean-ing in an arbitrary way without reference to a prior negotiation in some meta-language(an assumption which would lead to an infinite regress). Rational players in a signal-ing game use/interpret signals in a certain way because they have certain expectationsabout the behavioral dispositions of the other players, and it doesn’t matter how theseexpectations are justified.
Lewis’ solution is arguably incomplete because it does not solve the problemof equilibrium selection. As the previous example illustrates, there may be severalNash equilibria in a game (affirmative nodding and negative head-shaking; affirmative

“13-ch09-0467-0492-9780444537263” — 2010/11/29 — 21:08 — page 470 — #4
470 Handbook of Logic and Language
head-shaking and negative nodding), and the players have no a priori reason to favorone over the other. The best candidate for a causal explanation here is precedent. Butthis seems to lead to an infinite regress again.
The evolutionary properties of signaling games have been studied extensively inthe context of Evolutionary Game Theory. The results from this strand of research goa long way to actually solve Lewis’ problem. In an evolutionary setting, a game is notplayed just once but many times over and over again. There is some positive feedbackfrom the utility that a certain strategy ! achieves on average, and the likelihood withwhich ! will be played in future iterations. If the interests of sender and receiverare sufficiently aligned, i.e. they both have an interest in successful communication,almost all initial states will evolve into a final state where signals do carry a meaningabout the information state of the sender. The phrase “almost all initial states” is to beinterpreted in its measure-theoretic sense here; even though there are initial states thatdo not evolve into meaningful signaling systems, their probability is infinitesimallysmall. Whether or not evolution leads to an optimal communication system dependson specific details of the underlying evolutionary dynamics. A discussion would leadbeyond the scope of this article. As a rule of thumb, a deterministic dynamics may getstuck in sub-optimal states, while a small but non-negligible amount of random noisefavors the emergence of optimal signaling systems.
In the biological domain, the positive reinforcement mentioned above is imple-mented via increased biological fitness as the result of successful communication. Thelogic of evolution, however, also applies if reinforcement is mediated via imitationand learning. So the emergence of stable equilibria in iterated signaling games canalso be explained via cultural evolution.
The evolutionary stability of various classes of signaling systems was established,inter alia, in Blume et al. (1993), Wärneryd (1993) and Trapa and Nowak (2000). Hut-tegger (2007), Pawlowitsch (2008) and Jäger (2008a) explore under what conditionsa system will converge towards a sub-optimal state with a positive probability.
A fairly recent line of research is inspired by Gärdenfors’ (2000) idea that theobjects of semantics—and thus the information states that are the input for Sally’schoices—are not objects in the real world but points or regions in a conceptual spacethat has a topological and metrical structure. The evolutionary consequences of thisassumption for signaling games are explored in Gärdenfors and Warglien (2006) and,in a slightly different setting, in Jäger et al. (2009).
In van Rooij (2004) and Jäger (2007) the hypothesis is entertained that naturallanguages constitute equilibria of signaling games, and that therefore high-likelihoodequilibria correspond to recurrent patterns in the languages of the world.
To conclude this section about signaling games and Nash equilibria, I’d like to men-tion an interesting connection between this kind of games and Hintikka-style semanticgames for IF-logics. Sandu and Sevenster (2008) point out that Hintikka games can bereconceptualized in a way that they contain signaling games as sub-games. Considerthe following IF formula:
!x"y"z/{x}(x = z) (9.3)

“13-ch09-0467-0492-9780444537263” — 2010/11/29 — 21:08 — page 471 — #5
Game-Theoretical Pragmatics 471
Even though this looks similar to the formula in (9.2), here the proponent has a win-ning strategy for domains with multiple elements. He can choose y to be identical tox, and z to be identical to y. You can consider such a game as a game between twocoalitions of players, the proponents and the opponents. Every member of a coali-tion is responsible for exactly one variable. In the game corresponding to (9.3), they-player knows which value the opponents chose for x, and he wants to communicatethis to the z-player. Choosing the value of y to be identical to x is a way to signal thisinformation to z. So here the winning strategy contains an equilibrium of an embeddedsignaling game.
9.3 Rational Communication
9.3.1 Equilibrium Analyses
The insight that signaling games are being played iteratively by the members of a pop-ulation helps to explain how signals may acquire and sustain a conventional meaningin the first place. However, even if a certain meaning-signal association is part of anequilibrium in the long run, it might not be rational to play that equilibrium in oneparticular situation. For instance, if a driver asks a passerby:
(1) Is this the right way to the station?
shaking the head (in western Europe) may be a semantically correct response, buta cooperative speaker will augment this with more detailed instructions of how toget to the station. In other words, even if a set of semantic conventions are commonknowledge, it is possible that some of them are not rational in a particular situation.It might even be rational to diverge from the conventions. This fact is well knownsince the work of Grice (1975), and it has also frequently been observed that Griceanpragmatics has a strong game-theoretic flavor because it involves strategic rationalityconsiderations.
In a series of publications (see for instance Parikh, 1987, 1991, 2001), PrashantParikh has developed a generalization of Lewisian signaling games that model theinference from an exogenously given semantic convention to the actual pragmaticinterpretation of a signal. His model differs from Lewis’ in a small but crucial way.In standard signaling games, Sally has the same set of messages at her disposal ineach situation. Also, Robin has a certain set of actions at his disposal which does notdepend on the message that he receives.
In Parikh style games,1 the set of messages that Sally can send may differ from sit-uation to situation, and the set of actions that Robin may take may differ from messageto message. More specifically, Robin’s possible actions are identified with the possiblereadings of the message that he received. So the literal meaning (or meanings, in thecase of ambiguous messages) of a message is part of the structure of the game itself.Also, in a given situation Sally can only send messages that are true in this situation
1 To stress this difference, Parikh speaks of games of partial information rather than signaling games.

“13-ch09-0467-0492-9780444537263” — 2010/11/29 — 21:08 — page 472 — #6
472 Handbook of Logic and Language
according to their literal interpretation. So the truth conditions of messages are alsopart of the structure of the game.
Parikh assumes that rational agents will settle on a Nash equilibrium of such agame, and only use messages that conform to this equilibrium. To see this fromRobin’s perspective, the very structure of the game ensures that he can infer the truthof a message (in one of its readings) from the fact that Sally has sent it. If he hasfurthermore reason to believe that Sally plays according to a certain equilibrium, hecan infer from an observed message that Sally is in a state where this message belongsto her equilibrium strategy. The former kind of inference is based on the meaning ofthe message; the latter is based on the belief in the sender’s rationality. Therefore thelatter can aptly be called a pragmatic inference or an implicature.
Parikh-style games may have more than one Nash equilibrium. Parikh thereforeponders criteria for equilibrium selection, and he argues in favor of the notion of aPareto–Nash equilibrium as the appropriate concept.2
It is a consequence of Parikh’s model that the sender always utters a message that istrue according to its literal meaning in one of its readings. This does not only excludelying but also any kind of non-literal interpretation like hyperboles or metaphors.Consequently, his model is successful mainly for studying the pragmatic resolutionof underspecification, like the resolution of ambiguities or the computation of scalarimplicatures.
Other approaches maintain the standard signaling game assumption that the set offeasible messages does not depend on the private information of the sender. Instead,the association between information states and messages that is defined by the literalmeaning of messages is given a special status in the reasoning of the agents. Also, itis not so clear whether the solution concept of a Nash equilibrium (or strengtheningsthereof ) is really appropriate to model the action of rational agents in one-shot games.
9.3.2 The Iterated-Best-Response Model
Nash equilibria are self-reinforcing ways to play a game. If every player has reasonto believe that the other players play according to a certain equilibrium, it is rationalto stick to play that very equilibrium oneself. However, it is not immediately obviouswhat these reasons would be. This question is especially pressing if we are dealingwith one-shot games where precedent or evolutionary arguments cannot be used. Sig-naling games usually have many equilibria.3 So the requirement that every playerplays according to some equilibrium strategy is not much stronger than the require-ment of rationality (plus common knowledge that each player is rational). Thereforerefinements of the equilibrium concept (like Parikh’s proposal to focus on Pareto–Nash equilibria) are necessary to derive non-trivial prediction. But even such refine-ments often do not guarantee a unique solution.
2 Parikh calls an equilibrium a Pareto–Nash equilibrium if it is not possible to switch to another equilibriumin such a way that all players receive a higher utility in the new equilibrium.
3 See for instance the discussion in Battigalli (2006).

“13-ch09-0467-0492-9780444537263” — 2010/11/29 — 21:08 — page 473 — #7
Game-Theoretical Pragmatics 473
On the other hand, equilibrium analyses place a considerable burden on the cogni-tive capabilities of the players. Calculating the set of equilibria of a sequential gameis a complex task. Research in behavioral game theory has shown that actual humans,in experimental settings, usually do not play according to some Nash equilibrium.Rather, test persons employ step-by-step reasoning heuristics when making a decisionin a strategic situation (see for instance Selten 1998).
For these reasons, various authors (like, inter alia, Rabin, 1990, Benz and vanRooij, 2007, Franke, 2008a,b, Jäger, 2008b) have explored solution concepts that donot make use of the notion of an equilibrium. Instead they have suggested iterativereasoning protocols to describe the rational usage of messages with an exogenouslygiven meaning in a given context. The basic idea that is common to these approachescan roughly be described as follows: One player, A, starts their reasoning process withthe provisional assumption that the other player, B, follows the semantic convention.Based on this assumption, B chooses the best possible strategy, i.e. the strategy thatmaximizes B’s payoff. If the semantic convention happens to be identical to a Nashequilibrium, the story ends here. Otherwise, A might anticipate B’s reasoning step andrevise their decisions accordingly. This procedure may be arbitrarily iterated manytimes.
There are many technical differences between the mentioned approaches, relatingto the questions of which player starts the reasoning procedure, how many iterationsare considered, how are multiple best responses to a certain assumption reconciled,etc. Below I will present one particular implementation in finer detail.
9.3.2.1 Rationalizability, Strong Belief and Justifiable Decisions
Let us start with a simple example. Suppose Sally is in either of two states. (For thetime being, we assume that all relevant aspects of the interaction are determined ineach state, so we can equate them with possible worlds.) She either prefers tea (w1) orshe prefers coffee (w2). Robin can take either of two actions: he can serve her tea (a1)or coffee (a2). However, Robin does not know in which state Sally is. He considersboth worlds as equally likely. Both Sally and Robin prefer a scenario where Sallygets her favorite beverage. These preferences are captured by a two-place functionfrom worlds and actions to real numbers vk # RW$A for each player k # {S, R}.If v is finite, it can be represented by a utility matrix where rows represent possibleworlds and columns represent actions. Table 9.1 gives the utility matrix for the currentexample. The two numbers in each cell give Sally’s and Robin’s utilities respectively.Before Robin takes an action, Sally can send one out of two messages, m1 (“I prefer
Table 9.1 A SimpleCoordination Scenario
a1 a2
w1 1; 1 0; 0w2 0; 0 1; 1

“13-ch09-0467-0492-9780444537263” — 2010/11/29 — 21:08 — page 474 — #8
474 Handbook of Logic and Language
tea.”) or m2 (“I prefer coffee.”). The literal interpretation of the messages is commonknowledge: %m1% ={ w1} and %m2% ={ w2}.
A strategy for Sally is a function which determines for each world which messageshe sends. Likewise, a strategy for Robin is a function from messages to actions. Theset of sender strategies is denoted by S = MW , and the set of receiver strategiesby R = AM . Which strategies will Sally and Robin choose if all that is commonknowledge is the structure of the game, the literal meaning of the messages, and thefact that they are both rational?
To address this question, we need some notation. The utility functions for the play-ers determine their payoff for a particular instance of the game, i.e. a particular world,a message, and an action. Let W be the set of possible worlds, M the set of signalsand A the set of actions. Then both us and ur (Sally’s and Robin’s utility functionsrespectively) are functions from W $ M $ A into R.
For the time being we assume that “talk is cheap”, i.e. the utility depends only onvk, not on the message send:
uk(w, m, a) = vk(w, a)
Let p& be a probability distribution over W, i.e. p& # "(W),4 such that for allw : p&(w) > 0. It represents Robin’s prior assumptions on the probability of the possi-ble worlds.
The expected utility of a player k # {S, R} for a pair of strategies (s, r) is given by
uk(s, r) =!
w#W
p&(w)uk(w, s(w), r(s(w)))
(Note the the symbols us and ur are overloaded here, referring to both the utility func-tions and the expected utilities. No confusion should arise from this though.)
On the basis of the publicly available information, Sally will figure out that theset of strategies that Robin could possibly play if it is common knowledge that bothplayers are rational is some set R. So Sally’s expectation about Robin’s strategy canbe represented as a probability distribution P over R. If Sally is rational, she will playa strategy that maximizes her expected utility, given P. Since Robin does not know P,all he can figure out is that Sally will play some strategy that maximizes her expectedutility for some P. The same kind of argument can be made with respect to Robin’sconsiderations. Let us make this more precise.
Even if Sally does not know for sure which strategy Robin plays, she has someexpectations about Robin’s possible reactions to each of the messages. Formally,Sally’s first-order beliefs5 about Robin are captured by a function # that maps each
4 I use the convention whereas for each finite set X,
"(X) = {p # [0, 1]X |!
x#X
p(x) = 1}
is the set of probability distributions over X.5 First-order beliefs are beliefs that only concern the actions of the other player. Second-order beliefs would
also include assumptions about the first-order beliefs of the other player, etc.

“13-ch09-0467-0492-9780444537263” — 2010/11/29 — 21:08 — page 475 — #9
Game-Theoretical Pragmatics 475
message to a probability distribution over actions. We write #(a|m) for the probabi-lity that # assigns to action a if Sally sends message m. Likewise, Robin’s first-orderbeliefs are captured by a function !1 from worlds to probability distributions overmessages. From this he can derive his posterior beliefs !2, which is a function frommessages to probability distributions over worlds.
A rational player will always play a strategy that maximizes his expected utility,given his beliefs. The notion of a best response captures this.
Definition 9.3.1. (Best response to beliefs) Let !2 # "(W)M be a posterior beliefof the receiver, and # # "(A)M be a first-order belief of the sender. The sets of bestresponses to these beliefs are defined as follows:
BRs(!2) = {r # R|!m.r(m) # arg maxa#A
!
w#W
!2(w|m)ur(w, m, a)}
BRr(#) = {s # S|!w.s(w) # arg maxm#M
!
a#A
#(a|m)us(w, m, a)}
The posterior beliefs !2 can usually be derived from Robin’s first-order beliefs andhis prior belief p& by using Bayesian updating:
!2(w|m) = !1(m|w)p&(w)"w'#W !1(m|w')p&(w')
(9.4)
provided maxw'#W
!1(m|w') > 0
If Robin encounters a message that had probability 0 according to his first-orderbeliefs, he has to revise those beliefs. Different belief revision policies correspond todifferent restrictions on the formation of posterior beliefs.
Battigalli and Siniscalchi (2002) propose the notion of strong belief. An agentstrongly believes a certain proposition A if he maintains the assumption that A is trueeven if he has to revise his beliefs, provided the new evidence is consistent with A.Now suppose that Robin strongly believes that Sally plays a strategy from the set S.Then the formation of the posterior belief is subject to the following constraint.
Definition 9.3.2. Let S ( S be a set of sender strategies and !1 be a first-order beliefof the receiver. !2 is a possible posterior belief for !1 and S (!2 # posterior(!1, S)) ifthe following conditions are met:
1. !2 # "(W)M
2. If maxw#W !1(m|w) > 0, then
!2(w|m) = !1(m|w)p&(w)"w'#W !1(m|w')p&(w')
.

“13-ch09-0467-0492-9780444537263” — 2010/11/29 — 21:08 — page 476 — #10
476 Handbook of Logic and Language
3. If maxw#W !1(m|w) = 0 and m ##
s#S range(s), then there is some probability distributionP # "(S) such that m #
#s#support(P) range(s) and some prior belief ! '
1 # "(M)W with! '
1(m|w) ="
s : s(w)=m P(s) for all w and m, such that
!2(w|m) =! '
1(m|w)p&(w)"
w'#W ! '1(m|w')p&(w')
.
The second clause captures the case where the observed message has a positive priorprobability, and the posterior belief can be derived via Bayesian updating. The thirdclause captures the case where the observed message m had a prior probability of 0, butis consistent with the assumption that Sally plays S. In this case the prior probabilityis revised to some alternative prior ! '
1 that is consistent with the belief that Sally playsstrategies from S. The posterior belief is then formed by applying Bayes’ rule to ! '
1.If the observed message is inconsistent with the belief that Sally plays a strategy fromS, no restrictions on the belief revision policy are imposed.
Now let X be a set of strategies of some player. The best responses to X are theset of strategies that the other player might conceivably play if he is rational and hestrongly believes that the first player plays X.
Definition 9.3.3. (Best response to a set of strategies) Let S ( S and R ( R besets of strategies.
BRr(S) = {r # R|"P # "S"!1(!m, w.!1(m|w) =!
s#S : s(w)=m
P(s))
"!2 # posterior(!1, S) : r # BRr(!2)}
BRs(R) = {s # S|"P # "(R)"#(!a, m.#(a|m) =!
r#R : r(m)=a
P(r)) :
r # BRs(#)}
Suppose a player has figured out, by just using publicly available information, thatthe other player will play a strategy from the set X. If the player is rational, he willplay a best response to X. Let Y be the set of best responses to X. The other playeris perfectly able to come to the same conclusion. He will thus play any of the bestresponses to Y . If the considerations that led the first player to the assumption that thesecond player uses a strategy from X were correct, the set of best responses to Y shouldequal X, and vice versa. This is exactly the intuition that is captured by the notion of astrongly rationalizable equilibrium (SRE).6
6 The notion of a rationalizable equilibrium is related to Bernheim’s (1984) and Pearce’s (1984) notionof rationalizability. Because we demand strong belief rather than simple belief, not every rationalizablestrategy is part of some strongly rationalizable equilibrium. Also note that Stalnaker (1997) uses the notionof “strongly rationalizable equilibrium” in a different sense.

“13-ch09-0467-0492-9780444537263” — 2010/11/29 — 21:08 — page 477 — #11
Game-Theoretical Pragmatics 477
Definition 9.3.4. (Strongly rationalizable equilibrium) (S, R) # POW(S) $POW(R) is a strongly rationalizable equilibrium iff
S = BRs(R)
R = BRr(S)
A game may have more than one of such equilibria though. Let us consider ourexample again. The four sender strategies can be denoted by 11, 12, 21 and 22, wherethe first and the second digit give the index of the message that Sally sends in worldw1 and w2 respectively. Robin’s strategies can be coded the same way.
There are three SREs for this game:
1. ({12}, {12})2. ({21}, {21})3. ({11, 12, 21, 22}, {11, 12, 21, 22})
The first one seems reasonable—Sally always sends an honest signal, and Robinbelieves her. In this way, both obtain the maximally possible utility. The second equi-librium is the one where Sally uses the messages ironically, and Robin is aware ofthat. It also yields the maximal payoff. However, to coordinate on this equilibrium,the players ought to have some clue that Sally is ironic. If they have no a priori infor-mation about each other, this equilibrium is counter-intuitive.
The third equilibrium is the one where the information about the literal interpre-tation of the messages plays no role. If only rationality considerations are taken intoaccount, every strategy can be justified. The expected utility of the players could be 1,but also just 0 or 0.5.
The criterion that we employed here to single out the first equilibrium seems tobe something like Choose the equilibrium where Sally always sends a true message!However, there may be equilibria where honesty is not rational. Consider the exam-ple given in Table 9.2, taken from Rabin (1990). All three worlds are assumed to beequally likely according to p&.
As far as Robin is concerned, the best action in world wk is ak, for all indicesi # {1, 2, 3}. However, Sally would prefer Robin to perform a2 both in w2 and inw3. So while Sally would prefer Robin to know the truth in w1 and in w2, she has anincentive to make Robin believe that w2 is the case if she is actually in w3. Robin is ofcourse aware of this fact. So if it is common knowledge that both players are rational,
Table 9.2 Partially Aligned Interests
a1 a2 a3
w1 10; 10 0; 0 0; 0w2 0; 0 10; 10 5; 7w3 0; 0 10; 0 5; 7

“13-ch09-0467-0492-9780444537263” — 2010/11/29 — 21:08 — page 478 — #12
478 Handbook of Logic and Language
they will not agree on a communication system that reliably distinguishes between w2and w3. Both do have an incentive though to distinguish {w1} from {w2, w3}.
Let us assume that there are three messages, m1, m2, and m3, with the literal inter-pretations %mk% = {wk} for all i. Strategies are denoted by triples of similarly to theprevious example.
The honest sender strategy, call it h, is 123. However, BRr({123}) = {123}, andBRs({123}) = {122}. So unlike in the previous example, ({h}, BRr({h})) does notform an SRE. Still, it is possible to make intuitively plausible predictions here.
The essential idea is that each player should be able to justify his choice of a strat-egy. One possible justification for a sender strategy is honesty. Another possible jus-tification is rationality: a given strategy is justifiable if it is a best response to a set ofjustifiable strategies of the other player. Nothing else is justifiable.
So formally we can define the set of justifiable strategies as the smallest pair of setsJ = (Js, Jr) with
h # Js
BRs(Jr) ( Js
BRr(Js) ( Jr
Since J is defined as a smallest fixed point of a monotonic7 operator, we can equiv-alently define it cumulatively as
H0 = {h}Hn+1 = Hn ) BRs(BRr(Hn))
H$ =$
n#NHn
J = (H$, BRr(H$))
In Rabin’s example, we have
J = ({122, 123, 132, 133}, {122, 123, 132, 133}).
This set forms an SRE. So we can infer that Sally will always send message m1in w1, and she will never use that message in another world. Robin will always reactwith a1 to m1. No further predictions can be derived.
In this example, J is an SRE. This is not necessarily the case. In the next example,there are two worlds, two messages, and three actions. The utility function is given inTable 9.3.
7 The BRr-operator is not generally monotonic due to the belief revision policy for unexpected messagesthat is implicit in the definition of BRr . It is monotonic though on a collection S ( POW(S) if for allS # S :
#s#S range(s) = M.

“13-ch09-0467-0492-9780444537263” — 2010/11/29 — 21:08 — page 479 — #13
Game-Theoretical Pragmatics 479
Table 9.3 Another Example withPartially Aligned Interests
a1 a2 a3
w1 10; 10 0; 0 1; 7w2 10; 0 0; 10 1; 7
J is calculated in the following way:
H0 = {12}H1 = {11, 12}H2 = H1
BRr(H0) = {12}BRr(H1) = {32, 12}
So J = ({12, 11}, {12, 32}). However, J is not an SRE, because h is not a bestresponse to Jr. So even though h can be justified because it is the honest strategy, it isnever rational to use it because it is not a best response to the set of justifiable receiverstrategies. Thus a rational player wouldn’t use it and this undermines the justificationfor the other strategies from J.
This example illustrates that honesty is not a sufficient justification for some senderstrategy. Rather, h must be doubly justifiable—a rational player might use it (a)because it’s the honest strategy, and (b) because rationality considerations do not speakagainst using it. This is the case if, and only if, J is a strongly rationalizable equilib-rium.
The discussion so far can be summarized by the following principle, which rationalinterlocutors are assumed to obey:
Pragmatic rationalizability: If J is a strongly rationalizable equilibrium,pragmatically rational players will play strategies from J.
If J is an SRE, we call the strategies from J the pragmatically rationalizable strate-gies.
9.4 Information States and Message Costs
In the previous section, we assumed that Sally has complete knowledge about thestate of the world. This is quite unrealistic; Sally might have only partial knowledgeherself. She is in a certain information state, which is a non-empty subset of W. Theset of information states is called I.
There is some function % that maps each world w to a probability distribution %(·|w)
over I, such that!
i*w
%(i|w) = 1

“13-ch09-0467-0492-9780444537263” — 2010/11/29 — 21:08 — page 480 — #14
480 Handbook of Logic and Language
In each world w, nature assigns the information state i * w to Sally with probability%(i|w).8
In the refined model, strategies for Sally are functions from I to M. If Sally is in aninformation state i ( W, her private beliefs contain some probability distribution overW. This distribution, call it P(·|i), is given by
P(w|i) = %(i|w)p&(w)"w'#W p&(w')%(i|w')
.
Robin’s epistemic state encompasses a probability distribution q& # "(I), his sub-jective probabilities that Sally is in a particular information state. It is given by
q&(i) =!
w
p&(w)%(i|w).
As a further refinement, we assume sending a message may incur a cost for Sally,and that these costs may differ between messages (regardless of the state Sally is in,and of Robin’s interpretation of the message). Formally, there is some function c # RM
that assigns costs to messages, and these costs are subtracted from Sally’s utility. Therelative weight of the payoff that is due to Robin’s action and the costs that sending amessage incurs need not be common knowledge. Rather, there is a set of cost functionsC, and Sally makes a private assessment about the probabilities of these cost functions.So Sally’s private information state consists of the function # that defines a probabilitydistribution over actions for each message, and a probability distribution & # "(C)
over cost functions.9
The expected utility in a certain information state i, depending on some & , isgiven by
us(i, m, a; & ) =!
w#i
P(w|i)!
c#C
& (c)(vs(w, a) + c(m))
ur(i, m, a; & ) =!
w#i
P(w|i)vr(w, a).
The normalized expected utilities for a strategy pair are
uk(s, r; & ) =!
i#I
q&(i)uk(i, s(i), r(s(i)); & ).
The definitions from the previous section apply to the new model as well, with themodifications that
8 I assume for the time being that Sally never has incorrect information.9 This can be implemented within the standard framework of an extensive two-person game with incomplete
information if we assume that there are different types of receivers that differ with respect to the sender’s,but not with respect to the receiver’s, utility function.

“13-ch09-0467-0492-9780444537263” — 2010/11/29 — 21:08 — page 481 — #15
Game-Theoretical Pragmatics 481
! possible worlds are to be replaced by information states,! p& is to be replaced by q&, and! the best response function has to be relativized to & .
Here are the revised definitions:
Definition 9.4.1. (Best response to beliefs [revised version]) Let !2 # "(W)M bea posterior belief of the receiver, # # "(A)M a first-order belief of the sender, and & aprobability distribution over cost functions. The sets of best responses to these beliefsare defined as follows:
BRs(!2, & ) = {r # R|!m.r(m) # arg maxa#A
!
w#W
!2(w|m)ur(w, m, a; & )}
BRr(#, & ) = {s # S|!w.s(w) # arg maxm#M
!
a#A
#(a|m)us(w, m, a, & )}
Definition 9.4.2. (Best response to a set of strategies [revised version]) Let S ( Sand R ( R be sets of strategies.
BRr(S) = {r # R|"P # "S"!1(!1(m|w) =!
s#S : s(w)=m
P(s))
"!2 # posterior(!1, S)"& # "(C) : r # BRr(!2, & )}
BRs(R) = {s # S|"P # "R"#(#(a|m) =!
r#R : r(m)=a
P(r))
"& : r # BRs(#, & )}
Strategy s is an honest sender strategy if in each information state i, Sally choosesa message which denotes precisely her information state, and which is the cheapestsuch message according to some & .
h = {s|"& # "(C)!i.s(i) # arg minm : %m%=i
!
c#C
& (c)c(m)} (9.5)
We make the rich language assumption: For each information state i, there is atleast one message m with %m% = i. In this way it is guaranteed that an honest andrational strategy always exists.
Let us turn to an example which illustrates the computation of a scalar implica-ture. In a context where question (2a) is under discussion, the sentence (2b) will bepragmatically strengthened to the interpretation corresponding to sentence (2d). Thisis due to the fact that (b) and (c) form part of a scale, and if the speaker utters (b) andis known to be competent, her decision to utter (b) rather than (c) indicates that sheconsiders (c) to be false.
(2) a. Who came to the party?b. Some boys came to the party.

“13-ch09-0467-0492-9780444537263” — 2010/11/29 — 21:08 — page 482 — #16
482 Handbook of Logic and Language
c. All boys came to the party.d. Some but not all boys came to the party.
To model this in a game, let us assume that there are two worlds, w1 (where all boyscame to the party) and w2 (where some but not all boys came). Both Sally and Robinhave an interest that as much information is conveyed to Robin as possible. There arethree messages, m1 = (2c), m2 = (2d) and m3 = (2b). m1 and m3 are about equallycomplex, while m2 is more complex. Let us say that there are two cost functions, c1and c2, with c1(m1) = c1(m3) = 0 and c1(m2) = 4, and c2(mk) = 0 for all k.
Regarding the literal meanings of the messages, we have %m1% ={ w1}, %m2% ={w2}, and %m3% ={ w1, w2}.
Robin has the choices to opt for w1 (action a1), for w2 (action a2) or to remainundecided and wait for further information (action a3). The functions vs/r are given inTable 9.4.
There are three information states in this game:
i1 = {w1}i2 = {w2}i3 = {w1, w2}
I assume that p&(w1) = p&(w2) = 12 , %(i1|w1) = 2
3 , %(i3|w1) = 13 , %(i2|w2) = 1
2 ,and %(i3|w2) = 1
2 . Hence q&(i1) = 13 , q&(i2) = 1
4 , and q&(i3) = 512 .
The expected utilities for the three information states are given in Table 9.5.As there are three information states and three messages, strategies can be repre-
sented as triples of numbers, similar to the previous example. There is just one honestand rational sender strategy here, namely 123. To calculate the pragmatically rational-izable strategies, we have to find the smallest H$ again:
H0 = {123}H1 = {123, 133}H2 = H1
BRr(H0) = {123}BRr(H1) = {123, 122}
So we have
J = ({123, 133}, {123, 122})
J is an SRE. In this equilibrium, Sally always says everything she knows if she is ini1 or i3, but she may either be maximally specific in i2 (using m2), or she may choose
Table 9.4 Scalar Implicature
a1 a2 a3
w1 10, 10 0, 0 8, 8w2 0, 0 10, 10 8, 8

“13-ch09-0467-0492-9780444537263” — 2010/11/29 — 21:08 — page 483 — #17
Game-Theoretical Pragmatics 483
Table 9.5 Utilities Relativized toInformation States
a1 a2 a3
i1 10, 10 0, 0 8, 8i2 0, 0 10, 10 8, 8i3 4, 4 6, 6 8, 8
the cheaper but less specific message m3. Robin will always interpret m1 and m2 lit-erally. m3 may either be interpreted literally as {w1, w2}, or it may be pragmaticallystrengthened to {w2}. If Robin believes that Sally is well informed (i.e. she is either ini1 or in i2), he will interpret m3 as {w2}. If he considers it sufficiently likely that she isnot very well informed, he will not make this implicature.
This example illustrates how the notion of pragmatic rationalizability captures apragmatic reasoning principle that Levinson (2000) called the Q-Heuristics: “Whatisn’t said, isn’t.” If Sally doesn’t say explicitly that all boys came to the party, Robincan assume that it is not the case.
Note that the set of pragmatically rationalizable strategies depends on the under-lying probability distributions in a subtle way. If we change % so such %(i3|w1) =%(i3|w2), the set of pragmatically rationalizable strategies turns out to be:
({123, 133, 121}, {123, 122}).
Now it is also pragmatically rationalizable for Sally to use message m1 in state i3.This may occur in a situation where Sally believes that Robin erroneously believesher to have complete knowledge of the state of the world, while she has only partialknowledge. In this case, every message that Sally can send will have the effect thatRobin extracts more information from it than Sally is justified to provide. All that Sallycan do in this situation is to do damage control and to send a message that minimizesthe loss of utility due to the possible misinformation while keeping costs low. Depend-ing on the expected probabilities in i3, m1 might be such a message. In a more realisticmodel, Sally might choose the option of sending a modalized statement instead, like“Some boys came to the party, perhaps even all.”
Levinson discusses a second pragmatic principle, the I-Heuristics: “What is sim-ply described is stereotypically exemplified.” These two heuristics jointly essentiallycapture the reasoning principles that, in classical Gricean pragmatics, are formulatedas conversational maxims (cf. Grice 1975). Here are a few examples that illustrate theeffects of the I-Heuristics.
(3) a. John’s book is good. ! The book that John is reading or that he has written is good.b. a secretary ! a female secretaryc. road ! hard-surfaced road
The notion of “stereotypically exemplification” is somewhat vague and difficultto translate into the language of game theory. I will assume that propositions with a

“13-ch09-0467-0492-9780444537263” — 2010/11/29 — 21:08 — page 484 — #18
484 Handbook of Logic and Language
high prior probability are stereotypical. Also, I take it that “simple description” can betranslated into “low signaling costs”. So the principle amounts to “Likely propositionsare expressed by cheap forms.”
Here is a schematic example that illustrates how the I-Heuristics is a consequenceof pragmatic rationalizability. Suppose there are two worlds, w1 and w2, such thatp&(w1) = 2
3 and p&(w2) = 13 . So we have three information states again, i1 = {w1},
i2 = {w2}, and i3 = {w1, w2}. Let us say that %(i1|w1) = %(i2|w2) = %(i3|w1) =%(i3|w2) = 1
2 . Hence q&(i1) = 38 , q&(i2) = 1
8 , and q&(i3) = 12 .
There are three actions: a1 is optimal in world w1 (Sally wants to refer to a hard-surfaced road), a2 in w2 (soft-surfaced road) and a3 (waiting for further information)is optimal under the prior probability distribution. The payoffs are given in Table 9.6.The payoffs are chosen such that they are inversely monotonically related to theamount of information that Robin is still missing. Picking the correct world is optimal(payoff 24), and picking the wrong world is bad (payoff 0). Maintaining the prior dis-tribution, i.e. action a3, is better in w1 (payoff 20) than in w2 because the surprise forRobin when learning the truth is higher in w2 than in w1 if he chooses a3.
There are three messages: %m1% ={ w1}, %m2% ={ w2}, and %m3% ={ w1, w2}. m1and m2 correspond to precise and complex expressions (like “hard-surfaced road” and“soft-surfaced road”), while m3 is a simple but less precise message (like “road”). Sowe assume again that there are two cost functions, with c1(m1) = c1(m2) = 5, andc1(m3) = c2(mk) = 0 for all k.
Here is the computation of the pragmatically rationalizable equilibrium:
H0 = {123}H1 = {123, 323}H2 = H1
BRr(H0) = {123}BRr(H1) = {121, 123}
so J, which is an SRE, turns out to be
J = ({123, 323}, {123, 121}).
So it is pragmatically rationalizable for Sally to be perfectly honest, or to use theunderspecified m3 in i1 (if she deems the costs of using m1 as too high). Robin willconsider m3 as pragmatically ambiguous, denoting either {w1} or {w1, w2}.
Table 9.6 I-implicature
a1 a2 a3 a1 a2 a3
w1 24, 24 0, 0 20, 20 i1 24, 24 0, 0 20, 20w2 0, 0 24, 24 16, 16 i2 0, 0 24, 24 16, 16
i3 18, 18 6, 6 21, 21

“13-ch09-0467-0492-9780444537263” — 2010/11/29 — 21:08 — page 485 — #19
Game-Theoretical Pragmatics 485
9.5 Connection to Optimality Theory
In a series of publications, Reinhard Blutner and co-workers have developed a newmodel of formal pragmatics (see for instance Blutner 2001, Jäger 2002, Blutner et al.2006). It is based on Prince and Smolensky’s (1993) Optimality Theory (OT), but itcombines OT’s constraint-based approach to compute preference with a novel evalu-ation procedure, which leads to Bidirectional Optimality Theory (BiOT).
The paradigmatic application of BiOT is a kind of pragmatic reasoning thatLevinson (2000) calls M-implicature. It can be illustrated with the following example:
(4) a. John stopped the car.b. John made the car stop.
The two sentences are arguably semantically synonymous. Nevertheless they carrydifferent pragmatic meanings if uttered in a neutral context. (4a) is preferably inter-preted as John stopped the car in a regular way, like using the foot brake. This wouldbe another example for the I-heuristics. (4b), however, is also pragmatically strength-ened. It means something like John stopped the car in an abnormal way, like drivingit against a wall, making a sharp u-turn, driving up a steep mountain, etc.
This pattern is predicted by BiOT. Informally, the reasoning can be described asfollows: If John stopped the car in a regular way, (4a) is an efficient and truthfulstatement for Sally. Also, if Robin assumes (4a) to be true, it is a good guess that Johnactually stopped the car in a regular way because this is the most likely scenario. So(4a) is to be pragmatically strengthened to “John stopped the car in a regular way.” IfJohn stopped the car in an irregular way, (4a) would therefore be misleading. ThereforeSally will consider (4b) instead, because this is the cheapest non-misleading message.Likewise, Robin will infer from hearing (4b) that (4a) was apparently inappropriate(because otherwise Sally would have chosen it). So if (4b) is true and the implicatureof (4a) is false, John must have stopped the car in an irregular way. Hence (4b) ispragmatically strengthened to “John stopped the car in an irregular way.”
To replicate this kind of reasoning in the present setup, the belief revision policythat is captured in Definition 9.3.2 has to be refined. The problem is that the morecomplex message (4b) is never sent in the honest sender strategy h because there isa less costly synonym. Therefore its probability is 0 for every probability distributionover H0, so neither clause 2 nor clause 3 of Definition 9.3.2 are applicable. So as faras the present system goes, Robin might assume any posterior belief upon observing(4b) in BR(H0). This is much too unrestricted.
Let us have a closer look at this problem. The scenario is essentially similar to theone in example (3), with a likely possible world w1 (where John stopped the car byusing the foot brake), a less likely world w2 (where John stopped the car by makinga u-turn), and a receiver who tries to guess which world is the true one. So let usassume that the utilities are as in that example; the utilities are given in Table 9.6. Letus furthermore assume that p&(w1) = .75 and p&(w2) = .25. Unlike in example (3),however, I take it that it is common knowledge that Sally has complete knowledge, so%(i3|w1) = %(i3|w2) = 0, and hence q&(i1) = .75, q&(i2) = .25, and q&(i3) = 0.

“13-ch09-0467-0492-9780444537263” — 2010/11/29 — 21:08 — page 486 — #20
486 Handbook of Logic and Language
Maintaining the rich language assumption, we still assume that there is a messagem1 with %m1% ={ w1} (“John stopped the car by using the foot brake.”), a message m2with %m2% ={ w2} (“John stopped the car by making a u-turn”), and an underspecifiedmessage m3 with %m3% ={ w1, w2}. Furthermore, we now have an additional messagem4 which is synonymous to m3, i.e. %m4% ={ w1, w2} as well.
The crucial point of this example is that the two specific messages m1 and m2 aremore expensive than the underspecified messages m3 and m4, and that m4 is moreexpensive than m3.
So let us say that there is just one cost function c, with c(m1) = c(m2) = 4,c(m3) = 1 and c(m4) = 2.
Using the definitions as they are, we have:
H0 = {123} BRr(H0) = {1211, 1212, 1213, 1221, 1222, 1223, 1231, 1232, 1233}Because m3 only occurs if Sally is in state i3, which has zero probability, and m4 doesnot occur in the range of any element of H0 at all, anyone of Robin’s possible actionsthat is a best response to some posterior belief !2 is a possible best response to m3 andm4, and this holds for all three actions in the present example.
This is too unrestricted. Even though Robin will have to give up his belief that Sallyplays a strategy from H0 in the current game if he observes m3 or m4, he will not revisehis beliefs in an arbitrary way. I will semi-formally sketch a cautious belief revisionpolicy here that captures the essence of the reasoning process underlying BiOT.
Suppose Robin strongly believes Sally to play a strategy from Hn, and he observesa message m that has probability zero under all probability distributions over Hn.I take it that Robin still tries to maintain his beliefs that (a) Sally is rational to degreen, (b) the literal meaning of m is %m%, and (c) the relative costs of messages are aspredicted by c. He may give up his assumptions about p& or %&, or he may scale c bya non-negative coefficient.10
Applied to the example at hand, observing m3 can be explained either by giving upthe assumption that %(i3|wi) = 0, or by setting all costs to 0. In either case, i3 wouldreceive a posterior probability 1, and the best response is a3. As for m4, a minimalbelief revision would require the assumption that the cost of m4 is not higher than m3.After revising his belief accordingly, Robin will assign the posterior probability 1 toi3 as well. So we now have:
H0 = {123}H1 = {123}
BRr(H0) = {1233}
In computing the best response to H1, the same considerations as above apply, so1233 is a best response. However, m3 can also be explained if the costs are scaled
10 You may detect an optimality-theoretic flavor here: Sally’s degree-n rationality, the literal meanings ofmessages and the relative costs of messages are the strongest constraints. The prior probabilities p& and%& and the cost coefficient are weaker constraints that are easier to give up, the belief in Hn is still weaker,and the specific probability distribution over Hn that Robin assumes in his !1-belief is given up first if itis inconsistent with the observation.

“13-ch09-0467-0492-9780444537263” — 2010/11/29 — 21:08 — page 487 — #21
Game-Theoretical Pragmatics 487
such that sending m1 is a rational decision for Sally in H1 (of this revised game) instate i1, but not in state i2. This would be the case if costs are scaled by a factor k #%
43 , 8
3
&. If Robin maintains his assumptions about the prior probabilities but revises his
assumptions about the costs in this way, his posterior belief after observing m3 assignsprobability 1 to i1. Hence 1213 is a best response as well. If costs are scaled by a factor83 , m3 is the only optimal message for Sally in H1 in state i1, while in i2 both m2 andm3 are optimal. Hence Robin will assign a posterior probability in [.75, 1] to i1 in thiscase, and the best response is either a1 or a3. Finally, if costs are scaled with a factork > 8
3 , m3 is the only optimal message in all information states, the posterior beliefequals the prior belief, and the optimal response is a3. Therefore we get
BR(H1) = {1233, 1213}
From this we derive straightforwardly
H2 = {123, 323}
Now Robin’s posterior upon observing m3 will assign probability 1 to i1. Upon observ-ing m4, he may revise his beliefs by multiplying all costs with 0, which leads to assign-ing the posterior probability 1 to i3. However, if he assigns a probability p > .25 tothe strategy 1213, he may also explain m4 by multiplying the costs with a coefficientk # [4, 16p], because with these parameters m4 is rational for Sally in H2 in state i2.So another possible posterior belief for Robin upon observing m4 would be one thatassigns probability 1 to i2. So we get
BR(H2) = {1212, 1213}
Hence
H3 = {123, 323, 343, 324}H4 = H3
BRr(H3) = {1212}
So the set of pragmatically rationalizable strategies comes out as
J = ({123, 323, 343, 324}, {1233, 1213, 1212})
So the messages are used and interpreted either according to their literal meaning oraccording to the M-implicature. Even stronger, if the players grant each other a levelof sophistication of at least 3, the M-implicatures arise with necessity.
On an intuitive level, the interpretation of m3 as i1/a1 comes about because a pos-sible explanation for the unexpected message m3 is that Sally is lazy and prefers thecheap m3 over a more precise message if the loss in utility is not too high. This is morelikely to be the case in i1 than in i2. This taken into account, a possible explanationfor m4 might be that Sally is lazy enough to prefer a cheap and vague message over a

“13-ch09-0467-0492-9780444537263” — 2010/11/29 — 21:08 — page 488 — #22
488 Handbook of Logic and Language
costly and precise one, but she cares enough about precision that it’s worth paying thedifferential costs between m3 and m4 if this prevents the risk of severe misunderstand-ings. This can only happen if m3, in its pragmatically strengthened interpretation, isseriously misleading, as in state i2.
The connection between BiOT and game theoretic reasoning that this example sug-gests is perhaps not that surprising after all. BiOT is concerned with the simultaneousevaluation of sender preferences and receiver preferences, and the two perspectivesare recursively intertwined. This is a version of strategic reasoning that can be mod-eled by game-theoretic means (a point which has already been noticed and exploited inDekker and van Rooy 2000). As the example also illustrates, the specifics of Blutner’sbidirectional evaluation procedure tacitly incorporate certain background assumptionsabout the mutual epistemic modeling of sender and receiver, and about a certain beliefrevision policy. It seems likely that various variants of optimality theoretic pragmaticscan be embedded into the game-theoretic model in a way that reduces differences inthe evaluation procedure to different epistemic attitudes of the interacting agents. Thegeneral connection of these two frameworks is still largely unexplored terrain though.
9.6 Conclusion
The topic of this paper was the issue of how rational communicators will communicatewith signals that have a commonly known exogenous meaning. Since this is essentiallythe question that Gricean pragmatics is concerned with, the game-theoretic approachcan be seen as an attempt to formalize the Gricean program.
The basic intuition underlying the proposal made in this paper can be summarizedas: A rational sender will be honest and maximally informative unless she has reasonsto do otherwise.11 “Reasons to do otherwise” are justified beliefs that the honest andinformative strategy is sub-optimal. If it is common knowledge that the sender fol-lows this principle, a rational receiver can rely on it, a rational sender can rely on thereceiver relying on it, etc.
The particular solution concept proposed here is in a sense hybrid, combininga cumulative notion of iterated best response—starting from some salient set ofstrategies—with an equilibrium notion.
The present proposal, as well as the related approaches mentioned above, is par-tially programmatic and opens up a series of questions for further research. I wouldlike to conclude with pointing out three issues that promise to be especially fertile:
! The details of the belief revision policy of the receiver (and the sender’s assump-tions about it) turned out to play a massive role in determining pragmatic infer-ences. This connection has only been tapped on so far and deserves further scrutiny.Belief revision plays a central role in many pragmatic phenomena beyond the
11 It is perhaps noteworthy that similar ideas are being pursued in philosophical circles in the context ofthe epistemology of testimony; cf. for instance Burge (1993). I thank Sanford Goldberg and MatthewMullins for pointing this connection out to me.

“13-ch09-0467-0492-9780444537263” — 2010/11/29 — 21:08 — page 489 — #23
Game-Theoretical Pragmatics 489
scope of (neo-)Gricean pragmatics. To mention just a few: (a) Presuppositionaccommodation works because a naive listener assigns probability zero to a presup-posing expression if its presupposition is not part of the common ground. This willlead to belief revision, and this can be exploited by a strategic speaker. (b) Rhetori-cal questions are utterances that are inappropriate in the actual utterance context. Anaive listener will adapt his assumptions about the context in a way that makes thequestion appropriate. This can be anticipated by a strategic speaker and exploitedfor a rhetorical effect. (c) Non-literal interpretations like active metaphors or indi-rect speech acts arise because a signal would be irrational in the actual utterancesituation, which in turn triggers a belief revision on the side of the hearer.
! When children acquire a language, they only observe the usage of signals in actualsituations, i.e. their pragmatic usage, not their underlying literal meaning. So inlanguage learning, the semantics has to be inferred from the pragmatics. Sincethe mapping from the conventionalized semantics to a pragmatically rationaliz-able equilibrium is usually many-to-one, this problem is not perfectly solvable. Ifthe learner only observes a small sample of game situations, mistakes in meaninginduction become even more likely. Under iterated learning, this leads to a dyna-mics of language change (cf. Kirby and Hurford, 2001). A possible direction ofchange is the semanticization of pragmatic inferences. A formal and computationalinvestigation of the iterated learning dynamics of the game-theoretic model, and itscomparison with the findings from historical semantics, seems to be a promisingundertaking.
! The computation of pragmatically rationalizable equilibria proceeds by the iteratedcomputation of the set of best responses, starting from the set of honest strategies. Itseems initially plausible that actual humans use a similar strategy, but only computea bounded, perhaps small, number of iterations. This leads to the prediction that thecognitive effort of a pragmatic inference is correlated with the number of iterationsaccording to the iterated best response algorithm. This hypothesis is empiricallytestable via psycholinguistic experiments.
Acknowledgments
I am grateful to Johan van Benthem for helpful comments on a previous version of this chapter,and to Christian Ebert and Michael Franke for many relevant discussions. The research thatled to this chapter has been carried out within the project A2 of the SFB 673 “Alignment inCommunication” at the University of Bielefeld.
References
Anscombre, J.-C., Ducrot, O., 1983. L’Argumentation dans la Langue. Mardaga, Brussels.Battigalli, P., 2006. Rationalization in signaling games: theory and applications. Int. Game
Theory Rev. 8, 67–93.

“13-ch09-0467-0492-9780444537263” — 2010/11/29 — 21:08 — page 490 — #24
490 Handbook of Logic and Language
Battigalli, P., Siniscalchi, M., 2002. Strong belief and forward induction reasoning. J. Econ.Theory, 106, 356–391.
Benz, A., van Rooij, R., 2007. Optimal assertions and what they implicate. Topoi Int. Rev.Philos., 27, 63–78.
Bernheim, D.B., 1984. Rationalizable strategic behavior. Econometrica 52, 1007–1028.Blume, A., Kim, Y.-G., Sobel, J., 1993. Evolutionary stability in games of communication.
Games Econ. Behav. 5, 547–575.Blutner, R., 2001. Some aspects of optimality in natural language interpretation. J. Semant. 17,
189–216.Blutner, R., de Hoop, H., Hendriks, P., 2006. Optimal Communication. CSLI Publications, Stan-
ford, CA.Burge, T., 1993. Content preservation. Philos. Rev. 102, 457–488.Clark, H.H., 1996. Using Language. Cambridge University Press, Cambridge, UK.Dekker, P., van Rooy, R., 2000. Bi-directional optimality theory: an application of game theory.
J. Semant. 17, 217–242.Ducrot, O., 1973. La preuve et le dire. Mame, Paris.Franke, M., 2008a. Interpretation of optimal signals, in: Apt, K., van Rooij, R. (Eds.),
New Perspectives on Games and Interaction. Amsterdam University Press, Amsterdam,pp. 297–310.
Franke, M., 2008b. Meaning & inference in case of conflict, in: Balogh, K. (Ed.), Proceedingsof the 13th ESSLLI Student Session. European Summer School in Logic, Language andInformation, Hamburg, pp. 65–74.
Gärdenfors, P., 2000. Conceptual Spaces. The MIT Press, Cambridge, MA.Gärdenfors, P., Warglien, M., 2006. Cooperation, conceptual spaces and the evolution of seman-
tics, in: Vogt, P., Sugita, Y., Tuci, E., Nehaniv, C. (Eds.), Symbol Grounding and Beyond,Lecture Notes in Computer Science, vol. 4211. Springer, pp. 16–30.
Glazer, J., Rubinstein, A., 2004. On optimal rules of persuasion. Econometrica 72, 1715–1736.Glazer, J., Rubinstein, A., 2005. A game theoretic approach to the pragmatics of debate: an
expository note, in: Benz, A., Jäger, G., van Rooij, R. (Eds.), Game Theory and Pragmatics.Palgrave MacMillan, Basingstoke, pp. 230–244.
Grice, P.H., 1975. Logic and conversation, in: Cole, P., Morgan, J. (Eds.), Syntax and Seman-tics 3: Speech Acts. Academic Press, New York, pp. 41–58.
Hintikka, J., 1973. Logic, Language Games and Information. Clarendon, Oxford.Hintikka, J., Sandu, G., 1997. Game-theoretical semantics, in: van Benthem, J., ter Meulen, A.
(Eds.), Handbook of Logic and Language. The MIT Press, Cambridge, MA, pp. 361–410.Huttegger, S.H., 2007. Evolution and the explanation of meaning. Philos. Sci. 74, 1–27.Jäger, G., 2002. Some notes on the formal properties of bidirectional Optimality Theory. J.
Logic Lang. Inf. 11, 427–451.Jäger, G., 2007. Evolutionary game theory and typology: a case study. Language 83, 74–109.Jäger, G., 2008a. Evolutionary stability conditions for signaling games with costly signals. J.
Theor. Biol. 253, 131–141.Jäger, G., 2008b. Game Theory in Semantics and Pragmatics. Manuscript, University of
Bielefeld, Deutschland.Jäger, G., Koch-Metzger, L., Riedel, F., 2009. Voronoi Languages. Manuscript, University of
Bielefeld/University of Tübingen, Deutschland.Kirby, S., Hurford, J.R., 2001. The Emergence of Linguistic Structure: An Overview of the
Iterated Learning Model. Manuscript, University of Edinburgh, Scotland, UK.Levinson, S.C., 2000. Presumptive Meanings. MIT Press, Cambridge, MA.

“13-ch09-0467-0492-9780444537263” — 2010/11/29 — 21:08 — page 491 — #25
Game-Theoretical Pragmatics 491
Lewis, D., 1969. Convention. Harvard University Press, Cambridge, MA.Merin, A., 1999a. Die Relevanz der Relevanz: Fallstudie zur formalen Semantik der Englischen
Konjuktion ‘but’, Habilitationschrift, University of Stuttgart, Deutschland.Merin, A., 1999b. Information, relevance, and social decision making, in: Moss, L., Ginzburg,
J., de Rijke, M. (Eds.), Logic, Language, and Computation, vol. 2. CSLI Publications,Stanford, CA, pp. 179–221.
Parikh, P., 1987. Language and Strategic Inference. PhD thesis, Stanford University, unpub-lished, Stanford, CA.
Parikh, P., 1991. Communication and strategic inference. Ling. Philos., 14, 473–514.Parikh, P., 2001. The Use of Language. CSLI Publications, Stanford, CA.Pawlowitsch, C., 2008. Why evolution does not always lead to an optimal signaling system.
Games Econ. Behav. 63, 203–226.Pearce, D.G., 1984. Rationalizable strategic behavior and the problem of perfection. Economet-
rica, 52, 1029–1050.Pietarinen, A.V. (Ed.), 2007. Game Theory and Linguistic Meaning. Elsevier, Oxford & Ams-
terdam.Prince, A., Smolensky, P., 1993. Optimality Theory: Constraint Interaction in Generative
Grammar. Technical Report TR-2, Rutgers University Cognitive Science Center, NewBrunswick, NJ.
Rabin, M., 1990. Communication between rational agents. J. Econ. Theory 51, 144–170.Sandu, G., Sevenster, M., 2008. Equilibrium Semantics. Manuscript, University of Helsinki,
Finland.Selten, R., 1998. Features of experimentally observed bounded rationality. Eur. Econ. Rev. 42,
413–436.Stalnaker, R., 1997. On the evaluation of solution concepts, in: Bacharach, M.O.L., Gérard-
Varet, L.-A., Mongin, P., Shin, H.S. (Eds.), Epistemic Logic and the Theory of Games andDecisions, Kluwer Academic Publisher, pp. 345–364.
Trapa, P., Nowak, M., 2000. Nash equilibria for an evolutionary language game. J. Math. Biol.41, 172–188.
van Benthem, J., 1991. Language in Action. Elsevier, Amsterdam.van Rooij, R., 2004. Signalling games select Horn strategies. Ling. Philos. 27, 493–527.Wärneryd, K., 1993. Cheap talk, coordination and evolutionary stability. Games Econ. Behav.
5, 532–546.

“13-ch09-0467-0492-9780444537263” — 2010/11/29 — 21:08 — page 492 — #26
This page intentionally left blank

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 493 — #1
Part 2
General Topics

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 494 — #2
This page intentionally left blank

“14-ch10-0493-0554-9780444537263” — 2010/11/30 — 3:44 — page 495 — #3
10 Compositionality!
Theo M.V. Janssen†, with an appendix by BarbaraH. Partee‡
†ILLC Universiteit van Amsterdam, P.O. Box 94242, 1090 GEAmsterdam, The Netherlands, E-mail: [email protected]
‡Department of Linguistics, University of Massachusetts, Amherst,MA 01003-7130, USA, E-mail: [email protected]
10.1 The Principle of Compositionality of Meaning
10.1.1 The Principle
The principle of compositionality reads, in its best known formulation:
The meaning of a compound expression is a function of the meanings of its parts
The principle of compositionality of meaning has immediate appeal, but at the sametime it arouses many emotions. Does the principle hold for natural languages? Thisquestion cannot be answered directly, because the formulation of the principle is suf-ficiently vague that anyone can put his own interpretation on the principle. One topicof investigation in this chapter is providing a more precise interpretation of the prin-ciple, and developing a mathematical model for the principle. The second topic ofinvestigation is to discuss challenges to the principle in the literature. It will be arguedthat the principle should not be considered an empirically verifiable restriction, but amethodological principle that describes how a system for syntax and semantics shouldbe designed.
10.1.2 Occurrences of the Principle
Compositionality of meaning is a standard principle in logic. It is hardly ever discussedthere, and almost always adhered to. Propositional logic clearly satisfies the principle:the meaning of a formula is its truth value and the meaning of a compound formulais indeed a function of the truth values of its parts. The case of predicate logic will bediscussed in more detail in Section 10.2.
The principle of compositionality is a well-known issue in philosophy of language;in particular it is the fundamental principle of Montague grammar. The discussions
* Revised version of the paper that appeared as Chapter 7 in J.F.A.K. van Benthem & A. ter Meulen (eds.),Handbook of Logic and Linguistics, Elsevier Science Publishers, Amsterdam
Handbook of Logic and Language. DOI: 10.1016/B978-0-444-53726-3.00010-4c" 2011 Elsevier B.V. All rights reserved.

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 496 — #4
496 Handbook of Logic and Language
in philosophy of language will be reviewed in several sections of this chapter. Inlinguistics the principle was put forward by Katz and Fodor (Katz, 1966, p. 152; Katzand Fodor, 1963, p. 503). They use it to design a finite system with infinite output:meanings for all sentences. There is also a psychological motivation in their argu-ment, as, in their view, the principle can explain how a human being can understandsentences never heard before, an argument proposed by Frege much earlier (see Sec-tion 10.1.3); see also the discussion in Section 10.7.5.
The principle is also adhered to in computer science. Programming languages are notonlyused to instruct computers toperformcertain tasks,but theyarealsousedamongsci-entists for the communication of algorithms. So they are languages with an (intended)meaning. To prove properties of programs, for example that the execution of the pro-gram terminates at some point, a formal semantics is required. A prominent school inthis area, Denotational Semantics, follows the methods of logic, and espouses thereforecompositionality as a fundamental principle; see Sections 10.4.2 and 10.10.1.
Another argument for working compositionally that is often put forward in computerscience is of a practical nature. A compositional approach enables the program designerto think of his system as a composite set of behaviors, which means that he can factorizehis design problem into smaller problems which he can then handle one by one.
Above we have met occurrences of the principle of compositionality in rather dif-ferent fields. They have a common characteristic. The problem to be dealt with is toodifficult to tackle at once and in its entirety; therefore it is divided into parts and thesolutions are combined. Thus compositionality forms a reformulation of old wisdom,attributed to Philippus of Macedonia: divide et impera (divide and conquer).
10.1.3 On the History of the Principle
Many authors who mention compositionality call it Frege’s Principle. Some assert thatit originates with Frege (e.g., Dummett, 1973, p. 152); others inform their readers thatit cannot be found in explicit form in his writings (Popper, 1976, p. 198). Below wewill consider the situation in more detail.
In the introduction to Grundlagen der Mathematik (Frege, 1884, p. xxii), Fregepresents a few principles he promises to follow, one being:
One should ask for the meaning of a word only in the context of a sentence, and notin isolation.
Later this principle acquired the name of “principle of contextuality”. Contextualityis repeated several times in his writings and ignoring this principle is, according toFrege, a source of many philosophical errors. The same opinion on these matters isheld by Wittgenstein in his Tractatus (Wittgenstein, 1921).
Compositionality requires that words in isolation have a meaning and that fromthese meanings the meaning of a compound can be built. The formulation of contex-tuality given above disallows speaking about the meaning of words in isolation andis therefore incompatible with compositionality. This shows that Frege was (at thetime he wrote these words) not an adherent of compositionality. In Dummett (1973,pp. 192–193) it is tried to reconcile contextuality with compositionality.

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 497 — #5
Compositionality 497
In Frege’s later writings one finds fragments that come close to what we call com-positionality of meaning. The most convincing passage, from “Compound thoughts”(Frege, 1923), is quoted here as it provides a clear illustration of Frege’s attitude (inthose days) with respect to compositionality. In the translation of Geach and Stoothoff(1977):
It is astonishing what language can do. With a few syllables it can express an incalcu-lable number of thoughts, so that even a thought grasped by a terrestrial being for thevery first time can be put into a form of words which will be understood by someoneto whom the thought is entirely new. This would be impossible, were we not able todistinguish parts in the thoughts corresponding to the parts of a sentence, so that thestructure of the sentence serves as the image of the structure of the thoughts.
In this passage one could read the idea compositionality of meaning. Yet it isnot the principle itself, as it is not presented as a principle but as an argument in awider discussion. Furthermore, one notices that Frege does not require that the ulti-mate parts of the thought have an independently given meaning (which is an aspect ofcompositionality).
The conclusion is that Frege rejected the principle of compositionality in the periodin which he wrote Grundlagen der Mathematik. Also in his later works he never men-tions compositionality as a principle. It is, therefore, inaccurate to speak of “Frege’sprinciple”. Compositionality is not Frege’s, but it was called “Fregean” to honor hiscontribution to the semantic analysis of language. For an extensive discussion ofFrege’s relation with the principles of “Compositionality” and “Contextuality”, seeJanssen (2001) and Pelletier (2001).
10.2 Illustrations of Compositionality
10.2.1 Introduction
In this section the principle of compositionality is illustrated with four examples; inlater sections more complex examples will be considered. The examples are takenfrom natural language, programming language and logic. All cases concern a phe-nomenon that at a first sight might be considered as non-compositional. But it turnsout that there is a perspective under which they are compositional.
10.2.2 Time Dependence in Natural Language
The phrase the Queen of Holland can be used to denote some person. Who this isdepends on the time one is speaking about. Usually the linguistic context (tense, timeadverbials) give sufficient information about whom is meant, as in (1) or (2):
(1) In 1990 the Queen of Holland was married to Prince Claus.(2) In 1910 the Queen of Holland was married to Prince Hendrik.

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 498 — #6
498 Handbook of Logic and Language
In (1) Queen Beatrix is meant, whereas in (2) Queen Wilhelmina is meant, becausethese were queens in the years mentioned.
These examples might suggest that the meaning of the Queen of Holland varieswith the time about which one is speaking. This is, however, not in accordance withcompositionality, which requires that the phrase, when considered in isolation, has ameaning from which the meaning of (1) and (2) can be built. The solution that leadsto a single meaning for the phrase is to incorporate the source of variation into thenotion of meaning. Accordingly, the meaning of the Queen of Holland is a functionfrom moments of time to persons. For other expressions there may be other factors ofinfluence (speaker, possible world, . . . ). Such factors are called indices and a functionwith indices as domain is called an intension. So compositionality leads us to con-sider intensions as meanings of natural language expressions. For a discussion of thisapproach to meaning, see Lewis (1970).
10.2.3 Identifiers in Programming Languages
Expressions like x+1 are used in almost every programming language. The expressiondenotes a number; which number this is depends on the contents of a certain cellin the memory of the computer. For instance, if the value 7 is stored for x in thememory, then x + 1 denotes the number 8. So one might say that the meaning ofx + 1 varies, which is not in accordance with compositionality. As in the previousexample, the source of variation can be incorporated in the notion of meaning, sothat the meaning of an expression like x + 1 is a function from memory states of thecomputer to numbers. The same notion of meaning is given in the algebraic approachto semantics of programming languages, initiated by Goguen, Thatcher, Wagner andWright (1977).
Interesting in the light of the present approach is a discussion in Pratt (1979). Hedistinguishes two notions of meaning: a static meaning (an expression gets a mean-ing once and for all) and a dynamic notion (the meaning of an expression varies).He argues that a static meaning has no practical purpose, because we frequently useexpressions that are associated with different elements in the course of time. There-fore he developed a special language for the treatment of semantics of programminglanguages: dynamic logic. Compositionality requires that an expression has a meaningfrom which in all contexts the meaning of the compound can be built, hence a staticnotion of meaning. In this subsection we have seen that a dynamic aspect of meaningcan be covered by a static logic by using a more abstract notion of meaning.
10.2.4 Tarski’s Interpretation of Predicate Logic
Compositionality requires that for each construction rule of predicate logic there is asemantic interpretation. It might not be obvious whether this is the case for predicatelogic. Pratt (1979) even says that “there is no function such that the meaning of !x!can be specified with a constraint of the form M(!x!) = F(M(!))”. In a composi-tional approach such a meaning assignment M and an operator F on meanings haveto be provided.

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 499 — #7
Compositionality 499
Let us consider Tarski’s standard way of interpreting predicate logic in more detail.It roughly proceeds as follows. Let A be a model and g an A-assignment. The inter-pretation inA of a formula ! with respect to g, denoted !g, is defined recursively. Oneof these clauses is:
[! " "]g is true iff !g is true and "gis true.
This suggests that the meaning of ! "" is a truth value that is obtained from the truthvalues for ! and " . But another clause of the standard interpretation is not compatiblewith this idea:
[#x!]g is true iff if there is a g$ %x g such that [!(x)]g$is true.
(Here g$ %x g means that g$ is the same assignment as g except for the possibledifference that g$(x) &= g(x) ). Since it obviously is not always possible to calculatethe truth value of #x! (for a given g) from the truth value of ! (for the same g),a compositional approach to predicate logic requires a more sophisticated notion ofmeaning.
Note that there is no single truth value which corresponds with !(x). It depends onthe interpretation of x, and in general on the interpretation of the free variables in !,hence on g. In analogy with the previous example, we will incorporate the variableassignment into the notion of meaning. Then the meaning of a formula is a functionfrom variable assignments to truth values, namely the function that yields true for anassignment in case the formula is true for that assignment. With this conception wecan build the meaning of ! " " from the meanings of ! and " : it is the function thatyields true for an assignment if and only if both meanings of ! and " yield true forthat assignment.
A reformulation is possible by which the compositional character is evidentbecause a closed form is used. Tarski himself provided one, when he, around 1960,became interested in the application of methods from algebra in logic (Henkin, Monkand Tarski, 1971). It requires a shift of perspective to appreciate the formulation. Themeaning of a formula is defined as the set of assignments for which the formula istrue. Then M(! " ") = M(!) ' M("). The clause for the existential quantifierreads M(#x!) = {h | h %x g and g ( M(!)}. This definition can be found in sometextbooks on logic (e.g., Kreisel and Krivine, 1976; Monk, 1976); however, usuallyTarski’s definition of satisfaction is used.
Note that same strategy can be followed for other logics. For instance, a compo-sitional meaning assignment to propositional modal logic is obtained by defining themeaning of a proposition to be the set of possible worlds in which the propositionholds.
It is interesting to take another perspective on the conception of meaning besidesas sets of variable assignments. An assignment can be seen as an infinite tuple ofelements: the first element of the tuple being the value for the first variable, the sec-ond element for the second variable, etc. So an assignment is a point in an infinite-dimensional space. If ! holds for a set of assignments, then the meaning of ! is a set

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 500 — #8
500 Handbook of Logic and Language
x3
x1
{g! "g = true}
{g! [#x3 "]g = true}x2
Figure 10.1 The interpretation of #x as a cylindrification operation.
of points in this space. The operator Cx applied to a point adds all points which dif-fer from this point only in their x-coordinate. Geometrically speaking, a single pointextends into an infinite line. When Cx is applied to a set consisting of a circle area, it isextended to a cylinder. Because of this effect, the operation Cx is called the x-th cylin-drification operation (see Figure 10.1). The algebraic structure obtained for predicatelogic, with cylindrifications as operators, is called a cylindric algebra. The originalmotivation for studying cylindric algebras was a technical one: to make the powerfultools from algebra available for studying logic (Henkin, Monk and Tarski, 1971).
The discussion can be summarized as follows. The standard (Tarskian) interpre-tation of predicate logic is not a meaning assignment but a recursive, parameterizeddefinition of truth for predicate logic. It can easily be turned into a compositionalmeaning assignment by incorporating the parameter (viz. the assignment to variables)into the concept of meaning. Then meaning becomes a function with assignments asdomain.
10.2.5 Situation Semantics
Situation Semantics (Barwise and Perry, 1983) presents an approach to meaning whichdiffers from the traditional model-theoretic one. The main new point is that a sentenceconveys information (about the external world or about states of mind), and is formal-ized in its approach as a relation: the meaning of a declarative sentence is a relationbetween utterances of the sentence and the situation described by the utterance. Moregenerally, the meaning of an expression is a relation between utterances and situations.The interpretation of an utterance at a specific occasion is the described situation.
To illustrate Situation Semantics, consider the following example (op. cit., p. 19):
(3) I am sitting.
The meaning of this sentence is a relation between utterance u and situation e whichholds just in case there is a location l and an individual a such that a speaks at l, and insituation e this individual a is sitting at l. The parts of a sentence provide the following

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 501 — #9
Compositionality 501
ingredients to build this meaning relation. The meaning of a referring noun phrase isa relation between an utterance and an individual; and the verb phrase is a relationbetween an utterance and a property. From the meanings of the subject and the verbphrase the meaning of the whole sentence is built in a systematic way. Thus, SituationSemantics satisfies the principle of compositionality of meaning.
This was a simple example because the domain of interpretation does not change.More challenging is sentence (4) with antecedent relations as indicated in (5) (Barwiseand Perry, 1983, pp. 136–137):
(4) Joe admires Sarah and she admires him.(5) Joe1 admires Sarah2 and she2 admires him1.
Sentence (4) has two parts (6) and (7):
(6) Joe admires Sarah.(7) She admires him.
Sentence (7), when considered in isolation, has two free pronouns for which suitableconnections must be found. This is not the case for the whole sentence (4); so (7)has another domain for the interpretation of pronouns than (4). For this reason, thestatement made with (4) cannot be considered as just a conjunction of two independentstatements: somehow the meaning of the first part has to influence the meaning of thesecond part.
The solution is based upon the meanings of names. Initially (op. cit., p. 131), themeaning of a name # was defined as a relation that holds between an utterance uand an individual a$ (in a discourse situation d) if and only if the speaker c of theutterance refers by # to that individual. For sentences like (4), the meaning of namesis augmented to make them suitable antecedents for co-indexed pronouns (op. cit.,p. 137), evoking a connection with the coindexed pronouns. In symbols:
d, c[[#i]]a$ , e iff c(#i) = a$ , a$ is named #, and if c(hei) = b then b = a$
With this extension the meaning of a sentence of the form ! and " can be obtainedfrom the meanings of ! and " in the following way:
d, c[[! and "]]e iff there is an extension c’ of c such that d, c$[[!]]e and d, c$[["]]e
Let us summarize the solution. The meaning of ! and " is a relation, and to findits value for the pair of coordinates )d, c*; the value of the meanings of ! and " forthese coordinates is not sufficient. Other coordinates c$ have to be considered too,so the whole meaning relation has to be known. This illustrates that (op. cit., p. 32):“a version of compositionality holds of meanings, but not of interpretations”. This isan analogy of the situation in Montague grammar, where there is compositionality ofmeaning, but not of extension.
This example illustrates that the relational approach to meaning is not an obstacle tocompositional semantics. The problem was that the initial meaning of names was too

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 502 — #10
502 Handbook of Logic and Language
poor to deal with co-indexed pronouns, and the solution was to augment the conceptof meaning. Again, the strategy was followed that if a given conception of meaning isnot suitable for a compositional semantics, a richer conception of meaning is defined.
10.2.6 Conclusion
These examples illustrate that compositionality is not too narrow. Using a sufficientlyabstract notion of meaning, it is flexible enough to cover many standard proposals inthe field of semantics. The strategy was to incorporate a possible source of variationof meaning into a more abstract notion of meaning. In this way meanings not onlycapture the semantic intuitions, but do so in a compositional way. The classical adviceof Lewis (1970, p. 5) is followed: “In order to say what a meaning is, first ask what ameaning does, and then find something that does that”.
10.3 Towards Formalization
10.3.1 Introduction
The principle of compositionality of meaning is not a formal statement. It containsseveral vague words which have to be made precise in order to give formal content tothe principle. In this section the first steps in this direction are made, giving us ways todistinguish compositional and non-compositional proposals (in Section 10.4). In latersections (viz. 10.8, 10.9) mathematical formalizations are given, making it possible toprove certain consequences of the compositional approach.
Suppose that an expression E is constituted by the parts E1 and E2 (according tosome syntactic rule). Then compositionality says that the meaning M(E) of E can befound by finding the meanings M(E1) and M(E2) of respectively E1 and E2, and com-bining them (according to some semantic rule). Suppose moreover that E1 is consti-tuted by E1a and E1b (according to some syntactic rule, maybe other than the one usedfor E). Then the meaning M(E1) is in turn obtained from the meanings M(E1a) andM(E1b) (maybe according to another rule than the one combining M(E1) and M(E2)).This situation is presented in Figure 10.2.
10.3.2 Assumptions
The interpretation in Section 10.3.1 is a rather straightforward explication of the prin-ciple, but there are several assumptions implicit in it. Most assumptions on composi-tionality are widely accepted; some will return in later sections, when the principle isdiscussed further.
The assumptions are:
1. In a grammar the syntax and the semantics are distinguished components connected by therequirement of compositionality. This assumption excludes approaches, as in some variants

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 503 — #11
Compositionality 503
E3 E4 M (E3) M (E4)
M (E1) M (E2)
M (E)
E1 E2
E
Figure 10.2 Compositionality: the compositional formation of expression E from its parts andthe compositional formation of M(E), the meaning of E, from its parts.
of Transformational Grammar, with a series of intermediate levels between the syntax andthe semantics.
2. It is assumed that the output of the syntax is the input for meaning assignment. This is forinstance in contrast to the situation in Generative Semantics, where the syntactic form isprojected from the meanings.
3. The rules specify how to combine the parts, i.e. they are instructions for combining expres-sions. So this gives a different perspective from the traditional view of a grammar as arewriting system.
4. The grammar determines what the parts of an expression are. It depends on the rules whetherMary does not cry has two parts Mary and does not cry, or three Mary, does not and cry.This illustrates that part is a technical notion.
5. All expressions that arise as parts have a meaning. This excludes systems in which only com-plete sentences can be assigned meanings (as in some variants of Transformational Gram-mar). Not only parts for which we have an intuitive meaning (as loves in John loves Mary),but also parts for which this is less intuitive (as only in Only John loves Mary). The choiceof what the meaning of a part is might depend on what we consider a suitable ingredient forbuilding the meaning of the whole expression.
6. The meaning of an expression is not only determined by the parts, but also by the rule whichcombines those parts. From the same collection of parts several sentences can be made withdifferent meanings (e.g., John loves Mary vs. Mary loves John). Several authors make thisexplicit in their formulation of the principle, e.g., Partee, ter Meulen and Wall (1990, p. 318):
The meaning of a compound expression is a function of the meanings of its partsand of the syntactic rule by which they are combined.
7. For each syntactic rule there is a semantic rule that describes its effect. In order to obtain thiscorrespondence, the syntactic rules should be designed appropriately. As a consequence,semantic considerations may influence the design of syntactic rules. This correspondenceleaves open the possibility that the semantic rule is a meaning-preserving rule (no change ofmeanings), or that different syntactic rules have the same meaning.
8. The meaning of an expression is determined by the way in which it is formed from its parts.The syntactic production process is, therefore, the only input to the process of determiningits meaning. There is no other input, so no external factors can have an effect on the meaningof a sentence. If, for instance, discourse factors should contribute to meaning, the conceptionof meaning has to be enriched in order to capture this.

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 504 — #12
504 Handbook of Logic and Language
9. The production process is the input for the meaning assignment. Ambiguous expressionsmust have different derivations: i.e. a derivation with different rules, and/or with differentbasic expressions.
10.3.3 Options in Syntax
In the above section it is not specified what the nature is of expressions and parts, i.e.what kind of objects are in the boxes in Figure 10.2. Such a decision has to be basedupon linguistic insights. Some important options are mentioned below.
10.3.3.1 Concatenation of Words
Close to the most naive conception of compositionality is that the boxes containstrings of words (the terminal boxes single words), and that the syntactic rules concate-nate their contents. However, all important theories of natural language have a moresophisticated view. Classical Categorical Grammar and classical Generalized PhraseStructure grammar (GPSG) do not use real words, but more abstract word-forms withfeatures. In all these cases the structure from Figure 10.2 is isomorphic to the con-stituent structure of the involved expression.
10.3.3.2 Powerful Operations on Strings
In some theories the syntactic rules are more powerful than just concatenation. It is asmall step from basic categorial grammars to allow a wrap-rule (a rule with two argu-ments, where the first argument is inserted in the second position of the second argu-ment). In PTQ (Montague, 1973) the syntactic rules are very powerful, for instancethere is a rule that substitutes a string for a pronoun (e.g., the wide scope reading ofEvery man loves a woman is obtained by substituting a woman for him in every manloves him). In these cases the grammar generates strings, and the derivation does notassign a constituent structure to them (since the parts are not constituents but strings).
10.3.3.3 Operations on Structures
Most theories concern structures. Tree Adjoining Grammar, for instance, assumes asits basic elements (small) trees, and two kinds of rules: adjunction and substitution.Another example is the M-grammars, introduced by Partee (1973), and used in thetranslation system Rosetta (1994). The boxes contain phrase-structure trees like thosein Transformational Grammar, and the rules are powerful operations on such trees. Inthis situation the tree that describes the derivation might differ considerably from thetree describing the structure of the string, as illustrated below.
Consider the following sentence:
(8) John seeks a unicorn.
There are semantic arguments for distinguishing two readings: the de re reading whichimplicates the existence of unicorns, and the de dicto reading which does not. But there

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 505 — #13
Compositionality 505
TV
seek
seek John
John
unicorn
Det
a unicorn
unicorn
seeks
John
seeksDet CN
a
CN
him1
him1
him1
NPTV
VP
NPNP
NPS
NP
NPTV
VP
NP
NP
TV NP
S
VP
Figure 10.3 The production of the de re reading of John seeks a unicorn. The resulting con-stituent structure is the same as the structure for the de dicto reading.
are no syntactic arguments for distinguishing two different constituent structures. In anM-grammar this unique constituent structure can be derived in two ways, one for eachmeaning. In Figure 10.3 the derivation of the de re reading of (8) is given, using atree-substitution rule.
10.3.4 Conclusion
Above it is argued that there are several options in syntax. In the previous sectionit has been shown that there are choices in defining what meanings are. The discus-sion whether natural language is compositional has to do with these options. If onehas a definite opinion on what parts, meanings and rules should be like, then it maybe doubted whether compositionality holds. But if one leaves one or more of thesechoices open, then the issue becomes: in which way can compositionality be obtained?These two positions will return in several discussions concerning the principle ofcompositionality.

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 506 — #14
506 Handbook of Logic and Language
10.4 Examples of Non-Compositional Semantics
10.4.1 Introduction
In this section examples of essential non-compositional semantics are presented,where their non-compositional character is not caused by the nature of the phenom-ena, but by the fundamental aspects of the approach taken. It is not possible to turnthese proposals into compositional ones without losing a fundamental aspect of theanalysis. Thus the examples illustrate the demarcation line between compositionaland non-compositional semantics. As in Section 10.2, the examples deal with severaltypes of languages: programming languages, natural languages and logic.
10.4.2 Arrays in Programming Languages
In programming languages one finds expressions consisting of an array identifier withsubscript, e.g., a[7]. Here a is an array identifier; it refers to a series of memory cells inthe computer. Between the [-sign and ]-sign the subscript is mentioned. That subscripttells us which of the cells is to be considered, so the expression a[7] refers to thecontents of this cell (e.g., a number). The subscript can be a compound expression thatdenotes a number, e.g., x + 1, and the syntax of this construction says that there aretwo parts: an array identifier, and an arithmetical expression.
In the semantics of programming languages one often interprets programs in anabstract computer with abstract memory cells. Then expressions like a[7] and a[x + 1]have as interpretation the value stored in such a memory cell (or alternatively a func-tion to such a value). The array identifier itself cannot be given an interpretation, sincein the abstract computer model there is nothing but cells and their contents, and a doesnot correspond to any one of them. As a consequence, every time the array identifierarises, it has to be accompanied by a subscript. This leads to complicated proof rules(de Bakker, 1980).
This interpretation is not in accordance with compositionality which requires thatall parts have a meaning; in particular the array identifier should have a meaning.Although in the given computer model an appropriate meaning is not available, it iseasy to define one: a function from numbers to cells. Changing the model in this wayallows a simpler reformulation of the proof rules, because array identifiers withoutsubscripts can be used (Janssen and van Emde Boas, 1977).
10.4.3 Syntactic Rules as Conditions
In several theories syntactic rules are formulated as conditions, or they are accompa-nied by conditions. First we will consider a simple example. A context sensitive ruleallows us to rewrite a symbol in a certain context. A context sensitive grammar isa grammar with such rules. An example is one with the rules S + AA, Ab + bb,bA + bb. This grammar does not produce any strings, because after application ofthe first rule, no further rules are applicable. MacCawley (1986) proposed to consider

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 507 — #15
Compositionality 507
S
A
b b
A
Figure 10.4 The context sensitive rules S + AA, Ab + bb, bA + bb used as node admissi-bility conditions.
context sensitive rules as “node-admissability conditions”. These specify which con-figurations in trees are allowed. For instance, the last rule says that a b immediatelydominated by an A is allowed, if there is a b immediately to the left of this b. Withthis interpretation, the tree in Figure 10.4 is allowed by the given grammar. So thestring bb belongs to the language of the grammar, although it cannot be generated inthe classical way. In this conception of grammar there are no rules, only conditions.Hence there is no syntactic algebra with operations, and an admissible structure hasno derivation. Consequently, a compositional meaning assignment (in the sense of theprinciple) is not possible.
A similar situation arises in the variant of Transformational Grammar known as“Principles and Parameters”. Conditions form the central part of the theory, but for-mally the situation is slightly different. One single transformation, called move-%, canin principle move any constituent to any position controlled by various conditions onmovement. So the interesting aspect of the theory does not lie in this transformation,but in the conditions. An algebraic formulation of this theory is possible, with onepartial rule which takes one argument as input. Since this single rule has to accountfor all phenomena, there is no semantic counterpart for this rule. So “Principles andParameters” is a theory where compositionality of meaning is impossible.
In Generalized Phrase Structure Grammar (GPSG) syntactic rules are consideredas expressing a tree admissibility condition, i.e. they say which trees are allowed givenan ID-rule or an LP-rule. This form of admissibility conditions does not disturb com-positionality: a rule can be considered as an abbreviation for a collection of rules, eachgenerating one of the admissible structures, and all rules from the collection have thesame semantic interpretation (the one associated with the original rule).
10.4.4 Discourse Representation Theory
Pronominal references in discourses may depend on previous sentences, as illustratedby the following two discourses which have identical second sentences.
(9) A man walks in the park. He whistles.(10) Not all men do not walk in the park. He whistles.
In (9), the pronoun he in the second sentence is interpreted as anaphorically linked tothe term a man in the first sentence. This is not possible in (10), where he has to referto a third party. The meanings of discourses (9) and (10) are, therefore, different.

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 508 — #16
508 Handbook of Logic and Language
Since their second sentences are identical, their first sentence (11) and (12) mustcontain the source of the meaning difference.
(11) A man walks in the park.(12) Not all men do not walk in the park.
However, (11) and (12) have identical truth-conditions, hence the discourses (9) and(10) seem to provide an argument against compositionality.
Discourse representation theory (henceforth “DRT”) is a theory about semanticrepresentations of texts, especially concerning pronominal references in texts (Kamp,1981; Kamp and Reyle, 1993). There are explicit rules how these representations areformed, and these rules follow the syntactic rules step by step. Parts of sentencesprovide building blocks for discourse representations. However, no semantic inter-pretation is provided for these parts of discourse representations. Furthermore, theinstructions may require specific information concerning already built parts of repre-sentations, and may change them. So the representation plays an essential role in thesystem and cannot be eliminated. DRT is a system for compositionally constructingrepresentations, but not for compositional semantics (then the representations shouldnot be essential; see also the discussion in Section 10.5). This is intended: the name ofthe theory explicitly states that it is about representations, and claims the psychologi-cal relevance of the representations. The solution DRT provides for the discourses westarted with, and roughly is as follows. Different representations are assigned to (11)and (12), and the two negations in (12) cause a difference that triggers a difference ininterpretation strategy, hence a difference in the pronominal reference.
However, a compositional treatment for this kind of discourse phenomena is quitefeasible. In fact, the principle of compositionality itself points to a solution. Since (11)and (12) have identical truth-conditions, a richer notion of meaning is required if theprinciple of compositionality is to be saved for discourses. Truth-conditions of sen-tences (which involve possible worlds and assignments to free variables) are just oneaspect of meaning. Another aspect is that the preceding discourse has a bearing onthe interpretation of a sentence (and especially of the so-called discourse pronouns).Moreover, the sentence itself extends this discourse and thus has a bearing on sen-tences that follow it. Hence a notion of meaning is required which takes the semanticcontribution into account that a sentence makes to a discourse. Sentences (11) and (12)make different contributions to the meaning of the discourse, especially concerning theinterpretation of later discourse pronouns. These ideas have led to Dynamic PredicateLogic (henceforth “DPL”). It is a compositional theory that accounts not only for thephenomena that are treated in DRT, but for other phenomena as well; see Groenendijkand Stokhof (1991). Thus we see that the requirement of compositionality suggesteda particular solution.
The difference in compositionality between DRT and DPL was initially a cen-tral point in the discussion, see Groenendijk and Stokhof (1991). Later developmentsmade the difference less crucial, because several reformulations of DRT were giventhat adhered to compositionality. Examples are Zeevat (1989), Muskens (1996), andChapter 3 in this handbook on DRT (van Eijck and Kamp, 1997). The concepts of

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 509 — #17
Compositionality 509
meaning used in these proposals are illuminating. For instance, in Zeevat’s proposalthe meanings are pairs consisting of sets of assignments (as in predicate logic), anda set of variables (discourse markers). So syntactic symbols act as component in thesemantics, which reflects the special role of representations in DRT.
10.4.5 Substitutional Interpretation of Quantifiers
For the interpretation of #x!, an alternative to the Tarskian interpretation has beenproposed that is not compositional. It is called the substitutional interpretation, andsays: #x!(x) is true if and only if there is some substitution a for x such that !(a)
is true. Of course, the substitutional interpretation is only equivalent to the standardinterpretation if there is a name for every element in the domain. The substitutionalinterpretation can be found in two rather divergent branches of logic: philosophicallogic and in proof theory, both considered below.
In philosophical logic the substitutional interpretation is advocated by Marcus(1962) with an ontological motivation. Consider:
(13) Pegasus is a winged horse.
Marcus argues that one might believe (13) without believing:
(14) There exists at least one thing which is a winged horse.
At the same time she accepts that (13) entails (15):
(15) #x(x is a winged horse)
This view implies that the quantification in (15) cannot be considered quantificationin the ontological sense. The substitutional interpretation of quantifiers allows us toaccept (15) as a consequence of (13), without accepting (14) as a consequence.
The substitutional interpretation is discussed more formally by Kripke (1976).According to his syntax !x!(x) is formed from !(x), whereas the interpretation is thesubstitutional one. About this situation Kripke (1976, p. 330) says: “Formulae whichare not sentences will be assigned no semantic interpretation”. So the meaning assign-ment is not compositional: the meaning of #x!(x) is not obtained from the meaningof its part !(x).
An author on proof theory is Schütte (1977). According to his syntax !x!(x) isformed from !(a), where a can be an arbitrary name (the expression !(x) is not inhis language). So the formula !x!(x) is syntactically ambiguous: there are as manyderivations as there are expressions of the form !(a). It is not possible to define theinterpretation of !x!(x) from one of its derivation, because !(a) might be true for thechosen a, whereas !x!(x) is false. Hence also in this case the substitutional interpre-tation is not compositional.
If one wishes to have the substitutional interpretation, and at the same time meet theprinciple of compositionality, then the syntax has to contain an infinitistic rule whichsays that all expressions of the form !(a) are a part of !x!(x). But such an infinitisticrule has not been proposed.

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 510 — #18
510 Handbook of Logic and Language
10.4.6 Conclusion
The examples illustrate that compositionality is a real restriction in the sense that thereare theories that are essentially non-compositional. Moreover, it illustrates that com-positionality is crucial in evaluating theories: not in the sense that it discriminates goodfrom bad (such arguments are not given above, but will be given in later sections), butin the sense that it exhibits a special aspect of those theories. The fact that there was nocompositional treatment of arrays exhibits that the semantic model used was ontologi-cally sparse (or too poor, if you prefer). It exhibits that the substitutional interpretationof quantifiers avoids assignments to variables with the price of introducing an infini-tistic aspect in the syntax. In DRT the rules refer in several ways to the particular formof the partial discourse representations that occur as their inputs. The compositionalreformulations exhibit in which respect this is essential. This brings us to the follow-ing advice: if you encounter a new proposal, and wish to find the innovative or deviantaspect, then look for the point where it departs from compositionality.
10.5 Logic as Auxiliary Language
10.5.1 Introduction
The principle of compositionality of meaning expresses that meanings of parts arecombined into the meaning of a compound expression. Since meanings are generallyformalized as model-theoretic entities, such as truth values and sets of sets, functionshave to be specified which operate on such meanings. An example of such an operationis Montague (1970a) and Thomason (1974, p. 194):
(16) G3 is that function f ( ((2I)A,A)A&such that, for all x ( A&, all u, t ( A and
all i ( I : f (x)(t, u)(i) = 1 if and only if t = u
Such descriptions are not easy to understand, or convenient to work with. Thereforealmost always a logical language is used to represent meanings and operations onmeanings. The main exception is Montague (1970a). So in practice associating mean-ings with natural language amounts to translating sentences into logical formulas.The operation described above is represented in intensional logic with the formula"'t'u[t = u]. This is much easier to grasp than the formulation in (16). This exampleillustrates that such translations into logic are used for good reasons. In the presentsection the role of translations into a logical language is investigated.
10.5.2 Restriction on the Use of Logic
Working in accordance with compositionality of meaning puts a strong restriction onthe translations into logic, because the goal of the translations is to assign meanings.The logical representations are just a tool to reach this goal. The representations are notmeanings themselves, and should not be confused with them. This means, for instance,that two logically equivalent representations are equally good as representations of theassociated meaning. A semantic theory cannot be based upon accidental properties ofmeaning representations, since it would then be a theory about representations, and

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 511 — #19
Compositionality 511
not about the meanings themselves. Therefore the logical language should only be anauxiliary tool and, in principle, dispensable.
If one has a logic for representing meanings, this logic will probably not haveall the operations on meanings one needs. For instance, logic usually has only oneconjunction operator (between formulas of type t), whereas natural language requiresseveral (not only between sentences, but also between verbs, nouns, etc.). So the logichas to be extended with new operations. We will consider two methods.
A new semantic operation can be introduced by introducing a new basic operatorsymbol, together with a model theoretic interpretation for it. Such an interpretation canbe given directly, speaking for example about functions from functions to functions.Another method is to denote the intended interpretation with a logical expression.Then one should not forget that this expression stands for its interpretation; see theexample below (in Section 10.5.3).
Another method is to describe the effects of the new operation using already avail-able ones. An example we have met above (in Section 10.5.1) is "'t'u[t = u]. This isan example of the standard method (introduced by Montague, 1970b): using polyno-mials. Probably everyone has encountered polynomials in studying elementary mathe-matics; an example (with two variables) is x2
1 + x1 + 3 , x2. This polynomial definesa function on two arguments; the resulting value is obtained by substituting the argu-ments for the variables and evaluating the result. For the arguments 2 and 1 it yields22 + 2 + 3 , 1, being 9. The method of polynomials can be used in logic as well. Forinstance, a polynomial over intensional logic with variables X1 and X2 is:
(17) 'y[X1(y) " X2(y)]
Note that y is not a variable in the sense of the polynomial. Polynomial (17) is anoperation which takes two predicates as inputs and yields a predicate as a result. Itcan be used to describe, for instance, the semantic effect of verb phrase conjunction.Usually Greek letters are used to indicate variables, in PTQ (Montague, 1973) onefinds for the above polynomial:
(18) 'y[( $(y) " )$(y)]
In Section 10.5.4 more examples of polynomials and non-polynomials will be given.
10.5.3 A New Operator: CAUSE
Dowty (1976) presents a treatment of the semantics of factive constructions like shakeJohn awake. For this purpose intensional logic is extended with an operator CAUSE.In order to define its interpretation the semantic apparatus is extended with a functionthat assigns to each well-formed formula ! and each possible world i a possible worldf (!, i). Intuitively speaking, f (!, i) is the possible world that is most like i with thepossible exception that ! is the case. Then the interpretation of CAUSE reads:
(19) If !, " ( MEt then (! CAUSE ")A,i,j,g is 1 if and only if [! " "]A,i,j,g is 1and [¬!]A,f (¬",i),j,g is 1.
The first argument of f is a formula, and not the interpretation of this formula. HenceCAUSE, which is based upon this function, is an operator on formulas, and not on

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 512 — #20
512 Handbook of Logic and Language
the meanings they represent. This suggests that the logic is not dispensable, that it isan essential stage and that the proposed solution is not compositional. This is shownas follows. Let f be such that f (¬[! " *], i) &= f (¬[* " !], i). Then it may be thecase that [(! " *) CAUSE "]A,i,j,g holds whereas this does not hold for * " !. So thetwo equivalent formulas ! " * and * " ! cannot be substituted for each other withoutchanging the resulting truth value – a consequence that was not intended. This illus-trates that the introduction of a new operator in a way that violates compositionalitybears the risk of being incorrect in the sense that the intended semantic operation is notdefined.
The proposal can be corrected by defining f for the meaning of its first argument(i.e. its intension). Then the last clause of the definition becomes “[¬!]A,k,j,g is 1,where k = f (["[¬* " !]]A,i,j,g, i)”.
10.5.4 An Operation on Logic: Relative Clause Formation
The syntactic rule for restrictive relative clause formation in PTQ (Montague, 1973)roughly is as follows:
(20) R3,n: If % is a CN and # a sentence, then % such that #+ is a CN, where #+
comes from # by replacing each occurrence of hen by the appropriate pronoun.
The corresponding semantic rule reads (neglecting intensions and extensions):
(21) If %$ is the translation of the common noun %, and # $ of the sentence #, thenthe translation of the CN with relative clause is 'xn[%$(xn) " # $].
The rule above forms from man and he2 loves Mary the common noun phrase mansuch that he loves Mary. Suppose that the meanings of these parts are represented byman and love-(x2, j). Then the meaning of the common noun phrase is given correctlyby 'x2[man(x2) " love-(x2, j)]. However, the translation rule yields incorrect resultsin the case where the translation of the common noun contains the occurrence of avariable that becomes bound by the '-operator introduced in the translation rule. Inorder to avoid this, the editor of the collection of Montague’s work on philosophy oflanguage, R. H. Thomason, gave in a footnote a correction (Thomason, 1974, p. 261):
(22) To avoid collision of variables, the translation must be 'xm[man(xm) " ")],where " is the result of replacing all occurrences of xn in # $ by occurrences ofxm, where m is the least even number such that xm has no occurrences in either%$ or # $.
This rule introduces an operation on expressions: the replacement of a variable byone with a special index. However, finding the least even index that is not yet usedis an operation that essentially depends on the form of the formulas. This is illus-trated by the two formulas x1 = x1 and x2 = x2, which are logically equivalent (theyare tautologies), but have a different least index that is not yet used. So Thomason’sreformulation is an operation on representations, and not on meanings.
Nevertheless, (22) is correct in the sense that it does correspond with an operationon meanings. The operation on meanings can be represented in a much simpler way,

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 513 — #21
Compositionality 513
using a polynomial, viz.:
(23) 'P['xn[P(xn) " # $]](%$)
This polynomial formulation avoids the binding of variables in %$ by 'xn, so the com-plication of Montague’s rule does not arise. Furthermore, it is much simpler thanThomason’s correction of the rule.
10.5.5 Conclusion
These examples illustrate a method to find dangerous spots in a proposal: find theplaces where the translation into logic is not a polynomial. It is likely that composi-tionality is violated there. Either the proposal is incorrect in the sense that it makesunintended predictions, or it is correct, but can be improved (simplified) considerablyby using a polynomial. The latter point, viz. that an operation on meanings can be exp-ressed by means of a polynomial (as illustrated in 10.5.3) can be given a mathematicalbasis (see Section 10.8). These applications of compositionality exhibit the benefits ofcompositionality as a heuristic method.
10.6 Alledged Counterexamples to Compositionality
10.6.1 Introduction
In this section we consider some examples from natural language that are used inthe literature as arguments against compositionality. Several other examples could begiven; see Partee (1984). The selection here is made in order to illustrate the methodsavailable to obtain compositionality. The presentation of the examples follows closelythe original argumentation; proposals for a compositional treatment are given after-wards. In the last section the methods to obtain compositional solutions are consideredfrom a general perspective.
10.6.2 Counterexamples
10.6.2.1 Would
The need for the introduction of the NOW-operator was based upon the classical exam-ple (Kamp, 1971):
(24) A child was born that will become ruler of the world.
The following more complex variants are discussed by Saarinen (1979), who arguesfor other new tense operators.
(25) A child was born who would become ruler of the world.(26) Joseph said that a child had been born who would become ruler of the world.(27) Balthazar mentioned that Joseph said that a child was born who would become
ruler of the world.
Sentence (25) is not ambiguous: the moment that the child becomes ruler of theworld lies in the future of its birth. Sentence (26) is twofold ambiguous: the moment

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 514 — #22
514 Handbook of Logic and Language
of becoming ruler can be in the future of the birth, but also in Joseph’s future. Andin (27) the child’s becoming ruler can even be in Balthazar’s future. So the numberof ambiguities increases with the length of the sentence. Therefore Hintikka (1983,pp. 276–279) presents (25)–(27) as arguments against compositionality.
10.6.2.2 Unless
Higginbotham (1986) presents arguments against compositionality; we discuss vari-ants of his examples (from Pelletier, 1993a). He claims that in (28) and (29) unlesshas the meaning of a (non-exclusive) disjunction.
(28) John will eat steak unless he eats lobster.(29) Every person will eat steak unless he eats lobster.
However, in (30) the situation is different.
(30) No person will eat steak unless he eats lobster.
This sentence is to be represented as:
(31) [ No: person ] (x eat steak " ¬ x eats lobster).
These examples show that the meaning of unless depends on the context of the sen-tence in which it occurs. Therefore compositionality does not hold.
10.6.2.3 Any
Hintikka (1983, pp. 266–267) presents several interesting sentences with any as chal-lenges to compositionality. Consider:
(32) Chris can win any match.
In this sentence it is expressed that for all matches it holds that Chris can win them,so any has the impact of a universal quantification. But in (33) it has the impact of anexistential quantification.
(33) Jean doesn’t believe that Chris can win any match.
Analogously for the pair (34) and (35), and for the pair (36) and (37):
(34) Anyone can beat Chris.(35) I’d be greatly surprised if anyone can beat Chris.(36) Chris will beat any opponent(37) Chris will not beat any opponent.
All these examples show that the meaning of the English determiner any depends onits environment.
The most exciting example is the one given below. As preparation, recall that Tarskirequired a theory of truth to result for all sentences in T-schemes of the form:
(38) “!” is true if and only if ! is the case.
A classical example of this scheme is:
(39) Snow is white is true if and only if snow is white

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 515 — #23
Compositionality 515
The next sentence is a counterexample against one half of the Tarskian T-scheme.
(40) Anybody can become a millionaire is true if anybody can become a millionaire.
This sentence happens to be false.
10.6.3 Compositional Solutions
10.6.3.1 Would
A compositional analysis of (41) is indeed problematic if we assume that it has to bebased on (42), because (41) is ambiguous and (42) is not.
(41) Joseph said that a child had been born who would become ruler of the world.(42) A child was born who would become ruler of the world.
However, another approach is possible: there may be two derivations for (41). In thereading that “becoming ruler” lies in the future of Joseph’s saying it may have (43) aspart.
(43) say that a child was born that will become ruler of the world
The rule assigning past tense to the main clause should then deal with the “sequenceof tense” in the embedded clause, transforming will into would. The reading in whichthe time of becoming ruler lies in the future of the birth could then be obtained bybuilding (41) from:
(44) say that a child was born who would become ruler of the world.
The strategy to obtain compositionality will now be clear: account for the ambi-guities by using different derivations. In this way the parts of (41) are not necessarilyidentical to substrings of the sentences under consideration (the involved tenses maybe different). Such an approach is followed for other scope phenomena with tenses inJanssen (1983).
10.6.3.2 Unless
Pelletier (1993a) discusses the arguments of Higginbotham (1986) concerning unless,and presents two proposals for a compositional solution.
The first solution is to consider the meaning of unless to be one out of a set oftwo meanings. If it is combined with a positive subject (as in every person will eatsteak unless he eats lobster) then the meaning “disjunction” is selected, and whencombined with negative subject (as in no person eats steak unless he eats lobster) theother meaning is selected. For details of the solution, see Pelletier (1993a). So unlessis considered as a single word, with a single meaning, offering a choice between twoalternatives. In the same way as in Section 10.2 this can be defined by a function fromcontexts to values.
The second solution is to consider unless a homonym. So there are two wordswritten as unless. The first one is unless[.neg], occurring only with subjects which bear(as is the case for every person) the syntactic feature [-neg], and having “disjunction”

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 516 — #24
516 Handbook of Logic and Language
as meaning. The second one is unless[+neg], which has the other meaning. Now unlessis considered to be two words, each with its own meaning. The syntax determineswhich combinations are possible.
10.6.3.3 Any
Hintikka (1983, p. 280) is explicit about the fact that his arguments concerning thenon-compositionality of any-sentences are based upon specific ideas about their syn-tactic structure. In particular it is assumed that (45) is a “component part” of (46)
(45) Anyone can beat Chris(46) I’ll be greatly surprised if anyone can beat Chris.
He claims that this analysis is in accordance with common sense, and in agreementwith the best syntactic analysis. But, as he admits, other analyses cannot be excludeda priori – for instance that (47) is a component of (46).
(47) I’ll be greatly surprised if — can beat Chris.
One might even be more radical in the syntax than Hintikka suggests, and introduce arule that produces (46) from:
(48) Someone can beat Chris.
Partee (1984) discusses the challenges of any. She shows that the situation is morecomplicated than suggested by the examples of Hintikka. Sentence (50) has two read-ings, only one of which can come from (49).
(49) Anyone can solve that problem.(50) If anyone can solve that problem, I suppose John can.
Partee discusses the literature concerning the context-sensitivity of any, and concludesthat here are strong arguments for two “distinct” any’s: an affective any and a free-choice any. The two impose distinct (though overlapping) constraints on the con-texts in which their semantic contributions “make sense”. The constraints on affectiveany can be described in model-theoretic terms, whereas those of the free-choice anyare less well understood. For references concerning this discussion, see Partee (1984,2004a) and Kadmon and Landman (1993).
We conclude that the any-examples can be dealt with in a compositional way bydistinguishing ambiguous any, with one or both readings eliminated when incompati-ble with the surrounding context.
10.6.4 General Methods for Compositionality
In this section we encounter three methods to obtain compositionality:
1. New meaningsThese are formed by the introduction of a new parameter, or, alternatively, a function fromsuch a parameter to old meanings. This was the first solution for unless.
2. New basic partsDuplicate basic expressions, together with different meanings for the new expressions, oreven new categories. This was the solution for any, and the second solution for unless.

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 517 — #25
Compositionality 517
3. New constructionsUse unorthodox parts, together with new syntactic rules forming those parts and rules oper-ating on those parts. This approach may result in abstract parts, new categories, and newmethods to form compound expressions. This was the solution for the would sentences.
For most counterexamples several of these methods are in principle possible, anda choice must be motivated. That is not an easy task because the methods are not justtechnical tools to obtain compositionality: they raise fundamental questions concer-ning the syntax and semantics interface. If meanings include a new parameter, thenmeanings have this parameter in the entire grammar, and it must be decided what rolethe parameter plays. If new basic parts are introduced, then each part should havemeaning, and each part is in principle available for every construction. If new con-structions are introduced, they can in principle be used everywhere. So expressionsmay then be produced in new ways, and new ambiguities may arise. Hence adopt-ing compositionality raises fundamental questions about what meanings are, what thebasic building blocks are and what ways of construction are.
The real question is not whether a certain phenomenon can be analyzed com-positionally, as enough methods are available, but what makes the overall theory(un)attractive or (un)acceptable. A case study which follows this line of argumentis presented in Appendix B: a study by Partee concerning genitives (also published inPortner and Partee, 2002, pp. 182–189).
10.7 Fundamental Arguments Against Compositionality
10.7.1 Introduction
In this section we discuss some arguments against compositionality which are notbased upon the challenge of finding a compositional solution for certain phenomena,but which concern issues of a more fundamental nature. The examples present theoriginal arguments, immediately followed by discussion.
10.7.2 Ambiguity
Pelletier presents arguments against compositionality based upon its consequences forthe analysis of ambiguities (Pelletier, 1993b, 1994). Some examples are:
(51) Every linguist knows two languages.(52) John wondered when Alice said she would leave.(53) The philosophers lifted the piano.
Sentence (51) is ambiguous regarding the total number of languages involved. In(52) the point is whether when asks for the time of departure, or the time of Alice’ssaying this, and in (53) the interpretation differs in whether they did it together orindividually.
The above sentences contain no lexically ambiguous words, and there are no syn-tactic arguments to assign them more than one constituent structure. Pelletier (1993b)says: “In order to maintain the Compositionality Principle, theorists have resorted toa number of devices which are all more or less unmotivated (except to maintain the

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 518 — #26
518 Handbook of Logic and Language
Principle): Montagovian “quantifying-in” rules, “traces”, “gaps”, “Quantifier Rais-ing”, . . .features, and many more.”
The issue raised by Pelletier with respect to (51) is a old one, and arises as well forthe classical de dicto – de re ambiguity of:
(54) John seeks a unicorn.
Because the quantifying-in rules of Montague grammar involve such a distortionfrom the surface form, various attempts have been made to avoid them. An influ-ential proposal was to use Cooper storage (Cooper, 1983): the sentence is interpretedcompositionally, but the NPs (every linguist and two languages) are exempted. Theirinterpretations are put in storage, and can be retrieved out of storage at a suitablemoment. The order in which they are retrieved reflects their relative scope. So Cooperstorage introduces an interpretation procedure and an intermediate stage in the model.Perhaps it is a compositional process, but it is questionable whether it constitutes acompositional semantics, because of the essential role of the storage mechanism.
Other approaches try to eliminate the ambiguity. Linguists have argued that thescope order is the surface order. This is known as “Jackendoff’s principle” (Jackendoff,1972). It has been said by semanticists that (51) has only one reading, viz. its weakestreading (every wide scope), and that the stronger reading is inferred when additionalinformation is available. Analogously for (54). These two approaches work well forsimple sentences, but they are challenged by more complicated sentences in which thesurface order is not a possible reading, or where the different scope readings are logicallyindependent. The latest proposal for dealing with scope ambiguities is by means of“lifting rules”. The meaning of a noun-phrase can, by means of rules, be “lifted” to amore abstract level, and different levels yield different scope readings. This techniqueis introduced in Partee (1986) and applied to quantifier scope by Hendriks (2001).
No matter which approach is taken to quantifier scope, the situation remains thesame with respect to other examples (as (52) and (53)). They are semantically ambigu-ous, even though there are no arguments for more than one constituent structure.
The crucial assumption in Pelletier’s arguments is that the derivation of a sentencedescribes its syntactic structure. But, as is explained in Section 10.3, this is not cor-rect. The derivation tree specifies which rules are combined in what order and thisderivation tree constitutes the input to the meaning assignment function. One shouldnot call something “syntactic structure” which is not intended as such and next refuteit because the notion so defined does not have the desired properties. The syntacticstructure (constituent structure) is determined by the output of the syntactic rules. Dif-ferent derivational processes may generate one and the same constituent structure, andin this way account for semantic ambiguities.
The distinction between derivation and resulting constituent structure is made invarious grammatical theories. In Section 10.3 it is illustrated how the quantifying-inrules in Montague grammar derive the de re version of (54) and how the rules producea syntactic structure that differs formally from the derivation tree. In Tree AdjoiningGrammars (TAGs) the different scope readings of (51) differ in the order in which thenoun-phrases are substituted in the basic tree for know. In transformational grammar

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 519 — #27
Compositionality 519
the two readings of (52) differ in their derivation. In the reading where when asks forthe time of leaving, it is formed from:
(55) John wondered Alice said she would leave when.
Another classical example is:
(56) The shooting of the hunters was bloody.
For this sentence transformational grammar derives the two readings from two differ-ent sources: one in which the hunters is in subject position and one in which it is inobject position.
So in all these grammatical theories a distinction is made between the constituentstructure of a sentence and the structure of its derivational history. Thus Pelletier’sobjection is met.
10.7.3 Ontology
In Hintikka (1983, Ch. 10), an extended version of Hintikka (1981), the issue of com-positionality is discussed. Besides counterexamples to compositionality (most havebeen considered in Section 10.6), he presents objections of a fundamental nature.
To illustrate Hintikka’s arguments we consider an example involving branchingquantifiers.
(57) Every villager has a friend and every townsman has a cousin who are membersof the same party.
The meaning representation with branching quantifiers is:
(58)!x#y!z#u
\/ M(x, y, z, u)
Note that the sequence of quantifiers is split into two branches: the upper and thelower branch. The representation indicates the (in)dependency of the quantifiers: thechoice of y depends only on x, and of u only on z. Formula (58) is an example from aformal language that does not adhere to compositionality. The information about the(in)dependencies of the quantifiers would be lost in a first-order representation.
As Hintikka says, it is easy to provide a linear representation with compositionalinterpretation when Skolem functions are used:
(59) #f #g!x!zM(x, f (x), z, g(z))
The connection with Hintikka’s own (game-theoretical) treatment for (57) is that (59)can be interpreted as saying that Skolem functions exist which codify (partially) thewinning strategy in the correlated game (op. cit., p. 281). See Chapter 8 of this Hand-book for more information on game-theoretical semantics.
So compositionality can be maintained by placing the first-order quantifiers byhigher-order ones. About this, Hintikka (1983, p. 20) says “It seems to me that this isthe strategy employed by Montague Grammarians, who are in fact strongly committedto compositionality. However, the only way they can hope to abide by it is to make

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 520 — #28
520 Handbook of Logic and Language
use of higher order conceptualizations. There is a price to be paid however. The higherorder entities evoked in this “type theoretical ascent” are much less realistic philo-sophically and psycholinguistically than our original individuals. Hence the ascent isbound to detract from the psycholinguistic and methodological realism of one the-ory”. Furthermore (op. cit., p. 283): “On a more technical level, the unnaturalness ofthis procedure is illustrated by the uncertainties that are attached to the interpretationof such higher order variables [..]”. Finally, (op. cit., p. 285): “Moreover, the first orderformulations have other advantages over higher order ones. In first order languages wecan achieve an axiomatization of logical truths and of valid inferences”.
Hintikka is completely right in his description of the attitudes of Montague gram-marians: they use higher-order objects without hesitation if this turns out to be useful.His objection against compositionality is, in a nutshell, objecting to the higher-orderontology required by compositionality.
Some comments here are in order (the first two originate from Groenendijk andStokhof, pers. comm.).
1. If first-order analysis is so natural and psychologically realistic, it would be extremely inter-esting to have an explanation why it took more than two thousand years since Aristotlebefore the notion “first order” was introduced by Frege. And it was presented in a notationthat differs considerably from our current notation, as it was not linear.
2. It is difficult to see why the first-order notation matters. If there are ontological commitments,then the notions used in the interpretation of the logic, in the metatheory, are crucial, and notthe notation itself. It is, for instance difficult to understand why a winning strategy for a gameis more natural than a function from objects to objects (cf. Hintikka’s comment on (59)).
3. If it is a point of axiomatizability, it would be interesting to have an axiomatization of game-theoretical semantics. As concerns intensional logic, one might use generalized models; withrespect to these models there is an axiomatization even for the case of higher-order logic(Gallin, 1975).
10.7.4 Synonymy
Pelletier discusses problems raised by the substitution of synonyms in belief-contexts(Pelletier, 1993b, 1994). Consider:
(60) Dentists usually need to hire an attorney.(61) Tooth doctors commonly require the professional services of a lawyer.
Suppose that these two sentences are synonymous. If we assume that (62) and (63)are formed from respectively (60) and (61) by the same rules, then compositionalityimplies that (62) and (63) are synonymous.
(62) Kim believes that dentists usually need to hire an attorney.(63) Kim believes that tooth doctors commonly require the professional services of
a lawyer.
However, it is easy to make up some story in which Kim believes the embedded sen-tence in (62), but not the one in (63). Pelletier formulates the following dilemma: eitherone has to state that (60) and (61) are not synonymous, and conclude that there are nosynonymous sentences at all in natural language, or one has to give up compositionality.

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 521 — #29
Compositionality 521
Let us consider the situation in more detail. The standard model of theoretic seman-tics says that the extension of dentist is a set of individuals; dependent on the possibleworld and the time under consideration. So the meaning of dentist is a function frompossible worlds and times. For most speakers the meaning of tooth doctor is the samefunction as for dentist. The source of the problem raised by Pelletier is that for Kimthese meaning functions for dentist and tooth doctor might differ. This shows that thestandard meaning notion is an abstraction that does not take into account that for some-one the generally accepted synonymy might not hold. In order to account for this, theinvolved individual can be used as an additional argument of the meaning function.Then (60) and (61) are no longer synonymous, nor are (62) and (63). Thus there is noproblem for compositionality: we have just found an additional factor.
Are we now claiming that, upon closer inspection, there are no synonymous sen-tences? The synonymy of belief-sentences is an old issue, and there is a lot of lit-erature about it; for references see Partee (1982) and Salmon and Soames (1988). Itseems that Mates (1950) already showed that almost any difference in the embed-ded clauses makes belief-sentences non-synonymous. But there are several cases ofconstructional (non-lexical) synonymy. Examples are (64) and (65), and (from Partee,1982) sentences (66) and (67).
(64) Kim believes that John gives Mary a book(65) Kim believes that John gives a book to Mary.(66) Mary believes that for John to leave now would be a mistake(67) Mary believes that it would be a mistake for John to leave now.
10.7.5 Psychology
An argument often put forward in defense of compositionality concerns its psycholog-ical motivation. The principle explains how a person can understand sentences he hasnever heard before (see also Sections 10.1.2 and 10.1.3). This psychological explana-tion is an important ingredient of the Gricean theory of meaning. However, this moti-vation for compositionality is rejected by Schiffer (1987). On the one hand he arguesthat compositionality is not needed in order to give an explanation for that power. Onthe other hand, he argues that such a compositional approach does not work. We willrestrict our attention to this aspect of his book.
A compositional semantic analysis of
(68) Tanya believes that Gustav is a dog.
assumes that belief is a relation between Tanya and some kind of proposition. Thereare several variants of the propositional theory of belief, some more representational,others more semantic. For all variants of these theories, Schiffer argues that they meetserious problems when they have to explain how Tanya might correctly come to thebelief expressed in (68). As examples, we will consider two cases of semantic theo-ries in which the proposition says that Gustav has the property of doghood (Schiffer,1987, pp. 56–57). One approach is that doghood is defined by more or less observableproperties. Then the problem arises that these properties are neither separately neces-sary, nor jointly sufficient, for being a dog. We might learn, for instance, that under

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 522 — #30
522 Handbook of Logic and Language
illusive circumstances dogs do not have a doggy appearance. As Schiffer remarks, thistheory was already demolished by Kripke (1972), and replaced by a theory which saysthat doghood means being an element of a natural kind. This kind most reasonably isthe species “Canis familiaris”. Membership of this kind is determined by some complexgenetic property and it is not something we are directly acquainted with. Now supposethat we encounter a race of dogs we do not recognize as such, and decide that “shmog”stands for any creature of the same biological species as those creatures. Then (68) canbe true, while (69) is false because Tanya may fail to believe that shmogs are dogs.
(69) Tanya believes that Gustav is a shmog
But in the explanation with natural kinds, the sentences have the same content.Since none of the theories offers a plausible account of the role that dog plays in
(68), there is no plausible account of the proposition that is supposed to be the contentof Tanya’s belief. Therefore there is nothing from which the meaning of (68) can beformed compositionally, so compositionality is not met.
Partee (1988) discusses Schiffer’s arguments against compositionality, and Ifully agree with her opinion that Schiffer does not make a sufficient distinctionbetween semantic facts and psychological facts. There is a fundamental differencebetween semantic facts concerning belief contexts (as implication and synonymy),and questions that come closer to psychological processes (how can a person sin-cerely utter such a sentence). What Schiffer showed was that problems arise if oneattempts to connect semantic theories with the relation between human beings andtheir language. Partee points out the analogy between these problems with belief andthose with the semantics of proper names (how can one correctly use proper nameswithout being acquainted with the referent). The latter is discussed and explained byKripke (1972). Partee proposes to solve the problems of belief along the same lines.Her paper is followed by the reaction of Schiffer (1988). However, he does not reactto this suggestion, nor to the main point: that a semantic theory is to be distinguishedfrom a psychological theory.
10.7.6 Flexibility
Partee argues that a finite complete compositional semantics that really deals withnatural language is not possible (Partee, 1982, 1988). The reason is that composi-tional semantic theories are based upon certain simplifying assumptions concerninglanguage, such as a closed language, closed world, a fixed set of semantic primitivesand a fixed conceptual frame for the language users. The limitations of model theo-retic semantics become clear when the relation is considered between the semantictheory and all the factors that play a role in the interpretation of natural language. Thefollowing cases can be distinguished.
1. For some parts of language the meaning can correctly be described as rigidly as just charac-terized. Examples are words like and and rectangle.
2. For other parts the semantics is jointly determined by the language users and the way theworld is. The language users are only partially acquainted with the meanings. Examples areproper names and natural kinds.

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 523 — #31
Compositionality 523
3. There are parts of language where the speaker and hearer have to arrive at a mutually agreedinterpretation. Examples are compounds like boat train and genitives like John’s team, theresolution of demonstrative pronouns, and most lexical items.
4. For certain theory dependent terms, i.e. words like socialism or semantics, there is no expec-tation of the existence of a “right” or “best” interpretation. These terms constitute the mainargument in Partee (1982).
Partee’s position is the following. Compositional model-theoretic semantics is pos-sible and important, but one should understand the limits of what it can do. In a systemof compositional semantics the flexibility of language is abstracted away. Therefore itis too rigid to describe the real-life process of communication, and limits the descrip-tion of language users to creatures or machines whose minds are much more narrowlyand rigidly circumscribed than those of human beings. This underscores the argument(mentioned above in Section 10.7.5) that a theory of natural language semantics shouldbe distinguished from a theory of natural language understanding.
The arguments of Partee describe limitations of the compositional possible worldsemantics. But most limitations are, in my opinion, just temporary, and not essen-tial. There are several methods to deal compositionally with factors such as personaldifferences, linguistic context, situational context or vagueness. One may use addi-tional parameters (as in Section 10.7.2 on ambiguity), context constants or variables(see Appendix B on genitives); the influence from discourse can be treated composi-tionally (see Section 10.4.4 on DRT), and vagueness by fuzzy logic. And if for sometechnical terms speaker and hearer have to come to agreement, and practically noth-ing can be said in general about their meaning, then we have not reached the limits ofcompositionality, but the limits of semantics (as is the title of Partee, 1982).
10.8 A Mathematical Model of Compositionality
10.8.1 Introduction
In this section a mathematical model is developed that describes the essential aspectsof compositional meaning assignment. The assumptions leading to this model havebeen discussed in Section 10.3. The model is closely related to the one presented in“Universal Grammar” (Montague, 1970b). The mathematical tools used in this sectionare tools from Universal Algebra, a branch of mathematics that deals with generalstructures; a standard textbook is Graetzer (1979). For easy reference, the principle isrepeated here:
The meaning of a compound expression is a function of the meanings of its parts andof the syntactic rule by which they are combined.
10.8.2 Algebra
The first notion to be considered is parts. Since the information on how expressions areformed is given by the syntax of a language, the rules of the grammar determine what

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 524 — #32
524 Handbook of Logic and Language
the parts of an expression are. The rules build new expressions from old expressions,so they are operators taking inputs and yielding an output. A syntax with this kindof rules is a specific example of what is called in mathematics an algebra. Informallystated, an algebra is a set with functions defined on that set. After the formal definitionssome examples will be given.
Definitions 10.8.1. An Algebra A, consists of a set A called the carrier of the alge-bra, and a set F of functions defined on that set and yielding values in that set. SoA = )A, F*. The elements of the carrier are called the elements of the algebra. Insteadof the name function, often the name operator is used. If an operator is not definedon the whole carrier, it is called a partial operator. If E = F(E1, E2,.., En), thenE1, E2, . . . , and En are called parts of E. If an operator takes n arguments, it is calledan n-ary operator.
The notion set is a very general notion, and so is the notion algebra which has aset as one of its basic ingredients. This abstractness makes algebras suitable modelsfor compositionality, because it is abstracted from the particular grammatical theory.Three examples of a completely different nature will be considered.
1. The algebra )N, {+, ,}* of natural numbers {0, 1, 2, 3, . . .}, with addition and multiplicationas operators.
2. The set of trees (constituent structures) and the operation of making a new tree from two oldones by giving them a common root.
3. The carrier of the algebra consists of the words boy, girl, apple, pear, likes, takes, the andall possible strings that can be formed from them. There are two partial defined operations.Rdef forms from a common noun a noun-phrase by placing the article the in front of it. RSforms a sentence from two noun-phrases and a verb. Examples of sentences are The boy likesthe apple and The pear takes the girl.
In order to avoid the misconception that anything is an algebra, finally a non-example. Take the third algebra (finite strings of words with concatenation), and addan operator that counts the length of a string. This is not an algebra any more, sincethe lengths (natural numbers) are not elements of the algebra.
10.8.3 Generators
Next we will define a subclass of the algebras, viz. the finitely generated algebras. Togive an example, consider the subset {1} in the algebra )N, {+}* of natural numbers.By application of the operator + to elements in this subset, that is by calculating 1+1,one gets 2. Then 3 can be produced (by 2 + 1, or 1 + 2), and in this way the wholecarrier can be obtained. Therefore the subset {1} is called a generating set for thisalgebra. Since this algebra has a finite generating set, it is called a finitely generatedalgebra. If we have in the same algebra the subset {2}, then only the even numberscan be formed. Therefore the subset {2} is not a generating subset of the algebra ofnatural numbers. On the other hand, the even numbers form an algebra, and {2} is agenerating set for that algebra. More generally, any subset is a generating set for some

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 525 — #33
Compositionality 525
algebra. This can be seen as follows. If one starts with some set, and adds all elementsthat can be produced from the given set and from already produced elements, then onegets a set that is closed under the given operators. Hence it is an algebra.
Definition 10.8.2. Let A = )A, F* be an algebra, and H be a subset of A. Then)[H], F* denotes the smallest algebra containing H, and is called the by H generatedalgebra. If )[H], F* =) A, F*, then H is called a generating set forA. The elements ofH are called generators. If H is finite, then A is called a finitely generated algebra.
The first example in Section 10.8.2 is a finitely generated algebra because
)N, {+, ,}* = )[{0, 1}], {+, ,}*.
The last example (with the set of strings over a lexicon) is finitely generated: thelexicon is the generating set. An algebra that is not finitely generated is )N, {,}*, thenatural numbers with multiplication (it is generated by the set of prime numbers).
A grammar for which a compositional meaning is possible, must be a generatedalgebra. Furthermore, some criterion is needed to select certain elements of the alge-bra as the generated language: for instance the expressions that are output of cer-tain rules, or (if the grammar generates tree-like structures) the elements with rootlabeled S.
Definition 10.8.3. A compositional grammar is a pair )A, S*, whereA is a generatedalgebra )A, F*, and S a selection predicate that selects a subset of A, so S(A) / A.
10.8.4 Terms
In Section 10.3 it was argued that way of production is crucial for the purpose ofmeaning assignment. Therefore it is useful to have a representation for such a produc-tion process or derivational history. In Section 10.3 we represented such a derivationby means of a tree. That is not the standard format. Let us first consider the linguis-tic example given in Section 10.8.2. By application of the operator RDef to the nounapple, the noun phrase the apple is formed, and likewise the boy is formed by applica-tion of RDef to boy. Next the operator RS is applied to the just formed noun phrases andthe verb like, yielding the sentence the boy likes the apple. This process is describedby the following expression (sequence of symbols):
(70) RS)RDef )boy*, RDef )apple*, like*
Such expressions are called terms. There is a simple relation of the terms with theelements in the original algebra. For instance, the term RDef )apple* corresponds withan element that is found by evaluating the term (i.e. executing the operator on itsarguments), viz. the string the apple. In principle, different terms may evaluate to thesame element, and the evaluation of a term usually is very different from the termitself. Terms can be combined to form new terms: the term (70) above, is formed from

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 526 — #34
526 Handbook of Logic and Language
the terms RDef )apple*, RDef )boy* and like. Thus the terms over an algebra form analgebra themselves.
Definition 10.8.4. Let B = )[B], F* be an algebra. The set of terms over B =)[B], F*, denoted as TB,F , is defined as follows:
1. for each element in B a new symbol b ( TB,F2. For every operator in F there is a new symbol f . If f corresponds with a n-ary operator and
t1, t2, . . . tn ( TB,F , then f )t1, t2, . . . tn* ( TB,F .
The terms over B = )[B], F* form an algebra with as operators, combinations of termsaccording to the operators of B. This algebra is called the term algebra over )[B], F*.This term algebra is denoted TB,F , or shortly TB.
In Section 10.3 it was argued that, according to the principle of compositionality ofmeaning, the derivation of an expression determines its meaning. Hence the meaningassignment is a function defined on the term algebra.
10.8.5 Homomorphisms
The principle of compositionality does not only tell us on which objects the meaningis defined (terms), but also in which way this has to be done. Suppose we have anexpression obtained by application of operation f to arguments a1, . . . , an. Then itstranslation in algebra B should be obtained from the translations of its parts; hence byapplication of an operator g (corresponding with f ) to the translations of a1, . . . , an.So, if we let Tr denote the translation function, we have
Tr(f )a1, . . . , an*) = g(Tr(a1), ..Tr(an))
Such a mapping is called a homomorphism. Intuitively speaking, a homomorphismh from an algebra A to algebra B is a mapping which respects the structure of Ain the following way. If in A an element a is obtained by means of application ofan operator f , then the image of a is obtained in B by application of an operatorcorresponding with f . The structural difference that may arise betweenA and B is thattwo distinct elements of A may be mapped to the same element of B, and that twodistinct operators of A may correspond with the same operator in B.
Definition 10.8.5. Let A = )A, F* and B = )B, G* be algebras. A mapping h : A+B is called a homomorphism if there is a 1-1 mapping h$ : F + G such that for allf ( F and all a1, . . . , an ( A holds h(f (a1, . . . , an)) = h$(f )(h(a1), . . . , h(an))
Now that the notions “terms” and “homomorphisms” are introduced, all ingredientsare present which are needed to formalize “compositional meaning assignment”.
A compositional meaning assignment for a language A in a model B is obtained bydesigning an algebra )[G], F* as syntax for A, an algebra )[H], F* for B, and by lettingthe meaning assignment be a homomorphism from the term algebra TA to )[H], G*.

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 527 — #35
Compositionality 527
10.8.6 Polynomials
Usually the meaning assignment is not directly given, but indirectly via a translationinto a logical language. In Section 10.5.1 it is explained that the operations in thesyntax of natural language often do not correspond with the operations in the logic(recall that there are and’s of different kinds, whereas there is only one connectivefor conjunction). New operations have to be introduced, and as is illustrated there, thestandard way to define them is by polynomials. Here the algebraic background of thismethod will be investigated.
First the definition. A polynomial is a term with variables, so
Definition 10.8.6. Let B = )[B], F* be an algebra. The set Poln)[B],F* – shortlyPoln – of n-ary polynomial symbols, or n-ary polynomials, over the algebra )[B], F*is defined as follows:
1. For every element in B there is a new symbol (a constant) b ( Poln.2. For every i, with 1 0 i 0 n, there is a variable xi ( Poln.3. For every operator in F there is a new symbol. If f corresponds with an n-ary operator, and
p1, p2, . . . , pn ( Poln then also f (p1, p2, . . . , pn) ( Poln.
The set Pol)[B],F* of polynomial symbols over algebra )[B], F* is defined as the unionfor all n of the n-ary polynomial symbols, shortly Pol =
!n Poln.
A polynomial symbol p ( Poln defines an n-ary polynomial operator; its value forn given arguments is obtained by evaluating the term that is obtained by replacing x1by the first argument, x2 by the second, etc.
Given an algebra )[B], F* and a set P of polynomials over A, we obtain a newalgebra )[B], P* by replacing the original set of operators by the polynomial operators.An algebra obtained in this way is a polynomially derived algebra.
If an operation is added to a given logic, it should be an operation on meanings. Inother words, whatever the interpretation of the logic is, the new operator should havea unique semantic interpretation. This is expressed in the definition below, where his a compositional meaning assignment to the original algebra, and h$ describes theinterpretation of new operators.
Definition 10.8.7. A collection of operators G, defined on the elements of an algebraA, is called safe if for each surjective homomorphism h from A onto some algebra Bthe following holds. If h$ is the restriction of h to the elements of a generated algebraA$ = )[A], G*, then there is a unique algebra B$ such that h$ is a surjective homomor-phism on B$.
This definition is illustrated in Figure 10.5.
Theorem 10.8.1 (Montague (1970b)). Polynomial operators are safe.
Proof. (sketch) Mimic the polynomial operators in the homomorphic image. !

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 528 — #36
528 Handbook of Logic and Language
A AF G,,
h'h
d
Figure 10.5 G is safe if for all B there is a unique B$ such that h$, the restriction of h, is asurjective homomorphism.
There are of course other methods to define operations on logic, but safeness is thennot guaranteed. Examples are:
– Replace all occurrences of x by yThere is no semantic interpretation for this operator because some of the new y’s maybecome bound. So there is no algebra B$ in the sense of the above theorem.
– Replace all existential quantifiers by universal onesFor equivalent formulas (e.g., where one formula has ! and the other ¬#¬) non-equivalentresults are obtained.
– Recursion on the length of a formulaIn the model for logic the notion length has no interpretation, hence the recursion is notwell-founded in the model.
In Section 10.5 several examples were given which show that it is advisable to useonly polynomially defined operators. This is not a restriction of the expressive power,as follows from the next theorem.
Theorem 10.8.2. Let )A, F* be an algebra with infinitely many generators, and Ga collection of safe operators over )A, F*. Then all elements of G are polynomiallydefinable.
Proof. A proof for this theorem is given by van Benthem (1979), and for many sortedalgebras by F. Wiedijk in Janssen (1986a). !
Theorem 10.8.2 is important for applications since it justifies the restriction topolynomially defined operators. Suppose one introduces a new operator, then eitherit is safe, and polynomially definable, or it is not safe, and consequently should notbe used. In applications the requirement of infinitely many generators is not a realrestriction, since the logic usually has indexed variables x1, x2, x3, . . .. Furthermore itis claimed (Wiedijk, pers. comm.) that the theorem holds for any algebra with at leasttwo generators.
We may summarize the section by giving the formalization of the principle of com-positionality of meaning.
Let L be some language. A compositional meaning assignment to L is obtained asfollows. We design for L a compositional grammar A = ))AL, FL*, SL*, and acompositional grammar B = ))B, G*, SB* to represent the meanings, where B hasa homomorphic interpretation in some model M. The meaning assignment for L is

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 529 — #37
Compositionality 529
defined by a homomorphism from TA to an algebra that is polynomially derivedfrom B.
10.8.7 Developments
The algebraic framework presented here is almost the same as the one developed byMontague in Universal Grammar (Montague, 1970b). That article was written at atime when the mathematical theory of universal algebra was rather young (the firstedition of the main textbook in the field (Graetzer, 1979) originates from 1968). Thenotions used in this section are the notions that are standard nowadays, and differ insome cases from the ones used by Montague. For instance, he uses a “disambiguatedlanguage”, where we use a “term algebra”, notions which, although closely related,differ not only by name. The algebraic model developed by Montague turned out tobe the same as the model used in computer science in the approach to semantics calledinitial algebra semantics (Goguen, Thatcher and Wagner, 1978), as was noticed byJanssen and van Emde Boas (1981).
Universal algebra became an important tool in computer science, and there thenotions from universal algebra were refined further. Since notions as coercion,overloading, subtyping and modularization play a role not only in computer science,but also in natural language semantics, the model presented in this section can berefined further. For instance, in linguistic applications the involved algebra always isa many sorted algebra (Goguen et al., 1977). An order sorted algebra (Goguen andDiaconescu, 1994) seems a very appropriate concept to cover the linguistic concept of“subcategorization”. Of course, the algebras have to be computable (see Bergstra andTucker, 1987). In Section 10.9.5 a restriction will be proposed that reduces the com-positional grammars to parsable ones. Further, one might consider the consequencesof partial rules (see Muskens, 1989). An overview of developments concerning uni-versal algebra in computer science is given in Wirsing (1990). Montague’s frameworkis redesigned using many sorted algebras in Janssen (1986a) and Janssen (1986b); thatframework is developed further in Hendriks (2001) (how to make the relation betweenexpression and meaning more flexible). Other properties are investigated in Hodges(2001) (when can a given language with a given compositional semantics be extendedwithout disturbing that semantics).
10.9 The Formal Power of Compositionality
10.9.1 Introduction
In this section the power of the framework with respect to the generated language andthe assigned meanings will be investigated. It will be shown that on the one hand com-positionality is restrictive in the sense that, in some circumstances, a compositionalanalysis is impossible. On the other hand it will be shown that compositionality doesnot restrict the class of languages that can be analyzed, or the meanings that can beassigned. Finally, a restriction will be considered that guarantees recursiveness.

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 530 — #38
530 Handbook of Logic and Language
10.9.2 Not Every Grammar Can be Used
In the preceding sections examples are given which illustrate that not every grammar issuitable for a compositional meaning assignment. The example below gives a formalunderpinning of this. A grammar for a language is given, together with the meaningsfor its expressions. It is proven that it is not possible to assign the given meanings in acompositional way to the given grammar.
Example 10.9.1. The basic expressions are the digits: {0, 1, 2, 3, 4, 5, 6, 7, 8, 9}.There are two operations in the algebra. The first one makes from a digit a numbername and is defined by G1(d) = d. The second one makes from a digit and a numbername a new number name by writing the digit in front of the number name: G2(d, n) =dn. So G2(2, G1(3)) = G2(2, 3) = 23, and G2(0, G1(6)) = G2(0, 6) = 06. The mean-ing of an expression is the natural number it denotes, so 007 has the same meaningas 7. This meaning function is denoted by M.
Fact 10.9.2. There is no function F such that M(G2(a, b)) = F(M(a), M(b)).
Proof. Suppose that there was such an operation F. Since M(7) = M(007), we wouldhave
M(27) = M(G2(2, 7)) = F(M(2), M(7)) = F(M(2), M(007))
= M(G2(2, 007)) = M(2007)
This is a contradiction. Hence no such operation F can exist. !
This result is from Janssen (1986a); in Zadrozny (1994) a weaker result is proved,viz. that there does not exist a polynomial F with the required property.
A compositional treatment can be obtained by changing rule G2. The digit shouldbe written at the end of the already obtained number: G3(d, n) = nd. Then there isa corresponding semantic operation F defined by F(d, n) = 10 , n + d, for instanceM(07) = M(G3(7, 0) = F(M(7), M(0)) = 10 , M(0) + M(7). So a compositionalassignment of the intended meaning is possible, but requires another syntax. This illus-trates that compositionality becomes possible if semantic considerations influence thedesign of the syntactic rules.
10.9.3 Power from Syntax
The next theme is the (generative) power of compositional grammars and of compo-sitional meaning assignment. In this section we will consider the results of Janssen(1986a), and in the next section those of Zadrozny (1994).
In the theorem below it is proved that any recursively enumerable language can begenerated by a compositional grammar. The recursively enumerable languages formthe class of languages which can be generated by the most powerful kinds of grammars

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 531 — #39
Compositionality 531
(unrestricted rewriting systems, transformational grammars, Turing machine lan-guages, etc.), or, more generally, by any kind of algorithm. Therefore, the theoremshows that if a language can be generated by any algorithm, it can be generated by acompositional grammar. The proof exploits the freedom of compositionality to choosesome suitable grammar. The basic idea is that the rules of the grammar (operations ofthe algebra) can simulate a Turing machine.
Theorem 10.9.1. Any recursively enumerable language can be generated by a com-positional grammar.
Proof. In order to prove the theorem, we will simulate a nondeterministic Turingmachine of the following type. The machine operates on a tape that has a beginningbut no end, and it starts on an empty tape with its read/write head placed on the initialblank. The machine acts on the basis of its memory state and of the symbol read bythe head. It may move right (R), left (L) or print a symbol, together with a change ofmemory state. Two examples of instructions are:
I1 : q1sq2R (= if the Turing machine reads in state q1 an s, then its state changes in q2 and itshead moves to the right)
I2 : q1sq2t (= if the Turing machine reads in state q1 an s, then its state changes in q2 and itwrites a t)
The machine halts when no instruction is applicable. Then the string of symbols onthe tape (neglecting the blanks) is the generated string. The set of all the strings thenondeterministic machine can generate is the generated language.
A compositional grammar is of another nature than a Turing machine. A grammardoes not work with infinite tapes, and it has no memory. These features can be encodedby a finite string in the following way. In any stage of the calculations, the head of theTuring machine has passed only a finite number of positions on the tape. That finitestring determines the whole tape, since the remainder is filled with blanks. The currentmemory state is inserted as an extra symbol in the string on a position to the left of thesymbol that is currently scanned by the head. Such strings are elements of the algebra.
Each instruction of the Turing machine will be mimicked by an operation of thealgebra. This will be shown below for the two examples mentioned before. Besidesthis, some additional operations are needed: operations that add additional blanks tothe string if the head stands on the last symbol on the right and has to move to theright, and operations that remove at the end of the calculations the state symbol andthe blanks from the string. These additional operations will not be described in fur-ther detail.
I1 : The corresponding operator F1 is defined for strings of the form w1qsw2 where w1 andw2 are arbitrary strings consisting of symbols from the alphabet and blanks. The effect ofF1 is defined by F1(w1q1sw2) = w1sq2w2.
I2 : The corresponding operator F2 is defined for strings of the form F2(w1q1sw2) = w1q2tw2.
Since the algebra imitates the Turing machine, the generated language is the same. !

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 532 — #40
532 Handbook of Logic and Language
The above result can be extended to meanings. The theorem below says that anygiven meaning assignment can be expressed in a compositional way; the language isassumed to be non-ambiguous.
Theorem 10.9.2. (Any language, any meaning)Let L be a recursively enumerable language, and M : L + D a computable functionof the expressions of L into D. Then there are algebras for L and D with computableoperations such that M is a homomorphism.
Proof. In the proof of Theorem 10.9.1 the existence is proven of an algebra A assyntax for the source language L. A variantA$ ofA is taken as grammar for L: the rulesproduce strings that end with a single #-sign, and an additional rule, say, R#, removesthat #. For the semantic algebra a copy of A$ is taken, but instead of R# there is a ruleRM that performs the meaning assignment M. Since M is computable, so is RM . Thesyntactic rules of A$ extended with R# are in a one to one correspondence with therules of A$ extended with RM . Hence the meaning assignment is a homomorphism. !
10.9.4 Power from Semantics
Zadrozny proves that any semantics can be dealt with in a compositional way. Hetakes a version of compositionality that is most intuitive: in the syntax only concate-nation of strings is used. On the other hand, he exploits the freedom to use unorthodoxmeanings. Let us quote his theorem (Zadrozny, 1994):
Theorem 10.9.3. Let M be an arbitrary set. Let A be an arbitrary alphabet. Let “.” bea binary operation, and let S be the set closure of A under “.”. Let m : S + M be anarbitrary function. Then there is a set of functions M- and a unique map µ : S + M-
such that for all s, t ( S
µ(s.t) = µ(s)(µ(t)), and µ(s)(s) = m(s)
The first equality says that µ obeys compositionality, and the second equality saysthat from µ(s) the originally given meaning can be retrieved. The proof roughly pro-ceeds as follows. The requirement of compositionality is formulated by an infinite setof equations concerning µ. Then a basic lemma from non-well-founded set theory isevoked, the solution lemma. It guarantees that there is a unique solution for this setof equations – in non-well-founded set theory. This non-well-founded set theory is arecently developed model for set theory in which the axiom of foundation does nothold. Zadrozny claims that the result also holds if the involved functions are restrictedto computable ones.
On the syntactic side this result is very attractive. It formalizes the intuitive versionof compositionality: in the syntax there is concatenation of visible parts. However, itremains to be investigated for which class of languages this result holds: with a par-tially defined computable concatenation operation only some subsets of the recursive

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 533 — #41
Compositionality 533
languages can be generated. So (with this obvious restriction) this result is not asgeneral as the previous one.
Zadrozny claims that the result also holds if the language is not specified by a(partial) concatenation operation, but by a Turing machine. However, then the attrac-tiveness of the result disappears (the intuitive form of compositionality), and thesame result is obtained as described in the previous section (older and with standardmathematics).
On the semantic side some doubts can be raised. The given original meanings areencoded using non-wellfounded sets. It is strange that this has the consequence thatsynonymous sentences get different meanings. Furthermore it is unclear, given twomeanings, how to define a useful entailment relation among them.
In spite of these critical comments, the result is an interesting contribution to thediscussion of compositionality. It shows that if we restrict the syntax considerably,but are very liberal in the semantics, a lot more is possible than expected. In this waythe result is complementary to the results in the previous section. Together the resultsof Janssen and Zadrozny illustrate that without constraints on syntax and semantics,there are no counterexamples to compositionality. This gives the pleasant feeling thata compositional treatment is somehow always possible. For a further discussion seeSection 10.11.
10.9.5 Restriction to Recursiveness
In this section a restriction will be discussed that reduces the generative capacity ofcompositional grammar to recursive sets. The idea is to use rules that are reversible.If a rule is used to generate an expression, the reverse rule can be used to parse thatexpression. Let us consider an example.
Suppose that there is a rule specified by R1(%, #, ( ) = % #s ( . So:
R1(every man, love, a woman) = every man loves a woman
The idea is to introduce a rule R.11 such that
R.11 (every man loves a woman) = )every man, love, a woman*
In a next stage other reverse rules might investigate whether the first element of thistuple is a possible noun phrase, whether the second element is a transitive verb, andwhether the third element is a noun phrase. A specification of R.1
1 might be: find aword ending on an s; consider the expression before the verb as the first element,the verb (without the s) as the second, and the expression after the verb as the thirdelement. Using reverse rules, a parsing procedure can easily be designed.
The following complications may arise with R.11 or with another rule:
– Ill-formed inputThe input of the parsing process might be a string that is not a correct sentence, e.g., Johnruns Mary. Then the given specification of R.1
1 is applicable. It is not attractive to make the

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 534 — #42
534 Handbook of Logic and Language
rule so restrictive that it cannot be applied to ill-formed sentences, because then rule R.11
would be as complicated as the whole grammar.– Applicable on several positions
An application of R.11 (with the given specification) to The man who seeks Mary loves Suzy
can be applied both to seeks, and to loves. The information that the man who is not a noun-phrase can only be available when the rules for noun-phrase formation are considered. Asin the previous case, it is not attractive to make the formulation of R.1
1 so restrictive so it isonly applicable to well-formed sentences.
– Infinitely many sourcesA rule may remove information that is crucial for the reversion. Suppose that a rule deletesall words after the first word of the sentence. Then for a given output, there is an infinitecollection of strings that have to be considered as possible inputs.
The above points illustrate that the reverse rule cannot be an inverse function in themathematical sense. In order to account for the first two points, it is allowed that thereverse rule yields a set of expressions. In order to avoid the last point, it is requiredthat it is a finite set.
Requiring that there is a reverse rule is not sufficient to obtain a parsing algo-rithm. For instance, it may be the case that y ( R.1
1 (y), and a loop arises. In order toavoid this, it is required that all the rules form expressions which are more complex(in some sense) than their inputs, and that the reverse rule yields expressions that areless complex than the input. Now there is a guarantee that the process of reversionterminates.
The above considerations lead to two restrictions on compositional grammarswhich together guarantee recursiveness of the generated language. The restrictionsare a generalization of the ones in Landsbergen (1981), and provide the basis of theparsing algorithm of the machine translation system “Rosetta” (see Rosetta, 1994) andof the parsing algorithm in Janssen (1989).
1. ReversibilityFor each rule R there is a reverse rule R.1 such that(a) for all y the set R.1(y) is finite(b) y = R(x1, x2, . . . , xn) if and only if )x1, x2, . . . , xn* ( R.1(y)
2. Measure conditionThere is a computable function µ that assigns to an expression a natural number: its measure.Furthermore(a) If y = R(x1, x2, ...xn), then µ(y) > max(µ(x1), µ(x2, ), . . . , µ(xn))
(b) If )x1, x2, . . . , xn* ( R.1(y) then µ(y) > max(µ(x1), µ(x2, )...µ(xn))
Assume a given grammar together with reverse rules and a computable measure con-dition. A parsing algorithm for M-grammars can be based upon the above two rest-rictions. Condition 1 makes it possible to find, given the output of a generative rule,potential inputs for the rule. Condition 2 guarantees termination of the recursive appli-cation of this search process. So the languages generated by grammars satisfying therequirements are decidable languages. Note that the grammar in the proof of Theorem10.9.1 does not satisfy the requirements, since there seems to be no sense in which thecomplexity increases when the head moves to the right or the left.

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 535 — #43
Compositionality 535
10.10 Other Applications of Compositionality
10.10.1 Semantics of Programming Languages
In this section some issues that emerge in semantics of computer science are addressedbecause they are interesting as regards compositionality.
10.10.1.1 Environments
In most programming languages names (identifiers) have to be declared: their typehas to be stated, in some cases they have to be initialized. Such names can only beused within a certain range: the scope of their declaration. Identifiers with a certaindeclaration can be hidden temporarily by a new declaration for the same identifier. Sothe meaning of an identifier depends on the context in which it arises.
Denotational semantics (de Bakker, 1980; Stoy, 1977) follows the methods of logic,and has compositionality therefore as a fundamental principle. In this approach anabstraction is used by which a compositional meaning assignment becomes possible.The notion “environment” encodes which declarations are valid on a certain moment,and the meaning of an identifier depends on (is a function of) the environment. Sothe same statement can get another effect, depending on the environment with res-pect to which it is evaluated. Thus these authors practiced a strategy, discussed inSections 10.2 and 10.7.
10.10.1.2 Jumps and Continuations
Some programming languages have the instruction to jump to some other part ofthe program text. The effect of the jump instruction depends on what that other textmeans. Providing compositionally a meaning to the jumping instruction requires thatit gets a meaning without having that other text of the program available. The solutionprovided in denotational semantics is to describe meanings with respect to possible“continuations”, i.e. with respect to all possible ways the computational process maycontinue.
10.10.1.3 Compositional Proof Systems
An important school is the Floyd-Hoare style of programming language semantics,which expresses meanings in terms of logical proofs (Floyd, 1976; Hoare, 1969).In doing so it makes use of another form of compositionality, viz. compositionality ofproofs: proofs for subprograms can be combined into a proof for the whole program.
10.10.1.4 Parameter Passing
There are several mechanisms for parameter passing; for example, call by refer-ence, call by value, and call by name. The last one is defined by means of syntacticsubstitution! In a compositional approach one would like to obtain the meaning of theentire construction by combining the meaning of the procedure name with the meaning

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 536 — #44
536 Handbook of Logic and Language
of the parameter. Such a compositional analysis is given by Hung and Zucker (1991).They present a uniform semantic treatment for all those mechanisms.
10.10.1.5 Parallelism
In computer science the recent development of large networks of processors hasfocussed attention on the behavior of such large systems with communicating pro-cessors. New theoretical concepts are needed as the size of the networks producesnew problems and the individual processors can themselves become quite complex.In the theory of such systems, compositionality is an important factor: a proof concer-ning the behavior of the system as a whole should be a function of the proofs for theseparate processors. Significant in this respect is the title of de Roever (1985): “Thequest for compositionality – a survey of proof systems for concurrency”.
10.10.2 Other Translations
A we have seen in Section 10.5, a compositional meaning assignment is realizedthrough compositional translation into logic. In other situations precisely the samehappens – compositional translation – but the motivation is different. Below we con-sider translations between logics, between programming languages, and between nat-ural languages; for more details, see Janssen (1998).
10.10.2.1 Embedding Logic
For many logical languages translations have been defined. The purpose is not toassign meanings, but to investigate the relation between the logics, for instance, theirrelative strength or their relative consistency. A famous example is Gödel’s translationof intuitionistic logic into modal logic. It illustrates the method of using polynomiallydefined algebras.
In intuitionistic logic the connectives have a constructive interpretation. Forinstance ! + " could be read as “given a proof for !, it can be transformed intoa proof for "”. The disjunction ! 1 " is read as “a proof for ! is available or a prooffor " is available”. Since it may be the case that neither a proof for ! nor for ¬! isavailable, it is explained why ! 1 ¬! is not a tautology in intuitionistic logic. Theseinterpretations have a modal flavor, made explicit in the translation into modal logic.
Let us write Tr for the translation function. Then clauses of the translation are:
1. Tr(p) = p, for p an atom2. Tr(! 1 ") = Tr(!) 1 Tr(")
3. Tr(! " ") = Tr(!) " Tr(")
4. Tr(! + ") = [Tr(!) + Tr(")].
Thus one sees that the disjunction and conjunction operator in intuitionistic logic cor-respond to the same operator of modal logic, whereas the implication corresponds to apolynomially defined operator. Since ¬! is an abbreviation for ! +2, the translationof p 1 ¬p is p 1 ¬ p (which is not a tautology in modal logic).
The above example illustrates that the Gödel translation is an example of themethod of compositional translation. A large number of translations between logics

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 537 — #45
Compositionality 537
is collected in Epstein (1990, Chapter: “Translations between Logic”, pp. 289–314).Almost all of them are compositional (there they are called grammatical translations).The few that are not are also in semantic respects deviant.
10.10.2.2 Compiler Correctness
Compilation of a computer program can be viewed as a form of translation, viz. froma programming language to a more machine oriented language. The purpose is toinstruct the machine how to execute the program. This translation has of course torespect the intended meaning of the programming language, an aim that is called com-piler correctness. It has been advocated that one can approach compiler correctnessby using algebraic methods (Morris, 1973; Thatcher, Wagner and Wright, 1979), inother words, by working compositionally. Other arguments are given in Rus (1991).
10.10.2.3 Between Natural Languages
Translating from one natural language to another one is an action that should be mean-ing preserving. The machine translation project “Rosetta” tries to reach this aim by fol-lowing the principle of compositionality of translation. It reads (Rosetta, 1994, p. 17):
Two expressions are each other’s translation if they are built up from parts which areeach other’s translation, by means of rules with the same meaning.
10.11 Conclusion and Further References
The principle of compositionality of meaning really means something: it is a restric-tion that rules out several proposals in the literature. On the other hand, it was shownthat there are several methods to obtain a compositional meaning assignment; so itis not an impossible task. Solutions were proposed for counterexamples to composi-tionality, and fundamental objections could be refuted. This practical experience wassupported by mathematical proofs that the sentences of any language can be assignedany meaning in a compositional way.
In this situation it has been suggested that restrictions should be proposed becausecompositionality is now a vacuous principle. That is not the opinion of this author. Thechallenge of compositional semantics is not to prove the existence of such a semantics,but to obtain one. The formal results do no help in this respect because the proofs ofthe theorems assume that some meaning assigning function is already given, and thenturn it into a compositional one. Compositionality is not vacuous, because we haveno recipe to obtain one, and because several proposals are ruled out by the principle.Restrictions should therefore have another motivation. The challenge of semantics isto design a function that assigns meanings, and this chapter argues that the best methodis to do so in a compositional way. So compositionality is seen as a methodologicalprinciple, not as an empirical one.
In this chapter several arguments are put forward which show that the composi-tional methodology is a good methodology. Compositionality requires a decision onwhat in a given approach the basic semantic units are: if one has to build meanings

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 538 — #46
538 Handbook of Logic and Language
from them, it has to be decided what these units are. Compositionality also requires adecision on what the basic units in syntax are, and how they are combined. If a pro-posal is not compositional, it is an indication that the fundamental question of whatthe basic units are is not answered satisfactorily. If such an answer is provided, thesituation under discussion is better understood. We have given several examples werethis type of reasoning has led to an improved treatment of the phenomenon underdiscussion (sometimes replacing an incorrect proposal by a correct one). So an impor-tant reason to obey the compositional methodology is that compositionality guidesresearch to better solutions!
The role of the principle has been discussed by several other authors, e.g., Dever(1999), Dowty (2007), Hodges (1998), Kazmi and Pelletier (1998) and Westerståhl(1998). Overview articles on compositionality can be found in Szabó (2007) andDowty (2007). A discussion of variants of compositionality can be found in Paginand Westerståhl (2010a) and Jönsson (2008). Alleged counterexamples are consideredin Pagin and Westerståhl (2010b). A collection of papers on compositionality in formalsemantics can be found in Partee (2004b). Westerståhl (2002) presents the theoreticalpossibilities for incorporating idioms. For a special journal issue on compositionalitysee Pagin and Westerståhl (2001). The proceedings of a large conference on compo-sitionality are found in Machery, Werning and Schurz (2005) and Werning, Macheryand Schurz (2005). For a handbook on compositionality see Hinzen, Machery andWerning (2010).
Acknowledgments
I am indebted to Yuri Engelhardt, Joe Goguen, Willem Groeneveld, Herman Hendriks,Lex Hendriks, Barbara Partee, Jeff Pelletier, the participants of the “handbook work-shop” and especially to Ede Zimmermann for their comments on the earlier versionsof this chapter. I am very grateful to Barbara Partee for the permission to include herwork on genitives as an appendix. Originally it was written as part of her paper oncompositionality (Partee, 1984), but it was not included in the final version. It has,in mutual concert, slightly been edited and updated in order to fit in the present con-text. I thank Dag Westerståhl and Peter Pagin for their valuable help in obtaining anotherwise untraceable reference. For their stimulating guidance during the preparationof this chapter I thank the editors Johan van Benthem and Alice ter Meulen, who fur-thermore tried to improve my extraordinary English. Almost all figures in this articlewere prepared using Paul Taylor’s package diagrams.sty.
A Appendix: Related Principles
In this section we present in brief several principles which arise in discussions in theliterature concerning compositionality. Some are variants of compositionality, othersare alternatives, or are independent of compositionality.

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 539 — #47
Compositionality 539
Compositionality of Meaning
The version one mostly finds in the literature is: The meaning of a compound expres-sion is built from the meanings of its parts. A more precise version is Partee, ter Meulenand Wall, 1990, p. 318: The meaning of a compound expression is a function of themeanings of its parts and of the syntactic rule by which they are combined. This prin-ciple is the main theme of this chapter.
Compositionality of Translation
The translation of a compound expression is built from the translations of its parts.This principle was a guideline in the design of a variant of Eurotra (Arnold et al.,1985; Arnold and des Tombes, 1987). A symmetric and more precise version (see alsoSection 10.10.2) is given in Rosetta (1994, p. 17): Two expressions are each other’stranslation if they are built up from parts which are each other’s translation, by meansof rules with the same meaning. This principle is analogous to the compositionalityprinciple.
Context Independence Thesis
The meaning of an expression should not depend on the context in which it occurs(Hintikka, 1983, p. 262). Closely related with the “inside outside principle”. This the-sis follows from the compositionality principle.
Contextuality Principle
A word has a meaning only in the context of a sentence, not in separation. (Frege,1884, p. x). This principle seems to be the opposite of compositionality, see the dis-cussion in Section 10.1.3.
Determinacy Thesis
The meaning of E must completely be determined by the meanings of the expressionsE1, E2, . . . , En from which it constructed (Hintikka, 1983, p. 264). This thesis followsfrom the compositionality principle.
Direct Compositionality
This principle has the slogan The syntax and the semantics work together in tandem(Barker and Jacobson, 2007, p. 1). Every syntactic operation must have a correspon-ding semantic one, and every expression computed in the syntax actually does have ameaning. This formulation is called weak direct compositionality, and is the same aswhat we called compositionality. By strong direct compositionality is understood therestriction that no reference is made to the internal syntactic (or semantic) structure ofthe input for a rule (Jacobson, 2002). As a consequence only concatenation is allowed.Equivalent principles are surface compositionality and the invariance thesis.

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 540 — #48
540 Handbook of Logic and Language
Frege’s Principle
“Frege’s Principle” is another name for the principle of compositionality. Whether theascription to Frege is accurate is discussed in Section 10.1.3.
Full Abstractness
A notion from computer science that is closely related to compositionality (Mosses,1990, p. 586; Wirsing, 1990, p. 736). A meaning assignment is called fully abstract incase two expressions have the same meaning if and only if they are interchangeable inall contexts without changing the resulting meaning. So the principle excludes seman-tic differences that have no consequences in the language. Hodges (2001) applied thenotion in Montague grammar.
Indifference Principle
The semantic value of a constituent (phrase marker) does not depend upon what it isembeddedin(Higginbotham,1986).Thisprincipleisaconsequenceofcompositionality.
Initial Algebra Semantics
In computer science a well-known approach to semantics (Goguen et al., 1977, 1978).It states that the syntax is an initial algebra, the meanings form an algebra of thesame type, and meaning assignment is a homomorphism. Intuitively the notion “Ini-tial” says that two elements in an algebra are different unless it is explicitly said thatthey are the same. A standard example of an initial algebra is a term algebra, hencecompositionality of meaning is an example of initial algebra semantics.
Inside Outside Principle
The proper direction of a semantic analysis is from the inside out (Hintikka, 1983,p. 262). This principle follows from the compositionality principle.
Invariance Thesis
The arguments of a rule are subexpressions of the resulting expression (Hintikka,1983, p. 263). This principle is equivalent with surface compositionality.
Leibniz’ Principle
A well-known principle concerning semantics of the philosopher Leibniz (Gerhardt,1890, p. 228) Eadem sunt, quorum substitui alteri, salva veritate. (Those-the-sameare, of-which is-substitutable for-the-other, with truth.)
The principle is understood as saying that two expressions refer to the same object ifin all contexts they can be interchanged without changing the truth value. We may gen-eralize it to all kinds of expressions, stating that two expressions have the same mean-ing if in all contexts the expressions can be interchanged without changing the truthvalue. This is the reverse of the consequences for meanings of the compositionality

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 541 — #49
Compositionality 541
principle. Note that, according to our standards, this principle is sloppily formulated,because it confuses the things themselves with the expressions referring to them (seeChurch, 1956, p. 300, or Quine, 1960, p. 116).
Parallelism Thesis
For each syntactic rule telling us how a complex expression E is constructed from sim-pler ones, say E1, E2, . . . , En, there corresponds a semantic rule which tells how themeaning of E depends on the meanings of those simpler expressions E1, E2, . . . , En.Name is due to Hintikka (1983, p. 263), following from the compositionality principle.
Rule to Rule Hypothesis
The name originates from Bach (1976). Is the same as the parallelism thesis.
Semantic Groundedness
An alternative for compositionality proposed by Pelletier (1994). It is, like composi-tionality, based on an inductively defined meaning assignment. The difference is thathere the induction does not follow the syntactic definition, but can be based on anyother grounded ordering. An example is a definition of propositional logic in whichthe syntax forms the biimplication ! 3 " from ! and " , but in which the meaning isdefined by means of the two implications ! + " and " + !.
Surface Compositionality
If expression E is built from expressions E1, E1 . . . En, then these parts are actual partsof the resulting expression, and they occur unchanged as subexpressions of E. A gram-mar obeying the principle is given in Hausser (1984). Equivalent to direct composi-tionality, invariance thesis and strong direct compositionality.
B Appendix: Genitives – A Case Study(by B. Partee)
B.1 Introduction
In this appendix we will consider a difficult case for compositionality: the variety ofmeanings of genitives. It will turn out that the problems can be solved compositionallyby methods discussed before. The aim of this section is to illustrate that this is not theend of the story. Designing a compositional solution for a given phenomenon mayimplicate decisions that have consequences in other parts of the grammar, and theseconsequences have to be taken into account as well. It is possible that the new insightsgive an improvement of the grammar as a whole, but it may also be the case thesystem becomes unnecessarily complicated. If certain decisions can be given no otherargumentation than to preserve compositionality, then we may have chosen the wrongsolution, or we may be working with a too narrow conception of compositionality.

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 542 — #50
542 Handbook of Logic and Language
B.2 The Problem
Here are some initial data:
(71) a. John’s teamb. A team of John’sc. That team is John’s
(72) a. John’s brotherb. A brother of John’sc. * That brother is John’s
(73) a. John’s favorite movieb. A favorite movie of John’sc. * That favorite movie is John’s
Informally, we can give a unified description of the interpretation of the genitivephrase John’s that applies to all these cases if we say that the genitive always expressesone argument of a relation (in intensional logic, something like 1R(j)). But the relationcan come from any of the three sources:
1. The context. In (71), the most salient relevant relation might be “plays for”, “owns”, “hasbet on”, “writes about for the local newspaper”, or any of an essentially open range of pos-sibilities (henceforth the “free R” reading).
2. An inherently relational noun, like brother in (72)3. A relational adjective, like favorite in (73).
I’ll refer to the last two cases as the “inherent R” readings.Compositionality asks for a uniform semantics of the genitive construction in syn-
tax. Since not all examples contain a relational noun or adjective, the best hope fora unified analysis would clearly seem to be to try to assimilate all cases to the “freeR case”. This is in fact the strategy carried out by Hellan (1980). Simplifying hisapproach, we may say that he points out that an inherently relational noun can be pre-sumed to make its associated relation salient in the context (while still being analyzedas a simple CN syntactically and a one-place predicate semantically).
Maybe this approach works for the given examples, but serious problems emergeif we consider the contrasts between NP-internal and predicative uses of genitives. Inaddition to the contrast among the (a) and (b) cases in (71)–(73) above, an interestingpattern of interpretations can be found in Stockwell, Schachter and Partee (1973).They give the following examples (the section on genitives was primarily done bySchachter and Frank Heny):
(74) a. John’s portrait. (ambiguous)
b. i. A portrait of John’s. (free R only)ii. A portrait of John. (inherent R only)
c. That portrait is John’s. (free R only)

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 543 — #51
Compositionality 543
What emerges from these examples is that while predicative genitives (the (c) casesin (71)–(74)) are easily interpreted in terms of a free relation variable which can getits value from the context, they do not seem able to pick up a relation inherent withinthe subject-NP as a value for that variable. The postnominal genitive and non-genitiveof-complements in (74b) seem to offer a minimal contrast which is neutralized in theprenominal genitive (74a), providing further evidence that the “free R” and the “inher-ent R” readings should be represented distinctly at some level within the grammar.
A caveat should be added concerning the predicative genitives. In some cases theyappear to get an inherent relational reading, as in:
(75) I knew there were three grandmothers behind the curtain, but I didn’t know oneof them was mine.
We can understand mine in (75) as my grandmother; but I believe the compli-cating factor is a result of the phenomenon described in transformational terms asone(s)-deletion (Stockwell et al., 1973). It seems that whenever a genuinely t/e-typegenitive appears, it must be interpreted with a free R variable. In the present sectionthe full-NP reading of bare genitives (of which (75) is an example) is omitted fromfurther consideration.
B.3 A Compositional Analysis
Above we have seen that the genitive construction seems to have two basic mean-ings. A strategy described in previous sections can be applied here: eliminating theambiguity by introducing new parts. This is done by enriching the syntax to includea category TCN of “transitive common noun phrases”, thus making the inherentlyrelational nature overt in their syntactic category and semantic type. The basic idea isthat there are two basic genitive constructions: a predicative one with a free R vari-able (context-dependent), and an adnominal one which applies to transitive commonnouns and fills in an argument place, yielding an ordinary one-place CN as result. Thepredicative one also has a postnominal counterpart, but of category CN/CN, and bothhave determiner counterparts of categories NP/TCN and NP/CN respectively.
Below a grammar for the genitive is presented; this grammar will be extended inthe next section. Details of the analysis not immediately relevant to the genitive issueare not to be taken too seriously.
1. Predicative Genitives ((71c)–(74c))– Syntax: [NP’s]t/e
– Semantics: 'x[1Ri(NP$)(x)] or equivalently 1Ri(NP$)
– Notes: The Ri in this interpretation is free; if context dependency should rather betreated by special constants, this would be one of those.
2. Postnominal genitives ((71b)–(74b))(a) Free R Type
– Syntax: [of NP’s]CN/CN

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 544 — #52
544 Handbook of Logic and Language
– Semantics: 'P'x[1P(x) "1 Ri(NP$)(x)]or in the notation of Partee and Rooth (1983): 'P[1P 4 1Ri(NP$)]
– Notes: This is exactly parallel to the conversion of t/e adjectives to CN/CN adjec-tives
(b) Inherent R type– Syntax: [of NP’s]CN/TCN[+gen]
– Semantics: 'R'x[1Ri(NP$)(x)]
– Notes: The symbol TCN[+gen] is used to mark the subcategory of relational nounswhich can take postnominal of + genitive (brother, employee, enemy, but not por-trait, description, height); some relational nouns take of + accusative, some cantake both. The data are messy; “heaviness” of the NP plays a role. Note that theagentive “by John” reading of (74b) counts as a free R reading; only the “of John’reading is blocked in (74b) and (74c).
3. Prenominal genitives ((71a)–(74a))(a) free R type
– Syntax: [NP’s]NP/CN– Semantics: Tantamount roughly to the the+[of NP’s]CN/CN, but see Notes below.
Using Montague’s treatment of the, this is:
'Q'P[NP$("'z[#x[!y[[1Q(y) "1 Ri(y)(z) 3 y = x] "1 P(x)]])]
– Notes: A quantifier in a prenominal genitive always has wide scope, while those inpostnominal genitives seem to be ambiguous. The uniqueness condition this analy-sis imputes to John’s brother is disputable, especially when the whole noun phraseoccurs in predicate position.
(b) Inherent R type– Syntax: [NP’s]NP/TCN– Semantics: Similarly tantamount to the the + [of NP’s]CN/TCN:
'R'P[NP$("'z[#x[!y[[1R(z)(y) 3 y = x] "1 P(x)]])]
– Notes: The order of the arguments of R are reversed in the two determiners; thisreflects the intuitive difference in natural paraphrases using, for example, owns forthe free R in John’s team and (is a) sister of for John’s sister. But this difference isnot predicted or explained here, and to be fully consistent the arguments in the twoother “free R” genitives should be reversed as well.
B.4 Consequences for Adjectives
In the previous section a compositional analysis is given for the genitive constructionby distinguishing two types of common nouns. But having more types of commonnouns implicates more types of prenominal adjectives, viz. CN/CN, TCN/TCN andTCN/CN. We consider examples of adjectives of the new types.
1. TCN/CN: favorite1, as in John’s favorite movie.– Syntax: [favorite]TCN/CN

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 545 — #53
Compositionality 545
– Semantics: Lexical; roughly
favorite$1 = 'P['y['x[1P(x) and y likes x best out of 1P]]]
2. TCN/TCN: favorite2, as in John’s favorite brother– Syntax: [favorite]TCN/TCN , probably derivable by lexical rule from favorite1.– Semantics: lexical, but derivative; roughly
favorite$2 = 'R['y['x[1R(y)(x) " favorite$
1("(1R(y)))(x)]]]
This analysis of inherently relational adjectives creates non-basic TCNs which actjust like basic TCNs with respect to genitives. Once these categories are admitted, itappears that a number of traditionally CN/CN adjectives like new also fit here as well;we can distinguish four separate (but related) new’s as follows:
1. [new1]t/e “hasn’t existed long” (a new movie)2. [new2]CN/CN “hasn’t been a CN long” (a new movie star)3. [new3]TCN/TCN “hasn’t been a TCN-of long” (my new friend)4. [new4]TCN/CN “hasn’t been in the (free) Ri-relation too long”
(John’s new car is an old car)
New4 is definable in terms of new3 and a free R as is shown in:
(76) new$4 = 'P['y['x[1P(x) " new$
3R(y)(x)]]]
Note the difference between [favorite]TCN/CN with an “inherent” R built into itsmeaning, and [new]TCN/CN which introduces a “free R”, which in turn acts as “inher-ent” for the genitive.
Thus the analysis of genitives has stimulated a more refined analysis of adjectives.The above treatment gives a reasonable account of the data: the distribution of “inher-ent” and “free” R readings is explained by treating the “inherent R” genitive as some-thing which must be in construction with a TCN, which can only happen within theNP, while the “free R” genitive is basically a predicate. The fact that TCNs can almostalways be used as plain CNs would be attributed to the existence of highly produc-tive lexical rules which “detransitivize” TCNs, interpreting the missing argument asexistentially quantified or as an indexical or variable.
B.5 Doubts About the Introduction of TCNs
Although the grammar from the previous two sections deals with the phenomena, andgives interesting insights, there can be serious reservations about introducing the cat-egory TCN into the syntax along with the associated distinctions in the categories ofadjectives and determiners. The distinction between transitive and intransitive verbshas clear syntactic and morphological, as well semantic, motivation in many lan-guages, while with nouns the motivation is almost entirely semantic. I believe thatthe analysis given above incorporates ingredients of a good explanation, but puts toomuch of it in the syntax.

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 546 — #54
546 Handbook of Logic and Language
Besides these general considerations, there are also phenomena which raise doubts.Consequences emerge when we consider what explanation to give of the semantics ofhave in sentences like (77)–(79).
(77) John has a car.(78) John has a sister.(79) John has three sisters and two brothers.
We could account for (77) and (78) by positing two have’s: one ordinary transitive verb(IV/NP) have1 interpreted as a free variable R (with typical values such as “own’, buthighly context dependent), plus a have2 of category IV/TCN interpreted as in:
(80) have$2 = 'R'x[#yR(x)(y)]
This requires us to treat a sister in (78) as not an NP, but a TCN, and similarly for evenmore complex indefinite noun phrases, as in (79). We could defend such a departurefrom apparent surface syntax with arguments about the inadequacy of Montague’streatment of predicate nominals as ordinary NPs and with appeals to the diversity andinterrelatedness across languages of constructions expressing possession, existence,and location, justifying the singling out of have for special treatment along with be.But putting this in terms of categorial distinctions in the syntax would predict theimpossibility of sentences like:
(81) John has piles of money and no living relatives.(82) John has a tutor, a textbook, and a set of papers.(83) John has a good job, a nice house, a beautiful wife, clever children, and plenty
of money (and an ulcer).
Conjoinability is a very strong test of sameness of syntactic and semantic category,and in this case it supports the traditional assumption that these are all NPs, and nota mixture of NPs and TCNs. This suggests that the interaction of the interpretationof have with relational nouns should not be dealt with by multiplying syntactic cat-egories. And while the conjunction test does not give similarly clear evidence in thegenitive construction, I expect that if we can find a way to treat the have data with-out TCNs in the syntax, we will be able to extend it to a treatment of the genitives(probably still recognizing two genitives, but without invoking TCNs to explain thedifference).
B.6 Genitives and Compositionality
There are several points at which the problems raised by the genitive constructionrelate to general issues concerning compositionality.
1. If we were not committed to local and deterministic compositionality, we could extract auniform core meaning that all the genitives described above share: [NPs] means 1R(NP $).And we could, I think, describe general principles that dictate what more must be “filledin” for the postnominal and determiner uses, and whether the variable is to be left free

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 547 — #55
Compositionality 547
or bound by a 'R operator. This approach would couple a uniform interpretation of thegenitive with a not totally implausible interpretation strategy that could be caricatured as“try to understand” (according to Bach a term originating from Philip Gough). Arguments forsuch an interpretation strategy for semantically open-ended expressions are given in Partee(1988).
2. Montague’s strategy for maintaining uniformity in the face of apparent diversity might becharacterized as “generalize to the worst case”. I don’t think that will work for the analysisof the genitives, since trying to assimilate all genitives to the “free R” case gives the wrongresult for the distribution of “inherent” readings. The only way I can see to give a uniformtreatment of all genitives in English is to leave part of the meaning out of the grammar assketched in paragraph (1) above. Perhaps a type-shifting along the lines of Partee (1986)could be explored.
3. If we do maintain the compositionality principle by building in the kind of multiple catego-rization described above, we simplify the process of determining semantic information fromsyntactic form, but complicate the task of parsing and ambiguity resolution, since we havesimultaneously increased lexical and syntactic ambiguity.
4. The motivation for the introduction of TCNs was a desire to make explicit the role of theimplicit second argument of relational nouns in the interpretation of genitives. In quantifica-tional genitives like every woman’s husband and in similar cases with have, the implicit argu-ment becomes a bound variable (for other examples of this phenomenon, see Section 10.4in Partee, 1984). This seems to give an obstacle to a treatment which would absorb theseimplicit arguments into meanings of the predicates, namely the absence of any way to des-cribe “variable binding” phenomena without an overt variable to bind. Since syntactic evi-dence goes rather strongly against introducing transitive common nouns, this adds to themotivation for seeking an alternative that would allow variable-like meanings as parts ofpredicate meanings, as argued in Partee (1989).
5. Although most of the above points suggest that the given treatment is not completely sat-isfactory, one aspect should be mentioned. For the compositional solution it is clear that itdeals with the phenomena, how it would work out in a grammar, and how it would interactwith other rules. For the suggested alternatives (interpretation strategy, partially unspecifiedmeanings, new variable mechanisms) this is unclear.
B.7 Recent Developments
A compositional analysis similar to the one proposed here is developed in detail inBarker (1995). A proposal that all (or perhaps most) genitive phrases should be ana-lyzed as arguments of the head noun, and that a plain common noun is coerced to“TCN” type when it occurs with a genitive, is made in Jensen and Vikner (1994) andVikner and Jensen (2002) and defended in Borschev and Partee (1999). On the basisof further cross-linguistic evidence, however, Partee and Borschev (2003) concludethat in at least some languages, including English, some possessives are arguments toa (possibly type-shifted) relational noun and others are modifiers of a plain noun. Thebroader issue of the role of type-shifting and lexical variability in adjunct/complementflexibility is addressed by Dowty (2003), who argues that a complete grammar shouldprovide a dual analysis of every complement as an adjunct, and potentially an analysisof any adjunct as a complement.

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 548 — #56
548 Handbook of Logic and Language
References
Arnold, D., des Tombes, L., 1987. Basic theory and methodology in EUROTRA, in: Nirenburg,S. (Ed.), Machine Translation. Theoretical and Methodological Issues, CambridgeUniversity Press, Cambridge, MA, pp. 114–134.
Arnold, D.J., Jaspaert, L., Johnson, R.L., Krauwer, S., Rosner, M., des Tombes, L. et al., 1985.A MU1 view of the CAT framework in EUROTRA, in Proceedings of the Conferenceon Theoretical and Methodological Issues in Machine Translation of Natural Languages.Colgate University, Hamilton NY, pp. 1–14.
Bach, E., 1976. An extension of classical transformational grammar, in: Problems in Lin-guistic Metatheory, Proceedings of the 1976 conference. Michigan State University, EastLansing, MI.
Barker, C., 1995. Possessive descriptions. CSLI Publications, Stanford, CA.Barker, C., Jacobson, P., 2007. Direct Compositionality, vol. 14 in Oxford Studies in Theoretical
Linguistics. Oxford University Press, Oxford.Barwise, J., Perry, J., 1983. Situations and Attitudes. Bradford Books, Cambridge, MA.Bergstra, J.A., Tucker, J.V., 1987. Algebraic specifications of computable and semicomputable
data types. Theor. Comput. Sci. 50, 137–181.Borschev, V., Partee, B.H., 1999. Semantic types and the Russian genitive modifier construc-
tion, in: Dziwirek, K. et al., (Eds.), FASL 7: Annual Workshop on Formal Approaches toSlavic Linguistics: the Seattle Meeting, 1998, Michigan Slavic Publications, Ann Arbor,MI, pp. 39–57.
Church, A., 1956. Introduction to Mathematical Logic, vol. 1. Princeton University Press,Princeton NJ.
Cooper, R., 1983. Quantification and Syntactic Theory, vol. 21 in Synthese Language Library.Reidel, Dordrecht.
Davidson, D., Harman, G. (Eds.), 1972. Semantics of Natural Language, vol. 40 in SyntheseLibrary. Reidel, Dordrecht.
de Bakker, J.W., 1980. Mathematical Theory of Program Correctness. Series in ComputerScience, Prentice Hall, London.
de Roever, W.P., 1985. The quest for compositionality – a survey of proof systems for concur-rency, part 1, in: Neuhold, E. (Ed.), Proceedings IFIP Working Group, The Role of AbstractModels in Computer Science. North-Holland, Amsterdam.
Dever, J., 1999. Compositionality as methodology. Ling. Philos. 22, 311–326.Dowty, D., 1976. Montague grammar and the lexical decomposition of causative verbs, in:
Partee, B. (Ed.), Academic Press, New York, pp. 201–245.Dowty, D., 2003. The dual analysis of adjuncts/complements in categorial grammar, in: Lang,
C.M.E., Fabricius-Hansen, C. (Eds.), Modifying Adjuncts. Mouton de Gruyter, Berlin andNew York, pp. 33–66.
Dowty, D., 2007. Compositionality as an empirical problem, in: Barker, C., Jacobson, P. (Eds.),Direct Compositionality, Oxford Studies in Theoretical Linguistics, vol. 14, Ch. 2. Oxford,pp. 23–101.
Dummett, M., 1973. Frege. Philosophy of Language. Duckworth, London. Second edition 1981.Epstein, R., 1990. The semantic foundation of logic. Vol. 1. Propositional logic, in: Nijhoff inter-
national philosophy series, vol. 35. Nijhoff/Kluwer, Dordrecht. Second edition publishedby Oxford University Press, Oxford.
Floyd, R.W., 1976. Assigning meanings to program, in: Schwartz, J. (Ed.), MathematicalAspects of Computer Science, vol. 19, Proceedings of Symposium in Applied Mathema-tics. American Mathematical Society, Providence RI, pp. 19–32.

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 549 — #57
Compositionality 549
Frege, G., 1884. Die Grundlagen der Arithmetik. Eine logisch-mathematische Untersuchung überden Begriff der Zahl, W. Koebner, Breslau. Reprint published by: Georg Olms, Hildesheim,1961, translation by Austin, J.L., (with original text): The Foundations of Arithmetic. ALogico-Mathematical Enquiry into the Concept of Number. Basil Blackwell, Oxford, 1953.
Frege, G., 1923. Logische Untersuchungen. Dritter Teil: Gedankengefüge, in: Beiträge zurPhilosophie des Deutschen Idealismus, Vol. III, pp. 36–51. Reprinted in Angelelli, I.,Frege, G., Schriften, K., Olms, G., (Eds.), Hildeheim, 1967, pp. 378–394. Translated asCompound Thoughts in Geach and Stoothoff, 1977, pp. 55–78.
Gallin, D., 1975. Intensional and Higher-Order Modal Logic, vol. 17 in Mathematics Studies.North Holland, Amsterdam.
Geach, P.T., Stoothoff, R., 1977. Logical investigations, in: Frege, G. (Ed.), Basil Blackwell,Oxford, pp. 1–30.
Gerhardt, C., 1890. Die philosphischen Schriften von Gottfried Wilhelm Leibniz, vol. 7.Weidmannsche Buchhandlung, Berlin.
Goguen, J., Diaconescu, R., 1994. An Oxford survey of order sorted algebra. Math. Struct.Comput. Sci. 4, 363–392.
Goguen, J., Thatcher, J.W., Wagner, E., 1978. An initial algebra approach to the specification,correctness and implementation of abstract data types, in: Yeh, R. (Ed.), Current Trends inProgramming Methodology. Prentice Hall, New Jersey, USA, pp. 80–149.
Goguen, J.A., Thatcher, J.W., Wagner, E.G., Wright, J.B., 1977. Initial algebra semantics andcontinuous algebras. J. ACM. 24, 68–95.
Graetzer, G., 1979. Universal Algebra, Second ed., Springer, New York. First edition publishedby van Nostrand, Princeton, New Jersey, USA, 1968.
Groenendijk, J., Stokhof, M., 1991. Dynamic predicate logic. Ling. Philos. 14, 39–100.Hausser, R.R., 1984. Surface Compositional Grammar, vol. 4 in Studies in Theoretical Linguis-
tics. Fink Verlag, Müenchen.Hellan, L., 1980. Toward an Integrated Theory of Noun Phrases. PhD thesis, University of
Trondheim.Hendriks, H., 2001. Compositionality and model-theoretic interpretation. J. Logic Lang. Inf. 10
(1), 29–48.Henkin, L., Monk, J.D., Tarski, A., 1971. Cylindric Algebras. Part I, vol. 64 in Studies in Logic
and the Foundations of Mathematics. North Holland, Amsterdam.Higginbotham, J., 1986. Linguistic theory and Davidson’s program in semantics, in: le Pore,
E. (Ed.), Truth and Interpretation. Perspectives on the Philosophy of Donald Davidson.Blackwell, Oxford, pp. 29–48.
Hintikka, J., 1981. Theories of truth and learnable languages, in: Kanger, S., Ohman, S.(Eds.), Philosphy and Grammar: Papers on the Occasion of the Quincentennial of Upp-sala University, Reidel, Dordrecht, pp. 37–57.
Hintikka, J., 1983. The Game of Language. Studies in Game-Theoretical Semantics and ItsApplications, vol. 22 in Synthese Language Library. Reidel, Dordrecht.
Hinzen, W., Machery, E., Werning, M. (Eds.), 2010. Oxford Handbook of Compositionality.Oxford University Press, Oxford, UK.
Hoare, C.A.R., 1969. An axiomatic base for computer programming. Commun. ACM 12, 576–580.
Hodges, W., 1998. Compositionality is not the problem. Logic philos. 6, 7–33.Hodges, W., 2001. Formal features of compositionality. J. Logic Lang. Comput. 10 (1), 7–28.Hung, H.-K., Zucker, J.I., 1991. Semantics of pointers, referencing and dereferencing with
intensional logic, in: Proceedings 6th Annual IEEE Symposium on Logic in ComputerScience. IEEE Computer Society Press, Los Almolitos, CA, pp. 127–136.

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 550 — #58
550 Handbook of Logic and Language
Jackendoff, R., 1972. Semantic Interpretation in Generative Grammar. MIT Press, Cam-bridge, MA.
Jacobson, P., 2002. The (dis)organization of the grammar: 25 years. Ling. Philos. 25, 601–626.Janssen, T.M.V., 1983. Scope ambiguities of tense, aspect and negation, in: Heny, F.,
Richards, B. (Eds.), Syntactic Categories: Auxiliaries and Related Puzzles, Synthese Lan-guage Library, Reidel, Dordrecht, pp. 55–99.
Janssen, T.M.V., 1986a. Foundations and Applications of Montague Grammar: Part 1,Philosophy, Framework, Computer Science, CWI tract, vol. 19 in Centre for Mathema-tics and Computer Science, Amsterdam.
Janssen, T.M.V., 1986b. Foundations and Applications of Montague Grammar: Part 2, Applica-tions to Natural Language, vol. 28 in CWI tracts. Centre for Mathematics and ComputerScience, Amsterdam.
Janssen, T.M.V., 1989. Towards a universal parsing algoritm for functional grammar, in:Conally, J.H., Dik, S.C. (Eds.), Functional Grammar and the Computer, Foris, Dordrecht,pp. 65–75.
Janssen, T.M.V., 1998. Algebraic translations, correctness and algebraic compiler construction.J. Theor. Comput. Sci. 199, 25–56.
Janssen, T.M.V., 2001. Frege, contextuality and compositionality. J. Logic Lang. Inf. 10 (1),115–136.
Janssen, T.M.V., van Emde Boas, P., 1977. On the proper treatment of referencing, derefer-encing and assignment, in: Salomaa, A., Steinby, M. (Eds.), Automata, Languages andProgramming, Proceedings 4th. colloquium Turku, Lecture Notes in Computer Science,vol. 52. Springer, Berlin, pp. 282–300.
Janssen, T.M.V., van Emde Boas, P., 1981. Some remarks on compositional semantics, in:Kozen, D. (Ed.), Logic of Programs, Springer Lecture Notes in Computer Science,vol. 131. Springer, Berlin, pp. 137–149.
Jensen, P.A., Vikner, C., 1994. Lexical knowledge and the semantic analysis of Danish geni-tive constructions, in: Hansen, S.L., Wegener, H. (Eds.), Topics in Knowledge-based NLPSystems, Samfundslitteratur, Copenhagen, pp. 37–55.
Jönsson, M.L., 2008. On Compositionality. Doubts about the Structural Path to Meaning. LundUniversity, Departmenty of Philosophy, Sweden.
Kadmon, N., Landman, F., 1993. Any. Ling. Philos. 16, 353–422.Kamp, H., 1971. Formal properties of now. Theoria 37, 227–273.Kamp, H., 1981. A theory of truth and semantic representation, in: Groenendijk, J., Janssen, T.,
Stokhof, M. (Eds.), Formal Methods in the Study of Language. CWI, Amsterdam,pp. 1–14. Reprinted in Groenendijk, J., Janssen, T., Stokhof, M. (Eds.), 1984. Truth, Inter-pretation and Information. Foris, Dordrecht, pp. 115–143, and in Portner and Partee, 2002,pp. 189–222.
Kamp, H., Reyle, U., 1993. From discourse to Logic. Introduction to the ModeltheoreticSemantics of Natural Language, vol. 42 in Studies in Linguistics and Philosphy. Reidel,Dordrecht.
Katz, J., 1966. The Philosophy of Language. Harper and Row, London.Katz, J., Fodor, J., 1963. The structure of a semantic theory. Language 39, 170–210.Kazmi, A., Pelletier, F., 1998. Is compositionality formally vacuous? Ling. Philos. 21, 629–633.Kreisel, G., Krivine, J., 1976. Elements of Mathematical Logic. Model Theory, vol. 2 in Studies
in Logic and the Foundations of Mathematics. North Holland, Amsterdam.Kripke, S., 1972. Naming and necessity, in: Davidson, D., Harman, G. (Eds.), Semantics of
Natural Language, vol. 40 in Synthese Library. Reidel, Dordrecht, pp. 254–355. Reprintedby Blackwell, 1980.

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 551 — #59
Compositionality 551
Kripke, S., 1976. Is there a problem about substitutional quantification? in: Evans, G.,McDowell, J.H. (Eds.), Truth and Meaning. Essays in Semantics, Clarendon Press, Oxford,pp. 325–419.
Landsbergen, J., 1981. Adaption of Montague grammar to the requirements of parsing, in:Groenendijk, J., Janssen, T.M.V., Stokhof, M. (Eds.), Formal methods in the study of lan-guage. Proceedings of the third Amsterdam colloquium, CWI Tracts, vol. 136. Centre forMathematics and Computer Science, Amsterdam, pp. 399–420.
Lewis, D., 1970. General semantics. Synthese 22, 18–67. Reprinted in Davidson and Harman,1972, pp. 169–248 and in Partee, 1976, pp. 1–50.
MacCawley, J., 1986. Concerning the base component in a transformational grammar. Founda-tions Lang. 4, 55–81.
Machery, E., Werning, M., Schurz, G. (Eds.), 2005. The Compositionality of Meaning andContent, Vol. II: Applications to Linguistics, Psychology and Neuroscience, Ontos Ver-lag, Heusenstamm. UK: [email protected], Am.: [email protected].
Marcus, R., 1962. Interpreting quantification. Inquiry 5, 252–259.Mates, B., 1950. Synonomy, in Meaning and Interpretation, vol. 25 in Publications in Philoso-
phy. University of California, pp. 201–226. Reprinted in Linsky, L., 1952. Semantics andthe Philosophy of Language. University of Illinois Press, Urbana, IL.
Monk, J.D., 1976. Mathematical Logic, vol. 32 in Graduate Texts in Mathematics. Springer,Berlin.
Montague, R., 1970a. English as a formal language, in: Visentini, B. et al. (Eds.), Linguagginella societa et nella technica. Edizioni di communita, Milan, pp. 188–221, distributed bythe Olivetti Corporation, Milan, reprinted in Thomason, 1974, pp. 188–221.
Montague, R., 1970b. Universal grammar. Theoria 36, 373–398. Reprinted in Thomason, 1974,pp. 7–27.
Montague, R., 1973. The proper treatment of quantification in ordinary English, in: Hintikka,K.J.J., Moravcsik, J.M.E., Suppes, P. (Eds.), Approaches to Natural Language, Syn-these Library, vol. 49, Reidel, Dordrecht, pp. 221–242. Reprinted in Thomason, 1974,pp. 247–270, and in Portner and Partee, 2002, pp. 17–35.
Morris, F., 1973. Advice on structuring compilers and proving them correct, in: ProceedingsACM Symposium on Principles of Programming Languages, Boston, USA, 1973. Associ-ation for Computing Machinery, pp. 144–152.
Mosses, P.D., 1990. Denotational semantics, in: van Leeuwen, J. (Ed.), Handbook of Theo-retical Computer Science, vol B. Formal Models and Semantics, Elsevier, Amsterdam,pp. 575–631.
Muskens, R., 1989. A relational reformulation of the theory of types. Ling. Philos. 12, 325–346.Muskens, R., 1996. Combining Montague semantics and discourse representation. Ling. Philos.
19, 143–186.Pagin, P., Westerståhl, D. (Eds.), 2001. Special issue on compositionality. (J. Logic Lang. Inf.
10), Kluwer, Dordrecht.Pagin, P., Westerståhl, D., 2010a. Compositionality I: definitions and variants. Philos. Compass.
5 (3), 250–264.Pagin, P., Westerståhl, D., 2010b. Compositionality II: arguments and problems, vol. 5. Philos.
Compass. 5: 265–282, published online.Partee, B., 1973. Some transformational extensions of Montague grammar. J. Philos. Logic 2,
509–534. Reprinted in Partee, 1976, 51–76.Partee, B. (Ed.), 1976. Montague Grammar. Academic Press, New York.Partee, B., 1982. Believe-sentences and the limits of semantics, in: Peters, S., Saarinen, E.
(Eds.), Processes, Beliefs, and Questions, Synthese Language Library, Reidel, Dordrecht,pp. 87–106.

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 552 — #60
552 Handbook of Logic and Language
Partee, B., 1984. Compositionality, in: Landman, F., Veltman, F. (Eds.), Varieties of FormalSemantics, GRASS, vol. 3. Foris, Dordrecht, pp. 281–311. Reprinted in Partee, 2004b,pp. 153–181.
Partee, B., 1986. Noun phrase interpretation and type-shifting principles, in: Groenendijk, J.,de Jongh, D., Stokhof, M. (Eds.), Studies in Discourse Representation Theory and the The-ory of Generalized Quantifiers, GRASS, vol. 8. Foris, Dordrecht, pp. 115–143. Reprintedin Portner and Partee, 2002, pp. 357–382, and in Partee, 2004b, pp. 203–224.
Partee, B., 1988. Semantic facts and psychological facts. Mind and Lang. 3, 43–52. Symposiumon Remnants of Meaning – contrib. 4.
Partee, B., 1989. Binding implicit variables in quantified contexts, in: Wiltshire, C., Music, B.,Graczyk, R. (Eds.), Papers from CLS 25. Chicago Linguistic Society, Chicago,pp. 342–365.
Partee, B., 2004a. The airport squib: any, almost and superlatives. in: Compositionality in formalsemantics. Selected papers by B. Partee, 31–40. Oxford Blackwell, pp. 231–240.
Partee, B., 2004b. Compositionality in formal semantics. Selected papers by Partee, B.H., in:Explorations in semantics, vol. 1. Blackwell, Malden, USA.
Partee, B., Borschev, V., 2003. Genitives, relational nouns, and argument-modifier ambiguity,in: Lang, C.M.E., Fabricius-Hansen, C. (Eds.), Modifying Adjuncts. Mouton de Gruyter,Berlin, pp. 67–112.
Partee, B., Rooth, M., 1983. Generalized conjunction and type ambiguity, in: Bauerle, R.,Schwartz, C., von Stechow, A. (Eds.), Meaning, Use and Interpretation of Language. deGruyter, Berlin, pp. 361–383. Reprinted in Portner and Partee, 2002, pp. 334–356.
Partee, B., ter Meulen, A., Wall, R.E., 1990. Mathematical Methods in Linguistics, vol. 30 inStudies in Linguistics and Philosophy. Kluwer, Dordrecht.
Pelletier, F.J., 1993a. On an argument against semantic compositionality, in: Westerståhl, D.(Ed.), Logic, Methodology and Philosophy of Science. Kluwer, Dordrecht.
Pelletier, F.J., 1993b. Some issues involving internal and external semantics, in: MacNamara, J.,Reges, G. (Eds.), The Logical Foundations of Cognition. Oxford University Press, Oxford.
Pelletier, F.J., 1994. The principle of semantic compositonality. Topoi 13, 11–24.Pelletier, F.J., 2001. Did Frege believe Frege’s principle? J. Logic Lang. Inf. 10 (1), 87–114.Popper, K., 1976. Unended Quest. An Intellectual Autobiography, Fontana, CA.Portner, P., Partee, B. (Eds.), 2002. Formal Semantics: The Essential Readings. Blackwell,
Oxford, UK.Pratt, V.R., 1979. Dynamic logic, in: de Bakker, J.W., van Leeuwen, J. (Eds.), Foundations of
Computer Science III, part 2, Languages, Logic, Semantics, CWI Tracts, vol. 100. Centrefor Mathematics and Computer science, Amsterdam, pp. 53–82.
Quine, W.V.O., 1960. Word and Object. The MIT Press, Cambridge, MA.Rosetta, M.T., 1994. Compositional Translation, vol. 230 in The Kluwer International Series in
Engineering and Computer Science. Kluwer, Dordrecht.Rus, T., 1991. Algebraic construction of compilers. Theor. Comput. Sci. 90, 271–308.Saarinen, E., 1979. Backwards-looking operators in tense logic and in natural language, in:
Hintikka, J., Niiniluotov, I., Saarinen, E. (Eds.), Essays on Mathematical and PhilosophicalLogic. Proceedings of the 4th. Scandinavian logic symposium, Synthese Library, vol. 122.Kluwer, Dordrecht, pp. 341–367.
Salmon, N., Soames, S., 1988. Propositions and Attitudes. Oxford Readings in Philosophy,Oxford University Press.
Schiffer, S., 1987. Remnants of Meaning. MIT Press, Cambridge, MA.

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 553 — #61
Compositionality 553
Schiffer, S., 1988. Reply to comments. Mind Lang. 3, 53–63. Symposium on Remnants ofMeaning – contrib. 5.
Schütte, K., 1977. Proof Theory, vol. 225 in Grundlehren der mathematische wissenschaften.Springer, Berlin.
Stockwell, R., Schachter, P., Partee, B., 1973. The major syntactic structures of English. Holt,Rinehart, and Winston, New York.
Stoy, J.E., 1977. Denotational Semantics: The Scott-Strachey Approach to Programming Lan-guage Theory. The MIT Press, Cambridge, MA.
Szabó, Z.G., 2007. Compositionality, in Stanford Encyclopedia of Philosophy. Internet ency-clopedia, http://plato.stanford.edu/.
Thatcher, J.W., Wagner, E.G., Wright, J.B., 1979. More on advice on structuring compilersand proving them correct, in: Maurer, H.A. (Ed.), Automata, languages and programming,Proceedings 6th. colloquium Graz, Lecture Notes in Computer Science, vol. 71. Springer,Berlin.
Thomason, R.H. (Ed.), 1974. Formal Philosophy. Selected Papers of Richard Montague. YaleUniversity Press, New Haven.
van Benthem, J.F.A.K., 1979. Universal Algebra and Model Theory. Two excursions on theborder, Technical Report ZW-7908, Department of Mathematics, Groningen University,Groningen, The Netherlands.
van Eijck, J., Kamp, H., 1997. Representing discourse in context, in: van Benthem, J., terMeulen, A. (Eds.), Handbook of Logic and Language, Ch. 3, Elsevier, Amsterdam andThe MIT Press, Cambridge, MA, pp. 179–237.
Vikner, C., Jensen, P.A., 2002. A semantic analysis of the English genitive. Interaction of lexicaland formal semantics. Studia Ling. 56, 191–226.
Werning, M., Machery, E., Schurz, G., (Eds.), 2005. The Compositionality of Meaning and Con-tent, Vol. I: Foundational Issues, Ontos Verlag, Heusenstamm. UK: [email protected], Am: [email protected].
Westerståhl, D., 1998. On mathematical proofs of the vacuity of compositionality. Ling. Philos.21, 635–643.
Westerståhl, D., 2002. On the compositionality of idioms. an abstract approach, in: Plummer,D.-P., Beaver, D.I., van Benthem, J., di Luzio, P.S. (Eds.), Words, Proofs and Diagrams,CSLI Lecture Notes, vol. 141. CSLI, Stanford, pp. 241–271.
Wirsing, M., 1990. Algebraic specification, in: van Leeuwen, J. (Ed.), Handbook of TheoreticalComputer Science, vol. B. Formal Models and Semantics, Ch. 13, Elsevier, pp. 675–780.
Wittgenstein, L., 1921. Tractatus logico-philosphicus. Logisch-philosphische Abhandlung, in:Ostwald, W. (Ed.), Annalen der Naturphilosphie. Reprint published by Blackwell, Oxford,1959.
Zadrozny, W., 1994. From compositional to systematic semantics. Ling. Philos. 17, 329–342.Zeevat, H., 1989. A compositional approach to Kamp’s DRT. Ling. Philos. 12 (1), 95–131.

“14-ch10-0493-0554-9780444537263” — 2010/11/29 — 21:08 — page 554 — #62
This page intentionally left blank

“15-ch11-0555-0606-9780444537263” — 2010/11/30 — 3:44 — page 555 — #1
11 TypesRaymond TurnerUniversity of Essex, Department of Computer Science,Wivenhoe Park, Colchester, CO4 35Q, UK,E-mail: [email protected]
Commentator: S. Feferman
11.1 Categories, Functions and Types
Syntactic categories reflect distributional phenomena in natural language. Types aremeant to play the role of their semantic counterparts. At least this is the traditionalwisdom in that approach to semantic theory which has its historical roots in the philo-sophical logic of Frege and Russell. The objective of this paper is to study the variousnotions of type and function which are (or could be) employed in the semantic enter-prise. In particular, we shall study various formulations of the typed lambda calculusand its logical extensions.
11.1.1 Functions and Types in Formal Semantics
From Frege and Russell formal semantics inherited two crucial notions. Frege intro-duced the idea that certain natural language expressions (predicative expressions)should be semantically analyzed as mathematical functions. Of course, Frege’s notionof function was the informal one of the contemporary mathematics of his time andthe regimentation of that notion obtained by its formalization within axiomatic set-theory is of later origin. Nevertheless, it is this original conceptual insight which laidthe groundwork for the development of a mathematical theory of natural languagesemantics.
The second important notion which underpins modern semantics is that of type.The original intention of Russell, in introducing both his simple and ramified typetheories, concerned the paradoxes. His arguments for the necessity of some kind oftyping regime were positive ones: he was not just concerned with blocking the para-doxes but with explaining the confusions in the conceptual systems that gave rise tothem. His arguments concerned the illegitimacy of impredicative notions in mathema-tics and logic; his belief that a type hierarchy should be imposed upon any universe ofdiscourse flows from these predicative strictures.
Semanticists, not primarily motivated by such philosophical scruples, nor with aburning concern with the paradoxes, have employed the notion of type as a form of
Handbook of Logic and Language. DOI: 10.1016/B978-0-444-53726-3.00011-6c! 2011 Elsevier B.V. All rights reserved.

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 556 — #2
556 Handbook of Logic and Language
mental hygiene; much like the role of dimensional analysis in elementary physics.Types are used as a semantic explanation for certain distributional phenomena innatural language. Roughly, the underlying syntactic structure is semantically explainedin terms of the corresponding constraints imposed by the type structure.
11.1.2 Categories and Types
The first systematic functional semantics for a reasonable fragment of English is dueto Montague (1970, 1973). Within his system, expressions in the various natural lan-guage categories are semantically represented as objects of the corresponding type.For example, one possibility within the traditional Noun-phrase/Verb-phrase struc-ture of sentences is to semantically unpack NP’s as individuals and VP’s as functionsfrom individuals to propositions. The semantic value of the sentence (a proposition)is then computed via functional application. Alternatively, one might follow Mon-tague’s account and take the semantic type of NP’s to be high-order functions whosedomain is the set of functions from individuals to propositions and whose range is theset of propositions. Application then operates in the opposite direction. This accounthas been taken to be necessary for a uniform treatment of NP’s since under it bothsimple and complex NP’s are assigned the same type. Whatever view is adopted thesemantic correlate of complex category formation is functional application. As a con-sequence this correspondence rapidly generates functions of higher and higher type asTable 11.1 illustrates.
Modern formulations of categorial grammar are much more flexible than Mon-tague’s. We shall discuss the relationship between these grammars and the variousformulations of type theory in the next section, although most of the emphasis of thispaper will be on the type systems themselves.
11.1.3 The Role of the Typed Lambda Calculus
In Montague semantics, English sentences are directly interpreted as expressions ofhis Intensional Logic. This is a system of higher order modal logic whose underlyingnotion of function is supplied by the typed lambda calculus. In this paper we shall notbe concerned with the modal notions embedded in his intensional logic but only withthose aspects which pertain to the types and their calculi. Montague further supplieda set-theoretic interpretation of his intensional logic. While it is certainly the case that
Table 11.1
Syntactic Category Type
Sentences PropositionsCommon Nouns Functions from individuals to propositionsVerb Phrases Functions from individuals to propositionsQuantifier Phrases Functions from individuals to propositions

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 557 — #3
Types 557
Montague saw this intermediate step via intensional logic as dispensable, since forhim the primary semantic interpretation was to be a set-theoretic one, there are nocompelling conceptual or formal reasons why this has to be so. All the lambda calculiwe shall consider do admit of a set-theoretic interpretation but they can also be viewedas axiomatic theories of functions in their own right. This perspective will form one ofthe main thrusts of the present paper and conforms to the original intuitions of Churchin developing the lambda calculus.
“Underlying the formal calculus we shall develop is the concept of a function, as itappears in various branches of mathematics, either under that name or under one ofthe synonymous names, “operation” or “transformation”. Church (1941).1
11.2 The Typed Lambda Calculus
This section is devoted to an exposition of the typed lambda calculus. We shall con-sider three different versions of the typed lambda calculus which differ from eachother according to the rigidity of the attachment between terms and types. In all threetheories the notion of type is the same: types are generated from a basic type (of indi-viduals) by forming the type of functions from one type to a second. The language oftype expressions thus takes the following form.
(i) I (type of individuals) is a type expression.(ii) If T and S are type expressions then so is T ! S (the type of functions from T to S).
However, the way in which terms get assigned types in the three theories is different.In the first system the types are hardwired into the syntax of terms whereas the lasttwo are less syntactically constrained in that the type information is not built into thesyntax but supplied by rules of type assignment.
11.2.1 The Church Calculus (CT)
Initially we study the original presentation of the typed lambda calculus due essentiallyto Church (1940). This corresponds to the form it takes within Montague’s intensionallogic.
11.2.1.1 The Language of the Church System
In this formulation the syntax of terms is dictated by the types. There are variables(and optionally constants) for each type together with the operations of abstractionand application.
(i) Every variable, xT , is a term of type T .(ii) Every constant, cT , is a term of type T .
1 This quote refers to the untyped lambda calculus which we shall get to later.

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 558 — #4
558 Handbook of Logic and Language
(iii) If t is a term of type S then !xT .t is a term of type T ! S.(iv) If t is a term of type T and s a term of type T ! S then st is a term of type S.
We shall write s : ET or sT to indicate that s is a term of type T . We adopt the standardconventions regarding free and bound variables: in !xT .t, x is bound throughout thebody t. The meta-expression s[t/x] denotes the result of substituting t for each freeoccurrence of x in s with the proviso that no free variable of t becomes accidentallybound by the substitution. For more details of these syntactic conventions the readershould consult Hindley and Seldin (1986).
Under one interpretation of this calculus the lambda abstracts denote functions (inthe set-theoretic sense) whose domains and ranges are dictated by their decoratingtypes; the operation of application is then understood as functional application. Weshall employ this informal set-theoretic interpretation in motivating the axioms of thetheory; shortly, we shall provide a precise account of it.
11.2.1.2 Equality
The axioms and rules of the theory govern the basic assertion of equality: given s : ET
and t : ET ,
s = T t
asserts that s and t are equal objects of type T . We shall often drop the subscript onthe equality symbol since it is a nuisance, and in any case is always recoverable fromthe terms themselves. The axioms and rules which govern this notion of equality aregiven as follows.
!xT .s = !yT .s[y/x] yT not free in s (")
(!xT .t)sT = t[sT/xT ] (#)
t = T!Ss u = T$
tu = Ss$(%)
s = s (&)
s = tt = s
(' )
s = t t = rs = r
(( )
We shall write "CT s = T t if there is a derivation of s = T t from these axioms andrules.

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 559 — #5
Types 559
There are further axioms which are suggested by the set-theoretic interpretation,namely the following axioms of extensionality.
t = s!xT .t = !xT .s
() )
!xT .txT = t xT not free in t (*)
tT!SxT = sT!SxT
tT!S = sT!S (ext)
All the lambda calculi we shall consider are usually formulated with ) (or its ana-logue) built in. This axiom is usually called a weak axiom of extensionality. The reasonfor this is best seen in its relationship to the strong axiom of extensionality, i.e. ext.The following is straightforward (see Barendregt, 1984).
Proposition 11.2.1. CT + * + ) is equivalent to CT + ext.
11.2.1.3 Set-Theoretic Models of the Extensional Theory
The set-theoretic interpretation is made precise in the following way. We first attacha set-theoretical meaning to the types by choosing some set D to stand proxy for thetype of individuals; the function space types are then modeled by forming classicalfunction spaces.
[[I]] = D,
[[T ! S]] = [[S]][[T ]] the class of functions from [[T]] to [[S]].
The terms are interpreted relative to an assignment function, g, which assigns amember of [[T]] to each variable of type T . The semantics of the pure term languagethen proceeds as follows.
[[xT ]]g = g(xT),
[[!xT .tS]]g = f # [[S]][[T ]] where for each d # [[T]] , f (d) = [[t]]g(d/xT ),
[[tT!SsT ]]g = [[tT!S]]g [[sT ]]g.
In the above, g(d/xT) is the same function as g except (perhaps) that xT is assignedthe value d. We shall say that t = Ts is true in such a model if [[t]]g = [[s]]g, for allassignments g.
Theorem 11.2.1. If "CT+*+) t = Ts then t = Ts is true in all set-theoretic models.
Proof. By induction on the derivations in Church system. All the cases are routineexcept the " and #-axioms. We illustrate with the latter. Observe that, [[(!xT .s)tT ]]g =

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 560 — #6
560 Handbook of Logic and Language
[[s]]g([[t]]g/xT ) – by definition of [[]]. To complete the argument we require the followinglemma. !
Lemma 11.2.1. [[s]]g([[t]]g/x) = [[s[t/x]]]g.
Proof. By induction on the terms. !
11.2.2 The Loosely Typed Calculus (C)
Working with such a rigid syntax is often quite inconvenient. Indeed, we have alreadytaken some liberties with the Church theory in that we have often not exhibited allthe type information. The second theory can be seen as a further step in this direction.In this theory types get attached to terms in a less syntactic fashion via rules of typeassignment.
11.2.2.1 The Language of the Theory
The terms are largely undecorated although we impose a minimal amount of typeinformation. They take the following form.
(i) x a variable, is a term.(ii) c a constant, is a term.
(iii) If t is a term, T a type expression and x a variable then !x # T.t is a term.(iv) If t and s are terms then so is st.
Notice that the type information is restricted to bound variables; free variables areuntyped. As a consequence, !x # T.xx and xx are syntactically well-formed, i.e. thetheory admits terms which can be applied to themselves; however, it says nothingabout them.
11.2.2.2 Type Assignment
In the CT system there is only one basic judgment, namely, the equality of terms. Inthe C theory we require a further judgment of type membership which replaces thesyntactic type impositions of CT. Indeed, we need to put this aspect of the theory inplace before we can deal with equality. Type information is imposed via rules whichfacilitate the attachment of types to terms. The basic judgment of the system takes theform:
t # T
i.e. the object t has type T . Moreover, such judgments are not made in isolation buttake place relative to a context or basis B which consists of a set of statements ofthe form
{x1 # T1, x2 # T2, . . . , xn # Tn}

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 561 — #7
Types 561
– where no variable is assigned more than one type. Our type assignment system isthen defined by the following axioms and rules. We shall often write B, x # T for thecontext B $ {x # T}.
B " x # T assump whenever x # T is in B
B, x # T " t # SB " !x # T.t # T ! S
funi function introduction rule
B " t # TB " s # T ! SB " st # S
fune function elimination rule
Not every term can be assigned a type. For example, !x # T.xx is syntactically well-formed but cannot be assigned a type in any context. However, if a term can beassigned a type it is unique.
Theorem 11.2.2. If B " s # S and B " s # T then T and S are the same typeexpression.
Proof. By induction on the structure of s. The base case is clear. For application,suppose B " st # T and B " st # S. This can only have arisen from derivationsB " t # U and B " s # U ! T , on the one hand, and B " t # V and B " s # V ! S,on the other. By induction, U = V and V ! S = U ! T . Hence S = T . For the caseof abstraction, B " !x # T.t # T ! S can only have arisen by an application of theintroduction rule from the premise B, x # T " t # S. In which case, by induction, Smust be unique. !
The system is monomorphic, i.e. every term can be assigned at most one type.This property is usually taken as the acid test of whether or not one has a genuineformulation of the typed lambda calculus. In the next system we consider, this propertywill fail. For more information on systems of type assignment see Barendregt (1991),Hindley (1969) and Hindley and Seldin (1986).
11.2.2.3 Equality
Type assignment is only part of the theory. By analogy with CT, we also require anotion of equality. Hence we introduce a second judgment which now interacts withthe first. As with CT, the formula
t = Ts
asserts that t and s are equal objects of type T . However, in contrast to the CT theory,the judgment make sense for arbitrary terms; although it will only be true for terms

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 562 — #8
562 Handbook of Logic and Language
which are provably of the same type. The axioms and rules for this notion parallelthose of CT but now they require a context.
B, x # T " s # SB " !x # T.s = T!S!y # T.s[y/x]
y not free in s (")
B, x # R " s # T B " t # RB " (!x # R.s)t = Ts[t/x]
(#)
B " s # TB " s = Ts
(&)
B " s = Ts%
B " s% = Ts(' )
B " s = Ts% B " s% = Ts%%
B " s = Ts%% (( )
B " s = T!Rs% B " t = T t%
B " st = Rs%t%(%)
We now have the complete system in place. We shall write B "C + (or just B " + ifthere is no danger of ambiguity) if + (a conclusion of the form t # T or t =T s) followsfrom the context B by the rules and axioms of type assignment and equality.
Our first result guarantees that two provably equal objects of type T are indeedobjects of type T .
Proposition 11.2.2. If B " s = T t then B " s # T and B " t # T.
Proof. By induction on the derivations. By way of illustration, consider the #-rule.Given the premise, we can conclude that B " !x # R.s # R ! T . It follows fromthe elimination rule that (!x # R.s)t # T . For the other half, namely s[t/x] # T , werequire the following lemma. !
Lemma 11.2.2. If B, x # T " s # S and B " t # T then B " s[t/x] # S.
Proof. By induction on s. If s is a variable the result is immediate. If it is an appli-cation it follows from the induction hypothesis and the definition of substitution. If itis an abstraction we employ induction, the definition of substitution and the introduc-tion rule. !

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 563 — #9
Types 563
We can add the extensionality axioms which, in the present context, take thefollowing form. Since ext is equivalent to the other two, we just give them.
B, x # T " s = RtB " !x # T.s = T!R!x # T.t
() )
B " t # T ! SB " !x # T.tx = T!St
x not free in t (*)
Once again, when and if we use these we shall indicate the fact explicitly. We shallstate the results with reference to the basic theory C but with the understanding that,unless we indicate to the contrary, they extend to the extensional theory.
11.2.2.4 Erasing and Decorating
There is a systematic relationship between the two theories CT and C which concernsthe decorating and erasing of type information. This is generated by two transforma-tions: in the first we erase the types from the terms of the CT system and in the secondwe decorate the terms in the C system.
erase(xT) & x,
erase(ts) & erase(t)erase(s),
erase(!xT .t) & !x # T.erase(t).2
Lemma 11.2.3. erase(tS[sT/xT ]) & erase(tS)[erase(sT)/erase(xT)].
Proof. By induction on the typed terms: we employ only the definitions of erase andsubstitution. !
For the reverse mapping we need to take the context into account: decorating is onlywell-formed on terms which are well-typed according to the typing rules. If B " r # T ,we define decorate by recursion on the structure of r as follows.
decorate(B " x # T) & xT
decorate(B " !x # T.t # T ! S) & !xT .decorate(B, x # T " t # S)
decorate(B " st # T) & decorate(B " s # S ! T)decorate(B " t # S)
where S is the unique type such that B " s # S ! T and B " t # S.The last clause makes sense because of the monomorphic nature of type assign-
ment. The following is also established by induction on the structure of terms; thistime those of C.
2 To avoid confusion, we shall often employ & for definitional equality.

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 564 — #10
564 Handbook of Logic and Language
Lemma 11.2.4. If B " t[s/x] # S then
decorate(B " t[s/x] # S)
= decorate(B, x # T " t # S)!decorate(B " s # T)/xT"
.
Theorem 11.2.3.
(i) For each t : ET , Bt " erase(t) # T where Bt = {x # T : xT is a free variable of t}. Moreover,if "CT s = T t then Bt $ Bs "C erase(t) = T erase(s).
(ii) If B "C t # T then decorate(B " t # T) : ET . Moreover, if B "C t = T s then "CTdecorate(B " t # T) =T decorate(B " s # T).
(iii) If B "C t # T then erase(decorate(B " t # T)) = t. Moreover, if t : ET then decorate(Bt "erase(t) # T) = t.
Proof.
(i) For the first part we employ induction on the terms of CT. We illustrate with abstraction.Suppose r is !xT .s where s : ES. By induction, BS " erase(s) # S. Hence, BS ' {x # T} "!x # T.erase(s) # T ! S. For the second part we require the substitution Lemma 11.2.3.
(ii) By induction on the derivations in the C system. The first part is straightforward. For thesecond part we require the substitution Lemma 11.2.4.
(iii) Employ induction on the CT terms for the second part and induction on the C terms forthe first. !
Thus we have essentially the same theory under two different guises. However,the C formulation has the advantage of not demanding that every term be explicitlydecorated with type information. It thus underwrites the practice of suppressing thetype information. It also facilitates the exploration of the connections between thetyped lambda calculus and categorial grammar; a topic we take up at the end of thissection.
11.2.3 The Untyped Lambda Calculus
In the final theory we remove all type information from the terms. Even the lambdaabstracts are undecorated. As a result monomorphism will fail and we will not be ableto decorate the terms in a unique way – no matter how much contextual information isgiven. This theory is usually called the Curry calculus (Curry, 1958, 1972). It is builtupon the (untyped) lambda calculus U (Church, 1941). We shall devote this subsectionto this. Our treatment will be brief since there are many excellent expositions available(e.g., Barendregt, 1984).
11.2.3.1 Language
Strictly speaking the untyped lambda calculus has no notion of type (except implicitlythe type of everything). This is reflected in the fact that the basic judgment of equality

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 565 — #11
Types 565
is an absolute one which is made independently of any explicit notion of type and theterms are void of any type information.
(i) x, a variable, is a term.(ii) c, a constant, is a term.
(iii) If t is a term and x a variable then !x.t is a term.(iv) If t and s are terms then so is st.
The only difference between this syntax and that of the C-theory concerns the lambdaabstracts but as we shall see it has some important implications.
11.2.3.2 The Formal System
The formal system is constituted by the following axiom and rules of equality.
!x.s = !y.s[y/x] y not free in s (")
(!x.s)t = s[t/x] (#)
s = s (&)
s = s%
s% = s(' )
s = s% s% = s%%
s = s%% (( )
s = s% t = t%
st = s%t%(%)
We shall write "U t = s if t = s follows from the rules and axioms of equality.3
Strictly speaking, the untyped calculus usually has the ) -rule built in and the*-axiom is optional. In the untyped calculus they take the following naked form.
s = t!x.s = !x.t
() )
!x.tx = t x not free in t (*)
The obvious formulation of ext is equivalent to ) + *. Once again, if we employany of the extensionality axioms, we shall explicitly say so.
3 Approaches where equality is partial are also possible (see Feferman, 1975, 1979). Such approaches mayprove attractive for dealing with partiality in natural language. For a version of type theory developed forsemantic purposes see Muskens (1989). See also the discussion of Partiality (Fenstad) in this volume.

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 566 — #12
566 Handbook of Logic and Language
11.2.3.3 The Computational Role of the Untyped Lambda Calculus
Although we have approached the lambda calculi from the perspective of their role innatural language semantics any discussion of the lambda calculus would be incompletewithout some mention of this computational aspect. We shall be brief and refer thereader to Barendregt (1984) for further details.
Definition 11.2.1. We define three relations (1 (reduction in one step), —!# (reduc-tion), = # (convertibility), by induction as follows
(i) (a) (!x.s)t (1 s[t/x](b) t (1 s implies rt (1 rs, tr (1 sr and !x.t (1 !x.s
(ii) (a) t —!# t(b) t (1 s implies t —!# s(c) t —!# s and s —!# r implies t —!# r
(iii) (a) t —!# s implies t = #s(b) t = #s implies s = # t(c) t = #s and s = #r implies t = #r.
We can now link up the two notion of equivalence.
Proposition 11.2.3. "U+) t = s iff t = #s.
Proof. From left to right is by induction on the derivations in U + ) . From right toleft employ induction on the definition of = # . !
Definition 11.2.2. A #-redex is a term of the form (!x.s)t. A term is in #-normalform if it does not have a #-redex as a subexpression. A term t has a #-normal form ift = #s for some term s in #-normal form.
The major theorem about reduction is the following. Elegant proofs of it and its corol-laries can be found in Barendregt (1991).
Theorem 11.2.4 (Church-Rosser). If s —!# t and s —!# r then for some term k onehas t —!# k and r —!# k.
Corollary 11.2.1. If s = # t then there is a term r such that s —!# r and t —!# r.
Corollary 11.2.2. If s has a #-normal form t then s —!# t. Moreover every term hasat most one #-normal form.
One of the fundamental features of this calculus, which illustrates its essentiallyuntyped nature and which is therefore not shared by its typed cousins, is the existence

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 567 — #13
Types 567
of a fixpoint operator. Consider the term
Y = !f .(!x.f (xx))(!x.f (xx)).
A little computation, using the rules and axioms, yields that, for any term t,
"U Yt = t(Yt).
It is this feature which gives the calculus its computational power since it is the basisof the representation of the general recursive functions. It is also the feature whichcauses problems when one tries to base logic upon the untyped calculus; a topic weshall return to later.
11.2.3.4 Models of the Extensional Calculus
Models of the extensional theory are a little more difficult to come by. Indeed, thereis a small academic industry involved in constructing and investigating models ofthe (extensional) untyped lambda calculus. The first two notions of model were dis-covered by Scott (1973), Plotkin (1972) and Scott (1975). We shall provide a briefintroduction to these models but first we provide a general notion introduced byMeyer (1982).
Definition 11.2.3. A Functional model is a structure of the form D = )D, [D (D], f , h* where D is a non-empty set, [D ( D] is some class of functions from Dto D and f : D ( [D ( D], h : [D ( D] ( D are functions such that for eachd # D, h( f (d)) = d.
The function f turns an arbitrary element of D into a function from D to D andthe function h does the reverse. As a consequence each term of the calculus can beassigned an element of D as follows.
[[x]]g = g(x),
[[!x.t]]g = h#!d. [[t]]g(d/x)
$,
[[ts]]g = f ([[t]]g) [[s]]g,
where g is an assignment of elements of D to variables.
Theorem 11.2.5. If "U+)+* t = s then, for each assignment g, [[t]]g = [[s]]g.
Proof. By induction on the derivations. The only non-trivial step involves the#-axiom and this requires the substitution result:
[[t[s/x]]]g = [[t]]g([[s]]g/x),
which is established by induction on the terms. !

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 568 — #14
568 Handbook of Logic and Language
This very general notion of model is not without its problems. Unless we insist thatthe functions
!d. [[t]]g(d/x)
are in the class [D ( D], the above interpretation is not well-defined. Mathematically,this is not a very attractive notion of model since the syntax of the theory is entering thedefinition of the model. Fortunately, there are models which satisfy this criterion andwhich are given in a syntax-independent way. We shall first deal with the so-calledDomain-Theoretic Models. There are many variations on the notion of domain. Afairly minimal one is given as follows.
Definition 11.2.4. A Domain is a partial-ordered set )D, "* (with a least element +)which admits the least upper bounds of ,-sequences of the following form: d0 " d1 "d2 " d3 " · · · . We shall write
%
n#,
dn
for the least upper bound of such a sequence.
With this basic notion in place we construct a domain from the functions from onedomain into a second. Such function spaces are restricted to monotone functions (i.e.d ! d% ( f (d) ,% f (d%)) which are continuous in the sense that they preserve theleast upper bounds of such ,-sequences, i.e.
f& %
n#,
dn
'=
%%
n#,
f (dn).
On this restricted class of functions [D ( D%] we impose an ordering.
f " g iff -d # D.f (d) "% ( f (d)),
which renders the function space a domain. Scott established the existence of a domainD such that D is continuously isomorphic to its own continuous function space. More-over, all the functions !d. [[t]]g(d/x) are continuous. Hence, we have an example of afunctional model which satisfies the closure conditions.
Our second example is the Graph Model. Let P(,) be the power set of the naturalnumbers partially ordered by inclusion. The construction of the model depends uponthe fact that a continuous function on P(,) can be coded as a set. The underlyingtopology is determined by finite information: the sets
BE = {B # P(,) : E , B} where E is finite

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 569 — #15
Types 569
form a basis for the topology. We next set up the following coding of ordered pairsand finite sets.
(n, m) = 12 (n + m)(n + m + 1) + m,
en = {k0, . . . , km'1} where k0 < · · · < km'1 and n =(
i<m
2ki .
A continuous function f : P(,) ( P(,) is determined by its values on the finite sets.Hence, f can be coded as an element of P(,). This provides a continuous mapping
graph : [P(,) ( P(,)] ( P(,) with an inverse
fun : P(,) ( [P(,) ( P(,)],
given as follows:
graph( f ) =)(n, m) : m # f (en)
*,
fun(u)x =)m : .en , x.(n, m) # u
*.
We thus have the required correspondence between the domain of the model and itscontinuous function space.
Both of these examples take place in a particular Cartesian closed category withreflexive objects. An general account of models in such categories can be found in(Barendregt, 1984).
11.2.4 The Curry Calculus (CU)
Despite the fact that the untyped calculus has no built-in notion of type we can assigntypes to the terms in much the same way as with CT. The Curry calculus is obtainedfrom the untyped calculus U by adding types and type assignment.
11.2.4.1 Type Assignment
Indeed, the rules of type assignment are almost identical to those of the C system. Theone difference concerns the introduction rule which now takes the following form.
B, x # T " t # SB " !x.t # T ! S
intro.
However, as a consequence of this small modification, a term can now possess morethan one type. For example, consider the following instance.
B, x # T " x # TB " !x.x # T ! T
.

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 570 — #16
570 Handbook of Logic and Language
Thus, !x.x has all types of the form T ! T . The theory is essentially polymorphic.4
We shall write B "CU t # T (or just B " t # T) if t # T follows from the context Bby the rules and axioms of type assignment.
We shall now examine the relationship between type assignment and reduction. Inorder to state the main theorem which connects type assignment and reduction weneed the following notion.
Definition 11.2.5. A term t is said to be strongly normalizing if all the reductionsequences starting with t terminate.
Theorem 11.2.6.
(i) (Strong Normalization). If B " t # S then t is strongly normalizing(ii) (Subject Reduction). If B " t # S and t —!# s then B " s # S.
The proof can be found in Barendregt (1991). The first part informs us a term whichcan be assigned a type must terminate – no matter how it is reduced. The subjectreduction part ensures that type correctness of terms is preserved throughout theirevaluation.
11.2.4.2 Models
We can easily extend the models of the untyped calculus to cater for type assignment.We illustrate with the general functional models. We interpret the types “internally”,i.e. as subsets of the set D.
[[I]] = D,
[[T ! S]] =)d # D : -e # [[T]] .f (d)e # [[S]]
*.
An assignment function g is consistent with a context B if for each x # T which is amember of B, g(x) # [[T]].
Theorem 11.2.7 (Soundness). For each term t, if B " t # T and g is consistent withB, then
[[t]]g # [[T]].
Proof. By induction on the rules of type assignment. It is a simple matter to checkthat all the rules preserve soundness. !
An alternative view of types is supplied by the quotient set semantics (Hindley,1983; Scott, 1976), in which the types are interpreted as partial equivalence relations.
4 The term polymorphism in CU is being employed in a schematic sense. There is no explicit way ofrepresenting polymorphism as in second-order lambda calculus (e.g. Girard, 1972; Reynolds, 1974). SeeSection 5.3.1 for further discussion.

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 571 — #17
Types 571
11.2.4.3 Erasing
We define the erasing mapping straight through from CT to U.
erase(xT) & x,
erase(ts) & erase(t)erase(s),
erase(!xT .t) & !x.erase(t).
Lemma 11.2.5. erase(tS[sT/xT ]) & erase(tS)[erase(sT)/x].
Proof. By induction on the typed terms: we employ only the definitions of erase andsubstitution. !
Our first result establishes that the erasing transformation is sound.
Theorem 11.2.8.
(i) For each t : ET we have: Bt " erase(t) # T.
(ii) If "CT s = T t then in U, erase(t) = erase(s).
Proof. Part (i) is by induction on the CT terms. Part (ii) is by induction on the CTderivations. !
If we assume the extensionality axioms in the two theories the result remains intact.We also have a form of completeness for type assignment.
Theorem 11.2.9. If B " t # T then there is a term sT of CT such that erase(sT) = t.
Proof. By induction on the Curry derivations. !
11.2.4.4 The Rule of Equality
Thus far the notions of equality and type membership are independent of each other;the axioms and rules of the two aspects of the theory have no overlap. In the CT systemthe judgment of equality can only be made with terms which are syntactically thesame type. Moreover, the C system is monomorphic and, if two terms are equal withrespect to a type, then they are members of that type. However, in the present theorythe subject reduction theorem only applies to reduction not equality. Consequently, theprinciple that a type of a term should be preserved under equality has to be enforced.
s = t B " s # TB " t # T
eq
We shall write B "CU+eq t # T if this follows from the axioms/rules of type assign-ment, equality and the eq rule. With this rule added we can formulate and prove a

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 572 — #18
572 Handbook of Logic and Language
standard completeness result for the formal theory with respect to the above seman-tics (see Coppo, 1984). The soundness theorem for erasing is of course unaffectedby the inclusion of eq but completeness for erasing fails. Indeed, eq has a non-effective nature which stems from the undecidability of the convertability relation. Wecan, however, postpone all applications of it to the final step in the deduction (seeBarendregt, 1991).
Theorem 11.2.10. If there is a deduction of B "CU+eq t # T then there exists a term ssuch that t = s and the sequent B "CU s # T is derivable, i.e. without rule eq.
This completes our rather brief exposition of the various forms of lambda calculi.Formal semantics has been based upon the first (CT). There is no reason why it couldnot be based on either of the other two. Indeed, the modern forms of flexible categorialgrammar sit more naturally with these more liberated calculi.
11.2.5 Categorial Grammar and the Typed Lambda Calculus
Categorial grammar traditionally supplies the other half of the syntax/semantic pair-ing. In this section we introduce the basic ideas of categorial grammar. We shall onlyprovide a brief introduction to this topic since it is covered at some length in Moortgat(this volume). Our main objective is to spell-out the relationships between the liber-ated typed lambda calculus and flexible categorial grammar.
11.2.5.1 Basic Categorial Grammar
The standard categorial grammars of Ajdukiewicz and Bar-Hillel are based on somefixed basic categories, which can be combined by a rule of functional application.
(a, b) ab
For example, consider the complex expression “Every dog with a bone”. Suppose thatthe lexical items are assigned the following categories
Every (N, NP) with (NP, (N, N)) bone Ndog N a (N, NP)
Then the rule of functional application facilitates the following analysis of the complexexpression.
Every dog with a bone(N, NP) N (NP, (N, N)) (N, NP) N
NP(N, N)
NNP

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 573 — #19
Types 573
Table 11.2
Category Type
Sentence PProper name IIntransitive verb I ! PTransitive verb I ! (I ! P)
Complex noun phrase (I ! P) ! PAdverb (I ! P) ! (I ! P)
Preposition ((I ! P) ! P) ! (I ! P) ! (I ! P)
Nouns I ! PAdjectives (I ! P) ! (I ! P)
There are more sophisticated versions which contain directed versions of the ruleof application but we shall not consider these here (see Moortgat (this volume)).Although categorial grammar is not committed to any particular correspondencebetween syntactic categories and semantic types the one given in Table 11.2 is theone that is most often encountered in the literature.
Notice that syntactic categories do not correspond one-one with semantic types.Indeed, this indicates a regularity of semantic behaviour between, for example,nouns and intransitive verbs in that they both semantically function as propositionalfunctions.
11.2.5.2 More Flexible Systems
The main drawback with this simple picture concerns its rigidity. In the last twentyyears versions of categorial grammar have been developed which enable a more flexi-ble association between categories and types. New rules of combination have beenadded to the grammars which seem necessary to reflect the rich variety of combina-tions available in natural language syntax. These are essentially rules which force typeshifting. Three of the most prominent are the following.
(i) The Geach Rule (Geach, 1972). Consider the following sentence. We employbasic categories i and p for proper names and sentences.
No man loves every woman((i, p), p) (i, (i, p)) ((i, p), p)
As matters stand we cannot parse this sentence with the simple rule of categorialgrammar since the categories do not match. One way forward is to add a rule whichallows categorial composition.
(a, b) (b, c)(a, c)
.

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 574 — #20
574 Handbook of Logic and Language
(ii) Montague Rule. This is the well known strategy of Montague to upgrade simpleproper names to noun phrases.
a((a, b), b)
.
So in particular, i is upgraded to ((i, p), p). Semantically, the type of a proper name istype-shifted to that of complex noun phrases.
(iii) Argument Lowering (Partee and Rooth, 1983). This has the general pattern
(((a, b), b), c)(a, c)
.
The standard example here is the lowering of complex intransitive verbs (((i, p), p), p)
to simple predicates (i, p). The general linguistic motivation for type-shifting seemsoverwhelming – see Montague Grammar (Partee [this volume]).
11.2.5.3 Flexible Grammars and the Typed Lambda Calculus
J. van Benthem (1991) offers a logical perspective on these flexible categorial gram-mars. He draws upon the analogy between derivations in the typed lambda calculusand derivations in categorial grammars. We can make the connection precise as fol-lows. Let
a1, . . . , an " a
be any derivable sequent (from the premises a1, . . . , an) in this enriched categorialgrammar, i.e. with the basic rule of application together with the Geach, Montagueand argument raising rules. We can interpret the categories as types in the obviousway – basic categories are assigned basic types and complex categories are interpretedas function spaces, i.e. (a, b) is interpreted as A ! B.
Theorem 11.2.11. If a1, . . . , an " a then for some term t, [x1 # A1, . . . , xn # An] "Ct # A.
Proof. By induction on the rules. The various cases are given as follows. For conve-nience, we employ a natural deduction style for type-assignment in C.
(i) Application
a (a, b)
bx # A f # A ! B
fx # B
(ii) Geach
(a, b) (b, c)(a, c)
f # A ! B g # B ! C [x # A]fx # B
g( fx) # C!x # A.g( fx) # A ! C

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 575 — #21
Types 575
(iii) Montague
a((a, b), b)
x # A [f # A ! B]fx # B
!f # A ! B. fx # (A ! B) ! B
(iv) Argument Lowering
(((a, b), b), c)(a, c)
g # ((A ! B) ! B) ! C [f # A ! B] [x # A]fx # B
!f # A ! B. fx # (A ! B) ! Bg(!f # A ! B. fx) # C
!x # A.g(!f # A ! B. fx) # A ! C
!
Van Benthem (1991) suggests that this correspondence provides a way of provingan operational interpretation of these more flexible categorial grammars.
11.3 Higher-Order Logic
Our notion of type is far too impoverished to support any semantic application: thepure calculi do not have enough logical content. Indeed, in our discussion of the rela-tionship between categorial grammars and type-systems we surreptitiously introducedthe type P of propositions. In this section we put flesh on this introduction: we add anew basic type P (propositions) to stand proxy for the syntactic category of sentences.We shall explore all three approaches to the typed lambda calculus and extend themby the addition of this new type. This leads to the various formulations of higher orderlogic.
11.3.1 Church Higher-Order Logic
We begin with CT. This results in (standard) higher-order logic. This approach isthe closest to that of Montague. It differs in that we take the type of propositions asprimitive rather than unpacking it in terms of possible worlds.
11.3.1.1 The Language of HOL
This is an extension of the language of CT obtained by adding a new basic type P ofpropositions together with logical connectives (implication and universal quantifica-tion). More precisely, the language of terms of CT is enriched as follows.
($) If - and . are terms of type P and T is a type expression then - ( .
and -xT .- are terms of type P.

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 576 — #22
576 Handbook of Logic and Language
The other logical connectives are definable in the following way.
- / . & -zP.(- ( (. ( z)) ( z,
- 0 . & -zP.((- ( z) / (. ( z)) ( z,
.xT .- & -zP.-yT .(-[y/x] ( z) ( z,
+ & -zP.zP,
1- & - ( +.
Indeed, the basic notions of typed equality and membership are also definable.
t = Ts & -zT!P.zt ( zs,
t # T & t = T t.
There are formulations where the notion of equality is taken as primitive but the abovebetter suits the development which follows. For more details of these other accountssee Andrews (1986).
11.3.1.2 Axioms and Rules
The axioms/rules of the theory include the axioms and rules for equality " and # fromthe typed lambda calculus (CT) (the other axioms and rules, i.e. &, µ, $, (, ' , arederivable from the definition of equality) together with the following rules of infer-ence. A context B is now a finite set of wff.
B, - " .
B " - ( .(( i)
B " - B " - ( .
B " .(( e)
B " -[xT ]B " -xT .-
(-i)B " -xT .-
B " -[tT/xT ](-e)
We assume the normal side-conditions on the rules, i.e. in (-i), xT must not occur freein any assumption on which the premise depends. This already gets us an intensionalintuitionistic system of higher-order logic (IHOL).
For the classical theory we add the following axiom.
LEM -uP.u 0 1u.
Finally, for the extensional version we add:
EXT (i) -zT!S.-yT!S.(-xT .zx = Syx) ( z = T!Sy.(ii) (- 2 .) ( - = P..
Notice that EXT yields the extensionality axioms of CT.

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 577 — #23
Types 577
11.3.1.3 Models
At this point we ought to pause and ask for the intended interpretation of this the-ory. In the case of CT, under the set-theoretic interpretation, the non-primitive typeswere interpreted as function spaces. But how is the type of propositions to be inter-preted? Within the formal semantic paradigm there are two common answers to thisquestion: truth-values and sets of possible worlds. Both of these options face well-known difficulties. In Fregean terms the former fails to account for the distinctionbetween the sense and the reference of a sentence. Frege took the sense of a sentenceto be that aspect of its meaning which determined its truth-value (its reference). Ifpropositions (Fregean thoughts) are taken as truth-values then there is no room for adifference between the sense of a sentence and its truth-value. Subsequently, we areunable to explain how two sentences with the same truth-value can express differentpropositions. This difficulty is somewhat circumvented within the Kripke-Hintikka-Montague tradition which takes propositions to be sets of possible worlds. This is astep forward in that for two sentences to express the same proposition they have tohave the same truth-value in all possible worlds. However, it has been argued that thisstill does not leave enough room between sense and reference. This becomes criticalwhen interpreting doxastic notions such as belief and knowledge. For example, underit all true assertions of mathematics denote the same proposition, hence believing onetrue proposition entails one believes them all. Neither space nor time permits a realis-tic discussion of these issues but for a strong defense of the possible world approachthe reader should consult Stalnaker (1984). We shall remain neutral as to the natureof propositions: we shall not identify them with truth-values nor with sets of possibleworlds – nor with any other more putatively primitive notion. However, the formaltheory admits both the above interpretations. To see this we need to extend our classi-cal set-theoretic models to this extended language. The notion of model for the CT hasto be extended to include a basic set of propositions. In addition, we require operatorswhich are the correlates of the logical constants. We provide a general notion whichspecializes to both the above examples but also admits of other more fine-grainedinterpretations.
Definition 11.3.1. A model of IHOL is a structure
M =+D, P, T,( ,
,T
-
where D, T, P are sets (with T , P, the true propositions), ( is a function from Pto PP and, for each type symbol T,
.T is a function from P[[T ]] to P. In addition, we
have the following closure conditions on the set T. In what follows we employ infixnotation.
(i) If d # P and e # P then d (e # T iff d # T implies e # T(ii) d # P[[T ]] then
.T d # T iff for all e # [[T]] , de # T

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 578 — #24
578 Handbook of Logic and Language
The language is interpreted in such a model by extending the interpretation of CT asfollows.
[[- ( .]]Mg = [[-]]Mg( [[.]]Mg ,
[[-xT .-]]Mg =,
T
#!d # [[T]] . [[-]]Mg(d/x)
$.
In general, we shall say that - is true inM if and only if [[-]]Mg # T for each assign-ment g.
Theorem 11.3.1. IHOL is sound in these models, i.e. if "IHOL - then - is true ineach such model.
Proof. We have only to check that the rules of inference preserve truth in the model.This is straightforward by induction on the proofs. !
If we wish to guarantee soundness for classical HOL we must first define ¬, afunction from P to P, by
¬p & p (/ where / =,
P!p # P.p,
and insist that, for d # P, ¬d # T iff d /# T. There are two obvious examples of suchmodels. Both satisfy the axioms of extensionality (EXT).
(i) Standard models of HOL
Here we take P = {0, 1} and T = {1}. The operator ( is the classical truth functionand
.T d = 1 iff for all e # [[T]] , de = 1.
(ii) Possible Worlds Models of HOL
Here we take P = P(W), where W is some set (of possible worlds), and T = {W}. Theoperator ( is the function which given two subsets of W (A and B, say), returns theset which is the union of W ' A and B. The function
.T , given a function f from [[T]]
to P(W), returns W, if for all d in [[T]] , fd = W, and the empty set otherwise. In thismodel we can add modal operators. For example, we can add ! with the interpretationthat !p = W, if p = W, and the empty set of worlds otherwise. This yields S5 modallogic. This is essentially the strategy adopted in Montague’s intensional logic. We shallnot pursue this further since we are primarily concerned with the notion of type notmodality.
Our notion of model also admits of other interpretations where the notion of propo-sition is more fine grained. The structured meanings of Cresswell (1985) form onesuch example. Indeed, this more general notion of model forces no interpretation

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 579 — #25
Types 579
on the notion of proposition and is consistent with the view that they be taken assui-generis. Such an approach is developed in Thomason (1980).
11.3.2 HOLC
We now develop the theory based upon the loosely typed lambda calculus. This willtake us one step in the direction of combinatory logic.
11.3.2.1 Language
In the standard presentations of the first and higher-order predicate logic the languageof wff is given via an explicit grammar. In contrast, within the C calculus the syntacticconstraints are rather meager and the rules of type assignment are employed to carveout the sensible objects. The same concept applies when we extend the C systemof the typed lambda calculus by the addition of propositions. We shall use HOL asour guide in developing the theory in that we shall mirror (almost) the grammaticallydetermined notion of proposition in HOL by rules of type assignment. To the languageof C we add a new constant ( (implication) and a family of constants 0T (universalquantification). The other logical connectives and the standard representation of thequantifiers can be defined in a similar way to HOL. We again employ infix notation.
-x # T.s & 0T(!x # T.s),
/ & !x # P.!y # P.-z # P.(x ( (y ( z)) ( z,
0 & !x # P.!y # P.-z # P.(x ( z) (#(y ( z) ( z
$,
.x # T.s & -z # P.-y # T.#s[y/x] ( z
$( z,
+ & -z # P.z,
1 & !x # P.x ( +,
QT & !x # T.!y # T.-z # T ! P.zx ( zy,
t # T & t = T t,
where we write QT ts as t = Ts. Judgments in the system are now made relative to acontext B = {t1, . . . , tn} which is now a set of arbitrary terms. Since the assertion ofmembership is now itself a term, this generalizes the previous notion of context.
11.3.2.2 Axioms and Rules
(Intensional intuitionistic) HOLC is defined by the following axioms and rules. Theaxioms/rules of the theory include the axioms and rules for equality " and # fromC (the other axioms and rules, i.e. &, µ, $, (, ' , are derivable from the definition ofequality) and the rules funi and fune from C. Observe, that these are now to be under-stood with respect to the new notion of context. In addition, we have the following

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 580 — #26
580 Handbook of Logic and Language
rules of inference.
B, s " t B " s # PB " s ( t
(( i)B, s " t # P B " s # P
B " (s ( t) # P(( P)
B " -x # T.g B " s # TB " g[s/x]
(-e)B " s B " s ( t
B " t(( e)
B, x # T " tB " -x # T.t
(-i)B, x # T " t # PB " -x # T.t # P
(-P)
B " sB " s # P
(P)
We assume the normal side conditions on (-i) and (-P). Once again, this already givesus an intuitionistic theory. For (classical) HOLC we add the law of excluded middleas an axiom.
LEM -u # P.u 0 1u.
Finally, for an extensional theory, we add an axioms of extensionality for typedequality.
EXT (i) -z # T ! S.-y # T ! S.(-x # T.zx = Syx) ( z = T!Sy.
(ii) -x # P.-y # P.(x 2 y) ( x = Py.
11.3.2.3 Erasing
We now explore the relationship between HOL and HOLC by extending the erasingtransformation from the corresponding lambda calculi. This is achieved as follows:
erase(-xT .-) & -x # T.erase(-),
erase(- ( .) & erase(-) ( erase(.).
Our first result ensures that this mapping is sound in that typing and derivability inHOL are preserved by erasing. The second is its completeness. First we require thefollowing.
Lemma 11.3.1. erase(tS[sT/xT ]) & erase(tS)[erase(sT)/x].
Proof. We extend the induction from the pure lambda calculus. !
Theorem 11.3.2 (Soundness).
(i) For each tT , Bt "HOLC erase(tT ) # T where
Bt =)erase(xT ) # T : xT is a free variable of t
*.

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 581 — #27
Types 581
(ii) If {-1, . . . ,-n} "HOL - then {erase(-1), . . . , erase(-n)} $ B- "HOLC erase(-).
Proof.
(i) By induction on the terms of HOL. The only new cases to check are those for the logicalconnectives and these are entirely straightforward.
(ii) By induction on the derivations in HOL. We have only to check the rules for the logicalconnectives. These are routine but the universal elimination rule requires the substitutionlemma. !
Theorem 11.3.3 (Completeness). Suppose B "HOLC t, where B = {t1, . . . , tn}, andthere exists tP1 , . . . , tPn such that erase(tPi ) & ti, for i = 1, . . . , n. Then there existsaterm tP such that erase(tP) & t and {tP1 , . . . , tPn } "HOL tP. Furthermore, if t has theform s # T then there exists a term sT such that erase(sT) & s.
Proof. By induction on the derivations in HOLC. We shall consider each of theaxioms/rules in turn. We have only to check the new rules. For (( i), assume B, t " sand B " t # P. From the latter, by induction, there exists tP such that erase(tP) & t.Hence, by induction, there exists a term sP such that erase(sP) & s. Moreover,{tP1 , . . . , tPn }, tP "HOL sP. Hence we have: {tP1 , . . . , tPn } "HOL tP ( sP. Finally,observe that erase(tP ( sP) & t ( s. For (P), assume that B " t. By induction, thereexists a term tP such that erase(tP) & t. Since, erase(tP # P) & t # P and, by definition,"HOL tP # P we are done. For (( e), assume B " s and B " s ( t. By inductionand the assumption s, let erase(sP) & s where {tP1 , . . . , tPn } "HOL sP. By induction andB " s ( t, there exists some rP such that erase(rP) & s ( t & erase(sP) ( t. Bydefinition of erase, rP must have the form sP ( tP, where erase(tP) & t. By induction,we can conclude {tP1 , . . . , tPn } "HOL sP ( tP. Consequently, {tP1 , . . . , tPn } "HOL tP.For (( P), assume that B, t " s # P and B " t # P. By induction and the latter,there exists a term tP such that erase(tP) & t. By B, t " s # P and induction, thereexists a term sP such that erase(sP) & s and {tP1 , . . . , tPn } "HOL (tP ( sP) # P.Finally, by definition, erase((tP ( sP) # P) & (t ( s) # P. For (-i), assumeB, x # T " t. Since we have erase(xT # T) & x # T , by induction, thereexists a term tP such that erase(tP) & t. Furthermore, {tP1 , . . . , tPn } "HOL tP. Itfollows in HOL that: {tP1 , . . . , tPn } "HOL -xT .tP. Finally, observe that, by defini-tion, erase(-xT .tP) & -x # T.t. For (-P), assume B, x # T " t # P. Then,by induction, there exists a term tP such that erase(tP) & t. By definition ofmembership in HOL : {tP1 , . . . , tPn } "HOL (-xT .tP) # P. Moreover, by definition,erase(-xT .tP # P) & (-x # T.t) # P. This leaves us to deal with (-e). Assume,B " -x # T.g and B " s # T . By the first assumption and induction, there existsa term tP such that erase(tP) & -x # T.g and {tP1 , . . . , tPn } "HOL tP. By the def-inition of erase, tP must have the form -xT .- for some -. Hence, g has the formerase(-). By assumption, s # T . By induction, there exists a term sT such thaterase(sT) & s. It follows that {tP1 , . . . , tPn } "HOL -[sT/xT ]. By the substitution lemma,erase(-[sT/xT ]) & g[s/x]. !
A consequence is the consistency of HOLC.

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 582 — #28
582 Handbook of Logic and Language
Corollary 11.3.1. HOLC is consistent.
Proof. Absurdity in HOLC can only be (definitionally) the erased image of absurdityin HOL. Moreover, absurdity in HOLC is provably of type P. The result now followsfrom the completeness of erasing since, if absurdity is provable in HOLC it must bein HOL. !
11.3.3 Higher-Order Logic and the Untyped Calculus
Before we proceed with the Curry version we attempt to develop logic based upon theuntyped calculus, i.e. with no notion of type. This will prove to be disastrous.
11.3.3.1 An Untyped Theory
Suppose we add one new logical constant ( to the untyped calculus (U) together withits standard introduction and elimination rules.
s " ts ( t
s s ( tt
We also add the rule of equality.
t = s ts
eq
11.3.3.2 The Curry Paradox
Unfortunately, even this impoverished logical system is inconsistent. To see this fix aterm t and let s be the term Y[!x.x ( (x ( t)]. Then consider the derivation
t, t ( s " s (i) ( elimination
(t ( (t ( s)) ( (t ( s) (ii) theorem
s = s ( (s ( t) (iii) properties of Y
s = (s ( (s ( t)) ( (s ( t) (iv) substitution from (iii)
(s ( (s ( t)) ( (s ( t) (v) from (ii)
s ( (s ( t) (vi) (iv) and rule eq
s (vii) (iii) and eq
s ( t (viii) (v), (vi) and (i)
t (ix) (vii), (i) and (viii)

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 583 — #29
Types 583
Hence, this simple system is inconsistent: every term is derivable. We cannot addlogical connectives to the untyped system and preserve consistency in this cavalierfashion.
11.3.4 The Curry Theory
The moral of this is that not everything can function as a proposition and, in particular,be a bearer of truth. This has to be taken into account in developing the theory.
11.3.4.1 HOLCU
The theory is formulated in the untyped lambda calculus and includes the (non-redex)constants 0, P, I and (.5 The other logical connectives and quantifiers can bedefined in a similar way to HOL. We again employ infix notation.
-x # t.s & 0t(!x.s),
/ & !xy.-z # P.(x ( (y ( z)) ( z,
0 & !xy.-z # P.(x ( z) ( ((y ( z) ( z),
.x # t.s & -z # P.-y # t.(s[y/x] ( z) ( z,
+ & -z # P.z,
1 & !x.x ( +.
Indeed in this theory the complex types themselves are definable. The types are formedfrom the basic types P and I by forming complex types via:
! & !xyz.-u # x.y(zu).
We shall employ upper case T , S etc. for type terms. Consistent with the above quanti-fier notation, and to make the presentation a little more palatable, we shall often writet # T for Tt. Equality at each type is defined as:
QT & !xy.-z # T ! P.zx ( zy
which we shall write as infix = T .Intensional intuitionistic HOLCU is defined by the following axioms and rules. We
assume the equality axioms and rules of the untyped lambda calculus (U)6 togetherwith the rules ( i, ( e, ( P, -i, -e, -P, and P. Once again, this already givesus an intuitionistic theory. For (classical) HOLCU we add the law of excluded middle(LEM) as an axiom and for an extensional theory,7 we add the axioms of extension-ality – both as in the theory HOLC.
5 Implication is also definable but we shall not fuss over this. In any case one still has to postulate all therules for implication except the elimination rule which is derivable.
6 Extensional versions (i.e. with respect to = in U) are also possible; we simply add the extensionalityaxioms ) and *.
7 Extensional with respect to the typed equality of the theory, i.e. not the underlying equality of the system U.

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 584 — #30
584 Handbook of Logic and Language
11.3.4.2 Erasing
We extend the erasing transformation from the corresponding lambda calculi asfollows.
erase(-xT .-) & -x # T.erase(-),
erase(- ( .) & erase(-) ( erase(.).
Theorem 11.3.4 (Soundness).
If {t1, . . . , tn} "HOL t then {erase(t1), . . . , erase(tn)} $ Bt "HOLCU erase(t).
Proof. By induction on the derivations in HOL. !
We also have a completeness result which follows the same pattern as that forHOLC.
Theorem 11.3.5 (Completeness). Suppose B "HOLCU t, where B = {t1, . . . , tn}, andthere exists tP1 , . . . , tPn such that erase(tPi ) & ti, for i = 1, . . . , n. Then there existsaterm tP such that erase(tP) & t and {tP1 , . . . , tPn } "HOL tP. Furthermore, if t has theform s # T then there exists a term sT such that erase(sT) & s.
So this theory is consistent. However, as with the pure calculus, we have no linkbetween what is provable via the rules of inference and the equality of U. To force thiswe require the following.
11.3.4.3 The eq Rule
This now takes the following more general form.
B " s = t B " sB " t
(eq)
The addition of the rule yields one version of a combinatory logic (HOPC) due toBunder (1983) – the version given in (Hindley and Seldin, 1986). As with the purecalculus completeness for erasing now fails. At present there is no strong consistencyproof for the whole of HOPC (for some progress see Barendregt et al., forthcom-ing, JSL).
11.4 Universal Types and Nominalization
The theories of types of the previous section allow a degree of flexibility in assigningtypes to terms which goes beyond that of the simple Church formulations. Howevercertain phenomena seem to require a more radical departure from the original formu-lations of type theory.

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 585 — #31
Types 585
11.4.1 Nominalization
We first examine the process of nominalization in natural language. This is a fairlywide-ranging topic so we shall concentrate on those aspects which seemingly causetrouble for the present theories.
11.4.1.1 Sentential Complements and Infinitives
Consider the following:
(1) John is strange.(2) That John has arrived is strange.
On the standard analysis, predicative expressions such as is strange are assigned thetype I ! P and proper names such as John are assigned the type I. The semanticanalysis of (1) proceeds as normal but what are we to make of (2)? If the predicativeexpression is strange has type I ! P then That John has arrived, which is traditionallytaken to be of type P, cannot be a legitimate argument.
Chierchia (1982) makes a similar point in the case of Infinitives, Gerunds, Bare-plurals and Mass terms. We shall only review the general form of his argument byreference to the former category. Consider the following sentences.
(3) To arrive late is strange.(4) John is strange.
Since we have assigned the type I ! P to is strange, (4) is well-typed but (3) isproblematic. There are at least two possible candidates for the semantic counterpartsof infinitives. According to one analysis they represent propositions and according tothe other propositional functions. However, Chierchia argues that the correct analysisis the latter. He does so on the basis of data of the following form:
(5)Mary tries to read PrincipiaJohn tries whatever Mary triesJohn tries to read Principia
The two proposals can be represented as follows:
(6)Try(M, !x.[RP(x)])-x.Try(M, x) ( Try(J, x)Try(J, !x.[RP(x)])
(7)Try(M, RP(M))
-x.Try(M, x) ( Try(J, x)Try(J, RP(J))
Argument (6) is valid whereas (7) is not. From such data he argues that infinitivesshould be semantically analyzed as propositional functions but whichever analysis isadopted we have a problem.
There are two obvious remedies. One way out is duplicate all such predicates:in the case of sentential complements one could be semantically represented as a

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 586 — #32
586 Handbook of Logic and Language
propositional function (i.e. of type I ! P) and the other as a function from propo-sitions to propositions (i.e. of type P ! P). This, however, will result in a great dealof complexity since the duplication will have to be inherited by complex predicativeexpressions (e.g., those formed by VP-conjunction and disjunction). An alternativeapproach is the one which maintains the intuition that predicative expressions denotepropositional functions but somehow allows them to take arguments of type other thanI. In particular, any such analysis must facilitate their attachment to propositions andpropositional functions themselves. It is our intention to explore such an approach.Theories which can handle this approach to these phenomena was the main motiva-tion for the development of theories of properties (Chierchia and Turner, 1988; Turner,1987). We shall not pursue these theories here but concentrate on those approacheswhich stem directly from the present theories of types. Before this we point out oneother analogy between sentential complements and infinitives.
11.4.1.2 Intensionality
While it is commonly accepted that that generates intensional contexts it is not oftenobserved that infinitive constructions do also. The inference (9) is intuitively invalidand the reason appears to be that extensional equivalence of the VP’s is not sufficientto guarantee the validity of the inference.
(8)To run is funEverything dies iff it runsTo die is fun
Hence, on this view infinitives and sentential complements seem to have a parallelbehaviour: both can be seen to function as singular terms and both induce intensionalcontexts.
11.4.2 Universal Types
We cannot formalize this analysis of nominalization and intensionality within thepresent theories of types. In the next two sections we present several theories in whichthese intuitions can be reflected. The first is essentially the theory of Frege Structures.
11.4.2.1 The Theory F
The first theory we develop is a version of the Theory of Frege Structures (Aczel,1980). The language of the theory is that of the untyped lambda calculus togetherwith distinguished constants: /, 0, (, -, ., =, /, P. We define 1t as t ( /. Weshall also abbreviate -!x.t as -x.t etc. The axioms and rules consist of those of U(extensionality is optional), the eq rule, plus the following rules.
B, s " t B " PsB " s ( t
(( i)B, s " Pt B " Ps
B " P(s ( t)(( P)
B " s B " s ( tB " t
(( e)
B " t B " sB " s / t
(/i)B " Pt B, t " Ps
B " P(s / t)(/P)
B " t / sB " t
(/e)

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 587 — #33
Types 587
B " tB " s 0 t
(0i)B " Pt B " Ps
B " P(s 0 t)(0P)
B " s 0 t B, s " r B, t " rB " r
(0e)
B " t[x]B " .x.t
(.i)B " .x, t B, t[x] " r
B " r(.e)
B " P(t[x])B " P(.x.t)
(.P)
B " -x.tB " t[s/x]
(-e)B " t[x]B " -x.t
(-i)B " P(t[x])B " P(-x.t)
(-P)
B " /
B " t(/)
B " tB " Pt
(P) P(s = t) (= P)
Again we assume the normal side conditions on the rules: in .e, x is not free in t, r orany open assumption except the one shown: in .P, -P and -i, x not free in t or anyopen assumption. This provides an intuitionistic system. For the full classical theory(F) we add the rule of absurdity.
B " Pt B,1t " /
B " t
We shall write B "F t if t follows in F from the context B. We shall often write t # ffor ft and abbreviate !x.t as {x : t}. With these conventions in place we can introducebounded quantification as follows.
-x # f .t & -x. fx ( t, .x # f .t & .x. fx / t.
11.4.2.2 Properties
Within this theory we can develop a theory of properties or classes where the notionof property/class is given as follows:
Pty( f ) = -x.P( fx).
These properties are closed under a rather extensive class of operations. In particular,we have closure under Cartesian products, disjoint unions, function spaces, intersec-tions, unions, complements, dependent products/functions spaces and dependent sums.
Proposition 11.4.1. If Pty( f ) and Pty(g) then Pty( f 3 g), Pty( f 4 g), Pty( f ! g),
Pty( f 5 g), Pty( f $ g) and Pty(1f ) where
f 3 g & {z : .x # f ..y # g.z = (x, y)},f 4 g & {z : .x # f .(z = inl x) 0 .x # g.(z = inr x)},( f ! g) & {z : -u # f .zu # g},f 5 g & {y : fy / gy},f $ g & {y : fy 0 gy},1f & {y : 1fy},

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 588 — #34
588 Handbook of Logic and Language
where (x, y) and inl and inr are any standard lambda calculus representations ofpairing and injections.
Proposition 11.4.2. Let 1fg = {z : .x # f ..y # gx.z = (x, y)} and 0fg = {z : -u #f .zu # gx} then the following rules are derivable in F
Pty( f ) -x # f .Pty(gx)Pty(0fg)
,Pty( f ) -x # f .Pty(gx)
Pty(1fg).
11.4.2.3 Types
The theory as presented above is in a sense type-free; there is no explicit notion oftype. However, types can be defined within the theory. First observe that the type ofindividuals is definable.
I & {y : y = y}.
By (P =) this is a property. Moreover, this functions as a universal type. We also haveP itself, built-in as a constant. Finally, we can form complex types via:
! & !xyz.-u.xu ( y(zu).
We shall employ upper case T, S etc. for types. It is easy to see that the introductionand elimination rules are derivable.
B, x # T " t # SB " !x.t # T ! S
,B " t # T B " s # T ! S
B " st # S.
As a consequence we can maintain the category type correspondence. For example,determiners have type (I ! P) ! ((I ! P) ! P). In particular, every = !fg.-x #f .x # g and some = !fg..x # f .x # g, are provable of this type. However, thefollowing rules are not derivable.
B, x # T " t # PB " (-x # T.t) # P
,B, x # T " t # P
B " (.x # T.t) # P.
Indeed, if they were then r & !y..x # I ! P.x 6 y/1xy would be a property. Assumerr then for some x # I ! P we have x 6 r / 1xr. Hence, 1rr. Conversely, if 1rrthen rr. Hence, if the theory is consistent, the above rules are not derivable. Hence,higher-order quantification is not Internally Representable: the theory is essentiallyfirst-order.
11.4.2.4 Models
The type-free nature of this theory may well dispose one to have doubts about itsconsistency. Fortunately models are relatively easy to come by. They are constructed

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 589 — #35
Types 589
via a simple inductive definition. We provide the bones of the idea. The present versionis essentially that of Aczel (1980). Similar consistency proofs are due to Scott (1975)and Fitch (1963).
Let D be any model of the lambda calculus. Define
= & !x.y.)0, x, y* - & !x.)6, x*
P & !x.y.)2, x, y* . & !x.)7, x*
0 & !x.y.)3, x, y* / & 8
/ & !x.y.)4, x, y*
( & !x.y.)5, x, y*
where we assume some coding of tuples and the numerals in the lambda calculus –and hence in the model D. These objects possess an independence property in that wecan never have for example, 0xy = /xy. Using these elements of the model we cannow define two subsets T and F as the least fixed points of the following simultaneousinductive definition.
d # Dd = d # T
d # D e # D d 7= ed = e # F
/ # F
d # TPd # T
d # FPd # T
d # Td 0 e # T
e # Td 0 e # T
d # F e # Fd 0 e # F
d # T e # Td / e # T
d # Fd / e # F
e # Fd / e # F
e # Td ( e # T
d # Fd ( e # T
d # T e # Fd ( e # F
fe # T, for some e # D.f # T
fe # F, for all e # D.f # F
fe # T, for all e # D-f # T
fe # F, for some e # D-f # F
This is a monotone induction and so admits a least fixed point. It is easy to check thatthe least fixed point of this inductive definition is a model of the theory. Models of theform )D, T, F* where T, F satisfy the above definition are essentially Aczel’s FregeStructures (Aczel, 1980). For further details about semantics in Frege structures thereader should consult Kamareddine (1992, 1993).

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 590 — #36
590 Handbook of Logic and Language
11.4.2.5 Is Such a First-Order Theory Enough?
One concern hinges on whether sentences such as:
Simon believes everything Mary does,
involve quantification over propositions. Implicitly, it clearly does. If we attempt toreflect this explicitly the appropriate formalization is:
-x # P. Belm
(x) ( Bels
(x).
This cannot be proven to be a proposition in the present theory. This causes prob-lems for nested belief contexts since, intuitively, in the following pair the embeddedsentence is required to be a proposition.
John believes that Simon believes everything Mary does
Belj
(-x # P. Belm
(x) ( Bels
(x)).
The worry here seems to be that, in the present theory, we have no guarantee thatwhat are truly believed are propositions. One way out is to impose some axiomaticconstraints on the belief operator to the effect that Bel(x) ( Px is taken as a axiomabout belief. Alternatively, one might try to develop some aspects of higher-orderquantification internally (see Kamareddine (1993) for such an approach).
11.4.3 Nominalized HOL (NHOL)
A rather different approach to the logic of nominalized predicates is that ofCocchiarella (1979). We first present his original second-order theory and then sketchhow it can be extended to HOL itself.
11.4.3.1 Cocchiarella’s Logic of Nominalized Predicates
We shall adopt the following version of (classical) second-order logic (SOL). Thelanguage has individual variables (lower case x etc.) and n-place relation variables(upper case Xn (n > 0)). The wff are constructed as follows.
(i) Xn(x1, . . . , xn) is an atomic wff.(ii) If - and . are wff then so are 1-, - / ., -x.- and -Xn.-.
The rules of the theory include those for negation, conjunction and universal quantifi-cation (both individual and relation) plus the following schemes of comprehension.
COMP For each wff - and distinct variables x1, . . . , xn.Zn.-x1, . . . ,-xn.Z(x1, . . . , xn) 2 -,
where Z is not free in -.

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 591 — #37
Types 591
Cocchiarella (1979) then allows relation variables to occupy individual positions inatomic wff. The theory T8 results from this addition to the language of SOL by extend-ing all the axioms and rules of second-order logic to this new language (including thescheme of comprehension) and adding a basic ontological axiom which insists thatevery relation is indiscernible from an individual
ONT -Xn..x.x 1= Xn,
where 1= is indiscernability. ONT is actually equivalent to:
-x I .- ( -xT .-!xT/xI",
which is the form given by Cocchiarella. Given the desire to provide a logic of nomi-nalized predicates this is a particularly natural theory. It does, however, have its oddi-ties. Before we discuss them we briefly indicate how one can extend the treatment tothe whole of HOL.
11.4.3.2 NHOL
In order to see how this might be possible we employ a more parsimonious version ofHOL. This is essentially the version F, given in (Andrews, 1986). We employ thisversion since it is much easier to grasp and investigate the inclusion of nominalizedpredicates. The language of types and terms is given as follows. We shall use lowercase Greek letters for terms of type P.
(i) P is a type.(ii) I is a type.
(iii) If T1, . . . , Tn are types then (T1, . . . , Tn) is a type (n # 1).(iv) A variable xT is of type T .(v) x(T1,...,Tn)( yT1 , . . . , yTn) is of type P.
(vi) If - and . are of type P then so are 1-, - / . and -xT .-.
Set-theoretically, (T1, . . . , Tn) denotes the power set of the Cartesian product ofT1, . . . , Tn. The rules of the theory include those for negation, conjunction and uni-versal quantification as in (classical) HOL plus the following schemes of compre-hension.
COMP (i) For each - of type P with distinct variables xT1 , . . . , xTn
.z(T1, . . . , Tn).-xT11 . . . -xTn
n .z(x1, . . . , xn) 2 -,
where z is not free in -.(ii) .zP.z 2 -, where z is not free in -.
For convenience, we shall continue to use HOL for this theory. The definitions of theother connectives and the relations of equality are as before. The extensional theory is

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 592 — #38
592 Handbook of Logic and Language
obtained by adding the axioms of extensionality which now take the following form.
ext (i) -xT11 . . . -xTn
n .u(T1,...,Tn)(x1, . . . , xn)
2 $(T1,...,Tn)(x1, . . . , xn) ( u = (T1,...,Tn)$.
(ii) (- 2 .) ( - = P..
To this version of HOL we add nominalized predicates along the lines of Coc-chiarella’s second order theory. Clause (v) of the syntax is replaced by:
(v%) x(T1,...,Tn)( yS1 , . . . , ySn) is of type Pwhere for i = 1, . . . , n, if Ti 7= I then Ti = Si.
This allows nominalized items of all types to occur in individual position. All therules/axioms remain as before but are extended to this new language. In addition werequire the ontological axiom.
ONT -xT ..yI .x = Iy.
This completes the description of the intensional theory (NHOL). For the extensionalversion we add EXT.
This theory can be translated into HOL. The non-individual types and wff are trans-lated as follows – the individual type evaporates under the translation. In what followswe assume that the variables are appropriately distinct in the concrete syntax. Noticethat the translation only employs a fragment of HOL (i.e. that fragment known aspropositional higher-order logic) where there is no individual quantification.
P8 = P(T1, . . . , Tn)
8 = (J81 , . . . , J8
m) if at least one of Ti 7= I and where J1, . . . , Jmare those elements of {T1, . . . , Tn} not equal toI = P otherwise
(x(T1,...,Tn)(yS1 , . . . , ySn))8 = x(J81 ,...,J8
m)(yJ81 , . . . , yJ8
m) if at least one ofTi 7= I = xPotherwise
(- / .)8 = -8 / .8
(1-)8 = 1(-8)(-xI .-)8 = -8
(-xT .-)8 = -xT8.-8 for T 7= I
Theorem 11.4.1. If - is provable in (extensional) NHOL then -8 is provable in(extensional) HOL.
Proof. By induction on the proofs in NHOL. All the rules are routine to check.Consider the comprehension scheme: .z(T1,...,Tn).-yT1 . . . -yTn .z(yT1 , . . . , yTn) 2 -.

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 593 — #39
Types 593
In the non-trivial case where at least one of Ti 7= I, this translates to:.z(J8
1 ,...,J8m).-yJ8
1 . . . -yJ8m .z(yJ8
1 , . . . , yJ8m) 2 -8, which is an instance of the scheme in
HPL. Where all Ti are I it reduces to the second form of the scheme. ONT translatesto an obvious logical truth. EXT translates to EXT in HOL. !
Despite its consistency this theory is not without its curiosities. In particular,given our observation about the intensional nature of nominalized items the followingshould hold.
IT -xT .-yT .x = Iy ( x = Ty
Intuitively, if two items of type T are equal as individuals (i.e. intensionally thesame) then they ought to equal as elements of type T . This is especially clear ifthe extensionality axioms are assumed. However, it is not derivable. Indeed its addi-tion leads to inconsistency. Consider the following variation on the Russell pro-perty: -[yI] = .x(I).x = Iy / 1x(y). By comprehension, there exists z(I) such that-yI .z(y) 2 .x(I).x = Iy/1x(y). Assume z(z). By ONT, z(z) 2 .x(I).x = Iz/1x(z).By IT, .x(I).x = (I)z / 1x(z). Let x(I) = (I)z / 1x(z). By comprehension, there existsu((I)) such
u#y(I)$ 2
#-wI .y(w) 2 x(I).(w)
$.
Since, u(x(I)), we have u(z). Hence, 1z(z). Conversely, if 1z(z) then clearly, z(z).Hence, we cannot have IT. In particular, x(T) = Iy(T) does not guarantee that x(T) andy(T) are extensionally equal.
11.4.3.3 A Theory with Equality
For a theory with such a notion of equality we must add it as a new primitive – just asin the case of first-order logic. To complete the picture we briefly illustrate how thismight be achieved – for the second-order case. We add to the language of nominalizedSOL a new atomic wff of equality
) = ) %
where ), ) % are variables of either kind (individual or relation). We assume the normalaxioms for equality, i.e. reflexivity and replacement.
ref ) = )
rep ) = ) % ( (-[) ] ( -[) %])
All the proof rules of SOL are extended to this new language but the comprehensionscheme is restricted to the wff of SOL itself (this is already enough for the application

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 594 — #40
594 Handbook of Logic and Language
at hand). In addition, we assume the ontological axiom but now in the form withequality
ONT -Xn..x.x = Xn.
Models of this theory can be constructed along the lines given by Feferman for his the-ory of operations and classes T0 + stratified comprehension (Feferman, 1979). Alter-natively the above theory can be easily translated into T0 + stratified comprehension.Beeson (1985) contains further information on Feferman’s theories but restricts thetheories to elementary or first-order comprehension.
11.5 Constructive Type Theories
Constructively, the meaning of a sentence is not given by spelling out its truth con-ditions but by indicating, for each sentence, what would count as a witness for itstruth. Theories of meaning along these lines have been advocated and defended byDummett (1975, 1976, 1991) and Sundholm (1986) – among others. In this chapterwe shall develop type theories which are more in line with this approach to semantictheory.
11.5.1 Propositional Theories
The idea behind all the theories we shall discuss is based on the so-called Curry-Howard correspondence. We first discuss the correspondence for propositional logic,beginning with implicational logic and its connection with the typed lambda calculus.We then examine its extension to deal with quantification – both first and higher-order.
11.5.1.1 Implicational Logic and the Typed Lambda Calculus
Implicational logic is determined by the following introduction and elimination rules.
B, - " .
B " - ( .,
B " - ( . B " -
B " ..
The Curry-Howard correspondence between propositions and types is based upon theconstructive interpretation of the connectives. In particular, the constructive interpre-tation of implication is given as follows.
(i) t is witness for the truth of - ( . iff t is an operation/function which given a witness for- yields a witness for . .
The second step is to set up the correspondence between propositions and the type oftheir witnessing data. For this we collect together the witnessing data for each propo-sition into a type. For implication, this takes the form of the type of functions from thetype of witnesses for - to the type of witnesses for . .
I[- ( .] 1= I[-] ! I[.]

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 595 — #41
Types 595
The correspondence between derivations in implicational logic and the typed lambdacalculus (C) is then evident.
B8, x # I[-] " t # I[.]B8 " !x # T.t # I[-] ( I[.]
,B8 " t # I[-] B8 " s # I[-] ! I[.]
B8 " st # I[.]
where B8 contains the witnesses for the assumptions in B. Indeed, it is easy to seethat this is a sound representation in the sense that if B " - then for some term twe have: B8 "C t # I[-]. This correspondence was also behind the scenes in ourdiscussion of the relationship between categorial grammars and the typed calculus.Indeed, derivations in categorial grammar can be directly unpacked as derivationsin implicational logic. Of course, for semantic purposes we require more than pureimplicational logic.
11.5.1.2 Disjoint Unions and Cartesian Products
If we add disjunctions and conjunctions to our logical language we must match thesewith corresponding type constructors. To motivate these we first provide the informalconstructive interpretation of these connectives.
(ii) t is a witness for the truth of - / . iff t is a pair (r, s) where r is a witness for - and s is awitness for . .
(iii) t is a witness for the truth of - 0 . iff either t is a left injection, inl r, where r is a witnessfor - or t is a right injection, inr s, where s is a witness for . .
To extend the correspondence between propositions and types we need a parallelextension to the typed lambda calculus. We extend the type syntax of C as follows.
(iv) If T and S are type expressions then so is T 3 S (the Cartesian product of T and S).(v) If T and S are type expressions then so is T 4 S (the disjoint union of T and S).
We need also to add the constructors and destructors for these new types. The lan-guage of terms is enriched with pairing, let-expressions, injections and case state-ments.
(vi) If t and s are terms then so is (t, s).(vii) If t and s are terms and x and y variables then let (x, y) be t in s is a term.
(viii) If t is a term then so are inl t and inr t.(ix) If t, s and r are terms and x and y variables then casexy r of [t, s] is a term.
The theory C is extended by providing introduction, elimination and equality rules forthese types.
B " t # TB " inlt # T 4 S
B " t # SB " inr t # T 4 S
DUI
B, x # T " t # R B, y # S " s # R B " r # T 4 SB " casexy r of [t, s] # R
DUE

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 596 — #42
596 Handbook of Logic and Language
B, x # T " t # R B, y # S " s # R B " r # TB " casexy inl r of [t, s] = Rt[r/x]
DUC1
B, x # T " t # R B, y # S " s # R B " r # SB " casexy inl r of [t, s] = Rs[r/x]
DUC2
B " t # T B " s # SB " (t, s) # T 3 S
CPI
B " t # T 3 S B, x # T, y # S " s # RB " Let (x, y) be t in s # R
CPE
B " (t, t%) # T 3 S B, x # T, y # S " s # RB " Let (x, y) be (t, t%) in s = Rs[t/x, t%/y]
CPC
We also require a general rule of substitution8 and general equality rules. In the ruleof substitution, + is a judgment of equality or membership.
B " t = Ts B " + [t]B " + [t]
sub
B " t = T tB " t # T
B " t # TB " t = T t
ref
B " t = TsB " s = T t
symB " t = Ts B " s = Tr
B " t = Trtrans
With this theory in place we can extend the Curry-Howard correspondence to thewhole of the language of the propositional logic.
I[- / .] 1= I[-] 3 I[.].
I[- 0 .] 1= I[-] 4 I[.].
If we add an uninhabited type to interpret absurdity we have an interpretation of thewhole of the language of the propositional calculus where each wff is interpreted as atype – the type of witnesses for the proposition. Under this interpretation all the laws ofintuitionistic logic are sound in the sense that if a formula is provable in intuitionisticlogic then its witnessing type is inhabited, i.e. we can find a term which is in thetype–and provable so within the extended type theory.
8 One also requires some general housekeeping rules such as a cut and thinning rules but we shall leavethese to the reader’s imagination.

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 597 — #43
Types 597
11.5.2 Dependent Types
To achieve a similar correspondence for predicate logic we need to add types that standproxy for the quantified wff and for atomic assertions. For simplicity we shall assumethat the atomic assertions of the language are just equality assertions. Informally, theconstructive interpretation of the equality assertions and the quantifiers is given asfollows.
(iv) t is witness for the truth of -x.- iff t is a function which given d, an element of the domain,yields a witness for -[d].
(v) t is a witness for the truth of .x. - iff t is a pair (d, s) where d is an element of the domainand s is a witness for -[d].
(vi) t is witness for the truth of s = t iff s = t.
Notice that atomic assertions are trivially witnessed or realized. To extend the corre-spondence for these types we must add new type constructors which collect togetherthe witnessing information. Before this we need to say a little about the domains overwhich quantification is permitted.
Wheresoever in logic the word all or every is used, this word, in order to make sense,tacitly involves the restriction: insofar as belonging to a mathematical structure whichis supposed to be constructed beforehand. Brouwer (1975, p. 76).
According to “Brouwer’s dictum” only bounded quantification is meaningful. Onecan only quantify over a domain which has already been constructed. If we follow thisstricture then quantification (and presumably, equality) should be bounded. It is thesetwo aspects – the Curry-Howard correspondence and the bounded nature of quantifi-cation – which lead to the following theory. The Theory (M) is based upon the theoriesof Martin-Löf (1975, 1979, 1982).9 We shall not present the full details of his theoriesbut merely sketch a theory which provides the flavor of his theories. We shall thenindicate a possible empirical advantage of these theories.
11.5.2.1 The Language of M
We enrich the type theory of the previous section as follows.
(i) If T and S are type expressions then so are T 4 T, 0x # T.S and 1x # T.S.(ii) If T is a type and t and s are terms then I[T, t, s] is a type.
The new types I[T, t, t] are the equality types and 0x # T.S and 1x # T.S the depen-dent generalizations of function spaces and Cartesian products, respectively. Apartfrom the terms of the previous theory we add a new term (e) for the equality types.Notice that via the equality types, type expressions can contain free variables – theyhave terms as components. Correspondingly, we write T[s/x] for type substitution. In0x # T.S and 1x # T.S the variable x is bound. When T does not contain x free, we
9 The major difference will be that the notion of type will be given as in the previous theories via an explicitsyntax not by rules as in his theories. The contexts have also to allow for dependencies.

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 598 — #44
598 Handbook of Logic and Language
shall write S ! T (the function space) for 0x # S.T and S3T (the Cartesian product)for 1x # S.T .
11.5.2.2 Rules
The rules themselves are generalizations of the previous theory to allow for depen-dencies. We assume the general rules of equality and the rule of substitution, plus thefollowing rules for the new type constructors.
B " t = TsB " e # I(T, t, s)
B " t # I[T, s, t]B " s = T t
B " t # I[T, s, s%]B " t = I[T,s,s%]e
B " t # TB " inl t # T 4 S
B " t # SB " inr t # T 4 S
B, x # T " t # R[inl x] B, y # S " s # R[inr x] B " r # T 4 SB " casexy r of [t, s] # R[r]
B, x # T " t # R[inl x] B, y # S " R[inr x] B " r # TB " casexy inl r of [t, s] = R[inl r]t[r/x]
B, x # T " t # R[inl x] B, y # S " s # R[inr x] B " r # SB " casexy inr r of [t, s] = R[inr r]s[r/y]
B, x # S " t # TB " !x # S.t # 0x # S.T
B " s # 0x # S.T B " t # SB " st # T[t]
B, x # S " t # T B " s # SB " (!x # S.t)s = T[s]t[s/x]
B " t # T B " s # S[t/x]B " (t, s) # 1x # T.S
B " t # 1x # T.S B, x # T, y # S[x] " s # R[(x, y)]B " Let (x, y) be t in s # R[t]
B " (t, s) # 1x # T.S B, x # T, y # S[x] " r # R[(x, y)]B " Let (x, y) be (t, s) in r = R[(t,s)]r[t/x, s/y]
This is a simplified version of Martin-Löf’s theories. The crucial difference is thathere the notion of type is given by an explicit syntax of type expressions. The aboveaccount is sufficient to illustrate the use of dependent types in semantics.

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 599 — #45
Types 599
11.5.2.3 Application to Semantics
Implicit in this theory is the identification of propositions and types. A propositionis taken to be true if one can construct an element of the proposition (as a type) viathe rules of the theory. The identification has a surprising side effect. The richness ofthe type theory enables the expression of the logical form of certain sentences whichseem impossible in the more traditional types theories. Consider the notorious donkeysentence.
Every man who owns a donkey beats it.
Ordinary predicate logic does not seem to provide an interpretation of this sentence.The best we can do is the following.
-x # Man .(.y # Donkey .(x, y) # Own) ( (x, ?) # beat .
Unfortunately, there is no way of filling the place marked with a ?; the variable y is notin scope. This has led to the development of Kamp’s Discourse Representation theory(Kamp, this volume). However, in the present type theory we can employ the richnessof the dependent types in conjunction with the identification of propositions and typesto facilitate a representation:
0z # (1x # Man .1y # Donkey . Own(x, y)). beat(iz, i(rz))
where we have used T(x, y) as an abbreviation for the equality type I[T, (x, y), (x, y)].Roughly, an object will be a member of this type if it is an operation which givenan object which is a triple (the first member of which is a man, the second a donkeyand the third which is a witness that the first owns the second), returns a witnessthat the first beats the second. This observation was made by Sundholm (1986). Moresystematic attempts at doing natural language semantics in constructive type theorycan be found in Ranta (1991).
11.5.2.4 An Interpretation of M in F
This theory can be interpreted in the theory F. Call the interpretation 8. We inductivelyassociate with each type T a property T8. This is possible since the properties of F areclosed under the type constructors of the present theory. The terms are mapped via 8 totheir representation in the pure lambda calculus and equality is interpreted as follows.
(t = Ts)8 & t8 = s8 / t # T8.
It is then routine to check that all the rules are soundly interpreted in the theory F. Inparticular, the closure conditions for properties satisfy the closure conditions for types;indeed they satisfy the conditions of Martin-Löf’s theory where the types themselvesare given via proof rules. More details of this interpretation are given in Smith (1984).
Finally it is worth observing that the class of properties of theory F is closed underdependent properties; hence the representation of the donkey sentences is also possi-ble in F.

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 600 — #46
600 Handbook of Logic and Language
11.5.3 Second-Order Theories and Beyond
Can the Curry-Howard correspondence be extended to higher-order quantification?One might think that such impredicative systems are highly non-constructive so thateven if this can be achieved it is philosophically irresponsible to do so. We shall nottakes sides on this issue; our objective is merely to report on the type theories whichcan provide such an interpretation and indicate their semantic applications.
11.5.3.1 Polymorphic Lambda Calculus
We first examine a fragment of second-order logic and its constructive interpreta-tion. The language of minimal second-order logic contains proposition variables andis closed under implication and universal quantification with respect to propositionvariables. The logic contains the standard introduction and elimination rules for impli-cation and (propositional) universal quantification. The type theory for this logic is theso-called polymorphic lambda calculus.
This can be motivated from a rather different perspective. We described the dif-ference between the two theories C and CU by saying that the latter was implicitlypolymorphic in that a term might be assigned more than one type. In the theory C wecould recover the unique type of a term from the syntax. Moreover, in CU it is clearthat the infinite number of types that a term might possess form a pattern. For example,!x.x has type T ! T for all type T . What we cannot do in CU is express this pattern.
In fact there are polymorphic extensions of all three theories but we illustrate withthe theory C. This theory is due independently to Girard (1972) and Reynolds (1974).We enrich the language of types by introducing type variables X, Y, Z and increasingthe stock of type expressions as follows.
(i) I (type of individuals) is a type expression.(ii) If T and S are type expressions then so is T ! S (the type of functions from T to S).
(iii) If X is a type variable then X is a type expression.(iv) If X is a type variable and T a type expression then 0X.T is a type expression.
The language of terms is also an extension of that of C.
(i) x, a variable, is a term.(ii) c, a constant, is a term.
(iii) If t is a term and x a variable and T a type then !x # T.t is a term.(iv) If t and s are terms then so is st.(v) If t is a term and X a type variable then !X.t is a term.
(vi) If t is a term and T a type expression then t.T is a term.
The rules of the theory C are enriched by the rules for polymorphic types.
B " t # TB " !X.t # 0X.T
(PI)B " t # 0X.T
B " t · S # T[S](PE)

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 601 — #47
Types 601
B " t # TB " (!X.t) · S = T[S/X]t[S/X]
(PC)
Usually the Calculus is formulated as a type assignment system without theequality/conversion axiom.
The existence of polymorphism in natural language is not hard to illustrate. Forexample, the Boolean particles “not”, “and” and “or” seem to be polymorphic.The type
0X.(X ! P) ! (X ! P)
seems to cover all cases for “not” (except sentential negation) but it also over-generates. However, even if we could make these instances work, they still do notsupport the full impredicative theory: the polymorphism is schematic and there are noobvious examples of iterated applications of 0. Predicative theories seem to suffice(see Van Benthem, 1991, Chapter 13 for further discussion). However, the second-order calculus has found semantic application via the following extension.
11.5.3.2 The Theory of Constructions
The Curry-Howard correspondence extended to (intuitionistic) higher-order (proposi-tional) logic leads to the theory of constructions (Coquand, 1990; Coquand and Huet,1985). To complete the present picture we provide a brief sketch. Here we have twoclasses of types: those that provide the constructive analogues for the propositions ofHOL and those which interpret the higher-order types of HOL. To provide a flavor ofthis theory we provide a syntax for the types and propositions as follows.
(i) If T and S are type expressions then so is 0x # T.S.(ii) If P is a proposition expression then P is a type expression.
(iii) If P is a proposition expressions and T is a type expression then0x # T .P is a propositionexpression.
Notice that this is a generalization of that which would arise naturally from HOL inthat the types required to interpret the types of HOL would only require closure underfunction spaces, whereas we have closure under dependent function spaces. Observealso that implication is interpreted as the function space P ! Q which is a specialcase of 0x # P.Q, where x is not free in Q. Given this syntax, and the familiarity withthe systems so far constructed, the reader should be able to construct the rules of thetheory. The rule for the dependent types parallel those for the theory M but of coursethe class of types is different. In particular, the polymorphism of the second-ordercalculus is given via the type 0x # P.T . For an accessible exposition of the completetheory see Huet (1990). A good general and detailed introduction to higher-order typetheories is Barendregt (1991).
As we said earlier, this theory has found some application in semantics: it has beenemployed to interpret Kamp’s Discourse representation theory (Ahn and Kolb, 1990).Whether the full power of this theory is necessary for this application remains to beseen. More details of this interpretation can be found in Kamp’s paper (this volume).

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 602 — #48
602 Handbook of Logic and Language
11.6 Types in Semantics, Logic and Computation
The majority of the type theories we have studied have been inspired by the foun-dations of computing science and mathematics. However, in our exposition we moti-vated matters from the perspective of natural language semantics. In this final sectionwe draw some of the disparate strands together and briefly compare the role of typesin these areas. This will set the scene for indicating more recent lines of research.
11.6.1 More Flexible Typing
Polymorphism comes in many flavors from overloading where the same symbol isemployed with several different meanings, through to the uniform polymorphism ofthe second-order lambda calculus. Van Benthem (1991, Chapter 13) distinguishes bet-ween various forms of polymorphism (e.g., variable, derivational, substitutional) tocope with the variety of type shifting phenomena in natural language. All of thesenotions have their counterparts in computer science. In particular, the substitutionalvariety is essentially that of the programming languages ML and MIRANDATM.Hendriks (1993) develops a flexible Montague semantics in which each syntactic cate-gory is associated with a whole family of types: the families are inductively generatedfrom some base types by closing under certain type constructors. Most of these formsof polymorphism can be represented in the second-order calculus. However, such rep-resentations are not descriptively adequate in the sense that the calculus goes waybeyond the empirical data. This is true in both computer science and natural language.This leads to a further consideration which pertains to the design of a sensible theoryof polymorphic typing.
11.6.2 Expressive Power Versus Proof Theoretic Strength
The expressive power of a theory is often contrasted with its proof-theoretic strength.These dimensions of a theory are of central concern to mathematical foundationsand, more recently, have become an issue in the foundations of computation (e.g.,Feferman, 1990; Turner, 1996). In particular, Feferman demonstrates that one candesign a theory (including a form of stratified polymorphism) which is expressiveenough to capture computational practice but which has only the computationalstrength of primitive recursive arithmetic.10 Thus far, these concerns have not beenof major interest to semanticists. However, ever since the emergence of Montaguesemantics it has been clear that semantics does not require the full expressive powerof higher-order intensional logic. More recently, Van Benthem (1991) has pointedout that one does not require the whole of the second order lambda calculus to cap-ture the various forms of polymorphism implicit in natural language. Moreover, itis clear that one does not require the whole of the theory of constructions to cap-ture discourse representation theory. A version of Martin-Löf’s type theory with a
10 Practice would be even better served with systems the strength of polynomial arithmetic.

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 603 — #49
Types 603
universe would do; and this would be a theory proof-theoretically equivalent to first-order arithmetic.11 More studies along these lines would be a welcome deterrent to theproliferation of ever stronger and, from the perspective of semantic and computationalapplications, hard to motivate systems. In both areas workers too often take the easyway out: expressive power is obtained by the brute force technique of increasing itsproof-theoretic strength.
11.6.3 Unifying Frameworks
The Barendregt cube (Barendregt, 1991) provides a framework in which many puretype systems can be accommodated. These include the simple type lambda calculusand progress through to the second-order calculus and eventually the theory of con-structions. This has enabled a more systematic study of the various metamathematicalproperties of these systems. The cube also offers some further conceptual clarificationof the theory of constructions itself. Recently, Borghuis (1994) has extended all thesetype systems to include modal operators and has introduced the modal cube. The moti-vation stems from the need for richer languages of knowledge representation whichin particular allow for the representation of intensional notions. Kamareddine (1995)suggests a theory in which many of the current property theories (apparently) emergeas special cases.
11.6.4 Universal Types
In natural language semantics the need for some form of universal type or propertyseems to arise in the semantics of nominalization. In computer science it emanatesfrom the untyped lambda calculus. Moreover, many computational theories oftypes/classes, aimed at program development and analysis, admit a universal type(e.g., Feferman, 1990). However, this is largely for convenience and elegance in stat-ing the theory. More explicitly, such theories are based upon a scheme of compre-hension which admits a universal type as an instance. It is not clear that such typesare useful or necessary in computational practice. Moreover, the usefulness of havinglogical theories like property theory as part of a computational logic is less than clear(see Kamareddine, 1995 for an alternative view).
11.6.5 Dependent Types
The term Constructive Functional Programming refers to the paradigm where theCurry-Howard correspondence between proofs and programs is employed to pro-vide a foundation for the specification and development of provably correct programs.Dependent types have found application in unpacking the Curry-Howard correspon-dence. Thompson (1991) is a simple introduction to the use of Martin-Löf’s typetheory from the computational perspective. However, the role of these types in natural
11 Provided that induction is restricted to first-order types.

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 604 — #50
604 Handbook of Logic and Language
language semantics is quite different: they have been employed to model discoursephenomena. On the face of it, the constructive paradigm in semantics seems essentialto this particular application. However, these types are available in certain propertytheories (e.g., Turner, 1987) and so, Sundholm’s treatment of discourse, is also avail-able here (see Fox, 1995).
11.6.6 Separation Types
These types have been employed in the foundations of computation/constructivemathematics to hide information. Fox (1995) employs them in semantics to analyzediscourse anaphora. Whether they can be employed to model underspecification e.g.,underspecified discourse representations (Reyle, 1995) remains to be seen.
References
Aczel, P., 1980. Frege structures and the notions of proposition, truth and set, in: Baranse, J.,Keisler, J., Kunen, K. (Eds.), The Kleene Symposium. North-Holland, Amsterdam,pp. 31–40.
Ahn, R., Kolb, H.P., 1990. Discourse Representation Meets Constructive Mathematics. Techni-cal Report 16, ITK, Tilbury.
Andrews, P.B., 1986. An Introduction to Mathematical Logic and Type Theory. Academic Press,New York.
Barendregt, H., 1984. The Lambda Calculus: Its Syntax and Semantics. North-Holland Studiesin Logic and the Foundations of Mathematics vol. 103. North-Holland, Amsterdam.
Barendregt, H., 1991. Lambda calculi with types, in: Abramsky, S., Gabbay, D.M., Maibaum,T.S.E. (Eds.), Handbook of Logic in Computer Science, Oxford University Press, Oxford,UK, pp. 118–279.
Beeson, M., 1985. Foundations of Constructive Mathematics. Springer, Berlin.Borghuis, T., 1994. Coming to Terms with Modal Logic. PhD thesis, University of Eindhoven,
the Netherlands.Brouwer, L.E.J., 1975. In: Heyting, A. (Ed.), Collected Works, vol. 1. Philosopy and foundations
of mathematics. North-Holland, Amsterdam.Bunder, M.W.V., 1983. Predicate calculus of arbitrarily high order. Arch. Math. Logic 23,
109–113.Chierchia, G., 1982. Nominalization and Montague grammar. Ling. Philos. 5, 3.Chierchia, G., Turner, R., 1988. Semantics and property theory. Ling. Philos. 11, 261–302.Church, A., 1940. A formulation of the simple theory of types. J. Symb. Logic 5, 56–68.Church, A., 1941. The Calculi of Lambda Conversion. Princeton University Press, Princeton,
NJ.Cocchiarella, N.B., 1979. The theory of homogeneous simple types as a second order logic,
Notre Dame J. Formal Logic 20, 505–524.Coppo, M., 1984. Completeness of type assignment in continuous lambda models. Theor.
Comput. Sci. 29, 309–324.Coquand, T., 1990. Metamathematical investigations of the calculus of constructions, in:
Odifreddi, P. (Ed.), Logic and Computer Science, Academic Press, New York, pp. 91–122.Coquand, T., Huet, G., 1985. A Theory of Constructions, Semantics of Data Types. Springer,
Berlin.

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 605 — #51
Types 605
Cresswell, M., 1985. Structured Meanings. MIT Press, Cambridge, MA.Curry, H.B., Feys, R., 1958. Combinatory Logic. North-Holland Studies in Logic vol. 1. North-
Holland, Amsterdam.Curry, H.B., Hindley, R., Seldin, J., 1972. Combinatory Logic. North-Holland Studies in Logic
vol. 2. North-Holland, Amsterdam.Dummett, M., 1975. What is a Theory of Meaning?: I, in: Guttenplan, S. (Ed.), Mind and Lan-
guage. Oxford University Press, UK.Dummett, M., 1976. What is a Theory of Meaning?: II, in: Evans, E.G., McDowell, J. (Eds.),
Truth and Meaning. Oxford University Press, UK.Dummett, M., 1991. The Logical Basis of Metaphysics. Duckworth, London, pp. 113–121.Feferman, S., 1975. A language and axioms for explicit mathematics. Algebra and Logic,
Lecture Notes in Mathematics, vol. 450. Springer-Verlag, Berlin, pp. 87–139.Feferman, S., 1979. Constructive theories of functions and classes, in: Boffa, M., Van Dalen, D.,
McAloon, K. (Eds.), Logic Colloquium 78, North-Holland Studies in Logic and the Foun-dations of Mathematics. North-Holland, Amsterdam, pp. 159–224.
Feferman, S., 1990. Polymorphic typed Lambda Calculi in a type-free axiomatic framework.Contemp. Math. 106, 101–136.
Fitch, F.B., 1963. The system CD of combinatory logic. J. Symb. Logic 28, 87–97.Fox, C., 1995. Representing Discourse in Property Theory. Internal report, University of
Essex, UK.Geach, P., 1972. A program for syntax, in: Davidson, D., Harman, G. (Eds.), Semantics of
Natural Language. Reidel, Dordrecht, pp. 483–497.Girard, J.Y., 1972. Interpretation fonctionnelle et elimination des coupures dans l’arithmetique
d’ordre superieur. These de doctorat d’etat, Universite Paris VII, France.Hendriks, H., 1993. Studied Flexibility. PhD thesis, Department of Philosophy, University of
Amsterdam. ILLC Dissertation Series 1993–1995, the Netherlands.Hindley, J.R., 1969. The principal type-scheme of an object in combinatory logics. Trans. Amer.
Math. Soc. 146, 29–60.Hindley, J.R., 1983. The completeness theorem for typing lambda terms. Theor. Comput. Sci.
22, 1–17.Hindley, J.R., Seldin, J.P., 1986. Introduction to Combinators and Lambda Calculus.
London Mathematical Society Students Texts, vol. 1. Cambridge University Press,New York, NY.
Huet, G., 1990. A uniform approach to type theory, in: Huet, G. (Ed.), Logical Foundations ofFunctional Programming, Addison-Wesley, New York, NY, pp. 337–399.
Kamareddine, F., 1992. Set theory and nominalization, part I. J. Logic Comput. 2 (5), 579–604.Kamareddine, F., 1993. Set theory and nominalization, part II. J. Logic Comput. 2 (6),
687–707.Kamareddine, F., 1995. Important issues in foundational formalism. Bull. IGPL 3 (2.3),
291–319.Martin-Löf, P., 1975. An Intuitionistic Theory of Types: Predicative Part, Logic Coll. 73. North-
Holland, Amsterdam.Martin-Löf, P., 1979. Preprint of (Martin-Löf, 1982). Report No. 11, University of Stockholm,
Sweden.Martin-Löf, P., 1982. Constructive mathematics and computer programming logic. Methodol.
Philos. Sci. 6, 153–179.Meyer, A., 1982. What is a model of the lambda calculus? Inform. Control 52, 87–122.Montague, R., 1970. A universal grammar, Theorem 36, 373–390.

“15-ch11-0555-0606-9780444537263” — 2010/11/29 — 21:08 — page 606 — #52
606 Handbook of Logic and Language
Montague, R., 1973. The proper treatment of quantification in ordinary English, in: Hintikkaet al. (Eds.), Approaches to Natural Language, Dordrecht.
Muskens, R., 1989. Meaning and Partiality. Dissertation, University of Amsterdam, theNetherlands.
Partee, B.H., Rooth, M., 1983. Generalized conjunction and type ambiguity, in: Bauerle, R.,Schwarz, C., von Stechow, A. (Eds.), Meaning, Use and Interpretation of Language, Walterde Gruyter, Berlin, pp. 361–383.
Plotkin, G., 1972. A Set-Theoretical Definition of Application. Memo MIP-R-95, University ofEdinburgh, UK.
Ranta, A., 1991. Intuitionistic categorial grammar. Ling. Philos. 14, 203–239.Reyle, U., 1995. Underspecified discourse representation structures and their logic. Bull. IGPL
3 (2.3), 473–489.Reynolds, J.C., 1974. Towards a theory of type structures. Proceedings of Programming Sym-
posium, Lecture Notes in Computer Science, vol. 19. Springer, Berlin, pp. 408–423.Scott, D., 1973. Models for various type-free calculi, in: Seppos et al. (Eds.), Logic, Method-
ology and Philosophy of Science IV. North-Holland Studies in Logic and Foundations ofMathematics. North-Holland, Amsterdam, pp. 157–187.
Scott, D.S., 1975. Combinators and classes, in: Bohm, C. (Ed.), Lambda Calculus and Com-puter Science Theory, Lecture Notes in Computer Science, vol. 37. Springer-Verlag, Berlin,pp. 1–26.
Scott, D.S., 1976. Data types as lattices. SIAM J. Comput. 5, 522–587.Smith, J.M., 1984. An interpretation of Martin-Löf’s type theory in a type-free theory of propo-
sitions. J. Symb. Logic 49 (3): 730–753.Stalnaker, R., 1984. Inquiry. MIT Press, Cambridge, MA.Sundholm, G., 1986. Proof theory and meaning, in: Gabbay, D., Guenthner, F. (Eds.), Handbook
of Philosophical Logic III. Reidel, Dordrecht. pp. 471–506.Thompson, S., 1991. Type Theory and Functional Programming. Addison-Wesley, New York,
NY.Turner, R., 1987. A theory of properties. J. Symb. Logic 52, 445–472.Turner, R., 1996. Weak theories of operations and types. J. Logic Comput. 6 (1), 5–31.Thomason, R., 1980. A model theory for the propositional attitudes. Ling. Philos. 4, 47–70.Van Benthem, J., 1991. Language in Action. North-Holland Studies in Logic. North-Holland,
Amsterdam.

“16-ch12-0607-0670-9780444537263” — 2010/11/30 — 3:44 — page 607 — #1
12 DynamicsReinhard Muskens!, Johan van Benthem†,Albert Visser††
!Tilburg Universiteit, Department of Philosophy, P.O. Box 90153,5000 LE Tilburg, The Netherlands, E-mail: [email protected]
†ILLC, Universiteit van Amsterdam, P.O. Box 94242,1090 GE Amsterdam, The Netherlands,E-mail: [email protected]
††Heidelberglaan 6–8, room 166, 3584 CS Utrecht, The Netherlands,E-mail: [email protected]
Commentators: D. McCarty
12.0 Introduction
Intriguing parallels can be observed between the execution of computer programsand the interpretation of ordinary discourse. Various elements of discourse, such asassertions, suppositions and questions, may well be compared with statements orsequences of statements in an imperative program. Let us concentrate on assertionsfor the moment. Stalnaker (1979) sums up some of their more or less obvious charac-teristics in the following way.
Let me begin with some truisms about assertions. First, assertions have content; anact of assertion is, among other things, the expression of a proposition – somethingthat represents the world as being a certain way. Second, assertions are made in acontext – a situation that includes a speaker with certain beliefs and intentions, andsome people with their own beliefs and intentions to whom the assertion is addressed.Third, sometimes the content of the assertion is dependent on the context in which it ismade, for example, on who is speaking or when the assertion takes place. Fourth, actsof assertion affect, and are intended to affect, the context, in particular the attitudesof the participants in the situation; how the assertion affects the context will dependon its content.
If we are prepared to think about assertions as if they were some special kind ofprograms, much of this behavior falls into place. That assertions are made in a con-text may then be likened to the fact that execution of a program always starts in agiven initial state; that the content of an assertion may depend on the context parallelsthe situation that the effect of a program will usually depend on this input state (for
Handbook of Logic and Language. DOI: 10.1016/B978-0-444-53726-3.00012-8c" 2011 Elsevier B.V. All rights reserved.

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 608 — #2
608 Handbook of Logic and Language
example, the effect of x := y + 7 will crucially depend on the value of y beforeexecution); and that a program or part of a program will change and is intended tochange the current program state is no less a truism as the contention that an actof assertion changes the context. After the change has taken place, the new state orthe new context can serve as an input for the next part of the program or the nextassertion.
The metaphor helps to explain some other features of discourse as well. Forinstance, it makes it easier to see why the meaning of a series of assertions is sen-sitive to order, why saying “John left. Mary started to cry.” is different from saying“Mary started to cry. John left.”. Clearly, the result of executing two programs will ingeneral also depend on the order in which we run them. If we think about sequences ofsentences as ordinary conjunctions on the other hand, this non-commutativity remainsa puzzle. The picture also helps us see how it can be that some assertions are inap-propriate in certain contexts, why we cannot say “Harry is guilty too” with a certainintonation just after it has been established that nobody else is guilty. This is likedividing by x just after x has been set to 0.
Discourse and programming then, seem to share some important structural prop-erties, to the extent that one can serve as a useful metaphor for the other. We neednot restrict application of the metaphor to that part of discourse that is expressed byovert linguistic means. Not only are assertions, suppositions and questions made in acontext; other, non-verbal, contributions to conversation, such as gestures and gazes,are too. These non-verbal acts of communication likewise have a potential to changethe current context state. A speaker may for instance introduce discourse referentsinto the conversation with the help of a gesture or a gaze, or may use such means(or more overt linguistic ones such as changes in tense and aspect or rise in pitch) toannounce the introduction of a new “discourse segment purpose” (Grosz and Sidner,1986; Polanyi, 1985). Appropriateness conditions for gestures or gazes do not seemto differ in principle from those for linguistic acts: a case of pointing where there isnothing to be pointed at may be likened to saying “The king is bald” where there is noking, or the use of a variable that has not been declared.
But if even gestures and gazes share the structural properties that we have seenare common to computer programs and linguistic acts, then we may wonder whetherthe properties involved are not simply those that all actions (or at least all rule-basedactions) have in common, and indeed we feel that this is the right level of abstractionto think about regarding these matters. An action – whether it be a communicative act,the execution of an assignment statement, a move in chess, or simply the movementof an arm – is performed in a given situation, typically changes that situation, and isdependent upon that situation for the change that it brings about. The effect of castlingis dependent on the previous configuration on the board and your friend’s steppingforward may result in his stepping on your toe in some situations but not in others.The order in which we perform our actions will typically affect the result, as we areall aware, and in many situations an action may be inappropriate – you cannot moveyour rook if this exposes your king.

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 609 — #3
Dynamics 609
The similarity between linguistic acts and moves in a game was stressed by thephilosopher Ludwig Wittgenstein (Wittgenstein, 1953), but the first paper with imme-diate relevance to theoretical linguistics that explicitly took such similarities as itspoint of departure was the influential Lewis (1979). In this article, which refers toWittgenstein in its title, Lewis compares conversation with baseball and says that“with any stage in a well-run conversation, there are many things analogous to thecomponents of a baseball score”. The latter is defined as a septuple of numbers: thenumber of home team runs, the number of runs that the visiting team has, the half (1 or2), and so on. And in a similar way Lewis lets conversational score consist of severalcomponents: a component that keeps track of the presuppositions at any moment ofconversation, a component that ranks the objects in the domain of discourse accord-ing to salience, the point of reference, the possible worlds that are accessible at anygiven point, and many others. Just as the rules of baseball tell us how the actions ofthe players alter the baseball score, the rules of conversation specify the kinematics ofcontext change. If you mention a particular cat during conversation, for example, therules bring it about that that cat will become salient and that a subsequent use of thedefinite description “the cat” will most likely refer to it. And if you say “John went toAmsterdam”, the point of reference will move to Amsterdam as well, so that if youcontinue by saying “Mary came the following day”, it will be understood that Marycame to Amsterdam and not to any other place.
Clearly, Lewis’ picture of a conversational scoreboard that gets updated throughlinguistic acts of the participants in a conversation has much in common with our pre-vious computational picture. In fact, we can imagine the conversational scoreboard tobe a list of variables that the agents may operate on by means of programs according tocertain rules. But a caveat is in order, for although there are important structural simi-larities between games and programs on the one hand and discourse on the other, thereare of course also many features that are particular to conversation and our metaphoris not intended to make us blind to these. An example is the phenomenon of accom-modation that Lewis describes. If at some point during a conversation a contributionis made that, in order to be appropriate, requires some item of conversational scoreto have a certain value, that item will automatically assume that value. For instance,if you say “Harry is guilty too” in a situation where the presupposition componentof conversational score does not entail that someone else is guilty (or that Harry hassome salient property besides being guilty), that very presupposition will immedi-ately come into existence. This accommodation does not seem to have a parallel ingames or computing: trying to divide by x after this variable has been set to 0 willnot reset x to another value and, to take an example used by Lewis, a batter’s walkingto first base after only three balls will not make it the case that there were four ballsafter all.
Such examples, however, need not change the basic picture. That conversation andother cognitive activities have many special properties besides the ones that they havein virtue of being examples of rule-governed activities in general need not surprise us.Accommodation can be thought of as such a special property and we may model it as

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 610 — #4
610 Handbook of Logic and Language
one of the particular effects that the programs that model communicative acts have –one of the effects that they have in virtue of being a special kind of program rather thanjust any program. It is the logic of the general properties that we are after in this paper.
The paper is divided into two sections. In Section 12.1, without any attempt atgiving a complete rubrication, we shall give an overview of some important dynamictheories in linguistics and artificial intelligence which have emerged in the last twodecades and we shall see how these fit into the general perspective on communicationsketched in this introduction. In Section 12.2 we shall offer some more general logicalconsiderations on dynamic phenomena, discussing various ways to model their logicand discussing how the logic that emerges is related to its classical static predecessors.
12.1 Some Specific Dynamic Systems
12.1.1 The Kinematics of Context Change: Stalnaker, Karttunen,Heim and Veltman
Certain things can only be said if other things are taken for granted. For example,if you say (1a) you signal that you take the truth of (1b) for granted, and a similarrelation obtains between (2a) and (2b) and between (3a) and (3b). The (b)-sentencesare presuppositions of the (a)-sentences and in a situation where the falsity of anyof the (b)-sentences is established, the corresponding (a)-sentence cannot be utteredfelicitously (for an overview of theories of presupposition cf. Beaver, 1996; Soames,1989).
(1a) The king of France likes bagels.(1b) France has a king.(2a) All of Jack’s children are fools.(2b) Jack has children.(3a) John has stopped seeing your wife.(3b) John was seeing your wife.
Stalnaker (1974) gives a rough definition of the notion of presupposition, whichruns as follows: a speaker presupposes that P at a given moment in a conversationjust in case he is disposed to act, in his linguistic behavior, as if he takes the truth ofP for granted, and as if he assumes that his audience recognizes that he is doing so.Note that this defines the notion of presupposition not only relative to a speaker andthe assumptions that he makes regarding his audience, but also relative to a momentin conversation. This leaves open the possibility that the set of propositions that canbe assumed to be taken for granted changes during discourse and indeed this is whatnormally happens. When you say: “John was seeing your wife”, you may from thatmoment on assume that your audience recognizes that you take it for granted that hedid. Consequently, in order to be able to say (4) you need not assume in advance thatyour audience recognizes anything at all about your views on his wife’s past fidelity;the necessary precondition for a felicitous uttering of the second conjunct will be inforce from the moment on that the first conjunct has been uttered, regardless of theassumptions that were made beforehand.

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 611 — #5
Dynamics 611
(4) John was seeing your wife but he has stopped doing so.(5) If France has a king, then the king of France likes bagels.(6) Either Jack has no children or all of his children are fools.(7) The king of France does not like bagels.
In (5) and in (6) something similar happens. If a speaker utters a conditional, hisaudience can be assumed to take the truth of the antecedent for granted during theevaluation of the consequent and hence a speaker need not presuppose that Francehas a king in order to utter (5) in a felicitous way. Similarly, when evaluating thesecond part of a disjunction, a hearer will conventionally take the falsity of the firstpart for granted and so (6) can be uttered by someone who does not presuppose thatJack has children. The presuppositions that a speaker must make in order to make afelicitous contribution to discourse with a negated sentence on the other hand do notseem to differ from those of the sentence itself and so (7) simply requires (1b) to bepresupposed.
Such regularities suggest the possibility of calculating which presuppositions arein force at any given moment during the evaluation of a sentence and indeed rules forcalculating these are given in Karttunen (1974). Let us call the set of sentences C thatare being presupposed at the start of the evaluation of a given sentence S the initialcontext of S. Then we can assign local contexts LC(S!) to all subclauses S! of S byletting LC(S) = C and, proceeding in a top-down fashion, by assigning local contextsto the proper subclauses of S with the help of the following rules.
(i) LC(not S) = C " LC(S) = C,
(ii) LC(if S then S!) = C " LC(S) = C & LC(S!) = C # {S},(iii) LC(S and S!) = C " LC(S) = C & LC(S!) = C # {S},(iv) LC(S or S!) = C " LC(S) = C & LC(S!) = C # {not S}.
The local context of a clause consists of the presuppositions that are in force atthe time the clause is uttered. The rules allow us to compute, for example, the localcontext of the first occurrence of S! in “if (S and S!) then (S!! or S!)” as C # {S}, whereC is the initial context, and the local context of the second occurrence of this sentencecan be computed to be C # {S and S!, not S!!}.
A speaker who presupposes an initial set of sentences C is now predicted to be ableto utter a sentence S felicitously just in case the local context of each subclause of Sentails all presuppositions that are triggered at the level of that subclause. If this is thecase we say that C admits or satisfies the presuppositions of S. Since, for example, Cneed not entail that Jack has children in order to admit (6) it is predicted that a speakerneed not presuppose that he has in order to be able to make a suitable contribution todiscourse with the help of this sentence.
Rules (i)–(iv) only allow us to compute the admittance conditions of sentences thatare built from atomic clauses with the usual propositional connectives, but Karttunenalso extends the theory to sentences constructed with complementizable verbs. Thelatter are divided into three: (a) verbs of saying such as say, mention, warn, announceand the like, which are called plugs; (b) verbs such as believe, fear, think, doubt andwant, which are filters; and (c) verbs such as know, regret, understand and force, which

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 612 — #6
612 Handbook of Logic and Language
are holes. Three extra rules are needed for assigning local contexts to the subclausesof sentences containing these constructions.
(v) LC(NP VplugS) = C " LC(S) = {$},(vi) LC(NP VfilterS) = C " LC(S) = {S! | NP believes S! % C},
(vii) LC(NP VholeS) = C " LC(S) = C.
For example, in (8) the local context for “the king of France announced that Johnhad stopped seeing his wife” is simply the initial context C, and so a speaker who isto utter (8) should presuppose that there is a king. But it need not be presupposed thatJohn was seeing Bill’s wife since the local context for the complement of announce issimply the falsum $, from which the required presupposition follows of course. Withrespect to (9) it is predicted that the initial context must entail that Sue believes thereto be a king of France and that she believes that Jack has children for the utterance tobe felicitous.
(8) Joe forced the king of France to announce that John had stopped seeing Bill’swife.
(9) Sue doubts that the king of France regrets that all of Jack’s children are fools.
Karttunen’s rules for the admittance conditions of a sentence are completely inde-pendent from the rules that determine its truth conditions (a feature of the theorycriticized in Gazdar, 1979), but Heim (1983a) shows that there is an intimate con-nection. Many authors (e.g., Stalnaker, 1979) had already observed that a sequenceof sentences S1, . . . , Sn suggests a dynamic view of shrinking sets of possibilities[S1], [S1]&[S2], . . . , [S1]& · · ·&[Sn], where each [Si] denotes the possibilities that arecompatible with sentence Si. The idea is illustrated by the game of Master Mind, wheresome initial space of possibilities for a hidden sequence of colored pegs is reduced bysuccessive answers to one’s guesses, encodable in conjunctions of propositions like“either the green peg is in its correct position or the blue one is”. Complete informationcorresponds to the case where just one possibility is left. Identifying the possibilitiesthat are still open at any point with the local context C, we may let the context changepotential 'S' of a sentence S be defined as the function that assigns C & [S] to any C.Processing S1, . . . , Sn will then reduce an initial context C to 'S1' ( · · · ( 'Sn'(C),where ( denotes composition of functions.
This last set-up defines the context change potential of a sentence in terms of itstruth conditions, but Heim takes the more radical approach of defining truth condi-tions in terms of context change potentials. The context change potential of a complexexpression in her theory is a function of the context change potentials of its parts.In particular, she dynamicizes the interpretation of the propositional connectives bygiving the following clauses for negation and implication.1
'not S'(C) = C ) 'S'(C),
'if S then S!'(C) = C ) ('S'(C) ) 'S!'('S'(C)).
1 Heim writes C + S where we prefer 'S'(C).

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 613 — #7
Dynamics 613
The functions 'S' considered here may be undefined in contexts C where thepresuppositions of S fail to hold and it is to be understood that if an argument of afunction is undefined, the value of that function also is. For example, 'if S then S!'(C)
is defined if and only if both 'S'(C) and 'S!'('S'(C)) are. This means that C acts asa local context of S, while 'S'(C) is the local context of S!. The local context for S in'not S'(C) simply is C. Essentially then, Karttunen’s local contexts for a sentence canbe derived from the definition of its context change potential, but the definition alsodetermines the sentence’s truth conditions, as we may define S to be true in a point iiff 'S'({i}) = {i} and false in i iff 'S'({i}) = *.2 For sentences not containing anypresupposition this is just the standard notion, but a sentence S may be neither true norfalse in i if 'S'({i}) is undefined.
Heim’s idea suggests adding a two-place presupposition connective / to the syntaxof propositional logic, where !/" is to mean that " holds but that ! is presupposed.3
We shall interpret the resulting system dynamically, letting contexts be sets of ordinaryvaluations V , and defining context change potentials as follows.
(i) 'p'(C) = C & {V | V(p) = 1} if p is atomic,(ii) '¬!'(C) = C ) '!'(C),
(iii) '! + "'(C) = '"'('!'(C)),
(iv) '!/"'(C) = '"'(C) if '!'(C) = C,= undefined otherwise.
The demand that '!'(C) = C is a way to express admittance of ! by the context C(compare the notion of acceptance in Venema, 1991). Again, it is to be understood thatif an argument of a function is undefined, the value of that function also is. Implicationand disjunction can be defined as usual, i.e. ! , " is to abbreviate ¬(! + ¬") and! - " is short for ¬! , " . The reader is invited to verify that the resulting logicgives us exactly the same admittance conditions as we had in (the propositional partof) Karttunen’s theory. In particular, we may formalize sentences (4), (5) and (6) asp + ( p/q), p , ( p/q) and ¬p - ( p/q) respectively and see that these are admittedby any context.
This then is a version of propositional logic which supports presuppositions and istruly dynamic, as its fundamental semantic notion is that of context change potentialrather than truth. The reader be warned though that an alternative static definitiongives exactly the same results. To see this, define the positive extension [!]+ and thenegative extension [!]) of each sentence ! as follows.
2 Heim (1983a) and Heim (1982, p. 330) let a context (or a file) be true iff it is non-empty. A sentence S isthen stipulated to be true with respect to a given C if 'S'(C) is true, and false with respect to C if C is trueand 'S'(C) is false. The case where both C and 'S'(C) are false is not covered. Heim notices this and inHeim (1982) makes an effort to defend the definition. The present definition is more limited than Heim’soriginal one, since it essentially instantiates C as {i}. But truth in i is always defined in our definition andthe definition serves its purpose of showing that classical truth conditions can be derived from contextchange potentials.
3 See Beaver (1992) for a unary presupposition connective ! which is interdefinable with /.

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 614 — #8
614 Handbook of Logic and Language
(i!) [p]+ = {V | V(p) = 1}, [p]) = {V | V(p) = 0}.(ii!) [¬!]+ = [!]), [¬!]) = [!]+.
(iii!) [! + "]+ = [!]+ & ["]+, [! + "]) = [!]) # ([!]+ & ["])).
(iv!) [!/"]+ = [!]+ & ["]+, [!/"]) = [!]+ & ["]).
The connectives ¬ and + are essentially treated as in Peters (1975) here (see alsoKarttunen and Peters, 1979), while / is the so-called transplication of Blamey (1986).An induction on the complexity of ! will show for any C (a) that '!'(C) is defined iffC . [!]+ # [!]) and (b) that '!'(C) = C & [!]+ if '!'(C) is defined. This meansthat Heim’s logic is not essentially dynamic after all, even if its dynamic formulationis certainly natural.
Essentially dynamic operators do exist, however. Let us call a total unary functionF on some power set continuous if it commutes with arbitrary unions of its arguments,i.e. if for any indexed set {Ci | i % I} it holds that #{F(Ci) | i % I} = F(#{Ci | i % I}).Call F introspective if F(C) . C for any C. Van Benthem (1986) shows that these twoproperties give a necessary and sufficient criterion for an operator to be static: F iscontinuous and introspective if and only if there is some P such that F(C) = C &P forall C (see also Groenendijk, Stokhof and Veltman, 1996). This means that an essen-tially dynamic operator must either not be continuous or not be introspective. A keyexample of a non-continuous operator is Venema’s (1991) epistemic might in a theorycalled Update Semantics. A minimal version of Veltman’s system can be obtained bytaking propositional modal logic and interpreting it by adding the following clause to(i)–(iii) above.
' / !'(C) = * if '!'(C) = *,
C otherwise.
The operator helps explain the difference between the acceptability of discoursessuch as (10) and (11).
(10) Maybe it is raining. . . . It is not raining.(11) It is not raining. . . . # Maybe it is raining.
A naive translation into modal logic would make this into the commutative pair /r +¬r, ¬r + /r. But dynamically, there is a difference. In (10) the initial state can stillbe consistently updated with the information that it is raining. Only after the secondsentence is processed is this possibility cut off. In (11), however, the information thatit is not raining has been added at the start, after which the test for possibility ofraining will fail. This modality is no longer a continuous function, and it does notreduce to classical propositions in an obvious way. Nevertheless, there are still strongconnections with classical systems. Van Benthem (1988) provides a translation intomonadic predicate logic computing the update transitions, and Van Eijck and De Vries(1995) improve this to a translation into the modal logic S5, where / behaves like amodality after all. This means that these systems are still highly decidable.
In addition to mere elimination of possibilities the update framework also supportsother forms of movement through its phase space. A phrase like unless !, for instance,

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 615 — #9
Dynamics 615
may call for enlargement of the current state by reinstating those earlier situationswhere ! held. Other plausible revision operators which are not introspective in thesense given above are not hard to come by.
Clearly the picture of updating information that is sketched here, with contextsor information states being flatly equated with sets of valuations, gives an extremelysimplified model of what goes on in actual natural language understanding and it isworthwhile to look for subtler definitions of the notion of information state and foroperations on information states subtler than just taking away possibilities or addingthem. Assertions, for example, may not only change our views as to which things arepossible; they may also upgrade our preferences between possibilities, i.e. change ourviews as to which possibilities are more likely than others. The latter phenomenon maybe represented in terms of preference relations between models, as it is currently done inArtificial Intelligence (Shoham, 1988) in a tradition that derives from Lewis’s possibleworlds semantics for conditional logic (cf. Lewis, 1973; Veltman, 1985). For instance,processing a conditional default rule if A, then B need not mean that any exceptions (i.e.A & not B worlds) are forcibly removed, but rather that the latter are downgraded insome sense. This idea has been proposed in Spohn (1988), Boutilier (1993), Boutilierand Goldszmidt (1993) – and most extensively, for natural language, in Veltman (1991).In the latter system, static operators may model adverbs like presumably or normally,whereas a default conditional leads to a change in expectation patterns. To simplifymatters, in what follows, !, " are classical formulas. States C now consist of a set ofworlds plus a preference order ! over them, forming a so-called expectation pattern.Maximally preferred worlds in such patterns are called normal. Incoming propositionsmay either change the former “factual” component, or the latter (or both). For instance,given C and ! we may define the upgrade C! as that expectation pattern which hasthe same factual component as C, but whose preference relation consists of ! withall pairs 0w, v1 taken out in which we have v |= ! without w |= !.
'normally !'(C) = C! if ! is consistent with some normal world,* otherwise.
'presumably !'(C) = C if ! holds in all maximally preferred situations in C,* otherwise.
A much more complicated explication takes care of the binary operator if !, then " .(Cf. Veltman, 1991, for details, basic theory and applications of the resulting system.)In particular, this paper provides a systematic comparison of the predictions of thissystem against intuitions about natural default reasoning. A more abstract perspectiveon update semantics is provided in Van Benthem, Van Eijck and Frolova (1993), whichalso includes connections with dynamized versions of conditional logic.
12.1.2 Change of Assignments: Heim, Kamp, Groenendijkand Stokhof
A person who is reading a text must keep track of the items that are being introduced,since these items may be referred to again at a later point. The first sentence of text

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 616 — #10
616 Handbook of Logic and Language
(12), for example, requires its reader to set up discourse referents (the term and theidea are from Karttunen, 1976) for the indefinite noun phrases a woman and a cat.The anaphoric pronoun it in the second sentence can then be interpreted as pickingup the discourse referent that was introduced for a cat and the pronoun her may pickup the referent for a woman. Thus, while you are reading, not only the set of sentencesthat you can be assumed to take for granted changes, but your set of discourse referentsgrows as well. This latter growth gives us another example of contextual change.
(12) A woman catches a cat. It scratches her.
There are many semantic theories that use this kind of change to explain thepossibilities and impossibilities of anaphoric linking in natural language. Here weshall briefly discuss three important ones, File Change Semantics (FCS, Heim, 1982,1983b), Discourse Representation Theory (DRT, Kamp, 1981; Kamp and Reyle, 1993;Van Eijck and Kamp, 1996), and Dynamic Predicate Logic (DPL, Groenendijk andStokhof, 1991). The first two of these theories were formulated independently in thebeginning of the eighties, address roughly the same questions and make roughly thesame predictions (see also Seuren, 1975, 1985), the third was formulated at a later timeand differs mainly from the first and second from a methodological point of view.
12.1.2.1 File Change Semantics
The basic metaphor underlying Heim’s theory is a comparison between the reader ofa text and a clerk who has to keep track of all that has been said by means of a file ofcards. Each card in the file stands for a discourse referent and the information that iswritten on the cards tells us what we have learned about this discourse referent thusfar. Reading text (12), for example, the clerk would first have to make a card for theindefinite noun phrase a woman.
x1x1 is a woman
His next step would be to set up a card for a cat. His file now looks as follows.
x1x1 is a woman
x2x2 is a cat
The information that the woman catches the cat is now written upon both cards,
x1x1 is a womanx1 catches x2
x2x2 is a catx2 is caught by x1

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 617 — #11
Dynamics 617
and finally the second sentence is interpreted. It is interpreted as x2 and her is identifiedwith x1. This leads to the following file.
x1x1 is a womanx1 catches x2x1 is scratched by x2
x2x2 is a catx2 is caught by x1x2 scratches x1
In this way our clerk proceeds, setting up a new card for each indefinite noun phrasethat he encounters and identifying each definite noun phrase with a card that wasalready there. A file is said to be true if there is some way of assigning objects to thediscourse referents occurring in it such that all the statements on the cards come outtrue, i.e. a file is true (in a given model) if there is some finite assignment satisfying allthe open sentences in it, it is false if there is no such assignment. In fact, for the pur-poses at hand we can identify a file F with a pair 0Dom(F), Sat(F)1, where Dom(F),the domain of F, is the set of all discourse referents (i.e. variables) occurring in F andSat(F), the satisfaction set of F, is the set of assignments with domain Dom(F) whichsatisfy F. The meaning of a text is now identified with its file change potential, the wayin which it alters the current file. Formally, it is a partial function from files to files.
Texts are connected to their file change potentials via a two-tier procedure inHeim’s system. First, at the level of syntax, the text is associated with its so-called log-ical form. Logical forms are then interpreted compositionally by means of file changepotentials. We shall look at each of these steps in a little detail.
The logical form of a sentence, which may be compared to the analysis tree thatit gets in Montague Grammar, or to its logical form (LF) in contemporary genera-tive grammar is obtained from the syntactic structure of that sentence via three rules.The first, NP Indexing, assigns each NP a referential index. For ease of expositionwe shall assume here that this index appears on the determiner of the noun phrase. Ifwe apply NP Indexing to (14) (which for our purposes we may take to be the surfacestructure of (13)), for instance, (15) is a possible outcome. The second rule, NP Prefix-ing, adjoins every non-pronominal NP to S and leaves a coindexed empty NP behind.A possible result of this transformation when applied to (15) is (16), but another pos-sibility (which will result in the wide scope reading for a cat) is (17). The last rule,Quantifier Construal, attaches each quantifier as a leftmost immediate constituent ofS. Determiners such as every, most and no count as quantifiers in Heim’s system, butthe determiners a and the do not. The result of applying the transformation to (16) is(18) and applying it to (17) gives (19).
(13) Every woman catches a cat,(14) [S[NPevery woman][VPcatches[NPa cat]]],(15) [S[NPevery1 woman][VPcatches[NPa2 cat]]],(16) [S[NPevery1 woman][S[NPa2 cat][Se1 catches e2]]],(17) [S[NPa2 cat][S[NPevery1 woman][Se1 catches e2]]],(18) [Severy[NP–1woman][S[NPa2 cat][Se1 catches e2]]],(19) [S[NPa2 cat][Severy[NP–1woman][Se1 catches e2]]].

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 618 — #12
618 Handbook of Logic and Language
The logical form of a text consisting of sentences S1, . . . , Sn (in that order) willsimply be [T#1 · · · #n], where each of the #i is the logical form of the corresponding Si.For example, (20) will be the logical form of text (12).
(20) [T[S[NPa1 woman][S[NPa2 cat][Se1 catches e2]]][Sit2 scratches her1]].
Logical forms such as (18), (19) and (20) can now be interpreted composition-ally; each will be associated with a partial function from files to files. The small-est building blocks that the interpretation process will recognize are atoms such as[NPa1 woman], [NP–1woman], [Se1 catches e2] and [Sit2 cratches her1], all of the form[xi1Rxi2 · · · xin ], with definite and indefinite determiners, pronouns, empty NPs and thetrace – identified with variables x. We shall assume that indefinite determiners and thetrace – carry a feature [)def] and that the other variables are [+def]. The followingcondition gives us the domain of the file change potential '[xi1Rxi2 · · · xin ]'.
(ia) '[xi1Rxi2 · · · xin ]'(F) is defined iff for each xik (1 ! k ! n):(Novelty) if xik is [–def] then xik /% Dom(F) and(Familiarity) if xik is [+def] then xik % Dom(F).
This requirement, which Heim calls the Novelty/Familiarity Condition, correspondsto the file clerk’s instruction to make a new card whenever he encounters an indefinitenoun phrase but to update an old card whenever he encounters a definite NP.
In order to define what '[xi1Rxi2 · · · xin ]'(F) is in case the Novelty/Familiarityrequirement is met, we suppose that a first-order model M = 0D, I1 that interpretsthe predicates of our language is given and stipulate the following.
(ib) If '[xi1Rxi2 · · · xin ]'(F) is defined thenDom('[xi1Rxi2 · · · xin ]'(F)) = Dom(F) # {xi1 , . . . , xin}Sat('[xi1Rxi2 · · · xin ]'(F)) = {a | dom(a) = Dom(F) # {xi1 , . . . , xin} &2b . a : b % Sat(F) & 0a(xi1), . . . , a(xin)1 % I(R)}.
For example, if we apply '[NPa1 woman]' to the empty file 0*, {*}1, i.e. the filewith empty domain and satisfaction set {*}, we obtain the file with domain {x1} andsatisfaction set (21). If we apply '[NPa2 cat]' to the latter we get (22) as our newsatisfaction set and {x1, x2} as the new domain. Applying '[Se1 catches e2]' to thisfile sets the satisfaction set to (23) and leaves the domain as it is. A last application of'[Sit2 scratches her1]' changes the satisfaction set to (24). Of course this set is non-empty if and only if (25) is true.
(21) {{0x1, d!1} | d! % I(woman)},(22) {{0x1, d!1, 0x2, d!!1} | d! % I(woman) & d!! % I(cat)},(23) {{0x1, d!1, 0x2, d!!1} | d! % I(woman) & d!! % I(cat) & 0d!, d!!1 % I(catches)},(24) {{0x1, d!1, 0x2, d!!1} | d! % I(woman) & d!! % I(cat) & 0d!, d!!1 % I(catches) &
0d!!, d!1 % I(scratches)},(25) 2x1x2(woman x1 + cat x2 + catches x1x2 + scratches x2x1).
Thus by successively applying the atoms of (20) in a left-to-right fashion we haveobtained its satisfaction set and thereby its truth conditions. Indeed, the general rule

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 619 — #13
Dynamics 619
for obtaining the file change potential of two or more juxtaposed elements from thefile change potentials of those elements is simply functional composition.
(ii) '[#1 · · · #n]'(F) = '#1' ( · · · ( '#n'(F).
Note that the interpretation process of (20) would have broken down if [NPa2 cat]would have been replaced by [NPa1 cat] (a violation of the Novelty condition) or if,say, it2 would have been replaced by it6, which would violate Familiarity. Thus someways to index NPs lead to uninterpretability.
With the help of rules (i) and (ii) we can only interpret purely existential texts;universals are treated somewhat differently. While an indefinite makes the domain ofthe current file grow, application of a universal sentence leaves it as it is. On the otherhand, in general it will cause the satisfaction set to decrease. The following definitiongives us the file change potential of a universal sentence.
(iii) Dom('[every #$ ]'(F)) = Dom(F),
Sat('[every #$ ]'(F)) = {a % Sat(F) | 3b 4 a : b % Sat('#'(F)) ,2c 4 b : c % Sat('#' ( '$'(F))}.
Here it is understood that '[every #$ ]'(F) is undefined iff '#'('$'(F) is. Applyingthis rule we can find truth conditions for logical forms (18) and (19): as the reader mayverify, the value of '(18)' applied to the empty file will have a non-empty satisfactionset if and only if (26) is true, and similarly Sat('(19)'(0*, {*}1)) will be non-emptyiff (27) holds. A crucial difference between these two readings is their impact on thedomain of any given file. While Dom('(18)'(F)) will simply be Dom(F) for anyF, Dom('(19)'(F)) will be Dom(F) # {x2}, which makes it possible to pick up thediscourse referent connected with a cat at a later stage in the conversation. And indeed(28) does not violate the Novelty/Familiarity constraint, provided that its first sentenceis analyzed along the lines of (19), not along the lines of (18).
(26) 3x1(woman x1 , 2x2(cat x2 + catches x1x2)).(27) 2x2(cat x2 + 3x1(woman x1 , catches x1x2)).(28) Every1 woman caught a2 cat. The2 cat scratched every3 woman.
Thus rule (iii) predicts that a definite element can only be anaphorically related toan indefinite occurring within the scope of the quantifier every if the definite itself alsooccurs within that scope. If the first sentence of (28) is analyzed as (18), the universalquantifier blocks a coreferential interpretation of a cat and the cat, but in (29) we seethat an anaphoric link between a donkey and it is possible since both elements arewithin the scope of every and, as the reader may verify, the file change potential of(30) is defined and leads to the truth conditions of (31).4
(29) Every farmer who owns a donkey beats it,(30) [Severy[NP[NP–1 farmer][S!who[S[NPa2 donkey][Se1 owns e2]]]][Se1 beats it2]](31) 3x1x2((farmer x1 + donkey x2 + owns x1x2) , beats x1x2).
4 Here 'who' may be interpreted as the identity function.

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 620 — #14
620 Handbook of Logic and Language
(29) of course is one of Geach’s famous “donkey” sentences and its treatmentmay serve to illustrate another important feature of Heim’s system. Since rule (iii)involves a universal quantification over all extensions of the finite assignment asatisfying '#'(F) and since indefinites in # will increase the domain of F, thoseindefinites will all be interpreted universally, not existentially. For a similar reasonindefinites occurring in $ will get an existential interpretation. This explains thechameleontic behavior of indefinites: if they are not within the scope of any operatorthey are interpreted existentially, within the “restrictor” # of a universal quantifieror the antecedent of an implication they behave universally, but occurring within the“nuclear scope” $ of a universal quantifier or within the consequent of an implicationthey are existentials again.
12.1.2.2 Discourse Representation Theory
The basic ideas of Heim’s FCS and Kamp’s Discourse Representation Theory (DRT)are very much the same. While in Heim’s theory the reader or hearer of a text repre-sents the information that he has obtained by means of a file, DRT lets him keep trackof that information with the help of a Discourse Representation Structure (a DRS orbox for short) and, just as a file is defined to be true iff some assignment satisfies allthe open sentences in it, a box is also defined to be true iff it is satisfied by someassignment. Simple DRSs are much like files, be it that all information is written uponone card only. Thus the DRS corresponding to the first sentence of (12) is (32) and thatcorresponding to both sentences is (33). The variables written at the top of these boxesare called discourse referents; the open sentences underneath are called conditions.
(32)
x1 x2
woman x1cat x2
x1 catches x2
(33)
x1 x2
woman x1cat x2
x1 catches x2x2 scratches x1
Boxes such as these are built from the discourses that they represent with the helpof a construction algorithm. Box (32), for instance, can be obtained from the treerepresenting the surface structure of the first sentence in (12) by (a) putting this treein an otherwise empty box and then (b) applying certain rules called constructionprinciples until none of these principles is applicable any longer. Box (33) can then beobtained by extending (32) with a tree for the second sentence of the text and applyingthe construction principles again. A sentence can thus be interpreted as an instruction

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 621 — #15
Dynamics 621
to update the current box, just as in FCS it can be interpreted as an instruction tochange the current file.
Unlike Heim’s files however, boxes can also directly represent universal informa-tion. (34), for instance, is a box that results from applying the construction algorithmto a tree for the surface structure of (13). It contains only one condition, an implicationwhose antecedent and consequent are themselves boxes, and it expresses that any wayto satisfy the condition in the antecedent box can be extended to a way to satisfy theconditions in the consequent.
(34)x1
woman x1"
x2
cat x2x1 catches x2
It would take us far too long to spell out the construction principles that lead to boxessuch as these in any detail here (see Kamp and Reyle, 1993, for these), but it shouldbe mentioned, firstly, that processing an indefinite noun phrase leads to the creationof a new discourse referent, and, secondly, that anaphoric pronouns must be linkedto already existing discourse referents. However, not all existing discourse referentsare accessible to a pronoun that is being processed at some level of embedding inthe DRS. For example, no pronoun may be linked to a discourse referent that existsat some deeper level of embedding, a pronoun in the antecedent of an implicationcannot be linked to a discourse referent in the consequent, and so on. With the helpof such accessibility conditions DRT makes predictions about the possibilities andimpossibilities of anaphoric linking that correspond to the predictions that are madeby FCS by means of the Novelty/Familiarity condition.
While Discourse Representation Structures are being thought of as psychologicallyreal, in the sense that a language user really creates representations analogous to themwhile interpreting a text, they also form the language of a logic that can be inter-preted on first-order models in a more or less standard way. It is handy to linearize thesyntax of this language. The following rules in Backus–Naur Form define the basicconstructs, conditions (% ) and boxes (K), for the core part of DRT.
% :: = Px | x1Rx2 | x1 = x2 | ¬K | K1 - K2 | K1 " K2,
K :: = [x1 · · · xn | %1, . . . , %m].
We can write (33) now more concisely as [x1x2 | woman x1, cat x2, x1 catches x2,
x2 scratches x1] and (34) as [|[x1 |woman x1] " [x2 |cat x2, x1 catches x2]]. These, bythe way, are examples of closed boxes, boxes containing no free discourse referents;5
all boxes that result from the construction algorithm are closed.
5 For the definition of a free discourse referent see Kamp and Reyle (1993).

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 622 — #16
622 Handbook of Logic and Language
The dynamic character of DRT does not only reside in the fact that the theoryinterprets sentences as instructions to change the current discourse representation, it alsomanifests itself in the formal evaluation of these discourse representations themselves.For a discourse representation structure in its turn can very well be interpreted as aninstruction tochange thecurrentcontext, contextsbeing formalizedwith thehelpoffiniteassignments here. Formally, we shall define the value 'K'M of a box K on a first ordermodel M = 0D, I1 (superscripts M will be suppressed) to be a binary relation betweenfinite assignments, the idea being that if 0a, b1 % 'K', carrying out the instruction Kwith a as input may nondeterministically give us b as output.6 The semantic value'% ' of a condition % will simply be a set of finite assignments for the given model.Clauses (i)–(iii) give a compositional definition of the intended meanings;7 in the lastclause we write a[x1 · · · xn]b for “a . b and dom(b) = dom(a) # {x1, . . . , xn}”.
(i) 'Px' ={ a | x % dom(a) & a(x) % I(P)},'x1Rx2' ={ a | x1, x2 % dom(a) & 0a(x1), a(x2)1 % I(R)},'x1 = x2' ={ a | x1, x2 % dom(a) & a(x1) = a(x2)}.
(ii) '¬K' ={ a | ¬2b 0a, b1 % 'K'},'K1 - K2' ={ a | 2b(0a, b1 % 'K1' - 0a, b1 % 'K2')},'K1 " K2' ={ a | 3b(0a, b1 % 'K1' , 2c 0b, c1 % 'K2')}.
(iii) '[x1 · · · xn | %1, . . . , %m]' = {0a, b1 | a[x1 · · · xn]b & b % '%1' & · · · & '%m'}.
A box K is defined to be true in a model M under an assignment a iff the domain of aconsists of exactly those discourse referents that are free in K and there is an assignmentb such that 0a, b1 % 'K'. The reader may verify that the closed box (33) is true in anymodel iff (25) is, and that the truth conditions of (34) correspond to those of (26).
The semantic definition given here differs somewhat from the set-up in Kamp andReyle (1993), but is in fact equivalent, as it is easy to show that a closed box is true inour set-up if and only if it is true in Kamp and Reyle’s. A slightly different semanticsfor DRT is given in Groenendijk and Stokhof (1991). The Groenendijk and Stokhofsemantics is obtained by letting a, b and c range over total assignments in the abovedefinition and letting a[x1 · · · xn]b stand for “a( y) = b( y) for all y /% {x1, . . . , xn}”. Inlater sections we will refer back to this definition as to the total semantics for DRT.
We have seen that DRT does not only predict certain possibilities of anaphoriclinking, but, like Heim’s FCS, also assigns truth conditions to the discourses thatit considers. Both theories, moreover, to a certain extent fit within the frameworkof semantics that was laid out by Richard Montague in his “Universal Grammar”(Montague, 1970). Both first replace the constructs of ordinary language by a “dis-ambiguated language”, which is the language of logical forms in Heim’s theory andthe language of conditions and boxes in Kamp’s case. The relation that connectsordinary language and unambiguous language (Montague’s R) is given by a set oftransformations in Heim’s theory and a construction algorithm in Kamp’s DRT. In
6 The first author to describe the dynamic potential of a discourse as a relation between finite variableassignments was Barwise (Barwise, 1987), a paper which was presented at CSLI in the spring of 1984and at the Lund meeting on generalized quantifiers in May 1985.
7 The definition is formally equivalent to the one given in Kamp and Reyle (1993) but its form is inspiredby the discussion in Groenendijk and Stokhof (1991). See especially Definition 26 of that paper.

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 623 — #17
Dynamics 623
both cases the “disambiguated language” can be interpreted in a fully compositionalway with the help of first-order models and assignments for these models.
12.1.2.3 Dynamic Predicate Logic
In an attempt to make the Kamp/Heim theory of discourse anaphora look even morelike a conventional Montagovian theory, Jeroen Groenendijk and Martin Stokhofhave published an alternative formulation called Dynamic Predicate Logic (DPL,Groenendijk and Stokhof, 1991), which offers a dynamic interpretation of the formu-lae of ordinary predicate logic and gives an interesting alternative to the Kamp/Heimapproach.
The usual Tarski truth definition for predicate logic provides us with a three-placesatisfaction relation |= between models, formulae and assignments and we can identifythe meaning of a formula in a model with the set of assignments that satisfy it in thatmodel. But here too, the definition can be generalized so that the meaning of a formulais rendered as a binary relation between (total) assignments. The DPL definition runsas follows (we write a[x]b for “a(y) = b(y) for all y 5= x”).
(i) 'R(x1, . . . , xn)' = {0a, a1 |0 a(x1), . . . , a(xn)1 % I(R)},'x1 = x2' = {0a, a1 | a(x1) = a(x2)}.
(ii) '¬!' = {0a, a1 | ¬2b 0a, b1 % '!'},'! - "' = {0a, a1 |2 b(0a, b1 % '!' - 0a, b1 % '"')},'! , "' = {0a, a1 |3 b(0a, b1 % '!' , 2c 0b, c1 % '"')},'! + "' = {0a, c1 |2 b(0a, b1 % '!' & 0b, c1 % '"')}.
(iii) '2x!' = {0a, c1 |2 b(a[x]b & 0b, c1 % '!')},'3x!' = {0a, a1 |3 b(a[x]b , 2c 0b, c1 % '!')}.
A formula ! is defined to be true under an assignment a if 0a, b1 % '!' for someassignment b. Note that '¬!' is given as the set of those 0a, a1 such that ! is not trueunder a, '! - "' as those 0a, a1 such that either ! or " is true under a. But the clausefor implication is close to the corresponding DRT clause and conjunction is treated asrelational composition.
The value of 2x! is in fact given as the relational composition of {0a, b1 | a[x]b}(random assignment to x) and the value of !; and 3x! is treated as ¬2x¬!. Operatorsthat have a semantics of the form {0a, a1 | · · · } are called tests.
By the associativity of relational composition we immediately see that 2x! + " isequivalent to 2x(! + ") in this set-up, even if x is free in " , and this enables Groe-nendijk and Stokhof to propose the following straightforward translation of text (12).
(35) 2x1x2(woman x1 + cat x2 + catches x1x2) + scratches x2x1.
The first conjunct of this formula clearly corresponds to the first sentence of thetext that is formalized, the second conjunct to the second sentence. But unlike in ordi-nary predicate logic, (35) is equivalent with (26), and since it is provable that truthconditions in DPL and ordinary logic correspond for closed sentences, the text gets theright truth conditions. In a similar way, since 2x! , " is equivalent with 3x(! , "),as the reader may verify, (29) can be rendered as (36), which is equivalent with (37)and hence with (31).

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 624 — #18
624 Handbook of Logic and Language
(36) 3x1((farmer x1 + 2x2(donkey x2 + owns x1x2)) , beats x1x2).(37) 3x1(2x2(farmer x1 + donkey x2 + owns x1x2) , beats x1x2).
Thus it is possible to give rather straightforward translations of texts into predicatelogical formulae in DPL, while at the same time accounting for the possibility ofanaphora between a pronoun and an indefinite in a preceding sentence, or betweena pronoun in the consequence of an implication and an indefinite in the antecedent.Anaphoric linking is predicted to be impossible if any test intervenes. This conformsto the predictions that are made by Kamp and Heim’s theories.
Extensions of DPL to dynamic theories of generalized quantifiers have been pro-posed (Chierchia, 1988; Kanazawa, 1993b; Van der Does, 1992; Van Eijck and DeVries, 1992), and extensions to full type theories have been achieved in the DynamicMontague Grammar of Groenendijk and Stokhof (1990), and the Compositional DRTof Muskens (1991, 1994, 1995a,b) (see also Section 12.2.3.3). Extensions such asthese raise the issue of systematic strategies of dynamization for existing systems ofstatic semantics, which would somehow operate uniformly, while transforming thetraditional semantic theory in systematic ways. For instance, in dynamic accounts ofgeneralized quantifiers, a key role has been played by the fate of the Conservativityand Monotonicity principles that play such a prominent role in the standard theory(cf. Keenan and Westerståhl, 1996).
Several variations have been investigated for the basic DPL framework. For instance,Van den Berg (1995) proposes a three-valued partial version, in which new operatorsappear (cf. also Beaver, 1992; Krahmer, 1995). This system allows for a distinctionbetween “false” transitions, such as staying in a state where an atomic test has failed, andmerely “inappropriate” ones, such as moving to a different state when testing. A moreradical partialization, using analogies with partial functions in Recursion Theory, hasbeen proposed in Fernando (1992). This will allow for a natural distinction betweenre-assignment to an old variable and pristine assignment to a new variable. Versionswith still richer accounts of data structures, and thereby of the dynamic function ofpredicate-logical syntax, may be found in Visser (1994), Vermeulen (1994).
12.1.2.4 Integrating Dynamic Predicate Logic and Update Semantics
Natural language involves different dynamic mechanisms. For instance, DRT and DPLhighlight changing anaphoric bindings, whereas Veltman’s Update Semantics (US),described in Section 12.1.1 focuses on information flow and epistemic statementsabout its stages. Obviously, a combination of the two is desirable. There have beensome technical obstacles to this endeavor, however, in that the two systems have dif-ferent flavors of implementation. DPL involves an algebra of binary relations overassignments, and US rather a family of functions operating on sets of valuations. Var-ious proposals have been made for a mathematical unification of the two, but the mostsophisticated attempt is surely Groenendijk, Stokhof and Veltman (1996). The latterpaper takes its empirical point of departure in the linguistic evidence which normallydrives modal predicate logic. Here is a typical example. Consider the pair of sentences
(38) A man who might be wearing a blue sweater is walking in the park.(39) A man is walking in the park. He might be wearing a blue sweater.

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 625 — #19
Dynamics 625
The relative clause in the first discourse expresses a property of the man introducedin the main clause: what we learn is that he might be wearing a blue sweater. Butintuitively, Groenendijk, Stokhof and Veltman argue, this is not the function of thesecond sentence in the second discourse. The latter rather serves to express the pos-sibility that some discourse individual introduced in the antecedent sentence mightbe wearing a blue sweater. A combined dynamic semantics will have to accountfor this. Since these two discourses are equivalent in standard DPL, some essentialdeparture is needed from the latter system, in which antecedent existentials need nolonger scope over free variables in succedents. The combined semantics is a moresophisticated follow-up to that of Van Eijck and Cepparello (1994), employing so-called “referent systems” from Vermeulen (1994). In particular, the new informa-tion states consist of three components, namely: (1) an assignment of variables to“pegs” (discourse individuals; as in Landman, 1986), (2) an assignment of pegs toindividuals in some standard domain, (3) a set of possible worlds over that domain(encoding the current range of descriptive uncertainty). Updating will now combineseveral processes: such as elimination of possibilities and enrichment of assignments.One noticeable feature of this approach is its treatment of the existential quantifier.In DPL, 2x is essentially a single instruction for performing a random assignment.Thus, in the current setting, it would denote an enrichment for a given state so as toinclude every possible assignment of objects to (the peg associated with) the vari-able x. A compound formula 2x! will then denote the composition of this movewith the ordinary update for !. But this account will yield unintuitive results on amodal statement like 2x / Px: the resulting state may still contain assignments to xdenoting objects which cannot have the property P. Therefore, the new proposal isto make 2x! a syncategorematic operation after all, whose update instruction is asfollows: “Take the union of all actions x := d ; ! for all objects d in the domain”.This will make an update for 2x / Px end up with x assigned only to those objectswhich have P in some available possible world. In this richer setting, one can alsoreview the vast semantic evidence surrounding the usual puzzles of modality andidentity in the philosophical literature, and propose a dynamic cut on their solution.(Groenendijk, Stokhof and Veltman, 1996, contains further innovations in its discus-sion of consistency and discourse coherence, which we must forego here.) Whatevertechnical theory exists for this paradigm is contained in this single reference (but cf.Cepparello, 1995).
12.1.3 Change of Attentional State: Grosz and Sidner
Discourse Representation Theory models the way in which anaphoric elements canpick up accessible discourse referents, it tells us which referents are accessible at anygiven point of discourse, but it tells us little about the question which referent must bechosen if more than one of them is accessible. There are of course obvious linguisticclues that restrict the range of suitable antecedents for any given anaphoric element,such as the constraint that antecedent and anaphoric element must agree in genderand number, but it is also believed that the structure of discourse itself puts importantfurther constraints on the use of referring expressions.

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 626 — #20
626 Handbook of Logic and Language
Thus theories of discourse structure, such as the ones discussed in Polanyi (1985),Scha and Polanyi (1988), Grosz and Sidner (1986), are a natural complement to thetheories discussed in Section 12.1.2. Since these discourse theories are also goodexamples of dynamic modeling of natural language phenomena in linguistics, we shallhave a closer look at one of them here. Of the theories mentioned, we shall chooseGrosz and Sidner’s, being the one that is most explicitly dynamic.
Grosz and Sidner distinguish three parts of discourse structure. The first of these,called linguistic structure, consists of a segmentation of any given discourse in vari-ous discourse segments. Experimental data suggest that a segmentation of this kind ispresent in discourses. Speakers, when asked to segment any given discourse, seem todo so more or less along the same lines. Moreover, the boundaries that are drawn bet-ween segments correspond to speech rate differences and differences in pause lengthswhen the text is read out aloud. There are also certain clue words that signal a dis-course boundary. For example the expressions “in the first place”, “in the secondplace” and “anyway” are such clues. Changes in tense and aspect also indicate dis-course boundaries.
In Figure 12.1 a segment of a dialog between an expert (E) and an apprentice (A)is given and factored into further discourse segments. Each segment comes with a dis-course segment purpose (DSP). The expert wants the apprentice to remove a flywheeland this, or rather DSP1 in Figure 12.2, is the purpose of the discourse segment asa whole. The apprentice adopts the intention to remove the flywheel, but in order todo this must perform certain subactions such as loosening screws and pulling off thewheel. In order to loosen the screws, he must first locate them, and, as it turns out thathe can only find one, DSP2 is generated. This intention is connected to a discoursesegment (DS2) that consists of utterances (e) to (k).
In the same manner two other discourse segment purposes that are connected tosubtasks of the apprentice’s task of removing the wheel come up, DSP3 and DSP4,and both intentions give rise to the creation of discourse segments (DS3 and DS4).The last, moreover, invokes DSP5 as a response from the expert, an intention relatedto DS5.
One discourse segment purpose may dominate another in the sense that satisfyingthe second segment’s purpose provides part of the satisfaction of the first segment’spurpose. For example, DSP4 in our example dominates DSP5. It may also occur thatthe satisfaction of one discourse segment purpose must precede another; it is thensaid to satisfaction-precede it. For example, since DSP2 and DSP3 both contribute toloosening the setscrews, DSP4 contributes to pulling off the wheel and, since world-knowledge tells us that the screws must be loosened before the wheel can be pulledoff, it can be inferred that DSP2 and DSP3 satisfaction-precede DSP4. The relations ofdominance and satisfaction-precedence constitute the second part of discourse struc-ture which is identified by Grosz and Sidner, the intentional state. The intentional stateconnected with the discourse segment in Figure 12.1 consists of the seven statementsgiven in Figure 12.3.
The third and last part of discourse structure, attentional state, is the part thatis most truly dynamic. It consists of a stack of focus spaces containing the objects
“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 627 — #21
Dynamics 627
(a) E: First you have to remove the flywheel.(b) A: How do I remove the flywheel?(c) E: First, loosen the two Allen head setscrews holding it to the shaft, then pull it off.(d) A: OK.(e) I can only find one screw. Where’s the other one?(f) E: On the hub of the flywheel.(g) A: That’s the one I found. Where’s the other one?(h) E: About ninety degrees around the hub from the first one.(i) A: I don’t understand. I can only find one. Oh wait, yes I think I was on the wrong wheel.(j) E: Show me what you are doing.(k) A: I was on the wrong wheel and I can find them both now.
(l) The tool I have is awkward. Is there another tool that I could use instead?(m) E: Show me the tool you are using.(n) A: OK.(o) E: Are you sure you are using the right size key?(p) A: I’ll try some others.(q) I found an angle I can get at it.
(r) The two screws are loose, but I’m having trouble getting the wheel off.(s) E: Use the wheelpuller. Do you know how to use it?(t) A: No.(u) E: Do you know what it looks like?(v) A: Yes.(w) E: Show it to me please.(x) A: OK.(y) E: Good. Loosen the screw in the center and place the jaws around the hub of the wheel, then tighten the screw onto the center of the shaft. The wheel should slide off.
DS2
DS3
DS4DS5 DS1
Figure 12.1 A segment of a task oriented dialog.
DSP1: E intends A to intend to remove the flywheelDSP2: A intends E to intend to tell him the location of the other setscrewDSP3: A intends E to intend to show him another toolDSP4: A intends E to intend to tell him how to get off the wheel DSP5: E intends A to know how to use the wheelpuller
Figure 12.2 Discourse Segment Purposes connected to task oriented dialog.
DSP1 dominates DSP2DSP1 dominates DSP3DSP1 dominates DSP4DSP4 dominates DSP5
DSP2 satisfaction-precedes DSP3DSP2 satisfaction-precedes DSP4DSP3 satisfaction-precedes DSP4
Figure 12.3 Intentional structure for the task oriented dialog.

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 628 — #22
628 Handbook of Logic and Language
!setscrewsflywheelDSP1 FS1
screw1screw2DSP2 FS2
setscrewsflywheelDSP1 FS1
Allen wrenchkeysDSP3 FS3
setscrewsflywheelDSP1 FS1
setscrewsflywheelDSP4 FS4
wheelpullerDSP5
FS5
setscrewsflywheelDSP1 FS1
! !
Figure 12.4 Focus stack transitions leading up to utterance (y).
(discourse referents), properties, relations and discourse purposes that are salient atany given moment. Each focus space is connected to a discourse segment and con-tains its purpose. The closer a focus space is to the top of the stack, the more salientthe objects in it are. Anaphoric expressions pick up the referent on the stack that ismost salient, so if more than one focus space on the stack would contain, say, a pinkelephant, then the definite description the pink elephant would refer to the elephantrepresented in the space that is nearer to the top of the stack.
Change is brought about by pushing and popping the stack. Entering a discoursesegment causes its focus space to be pushed onto the stack and leaving a segmentcauses its space to be popped. In Figure 12.4 a series of stacks leading up to theutterance in (y) is given. Note that the theory predicts that in DS5 no reference tothe Allen wrench is possible: its discourse referent was contained in FS3, which ispopped from the stack at the time that DS5 is processed. Note also that the nounphrase the screw in the center refers to a screw on the wheelpuller, not to one of thetwo setscrews. Since the wheelpuller is in the focus space on top of the stack at themoment this noun phrase is uttered, its central screw is chosen as a referent instead ofone of the setscrews that are in a lower focus space.
Two similarities strike us when we consider the Grosz and Sidner model of dis-course. First there is a strong resemblance between the structure that the model assignsto ordinary discourse and the structure of programs in an imperative language such asPASCAL. The nested discourse segments of Figure 12.1 remind us of the nested loopsand subloops that we find in a typical program. We can also compare the nested struc-ture with the structure of procedures calling subroutines, which may in their turn alsocall subroutines etc. In this case the stack of focus spaces which constitutes attentionalstate finds its equivalent in the computer stack.
A second similarity that is to be noted is that between the structure of discourseand the structure of proofs in a natural deduction system. The discourse segments inFigure 12.1 here compare to those fragments of a proof that start with the adoptionof an assumption and end when that assumption is discharged. The purpose of such asegment may perhaps be compared with the conclusion it is intended to establish andthere is a clear notion of satisfaction-precedence since one such segment may need the

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 629 — #23
Dynamics 629
conclusion of another. That there is also a natural connection to the concept of a stackwill be shown in the next section where we shall discuss the semantics of proofs.
12.1.4 Change of Assumptions: Intuitionistic Propositional Logic inZeinstra’s Style
Douglas Hofstadter, in his delightful work (Hofstadter, 1980), gives an expositionof natural deduction systems using the idea of fantasies. Making an assumption is“pushing into fantasy”, discharging one is “popping out of fantasy” in his terminology.Hofstadter’s system has explicit push and pop operators, “[” and “]” respectively, anda simple derivation looks as follows.
[ push into fantasy,p assumption,¬¬p double negation rule,] pop out of fantasy.
The next step in this derivation would be an application of detachment (the “fantasyrule” in Hofstadter’s words) to obtain p , ¬¬p. It is usual of course to distinguishbetween the latter (object level) sentence and the (metalevel) derivation given above,which we shall write in linear form as ([p, ¬¬p]). For some purposes, however, onemight want to have a system in which the distinction between metalevel entailmentand object level implication is not made. Consider the following pair of texts.
(A) Suppose x > 0. Then x + y > 0.(B) If x > 0, then x + y > 0.
The assertive production of (A) can be described as follows. First an assumption isintroduced. Then a conclusion is drawn from it (possibly in combination with infor-mation derived from preceding text). Finally there is the hidden act of canceling theassumption. The assertion of (B), on the other hand, on the classical account does notinvolve introducing, canceling, etc. It is simply an utterance with assertive force ofa sentence. What, then, are we to do with the strong intuition that (A) and (B) are“assertively equivalent”?
The intuition that (A) and (B) should be treated on a par motivated Zeinstra (1990)to give a semantics for a simple propositional system which bases itself upon Hofs-tadter, has explicit push and pop operators, but retains the equivalence. The assertiveutterance of a sentence is viewed – quite in the spirit of the more general dynamicprogram – as consisting of a sequence of all kinds of acts, and an utterance of if istaken as being just a variant of an utterance of suppose. Before we give an expositionof Zeinstra’s logic, let us rehearse the Kripke semantics for the {$, +, ,} fragment ofintuitionistic propositional logic (IPL[$, +, ,]), as Zeinstra’s system can be viewedas an extension of the latter. A model K for this logic is a triple 0W, !, V1 such that – inthe present set-up – W, the set of worlds, contains the absurd world T; the relation !is a reflexive and transitive ordering on W, such that w ! T for all w % W; and V

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 630 — #24
630 Handbook of Logic and Language
is a function sending propositional letters to subsets of W such that (a) w % V(p)
implies w! % V(p) if w ! w! and (b) T % V(p) for each propositional letter p. Therelation w |=K ! (! is true on a model K = 0W, !, V1 in a world w % W) is definedinductively as follows (we suppress subscripts K).
(i) w |= p iff w % V(p), for propositional letters p,(ii) w |= $ iff w = T ,
(iii) w |= ! + " iff w |= ! and w |= " ,(iv) w |= ! , " iff 3w! 6 w : w! |= ! " w! |= " .
The language of Zeinstra’s logic is given by the following Backus–Naur Form.
! :: = p | $| ] | [ | (!1, !2) | !1; !2.
Here p stands for arbitrary propositional letters, $ is the falsum, ] and [ are the pop andpush operators we have met before, (!, ") is to be read as !, hence " , and the semi-colon is our sign for conjunction. We prefer the latter over the more conventional +since its semantics will be relational composition as in Groenendijk and Stokhof’s sys-tem, not intersection or meet as in standard logic. We usually write !" for ! ; " . Sincethe negation ¬! of a formula ! can be considered to be an abbreviation of ([!, $])the toy derivation in Hofstadter’s system given above can now indeed be representedas ([p, ¬¬p]) or ([p, ([([p, $]), $])]). The latter are examples of formulae in whichthe push and pop brackets are well-balanced, but in general no such condition need beimposed.
Kripke’s semantics for IPL provides us with good candidates for the explicationof Hofstadter’s fantasies: fantasies are worlds. Since fantasies can be nested, weneed stacks (sequences) of worlds for our semantics. For stacks & = 0w1, . . . , wn1 wedemand that wi ! wi+1, for all i < n, i.e. worlds that are higher in a stack, are alsohigher in the underlying model. We write Last(0w1, . . . , wn1) to refer to wn and wewrite & !1 ' if & = 0w1, . . . , wn1 and ' = 0w1, . . . , wn, w1, i.e. if ' is a possibleresult of pushing the stack & . The meaning '!' of a formula ! in Zeinstra’s languageis a binary relation between stacks of worlds in a Kripke model K, defined with thehelp of the following clauses.
(i) &'p'' iff & = ' and Last(& ) % V(p), for propositional p,(ii) &'$'' iff & = ' and Last(& ) = T ,
(iii) &' [ '' iff & !1 ' ,(iv) &' ] '' iff ' !1 & ,(v) &'(!, ")'' iff 2((&'!'( & ('"'' ) and 3((&'!'( " 2)('"')),
(vi) &'!; "'' iff 2((&'!'( & ('"'' ).
Truth is defined just as it was done in Discourse Representation Theory or in Dyna-mic Predicate Logic: in terms of the domain of the given relation. Formally, we writeK, & |= ! if &'!'' for some stack ' .
As an example of how this semantics works consider the formula ([p, q]). We have:
&'([p, q])'' iff 2((&'[p'( & ('q]'' ) and 3((&'[p'( " 2)('q]')),
iff & = ' and 3((&'[p'( " 2)('q]')),

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 631 — #25
Dynamics 631
iff & = ' and 3( "1 & (( |= p " ( |= q),
iff & = ' and 3w " Last(& )(w |= p " w |= q),
iff & = ' and Last(& ) |= p , q.
The first equivalence is an instantiation of clause (v), the second follows since therequired ( in 2((&'[p'( & ('q]'' ) can simply be & extended with T , and the lasttwo equivalences are simple consequences of the definitions. It may amuse the readerto try her hand at ([p[q, r]s]).
The equivalence given above shows a connection between the formula ([p, q])in Zeinstra’s language and the implication p , q in IPL and indeed there is amore systematic connection between the two logics. Let (·)( be the translation ofIPL[$, +, ,] into Zeinstra’s language such that (p)( = p for all propositional p,
($)( = $, (! + ")( := !(; "(, and (! , ")( = ([!(, "(]). Then K, 0w1 |= !(
iff w |=K !, for all formulae in IPL[$,+, ,], as the reader may care to verify. Buta converse holds as well since Zeinstra has shown that for all formulae ! in her lan-guage such that the pop and push operators ] and [ are well-balanced in ! there is anIPL[$,+, ,] formula !! such that K, 0w1 |= ! iff w |=K !! for any K and w.
In essence then, the logic contains a fragment of well-balanced formulae whichis equivalent to IPL[$,+, ,] and in which there is no longer a distinction betweenimplication and entailment. But the logic is a true extension of that fragment, as italso gives a semantics for formulae that are not well-balanced. The latter correspondto almost arbitrary segments of proofs in which assumptions may be made withoutdischarging them and where even pops may occur without the corresponding pushes.
12.1.5 Change of Beliefs: Gärdenfors’ Theory of Belief Revision
Let us return to the Stalnaker–Karttunen theory of presuppositions temporarily andask ourselves what will happen when a speaker utters a sentence A that carries a pre-supposition B which the hearer in fact does not take for granted. In many cases noproblem will arise at all, because the very utterance of A will tell the hearer that B ispresupposed by the speaker and the hearer may tacitly add B to his stock of beliefs or,in any case, he may pretend to do so. This process, which is called accommodation inLewis (1979), allows a presupposition to spring into existence if it was not there whenthe sentence requiring it was uttered. But what if the required presupposition cannotbe accommodated because it is not consistent with the hearer’s existing set of beliefs?Karttunen (1973) remarks that this problem is reminiscent of a problem that arises inconnection with conditionals. An influential theory about the evaluation of the latter,first proposed by Ramsey (1929), and later formalized in Stalnaker (1968) and Lewis(1973), wants you to hypothetically add the antecedent of a conditional to your stockof beliefs. If it turns out that the consequent of the conditional follows from this newset of beliefs, you may conclude that the conditional itself is true. Again the problemarises how consistency can be maintained. Disbelieving the antecedent of a counter-factual should not necessarily lead to acceptance of the counterfactual itself, simplybecause adding the antecedent to your stock of beliefs would lead to inconsistency.

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 632 — #26
632 Handbook of Logic and Language
This means that some beliefs must be given up (hypothetically) before the (hypothet-ical) addition can take place. But not all ways to discard beliefs are equally rational;for instance, you do not want to end up with a proper subset of some set of beliefs thatis consistent with the antecedent.
Of course the question how beliefs can be given up and how opinions can be revisedrationally in the light of new evidence is a general one. The problem is central to aninteresting research line that was initiated by Peter Gärdenfors and that is exemplifiedby papers such as Makinson (1985), Gärdenfors (1988), Gärdenfors and Makinson(1988), Rott (1992). Suppose we have a set of beliefs K, which we may for presentpurposes take to be a deductively closed theory of predicate logic, and a new insight! (a predicate logical sentence) and suppose we revise K in the light of !, obtaininga new theory K7!. What are the properties that K7! should conform to? Gärdenforsgives eight postulates. Writing K + ! for {" | K, ! 8 "} (the expansion of K by !),he demands the following.
(71) K7! is deductively closed,(72) ! % K7!,(73) K7! . K + !,(74) If K + ! is consistent then K + ! . K7!,(75) K7! is consistent if {!} is consistent,(76) If ! is equivalent with " then K7! = K7" ,(77) K7! + " . (K7!) + " ,(78) If (K7!) + " is consistent then (K7!) + " . K7! + " .
We can think of the first of these postulates as being merely a matter of technicalconvenience: it allows us to formulate principles about K7! instead of principles aboutits deductive closure. Postulates (72)–(76) seem reasonable in view of the intendedmeaning of K7!: (72) states that after revising K in the light of ! we should come tobelieve !, (73) and (74) that revising in the light of ! is just adding ! to one’s set ofbeliefs, if this can be done consistently, (75) is the requirement that consistency shouldbe maintained if at all possible and (76) demands that K7! depends on the contentrather than on the form of !. Principles (77) and (78) are supplementary postulatesabout iterated revisions, the idea being that K7! + " ought to be the same as theexpansion of K7! by " , as long as " does not contradict the beliefs in K7!.
Gärdenfors also considers the process of giving up a belief, i.e. subtracting somebelief ! from a set of beliefs K. The result K ·)!, the contraction of K with respect to!, should conform to the following axioms.
(·)1) K ·)! is deductively closed,(·)2) K ·)! . K,
(·)3) If ! /% K then K ·)! = K,(·)4) If ! % K ·)! then 8 !,(·)5) K . (K ·)!) + !,(·)6) If ! is equivalent with " then K ·)! = K ·)" ,

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 633 — #27
Dynamics 633
(·)7) (K ·)!) & (K ·)") . K ·)(! + "),(·)8) If ! /% K ·)(! + ") then K ·)(! + ") . K ·)!.
Again, motivations for the basic postulates (·) 1)–(·) 6) follow readily from theintended meaning of ·). For a motivation of the (supplementary) postulates (·)7) and(·)8) see Gärdenfors (1988).
The operations 7 and ·) are not unrelated, as revising in the light of ! can in factbe thought to consist of two operations, namely first contracting with respect to thenegation of ! and then adding ! itself. Conversely, we may define the contractionwith respect to ! as the set of those of our original beliefs that would still hold after arevision in the light of the negation of !.
(Def L) K7! := (K ·)¬!) + ! (Levi Identity).(Def H) K ·)! := K & K7¬! (Harper Identity).
Write L(·)) for the revision function obtained from ·) by the Levi identity and H(7)for the contraction function obtained from 7 by the Harper identity. The followingtheorem (see Gärdenfors, 1988) connects revisions and contractions and states theduality of L and H.
Theorem 12.1.1.
(i) If 7 satisfies (71)–(78) then H(7) satisfies (·)1)–(·)8),(ii) If ·) satisfies (·)1)–(·)8) then L(·)) satisfies (71)–(78),
(iii) If 7 satisfies (71)–(76) then L(H(7)) = 7,(iv) If ·) satisfies (·)1)–(·)6) then H(L(·))) = ·) .
In fact this theorem can be generalized to some degree since the number 8 canbe replaced uniformly by 6 or 7 in each of the first two clauses. This is satisfac-tory as in both sets of postulates the first six seem to give some very general prop-erties of the concept under investigation, while the last two in particular pertain toconjunctions.
It is one thing to give a set of postulates for a concept and another to give structureswhich satisfy them. One need not go as far as Russell, who said that the method ofpostulation has “the advantages of theft over honest toil” (the quote is from Makinson,1985), to feel that an abstract set of postulates should be complemented with moreexplicit constructions if at all possible. But there are many ways to obtain constructssatisfying the Gärdenfors postulates and we shall consider three of them. The firstconstruction – from Alchourrón, Gärdenfors and Makinson (1985) – takes K ·)! tobe the intersection of some maximal subsets of K that fail to imply !. More precisely,let K$! (K less !) be the set of all such maximal subsets, i.e. the set {X . K |X ! ! & 3Y(X . Y . K & Y ! ! " X = Y)}, and let % be a function suchthat % (K$!) 5= *, % (K$!) . K$! if K$! 5= * and % (K$!) = {K} otherwise.Then the partial meet contraction K ·)! can be defined as &% (K$!). The followingrepresentation theorem holds.

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 634 — #28
634 Handbook of Logic and Language
Theorem 12.1.2. The operation of partial meet contraction satisfies (·)1)–(·)6). Con-versely, any operation that satisfies (·) 1)–(·) 6) is itself a partial meet contractionoperation.
The theorem can be extended to a representation theorem for (·)1)–(·)8) by placingextra conditions on % . Of course, the Levi identity also allows us to obtain an operationof partial meet revision from the operation of partial meet contraction. This operationthen satisfies (71)–(76), or (71)–(78) if extra conditions are added.
Another way to construct a contraction function makes use of the notion ofepistemic entrenchment. Giving up some beliefs will have more drastic consequencesthan giving up others and consequently some beliefs have preferential status over oth-ers. Write ! ! " (" is at least as epistemologically entrenched as !) if ! and " areboth logical truths (and hence cannot be given up), or if ! is not believed at all, or if aneed to give up one of ! or " will lead to discarding ! (or both). It seems reasonableto demand the following.
(EE1) If ! ! " and " ! * , then ! ! * ,(EE2) If ! 8 " then ! ! " ,(EE3) ! ! ! + " or " ! ! + " ,(EE4) If K is consistent then ! /% K iff ! ! " for all " ,(EE5) If ! ! " for all ! then 8 " .
Transitivity of ! (EE1) must be required if ! is to be an ordering relation. If !
entails " , then " cannot be given up without giving up !, whence (EE2). Since achoice between giving up ! or ! + " is in fact a choice between giving up ! or " ,(EE3) in fact states that ! ! " or " ! !, a natural requirement. (EE4) identifies thesentences that are not believed with those that are least entrenched and the last require-ment says that only logically valid sentences are maximal in !, i.e. that anything canbe given up, logical truths excepted.
Given a contraction relation we can define a relation of epistemic entrenchmentwith the help of (C) below. Conversely, supposing that an entrenchment relation ! isgiven, then (E) defines a contraction relation in terms of it. (“! < "” is defined as“! ! " and not " ! !”.)
(C) ! ! " iff ! /% K ·)(! + ") or 8 ! + " .(E) K ·)! = K & {" | ! < ! - "} if ! !,
= K otherwise.
Write C(!) for the contraction function obtained from ! by (C) and E(·)) for the rela-tion of epistemic entrenchment obtained from ·)by def (E). The following representa-tion theorem is proved in Gärdenfors and Makinson (1988).
Theorem 12.1.3.
(i) If ! satisfies (EE1)–(EE5) then C(!) satisfies (·)1)–(·)8).(ii) If ·) satisfies (·)1)–(·)8) then E(·)) satisfies (EE1)–(EE5).
(iii) If ! satisfies (EE1)–(EE5) then E(C(!)) = !.(iv) If ·) satisfies (·)1)–(·)8) then C(E(·))) = ·).

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 635 — #29
Dynamics 635
A third way to construct operations satisfying the Gärdenfors postulates that wewant to mention is the oldest of them all and in fact precedes the formulation of thepostulates themselves. Gärdenfors (1988) notes that the probability functions that wefind in the Bayesian tradition provide us with the necessary material to construct suchoperations. For example, the conditional probability functions axiomatized in Popper(1959) immediately give us revision functions satisfying (71)–(78) above and again arepresentation theorem can be proved. For more details and a careful discussion seeGärdenfors (1988).
12.2 Logical Observations
12.2.1 General Dynamic Logic
Dynamic semantics provides a fresh look at most aspects of logical theory. In thissection we shall use the paradigm of Dynamic Logic (Goldblatt, 1987; Harel, 1984;Harel and Kozen, 1994; Pratt, 1976), broadly conceived, and twisted to suit our pur-poses wherever this is needed, for bringing out some of these. To appreciate whatfollows, there is a useful analogy with Generalized Quantifier Theory (cf. Keenan andWesterståhl, 1996): Dynamic Logic provides a broad logical space for dynamic oper-ators and inference and this logical space may be contrasted fruitfully with the empir-ical space of what we find realized in natural language and human cognition. But themost fruitful analogy is the earlier one of the Introduction. Dynamic semantics hasmany counterparts in computer science, for obvious reasons. There are striking sim-ilarities between variable binding mechanisms in programming languages and whatis currently being proposed for natural language. Similar observations may be madeabout Artificial Intelligence; witness the parallels in the study of default reasoningbetween Veltman (1991), Boutilier (1993), Boutilier and Goldszmidt (1993), and VanBenthem, Van Eijck and Frolova (1993). For our current purposes, we wish to empha-size the richer process theory available in the computational literature. We hope that,eventually, natural language semantics will come up with a similar refined view of itsdynamic structures.
12.2.1.1 Dynamic Logic
The expressions of Propositional Dynamic Logic (PDL) are divided into two cate-gories: the category of formulae, which form the static part of the language, and thecategory of programs, the truly dynamic part. But formulae can be constructed fromprograms and vice versa, so that there is an active interplay between the two parts.The following Backus–Naur Form defines formulae (!) and programs (+) from basicpropositional letters (p) and atomic programs (,).
! ::= p | $| !1 , !2 | [+ ]!,
+ ::= , | !? | +1; +2 | +1 # +2 | +7.
The intuitive meaning of [+]! is the statement that ! will be true after any suc-cessful execution of + . A test program !? tests whether ! is true, continues if it is,

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 636 — #30
636 Handbook of Logic and Language
but fails if it is not. The sequence +1; +2 is an instruction to do +1 and then +2. Thechoice program +1 # +2 can be executed by either carrying out +1 or by doing +2 andthe iteration +7 is an instruction to do + any number (6 0) of times.
The last two constructs introduce nondeterminism into the language. An executionof p ; p ; q will count as an execution of ( p # q)7, but an execution of q alone, or ofany finite sequence of p’s and q’s, will do as well. Programs are regular expressionsand an execution of any sequence in the denotation of such an expression will countas an execution of the program itself.
The semantics of PDL is obtained by considering poly-modal Kripke models (alsoknown as labeled transition systems) 0S, {R, | , % AT}, V1, consisting of a set ofabstract program states S, a set of binary relations R, over S, indexed by the set ofatomic programs AT, and a valuation function V which assigns a subset of S to eachpropositional letter in the language. In general, the meaning of a formula is identifiedwith the set of all states where the formula is true, the meaning of a program with theset of pairs 0a, b1 such that the program, if started in state a, may end up in state b.Writing R ( R! for the relational composition of R and R! and (R)7 for the reflexivetransitive closure of R, we can define the meaning '!'M of a formula ! and the mean-ing '+'M of a program + with respect to a given model M = 0S, {R, | , % AT}, V1as follows.
(i) 'p' = V(p),
(ii) '$' = *,(iii) '!1 , !2' = (S ) '!1') # '!2',(iv) '[+ ]!' ={ a | 3b(0a, b1 % '+' , b % '!')},(v) ',' = R, ,
(vi) '!?' = {0a, a1 | a % '!'},(vii) '+1; +2' =' +1' ( '+2',
(viii) '+1 # +2' =' +1' # '+2',(ix) '+7' = ('+')7.
We see that [+ ]! is in fact interpreted as a modal statement (“in all + -successors!”) with the modal accessibility relation given by the denotation of + and we maydefine a dual modality by letting 0+1! be an abbreviation of ¬[+ ]¬!. This new state-ment will then have the meaning that it is possible that ! will hold after execution of+ . Abbreviations will also give us a host of constructs that are familiar from the usualimperative programming languages. For example, while ! do + od can be viewed asan abbreviation of (!? ; +)7; ¬!?; a little reflection will show that the latter has theintended input/output behavior. Correctness statements (in Hoare’s sense) about suchprograms can be formalized too; for example {!}+{"}, the assertion that in any statewhere ! holds any successful execution of + will lead to a state where " holds, canbe taken to be an abbreviation of ! , [+ ]" .
A formula ! is said to be universally valid if '!' = S for each model 0S, {R, | , %AT}, V1. Segerberg (1982) shows that this notion is axiomatizable by means of thefollowing seven axiom schemes and two rules of inference.

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 637 — #31
Dynamics 637
(A1) all instances of tautologies of the propositional calculus(A2) [+ ](! , ") , ([+ ]! , [+ ]") (Distribution)(A3) [!?]" 9 (! , ") (Test axiom)(A4) [+1; +2]" 9 [+1][+2]" (Sequence axiom)(A5) [+1 # +2]" 9 ([+1]" + [+2]") (Choice axiom)(A6) [+7]" 9 (" + [+ ][+7]") (Iteration axiom)(A7) (! + [+7](! , [+ ]!)) , [+7]! (Induction axiom)(MP) from ! and ! , " to infer " (Modus Ponens)
(N) from ! to infer [+ ]! (Necessitation)
As a simple illustration we give a derivation of one of Hoare’s rules of Composition,the rule that {!}+1; +2{*} can be inferred from {!}+1{"} and {"}+2{*}.
1. ! , [+1]",
2. " , [+2]* ,
3. [+1](" , [+2]*), necessitation, 2,4. [+1]" , [+1][+2]* , distribution, 3,5. ! , [+1][+2]* , propositional logic, 1, 4,6. ! , [+1; +2]* , sequence axiom, 5.
We invite the reader to show that {!}while " do + od{! + ¬"} can be derived from{! + "}+{!}.
The system of Quantificational Dynamic Logic (QDL) can be obtained from PDLby specifying the structure of atomic formulae and atomic programs. In particular, theatomic formulae of standard predicate logic will be atomic formulae of the new logicand assignment statements of the forms x :=? (random assignment) and x := t are itsatomic programs. The following Backus–Naur Form gives a precise syntax.
! :: = R(t1, . . . , tn) | t1 = t2 | $| !1 , !2 | [+ ]!,
+ :: = x := ? | x := t | !? | +1; +2 | +1 # +2 | +7.
The idea here is that x := ? sets x to an arbitrary new value and that x := t sets xto the current value of t. The semantics of this logic is given relative to ordinary first-order models M = 0D, I1 with the set of states S now being played by the set of allM-assignments, i.e. the set of all (total) functions from the variables in the language toD. Letting 't'a (the value of a term t under an assignment a) be defined as usual, wecan define '!'M and '+'M by taking the clauses for the PDL semantics given above,but replacing those for atomic formulae and programs by the following. (Here a[x]bis to mean that a(y) = b(y) if x 5= y.)
'R(t1, . . . , tn)' = {a | 0't1'a, . . . , 'tn'a1 % I(R)},'t1 = t2' = {a | 't1'a = 't2'a},'x := ?' = {0a, b1 | a[x]b},'x := t' = {0a, b1 | a[x]b & b(x) = 't'a}.

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 638 — #32
638 Handbook of Logic and Language
We say that " follows from !, ! |=QDL ", iff '!'M . '"'M for every model M.The logic thus obtained is a truly quantificational logic since 3x! can be taken to be anabbreviation of [x := ?]! and 2x! of 0x := ?1!. Note also that [x := t]! and 0x := t1!are both equivalent with the result of substitution of t for x in !. However, the logicreally extends first-order logic. Consider [x := ?]0y := 0; (y := Sy)71x = y in thelanguage of Peano Arithmetic. Together with the usual first-order Peano axioms thissentence will characterize the natural numbers, a feat which first-order logic cannotperform.
The price that must be paid is non-axiomatizability of the system, of course. How-ever, there is a simple proof system which is complete relative to structures containinga copy of the natural numbers (see Harel, 1984). Note that the iteration operator 7
is the sole culprit for non-axiomatizability: the Segerberg axioms (A3)–(A5) plus theequivalences between [x :=?]! and 3x! and [x := t]! and [t/x]! provide an easymethod to find a predicate logical equivalent for any formula [+]! not containing thestar (see also the “weakest precondition” calculi in Section 12.2.3.4).
The interest of QDL for natural language semantics derives partly from the fact thatthe DRT and DPL systems that were considered in Section 12.1.2 can easily be shownto be fragments of the star free part of this logic. For example, we can translate DRTinto QDL in the following way.
(!)† = ! if ! is atomic,(¬K)† = [K†]$,
(K1 - K2)† = 0K†
21: - 0K†21:,
(K1 " K2)† = [K†
1]0K†21:,
([x1, . . . , xn | !1, . . . ,!m])† = x1 := ? ; . . . ; xn := ? ; !†1? ; . . . ; !
†m?.
If we let DRT be interpreted by means of its total semantics (see Section 12.1.2.2), wehave that '-'DRT = '-†'QDL for any condition or DRS -. If both DRT and QDL areprovided with a semantics based on partial assignments an embedding is possible aswell – see Fernando (1992). The reader will have no difficulty in defining a translationfunction from DPL to QDL either (see also Groenendijk and Stokhof, 1991).
12.2.1.2 Dynamization of Classical Systems
Systems of dynamic semantics may often be derived from static predecessors. Forthis purpose one has to identify parameters of change in classical systems, and thendesign dynamic logics exploiting these. For instance, consider Tarski’s basic truthdefinition for a formula ! in a model M = 0D, I1 under some variable assign-ment a. Its atomic clause involves a static test whether some fact obtains. But intu-itively, the clause for an existential quantifier 2x involves shifting an assignmentvalue for x until some verifying object has been found. A system like DPL makesthe latter process explicit, by assigning to each formula a binary relation consistingof those transitions between assignments which result in its successful verification.Entirely analogously, other components of the truth definition admit of such shifts

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 639 — #33
Dynamics 639
too. For instance, shifting interpretation functions I are involved in questions (cf.Groenendijk and Stokhof, 1984) and ambiguity (Van Deemter, 1991), and shifting ofindividual domains D occurs with ranges for generalized quantifiers across sentences(Westerståhl, 1984).
In addition to these “Tarskian Variations” for extensional logics (Van Benthem,1991a), there are also “Kripkean Variations” for intensional logics. Consider, forexample, the best-known classical information-oriented model structures, namelyKripke models for intuitionistic logic. Here, worlds stand for information states,ordered by a relation of growth ., which are traversed by a cognitive agent.Intuitively, intuitionistic formulas refer to transitions in this information pattern (cf.Troelstra and Van Dalen, 1988). For example, to see that ¬! holds, one has to inspectall possible extensions of the current state for absence of !. Van Benthem (1991a)makes this dynamics into an explicit part of the logic, by creating a system of cogni-tive transitions, such as updates taking us to some minimal extension where a certainproposition has become true. While intuitionistic negation, which is expressible as.P.x. 3y(x . y , ¬Py), takes us from sets of worlds to sets of worlds, Van Benthemis also interested in functions which take us from sets of worlds to binary relationsbetween worlds, such as for example:
.P..xy.x . y + Py (loose updating)
.P..xy.x . y + Py + ¬2z(x . z ; y + Pz) (strict updating)
.P..xy.y . x + ¬Py (loose downdating)
.P..xy.y . x + ¬Py + ¬2z(y ; z . x + ¬Pz) (strict downdating)
Standard intuitionistic logic is a forward-looking system, but the full dynamiclogic will include backward-looking downdates and revisions. The resulting Dyna-mic Modal Logic covers all cognitive tasks covered in the Gärdenfors theory ofSection 12.1.5, and admits much more elaborate statements about them. The sys-tem has been studied extensively in De Rijke (1993), which has results on its expres-sive power and axiomatization and proves its undecidability. (Van Benthem, 1993b,presents a decidable reformulation.) Extensions of the formalism may be defined usingoperators from Temporal Logic. For instance, appropriate pre- and postconditions forstrict updating and downdating will involve the well-known temporal operators sinceand until.
Other static systems which have been turned into dynamic ones include the theoryof generalized quantifiers. There are many forms of change here: in bindings, ranges ofquantification, drawing samples from domains, and model construction. (Cf. Hintikkaand Sandu, 1996; Kanazawa, 1993b; Keenan and Westerståhl, 1996; Van den Berg,1995; Van Eijck and De Vries, 1992; Van Eijck and Kamp, 1996.)
12.2.1.3 Dynamic Constants as Operators in Relational Algebra
Our general perspective employs the usual mathematical notion of a state space (i.e.poly-modal Kripke model) 0S, {R, | , % AT}, V1. Over the atomic actions R, , thereis a procedural repertoire of operations creating compound actions. Examples of such

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 640 — #34
640 Handbook of Logic and Language
procedural operations are sequential composition, choice, and iteration as found incomputer programs. Less standard examples include the DPL test negation:
¬R = {0x, x1 | ¬2y0x, y1 % R}
or the directed functions of categorial grammar (cf. Moortgat, 1996):
A\B = {0x, y1 |3 z(0z, x1 % A , 0z, y1 % B)},B/A = {0x, y1 |3 z(0y, z1 % A , 0x, z1 % B)}.
What we see here is a move from a standard Boolean Algebra of propositions to aRelational Algebra of procedures. The standard repertoire in relational algebras is:
Boolean operations: – (complement) & (intersection) # (union)Ordering operations: ( (composition) #(converse)
with a distinguished diagonal / for the identity relation. These operations are defin-able in a standard predicate logic with variables over states:
)R .xy.¬Rxy,R & S .xy.Rxy + Sxy,R # S .xy.Rxy - Sxy,R ( S .xy.2z(Rxz + Szy),R# .xy.Ryx.
This formalism can define many other procedural operators. In particular,
¬R / & )(R ( R#),
A\B )(A# ( )B),
B/A )()B ( A#).
The literature on Relational Algebra contains many relevant results concerningaxiomatization of valid identities between such relational expressions, as well asexpressive power of various choices of operators (see Németi, 1991). One naturalmeasure of fine-structure here is the number of state variables needed in their def-initions. This tells us the largest configuration of states involved in determining theaction of the operator. The resulting Finite Variable Hierarchy of semantic complexityrelates Relational Algebra with Modal Logic (cf. Andréka, Van Benthem and Németi,1994). Its mathematical properties seem significant for dynamic logical operators ingeneral: (1) the above vocabulary of Relational Algebra suffices for defining all rela-tional operators with a 3-variable first-order definition (these include most commoncases); (2) each n-variable level has a finite functionally complete set of operators;(3) there is no finite functionally complete set of algebraic operators for the wholehierarchy at once. The latter result shows how the logical space of dynamic proposi-tional operators is much richer than that of classical Boolean Algebra.

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 641 — #35
Dynamics 641
12.2.1.4 Process Equivalences and Invariance
In order to understand a certain kind of process, one has to set up a criterion of identityamong its different representations. One important notion to this effect is bisimulation,prominent in the computational literature, which tends to be richer in this respect thantraditional logical semantics (cf. Hennessy and Milner, 1985; Milner, 1980). A bisim-ulation is a binary relation C between states in two “labeled transition systems” (i.e.our dynamic transition models) 0S, {R, | , % AT}, V1 and 0S!, {R!
, | , % AT}, V !1which connects only states with the same atomic valuation, and which satisfies thefollowing back-and-forth clauses:
if xCx!, xR,y, then there exists some y! with yCy!, x!R!,y!,
if xCx!, x!R!,y!, then there exists some y with yCy!, xR,y.
This allows mutual tracing of the process in the two transition models, includingits choice points. There are many other notions of process simulation: a coarser oneis the “trace equivalence” discussed in Van Benthem and Bergstra (1993), and a finerone is the “generated graph equivalence” discussed in the same paper.
There is a close connection between process equivalences and the design of a dyna-mic language. In particular, bisimulation is the key semantic invariance for a modallanguage describing labeled transition systems, which has the usual Boolean opera-tors as well as indexed modalities 0a1 for each atomic action a % A. Whenever C is abisimulation between two models M, M! with sCs!, we have
s % '!'M iff s! % '!'M!, for all modal formulas !.
This observation can be reversed:
A first-order formula over labeled transition systems is invariant for bisimulation iffit is definable by means of a modal formula.
In propositional dynamic logic, this invariance persists for formulas, but there isalso a new aspect. The above back-and-forth clauses in bisimulation are inheritedby all program relations '+', not just the atomic ones. More specifically, all regularprogram operations O are safe for bisimulation, in the sense that, whenever C is abisimulation between two models with transition relations R1, . . . , Rn, it must also bea bisimulation for the transition relation O(R1, . . . , Rn). This observation, too, can bereversed (Van Benthem, 1993b):
A first-order relational operation O(R1, . . . , Rn) is safe for bisimulation iff it can bedefined using atomic relations R,xy and atomic tests ,?, using only the three rela-tional operations of ( (composition), # (union) and ¬ (DPL negation).
Thus, bisimulation seems very close to the mark for dynamic semantic operatorswith a modal flavor. Different outcomes will be obtained with coarser or finer notionsof process equivalence. It would be of interest to see which level of invariance isplausible for the procedures involved in processing natural language.

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 642 — #36
642 Handbook of Logic and Language
12.2.1.5 Typology of Dynamic Procedures
Another source of more specific dynamic structure is the search for denotational con-straints, suggested by semantic analysis of key linguistic items (cf. again the theoryof generalized quantifiers). For instance, relational operators may obey various natu-ral Boolean constraints (cf. Keenan and Faltz, 1985; Van Benthem, 1986), often of acomputational character. One well-known example is continuity of an operator in oneof its arguments:
O!
. . . ,"
i%I
Ri, . . .
#=
"
i%I
O(. . . , Ri, . . .).
Continuous operations compute their values locally, on single transitions (note thatR = #{{0x, y1} | Rxy}). Boolean intersection and union are continuous in both argu-ments, and so are relational composition and converse. A non-example is Booleancomplement. This restriction has some bite. Van Benthem (1991a) proves that, foreach fixed arity, there are only finitely many continuous permutation-invariant rela-tional operators. (Belnap, 1977, proposes a weaker notion of Scott continuity admittingmore candidates.) Another source of constraints in dynamic semantics is the typologyof cognitive actions themselves. For instance, updates are often taken to be idempo-tent: repeating them is unnecessary (3xy(Rxy , Ryy)). Veltman (1991) wants them tobe functions. Such basic choices will influence the choice of a procedural repertoire.For instance, if all admissible actions are to be idempotent, then composition is not asafe combination, while choice or iteration are. Likewise, special atomic repertoiresmay be of interest. For instance, the basic DPL actions R of propositional test andrandom assignment both satisfy the identity R ( R = R, and both are symmetric rela-tions. Other interesting denotational constraints of this kind occur in Zeinstra (1990)(cf. Section 12.1.4).
12.2.1.6 Styles of Inference
We now turn from matters of dynamic vocabulary and expressive power to the issueof dynamic inference. The standard Tarskian explication of valid inference expressestransmission of truth: “in every situation where all premises are true, so is the con-clusion”. But what is the sense of this when propositions are procedures changinginformation states? There are plausible options here, and no single candidate has wonuniversal favor so far. Here is a characteristic general feature. If premises and conclu-sions are instructions for achieving cognitive effects, then their presentation must becrucial, including sequential order, multiplicity of occurrences, and relevance of eachmove. This brings us into conflict with the basic structural rules of standard logic thatallow us to disregard such aspects in classical reasoning (cf. Moortgat, 1996). Hereare some dynamic styles of inference. The first employs fixed points for propositions(where their update procedure effects no state change) as approximations to classicaltruth, the second focuses on transitions to achieve an effect, and the third is a compro-mise between the two (Van Benthem, 1991a; Veltman, 1991).

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 643 — #37
Dynamics 643
test-test consequenceIn all models, each state which is a fixed point for all premises is also a fixed pointfor the conclusion:
!1, . . . ,!n |=test)test " iff / & '!1'M & · · · & '!n'M . '"'M,
for all models M.
update-update consequencein all models, each transition for the sequential composition of the premises is atransition for the conclusion:
!1, . . . ,!n |=update)update " iff '!1'M ( · · · ( '!n'M . '"'M,
for all models M.
update-test consequencein all models, each state reached after successful processing of the premises is afixed point for the conclusion:
!1, . . . ,!n |=update)test " iff range('!1'M ( · · · ( '!n'M) . fix('"'M),
for all models M.
Thus a variety of dynamic styles of inference emerges, reflecting different intuitionsand possibly different applications. These show a certain coherence. For instance,Beaver (1992) analyzes presupposition as a test-update consequence stating that thepremises can be processed only from states where the conclusion has a fixed point.Groenendijk and Stokhof (1991) require that the conclusion be processable after thepremises have been processed successfully.
DPL consequencein all models, in each state that is reached after successful processing of thepremises, processing of the conclusion is possible:
!1, . . . ,!n |=DPL " iff range('!1'M ( · · · ( '!n'M) . dom('"'M),
for all M.
Here, the existential quantification for the conclusion takes care of free variablesthat are to be captured from the premises. (This “for all – there exists” format mayalso be observed with implications in DRT.) Van Eijck and De Vries (1995) requirea converse, proposing that the domain of the composed premises be contained in thedomain of the conclusion.
One way of defining a style of inference is through its general properties, expressedin structural rules. For instance, test-test consequence behaves like standard inference:
! " !, Reflexivity,
X " ! Y, !, Z " "
Y, X, Z " ", Cut Rule,
X, !1, !2, Y " "
X, !2, !1, Y " ", Permutation,

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 644 — #38
644 Handbook of Logic and Language
X, !, Y, !, Z " "
X, !, Y, Z " ", Right Contraction,
X, !, Y, !, Z " "
X, Y, !, Z " ", Left Contraction,
X, Y " "
X, !, Y " ", Monotonicity.
By contrast, update-update satisfies only Reflexivity and Cut. There are some exactrepresentation results (Van Benthem, 1991a): (1) {Monotonicity, Contraction, Reflex-ivity, Cut} completely determine test-test consequence, (2) {Reflexivity, Cut} com-pletely determine update-update inference. But this is not an all-or-nothing matter.Inferential styles may in fact modify standard structural rules, reflecting a more deli-cate handling of premises. Update-test consequence has none of the above structuralproperties, but it is completely characterized by
X " "
!, X " ", Left Monotonicity,
X " ! X, !, Z " "
X, Z " ", Left Cut.
The DPL style of inference is also non-classical, in that various structural rulesfrom classical logic fail. For instance, it is
non-monotonic: 2xAx |=DPL Ax, but not 2xAx, ¬Ax |=DPL Ax,non-contractive: 2xAx, ¬Ax, 2xAx |=DPL Ax, but not 2xAx, ¬Ax |=DPL Ax,non-transitive: 2xAx, ¬Ax |=DPL 2xAx |=DPL Ax, but not 2xAx, ¬Ax |=DPL Ax.
The only valid structural rule of inference is Left Monotonicity. It is not completelyclear, however, that this is the last word. In practice, applications of DPL to natu-ral language will use only very special “decorations” of grammatical structures withindividual variables. For instance, it seems reasonable to require that every quantifierhave a unique bound variable associated with it. But then, the DPL fragment withthis property may be shown to satisfy unrestricted monotonicity, allowing insertionof premises in arbitrary positions (Van Benthem, unpublished). Other well-behavedfragments may be relevant for natural language analysis, too.
Often, one inferential style can be simulated inside another, by adding suitablelogical operators. Here is an illustration. Test-test consequence may be reduced toupdate-update consequence using a relational fixed point operator 0 sending relationsR to their diagonal .xy.Rxy + y = x:
!1, . . . ,!n |=test-test " iff 0(!1), . . . ,0(!n) |=update-update 0(").
There is no similar faithful converse embedding. (This would imply Monotonic-ity for update-update consequence.) Another interplay between structural rules andlogical constants arises as follows. Operators may license additional structural beha-vior, not for all propositions, but for special kinds only (cf. Girard, 1987). For instance,

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 645 — #39
Dynamics 645
in dynamic styles of inference, let O be some operator that is to admit of arbitrarymonotonic insertion:
X, Y " "
X, O(!), Y " ".
This can only be the case if O(!) is a test contained in the diagonal relation. Itwould be of interest to see how the linguistic formulation of actual arguments providescues for adopting and switching between inferential styles.
Completeness theorems for dynamic styles of inference in various fragments ofpropositional dynamic logic may be found in Kanazawa (1993a) and Blackburnand Venema (1993). These results exemplify one direction of thinking in logic:from semantic notions of inference to their complete axiomatic description. Anotherline in the literature starts from given axiomatic properties of dynamic operators,and then determines corresponding complete semantics via representation theorems(cf. Alchourrón, Gärdenfors and Makinson, 1985), and the ensuing tradition). Eventu-ally, both logical treatments of dynamic inference may be too conservative. Perhaps,the very notion of formal proof needs re-thinking in a dynamic setting (a first attemptat defining “proofs as texts” may be found in Vermeulen, 1994). Natural reasoningseems to involve the interplay of a greater variety of mechanisms at the same time(inferring, updating, querying, etc.).
12.2.2 Categories for Dynamic Semantics
Dynamic logic is by no means the only mathematical paradigm for implementing thefundamental ideas of dynamic semantics. As a counterpoint to the preceding sec-tions, we outline an alternative logical framework based on category theory, some-times called the “Utrecht approach”. Its basic tenet is this: the business of dynamicsemantics is modeling interpretation processes. Thus, it is not sufficient to composi-tionally specify correct meanings: one should also specify these in a way that reflectstemporal processes of interpretation. Category Theory provides the tools to do this.
Category theory is a branch of mathematics that is widely applied in both mathe-matics and computer science. (Some good textbooks are Barr and Wells, 1989; Manesand Arbib, 1975; McLane, 1971.) The uses of Category Theory in linguistics are lesswidespread, but multiplying. The reader is referred to Reyes and Macnamara (1994)for another application in linguistics.
12.2.2.1 The Program of Monoidal Updating
The Utrecht approach develops radical versions of file-change semantics/DRT (seeVisser and Vermeulen, 1995). Consider a simple sample sentence: John cuts the breadwith a sharp knife. This will be analyzed as follows:
((subject Johnj) cuts (object theu bread) (with av sharp knife)).

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 646 — #40
646 Handbook of Logic and Language
Here, virtually all grammatical structure will be interpreted as semantic actionssuch as pushing a new file to a data stack or popping the last file from the stack. In analternative notation:
push push subject John j pop cuts push object theu bread pop push with av sharp knifepop pop.
In other words, all grammatical structure gets a dynamic potential similar to theexistential quantifier in DPL/DRT or to the dynamic suppose operator in Zeinstra’slogic. As a consequence, the usual components of a sentence, such as (object theubread), are not necessarily the only possible inputs in a compositional interpretation.In fact, the meaning of any contiguous linguistic chunk of text can be specified. Thus,the source algebra of the interpretation is the language of arbitrary strings over analphabet including such characters as subject, with, av, pop, whose basic operationis concatenation. This syntactic operation is matched at the semantic level with adynamic operation, say merge or composition. This merge will be associative, thusreflecting the associativity of concatenation at the syntactic level. This has, as a con-sequence, that the ambiguity of dividing up a sentence into chunks does not result inthe assignment of different meanings. Components in the traditional sense, i.e. chunkswith matching opening and closing brackets, correspond to local files that are intro-duced, used for some time and then discarded. (The words subject, object, and withcontain machinery to arrange that the information of the discarded files is stored in thecorrect files associated with cuts at the sentence level.) So far, this semantics has beendeveloped for narrative with existential quantifiers only. Even so, it exemplifies somebroad programmatic features for a full-fledged dynamic semantics in the above sense.
In this approach, genuine grammaticality is decided at the semantic level, since thesyntactic specification language does not have any interesting grammar at all. The factthat tasks that are traditionally assigned to grammar are now shifted to the semanticlevel, reflects a move that is typical in dynamic semantics: redivision of labor betweensyntax and semantics.
Since the semantic objects form a monoid (the basic operation is associative andthere is a unit element), the semantics satisfies the break-in principle: any contigu-ous chunk of text can be assigned a meaning. As a result, one can process meaningsincrementally. This seems a linguistically realistic and, hence, desirable feature.
12.2.2.2 Meanings and Contexts
Meanings in this approach are databases, just as in DRT. The main difference withordinary DRT is that much more “dynamic potential” is present in contexts. Contextscontain both global information connected to the anaphoric machinery (“variables”)and local syntactic information (e.g., a file that stores local information about the sub-ject of a sentence). Contexts regulate the way in which information is stored in thecase where new information is added to a database.
Words like with and object stand for argument places. Their meanings are littlemachines that look for the place where information connected with the word (with aknife) is to be stored in the database that is being built. (“The knife is the Instrument ofthe cutting” – compare Davidson, 1967; Parsons, 1990.) An anaphor like hev links files

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 647 — #41
Dynamics 647
introduced in the sentence (thematic roles such as Agent and Instrument) with filesglobally present in the discourse. In this way the chunk (subj hev) ensures that the filelocally known as the subject is connected to the file globally known as v. Thus, hevgets the correct role in the semantics: it is a locus where local and global informationare fused.
12.2.2.3 Diachronic Information Orderings as Categories
Let us look at some chunks of our earlier example.
((subject Johnj) cuts (object
and
theu bread) (with av sharp knife)).
The meanings associated with these chunks are databases containing files/discourseobjects. These databases have a layered structure that reflects some aspects of the localsyntactic structure – e.g., the discourse objects are stored on the levels of a stack thatrepresents part of the bracket structure. This structure on discourse objects occurs inthe context part of the databases. Our problem now becomes to describe what happensif two dynamic databases are “clicked together”. We do not only want to describe whatthe new object looks like, but also want to describe the flow of files: where do the filesof the original databases re-occur in the new one? Apart from philosophical reasonsto insist on describing the flow of files there is a pragmatic one: the description ofthe new meaning object and the verification that it has the desired properties quicklybecomes too complicated if we do not have a principled way of describing the flow.This is where categories make their appearance: the flow of files is described by adiachronic information ordering and this ordering turns out to be a category.
One should distinguish (at least) two ways of ordering linguistic information. First,there is a synchronic ordering. For example, consider two slips of paper. One statesJan is wearing something new, the other Jan is wearing a new hat. Evidently, the firstslip is less informative than the second. Whatever information state someone is in,being offered the second slip will make her at least as informed as being offered thefirst. So we compare the effects of pieces of information offered at the same time tothe same person in different possible situations. The second ordering is the one weare after presently: the diachronic ordering, which looks at information as it occurs intime. Consider Genever is a wonderful beverage. Not only the Dutch are fond of it. Theinformation content of these two statements forms an indissoluble whole, by virtue oftheir consecutive presentation. A mathematical analysis of the diachronic ordering !leads to the core of the Utrecht approach. For a start, assume that ! is a pre-order, i.e. atransitive and reflexive binary relation. (There is no strong evidence for antisymmetry,and hence partial order.) But, there is further relevant dynamic structure. Considerthis example:
(40) Genever is a wonderful beverage, I like it. Cognac is not too bad either. I likeit too.

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 648 — #42
648 Handbook of Logic and Language
Here, the meaning of I like it is embedded in the meaning of the whole text twice.But not in the same way: the first it will be linked to Genever, the second one toCognac. This suggests that the diachronic ordering should rather be a labeled pre-ordering, which adds information about the kind of embedding involved.
The preceding observation suggests a move to “labeled transition systems” similarto those encountered in Section 12.2.1 above. Such transition systems can be describedin many ways. We describe them here as logical generalizations of partial pre-orders.We have structures 0O, L, R1, where O is a domain of objects, L a set of labels, and Ra ternary relation between objects, labels and objects. A triple 0x, ., y1 in R is calledan arrow. We shall write x !. y for: 0x, ., y1 % R . Here are the analogs of thepre-order principles. Reflexivity says that everything can be embedded into itself ina trivial way. This requires a special label id such that, for every x, y in O, x !id yiff x = y. Next, transitivity says we can compose ways of embedding in suitablecircumstances. Suppose we have x !. y and y !µ z. Then . ( µ is defined and wehave: x !.(µ z. We demand that id ( . = . ( id = . and . ( (µ ( )) = (. ( µ) ( ).(Here an equation % = - states that % is defined iff - is, and that % and - are equalwhere defined.) Finally, for the sake of parsimony, we demand that every label is usedat least once in some arrow. (There are obvious analogies here with Dynamic Logicand the Arrow Logic of Section 12.2.4.8.) Now, with the label id we can associate afunction from objects to arrows. Moreover the partial operation ( on labels induces oneon arrows. The resulting structure of objects and arrows is a category in the sense ofCategory Theory. (In fact our labeled pre-orderings have slightly more structure thana category.) Thus dynamic semantics can now avail itself of useful notions from anestablished mathematical discipline. (For instance, an arrow x !. y is an isomorphismif there is an arrow y !µ x such that . ( µ = µ ( . = id.)
The diachronic ordering may be viewed as a special kind of category, suitable fordynamic meanings. We already had a monoidal merge • on objects. We relax the notionof monoid by allowing that (x • y) • z is not strictly identical to x • (y • z), but thatthere is a standard isomorphism ,(x, y, z) from (x • y) • z to x • (y • z). (This ensurescategory-theoretic coherence: see McLane, 1971, pp. 161–176.) To make updatingyield information growth along our ordering, we also assume standard embeddings ofx and y into x • y, say, via in1(x, y) : x , x • y and in2(x, y) : y , x • y. For example,then, x may be embedded in (x•y)•z as follows. First x is embedded in x•y by in1(x, y),and (x • y) in its turn is embedded in (x • y) • z by in1(x • y, z). Now (x • y) • z is identifiedwith x • (y • z) by ,(x, y, z). Alternatively, x is embedded in x • (y • z) by in1(x, y • z).Putting all this together, one obtains equalities like the following.
in1(x, y) ( in1(x • y, z) ( ,(x, y, z) = in1(x, y • z).in2(x, y) ( in1(x • y, z) ( ,(x, y, z) = in1(y, z) ( in2(x, y • z).in2(x • y, z) ( ,(x, y, z) = in2(y, z) ( in2(x, y • z).
The resulting mathematical structures are called m-categories. m-categories are thenatural medium for thinking about dynamic updating and dynamic contexts. Startingfrom simple m-categories that describe contexts and contents, we can now assem-ble meanings by the well-known categorical Grothendieck construction (see Barr andWells, 1989; Visser and Vermeulen, 1995).

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 649 — #43
Dynamics 649
12.2.3 Dynamics Related to Statics
12.2.3.1 Translations
It is often useful to define functions from the expressions of one logic to those ofanother. If such a function preserves logical consequence it is called a translation andin the following section we shall define translations from PDL and QDL to classicallogic. Our method will be to take the truth conditions of the source logics and tran-scribe them in the object language of the target logic. This is in fact an old proce-dure, as the so-called standard translation from modal logic into predicate logic maywitness. To obtain this translation, associate a unary predicate symbol P with eachpropositional letter p of the modal language and let R be some binary relation symbol.Then define the translation ST, sending sentences from propositional modal logic toformulae of predicate logic having at most the fixed variable i free, as follows.
ST(p) = Pi,
ST($) = $,
ST(! , ") = ST(!) , ST("),
ST(/!) = 2 j(Rij + [ j/i]ST(!)).
Whether this function really preserves entailment depends on the modal systemunder investigation, of course. For the minimal modal logic K the translation will doas it stands, but for stronger logics we need to put additional constraints on the relationdenoted by R. For many modal systems S a lemma of the following form will hold.
Embedding Lemma. ! |=S " iff AX, ST(!) |= ST(").
Here AX is some set of axioms putting extra requirements on R. For example, wecan take AX to be the requirement that R be reflexive and transitive, while instantiatingS as the system S4. In general, the correctness of a translation may require workingwith special classes of models.
There are various reasons why it is handy to have translations around wheneverthey are available. One reason is that it is often possible to derive information aboutthe source logic of a translation from properties of the target logic that are alreadyknown. For example, the standard translation immediately tells us that the modal log-ics that can be treated in this way are recursively axiomatizable and will have theLöwenheim–Skolem property. Other translations often give us decidability of a sys-tem. Some information may not be obtainable in this easy way, of course. For exam-ple, although the above translation shows that there are recursive axiomatizations ofthe modal logics under consideration, it does not tell us what these axiomatizationslook like. Moreover, some semantic characteristics of the original logic may be lost intranslation. Traduttore traditore, not only in real life, but in logic as well.
Reasons for studying translation functions also include some of a more appliedcharacter. One is that a translation into classical logic will make it possible to usea general purpose classical theorem prover for the source logic. Another reason isthat for applied purposes we often need to have many logics working in tandem. In

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 650 — #44
650 Handbook of Logic and Language
linguistics, for example, we need logics that can deal with modalities, with tempo-ral expressions, with verbs of perception, with propositional attitudes, with defaults,with dynamics, and with many other things. Trying to set up a logic that can simul-taneously deal with all these things by adding up the characteristics of modal logic,temporal logic, default logic, dynamic logic, etc. will almost certainly result in disas-ter. Translating all these special logics into one common general purpose target logicmay be a viable strategy, however.
12.2.3.2 From Dynamic Logic to Classical Logic
In this section we shall give translations of Dynamic Logic into classical logic. It willnot be possible to let elementary predicate logic be our target language, because of theinfinitary nature of the iteration operator. However, if we allow infinite disjunctions,and thus obtain the logic known as L111, translations are possible. The following func-tion ' sends PDL constructs to classical formulae. The idea is that each PDL formulais translated as a formula which may have one variable i free and that a PDL programgoes to a formula which may contain an additional free variable j. The variables i andj are fixed in advance, say as the first and second variables in some given ordering.Think of i as being the input state, of j as the output state. Each propositional letter p isassociated with a unary predicate symbol P and each atomic program , with a binaryrelation symbol R, . Let +0 stand for :? (the skip command) and +n+1 for +n; +.
' (p) = Pi,
' ($) = $,
' (! , ") = ' (!) , ' ("),
' ([+ ]!) = 3k(' (+) , [k/i]' (!)), where k is new,
' (,) = R,ij,
' (!?) = i = j + ' (!),
' (+1; +2) = 2k([k/j]' (+1) + [k/i]' (+2)), where k is new,
' (+1 # +2) = ' (+1) - ' (+2),
' (+7) =$
n
' (+n).
This translation, which obviously follows the semantics for PDL given inSection 12.2.1.1 above, can be extended to a translation of QDL into L111 (cf. Harel,1984). PDL may also be translated into second-order logic: with clauses as before,except that now
' (+7) = 3X%(Xi + 3kh((Xk + [k/i, h/j]' (+)) , Xh) , Xj
&,
where k and h are fresh variables and X varies over sets of states. The formula saysthat i and j are in the reflexive transitive closure of the denotation of + , which is trueiff j is in all sets containing i which are closed under + successors.

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 651 — #45
Dynamics 651
We shall extend the last translation to a translation of QDL into three-sorted secondorder logic plus some axioms. There will be three types of objects: states, entities andregisters. We use the following notation: u (with or without superscripts or subscripts)will be a constant that denotes a register; v will be a variable over registers; ( willvary over terms of type register. The constant V will denote a two-place function fromregisters and states to entities; V((, i) can be thought of as the value of register ( instate i. We define i[(1 · · · (n] j to be short for 3v(((1 5= v + · · · + (n 5= v) , V(v, i) =V(v, j)) (i and j differ at most in (1, . . . , (n). We require the following: for each state,each register and each entity, there must be a second state that is just like the first one,except that the given entity is a value of the given register. Moreover, we demand thatdifferent constants denote different registers.
AX1 3i3v3x2 j(i[v] j + V(v, j) = x),AX2 u 5= u! for each two syntactically different constants u and u!.
The translation is now obtained in the following way. We assume the set of QDLvariables and the set of register constants to have a fixed ordering each. We let ' (xn) =V(un, i); ' (c) = c, for each constant c and ' (f (t1, . . . , tn)) = f (' (t1), . . . , ' (tn)).Moreover, we let
' (R(t1, . . . , tn)) = R(' (t1), . . . , ' (tn)),
' (t1 = t2) = ' (t1) = ' (t2),
' (xn := ?) = i[un] j,
' (xn := t) = i[un] j + V(u, j) = [ j/i]' (t).
The remaining constructs of QDL are translated as before. It is not difficult to provethe following lemma.
Embedding Lemma. Let |=2 be the semantical consequence relation of three sortedsecond order logic, then
! |=QDL " iff AX1, AX2, ' (!) |=2 ' (").
Since we have already observed (in Section 12.2.1.1) that both DRT and DPL canbe embedded in the star free part of QDL, this immediately gives us embeddings fromDRT and DPL into (three-sorted) predicate logic; for each DRS K we have a predicatelogical formula with at most the state variables i and j free which shows the sameinput/output behavior as K. In the next section we shall see an application of this.
12.2.3.3 An Application: Compositional DRT
Several researchers (e.g., Asher, 1993; Bos et al., 1994; Groenendijk and Stokhof,1990) have stressed the desirability to combine the dynamic character of DRT andDPL with the possibility to interpret expressions compositionally as it is done in Mon-tague Grammar (see also Van Eijck and Kamp, 1996). To this end one must have a

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 652 — #46
652 Handbook of Logic and Language
logic that combines the constructs of DRT with lambda abstraction, but until recentlyno simple semantically interpreted system supporting full lambda conversion has beenforthcoming. Using the ideas from the previous section it is easy to define such a logic,however. We shall follow Muskens (1991, 1994, 1995a,b) in giving an interpretationof DRT in the first-order part of classical type logic.
To get the required embedding, let V be a constant of type +(se) (where + is thetype of registers) and identify discourse referents with constants of type + . The orig-inal DRT constructs can now be obtained by means of the following abbreviations;conditions will be terms of type st DRSs terms of type s(st).
Pu abbreviates .i.P(V(u)(i)),u1Ru2 abbreviates .i.R(V(u1)(i))(V(u2)(i)),u1 is u2 abbreviates .i.(V(u1)(i)) = (V(u2)(i)),not K abbreviates .i¬2 jK(i)( j),K1 or K2 abbreviates .i2 j(K1(i)( j) - K2(i)( j)),K1 " K2 abbreviates .i3j(K1(i)( j) , 2kK2( j)(k)),[u1 · · · un | %1, . . . , %m] abbreviates .i.j.i[u1, . . . , un] j + %1( j) + · · · + %m( j),K1; K2 abbreviates .i.j2k(K1(i)(k) + K2(k)( j)).
To allow for the possibility of compositional interpretation we have added the PDLsequencing operator (DPL conjunction) to the constructs under consideration. Thefollowing simple lemma is useful.
Merging Lemma. If u!1, . . . , u!
k do not occur in any of !1, . . . ,!m then |=AX[u1 · · · un | !1, . . . ,!m] ; [u!
1 · · · u!k | %1, . . . , %r] = [u1 · · · unu!
1 · · · u!k | !1, . . . ,!m,
%1, . . . , %r].
We sketch the treatment of a small fragment of ordinary language in this system.It will be assumed that all determiners, proper names and anaphoric pronouns areindexed on the level of syntax. Here are translations for a limited set of basic expres-sions (variables P are of type +(s(st)), variables p and q are of type s(st) and variableQ is of type (+(s(st)))(s(st))).
an translates as .P!.P([un | ] ; P!(un) ; P(un)),
non translates as .P!.P[ | not([un | ] ; P!(un) ; P(un))],everyn translates as .P!.P[ | ([un | ] ; P!(un)) " P(un)],hen translates as .P(P(un)),
who translates as .P!.P.v(P(v) ; P!(v)),man translates as .v[ | man v],woman translates as .v[ | woman v],stink translates as .v[ | stinks v],adore translates as .Q.v(Q(.v![ | v adores v!])),if translates as .pq[ | p " q].
“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 653 — #47
Dynamics 653
S[u1, u2| man u1, woman u2, u1 adores u2]
NP!P([u1| man u1] ; P(u1))
NP!P([u2| woman u2] ; P(u2))
V'!v [u2| woman u2, v adores u2]
DET
a1
N'
N
man
VP
Vt
DET
a2
N'
N
woman
adores
Note that the translation of (say) no3 applied to the translation of man can be reduced to.P[ | not([u3 | man u3] ; P(u3))] with the help of lambda-conversion and the merginglemma. In a similar way the sentence a1 man adores a2 woman can be translated assuggested in the tree below.
The method provides us with an alternative for the construction algorithm in stan-dard DRT and with a fusion of insights from the Montague tradition with those ofDRT. (For more applications see also Van Eijck and Kamp, 1996.)
12.2.3.4 Two-level Architecture and Static Tracing of Dynamic Procedures
The two-level approach of PDL suggests the following two-level architecture. Declar-ative propositions and dynamic procedures both have reasonable motivations. Presum-ably, actual inference is a mixture of more dynamic sequential short-term processesand more static long-term ones, not necessarily over the same representations. Thus,both systems must interact:
BooleanAlgebra
propositions procedures RelationalAlgebra
modes
projections
In such a picture, logical connections between the two levels become essential.There will be modes taking standard propositions to correlated procedures, such as“updating” to make a proposition true, or “testing” whether the proposition holdsalready. In the opposite direction, there are projections assigning to each procedurea standard proposition recording some essential feature of its action. Examples are thefixed point operator 0 giving the states where the procedure is already satisfied, or

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 654 — #48
654 Handbook of Logic and Language
set-theoretic domain, giving the states where it can be performed at all. These newoperators of “logical management” may be analyzed technically much as those inSection 12.2.1, e.g., through type-theoretic analysis (cf. Turner, 1996). For instance,fixed-point is the only permutation-invariant projection that is a Boolean homomor-phism (Van Benthem, 1991a). This style of analysis has been extended to eliminativeupdate logic in Van Benthem and Cepparello (1994).
The above setting can also be analyzed using concepts from computer science.In particular, one can trace a dynamic process by means of propositions describingsuccessive images of sets of states under its action. Define strongest postconditionsand weakest preconditions as follows.
SP(A, R) = R[A] (= {b | 2a % A : 0a, b1 % R}),
WP(R, A) = R)1[A] (= {b | 2a % A : 0b, a1 % R}).
The set WP(R, A) is also known as the Peirce product of R and A (cf. Brink, Britzand Schmidt, 1992). Note that '0+1!' = WP('+', '!'). These notions may be usedto render dynamic validity. For example, for update-update consequence, we have
!1, . . . ,!n |=update-update " if and only if
SP(A, '!1' ( · · · ( '!n') . SP(A, '"') for arbitrary sets A.
Moreover, there is an inductive calculus for computing weakest preconditions andstrongest postconditions, with clauses such as:
SP(A, R ( S) = SP(SP(A, R), S),
WP(R ( S, A) = WP(R, WP(S, A)),
SP(A, R # S) = SP(A, R) - SP(A, S),
WP(R # S, A) = WP(R, A) - WP(S, A),
SP(A, R#) = WP(R, A),
WP(R#, A) = SP(A, R).
As an application we give a weakest preconditions calculus which computes thetruth conditions of any DRS or condition, given the total semantics for DRT discussedin Section 12.1.2.2. A simple induction will prove that TR(!) is a predicate logi-cal formula which is true under the same assignments as the condition ! is and thatWP(K, *) is true under a iff there is some b such that 0a, b1 % 'K' and * is true underb. In particular, WP(K, :) will give the truth conditions of K.
TR(!) = ! if ! is atomic,
TR(¬K) = ¬WP(K, :),
TR(K1 - K2) = WP(K1, :) - WP(K2, :),
TR(K1 " K2) = ¬WP(K1, ¬WP(K2, :)),
WP([x1, . . . , xn | !1, . . . ,!m], *) = 2x1 · · · xn(TR(!1) + · · · + TR(!m) + *).

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 655 — #49
Dynamics 655
A similar calculus can be given for DPL:
WP(¬!, *) = ¬WP(!,:) + * ,
WP(! , ", *) = ¬WP(!,¬WP(",:)) + * ,
WP(! + ", *) = WP(!, WP(", *)),
WP(2x!, *) = 2xWP(!, *), etc.
And again WP(!,:) gives !’s truth conditions. Van Eijck and De Vries (1992)extend a calculus such as this one with clauses for generalized quantifiers and a des-cription operator (see also Van Eijck and De Vries, 1995; Van Eijck and Kamp, 1996,where the format of the Segerberg axioms of Section 12.2.1.1 is used).
12.2.4 General Perspectives
In this final section, we summarize our main logical themes, and point out some furtherissues and lines of formal investigation in dynamic semantics.
12.2.4.1 Models for Dynamics
Our main logical paradigm has been Dynamic Logic, broadly conceived (Harel, 1984),viewing procedures as sets of transitions over spaces of (information) states. Dyna-mic operators then resemble those found in the relation-algebraic literature. Alter-native universal-algebraic approaches are Process Algebra (Baeten and Weyland,1990) or Arrow Logic (Venema, 1994). More sensitive notions of computation mightinvolve “failure paths” (Segerberg, 1991) or “trace models” (Vermeulen, 1994). Thesemay suggest richer languages. With processes as sets of state transition sequences(“traces”), the proper formalism is a “branching time logic” combining evaluation atstates with that on traces (“epistemic histories”). But further mathematical paradigmswere available. Gärdenfors’ original theory of belief change (Section 12.1.5) usesCategory Theory, with dynamic procedures as morphisms that can be combined viacategorial limit constructions. Also, Arrow Logic has categorial models (Van Ben-them, 1994a). And we have seen some Utrecht-style examples of concrete category-theoretic analysis for anaphora. Clearly, this alternative route deserves exploration.
Dynamic semantic paradigms have proof-theoretic alternatives – with Curry–Howard–deBruyn isomorphisms assigning algorithmic procedures to derivations forassertions. (Cf. this Handbook, the chapters by Moortgat and Turner.) Proof Theoryhas been proposed as a general paradigm of linguistic meaning in Kneale and Kneale(1962) and Dummett (1976), as well as Van Benthem (1991a) (categorial logic andtyped lambda calculus), Ranta (1991) (Martin-Löf style type theories), Gabbay andKempson (1992) (“labeled deductive systems”). We also briefly considered GameTheory as yet another alternative (Hintikka and Sandu, 1996), which provides logicalgames for evaluating statements, comparing model structures, or carrying on debates,with suitably assigned roles for players and winning conventions (cf. the survey of VanBenthem, 1988). Winning strategies in evaluation or debating games provide analyses

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 656 — #50
656 Handbook of Logic and Language
for truth and consequence in the work of Lorenzen (1959) and Hintikka (1973). Formodel-theoretic “Ehrenfeucht Games”, cf. Doets (1993).
The paradigms of programs, proofs and games are not mutually exclusive. Allinvolve movement through a space of deductive stages, information states, or gameconfigurations. This requires a repertoire of atomic moves over states, that can be com-bined into complex procedures through “logical constructions”. Thus, proofs involvebasic combinatorics for trees: “combination”, “arguing by cases” and “hypothesiz-ing”, creating a dynamic block structure. Programs involve the usual constructionsfor instructions or plans such as “sequential composition”, “indeterministic choice” or“iteration”, possibly guided by “control assertions”. Finally, game operations reflectroles of different players, such as conjunctions or disjunctions indicating their rights ofchoice and duties of response, as well as the notion of “role change” (signaled by nega-tion). Finally, all three paradigms involve an explicit interplay between actions chang-ing states, and standard declarative statements about the states traversed by actions.
12.2.4.2 Higher Levels of Aggregation
Language use is guided by global strategies, such as “preferring the more spe-cific interpretation” (Kameyama, 1992, has computational linguistic architecturesreflecting this). Global strategies have been most prominent in the game-theoreticalliterature. As a result, one also needs global structures, viz. texts or theories, and themeta-rules that govern our activities at these higher levels. Early work on logical struc-ture of scientific theories in the Philosophy of Science is suggestive here (cf. Suppe,1977), as well as the analysis of global structures of definition, proof and refutationin Lakatos (1976), or recent computational work on structured data bases (cf. Ryan,1992). But these have not yet been integrated with mainstream logic. Another globalchallenge is the fact that cognition is usually a social process with more than oneparticipant. The role of multiple agents has been taken seriously in the game-theoreticapproach, but hardly in the other two (but cf. Halpern and Moses, 1985). Many-personversions of dynamic theories are needed, replacing programs by protocols for a groupof distributed agents, and proofs by more interactive formats of reasoning. (Jaspars,1994, is an exploration.)
12.2.4.3 Resources
Our “dynamic turn” crucially involves cognitive resources. There are no unlimitedsupplies of information or “deductive energy”, and logical analysis should bring outwhich mechanisms are adopted, and which cost in resources is incurred. This requiresmanagement of occurrences of assertions or instructions in proofs, programs andgames. Stating a formula twice in a proof means two calls to its evidence, repeat-ing the same instruction in a program calls for two executions, and repeating it inthe course of a game will signal a new obligation as to its defense or attack. (Unlim-ited energy or standing commitment must be encoded explicitly via a logical “repe-tition operator” (Girard, 1987; Van Benthem, 1993a.) Thus, many recent logics work

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 657 — #51
Dynamics 657
with occurrences, at a finer level of detail than the usual classical or intuitionisticcalculi. Moortgat (1996) and Buszkowski (1996), provide detailed linguistic motiva-tion for this shift in emphasis.) Another form of fine-structure is dependence. Stan-dard logics assume that all individuals under discussion can be freely introduced intodiscourse. But in general, some objects may depend on others (cf. Fine, 1985; Hin-tikka and Sandu, 1996; Meyer Viol, 1995), either “in nature” or procedurally, in thecourse of dynamic interpretation. This further degree of freedom has interesting con-sequences. For example, on the usual proof-theoretic account, non-standard generali-zed quantifiers like most or many are difficult to analyze (Sundholm, 1986). But VanLambalgen (1991) gives a Gentzen calculus with “dependence management” for vari-ables in quantifier rules to provide complete logics for non-standard quantifiers, wherethe classical ones become the limiting case with “unlimited access”. Alechina (1995)is a more systematic study of various current dependence semantics with a dynamicflavor.
12.2.4.4 States and Atomic Actions
In this chapter, we have tried to identify some general strands in a process theory fornatural language, at a suitable level of abstraction. In particular, no single notion ofcognitive state can serve all of natural language. For instance, the DRT/DPL treatmentof anaphora uses (partial or total) Tarskian variable assignments. Dynamic accountsof learning or updating have used probability functions over propositions, sets ofworlds, states in Kripke models, or data bases. More complex syntactic discoursestates occur in the computational literature. Nevertheless, useful general distinctionshave emerged, such as that between constructive and eliminative views of informationprocessing (cf. Landman, 1986), where epistemic states become “richer” under updat-ing in the former case, but “simpler”, by dropping alternatives, in the latter. (The twoviewpoints may be combined in a dynamic epistemic logic; cf. Jaspars 1994.) Anothergeneral feature is “dynamization”. Many update calculi may be viewed as “dynamiza-tions” of ordinary modal logics (cf. Van Benthem, 1991a), and standard extensionalor intensional semantics may dynamicized through their natural parameters of varia-tion (Cepparello, 1995). A final interesting issue is combination of different notionsof state, with the resulting marriage of the corresponding logics, as in the merges ofDPL and Update Semantics mentioned in Section 12.1.2.4.
Atomic actions in linguistics include testing of propositions, as well as the updat-ing, contracting and revision found in the computational literature. Other speech actshave only been touched upon, such as questions (cf. Groenendijk and Stokhof, 1984).There is little uniformity in basic actions for different notions of state (compareassignment change versus updating), unless we either (i) move to a higher level ofabstraction, where pops or pushes are general computational moves (Visser, 1994),or (ii) analyze atomic actions into a combination of “modes” plus resultative staticpropositions, such as test(!), achieve(!), query(!), where modes may be uniformacross many different situations (Van Benthem, 1991a).

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 658 — #52
658 Handbook of Logic and Language
12.2.4.5 Dynamic Operators and Invariance
Which dynamic operations construct complex programs, plans, actions? One canapproach this question at the level of linguistic items (programs, scripts) or theirdenotations (executions). There is great diversity here; witness our earlier survey. Theproper definition for various dynamic operators is still under debate; witness the exten-sive discussion of an appropriate dynamic negation for natural language in Dekker(1993). Moreover, different dynamic paradigms may cut the cake in different ways.For example negation is less at home in the proof-theoretic perspective, unless onetreats refutation on a par with proof (cf. Wansing, 1992). Likewise, negation as com-plement of programs is a marginal operation (“avoidance”) – but negation as roleswitching is a crucial element in games. Another difference occurs with quantifiers,which are no longer on a par with propositional connectives in some dynamic seman-tics. They rather signal atomic moves establishing some binding or drawing someobject, plus (in some cases) some further assertion following these. Thus, the syntaxof the usual formal languages may even be misleading, in that it does not allow usto regard, say, a prefix 2x as an independent instruction by itself (say, “pick an object(2), and assign it a temporary name (x)”). A more sensitive account of quantificationalactivity, involving changing data structures and bindings, was found in Section 12.2.2.
What we have outlined in this chapter is a general framework for the whole logicalspace of possibilities. Dynamic logic is all about control operators that combine pro-cedures. Much dynamic semantics investigates what standard logical constants meanwhen viewed as procedural combinators. But dynamics allows for finer distinctionsthan statics, so that there may not be any clear sense to this. Standard conjunctionreally collapses several notions: sequential composition, but also various forms of par-allel composition. Likewise, standard negation may be either some test as in DPL, ormerely an invitation to make any move refraining from some forbidden action (“youcan do anything, but don’t step on my blue suede shoes”). Some natural operatorsin dynamic logic even lack classical counterparts altogether, such as “conversion” or“iteration” of procedures. One general perspective of semantic invariance relates thestatic and dynamic notions (Sher, 1991; Van Benthem, 1989). Truly logical operatorsdo not depend on specific individuals in their arguments. This is also true for procedu-ral operators. What makes, say, a complement )R a logical negation is that it worksuniformly on all ordered pairs (or arrows) in R, unlike an adjective like “clever” whichdepends on the content of its relational arguments. The mathematical generalizationis invariance under permutations + of the underlying universe of individuals (here,information states). Dynamic procedures denote binary relations between states, andhence procedural operators satisfy the commutation schema:
+ [O(R, S, . . .)] = O(+[R], +[S], . . .).
For a general type-theoretic formulation of this notion, cf. Van Benthem (1991a).Permutation invariance leaves infinitely many potential dynamic logical constants.
There are several ways of tightening up. One insists on suitable forms of linguisticdefinability. For instance, many dynamic operators have first-order definitions with

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 659 — #53
Dynamics 659
variables over states and binary relation letters for procedures. We shall encounterthis view-point in the next section. Another strengthening increases the demands oninvariance, by requiring commutation for much looser forms of process equivalencethan isomorphism over the same base domain. A typical example was the “safety forbisimulation” discussed earlier.
12.2.4.6 Dynamic Styles of Inference
We have identified several dynamic styles of inference. These may still vary accord-ing to one’s dynamic paradigm. The proof-theoretic perspective justifies an inferenceby composing it as the result of a number of basic moves. For instance, the basicinference A - B, ¬A/B is a combination of argument by cases and one basic negationstep:
A ¬AA - B B B
B.
In the programming perspective, this same inference would rather be viewed as aprocedural update instruction:
Updating any information state by A - B and then by ¬A (given some suitable pro-cedural meaning for these operations) leads to a new information state which may betested to validate B.
In the context of games, the story is different again. For instance, the “agonistic”Lorenzen style would express the relevant validity as follows:
There exists a winning strategy for defending the claim B in a dialogue game againstany opponent who has already granted the two concessions A - B, ¬A.
One locus of difference here lies in the structural rules governing inference.Important examples are the admissibility, without loss of previous conclusions, ofshuffling premises by Permutation, or of adding new premises by Monotonicity(Section 12.2.1.6 provided detailed formulations). For instance, Permutation is reason-able on both proof-theoretic and game-theoretic views, whereas it seems unreasonableon the programming view, since the sequential order of instructions is usually crucialto their total intended effect. Likewise, Monotonicity is plausible in games (the moreconcessions from one’s opponent the better), but less so on the other two accounts.Still, if premise ordering in a game encodes priority of commitments incurred, thenPermutation loses its appeal in the latter model too.
But also, analyzing cognitive activity via different interacting mechanisms raisesissues of logical architecture. What systematic methods are available for switchingbetween components (proof-theoretic, algorithmic, game-theoretic – and within these,between different facilities), and how do we transport information from one to theother? In other words, what are natural constructions of heterogeneous logical calculi?

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 660 — #54
660 Handbook of Logic and Language
Some relevant material on these issues exists in the logical literature (cf. Gabbay,1996), but no general theory exists.
12.2.4.7 Connections with Computer Science
Process Algebra views the denotations of procedures, not as binary relations, but ratheras labeled transition models themselves (identified modulo bisimulation, or some otherappropriate semantic equivalence). Some key references in this extensive field areMilner (1980), Bergstra and Klop (1984), Baeten and Weyland (1990). The result isa family of equational calculi for operations on, rather than inside, labeled transitionsystems. These provide abstract algebraic axiomatizations for various program con-structions, including a much richer repertoire than what has been considered in dyna-mic semantics. Examples are various parallel merges, as well as operators for “hiding”structure, or for performing recursion. (For connections between Process Algebra andDynamic Logic, see Hennessy and Milner, 1985; Van Benthem and Bergstra, 1993;Van Benthem, Van Eijck and Stebletsova, 1993, Van Benthem, 1994a.) An eventualprocess theory for natural language may well have to be of this level of semanticsophistication.
12.2.4.8 Lowering Complexity: Arrow Logic and Modal State Semantics
One immediate concern in dynamic semantics is computational complexity. Manysystems in Section 12.1 are supposed to mirror mechanisms in human cognition, andpresumably, these procedures are geared towards speed and efficiency. Nevertheless,little is known about the complexity of various procedural logics – and what little isknown, often makes their behavior more complex than that of standard static systems(cf. Harel, 1984). For example, static propositional logic is decidable, relational alge-bra is not. Some recent logical proposals exist for coming to terms with such apparentparadoxes. We mention two of these.
Relational Algebra is not the only candidate for analyzing dynamic procedures.Intuitively, the latter seem to consist of transitions or arrows as objects in their ownright. This alternative view is brought out in Arrow Logic, a modal logic over arrowframes 0W, C, R, I1 with a set W of arrows, a ternary relation C of composition, abinary relation R of reversal and a set I of identical arrows. Formulas ! will describesets of arrows '!', i.e. transition relations in the new sense. Some key clauses in thebasic truth definition are as follows.
'! & "' =' !' & '"','! ( "' ={ a | 2bc(0a, b, c1 % C & b % '!' & c % '"')},'!#' ={ a | 2b(0a, b1 % R & b % '!')},'/' = I.
Arrow Logic is a minimal theory of composition of actions, which may be stud-ied by well-known techniques from Modal Logic (cf. Van Benthem, 1991a; Venema,

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 661 — #55
Dynamics 661
1991, 1994). Standard principles of Relational Algebra then express constraints onarrow patterns, which can be determined via frame correspondences (De Rijke, 1993;Van Benthem, 1994a). For instance, the algebraic law (! # ")# = (!# # "#) is auniversally valid principle of modal distribution on arrow frames, but (! & ")# =(!# & "#) expresses the genuine constraint that the conversion relation be a partialfunction f , whose idempotence would be expressed by the modal axiom !## = !.As an illustration, basic categorial laws of natural language (cf. Moortgat, 1996) nowacquire dynamic content.
A • (A\B) " B expresses that 3abc(0a, b, c1 % C , 0c, f (b), a1 % C).
(B/A) • A " B expresses that 3abc(0a, b, c1 % C , 0b, a, f (c)1 % C).
In particular, one can now study dynamic counterparts of the Lambek Calculus (cf.Kurtonina, 1995, for a full development).
More radically, one can take this same deconstructionist line with respect to first-order predicate logic, the lingua franca of modern semantics – which suffers fromundecidability. What makes first-order predicate logic tick at an abstract computationallevel? As we saw, the basic Tarski truth definition makes choices that are inessential toa compositional semantics for first-order quantification. In particular, concrete assign-ments and the concrete relation a[x]b between assignments are not needed to make thesemantic recursion work. The abstract core pattern that is needed replaces assignmentsby abstract states and the relations [x] by arbitrary binary relations Rx between states.Models will then be poly-modal Kripke models 0S, {Rx}x%VAR, V1, where S is the setof states and the valuation function V assigns a subset of S to each atomic sentenceR(x1, . . . , xn). The standard truth definition now generalizes to the following modalset-up.
(i!) 'R(x1, . . . , xn)' = V(R(x1, . . . , xn)).
(ii!) '¬!' = S ) '!','! - "' =' !' # '"'.
(iii!) '2x!' ={ a % S | 2b(aRxb & b % '!')}.
This semantics treats existential quantifiers 2x as labeled modalities 0x1. Its uni-versal validities constitute the well-known minimal modal logic, whose principles are(a) all classical propositional laws, (b) the axiom of Modal Distribution: 2x(! -") 9(2x! - 2x"), and (c) the rule of Modal Necessitation: if 8 !, then 8 ¬2x¬!.A completeness theorem may be proved using the standard Henkin construction. Thispoly-modal logic can be analyzed in a standard fashion (Andréka, Van Benthem andNémeti, 1994, is a modern treatment), yielding the usual meta-properties such as theCraig Interpolation Theorem, and the !os–Tarski Preservation Theorem for submod-els. In particular, the logic can be shown to be decidable via any of the usual modaltechniques (such as filtration). This means that the particular set-theoretic implemen-tation of the set S and the relations Rx that we find in the usual Tarski semantics canbe diagnosed as the source of undecidability of elementary logic.
The modal perspective on classical logic uncovers a whole fine-structure ofpredicate-logical validity. The minimal predicate logic consists of those laws which

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 662 — #56
662 Handbook of Logic and Language
are “very much valid”. But we can analyze what other standard laws say too by thetechnique of modal frame correspondence. Here are some illustrations.
(! + 2x!) 9 ! expresses that Rx is reflexive.2x(! + 2x") 9 (2x! + 2x") expresses that Rx is transitive and euclidean,2x2y! 9 2y2x! expresses that Rx ( Ry = Ry ( Rx,
2x3y! , 3y2x! expresses that whenever aRxbRyc, there is ad such that aRydRxc.
The first two constraints make the Rx into equivalence relations, as with the modallogic S5. They do not impose existence of any particular states in frames. The thirdaxiom, by contrast, is existential in nature; it says that sequences of state changes maybe traversed in any order. Abstract state models need not have enough intermediatestates to follow all alternative routes. The fourth example says that another well-knownquantifier shift expresses a Church–Rosser property of computational processes. Thus,the valid laws of predicate logic turn have quite different dynamic content when ana-lyzed in the light of this broader semantics.
We have found a minimal decidable system of predicate logic in addition to thestandard undecidable one. Intermediate systems arise by varying requirements onstates and updates Rx. Thus a whole landscape of intermediate predicate logics isopened up to us. Here, we seek expressive logics that share important properties withpredicate logic (Interpolation, Effective Axiomatizability) and that even improve onthis, preferably by being decidable. An attractive option, already known from Cylin-dric Algebra (cf. Henkin, Monk and Tarski, 1985; Németi, 1991) is CRS, the logicconsisting of all predicate-logical validities in the state frames satisfying all univer-sal frame conditions true in standard assignment models. These are the general log-ical properties of assignments that do not make existential demands on their supply.(The latter would be more “mathematical” or “set-theoretic”.) CRS is known to bedecidable, though non-finitely axiomatizable. Moreover, its frame definition needsonly universal Horn clauses, from which Craig Interpolation follows (Van Benthem,1994a). Another way of describing CRS has independent appeal. Consider state frameswhere S is a family of ordinary assignments (but not necessarily the full functionspace DVAR), and the Rx are the standard relations [x]. Such frames admit “assignmentgaps”, i.e. essentially they need not satisfy axiom AX1 of Section 12.2.3.2 above. Thiscan be used to model dependencies between variables: changes in value for one vari-able x may induce, or be correlated with, changes in value for another variable y (cf.our earlier discussion of resources). This phenomenon cannot be modeled in standardTarskian semantics, the latter being a degenerate case where all interesting dependen-cies between variables have been suppressed. From CRS one can move upward in thehierarchy of logics by considering only families of assignments that satisfy naturalclosure conditions. Such further structure supports the introduction of further opera-tors into the language (e.g., permutation or substitution operators). (For the resultinglogics, cf. Marx, 1994; Mikulas, 1995.)

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 663 — #57
Dynamics 663
12.2.4.9 Philosophical Repercussions
We conclude with some sweeping thoughts. Dynamic paradigms suggest generalcognitive claims. The programming model supports Church’s Thesis which claimsthat any form of effective (cognitive) computation can be programmed on a TuringMachine, or some equivalent device from Recursion Theory. In its broader sense, theTuring Test is a well-known dramatized version. But similar claims can be made con-cerning proofs or games (in the setting of a suitably general Proof Theory or GameTheory), and that even in two ways. Church’s Thesis may be interpreted as the exten-sional statement that the input-output behavior of every effective function can be ade-quately programmed on some abstract machine. But it also has a stronger intensionalversion, stating that any algorithm can be reflected faithfully in some specific universalprogramming repertoire (cf. Moschovakis, 1991). This intensional question returns forproof-theoretic and game-theoretic approaches. What are their natural repertoires oflogical constructions that should suffice for faithful modeling of any rational formof inference or cognitive play? (Compare the proof-theoretic functional complete-ness results in Sundholm, 1986; or the hierarchies of programming operators in VanBenthem, 1996.) There could also be “Small Church Theses” at lower levels of com-putational complexity, closer to actual linguistic processing (cf. various equivalenceresults in Kanovich, 1993). Of course, one will have to analyze more carefully towhich extent the computational metaphor is realistic for natural language (Fernando,1992, proposes recursion-theoretic models for this purpose). In this respect, anotherdesideratum emerges. Our paradigms mostly provide kinematics: an extensional ana-lysis of transitions made, whereas one eventually wants genuine dynamics: an accountof the underlying processes, which explains observed transition behavior. So far, muchof logical semantics has had an extensional engineering flavor, following Lewis’s(1972) dictum: In order to say what a meaning is, we may first ask what a meaningdoes, and then find something that does that.
References
Alchourrón, C., Gärdenfors, P., Makinson, D., 1985. On the logic of theory change: partial meetfunctions for contraction and revision. J. Symb. Logic 50, 510–530.
Alechina, N., 1995. Modal Quantifiers. Dissertation, Institute for Logic, Language and Compu-tation, University of Amsterdam, the Netherlands.
Andréka, H., Van Benthem, J., Németi, I., 1994. Back and Forth between Modal Logicand Classical Logic. Mathematical Institute, Hungarian Academy of Sciences, Budapest/Institute for Logic, Language and Computation, University of Amsterdam, the Nether-lands, Report ILLC-ML-95–04.
Asher, N., 1993. Reference to Abstract Objects in Discourse. Kluwer, Dordrecht.Baeten, J., Weyland, P., 1990. Process Algebra. Cambridge University Press, Cambridge, MA.Barr, M., Wells, C., 1989. Category Theory for Computing Science. Prentice-Hall, New York.Barwise, J., 1987. Noun phrases, generalized quantifiers and anaphora, in: Gärdenfors, P. (Ed.),
Generalized Quantifiers. Logical and Linguistic Approaches. Reidel, Dordrecht, pp. 1–29.

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 664 — #58
664 Handbook of Logic and Language
Beaver, D., 1992. The kinematics of presupposition, in: Dekker, P., Stokhof, M. (Eds.),Proceedings of the Eighth Amsterdam Colloquium. Institute for Logic, Language andComputation, University of Amsterdam, the Netherlands, pp. 17–36.
Beaver, D., 1996. Presupposition, in: van Benthem, J., ter Meulen, A. (Eds.), Handbook ofLogic and Language, pp. 939–1009, MIT Press, Cambridge, MA.
Belnap, N., 1977. A useful four-valued logic, in: Dunn, J.M., Epstein, G. (Eds.), Modern Usesof Multiple-Valued Logics. Reidel, Dordrecht, pp. 8–37.
Bergstra, J., Klop, J.-W., 1984. Process algebra for synchronous communication. Inform.Control 60, 109–137.
Blackburn, P., Venema, Y., 1993. Dynamic Squares. Logic Preprint 92, Department ofPhilosophy, University of Utrecht, the Netherlands. (J. Philos. Logic)
Blamey, S., 1986. Partial logic, in: Gabbay, D., Günthner, F. (Eds.), Handbook of PhilosophicalLogic, vol. III, Reidel, the Netherlands, pp. 1–70.
Bos, J., Mastenbroek, E., McGlashan, S., Millies, S., Pinkal, M., 1994. A compositional DRS-based formalism for NLP applications, in: Bunt, H., Muskens, R., Rentier, G. (Eds.),Proceedings of the International Workshop on Computational Semantics. Institute forLanguage Technology and Artificial Intelligence, Tilburg, pp. 21–31.
Boutilier, C., 1993. Revision sequences and nested conditionals, in: Bajcsy, R. (Ed.), Proceed-ings of the 13th IJCAI. Morgan Kaufmann, Washington, DC, pp. 519–525.
Boutilier, C., Goldszmidt, M., 1993. Revision by conditional beliefs, in: Proceedings of the 11thNational Conference on Artificial Intelligence (AAAI). Morgan Kaufmann, Washington,DC, pp. 649–654.
Brink, C., Britz, K., Schmidt, R., 1992. Peirce Algebras. Report MPI-I-92-229, MPI,Saarbrücken.
Buszkowski, W., 1996. Mathematical Linguistics and Proof Theory, in: van Benthem, J.,ter Meulen, A. (Eds.), Handbook of Logic and Language, MIT Press, Cambridge, MA,pp. 683–737.
Cepparello, G., 1995. Dynamics: Logical Design and Philosophical Repercussions. Dissertation,Scuola Normale Superiore, Pisa.
Chierchia, G., 1988. Dynamic Generalized Quantifiers and Donkey Anaphora, in: Krifka, M.(Ed.), Genericity in Natural Language. University of Tübingen, Germany, SNS, pp. 53–84.
Davidson, D., 1967. The Logical Form of Action Sentences. Reprinted: Davidson, D., 1980.Essays on Actions and Events, Clarendon Press, Oxford.
Dekker, P., 1993. Transsentential Meditations. ILLC Dissertation Series 1993-1, Institute forLogic, Language and Computation, University of Amsterdam, the Netherlands.
De Rijke, M., 1993. Extending Modal Logic. Dissertation Series 1993–4, Institute for Logic,Language and Computation, University of Amsterdam.
Doets, K., 1993. Model Theory. Lecture Notes for the Fifth European Summer School in Logic,Language and Information, University of Lisbon.
Dummett, M., 1976. What is a theory of meaning?, in: Evans, G., McDowell, J. (Eds.), Truthand Meaning. Oxford University Press, Oxford, pp. 67–137.
Fernando, T., 1992. Transition Systems and Dynamic Semantics. Logics in AI, LNCS 633,Springer, Berlin.
Fine, K., 1985. Reasoning with Arbitrary Objects. Blackwell, Oxford.Gabbay, D., 1996. Labeled Deductive Systems. Oxford University Press, Oxford.Gabbay, D., Kempson, R., 1992. Natural language content: a proof-theoretic perspective, in:
Dekker, P., Stokhof, M. (Eds.), Proceedings of the Eighth Amsterdam Colloquium. Institutefor Logic, Language and Computation, University of Amsterdam, the Netherlands,pp. 173–195.

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 665 — #59
Dynamics 665
Gärdenfors, P., 1988. Knowledge in Flux. Modelling the Dynamics of Epistemic States, MITPress, Cambridge, MA.
Gärdenfors, P., Makinson, D., 1988. Revisions of knowledge systems using epistemic entrench-ment, in: Vardi, M. (Ed.), Theoretical Aspects of Reasoning about Knowledge. MorganKaufmann, Los Altos, CA, pp. 83–95.
Gazdar, G., 1979. Pragmatics. Academic Press, New York.Girard, J.-Y., 1987. Linear logic. Theor. Comput. Sci. 50, 1–102.Goldblatt, R., 1987. Logics of Time and Computation. CSLI Lecture Notes, Chicago University
Press, Chicago.Groenendijk, J., Stokhof, M., 1984. Studies in the Semantics of Questions and the Pragmatics
of Answers. Doctoral Dissertation, University of Amsterdam, the Netherlands.Groenendijk, J., Stokhof, M., 1990. Dynamic Montague grammar, in: Kálmán, L., Pólos, L.
(Eds.), Papers from the Second Symposium on Logic and Language. Akadémiai Kiadó,Budapest, pp. 3–48.
Groenendijk, J., Stokhof, M., 1991. Dynamic predicate logic. Ling. Philos. 14, 39–100.Groenendijk, J., Stokhof, M., Veltman, F., 1996. Coreference and modality, in: Lappin, S. (Ed.),
The Handbook of Contemporary Semantic Theory. Blackwell, Oxford, pp. 179–214.Grosz, B., Sidner, C., 1986. Attention, intention, and the structure of discourse. Comput. Ling.
12, 175–204.Halpern, J., Moses, Y., 1985. Towards a theory of knowledge and ignorance, in: Apt, K. (Ed.),
Logics and Models of Concurrent Systems. Springer, Berlin, pp. 459–476.Harel, D., 1984. Dynamic Logic, in: Gabbay, D., Günthner, F. (Eds.), Handbook of Philosophi-
cal Logic vol. II. Reidel, Dordrecht, pp. 497–604.Harel, D., Kozen, D., 1994. Dynamic Logic. Department of Computer Science, Technion,
Haifa/Department of Computer Science, Cornell University.Heim, I., 1982. The Semantics of Definite and Indefinite Noun Phrases. Dissertation, University
of Massachusetts, Amherst, published in 1989 by Garland, New York.Heim, I., 1983a. On the projection problem for presuppositions, in: Proceedings of the
West Coast Conference on Formal Linguistics vol. II. Stanford Linguistic Association,Stanford, CA, pp. 114–125. Reprinted in: Davies, S. (Ed.), 1991. Pragmatics, OUP, Oxford,pp. 397–405.
Heim, I., 1983b. File change semantics and the familiarity theory of definiteness, in: Bäuerle, R.,Schwarze, C., Stechow, von A. (Eds.), Meaning, Use and Interpretation of Language.De Gruyter, Berlin, pp. 164–189.
Henkin, L., Monk, D., Tarski, A., 1985. Cylindric Algebra, part II. North-Holland, Amsterdam.Hennessy, M., Milner, R., 1985. Algebraic Laws for Nondeterminism and Concurrency.
J. Assoc. Comput. Mach. 32, 137–161.Hintikka, J., 1973. Logic, Language Games and Information. Clarendon Press, Oxford.Hintikka, J., Sandu, G., 1996. Game-Theoretical Semantics, in: van Benthem, J., ter
Meulen, A. (Eds.), Handbook of Logic and Language, MIT Press, Cambridge, MA,pp. 361–411.
Hofstadter, D., 1980. Gödel, Escher, Bach: An Eternal Golden Braid. Vintage Books, New York.Jaspars, J., 1994. Calculi for Constructive Communication. ILLC Dissertation Series 1994-1,
Institute for Logic, Language and Computation, University of Amsterdam/Institute forLanguage Technology and Artificial Intelligence, Tilburg University, the Netherlands.
Kameyama, M., 1992. The Linguistic Information in Dynamic Discourse. Research ReportCSLI-92-174, Center for the Study of Language and Information, Stanford University,Stanford, CA.

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 666 — #60
666 Handbook of Logic and Language
Kamp, H., 1981. A theory of truth and semantic representation, in: Groenendijk, J. et al. (Eds.),Truth, Interpretation and Information. Foris, Dordrecht, pp. 1–41.
Kamp, H., Reyle, U., 1993. From Discourse to Logic. Kluwer, Dordrecht.Kanazawa, M., 1993a. Completeness and decidability of the mixed style of inference with com-
position, in: Dekker, P., Stokhof, M. (Eds.), Proceedings of the Ninth Amsterdam Col-loquium. Institute for Logic, Language and Computation, University of Amsterdam, theNetherlands, pp. 377–390.
Kanazawa, M., 1993b. Dynamic Generalized Quantifiers and Monotonicity. Report LP-93-02,Institute for Logic, Language and Computation, University of Amsterdam.
Kanovich, M., 1993. The Expressive Power of Modalized Purely Implicational Calculi. ReportCSLI-93-184, Center for the Study of Language and Information, Stanford University,Stanford, CA.
Karttunen, L., 1973. Presuppositions of compound sentences. Ling. Inq. 4, 167–193.Karttunen, L., 1974. Presupposition and linguistic context. Theor. Ling. 1, 181–194.Karttunen, L., 1976. Discourse referents, in: McCawley, J. (Ed.), Syntax and Semantics 7: Notes
from the Linguistic Underground. Academic Press, New York, pp. 363–385.Karttunen, L., Peters, S., 1979. Conventional implicature, in: Oh, C.-K., Dinneen, D. (Eds.),
Syntax and Semantics 11: Presupposition. Academic Press, New York, pp. 1–56.Keenan, E., Westerståhl, D., 1996. Quantifiers, in: van Benthem, J., ter Meulen, A. (Eds.), Hand-
book of Logic and Language, MIT Press, Cambridge, MA, pp. 837–895.Keenan, E., Faltz, L., 1985. Boolean Semantics for Natural Language. Reidel, Dordrecht.Kneale, W., Kneale, M., 1962. The Development of Logic. Clarendon Press, Oxford.Krahmer, E., 1995. Discourse and Presupposition: From the Man in the Street to the King of
France. Doctoral Dissertation, Tilburg University, the Netherlands.Kurtonina, N., 1995. Frames and Labels. A logical Investigation of Categorial Structure.
Dissertation, Onderzoeksinstituut voor Taal en Spraak, Universiteit Utrecht, the Nether-lands.
Lakatos, I., 1976. Proofs and Refutations. Cambridge University Press, Cambridge.Landman, F., 1986. Towards a Theory of Information. The Status of Partial Objects in Seman-
tics. Foris, Dordrecht.Lewis, D., 1972. General semantics, in: Davidson, D., Harman, G. (Eds.), Semantics of Natural
Language. Reidel, Dordrecht, pp. 169–218.Lewis, D., 1973. Counterfactuals. Blackwell, Oxford.Lewis, D., 1979. Score keeping in a language game. J. Philos. Logic 8, 339–359.Lorenzen, P., 1959. Ein dialogisches Konstruktivitätskriterium. Lecture Reprinted: Lorenzen, P.,
Lorenz, K., 1978. Dialogische Logik, Wissenschaftliche Buchgesellschaft, Darmstadt.Makinson, D., 1985. How to give it up: a survey of some formal aspects of the logic of theory
change. Synthese 62, 347–363.Manes, E., Arbib, M., 1975. Arrows, Structures and Functors, the Categorical Imperative. Aca-
demic Press, New York.Marx, M., 1994. Arrow Logic and Relativized Algebras of Relations. Dissertation, CCSOM,
Faculty of Social Sciences/Institute for Logic, Language and Computation, University ofAmsterdam, the Netherlands.
McLane, S., 1971. Categories for the Working Mathematician. Springer, Berlin.Meyer Viol, W., 1995. Instantial Logic. Dissertation, Onderzoeksinstituut voor Taal en Spraak,
Universiteit Utrecht, the Netherlands.Mikulas, S., 1995. Taming Logics, Dissertation, Institute for Logic Language and Computation,
University of Amsterdam, the Netherlands.

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 667 — #61
Dynamics 667
Milner, R., 1980. A Calculus of Communicating Systems. Springer, Berlin.Montague, R., 1970. Universal Grammar. Reprinted: Montague, R., 1974. Formal Philosophy.
Yale University Press, New Haven, CT, pp. 222–246.Moortgat, M., 1996. Categorial Grammar, in: van Benthem, J., ter Meulen, A. (Eds.), Handbook
of Logic and Language, MIT Press, Cambridge, MA, pp. 93–179.Moschovakis, Y., 1991. Sense and Reference as Algorithm and Value. Department of Mathe-
matics, University of California, Los Angeles, CA.Muskens, R., 1991. Anaphora and the logic of change, in: van Eijck, J. (Ed.), JELIA
’90, European Workshop on Logics in AI, Springer Lecture Notes, Springer, Berlin,pp. 414–430.
Muskens, R., 1994. Categorial grammar and discourse representation theory, in: Proceedings ofCOLING 94. Kyoto, Japan, pp. 508–514.
Muskens, R., 1995a. Tense and the logic of change, in: Egli, U., Pause, P.E., Schwarze, C.,von Stechow, A., Wienold, G. (Eds.), Lexical Knowledge in the Organization of Language.Benjamin, Amsterdam, pp. 147–183.
Muskens, R., 1995b. Combining Montague semantics and discourse representation. Ling.Philos. 19, 143–186.
Németi, I., 1991. Algebraizations of Quantifier Logics: An Introductory Overview. Mathemati-cal Institute, Hungarian Academy of Sciences, Budapest.
Parsons, T., 1990. Events in the Semantics of English. MIT Press, Cambridge, MA.Peters, S., 1975. A Truth-Conditional Formulation of Karttunen’s Account of Presuppositions.
Texas Linguistic Forum, University of Texas, Austin, TX, pp. 137–149.Polanyi, L., 1985. A Theory of Discourse Structure and Discourse Coherence. Papers from the
General Session of the Chicago Linguistic Society, University of Chicago, IL, CLS vol. 21,pp. 306–322.
Popper, K., 1959. The Logic of Scientific Discovery. Hutchinson, London.Pratt, V., 1976. Semantical considerations on Floyd–Hoare logic, in: Proceedings of 17th IEEE
Symposium on Foundations of Computer Science, IEEE Computer Society, Long Beach,CA, pp. 109–121.
Ramsey, F.P., 1929. General Propositions and Causality. Reprinted: Ramsey, F.P., Foundations:Essays in Philosophy, Logic, Mathematics and Economics. Routledge and Kegan Paul,London, 1978.
Ranta, A., 1991. Intuitionistic categorial grammar. Ling. Philos. 14, 203–239.Reyes, G.E., Macnamara, J., 1994. The Logical Foundations of Cognition. Oxford University
Press, New York/Oxford.Rott, H., 1992. Preferential belief change using generalized epistemic entrenchment. J. Logic
Lang. Inform. 1, 45–78.Ryan, M., 1992. Ordered Presentations of Theories: Default Reasoning and Belief Revision.
PhD Thesis, Department of Computing, Imperial College, University of London.Scha, R., Polanyi, L., 1988. An augmented context free grammar for discourse, in: Proceedings
of the 12th International Conference on Computational Linguistics. Budapest, Hungary,pp. 573–577.
Scott, D.S., 1982. Domains for denotational semantics, in: Nelsen, M., Schmidt, E.T. (Eds.),Proceedings of the 9th International Colloquium on Automata, Languages and Program-ming. Lecture Notes Comput. Science, vol. 140, Springer, Berlin, pp. 577–613.
Segerberg, K., 1982. A completeness theorem in the modal logic of programs, in: Traczyk, T.(Ed.), Universal Algebra and Applications. Banach Centre Publications 9, PWN – PolishScientific, Warsaw, pp. 31–46.

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 668 — #62
668 Handbook of Logic and Language
Segerberg, K., 1991. Logics of Action. Abstracts of the 9th International Congress on Logic,Methodology and Philosophy of Science, Uppsala.
Seuren, P., 1975. Tussen Taal en Denken. Scheltema, Holkema en Vermeulen, Amsterdam.Seuren, P., 1985. Discourse Semantics. Blackwell, Oxford.Sher, G., 1991. The Bounds of Logic. A Generalised Viewpoint. Bradford Books/MIT Press,
Cambridge, MA.Shoham, Y., 1988. Reasoning About Change. Time and Causation from the Standpoint of Arti-
ficial intelligence. Yale University Press, New Haven, CT.Soames, S., 1989. Presupposition, in: Gabbay, D., Günthner, F. (Eds.), Handbook of Philosoph-
ical Logic vol. IV. Reidel, Dordrecht, pp. 553–616.Spohn, W., 1988. Ordinal conditional functions: a dynamic theory of epistemic states, in:
Harper, W.L. et al. (Eds.), Causation in Decision, Belief Change and Statistics II. Kluwer,Dordrecht, pp. 105–134.
Stalnaker, R., 1968. A theory of conditionals, in: Rescher, N. (Ed.), Studies in Logical Theory.Basil Blackwell, Oxford, pp. 98–112.
Stalnaker, R., 1974. Pragmatic presuppositions, in: Munitz, M., Unger, P. (Eds.), Semantics andPhilosophy. New York University Press, New York, pp. 197–213.
Stalnaker, R., 1979. Assertion, in: Cole, P. (Ed.), Syntax and Semantics 9: Pragmatics. AcademicPress, New York, pp. 315–332.
Sundholm, G., 1986. Proof theory and meaning, in: Gabbay, D., Guenthner, F. (Eds.), Handbookof Philosophical Logic vol. III. Reidel, Dordrecht, pp. 471–506.
Suppe, F., 1977. The Structure of Scientific Theories. University of Illinois Press, Urbana, IL.Troelstra, A., Van Dalen, D., 1988. Constructivism in Mathematics, two vol. North-Holland,
Amsterdam.Turner, R., 1996. Types, in: van Benthem, J., ter Meulen, A. (Eds.), Handbook of Logic and
Language, MIT Press, Cambridge, MA, pp. 535–587.Van Benthem, J., 1986. Essays in Logical Semantics. Studies in Linguistics and Philosophy,
vol. 29. Reidel, Dordrecht.Van Benthem, J., 1988. Games in logic: a survey, in: Hoepelman, J. (Ed.), Representation and
Reasoning. Niemeyer Verlag, Tübingen, pp. 3–15.Van Benthem, J., 1989. Semantic parallels in natural language and computation, in: Ebbing-
haus, H.-D. et al. (Eds.), Logic Colloquium. Granada 1987. North-Holland, Amsterdam,pp. 331–375.
Van Benthem, J., 1991. Language in Action. Categories, Lambdas and Dynamic Logic. North-Holland, Amsterdam.
Van Benthem, J., 1991a. General dynamics. Theor. Ling. 17, 159–201.Van Benthem, J., 1993. Logic and the flow of information, in: Prawitz, D., Skyrms, B., West-
erståhl, D. (Eds.), Proceedings of the 9th International Congress of Logic, Methodologyand Philosophy of Science. Uppsala 1991. Elsevier, Amsterdam, pp. 693–724.
Van Benthem, J., 1993a. Modeling the kinematics of meaning, in: Proceedings of the Aristote-lean Society, London 1993. pp. 105–122.
Van Benthem, J., 1993b. Programming Operations That Are Safe for Bisimulation. Report93–179, Center for the Study of Language and Information, Stanford University.
Van Benthem, J., 1994a. A Note on Dynamic Arrow logic, in: van Eijck, J., Visser, A. (Eds.),Dynamic Logic and Information Flow. MIT Press, Cambridge, MA, pp. 15–29.
Van Benthem, J., 1994b. Modal Foundations for Predicate Logic. Research Report CSLI-94-191, Center for the Study of Language and Information, Stanford University, Stanford, CA.

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 669 — #63
Dynamics 669
Van Benthem, J., 1996. Exploring Logical Dynamics, CSLI Publications, Stanford, CA.Van Benthem, J., Bergstra, J., 1993. Logic of Transition Systems. Report CT-93–03, Institute
for Logic, Language and Computation, University of Amsterdam, the Netherlands.Van Benthem, J., Cepparello, G., 1994. Tarskian Variations. Dynamic Parameters in Classical
Semantics. Technical Report CS-R9419, CWI, Amsterdam.Van Benthem, J., Van Eijck, J., Frolova, A., 1993. Changing Preferences. Technical Report
CS-R9310, CWI, Amsterdam.Van Benthem, J., Van Eijck, J., Stebletsova, V., 1993. Modal logic, transition systems and pro-
cesses, Logic Comput. 4 (5), 811–855.Van den Berg, M., 1995. Plural Dynamic Generalized Quantifiers. Dissertation, Institute for
Logic, Language and Computation, University of Amsterdam, the Netherlands.Van Deemter, K., 1991. On the Composition of Meaning. Dissertation, Institute for Logic, Lan-
guage and Information, University of Amsterdam, the Netherlands.Van der Does, J., 1992. Applied Quantifier Logics. Dissertation, Institute for Logic, Language
and Computation, University of Amsterdam, the Netherlands.Van Eijck, J., Cepparello, G., 1994. Dynamic modal predicate logic, in: Kanazawa, M., Piñon,
Ch. (Eds.), Dynamics, Polarity and Quantification, CSLI, Stanford, pp. 251–276.Van Eijck, J., De Vries, F.-J., 1992. Dynamic interpretation and Hoare deduction. J. Logic Lang.
Inform. 1, 1–44.Van Eijck, J., De Vries, F.-J., 1995. Reasoning about update logic. J. Philos. Logic 24, 19–45.Van Eijck, J., Visser, A. (Eds.), 1994. Dynamic Logic and Information Flow. MIT Press,
Cambridge, MA.Van Eijck, J., Kamp, H., 1996. Representing Discourse in Context, in: van Benthem, J.,
ter Meulen, A. (Eds.), Handbook of Logic and Language, MIT Press, Cambridge, MA,pp. 179–239.
Van Lambalgen, M., 1991. Natural deduction for generalized quantifiers, in: van der Does, J.,van Eijck, J. (Eds.), Generalized Quantifiers: Theory and Applications. Dutch PhD Net-work for Logic, Language and Information, Amsterdam, pp. 143–154.
Veltman, F., 1985. Logics for Conditionals. Dissertation, University of Amsterdam, the Nether-lands.
Veltman, F., 1991. Defaults in Update Semantics. Report LP-91-02, Institute for Logic, Lan-guage and Computation, University of Amsterdam.
Venema, Y., 1991. Many-Dimensional Modal Logic. Dissertation, Institute for Logic, Languageand Computation, University of Amsterdam.
Venema, Y., 1994. A crash course in arrow logic, in: Masuch, M., Polos, L. (Eds.), Knowl-edge Representation and Reasoning under Uncertainty, Logic at Work. Lecture Notes inArtificial Intelligence, vol. 808. Springer, Berlin, pp. 3–34.
Vermeulen, K., 1994. Exploring the Dynamic Environment. Dissertation, Onderzoeksinstituutvoor Taal en Spraak, University of Utrecht, the Netherlands.
Visser, A., 1994. Actions under presuppositions, in: van Eijck, J., Visser, A. (Eds.), Logic andInformation Flow. MIT Press, Cambridge, MA, pp. 196–233.
Visser, A., Vermeulen, K., 1995. Dynamic Bracketing and Discourse Representation.Logic Group Preprint Series 131, Department of Philosophy, University of Utrecht,the Netherlands.
Wansing, H., 1992. The Logic of Information Structures. Dissertation, Department of Philoso-phy, Free University, Berlin.

“16-ch12-0607-0670-9780444537263” — 2010/11/29 — 21:08 — page 670 — #64
670 Handbook of Logic and Language
Westerståhl, D., 1984. Determiners and context sets, in: van Benthem, J., ter Meulen, A. (Eds.),Generalized Quantifiers in Natural Language. Foris, Dordrecht, pp. 45–71.
Wittgenstein, L., 1953. Philosophische Untersuchungen/Philosophical Investigations. (Englishtranslation by Anscombe, G.E.M., Rees, R. and von Wright, G.H.). Blackwell, Oxford.
Zeinstra, L., 1990. Reasoning as Discourse. Master’s Thesis, Department of Philosophy, Uni-versity of Utrecht, the Netherlands.

“17-ch13-0671-0690-9780444537263” — 2010/11/30 — 3:44 — page 671 — #1
13 Dynamic Epistemic Logic(Update of Chapter 12)
Barteld KooiFaculty of Philosophy, University of Groningen, Oude Boteringestraat52, 9712 GL Groningen, The Netherlands, E-mail: [email protected]
13.1 Introduction
This chapter supplements Chapter 12 with an overview of dynamic epistemic logic(DEL): a branch of logic mainly developed in the decade after the first edition ofthis handbook was published. For a broader view on recent developments in dyna-mics in general I recommend the reader to consult van Eijck and Stokhof (2006), whoprovide an overview of dynamic logic, broadly conceived, including DEL and dyna-mic approaches to language, and Dekker (2008), who provides an up-to-date guide todynamic semantics.
DEL fits well with the systems described in Chapter 12. It is much like Velt-man’s update semantics (US), discussed in Section 12.1.1 of Chapter 12, but has aricher notion of information state. It is also much like the Alchourrón, Gärdenfors andMakinson (AGM) approach to belief revision, discussed in Section 12.1.5 of Chap-ter 12, but it is more model theoretic in flavor in the sense that the starting point isnot belief sets of formulas and rationality postulates, but epistemic Kripke models andtransformations of those. Like discourse representation theory (DRT) and dynamicpredicate logic (DPL), DEL too can be seen as a fragment of dynamic logic.1 Its richnotion of information and information change enables DEL to model a wide range ofscenarios involving multiple agents and complex information change.
Information has many aspects, witness the many approaches to the subject (cf.Adriaans and van Benthem (2008)). Groenendijk et al. (1996) distinguish two kindsof information that play a role in discourse: information about the world and discourseinformation, where the first can be thought of simply as the factual information con-veyed in discourse, and the second as the kind of information that enables one to keeptrack of what is being talked about. DEL is mostly about the first kind of information.
Groeneveld (1995, p. 114) characterizes DEL as being (i) dynamic, (ii) multi-agent,and (iii) higher-order. It is dynamic since its focus is on information change. It ismulti-agent because the phenomena studied in DEL, such as communication, usuallyinvolve more than one agent. It is higher-order in the sense that the information anagent has about the world (which contains other agents) includes information about
1 See Section 12.2.1.1 of Chapter 12 for DRT and DPL, and van Eijck (2004) for DEL.
Handbook of Logic and Language. DOI: 10.1016/B978-0-444-53726-3.00013-Xc! 2011 Elsevier B.V. All rights reserved.

“17-ch13-0671-0690-9780444537263” — 2010/11/29 — 21:08 — page 672 — #2
672 Handbook of Logic and Language
the other agents’ information: higher-order information.2 In short, DEL aims to trackthe (higher-order) information of many agents as information flows.
The starting point of DEL is epistemic logic: the logic of knowledge (seeHendricks and Symons (2006) for an overview of epistemic logic and references).One of the key features of epistemic logic is that the information states of severalagents can be represented by a single Kripke model consisting of a set of states, a setof accessibility relations, and a valuation (see Section 12.2.1 of Chapter 12 for thedefinition of Kripke models). In epistemic logic the set of states of a Kripke model isinterpreted as a set of epistemic alternatives. The set of atomic programs of a Kripkemodel is interpreted as the set of all agents. The information state of an agent con-sists of those epistemic alternatives that are possible according to the agent, whichis represented by the accessibility relation R! . An agent ! knows that a proposition" is true in a state a (M, a |= K!"), if and only if that proposition " is true in allthe states that agent ! considers possible in that state (i.e. which are R!-accessiblefrom a). A proposition known by agent ! may itself pertain to the knowledge of someagent (for instance if one considers the formula K!K#$). In this way, a Kripke modelwith accessibility relations for all the agents represents the (higher-order) informationof all relevant agents simultaneously.
In DEL, information change is modeled by transforming Kripke models. SinceDEL is mostly about information change due to communication, the model transfor-mations usually do not involve factual change. The bare physical facts of the worldremain unchanged, but the agents’ information about the world changes. In terms ofKripke models this means that the accessibility relations of the agents have to change(and consequently the set of states of the model might change as well). Modal opera-tors in dynamic epistemic languages denote these model transformations. The accessi-bility relation associated with these operators is not one within the Kripke model, butpertains to the transformation relation between the Kripke models (see the example inthe next section).
In Section 13.2 an example scenario is presented which can be captured by DEL.In Section 13.3 a historical overview of the main approaches in DEL is presented.Section 13.4 is a look towards the future which attempts to connect ideas from dyna-mic approaches to language with DEL.
13.2 An Example Scenario
Consider the following scenario: Ann and Bob are each given a card that is either redor white. They only see their own card, and so they are ignorant about the other agent’scard. There are four possibilities: both have white cards, both have red cards, Ann hasa white card and Bob has a red card, or the other way round. These are the states of the
2 The view that higher-order information is information about the world contrasts with Groenendijk andStokhof’s view that information is only part of the world in a secondary, derivative sense (Groenendijkand Stokhof, 1997, p. 1072).

“17-ch13-0671-0690-9780444537263” — 2010/11/29 — 21:08 — page 673 — #3
Dynamic Epistemic Logic 673
model, and are represented by informative names such as rw, meaning Ann was dealta red card (r) and Bob was dealt a white card (w). Let us assume that both have redcards, i.e. let the actual state be rr. This is indicated by the double lines around staterr in Figure 13.1(a). The states of the Kripke model are connected by lines, which arelabeled (! or #, denoting Ann or Bob respectively) to indicate that the agents cannotdistinguish the states thus connected.3 In the model of Figure 13.1(a) there are no!-lines between those states where Ann has different cards, i.e. she can distinguishstates at the top, where she has a red card, from those at the bottom, where she hasa white one. Likewise, Bob is able to distinguish the left half from the right half ofthe model. This represents the circumstance that Ann and Bob each know the color oftheir own card and not that of the other’s one.
rr rw
wr ww
!
#
!
#
(a) A Kripke model for thesituation where two agentsare each given a red or a whitecard.
rr rw!
(b) A Kripke model for thesituation after Ann tells Bobshe has a red card.
rr rw
rr rw
!
##
(c) A Kripke model for thesituation after Ann mighthave looked at Bob’s card.
Figure 13.1 Three Kripke models for a scenario involving two agents and two cards.
In the Kripke model of Figure 13.1(a) we also see that the higher-order informationis represented correctly. Both agents know that the other agent knows the color of hisor her card, and they know that they know this, and so on. It is remarkable that a singleKripke model can represent the information of both agents simultaneously.
Suppose that after picking up their cards, Ann truthfully says to Bob “I havea red card”. The Kripke model representing the resulting situation is displayed inFigure 13.1(b). Now both agents know that Ann has a red card, and they know thatthey know she has a red card, and so on: it is common knowledge among them.4 Hencethere is no need anymore for states where Ann has a white card, so those do not appearin the Kripke model. Note that in the new Kripke model there are no longer any lines
3 To be complete it should also be indicated that no state can ever be distinguished from itself. For readabilitythese “reflexive lines” are not drawn, but indeed the accessibility relations R! and R# are equivalencerelations, since epistemic indistinguishability is reflexive, symmetric and transitive.
4 A formula " is common knowledge among a group of agents if everyone in the group knows that ",everyone knows that everyone knows that " and so on.

“17-ch13-0671-0690-9780444537263” — 2010/11/29 — 21:08 — page 674 — #4
674 Handbook of Logic and Language
labeled #. No matter how the cards were dealt, Bob only considers one state to bepossible: the actual one. Indeed, Bob is now fully informed.
Now that Bob knows the color of Ann’s card, Bob puts his card face down onthe table, and leaves the room for a moment. When he returns he considers it possi-ble that Ann took a look at his card, but also that she didn’t. Assuming she did notlook, the Kripke model representing the resulting situation is the one displayed inFigure 13.1(c). In contrast to the previous model, there are in this model lines for Bobagain. This is because he is no longer completely informed about the situation. Hedoes not know whether Ann knows the color of his card, yet he still knows that bothAnn and he have a red card. Only his higher-order information has changed. Ann onthe other hand knows whether she has looked at Bob’s card and also knows whethershe knows the color of Bob’s card. She also knows that Bob considers it possible thatshe knows the color of his card. In the model of Figure 13.1(c) we see that two statesrepresenting the same factual information can differ by virtue of the lines connect-ing them to other states: the state rr on the top and rr on the bottom only differ inhigher-order information.
In this section, we have seen two ways in which information change can occur.Going from the first model to the second, the information change was public, in thesense that all agents received the same information. Going from the second to the thirdmodel involved information change where not all agents had the same perspective,because Bob did not know whether Ann looked at his card while he was away. Thetask of DEL is to provide a logic with which to describe these kinds of informationchange.
13.3 A History of DEL
DEL did not arise in a scientific vacuum. The “dynamic turn” in logic and semantics(sketched in Chapter 12 and also by van Benthem (1996), Gochet (2002) and Peregrin(2003)) very much inspired DEL, and can also be seen as a part of the dynamic turn.DEL was influenced by the systems described in Section 12.1.1 and Section 12.1.5of Chapter 12. The formal apparatus of DEL is a lot like propositional dynamic logic(PDL) and quantified dynamic logic (QDL) (also described in Chapter 12). Not allformulas are interpreted dynamically, as in DPL and US, but formulas and updates areclearly distinguished.
The study of epistemic logic within computer science and AI led to the devel-opment of epistemic temporal logic (ETL) in order to model information change inmulti-agent systems (see Fagin et al. (1995) and Meyer and van der Hoek (1995)).Rather than model change by modal operators that transform the model, change ismodeled by the progression of time in these approaches. Yet the kinds of phenomenastudied by ETL and DEL largely overlap.
After this brief sketch of the context in which DEL was developed, the remainderof the section will focus on the development of its two main approaches. The first ispublic announcement logic, which will be presented in Section 13.3.1. The second,

“17-ch13-0671-0690-9780444537263” — 2010/11/29 — 21:08 — page 675 — #5
Dynamic Epistemic Logic 675
presented in Section 13.3.2, is the dominant approach in DEL (sometimes identifiedwith DEL).
13.3.1 Announcements
13.3.1.1 The Dominant Approach: Plaza
The first dynamic epistemic logic, called public announcement logic (PAL), wasdeveloped by Plaza (2007, originally published in 1989). The example where Annsays to Bob that she has a red card is an example of a public announcement. A publicannouncement is a communicative event where all agents receive the same informa-tion and it is common knowledge among them that this is so. The language of PAL isgiven by the following Backus-Naur Form:
" ::= p |!| ("1 " "2) | K!" | ["1]"2
Besides the usual propositional language, K!" is read as agent ! knows that ", and["]$ is read as after " is announced $ is the case. In the example above, we could forinstance translate “After it is announced that Ann has a red card, Bob knows that Annhas a red card” as [r!]K#r! .
An announcement is modeled by removing the states where the announcement isfalse, i.e. by going to a submodel. This model transformation is the main feature ofPAL’s semantics.
(i) M, a |= p iff a # V(p)
(ii) M, a $|= !(iii) M, a |= " " $ iff if M, a |= ", then M, a |= $
(iv) M, a |= K!" iff M, b |= " for all b such that %a, b& # R!
(v) M, a |= ["]$ iff M, a |= " implies that M|", a |= $
In clause (v) the condition that the announced formula be true at the actual state entailsthat only truthful announcements can take place. The model M|" is the model obtainedfrom M by removing all non-" states. The new set of states consists of the "-states ofM. Consequently, the accessibility relations as well as the valuation are restricted tothese states. The propositional letters true at a state remain true after an announcement.This reflects the idea that communication can only bring about information change, notfactual change.
13.3.1.2 Relation to Other Dynamic Systems
The expressions of PDL and QDL form distinct categories: formulas and programs. InPAL both these roles are fulfilled by the same syntactical objects: formulas are inter-preted both statically and dynamically (cf. Groeneveld (1995, p. 115))—statically inthe sense that formulas are true or false in a state of a Kripke model, and dynamicallyin the sense that they transform one model into another. In this sense PAL stands inthe middle between standard logics, where all formulas are interpreted statically, andsystems such as DPL where all formulas are interpreted dynamically.

“17-ch13-0671-0690-9780444537263” — 2010/11/29 — 21:08 — page 676 — #6
676 Handbook of Logic and Language
The semantics of announcements is very much like the dynamic systems describedin Section 12.1.1 of Chapter 12, such as US, where sentences uttered in contextsare modeled by eliminating possibilities. The main difference is that an informationstate in those systems merely consists of a set of valuations, whereas Kripke modelsfor many agents provide more structure by having an accessibility relation for eachagent. Moreover, in PAL one of the states is taken to be the actual state, which is notthe case in the systems in Section 12.1.1 of Chapter 12. Nevertheless, the eliminationprocedure is the same as that of PAL.
13.3.1.3 Gerbrandy and Groeneveld’s Approach
A logic similar to PAL was developed independently by Gerbrandy and Groeneveld(1997), which is more extensively treated in Gerbrandy’s PhD thesis 1998. There arethree main differences between this approach and Plaza’s approach.
First of all, Gerbrandy and Groeneveld do not use Kripke models in the semanticsof their language. Instead, they use structures called possibilities which are definedby means of non-wellfounded set theory—a branch of set theory where the founda-tion axiom is replaced by another axiom. Possibilities and Kripke models are closelylinked: possibilities correspond to bisimulation classes of Kripke models (see Sec-tion 12.2.1.4 of Chapter 12 for the definition of bisimulation).5
The second difference is that Gerbrandy and Groeneveld also consider announce-ments that are not truthful. In their view, a logic for announcements should modelwhat happens when new information is taken to be true by the agents. Hence, accord-ing to them, what happens to be true deserves no special status. This is more akin tothe notion of update in US. In terms of Kripke models this means that by updating,agents may no longer consider the actual state to be possible, i.e. R! may no longerbe reflexive. In a sense it would therefore be more accurate to call this logic a dyna-mic doxastic logic (a dynamic logic of belief) rather than a dynamic epistemic logic,since according to most theories, knowledge implies truth, whereas beliefs need notbe true.
Thirdly, their logic is more general in the sense that subgroup announcements aretreated (where only a subgroup of the group of all agents acquires new information);and especially private announcements are considered, where only one agent gets infor-mation. These announcements are modeled in such a way that the agents who do notreceive information do not even consider it possible that anyone has learned anything.In terms of Kripke models, this is another way in which R! may lose reflexivity.
13.3.1.4 Adding Common Knowledge
Semantics for public, group and private announcements using Kripke models wasproposed by Baltag, Moss, and Solecki (1998). This semantics is equivalent toGerbrandy’s semantics (as was shown by Moss (1999)). Baltag, Moss, and Solecki’s
5 Later, Gerbrandy provided semantics without using non-wellfounded set theory for a simplified versionof his public announcement logic (Gerbrandy, 2007).

“17-ch13-0671-0690-9780444537263” — 2010/11/29 — 21:08 — page 677 — #7
Dynamic Epistemic Logic 677
main contribution to PAL was that their approach also covered common knowledge,which is an important concept when one is interested in higher-order information, andplays an important role in social interaction (cf. Vanderschraaf and Sillari (2007)).The inclusion of common knowledge poses a number of interesting technical prob-lems, which will not be discussed here.
13.3.2 Other Informative Events
13.3.2.1 Gebrandy and Groeneveld’s Approach
In addition to a logic for announcements, Gerbrandy and Groeneveld (1997) alsodeveloped a system for more general information change involving many agents, eachof whom may have a different perspective. This is for instance the case when Annmay look at Bob’s card.
In order to model this information change it is important to realize that distinct lev-els of information are not distinctly represented in a Kripke model. For instance whatAnn actually knows about the cards depends on R! , but what Bob knows about whatAnn knows about the cards depends on R! as well. Therefore changing something inthe Kripke model, such as cutting a line, changes the information on many levels. Inorder to come to grips with this issue it really pays to use non-wellfounded semantics.One of the ways to think about the possibilities defined by Gerbrandy and Groeneveldis as infinite trees. In such a tree, distinct levels of information are represented by cer-tain paths in the tree. By manipulating the appropriate part of the tree, one can changethe agents’ information at the appropriate level.6 We will not however present detailsof their approach.
13.3.2.2 Van Ditmarsch’s Approach
Inspired by Gerbrandy and Groeneveld’s work, van Ditmarsch developed a dynamicepistemic logic for modeling information change in knowledge games, where the goalof the players is to obtain knowledge of some aspect of the game. Clue and Battleshipsare typical examples of knowledge games. Players are never deceived in such gamesand therefore the dynamic epistemic logic of Gerbrandy and Groeneveld, in whichreflexivity might be lost, seems unsuitable. In van Ditmarsch’s Ph.D. thesis 2000,a logic is presented where all model transformations are from Kripke models withequivalence relations to Kripke models with equivalence relations, which is thus tai-lored to information change involving knowledge. This approach was further stream-lined by van Ditmarsch (2002) and later extended to include concurrent actions (whentwo or more events occur at the same time) by van Ditmarsch et al. (2003). One ofthe open problems of these logics is that a completeness proof for the axiom sys-tems has not been obtained, and therefore we will not present details of this approacheither.
6 This insight stems from Groeneveld (1995) and was also used by Renardel de Lavalette (2004), who intro-duces tree-like lean modal structures using ordinary set theory in the semantics of a dynamic epistemiclogic.

“17-ch13-0671-0690-9780444537263” — 2010/11/29 — 21:08 — page 678 — #8
678 Handbook of Logic and Language
13.3.2.3 The Dominant Approach: Baltag, Moss and Solecki
Another way of modeling complex informative events was developed by Baltag,Moss, and Solecki (1998), which has become the dominant approach in DEL. Theirapproach is highly intuitive and lies at the basis of many papers in the field: indeed,many refer to this approach simply as DEL. Their key insight was that informationchanging events can be modeled in the same way as situations involving information.Given a situation, such as when Ann and Bob each have a card, one can easily pro-vide a Kripke model for such a situation. One simply considers which states mightoccur and which of those states the agents cannot distinguish. One can do the samewith events involving information. Given a scenario, such as Ann possibly looking atBob’s card, one can determine which events might occur: either she looks and sees it isred (she learns that r# ) or she sees that it is white (she learns that w# ), or she does notlook at the card (she learns nothing new, indicated by the tautology '). It is clear thatAnn can distinguish these particular events, but Bob cannot. Such models are calledaction models or event models.
An event model A is a triple %E, {Q! | ! # Ag}, pre&, consisting of a set of events E,a binary relation Q! over E for each agent, and a precondition function pre : E " Lwhich assigns a formula to each event. This precondition determines under what cir-cumstances the event can actually occur. Ann can only truthfully say that she has ared card, if in fact she does have a red card. The event model for the event whereAnn might have looked at Bob’s card is given in Figure 13.2(a), where each event isrepresented by its precondition.
The Kripke model of the situation following the event is constructed with a proce-dure called a product update. For each state in the original Kripke model one deter-mines which events could take place in that state (i.e. one determines whether theprecondition of the event is true at that state). The set of states of the new model con-sists of those pairs of states and events (a, e) which represent the result of event eoccurring in state a. The new accessibility relation is now easy to determine. If twostates were indistinguishable to an agent and two events were also indistinguishableto that agent, then the result of those events taking place in those states should alsobe indistinguishable. This implication also holds the other way round: if the result oftwo events happening in two states are indistinguishable, then the original states andevents should be indistinguishable as well.7 The basic facts about the world do notchange due to a merely communicative event. And so the valuation simply followsthe old valuation.
More formally, the product update M ( A of Kripke model M = %S, {R! | ! #Ag}, V& and event model A = {E, {Q! | ! # Ag}, pre} yields Kripke model %S), {R)
! |! # Ag}, V )} where:
(i) S) = {%a, e& | M, a |= pre(e)}(ii) R)
! = {%%a, e&, %b, f && | %a, b& # R! and %e, f & # Q!}(iii) V )(p) = {%a, e& | a # V(p)}
7 van Benthem (2001a) characterizes product update as having perfect recall, no miracles, and uniformity.

“17-ch13-0671-0690-9780444537263” — 2010/11/29 — 21:08 — page 679 — #9
Dynamic Epistemic Logic 679
The model in Figure 13.2(b) is the result of a product update of the model inFigure 13.1(b) and the event model of Figure 13.2(a). One can see that this is the sameas the model in Figure 13.1(c) (except for the names of the states), which indicatesthat product update yields the intuitively right result.
One may wonder whether the model in Figure 13.2(a) represents the event accu-rately. According to the event model Bob considers it possible that Ann looks at hiscard and sees that it is white. Bob, however, already knows that the card is red, andtherefore should not consider this event possible. This criticism is justified and onecould construct an event model that takes this into account, but the beauty of the eventmodel is precisely that it is detached from the agents’ information about the world insuch a way that it provides an accurate model of just the information the agents haveabout the event. This means that product update yields the right outcome regardlessof the Kripke model of the situation in which the event occurred. For instance takingthe product update with the model of Figure 13.1(a) yields the Kripke model depictedin Figure 13.2(c), which represents the situation where Ann might look at Bob’s cardimmediately after the cards were dealt. The resulting model also represents that situa-tion correctly. This indicates that in DEL static information and dynamic informationcan be separated.
In the logical language of DEL these event models appear as modalities [A, e],where e is taken to be the event that actually occurs. The language is given by the
r# w#
'
#
#
#
(a) An event model forwhen Ann might look atBob’s card.
rr,' rw,'
rr,r# rw,w#
!
##
(b) The product update for themodels of Figure 13.1(c) andFigure 13.2(a).
rr,'rr,r# rw,' rw,w#
wr,'wr,r# ww,' ww,w#
# !
#
!
#
#
#
#
#
##
#
#
#
(c) The product update for the models of Figure 13.1(a) and Figure 13.2(a).
Figure 13.2 An event model and two Kripke models that result from taking a product update.

“17-ch13-0671-0690-9780444537263” — 2010/11/29 — 21:08 — page 680 — #10
680 Handbook of Logic and Language
following Backus-Naur Form
" ::= p | !| "1 " "2 | K!" | C%" | [& ]"& ::= A, e | &1 * &2 | &1; &2
Formulas of the form C%" are read as: it is common knowledge among the members ofgroup % that "; [A, e]" is read as: after event A, e occurs, " is the case. The semanticsfor the event modalities uses product update.
(i) M, a |= p iff a # V(p)
(ii) M, a $|= !(iii) M, a |= " " $ iff M, a |= " implies that M, a |= $
(iv) M, a |= K!" iff M, b |= " for all b such that %a, b& # R!
(v) M, a |= C%" iff M, b |= " for all b such that %a, b& # R+%
(vi) M, a |= [& ]" iff M), a) |= " for all M), a) such that%(M, a), (M), a))& # ||& ||
(vii) ||A, e|| = {%(M, a), (M ( A, %a, e&)& | M, a |= pre(e)}(viii) ||&1 * &2|| = ||&1|| * ||&2||
(ix) ||&1; &2|| = ||&1|| , ||&2||
Clauses (i)–(iv) are the same as for PAL. In clause (v) R+% is the reflexive transitive
closure of the union of the accessibility relations of members of %. Clause (vi) isa standard clause for dynamic modalities, except that the accessibility relation fordynamic modalities is a relation on the class of all Kripke models. In clause (vii)it is required that the precondition of the event model is true in the actual state, thusensuring that %a, e&, the new actual state, exists in the product update. Clauses (viii) and(ix) are the usual semantics for non-deterministic choice and sequential composition(cf. Section 12.2 of Chapter 12).
Not only informative events where different agents have a different perspectivecan be modeled in DEL, but also public announcements can be thought of in terms ofevent models. A public announcement can be modeled by an event model containingjust one event: the announcement. All agents know this is the actual event, so it is theonly event considered possible. Indeed, DEL is a generalization of PAL.
13.3.2.4 Criticism, Alternatives, and Extensions
Many people feel somewhat uncomfortable with having models as syntactical objects(I myself have even suggested that this blurs the distinction between syntax andsemantics (Kooi, 2003, p. 55), but I no longer feel this to be the case). Baltagand Moss have tried to accommodate this by proposing different languages whilemaintaining an underlying semantics using event models (Baltag, 1999, 2002; Bal-tag and Moss, 2004). This issue is extensively discussed by van Ditmarsch, van derHoek, and Kooi (2007, Section 6.1). There are alternatives using hybrid logic (tenCate, 2002), and algebraic logic (Baltag, Coecke, and Sadrzadeh, 2005, 2007). As yetmost papers just use event models in the language.
DEL has been extended in various ways. Operators for factual change and pastoperators from temporal have been added. DEL has been combined with probability

“17-ch13-0671-0690-9780444537263” — 2010/11/29 — 21:08 — page 681 — #11
Dynamic Epistemic Logic 681
logic, justification logic and extended such that belief revision is also within its grasp.Connections have been made between DEL and various other logics. Its relation toPDL, ETL, AGM belief revision, and situation calculus has been studied. DEL hasbeen applied to a number of puzzles and paradoxes from recreational mathematicsand philosophy. It has also been applied to problems in game theory, as well as issuesin computer security. Unfortunately this appendix is too short to provide more detailsand references regarding these issues.
13.4 DEL and Language
The connection between DEL and speech act theory is discussed in Section 13.4.1.The most tentative material of this appendix is presented in Section 13.4.2, where therelation between DEL and dynamic semantics is explored.
13.4.1 Speech Acts
Speech act theory started with the work of Austin (1962), who argued that languageis used to perform all sorts of actions; we make promises, we ask questions, we issuecommands, etc. An example of a speech act is a bartender who says “The bar willbe closed in five minutes” (Bach, 1998). Austin distinguishes three kinds of acts thatare performed by the bartender: (i) the locutionary act of uttering the words, (ii) theillocutionary act of informing his clientele that the bar will close in five minutes,and (iii) the perlocutionary act of getting the clientele to order one last drink andleave.
Truth conditions, which determine whether an indicative sentence is true of false,are generalized to success conditions to determine whether a speech act is successfulor not.8 Searle (1969, p. 66) gives the following success conditions for an assertionthat p by speaker S to hearer H:
[. . . ] S has evidence (reasons, etc.) for the truth of p[. . . ] It is not obvious to both S and H that H knows (does not need to be reminded of,etc.) p[. . . ] S believes p[. . . ] Counts as an undertaking to the effect that p represents an actual state of affairs.
It is worthwhile to join this analysis of assertions to the analysis or publicannouncements in PAL. It is clear from the list of success conditions that one usu-ally only announces what one believes (or knows) to be true. So, an extra preconditionfor an announcement that " by an agent ! should be that K!". Public announcementsare indeed modeled in this way by Plaza (2007).
As an example, consider the case when Ann tells Bob she has a red card: it is moreappropriate to model this as an announcement that K!r! , rather than the announcement
8 In speech act theory there are several distinctions when it comes to the ways in which something can bewrong with a speech act (Austin, 1962, p. 18). Here we do not make such distinctions and simply speakof success conditions.

“17-ch13-0671-0690-9780444537263” — 2010/11/29 — 21:08 — page 682 — #12
682 Handbook of Logic and Language
rr rw
wr
!
#
(a) A Kripke model forthe situation after theannouncement that notboth Ann and Bob havewhite cards.
rr rw!
(b) A Kripke model forthe situation after theannouncement that Annknows not both she andBob have white cards.
rr rw
rr rw
!
##
(c) A Kripke model forthe situation after Annmight have looked atBob’s card and in factdid.
rr rw
ww
!
#
(d) A Kripke model forthe situation after Annsays she does not knowthat Bob has a white card.
Figure 13.3 An illustration of the difference between the effect of the announcement that "
and the announcement that Ka" and an announcement that only changes the agents’ higher-order information.
that r! . Fortunately, these formulas were equivalent in the model under consideration.Suppose that Ann had said “We do not both have white cards”. When this is modeledas an announcement that ¬(w!-w#), we obtain the model in Figure 13.3(a). However,Ann only knows this statement to be true when she in fact has a red card herself.Indeed, when we look at the result of the announcement that K!¬(w! -w#) we obtainthe model in Figure 13.3(b). We see that the result of this announcement is the same aswhen Ann says that she has a red card (see Figure 13.1(b)). By making presuppositionspart of the announcement, we are in a way accommodating the precondition (see alsoHulstijn (1996)).
The second success condition in Searle’s analysis conveys that an announcementought to provide the hearer with new information. In the light of DEL, one oughtto revise this second success condition by saying that p is not common knowledge,thus taking higher-order information into account. It seems natural to assume that aspeaker wants to achieve common knowledge of p, since that plays an important rolein coordinating social actions; and so lack of common knowledge of p is a conditionfor the success of announcing p.

“17-ch13-0671-0690-9780444537263” — 2010/11/29 — 21:08 — page 683 — #13
Dynamic Epistemic Logic 683
Consider the situation where Ann did look at Bob’s card when he was away andfound out that he has a red card (Figure 13.3(c)). Suppose that upon Bob’s return Anntells him “I do not know that you have a white card”. Both Ann and Bob alreadyknow this, and they also both know that they both know it. Therefore Searle’s secondcondition is not fulfilled, and so according to his analysis there is something wrongwith Ann’s assertion. The result of this announcement is given in Figure 13.3(d). Wesee that the information of the agents has changed. Now Bob no longer considers itpossible that Ann considers it possible that Bob considers it possible that Ann knowsthat Bob has a white card. And so the announcement is informative. One can givemore and more involved examples to show that indeed change of common knowl-edge is a more natural requirement for announcements than Searle’s second condition,especially multi-agent scenarios such as the barman’s announcement.
van Benthem (2006) analyzes question and answer episodes using DEL. One ofthe success conditions of questions as speech acts is that the speaker does not knowthe answer (Searle, 1969, p. 66). Therefore posing a question can reveal crucial infor-mation to the hearer in such a way that the hearer only knows the answer after thequestion has been posed (van Benthem (2001b),van Ditmarsch, van der Hoek, andKooi (2007, p. 61)).
Example 13.4.1. Professor a is program chair of a conference on Changing Beliefs.It is not allowed to submit more than one paper to this conference, a rule all authorsof papers did abide to (although the belief that this rule makes sense is graduallychanging, but this is besides the point here). Our program chair a likes to have alldecisions about submitted papers out of the way before the weekend, since on Saturdayhe is due to travel to attend a workshop on Applying Belief Change. Fortunately,although there appears not to be enough time to notify all authors, just before he leavesfor the workshop, his reliable secretary assures him that she has informed all authorsof rejected papers, by personally giving them a call and informing them about the sadnews concerning their paper.
Freed from this burden, Professor a is just in time for the opening reception of theworkshop, where he meets the brilliant Dr b. The program chair remembers that bsubmitted a paper to Changing Beliefs, but to his own embarrassment he must admitthat he honestly cannot remember whether it was accepted or not. Fortunately, hedoes not have to demonstrate his ignorance to b, because b’s question ‘Do you knowwhether my paper has been accepted?’ does make a reason as follows: a is sure thatwould b’s paper have been rejected, b would have had that information, in which caseb had not shown his ignorance to a. So, instantaneously, a updates his belief with thefact that b’s paper is accepted, and he now can answer truthfully with respect to thisnew revised belief set.
This phenomenon shows that when a question is regarded as a request (Lang, 1978),9
the success condition that the hearer is able to grant the request, i.e. provide the answer
9 It is not commonly agreed upon in the literature that questions can be regarded as requests (cf. Groenendijkand Stokhof (1997, Section 3)).

“17-ch13-0671-0690-9780444537263” — 2010/11/29 — 21:08 — page 684 — #14
684 Handbook of Logic and Language
to the question, must be fulfilled after the request has been made, and not before. Thisanalysis of questions in DEL fits well within the broad interest in questions in dynamicsemantics (Aloni, Butler, and Dekker, 2007).
Based on DEL, Yamada (2008) analyzes commands, another typical example ofa speech act, where the semantics of commands is very much like the semantics ofpublic announcements. States where the command would not be fulfilled are no longerdeontically accessible.
13.4.2 DEL and Dynamic Semantics
Dynamic semantics is first and foremost a theory of meaning. It is contrasted withother theories of meaning, especially Tarskian accounts of meaning, which definemeaning in terms of truth conditions. In dynamic semantics meaning is determinedby the way the context or the information state changes due to discourse. This is moti-vated by observing that often the order in which elements of discourse are presentedplays an important role in determining the meaning of those elements. Thus in dyna-mic semantics formulas are interpreted very much like programs are interpreted inPDL: as the way they change the state. Dynamics semantics has been applied to manydynamic linguistic phenomena. For an overview of recent developments, see Dekker(2008).
On a philosophical level it seems that there is a significant gap between DEL anddynamic semantics, since DEL has a Tarskian truth definition, which is not in line withdynamic semantics (van Benthem, personal communication). Of course the problemsthe two systems started out trying to address are quite different and so is the focus onthe kind of information involved in the two systems. There are also technical differ-ences which make it difficult for the DEL and dynamic semantics to meet. Yet thereare common patterns: the order in which information is processed matters, process-ing the same information twice is different from processing it once, etc. Therefore itseems worthwhile to further understand the logical connection between the two fields.In this section I explore one such logical connection having to do with the distinctionbetween de dicto and de re. This issue can only be studied in logics which involveboth quantification and modality. Let us focus on approaches in dynamic semanticsand DEL that have both of these.
Both systems of dynamic semantics and DEL can be seen as fragments of dyna-mic logics such as PDL and QDL. Systems of dynamic semantics, such as DPL,are embedded in QDL by reading DPL formulas as programs of QDL, i.e. purelydynamically. For instance p - q is read as a sequential composition ?p; ?q. DEL isembedded in PDL by reading DEL formulas as epistemically interpreted PDL for-mulas. For instance K!p is read as [!]". van Benthem et al. (2006) suggest thatepistemically interpreted PDL is quite suited as a dynamic epistemic logic in itself.This suggestion is further explored by van Eijck and Wang (2008). Kooi (2007)interprets QDL epistemically. This suggests bridges can be built between dynamicsemantics and DEL at the level of QDL.
One of the most advanced approaches in dynamic semantics is the combinationof DPL and US developed by Groenendijk, Stokhof, and Veltman (1996), which I

“17-ch13-0671-0690-9780444537263” — 2010/11/29 — 21:08 — page 685 — #15
Dynamic Epistemic Logic 685
call dynamic predicate update logic (DPUL). It is presented in Section 12.1.2.4 ofChapter 12. As was remarked earlier, according to Groenendijk, Stokhof, and Veltman(1996) two kinds of information play a role in discourse: discourse information andinformation about the world. These are represented separately in the structures onwhich the language of DPUL is interpreted. By interpreting the language dynamically,both kinds of information change can be modeled as well as the way these two kindsof information change interact.
The discourse information is represented with a referent system taken fromVermeulen (1995). The referent system joined with an assignment determines whatelement of the domain each variable denotes. The information about the world isrepresented with an information state, which consists of possibilities. A possibilitydetermines what the individual constants, variables and predicate symbols denote.Existentially quantified formulas are interpreted in a similar way as they are inter-preted in DPL: they transform the referent system. So, each time an existential quan-tifier is processed the discourse information changes, but the information about theworld changes as well. The existential quantifier generates possibilities, but those pos-sibilities which do not support the formula are eliminated, just as in US and PAL.
Therefore the existential quantifier is not read categorematically, as is the case inDPL, and which is also the case in other systems which combine US and DPL (Aloni,2001), but not all (van Eijck and Cepparello, 1994). This feature only plays a role whenone quantifies into a modal context, as is illustrated by Groenendijk, Stokhof, andVeltman (1996). They describe a scenario where both anaphora (one of the phenomenaanalyzed with DPL) and “might” (one of the phenomena analyzed with US) occur. Acouple have three sons and they know that one of the younger two (i.e. not the oldest)has broken a vase. The mother discovers someone is hiding in the closet and says tothe father:
(1) There is someone hiding in the closet. He might be guilty.
Suppose that the mother discovers that one of the younger two children is hiding inthe closet and instead of saying (1) she says:
(2) There is someone hiding in the closet who might be guilty.
Groenendijk, Stokhof and Veltman (1996) argue that uttering (1) does not imply thatthe one hiding in the closet must be one of the younger two children and (2) does. Thesentences are translated in DPUL respectively as follows:
(3) .xP(x) - !Q(x)
(4) .x(P(x) - !Q(x))
At first it seems surprising that these formulas are not logically equivalent, since theformulas .xP(x) - Q(x) and .x(P(x) - Q(x)) are logically equivalent in DPL.
If one initially takes an information state with six possibilities, it is not knownwhich of the children is in the closet and it is not known which of the younger childrenis guilty. Then, after updating with (4) those possibilities are left in which the child

“17-ch13-0671-0690-9780444537263” — 2010/11/29 — 21:08 — page 686 — #16
686 Handbook of Logic and Language
hiding in the closet is one of the younger ones, whereas after updating with (3) it mightbe the oldest hiding in the closet.
I will argue that the difference in meaning of (1) and (2) can best be seen as adifference between a de re and a de dicto assertion about the person in the closet. Intwo papers from 1968 Stalnaker and Thomason develop a formal account of de re andde dicto when it comes to predication. They consider the following example:
(5) The President of the US is necessarily a citizen of the US.
Thomason and Stalnaker (1968) deem this sentence to be ambiguous. The ambiguityis resolved in the following paraphrases:
(6) It is necessarily the case that the President of the US is a citizen of the US.(7) The President of the US has the property of being necessarily a citizen of the
US.
The first is the de dicto reading of the sentence, the second is the de re reading of thesentence. The formal apparatus developed by Thomason and Stalnaker (1968) useslambda abstraction to make complex predicate (see Fitting and Mendelsohn (1998)for a textbook discussion of this technique). Now we will present an epistemic inter-pretation of QDL with which the difference between de dicto and de re can be madeas well.
The version of QDL which we consider here is slightly richer than the versionpresented in Section 12.2.1.1 of Chapter 12 in that there are also atomic programs.The accessibility relations associated with the atomic programs are interpreted asaccessibility relations of agents. The language is given by the following Backus-NaurForm.
" ::= Pn(t1 . . . tn) | t1 = t2 |!| "1 " "2 | [& ]"t ::= c | x& ::= ! |?" | x := t | x :=? | &; & | & * & | &+
In this language a formula of the form [!]" is read as agent ! knows that ". A modelM on which the language can be interpreted is a tuple (S, D, Ag, R, I) where
(i) S $= / a non-empty set of states,(ii) D $= / a non-empty domain of discourse,
(iii) Ag $= / a non-empty set of agents,(iv) R : Ag " ' (W 0 W) assigns an accessibility relation to each agent,(v) I is a function from W to n-ary predicate letters to Dn, and from W
to constant to elements of D.
In order to interpret the language one also needs a separate assignment g that mapseach variable to an element of the domain.10 The semantics are a straightforwardextension of the version of QDL presented in Section 12.2.1.1 of Chapter 12.
10 In contrast to the version of QDL presented in Section 12.2.1.1 of Chapter 12, states are not identifiedwith first-order assignments

“17-ch13-0671-0690-9780444537263” — 2010/11/29 — 21:08 — page 687 — #17
Dynamic Epistemic Logic 687
An important feature of this logic is that the assignment function g does not dependon the state a, but the interpretation function does. The interpretation of ! only relatesstate assignment pairs where the assignment remains fixed. Consequently, variablesact as rigid designators (as long as they are not changed by an assignment) and indi-vidual constants are non-rigid designators, when the assignment is taken to representdiscourse information that means that the agents know what the variables refer to.This is not the case in DPUL, where the same information state can contain possibili-ties with different assignments (although the referent system is the same).
Now let us consider the following sentence.
(8) Mother considers it possible that the person in the closet is guilty.
According to the analysis of Stalnaker and Thomason (1968) above, this sentence isambiguous. Let us take a constant c to be the definite description “the person in thecloset”. Now (8) can be formalized in two ways:
(9) %!&[x := c]Q(x)(10) [x := c]%!&Q(x)
where (9) is the de dicto reading and (10) the de re reading of the sentence. Thedifference is whether the denotation of c is fixed inside or outside the scope of theepistemic operator. As it turns out, (9) is true in a model where the oldest (innocent)child is hiding in the closet, whereas (10) is false in that model, but true in thosemodels where one of the younger children, one of whom is guilty, is hiding in thecloset. And so we observe the same phenomenon here. In view of this one can say thatin (1) and (2) the difference is that in the second sentence of (1) the interpretation isde dicto and in the relative clause of (2) the interpretation is de re.
This link between DPUL and epistemically interpreted QDL might provide themeans to build further bridges between DPUL and DEL. In Kooi (2007) event modelsare added to QDL, which allows one to study more complex updates in a first-ordersetting. It would also allow one to model what the mother says as public announce-ments that eliminate states. As of yet the question is how exactly DPUL can be seenas a fragment of epistemically interpreted QDL, thus enabling a further connectionbetween these dynamic logics.
Acknowledgments
I would like to thank Maria Aloni, Johan van Benthem, Boudewijn de Bruin, PaulDekker, Hans van Ditmarsch, Jan van Eijck, Erik Krabbe, Peter McBurney, the PCCP,Jeanne Peijnenburg, and Allard Tamminga for their comments and discussion on thetopics in this appendix.

“17-ch13-0671-0690-9780444537263” — 2010/11/29 — 21:08 — page 688 — #18
688 Handbook of Logic and Language
References
Adriaans, P.W., van Benthem, J. (Eds.), 2008. Handbook of the Philosophy of Information.Elsevier, Amsterdam.
Aloni, M., 2001. Quantification under Conceptual Covers. PhD thesis, University ofAmsterdam, Amsterdam. ILLC Dissertation Series DS-2001-01.
Aloni, M., Butler, A., Dekker, P. (Eds.), 2007. Questions in Dynamic Semantics. Elsevier,Amsterdam.
Austin, J.L., 1962. How to Do Things with Words. Clarendon Press, Oxford.Bach, K., 1998. Speech acts, in: Craig, E. (Ed.), Routledge Encyclopedia of Philosophy, Rout-
ledge, London, vol. 8, pp. 81–87.Baltag, A., 1999. A logic of epistemic actions, in: van der Hoek, W., Meyer, J.-J., Witteveen,
C. (Eds.), (Electronic) Proceedings of the ESSLLI 1999 Workshop on Foundations andApplications of Collective Agent-Based Systems. Utrecht University, Utrecht, pp. 16–29.
Baltag, A., 2002. A logic for suspicious players: epistemic actions and belief-updates in games.Bull. Econ. Res., 54 (1), 1–45.
Baltag, A., Coecke, B., Sadrzadeh, M., 2005. Algebra and sequent calculus for epistemicactions. Electron. Notes Theor. Comput. Sci. 126, 27–52.
Baltag, A., Coecke, B., Sadrzadeh, M., 2007. Epistemic actions as resources. J. Logic Comput.17 (3), 555–585.
Baltag, A., Moss, L.S., 2004. Logics for epistemic programs. Synthese 139, 165–224.Baltag, A., Moss, L.S., Solecki, S., 1998. The logic of public announcements, common know-
ledge, and private suspicions, in: Gilboa, I. (Ed.), Proceedings of TARK 98, MorganKaufmann, San Franscisco, pp. 43–56.
Dekker, P., 2008. A guide to dynamic semantics. ILLC Prepublications PP-2008-42, Amster-dam.
Fagin, R., Halpern, J.Y., Moses, Y., Vardi, M.Y., 1995. Reasoning About Knowledge. MIT,Cambridge, Massachusetts.
Fitting, M., Mendelsohn, R.L., 1998. First-Order Modal Logic. Kluwer, Dordrecht.Gerbrandy, J., 1998. Bisimulations on Planet Kripke. ILLC Dissertation Series DS-1999-01.
PhD thesis, University of Amsterdam, Amsterdam.Gerbrandy, J., 2007. The surprise examination in dynamic epistemic logic. Synthese 155 (1),
21–33.Gerbrandy, J., Groeneveld, W., 1997. Reasoning about information change. J. Logic. Lang.
Inform. 6, 147–169.Gochet, P., 2002. The dynamic turn in twentieth century logic. Synthese 130 (2), 175–184.Groenendijk, J., Stokhof, M., 1997. Questions, in: van Benthem, J., ter Meulen, A. (Eds.), Hand-
book of Logic and Language, Elsevier, Amsterdam, pp. 1055–1124.Groenendijk, J., Stokhof, M., Veltman, F., 1996. Coreference and modality, in: Lappin, S. (Ed.),
The Handbook of Contemporary Semantic Theory, Blackwell, Oxford, pp. 179–214.Groeneveld, W., 1995. Logical Investigations into Dynamic Semantics. ILLC Dissertation
Series DS-1995-18. PhD thesis, University of Amsterdam, Amsterdam.Hendricks, V., Symons, J., 2006. Epistemic logic, in: Zalta, E.N. (Ed.), The Stanford Encyclo-
pedia of Philosophy, The Metaphysics Research Lab, CSLI.Hulstijn, J., 1996. Presupposition accommodation in a constructive update semantics, in:
Durieux, G., Daelemans, W., Gillis, S. (Eds.), Proceedings of CLIN VI, University ofAntwerp.

“17-ch13-0671-0690-9780444537263” — 2010/11/29 — 21:08 — page 689 — #19
Dynamic Epistemic Logic 689
Kooi, B., 2003. Knowledge, Chance, and Change. ILLC Dissertation Series DS-2003-01. PhDthesis, University of Groningen, Groningen.
Kooi, B., 2007. Dynamic term-modal logic, in: van Benthem, J., Ju, S., Veltman, F. (Eds.), AMeeting of the Minds, Proceedings of LORI, Beijing, 2007, College Publications, London,pp. 173–185.
Lang, R., 1978. Questions as epistemic requests, in: Hiż, H. (Ed.), Questions, Reidel, Dordrecht,pp. 301–318.
Meyer, J.-J.C., van der Hoek, W., 1995. Epistemic Logic for AI and Computer Science.Cambridge University Press, Cambridge.
Moss, L.S., 1999. From hypersets to Kripke models in logics of announcements, in: Gerbrandy,J., Marx, M., de Rijke, M., Venema, Y. (Eds.), JFAK. Essays Dedicated to Johan vanBenthem on the Occasion of his 50th Birthday, Amsterdam University Press, Amsterdam.
Peregrin, J. (Ed.), 2003. Meaning: The Dynamic Turn. Elsevier, Amsterdam.Plaza, J., 2007. Logics of public communications. Synthese 158 (2), 165–179. This paper was
originally published as Plaza, J.A., 1989. Logics of public communications, in: Emrich,M.L., Pfeifer, M.S., Hadzikadic, M., Ras, Z.W. (Eds.), Proceedings of ISMIS: Poster ses-sion program, Oak Ridge National Laboratory, ORNL/DSRD-24, pp. 201–216.
Renardel de Lavalette, G.R., 2004. Changing modalities. J. Logic Comput. 14 (2), 253–278.Renne, B., 2008. A survey of dynamic epistemic logic. Manuscript.Searle, J.R., 1969. Speech Acts, An Essay in the Philosophy of Language. Cambridge University
Press, Cambridge.Stalnaker, R.C., Thomason, R.H., 1968. Abstraction in first-order modal logic. Theoria 34,
203–207.ten Cate, B.D., 2002. Internalizing epistemic actions, in: Martinez, M. (Ed.), Proceedings of the
NASSLLI 2002 student session, Stanford University, Stanford, pp. 109–123.Thomason, R.H., Stalnaker, R.C., 1968. Modality and reference. Noûs 2 (4), 359–372.van Benthem, J., 1996. Exploring Logical Dynamics. CSLI Publications, Stanford.van Benthem, J., 2001a. Games in dynamic-epistemic logic. Bull. Econ. Res. 53 (4), 219–248.van Benthem, J., 2001b. Logics for information update, in: van Benthem, J. (Ed.), Proceedings
of TARK 2001, Morgan Kaufmann, San Francisco, pp. 51–67.van Benthem, J., 2006. ‘one is a lonely number’: on the logic of communication, in: Chatzidakis,
Z., Koepke, P., Pohlers, W. (Eds.), Logic Colloquium ’02. ASL, Poughkeepsie, pp. 96–129.van Benthem, J., van Eijck, J., Kooi, B., 2006. Logics of communication and change. Inform.
Comput. 204 (11), 1620–1662.van Ditmarsch, H.P., 2000. Knowledge Games. ILLC Dissertation Series DS-2000-06. PhD
thesis, University of Groningen, Groningen.van Ditmarsch, H.P., 2002. Descriptions of game actions. J. Logic. Lang. Inform. 11,
349–365.van Ditmarsch, H.P., van der Hoek, W., Kooi, B., 2003. Concurrent dynamic epistemic logic, in:
Hendricks, V.F., Jørgensen, K.F., Pedersen, S.A. (Eds.), Knowledge Contributors, Kluwer,Dordrecht, pp. 45–82.
van Ditmarsch, H.P., van der Hoek, W., Kooi, B., 2007. Dynamic Epistemic Logic. Springer,Berlin.
van Eijck, J., 2004. Reducing dynamic epistemic logic to PDL by program transforma-tion. Technical Report SEN-E0423, CWI, Amsterdam. Available from http://db.cwi.nl/rapporten/.
van Eijck, J., Cepparello, G., 1994. Dynamic modal predicate logic, in: Kanazawa, M., non, C.P.(Eds.) Dynamics, Polarity and Quantification, CSLI, Stanford, pp. 251–276,

“17-ch13-0671-0690-9780444537263” — 2010/11/29 — 21:08 — page 690 — #20
690 Handbook of Logic and Language
van Eijck, J., Stokhof, M., 2006. The gamut of dynamic logics, in: Gabbay, D.M., Woods, J.(Eds.), Handbook of the History of Logic, vol. 7, Elsevier, Amsterdam, pp. 499–600.
van Eijck, J., Wang, Y., 2008. PDL as a logic of belief revision, in: Hodges, W., de Queiros, R.(Eds.), Wollic’08, number 5110 in LNCS, Springer, Berlin, pp. 136–148.
Vanderschraaf, P., Sillari, G., 2007. Common knowledge, in: Zalta, E.N. (Ed.), The StanfordEncyclopedia of Philosophy, The Metaphysics Research Lab, CSLI.
Vermeulen, C., 1995. Merging without mystery. Variables in dynamic semantics. J. Philos.Logic 24 (4), 405–450.
Yamada, T., 2008. Logical dynamics of some speech acts that affect obligations and preferences.Synthese 165 (2), 295–315.
Further Reading
In this follow up chapter to Chapter 12 on dynamics an overview of dynamic epis-temic logic (DEL) and connections between DEL and dynamic approaches to languagewere presented. This is not the only overview of DEL available. The textbook by vanDitmarsch, van der Hoek, and Kooi (2007) provides many more technical details thanare presented here. Renne (2008) gives a detailed survey of DEL.

“18-ch14-0691-0724-9780444537263” — 2010/11/30 — 3:44 — page 691 — #1
14 PartialityJens Erik FenstadUniversity of Oslo, Institute of Mathematics, P.O. Box 1053 Blindern,N-0316 Oslo, Norway, E-mail: [email protected]
Commentator: L. Humberstone
14.0 Introduction
Partiality is both complex and widespread. Aspects of it has been the object of inten-sive study in logic and mathematics. In this chapter our aim is to survey issues inpartiality of possible relevance to theoretical and computational linguistics. Our expo-sition is aimed at an audience of linguists and, therefore, while technically sound, isnot intended to be technically complete at every point.
The chapter is divided into three parts. In the first part we survey various sourcesof partiality arising from grammatical form, structure of knowledge, complexities ofrule-following and the paradoxical properties of self-referential possibilities in naturallanguages.
In the second part we present in brief outline a model for linguistic structure. Wedo this, not in order to advocate the “correctness” of this particular model, but to useit as a vehicle to sort out some of the aspects of partiality identified in the first part.
In the final part we turn to partiality and the structure of knowledge. The focus ofour discussion in this part will be the logic and model theory of partial structures, bothpropositional, first order and higher types. Although technical in form we shall notaltogether lose sight of the connection to natural language modeling.
14.1 Sources of Partiality
We start out with some observations on issues of partiality connected to grammaticalform. We then turn to partiality and the structure of knowledge. This leads on to adiscussion of some aspects of partiality related to algorithms and rule-following. Wefinish with a brief review of the complexities of self-reference in natural language.
14.1.1 Grammatical Form
The Norwegian Prime Minister recently (i.e. early 1993) refused the publication of aninterview with her. Not because anything incorrect was explicitly written or implied
Handbook of Logic and Language. DOI: 10.1016/B978-0-444-53726-3.00014-1c! 2011 Elsevier B.V. All rights reserved.

“18-ch14-0691-0724-9780444537263” — 2010/11/29 — 21:08 — page 692 — #2
692 Handbook of Logic and Language
by the journalist, but because the journalist had been too correct, proposing to printexactly the “stream of utterances” of the prime minister during the interview. We sym-pathize with the prime minister, the partiality, even incoherence, of actual utterancesrarely reproduce the meaning content of a communicative act.
The lesson to be learned is that the complexity of actual communication is toodifficult for both the logician and the linguist; we shall, therefore, immediately abstractfrom reality and start from what is grammatically correct. But even in the domain ofthe grammatically correct there are issues of partiality.
14.1.1.1 Sortal Incorrectness
One aspect of partiality is connected with sortal incorrectness. A favorite example oflinguists is the following sentence:
Colorless green ideas sleep furiously.
This is taken as an example of a grammatically correct but meaningless sentence. Theexample is, perhaps, a bit too clever and confuses several issues. One is the predicationof contradictory properties, such as colorless and green, to the same object. In mostcases contradiction does not result in partiality, but in falsity, and this is of no furtherconcern to us. We must, however, exercise some care; there are important examples,e.g., in connection with algorithms and rule-following, where contradiction is betterresolved through partiality.
The oddness of the example (and in a sense the justification for the label of sortalincorrectness) lies in the combination of the noun phrase (NP) with the verb phrase(VP). An NP may play a large number of rôles, the VP may be more restrictive incalling for an actor for the rôle it describes. Thus there may even at the linguisticlevel be so-called selection rules, and violation of such rules may result in partiality,i.e. suspension in the assignment of truth-values, or of lack of meaning, rather than inclaims of falsity.
14.1.1.2 Indexicals and Definite Descriptions
Another source of grammatical partiality is associated with the use of indexicals.Uttered among a crowd of mothers of school children,
she loves her children,
is underdetermined in the sense that she does not by itself pick out a unique refer-ent. The same phenomenon may occur with definite descriptions, the woman withthe outrageous hat is not a very appropriate mode of identification at Ascot. Definitedescriptions may even fail to refer at all.
14.1.1.3 Presupposition
Sortal incorrectness and indexicals lead on to the broader topic of presuppositionswhich lives on the border line between grammatical form and semantical content

“18-ch14-0691-0724-9780444537263” — 2010/11/29 — 21:08 — page 693 — #3
Partiality 693
where partiality or truth-value gaps may enter. An utterance of
Mary loves her children,
carries the presupposition that this particular Mary has children. So if our Mary hasno children (born to her or legally adopted), we are at a loss of how to assign a truthvalue to what is expressed by the utterance. Note that a denial of the utterance is notnecessarily a denial of the presuppositions of the utterance. We shall in later parts bedealing with issues concerning partiality of facts and partiality of information aboutfacts.
Not every less-than-perfect feature of language should count as an example of par-tiality. There are a number of phenomena associated with, e.g., quantifier scoping andellipsis which result in ambiguities and multiplicities of readings, but which we willnot count as examples of partiality.
In Section 14.2 on models for linguistic structure we shall briefly return to some ofthe problems of this section and indicate how they can be accounted for. We now turnto some topics connected with knowledge and partiality.
14.1.2 The Structure of Knowledge
Even if its mechanisms are not well understood, we use language to express knowl-edge about the world. Thus there are cases where a sentence is supported by the world,i.e. there are facts in the world which show the correctness of the sentence. And thereare cases where a sentence is rejected by the world, i.e. there are facts in the worldwhich refute or contradict the sentence. Ordinarily, we strive for coherence, a sen-tence cannot at the same time and place be both supported and rejected by the factsof our world. We may wish for completeness, that a sentence is either supported orrejected by the facts, but this is not always to be obtained; we may be in a situation of“partial knowledge”.
Note that this kind of partiality is different from those discussed in the previoussection. No fact added to the world would resolve problems concerning sortal incor-rectness, presuppositions and the use of indexicals.
14.1.2.1 Models
To make the above intuitive remarks more precise we shall follow a tradition fromformal or mathematical logic. The development of a theory of semantics has a longhistory. One crucial step in this development was Tarski’s work on the notion of truthfor formalized languages in the early 1930’s; see Tarski (1956). Truth, as conceivedby Tarski, was a relation between a sentence of a language and the “world”. To obtaintechnical results he replaced language by formal (first order or higher type) languageand world by the set-theoretic notion of model.
A model, as understood by contemporary mathematical logic, is determined bya non-empty set, the domain of individuals/objects of the model, and a collection ofrelations and functions. An n-ary relation is at this level understood as a set of n-tuples

“18-ch14-0691-0724-9780444537263” — 2010/11/29 — 21:08 — page 694 — #4
694 Handbook of Logic and Language
from the domain, and functions are viewed as a special kind of relations. A model ofa first order theory has a domain which is just a collection of individuals; higher-ordertheories require a type-theoretic structure on the domain. The relevance of this forlinguistics will be the topic of later sections. Here we shall make some remarks ontotality versus partiality in relation to model theory.
Models, including the “possible worlds” of intensional logic, have a certain com-pleteness property, i.e. given any property (i.e. unary relation) P and individual a ofthe model, we have either the positive fact that a has the property P, or the negativefact that a does not have the property P. We have a partition of the domain into P’sand non-P’s. The model aims to capture all knowledge with respect to the relationsand the individuals it contains.
This is a reasonable requirement if one starts, as did the pioneers of the develop-ment of formal logic in the first third of this century, with mathematical applicationsin mind, where the domain of a model might be the natural numbers or some otheralgebraic structure. This is not the only possibility, taking our clue from the historyof logic and linguistics we could try to capture a different intuition. With respect toa language-user a “model” could try to capture his or her perspective in a particularutterance situation. In such a perspective a sentence uttered may or may not be sup-ported or rejected by the facts available. This is an intuition which has always beenpresent, but was neglected in the technical development of mathematical logic since“mathematical truths” do not seem to need a “speaker”. We did, however, see variousattempts in philosophical logic to add a dimension of pragmatics to the syntax andsemantics of mathematical logicians; see the survey in Fenstad, Halvorsen, Langholmand Van Benthem (1987).
The use of small (e.g., finite) but standard (i.e. total) models is one way of capturingthe partiality of one particular perspective on a “global” world. There are, however,more radical ways.
14.1.2.2 Situation Theory
A more systematic attempt to capture the partiality of an utterance-situation withinthe semantics has recently been advocated by J. Barwise and J. Perry in their work onSituation Theory; see Barwise and Perry (1983), and Barwise (1989).
In their original set-up the starting point was a collection of facts. Facts are built outof locations, relations and individuals. Locations are taken as (connected) regions ofspace-time. Relations are understood as primitives or irreducibles, i.e. a relation is notgiven as a set of n-tuples of individuals. Relations may be used to classify individuals,but the “meaning” of the relation is not the resulting set theoretic construct. The notionof individual is quite liberal in order to account for the referential mechanisms ofnatural languages, e.g., facts can be arguments of relations inside other facts. Finally,facts come with a certain polarity, a fact is positive if it asserts of some individualsa1, . . . , an that they stand in a relation r at some location l; it is negative if it assertsof some individuals a1, . . . , an that they do not stand in the relation r at location l.

“18-ch14-0691-0724-9780444537263” — 2010/11/29 — 21:08 — page 695 — #5
Partiality 695
Note that the denial of a positive fact is not the same as asserting the correspondingnegative fact.
A situation is a collection of (located) facts with respects to some domain L oflocations, R of relations and I of individuals. Thus a situation supports some facts(i.e. the positive facts in the situation) and rejects some facts (i.e. the negative factsin the situation). A situation may be partial in the sense that it need not contain eitherthe positive or negative version of the facts possible with respect to the domains L, Rand I.
Partial structures and their logic will be the topic of part three of this chapter. Forthe particular theory of situation semantics the reader is referred to the appropriatechapter of the Handbook. We shall, however, as part of our motivation for the use ofpartial structures, sketch an early analysis of the attitude verb “see” within situationsemantics.
14.1.2.3 See
The relationship between logical entailment and sameness of meaning or synonomyin natural language is problematic. In standard logic we have the mutual entailment of
(i) Mary walks.(ii) Mary walks and Sue talks or does not talk.
From this equivalence accepted principles of compositionality would give the furtherequivalence
(iii) John sees Mary walk.(iv) John sees Mary walk and Sue talk or not talk.
This is odd, not only for the linguists but also for the logician. On the standard analysis(iv) would entail that John sees Sue. This is not entailed by (iii) since this sentence doesnot mention Sue. The situation can be saved in various ways. We can tamper with thenotion of logical entailment, we can restrict the uses of compositionality, or we can letgo the commitment to totality.
In the early framework of Situation and Attitudes (Barwise and Perry, 1983), theproblem was analyzed as follows. A situation s supports the sentence John sees Marywalk if there is some other situation s! such that s supports the fact that s! and Johnstand in the relation see, and s! support the fact that Mary walks. There may be nos! which in s stands in the relation see to John and which supports or reject the factthat Sue talks. Thus a situation s which supports (iii) need not support (iv). We are notforced on logical grounds alone to accept their equivalence.
The example shows that partiality has a role to play in the analysis of the relation-ship between language and the world. Not every fact, be it positive or negative, ispresent in every perspective on the world. Nevertheless, a particular perspective sup-ports some and rejects other sentences. We conclude that partial models, whether theyintend to model the absence of facts or the lack of information about facts, are usefulconstructs. With this disclaimer we shall abstain from further discussion if partiality is

“18-ch14-0691-0724-9780444537263” — 2010/11/29 — 21:08 — page 696 — #6
696 Handbook of Logic and Language
sometimes natural, i.e. a property of the world, or always man-made, i.e. a feature ofour theories about the world.
14.1.2.4 Knowledge Representation
An important trend in “applied logic” has been the use of model theory in the studyof knowledge representation. In a certain sense, model theory is knowledge represen-tation – the diagram of a (finite) model (i.e. the set of valid atomic or negated atomicstatements) is a database representation; see, e.g., Gurevich (1987) and Makowsky(1984), for a sample of some recent results.
Partiality enters in a natural way from this perspective, partial databases are roughlythe same as partial structures in our sense. For recent theory and applications seeMinker (1988), and Doherty (1996).
The study of partial structures and their associated logic will, as mentioned above,be the topic of Section 14.3 of this chapter. We conclude this section by some remarkson partiality versus issues of vagueness, fuzziness and probability.
Vagueness is an important source of indeterminateness in language use. It is, per-haps, mostly associated with the meaning of lexical items. Does or does not this entityfall under this concept, is or is not this colored patch green or blue? The polaritiesof situation theory (and of classical logic) are sharp. To the question “Does a havethe property P?” the answer is yes, no or neither. The membership of a in P is nevervague, fuzzy or probabilistic. The latter phenomena merit study, but they are not ourconcern in this chapter.
14.1.3 Rules
A system for natural language analysis must in some systematic way relate linguis-tic form and semantic content. If we want to be computational linguists, we must inaddition insist that the relationship be algorithmic.
There are (at least) two sides to rule-following: efficiency and limitations. We shallnot have much to add to the first topic. A great deal of effort has been spent within thecomputational linguistic community on the construction of efficient algorithms and onimproving the performance of existing ones. This is still much of an art and thereforequite eclectic in methodology.
The situation changes when doubts arise about the existence of an algorithmic solu-tion to a problem. The affirmative, i.e. the actual existence of an algorithm, is mostconvincingly proved through explicit construction, and there is no need to be too pre-cise about the general notions. To prove non-existence is different. If you do not knowwhat an algorithm is, how can you conclude that none exists; a general theory of algo-rithms is needed for this task.
In this section we shall make some brief remarks on the general notion of algo-rithm, connecting it to issues of partiality and self-reference. This will lead up to thediscussion in the last section of this part on the paradoxial power of self-reference innatural languages.

“18-ch14-0691-0724-9780444537263” — 2010/11/29 — 21:08 — page 697 — #7
Partiality 697
14.1.3.1 Partial Algorithms
We may “compute”, i.e. perform effective operations, on objects of many kinds, suchas syntactic structures and semantic representations, but familiar devices of codingalways reduce such computations to computations with numbers. So let our computa-tional domain be the natural numbers 0, 1, 2, . . . . Let us assume that our computationsare performed by some “machine” M; we let M(x1, . . . , xn) " y express the fact thatthe machine M when given the numbers x1, . . . , xn as input eventually produces theanswer or output y. We use the arrow " instead of the equality symbol = to empha-size that computations may fail, i.e. no output may be forthcoming. Most readers willbe familiar with some concrete version of this notion, either through the theory ofTuring Machines, general recursive functions, !-definability, or one of the many otheralternatives; a good survey is given in Odifreddi (1989).
A basic result of the theory is the existence of a universal machine U with theproperty that given any machine M there exists a number m such that M(x) # U(m, x)for all x. We use # to indicate that M and U are defined for exactly the same inputsx, and that they yield the same output whenever defined. We use M(x)$ to expressthat the procedure M terminates for the input x, i.e. there exists a number y such thatM(x) " y.
One may conjecture that universal machines, encoding all possible forms of effec-tive computations, must be monstrous creatures. We cannot resist including thefollowing simple example of a universal machine (Fig. 1); see Aanderaa (1993).
But we warn the reader against using this machine for syntactic analysis.
ay
dR
q1c
b
B
q4
L
q0
R
q2
L
q3
Rd
c
q5
L
AA A
0
00
1
1
B cb
a d
xyH
1B
B
B
A
B
Ax
AB
A0 1y
Figure 14.1 Universal Turing machine: UTm.

“18-ch14-0691-0724-9780444537263” — 2010/11/29 — 21:08 — page 698 — #8
698 Handbook of Logic and Language
The possibility of partiality was built into the definition of a computing device, andthis for good reasons. We cannot impose totality. Suppose that we could, i.e. that wecould replace " and # by = and assume that any M is total. If there exists a totaluniversal machine U, we can by diagonalization construct a new machine U1(x) =U(x, x); let U2(x) = U1(x) + 1 (i.e. U2 is defined by feeding the output of U1 into thesuccessor function, which certainly is computable by some total machine S). By theuniversality of U we get a number m0 such that U2(x) = U(m0, x), for all x. Choosex = m0 as input, then U(m0, m0) = U2(m0) = U1(m0) + 1 = U(m0, m0) + 1;a contradiction.
The only way out of this predicament is to deny the assumption of totality. To havean enumeration or universal function inside the class we need the extension from totalto partial objects. But we have proved more. Given any specific version of the theory,a witness m0 to partiality has been effectively found. Let us pursue this a bit further.A machine M is a description of an algorithm; the partiality of M means that thereare inputs x such that M(x)$ is false. For the machine U2 we can effectively computean m0 such that U2(m0) is undefined. Can we more generally decide if algorithmsconverge? This is the famous Halting Problem.
14.1.3.2 The Combinatorial Core of Undecidability
To answer this question we need one more notion. A set A of numbers is called recur-sively enumerable (r.e.) if it is the domain of some machine, i.e. A = {x | M(x)$}.A set is called recursive if and only if both it and its complement are r.e.
If a set A is recursive we can effectively decide for any x if x % A or x % Ā (Ā beingthe complement of A in the domain of natural numbers): Since A is recursive there aremachines M1 and M2 such that A is the domain of M1 and Ā is the domain of M2. Forany number x we start the computations M1(x) and M2(x). Since x belongs to either Aor Ā, there is some y such that either M1(x) " y or M2(x) " y. Since computationsare finite, we will eventually know the answer.
Returning to the Halting Problem, let us take a closer look at the set K = {x |U(x, x)$}. We claim that K is not recursive. Suppose otherwise; then the complementK would be r.e., i.e. there is some number mk such that x % K if and only if U(mk, x)$.This leads – once more – to a contradiction: mk % K iff U(mk, mk)$ iff mk % K. Inthis case K is really a Russellian paradoxical set since K is the set of all x such that x(as a code of a function) does not apply to itself (as an argument).
Simple as it is, the fact that K is r.e. but not recursive, is in a sense the combinatorialcore of undecidability results. It basically asserts the undecidability of the HaltingProblem. A number of algorithmic problems can be proved unsolvable by suitablereductions to this problem; for examples of relevance to linguistic theory, see Barton,Berwick and Ristad (1987).
Logicians and recursion theorists have learned to live with paradoxes and haveoccasionally been able to turn contradictions into technical tools. But, even if powerfuland universal, computation theories are not all there is. In the next section we shall turn

“18-ch14-0691-0724-9780444537263” — 2010/11/29 — 21:08 — page 699 — #9
Partiality 699
to self-reference in the broader context of natural languages and see how this is yetanother source of partiality.
14.1.4 Self-Reference
Human languages are in important respects open systems. There are, of course, rulesof grammar and “correct usage”, but language-in-use shows a remarkable creativityin circumventing such restrictions if that is necessary for enhancing its efficiency inhuman communication. Nevertheless, certain uses of language connected with fun-damental properties of truth and reference seem to cross the boundary line of theparadoxical. If the “this” of “this is not true” refers to itself – and why should it not?– then this is not true if and only if it is true. Language in use is not free from contra-dictions, but when paradox emerges from “self-evident” properties of truth, referenceand negation any linguist whose aim it is to explore the systematic connection betweenlinguistic form and semantical content, must take notice.
14.1.4.1 The Paradoxes
Logic has lived with paradox for a long time, the one just recalled, the Liar Paradox,has roots in antiquity. We must, with some regret, enter the story at the contemporarystage. Since Ramsey in 1925 it has been customary to make a distinction betweensemantical paradoxes dealing with notions such as truth, assertions and definitionsand mathematical or logical paradoxes, dealing with membership, classes, functions –both types of paradoxes, however, involving notions of self-reference and negation.
We shall recall a few facts following an exposition of Feferman (1984).To fix ideas assume that some logical formalism or language L is given with the
usual apparatus of syntactic notions such as term, formula, sentence, free and boundvariables etc. The presence of paradox depends upon what further assumptions weimpose on the language L, the logic of L and the basic principles L admits concerningtruth and set existence.
The Liar is the proto-type of a semantical paradox. In this case since we are dis-cussing self-reference, we assume that the language of L has a naming mechanism,i.e. for every sentence A of L there is a closed term &A' which functions as the nameof A in L. We also assume that L satisfies the basic property of self-reference, i.e. forevery formula B(x) there is a sentence A which is equivalent in L to B(&A'). The logicof L is assumed to be standard classical logic. Concerning basic principles we havethe “truth”-principle which asserts that there is a truth predicate Tr(x) in L such thatfor any sentence A of L, A is equivalent in L to Tr(&A'), i.e. we have a truth definitionfor L within L.
The construction of paradox is now straightforward. Take the formula ¬Tr(x), bynaming and self-reference there is a sentence A0 in L equivalent to ¬Tr(&A0') (i.e. theLiar sentence). By the truth-principle A0 is also equivalent to Tr(&A0'), i.e. A0 is trueif and only if it is not true. Since truth is a complete property, we have a paradox.

“18-ch14-0691-0724-9780444537263” — 2010/11/29 — 21:08 — page 700 — #10
700 Handbook of Logic and Language
The Russell set, i.e. the set of all sets which are not element of themselves, is theproto-type of a mathematical paradox. In this case the basic relation of the languageL is the membership relation x % y and the naming device allows for unrestricted setformation, i.e. for every formula A(x) there is a set-term {x | A(x)} with the intendedmeaning of naming the set of all x such that A(x) is true in L. The logic of L is oncemore standard classical logic, and the basic principle is one which determines setmembership: a % {x | A(x)} if and only if A(a). The Russell set, {x | ¬(x % x)}, imme-diately yields a contradiction, a % a if and only if ¬(a % a). Since the membershiprelation is complete, we have our paradox.
14.1.4.2 Paradoxes and Partiality
In the previous section on algorithms and partiality we saw how the recursion theoristwas able to find his way through the complexities of truth, self-reference and paradox.The Russell construction was used to prove the existence of a recursively enumerablebut non-recursive set. The ability of the universal machine U(m, x) to refer to itselfdid not lead to paradox, but to partiality.
The Gödel incompleteness theorem is another celebrated case where paradox hasbeen put to constructive use. The witness to incompleteness of the provability pred-icate is a statement A which asserts its own unprovability. Here there is no paradoxbecause of the difference between asserting the provability of ¬A and the non-provability of A. This is a typical example of a partial relation. Let Pr be the setof all A provable in the system and Pr the set of all A such that ¬A is provable in thesystem. The pair (Pr, Pr) is a partial relation, in fact, the Gödel sentence A is neitherin Pr nor in Pr.
In a similar way, for the Liar Paradox, let Tr be the set of all A such that Tr(&A')and Tr be the set of all A such that Tr(&¬A'). Since the logic is classical the formulaA * ¬A is valid, hence by the basic truth-principle (Tr, Tr) forms a complete pair, i.e.for any A, either A % Tr or A % Tr. In this case completeness enforces paradox.
The recursion theorist and the proof theorist have successfully met the challengeof the “paradoxes of self-application” and been able to turn contradiction into pow-erful techniques. For recursion theory this was evident already in Kleene’s influentialtext-book from 1952. The step beyond Gödel took longer within the proof-theory com-munity; for a recent survey of the history and of present applications, see Smorynski(1991). For us it remains to add some comments on responses and proposals in a widercontext. First some remarks on the mathematical paradoxes.
14.1.4.3 Paradoxes and the Foundation of Mathematics
One observation on the Russell paradox is that it is made possible by the vagueness ofthe notion of set. Successful axiomatization is not a play with symbols and rules, butrests on sharp intuitions and a careful preformal analysis. This is indeed brought out byhistory. The axiomatization of set theory initiated by Zermelo, Fraenkel and Skolemand further developed by von Neumann and Bernays rests upon the intuition of setsbeing presented or constructed in stages. In the resulting “cumulative hierarchy” there

“18-ch14-0691-0724-9780444537263” — 2010/11/29 — 21:08 — page 701 — #11
Partiality 701
will be no Russell set since every element of a set x must be “constructed” before xitself is secured. The condition x % x is contradictory and will give nothing but theempty set. A parallel analysis of functions and functional application including self-application has beyond recursion theory led to a rich theory of types and properties,both classical, constructive and partial.
This is the topic of the chapter on Type Structures. Here we add a few words ona recent development which skirts close to the difficulties of the Russell paradox. Inmany branches of mathematics one would like to organize all structures of some givenkind into a new mathematical structure with new operation and relations. These ideaswas made precise in the early 1940 by Eilenberg and MacLane (for an introduction seeMacLane, 1971), and the resulting theory, category theory, has proved to be a fruitfultool in many areas of mathematics. In the 1960s there was an interesting encounter oflogic and category theory which has grown into a rich theory, see, e.g., Bell (1988).
But category theory rests on a different intuitive notion of set than the cumula-tive hierarchy of standard axiomatic set theory. The situation is complicated, but notuntypical. Category theory is too useful to throw away, even if there could be para-doxes hiding behind “the category of all categories”; for a full discussion see MacLaneand Moerdijk (1992).
14.1.4.4 Paradoxes and Truth
It remains to conclude with some remarks on the Liar and related semantical para-doxes. As remarked the history of these paradoxes is old. With some justification wecan date the modern development to Tarski’s study on the concept of truth in formal-ized languages in the early 1930’s; see Tarski (1956). The Liar paradox told us thattruth of sentences in a formal language L is not definable in L. Tarski’s response wasto restrict the naming and self-referential strength of L. His proposal was to introducean extension ML of L, ML being a “metalanguage” of L, which would allow for thenaming of sentences of L, i.e. for each A of L there is a name (a closed term) &A' ofML which serves as a name of A in ML. But there is in ML no general mechanism forintroducing names for arbitrary formulas of ML. The basic truth-principle is retainedby Tarski, i.e. for any sentence A of L, A is equivalent in ML to Tr(&A'). By restrictingthe power of naming and self-reference there is no longer any paradox. But there is aprice to pay, the truth predicate for ML is not definable in ML, but in a metalanguageof ML, i.e. in a meta-metalanguage of L. This leads to a hierarchy of languages ofincreasing strength.
From the point of view of mathematical logic there are no objections. The workof Tarski in the early 1930’s lead in the late 1940’s and early 1950’s to a generaldevelopment of model theory as a discipline at the interface of logic and mathematics;see Chang and Keisler (1977).
But neither for the philosopher of language nor the linguist is Tarski’s analysissatisfactory. A major step forward was taken by Kripke (1975). There are two partsto his work, a critique in depth of the Tarskian approach and suggestions for a wayout. As to the critique Kripke emphasized that the phenomenon of self-reference or

“18-ch14-0691-0724-9780444537263” — 2010/11/29 — 21:08 — page 702 — #12
702 Handbook of Logic and Language
circularity is so widespread in natural languages that no extension of the Tarskiantrick of the language-metalanguage distinction would prove satisfactory. On the con-structive side Kripke presented an analysis which allows for both self-reference andinternal truth-definition. The price he paid was to turn the total truth predicate intoa partial predicate (Tr, Tr), which would allow for truth-value gaps. In fact, the Liarsentence would belong to neither Tr nor Tr (under reasonable assumptions). The partialpredicate (Tr, Tr) was for the particular examples Kripke discussed, defined in stages(Tr", Tr"). Starting from a reasonable base pair (Tr0, Tr0), e.g., (+, +), one wouldpass from stage " to " + 1 by stipulations such as putting Tr(&A') into Tr"+1 and¬Tr(&A') into Tr"+1 for any A true at stage " (i.e. A % Tr"). Thus, in a sense, theTarskian sequence of metalanguages, each extending its predecessor by adding thetruth-definition, is internalized as a sequence of “approximations” to the full determi-nation of truth and falsity for the language. Kripke shows for the examples that heconsidered, that there are fixed-points, i.e. pairs (Tr# , Tr# ) such that Tr# = Tr#+1 andTr# = Tr#+1, and such that Tr# , Tr# = +. A fixed-point provides a truth defini-tion within the language and avoids the paradox of the Liar by the fact that the Liarsentence is neither in Tr# nor in Tr# .
The pair (Tr# , Tr# ) is yet another example of a partial predicate. We shall notpursue the study of self-reference and paradoxes further in this chapter. An importantpost-Kripke paper is Herzberger (1982). There is a rich literature, some additionalreferences are Martin (1981); Visser (1989); Gupta and Belnap (1993); Feferman(1991). In Section 14.3 we shall return to a study of partial predicates, not in the con-text of paradoxes, but in connection with issues dealing with partiality of knowledgein the sense of Section 14.1.2.
14.1.4.5 Non-Wellfounded Structures
We conclude this section with a report on a different concept of set which has beenused – among other things – to analyze the Liar Paradox. This is the concept of non-well founded set, i.e. a concept of set which admits sets A such that A % A. This opensup for various direct ways of naming or coding with self-referential possibilities.
The notion of non-wellfounded set has an interesting history. A convenient con-temporary starting point is the monograph by Aczel (1988), which also has somehistorical remarks. Aczel was motivated by the need for a mathematical analysis of(computational) process which may apply to themselves; such processes occurs natu-rally in parts of computer science. In graph theoretic terms these processes correspondto cyclic graphs (whereas the membership relation of a wellfounded set leads to anacyclic graph). Recasting the theory in terms of non-wellfounded sets opens up for anapplication of powerful set-theoretical techniques, in particular, fixed-point theorems.
This possibility was exploited by Barwise and Etchemendy (1987), in their ana-lysis of the Liar Paradox. Lack of space prevents us from giving an account of theirwork. It is precisely a fixed-point construction which gives a Liar sentence with theright self-referential properties. On the surface there seems to be no need for cod-ing and partiality. Coding is circumvented in the fixed-point construction because ofnon-wellfoundedness. However, partiality is implicitly present through the restricted

“18-ch14-0691-0724-9780444537263” — 2010/11/29 — 21:08 — page 703 — #13
Partiality 703
power of the language to refer to the world. We must leave to the reader to decideif non-wellfoundedness adds more to the theory of cyclic graphs than set-theoretictechniques, i.e. if there is a “sharp” intuition of non-wellfounded membership.
This concludes our survey of sources of partiality. We next turn to a discussion ofsome issues of partiality in connection with linguistic form. This is a natural follow-upto the discussion in Section 14.1.1, but we shall also encounter some new aspects ofpartiality.
14.2 Partiality and Models for Linguistic Structure
“. . . we have to make a distinction between a computational structure and a moreor less independent conceptual structure . . . The conceptual module includes whatis often referred to as knowledge of the world, common sense and beyond. It alsoincludes logical knowledge and knowledge of predicate-argument structure. The com-putational module concerns the constraints on our actual organization of discrete units,like morphemes and words, into phrases and constraints on relations between phrases”(Koster, 1989, p. 593). “If the two basic modules are autonomous and radically dif-ferent in architecture and evolutionary origin, there must be . . . an interface . . . Myhypothesis is that the interface we are looking for is the lexicon . . .” (Koster, 1989,p. 598).
The point of view expressed by Koster is fairly conventional, there are two mod-ules: grammatical space and semantical space. The link between the two could eitherbe a logical formalism in the style of Montague or an attribute-value formalism inthe style of Lexical-Functional Grammar. There are also intermediate forms such asthe Discourse Representation Structures of Kamp; see Kamp (1981), Kamp and Reyle(1993) and the chapter on Discourse Representation in Context.
Not every approach adheres to the modular format. We specifically direct attentionto the chapter on Game-Theoretical Semantics. A particular reason for doing so is theconnection of this approach to the issue of partiality. The semantics is defined in termsof games and strategies. Games are not always determined, i.e. winning strategies maynot always exist. This holds true for the games considered in the game-theoreticalapproach to natural language semantics. In particular, the law of excluded middle failssince there are easy and general examples when the associated game is not determined.We refer the reader to the game-theoretical chapter for a discussion of what this meansfor the notion of negation.
In this part we will choose an attribute-value formalism, but we will return tohigher-order logic and partiality in Section 14.3. We emphasize, however, that the par-ticular model chosen is just a vehicle used to sort out some of the aspects of partialitydiscussed in Section 14.1.
14.2.1 Representional Form
Syntactic analysis aims to unravel the structure of a phrase. Part of this task consistsin exhibiting the features and roles carried by or embedded into the phrase. Subpartsof it may belong to different syntactic categories, they may function in a variety of

“18-ch14-0691-0724-9780444537263” — 2010/11/29 — 21:08 — page 704 — #14
704 Handbook of Logic and Language
roles such as subject, object, etc., and they may be marked for various types of agree-ment features. Such information can be conveniently represented in an attribute-valueformat.
Feature-value systems and their logic is the topic of other chapters in the 1997edition of the Handbook, Unification Grammars by Martin Kay and Feature Logicsby W.C. Rounds. Let us here remark that this format of analysis was pioneered withincomputational linguistics by Martin Kay. It was also the format chosen by Kaplanand Kaplan and Bresnan (1982), in their theory of Lexical-Functional Grammar, withan emphasis on grammatical attributes such as SUBJ, OBJ, TENSE, PRED, etc. Inour theory of Situation Schemata we shifted from a focusing on grammatical roles toan emphasis of semantical roles such as REL, ARG, LOC; see Fenstad, Halvorsen,Langholm and Van Benthem (1987).
14.2.1.1 A Theory of Signs
From our point of view we can also view the class of Head-Driven Phrase StructureGrammars (HPSG) as attribute-value theories; see the basic text by Pollard and Sag(1987). HPSG is a theory of signs, where the basic format is
!
""""""""""#
PHON · · ·
SYN
!
""#LOC
!
#HEAD · · ·
SUBCAT · · ·LEX · · ·
$
%
BIND · · ·
$
&&%
SEM · · ·
$
&&&&&&&&&&%
.
A sign can be phrasal or lexical, according to whether the LEX feature is unmarkedor marked. Within this framework Pollard and Sag developed a rich theory of gram-matical structure. We shall only comment on one aspect of relevance to partiality. Theinformation carried by sign is possibly partial. A noun – or rather its sign – is not initself complete or saturated, but calls for a determiner to form a full sign, an NP. Inthe same way a VP subcategorizes for an NP to form a full sign, in this case a signof category S. In HPSG this process is governed by the subcategorization principle.In this way the theory is able to deal with partiality phenomena classified as sortalincorrectness; see Section 14.1.1.1.
We have dwelt upon this issue at some length in order to highlight the phenomenonof partiality associated with grammatical signs. In order to carry “meaning” (as in thecase of a sign of category S) or “reference” (as in the case of a sign of category NP)the sign must be saturated.
14.2.1.2 The Algebra of Signs
This partiality is also reflected in the algebraic theory of signs. This theory can be castin several different forms. In one version we look upon an attribute-value matrix as

“18-ch14-0691-0724-9780444537263” — 2010/11/29 — 21:08 — page 705 — #15
Partiality 705
a finite or partial function, where complex matrices correspond to iterated functions.An approach along these lines has been developed by Johnson (1988). Alternatively,we can look upon attribute-value matrices as a collection of paths; see the pioneeringwork of Rounds and Kaspar (1986). In the following example
!
""""#
SUBJ [PRED MARY]
OBJ [PRED JOHN]
PRED KISS
$
&&&&%
we have a set A = {MARY, JOHN, KISS, . . .} of atomic values and a set L ={SUBJ, OBJ, PRED, . . .} of labels. The matrix can be redrawn as a graph where we
KISS
JOHN
OBJ
MARY
PRED
PRED PRED
SUBJ
q0
have six nodes, including an initial node; labels are attached to the arcs between nodes,and atomic values are assigned to some nodes. Formally a complex feature structureis defined as
M = (Q, q0, $,"),
where Q is the set of nodes; q0 is the initial node; $ is a transition function, i.e. apartial function $ : Q - L " Q; and " is an assignment function, i.e. a partial (andinjective) function " : Q " A.
How the theory proceeds from this basis can be seen in the expositions in Carpenter(1992) and Keller (1993). We have included this brief hint to highlight how partialityis present at a rather fundamental structural level in the theory of grammatical form.Signs need not be saturated but may only encode partial information. The transitionand assignment functions of a complex feature-valued structure are partial predicates

“18-ch14-0691-0724-9780444537263” — 2010/11/29 — 21:08 — page 706 — #16
706 Handbook of Logic and Language
in the sense of Section 14.1. Lack of subsumption and failure of unification can beused to block the occurrence of sortal incorrectness.
We are still at the level of grammatical form; our next task is to discuss how to copewith problems of partiality associated with reference and indexicality. But the readershould bear in mind that this structure partiality has not called for a parallel partialityin the logic; for further discussion see Section 14.3.2.6.
14.2.2 A Relational Theory of Meaning
The sentences of mathematics do not need a speaker. And since mathematical praxishad a decisive influence on the development of logic, we may well ask how appropriatethe deductive chains and proof figures of formal logic are for “seeing” the validity ofarguments in natural language contexts. We shall not discuss the adequacy of prooftheory as a paradigm for natural language reasoning; see Barwise and Etchemendy(1991), for recent work see Allwein and Barwise (1993). Our problem is to accountfor the “I” and “you” of natural language use; i.e. how to include the speaker andhearer as part of the communicative act. To fix ideas we shall follow the approach ofFenstad, Halvorsen, Langholm and Van Benthem (1987).
14.2.2.1 Situation Schemata
A situation schema is an attribute-value matrix where the features have been chosen toreflect the primitives of situation theory; see Section 14.1.2.2. Thus we have a featurelabel REL corresponding to the set R of relations; we have feature labels IND cor-responding to individuals in I or elements of L; labels LOC corresponding to the setof locations L; and a label POL to indicate the polarities of basic facts. The situationschema corresponding to the sentence A = John is running is
SIT.A =
!
""""""""""""""#
REL runARG.1 John
LOC
!
""""#
IND IND.1
COND
!
#REL oARG.1 IND.1ARG.2 IND.0
$
%
$
&&&&%
POL 1
$
&&&&&&&&&&&&&&%
The set L of locations consists of regions of space-time. L can be given a rich geomet-ric structure, we always assume that we have the relations precede and overlap withrespect to the time dimension.

“18-ch14-0691-0724-9780444537263” — 2010/11/29 — 21:08 — page 707 — #17
Partiality 707
14.2.2.2 A Relational Theory of Meaning
The interpretation of a situation schema in a situation structure is always relative to anutterance situation u and a described situation s. Thus meaning is relational and weuse the notation:
u[|SIT.A|]s
to express this fact. We shall use our simple example to illustrate the meaning relation;for details of the full theory see Fenstad, Halvorsen, Langholm and Van Benthem(1987).
The utterance situation is decomposed into two parts: the discourse situation d andthe speaker’s connection c. The former tells us who the speaker is, who the addresseeis, the sentence uttered, and the discourse location in space and time. The latter deter-mines the speaker’s meaning of lexical items.
We return to SIT.A and to the explanation of its “meaning”. The atomic valuesIND.0 and IND.1 in SIT.A are called indeterminates. A map g defined on the set ofindeterminates of SIT.A.LOC (i.e. on the embedded attribute-value matrix which isthe value of the feature LOC in SIT.A) is called an anchor on SIT.A.LOC relative tothe utterance situation d, c if
g(IND.0) = ld
and
g(IND.1) overlap ld,
where ld is the discourse location determined by d, and where the “value” 0 in SIT.A(which is computed from the tense marker of the given sentence) is interpreted as theoverlap-relation of L. Then
d, c[|SIT.A|]s
if and only if there exists an anchor g on SIT.A.LOC relative to d such that
in s : at g(IND.1) : c(run), c(John); 1,
i.e. “c(John) stands in the relation c(run) at the location g(IND.1)” is a positive factin s. Observe the speaker’s connection c is a map defined on parts of the expression Aand with values in the appropriate domains, i.e. c(run) is in R and c(John) is in I.
Our example is simple, but the reader will appreciate how the mechanisms intro-duced above can be used to analyze indexicals and definite descriptions; see Barwiseand Perry (1983). We should note that the partiality of situations is not an issue atthis point. Situations could be complete; for a further discussion on the relationship ofthe present theory to other approaches the reader is referred to Sem (1988). Whetherthe same mechanisms are useful in the analysis of conditionals and presuppositions ismore uncertain; the reader is referred to the appropriate chapters of the Handbook.

“18-ch14-0691-0724-9780444537263” — 2010/11/29 — 21:08 — page 708 — #18
708 Handbook of Logic and Language
14.2.2.3 The Geometry of Models
Situation theory locates the basic entities of the meaning analysis in the world, i.e.situations, locations, relations and individuals are part of the actual world. In recentcognitive science there have been much written about “mental models” and how thebasic constructs are cognitive structures in the mind. This is a topic beyond our briefin this chapter; for a few references see Johnson-Laird (1983) and Gärdenfors (2000).However, much of the mathematics will remain the same whether the structures are inthe world or in the mind. And on both approaches there is a need to supplement thestandard model theory with a richer geometric structure on the semantical space. Toput it in slogan form: The geometry of meaning is not a homomorphic image of thealgebra of syntax; for an elaborations of this point of view, see Fenstad (1998).
Let us briefly summarize the discussion so far. We have surveyed several sources ofpartiality of importance to theoretical and computational linguistics. We made a dis-tinction between two modules in linguistic analysis, grammatical form and semanticalcontent. Partiality enters at a structural level in both components, complex feature-value structures in connection with representational form and “situations” or partialmodels in connection with the theory of meaning. Many phenomena of partiality inlinguistics can be “explained” in terms of this structural partiality. In addition we sur-veyed various issues of partiality in connection with computations and self-reference.From this the importance of the notion of partial predicates emerged. This will be afocus of attention in the last part of this chapter.
14.3 Partiality and the Structure of Knowledge
One lesson drawn from the introductory discussion in Section 14.1.2 was that partialmodels, whether they are intended to model the absence of facts or the lack of infor-mation about facts, are useful constructs. With respect to models of this class we havecertain positive facts, i.e. facts supported by the model, and certain negative facts, i.e.rejected by the model. Since the model is partial there may be facts that are neithersupported nor rejected. The logic of partial structures thus recognizes three possibili-ties, true, false, neither.
One domain of application where this is of particular importance, is the theory ofpartial recursive functions; see Section 14.1.3. Let us restrict attention to functionstaking values 0 or 1. Any such function f defines a number-theoretic predicate Pfconsisting of all n % N such that f (n) = 1. If f is total, the complement of Pf in Nis the set of all n % N such that f (n) = 0. Conversely, any total predicate P . Ndetermines a function fP, defined by the requirements that fP(n) = 1, if n % P; andfP(n) = 0, if n /% P. fP is called the characteristic function of P.
What happens when our characteristic functions are partial recursive functions?Any such function is given by a machine M; see Section 14.1.3. In this case the domainof definition of M, i.e. the set of all n % N such that M(n)$, need not be all of N. Thisleads to an associated partial predicate (PM, PM), where PM / PM is the domain ofdefinition of M; n % PM , if M(n) # 1; and n % PM , if M(n) # 0. From this perspective

“18-ch14-0691-0724-9780444537263” — 2010/11/29 — 21:08 — page 709 — #19
Partiality 709
the third possibility neither is different from the proper truth-values; it represents a“truth-value gap”, in this case represented by the co-domain N 0 (PM / PM), i.e.the set where M is not defined. We use the word gap to indicate the possibility ofcompletion, e.g., if the domain of M is recursive, we can extend M to a total recursivefunction M! simply by setting
M!(n) = 1 for all n % N 0 (PM / PM).
This is justified by the simple fact that the complement of a recursive set is recursive.Many-valued logic is a separate topic; for an introduction see Urquhart (1986).
However, drawing the exact dividing line between partial logic and many-valued logicis not an easy task. The mathematics tends to be the same, it is the interpretation (truth-value gap versus a third truth value) and the questions asked which reflect a differencein perspective.
The remainder of this part will be somewhat technical. We first study propositionalconnectives, their semantics and axiomatization. Next we discuss partial predicates,both in the frame-work of first order theories and in higher types. The final topicconcerns reductions. We have argued for the necessity of partial structures. But dopartial structures need a special kind of partial logic?
14.3.1 Partiality and Propositional Logic
The classical truth functions are given by the tables:
¬Q Q * R Q 1 R Q " R
Q t ff t
R t fQ t t t
f t f
R t fQ t t f
f f f
R t fQ t t f
f t t
In extending from total to partial predicates we have to account for the third possibility,neither. We shall use the case of partial recursive functions as our guiding example.We do this with some justification, since the extension that we are going to propose,was introduced by Kleene (1952) to handle exactly this case. There is also an added“moral lesson”. Formal analysis is not an arbitrary play with symbols, but needs to begrounded in experience, insight and precise preformal analysis.
14.3.1.1 Partial Connectives
Following Kleene, let us concentrate on the case of disjunction, Q * R. In this case,let Q be the proposition that M1(x) # 1, i.e. Q is the positive part of the partialpredicate (Q, Q) determined by the algorithm M1; similarly, let R be the propositionthat M2(x) # 1. We want Q*R to be represented by an algorithm M; the problem is todecide how the behavior of M shall be determined by the behavior of M1 and M2. Thealready filled in parts of the truth table presents no problems: If for a given value of

“18-ch14-0691-0724-9780444537263” — 2010/11/29 — 21:08 — page 710 — #20
710 Handbook of Logic and Language
x, M1(x) # 0 and M2(x) # 0, then the predicates Q and R have the value f for this x.In this case we want M(x) # 0, i.e. Q * R to have the value f .
Suppose the algorithm for Q * R is defined, say M(x) # 1, giving the value t toQ*R, in a case where M1(x) is undefined. This means that M gives an answer withoutusing any information about Q, but depends only on the information that M2(x) # 1.In this particular case, changing the Q-predicate to one giving the value t or f , wouldnot change the computation of M as long as the value of R is kept fixed.
Carrying through this kind of analysis for all cases, we see that in order for thepropositional connectives to reflect the behavior of partial recursive operation, theymust be regular (in the following sense of Kleene, 1952): A given column (row) con-tains t in the u (undefined) row (column), only if the column (row) consists entirely oft’s; similarly for f . The Kleene truth tables are the strongest possible regular extensionof the total tables, i.e. they have a t or an f whenever it is compatible with being aregular extension. The reader may verify that this leads to the tables:
¬Q Q * R Q 1 R Q " R
Q t ff tu u
R t f uQ t t t t
f t f uu t u u
R t f uQ t t f u
f f f fu u f u
R t f uQ t t f u
f t t tu t u u
There are other connectives of interest in the study of partial logic. In addition to thestrong (Kleene) negation, ¬Q, we can introduce a “weak” negation, 2Q, given by thetable
2 Q
Q t ff tu t
which corresponds to a kind of denial, since to deny a positive fact is either to assertthat the situation is not defined or, if defined, that the corresponding negative factobtains. In terms of partial predicates (P, P), strong negation interchanges P and P,weak negation correspond to set-theoretic complement. There is also an alternative tothe implication Q " R, viz. Q 3 R defined as 2 Q * R. Both 2 and 3 are non-persistent, i.e. adding new facts may change truth-values. We shall return to the topicof persistence in connection with the discussion of partial predicates.
The fact that we have written down truth-tables in the “values” t, f and u does notmean that we have changed from partiality to many-valued logic. If “values” werepart of our calculus, we would have to show some care; there are, e.g., differencesbetween partial functions f : N " {0, 1} and total functions f : N " {0, 1, u}. Thisis well known to every recursion theorist; in our context we can refer to the systemof Johnson (1988) mentioned in Section 14.2.1.5. We also need the perspective ofpartiality in the discussion of persistence, see Section 14.3.2.2.

“18-ch14-0691-0724-9780444537263” — 2010/11/29 — 21:08 — page 711 — #21
Partiality 711
There is a large body of results on connectives and definability in partial proposi-tional logic. Particularity noteworthy are various results on functional completenessof sets of connectives. This is of great importance for the systematic study of partiallogic, but may be of more marginal interest for the linguist. The reader is referred tothe technical literature; some key references are Blamey (1986), Langholm (1988),Thijsse (1992) and Jaspars (1994).
14.3.1.2 Partiality and the Consequence Relation
Let us be a bit more precise about the technical machinery of propositional logic.Formulas %, & are built from a finite set P1, . . . , Pn of propositional variables usingthe connectives 1, *, ¬, ". Occasionally we consider a larger set of connectives, e.g.,the “weak” connectives 2, 3; this will always be explicitly mentioned. Models arevaluations, i.e. maps from the set of propositional variables to the set of “truth”-valuest, f and u, extended to the class of all formulas by the use of (Kleene’s) truth-tables.
In the partial case we see that there is a difference between non-true and false, andbetween non-false and true. For let V be a valuation in which not V(%) = t, for some%. This means that V(%) = f or V(%) = u; thus non-truth of % with respect to themodel V does not imply the falsity of % with respect to V (i.e. V(%) = f ).
This distinction means that the notion of consequence splits into two versions whenwe pass from classical to partial logic. Let ' and ( be finite sets or sequences offormulas. (If we were to enter into the finer details of proof theory, we would have tobe more careful about the nature of ' and (, whether they be sets, sequences, multi-sets etc.; see Langholm (1989).) Let ' = {%1, . . . ,%n} and ( = {&}. The classicalconsequence relation ' |= ( is intended to express that the truth of & follows fromthe validity of all of %1, . . . ,%n, i.e. from the truth of the conjunction %1 1 · · · 1 %n.In the general case where ( = {&1, . . . ,&m} the single formula & is replaced by thedisjunction &1 * · · · * &m. From the classical truth tables we conclude that ' |= (,if there is no valuation V such that V(%i) = t, for all i = 1, . . . , n and V(&j) = f , forall j = 1, . . . , m. Since non-true is different from false in partial logic, the classicalconsequence relation splits into two parts:
' |=S ( if and only if there is no partial model (valuation) in which allformulas of ' are true and all formulas of ( are non-true.
' |=W ( if and only if there is no partial model (valuation) in which allformulas of ' are true and all formulas of ( are false.
The distinction between the two is easily seen, since we always have |=W %, ¬%, butnot always |=S %, ¬% – take a case where V(%) = V(¬%) = u.
14.3.1.3 Validity
Langholm (1989) suggested how to combine the two versions into a single “figure” orconsequence relation:
' (
) *(4)

“18-ch14-0691-0724-9780444537263” — 2010/11/29 — 21:08 — page 712 — #22
712 Handbook of Logic and Language
which is valid, if and only if there exists no model in which
all formulas of ' are true;all formulas of ( are non-true;all formulas of ) are false;all formulas of * are non-false.
Thus |=S corresponds to
' (
and |=W corresponds to
'
(
What we in fact have done is to replace the set of “truth”-values t, f and u (undefined)with the set t, f , nt and nf , where nt stands for non-true and nf for non-false. We seethat old values correspond to pairs of new values, thus u corresponds to nt and nf ; tcorresponds to t and nf (but since t is stronger or more informative than nf , we shallomit the latter); and f corresponds to f and nt (where we for the same reason omit thent-part of the pair).
14.3.1.4 Derivability
Corresponding to the validity relation we introduce the proof relation:
' (
) *(44)
We shall indicate in a few cases how to give axioms and rules for this proof relation.Of the six possible pairs of truth values three are allowed
t, nf f , nt nt, nf
and three are impossible
t, nt f , nf t, f .
The latter pairs translate into the following three axioms:
', % (, %
) *
' (
), % *, %
', % (
), % *

“18-ch14-0691-0724-9780444537263” — 2010/11/29 — 21:08 — page 713 — #23
Partiality 713
which are all seen to be valid by the definition of (4). The truth table for strong nega-tion can be replaced by the following truth table
% ¬%
t ff tnt nfnf nt
We see how the two tables correspond, t which is the same as the pair t and nf , ischanged by ¬ to the pair f and nt. Likewise nt and nf is changed by ¬ to nf and nt,which corresponds to u being transformed to u by ¬.
The table translates into the following rules:
', % (
) *
' (
), % *
' (, %
) *
' (
) *, %
5 5 5 5
' (
), ¬% *
',¬% (
) *
' (
) *, ¬%
' (, ¬%
) *
We see how these rules preserve validity, e.g., in the first case, if there is no modelin which % is t, then there is no model in which ¬% is f .
Let us have a brief look at conjunction. In this case the truth-table in t, f and utranslates to the following table:
% & % 1 &
t t tnt 0 nt0 nt ntf 0 f0 f fnf nf nf
(where a line – indicates that any of the values t, f , nt and nf can be inserted). Weleave it to the reader to argue in detail how this table corresponds to the table forconjunction in Section 14.3.1.1. Rules can now be extracted from the table; we indicatea few cases:
', %,& (
) *
5', (% 1 &) (
) *

“18-ch14-0691-0724-9780444537263” — 2010/11/29 — 21:08 — page 714 — #24
714 Handbook of Logic and Language
This is the rule corresponding to line one of the table. Matching lines two and threewe get the rule:
' (, %
) *
' (, &
) *
5' (, (% 1 &)
) *
Likewise lines four and five and line six allow us to introduce conjunction in the lasttwo quadrants in complete symmetry to the two cases exhibited above.
14.3.1.5 Completeness
We shall not pursue the proof theory to any extent in this chapter; however, one remarkon completeness. In (4) and (44) we have discussed certain sequents of formulas(', (,), *). In (4) we introduced the notion of validity of a sequent. The axiomsand rules developed in connection with (44) leads to a notion of derivability. The wayin which we have introduced axioms and rules leads almost directly to the followingcompleteness result:
A sequent is derivable if and only if it is valid.
The format of analysis which we have used, was introduced by Langholm (1989); seealso Langholm (1996), where he presents a general scheme for the introductions ofaxioms and rules (of which we have given only some specific examples), and wherehe proves some general definability and completeness theorems.
The sequent formalism and the axioms and rules arising from it is particularitysuitable for an algorithmic analysis of the derivability relation. If partial logic is toplay any role in computational linguistics it must be as part of an inference mechanismfor some natural-language system. We shall return to this point later.
14.3.1.6 Supervaluations and Implicit Truth
Before turning to partial predicates in first and higher-order logic there are a fewremarks to be added. We have focused on the consequence relation associated withthe strong Kleene truth tables and the corresponding proof theory. But this is not theonly possible consequence relation in partial logic. Adding some weak connectionssuch as 2 and 3 do not change the format of the analysis. There are, however, othermore radical departures which we briefly touch.
If partiality is seen as lack of knowledge, we could suspend judgment and definetruth in terms of all possible ways of completing our knowledge. To be a bit moreprecise, a valuation V can be seen as a partial map from propositional variables to thetruth-values t and f . This means that the “value” u is now really taken as undefined.A partial V can be extended to a complete, i.e. totally defined, 'V in many ways. This

“18-ch14-0691-0724-9780444537263” — 2010/11/29 — 21:08 — page 715 — #25
Partiality 715
gives rise to a notion of implicit truth; we say that % is implicitly true in a model V if'V(%) = t for all completions 'V of V; % is called implicitly false if 'V(%) = f for allcompletions 'V of V .
Implicit truth is not the same as true with respect to the model, e.g., (% 1 &) *(% 1¬&) is implicitly true in any model V where % is true and & is undefined, but it isnot true in V . The notion of implicit truth (i.e. truth in every completion or superval-uation) was introduced by Van Fraassen (1986), with applications to free logic and tothe analysis of the Liar Paradox. There is a rich theory concerning implicit truth andother truth definitions, the reader will find an introduction and technical discussions inthe papers referred to in Section 14.3.1.1.
We must also mention another omission of this chapter. Partiality has been extendedto modal notions. In addition to the intrinsic study of partiality in modal logic, his the-ory has been used to obtain many interesting results on definability and interpretabilityboth in classical and partial logic; see Van Benthem (1985), Jaspars and Thijsse (1996),Thijsse (1992), and Jaspars (1994).
Let us, however, add one remark concerning partiality, small models and modality.It would not be unreasonable to expect that with partiality one would in general havemuch smaller (minimal) models for a set of consistent sentences since there is no needto represent the undefined part by sets of total alternatives. Perhaps surprisingly, inpartial model logic this need not be so. In worst cases minimal partial model structuresmay have to be larger than in the corresponding total semantics; see Thijsse (1992).
14.3.2 Partial Predicates
Partiality can be introduced into first-order logic in a number of ways. We have repeat-edly argued for the usefulness of partial predicates and shall in this section restrictpartiality to precisely this point.
14.3.2.1 Partiality and First Order Logic
To keep technicalities to a minimum we assume that our language has variables, con-stants, relation symbols, some propositional connectives and the universal and exis-tential quantifiers. Formulas are defined as usual. A model M is determined by a non-empty domain D = DM of individuals. M assigns to each constant c of the languagean element [|c|]M % D. So far nothing is changed.
Relation symbols, however, will be interpreted as partial relations. Let R be an n-ary relation symbol of the language. M assigns to R a pair ([|R|]+M, [|R|]0M), where boththe “positive part” [|R|]+M and the “negative part” [|R|]0M are subsets of the set Dn, theset of all n-tuples over D.
A formula % of the language has a truth value t, f or u with respect to a modelM and a variable assignment (which is a map from variables of the language to thedomain D of M). The truth-definition is exactly as in the classical case, using thepartial tables for propositional connections where the classical definition uses the two-valued ones. The only change comes with relation symbols. Let R be an n-ary relation

“18-ch14-0691-0724-9780444537263” — 2010/11/29 — 21:08 — page 716 — #26
716 Handbook of Logic and Language
symbol and c1, . . . , cn constants. The value of R(c1, . . . , cn) in the model M is
[|R(c1, . . . , cn)|]M =(
t, if ([|c1|], . . . , [|cn|]) % [|R|]+
f , if ([|c1|], . . . , [|cn|]) % [|R|]0
If ([|c1|], . . . , [|cn|]) % Dn 0 ([|R|]+ / [|R|]0), which well may happen, the value is uor undefined. (When the particular model M is clear from the context, we drop the sub-script M on [| |]M .) The analysis of the derivability notion, see (44) of Section 14.3.1,easily extends to the first order case, and one has the “correct” completeness results.We shall not pursue the proof theory here, but touch a topic of relevance to the “growthof information” issue.
On the present perspective partiality is restricted to relation symbols only. Thismeans that an assertion can change value from undefined to true or false only byadding new elements to either the positive or negative part of a partial relation.To illustrate let us assume that our languages for the remainder of this discussioncontains the “weak” connectives 2%, % 3 & (defined as 2% * &), and % 6 &
(defined as (% 3 &) 1 (& 3 %)) in addition to the strong connectives 1, *, ¬. LetR(c1, . . . , cn) be an atomic formula and M a model such that [|R(c1, . . . , cn)|]M isundefined. It is then possible to extend M to models N1 and N2, where N1 comesfrom M by adding ([|c1|]M, . . . , [|cn|]M) to [|R|]+M , and N2 comes from M by adding([|c1|]M, . . . , [|cn|]M) to [|R|]0M . Thus we have in N1 the added information that[|R(c1, . . . , cn)|]N1 = t and in N2 that [|R(c1, . . . , cn)|]N2 = f .
The situation is more complicated when we look at the formula 2R(c1, . . . , cn).In this case [|2R(c1, . . . , cn)|]M = t (weak negation), but [|2R(c1, . . . , cn)|]N1 = ffor the extended model N1. In this case we have a revision rather than an extension ofinformation. Let us discuss the situation in some more details.
14.3.2.2 Persistence
Let M and N be two models for the language, we say that N extends M, in symbols,
M 7 N,
if and only if:
(i) DM = DN ;(ii) [|c|]M = [|c|]N , for all constants c; and
(iii) [|R|]+M . [|R|]+N and [|R|]0M . [|R|]0N , for all relation symbols R.
A sentence % of the language is called t-persistent if [|%|]M = t and M 7 N imply[|%|]N = t; it is called f -persistent if [|%|]M = f and M 7 N imply [|%|]N = f . % iscalled persistent if it is both t- and f -persistent. It is of obvious importance to be ableto decide which sentences of the language are persistent, i.e. preserved under modelextensions.
From the example above we saw that 2R(c1, . . . , cn) is not persistent; on the otherhand every formula containing only the strong connectives 1, *, ¬ is persistent. Call

“18-ch14-0691-0724-9780444537263” — 2010/11/29 — 21:08 — page 717 — #27
Partiality 717
a formula pure if it contains only strong connectives. We have seen that pure impliespersistent. It is a remarkable and not entirely trivial fact that the semantic notion ofpersistence is characterized by the syntactic notion of purity. This was proved byLangholm (1988):
Let % be a persistent sentence, then there exists a pure sentence & such that % 6 &
and ¬% 6 ¬& are provable
14.3.2.3 Higher Types
We now turn to a brief discussion of partial predicates in higher types. In the chapteron Montague Grammar we have seen an approach where higher type intensional logicis used for the semantical analysis of natural languages. Is there a partial version ofthis theory?
Partiality in higher types has always been a troublesome issue. Kleene’s theory ofpartial recursive functionals in finite types always assumed that arguments were total,otherwise one tended to lose control over the structure of subcomputations. A math-ematically successful analysis was carried through by Platek (1966) (see Moldestad,1977, for a careful analysis) through his introduction of the hereditarily consistentobjects of higher types. But it was almost impossible to come to grips with the “intu-itive” meaning of the structure of the hereditarily consistent objects. And withoutinsight there can be no applications beyond formal calculations. Such was the stateof the art within the recursion theory community for many years. Types and partialitywas also a topic of interest in proof theory and foundational studies, see, e.g., Fefer-man (1984); for recent contributions and surveys, see also Cantini (1993). Importantas these topics may be, this is not the place for a more extensive survey; we shall turnto topics at the interface of logic and linguistics.
Montague Grammar established a link between categorial grammar and higherorder intensional logic; see the collection of papers by Montague in Thomason (1974).This was a “total” theory, but issues of partiality was not far away in this type of theo-retical modeling; see Section 14.1 on sources of partiality. The “obvious” idea was toextend systems of first order partial logic to higher types. But the resulting complexi-ties made this approach rather unattractive.
Recently we have seen a re-emergence of partiality in higher types. Muskens (1989)first recast the standard theory as a theory of relations in higher types and then showedhow to extend this theory to partial relations. His motivation was to obtain a partializedversion of Montague Grammar, and in this he succeeded.
Notice that this is a purely “structural” use of types, we are using type theory todescribe higher order structures. There is also a “computational” side to type theory inwhich the objects of higher types are primarily seen as algorithms or procedures (seethe references to Feferman and Cantini above). The distinction between the structuraland the computational perspective is not always sharp; in our case it should be, ourfocus being elements, sets, sets of sets, etc...
Muskens’ approach was relational. Later we also got functional versions of highertypes partiality. In Lapierre (1992) we find a study of a functional partial semantics for

“18-ch14-0691-0724-9780444537263” — 2010/11/29 — 21:08 — page 718 — #28
718 Handbook of Logic and Language
higher order intensional logic, and in Lepage (1992) we find a general study of partialfunctions in type theory. It is beyond the scope of this chapter to give a technical expo-sition of these developments. We shall, however, give a brief introduction to partialpredicates in higher types and remark how this is related both to Montague Grammarand Situation Theory.
Types and FramesThe set of types is defined by the following recursive clauses:
(i) e, s are types;(ii) if "1, . . . ,"n are types (n 8 0), then ("1, . . . ,"n) is a type.
e is the type of individuals, s is the type of “possible worlds” or “situations”.A frame is a collection:
F = {D" | " is a type},
where
(i) Ds, De are non-empty.(ii) D("1,...,"n) . Pow(D"1 - · · · - D"n),
where Pow(D) is the set of all subsets of D, and D"1 - · · · - D"n is the set of alln-tuples (d1, . . . , dn), where di % D"i , i = 1, . . . , n. Thus if k % De, then k is anindividual. If P % D(e), then P % Pow(De), i.e. P is a subset of De.
If P % D(s,e) and w0 % Ds, let
Pw0 = {a % De | (w0, a) % P};
we may think of Pw0 as the extension of P at “world w0” or in the “situation w0”.We need not include a special type for truth-values, since we always require that
D( ) = Pow({+}), where P({+}) is a set of two elements which can be identified withthe values true and false.
Termsof the language are specified by the following clauses:
(i) For each type " there are constants and variables of type ".(ii) If % and & are terms of type ( ), then ¬% and % 1 & are terms of type ( ).
(iii) If % is a term of type ( ) and x a variable, then 9x% is a term of type ( ).(iv) If A is a term of type (+, "1, . . . ,"n) and B a term of type +, then (AB) is a term of type
("1, . . . ,"n).(v) If A is a term of type ("1, . . . ,"n) and x a variable of type +, then !xA is a term of type
(+, "1, . . . ,"n).(vi) If A and B are terms of the same type, then A = B is a term of type ( ).

“18-ch14-0691-0724-9780444537263” — 2010/11/29 — 21:08 — page 719 — #29
Partiality 719
InterpretationsA frame F = {D"} is extended to a model or interpretation
M = (F, I, a),
by adding an interpretation function I which maps a constant c of type " to an elementin D" , and a variable assignment a which map variables of type " to D" . We use[|A|] = [|A|]M to denote the value of A in the model M. [|A|] is inductively defined bysix clauses, corresponding to the clauses in the definition of terms:
(i) [|c|] = I(c), c constant term,[|x|] = a(x), x variable symbol.
The clauses (ii), (iii) and (vi) are identical to the standard definitions in first orderlogic.
(iv) Let the values [|A|] and [|B|] be given. Then [|AB|] is the subset of D"1 - · · ·-D"n definedby the condition
(d1, . . . , dn) % [|(AB)|] if and only if ([|B|], d1, . . . , dn) % [|A|].
To explain clause (v) we need an extra bit of notation. The value [|A|] of a term A iscalculated with respect to a model M = (F, I, a). Let x be a variable of type + and d anelement of D+ . Let M(x/d) denote the model obtained from M by modifying the variableassignment a at (possibly) one point, viz. by setting a(x) = d; let us denote the resultingvalue of a term A by [|A|](x/d).
(v) [|!xA|] is the relation defined by:
(d, d1, . . . , dn) % [|!xA|] if and only if (d1, . . . , dn) % [|A|](x/d),
for all elements d % D+ .
To give a simple illustration, let R be a constant of type (s, e) and i0 a constant oftype s. Let P = [|R|] and w0 = [|i0|], by use of clause (iv) we see that for any d % De:d % [|Ri0|] if and only if d % Pw0 , i.e. [|Ri0|] is the extension of R in world w0 = [|i0|].
In Muskens (1989) it is shown how this theory of relations in higher types can beused to give a Montague-type semantics. Changing from functionals and applicationsto relations necessitates some revisions, but nothing really unexpected.
14.3.2.4 Partial Predicates in Higher Types
Partiality is easily fitted into the relational framework. Let D1, . . . , Dn be sets, a par-tial relation R on D1, . . . , Dn is a pair (R+, R0), where R+, R0 . D1 - · · · - Dn. LetPPow(D) = Pow(D)-Pow(D) = {(R1, R2) | R1, R2 . D}. A frame F in the extendedpartial sense is a collection
F = {D" | " is a type},

“18-ch14-0691-0724-9780444537263” — 2010/11/29 — 21:08 — page 720 — #30
720 Handbook of Logic and Language
where De and Ds are non-empty sets and
D("1,...,"n) . PPow(D"1 - · · · - D"n).
There are a number of remarks that we ought to add in order to be technically completeand correct in every detail, in particular, in connection with the evaluation of terms ina model. Let us just note that if R is a constant of type (s, e) and i0 a constant of type s,then w0 = [|i0|] is an element of Ds and [|R|] is a partial relation ([|R|]+, [|R|]0),where both [|R|]+, [|R|]0 . Ds - De. The interpretation of the term [|Ri0|] is thepartial predicate (P+, P0), where d % P+ if and only if (w0, d) % [|R|]+, and d % P0,if and only if (w0, d) % [|R|]0. Thus [|Ri0|] is the partial predicate which is theextension of R in the situation w0.
We have restricted our exposition to partial predicates. But there is more to partial-ity in types and !-calculi than the issue of partial predicates. However, an adequateintroduction to these matters is beyond the limits set for this chapter. The interestedreader is referred to the current research literature; see Lapierre (1992), and Lepage(1992). We conclude with a remark on partiality in higher types and situation theory.
Partial relations in first order logic gave an analysis of some aspects of situation the-ory, see Fenstad, Halvorsen, Langholm and Van Benthem (1987). Partial relations inhigher type can be seen as an extension, but in a way which differs considerably fromcurrent developments in situation theory; see Barwise (1989). In our approach we usedan attribute-value formalism for the syntactic part; partiality in higher types allows youto keep the “homomorphism” (i.e. the structure preserving map) between the syntacticalgebra of categorial grammar and the semantic algebra of partial higher types. Theidea of having a “homomorphism” between the syntactic algebra and the semanticalgebra has always proved appealing to the mathematically minded. In my view it isthe kind of mathematical neatness which in this case needs to be resisted. Syntax isnot the only input to semantic processing, see the discussion in Fenstad, Halvorsen,Langholm and Van Benthem (1987), and semantic space has a richer geometric struc-ture than can be derived from any syntactic algebra, see Gärdenfors (2000). Mathema-tics and logic are powerful tools in the study of natural languages, but tools must bechosen for the tasks of hand.
14.3.2.5 Reducibilities
It remains to add some words on the topic of reducibility and to explore to which extentquestions about partial propositional logic and partial first-order logic can be reducedto or translated into questions about classical logic. There is an extensive literature onthis topic; we shall treat only one topic related to first order logic with partial predi-cates. To keep technicalities to a minimum we assume once more that our languagehas variables, constants, relation symbols, the propositional connectives 1, *, ¬ and2 (remember that 3 and 6 are definable), and the universal and existential quantifiers.In any model or interpretation a relation symbol R is interpreted as a partial predicate([|R|]+, [|R|]0). We assume that derivability and validity notions are given.

“18-ch14-0691-0724-9780444537263” — 2010/11/29 — 21:08 — page 721 — #31
Partiality 721
A very simple, but basic observation on the proof theory is the following NormalForm: For any formula % there is a formula & such that % 6 & is provable in thesystem and strong negation ¬ occurs in & only with atomic formulas R(t1, . . . , tn).
This Normal Form immediately admits a translation into classical first-order logic:Let % be a formula in normal form, the translation %4 of % is obtained by substitutinga new predicate symbol P0 for occurrences of ¬P and a new predicate symbol P+ forunnegated occurrences of P.
To establish a correspondence between partial and classical models there is oneminor point to take care of. In partial logic we assume consistency in the form [|R|]+,[|R|]0 = %. In classical logic there is nothing to prevent that [|P+|] and [|P0|] have anon-empty intersection. This is taken care of by adding an extra axiom
¬:x1 . . . :xn)R+(x1, . . . , xn) 1 R0(x1, . . . , xn)
*
for each original relation symbol R. This done, there is a natural correspondencebetween partial models and classical models satisfying the extra axioms. Throughthis correspondence, completeness and compactness for partial first-order logic is animmediate corollary of the corresponding results for classical first-order logic.
This reduction technique was first introduced by Gilmore (1974), and laterexploited by Feferman (1984). It was used in Langholm (1988), and has later beenthe topic of extensive studies; see Thijsse (1992), for further references. One may getthe impression that this reduction “trivializes” the logic of partial predicates. But thisimpression is wrong as we now shall see in connection with the strong persistencetheorem, see Section 14.3.2.2. We should also add that this reduction technique doesnot apply to the notion of implicit truth, see Section 14.3.1.6.
Looking closer at the proof of the strong persistence theorem we see that the trans-lation techniques with some efforts proves the result for t-persistence, i.e. a formula %
is t-persistent if and only if there exists a pure formula & such that % 6 & is provable.Duality gives a similar result for f -persistence. This means that if % is persistent, i.e.both t- and f -persistent, then there exist pure formulas &1 and &2 such that % 6 &1and ¬% 6 ¬&2 are provable. More than mere reduction techniques are needed toshow that &1 and &2 can be taken to be one and the same formula. This was provedby Langholm (1988). The intricate interplay between partial and classical logic alsoshows up in Langholm’s analysis of Horn Clauses in Partial logic; see Langholm(1990).
14.3.2.6 Do Partial Structures need Partial Logic?
We are at the end of our discussion. We have surveyed various sources of partiality inconnection with theoretical and computational linguistics. Some of these issues were“explained” within the framework of feature-valued systems and a relational theory ofmeaning. Moving beyond grammatical form the situation is less clear. Partial predi-cates turn up in a number of connections. But do partial predicates need a partial logic?The discussion in Section 14.3.2.5 showed that there is no easy answer. In some waythis is analogous to the question whether constructive logic has something significant

“18-ch14-0691-0724-9780444537263” — 2010/11/29 — 21:08 — page 722 — #32
722 Handbook of Logic and Language
to add to computational mathematics beyond the classical theories of combinatorialand numerical analysis.
Let us return briefly to feature-valued systems. This theory deals with a certainclass of algebraic structures. Associated with this class is a certain algebra of featureterms. This algebra can be “embedded” within first-order classical logic and standardPROLOG techniques can be used in the algorithmic study of feature-valued systems.This is similar to the role of constructive logic in the analysis of computational mathe-matics; here a possibly added value is the technique of how to extract algorithms fromconstructive proofs.
Can we make similar claims for partial logic? Let us grant that partial structures andpartial predicates are important. Let us not argue for a possible philosophical or epis-temological value of partial logic, but ask whether it is a good “algebra” for the studyof partial structures. The adequacy of this algebra is shown through the completenessand compactness results of the logic. From the perspective of computational linguis-tics we would be interested in the efficiency of this algebra as a tool in an algorithmicanalysis. A theoretical foundation for this analysis has been laid through the work ofLangholm (1989); for a brief introduction see the presentation in Section 14.3.1.4. Butwe should note that in an actual implementation of a system for answering questionsbased on situation schemata and partial logic Vestre used the reduction theorem; seethe exposition in Fenstad, Langholm and Vestre (1992). Thus our survey ends on anote of uncertainty.
References
Aanderaa, S., 1993. A universal Turing machine, in: Börger, E., et al. (Eds.), Computer ScienceLogic, Lecture Notes in Computer Science, Springer, Berlin, pp. 1–4.
Aczel, P., 1988. Non-Well-Founded Sets. CSLI Lecture Notes no. 14, CSLI, Stanford, CA.Allwein, G., Barwise, J. (Eds.) 1993. Working Papers on Diagrams and Logic, Indiana Univer-
sity, Bloomington, IL.Barton, G.E., Berwick, R.C., Ristad, E.S., 1987. Computational Complexity and Natural Lan-
guages. MIT Press, Cambridge, MA.Barwise, J., 1989. The Situation in Logic. CSLI Lecture Notes no. 17, CSLI, Stanford, CA.Barwise, J., Etchemendy, J., 1987. The Liar. Oxford University Press, Oxford.Barwise, J., Etchemendy, J., 1991. Visual information and valid reasoning, in: Zimmermann,
W., Cunningham, S. (Eds.), Visualization in Mathematics. MAA, Washington, DC.Barwise, J., Perry, J., 1983. Situations and Attitudes. MIT Press, Cambridge, MA.Bell, J.L., 1988. Toposes and Local Set Theories. Oxford Logic Guides no. 14, Clarendon Press,
Oxford.Blamey, S., 1986. Partial logic, in: Gabbay, D., Guenthner, F. (Eds.), Handbook of Philosophical
Logic, vol. III. Reidel, Dordrecht, pp. 1–70.Cantini, A., 1993. Logical frameworks for truth and abstractions, Firenze, Dipartimente de
Filosofia, Universita degli Studi di Firenze, Italy.Carpenter, B., 1992. The Logic of Typed Feature Structures. Cambridge University Press, Cam-
bridge, UK.Chang, C., Keisler, H.J., 1977. Model Theory. North-Holland, Amsterdam.

“18-ch14-0691-0724-9780444537263” — 2010/11/29 — 21:08 — page 723 — #33
Partiality 723
Doherty, P. (Ed.) 1996. Partiality, Modality, and Nonmonotonicity Logic, in: Studies in Logic,Language, and Information. CSLI Publication, Stanford, CA.
Feferman, S., 1984. Towards useful type-theories. J. Symb. Logic 49, pp. 75–111.Feferman, S., 1991. Reflecting on incompleteness. J. Symb. Logic 56, 1–49.Fenstad, J.E., 1998. Formal Semantics, Geometry and Mind, in: Arrazola, X., et al. (Eds.),
Discourse, Interaction, and Communication. Kluwer, Amsterdam, pp. 85–103.Fenstad, J.E., Halvorsen, P.-K., Langholm, T., Van Benthem, J., 1987. Situations, Language and
Logic, in: Studies in Linguistics and Philosophy, vol. 34. Reidel, Dordrecht.Fenstad, J.E., Langholm, T., Vestre, E., 1992. Representations and interpretations, in: Rosner,
M., Johnson, R. (Eds.), Computational Linguistics and Formal Semantics. Cambridge Uni-versity Press, Cambridge, UK.
Gärdenfors, P., 2000. Conceptual Spaces. The MIT Press, Cambridge, MA.Gilmore, P.C., 1974. The consistency of partial set theory without extensionality, in: Axiomatic
Set Theory, Proceedings of Symposia in Pure Mathematics, vol. 13, part II, AMS, Provi-dence, RI.
Gupta, A., Belnap, N.D., 1993. The Revision Theory of Truth, MIT Press, Cambridge, MA.Gurevich, Y., 1987. Logic and the challenge of computer science, in: Brger, E. (Ed.), Cur-
rent Trends in Theoretical Computer Science. Computer Science Press, Rockville, MD,pp. 1–57.
Herzberger, H., 1982. Notes on naive semantics. J. Philos. Logic 11, 1–60.Jaspars, J., 1994. Calculi for Constructive Communication. Thesis, ILLC, Amsterdam; MK,
Tilburg.Jaspars, J., Thijsse, E., 1996. Fundamentals of Partial Model Theory, in: Doherty, P. (Ed.),
Partiality, Modality and Nonmonotonicity, CSLI, Stanford, CA, pp. 111–140.Johnson, M., 1988. Attribute-Value Logic and the Theory of Grammar. CSLI Lecture Notes no.
16, CSLI, Stanford University, Stanford, CA.Johnson-Laird, V.P.N., 1983. Mental Models. Cambridge University Press, Cambridge, UK.Kamp, H., 1981. A theory of truth and semantic representation, in: Groenendijk, J., et al. (Eds.),
Formal Methods in the Study of Language. MC Tract 135, Amsterdam, pp. 277–322.Kamp, H., Reyle, U., 1993. From Discourse to Logic. Kluwer, Dordrecht.Kaplan, R.M., Bresnan, J., 1982. Lexical-functional grammar, in: Bresnan, J. (Ed.), The Mental
Representation of Grammatical Relations. MIT Press, Cambridge, MA.Keller, B., 1993. Feature Logics, Infinitary Descriptions and Grammar. CSLI Lecture Notes no.
44, CSLI, Stanford, CA.Kleene, S.C., 1952. Introduction to Metamathematics. Van Nostrand Reinholds, Princeton, NJ.Koster, J., 1989. How natural is natural language?, in: Fenstad, J.E., Frolor, I.I., Hilpinen, R.
(Eds.), Logic, Methodology and Philosophy of Science VIII. North-Holland, Amsterdam,pp. 591–606.
Kripke, S., 1975. Outline of a theory of truth. J. Philos. 72.Langholm, T., 1988. Partiality, Truth and Persistence. CSLI Lecture Notes no. 15, CSLI, Stan-
ford, CA.Langholm, T., 1989. Algorithms for Partial Logic. COSMOS Report no. 12, Department of
Mathematics, University of Oslo, Norway.Langholm, T., 1990. What is a Horn clause in partial logic?, in: van Eijck, J. (Ed.), Logics in AI.
Proceedings of the European Workshop JELIA’90, Lecture Notes in Artificial Intelligence478, Springer, Berlin.
Langholm, T., 1996. How Different is Partial Logic?, in: Doherty, P. (Ed.), Partiality, Modalityand Nonmonotonicity, CSLI Publications, Stanford, CA, pp. 3–42.

“18-ch14-0691-0724-9780444537263” — 2010/11/29 — 21:08 — page 724 — #34
724 Handbook of Logic and Language
Lapierre, S., 1992. A functional partial semantics for intentional logic. Notre Dame J. FormalLogic 33, pp. 571–541.
Lepage, F., 1992. Partial functions in type theory. Notre Dame J. Formal Logic 33, pp. 493–516.MacLane, S., 1971. Categories for the Working Mathematician. Springer, Berlin.MacLane, S., Moerdijk, I., 1992. Sheaves in Geometry and Logic. Springer, Berlin.Makowsky, J., 1984. Model theoretic issues in theoretical computer science, part I: Relational
data bases and abstract data types, in: Looli, G., Longo, G., Marcja, A. (Eds.), Logic Col-loquium ’82, North-Holland, Amsterdam.
Martin, R.L. (Ed.) 1981. Recent Essays on Truth and the Liar Paradox. Clarendon Press, Oxford.Minker, J. (Ed.) 1988. Deductive Databases and Logic Programming. Morgan Kaufmann, Los
Altos, CA.Moldestad, J., 1977. Computations in Higher Types. Lecture Notes in Mathematics, Springer,
Berlin.Muskens, R., 1989. Meaning and Partiality. Thesis, University of Amsterdam, the Netherlands.Odifreddi, P., 1989. Classical Recursion Theory. North-Holland, Amsterdam.Platek, R.A., 1966. Foundations of recursion theory. Thesis, Stanford University, Stanford, CA.Pollard, C., Sag, I., 1987. Information-Based Syntax and Semantics. CSLI Lecture Notes no.
13, CSLI, Stanford.Rounds, W.C., Kaspar, R., 1986. A complete logical calculus for record structures represent-
ing linguistic information, Proceedings of First IEEE Symposium on Logic in ComputerScience, Boston.
Sem, H.F., 1988. Discourse representation theory, situation schemata and situation semantics:A comparison, in: Rosén, V. (Ed.), Papers from the Tenth Scandinavian Conference onLinguistics.
Smorynski, C., 1991. The Development of Self-Reference, in: Drucker, T. (Ed.), Perspectiveson the History of Mathematics. Birkhuser, Boston, pp. 110–133.
Tarski, A., 1956. Logic, Semantics and Metamathematics, in: Woodger, J.H. (Ed.), Papers from1923 to 1938. Clarendon Press, Oxford.
Thomason, R.H. (Ed.) 1974. Formal Philosophy: Selected Papers of Richard Montague. YaleUniversity Press, New Haven, CT.
Thijsse, T., 1992. Partial Logic and Knowledge Representation. Thesis, Eburon Publishers,Delft.
Urquhart, A., 1986. Many-valued logic, in: Gabbay, D., Guenthner, F. (Eds.), Handbook ofPhilosophical Logic, vol. III. Reidel, Dordrecht.
Van Benthem, J., 1985. Manual of Intentional Logic. CSLI Lecture Notes no. 1, CSLI, Stanford.Van Fraassen, B., 1986. Presupposition, implication and self-reference. J. Philos. 65.Visser, A., 1989. Semantics and the Liar paradox, in: Gabbay, D., Guenthner, F. (Eds.), Hand-
book of Philosophical Logic, vol. IV. Reidel, Dordrecht.

“19-ch15-0725-0764-9780444537263” — 2010/11/30 — 3:44 — page 725 — #1
15 Formal Learning Theory!
Daniel Osherson!!, Dick de Jongh†, Eric Martin‡
and Scott Weinstein§
!!Princeton University, Department of Psychology, Green Hall,Princeton, NJ 08544, USA, E-mail: [email protected]
†FNWI, ILLC, Universiteit van Amsterdam, P.O. Box 94242, 1090 GEAmsterdam, The Netherlands, E-mail: [email protected]
‡Department of Artificial Intelligence, School of Computer Science andEngineering, University of New South Wales, UNSW SYDNEY NSW 2052,Australia, E-mail: [email protected]
§Department of Philosophy, Logan Hall, Room 433, Universityof Pennsylvania, Philadelphia, Pennsylvania 19104-6304, USA,E-mail: [email protected]
15.1 Introduction
The present chapter is devoted to formal models of language acquisition, and of empir-ical inquiry more generally. We begin by indicating the issues that motivate our studyand then describe the scope of the chapter.
15.1.1 Empirical Inquiry
Many people who have reflected about human intellectual development have noticedan apparent disparity. The disparity is between the information available to childrenabout their environment, and the understanding they ultimately achieve about thatenvironment. The former has a sparse and fleeting character whereas the latter isrich and systematic. This is especially so in the case of first language acquisition,as has been pointed out repeatedly.1 A similar disparity characterizes other tasks ofchildhood. By an early age the child is expected to master the moral code of hishousehold and community, to assimilate its artistic conventions and its humor, andat the same time to begin to understand the physical principles that shape the materialenvironment. In each case the child is required to convert data of a happenstance
* Research support was provided by the Office of Naval Research under contracts Nos. N00014-87-K-0401 N00014-89-J-1725 and by the Swiss National Science Foundation under grant number 21-32399.91.Correspondence to D. Osherson, DIPSCO, Istituto San Rafaelle, Via Olgettina 60, I-20132 Milano, Italy.
1 See, for example, Chomsky (1975), Matthews (1984), Hornstein and Lightfoot (1981). A review of empir-ical findings on first language acquisition is available in Pinker (1990).
Handbook of Logic and Language. DOI: 10.1016/B978-0-444-53726-3.00015-3c" 2011 Elsevier B.V. All rights reserved.

“19-ch15-0725-0764-9780444537263” — 2010/11/29 — 21:08 — page 726 — #2
726 Handbook of Logic and Language
character into the understanding (implicit or explicit) that renders his world predictableand intelligible.
Little is known about the mental processes responsible for children’s remarkableintellectual achievements. Even elementary questions remain the subject of contro-versy and inconclusive findings. For example, there is little agreement about whetherchildren use a general-purpose system to induce the varied principles bearing on lan-guage, social structure, etc., or whether different domains engage special-purposemechanisms in the mind.2 Although some suggestive empirical findings are avail-able (Gleitman, 1986; Johnson and Newport, 1989; Newport and Supalla, 1989), thematter still engenders controversy (e.g., Bickerton, 1981).
The disparity noted above for intellectual development has also been observed inthe acquisition of scientific knowledge by adults. Like the child, scientists typicallyhave limited access to data about the environment, yet are sometimes able to convertthis data into theories of astonishing generality and (apparent) veracity. At an abstractlevel, the inquiries undertaken by child and adult may be conceived as a process oftheory elaboration and test. From this perspective, both agents react to available databy formulating hypotheses, evaluating and revising old hypotheses as new data arrive.In the favorable case, the succession of hypotheses stabilizes to an accurate theory thatreveals the nature of the surrounding environment. We shall use the term “empiricalinquiry” to denote any enterprise that possesses roughly these features.
It is evident that both forms of empirical inquiry – achieved spontaneously in theearly years of life, or more methodically later on – are central to human existenceand cultural evolution. It is thus no accident that they have been the subject of spec-ulation and inquiry for centuries, and of vigorous research programs within severalcontemporary disciplines (namely, Psychology, Artificial Intelligence, Statistics andPhilosophy). We shall not here attempt to synthesize this vast literature but ratherlimit ourselves to a single line of investigation that descends from the pioneering stud-ies (Blum and Blum, 1975; Gold, 1967; Putnam, 1965, 1975; Solomonoff, 1964). Itis this tradition that appears to have had the greatest impact on linguistics, and to alimited extent on epistemology.3
Our topic has been named in various ways, often as “Formal Learning Theory”which we adopt here usually without the qualifier “Formal”. Central to the theory isthe concept of a paradigm (or model) of empirical inquiry. The inquiry in questionmight be that of a child learning language, or of a scientist investigating nature. Everyparadigm in the theory has essentially the same stock of component concepts, whichwe now explain.
15.1.2 Paradigms
A paradigm offers formal reconstruction of the following concepts, each central toempirical inquiry.
2 For discussion, see Chomsky (1975), Osherson and Wasow (1976).3 Within linguistics, relevant papers include Wexler and Culicover (1980); Borer and Wexler (1987); Lasnik
(1989); Matthews (1989); Truscott and Wexler (1989). Within epistemology, see, for example, Kelly andGlymour (1993), Earman (1992, Chapter 9).

“19-ch15-0725-0764-9780444537263” — 2010/11/29 — 21:08 — page 727 — #3
Formal Learning Theory 727
(1) (a) a theoretically possible reality(b) an intelligible hypothesis about reality(c) the data available about any given reality, were it actual(d) a scientist (or child)(e) successful behavior by a scientist working in a given, possible reality
The concepts figure in the following picture of scientific inquiry, conceived as agame between Nature and a scientist. First, a class of possible realities is specifiedin advance; the class is known to both players of the game. Nature is conceived aschoosing one member from the class, to be the “actual world”; her choice is initiallyunknown to the scientist. Nature then provides a series of clues about this reality.These clues constitute the data upon which the scientist will base his hypotheses. Eachtime Nature provides a new clue, the scientist may produce a new hypothesis. The sci-entist wins the game if there is sufficient guarantee that his successive conjectures willstabilize to an accurate hypothesis about the reality Nature has chosen.
Different paradigms formalize this picture in different ways, resulting in differ-ent games. Whether a particular game is winnable depends, among other things, onthe breadth of the set of possible realities. Wider sets make successful learning moredifficult, to the point of impossibility. The dominant concern of Learning Theory isto formulate an illuminating characterization of the paradigms in which success isachievable.
15.1.3 Scope of the Chapter
Contemporary Learning Theory has two principal branches, which may be termed“recursion theoretic”, and “model theoretic”. They are distinguished, as indicated, bythe tools used to define and study paradigms. The recursion theoretic side of the dis-cipline is older and better developed. The next three sections overview some prin-cipal results. A few proofs are lightly sketched, just for “feeling”. The others maybe found in Osherson, Stob and Weinstein (1986c). A more complete survey will beavailable in Sharma, Jain, Royer, Martin, Osherson and Weinstein (1999). Concernsabout recursion theoretic modeling are voiced in Section 15.5, and the alternative per-spective is introduced. The subsequent five sections are devoted to Learning Theoryfrom the point of view of model theory. We have chosen to follow one particular lineof research, ending with some new results (proofs are given in the appendix). Thematerial presented here is intended to be illustrative of central ideas and concepts;a comprehensive survey is not attempted. More systematic coverage is available inSharma, Jain, Royer, Martin, Osherson and Weinstein (1999).
15.2 Identification
There is no better introduction to Learning Theory than presentation of its most fun-damental paradigm. Such is the goal of the present section, whose essential ideas are

“19-ch15-0725-0764-9780444537263” — 2010/11/29 — 21:08 — page 728 — #4
728 Handbook of Logic and Language
due to Gold (1967). To proceed, we consider in turn the components of paradigmslisted in (1).
Realities. Possible realities are represented by nonempty, r.e. subsets of non-negative integers. (The non-negative integers are denoted by N in the sequel.) Think-ing of such sets as potential natural languages, the paradigm is usually called languageidentification, and the sets themselves “languages”. It will be convenient in what fol-lows to drop the “language” qualifier when referring to identification.
Hypotheses. Intelligible hypotheses are the r.e. indices for languages, relative tosome background, acceptable ordering of the Turing Machines (see Machtey andYoung, 1978 for “acceptable ordering”).
Data. To specify the data that Nature makes available about a given language L,we rely on the following terminology. An !-sequence of natural numbers is called atext. The set of numbers appearing in a text t is denoted content (t). Text t is said tobe for L just in case content (t) = L. After choosing L as reality, Nature presents thescientist with an arbitrary text for L, that is, an infinite listing of L with no intrusionsor omissions. If L has at least two elements, the class of texts for L is uncountable.
Let t be a text for L. The initial finite sequence of length n in t is denoted t[n]. t[n]may be thought of as an “evidential position” since it contains all the data about Lmade available by t at the nth moment of inquiry. The set {t[n] | n ! N and t is a text}of all evidential positions is denoted SEQ. Note that SEQ is the set of all finitesequences of natural numbers and hence is recursively isomorphic to N.
Scientists. A “scientist” is any function (not necessarily total or recursive) fromSEQ to N, where the latter are conceived as r.e. indices. Thus, a scientist is a systemthat converts its current, evidential position into an hypothesis about the languagegiving rise to his text.
Success. Success is defined in stages.
Definition 15.2.1. Let scientist " , text t, and i ! N be given.
(a) " converges on t to i just in case for all but finitely many n ! N, " (t[n]) = i.(b) " identifies t just in case there is i ! N such that " converges to i on t, and i is an index for
content(t).(c) " identifies language L just in case " identifies all the texts for L.(d) " identifies a collection L of languages just in case " identifies every L ! L. In this case
L is said to be identifiable.
Thus, " identifies L just in case for every text t for any L ! L, " identifies t.Note that any singleton collection of languages is trivially identifiable (by a constantfunction). Scientists (and children) are challenged only by a wide range of theoreticalpossibilities.
To illustrate, the collection F of finite sets is identifiable by " defined this way: Forall # ! SEQ, " (# ) is the smallest index for content(# ), where the latter is the set ofnumbers appearing in # . F has the interesting property that no extension is identifiable(Gold, 1967), whereas every other identifiable collection can be extended to anotherone. The collection L = {N} " {N # {x} | x ! N} is also unidentifiable, whereas it iseasy to define a scientist that identifies L # {N}.

“19-ch15-0725-0764-9780444537263” — 2010/11/29 — 21:08 — page 729 — #5
Formal Learning Theory 729
To prove the non-identifiability facts cited above, we rely on the “lockingsequence” lemma. Its basic idea is due to Blum and Blum (1975).
Definition 15.2.2. Let scientist " , language L, and # ! SEQ be given. # is a lockingsequence for " and L just in case:
(a) " (# ) is defined; and(b) for all $ ! SEQ drawn from L that extend # , " ($ ) = " (# ).
Intuitively, # locks " onto its conjecture " (# ), in the sense that no new data fromL can lead " to change its mind.
Lemma 15.2.1. Let language L and scientist " be such that " identifies L. Then thereis a locking sequence # for " and L. Moreover, " (# ) is an index for L.
A proof is given in Section 15.12.1.Now suppose that scientist " identifies some infinite language L. By the lemma,
let # be a locking sequence for " and L, and let t be a text that consists of endlessrepetitions of # . By the choice of # , " converges on t to an index i for L. Since L isinfinite, i is not for content(t) since the latter is finite. Hence, " fails to identify sometext for a finite language, and thus does not identify F. This is enough to show that noscientist identifies a proper extension of F, as noted above. The nonidentifiability of{N} "{ N # {x} | x ! N} is shown similarly.
More generally, Lemma 15.2.1 allows us to provide the following characterizationof identifiability (see Osherson, Stob and Weinstein, 1986c, Section 15.2.4, for thesimple proof).
Proposition 15.2.1 (Angluin, 1980). Let collection L of languages be given. L isidentifiable if and only if for all L ! L there is finite DL $ L such that for all L% ! L,if DL $ L% then L% &' L.
15.3 Remarks About the Identification Paradigm
Identification evidently provides a highly simplified portrait of first language acqui-sition and of empirical inquiry generally. Learning theorists have exercised consider-able ingenuity in refining and elaborating the basic paradigm in view of more realisticmodels. Illustrations will be provided in the next section. First it may be useful tocomment on a few aspects of the bare paradigm defined above.
15.3.1 Possible Realities as Sets of Numbers
Limiting possible realities to r.e. subsets of N is mathematically convenient, and hasbeen a feature of much work in Learning Theory.4 The numbers are to be conceived as
4 An exception is Kugel (1977), who drops the r.e. requirement.

“19-ch15-0725-0764-9780444537263” — 2010/11/29 — 21:08 — page 730 — #6
730 Handbook of Logic and Language
codes for objects and events found in scientific or developmental contexts. The detailsof such coding reflect substantive hypotheses concerning the kind of phonological,semantic, and other information available to children about the ambient language, orabout the character of the data that drives scientific research. Unfortunately, mathe-matical studies of learning often neglect this aspect of formalization, simply startingwith N as the base of inquiry. Until Section 15.6 we shall follow suit.
Some sets of numbers are “single-valued”, in the sense of Rogers (1967,Section 5.7). By limiting attention to collections of single-valued, r.e. sets, one treatsthe important problem of synthesizing a computer program from examples of its graph(as in Shapiro, 1983). Indeed, there have been more studies of function learning thanof pure language learning (see Sharma, Jain, Royer, Martin, Osherson and Weinstein,1999). In view of our present concern with natural language, no more will here be saidabout function learning (except for a remark in Section 15.4.9).
15.3.2 Reliability
The concepts of accuracy and stability are central to identification. Identifying a textt requires the scientist to ultimately issue an index i that enumerates content (t) andthen to remain with i for the remainder of t, that is, it requires eventual accuracy andstability of the scientist’s hypotheses. When we consider collections of languages athird concept arises. To identify collection L, a scientist " must succeed on any textfor any member of L. In this sense, " is required to be a reliable agent of inquiry,succeeding not just on a happenstance collection of texts, but on all of them. Being ableto reliably stabilize to an accurate conjecture is the hallmark of scientific competencein all of Learning Theory, and alternative paradigms provide varied reconstructionsof these concepts. Kindred notions of reliability are studied in epistemology (e.g.,Goldman, 1986; Kornblith, 1985; Pappas, 1979), which is one reason Learning Theoryis considered pertinent to philosophical investigation (as in Kelly, 1994).
There is another aspect of successful performance that is pertinent to defining real-istic models of language acquisition and of inquiry generally. Discovery should bereasonably rapid. The identification paradigm imposes no requirements in this con-nection, since successful scientists can begin convergence at any point in a text (andat different points for different texts, even for the same language). However, otherparadigms build efficiency into the success criterion (as in Daley and Smith, 1986).5
One requirement on scientists that is usually not imposed by Learning Theory isworth noting. To succeed in identification, the scientist must produce a final, correctconjecture about the contents of the text he is facing. He is not required, however,to “know” that any specific conjecture is final. To see what is at issue, consider theproblem of identifying L = {N # {x} | x ! N}. Upon seeing 0, 2, 3, 4, . . . , 1000 there
5 Efficiency is of paramount concern within the “PAC-learning” approach to inductive inference (seeAnthony and Biggs, 1992). PAC-learning is less relevant than Formal Learning Theory to language acqui-sition by children, and is not treated here. For one attempt to relate the two approaches, see Osherson,Stob and Weinstein (1991a).

“19-ch15-0725-0764-9780444537263” — 2010/11/29 — 21:08 — page 731 — #7
Formal Learning Theory 731
are no grounds for confidence in the appealing conjecture N # {1} since the next bit oftext might contradict this hypothesis. The identifiability of L does warrant a differentkind of confidence, namely, that systematic application of an appropriate guessing rulewill eventually lead to an accurate, stable conjecture on any text for a member of L.
Distinguishing these two kinds of confidence allows us to focus on scientific suc-cess itself, rather than on the secondary question of warranted belief that success hasbeen obtained. Thus, the fundamental question for Learning Theory is:
What kind of scientist reliably succeeds on a given class of problems?
rather than:
What kind of scientist “knows” when it is successful on a given class of problems?
Clarity about this distinction was one of the central insights that led to the mathemati-cal study of empirical discovery (see Gold, 1967, pp. 465–466).6
15.3.3 Comparative Grammar
In the linguistic context, possible realities are the languages that children might becalled upon to master. Now it seems evident to many linguists (notably, Chomsky,1975, 1986) that children are not genetically prepared to acquire any, arbitrary lan-guage on the basis of the kind of casual linguistic exposure typically afforded theyoung. Instead, a relatively small class H of languages may be singled out as “humanlypossible” on the basis of their amenability to acquisition by children, and it falls to thescience of linguistics to propose a nontrivial description of H. Specifically, the disci-pline known as “comparative grammar” attempts to characterize the class of (biologi-cally possible) natural languages through formal specification of their grammars; anda theory of comparative grammar is a specification of some definite collection. Con-temporary theories of comparative grammar begin with Chomsky (1957, 1965), butthere are several different proposals currently under investigation (see Wasow, 1989;and J. Higginbotham’s Chapter 6 in this Handbook).
Theories of linguistic development stand in an intimate relation to theories of com-parative grammar inasmuch as a theory of comparative grammar is true only if itembraces a collection of languages learnable by children. For this necessary condi-tion to be useful, however, it must be possible to determine whether given collec-tions of languages are learnable by children. How can this information be acquired?Direct experimental approaches are ruled out for obvious reasons. Investigation ofexisting languages is indispensable, since such languages have already been shown tobe learnable by children; as revealed by recent studies much knowledge can be gainedby examining even a modest number of languages (see Van Riemsdijk and Williams,1986).
6 In “finite learning” scientists are allowed but a single conjecture so their attachment to it can be consideredstronger than is the case for identification. See Jain and Sharma (1990b) for an illuminating study.

“19-ch15-0725-0764-9780444537263” — 2010/11/29 — 21:08 — page 732 — #8
732 Handbook of Logic and Language
We might hope for additional information about learnable languages from the studyof children acquiring a first language. Indeed, many relevant findings have emergedfrom child language research. For example, the child’s linguistic environment appearsto be largely devoid of explicit information about the nonsentences of the target lan-guage (see Brown and Hanlon, 1970; Demetras, Post and Snow, 1986; Hirsh-Pasek,Treiman and Schneiderman, 1984; Penner, 1987). The acquisition process, moreover,is relatively insensitive to the order in which language is addressed to children (seeNewport, Gleitman and Gleitman, 1977; Schieffelin and Eisenberg, 1981). Finally,certain clinical cases suggest that a child’s own linguistic productions are not essentialto mastery of the incoming language (Lenneberg, 1967). These facts lend a modicumof plausibility to the use of texts as a model of the child’s linguistic input. Other per-tinent findings bear on the character of immature grammar, which appears not to bea simple subset of the rules of adult grammar but rather incorporates distinctive rulesthat will be abandoned later (see Pinker, 1990).
For all their interest, such findings do not directly condition theories of compar-ative grammar. They do not by themselves reveal whether some particular class oflanguages is accessible to children or whether it lies beyond the limits of their learn-ing. Learning Theory may be conceived as an attempt to provide the inferential linkbetween the results of acquisitional studies and theories of comparative grammar. Itundertakes to translate empirical findings about language acquisition into informationabout the kinds of languages assimilable by young children. Such information can inturn be used to evaluate theories of comparative grammar.
To fulfill its inferential role, Learning Theory offers a range of models of languageacquisition. The models arise by precisely construing concepts generally left vaguein studies of child language, namely, the five concepts listed in (1). The interestingparadigms from the point of view of comparative grammar are those that best rep-resent the circumstances of actual linguistic development in children. The deductiveconsequences of such models yield information about the class of possible naturallanguages.
Many of the paradigms investigated within the theory have little relevance to com-parative grammar, for example, studies bearing on team-learning (Daley, 1986; Jainand Sharma, 1990b; Pitt, 1989). On the other hand, considerable effort has beendevoted to paradigms which bear on aspects of language acquisition. For purposes ofillustration, the next section is devoted to refinements of the Identification paradigm.7
15.4 More Refined Paradigms
Refinements of identification can alter any or all of the five components of paradigms,(1a)–(1e). We limit ourselves here to some simple illustrations bearing on the concepts:
7 For further discussion of the role of Learning Theory in comparative grammar see Osherson, Stob andWeinstein (1984), Wexler and Culicover (1980). Other constraints on theories of comparative grammarmight be adduced from biological considerations, or facts about language change. See Lightfoot (1982)for discussion.

“19-ch15-0725-0764-9780444537263” — 2010/11/29 — 21:08 — page 733 — #9
Formal Learning Theory 733
• scientist (or child);• data made available;• successful inquiry.
More comprehensive surveys are available in Angluin and Smith (1983),Osherson, Stob and Weinstein (1986c), Sharma, Jain, Royer, Martin, Osherson andWeinstein (1999). The latter two references provide proofs for claims made inthis section.
15.4.1 Memory Limitation
It seems evident that children have limited memory for the sentences presented tothem. Once processed, sentences are likely to be quickly erased from the child’s mem-ory. Here we shall consider scientists that undergo similar information loss. The fol-lowing notation is used. Let # ! SEQ be given (SEQ is defined in Section 15.2). Theresult of removing the last member of # is denoted by ## (if length(# ) = 0, then## = # = (). The last member of # is denoted by # last (if length(# ) = 0, then # lastis undefined).
The following definition says that a scientist is memory limited if his current con-jecture depends on no more than his last conjecture and the current datum.
Definition 15.4.1 (Wexler and Culicover, 1980). Scientist " is memory limited justin case for all #, $ ! SEQ, if " (##) = " ($#) and # last = $ last, then " (# ) = " ($ ).
Intuitively, a child is memory limited if her conjectures arise from the interaction ofthe current input sentence with the latest grammar that she has formulated and stored.The stored grammar, of course, may provide information about other sentences seen todate. To illustrate, it is not hard to prove that the class of finite languages is identifiableby memory-limited scientist. Thus, it is sometimes possible to compensate for mem-ory limitation by retrieving past data from current conjectures. Nonetheless, memorylimitation places genuine restrictions on the identifiable collections of languages, asshown by the following proposition.
Proposition 15.4.1. There is an identifiable collection of languages that is not identi-fied by any memory-limited scientist.
We give an idea of the proof (for details, see Osherson, Stob and Weinstein, 1986c,Proposition 4.4.1B). Let E be the set of even numbers, and consider the collection Lof languages consisting of:
(a) E,(b) for every n ! N, {2n + 1} " E, and(c) for every n ! N, {2n + 1} " E # {2n}.
It is easy to verify that L is identifiable without memory limitation. In contrast,suppose that memory limited " identifies E, and let # ! SEQ be a locking sequencefor " and E. Pick n ! N such that 2n /! content(# ). Then, " will have the same value

“19-ch15-0725-0764-9780444537263” — 2010/11/29 — 21:08 — page 734 — #10
734 Handbook of Logic and Language
on # and # extended by 2n. From this point it is not difficult to see that " will fail toidentify at least one text for either {2n + 1}" E or {2n + 1}" E # {2n}. Hence, " doesnot identify L. As is common in results of this form one may now further establishthat there are uncountably many such identifiable classes of languages not identifiedby any memory-limited scientist.
Proposition 15.4.1 shows that, compared to the original paradigm, the memory-limited model of linguistic development makes a stronger claim about comparativegrammar, imposing a more stringent condition on the class of human languages.According to the refined paradigm, the human languages are not just identifiable, butidentifiable by a memory-limited learner. Of course, this greater stringency representsprogress only if children are in fact memory limited in something like the fashionenvisioned by Definition 15.4.1.
15.4.2 Fat Text
It may be that in the long run every sentence of a given human language will be utteredindefinitely often. What effect would this have on learning?
Definition 15.4.2.
(a) A text t is fat just in case for all x ! content(t), {n | t(n) = x} is infinite.(b) Let scientist " and collection L of languages be given. " identifies L on fat text just in case
for every fat text t for any L ! L, " identifies t. In this case, L is identifiable on fat text.
Thus, every number appearing in a fat text appears infinitely often. It is easy toprove that every identifiable collection L of languages is identifiable on fat text, andconversely.
Fat text is more interesting in the context of memory limitation. The followingproposition shows that the former entirely compensates for the latter.
Proposition 15.4.2. Suppose that collection L of languages is identifiable. Then somememory-limited scientist identifies L on fat text.
15.4.3 Computability
The Turing simulability of human thought is a popular hypothesis in CognitiveScience, and the bulk of Learning Theory has focused on scientists that implementcomputable functions. Obviously, any collection of languages that is identifiable bycomputable scientist is identifiable tout court. The converse question is settled by thefollowing.
Proposition 15.4.3. Let S be any countable collection of functions from SEQ to N(conceived as scientists). Then there is an identifiable collection L of languages suchthat no member of S identifies L.
One argument for 10 proceeds by constructing for each Q $ N an identifiablecollection LQ of languages such that no single scientist can identify two such classes.

“19-ch15-0725-0764-9780444537263” — 2010/11/29 — 21:08 — page 735 — #11
Formal Learning Theory 735
The proposition then follows from the fact that there are uncountably many subsetsof N but only countably many Turing machines. (See Osherson, Stob and Weinstein,1986c, Proposition 4.1A, for details.)
The assumption that children are Turing simulable is thus a substantive hypothesisfor comparative grammar inasmuch as it renders unlearnable some otherwise iden-tifiable collections of languages (assuming the empirical fidelity of the other com-ponents of the identification paradigm, which is far from obvious). On the otherhand, under suitable assumptions of uniform recursivity of the class of languages, thecharacterization of (ineffective) identifiability offered by 15.2.1 can be transformedinto a characterization of identifiability witnessed by Turing-computable scientist (seeAngluin, 1980; and for applications Kapur, 1991; Kapur and Bilardi, 1992).
It might be thought that Proposition 15.4.3 points to a complexity bound on thelanguages that co-inhabit collections identifiable by computable scientist. However,the following proposition shows that such a bound cannot be formulated in terms ofthe usual notions of computational complexity, as developed in (Blum, 1967).
Proposition 15.4.4 (Wiehagen, 1978). There is a collection L of languages with thefollowing properties.
(a) Some computable scientist identifies L.(b) For every r.e. S $ N there is L ! L such that S and L differ by only finitely many elements
(that is, the symmetric difference of S and L is finite).
One such collection turns out to consist of all languages L whose least memberis an index for L. This collection is easily identified (indeed, by a Turing Machinethat runs in time linear in the length of the input), and an application of the recursiontheorem shows it to satisfy 11(b). This argument is Wiehagen’s (see Osherson, Stoband Weinstein, 1986c, Proposition 2.3A).
Once alternative hypotheses about scientists have been defined and investigatedit is natural to consider their interaction. We illustrate with the following fact aboutmemory limitation (Definition 15.4.1).
Proposition 15.4.5. There is a collection L of languages with the followingproperties.
(a) Some memory-limited scientist (not computable) identifies L.(b) Some computable scientist identifies L.(c) No computable, memory-limited scientist identifies L.
15.4.4 Consistency, Conservatism, Prudence
At the intuitive level, learning theorists use the term “strategy” to refer to a policyfor choosing hypotheses in the face of data. Formally, a strategy is just a subset ofscientists, such as the class of memory-limited scientists. Further illustration is pro-vided by the next definition, which relies on the following notation. The finite setof numbers appearing in # ! SEQ is denoted content(# ). If scientist " is defined

“19-ch15-0725-0764-9780444537263” — 2010/11/29 — 21:08 — page 736 — #12
736 Handbook of Logic and Language
on # , then the language hypothesized by " on # is denoted W" (# ) (notation familiarfrom Rogers, 1967).
Definition 15.4.3. Let scientist " be given.
(a) (Angluin, 1980) " is consistent just in case for all # ! SEQ, content(# ) $ W" (# ).(b) (Angluin, 1980) " is conservative just in case for all # ! SEQ, if content(# ) $ W" (##)
then " (# ) = " (##).(c) (Osherson, Stob and Weinstein, 1982) " is prudent just in case for all # ! SEQ, if " (# ) is
defined then " identifies W" (# ).
Thus, the conjectures of a consistent scientist always generate the data seen so far.A conservative scientist never abandons a locally successful conjecture. A prudentscientist only conjectures hypotheses for languages he is prepared to learn.
Conservatism has been the focus of considerable interest within linguistics anddevelopmental psycholinguistics.8 The prudence hypothesis is suggested by “prestor-age” models of linguistic development (as in Chomsky, 1965). A prestorage modelposits an internal list of candidate grammars that coincides exactly with the naturallanguages; at any moment in language acquisition, the child is assumed to respond toavailable data by selecting a grammar from the list. Regarding consistency, it is likelynot a strategy adopted by children since early grammars are inconsistent with mosteverything the child hears; on the other hand, consistency is a property of learners thathas attracted the attention of epistemologists (e.g., Juhl, 1993; Kelly, 1994).
Consistency and conservatism are substantive strategies in the following sense.
Proposition 15.4.6.
(a) There is a collection of languages that is identifiable by computable scientist but by noconsistent, computable scientist.9
(b) (Angluin, 1980) There is a collection of languages that is identifiable by computable scien-tist but by no conservative, computable scientist.10
In contrast, we have the following fact about prudence.
Proposition 15.4.7 (Fulk, 1990). Suppose that collection L of languages can beidentified by computable scientist. Then L can be identified by computable, prudentscientist.
Indeed, the prudent scientist can be constructed uniformly from an index for theoriginal one (Kurtz and Royer, 1988). Fulk’s proof proceeds by showing that everyclass of languages identified by a computable scientist can be extended to a similarlyidentifiable collection with an r.e. index set. Proposition 15.4.7 then follows easily (seeOsherson, Stob and Weinstein, 1986c, Lemmas 4.3.4A,B).
8 See Berwick (1986), Baker and McCarthy (1981), Mazurkewich and White (1984), Pinker (1989, 1990).9 For more information about consistency and cognate notions, see Fulk (1988).10 See Kinber (1994) for thorough analysis of conservatism and related concepts.

“19-ch15-0725-0764-9780444537263” — 2010/11/29 — 21:08 — page 737 — #13
Formal Learning Theory 737
15.4.5 Noisy and Incomplete Texts
Although it appears that children’s linguistic environments are largely free of gram-matical error (Newport, Gleitman and Gleitman, 1977), imperfections of two sorts arebound to arise. On the one hand, ungrammatical strings might find their way into thecorpus; on the other hand, certain grammatical strings might be systematically with-held. Texts with simple forms of these defects may be defined as follows.
Definition 15.4.4. Let language L and text t be given.
(a) t is a noisy text for L just in case there is finite D ' N such that t is an (ordinary) text forL " D.
(b) t is an incomplete text for L just in case there is finite D ' N such that t is an (ordinary)text for L # D.
(c) Scientist " identifies L on noisy text just in case for every noisy text t for L, " convergeson t to an index for L. " identifies collection L of languages on noisy text just in case "
identifies every L ! L on noisy text.(d) Scientist " identifies L on incomplete text just in case for every incomplete text t for L, "
converges on t to an index for L. " identifies collection L of languages on incomplete textjust in case " identifies every L ! L on incomplete text.
It is easy to see that noise and incompletion interfere with learning languages dif-fering only finitely from each other. A more substantial fact is the following.
Proposition 15.4.8. There is a collection L of languages with the followingproperties.
(a) Every L ! L is infinite.(b) Every distinct pair of languages in L is disjoint.(c) Some computable scientist identifies L (on ordinary text).(d) No computable scientist identifies L on noisy text.
A parallel fact holds for incompletion. Indeed, it is shown in Fulk, Jain and Osher-son (1992, Theorem 1) that incompletion is substantially more disruptive for identifi-cation than is noise.
15.4.6 Exact Identification
The dictum that natural languages are learnable by children (via casual exposure, etc.)has a converse, namely, that nonnatural languages are not learnable. We are thus led toconsider a variant of identification in which successfully learning collection L entailsidentifying L and no more. But a complication arises. It may be that certain degeneratelanguages (e.g., containing but a single word) can be learned by children, even thoughwe do not wish to classify them as natural.
There are findings to suggest, however, that children are not inclined to learn pro-foundly inexpressive languages. Some of the evidence comes from studies of childrenraised in pidgin dialects (Sankoff and Brown, 1976); other work involves the lin-guistic development of sensorily deprived children (Feldman and Goldin-Meadow,

“19-ch15-0725-0764-9780444537263” — 2010/11/29 — 21:08 — page 738 — #14
738 Handbook of Logic and Language
1978; Landau and Gleitman, 1985). If we accept the thesis that learnability impliesexpressiveness, then it is appropriate to define the natural languages as exactly thecollection of learnable languages.
Within Learning Theory these ideas give rise to the following definition.
Definition 15.4.5 (Osherson and Weinstein, 1982a). Let scientist " and collectionL be given. " identifies L exactly just in case " identifies L and identifies no propersuperset of L.
The requirement of exact identification interacts with hypotheses about strategies.This is illustrated by comparing Proposition 15.4.7 with the following.
Proposition 15.4.9. There is a collection L of languages with the followingproperties.
(a) Some computable scientist exactly identifies L,(b) No prudent, computable scientist exactly identifies L.
More generally, exact identifiability by computable scientist is possible only in thecircumstances described below.
Proposition 15.4.10. Let collection L of languages be given. Some computable scien-tist exactly identifies L if and only if L is %1
1 indexable and some computable scientistidentifies L.
The %11 indexability of L here means that there is a %1
1 subset of N that holdsindexes for just the members of L. We note that 15.4.9 is a corollary to 15.4.10. For,there are computably identifiable, properly %1
1 collections of languages whereas anycollection that is identified by prudent, computable scientist is r.e. indexable. (SeeOsherson, Stob and Weinstein, 1986c, Section 7, for discussion.)
15.4.7 Efficiency
First language acquisition by children has struck many observers as remarkablyrapid.11 It is thus pertinent to examine paradigms in which success requires efficientuse of data. To define a simple paradigm of this character, we use the following termi-nology. Let scientist " , text t, and n ! N be given. Suppose that " converges on t toindex i ! N. Then n is called the convergence point for " on t just in case n is smallestsuch that " conjectures i on all initial segments of t of length n or greater. If " doesnot converge on t we take the convergence point to be ).
Definition 15.4.6 (Gold, 1967). Let scientists "0 and "1, and collection L of lan-guages be given.
11 But not everyone. See Putnam (1980).

“19-ch15-0725-0764-9780444537263” — 2010/11/29 — 21:08 — page 739 — #15
Formal Learning Theory 739
(a) "0 identifies L strictly faster than "1 just in case:(i) both "0 and "1 identify L;
(ii) for every text t for every L ! L, the convergence point for "0 on t is no greater thanthat for "1 on t;
(iii) for some text t for some L ! L, the convergence point for "0 on t is smaller than thatfor "1 on t.
(b) "0 identifies L efficiently just in case "0 identifies L, and no scientist "1 identifies L strictlyfaster than "0.
The next proposition shows that the three strategies examined in Section 15.4.4guarantee efficient learning.
Proposition 15.4.11. Suppose that scientist " identifies collection L of languages. If" is consistent, conservative and prudent then " identifies L efficiently.
The preceding proposition can be used to show that in the absence of computabilityconstraints, efficiency imposes no restriction on identification (see Osherson, Stob andWeinstein, 1986c, Section 4.5.1). In contrast, the work of computable scientists cannotalways be delegated to efficient, computable ones.
Proposition 15.4.12. There is a collection L of languages with the followingproperties.
(a) Some computable scientist identifies L.(b) For every computable scientist " that identifies L there is a computable scientist that iden-
tifies L strictly faster than " .
A rough idea of the proof may be given as follows (see Osherson, Stob andWeinstein, 1986c, Proposition 8.2.3A for details). Suppose that Q ' N is an r.e., non-recursive set, and that " ’s speed is aided by quickly deciding whether n ! N belongsto Q. Then " cannot do this for at least one n since otherwise Q would be recursive.Hence, there is a scientist strictly faster than " which has built-in information aboutthis n but which otherwise behaves like " .
15.4.8 Stability and Accuracy Liberalized
Identification proposes strict criteria of hypothesis stability and accuracy (in the senseof Section 15.3.2), and many liberalizations have been examined. For example, weakercriteria of stability might allow successful learners to switch indefinitely often amongindices for the same language, or alternatively, to cycle among some finite set of them(Jain, Sharma and Case, 1989; Osherson and Weinstein, 1982). Weaker criteria ofaccuracy might allow a finite number of errors into the final conjecture (Case andSmith, 1983), or else allow the final conjecture to “approximate” the target in a varietyof senses (Fulk and Jain, 1992; Royer, 1986). These and other liberalizations havebeen studied extensively, both separately and in combination. For a review of findings,see Sharma, Jain, Royer, Martin, Osherson and Weinstein (1999).

“19-ch15-0725-0764-9780444537263” — 2010/11/29 — 21:08 — page 740 — #16
740 Handbook of Logic and Language
15.4.9 Identifying the Child’s Program for Language Acquisition
Whereas the child’s task is to discover a grammar for the ambient language, the taskof developmental psycholinguists is to discover the mental program animating thechild’s efforts. By focusing on the child’s learning program rather than on what itlearns, we may attempt to define paradigms that illuminate the prospects for successin discovering the mechanisms of first language acquisition. In this case the learneris the psycholinguist and her data may be conceived as the graph of the acquisitionfunction implemented by the child. Successful inquiry consists of converging on thegraph to an index for the child’s learning function. A less stringent requirement isconvergence to a program that identifies at least as many languages as children do,irrespective of its similarity to the child’s method. This latter success criterion is called“weak delimitation”.
We would like to know how wide a class of potential children can be identified orweakly delimited. If the class is narrow, there may be no reliable means of investigat-ing first-language acquisition. Success in psycholinguistics would depend in this caseupon the fortuitous circumstance that the child’s learning function falls into the smallclass of possibilities for which our scientific methods are adapted.
In Osherson and Weinstein (1995) it is shown that some narrow classes of potentialchildren can be neither identified nor weakly delimited. One such class consists of justthose children that identify less than three, nonempty languages, none of them finite.
15.5 The Need for Complementary Approaches
A quarter century of research within Formal Learning Theory has provided sugges-tive findings for both epistemology and linguistics. It seems fair to say, however,that its impact on the latter discipline has as yet been meager, despite efforts to con-front theories of comparative grammar with results about learning (as in Berwick,1986; Osherson, Stob and Weinstein, 1984; Truscott and Wexler, 1989; Wexler andCulicover, 1980). One reason for the lack of interaction is the abstract character oflearning theoretic results. Indeed, the majority of findings remain true under recursivepermutation of N, and hence have little to do with the grammatical structure of naturallanguage.
A more recent tradition of research on learning shows greater promise in thisregard. For example, Shinohara (1990) considers languages defined via elementaryformal systems (EFS’s) in the sense of Smullyan (1961). He proves that for any n ! N,the class of languages definable by length-bounded EFS’s with at most n axioms iscomputably identifiable. From this it follows that for any n ! N, the class of lan-guages with context-sensitive grammars of at most n rules is similarly identifiable.Another notable finding is due to Kanazawa (1993). He shows that the class of clas-sical categorial grammars assigning at most k types to each symbol is identifiable bycomputable scientist in the sense of Definition 15.2.1, above. As Kanazawa notes, itfollows that the entire class of context-free languages is similarly learnable, provided

“19-ch15-0725-0764-9780444537263” — 2010/11/29 — 21:08 — page 741 — #17
Formal Learning Theory 741
that texts are enriched with information about the type-ambiguity of each symbol. (Forfurther results, see Kanazawa, 1994.)
Results like the foregoing are of potentially greater interest to linguistic theorythan those bearing on arbitrary r.e. sets. However, research in the new tradition has yetto investigate the special character of children’s learning, e.g., its memory-limitationand resistance to noise. These are just the topics given greatest attention in the olderliterature.
To understand a second reason for Learning Theory’s lack of impact on linguistics,let us recall that comparative grammar is supposed to contribute to the theory ofinnate ideas. In particular, the universal elements of grammar, invariant across naturallanguages, correspond to what the prelinguistic child already knows about the lan-guage into which he is plunged. Extensive debate has arisen about the form in whichsuch knowledge might be lodged in the infant’s mind – and even whether it shouldbe called “knowledge” at all, instead of simply “predisposition” (see, for example,Chomsky (1975), Matthews (1984), Putnam (1967), Stich (1978)). To address theissue squarely, let us conceive of the child’s innate preparation to learn languageas a prestored message that characterizes the class of potential natural languages.Then it is difficult to locate this message within the learning paradigms of thePutnam/Gold/Solomonoff tradition. There are just classes of languages in play, underno particular description. Given specific assumptions about data-presentation and soon, either the child can learn the languages or not. There is no innate starting point insight.12
To remedy this shortcoming, some recent paradigms have conceived of innateknowledge as a first-order theory in a countable language (e.g., Osherson, Stob andWeinstein, 1991b, 1992). In the usual case, the innate theory is not complete; other-wise, there is nothing to learn and there would be no linguistic variation across cul-tures. So the child’s task is to extend the innate theory via new axioms that are trueof the particular language spoken in his environment. Consequently, these paradigmsconsider a single sentence in the language of the original theory, and ask what sortof learning device could determine the truth-value of the sentence by examining datafrom the environment. The environment is assumed to be consistent with the child’sbackground theory, which thus serves as prior information about the range of theoret-ical possibilities.
The remainder of the chapter provides details about this approach. To keep the dis-cussion manageable, it is limited to a single strand of inquiry, leaving several relevantstudies aside (e.g., Glymour and Kelly, 1989; Kelly and Glymour, 1993). The work to bediscussed was stimulated by the seminal papers (Glymour, 1985; Shapiro, 1981, 1991).
We proceed as follows. Background ontology and basic concepts occupy Sec-tion 15.6. An elementary but fundamental paradigm is described in Section 15.7and some basic facts presented. More sophisticated paradigms are advanced inSections 15.8 and 15.9. Their relevance to first language acquisition is taken up in
12 A preliminary attempt to communicate “starting points” to learners within a recursion theoretic frame-work is reported in Osherson, Stob and Weinstein (1988).

“19-ch15-0725-0764-9780444537263” — 2010/11/29 — 21:08 — page 742 — #18
742 Handbook of Logic and Language
Section 15.10. Unless noted otherwise, verification of examples and proofs of propo-sitions are given in the appendix to this chapter.
15.6 Ontology and Basic Concepts
15.6.1 Overview
The paradigms in the remainder of this chapter are embedded in a first-order logicalframework. By this is meant that the “possible worlds” in which the scientist mightfind herself are represented by relational structures for a first-order language. More-over, the hypotheses that the scientist advances about her world are limited to sen-tences drawn from the same language. Generalizations are of course possible (as inKelly and Glymour (1992), Osherson and Weinstein (1989a), for example), but ouraim here is to exhibit significant results within the simplest framework possible.
15.6.2 Language, Structures, Assignments
We fix a countably infinite collection D of individuals d0, d1, . . . . D is the domainof all structures to be considered in the sequel. In particular, given a set T of first-order sentences, mod(T) denotes the class of structures with domain D that satisfyT . The exclusion of finite models from the remainder of the discussion is only forconvenience. In contrast, the exclusion of uncountable models is necessary to avoidunresolved conceptual questions (see Osherson and Weinstein 1986, Section 6.1).
By a “D-sequence” is meant an !-sequence onto D (i.e. with range equal to all ofD). Given D-sequence d and i ! N, di denotes the ith member of d, and d[i] denotesthe initial segment of length i in d. The set {d[i] | d is a D-sequence andi ! N} of allfinite initial segments of D-sequences is denoted D<!.
We also fix a language L with a countable set VAR = {vi | i ! N} of variables.The vocabulary of L is assumed to be finite and include only constants and relationsymbols (including identity).13 The sets of L-formulas and L-sentences are denotedby Lform and Lsen, respectively. The set of free variables occurring in & ! Lform isdenoted var(&). We use BAS to denote the set of basic formulas, that is, the subset ofLform consisting of atomic formulas and negations thereof.
A D-sequence d will be used to assign objects from D to variables in VAR. In par-ticular, for every i ! N, d(vi) = di. Similarly, the finite sequence d̄ = (d0, . . . , dn) !Dn+1 corresponds to the finite assignment {(v0, d0), . . . , (vn, dn)}. By domain(d̄) ismeant the set of variables that d̄ interprets, i.e. {vi ! VAR | i < length(d̄)}.
15.6.3 Environments
Definition 15.6.1. Let structure S and D-sequences d be given. By the environmentfor S and d is meant the !-sequence e such that for all i ! N, ei = {' ! BAS |var(') $ domain(d[i]) and S |= '[d[i]]}. An environment for S is an environment
13 The exclusion of function symbols is for convenience only. Their presence would slightly complicate thedefinition of environments, below.

“19-ch15-0725-0764-9780444537263” — 2010/11/29 — 21:08 — page 743 — #19
Formal Learning Theory 743
for S and d, for some D-sequence d. An environment is an environment for somestructure.
Thus, an environment is a sequence of ever-more-inclusive, finite, consistent setsof basic formulas. (The sets are finite by our choice of L.) It is as if Nature chooseselements from D one by one, and after each selection tells us everything she can aboutthe new element and its relation to all the previously chosen elements. For exam-ple, suppose that the predicates of L are {=, R}, and that structure S interprets R as{(di, dj) | i < j}. If D-sequence d is d0, d1, d2, . . . then the environment for S and dbegins this way:
!v0 = v0¬Rv0v0
"#$$%
$$&
v0 = v0 v1 &= v0v1 = v1 Rv0v1v0 &= v1 ¬Rv1v0¬Rv0v0 ¬Rv1v1
'$$(
$$)
#$$%
$$&
v0 = v0 v2 = v2 v2 &= v1 Rv0v1 ¬Rv1v1v1 = v1 v0 &= v2 ¬Rv1v0 Rv0v2 ¬Rv2v2v0 &= v1 v2 &= v0 ¬Rv2v0 Rv1v2v1 &= v0 v1 &= v2 ¬Rv2v1 ¬Rv0v0
'$$(
$$). . .
The following lemma is straightforward (a proof appears in Osherson andWeinstein, 1986).
Lemma 15.6.1. Let environment e and structures S and U be given. If e is for both Sand U then S and U are isomorphic.
15.6.4 Scientists
The finite segment of length i in environment e is denoted e[i], and the set {e[i] | eis an environment and i ! N} is denoted SEQ (there is no risk of confusion with ourprevious use of SEQ in Section 15.2). Since L is a finite relational language, SEQ is acollection of finite sequences of finite subsets of a fixed countable set; hence, SEQ iscountable.
A (formal) scientist is defined to be any function from SEQ to Lsen. Accordingto this conception, scientists examine the data embodied in finite initial segments ofenvironments, and emit hypotheses about the underlying structure in the guise of first-order sentences.
Definition 15.6.2. Let ( ! Lsen, environment e, and scientist " be given. " con-verges on e to ( just in case " (e[i]) = ( for all but finitely many i ! N.
15.6.5 Solvability for Environments
To succeed in a given environment, we require the scientist’s hypotheses to stabilizeto a single, true, interesting sentence. The idea of stabilization is defined by 15.6.2,above. Rather than attempt to formalize the concept of “interesting sentence”, we leaveit as a parameter in the definition of scientific success. The parameter takes the formof a subset X of sentences, which count as the interesting ones.
Definition 15.6.3. Let X $ Lsen, scientist " and structure S be given. Suppose thatenvironment e is for S. Then " X-solves e just in case there is ( ! X such that:
(a) " converges on e to ( , and(b) S |= ( .

“19-ch15-0725-0764-9780444537263” — 2010/11/29 — 21:08 — page 744 — #20
744 Handbook of Logic and Language
It is Lemma 15.6.1 that renders clause (b) unambiguous: up to isomorphism, S isthe unique structure for which e is an environment.
Example 15.6.1. For ( ! Lsen, let X = {( ,¬(}. Then, scientist " X-solves environ-ment e for structure S just in case " converges on e to whichever of ( , ¬( is true in S.This choice of X yields the paradigm of “truth-detection”, analyzed in Glymour andKelly (1989); Osherson, Stob and Weinstein (1991b).
Other choices of X are discussed in Osherson and Weinstein (1995); Osherson,Stob and Weinstein (1992).
15.6.6 Solvability for Structures
All of the paradigms discussed below share the foregoing apparatus. They differ onlyin the definition given to the idea of solving a given structure S. In each case a scien-tist will be credited with solving S if she solves enough environments for S, but theparadigms differ in their interpretation of “enough”. The first (and simplest) paradigmconceives the matter in absolute terms: To solve S the scientist must be able to solveall of its environments. Subsequent paradigms offer probabilistic conceptions.
A scientist " solves a collection K of structures just in case " solves all the struc-tures in K. This is a constant feature of our paradigms, regardless of how the solu-tion of individual structures is defined. Of particular interest is the case of elementaryclasses of structures, picked out by a first-order theory. The results discussed belowbear principally on this case.
15.6.7 Relation to Language Acquisition
Let us relate the concepts discussed above to the child’s acquisition of a first language.The collection X of sentences represents alternative, finitely axiomatized theories
of some circumscribed linguistic realm, for example, well-formedness or pragmaticforce. Each member of X provides an adequate description of a potential human lan-guage (relative to the realm in question). The description is “adequate” in the sense ofrepresenting the implicit knowledge accessible to mature speakers. The child’s task isto find a member of X that is true of the particular language presented to him.
The class K of structures embodies the range of linguistic realities for which chil-dren are genetically prepared. These realities are the “human” or “natural” ones, inthe terms of Section 15.3.3. If K is elementary, then the child is assumed compe-tent for any linguistic situation that satisfies a certain theory. The theory can thus beconceived as a component of Universal Grammar, embodying linguistic informationavailable innately to the child at the start of language acquisition.
Environments represent the linguistic data from which a theory can be inferred. Inthis perspective, D might consist of vocalic events (perhaps with associated context)which are classified by the predicates of L. For example, if the theories in X bear onpragmatic force, then predicates might code the intonational contours of utterances, the

“19-ch15-0725-0764-9780444537263” — 2010/11/29 — 21:08 — page 745 — #21
Formal Learning Theory 745
apparent emotional state of the speaker, etc. Note that environments give direct accessto “negative data”, whereas this is often assumed not to be a feature of linguistic inputto children (see the discussion in Section 15.3.3, above). To exclude negative data fromenvironments it suffices to restrict their content to atomic formulas, suppressing basicformulas containing negations. We have not adopted this convention since it is unclearwhether negative evidence is lacking in linguistic realms other than syntax; in learningthe semantics of quantifiers, for example, negative feedback might be available fromthe failure to communicate an intended meaning. In any event, it remains to determinehow well our theorems transfer to the case of “positive environments”.
Formal scientists play the role of children. Their mission is to stabilize to a truetheory drawn from X. In the model of Section 15.7 it will be assumed that childrenachieve such stability with perfect reliability, i.e. no matter how the data are presented.The models of Sections 15.8 and 15.9 admit the possibility that language acquisitionfails when data are presented in an unlikely order.
Suppose that we’ve established a linguistic realm of interest (e.g., well-formedness). Suppose furthermore that X holds the kind of theories achieved by adultsfor that realm. Then, a nontrivial property can be attributed to the class of natural lan-guages, namely, X-solvability in the relevant sense. The paradigms now presentedprovide alternative definitions of X-solvability.
15.7 First Paradigm: Absolute Solvability
The idea of solving an environment was formulated in Definition 15.6.3 above. Tosolve a structure, our first paradigm requires the scientist to solve all of its environ-ments. Subsequent paradigms adopt a probabilistic stance.
15.7.1 Solving Arbitrary Collections of Structures
Definition 15.7.1. Let X $ Lsen and scientist " be given.
(a) " X-solves structure S just in case " X-solves every environment for S.(b) " X-solves collection K of structures just in case " X-solves every S ! K. In this case, K
is said to be X-solvable.
For the examples to follow, we suppose that L is limited to a sole binary relationsymbol R (plus identity).
Example 15.7.1. Let X = {( ,¬(} for ( = *x+yRxy (“there is no greatest point”). Wedescribe the extensions of R in a collection K = {Sj | j ! N}. RS0 is the successorfunction {(di, di+1) | i ! N}. For j > 0, RSj is {(di, di+1) | i < j}. Then K is notX-solvable.
Example 15.7.2. Let K be as defined in Example 15.7.1. Given n ! N # {0}, let
(n = +x1 · · · xn+1(Rx1x2 , · · · , Rxnxn+1 , *y¬Ryx1 , *z¬Rxn+1z),

“19-ch15-0725-0764-9780444537263” — 2010/11/29 — 21:08 — page 746 — #22
746 Handbook of Logic and Language
i.e. there is an R-chain of length exactly n. Then, for all n ! N # {0},K is Xn-solvable,where Xn = {(n, ¬(n}. The simple proof is left for the reader.
Example 15.7.3. Let T be the theory of linear orders (with respect to R). Let ) =+x*yRxy (“there is a least point”), * = +x*yRyx (“there is a greatest point”), andX = {), ¬)}. Then mod(T " {) - *, ¬() , * )}) is X-solvable whereas mod(T)
is not.
For verification of Example 15.7.3, see Osherson, Stob and Weinstein (1991b,Example 5). Additional examples are given in Osherson and Weinstein (1989b);Osherson and Weinstein (1995).
Example 15.7.3 reveals that inductive inference within our paradigm does notamount to “waiting for deduction to work”. For, no # ! SEQ implies either ) or¬) in the models of T " {)-*, ¬(),* )}. The latter class is nonetheless {), ¬)}-solvable.
15.7.2 Solving Elementary Classes of Structures
The theory of solvability has a simple character when limited to first-order defin-able classes of structures (as in Example 15.7.3, above). The theory defining sucha class may be conceived as a scientific “starting point” since it embodies all theprior information that is available about a potential environment. In this case there isa computable learning method that is optimal, even compared to methods embodiedby noncomputable scientists. We state the matter precisely in the following proposi-tion (whose formulation presupposes familiarity with the arithmetical hierarchy andin particular with the notion of a +0
2 subset of Lsen).
Proposition 15.7.1. Suppose that X $ Lsen is +02 . Then there is an oracle machine
M such that for all T $ Lsen, if mod(T) is X-solvable, then MT X-solves mod(T).
The proposition follows immediately from the following lemmas. Their statementrequires a preliminary definition, along with the following notation: & ! Lsen will becalled “+*” if it is existential-universal in form; either or both sets of quantifiers maybe null.
Definition 15.7.2. Let X $ Lsen and T $ Lsen be given. X is confirmable in T justin case for all S ! mod(T) there is & ! Lsen such that:
(a) & is +*,(b) S |= &, and(c) for some ( ! X, T " {&} |= ( .
Lemma 15.7.1. Let a +02 subset X of Lsen be given. Then there is an oracle machine
M such that for all T $ Lsen, if X is confirmable in T then MT X-solves mod(T).
Lemma 15.7.2. Let X $ Lsen be given. For all T $ Lsen, if mod(T) is X-solvable, thenX is confirmable in T.

“19-ch15-0725-0764-9780444537263” — 2010/11/29 — 21:08 — page 747 — #23
Formal Learning Theory 747
Lemma 15.7.1 is an exercise in “dovetailing” and +02 -programming, some of the
basic ideas already appearing in Gold (1965); Putnam (1965). A complete proof in aclosely related paradigm is given in Osherson and Weinstein (1995). We do not repeatit here. (Lemma 15.7.2 is proved in Section 15.12.5, below.)
In Osherson, Stob and Weinstein (1991b) the following corollary is derived fromLemma 15.7.2 and a weaker version of Lemma 15.7.1.
Corollary 15.7.1. Let ( ! Lsen and T $ Lsen be given. Then mod(T) is {(, ¬(}-solvable if and only if both ( and ¬( are equivalent over T to existential-universalsentences.
As an immediate consequence of Corollary 15.7.1 and Chang and Keisler (1977,Theorem 3.1.16), we obtain the following fact, demonstrated independently inKelly (1994) (cited in Earman, 1992, Chapter 9).
Corollary 15.7.2. Let ( ! Lsen and T $ Lsen be given. Then mod(T) is {(, ¬(}-solvable if and only if ( is equivalent over T to a Boolean combination of existentialsentences.
We note in passing that Proposition 15.7.1 can be extended to no regular logicstronger than the predicate calculus which meets the Löwenheim-Skolem condition.See Osherson, Stob and Weinstein (1991b, Section 4).
15.8 Second Paradigm: Probabilistic Solvability
In the present section and the next we conceive of environments as created by astochastic process. In particular, the entities in our universal domain D are assumed tobe delivered for inspection via independent, identically distributed sampling accordingto a probability law which may be unknown to the scientist. The associated paradigmmeasures successful performance in probabilistic rather than all-or-none fashion, andthus differs from most earlier investigations of scientific discovery within a model-theoretic context. It also takes a different approach than that offered in Gaifman andSnir (1982) inasmuch as probabilities are attached to the countable set D rather than touncountable classes of structures. Within the recursion-theoretic literature on induc-tive inference, related paradigms are treated by Angluin (1988) and Osherson, Stoband Weinstein (1986b, Chapter 10.5).
The core idea of our paradigm is to allow scientists to fail on “small” sets of envi-ronments, namely, of measure 0. It will be seen that such liberalization has no effecton the solvability of elementary classes of structures. Moreover, the universal machinefor absolute solvability is universal in the present setting as well.
15.8.1 Measures Over Environments
The class of all positive probability distributions over D is denoted P. (P ! P ispositive just in case P(d) > 0 for all d ! D.) Given P ! P, we extend P to the

“19-ch15-0725-0764-9780444537263” — 2010/11/29 — 21:08 — page 748 — #24
748 Handbook of Logic and Language
product measure over D! (as reviewed, for example, in Levy (1979, Section VII.3)).Given a structure S, this measure is extended to sets E of environments for S viatheir underlying D-sequences . That is, the P-measure of E is the P-measure of {d !D! | for some e ! E, e is for S and d}. (All sets of environments measured below areBorel.)
In what follows we ignore members of D! that are not onto D. This is becausethe class of such sequences has measure zero for any P ! P, by the positivity of P(for discussion see Billingsley (1986, Chapter 4)). Recall from Section 15.6.2 thatD-sequences are, by definition, onto D. The following lemma is easy to demonstrate.
Lemma 15.8.1. Let structure S be given, and let E be the class of environments for S.Then for all P ! P, E has P-measure 1.
15.8.2 Success Criterion
To give probabilistic character to scientific success we modify only the conceptof solving a structure. The same success criterion as before applies to individualenvironments (see Definition 15.6.3).
Definition 15.8.1. Let X $ Lsen, P0 $ P, and scientist " be given.
(a) Let structure S be given. " X-solves S on P0 just in case for every P ! P0, the set ofenvironments for S that " X-solves has P-measure 1.
(b) Let collection K of structures be given. " X-solves K on P0 just in case " X-solves everyS ! K on P0. In this case, K is said to be X-solvable on P0.
If P0 is a singleton set {P}, we drop the braces when employing the foregoingterminology.
Of course, if P0, P1 are classes of distributions with P0 $ P1 then X-solvabilityon P1 implies X-solvability on P0. Lemma 15.8.1 implies that if " X-solves K (inthe absolute sense), then " X-solves K on P. Definition 15.8.1 thus generalizes theabsolute conception of solvability.
Example 15.8.1. Let L, X, and K be as described in Example 15.7.1. Let P0 ' P beany class of distributions such that for all i ! N, glb{P(di) | P ! P0} > 0. Then K isX-solvable on P0.
A recursion-theoretic analogue of the contrast between Examples 15.7.1 and 15.8.1appears in Osherson, Stob and Weinstein (1986c, Proposition 10.5.2.A). Further ana-lysis is provided by Angluin (1988).
15.8.3 Comparison with Absolute Solvability
Examples 15.7.1 and 15.8.1 show that absolute and probabilistic solvability do notcoincide for arbitrary collections of structures. However, for elementary collections

“19-ch15-0725-0764-9780444537263” — 2010/11/29 — 21:08 — page 749 — #25
Formal Learning Theory 749
of structures things are different. In this case the same concept of confirmability(Definition 15.7.2) governs solvability in both the absolute and probabilistic senses.This is revealed by the next two lemmas, which parallel Lemmas 15.7.1 and 15.7.2.The first is an immediate consequence of Lemmas 15.7.1 and 15.8.1.
Lemma 15.8.2. Let a +02 subset X of Lsen be given. Then there is an oracle machine
M such that for all T $ Lsen, if X is confirmable in T then MT X-solves mod(T) on P.
Lemma 15.8.3. Let X $ Lsen be given. Then for all P ! P and T $ Lsen, if mod(T) isX-solvable on P then X is confirmable in T.
Lemmas 15.8.2 and 15.8.3 directly yield the following proposition.
Proposition 15.8.1. Suppose that X $ Lsen is +02 . Then there is an oracle machine M
such that for all P ! P and T $ Lsen, if mod(T) is X-solvable on P then MT X-solvesmod(T) in the absolute sense (hence MT X-solves mod(T) on P, as well).
As a corollary we obtain:
Corollary 15.8.1. Let ( ! Lsen be given. Then for all T $ Lsen the followingconditions are equivalent.
(a) mod(T) is {(, ¬(}-solvable.(b) mod(T) is {(, ¬(}-solvable on P.(c) For some P ! P, mod(T) is {(, ¬(}-solvable on P.(d) ( is equivalent over T to a Boolean combination of existential sentences.
15.9 Third Paradigm: Solvability with Specified Probability
So far in our discussion we have considered the natural-nonnatural boundary to besharp. A more liberal attitude would define the natural languages as those for whichthere is some positive probability of successful acquisition by children, and recognizethat different members of this class are associated with different probabilities. Suchis the approach of the present section. We preserve the assumption of a sharp dis-tinction between success and failure in any given environment, but allow the class ofenvironments that lead to success to have measure between 0 and 1.
Formulation of this idea requires reflection about the case in which success is notachieved. In particular, we rely on the following hypothesis, which is substantive butstrikes us as plausible. When the acquisition process breaks down, we assume that thechild fails to converge to any grammar, rather than stabilizing to an incorrect one.
It may be interesting to view the foregoing hypothesis from a normative perspec-tive (that is, independently of the empirical question of its veridicality for children).A scientist who solves a given structure with small probability is worse than uselessif he exhibits high probability of misleading an external observer. In particular, it is

“19-ch15-0725-0764-9780444537263” — 2010/11/29 — 21:08 — page 750 — #26
750 Handbook of Logic and Language
misleading to converge to a false theory; for in this case the mistaken theory appears tobe held with confidence, and risks being accredited. If the probability that the scientistmisleads us this way is high, and the probability of genuine success low, it might bebetter to show him no data at all.
15.9.1 Definitions and Principal Theorem
These considerations suggest the following definitions.
Definition 15.9.1. Let scientist " , structure S and environment e for S be given. "
is misleading on e just in case " converges on e to ( ! Lsen such that S &|= ( .
Given X $ Lsen, if " X-solves structure S then " is not misleading on any envi-ronment for S. Definition 15.9.1 is inspired by the concept of “reliability” from therecursion theoretic literature (see Blum and Blum, 1975).
Definition 15.9.2. Let r ! [0, 1], X $ Lsen, P0 $ P, and scientist " be given.
(a) Given structure S, we say that " X-solves S on P0 with probability r just in case thefollowing conditions hold for all P ! P0.(i) The set of environments for S that " X-solves has P-measure at least r.14
(ii) The set of environments for S on which " is misleading has P-measure 0.(b) Given collection K of structures, we say that " X-solves K on P0 with probability r just
in case " X-solves every S ! K on P0 with probability r. In this case, K is said to beX-solvable on P0 with probability r.
Clause (a-ii) of the definition embodies our hypothesis that acquisition failureresults in nonconvergence. On the normative side, it renders useful any scientist whosechance of success is positive. In particular, the hypotheses of such a scientist lendthemselves to aggregation within a larger scientific community (see Jain and Sharma,1990a; Osherson, Stob and Weinstein, 1986a; Pitt and Smith, 1988, for discussion ofaggregating scientific competence).15
Definition 15.9.2 generalizes the earlier paradigms. This is shown by the followinglemma, which follows immediately from our definitions.
Lemma 15.9.1. Let P ! P, scientist " , X $ Lsen, and structure S be given. If either
(a) " X-solves S or(b) " X-solves S on P
then " X-solves structure S on P with probability 1.
14 Recall from Section 15.8.1 that the measure of a set of environments is defined via their underlyingD-sequences.
15 We note that the aggregation problem is distinct from “team learning” in the sense of Daley (1986), Jainand Sharma (1990b), Pitt (1989). The latter paradigm requires only that a single scientist arrive at thetruth, not that divergent opinions be unified into a correct one.

“19-ch15-0725-0764-9780444537263” — 2010/11/29 — 21:08 — page 751 — #27
Formal Learning Theory 751
The present conception of scientific success has a “zero-one” character, as revealedby the following proposition.
Proposition 15.9.2. Let X $ Lsen, P0 $ P, and collection K of structures be given.Then K is X-solvable on P0 with probability greater than 0 if and only if K is X-solvable on P0.
From Proposition 15.8.1, Corollary 15.8.1, and Proposition 15.9.2 we have the fol-lowing immediate corollaries.
Corollary 15.9.1. Suppose that X $ Lsen is +02 . Then there is an oracle machine M
such that for all P ! P and T $ Lsen, if mod(T) is X-solvable on P with probabilitygreater than 0, then MT X-solves mod(T) in the absolute sense.
Corollary 15.9.2. Let ( ! Lsen be given. Then for all T $ Lsen the followingcondition is equivalent to (a)–(d) of Corollary 45.
(e) For some P ! P, mod(T) is {(, ¬(}-solvable on P with probability greater than 0.
15.10 Empirical Evaluation
The paradigms discussed above provide at best a crude picture of first language acqui-sition by children. We provide a partial list of their deficiencies.
(a) The linguistic data available to children are not adequately represented by the formal con-cept of environment. The issue of negative information was already noted in Section 15.6.7,above. In addition, the concept of probabilistic solvability portrays data as arising via iden-tically distributed, stochastically independent sampling. It is easy to see that real langu-age does not arise in this way (for discussion see Angluin, 1988; Osherson, Stob andWeinstein, 1986b).
(b) Except for computability, our paradigms provide no constraint on the class of formal scien-tists whereas the inductive mechanisms of children surely operate under severe limitations.At the least, we can assume that children have limited memory for the precise form ofspoken sentences, and that the time devoted to processing any given datum is recursivelybounded. Building these constraints into formal scientists alters the collections of structuresthat can be solved.16
(c) The criterion of solvability is both too weak and too strong compared to actual languageacquisition. It is too strong in requiring selection of ( ! X that is “exactly” true in theunderlying structure. Since the grammatical theories issuing from normal language acqui-sition are not likely to be entirely accurate reflections of the input language, more realisticparadigms would incorporate a suitable notion of “approximate truth” (for discussion ofthis notion, see Kuipers, 1987; Osherson, Stob and Weinstein, 1989). On the other hand,solvability is too weak inasmuch as it imposes no requirements on the number of data that
16 Preliminary work on restricted classes of scientists within the model theoretical perspective is reportedin (Gaifman, Osherson and Weinstein, 1990; Osherson and Weinstein, 1986).

“19-ch15-0725-0764-9780444537263” — 2010/11/29 — 21:08 — page 752 — #28
752 Handbook of Logic and Language
must be examined before convergence begins. In contrast, the rapidity of first languageacquisition is one of its striking features. Note also that solvability for individual environ-ments is defined here as an all-or-nothing affair. In reality, children might harbor randomprocesses that yield only probable success within any fixed set of circumstances.17
As seen in Section 15.4, the foregoing issues (among others) have begun to beaddressed within the recursion theoretic tradition in Learning Theory. In contrast, theirexploration within a first-order framework has hardly been initiated.
15.11 Concluding Remarks
Apart from concerns about first language acquisition, the model theoretic paradigmsdiscussed in this chapter may be examined from an epistemological point of view. Forexample, Proposition 15.7.1 indicates that there is an upper bound on scientific compe-tence, at least for elementarily defined starting points (in the sense of Section 15.7.2).Moreover, this bound is already reached by a Turing Machine whose sole recourseto an oracle is to determine the axioms of the background theory. The theorem mightthus be relevant to the thesis T according to which human mentation is computer sim-ulable. Although T might imply various bounds on human knowledge or capacity,Proposition 15.7.1 provides one sense in which the scope of scientifically attainableknowledge is not affected by the status of T .18 Corollary 15.9.1 provides an evenstronger sense.
Theorem 15.7.1 raises questions about the character of first-order logic itself. Towhat extent is the theorem linked to the special properties of the predicate calculus?Are there analogous theorems for stronger logics? Inversely, are all of the deductiveconsequences of first-order logic necessary for conducting scientific inquiry, includingsuch inferences as p |= p-q (sometimes thought to have an odd character (Schurz andWeingartner, 1987))? Some preliminary results that bear on these questions are pre-sented in Osherson, Stob and Weinstein (1991b, Section 4); Osherson and Weinstein(1993).
15.12 Appendix: Proofs
15.12.1 Proof of Lemma 4
We restrict attention to scientists that are total functions; that no generality is lostfollows from Osherson, Stob and Weinstein (1986c, Proposition 4.3.1A,B). Assumethat " identifies L but no locking sequence for " and L exists. Moreover assume thata0, a1, a2, . . . is an enumeration of L. We now construct in stages a special text t for L.
17 For an analysis of random processes in learning, see Daley (1986); Pitt (1989).18 For discussion of the machine simulability of thought, see Glymour (1992, Chapter 13) and references
cited there.

“19-ch15-0725-0764-9780444537263” — 2010/11/29 — 21:08 — page 753 — #29
Formal Learning Theory 753
Stage 0: Start t with a0.
Stage n + 1: Suppose that t[m0] has been constructed at stage n. By assumption, thissequence is not a locking sequence. So, it can be extended by elements of L to some$ such that either " ($ ) is not an index for L or " ($ ) &= " (t[m0]). Let $ followedby an+1 be the segment of t constructed in the present stage.
It is easy to see that t is a text for L, and that " does not converge on t to an indexfor L. Hence " does not identify L, contradicting our assumption.
15.12.2 Notation
The following notation will be helpful in the sequel. Given D-sequence d and structureS, we let [S, d] denote the environment for S and d. Given structure S and d̄ ! D<!
of length n ! N, we let [S, d̄] denote e[n], where e = [S, d] and d extends d̄. Forexample, with S and d as in Section 15.6.3, [S, d[3]] is displayed just above Lemma15.6.1 (ignoring the . . . ). It is helpful to note that for structures S, U , and d̄, ū ! D<!,[S, d̄] = [U, ū] iff S restricted to d̄ is isomorphic to U restricted to ū.
15.12.3 Model-Theoretic Locking Sequences
In the model-theoretic paradigms the following version of the locking sequence lemmais used. It has been demonstrated elsewhere in diverse forms (e.g., Osherson and Wein-stein, 1982, Lemma B; Osherson, Stob and Weinstein, 1991b, Lemma 24). The proofresembles that for Lemma 15.2.1, and we do not rehearse it here.
Definition 15.12.1. Let scientist " , structure S, and d̄ ! D<! be given. d̄ is a lockingsequence for (" ,S) just in case:
(a) " ([S, d̄]) ! Lsen, i.e. " is defined on [S, d̄], and(b) for all d̄% ! D<! that extend d̄, " ([S, d̄%]) = " ([S, d̄]).
Lemma 15.12.1. Let X $ Lsen, scientist " , and structure S be given. Suppose that" X-solves every environment for S. Then there is a locking sequence d̄ for (" ,S).Moreover, S |= " ([S, d̄]).
15.12.4 Proof of Example 30
Suppose that " X-solves S0. Then, because S0 |= ( , Lemma 15.12.1 implies theexistence of d̄ ! D<! such that:
(54) for all d̄% ! D<! that extend d̄, " ([S0, d̄%]) = ( .
Choose i ! N large enough so that Si |= [S0, d̄]. Let D-sequence h extend d̄. Then itis easy to verify that:
(55) for all j ! length(d̄) there is d̄% ! D<! of length j such that:(a) d̄% extends d̄, and(b) [Si, h̄j] = [S0, d̄%].

“19-ch15-0725-0764-9780444537263” — 2010/11/29 — 21:08 — page 754 — #30
754 Handbook of Logic and Language
By (54) and (55), " converges on [Si, h] to ( . It follows that " does not X-solveSi since Si &|= ( .
15.12.5 Proof of Lemma 36
We rely on the following notation.
Definition 15.12.2. Let structure S and d̄ ! D<! be given.
(a) The set
*, ! Lform | , is universal, var(,) $ domain
+d̄
,, and S |= ,
-d̄
./
is denoted by *-type(d̄ S).(b) The set
*, ! Lform | , is existential, var(,) $ domain
+d̄
,, and S |= ,
-d̄
./
is denoted by +-type(d̄ S).
Let scientist " , X $ Lsen, and T $ Lsen be such that " X-solves mod(T). Wesuppose that T is satisfiable and X &= ( (the other cases are trivial). By Lemma 15.12.1choose d̄ ! D<! and ( ! X such that:
(57) (a) d̄ is a locking sequence for (" ,S), and(b) " ([S, d̄]) = ( .
It is sufficient to show that there is & ! Lsen such that:
(58) (a) & is of form +*,(b) S |= &, and(c) T " {&} |= ( .
Fact 15.12.1. Suppose that U ! mod(T) and sequence ū are such that length(ū) =length(d̄) and +-type(ū, U) $ +-type(d̄, S). Then U |= ( .
Proof. Suppose that U , ū satisfy the assumptions, and let ū% extend ū. Let - ! Lformbe the conjunction of the basic formulas in [U, ū%]. Then
U |= +xlength(ū) · · · +xlength(ū%)#1- [ū].
Hence, because +-type(ū, U) $ +-type(d̄, S), S |= +xlength(ū) · · · +xlength(ū%)#1- [d̄].
Hence, some extension d̄% of d̄ of the same length as ū% satisfies [S, d̄%] = [U, ū%]. So,by (57)a, " ([U, ū%]) = " ([S, d̄%]) = " ([S, d̄]). We infer immediately that:
(60) ū is a locking sequence for (" ,U).
From the same equality (with ū% = ū) and (57b), we obtain:
(61) " ([U, ū]) = ( .

“19-ch15-0725-0764-9780444537263” — 2010/11/29 — 21:08 — page 755 — #31
Formal Learning Theory 755
Finally, Fact 15.12.1 follows from (60), (61) and the assumptions that U ! mod(T)
and " X-solves mod(T). "
Using Fact 15.12.1, we now show that:
Fact 15.12.2. T " *-type(d̄, S) |= ( .
Proof. By the Löwenheim-Skolem theorem it is sufficient to show that ( holds in anycountable model U ! mod(T) in which *-type(d̄, S) is satisfied by a sequence ū ofthe same length as d̄. So assume that U and ū are such a model and sequence. Then+-type(ū, U) $ +-type(d̄, S). Hence, by Fact 59, ( holds in U . "
By compactness there is a finite subset % of *-type(d̄, S) such that
(63) T " % |= ( .
To witness (58), let & be the existential closure of the conjunction of % . Then,& can immediately be seen to satisfy (58a,b). That & satisfies (58c) follows directlyfrom (63).
15.12.6 Proof of Example 41
Let P0, X and K be as specified in the example.Given i, j ! N, let Ai,j ' D! be the collection of D-sequences d such that not all
of d0, . . . , di occur in d[j]. By the assumption on P0, let strictly increasing f : N . Nbe such that for all i ! N and P ! P0, P(Ai, f (i)) < 1/2i. So for each P ! P0,0
i P(Ai, f (i)) converges. Hence, by the first Borel-Cantelli lemma (Billingsley, 1986,Theorem 4.3):
(64) P(lim supi Ai, f (i)) = 0 for every P ! P0.
Via the definition of Ai,j, (64) yields:
(65) For every P ! P0 the class of D-sequences d such that
{d0, . . . , di} &$ range(d[f (i)])
for infinitely many i ! N has P-measure 0.
Define scientist " as follows. For all environments e and all j ! N:
(a) if j ! range( f ) and1
e[j] implies the existence of an R-chain of length at least f #1( j), then" (e[j]) = ( ; (since f is strictly increasing, f #1( j) is well-defined).
(b) if j ! range( f ) and1
e[j] does not imply the existence of an R-chain of length at leastf #1( j), then " (e[j]) = ¬( ;
(c) if j /! range( f ), then " (e[j]) = " (e[j # 1]) (if j = 0, in which case " (e[j]) = *x(x = x)).
Now let Sj ! K be given, with j > 0. Let D-sequences d and environment e forSj and d also be given. Then for all but finitely many i ! N,
1e[f (i)] does not imply
the existence of an R-chain of length at least i (because there is no such chain). Hence,case (b) above arises for a cofinite subset of range( f ) whereas case (a) arises for only

“19-ch15-0725-0764-9780444537263” — 2010/11/29 — 21:08 — page 756 — #32
756 Handbook of Logic and Language
a finite subset of range( f ). It follows that " converges to ¬( on e. Hence, " X-solvesSj, so " X-solves Sj on P0.
Regarding S0, let e be for S0 and d. Call e “bad” just in case for infinitely manyi ! N,
1e[f (i)] does not imply the existence of an R-chain of length at least i. It
follows directly from (65) that for every P ! P0, the class of bad environments forS0 has P-measure 0. Hence, the P-probability is 1 that case (a) arises for a cofinitesubset of range( f ) whereas case (b) arises for only a finite subset of range( f ). Thus,for every P ! P0, " converges to ( on a class of environments for S0 of P-measure 1,so " X-solves S0 on P0.
15.12.7 Proof of Lemma 15.8.3
Our demonstration of Lemma 15.8.3 proceeds via the following definition andpropositions.
Definition 15.12.3. Let P ! P be given. The class of P% ! P such that for somepermutation , : N . N, P% = {(di, P(d,(i))) | i ! N} is denoted PERM(P).
Proposition 15.12.1. Let X $ Lsen, P ! P, and T $ Lsen be given. If mod(T) isX-solvable on P then mod(T) is X-solvable on PERM(P).
Proposition 15.12.2. Let X $ Lsen, P ! P, and T $ Lsen be given. If X is notconfirmable in T then for some P% ! PERM(P), mod(T) is not X-solvable on P%.
To obtain Lemma 15.8.3 from the foregoing, let X $ Lsen, P ! P, and T $ Lsen begiven, and suppose that mod(T) is X-solvable on P. Then by Proposition 67, mod(T)
is X-solvable on PERM(P). So, by Proposition 68, X is confirmable in T .It remains to prove the two propositions.
15.12.8 Proof of Proposition 67
Suppose that scientist " X-solves mod(T) on P, and let S ! mod(T) be given. Let ,
be any permutation of N, and let P% = {(di, P(d,(i))) | i ! N}. It suffices to show that" X-solves S on P%.
Given D-sequence d, let ,(d) be its permutation (via the indexes of D) under , .Given subset D of D-sequences, let ,(D) = {,(d) | d ! D}. Since the measure ofa collection of D-sequences is determined only by the probabilities applying to eachcoordinate (and not by their names), we have:
(69) For every set D of D-sequences, P(,(D)) = P%(D).
Let S % be the structure whose vocabulary is interpreted in the following way.For individual constant c, cS
% = d,( j) iff cS = dj. For n-ary relation symbol R,(d,(j1), . . . , d,(jn)) ! RS
%iff (dj1 , . . . , djn) ! RS . Evidently, S % ! mod(T) since S and
S % are isomorphic. Hence:

“19-ch15-0725-0764-9780444537263” — 2010/11/29 — 21:08 — page 757 — #33
Formal Learning Theory 757
(70) " X-solves S % on P.
Let D be the set of D-sequences d such that " X-solves [S %, ,(d)] on P. By (70),P(,(D)) = 1, so by (69) the proof is completed if we show that for almost every d !D, " X-solves [S, d] on P%. However, this follows immediately from the followingfact, easy to verify: for all D-sequences d, [S %, ,(d)] = [S, d].
15.12.9 Proof of Proposition 68
The proposition follows from a stronger result demonstrated in Martin and Osh-erson (1998); to avoid a lengthy argument, we refer the reader to the lattersource.
15.12.10 Proof of Proposition 47
The right-to-left direction of the proposition is immediate. For the other direction, LetX $ Lsen, collection K of structures, and P0 $ P be given. Suppose that scientist" X-solves K on P0 with probability greater than 0. We shall exhibit scientist "0that X-solves K on P0. For this purpose some definitions and facts are needed.
Definition 15.12.4.
(a) Given n ! N and D-sequences d, the tail of d that begins at dn is denoted dn.(b) Given structure S, we denote by 2dS the class of D-sequences d such that for some n ! N:
(i) range(dn) = D, and(ii) " X-solves [S, dn].
Fact 15.12.3. For all S ! K and P ! P0, P(2dS) = 1.
Proof. Let P ! P0 and S ! K be given. By choice of " , let 2d be a measurable classof D-sequences such that:
(73) a. for all d ! 2d,
(i) range(d) = D,(ii) " X-solves [S, d].
b. P(2d) > 0.
By (73a), 2d $ 2dS , so (73b) implies P(2dS) > 0. It follows immediately fromKolmogorov’s zero-one law for tail events (Billingsley, 1986, Theorem 4.5) thatP(2dS) = 1. "
By Definition 15.9.2 and the choice of " we also have:
Fact 15.12.4. Let P ! P0, n ! N, and S ! K be given. Let 2d be the class ofD-sequences d such that " is misleading on [S, dn]. Then P(2d) = 0.

“19-ch15-0725-0764-9780444537263” — 2010/11/29 — 21:08 — page 758 — #34
758 Handbook of Logic and Language
As a final preliminary, we make use of the following definition and fact.
Definition 15.12.5. Let # be the initial finite segment of length m in some environ-ment e. Let scientist " also be given. The score for " on # is the smallest j ! N suchthat " (e[i]) = " (# ) for all i with j # i # m.
Intuitively, the lower the score for " on # , the greater sign " gives of having begunits convergence within # . We record two obvious facts about score.
Fact 15.12.5.
(a) Suppose that scientist " converges on environment e. Then there is s ! N such that for allk ! N, the score for " on e[k] is bounded by s.
(b) Suppose that scientist " does not converges on environment e. Then for every s ! N thereis . ! N such that the score for " on e[k] exceeds s if k ! ..
In what follows we assume the existence of a uniform recursive procedure whichconverts finite initial segments of environments into new segments that “start over”at a specified position n. That is, for all structures S, D-sequences d, and m ! N, theprocedure converts [S, d[m]] into [S, b[m # n]] where b = dn (if m < n, we takeb = d, so [S, d[m]] remains unchanged). It is easy to verify the existence of thisprocedure. Facts 72, 74 and 76 make it clear how to construct the desired scientist "0.We provide an informal description. Let E be an enumeration of N / N.
Given incoming environment e, "0 works in stages to create ever longer initialsegments e0, e1, . . . of e, where ei is the environment that “starts over” at position iof e. At stage zero we have "0(() = " ((). Between two stages, while not enoughof e is available to proceed to the next stage, "0 repeats its last conjecture on eachnew position in e. At the nth stage (n ! 1), "0 has examined enough of e to constructthe initial segments of length n for each of e0, . . . , en. Let these initial segments bedenoted # 0 · · · # n. Let (x, y) be the first pair enumerated in E such that x, y # n and" ’s score on # x is y. Then at the nth stage "0 conjectures " (# x). Intuitively, "0 looksfor a tail of e on which " ’s conjectures appear eventually to stop changing. For each(x, y) in turn, "0 conjectures that one such tail is ex and that " ’s hypotheses on ex
stopped changing at position y. This conjecture is kept until " ’s score on some initialsegment of ex is shown to be greater than y.
To see that "0 X-solves K on P0, let structure S ! K, environment e for S, andP ! P0 be given. By Fact 72 the probability (according to P) is 1 that there is n ! Nsuch that en is also an environment for S and that " X-solves en. Call such a tail ofe “good”, the others “bad”. By Facts 74 and 76 the probability is 1 that " ’s scoreson initial segments of any bad tail ex eventually defeat any hypothesis (x, y). It isthus straightforward to verify that "0 converges on e to " (# ) for some # with thefollowing properties:
(a) # is an initial segment of a good tail en of e, and(b) for all extensions $ of # in en, " ($ ) = " (# ).

“19-ch15-0725-0764-9780444537263” — 2010/11/29 — 21:08 — page 759 — #35
Formal Learning Theory 759
Since en is a good tail, for this # we have " (# ) ! X and S |= " (# ). Hence withprobability 1, "0 converges on e to a sentence of X true in the underlying structure S.This completes the proof.
We note that straightforward modifications to the foregoing proof demonstrate thefollowing version of Proposition 15.9.2.
Proposition 15.12.3. Let P0 $ P, recursive X $ Lsen, and collection K of structuresbe given. Suppose that some computable scientist " X-solves K on P0 with proba-bility greater than 0. Then there is computable scientist "0, constructible in uniformrecursive fashion from " , that X-solves K on P0.
References
Angluin, D., Smith, C.H., 1983. A survey of inductive inference: theory and methods. ACMComput. Surv. 15 (3), 237–269.
Angluin, D., 1980. Inductive inference of formal languages from positive data. Inform. Control45 (2), 117–135.
Angluin, D., 1988. Identifying Languages from Stochastic Examples. Technical ReportYALEU/DCS/RR-614, Yale University, Department of Computer Science, NewHaven, CT.
Anthony, M., Biggs, N., 1992. Computational Learning Theory, Cambridge Tracts inTheoretical Computer Science vol. 30. Cambridge University Press, Cambridge, MA.
Baker, C.L., McCarthy, J. (Eds.), 1981. The Logical Problem of Language Acquisition. MITPress, Cambridge, MA.
Berwick, R., 1986. The Acquisition of Syntactic Knowledge. MIT Press, Cambridge, MA.Bickerton, D., 1981. The Roots of Language. Karoma, Ann Arbor, MI.Billingsley, P., 1986. Probability and Measure, second ed. Wiley, New York.Blum, L., Blum, M., 1975. Toward a mathematical theory of inductive inference. Inform. Con-
trol 28 (2), 125–155.Blum, M., 1967. A machine independent theory of the complexity of the recursive functions.
J. Assoc. Comput. Mach. 14 (2), 322–336.Borer, H., Wexler, K., 1987. The maturation of syntax, in: Roeper, T., Williams, E. (Eds.),
Parameter Setting. Reidel, Dordrecht, pp. 123–172.Brown, R., Hanlon, C., 1970. Derivational complexity and the order of acquisition in child
speech, in: Hayes, J.R. (Ed.), Cognition and the Development of Language. Wiley,New York, pp. 11–54.
Case, J., Smith, C., 1983. Comparison of identification criteria for machine inductive inference.Theor. Comput. Sci. 25, 193–220.
Chang, C.C., Keisler, H.J., 1977. Model Theory, second ed. North-Holland, Amsterdam.Chomsky, N., 1957. Syntactic Structures. Mouton, Berlin.Chomsky, N., 1965. Aspects of the Theory of Syntax. MIT Press, Cambridge, MA.Chomsky, N., 1975. Reflections on Language. Pantheon, the Netherlands.Chomsky, N., 1986. Knowledge of Language: Its Nature, Origin and Use. Praeger, New York.Daley, R., Smith, C., 1986. On the complexity of inductive inference. Inform. Control 69,
12–40.

“19-ch15-0725-0764-9780444537263” — 2010/11/29 — 21:08 — page 760 — #36
760 Handbook of Logic and Language
Daley, R.P., 1986. Inductive inference hierarchies: probabilistic vs pluralistic. Lect. NotesComput. Sci. 215, 73–82.
Demetras, M., Post, K., Snow, C., 1986. Feedback to first language learners: the role of repeti-tions and clarification questions. J. Child Lang. 13, 275–292.
Earman, J., 1992. Bayes or Bust? MIT Press, Cambridge, MA.Feldman, H., Goldin-Meadow, L., Gleitman, S., 1978. Beyond Herotodus: the creation of
language by linguistically deprived deaf children, in: Lock, A. (Ed.), Action, Symbol, andGesture: The Emergence of Language. Academic Press, San Diego, CA, pp. 351–414.
Fulk, M., 1988. Saving the phenomenon: requirements that inductive machines not contradictknown data. Inform. Comput. 79 (3), 193–209.
Fulk, M., 1990. Prudence and other conditions on formal language learning. Inform. Comput.85 (1), 1–11.
Fulk, M.A., Jain, S., 1992. Approximate inference and scientific method. Inform. Comput.114 (2), 179–191.
Fulk, M., Jain, S., Osherson, D., 1992. Open problems in systems that learn. J. Comput. Syst.Sci. 49, 589–604.
Gaifman, H., Snir, M., 1982. Probabilities over rich languages. J. Symb. Logic 47, 495–548.Gaifman, H., Osherson, D., Weinstein, S., 1990. A reason for theoretical terms. Erkenntnis 32,
149–159.Gleitman, L., 1986. Biological dispositions to learn language, in: Demopoulos, W., Marras, A.
(Eds.), Language Learning and Concept Acquisition. ABLEX, Norwood, NJ, pp. 3–28.Glymour, C., 1985. Inductive inference in the limit. Erkenntnis 22, 23–31.Glymour, C., 1992. Thinking Things Through. MIT Press, Cambridge, MA.Glymour, C., Kelly, K., 1989. On convergence to the truth and nothing but the truth. Philos.
Sci. 56 (2), 185–220.Gold, E.M., 1965. Limiting recursion. J. Symb. Logic 30 (1), 28–48.Gold, E.M., 1967. Language identification in the limit. Inform. Control 10, 447–474.Goldman, A., 1986. Epistemology and Cognition. Harvard University Press, Cambridge, MA.Hirsh-Pasek, K., Treiman, R., Schneiderman, M., 1984. Brown and Hanlon revisited: mothers’
sensitivity to ungrammatical forms. J. Child Lang. 11, 81–88.Hornstein, N., Lightfoot, D. (Eds.), 1981. Explanation in Linguistics. Longman, London.Jain, S., Sharma, A., 1990a. Finite learning by a team. Proceedings of 3rd Annual Workshop on
Computational Learning Theory. Morgan Kaufmann, San Mateo, CA, pp. 163–177.Jain, S., Sharma, A., 1990b. Language learning by a team, in: Paterson, M.S. (Ed.), Proceedings
of the 17th International Colloquium on Automata, Languages and Programming. Springer,Berlin, pp. 153–166.
Jain, S., Sharma, A., Case, J., 1989. Convergence to nearly minimal size grammars by vacil-lating learning machines, in: Rivest, R., Haussler, D., Warmuth, M. (Eds.), Proceedingsof 2nd Annual Workshop on Computational Learning Theory. Morgan Kaufmann, SanMateo, CA, pp. 189–199.
Johnson, J.S., Newport, E.L., 1989. Critical period effects in second language learning: theinfluence of maturational state on the acquisition of English as a second language. Cogn.Psych. 21, 60–99.
Juhl, C., 1993. Bayesianism and reliable scientific inquiry. Philos. Sci. 60, 302–319.Kanazawa, M., 1993. Identification in the Limit of Categorial Grammars. Technical Report,
Department of Linguistics, Stanford University, Stanford, CA.Kanazawa, M., 1994. Learnable Classes of Categorial Grammars. PhD thesis, Department of
Linguistics, Stanford University, Stanford, CA.

“19-ch15-0725-0764-9780444537263” — 2010/11/29 — 21:08 — page 761 — #37
Formal Learning Theory 761
Kapur, S., Bilardi, G., 1992. On uniform learnability of language families. Inform. Process. Lett.44, 35–38.
Kapur, S., 1991. Computational Learning of Languages. Technical Report TR 91-1234, Depart-ment of Computer Science, Cornell University, Italy.
Kelly, K.T., 1994. The Logic of Reliable Inquiry. MIT Press, Cambridge, MA.Kelly, K.T., Glymour, C., 1992. Inductive inference and theory-laden data. J. Philos. Logic
21 (4), 391–444.Kelly, K.T., Glymour, C., 1993. Theory discovery from data with mixed quantifiers. J. Philos.
Logic 19, 1–33.Kinber, E., 1994. Monotonicity versus Efficiency for Learning Languages from Texts. Techni-
cal Report 94-22, University of Delaware Wilmington, DE, Department of Computer andInformation Sciences.
Kornblith, H. (Ed.), 1985. Naturalizing Epistemology. MIT Press, Cambridge, MA.Kugel, P., 1977. Induction, pure and simple. Inform. Control 35, 276–336.Kuipers, T.A. (Ed.), 1987. What is Closer-to-the-Truth? Rodopi, Amsterdam.Kurtz, S.A., Royer, J.S., 1988. Prudence in language learning, in: Haussler, D., Pitt, L.
(Eds.), Proceedings of 1st Annual Workshop on Computational Learning Theory. MorganKaufmann, Los Altos, CA, pp. 143–156.
Landau, B., Gleitman, L., 1985. Language and Experience. Harvard University Press, Cam-bridge, MA.
Lasnik, H., 1989. On certain substitutes for negative data, in: Mathews, R.J., Demopoulos, W.(Eds.), Learnability and Linguistic Theory. Kluwer, Dordrecht, pp. 89–105.
Lenneberg, E., 1967. Biological Foundations of Language. Wiley, New York.Levy, A., 1979. Basic Set Theory. Springer, Berlin.Lightfoot, D., 1982. The Language Lottery. MIT Press, Cambridge, MA.Machtey, M., Young, P., 1978. An Introduction to the General Theory of Algorithms. North-
Holland, New York.Martin, E., Osherson, D., 1998. Elements of Scientific Discovery. MIT Press, Cambridge.Matthews, R.J., 1984. The plausibility of rationalism. J. Philos. 81, 492–515.Matthews, R.J., 1989. Learnability and linguistic theory, in: Matthews, R.J., Demopoulos, W.
(Eds.), Learnability and Linguistic Theory. Kluwer, Dordrecht.Mazurkewich, I., White, L., 1984. The acquisition of dative-alternation: unlearning overgener-
alizations. Cognition 16 (3), 261–283.Newport, E.L., Supalla, T., 1989. A critical period effect in the acquisition of a primary lan-
guage. Science.Newport, E., Gleitman, L., Gleitman, H., 1977. Mother i’d rather do it myself: some effects and
noneffects of maternal speech style, in: Snow, C., Ferguson, C. (Eds.), Talking to Children:Language Input and Acquisition. Cambridge University Press, Cambridge, MA.
Osherson, D., Wasow, T., 1976. Species specificity and task specificity in the study of language:a methodological note. Cognition 4 (2), 203–214.
Osherson, D., Weinstein, S., 1982a. A note on formal learning theory. Cognition 11, 77–88.Osherson, D.N., Weinstein, S., 1982b. Criteria of language learning. Inform. Control 52,
123–138.Osherson, D.N., Weinstein, S., 1986. Identification in the limit of first order structures. J. Philos.
Logic 15, 55–81.Osherson, D., Weinstein, S., 1989a. Identifiable collections of countable structures. Philos. Sci.
18, 1–42.Osherson, D., Weinstein, S., 1989b. Paradigms of truth-detection. J. Philos. Logic 18, 1–42.

“19-ch15-0725-0764-9780444537263” — 2010/11/29 — 21:08 — page 762 — #38
762 Handbook of Logic and Language
Osherson, D., Weinstein, S., 1993. Relevant consequence and scientific discovery. J. Philos.Logic 22, 437–448.
Osherson, D., Weinstein, S., 1995. On the danger of half-truths. J. Philos. Logic 24, 85–115.Osherson, D., Weinstein, S., 1995. On the study of first language acquisition. J. Math. Psychol.
39 (2), 129–145.Osherson, D., Stob, M., Weinstein, S., 1982. Learning strategies. Inform. Control 53 (1), 32–51.Osherson, D.N., Stob, M., Weinstein, S., 1984. Learning theory and natural language. Cognition
17 (1), 1–28.Osherson, D., Stob, M., Weinstein, S., 1986a. Aggregating inductive expertise. Inform. Control
70 (1), 69–95.Osherson, D., Stob, M., Weinstein, S., 1986b. Analysis of a learning paradigm, in: Demopoulos,
W., Marras, A. (Eds.), Language Learning and Concept Acquisition. Ablex, Norwood, NJ.Osherson, D.N., Stob, M., Weinstein, S., 1986c. Systems that Learn: An Introduction to Learn-
ing Theory for Cognitive and Computer Scientists. MIT Press, Cambridge, MA.Osherson, D., Stob, M., Weinstein, S., 1988. Synthesising inductive expertise. Inform. Comput.
77, 138–161.Osherson, D.N., Stob, M., Weinstein, S., 1989. On approximate truth. Proceedings of 2nd
Annual Workshop on Computational Learning Theory. Morgan Kaufmann, San Mateo,CA, pp. 88–101.
Osherson, D., Stob, M., Weinstein, S., 1991a. New directions in automated scientific discovery.Inform. Sci. 57, 217–230.
Osherson, D., Stob, M., Weinstein, S., 1991b. A universal inductive inference machine. J. Symb.Logic 56 (2), 661–672.
Osherson, D., Stob, M., Weinstein, S., 1992. A universal method of scientific inquiry. Mach.Learn. 9, 261–271.
Pappas, G. (Ed.), 1979. Justification and Knowledge. Reidel, Dordrecht.Penner, S., 1987. Parental responses to grammatical and ungrammatical child utterances. Child
Dev. 58, 376–384.Pinker, S., 1989. Markedness and language development, in: Matthews, R.J., Demopoulos, W.
(Eds.), Learnability and Linguistic Theory. Kluwer, Dordrecht, pp. 107–128.Pinker, S., 1990. Language acquisition, in: Osherson, D., Lasnik, H. (Eds.), Invitation to Cog-
nitive Science: Language. MIT Press, Cambridge, MA, pp. 199–241.Pitt, L., 1989. Probabilistic inductive inference. J. Assoc. Comput. Mach. 36 (2), 383–433.Pitt, L., Smith, C., 1988. Probability and plurality for aggregations of learning machines. Inform.
Comput. 77, 77–92.Putnam, H., 1965. Trial and error predicates and a solution to a problem of Mostowski. J. Symb.
Logic 30 (1), 49–57.Putnam, H., 1967. The ‘innateness hypothesis’ and explanatory models in linguistics. Synthese
17 (1), 12–22.Putnam, H., 1975. Probability and confirmation, Mathematics, Matter and Method. Cambridge
University Press, Cambridge, MA.Putnam, H., 1980. What is innate and why, in: Piatelli-Palmarini, M. (Ed.), The Debate between
Jean Piaget and Noam Chomsky. Harvard University Press, Cambridge, MA.Rogers, H., 1967. Theory of Recursive Functions and Effective Computability. McGraw-Hill,
New York.Royer, J., 1986. Inductive inference of approximations. Inform. Control 70, 156–178.Sankoff, G., Brown, P., 1976. The origins of syntax in discourse: a case study of tok pisin
relatives. Language 52, 631–666.

“19-ch15-0725-0764-9780444537263” — 2010/11/29 — 21:08 — page 763 — #39
Formal Learning Theory 763
Schieffelin, B., Eisenberg, A., 1981. Cultural variation in children’s conversations, in: Schiefel-busch, R., Bricker, D. (Eds.), Early Language: Acquisition and Intervention. University ofPark Press, Baltimore, MO, pp. 377–420.
Schurz, G., Weingartner, P., 1987. Verisimilitude defined by relevant consequence-elements.A new reconstruction of Popper’s idea, in: Kuipers, T.A. (Ed.), What is Closer-to-the-Truth? Rodopi, Amsterdam, pp. 47–78.
Shapiro, E.Y., 1981. A general incremental algorithm that infers theory from facts. Proceedingsof the Seventh International Joint Conference on Artificial Intelligence, vol. 1. MorganKaufmann, Los Altos, CA, pp. 446–451.
Shapiro, E.Y., 1983. Algorithmic Program Debugging. MIT Press, Cambridge, MA.Shapiro, E.Y., 1991. Inductive inference of theories from facts, in: Lassez, J.-L., Plotkin, G.
(Eds.), Computational Logic: Essays in honor of Alan Robinson. MIT Press, Cambridge,MA, pp. 199–254.
Sharma, A., Jain, S., Royer, J., Martin, E., Osherson, D., Weinstein, D., 1999. Systems thatLearn (second ed.), MIT Press, Cambridge.
Shinohara, T., 1990. Inductive inference from positive data is powerful. Proceedings of 3rdAnnual Workshop on Computational Learning Theory. Morgan Kaufmann, Los Altos, CA,pp. 97–110.
Smullyan, R.M., 1961. Theory of Formal Systems. Princeton University Press, Princeton, NJ.Solomonoff, R.J., 1964. A formal theory of inductive inference: part 1. Inform. Control 7, 1–22.Stich, S., 1978. Empiricism, innateness, and linguistic universals. Philos. Stud. 33 (3), 273–286.Truscott, J., Wexler, K., 1989. Some problems in the parametric analysis of learnability, in:
Matthews, R.J., Demopoulos, W. (Eds.), Learnability and Linguistic Theory. Kluwer,Dordrecht, pp. 155–176.
Van Riemsdijk, H., Williams, E., 1986. Introduction to the Theory of Grammar. MIT Press,Cambridge, MA.
Wasow, T., 1989. Grammatical theory, in: Posner, M. (Ed.), Foundations of Cognitive Science.MIT Press, Cambridge, MA, pp. 161–205.
Wexler, K., Culicover, P., 1980. Formal Principles of Language Acquisition. MIT Press,Cambridge, MA.
Wiehagen, R., 1978. Characterization problems in the theory of inductive inference. Proceed-ings of 5th Colloquium on Automata, Languages, and Programming. Springer, Berlin,pp. 494–508.

“19-ch15-0725-0764-9780444537263” — 2010/11/29 — 21:08 — page 764 — #40
This page intentionally left blank

“20-ch16-0765-0780-9780444537263” — 2010/11/30 — 3:44 — page 765 — #1
16 Computational LanguageLearning(Update of Chapter 15)Menno van Zaanen!, Collin de la Higuera†
!Tilburg Centre for Cognition and Communication, Department ofCommunication and Information Sciences, Faculty of Humanities,Tilburg University, P.O. Box 90153, NL-5000 LE Tilburg,The Netherlands, E-mail: [email protected]
†Laboratoire LINA UMR CNRS 6241, UFR de Sciences et Techniques,2 rue de la Houssiniêre, BP 92208, 44322 Nantes Cedex 03, France,E-mail: [email protected]
16.1 Introduction
When dealing with language, (machine) learning can take many different faces, ofwhich the most important are those concerned with learning formal languages andgrammars from data. Questions in this context have been at the intersection of thefields of inductive inference and computational linguistics for the past 50 years. To goback to the pioneering work, Chomsky (1955) and Solomonoff (1964) were interested,for very different reasons, in systems or programs that could deduce a language whenpresented information about it.
Gold (1967) proposed a little later a unifying paradigm called identification in thelimit, and the term of grammatical inference seems to have appeared in Horning’s(1969) PhD thesis.
Out of the field of linguistics, researchers and engineers dealing with pattern recog-nition, under the impulsion of Fu (1974), invented algorithms and studied subclassesof languages and grammars from the point of view of what could or could not belearned (Fu and Booth, 1975).
Researchers in machine learning tackled related problems (the most famous beingthat of inferring a deterministic finite automaton, given examples and counter-examples of strings). Angluin (1981, 1987) introduced the important setting of activelearning, or learning from queries, whereas Pitt and Warmuth (1993) and Pitt (1989)gave several complexity inspired results, exposing the hardness of the different learn-ing problems.
In more applied areas, such as computational biology, researchers also worked onlearning grammars or automata from strings, e.g., Brazma et al. (1998). Similarly,
Handbook of Logic and Language. DOI: 10.1016/B978-0-444-53726-3.00016-5c" 2011 Elsevier B.V. All rights reserved.

“20-ch16-0765-0780-9780444537263” — 2010/11/29 — 21:08 — page 766 — #2
766 Handbook of Logic and Language
stemming from computational linguistics, one can point out the work relating languagelearning with more complex grammatical formalisms (Kanazawa, 1998), the more sta-tistical approaches based on building language models, or the different systems intro-duced to automatically build grammars from sentences (Adriaans, 1992; van Zaanen,2000). Surveys of related work in specific fields can be found in Sakakibara (1997),de la Higuera (2005) and Wolff (2006).
When considering the history of formal learning theory, several trends can be iden-tified. From “intuitive” approaches described in early research, more fundamentalideas arose. Based on these ideas and a wider availability of data, more research wasdirected into applied language learning. Recently, there has been a trend asking formore theoretically founded proofs in the applied area, mainly due to the increasingsize of the problems and the importance of having guarantees over the results. Thesetrends have led to the highly interdisciplinary character of formal language learning.Aspects of natural language learning (as an application arena), machine learning, andinformation theory can all be found here.
When attempting to find the common features of work in the field of languagelearning, one should at least consider two dimensions. Learning takes place in a set-ting. Issues in this dimension are properties of training data, such as positive/negativeinstances, amount, or noise levels, but also the measure of success. The other dimen-sion deals with paradigms with respect to generalization over the training data. Thegoal of language learning is to find the language that is used to generate the train-ing data. This language is typically more general than the training data, requiring ageneralization approach.
This chapter is organized along the learning setting and paradigms dimensions.Firstly, we will look at different learning settings and their parameters. Secondly, dif-ferent learning paradigms are discussed, followed by a conclusion.
16.2 Settings
The task of language learning deals with finding a language given a sample taken fromthat language. Typically, this language is described using a grammar, which is a com-pact, finite representation of a possibly infinite language. This general description oflanguage learning leaves many questions open with two main questions in particular.What does the sample look like? When are we successful in learning the language? Inthe next sections we will concentrate on possible answers to these questions.
16.2.1 Learning Settings
To describe a learning setting we can discuss the sort of information we have accessto, the process that is allowing us to access this information and the quality of thisinformation. These are parameters that define the learning settings.
In general, language learning is performed given strings sampled from a language.Alternatively, both examples and counter-examples, i.e. strings with the appropriate

“20-ch16-0765-0780-9780444537263” — 2010/11/29 — 21:08 — page 767 — #3
Computational Language Learning 767
labels, can be provided. This is called positive versus positive and negative input, andcorresponds to learning from an informant.
The examples the learner receives from a language may be in the shape of plaintext (learning from text), but the strings may also arrive with additional information,such as brackets or tags (structured input). This provides the learner with structuredinput (learning from text).
Additional information may also come from an underlying distribution over thestrings that might be stable enough over time. This kind of additional information iscalled distributional input.
The learner may have interaction with the environment and ask for the status ofsome particular string or for some external expertise, which allows for exploration ofthe input.
Finally, the strings may have been corrupted, indicating the presence of noise.
16.2.1.1 Positive Versus Positive and Negative Input
Given data, a language learning system is supposed to make some hypothesis as towhat the corresponding language may be. There are two ways the system may receiveinformation about the language. In the first setting, which is usually called learningfrom text, the learner is given only examples of strings in the language. In the secondsetting, called learning from an informant, the learner is also given some negativeexamples, or counter-examples.
The first situation is considered closer to natural language acquisition problems.The child is being talked to and only positive instances of the language are used.1 Thesecond situation is closer to a pattern recognition or classification task, where we mustlearn to separate one class (the language) from the complement.
16.2.1.2 Structured Input
In some cases, the data will not just be raw strings, but will also contain some form ofstructure. Various levels of help are possible. In the simplest form, sequences containsome partial bracketing. More information is contained when the bracketing is com-plete. In this case, the string can be read as a tree whose leaves are the symbols inthe string and whose internal nodes are unlabeled. More information is provided whenthe nodes of the tree are labeled. Clearly, when the data contains more annotation, thelearner will have more information to build its hypothesis from.
16.2.1.3 Distributional Input
If we suppose that the data has been obtained through sampling, then there is anunderlying probability distribution over the strings. In most cases, however, we donot have a description of this distribution. We identify three approaches that take thisinto account.
1 Note that the amount of information provided to children is also under discussion (Sokolov and Snow,1994).

“20-ch16-0765-0780-9780444537263” — 2010/11/29 — 21:08 — page 768 — #4
768 Handbook of Logic and Language
The first approach assumes that the data is sampled according to an unknowndistribution, and that what we learn will be measured with respect to the unknowndistribution. This corresponds to the well studied PAC-learning (Probably Approxi-mately Correct) setting (Valiant, 1984).
The second approach assumes that the data is sampled according to a distributionitself defined by a grammar or an automaton. The goal is now no longer to classifystrings, but to learn this distribution. The learning process can be evaluated either byaccepting a small error (which happens most of the time, since a particular samplingcould have been corrupted), or in the limit, with probability one (Carrasco and Oncina,1994).
One can even hope for a combination of both these criteria, which is the thirdapproach. A probabilistic language2 D is a probability distribution over !". Theprobability of a string x ! !" under the distribution D is denoted by a positive valuePrD(x), where
!x!!" PrD(x) = 1. If the distribution is modelled by some syntactic
machine A, the corresponding probability distribution is denoted PrA (de la Higueraand Oncina, 2004).
16.2.1.4 Exploration of the Input
It is argued by a number of authors that (child or natural) language acquisition is nota one-directional process. For instance, a child can interact with its mother through anumber of means. Having access to an expert may help learning.
A framework to study learning through interaction with the teacher, or oracle, isthat of active or query learning (Angluin, 1987). In this setting, a learner can queryan oracle by means of questions in a predefined format. Typically, the learner maymake a membership query (a string is submitted and the oracle labels it), or an equiv-alence query (a machine is submitted and the oracle answers whether the corres-ponding language is the target or not). Many alternative queries have been defined(Angluin, 2004). Recently, correction queries have been introduced (Becerra-Bonacheand Yokomori, 2004; Becerra-Bonache et al., 2008): if the query string is not in thetarget language, a correction inside the language is provided.
16.2.1.5 Noise
There are many situations where the data is noisy. For example, in a speech recognitiontask, there are several situations where transcription can have gone wrong, where thesentences do not follow the ideal grammar one is hoping to learn, or where a variety ofutterances are possible. Transcription problems can lead to data sets that, without beingcorrupt, are far away from the idealized situation one encounters in formal languagetheory (Tantini et al., 2006).
2 We denote by L a class of languages. G is a class of representation of objects in this class and L : G " L isthe naming function, i.e. L(G) (with G ! G) is the language denoted, accepted, recognized or representedby G. As usual, ! is the alphabet of the language.

“20-ch16-0765-0780-9780444537263” — 2010/11/29 — 21:08 — page 769 — #5
Computational Language Learning 769
16.2.2 Evaluation Settings
When learning a language given a sample, a selection has to be made from manylanguages that fit the sample. In order to evaluate effectiveness of learning, a measureof success has to be defined. In this section different measures of success in learningwill be considered.
A distinction can be (and often is) made between formal language learning inSections 16.2.2.1–16.2.2.3 (aiming to proof learnability of classes of languages andtherefore yielding clarity and formalism) and empirical learning in Section 16.2.2.5(aiming to build working models of naturally occurring data, addressing practicallearning situations). These two fields have been and still are relatively distinct. Itseems more work is necessary to define models that are both practically applicableand at the same time provide users with mathematical guarantees. Research in thisdirection is mentioned in Section 16.2.2.4.
16.2.2.1 Identification in the Limit
Identification in the limit (Gold, 1967) describes a process where learning is a neverending process. The learner is given information, builds a hypothesis, receives moreinformation, updates the hypothesis, and so on. This setting may seem an unnaturalprocess, completely abstract, and incapable of corresponding to a concrete learningsituation. However, it provides some useful insights.
Firstly, identification in the limit requires the notion of target. A target language,from which the data is extracted, pre-exists to the learning process.
Secondly, even if more typical learning situations are not incremental, it is stillworth studying a learning session as part of a process. It may be that at some particularmoment the learning process returned a good hypothesis, but unless we have somecompleteness guarantee about the data we have got, there is no way we can be sure.In other words, one can study the fact that we are learning a language but not that wehave finished learning one.
Thirdly, even knowing that our algorithm does identify in the limit does not giveus any guarantee on a specific situation. What we do know is that if the algorithmdoes not identify in the limit, there is necessarily a hidden bias. There is at least onepossible language which, for some unknown or undeclared reason, is not learnable.
The advantage of using an algorithm that has the propriety of identifying in thelimit is that you can argue, if the algorithm fails: “Don’t blame me, blame the data”(de la Higuera, 2006).
Definition 16.2.1. Let L be a class of languages. A presentation is a function f : N "X where X is some set. The set of all admitted presentations for L is denoted byPres(L) which is a subset of
"N " X
#.
In some way these presentations denote languages from L, i.e. there exists a func-tion Yields : Pres(L) " L. If L = Yields( f ) then we will say that f is a presentationof L. We also denote by Pres(L) the set { f ! Pres(L) : Yields( f ) = L}.

“20-ch16-0765-0780-9780444537263” — 2010/11/29 — 21:08 — page 770 — #6
770 Handbook of Logic and Language
Figure 16.1 The learning setting.
A presentation of a language has to be meaningful. In other words, we should beable to associate presentations with a unique language which means that for the settingto be valid we require that Yields( f ) = Yields( g).
We summarize these notions in Figure 16.1. The general goal of learning (in theframework of identification in the limit) is to find a learning algorithm A such that#f ! Pres(L), $n ! N : #m % n, L(A( fm)) = Yields( f ). When this is true, we willsay that class L is identifiable in the limit by presentations in Pres(L).
Gold (1978) proved the first and essential results in this setting.
Theorem 16.2.1. Any recursively enumerable class of recursive languages is identifi-able in the limit from an informant and no super-finite class of languages is identifiablein the limit from text.
A super-finite language class is a class that contains all finite languages and at leastone infinite language. Of course, the theorem holds for the usual classes of languagesfrom the Chomsky hierarchy.
16.2.2.2 Identification in the Limit with Probability One
Let us suppose that we have a distribution over the set !" of all strings. If we canidentify this distribution, we can predict the next string, or the next symbol in a string.For this, we need to extend the results of identification in the limit to the probabilis-tic case. In this case, we assume that the distributions are generated by probabilisticmachines (Vidal et al., 2005).
In the framework of identification in the limit with probability one, the learner isgiven an increasing sequence of strings and identification can only be avoided fora finite period of time. Just like in the case of identification in the limit, the actualmoment at which identification will be achieved is usually not guaranteed.
The analysis in this setting of the well-known algorithm Alergia is given inCarrasco and Oncina (1999). A variety of alternative settings are scrutinized by de laHiguera and Oncina (2004).
16.2.2.3 PAC-Learning
In a probabilistic setting, it is unclear whether we need exact identification. The distri-bution gives us a notion of distance to the target, which can be used to define “not toofar” identification. Since we do not have full control over the sampling process, we

“20-ch16-0765-0780-9780444537263” — 2010/11/29 — 21:08 — page 771 — #7
Computational Language Learning 771
can only hope that in most cases (probably) we will be approximately correct. This isthe PAC (Probably Approximately Correct) framework (Valiant, 1984).
PAC-Learning GrammarsWe suppose there is an unknown distribution under which strings can be sampled.After learning, we hope to end up with an #-good hypothesis:
Definition 16.2.2 (#-good hypothesis). Let G be the target grammar and H be ahypothesis grammar over !. Let D be a distribution over !". For # > 0, H is an#-good hypothesis with respect to G if PrD
$x ! L(G) & L(H)
%' #.
A learning algorithm is now asked to learn a grammar given a confidence parameter$ and an error parameter #. The algorithm must also know an upper bound on the sizeof the target grammar and on the length of the samples.
The model has been adapted by taking into account only certain types of distribu-tions and simple PAC-learning has been considered with more success (Denis et al.,1996).
PAC-Learning DistributionsWhen trying to learn a probabilistic automaton or grammar (instead of a classifier)we require an algorithm that makes an error of less than # with high probability afterseeing just a polynomial number of examples. In this case, the problem is in keep-ing track of #. Typically, one will define a distance over distributions and requirethat the distance between the target and the hypothesis be less than #. Only recently,we have received some insight in the importance of selecting a specific distance. Anexploratory publication on this topic is that of Thollard and Clark (2004).
16.2.2.4 Restrictions
The general setting described in the sections above is close to what has typicallybeen called inductive inference. But if we want to apply the theoretical algorithmsin practice, it is necessary to come up with algorithms whose resources are bounded insome way.
Bounding Quantity of DataEven if an a priori bound on the number of examples needed for a particular learn-ing algorithm to converge is not going to mean anything (remember that we do nothave any control over the sequence of examples) (Pitt, 1989), it is possible to have anoptimistic point of view.
We can bound the size of a set, called the characteristic set, whose presence in thelearning sample ensures identification. It is known that this quantity is polynomial forDFA but not for NFA nor for context-free grammars (de la Higuera, 1997).

“20-ch16-0765-0780-9780444537263” — 2010/11/29 — 21:08 — page 772 — #8
772 Handbook of Logic and Language
Bounding TimeIf we try to bound the overall time, the learning algorithm is only allowed to accessa polynomial number of items of data before returning a correct hypothesis, or tosay that the learner has update polynomial time: constructing Hn = A( fn) requiresO( p(( fn()), where p() is a polynomial.
However, neither definition is entirely convincing. In the first case, since we haveno control over the actual presentation, we cannot avoid the presentation starting withvery long and uninteresting examples. In the second case, Pitt (1989) proves that iden-tification can be postponed in such a way as to make any identification in the limitalgorithm have polynomial update time.
Bounding MemoryPractically speaking it seems to be unreasonable to consider that one should learn andkeep track of all the data. In fact, learning is about generalization, and hence allowsforgetting. The question of studying learners that have access only to their previoushypothesis and to only some of the examples seen up to then has not received sufficientattention. These learners are called memory-limited scientists (Osherson et al., 1997).
Bounding Prediction ErrorsIt is possible to put a bound on the number of times the learning algorithm may outputwrong hypotheses before converging. The algorithm is therefore required to make apolynomial number of implicit prediction errors (IPE), where an implicit predictionerror is made whenever A( fn)1) ! f(n). An algorithm that changes its mind when anewly presented string is in error with respect to the current hypothesis is said to beconsistent.
Identification in IPE-polynomial time of G takes place when there is a learningalgorithm which: 1. identifies G in the limit, 2. has polynomial update time, and 3.makes a polynomial number of implicit prediction errors. Pitt (1989) showed thatDFA could not be identified in IPE-polynomial time.
Bounding Mind ChangesAn alternative to counting the number of errors is that of counting the number ofchanges of hypothesis. In general, there is no reason why change is required, but com-bined with identification in the limit the definition makes sense. A mind change (MC)is made whenever A( fn) *= A( fn)1).
An algorithm that never changes its mind when the current hypothesis is consistentwith the new presented element is said to be conservative.
Algorithm A is said to make a polynomial number of mind changes(MC) if for anypresentation of L = L(G) the number of mind changes is polynomial in (G(, and analgorithm A identifies a class G in the limit in MC-polynomial time if: 1. A identifiesG in the limit, 2. has polynomial update time, and 3. A makes a polynomial numberof mind changes.

“20-ch16-0765-0780-9780444537263” — 2010/11/29 — 21:08 — page 773 — #9
Computational Language Learning 773
16.2.2.5 Real World Evaluation
The evaluation methods described so far assume that the underlying grammar to belearned is known. Learning grammars in a real world setting, where the underlyinggrammar is typically unknown, requires other evaluation techniques.
The evaluation methods can roughly be divided into four groups; van Zaanen(2002, pp. 58–62) describes three of them and van Zaanen et al. (2004) also men-tions the fourth group. Here, we will discuss all groups of evaluation methods in moredetail.
Looks-Good-to-MeIn the looks-good-to-me approach, the output of the GI system is analyzed manually.Since the output of the system can be a fair amount, the analysis often focuses onparticular aspects of the GI system, such as whether recursive structures occur.
This approach has two main advantages. Firstly, only unstructured data is requiredas input, since the structured output is analyzed by hand. This makes it easy to applythe system to different data sets, for example natural language for which no manuallyannotated corpora exist. Secondly, the evaluation can focus on specific structures. Notonly can the output of the GI system be easily searched for in this structure, the inputof the system can be tailored to learning these structures as well.
The main disadvantage of this approach is that it can only provide a useful meansof comparison of systems if the evaluation is performed by an independent expert (orexperts) comparing outputs of rival systems at the same time.
In practice, however, several GI developers have applied the looks-good-to-meevaluation to their own systems, rather than perform objectively quantifiable com-parisons. This gives rise to the name of the approach. Most often, according to thisevaluation method the system seems to perform well.
It has to be noted that human evaluation of output is accepted standard practicein some other fields, for example in machine translation evaluation where a range oftranslations may be equally valid (Elliott et al., 2003).
Rebuilding Known GrammarsIn this evaluation approach, one or more “toy” grammars are selected beforehand.These grammars are most often relatively small and typically have known properties,such as context-freeness. In practice, there are some grammars that are considered“standard” test grammars (Cook et al., 1976; Hopcroft et al., 2001).
Using these grammars sentences are generated, which are then used as input for theGI system. The output of the system (i.e. the grammar or the structured version of theinput) is then compared against the original data or grammar.
There are two ways of testing for grammar equivalence: language equivalence,where the languages of two grammars should be the same, and structural equivalence,where the language as well as the analyzes, modulo the naming of non-terminal typelabels are the same.

“20-ch16-0765-0780-9780444537263” — 2010/11/29 — 21:08 — page 774 — #10
774 Handbook of Logic and Language
Whereas measuring structural equivalence is possible (automatically) by analyzingthe grammar rules, evaluating language equivalence is undecidable. Whereas for finitelanguages all sentences can be generated and compared, this is not possible for infi-nite languages. This also explains scalability problems, resulting in the use of smallartificial grammars.
There are other problems with this approach as well. Firstly, grammars can beselected specifically for the algorithm under consideration, allowing for unfair com-parisons. Secondly, the way strings are generated from the grammar may have aninfluence on the learning as well. Instead of trying to learn the grammar, this mayresult in learning the distribution that is used to generate the strings. From the genera-tion point of view, requirements need to be made as well, for instance at some point allgrammar rules have to be used or it may be necessary to restrict the generation methodto limit the sentence length.
Compare against TreebankThe next approach evaluates GI systems based on information contained in an anno-tated treebank. This treebank is considered a “gold standard” and the full content istaken as correct. To evaluate a system, all structure is stripped from the treebank.The plain strings are given to the GI system and the resulting structures are comparedagainst the gold standard, which measures how well the GI system can find the originalstructure.
The gold standard may contain manually annotated data or structures generatedby a grammar, allowing flexibility in the data or grammars used. Different naturallanguages or data from specific domains can be tested and like “standard” evaluationgrammars, “standard” evaluation treebanks can be designed.
Note that GI systems may need to be adapted to generate structured versions ofthe input sentences. When GI systems output grammars, the test sentences need to beparsed, which may introduce problems when the grammar is ambiguous. Compare thiswith the rebuilding known grammars evaluation approach, where the output of the GIsystem needs to be a grammar.
The main problem with this approach is that a collection of structured sentencesis needed, which may not be a problem when evaluating known grammars, but whenevaluating on natural languages, a treebank will need to be built manually (or semi-automatically).
Language MembershipThis method has been used in GI competitions such as Abbadingo (Lang et al., 1998a),Gowachin, Omphalos (Starkie et al., 2005), and Tenjinno (Starkie et al., 2006).3 GIsystems are tested according to their effectiveness to decide on language membershipof test sentences.4
3 In fact, these competitions only considered the precision metric in this context.4 Implemented as such, no actual learning of a grammar is required. A generic machine learning classifier
may suffice.

“20-ch16-0765-0780-9780444537263” — 2010/11/29 — 21:08 — page 775 — #11
Computational Language Learning 775
The precision-oriented language membership evaluation method measures theeffectiveness of the system to decide language membership. After training, the GIsystem should decide given a set of sentences which of these are in the language. Theclassifications can be correct (which means that the sentence was classified correctly)or incorrect. Precision is defined as the ratio of correctly classified sentences.
Measuring coverage can be done by generating sentences using the learned gram-mar. This shows how much of the original language is covered by the grammar andhow many sentences outside the language can be generated. It is essential ( just aswith the computation of precision) that the sentences generated are distinct and differ-ent from the sentences in the training data.
Increased precision means that more sentences of the learned language are con-tained in the original language. With perfect precision, all sentences of the learnedlanguage are in the original language. Conversely, increasing recall means more sen-tences in the original language described by the learned language. Perfect recall occurswhen all sentences of the target language are in the learned language.
Another metric, which can be used to describe the descriptive power of grammars,or language models in general, is perplexity. The perplexity of a string a1 . . . an iscomputed as 2H with H being entropy H = )
!ni=1
P(ai) log2 P(ai)n . This measures
how well the probability distribution P, defined by the language model, predicts theelements in the string. Lower perplexity means that fewer bits are needed to describethe sequence.
16.3 Paradigms
Over the years different language learning approaches have been investigated. Theseapproaches can be roughly divided into three different paradigms. The first twoparadigms (state-merging and substitutability) start with a simple structure describingthe samples and then use different approaches to generalize the structure. The thirdparadigm (counting) fixes the structure first and then learns weights on parts of thestructure.
16.3.1 State-Merging
State-merging algorithms start by building tree-like automata based on the trainingdata. Next, pairs of states are chosen and a compatibility test is performed. Two statesare compatible when merging them into a unique state results in a better automaton,i.e. consistent with the data and/or with some extra combinatorial properties. Sincestate merging can lead to non-determinism, more node merges, or a folding operation,might be needed.
The crucial issue is how to choose the pairs to be tested, and, when various mergesare possible, how to find the best one. Evidence-driven methods (Lang et al., 1998b)use the quantity of resulting merges for this.

“20-ch16-0765-0780-9780444537263” — 2010/11/29 — 21:08 — page 776 — #12
776 Handbook of Logic and Language
State-merging algorithms have been used to learn finite state automata andextensions of these algorithms for probabilistic automata (Carrasco and Oncina, 1994),Büchi automata (de la Higuera and Janodet, 2004), or transducers (Castellanos et al.,1998) have been proposed.
16.3.2 Substitutability
The idea behind substitutability-based approaches is that when substrings occur in thesame context, they have properties in common. Such substrings are therefore com-bined in a cluster, which is denoted by a non-terminal.
Essentially, the idea is that substitutability is derived from Harris (1951), whostates: “If [elements] are freely substitutable for each other they are descriptively equi-valent, in that everything we henceforth say about one of them will be equally appli-cable to the others.” Harris also explains how substitutable elements can be found,which comes down to: unequal parts are substitutable.
More formally, consider two strings w = lur and x = lvr. Applying substitutabilityresults in w = l(u)Xr and x = l(v)Xr. The evidence in the form of the strings leads tothe assumption that both u and v can be generated from an underlying non-terminal X,which is used in the context of l and r. It may be clear that the idea of substitutability,as shown in these strings, can be generalized with multiple substitution in one pair ofstrings.
Alignment-Based Learning (ABL) (van Zaanen, 2000, 2002) makes direct use ofthe idea of substitutability. Comparing natural language sentences pair-wise, struc-ture is learned. A more efficient implementation based on suffix-trees is proposedin Geertzen and van Zaanen (2004). A similar system, EMILE, finds more structureby replacing all occurrences of substrings that have been grouped together with thecorresponding non-terminal (Adriaans, 1992). More recently, the idea of substitutabil-ity has also led to formal proofs of learnability (Clark and Eyraud, 2007; Yoshinaka,2008).
16.3.3 Counting
In contrast to the approaches discussed so far, we are often not necessarily concernedwith the exact underlying structure. Instead, we would only like to know whetherstrings are elements of the language or not. To decide this, the shape of the structureis irrelevant.
There are several approaches that, instead of learning the structure, fix a struc-ture beforehand and estimate probabilities on the structure. Well-known examplesare the Baum–Welch algorithm, which finds unknown parameters of Hidden-MarkovModels (Baum et al., 1970). This algorithm is a generalized version of the Expec-tation Maximization algorithm (Dempster et al., 1977). A similar algorithm, whichcan be used to estimate probabilities in a probabilistic context-free grammar is theInside Outside algorithm (Lari and Young, 1991). More recently, another approach

“20-ch16-0765-0780-9780444537263” — 2010/11/29 — 21:08 — page 777 — #13
Computational Language Learning 777
has been investigated, taking many possible (sub)structures concurrently into accountand allowing statistics to select preferred structures (Bod, 2006).
16.4 Conclusion
The research performed in the area of formal learning theory deals with learning com-pact representations of languages. This can be tackled from many different points ofview. Depending on specific settings, one may wonder whether a particular class oflanguages can be learned efficiently. We recognize different means of measure successwhich all lead to different learnability results.
In addition to the different settings and parameters, there is the dimension ofparadigms. Many different approaches to language learning have been proposed.
In this chapter we have provided an overview of the most well-known settings andparadigms. This should provide enough information for people to investigate in moredetail the existing literature on language learning in this field and related fields, suchas computational linguistics, computational biology, or pattern recognition.
References
Adriaans, P., 1992. Language Learning from a Categorial Perspective. PhD thesis, Universityof Amsterdam, Amsterdam.
Angluin, D., 1981. A note on the number of queries needed to identify regular languages.Inform. Control 51, 76–87.
Angluin, D., 1987. Queries and concept learning. J. Mach. Learn. 2, 319–342.Angluin, D., 2004. Queries revisited. Theor. Comput. Sci. 313 (2), 175–194.Baum, L.E., Petrie, T., Soules, G., Weiss, N., 1970. A maximization technique occurring in
the statistical analysis of probabilistic functions of Markov chains. Ann. Math. Stat. 41,164–171.
Becerra-Bonache, L., dela Higuera, C., Janodet, J.C., Tantini, F., 2008. Learning balls of stringsfrom edit corrections. J. Mach. Learn. Res. 9, 1841–1870.
Becerra-Bonache, L., Yokomori, T., 2004. Learning mild context-sensitiveness: toward under-standing children’s language learning, in: Paliouras, G., Sakakibara, Y. (Eds.), GrammaticalInference: Algorithms and Applications. Springer-Verlag, Heidelberg, pp. 53–64.
Bod, R., 2006. Unsupervised parsing with u-dop. CoNLL-X ’06: Proceedings of the TenthConference on Computational Natural Language Learning. Association for ComputationalLinguistics, June 8–9, Morristown, NJ, pp. 85–92.
Brazma, A., Jonassen, I., Vilo, J., Ukkonen, E., 1998. Pattern discovery in biosequences, in:Honavar, V., Slutski, G. (Eds.), Grammatical Inference, Proceedings of ICGI ’98, number1433 in LNAI. Springer-Verlag, Berlin, pp. 257–270.
Carrasco, R.C., Oncina, J., 1994. Learning stochastic regular grammars by means of astate merging method, in: Carrasco, R.C., Oncina, J. (Eds.), Grammatical Inference andApplications, Proceedings of ICGI ’94, number 862 in LNAI. Springer-Verlag, Berlin,pp. 139–150.

“20-ch16-0765-0780-9780444537263” — 2010/11/29 — 21:08 — page 778 — #14
778 Handbook of Logic and Language
Carrasco, R.C., Oncina, J., 1999. Learning deterministic regular grammars from stochastic sam-ples in polynomial time. RAIRO (Theoretical Informatics and Applications) 33 (1), 1–20.
Castellanos, A., Vidal, E., Varó, M.A., Oncina, J., 1998. Language understanding andsubsequential transducer learning. Comput. Speech and Lang. 12, 193–228, Elsevier,Amsterdam.
Chomsky, N., 1955. The Logical Structure of Linguistic Theory. PhD thesis, MassachusettsInstitute of Technology, Plenum, New York, NY.
Clark, A., Eyraud, R., 2007. Polynomial identification in the limit of substitutable context-freelanguages. J. Mach. Learn. Res. 8, 1725–1745.
Cook, C.M., Rosenfeld, A., Aronson, A.R., 1976. Grammatical inference by hill climbing. Inf.Sci. 10, 59–80.
de la Higuera, C., 1997. Characteristic sets for polynomial grammatical inference. J. Mach.Learn. 27, 125–138.
de la Higuera, C., 2005. A bibliographical study of grammatical inference. Pattern Recognit.38, 1332–1348.
de la Higuera, C., 2006. Data complexity issues in grammatical inference, in: Basu, M.,Ho, T.K. (Eds.), Data Complexity in Pattern Recognition. Springer-Verlag, Berlin,pp. 153–172.
de la Higuera, C., Janodet, J.-C., 2004. Inference of %-languages from prefixes. Theor. Comput.Sci. 313 (2), 295–312.
de la Higuera, C., Oncina, J., 2004. Learning probabilistic finite automata, in: Paliouras, G.,Sakakibara, Y. (Eds.), Grammatical Inference: Algorithms and Applications. Springer-Verlag, Berlin, pp. 175–186.
Dempster, A., Laird, N., Rubin, D., 1977. Maximum likelihood from incomplete data via theem algorithm. J. R. Stat. Soc. Series B (Methodological) 39 (1), 1–38.
Denis, F., d’Halluin, C., Gilleron, R., 1996. PAC learning with simple examples, in: 13th Sym-posium on Theoretical Aspects of Computer Science, STACS ’96, LNCS, Springer, Berlin,pp. 231–242.
Elliott, D., Hartley, A., Atwell, E., 2003. Rationale for a multilingual aligned corpus for machinetranslation evaluation, in: Archer, D., Rayson, P., Wilson, A., McEnery, T. (Eds.), Proceed-ings of the Corpus Linguistics 2003 conference, March 28–31. UCREL technical papernumber 16. UCREL, Lancaster University, UK. ISBN 1-86220-131-5.
Fu, K.S., 1974. Syntactic Methods in Pattern Recognition. Academic Press, New York.Fu, K.S., Booth, T.L., 1975. Grammatical inference: introduction and survey. Part I and II. IEEE
Trans. Syst. Man Cybern. 5, 59–72; 409–423.Geertzen, J., van Zaanen, M., 2004. Grammatical inference using suffix trees, in: Paliouras, G.,
Sakakibara, Y. (Eds.), Grammatical Inference: Algorithms and Applications. Springer-Verlag, Berlin, pp. 163–174.
Gold, E.M., 1967. Language identification in the limit. Inform. Control 10 (5), 447–474.Gold, E.M., 1978. Complexity of automaton identification from given data. Inform. Control 37,
302–320.Harris, Z.S., 1951. Structural Linguistics. University of Chicago Press, Chicago, IL, and
London, 7th (1966) edition. Formerly Entitled: Methods in Structural Linguistics.Honavar, V., Slutski, G. (Eds.), 1998. Grammatical Inference, Proceedings of ICGI ’98, num-
ber 1433 in LNAI. Learning Stochastic Finite Automata for Musical Style Recognition,Springer-Verlag, Berlin, pp. 211–222.

“20-ch16-0765-0780-9780444537263” — 2010/11/29 — 21:08 — page 779 — #15
Computational Language Learning 779
Hopcroft, J.E., Motwani, R., Ullman, J.D., 2001. Introduction to Automata Theory, Languages,and Computation. Addison-Wesley Publishing Company, Reading, MA.
Horning, J.J., 1969. A Study of Grammatical Inference. PhD thesis, Stanford University,Stanford, CA.
Kanazawa, M., 1998. Learnable Classes of Categorial Grammars. CSLI Publications,Stanford, CA.
Lang, K., Pearlmutter, B.A., Coste, F., 1998a. The Gowachin Automata Learning Competition,http://www.irisa.fr/Gowachin.
Lang, K.J., Pearlmutter, B.A., Price, R.A., 1998b. Results of the Abbadingo one DFA learn-ing competition and a new evidence-driven state merging algorithm, in: Honavar, V.,Slutski, G. (Eds.), Grammatical Inference, Proceedings of ICGI ’98, number 1433 in LNAI.Springer-Verlag, the Netherlands, pp. 1–12.
Lari, K., Young, S.J., 1991. Applications of stochastic context-free grammars using the inside-outside algorithm. Comput. Speech Lang. 5, 237–257.
Osherson, D., deJongh, D., Martin, E., Weinstein, S., 1997. Handbook of Logic and Language,Chapter Formal Learning Theory. MIT Press, Cambridge, MA, pp. 737–775.
Paliouras, G., Sakakibara, Y. (Eds.), 2004. Grammatical Inference: Algorithms and Applica-tions, Proceedings of ICGI ’04, vol. 3264 of LNAI. Springer-Verlag, Berlin.
Pitt, L., 1989. Inductive inference, DFA’s, and computational complexity, in: Analogical andInductive Inference, number 397 in LNAI. Springer-Verlag, Berlin, pp. 18–44.
Pitt, L., Warmuth, M., 1993. The minimum consistent DFA problem cannot be approximatedwithin any polynomial. J. ACM 40 (1), 95–142.
Sakakibara, Y., 1997. Recent advances of grammatical inference. Theor. Comput. Sci. 185,15–45.
Sakakibara, Y., Kobayashi, S., Sato, K., Nishino, T., Tomita, E. (Eds.), 2006. Grammatical Infer-ence: Algorithms and Applications, Proceedings of ICGI ’06, vol. 4201 of LNAI. Springer-Verlag, Berlin.
Sokolov, J.K., Snow, C.E., 1994. The changing role of negative evidence in theories of languagedevelopment, in: Gallaway, C., Richards, B.J. (Eds.), Input and Interaction in LanguageAcquisition. Cambridge University Press, Cambridge, UK, pp. 38–55.
Solomonoff, R., 1964. A formal theory of inductive inference. Inform. Control 7 (1), 1–22;224–254.
Starkie, B., Coste, F., van Zaanen, M., 2005. Progressing the state-of-the-art in grammaticalinference by competition. AI Commun. 18 (2), 93–115.
Starkie, B., van Zaanen, M., Estival, D., 2006. The Tenjinno machine translation competi-tion, in: Sakakibara et al. (Eds.), Grammatical Inference: Algorithms and Applications.Springer-Verlag, pp. 214–226.
Tantini, F., dela Higuera, C., Janodet, J.-C., 2006. Identification in the limit of systematic-noisylanguages, in: Sakakibara et al. (Eds.), Grammatical Inference: Algorithms and Applica-tions. Springer-Verlag, pp. 19–31.
Thollard, F., Clark, A., 2004. PAC-learnability of probabilistic deterministic finite stateautomata. J. Mach. Learn. Res. 5, 473–497.
Valiant, L.G., 1984. A theory of the learnable. Commun. ACM 27 (11), 1134–1142.van Zaanen, M., 2000. ABL: Alignment-Based Learning, in: Proceedings of the 18th Inter-
national Conference on Computational Linguistics (COLING); Association for Computa-tional Linguistics. Saarbrücken, Germany, pp. 961–967.

“20-ch16-0765-0780-9780444537263” — 2010/11/29 — 21:08 — page 780 — #16
780 Handbook of Logic and Language
van Zaanen, M., 2002. Bootstrapping Structure into Language: Alignment-Based Learning. PhDthesis, University of Leeds, Leeds, UK.
van Zaanen, M., Roberts, A., Atwell, E., 2004. A multilingual parallel parsed corpus asgold standard for grammatical inference evaluation, in: Kranias, L., Calzolari, N.,Thurmair, G., Wilks, Y., Hovy, E., Magnusdottir, G., et al. (Eds.), Proceedings of theWorkshop: The Amazing Utility of Parallel and Comparable Corpora. Lisbon, Portugal,pp. 58–61.
Vidal, E., Thollard, F., dela Higuera, C., Casacuberta, F., Carrasco, R.C., 2005. Probabilis-tic finite state automata – part I and II. Pattern Anal. Mach. Intell. 27 (7), 1013–1025;1026–1039.
Wolff, J.G., 2006. Unifying Computing and Cognition. CognitionResearch.org.uk, MenaiBridge, UK. This is an ebook.
Yoshinaka, R., 2008. Identification in the limit of k, l-substitutable context-free languages, in:Clark, A., Coste, F., Miclet, L. (Eds.), Grammatical Inference: Algorithms and Applica-tions, Proceedings of ICGI ’08, vol. 5278 of LNCS. Springer-Verlag, the Netherlands,pp. 266–279.

“21-ch17-0781-0838-9780444537263” — 2010/11/30 — 3:44 — page 781 — #1
17 Non-monotonicity in LinguisticsRichmond H. ThomasonDepartment of Philosophy, University of Michigan, Ann Arbor, MI48109-1003, USA, E-mail: [email protected]
17.1 Non-monotonicity and Linguistic Theory
Unlike many other chapters of this Handbook, this contribution is more an intimationof new opportunities than a survey of completed developments. Fulfilling the promiseof these opportunities will require the creation of a group of theoretical linguists whoare also familiar with some of the details of a complex and often bewildering newarea of logic. I will try to provide an outline of the logical issues, with pointers to theliterature, to indicate some of the applications in linguistics, and to provide referencesto the work that has already been done in applying nonmonotonic logic in linguistics.1
17.1.1 Monotonicity and Non-monotonicity are Properties of LogicalConsequence
Associated with any logic there is a consequence relation !, between sets of formulasand formulas. Interpreted proof theoretically, ! ! A means that there is a hypotheticalproof, or deduction, of A from !. Interpreted model theoretically, ! ! A means that Ais true in every model of !.
Some properties of the logical consequence relation will vary from logic to logic:
{A " B, ¬A " B} ! B,
for instance, will hold in Boolean logics, but not in constructive logics, such as intu-itionistic logic. Other properties of logical consequence relations seem very basic, andhold quite generally. Among these very general properties is monotonicity:
If ! ! B then ! # {A} ! B.
1 I will try to make information on the topics discussed in this chapter available through the World WideWeb and anonymous ftp; this seems to be the best way to deal with changes in this rapidly develop-ing field. My current e-mail and World Wide Web addresses are [email protected] and http://www.pitt.edu/˜thomason/thomason.html.
Handbook of Logic and Language. DOI: 10.1016/B978-0-444-53726-3.00017-7c$ 2011 Elsevier B.V. All rights reserved.

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 782 — #2
782 Handbook of Logic and Language
This property says that the logical consequences of a set of hypotheses grow mono-tonically in relation to the hypotheses; in other words, adding new information A tothe hypotheses ! can’t result in the retraction of any consequence B.
The monotonicity property follows trivially from the definitions of provability andvalidity that are used in familiar systems of logic. Proof theoretically, we use the factthat mathematical proofs only depend on the presence of information, and are notsensitive to its absence: if P is a proof relative to a set ! of hypotheses, then P is alsoa proof relative to any larger set ! !". Model theoretically, we use the fact that everymodel of ! ! " is also a model of !.
Non-monotonicity is simply the failure of monotonicity. So non-monotonicity is aproperty of the consequence relation – and a system of logic is said to be nonmono-tonic if its consequence relation has the non-monotonicity property. Non-monotonicityis intimately connected with default inferences. Suppose we want to infer B unless Ais known, and that ! does not entail A. If we elect to satisfy this need by altering thelogical consequence relation, we then have a failure of monotonicity: we would have! " B, but not ! ! {A} " B.
17.1.2 Motivating Non-monotonicity
Although defaults are a part of life, we are supposed to avoid them in mathematics (andin theoretical science in general). The standards for mathematical proof are designedso that what is proven will never need to be retracted under any possible assumptions.Mathematicians are trained not to claim theorems until their proofs have covered allthe possible cases; any exceptional cases in which the result does not hold have to beformulated and explicitly excluded in the statement of the theorem. In retrospect, wecan see the fundamental status of monotonicity in symbolic logic as a byproduct ofthe early emphasis in symbolic logic on mathematical reasoning.
The need to formulate and investigate nonmonotonic logics arose out of a recog-nition that other forms of reasoning are not always subject to this constraint, togetherwith a reluctance to explain away the nonmonotonic effects by using mechanisms,such as probability, that are orthogonal to logical consequence. Most of the recentmotivation for this work has been associated with research programs in Artificial Intel-ligence (AI) that stress the importance of formalizing common sense reasoning,2 andthat seek to apply logical techniques to formalize the knowledge involved in reasoningtasks like planning and problem solving.
Closed world reasoning provides a simple example of the need for non-monotonicity, and still may remain the most widespread application of nonmonotonicreasoning. This type of reasoning arises whenever we think that we have been givencomplete information on a given topic. In such cases, we are willing to answer “no”to a question on a topic when we fail to find a reason for it in our data.3
2 See Hobbs and Moore (1985).3 In the simplest form of closed world reasoning, these “questions” will correspond to positive and negative
literals.

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 783 — #3
Non-monotonicity in Linguistics 783
In planning my time, for instance, I may carefully write down all my appointmentsand deadlines in a calendar. But no matter how meticulous I am, I won’t try to enter allthe things that I don’t have to do. I take this information to be implicit in my calendar;I infer that I don’t have an appointment at 1 pm today by noticing that there is noappointment entered for 1 pm in my calendar. This “closed-world” inference makesthe calendar’s consequence relation |# nonmonotonic.4 If T is my current calendarand A is “Dentist appointment at 1 pm”, we have T |# ¬A. But we do not want tohave T ! {A} $|# ¬A. When the hypothesis is added that I have a dentist appointmentat 1pm, it would of course be wrong to continue to infer that I don’t have a dentistappointment at that time.
17.1.3 Non-monotonicity and Linguistics
The origins of nonmonotonic logics in AI share a motive with a research tradition thatattempts to see linguistic meaning as a systematic source of insights into thought andreasoning. This tradition goes back at least to Wilhelm von Humboldt’s work in thenineteenth century; it continued into this century with linguists such as Otto Jespersenand philosophers such as Ernst Cassirer. More recent linguistic work attempts to linkthis tradition to formal logic.5 Because the projects of formalizing basic areas of com-mon sense reasoning and of providing logical tools for interpreting natural languageare so closely related, this is perhaps the most obvious application for nonmonotoniclogics in linguistic theory, and there is a growing body of work in linguistic seman-tics that makes use of nonmonotonic logic. The matter is pursued in Section 17.7,below.
But the relations between nonmonotonic logic and linguistic theory are much morepervasive than this; non-monotonicity can be recognized in many areas of linguisticresearch that have little or nothing to do either with meaning or common sense. Everyarea of linguistics encounters generalizations that have exceptions. As long as linguis-tic theory lacks direct a way to represent such generalizations, they can’t be expressedin the theories that explain them. In practice, this often means that the generalizationsare saved by ad hoc maneuvers.
Most of the available applications of non-monotonicity in linguistics have beendeveloped by computer scientists, or by linguists with computational interests. See, forinstance, Gazdar (1987) for an excellent survey of applications of default reasoningin various areas of linguistics; Gazdar has also played a central part in the develop-ment of datr, a system for representing morphological information that makes use ofdefaults.6 For a more recent general paper exploring these applications, see Briscoe,Copestake and Lascarides (1995). There is a fairly extensive literature devoted tomotivating uses of defaults and nonmonotonic reasoning in reasoning about lexical
4 Here we follow the common practice of using |# for nonmonotonic consequence.5 Much of the work in Montague grammar has this goal; see Bach (1989) for a good general work that is
explicit about this motivation for “natural language metaphysics”.6 See Evans and Gazdar (1989a,b, 1990) and Evans, Gazdar and Moser (1994).

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 784 — #4
784 Handbook of Logic and Language
information and describing systems that use this sort of information in managingthe lexicon. For instance, see Shieber (1986), Daelemans (1987a), Flickinger (1987),Boguraev and Pustejovsky (1990), De Smedt (1990), Russell, Carroll and Warwick(1991), Flickinger and Nerbonne (1992), Briscoe, De Paiva and Copestake (1993),and Krieger and Nerbonne (1993).
But I think that the computational slant of much of this work is accidental. It mayhave more to do with the fact that computational linguists are less bound to traditionallinguistic theory, and are more likely to be familiar with the new logical formalisms,than with any intrinsic connection between computation and defeasible theories oflanguage. (Indeed, nonmonotonic logic has been used so far more as a theoretical thanan applied tool.)
This chapter will not exclude computational applications, but it is also meant tomake a case for a more radical suggestion: that nonmonotonic logics are not onlyuseful for representing common sense reasoning, but also provide appropriate foun-dations for some scientific theories, and in particular for linguistics.
The claim that some sciences study exceptionless rules, while others must dealwith rules that have exceptions, goes back to Aristotle’s works in the methodology ofscience. But Aristotle placed the latter sciences in a vulnerable position by failing toprovide any logical foundation for them, and by basing the separation between the twoon a false cosmology. Now, we may be in a better position to articulate a science thatdeals with defeasible rules. The nonmonotonic logics provide the missing foundation,and linguistics gives us a well developed theoretical domain that is rich in defeasiblerules. The larger project is challenging: the logics are complex and diverse, there aremethodological problems,7 and the sheer size of the project is frightening. But it isa tremendous opportunity for a strategic innovation in scientific methodology. Thislarger project is certainly not going to be much advanced without strong motivationswithin the discipline, so in the remainder of this chapter I will concentrate on casestudies that provide the motivation.
17.2 Overview of Nonmonotonic Reasoning
Let me explain my expository predicament. Many readers of this Handbook willnot be familiar with nonmonotonic logic. But (due mainly to intensive work bylogically minded researchers in AI) the technical dimension of the topic has maturedrapidly – without, however, generating any consensus on a single approach. I will nottry here to provide even a barely adequate technical introduction to this area; instead,I will sketch a map, with pointers to the literature. What follows is not really an ade-quate introduction to the theory of nonmonotonic reasoning. I tried to produce a guide,with references to the places where a more adequate introduction can be found.
As usual with any new field, it is hard to avoid consulting the primary researcharticles. But readers who want a more systematic general introduction to the topic
7 See Section 17.5.1, below, for a discussion of some of these.

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 785 — #5
Non-monotonicity in Linguistics 785
could consult Ginsberg (1988a), Besnard (1989), Brewka (1991), or Davis (1990,Section 3.1). Reiter (1988) provides a briefer overview.8
The only specific approach to nonmonotonic logic that I will discuss in any detailis Reiter’s default logic.
17.2.1 Default Logic
This approach, due to Raymond Reiter (see Reiter, 1980) is relatively conservativefrom a logical standpoint and yet exemplifies many of the themes of nonmonotoniclogic. Therefore it can be used as an model for illustrating the features and problemsof this area of logic. That is what I will try to do in this section. But default logic isimportant in its own right, and represents one of the better developed areas in non-monotonic logic. The introduction that follows will orient readers to the ideas, I hope,but will not begin to develop technical details. For these details, readers may want toconsult Reiter (1980), Besnard (1989), Brewka (1991, Chapter 3), and the referencesfrom the last two of these.
17.2.1.1 Elements of Default Logic
A default theory is formed, according to Reiter, by adding new rules of inference,called default rules, to a first-order theory. These rules have the form
A : BC
, where A, B, and C are ordinary first-order formulas. (17.1)
The informal interpretation of such a rule is that C can be concluded provided A hasbeen concluded and B can be consistently assumed. Thus, if B is a tautology, such adefault rule specializes to a familiar monotonic rule with premiss A and conclusion C.
Defaults are not first-class citizens of default logic: they appear only as rules, not asformulas that enter into logical constructions or can themselves enter into inferentialrelations. Thus, it makes no sense in default logic to negate a default, to conjoin it withsomething, or to ask what defaults follow from a given default theory. There is onestriking disadvantage to this limitation. Almost all useful default rules are general, andone wants to capture this generality using a universal quantifier. But it is illegitimateto write things like (%x) [Bird(x) : Flies(x)/Flies(x)].9
So default logic doesn’t provide a direct way of capturing the rule that birds fly –everyone’s stock example of a default. This limitation can be circumvented by treatingBird(x) : Flies(x)/Flies(x) as an abbreviation for a rule scheme, the set of all defaultsof the form Bird(t) : Flies(t)/Flies(t), where t is any closed term. In many papers on
8 Ginsberg (1988a) is a collection of early articles in the area. Ginsberg’s introduction to the volume remainsone of the best ways to become better acquainted with the subject. Its readability and coverage make upfor the fact that it is now somewhat out of date. A recent general work (Brewka, 1991), covers most of thetopics that would be of importance to those interested in linguistic applications. I recommend these twogeneral introductions. And see below for references to more specialized sources.
9 We will often write defaults in this linear notation.

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 786 — #6
786 Handbook of Logic and Language
default logic and similar topics, the authors speak as if defaults involved predicatesrather than closed formulas; this way of speaking has to be understood as an appeal tothis schematic device.
The special case
A : BB
(17.2)
where B and C are identified, which is called a normal default, is particularly impor-tant: this amounts to concluding B by default on condition A. It may well be that allthe applications of default logic that might be valuable in linguistics would involveonly normal defaults; if so, this would be very pleasant, since these defaults constitutea special case that is better behaved in many ways than the general one where arbitrarydefault rules are allowed.
We can think of a default theory, then, as a pair &T, D', where T is a first ordertheory and D is a set of default rules. The novel logical component is D; what is newhere is the dependency of these rules not only on the provability of certain formulasbut on the nonprovability of others. (To say that B can be consistently assumed is tosay that ¬B is not provable.)
The generalization may seem straightforward at first glance, but on closer exam-ination the motivating idea contains a circularity. Provability depends on the notionof a correct proof; a proof is a series of steps in which the rules have been correctlyapplied; but in order to tell if a rule has been correctly applied we have to alreadyknow what is provable in order to apply consistency tests.
In monotonic logics, this same circularity is present: to proceed from A to B in aproof, A must be provable. Here the circularity is so harmless that it is hardly notice-able; it is removed by a simple recursion on length of proof. But if proofs are genera-lized to depend on nonprovability, it is not so easy to banish the circularity. A closeranalysis of the logical situation shows that in this more general case we will haveto make several changes, which taken together represent fairly fundamental depar-tures from the classical idea of logical consequence: (1) we can’t expect constructiveaccounts of proof, except in some special cases, (2) we must give up the determinismof monotonic logic, and replace it with the idea that a theory can support different butmutually exclusive choices of appropriate conclusions, (3) we have to be prepared tofind that some theories are incoherent, in that they allow no coherent conclusion setsto be derived.
The first point should be surprising to those who thought that nonmonotonic reason-ing was motivated by a need for efficient reasoning. Readers who have this impres-sion may want to glance again at the earlier motivation for nonmonotonic logic inSection 17.1.2. I tried there to provide reasons having to do with the need for naturalrepresentations and appropriate reasoning. These reasons are independent of efficiencyconsiderations. I believe that it is best to think of nonmonotonic formalisms as logicalspecifications of valid reasoning. As in most other areas of AI, one has to be cau-tious in making cognitive claims about these formalisms, and it may be necessary tointroduce heuristics or approximations if efficient implementations are wanted. From

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 787 — #7
Non-monotonicity in Linguistics 787
a logical standpoint, the nonconstructivity of nonmonotonic logics is not a novelty;nonconstructivity is also a feature of monotonic higher-order logics. But the otherpeculiarities of nonmonotonic logic require a more profound rearrangement of ourlogical expectations.
The second point is illustrated by a famous example of Reiter’s, in which defaultsconflict: we have the following two default rules, which say that if Nixon is a Quakerhe is a pacifist and if Nixon is a Republican he is not a pacifist. And our monotonicaxioms tell us that Nixon is a Quaker and a Republican.
D1 =!
Quaker(n) : Pacifist(n)
Pacifist(n),
Republican(n) : ¬Pacifist(n)
¬Pacifist(n)
",
T1 = {Republican(n) ( Quaker(n)}.
It’s important to realize that the potentiality for cases like this does not mean that thetheories that produce the conflicts are incoherent or inadequate in any way. The exam-ple is chosen to make this clear; the defaults it contains are perfectly plausible. On anybroad interpretation of defaults – as norms or as generally reliable rules – we can’trequire that when a system of defaults contains potentially conflicting conclusions tobe drawn, we will never encounter cases in which the conflicting rules are applicable.Even when we attempt to reduce conflicts between rules by some sort of scheme thatassigns priorities to defaults, we can’t be sure that conflicts will never arise. Of course,a default theory might be so full of spurious conflicts that it is unusable; but even thenit will not be strictly inconsistent.
When conflicts arise that cannot be resolved in any principled way, the conflictingconclusions are equally reasonable. It is very natural in these cases to say that bothchoices represent correct ways of drawing conclusions from the theory. This makesthe relation of logical consequence nondeterministic, and requires us to associate mul-tiple, competing conclusion sets with a default theory. Reiter calls these conclusionsets extensions. It’s helpful to think of the resulting account of logical consequence asa generalization of proof theory. In monotonic proof theory, proofs are central: takingtogether the conclusions of all the proofs produces the set of consequences. In defaultlogic, we have to somehow characterize the conditions under which proofs are mutu-ally coherent, in that they represent the same choices of competing defaults. We thendefine an extension by taking the conclusions of a coherent family of proofs.10
We want to say that two proofs are mutually coherent if a single policy is exercisedthroughout both. We represent this idea of a policy by imagining that, prior to the proofprocess, we have guessed at the conclusions we want to draw; we choose a logicallyclosed set E) of formulas to guide the consistency judgments that are required when adefault rule is applied. In effect, we are guessing at the results of our proof procedurebefore we apply it, and are using this guess to guide our application of default rules.
10 Those familiar with the details of default logic will realize that I am not using Reiter’s original defini-tion here, but am referring to an early theorem characterizing extensions. This characterizing theorem,I believe, is easier to relate directly to intuitions about consequence, and I prefer to work with it.

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 788 — #8
788 Handbook of Logic and Language
We can now define the set NM-Proofs(D, T, E)) of proofs that are generated by adefault theory &D, T' and policy set E). First, some notation: where T is a first ordertheory, M-Theorems(T) is the set of first order consequences of T .
Definition 17.2.1. (NM-Proofs(D, T, E)))
(1) & ' * NM-Proofs(D, T, E)).(2) If &A0, . . . , An' * NM-Proofs(D, T, E)), then
&A0, . . . , An, An+1' * NM-Proofs(D, T, E)),where An+1 * M-Theorems(T ! {A0, . . . , An}).
(3) If &A0, . . . , An' * NM-Proofs(D, T, E)), then&A0, . . . , An, An+1' * NM-Proofs(D, T, E)),where for some B and some i + n, Ai : B/An+1 * D and ¬B /* E).
Clause (1) of this definition initializes the E)-proofs by admitting the emptysequence as a proof. Clauses (2) and (3) allow E)-proofs to be extended by rules ofproof: Clause (2) provides for monotonic consequence, and Clause (3) allows closureunder defaults that are compatible with the policy E).
The set NM-Theorems(D, T, E)) of theorems that result from such a coherent setof proofs is – just as in classical logic – the set of provable formulas. (But in this casethe proofs are relativized to a single policy.)
Definition 17.2.2. (NM-Theorems(D, T, E))) NM-Theorems(D, T, E)) =#
{A : Aoccurs in some P * NM-Proofs(D, T, E))}.
Not every set of theorems that results from guessing an E) will correspond to anextension: our guess may be incorrect! This can happen in two ways: E) may be toosmall; it may fail to contain consequences that follow legitimately from &T, D'. Or E)
can be too big: it can contain some of these consequences. In the former case, E) willbe larger than NM-Theorems(D, T, E)), and in the latter case, E) will be smaller thanNM-Theorems(D, T, E)). Thus, we define an extension as a self-proving guess: if youguess it, it then returns itself as a set of theorems.
Definition 17.2.3. (Extension of &T, D') E is an extension of &T, D' if and only ifE = NM-Theorems(D, T, E).
For instance, in the default theory &T1, D1' given above, consider the following setsof formulas.
A = The set of all formulas.
E2 = M-Theorems(T1 ! {Pacifist(n)}).E3 = M-Theorems(T1 ! {¬Pacifist(n)}).
Now, (1) , is not an extension of &T1, D1', because NM-Theorems(T1, D1, ,) = A;, does not provide enough information to prevent both of the incompatible defaults

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 789 — #9
Non-monotonicity in Linguistics 789
from applying. And (2) A is not an extension, since NM-Theorems(T1, D1, A) =M-Theorems(T1); because nothing is consistent with A, this guess blocks every defaultfrom applying. But (3) E2 is an extension, since the only default it licenses is the onewhose conclusion it already contains. And similarly, E3 is also an extension.
In this case, then, though we can’t regard a theory that involves competing defaultsas having a single, determinate set of consequences, we can give an account of multi-ple coherent consequence sets that is a recognizable generalization of the monotonicnotion of consequence. Built into the idea of extension that we have been present-ing here is a credulous approach to reasoning with defaults: the assumption is that anextension should use as many default rules as can consistently be applied.11
In general, we can’t assume that an arbitrary default theory has any extensions atall. This means that some syntactic possibilities may be proof-theoretically incoherent.We won’t provide examples or go into details on this matter: examples and discussioncan be found in Reiter (1980) and Besnard (1989, Section 7.1).
17.2.1.2 Some Refinements of Default Logic
Model theory. There are several ways to provide a model theory for default logic. Themost straightforward method, due to W. !ukaszewicz, associates with a normal default(17.2) a function that takes a set M of first-order models into one of its subsets – theset of models that satisfy the default.12 The extensions of a normal default theory&T, D' are then characterized as limits obtained by applying these functions to the setof models of T .
Another method, due to Kurt Konolige and developed further by others13 yieldsa model theory indirectly, by way of a translation of default logic into autoepistemiclogic. (See Section 17.2.2 for a brief discussion of autoepistemic logic; all that needsto be said now is that this is approach uses modal logic.) The idea is to representa default (17.1) with a modal formula [!A ( -B] . C. The extensions of defaultlogic then correspond to certain strongly grounded expansions of the associated modaltheory. A model theory can now be obtained for default logic by appealing to thepossible-worlds semantics for modal logic.
Konolige’s idea provides a way of converting defaults to first-class logical citi-zens: as we noted, they appear in autoepistemic logic as conditional formulas, such as[!Bird(Tweety) ( -Flies(Tweety)] . !Flies(Tweety). This enables us to examinethe inferential properties of defaults; but unfortunately the results are disappointing.For instance (because of the use of the material conditional in formalizing defaults),(17.2) implies A ( C : B/B. This, of course, seems to undermine the whole idea ofnon-monotonicity. We should probably conclude that default logic is not designed to
11 Another approach to extensions is based on the skeptical idea that it is best to suspend judgment whenpresented with conflicting rules. But the simplest way to implement this skeptical idea is to take theintersection of all credulous extensions; which makes the credulous approach seem more fundamental.
12 M belongs to this subset in case either A is false in some member ofM or B is false in every member ofM, or B is true in M.
13 See Konolige (1988) and Marek and Truszczyński (1989).

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 790 — #10
790 Handbook of Logic and Language
provide an account of the inferential interrelationships among defaults, and this is ref-lected in its modal semantics.
Preferences among defaults. Extensions are treated as equal in default logic; if thisrestriction is taken seriously, any preferences that a reasoner may have among compet-ing defaults have to be treated as extralogical. But in developing realistic applicationsof nonmonotonic logic, one soon discovers a need to express priorities among defaults,so that when a conflict arises one default may override another. Many of these pref-erences have been proposed for various domains; but the single example that is mostimportant for linguistic applications is specificity. According to the specificity crite-rion, when two defaults conflict and one of them is more specific than the other, theformer should override the latter. For normal defaults, the natural criterion of speci-ficity is this: A : B/B is more specific than A/ : B//B/ in the context of a default theory&T, D' if A is a logical consequence of T ! {A/}.
The stock example of specificity is Tweety the penguin. In this example, T consistsof %x[Penguin(x) . Bird(x)] and Penguin(Tweety), and D consists of the two normaldefault schemes
Bird(x) : Flies(x)Flies(x)
andPenguin(x) : ¬Flies(x)
¬Flies(x).
If no principle of specificity is added to the definition of extension, this default the-ory will have two extensions: one in which Tweety flies, and one in which Tweetydoes not. But on the most natural interpretation of the example, the default rulePenguin(x) : ¬Flies(x)/¬Flies(x) is intended to mark an exception to the more gen-eral default Bird(x) : Flies(x)/Flies(x); and on this interpretation, the first extensionis anomalous and unwanted.
One way to introduce priorities into default logic is by iterating the extension con-struction, applying more preferred defaults first. For simplicity, assume that thereare only two rankings for defaults: more preferred (priority 1) and less preferred(priority 2); let D1 be the set of defaults of priority 1 and D2 be the set of defaults ofpriority 2.
Using Definition 17.2.3, construct the set E1 of extensions of &T, D1'. Then,for each E * E1, construct the set EE
1 of extensions of &E, D2'. The collection#{EE
1 : E * E1} is the set of all extensions, subject to the prioritization constraints.14
17.2.2 Autoepistemic Logic
Some of the very earliest work in nonmonotonic logic exploited modal logic.15 Thebasic idea – to use possibility to represent the notion of consistency that is involvedin the application of a default – is very natural. But a clear, straightforward theory didnot emerge until other approaches had been developed.16
14 See Brewka (1993, 1994), and Delgrande and Schaub (1994) for more discussion of prioritized defaults.15 See McDermott and Doyle (1980).16 See Moore (1985), in which the theory is motivated and reformulated; see Konolige (1988) and Levesque
(1990) for refinements and developments.

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 791 — #11
Non-monotonicity in Linguistics 791
The intuitive interpretation of the modal operator ! is belief; and deontic S5 (i.e.the system KD45 of Chellas, 1980, p. 193) is the underlying modal logic. The idea isto represent a default like
(1) ‘Tweety flies if she is a bird’
as
[!Bird(Tweety) ( -Flies(Tweety)] . !Flies(Tweety).
Thus, on this approach, defaults represent constraints on an agent’s beliefs: “If Ibelieve that Tweety is a bird, and have no reason to think that Tweety doesn’t fly,let me believe that Tweety flies”.
So far, there is no non-monotonicity; all this has been carried out in DS5, which isa monotonic logic. Non-monotonicity is introduced by following through on the ideathat we are interested in theories that represent the beliefs of an agent with introspec-tive powers. This means that the propositions in the theory should be beliefs, and thepropositions not in the theory should be nonbeliefs. Thus, a logically closed set ofsentences E is said to be stable if E 0 !E and E 0 ¬!E, where !E = {!A : A * E},¬!E = {¬!A : A * E}, and E is the complement of E.
The stable sets represent the epistemic states of ideal introspective agents. We nowwant to define the states that are justified by a set of premisses T . (Note that T cancontain modal formulas, so that defaults as well as facts are incorporated in the pre-misses; because defaults can conflict, there may be more than one state that is ratio-nally justified by T .) We want to ensure that the only beliefs in this state are onesthat are somehow licensed by T . This is done by letting E be grounded in T if for allA * E, T ! !E ! ¬!E " A; a stable expansion of E is then a stable set that isgrounded in E. Stable expansions play a role in autoepistemic logic that is analogousto that of extensions in default logic.
17.2.3 Circumscription
Circumscription attempts to provide a formalization of nonmonotonic reasoning that isclose to familiar logics. Rather than maximizing conclusions, circumscription aims atminimizing certain semantic values: in particular, the extensions of certain predicates.Minimization constraints on predicates can be expressed in second-order logic: forinstance, let A(p) be a formula containing occurrences of a second-order variable p.We can then express the claim that a one-place predicate P is the smallest possiblepredicate satisfying A(p) as follows:
A(P) ( %p$A(p) .
$%x
$p(x) . P(x)
%. %x
$p(x) 1 P(x)
%%%.
(This says that P satisfies A and any predicate that also satisfies A and is includedin P is equivalent to P.) Thus, second-order logic provides the logical foundation forcircumscription theory.

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 792 — #12
792 Handbook of Logic and Language
In the earliest versions of circumscription, the motivation for minimization was asort of closed world assumption; assume that objects that can’t be inferred from yourdata aren’t there at all. In later versions, certain predicates are listed as abnormali-ties, and these abnormalities are minimized. As abnormalities were used to formalizemore complicated domains, more powerful methods of circumscription were felt to beneeded, and the framework evolved into something much more complex and flexiblethan the original versions.
Though in the usual applications this logic is extensional and only second-order,it is quite easy to generalize the underlying logic for circumscription to Montague’sIntensional Logic. Because it mates well with the higher order semantic apparatus ofMontague Semantics, circumscription may appeal to linguists interested in semanticapplications of nonmonotonic reasoning; in fact, I will use circumscription below inillustrating applications of nonmonotonic logic in lexical semantics.
The following example illustrates the simplest kind of circumscription, “Single-predicate global circumscription”. We consider a theory incorporating the defeasiblerule that birds fly; the theory also contains the claims that Tweety is a bird and Opus isa nonflying bird. To do this, we invoke an abnormality predicate Ab1; we declare thatany nonflying bird has this property; and we then use circumscription to minimize Ab1with respect to the theory. In order to carry out the circumscription, the theory mustbe packed into a single formula; we can only circumscribe theories that are finitelyaxiomatized.
The formula T that axiomatizes the theory is presented as a function T(P1, . . . , Pn)
of its constituent predicates. In our example, T(Ab1, Bird, Flies) is the formula:
%x$$
Bird(x) ( ¬Flies(x)%
. Ab1(x)%
( Bird(Tweety)
( Bird(Opus)
( ¬Flies(Opus)
( ¬Tweety = Opus.
In circumscribing T(Ab1, Bird, Flies), we need to decide what to do with the pred-icates Bird and Flies; do we vary them, or hold them constant? In this case, we get themost natural results by holding Bird constant and allowing Flies to vary; this corre-sponds to the most likely situation, in which we know what the birds are, but are usinga certain amount of guesswork about what things fly. The result of circumscribing Ab1in T , varying Flies and holding Bird constant, is
T(Ab1, Bird, Flies) ( %p, q[T(p, Bird, q) . p $2 Ab1],
where ‘p $2 Ab1’ is short for 3x[p(x) ( ¬Ab1(x)] 4 %x[p(x) 1 Ab1(x)].In many simple cases the circumscribed theory is equivalent to something that
is much easier to understand; our example is equivalent to the result of adding%x[[Bird(x) ( ¬x = Opus] . Flies(x)] to T .

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 793 — #13
Non-monotonicity in Linguistics 793
Model theoretically, circumscription is an operation that takes a theory (which hasmany models) into a circumscribed theory, which in general also will have manymodels. The formulas valid in the circumscribed theory will be those that are truein all of the latter models.
This approach to nonmonotonic logic was developed by John McCarthy;17 muchof the technical work in this area has been carried out by Vladimir Lifschitz.18 Inthe most advanced versions of the theory, Lifschitz introduces a formal frameworkin which circumscriptive policies, especially policies about variation of predicates inminimization, can be expressed.
17.2.4 Model Preference Theories
There is a very direct and natural way to render the model theoretic definition oflogical consequence nonmonotonic. According to this definition, ! implies A whenevery model of ! satisfies A. But to have expectations is to ignore certain models.Therefore, we can represent a nonmonotonic reasoner as a function expected fromsets of models to subsets of these sets (the subsets that are viable after expectationshave ruled some possibilities out). We can then say that a set ! of formulas, withcorresponding set M of models, nonmonotonically implies A when A is satisfied byall models in expected(M).
Yoav Shoham explored this idea, concentrating on the special case in whicha partial ordering is given on models (representing epistemic preferences), andexpected(M) is the set of models that are minimal in M with respect to this order-ing.19 He is able to show that this idea delivers a very general semantical frameworkfor nonmonotonic logic that can account for many of the leading approaches.20
A version of model preference semantics has recently been used to provide aninterpretation of datr, the approach to formalizing morphology and implementingmorphological processing that was mentioned above in Section 17.1.3; see Keller(1995). This semantics is not quite the same as Shoham’s classical version, since italso involves partial models.
Shoham’s ideas should seem familiar to readers who are acquainted with the logicof conditionals, where the idea is to interpret a conditional A > B as true at a world incase A is true at all the “most preferred” worlds at which A is true. Though, of course,models and possible worlds are not the same, and there was much confusion betweenthe two in the early days of modal logic, there are strong analogies – and in particular,it is often possible to build a modal logic that to some extent “reflects” model-theoretic
17 See, for instance, McCarthy (1980).18 See Lifschitz (1986, 1989).19 See Shoham (1988).20 To appeal to preferences among models assumes that some policy has been applied that systematically
resolves conflicts among defaults. Note that this theory delivers a single, unitary notion of logical conse-quence rather than competing families of consequences (or extensions). For this reason, there is no verygood model here of unresolved reasoning conflicts.

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 794 — #14
794 Handbook of Logic and Language
structure. We have already seen one example of this, since autoepistemic logic is justsuch a reflection of default logic.
The model preference theories, then, provide a natural transition to the conditionalapproaches to nonmonotonic logic.
17.2.5 Conditional Theories
I will assume here a general familiarity with the logic of conditionals.A primary purpose of conditional logic, as developed by Robert Stalnaker and
David Lewis, was to provide a logical account that accommodated non-monotonicityin the antecedents of conditionals. This phenomenon is very similar to the ones thatmotivated nonmonotonic logic: consider, for instance, the fact that (2a) does notimply (2b).
(2) a. ‘If I were a bird, I could fly’.b. ‘If I were a penguin, I could fly’.
Despite these similarities, the developers of conditional logic never entertained theidea of making the logical consequence relation nonmonotonic; the conditional logicsare all straightforward versions of modal logic, featuring a connective > in whichA > C does not imply [A ( B] > C. Although in these logics, if {A} " C then{A, B} " C, this is independent of the behavior of >, since of course we do not have aversion of the deduction theorem and its converse for >.
The earlier work in nonmonotonic logic did not make any direct use of conditionallogics. But starting with Delgrande (1988), there is a growing literature that seeks todevelop a conditional-based approach to non-monotonicity. These approaches explorealternatives that are quite diverse, but they all relax one constraint that the standardconditional logics observed: they no longer treat conditional modus ponens,
A, A > BC
,
as valid. Assuming the most natural correspondence between conditionals anddefaults – i.e. assuming that, for instance, (1) is represented as a conditional
Bird(Tweety) > Flies(Tweety)5
it is clear why modus ponens has to go. To accommodate defaults, we have to pro-vide for the possibility that the antecedent is true and the consequent is false. Withoutallowing for this possibility, we can’t accommodate even the simplest examples, suchas Tweety and Nixon, since these involve conflicting defaults whose antecedents caneasily be true. We are interested, then, in conditional logics that stand to the familiarconditional logics as deontic modal logics stand to alethic logics. This relaxed condi-tional has two natural interpretations: as a logic of conditional belief, or as a logic ofconditional epistemic norms. (These interpretations, of course, are closely related.)

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 795 — #15
Non-monotonicity in Linguistics 795
Readers interested in this topic should study the work of Craig Boutilier.21 Though,as far as I know, there have been no applications of Boutilier’s work in linguistics,another conditional approach – commonsense entailment, due to Nicholas Asher andMichael Morreau – has been applied in several areas of interest to linguists. Theremainder of this section will be devoted to their approach. For accounts of the log-ical theory, readers should consult Asher and Morreau (1991), Morreau (1992a,b).For a related, much simpler theory, see Morreau (1995). For an approach to condi-tional entailment that is similar in motivation but different in logical development, seeGeffner and Pearl (1992).
Commonsense entailment, unlike most other approaches to default logic, aimsexplicitly at the highest degree of “nonmonotonic commitment”. Defaults are treatedas first-class logical citizens, and the aim is to explicate their logical interrelationships.This is a very ambitious goal, and it comes as no surprise that the theory itself is rathercomplicated. In brief outline, these are the ideas.22
Like autoepistemic logic, the theory is deployed in two stages; (1) a monotonicmodal logic, and (2) a phase in which a nonmonotonic consequence relation is added.The modal logic of the first phase interprets the conditional using a function ) frompossible worlds and sets of possible worlds to possible worlds; A > B is true at aworld w if and only if )(w, [[A]]) 2 [[B]]. Like most possible worlds theories, thetheory identifies propositions with sets of possible worlds. At each world, then, >
takes a proposition into an arbitrary Kripke-style modal operator. Thus, this is themost general possible sort of conditional logic that can be based on a possible worldsapproach, on the assumption that, for each antecedent, a conditional delivers a sort ofnecessity operator at each world. The idea here is that ) picks out the worlds in whichthe antecedent is true in a way that is epistemically normal.
Two conditions are imposed on ):
(3) a. )(w, p) 0 p.
b. )(w, p ! q) 0 )(w, p) ! )(w, q).
Condition (3a) is easy to motivate; it is common to all conditional logics that theconsequent is to be evaluated in certain preferred worlds in which the antecedent istrue. Condition (3b) says that any normal p ! q world is either a normal p or a normalq world. This condition is harder to motivate; but in Morreau (1992b, pp. 126–128),it is shown that it validates a nonmonotonic version of the specificity principle.23
In the second phase of the project, ideas that have already appeared in connectionwith other nonmonotonic formalisms – possible worlds models of epistemic statesand a notion of extension – are combined to furnish an account of nonmonotonicconsequence. The account invokes two new devices: an operation of normalizationand a special epistemic state.
21 See, for instance, Boutilier (1992).22 The presentation follows the formulation of Asher and Morreau (1991).23 Asher and Morreau argue that specificity needs to be captured in terms of the underlying logic. In most
other nonmonotonic formalisms, specificity appears as (possibly one of many) priority constraints ondefaults, if it is captured at all.

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 796 — #16
796 Handbook of Logic and Language
(i) The operation normalize takes an epistemic state s and a singular proposition p(P, d)24
into an epistemic state normalize(s, p(P, d)). Normalization is defined in terms of the epis-temic normality operator ); it cancels out worlds in which d is not as normal as possible,compatible with s and the assumption P(d).
(ii) Bliss is a sort of minimal epistemic state.
Using normalization, a construction can be defined like the constructions of exten-sions in default logic. The construction inputs an epistemic state s and a set ! ofhypotheses. A set P of singular propositions is associated with a premiss set,25 andis well ordered. The normalization construction then iteratively applies normalization,beginning with the epistemic state s and choosing singular propositions from the wellordering. From the least fixpoint of the construction, we can recover an epistemic states/, from s and !; this state will in general depend on how the singular propositions areordered. Finally, commonsense entailment is defined by taking the formulas that hold inall extensions beginning with the epistemic state s resulting from updating Bliss with !:! nonmonotonically implies A if and only if s/ 0 [[A]], for all information states obtainedby ordering the singular propositions in ! and applying the successive normalizationconstruction to the epistemic state s/ and these ordered singular propositions.
Asher and Morreau are able to show that this definition has a number of interestingproperties. Among these, defeasible modus ponens is particularly important from thestandpoint of the theory of conditionals: under certain independence conditions on Aand B, {A, A > B} nonmonotonically implies B. The importance of this result lies inthe fact that with it, one can hope to axiomatize a domain using conditionals for whichmodus ponens is logically invalid, and nevertheless to be able to extract defeasibleconclusions from the axiomatization using modus ponens.
17.2.6 Inheritance
Inheritance hierarchies (or inheritance networks, or inheritance graphs) at first glancelook very different from logic-inspired approaches like those that we have discusseduntil now. And in fact they originated in a very different tradition, inspired in partby neurological modeling and parallel processing. But as the ideas have developed,inheritance networks have come to resemble familiar logics – and that is how theywill be presented here.
A general survey of work in inheritance networks is available in (Thomason, 1992),which tries to be comprehensive, and is still more or less up to date. Another survey,containing a detailed comparative treatment of many inheritance policies, can be foundin Horty (1994). With these references in place, I will try to be very brief.26
24 Where d is an individual and P is a property – i.e. a function from individuals to propositions – thecorresponding singular proposition p(P, d) = {w : w * P(d)}.
25 I do not give details here, since this part of the definition is somewhat ad hoc.26 It is easy to get distracted by esoteric details in this area, so whenever possible I will make simplifications
for the sake of exposition, in an effort to get beyond systems that are very weak expressively to ones thatcould be potentially applied to linguistics. Because of this simplifying strategy, I will be using someinheritance formalisms that diverge from the ones that have been most discussed in the literature. I willtry to mark the divergences when they occur.

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 797 — #17
Non-monotonicity in Linguistics 797
17.2.6.1 Strict Taxonomic Inheritance
We begin with monotonic or strict inheritance: this will provide a simple introductionto notation, and to techniques for defining inheritance. This form of inheritance is lim-ited in two ways: (1) there is no non-monotonicity, and (2) the only relations betweenconcepts that can be expressed are inclusion (or subsumption, or “is-a”) and exclusion(or contradiction).
An inheritance network (with positive and negative strict is-a links only) is alabeled directed graph !. We can think of ! as a set of labeled edges (or links ofvarious types) between vertices (or nodes). We associate a set of statements with sucha network. An inheritance definition for the network defines a consequence relation |>between networks and statements; we write ! |> A to say that statement A is a conse-quence of network !. In the case of strict taxonomic inheritance, all links have eitherthe form x 6 y or the form x $6 y. The statements associated with such a networkhave the form is(x, y) or the form isnot(x, y). (We use capital letters to distinguishstrict from defeasible statements; nonmonotonic networks will allow defeasible state-ments of the form is(x, y).)
The inheritance definition for these networks is a simple induction.27 In effect,we are characterizing the inheritable statements as the smallest set closed under thefollowing rules.
Definition 17.2.4. (Strict inheritance)
(i) If x = y or x 6 y * ! then ! |>1 is(x, y), and if x $6 y * ! then ! |>1 isnot(x, y).(ii) ! |>1 isnot(y, x) then ! |>1 isnot(x, y).
(iii) If ! |>1 is(x, y/) and ! |>1 is(y/, y) then ! |>1 is(x, y).(iv) If ! |>1 is(x, y/) and ! |>1 isnot(y/, y) then ! |>1 isnot(x, y).
Inheritance definitions yield prooflike constructions, but here “proofs” take ona graph-theoretic character and correspond to certain paths through networks. Forinstance, it’s easy to verify that ! |>1 is(x, y) if and only if x = y or there is a pathlikesequence of links x1 6 x2, xn 6 · · · 6 xn+1 in !, with x1 = x and xn+1 = y. Inheri-tance definitions are usually path-based, and the theory itself can’t be developed veryfar without going into considerable detail concerning inheritance paths.28 But in thispresentation of inheritance theory, I will concentrate on inductive definitions of ! |> A,where ! is a network and A is a statement in an appropriate “network language”.
27 In fact, this is an induction over the monotonic distance from node x to node y. This distance is themaximum of the positive and the negative monotonic distance from x to y. The positive monotonicdistance is the length of the shortest chain of positive links from x to y. The negative monotonic distanceis the length of the shortest chain of links consisting of a positive chain from x to x/, and a positive chainfrom y to y/, where x/ and y/ are connected by a negative link.
28 This was one reason why I first became interested in inheritance theory. I didn’t feel satisfied with themotivation of the expressively strong, semantically based approaches, and felt that inheritance graphswould provide a level of granularity at which the intuitions could be better developed. I still believe thatthere is still some truth in this, thought the complexity of the theoretical issues that have emerged issomewhat discouraging.

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 798 — #18
798 Handbook of Logic and Language
It is best to think of the strict networks as expressively limited logics for subsump-tion and disjointness relations between concepts; individuals can be treated as individ-ual concepts.29 The inheritance definition provides for reflexivity and transitivity ofsubsumption, for the symmetry of exclusion, and for a form of modus tollens. Despitethe simplicity of the rules, the logic is nonclassical. Because statements is(x, y) areonly provable when there is a path connecting x and y, the semantics of negationin networks is four-valued and so incorporates a limited amount of “relevance”; seeThomason et al. (1987) for details.
17.2.6.2 Simple Mixed Inheritance
Now consider networks in which defeasible links . are also allowed. These net-works contain positive and negative strict subsumption links and positive defeasi-ble subsumption links. Negative defeasible links are not needed; these have the formx . y # , where # is a strict negative path.
The inheritance definition is an induction on the longest path from x to y, wherethe size of a path is measured by the number of defeasible links it contains. For thisquantity to be defined in a network, we must make a strong acyclicity assumption: thatif any path through the network contains a cycle, then the path must contain only strictlinks. Even though such acyclicity assumptions are somewhat awkward, dispensingwith them raises problematic theoretical considerations. There are examples showingthat if unrestricted cycles are allowed, nets can be constructed in which there simplyis no sensible account of inheritance.30
Definition 17.2.5 assumes the above definition of |>1. Clauses labeled as “strict” inthe definition are applied before defeasible clauses whenever this is compatible withthe outermost induction on degree.31
Definition 17.2.5. (Mixed inheritance)
(i) (Strict.) If ! |>1 is(x, y) then ! |>2 is(x, y).(ii) (Strict.) If x . y * ! and not ! |>2 isnot(x, y) then ! |>2 is(x, y).
(iii) (Strict.) If ! |>2 is(x, y/) and ! |>2 is(y/, y) then ! |>2 is(x, y).(iv) (Strict.) If ! |>2 is(x, y/) and ! |>2 isnot(y/, y) then ! |>2 isnot(x, y).(v) (Defeasible.) If ! |>2 is(x, y/) or ! |>2 is(x, y/), and y/ . y * !, then ! |>2 is(x, y) if
(a) ! $ |> isnot(x, y) and (b) for all v, v/ such that ! |>2 is(x, v) and v . v/ * ! where! |>2 isnot(v/, y), there are w, w/ such that ! |>2 is(x, w), ! |>2 is(w, v), w . w/ * !, and! |>2 is(w/, y).
The crucial part of this definition is clause v. To understand this clause, compare theverbal presentation with Figure 17.1. Clause v specifies when a subsumption relation
29 Throughout this chapter, “concepts” are monadic concepts of individuals. I will use Capitalized-Italicwords or phrases for concepts, except when feature structures are under discussion, when I will useSmall capitals.
30 See Horty (1994).31 See Horty (1988).

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 799 — #19
Non-monotonicity in Linguistics 799
Figure 17.1 Skeptical inheritance.
(strict or defeasible) can be extended through a defeasible link y/ . y to complete apath from x to y, thereby producing a defeasible conclusion is(x, y).
The conclusion holds as long as there is no viable competing conclusion. A com-peting conclusion isnot(x, y) arises when there is an established subsumption relationis(x, v), and a link v . v/ from v to a v/ that is strictly inconsistent with y. And theconclusion isnot(x, y) is viable if it is not preempted by a more specific reason tothe contrary. Such a preempting reason consists of a node w such that is(x, w) andis(w, v) hold, with a link w . w/ from w to a w/ that is strictly subsumed by y.32
Thus, in Figure 17.1, the path from x through y/ to y is good in the case where forevery conflicting path like the one from from x through v to y, there is a preemptingpath from x through w to y.
This inheritance definition is skeptical, in the sense that it withholds conclusions inthe case of an unresolved conflict between between defaults. In the following example,for instance, neither the conclusion is(Quaker-Republican, Pacifist) nor the conclusionis(Quaker-Republican, Nonpacifist) follows.
Much of the conceptual complexity of inheritance theory derives from problems ofconflict resolution. But these complexities can be ignored in many linguistic applica-tions, since linguistic subsystems – at least, subsystems that are synchronically stable –seem to resist conflicts that are not resolved by specificity. This feature makeslinguistic systems particularly attractive as applications of inheritance theory.
Systematic preference for more specific defaults is built into almost all inheritancedefinitions. To see how Definition 17.2.5 accomplishes this, compare Figure 17.3 withFigure 17.2.
32 Note that the specificity path must be strict. This is the major difference between this inheritance defini-tion and that of Horty, Thomason and Touretzky (1988).

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 800 — #20
800 Handbook of Logic and Language
Figure 17.2 Unresolved conflict.
Figure 17.3 Conflict resolved by specificity.
17.2.6.3 Strict Inheritance with Roles
Although you can provide a sort of outline of the conceptual hierarchy of a domainusing only taxonomic links, such formalisms lack the expressive power to reason ade-quately about the structure of domains in an interesting way. The very powerful non-monotonic formalisms discussed above in Sections 2.1–2.5 provide this expressivepower in one way. But more constrained formalisms are also worth exploring. It isalways of logical interest to explore the possibilities of formalizing a domain withlimited resources, and this is especially important in the nonmonotonic arena, wherethe more expressive systems are not even axiomatizable and basic logical issues arenot yet fully understood.
In inheritance approaches, expressive power is increased by adding role links to theformalism, as well (perhaps) as some specialized relational links. The ideas involved

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 801 — #21
Non-monotonicity in Linguistics 801
Figure 17.4 Two-room efficiency apartments.
in networks with roles, feature structures, and frame-based knowledge representationformalisms33 are very similar. All of these role formalism approaches seek to usefunctional expressions to capture a limited amount of relational and quantificationalreasoning. All of the approaches incorporate, to a greater or lesser extent, (1) con-ventions for diagramming information, (2) algorithms for computing the reasoningfunctions, and (3) a logical specification of the valid reasoning.
The general idea has no intrinsic connection with linguistic representations or rea-soning. Consider, for instance, the following definition:
A Two-Room-Efficiency is an apartment with two rooms: a living-dining-room and abedroom.
Role formalisms seek to organize such information by bringing out the hierarchicalrelations between concepts. We can begin by saying that Two-Room-Efficiencies areEfficiencies, that the number-of-rooms of an Efficiency is a Number, that the living-dining-room of a Two-Room-Efficiency is a Living-Dining-Room, and that the bedroomof a Two-Room-Efficiency is a Bedroom.
The relationships between concepts in our examples can be diagrammed as follows.Here, we are appealing to relations of “having” between concepts, as well as to
relations of “being”. Efficiencies have bedrooms, and this is represented as a rela-tion between the Two-Room-Efficiency concept and the concept Bedroom-of-a-Two-Room-Efficiency. There is a Bedroom concept, which is invoked when we say that thebedroom of an Efficiency is a Bedroom, but there is also a bedroom role, which can
33 See Winston (1984, Chapter 8).

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 802 — #22
802 Handbook of Logic and Language
be thought of as a partial function on individuals (and derivatively, as a function onconcepts).34
The labeled links in the diagram are role links. The number-of-rooms role, forinstance, corresponds to a function taking a dwelling into its number of rooms. Thisdiagram also distinguishes between individuals (which are best thought of as indi-vidual concepts) and other concepts; the former appear as squares, the latter as cir-cles. Inheritance networks with roles may also incorporate relational links, as wellas role links: for instance, a logical relation of equality (corresponding to reentrancyin feature structures), or relations like linear precedence of morphemes, that apply tospecial-purpose types.
The formal theory of networks with roles – especially the nonmonotonic theory –has not been developed as much as one would like. Informal remarks can be foundin Winston (1984) and Fahlman (1979). Formalizations of the monotonic case canbe found in Thomason and Touretzky (1990) and Guerreiro, Hemerly and Shoham(1990). Not much has been done towards formalizing the nonmonotonic case. I hopeto remedy this at some point in the future – but here I can only sketch some of theideas and show their relevance to linguistic concerns.
The diagram following (Fig. 17.5) indicates how these relational notions might beused to formalize information about the English passive participle. In this diagramsolid, labeled arrows are used for relations other than subsumption relations. Thus, thediagram tells us that the past-participle of a Regular-Verb35 consists of a stem and asuffix, that the suffix is “-d”, that the stem precedes the suffix, and that the passive-participle of a Transitive-Verb is the same as its past-participle.
With the addition of role links and identity, the interpretation of nodes as conceptsis affected. It would not do in Figure 17.5 to treat Transitive-Verb’s-past-participleand Transitive-Verb’s-passive-participle as mere sets. For then, the relation of equalitywould have to denote equality of the sets. And then, to take a numerical example, theequality relation would hold between Integer’s-predecessor and Integer’s-successor,since the sets are the same. But this is not the intended interpretation of equality; inFigure 17.5, for instance, the meaning of the equality link is that a Transitive-Verb’s-past-participle is the same as the Transitive-Verb’s-present-participle.
I prefer an interpretation of nets with roles in which concepts, as well as roles,are interpreted as partial functions. In Figure 17.5, for instance, part of the intendedinterpretation would go as follows.
– “Regular-Verb” denotes the partial function that is the restriction of the identity function tothe domain of regular verbs;
– “past-participle” denotes the partial function that is defined on individuals with past par-ticiples and that takes these individuals into their past participles;
– “suffix” denotes the partial function that is defined on individuals with suffixes and thattakes these individuals into their suffixes;
34 Since the distinction between concepts and roles can be confusing, I’ve elected to capitalize referencesto concepts.
35 We are still working in a monotonic framework, so we aren’t yet in a position to deal with irregular verbsas exceptions.

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 803 — #23
Non-monotonicity in Linguistics 803
Figure 17.5 English passive participles.
– “Regular-Verb’s-past-participle’s-suffix” denotes the partial function that is defined on reg-ular verbs and that takes individuals into the suffix of their past participle.
Negation can be added explicitly to role formalisms such as this, in the form ofnegative links. Or it can be added as it is in feature structure formalisms, by invok-ing the unique names assumption – that distinct individual nodes implicitly denotedistinct individuals. In either case, the informal semantics that was sketched abovefor roles would have to be complicated, because of the considerations mentioned inSection 17.2.6.1.
17.2.6.4 Mixed Inheritance with Roles
Inheritance systems with roles and relations contain multiple link types; and sinceany strict link type can be made defeasible, there are a great many ways to extenda strict inheritance system with roles to mixed systems that contain defeasible linktypes. A choice that seems particularly suitable for many linguistic purposes has strictequality as its only strict relational link type, defeasible is-a and equality as its onlydefeasible link types, and introduces negation by means of the unique names assump-tion; this would suffice to formalize the inflectional properties of the Dutch verb thatare discussed in Section 17.5.3, below. The example given there should also help toillustrate how mixed inheritance with roles should work in one moderately complexexample.
I have not tried here to specify even the system of strict inheritance with roles, con-tenting myself with an informal presentation of the semantics for part of the positivetheory. Since the logical issues concerning the formalization of defeasible inheritancewith roles are more complex and are still unclear in some ways, I won’t attempt a

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 804 — #24
804 Handbook of Logic and Language
formal account. As I explained in footnote 1, I will try to make further information onthese topics available by means of the Internet.
17.3 Non-monotonicity and Feature Structures
17.3.1 Classical Feature Structures and Unification
Unification-based grammars (or, more generally, constraint-based grammars) pro-vide a good starting point for describing the issues that arise when non-monotonicityis to be integrated into a linguistic formalism. Two reasons contribute in particularto this explanatory advantage: (1) because these grammar formalisms are intendedto be used for automatic natural language processing, they are generally formalizedwith more care than approaches intended solely for linguistic purposes, and (2) theirconnection to processing algorithms is better understood. These features of the mono-tonic formalisms make it easier to see the shape of the corresponding nonmono-tonic representations and reasoning. Fortunately, this class of theories is very general,and includes a number of approaches that have been extensively used for descri-bing languages and for implementing natural language processing systems. For anoverview of these grammar formalisms, including historical material, see Shieber1992 (Chapter 2).
Feature structures serve as a fundamental representation device in these for-malisms, and unification of feature structures serves as a fundamental reasoning pro-cess. The broad idea is to think of linguistic units as information items. Informationcan be combined; linguistic theories constrain the possible combinations. The appli-cable notion of information is intended to be very general, and perhaps even universalfor purposes of linguistic representation; thus, we can think of information items aswords, phrases, or linguistic units of any kind.
These ideas are made more concrete by adopting an approach that, like inheritancewith roles and frame-based knowledge representation systems, eschews relations infavor of functions, identity, and monadic predicates. Some things can be very naturallyrepresented on this approach: “Barbara’s hair is red”, for instance becomes “The valueof Barbara for the feature haircolor is Red”, and “Andy and Barbara are (full)siblings” becomes “The values of Andy and of Barbara for the feature mother arethe same”, and “The values of Andy and of Barbara for the feature father arethe same”.
Of course, some things are less easy to put in this form than others – in the finalanalysis, though, the limits of this representation policy are a matter of what complex-ity and abstractness you are willing to put up with in your features and values. Forinstance, to represent “Andy and Barbara are married”, you need to invoke marriedcouples as values; to represent “Alice likes Ben more than Anne” (on either reading),you might invoke degrees of liking. This policy of value inflation reaches a system-atic extreme in Alonzo Church’s formulation of higher-order logic; here, to represent“Andy is older than Barbara”, you invoke a function older than whose values arefunctions from individuals to truth values.

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 805 — #25
Non-monotonicity in Linguistics 805
If value assignments were defined at all arguments, different information unitscouldn’t combine consistently. Thus, value assignments are partial functions. At pointswhere a feature value is undefined, either the feature is inappropriate or the value isin some way unknown or indeterminate. As usual when partial functions are allowed,there is a temptation to use a nonclassical logic to systematize things: various alterna-tives have been tried with respect to feature structures.
The constraint that is presupposed in applying this idea to linguistic theory, Isuppose, is that the features and values that come up when linguistic information isrepresented in this way should be linguistically natural and explanatory. (In specificapproaches, other constraints might be added: for instance, that there should only befinitely many features and values.)
In Chapter 8, Rounds finds the linguistic origin of this approach in the use offeature-based representations in phonology, and ascribes the idea to Chomsky andHalle (1968), which certainly systematized and popularized this sort of mechanismin phonology. But the idea has come up so often, in so many fields, that it is hard topinpoint a historical source.
According to the standard account of feature structures, an information item willinvolve (perhaps among other things) an assignment of values to certain features, anddeclarations of identity for certain pairs of feature paths. The values of these featuresmay be information items, which in turn will involve values for certain features. If wetrace out these relations we obtain a graph whose nodes are information items. Thearcs of the graph are labeled with features; an arc of the graph relates an informationitem to the value for this item of the feature whose label it bears. We can think ofatomic values, such as truth values, or Red in the the above example, or Plural, asdegenerate information items all of whose feature values remain undefined. The graphrepresentation provides a useful way of associating algorithms with information items.
Unification is the fundamental operation of putting together the information in fea-ture structures. If two feature structures are incompatible, they have no unification;otherwise, unification combines their value assignments and identities. See Chapter 8,Kay (1992), and Shieber (1986) for examples, detailed definitions, and theoreticaldevelopment.
So much for the classical approach to feature structures and unification.
17.3.2 Need for Nonmonotonic Unification
In his broad motivation of feature-based grammar formalisms,36 Stuart Shieber listspartiality, equationality, and modular structure as the broadly desirable characteristicsthat motivate these formalisms. Modularity, in particular, is obtained by separatingout distinct feature values, across which generalizations can be stated. To motivatenonmonotonic unification, we extend Shieber’s notion of modularity to includemaintainability. If we think of a grammar formalism as a knowledge resource that
36 Shieber 1992 (Chapter 2).

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 806 — #26
806 Handbook of Logic and Language
needs to be engineered, updated, and validated, we may not only wish appropriategeneralizations to be expressible, but to be natural and nonredundant, so that naturalconstraints need only be stated once. This goal enhances the formalism’s maintain-ability because, if things that intuitively count as a single generalization are enteredin many separate places in a grammar, the grammar becomes difficult to check forintegrity, and changes in the grammar are more liable to contain errors.
These concerns lead to the idea of organizing information into more and less gen-eral types; generalizations can then be attached to general types, and these generaliza-tions can be inferred (or inherited) at more specific types without having to be statedexplicitly there. This conforms well with the basic architecture of feature structuresand unification:
(1) The items that are described by feature structures can either be specific (e.g., they can beparticular words or phrases, like “these”) or general (e.g., they can be linguistic types, like“definite determiner”).
(2) The operation of inheritance is a special case of unification – unification of the more specificitem with the more general one from which it inherits.
With this addition, feature structure formalisms become related to similar ideas inother areas of knowledge representation and theoretical computer science: in inheri-tance theory, in taxonomic logics, and in type hierarchies for general purpose formallanguages. This is a large topic, and it is difficult to provide comprehensive references,but see Shieber (1992) and Carpenter (1992); the latter of these two works, especially(as the title indicates) concentrates on combining a type hierarchy with feature struc-ture formalisms.
The modifications described so far could be carried out using a monotonic inferencemechanism; the need for non-monotonicity lies in the fact (to which we alluded inSection 17.1.3) that many linguistic generalizations are most naturally stated as defea-sible generalizations. If, for instance, we describe the generic English verb so that thesuffix of its past tense form is “-d”, we will then have to unify this with an item like“freeze” whose past tense suffix is “-,”. With monotonic unification, this operationwill fail.
Of course, we can restore monotonicity by bringing the exceptions explicitly intothe statement of the rules. For instance, we could introduce a type of regular verbs, anda type of strong verbs, and move the generalization about past tense suffix “-d” to reg-ular verbs. We can then handle the example by classifying “freeze” as a strong verb.But in doing this, we have impaired naturalness by having to create a distinct type foreach generalization that has a peculiar pattern of exceptions. Also, maintainability isthreatened, because (unless we treat regularity as a default, which defeats the goal ofmonotonicity) we have to explicitly classify each specific lexical item with respect tothe generalizations that it satisfies. This is not a large price to pay with relatively smallsystems, but with full-scale grammars and realistic lexicons it is much more natural toattach default information to general types, attaching only exceptional information tospecific lexical items. To carry this through, however, we need to provide a character-ization of default unification.

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 807 — #27
Non-monotonicity in Linguistics 807
17.3.3 Bouma’s Default Unification
The project of Bouma (1992) is to define a nonmonotonic unification operation 7. Intu-itively, A 7 B is the result of combining the information in the feature structures A andB, treating all the information in A as default information that is overridden by B. Thisinterpretation is natural if we think of B as lexical information, while A is the templatefor a linguistic type. Bouma offers several definitions of the appropriate unificationoperation and investigates their properties; the first definition is fairly straightforward(take the most specific generalization of A that is compatible with B and unify thisclassically, i.e. strictly, with B), but the later definitions get rather complex because ofdifficulties raised by reentrancy, i.e. by path equality.
Bouma is able to show that default unification can handle a number of linguisticallyinteresting cases. This formalization of nonmonotonic unification is rather restrictivein its representational power. For instance, it doesn’t enable us to differentiate bet-ween strict and default information that may be contained in a general template. Andit gives no account of how to unify two items that may conflict, when neither is morespecific than the other. In general, it may happen that we want to unify two structures,which contain conflicting defaults that are not reconciled by any priorities. (This is thepoint of the Nixon Diamond.) Also, it may happen that overriding information is con-tributed by both structures. Consider a case in which the concept Native-Speaker-of-Albanian is combined with Born-in-Kansas. The first item strictly contains theinformation Native-Speaker-of-Albanian and by default contains the information Not-Born-in-the-USA. The second item strictly contains the information Born-in-the-USAand by default contains the information Not-a-Native-Speaker-of-Albanian. By rulingout such cases Bouma, in effect, is assuming that in the linguistic applications that heenvisages, inheritance is “orthogonal”, in the sense of Touretzky (1986).37
In fact, morphological and lexical information in diachronically stable linguisticsystems does seem to be organized so as to avoid unresolvable conflicts betweendefaults. But taking too much advantage of orthogonality in seeking to define defeasi-ble unification will make the resulting theory more restrictive, and may make it harderto relate it to work in nonmonotonic reasoning, which treats such unresolvable con-flicts as central.
17.3.4 Young and Rounds’ Nonmonotonic Sorts
Subsequent work by William Rounds and collaborators38 develops a more radicalapproach to defeasibility in grammar formalisms, by reworking feature structure
37 Touretzky defined orthogonality assuming that the only way in which overriding can occur is throughspecificity; but in a more general setting, it amounts to restricting conflict between two items to cases inwhich information from one of the structures overrides all conflicting information from the other.
38 See Young (1992) and Young and Rounds (1993). The first paper introduces the basic theory of nonmono-tonic sorts, and the second develops it and relates it to Reiter’s default logic. The following discussionis mainly a summary and explanation of the second of these papers. For later developments, see Young(1994), Rounds and Zhang (1995), Rounds and Zhang (1997), Zhang and Rounds (1997), and Roundsand Zhang (1995).

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 808 — #28
808 Handbook of Logic and Language
representation so that strict information is kept separate from defeasible information.The formalism is a generalization of typed feature structures (also known as sortedfeature structures), as in (Carpenter, 1992).
Definition 17.3.1. (Typed feature structure) Let S and F be finite, nonempty sets(the sets of types and of features), and let 8 be a reflexive partial order on S such thatevery subset of S with a lower bound has a greatest lower bound. Then a typed featurestructure FS on the signature &F,S, 9' consists of: (1) a finite, nonempty set Q (thenodes of the FS), (2) a designated element r of Q (the root of the FS), (3) a partialfunction $ with $(q, f ) * Q where q * Q and f * F (the feature value function of theFS), (4) a function % from Q to S (the typing function of the FS).
According to the definition, a feature structure is a directed graph in which thenodes (which are mere abstract locations) are connected by arcs labeled with fea-tures; the labeled arcs are determined by the feature value function. We assume thatthis graph is connected, and rooted in r; frequently, the graph is also assumed to beacyclic.
The types induce a specificity ordering on nodes; when q 8 q/, q represents amore specific concept than q/. Young generalizes this more or less standard accountby adding a set of defaults. The idea here is somewhat like Reiter’s default logic, wherea theory is partitioned into a classical part and a set of default rules: a nonmonotonictype consists of a strict type and a set of defaults (here represented as a set of types).39
A natural unification operation can be defined on these generalized types.
Definition 17.3.2. (Nonmonotonic types and unification) A nonmonotonic type is apair &s, "', where s * S and for all s/ * ", s/ 8 s. The nonmonotonic unification ofnonmonotonic types &s, "' and &s/, "/' is &s : s/'{t : s : s/ : t * " or t * "/}.
The requirement that s/ 8 s for s/ * " makes sense if we think of the defaultsassociated with a type as ways of further specifying the strict information in the type;but it wouldn’t in fact make any formal difference if this condition were dropped,since defaults that conflict with the strict information in a type will be automaticallyoverridden.
Default unification of feature structures can then be characterized in terms of unifi-cation on the types, by a definition that parallels the monotonic case.40 This approachis more general than Bouma’s in several respects: in particular, it is easily possible forincompatible types to appear among defaults of a nonmonotonic type.41 Therefore,the problem of multiple conclusion sets that was mentioned above in Section 17.2.1.1arises; Young and Rounds solve this by defining the solutions of a nonmonotonic type;
39 A set of types is needed here (rather than a single, conjoined type) because some of the defaults may wellbe mutually inconsistent.
40 See, for instance, Carpenter (1992, pp. 45–47).41 In this formalism, incompatibility is nonunifiability; it is not expressed by means of a negation operator.

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 809 — #29
Non-monotonicity in Linguistics 809
these are monotonic types that stand to nonmonotonic types as extensions stand todefault theories in Reiter’s default logic. In fact, Young and Rounds develop the anal-ogy formally by presenting a nonmonotonic version of the Kasper–Rounds logic forfeature structures, and showing that the solutions of a type correspond to extensionsof this logic. (This logical line of thought is developed further in Rounds and Zhang,1995; Rounds and Zhang, 1997; Zhang and Rounds, 1997; Rounds and Zhang, 1995.)
Rounds and Young provide one linguistic example: inflectional properties of theGerman verb. The facts in question are that middle verbs are a subtype of verbs,and strong verbs are a subtype of the middle verbs. The default past tense suffixfor verbs is “-te” and the default past participle suffix for verbs is “-t”; the pastparticiple prefix is “ge-”. For middle verbs, the past tense suffix is “-en”, and forstrong verbs, the past tense suffix is -,. The lexical item “spiel” is a verb; “mahl”is a middle verb, “zwing” is a strong verb. This information is readily encodedusing the apparatus of nonmonotonic types: the type for Verb, for instance, is theordered pair whose first member (containing the strict information) is the type cor-responding to past:participle:prefix:“-ge”, and whose second member (contain-ing the default information) is the set consisting of the types corresponding topast:tense:suffix:“-te” and past:participle:suffix:“-t”. The example shows thatthe system is capable of formalizing some of the lexical defaults that are needed tocharacterize an inflectional system.
The very pleasant formal properties of this work are possible because of a num-ber of simplifying assumptions. Nodes cannot enter into hierarchical relationships, asin inheritance networks.42 All hierarchical relationships are strict; there is no defaultsubsumption. There is no account of path identity. And – perhaps the most severerestriction – the only way that overriding can occur in this theory is for strict informa-tion to override conflicting default information. However, it is not difficult to think oflinguistic cases where there can be three or more layers of overriding by conflicting,increasingly specific defaults.43
17.3.5 More Recent Work
At present, work in the theory of default unification has not yet produced a systemthat provides satisfactory logical foundations for a suitably expressive system. Thework of Young and Rounds has the desirable logical properties, but it is not clearhow to extend these to a formalism that provides for more reentrancy and more flex-ible overriding of defaults. Research in closely related areas is similarly incomplete.Inheritance theory provides useful insights, but the complexities of inheritance defi-nitions have prevented a satisfactory formulation of nonmonotonic inheritance when
42 See Thomason and Touretzky (1990).43 Here is a case from two-level English morphophonemics: underlying “y” corresponds by default to
surface “y”; but before a morpheme boundary it corresponds by default to “i”; but in some foreign loanwords, such as “Sonys”, it corresponds to surface “y” before a morpheme boundary.

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 810 — #30
810 Handbook of Logic and Language
roles and identity are present; also, the semantics of nonmonotonic inheritance remainsproblematic.
The most recent attempt to extend the theoretical results with which I am familiaris described in Lascarides, Asher, Briscoe and Copestake (1995). This paper approa-ches the problem of default unification using the theory of commonsense entailment,discussed above in Section 17.2.5. A conditional theory based on possible worlds canbe applied to feature structures in a rather natural way by using the modal approachto feature structure logic.44 Since Lascarides, Asher, Briscoe and Copestake (1995) isat present an unpublished manuscript representing work in progress I will not discussdetails, except to note that the paper envisages a number of applications of the the-ory besides the ones that concentrate on morphological information. In particular, theauthors have in mind applications in lexical semantics and in the semantics-discourseinterface.
Anyone interested in research in nonmonotonic feature structures should realizethat the issues are very similar to those that arise in attempts to introduce defeasibilityinto taxonomic logics or classification-based knowledge representation systems. See,for instance, Quantz and Royer (1992) and Baader and Hollunder (1992).
17.4 Applications in Phonology
Though the phenomena of phonology provide many plausible instances of defeasiblereasoning, the opportunities for actually applying nonmonotonic logic to this area oflinguistics are limited by the need for preliminary foundational work. Such applica-tions require a degree of formalization that is not really to be found in the area atpresent. As usual, the task of providing these formalizations can require rethinkingsubstantive issues in phonology. The recent work in this direction45 still leaves muchroom for more development. Also, this work has mainly been carried out by compu-tational linguists, and it is not clear to what extent efforts in this direction will engagethe interests of mainstream linguistic phonologists. For these reasons, this section hasto be fairly speculative.
17.4.1 Declarative Formalisms
Nonmonotonic formalisms arose in AI out of a sense that procedural approaches areunsatisfactory in many respects. Purely procedural solutions to the representation ofknowledge were felt to be neither easily communicable nor understandable; also, with-out a specification of correct reasoning, it may be much more difficult to extend asolution or adapt it to new problems, because the consequences of changes will not betransparent. For reasons such as this, the knowledge representation community tendsto prefer representation systems that have a clear semantics.
44 See Blackburn (1992).45 See Bird (1990), Scobbie (1991), Bird and Ellison (1994), Mastroianni and Carpenter (1994), Bird and
Klein (1994), and Bird (1995).

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 811 — #31
Non-monotonicity in Linguistics 811
Dependence of a solution on the order of the procedures by which it was maintainedis one of the hallmarks of a procedural approach. The order of the steps of a proof isimmaterial, so long as the rules of wellformedness for a proof of A are observed. Butcare must be taken with the order of steps in a program, since in general the order hasan independent effect on the resulting machine state.
By this criterion, phonological formalisms modeled on Chomsky and Halle (1968)(SPE) are certainly procedural, since they involve derivations whose outcome dependson the order in which rules are applied. Therefore, rule ordering constraints have to beimposed in a separate part of the theory.46
Though there are important differences between the goals of linguists and thoseof computer scientists, the idea of seeking less procedural approaches should havethe same strong motivations in phonology that it does in other theoretical areas ofcognitive science. If such approaches can be shown to be as adequate on linguisticcriteria as procedural alternatives, many linguists might find them preferable becauseof the formal and practical advantages that go along with declarative, semanticallyarticulated formalisms.
Since many central phonological phenomena are intuitively defeasible, nonmono-tonic approaches provide a promising way to develop a declarative formalism that alsois linguistically plausible.
17.4.2 Making Phonological Theories Declarative
The most obvious ways of making SPE-like phonological theories more declarativedepend on substantive phonological assumptions. Just as some SPE-style systemsmight be equivalent to finite state transducers, some systems might be reformulablein terms of declarative constraints. Two-level theories47 provide the simplest way ofdoing this, by replacing SPE-style rules with declarative constraints on a predicateUnderlies(x, y) which provide a theory of the admissible pairings of underlying withsurface forms. Reformulations such as this depend on there being a constant limit tothe number of intermediate levels of representation (0 in the case of a two-level refor-mulation, and in general n 5 2 in the case of an n-level reformulation). This techniqueis not fully general, since there is no limit in principle to the number of intermediatelevels that could be invoked by an SPE-like theory.48
46 Some phonologists have challenged the need for rule ordering (largely because of appeals to economyof methods rather than to declarativism). See Vennemann (1972). But this group is a minority; mostphonologists believe in the classic arguments for rule ordering.
47 See Sproat (1992, Sections 3.3–3.5) for information and references.48 SPE could, of course, be reformulated by leaving the number of levels unbounded. Since first-order
predicates can only take a finite number of arguments, this would force us to use a set theoretic repre-sentation of arbitrary sequences of intermediate forms – in effect, the procedural derivations would beadmitted into the ontology. Though the resulting theory might be technically declarative, I think it wouldbe linguistically implausible.

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 812 — #32
812 Handbook of Logic and Language
Applications of the “ ‘elsewhere’ principle”49 are a natural source of defaults intwo-level phonology. For instance, two-level theories usually treat any difference bet-ween underlying and surface forms as a deviation from the norm; this means that instating a theory, only the deviations need to be stated explicitly. But such defaultshave mostly been accommodated procedurally in two-level phonology: e.g., they maybe implemented in a two-level finite state compiler, but are not incorporated in thelinguistic theory itself. In a recent paper,50 Gerald Penn and Richmond Thomasondescribe a procedural method of capturing the “elsewhere” principle in two levelphonology, which appeals to an abstract device called a “default finite state trans-ducer”. They conjecture that in linguistically natural cases these devices can be mod-eled declaratively in a prioritized form of Reiter’s default logic, but the details of therepresentation have not yet been worked out.
17.4.3 Underspecification Theory
There is a long tradition in logic dealing with the management of partial information.The ideas from this tradition combine very naturally with ideas from nonmonotoniclogic: you can think of defaults as rules for filling in information gaps.51 In phonology,these ideas have been applied informally in underspecification theory,52 which usespartial feature assignments to characterize underlying forms, and invokes default rulesin deriving surface forms (e.g., the rule that an otherwise unspecified underlying vowelis realized as schwa).
Unfortunately, the default rules that are readily extracted from underspecificationtheory are too simple to be very interesting from a logical standpoint.53 But oppor-tunities for more sophisticated applications of nonmonotonic logic would doubtlessemerge from collaborative work between logicians and phonologists working in thisarea. There are many good opportunities at the moment for productive collaborationsof this kind: that is one of the chief messages, of course, of this chapter.
17.4.4 Optimality Theory and Prosodic Phenomena
The recent approach known as optimality theory, which has mainly addressed issuesin prosodic phonology,54 displays many interesting cases of constraint interaction, butis less easily related to any existing logical theory of nonmonotonic reasoning. Likeother constraint-based approaches to grammar, the approach assumes a mechanismthat generates a large number of candidate surface forms for a given input: constraints
49 This is the term used by linguists for the reasoning principle that more specific defaults should overrideless specific defaults.
50 Penn and Thomason (1994).51 For examples of this sort of logical approach, see Veltman (1996) and Ginsberg (1988c).52 See, for instance, Archangeli (1988).53 See Bird and Calder (1991) for a survey of such rules.54 See Prince and Smolensky (1993) and McCarthy and Prince (1993).

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 813 — #33
Non-monotonicity in Linguistics 813
then filter out the unwanted candidates. On this approach, however, the fully gram-matical forms are those that, in competition with the alternative candidates, minimallyviolate the constraints.55
In stressing constraint competition, and in allowing forms to be grammatical eventhough they violate certain constraints, optimality theory touches on themes from non-monotonic logic. The inspiration of optimality theory, however, comes from a combi-nation of constraint-based grammar and connectionism, rather than from the world oflogic and defeasible reasoning, and as far as I know, optimality theory has not beenformalized using a nonmonotonic formalism. However, I suspect that the similaritiesare more than impressionistic; the idea of minimizing constraint violations matcheswell the motivation of circumscription, and I believe that optimality theory could befaithfully formalized using the techniques for prioritizing sources of abnormality thatare discussed in Lifschitz (1989, Section 14). Whether such a project would advancethe phonological enterprise is another matter; I am not sure that formalizations ofthis sort would yield results that would seem useful to the phonologists. But interest-ing results might well emerge from such formalizations, and in any case it would beinteresting from a methodological standpoint that a high-level formalism that emergedout of connectionist insights can be captured using one of the standard nonmonotonicformalisms.
17.5 Applications in Morphology
It is very natural to state morphological rules so that they admit exceptions. Forinstance, if we wish to treat
(4) The plural of a noun with stem x is x + “s”
as a rule of English morphology, we then have exceptions like “deer” and “children”.A nonmonotonic formalism for morphology therefore has very strong motivations inlinguistic intuition. If we wish to think of items like (4) as genuine rules, rather thanpre-scientific generalizations, we are in fact inevitably committed to a nonmonotonicapproach.
17.5.1 Implications for Linguistic Theory: A Preliminary Examination
Think of an inflectional morphological rule as a constraint (which may be general or adhoc), concerning the relation between an abstract specification of an inflected form andits surface realization. Axiomatizing a representative sample of such morphologicalrules, using any of the standard nonmonotonic logic formalisms, would be a relatively
55 Minimal violation is defined in terms of a ranking of the constraints; form A is better than form B in thecase where A satisfies the highest-ranking constraint on which the two forms differ.

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 814 — #34
814 Handbook of Logic and Language
straightforward exercise.56 In a conditional logic, (4) and one of its exceptions couldbe formalized as follows.
(5) a. %x$Plural-Noun(x) > 3y
$Suffix(x, y) ( Phonology(y) = “s”
%%.
b. 3x$Plural-Noun(x) ( Phonology(x) = “children”( 3y
$Suffix(x, y) ( Phonology(y) = “ren”
%%.
Exercises such as this show that nonmonotonic formalisms can be brought to bearon morphological domains. Whether these ideas can be used to illuminate theoreti-cal issues in morphology depends on whether such examples can be systematicallydeployed in a way that genuinely advances the theoretical issues. This much moredifficult project of systematically developing morphology on a nonmonotonic basishas not, as far as I know, been carried out. It would involve foundational work aswell as original work in morphology. Rather than pursuing this matter here, I’ll onlypoint out that the options that are opened up by a nonmonotonic formalism do seem toprovide important new ways of looking at the linguistic issues. Here is one example.
In a monotonic setting, the universal quantifier is the only appropriate resource forformalizing a generalization. But in formalizing generalizations in a nonmonotonicsetting, we will have to judge whether the generalization is strict or defeasible. Itwould pretty clearly be wrong to treat “Transitive verbs can take a direct object” asdefeasible, or “The past tense form of a verb consists of the verb stem and the suffix‘-ed’ ” as strict. But in many cases, there is room for judgment. For instance, take thegeneralization that the underlying form of an English plural noun has a plural suffix.We can either take this generalization to be strict, and formalize it as
(6) %x$Plural-Noun(x) . 3y Plural-Suffix(y, x)
%,
or we can interpret it defeasibly, and formalize it as
(7) %x$Plural-Noun(x) > 3y Plural-Suffix(y, x)
%.
On the former axiomatization it will be inconsistent to suppose that there are anyplural nouns without plural suffixes. So, to save the generalization, we are forced totreat plurals like “deer” as having a null suffix. That is, we have to postulate somethinglike the following claim:
(8) 3x$Plural-Noun(x) ( Phonology(x) = “deer”( 3y
$Plural-Suffix(y, x)Phonology(y) = ,
%%.
But in a nonmonotonic setting, we have another option. We can say that plurals like“deer” lack a suffix – our lexical entry for “deer” can contain (or entail) the followingclaim:
(9) 3x$Plural-Noun(x) ( Phonology(x) = “deer”( ¬3y
$Plural-Suffix(x, y)
%%.
56 In particular, the axioms corresponding to morphological rules present no difficulties. In many nonmono-tonic formalisms, however, it may be awkward to secure a preference for more specific defaults; this iswhy a nonmonotonic conditional approach is particularly suitable for this task.

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 815 — #35
Non-monotonicity in Linguistics 815
If the evidence is limited to pairings of English noun stems with their plural forms,then both formalizations match the evidence. To distinguish between these two for-malizations, we must either find other linguistic evidence that can be brought to bearon the issue, or establish conventions which favor one of the two.
Arnold Zwicky has criticized the widespread practice in linguistics (and especiallyin areas that are influenced by fashions in syntax) of saving generalizations by postu-lating ad hoc levels of representation at which the generalizations hold.57 Though heis able to point to many cases where the technique is abused, the force of Zwicky’scriticisms is weakened without a demonstration that natural, intuitive generalizationswill be forthcoming in a monotonic framework that entirely eschews the use of levelsof representation to preserve the generalizations. One can of course hope that goodgeneralizations will be forthcoming under harsher conditions. But if this hope fails,we are faced with an unpleasant dilemma: either we can have a modular theory withappealing local generalizations, but which is cumbersome and ad hoc at a more gen-eral level, or a more unified theory in which generalizations apply broadly but areneither natural nor well motivated.
Nonmonotonic foundations for morphology offer a third alternative. If a rule isdefeasible, we do not need to invoke new levels of representation to protect it fromapparent exceptions. Apparent exceptions can simply be treated as real exceptions,and we can proceed to look for subregularities among the exceptions. In a nonmono-tonic theoretical context, conservatism about the propagation of hidden representa-tions turns into the following policy:
(10) When given a choice between (1) formulating a linguistic generalizationstrictly, and preserving it by postulating a hidden construct, such as a newlevel of representation or a null item, and (2) formulating the generalizationdefeasibly, prefer option (2) unless the hidden construct is independentlywell motivated.
Genuine linguistic problems can’t be defined away by logical maneuvering, thoughthey can be relocated. To be clear where we stand, we need to ask where the conflictbetween the plausibility and generality of linguistic rules will reappear in a nonmono-tonic framework. The relocated problem, I think, is the question of how to decideunder what conditions a defeasible generalization is tenable. A few counterexamplesdo not threaten a defeasible rule; an overwhelming concurrence of counterexamplesmake it untenable. But many linguistic rules will be somewhere in the middle, and herethe criteria are more difficult to apply; therefore, it becomes harder to decide betweencompeting theories. This problem has occasionally surfaced in the form of sweepingcriticisms of nonmonotonic formalisms.58 Although the difficulty is genuine, it is toosoon to tell how much of an obstacle it will be in formulating linguistic theories; themain question seems to be how successful we can be in agreeing on viability criteriafor nonmonotonic generalizations.
57 The criticisms appear in several recent works; see Zwicky (1986) and Zwicky (1989), for instance.58 For instance, this is one way of reading the argument in Brachman (1985).

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 816 — #36
816 Handbook of Logic and Language
As far as I know, no one has attempted to develop a systematic account of mor-phology on nonmonotonic foundations, using one of the general-purpose nonmono-tonic logics. But the project is promising. The logical and linguistic resources are wellenough understood, and – as I argued above – the introduction of defeasible rulesprovides theoretical alternatives that are well worth exploring.
17.5.2 Taking Procedures into Account
The general-purpose nonmonotonic logics are very powerful, and are not immediatelyconnected with sound and complete inference procedures of any kind, much less withprocedures that are efficient. But morphology is a relatively constrained domain; andmorphological processing, as part of a larger task like natural language interpretation,seems to call for inference procedures that are highly efficient, even in the presence ofrather large lexical knowledge bases.
To look at the task of formalizing natural language morphology as one of designingrepresentations that will describe the phenomena, will facilitate generalizations aboutthe domain, and also will support efficient core procedures (such as recognition ofan underlying form, when presented with a surface form), and is to see the problemfrom the standpoint of knowledge representation and reasoning.59 Though researchin knowledge representation is far from producing a complete system that could beapplied to representation problems in linguistics, or even in morphology, it has cer-tainly produced ideas and partial results that interface well with linguistic purposes,and that can be applied piecemeal. In fact, we have a number of instances in whichthey are already being applied in this way.
The following considerations reflect on the expressive features that would be desir-able in a system for representing and managing morphological information, and onrelated algorithmic requirements.
Hierarchical structure and inheritance reasoning. Let’s assume that any tool forrepresenting information about words should provide for hierarchical structuring ofthe relevant concepts, and also allow some form of inheritance reasoning. The advan-tages of storing information at the most general appropriate concept and allowing itto be inferred at more specific concepts are pretty general. They show up in almostany area where general reasoning is combined with a relatively large amount ofdata; object-oriented programming and object-oriented databases, as well as manyknowledge-related applications in AI are examples.60 For the need for concept hierar-chies and inheritance in lexical applications, see, for instance, Briscoe (1993), Copes-take (1993), and Krieger and Nerbonne (1993). But – as Section 17.2.6 illustrates –the complexity of inheritance depends on the other constructs that are integrated withhierarchical reasoning. And here, there is a lot more to be said about the requirementsof linguistic applications.
59 Linguists, of course, are also interested in “linguistic adequacy”, or ability to explain phenomena at a verygeneral level. I haven’t added this to my list because this is not a typical goal of knowledge representation,though it is certainly compatible with the more typical goals.
60 See, for instance, Meyer (1988) and Zdonik and Maier (1990).

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 817 — #37
Non-monotonicity in Linguistics 817
Definitions and classification. Even linguists who work with fairly informal theo-ries often use definitions to organize concepts, and the ability to define concepts andreason appropriately with definitions should rate highly on our list of desirable fea-tures. For instance, it should be possible to define a third person singular noun as anoun that is third in person and singular in number, or (to sharpen the attribute-valuegrammar flavor) to say that a third-person singular noun is a symbol whose value forthe attribute cat is N, whose value for the attribute number is Singular, and whosevalue for the attribute person is Third.
Once a definition is declared, a defined concept should automatically be positionedin the hierarchy of concepts so that the definition will determine appropriate relationsto the other concepts. For instance, we want all the strict information that applies to theconcept Singular-Noun to apply to the concept Third-Person-Singular-Noun;and we want all the strict information that attaches to third-person-singular-nounto apply to any symbol whose value for the attribute cat is N, whose value for theattribute number is Singular, and whose value for the attribute person is Third.
We will have a much better notion of the expressive and algorithmic complexityof morphological information if we can characterize the constructs that are needed todefine the concepts that are required by a morphological theory. A reliable character-ization could only emerge from an extensive process of trial-and-error formalization.But at least we can indicate here the sort of constructs that are likely to be needed.61
Value assignment. We need to be able to specify that a feature takes a certain value.This construct, of course, was used in the example definition of the concept Third-Person-Singular-Noun.
Boolean connectives. The need for conjunction is pervasive; this construct was alsoused in our initial example. In classification-based knowledge representation, theuse of negation and disjunction is often limited. But they occur in many naturalmorphological examples. Consider the following example, from Aronoff (1976,p. 60).
Citing an unpublished work of Emonds, Chapin states that thedistribution of these affixes [English nominal suffixes ‘#ment’ and‘+Ation’] is by and large governed by phonological properties ofthe base: verbs with the prefixes ‘eN-’ and ‘be-’ take ‘#ment’; verbsending in oral or nasal stops take ‘+Ation’ (‘starve’, ‘sense’, ‘fix’);verbs with a liquid preceded by a vowel take ‘+Ation’ (‘console’,‘explore’). All others take ‘#ment’.
The use of disjunction is evident in characterizing these root classes. Cases inwhich negation is used to define a residue class (“all others” here) are especiallydifficult to eliminate.
Equality and quantification. Universally quantified equations are familiar from unif-ication-based grammar formalisms. The need for this sort of construct can also be
61 All of these constructs have been studied in connection with taxonomic logics; see Woods and Schmolze(1992) and the references there. The trend in this area has been to implement expressively weak systems,and a system supporting all of the constructs mentioned below would be expressively strong.

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 818 — #38
818 Handbook of Logic and Language
directly motivated by morphological considerations. For instance, this is preciselywhat is meant by syncretism,62 where, for instance, a rule is wanted to the effectthat two inflected forms are always identical (as, for instance, plural accusativeand dative forms are in German). Similarly, universal quantifications of the form
%x[Type1(x) 1 Type2(Path(x))]
are generally useful for purposes of knowledge representation.63 And generaliza-tions of this kind are needed in morphology: the constraint that in Arabic, all rootshave the form C V C is an example, and (if an example with a nonempty path iswanted) so is the constraint that for the class of English verbs with regular per-fective forms, the root of the plural form is identical to the root of the presentform.
String types and their properties. Many morphological constraints deal with theorder of morphemes in words. The rule that the English derivational suffixes “-al”,“-ize”, and “-tion” occur in that order, so that “verbalization” is a word, but not“verbizational”, is an instance. Such constraints might well enter into definitions.For instance, in Pir̃aha (an Amazonian language), a word is a phrase consistingof a (possibly compound) root, followed by any number of sixteen suffixes – andthese suffixes have to occur in a fixed, linear order.64
To deal with such constraints, morphological definitions need to include constraintson string types.65 Of course, as soon as a construct is added to the definitional appa-ratus, the appropriate reasoning has to be integrated into the classifier. Adding stringsraises a number of problems, but the computational issues have at least been exploredin a preliminary way, in connection with a project that attempts to apply classificationto plans.66 Details can be found in Devanbu and Litman (1991), where classificationalgorithms are developed for a classification-based system supporting string types.
Once defeasibility is added to such a system, as well as the other constructs thatwe have mentioned, the logical details of what is wanted are not entirely clear. It is,of course, possible to specify the system in one of the general-purpose nonmonotoniclogics, such as circumscription theory, but because of the power of these logics thisdoes not provide any assurance that there will be sound and complete algorithms forbasic operations such as unification, classification, or even inheritance.
62 If the term is used without historical connotations, as it is in Spencer (1991).63 This is a special case of what is known as “value restriction” in classification-based systems.64 Personal communication, Dan Everett.65 The Pir̃aha constraint might then emerge as a definition of a word as a string of morphemes such that (1)
its first element is a root, and (2) the list of its remaining elements is a sublist of a certain 12 element list ofmorphemes. This bare definition, of course, would need to be augmented, by assignment of appropriateattributes to words: e.g., prosodic attributes, semantic attributes.
66 In Artificial Intelligence, plans are recipes that license certain sequences (i.e. strings) of actions; this iswhy string types are needed for extensions of classification to cover planning. This is another instanceof close interrelationships between the sorts of reasoning that are needed for linguistic applications andgeneral purpose reasoning.

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 819 — #39
Non-monotonicity in Linguistics 819
The goal of designing such a system has emerged in three separate research fields:inheritance, taxonomic logics, and grammar formalisms. The work in inheritancestarts with very simple nonmonotonic formalisms, so here the problem appears as oneof adding relational reasoning, Boolean constructs, and the like to the basic systems.This has turned out to be surprisingly difficult. I said in Section 17.2.6.4 that a lot ofmy own work in this area is still unpublished because I don’t feel that I have beenable to think the issues through. In the taxonomic logic community, the desirabilityof adding defeasibility and classification is somewhat controversial.67 But see Quantzand Royer (1992) and Baader and Hollunder (1992) for work that explores the issuesthat arise in this area when non-monotonicity is added. We discussed the issues thatarise from the perspective of unification grammar formalisms in Section 17.3, above.
This research area seems to be problematic because of the proliferation of logi-cal theories of non-monotonicity and the relatively undeveloped state of the intuitionsthat are needed to sort them out. But another reason for the difficulty is that our ini-tial intuitions lead to formalisms that range from totally noncomputable to relativelyintractable. There has been some success in finding implementable special cases ofnonmonotonic theories, but it is hard to point to even a single application area inwhich these special cases might be useful.68 For this reason, the domain of linguis-tic morphology is a very promising area of investigation for the nonmonotonic logiccommunity. It is rich in logical texture and provides a good variety of defeasible gener-alizations; and there are useful applications in natural language processing. There area number of special purpose systems that implement complex applications in somedetail.69
But at the same time, the area is sufficiently complex to offer many genuine chal-lenges to the theoretical community.
17.5.3 An Example: The Dutch Verb
The ideas in Figure 17.6 derive originally, I believe, from De Smedt (1984); similartreatments of Germanic verb morphology have also appeared in the datr literature,and in the literature on default unification, though the example is seldom presentedin its full complexity. This beautiful example illustrates complex interactions betweendefaults, specificity, and the logical properties of identity. It was this example that con-vinced me that linguistic applications could illuminate logical issues in nonmonotonicreasoning, and that the logical theories might be useful in illuminating the organiza-tion of lexical information. Figure 17.6 is a more or less straightforward rendering ofthe account of De Smedt (1984) in the graphical notation of inheritance theory.
Figure 17.6 declares inflectional information about three types of Dutch verbs:Verbs, Mixed Verbs, and Strong Verbs. Double shafted arrows contain strict informa-tion; single shafted arrows contain defeasible information. Single headed unlabeled
67 See Brachman (1985).68 The situation looks better if you count negation as failure in logic programming as an application area,
but this application didn’t arise directly out of the work in nonmonotonic logics.69 See Evans and Gazdar (1990), De Smedt (1990), and Daelemans (1987b).
“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 820 — #40
820 Handbook of Logic and Language
Figure 17.6 The Dutch verb.
arrows are is-a links; double headed unlabeled arrows are identity links.70 Labeledarrows represent attribute links. Information attaching to general types is always gen-eral; i.e. it is always implicitly universally quantified. Squares represent objects andcircles represent concepts.
Some information in the network is left implicit. We assume that the present-finite-stem of each Verb evaluates to the citation form that serves as the label for the Verb (sothat there is an implicit is-a link71 from bak to “bak” that serves to evaluate the present-finite-stem of the verb bak). And we assume that individuals with different quotedlabels are different (so that there is an implicit strict exclusion link from “-n” to “-d”).
70 Note that these diagrams differ from feature structure diagrams in representing identity explicitly; thereis no literal reentrancy.
71 Identity links to individuals do not need to be distinguished from is-a links, since for individual conceptssubsumption is the same as identity.

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 821 — #41
Non-monotonicity in Linguistics 821
Figure 17.7 Focusing on part of the Dutch verb.
Figure 17.6 directly contains, for instance, the information that Mixed Verbs arenecessarily Verbs, that Verbs have present-finite-stems, that the present-finite-stem of aVerb is in general the same as its past-finite-stem, and that the past-participle-suffix ofa Mixed Verb is in general “-n”. And there are a number of implicit inferences. We caninfer by inheritance, for example, that the past-participle-stem of “bak” is “bak”, and(allowing more specific defaults to override less specific ones) that the past-participle-suffix of “bak” is “-n”.
Perhaps the most interesting inference produced by this network is the evaluationof the past-participle-stem for “zwem”. It is “zwom”, so that (using other inferencesdelivered by the network) the past participle of this verb will be “ge-zwom-n”.72
Since “zwem” is classified as a verb, the network also provides a path that eval-uates its past-participle-stem to “zwem”. But this path is overridden by the path thatproduces “zwom”. The simplified diagram in Figure 17.7 focuses on the reasoninghere. In this diagram, f represents the path present-finite-stem, g represents the pathpast-finite-stem, and h represents the path past-participle-stem. The diagram makesit clear that the inherited default identity between b and c is overridden by the strictexclusion between b/ and c/. (In all formalizations of default reasoning, strict informa-tion overrides competing default information.) However, the identity between c and dis unopposed, and should be inherited.
In the earlier discussion of inheritance I didn’t provide a general inheritance defini-tion to cover this case. As far as I know, there is none provided in the inheritance litera-ture, though I have explored the some of the issues in unpublished work. The exampleis important because it produces nontrivial, interesting reasoning in a linguistically
72 This is an analysis of the underlying form; a regular morphophonemic rule of epenthesis produces thesurface form “gezwomen”.

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 822 — #42
822 Handbook of Logic and Language
interesting example from morphology, and because it shows that an assumption thatis incorporated in the assumptions and notation of the unification grammar commu-nity is not appropriate in a nonmonotonic setting. Note that this example dependsessentially on breaking the transitivity of a default identity. In order to represent thereasoning appropriately, it is essential not to represent identity of path values usingreentrancy. That is, in a nonmonotonic setting we need to represent identities “inten-sionally” as links between different locations, rather than as pointers to the samelocation.
17.6 Syntax
The need for applications of non-monotonicity is probably harder to demonstrate con-clusively for syntax than for any other area of linguistics, and it is not easy to findsyntactic phenomena that make sophisticated demands on nonmonotonic logic; so thissection will be brief.
Bouma (1992) provides a useful list of reasons for introducing non-monotonicityinto syntax.73 Bouma cites the following applications:
(i) Exceptional rules,(ii) Feature percolation principles, and
(iii) Gapping.
A syntactic rule that held by default but failed to apply in certain cases would of coursebe a direct source of non-monotonicity in syntax. As far as I know, however, it is hardto argue convincingly for such rules; the difficulty is in finding compelling argumentsthat a nonmonotonic solution is clearly superior to spelling out the exceptional casesexplicitly in the statement of the rule.
Of the cases that Bouma mentions, (ii) is probably the strongest. But though fairlyconvincing intuitive arguments can be given for making the “head feature conven-tion” hold by default,74 the use of defaults doesn’t seem to result in a theory that isinterestingly different.
17.7 Applications in Semantics
In Section 17.1.3 I mentioned ways in which the project of using nonmonotonic logicto formalize common sense overlaps with the efforts of linguists to provide a logicalframework for natural language metaphysics. Several works have already appearedthat explicitly pursue projects of this sort, such as Asher (1992) (which has to do withthe interpretation of progressive aspect) and Morreau (1992b) (which has to do with
73 Bouma is thinking of constraint-based grammars, but even so, the list provides a reasonably comprehen-sive view of opportunities for defeasible rules in syntax.
74 This convention says in effect that a phrase will share feature values with its head.

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 823 — #43
Non-monotonicity in Linguistics 823
generic constructions).75 The connection between cases such as these and defeasiblereasoning is very natural, but in both cases the formal treatment is rendered problem-atic by elements of context-sensitivity that also enter into the interpretation of theseconstructions in ways that are not yet, I think, very well understood.76
One of Richard Montague’s original goals for semantic theory was to provide aframework that would enable the meanings of semantically complex words to bespecified by means of meaning postulates. Intensional Logic was meant to serve asa vehicle for stating such postulates; and in fact Montague’s most extended argumentfor the appropriateness of Intensional Logic for semantic purposes was, essentially,that it allowed one to write meaning postulates relating derived nominals to the verbalelements from which they are derived.77
Of course, this area has received further attention. But despite major achievementssuch as by Dowty (1979), it seems to me that Montague’s goal of providing anadequate foundation for lexical semantics has not been realized in subsequent work.The part of the field that is formalizable is small in relation to the richness of semanticrelations between words; and many researchers in lexical semantics aren’t convincedthat formal methods are able to come to grips with what is linguistically important inthe area.
These considerations provide good motivation for exploring extensions of Mon-tague’s logical framework, and evaluating the extensions by testing their adequacy asresources for lexical semantics. I believe that a nonmonotonic extension of IntensionalLogic is one of the most promising such ideas.78 The most natural vehicle for thisproject is circumscription theory. (I have already mentioned that a higher-order,intensional version of John McCarthy’s circumscription theory yields a formalismthat is particularly close to Montague’s original framework; see Thomason, 1990, formore details.)
The need for a nonmonotonic theory is illustrated by notions such as causality,agency, telicity, and ability, which are pervasive in word formation processes. Here,I will only try to sketch some of the relevant issues.79
17.7.1 Causality
Causality is pervasive in word formation processes; but despite its centrality, it isgenerally treated as a primitive in linguistic semantics. Part of the difficulty hereis that causality is an elusive notion that belongs more to common sense than tomore readily formalized domains. (Philosophers have often pointed out that there
75 There is a general discussion of nonmonotonic formalisms in connection with the semantics of genericsin Krifka, Pelletier, Carlson, Ter Meulen, Chierchia and Link (1995, pp. 58–63). The upshot of this isthat while nonmonotonic logic may have something to contribute, it is not the whole story.
76 Some light may be shed on these matters by the development of a separate theory of contextual effects. Inthis regard, see Guha (1991). The issues explored in this dissertation are becoming quite popular, and wecan expect to see more research in this area. How relevant it will be to the concerns of linguists remainsto be seen.
77 Montague (1969, pp. 148–155).78 See Thomason (1991) for background.79 This is part of an ongoing project; for more information, see Thomason (1991, 1994).

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 824 — #44
824 Handbook of Logic and Language
seems to be no direct element of causality in the more developed physical sciences.)Nonmonotonic logics offer at least some hope for a deeper logical analysis, thoughthe issues here remain somewhat problematic. See Shoham (1988, 1990, 1991),Simon (1991), and Geffner (1992).
17.7.2 Agency and Telicity
When it is analyzed at all these days,80 agency involves some underlying element ofnecessity – with the consequence that for an act to be performed by the agent, the agentmust do something that makes the result inevitable. Words for acts, however, are oftenlexically related to terms for goals which will normally, but not inevitably be achievedby invoking certain procedures. Thus, it seems wrong to say that in a case in which(1) An agent invokes the normal procedure for closing a door, and (2) The door infact closes in the expected way, the agent didn’t in fact close the door, because a gustof wind might have prevented the door from closing. These considerations suggestthat nonmonotonic logic might provide a more adequate foundation for dealing withagency and telicity.
17.7.3 Resultatives
One of the first constructions to be carefully studied in connection with the logicalsemantics of lexical decomposition is exemplified by the semantic relation of the verb“hammer” and adjective “flat” to the phrase “hammer flat”. There is a fairly extensivetreatment of the phenomenon in Dowty (1979). He offers an analysis of “x hammersy flat” that amounts to “x causes y to become flat by hammering on it”.
However, this sort of definition misses something: these constructions also incor-porate manner to some extent. They imply that the action is done in the usual way.Thus, for instance, if Fritz causes the metal to become flat by hammering on it as asignal for Natasha to run it through a metal press, he certainly caused it to become flat,but didn’t hammer it flat.
If I say simply that Fritz used a hammer to make the metal flat, you would beentitled to assume that Fritz used the hammer in a normal way. It is just this sort ofnormality that seems to be incorporated in resultative constructions: “Fritz hammeredthe metal flat” means “Fritz used a hammer on the metal in the normal way (withrespect to the event type of hammering) to make it flat”. We could encode this usinga predicate, normal(x, y), which is true of an event e and an event type & if and onlyif e is carried out in a normal manner with respect to expectations pertaining to &.For instance, Fritz’s hammering on the metal was not a normal event with respectto expectations attaching to hammering. (Notice that the relevant sort of normalcy isconventional; it is pretty normal to use a hammer to pull nails, but wrong to say “Fritzhammered the nail out of the floor”. It’s also worth noticing that the information aboutnormalcy that is needed in such examples is exactly the sort of information that isneeded for practical planning.)
80 See, for instance, Belnap and Perloff (1990).

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 825 — #45
Non-monotonicity in Linguistics 825
Though the modification that I am suggesting to Dowty’s meaning postulate for“hammer flat” does not involve the use of a nonmonotonic logic, it does help to pro-vide some independent motivation for the need in lexical semantics of the normality(or abnormality) predicates that are required by a circumscriptive theory.
17.7.4 The -able Suffix
Among the semantic patterns that occur fairly commonly with the -able suffix is an“action-outcome” meaning, exemplified by “believable”, “detectable”, “soluble”, and“transportable”. Here, the interpretation seems to be that a “test action” will normallyresult in the indicated outcome. (The appropriate test action is inferred somehow;probably commonsense knowledge is involved in the inference.) To call a storybelievable is to say that a person will believe the story when told it, under normalcircumstances.
Nonmonotonic logic (and especially the versions that use a form of commonsenseentailment) delivers a natural formalization for this lexical meaning relation. Thefact that using such an approach provides some hope hope of giving necessary andsufficient conditions of the meaning of, say, “x is water-soluble” in terms of “xdissolves in water” has some historical importance in connection with the analysis ofdispositionals.81
17.7.5 Other Applications
Accounting for polysemy (systematically related meanings of lexical items) hasemerged as one of the most important problem areas in lexical semantics.82 Predictingpatterns of polysemy for lexical items can involve nonmonotonic inheritance. Moreinterestingly, the interpretation of polysemous words in context certainly calls forsome form of reasoning that is broadly nonmonotonic; but it is not clear to me at thispoint whether one of the nonmonotonic logics, or other methods – such as abductionor probabilistic reasoning – are most appropriate for this task. See Kilgarrif (1995) foran approach using nonmonotonic inheritance.
17.8 Applications in Discourse
Defeasibility was implicitly recognized as characteristic of discourse phenomena ineven the earliest attempts to separate discourse effects from what is conventional inlanguage. Grice (1989), which for many years was circulated in various unpublishedforms, and has been highly influential in the theory of discourse, uses defeasibility asa way of testing whether an interpretive effect is conventional or nonconventional.
Though discourse is thus a very natural application area for defeasible reasoning, itis only recently that we have seen any very systematic attempts to use nonmonotonic
81 For more details, see Thomason (1994).82 The literature on this topic is fairly extensive; but see, for instance, Pustejovsky (1991).

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 826 — #46
826 Handbook of Logic and Language
reasoning to formalize the phenomena. As we might expect, we find much the sameoutcome that we see in other cases where nonmonotonic formalisms are applied tophenomena with complex interacting defaults: we can achieve some success in for-malizing regularities in limited domains, but it is difficult to obtain similar results ina very general way. And in general, formalisms that are less principled in their designmay be more robust in actual applications.
I will briefly describe some representative work that has been done in this area.
17.8.1 Speech Acts
The reasons for importing non-monotonicity into a theory of speech acts are much thesame as those that motivated nonmonotonic theories of planning and action in general.The conclusions that should be inferred about the state of the world (or the state of aconversation) after an act has been performed will in general be defeasible. Withouta nonmonotonic formalism, it is very difficult to see how to axiomatize a realisticplanning domain, because the ways in which an effect may fail to be achieved, or inwhich a background condition may fail to continue to hold after the action has beenperformed, are practically impossible to enumerate.83
Appelt and Konolige (1988) represents an attempt to formalize speech acts usingideas similar to those used in planning problems. The work builds on earlier mono-tonic axiomatizations by Levesque, Cohen, and Perrault of speech acts, and on Per-rault’s nonmonotonic reformulation of this work. The central idea of the monotonicformulations in Cohen and Levesque (1985, 1987) and Cohen and Perrault (1987)is to axiomatize speech acts in such a way that theorems can be proved to supportthe efficacy of certain speech acts in achieving their conventional goals. In the caseof assertion, for instance, this means that there will be a theorem to the effect that theutterance of a declarative sentence expressing p will result in a state in which the hearerbelieves p.
There is a dilemma close to the surface of this line of research. On the one hand,one needs to be able to prove these “efficacy” theorems, since otherwise the planningagent will not have the beliefs that it needs about the consequences of actions in orderto plan effectively. On the other hand, the theorems will either be false or will involveconditions beyond the agent’s control – for instance, there will be countless ways inwhich the hearer may fail to believe p, even though the appropriate sentence has beenuttered.
Reacting to this difficulty, C. Raymond Perrault provides a nonmonotonic solution,in which the theory of speech acts is reformulated using Reiter’s default logic; rulessuch as the declarative rule formulated above are then treated as defaults.84 In laterwork, Appelt and Konolige (1988) provide an improved formulation of the idea usingKonolige’s hierarchical autoepistemic logic. This work has also been implemented ina discourse planner.
83 In the literature on non-monotonicity, this is called the ramification problem. See Ginsberg (1988b).84 See Perrault (1990).

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 827 — #47
Non-monotonicity in Linguistics 827
As far as I know, all of the work done in this area is able to model only the effectsof speech acts that are more or less direct, or “conventional”, as J.L. Austin would putit. This work does not provide the means to plan implicatures, for instance. If Gricewas at all correct about the rational source of implicatures, a much more detailed andcomplex model of the hearer’s reasoning process would be needed in order to providea theoretical basis for this sort of speech act.
17.8.2 Recognizing Intentions and Discourse Structure
Turning to the other side of the discourse process, let’s consider the interpretation ofutterances.
17.8.2.1 Interpretation as Abduction
A large part of the reasoning task in interpreting utterances that are part of largercommunicative units is the assignment of appropriate relations to the utterances. Forinstance, the task of interpreting the following discourse isn’t over even when eachsentence has been correctly interpreted; it is also necessary to determine whether (a)and (b) are items in a list of disadvantages of fossil fuel, or whether (b) is a reasonfor (a).
(a) Fossil fuel is expensive.(b) It pollutes the environment.
There is some disagreement in the field about whether there are discourse relations thatneed to be inferred at the multisentential level by some sort of knowledge intensiveparsing, or to what extent this is a special case of inferring speaker intentions: butin either case one is dealing with plausible hypotheses about the meaning, which arehighly defeasible.
The abductive approach of Hobbs, Stickel, Appelt and Martin (1993), implementedin SRI’s tacitus system, models understanding a text as the process of producing aproof that leads from given information to an interpretation of the text. (In simplecases, the interpretation may simply be the proposition or propositions expressed bythe text. In more complex cases, the interpretation may involve other elements, suchas the proposition that the text is coherent.) Auxiliary hypotheses may need to beadded in providing this proof; the idea, then, is that these hypotheses are part of theinterpretation of the text (or of what the speaker meant by the text).
In this system, abduction is viewed as the process of finding a minimally (or rela-tively) inexpensive proof. Part of the process of knowledge representation, therefore,consists of axiomatizing domain information using familiar logical tools. This task isdeclarative, relatively domain independent, and grounded in representation techniquesthat are fairly objective. The other part of the process, which consists in assigning coststo proofs, is more problematic in these respects.85 And, though Hobbs and his col-leagues have explored how to treat a wide variety of discourse phenomena using their
85 See pp. 132–137 of Hobbs, Stickel, Appelt and Martin (1993) for a discussion of the issues.

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 828 — #48
828 Handbook of Logic and Language
abductive apparatus, the applications that they have implemented, as far as I know,have not yet tried to treat all of these problems simultaneously.
Nevertheless, the ideas have been implemented to produce natural language under-standing systems that are remarkably successful in several different tasks and domains.Even though the theory of this version of nonmonotonic reasoning is not yet workedout in a way that connects it successfully with the best theoretical work in nonmono-tonic reasoning, its power and its success in applied areas make it a highly importantdevelopment. As Gazdar says (Gazdar, 1987), we should beware of simplistic modelsof the relation between theory and applications in linguistics. We should not expectwork in any major area of artificial intelligence, including natural language process-ing, to proceed smoothly from general theories to applications, or expect new theoriesto emerge smoothly from successful applications. We are unlikely, I think, to obtainrobust relations between theory and applications without independent work in bothdirections.
17.8.3 Discourse and Commonsense Entailment
In a number of recent papers, Asher, Lascarides, and Oberlander have developed anapplication of a theoretically motivated approach to nonmonotonic reasoning to theproblem of inferring discourse relations from texts.86 The idea is to use common-sense entailment87 to formalize defaults concerning the temporal interpretation andcoherence of texts. Assume a sentence-level interpreter that assigns an event (or moregenerally a state or event, an “eventuality”) eA to a sentence A.
In their rules, they take event time to be incremented with each new sentence bydefault: this would explain why in a text like
Linda drove to work.She entered her office.She picked up the telephone.
we assume that three events occurred in temporal sequence. In formalizing this, thetemporal inference is mediated by a discourse relation of Narration. The defaultassumption is that sentences in sequence are in this discourse relation; a separateaxiom ensures that the corresponding events are temporally ordered.
Narration 1: Subtext(A, B) > Narration(A, B).
Narration 2: Narration(A, B) . eA 9 eB.
However, the default can be overridden in a number of ways. For instance, in a caselike
Linda drove to work.She got in her car.She found a parking place near her office.She entered her office.She picked up the telephone.
86 See Lascarides and Oberlander (1991), Lascarides and Asher (1991, 1993a,b).87 See Asher and Morreau (1991), Morreau (1992a,b), and Section 17.2.5 of this chapter.

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 829 — #49
Non-monotonicity in Linguistics 829
we do not want to infer that Linda drove to work before she got in her car. To pro-vide for this, we appeal to another discourse relation of Elaboration. We postulatethat elaboration implies temporal non precedence and that normally when eB is apreparatory condition for eA, A and B stand in the Elaboration relation.
Elaboration 1: [Subtext(A, B) ( Preparation(eB, eA)] > Elaboration(A, B).
Elaboration 2: Elaboration(A, B) . eA $9 eB.
To apply these rules to our text, we need to know that Linda’s getting in the car isa preparatory part of Linda’s driving to work. This is clearly based on the everydayknowledge that, in general, getting into a car is a preparatory condition for drivingsomewhere; this domain information would somehow license a default to the effectthat if contiguous sentences B and A in a text express events of this kind, i.e. if eB isan event of getting into a car and eA is an event of driving the car somewhere, then Bis an elaboration of A in the text.
In the presentations that I have seen of this approach to discourse relations, theneeded information is simply posited in the required form. In this case, for instance,two things are needed: the domain fact that the events stand in the Preparation relation,and the discourse inference that when the events in question stand in this relation, thesentences are in an Elaboration relation.
Discourse Rule 1:[Subtext(A, B) ( Express(A, eA) ( Express(B, eB)
( Preparation(eB, eA)] > Elaboration(A, B).
Domain Fact 1: Preparation(eB, eA).
Notice, however, that to infer Domain Fact 1, we will need to know that eA is anevent in which Linda drove her car to work; in other words, we will have to performan instance of the discourse inference that Hobbs et al. call coersion (Hobbs, Stickel,Appelt and Martin, 1993). This, and examples that are generated by considering almostany realistic text, make it clear that in order to apply the ideas, it will be necessary tohave an account in this framework not only of inferred discourse relations but of awide range of other interpretive processes.
Based as it is on commonsense entailment, the main device available to thisapproach of resolving competing defaults is specificity of default rules. It remainsto be seen whether in a reasoning domain as complex as this, this approach to conflictresolution will be manageable even in moderately complicated domains and reason-ing tasks. It will be very interesting to compare the success of this approach with thatof the more flexible, but less principled abductive approach, as efforts are made toformulate them for comparable domains. The results should be important not only fordiscourse, but for applied nonmonotonic reasoning in general.
17.8.4 Modeling Presupposition and Implicature
Computer scientists have initiated several projects that make use of nonmonotonicformalisms to improve on theories that have been presented in the philosophical and

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 830 — #50
830 Handbook of Logic and Language
linguistic literature of discourse phenomena. Robert Mercer applied default logic tothe theory of presupposition, and Jacques Wainer developed a circumscriptive theoryof implicature phenomena. See Mercer and Reiter (1982), Mercer (1987, 1988), andWainer (1991).
17.8.5 Mutual Defaults
Richmond Thomason has explored the use of mutual defaults (defaults about conver-sation that are mutually believed by the speaker and hearer in modeling ideas aboutconversation due to Robert Stalnaker and David Lewis.88 These philosophers treatcertain conversational variables (such as what has been established at a given point inthe conversation) as information that is dynamically updated and maintained by theparticipants in a conversation. To preserve conversational coherence, it is importantto show that the conversational participants can maintain the same view of the con-versational context throughout a normal conversation in which various speech actsare performed; Thomason’s paper uses a version of circumscription theory based onMontague’s Intensional Logic (rather than on extensional second-order logic) to modela very simple example. The author hoped that using a more elaborate theory of mutualdefaults, it would be possible to model the effects of some conversational implica-tures, but it appears that that the conversational phenomena are too complex to modelwith even these very powerful formal tools.
References
Appelt, D., Konolige, K., 1988. A practical nonmonotonic theory for reasoning about SpeechActs. 26th Annual Meeting of the Association for Computational Linguistics: Proceed-ings of the Conference, Association for Computational Linguistics. Morristown, NJ,pp. 170–178.
Archangeli, D., 1988. Aspects of underspecification theory. Phonology 5, 183–207.Aronoff, M., 1976. Word Formation in Generative Grammar. MIT Press, Cambridge, MA.Asher, N., Morreau, M., 1991. Commonsense entailment: a modal theory of nonmonotonic
reasoning, in: Mylopoulos, J., Reiter, R. (Eds.), Proceedings of the Twelfth Interna-tional Joint Conference on Artificial Intelligence. Morgan Kaufmann, Los Altos, CA,pp. 387–392.
Asher, N., 1992. A default, truth conditional semantics for the progressive. Ling. Philos. 15,469–508.
Bach, E., 1989. Informal Lectures on Formal Semantics. State University of New York Press,Albany, NY.
Baader, F., Hollunder, B., 1992. Embedding defaults into terminological knowledge representa-tion systems, in: Nebel, B., Rich, C., Swartout, W. (Eds.), Principles of Knowledge Repre-sentation and Reasoning. Morgan Kaufmann, San Mateo, CA, pp. 306–317.
Belnap, N., Perloff, M., 1990. Seeing to it that: a canonical form for agentives, in: Kyburg, H.,et al. (Eds.), Knowledge Representation and Defeasible Reasoning. Kluwer, Dordrecht,pp. 167–190.
Besnard, P., 1989. Default Logic. Springer, Berlin.
88 See Thomason (1990).

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 831 — #51
Non-monotonicity in Linguistics 831
Blackburn, P., 1992. Modal logic and attribute value structures, in: deRijke, M. (Ed.), Diamondsand Defaults. Kluwer, Dordrecht, pp. 19–65.
Bird, S., 1990. Constraint-Based Phonology. PhD Dissertation, University of Edinburgh,Edinburgh, Scotland.
Bird, S., 1995. Computational Phonology: A Constraint-Based Approach. Cambridge Univer-sity Press, Cambridge, UK.
Bird, S., Calder, J., 1991. Defaults in underspecification phonology, in: Kamp, H. (Ed.), DefaultLogics for Linguistic Analysis. DYANA Deliverable R2.5.B, Stuttgart, pp. 129–139.
Bird, S., Ellison, T., 1994. One level phonology: autosegmental representations and rules asfinite automata. Comput. Ling. 20 (1), 55–90.
Bird, S., Klein, E., 1994. Phonological analyses in typed feature structures. Comput. Ling. 20,455–491.
Boguraev, B., Pustejovsky, J., 1990. Lexical ambiguity and the role of knowledge represen-tation in Lexicon design. Proceedings of the 13th International Conference on Computa-tional Linguistics. Helsinki, Association for Computational Linguistics. Morristown, NJ,pp. 36–42.
Bouma, G., 1992. Feature structures and nonmonotonicity. Comput. Ling. 18, 165–172.Boutilier, C., 1992. Conditional Logics for Default Reasoning and Belief Revision. Tech-
nical Report KRR-TR-92-1. Computer Science Department, University of Toronto,Toronto, ON.
Brachman, R., 1985. I lied about the trees or, defaults and definitions in knowledge representa-tion. Artif. Intell. Mag. 6, 80–93.
Bresnan, J. (Ed.), 1982. The Representation of Grammatical Relations. MIT Press,Cambridge, MA.
Brewka, G., 1991. Nonmonotonic Reasoning: Logical Foundations of Commonsense.Cambridge University Press, Cambridge, UK.
Brewka, G., 1993. Adding Priorities and Specificity to Default Logic. DMG Technical Report,Gesellschaft für Mathematik und Datenverarbeitung, Sankt Augustin, Germany.
Brewka, G., 1994. Reasoning about priorities in default logic, in: Hayes-Roth, B., Korf, R.(Eds.), Proceedings of the Twelfth National Conference on Artificial Intelligence. AAAIPress, Menlo Park, CA, pp. 940–945.
Briscoe, T., 1993. Introduction, in: Briscoe, T., et al. (Eds.), Inheritance, Defaults, and the Lex-icon. Cambridge University Press, Cambridge, UK, pp. 1–12.
Briscoe, T., De Paiva, V., Copestake, A. (Eds.), 1993. Inheritance, Defaults, and the Lexicon.Cambridge University Press, Cambridge, UK.
Briscoe, T., Copestake, A., Lascarides, A., 1995. Blocking, in: Saint-Dizier, P., Viegas, E. (Eds.),Computational Lexical Semantics. Cambridge University Press, UK, pp. 273–302.
Carlson, G., Pelletier, F.J. (Eds.), 1995. The Generic Book. Chicago University Press,Chicago, IL.
Carpenter, B., 1993. Skeptical and credulous default unification with applications to templatesand inheritance, in: Briscoe, T., Copestake, A., de Paiva, V. (Eds.), Inheritance, Defaults,and the Lexicon. Cambridge University Press, Cambridge, UK, pp. 13–37.
Carpenter, B., 1992. The Logic of Typed Feature Structures. Cambridge University Press,Cambridge, UK.
Chellas, B., 1980. Modal Logic: An Introduction. Cambridge University Press, Cambridge, UK.Chomsky, N., Halle, M., 1968. The Sound Pattern of English. Harper and Row, New York.Church, A., 1940. A formulation of the simple theory of types. J. Symb. Logic 5, 56–68.Cohen, P., Perrault, C.R., 1987. Elements of a plan-based theory of speech acts. Cogn. Sci. 3,
117–212.

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 832 — #52
832 Handbook of Logic and Language
Cohen, P., Levesque, H., 1985. Speech Acts and Rationality. 23rd Annual Meeting of the Asso-ciation for Computational Linguistics: Proceedings of the Conference. Association forComputational Linguistics. pp. 49–59.
Cohen, P., Levesque, H., 1987. Rational Interaction as the Basis for Communication. TechnicalReport, Center for the Study of Language and Information.
Copestake, A., 1993. Defaults in lexical representation, in: Briscoe, E.J., Copestake, A.,de Paiva, V. (Eds.), Inheritance, defaults and the lexicon. Cambridge University Press,Cambridge, UK, pp. 223–245.
Daelemans, W., 1987a. Studies in Language Technology: An Object-oriented Computer Modelof Morphophonological Aspects of Dutch. PhD Dissertation, Katholieke UniversiteitLeuven.
Daelemans, W., 1987b. A tool for the automatic creation, extension, and updating of lexicalknowledge bases. Proceedings of the Third Conference of the European Chapter of theAssociation for Computational Linguistics. Copenhagen, Morristown, NJ, pp. 70–74.
Daelemans, W., De Smedt, K., Gazdar, G., 1992. Inheritance in natural language processing.Comput. Ling. 18, 205–218.
Davis, E., 1990. Representations of Commonsense Knowledge. Morgan Kaufmann, Los Altos,CA.
De Smedt, K., 1984. Using object-oriented knowledge-representation techniques in morphol-ogy and syntax programming. Proceedings, Sixth European Conference on Artificial Intel-ligence. Elsevier, Amsterdam, pp. 181–184.
De Smedt, K., 1990. Incremental Sentence Generation: A Computer Model of GrammaticalEncoding. PhD Dissertation, Katholieke Universiteit te Nijmegen. Also, Nijmegen Insti-tute for Cognition Research and Information Technology Technical Report 90-01, 1990.
Delgrande, J., 1988. An approach to default reasoning based on a first-order conditional logic:revised report. Artif. Intell. 36, 63–90.
Delgrande, J., Schaub, T., 1994. A general approach to specificity in default reasoning, in:Doyle, J., Sandewall, E., Torasso, P. (Eds.), Principles of Knowledge Representation andReasoning. Morgan Kaufmann, San Mateo, CA, pp. 146–157.
Devanbu, P., Litman, D., 1991. Plan-based terminological reasoning, in: Allen, J., Fikes, R.,Sandewall, E. (Eds.), Principles of Knowledge Representation and Reasoning. MorganKaufmann, San Mateo, CA, pp. 128–138.
Dowty, D., 1979. Word Meaning and Montague Grammar. Reidel, Dordrecht.Evans, R., Gazdar, G., 1989a. Inference in DATR, Proceedings, Fourth Meeting of the European
Chapter of the Association for Computational Linguistics. Manchester, pp. 66–71.Evans, R., Gazdar, G., 1989b. The semantics of DATR, in: Cohn, A. (Ed.), Proceedings, Seventh
Conference of the Society for the Study of Artificial Intelligence and the Simulation ofBehaviour. Pitman/Morgan Kaufmann, London, pp. 79–87.
Evans, R., Gazdar, G. (Eds.), 1990. The DATR papers. Technical Report, Cognitive StudiesProgramme. The University of Sussex, UK.
Evans, R., Gazdar, G., Moser, L., 1994. Prioritized multiple inheritance in DATR, in: Briscoe,et al. (1993), pp. 38–46.
Fahlman, S., 1979. NETL: A System for Representing and Using Real-World Knowledge. MITPress, Cambridge, MA.
Flickinger, D., 1987. Lexical Rules in the Hierarchical Lexicon. PhD thesis, Stanford University,Stanford, CA.

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 833 — #53
Non-monotonicity in Linguistics 833
Flickinger, D., Nerbonne, J., 1992. Inheritance and complementation: a case study of easy adjec-tives and related nouns. Comput. Ling. 18, 269–310.
Gazdar, G., 1987. Linguistic Applications of Default Inheritance Mechanisms. TechnicalReport, Cognitive Studies Programme, The University of Sussex, 1985. Linguistic The-ory and Computer Applications, Whitelock, P., et al. (Eds.), Academic Press, New York,pp. 37–67.
Gazdar, G., Klein, E., Pullum, G., Sag, I., 1985. Generalized Phrase Structure Grammar. Black-well, Oxford, England; Harvard University Press, Cambridge, MA.
Geffner, H., 1992. Default Reasoning: Causal and Conditional Theories. MIT Press, Cambridge,MA.
Geffner, H., Pearl, J., 1992. Conditional entailment: bridging two approaches to default reason-ing. Artif. Intell. 53, 209–244.
Ginsberg, M. (Ed.), 1988a. Nonmonotonic Reasoning. Morgan Kaufmann, Los Altos, CA.Ginsberg, M., 1988b. Introduction, in: Ginsberg, M. (Ed.) (1988a), Nonmonotonic Reasoning.
Morgan Kaufmann, Los Altos, CA, pp. 1–23.Ginsberg, M., 1988c. Multi-valued logics: a uniform approach to reasoning in artificial intelli-
gence. Comput. Intell. 4, 265–316.Grice, H.P., 1989. Studies in the Way of Words. Harvard University Press, Cambridge, MA.Guerreiro, R.A. de T., Hemerly, A., Shoham, Y., 1990. On the complexity of monotonic inher-
itance with roles, AAAI-90. Proceedings of the Ninth National Conference on ArtificialIntelligence. AAAI Press, Menlo Park, CA; MIT Press, Cambridge, MA, 627–632.
Guha, R., 1991. Contexts: A formalization and Some Applications. Technical Report STAN-CS-91-1399, Stanford University Computer Science Department, Stanford, CA.
Hobbs, J., Stickel, M., Appelt, D., Martin, P., 1993. Interpretation as abduction. Artif. Intell. 63,69–142.
Hobbs, J., Moore, R. (Eds.), 1985. Formal Theories of the Commonsense World, Ablex,Norwood, NJ.
Horty, J., 1994. Some direct theories of nonmonotonic inheritance, in: Gabbay, D., Hogger, C.,Robinson, J. (Eds.), Handbook of Logic in Artificial Intelligence and Logic Programming,vol. 3. Nonmonotonic Reasoning and Uncertain Reasoning. Oxford University Press, UK,pp. 111–187.
Horty, J., Thomason, R., 1988. Mixing strict and defeasible inheritance. Proceedings of AAAI-88. Morgan Kaufmann, Los Altos, CA.
Horty, J., Thomason, R., Touretzky, D., 1988. A skeptical theory of inheritance in nonmono-tonic semantic nets, AAAI-87. Proceedings of the Sixth National Conference on ArtificialIntelligence, vol. 2. Morgan Kaufmann, Los Altos, CA, pp. 358–363.
Horty, J., Thomason, R., 1990. Boolean extensions of inheritance networks. Proceedings ofAAAI-90. Morgan Kaufmann, Los Altos, CA, pp. 663–669.
Horty, J., Thomason, R., 1991. Conditionals and artificial intelligence. Fund. Inform. 15,301–324.
Kaplan, R., 1987. Three seductions of computational linguistics, in: Whitelock, P., et al. (Eds.),Linguistic Theory and Computer Applications. Academic Press, London, pp. 149–188.
Kay, M., 1992. Unification, in: Rosner, M., Johnson, R. (Eds.), Computational Linguistics andFormal Semantics. Cambridge University Press, Cambridge, UK, pp. 1–29.
Keller, B., 1995. DATR theories and DATR models. Proceedings of the 33rd Meeting ofthe Association for Computational Linguistics. Morgan Kaufmann, San Mateo, CA,pp. 55–69.

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 834 — #54
834 Handbook of Logic and Language
Kilgarrif, A., 1995. Inheriting polysemy, in: Saint-Dizier, P., Viegas, E. (Eds.), ComputationalLexical Semantics. Cambridge University Press, Cambridge, UK, pp. 319–335.
Kiparsky, P., 1973. Elsewhere in phonology, in: Anderson, S., Kiparsky, P. (Eds.), A Festschriftfor Morris Halle. Holt, Reinhart and Winston, New York, pp. 93–106.
Konolige, K., 1988. On the relation between default and autoepistemic logic. Artif. Intell. 35,343–382.
Krifka, M., Pelletier, F.J., Carlson, G., Ter Meulen, A., Chierchia, G., Link, G., 1995. Genericity:an introduction, in: Carlson, G., Pelletier, F.J. (Eds.), The Generic Book, pp. 1–124.
Krieger, H.U., Nerbonne, J., 1993. Feature-based inheritance networks for computational lex-icons, in: Briscoe T., Copestake A., de Paiva, V. (Eds.), Default Inheritance withinUnification-Based Approaches to the Lexicon. Cambridge University Press, Cambridge,UK, pp. 90–136.
Lascarides, A., Oberlander, J., 1991. Temporal coherence and defeasible knowledge. Proceed-ings of the Workshop on Discourse Coherence. Edinburgh.
Lascarides, A., Asher, N., 1991. Discourse relations and common sense entailment. Proceed-ings of the 29th Meeting of the Association for Computational Linguistics, Berkeley, CA,pp. 55–63.
Lascarides, A., Asher, N., 1993a. Temporal interpretation, discourse relations and commonsense entailment. Ling. Philos. 16, 437–494.
Lascarides, A., Asher, N., 1993b. Lexical disambiguation in a discourse context. TechnicalReport, Centre for Cognitive Science, University of Edinburgh, Edinburgh, UK.
Lascarides, A., Asher, N., Briscoe, T., Copestake, A., 1995. Order independent and persis-tent typed default unification, vol. 19. Linguistics and Philosophy. Springer, Netherlands,pp. 1–90.
Lewis, D., 1973. Counterfactuals. Harvard University Press, Cambridge, MA.Levesque, H., 1990. All I know: a study in autoepistemic logic. Artif. Intell. 42, 263–309.Lifschitz, V., 1986. Pointwise circumscription. Proceedings of AAAI-86. Morgan Kaufmann,
Los Altos, CA, pp. 406–410.Lifschitz, V., 1989. Circumscriptive theories, in: Thomason, R. (Ed.), Philosophical Logic and
Artificial Intelligence. Reidel, Dordrecht, pp. 109–159.Lukaszewicz, W., 1985. Two results on default logic, in: Joshi, A. (Ed.), Proceedings of the
Ninth International Joint Conference on Artificial Intelligence. Morgan Kaufmann, LosAltos, CA, pp. 459–461.
Marek, W., Truszczyński, M., 1989. Relating autoepistemic and default logics, in: Brachman,R., Levesque, H., Reiter, R. (Eds.), Proceedings of the First International Conference onPrinciples of Knowledge Representation and Reasoning. Morgan Kaufmann, Los Altos,CA, pp. 276–288.
Mastroianni, M., Carpenter, B., 1994. Constraint-based morpho-phonology. Proceedings of theFirst Meeting of the Association for Computational Phonology. Association for Computa-tional Linguistics, New Mexico, pp. 13–24.
McCarthy, J., 1980. Circumscription – a form of nonmonotonic reasoning. Artif. Intell. 13,27–39.
McCarthy, J., Prince, A., 1993. Prosodic Morphology I. Technical Report TR-3, Center forCognitive Science, Rutgers University Center for Cognitive Science, New Jersey.
McDermott, D., Doyle, J., 1980. Nonmonotonic logic I. Artif. Intell. 13, 41–72.Mercer, R., Reiter, R., 1982. The representation of presuppositions using defaults. Proceedings
of the Fourth National Conference of the Canadian Society for Computational Studies ofIntelligence Conference. Saskatoon, pp. 103–107.

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 835 — #55
Non-monotonicity in Linguistics 835
Mercer, R., 1987. A Default Logic Approach to the Derivation of Natural Language Presuppo-sitions. Doctoral thesis, Department of Computer Science, University of British Columbia.Available as Technical Report TR 87-35, Department of Computer Science, University ofBritish Columbia, Canada.
Mercer, R., 1988. Using default logic to derive natural language presupposition. Proceedings ofthe Canadian Society for Computational Studies of Intelligence Conference. Edmonton.
Meyer, B., 1988. Object-Oriented Software Construction. Prentice-Hall, New York.Moore, R., 1985. Semantical considerations on nonmonotonic logic. Artif. Intell. 25, 75–94.Montague, R., 1969. On the nature of certain philosophical entities, in: Thomason, R. (Ed.),
Formal Philosophy: Selected Papers of Richard Montague. Yale University Press, NewHaven, CT, pp. 148–187.
Morreau, M., 1992a. Epistemic semantics for conditionals. J. Philos. Logic 21, 33–62.Morreau, M., 1992b. Conditionals in Philosophy and Artificial Intelligence. PhD Dissertation,
University of Amsterdam, Faculteit Wiskunde en Informatica.Morreau, M., 1995. Allowed inference. Proceedings of the Fourteenth International
Joint Conference on Artificial Intelligence. Morgan Kaufmann, San Mateo, CA,pp. 1466–1473.
Penn, G., Thomason, R., 1994. Default finite state machines and finite state phonology. Proceed-ings of the First Meeting of the Association for Computational Phonology. Association forComputational Linguistics. Las Cruces, New Mexico, pp. 33–42.
Perrault, C.R., 1990. An application of default logic to speech act theory, in: Cohen, P.,Morgan, J., Pollack, M. (Eds.), Intentions in Communication. MIT Press, Cambridge, MA,pp. 161–185.
Pollard, C., Sag, I., 1987. Information-Based Syntax and Semantics. CSLI, Stanford, CA.Prince, A., Smolensky, P., 1993. Optimality Theory: Constraint Interaction in Generative Gram-
mar. Technical Report TR-2, Center for Cognitive Science, Rutgers University Center forCognitive Science, New Jersey.
Pustejovsky, J., 1991. The generative lexicon. Comput. Ling. 17, 409–441.Quantz, J.J., Royer, V., 1992. A preference semantics for defaults in terminological logics, in:
Nebel, B., Rich, C., Swartout, W. (Eds.), Principles of Knowledge Representation andReasoning. Morgan Kaufmann, San Mateo, CA, pp. 294–305.
Reiter, R., 1980. A logic for default reasoning. Artif. Intell. 13, 81–132.Reiter, R., 1988. Nonmonotonic reasoning, in: Shrobe, H. (Ed.), Exploring Artificial Intelli-
gence. Morgan Kaufmann, San Mateo, CA, pp. 439–482.Rounds, W., Zhang, G.-Q., 1995. Domain theory meets default logic. Logic Comput. 5, 1–25.Rounds, W., Zhang, G.-Q., 1997. Logical considerations on default semantics. Ann. Math. Artif.
Intell. 20 (1–4), 195–226.Rounds, W., Zhang, G.-Q., 1995. Suggestions for a non-monotonic feature logic. CWI Technical
Report CS-R9551, ISSN 0169-118X, Amsterdam.Russell, G., Carroll, J., Warwick, S., 1991. Multiple default inheritance in a unification-based
lexicon. 29th Meeting of the Association for Computational Linguistics: Proceedings ofthe Conference, Association for Computational Linguistics. Tilburg University, the Nether-lands. pp. 211–215.
Saint-Dizier, P., Viegas, E. (Eds.), 1995. Computational Lexical Semantics. Cambridge Univer-sity Press, Cambridge, UK.
Scobbie, J., 1991. Attribute Value Phonology. PhD Dissertation, University of Edinburgh,Edinburgh, Scotland.

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 836 — #56
836 Handbook of Logic and Language
Sells, P., 1985. Lectures on Contemporary Syntactic Theories. Center for the Study of Languageand Information, Stanford, CA.
Shieber, S., 1986. An Introduction to Unification-Based Approaches to Grammar. CSLI LectureNotes no.4, University of Chicago Press, Chicago, IL.
Shieber, S., 1987. Separating linguistic analyses from linguistic theories, in: Whitelock, P., et al.(Eds.), Linguistic Theory and Computer Applications. Academic Press, London, pp. 1–36.
Shieber, S., 1992. Constraint-Based Grammar Formalisms: Parsing and Type Inference for Nat-ural and Computer Languages. MIT Press, Cambridge, MA.
Shoham, Y., 1988. Reasoning About Change: Time and Causation from the Standpoint of Arti-ficial Intelligence. MIT Press, Cambridge, MA.
Shoham, Y., 1990. Nonmonotonic reasoning and causation. Cogn. Sci. 14, 213–252.Shoham, Y., 1991. Remarks on Simon’s comments. Cogn. Sci. 15, 300–303.Simon, H., 1991. Nonmonotonic reasoning and causation: comment. Cogn. Sci. 15, 293–300.Spencer, A., 1991. Morphological Theory. Cambridge University Press, Cambridge, UK.Sproat, R., 1992. Morphology and Computation. MIT Press, Cambridge, MA.Stalnaker, R., Thomason, R., 1970. A semantic analysis of conditional logic. Theoria 36, 23–42.Steedman, M., Moens, M., 1987. Temporal ontology in natural language. Proceedings of the
25th Annual Conference of the Association for Computational Linguistics. Associationfor Computational Linguistics, Morristown, NJ, pp. 1–7.
Thomason, R., Horty, J., Touretzky, D., 1987. A calculus for inheritance in monotonic semanticnets, in: Ras, Z., Zemankova, M. (Eds.), Methodologies for Intelligent Systems. North-Holland, Amsterdam, pp. 280–287.
Thomason, R., 1990. Propagating epistemic coordination through mutual defaults I, in: Parikh,R. (Ed.), Proceedings of the Third Conference on Theoretical Aspects of Reasoning aboutKnowledge. Morgan Kaufmann, San Mateo, CA, pp. 29–39.
Thomason, R., Touretzky, D., 1990. Inheritance theory and networks with roles, in: Sowa, J.(Ed.), Principles of Semantic Networks. Morgan Kaufmann, Los Altos, CA, pp. 231–266.
Thomason, R., 1991. Logicism, artificial intelligence, and common sense: John McCarthy’sprogram in philosophical perspective, in: Lifschitz, V. (Ed.), Artificial Intelligence andMathematical Theory of Computation. Academic Press, San Diego, CA, pp. 449–466.
Thomason, R., 1992. NETL and subsequent path-based inheritance theories. Comput. Math.Appl. 23, 179–204. Reprinted in Semantic Networks in Artificial Intelligence, Lehmann,F. (Ed.), Pergamon, Oxford, pp. 179–204.
Thomason, R., 1994. Non-monotonic formalisms for lexical semantics. Unpublished manu-script. Currently available via www.pitt.edu/thomason/thomason.html.
Touretzky, D., 1986. The Mathematics of Inheritance Theories. Morgan Kaufmann, San Mateo,CA.
Veltman, F., 1996. Defaults in update semantics. J. Philos. Logic. 25, 221–261.Vennemann, T., 1972. Phonological uniqueness in natural generative grammar. Glossa 6,
105–116.Wainer, J., 1991. Uses of Nonmonotonic Logic in Natural Language Understanding: Generali-
zed Implicatures. PhD Dissertation, The Pennsylvania State University, State College, PA.Winston, P., 1984. Artificial Intelligence, second ed. Addison-Wesley, Reading, MA.Woods, W., Schmolze, J., 1992. The kl-one family. Comput. Math. Appl. 23, 133–179.
Reprinted in Semantic Networks in Artificial Intelligence, Lehmann, F. (Ed.), Pergamon,Oxford, pp. 133–179.
Young, M., 1992. Nonmonotonic sorts for feature structures. Proceedings of AAAI-92. SanJose, CA, pp. 596–601.

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 837 — #57
Non-monotonicity in Linguistics 837
Young, M., 1994. Features, Unification, and Nonmonotonicity. PhD thesis, University of Michi-gan, Ann Arbor, MI.
Young, M., Rounds, W., 1993. A logical semantics for nonmonotonic sorts. Proceedings ofACL-93. Columbus, OH, pp. 209–215.
Zdonik, S., Maier, D., 1990. Readings in Object-Oriented Database Systems. Morgan Kauf-mann, San Mateo, CA.
Zhang, G.-Q., Rounds, W., 1997. Non-monotonic consequences in default domain theory. Ann.Math. Artif. Intell. 20 (1–4), 227–265.
Zwicky, A., 1986. The general case: basic form versus default forms, in: Nikiforidou, V., et al.(Eds.), Proceedings of the Twelfth Annual Meeting of the Berkeley Linguistics Society.Berkeley Linguistics Society, Berkeley, CA, pp. 305–314.
Zwicky, A., 1989. What’s become of derivations? Defaults and invocations, in: Hall, K., et al.(Eds.), Proceedings of the Fifteenth Annual Meeting of the Berkeley Linguistics Society.Berkeley Linguistics Society, Berkeley, CA, pp. 303–320.

“21-ch17-0781-0838-9780444537263” — 2010/11/29 — 21:08 — page 838 — #58
This page intentionally left blank

“22-ch18-0839-0856-9780444537263” — 2010/11/30 — 3:44 — page 839 — #1
18 Non-Monotonic Reasoningin Interpretation(Update of Chapter 17)Robert van Rooij !, Katrin Schulz†
!Faculteit der Geesteswetenschappen, ILLC,Universiteit van Amsterdam, P.O. Box 94242,1090 GE Amsterdam, The Netherlands,E-mail: [email protected]
†Faculteit der Geesteswetenschappen, ILLC,Universiteit van Amsterdam, P.O. Box 94242,1090 GE Amsterdam, The Netherlands,E-mail: [email protected]
18.1 Introduction
The previous chapter by Thomason pursues two goals: first to outline the central log-ical issues of non-monotonic reasoning, and second to indicate possible applicationsof non-monotonic reasoning techniques in linguistics. This chapter will follow up onThomason’s second goal and show that linguists have taken up his invitation to usenon-monotonic logic as a formal tool. Particularly in the new and very vivid areaof formal pragmatics, and at the intersection of semantics and cognitive psychology,non-monotonic logics are playing an important role.
The chapter is structured as follows. The purpose of its first part is to present therecent progress made in formal pragmatics by using non-monotonic logic to describepragmatic meaning. We will show how minimal models can be used to describe andexplain inferences of language use, in particular Gricean conversational implicatures.After this we will discuss how non-monotonic logic can be used at the semantic-pragmatic interface to account for the preferred interpretation of a sentence. In the lastpart of the chapter we will discuss the role of non-monotonic logic for human reason-ing in general. Here we will focus in particular on Stenning and van Lambalgen (2008).
18.2 Implicatures as Non-Monotonic Inferences
18.2.1 Grice’s Theory of Conversational ImplicaturesWe often make assumptions based on what is not said, and communicators make useof this. The standard example for this type of reasoning in artificial intelligence isthe following: if a timetable does not mention any direct flight from A to B, we
Handbook of Logic and Language. DOI: 10.1016/B978-0-444-53726-3.00018-9c" 2011 Elsevier B.V. All rights reserved.

“22-ch18-0839-0856-9780444537263” — 2010/11/29 — 21:08 — page 840 — #2
840 Handbook of Logic and Language
routinely assume that no such flight exists, which, in turn, allows the planner to rep-resent this information simply by not listing such a flight. This type of reasoning iscalled in AI “Negation as Failure”. Such reasoning is defeasible, however, becausethe underlying ‘convention’ can be explicitly abrogated or suspended. Many systemsof non-monotonic reasoning developed within AI—e.g. McCarthy’s Circumscription(McCarthy, 1980, 1986) and various variants of Logic Programming—are meant toaccount for this type of defeasible reasoning.
In linguistics inferences of this type, going beyond what the sentence explicitlysays, are called conversational implicatures. They are often illustrated with exampleslike the following: if the question whether Mr. X is a good linguist is answered by“Well, he speaks excellent English”, you normally will infer that he is not a goodlinguist. The fact that this type of inference can be thought of in terms of negation asfailure strongly suggests that such inferences can be modeled in terms of systems ofnon-monotonic reasoning. The purpose of the first part of this chapter is to work outthis suggestion.
Conversational implicatures are in linguistics essentially connected with the nameof Paul Grice (Grice, 1989), who proposed the name and claimed that these infer-ences play an important and systematic role in interpretation and need the theoreticalattention of linguists. Grice proposed that conversational implicatures result from theassumption that speakers obey a number of maxims of conversation—the maxims ofquality, quantity, relevance, and manner. These maxims—best thought of as rules ofthumb of how speakers (ought to) behave—are stated in a very informal way. Overthe years many phenomena have been explained in terms of the Gricean maxims ofconversation and especially the first submaxims of quantity: Make your contributionas informative as is required (for the current purposes of the exchange).
The most famous class of inferences that have been explained using this maximare the scalar implicatures (see Horn (1972), Gazdar (1979) and many others). Clas-sical examples of scalar implicature are, for instance, the inferences from ‘! or "’ to‘not (! and ")’ and from ‘John has two children’ to ‘John doesn’t have more thantwo children’. According to the standard analysis, scalar implicatures are thought ofas generalized conversational implicatures (GCIs) triggered by specific lexical items.Specific items like ‘some’, ‘or’, ‘two’, and ‘possible’ are said to come with a conven-tionally given scale of alternative expressions which determine what the implicatureis. If two lexical expressions S(trong) and W(eak) form a conventionally given linearscale, !S, W", a (non-complex) sentence in which the weaker expression W occurswill, according to the GCI view on implicatures, always trigger the implicature thatthe corresponding stronger sentence where S is substituted for W is not true. Horn,Gazdar, and others argued that we require such linguistically given scales, because anunlimited use of negation as failure in the message will overgenerate enormously.
18.2.2 Scalar Implicatures in Empirical Perspective
Based on the idea that scalar implicatures are due to interpretation by default, trig-gered by a conventional given scale, prompted Levinson (2000) to make the strong

“22-ch18-0839-0856-9780444537263” — 2010/11/29 — 21:08 — page 841 — #3
Non-Monotonic Reasoning in Interpretation 841
psychological claim that scalar implicatures are fast and automatic inferences, i.e.inferences which don’t take any more time to draw than inferences based on stan-dard semantic/conventional meaning. Psycholinguistic evidence of at least three dif-ferent types strongly suggests that scalar implicatures should not be accounted foras automatic, ‘grammatical-like’ inferences as suggested by Levinson. The first typeof evidence comes from psychological research on human reasoning (e.g. Evans andNewstead (1980); Paris (1973)).1 In this type of research, participants are presentedwith simple sentences in which a scalar term like ‘or’ occurs, such that: (i) the disjunc-tive sentences are completely unrelated to each other (as in ‘The bird is in the nest, orthe shoe is on the foot’) and (ii) the contextual factors are factored out. It turns out thatmore than two-thirds of the participants prefer (in our terms) the reading without thescalar implicature to the one with the implicature. This suggests that scalar inferencesare anything but ‘automatic’.2
The second type of evidence pointing in the same direction is that especially youngchildren are bad in inferring scalar implicatures. Noveck (2001), for instance, finds thatin contrast to adults, most children below age four treat ‘Some elephants have trunks’as not being false or misleading if all (shown) elephants have trunks. Later exper-iments (e.g. Papafragou and Tantalou (2004); Pouscoulous (2006)) have confirmedthese results. Other well-known experiments (such as ‘False belief’-tasks) indicatethat very young children cannot reason about other people’s beliefs, goals, and inten-tions. This suggests that these abilities are also needed to account for the derivation ofscalar implicatures, which rules out a ‘grammatical-like’ view on them.
One reason such abilities might be relevant is to account for the fact that scalarinferences are context dependent. As observed by Levinson (2000), for instance, thescalar implicature (1-c) of (1-b) due to the !all, some" scale, is not available in the con-text of question (1-a) where all that matters is whether at least some of the documentsare forgeries.
(1) a. Is there any evidence against them?b. Some of their identity documents are forgeries.c. Not all of their identity documents are forgeries.
Levinson (2000) accounts for this by proposing that the implicature is still triggered,but later cancelled for reasons of relevance. Alternatively, one might propose that itdepends on what is taken to be relevant by speaker and hearer whether an implica-ture is even triggered.3 Most naturally, only Levinson’s proposal predicts that in thecontext of question (1-a) the reading time of (1-b) takes longer than when the latterwas uttered in a more neutral context. Looking at the reading times of expressions
1 Thanks to Bart Geurts for pointing us to this literature.2 A different experiment, but leading to the same conclusion, is conducted by Breheny (2006). He looks
at the difference between the time needed to read and comprehend a sentence with and without animplicature.
3 Proponents of this alternative view of scalar implicatures include Hirschberg (1985), van Kuppevelt(1996), Carston (1998), and the present authors.

“22-ch18-0839-0856-9780444537263” — 2010/11/29 — 21:08 — page 842 — #4
842 Handbook of Logic and Language
containing scalar terms in different types of contexts, Noveck and Posada (2003),Bott and Noveck (2004), Breheny and Williams (2006), and Zondervan (in press)consistently find that this prediction of Levinson is wrong.4 A natural conclusion isthat whether a scalar implicature is triggered depends on what is relevant in the con-text. For instance, on which question the sentence in which the trigger occurs gives ananswer to.
18.2.3 Scalar Implicatures in Minimal Models
In the previous section we have seen that there is good empirical evidence that scalarimplicatures are pragmatic inferences that are dependent on the utterance context. Inthis section we focus on formally describing these implicatures with their characteris-tic properties.
Scalar implicatures can often be paraphrased in terms of ‘only’. In a context whereit is relevant how many students passed, for example, (2-a) gives rise to the scalarimplicature that not all students passed. This inference can also be derived from(2-b)—but now it follows from the semantic meaning of the sentence.
(2) a. Some of the students passed.b. Only [some]F of the students passed.5
Given this, it is natural to connect the analysis of scalar implicatures with the semanticanalysis of ‘only’. The standard analyses (especially Krifka (1995); Rooth (1985))of ‘only’ proposes that ‘Only !’ should be interpreted as (3)6 ([[!]] stands for thedenotation of ! and Alt(!) for the set of alternatives of !.)
(3) [[only(!, Alt(!))]]def= {w # [[!]]|$" # Alt(!) : w # [["]] % [[!]] & [["]]}.
To account for the scalar implicatures of ‘!’, one could assume that a sentence simplyhas a silent ‘only’ in front of it, which we will call ‘Prag’:7
(4) Prag(!, Alt(!))def= {w # [[!]]|$" # Alt(!) : w # [["]] % [[!]] & [["]]}.
In case the alternative of (2-a) is ‘All of the students passed’, the desired scalar impli-cature is indeed accounted for.
McCawley (1993) noticed that in case one scalar item is embedded under anotherone—as in (5),8—an interpretation rule like Prag does not give rise to the desiredprediction that only one student passed.
4 It should be remarked, though, that a substantial ammount of research in this area is performed by pro-ponents of Relevance theory. As an antidote, see Storto and Tannenhaus (2004) for evidence which mightpoint in the opposite direction.
5 The notation [·]F means that the relevant item receives focal stress, i.e. an H'L prosodic contour.6 In this representation the distinction between presupposition and assertion is ignored.7 Krifka (1995) introduces our Prag under the name ‘Scal.Assert’. Chierchia (2008) explicitly propose that
sentences, as well as subsentences, might have such a silent ‘only’ in front of them in their logical form.8 Landman (2000) and Chierchia (2004) discuss structurally similar examples like ‘Mary is either working
at her paper or seeing some of her students.’

“22-ch18-0839-0856-9780444537263” — 2010/11/29 — 21:08 — page 843 — #5
Non-Monotonic Reasoning in Interpretation 843
(5) Alice passed, Bob passed, or Cindy passed.
This observation can be straightforwardly accounted for if we adopt a differentpragmatic interpretation rule together with a different way to determine alternatives.First, we will assume that the set of alternatives is not so much dependent onthe particular sentence ‘!’ that is uttered, but is just a set of sentences L whosetruth or falsity is relevant in the context. What is relevant depends on what isat issue, and if the issue is who passed, it is natural to think of L as a setlike {Alice passed, Bob passed, Cindy passed, Delia passed} (which should perhapsbe closed under conjunction and disjunction). According to the new pragmatic inter-pretation rule—call it PragL—, w is compatible with the pragmatic interpretation of! iff: (i) ! is true in w, and (ii) there is no other world v in which ! is true whereless alternatives in L are true than are true in w, see (6). Notice that by pragmaticallyinterpreting a sentence in terms of PragL, we do not assume, or are not required toassume, that certain expressions come with a conventionally triggered set of alterna-tive expressions which are linearly ordered as was standardly assumed. The pragmaticinterpretation rule PragL correctly predicts that from (5) we can pragmatically infer:(i) that only one of Alice, Bob, and Cindy passed, and (ii) that Delia did not pass.
(6) PragL(!)def= {w # [[!]]|¬(v # [[!]] : $" # L : v # [["]] % w # [["]]}.
As it turns out, this new interpretation rule is closely related to McCarthy (1980)’spredicate circumscription. Circumscription was introduced in AI to account for thetype of reasoning called ‘Negation as Failure’ as mentioned in section 18.2.1. To seethe connection with PragL, let us first observe that PragL describes a minimal inter-pretation of !. Certain worlds among those where ! is true are selected, and theseare worlds that are in some sense minimal. The relevant order is defined in terms ofthe language L. A world is the more minimal, the fewer L-sentences it makes true:v )L w iffdef $" # L : v # [["]] % w # [["]]. In case L is defined as above asdescribing the extension of some predicate, i.e. L consists of sentences P(a), P(b), ...
for some predicate P (probably closed under conjunction and disjunction) and if thelanguage is rich enough, then the order is equivalent to one comparing the extensionof P: v )P w iffdef P(v) & P(w). That means that Prag is equivalent to circ definedas given in (7). But this comes very close to the model theoretic idea of predicate cir-cumscription, in fact it is the special case of McCarthy’s predicate circumscription inwhich everything else in the formal language is allowed to vary.9
(7) circ(!, P)def= {w # [[!]] | ¬(v # [[!]] : v <P w}.
9 There is a strongly related link from linguistics predicate circumscription. As has been pointed out byvan Benthem (1989), predicate circumscription is also closely related to the exhaustivity operator Exhintroduced by Groenendijk and Stokhof (1984). This operator takes as arguments: (i) the predicate P of aquestion, and (ii) the meaning of a term-answer, and turns it into a new formula describing the exhaustiveinterpretation of the answer: exh(F, P) =def F(P) * ¬(P+ & D : F(P+) * P+ , P.

“22-ch18-0839-0856-9780444537263” — 2010/11/29 — 21:08 — page 844 — #6
844 Handbook of Logic and Language
18.2.4 Prospects and Problems of the Circumscription Account
Quite a number of conversational implicatures (including scalar ones) can be accountedfor in terms of a minimal model analysis.10 Except for the obvious result that fromthe answer ‘Alice passed’ to the question ‘Who passed?’ we derive that Alice isthe only one who passed, we also derive: (i) the exclusive reading of a disjunctiveanswer like ‘Alice passed or Bob passed’ to the same question, and (ii) the read-ing that one and only one person passed from ‘Alice passed, Bob passed, or Cindypassed’; (iii) the implicature that not everybody passed from the answer that most did;and (iv) the so-called conversion-inference that only men passed, if the answer is ‘Everyman passed’. We also derive (v) for ‘Alice ate three apples’ that Alice ate exactly threeapples,11 and (vi) the biconditional reading of ‘Alice will pass if Bob will’, if thissentence is given as answer to the polar question ‘Will Alice pass?’. Another pleasingproperty of a circumscription analysis of implicatures is that it predicts that it dependson the context, or question-predicate, whether we observe these inferences.
Schulz and van Rooij (2006) suggest that some obvious problems of standard prag-matic interpretation rules (such as the rule given in Groenendijk and Stokhof (1984) ofexhaustive interpretation) can be solved when we take the minimal models into account.They propose, for instance, that to account for the context-dependence of exhaustiveinterpretation, the beliefs and preferences of agents are relevant to determine the order-ing relation between worlds required to define the minimal models. In this way theyget a better grasp of the context (and relevance) dependence of implicatures, and canaccount for, among others, both mention-all and mention-some readings of answers(which Groenendijk and Stokhof could not). Thinking of pragmatic interpretation interms of minimal models also might help to tackle the so-called functionality problem.The functionality problem follows from the fact that circumscription works immedi-ately on the semantic meaning of an expression. It follows that if two sentences havethe same semantic meaning, they are predicted to give the same implicatures as well.It is, for instance, standardly assumed that ‘three men’ has the same semantic meaningas ‘at least three men’, and that ‘Alice passed or Bob passed’ has the same semanticmeaning as ‘Alice passed, Bob passed, or both passed’. But sentences in which theformer examples occur give rise to a ‘scalar’ implicature, while the latter do not. Thisproblem suggests that the notion of meaning adopted is too coarse-grained.12 Theremight be several ways to solve this problem: Schulz and van Rooij (2006) proposedthat instead of thinking of meanings just in terms of possible worlds, we should thinkof them in terms of world-assignment pairs, as is standard in dynamic semantics. Sevi(2006), instead, proposed to make use of recent insights of how to represent pluralities.
10 Wainer (1991, 2007) also makes use of circumscription to account for scalar implicatures. He doesso, however, by making use of an explicit abnormality predicate in the logical representation of thesentence. Accounting for implicatures in this way is thus not really in the spirit of Grice, though morestandard in AI and also used in Section 18.3 of this chapter.
11 Given an at least semantics for numerals and in the context of a question ‘How many apples did Aliceeat?’.
12 The well-known problem of ‘logical omniscience’ is closely related, and adopting a more fine-grainednotion of meaning has been suggested by various authors to solve this problem as well.

“22-ch18-0839-0856-9780444537263” — 2010/11/29 — 21:08 — page 845 — #7
Non-Monotonic Reasoning in Interpretation 845
18.2.5 Grice and The Theory of ‘Only Knowing’
The interpretation function circ described above only provides a description of certainconversational implicatures, but does not explain where these inferences come from.When Grice discussed conversational implicatures, he wanted to derive them fromhis maxims of conversation. The implicatures discussed above should intuitively bebased on Grice’s maxim of quality, according to which a speaker may only say whathe knows to be true, and his combined maxim of relevance and (the first submaxim of)quantity. In order to make this derivation precise, we would need a formalization ofthe inferences that an interpreter can derive given that she assumes the speaker to obeythese maxims. In a second step we can then evaluate this formalization by comparingits predictions with those made by circ. It turns out that such a formalization can beprovided. It builds on autoepistemic logic (e.g. Levesque (1990)), in particular, ontheories of ‘only knowing’ (Halpern and Moses (1984), van der Hoek et al. (1999)).
The Gricean maxims concern the epistemic state of the speaker. To be able to speakabout what the speaker knows, one can use basic modal logic. Assume that M =!W, R, V" is a Kripke model with W a set of possible worlds, V an interpretationfunction, and R an accessibility relation connecting a world w0 with all those worldsconsistent with what the speaker knows in w0. K! is true given a world w0 and amodel M if ! holds in all worlds w accessible from w0 by R. What kind of informationcan an interpreter infer on hearing an utterance of !? If the interpreter assumes thatthe speaker obeys the maxim of quality, she can conclude that K! holds.13 If ‘K’represents knowledge, it follows that ! is the case.
But how to formalize the maxims of quantity and relevance? How can we formalizethat the speaker has provided with ! all the relevant knowledge she has? FollowingHalpern and Moses (1984), Shoham (1988), and van der Hoek et al. (1999) the ideais again to select for minimal models. But this time minimal means minimal withrespect to the knowledge of the speaker. There are different ways to define orderscomparing what the speaker knows. One way is to use a formal language L. This lan-guage is supposed to express exactly the information relevant in the utterance context.Then one can define an order that compares pairs of a world and a model with res-pect to how many L sentences the speaker knows in them: !M, w" )K
L !M+, w+" iff$# # L : M, w |= K# % M+, w+ |= K#. Based on this order we can define a newGricean interpretation function Grice that is supposed to capture the maxims of qual-ity, quantity, and relevance by selecting among those worlds where the speaker knows! to be true those that are minimal with respect to the newly defined order.14
13 In this way Gazdar (1979) explains why nobody can appropriately say things like ‘The earth is round,but I don’t know it’. A speaker of this sentence violates the maxim of quality, if R is transitive.
14 Some formulas have more than one minimal state. The formula ‘Kp - Kq’, for instance, has two incom-patible minimal states: one in which the speaker only knows p, and one in which she only knows q.Halpern and Moses (1984) dubbed those formulas that don’t have a unique minimal state ‘dishonest’,because one cannot consistently claim that one only knows the information expressed by such a formula.A natural proposal would be that except for selecting minimal states, the maxim of quantity also demandsthat a sentence ! can only be uttered appropriately if it gives rise to a unique minimal state.

“22-ch18-0839-0856-9780444537263” — 2010/11/29 — 21:08 — page 846 — #8
846 Handbook of Logic and Language
(8) GriceL(!)def= {!M, w" # [[K!]] : $!M+, w+" # [[K!]] : !M, w" )K
L !M+, w+"}.
So far we have still left open how exactly the language L, describing what counts asrelevant information, has to be defined. This is not at all trivial. For instance, if Lcontains all epistemic formulas, then no two knowledge states are comparable.15 Achoice that works well is to select a set of relevant primitive expressions and closethis set under conjunction and disjunction. It remains to be seen whether this kind ofpositive closure can be given a Gricean motivation.
Let us now assume that what is relevant in a particuar context is the extension ofsome predicate P. In this case L is determined as the positive closure of primitive sen-tence P(a), P(b), ...—let us call this language L+(P). The approach just developedallows one then to derive from the assertion ‘P(a)’ that the speaker doesn’t knowthat ‘P(a) * P(b)’ is true, and thus that the speaker doesn’t know that ‘P(b)’ is true.Similarly, from the assertion ‘[Alice or Bob]F passed’ we conclude that the speakerdoes not know of anybody that he or she passed. This is a nice result, but in manycases we conclude something stronger: in the first example that Bob did not pass, andsomething similar for the second example. How do we account for this extra infer-ence in terms of our modal-logical setting? This can be accounted for by assumingthat speakers, in addition to obeying the Gricean maxims, are maximally competent(as far as this is consistent with obeying these maxims).16 This can be described byselecting among the elements of GriceL+(P)(!), the ones where the competence of thespeaker with respect to the extension of property P is maximal. This can be formal-ized using the same techniques as before. We simply use as order-defining languagethe full closure of the primitive sentences P(a), P(b), ...17—let us call this languageL(P). On the result of the function Grice we define a new order .K
P comparing thespeaker’s knowledge on P relative to L(P). This order is then used in the definition ofa new interpretation function Comp selecting model-world pairs where the speaker ismaximally competent—see (9). Comp applied on top of Grice gives us then our newpragmatic interpretation function.
(9) CompL(P)(S)def= {!M, w" # S : $!M+, w+" # S : !M, w" /K
L(P) !M+, w+"}.
By Comp we strengthen the Gricean inference that the speaker does not know, forinstance, that Bob passed from the utterance of ‘Alice passed’ to the inference that thespeaker knows that Bob did not pass.
At the beginning of this section we formulated the goal of providing a formalizationof common sense conversational inferences based on the maxim of quality, the first
15 The problem is that if R is serial, transtive, and euclidean, and !W, R, V" thus a KD45 model, it holdsfor all formulas ! that M, w 0|= K! iff M, w |= ¬K!. Switching to S4 helps, but as explained by van derHoek et al. (1999), perhaps so for accidental reasons. The system S4.2, for instance, popular to modelknowledge, has similar problems.
16 For a related notion, see Sauerland (2004).17 Closure under conjunction and negation.

“22-ch18-0839-0856-9780444537263” — 2010/11/29 — 21:08 — page 847 — #9
Non-Monotonic Reasoning in Interpretation 847
submaxim of quantity, and the maxim of relevance, and then checking the predictionsby comparing the output with the interpretation function circ. Now it can be shown thatif we model a Gricean speaker in terms of Grice(!, P), assume that she is maximallycompetent and limit ourselves to non-modal statements !,18 we derive exactly thesame implicatures as we can derive using predicate circumscription.19
Fact 18.2.1. For all modal-free !, ": CompL(P)(GriceL+(P)(!)) |= " iff circ(!, P)
|= " .
On the basis of this fact, we can claim that we have provided a Gricean motivationof an analysis of conversational implicatures in terms of predicate circumscription.
18.2.6 Implicatures in Embedded Contexts
The above analyses of implicatures assumed that implicatures work on the output ofthe grammar. This is in line with the Gricean view that the conversational implicaturesof an utterance are generated globally, after the grammar assigned a meaning to it.More recently, a so-called localist view (e.g. Chierchia (2004), Landman (2000)) hasbecome rather popular. According to this view the pragmatic interpretation functionneed not be applied only to the whole asserted sentence, but can be applied to subpartsof what is asserted as well.
The arguments against the standard global picture of implicatures go back a longway. One serious type of problem was already discussed by Cohen (1971), who notedthat if we use a scalar term within the scope of ‘believe’ as in (10)
(10) John believes that some students passed the examination.
we can interpret the sentence as saying that John believes that it is not the case thatall students passed. The problem with the standard analysis is that it only predicts thatJohn does not believe some students passed, which is much weaker.20
Geurts and Pouscoulous (2008) experimentally compared the interpretation of thescalar term ‘some’ occurring in a non-embedded position with occurrences of the sameword embedded in the scope of ‘think’, ‘want’, deontic ‘must’, and the universal ‘all’.They found that the rates in which scalar implicatures are derived drop dramaticallyunder embedding, which is not what localist theories would lead us to expect. Butthey also found that scalar terms embedded under ‘want’ hardly ever give rise to localimplicatures, while scalar terms embedded under ‘think’ do so much more often. Thisfinding is hard to explain under a localist view. It might be explained, however, usinga standard ‘globalist’ story. Suppose for a moment that the alternatives of a sentence
18 The Gricean interpretation makes better predictions, though, for modal statements, especially those thatrefer to the speaker’s own information state.
19 For proof, see van Rooij and Schulz (2004) and Spector (2003).20 Cohen (1971) proposed to account for this reading by assuming that ‘or’ is ambiguous between the
inclusive and the exclusive reading. Unfortunately, neither reading of ‘or’ can account for the intuitionthat (5) is true iff only one of the three disjuncts is true.

“22-ch18-0839-0856-9780444537263” — 2010/11/29 — 21:08 — page 848 — #10
848 Handbook of Logic and Language
of the form ‘!j!’ are all of the form ‘!j"’. Following Schulz (2005), van Rooij andSchulz (2004) and Russell (2006) propose that implicatures under modal operators canbe strengthened in case a competence assumption is made: If the speaker knows thatfor all (local) alternatives " it holds that John is competent about "—meaning thateither !j! holds, or that !j¬" holds —, we can infer from the assertion that !j! istrue to the conclusion that (the speaker knows that) !j¬" for all " stronger than !.This required competence assumption might explain the drop of scalar implicaturesunder embedding. Geurts and Pouscoulous (2008) naturally assume furthermore thatthe competence assumption is much more natural for ‘think’ than for ‘want’, and pro-pose to explain in this way the difference between ‘local implicatures’ under these twoverbs.
A global analysis by itself doesn’t immediately explain implicatures in embed-ded contexts. This is neither the case for embedded items under ‘necessity’ operators,nor for ones embedded under ‘possibility’ operators. Consider, for instance, the ‘freechoice permission’ problem. The problem is how to account for the fact that from (11)one can infer that John may take an apple and that he may take a pear.
(11) You (John) may take an apple or a pear.
According to Kamp (1973), permissions are special speech acts and he proposes asolution to the problem in which this idea is essential. But (11) can be used as anassertion as well and still give rise to the free choice inference. Schulz (2005), there-fore, proposes that the inference is a Gricean implicature, and accounts for it in aglobal way in terms of minimal models. This analysis works very well, but is basedon the disputed assumption that ‘John may not take an apple’ is a relevant alterna-tive.21 To preserve a global explanation without assuming such alternatives, it seemsmost natural to assume that pragmatic interpretation is crucially bidirectional, takingalso into account how the speaker would have expressed his alternative informa-tion states. We have nothing against such a move,22 but it again does complicate thepicture.
18.3 More on Non-Monotonic Reasoning and Linguistics
18.3.1 Preferred Interpretation
Conversational implicatures are not the only part of interpretation where non-monotonic reasoning plays a role. It is well known that for counterfactual conditionals,already the truth conditions show non-monotonic behavior. But as shown already byLewis (1973), other semantic phenomena show exactly the same pattern. For instance,contextually definite descriptions: ‘The pig is grunting, but the pig with floppy ears is
21 For a popular ‘localist’ analysis of (11), see Fox (2007).22 This move is made in bidirectional optimality theory (cf. Blutner (2000)), as well as in game-theoretical
analyses of pragmatic interpretation.

“22-ch18-0839-0856-9780444537263” — 2010/11/29 — 21:08 — page 849 — #11
Non-Monotonic Reasoning in Interpretation 849
not grunting.’ What is intuitively going on here is that the description ‘the N’ picksup the unique most salient individual with property N. But the most salient pig neednot have floppy ears, which allows for the non-monotonic behavior. What is a salient,or normal, exemplar also seems crucial for the interpretation of generic sentences. Infact, researchers in AI have produced many theories of non-monotonic reasoning thatcan be seen as attempting to give a semantics for genericity. If we know that x is abird, our acceptance of the generic sentence ‘Birds fly’ allows us to expect that x flies,without guaranteeing that she can. Non-monotonic theories of generics are attractivenot only because they allow for exceptions, but also because they immediately accountfor the intuition that a generic sentence like ‘A lion has a mane’ makes a claim aboutevery possible lion, rather than a claim about the closed class of all existing lions.Some of the most detailed theories of generics (Asher and Morreau (1995), Delgrande(1998), and Veltman (1996)) are built on conditional logics like Lewis (1973). Suchtheories predict that generic sentences have truth conditions, and thus can account fornested generic statements. Moreover, such theories can naturally account for conflict-ing rules, where some take priority over others. Being able to rank non-monotonicrules seems very important in linguistic pragmatics as well.
Non-monotonic logic is used in semantics, but its role is (potentially, at least) muchmore important in pragmatics. The reason is that these logics can be used especiallyto account for preferred interpretation. Take, for instance, the interpretation of pluralreciprocals. It is well known that sentences like ‘The children followed each other’allow for many different interpretations. Still, such sentences are most of the timeunderstood pretty well. Dalrymple et al. (1998) propose that this is due to a particularinterpretation strategy. According to their ‘Strongest meaning hypothesis’ a sentenceshould preferentially be interpreted in the strongest possible way consistent with its(underspecified) semantic meaning. This simple strategy predicts surprisingly well,and has become popular to account for other phenomena too. But it is important tonote here that the hypothesis used is a non-monotonic interpretation strategy becauseadding more information might make a stronger interpretation impossible. If we add‘into the church’, for instance, our original sentence cannot be interpreted anymore assaying that all children followed another child, but can at most mean that any childfollowed, or was followed, by another child.
A systematic theory of preferred interpretation is also crucial for the resolution ofpronouns, which clearly involves non-monotonic inference patterns. This can alreadybe illustrated by the following simple discourse (12).
(12) John met Bill at the station. He greeted him.
The pronouns he and him could refer to either John or Bill. For reasons of syntacticparallelism, however, there seems to be a preference for interpreting he as John andhim as Bill. But this preference can be overruled if we add additional information.For instance, if we add ‘John greeted him back’, we have to reinterpret he as Bill,and him as John, due to the indefeasible semantics associated with the adverb back.In other cases, a non-preferred interpretation is suggested due to inconsistency with

“22-ch18-0839-0856-9780444537263” — 2010/11/29 — 21:08 — page 850 — #12
850 Handbook of Logic and Language
world-knowledge (e.g. in ‘John hit Bill. He got injured.’), or emphatic stress (‘Johncalled Bill a republican. Then HE insulted HIM.’). It has been argued that even (someof) Chomsky’s binding rules in syntax can be violated. The well-formedness of thefollowing discourse due to Evans (1980), for instance, suggests this for Chomsky’sconstraint saying that a non-reflexive pronoun like ‘him’ cannot be bound locally.
(13) Everyone despises poor John1. Mary despises him1. Sue despises him1, andeven John1 despises him1.
Centering theory Grosz (1995) was specifically designed to account for pronoun reso-lution, and is stated in terms of a set of defeasible, or non-monotonic, rules. Hendriksand de Hoop (2001), Beaver (2004), and others seek to account for anaphora andpronoun resolution in terms of Optimality Theory (OT), a more general theory ofinterpretation which makes use of violable constraints. It is clear, however, that anysystem of ranked violable rules can be seen as a non-monotonic logic that can accountfor conflicting rules, where some take priority over others (compare the discussion ongenerics). Using such a logic is exactly what was proposed by Kameyama (1996) forthe case of pronoun resolution.23
Non-monotonic logic plays a dominant role in the work of Asher and collaborators.As mentioned already by Thomason, they were pioneers in their use of non-monotoniclogic to infer discourse relations and employ that for inferring temporal anaphora,lexical disambiguation, bridging, and many other things (e.g. Asher and Lascarides,1993, 1995). This work has been extended on significantly and elaborated over thelast 15 years (see especially Asher and Lascarides (2003)). In their work on temporalanaphora, for instance, they observed that syntax sometimes only provides preferenceswhich can be overridden by world-knowledge. Normally the event a first sentencein simple past is about is temporally located before the event the consecutive sen-tence with simple past is about. But world-knowledge sometimes forces us to interpretotherwise, as in the discourse ‘John fell. Mary pushed him’. The theory of Asherand Lascarides (2003) deals with many other things required for interpreting texts,including inferring speech acts, and presupposition resolution. Most of these phenom-ena have been accounted for separately before (e.g., the treatment of speech acts inAppelt and Konolige (1988) and the analysis of bridging using abduction in Hobbs(1993)), but Asher and Lascarides brought them all under a very general theory ofnon-monotonic discourse interpretation.
18.3.2 Bringing Psychology into the Picture
Why does non-monotonic reasoning play a role in such diverse areas of interpretation?A very interesting answer to this question has been brought forward by van Lambal-gen and Hamm (2005). They propose that in order to interpret discourse, humans
23 It is one thing to state violable rules and rank them, but quite another to explain these. Reinhart (1983),Levinson (1991), and others made interesting attempts to derive (some of) the binding constraints fromsome more general pragmatic principles, and much of the more recent interest in Bidirectional OptimalityTheory (e.g. Blutner and Zeevat (2004)) and (evolutionary) Game Theory (e.g. Benz et al. (2005)) shouldbe seen in this light as well.

“22-ch18-0839-0856-9780444537263” — 2010/11/29 — 21:08 — page 851 — #13
Non-Monotonic Reasoning in Interpretation 851
have excepted the cognitive processes and facilities involved in off-line planning.Furthermore, they claim that off-line planning involves mentally constructing mini-mal models, i.e. non-monotonic reasoning.24 In van Lambalgen and Hamm (2005) thefocus lies on temporal discourse. In this case a relation to planning is very intuitive,especially to interpret progressives like ‘building a barn’. Following Moens and Steed-man (1988), they argue that our construction of time essentially involves our planningfacilities and our conception of causal dependencies. But van Lambalgen and Hamm(2005) propose that the cognitive planning device is used for discourse interpretationin general. Thus, when processing incoming sentences, an interpreter is constantlybuilding and revising a minimal discourse model. This is consistent with the analy-ses of (temporal) pronoun resolution discussed above: ‘linguistic’ constraints can beoverruled by additional information and world knowledge. This raises the question ofwhat the role of classical logic, or compositional semantics, is in such a picture. Thisquestion touches upon topics studied in psychology.
There exists a substantial literature on reasoning within psychology. This work isnearly independent from related work in AI and linguistics in this area. This inde-pendence might partly be an effect of the conviction among psychologists that logicdoes not provide the right framework to describe or explain human reasoning. Origi-nally, things were quite different: psychologists started out with the idea that to reasonis to be logical. But the picture of logic psychologists embraced was an absolute one:classical logic. Thus to test the thesis that people reason logically in this sense one dis-tinguished a set of premises, translated them into classical logic, calculated the validinferences—valid in the sense of classical logic—and then checked whether humanspresented with this set of premisses count the same sentences as valid or invalid infer-ences. Unfortunately, it turned out that the classical notion of inference does not matchhuman reasoning. This led to the growing conviction among psychologists that logicis not the proper framework to describe human reasoning behavior.
Of course, this is not the only way to deal with these results: one could, for instance,also hypothesize that humans do not reason classically but non-monotonically. Thoughthe predictions become better if one adopts this hypothesis, what still cannot beexplained is the fact that there remains a lot of variation between the performance ofhumans in these reasoning tasks. A crucial observation in this respect is that the rea-soning strategies people apply to particular tasks appear to vary in correlation withhow they interpret the reasoning task they have to perform. Should the reasoninginvolve inference to the preferred interpretation, or not? If so (and only if so), thereasoner will try to integrate the given information in a representation of one singlemodel and will add as much as possible additional assumptions available. The resultwill be a non-monotonic notion of inference based on constructing minimal models.
18.3.3 An Application: The Suppression Task
The suppression task is one of the classical experiments in the psychology of reason-ing. It was originally designed by Byrne (1989). The subjects are presented with the
24 For a similar view on the semantics of perception reports see van der Does and van Lambalgen (2000).

“22-ch18-0839-0856-9780444537263” — 2010/11/29 — 21:08 — page 852 — #14
852 Handbook of Logic and Language
information given in (14-a) and (14-b). When asked whether from this information(14-c) can be infered, 90% of the subjects agree. However, if (14-d) is added to thepremisses the percentage drops to 60% while if case (14-e) is added the percentage isapproximately the same as in the first setting.
(14) a. If she has an essay to write she will study late in the libary.b. She has an essay to write.c. She will study late in the libary.d. If the libary is open she will study late in the libary.e. If she has a textbook to read she will study late in the libary.
These results suggested to many psychologists that formal logic should not be used todescribe human reasoning. For if logic were fit to describe human reasoning, expres-sions with the same logical form should allow the same type of inferences. However,(14-d) and (14-e) have the same logical form, but while in the first case the inferenceto (14-c) is suppressed, in the second case the inference is still available.
Stenning and van Lambalgen (2008) argue, instead, that this conclusion was basedon the mistaken assumption that (14-d) and (14-e) by necessity have the same logi-cal form. In their preferred interpretation, (14-a)/(14-b) + (14-d) and (14-a)/(14-b) +(14-e) have to be assigned a different logical form. Conditional sentences are analyzedas law-like relations If A and nothing abnormal is the case, then B. Stenning and vanLambalgen (2008) propose to formalize law-like relations making use of propositionallogic programming with negation as failure.25 The logical form of the first conditionalsentence is given by the program essay.to.write * ¬ab1 1 stays.in.library, togetherwith the condition 2 1 ab1. Obviously, ab1 is an abnormality clause, expressingthat something abnormal is happening. The extra condition demands that abnormalityshould be minimized. Notice that the 1 in these logical forms is simply a markerdistinguishing body and head in a program clause, and should not be interpreted asa truth-conditional connective. The intended denotation of the program is a minimalmodel. To reach it, a notion of completion for logic programs is defined that makessure that negation as failure is only applied to abnormality clauses, and not to arbitrarypropositional variables. The authors show that the minimal models the completion des-cribes can be constructed as the fixed points of a monotonic operator on three-valuedmodels that can be reached in finitely many steps.
To account for the difference between (14-a)/(14-b) + (14-d) and (14-a)/(14-b) +(14-e), Stenning and van Lambalgen (2008) argue that whereas (14-d) is inter-preted as interacting with the abnormality condition ab1, this is not the case for(14-e). The conditional in (14-e) adds to the scenario built up by (14-a) and(14-b) a program clause book.to.read * ab2 1 study.in.library with the abnor-mality minimization clause 2 1 ab2. From these conditions one can infer withclosed world reasoning that she will study late in the library. Thus the theory predictscorrectly that in the scenario extended with (14-e) no suppression of the inference(14-c) is observed. Also the conditional (14-d) adds to the scenario a program clause
25 In their use of logical programming they follow Suppes (1980) and others in taking a procedural stancetowards meaning.

“22-ch18-0839-0856-9780444537263” — 2010/11/29 — 21:08 — page 853 — #15
Non-Monotonic Reasoning in Interpretation 853
library.open * ab2 1 study.in.library with the abnormality minimization clause2 1 ab2. But due to inferring to preferred interpretation, two constraints on theinteraction of the involved abnormality clauses are added: ¬library.open 1 ab1 and¬essay.to.write 1 ab2. In this case, one cannot infer that she will study late in thelibrary by applying closed world reasoning. This explains suppression in case (14-d).
How do we determine whether the antecedent of one conditional will affect theabnormality clause of the other? Stenning and van Lambalgen (2008) say that it isbased on context and world knowledge. Thus, as far as ‘linguistic’ constraints areconcerned, almost anything goes. To a certain extent this is also what Stenning andvan Lambalgen want, because as they show in their reports on dialog experiments,people exploit the most diverse interpretation strategies.
18.4 Conclusions
In this chapter we have discussed some recent applications of non-monotonic logicin linguistics. As already mentioned at the beginning, it is remarkable to see thatsome of the phenomena we discussed were already among the original motivationsfor the development of non-monotonic logic. For instance, when McCarthy (1986)discusses possible applications of non-monotonic logic in general, and circumscrip-tion in particular, he also mentions communicational conventions. The example heprovides actually involves Grice’s maxims of conversation.26 Given this observation,the recent developments in the area appear to mark only a shift in perspective. In the1970s and particularly the 1980s in AI one came across some interesting questionsconcerning reasoning and intelligent behavior in general. This led to the develop-ment of very sophisticated logical tools in order to answer these questions. However,the study of the involved phenomena (reasoning, communication) itself stayed at arelatively basic level, compared with the expertise available for instance in linguis-tics and psychology. At the same time—or even before that—similar problems havealso been discussed in linguistics and psychology, but without the means of devel-oping a formal tool to deal with them. At a certain point in the 1990s the interestsof AI in non-monotonic logic weakened, because the conviction emerged that non-monotonic logic is not fit to deal with modeling the relevant phenomena in an efficientway. But now linguistics and psychology are taking over, with a more sophisticatedunderstanding of communication. Non-monotonic logic is rediscovered as a very use-ful tool to describe and explain certain aspects of interpretation and reasoning. Whatwe might observe in the near future is that the more sophisticated applications of theoriginal techniques will stimulate the development of the formalisms. In the end itmight turn out that the situation for non-monotonic logic is not as devastating as wasthought before. For instance, it might well prove to be the case that those restric-tions needed to obtain computationally tractable versions of non-monotonic logicsare empirically very natural. This is suggested by Asher and Lascarides (2003),
26 Though McCarthy (1986) doesn’t seem to be aware of Grice’s work.

“22-ch18-0839-0856-9780444537263” — 2010/11/29 — 21:08 — page 854 — #16
854 Handbook of Logic and Language
and is certainly the case for the formalism of logic programming as employed invan Lambalgen and Hamm (2005) and Stenning and van Lambalgen (2008). In thelatter book it is shown that the employed solution concept—i.e. executing logical pro-gram by means of monotonic operators—corresponds to computation in a suitablerecurrent neural network. This implementation of the formalism into neural networksallows grounded speculation about the neural reality underlying reasoning.
References
Appelt, D., Konolige, K., 1988. A practical non-monotonic theory for reasoning about speechacts, in: Proceedings of the 26th Meeting of the Association for Computational Linguistics.Association for Computational Linguistics, pp. 170–178.
Asher, N., Lascarides, A., 1993. Temporal interpretation, discourse relations, and commonsenseentailment. Ling. Philos. 16, 437–493.
Asher, N., Lascarides, A., 1995. Lexical disambiguation in a discourse context. J. Semant. 12,96–108.
Asher, N., Lascarides, A., 2003. Logics of Conversation. Cambridge University Press,Cambridge.
Asher, N., Morreau, M., 1995. What some generic sentences mean, in: Carlson, G., Pelletier, J.(Eds.), The Generic Book. Chicago University Press, Chicago, pp. 300–338.
Beaver, D., 2004. The optimization of discourse anaphora. Ling. Philos. 27, 3–56.Benz, A., Jaeger, G., van Rooij, R., 2005. Games and Pragmatics. Palgrave Macmillan,
Hampshire.Blutner, R., 2000. Some aspects of optimality in natural language interpretation. Nat. Lang.
Semant. 17, 189–216.Blutner, R., Zeevat, H., 2004. Optimality Theory and Pragmatics. Palgrave Macmillan,
Hampshire.Bott, L., Noveck, I., 2004. Some utterances are underinformative: the onset and time course of
scalar implicatures. J. Mem. Lang. 51, 437–457.Breheny, N.K., Williams, R.J., 2006. Are genearised scalar implicatures generated by default.
Cognition. 100, 434–463.Breheny, R., 2006. Communication and folk psychology. Mind. Lang. 21, 74–104.Byrne, R.M.J., 1989. Suppressing valid inferences with conditionals. Cognition. 31, 61–83.Carston, R., 1998. Informativeness, relevance and scalar implicature, in: Carston, R., Uchida,
S. (Eds.), Relevance Theory: Applications and Implications. John Benjamins, Amsterdam,pp. 179–236.
Chierchia, G., 2004. Scalar implicatures, polarity phenomena and the syntax/pragmatics inter-face, in: Belletti, A. (Ed.), Structures and Beyond. Oxford University Press, Oxford.
Chierchia, G., Fox, D., Spector, B., 2008. The grammatical view of scalar implicatures and thesemantics pragmatics interface, in: Portner, P., Maienbon, C., von Heusinger, K. (Eds.),Handbook of Semantics. Mouton de Gruyter, New York.
Cohen, L.J., 1971. The logical particles of natural language, in: Bar-Hillel, Y. (Ed.), Pragmaticsof Natural Language. Reidel, Dordrecht, pp. 50–68.
Dalrymple, M., Kanazawa, M., Kim, Y., Mchombo, S., Peters, S., 1998. Reciprocal expressionsand the concept of reciprocity. Ling. Philos. 21, 159–210.
Delgrande, J., 1998. An approach to default reasoning based on a first-order conditional logic.Artif. Intell. 36, 63–90.

“22-ch18-0839-0856-9780444537263” — 2010/11/29 — 21:08 — page 855 — #17
Non-Monotonic Reasoning in Interpretation 855
Evans, G., 1980. Pronouns. Ling. Inq. 11, 337–362.Evans, J.S., Newstead, S.E., 1980. A study of disjunctive reasoning. Psychol. Res. 41, 373–388.Fox, D., 2007. Free choice disjunction and the theory of scalar implicatures. Technical report,
MIT Press, Cambridge, MA.Gazdar, G., 1979. Pragmatics. Academic Press, London.Geurts, B., Pouscoulous, N., 2008. Local implicatures? Technical report, Radboud University
of Nijmegen, the Netherlands.Grice, H.P., 1989. Logic and conversation, in: Grice, H.P., Studies in the Way of Words. Har-
vard University Press, Cambridge. Typescript from the William James Lectures, HarvardUniversity, 1967, 41–57.
Groenendijk, J., Stokhof, M., 1984. Studies in the Semantics of Questions and the Pragmaticsof Answers. PhD thesis, University of Amsterdam, the Netherlands.
Grosz, B., Joshi, A., Weinstein, S., 1995. Centering: a framework for modeling the local coher-ence of discourse. Comput. Ling. 21, 203–226.
Halpern, J.Y., Moses, Y., 1984. Towards a theory of knowledge and ignorance, in: Proceed-ings 1984 Non-monotonic reasoning workshop, American Association for Artificial Intel-ligence. New Paltz, NY, pp. 165–193.
Hendriks, P., de Hoop, H., 2001. Optimality theoretic semantics. Ling. Philos. 24, 1–32.Hirschberg, J., 1985. A Theory of Scalar Implicature. PhD thesis, University of Pennsylvania,
Philadelphia, PA.Hobbs, J., 1993. Interpretation as abduction. Artif. Intell. 63, 69–142.Horn, L., 1972. The Semantics of Logical Operators in English. PhD thesis, Yale University,
New Haven Connecticut.Kameyama, M., 1996. Indefeasible semantics and defeasible pragmatics, in: Kanazawa, M.,
Pinon, C., de Swart, H. (Eds.), Quantifiers, Deduction, and Context. CSLI, Stanford,pp. 111–138.
Kamp, H., 1973. Free choice permission. Proceedings of the Aristotelian Society, N.S., 74,57–74.
Krifka, M., 1995. The semantics and pragmatics of polarity items. Ling. Anal. 25, 209–258.Landman, F., 2000. Events and Plurality. Kluwer, Dordrecht.Levesque, H.J., 1990. All I know: a study in autoepistemic logic. Artif. Intell. 42, 263–309.Levinson, S.C., 2000. Presumptive Meaning. The Theory of Generalized Conversational Impli-
catures. MIT Press, Massachusetts.Levinson, S.C., 1991. Pragmatic reduction of the biding conditions revisited. J. Ling. 27,
107–161.Lewis, D., 1973. Counterfactuals. Blackwell, Oxford.McCarthy, J., 1980. Circumscription—a form of Non-monotonic reasoning. Artif. Intell. 13,
27–39.McCarthy, J., 1986. Applications of circumscription to formalizing common sense knowledge.
Artif. Intell. 28, 89–116.McCawley, J., 1993. Everything that Linguists Always Wanted to Know About Logic', vol. 2.
The University of Chicago Press, Chicago.Moens, M., Steedman, M., 1988. Temporal ontology and temporal reference. Comput. Ling. 14
(2), 15–27.Noveck, I., 2001. When children are more logical than adults: experimental investigations of
scalar implicatures. Cognition. 78, 2165–2188.Noveck, I., Posada, A., 2003. Characterizing the time course of implicature: an evoked potential
study. Brain. Lang. 85, 203–210.

“22-ch18-0839-0856-9780444537263” — 2010/11/29 — 21:08 — page 856 — #18
856 Handbook of Logic and Language
Papafragou, A., Tantalou, N., 2004. Children’s computation of implicatures. Lang. Acquisition.12, 71–82.
Paris, S.G., 1973. Comprehension of language connectives and propositional relationships.J. Exp. Child Psychol. 16, 278–291.
Pouscoulous, N., 2006. Processing Scalar Implicatures. PhD thesis, EHESS, Paris.Reinhart, T., 1983. Anaphora and Semantic Interpretation. Croom Helm, London.Rooth, M., 1985. Association with Focus. PhD thesis, University of Massachusetts, Amherst.Russell, B., 2006. Against grammatical computation of scalar implicatures. J. Semant. 23,
361–382.Sauerland, U., 2004. Scalar implicatures of complex sentences. Ling. Philos. 27, 367–391.Schulz, K., 2005. A pragmatic solution for the paradox of free choice permission. Synth. Knowl-
edge. Rationality. Action. 147 (2), 343–377.Schulz, K., van Rooij, R., 2006. Pragmatic meaning and Non-monotonic reasoning: the case of
exhaustive interpretation. Ling. Philos. 29 (2), 205–250.Sevi, A., 2006. Exhaustivity. A Semantic Account of ‘Quantity’ Implicatures. PhD thesis, Tel
Aviv University, Tel Aviv.Shoham, Y., 1988. Reasoning About Change. MIT Press, Boston, MA.Spector, B., 2003. Scalar implicatures: exhaustivity and gricean reasoning? in: ten Cate, B.
(Ed.), Proceedings of the ESSLLI 2003 Student session, Vienna, Austria.Stenning, K., van Lambalgen, M., 2008. Human Reasoning and Cognitive Science. MIT Press,
Cambridge, Massachusetts.Storto, G., Tannenhaus, M.K., 2004. Are scalar implicatures computed online? in: Proceedings
of WECOL. In Alcazar, A., Mayoral Hernandez, R., Martinez, M.T. (Eds.), Proceedingsof the Western Conference on Linguistics 2004. Fresno: California State University atFresno, CA.
Suppes, P., 1980. Procedural semantics, in: Haller, R., Grassl, W. (Eds.), Language, Logic,Philosopy, Hölder-Pichler-Tempsky, Vienna, pp. 27–35.
van Benthem, J., 1989. Semantic parallels in natural language and computation, in: Ebbing-haus, H.D. et al. (Eds.), Logic Colloquium ’87, Elsevier Science Publishers, Amsterdam,pp. 331–375.
van der Does, J., van Lambalgen, M., 2000. A logic of vision. Ling. Philos., 23, 1–92.van der Hoek, W. et al., 1999. Persistence and minimality in epistemic logic. Ann. Math. Artif.
Intell. 27, 25–47.van Kuppevelt, J., 1996. Inferring from topics. Scalar implicatures as topic-dependent infer-
ences. Ling. Philos. 19, 393–443.van Lambalgen, M., Hamm, F., 2005. The Proper Treatment of Events. Blackwell Publishing,
Oxford.van Rooij, R., Schulz, K., 2004. Exhaustive interpretation of complex sentences. J. Log. Lang.
Inf. 13, 491–519.Veltman, F., 1996. Defaults in update semantics. J. Philos. Log. 25 (3), 221–261.Wainer, J., 1991. Uses of Non-Monotonic Logic in Natural Language Understanding: Genera-
lized Implicatures. Ph.D. dissertation, Pennsylvania State University, PA.Wainer, J., 2007. Modeling generalized implicatures using non-monotonic logic. J. Log. Lang.
Inf. 16 (2), 195–216.Zondervan, A., in press. Experiments on qud and focus as a contextual constraint on scalar
implicatures calculation, in: Sauerland, U., Yatsushiro, K. (Eds.), Semantics and Pragmat-ics: From Experiment to Theory. Palgrave MacMillan.

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 857 — #1
Part 3
Descriptive Topics

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 858 — #2
This page intentionally left blank

“23-ch19-0857-0910-9780444537263” — 2010/11/30 — 3:44 — page 859 — #3
19 Generalized Quantifiers inLinguistics and Logic!
Edward L. Keenan†, Dag Westerståhl††
†UCLA, Department of Linguistics, 405 Hilgard Ave.,Los Angeles, CA 90095-1543, USA,E-mail: [email protected]
††University of Gothenburg, Department of Philosophy, Linguistics,and Theory of Science, Box 200, 405 30,Gothenburg, Sweden,E-mail: [email protected]
19.1 Introduction
In the past 2–3 decades the study of generalized quantifiers has deepened,considerably, our understanding of the expressive power of natural language. It hasprovided answers to questions arising independently in language study, and it hasraised, and often answered, new questions, ones that were largely inconceivable with-out the basic concepts of generalized quantifier theory. In turn our new linguis-tic understanding has prompted novel mathematical questions (and an occasionaltheorem) whose interest derives, in part at least, from their natural interpretation ina non-mathematical domain.
In this chapter we survey these linguistic results and we synthesize the mathemat-ical observations they have given rise to, relating them to independent work fromlogic.
By way of historical perspective (see Westerståhl, 1989, for detailed discussion upto 1987), it was Montague (1974) who set in motion the work we report on here. Thatwork first told us how to interpret simple Noun Phrases (e.g., John) directly as func-tions mapping predicate denotations to {True, False}, that is as generalized quantifiers(a terminology not used by Montague). But it was only in the early 80s that linguis-tic applications of generalized quantifier theory came into their own, in several casesdue to joint work between linguists and logicians. The first and most influential paperhere was Barwise and Cooper (1981). Higginbotham and May (1981) also appeared
* We wish to thank the editors, the participants at the workshop “Integrating Logic and Linguistics” inAmsterdam December 1993, and in particular Jaap van der Does, for helpful comments on the first versionof this chapter. We are also grateful to Jakub Szymanik for help with the second version. During therewrite, the second author was supported by a grant from the Swedish Research Council.
Handbook of Logic and Language. DOI: 10.1016/B978-0-444-53726-3.00019-0c" 2011 Elsevier B.V. All rights reserved.

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 860 — #4
860 Handbook of Logic and Language
at that time (focusing on certain types of polyadic quantification which became moreimportant later), and early versions of Keenan and Stavi (1986) circulated, influenc-ing later formal developments. The latter, especially van Benthem (1984, 1986), con-cerned both original constraints on natural language quantifiers and the interpretationof that work in a more classical logical setting. Two collections that reflect the status ofthis work by the late eighties are van Benthem and ter Meulen (1985) and Gärdenfors(1987). A survey of research issues in generalized quantifier theory in the early 90s,many of them with a linguistic flavour, is van Benthem and Westerståhl (1995).
There are also earlier works which anticipated several of the ideas to becomeimportant later. We note Fenstad (1979) and Altham and Tennant (1975) in partic-ular (the latter anticipating recent work, discussed here, on polyadic quantification),which drew explicitly on the logical notion of generalized quantifiers from Mostowski(1957) and Lindström (1966).
There is now a book-length treatment of the theory of generalized quantifiers andits applications to language: Peters and Westerståhl (2006). Several of the issues dis-cussed here are taken further and dealt with in greater detail in that volume. We dofeel, however, that the introduction given in the present chapter, although writtensome 13 years ago, still serves its purpose. Our focus here is on the linguistic issues,and on making the reader see that logic can sometimes actually help clarify some ofthese. For this reason, we have not made a substantial rewrite of the chapter since thefirst edition. What we have done, besides some polishing and pruning of the text, is(a) to expand it on a few occasions where we felt things could be made clearer, e.g., byadding some more linguistic examples, (b) to leave out some parts that can now easilybe found in greater detail elsewhere,1 and (c) to give references to work that appearedin the meantime.
One important aspect of quantification, however, is missing from this chapter,namely, the computational aspect. We are therefore extremely pleased that RobinClark agreed to write a companion chapter, Chapter 20 in this volume, dealing withthis aspect, and more specifically with an automata-theoretic approach to the learn-ing of expressions involving quantification. Together, these two chapters now cover awell-defined and central part of quantification theory.
This does not mean that we cover everything. Research into the nature of quantifi-cation in natural language has not been limited to the work we survey here. We do nottouch upon the work on ‘unselective binding’ initiated in Lewis (1975) and developedfor example in Heim (1982) and within Discourse Representation in Context (Kamp& van Eijck, Chapter 3). Nor do we consider the differential pronoun/variable bind-ing of different sorts of Noun Phrases, a topic of considerable linguistic interest andone that is pursued for example within DRT and various approaches to dynamic logic(Muskens & van Benthem, Chapter 12; see also the collections van der Does and vanEijck (1991) and Kanazawa and Piñon (1994). Finally we do not treat specifically of
1 In particular, the final part on the expressive power of polyadic quantifiers. Also, the original chapter hada discussion of the notion of constancy for quantifiers, and a sketch of one way to treat vague quantifiers,which have been left out here. Note, however, that the original chapter is still in print.

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 861 — #5
Generalized Quantifiers in Linguistics and Logic 861
plurals and group level quantification of the sort discussed in Lønning (Chapter 23),and van der Does (1992, 1994a). Let us turn now to the work we do consider.
19.2 Generalized Quantifiers in Natural Language:Interpretations of Noun Phrases and Determiners
We are primarily concerned here with the semantic interpretation of NPs (NounPhrases) like those italicized in (1)–(3). (We extend our concerns in Section 19.3).
(1) John laughed; Neither Bill nor Fred smiled(2) All poets daydream; No healthy doctor smokes; Most linguists are bilingual(3) More students than teachers work hard; Not as many boys as girls did well on
the exam
These NPs have combined here with P1s (one place predicates) like laughed andwork hard to form Ss (sentences). P1s express properties of objects and we limit our-selves to extensional NPs, ones which distinguish between properties only if differentobjects have them. So given a universe E of objects we treat P1s as denoting subsetsof E. Ss denote 1 (true) or 0 ( false) and NPs denote type!1" (generalized) quantifiersover E, namely functions from P(E), the power set of E, into 2 = {0, 1}. This set isnoted [P(E) # 2] and called TYPE!1". In general, [X # Y] is the set of functionsfrom X to Y .
In (2), all, no, and most are Det1s (one place determiners). They combine with(property denoting) common noun phrases like linguist, healthy doctor, . . . to formtype !1" expressions. Semantically they map P(E) into TYPE!1" and so are quantifiersof type !1, 1" (over E).
In (3), more. . . than and not as many. . . as are of type !!1, 1", 1". We call themDet2s. They combine with pairs of property denoting expressions to form NPs, andare interpreted as maps from P(E)$ P(E) into TYPE!1". We study these types in turn.
Quantifiers of these types can equivalently been viewed as relations between sub-sets of E. For example, a type !1, 1" function F in [P(E) # [P(E) # 2]] correspondsto the binary relation Q between sets defined by QAB % F(A)(B) = 1. The relationalview on quantifiers is common in logic. The functional view fits better into a compo-sitional semantics for natural language, and later we will see that it also allows somenatural generalizations to functions that do not correspond to relations between sets.
19.2.1 Type !1" Quantification
Given a type ! and a natural language L the following questions are considered inSection 19.2:
Q1. Syntactically, what sorts of expressions of type ! does L provide?Q2. Are there constraints on which functions of type ! may be denoted in L? Viz., for arbitrary
E and arbitrary F of type ! , is there an L expression which may be interpreted as F?

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 862 — #6
862 Handbook of Logic and Language
Q3. Does L distinguish subclasses of expressions of type ! in any syntactically or semanticallyregular way? More generally, what generalizations does L support regarding expressionsof type ! , and are they valid for all natural languages?
We focus on Q2 and Q3, exemplifying answers to Q1 as we go along. We assume anarbitrary universe E held constant throughout our discussion unless noted otherwise.
Important insights into the nature of TYPE!1" in English build in part on theorder relations carried by the domain and range of these functions. The relation is &in the case of P(E). Independent of our concern with quantifiers we use this relation instating semantic properties of P1s. E.g. manner adverbs like loudly are restricting inthat for any P1 denotation B, loudly(B) & B, whence John laughed loudly entails Johnlaughed. (We note nonce denotations in boldface.)
Equally it is with respect to the subset relation that the interpretations of conjunc-tions and disjunctions of P1s are defined as greatest lower bounds (glbs) and leastupper bounds (lubs) respectively. Thus the denotation B of both laughed and cried isthe glb of X = {laugh, cry}. That is, B is a lower bound for X('A ( X, B & A) and itis greatest among the lower bounds (for all lower bounds C for X, C & B). In a similarway the denotation of either laughed or cried is the lub for X. Also we use later thatP(E) is complemented. Thus not laugh denotes – laugh, that is, E – laugh.
Similarly the set 2 = {0, 1} comes equipped with a natural order relation, ), theimplication order. For x, y ( 2 we say that x ) y iff an arbitrary conditional sentenceif P then Q is true whenever P denotes x and Q denotes y. So x ) y iff x = 0 orx = y = 1. And as with P1s, it is in terms of the order relation that denotations ofconjunctions and disjunctions of Ss are characterized as glbs and lubs (given by thetruth tables for conjunction and disjunction respectively). Also 2 is complemented, thecomplement function being given by the truth table for negation.
So type !1" functions map one poset (partially ordered set) to another and may thusbe classified according to their monotonicity properties. Standardly:
Definition 19.2.1. Let A and B be partially ordered sets and F a function from Ainto B.
a. F is increasing (= order preserving) iff 'a, b ( A, a ) b * F(a) ) F(b)
b. F is decreasing (= order reversing) iff 'a, b ( A, a ) b * F(b) ) F(a)
c. F is monotonic iff F is increasing or F is decreasing
An expression is called increasing (decreasing, monotonic) iff it is always interpretedas an increasing (decreasing, monotonic) function. And we claim:
Generalization 19.2.1. Lexical (= syntactically simple) NPs are monotonic — in factmonotonic increasing with at most a few exceptions.
To check informally that an NP is increasing, verify that when substituted for Xin paradigms like (4), changing plurals to singulars as appropriate, the resulting argu-ment is valid – that is, the third line is true in any situation in which the first twoare true.

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 863 — #7
Generalized Quantifiers in Linguistics and Logic 863
(4) All socialists are vegetariansX are socialists
! X are vegetarians
The lexical NPs of English are mainly the proper nouns (PNs): John, Mary,. . . ,Siddartha, Chou en Lai, . . . (This set is open in that new members may be added with-out changing the language significantly). Lexical NPs also include listable sprinklingsof (i) personal pronouns – he/him, . . . and their plurals they/them; (ii) demonstratives– this/that and these/those; and (iii) possessive pronouns – his/hers . . . /theirs. Somegrammarians would include “indefinite pronouns” such as everyone, everybody, some-one, somebody, no one, and nobody, but these appear to have internal syntactic struc-ture (e.g., everyone consists of the independent expressions every and one). We mightalso include some (restricted) uses of Dets as NPs, e.g., all in A good time was hadby all, some in Some like it hot, and many and few in Many are called but few arechosen, though such uses seem limited to fixed expressions or to constrained contextsin which, in effect, a noun argument of the Det is provided. Thus an S like All read theNew York Times is bizarre unless context makes it clear what all is quantifying over,e.g., students, students in my class, etc.
We note (cf. Q1) that PNs may be structured, as with first and last names: JohnSmith; titles of address: Mistress Mary, Doctor Jones; sobriquets: Eric the Red,Charles the Bald; adjectives: Lucky Linda, Tricky Dick; and appositives: the philoso-pher David Hume.
Of the lexical NPs mentioned above, PNs (structured or not), the pronouns anddemonstratives are increasing. Only few, no one, and nobody are not increasing, andthey are decreasing. Thus, with only limited exceptions lexical NPs in English aremonotonic increasing. By contrast the NPs in (5) below are not monotonic.
(5) every student but not every teacher, every/no student but John, exactly five stu-dents, between five and ten cats, John but neither Bill nor Sam, most of thestudents but less than half the teachers, either fewer than five students or elsemore than a hundred students, approximately a hundred students, more studentsthan teachers, exactly as many students as teachers
Thus Generalization 19.2.1 is a strong empirical claim – many functions denotableby NPs in English are not denotable by lexical NPs. Keenan (1986) presents furtherconstraints of this sort.
Generalization 19.2.1 has a companion generalization at the level of type !1, 1"Det1s: type !1" expressions built from lexical Det1s are monotonic, usually increasing,though no, neither, and few build decreasing type !1" quantifiers.2 See (19a) for somelexical Det1s of English.
2 Sometimes a numeral Det1 like ten appears to denote exactly ten rather than at least ten. It can be arguedthat this interpretation is not the basic one. But if it should be taken as basic, the generalization saysinstead that expressions built from lexical Det1s denote either monotonic quantifiers or conjunctions ofsuch quantifiers (exactly ten = at least ten & at most ten).

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 864 — #8
864 Handbook of Logic and Language
We offer another monotonicity generalization shortly, but first we consider thequantifiers denotable by proper nouns. We call those quantifiers individuals:
Definition 19.2.2. For each b ( E define Ib from P(E) into 2 by setting Ib(A) = 1 iffb ( A (equivalently, Ib is the set of subsets of E containing b). A type !1" quantifier Fis a (Montagovian3) individual iff F = Ib for some b ( E.
So where John denotes Ij, John walks will be true iff Ij(walk) = 1; that is, iff j (walk – just the classical truth conditions for such Ss. Clearly individuals are increas-ing: if A & B then b ( A * b ( B, so Ib(A) = 1 * Ib(B) = 1, so Ib(A) ) Ib(B).In fact individuals preserve, and are exactly the functions that preserve, the entireBoolean structure of P(E).4
Observe that type !1" expressions allow the formation of Boolean compounds inand/but, or, not, and neither. . . nor with significant freedom:
(6) a. Either both John and Sue or else both Sam and Mary will represent usb. Neither John nor John’s doctor wanted to ignore the reportc. John and some student just came ind. Just two teachers and not more than ten students attended the meetinge. All the doctors and all the nurses but not more than half the patients had the radio on
Unsurprisingly, TYPE!1" is a Boolean lattice. The order relation ) is given point-wise: F ) G iff 'A ( P(E), F(A) ) G(A). We note for later reference:
(7) Given ) defined on TYPE!1" = [P(E) # 2],
a. 0 maps all A & E to 0, 1 to 1. 0 and 1 are called trivial.b. For K & TYPE!1",
the glb of K, +K, is that map sending A ( P(E) to 1 iff each F ( K maps A to 1, thelub of K,,K, maps a subset A of E to 1 iff for some F ( K, F(A) = 1.
c. For F ( TYPE!1", ¬F is that map sending each A ( P(E) to E - F(A).d. Besides these Boolean operations, quantifiers have another form of negation, called
inner negation or post-complement, defined, for F ( TYPE!1", as the map F¬ sendingA ( P(E) to F(E - A).
Post-complement corresponds to verb phrase negation. For example, At least threestudents don’t smoke means that the complement of smoke is in at least three stu-dents, i.e. that smoke ( (at least three students)¬.
We now answer Q2 above for TYPE!1". Namely, for E finite, English does presentenough NPs to permit any type !1" function to be denoted. All we need is thecapacity to denote each of finitely many individuals and to form Boolean compoundsof NPs.
3 Montague (1974) innovated this notion of proper noun denotation.4 The individuals are exactly the complete homomorphisms from P(E) into 2. We see directly that Ib(-A) =
-Ib(A) and Ib(+iAi) = +iIb(Ai). For the converse: if h is a complete homomorphism from P(E) into 2then the set of subsets of E that h is true of is a principal ultrafilter, and thus generated by an atom {b},whence h(A) = 1 iff {b} & A iff b ( A iff h = Ib. Thus proper noun denotations are characterized up toisomorphism in terms of their properties as type !1" quantifiers.

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 865 — #9
Generalized Quantifiers in Linguistics and Logic 865
Generalization 19.2.2. (Type !1" Effability) Over a fixed finite universe each type !1"quantifier is denotable by an English NP.
Proof. Let E be finite and F ( [P(E) # 2] arbitrary. We show how to build an NP inEnglish which may be interpreted as F.
i. For each B ( P(E) define FB : P(E) # 2 by: FB(A) = 1 iff A = B. Clearly
F = ,{FB | B ( P(E) & F(B) = 1}.
Moreover,
'B ( P(E), FB = +b(BIb + +b /( B¬Ib.
Thus F is a Boolean function of individuals.ii. Since E is finite any FB is expressible by a Boolean compound of individual denoting NPs
like John and Bill and Sam but not Frank or Joe or Moe. Hence any F over a finite E isdenotable by a finite disjunction of such NPs.5 "
Type !1" Effability tells us that in designing semantic interpretations for Englishexpressions we cannot limit (over finite universes) the set in which type !1" expres-sions denote. By contrast there do appear to be very general constraints limiting thepossible denotations of type !1, 1" expressions (Section 19.2.2.2).
Note that Type !1" Effability is a local claim. It does not say that English candenote an arbitrary functional F which associates with each (finite) universe E a type!1" quantifier. Such a claim would concern uniform definability (cf. Section 19.2.2.4).Type !1" Effability simply says that once a finite E is given then for any F ( TYPE !1"we can ad hocly cook up an English expression which is interpreted, in that universe,as F.
We turn now to our second monotonicity generalization. It exemplifies a case wherethe study of generalized quantifiers has enabled us to make progress on a problemwhich arose independently in generative grammar.
Negative Polarity Items (npi’s)To characterize the set of expressions judged grammatical by native speakers ofEnglish, we must distinguish the grammatical expressions (8a) and (9a) from theungrammatical (= asterisked) (8b) and (9b).
(8) a. John hasn’t ever been to Moscowb. *John has ever been to Moscow
(9) a. John didn’t see any birds on the walkb. *John saw any birds on the walk
5 The first version of this chapter, footnote 4, has a variant of the proof that doesn’t assume that Englishpresents indefinitely many proper nouns.

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 866 — #10
866 Handbook of Logic and Language
Npi’s, such as ever and any above, do not occur freely; classically Klima (1964) theymust be licensed by a “negative” expression, such as n’t ( = not). But observe:
(10) a. No student here has ever been to Moscowb. *Some student here has ever been to Moscow
(11) a. Neither John nor Mary saw any birds on the walkb. *Either John or Mary saw any birds on the walk
(12) a. Fewer than five students here have ever been to Moscowb. *More than five students here have ever been to Moscow
(13) a. At most four students here have ever been to Moscowb. *At least four students here have ever been to Moscow
(14) a. Less than half the students here have ever been to Moscowb. *More than half the students here have ever been to Moscow
The a-expressions here are grammatical, the b-ones are not. But the pairs differ withrespect to their initial NPs, not the presence vs. absence of n’t.
The linguistic problem: define the class of NPs which license the npi’s, and statewhat, if anything, those NPs have in common with n’t/not.
One could try to argue that the initial NPs in (10) and (11) are reduced forms ofexpressions with not, but this strategy doesn’t work for (12)–(14). A hypothesis whichdoes yield correct results is a semantic one discovered by Ladusaw (1979, 1983) build-ing on the work of Fauconnier (1975, 1979). (See also Zwarts, 1981).
Generalization 19.2.3. The Ladusaw-Fauconnier Generalization (LFG) Occurrencewithin the argument of a decreasing function licenses negative polarity items, butoccurrence within the argument of an increasing one does not.
To check that an NP is decreasing verify that (15) is valid when substituted for X.
(15) All linguists can danceX can dance
! X is a linguist (are linguists)
This test shows that the NPs in (10)–(14) which license npi’s are decreasing whereasthose that do not are not. Further the LFG yields correct results on expressions like(16) and (17) below, not considered by Ladusaw or Fauconnier.
(16) No player’s agent should ever act without his consent*Every player’s agent should ever act without his consentNeither John’s nor Mary’s doctor has ever been to Moscow
(17) None of the teachers and not more than three of the students have ever been toMoscow
(16) draws on the fact that possessive NPs, ones of the form [X’s N] such as John’sdoctor, inherit their monotonicity from that of the possessor X. Viz., X’s doctor isincreasing (decreasing) if X is. (17) is predicted since conjunctions (and disjunctions)of decreasing NPs are decreasing.

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 867 — #11
Generalized Quantifiers in Linguistics and Logic 867
The LFG is pleasingly general. Denotation sets for most categories in English areordered (Keenan and Faltz, 1985), so expressions in these categories are classifiableas increasing, decreasing or non-monotonic. We may expect then to find npi licensersin many categories, and we do. For example, ordinary negation not (n’t) in generaldenotes a complement operation in the set in which its argument denotes. E.g. at theP1 level didn’t laugh denotes E – laugh, the set of objects under discussion that are notin the laugh set. So not (n’t) maps A & E to E-A and is thus decreasing. Generalizing,the binary operator neither. . . nor is decreasing on each argument (regardless of thecategory of expression it combines with). Thus we expect, and obtain, npi’s in caseslike (18):
(18) Neither any students nor any teachers attended the meetingJohn neither praised nor criticized any student
Thus the LFG finds an independently verifiable property which NPs like no studenthave in common with simple negation. For further discussion see Nam (1994) andZwarts (1998).
Observe finally that whether an NP of the form [Det + N] is increasing, decreasingor neither, is determined by the choice of the Det, not that of the N: if no studentlicenses npi’s so does no cat. In later sections we shall be concerned to characterizeother classes of NPs studied by linguists – e.g. “definite” vs. “indefinite” ones – andagain, whether an NP of the form [Det + N] is definite or indefinite in the relevantsense is, like its monotonicity properties, determined by its choice of Det. This arrayof facts is consistent with and even supportive of the trend, in generative grammar(Abney, 1987; Stowell, 1991) to treat, for example, every as the “head” of the phraseevery man (and assign it the category DP for “Determiner Phrase”, though in this paperwe retain the more traditional terminology).
19.2.2 Type !1, 1" Quantification
This is the best studied of the types we consider and includes those expressions whichcorrespond most closely to generalized quantifiers in logic. (19) presents some fairlysimpleDet1sand(20)somemorecomplexoneswhoseuse isexemplifiedin(21)and(22).
(19) a. some, a, all, every, each, no, several, most, neither, the, both, this, these, my, John’s,many, few, enough, a few, a dozen, ten,
b. the ten, John’s ten, at least/more than/fewer than/at most/exactly/only ten, onlyJohn’s, all but ten, half the, half John’s, infinitely many, about/approximately twohundred, almost every/no, nearly a hundred, most of John’s, a large/even number of,a third of the, less than ten per cent of the, between five and ten, hardly any
(20) no more than ten, most but not all, at least two but not more than ten, neither John’snor Mary’s, either fewer than five or else more than a hundred, no child’s, most maleand all female, more male than female, not one of John’s, more of John’s than of Bill’s,John’s biggest, no/every. . . but John, all but finitely many, seven out of ten, the first (next,last). . . to set foot on the Moon, the most difficult. . . to talk to, whatever. . . you find in thecupboard, not one. . . in ten

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 868 — #12
868 Handbook of Logic and Language
(21) a. At least two but not more than ten students [will get scholarships]b. Most male and all female doctors [read the New England Journal]c. More male than female students [laughed at John’s costume]d. More of John’s than of Bill’s articles [were accepted]
(22) a. Every student but John [attended the party]b. Whatever dishes you find in the cupboard [are clean]c. The easiest village to reach from here [is still a hundred kilometers away]d. The first man to set foot on the Moon [was Alfred E. Newman]e. John’s biggest cat [is fat]
The Det1s above include many that appear to be mathematically unruly. InSection 19.2.2.1 we find a property shared by the “logical” Dets, which will be singledout for special study, but our initial concern is with the larger class, and this for severalreasons.
First, there are several non-trivial semantic properties, such as Conservativity andExtension (Section 19.2.2.2) shared by basically all the Det1s noted above, so the largeclass is less unruly than it appears to be. Second, many generalizations of linguisticinterest use subclasses of Det1s which include both logical and non-logical ones. Andthird, apparent alternative linguistic analyses of the complex Det1s above are prob-lematic in practice. One might claim for example that in (23a) we need not interpretmore male than female as a Det1, rather we just interpret (23a) as (23b) from whichwe derive it by some syntactic transformation.
(23) a. more male than female studentsb. more male students than female students
But this approach does not give consistently correct results. (24a,b) are paraphrases,like (23a,b), but (25a,b) are not.
(24) a. more male than female students at Yaleb. more male students at Yale than female students at Yale
(25) a. more male than female students at a certain Mid-Western universityb. more male students at a certain mid-Western university than female students at a
certain mid-Western university
Finally, we treat the italicized expressions in (22) as complex Det1s since their twoparts do not occur independently with the same interpretation. In (22a) the excep-tion phrase but John basically constrains the choice of prenominal expression to everyand no (Hoeksema, 1989; Moltmann, 1995, 1996; Reinhart, 1991; von Fintel, 1993,Ch. 19; Keenan and Westerståhl, 2006). In (22b) prenominal whatever forces thepresence of a postnominal expression: *John cleaned whatever dishes. In (22c,d) theabsence of the postnominal expression forces (at best) a context dependent interpre-tation of easiest village and first man (?Adam?) and the presence of superlatives likeeasiest, and “ordinals” like first, last, and next forces the choice of the: *Most easi-est villages, *Each first man. In (22e) if we interpreted biggest as forming a complexcommon noun with cat excluding John’s then John’s biggest cat would denote thebiggest cat (which John just happens to possess). But it doesn’t. John’s biggest cat

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 869 — #13
Generalized Quantifiers in Linguistics and Logic 869
might be small as cats go. Rather we evaluate the superlative biggest with respect tothe property cat which John has.
But we do exclude from consideration non-extensional Dets like too many andnot enough. (26a) and (26b) may have different truth values in a context in which(possibly unbeknownst to everyone) the doctors and the lawyers are the sameindividuals.
(26) a. Not enough doctors attended the meetingb. Not enough lawyers attended the meeting
By contrast replacing not enough by exactly ten in (26) yields Ss which must havethe same truth value when the doctors and the lawyers are the same. So exactly ten isextensional.
(27) Some non-extensional Dets: too many, far too many, surprisingly few, enough,not enough, a large number of, ?many, ?few6
19.2.2.1 Logical Quantifiers
Familiar “logical constants” like every, some, no and exactly one as well as Dets likethe ten, just finitely many, and less than half the are distinguishable from their moreunruly cousins above. Here are some sample denotations.
(28) a. all(A)(B) = 1 iff A & Bb. some(A)(B) = 1 iff A . B /= 0c. no(A)(B) = 1 iff A . B = 0d. exactly one(A)(B) = 1 iff |A . B| = 1e. the ten(A)(B) = 1 iff |A| = 10 and A & Bf. just finitely many(A)(B) = 1 iff for some natural number n, |A . B| = ng. less than half the(A)(B) = 1 iff |A . B| < |A - B|
So we interpret the S All poets daydream as all(poet)(daydream), which is trueiff the set of objects in E which are poets is a subset of the set of objects whichdaydream.
In the same spirit we invite the reader to provide denotations for more than ten, atmost ten, all but ten, all but finitely many, two of the ten, uncountably many, less thanten per cent of the, and two out of three
Now the quantifiers in (28) are permutation invariant7, meaning, informally first,that they ignore the identity of individuals. Formally, we have
Definition 19.2.3. Given E, F ( TYPE!1, 1" is permutation invariant (PI, or moreprecisely, PIE) iff for all permutations " of E and all A, B & E, F("A)("B) =F(A)(B).
6 Keenan and Stavi (1986) dismiss many and few as non-extensional. Barwise and Cooper (1981),Westerståhl (1985), and Lappin (1988) attempt an extensional semantic analysis.
7 The term is from van Benthem (1984). Keenan and Stavi (1986) use automorphism invariance, thinkingof the relevant functions as Boolean automorphisms of P(E).

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 870 — #14
870 Handbook of Logic and Language
Of course by "A we mean {"b | b ( A}.8 And for R & Ek, "(R) = {"d | d ( R},where "!d1, . . ., dk" =! "d1, . . ., "dk". Finally "(F) itself is that type !1, 1" mapsending each "A, "B to F(A)(B). So
F of type !1, 1" is PI iff for all permutations " of E, "(F) = F.
That is, the PI elements of TYPE!1, 1" (in fact of any denotation set) are just the fixedpoints of the (extended) permutations of E (extend to the identity map on 2).
In studying PI quantifiers it is helpful to note that (1), for A, B & E, A may bemapped to B by a permutation of E iff |A| = |B| and |E - A| = |E - B|. Either con-dition alone suffices when E is finite but not otherwise. And (2), the “lifts” of thepermutations " of E to maps: P(E) # P(E) as above are exactly the Boolean auto-morphisms of P(E). So PI functions are just those which respect the Boolean structureof P(E).
One checks directly that the quantifiers in (28) are PI. We take being PI to be anecessary ingredient of logicality. However, PI is a “local” condition. We need notcompare universes to see if it holds. But PI expressions normally satisfy a strongerisomorphism invariance condition which is global. To see the intuition, imagine aDet1 D interpreted as every if 7 ( E and as some otherwise. For each E, D denotesa PI quantifier over E, but in a statable sense it is not the same quantifier for all E.Expressions like all, exactly one, etc. are not fickle in this way. The statement thatthey are not requires a global perspective in which the interpretation of a Det takes theuniverse as a parameter. So we now think of, for example, all as a functional mappingeach E to a type !1, 1" quantifier allE over E, one whose value at a pair A,B of subsetsof E is 1 iff A & B. Indeed, this global perspective is natural for all Det denotations:
Definition 19.2.4. A (global) generalized quantifier of type !1, 1" is a functional Qwhich maps each universe E to a (local) quantifier QE of type !1, 1" over E.
Now the PI property generalizes to global quantifiers as follows. First, if F is a type!1, 1" function over E and " a bijection with domain E, then, just as before (when "
was a permutation, i.e. "E = E), "(F) is that type !1, 1" function over "E sendingeach "A, "B to F(A)(B), for all A, B & E.
Definition 19.2.5. A global generalized quantifier Q of type !1, 1" is isomorphisminvariant (ISOM) iff for all E and all bijections " with domain E, Q"E = "(QE).
Standardly, ISOM is taken to be necessary condition of logicality.9 If Q is ISOM itis PIE for all E, but the converse fails as the example just before Definition 19.2.4
8 In general, we write either fa or f (a) for the value of the function f at the argument a.9 The ISOM and PI properties can be extended to function(al)s of all types. For type !1, 1" quantifiers, the
term “logical” is in the literature sometimes taken to stand for ISOM + CONS + EXT; cf. Section 19.2.2.2.In the general case, some authors take ISOM to be both necessary and sufficient for logicality, whereasothers argue that some mathematical quantifiers satisfying ISOM do not qualify as logical. See Bonnay(2008) for a recent overview (and a suggested resolution) of the issues involved here.

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 871 — #15
Generalized Quantifiers in Linguistics and Logic 871
shows (consider E and " such that 7 ( E - "E). One may verify directly that the Detdenotations in (28) are ISOM; a simpler method will be given in Section 19.2.2.2.
Definitions 19.2.4 and 19.2.5 extend to type !1" quantifiers in an obvious way (infact to quantifiers of any type). But note that NP denotations are usually not ISOM oreven PI. The reason is that they typically involve particular N denotations (sets) – allhorses, the ten boys, two of the ten poets – or PN denotations (individuals) – Eve orHarry, John’s friends. But the latter denotations are rarely PI. For example, a subset Aof E is PI iff for all permutations " of E, "A = A, and this holds only when A = E orA = 0. Similarly, most NP denotations are not PI. With Det1 denotations, on the otherhand, the N is not fixed but an argument, and this is what allows them to be ISOM.But Det1s that do involve a fixed N or PN, such as John’s, no. . . but Eve, most maleand all female, will typically not be ISOM.
To find ISOM type !1" quantifiers we need to look at mathematical or logical lan-guages such as predicate logic and its extensions. Examples are
(29) a. 1E(A) = 1 iff A /= 0b. 'E(A) = 1 iff A = Ec. (12n)E(A) = 1 iff |A| 2 nd. (QR)E(A) = 1 iff |A| > |E - A| (the Rescher quantifier)e. (QC)E(A) = 1 iff |A| = |E| (the Chang quantifier)
(note, however, that 1 and ' are denotations of the NPs something and everything,respectively).
19.2.2.2 Conservativity and Extension: General Constraintson Det Denotations
In evaluating Ss of the form [Det1 N]+P1 we are thinking of the Det as mapping thenoun argument to a type !1" function, one that takes the predicate argument to true orfalse. Now the role of the noun argument in this computation is quite different fromthat of the predicate argument. Informally we note,
(30) (Domain Restriction) In evaluating [Det1 N]+P1, the noun property delimitsthe objects we need to consider. It suffices to know which of them have thepredicate property and which do not. But we need not consider individualswhich lack the noun property.
The domain-restricting role of the noun property has no obvious analog among theproperties of quantifiers studied in mathematical languages. Quantifiers, like 'x and1y, are understood as quantifying over the entire intended universe of discourse (andso paraphrase the NL expressions everything and something of type !1", not !1, 1").But NLs are inherently multi-purpose. We use them to talk about anything (enrichingvocabulary as needed). And the noun arguments of Dets function to delimit “on line”,as we speak, the range of things we are talking about. In logic, domain restriction of 'xand 1y to a set A is achieved using 'x(Ax # . . .) and 1y(Ay+. . .) instead, i.e. effectingtype !1, 1" quantification by means of type !1" quantification and logical operators. But(i) this added logical complexity is not used in NLs, and, more importantly, (ii) while

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 872 — #16
872 Handbook of Logic and Language
the reduction works for every and some, there are many Dets for which there simplyis no such reduction.
The apparently simple notion of Domain Restriction is expressed in the literatureas the conjunction of two independent properties, conservativity and extension.
ConservativityEarly work (Barwise and Cooper, 1981; Higginbotham and May, 1981; Keenan, 1981)recognized that Dets satisfied a condition now called conservativity:
Definition 19.2.6. F ( TYPE!1, 1" is conservative (over E) iff 'A, B, B3 & E,
if A . B = A . B3 then F(A)(B) = F(A)(B3)
An equivalent and commonly given defining condition is that 'A, B & E,
F(A)(B) = F(A)(A . B)
CONS (or CONSE) is the set of conservative functions of TYPE!1, 1" over E. A globaltype !1, 1" quantifier Q is conservative iff each QE is conservative.
The underlying intuition is that to know whether Det As are B it is sufficient toknow which individuals have A and which of those As have B (an intuition built intothe interpretation of quantifiers in DRT; cf. Kamp and Reyle, 1993, p. 317). The Bsthat lack A are irrelevant. One checks directly that the functions exhibited in (28) areconservative, and that conservativity guarantees the logical equivalences in (31).
(31) a. Most cats are grey 4 Most cats are cats and are greyb. John’s cats are black 4 John’s cats are cats and are black
In spite of the apparent triviality of these equivalences conservativity is not a weakconstraint. An easy computation (e.g., van Benthem, 1984) shows
(32) For |E| = n, |TYPE!1, 1"E| = 24n and |CONSE| = 23n
Thus in a universe with just two objects there are 216 = 65, 536 elements inTYPE!1, 1", only 29 = 512 of which are in CONS. So conservativity rules out mostways a natural language might associate properties with NP denotations. For example,quantifiers like those in (33) are not conservative (the first two, which are ISOM, havebeen studied in mathematical logic).
(33) a. M(A)(B) = 1 iff |A| > |B|b. I(A)(B) = 1 iff |A| = |B| (the Härtig quantifier)c. For each b ( E, Hb(A)(B) = 1 iff b ( B - A
Thus we do not have the equivalent of TYPE!1, 1" effability. But we do have:
Generalization 19.2.4. (Keenan and Stavi, 1986) Over a finite universe E, all elementsof CONSE are denotable by an English Det.

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 873 — #17
Generalized Quantifiers in Linguistics and Logic 873
As an aid to counting subsets of TYPE!1, 1" of interest and in proving effabilityresults like Generalization 19.2.4 we note that TYPE!1, 1" is a complete and atomic(ca) Boolean algebra (BA) and in general subsets B of interest, like CONS, are casubalgebras of TYPE!1,1". So |B| = 2m, where m is the number of atoms of B. Keenanand Stavi compute that there are 3|E| atoms in CONSE. And to show finite effabilityit is enough to show that any finite number of atoms is denotable. Taking (finite)disjunctions then gives the effability result.
It is also fair to wonder just how we support the claim that the diverse Dets in (20)always denote in CONS.10 Of course in part we sample. But this sampling is supportedby more systematic observations. Namely,
(34) a. lexical Det1s are conservative, andb. the major ways of building Dets from Dets preserves conservativity.
The lexical or near lexical Det1s of English are given in (19a) above. Of ways ofbuilding complex Dets we note four. First,
(35) The trivial functions 0!1,1"(A)(B) = 0 and 1!1,1"(A)(B) = 1, all A, B & E, arein CONS.
(36) Second, conservativity is preserved under definition by cases in terms of con-servative functions. E.g., the ten ( CONS given that every and 0 are.
the ten(A) =!
every(A) if |A| = 10
0!1,1"(A) otherwise
Third, and crucial for non-logical Dets like John’s ten, composition with restrictingfunctions preserves CONS. More explicitly,
(37) a. f : P(E) # P(E) is restricting iff 'A ( P(E), f (A) & A.b. For F ( CONS and f restricting, Ff ( CONS, where Ff (A)(B) =df F( f (A))(B).
From (36) and (37) we infer immediately that John’s ten and none of John’s tendefined below are conservative:
(38) John’s ten(A) =!
every(A which John has) if |A which John has| = 10
0!1,1"(A) otherwise
(We write A which John has for the set of b ( A which John stands in the hasrelation to, where this relation is given by the context (model). To show conservativityit suffices that the map sending each A to A which John has is restricting.)
(39) none of John’s ten(A) =!
no(A which John has) if |A which John has| = 10
0!1,1"(A) otherwise
10 For some questionable cases see Keenan and Stavi (1986), Johnsen (1987), and the more systematicdiscussion in Herburger (1994).

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 874 — #18
874 Handbook of Logic and Language
Finally, CONS is closed under the pointwise Boolean functions. So the denotationsof the expressions in (40) are in CONS given that denotations of the Dets they arebuilt from are
(40) not more than ten, at least ten and not more than a hundred, neither fewer thanten nor more than a hundred, most but not all, neither John’s nor Mary’s, mostmale but only a few female, most of John’s and all of Mary’s.
One shows many of the unruly looking expressions in (20) to be conservative byshowing that they are expressible as some combination of definition by cases, restric-tions, or Boolean functions of conservative functions.
Now, stepping back from our discussion, we see that Conservativity expresses partof what is covered informally by Domain Restriction. Conservativity says that we maylimit our consideration of objects with the predicate property to those which also havethe noun property. But Domain Restriction says more. It says that in evaluating S =[Det N] + P1 we need not consider any individuals that lie outside the extension of thenoun argument. Leafing through the OED we will not find some archaic Det blik withthe sense that Blik cats are black is true iff the number of non-cats is 3. Yet the F in(41) is conservative.
(41) F(A)(B) = 1 iff |- A| = 3.
So the denotations of the English Dets given earlier satisfy additional constraints,challenging perhaps the effability claim (34) of Keenan and Stavi (1986). But theneeded constraints are global. Once we fix a finite E, the F in (41) is expressible. Tosee this, note that the functions in (42) are conservative, all n, m.
(42) at most n of the m(A)(B) = 1 iff |A| = m and |A . B| ) n.
Now for |E| < 3, the F in (41) is just 0!1,1" which is CONS. If |E| 2 3, E finite,let m be such that |E| - m = 3. Then the F in (41) is denoted by at most m of the m.
The type of global constraint we need to eliminate quantifiers like that in (41) wasfirst given in van Benthem (1984), and is called extension.
Definition 19.2.7. Let Q be a global type !1,1" quantifier. Then Q satisfies extension(EXT) iff 'E, E3 with E & E3, QE3 is an extension of QE.
To say that every satisfies Extension (which it does) is to say that whenever E & E3
the function everyE3 extends the function everyE. That is, 'A, B & E, everyE(A)(B) =everyE3(A)(B). So quantifiers that satisfy EXT must make the same decision regardinga pair A, B of sets regardless of what the underlying universe is. The F in (41), treatedas a functional FE(A)(B) = 1 iff |E - A| = 3, fails Extension. Similarly the quantifierQ below fails Extension.
(43) QE =!
everyE if E is finite
infinitely manyE if E is infinite

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 875 — #19
Generalized Quantifiers in Linguistics and Logic 875
Note that Extension is equivalent to the following condition:
(44) QE(A)(B) = QE3(A)(B), all E, E3 (5 A, B
Reason: QE(A)(B) = QE6E3(A)(B) = QE3(A)(B). So we see that Extension indeedcaptures a notion of universe-independence, or put differently, of having the sameinterpretation in different universes.11
We have so far been somewhat sloppy distinguishing global and local quantifiers:the underlying universe of a local quantifier has often been tacitly understood butnot explicitly given. Now we see that for quantifiers in EXT such sloppiness can beformally justified. If Q is a global quantifier satisfying Extension and A, B are sets, wemay drop the subscript and simply write
Q(A)(B) = 1
meaning “for some E with A, B & E, QE(A)(B) = 1”. Extension guarantees that thisis equivalent to “for all E with A, B & E, QE(A)(B) = 1”, or, if we have a particularuniverse E3 with A, B & E3 in mind, to “QE3(A)(B) = 1”.
Consider now typical non-logical Dets like John’s ten or most male. To interpretthese as ordinary global quantifiers we think of John, the has relation, and the maleproperty as fixed in advance. Then, for example, most male is that functional whichmaps each E to the quantifier most maleE(A)(B) = 1 iff |male . A . B| > |(male .A) - B|, all A, B & E. This is a CONS and EXT (but not ISOM) global quantifier.
Logicality RevisitedOur study of ISOM Dets is made more tractable by limiting ourselves to ones that areboth CONS and EXT. Note that ISOM is independent of these conditions. For examplethe quantifier Q given by QE(A)(B) = 1 iff |- A| = |- B| is ISOM but neither CONSnor EXT. Observe now,
Proposition 19.2.1. A global type !1, 1" quantifier Q is in CONS . EXT . ISOM iff'E 'A, B & E 'E3 'A3, B3 & E3,
(|A . B| = |A3 . B3| and |A - B| = |A3 - B3|) * QE(A)(B) = QE3(A3)(B3)
Thus, given Conservativity and Extension, ISOM Dets base their decision at a pairA, B on the two quantities |A . B| and |A - B|.12 Using Proposition 19.2.1 one easilyverifies that the quantifiers in (28) are ISOM. The atoms of (CONS . EXT . ISOM)Eare the maps (exactly n + all but m) which send a pair A, B to 1 iff |A . B| = n & |A
11 For further discussion of the role of Extension, see Peters and Westerståhl (2006) Chs 3.4–5 and 4.5.12 The fact that such quantifiers on finite universes can be identified with binary relations between natural
numbers allows a useful and perspicuous representation of them, and of many of their properties, in theso-called tree of numbers, first introduced in van Benthem (1986). See Chapter 20 of this volume fordefinitions and an application to learning theory.

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 876 — #20
876 Handbook of Logic and Language
-B| = m, all cardinals n, m with n+m ) |E|. And the Dets in (CONS.EXT.ISOM)Eare the lubs of these atoms. Note that these claims do not require that E be finite.13
Domain Restriction RevisitedConservativity and Extension are independent. F in (41) is CONS but fails EXT,I in (33) satisfies EXT but fails CONS. And we have: Conservativity + Extension =Domain Restriction. Can we find a conceptually unified condition on the role of thenoun argument which yields conservativity and extension as special cases?
One answer to this query uses the logical notion of relativization.14 For each(global) type !1" quantifier Q we can define a type !1,1" quantifier Qrel which sim-ulates in the verb argument the behaviour of Q over the universe determined by thenoun argument:
Definition 19.2.8. The relativization of a global type !1" quantifier Q is the globaltype !1, 1" quantifier Qrel given by Qrel
E (A)(B) = QA(A.B) for all E and all A, B & E.
Fact 19.2.1. A type !1, 1" quantifier is CONS + EXT iff it is equal to Qrel for sometype !1" quantifier Q.
To see this, one verifies directly from the definitions that Qrel is always CONS andEXT. In the other direction, if Q3 is CONS and EXT, define the type !1" counterpartQ of Q3 by QE(B) = Q3
E(E)(B). Then Q3 = Qrel, since QrelE (A)(B) = QA(A . B) =
Q3A(A)(A . B) = Q3
E(A)(A . B) (by EXT) = Q3E(A)(B) (by CONS).
Thus, the Domain Restricted type !1,1" quantifiers – among which we claim to findall Det1 denotations – are precisely the relativizations of type !1" quantifiers. Indeedtheir type !1" counterparts are often familiar:
(46) a. every = 'rel
b. some = 1rel
c. at least n = 1rel2n
d. most = (QR)rel (QR was defined in (29))e. John’s = Qrel, where Q interprets the NP everything that John has
GeneralizationIn evaluating Ss of the form [Det N] + P1 the noun argument is distinguished fromthe verb one in determining the domain restriction. A type notation reflecting thisasymmetry would be !!1",1". The standard notation !1,1" rather reflects the commonview in which Det1s denote simply binary relations over P(E). But the functionalview we have been using generalizes more naturally than the relational view in twodirections.
13 In finite models the atoms are expressible by the Dets exactly n of the m, for n ) m, but in the infinitecase we cannot reconstruct |A . B| from |A| and |A - B|.
14 Ben-Shalom (2001), drawing on modal logic, provides a somewhat diffferent approach to unifying theCONS and EXT conditions.

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 877 — #21
Generalized Quantifiers in Linguistics and Logic 877
First, the statements of Conservativity and Extension do not depend on the rangeof type !1" functions, they merely say that under certain conditions QE(A)(B) =QE3(A3)(B3). The functional view then enables us to say without change that inter-rogative Dets such as which? and whose? are conservative and satisfy Extension.Conservativity for example just says that which?(A)(B) = which?(A)(A . B). SoConservativity yields the equivalence of the (a,b) questions in (47).
(47) a. Which roses are red? b. Which roses are roses and are red?a. Whose cat can swim? b. Whose cat is a cat that can swim?
Second, the noun argument of Det1s forms a type !1" constituent (NP) with theDet1, one that occurs as an argument of transitive and ditransitive verbs, as in Noteacher criticized every student and John gave every teacher two presents. These factswill prompt us in Section 19.3 to generalize the type !1" functions to ones taking(n + 1)-ary relations as arguments yielding n-ary ones as values, not just functionstaking unary relations to zero-ary ones as at present.
For further extensions of these ideas to predicate modifiers of various sorts we referthe reader to ter Meulen (1990) and Loebner (1986). Here we turn to:
19.2.2.3 Basic Subclasses: Intersective (existential) & Co-intersective(universal)
The (local) value of a Det1 denotation F at A,B depends at most on A.B and A–B. IfF(A)(B) depends only on A.B we call F intersective, and if it depends only on |A.B|we call it cardinal. If F(A)(B) depends only on A-B we call F co-intersective.
Definition 19.2.9. Let F ( [P(E) # [P(E) # 2]]. Then,
a. F is intersective iff
'A, B, A3, B3 & E, A . B = A3 . B3 * F(A)(B) = F(A3)(B3).
b. F is co-intersective iff
'A, B, A3, B3 & E, A - B = A3 - B3 * F(A)(B) = F(A3)(B3).
c. F is cardinal iff
'A, B, A3, B3 & E, |A . B| = |A3 . B3| * F(A)(B) = F(A3)(B3).
Equivalently, F is co-intersective iff F¬ is intersective (see (7d)).We write INT (or INTE!1, 1"), CO-INT (or CO-INTE!1, 1"), and CARD (or
CARDE!1, 1"), for the set of intersective, co-intersective, and cardinal functions oftype !1,1" over E, respectively.
(48) a. Some intersective (= Generalized Existential) Dets in English
Cardinal: some, no, a, at least n, more than n, exactly n, between n and m, fewer than n, atmost n, infinitely many, forty odd, forty or more, about forty, at least two and atmost ten, not more than ten.

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 878 — #22
878 Handbook of Logic and Language
Non-PI: more male than female, exactly five male, no...but John.
b. Some co-intersective (= Generalized Universal) Dets in Englishevery, all but n, all but at most n, every. . . but John, almost all.
Where John denotes an individual Ij, no. . . but John (as in No student but Johnlaughed) maps A,B to 1 iff A . B = {j} and thus is intersective. every. . . but Johnmaps A,B to 1 iff A - B = {j} and so is co-intersective. Indeed, every. . . but John =(no. . . but John)¬.
INT and CO-INT are basic subclasses of Dets in several respects. We note first
Proposition 19.2.2. (Keenan, 1993)
i. Both INT and CO-INT are ca subalgebras of CONS. CARD is a ca subalgebra of INT. Infact, CARD = INT . PI, when E is finite (but not when E is infinite).
ii. For A = INT or CO-INT, the function 7 from A into [P(E) # 2] given by F7(B) = F(E)(B),is an isomorphism. Also, INT is isomorphic to CO-INT via the function that maps F to F¬.
iii. INT . CO-INT = {0!1,1", 1!1,1"}.
Proposition 19.2.2 (i) guarantees that Dets like at least two but not more than tenare intersective given that the ones they are built from are.
Proposition 19.2.2 (ii) says that INT and CO-INT are very limited types of Dets,each being isomorphic to TYPE!1", the set of possible NP denotations. One computesthat of the 23n
conservative functions only 22n+1 -2 are generalized universal or exis-tential. For example, for |E| = 3, |INT6CO-INT| = 510 and |CONS| > 130 million.Still, in addition to generalizing the standard notions of existential and universal quan-tification, INT and CO-INT are fundamental subsets of CONS in two respects: (i) theygenerate all of CONS under the Boolean operations (Theorem 19.2.1) and (ii) they areprecisely the type !1,1" quantifiers which do not make essential use of the DomainRestricting property of their noun arguments (Theorem 19.2.2).
Theorem 19.2.1. (Keenan, 1993; Keenan and Stavi, 1986) For each E, CONSE is thecomplete Boolean closure of INTE 6 CO-INTE.
Leading up to our second result, observe that (classically) (49a) and (49b) are logi-cally equivalent.
(49) a. Some students are vegetarians.b. Some individuals are both students and vegetarians.
This equivalence says that for Det = some we may eliminate the restriction (stu-dents) on the domain of quantification, compensating by an appropriate Boolean com-pound in the predicate. But if some is replaced by most in (49a) we find no analogof (49b). Most then appears inherently sortal: we cannot eliminate restrictions on itsdomain of quantification, compensating by some Boolean modification of the predi-cate. Just which Dets in English are inherently sortal in this sense?
Definition 19.2.10. F of type !1,1" is sortally reducible iff there is a Boolean func-tion h of two variables such that 'A, B & E, F(A)(B) = F(E)(h(A, B)). Otherwise, Fis called inherently sortal.

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 879 — #23
Generalized Quantifiers in Linguistics and Logic 879
Theorem 19.2.2. (Keenan, 1993) A conservative F is sortally reducible iff F is inter-sective or co-intersective.
The class of intersective Dets also provides a fair solution to a properly linguisticproblem. To state the problem with generality we shall anticipate Section 19.2.3 andgeneralize the notion intersective to Dets of type !!1,1",1". Recall that we treat expres-sions like those italicized in (50) as Det2s – they combine with two common nouns toform a type !1" expression:
(50) a. More students than teachers attended the partyb. Every man and woman jumped overboardc. The same number of students as teachers signed the petition
A type !!1,1",1" Det is intersective if the truth value of an S it builds depends onlyon the intersection of the predicate property with each of the noun properties. Somore. . . than in More dogs than cats are in the garden is intersective since the truthof the S is determined given the two sets dog . in the garden and cat . in thegarden.
Definition 19.2.11. A function F mapping k-tuples of subsets of E to [P(E) # 2]is intersective iff for all (A1, . . ., Ak) and (B1, . . ., Bk) and all sets C, C3, if Ai . C =Bi . C3, all 1 ) i ) k, then F(A1, . . ., Ak)(C) = F(B1, . . ., Bk)(C3).
Of the Det2s in (50) one verifies that every. . . and is not intersective but more. . . thanand the same number of. . . as are, as are cardinal comparatives in general, e.g.,fewer. . . than, exactly as many. . . as, more than twice as many. . . as.
Now consider Existential There Ss like those in (51):
(51) a. There wasn’t more than one student at the party.b. Are there more dogs than cats in the garden?c. There was no one but John in the building at the time.
Such Ss affirm, deny or query the existence of objects with a specified property. NPslike more than one student which naturally occur in such Ss will be called existentialNPs. So the NPs italicized in (52) are not existential.
(52) a. *There wasn’t John at the partyb. *Were there most students on the lawn?c. *There wasn’t every student in the garden
The linguistic problem: define the set of existential NPs in English. And a good firstapproximation to an answer here is Generalization 19.2.5.15
Generalization 19.2.5. The NPs which occur naturally in Existential There Ss are(Boolean combinations of) ones built from intersective Dets.
15 See Barwise and Cooper (1981) for a related approach, the first properly semantic one in the literature,Reuland and ter Meulen (1987) for an overview of recent work on this thorny linguistic issue. Ch. 6.3 inPeters and Westerståhl (2006) compares several proposals, including the present one.

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 880 — #24
880 Handbook of Logic and Language
This correctly predicts the judgments in (51) and (52) as well as those in (53):
(53) a. There are the same number of students as teachers on the committeeb. There aren’t more than twice as many children as adults at the partyc. There are at least two dogs but not more than ten cats in the yardd. *There are two out of three students on the committeee. *Was there every student but John in the building at the time?f. *There weren’t John’s cats in the garden
Turning now to Dets which are neither intersective nor co-intersective there are atleast two classes of interest: the “definite” ones, and the proportional ones.
Partitives and Definite NPsConsider partitive NPs like at least two of the students, all but one of John’s childrenand most of those questions. Most linguists treat them as having the form [Det1 ofNP], and more generally [Detk (of NP)k], like more of the boys than of the girls. SeeLadusaw (1982) and references cited there for discussion of partitives in a linguisticsetting.
The linguistic issue: For which choices of NP is the partitive [Det1 of NP] gram-matical? Some partial answers:
(54) a. at least two of X is a grammatical NP when X = the boys; the ten or more boys;these boys; these ten boys; John’s cats; John’s ten or more cats; my cats; the child’stoys; that child’s best friend’s toys; his toys
b. at least two of X is ungrammatical when X = each boy; all boys; no boys; the boy;some boys; most boys; exactly ten boys; ten boys; no children’s toys; most of thehouses; at least nine students; more students than teachers; five of the students.
Thus whether an NP of the form Det1 + N occurs grammatically in the partitivecontext [two of ] depends significantly on its choice of Det1 (which is in part whywe suggested to treat, for example, most of those in most of those questions as a com-plex Det1 of the form [Det1 of Det1]). Det1s acceptable here were first characterizedsemantically in Barwise and Cooper (1981). Extending their analysis slightly:
Definition 19.2.12. A functional F mapping each E to a type !1,1" quantifiers over Eis definite iff F is non-trivial and 'E'A & E, F(A) = 0 or F(A) is the filter generatedby some non-empty C & A. If C always has at least two elements Q is called definiteplural.
NB: that F(A) is the filter generated by C means that F(A)(B) = 1 iff C & B
(55) Some definite plural Det1sthe ten, the two or more, thepl, John’s ten, John’s two or more, John’spl, these,these ten, those ten or more, John and Bill’s ten, his ten,. . .
Note that every is not definite and the one, and John’s one are definite but not definiteplural.
Generalization 19.2.6. An NP X is grammatical in plural partitive contexts iff X =[Det N] where Det is semantically definite plural or X is a conjunction or disjunctionof such NPs.

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 881 — #25
Generalized Quantifiers in Linguistics and Logic 881
We note that NPs such as this student and that teacher are excluded by this defini-tion (though by certain other criteria in Linguistics it would count as definite plural).16
19.2.2.4 Proportionality Quantifiers and Logical Definability
A question that has arisen now and then in linguistics is: Can semantic interpreta-tions for natural language be given in first-order logic? Various authors (e.g., Boolos,1981, 1984; Gabbay and Moravcsik, 1974; Hintikka, 1973) have presented sometimessubtle, often debated, arguments to show that the answer was negative. However, thetheory of generalized quantifiers provides a straightforward and undisputable argu-ment (for the same answer): even if we restrict attention to finite universes, it can beproved by standard model-theoretic techniques (cf. Barwise and Cooper, 1981) thatthe denotation of most (in the sense of more than half) is not first-order definable.And nothing in this proof crucially distinguishes more than half from more thantwo thirds or other ISOM type !1, 1" quantifier whose value at a pair A, B properlycompares |A . B| with |A| (or |A - B|).
Generalizing, we say that F ( [P(E) # [P(E) # 2]] is proportional – an elementof PROP – if
(56) 'A, B, A3, B3 & E, |A . B|/|A| = |A3 . B3|/|A3| * F(A)(B) = F(A3)(B3).
The denotations of, for example, most, at least half, half the, more than ten percent ofthe, are proportional. Let us introduce the following notation:
(57) The basic proportionals are the type !1,1" quantifiers (m/n) and [m/n], 1 ) m <
n, defined, for A, B & E, by(m/n)(A)(B) = 1 iff |A . B|/|A| > m/n[m/n](A)(B) = 1 iff |A . B|/|A| 2 m/n
We note that ordinary usage of proportional Dets assumes the relevant sets are finiteand non-empty, so in the rest of this subsection, we restrict attention to finite universes.Clearly, the basic proportionals are in PROP, and one easily verifies that PROP isclosed under Boolean combinations. Thus, negations of basic proportionals, like thedenotations of less than a third of the and at most ten percent of the are in PROP,as well as meets and joins of these functions, such as the denotations of exactly tenpercent of the, between two fifths and three fifths of the, etc.
Proposition 19.2.3. The basic proportionals are not first-order definable.
Proposition 19.2.3 extends immediately to negations of basic proportionals. It alsoextends to many meets and joins of basic proportionals, although we must excludetrivial Boolean combinations like at most a third and at least two thirds of the.
Note that here we are talking about global quantifiers and uniform definability.A type !1, 1" quantifier Q is first-order definable iff there is a first-order sentence #
16 For further discussion of the semantic notion of definiteness, see Peters and Westerståhl (2006), Chs 4.6and 7.11.

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 882 — #26
882 Handbook of Logic and Language
whose non-logical symbols are exactly two unary predicate symbols P1 and P2, suchthat for any interpretation (model) E = !E, A1, A2", where A1, A2 & E,
(58) QE(A1)(A2) = 1 % !E, A1, A2" # #
So the same definition # works in every universe.17 For example, obviously at leasttwo is first-order definable, since |A1 .A2| 2 2 is expressed by the first-order sentence
1x1y(x /= y + P1x + P1y + P2x + P2y)
and similarly all but at most two is first-order definable by
'x'y'z(P1x + P1y + P1z + ¬P2x + ¬P2y + ¬P2z # x = y , y = z , x = z)
And the result above says that when Q = most, for example, there exists no first-ordersentence of the required kind such that (58) holds.
In fact, much stronger undefinability claims hold, some of which are linguisti-cally relevant. To formulate these, we need to consider definability in terms of certaingiven quantifiers. To see some examples, note first that most is definable in terms ofmore. . . than of type !!1, 1", 1":
(59) most(A1)(A2) = (more A1 . A2 than A1 - A2)(E)
since most A1’s are A2’s iff more A1’s who are A2’s than A1’s who are not A2’s exist.From (59) it is clear that if we had a first-order sentence defining more. . . than, wecould construct another one defining most. Hence, more. . . than, and in general thenon-trivial comparative Dets of type !!1, 1", 1" (cf. Section 19.2.3), are not first-orderdefinable.
For another example, on finite models (not on infinite ones), the quantifiers I andM from (33) are definable in terms of most. First,
(60) I(A)(B) = 1 iff M(A)(B) = M(B)(A) = 0
so I is definable in terms of M, and second, for finite A, B we have
(61) M(A)(B) = 1 iff |A| > |B|iff |A - B| > |B - A|iff most((A - B) 6 (B - A))(A - B) = 1
This notion of definability can be made precise with the concept of a logic withgeneralized quantifiers (Lindström, 1966; Mostowski, 1957). Let Q be a quantifier oftype !1, 1", or more generally of type !1, . . . , 1" with k 1’s, k 2 1 (in this contextthere is no need to separate noun arguments from verb arguments). The logic L(Q) isobtained from first-order predicate logic by adding the new formation rule
17 Note that a first-order definable quantifier is automatically ISOM, since first-order sentences are invariantfor isomorphic models.

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 883 — #27
Generalized Quantifiers in Linguistics and Logic 883
(62) if #1, . . . ,#k are formulas and x is a variable then Qx(#1, . . . ,#k) is aformula
(here Qx binds each free occurrence of x in each of #1, . . . ,#k), and a correspondingclause in the truth definition:
(63) E # Qx(#1, . . . ,#k) [g] (i.e. the assignment g satisfies Qx(#1, . . . ,#k) in themodel E with universe E) iff QE((#
E,x,g1 ), . . . , (#
E,x,gk )) = 1
where #E,x,gi is the subset of E defined by #i relative to x and g:
#E,x,gi = {a ( E : E # #i[g(x/a)]}
(g(x/a) is like g except that x is assigned to a). Likewise, one defines logicsL(Q1, . . . , Qn) where Q1, . . . , Qn are given quantifiers (of arbitrary types).
Finally, a quantifier Q of type !1, 1" is definable in L(Q1, . . . , Qn) iff (58) holds forsome L(Q1, . . . , Qn)-sentence # (similarly if Q is of type !1, . . . , 1").
For example, our statement above that (59) defines most in terms of more. . . thanbecomes the claim that most is definable in L(more. . . than), by means of thesentence
more. . . than x(P1x + P2x, P1x + ¬P2x, x = x)
Similarly, from (61) we see that M is definable (for finite E) by the L(most)-sentence
most x((P1x + ¬P2x) , (P2x + ¬P1x), P1x + ¬P2x)
Recall now from Section 19.2.2.2 (Fact 19.2.1 and (46)) that each CONS and EXTtype !1, 1" quantifier Q3 has a type !1" counterpart Q, such that Q3 = Qrel. If Q3 isdefinable in terms of its type !1" counterpart, i.e. if Qrel is definable in L(Q), then thetype !1" counterpart is semantically sufficient. And this holds for many Det1 denota-tions, for example,
(64) a. every = 'rel is defined by 'x(P1x # P2x)b. some = 1rel is defined by 1x(P1x + P2x)c. all but at most three = 1rel
)3 /= is defined by 1)3x(P1x + ¬P2x)
If similar definitions could be given for all Det1 denotations then at least from a logicalpoint of view type !1" quantification would be enough. But it was proved in Barwiseand Cooper (1981) that not only is most not first-order, it is not even definable in termsof its counterpart QR. Generalizing,
Proposition 19.2.4. The basic proportionals are not definable in terms of their type!1" counterparts.

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 884 — #28
884 Handbook of Logic and Language
This strengthens Proposition 19.2.3 (if Qrel is not definable in L(Q) it is certainlynot first-order definable), and shifts the focus from first-order definability to the seman-tic necessity of type !1, 1" quantification for natural language.18
More can be said. Note that in (64) all the type !1" quantifiers are first-order defin-able, and either increasing or decreasing. Indeed we have
Theorem 19.2.3. (Kolaitis and Väänänen, 1995; Westerståhl, 1991) Let Q be a mono-tonic type !1" quantifier. Then, over finite universes, Qrel is definable in L(Q) iff Q isfirst-order definable.
It can be seen that Proposition 19.2.4 follows from Theorem 19.2.3 and Proposi-tion 19.2.3. But the strongest possible generalization of Propositions 19.2.3 and 19.2.4is due to Kolaitis and Väänänen (1995) and uses advanced finite combinatorics for itsproof.19 It shows that this kind of non-definability for basic proportional Det1s reallyhas nothing to do with their type !1" counterparts; no type !1" quantifiers at all willdo! Thus in a very strong and precise sense, type !1, 1" quantification is necessary fornatural language.
Theorem 19.2.4. (Kolaitis and Väänänen, 1995) Let Q be a basic proportional quan-tifier. Then for no finite number of type !1" quantifiers Q1, . . . , Qn is it the case that Qis definable in L(Q1, . . . , Qn).
(Basic) proportional Dets exhibit some characteristic inference patterns. To begin,(65c) follows from (65a) and (65b):
(65) a. At least two-thirds of American teenagers are overweight.b. More than one-third of American teenagers read comic books. Ergo,c. At least one American teenager is both overweight and reads comic books.
To see what is going on here, it is convenient to use the notion of the dual of a quan-tifier, which can be expressed in terms of complements and post-complements; thesewere defined in (7) for type !1" quantifiers. Let Q ( [P(E) # 2].
(66) Qd, the dual of Q, is defined by Qd = ¬(Q¬)(= (¬Q)¬). These oper-ations extend pointwise to F ( [P(E) # [P(E) # 2]] : (¬F)(A) =¬(F(A)), (F¬)(A) = (F(A))¬, Fd(A) = F(A)d.
For example, (every student)d = some student, (no teachers)d = not all teachers,(at most 70% of Americans)d = less than 30% of Americans, and so (every)d =some, (no)d = not all, (at most 70% of)d = less than 30% of. The last exampleillustrates a general fact: an easy calculation shows that
18 For techniques by means of which Propositions 19.2.3 and 19.2.4 can be proved, with applications tovarious quantifiers, see Peters and Westerståhl (2006), Chs 13–14.
19 Kolaitis and Väänänen (1995) prove the theorem for the quantifiers I and M, but Väänänen has pointedout (p.c.) that the methods generalize to other proportions.

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 885 — #29
Generalized Quantifiers in Linguistics and Logic 885
(67) (m/n)d = [(n - m)/n] and [m/n]d = ((n - m)/n)
Now we see that the inference (65) has the general form
(68) a. F A are Bb. Fd A are C
Ergo, c. Some B are C
And this is valid whenever F is a basic proportional. Somewhat surprisingly, the valid-ity of (68) doesn’t turn on proportionality, however; it only uses the fact that basicproportionals are monotonic increasing. In fact, the following holds:
Proposition 19.2.5. (Peters and Westerståhl, 2006, Ch. 5.7) If F is CONS, it satisfiesthe inference pattern (68) if and only if it is monotonic increasing.
For example, with F = some we have the familiar syllogism
(69) a. Some A is Bb. Every A is C
Ergo, c. Some B is C
The most interesting instances of (68), however, come from the basic proportionals.Next, consider the equivalence of (70a) and (70b):
(70) a. Between forty and sixty percent of Americans vote Green.b. Between forty and sixty percent of Americans don’t vote Green.
Seeing that these two are indeed equivalent involves a small calculation. What thiscalculation shows, in fact, is that the quantifier between forty and sixty percent of isa fixed point of the post-complement operation, i.e. that it satisfies
(71) F¬ = F
Moreover, the equivalence in (70) is an instance of a general fact:
Theorem 19.2.5. (Mid-point Theorem) (a) All type !1, 1" quantifiers of the form F +F¬ or F , F¬ satisfy (71). (b) The class of quantifiers satisfying (71) is closed underBoolean operations (including post-complement).
For example, since not more than half is the post-complement of at least half,exactly half = at least half and not more than half is a fixed point of ¬. Similarly,the following are equivalent:
(72) a. Either less than 1/3 or else more than 2/3 of the As are Bs.b. Either less than 1/3 or else more than 2/3 of the As are not Bs.
Again, Theorem 19.2.5 provides examples of non-proportional quantifiers satisfying(71), such as exactly five or else all but five, although the proportional examples aremore natural in English. We may note, finally, that no lexical Dets in English denotequantifiers that are fixed points of ¬.

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 886 — #30
886 Handbook of Logic and Language
19.2.3 Type !!1, 1", 1" Quantification
This type of quantification is less well studied than type !1, 1", the main studies beingKeenan and Moss (1985), Beghelli (1992, 1994). Here we simply show how the basicconcepts for type !1, 1" quantifiers extend to this type. (3), (50) and (53a–c) givesome examples. Others are given in (73) and (74), with some sample denotationsin (75).
(73) a. [Almost as many teachers as students] attended the meeting.b. [Five more students than teachers] attended.c. [Some student’s hat and coat] were on the table.d. [More of John’s dog’s than cats] were innoculated.e. [Exactly four students and two teachers] objected to the proposal.f. [At least three times as many students as teachers] attended the meeting.
(74) fewer. . . than, proportionately more. . . than, a greater percentage of. . . than,John’s two. . . and three, exactly half the. . . and a third of the, fewer. . . than,not more than ten times as many. . . as, the ninety-two. . . and, ten per centfewer. . . than.
(75) a. (fewer A than B)(C) = 1 iff |A . C| < |B . C|.b. (at least twice as many A as B)(C) = 1 iff |A . C| 2 2 · |B . C|.c. (every A and B)(C) = every(A)(C) + every(B)(C).
d. (exactly two A and three B)(C) = 1 iff |A . C| = 2 and |B . C| = 3.
Our type notation !!1, 1", 1" taken from Beghelli (1992, 1994), contrasts with!1, !1, 1"" used for more. . . than in (76a) and !!1, 1", !1, 1"" in (76b).
(76) a. More students came early than left late.b. More students came early than teachers left late.
In (76a) there is just one noun property, student, and two predicate properties, cameearly and left late. No part of (76a) functions as a type !1" expression. Similarly in(76b) there are two noun properties, student and teacher, and two predicate prop-erties, came early and left late. Again, however, (76b) presents no expression oftype !1".
We write !12, 1" for !!1, 1", 1" and in general given E, TYPE!1k, 1" is the set offunctions from k-tuples of subsets of E to type !1" functions over E. Detks denote inTYPE!1k, 1". The major notions used in discussing Det1s extend straightforwardly toDetks. For example,
(77) For F of type !1k, 1",a. F is CONS iff 'A1, . . . , Ak, B, B3 & E, (F(A1, . . . , Ak)(B) = F(A1, . . . , Ak)(B3) if
Ai . B = Ai . B3, all 1 ) i ) k.b. F is CO-INT iff 'A1, . . . , Ak, B1, . . . , Bk, C, C3 & E, (F(A1, . . . , Ak)(C) =
F(B1, . . . , Bk)(C3) if Ai - C = Bi - C3, all 1 ) i ) k.c. A functional Q satisfies EXT iff QE(A1, . . . , Ak)(B) = QE3(A1, . . . , Ak)(B), all E, E3
with Ai, B & E, E3, all 1 ) i ) k.

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 887 — #31
Generalized Quantifiers in Linguistics and Logic 887
And we observe that the expressions of type !1k, 1" considered in the literaturesatisfy CONS and EXT.20 The most natural expressions in type !12, 1", the cardi-nal comparatives like fewer. . . than. . . , exactly as many. . . as. . . , more than six timesas many. . . as. . . , etc., are intersective. But Dets such as every. . . and. . . in Every man,woman and child jumped overboard (of type !13, 1") are not intersective, though theyare of course CONS and EXT.
Now consider Dets of type !1, !1, 1"" (cf. Beghelli, 1994) as in (76a) or
(78) More women are ballet dancers than springboard divers.
They have one noun property and two predicate properties, so conservativity and inter-sectivity are now determined by intersecting the two predicate properties with the fixednoun property. Again, the cardinal comparatives as in (76a) and (78) are conservativeand intersective, in fact cardinal. And this guarantees, as Zuber (2007) points out, that(78) is equivalent to (79), which uses a type !!1, 1", 1" quantifier:
(79) More ballet dancers than springboard divers are women.
This fails if we replace more. . . than. . . with the non-intersective every. . . and. . .(80a,b) are not true in exactly the same conditions:
(80) a. Every ballet dancer and springboard dancer is a woman.b. Every woman is a ballet dancer and a springboard diver.
Much more can obviously be said about forms of quantification applying to morethan two properties, but we shall leave the matter here.
19.3 Polyadic Quantification
So far we have discussed monadic quantification: the arguments of the quantifiers aresets, being interpretations of nouns and intransitive verbs. But NPs can also be objects(and indirect objects) of transitive (ditransitive) verbs, for example,
(81) Most critics reviewed just four films.(82) At least three girls gave more roses than lilies to John.
Clearly, the interpretations of the NPs and the verb in these sentences are somehowcompositionally combined to form the interpretation of the whole sentence. Below wewill discuss extensively this and other modes of combining quantifiers. But forgettingfor the moment about these combinations, we could also give the interpretations as inthe previous simpler examples, with one quantifier applied to many arguments. Someof these arguments are then relations, not sets. Such quantifiers are called polyadic.
20 Further, as Jaap van der Does has observed (p.c.), there are easy generalizations of Proposition 19.2.2and Theorem 19.2.1 to type !1k, 1" quantifiers. He also discusses Theorem 19.2.2 on sortal reducibility;here a proper generalization appears to be harder to find.

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 888 — #32
888 Handbook of Logic and Language
The quantifier in (81) is then applied to two noun arguments critic and film, and oneverb argument reviewed. Its type would be !!1, 1", 2", since it is (over E) a functiontaking two subsets of E to a function from binary relations on E to truth values, namely,(in one of the readings of (81)) the function F defined by
(83) F(A, B)(R) = 1 iff|{a ( A : |{b ( B : Rab}| = 4}| > |{a ( A : |{b ( B : Rab}| /= 4}|
for A, B & E and R & E2.Likewise, consider (82). It has three NPs and a ditransitive verb. The first NP
involves one noun, the second two, and the third none. To put this information inthe type notation, we might write the type
(84) !!1, 12, 0", 3"
Semantically, a function of this type takes three subsets of E and one ternary relationon E to a truth value. Or, it takes one subset of E to a function from two subsets of E toa function from ternary relations on E to truth values. Indeed, there are many equiva-lent ways of describing this object. For polyadic quantifiers in general, the relationalview used in logic is often the simplest: then the type is simply !1, 1, 1, 3", and thequantifier is (over E) a relation between three sets and a ternary relation. But then ofcourse the information about the number of NPs and their respective nouns is lost.
The polyadic quantifier involved in (the most natural reading of) (82) is defined by
(85) G(A, B, C)(R) = 1 iff |{a ( A : |{b ( B : Rabj}| > |{b ( C : Rabj}|}| 2 3
for A, B, C & E and R & E3.The functions F and G give correct truth conditions for (81) and (82). The issue
then is to give an account of how these polyadic functions result from the monadicfunctions used in the NPs. For example, there are three monadic functions involvedin (82) – the type !1, 1" at least three, the type !12, 1" more. . . than, and the type!1" John – and somehow these three yield G in (85). Put slightly differently, the threetype !1" functions at least three girls, more roses than lilies, and John, yield thetype !3" function G(girl, rose, lily). In the next section we will see that this kind ofcombination of type !1" functions can be described simply as composition, providedwe allow a natural extension of the concept of a type !1" function. This results in ageneral operation on arbitrary monadic quantifiers which we call iteration.
19.3.1 Iteration
19.3.1.1 Extending the Domains of Type !1" Quantifiers
There are various accounts in the literature of the semantics of sentences like (81) witha transitive verb and quantified subject and object phrases, starting with Montague’s(cf. Partee, Chapter 1 and Janssen, Chapter 7), where transitive verbs are interpreted ashigher type functions which take type !1" quantifiers as arguments. Here, on the other

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 889 — #33
Generalized Quantifiers in Linguistics and Logic 889
hand, we let transitive verbs simply denote binary relations between individuals, and“lift” type !1" quantifiers so that they can take such relations as arguments. The valueshould then be a unary relation. Similarly, to handle (82) we need to apply a type !1"function to a ternary relation yielding a binary one. Thus, type !1" quantifiers reducearity by 1: they take an (n + 1)-ary relation to an n-ary one. Informally, for example,in John reviewed just four films we think of the NP just four films as semanticallymapping the binary relation reviewed to the set of objects that stand in the reviewedrelation to exactly four films; that is we interpret it as follows:
John
John(F(R))
reviewed
R F
just four films
F(R) = {a|F(Ra) = 1} (where Ra = {b|Rab})
We call the class of all such functions AR!-1": a general definition follows.Fix a universe E. In what follows we let Rn = P(En), the set of n-ary relations over
E, n > 0, and R0 = 2 = {0, 1}.
Definition 19.3.1. For k 2 1,
F ("#
n
Rn+k ##
n
Rn
$
is in AR!-k" if
'R ( Rn+k F(R) ( Rn (n 2 0).
Also, let
AR =#
k21
AR!-k".
We want to treat type !1" quantifiers as a particular kind of AR!-1" functions. Justwhich degree 1 arity reducers do we need as denotations of English expressions? Theseissues are pursued in Ben-Shalom (1996) and will just be touched upon enough here tohelp the reader realize that the obvious answers are not adequate. Now AR!-1" includesmany functions whose values at relations of high arity is completely independent oftheir values at lower arities. It seems unlikely that we need all these functions as possibledenotations for English NPs. But a lower bound on the degree 1 arity reducers neededare the “lifts” of maps from R1 = P(E) into R0 = 2, defined in (88) below.
The following notation will be used. If R ( Rn, 0 ) k < n, and a1, . . . , ak ( E,

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 890 — #34
890 Handbook of Logic and Language
(86) Ra1...ak = {(ak+1, . . . , an) ( En-k | Ra1 . . . an}
Note that when k = 0, Ra1...ak = R. We also observe that
(87) (Ra1...ak)b1...bm = Ra1...akb1...bm (k + m < n)
Now suppose F is a type !1" quantifier over E, i.e. a function from R1 to R0. Weextend F to a function in AR!-1", also denoted F, by
(88) For R ( Rn+1, F(R) = {(a1, . . . , an) ( En | F(Ra1...an) = 1}
The extended F is still called a type !1" quantifier. So type !1" quantifiers map unaryrelations to truth values as before, but they now also map (n+1)-ary relations to n-aryones. But their values at the (n + 1)-ary relations are determined in a particular wayfrom their values on the unary relations. Thus we may define a type !1" quantifier justby stating its values on the subsets of E as before.
Now we can correctly interpret (81), using the (extended) type !1" quantifiersmost critics and ( just) four films, as follows:
(89) most critics (four films (reviewed))
= most critics ({a ( E | four films (revieweda) = 1})= most critics ({a ( E | four films ({b ( E | reviewedab}) = 1})= F(critic, film) (reviewed)
where F is from (83).Similarly we calculate the interpretation of (82) (where G is from (85)):
(90) at least three girls (more roses than lilies (John (gave-to)))
= at least three girls (more roses than lilies ({(c, b) | John (gave-tocb)
= 1}))= at least three girls ({a | more roses than lilies ({(c, b) | John
(gave-tocb) = 1}a) = 1})= at least three girls ({a | more roses than lilies ({b | John (gave-toab)
= 1}) = 1})= at least three girls ({a | more roses than lilies ({b | gave-toabj}) = 1})= G(girl, rose, lily)(gave-to)
Ben-Shalom (1996) gives the following direct characterization of the extended type!1" quantifiers:
Fact 19.3.1. Let F ( AR!-1". F is an extended type !1" quantifier iff'n, m 2 0, 'R ( Rn+1 'S ( Rm+1 'a1, . . . , an, b1, . . . , bm ( E,
(7) Ra1...an = Sb1...bm * ((a1, . . . , an) ( F(R) % (b1, . . . , bm) ( F(S))
When m = 0 (and so Sb1...bm = S), (7) is to be understood as
Ra1...an = S * ((a1, . . . , an) ( F(R) % F(S) = 1)21
21If we stipulate (b1, . . . , bm) = 0 when m = 0, and 1 = {0}, this follows from (7).

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 891 — #35
Generalized Quantifiers in Linguistics and Logic 891
From this it follows that
'R ( Rn+1 'a1, . . . , an ( E, (a1, . . . , an) ( F(R) % F(Ra1...an) = 1.
Hence, if F satisfies (7) it is an extended type !1" quantifier. Conversely, one verifiesthat all extended type !1" quantifiers satisfy (7).
The interest of Fact 19.3.1 stems from the fact that English presents expressionswhich semantically map R2 to R1 but fail to satisfy (7). They do, however, satisfynatural generalizations of (7). Good examples are referentially dependent expressions,himself, his doctor, etc. We will return to these in Section 19.3.2.5.
19.3.1.2 Composition and Iteration of Quantifiers
It is clear already from (89) and (90) that (extended) type !1" functions can becomposed. To make this precise we note first that the class AR of all arity reduc-ers is closed under composition in the sense that if F ( AR!-k" and G ( AR!-m",then F 8 G = FG ( AR!-(k + m)"22: if R ( Rn+k+m, then G(R) ( Rn+k, so FG(R) =F(G(R)) ( Rn. Note that composition is associative,
F(GH) = (FG)H
so we don’t need parentheses. Thus, the notation
F1· · ·Fk
makes sense. In particular, we have
(91) If F1, . . . , Fk ( AR!-1", then F1 · · · Fk ( AR!-k"
Next we observe that the extension of type !1" quantifiers to AR!-1" in the pre-vious subsection works in exactly the same way for type !k" quantifiers, according tothe following definition, which generalizes (88).
Definition 19.3.2. Every type !k" quantifier F ( [Rk # R0] (for k 2 1) extends to afunction in AR!-k", also denoted F, by letting, for R ( Rn+k,
F(R) = {(a1, . . . , an) ( En | F(Ra1...an) = 1}
There is a corresponding generalization of the characterization given in Fact 19.3.1.Now let F be a type !k" quantifier and G a type !m" quantifier. To compose F andG (in that order), extend the functions to AR!-k" and AR!-m", respectively, by
22 Writing FG is a slight but convenient abuse of notation. Indeed, the domain of FG is not the domain ofG but rather
%n Rn+(k+m), so we are really composing F with the restriction of G to
%n Rn+(k+m).

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 892 — #36
892 Handbook of Logic and Language
Definition 19.3.2, and then compose as usual, which gives a function in AR!-(k+m)".Restricted to Rk+m, this is the type !k + m" quantifier given by
FG(R) = F({(a1, . . . , ak) ( Ek | G(Ra1...ak) = 1}),
for R ( Rk+m. If on the other hand we start with this type !k + m" quantifier – callit H, so H(R) = F({(a1, . . . , ak) ( Ek | G(Ra1...ak) = 1}) – and then extend H toAR!-(k + m)" by Definition 19.3.2, one can verify that this is precisely the extensionof F composed with the extension of G. This shows that our notion of composition isrobust. Summarizing,
Fact 19.3.2. If F is a type !k" quantifier and G a type !m" quantifier, the compositionof F with G is the type !k + m" quantifier FG given by
FG(R) = F({(a1, . . . , ak) ( Ek | G(Ra1...ak) = 1})
for R ( Rk+m. Also, the extension of FG to AR !-(k + m)" is the composition of theextension of F to AR !-k" with the extension of G to AR !-m".
For example, in (89) we composed the type !1" quantifiers most critics andfour films, resulting in the type !2" quantifier F(critic, film)(R) = most critics({a (E | four films (Ra) = 1}).
Fact 19.3.2 takes care of composition of polyadic quantifiers without noun argu-ments. In fact we can easily extend this operation to (practically) all the polyadicquantifiers we consider in this chapter, i.e. polyadic quantifiers with k noun arguments(k 2 0) and one verb argument. Just fix the noun arguments and apply Fact 19.3.2. Wecall this more general operation iteration. For example, (89) also indicates the iterationof the type !1, 1" quantifiers most and four to the type !!1, 1", 2" quantifier F.
It is convenient to use a superscript notation for quantifiers resulting from fixingthe noun arguments. So we write mostA for most(A), fourcritic for four(critic) (orfour critics), and Fcritic,film for F(critic, film). Thus, the iteration of most and four toF is given, for A, B & E and R & E2, by
(92) F(A, B)(R) = FA,B(R) = most Afour B(R)
where, for each A and B, the right hand side is well defined by Fact 19.3.2.For a slightly more involved example, let G be of type !1, 1" and H of type
!!12, 0", 2". Then the iteration of G and H, also written GH, is the type !!1, 12, 0", 3"quantifier
(93) GH(A, B, C)(R) = GAHB,C(R)
for all A, B, C & E and all R ( R3. In general,
Definition 19.3.3. If F has n noun arguments and one k-ary verb argument, and Ghas l noun arguments and one m-ary verb argument, the iteration FG or F 8 G is the

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 893 — #37
Generalized Quantifiers in Linguistics and Logic 893
quantifier with n + l noun arguments and one (k + m)-ary verb argument given by
FG(A1, . . . , An, B1, . . . , Bl)(R) = FA1,... ,An GB1,... ,Bl(R)
= FA1,... ,An({(a1, . . . , ak) ( Ek | GB1,... ,Bl(Ra1...ak) = 1})
for A1, . . . , An, B1, . . . , Bl & E and R ( Rk+m.
Observe that composition is a special case of iteration, and that iteration too is anassociative operation. For example, the quantifier G in (85, 90) is
G = at least three 8 more. . . than 8 John
What about the inverse scope reading of sentences such as (81), Most criticsreviewed four films? Though there is a linguistic issue as to when such readings arepossible and how one arrives at them, they are easily represented in the present frame-work: simply permute the order of iteration. However, this brings up a perhaps subtlepoint of our notation that we have so far been silent about. When we represent theinterpretation of (81) using a polyadic quantifier Fcritic,film(reviewed), or compos-ing monadic quantifiers, mostcritic(fourfilm(reviewed)), it is understood that critic islinked to the first argument of reviewed (the reviewer), and film to the second argu-ment (the thing reviewed). But which argument is first and second is purely conven-tional; we have simply stipulated that the order in which the noun arguments are givencorresponds to the order of the arguments of the relation (= the verb argument).
This means that the inverse scope reading of (81) must be rendered
(94) fourfilm&
mostcritic(reviewed-1)'
(where R-1ab iff Rba), so that again the first (leftmost) noun argument film is linkedto the first argument of the relation reviewed-1, – the thing reviewed, etc. So (94)says, as it should, that there were exactly four films such that the number of criticswho reviewed them was greater than the number of critics who didn’t.
Note that if we had used a more logical language (rather than an informal set theo-retic one), the “problem” would have disappeared, since the relevant links are carriedby the bound variables instead:
(95) most x(critic(x), four y( film(y), reviewed(x, y)))(96) four y( film(y), most x(critic(x), reviewed(x, y)))
19.3.1.3 Properties of Iterations
There are a number of studies of iteration, e.g., van Benthem (1989), Keenan (1992,1993), Ben-Shalom (1994), Westerståhl (1994, 1996), Zuber (2007), and Kuroda(2008). We review here some of their results.
The properties ISOM and EXT extend directly to polyadic quantifiers of the typesconsidered here. CONS also extends in a natural way. Instead of a general definition

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 894 — #38
894 Handbook of Logic and Language
we give a characteristic example, again using the type !!1, 12, 0", 3". Here there arethree NPs, linked to the corresponding arguments of the 3-place verb argument R.The first NP has one noun argument A, the second two, B and C, and the third none.So CONS should restrict the first argument of R to A, and the second to B and C inthe sense of (77) in Section 19.2.3, i.e. to the union of B and C (note that (B . D =B . D3 & C . D = C . D3) % (B 6 C) . D = (B 6 C) . D3). The third NP gives norestriction. Thus, we define
(97) F of type !!1, 12, 0", 3" is conservative iff for all A, B, C & E and all R ( R3,
FA,B,C(R) = FA,B,C((A $ (B 6 C) $ E) . R). As usual, a global quantifier Q isconservative if each QE is conservative.
Iteration is well behaved with respect to these basic properties of quantifiers.
Fact 19.3.3. If the monadic F1, . . . , Fk are CONS (EXT, ISOM), then so is F1 · · · Fk.
Certain other properties of monadic quantifiers also extend to our polyadic case.We use again our standard example:
(98) Let F be of type !!1, 12, 0", 3":a. F is increasing (decreasing) iff for all A, B, C & E, FA,B,C is increasing (decreasing).b. F is intersective iff for all A, B, C, A3, B3, C3 & E and all R, R3 ( R3, if (A $ (B 6
C) $ E) . R = (A3 $ (B3 6 C3) $ E) . R3, then FA,B,C(R) = FA3,B3,C3(R3).
Fact 19.3.4. If F, G are increasing (decreasing, intersective), so is FG.
Next, we see how iteration relates to negation. Post-complements of our polyadicquantifiers are obtained, as before, by taking the complement of the verb argument.Thus for F of type !!1, 12, 0", 3",
(99) (F¬)A,B,C(R) = FA,B,C(E3 - R)
And as before (cf. (66)), the dual of F is the complement of its post-complement:Fd = ¬(F¬). One verifies that Fd = (¬F)¬ and that all these negation operations areidempotent: F = ¬¬F = F¬¬ = Fdd.
Fact 19.3.5. For all quantifiers F, G:
(i) FG = (F¬)(¬G)
(ii) ¬(FG) = (¬F)G(iii) (FG)¬ = F(G¬)
(iv) (FG)d = FdGd
These facts, and in particular (i) – “facing negations” cancel – are responsiblefor certain characteristic inference patterns. The following equivalent pairs are allinstances of “facing negations”:

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 895 — #39
Generalized Quantifiers in Linguistics and Logic 895
(100) a. More than half the students answered no question correctly.b. Less than half the students answered one or more questions correctly.
(101) a. Each critic read at most six plays.b. No critic read more than six plays.
(102) a. All but one witness told more than half the detectives at least one lie.b. Just one witness told at least half the detectives no lie at all.
In (102a), for example, all but one witness is the post-complement of just (exactly)one witness, and, as we saw in (67), more than half the detectives is the dual of atleast half the detectives, i.e. it is ¬(at least half the detectives¬). Thus, two appli-cations of “facing negations” take us from (102a) to (102b) (and back).
Call a type !k" quantifier G positive if G(0) = 0. For example, some dog, mostcats, John, Mary’s three bikes, more students than teachers are positive, but nodean, at most three professors are not. From Fact 19.3.5 (i) we see that if a type !k"quantifier H is an iteration FG, we may always assume that G is positive, a simple butuseful fact.
The next few results concern the “product behavior” of iterations, which is rathercharacteristic and will enable us to see how few properties of binary relations areexpressible by type !1" quantifiers. Cartesian products of the form R1 $ · · ·$Rk, rarelyif at all occur as denotations of verbs, but they are useful technically. For example, asillustrated in Keenan (1992), and as explained by the Product Theorem below, thebehavior of a quantifier on products can sometimes be used to prove that it is not aniteration.
First, we note that iterations “decompose” into their components on products.
Fact 19.3.6. If F is of type !k", G of type !m", G positive (recall that this is no restric-tion), and R ( Rk, S ( Rm, then
FG(R $ S) = 1 iff (F(R) = G(S) = 1) , (F(!) = 1 & G(S) = 0)
The next theorem shows that not only do iterations behave in a very simple fash-ion on products; they are also determined by that behavior. If F and G are type !k"quantifiers, we let
F =prod G
mean that for all A1, . . . , Ak & E, F(A1 $ · · · $ Ak) = G(A1 $ · · · $ Ak).
Theorem 19.3.1. (Product Theorem, Keenan, 1992) Let F1, . . . , Fk, G1, . . . , Gk be oftype !1". Then F1 · · · Fk =prod G1 · · · Gk implies F1 · · · Fk = G1 · · · Gk
Finally, we consider the following (related) issue: Given F = F1 · · · Fk, where theFi are of type !1", to what extent are F1, . . . , Fk determined by F? We know they

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 896 — #40
896 Handbook of Logic and Language
cannot be uniquely determined, since by Fact 19.3.5 (i) inner and outer negations canbe distributed in certain ways over F1, . . . , Fk without changing F. Another obstacle isthat one of the Fi may be trivial; this will in fact make F trivial, and so its componentscannot be recovered. We repeat the notion of triviality used here (cf. Section 19.1, (7)):
(103) A quantifier G is trivial on E if G is constant, i.e. it maps either all (appropri-ate) arguments to 1 or all arguments to 0.
As it turns out, triviality and distribution of negations are the only obstacles. Call thepair of sequences F1, . . . , Fk and G1, . . . , Gk balanced, if for 1 ) i ) k, Fi(!) =Gi(!). This rules out “facing negations”, as in (100)–(102).
Theorem 19.3.2. (Prefix Theorem, Keenan, 1993; Westerståhl, 1994) Suppose thatF1, . . . , Fk and G1, . . . , Gk are balanced, that each Fi and Gi is non-trivial and oftype !1", and that F1 · · · Fk = G1 · · · Gk. Then Fi = Gi, for 1 ) i ) k.
Using the Prefix Theorem one may show by direct calculation that very few type !2"functions (on a given finite universe) are iterations of type !1" quantifiers. Specificallyover a universe E with cardinality n the number of type !2" functions is
22n2
and the total number of iterations of type !1" quantifiers is
(104) 22n+1-1 - 22n+1 + 4
E.g. in a model with 2 individuals there are 216 = 65536 type !2" functions only 100of which are iterations of type !1" quantifiers. Thus very few of the properties ofbinary relations are expressible by iterations of the kind of functions denotable bysubjects of intransitive verbs. We will see moreover that English presents many waysof expressing some of these other type !2" functions.
19.3.2 Other Polyadic Quantifiers
If iterations were the only polyadic quantifiers encountered in natural languages, wecould safely say that natural language quantification is essentially monadic: itera-tions are built (compositionally) from monadic quantifiers. There are, however, severaltypes of polyadic quantification which cannot be treated as iterations. Some of theseinvolve other modes of combining monadic quantifiers into polyadic ones. Others are,so far, merely examples with a certain structure.
In this situation, the issue of whether quantification in natural languages is essen-tially monadic becomes non-trivial. The question has two aspects. One is a matter ofgrammar: to what extent, if at all, does an adequate grammar for, say, English, need totake polyadic quantification into account? The other aspect is one of expressive power.Are there things which can naturally be said with polyadic quantifiers but which can-not be expressed at all with monadic ones?

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 897 — #41
Generalized Quantifiers in Linguistics and Logic 897
In this section we briefly list a number of examples of polyadic quantifiers whichhave been claimed to occur in the interpretations of (mostly) English sentences, butwhich are not iterations. Most of the examples come from Keenan (1992), to which werefer for additional examples, elaborations and references. The issue of the expressivepower of these quantifiers will be touched on briefly in Section 19.3.3.
With each sample sentence below a polyadic quantifier will be associated. We usethe convention that quantifier Gm corresponds to sentence no. (m). The sentences usu-ally have two NPs and a transitive verb; Ben-Shalom (1994) extends several of theseexample types to sentences with ditransitive verbs and three NPs. As before, a uni-verse E is assumed given unless otherwise stated, and A, B, C, . . .range over subsetsof E, whereas R, S, . . .range over binary relations on E.
19.3.2.1 “Different” and “Same”
An NP containing different or same is often dependent on another NP in the sentencein a way which cannot be described by iteration.
(105) Different students answered different questions (on the exam).(106) Every boy in my class dates a different girl.(107) Every student answered the same questions.
A reasonable interpretation of (105) uses the type !!1, 1", 2" quantifier G105:
GA,B105(R) = 1 iff 'a, b ( A(a /= b * B . Ra /= B . Rb)
(There may also be a condition that |A| > 1; this is omitted in G105 and in similarcases to follow.) This could be varied: we might require that 'a, b ( A(a /= b *B . Ra . Rb = !). van Benthem (1989) suggests a weaker (non-first-order definable)reading:
HA,B105 (R) = 1 iff R includes a 1–1 function from A to B
But this is compatible with there being a set B of questions such that each studentanswered each question in B and no others (provided B is large enough), so that, in fact,all the students answered the same questions! A much stronger requirement (implyingthose suggested so far) would be that R . (A $ B) is a 1–1 function from A to B.
For (106), it seems we can take G106 = G105. For (107),
GA,B107(R) = 1 iff 'a, b ( A(a /= b * B . Ra = B . Rb)
There are variants of (106) and (107) with other subject NPs, e.g.,
(108) At least four boys in my class date the same girls
GA,B108(R) = 1 iff 1C & A[at least four A(C) = 1
& 'a, b ( C(a /= b * B . Ra = B . Rb)

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 898 — #42
898 Handbook of Logic and Language
which suggests the following general construction, where H is a type !1, 1" quantifier:
(109) FA,B(R) = 1 iff 1C & A[HA(C) = 1
& 'a, b ( C(a /= b * B . Ra = B . Rb)
Then, for example, G107 is obtained from (109) with H = every.23
We may note that in addition to the seemingly “logical” different and same,there are other adjectives or complex modifiers which incorporate these or similarnotions; cf.
(110) John and Bill support rival political parties.(111) The two students live in neighboring villages.(112) The three professors asked similar questions on the oral exam.
We also note that the analysis above may be awkward for compositionality, sincethe two apparent NPs, such as different students, different questions in (105), for exam-ple, do not seem to form syntactic constituents.24
19.3.2.2 Exception Anaphora
Consider
(113) John criticized Bill and no one else criticized anyone else.(114) John didn’t praise Mary but everyone else praised everyone else.(115) Every man danced with every woman except Hans with Maria.
What (113) means is given simply by
G113(R) = 1 iff R = {( j, b)}
and G114 is similar. This cannot be obtained as an iteration of the quantifiers no oneexcept John and no one except Bill. We do have, however,
(116) G113(R) = 1 iff (no one except John)(some(R)) == (no one except Bill)(some(R-1)) = 1
23 (109) gives the simplest generalization. Jaap van der Does pointed out (p.c.) that a drawback is that itonly works for increasing H (in the right argument), whereas the construction should work for decreasingor non-monotonic quantifiers (four, at most four). He proposes the two “lifts”
(i) LA,B1 (R) = HA{a ( E | 1b ( A(a /= b + B . Ra = B . Rb)}
(ii) LA,B2 (R) = HA{a ( E | 'b ( A(a /= b * B . Ra = B . Rb)}
instead, and conjectures that the choice between these is related to the monotonicity behavior of H. Notethat with H = every, L2 correctly gives G107, whereas with H = no one needs to use L1. In fact, therelation between these “weak” and “strong” readings and monotonicity seems interestingly similar toregularities observed for donkey sentences in Kanazawa (1994) and in van der Does (1994).
24 However, Kuroda (2008) finds some support for a compositional type !1,1,2" analysis in Japanese sen-tences we might translate as Five dogs were herding thirty cows (in its cumulative reading; cf. Section19.3.2.4).

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 899 — #43
Generalized Quantifiers in Linguistics and Logic 899
For (115) we get
GA,B115 (R) = 1 iff (h, m) ( A $ B & '(a, b) ( A $ B((a, b) ( R % (a, b) /= (h, m)).
Moltmann (1995), from which (114) and (115) are taken, discusses which quan-tifiers allow this sort of exception constructions, and gives a semantics for except.25
Again, G115 is not an iteration, but as in (116) it can be written as a conjunction:
(117) Gman,woman115 (R) = 1 iff (every man except Hans)(every woman(R)) =
= (every woman except Maria)(every man(R-1)) = 1
19.3.2.3 Resumption
By the resumption of a monadic quantifier we mean the polyadic quantifier result-ing from application of the original quantifier to k-tuples, instead of individuals. Thisof course presupposes the global notion of quantifier, where Q with each domain Eassociates a quantifier QE over E. Thus, Q also associates a quantifier to Ek.
Various instances of resumption in natural languages have been noted. For oneexample, resumption underlies the treatment of donkey sentences in “classical” DRT;cf., for example, Kanazawa (1994) and van der Does (1994). For another, van Benthem(1983) and May (1985) consider Ss like
(118) No man loves no woman
which seems to have one reading that there is no man-woman pair in the love relation.This is not an iteration, but the following resumption is:
(119) Every man loves every woman
Such examples seem to be rare (cf. Liu, 1991), but they suggest that the binaryresumption of a type !1, 1" quantifier Q should be the quantifier Q3 given by
Q3A,BE (R) = QA$B
E2 (R)
(note that A $ B and R are subsets of E2) and thus be of type !!1, 1", 2". However,other examples indicate that this is not general enough.
(120) Most twins never separate(121) Most lovers will eventually hate each other(122) Most neighbors are friends
Here it is reasonable to construe the Ns as denoting sets of pairs, and most as quan-tifying over these pairs.26 In (120), separate is not a property of individuals, andso cannot apply to individual twins. Of course, for pairs it can be defined in terms
25 For a recent overview of various approaches to exception constructions, and a proposal for a uniformtreatment of several of these, see Peters and Westerståhl (2006), Ch. 8.
26 Actually, unordered pairs rather than ordered ones, but this just divides the quantities involved by 2.Quantification over unordered pairs in effect is quantification over sets or collections, or perhaps groups,a subject treated in detail in Lønning, (Chapter 23). Indeed, using collective quantification, slightly dif-ferent analyses of (120)–(122) have been proposed.

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 900 — #44
900 Handbook of Logic and Language
a binary relation separate from, and (120) is equivalent to a sentence quantifyingover individuals. But this does not work for (121) (due to Hans Kamp): a person maybelong to several lover pairs, and there is no obvious way to reduce (121) to monadicquantification.
Thus, most in these examples denotes a type !2, 2" quantifier, namely, the old mostapplied to pairs. This motivates the following definition.
Definition 19.3.4. If Q is of type !1, 1", the k-ary resumption of Q, Resk(Q), isdefined for R, S & Ek by
Resk(Q)RE(S) = QR
Ek(S)
and similarly for other monadic types.
For example, for all R, S & E2, Res2(most)R(S) = 1 iff |R . S| > |R - S|.And (118), (119) can be construed with Res2(no) and Res2(every), respectively, andR = A $ B.
A final type of example comes from Srivastav (1990), according to whom the fol-lowing sentences in Hindi,
(123) jis laRkii-ne dekhaa jis leRke-ko usne usko cahaaWH girl-erg saw WH boy-acc she him liked
(124) jin laRkiyone jin leRkoko dekha, unhone unko cahaaWH girls-erg WH boys-acc saw, they them liked
have the truth conditions given by
GA,B123(R, S) = 1 iff |(A $ B) . R| = 1 & (A $ B) . R & S
GA,B124(R, S) = 1 iff (A $ B) . R is an injection & (A $ B) . R & S
Thus, if FA(B, C) = 1 % |A . B| = 1 & A . B & C, then
GA,B123(R, S) = Res2(F)A$B(R, S),
and similarly for G124.27 Srivastav (1990) notes that this is similar to certain Englishconstructions with interrogative quantifiers:
(125) Which dog chased which cat?(126) Which dogs chased which cats?
An appropriate answer here presents a pair of a cat and a dog (or a set of such pairs),not an individual cat or dog.
27 This monadic F would be of type !1, !1, 1"" — cf. Section 19.2.3, (76a,b).

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 901 — #45
Generalized Quantifiers in Linguistics and Logic 901
19.3.2.4 Independent Quantification: Branching and Cumulation
An iteration FG introduces a scope dependency of G on F (for most F and G; cf.van Benthem, 1989; Zimmermann, 1993). But there are also scope-independent waysto combine F and G. Hintikka (1973) proposed that branching quantification occursin English, starting a debate which still goes on. Hintikka discussed the so-calledHenkin quantifier, but since Barwise (1979) the issue has focused also on branchingof monadic generalized quantifiers.28 Here there are more easily convincing exam-ples of branching in English, but on the other hand it is not quite clear what a generaldefinition of branching looks like. See Westerståhl (1987), Sher (1990), Liu (1991),Spaan (1993) for discussion. Here we consider only the case which is most uncontro-versial for English and where there is unanimity over the definition, namely, branchingof increasing monadic quantifiers.
Definition 19.3.5. Suppose F1, . . . , Fk are increasing (in the verb argument) type!1, 1" quantifiers. The branching of F1, . . . , Fk, Br(F1, . . . , Fk), is the type !1k, k"quantifier defined, for A1, . . . , Ak & E and R & Ek, by
Br(F1, . . . , Fk)A1,... ,Ak(R) = 1 iff
1X1 & A1 · · · 1Xk & Ak[FA11 (X1) = · · · = FAk
k (Xk) = 1
& X1 $ · · · $ Xk & R].
Here is one of Barwise’s examples.
(127) Quite a few of the boys in my class and most of the girls in your class have alldated each other
This is not equivalent to any of the iterations
(128) Quite a few of the boys in my class have dated most of the girls in your class(129) Most of the girls in your class have dated quite a few of the boys in my class
or to the conjunction of these two. Instead, it seems to have a reading that there is aset of boys in my class, containing quite a few of them, and a set of girls in your class,containing more than half of those girls, such that for any pair (a, b) of a boy a in thefirst set and a girl b in the second, a and b have dated each other. That is,
G127 = Br(quite a few, most)
The formal expression of the fact that branching is scope-independent is the fol-lowing (for k = 2), which is immediate from the definition.
(130) Br(F1, F2)A1,A2(R) = Br(F2, F1)
A2,A1(R-1)
28 The Henkin quantifier can be defined as the branching, as in Definition 19.3.5, of the (increasing) type!2" quantifier '1 (defined by '1(R) = 1 iff 'a ( E 1b ( E Rab) with itself, i.e. Br('1, '1).

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 902 — #46
902 Handbook of Logic and Language
This is of course far from true (except in a few exceptional cases) if Br(F1, F2) isreplaced by F1F2.
Another case of independent quantification is the cumulatives, first discussed byScha (1981). Consider
(131) Forty contributors wrote thirty-two papers for the Handbook.
Reasonably, this does not mean that each of the 40 contributors wrote 32 papers for theHandbook as the iteration would say, but rather that each of them wrote some paper(perhaps more than one, perhaps jointly with other contributors) for the Handbook,and that each of the 32 papers were authored by some of these contributors. This leadsto the following definition, which we again state for the “cumulation” of k monadicquantifiers.
Definition 19.3.6. Let F1, . . . , Fk be type !1, 1" quantifiers. If A1, . . . , Ak & E, R &Ek, and 1 ) i ) k, let
Ri = {ai| 1a1 ( A1 · · · 1ai-1 ( Ai-11ai+1 ( Ai+1 · · · 1ak ( AkRa1 · · · ak}
The cumulation of F1, . . . , Fk, Cum(F1, . . . , Fk), is the type !1k, k" quantifier definedby
Cum(F1, . . . , Fk)A1,... ,Ak(R) = 1 iff FA1
1 (R1) = · · · = FAkk (Rk) = 1
For k = 2 we can express this by
(132) Cum(F1, F2)A1,A2(R) = 1 iff
FA11 (someA2(R)) = FA2
2 (someA1(R-1)) = 1
and we see that G113 = Cum(forty, thirty-two). Again, independence holds:
(133) Cum(F1, F2)A1,A2(R) = Cum(F2, F1)
A2,A1(R-1)
19.3.2.5 Argument and Predicate Invariant Functions
Consider
(134) John criticized himself(135) Mary praised every student but herself(136) Bill blamed his teacher
The functions needed to interpret these, for example, self(R) = {a | a ( Ra} and(every but self)B(R) = {a ( B | Ra . B = B - {a}} are functions from R2 to R1, butthey are not (extensions of) type !1" quantifiers. They do, however, satisfy a natural

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 903 — #47
Generalized Quantifiers in Linguistics and Logic 903
weakening of the characteristic invariance condition for type !1" quantifiers given inFact 19.3.1:
(137) F ( AR!-1" is predicate invariant iff 'R, S ( Rn+1 'a1, . . . , an ( E,
Ra1···an = Sa1···an * ((a1, . . . , an) ( F(R) % (a1, . . . , an) ( F(S)).29
Returning to the issue mentioned in Section 19.3.1.1 of which degree 1 arity reduc-ers are needed, one shows that over a finite E all predicate invariant maps from R2 toR1 are denotable in English. Whether the class of functions needed for NP interpreta-tions should be further enlarged is a matter of current investigation. See also Reinhart(1993) for a discussion of reflexives in a linguistic setting.
An equally natural weakening of that condition in Fact 19.3.1 is argument invari-ance:
(138) F ( AR!-1" is argument invariant iff'R ( Rn+1 'a1, . . . , an, b1, . . . , bn ( E,
Ra1···an = Rb1···bn * ((a1, . . . , an) ( F(R) % (b1, . . . , bn) ( F(R))
This condition holds of another interesting class of anaphors in English, exemplifiedby
(139) John read more books than Tom (did)(140) Most students know more girls than every teacher (does)
To analyze these, let, for B & E and R & E2, moreB(R) be the binary relation givenby
(141) (a, b) ( moreB(R) iff |B . Ra| > |B . Rb|
so that GB139(R) = 1 iff ( j, t) ( moreB(R). Then, for any type !1" quantifier F, define
the function
(142) (more B than F)(R) = {a | F((moreB(R))a) = 1}
One verifies that this function is argument invariant (for each B and F)30, and that
GB139(R) = John((more B than Tom)(R))
GA,B,C140 (R) = mostA((more B than everyC)(R))31
29 The notions of predicate and argument invariance are from Ben-Shalom (1996). self and every but selfclearly satisfy the predicate invariance condition for n = 1. For the general case we need to extend thesefunctions to AR!-1". For example, for R ( Rn+1, self(R) = {(a1, . . . , an) | a1 ( Ra1···an }. This willhandle sentences like Mary protected Bill from herself and Mary protected herself from Bill (but notMary protected Bill from himself ).
30 Again, a suitable extension to AR!-1" is needed.31 The analysis also shows that, if we were willing to let not read but read more books than be the predicate
in (139), and interpret it with (141), and similarly for (140), then these sentences would be iterations.

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 904 — #48
904 Handbook of Logic and Language
19.3.2.6 Comparative Dependent Det1s
(143) A certain number of professors interviewed a much larger number of schol-arship applicants.
Clearly there are context-dependent factors here, but a first approximation could be
GA,B143(R) = 1 iff |dom(R . (A $ B)| < |ran(R . (A $ B)|
Dependencies of this sort are frequent when the NPs occur in different Ss, as in A fewstudents came to the party early, but many more stayed late.
19.3.2.7 Reciprocals
The semantics of reciprocals is a complex matter; cf. Langendoen (1978) for a clas-sical discussion, and Dalrymple, Kanazawa, Kim, Mchombo and Peters (1998) for arecent systematic proposal. Here we only give a few examples to show that they oftengenerate polyadic quantifiers. A simple kind of reciprocal English S can be given theform Det1 N V RECIP, where Det1 is often but not always a definite plural (Defini-tion 19.2.12), V a transitive verb, and RECIP is each other. So Det1 denotes a quanti-fier F, N a set A, and V a relation R. each other can be described as denoting a relationbetween a subset B of A and R, EO(B, R) (or a type !1, 2" quantifier), although notalways the same relation. Consider
(144) Most of the boys in your class like each other(145) The members of the board were chatting with each other(146) My books are piled on top of each other
(144) can be read as saying that there is a set B of boys in your class, containing morethan half of those boys, such that any two distinct boys in B like each other. So
EO(B, R) iff 'a, b ( B (a /= b * Rab)
But in (145) it doesn’t seem necessary that each pair of board members were chat-ting; a number of “chatting subsets” of the set of board members suffices, providedeach subset has at least two members, their union is the the whole set of board mem-bers, and each member belongs to one of these subsets. More simply, this can beexpressed as
EO(B, R) iff 'a ( B1b ( B (a /= b & Rab & Rba).
The reciprocal relation in (146) is more complex; suffice it to note here that there canbe several piles of books, and we need to say something like that the “piled on top of”relation restricted to each pile is a linear order.
The simplest of these cases leads to the following definition.

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 905 — #49
Generalized Quantifiers in Linguistics and Logic 905
Definition 19.3.7. Let F be a type !1, 1" quantifier which is increasing in the verbargument. We define a type !1, k" quantifier Ramk by, for A & E and R & Ek,
Ramk(F)A(R) = 1 iff 1X & A [FA(X) = 1 &
'a1, . . . , ak ( X(a1, . . . , ak distinct * Ra1 · · · ak)]
Thus, G126 = Ram2(most). The notation comes from the fact that these quantifiersare already familiar in mathematical logic under the name of “Ramsey quantifiers”.(Then A = E and F is some cardinality condition, say, FE(B) = 1 iff B is infinite.)
19.3.3 Polyadic Lifts
The list of examples in the previous section indicates that polyadic quantifiers in nat-ural languages are often built in systematic ways from monadic ones. The canoni-cal way is iteration, but we found several other polyadic lifts: cumulation, Booleancombinations of iterations in any order, resumption, branching, etc. These lifts canbe studied in their own right. For one thing, they preserve basic properties such asCONS, EXT, and ISOM, but they also have their own characteristic properties. Forexample (cf. Section 19.2.4), branching and cumulation, but not iteration, are (order)independent, in that the arguments to the lift can be taken in any order. van Benthem(1989), Keenan (1992), and Westerståhl (1994, 1996) are early examples of studies ofproperties of polyadic lifts.
The lifts have also been investigated in non-linguistic contexts. For example,resumption turns up in the attempts in to find a logical characterization of the class ofPolynomial Time problems (cf. Dawar, 1995). In general, both monadic and polyadicquantifiers have been studied from the point of view of computational complexity intheoretical computer science.32
Mathematical logicians have looked at the expressive power of polyadic quantifiers,and of the polyadic lifts. Although these issues can be much more difficult than thosefor monadic quantifiers, some results are known. Using the machinery presented inSection 19.3.1.3, Keenan (1992) shows that practically all the examples given in Sec-tion 19.3.2 are not iterations (the method is generalized in Ben-Shalom, 1994). Withheavier tools from finite model theory, one can sometimes get much stronger results. InSection 19.2.2.4 we mentioned the notion of a logic L(Q1, . . . , Qn) obtained by addingto first-order logic arbitrary monadic quantifiers Q1, . . . , Qn. With a little more atten-tion to the variable-binding mechanism, this works for polyadic quantifiers as well.One can then ask if a lifted polyadic quantifier O(Q1, . . . , Qn) is definable by any sen-tence in the language of L(Q1, . . . , Qn).33 The question of whether, say, O(Q1, Q2),
32 For a recent survey, see Grädel et al. (2007), especially Ch. 3. Also, see the introduction to Chapter 20 ofthis volume below.
33 Note that the notion of definability used here is global, i.e., independent of the domain. If Q can bedefined from Q1, . . . , Qn over a domain E, then the same definition should work for other domains aswell. This is in contrast with the local notion of effability, which was discussed in Section 19.2.1.

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 906 — #50
906 Handbook of Logic and Language
for type !1" Q1, Q2, is an iteration, is then the special case of defining sentences of theform
Q1xQ2yRxy,
but the general question is harder. In Westerståhl (1989) it was proved thatBr(most,most) and Res2(most) are not definable in L(most), not even on finitedomains. The latter result was significantly strengthened by Luosto (2000), who usedadvanced finite combinatorics to show that Res2(most) is not definable even if oneadds any finite number of any monadic quantifiers to first-order logic. As a furtherexample, Hella, Väänänen and Westerståhl (1997) gave exact characterizations ofwhen the branching or “Ramseyfication” of increasing CONS, EXT, and ISOM type!1, 1" quantifiers is definable in terms of those quantifiers (or in terms of any monadicquantifiers) over finite models; for example, the branching of basic proportional quan-tifiers is never definable in any logic of the form L(Q1, . . . , Qn) with monadic Qn.34
Thus, in terms of natural notions of expressive power, monadic quantifiers are notsufficient to express the quite common constructions exemplified in Section 19.3.2involving polyadic quantifiers. On the other hand, the considerable range of polyadicquantifiers we have discussed are quite generally built in regular ways from monadicquantifiers. It may well be then that the range of polyadic quantifiers accepted bynatural languages is constrained in just these ways.
Generalization 19.3.1. Polyadic quantification in natural languages in general resultsfrom lifting monadic quantifiers.
References
Abney, S., 1987. The English Noun Phrase in its Sentential Aspect. PhD Dissertation, Dis-tributed by MIT Working Papers in Linguistics, 20D-219 MIT, Cambridge, MA.
Altham, J.E.J., Tennant, N.W., 1975. Sortal quantification, in: Keenan, E. (Ed.), Formal Seman-tics of Natural Language. Cambridge University Press, Cambridge, UK. pp. 46–58.
Barwise, J., 1979. On branching quantifiers in English. J. Philos. Logic 8, 47–80.Barwise, J., Cooper, R., 1981. Generalized quantifiers and natural language. Ling. Philos. 4,
159–219.Beghelli, F., 1992. Comparative quantifiers, in: Dekker, P., Stokhof, M. (Eds.), Proceedings of
the Eighth Amsterdam Colloquium. ILLC, University of Amsterdam, the Netherlands.Beghelli, F., 1994. Structured quantifiers, in: Kanazawa, M., Piñon, Ch. (Eds.), Dynamics,
Polarity, and Quantification. CSLI Publications, pp. 119–145.Ben-Shalom, D., 1994. A tree characterization of generalized quantifier reducibility, in:
Kanazawa M., Piñon, Ch. (Eds.), Dynamics, Polarity, and Quantification. pp. 147–171.
34 More results on the properties and expressive power of polyadic quantifiers are stated in Section 19.2.3of the first version of this chapter. Proofs and many more details can be found in Peters and Westerståhl(2006), Ch. 15.

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 907 — #51
Generalized Quantifiers in Linguistics and Logic 907
Ben-Shalom, D., 1996. Semantic Trees. UCLA PhD Dissertation.Ben-Shalom, D., 2001. One connection between standard invariance conditions on modal
formulas and generalized quantifiers. J. Logic Lang. Inf. 10, 1–6.Bonnay, D., 2008. Logicality and invariance. Bull. Symb. Logic 14 (1), 29–68.Boolos, G., 1981. For every A there is a B. Ling. Inq. 12, 465–467.Boolos, G., 1984. Non-first orderizability again. Ling. Inq. 15, 343.Dalrymple, M., Kanazawa, M., Kim, Y., Mchombo, S., Peters, S., 1998. Reciprocal expressions
and the concept of reciprocity. Ling. Philos. 21, 159–210.Dawar, A., 1995. Generalized quantifiers and logical reducibilities. J. Logic Comput. 5 (2),
213–226.Fauconnier, G., 1975. Polarity and the scale principle. Papers from the Eleventh Regional Meet-
ings of the Chicago Linguistic Society. University of Chicago, Chicago, IL.Fauconnier, G., 1979. Implication reversal in natural language, in: Guenthner, F., Schmidt, S.
(Eds.), Formal Semantics for Natural Language. Reidel, Dordrecht, the Netherlands,pp. 289–301.
Fenstad, J.-E., 1979. Models for natural languages, in: Hintikka, J., et al. (Eds.), Essays onMathematical and Philosophical Logic. D. Reidel, Dordrecht, pp. 315–340.
Gabbay, D., Moravcsik, J., 1974. Branching quantifiers and Montague-Grammar. Theor. Ling.1, 139–157.
Gärdenfors, P. (Ed.), 1987. Generalized Quantifiers. Linguistic and Logical Approaches. Reidel,Dordrecht.
Grädel, E., Kolaitis, Ph., Libkin, L., Marx, M., Spencer, J., Vardi, M., et al. 2007. Finite ModelTheory and its Applications. Springer, New York.
Heim, I., 1982. The Semantics of Definite and Indefinite Noun Phrases. PhD thesis, Universityof Massachusetts, Boston, MA.
Hella, L., Väänänen, J., Westerståhl, D., 1997. Definability of polyadic lifts of generalized quan-tifiers. J. Logic Lang. Inf. 6, 305–335.
Herburger, E., 1994. Focus on noun phrases, in: Spaelti, P., Farkas, D., Duncan, E. (Eds.), Pro-ceedings of WCCFL XII. CSLI Lecture Notes, Stanford, CA.
Higginbotham, J., May, R., 1981. Questions, quantifiers, and crossing. Ling. Rev. 1, 41–79.Hintikka, J., 1973. Quantifiers vs. quantification theory. Dialectica, 27, 329–358. Reprinted in
Linguistic Inquiry V, 1974, 153–177.Hoeksema, J., 1989. The semantics of exception phrases, in: Torenvliet, L., Stokhof, M. (Eds.),
Proceedings of the Seventh Amsterdam Colloquium. ITLI, Amsterdam.Johnsen, L., 1987. There-sentences and generalized quantifiers, in: Gärdenfors, P. (Ed.), Gene-
ralized Qunatifiers: Linguistic and Logical Approaches. Reidel, Dordrecht, pp. 93–107.Kamp, H., Reyle, U., 1993. From Discourse to Logic. Kluwer, Dordrecht/Boston/London.Kanazawa, M., 1994. Dynamic generalized quantifiers and monotonicity, in: Kanazawa, M.,
Piñon. Ch. (Eds.), Dynamics, Polarity, and Quantification. pp. 213–249.Kanazawa, M., Piñon, Ch. (Eds.), 1994. Dynamics, Polarity and Quantification. CSLI Lecture
Notes, Stanford, CA.Keenan, E.L., 1981. A Boolean approach to semantics, in: Groenendijk, J., et al. (Eds.), Formal
Methods in the Study of Language. Math. Centre, Amsterdam, pp. 343–379.Keenan, E.L., 1986. Lexical freedom and large categories, in: Groenendijk, J., et al. (Eds.),
Studies in Discourse Representation Theory and the Theory of Generalized Quantifiers,GRASS 8. Foris, Dordrecht.
Keenan, E.L., 1992. Beyond the Frege boundary. Ling. Philos. 15, 199–221.

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 908 — #52
908 Handbook of Logic and Language
Keenan, E.L., 1993. Natural language, sortal reducibility and generalized quantifiers. J. Symb.Logic 58, 314–325.
Keenan, E.L., Faltz, L., 1985. Boolean Semantics for Natural Language. Reidel, Dordrecht.Keenan, E.L., Moss, L., 1985. Generalized quantifiers and the expressive power of natural
language, in: van Benthem, J., ter Meulen, A. (Eds.), Generalized Quantifiers. Foris,Dordrecht, pp. 73–127.
Keenan, E.L., Stavi, J., 1986. A semantic characterization of natural language determiners. Ling.Philos. 9, 253–326.
Klima, E., 1964. Negation in English, in: Fodor, J.A., Katz, J.J. (Eds.), The Structure of Lan-guage. Prentice-Hall, Englewood Cliffs, New Jersey, pp. 264–323.
Kolaitis, Ph., Väänänen, J., 1995. Generalized quantifiers and pebble games on finite structures.Ann. Pure Appl. Logic 74, 23–75.
Kuroda, S.-Y., 2008. Head-internal clauses, quantifier float, and the definiteness effect and themathematics of determiners. San Diego Linguistic Papers 3. Department of Linguistics,University of California, San Diego, CA, pp. 126–183.
Ladusaw, W., 1979. Polarity Sensitivity as Inherent Scope Relations. PhD Dissertation, Univer-sity of Texas, Austin, TX.
Ladusaw, W., 1982. Semantic constraints on the English partitive construction, in: Flickinger,D., et al. (Eds.), Proceedings of the First West Coast Conference on Formal Linguistics.Stanford Linguistics Association, Stanford University.
Ladusaw, W., 1983. Logical form and conditions on grammaticality. Ling. Philos. 6, 389–422.Langendoen, D.T., 1978. The logic of reciprocity. Ling. Inq. 9, 177–197.Lappin, S., 1988. The semantics of ‘many’ as a weak determiner. Linguistics 26, 977–998.Lewis, D., 1975. Adverbs of quantification, in: Keenan, E. (Ed.), Formal Semantics of Natural
Language. Cambridge University Press, Cambridge, MA, pp. 3–15.Lindström, P., 1966. First-order predicate logic with generalized quantifiers. Theoria 35,
186–195.Liu, F., 1991. Branching quantification and scope independence, in: van der Does, J., van Eijck,
J. (Eds.), Quantifiers, logic and language. CSLI Lecture Notes, Stanford, 1996, 375–383;pp. 315–329.
Loebner, S., 1986. Quantification as a major module of natural language semantics, in: Groe-nendijk, J., Stokhof, M., de Jongh, D. (Eds.), Studies in Discourse Representation Theoryand the Theory of Generalized Quantifiers, GRASS 8. Foris, Dordrecht, pp. 53–85.
Luosto, K., 2000. Hierarchies of monadic generalized quantifiers. J. Symb. Logic 65,1241–1263.
May, R., 1985. Interpreting logical form. Ling. Philos. 12, 387–435.Moltmann, F., 1995. Exception sentences and polyadic quantification. Ling. Philos. 18,
223–280.Moltmann, F., 1996. Resumptive quantification in exception phrases, in: Kanazawa, M., Piñon,
Ch., de Swart, H. (Eds.), Quantifiers, Deduction, and Context. CSLI Publications, Stanford,CA, pp. 139–170.
Montague, R., 1974. English as a formal language, in: Thomason, R. (Ed.), Formal Philosophy.Yale UP, New Haven, pp. 188–221. Originally Published 1969.
Mostowski, A., 1957. On a generalization of quantifiers. Fund. Math. 44, 12–36.Nam, S., 1994. Another type of Negative Polarity Item, in: Kanazawa, M., Piñon, Ch. (Eds.),
Dynamics, Polarity, and Quantification. pp. 3–15.Peters, S., Westerståhl, D., 2006. Quantifiers in Language and Logic. Oxford University Press,
Oxford.

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 909 — #53
Generalized Quantifiers in Linguistics and Logic 909
Reinhart, T., 1991. Non-quantificational LF, in: Kasher, A. (Ed.), The Chomskyan Turn. Black-well, Cambridge, MA, pp. 360–384.
Reinhart, T., Reuland, E., 1993. Reflexivity. Ling. Inq. 24 (4), 657–720.Reuland, E., ter Meulen, A. (Eds.), 1987. The Representation of (In)Definiteness, Current Stud-
ies in Linguistics 14. MIT Press, Cambridge, MA.Scha, R., 1981. Distributive, collective and cumulative quantification, in: Groenendijk, J., et al.
(Eds.), Formal Methods in the Study of Language. Mathematisch Centrum, Amsterdam,pp. 483–512.
Sher, G., 1990. Ways of branching quantifiers. Ling. Philos. 13, 393–422.Spaan, M., 1993. Parallel quantification. Report, Institute for Logic, Language and Information,
LP-93-01, University of Amsterdam, the Netherlands.Srivastav, V., 1990. Multiple relatives and polyadic quantification, in: Halpern, A.L. (Ed.), Pro-
ceedings of the Ninth West Coast Conference on Formal Linguistics. Stanford LinguisticsAssociation, Stanford, CA.
Stowell, T., 1991. Determiners in NP and DP, in: Leffel, K., Bouchard, D. (Eds.), Views onPhrase Structure. Kluwer, Dordrecht, the Netherlands.
ter Meulen, A., 1990. English aspectual verbs as generalized quantifiers, in: Halpern, A.L. (Ed.),Proceedings of the Ninth West Coast Conference on Formal Linguistics. Stanford Linguis-tics Association, University of Chicago, Chicago, IL, pp. 347–360.
van Benthem, J., 1983. Five easy pieces, in: ter Meulen, A. (Ed.), Studies in Model TheoreticSemantics. Foris, Dordrecht, pp. 1–17.
van Benthem, J., 1984. Questions about quantifiers. J. Symb. Logic 49, 443–466.van Benthem, J., 1986. Essays in Logical Semantics. Reidel, Dordrecht.van Benthem, J., 1989. Polyadic quantifiers. Ling. Philos. 12, 437–465.van Benthem, J., ter Meulen, A. (Eds.), 1985. Generalized Quantifiers. Foris, Dordrecht.van Benthem, J., Westerståhl, D., 1995. Directions in Generalized Quantifier Theory. Studia
Logica 55, 389–419. University of Amsterdam, the Netherlands.van der Does, J., 1992. Applied Quantifier Logics. Dissertation, University of Amsterdam, the
Netherlands.van der Does, J., 1994a. On complex plural noun phrases, in: Kanazawa, M., Piñon, Ch. (Eds.),
Dynamics, Polarity, and Quantification. pp. 81–115.van der Does, J., 1994b. Formalizing E-type anaphora, in: Dekker, P., Stokhof, M. (Eds.), Pro-
ceedings of the 9th Amsterdam Colloquium. ILLC, University of Amsterdam, the Nether-lands, pp. 229–248.
van der Does, J., van Eijck, J. (Eds.), 1991. Generalized Quantifier Theory and Applications,Institute of Logic, Language and Information. Amsterdam.
von Fintel, K., 1993. Exceptive constructions. Nat. Lang. Semant. 1 (2), 123–148.Westerståhl, D., 1985. Logical constants in quantifier languages. Ling. Philos. 8, 387–413.Westerståhl. D., 1987. Branching generalized quantifiers and natural language, in: Gärdenfors,
(Ed.), Generalized Qunatifiers: Linguistic and Logical Approaches. Reidel, Dordrecht,269–298.
Westerståhl, D., 1989. Quantifiers in formal and natural languages, in: Gabbay, D., Guenthner,F. (Eds.), Handbook of Philosophical Logic, vol. IV. Reidel, Dordrecht, pp. 1–131.
Westerståhl, D., 1991. Relativization of quantifiers in finite models, in: van der Does J., vanEijik, J. (Eds.), Generalized Quantifier Theory and Application. ILCC, University of Ams-terdam, pp. 187–205.
Westerståhl, D., 1994. Iterated quantifiers, in: Kanazawa M., Piñon, Ch. (Eds.), Dynamics,Polarity, and Quantification. pp. 173–209.

“23-ch19-0857-0910-9780444537263” — 2010/11/29 — 21:08 — page 910 — #54
910 Handbook of Logic and Language
Westerståhl, D., 1996. Self-commuting quantifiers. J. Symb. Logic 61, 212–224.Zimmermann, E., 1993. Scopeless quantifiers and operators. J. Philos. Logic 22, 545–561.Zuber, R., 2007. Symmetric and contrapositional quantifiers. J. Logic Lang. Inf. 16, 1–13.Zwarts, F., 1981. Negatief polaire uitdrukkingen I. Glot 4, 35–132.Zwarts, F., 1998. Three types of polarity, in: Hamm, F., Hinrichs, E. (Eds.), Plurality and Quan-
tification. Kluwer, Dordrecht, pp. 177–238.

“24-ch20-0911-0924-9780444537263” — 2010/11/30 — 3:44 — page 911 — #1
20 On the Learnability ofQuantifiers*(Update of Chapter 19)Robin ClarkDepartment of Linguistics, University of Pennsylvania, Philadelphia,PA 19104-305, USA, E-mail: [email protected]
We will consider, in this chapter, some computational properties of quantifiers and,in particular, how a learner could come to associate specific determiners with theirdenotations on the basis of experience. We will, in particular, be interested in the cor-respondence between natural language quantifiers and formal automata. The computa-tional approach to monadic quantifiers was pioneered by van Benthem (1986; see alsoMostowski, 1998) who discusses the minimal automata needed to simulate variousquantifiers. For present purposes, van Benthem establishes that first-order quantifierscan be simulated by finite state automata, while some higher-order quantifiers requiremore powerful means, push-down automata and beyond. As we will see below, thiswill play a role in the study of the learnability.
Quantifiers are used and understood by finite computational agents. The compu-tational approach to quantifiers promises to advance our understanding of quanti-fiers both within theoretical computer science—where the descriptive complexity ofquantifiers can tell us about the time and space complexity of queries with differ-ent quantifiers—and psycholinguistics—how humans process quantifiers and whetherthere are hard computational constraints on our understanding of quantifiers. Recently,Mostowski and Wojtyniak (2004) have shown that branching interpretation of quan-tifiers as in (1)a is NP-complete. Sevenster (2006) has an analogous result for theproportional branching reading in (1)b:
(1) a. Some relative of each villager and some relative of each townsman hate each other.b. Most villagers and most townsmen hate each other.
More recently, Szymanik (2009) has provided a detailed taxonomy of a wide vari-ety of generalized quantifiers in natural language—from different distributive con-structions to collective quantification (see also Kontinen and Szymanik, 2008)—interms of both time and space complexity. He argues that, given the bounded natureof our computational resources, certain readings for sentences containing branching
* Many thanks for comments from Johan van Benthem, Ed Keenan, Jakub Szymanik and Dag Westerståhl.This work was supported by NIH grant NS44266.
Handbook of Logic and Language. DOI: 10.1016/B978-0-444-53726-3.00020-7c! 2011 Elsevier B.V. All rights reserved.

“24-ch20-0911-0924-9780444537263” — 2010/11/29 — 21:08 — page 912 — #2
912 Handbook of Logic and Language
quantifiers are inaccessible and, as a result, receive a simpler interpretation (see alsoGierasimczuk and Szymanik, 2009). Szymanik (2009) continues to test his complex-ity hierarchy via behavioral experiments; subjects’ response times to truth-value judg-ments increases as of function of the complexity of the quantifier (see also Szymanikand Zajenkowski, 2010).
Similar ideas can be found in the work of Geurts and van der Slik (2005). Theyinvestigate the facility with which subjects drew inferences from monotonic quanti-fiers. They show, among other things, that downward-entailing quantifiers built fromcardinals (“at most n”) are more difficult than other quantifiers; that sentences con-taining a mix of upward and downward entailing quantifiers are more difficult thansentences with only upward entailing quantifiers; and that inferences from subsets tosupersets are easier than inferences from supersets to subsets. This kind of work admitsthe possibility of enriching semantics, not only computationally, but experimentally,to develop a “behavioral” semantics.
The computational approach to quantifiers has consequences, too, for the studyof the neuroanatomy of quantifier interpretation. We would expect that more com-plex quantifiers would make extra demands on the brain’s computational resources.McMillan et al. (2005; see also Clark and Grossman, 2007) gave subjects a truth-value verification task by presenting them with a simple, finite model and a sentencecontaining a single quantifier. The subjects were scanned in an fMRI machine whilethey decided whether or not the sentence was true of the given model. The resultsshow neuroanatomical differences between different type of quantifiers. All quantifiersmarshal areas of the parietal lobe normally involved with number processing; higher-order quantifiers like parity (“an even/odd number of”) and majority (“more than halfof”) involved areas of the frontal lobe normally associated with working memory.The results have been replicated with patients (McMillan et al., 2006). Patients withcortico-basal degeneration, which affects the parietal lobes resulting in acalculia, showgeneral impairment in their understanding of quantifiers; fronto-temporal dementiapatients, who have spared number sense but an impairment in working memory, showimpairment specific to parity and majority quantifiers; their understanding of first-order quantifiers is spared.
In this chapter, we will consider the learnability of the denotations of determinersfrom the point of view of learning in the limit (Gold, 1967; Osherson, Stob, and Wein-stein, 1986). In particular, we will suppose that the learner is presented with a pairconsisting of a sentence containing a determiner whose denotation the learner must fixand a subpart of a model, against which the learner will “test” the sentence.1
20.1 Some Computational Properties of Determiners
We adopt the perspective in van Benthem (1986) who showed how to model Detdenotations with familiar automata. The idea is that learning the meaning of the Det
1 Learning in the limit was first applied to the problem of learning quantifier denotations in Clark (1996).See also Tiede (1999) for an important application. More recently, Gierasimczuk (2007, 2009) developsthe framework in some important and interesting directions.

“24-ch20-0911-0924-9780444537263” — 2010/11/29 — 21:08 — page 913 — #3
On the Learnability of Quantifiers 913
amounts to learning which strings over a given alphabet belong in the denotation ofthe Det. From now on we restrict attention to finite universes. We may then representquantifiers in terms of the “tree of numbers” (van Benthem, 1986). We know, givenplausible constraints on quantifier denotations, that a quantifier Det(A, B) can be rep-resented by an ordered pair of numbers, (|A ! B|, |A " B|); the tree of numbers is thenon-negative orthant of a Cartesian coordinate system, usually shown as having beenrotated 90#. If an ordered pair, (x, y), is in the quantifier Det, we will mark its placeby a ‘+’, otherwise we will mark it with a ‘"’.
In general, any quantifier can be represented as a region (possibly infinite) on thetree of numbers. First-order definable quantifiers have a further property that is par-ticularly important from the point of view of learnability. The tree of numbers allowsa geometric interpretation of first-order definability. In particular, for each first-orderdefinable quantifier, there is a finite upper isosceles triangle of the tree of numberswith the following properties (van Benthem, 1986):
1. the base of the triangle is a line a + b = 2n called the Fraı̈ssé Threshold;2. the truth value at (n, n) determines that of its generated downward triangle;3. all truth values at (n + k, n " k) are propagated along their downward left lines, parallel to
the edge;4. all truth values at (n " k, n + k) are propagated along their downward right lines, again
parallel to the edge.
The significance of the above becomes clearer when we consider an alternative inter-pretation of a point in the tree of numbers. Consider a point like (3, 2) marked with aplus in the tree. This means that in a corresponding model (E, A, B) that satisfies Detthere are three entities in A ! B and two entities in A " B.2 If we represent the entitiesin A ! B with a 1 and the entities in A " B with a 0, then the point (3, 2) represents theset of all strings on {0, 1} of length 5 containing three 1s and two 0s. Since a quantifieris a collection of points in the tree of numbers, we can translate the tree of numbersrepresentation into a string representation: a quantifier is a set of strings on 0 and 1;that is, a quantifier is a language in the sense of automata theory.3
The Fraı̈ssé Threshold has an obvious automata-theoretic interpretation. We definethe collection of regular sets (or regular languages) over an alphabet ! recursively asfollows:
1. the empty language $ is a regular language;2. the empty string language {"} is a regular language;3. for each a % !, the singleton language {a} is a regular language;4. if A and B are regular languages, then A & B (union), A # B (concatenation), and A' (Kleene
star, the set of all strings over the symbols in A) are regular languages;5. no other languages over ! are regular.
2 Saying that a model (E, A, B) satisfies Det is just another way of saying that DetE(A, B) holds. Thisreflects yet a third natural way to think about generalized quantifiers (besides taking them to be functionsor relations), namely, as collections of models. In fact, that was how they were introduced in Lindström(1966).
3 Thanks to Scott Weinstein for some useful discussion of these points!

“24-ch20-0911-0924-9780444537263” — 2010/11/29 — 21:08 — page 914 — #4
914 Handbook of Logic and Language
Now, the following is a well-known theorem, where z is a string, and we use |z| todenote the length of z (for a proof, see Sipser, 1997):
(2) Theorem: (The Pumping Lemma for Regular Sets)Let L be a regular set. Then there is a constant n such that if z is a string in L and|z| ( n, we may write z = uvw in such a way that |uv| ) n, |v| ( 1 and for alli ( 0, uviw is in L. Furthermore, n is no greater than the number of states of thesmallest finite state automaton accepting L.
The Pumping Lemma in (2) implies that a string of length greater than or equal tothe Fraı̈ssé Threshold can be “pumped.” That is, it can be broken into a string uvwwhere the substring v can be repeated any number of times to create a new stringuviw with the property that this new string is also in the language L. If we restrict vto be one symbol long, we get exactly the language that corresponds to a given first-order definable quantifier.4 It is easy to see, in turn, that first-order quantifiers can besimulated by finite state automata.
The basic idea is this: Given a generalized quantifier Det, we map a model (E, A, B)
to a point (m, n) in the tree of numbers, where m = |A ! B| and n = |A " B|; wecan then translate this point to a string, #
(m,n)i from the set of strings named by (m, n).
This string #(m,n)i can now be input to the automaton,ADet. The automaton starts in its
initial state, q0, and the string is input one symbol at a time. At each step, the new stateis determined by the transition function, $, on the basis of the state that the automatonis currently in and the identity of the symbol it is currently scanning. The automatonaccepts #
(m,n)i if it is in an accepting state, qj % F, after it scans the final symbol of
#(m,n)i .
In the next subsection, we will turn to some algebraic properties that will makethe set of first-order determiners straightforward to learn. We note here some usefulproperties of the automata we need for the construction. As van Benthem (1986) hasshown:
(3) Theorem: The first-order definable quantifiers are precisely those that can beaccepted by permutation invariant acyclic finite state automata.
“Permutation invariant” here means that the symbols in the strings can be permuted toany order (as we would expect given the construction relative to the tree of numbers).“Acyclic” means that the automaton will never revisit a state once it has moved toa new state. If we remove the acyclic restriction, we include the parity quantifiers,an-even/odd-number-of. Thus:
4 The restriction to one symbol is necessary because of parity determiners like an even number of whichcorrespond to a regular set, but which is not first-order. It is straightforward to see that the language thatcorresponds to an even number of cannot be pumped with a single symbol. Thus, ‘11’ is in the language,but ‘111’ is not. The problem is solved if we set v to ‘11’, among other possibilities.

“24-ch20-0911-0924-9780444537263” — 2010/11/29 — 21:08 — page 915 — #5
On the Learnability of Quantifiers 915
(4) Theorem: (van Benthem, 1986): The permutation-closed quantifiers recognizedby finite two state automata are:
all, some, no, not all, an even number of, an odd number of, allbut an even number of, all but an odd number of.
If we allow for more than two states, we can build finite state automata that will simu-late any cardinal quantifier. Furthermore, if we interpret simple possessives like John’sby a’s(A, B) * every(A ! {b : a has b}, B) (where has is some suitable ‘possessor’relation),5 then it is apparent that finite state automata can simulate a large range offirst-order quantifiers including the Aristotelians, the cardinals, simple possessives, aswell as parity quantifiers.
It is clear, though, that not all generalized quantifiers can be simulated by finitestate machines. Consider, first, majority quantifiers like most or exactly-half as in:
(5) a. Most dogs bark.b. Exactly half (of) the students passed the exam.
Although these quantifiers can be represented as a collection of points in the Treeof Numbers, they do not have a Fraı̈ssé Threshold and, hence, cannot be pumped inaccordance with the Pumping Lemma for Regular Sets in (2). Indeed, the collectionof points for exactly half will consist of those of the form (m, m), which works out tobe the set of strings on {0, 1}' that have the same number of 1s and 0s. It is easy to seethat if we pump such a string as described above, we won’t preserve this property.
Higher-order quantifiers are, unsurprisingly, inherently more complex than the first-order quantifiers; they require a more complex type of machine to simulate them. Forexample, majority quantifiers need to keep track of the cardinalities in A ! B andA"B in order to compare these cardinalities. Since finite state automata are essentiallymemory-free devices (aside from the implicit memory derived from their states), weneed additional computational power in order to simulate majority quantifiers.
Majority quantifiers like most can be recognized by push-down automata; that is,a finite state automaton equipped with a push-down stack that acts like a simple mem-ory. An element may be added to the top of the stack ( pushing) or an element maybe removed from the top of the stack (popping). The behavior of the automaton isdetermined by its current state, the symbol from the input string that it has read andthe symbol on the top of the push-down stack. Push-down automata accept just thecontext-free languages (Hopcroft and Ullman, 1979; Sipser, 1997).
Consider most; this corresponds to the set of pairs (m, n), m > n, in the tree ofnumbers. From each set named by one of these points, we can select the string 1m0n—a string where all the 1’s occur before the 0’s—as a representative; this will simplifythe computation. When the automaton reads a 1, it pushes a symbol onto its stack.When the automaton reads a 0, it pops the stack. If the automaton reaches the end of
5 This is a first approximation of the meaning of possessives. For a detailed treatment of the semantics ofpossessive quantifiers, see Peters and Westerståhl (2006), Ch. 7.

“24-ch20-0911-0924-9780444537263” — 2010/11/29 — 21:08 — page 916 — #6
916 Handbook of Logic and Language
the string and its stack is not empty, then it accepts the string. It follows, though, thatat least some natural language quantifiers have denotations that cannot be simulatedby finite state automata.
20.2 The Learnability of First-Order Determiners
Given the background in Section 20.1, we can turn to the formal problem of learningquantifier denotations. The computational analysis of generalized quantifiers suggeststhat we can break the problem down into subproblems according to the complexityof the automaton that simulates the quantifier. Thus we will begin with first-orderdeterminers—in particular, Aristotelians and cardinals—and then move to higher-order determiners like parity and majority determiners.
We will suppose, throughout, that for each quantifier the learner is presented withevidence in the form of a text, a (potentially infinite) sequence of examples that arepresented to the learner one at a time. The learner converges (successfully learns) aquantifier denotation if she posits an automaton that correctly accepts all and only thestrings associated with quantifier’s set of points in the tree of numbers. Since we caneasily translate from automata to grammars, we lose nothing by thinking in terms ofautomata.
We will assume that the text for each quantifier is constrained to simple sentencescontaining a single quantifier in subject position; we will not be concerned with theproblem of associating scopes to multiple determiners. This simplifying assumptionmeans that the syntactic context in (6) is a straightforward structural cue to initiatelearning:
(6) [NP (Adj) CN] Pred
Next, we will note that many determiners can be treated as Boolean combinationsof more basic determiners:
(7) a. Not every student passed the exam.b. Some but not all democrats belong to unions.c. One or two faculty representatives attended the meeting.
We will assume, following Keenan and Stavi (1986) that the examples in (7) can beconstructed compositionally as a function of Boolean operations on their constituentparts and need not be the target of learning. The learner will focus her attention ondeterminers that cannot be so decomposed.
Note, however, that some “basic” determiners can be morphologically complex:
(8) a. At most five students completed the assignment.b. Exactly three senators attended the hearing.c. Less than seven guests arrived early.
Although the quantifiers in (8) may be constructed semantically from other quantifiers,their syntactic form does not transparently reflect this. For example, exactly three may

“24-ch20-0911-0924-9780444537263” — 2010/11/29 — 21:08 — page 917 — #7
On the Learnability of Quantifiers 917
be constructed from more than two and less than four, although the learner could notdiscover this simply by morpho-syntactic analysis of exactly three. Thus, the learnerwill have to morphologically analyze determiners in the text to determine which ofthem must be learned and which can be treated in a directly compositional way fromthe morpho-syntax.
Suppose the learner has initiated the learning of a new determiner. We will supposethat input the learner receives will consist of a sequence of pairs consisting of a quan-tified claim of the form Det(A, B) and a point (m, n) in the tree of numbers, wherem = |A ! B| and n = |A " B| and the contents of A and B are given by the currentcontext. Thus, an utterance of Some toy is broken in a context where there are fiveunbroken toys and one broken toy would be represented as:
(9) +some(TOY,, BROKEN,), (1, 5)-A string could then be selected from the set named by (m, n) and the learner couldupdate her hypothesis based on that string.
This method of presentation has the interesting result that the learner receives infor-mation both about what strings are in the language LDet but also about strings that areoutside the language. Consider an example like:
(10) Every toy isn’t broken.
in the context where there are five toys, three of which are broken. The learner nowhas the information that (3, 2) .% LDet. In other words, the learner can use this kind ofexample as negative evidence about her hypothesis.6
There is a final set of properties of first-order determiners and the finite statemachines that simulate them that make their learning straightforward. As noted above,we can think of generalized quantifiers as being constructed algebraically from arbit-rary boolean meets, joins and complements of a handful of basic determiner functions(Keenan and Stavi, 1986). As it happens, we can use a similar construction to generatefinite state automata that will simulate first-order determiners.
First, consider the relationship between the automata that simulate no and someor the automata that simulate every and not all. The pairs differ only as to whichstate is designated as the accept state. In fact, no is the complement of some, and notall is the complement of every. In general, the regular languages are closed undercomplementation (Sipser, 1997) where the operation of complementation is given by:
(11) Let M = (Q, !, $, q0, F) be a finite state automaton. The complement of M, M, =(Q, !, $, q0, F,), is given by setting F, = Q " F.
We can use this construction to deliver “complementary” determiners from existingfinite state machines. For example, the complement of the automaton that simulates atleast two’ would remove the original automaton’s accept state, but make all the other
6 Syntactic learning is often taken to be based on positive-only texts. That is, the learner receives reliableevidence about sentences in the language, but receives no evidence about strings that lie outside thelanguage.

“24-ch20-0911-0924-9780444537263” — 2010/11/29 — 21:08 — page 918 — #8
918 Handbook of Logic and Language
states accept states; such an automaton would simulate less than two. The followingis a theorem (see Hopcroft and Ullman, 1979; Sipser, 1997):
(12) Theorem: The class of regular sets is closed under complementation.
We can define a simple operation on finite state machines to assemble automata thatwill simulate the cardinal determiners. First, note that the automaton that simulatessome works to simulate at least one. Let us denote this automaton by M1). We nowdefine an operation “+” as follows:
(13) Let M1 = (Q1, !, $1, q1, F1) and M2 = (Q2, !, $2, q2, F2) be two finitestate automata whose states have been named so as to be disjoint. The assem-bly M1 + M2 is that finite state automaton given by (Q1 & Q2, !, $0, q1, F2)
where:
1. the final state of M1 is identified with the initial state of M2; we can do this byallowing an “empty” transition labeled “"” from any state in F1 the set of final statesin M1 to q2, the initial state of M2;
2. the transition function $0 is given by $1 & $2 with the following transitions removed:$1(qF, %), where qF % F1 and % .= ". Thus, $0(qF, ") = q2 and nothing else.
The operation in (13) assembles two automata, M1 and M2, by making the finalstates of M1 into non-final states and connecting these states to the initial state of M2;in fact, this is just concatenation. This new automaton will accept a string if it cansimulate M1 on a prefix of the string and then simulate M2 on the remainder.
Of course, we can use the assembly operation to construct an automaton that willsimulate at least n. We define the set MCARD:
(14) The set MCARD of basic cardinal automata is the smallest set given by:
1. M1) % MCARD;2. If Mi, Mj % MCARD then Mi + Mj % MCARD.
We identify MCARD with the structure +{M)1}, +-. If we combine the assemblyoperation with complementation, we can simulate any determiner of the form at mostn by finding the automaton that simulates at least n + 1 in MCARD and taking its com-plement.
Consider, now, an example like:
(15) Exactly three students finished the exam.
exactly three can be simulated by taking the intersection of two regular languages:One language corresponds to the language accepted by Mat least n and the other languageaccepted by Mless than n + 1 (the latter being the complement of Mat least n + 1). We can relyhere on the following theorem (Sipser, 1997):
(16) Theorem: The regular sets are closed under intersection.
The proof is straightforward. Given two finite state automata, M1 and M2, a string #
is in their intersection if and only if both M1 and M2 accept #.

“24-ch20-0911-0924-9780444537263” — 2010/11/29 — 21:08 — page 919 — #9
On the Learnability of Quantifiers 919
Given the theorems in (12) and (16) we have the immediate corollary:
(17) The regular languages are closed under union.
since we can define union relative to intersection and complementation. More gene-rally, the following theorem holds of the regular languages (Hopcroft and Ullman,1979):
(18) Theorem: The regular sets are closed under union, concatenation, complemen-tation and Kleene closure.
Here, the Kleene closure is the closure of the set under string concatenation. Thistheorem in (18), along with our observations about the automata which acceptthe Aristotelians, and the relationship between the tree of numbers and finite stateautomata, are sufficient to establish the learnability of the first-order determiners. Wedefine the following set of “basic” semantic automata:
(19) BasicM = {+{M(1}, +-} & {Mall}That is, BasicM consists of our structure for generating automata which simulate thecardinal determiners along with the automaton which simulates all. From this setwe can, using concatenation (‘+’), union, intersection and complementation, gener-ate semantic automata which will simulate any first-order determiner. The techniquehere is essentially that of Keenan and Stavi (1986) except that they allow for arbitrarymeets and joins of determiner functions to generate higher-order functions. Since weare dealing with automata, we are constrained to finite intersections and unions, inorder to guarantee that the resulting automaton has a finite set of states.
Recall that the behavior of a first-order quantifier can be exhaustively described bya finite upper triangle of the tree of numbers. This means that there is a small sample ofpoints from the tree of numbers that the learner can use to distinguish each automatonthat simulates a quantifier—no two distinct quantifiers will have identical behavioron this triangle. Furthermore, the behavior of functions beyond the Fraı̈ssé Thresholdis entirely predictable (van Benthem, 1986); this was related above to the pumpinglemma for regular languages.
All of the above implies that the learner will eventually assemble a “lockingsequence”—that is a text on which the learner is guaranteed to converge to the correcthypothesis—by simply accumulating, for each first-order quantifier, the set of points inthe upper triangle of the tree of numbers bounded by the number n that is the Fraı̈sséThreshold for that quantifier; recall that n is also the pumping length of the stringsaccepted by the automaton that simulates the quantifier (as well as a bound on thenumber of states in the automaton). Since the text is infinite, we can assume that even-tually all such points will occur in the text.
The learner need only test the automata generated by the basic automata closedunder concatenation, union, intersection and complementation. The number n pro-vides a bound on the number of such automata. Thus, there are finite texts that willserve to distinguish any first-order semantic automaton from the others and we haveestablished the learnability of the first-order determiners.

“24-ch20-0911-0924-9780444537263” — 2010/11/29 — 21:08 — page 920 — #10
920 Handbook of Logic and Language
20.3 Higher-Order Determiners
The learnability of first-order determiners rests on the straightforward structure of thefunctions that interpret the first-order determiners. A well-known result of the learningtheory is that even the regular sets are not text-learnable in the limit (Gold, 1967;Niyogi, 2006; Osherson, Stob, and Weinstein, 1986). As we have seen, a well-definedsubset of the regular sets can be learned, if the learner is sensitive to the structureof the subset. The simple structure of the first-order determiners—the fact that thegenerators of the set are simple and that the set is closed under union, intersection,complementation and concatenation—is a boon for the learner.7
Although higher-order determiners can also be simulated by automata, we herecross the threshold into the context-free languages and above. The simple closureproperties associated with the regular languages do not hold here. For example,anbncm—a string of n as followed by the same number of bs followed by any numberof cs—is a context-free language; such is the case for ambncn as well. The intersec-tion of these two languages is anbncn which is not a context-free language. Thus, theobvious techniques for enumerating hypotheses are not available.
Although we do not have a simple algorithm for learning a set of higher-order deter-miners, we can outline some results that should prove useful in studying the semanticlearnability of these determiners. We begin by defining a less stringent requirementon the learner than learnability in the limit. Suppose that A is a function from datasequencesD to hypothesesH. That is, given a text t % D,A(t) is a hypothesis, h % H.Learnability in the limit is the requirement:
limk/0
d(A(tk), gt) = 0
where d measures the distance between the learner’s hypothesis and gt, where gt is thetarget. Let us instead require:
limk/0
P[d(A(tk), gt) > "] = 0
that is, the probability that the learner’s hypothesis is farther from the target than somedistance bounded by ", is zero as the text grows. This is Probably ApproximatelyCorrect (PAC) learning.
We should note that if the learner knows the source distribution of each of thepossible target languages—in our case, the distribution of points in the tree of numbersassociated with a given higher-order determiner—then the family is learnable withmeasure 1; in other words, the learner must have some priors about the nature of theset to be learned. We turn now to a general discussion of some well-known learningtheoretic results.
7 The learner may also get negative information about the language of the quantifier via negation; althoughthe exact interpretation of negation is difficult and may present the learner with other difficulties. Ourconstruction allows us to sidestep this problem.

“24-ch20-0911-0924-9780444537263” — 2010/11/29 — 21:08 — page 921 — #11
On the Learnability of Quantifiers 921
Recall that each determiner corresponds to a collection of points in the tree ofnumbers; this collection of points can be treated as a language in the sense that eachpoint corresponds to a (finite) set of strings, each of which is in the language acceptedby the automaton that simulates the determiner. Furthermore, because of sententialnegation, the learner can be presented with negative evidence; that is, she can be toldexplicitly that a point is not in the language accepted by the determiner. We can imag-ine, without loss of generality, that for each higher-order determiner DET, there is afunction:
1DET : !' / {0, 1}
where !' is the set of all strings on 0 and 1. The function 1DET is, of course, thecharacteristic function for the determiner.
Suppose, now, thatF is the set of characteristic functions for the higher-order deter-miners. The setF would be learnable if the characteristic function for each determinercan be distinguished from all the others on at least one data point; that data point (orset of data points) might be different for each determiner, but each function is distin-guished from all the others somewhere. The learner could then enumerate the data foreach determiner, waiting for the data point that would indicate to the learner whichfunction to select for the determiner denotation. This is the idea behind the followingdefinition:
(20) ShatteringA set of points x1, . . . , xn is shattered by a hypothesis set H if for every set ofbinary vectors b = (b1, b2, . . . , bn), there exists a function hb % H such thathb = 1 if and only if bi = 1.
In the above, the hypothesis set H corresponds to the set of higher-order determinerdenotations. The set of points x1, . . . , xn is a collection of points in the tree of numbers.This set of points is “shattered” by the hypothesis setH of functions that would inter-pret higher-order determiners, if we can distinguish each function inH by its behavioron some vector of data points. The set of n points is shattered by a hypothesis set ifthe hypothesis set has at least 2n different functions in it. Shattering is a measure ofthe degrees of freedom of a set in the sense that if H shatters a set X then any stringx % X is independent of the others (Natarajan, 1991).
We now define the Vapnik-Chervonenkis (VC) dimension of a set:
(21) The VC dimension of a set of functionsH is d if there exists at least one set ofcardinality d that can be shattered and no set of cardinality greater than d thatcan be shattered byH. If no such finite d exists, the VC dimension ofH is saidto be infinite.
The set of higher-order determiner denotations would have a finite VC dimension, forexample, if we could collect a finite set of points in the tree of numbers that couldbe shattered by the set of higher-order determiner denotations. That is, the set wouldcontain a data point for each determiner function that distinguishes that function fromthe others.

“24-ch20-0911-0924-9780444537263” — 2010/11/29 — 21:08 — page 922 — #12
922 Handbook of Logic and Language
The following is a theorem:
(22) Theorem: Let L be a collection of languages and H be the correspondingcollection of functions. Then L is learnable if and only if H has finite VCdimension.
For a proof, see Niyogi (2006).Intuitively, the learner would collect the data from the incoming text for each
higher-order determiner, waiting for a unique bit of information that would tell herwhich function to associate with that determiner.
In summary, the question of the learnability of F the set of higher-order determin-ers now reduces to whether it has finite VC dimension. One way to think of this is,again, in terms of the tree of numbers. Suppose that F is the collection of higher-orderdeterminers to be learned. If F is finite, then there is a finite collection of points in thetree of numbers, x1, . . . , xn, on which the members of F can be distinguished. If thisis true then F shatters x1, . . . , xn with a finite VC dimension, since the power set of{x1, . . . , xn} is itself finite. We leave the precise details of this analysis as a problemfor future research.
References
Clark, R., 1996. Learning first order quantifier denotations: An essay in semantic learnability.IRCS Technical Report, 96–19, University of Pennsylvania, Philadelphia, USA.
Clark, R., Grossman, M., 2007. Number sense and quantifier interpretation. Topoi 26, 51–62.Geurts, B., van der Slik, F. 2005. Monotonicity and processing load. J. Semant. 22, 97–117.Gierasimczuk, N., 2007. The problem of learning the semantics of quantifiers, in: ten Cate, B.,
Zeevat, H. (Eds.), Logic, Language, and Computation, 6th International Tbilisi Symposiumon Logic, Language, and Computation, Lecture Notes in Computer Science (vol. 4363,pp. 117–126). Springer, New York.
Gierasimczuk, N., 2009. Identification through inductive verification. Application to monotonequantifiers, in: Bosch, P., Gabelaia, D., Lang, J. (Eds.), Logic, Language, and Computation,7th International Tbilisi Symposium on Logic, Language, and Computation, TbiLLC 2007,Lecture Notes on Artificial Inteligence (vol. 5422, pp. 193–205) Springer, Tbilisi, Georgia.
Gierasimczuk, N., Szymanik, J., 2009. Branching quantification vs. two-way quantification.J. Semant. 26 (4), 367–392.
Gold, E.M., 1967. Language identification in the limit. Inf. Control 10, 447–474.Hopcroft, J., Ullman, J., 1979. Introduction to Automata Theory, Languages, and Computation.
Addison Wesley Publishing Company, Reading, MA.Keenan, E.L., Stavi, J., 1986. A semantic characterization of natural language determiners.
Linguist. Philos. 9, 253–326.Kontinen, J., Szymanik, J., 2008. A remark on collective quantification. J. Log. Lang. Inf. 17
(2), 131–140.Lindström, P., 1966. First order predicate logic with generalized quantifiers, in: Theoria, vol. 32,
pp. 186–195.McMillan, C.T., Clark, R., Moore, P., DeVita, C., Grossman, M., 2005. Neural basis for gene-
ralized quantifier comprehension. Neuropsychologia 43, 1729–1737.

“24-ch20-0911-0924-9780444537263” — 2010/11/29 — 21:08 — page 923 — #13
On the Learnability of Quantifiers 923
McMillan, C.T., Clark, R., Moore, P., Grossman, M., 2006. Quantifier comprehension in corti-cobasal degeneration. Brain Cogn. 65, 250–260.
Mostowski, M., 1998. Computational semantics for monadic quantifiers. J. Appl. Non-Class.Log. 8, 107–121.
Mostowski, M., Wojtyniak, D., 2004. Computational complexity of the semantics of some nat-ural language constructions. Ann. Pure Appl. Log. 127 (1-3), 219–227.
Natarajan, B.K., 1991. Machine Learning: A Theoretical Approach. Morgan Kaufmann Pub-lishers Inc., San Mateo, CA.
Niyogi, P., 2006. The Computational Nature of Language Learning and Evolution. The MITPress, Cambridge, MA.
Osherson, D., Stob, M., Weinstein, S., 1986. Systems that Learn: An Introduction to LearningTheory for Cognitive and Computer Scientists. The MIT Press, Cambridge, MA.
Peters, S., Westerståhl, D., 2006. Quantifiers in Language and Logic. Oxford University Press,Oxford, UK.
Sevenster, M., 2006. Branches of Imperfect Information: Logic, Games, and Computation. PhDthesis, University of Amsterdam, Amsterdam, the Netherlands.
Sipser, M., 1997. Introduction to the Theory of Computation. PWS Publishing Company,Boston, MA.
Szymanik, J., 2009. Quantifiers in TIME and SPACE: Computational Complexity of Generali-zed Quantifiers in Natural Language. PhD thesis, University of Amsterdam, Amsterdam,the Netherlands.
Szymanik, J., Zajenkowski, M., 2010. Comprehension of simple quantifiers. Empirical evalua-tion of a computational model. Cogn. Sci. 30 (3), 521–532.
Tiede, H.J., 1999. Identifiability in the limit of context-free generalized quantifiers. J. Lang.Comput. 1, 93–102.
van Benthem, J., 1986. Essays in Logical Semantics. D. Reidel Publishing Co., Dordrecht, theNetherlands.

“24-ch20-0911-0924-9780444537263” — 2010/11/29 — 21:08 — page 924 — #14
This page intentionally left blank

“25-ch21-0925-0970-9780444537263” — 2010/11/30 — 3:44 — page 925 — #1
21 TemporalityMark SteedmanSchool of Informatics, University of Edinburgh, InformaticsForum 415, 10 Crichton Street, Edinburgh, EH8 9AB,Scotland, UK, E-mail: [email protected]
Commentator: A. ter Meulen
21.1 A Case-study in Knowledge Representation
In thinking about the logical and computational semantics of temporal categories innatural languages, issues of temporal ontology, or metaphysics, must be distinguishedfrom issues of temporal relation. Categories of the first kind determine the sorts oftemporal entities that can be talked about – examples that are discussed below includevarious kinds of states and events. We shall be concerned with what Cresswell (1990),following Quine (1960), calls the “ontological commitment” of the semantics – thatis, the variety of types that can be quantified over, or otherwise formally operatedupon. Temporal relational categories determine the relations that may be predicatedover such entities – examples to be discussed include temporal order, inclusion andoverlap, together with various causal, teleological, and epistemic relations. Some ofthese relations depend for their identification upon inference from discourse structureand context. It follows that we must distinguish a third kind of phenomenon, thatof temporal reference. These three distinct but interrelated kinds of phenomena areconsidered in turn in the three main sections of the paper that follow.
As in any epistemological domain, neither the ontology nor the relations shouldbe confused with the corresponding descriptors that we use to define the physics andmechanics of the real world. The notion of time that is reflected in linguistic cate-gories is only indirectly related to the common-sense physics of clock-time and therelated Newtonian representation of it as a dimension comprising an infinite numberof instants corresponding to the real numbers, still less to the more abstruse represen-tations of time in modern physics.
This observation may not seem too surprising, since it is only a more extremeversion of Russell’s, Wiener’s and Whitehead’s (1929) observation of the need to dis-tinguish between external and individual representations of time. However, the partic-ular conceptualization of temporality that underlies language is by no means obvious.
Handbook of Logic and Language. DOI: 10.1016/B978-0-444-53726-3.00021-9c! 2011 Elsevier B.V. All rights reserved.

“25-ch21-0925-0970-9780444537263” — 2010/11/29 — 21:08 — page 926 — #2
926 Handbook of Logic and Language
Like the concept of an entity or individual discussed elsewhere in this volume byLønning, it is confounded with practical aspects of our being in the world of a kindthat physics does not discuss. In particular, it is confounded with notions of teleologythat are explicitly excluded from even the most informal and common-sense varietiesof physics. On the assumption that linguistic categories are fairly directly related tounderlying conceptual categories (for how else could children learn them), it is to thelinguists that we must turn for insights into the precise nature of this ontology.
In this connection it may seem surprising that the present paper is confined to anal-yses of English temporal categories. However, it will soon be apparent that we cannotanalyze the categories of English without appealing to notions of underlying meaningthat are closely related to a level of knowledge about events that is independent of theidiosyncracies of any particular language. The paper returns briefly to the question ofthe universality of this semantics in the conclusion.
Because of this psychological grounding of the natural semantics of temporality, acertain caution is appropriate in assessing the relevance to linguistic inquiry of sys-tems of logic and computational theory that trade under names like “Tense Logic”.Such logics frequently come with very minimal ontologies, restricted to states andNewtonian instants, or to the simplest kind of interval, and similarly minimal, purelytemporal, relations among them. Their authors are usually careful to stress that theirsystems do not reflect linguistic usage. Their raison d’être is analogous to that ofPeano’s axioms in arithmetic – that is, to characterize the metamathematical proper-ties of physical time. Such concerns are not necessarily those of the working linguistor computational linguist, who is mainly interested in performing inference. One doesnot calculate via proofs in Peano arithmetic.
Many properties of natural language semantics, particularly those involving thenotion of discourse context, are most directly modeled by dynamic processes. Sincecomputer programs are a very direct expression of procedures, many of the logicalframeworks that we shall find most useful draw upon ideas from computer scienceand studies in artificial intelligence as frequently as from the declarative logical tra-dition itself. In particular, many recent formalisms invoke the computer scientist’sconcept of a side-effect or update to a database, in order to talk about the changingcontext of reference, including the temporal variety. This move introduces notions ofnon-monotonicity, of a kind discussed by Thomason elsewhere in the volume. Weshall combine this notion with the modal logicians’ device of an accessibility relation,defining a structure on models, where models are databases, or partial models, in whathas come to be called dynamic logic.
In developing an account of this very diverse and ramifying literature, it will some-times be necessary to concentrate on one of these approaches, and there may be adanger of temporarily losing sight of the others. Nevertheless, they will meet up againas the chapter proceeds, for linguists, computer scientists and logicians are linked inthis venture like mountaineers roped together during a climb. Sometimes the lead istaken by one, and sometimes another, but progress will in future, as in the past, onlybe made by the team as a whole.

“25-ch21-0925-0970-9780444537263” — 2010/11/29 — 21:08 — page 927 — #3
Temporality 927
21.2 Temporal Ontology
21.2.1 Basic Phenomena and Descriptive Frameworks
The first thing to observe about the temporal ontology implicit in natural languagesis that it is not purely temporal. To take a simple example, the English perfect, whenpredicated of an event like losing a watch, says that some contextually retrievableconsequences of the event in question hold at the time under discussion. (Such con-sequences have sometimes been described under the heading of “present relevance”of the perfect – cf. Inoue (1979). In restricting the perfect to this single meaning,English differs from most other European languages, in which the perfect also actsas a past tense.) Thus, conjoining such a perfect with a further clause denying thoseconsequences is infelicitous:
(1) I have lost my watch (# but I have found it again).
In this respect the English perfect (unlike the perfect in many other languages) standsin contrast to the more purely temporal tenses, such as the past, which make no com-parable claim about the consequences of the core event:
(2) Yesterday, I lost my watch (but I (have) found it again).
Further evidence for the claim that the perfect is concerned with causal effects orconsequences, and that the availability of such “contingencies” depends upon worldknowledge is provided by examples like the following. Example (3)a, below, is onein which no obvious consequences are forthcoming from the knowledge base. Exam-ple (3)b is one in which all the obvious consequences of the core event are conse-quences for Einstein, which our knowledge tells us cannot still hold. Both examplesare therefore anomalous unless supported by rather unusual contexts.
(3) a. # I have breathed.b. # Einstein has visited New York.
It is because categories like the perfect are not purely temporal that it is usual todistinguish them from the tenses proper as “aspects”. Another aspect whose meaningis not purely temporal is the progressive or imperfective. The predication that it makesconcerning the core event is a subtle one. While the progressive clearly states thatsome event is ongoing at the time under discussion, it is not necessarily the event thatis actually mentioned. Thus in (4)a, below, there seems to be a factive entailment aboutan event of writing. But in (4)b, there is no such entailment concerning an event ofwriting a sonnet, for (4)b is true even if the author was interrupted before he couldcomplete the action.
(4) a. Keats was writing ! Keats wrote.b. Keats was writing a sonnet ! Keats wrote a sonnet.
Dowty (1979) named this rather surprising property of the progressive the “imper-fective paradox”, and we shall return to it below. It reflects the fact that events like

“25-ch21-0925-0970-9780444537263” — 2010/11/29 — 21:08 — page 928 — #4
928 Handbook of Logic and Language
Keats writing, unlike those like Keats writing a sonnet, are what White (1994) callsdownward entailing, which we can define as follows:
(5) A proposition ! holding of an interval t is downward entailing if it entails that !
also holds of all subintervals of t down to some reasonable minimum size.
The imperfective paradox is the first sign that we must distinguish various types orsorts of core event in natural language temporal ontology.
The key insight into this system is usually attributed to Vendler (1967), thoughthere are precedents in work by Jesperson, Kenny and many earlier authorities includ-ing Aristotle. Vendler’s taxonomy was importantly refined by Verkuyl (1972, 1989),and Dowty (1982, 1986), and further extended by Hinrichs (1985, 1986), Bach (1986),Moens (1987), Smith (1991), Krifka (1989, 1992), Jackendoff (1991), and White(1994). The following brief summary draws heavily on their work.
Vendler’s original observation was that a number of simple grammatical tests couldbe fairly unambiguously applied to distinguish a number of distinct aspectual cate-gories. The term “aspectual” here refers to the intrinsic temporal profile of a proposi-tion, and such categories are to be distinguished from the sentential aspects, the perfectand the progressive. For this reason they are often referred to under the German termAktionsarten, or action-types. Vendler talked of his categorization as a categorizationof verbs, but Verkuyl and Dowty argued that it was properly viewed as a classificationof the propositions conveyed by verbs and their arguments and adjuncts – that is, ofpropositions concerning events and states.
We will consider just four tests used by Vendler and those who followed, althoughthere are others. The first is compatibility with adverbials like for fifteen minutes. Thesecond is compatibility with adverbials like in fifteen minutes and the related con-struction It took (him) fifteen minutes to ... . The third is the entailment arising fromthe progressive. The fourth is compatibility with the perfect.
Vendler identified a category of event such as arriving, reaching the top or finish-ing a sonnet, which he called achievements. These events are characterized by beinginstantaneous, and by resulting in a distinct change in the state of the world. Theycan be detected by the fact that they combine happily with in-adverbials, do not com-bine with for-adverbials, do not carry a factive entailment under the progressive, andcombine happily with the perfect.
(6) a. Keats finished the sonnet in fifteen minutes.b. # Keats finished the sonnet for fifteen minutes.c. Keats is finishing the sonnet (! Keats will have finished the sonnet).d. Keats has finished the sonnet.
Achievements are to be contrasted with a category of events like walking, climbingand writing, which Vendler called activities. Activities are extended in time, and donot seem to result in any very distinct change in the state of the world. They can bedetected by the fact that they combine with for-adverbials but not with in-adverbials,that the progressive does carry a factive entailment, and that they are distinctly oddwith the perfect.

“25-ch21-0925-0970-9780444537263” — 2010/11/29 — 21:08 — page 929 — #5
Temporality 929
(7) a. Keats wrote for fifteen minutes.b. # Keats wrote in fifteen minutes.c. Keats is writing (! Keats will have written).d. # Keats has written.
Both of these categories are to be contrasted with a third category of event such aswriting a sonnet or flying to Paris. Vendler called such events accomplishments. Theysuperficially have the same test profile as achievements:
(8) a. Keats wrote In Disgust of Vulgar Superstition in fifteen minutes.b. # Keats wrote the sonnet for fifteen minutes.c. Keats is writing the sonnet (! Keats will have written the sonnet).d. Keats has written the sonnet.
(See Garrod (1954, p. 532) for some historical background to this example.) However,accomplishments differ from achievements in being extended in time, like activities.As a consequence, they differ in entailments when combined with in-adverbials andprogressives. In (8)a and c it is part of the event (namely the writing) that respectivelytakes fifteen minutes and is reported as in progress. It is precisely not part of finishingitself that takes fifteen minutes in (6)a, or is in progress in (6)c. It is some other event.In fact it is presumably an event of writing, since the overall entailments of the twopairs of sentences are very similar. Because of this relation, both Verkuyl and Dowtyproposed that accomplishments should be regarded as composites of an activity and aculminating achievement.
Vendler also identified a class of states. States are characterized syntactically bybeing almost the only propositions that can be expressed in English by simple presenttense. (The exceptions are performatives like the following, which in all other respectsare archetypal achievements):
(9) I name this ship the Nice Work If You Can Get It.
States differ from events in that they lack explicit bounds. Some lexical concepts arestates, notably those expressibly using the copula, as in (10)a, below. The progressivesand perfects considered above, as well as certain predications of habitual action, arealso archetypal states, as in (10)b, c, and d:
(10) a. Keats is a genius.b. Keats is looking into Chapman’s Homer.c. I have lost my watch.d. I work for the union.
It should be stressed that any claim that an event like Keats writing is intrinsically anactivity is no more than a convenient shorthand. It is true that in most contexts thefollowing sentence is odd.
(11) Keats wrote in fifteen minutes.
However, as Dowty pointed out for a related example, in a discourse context inwhich the speaker and the hearer both believe that Keats is in the habit of writing

“25-ch21-0925-0970-9780444537263” — 2010/11/29 — 21:08 — page 930 — #6
930 Handbook of Logic and Language
a sonnet to time every Sunday, and the speaker knows that on the particular Sundayunder discussion, say 23rd December 1816, Keats took fifteen minutes at it, then theutterance is felicitous. Such examples show that aspectual categories like activityand accomplishment are ways of viewing a happening, rather than intrinsic proper-ties of verbs and the associated propositions, or of objective reality and the externalworld.
The fact that the same form of words can convey more than one aspectual category,provided contextual knowledge supports this view of the passage of events, is the firstclue to an explanation for the imperfective paradox. The semantics of the progressivemust demand an activity as the only event type that it can map onto the correspondingprogressive states. When combined with an accomplishment, as in example (8)c, itmust first turn it into an activity, by decomposing the accomplishment into its compo-nents, and discarding the culminating achievement. When combined with an achieve-ment, as in (6)c, it must first turn it into an accomplishment, identifying an associatedactivity from the knowledge base and the context. Then the original achievement canbe discarded. Such an account would explain the fact that in normal contexts examples(6)c and (8)c hold of identical situations.
Events can turn into activities by turning into an iteration of the core event.
(12) Chapman sliced the onion (into rings).
Such iterations may themselves iterate (as in slicing onions), and in the progressivemay be predicated of a time at which one is not performing the core event at all:
(13) I am slicing the onions.
Such iterated activities are investigated by Karlin (1988). A similar transition to ahabitual state can occur if, to extend an earlier example, Keats not only writes sonnetsto time, but also regularly manages it in fifteen minutes or less. Under these circum-stances he can say the following on an occasion on which he is not writing at all:
(14) I am writing a sonnet in fifteen minutes (these days).
There is more to NPs like the onions and a sonnet in the above examples than maymeet the eye. Verkuyl and Dowty also pointed out that some similar protean shifts inaspectual category of the event conveyed by a sentence depended upon the semantictype of the nominal categories involved as arguments of the verb. Thus Chapmanarriving is an archetypal achievement, which happens to be resistant to combinationwith a for-adverbial, because the state that it gives rise to seems to preclude iteration,as shown by (15)a, below. But visitors arriving is necessarily an iteration, as in (15)b.
(15) a. # Chapman arrived all night.b. Visitors arrived all night.
Such aspectual changes, which include several further varieties that cannot be con-sidered here, may compose indefinitely, especially under the influence of stackedadverbial modifiers, as in:

“25-ch21-0925-0970-9780444537263” — 2010/11/29 — 21:08 — page 931 — #7
Temporality 931
(16) It took me two years to play the “Minute Waltz” in less than sixty seconds forone hour without stopping.
The complexities of this kind of aspectual type-shift or “coercion” are very thoroughlyexplored by the authors already cited. Accordingly we will pass over further detailshere, merely offering the chart shown in Figure 21.1, by way of an informal sum-mary. The chart divides the aspectual categories into states and events, the latter beingsubdivided into four sorts, based on two features representing the semantic propertiesof telicity, or association with a particular change of state, and decomposability. Thelatter property is often referred to as “durativity”, but it is really to do with decompo-sition into sub-events, rather than temporal extent. To Vendler’s three event categorieswe follow Miller and Johnson-Laird (1976) in adding a fourth, atomic atelic, category,here called a point. (They are what Smith (1991) calls “semelfactives”.) These authorssuggest that events like stumbling and breathing a sigh of relief may be basic conceptsof this type, but the real significance of the category is to act as a way-station, wherethe internal structure of an event is “frozen” on the way to being iterated or turnedinto a consequent state by the perfect. Arrows indicate permissible type-transitions,with annotations indicating the nature of the aspectual change. Some of these, likeiteration, are “free”, provided that the knowledge base supports the change. Others,like the transition to a consequent state (constate) or a progressive state (progstate),can only occur under the influence of a particular lexical item or construction, such asthe perfect or the progressive. Such restrictions are indicated by bold-face annotations.
Figure 21.1 A scheme of aspectual coercion (adapted from Moens and Steedman, 1988).

“25-ch21-0925-0970-9780444537263” — 2010/11/29 — 21:08 — page 932 — #8
932 Handbook of Logic and Language
Figure 21.2 The event nucleus (adapted from Moens and Steedman, 1988).
A more extensive system of coercions and lexically-based restrictions has been devel-oped by Pustejovsky (1991).
Whether free or lexically determined, these type-changes appear to reflect a know-ledge representation in which events of all kinds are associated with a preparation,preparation or activity that brings the event about, and a consequent, or ensuingstate, in a tripartite data-structure proposed by Moens (1987) that can be viewed asin Figure 21.2. This structure, or “nucleus” can be regarded as composed of the typesdescribed in Figure 21.1. Thus the preparation is an activity, the consequent is the samekind of state that the perfect gives rise to, while the event itself is an achievement. (Thenucleus itself is therefore closely related to the category of accomplishments.) Eachof these components may itself be compound. Thus the preparation may be an itera-tion of some kind, the consequent state may identify a chain of consequences, and thecore event may itself be a complex event, such as an accomplishment. The tripartitenucleus has been adopted and used extensively in the DRT theory of Aktionsarten ofKamp and Reyle (1993, pp. 557–570 et seq.) – cf. the chapter by Kamp in the presentvolume, Blackburn, Gardent and De Rijke (1993), and Gagnon and Lapalme (1995).
21.2.2 Logical and Computational Approaches
So much for the natural history of temporal ontology: how do we formalize this quitecomplex ontology? Simplifying somewhat, two basic approaches can be distinguishedin this voluminous literature.
The first approach is to attempt to define the neo-Vendlerian ontology via quan-tification over more or less classical Priorian instants, or their dual, intervals. Bennettand Partee (1972), Taylor (1977), Cresswell (1974), Dowty (1979), Heinämäki (1974),Bach (1980), Galton (1984), and the computational work of McDermott (1982), Allen(1984), Crouch and Pulman (1993), and McCarty (1994) are of this kind.
This approach was extremely important in opening up the territory to include tem-porally extended events, which had largely been ignored in the situation calculusand modal-logic based approaches (see the discussion below). However, the recur-sive structure of events that follows from the ontology illustrated in Figure 21.1, andin particular the problems of granularity and non-continuity in iterated events, meanthat some of the definitions of for-adverbials and related categories in Dowty’s treat-ment can be criticized, as he himself has pointed out (Dowty, 1979, preface to secondedition).
The second approach is to take certain types of events themselves as primitive,without any appeal to notions like truth of a predicate over an interval or set of instants.Such events involve a temporal extension, which for connected continuous events is an

“25-ch21-0925-0970-9780444537263” — 2010/11/29 — 21:08 — page 933 — #9
Temporality 933
interval (or equivalently a pair of points, but modifiers like “slowly” are predicationsof the event rather than the interval that it occupies. This then opens up the furtherpossibility of defining relations between event-sorts in terms of various lattices andsort hierarchies. The algebraic event-based approach was pioneered by Kamp (1979),Kamp and Rohrer (1983), and characterizes the work of Bach (1986), Link (1987),Hinrichs (1985, 1986), Ter Meulen (1984, 1986), Dowty (1986), Krifka (1990), Eberle(1990) and White (1993, 1994), and builds upon Carlson’s (1977), Link (1983) andLandman’s (1991) accounts of the ontology of entities. The work of Davidson, asdeveloped in Parsons (1990), and of Jackendoff (1991) as formalized by Zwarts andVerkuyl (1994), can also be seen as belonging to this school.
The latter approach can be seen as a logical continuation of the earlier work,for Dowty (1979) had observed the parallel between the telic/atelic distinction inthe event domain, and the count/mass distinction in the entity domain. Not only isthe downward-entailing property characteristic of both activities and mass terms: theinvolvement of mass or count terms as arguments can also determine the event type ofa proposition, as in the following minimal pair.
(17) a. Chapman drank beer (for an hour/#in an hour).b. Chapman drank two pints of beer (#for an hour/in an hour).
The technicalities involved in these different accounts are considerable, and some-what orthogonal to the main concerns of the chapter. We will pass over them here,referring the interested reader to the chapter in the present volume by Pelletier fortechnical background, and to White (1994, Chapter 2) for a recent comprehensivereview and one of the few extensive computational implementations of a system ofthis kind.
21.3 Temporal Relations
21.3.1 Basic Phenomena and Descriptive Frameworks
Having established an ontology, or taxonomy of temporal types, we turn to therelational apparatus. The linguistic system that conveys temporal relations betweenindividuals of these different sorts comprises in English the subsystems of tense, (pro-gressive and perfect) aspect (which we have so far only treated in terms of their effectupon ontological type), and modality.
21.3.1.1 Tense
The most fundamental of these systems is tense. In the case of tense, as in the caseof propositional aspect or Aktionsart, there is one early modern piece of insightfuldescriptive work which most theories build upon, and which those who ignore seemdoomed to reconstruct. This work is contained in two short and highly elliptical sec-tions in Reichenbach’s Elements of Symbolic Logic (1947, Chapter VII, Sections 48and 51). (Again there are direct precedents in work by Jespersen and Cassirer.)

“25-ch21-0925-0970-9780444537263” — 2010/11/29 — 21:08 — page 934 — #10
934 Handbook of Logic and Language
Reichenbach can be read as making two points about temporal expressions. Thefirst is that there is a referential or extensional relation between propositions and factsor events, expressible by the inclusion of events or times as values of bound variables.This observation is the direct antecedent of Davidson’s theory (cf. Davidson, 1967,pp. 115–116) and much subsequent work in formal semantics (cf. Parsons, 1990, p. 5),and is less directly related to the situation calculus of McCarthy and Hayes (1969,cf. pp. 498–500) and much subsequent work in artificial intelligence and computerscience, discussed below.
Reichenbach’s second point is more specifically linguistic. He argued that the tensesystem could be understood as a predication not over two times, “now” and “then”,but rather over three underlying times. These times he called S (speech point), R (ref-erence point), and E (event point). E can be thought of as the temporal extension of theproposition itself – essentially the Davidsonian e, or its modern equivalent, generali-zed to cope with the kind of ontological questions that concerned us in the last section,as for example in work discussed earlier by Parsons (1990) and Schein (1993). S can,as its name suggests, be thought of as the speaker’s time of utterance (although weshall see that it must be generalized to cover embedded times of utterance and nar-rative point-of-view). Reichenbach’s real innovation was the reference point, whichcan be identified with the notion “the time (or situation, or context) that we are talkingabout”. It is easiest to convey the idea by example. Reichenbach offers the diagramsin Figure 21.3, in which the arrow indicates the flow of time, to show the distinctionsbetween the past perfect, the simple past (or preterit) and the present perfect (all ofwhich he includes under the heading of “tenses of verbs”). The important insight hereis that the simple past is used to make a statement about a past time, whereas the per-fect is used to make a statement about the present, as was noted earlier in connectionwith the “present relevance” property of examples like (1).
As Isard and Longuet-Higgins (1973) have pointed out, this claim is consistent withthe observation that past tense, unlike the perfect, demands that the past referencepoint be explicitly established, either by a modifier, such as a when clause, or bythe preceding discourse. Thus (18)a, below, is inappropriate as the first utterance ofa discourse, except to the extent that the reader accommodates a temporal referent,in Lewis’ (1979) sense of that term – that is, introduces an appropriate individualin the database, as one often must at the beginning of a modern novel. But (18)b isappropriate, on the assumption that the hearer can identify the time in the when clause:
Figure 21.3 Past vs. Perfect (from Reichenbach, 1947).

“25-ch21-0925-0970-9780444537263” — 2010/11/29 — 21:08 — page 935 — #11
Temporality 935
(18) a. # Chapman breathed a sigh of relief.b. When Nixon was elected, Chapman breathed a sigh of relief.
(In many North American dialects of English, the past tense does double duty for theperfect. I am assuming that this reading is excluded in this case by the most readilyaccessible aspectual category of breathing a sigh of relief .)
The fact that the discourse can establish the “anchor” for the reference point has leda number of authors, including McCawley (1971), Partee (1973, 1984), Isard (1974),Bäuerle (1979), Hinrichs (1985), Webber (1988), Song and Cohen (1988), Abusch(in press), and others to identify tense, and by implication R, as “pronominal” or oth-erwise anaphoric in character.
We should distinguish this referent-setting function of such adverbials from theaspect-setting function that we encountered in Section 2, concerning Aktionsarten.The adverbials like in fifteen minutes and for fifteen minutes were there predicatedover the event point E. In the cases to hand, they are predicated over R. Many of theadverbials that relate two propositions temporally, particularly when clauses, do so byidentifying or predicating a relation over the reference points of the two clauses, viawhat Reichenbach called the “positional use of the reference point”. The following areall cases of this kind.
(19) a. In ten minutes, I looked at my watch.b. When Chapman arrived, the band was playing Nice Work If You Can Get It.c. After Einstein arrived in Princeton, he may have visited Philadelphia.
We return to the anaphoric role of tense in a later section.With the benefit of the discussion in the earlier sections, we can go a little further
than Reichenbach, and say that the predication which the perfect makes about thereference point, present or past, is that the consequent state that is contingent upon thepropositional referent E holds at the reference point R.
Reichenbach extended his account of tense and the perfect to the progressives andfuturates, including habituals, and to sequence of tenses in compound sentences. Someof the details of his original presentation are unclear or incorrect. For example, theexact relation of E and R in the past progressive is unclear, possibly because of a typo-graphical error. The account of the futurates does not correctly separate the respectivecontributions of tense and modality. The account of sequence of tense in compoundsentences omits any discussion of examples with subordinate complements requiringmore than one S and/or R, such as He will think that he has won. He similarly seems tohave failed to notice that there is a second “narrative” pluperfect, involving an embed-ded past tense, relative to a past speech point, distinct from the true past perfect. It isthe only realization that English affords for the past tense of indirect speech, or oratioobliqua, exemplified in examples like the following:
(20) I had arrived in Vermilion Sands three months earlier. A retired pilot, I waspainfully coming to terms with a broken leg and the prospect of never flyingagain. ...

“25-ch21-0925-0970-9780444537263” — 2010/11/29 — 21:08 — page 936 — #12
936 Handbook of Logic and Language
This pluperfect cannot be the past tense of a perfect, as perfects like # I have arrivedin Vermilion Sands three months ago are infelicitous (for reasons discussed by Moensand the present author (1988)). It is rather a past tense of a past tense, identifyingthe proposition I arrived in Vermilion Sands three months before now as uttered by anarrator with their own now. (Most of Reichenbach’s own examples of the pluperfectare in fact of this other kind.)
For these and other reasons the following account is something of a reconstructionof Reichenbach’s theory. (See Caenepeel, 1989; Enç, 1981, 1987; Hornstein, 1977,1990; Kamp and Rohrer, 1983; Smith, 1991, Chapter 5; and Crouch and Pulman,1993 for related proposals. See also the discussions of Kamp and Reyle, 1993; andLascarides and Asher, 1993b, below.)
According to this view, English and presumably other languages can be seen ashaving three tenses in the narrow sense of the term – the familiar past, present, andfuture tenses, in all of which the Reference point R and the event point E coincide. Thepast tense is, as we have seen, one in which the pair R, E precedes S. The present tense(which we noted earlier is in English restricted as far as events go to performative actslike naming and promising) is one in which all three coincide. The true future tense inEnglish (as opposed to other languages) is realized by the syntactic present tense, asin I go to London (next Tuesday) and is symmetric to the past tense, with the pair R, Elater than S, as in Figure 21.4 (cf. Hornstein, 1977, 1990). Here I depart from Reichen-bach himself, and Bennett and Partee (1972), who regarded the future as not merelythe mirror image of the past tense, but as combining the characteristics of a tense and afuturates aspect, mirroring the perfect. Smith (1991, p. 246) also regards what is herecalled the simple future as having a present reference point. Nevertheless, the claimthat it is a pure tense, with R co-temporal with E, is supported by the observation thatthe futurate is anaphoric, like the past, with exactly the same need for an “anchored”reference point. Hence (21)a, below, is inappropriate when discourse-initial, whereasthe anchored (21)b is fine (cf. (18)):
(21) a. # Harry moves to Philadelphia.b. Next Tuesday, Harry moves to Philadelphia.
The modal future, I shall go should be understood as identical to the simple futureas far as Reichenbach’s underlying times are concerned, with the modal itself con-tributing meaning of a quite orthogonal kind, which we shall discuss in a separatesection below.
The ontology of events discussed in the previous section should be viewed as anontology of the Reichenbachian E, so that the past and (simple or modal) future tenses
Figure 21.4 The tenses.

“25-ch21-0925-0970-9780444537263” — 2010/11/29 — 21:08 — page 937 — #13
Temporality 937
Figure 21.5 The tenses for composite events.
Figure 21.6 The narrative tenses.
can be applied to durative or composite events, as in Figure 21.5. (On the assumptionthat the performative achievement performed in saying “I name this ship the PrimeDirective” lasts at least as long as the utterance, the present too can be regarded ashaving an extended R.) With the simple tenses, as opposed to the sentential aspectsconsidered below, the reference point R continues to be coextensive with E for durativeor composite events.
The reference point R itself is nevertheless distinct from E, and not a part of thisontology. Davidsonians accordingly distinguish it from the Davidsonian e (Parsons,1990, p. 209, uses I for essentially this purpose in discussing tenses and temporaladverbials).
We noted earlier that past tense has a second meaning in English that is predicatedof propositions in which the speaker’s reference point R coincides with an epistemicpoint of view S! that is not the same as the speaker’s present S, in the novellisticdevice of oratio obliqua. The syntactic past and pluperfect in the earlier example (20)are therefore represented by the diagram in Figure 21.6. This analysis is related to oneproposed by Kamp and Rohrer (1983) (cf. Kamp and Reyle, 1993, p. 593), and byHwang and Schubert (1992), all of whom postulate multiple reference points to copewith related observations. The present account differs only in preserving Reichen-bach’s insight that for each reference point R there is an S.
The existence of these narrative or quotational tenses in English may explain thephenomenon of “sequence of tense”, in which complements of tensed verbs likesaid and thought tend to “inherit” the tense of the matrix verb. As Hornstein (1990,Chapter 4) points out, this phenomenon is naturally captured in a Reichenbachianframework by similarly assuming that each tensed clause has its own S, R, E triple.The embedded S!, which is naturally thought of as an embedded utterance point, or(more generally) an embedded epistemic point of view, is then coincident with thematrix event E, the event of utterance or epistemic consciousness. However, in the

“25-ch21-0925-0970-9780444537263” — 2010/11/29 — 21:08 — page 938 — #14
938 Handbook of Logic and Language
grammar of English, embedded clauses are specified to be semantically like quotedpresent tensed utterances, with past tense denoting the structures in Figure 21.6. S andR in these relational structures then coincide with S and R in the matrix clause. Thus aand b, below, mean that Chapman said something like “I arrived in Vermillion Sandsthree months ago”, and “I am painfully coming to terms with a broken leg”, just likethe narrator in the following examples:
(22) a. Chapman said that he had arrived in Vermillion Sands three months earlier.b. Chapman said that he was painfully coming to terms with a broken leg.
The fact that English complement verbs specify only quotational complements is whatmakes English a relatively strict “sequence of tense (SOT) language”. However, thisis a syntactic convention, rather than a semantic necessity, and other languages (suchas ancient and modern Greek) may allow (or insist upon) the basic tenses in thesecontexts.
One further remark about quotational and complement pluperfects is in order. Theyare in fact ambiguous in English, since besides the narrative pluperfect illustrated inFigure 21.6a, they may denote the narrative past of a perfect, obtained by replacingthe progressive state in (22)b by a perfect, or consequent, state, as in the followingvariant:
(23) Chapman said that he had just broken his leg.
Such an account of sequence of tense phenomena is essentially equivalent to theaccounts of Enç (1981) and Dowty (1982), who invoke related notions of “anchoring”.
We shall return later to the fact that past tense is also used in English to markcounterfactuality of the core proposition with respect to the reference point, as in thefollowing conditional sentence.
(24) If he were taller, he could reach the book himself.
(Some languages have a distinct subjunctive mood for this purpose. English retainsa distinct subjunctive in the first person of the copular verb be.) When the referencepoint itself is past, this means that counterfactuals also surface as pluperfects. Weshall have more to say about the counterfactual relation of E to R below. However, asfar as purely temporal relations go, their temporal profile is the same a past tense, asin Figure 21.7. Because of this multiplicity of functions of English past tense, Isard(1974) and Lyons (1977) suggest that syntactic past tense should be identified with anon-temporal semantic primitive REMOTE, rather than a time as such.
21.3.1.2 The Perfect and the Progressive
With the tensesperfect and progressive established as in Figure 21.4, we can see thatthe perfect and the progressive (both of which we saw earlier to be states, rather thanevents) compose correctly with tense, as in Figures 21.8 and 21.9. In the case of theformer, the reference point R lies within a Consequent State, derived from the original

“25-ch21-0925-0970-9780444537263” — 2010/11/29 — 21:08 — page 939 — #15
Temporality 939
Figure 21.7 The counterfactual pluperfect.
Figure 21.8 The perfect.
Figure 21.9 The progressive.
event E, which must in the terminology of Section 1 be an achievement. In the case ofthe progressives, R lies within a Progressive State, derived from the original event E,which must in the terminology of Section 1 be an activity. In neither case does E in thesense of the event directly figure in the representation. It is the (progressive or conse-quent) state derived from the event E, here indicated by hashing, that is predicated ofR. Unlike the tenses with E, R is not coextensive in temporal terms with such states,but temporally included within them. The position of the event E relative to S and R isnot in fact fully determined by the perfect and the progressive – hence its appearancein brackets in the figures. This becomes important in the case of the future perfect, inwhich the relation of E to S may be either prior or posterior. (Here we depart slightlyfrom standard Reichenbachian accounts such as Hornstein (1990).)
Both in the tenses and the aspects the core event E may be derived from a differentevent category E!, via type coercion. For example, the achievement of winning therace can turn into a corresponding accomplishment, by the knowledge-based associa-tion of a characteristic preparatory activity, such as running. The progressive can thenstrip off the original achievement, to leave the bare activity, which is then mapped

“25-ch21-0925-0970-9780444537263” — 2010/11/29 — 21:08 — page 940 — #16
940 Handbook of Logic and Language
Figure 21.10 The futurate progressive.
onto the corresponding state, which is predicated of R, the time under discussion. Thisexplains the possibility of “futurate” progressives like a, below:
(25) a. I am winning!b. I was winning.
As Smith (1991, p. 247) reminds us, (25)a is not really a predication about winning.It is simply a present progressive of an activity culminating in winning, which inReichenbachian terms looks like Figure 21.10. Since E, the original achievement ofwinning, is not predicated of any underlying time, we seem to be even closer to aresolution of the imperfective paradox, which applies to both present (including futu-rate), and past, progressives. However, to get to that point we must consider the thirdtemporal-relational system, that of modality.
21.3.1.3 Epistemic and Deontic Modality
The modal verbs of English, such as will, must, and may, like those of many otherlanguages, carry two distinct senses. The first concerns such notions of necessity, pos-sibility, inferability, or predictability of the core proposition, and is usually referred toas “epistemic” modality. The following are some examples for which this is the onlyreadily accessible interpretation:
(26) a. It must have died.b. That will be the mailman.c. She may be weary.
The other set of senses concerns notions like feasibility and permissibility of the coreproposition, and ability and obligation of the agent, and is usually referred to as “deon-tic” modality. Some relatively unambiguous examples are the following:
(27) a. You must sit down.b. You may smoke.c. I can do the Boogaloo.
While the pairs of senses subsumed under a verb like must are clearly related, therelation is indirect and appears to be somewhat arbitrarily conventionalized. Whilemany of the deontic modals can be viewed as creating or explaining the correspon-ding epistemic state, there are a number of complications and lacunæ in the system

“25-ch21-0925-0970-9780444537263” — 2010/11/29 — 21:08 — page 941 — #17
Temporality 941
as a whole. For present purposes we shall consider the deontic modals as essentiallydistinct from the epistemic modals.
Because of their involvement with necessity and possibility, the epistemic modalsdiffer from the systems of tense and sentential aspect in requiring us to consider morethan one domain of reference or classical model. It was possible to capture the seman-tics of Aktionsart, tense, and sentential aspect in terms of a single deterministic worldhistory, represented informally as a time-line in Reichenbach’s diagrams. Instead wemust think of the flow of time as a tree, so that any particular history (such as that ofthe real physical universe) becomes a path of branching points in a discrete graph ofstates, each of which gives rise to alternative continuations, which themselves branchinto alternatives. Such a tree can be pictured as in Figure 21.11. We use bold lines andstates to indicate the states and transitions of actual time. It should be noted that thisrepresentation does not distinguish the future history from the past in this respect. Thisreflects the fact that the simple future tense, which in English we have seen is realizedas the present, treats the future as determinate. Of course, in actual fact, our access topast history is different in kind to our access to the future. There is a privileged set ofpast states which are distinguished as the actual history of the world, and we can onlymake more or less well-informed guesses about which states will turn out to be actualin future. We shall return to the consequences of this observation in the later sectionon modality.
We shall see below that this structure is closely related to the modal logician’snotion of an accessibility relation over possible worlds (although the logicians fre-quently regard such “worlds” as including entire histories – that is, of comprisingmany states). It will be important to ask then how states should be represented, andwhat defines this relation. (For the present purpose, as in other computational appli-cations of modal logic (cf. Goldblatt, 1992), the accessibility relation is the centralconstruct in a modal logic.) However it is important first to see that the modal verbs,seen as predications over the elements in such structures, are straightforwardly com-patible with the Reichenbachian view of tense and modality.
First, we must be clear that such structures are different from the continuous tem-poral dimension that is implicit in the earlier figures. We must now think of time asa (partial) ordering on discrete states corresponding to instants at which changes to amodel occur (or can occur).
Figure 21.11 Modal temporal structure.

“25-ch21-0925-0970-9780444537263” — 2010/11/29 — 21:08 — page 942 — #18
942 Handbook of Logic and Language
We could in principle think of such states as densely packed, mapping to the realnumbers. When modal logics of the kind discussed below have been used to modelphysical time according to the special theory of relativity, they have represented timein this way – cf. Van Benthem (1983), Goldblatt (1980). (The latter achieves the tourde force of axiomatizing the Minkowski chronsynclastic infundibulum as a modallogic – see Van Benthem (1995) for discussion.) However, for linguistic and computa-tional purposes, we shall invariably be interested in much sparser temporal structures.Sometimes (particularly when thinking about the theory of digital computation) statesin these structures correspond to the cycles of a clock – that is, to the integers ratherthan the reals. In linguistics and related AI tasks like planning, we may be concernedwith even sparser representations, in which only changes of state are represented.
We will continue to defer the discussion of how this is to be done formally. We maynote however that in the latter case, transitions between points in the structure 21.11are naturally associated with events that precipitate those changes. For example, thiswould be a natural way of representing the history of a board game of simple moveslike W:P-K4, as Isard (1974) does. We shall see later how to generalize this represen-tation to durative or composite events.
The Reichenbachian underlying times S and R can provisionally be identified withpoints in this structure, which will now support modality in the following way (againwe go beyond anything specifically claimed by Reichenbach here).
We saw in earlier sections that the possibility of present epistemic modal statementslike (28)a, below, is most naturally captured by assuming that the models or databasesrepresenting nodes in the structure specify partial information about worlds. A similarproposal has frequently been made for more standard model-theoretic semantics – cf.Hintikka (1962), Kripke (1965), Van Fraassen (1971), Kratzer (1977), Turner (1981),Veltman (1983), Cresswell (1985, Chapter 5; 1988), and Landman (1986). It is alsocentral to the notions of Discourse Representation Structure in DRT and of “situation”in situation semantics – see Kamp and Reyle (1993), Barwise and Perry (1983), andCooper (1986).
This observation can be extended to the domain of relations when we observethat modals and conditionals are essentially predications about R. In (28)a, below, themodal is predicated about a present R. Example (28)b is predicated of an R in the past.
(28) a. She may be weary.b. Einstein may have visited Philadelphia.
(Being infinitival, this past shows up as a perfect. However it is clear that we aredealing with the modalization of the past reference point, rather than of a presentperfect, because the corresponding declarative perfect, below, is pragmaticallyanomalous, for reasons discussed in Section 1.
(29) # Einstein has visited Philadelphia.
So the predication must be over R.)Such “modal pasts” do in general require the reference point to be previously estab-
lished or accommodatable. This can be seen in the fact that they are compatible with

“25-ch21-0925-0970-9780444537263” — 2010/11/29 — 21:08 — page 943 — #19
Temporality 943
temporal adverbials like yesterday, which present perfects in general are not, as wehave noted:
(30) a. She must have visited Philadelphia yesterday.b. # She has visited Philadelphia yesterday.
One way to capture the above facts is in terms of the assumption that R is a partialmodel or database of the kind discussed above. Modals like may assert that the refer-ence point in question is consistent with extension by the core proposition. Modals likemust assert that the reference point in question implicates the core proposition undersome argument or line of reasoning, as proposed by Kratzer (1991) and Stone (1994).
All of the above examples involve modal predications over states of one kind oranother. To capture the meaning of epistemic modal predications over events, as in thefollowing example, we must generalize the above apparatus.
(31) (If you take my queen), you may win the game.
This implies that the reference point must include or give access to the entire acces-sible subtree of futures after the core event. This suggests that the reference point ismore like the nucleus of Figure 21.2 than like a situation or a time. We shall return tothis point below.
I have already argued that in connection with the non-modal future tense thatEnglish and other languages treat the future part of the structure in Figure 21.11 sym-metrically with the past, as having a determined set of states constituting actual futurehistory. Of course, our information about future actuality is in fact limited, and ourknowledge merely probabilistic. Because of this practical fact of human existence, themost common kinds of statement about the future are modal, so it is not too surprisingthat the modal system is in English somewhat confounded with the future componentof the tense system. Nevertheless, in sentences like the following, we should clearlydistinguish the contribution of the modal in (32)a, below, from the fact that it is predi-cated of a future reference point, as has been pointed out by Boyd and Thorne (1969)in connexion with examples like (32)b, below, where the same modal is predicated ofa present reference point:
(32) a. You will marry a tall dark stranger.b. It’s late. Your mother will be worried about you.
(This point was also a subject of lively debate among 19th century linguists, as Verkuyl(1989) has shown.)
21.3.1.4 Counterfactuals
The system of linguistic modality is closely related to that of counterfactuality in con-ditionals, which in English is marked by past tense, and which will turn out to becentral to the resolution of the imperfective paradox.
In order to capture the meaning of counterfactual implication, and hence causation,Lewis suggested that the meaning of counterfactuals in sentences like the following

“25-ch21-0925-0970-9780444537263” — 2010/11/29 — 21:08 — page 944 — #20
944 Handbook of Logic and Language
depends on the notion of similarity between possible worlds in a modal structure likeFigure 21.11.
(33) If you had taken my queen, you would have won the game.
The proposal was that P (your taking my queen) in the situation W under discussioncounterfactually implies Q (your winning the game) (written P""Q) if among all theworlds accessible from W satisfying P, all the ones that are most similar to W alsosatisfy Q. (It should be observed here that “worlds” are entire world histories, not thetransitional states of the situation calculus.)
This works well for the example to hand, because the only counterfactual worldis the one that results from your taking the queen instead of making the move youactually made. By definition it is the most similar counterfactual world, so providedall continuations of the game result in your winning the game, the claim is true.
However, as Fine (1975) pointed out, not all actions are like this. His example wasthe following:
(34) If Nixon had pushed the button, there would have been a nuclear war.
This statement might well be true, despite the fact that worlds in which that leastmonotonic of presidents pressed the button, but war did not ensue, seem to be moresimilar to the actual world, on the reasonable assumption that nuclear war changesjust about everything. Thomason and Gupta (1980) point out that Lewis’ account iscompatible with an alternative notion of closeness over worlds, defined in terms ofcausality, a suggestion that we shall return to below, in discussing the situation calculusof McCarthy and Hayes, and its extensions.
The problems of modality and counterfactuality are closely related to the imper-fective paradox, which will be recalled as arising from the existence of occasions ofwhich it can be claimed that Keats was crossing the road, in spite of the fact that he washit by a truck before the action could be completed. The problem for possible worldssemantics is precisely the same as the problem of counterfactuals, namely to specifythe worlds which are most similar to the actual one, differing only in relevant respects.To specify this in terms of worlds themselves is very difficult: as Vlach (1981) pointedout, there are a great many world-histories that differ in minor respects from the actualone, but where Keats is still hit by the truck. As Landman (1992) has pointed out,there are cases of world-histories which differ from the actual world only in that Keatsis not hit by the truck, but in which Keats would nevertheless not have succeeded incrossing the road – as when there is a second equally inattentive truck right behind.Even if there were an infinite number of such trucks, requiring an infinitely differentworld for Keats to succeed, it still seems true that Keats was crossing the street if thatis what he intended, and if our knowledge of the world supports no other obstacle tothe causal realization of that intention. Even more strikingly (to adapt another of Land-man’s examples), it seems not to be true in any of these situations to make this claimif Keats did not have that intention, or if there is some other obstacle to its realization.If he knew perfectly well that he could not possibly get to the other side, and set outwith suicidal intentions, or if he intended to turn around just short of the opposite kerb

“25-ch21-0925-0970-9780444537263” — 2010/11/29 — 21:08 — page 945 — #21
Temporality 945
and come back again, or if he fully intended to cross but was unaware of a glass wallin the middle of the road, then the claim is false. Yet, apart from the intention itself,and its consequences for Keats’ projected future actions, the counterfactual worlds areall identical.
Because of these difficulties, most theories of the progressive have invoked a func-tion mapping possible states onto relevant continuations. Dowty (1979, p. 148) “reluc-tantly” assumed a primitive function Inr, mapping world-time indices onto “inertiaworlds”. Landman (1992) defines a function C which maps an event e and a worldindex onto their “continuation branch”, invoking a primitive function R which mapssuch pairs onto event-indexed inertia worlds or “reasonable options”. Some relatedideas have been invoked within the DRT camp (cf. Roberts, 1989).
However, both Inr and R are unanalysed, and the involvement of intention makes itseem unlikely that there could be any definition other than one in terms of an action-based accessibility relation.
21.3.2 Logical and Computational Approaches
So much for the natural history of temporal relations: how do we formalize them? Weshould at this point distinguish two kinds of question that are somewhat confoundedin the computational literature. One is the use of abstract computations to do the samejob as a traditional model theoretic semantics. The other is the efficient implementa-tion of such a semantics, to minimize costs such as search. In this section, we shall firstdevelop a Kripke-like semantics including a representation of states and the accessibil-ity relation. We shall then consider an efficient representation of this semantics, whichbuilds in certain “inertial” properties of the world as it is conceptualized by humanbeings, via a constrained use of defaults. Finally we shall consider a reformulation ofthis system in terms of dynamic logic.
We noted a resemblance between the structures like Figure 21.11 and the notion ofa frame in the standard semantics of Kripke (1972) for a modal logic. A frame is astructure defined in terms of a set of worlds or states W and an accessibility relation "
over them. For the present purpose, the worlds or states can be thought of as classicalmodels of the kind used in first-order predicate calculus (that is, sets of individualsand relations, possibly typed or sorted), except that we shall assume that states whichhappen to have the same individuals and relations may nevertheless be distinct. Onecan then define "p (“necessarily p”), to mean that p necessarily holds in a state s # W,just in case p hold in every state accessible from s. Similarly, $p, (“possibly p”), canbe defined to hold in s if p holds in at least one state accessible from s under ". In mostmodal logics, these operators are duals, interdefinable via negation.
Possible worlds are generally assumed by modal logicians to include entirehistories of the universe of discourse through many different states. However, thisassumption is based on a view of time that is not the one pursued here, and for presentpurposes it is more useful to identify the elements under the accessibility relation withsingle states, as the computer scientists tend to. The accessibility relation can be anyrelation whatsoever, but for present purposes it is appropriate to think of it as definingthe ways in which one state of the world can lawfully turn into others.

“25-ch21-0925-0970-9780444537263” — 2010/11/29 — 21:08 — page 946 — #22
946 Handbook of Logic and Language
In taking advantage of this affinity between the linguistic phenomena and modallogic, we must be careful to avoid being distracted by two related concerns that havegreatly occupied modal logicians. One is an interest in distinguishing between nec-essary propositions, such as theorems of arithmetic, and contingent ones, such as thefact that this sentence happens to have been written at 5.25 p.m on an October evening.This notion is naturally captured in a logic in which the accessibility relation is reflex-ive, transitive, and symmetric – that is, an equivalence relation under which all worldsin W are accessible to all others. (This is the modal logic known as S5.) However,this distinction may not be particularly relevant to everyday reasoning, which typi-cally concerns an uncertain world. It does not appear to be reflected in the linguisticontology.
The second is the representation of physicists’ notions of time and causality. Themere fact that quantum theory discusses processes which reverse the arrow of time andcausality does not entail that a theory of the knowledge involved in linguistic seman-tics should do the same. The logics we shall consider have an accessibility relationwhich is asymmetric, reflecting the directionality of the flow of time and causality.(They are therefore somewhat more like the modal logic known as S4, although infact their accessibility relation will turn out to be more restricted still.)
21.3.2.1 The Situation/event Calculus
While modal logics offer an elegantly terse notation for quantifying over states ormodels, many of them, probably including all those of interest for linguistic purposes,can be simulated in entirely first-order terms, via the technique of “reification”, whichtakes possible states themselves to be individuals that can be quantified over, repre-sented either by constants ti, tj etc, or by more complex terms.
One such reified modal logic is the “situation calculus” of McCarthy and Hayes(1969). This system was developed within a computational framework for reasoningabout actions, and is interesting from the point of view of our earlier assumption thatthe linguistic categories need to be based in a theory of action rather than of time.One of the most useful and attractive features of the situation calculus was the useof terms like result(arrive(person), s) as individuals denoting situations or states asfunctions of other situations. Functions like result were called situational fluents byMcCarthy and Hayes. Such terms can be used in rules like the following to transpar-ently capture the notion that a person is present in the situation that results from theirarriving:
(35) %s, %person, present(person, result(arrive(person), s))
This particular logic (which is, as McCarthy and Hayes point out, quite closelyrelated to von Wright’s (1964, 1967) “logic of action”) embodies only the mostminimal ontology of states (represented by predicates that hold over situations,such as present(person, s)) and atomic actions (represented by expressions likearrive(person)). We shall look in a moment at some descendants of the situationcalculus which attempt to include a richer ontology.

“25-ch21-0925-0970-9780444537263” — 2010/11/29 — 21:08 — page 947 — #23
Temporality 947
McCarthy and Hayes were interested in the use of such rules to construct plans ofaction, via inference. For example, given the following rules, one might expect to beable to infer a successful plan for bringing about a situation s in which three blockssatisfy the condition on(a, b, s) & on(b, c, s):
(36) a. clear(a, s0) & clear(b, s0) & clear(c, s0)
b. %x, %y, %s, clear(x, s) & clear(y, s) & x '= y" clear(x, result(puton(x, y, s)))
& ¬clear(y, result(puton(x, y, s)))& on(x, y, result(puton(x, y, s)))
The formulæ say, first, that everything is clear in a particular situation s0, and second,that if two distinct things x and y are clear in a situation s, then in the situation thatresults from putting x on y in that situation, x is on y, x is clear and y is no longerclear. (The rule embodies the idea that only one thing at a time can be manipulated, instipulating that y is no longer clear.)
Using standard inference rules of conjunction elimination, modus ponens, etc., wemight expect to be able to prove the following, in which the situational terms neatlydescribe the sequence of putting b on c, then putting a on b:
(37) on(a, b, result(puton(a, b, result(puton(b, c, s0)))))
& on(b, c, result(puton(a, b, result(puton(b, c, s0)))))
As yet, this doesn’t quite work. While we can prove the intermediate resulton(b, c, result(puton(b, c, s0))) (which looks useful) we cannot go on to prove thefirst conjunct, because the formulæ in (36) do not capture the fact that a remains clearafter putting b on c. Nor can we prove the second conjunct, because the same formulæfail to capture the fact that b remains on c after putting a on b.
McCarthy and Hayes point out that we can fix this by adding further “frameaxioms” to the effect that if u is on v in a situation s, then u is still on v in the sit-uation that results from putting something x on something y, so long as u is not thesame as x. Similarly, if u is clear in s, it is still clear after putting something x onsomething y, so long as u is not the same as y:
(38) a. %u, %x, %y, %s, clear(u, s) & u '= y " clear(u, result(puton(x, y, s)))b. %u, %v, %x, %y, %s, on(u, v, s) & u '= x " on(u, v, result(puton(x, y, s)))
The addition of these rules allows the proof (which is suggested as an exercise) toproceed to completion.
Such a system, whose affinities to von Wright’s logic of action we have alreadyremarked upon, seems to offer a very natural expression for states and the accessibilityrelation between them. However, as McCarthy and Hayes were aware, for computa-tional purposes, this logic seems cumbersome. If we want to represent a less trivialuniverse with more state predicates and more actions or action sequences, we shallneed a frame axiom pairing every predicate with every action. This exacerbates thesearch problem for the computational purposes that originally motivated the situationcalculus.

“25-ch21-0925-0970-9780444537263” — 2010/11/29 — 21:08 — page 948 — #24
948 Handbook of Logic and Language
It also somehow misses the point as a representation of action. The way we thinkof actions is precisely as local operations that affect just a few properties, leavingmost facts unchanged. There seems to be something wrong with a notation that wouldmake it no more inconvenient to define a highly distributed event which inverted thetruth value of every fact about the world. Even the action of dropping a hydrogenbomb doesn’t do that. McCarthy and Hayes christened this the “frame problem”, anddiscuss a number of possible solutions, including one which they attribute to Rescher(1964), which was to assume that all facts that held at the start of an action held in itsresult, and then to eliminate any inconsistencies via what would now be recognized asa “Truth Maintenance” system (De Kleer, 1984; Doyle, 1979). However, they did notin this early paper offer a definitive solution. The search for a solution has engenderedmuch research, not least their own (for example, McCarthy, 1977).
A solution that was related in spirit to Rescher’s was nevertheless at hand in workthat was being done contemporaneously in robot planning. The idea was to build intothe model itself the “inertial” property just identified. The simplest way to do thisis to specify actions in terms of the facts about the that world that become untrueand the new facts that become true when they occur. One computationally convenientway to do this is to represent the starting state of the world as a collection of facts,and to represent actions in terms of a triplet. Each such triplet consists of 1) a list ofpreconditions that must hold if the action is to apply in the current state, 2) deletionsor facts that become false in the state that results from the action, 3) additions or factsthat become true in that state. The history of an episode up to any given state canthen be determined from the current state and the sequence of actions that led to it.Any earlier state can be fully determined by running the sequence of additions anddeletions backwards to the relevant point.
It is not clear who first proposed this idea, because its transparent representationin terms of “assignment”, database “updates” and other computational side-effectsmakes it almost the first thing a computer scientist would think of as a representationfor action. It usually goes by the name of the “STRIPS solution” to the frame problem,because it was first made explicit in the context of a robot action planner by that name(Fikes and Nilsson, 1971).
It is also natural for this purpose to further economize by representing the stateof the world solely in terms of positive truths, and to represent the (generally muchlarger) set of negative facts via a “closed world assumption” (Reiter, 1978), accordingto which any fact that cannot be proved true is assumed by default to be false. (It shouldbe noted that this move demands that everything true be provable, if consistency is tobe maintained.)
21.3.2.2 A Declarative Solution
Although the STRIPS representation of actions was originally thought of in non-declarative terms, Kowalski (1979, circulated in 1974) showed it to be elegantlyrealizable in entirely declarative terms, via the introduction of the closed world

“25-ch21-0925-0970-9780444537263” — 2010/11/29 — 21:08 — page 949 — #25
Temporality 949
assumption and a more radical use of reification to simulate modal quantification. (SeeNilsson (1980, pp. 308–316) for a more extensive discussion of Kowalski’s proposal.)He proposed a predicate holds, which applies to a proposition, represented as a term,and a state. The earlier state (36)a can therefore be written as follows:
(39) holds(clear(a), s0) & holds(clear(b), s0) & holds(clear(c), s0)
The action of putting x on y can be represented as a STRIPS rule, as follows. Thepreconditions are defined by the following rule which says that if you can get at x andyou can get at y, the preconditions for putting x on y hold:
(40) holds(clear(x), s) & holds(clear(y), s) & (x '= y)" preconditions(puton(x, y), s)
(In this rule, and henceforth, we adopt a convention whereby universal quantificationover bound variables is left implicit.) The new facts that result from the action ofputting x on y can be defined as follows:
(41) a. holds(on(x, z), s) " holds(clear(z), result(puton(x, y), s))b. holds(on(x, y), result(puton(x, y), s))
Kowalski assumes negation as failure, and so avoids the need to state explicitly that yis no longer clear. This fact is implicit in the following frame axiom, which is the onlyframe axiom we need for the action of putting x on y. It says that any fact which holdsin s holds in the result of putting x on y in s except the fact that y is clear, and the factthat x was on something else z (if it was).
(42) holds(p, s) & (p '= clear(y)) & (p '= on(x, z))" holds(p, result(puton(x, y), s))
Note that there is an assumption implicit in the use of inequality (rather than arelated notion involving implication) that p is a term rather than a formula likegraspable(y) & on(x, y). This assumption is in effect a restriction to Horn logic, inwhich the consequent may not include conjunction, disjunction, implication or nega-tion, modulo the reification.
Kowalski’s proposal was followed by much work on tense using reified calculi(Allen, 1984; Kowalski and Sergot, 1986; McDermott, 1982). It was also closelyrelated to the notion of “circumscription of qualifications” – see McCarthy (1977,esp. p. 1040), and much other subsequent work, collected and reviewed in Ginsberg(1987). In particular, Reiter (1991) shows how the restricted frame axioms or “succes-sor state axioms” can be derived automatically. We can now define a predicate poss,closely related to the familiar modal operator $, over the set of possible states, via thefollowing rules, which say that the start state s0 is possible, and the result of an actionin a state is possible if its preconditions hold:
(43) a. poss(s0)
b. poss(s) & preconditions(action, s) " poss(result(action, s))

“25-ch21-0925-0970-9780444537263” — 2010/11/29 — 21:08 — page 950 — #26
950 Handbook of Logic and Language
The earlier goal of stacking a on b on c can now be realized as the goal of finding aconstructive proof for the following conjunction
(44) poss(s) & holds(on(a, b), s) & holds(on(b, c), s)
These rules can be very straightforwardly realized in Prolog, and can be made to yielda proof (although the search problem of finding such proofs automatically remainshard in general) in which
(45) s = result(puton(a, b), result(puton(b, c), s0))
This technique restores declarativity to the logic embodying the STRIPS solution.There is a sense in which – despite the involvement of the closed world assumption –it also restores monotonicity, for so long as we do not add new facts (like some previ-ously unsuspected object being present, or a familiar one having fallen off its support)or some new rule or frame axiom (say defining a new action or stating a new pre-condition on an old one) then we can regard negation-as-failure as merely efficientlyencoding classical negation.
Of course, in the real world we do learn new facts and rules, and we encounterexceptions to the closed world assumption of complete knowledge. These problemsare known in AI as the ramification problem (that is, that actions may have indefinitelymany unforeseen consequences that our default model does not and cannot predict)and the qualification problem (that actions may have indefinitely many preconditionsthat our default model does not and cannot anticipate). In many recent papers, theframe problem is assumed to include these further problems. However, if we are inpossession of an efficient default model which works reasonably well most of thetime, it may well be wiser to regard the problem of coping with new information asresiding outside the logic itself, in the truth-maintenance or “housekeeping” system.Rather than coping with ramification and qualification in the logic itself, we shouldthink in terms of a system of truth-maintaining transitions between entirely monotoniclogics.
Related techniques and their relation to ramification and qualification in a narrowersense of known or anticipated causal or contingent relations between events are fur-ther explored by Schubert (1990, 1994), and Reiter (1991, 1993). The Horn clauseform and closed world assumption of the present system offer some hope of computa-tional efficiency (cf. Levesque, 1988). (This is not of course to claim that it solves theexplosive search problem implicit in finding plans.)
The STRIPS version of the situation calculus, with one class of situational fluentand one class of state-predicate, did not embody any of the ontological richness dis-cussed in earlier sections. However, a number of systems subsequently generalizedthe situation calculus to deal with richer event ontologies. Allen (1984) was the first todo so, defining a number of reifying predicates of which the most basic were HOLDSand OCCURS, respectively relating properties and events to intervals. Events couldbe events proper, or processes, after the Vendler-like scheme of Mourelatos (1978),those events that in other systems are points or instants being represented as very

“25-ch21-0925-0970-9780444537263” — 2010/11/29 — 21:08 — page 951 — #27
Temporality 951
short intervals, unlike instants in the related extension of the situation calculus pro-posed by McDermott (1982), which introduced further temporal types such as “chron-icles”. Galton (1990) proposes an elegant revision of Allen’s theory in these respects,according to which Allen’s processes correspond to progressive states in the terms ofthe earlier sections. A number of causal and temporal predicates allowed events andtimes to be related in ways that permitted a treatment of phenomena such as inaction,propositional attitudes and interacting subgoals in plans. Steedman (1982) defines thedurative or composite event categories in terms of instants of starting, stopping and(in the case of accomplishments) culminating, using a STRIPS-like representation tohandle the related progressive states, which (like perfects, habituals etc.) are treated asinertial properties of intervening times. (A similar approach has recently been advo-cated by Lin (1995) and Lin and Reiter (1995).) All of these approaches are closelyrelated to the “event calculus” of Kowalski and Sergot (1986), itself a descendantof Kowalski’s earlier work on the situation calculus, although their own ontology ofevents was still more minimal than these other approaches.
If possible states are defined as databases of facts exploiting a closed world assump-tion, then the above definition of the accessibility relation in terms of actions is essen-tially identical to the branching modal frame identified in Figure 21.11 in the lastsection. We noted there that in order to capture linguistic modality we seemed to needpartial, or underspecified, states.
The accessibility relation in question is (in a sense) transitive, but it is asymmetric(and therefore irreflexive) – that is, a partial order. This relation defines an even weakerlogic than S4, which has a transitive and antisymmetric accessibility relation.
We have already noted the similarity to the system of von Wright (1967). The statesin this structure are counterfactual in the sense that the actions or action sequencesthat take the place of situational fluents, generating the successors of any given state,are disjunctive, and only one of them can correspond to the actual history of events.In this respect, our system has some affinities to proposals by Stalnaker (1968, 1984),Thomason (1970), and Lewis (1971, 1973a), and the related computational work ofGinsberg (1986). However, the definition of accessibility and counterfactuality interms of events rather than states avoids the problem with some of these accounts thatwas noted earlier in connection with Fine’s example (34), repeated here:
(46) If Nixon had pushed the button, there would have been a nuclear war.
According to the event-based system, there is exactly one counterfactual world inwhich Nixon pressed the button, rather than doing whatever else he did, and itsaccessibility is defined by the action itself. (Cf. Stalnaker, 1984, Chapter 7, esp.pp. 133–134.)
Such a system similarly resolves the imperfective paradox. We noted earlier that Inrand R were unanalysed in the systems of Dowty and Landman. However, in the presentsystem they can be identified with the event-based accessibility relation proposed here.Since that appears to be the only accessibility relation that we need, the event-basedaccount appears to have an advantage. In fact, to make the identification of these

“25-ch21-0925-0970-9780444537263” — 2010/11/29 — 21:08 — page 952 — #28
952 Handbook of Logic and Language
inertial functions with the accessibility relation itself seems to be a very natural movewithin all of these theories, particularly in view of the close relation in other respectsthat Dowty notes between his theory and the logic of action. (Cf. Dowty, 1979, p. 144.)Thomason (1991, p. 555) also notes the close relation between inertia worlds and thesituation calculus, and suggests a rather different analysis in terms of defaults in anon-monotonic logic.
This is not of course to claim that the situation calculi described above solve theproblem of representing causality, agency, and the like (although here too von vonWright (1967) made a start). Shoham (1988), Morgenstern and Stein (1988) and Stein(1991, pp. 117–118), in contrast to Ginsberg (1986) and Ortiz (1994), eschew coun-terfactuals and situation-calculus like systems in favor of some more general notionof the accessibility relation based on causality (usually on several distinct causal oper-ators, including as enabling, generating and preventing as well as simple causation).Schank (1975), Wilensky (1983), and Lansky (1986) are also important in this con-nection.
21.3.2.3 Dynamic Semantics
There is another way of looking at all of these variants of the situation/event calculus.To the extent that the accessibility relation is defined in terms of a number of differentevents or causal primitives, possibly a large number, it is possible to regard each ofthese as defining its own distinct accessibility relation, possibly differing from othersin properties like transitivity. Such systems can then be viewed as instances of the“dynamic” logics that were developed in the first place for reasoning about computerprograms – see Pratt (1979), Harel (1980), and Goldblatt (1992), and the chapter byVan Benthem in the present volume. The application of various forms of dynamiclogic in knowledge representation and natural language semantics has been advocatedby Moore (1980), Rosenschein (1981), Webber (1983), Pednault (1989), and Scherland Levesque (1993). (It should be noted that this original notion of dynamic logic isnot the same as the “dynamic predicate logic” (DPL) of Groenendijk and Stokhof –see below.)
Dynamic logics relativize the modal operators to individual actions, events, or pro-grams. For example, if a (possibly nondeterministic) program or command # com-putes a function F over the integers, then we may write the following:
(47) n ( 0 " [#](y = F(n))
(48) n ( 0 " )#*(y = F(n))
The intended meaning of the first of these is “for n ( 0, after every execution of #
that terminates, y = F(n)”. That of the second is (dually) that “there is an executionof # which terminates with y = F(n)”.
While all of the calculi that we have considered so far are ones in which the ele-mentary programs # are deterministic, dynamic logics offer a framework which read-ily generalizes to concurrent and probabilistic events, offering a notation in which allof the theories discussed here can be compared. (In some of these, the modal operators[#] and )#* are no longer interdefinable – cf. Nerode and Wijesekera, 1990.)

“25-ch21-0925-0970-9780444537263” — 2010/11/29 — 21:08 — page 953 — #29
Temporality 953
The particular dynamic logic that we are dealing with here is one that includes thefollowing dynamic axiom (the operator ; is sequence, an operation related to compo-sition, and to von Wright’s T):
(49) [#][$]P " [#; $]P
In this we follow Moore (1980, Chapter 3) and Rosenschein (1981). The situationcalculus and its many variants can be seen as reified versions of this dynamic logic.
We achieve an immediate gain in perspicuity by replacing the reified notationin (50)a, below, by the equivalent dynamic expression (50)b.
(50) a. holds((on(a, b) & on(b, c)), result(puton(a, b), result(puton(b, c), s0)))
b. [puton(b, c); puton(a, b)](on(a, b) & on(b, c))
Kowalski’s “vivid” version of STRIPS can be very simply represented in this logic.The initial state of the world is as follows:
(51) clear(a) & clear(b) & clear(c)
The axiom defining the preconditions of puton(x, y) is now directly definable interms of the predicate possible, which can now be identified with a subtly differentmodal operator, which applies to events, rather than states:
(52) ! clear(x) & clear(y) & (x '= y) " possible(puton(x, y))
The consequences of puton(x, y) are now written as follows:
(53) a. ! on(x, z) " [puton(x, y)]clear(z)b. ! [puton(x, y)]on(x, y)
The frame axiom is written as follows:
(54) ! p & (p '= clear(y)) & (p '= on(x, z)) " [puton(x, y)]p
(Again the use of inequality presupposes the Horn Logic property that p is a positiveliteral.)
The transitive part of the possibility relation is now reduced to the following:
(55) ! possible(#) & [#]possible($) " possible(#; $)
This fragment preserves the virtues of Kowalski’s treatment in a modal notation.That is, the following conjunctive goal can, given a search control, be made to delivera constructive proof where # = puton(b, c); puton(a, b). (The proof, which solelyinvolves backward-chaining on the consequents of rules, is suggested as an exercise):
(56) possible(#) & [#](on(a, b) & on(b, c))
The suppression of state variables in dynamic logic affords some improvement inperspicuity over the related proposals of Kowalski, McCarthy, Schubert, and Reiterthat it is here used to capture, and makes it easier to extend the calculus.
The above example only concerns non-composite or “non-durative” events, likethe original situation calculus. However, the following dynamic Horn clauses beginto capture the composite events discussed earlier, along the lines suggested by

“25-ch21-0925-0970-9780444537263” — 2010/11/29 — 21:08 — page 954 — #30
954 Handbook of Logic and Language
Steedman (1982), Moens (1987) and White (1994). (The example is greatly simpli-fied, and omits many rules needed to capture even this small domain completely.) Firstwe need axioms defining the consequent and preconditions for starting and stopping.
(57) a. ! [start(p)]in progress(p)
b. ! not(in progress(p)) & preconditions(p) " possible(start(p))
c. ! p " [start(q)]p
(58) ! in progress(p) " possible(stop(p))
We also need a frame axiom for stopping (which could be derived as in Reiter,1991):
(59) + p & (p '= in progress(q)) " [stop(q)]p
This axiom is not as strong as it looks. It merely says that the only state to changein this state transition is the in-progress state in question. Of course stop(q) may havefurther ramifications, such as causing some other process to stop, but these must bemediated by relations between events not states. Such known ramifications should beexplicitly represented in the logic. This raises the question of how concurrency is tobe represented in dynamic situation or event calculi. We will return briefly to thisquestion below, but it should be noted that this problem, like that of relating events tochronology or clock-time, is likely to be considerably simplified by the fact that theprimitive events in these calculi are all instantaneous.
Finally we need a definition of the progressive, coercing achievements to accom-plishments and accomplishments to preparatory activities. (Note that in (60)b, below,we assume, in line with the discussion in Section 21.1, that accomplishments can berepresented by terms relating an activity and a culminating achievement. These sortsare here represented as terms in lieu of a proper system of sorts.)
(60) a. ! in progress(p) " progressive(activity(p))
b. ! preparation(q, p) & progressive(activity(p))
" progressive(accomplishment(activity(p), achievement(q)))
c. ! preparation(q, p)
& progressive(accomplishment(activity(p), achievement(q)))
" progressive(achievement(q))
These rules say that the progressive of an activity act is true if act is in progress, thatof an accomplishment is true if the progressive of its component activity is true, andthat the progressive of an achievement is true if the progressive of an accomplishmentmade up of the achievement and its preparatory activity is true – cf. Figure 21.1.
The following query asks for a plan # yielding a state where Keats is finishingwriting the sonnet In Disgust of Vulgar Superstition:
(61) possible(#) & [#]progressive(achievement(finish(write(keats, sonnet))))
(The function finish maps an accomplishment onto its culminating achievement, andis distinct from stop, the endpoint of an activity.) To find the plan, we must assume thatthe knowledge base also makes explicit the relation between finishing an activity and

“25-ch21-0925-0970-9780444537263” — 2010/11/29 — 21:08 — page 955 — #31
Temporality 955
its characteric preparation, the activity itself, implicit in the nucleus of Figure 21.2. (Tosimplify the example, we assume that the preparation for finishing writing a sonnet isjust writing it, although in real life it is a little more complicated than that.)
(62) ! preparation(achievement(finish(e)), activity(e))
If we assume that events of Keats writing has no preconditions, then the accessibilityrelation implicit in definition (55) gives rise to a proof where
(63) # = start(write(keats, sonnet))
A further simplification in the example is the assumption that all instances of writ-ing a sonnet are preparations for finishing it. In more complicated domains, such asthe traditional road-crossing domain that was used earlier to introduce the imperfec-tive paradox, we shall want to distinguish particular instances of preparatory activitieslike walking that are associated with goals like reaching the other side of the roadfrom similar activities that are not associated with such goals. This can be done viathe same preparation relation, provided that we further individuate events via David-sonian indices. Such individuation is also of course necessary to distinguish distinctevents with the same description, and to identify which start belongs with which stopamong distinct durative events of the same type. We will continue to pass over thiscomplication here.
The proof that generates the above plan (which is again suggested as an exercise)does not involve the subgoal of showing [#] finish(write(keats, sonnet)). Indeed theproof would be quite consistent with adding the denial of that fact, because the variableach in rule (60) is not involved in the antecedent, capturing the imperfective paradox.
Of course, asking for a plan to bring about a situation in which Keats is finishingwriting In Disgust of Vulgar Superstition is slightly artificial, because such states areextensive, and there may be several such plans. For example, consider the effect ofadding the following rule defining the consequences and preconditions of arriving.
(64) a. ! [arrive(x)]present(x)b. ! not(present(x)) " possible(arrive(x))c. ! p " [arrive(x)]p
The accessibility relation (55) now allows
(65) # = start(write(keats, sonnet)); arrive(x)# = start(write(keats, sonnet)); arrive(x); arrive(y). . .
As plans, these are rather foolish, because of well-known inherent limitations in thesimplest STRIPS planners, although incorrect plans such as the following are stillcorrectly excluded for the goal in question:
(66) # = start(write(keats, sonnet)); arrive(x); stop(write(keats, sonnet)
Part of the problem is that we are not yet distinguishing true consequences, includ-ing ramifications or causal relations among events themselves, from facts that are

“25-ch21-0925-0970-9780444537263” — 2010/11/29 — 21:08 — page 956 — #32
956 Handbook of Logic and Language
merely coincidentally true in the state that results, because of the inertial property ofthe frame axiom. Nor are we distinguishing causal relations between event sequencesfrom mere temporal sequence.
We can remedy this shortcoming by distinguishing the temporal sequence oper-ator (i.e. ; ) from a causal or contingent sequential operator, which we will followMoens and Steedman (1988) in writing as @, because of its relation to one of anski’s(1986) operators. (A related proposal to involve causality as a primitive is made byLin (1995).) Accordingly, we need to add some further rules parallel to (55), reflect-ing a relation of modal necessity across sequences of events, including the following:
(67) |= (possible(#) & [#]necessary($)) " possible(#@$)
We now add a rule saying that anyone else being present implies that Keats must stopwriting:
(68) ! present(x) & (x '= keats) & in progress(write(keats, y))" necessary(stop(write(keats, y)))
We can now search for plans which make an event of Keats stopping writing neces-sarily occur, like (69)a, below, as distinct from those that merely make it possible,like (69)b, by constructively searching for a proof for an event sequence # such thatpossible(#@stop(write(keats, y))):
(69) a. # = start(write(keats, y)); arrive(x)b. # = start(write(keats, y))
Again the examples are artificial: their usefulness for an account of tense and temporalanaphora will become apparent in the next section.
There is a close relation between [#] and von Wright’s “and Next” operator T,which is often written , in other temporal logics – cf. Goldblatt (1992, Chapter 9).Von Wright’s operator in turn has its origin in deontic logic (cf. Thomason, 1981), andthere is in general a considerable affinity between deontic logic and dynamic logic. Theinteresting property of the system for present purposes is that it represents causally orcontingently related sequences of actions.
Such a logic can be captured in the kind of axiomatization standard in the literatureon dynamic logic – Harel (1980, p. 512 et seq.) provides a model which can be adaptedto the more restricted deterministic logic that is implicit here by omitting some axiomsand adding a further axiom of determinism. (See p. 522 et seq. I am indebted to RichThomason for suggesting this approach.) However, such a toy needs considerable fur-ther work to make it into a linguistically interesting object. In particular, it stands badlyin need of a type system of the kind discussed in Section 21.2. We must also extend itto capture the fact that not only states but events may be simultaneous, and that eventsmay in particular be embedded within other events. We are likely to find ourselvesneeding to express a variety of distinct causal and modificational relations betweenevents, as Shoham (1988) and other authors cited earlier have suggested, rather thanthe single contingent von Wrightian relation, and needing to introduce some coindex-ing device equivalent to Davidsonian e variables. We also need to relate the contingent

“25-ch21-0925-0970-9780444537263” — 2010/11/29 — 21:08 — page 957 — #33
Temporality 957
sequences to clock-time. Some of these extensions are touched on in the next section,which considers how to bring this apparatus more appropriately under the control oflanguage, by making it refer to an actual historical sequence of events.
21.4 Temporal Reference
21.4.1 Basic Phenomena and Descriptive Frameworks
In the discussion so far, we have largely ignored the question of how the Reichen-bachian reference point is represented and accessed, and the anaphoric nature of tense.Several logical and computational approaches have explored this possibility.
Temporal anaphora, like all discourse anaphora and reference resolution, is evenmore intimately dependent upon world knowledge than the other temporal categoriesthat we have been considering. In order to control this influence, we will follow thestyle of much work in AI, drawing most of our examples from a restricted domain ofdiscourse. We will follow Isard (1974) in taking a board game as the example domain.Imagine that each classical model in the structure of Figure 21.11 is represented asa database, or collection of facts describing not only the position of the pieces in agame of chess, and the instantaneous moves at each frame, but the fact that at certaintimes durative or composite events like exchanging Rooks or White attacking the BlackQueen are in progress across more than one state.
Consider the following examples from such a domain:
(70) a. When I took your pawn, you took my queen.b. I took your pawn. You took my queen.
The when-clause in a, above, establishes a reference point for the tense of the mainclause, just as the definite NP Keats establishes a referent for the pronoun. Indeed thewhen-clause itself behaves like a definite, in that it seems to presuppose that the eventof my taking your pawn is identifiable to the hearer. (Of course, the reader will haveeffortlessly accommodated this presupposition.) The first sentence in (70)b, above,behaves exactly like the when clause in setting the reference point for the second.The only difference is that the simple declarative I took your pawn itself demands apreviously established reference point to be anaphoric to, whereas the when clausecauses a new reference point to be constructed.
As has been frequently noticed, the state to which the tense in you taking my queenrefers in (70)a, above, is not strictly the state in which I took your pawn. It is thestate that resulted from that action. However, it is not invariably the case that thetemporal reference point moves on in this way. Most obviously, a stative main clauseis primarily predicated of the original reference point of the when-clause:
(71) When I took your pawn, I did not know it was protected by your knight.
(Presumably, the ignorance in question may have ended with that very move.) Eventsalso may be predicated of the original reference point, rather than moving the action on:
(72) When I took your pawn, I used a rook.

“25-ch21-0925-0970-9780444537263” — 2010/11/29 — 21:08 — page 958 — #34
958 Handbook of Logic and Language
Figure 21.12 The nucleus again.
In fact, as Ritchie (1979) and Partee (1984) have pointed out, in strictly temporalterms, we can find main clauses that precede the reference point established by a whenclause:
(73) When I won my only game against Bobby Fischer, I used the Ruy Lopezopening.
These phenomena arise because the temporal referent is not strictly temporal.Rather than being a time or an interval, it is (a pointer to) an event-nucleus of exactlythe kind that was used earlier to explain the aspectual sort hierarchy and possiblecoercions among the Aktionsarten. That is, it is a structure of the kind shown inFigure 21.2, repeated here as Figure 21.12. It will be recalled that the preparationis an activity, the consequent is a (perfect) state, and that the core event is an achieve-ment. (Recall that any event-type can turn into an achievement via the sort-transitionschema in Figure 21.1.)
In the terms of our modal frame, the preparation of an event is the activity or actionthat led to the state in which that achievement took place. The consequent is the con-sequent state, and as we saw in the earlier discussion of the modals, includes the entiresubtree of states accessible from that state. The referent-setting effect of a when-clausecan then be seen as identifying such a nucleus. The main clause is then temporallylocated with respect to the nucleus. This may be by lining it up with the core eventitself, either as a property of the initial state, as in example (71), or as a property ofthe transition itself, as in (72). Alternatively, since accessibility is defined in termsof the subsequent actions, the actual subsequent action is a possible main clause, asin (70). Or the main clause may be located with respect to the preparation, as in (73).Which of these alternatives a given example gives rise to is a matter determined bythe knowledge representation, not by rules of the semantics.
On the assumption that the consequent in the nuclear referent includes the entiresubtree of future states, the information needed by conditionals, modals, and otherreferent-setting adverbials will be available:
(74) a. If you take my queen, you may win.b. If you had taken my queen, you might have won.c. Since you took my queen, you have been winning.
All of this suggests that states or partial possible worlds in a logic of action derivingultimately from von Wright and McCarthy and Hayes, with a much enriched ontologyinvolving a rather intimate connection to the knowledge-base, are appropriate candi-dates for a Reichenbachian anaphoric account of tense and temporality. But this doesnot tell us how the temporal referent is set up to act as a referent for anaphora.

“25-ch21-0925-0970-9780444537263” — 2010/11/29 — 21:08 — page 959 — #35
Temporality 959
21.4.2 Logical and Computational Approaches
It is possible in principle to embody a Reichenbachian account in a pure modal logic,say by developing “multi-dimensional” tense logics of the kind used by Nerbonne(1984) (see Van Benthem, 1991, 1995, Section III.3). However, the event-based cal-culus over counterfactual partially specified states discussed in Section 21.3 offers apromising candidate for a representation of Riechenbach’s reference point R, in theform of deterministic event sequences [#]. This opens up the possibility of applyingthe general modal apparatus developed so far, not only for quantifying over states,but to act as the temporal link between sentences and clauses, as in when-clauses andmulti-sentence discourse.
Most computational approaches have equated sentential temporal anaphora withdiscourse temporal anaphora, rather than any structurally bound variety. ThusWinograd (1972), Isard (1974), and the present author treated the establishment oftemporal (and pronominal) referents as temporary side-effects to a single STRIPS-likedatabase. A reference-point establishing when-clause or conditional had the effect ofsetting the database to the state of the world at the (in Isard’s case, possibly coun-terfactual) time in question. The way this was actually done was to “fast-forward”(or -backward) the world to the situation in question, using the history of events tocarry out the sequence of updates and retractions necessary to construct the state ofthe world at the reference point.
Within the situation calculus and its descendants including the dynamic version, thisstrategem is unnecessary. The history of events is a sequence such as the following:
(75) start(write(keats, sonnet)); arrive(chapman)
@stop(write(keats, sonnet))
The referent of a when-clause, such as When Chapman arrived, is simply the sequenceup to and including arrive(chapman), namely:
(76) start(write(keats, sonnet)); arrive(chapman)
To identify the referent we need the following definition of a relation we might call evoke.This is merely a logic-programming device which defines a search for a deterministicevent sequence of the form [#; $] or [#@$] over a history in which the sequenceoperators are “left-associative” (we only give the rules for the operator ; here):
(77) a. ! evoke((#; $), (#; $))
b. ! evoke((#; $), % ) " evoke((#; $), (% ; &))
Evokable # are by definition possible, even for counterfactual histories.The referent-setting effect of when can now be captured to a first approximation in
the following rules, which first find the current history of events, then evoke a suitablereference point, then test for the appropriate relation when. (Again this is a logic pro-gramming hack which could be passed over, and again there are two further rules with@ for ; that are omitted here):
(78) a. ! state(% ) & S(history) & evoke((#; $), history) & [#; $]% " when($, % )
b. ! event(') & S(history) & evoke((#; $@'), history) " when($, ')

“25-ch21-0925-0970-9780444537263” — 2010/11/29 — 21:08 — page 960 — #36
960 Handbook of Logic and Language
The predicate S determines the Reichenbachian speech point, which is an event orsequence of events. S(history) is assumed to be available in the database, as a fact.The first rule, a, applies to when sentences with state-type main clause propositions,and says that when ($, % ) is true if % is a state, and you can evoke an event sequenceending in $ after which % holds. The second applies to when sentences with event-type main clauses, and says that when ($, ') is true if ' is an event and you can evokean event sequence whose last two events are $ and then '. The question a, below,concerning the ensuing state, therefore translates into the query b:
(79) a. When Chapman arrived, was Keats finishing writing In Disgust of Vulgar Supersti-tion?
b. when((#; arrive(chapman)),
progressive(achievement(finish(write(keats, sonnet)))))
The progressive is, it will be recalled, a state, so in our greatly simplified world, thisis true, despite the fact that under the closed world assumption Keats did not finish thepoem, because of the earlier elimination of the imperfective paradox.
A when-question with an event in the main clause, as in a, below, translates as in b:
(80) a. When Chapman arrived, did Keats stop writing In Disgust of Vulgar Superstition?b. when((#; arrive(chapman)), stop(write(keats, sonnet)))
In the case to hand, this last will yield a proof with the following constructive instan-tiation:
(81) when((start(write(keats, sonnet)); arrive(chapman)),
stop(write(keats, sonnet)))
In either case, the enduring availability of the Reichenbachian reference point forlater simple tensed sentences can be captured on the assumption that the act of evok-ing a new referent causes a side-effect to the database, causing a new fact (say of theform R(#)) to be asserted, after any existing fact of the same form has been removed,or retracted. (We pass over the formal details here, merely noting that for this pur-pose a blatantly non-declarative STRIPS-like formulation seems to be the natural one,although we have seen how such non-declarativity could in principle be eliminatedfrom the system. Lin and Reiter (1995) show how such a process of “progressing” thedatabase can be defined on the basis of the declarative representation.)
The representation captures the fact that Keats stopped writing the poem becauseChapman arrived, whereas Chapman merely arrived after Keats started writing, notbecause of it.
Of course, it will be clear from the earlier discussion that such a system remainsoversimplified. Such sentences also suggest that the event sequences themselvesshould be considerably enriched on lines suggested in earlier sections. They needa system of types or sorts of the kind proposed by various authors discussed inSection 21.2. They should also be structured into nested structures of causal or, moregenerally, contingent sequences.

“25-ch21-0925-0970-9780444537263” — 2010/11/29 — 21:08 — page 961 — #37
Temporality 961
Since we have also observed that main clause events may be simultaneous with,as well as consequent upon, the when clause event, events must also be permittedto be simultaneous, perhaps using the connective - introduced by Peleg (1987) tocapture the relation between embedded events like starting to write “In Disgust ofVulgar Superstition” and starting to write, generalizing the above rules accordingly.Partial ordering of events must also be allowed. The inferential possibilities implicitin the notion of the nucleus must be accommodated, in order to capture the fact thatone event may cause the preparation of another event to start, thereby embodying anon-immediate causal effect.
Very little of this work has been done, and it may be unwise to speculate in advanceof concrete solutions to the many real problems that remain. However the limited frag-ment outlined above suggests that dynamic logic may be a promising framework inwhich to pursue this further work and bring together a number of earlier approaches.In this connection, it is perhaps worth remarking that, of the seven putative limitationsof the situation calculus and its relatives claimed in the critical review by Shoham andGoyal (1988, pp. 422–424), five (limitation to instantaneous events, difficulty of rep-resenting non-immediate causal effects, ditto of concurrent events, ditto of continuousprocesses, and the frame problem) either have been overcome or have been addressedto some extent in the published work within the situation calculus. Of the remainingtwo (the qualification problem and the ramification problem) the ramification problemin the narrow sense of known causal effects of actions has been addressed above andby Schubert and Reiter. In the broader sense of unanticipated contingencies or rami-fications, and similarly unanticipated preconditions, or qualifications, these problemshave not been overcome in any framework, possibly because they do not belong in thelogic at all.
The non-computational approaches to temporal anaphora, in contrast, to thosejust described, have tended to equate all temporal anaphora with structurally boundanaphora. DRT treats temporal referent(s) much like nominal referents, as localizedside-effects. This mechanism is used to extend the scope of the temporal referentbeyond the scope that surface syntax would most immediately suggest, in much thesame way that the scope of nominal referents is extended to capture such varieties ofnominal anaphor as “donkey pronouns”, and the approach is generalized to modals andconditionals by Roberts (1989), and Kamp and Reyle (1993). They, like Dowty (1986),assume that events invariably move the temporal reference point forward while statesdo not – cf. Kamp and Reyle (1993, p. 528), which in general is not the case. (Indeedin the case of the latter authors, this assumption is somewhat at odds with their adop-tion elsewhere of a nucleus-like structure over events – cf. p. 558.) However, bothnote the oversimplification, and their theories remain entirely compatible in principlewith the present proposal to bring this question under the control of context and infer-ence, perhaps along lines suggested by Lascarides and Asher (1993a), who incorporatepersistence assumptions of the kind discussed above.
Interestingly, Groenendijk and Stokhof (1991, p. 50) show how the scope-extending mechanism of DRT can be captured straightforwardly in a first-order variety

“25-ch21-0925-0970-9780444537263” — 2010/11/29 — 21:08 — page 962 — #38
962 Handbook of Logic and Language
of dynamic logic, dynamic predicate logic (DPL – cf. Dekker (1979), and the chap-ter on ‘Dynamics’ in the present volume). While DPL is quite distantly related todynamic logic in the sense that the term is used here, the mechanism that Groendijkand Stokhof propose, which directly models the side-effects implicit in assignmentto variables, seems to be generalizable to the DRT treatment of inter-clause temporalanaphora and the Reichbachian reference point, suggesting a way to unify all of theapproaches discussed here.
21.5 Conclusion
The analysis so far has built solely upon observations from English. Nevertheless, theclaim that the semantics outlined above depends directly upon the conceptual repre-sentation of action and contingency suggests that this semantics might be universal,despite considerable differences in its syntactic and morphological encoding acrosslanguages. Discussion of the evidence for this claim would take us beyond the scopeof this essay. However, the available reviews of this extensive literature (e.g. Dahl,1985; Smith, 1991) seem to lend some support to the following brief observation onthis question.
Benjamin Lee Whorf once observed that the auxiliaries and inflections associatedwith verbs in Amerindian languages appeared to be semantically quite unlike the cor-responding categories in English and other European languages. The Amerindian cat-egories seemed to be more concerned with various aspects of the speakers’ evidentialand consequential relation to events, rather than the strictly temporal relations whichWhorf assumed were implicated in the corresponding devices of English. He sug-gested, controversially, that these differences reflected differences in modes of think-ing about events and time.
The work described above suggests that such differences across languages aresuperficial. Ironically, the English tense/aspect system seems to be based on semanticprimitives remarkably like those which Whorf ascribed to Hopi. Matters of temporalsequence and temporal locality seem to be quite secondary to matters of perspectiveand contingency. This observation in turn suggests that the semantics of tense andaspect is profoundly shaped by concerns with goals, actions and consequences, andthat temporality in the narrow sense of the term is merely one facet of this systemamong many.
Such concerns seem to be the force that determines the logic that is required tocapture its semantics as the particular kind of dynamic system outlined above, whosestructure is intimately related to knowledge of action, the structure of episodic mem-ory, and the computational process of inference.
21.6 Further ReadingThe literature on temporality and representation of causal action is vast, and Iam painfully aware of having been forced to pass over entirely or to treat rather

“25-ch21-0925-0970-9780444537263” — 2010/11/29 — 21:08 — page 963 — #39
Temporality 963
superficially a great deal of important and relevant work. Besides numerous chaptersin the present volume referred to in the text, the following sources are offered as ameans of entry to a more extensive literature.
Hughes and Cresswell (1968) remains an important source for early axiomaticapproaches to modal logic, and its early historical development. Van Benthem (1983)is a very readable survey of Tense Logic, with particular attention to the effectsof different ontological commitments, including those related to the representation ofvarious views of time implicit in modern physics. A number of papers in Volume II ofGabbay and Guenthner’s (1984) Handbook of Philosophical Logic cover recent devel-opments, including those by Bull and Segerberg, Burgess, Thomason, Van Benthem,and Åqvist. Harel (1980) in the same volume and Goldblatt (1992) are resources fordynamic logic and related systems, including temporal logic. Kamp and Reyle (1993)discuss tense and aspect within DRT. Groenendijk and Stokhof (1991) discuss theexpressibility of DRT in dynamic predicate logic. The early paper by McCarthy andHayes (1969) remains an excellent review of modal logic from a computational per-spective, and is one of the few sources to explicitly relate computational and logicalapproaches, as is Nilsson’s elegant 1980 text. The invaluable collections of readings inartificial intelligence, non-monotonic reasoning, and planning respectively edited byWebber and Nilsson (1981), Ginsberg (1987), and Allen, Hendler and Tate (1990) aresources which reprint many of the computational papers discussed above, and muchother recent work in AI knowledge representation which it has not been possible tosurvey here. Galton (1987) is a recent collection of essays bringing together logiciansand computer scientists on the question of temporal representations. The special issueon tense and aspect of Journal of Computational Linguistics (Volume 14.2) is anothersource for computational linguistic approaches. Dahl (1985) and Smith (1991) sur-vey the tense and aspectual systems of a considerable number of languages from alinguistic standpoint similar to that presented here.
Acknowledgments
An early draft of some parts of Sections 21.3.2 and 21.4.2 appeared in a different form asSteedman (1995). I am grateful to Johan van Benthem, Pat Hayes, Stephen Isard, David Israel,Mark Johnson, Alex Lascarides, Alice ter Meulen, Marc Moens, Charlie Ortiz, Jong Park, LenSchubert, Matthew Stone, Rich Thomason, Bonnie Webber, and Michael White for advice andcriticism. They are not to blame for any errors that remain. Support was provided in part byNSF grant nos. IRI91-17110, and IRI95-04372, DARPA grant no. N660001-94-C-6043, andARO grant no. DAAH04-94-G0426.
References
Abusch, D., In press. Sequence of tense and temporal de re. Ling. Philos. (to appear).Allen, J., 1984. Towards a general theory of action and time. Artif. Intell. 23, 123–154.Allen, J., Hendler, J., Tate, A., 1990. Readings in Planning. Morgan Kaufmann, Palo Alto, CA.

“25-ch21-0925-0970-9780444537263” — 2010/11/29 — 21:08 — page 964 — #40
964 Handbook of Logic and Language
Bach, E., 1980. Tenses and aspects as functions on verb-phrases, in: Rohrer, C. (Ed.), Time,Tense, and Quantifiers. Niemeyer, Tubingen.
Bach, E., 1986. The algebra of events. Ling. Philos. 9, 5–16.Barwise, J., Perry, J., 1983. Situations and Attitudes. Bradford, Cambridge, MA.Bauerle, R., 1979. Tense logics and natural language. Synthese 40, 225–230.Bennett, M., Partee, B., 1972. Towards the Logic of Tense and Aspect in English. Published
by Indiana University Linguistics Club 1978, System Development Corporation, SantaMonica, CA.
Blackburn, P., Gardent, C., De Rijke, M., 1993. Back and forth through time and events, in: Pro-ceedings of the 9th Amsterdam Colloquium, December, ILLC, University of Amsterdam,pp. 161–175.
Boyd, J., Thorne, J., 1969. The semantics of modal verbs. J. Ling. 5, 57–74.Caenepeel, M., 1989. Aspect, Temporal Ordering, and Perspective in Narrative Fiction. PhD
Dissertation, University of Edinburgh.Carlson, G., 1977. Reference to Kinds in English. PhD Dissertation, University of Massachus-
sets, Amherst, MA.Cooper, R., 1986. Tense and discourse location in situation semantics. Ling. Philos. 9, 17–36.Cresswell, M., 1974. Adverbs and events. Synthese 28, 455–481.Cresswell, M., 1985. Structured Meanings. MIT Press, Cambridge, MA.Cresswell, M., 1988. Semantical Essays. Kluwer, Dordrecht.Cresswell, M., 1990. Entities and Indices. Kluwer, Dordrecht.Crouch, R., Pulman, S., 1993. Time and modality in a natural language interface. Artif. Intell.
63, 265–304.Dahl, Ö., 1985. Tense and Aspect Systems. Basil Blackwell, Oxford.Davidson, D., 1967. The logical form of action sentences, in: Rescher, N. (Ed.), The Logic of
Decision and Action. University of Pittsburgh Press, Pittsburgh, PA.De Kleer, J., 1984. Choices without backtracking, in: Proceedings of the 4th National Confer-
ence on Artificial Intelligence, pp. 79–85.Dekker, P., 1979. Transsentential Meditations: Ups and Downs in Dynamic Semantics. PhD
Dissertation, University of Amsterdam, ILLC Dissertation Series, 1993, no. 1.Dowty, D., 1979. Word Meaning and Montague Grammar, second ed. 1991. Reidel, Dordrecht.Dowty, D., 1982. Tenses, time-adverbs, and compositional semantic theory. Ling. Philos. 5,
23–55.Dowty, D., 1986. The effects of aspectual class on the temporal structure of discourse semantics
or pragmatics? Ling. Philos. 9, 37–62.Doyle, J., 1979. A truth maintenance system. Artif. Intell. 12, 231–272.Eberle, K., 1990. Eventualities in natural language understanding systems, in: Blasius, K.,
Hedtstuck, U., Rollinger, C. (Eds.), Sorts and Types in Artificial Intelligence, Springer,Berlin.
Enç, M., 1981. Tense without Scope. PhD Dissertation, University of Madison, Wisconsin.Enç, M., 1987. Anchoring conditions for tense. Ling. Inq. 18, 633–657.Fikes, R., Nilsson, N., 1971. STRIPS: a new approach to the application of theorem proving to
problem solving. Artif. Intell. 2, 189–208.Fine, K., 1975. Critical notice of Lewis, Counterfactuals. Mind 84, 451–458.Gabbay, D., Guenthner, F., (Eds.), 1984. Handbook of Philosophical Logic, vol. II. Reidel,
Dordrecht.Gagnon, M., Lapalme, G., 1995. From conceptual time to linguistic time. Comput. Ling. (to
appear).

“25-ch21-0925-0970-9780444537263” — 2010/11/29 — 21:08 — page 965 — #41
Temporality 965
Galton, A., 1984. The Logic of Aspect. Clarendon Press, Oxford.Galton, A., (Ed.), 1987. Temporal Logics and Their Applications. Academic Press, New York.Galton, A., 1990. A critical examination of Allen’s theory of action and time. Artif. Intell. 42,
159–188.Garrod, H., 1954. Commentary on Keats’ sonnet ‘Written in disgust of vulgar superstition,’ in:
Garrod, H. (Ed.), Keats’ Poetical Works, second ed. Clarendon Press, Oxford.Ginsberg, M., 1986. Counterfactuals. Artif. Intell. 30, 35–81.Ginsberg, M., 1987. Readings in Nonmonotonic Reasoning. Morgan Kaufmann, Palo Alto, CA.Goldblatt, R., 1980. Diodorean modality in Minkowski spacetime. Stud. Logica 39, 219–236.Goldblatt, R., 1992. Logics of Time and Computation, second ed. CSLI/Chicago University
Press, Chicago.Groenendijk, J., Stokhof, M., 1991. Dynamic Predicate Logic. Ling. Philos. 14, 39–100.Harel, D., 1980. Dynamic logic, in: Gabbay, D., Guenthner, F. (Eds.), Handbook of Philosophi-
cal Logic, vol. II. Reidel, Dordrecht.Heinamaki, O., 1974. Semantics of English Temporal Connectives. PhD Dissertation, Univer-
sity of Texas, Austin, TX.Hinrichs, E., 1985. A Compositional Semantics for Aktionsarten and NP Reference in English.
PhD Dissertation, Ohio State University.Hinrichs, E., 1986. Temporal anaphora in discourses of English. Ling. Philos. 9, 63–82.Hintikka, J., 1962. Knowledge and Belief. Cornell University Press, Ithaca, NY.Hornstein, N., 1977. Towards a theory of tense. Ling. Inq. 8, 521–557.Hornstein, N., 1990. As Time Goes By: Tense and Universal Grammar. MIT Press,
Cambridge, MA.Hughes, G., Cresswell, M., 1968. Introduction to Modal Logic. Methuen.Hwang, C., Schubert, L., 1992. Tense trees as the fine structure of discourse, in: Proceedings of
the 30th Annual Meeting of the Association for Computational Linguistics, pp. 232–240.Inoue, K., 1979. An analysis of the English present perfect. Linguistics 17, 561–590.Isard, S., 1974. What would you have done if .... Theor. Ling. 1, 233–255.Isard, S., Longuet-Higgins, H.C., 1973. Modal Tictacto, in: Bogdan, R., Niiniluoto, I. (Eds.),
Logic, Language and Probability. Reidel, Dordrecht, pp. 189–195.Jackendoff, R., 1991. Parts and boundaries. Cognition 41, 9–46.Kamp, H., 1979. Events, instants, and temporal reference, in: Bauerle, R., Egli, U., von
Stechow, A. (Eds.), Semantics for Different Points of View. Springer, Berlin.Kamp, H., Reyle, U., 1993. From Discourse to Logic. Kluwer, Dordrecht.Kamp, H., Rohrer, C., 1983. Tense in texts, in: Bauerle, R., Schwarze, C., von Stechow, A.
(Eds.), Meaning, Use, and Interpretation in Language. De Gruyter, Berlin, pp. 250–269.Karlin, R., 1988. Defining the semantics of verbal modifiers in the domain of cooking tasks, in:
Proceedings of the 26th Annual Meeting of the Association for Computational Linguistics.pp. 61–67.
Kowalski, R., 1979. Logic for Problem Solving. North-Holland, Amsterdam.Kowalski, R., Sergot, M., 1986. A logic-based calculus of events. New Gener. Comput. 4,
67–95.Kratzer, A., 1977. What must and can can and must mean. Ling. Philos. 1, 337–355.Kratzer, A., 1991. Modality, in: von Stechow, A., Wunderlich, D. (Eds.), Semantics: An Inter-
national Handbook of Contemporary Research. De Gruyter, Berlin.Krifka, M., 1989. Nominal reference, temporal constitution, and quantification in event seman-
tics, in: Bartsch, R., van Benthem, J., van Emde Boas, P. (Eds.), Semantics and ContextualExpressions. Foris, Dordrecht, pp. 75–115.

“25-ch21-0925-0970-9780444537263” — 2010/11/29 — 21:08 — page 966 — #42
966 Handbook of Logic and Language
Krifka, M., 1990. Four thousand ships passed through the lock: object-induced measure func-tions on events. Ling. Philos. 13, 487–520.
Krifka, M., 1992. Thematic relations as links between nominal reference and temporal consti-tution, in: Sag, I., Szabolcsi, A. (Eds.), Lexical Matters. CSLI/Chicago University Press,Chicago.
Kripke, S., 1965. Semantical analysis of intuitionistic logic I, in: Crossley, J., Dummett, M.(Eds.), Formal Systems and Recursive Functions. North-Holland, Amsterdam.
Kripke, S., 1972. Naming and necessity, in: Davidson, D., Harman, G. (Eds.), Semantics ofNatural Language. Reidel, Dordrecht.
Landman, F., 1986. Towards a Theory of Information. Foris, Dordrecht.Landman, F., 1991. Structures for Semantics. Kluwer, Dordrecht.Landman, F., 1992. The progressive. Nat. Lang. Semant. 1, 1–32.Lansky, A., 1986. A representation of parallel activity based on events, structure and casusality.
Proceedings of the Workshop on Planning and Reasoning About Action, TimberlineLodge, Mount Hood, OR, pp. 50–86.
Lascarides, A., Asher, N., 1993a. Temporal interpretation, discourse relations, and common-sense entailment. Ling. Philos. 16, 437–494.
Lascarides, A., Asher, N., 1993b. A semantics and pragmatics for the pluperfect, in: Proceedingsof the Annual Meeting of the European Chapter of the Association for ComputationalLinguistics. Utrecht, NL, pp. 250–259.
Levesque, H., 1988. Logic and the complexity of reasoning. J. Philos. Logic 17, 355–389.Lewis, D., 1971. Completeness and decidability of three logics of counterfactual conditionals.
Theoria 37, 74–85.Lewis, D., 1973a. Causation. J. Philos. 70, 556–567.Lewis, D., 1979. Scorekeeping in a language game. J. Philos. Logic 8, 339–359.Lin, F., 1995. Embracing causality in specifying the indirect effect of actions, in: Proceed-
ings of the 14th International Joint Conference on Artificial Intelligence. Montreal, QC,pp. 1985–1991.
Lin, F., Reiter, R., 1995. How to progress a database II: the STRIPS connection. in: Proceed-ings of the 14th International Joint Conference on Artificial Intelligence. Montreal, QC,pp. 2001–2007.
Link, G., 1983. The logical analysis of plurals and massterms, in: Bauerle, R., Schwarze, C.,von Stechow, A. (Eds.), Meaning, Use, and Interpretation in Language. De Gruyter, Berlin,pp. 302–323.
Link, G., 1987. Algebraic semantics of event structures, in: Groenendijk, J., Stokhof, M.,Veltman, F. (Eds.), Proceedings of the 6th Amsterdam Colloquium.
Lyons, J., 1977. Semantics, vol. II. Cambridge University Press, Cambridge, MA.McCarthy, J., 1977. Epistemological problems of artificial intelligence, in: Proceedings of the
5th International Joint Conference on Artificial Intelligence. pp. 1038–1044.McCarthy, J., Hayes, P., 1969. Some philosophical problems from the standpoint of Artificial
Intelligence, in: Meltzer, B., Michie, D. (Eds.), Mach. Intell. 4. Edinburgh University Press,Edinburgh, pp. 473–502.
McCarty, T., 1994. Modalities over actions I: model theory. Proceedings of the 4th InternationalConference on Principles of Knowledge Representation and Reasoning. Bonn, Germany,pp. 437–448.
McCawley, J., 1971. Tense and time reference in English, in: Fillmore, C., Langendoen,T. (Eds.), Studies in Linguistic Semantics. Holt, Rinehart and Winston, New York,pp. 96–113.

“25-ch21-0925-0970-9780444537263” — 2010/11/29 — 21:08 — page 967 — #43
Temporality 967
McDermott, D., 1982. A temporal logic for reasoning about processes and actions. Cogn. Sci.6, 101–155.
Miller, G., Johnson-Laird, P., 1976. Language and Perception. Cambridge University Press,Cambridge, MA.
Moens, M., 1987. Tense, Aspect and Temporal Teference. PhD Dissertation, University ofEdinburgh.
Moens, M., Steedman, M., 1988. Temporal ontology and temporal reference. Comput. Ling. 14,15–28.
Moore, R., 1980. Reasoning About Knowledge and Action. PhD Dissertation, Cambridge MA,MIT, published as TN-191, SRI International, Menlo Park, CA.
Morgenstern, L., Stein, L., 1988. Why things go wrong: a formal theory of causal reasoning, in:Proceedings of the 7th National Conference on Artificial Intelligence. AAAI, pp. 518–523.
Mourelatos, A., 1978. Events, processes and states. Ling. Philos. 2, 415–434.Nerbonne, J., 1984. German Temporal Semantics: Three-Dimensional Tense-Logic and a GPSG
Fragment. PhD Dissertation, Ohio State University, Columbus, OH.Nerode, A., Wijesekera, D., 1990. Constructive Concurrent Dynamic Logic I, Technical Report
90-43. Mathematical Sciences Institute, Cornell University, Ithaca, NY.Nilsson, N., 1980. Principles of Artificial Intelligence. Tioga, Palo Alto, CA.Ortiz, C., 1994. Causal pathways of rational action, in: Proceedings of the Twelfth National
Conference on Artificial Intelligence. pp. 1061–1066.Parsons, T., 1990. Events in the Semantics of English. MIT Press, Cambridge, MA.Partee, B., 1973. Some structural analogies between tenses and pronouns in English. J. Philos.
70, 601–609.Partee, B., 1984. Nominal and temporal anaphora. Ling. Philos. 7, 243–286.Pednault, E., 1989. ADL: exploring the middle ground between STRIPS and the situation cal-
culus, in: Brachman, R., et al. (Eds.), Proceedings of the 1st International Conference onPrinciples of Knowledge Representation and Reasoning. Morgan Kaufmann, Palo Alto,CA, pp. 324–332.
Peleg, D., 1987. Concurrent dynamic logic. J. Assoc. Comput. Mach. 34, 450–479.Pratt, V., 1979. Process logic, in: Proceedings of the 6th Annual ACM Conference on Principles
of Programming Languages. pp. 93–100.Pustejovsky, J., 1991. The syntax of event structure. Cognition 41, 47–82.Quine, W., 1960. Word and Object. MIT Press, Cambridge, MA.Reichenbach, H., 1947. Elements of Symbolic Logic. University of California Press,
Berkeley, CA.Reiter, R., 1978. On closed world databases, in: Gallaire, H., Minker, J. (Eds.), Logic and
Databases. Plenum, New York, pp. 119–140.Reiter, R., 1991. The frame problem in the situation calculus: a simple solution (sometimes)
and a completeness result for goal regression, in: Lifshitz, V. (Ed.), AI and MathematicalTheory of Computation: Papers in Honour of John McCarthy. Academic Press, New York,pp. 359–380.
Reiter, R., 1993. Proving properties of states in the situation calculus. Artif. Intell. 64, 337–351.Rescher, N., 1964. Hypothetical Reasoning. North-Holland, Amsterdam.Ritchie, G., 1979. Temporal clauses in English. Theor. Ling. 6, 87–115.Roberts, C., 1989. Modal subordination and pronominal anaphora in discourse. Ling. Philos.
12, 683–721.Rosenschein, S., 1981. Plan synthesis: a logical perspective, in: Proceedings of the 7th Interna-
tional Joint Conference on Artificial Intelligence. Vancouver, pp. 331–337.

“25-ch21-0925-0970-9780444537263” — 2010/11/29 — 21:08 — page 968 — #44
968 Handbook of Logic and Language
Schank, R., 1975. The structure of episodes in memory, in: Bobrow, D., Collins, A. (Eds.),Representation and Understanding. Academic Press, New York, pp. 237–272.
Schein, B., 1993. Plurals and Events. MIT Press, Cambridge, MA.Scherl, R., Levesque, H., 1993. The frame problem and knowledge-producing actions, in: Pro-
ceedings of the 11th National Conference on Artificial Intelligence, Washington. AAAI,pp. 689–695.
Schubert, L., 1990. Monotonic solution of the frame problem in the situation calculus:an efficient method for worlds with fully specified actions, in: Kyburg, H., Loui, R.,Carlson, G. (Eds.), Knowledge Representation and Defeasible Reasoning. Kluwer,Dordrecht, pp. 23–67.
Schubert, L., 1994. Explanation closure, action closure, and the Sandewall test suite for reason-ing about change. J. Logic Comput. (to appear).
Shoham, Y., 1988. Reasoning about Change. MIT Press, Cambridge, MA.Shoham, Y., Goyal, N., 1988. Temporal reasoning in AI, in: Shrobe, H. (Ed.), Exploring Artifi-
cial Intelligence. Morgan Kaufmann, Palo Alto, CA, pp. 419–438.Smith, C., 1991. The Parameter of Aspect. Reidel, Dordrecht.Song, F., Cohen, R., 1988. The interpretation of temporal relations in narrative, in: Proceedings
of the 7th National Conference of the American Association for Artificial Intelligence.pp. 745–750.
Stalnaker, R., 1968. A theory of conditionals, in: Rescher, N. (Ed.), Studies in Logical Theory.Basil Blackwell, Oxford.
Stalnaker, R., 1984. Inquiry. MIT Press, Cambridge, MA.Steedman, M., 1982. Reference to past time, in: Jarvella, R., Klein, W. (Eds.), Speech, Place,
and Action. Wiley, New York, pp. 125–157.Steedman, M., 1995. Dynamic semantics for tense and aspect, in: Proceedings of the 14th Inter-
national Conference on Artificial Intelligence. Montreal, QC, pp. 1292–1298.Stein, L., 1991. Resolving Ambiguity in Non-Monotonic Reasoning. PhD Dissertation, Brown
University, Providence, RI.Stone, M., 1994. The reference argument of epistemic must, in: Proceedings of the Inter-
national Workshop on Computational Semantics. Tilburg University, The Netherlands,pp. 181–190.
Taylor, B., 1977. Tense and continuity. Ling. Philos. 1, 199–220.Ter Meulen, A., 1984. Events, quantities, and individuals, in: Landman, F., Veltman, F. (Eds.),
Varieties of Formal Semantics. Foris, Dordrecht.Ter Meulen, A., 1986. Locating events, in: Groenendijk, J., de Jonge, D., Stokhof, M. (Eds.),
Foundations of Pragmatics and Lexical Semantics. Foris, Dordrecht.Thomason, R., 1970. Indeterminist time and truth-value gaps. Theoria 36, 246–281.Thomason, R., 1981. Deontic logic as founded in tense logic, in: Hilpinen, R. (Ed.), New Studies
in Deontic Logic. Reidel, Dordrecht.Thomason, R., 1991. Logicism, AI, and common sense: John McCarthys program in philo-
sophical perspective, in: Lipschitz, V. (Ed.), AI and Mathematical Theory of Computation:Papers in Honour of John McCarthy. Academic Press, New York, pp. 449–466.
Thomason, R., Gupta, A., 1980. A theory of conditionals in the context of branching time.Philos. Rev. 88, 65–90.
Turner, R., 1981. Counterfactuals without possible worlds. J. Philos. Logic 10, 453–493.Van Benthem, J., 1983. The Logic of Time. Kluwer, Dordrecht.Van Benthem, J., 1991a. General Dynamics. Theor. Ling. 16, 159–172.Van Benthem, J., 1991b. Language in Action. North-Holland, Amsterdam.

“25-ch21-0925-0970-9780444537263” — 2010/11/29 — 21:08 — page 969 — #45
Temporality 969
Van Benthem, J., 1995. Temporal logic, in: Gabbay, D., et al. (Eds.), Handbook of Logic inArtificial Intelligence and Logic Programming. Clarendon, Oxford.
Van Fraassen, B., 1971. Formal Semantics and Logic. Macmillan, New York.Veltman, F., 1983. Data semantics, in: Groenendijk, J., Janssen, M., Stokhof, M. (Eds.), Truth,
Interpretation, Information, GRASS 3. Foris, Dordrecht.Vendler, Z., 1967. Linguistics in Philosophy. Cornell University Press, Ithaca, NY.Verkuyl, H., 1972. On the Compositional Nature of the Aspects. Reidel, Dordrecht.Verkuyl, H., 1989. Aspectual classes and aspectual composition. Ling. Philos. 12, 39–94.Vlach, F., 1993. Temporal adverbials, tenses, and the perfect. Ling. Philos. 16, 231–283.von Wright, G., 1964. Norm and Action: A Logical Enquiry. Routledge and Kegan Paul,
London.von Wright, G., 1967. The logic of action – a sketch, in: Rescher, N. (Ed.), The Logic of Decision
and Action. University of Pittsburgh Press, Pittsburgh, PA.Webber, B., 1983. Logic and natural language. IEEE Comput. Special Issue on Knowledge
Representation, 43–46.Webber, B., 1988. Tense as discourse anaphor. Comput. Ling. 14, 61–73.Webber, B., Nilsson, N., 1981. Readings in Artificial Intelligence. Tioga, Palo Alto, CA.White, M., 1993. Delimitedness and trajectory of motion events, in: Proceedings of the 6th
Conference of the European Chapter of the Association for Computational Linguistics.Utrecht, pp. 412–421.
White, M., 1994. A Computational Approach to Aspectual Composition. PhD Dissertation,University of Pennsylvania, Philadelphia.
Whithead, A.N., 1929. Process and Reality. Macmillan, New York.Wilensky, R., 1983. Planning and Understanding. Addison-Wesley, Reading, MA.Winograd, T., 1972. Understanding Natural Language. Academic Press, New York.Zwarts, J., Verkuyl, H., 1994. An algebra of conceptual structure: an investigation into Jackend-
off’s conceptual semantics. Ling. Philos. 17, 1–28.
Further Reading
Asher, N., 1990. A default truth conditional semantics for the progressive. Ling. Philos. 15,469–598.
Brennan, V., 1993. Root and Epistemic Modal Auxiliary Verbs. PhD Dissertation, University ofMassachussets, Amherst, MA.
De Swart, H., 1991. Adverbs of Quantification: A Generalized Quantifier Approach. PhD Dis-sertation, Rijks Universiteit, Groningen.
Enç, M., 1986. Towards a referential analysis of temporal expressions. Ling. Philos. 9, 405–426.Heyting, A., 1956. Intuitionism: An Introduction. North-Holland, Amsterdam.Lewis, D., 1973b. Counterfactuals. Harvard Univ. Press, Cambridge, MA, pp. 556–567.Prior, A., 1967. Past, Present and Future. Clarendon Press, Oxford.Ter Meulen, A., 1995. Representing Time in Natural Language: The Dynamic Interpretation of
Tense and Aspect. MIT Press, Cambridge, MA.Vlach, F., 1981. The semantics of the progressive, in: Tedeschi, P., Zaenen, A. (Eds.), Syntax
and Semantics 14. Academic Press, New York.

“25-ch21-0925-0970-9780444537263” — 2010/11/29 — 21:08 — page 970 — #46
This page intentionally left blank

“26-ch22-0971-0988-9780444537263” — 2010/11/30 — 3:44 — page 971 — #1
22 Tense, Aspect, and TemporalRepresentation(Update of Chapter 21)
Henk VerkuylDe Lairessestraat 163HS, 1075 HK Amsterdam, The Netherlands,E-mail: [email protected]
22.1 Introduction
This chapter covers the decennium following Steedman (1997), and under the labelof temporality discusses aspectuality and tense mainly as operative at the sententiallevel, with matters of discourse structure being treated in other chapters. The chap-ter addresses the same domain, although it should be underlined that the two temporalnotions cannot be properly analyzed without taking their contribution to discourse intoaccount. The notion of aspectuality is used here as a term covering both predicationalaspect (often named Aktionsart and unhappily called lexical aspect) and grammaticalaspect. Predicational aspect pertains to situational types (eventualities) described bythe sentence; grammatical aspect expresses a temporal viewpoint necessary for giv-ing sentential information its proper place in a discourse, for example by indicatingwhether the sentence is about something that was going on or about something thatoccurred. In the last decennium no important paradigm shift has taken place, neither inthe domain of aspectuality nor in the domain of tense, so work that has been publishedis either a way of further exploring theoretical proposals, or a way to solve problemsraised by the current theory, or a testing of alternatives that are available. It is alsoimportant to see that on the comparative side much work has been done.1
22.2 Issues of Aspectuality
There is an interesting split between two sorts of linguistic reactions to the philosophi-cal quadripartition of the four aspectual classes—States, Activities, Accomplishmentsand Achievements—as proposed in Vendler (1957) and discussed in Steedman (1997).
1 This involves studies outside the domain of English and Slavic languages, such as Bittner (2008),Nurse (1999), Soh and Kuo (2005), Sybesma (2004), Tatevosov (2005), Van Geenhoven (1998), amongmany others. The bibliographical source for all sorts of research on tense and aspect is, of course:http://www.utsc.utoronto.ca/!binnick/old tense/BIBLIO.html
Handbook of Logic and Language. DOI: 10.1016/B978-0-444-53726-3.00022-0c" 2011 Elsevier B.V. All rights reserved.

“26-ch22-0971-0988-9780444537263” — 2010/11/29 — 21:09 — page 972 — #2
972 Handbook of Logic and Language
The first one is to apply it and to explain away the difficulties that arise with compo-sitionality by appealing to common knowledge about what the world looks like. Thisstrategy, which turns out to be quite popular, will be dealt with in §22.2.1 and in§22.2.2. The second one, discussed in §22.2.3, is to follow compositionality as strictlyas possible in order to see what this yields, in an attempt to discover the way in whichlanguage encodes temporal information. By discussing the two ways of dealing withsituational types, it will be possible to show underlying assumptions that play a rolein the linguistic study of temporality.
22.2.1 Aspectual Classes
Vendler’s quadripartition is built up from two oppositions: (a) instant vs. interval; and(b) definiteness vs. indefiniteness.2 The opposition between an instant and an intervalsets States and Achievements apart from Activities and Accomplishments. It raisesthe question: can one make this difference visible by isolating semantic elements thatare sensitive to the absence or presence of a point (or interval)? Is information aboutan instant or a stretch lexically encoded in language units expressing it? Does it, forexample, determine an aspectual difference between (1a) and (1b)?
(1) a. Mary discovered a letter.b. Mary wrote a letter.
If this question is straightforwardly answered as asserting that the lexical meaning ofa verb may express aspectual information of this sort, ontology is nearby indeed. Notmany scholars are put off by this and they label discover as an Achievement verband write as an Accomplishment verb and see this distinction as aspectually relevant.3
This position has a price to pay: by assigning a meaning element [+point] to thepoint-verb discover one is forced into assuming that one has an interval-verb discoverin sentences like (2), because obviously they assign a complex structure to Mary’sdiscoveries.
(2) a. Mary discovered letters of her father by browsing his library.b. Mary discovered (gradually) that her husband had a secret life.
Linguists do not like to have two verbs discover, so one is forced into assuming a basicpoint-meaning for discover and into assuming rules that “coerce” the point-verb intoan interval use not unsimilar to interval-verbs like write. Indeed, those who acceptVendler’s classes, generally also assume coercion.4 This ensures the possibility of
2 For detailed analyses of the Vendler classes and their underlying parameters, see Verkuyl (1993), van Valinand LaPolla (1997), Rothstein (2008); see also: Levin and Rappaport Horav (1998), Rappaport Hovav(2008).
3 Rothstein (1999), Kearns (2003), Piñón (1997), van Valin and LaPolla (1997), Ter Meulen (1995), amongmany others.
4 De Swart (1991), Moens and Steedman (1987), Kamp and Reyle (1993), Pustejovsky (1991), amongothers. On the delicate balance between compositionality and coercion, see Partee (2007).

“26-ch22-0971-0988-9780444537263” — 2010/11/29 — 21:09 — page 973 — #3
Tense, Aspect, and Temporal Representation 973
Preparatory phase
Culmination
Consequent state
I II III
Figure 22.1 Phasal structure.
maintaining Vendler’s classification on the basis of lexical information and implicitlyit provides the basis for seeing the four classes as logical types.
The second opposition underlying Vendler’s classification opposes States andActivities to Accomplishments and Achievements. For the latter two classes it resultsin the aspectual event structural scheme in Figure 22.1 proposed in Moens andSteedman (1988) and also occurring in Steedman (1997).5 It comes quite close to com-mon sense physics: it is not unnatural to accept a paraphrase of an Accomplishmentsentence like (1b) Mary wrote a letter in which the event talked about had somethinglike a preparatory phase before the letter was completed and in which there is a sort ofresult state after the letter had been written. The same is said to apply to Achievementsentences like Mary reached the top in which the preparatory phase may even consistof “the stages of climbing, having lunch or whatever, leading to the culmination ofreaching the top” (Moens and Steedman, 1988:4).
Moens and Steedman’s notion of consequent state has been used in the treatment ofthe Present Perfect in Kamp and Reyle (1993:558). The Perfect is taken to operate oneventualities of any aspectual type mapping onto a state because in their view Perfectsentences are stative. So, for sentences like (3) they define a function perf yielding aconsequent (or result) state directly following the culmination point.
(3) Mary has written the letter.(pres)(perf)(Mary write the letter)
The DRT-box accounting for this is given in Figure 22.2. The formula s ! t expressesthat the time identified as “now” (by t = n) overlaps with a state s and the formulae"# s ensures that s directly follows the event “Mary write the letter”.
A crucial question here is: how is the culmination point in (3) encoded in language;and how the preparatory phase; and how the consequent state? Is this all a matter ofthe lexical semantics of verbs like write? Or does the letter also contribute to the senseof culmination? If culmination means “the attainment of the highest point” in what-ever figurative sense, which constituent in (3) does contribute this meaning element:Mary, write, a or letter? And if it is formed at a higher level, which meaning elementforces one into introducing the notion of an increase ending in a final result? These are
5 Steedman replaces the term Culmination in Moens and Steedman (1988) by the term Event and underlinesthat the whole scheme can be seen as reflecting an Accomplishment, but also that each of its elementsmay occur as an independent aspectual class (Preparatory phase : Activity, Consequent State : State,and Culmination : Achievement but also, by extension, Culmination : Accomplishment). This multipleuse of Figure 22.1 is due to its being closely connected to an aspectual coercion scheme; see Steedman(1997:903).

“26-ch22-0971-0988-9780444537263” — 2010/11/29 — 21:09 — page 974 — #4
974 Handbook of Logic and Language
n e s t x y
t = nMary(x)
the-letter(y)s ! t
e "# se: write(x,y)
Figure 22.2 Mary has written the letter.
not irrelevant questions. One may not exclude that the metaphor of culmination itselfdictates notions like preparatory phase and consequent state rather than that some spe-cific meaning element can be held responsible for it. Is encoding semantic informationa matter of metaphor? Evading the metaphor of culmination point (or telicity) seemsto characterize the second reaction to Vendler’s proposal as discussed in §22.2.3.
22.2.2 Event Semantics
The box in Figure 22.2 displays so-called Davidsonian event semantics in a DRT-notation. Davidson (1980) proposed a three-place predicational format in (4) for (tense-less)sentenceslike(3)bygivingthetwo-placepredicate“Write”anextraargument-placefor events.
(4) $e[Write(m, the letter, e)]
In this way, one can easily account for the inference relation between (5a) and (5b)and between (5a/b) and (3).
(5) a. Mary wrote the letter in the bathroom at midnighta%. $e[Write(m, the letter, e) & In(e, bathroom) & At(e, midnight)]b. Mary wrote the letter in the bathroom.
One way to capture the notion of culmination discussed in §22.2.1 formally is the oneproposed in the so-called neo-Davidsonian tradition that developed fully in the 1990son the basis of Parsons (1990) and that has continued to be an important line of thoughtin the present decennium. The Davidsonian part of it is the decision to quantify overevents; the “neo-part” of it is the decision to analyze sentences like (3) as in (6):
(6) $e[Write(e) & Subj(e, m) & Obj(e, the letter) & Cul(e, t)]
Here the arguments of the verb write are detached from the predicate and takenas fulfilling a role in the event structure.6 Aspectually, the predicate Cul expresses
6 One also uses predicates like Agent (instead of Subj) and Patient (instead of Obj). For collections ofpapers using neo-Davidsonian tools, see Rothstein (1998), Higginbotham et al. (2000), Verkuyl et al.(2005), among others. For a thorough evaluation of the Davidsonian and the neo-Davidsonian approach,see Landman (2000).

“26-ch22-0971-0988-9780444537263” — 2010/11/29 — 21:09 — page 975 — #5
Tense, Aspect, and Temporal Representation 975
the information that the predication expressed by (3) is terminative (or telic). TheCul-predicate has a stative counterpart Hold as in the representation (7) for Mary car-ried the letter:
(7) $e[Carry(e) & Subj(e, m) & Obj(e, the letter) & Hold(e, t)]
The neo-Davidsonian tradition has become a major force in the domain of temporalitybecause it offers the advantages of first-order logic in the representation of complexinformation. In particular, the logical forms in both traditions are quite apt to accountfor the logical inferences of sentences like (5). Apart from that, it should also be under-scored that for the analysis of discourse, eventualities are very handy tools becausefrom a macro point of view they function as atomic particles to which all sorts ofinformation can be attached. From the micro point of view of structural semantic ana-lysis, representations like (6) and (7) raise the question of how much room is left forMontague’s leading idea of compositionality. Culmination as a predicate does not rep-resent complex information built up from components present in different parts of thesentence. The same applies to Hold. Here one meets the problem of getting beyondthe level of observational adequacy.7
22.2.3 Aspectual Composition
In Verkuyl (1993), Verkuyl et al. (2005) a sort of informal feature algebra is used inwhich a verbal feature [±addto] and a nominal feature [±sqa] yield complex phrasefeatures as shown in (8).
(8) a. [s Mary [vp wrote the letter]][+tS [+sqa] [+tVP [+addto] [+sqa]]] ' terminative
b. [s Mary [vp wrote letters]][(tS [+sqa] [(tVP [+addto] [(sqa]]] ' durative
c. [s No one here [vp wrote the letter]][(tS [(sqa] [+tVP [+addto] [+sqa]]] ' durative
d. [s Mary [vp expected the letter]][(tS [+sqa] [(tVP [(addto] [+sqa]]] ' durative
The feature [+addto] sets non-stative verbs expressing progress in time apart fromstative verbs labeled [(addto]. The nominal feature [+sqa] assigned to the NPand built up from its determiner and its Noun, indicates that its referent is discrete,delineated, delimited, quantized or whatever informal term one may use to pertain toa specified quantity of entities indicated by the N of the NP. The feature algebra leadsto the formulation of the Plus-principle saying that one minus-value at a lower levelis sufficient to yield a [–T] at the S-level, which means that the sentence in questionis durative. In other words, (8b) is durative because the NP letters is a bare plural
7 For a detailed criticism of the Hold- and Cul-predicates, see Verkuyl (1999:ch.1.3) and for problemswith respect to inferencing from monotone decreasing counterparts of (5a) to sentences with less or zeroadverbials, see Verkuyl (1993: 245–251).

“26-ch22-0971-0988-9780444537263” — 2010/11/29 — 21:09 — page 976 — #6
976 Handbook of Logic and Language
[±sqa] [–sqa] [+sqa]
[+add to][–add to]
State Process Event
Figure 22.3 Construal of three aspectual classes.
lacking a determiner that contributes to insulating a specified quantity, (8c) is durativebecause the first argument no one here prevents the NP from referring to a countableunit having the effect of a multiplication (0 ) a = 0), and (8d) is durative because theverb lacks the semantic element expressing progress in time. The algebra characterizesterminativity in (8a) as the marked aspectual category [+T] requiring three plusses.
The feature algebra in (8) can be used to create an aspectual tripartition into States,Processes and Events as shown in Figure 22.3. The classification in Figure 22.3 differsessentially from Vendler’s classification in the sense that sentence (1a) Mary discov-ered a letter is taken as expressing an event just like (1b) Mary wrote a letter, whereassentence (2a) Mary discovered letters of her father by going through his library maybe taken as describing a process in which she discovered letters.
The approach connected with schemes like (8) is essentially quantificational inthe sense that temporal information expressed by the verb is combined with quan-tificational information contributed by nominal elements such as noun phrases. Thehigher level information [±sqa] and [±t] is composed of semantic information con-tributed by different sources in the phrase structure.8 The difference between Vendler’sclassification and the above tripartition is that the latter does away with the opposi-tion between point and interval as aspectually relevant in favor of an opposition inwhich quantificational information plays a role. By so doing it places discretenenessas opposed to continuity as an essential feature of aspectual information in the fore-ground.9
This is an interesting controversy leading to questions like: is the differencebetween the three eventualities in (9) is a matter of length or not? And: is there anaspectually relevant difference between the sentences in (1a) Mary discovered a letterand (1a) Mary wrote a letter or not?
(9) a. He broke a window.b. He broke 50 windows.c. He broke windows.
8 The scheme in (8) captures distinctions made by Comrie (1976), Bach (1986), Mourelatos (1978), amongothers. A mereological formalization of the compositionality scheme (8) has been proposed in Krifka(1989). The feature algebra underlying it has been given an interpretation in terms of generalized quan-tification in Verkuyl (1993).
9 An interesting work discussing these issues from a mereological and a philosophical point of view is Link(1998).

“26-ch22-0971-0988-9780444537263” — 2010/11/29 — 21:09 — page 977 — #7
Tense, Aspect, and Temporal Representation 977
If so, then (9b) and (9c) are more similar to one another than (9a) and (9b) becausethey take more time so that [+point] should be assigned to the first one and [+interval]to the second and the third. One may even argue that extensionally it is possible for(9b) and (9c) to apply to the same situation so that (9c) can be taken as more sloppya description than (9b). Linguistically, however, one is forced to group (9a) and (9b)because they behave similarly in certain contexts, such as exemplified in (10).
(10) a. #For hours he broke a window.b. #For hours he broke 50 windows.c. For hours he broke windows.
In other words, they contain quantificational information which in interaction withthe verbal information groups them together. This fact has nothing to do with ourknowledge of the world, but rather with a way of structuring information. In the samevein, discovering a letter in (1a) takes generally less time than writing a letter in (1b).Aspectually this is not relevant just as the sentence She dialed the wrong number hasnot changed aspectually during the period in which turning a dial has been replaced bytechnological innovations like pressing buttons or even just one button. If a discoverytakes more time than the writing of a letter, nothing changes aspectually.
Structural semantics, i.e. semantics at the level at which the information contributedby different lexical units comes together, is of course highly determined by the lowerlevel information, including our knowledge of the world as stored in lexical units. Onthe other hand, one should observe that the interaction between atemporal information(coming from the NP) and temporal information (coming from the Verb) is governedby principles that are non-lexical. One cannot deny that speakers have disposal ofthe concept of a point, so that they may be inclined to speak about a point event ifthey have to characterize the verbs die, explode, burst, stumble, etc. But from thisprototypical conceptualization of the meaning of these verbs it does not follow thatthis translates into a meaning element concerning length in order to distinguish point-events from interval-events.
22.2.4 Events or Perspective?
It is interesting to see how happy a research community can be if it decides to drawa line after which an insight becomes standard and before which nothing seems tohave happened. Davidson (1980) is such a case of becoming a standard. It arguesfor allowing quantification over event variables and so life began for events, mind-ful of Quine’s slogan “to be is to be the value of a variable”. Right before Davidson,Reichenbach (1947) was the one who spoke about quantification over events and hewould have been the father of event semantics rather than Davidson, had he not com-mitted a logical impurity. But in fact, what Reichenbach aimed at in an intriguingsection “The problem of individuals” (1947: 266–274) was not finding an ontology ofevents—what he did was rather to work out the idea of a perspective: one may shiftfrom a thing-type perspective to an event-type perspective and vice versa, dependenton needs determined by discourse. He warned against “an unfortunate absolutism incertain philosophical systems” (p. 273).

“26-ch22-0971-0988-9780444537263” — 2010/11/29 — 21:09 — page 978 — #8
978 Handbook of Logic and Language
Reichenbach’s plea for taking into account a perspectival shift as a part of seman-tic interpretation got lost under the event-semantical avalanche following Davidson(1980) and Parsons (1990) briefly described in §22.2.2. Otherwise, one could havemade more room for the basic linguistic need to let language users operate lenientlyin view of their cognitive organization. In other words, rather than allowing eventsas hard-core entities “that are (always) out there”, one could say that language usersdispose of the capacity to use more abstract units in dealing with temporality.
One possibility is to use numbers. Discreteness (and hence countability) can beexpressed by natural numbers or integers, continuity and density by rational and/orreal numbers. The question that arises is then, of course: why should we treat aspec-tual information in terms of a more abstract distinction than, say, the distinction bet-ween states and events? An answer is: this may be better because at a more abstract(supra-) ontological level one may account for perspectival shift without being ham-pered by early ontological commitments.
The underlying issue can be made clear by giving an example. In Reichenbach(1947: 288) we find the sentence The point of reference is here the year 1678, wherehere refers back to a quotation from the writer T.B. Macaulay in which the sentence In1678 the whole face of things had changed . . . appeared. For Reichenbach the notionof point is as lenient as one should have it, namely as both a point and an interval.In other words, as a speaker of natural language Reichenbach compresses an intervalbecause the year 1678 certainly can be compressed into a point after which he is ableto blow up the point 1678 to an interval, when necessary, from a certain point of view.
One way to come close to what Reichenbach is doing in his explanation of thenotion “point of reference” is to consider what happens if one construes natural num-bers as sets, while making use of their status as individuals. Partee et al. (1990:75f.)sketches a method to treat the numbers 0, 1, 2, 3, . . . as sets. In other words, the num-ber 3 is taken as a set with 0, 1 and 2 as its elements. If we say that 3 * 4 (“3 pre-cedes 4”), we say that on one perspective 3 < 4 and in the other perspective 3 # 4,because {0, 1, 2} # {0, 1, 2, 3}. In this way, an opposition between point and intervalas assumed by Vendler becomes even more dubious because it might be central to ourlanguage capacity to switch from point to interval and from interval to point dependenton the perspective that we want to express. If so, one of the two parameters underlyingVendler’s quadripartition would no longer be available.
Preparing the ground for the treatment of tense in the next section, let us supposenow that the operator perf assumed by Kamp and Reyle (1993) in (3) was defined asin (11), where the index k is the eventuality index (comparable with Reichenbach’s E)and the index j represents the present of k under the assumption that all events have apresent in which their so-called running time, roughly equivalent to k (but see below),is located.
(11) perf := !"!j%$k["[k] & k * j%]
Then (11) says that the eventuality k precedes its present j in the sense that it is anearlier part of j, in the same sense in which 2 is an “earlier part” of 3 and this morning

“26-ch22-0971-0988-9780444537263” — 2010/11/29 — 21:09 — page 979 — #9
Tense, Aspect, and Temporal Representation 979
is an earlier part of today. The precedence symbol * as a connective between indicesgeneralizes over the use of the symbols “<” and #, for example in 3 < 4 and 3 # 4.
Suppose now that the tense operator pres in (3) expresses that the present i of thespeaker/hearer is synchronous to the present j of the eventuality k. Then it follows thatk is located in the present i forming an earlier part of i. This is a very natural wayof looking at things although the notion of present is no longer the floating point ofspeech but rather a temporal domain containing it. Note that there would no longer be areason for thinking of perf in terms of introducing an aspectual consequent state. Theeventuality index k is in its own present j and this present j turns out to be synchronouswith the present i of speaker and hearer so that they experience k as belonging to theirown present. Again, this illustrates what it means to operate on the language side: whathappened today so far is presented in English and Dutch as belonging to the present iof the speaker/hearer only if one makes use of the Present tense form. This diminishesthe need to appeal to aspectual information as a way to distinguish Past and PresentPerfect. In other words, we hit on a sort of trade-off between a theory of aspectualityand a theory of tense: Germanic languages have abolished the aspectual Perfective infavor of Perfect as belonging to one of the tense oppositions.
The use of a Past tense form in (12) can thus be seen as presenting the eventual-ity as belonging to a Past domain separated from the present of speaker and hearereven if k is located today. In both sentences (12) the eventuality itself precedes thepoint of speech but in (12a) the use of the Past tense form embeds the index k ina domain j that is not synchronous to the present index i and hence not directlyaccessible.
(12) a. I saw him todayb. I have seen him today
In (12b) the eventuality k is simply located in an earlier part j of today and directlyaccessible because i and j are synchronous. At this point the term “accessible” is beingused intuitively, but below it will be clarified in discussing tense more systematically.One of the crucial issues to be discussed will be the notion of present.
22.3 Tense
Steedman (1997) gives a detailed account of Reichenbach’s tense system including ananalysis of its strong and weak points. So there is no need to repeat that informationhere and therefore §22.3.1 will only pay attention to two attempts to escape from theinadequacies of a ternary system, that is, a system in which time is fundamentally par-titioned into three domains. Therefore the present section will make room consideringa serious binary alternative to Reichenbach’s ternary system in §22.3.2. Binary tensesystems are proposed and/or discussed in Te Winkel (1866), Comrie (1985), Lindstedt(1985), Vikner (1985) and more recently in Verkuyl (2008), which has formalized TeWinkel’s original ideas.

“26-ch22-0971-0988-9780444537263” — 2010/11/29 — 21:09 — page 980 — #10
980 Handbook of Logic and Language
Table 22.1 Two Crossing Tripartitions.
A: Speaker-Based B: Event-BasedOrdering + Ordering +
Earlier than R < S (past) E < R (anterior)Simultaneous with R = S (present) E = R (simple)Later than S < R (future) R < E (posterior)
22.3.1 Reichenbach’s Ternary Tense System
Reichenbach’s 3)3-matrix is based on two tripartitions displayed in Table 22.1 whichexpress relations between temporal units assumed to be “out there” independently oflanguage. The two tripartitions are: (A) Past vs. Present vs. Future; and (B) Anteriorvs. Simultaneous vs. Posterior. This yields a matrix with nine cells.
Obviously, this creates problems for English, which is generally assumed to haveeight tense forms. Reichenbach accounts for only seven of them. There are a lot ofother problems with his proposal but in spite of these Reichenbach (1947) still countsas the standard system due to the fact that he enriched the traditional analysis of tenseby introducing an auxiliary point of reference R which is intermediate between thepoint of speech S and the point of event E by attuning the two tripartitions.10
Two issues have determined the discussions in the past decennium. One importantline of research during the update decennium has been the exploration of the idea of anExtended Now, as a correction on Reichenbach’s S. The other line of research focusseson the need of having what has become known as a topic time as a modification of thenotion of reference time R or an enrichment of the tense system with an extra point.
The notion of Extended Now is developed by McCoard (1978) on the basis ofBryan (1936) and drawn into formal semantics by Dowty (1979). It became quitepopular at the end of the 1990s in the circle of students around von Stechow.11
It involves two ingredients: (a) a time unit t is taken as n; and (b) an interval i isanchored in n and stretched back from the present n into the past to which the predica-tion expressed by the sentence is applied. The intuition behind the notion is to make asort of bridge between the sense of pastness (of the eventuality described by the pred-ication) and the sense of present relevance. It is given a formal place, for example, inthe definition of the German Present Perfect in (13) as proposed in Rathert (2003).12
(13) [[pres(perf)(")]] = 1 iff $t , I[t = n & $k , I[k "# t & "[k]]]
Ingredient (a) is made visible in t = n and ingredient (b) is given the form of the abut-relation "#. The definition in (13) locates the index k of the predication as abutting
10 For a survey of problems with Reichenbach’s system, see Verkuyl (2008).11 von Stechow (1999), Musan (2001), Rathert (2003), among others.12 For convenience, symbols that have been used so far in the index-formalism will be used in Rathert’s
formulas as well: n rather than Rathert’s s-, etc.

“26-ch22-0971-0988-9780444537263” — 2010/11/29 — 21:09 — page 981 — #11
Tense, Aspect, and Temporal Representation 981
to n. In this way a new sort of present is created: the Extended Now. For English,Rathert proposes (14).
(14) [[pres(perf)(")]] = 1 iff $t , I[t = n & $k , I[k ". t & "[k]]]
In this way she accounts for a difference between the German and English PresentPerfect: German excludes n from the Extended Now interval, English includes it byhaving ".. Essential for this approach is that n is considered as the present and thatthe extension of this point is a sort of operation on n.
The other correction on Reichenbach’s system is the notion of topic time as developedin Klein (1992, 2000) and in work based on it such as Bohnemeyer and Swift (2004)and Lin (2006). Klein defines the topic time as “the time span to which the claim madeon a given occasion is constrained” (p. 535). In the case of a sentence like When hechecked the cellar, the door was open the topic time of the sentence The door was openwould be the time in which he checked the cellar. It makes the time outside the topictime irrelevant for the predication, because the door could have been open before andafter the checking of the cellar, but that does not matter for the interpretation of thisparticular sentence. In this way, Klein’s notion is a correction on Reichenbach’s notionof point of reference, but in general Klein remains in the Reichenbachian framework.Klein explicitly allows the time of the eventuality to contain the topic time, in particularwhen the situation time is a state. This makes the notion of topic time quite differentfrom what has been discussed in §22.2.4 above as the present j of an eventuality:whatever topic time is, it is always properly included in j and hence different.
22.3.2 A Compositional Binary Tense System
The nineteenth century Dutch linguist L.A. te Winkel proposed a binary tense systemthat does not meet the difficulties haunting Reichenbach’s approach. There are threeimportant features making his system superior to Reichenbach’s 3 ) 3-system: (i) itis compositional in the formal semantic sense; (b) it provides indices (= the auxiliarypoints) as part of the system itself because each of the three oppositions introducesthem; (c) its perspective is on the language side in the sense that the use of a certaintense form reveals how the information is being encoded.13
Te Winkel (1866) used three oppositions accounting for the eight Dutch tenseforms:
1. Present (i ! n) - Past (i < n)2. Synchronous (i / j) - Posterior (i < j)3. Incompleted (k 0 j) - Completed (k * j)
13 For an extensive discussion of the (hybrid) binary systems proposed in Comrie (1985) and Lindstedt(1985) leading to the conclusion that Te Winkel’s system does not suffer from the Reichenbachian incon-sistencies in the two proposals, see Verkuyl (2008). It also discusses languages having less than eighttenses (Russian, Chinese) and languages having more than eight tenses (Bulgarian, French, Georgian)and it argues that a binary approach turns out to be more fruitful in dealing with them than a ternaryapproach.

“26-ch22-0971-0988-9780444537263” — 2010/11/29 — 21:09 — page 982 — #12
982 Handbook of Logic and Language
Due to the three steps in which these are built up, there are more auxiliary pointsavailable: n stands for the point of speech, i for the index involved in locating n inthe present of the speaker/hearer or in their past, j for the index relating the even-tuality information to i or not, and k for the information about how the (tenseless)eventuality index relates to its present j. As said earlier, rather than being taken as anevent variable in the sense of event semantics, k may be taken as an abstract num-ber. In this way, one can stay clear from ontologically driven implications followingfrom event semantics, in particular from its mereological adventures based on “naivephysics”.
A natural consequence of seeing j as the present for the eventuality index k is toconsider i as the present domain for speaker/hearer. Continuing that line of thought onecan now interpret the connective between j and i as expressing a relation between twosorts of present. If j / i holds, the present of the eventuality is considered synchronousto the present of the speaker/hearer, due to i ! n. This accounts for the Present Perfectas a tense making the present of the eventuality synchronous to the present of thespeaker/hearer. In the case of the Past Perfect the indices j and i are synchronous butneither overlaps with n, due to i < n.
Reduced to a bare minimum the formalism employed says, for instance, that thePresent Perfect in sentences like (3) Mary has written the letter is to be representedas: k * j & j / i & i ! n, where k * j accounts for completedness of the eventuality,j / i for synchronicity between the index j associated with k and the index i providinginformation about n, and i!n for the embedding of the point of speech n in the domaini considered as the present for the speaker and hearer. In other words, the eventualityindex k is properly embedded in its present j which is synchronous to the domainindexed by i of which the point of speech n is a part. The Simple Past in (15) wouldbe characterized as k 0 j & j / i & i < n, saying that the eventuality index k is smallerthan or equal to j (one is underinformed about this) which is synchronous to i whichis anterior to n.
(15) Mary wrote the letter
Note that the sense of pastness expressed in (15) is due to the first opposition i < n.Metaphorically, the Imperfect can be seen as the “camera-view” on what happened:i < n “brings us back” to a present-in-the-past, say i%, that is said to be synchronous tothe domain j in which k is located. With respect to j no information is given about thecompletedness of k, so with the lack of information to the contrary one may assumethat the eventuality indexed by k was going on.
In (3) Mary has written the letter the k * j-information can be seen as a pictureshot: it locates the eventuality in the earlier part of the present. It follows that Per-fect and Imperfect tense information should be seen as contributing to text structurebecause both types of view presume larger units than a single sentence sui generis. Italso follows that the difference between Perfect and Imperfect is quite different fromthe difference between Perfective and Imperfective: in Germanic languages the latteropposition concerns the nature of the predication associated with k itself, whereas theformer provides information about the way a predication is made part of the larger

“26-ch22-0971-0988-9780444537263” — 2010/11/29 — 21:09 — page 983 — #13
Tense, Aspect, and Temporal Representation 983
discourse. In this way, Te Winkel’s binary system can be argued to do better thanReichenbach’s ternary system.
An important consequence of having the second opposition Synchronous/Posterioris that there is no longer a notion of the future as being bound to the point of speechso that the present i serves as the domain containing posteriority. This means that n istaken as the floating dividing line between the actualized part of the present domaini, called ia, and the not-yet-actualized part of i, called i!. This means that insteadof saying that i < j holds, one has to say that ia < j holds (the actualized part of thepresent is anterior to j), or equivalently: j 0 i!. This applies also to Past Posterior tensein Mary would write the letter, where the position of n is mirrored by its counterpartn% in the past (the then-point-of-speech, so to say). It means that there is no futureoutside the present i in languages where the Present/Past-opposition determines thetense system.
As to the last remark, the distinction between i and n in i ! n and i < n makes itpossible to see i as an n-dependent present. Therefore it is possible to see i in i < n asthe then-present in the past containing its own virtual point of speech n%. This insightis based on one of the characterizing features of Te Winkel’s original system: the par-allelism between any four tense forms in an opposition with respect to the other four.Formally, the binary system connects the pair 1k, j2—the eventuality and the present inwhich it occurs—with the pair 1i, n2, the present connected with speaker/hearer eitherdirectly via i!n or indirectly via i < n. In the latter case, i is the virtual then-present inthe past. The connection between the two pairs is made by the pair 1 j, i2 as an interme-diate dimension. The room for the matching of two sorts of present ( j and i) cruciallyfollows from the three available oppositions. In this way, the notion of present can bedefined in terms of the need to eliminate past structure.
In the binary system sketched above both the notions of Extended Now and topictime are incorporated in notions that follow automatically from the way in which theoppositions are defined: the Extended Now notion still clings to the idea that the pointof speech is the real now and it says that one should extend that notion. In the binarysystem, the notion of present applies to a temporal domain containing n. A similarremark holds for the notion of topic time: given the index j as the present of an even-tuality which may or may not be matched to the present i of the speaker/hearer, there isno need for a notion used to overcome the shortcomings of the Reichenbachian pointof reference R.
The distinction between two sorts of present, one for the speaker/hearer and one forthe eventuality, turns out to be quite natural in view of the fact that languages having anAorist tense can be argued to belong to the group of languages where the n of speakerand hearer does not occur as part of the available tense configurations, whereas theabsence or gradual disappearance of the Aorist from the system is a feature of lan-guages that position the speaker and hearer in the computational center. This wouldmean that apart from the three oppositions mentioned above, there seems to be roomfor a fourth binary opposition between Now-bound languages and Not-Now-boundlanguages. The latter seem to be on the retreat in the sense that languages with anAorist tense have developed tense forms in which the speaker and hearer are directly

“26-ch22-0971-0988-9780444537263” — 2010/11/29 — 21:09 — page 984 — #14
984 Handbook of Logic and Language
involved. This penetration of Now-bound-configurations into the system inevitablyhas led to a sort of Darwinian reshuffle of tense forms: they have to conquer their ownplace in the resulting system at the cost of disappearing. In French, for example, thePassé Simple has practically disappeared from spoken language to the benefit of thePassé Composé and the Imparfait, which have been subjected to a process of restruc-turing the semantic space in the domain left by the Passé Simple.14 In Georgian, ahighly synthetic language, three analytic tense forms have appeared some three cen-turies ago in which the 1i, n2-pair of a Now-bound system is central, as a result ofwhich the Aorist had to find its own niche in order to survive. Aorist forms are notalways on the defensive side: the Spanish counterpart of the French Passé Simple hasobtained the primary place in spoken language at the cost of the counterpart of theFrench Passé Composé.
22.4 Preparing for Discourse
Chapters 3 and 4 provide information about the role of tense and aspect in discoursestructure. In general, the contribution of the tense and aspect of a particular propo-sition "i is seen as providing links to temporal information in the discourse chain"0 . . . "i(1 . . . "i+1 . . . "n. There seems to be a broad consensus about the way tempo-ral information from "i is to be packaged: generally all major semantic theories dealingwith this problem—DRT, Situation Semantics and Dynamic Predicate Logic—reducethe number of three or four aspectual classes to two: States/Activities and Events.Event sentences are said to move the story line forward by making a next step, whereassentences expressing states and activities provide background information so that thestory line is not moved forward.
Now, all approaches just mentioned seem to assume that it is aspectual informationthat decides whether or not a new step is made in the flow of discourse information:events are identified as [+T] and so there is a step forward, states and activities aretaken as [(T], so there is no step forward. This looks very much like an equipollentopposition. Even though this seems a reasonable position, one cannot escape from awarning against its simplicity because the aspectual opposition itself is not equipol-lent. There are good arguments for assuming that [+T]-predications are marked andthat [(T] is an aspectual “garbage can”, as argued for in Verkuyl (1993). If the oppo-sition between [+T] and [(T] is indeed not equipollent, one may expect that [(T]-predications do not always contribute the opposite of [+T]-information.
This point can be demonstrated with the help of observations discussed byTer Meulen (1995; 2000) in explaining her theory of Dynamic Aspect Trees asdeveloped on the basis of Seligman and Ter Meulen (1995). The architecture of therepresentation consists of nodes introduced by sentences making up a discourse. Con-sider the sentences in (16).
14 Cf. Corblin and de Swart (2004: part III) for detailed analyses of the French tense forms.

“26-ch22-0971-0988-9780444537263” — 2010/11/29 — 21:09 — page 985 — #15
Tense, Aspect, and Temporal Representation 985
(16) a. Jane patrolled the neighborhood (hole). She noticed a car parked in an alley (plug)b. Jane turned the corner (plug). She noticed a car parked in an alley (plug).c. Jane was turning the corner (Prog sticker). She noticed a car parked in an alley
(plug).
The theory differentiates between a hole (instruction: in the case of processes remainat the current node, so [–T]), a plug (instruction: in the case of accomplishments andachievements go to the next plug, so [+T]) and a sticker (instruction: in the caseof stative information add it to existing nodes).15 In (16a), the event of the secondsentence is embedded in the hole-situation, in (16b) the plug-node triggers a step toa (discrete) next plug node and in (16c) the noticing of the car is embedded in theturning of the corner. In this respect, Ter Meulen explains what the other discoursetheories do in their terms.
However, consider the sentences in (17). All discourse theories mentioned earlierwill treat (17a) the way in which Ter Meulen treats it: its second sentence is a simplecontinuation of the present state.
(17) a. Jane patrolled the neighborhood. She didn’t notice the car parked in an alleyb. Jane patrolled the neighborhood (hole). Jane turned the corner (plug). She did not
notice the car parked in an alley (plug) and turned the next corner (plug)
Due to negation the stative nature of the third sentence in (17b) does not prevent itfrom being interpreted as applying to something that took place after Jane had turnedthe corner and before she turned the next corner. The speaker presents her not-noticingthe car as an event of the same kind as her noticing the car in (16a): it expresses aplug, in Ter Meulen’s terms, in a series of similar information pieces. It does not seemcorrect to say that She did not notice the car parked in an alley is to be treated here ascontributing state-information because it cannot be seen as information about Jane’sturning of the corner. Rather it applies to a discrete eventuality in between two otherevents that are part of her patrolling the neighborhood—in particular, the event of hermissing information about the car—in spite of its [–T]-information. This suggests thatit is not yet really well-established how, and how much, aspectual information fromatomic predications making up a discourse is involved in structuring it.
22.5 Conclusion
This chapter aims at providing information about the continuation of mainstreamresearch on temporality, but it also tries to discuss alternatives that have been avail-able in the past decennia. One major issue seems to be the question of how muchontology is allowed in dealing with matters of aspectuality. Dependent on the answersgiven, it seems as if a plea for a stricter form of compositionality automatically reducesthe role of ontology as it manifests itself in lexical semantics. Perhaps one shouldadd that from the methodological point of view a stricter compositional option looks
15 In this respect, Ter Meulen seems to make use of the tripartition in Figure 22.3.

“26-ch22-0971-0988-9780444537263” — 2010/11/29 — 21:09 — page 986 — #16
986 Handbook of Logic and Language
more attractive in the sense that it is more vulnerable in terms of predictions that aremade.
This chapter also pays attention to what can be considered a typical linguisticapproach to tense, namely a binary approach in terms of oppositions that carry theindices playing a role in determining temporal location. This alternative to Reichen-bach, dating back to the pre-structuralist period, appears to give more room to tenseas a factor in the cognitive organization of temporal information.
One of the factors playing a role in the alternatives under discussion is an increasein the importance of the role of perspective. Tense information and aspectual informa-tion seem to be encoded as ways to shape perspective. In general, this chapter shouldbe seen as an attempt to sharpen the distinction between tense and aspect as much aspossible before allowing them to interact diffusely.
References
Bach, E., 1986. Natural language metaphysics, in: Barcan-Marcus, R., Dorn, G.J., Weingartner,P. (Eds.), Logic, Methodology and Philosophy of Science VII. North-Holland, Amsterdam,pp. 573–595.
Bittner, M., 2008. Aspectual universals of temporal anaphora, in: Rothstein, S. (Ed.), The-oretical and Crosslinguistic Approaches to the Semantics of Aspect. John Benjamins,Amsterdam, pp. 349–385.
Bohnemeyer, J., Swift, M., 2004. Event realization and default aspect. Ling. Phil. 27, 263–296.Bryan, W., 1936. The preterite and the perfect tense in present-day English. J. English and
German Philol. 35, 363–382.Comrie, B., 1976. Aspect. Cambridge Textbooks in Linguistics. Cambridge University Press,
Cambridge.Comrie, B., 1985. Tense. Cambridge Textbooks in Linguistics. Cambridge University Press,
Cambridge.Corblin, F., de Swart, H. (Eds.), 2004. Handbook of French Semantics. CSLI Lecture Notes,
vol. 170. CSLI Publications, Stanford, CA, Ch. 15: ‘Meaning and Use of Past Tenses inDiscourse’ and Ch. 16: ‘Tense, Connectives and Discourse Structure’.
Davidson, D., 1980. The logical form of action sentences, in: Essays on Actions and Events,(third Ed.). Clarendon Press, Oxford, pp. 105–148, [Paper 1967].
De Swart, H., 1991. Adverbs of Quantification: A Generalized Quantifier Approach. PhD thesis,Rijksuniversiteit Groningen, Groningen, published by Garland, New York, 1993.
Dowty, D., 1979. Word Meaning and Montague Grammar. The Semantics of Verbs and Timesin Generative Semantics and in Montague’s PTQ. Synthese Language Library, vol. 7.D. Reidel Publishing Company, Dordrecht.
Higginbotham, J., Pianesi, F., Varzi, A.C. (Eds.), 2000. Speaking of Events. Oxford UniversityPress, New York, Oxford.
Kamp, H., Reyle, U., 1993. From Discourse to Logic. Introduction to Modeltheoretic Seman-tics of Natural Language, Formal Logic and Discourse Representation Theory. Studies inLinguistics and Philosophy, vol. 42. Kluwer Academic Publishers, Dordrecht.
Kearns, K., 2003. Durative achievements and individual-level predicates on events. Ling. Phil.26, 595–635.
Klein, W., 1992. The present perfect puzzle. Language 68, 525–552.

“26-ch22-0971-0988-9780444537263” — 2010/11/29 — 21:09 — page 987 — #17
Tense, Aspect, and Temporal Representation 987
Klein, W., 2000. An analysis of the German perfect. Language 76, 358–383.Krifka, M., 1989. Nominal reference, temporal constitution, and quantification in event seman-
tics, in: Bartsch, R., van Benthem, J., van Emde Boas, P. (Eds.), Semantics and ContextualExpression. Foris, Dordrecht, pp. 75–115.
Landman, F., 2000. Events and Plurality: The Jerusalem Lectures. Studies in Linguistics andPhilosophy, vol. 76. Kluwer Academic Publishers, Dordrecht.
Levin, B., Rappaport Horav, M., 1998. Building verb meanings, in: Butt, M., Geuder, W. (Eds.),The Projection of Arguments: Lexical and Compositional Factors. CSLI Publications,Stanford, CA, pp. 97–134.
Lin, J.-W., 2006. Time in a language without tense. J. Semant. 23, 1–53.Lindstedt, J., 1985. On the Semantics of Tense and Aspect in Bulgarian. Slavica Helsigiensia,
Helsinki.Link, G., 1998. Algebraic Semantics for Natural Language. CSLI Lecture Notes, vol. 100. CSLI
Publications, Stanford, CA.McCoard, R.W., 1978. The English Perfect. Tense Choice and Pragmatic Inferences. North-
Holland, Amsterdam.Moens, M., Steedman, M., 1987. Temporal ontology in natural language, in: Proceedings of
the 25th Annual Meeting of the Association for Computational Linguistics. ACL, StanfordUniversity, pp. 1–7.
Mourelatos, A.P., 1978. Events, processes and states. Ling. Phil. 2, 415–434.Musan, R., 2001. Narrowing down the Extended Now, in: Féry, C., Sternefeld, W. (Eds.),
Audiatur Vox Sapientiae. A Festschrift for Arnim von Stechow. Akademie Verlag, Berlin,pp. 372–391.
Nurse, D., 1999. Tense and aspect in great lakes bantu languages, in: Hymen, L., Hornbert,J.-M. (Eds.), Recent Advances in Bantu Historical Linguistics. CSLI Publications,Stanford, CA, pp. 517–544.
Parsons, T., 1990. Events in the Semantics of English. A Study of Subatomic Semantics. CurrentStudies in Linguistics Series, vol. 19. The MIT Press, Cambridge, MA.
Partee, B.H., 2007. Compositionality and coercion in semantics: the dynamics of adjectivemeaning, in: Bouma, G., Krämer, I., Zwarts, J. (Eds.), Cognitive Foundations of Inter-pretation. Royal Netherlands Academy of Arts and Sciences, Amsterdam, pp. 145–161.
Partee, B.H., ter Meulen, A., Wall, R. E., 1990. Mathematical Methods in Linguistics. Studiesin Linguistics and Philosophy, vol. 30. Kluwer Academic Publishers, Dordrecht.
Piñón, C. J., 1997. Achievements in an event semantics, in: Lawson, A. (Ed.), Proceedings fromSemantics and Linguistic Theory, Vol. VII. SALT, Ithaca, NY, pp. 276–293.
Pustejovsky, J., 1991. The syntax of event structure. Cognition 21, 47–81.Rappaport H.M., 2008. Lexicalized meaning and the internal temporal structure of events,
in: Rothstein, S. (Ed.), Theoretical and Crosslinguistic Approaches to the Semantics ofAspect. John Benjamins, Amsterdam, pp. 13–42.
Rathert, M., 2003. Textures of Time. The interplay of the Perfect, Durative Adverbs, andExtended-Now-Adverbs in German and English. PhD thesis, Universität Tübingen,Tübingen.
Reichenbach, H., 1947. Elements of Symbolic Logic. The Macmillan Company, first free presspaperback edition 1966 edition, NewYork.
Rothstein, S. (Ed.), 1998. Events and Grammar, Studies in Linguistics and Philosophy, vol. 70.Kluwer Academic Publishers: Dordrecht, Boston, London.
Rothstein, S., 1999. Derived accomplishments and lexical aspect, in: Gueron, J., Lacarme, J.(Eds.), The Syntax of Time. The MIT Press, Cambridge, MA, pp. 539–553.

“26-ch22-0971-0988-9780444537263” — 2010/11/29 — 21:09 — page 988 — #18
988 Handbook of Logic and Language
Rothstein, S., 2008. Telicity, atomicity and the Vendler classification of verbs, in: Rothstein,S. (Ed.), Theoretical and Crosslinguistic Approaches to the Semantics of Aspect. JohnBenjamins, Amsterdam, pp. 43–78.
Seligman, J., Ter Meulen, A.G., 1995, Dynamic aspect trees, in: Polos, M. (Ed.), Applied Logic:How, What and Why? D. Reidel Publishing Company, Dordrecht, pp. 287–320.
Soh, H.L., Kuo, J.Y.-C., 2005. Perfective aspect and accomplishment situations in mandarinChinese, in: Verkuyl, H., de Swart, H., van Hout, A. (Eds.), Perspectives on Aspect, Studiesin Theoretical Psycholinguistics, vol. 32. Springer, Dordrecht, pp. 199–2167.
Steedman, M., 1997. Temporality, in: van Benthem, J., ter Meulen, A. (Eds.), Handbook ofLogic and Language. Elsevier, Amsterdam, pp. 895–938.
Sybesma, R., 2004. Exploring Cantonese tense, in: Cornips, L., Doetjes, J. (Eds.), Linguisticsin the Netherlands 2004, vol. AVT21. John Benjamins Publishing Company, Amsterdam,pp. 169–180.
Tatevosov, S., 2005. From habituals to futures; discerning the path of diachronic development,in: Verkuyl, H., de Swart, H., van Hout, A. (Eds.), Perspectives on Aspect. Studies inTheoretical Psycholinguistics, vol. 32. Springer, Dordrecht, pp. 181–197.
Te Winkel, L., 1866. Over de wijzen en tijden der werkwoorden. De Taalgids 8, 66–75.Ter Meulen, A., 1995. Representing Time in Natural Language. The Dynamic Interpretation of
Tense and Aspect. A Bradford Book. The MIT Press, Cambridge, MA, London.Ter Meulen, A.G., 2000. Chronoscopes: The dynamic representations of facts and events, in:
Higginbotham, J., Pianesi, F., Varzi, A.C. (Eds.), Speaking of Events. Oxford UniversityPress, New York, Oxford, pp. 151–168.
Van Geenhoven, V., 1998. Semantic Incorporation and Indefinite Descriptions. Semantic andSyntactic Aspects of Noun Incorporation in West Greenlandic. Dissertations in Linguistics.CSLI Publications, Chicago, IL.
van Valin, R., LaPolla, R., 1997. Syntax: Structure, Meaning and Function. Cambridge Univer-sity Press, Cambridge, MA.
Vendler, Z., 1957. Verbs and times. Philos. Rev. 66, 143–160.Verkuyl, H.J., 1993. A Theory of Aspectuality. The Interaction between Temporal and Atem-
poral Structure. Cambridge Studies in Linguistics, vol. 64. Cambridge University Press,Cambridge, MA.
Verkuyl, H.J., 1999. Aspectual Issues. Studies on Time and Quantity, vol. 98. CSLI LectureNotes. CSLI Publications, Stanford, CA.
Verkuyl, H.J., 2008. Binary Tense. CSLI Lecture Notes, vol. 187. CSLI Publications, Stanford,CA.
Verkuyl, H.J., de Swart, H., van Hout, A. (Eds.), 2005. Perspectives on Aspect. Studies in The-oretical Psycholinguistics, vol. 32. Springer, Dordrecht.
Vikner, S., 1985. Reichenbach revisited: one, two or three temporal relations? Acta Linguist.Hafniensis 19, 81–95.
von Stechow, A., 1999. Eine erweiterte Extended-Now theorie für perfekt und futur. Zeitschriftfür Literaturwissenschaft und Linguistik 113, 86–118.

“27-ch23-0989-1034-9780444537263” — 2010/11/30 — 3:44 — page 989 — #1
23 Plurals and CollectivesJan Tore Lønning!
Department of Informatics, P.O. Box 1080 Blindern, N-0316 Oslo,Norway, E-mail: [email protected]
Commentator: G. Link
23.1 Introduction
Plural is a grammatical notion. Common nouns in English are customarily sorted intotwo classes, mass nouns and count nouns. Count nouns, like child, cat, car, thought,apply to discrete objects which can be counted. These nouns have a singular and a plu-ral form, e.g., child–children. Intuitively, the singular noun denotes one object, whilethe plural noun denotes two or more objects. Mass nouns, like ink, stuff, informa-tion, apply to non-discrete stuff, substances, abstract entities, etc. They only occur inthe singular, and the determiners they take are different from the ones taken by thecount nouns, e.g., much water, two liters of water, *an information. Many nouns occurin both classes; hence it has been proposed to consider the distinction to be betweennoun occurrences rather than between lexical items (Pelletier, 1975).
Collective, in contrast, we will use as a semantic notion. It applies to the meaningof certain occurrences of plural NPs as in the following examples.
(1) a. Bunsen and Kirchoff laid the foundations of spectral theory.b. The Romans conquered Gaul.c. The students gathered.d. The disciples were twelve in number.e. The soldiers surrounded the Alamo.f. Some girls gathered.g. Three thousand soldiers surrounded the Alamo.
The first sentence does not say that Bunsen laid the foundations of spectral theoryand that Kirchoff did it, even though they both contributed. This contrasts with thesentences (2a), (2c), and (2d).
(2) a. Armstrong and Aldrin walked on the moon.b. Armstrong walked on the moon and Aldrin walked on the moon.c. Six hundred tourists visited the castle.d. Some of Fiorecchio’s men entered the building unaccompanied by anyone else.
*Thanks to the Research Council of Norway for partial support, grants no 102137/520 and 101335/410.
Handbook of Logic and Language. DOI: 10.1016/B978-0-444-53726-3.00023-2c" 2011 Elsevier B.V. All rights reserved.

“27-ch23-0989-1034-9780444537263” — 2010/11/29 — 21:09 — page 990 — #2
990 Handbook of Logic and Language
Sentence (2a) says the same as (2b); (2c) is true if each one of six hundred touristsvisited the castle; while (2d) has, according to Quine (1974), a reading upon which itis true if some of Fiorecchio’s men each entered the castle only accompanied by otherof Fiorecchio’s men. We will call the most prominent reading of the plural NPs in (1)collective and the reading of the plural NPs in (2a), (2c), (2d) distributive.
The framework of modern logic, as developed by Frege and others in the secondhalf of the last century, was able to analyze large parts of natural language. But itwas soon observed that there are phenomena which are not easily accommodated. Infact, the problems to which the collectively read plural NPs gave rise were discussedalready in letters between Frege and Russell in 1902, where the examples (1a) and(1b) can be found (Frege, 1980, p. 140).
The goal of this chapter is to discuss how a logical approach to natural languagesemantics best should be modified and extended to accommodate collective pluralNPs. Distributive plural NPs and mass nouns will be considered to bring out the sim-ilarities and differences between them and the collective plural NPs. The emphasiswill be on the reportive uses, while generic uses will be more or less ignored becauseof lack of space. (For bare plurals and genericity, see Pelletier and Asher (1996),Carlson (1977), Link (1991), Carlson and Pelletier (1995).) Moreover, there will notbe much room for discussing the interactions of plurality and other phenomena, likeanaphora or tense. Finally, emphasis will be on English and closely related languages.Other languages may behave quite differently. There are languages with three differ-ent numbers – dual in addition to singular and plural – and languages with no numbersat all.
Most proposals for the semantics of plurals assume some sort of collections –objects denoted by phrases like Bunsen and Kirchoff and the soldiers and ascribedproperties like surrounding the castle. We will allow ourselves from the beginningto talk about collections as existing objects in a pretheoretical way, and return to thequestion on whether we can do without them in Section 23.6. There are two mainviews on the status of collections. One is to consider them to be higher-order individ-uals, Section 23.3, the other is to consider them to be first-order individuals similar tothe ones described by singular NPs, Section 23.4.
23.2 Setting the Stage
23.2.1 The Rules of the Game
23.2.1.1 Ontology
Our task is to give a formal semantic analysis. We start with recollecting some of theassumptions underlying such an approach. We assume some sort of first-order logicalanalysis of a core of English containing singular NPs. Central to such an analysis isthe concept of a (first-order) model. It consists of a domain, E, and an interpretationfunction, [[ · ]], which ascribes denotations to the words. The denotation of a name orvariable is a member of E, [[ john]] ! E, the denotation of a predicate (unary relation)

“27-ch23-0989-1034-9780444537263” — 2010/11/29 — 21:09 — page 991 — #3
Plurals and Collectives 991
is a subset of E, [[Girl]] " E, the denotation of a binary relation symbol is a relationover E, [[Kiss]] " E # E, etc.
Inherent to the concept of a first-order model is a certain minimal ontology, thechoice to model the world as a set of individuals and properties as sets of individuals.One task in the sequel will be to extend this ontology to the collective plural NPs.This is not a purely ontological task, however, the starting point should be language.The question will be, what sort of objects are needed as denotations for such and suchphrases, in our case, the plural phrases.
Each particular first-order model is intended to reflect one particular state of affairs.In addition, it models the meaning of the individual words. The underlying ontologyis in a sense weak. It allows models where a book is on and under the same table at thesame time. This does not reflect a possible state of affairs. The model concept of formalsemantics is carried over from logic. The tasks of logic and of semantics are partlydifferent. Logic studies inferences which are valid from structure alone, independentlyof ontology and the meaning of words. But in the study of the semantics of English, itseems legitimate to take into consideration the meaning of words like under and on.The strategy chosen in formal semantics has been to split semantics into two parts, thelogical part which is captured in terms of what counts as a legal first-order model, andthe lexical semantic part which in some way or other tries to exclude the unintendedmodels. When extending the framework to plural NPs, a reemerging question will beexactly which phenomena are the formal semantics expected to answer and which canbe said to belong to the realm of lexical semantics.
23.2.1.2 Compositionality
The model contains the assignment of denotations to a finite vocabulary. The goal forthe formal semantic theory is to show how the denotation of infinitely many differentsentences and other phrases can be constructed from this finite base. For this some sortof systematic recursive rules are needed.
Logical languages, like first-order logic, have well defined compositional seman-tics. By representing sentences from natural language in such a calculus, their meaningmay be spelled out. But this spells out the meaning of the sentence in terms of the partsof the logical formula representing it, not in terms of the parts of the sentence itself.Montague (1973) showed how one could ascribe a systematic semantics to parts ofEnglish in a direct way, similarly as for logic (cf. Janssen, 1966; Partee, 1966). Healso showed that exactly the same could be achieved through a systematic transla-tion into a logical calculus containing lambda abstraction. The logical language wouldthereby contain terms corresponding to the phrases of the natural language.
The analysis of a natural language sentence may be more complex than that ofa logical formula. In particular, one and the same sentence, e.g., Every man lovesa woman, may have several readings thanks to differences in scope. Moreover, thestudy of anaphoric phenomena has revealed a more complex relationship between lan-guage and its interpretation currently investigated in the different dynamic approachesto semantics. In this chapter we will assume a static interpretation in the spirit of

“27-ch23-0989-1034-9780444537263” — 2010/11/29 — 21:09 — page 992 — #4
992 Handbook of Logic and Language
Montague and consider how it must be modified and extended to accommodate thecollective readings. Most of what we will say here may be combined with a dynamicapproach, while there are phenomena where plurality and dynamicity interact, in par-ticular with respect to plural anaphora (cf. Kamp and Reyle, 1993, for an extensivetreatment).
23.2.1.3 Logic
After proposing possible frameworks, it will be time for studying their formal proper-ties. In this respect plurals differ from several other semantic phenomena. Plural logicdid not establish itself as a field similarly to, say, modal logic. When the semantics ofplurals were developed after 1970, most of the logical tools, as set theory, algebraicstructures, higher-order logic, were already developed for more basic foundationalstudies in logic and the task for the semanticist became more to choose between thesetools than to actually build them.
But there is another aspect to this history. Even though set theory, type theory,higher-order logics etc., were developed to yield a foundation to logic and mathema-tics and not to ascribe a formal semantic analysis to natural language, they were notdeveloped in a vacuum. The intuition which the logicians and philosophers wanted toformalize could already be expressed (more or less vaguely) in natural languages, andthe plural NPs were vital. Thus Russell (1919) introduces the chapter on classes bysaying that “In the present chapter we shall be concerned with the in the plural: [ . . . ]”(p. 181). Hence some of the most fundamental questions in logic have all along beeninterwoven with the question of what the plural NPs mean.
23.2.2 Plurals, But Not Collective
As mentioned in the introduction, not all plural NPs are read collectively. Some behavesemantically similarly to the singular ones.
(3) a. All boys like to sing.b. Every boy likes to sing.c. Some boys like to sing.d. Some boy likes to sing.
Sentence (3a) and (3b) say the same. In this context, all boys may be interpreted bya universal individual quantifier. Similarly, (3c) and (3d) say nearly the same; thedifference may be that (3c) claims that at least two boys like to sing. This can beexpressed in first-order logic by formula (4a).
(4) a. $u$v (u %= v & Boy(u) & Boy(v) & Sing(u) & Sing(v))b. !X!Y [$u$v (u %= v & X(u) & X(v) & Y(u) & Y(v))]
A compositional Montagovian analysis can be achieved by ascribing some in con-texts like (3c) the interpretation (4b). Alternatively, one may extend the representationlanguage with a constant SOMEPL of type ((e, t), ((e, t), t)) with the interpretation[[SOMEPL]](P)(Q) = t if and only if |P ' Q| ( 2.

“27-ch23-0989-1034-9780444537263” — 2010/11/29 — 21:09 — page 993 — #5
Plurals and Collectives 993
By introducing more constants of type ((e, t), ((e, t), t)), which combine with termsof type (e, t) to generalized quantifiers of type ((e, t), t), we can similarly interpretother distributive plural NPs in sentences like (2) and (5):
(5) a. Most girls like to sing.b. At least five thousand girls like to sing.c. More girls than boys like to sing.
Here a possible interpretation of most is [[MOST ]](P)(Q) = t if and only if |P ' Q| >
|P ' Q|. For more on the interpretation of generalized quantifiers ranging over thebasic domain E (see Keenan and Westerståhl, 1996).
23.2.3 Collectively Read NPs
Which plural NPs may be read collectively, and in which contexts do they get thisreading? The following rough classification of the singular NPs can serve as a usefulbackground:
! Proper nouns: Mary, John, Rome.! Other definite noun phrases: The girl, John’s car, my nose.! Indefinite noun phrases: A girl, one of John’s friends.! Proper quantifiers: Every girl.
This classification can be done on a mixture of syntactic and semantic criteria. It ismeant to be theory neutral and should not be taken as a claim that definite or indefiniteNPs shall not be considered to be quantifiers, but it is compatible with such an analysis.
The following is a similar rough first classification of the plural NPs which admit acollective reading.
! Proper nouns: Simpsons, Torkelsons.! Other definite noun phrases: The girls, John’s cars, my two ears.! Bare plural NPs: Apples, boats.! Other indefinite noun phrases: Some girls, two of John’s friends.! Conjoined noun phrases: Ann and Mary, John and two of his friends.
The plural proper nouns may behave similarly to the plural definite descriptions, e.g.,The Torkelsons bought a boat. Notice also that a name can be conceived as singular,say as the name of a TV series, even though it is morphologically plural. The otherplural definite NPs are quite similar to the singular definite NPs, except for the number.In addition, the plural NP may contain words which restrict the size of its denotation,say a numeral like two.
A singular indefinite NP has to contain a determiner in English, while a pluralindefinite NP may be bare as in John ate apples or Wolves attacked him. (Bare pluralswill not be covered in this chapter. See Link (1991) for a comprehensive discussion.)The indefinite NP may also contain a numeral similarly to the definite NP, e.g., twoapples, or another determiner, e.g., some apples.
In addition, when two NPs are conjoined, the result requires plural agreement andis classified as a plural NP accordingly. It may be read collectively, as indicated in

“27-ch23-0989-1034-9780444537263” — 2010/11/29 — 21:09 — page 994 — #6
994 Handbook of Logic and Language
sentence (1a). This is the case whether the conjuncts are definite or indefinite, singularor plural.
The NPs which may be read collectively may also be read distributively, in partic-ular if such a reading is forced by an explicit adverb, like (6c), (6d).
(6) a. Three girls brought a cake.b. Ann and Mary brought a cake.c. Cocke, Younger and Kasami independently discovered the algorithm.d. They wrote a paper each.
What about the other direction? Can all plural NPs be read collectively? For an NPwith the determiner many or few a distributive reading is clearly preferred as seen in(7a) in contrast to an NP where the determiner is a numeral and where a collectivereading is preferred (6a).
(7) a. Many girls brought a cake.b. Many girls gathered.
But these determiners can also occur in contexts where only a collective reading ispossible, as in (7b), in which case they have to be read collectively. When it comes todeterminers which cannot be read as specifying the size of a set, but which is inher-ently relational, like most, it seems even harder to find contexts where they may beread collectively, i.e. where Most girls " is read something like There is a group Xcontaining most girls and X ". But we will not totally exclude the possibility that itcan be used in a setting where only a collective reading is possible. Thus it seems hardto specify a fixed class of NPs which may be read collectively. Rather, it seems thatsome NPs are easily read collectively, while others may only be read collectively incontexts where other readings are impossible or highly unlikely.
As far as we can see, there is no plural determiner which does the same for thecollections as every does for individuals, i.e. a determiner which imposes a readingcorresponding to (8a).
(8) a. Every collection of boys lifted the stone.b. Every two persons resemble each other.c. Three bananas cost 50 cents.d. A banana costs 20 cents.
There are, however, constructions which may entail a universal quantification overcertain classes of collections, in particular classes of a certain specified size, (8b).Moreover, a reading similar to the universal one may, in certain cases, be obtainedby other constructions. In particular, one may observe a “nearly universal” use of theindefinite plural NP, as in sentence (8c), which resembles a similar use of the singularindefinite NP as in sentence (8d).
Nor do the other plural determiners impose generalized quantifiers ranging overcollections. The plural NP most girls cannot mean most collections of girls. Either itis read distributively, saying that most girls individually have a certain property, or,in rare cases, it may be read collectively, saying that a certain collection consistingof most girls has a certain property. See Link (1987) for more on the possibility ofquantifiers ranging over collections.

“27-ch23-0989-1034-9780444537263” — 2010/11/29 — 21:09 — page 995 — #7
Plurals and Collectives 995
There is a class of nouns which do not fit into what we have said so far, “wordswhich denote a unit made up of several things or beings which may be countedseparately” (Jespersen, 1924, p. 195), family, crew, crowd, committee, army, nation,mob, etc. In traditional grammar, the word collective is used for these words. As wehave used this word for other purposes, we will call them group-denoting. In somerespects, the group-denoting nouns in the singular behave like other words in the plu-ral. In particular, they may in the singular combine with properties which are otherwiseonly ascribed to collective plural NPs, and they may show plural agreement in BritishEnglish.
(9) a. The girls meet in secret.b. *The girl meet(s) in secret.c. The group meet in secret.
In other respects, these words behave like other nouns, they may themselves be plural-ized and quantified the groups/every group. Moreover, they do not generate distribu-tive readings in the same way as the plural NPs do.
(10) a. *The family own two cars each.b. The members of the family own two cars each.
Whether a plural NP actually is read collectively or not is to a large degree deter-mined by the context. There are several different possibilities for how the contextinteracts with the NP.
Collective properties are properties which entail some sort of collectivity andthereby triggers a collective reading. They can be further divided into three types.
! Simple collective properties, like met in secret, collided. These can combine withindefinite and definite plural NPs as well as conjoined NPs and induce an unam-biguous collective reading. They may also combine with singular group-denotingnouns and with definite and indefinite plural group-denoting nouns. In the last case,the result is ambiguous, The groups met in secret.
! Relational collective properties, like are friends, love each other. These behaveas the simple collective properties except that they cannot be combined with group-denoting nouns in the singular and they are unambiguous if combined with group-denoting nouns in the plural.
! Cardinal collective properties, like are many, are twelve in number. They do notcombine with the group-denoting nouns in the singular, nor with simple conjoinedNPs, *John and Harry are many. Even the indefinite NPs are odd with them, ?Somegirls are twelve in number, while they do combine with definite plural NPs.
Ordinary properties. These fall into two groups.
! Properties like bought a house, lifted five stones which are ambiguous whencombined with the definite and indefinite plural NPs and with conjoined NPs, butunambiguous when combined with singular NPs including the group-denoting NPsin the singular.

“27-ch23-0989-1034-9780444537263” — 2010/11/29 — 21:09 — page 996 — #8
996 Handbook of Logic and Language
! Properties which do not seem to be ambiguous like slept, likes to sing, wroteoperas. These combine with all NPs. Some of them may seem odd when combinedwith some group-denoting NPs for reasons that have to do with the meanings ofthe words. Observe also that the ordinary properties which are ambiguous may bedisambiguated by adding an adverb, between them/each. The result may be a pro-perty which only combine with a plural NP which may be read collectively. But atthe same time the resulting sentence is read distributively, ate an apple each.
23.3 Higher-Order Approaches
23.3.1 Ontology
The founding fathers of logic, Frege and Russell, did not restrict logic to first-order,but included higher-order variables and quantifiers as well. In such a setting, the firstapproach to the semantics of the collectives is evident. Let the students denote thesame set of individuals as student denotes in other contexts and let gather and to betwelve in number be second-order properties. Then the sentences (1c) and (1d), can berepresented as (11a) and (11b).
(11) a. GATHER(Student)b. TWELVE(Disciple)
Here GATHER and TWELVE are second-order predicates, each denoting a set of setsof individuals. This proposal can be traced back at least to Russell (1903), cf. also thequotation from Russell (1919) cited above. To take into consideration the assumptionof the use of the plural definite description, the Russellian representation would be(12a) where TM(") is shorthand for (12b), where x and y are variables not occurringin ".
(12) a. GATHER(Student) & TM(Student)b. $x$y ("(x) & "(y) & x %= y)
If one thinks that the claim that the collection consists of at least two individuals israther presupposed than stated, one may accommodate for it in other ways. This is notessential for the discussions in the sequel, and we will mostly skip the claim in (12)and stick to the simpler representations as in examples (11).
Russell did little more than hint on such an interpretation. But it is easy to see thatit may also be extended to other collectively read plural NPs. Thus the sentences (1e),(1f ) and (1g) can be represented by (13a), (13b), and (13c), where THREETH is asecond-order predicate representing three thousand, while SURR denotes a relationbetween sets of individuals and individuals.
(13) a. SURR(Soldier, alamo)
b. $X (X " Girl & TM(Girl) & GATHER(X))
c. $X (X " Soldier & THREETH(X) & SURR(X, alamo))
Here and throughout (" " #) in a formula is shorthand for )x("(x) * #(x)), where xis a variable not occurring in " or #. For constants, the typeface convention followed

“27-ch23-0989-1034-9780444537263” — 2010/11/29 — 21:09 — page 997 — #9
Plurals and Collectives 997
is to write names of individuals in all lower-case, relations between individuals startswith a capital and the rest is in lower-case, while relations where one or more of thearguments are first-order predicates are typed in all capitals. Greek letters are used asmetavariables irrespectively of type.
23.3.2 Compositionality
The interest for more systematic semantic rules emerged in the late sixties, in particularby the work of Richard Montague (1973) (cf. Partee, 1966). In 1974 two PhD Thesisappeared presenting similar ideas for interpreting collectively read plurals (Bennett,1975; Hausser, 1974). Some related ideas were also presented by Bartsch (1973). Thecommon core of Bennett and Hausser’s proposals is the following. If we are to extendPTQ (Montague, 1973) with plural NPs, we need two new categories, the distribu-tively read plural NPs with the same semantic type as the singular NPs, ((e, t), t), andthe collectively read plural NPs with type (((e, t), t), t). Other categories will corre-spondingly need several entries as summed up in the table. We simplify and assume apurely extensional version of PTQ.
Singular orPlural Distributive Plural Collective
NP ((e, t), t) (((e, t), t), t)VP (e, t) ((e, t), t)CN (e, t) (e, t)Det ((e, t), ((e, t), t)) ((e, t), (((e, t), t), t))
All forms and occurrences of a CN get the same denotation. The part of the NP whichyields the difference between the collective and the distributive interpretation is theDet. The following examples should suffice to illustrate how this works. The deter-miners are combined with plural CNs.
Distributive Collective
((e, t), ((e, t), t)) ((e, t), (((e, t), t), t))Some !X!Y[TM(X ' Y)] !X!Y[$Z(Z " X & TM(Z) & Y(Z))]Six !X!Y[SIX(X ' Y)] !X!Y[$Z(Z " X & SIX(Z) & Y(Z))]The !X!Y[TM(X) & X " Y] !X!Y[TM(X) & Y(X)]The six !X!Y[SIX(X) & X " Y] !X!Y[SIX(X) & Y(X)]
Here "'# is shorthand for !z["(z)&#(z)], while TM is true of a set of cardinality atleast two, as in (12). First-order variables are in lower caseand second-order variables

“27-ch23-0989-1034-9780444537263” — 2010/11/29 — 21:09 — page 998 — #10
998 Handbook of Logic and Language
are capitals, as usual, while third-order variables (sets of sets of individuals) are incalligraphic capitals.
The distributive interpretation of some is the same interpretation as we consideredin Section 23.2.2. By expressing both readings syntactically in terms of TM, one mayrecognize the common semantic core of the two. The determiner consisting of thesimple numeral six can be handled similarly. We assume the simple numeral six isread as exactly six. This is correct for the collective reading; observe that a group ofexactly six men bought a boat does not exclude that also other men bought boats. Forthe distributive reading, it has been discussed whether an exactly or at least readingbest captures the simple numeral. If one prefers an at least reading, the relationshipbetween the collective and the distributive readings would be less direct.
The same noun may occur as the head of a collective or a distributive NP while theverbs are lexically marked for collectivity vs. distributivity. Some verbs are inherentlydistributive, like run, and will always be of type (e, t), whether it is in the singular orin the plural. Other verbs will be inherently collective, like gather, and can only occurin the plural with the collective type ((e, t), t). There are four different categoriesof transitive verbs according to whether the subject NP and the object NP are readcollectively or distributively. The picture gets even more complicated by the fact thatsome verbs may belong to several categories. While kiss and love are distributive inboth argument places, the subject NP of surround has to be collective, while the objectNP can be either collective or distributive. A verb like applaud belongs, according toBennett, to all four classes.
In addition, Bennett considered group-denoting nouns. The nouns themselves areintroduced as of a new category, corresponding to the type ((e, t), t), and they canoccur both in the singular and the plural. Thus the sentences (14a), (14b), (14c) can beinterpreted as (14d), (14e), (14f ), respectively.
(14) a. A group gathered.b. Three groups gathered.c. The groups gathered.d. $X (GROUP(X) & GATHER(X))
e. three(GROUP ' GATHER)
f. )X (GROUP(X) * GATHER(X))
Here three is of type (((e, t), t), t) saying that a set of sets has cardinality three.The way to achieve these readings is by allowing the collective VPs of type ((e, t), t)to occur in the singular with the same semantics as when they occur in the plural.In addition, to each determiner resulting in a singular NP or a distributive pluralNP, i.e. of type ((e, t), ((e, t), t)), there is a corresponding determiner “one levelup”, i.e. of type (((e, t), t), (((e, t), t), t)), with a parallel semantics. For example,three when combined with a collective noun in the plural will have the interpretation!X!Y[three(X ' Y)].
This approach to the group-denoting nouns explains why they may combine withverbs that otherwise only combine with plural NPs read collectively. But it doesnot include a collective reading of the group-denoting nouns themselves. Both (14b)and (14c) have collective readings, which are not captured. Already Hausser (1974)

“27-ch23-0989-1034-9780444537263” — 2010/11/29 — 21:09 — page 999 — #11
Plurals and Collectives 999
noticed this problem and did for this reason not include group-denoting nouns in hisfragment. Another problem is to say exactly what the identity conditions for a groupor committee is. Should it be identified with the set of its members as this approachassumes? Bennett (1977) himself later raised doubts about it when it came to the moreintentional ones, like committee.
23.3.3 Logic
23.3.3.1 Second-Order Logic
How much of higher-order logic is actually needed to represent plural NPs? Firstobserve that the !-abstraction of second- and higher-order variables is a tool for com-position. In the end result they may be #-converted and will disappear. The extensionsof first-order logic which will remain in the representations of full sentences are quan-tification over second-order variables as in the examples (13) and first-order lambdaabstraction as inexample (15).
(15) a. The men that love Mary gathered.b. GATHER(!x[Man(x) & Love(x, mary)])
We will in this section disregard the group-denoting nouns. So far we have been abit sloppy with the logical notation, mixing elements from different frameworks. Wewill now be precise and give a definition for a sufficient tool, choosing a relationalvariant of second-order logic. We refer to the following types:
Definition 23.3.1 (SOLID types).
(a) 0 is a type.(b) +0, is a type.(c) For any n, +$1, $2, . . . , $n, is a type, if each $i equals 0 or +0,.
Strictly speaking, (b) is a special case of (c). We will write 1 for +0,.
Definition 23.3.2 (SOLID). A similarity type X is a set of constants where eachconstant belongs to exactly one type from some finite set of SOLID types. TheSecond-order language for representing indefinite and definite collective NPs(SOLID) of similarity type X is defined as follows:
(a) The constants in X are terms of the corresponding type. There is a designated constant, andterm, =, of type +0, 0,.
(b) Variables of type 0: x, y, z, x1, y1, . . . are terms of type 0.(c) Variables of type 1: X, Y, Z, X1, Y1, . . . are terms of type 1.(d) If R is a term of type +$1, $2, . . . , $n, and t1, t2, . . . , tn are terms with ti of type $i for
i = 1, . . . , n then R(t1, t2, . . . , tn) is an (atomic) formula.(e) If % and & are formulas then so are (% & &), (% - &) and (¬%).(f ) If % is a formula and v a variable of type 0, $v % and )v % are formulas.(g) If % is a formula and V a variable of type 1, $V % is a formula.(h) If % is a formula and v a variable of type 0, v̂[%] is a term of type 1.

“27-ch23-0989-1034-9780444537263” — 2010/11/29 — 21:09 — page 1000 — #12
1000 Handbook of Logic and Language
We will call a term of the form v̂[%] a set term. This set abstraction will take theplace of the !-abstraction in examples like (15) and is included to give a direct repre-sentation of the definite plural NPs without the use of second-order quantifiers. Thenthe semantics:
Definition 23.3.3. A standard structure for a SOLID language L is a pair, +E, [[·]],,where E is non-empty and [[·]] is an interpretation function such that
(a) E0 = E.
(b) For each type +$1, $2, . . . , $n,, E+$1,$2,...,$n, = Pow(E$1 # E$2 # · · · # E$n), in particular,E1 = Pow(E).
(c) If " is a constant of type $ , then [["]] ! E$ .
A variable assignment, g, maps variables of type 0 to elements in E0, and variablesof type 1 to elements in E1. The interpretation [[%]]g of the expression % with respectto the assignment g is standard with respect to atomic formulas, the propositional partand quantifiers. Set abstraction is interpreted by:
(16) [[v̂[%]]]g = {a ! E | [[%]]gva
= t}
Second-order logic is a giant extension of first-order logic. A lot more can be saidwithin second-order logic than within first-order logic, and a lot less can be said aboutit, as summed up in the following theorem.
Theorem 23.3.1. SOLID is not compact, does not have any complete axiomatization,and does not satisfy the Skolem-Löwenheim properties with respect to the standardstructures.
A proof for this and other interesting properties of second-order logic may be foundin (Shapiro, 1991) and (Van Benthem and Doets, 1983). They prove the result for moreexpressive languages. But the only resources beyond first-order logic exploited by theproofs are quantifiers ranging over subsets of the basic domain. Hence the proofs maybe reconstructed within SOLID.
Some authors, in particular Quine (1970), claim that second-order logic is not logicbut set theory in disguise. The point rests in a rigid distinction between truths of logic,which are truths defined by form alone, void of any content, and other truths. State-ments in set theory presuppose the existence of sets, an ontology. They are not purelyformal. Many logicians consider things differently. They are less concerned aboutfinding the logic. Rather they study a whole family of different logics, extensionsto first-order logic, and the properties of these logics, and then ask which logic is con-venient for a particular task. As such there is no sharp border line between logicaland other truths but rather a gradual shift, more in the spirit of Quine’s own holis-tic program (cf. Van Benthem and Doets, 1983; and in particular, Shapiro, 1991).Quine’s arguments against considering second-order logic as logic proper are not nec-essarily arguments against founding a semantics for natural language on second-orderlogic. As pointed out in Section 23.2.1.1, the intuitive semantic entailment relation of

“27-ch23-0989-1034-9780444537263” — 2010/11/29 — 21:09 — page 1001 — #13
Plurals and Collectives 1001
English goes beyond traditional logic and admits for ontological considerations. Forour purposes, the question rather becomes how much of this entailment relation wewant to model and how much ontology we are willing to include to reach this goal.
There are two possible routes to proceed to overcome the incompleteness ofSOLID; to extend the class of structures or to restrict the language. We start withextending the class of structures.
Definition 23.3.4. A generalized structure (g-structure) for a SOLID language Lis a triple +E0, E1, [[ · ]], where
(a) E0 is non-empty.(b) E1 " Pow(E0) and for each definable subset X of E0, X ! E1.
(c) The other domains and the interpretation function is as in the definition of the standardstructure.
If L is a SOLID language and +E0, E1, [[ · ]], a g-structure for L, X " E0 is calleddefinable provided it equals {a ! E0 | [[%]]gv
a= t} for some formula %, variable v and
assignment g.
The domain E1 must contain the definable subsets to assure denotations for the setterms, cf. condition (16) above. Observe that often second-order languages are definedwithout set abstraction in which case g-structures might be defined such that E1 is anysubset of Pow(E0). With respect to the g-structures, SOLID behaves pretty much likefirst-order logic:
Theorem 23.3.2. SOLID is compact and can be completely axiomatized with respectto the g-structures.
Proof. This was studied by Mostowski (1947) and Henkin (1950), cf. Van Benthemand Doets (1983). We will give an idea of the proof since the construction is revealingfor issues to be considered in the sequel.
We start with a SOLID language L. Observe that the following schema is valid inall g-structures if Y does not occur in % or & .
(17) &(!x[%]) . $Y ()x(% . Y(x)) & &(Y))
By repeated use of the schema, one can show that each formula % is equivalent to aformula %/ without set terms. Hence we can consider set terms to be defined terms andfor the rest of the proof assume that L does not contain set terms.
Introduce a new relation symbol ! of type +0, 1, and exchange all subformulas ofthe form T(s), with s a term of type 0 and T of type 1, with s ! T . The resultinglanguage L+ can be considered a sorted first-order language with 0 and 1 as basicsorts. The predicates of type +0, in L will correspond to constants in L+, while theother relation symbols in L will be relation symbols in L+. A generalized structure Afor L will also serve as a sorted first-order structure A+ for L+, where ! is ascribedthe obvious interpretation. One sees immediately that A |= % iff A+ |= %+ for allsentences %.

“27-ch23-0989-1034-9780444537263” — 2010/11/29 — 21:09 — page 1002 — #14
1002 Handbook of Logic and Language
There are more structures for L+ than those which may be derived from g-structures for L. We will therefore try to find a set of formulas ' in L such thatB |= '+ if and only if there is a g-structure A such that B and A+ ascribe thesame truth value to all sentences. Let ' contain the following:
1. A formula which claims E0 to be non-empty, say $x (x = x).2. Equality schema: For any type $ = +$1, $2, . . . , $n,, relation symbol R of type $ , terms
t1, t2, . . . , tn and s1, s2, . . . , sn where ti and si are of type $i:
(t1 0 s1 & · · · & tn 0 sn) * (R(t1, . . . , tn) * R(s1, . . . , sn))
where t 0 s is t = s if t and s are of type 0 and )x(t(x) . s(x)), where x is some variablethat neither occurs in s nor in t, if s and t are of type 1.
3. Comprehension schema: For any formula % and variable x, a formula of the following form,where Y is some variable not occurring in %:
$Y()x(% . Y(x)))
If B = +B0, B1, [[·]]B, is a sorted first-order structure for '+ and {a ! B0 | a !B
b} = {a ! B0 | a !B c} for some b, c ! B1 then ideally b = c. If identity oftype +1, 1, was part of SOLID, this could have been achieved with an extensional-ity schema: (t1 0 s1) * (t1 = s1). In lack of identity, we construct the g-structureA = +A0, A1, [[·]]A, for L by letting A0 = B0 and A1 = {X " B0 | $b ! B1(X ={a ! B0 | a !B b})}. Thanks to the equality schemata, this will induce a well definedinterpretation function [[·]]A such that [[%]]A = [[%+]]B for all sentences %. The com-prehension schema will guarantee A1 to contain all the definable subsets of A0.
Compactness for a set of L-sentences ( now reduces to first-order compactness of( + 1 '+. To get a complete axiomatization for L, take as starting point a first-orderaxiomatization for L+, use the inverse of the +-translation and add the set ' . !
The Skolem-Löwenheim results carry over from the sorted first-order structuresto the g-structures too. Observe, however, that these theorems would not only saysomething about the cardinality of E0, but of E1 as well. Thus if a countable SOLIDlanguage has an infinite g-model, it will have one where both E0 and E1 are countable.
23.3.3.2 Definite Collective NPs
The standard structures come closest to our intuitions about the correct semantics forcollective NPs, while the g-structures have a well behaved logic. There are inferencesin SOLID for which it matters which class of structures are considered. Do any suchinferences model inferences in English? To study this, whenever we have a g-structurewe are interested in finding a standard structure as similar as possible to the g-structureand then see which formulas get the same truth value in the two.
Definition 23.3.5.
(a) If A = +A0, A1, [[ · ]]A, and B = +B0, B1, [[ · ]]B, are two g-structures, we will call A a sub-structure of B and B an extension of A, provided A0 " B0, A1 " B1, [[a]]A = [[a]]B

“27-ch23-0989-1034-9780444537263” — 2010/11/29 — 21:09 — page 1003 — #15
Plurals and Collectives 1003
for all names a, and if R is of type +$1, $2, . . . , $n,, then [[R]]A = ([[R]]B ' A$1
# · · · # A$n).
(b) If in addition A0 = B0, B will be called a basic extension of A.
(c) If B is a basic extension of A and [[R]]A = [[R]]B for all relation symbols R, we will call Ba minimal basic extension of A, in symbols A 2 B.
(d) If B is a standard structure and a (minimal) basic extension of A, we will call B a (minimal)completion of A.
We first restrict attention to the definite collective NPs. Let a SOLD languagebe defined as a SOLID language (Definition 23.3.2) without second-order variables(point c) and quantifiers (point g). SOLD extends FOL with second-order relationsand set abstraction. This is sufficient for representing the definite collectively readplural NPs as in example (15).
Theorem 23.3.3. SOLD is compact and admits a complete axiomatization with res-pect to the standard structures.
Proof. By induction on the construction of formulas, one checks that whenever Bis a basic extension of A, any SOLD sentence will have the same truth value in Aand B. Hence, if a set ( of SOLD sentences has a g-model, it will also have a model.Compactness follows from the compactness of SOLID with respect to the g-structures.To get an axiomatization of SOLD, the following is needed:
1. A set of axioms and inference rules for the propositional part and the first-order quantifiers.2. The equality schema introduced above.3. (#-conversion): For all formulas %, variables x and terms t substitutable for x in %: x̂[%](t) .
[t/x]%.
That this yields a complete axiomatization belongs to the folklore of logic. Keisler(1970) showed it for languages containing relations of type +1, as part of the study ofgeneralized quantifiers, and Barwise (1978) considered relations of type +0, 1,. Morecomplex types does not add anything new, the proof is straightforward but tedious(Lønning, 1989). !
23.3.3.3 Indefinite Collective NPs
Turning to the indefinite NPs, one faces two competing intuitions. We did not findany lexical items in English corresponding to universal quantifiers ranging over col-lections. From this we would not expect the full second-order logic to be exploited.On the other hand, we know that ) may be defined from $ and ¬, that the indefinitesare represented by $, and that negation flourish in English.
Definition 23.3.6.
(a) A SOLID formula % will be called persistent if for all A, B such that A 2 B and allvariable assignments f that take values in A: A |= %[ f ] if and only if B |= %[ f ].
(b) A formula % is called standard if for all A, B such that A 2 B and all variable assignmentsf that take values in A: if A |= %[ f ] then B |= %[ f ].

“27-ch23-0989-1034-9780444537263” — 2010/11/29 — 21:09 — page 1004 — #16
1004 Handbook of Logic and Language
A consistent set of persistent SOLID sentences, ( , will always have a model; ithas a g-model and since all the formulas are persistent, they will also be true in theminimal completion. We have already seen that the SOLD-formulas are persistent. Thequestion is which further formulas representing English sentences are persistent andwhich are not. The following observation going back to Orey (1959) gives a syntacticclass of formulas which are clearly persistent. If B is an extension of A, a formula ofthe form $X % may be true in B and false in A because all witnesses for X belongs toB1 3 A1. But if A 2 B and the formula has the form $X(P(X) & &) for some non-logical P, then a witness c ! B1 will be in A1 since [[P]]B = [[P]]A. The followingdefinition generalizes the observation.
Definition 23.3.7. For a second-order variable X, let the class of X-securers be thesmallest class of formulas that contains all formulas % such that:
(a) % has the form R(t1, . . . , tn) for a non-logical n-ary relation symbol R and X is one of theti’s.
(b) % has the form "1 & · · · & "n for some n ( 2 and at least one "i is an X-securer.(c) % has the form "1 - · · · - "n for some n ( 2 and each "i is an X-securer.(d) % has the form $x & or )x & where x is a first-order variable and & is an X-securer.(e) % has the form $Y & and & is both an X-securer and a Y-securer.
A formula % is called secure if and only if in each subformula of the form $X & , & isan X-securer.
Theorem 23.3.4. All secure sentences are persistent.
Proof. For languages without set abstraction, this is a corollary of a more gen-eral result by Orey (1959) or it may be shown by simple induction. To handle setabstraction, we will for each formula % construct a formula %/ without set termssuch that % . %/ is valid on all g-structures and if % is secure or an X-securerthen so is %/. To construct %/, first exchange each sub-formula of the form x̂[)](t)with [t/x]) (after possibly renaming variables). Then exchange each subformula ofthe form R(. . . , x̂[)], . . .) with $Y ()x(Y(x) . )) & R(. . . , Y, . . .)), where Y is a newvariable not occurring elsewhere in the formula. !
A similar class of persistent formulas within the intensional logic IL of Montague(1973) was identified by Gallin (1975) who concluded that the extensional part of thePTQ-fragment is persistent.
To see the relevance of the theorem, consider the representation (13c) of sentence(1g) again, here repeated as (18b) and (18a).
(18) a. Three thousand soldiers surrounded the Alamo.b. $X (X " Soldier & THREETH(X) & SURR(X, alamo))
c. [S[NP[Det*][N"]][VP#]]d. $X(X " "/ & */(X) & # /(X))
Sentence (18b) is secure, hence persistent. It is the non-logical predicate SURR whichrepresents the verb surround, which secures X. The noun will in general not be a

“27-ch23-0989-1034-9780444537263” — 2010/11/29 — 21:09 — page 1005 — #17
Plurals and Collectives 1005
securer, as [["]]A = [["]]B, A 2 B do not force {X ! A1 | X " [["]]A} to equal{X ! B1 | X " [["]]B}. The same goes for the general case (18c), (18d). The mostobvious candidates for securers are the verbs, # in (18c). A determiner, like * in (18c),may be a securer provided it has a free interpretation and hence gets a representation, */
in (18d), which is a non-logical predicate. A logical determiner can serve as a securerif it denotes a set of finite subsets of the basic domain, e.g., exactly six since {X | X !A1 & |X| = 6} = {X | X ! B1 & |X| = 6} = {X | X " A0 & |X| = 6}. Whilea determiner like two or more will not be a securer, cf. the definition for TM inexample (12b).
The example illustrates why simple sentences where the indefinite collective NPis argument to a verb or preposition are persistent. It also indicates a strategy forconstructing non-persistent sentences; just negate the VP.
(19) a. Some boys did not lift a stone.b. $X (X " Boy & TM(X) & ¬$y(Stone(y) & LIFT(X, y)))
In (19b) LIFT is not a securer of X, and if TM is ascribed the logical interpretation:all set of individuals of cardinality at least two, then it is not a securer either. Formula(19b) is not persistent.
Some authors cast doubts about whether (19b) is a correct representation of (19a),however. It should be observed that it is not easy to determine what the sentence shouldmean. The formal fragment would easily generate four different readings dependingon whether the subject NP is read collectively or distributively, and whether the nega-tion has narrow or wide scope. Formula (19b) represents the collective reading withnarrow scope negation. This reading seems the less likely one. To see why, supposethere are 10 boys present. Then there are 210 3 11, i.e. 1013, different collections con-sisting of two or more boys. For (19b) to be false, all these collections would have tohave lifted a stone. Verkuyl (1988) says that the distinction between the collective anddistributive reading vanishes when the verb is negated. In the same spirit, Link (1990)proposes to read (19a) roughly as (20a).
(20) a. There are some boys such that no one of them has participated with other boys inlifting a stone.
b. There are at least two boys who have not participated with other boys in lifting astone.
We could have expressed this as a formula in SOLID, but the representation is muchmore elegant in a system which handles individuals and collections to be of the sametype, cf. Section 23.4. Observe that sentence (20a) is equivalent to the persistent sen-tence (20b). We will not here try to reach any conclusion with respect to the questionon whether formula (19b) represents a possible reading of sentence (19a), but ratherconclude Solomonicly that to answer whether negation gives rise to non-persistentformulas, one has to determine the meaning of the negation.
In Section 23.2.3 we observed some effects of universal quantification ranging overcollections of a specific size. Thus sentence (8) repeated as (21a) can be representedby (21b).

“27-ch23-0989-1034-9780444537263” — 2010/11/29 — 21:09 — page 1006 — #18
1006 Handbook of Logic and Language
(21) a. Every two persons resemble each other.b. )X(X " Person & TWO(X) * RESEMBLE(X))
c. Competing companies have common interests.d. )X(X " Company & COMPETE(X) & TM(X) * COMMON(X))
In (21a) TWO is naturally read as exactly two, hence a securer, and (21b) is persistent.Similarly, if (21c) from Link (1987) is read as (21d), one may simply assume thatCOMPETE is a non-logical predicate and a securer.
We have so far considered examples where the plural NP only fills one argumentposition within the sentence. But more may be achieved by anaphoric pronouns. Con-sider example sentence (22a) taken from Boolos (1984a) who symbolizes it as (22b)presupposing quantification over horses and using 0, s, F for Zev, the sire of, is fasterthan, respectively.
(22) a. There are some horses that are all faster than Zev and also faster than the sire of anyhorse that is slower than all of them.
b. $X($z(X(z)) & )z(X(z) * F(z, 0))
& )z()z(X(z) * F(z, y)) * )z(X(z) * F(z, s(y)))))
This formula is not persistent. As Boolos points out, if (22b) is reinterpreted in stan-dard arithmetic, reading s as the successor function and F as greater than, it becomesfalse in the standard model of arithmetic and true in all non-standard models. Boolos(1984b) also argues that sentence (2d), here repeated as (23a), which Quine (1974)represented as (23b), in addition has another reading represented as (23c), where F(x),E(x), A(x, y) mean “x was one of Fiorecchio’s men”, “x entered the building”, and “xwas accompanied by y”, respectively.
(23) a. Some of Fiorecchio’s men entered the building unaccompanied by anyone else.b. $x(F(x) & E(x) & )y(A(x, y) * F(y)))c. $X($z (X(z)) & )z (X(z) * F(z))
& )z (X(z) * E(z)) & )z)y (X(z) & A(z, y) * X(y)))
The second-order sentence (23c) is not equivalent to any first-order sentence, and notpersistent. This can be observed by substituting z > 0 for F(z) and E(z) and z = y + 1for A(z, y). Then the sentence claims the existence of a set of numbers which is notwell founded. Hence it is true in any non-standard model for arithmetic, but not in thestandard model.
If we think that each sentence has a truth condition which can be expressed by alogical formula independently of reference to the speaker or hearer, what Kripke (1977)calls sentence meaning, then there does not seem to be any alternative to saying thatoccurrences of collective NPs in English exemplify non-persistent sentences.
Others have argued that the meaning of an utterance cannot always be reduced tosentence meaning. Sometimes, a speaker uses a definite description (Donnellan, 1966)or an indefinite NP (Fodor and Sag, 1982) with a particular referent in mind, and theutterance is then about that object. I have argued elsewhere that if one accepts theconcept of referential use then (22a) and (23a) are examples of such referential uses(Lønning, 1989). If one further holds the view that the utterance is not true unless itis the object to which the speaker intends to refer which has the ascribed property,

“27-ch23-0989-1034-9780444537263” — 2010/11/29 — 21:09 — page 1007 — #19
Plurals and Collectives 1007
then there is no simple formula which corresponds to the utterance. The closest onewould get would be to introduce a constant of type 1 for the object to which thespeaker intends to refer. In that case the representation becomes persistent but not arepresentation of the sentence as such. In other words, the logical complexity of thecollective NPs will depend on the view one holds with respect to reference and therelationship between sentence meaning and utterance meaning.
All candidates for non-persistent sentences considered so far are standard. Dothe collectively read plural NPs of English exemplify even more complex logicalformulas? When the language contains anaphoric pronouns, negation and universalquantification might also be expressed by conditional sentences. Boolos (1984b) con-siders examples which might need +1
1 -formulas for their interpretation. One mightalso consider how negation and anaphora interact and whether there are general recur-sive mechanisms in English generating arbitrary complex quantifier prefixes. Boolosargues that any second-order sentence can be translated into English, while Lønning(1989) casts doubt on this.
23.4 First-Order Approaches
23.4.1 Background
We will now consider a different approach to collections, to regard them as individ-uals. Rather than adding levels to the logical hierarchy, add structure to the basicdomain. While we traced the higher-order approach back to Russell, there might besome evidence for attributing the current approach to Frege. In the before mentionedletter to Russell, he separated the collective reading of (1a) and (1b) both from thedistributive reading of (24a) and from a reading in terms of classes, as in (24b).
(24) a. Socrates and Plato are philosophers.b. The class of prime numbers comprises infinitely many objects.
The collection is regarded as a whole, while the class is not, “Secondly, if we are givena whole, it is not yet determined what we envisage as its parts. As parts of a regimentI can regard the battalions, the companies or the individual soldiers [ . . . ] On the otherhand, if we are given a class, it is determined what objects are members of it.” (Frege,1980, p. 140). Like Russell, Frege more pointed to a solution than worked it out, andshould not be made responsible for any details in the proposal we present. He neverpublished the mentioned remarks, and, as the quotation shows, he did not distinguishclearly between the plural NPs and the group-denoting NPs. Besides, Frege’s systemwas not typed and can strictly speaking not be taken as a defense for a first-orderapproach, but rather for a type free approach.
Another root to this approach can be found in Lésniewski’s mereology whichinspired Leonard and Goodman’s (1940) Calculus of individuals (see (Eberle, 1970)for a systematic overview of the formal theory). Lésniewski’s goal was an alternativeto set theory for the foundations of mathematics, Leonard and Goodman’s aim wasa formal ontology, while Lewis (1991) attempts to build a common framework forontology and set theory.

“27-ch23-0989-1034-9780444537263” — 2010/11/29 — 21:09 — page 1008 — #20
1008 Handbook of Logic and Language
One step in the direction from ontology towards semantics was the paper by Massey(1976) based on the calculus of individuals. The most influential paper within thisparadigm is Link (1983), where algebraic structures are used. Another important sourceis Scha (1981), which shares many assumptions with Link but states the theory in asomewhat different framework based on sets. Mentioned should also be Blau (1981)which discussed a first-order approach to the plural definite description.
23.4.2 Basics
To a question like, Who ate the chicken?, one may answer John or the girls. This sug-gests that a plural NP like the girls should denote an object of the same type as John,and a VP like ate the chicken should have one denotation which includes both ordinaryindividuals and collections. To achieve this, one may regard the individual domain, E,as a subset of a larger set of objects, O, and let proper nouns denote members of E,[[Ann]] ! E, and common count nouns in the singular denote subsets of E. The largerset, O, in addition has as members collections, like [[Ann and Mary]] and [[the girls]],and a VP denotes a subset of O.
Most proposals assume the domain O to be structured in a way which relates thecollections to each other and to the individuals. The proposals have differed with res-pect to whether the structure should be expressed by set theoretic or algebraic means,and with respect to what sort of algebraic structure to choose. We think the structureshould not be founded on ontological intuitions alone, but on the effect it has on theinterpretation of the collective NPs. Accordingly, our strategy will be to first introducea language for representing the collective NPs and interpretations where we assumeno particular structure on O, nor assume anything about the relationship between Eand O besides E " O. Then we will proceed to discuss constraints on the interpreta-tions of the NPs and which structure these constraints induce on O. The language willbasically be a first-order language with identity and quantifiers ranging over the wholedomain O. We want to be able to restrict attention to E. One possibility is to let thefirst-order language be sorted with two sorts e and o corresponding to the two sets Eand O. Hence e will be a subsort of o; the terms of sort e will also be of sort o. Allconstants and variables will belong to one of the two sorts and each argument place ofa relation will have an associated sort. The intended application is to represent propernouns by terms of sort e, simple common nouns in the singular, like soldier, by unaryrelations of type +e,, while a VP will be of type +o, and a TV of type +o, o,. As aconvention, x, x1, x2, . . . will be e-variables and y, y1, y2, . . . will be o-variables.
To interpret the plural definite description, we will extend the language at one point:
Definition 23.4.1 (Tau).
(a) If v is an e-variable and % a formula, then $v[%] is an o-term.(b) There is a partial function T , T : Pow(E) * O, such that
a. If X " E is definable and X %= 4 then X ! Dom(T).b. [[$v[%]]]g = T({a ! E | [[%]]gv
a= t}).
c. In particular, for all e ! E, T({e}) = e.

“27-ch23-0989-1034-9780444537263” — 2010/11/29 — 21:09 — page 1009 — #21
Plurals and Collectives 1009
As an example, sentence (1e) can be represented as (25a) where x and alamo areterms of type e, Soldier of type +e, and Surround of type +o, o,.
(25) Surround($x[Soldier(x)], alamo)
A minimal assumption we will keep throughout is that the definite description is exten-sional, if, e.g., [[girl]] = [[kind girl]], then [[the girls]] = [[the kind girls]]. This corre-sponds to expressing the interpretation of $ in terms of a function T .
One notorious problem is what to do with a term like the soldiers when there are nosoldiers. The term $x[Soldier(x)] will be defined, and the first alternative is to ascribeit an interpretation by letting 4 ! Dom(T). The proper representation of sentence (1e)should then contain the claim that there are at least two soldiers in a similar way as wedid it in the higher-order approach.
(26) Surround($x[Soldier(x)], alamo)
& $x1$x2 (x1 %= x2 & Soldier(x1) & Soldier(x2))
The second alternative is to exclude 4 from Dom(T), stick to the representation (25)and let the extra claim be part of the interpretation schema for $x[%]. The extra claimmay then either be stated, leading to a false statement if it is not fulfilled (Link, 1983),or presupposed leading to an undefined statement (Blau, 1981). Many proposals forthe semantics of plurals have used structures where 4 /! Dom(T) (e.g., Landman,1989, 1991; Link, 1990). From a semantic point of view, it does not matter whetherT(4) is defined, as long as it is not taken as a possible denotation for the plural NPs.But as we will see, it will affect which class of algebraic structures we end up with.
A similar discussion may be raised concerning T applied to singletons. We havehere chosen the alternative to include singleton sets in the domain of T . Thereby,both definite descriptions in the singular and definite descriptions in the plural may berepresented by $ and interpreted by T . The difference between the singular and theplural will have to be captured by different additional claims in the representations;e.g., formula (26) should only be used for the plural.
While the noun in the singular, girl, denotes a subset of E, the noun in the plu-ral, girls, will denote a subset of the larger domain O. There is a natural connectionbetween the semantics of the plural noun and that of the plural definite description.If there are some young girls, we will assume [[the young girls]] to be a member of[[girls]]. Conversely, we may assume all members of [[girls]] to be composed fromindividual girls in this way. We will introduce a new symbol 5 into the formal lan-guage to model the plural nouns, such that
Definition 23.4.2 (Star).
(a) If % is a formula and v an e-variable then 5v[%] is a relation of type +o,.(b) [[5v[%]]]g = {T(X) | X " {a ! E | [[%]]gv
a= t} & X ! Dom(T) & X %= 4}.
Sentence (1f ) can be represented
(27) $y(5x[Girl(x)](y) & Gather(y))

“27-ch23-0989-1034-9780444537263” — 2010/11/29 — 21:09 — page 1010 — #22
1010 Handbook of Logic and Language
As we assumed T({g}) to be defined and equal to g for g ! E, [[Girl]] will bea subset of [[5x[Girl(x)]]], i.e. each individual girl will belong to [[5x[Girl(x)]]]. Thisseems appropriate if girls in the NP no girls is represented by 5x[Girl(x)]. Similarly,Kamp and Reyle (1993) show that dependent plurals include simple individuals intheir denotations. A sentence like every mother loves her children entails that motherswho have only one child love it. Again some representation which includes both indi-viduals and collections are appropriate. On the other hand, by choosing this interpre-tation of 5x[Girl(x)] in example (27), something more must be added to the formula toexpress that the NP Some girls refers to a collection consisting of at least two individ-uals, similarly as we proposed in the second-order approach and for the plural definitedescription in formula (26).
To interpret the collective conjunction, we introduce a binary operator, +, definedon O, such that [[Hillary and Bill]] = [[Hillary]] + [[Bill]] and a corresponding functionsymbol, 6, written infix.
Definition 23.4.3 (O plus).
(a) If t and s are o-terms, then so is t 6 s.(b) A structure contains a function + : O # O * O, and [[t 6 s]] = [[t]] + [[s]].
Sentence (1a) can be represented by the following formula where Lfs is shorthandfor laid the foundations of spectral theory.
(28) Lfs(bunsen 6 kirchoff )
Observe that this same operator can handle conjunction between collections, the sec-retaries and the assistants or between an individual and a collection Bill and hissecretaries. If we were to introduce conjunction in the higher-order framework ofSection 23.3, we would have to handle these cases separately.
We will call a language as described in this section, with the two sorts e and oand the special symbols $ , 5 and 6 a first-order language for plurals (FOLP). Astructure for a FOLP language can be written +O, E, T, +, [[ · ]], where [[ · ]] interpretsthe nonlogical symbols.
23.4.3 Ontology
Plural definite descriptions and collective conjunction have more semantic propertiesthan what is reflected by these quite general structures. We will consider some possi-ble constraints on the functions T and + to capture these intuitions. There are threepossible constraints on +:
C1 (Commutativity). For all a and b in O : a + b = b + a.
C2 (Idempotency). For all a in O : a + a = a.
C3 (Associativity). For all a, b, and c in O : ((a + b) + c) = (a + (b + c)).
The assumption underlying constraint (C1) is that Hillary and Bill and Bill andHillary denote the same collection and are ascribed the same collective properties.

“27-ch23-0989-1034-9780444537263” — 2010/11/29 — 21:09 — page 1011 — #23
Plurals and Collectives 1011
If every doctor is a lawyer and every lawyer is a doctor, the lawyers and the doctorsand the doctors should denote the same, hence idempotency (C2). An NP like Ann,Mary and Frances is interpreted by repeated use of +. Associativity together withcommutativity will then assure it to have the same denotation as Mary, Frances andAnn. We consider possible counter examples in Section 23.4.7.
One type of structure often used for interpreting plural NP’s is semilattices. A par-tially ordered set is a set X together with a binary relation 2 on X which is reflexive,transitive and anti-symmetric. A partially ordered set is a join-semilattice if any twoelements a, b have a least upper bound c, i.e. a 2 c and b 2 c and for all d, if a 2 dand b 2 d then c 2 d. This least upper bound, or supremum, is called the sum or joinof a and b, in symbols often written a - b. Similarly, a partially ordered set is a meet-semilattice if any two elements have a greatest lower bound called meet or product(in symbols a & b) and a lattice if it is both a join-semilattice and a meet-semilattice.It is a standard observation in lattice theory that a semilattice can be defined from thejoin operation as from the ordering:
Theorem 23.4.1. If a 2 b is defined on O by a + b = b, then +O, 2, becomes a join-semilattice with + as join if and only if + is commutative, idempotent and associative.
For a proof of this and other lattice theoretical results in the sequel, consult atext book like Grätzer (1978) or Landman (1991). Thus, to say that the domain isa semilattice amounts to nothing else than saying that conjunction has these threeproperties. We will use SL to denote the class of structures satisfying the threeconstraints.
We turn to the function T and the following possible constraints:
C4 (Supremum). T(X) ="
X for all X ! Dom(T).
C5 (Generation). For each element o ! O there is an X " E s.t. o = T(X).C6 (Completeness). Each non-empty X " E is a member of Dom(T).
On a semilattice the sum operation generalizes to any non-empty finite subset ofthe domain by
"{a1, a2, . . . , an} = a1 + a2 + · · · + an. If Tom, Dick and Harry are
the boys and the only boys, then it is reasonable to assume that Tom, Dick and Harryand the boys denote the same. Correspondingly, one may let T be interpreted as latticesupremum as expressed by constraint (C4). The constraint (C5) claims all objects tobe built up from individuals. It excludes the possibility of e.g., individuals being builtup from atoms which are not individuals. From the interpretation rule for 5, if X is anonempty definable subset of Girl, it will form a collection in 5Girl. But what if X isnot definable? From constraint (C6), X will form a collection whether it is definableor not.
In the literature on plurals, structures where the supremum of each non-empty set,finite or infinite, is defined, have been called complete join-semilattices. We willfollow this practice, but one should be aware that in most of the algebraic literature,the term complete structure entails that the relevant operations are defined for theempty set as well.

“27-ch23-0989-1034-9780444537263” — 2010/11/29 — 21:09 — page 1012 — #24
1012 Handbook of Logic and Language
Theorem 23.4.2. a) If a SL-structure satisfies (C4), (C5) and (C6) then O is a com-plete join-semilattice.b) If in addition 4 ! Dom(T) then O is a complete lattice.
Proof. Observe first that if b ! O then b ="
{e ! E | e 2 b} from (C4) and (C5).Let B be a nonempty subset of O. Then
"{e ! E | $b ! B (e 2 b)} will be defined
from (C6) and from the observation it will equal"
B.For the second part of the theorem, if 4 ! Dom(T) then
"4 = 0 is defined from
(C4). If B is a subset of O,#
B ="
{a ! O | )b ! B (a 2 b)} will always bedefined. !
We will accordingly call the class of structures satisfying constraints (C1)–(C6)for complete join-semilattice structures, CJ SL. If 4 ! Dom(T) we will call themcomplete lattice structures, CL. A CJ SL-structure without a bottom element, wewill call a CJ SL+-structure. As mentioned earlier, many of the proposals from theliterature assume 4 /! Dom(T) and make use of CJ SL+- structures (e.g., Landman,1989, 1991; Link, 1990).
The restrictions introduced so far force certain objects to be equal but do not preventany objects from being equal. For example, there are CJ SL+-structures where john,bill, harry, dick all denote different objects, still bill 6 john and harry 6 dick denotethe same. To avoid this, the following constraint may be added:
C7 (Free). For all X, Y ! Dom(T): if T(X) = T(Y) then X = Y.
If this is added to the other constraints, E will be called a set of free generatorsfor O as a complete join-semilattice (see Landman, 1989).
Theorem 23.4.3. a) A CL-structure +O, E, [[ · ]], satisfies (C7) if and only if O is acomplete atomic Boolean algebra with E the set of atoms.b) A CJ SL+-structure satisfies (C7) if and only if O is the substructure of a com-plete atomic Boolean algebra with E the set of atoms one gets by deleting the bottomelement.
Proof. From constraint (C4), T is a homomorphism from +Dom(T), 1, to +O, +,.From (C5), T is onto O. If T in addition is injective, (C7), then the two structures areisomorphic. From (C6) Dom(T) = Pow(E), and +Pow(E), 1, is a complete atomicBoolean algebra with {{e} : e ! E} the set of atoms. !
We will accordingly call these two classes of structures CABA (complete atomicBoolean algebra) and CABA+, respectively. The models and language we end upwith are quite similar to (a part of ) those proposed by Link (1983, 1991). There isa difference between FOLP and the language used there, LP, with respect to whichsymbols are basic and which ones are defined. Another difference is that the denotationof a singular common noun is not necessarily a set of atoms in Link’s proposals. Theinterpretation of the plural phrases remain similar, however, [[the P]] =
"[[P]] and
[[5P]] = {"
Y | Y %= 4 & Y " [[P]]}.

“27-ch23-0989-1034-9780444537263” — 2010/11/29 — 21:09 — page 1013 — #25
Plurals and Collectives 1013
In the literature on collective readings, some proposals are based on lattices (e.g.,Link, 1987), while others are given in terms of Boolean algebras (e.g., Link, 1983).The reason to use Boolean algebras in other contexts is the wish to model all the con-nectives; disjunction, negation as well as conjunction. The only Boolean connectiveused in constructing collective NP’s is and, but the proposition shows that it has afunction to use Boolean algebras as models; they are special kinds of join-semilatticesthat put special constraints on the behavior of the join operation (cf. Landman, 1989,1991; Lønning, 1989; and Link, 1990).
Each complete atomic Boolean algebra is isomorphic to a power set of some set andeach CABA-structure corresponds to a power set structure +O, E,
$, 1, [[·]],, where
O = Pow(X) and E = {{i} : i ! X} for some set X %= 4, where [[$v[%]]]g =$
({a !E | [[%]]gv
a= t}) and [[a 6 b]]g = [[a]]g 1 [[b]]g. Similar structures were proposed by
Scha (1981). If semantics is viewed first and foremost in terms of entailment, thenthere is no difference between the two model concepts. If one, on the other hand,thinks that semantics carry some deeper ontological commitments, and that the useof sets forces one to a certain ontological view, then one might claim there to be adifference (cf., Lewis, 1991; Link, 1983, 1984; Massey, 1976).
We gave an example which motivated the freeness constraint (C7). But observe thata consequence will be that two NPs like the window parts and the windows cannot getthe same denotation if there are window parts which are not windows. At this point,we depart from the mereological tradition, where the sum formation is thought of asthe summation of physical stuff (Leonard and Goodman, 1940). Blau (1981) discussesthe injectivity of T for examples like the cards and the decks of cards, and concludesthat it should be possible for the two to get the same denotation. Hence, T should notbe injective. In a footnote added in print, however, he casts doubt on the identificationbecause of the effect of predicates like are counted. Link (1983) includes two differ-ent preorders on the plural domain, the individual or i-ordering corresponding to theinjectivity of T , and the material or m-ordering which could identify the windows andthe window parts.
23.4.4 Compositionality
The interpretations described so far are compatible with different approaches to thesyntax-semantics interface, whether Montague grammar, generalized quantifiers orDRT. We will sketch an extensional Montagovian approach to bring out the simi-larities and differences to the higher-order proposal from Section 23.3.2. Both e ando will be basic types besides t, and e is a subtype of o. A VP will be of type (o, t),whether it is collective or distributive, a noun in the singular will be of type (e, t),and the determiner every will be of type ((e, t), ((o, t), t)) with the interpretation!X(e,t)!Y(o,t)()xe(X(e,t)(xe) * Y(o,t)(xe))). When it comes to the plural NPs, likethree girls, one possibility is to assume two different entries, one collective and onedistributive, both of the type ((o, t), t) (but see Section 23.5.1). As the plural nounswhen read distributively are handled exactly as the singular nouns, plural nouns willget the same interpretation as the corresponding singular noun, of type (e, t). Theeffect of the collectivization, 5, will be incorporated into the collective determiner.

“27-ch23-0989-1034-9780444537263” — 2010/11/29 — 21:09 — page 1014 — #26
1014 Handbook of Logic and Language
The two interpretations of the determiners will then be as in (29a) and (29b), whereThree(y) claims that y has exactly three different individuals as parts.
(29) a. !X(e,t)!Y(o,t) [Three($x[X(e,t)(x) & Y(o,t)(x)])]b. !X(e,t)!Y(o,t) [$yo (5X(e,t)(yo) & Y(o,t)(yo) & Three(yo))]
One might try to incorporate the collective conjunction into this framework, as aconjunction of two quantifiers of type ((o, t), t). But as the natural type of the conjunc-tion is to conjoin terms of type o, it seems more natural to depart from the Montago-vian approach of handling all NPs as quantifiers and rather let definite and indefiniteNPs get type o and let the existential quantifier be introduced by a larger context(cf. Hoeksema, 1983; Lønning, 1987b). This is the way the collective readings arehandled in DRT (Kamp and Reyle, 1993).
How should the group-denoting nouns be accommodated in the first-orderapproach? There are several alternatives depending on how one answers the follow-ing question. Should a group, a committee, a set be identified with its members; e.g.,should the committee and the members of the committee denote the same object?
If one answers no to this question, then the group-denoting nouns may be handledas other nouns, i.e., as of type (e, t) (e.g., Barker, 1992). Such an approach makes noattempt at explaining semantically why group-denoting nouns in the singular may co-occur with verbs in the plural. A sentence like (30a) will not be excluded on structuralsemantic grounds and maybe neither on syntactic grounds. The strangeness of thesentence will be ascribed to the meaning of the involved words, cf. that (30b) is wellformed.
(30) a. ? John surrounded Alamo.b. The wall surrounded the city.
If one, on the other hand, finds it correct to always identify the committee and themembers of the committee, one possibility is to represent committee by a predicateof type (o, t). This will explain why the group-denoting NP in the singular agreeswith a plural verb. On the other hand, it does not explain why such an NP may alsoagree with a verb in the singular. This approach will come close to Bennett’s proposalconsidered in Section 23.3.2, except that it will be easy to consider the collectivereading of the committees, as well, by interpreting the plural definite description asthe supremum operator on O, and not only on E. This process will stop in the sensethat it will identify the “new” collections with “old” ones, e.g., given some groupof committees of women, the following NPs will all get the same denotation: thewomen who are members of a committee, the committees, the group of committees(cf. Section 23.4.7).
23.4.5 Logic
A FOLP language extends a first-order language with expressions of the form $v[%]and 5v[%]. To get an axiomatization corresponding to the quite general structures inSection 23.4.2, we could start with a first-order axiomatization and add schemataexpressing the extensionality of $ , the interpretation of $ with respect to the singletons,

“27-ch23-0989-1034-9780444537263” — 2010/11/29 — 21:09 — page 1015 — #27
Plurals and Collectives 1015
and the relationship between $ and 5. We will not give the details, but move on tothe more restricted structures considered in Section 23.4.3. We consider the follow-ing schemata where t, s, u vary through all terms, %, & through all formulas and xand y through all e-variables and o-variables, respectively. t 7 s is shorthand fort 6 s = s.
(A1) t 6 s = s 6 t(A2) t 6 t = t(A3) (t 6 s) 6 u = t 6 (s 6 u)
(A4) $x % * ()x (% * x 7 $x[%]) & )y ()x (% * x 7 y) * $x[%] 7 y))(A5) )y (y = $x[x 7 y])(A6) $x % * ($x[%] = $x[&] * )x (% . &))
The first three schemata correspond exactly to the first three constraints. On the SL-structures, if 4 /! Dom(T), (A4) corresponds to (C4), and it is not too difficult to seethat (A4) and (A5) correspond to (C4) and (C5), and that (A6) corresponds to (C7).If 4 ! Dom(T), one gets similar correspondences by deleting the antecedent in (A4)and (A6).
We will soon see that it is not possible to express the completeness constraint (C6)within FOLP. On the other hand, the theorems we showed for the structures satisfying(C1)–(C6) have variants based on (C1)–(C5). Thus in a structure satisfying (C1)–(C5), each definable subset of the full domain O will have a supremum, and we willrefer to the class as the definable complete join-semilattice structures, DCJSL. Ifin addition 4 ! Dom(T), the structure will be a lattice where each definable subset hasboth a supremum and an infimum, hence a definable complete lattice structure, DCL.If a DCL-structure also satisfies (C7), it will be a Boolean algebra, hence a definablecomplete Boolean algebra structure, DCABA. Such a structure will correspond toa generalized set structure +O, E,
$, 1, [[·]], where there is a set X such that E =
{{x} | x ! X} and O " Pow(X). If 4 /! Dom(T) and (C1)–(C5), (C7), one gets thesubstructure of a DCABA where the bottom element is deleted, hence a DCABA+-structure. All these results follow by inspecting the proofs for the similar results when(C6) is included.
The easiest way to get an axiomatization of FOLP with respect to the consideredclasses of structures is by observing that (C4), and hence (A4), expresses two claims;that each definable subset of E has a supremum and that $x[%] denotes this supremum.The first part, call it (C4/), can be expressed by:
(A4/) $x % * $y2 ()x (% * x 7 y2) & )y1 ()x (% * x 7 y1) * y2 7 y1))
If this holds, the term $x[%] can be considered a defined term by the repeated useof (31a). Similarly 5x[%] may be defined by (31b) provided (C1)–(C5) hold.
(31) a. R(. . . , $x[%], . . .) . $x % & $y2 ()x (% * x 7 y2)
&)y1()x(% * x 7 y1) * y2 7 y1) & R(. . . , y2, . . .))
b. 5x[%](y) . )x (x 7 y * %) & $x (x 7 y)
Theorem 23.4.4. FOLP is compact and has complete axiomatization with respect tothe classes of structures: DCJSL, DCL, DCJSL+,DCABA, DCABA+.

“27-ch23-0989-1034-9780444537263” — 2010/11/29 — 21:09 — page 1016 — #28
1016 Handbook of Logic and Language
Proof. Since the terms which are not strictly first-order can be considered tobe defined terms, it reduces to showing that the classes of structures mentioned canbe defined within the sorted first-order language with the binary function symbol 6.The axiom schemata discussed above show how this can be done. !
At this point the reader probably recognizes certain similarities to the second-order framework in Section 23.3.3, in particular, the similarities between the powerset structures and hence also the CABA-structures and the standard structures forSOLID, and between the DCABA and generalized set structures and the g-structuresfor SOLID:
Theorem 23.4.5. FOLP is not compact, does not have any complete axiomatiza-tion, and does not satisfy the Skolem-Löwenheim properties with respect to CABA-structures, nor with respect to CJ SL-structures.
Proof. Given a SOLID language L without set abstraction, and let '+ be the trans-lation into the corresponding first-order language L+ with the symbol ! of sort +0, 1,considered in the proof of Theorem 23.3.2. We will define a corresponding FOLP lan-guage L5 and translation from L+ (and L) into L5 by exchanging the two disjoint sorts0, 1 with the sorts e, o, respectively, and translating the atomic formula t+ ! S+ inL+, derived from T(s) in L, into t5 2 S5 in L5 (where t+ is of sort 0, S+ of sort 1, t5
of sort e and S5 of sort o). The rest of the translation is structure preserving.From a given structure A = +A, [[·]], for L we shall construct a power set structure,
A5 = +O, E,$
, 1, [[·]]5, for L5 as follows. Let O = Pow(A) and E = {{a} | a ! A}.Let f : A1 Pow(A) * Pow(A) be defined by f (x) = {x} for x ! A and f (X) = X forX " A. Define [[·]]5 by [[t5]]5 = f ([[t]]) if t is a constant of sort 0 or 1, and [[R5]]5 ={+f (x1), f (x2), . . . , f (xn), | +(x1), (x2), . . . (xn), ! [[R]]}, for relation symbols R. Onemay prove by induction that A |= % if and only if A5 |= %5.
Each power set structure B for L5 can be seen to be of the form A5 for someL-structure A. Hence the results follow for the power set structures and for theCABA-structures. Since a structure belongs to CABA if it belongs to both CJ SLand DCABA the result also follows for the CJ SL-structures, and similarly for theclasses CL, CJ SL+ and CABA+. !
Observe that the correspondence between standard structures for L and power setstructures for L5 can be extended to a correspondence between g-structures for L andDCABA-structures for L5. One might also construct a translation in the other direc-tion, from a FOLP language L and into a SOLID language LS, which yields a similarequivalence between classes of structures (Lønning, 1989). This translation may bedone such that e-variables translate into first-order variables and o-variables trans-late into second-order variables and may be used for studying the properties of frag-ments of FOLP. Consider the part of FOLP used for the definite NPs, i.e. $ -terms ande-quantification, but no o-quantification. If a set of sentences from this fragment hasa DCABA model, one where T is a partial function, any completion to a full CABAstructure where T is total will be a model as well. This fragment will be compact andadmits a complete axiomatization also with respect to the classes CABA and CJ SL.

“27-ch23-0989-1034-9780444537263” — 2010/11/29 — 21:09 — page 1017 — #29
Plurals and Collectives 1017
The discussion of the indefinites carries over, too. Concepts like securer, and secureformula can be defined by translation.
(32) a. $y( 5Boy(y) & Tm(y) & Meet(y))b. $y($x1(x1 7 y) & )x1(x1 7 y * F(x1, 0))
& )x2()x3(x3 7 y * F(x3, x2)) * )x3(x3 7 y * F(x3, s(x2)))))
In formula (32a) the verb Meet is a securer of y, while *Boy is not. That Boy gets thesame denotation in a structure and its extension does not secure that *Boy does. Insentence (32b), a representation of sentence (22) from Section 23.3.3.3, the variabley is not secured, however. In other words, the results with respect to the complexityof the entailment relation between English sentences are the same whether we modelthem in the second-order logic or in this first-order theory.
23.4.6 Mass Terms
There are obvious semantic parallels between mass nouns and plural count nouns;consider the similarities between the sentences (1e) and (33a) and between (1g)and (33b).
(33) a. The water surrounded the castle.b. Three thousand tons of water surrounded the castle.
We will call the readings of these mass NPs collective, as well. Observe that eventhough there are many quantities of water, the water picks out a unique object. More-over, an NP like the water that John drank, will also denote a unique quantity, thesum of the quantities of water that John drank, which is again a quantity of water. Thisreflects a well known and universally accepted property of mass nouns, what Quine(1960) has called the property of referring cumulatively (p. 91): “any sum of partswhich are water is water”. A similar property may be observed for plural nouns: if youadd some horses and some other horses then you still have some horses (Link, 1983).In contrast to the higher-order approach, the algebraic first-order approach allows fora similar treatment of mass terms as of plurals.
One way to do this goes as follows. Let the domain of quantities, Q, be a com-plete join-semilattice. Let a mass noun, like water, denote a complete sub-semilattice,i.e. a set of the form W " Q where for each non-empty Y " W,
"Y ! W, and
let [[the water]] ="
[[water]]. This will correspond to the denotation of a pluralnoun, e.g., [[5x[Horse(x)]]] is a complete sub-semilattice generated from [[Horse]], and"
[[Horse]] ="
[[5x[Horse(x)]]]. The difference between mass nouns and plurals willbe that [[Water]] will not necessarily be generated from a set of atoms. Correspond-ingly, we will not assume the join-semilattice Q to be atomic. What might be moresurprising is that it is hard to find good arguments for claiming it to be non-atomic,as well.
To analyze both mass terms and plurals, the two models should be integrated insome way, e.g., by considering both O and Q to be subsets of one big domain, D,where a VP denotes a subset of D. There have been several different proposals forhow the countable domain shall be considered in this larger setting. One possibility isto let D be a complete join-semilattice, E the atoms in D, and O the set generated from

“27-ch23-0989-1034-9780444537263” — 2010/11/29 — 21:09 — page 1018 — #30
1018 Handbook of Logic and Language
E as explained earlier. Other possibilities comprise to let E also contain non-atoms(Link, 1983) or to not include one set of individuals, but rather let each count nounchoose its own individuals (Krifka, 1989).
Should the denotation of a mass term be more constrained? A property of massterms which has been more disputed than the cumulative reference is distributive ref-erence: “Any part of something which is water is water”. Quine (1960, p. 99), e.g.,rejects this property because “There are parts of water too small to count as water”. Tosee the formal consequences of this, observe that if W is both cumulative and distribu-tive it will equal a set of the form {x | x 2 w} for some w. If then P = {x | x 2 p} forsome p,
"W =
"P entails W = P, i.e., the definite description becomes injective.
Without distributivity, however, a possible case is that [[ furniture]] %= [[wood]], but[[the furniture]] = [[the wood]]. This may model a situation where all furniture is madeout of wood and all wood is made into furniture; there may still be pieces of woodwhich are not pieces of furniture.
As in the plural case, one may ask whether the definite description is injective.There have been two different views depending on how part of is read. One mayfollow Quine and the mereological tradition and read it material part of and rejectdistributive reference. Or one may read it in a more abstract sense and say that Quine’sobservation is not semantically relevant (Bunt, 1976, 1985; Lønning, 1987a), in whichcase one will not necessarily claim that [[the furniture]] = [[the wood]] in the exampleabove, cf. the discussion on whether [[the windows]] and [[the window parts]] shouldbe identical. Link (1983) made a compromise where he read part of as material partof in the mass domain, but not in the plural domain (cf. Section 23.4.3).
As the mass noun denotations are not generated from atoms in the same way asthe denotations of the plural count nouns, injectivity is not sufficient to introduce aBoolean structure. But there may be other reasons. If John drank some of the water,but not all of the water, there will be many quantities of water that he partly drankand partly did not drink. If did not drink is ascribed the complement set of [[drank]] asdenotation, then it will contain all the mixed quantities including [[the water]], hence[[the water that John did not drink]] = [[the water]]. But this is not correct. What wewant is something like the maximal quantity of water which is such that John did notdrink any part of it. This and similar arguments have been given for ascribing the massdomain a Boolean structure (Lønning, 1987a; Roeper, 1983). Then the set of quantities[[that John did not drink]] may be interpreted as {x | x 2
"[[that John drank]]}.
Purdy (1992) uses a different approach where the denotations of the mass nounsare slightly different from complete sub-semilattices, and shows that this induces aBoolean structure on the set of possible mass noun denotations.
Does the mass NP in addition to the collective reading also show a reading corres-ponding to the distributive reading in the count case? Consider sentence (34a) with itssimilarity to the distributive (34b).
(34) a. John drank most of the water.b. John ate most of the apples.c. *Most of the water weigh 3 kilos.d. Most of the apples weigh 3 kilos.e. ?Most of the water surrounds the castle.

“27-ch23-0989-1034-9780444537263” — 2010/11/29 — 21:09 — page 1019 — #31
Plurals and Collectives 1019
Most of the water cannot be analyzed by counting quantities. One cannot countall the quantities of water that John drank, nor are there any well defined minimal,disjoint quantities corresponding to individuals which may be counted. Rather what(34a) claims is that the maximal quantity of water that John drank, which equals thesum of all the quantities of water he drank, counts as most of the water. Sentence(34c) seems odd, if at all well formed. It seems like the predicates which may easilyco-occur with quantified mass NPs refer themselves both cumulatively and distribu-tively (Lønning, 1987a). As these readings seem to claim that both a quantity andits parts have a certain property, we will call it homogeneous. Roeper (1983, 1985)studied homogeneous readings of the logical quantifiers all and some in a logical set-ting, including sentences with several NPs, like (35a). Lønning (1987a) studied moregeneral quantifiers like (35b), but only with monadic predicates. Thereby the systembecame decidable.
(35) a. All water is denser than some alcohol.b. John drank two liters of beer.
These quantified mass NPs can be considered a generalization of the concept ofgeneralized quantifiers from only considering the cardinalities of the involved sets toconsidering measures on the sets, cf., two liters of . This subject remains to be scruti-nized in the same systematic way as the generalized quantifiers on the count domain,cf. Keenan and Westerståhl (1996).
23.4.7 Alternatives
So far, one particular set of constraints on the interpretations leading to the CABA-structures have been assumed. Several of these constraints have been challenged, inparticular the associativity of the conjunction (Hoeksema, 1983).
(36) a. (Blücher and Wellington) and Napoleon fought against each other near Waterloo.b. Blücher and (Wellington and Napoleon) fought against each other near Waterloo.
There is a difference between Wellington fighting with Blücher against Napoleonor with Napoleon against Blücher. Hoeksema therefore proposed to treat conjunctionroughly as set formation and let the two NPs denote something like {{b, w}, n} and{b, {w, n}}, respectively. In principle, the conjunction process could be iterated. Thusone would need all the hereditary finite sets generated by the basic individuals aspossible denotations.
The group-denoting nouns may lead to a similar move for definite descriptions. Asremarked earlier, Bennett’s (1975) approach cannot capture the collective reading ofthe group-denoting nouns themselves. But there is no problem to introduce third-orderobjects: sets of individuals and third-order properties that are ascribed to third-orderobjects. The process does not stop, however. As Chierchia (1982) observes, if thegroup of groups of boys denotes a third-order object, the group of groups of groupsof boys will have to denote a fourth-order object, and so forth. In principle, objects ofevery finite type are needed. Instead of doing this in a logic of higher and higher types,it can be done in a first-order setting with a set theoretical domain.

“27-ch23-0989-1034-9780444537263” — 2010/11/29 — 21:09 — page 1020 — #32
1020 Handbook of Logic and Language
Definition 23.4.4. Let A be a set of basic objects or urelements. By the set universeabove A, in symbols VA, we mean the usual:
(a) A0 = A.
(b) An+1 = An 1 {X " An}.(c) A# =
$"<# A" , for # a limit ordinal.
(d) VA =$
"!On A" , where On is the class of ordinals.
Definition 23.4.5. Call a structure for FOLP, +O, E, +, T, [[ · ]],, a hierarchical setstructure provided there is a set A of basic elements and
(a) O " VA.
(b) T(X) = X for all subsets X of E such that |X| ( 2.
This a very general concept which may be further constrained, in particular withrespect to the relationship between E and O. If E equals A, we get roughly the CABA-structures. At the other end, we may want E to contain as much as possible. Thiswill make possible the sketched treatment of the group-denoting nouns. A similarinterpretation was proposed by Landman (1989).
Some care should be taken here. If a word like entity denotes E and one wantsto interpret the description the entities, history has taught us that we may run intoproblems if we let this again denote a member of E. Since there cannot be a set of allsets, the entities cannot be an entity. Hence E cannot equal O. Moreover E must be asubset of VA, while O may be a proper class.
We will conclude with a more general comment on Russell’s paradox. Given E "O and T a partial function T : Pow(2(E) * O, we know already from Cantor thatthe following properties are incompatible
a. T is total.b. E = O.
c. T is injective.
The properties are pairwise compatible, however. What we have pursued in thissection is the possibility of keeping (a) and (c) and giving up (b). On the other hand,one may get (b) if one is willing to give up totality or injectivity.
23.5 Reading Plural NPs
23.5.1 Collective and Distributive Readings
We will now consider in some more depth how the plural NPs should be interpretedin the formal models introduced so far, a question which is mainly independent ofwhether a first-order or higher-order approach is chosen. We have throughout assumeda two way ambiguity between collective and distributive readings. In Section 23.3.2we considered the cause of this to be an ambiguity in the plural NP and furthermore

“27-ch23-0989-1034-9780444537263” — 2010/11/29 — 21:09 — page 1021 — #33
Plurals and Collectives 1021
in the plural determiner. This was Bennett’s (1975) approach to the indefinite NPs; hisapproach to the definite NPs was a little different, but we will not consider it here. InSection 23.4.4 we considered a similar treatment within the first-order framework.
It is a problem for proposals which try to locate the difference between the col-lective and the distributive reading to an ambiguity in the NP that the same NP maybe read both collectively and distributively, as pointed out already by Hausser (1974)who came up with the following example.
(37) The horses gather and graze.
Hausser’s own proposal, which we will not consider here, was based on an inge-nious use of quantifying-in. Another alternative is to locate the distribution effect tothe meaning of the intransitive verb graze.
(38) a. For all non-empty X " E, if X ! [[GRAZE]] then X " [[Graze]].b. For all non-empty X " E, if T(X) ! [[Graze]] then X " [[Graze]].
We have here given the constraint both in a version for the second-order framework(38a) and a version for the first-order framework (38b). One might consider whetherthere should be an implication also in the other direction, e.g., if X " [[Graze]] thenX ! [[GRAZE]], a discussion which is on the side of our main issue. Exactly howthe constraint should be implemented depends on one’s view with respect to lexicalconstraints. One possibility is to use 5 to mark the representation of certain distributiveverbs, say 5x[Graze(x)] (Link, 1983).
A similar approach could be used for explaining certain distributions involvingtransitive verbs.
(39) a. The squares contain the circles.b. Every circle is contained in some square.c. Hammerstein, Rodgers and Hart wrote musicals.
Scha (1981) gave a context where (39a) can be interpreted as (39b). The intendedreading is obtained from a collective interpretation of both NPs in (39a) through an(optional) meaning postulate associated with the lexical entry of contain. Sentence(39c) may also be true, though it has been claimed that it is neither fully collective nordistributive (Gillon, 1987). None of the men wrote any musical all by himself, nor didall three of them collaborate on one. But Hammerstein and Rodgers together wrote(at least) one musical Hart and Rodgers did the same. This situation may be describedwith a collective interpretation of both NPs and a more detailed analysis of the lexicalmeaning of the verb.
One cannot get everything this way.
(40) The boys carried the piano upstairs and got a cookie as reward.
Whatever one does to the verb get, with a collective interpretation of the boys, onlyone cookie is given out. A third type of proposal has therefore been to locate theambiguity to the VP, but not in the lexical verb meaning. Instead one introduces anoperator on VPs.

“27-ch23-0989-1034-9780444537263” — 2010/11/29 — 21:09 — page 1022 — #34
1022 Handbook of Logic and Language
Definition 23.5.1 (Distribution operator).
(a) If % is a formula and v an o-variable then Dv[%] is a relation of type +o,.(b) [[Dv[%]]]g = {b ! O | b %= 0 & )a ! E (a 2 b * [[%]]gv
a= t)}.
This D-operator will correspond to an explicit floated quantifier as each in got a cookieeach. Thus, if , represents got a cookie, got a cookie each is represented Dv[, (v)].This interpretation is also an optional reading of got a cookie, where no explicit eachis present. Such an approach was first proposed by Link (1991, written in 1984) anddeveloped further by Lønning (1987b) and Roberts (1987). She gave the followingexample sentence (41).
(41) Five insurance associates gave a $25 donation to several charities.
The sentence has a reading where only five insurance associates were involved,they gave the donations collectively, but each charity received $25. The example indi-cates that the D-operator should not only be applied to properties which correspond tosyntactic constituents, it will interact with other scoping operators, like quantifiers.
Observe that for this to work on a CJ SL structure, it has to be a CABA, or moregenerally, T must be injective. Assume to the contrary that we allow john 6 harry =dick 6 tom. Then it will be impossible for John and Harry to each get a cookie unlessalso Dick and Tom each get a cookie. But observe that if E is the set of atoms in aBoolean structure, as we have assumed, 5 and D will be equivalent.
For the definite plural NPs, this approach will yield the same result as the ambigu-ous NP approach, but not necessarily for the indefinite NPs. Consider a sentence like(42a) with its collective representation (42b). With an ambiguous NP, the distributivereading is expressed by (42c); with a D-operator it is (42d) which is equivalent to(42e), but not necessarily to (42c). To see this let "/ be woman, */ be five, and # betrue about exactly six women. Then (42d) yields a true sentence and (42c) a false one.
(42) a. [S[NP[Det */][N"/]][VP # /]]
b. $y(5"(y) & *(y) & #(y))c. *($x["(x) & #(x)])d. $y(5"(y) & *(y) & D#(y))e. $y(5"(y) & *(y) & )x 7 y (#(x)))
The two interpretations are equivalent whenever * is monotone increasing, i.e. if forall b, c ! O, b ! [[*]] and b 2 c, c ! [[*]], e.g., three or more. In general only (42d) willentail (42c) (Lønning, 1987b). It is rather obvious that for a non-increasing determiner,like at most five, it is the exactly reading in (42d) and not the at least reading in (42c),which is the correct one.
To sum up, all three proposals: the ambiguous NP, the lexical analysis of the verb,and the D-operator analysis have their problems. One possibility is to assume both theD-operator and the ambiguous NP, and get three different readings of sentences withindefinite NPs. The problem for such a solution is to explain why we do not experiencea three way ambiguity. Another alternative is to stick to the ambiguous VP only, andclaim that the exactly effect is pragmatic, generated by some Gricean principles.

“27-ch23-0989-1034-9780444537263” — 2010/11/29 — 21:09 — page 1023 — #35
Plurals and Collectives 1023
Finally, in frameworks with a more flexible relationship between syntax and seman-tics, one might possibly get one’s cake and eat it too. Thus Kamp and Reyle (1993)initially (their Section 4.1.5) discuss two approaches to distribution which can be clas-sified as DRT implementations of the ambiguous NP and the D-analysis. But finally(their Section 4.4.4), they come up with a third proposal which may be used for VP-conjunction and at the same time yield an exactly reading. Link (1998) gives an alter-native proposal for overcoming the problems of the exactly/at least distinction with aD-operator.
Related to the relationship between the collective and the distributive readings arealso the so-called intermediate readings between collective and distributive, as in(43a) and (43b) where the girls collectively got $10 000 for the match and so did theboys.
(43) a. Mary and Eve and Bill and Tom got $10 000 for the match.b. The girls and the boys got $10 000 for the match.c. The young cows and the old cows were separated.
These readings have together with the structured group reading of (43c) wherethe old cows are separated from the young cows, cf. also example (36), been used asarguments for imposing morestructure on the domain (Landman, 1989; Link, 1984;cf. Section 23.4.7). Schwarzschild (1992), on the other hand, argues that collectivereadings will do and that the structuring of the separation in (43c) should be ascribedto pragmatic principles.
23.5.2 Neutral Readings
Can all possible readings of plural NPs be characterized in terms of the collective anddistributive readings? Scha (1981) considered a second type of collective reading, inaddition. Sentence (44a) may be true even though it is not the case that there is onegathering involving all the boys, but where there are several gatherings and the totalnumber of boys involved in these equals six. This can be spelled out as (44b), and thegeneral form of the NP will be as in (44c). We allow ourselves here to use a mixtureof object- and metalanguage, but hope the result is sufficiently clear. We will call thisa neutral reading.
(44) a. Six boys gather.b. |{x ! E | x 2
"{y | 5Boy(y) & Gather(y)}}| = 6
c. !X[*("
{y | 5"(y) & X(y)})]d. !X[$y(5"(y) & *(y) & y =
"{y2 | y2 2 y & X(y2)})]
Interpretations similar to (44b) have been proposed by several authors under differentnames: The partitional reading (Higginbotham, 1980), the pseudo partitional reading(Verkuyl and Van der Does, 1991) and the minimal cover reading (Gillon, 1987). Theproposals differ in detail, e.g., with respect to whether boys participating in gatheringswith individuals that are not boys should be counted. We will not discuss all the differ-ent options, except for one. There is a certain similarity between (44c) and the exactly

“27-ch23-0989-1034-9780444537263” — 2010/11/29 — 21:09 — page 1024 — #36
1024 Handbook of Logic and Language
distributive reading, and one may imagine an alternative at least neutral reading as in(44d). In parallel with the distributive readings, (44c) will always entail (44d), whilethe other direction will hold for monotone increasing *. The at least reading (44d) maybe derived from a collectively read NP by a lexical analysis, cf., example (39c), or bysome operator similar to the D-operator, the exactly analysis cannot.
Observe also that to a certain degree the collective and distributive readings areamplifications of the neutral ones; the exactly distributive reading (42c) entails theexactly neutral reading (44c), the at least distributive reading (42d) entails the atleast neutral reading (44d), and the collective reading (42b) entails the at least neutralreading (44d). Van der Does (1993) discussed in more detail the logical relationshipbetween these readings and also other variants of the neutral readings under variousassumptions concerning the monotonicity type of *.
In spite of the differences of detail between the proposed neutral readings, we thinkthe intuitions underlying these proposals are the same. The proposals should not becounted as different readings but rather as different ways to interpret one and the samereading. Even Van der Does (1993), starting out with three candidate neutral readings,concluded that only one of them should count as a genuine reading.
Is the neutral reading a separate reading of the plural NP, or should it be accommo-dated in other ways, e.g., by vagueness? The first possibility is, as Scha (1981) did forthe indefinite NPs, to say that the plural NPs are three ways ambiguous. They have acollective (42b), an (exactly) distributive (42c) and an (exactly) neutral reading (44c).A problem for such an approach is the following observation.
(45) a. Three boys bought a book.b. Three men wrote musicals.c. Three hundred soldiers gathered.
Sentence (45a) has a collective and a distributive reading, but not the neutral read-ing. It cannot be used for expressing that two boys collectively bought one book and athird boy bought another book. In sentence (45b) and (45c), however, we may observea neutral reading. But then it is not obvious that we in addition see a collective and adistributive reading in these examples, when the neutral reading will do. The problemis to explain why the NP is three ways ambiguous when there are no contexts wherewe can find a three-way ambiguity, and moreover to explain how the context selectsthe right readings and exclude the wrong ones.
The second possibility, which was proposed by Verkuyl and Van der Does (1991), isto take the clue from the entailment relationship between the readings to the extreme,and to say that we only need the weakest reading, the neutral one. This approach alsofaces a problem in explaining why (45a) cannot be true in the described situation.
The third possibility is to only stick to the collective and the distributive readingand to try to ascribe the neutral reading to the meaning of the involved verb (Link,1991). It is interesting to compare the distributive and the neutral reading at this point.A lexical analysis of the verb is not sufficient for the distributive readings becausedistribution may involve scope over other NPs in the sentence. The neutral readings,on the other hand, is impossible in cases where scope is involved as exemplified by

“27-ch23-0989-1034-9780444537263” — 2010/11/29 — 21:09 — page 1025 — #37
Plurals and Collectives 1025
(45a). The problem for this approach is similar as for the D-operator approach to thedistributive reading. It generates the at least rather than the exactly reading.
The claim that the neutrally read NPs cannot take scope over other NPs has notbeen universally accepted, though. It has given rise to some lively discussion betweenGillon (1987, 1990) and Lasersohn (1989), where Gillon (1990) argues that there areexamples where one may find neutral readings taking scope over other NPs.
23.5.3 Cumulative Readings
What happens if a sentence contains several plural NPs? If we assume that each ofthe NPs can be read collectively or distributively, sentence (46a) becomes four waysambiguous. If a reversed scope reading is possible, the total number becomes seven –if both NPs are collective there is no scope involved. Introducing the neutral read-ings increases the number further. Several authors have raised doubts about naturallanguage being this ambiguous, but there has not appeared any formal proposals forhow the number should be reduced. We will consider the opposite question, whetherwhat we have done so far is sufficient for representing all the possible readings of thesentences with several plural NPs.
(46) a. Two examiners marked five papers.b. Six hundred Dutch firms use five thousand American computers.c. Two hundred delegates from ten countries were gathered for one week.
Scha (1981) claims sentences (46a) and (46b) to have additional readings, calledcumulative, where sentence (46b) says that the total number of Dutch firms usingan American computer is six hundred and the total numbers of American computersused by Dutch firms equals five thousand. This may be spelled out by something like(47a) in the first-order setting.
(47) a. Sixh("
{y1 | 5Comp(y1) & $y2 ( 5Firm(y2) & Use(y1, y2))})& Fiveth(
"{y2 | 5Firm(y2) & $y1(
5Comp(y1) & Use(y1, y2))})b. $y1(Sixh(y1) & 5Comp(y1) & $y2(Fiveth(y2) & 5Firm(y2)
& y1 ="
{y3 2 y1 | $y4 2 y2(Use(y3, y4))}& y2 =
"{y4 2 y1 | $y3 2 y1(Use(y3, y4))}))
Formula (47b) could have been obtained from a double collective reading by a furtheranalysis of the verb. It is entailed by the simple double collective reading and also by(47a), but not the other way around. Again the same at least/exactly conflict may beobserved. The cumulative reading raises problems for a strict compositional analysis.Scha’s (1981) proposal is to simultaneously combine the two NPs and the transitiveverb. Logically, however, the cumulative reading does not introduce anything new, itcan be expressed by well known tools.
Whether the cumulative reading represents a separate reading has also been dis-cussed. If one considers a sentence like (46c) then an exactly effect seems to beobserved. Each delegate has to come from one of the ten countries. Each of the tencountries has to be represented by at least one delegate. And the sentence is most oftennot felicitous in contexts where there are altogether five hundred delegates and twenty

“27-ch23-0989-1034-9780444537263” — 2010/11/29 — 21:09 — page 1026 — #38
1026 Handbook of Logic and Language
countries represented even though exactly two hundred of the five hundred delegatesare all the delegates from ten of the represented countries. This is quite similar to theexactly effect we observed for the distributive readings.
We have in this section considered some issues in the reading of plural NPs, butthere are many more issues discussed in the literature which space prevents us fromconsidering, including partitive constructions, like two of the cars, reciprocals, likethe professors hate each other, in particular, the relationship between the reciprocalsand the collectively read NPs, cf. example (36) and (49). Mentioned should also becollective readings with relational nouns, Mary’s and John’s daughters (Eschenbach,1993), and plural anaphora which have, in particular, been discussed within DRT(Kamp and Reyle, 1993).
23.6 Non-Denotational Approaches
23.6.1 Reducing the Collective Readings?
We have so far assumed existence of collections in one form or another. But are theyreally necessary for modeling plural NPs? In this section we will consider attempts atexplaining some of the readings we have so far classified as collective without the useof collections. Some of the earlier semantic literature (e.g., Gil, 1982; Kempson andCormack, 1981) propose four different readings of a sentence containing two pluralNPs, like the ones from example (46).
(48) a. $X(TWO(X) & X " Examiner & )x ! X($Y(FIVE(Y) & Y " Paper & )y ! Y(Mark(x, y)))))
b. $Y(FIVE(Y) & Y " Paper & )y ! Y($X (TWO(X) & X " Examiner & )x ! X(Mark(x, y)))))
c. $X(TWO(X) & X " Examiner & $Y(FIVE(Y) & Y " Paper& )x ! X()y ! Y(Mark(x, y)))))
d. $X(TWO(X) & X " Examiner & $Y(FIVE(Y) & Y " Paper& )x ! X($y ! Y(Mark(x, y))) & )y ! Y($x ! X(Mark(x, y)))))
These correspond to readings encountered already. The first two are the doubledistributive readings, while the last two, called the strong group reading and the weakgroup reading, respectively, may be obtained from a double collective reading by alexical analysis of the verb. What is common to all these readings is that even thoughone quantify over sets of individuals, the objects that actually are counted, and whichin particular enter the mark relation, are simple individuals. Thus the readings areexplained in terms of – or reduced to – facts about simple individuals.
One may wonder whether all collective readings may be reduced in this way. Mostof the newer literature on plurals will say no. Even the sentence (46a) may become truein a situation where there are papers which were not marked by any single examiner;say, they marked half the paper each. This is not reflected by any of the readings in(48). And throughout we have seen many similar examples with other relations likegather or own, which cannot be reduced to properties of individuals.

“27-ch23-0989-1034-9780444537263” — 2010/11/29 — 21:09 — page 1027 — #39
Plurals and Collectives 1027
23.6.2 Branching Generalized Quantifiers
A formula in first-order logic is normally interpreted from outside and inward. Hence,a quantifier will depend on a quantifier with wider scope. There have been exten-sions of first-order logic with partially ordered prefixes where the dependence relationbetween the quantifiers is more complex (see Hintikka and Sandu, 1996), and therehas been a lively discussion on whether natural language exemplify such non-linearreadings of the familiar quantifiers, ) and $. What is more relevant here is Barwise’s(1979) claim that branched readings are more easily found with other natural languagequantifiers like most or at least three. He proposed two schemata for interpreting suchquantifiers, one to be applied when both quantifiers are monotone increasing, whichwill interpret sentence (49a), symbolized as (49b), as (49c), and another one whichshould be applied when both quantifiers are monotone decreasing, which will inter-pret (49d), symbolized as (49e), as (49f ).
(49) a. Most linguists and most logicians respect each other.
b.%
MOST(Linguist) xMOST(Logician) y
&(Respect each other(x, y))
c. $X$Y(MOST(Linguist)(X) & MOST(Logician)(Y)
& X # Y " Respect each other)d. Few linguists and few logicians respect each other.
e.%
FEW(Linguist) xFEW(Logician) y
&(Respect each other(x, y))
f. $X$Y(FEW(Linguist)(X) & FEW(Logician)(Y)
& (Respect each other ' (Linguist # Logician)) " X # Y)
The interpretation of the two NPs in sentence (49a) as branching monotone increas-ing quantifiers (49c) is similar to the strong group reading (48d) or what can beobtained by a collective interpretation of both NPs and a further analysis of the transi-tive verb. The interpretation of the monotone decreasing quantifiers (49f ) is remark-able similar to the cumulative interpretation. One difference is that the branchingproposal assumes that the relation should be ascribed to individuals only, while thecumulative interpretation also considers what went on between collections. But if thestars are removed from the representation in formula (47a), it will be a first-order rep-resentation which corresponds to (49f ) in the higher-order framework provided * ismonotone decreasing. But there is a difference in when they are applied. Cumulativereadings is thought as an option for non-decreasing determiners, like simple numerals,as well.
The proposal to interpret some occurrences of plural NPs in terms of branchingquantifiers is not by itself an argument against collections. As for the proposals consid-ered in the last section, there are uses of plural NPs not covered by such an approach.
23.6.3 Rejecting Collections
In a series of papers George Boolos (1984a, 1984b, 1985) has rejected the necessityof assuming collections (1984b, p. 442): “Abandon, if one ever had it, the idea that

“27-ch23-0989-1034-9780444537263” — 2010/11/29 — 21:09 — page 1028 — #40
1028 Handbook of Logic and Language
use of plural forms must always be understood to commit one to the existence of sets(or “classes”, “collections”, or “totalities”) of those things to which the correspondingsingular forms apply”. But at the same time, he argued that there are occurrences ofplural NPs which may be paraphrased into second-order logic, but not into first-orderlogic (cf. Section 23.3.3.3 above). Boolos’ solution to these apparently incompati-ble claims is to rethink the semantics of second-order logic. The sentence (22), e.g.,is about horses, about one horsebeing the sire of another horse or being faster thananother horse. But the sentence is not about collections of horses. It is not necessaryto enrich the ontology to interpret the sentence. The only thing that has to be enrichedare the rules for interpreting formulas in the models. Boolos’ approach has certainsimilarities to the branching quantifiers. The branching quantifiers may be representedin terms of a second-order formula which interpretation one may think of in terms ofsets. But these quantifiers may alternatively be thought of as an extension to a first-order language which may still be interpreted in a first-order model through additionalinterpretation rules. Similarly, second-order formulas in general can be considered assuch extensions to first-order logic. Boolos (1985) presents a formal proposal for howthe second-order quantifiers may be interpreted in a first-order model.
One may say that Boolos’ main goal is different from what we have considered thisfar. It is not as much to state the correct semantics of plural NPs in natural language,as the correct semantics of second-order logic. The fact that there are natural languagesentences corresponding to second-order formulas is then taken as a clue for translat-ing monadic second-order logic into natural language, while the ease with which weunderstand plural NPs is taken as the clue for the semantics of natural language, whichthen induces the semantics of the second-order logic.
The current space forbids a satisfactory presentation of Boolos’ views and a full dis-cussion of whether one may do without collections, but we will consider some issues.The formal language Boolos considers can be regarded as a sublanguage of SOLID.It extends first-order logic with second-order variables and quantifiers. The relationsymbols considered are all of type +0, 0, . . . , 0,, however. There are no relation sym-bols of type +1,. Second-order variables and constants occur in predicate position, butnever in argument position. Thus the representation of sentence (1c) as
(50) GATHER(Student)
is beyond what can be expressed in the fragment. Moreover, there is no obvious wayto extend Boolos’ interpretation schema to such formulas and the whole SOLID. Whatwe have taken to be genuine collective readings cannot be described. The readings thatmay be captured in the fragment are the ones where the properties distribute down toindividuals in some way or other.
An argument in favor of Boolos’ view is the following. Russell’s paradox has taughtus that there cannot be a set which has as members all sets that are not members ofthemselves. Still, the definite description the sets that are not members of themselvesis all right. If we take a plural definite description in general to denote a set, thisdescription should denote a set as well, and we are in for problems. The defense a setbased, or, more generally, a collection based, approach may take to this attack goes as

“27-ch23-0989-1034-9780444537263” — 2010/11/29 — 21:09 — page 1029 — #41
Plurals and Collectives 1029
follows. It is necessary to distinguish between an “inner” and an “outer” interpretation.Seen from within a model, something counts as a set if and only if it belongs to [[Set]].Since [[Set]] will not belong to [[Set]] sentence (51) will simply be false – even though[[Set]] is a set when seen from outside the model.
(51) The sets are a set.
This corresponds to saying that the exact meaning of the word set is not a part offormal semantics. One should not accept all truths of set theory to count as semanticor logical truths. Whether it is philosophically satisfactory to let the denotation of theword set be different from its real extension is another question. There is a strikingparallel to axiomatic set theory. Axiomatic set theory, i.e. the discourse about sets,must admit as possible models so-called inner models where the domain itself is a setin what is regarded as the full domain of set theory.
23.7 Further Directions
There are many issues relating to plurals that we have not considered or only men-tioned in passing. One is the generic use of plurals and the use of plurals to refer tokinds. Another is the relationship between events and plurals, where several issuesarise. Which readings do sentences with plural NPs have when tense is considered?What about sentences like 23.7 studied by Krifka (1990), where the same ship mayhave to be counted more than once?
(52) Three hundred ships passed the lock last year.
Events are also essential in the approaches to plurality by Lasersohn (1988) and Schein(1993). Should events themselves have a similar structure to the collective domain andhow shall models with both events and collections be framed?
At several places in this chapter we have seen how the analysis of plurals inter-act with some of the most fundamental questions concerning the relationship betweenlogic and language. Firstly, what counts as a reading of a sentence, how should ambi-guity be distinguished from vagueness? The basic intuition about an ambiguity bet-ween a collective and distributive reading of plural NPs yields an explosion in thenumber of readings for sentences containing several plural NPs. Still it seems difficultto restrict this number in any principal way.
Secondly, where shall the borderline between semantics and pragmatics be drawn?In Section 23.3.3.3 we saw that for sentences with indefinite plural NPs, a speaker’smeaning in terms of a referentially used NP might be logically less complex than asentence meaning where one tries to capture an attributive use.
This interacts with the third issue; what is the borderline between semantics andlogic, and how much ontology and word meaning belong to formal semantics? Thisquestion shows up in the interpretation of part of , the question regarding whetherdifferent plural descriptions may denote the same object, and the question regardinghow the group-denoting nouns best should be handled.

“27-ch23-0989-1034-9780444537263” — 2010/11/29 — 21:09 — page 1030 — #42
1030 Handbook of Logic and Language
And fourthly, the semantics of plural NPs is interwoven with some fundamentalproblems related to set theory and higher-order logic, as we pointed out already in theintroduction, and as pointed out by Boolos. The use of plural NPs is fundamental tohow we reason about logic.
Acknowledgment
I am grateful to Jens Erik Fenstad, Godehard Link, Helle Frisak Sem and Jarle Stabell for helpfuladvices at different stages in the preparation of this manuscript.
References
Barker, C., 1992. Group terms in English: representing groups as atoms. J. Semant. 9, 69–93.Bartsch, R., 1973. The semantics and syntax of number and numbers, in: Kimball, J.P. (Ed.),
Syntax and Semantics vol. 2. Seminar Press, New York, pp. 51–93.Barwise, J., 1978. Monotone quantifiers and admissible sets, in: Fenstad, J.E., Gandy,
R.O., Stacks, G.E. (Eds.), Generalized Recursion Theory II. North-Holland, Amsterdam,pp. 1–38.
Barwise, J., 1979. On branching quantifiers in English. J. Philos. Logic 8, 47–80.Bennett, M.R., 1975. Some Extensions of a Montague Fragment of English. Dissertation, Dis-
tributed by the Indiana University Linguistics Club. Los Angeles, CA.Bennett, M.R., 1977. Mass nouns and mass terms in Montague grammar, in: Davis, S., Mithun,
M. (Eds.), Linguistics, Philosophy, and Montague Grammar. University of Texas Press,Austin, TX, pp. 263–285.
Blau, U., 1981. Collective objects. Theor. Ling. 8, 101–130.Boolos, G., 1984a. Nonfirstorderizability again. Ling. Inq. 15, 343.Boolos, G., 1984b. To be is to be a value of a variable (or to be some values of some variables).
J. Philos. 81, 430–449.Boolos, G., 1985. Nominalist platonism. Philos. Rev. 94, 327–344.Bunt, H., 1976. The formal semantics of mass terms, in: Karlsson, F. (Ed.), Papers from the
Third Scandinavian Conference of Linguistics. Academy of Finland, Turku, pp. 71–82.Bunt, H., 1985. Mass Terms and Model-Theoretic Semantics. Cambridge University Press,
Cambridge, UK.Carlson, G., 1977. A unified analysis of the English bare plural. Ling. Philos. 1, 413–457.Carlson, G.N., Pelletier, F.J. (Eds.), 1995. The Generic Book. University of Chicago Press,
Chicago, IL.Chierchia, G., 1982. Nominalization and Montague grammar: a semantics without types for
natural languages. Linguist. Philos. 5, 303–354.Donnellan, K.S., 1966. Reference and definite descriptions. Philos. Rev. 75, 281–304.Eberle, R.A., 1970. Nominalistic Systems. Reidel, Dordrecht.Eschenbach, C., 1993. Semantics of number. J. Semant. 10, 1–31.Fodor, J.D., Sag, I.A., 1982. Referential and quantificational indefinites. Ling. Philos. 5,
355–398.Frege, G., 1980. Philosophical and Mathematical Correspondance, in: Gabriel, G., Hermes, H.,
Kambartel, F., Thiel, C., Veraart, A. (editors of the German edition), Philosophical andMathematical Correspondence. Basil Blackwell, Oxford. (Trans. Kaal, H.)

“27-ch23-0989-1034-9780444537263” — 2010/11/29 — 21:09 — page 1031 — #43
Plurals and Collectives 1031
Gallin, D., 1975. Intensional and Higher-Order Modal Logic. with Applications to MontagueSemantics, North-Holland, Amsterdam.
Gil, D., 1982. Quantifier scope, linguistic variation, and natural language semantics. Ling. Phi-los. 5, 421–472.
Gillon, B., 1987. The readings of plural noun phrases in English. Ling. Philos. 10, 199–219.Gillon, B., 1990. Plural noun phrases and their readings: a reply to Lasersohn. Ling. Philos. 13,
477–485.Gratzer, G., 1978. General Lattice Theory. Academic Press, New York.Hausser, R.R., 1974. Quantification in an Extended Montague Grammar. Dissertation, Univer-
sity of Texas, Austin, TX.Henkin, L., 1950. Completeness in the theory of types. J. Symb. Logic 15, 81–91.Higginbotham, J., 1980. Reciprocal interpretation. J. Ling. Res. 1, 97–117.Hintikka, J., Sandu, G., 1996. Game-theoretical semantics, in: van Benthem, J., ter Meulen, A.
(Eds.), Handbook of Logic and Language. Elsevier, Amsterdam, pp. 361–410.Hoeksema, J., 1983. Plurality and conjunction, in: ter Meulen, A.G.B. (Ed.), Studies in Mod-
eltheoretic Semantics. Foris, Dordrecht, pp. 63–83.Janssen, T.M.V., 1966. Compositionality, in: van Benthem, J., ter Meulen, A. (Eds.), Handbook
of Logic and Language. Elsevier, Amsterdam, pp. 417–473.Jespersen, O., 1924. The Philosophy of Grammar. University of Chicago Press, Chicago, IL.Kamp, H., Reyle, U., 1993. From Discourse to Logic. Kluwer, Dordrecht.Keenan, E., Westerståhl, D., 1996. Quantifiers, in: van Benthem, J., ter Meulen, A. (Eds.), Hand-
book of Logic and Language. Elsevier, Amsterdam, pp. 837–893.Keisler, H.J., 1970. Logic with the quantifier ‘there exists uncountably many’. Ann. Math. Logic
1, 1–93.Kempson, R.M., Cormack, A., 1981. Ambiguity and quantification. Ling. Philos. 4, 259–309.Kripke, S., 1977. Speaker’s reference and semantic reference, in: French, P.A., Uehling, T.E.,
Wettstein, H. (Eds.), Contemporary Perspectives in the Philosophy of Language. Univer-sity of Minnesota Press, Minneapolis, MN, pp. 6–27.
Krifka, M., 1989. Nominal reference, temporal constitution and quantification in event seman-tics, in: Bartsch, R., van Benthem, J., van Embde Boas, P. (Eds.), Semantics and ContextualExpressions. Foris, Dordrecht, pp. 75–115.
Krifka, M., 1990. Four thousand ships passed through the lock: object-induced measure func-tions on events. Ling. Philos. 13, 487–520.
Landman, F., 1989. Groups, Part I, II. Ling. Philos. 12, 559–605; 723–744.Landman, F., 1991. Structures for Semantics. Kluwer, Dordrecht.Lasersohn, P.N., 1988. A Semantics for Groups and Events. Dissertation, Ohio State University,
Columbus, OH.Lasersohn, P., 1989. On the readings of plural noun phrases. Ling. Inq. 20, 130–134.Leonard, H.S., Goodman, N., 1940. The calculus of individuals and its uses. J. Symb. Logic 5,
45–55.Lewis, D., 1991. Parts of Classes. Basil Blackwell, Oxford.Link, G., 1983. The logical analysis of plurals and mass terms: a lattice-theoretical approach,
in: Bauerle, R., Schwarze, C., von Stechow, A. (Eds.), Meaning, Use and Interpretation ofLanguage. Walter de Gruyter, Berlin, pp. 302–323.
Link, G., 1984. Hydras: on the logic of relative constructions with multiple heads, in: Landaman,F., Veltman, F. (Eds.), Varieties of Formal Semantics. Foris, Dordrecht, pp. 245–257.
Link, G., 1987. Generalized quantifiers and plurals, in: Gardenfors, P. (Ed.), Generalized Quan-tifiers, Linguistic and Logical Approaches. Reidel, Dordrecht, pp. 151–180.
Link, G., 1990. First order axioms for the logic of plurality. To appear in Link (forthcoming).

“27-ch23-0989-1034-9780444537263” — 2010/11/29 — 21:09 — page 1032 — #44
1032 Handbook of Logic and Language
Link, G., 1991. Plural, in: von Stechow, A., Wunderlich, D. (Eds.), Semantik/Semantics. Walterde Gruyter, Berlin, pp. 418–440.
Link, G., 1998. Ten years of research on plurals – where do we stand? in: Hamm, F., Hinrichs,E. (Eds.), Plurality and Quantification, Studies in Linguistics and Philosophy, Kluwer,pp. 19–54.
Lønning, J.T., 1987a. Mass terms and quantification. Ling. Philos. 10, 1–52.Lønning, J.T., 1987b. Collective readings of definite and indefinite noun phrases, in: Gardenfors,
P. (Ed.), Generalized Quantifiers. Linguistic and Logical Approaches. Reidel, Dordrecht,pp. 203–235.
Lønning, J.T., 1989. Some Aspects of the Logic of Plural Noun Phrases. Dissertation, Depart-ment of Mathematics, University of Oslo, Norway, Cosmos preprint no. 11.
Massey, G., 1976. Tom, Dick and Harry, and all the King’s men. Amer. Philos. Q. 13, 89–107.Montague, R., 1973. The proper treatment of quantification in ordinary English, in: Hintikka,
K.J.J., Moravcsik, M.E., Suppes, P. (Eds.), Approaches to Natural Language. Reidel, Dor-drecht, pp. 221–242.
Mostowski, A., 1947. On absolute properties of relations. J. Symb. Logic 12, 33–42.Orey, S., 1959. Model theory for higher order predicate calculus. Trans. Amer. Math. Soc. 92,
72–84.Partee, B.H., 1966. Montague grammar, in: van Benthem, J., ter Meulen, A. (Eds.), Handbook
of Logic and Language. Elsevier, Amsterdam, pp. 5–91.Pelletier, F.J., 1975. Non-singular reference: some preliminaries. Philosophia 5, 4. Reprinted:
Pelletier, F.J. (Ed.), 1979. Mass Terms: Some Philosophical Problems. Reidel, Dordrecht,pp. 1–14.
Pelletier, F.J., Asher, N., 1996. Generics and defaults, in: van Benthem, J., ter Meulen, A. (Eds.),Handbook of Logic and Language. Elsevier, Amsterdam, pp. 1125–1177.
Purdy, W.C., 1992. A variable-free logic for mass terms. Notre Dame J. Formal Logic 33, 348–358.
Quine, W.V.O., 1960. Word and Object. MIT Press, Cambridge, MA.Quine, W.V.O., 1970. Philosophy of Logic. Prentice-Hall, Englewood Cliffs, NJ.Quine, W.V.O., 1974. Methods of Logic, third ed. Routledge and Kegan Paul, London.Roberts, C., 1987. Modal Subordination, Anaphora, and Distributivity. Dissertation, University
of Massachusetts, Boston, MA.Roeper, R., 1983. Semantics for mass terms with quantifiers. Nous 17, 251–265.Roeper, R., 1985. Generalisation of first-order logic to nonatomic domains. J. Symb. Logic 50,
815–838.Russell, B., 1903. The Principles of Mathematics. George Allen and Unwin, London. (second
ed. 1937.)Russell, B., 1919. Introduction to Mathematical Philosophy. George Allen and Unwin, London.Scha, R., 1981. Distributive, collective and cumulative quantification, in: Groenendijk, J.A.G.,
Janssen, T.M.V., Stokhof, M.B.J. (Eds.), Formal Methods in the Study of Language. Math-ematical Centre Tracts 136, Amsterdam, pp. 483–512.
Schein, B., 1993. Plurals and Events. MIT Press, Cambridge, MA.Schwarzschild, R., 1992. Types of plurals individuals. Ling. Philos. 15, 641–675.Shapiro, S., 1991. Foundations without Foundationalism. A Case for Second-Order Logic,
Clarendon Press, Oxford.Van Benthem, J., Doets, K., 1983. Higher-order logic, in: Gabbay, D., Guenthner, F. (Eds.),
Handbook of Philosophical Logic vol. 1. Reidel, Dordrecht, pp. 275–329.Van der Does, J., 1993. Sums and quantifiers. Ling. Philos. 16, 509–550.

“27-ch23-0989-1034-9780444537263” — 2010/11/29 — 21:09 — page 1033 — #45
Plurals and Collectives 1033
Verkuyl, H.J., 1988. Aspect, quantification and negation, in: Groenendijk, J. Stokhof, M., Velt-man, F. (Eds.), Proceedings of the Sixth Amsterdam Colloquium, April 13–16 1987, ITLI,University of Amsterdam, the Netherlands, pp. 353–372.
Verkuyl, H.J., Van der Does, J., 1991. The semantics of plural noun phrases, in: van der Does,J., van Eijck, J. (Eds.), Generalized Quantifier Theory and Applications. Dutch Networkfor Language, Logic and Information, Amsterdam, pp. 403–441.

“27-ch23-0989-1034-9780444537263” — 2010/11/29 — 21:09 — page 1034 — #46
This page intentionally left blank

“28-ch24-1035-1058-9780444537263” — 2010/11/30 — 3:44 — page 1035 — #1
24 Plural Discourse Reference(Update of Chapter 23)Adrian Brasoveanu!
Department of Linguistics, University of California at Santa Cruz,CA 950641077, USA, E-mail: [email protected]
24.1 Plural Reference and Plural Discourse Reference
The goal of this chapter is to explore the semantic notion of plurality and argue that,in addition to plural reference to collections, natural language interpretation involvesa notion of plural discourse reference that is essential for the interpretation of quantifi-cationally dependent pronouns (and anaphoric expressions in general, e.g., definites,partitives, reciprocals, etc.), irrespective of whether these pronouns are morphologi-cally singular or plural.
Plural discourse reference is reference to a quantificational dependency betweensets of objects (e.g., atomic individuals or collections, but also times, eventualities,possible worlds, etc.) that is established and subsequently elaborated upon in dis-course. Consider, for example, the sentence in (1) below—where antecedents aresuperscripted with the discourse referent (dref) they introduce, while anaphors aresubscripted with the dref they retrieve (following the convention in Barwise, 1987).
(1) Linus bought au1 gift for everyu2 girl in his class and asked theiru2 deskmates towrap themu1 .
The first conjunct in (1) introduces a quantificational dependency between the set u2 ofgirls in Linus’s class and the set u1 of gifts bought by Linus: each u2-girl is correlatedwith the u1-gift(s) that Linus bought for her. This correlation/dependency is elaboratedupon in the second conjunct: for each u2-girl, Linus asked her deskmate to wrap heru1-gift(s).
The idea of plural discourse reference surfaces in various guises in the dynamicsemantics literature (e.g., Rooth (1987); Kamp and Reyle (1993); Dekker (1994);Krifka (1996); van Benthem (1996); Nouwen (2003); Asher and Wang (2003)), butis for the first time brought to the fore as such in the Dynamic Plural Logic (DPlL) ofvan den Berg (1996).
!I want to thank Johan van Benthem and Alice ter Meulen for their detailed comments and Donka Farkasand Bill Ladusaw for discussion. The usual disclaimers apply.
Handbook of Logic and Language. DOI: 10.1016/B978-0-444-53726-3.00024-4c" 2011 Elsevier B.V. All rights reserved.

“28-ch24-1035-1058-9780444537263” — 2010/11/29 — 21:09 — page 1036 — #2
1036 Handbook of Logic and Language
The basic proposal in DPlL is to model plural discourse reference as sets of variableassignments; that is, unlike classical dynamic semantics, i.e., Discourse Representa-tion Theory (DRT; Kamp (1981); Kamp and Reyle (1993)), File Change Semantics(FCS; Heim, 1982) and Dynamic Predicate Logic (DPL; Groenendijk and Stokhof,1991), DPlL takes natural language expressions to be evaluated relative to sets ofassignments and not relative to single assignments, and models their context-changepotentials as updates of sets of assignments (taken collectively) and not as updates ofsingle assignments (or, equivalently, as updates of sets of assignments taken distribu-tively). These sets I, J, . . . of assignments i1, i2, . . . , j1, j2, . . . , i.e., these plural infor-mation states, can be represented as matrices with assignments/sequences as rows:
Plural Info State I . . . u1 u2 u3 . . .
i1 . . . !1 "1 #1 . . .i2 . . . !2 "2 #2 . . .i3 . . . !3 "3 #3 . . .. . . . . . . . . . . . . . . . . .
Plural info states/matrices are two-dimensional and encode two kinds of discourseinformation: values and structure. The values are the sets of objects that are stored inthe columns of the matrix, e.g., relative to the plural info state I above, the dref u1stores the set of individuals {!1, !2, . . . } since u1 is assigned an individual by eachassignment/row, the dref u2 stores the set of individuals {"1, "2, . . . }, etc. Each indi-vidual can be atomic or non-atomic/a collection, i.e., singular or plural at the domainlevel. The structure/quantificational dependency is encoded in the rows of the matrix,which induce n-ary relations between objects: for example, for each row in I, the indi-vidual assigned to the dref u1 by that row is correlated with the individual assignedto the dref u2 by the same row—so, the plural info state I induces the binary rela-tion {!!1, "1", !!2, "2", . . . }. Similarly, I induces the ternary relation {!!1, "1, #1",!!2, "2, #2", . . . } between the drefs u1, u2 and u3, etc.
24.2 Multiple Interdependent Anaphora
Most of the empirical arguments in the literature for an independent notion of pluraldiscourse reference rely on morphologically plural anaphora of the kind instantiatedin (1) above. Plural anaphora, however, does not provide a clear-cut argument fordistinguishing plural reference (to collections) and plural discourse reference, sinceeither of them could be involved in the interpretation of (1). Nor does it provide aforceful argument for a semantic—as opposed to a pragmatic—encoding of discourse-level reference to quantificational dependencies: it might be that the second conjunctin (1) is cumulatively interpreted (in the sense of Scha, 1981) and that the correlationbetween girls and gifts, brought to salience by the first conjunct, is only pragmaticallysupplied when we interpret the second conjunct.

“28-ch24-1035-1058-9780444537263” — 2010/11/29 — 21:09 — page 1037 — #3
Plural Discourse Reference 1037
This is why sentences with multiple instances of singular anaphora provide morecompelling evidence for a semantics based on plural info states: the fact that theanaphors are morphologically singular enables us to factor out plural reference to col-lections and the fact that we have multiple anaphoric connections that are simultaneousand interdependent (while being embedded under a quantifier) motivates a semanticsthat relies on plural info states, i.e., that crucially involves plural discourse reference.
24.2.1 Multiple Singular Donkey Anaphora
For example, sentences with multiple instances of singular donkey anaphora like (2)and (3) below support the idea of a semantics based on plural info states.
(2) Everyu1 person who buys au2 book on amazon.com and has au3 credit card usesitu3 to pay for itu2 .
(3) Everyu1 boy who bought au2 gift for au3 girl in his class asked heru3 deskmate towrap itu2 .
Donkey anaphora provided one of the main incentives for developing a dynamicsemantics for natural language (for more details, see Chapter 3 Discourse Representa-tion in Context). To see why, consider the example of donkey anaphora in (4) below:the indefinite au2 ‘Harry Potter’ book seems to be able to semantically bind the pro-noun itu2 despite the fact that the pronoun is not in its syntactic scope (i.e., the indef-inite does not c-command the pronoun). The fact that the pronoun is not in the scopeof the indefinite is shown by the minimally different sentence in (5), the infelicity ofwhich (symbolized by #) is due to the failure of the quantifier everyu2 ‘Harry Potter’book to bind the pronoun itu2 .
(4) Everyu1 boy who read au2 ‘Harry Potter’ book recommended itu2 to his friends.(5) #Everyu1 boy who read everyu2 ‘Harry Potter’ book recommended itu2 to his
friends.
Going dynamic enables us to account for donkey anaphora because, unlike in staticsemantics, we can take the variable assignment modified by the indefinite au2 ‘HarryPotter’ book in the restrictor of the quantificational determiner everyu1 and pass it onto the nuclear scope of the quantificational determiner. In this way, we are able tointerpret the pronoun itu2 as if it was in the scope of the indefinite.
This (classical) dynamic account of donkey anaphora faces a couple of problems,one of which is the availability of both weak and strong readings for donkey sen-tences. The weak vs strong contrast is exemplified by sentence (6) below, which hasa weak reading, and the classical donkey sentence in (7), which has a strong reading.Sentence (6) has a weak reading in the sense that its most salient interpretation is thatevery person who has a dime will put some dime s/he has in the meter—and not allher/his dimes. Sentence (7) has a strong reading in the sense that its most salient inter-pretation is: every farmer beats every donkey s/he owns. This contrast is problematicfor the classical dynamic account because this account can derive only strong donkeyreadings.

“28-ch24-1035-1058-9780444537263” — 2010/11/29 — 21:09 — page 1038 — #4
1038 Handbook of Logic and Language
(6) Everyu1 person who has au2 dime will put itu2 in the meter. (Pelletier andSchubert, 1989)
(7) Everyu1 farmer who owns au2 donkey beats itu2 . (based on Geach, 1962)
There are a variety of proposals in the literature to revise the notion of quantification inclassical dynamic semantics in such a way that both weak and strong donkey readingsare allowed (see, for example, Heim (1990); van Eijck and de Vries (1992); Kampand Reyle (1993); Kanazawa (1994); Chierchia (1995)). All the revised systems canhandle simple weak or strong donkey sentences—however, just like classical dynamicsemantics, they rely on singular info states, i.e., they update single assignments and notsets of assignments, and cannot compositionally account for mixed weak and strongrelative-clause donkey sentences like the one in (2) above.
Consider sentence (2) more closely: its most salient interpretation is that, for everybook (strong reading) that any credit-card owner buys on amazon.com, there is somecredit card (weak reading) that s/he uses to pay for the book. Note, in particular, thatthe credit card can vary from book to book, e.g., I can use my MasterCard to buyset theory books and my Visa to buy detective novels, which means that even weakindefinites like au3 credit card can introduce non-singleton sets.
For each buyer, the two sets of objects, i.e., all the books purchased on amazon.comand some of the credit cards that the buyer has, are correlated and the dependencybetween these sets—left implicit in the restrictor of the quantification—is specified inthe nuclear scope: each book is correlated with the credit card that was used to payfor it. This paraphrase of the meaning of sentence (2) is formalized in classical (static)first-order logic as shown in (8) below.
(8) #x(pers(x) $ %y(bk(y) $ buy(x, y)) $ %z(card(z) $ hv(x, z))& #y'(bk(y') $ buy(x, y') & %z'(card(z') $ hv(x, z') $ use to pay(x, z', y'))))
Given that (2) is intuitively interpreted as shown in (8) above, a plausible hypoth-esis is that singular donkey anaphora involves plural reference, i.e., reference tocollections/non-atomic individuals—as proposed in Lappin and Francez (1994), forexample. That is, (multiple) singular donkey anaphora is analyzed in much the sameway as the (multiple) plural anaphora in sentence (9) below, where the two pluralpronouns themu2 and themu1 are anaphoric to the plural individuals obtained by sum-ming the domains (i.e., restrictors) of the quantifier everyu2 girl in his class and of thenarrow scope indefinite au1 gift, respectively.
(9) Linus bought au1 gift for everyu2 girl in his class and asked themu2 /theu2 girls towrap themu1 /theu1 gifts.
This kind of approach analyzes the mixed-reading donkey sentence in (2) as follows.The strong donkey anaphora to u2-books involves the maximal sum individual (i.e.,the maximal collection) y containing all and only the books bought by a given u1-person. At the same time, the weak donkey anaphora to u3-credit cards involves anon-maximal individual z (possibly non-atomic) containing some of the credit cards

“28-ch24-1035-1058-9780444537263” — 2010/11/29 — 21:09 — page 1039 — #5
Plural Discourse Reference 1039
that said u1-person has. Finally, the nuclear scope of (2) is cumulatively interpreted,i.e., given the maximal sum y of books and the sum z of some credit cards, we have:(i) for any atomic individual y' such that y' ( y (i.e., y' is a part of the collection y),there is an atom z' such that z' ( z and z' was used to pay for y' and, also, (ii) for anyatom z' ( z, there is an atom y' ( y such that z' was used to pay for y'.
As noticed in Kanazawa (2001), such a plural reference approach to weak/strongdonkey anaphora incorrectly predicts that the infelicitous sentence in (10) below(based on Kanazawa, 2001:396, (56)) should be acceptable—at least in a situation inwhich all donkey-owning farmers have more than one donkey. This is because singulardonkey anaphora is guaranteed in such a situation to involve reference to non-atomicindividuals, hence to be compatible with collective predicates like gather.
(10) #Everyu1 farmer who owns au2 donkey gathers itu2 around the fire at night.
One way to maintain the plural reference approach and derive the infelicity of (10)is to assume (following a suggestion in Neale, 1990) that singular donkey pronounsalways distribute over the non-atomic individual they are anaphoric to. For example,the singular pronoun itu2 in (10) contributes a distributivity operator and requires eachdonkey atom in the maximal sum of u2-donkeys to be gathered around the fire atnight. The infelicity of (10) follows from the fact that collective predicates apply onlyto collections/non-atomic individuals.
But this domain-level (as opposed to discourse-level) distributivity strategy will nothelp us with respect to (3) above. Sentence (3) contains two instances of strong donkeyanaphora: we are considering every gift and every girl. Moreover, the restrictor of thequantification in (3) introduces a dependency between the set of gifts and the set ofgirls: each gift is correlated with the girl it was bought for. Finally, the nuclear scoperetrieves not only the two sets of objects, but also the dependency between (i.e., thestructure associated with) them: each gift was wrapped by the deskmate of the girl thatthe gift was bought for. Thus, we have here donkey anaphora to structure/dependenciesin addition to donkey anaphora to values/objects.
Importantly, the structure associated with the two sets of atoms, i.e., the dependencybetween gifts and girls that is introduced in the restrictor and elaborated upon in thenuclear scope of the quantification, is semantically encoded and not pragmaticallyinferred (we would—incorrectly—expect this kind of pragmatic, cumulativity-basedapproach to work for (3) in view of sentences like (9) above). That is, the nuclearscope of the quantification in (3) is not interpreted cumulatively and the correlationbetween the sets of gifts and girls is not left vague/underspecified and subsequentlymade precise only at the pragmatic level, based on various extra-linguistic factors.
To see that the structure/dependency in (3) is semantically—and notpragmatically—encoded, consider the following situation: suppose that Linusbuys two gifts, one for Megan and the other for Gabby; moreover, the two girls aredeskmates. Intuitively, sentence (3) is true if Linus asked Megan to wrap Gabby’sgift and Gabby to wrap Megan’s gift and it is false if Linus asked each girl to wrapher own gift. But if the ‘wrapping’ relation between gifts and girls were semanticallyvague/underspecified and only pragmatically supplied (as it is in sentence (9) above),

“28-ch24-1035-1058-9780444537263” — 2010/11/29 — 21:09 — page 1040 — #6
1040 Handbook of Logic and Language
we would predict sentence (3) to be intuitively true even in the second kind ofsituation.
In sum, we need plural discourse reference (in addition to plural reference) to(i) account for singular weak/strong donkey anaphora to structured sets of individuals(see (2) and (3) above) and (ii) derive the incompatibility between singular donkeyanaphora and collective predicates (see (10) above).
Plural info states enable us to capture the semantic non-singularity intuitions asso-ciated with morphologically singular donkey anaphora and to give a compositionalaccount of mixed weak and strong donkey sentences by locating the weak/strong don-key ambiguity at the level of the indefinite articles. A weak indefinite stores in a pluralinfo state some of the individuals that satisfy its restrictor and nuclear scope, i.e., anon-maximal witness set that satisfies the nuclear scope, while a strong indefinite arti-cle stores in a plural info state all the individuals that satisfy its restrictor and nuclearscope.
We account for the incompatibility between singular donkey anaphora and collec-tive predicates by taking singular donkey anaphora to be (i) distributive at the dis-course level, i.e., predicates need to be satisfied relative to each individual assignmenti in a plural info state I, and (ii) singular/atomic at the domain level, that is, for eachi ) I, the individual i assigns to the dref u, symbolized as ui, is atomic. Since collec-tive predicates apply only to collections/non-atomic individuals, they are felicitous ifeither (i) the individuals stored by each variable assignment are non-atomic, i.e., wehave domain-level plurality, or (ii) they are interpreted collectively at the discourselevel, e.g., we sum all the individuals stored in a plural info state and require theresulting sum individual ui1 * ui2 * . . . to be gathered around the fire. Neither caseobtains with singular donkey anaphora.
24.2.2 Multiple Plural Donkey Anaphora
Having established the need for plural discourse reference, the question arises whetherwe can do away with plural reference by deriving collections (sets of individuals) fromplural info states (sets of assignments). This is the last question raised in Chapter 23,Plurals and Collectives (section 6).
Dynamic approaches that countenance plural discourse reference usually treat thetwo notions of plurality asymmetrically. They fall into roughly two classes. The firstkind of approaches (e.g., van den Berg (1996); Nouwen (2003); Asher and Wang(2003)) make plural reference dependent on plural discourse reference, i.e., they allowvariable assignments to store only atomic individuals. Collections/non-atomic individ-uals can be accessed in discourse only by summing over plural info states. The sec-ond kind of approaches (e.g., Krifka, 1996) make plural discourse reference depen-dent on plural reference: the central notion of parametrized sum individuals (due toRooth (1987) and developed in Krifka (1996)) associates each atom that is part ofa collection, i.e., part of a non-atomic/sum individual, with a variable assignmentthat ‘parametrizes’/is dependent on that atom. For example, the universal quanti-fier in Geach’s original donkey sentence introduces a collection containing all and

“28-ch24-1035-1058-9780444537263” — 2010/11/29 — 21:09 — page 1041 — #7
Plural Discourse Reference 1041
only the farmer-atoms that are donkey owners—and each farmer-atom is associated/parametrized with one or more variable assignments that each store (relative to a newdref) a donkey-atom that the farmer owns.
Both kinds of approaches have difficulties with plural donkey anaphora stemmingfrom their asymmetric treatment of domain-level and discourse-level plurality. Thesecond kind of approaches find it difficult to account for the incompatibility betweensingular donkey anaphora and collective predicates exemplified in (10) because thediscourse-level plurality associated with strong donkey anaphora requires domain-level plurality, which in turn predicts that the collective predicate gather should befelicitous. These approaches also have difficulties with examples of donkey anaphorato structure like (3), in which the order/‘relative scope’ of the anaphors does not repro-duce the order/‘relative scope’ of the antecedents—because the nested structure of thedependencies stored in parametrized sum individuals predicts that we can anaphor-ically retrieve the entities stored in the parametrizing assignments only if we firstretrieve the collection/sum individual that those assignments actually parametrize.
The first kind of approaches have a different set of problems: they do not gener-alize to morphologically plural donkey anaphora. In particular, they have difficulties(i) accounting for plural sage plant examples and (ii) capturing the intuitive parallelsbetween singular and plural donkey anaphora. Consider first the singular and pluralsage plant examples in (11) (see Heim, 1982, 89, (12)) and (12) (based on example(49) in Kanazawa (2001:393), adapted from Lappin and Francez (1994)) below.
(11) Everybodyu1 who bought au2 sage plant here bought eightu3 others along withitu2 .
(12) Everybodyu1 who bought twou2 sage plants here bought sevenu3 others alongwith themu2 .
Dynamic approaches that countenance only plural discourse reference (but not pluralreference, i.e., collections) can account for singular sage plant examples. In the case ofthe plural example in (12), however, they need to ‘distribute’ over the purchased sageplants in such a way that they look at all the pairs of sage plant atoms and predicatethe nuclear scope bought sevenu3 others. . . of such pairs. This, in turn, requires anoperator that distributes over all the pairs of assignments in a plural info state (notover individual assignments)—and it is not clear how to define such an operator orwhat particular lexical item in (12) contributes it.
Similarly, these approaches cannot capture the intuitive parallel between the mul-tiple plural donkey sentence in (13) below and the multiple singular sentence in (3)above. Note that the collective predicate fight (each other) in (13) is felicitous because,in contrast to example (10), we have domain-level non-atomicity introduced by theplural cardinal indefinite twou3 boys.
(13) Everyu1 parent who gives au2 balloon/threeu2 balloons to twou3 boys expectsthemu3 to end up fighting (each other) for itu2 /themu2 .
Thus, (multiple) plural donkey anaphora provides evidence that natural languageinterpretation requires both plural discourse reference and plural reference and that

“28-ch24-1035-1058-9780444537263” — 2010/11/29 — 21:09 — page 1042 — #8
1042 Handbook of Logic and Language
these two semantic notions of plurality should be formalized as two independent (yetinteracting) meaning components. This enables us to derive the correct interpretationsfor plural sage plant examples and instances of multiple plural donkey anaphora, whilecapturing the intuitive parallels between them and their singular counterparts.
Finally, allowing for both notions of plurality opens the way to an account ofweak/strong plural donkey readings that is parallel to the account of weak/strong sin-gular donkey readings. For example, cardinal indefinites like two can be either strong,e.g., twou3 boys in (13) above, or weak, e.g., twou2 dimes in (14) below—which is aminimal variation on the classical weak donkey sentence in (6) above.
(14) Everyu1 driver who had twou2 dimes put themu2 in the meter.
24.2.3 Multiple Anaphora Generalized
Introducing and incrementally elaborating on dependencies between multiple inter-related objects is a common occurrence in natural language discourse and it is notrestricted to dependencies between individuals. For example, the discourse in (15)below (from Karttunen, 1976) introduces and elaborates on a dependency betweenindividuals (the courted women) and events (the conventions during which the womenare courted). The naturally occurring discourse in (16)1 instantiates a similar depen-dency between children and the various events they participate in, e.g., being con-gratulated again, being given another pizza, etc. Finally, the discourse in (17) (basedon examples in Roberts, 1989), introduces and elaborates on a dependency betweenpossibilities—possible scenarios in which a wolf comes in—and individuals—thewolves featuring in each of the possible scenarios.
(15) a. Harvey courts au1 woman at every$2 convention.b. Sheu1 always$2 comes to the banquet with him.c. Theu1 woman is usually$2 also very pretty.
(16) a. [In the BOOK IT! program] You set monthly reading goals for each child in theclass.
b. As soon as a monthly reading goal has been met, you present the child with a pizzaaward certificate.
c. The child takes the certificate to a Pizza Hut restaurant, where he or she is congrat-ulated and given a free, one-topping pizza.
d. On the first visit, the child also receives recognition of their accomplishment and asurprise gift.
e. On each subsequent visit, the child is again congratulated and given another pizzaand a sticker to recognize reading achievement.
(17) a. Au1 wolf mightp1 come in.b. Itu1 wouldp1 attack Harvey first.
1 The example is a lightly edited version of the text available at http://www.pizzahutmhat.com/bookit/about.html.

“28-ch24-1035-1058-9780444537263” — 2010/11/29 — 21:09 — page 1043 — #9
Plural Discourse Reference 1043
24.3 Ontology and Logic
We can think of drefs, i.e., variables, and variable assignments, i.e., assignments ofvalues to drefs, in two ways. Classical dynamic semantics (DRT/FCS/DPL) takesdrefs to be atomic, basic entities and variable assignments to be composite objects,namely functions from drefs to appropriate values. Taking drefs to be the basic build-ing blocks is pre-theoretically appealing: as Karttunen (1976) and Webber (1978) firstargued, natural language interpretation involves an irreducible notion of discourse-level reference and the referents/entities that are introduced, constrained and relatedto each other in discourse are distinct from the actual referents/entities (in the static,Fregean/Tarskian sense).
The ontology and logic of the classical dynamic formalization do not, however,perspicuously reflect the main point of the present section, namely the existence of anotion of plural discourse reference that is independent from and parallel to domain-level plural reference. We will, therefore, follow Landman (1986) and Muskens(1996) and take assignments to be atomic, basic entities, while drefs will be mod-eled as composite objects, namely as functions from assignments to appropriate staticentities.
The ontological commitment to the existence of singular and plural info statesimplicit in this formalization of discourse-level plurality is parallel to the ontologi-cal commitment to individuals and collections in Link-style theories of domain-levelplurality (see Link, 1983).
We will see that, although they make different ontological commitments, the twoways of formalizing drefs and variable assignments are very similar from a technicalpoint of view.
24.3.1 Dynamic Ty2
Following Muskens (1996), we will use classical (many-sorted) type logic as theunderlying logic for the entire dynamic system. This logic, together with the defi-nition of dref types, the set of axioms that ensure the proper behavior of variableassignments, etc., is labeled Dynamic Ty2 because, just as the Logic of Change ofMuskens (1996), it is a variant of Gallin’s Ty2 (Gallin, 1975).
There are three basic types: type t (truth values), type e (atomic and non-atomicindividuals) and type s, modeling variable assignments as they are used in DPL(Groenendijk and Stokhof, 1991). A suitable set of axioms, provided in (20) below,ensures that the entities of type s behave as assignments.
The recursive definition in (18) below isolates a proper subset of types as dreftypes: these are functions from assignments (type s) to static objects of arbitrary types.We restrict our drefs to such functions because, if we allow for arbitrary dref types,e.g., s(st), we might run into counterparts of Russell’s paradox (see Muskens (1995:179–180, fn. 10)).

“28-ch24-1035-1058-9780444537263” — 2010/11/29 — 21:09 — page 1044 — #10
1044 Handbook of Logic and Language
(18) Dynamic Ty2—the set of dref types DRefTyp and the set of types Typ.a. BasSTyp (basic static types): {t, e} (truth values and individuals).b. STyp (static types): the smallest set including BasSTyp and s.t., if %, & ) STyp,
then (%& ) ) STyp.c. BasTyp (basic types): BasSTyp + {s} (variable assignments).d. DRefTyp (dref types): the smallest set s.t., if & ) STyp, then (s& ) ) DRefTyp.
e. Typ (types): the smallest set including BasTyp and s.t., if %, & ) Typ, then (%& ) )Typ.
(19) Dynamic Ty2—terms (subscripts on terms indicate their type).a. Basic expressions: for any type & ) Typ, there is a denumerable set of
& -constants Con& and a denumerably infinite set of & -variables Var& =!'&,0, '&,1, . . .
", e.g.:
i. Cone = {linus, mary, dobby, . . .} , Conet = {donkey, farmer, . . . , walk,arrive, . . . }, Cone(et) = {own, beat, . . .}
ii. Conse =!u1, u2, . . . , u, u', . . .
"(drefs for individuals are constants)
iii. Vare = {x, y, . . .}, Vars = {i, j, . . .}; in general, Var& =!v1, v2, . . . , v,
v', . . ."
for any & ) Typb. For any type & ) Typ, the set of & -terms Term& is the smallest set s.t.:
i. Con& + Var& , Term&
ii. !(") ) Term& if ! ) Term%& and " ) Term% , for any % ) Typiii. ((v. !) ) Term& if & = (%)), v ) Var% and ! ) Term) , for any %, ) ) Typiv. (! = ") ) Term& if & = t and !, " ) Term% , for any % ) Typ
v. (i[*] j) ) Term& if & = t and i, j ) Vars and * ) Term% , for any % )DRefTyp
c. Abbreviation: Dobbyse := (is. dobbye, Maryse := (is. marye, etc.
We take a first-order approach to domain-level plurality and lump together atomicindividuals and collections/non-atomic individuals into the domain of type e, for-malized as the power set of a given non-empty set IN of entities. In this way, we cansimplify the types we assign to natural language expressions, which in turn enables usto focus on discourse-level plurality. However, everything we will say is compatiblewith a higher-order approach to domain-level plurality (see Chapter 23, Plurals andCollectives for a detailed discussion of higher-order vs first-order approaches todomain-level plurality).
In more detail, the domain of type e is ++(IN) := + (IN)\ {-}. The sum of twoindividuals xe * ye is the union of the sets x and y, e.g., {megan} * {gabby} ={megan, gabby}. For a set of atomic/non-atomic individuals Xet, the sum of the indi-viduals in X (i.e., their union) is *X, e.g., * {{megan, gabby} , {gabby} , {linus}} ={megan, gabby, linus}. The part-of relation over individuals x ( y (x is a part of y)is the partial order induced by inclusion , over the set ++(IN). Atomic individualsare the singleton subsets of IN, identified by means of the predicate atom(x) := #y (x(y = x).
A dref for individuals u is a function of type se from assignments is to individualsxe. Intuitively, the individual useis is the individual that the assignment i assigns to the

“28-ch24-1035-1058-9780444537263” — 2010/11/29 — 21:09 — page 1045 — #11
Plural Discourse Reference 1045
dref u. Dynamic info states I, J, etc. are plural: they are sets of variable assignments,i.e., terms of type st. An individual dref u stores a set of atomic and/or non-atomicindividuals with respect to a plural info state I, abbreviated as uI := {useis : is ) Ist},i.e., uI is the image of the set of assignments I under the function u.
(20) Dynamic Ty2—frames, models, assignments, interpretation and truth.a. A standard frame F for Dynamic Ty2 is a set {D& : & ) Typ} s.t. Dt, De and Ds
are pairwise disjoint sets (Dt = {T, F}) and, for any %, & ) Typ,D%& = {f : f is a total function from D% to D& }
b. A model M for Dynamic Ty2 is a pair#FM, [[ · ]]M
$s.t.:
i. FM is a standard frame for Dynamic Ty2
ii. [[ · ]]M assigns an object [[!]]M ) DM& to each ! ) Con& , for any & ) Typ,
i.e., [[ · ]]M respects typing
iii. M satisfies the following axioms/axiom schemata:Ax1. udref(*), for any unspecific dref name * of any type & ) DRefTyp2
(e.g., udref(u1), udref(u2), etc.,but¬udref(Dobby),¬udref(Mary),etc.)
Ax2. udref(*) $ udref(*') & * .= *', for any two distinct dref names *
and *' of type & , for any type & ) DRefTyp (drefs have unique drefnames, i.e., we ensure that we do not accidentally update *' when weupdate *)3
Ax3. #is#js(i[ ]j & i = j) (identity of ‘assignments’: two ‘assignments’ iand j are identical if they they don’t differ with respect to the valueof any dref)
Ax4. #is#vs& #f& (udref(v) & %js(i[v] j $ vj = f )) (enough ‘assignments’)
c. An M-assignment , is a function that assigns to each variable v ) Var&
an element ,(v) ) DM& , for any & ) Typ. Given an M-assignment , ,
if v ) Var& and d ) DM& , then ,v/d is the M-assignment identical to ,
except that it assigns d to v.
d. The interpretation function [[ · ]]M,, is defined as follows:
i. [[!]]M,, = [[!]]M if ! ) Con& , for any & ) Typii. [[!]]M,, = ,(!) if ! ) Var& , for any & ) Typiii. [[!(")]]M,, = [[!]]M,, ([["]]M,, )
iv. [[(v. !]]M,, =#[[!]]M,,v/d
: d ) DM%
$, if v ) Var%
v. [[! = "]]M,, = T if [[!]]M,, = [["]]M,, ; F otherwise
2 udref is a non-logical constant intuitively identifying the ‘variable’ drefs, i.e., the non-constant functionsof type s% (for any % ) STyp) intended to model DPL-like variables. In fact, udref stands for an infi-nite family of non-logical constants of type & t, for any & ) DRefTyp. Alternatively, we can assume apolymorphic type logic with infinite sum types, in which udref is a polymorphic function.
3 Importantly, recall that unspecific drefs *, *', etc. (which model DPL-style variables) are non-logicalconstants in Dynamic Ty2, not variables. Ax2 requires any two such distinct constants to denote distinctfunctions.

“28-ch24-1035-1058-9780444537263” — 2010/11/29 — 21:09 — page 1046 — #12
1046 Handbook of Logic and Language
vi. [[i[*]j]]M,, = T if * ) Term% , % ) DRefTyp, [[#v% (udref(v) $ v .=* & vi = vj)]]M,, = T and [[#v& (udref(v) & vi = vj)]]M,, = T, forall & .= %, & ) DRefTyp; F otherwise
e. Truth. A formula - ) Termt is true in M relative to , iff [[-]]M,, = T.A formula - ) Termt is true in M iff it is true in M relative to any , .
Drefs are modeled like individual concepts in Montague semantics: just as the sense ofthe definite description the chair of the UC Santa Cruz linguistics department (where,following Frege, sense is a way of giving the reference) is modeled as an individualconcept, i.e., as a function from indices of evaluation to individuals, the meaning ofa pronoun is basically a dref, i.e., a discourse-relative individual concept, which ismodeled as a function from discourse salience states to individuals (in Dynamic Ty2,a discourse salience state is just a Tarskian, total variable assignment).
Modeling drefs as functions that take assignments as arguments (i.e., entities oftype s) and return static objects as values, e.g., individuals (type e), is not as dif-ferent from the DRT/FCS/DPL way of modeling drefs and variable assignments asit might seem. Classically, drefs are modeled as variables and a variable x is basi-cally an instruction to look at the current index of evaluation (i.e., the current vari-able assignment) g, and retrieve whatever individual g associates with x, i.e., g(x).So, instead of working directly with variables, we can work with their ‘type-lifted’versions, i.e., instead of x, we can take a dref to be a function of the form (g. g(x),which is the (set-theoretic) xth projection function that projects the sequence g onto thecoordinate x.
This is what happens in Dynamic Ty2: we model variable assignments as atomicentities (of type s) and drefs as functions taking assignments as arguments and return-ing appropriate static entities as values. This way of modeling drefs and assignments ispreferable because it makes formally explicit the parallel between domain-level singu-larity/plurality, encoded by ++(IN), and discourse-level singularity/plurality, encodedby ++(Ds), where Ds is the domain of assignments.
24.3.2 Dynamic Conditions
A sentence is interpreted as a Discourse Representation Structure (DRS), i.e., as arelation of type (st)((st)t) between an input info state Ist and an output info state Jst.As shown in (21) below, a DRS is represented as a [new drefs | conditions] pair,which abbreviates a term of type (st)((st)t) that places two kinds of constraints on theoutput state J: (i) J differs from the input state I at most with respect to the new drefsand (ii) J satisfies all the conditions. An example is provided in (22).
(21) [new drefs | conditions] := (Ist.(Jst. I[new drefs]J $ conditionsJ(22) [u1, u2 | person{u1}, book{u2}, buy{u1, u2}] :=
(Ist.(Jst. I[u1, u2]J $ person{u1}J $ book{u2}J $ buy{u1, u2}J

“28-ch24-1035-1058-9780444537263” — 2010/11/29 — 21:09 — page 1047 — #13
Plural Discourse Reference 1047
DRSs of the form [conditions] that do not introduce new drefs are tests and theyabbreviate terms of the form (Ist.(Jst. I = J $ conditionsJ, e.g., [book{u2}] :=(Ist.(Jst. I = J $ book{u2}J.
Conditions, e.g., lexical relations like buy{u1, u2}, are sets of plural info states, i.e.,they are terms of type (st)t. Lexical relations are unselectively distributive with respectto the plural info states they accept, where “unselective” is used in the sense of Lewis(1975). That is, lexical relations universally quantify over variable assignments—orcases, to use the terminology of Lewis (1975): a lexical relation accepts a plural infostate I iff it accepts, in a pointwise manner, every single assignment i ) I, as shownin (23) below. The first conjunct in (23), i.e., I .= -, rules out the possibility that theuniversal quantification in the second conjunct #is ) I(. . . ) is vacuously satisfied.
The curly braces used in the representation of conditions indicate that the staticconstant R of type ent does not directly apply to the drefs u1, . . . , un of type se thatare its arguments.4 Thus, this brace convention is closely related to the Montagovianbrace convention.
(23) R{u1, . . . , un} := (Ist. I .= - $ #is ) I(R(u1i, . . . , uni)), for any constant R oftype ent.
(24) I is a complete ideal without a bottom element (abbreviated as c-ideal) withrespect to the partial order induced by set inclusion , on the set of sets ++(Ds)
iff (i) I , ++(Ds) and (ii) I is closed under non-empty subsets and underarbitrary unions.
(25) For any c-ideal I, we have that: I = ++(%
I). That is, c-ideals are complete(atomic) Boolean algebras without a bottom element.
(26) Lexical relations as c-ideals. For any constant R of type ent and sequence ofdrefs !u1, . . . , un", let I(R, !u1, . . . , un") := (is. R(u1i, . . . , uni), abbreviatedIR whenever the sequence !u1, . . . , un" can be recovered from context. Then,R{u1, . . . , un} = ++(IR).5
Given unselective distributivity, the denotation of lexical relations has a lattice-theoretic ideal structure. The definition of lexical relations in (23) above ensuresthat they always denote c-ideals in the atomic lattice + (Ds). We can in fact char-acterize them in terms of the supremum of their denotation, as shown in (26) above(which freely switches between function talk and set talk). The fact that lexical rela-tions denote c-ideals endows the notion of natural language dynamic meaning with arange of desirable formal properties. For example, as we will see in the next subsec-tion, DRSs, which are binary relations between sets of assignments of type (st)((st)t),can be defined in terms of simpler binary relations between assignments of type s(st).
4 Types of the form ent are defined as the smallest set of types such that e0t := t and em+1t := e(emt) (seeMuskens, 1996).
5 Convention: ++(-st) := -(st)t .

“28-ch24-1035-1058-9780444537263” — 2010/11/29 — 21:09 — page 1048 — #14
1048 Handbook of Logic and Language
24.3.3 New Drefs and DRSs
The other component of the definition of DRSs in (21) above is new dref introduction.We already have a Dynamic Ty2 notion of dref introduction, i.e., random assignmentof value to a dref u. This notion, symbolized as i[u]j, relates two assignments is and jsand can be informally paraphrased as: assignments i and j differ at most with respectto the value they assign to the dref u (see (20) above for the exact definition).
The problem posed by new dref introduction in dynamic systems based on pluralinfo states is how to generalize the Dynamic Ty2 notion of new dref introduction,which is a relation between assignments, to a relation between sets of assignments (i.e.,between plural info states). Various options have been explored in the literature (seevan den Berg (1996); Krifka (1996); Nouwen (2003); Brasoveanu (2007)) and theygenerally are stronger versions of the minimal definition in (27) below. The definitionin (27) is minimal in the sense that it is just the pointwise, cumulative-quantificationstyle generalization of the Dynamic Ty2 notion.
(27) [u] := (Ist.(Jst. #is ) I(%js ) J(i[u]j)) $ #js ) J(%is ) I(i[u]j))
Informally, I[u]J means that each input assignment i has a [u]-successor outputassignment j and, vice-versa, each output assignment j has a [u]-predecessor inputassignment i. This ensures that we preserve the values and structure associated withthe previously introduced drefs u', u'', etc. The definition in (27) treats the structureand value components of a plural info state in parallel, since we non-deterministicallyintroduce both of them, namely: (i) some new (random) values for u and, also,(ii) some new (random) structure associating the u-values and the values of any other(previously introduced) drefs u', u'', etc.
The definition in (27) is motivated on both empirical and theoretical grounds.Empirically, it enables us to account for mixed-reading donkey sentences like (2)above. Recall that, intuitively, we want to allow the credit cards to vary from bookto book. That is, we want the restrictor of the every-quantification in (2) to non-deterministically introduce some set of u3-cards and non-deterministically associatethem with the u2-books and let the nuclear scope filter the non-deterministicallyassigned values and structure by requiring each u3-card to be used to pay for the cor-responding u2-book.
Theoretically, the definition in (27) is the natural generalization of the Dynamic Ty2definition insofar as it preserves its formal properties: just as i[u]j is an equivalencerelation of type s(st) between assignments, I[u]J is an equivalence relation of type(st)((st)t) between sets of assignments. Moreover, the fact that [u] is an equivalencerelation enables us to simplify the definition of DRSs as shown in (30) below.
The dynamic definition of truth—which has the expected form, namely existentialquantification over output info states (aka existential closure)—is provided in (31).
(28) Dynamic conjunction. D; D' := (Ist.(Jst. %Hst(DIH $ D'HJ)
(29) [u1, . . . , un] := (Ist.(Jst. ([u1]; . . . ; [un])IJ(30) DRSs in terms of c-ideals over relations of type s(st).
For any DRS D := [u1, . . . , un | C1, . . . , Cm], where the conditions

“28-ch24-1035-1058-9780444537263” — 2010/11/29 — 21:09 — page 1049 — #15
Plural Discourse Reference 1049
C1, . . . , Cm are c-ideals, let RD := (is.(js. i[u1, . . . , un]j $ j )&%
C1 / . . . /%Cm
'.6 Then:
D = (Ist.(Jst. %Rs(st) .= -(I = Dom(R) $ J = Ran(R) $ R , RD)
= (Ist.(Jst. %Rs(st) ) ++(RD)(I = Dom(R) $ J = Ran(R)).7
(31) Truth. A DRS D is true with respect to an input info state Ist iff %Jst(DIJ).
24.4 Compositionality
Given the underlying type logic, compositionality at sub-clausal level followsautomatically and standard techniques from Montague semantics become avail-able. More precisely, the compositional aspect of interpretation in an extensionalFregean/Montagovian framework is largely determined by the types for the (exten-sions of the) ‘saturated’ expressions, i.e., names and sentences. Let us abbreviate themas e and t. An extensional static logic with domain-level plurality identifies e with e(atomic and non-atomic individuals) and t with t (truth values). The denotation of thenoun book is of type et, i.e., et: book ! (xe. booket(x). The generalized determinerevery is of type (et)((et)t), i.e., (et)((et)t): every ! (Xet.(X'
et. #xe(X(x) & X'(x)).We go dynamic with respect to both value and structure by making the ‘meta-
types’ e and t more complex, i.e., by assigning finer-grained meanings to names andsentences. The ‘meta-type’ talk should not be taken literally—formally, e and t arejust abbreviations, i.e., syntactic sugar meant to show in a perspicuous way how thevery general Montagovian solution to the compositionality problem is formalized inthis case. In particular, we assign the following dynamic types to the ‘meta-types’ eand t: t := (st)((st)t), i.e., a sentence is interpreted as a DRS, and e := se, i.e., aname is interpreted as a dref for individuals. The denotation of the noun book is stillof type et, as shown in (32) below. The denotations of pronouns, indefinite articles andgeneralized determiners are provided in the following three subsections.
(32) book ! (ve. [book {v}], i.e., book ! (ve.(Ist.(Jst. I = J $ book {v} J
24.4.1 Pronouns
A pronoun anaphoric to a dref u is interpreted as the Montagovian quantifier-lift of thedref u (of type e), i.e., its type is (et)t. Singular number morphology on pronouns con-tributes domain-level atomicity, as shown in (33) below. For simplicity, the atom {u}condition is formalized as part of the assertion and not as a presupposition. Pluralnumber morphology on pronouns makes a fairly weak contribution: it just indicatesthe absence of a domain-level atomicity requirement. The stronger requirement ofdomain-level non-atomicity that is associated with many uses of plural pronouns can
6 Where i[u1, . . . , un]j := i([u1]; . . . ; [un])j. In this case, dynamic conjunction ; is defined as relationcomposition over terms of type s(st), i.e., [u]; [u'] := (is.(js. %hs(i[u]h $ h[u']j), where [u] and [u'] areDynamic Ty2 terms of type s(st).
7 Where Dom(R) := {is : %js(Rij)} and Ran(R) := {js : %is(Rij)}.

“28-ch24-1035-1058-9780444537263” — 2010/11/29 — 21:09 — page 1050 — #16
1050 Handbook of Logic and Language
be derived in various ways, e.g., following Sauerland (2003), we can assume that aMaximize Presupposition principle of the kind proposed in Heim (1991) requires usto use singular pronouns whenever we can.
(33) atom {u} := (Ist. atom(*uI)(34) heu ! (Pet. [atom {u}]; P(u)
(35) theyu ! (Pet. P(u)8
The fact that singular pronouns contribute an atom condition enables us to derive theincompatibility between collective predicates and singular pronouns exemplified in(10) above, while allowing for collective predicates with plural pronouns, as in (13).Also, the atom condition on singular pronouns captures the intuition that deictic (i.e.,discourse-initial) uses of singular pronouns refer to atomic individuals. In particular,it is crucial that the atom condition is collectively interpreted relative to a plural infostate I, i.e., that it is collective at the discourse level. This ensures two things: (i) anytwo assignments i, i' ) I assign the same individual x to u, i.e., #is, i's ) I(ui =ui'), and (ii) the individual x assigned to u throughout the info state I is an atomicindividual, i.e., #is ) I(atom(ui)).
24.4.2 Indefinites
The translation of indefinite articles has the expected type (et)((et)t), as shown in (36)below. An indefinite article takes two dynamic properties P (the restrictor) and P' (thenuclear scope) as arguments and returns a DRS (i.e., a term of type t) as value. ThisDRS consists of two sub-DRSs that are dynamically conjoined: the first one, namely[u], introduces a new dref u (the dref with which the indefinite article is indexed);the second sub-DRS, i.e., dist([atom {u}]; P(u); P'(u)), constrains the value of thisnewly introduced dref. Just as in the case of pronouns, singular number morphologyon indefinites contributes domain-level atomicity, i.e., a condition atom {u}. This con-dition, however, is within the scope of a discourse-level distributivity operator dist,defined in (37) below.
(36) awk:u ! (Pet.(P'et. [u]; dist([atom {u}]; P(u); P'(u))
(37) dist(D) := (Ist.(Jst. %Rs((st)t) .= -(I = Dom(R) $ J =%
Ran(R) $#ks#Lst(RkL & D {k} L))
- D is a DRS (type (st)((st)t))- R is a relation between assignments and sets of assignments (type s((st)t)) such
that Dom(R) := {ks : %Lst(RkL)} (type st) and Ran(R) := {Lst : %ks(RkL)} (type(st)t)
- R encodes a partial function from assignments k ) I to sets of assignments L, i.e.,R is such that #ks ) Dom(R)#Lst#L'
st(RkL $ RkL' & L = L')- {k} is the singleton set of assignments (type st) containing only k
8 Anaphoric definite articles receive similar translations: thesg:u ! (Pet.(P'et. [atom {u}]; P(u); P'(u) and
thepl:u ! (Pet.(P'et. P(u); P'(u).

“28-ch24-1035-1058-9780444537263” — 2010/11/29 — 21:09 — page 1051 — #17
Plural Discourse Reference 1051
Distributively updating an input info state I with a DRS D means that we update eachassignment i ) I with the DRS D and then take the union of the resulting outputinfo states. Thus, the operator dist is unselectively distributive at the discourse level:distributive at the discourse level in the sense that it distributes over plural info statesand unselective in the sense of Lewis (1975)—we update one case, i.e., one assignmenti, at a time.
We need the dist operator in the translation of indefinites because singular (weakand strong) donkey anaphora is neutral with respect to semantic number—recall that,in (2) above, we are not quantifying only over people that buy exactly one book andhave exactly one credit card, but over people that buy one or more books and use oneor more of their credit cards to buy them. The fact that the dist operator takes scopeover the atom {u} condition contributed by singular number morphology effectivelyneutralizes the atomicity requirement, which has to be satisfied only relative to eachassignment i ) I and not relative to the entire plural info state I, thereby capturing thesemantic number neutrality of donkey anaphora.
The translation in (36) above provides the meaning for weak indefinite articles,i.e., the meaning needed for weak donkey readings. The translation for strong indefi-nite articles is provided in (38) below. The only difference between weak and strongindefinites is the absence vs presence of a maximization operator max, defined in (39)below, that takes scope over both the restrictor and the nuclear scope of the indefinites.Attributing the weak/strong ambiguity to the indefinites enables us to give a composi-tional account of the mixed-reading sentence in (2) above because we locally decidefor each indefinite whether it receives a weak or a strong reading.
(38) astr:u ! (Pet.(P'et. maxu(dist([atom {u}]; P(u); P'(u)))
(39) maxu(D) := (Ist.(Jst. ([u]; D)IJ $ #Kst(([u]; D)IK & uK , uJ)
The first conjunct in (39) introduces u as a new dref and makes sure that each individ-ual in uJ satisfies D, i.e., uJ stores only individuals that satisfy D. The second conjunctenforces the maximality requirement: any other set uK obtained by a similar proce-dure (i.e., any other set of individuals that satisfies D) is included in uJ. So, uJ storesall the individuals that satisfy D.
The DRS maxu(D) can be thought of as dynamic (-abstraction over individu-als: the abstracted variable is the dref u, the scope is the DRS D and the result ofthe abstraction is a set of individuals uJ containing all and only the individuals thatsatisfy D.
The max operator ensures that, after we process a strong indefinite, the output plu-ral info state stores with respect to the dref u the maximal set of individuals satisfyingboth the restrictor property P and the nuclear scope property P'. In contrast, a weakindefinite will non-deterministically store some set of individuals satisfying its restric-tor and nuclear scope. Since the only difference between weak and strong indefinites isthe absence vs presence of the max operator, we can think of indefinites as underspeci-fied with respect to maximization: the decision to introduce max or not is made onlinedepending on the discourse and utterance context—much like aspectual coercion or

“28-ch24-1035-1058-9780444537263” — 2010/11/29 — 21:09 — page 1052 — #18
1052 Handbook of Logic and Language
the selection of a particular type for the denotation of an expression are context-drivenonline processes.
The weak and strong meanings for cardinal indefinites differ from the ones forindefinite articles only with respect to the domain-level requirement. As (40) and (41)below show, each cardinal indefinite comes with its corresponding domain-level con-dition requiring the newly introduced individuals to have a particular number of atoms.For example, in the case of two, the condition 2 atoms {u} requires each individual tocontain exactly two atomic parts.
(40) twowk:u ! (Pet.(P'et. [u]; dist([2 atoms {u}]; P(u); P'(u))
(41) twostr:u ! (Pet.(P'et. maxu(dist([2 atoms {u}]; P(u); P'(u)))
(42) 2 atoms {u} := (Ist. 2 atoms(*uI),where 2 atoms(xe) := | {ye : y ( x $ atom(y)} | = 2
24.4.3 Generalized Quantification
The notions of dynamic generalized quantification defined in the dynamic semanticsliterature fall into broad classes. The first class of notions is defined in frameworksbased on singular info states, e.g., DRT/FCS/DPL, and takes generalized quantifi-cation to be internally dynamic (this is needed for donkey anaphora) and externallystatic. The main idea is that the restrictor set of individuals is extracted based on therestrictor dynamic property, while the nuclear scope set of individuals is extractedbased on both the restrictor and the nuclear scope dynamic property, so that theanaphoric connections between them are captured (for more details, see Chapter 3Discourse Representation in Context).
The second class of notions is defined in frameworks based on plural info states andtakes generalized quantification to be both internally and externally dynamic (see vanden Berg (1996); Krifka (1996); Nouwen (2003)). The main idea is that the restric-tor set of individuals is extracted based on the restrictor dynamic property and thenuclear scope set of individuals is the maximal structured subset of the restrictor setof individuals that satisfies the nuclear scope dynamic property.
Given that the notion of a dref being a structured subset of another dref requiredfor the second kind of definitions involves non-trivial complexities that are orthogonalto the issues at hand, we will define selective generalized quantification following theformat of the DRT/FCS/DPL-style definition. However, since we are working in asystem based on plural info states, the definition of dynamic quantification providedby the translation in (43) and the condition in (44) below is intermediate between thetwo kinds of definitions explored in the literature and, thus, it is useful in formallyexhibiting the commonalities and differences between them.
(43) detu ! (Pet.(P'et. [detu(dist(P(u)), dist(P'(u)))]
(44) detu(D, D') := (Ist. I .= - $ DET(u[DI], u[(D; D')I])
- DET is the corresponding static determiner- u[DI] := {*uJ : ([u | atom {u}]; D)IJ}

“28-ch24-1035-1058-9780444537263” — 2010/11/29 — 21:09 — page 1053 — #19
Plural Discourse Reference 1053
The condition detu(D, D') defined in (44) above has four components: the dref u thatwe quantify over, the restrictor DRS D, the nuclear scope DRS D' and the static gene-ralized determiner DET that relates two sets of individuals.9
This condition tests that the static determiner DET relates the restrictor set ofatomic individuals u[DI] and the nuclear scope set of atomic individuals u[(D; D')I].The restrictor set u[DI] is the set of atomic individuals assigned to the dref u thatsatisfy the restrictor DRS D. The nuclear scope set u[(D; D')I] is the set of atomicindividuals assigned to the dref u that satisfy the dynamically conjoined restrictorand nuclear scope DRSs D and D'. Dynamically conjoining the restrictor and nuclearscope DRSs ensures that the donkey pronouns in the nuclear scope can be successfullylinked to their antecedents in the restrictor.
Since the determiners defined in (43)-(44) above relate sets of individuals, they con-tribute a selective kind of generalized quantification (“selective” in the sense of Lewis(1975), i.e., quantification over individuals, not over cases/assignments) and, there-fore, avoid the proportion problem of classical DRT/FCS/DPL. Also, the determinersare neutral with respect to weak vs strong donkey readings (they are compatible witheither one) and the selection of a particular donkey reading is exclusively determinedby indefinite articles.
The dynamic determiners defined above have two important characteristics. First,they are domain-level atomic and discourse-level distributive relative to the dref u theyquantify over—this is ensured by the condition atom {u} in the definition of u[DI] in(44). Secondly, they are discourse-level distributive relative to all the drefs introducedand/or retrieved in their restrictor and nuclear scope. In particular, they are discourse-level distributive relative to donkey anaphora—this is ensured by the dist operators in(43) taking scope over the restrictor and nuclear scope DRSs P(u) and P'(u).
24.4.4 The Analysis of Multiple Interdependent Anaphora
The compositionally obtained representation for the most salient reading of the mixed-reading donkey sentence in (2) above is given in (45) below (the representationis simplified based on various type-logical equivalences). Under this (pragmaticallymost plausible) reading, the indefinite astr:u2 book is strong and the indefinite awk:u3
credit card is weak. Based on the representation in (45), we derive the intuitivelycorrect truth conditions, provided in (46).
(45) [everyu1(dist([person {u1}]; maxu2(dist([atom {u2} , book {u2} , buy {u1, u2}]));
[u3]; dist([atom {u3} , card {u3} , have {u1, u3}])),dist([atom {u2} , atom {u3} , use to pay {u1, u2, u3}]))]
(46) (Ist. I .= - $ #xe#ye(atom(x) $ person(x) $ atom(y) $ book(y) $ buy(x, y) $%ze(atom(z)$ card(z)$ have(x, z)) & %z'
e(atom(z')$ card(z')$ have(x, z')$use to pay(x, y, z')))
9 For example, the determiner EVERY requires the first set of individuals to be included in the second set,NO requires their intersection to be empty etc. See Chapter 19 Generalized Quantifiers for more details.

“28-ch24-1035-1058-9780444537263” — 2010/11/29 — 21:09 — page 1054 — #20
1054 Handbook of Logic and Language
The update in (45) proceeds as follows. After the input info state is updated withthe restrictor of the quantification in (2), we obtain a plural info state that stores,for each u1-person that is a book buyer and a card owner: (i) the maximal setof purchased book-atoms, stored relative to the dref u2 (since the indefinite astr:u2
book is strong), (ii) some non-deterministically introduced set of credit-card atoms,stored relative to the dref u3 (since the indefinite awk:u3 credit card is weak) and,finally, (iii) some non-deterministically introduced structure correlating the u2 and u3atoms.
The nuclear scope of the quantification in (2) is anaphoric to both values (inthis case, atomic individuals) and structure/dependencies: we test that the non-deterministically introduced values for u3 and the non-deterministically introducedstructure associating u3 and u2 satisfy the nuclear scope update (the structure is testedby means of the dist operator). That is, we test that, for each assignment in the infostate, the u3-card stored in that assignment is used to pay for the u2-book stored inthe same assignment. Thus, the nuclear scope update elaborates on the dependencybetween u3 and u2 that was non-deterministically introduced in the restrictor.
The pseudo-scopal relation between astr:u2 book and awk:u3 credit cardemerges as a consequence of the fact that we use plural information states, whichstore and pass on information about both objects and dependencies between them.The relation between the two indefinites is “pseudo-scopal” in the sense that the weakindefinite semantically co-varies with the strong indefinite (people can use differentcards to buy different books)—but syntactically, the strong indefinite cannot takescope over the weak indefinite because this would violate the Coordinate StructureConstraint.10
The representation for sentence (3) is parallel to the one for sentence (2) except forthe fact that both indefinites (astr:u2 gift and astr:u3 girl) are strong. The analysis ofthe plural donkey example in (13) above is completely parallel to the analysis of (3).Similarly, the singular and plural weak donkey sentences in (6) and (14) above receiveparallel analyses (see Brasoveanu (2008) for more details and for the account of theseexamples and the sage plant sentences in (11) and (12)). The incompatibility betweensingular (but not plural!) donkey anaphora and collective predicates exemplified in(10) above follows from the fact that the singular number morphology on donkey pro-nouns contributes an atom condition that contradicts the collective, i.e., non-atomicnature, of the verb gather. Finally, we can account for examples involving anaphorato events, times or possibilities, e.g., (15), (16) and (17) above, by simply adding newbasic static types (for events, times, possible worlds etc.), which automatically makesavailable the drefs necessary for their analysis.
10 The Coordinate Structure Constraint ensures that, although the declarative sentence You ate the eggs andthe bacon is acceptable, the question *What did you eat the eggs and ? is unacceptable because wecannot asymmetrically displace (material from) only one conjunct in a conjunction.

“28-ch24-1035-1058-9780444537263” — 2010/11/29 — 21:09 — page 1055 — #21
Plural Discourse Reference 1055
24.5 Conclusion
Natural language interpretation requires two independent yet parallel notions ofplurality, plural reference and plural discourse reference. The interpretation of multiplesimultaneous anaphoric connections in the scope of quantifiers motivates a semanticsthat relies on plural info states, i.e., that crucially involves discourse-level plurality,and the fact that these anaphoric connections involve reference to both individualsand collections motivates a semantics that also involves domain-level plurality. Futureresearch will hopefully investigate the interplay between these two notions from across-linguistic perspective (especially given the recent work on domain-level plural-ity in Zweig (2009); Champollion (2010) and Farkas and de Swart (2010), buildingon Schein (1993); Schwarzschild (1996); Kratzer (2000) and Landman (2000) amongothers)—and, also, their connections with recent compositionality-related debates ingame-theoretical semantics and independence-friendly and dependence logic.
References
Asher, N., Wang, L., 2003. Ambiguity and Anaphora with Plurals in Discourse, in: Young, R.,Zhou, Y. (Eds.), Proceedings of SALT XIII, CLC Publications, Ithaca, NY, pp. 19–36.
Barwise, J., 1987. Noun Phrases, Generalized Quantifiers and Anaphora, in: Gärdenfors, P.(Ed.), Generalized Quantifiers. Kluwer, Dordrecht, pp. 1–29.
Brasoveanu, A., 2007. Structured Nominal and Modal Reference. PhD dissertation, RutgersUniversity, New Brunswick, NJ.
Brasoveanu, A., 2008. Donkey pluralities. Linguistics and Philosophy, vol. 31, pp. 129–209.Champollion, L., 2010. Cumulative Readings of Every Do Not Provide Evidence for Events
and Thematic roles, Proceedings of the 17th Amsterdam Colloquium, in press.Chierchia, G., 1995. The Dynamics of Meaning. University of Chicago Press, Chicago and
London.Dekker, P., 1994. Predicate Logic with Anaphora, in: Santelmann, L., Harvey, M. (Eds.), Pro-
ceedings of SALT IV, DMLL, Cornell University, Ithaca, NY, pp. 79–95.van Eijck, J., de Vries, F.-J., 1992. Dynamic interpretation and Hoare deduction. J. Log. Lang.
Inf. 1, 1–44.Farkas, D.F., de Swart, H., 2010. The Semantics and Pragmatics of Plurals, in Semantics and
Pragmatics, vol. 3, pp. 1–54.Gallin, D., 1975. Intensional and Higher-Order Modal Logic. North-Holland Mathematics Stud-
ies, Amsterdam.Geach, P., 1962. Reference and Generality. Cornell University Press, Ithaca, NY.Groenendijk, J., Stokhof, M., 1991. Dynamic predicate logic, in: Linguistics and Philosophy,
vol. 14, pp. 39–100.Heim, I., 1982. The Semantics of Definite and Indefinite Noun Phrases. PhD dissertation,
UMass Amherst.Heim, I., 1990. E-Type pronouns and donkey anaphora, in: Linguistics and Philosophy, vol. 13,
pp. 137–177.

“28-ch24-1035-1058-9780444537263” — 2010/11/29 — 21:09 — page 1056 — #22
1056 Handbook of Logic and Language
Heim, I., 1991. Artikel und Definitheit, in: von Stechow, A., Wunderlich, D. (Eds.), Semantik:Ein internationales Handbuch der zeitgenössischen Forschung, Walter de Gruyter, Berlin,pp. 487–539.
Kamp, H., 1981. A theory of truth and semantic representation, in: Groenendijk, J., Janssen,T., Stokhof, M. (Eds.), Formal Methods in the Study of Language, part 1, MathematicalCenter, Amsterdam, pp. 277–322.
Kamp, H., Reyle, U., 1993. From Discourse to Logic. Kluwer, Dordrecht.Kanazawa, M., 1994. Weak vs strong readings of donkey sentences and monotonicity inference
in a dynamic setting, in: Linguistics and Philosophy, vol. 17, pp. 109–158.Kanazawa, M., 2001. Singular donkey pronouns are semantically singular, in: Linguistics and
Philosophy, vol. 24, pp. 383–403.Karttunen, L., 1976. Discourse referents, in: McCawley, J.D. (Ed.), Syntax and Semantics. Aca-
demic Press, New York, vol. 7, pp. 363–385.Kratzer, A., 2000. The Event Argument and the Semantics of Verbs. UMass ms. www
.semanticsarchive.net, Amherst.Krifka, M., 1996. Parametric sum individuals for plural anaphora, in: Linguistics and Philoso-
phy, vol. 19, pp. 555–598.Landman, F., 1986. Towards a Theory of Information. The Statues of Partial Objects in Seman-
tics, GRASS 6, Foris, Dordrecht.Landman, F., 2000. Events and Plurality. Kluwer, Dordrecht.Lappin, S., Francez, N., 1994. E-type pronouns, I-sums and donkey anaphora, in: Linguistics
and Philosophy, vol. 17, pp. 391–428.Lewis, D., 1975. Adverbs of quantification, in: Keenan, E. (Ed.), Formal Semantics of Natural
Language. Cambridge University Press, Cambridge, pp. 3–15.Link, G., 1983. The logical analysis of plurals and mass terms: A lattice-theoretical approach,
in: Baerle, R., Schwarze, C., von Stechow, A. (Eds.), Meaning, Use and Interpretation ofLanguage. Walter de Gruyter, Berlin, pp. 302–323.
Muskens, R., 1995. Tense and the logic of change, in: Egli, U., Pause, P.E., Schwarze, C., vonStechow, A., Wienold, G. (Eds.), Lexical Knowledge in the Organization of Language.Benjamins, Amsterdam, the Netherlands, pp. 147–183.
Muskens, R., 1996. Combining Montague semantics and discourse representation, in: Linguis-tics and Philosophy, vol. 19, pp. 143–186.
Neale, S., 1990. Descriptions. MIT Press, Cambridge.Nouwen, R., 2003. Plural Pronominal Anaphora in Context. PhD Dissertation, University of
Utrecht, the Netherlands.Roberts, C., 1989. Modal subordination and pronominal anaphora in discourse, in: Linguistics
and Philosophy, vol. 12, pp. 683–721.Rooth, M., 1987. Noun phrase interpretation in Montague grammar, file change semantics and
situation semantics, in: Gärdenfors, P. (Ed.), Generalized Quantifiers. Kluwer, Dordrecht,pp. 237–268.
Pelletier, F.J., Schubert, L.K., 1989. Generically speaking, in: Chierchia, G., Partee, B.H.,Turner, R. (Eds.), Properties, Types and Meanings. Kluwer, Dordrecht, vol. 2, pp. 193–268.
Sauerland, U., 2003. A new semantics for number, in: Young, R., Zhou, Y. (Eds.), Proceedingsof SALT XIII, CLC Publications, Ithaca, NY, pp. 258–275.
Scha, R., 1981. Distributive, collective and cumulative quantification, in: Groenendijk, J.,Janssen, T., Stokhof, M. (Eds.), Formal Methods in the Study of Language, part 2,University of Amsterdam, Amsterdam, pp. 483–512.
Schein, B., 1993. Plurals and Events. MIT Press, Cambridge, MA.

“28-ch24-1035-1058-9780444537263” — 2010/11/29 — 21:09 — page 1057 — #23
Plural Discourse Reference 1057
Schwarzschild, R., 1996. Pluralities. Kluwer Academic Publishers, Dordrecht/Boston/London.van Benthem, J., 1996. Exploring Logical Dynamics. CSLI, Stanford, CA.van den Berg, M., 1996. Some Aspects of the Internal Structure of Discourse. PhD dissertation,
University of Amsterdam, Amsterdam.Webber, B., 1978. A Formal Approach to Discourse Anaphora. PhD dissertation, Harvard
University, Cambridge, MA (published in the series Outstanding Dissertations in Linguis-tics, Garland Publishing, NY).
Zweig, E., 2009. Number-neutral bare plurals and the multiplicity implicature, in: Linguisticsand Philosophy, vol. 32, pp. 353–407.

“28-ch24-1035-1058-9780444537263” — 2010/11/29 — 21:09 — page 1058 — #24
This page intentionally left blank

“29-ch25-1059-1132-9780444537263” — 2010/11/30 — 3:44 — page 1059 — #1
25 QuestionsJeroen Groenendijk, Martin StokhofFaculteit der Geesteswetenschappen, ILLC, Universiteit vanAmsterdam, P.O. Box 94242 1090, GE Amsterdam, The Netherlands,E-mail: [email protected]
Commentator: J. Ginzburg
25.1 Preliminary
In common parlance, the term question is used in at least three different ways, which,in order to avoid misunderstanding, will be distinguished terminologically in thischapter. First of all, the term may be used to refer to a particular type of sentences,characterized (in English) by word order, intonation, question mark, the occurrence ofinterrogative pronouns. In the sequel such sentences will be referred to by the terminterrogative sentences, or interrogatives for short. Another way of using the termquestion is to refer to the speech act that is typically performed in uttering interrog-ative sentences, i.e. to denote a request to an addressee to provide the speaker withcertain information, a request to answer the question. The phrase interrogative actwill be used to refer to such speech acts. An interrogative act can be described as theact of asking a question. In this description a third use is made of the term question,viz., the one in which it refers to the “thing” which is being asked, and which, as aconsequence, may be (partially) answered. This object can be viewed as the seman-tic content, or sense, of an interrogative. In what follows, the term question will bereserved exclusively for this latter use. Of course, several people have doubted thatthere are such things as questions in this restricted sense of the word. To establishthat there are, and to argue that they constitute the primary domain for a logical andsemantical theory, is one of the main aims of this chapter.
It should be noted at the outset that although questions are typically asked andanswered, one can also do a lot of other things with them: one can discuss them, won-der about them, formulate them, etc. Such acts are typically reported by indicativesentences. Hence questions are not exclusively tied to either interrogative sentences,or to the speech act of asking a question. Note furthermore that an interrogative sen-tence need not always be used to ask a question, i.e. to perform an interrogative act,witness so-called “rhetorical questions”. And questions can also be asked by othermeans than through the use of interrogative sentences. Example: “Please, tell me whythere is something rather than nothing”. Or: “I hereby request you to let me know whythere is something rather than nothing”. Similar observations pertain to answers, by
Handbook of Logic and Language. DOI: 10.1016/B978-0-444-53726-3.00025-6c! 2011 Elsevier B.V. All rights reserved.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1060 — #2
1060 Handbook of Logic and Language
the way: an answer may be, but need not be expressed by, an indicative sentence. So-called “rethorical questions” are not interrogative but assertive acts, and are often usedto formulate an answer to a question.
Be that as it may, the relation between interrogatives and questions is obviouslymore than coincidental: in reality it is pretty hard to ask questions without usinginterrogatives at some points. And likewise, answering a question without the useof indicatives seems not to be the default case. A proper theory of the meaning anduse of interrogatives should account for this.
Just like indicative sentences, interrogatives come in two forms: on their own, andembedded. The former are often referred to as “stand alone” interrogatives. Note thatin the examples just given, in which a question is asked by means of a sentence inthe imperative mood or in the indicative mood, rather than by the use of a properinterrogative, embedded interrogatives occurred. If it is assumed that both stand aloneand embedded interrogatives express questions, then questions are around also whenthe speech act of asking a question is made by non-interrogative means.
This points towards the existence of questions as a separate kind of entity, to bedistinguished both from the linguistic object that an interrogative sentence is, andfrom the pragmatic entity that the act of asking a question constitutes. No one willdeny the reality of the latter kinds of entities, but, as was already remarked above, forvarious reasons many have disputed the existence of questions as a separate semanticcategory. The study of interrogative sentences obviously belongs to the syntactic partof linguistics, and the study of interrogative acts to that of pragmatics, in particularto speech act theory. Questions, conceived of as is done here, i.e. as the senses ofinterrogative sentences, or as the contents of interrogative acts, would constitute thedomain of a semantics, or logic, of questions. But the existence of this realm is yet tobe established.
25.2 Setting the Stage
The semantics of interrogatives is a strange affair. It seems fair to say that in a senseit is an underdeveloped part of natural language semantics. Part of the reason for that,it seems, is that there is no standard framework that is generally acknowledged asproviding a common starting point for semantic analyses of various phenomena withinthe field. No set of concepts exists that can be used to formulate and compare rivalanalyses. In fact, there even seems no clear communis opinio on what constitutes thesubject of investigation in the first place. Clearly this forms a stumbling block for realprogress.
For indicative sentences such a common framework is available, viz., that of somevariety of denotational semantics. This framework provides some starting points andconcepts that various analyses can exploit, even when they want to deviate from it. Inother words, denotational semantics provides us with a picture, which can be applied,filled in, modified (up to distortion, in some cases), and so on. Elements of the pic-ture are familiar, almost “common sense” ideas such as the following. The meaning of

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1061 — #3
Questions 1061
a sentence is given by its truth conditions. The meaning of subsentential expressionsresides in the contribution they make to the meanings of sentences. Synonymy is iden-tity of meaning; entailment comes down to inclusion of meaning. Thus this frameworkestablishes the reality of certain types of objects and of certain relationships betweenthem. The term proposition is generally used to refer to the truth conditional contentof a sentence. Likewise, property refers to the content of a predicative expression, andso on.
Calling denotational semantics a “common framework” does not imply that every-one subscribes to it in all details. However, it is important to note that even those whochallenge the established view, e.g., the situation semanticists, or the dynamic seman-ticists, acknowledge that traditional denotational semantics provides a viable frame-work which is adequate as a semantic theory for at least a certain variety of formallanguages and for interesting fragments of natural language. Few would deny that, forexample, first order logic and its standard semantics, or possible worlds semantics formodal predicate logic, are systems that give useful and interesting insights in certainaspects of the meaning of central parts of language, including natural language. It is inthis sense that classical denotational semantics provides a common frame of referencefor sometimes radically divergent alternative views. It is precisely such a commonframe of reference that seems to be lacking when one switches from the analysis ofindicatives to that of interrogatives.
The difference seems to lie in this, that in discussing indicatives a distinction ismade between the contents of a sentence and the act that is performed by utteringit, with no questions asked.1 One is usually not bothered by the fact that indicativesentences are typically, though not exclusively, used by speakers to make assertions,to inform hearers, and so on. That is to say, one abstracts away from the (typical) useof indicatives, assuming that their contents can be studied (relatively) independently.Likewise, the specific goals that speakers try to achieve in making assertions, andthe strategies they follow in doing so, are considered to be irrelevant in that respect,too. One may acknowledge the importance of these issues from the point of view ofan overall theory of language use, and nevertheless consider it justified to abstractaway from these pragmatic aspects of meaning, and to concentrate on the informative,propositional content of indicative sentences as such.
When one comes to consider the semantics of interrogatives, however, this perspec-tive is not generally adopted. One of the reasons may be the following. By and large,formal semanticists have directed their attention almost exclusively to the analysisof indicatives. In this their enterprise bears the traces of its logical ancestry. Certainlythis may have given people – proponents and opponents alike – the impression that thenotions of truth and falsity are at the heart of logical semantics. Observing that thesenotions indeed do not apply to non-assertive uses of language, some have rushed tothe conclusion that the semantics of sentence types that are typically employed in per-forming non-assertive speech acts, are outside the reach of logical semantics, which
1 Nowadays, that is. But the distinction did present a problem to Frege, who wrestled with the differencebetween asserted and non-asserted propositions, and distinguished them notationally in his Begriffsschrift.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1062 — #4
1062 Handbook of Logic and Language
would be reason enough to doubt its viability as (part of) an overall theory of naturallanguage meaning.
Others, who would like to deny this conclusion, but who share the assumption onwhich it is based, have seen themselves forced to somehow “reduce” non-indicativesto indicatives. One popular line of defense is that logical semantics can ignore non-indicatives, precisely because logic is only concerned with propositional content, andthe content of an interrogative is a proposition just like that of an indicative. Indicativesand interrogatives, it is claimed, have a different mood, but their logical content is thesame. The (unmistakable) difference between the two is not one of meaning, i.e. amatter of semantics, but solely one of use, i.e. it belongs to pragmatics. There areseveral variants of this type of parrying questions, but, as will be argued below, noneof them is very convincing. For one thing, such reductionist approaches do not dojustice to the fact that whereas indicatives2 can be said to be true or false irrespectiveof the particular use they are put to, this does not hold for interrogatives. Yet, in thecase of the latter, too, there are aspects of content which can be separated from theparticular ways in which they are used. If this observation is correct, a reduction of(the contents of) interrogatives to (the contents of) indicatives is fundamentally on thewrong track.
Where does this leave one? It seems that in order to argue that the development ofa logical semantics of interrogatives is a viable enterprise, two views must be shownto be inadequate: one that says that they can be analyzed fruitfully only at the levelof interrogative acts, and one that holds that there is no significant difference betweenindicatives and interrogatives, at least as far as semantic content is concerned. It isimportant to note that one may hold both views at the same time. Specifically, onemay adduce the second view as an argument for holding the first.
If the proper arguments against these positions can be produced, this will in effectshow ex negativo that a separate domain of questions, in the technical sense introducedabove, exists. A subsequent task is to approach this domain in a more positive way, i.e.to give an indication of the phenomena that a semantics of interrogatives has to dealwith, to outline various approaches that have been tried, and to provide an assessmentof the main results.
By and large, it is by such considerations that the remainder of this chapter is orga-nized. First the pragmatic view, that interrogatives can be studied fruitfully only at thelevel of speech acts, is considered and scrutinized. The approach here is mainly direct.An attempt is made to show that this view in effect presupposes a semantic theoryof questions. The other line of reasoning, according to which there are no semanticdifferences between indicatives and non-indicatives, is dealt with along the way, in amore indirect fashion. Various theories that instantiate aspects of the pragmatic vieware briefly characterized and discussed, but since our main interest is systematic andnot historic, we focus on one particular instance.
Then we move to a discussion of semantic views. First we sketch an approach thatstarts out from some rather strict postulates concerning interrogatives and answers.
2 Barring perhaps explicit performative sentences.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1063 — #5
Questions 1063
The adequacy of the result is discussed with reference to some general methodologicalconsiderations. Then a similar kind of view is developed from a different startingpoint. First we consider whether, and if so how, interrogatives can be added to thelanguage of propositional logic. One of the results of this investigation establishesthe essentially intensional nature of the notion of a question. Next we consider theaddition of interrogatives to the language of predicate logic, and show that, given somegeneral requirements, the resulting analysis resembles the approach developed earlierin important respects. After a brief discussion of the goals and characteristic issuesof logical and computational approaches we turn to a survey of the main semanticapproaches that can be found in the linguistic literature. Then we turn to a descriptionof some key data, empirical phenomena that any semantics of interrogatives has tocope with, explaining how the various approaches are motivated by them. Finally, wediscuss some other empirical issues, and we end by briefly pointing out directions forfuture research.
Throughout, our main goal is not to give an exhaustive list of all the analyses andvariants that have been proposed over the years, but to provide the reader with a sys-tematic argument that there is such a thing as a semantics of interrogatives, and witha general characterization of its contents.3
Finally, the reader should be warned that the discussion that follows will not pro-ceed in a strictly linear fashion. At certain points in the discussion of certain theo-ries reference must be made to views that have not been treated in detail (yet). In anoverview like this, where like a bird one spirals up and down, now trying to get aglobal view of the territory and now scrutinizing some part of it, such “circularities”cannot be avoided.
25.3 The Pragmatic Approach
A general characterization of the pragmatic point of view, which was given above,was that it holds that the meaning of interrogative sentences in natural language canbe studied fruitfully only at the level of the (speech) acts that are typically performedby uttering such sentences. This point of view can be argued for both in a more prin-cipled manner, and in a more ad hoc fashion. The principled approach springs forthfrom a theoretical view on natural language meaning as such. It holds that the speechact is the primary unit of semantic analysis, and that the meanings of sentences andsubsentential expressions must be analyzed in terms of the part they play in such acts.Other analyses are not likewise theoretically motivated. They stay within the traditionof logical semantics (broadly conceived), but hold that at the level of semantic con-tent no distinction between indicatives and interrogatives can, or need be made, andthat hence the difference in meaning must be accounted for at another, i.e. pragmaticlevel.
3 Two excellent overviews are those of Bäuerle and Zimmermann (1991) and Higginbotham (1995). Theoverview of Harrah (1984) deals almost exclusively with logical approaches.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1064 — #6
1064 Handbook of Logic and Language
Before turning to a detailed discussion of (one version of) the principled approach,let us briefly consider some of the forms that pragmatically oriented analyses havetaken. In what follows we will not deal with the details of the various theories thathave been proposed,4 but will try to indicate what has inspired them, and what weak-nesses they share. Essentially, all these analyses are what might be called “paraphrasetheories”. They analyze the meaning of interrogatives not on the level of semanticsproper, but through a paraphrase of what is taken to be their typical use, i.e. by takingrecourse to the level of pragmatics. In what exactly they take this paraphrase to con-sist, and in the way in which they implement it within a semantic framework, thevarious analyses distinguish themselves from each other, but this is the assumptionthey share: the meaning of an interrogative is given by an expression which describesits typical use.
One of the more obvious ways of implementing the paraphrase view is by making a(grammatically inspired) distinction between the mood of a sentence, and its radical.This approach has been taken by, among others, Frege (1918) and Stenius (1967).The radical is the (propositional) content of the sentence, the mood the way in whichthis content is presented. Thus the indicative “John is coming to the party, too.” andthe interrogative “Is John coming to the party, too?” share their radical, and differ inmood. The first sentence presents the content, viz., the proposition that John is comingto the party, too, in the assertive mood, whereas the same content is presented in theinterrogative mood in the second example. As Frege (1918, p. 62) puts it:
Fragesatz und Behauptungssatz enthalten denselben Gedanken; aber der Behaup-tungssatz enthält noch etwas mehr, nämlich eben die Behauptung. Auch der Fragesätzenthält etwas mehr, nämlich eine Aufforderung.
The indicative mood indicates that the thought expressed5 is asserted, i.e. is presentedas true. The interrogative mood corresponds to an exhortation, viz., to affirm or todeny the truth of the thought expressed. Only sentences which express a thought canbe thus analyzed. Hence, Frege claims,6 this analysis is not applicable to what hecalls “Wortfragen”, which are interrogatives such as “Who is coming to the party?”.Such sentences Frege calls “incomplete”, presumably because they do not expressa thought. Thus his reductionist approach is limited in scope. This points towards ageneral problem. All speech act type approaches, and in this respect the mood-radicalview is similar, assume that interrogatives involve the expression of an attitude (ofasking, or requesting, or not knowing, or telling) towards some kind of entity, whichis what the attitude is an attitude towards. The problem is to find one kind of entitythat will serve this purpose both for sentential interrogatives, and for interrogativescontaining a wh-phrase. If one takes one’s lead from the attitude, some propositionalkind of entity, such as a Fregean thought, easily suggests itself. But this will do onlyfor the first case, not for the second one.
4 See the overviews referred to above.5 Which in this context can be equated with the propositional content.6 ibid.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1065 — #7
Questions 1065
Another line that has been explored in the literature is what might be called the “per-formative approach”, defended, among others, by Lewis and Cresswell (see, for exam-ple, Cresswell, 1973; Lewis, 1970). The meaning of an interrogative, it is claimed, isgiven by an explicit performative paraphrase of the illocutionary act performed. Onthis view the interrogative “Is John coming to the party, too?” means the same as: “Ihereby ask you whether John is coming to the party, too”. One obvious problem withthis analysis, when taken as an analysis of the meaning of interrogatives, is that it mustbe assumed, to avoid circularity, that the meaning of embedded interrogatives can bespecified independently. This assumption seems unattractive, if not unlikely. The ana-lysis as such has never been worked out in sufficient detail to solve this problem.
A third kind of analysis, also starting from a semantic point of view and insome respects quite akin to the performative approach, is what is often dubbed the“epistemic-imperative” approach, mainly associated with the work of Åqvist andHintikka (see, for example, Åqvist, 1965; Hintikka, 1976, 1983a). According toÅqvist’s original analysis, the meaning of our sample interrogative can be paraphrasedas “Let it be the case that I know whether John is coming to the party, too”. Hintikkaopts for a similar analysis and gives the following paraphrase: “Bring it about that Iknow whether John is coming to the party, too”.
Both paraphrases display the imperative and epistemic elements involved.A remarkable feature of this variant is that it ties the meaning of interrogatives tothe existence of a state of (partial) ignorance of the speaker. As a precondition on theproper use of interrogatives this might be defensible, although it implies that the useof interrogatives in circumstances where this condition is not met (such as in exam-situations) has to be explained as somehow deviant. Such an account seems possible,which is not to say that this view on such uses is necessarily correct. But by buildingthis condition into the meaning proper of interrogatives, the present approach faces adifferent, and more difficult task, viz., of somehow accounting for the fact that inter-rogatives can be used felicitously in circumstances in which the condition is not metwithout an apparent shift in meaning.
It should be noticed, in defense of the proponents of this analysis, that their pri-mary objective is not a systematic account of the meaning (and, perhaps, the use) ofinterrogative constructions as they appear in natural language. Rather, they want todevelop a systematic logic of questions as abstract, logical objects (which, to be sure,is inspired by properties of natural language interrogatives). Various other aspects ofthe analyses of Åqvist and Hintikka bear witness to this.
For example, Hintikka analyzes interrogatives in a basic two-part fashion, whichis reminiscent of the mood-radical distinction, which he calls the “request part” andthe “desideratum”. According to this scheme, the sample interrogative used aboveis divided into the request part “Bring it about that” and the desideratum “I knowwhether John is coming to the party, too”. Thus interrogatives share their request part(up to differences with stem from the presuppositions of the desiderata) and are dif-ferentiated according to their desideratum. The imperative operator is sensitive to thepresupposition associated with an interrogative. For example, a simple constituentinterrogative such as “Who came to the party?” has as its presupposition “Someone

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1066 — #8
1066 Handbook of Logic and Language
came to the party”, and the imperative operator is restricted by the assumption that thispresupposition is fulfilled. Different kinds of interrogative constructions have differentpresuppositions.7
What is interesting to note from the perspective of a semantics of natural languageinterrogatives is that in Hintikka’s analysis embedded interrogatives take priority overstand alone interrogatives: the former occur in the paraphrase of the meaning of thelatter. This seems unnatural. The problem that arises is how to supply a semantics ofthe paraphrase which does not presuppose an independent semantics of the embeddedpart. This is a general problem with the kind of paraphrase theories we are dealingwith here. Hintikka tries to work his way around this problem by giving a specialtreatment of the epistemic operator know combined with a wh-complement. Thus,“I know whether John is coming to the party, too” is further analyzed as “I know thatJohn is coming to the party, too”, or “I know that John is not coming to the party,too”. Thus, “know whether” is analyzed in terms of the familiar “know that”. Noticethat this analysis does not ascribe a meaning to the embedded interrogative as such,but only provides an analysis for the combination of embedding verb and embeddedinterrogative.
Whether this move is descriptively adequate or not is not what is at stake here.8 Thepoint is rather that as an analysis of the natural language construction it goes against astrong intuition, and a major methodological principle. The intuition is that the mean-ing of direct interrogatives is somehow prior to, or at least not dependent on, that ofsentences containing their embedded counterparts. Correspondingly, one would like touphold, if possible, the methodological principle of compositionality, which dictatesthat the meaning of a compound expression be construed as a function of the meaningsof its component parts. That the embedded interrogatives in paraphrases of the kindwe encountered above, are independent parts, both syntactically and semantically, canbe argued for by pointing out that they can be moved (“Whether John was coming tothe party, too, was what he asked me”), can function as the antecedent of anaphoricexpressions (“Mary still wondered whether John was coming to the party, too, but Billknew it”), and so on. Thus, it seems that, at least from the perspective of natural lan-guage, one would prefer an analysis which treats embedded interrogatives as distinctparts of the construction in which they occur. But then paraphrase theories run into aserious difficulty. For it seems most natural to treat the independent meaning assignedto an embedded interrogative on a par with that of its stand-alone counterpart, whichmakes the paraphrase treatment of the latter patently circular. For better or worse, itseems that on the basis of fairly general considerations, one is forced to abandon theparaphrase approach, and to treat the meaning of interrogatives as sui generis.9
7 See Hintikka (1983a, p. 174 ff).8 One obvious problem is with such embedding verbs as wonder, which do not admit of a straightforward
paraphrase along these lines.9 This point was argued for forcefully by Nuel Belnap jr, in the form of his celebrated “independent meaning
thesis”. See Belnap (1981).

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1067 — #9
Questions 1067
This summary indication of the various forms that paraphrase analyses may take,shows that they are not without problems. Trying to elucidate the semantics of inter-rogatives, these analyses resort to what are essentially paraphrases of the pragmaticsof these constructions, i.e. of the way in which they are typically used. But in doingso, the problem of specifying an independent semantic content of interrogatives cannot be avoided altogether, it seems. In view of this, one might well think that perhapsa more principled approach, which starts from the assumption that meaning as suchhas to be defined in terms of use, might fare better. Therefore, we will concentrate inthe remainder of this section on the more principled approach. The main objections tothe latter also apply to the former, as will be pointed out along the way. As we willargue, the pragmatic point of view, although certainly not without an intuitive appeal,is not able to account for some simple, but basic facts. This in itself provides amplereason to reject the pragmatic approach as such, and to investigate whether taking atruly semantically oriented point of view will enable one to do better in this respect.
25.3.1 Starting Points
Speech act theory, as it was developed systematically in the pioneering work of Searlein the late sixties, which in its turn depended heavily on Austin’s work on performativ-ity, provides a more principled approach than the ones discussed above. It starts “fromthe other end”, as it were, and regards the act performed by the utterance of a sentenceas the primary unit of semantic analysis. Combined with the observation that assertionis but one among the many acts that can be performed through the use of language,this view radically opposes the “propositional bias” supposedly inherent in traditionallogical analysis.
Interrogatives as such have been given due attention in Searle’s original work(Searle, 1969), but the concrete analyses he provides there do not really extend thecoverage of the proposals discussed above. The main advantage of Searle’s analysisseems to lie in this: that it is carried out in a systematic framework, which takes thepragmatic point of view as its starting point in the analysis of natural language assuch. As said, its empirical coverage remains rather limited, and it does not contain aprincipled discussion of how it relates to other types of analyses of interrogatives.
It is in these two respects that the work of Vanderveken (1990) constitutes an impor-tant step forward in the development of a pragmatic analysis of interrogatives. Espe-cially through its discussion of logical and semantical theories, Vanderveken’s workprovides a much more detailed picture of what a speech act analysis of interrogativesamounts to. Also it poses some interesting challenges for semantic theories, which willbe important for a proper assessment of the latter. For these reasons we will discussVanderveken’s work in some detail.
25.3.2 General Framework
Vanderveken formulates a general semantic framework, which he views as a conserva-tive extension of Montague’s universal grammar. His aim is not to develop speech act

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1068 — #10
1068 Handbook of Logic and Language
theory as a rival of truth-conditional semantics, but to provide “a systematic unifiedaccount of both the truth conditional and the success conditional aspects of sentencemeaning” (Vanderveken, 1990, Volume i, p. 11). However, in this general frameworkthe speech act point of view prevails: “My fundamental hypothesis is that completeillocutionary acts [. . .] are the primary units of literal meaning in the use and com-prehension of natural languages” (ibid.). The system of illocutionary logic that Van-derveken aims to develop, characterizes the space of possible illocutionary acts.10
This “transcendental” (Volume i, pp. 55–56) tool, also called “general semantics”, canthen be applied in the description of sentence meaning in natural languages. That truthconditional semantics alone will not suffice, Vanderveken argues, by pointing out that,e.g., “John will do it.”, “Please, John, do it!” and “If only John would do it.”, expressthe same proposition with respect to some context of utterance, but are used to per-form different illocutionary acts with different forces. The illocutionary component,Vanderveken concludes, is an integral part of linguistic meaning. Not all languagesrelate to the space of possible illocutionary acts in the same way. Linguistic analysiswill reveal a variety of relationships that exist between the types of sentences and otherexpressions that a given language displays and the kinds of illocutionary acts that aretypically performed by (literal) utterances of them.
The characterization of the realm of possible illocutionary acts proceeds recur-sively. Elementary illocutionary acts are of the form F(P) and consist of an illo-cutionary force F and a propositional content P. Besides elementary illocutionaryacts, Vanderveken acknowledges also complex ones, such as conditional illocution-ary acts, illocutionary negation, etc.11 These complex illocutionary acts can not bereduced to elementary ones. Complex speech acts are built using illocutionary con-nectives, and by means of certain performative verbs. The details of this aspect ofVanderveken’s illocutionary logic need not concern us here, so we will refrain fromfurther discussing it.
What is relevant is the distinction between success conditions and satisfaction con-ditions. The first type of condition determines whether a speaker through an utter-ance of a sentence has indeed succeeded to perform the corresponding illocutionaryact. For example, certain conditions must be fulfilled for a speaker to have made arequest by uttering “Please, pass me the salt”. Success conditions are determined bythe illocutionary force F of an illocutionary act. Satisfaction conditions depend on itspropositional content P. Thus, in the above example the satisfaction conditions spec-ify that the request is satisfied if the hearer has realized the situation characterized bythe propositional content, viz., that the hearer passes the salt. In this example the satis-faction condition has what is called a “world-to-word” direction of fit: in order for thesatisfaction condition to be fulfilled the world has to fit the words. The other direction,the “word-to-world” fit, is characteristic for the satisfaction condition of assertions:
10 Vanderveken uses Austin’s term “illocutionary act” in distinction to the term “speech act”, which coversmore ground (see below). According to Austin’s original formulation an illocutionary act is “an act[performed] in saying something” (Austin, 1962, p. 99).
11 See Volume i, pp. 24–25, for further details.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1069 — #11
Questions 1069
for an assertive illocutionary act to be satisfied its propositional content should matchan existing state affairs, i.e. it should be true.
An interesting problem arises when we consider the satisfaction conditions of inter-rogative illocutionary acts. Vanderveken classifies such acts as directive speech acts,along with requests (Volume ii, p. 11). That implies that the satisfaction condition ofan interrogative act has the world-to-word direction of fit: it requires the hearer tomake true the propositional content of the interrogative. The question then arises whatthis propositional content is. We will come back to this later on.
25.3.3 Criticisms of the Semantic Approach
After this very summary sketch of the aims of Vanderveken’s enterprise, let us nowturn to the more concrete issue of the critical remarks he makes on more tradi-tional semantic approaches. Here a distinction can be made between logically ori-ented approaches, which aim at the development of a pure logic of questions, withoutpaying attention to the relationship with natural language, and more linguistically ori-ented work, for example within the framework of an (extended) Montague grammar.According to Vanderveken both lines of investigation share a common methodology,which is largely due to Belnap:12 all analyses “tend to identify a question with a set (ora property) of possible answers to that question” (Volume ii, p. 9). Moreover, the var-ious analyses also “tend to identify answers with propositions or other senses” (ibid.).Vanderveken refers to this as a theoretical reduction of questions to senses, and distin-guishes the following principles on which such a reduction is based:
(i) To understand a question is to understand what counts as an answer to that question.(ii) An answer to a question is an assertion or a statement.
(iii) An assertion is identical with its propositional content.
Of course, he notes, these principles leave considerable leeway for actual analyses:e.g., Hamblin (1973) identifies a question with the set of propositional contents of itspossible answers, whereas for Karttunen (1977) it is the smaller set of its true answers.And in some other variants, e.g., Hausser (1983), answers are identified with the sensesof noun phrases rather than those of sentences.
Vanderveken’s main objection is that this type of approach is reductionistic: ques-tions are not treated as constituting a category in their own right, but are reducedto other types of entities, viz., propositions. Thus, this methodology does not takeillocutionary force into account, or, rather, it reduces illocutionary force to sense.And this is incompatible with the main motivation of speech act theory. Accordingly,Vanderveken argues that the three principles mentioned above are incompatible withbasic facts of language use.
However, it is not that obvious that (all of) the theories Vanderveken mentions aimat a reduction of illocutionary force to sense. (And even if they pretend to do so, itremains to be seen whether they really have to be taken that way, i.e. whether the
12 According to Vanderveken. But cf. the Hamblin postulates, discussed in Section 25.4.1.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1070 — #12
1070 Handbook of Logic and Language
results they obtain really depend on this avowed starting point.) Rather, it seems thatthe primary aim of theories in this tradition is to characterize a notion of (cognitive)content for interrogative language use, c.q., for interrogative sentences. And the under-lying assumption seems to be that one can do so without subscribing to a reductionistmethodology, i.e. without claiming that once the contents of interrogatives have beencharacterized an illocutionary analysis of their function is superfluous. For can onenot do truth conditional semantics for assertive language, without claiming that thismakes a speech act analysis superfluous?
This is not to say that Vanderveken’s characterization of the theories in this traditionis completely off the mark. Indeed, (some version of) the first of the three principlesVanderveken distinguishes seems to be subscribed to, be it sometimes only implicitly,by most protagonists of erotetic logic. The basic semantic intuition underlying this isthe following. To understand an indicative sentence, i.e. to grasp the contents of anassertive act, is to know under what conditions it is true. Similarly, to understand aninterrogative sentence, i.e. to grasp the contents of an interrogative act, is to knowunder what conditions it is answered. As indicatives are associated with truth condi-tions, interrogatives are linked to answerhood conditions. But it should be noted at theoutset that this leaves very much undetermined: although the association of answerswith propositions is an obvious one, it is by no means necessary. Answers can be givenin many different ways, even if we consider only linguistic means to do so. Exclama-tions, subsentential expressions such as noun phrases (“Who did you meet there?”“Some linguists.”) or prepositional phrases (“How did you get here?” “By train.”),but also non-indicative sentences (“Did you really hear him say that?” “Would I lie toyou?”) may be used to answer interrogatives. So, although indeed some analyses con-centrate on answers expressed by indicative sentences, this restriction does not followfrom the basic intuition described above.
Hence, Vanderveken’s second and third principles are not necessarily subscribed toby an erotetic logician who adheres to the first one. Nevertheless, what would makeone think so? There is a chain of associations at work here. Clearly, whatever linguistic(or non-linguistic) form they have, answers convey information, in a broad sense. Aninterrogative act is a request to tell the hearer something (not necessarily something hedoes not already know). And, by definition, an answer is something that does that, i.e.something that conveys information which is pertinent to the request. From a semanticperspective, propositions are the natural “units of information”.13 Of course, the con-cept of a proposition is a theoretical one: unlike linguistic expressions, or speech acts,propositions are not observable entities. Thus, the assumption of their existence hasto be licensed in some other way, e.g., by reference to their usefulness in descriptiveand explanatory contexts. One of these is the speech act analysis of assertive acts, orthe semantic analysis of indicative sentences. Here, it is commonly assumed that whatan assertive act conveys, or what an indicative sentence means, is a proposition. Butnotice that it is only when we define the notion of a proposition in such a way, i.e. as
13 Which does not mean that the concept is used uniformly. Various divergent analyses exist, but they allshare the idea of a proposition as a unit of information.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1071 — #13
Questions 1071
that which is expressed by an assertion, that Vanderveken’s second and third principlemake sense. But obviously, no such conception is forced upon us by adherence to thefirst principle. A simple observation makes clear that we had better refrain from thisidentification of propositions with contents of assertions, or indicative sentences: inthe examples given above the function of the various linguistic expressions in the con-text of the preceding interrogatives can very well be described as that of “conveying aproposition”.
In view of the above, it seems that Vanderveken’s charge of “reductionism” isunwarranted, at least in this sense that the idea that interrogatives be analyzed in termsof answers, or answerhood conditions, in itself does not lead to a reduction of inter-rogatives to assertions. There seems to be room for a perspective on the meaningof interrogatives according to which a consistent and useful distinction can be madebetween an analysis of their contents, at the level of semantics, and one of the inter-rogative acts typically performed by the use of them, at the level of pragmatics. Thesemantic analysis is carried out in terms of answers, but these should be taken to bethe contents of whatever linguistic expressions that can be used to answer questions,which are not tied exclusively to assertions as a separate kind of speech act.14
Another claim that Vanderveken makes in the context of his charge of reductionismis interesting to consider, for it, too, seems to rest on a misapprehension if not ofconcrete analyses, then at least of the potential thereof. What Vanderveken suggests isthat erotetic logicians in their reductionist enthusiasm identify questions with (sets of)propositions, viz., the propositions expressed by (true) answers. But this is only true ina certain sense, and only for some of them. In this context it is important to keep trackof the distinction between sense and denotation. For ordinary indicative sentences,those which are normally used to make assertions, the standard analysis identifies theirsense with a proposition, and their denotation in a particular world or context with atruth value. The reductionist principles that Vanderveken ascribes to semantic analysesmight suggest that interrogatives receive the same kind of propositional sense, andhence, contrary to the most basic intuitions, would denote truth values. But as we sawabove, the sense of an interrogative is identified with answerhood conditions, not truthconditions. To the extent that these answerhood conditions are explicated in terms ofpropositions, the denotation of an interrogative in a particular world or context wouldnot be a truth value, but rather a proposition (or a set thereof), viz., the proposition(s)that in that context would be expressed by a true answer. And, its denotation beingof such a propositional nature, the sense of an interrogative, conceived of in the usualway as a function from contexts to denotations, would be a propositional concept,rather than a proposition.
In view of this observation it is clear that Vanderveken’s charge of reductionism ismisdirected, also for analyses which do make use of propositions: such analyses donot reduce the content of interrogatives to that of indicatives. The contents ascribedto both are different, and the differences correspond to the difference between truth
14 Needless to say that a speech act analysis of interrogative acts according to which they can be (shouldbe) reduced to assertive acts, stands in need of justification, too.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1072 — #14
1072 Handbook of Logic and Language
conditions and answerhood conditions. Here the pragmatic distinction between thekinds of speech acts typically performed by the use of interrogatives and indicativesis reflected in the type of their semantic contents, as is to be expected. By no meansshould the acknowledgement of a distinct kind of semantic object to serve as the con-tents of interrogative sentences be taken as an implicit argument that a speech actanalysis of interrogative acts is no longer needed. But it does amount to the claim that,speech act theory or no speech act theory, interrogatives are distinguished not onlythrough their illocutionary force, but also through their contents, which is related to,but distinct from the contents of assertions. What needs to be noted is that this claim,at least at first sight, seems at odds with the central thesis of speech act theory thatall (elementary) illocutionary acts are of the form F(P), where F is the illocution-ary force, connected with conditions of success, and P is the propositional content, tobe explicated in terms of satisfaction conditions. Semantic analyses of the kind out-lined above would lead one to conclude that interrogative illocutionary acts do nothave a proposition as their content, but rather some kind of propositional concept,to which the notion of satisfaction does not seem to apply. We return to this pointbelow.
We conclude that Vanderveken’s main criticism, that semantic analyses which ana-lyze the contents of interrogatives in terms of answers are reductionist in nature, isunfounded.15 However, the perspective of speech act analysis leads him to formu-late some other points, which constitute interesting challenges for an overall theory.One thing Vanderveken notes is that full sentential linguistic answers to interrogativesare not necessarily assertions (1990, Vol. ii, p. 10). For example, the interrogative“Do you confirm his nomination?”, can be answered by a so-called declaration: “Yes,I hereby confirm it”. And similar things can happen in case of such interrogatives as“Do you promise to come?”, which can typically be answered with a performative“Yes, I promise to be there”. An approach which analyzes interrogatives in terms ofanswers, ànd which identifies answers with assertions is in trouble here. But as wepointed out above, the latter move is not necessary. Still, it remains to be seen in whatway a semantic analysis of interrogatives in terms of answers will be able to cope withexamples such as these. For it seems that such approaches are wedded to the idea thatanswers provide information. That is, they seem to presuppose that answers, whateverillocutionary act is performed by the use of them, have propositional content. To whatextent such examples as cited above fit this scheme is not obvious. The performativesentences provide information, but not in the sense intended. One way to account forthis is to uphold that this is in fact due to the interrogatives. For example, one might saythat such an interrogative as “Do you promise to come?” does not request the hearer toprovide information, but asks for a promise. (Cf., the contrasting “Did you promise tocome?”) Or consider the interrogative “What shall we have for dinner tonight?”. Thisinterrogative is typically used to elicit some discussion or suggestions about what toeat tonight. (Cf., the contrasting “What are we having for dinner tonight?”) In view
15 To be sure, we refer here to what such analyses in principle are forced to acknowledge. This does notmean that there may not be proponents of this approach which do have reductionist aims.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1073 — #15
Questions 1073
of such examples it may make sense to distinguish informative from non-informativeinterrogatives. The latter do not primarily ask to provide information, but to performsome other action, even though either a positive or a negative answer will also pro-vide the information that the action will, or will not, be performed. The challengeto semantical theories of the kind outlined above now is to come to grips with thisphenomenon. One move might be simply to restrict the application of the theory toinformative interrogatives. But this seems unsatisfactory. Another position one couldtake is to generalize and say that what all interrogatives have in common is that theypresent some potential alternatives. In the case of informative interrogatives these arealternative ways the world is like, in the case of non-informative ones such as thosementioned above, the alternatives concern actions of the hearer.
Another point that Vanderveken raises and that constitutes a challenge for any the-ory is the following. Interrogative acts are just one type of illocutionary act embeddedin a whole field of linguistic acts which are interrelated in various ways. Hence, a logicof questions can not be an isolated affair, but should be integrated within a generallogic of illocutionary acts. An exposition of how Vanderveken wants to realize this,would take us too far afield. Suffice it to notice that, as is not unusual, Vandervekentakes the use of an interrogative sentence to constitute a kind of request, the contentsof which he describes as follows: “A speaker who asks a question requests the hearerto make a future speech act which is a (non-defective or true) answer to that question”(Volume ii, p. 11). Requests are considered to be a subclass of directives, which area basic type of illocutionary act. In this way, Vanderveken wants to account for thesystematic relationships that exist between interrogative acts and other illocutionaryacts. The challenge for a semantic theory is, of course, not to provide such an accountitself, but rather to lend itself to it. Granting that there is such a thing as a logic ofillocutionary acts, in which interrogatives are to be treated as a kind of requests, asemantic analysis of the contents of interrogative sentences must be such that it can beembedded in such a logic. But, of course, this demand does not exclude the existenceof a logic of questions, not as acts of requesting, but as the particular kind of semanticobjects that constitute the cognitive contents of interrogative sentences.
And we may even take a stronger position with regard to the relationship betweenthe two. Vanderveken recognizes that a logic and semantics of the contents of assertivelanguage use is important, and is part of a richer illocutionary logic. Would not thesame hold for the logic and semantics of the contents of interrogative language use?One argument for that would be that an illocutionary analysis of interrogatives willneed to appeal to questions as the contents of interrogatives, i.e. that a logic of ques-tions is needed as a preliminary for a pragmatic analysis. That this is indeed the casemay in fact be argued on the basis of the illocutionary paraphrases that Vandervekenand others give of interrogative acts.
25.3.4 Questions as Requests
What does Vanderveken’s analysis of interrogative acts amount to? As we saw above,the illocutionary force of an interrogative act is that of a request of the speaker to

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1074 — #16
1074 Handbook of Logic and Language
the hearer. The propositional content is special: the request is that the hearer perform afuture speech act which is a correct answer to his question. Thus, an explicit performa-tive paraphrase would be something like the following: “I (hereby) ask you to answer(the question) Q”, where Q is some specific interrogative. Paraphrasing in terms of anexplicit directive of the request type we would get something like: “Please, tell me Q”,with Q the same as above.
What needs to be noticed is that in such paraphrases interrogatives again appear, notas illocutionary acts, but as entities which characterize the contents thereof. Thus, itwould seem that a specification of the propositional contents of interrogative acts cannot get around acknowledging the existence of questions as semantic objects, giventhat, as Vanderveken recognizes, the content of a whole is determined by the contentsof its parts.
This conclusion runs contrary to Vanderveken’s intentions. It is no coincidence,perhaps, that the one particular example that is provided (Volume ii, p. 158) concernsa simple sentential interrogative: “Is it raining?”. In such examples, it is indeed possi-ble to avoid reference to anything like questions as semantic objects. Informally, theanalysis amounts to the following: “I request that you assert that it rains or deny thatit rains”. This does indeed seem to avoid the introduction of questions. But it is notquite obvious that Vanderveken’s treatment is correct as far as it goes, nor that it canbe generalized. As for the first, asking a question is not simply a request to the hearerto make one of two assertions at his or her liberty. What we want is not merely someclaim, but the truth: we want to know whether it is raining, not merely to be told that itis, or that it is not. Thus, a more adequate paraphrase along Vanderveken’s lines wouldbe: “I request that if it rains, you assert that it rains, and if it does not rain, you denythat it rains”. Granting that this modified paraphrase is more correct, it is still not soeasy to see how this strategy of paraphrasing questions away, can be applied generally.There seem to be different kinds of interrogatives, and different kinds of contexts inwhich they occur, that defy this analysis. To start with the latter, the modified para-phrase is adequate for certain contexts, such as request, know, tell, and the like. But asa paraphrase for interrogatives embedded under such verbs as wonder, or investigate,the result is clearly incorrect. And moreover, not all direct interrogatives seem to bendto the reduction as easily as simple sentential interrogatives. Consider a simple con-stituent interrogative such as “Which students have passed the test?”. The followingparaphrase suggests itself: “I request that for each student that if (s)he passed the testyou assert that (s)he passed the test, and if (s)he did not pass the test, you deny that(s)he passed the test”. But this will not quite do. For the proposition we want to beasserted should also claim of the person who passed that (s)he is a student, which issomething this analysis leaves out of consideration. And notice that a more straight-forward paraphrase, such as “I request you to tell me which students passed the test”,where the question occurs in the content explicitly, potentially avoids this problem,since it allows us to build this into the content itself. Thus it seems that Vanderveken’sstrategy of avoiding an appeal to questions as contents of interrogatives in his analysisof the meaning of stand alone interrogatives fails. Acknowledgement of this type ofsemantic objects simply can not be avoided.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1075 — #17
Questions 1075
And of course there is no principled reason for Vanderveken to want to avoid ques-tions as contents to play a role in determining the propositions that present the con-tents of speech acts, be it asking a question or otherwise. Their existence constitutesno threat whatsoever against his general enterprise, and actually might make thingseasier. Embedded interrogatives play a part in many types of sentences, also simpledeclarative ones. In such contexts, it seems far from obvious that a speech act type ofanalysis is what is called for.
The above considerations suggest that the pragmatic approach, whatever its inher-ent virtues as an analysis of the use of interrogatives, i.e. of interrogative acts, willnot do as an account of the meaning of interrogative sentences, given that we wantsuch an account to satisfy certain requirements. For example, it seems desirable thatinterrogatives be treated as independent parts of sentences and that related meaningsbe assigned to stand alone and embedded interrogatives. But also when taken as ananalysis of interrogative acts, the pragmatic approach as worked out by Vandervekenfaces some difficulties which are worth pointing out.
25.3.5 Asking a Question as a Basic Speech Act
The above considerations criticize the pragmatic approach “from the outside” as itwere. In this section we take up an issue that constitutes an internal criticism of theanalysis put forward by Vanderveken. One remarkable aspect of his analysis is that inVanderveken’s typology asking a question is not a basic speech act. It belongs to thebasic type of directives. The illocutionary point of a directive is making an attemptto get the hearer to do something (Volume i, p. 105). Like commissives, directiveshave the “world-to-words” direction of fit: their point is to make the world fit thewords. The world is to be transformed by some future act, of the hearer in the caseof a directive, of the speaker in the case of a commissive, in order to match (satisfy)the propositional content of the speech act. The transforming act is specified by thepropositional content of the speech act. And the success of the speech act depends onthe world coming to satisfy this content.
According to Vanderveken, asking a question is a special kind of directive. It is arequest, which means that unlike other directives, it allows for the option of refusal.Furthermore, it has a specific kind of content: it asks for some future speech act ofthe hearer which gives the speaker a correct answer to her question. Notice that the“intuitive” notion of question-as-content appears here, too, not as the (propositional)content of the act of asking a question, but embedded, as the paraphrase given justabove suggests. (Note that one cannot replace “question” again by “request etc.”, onpain of getting into an infinite regress.)
The peculiar thing to note is that the world-to-words fit that is the illocutionarypoint of an interrogative act, seems to be of a different kind than that of a simplerequest, such as “Please, open the door for me”. The latter calls for an action thattransforms the world as such, whereas asking an informative question, such as “WillMary come tonight?”, does not. What it demands is that a change be brought aboutin the information state of the speaker, an effect that can typically be achieved by the

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1076 — #18
1076 Handbook of Logic and Language
performance of a speech act of assertion or denial with the appropriate content. Ofcourse, any utterance transforms the world in this, admittedly rather trivial, sense thatafter the act has been been performed it has been performed. But for these kinds ofspeech acts that is not the real point: they require a change in information about theworld, not in the world itself.
Of course, in a certain sense, the information a speech participant has about theworld, and about the information of other speech participants, also forms part of theworld, but it does so only in a secondary, derivative sense. The world and the infor-mation one may have about it, are clearly to be distinguished. The following conside-ration may perhaps clarify why. One can imagine languages that only express thingsabout the world, sensu strictu, and not about information, or about speech acts. Nev-ertheless, such a language may very well contain assertives, directives, maybe evencommissives, and interrogatives. And it seems that the meaning of such sentences canbe stated without any overt or covert reference to information as such. In other words,the ontology of both the object and the meta-language may be stated without referenceto anything but objects constructed with set-theoretical means from things in the worlditself.16
This is a strong indication that, systematically, these levels, of the world and ofinformation about it, are to be kept apart. Moreover, it shows that the “merge” betweendenotational and pragmatic aspects of meaning that speech act theory presupposes, isnot forced upon us, at the very least, and that it may even be wise to distinguish thetwo as much as possible. In Section 25.4 two examples are discussed that corroboratethis point.
Now to return to Vanderveken’s typology, it seems that from the perspectiveadopted above, there is no reason to classify interrogative acts as a subtype of direc-tives. Assuming with Vanderveken that the latter call for an action of the hearer tochange the world, their contents can indeed be identified with the specific change inthe world required.17 But assuming that interrogative acts call for an act of conveyinginformation, and adopting the perspective that distinguishes between information andwhat information is about, interrogatives simply are not of the same type as directives,but rather must be regarded as constituting a basic type of speech act in their ownright.18 And one might even go further and argue that interrogative acts do not neces-sarily direct the hearer towards any kind of action, except perhaps that of considering
16 Information states in dynamic semantics, for example, are of this nature.17 Of course, although primarily concerned with changing the world, directives also involve a change in
information. The information they convey is that the speaker wants the hearer to change the world in acertain way. And the accommodation of this piece of information, i.e. the actual change in the informationstate of the hearer this brings about, may even be important in bringing about what the speaker wants. Forexample, an explicit recognition of a certain wish that the speaker entertains on part of the hearer, may bewhat drives him to try and bring about the desired transformation in the world. But the important point isthat this change of information does not constitute the primary point of a directive, which is directed atthe world, and not at the information the hearer has about the wishes and needs of the speaker.
18 Notice that the Åqvist/Hintikka approach explicitly recognizes that to bring about a change in the infor-mation state of the speaker is what is being requested of the hearer.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1077 — #19
Questions 1077
the question. To ask a question and to ask someone to answer a question do not neces-sarily seem to be the same thing. On this view, the content of an interrogative act neednot be propositional at all.
Thus it seems that we must conclude that Vanderveken’s typology overgeneralizes,and does not fully do justice to the own nature of interrogatives as a separate kind ofspeech act.19
25.3.6 Summing up Sofar
Let us take stock. In the above we have distinguished two major streams in the theoryof interrogatives. One, which we dubbed the “pragmatic approach”, analyzes interrog-atives at the level of speech acts. Major proponents of this approach, in one variantor other, are Åqvist, Hintikka, Searle, Vanderveken. Within the other approach inter-rogatives are analyzed at the level of semantic content, i.e. interrogatives are viewedas a particular type of expressions, with a particular type of sense and denotation. Thework of Belnap, Hamblin, Karttunen, Higginbotham and May, and Groenendijk andStokhof exemplifies this trend.
Besides these a third position can be distinguished, which is a really reductionistone. It identifies interrogatives with statements, for example in Lewis’ explicit per-formative hypothesis (Lewis, 1970). Another example is provided by the work ofTichy (1978). Here there is neither recourse to speech act theory, nor to any spe-cial type of semantic content. Plain truth conditional semantics, it is claimed, is allwe need.
The argument against the third view is clear. The performative analysis is circu-lar if not combined with an independent analysis of the meaning of embedded inter-rogatives. And Tichy’s analysis, according to which there is no semantic distinctionbetween interrogatives and indicatives, and which therefore must take recourse to a“difference in pragmatic attitude of the speaker” (Tichy, 1978, p. 276) in order to keepthem apart, simply fails to account for what are obvious semantic differences, suchas exemplified by sentences in which interrogatives are embedded. Consider “Johnknows that Bill walks” and “John knows whether Bill walks”. If the embedded inter-rogative and the embedded indicative really have the same semantic value, then eachof these sentences should have the same value, too. If Bill walks, and John knowsthis, we might say that that is indeed the case: both are true. But if Bill does not walk,and John knows this, then they differ in value: in that case the first sentence is false,whereas the second is true.
19 Which is remarkable, in a certain sense. For did not the pragmatic approach claim to be heir to Wittgen-stein’s later work? But as the latter wrote (Philosophical Investigations, Section 14):
Denke dir, jemand sagte: “Alle Werkzeuge dienen dazu, etwas zu modifizieren.” [. . .] Wäre mitdieser Assimilation des Ausdrucks etwas gewonnen?
In this case not, it seems.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1078 — #20
1078 Handbook of Logic and Language
Such a simple example suffices to show that there are semantic differences betweeninterrogatives and indicatives, and that the semantic content of interrogatives needs tobe accounted for.
As said, the pragmatic approach, unlike this reductionist view, tries to do so,although it does not regard the semantic content of interrogatives as a kind of semanticentity of its own. But it encounters difficulties of its own, as we have seen. Does thismean that the pragmatic approach is wrong, and that hence only a semantic analysiscan be pursued? Not necessarily. It is of some importance to notice that a priori thereis no clash between the two. The case of indicatives may serve to illustrate this.
It seems that most people would agree that one can make a fruitful study of impor-tant aspects of the propositional content of assertive language use, without taking intoaccount aspects of illocutionary force. In other words there are systematic aspects ofthe meaning of indicatives which can be studied independently of their use. Of course,such a semantic account will be limited, it will not cover all aspects of meaning in theintuitive sense, since some of these are intrinsically connected with the speech actswhich are characteristically performed with indicative sentences. But granting that,most people would grant as well that there is such a thing as a “pure semantics” ofindicatives.
This point is even reinforced if we consider the pragmatic approach. For accordingto Vanderveken every illocutionary act is of the form F(P), i.e. it has a propositionalcontent, and nothing seems to exclude a restricted, but independent, theory of propo-sitional content as part of his overall scheme.20
As the discussion above has shown, there seem to be no principled reasons for notviewing the meaning of interrogatives in the same way. They, too, have a semanticcontent (propositional or otherwise), which, it seems, can be studied systematicallyand fruitfully independent of a study of their characteristic illocutionary uses. Again,such a semantic analysis would only be part of the whole story, but a necessary, andnot altogether unimportant or uninteresting one.
So it seems that no a priori considerations would prevent one from taking up theposition that both approaches, the pragmatic and the semantic one, are justified intheir own right, if put in the proper perspective. An overall theory of meaning has todeal with both cognitive content and illocutionary force, as two aspects of meaning.At least to some extent, it seems, both can be studied independently. When appliedto interrogatives this means that one may hold that questions do constitute a separatesemantic category, distinct from that of propositions. The latter being the cognitivecontent of assertive language (use), the former are the contents of interrogative lan-guage (use). And one can even push this a little bit further, and argue that in a speechact theory, which deals with both content and illocutionary force, the special contentof interrogative language use has to be taken into account.
This may suggest a more or less traditional division of labor between semantics andpragmatics. However, it must be borne in mind that where the borderline between the
20 Caveat: there are sentences, such as explicit performatives, of which it seems reasonable to assume thattheir content can be dealt with only if both aspects of meaning are taken into account at the same time.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1079 — #21
Questions 1079
two is actually drawn may change over time. For example, until recently one would,with respect to assertives anyway, make a neat distinction between truth-conditionalaspects of meaning, constituting the domain of semantics, and illocutionary aspects,including conversational implicatures and the like, which were supposed to be han-dled in pragmatics. The development of theories of dynamic semantics has changedthis picture. On empirical and theoretical grounds various people have argued that nottruth, but information change potential is the core notion of semantics, thereby signifi-cantly extending its coverage. So what exactly constitutes a semantics of interrogativesis a different question than whether there is such a thing in the first place.
We take it that by now we have made it at least plausible that the latter questionmust be answered affirmatively. We will therefore turn in the next section to someconsiderations concerning the character and contents of a semantics of interrogatives.
25.4 The Semantic Approach
Above we have argued that the interpretation of interrogatives in terms of the successand satisfaction conditions of performing the illocutionary act of asking a questionpresupposes the notion of a question as a distinct type of semantic object. In orderto be able to analyze what it is to ask a question, and what counts as an answer, wehave to establish what questions are. In this section we will discuss some fundamentalprinciples which have guided much of the research into the semantics of questionsover the past two decades, and we will show that they guide us towards a relativelysimple, but explanatory powerful picture of what kind of semantic objects questionsare. The various concrete analyses that have been put forward in the literature can becharacterized in terms of variations on this one common theme. We will also discusssome criteria of adequacy which, be it often implicitly, have been used to evaluatevarious proposals and which direct further research. The resulting picture does haveits limits, however. We will discuss some of these, and point out in which way onemight try to overcome them.
25.4.1 “Hamblin’s Picture”
The general picture of questions as semantic objects that we are about to sketch wecall “Hamblin’s picture”, because we derive it from three general principles whichHamblin was the first to formulate (Hamblin, 1958). The quotes, however, are (also)scare quotes: we do not claim that Hamblin actually would agree with the outcome. Infact, his own analysis in Hamblin (1973) does not (quite) conform to it.
The principles in question were already referred to above, when we were discussingVanderveken’s objections to what he considers the methodology of reducing questionsto answers. Hamblin’s postulates read as follows:
(i) An answer to a question is a sentence, or statement.(ii) The possible answers to a question form an exhaustive set of mutually exclusive
possibilities.(iii) To know the meaning of a question is to know what counts as an answer to that question.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1080 — #22
1080 Handbook of Logic and Language
In what follows we will discuss these three principles separately. In doing so, weare not after a reconstruction of Hamblin’s intentions (recall the scare quotes), butrather want to investigate the systematic impact of the principles as such.
The main impact of Hamblin’s first postulate is to turn attention away from “sur-face” syntactic form. On the linguistic surface, answers often appear as subsententialphrases: for example as nps (“Who came early?” “John.”), pps (“Where are you going?“To Amherst.”), vps (“What do you want to do?” “Have fun.”), and so on. However,the first postulate emphasizes that the function of answers, whether subsentential orsentential, or even when provided by non-linguistic means, is to provide information,and hence that their semantic status is that of a proposition.21
The second postulate specifies the nature of the propositions that count as answersto a question. One thing it says is that the propositions that count as answers to aquestion logically exclude one another: the truth of each of the answers implies thefalsity of the others. This means that individual answers are regarded as “exhaustive”in the sense that each answer, if true, provides completely and precisely the informa-tion the question asks for. Furthermore, the postulate states that the set of answers isalso exhaustive in the sense that the union (disjunction) of its members completelyfills the logical space defined by the question. In other words, no possible answersdefined by the question are left out.
The logical space defined by a question is the space of possibilities it leaves for theworld to be like. It can either be taken to be the entire logical space, or that part of itin which the presuppositions of the question are fulfilled. If in a particular situationthe presuppositions of a question are not fulfilled, then, one might reason, it has noanswer in that situation. In such a case, the only appropriate reply would be to expressthe proposition that denies that the presuppositions are fulfilled.
The picture that emerges from these two postulates, is that the possible answers toa question form a partition of the logical space. Taking presuppositions into account,one block in the partition has a special status, being marked as that part of logicalspace in which the presuppositions of the question do not hold. (Alternatively, on anon-presuppositional approach, the proposition that expresses that the presuppositionsdo not hold is counted as one of the answers.)
An immediate consequence of the exhaustive and mutually exclusive nature of theset of possible answers is the following: in each situation (in which its presuppositionsare fulfilled) a question has a unique complete and precise true answer, viz., the unique
21 This postulate is reflected in early systems of erotetic logic in the identification of interrogatives withsets of formulae. To provide an answer to an interrogative is then to choose the true element(s) fromthe corresponding set. This syntactic set-up relates directly to the primary goal of such systems, whichis not primarily the description of the semantics of interrogatives in natural language, but rather thedevelopment of formal tools, which can be put to a variety of uses, for example to query databases. (Cf.,e.g., Belnap and Steel (1976, p. 2): “our primary aim here is rather to design a good formal notation forquestions and answers and a good set of concepts for talking about them”.) But here we are after a propersemantic notion, i.e. one that can be stated in terms of semantic objects, to serve as the interpretation ofexpressions of natural language.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1081 — #23
Questions 1081
proposition among the possible answers that is true in that situation.22 This is not to saythat this feature cannot be challenged. However, if one thinks that there are reasons togive it up, one must be willing to modify at least one of the two postulates from whichit follows.
It may be worthwhile to stress at this point that the notion of answerhood thatis under discussion here does not refer to linguistic objects, but to semantic objects:propositions. The existence of a unique true, complete and precise semantic answerdoes not imply that it can be expressed by linguistic (or other) means, nor that if it canbe expressed, it can be expressed in a unique way. Also, even in case we are unable toexpress a semantically complete and precise answer, circumstantial pragmatic factorsmay still make it possible to actually convey such an answer. Likewise, pragmaticfactors may determine that under different circumstances, depending, for example,on common knowledge among questioner and questionee, different propositions aremost effective in actually conveying precisely the information the question asks for. Inshort, the everyday observation that one and the same question can often be answeredin many different ways, is not necessarily at odds with the existence of a unique trueand complete semantic answer.
The importance of the third postulate, finally, is that it identifies the meaning ofan interrogative with the partition of logical space which is constituted by the set ofits possible answers. That is to say, questions, as semantic objects, are taken to bepartitions of logical space. Notice that, Vanderveken’s qualms (see Section 25.3.3)notwithstanding, the charge of reductionism is not justified: the meaning of an inter-rogative is a separate kind of entity, it is not reduced to the meanings of expressionswhich serve as answers, viz., to propositions. Of course, the two kinds of semanticobjects are related: the elements of a partition are propositions. In this respect, thecase of interrogatives is quite comparable to that of indicatives. Knowing the meaningof an indicative, i.e. knowing under which circumstances it would be true, obviouslydoes not imply knowing whether it is true. Likewise, knowing the meaning of an inter-rogative, i.e. knowing what would count as the true answer in which situation, doesnot include knowing what its true answer is.
The picture that emerges from Hamblin’s three postulates is extremely elegant, and(hence?) (onto-)logically compelling. But at the same time there are at least two rea-sons to doubt its correctness. The first one is that the picture presupposes that everyquestion (with non-contradictory presuppositions) has an answer. This we call the“Existence Assumption”. But, one may ask, is this assumption justified? Are therenot unanswerable questions?23
The second objection that can be raised, is that the picture presupposes that everyinterrogative has precisely one true (and complete) answer in a situation (in which its
22 Assuming that the question has a true answer.23 This might be a moot point. Consider the question after the truth of an undecidable mathematical propo-
sition. Or “paradoxical” interrogatives, such as “Does the Liar lie?”. But the corresponding indicativesdo not fit the standard circumscription of their semantics, either.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1082 — #24
1082 Handbook of Logic and Language
presuppositions are fulfilled). This we may dub the “Uniqueness Assumption”.24 Arethere not interrogatives with several alternative equally true and complete (equallysatisfactory) answers which are not logically equivalent? Potential candidates areso-called “mention-some” readings (“Where can I buy an Italian newspaper?”) and“choice” readings (“What do two of these computers cost?”) of interrogatives, andcertain types of coordinated interrogatives (“Where is your father? Or your mother?”).We will return to these issues below. For now, we want to remark only the following.
There is no a priori need to suppose that there is a single notion of a question,i.e. only one kind of semantic object that serves as the content of an interrogative.There may be several. Thus Hamblin’s picture need not be interpreted as a picture ofthe essential question. One may also look upon it as a specification of the content ofa particular type of interrogatives. Of course, our natural tendency would be to lookfor one type of object to serve as content of all the various kinds of interrogativesthere are, and, sure enough, uniformity would be an important asset of an analysis.However, the possibility that questions do not form a homogeneous class should notbe ruled out. And it should also be borne in mind that an assessment of a proposedanalysis in semantics not only depends on its fitting all the relevant empirical facts,but also on its logical simplicity and beauty, and on its conforming to general semanticprinciples.
Some examples of the latter, which are important for the realm of questions, arediscussed in the following section.
25.4.2 Criteria of Adequacy
For a semantics of indicatives, the two most important criteria of adequacy are that itspecify a notion of semantical identity (equivalence), and give an account of meaninginclusion (entailment). A semantic analysis is materially adequate to the extent thatthe equivalence and entailment relations that it accounts for are in accordance withour intuitive understanding of the meanings of the expressions involved.
Similar criteria of adequacy can be formulated for a semantic analysis of interroga-tives. Thus, we require that identity criteria for questions be forthcoming, giving rise toan appropriate notion of equivalence between interrogatives. This will allow us to testthe proposed analysis against our intuitions concerning when two interrogatives “posethe same question”. Likewise we want the analysis to specify an appropriate relation ofentailment between interrogatives, thus giving an account of when the question posedby one interrogative can be said to be part of the wider question posed by another.
Some decades of thinking about the semantics of indicatives have provided us withreasonably clear judgments on how we want these requirements to be met. The ideaof truth conditions, alternative approaches not withstanding, has become entrenchedin our intuitions, and serves as a bench mark. Equivalence and entailment defined in
24 Which is no other than the “Unique Answer Fallacy” of Belnap (1982), who obviously was convincedthat it is not justified. For the time being we would like to remain neutral on this point, and thus prefer torefer to this feature as an “assumption”, rather than a “fallacy”.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1083 — #25
Questions 1083
terms of truth conditions likewise have become part and parcel of our thinking aboutthe meanings of declarative expressions.
With interrogatives things are perhaps not yet as clear. But something like therole that truth conditions play, is inherent in the relationship between questions andanswers. No matter in what particular way we might want to account for it, the notionof a question is intrinsically related to that of an answer. Thus (intuitions about)“answerhood conditions”, though a less familiar item in our semantic vocabulary,seem a good candidate for testing analyses against. Hence, providing an appropri-ate notion of answerhood can be seen as another criterion for the adequacy of a theoryof questions. Such an account links the semantics of indicatives and interrogatives,answers being provided by indicative expressions.
Regarding an account of answerhood as an integral part of one of questions, mayalso give a firmer grip on the relations of equivalence and entailment between inter-rogatives. If a semantic analysis specifies an appropriate notion of answerhood bet-ween the indicatives and the interrogatives of a language which accords with ourintuitive understanding of when an indicative resolves the question posed by a par-ticular interrogative, then this may give us a test for deciding whether the semanticsassigns appropriate meanings to the interrogatives of the language. If two interroga-tives are assigned the same meaning, then they should have the same answers under theattested notion of answerhood. And if one interrogative is predicted to entail another,then an indicative which is an answer to the first, should also be an answer to thesecond.
Note that although being answered by the same indicatives is a necessary conditionfor the equivalence of two interrogatives, it cannot always be taken to be a sufficientcondition (and similarly for the relation between answerhood and entailment). It isonly both a necessary and a sufficient condition in case we are dealing with a languageof which we can be sure that the questions posed by its interrogatives can always beresolved by the indicatives that can be expressed in the language. To take the extremecase: if two interrogatives have no expressible answers at all, we do not necessarilywant to conclude that, hence, they are equivalent.25
Expressibility of answers is a traditional topic in erotetic logic, and it is of practicalimportance for the design of query systems, where the aim is to make sure that thequeries that can be formulated in the language can always be appropriately answered.Likewise, it is important in this context that it is guaranteed that all information thatcould sensibly be obtained from an information base is expressible in a query. Fromthis perspective one could add as an additional criterion of adequacy for a theory ofquestions and answers that it can shed light on the issue of expressibility of inter-rogatives relative to information about a particular domain, and the expressibility ofpossible answers relative to the interrogatives that can be expressed.
25 As we shall see later on, this is not just a theoretical possibility. If the language of predicate logic isextended with elementary interrogatives, then even very simple and meaningful questions have hardlyany expressible answers that completely resolve them. Fortunately, under suitable restrictions expressibleanswers are forthcoming.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1084 — #26
1084 Handbook of Logic and Language
From the same perspective, there are further topics that can be addressed. Even incase a complete answer is not expressible, or when an information base (is “aware”that it) contains only partial information, it may still be possible to come up witha partial answer. This raises the issue what under such circumstances is an optimalanswer. If a semantic theory is to shed light on this, it should give rise to a notion ofpartial answerhood, and to a comparative notion of when one indicative gives moreinformation about a certain question than another.
Although potentially related to practical applications, these questions can still bethought of as belonging to pure, theoretical semantics. At best, answering them couldcontribute to a “static” characterization of whether a certain indicative is an optimalreply to a particular interrogative under particular circumstances. A computationalsemantics of interrogatives should presumably also address the “dynamic” issue ofwhether and how one can effectively process a question, decide what the optimalanswer is, and produce it in the most understandable way. About these latter issueswe will have nothing to say, but concerning the former we at least hope to indicatethat theoretical semantics may have some contribution to make here.
The criteria of adequacy discussed so far are of a general, framework independentnature. We end this section by formulating some criteria which are peculiar to a partic-ular framework: standard denotational semantics. Within a denotational semantics, theexpressions of a language are assigned semantic objects in a systematic compositionalway. One may expect of an analysis along these lines that equivalence is determinedby sharing the same semantic value, and that whether one expression entails the otherdepends on whether the value of the first is “included” in the value of the second. Thelatter presupposes that the semantic values of expressions within the relevant syntacticcategories come with a “natural” relation of inclusion.26 Finally, it may be expectedthat equivalence amounts to mutual entailment. These framework specific principleswill be referred to as formal criteria of adequacy.27 By default, an adequate denota-tional semantics of interrogatives should be no exception to these rules.
25.4.3 Adequacy of the Hamblin-Picture
That an analysis which conforms to the Hamblin-picture outlined above can be turnedinto an account that satisfies the adequacy criteria, of course comes as no surprise: itwas designed to be that way. In particular, the third postulate forges a strong link bet-ween indicative and interrogative, thus making an account of the answerhood relationthe heart of the picture. But it will be illustrative to investigate in some detail how thistype of analysis complies with these requirements, if only because that will provide uswith a handle on the alternatives that will be discussed later.
Since the third postulate establishes a relation between the semantics of interrog-atives and that of indicatives, we must start with some assumption concerning the
26 If the semantic objects are sets, the natural relation is set inclusion.27 That these criteria are framework dependent is illustrated by the fact that in dynamic semantics, where the
meanings of indicatives are identified with update functions, logical equivalence is not always defined interms of identity of update functions, but in terms of a weaker equivalence relation.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1085 — #27
Questions 1085
latter. So, suppose indicatives are assigned a proposition as semantic value, wherea proposition is taken to be something that “carves out” a particular part of logicalspace, viz., the part consisting of those possibilities in which the indicative holds (istrue).28 Without a need for any additional assumptions on what these possibilities are,we can stipulate that one indicative entails another iff the proposition expressed by thefirst carves out a part of logical space that is contained in the part carved out by thesecond.
In accordance with the Hamblin-picture as it was developed above, we assume thatan interrogative is assigned a partition of logical space (or, alternatively, of that partof it in which its presuppositions hold). The elements of the partition are propositions,viz., those propositions expressed by possible answers. Two interrogatives are thensaid to be equivalent iff they make the same partition of logical space.
Entailment between interrogatives can be defined in the standard way. By “?!”we indicate an interrogative. Then we define that ?! entails ?" iff every element inthe partition made by ?! is included in some element in the partition made by ?" .Recalling that the elements of the partition expressed by an interrogative are intendedas the propositions expressed by its answers, we note that if these propositions canbe expressed in the language under consideration, this definition boils down to thefollowing: ?! entails ?" iff every possible answer to ?! entails some possible answerto ?" .
This is borne out by the following definition of answerhood. An indicative ! is ananswer to an interrogative ?" iff the part of logical space carved out by ! is included insome block in the partition of logical space made by ?" . Thus, an indicative answersan interrogative iff it expresses a proposition which entails one of the semantic answersto the question expressed by the interrogative. As required, this notion of answerhoodis such that if two interrogatives are logically equivalent then their possible answersare the same. Likewise, if ?! entails ?" then every complete answer to ?! also isa complete answer to ?" . And to the extent that the semantic answers are express-ible by the indicatives of the language both implications also hold in the oppositedirection.
The notion of answerhood indicated above, is a notion of complete answerhood.Next to this notion of complete answerhood, a notion of partial answerhood can bedefined: ! partially answers ?" iff the proposition expressed by ! excludes at leastone possible answer to ?" . Complete answerhood is a limit of partial answerhood,in which every block in the partition but one is excluded. Partial answerhood deter-mines whether a proposition provides relevant information about a certain question.And, in principle, we can compare answers as to the amount of relevant informationthat they provide concerning a certain question. On the one hand, the more possibleanswers are excluded, the better it is. This favors stronger propositions over weakerones. On the other hand, if two propositions exclude the same possible answers, andone is stronger than the other, the weaker one is to be preferred, since it containsless irrelevant information, i.e. information the question does not ask for. In the end,
28 For convenience sake we assume that the semantics is total, but nothing hinges on this.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1086 — #28
1086 Handbook of Logic and Language
answers which express propositions which precisely fill one block in the partition thata question makes of logical space will come out as providing the best answers. Butone may be forced to compromise, either because one’s information simply does notsupport such an optimal answer, or because the linguistic means to express such ananswer effectively are lacking.
We take it that these observations suffice to show that the Hamblin-picture maylead to analyses that satisfy the adequacy criteria. Of course, the empirical importof such accounts still needs to be tested against observations concerning the mean-ings of actual interrogatives. What we have sketched above are the contours of ananalysis, not a full-fledged theory of the semantics of the interrogative structures ina particular language. Two such concrete instances will be discussed below. In thenext section we consider the case of a language of propositional logic extended withyes/no-interrogatives. In the subsequent section we discuss the predicate logical case,and extend the indicative language with elementary interrogatives asking to specifythe denotation of a property or relation.
25.4.4 Questions in Propositional Logic
Above we have sketched an analysis of questions and answers which remained on aconceptual level and did not make reference to a particular language. In this sectionwe will consider language, albeit a logical one. We will investigate how the languageof classical propositional logic can be extended with yes/no-interrogatives.
Syntactically, yes/no-interrogatives are formed by prefixing a question-mark to theformulae of a standard language of propositional logic. So, there are two distinct sen-tential categories in the extended language: indicatives and interrogatives. The con-nectives only apply to indicatives. This means that the question-mark can only occuras an outermost operator. Hence, compound interrogatives do not occur in the lan-guage under consideration.29
The interpretation of the indicative part of the language is classical, i.e. exten-sional and bivalent. With respect to a model (valuation function), each indicative eitherdenotes the value true or the value false. And the connectives receive their usual truth-functional interpretation.
What remains to be decided is how to interpret the interrogatives in the language.Of course, we might let the conceptual framework outlined above guide us here. Andin the end the analysis we will come up with does conform to that. However, in thepresent context it is illuminating to take another route, and observe that it leads to thesame result.
29 When dealing with yes/no-interrogatives, this is no real limitation. Conjunctions of interrogatives, such as“Does Mary come? And does Peter?”, and interrogatives expressing alternative questions, such as “DoesMary come or Peter?” cannot be answered appropriately by a simple “yes” or “no”. And although aconditional interrogative such as “If Mary comes, does Peter come, too?” can sometimes be so answered,it can also be answered by “Mary doesn’t come”, which shows that such interrogatives, too, are notsimple yes/no-interrogatives.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1087 — #29
Questions 1087
Forgetting about the conceptual analysis outlined above, it seems natural to raisethe following issue in the present case:
Is it possible to provide an adequate interpretation for yes/no-interrogatives byextending the standard bivalent extensional semantics of propositional logic?
We will argue that this question must be answered in the negative, i.e. we will showthat no extensional interpretation of the question-mark operator can be provided thatmeets the criteria of adequacy formulated above.30 More in particular, we will showthat although it is possible to meet the criteria of material adequacy, the criteria offormal adequacy cannot be met. An extensional interpretation gives rise to materiallyadequate notions of answerhood, entailment and equivalence. The notion of equiva-lence accounts for the fact that two interrogatives are equivalent iff they have the sameanswers, but it is not the standard notion under which two expressions are equivalentiff they have the same semantic value.
The argument as such could be stated in a few paragraphs. However, preciselybecause the extensional analysis is materially fully adequate, we will work it out insome detail. The logical and semantical facts we will discuss with respect to the for-mally inadequate extensional semantics, will simply go through after the formal defi-ciencies have been repaired.
25.4.4.1 Yes/no-Semantics
For the indicative part of the language the standard semantics specifies the truth valueof an indicative ! in a model w as a function of its component parts, in such a waythat either [!]w = 1 or [!]w = 0. Given that interrogatives are built from indicatives,obtaining an extensional interpretation for the question-mark operator means that wehave to specify the value of an interrogative ?! in a model w in such a way that thefollowing extensionality principle holds:
[!]w = ["]w =! [?!]w = [?"]w.
Since there are just two possible values for the indicatives, this means that there canbe at most two values for the interrogatives. Obviously, opting for a single semanticvalue has absurd consequences: all interrogatives would be assigned the same mean-ing. Hence, we must conclude that within a bivalent extensional semantics there areexactly two possible semantic values for yes/no-interrogatives, which, moreover, areone-to-one related to the two truth values.
We cannot identify the semantic values for interrogatives with the truth values,since then there would be no semantic difference between an indicative ! and thecorresponding yes/no-interrogative ?!. That would bring us back to a position wehave already rejected, viz., that the difference between interrogatives and indicativesis not a difference in semantic content, but resides elsewhere.
30 Although we present the argumentation against an extensional interpretation with respect to a bivalent(total) interpretation, this is not essential. A similar argumentation can be given against a three-valued(partial) extensional interpretation.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1088 — #30
1088 Handbook of Logic and Language
Hence, ?! should be assigned one value in case ! is true, and another other value,in case ! is false. Let us call these values yes and no respectively.
Definition 25.4.1. (Extensional interpretation).
[?!]w = yes if [!]w = 1
= no if [!]w = 0.
As long as one remembers that yes and no are not the linguistic expressions “yes”and “no” – which do not have counterparts in this logical language, anyway – butarbitrary semantic objects, it will do no harm to refer to them as answer values.31 Theuse of this terminology highlights that the meanings of interrogatives and indicativesare different: indicatives are related to truth, interrogatives to answers. At the sametime it enables us to verbalize the semantic content of both categories of sentencesin a uniform way: just as the meaning of an indicative lies in its truth conditions, themeaning of an interrogative is given by its answerhood conditions.32
25.4.4.2 Answerhood
One of the criteria of adequacy we encountered above is that the semantics give riseto an appropriate relation of answerhood between indicatives and interrogatives. Wedefine the following notion:
Definition 25.4.2. (Answerhood). ! is an answer to ?" iff "w, w# : [!]w = [!]w# =1 ! [?"]w = [?"]w# .
According to this definition, ! is an answer to ?" iff in all models in which ! istrue, the answer value of ?" is the same, i.e. the question ?" is settled in the set ofmodels in which ! is true. For trivial reasons, the contradiction is an answer to anyquestion. However, as one would expect, it can never give a true answer to a question.
Although our basic argument in this section is that an extensional interpretationdoes not provide us with an adequate semantic analysis of yes/no-interrogatives, thefollowing fact shows that the notion of answerhood that it gives rise to is materiallyadequate:
Fact 25.4.1. ! is an answer to ?" iff ! |= " or ! |= ¬".
This fact shows that both ! and ¬! are possible answers to ?!.
31 One way of interpreting these two values – without introducing new elements in the ontology – is as one-place truth functions: yes as the identity function, and no as the truth function corresponding to negation.In some systems of erotetic logic, yes/no-interrogatives are interpreted along these lines.
32 Note that – whatever is wrong with it – it does not make sense to object that the yes/no-semantics is a“reductive analysis of questions in terms of answers”. The mere fact that we refer to the semantic valuesof interrogatives as “answers” is irrelevant. If that would constitute a reduction of questions to answers,then a truth conditional semantics for indicatives would be a reduction of propositions to truth values.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1089 — #31
Questions 1089
Note that the syntax of the language guarantees that if an interrogative ?! is is awell-formed expression, then so are ! and ¬!. In other words, the possible completeanswers to any yes/no-interrogative are expressible.
25.4.4.3 Formal Inadequacy
The expressibility of possible answers gives us the means to test the adequacy of theanalysis by checking whether the following holds:33
Requirement 25.4.1. ?! and ?" are logically equivalent iff ?! and ?" have the sameanswers.
From Fact 25.4.1, we can immediately see:
Fact 25.4.2. ?! and ?¬! have the same answers.
Hence, if our semantics is to be adequate it should support the fact that ?! and?¬! are logically equivalent. Under the standard notion of equivalence this requiresthat "w : [?!]w = [?¬!]w. But quite the opposite holds for an extensional yes/no-semantics: in each model ?! and ?¬! have a different value, if the answer value ofthe one is yes, the answer value of the other is no.
This shows that an extensional semantics for yes/no-interrogatives, although itmeets the criterion of material adequacy, viz., that it give rise to an appropriate notionof answerhood, is inadequate. It fails to meet the formal criterion that within a deno-tational semantics, logical equivalence amounts to identity of semantic value in eachmodel.
25.4.4.4 Non-Standard Equivalence and Entailment
In the present set-up there are two answer values, and the interrogatives ?! and ?¬!
have a different value in each model. What then do they have in common? Their valuepattern over the set of models is the same. And in fact, this characterizes when twoyes/no-interrogatives have the same possible answers:
Fact 25.4.3. ?! and ?" have the same answers iff "w, w# : [?!]w = [?!]w# $[?"]w = [?"]w# .
This observation immediately supplies us with a materially adequate criterion ofidentity of semantic content of two interrogatives:
Definition 25.4.3. (Non-standard equivalence). ?! is logically equivalent with ?"iff "w, w# : [?!]w = [?!]w# $ [?"]w = [?"]w# .
33 Recall from our discussion of the adequacy criteria that if some answers are not expressible, having thesame answers is not sufficient for being equivalent.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1090 — #32
1090 Handbook of Logic and Language
The notion of equivalence suggests the following non-standard notion ofentailment:
Definition 25.4.4. (Non-standard entailment). ?! entails ?" iff "w, w# : [?!]w =[?!]w# ! [?"]w = [?"]w# .
This notion meets the standards that equivalence amounts to mutual entailment,and it supports the following fact, which shows its material adequacy:
Fact 25.4.4. ?! entails ?" iff every answer to ?! is an answer to ?" .
The relations of equivalence and entailment are characterized by the followingfacts:
Fact 25.4.5.
(i) ?! entails ?" iff ! % " , or ! % ¬" or " is non-contingent.(ii) ?! is logically equivalent with ?" iff ! % " or ! % ¬".
So, the only “interesting” pair of equivalent interrogatives are ?! and ?¬!.Entailment between yes/no-interrogatives differs minimally from equivalence and
is also rather “poor”. We have already seen that ?! and ?¬! are equivalent, so, obvi-ously, they also entail each other. The only other entailment relation that is of interestis that any interrogative entails both ?(! & ¬!) and ?(! ' ¬!). Both have the entirespace of possibilities as the only block in the partition they make. And we might callboth interrogatives tautological. Any question includes the tautological question.
Entailment between interrogatives does not mirror entailment between the corres-ponding indicatives. For example, although ! ' " entails !, not every answer to?(! ' ") is an answer to ?!. For, although ¬(! ' ") is an answer to ! ' " , it isnot an answer to !. Of course, ! ' " is an answer to both.
The poverty of the entailment relation between yes/no-interrogatives reflects thatthey are the atoms in the question-hierarchy induced by the entailment relation. Sincethere are no complex interrogatives in the language, this was to be expected.
25.4.4.5 An Intensional Semantics for Yes/no-Interrogatives
All seems well with the extensional semantics for yes/no-interrogatives, except forone flaw, viz., that equivalence cannot be defined in terms of having the same semanticvalue and that entailment cannot be defined in terms of inclusion of semantic values.
Note that the identity criterion as formulated in the definition of non-standardequivalence, can also be written as follows:
"w :!w# | [!]w# = [!]w
"=
!w# | ["]w# = ["]w
".
This means that if {w# | [!]w# = [!]w}, the set of models where ! has the same truthvalue as in w, can be taken to be the semantic value of ?! in w, and equivalence can

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1091 — #33
Questions 1091
be defined in terms of having the same semantic value in each model, and entailmentas inclusion of semantic values.
However, we cannot proceed in exactly this fashion. One cannot specify the seman-tic value of an expression within a certain model by referring to other models. An easyand standard way to get around this is to introduce the notion of a possible world. Weidentify a world w with what we used to call a model. And a model M is now a set ofpossible worlds. The extension of an indicative ! relative to a model M and a worldw, [!]M,w, is the truth value assigned by w to !. The intension of ! in a model M is theset of worlds in M in which ! is true: [!]M = {w ( M | [!]M,w = 1}. A set of worldsis called a proposition, [!]M is the proposition expressed by ! in M. ! entails " iffin every model M the proposition expressed by ! in M is included in the propositionexpressed by " in M, i.e. ! |= " iff "M : [!]M ) ["]M . The interpretation of theindicative part of the language consists in a recursive specification of the extension ofthe indicatives of the language relative to a model and a world.
Having thus set the stage, and using the observation made above, we are ready tostate the intensional interpretation of interrogatives:
Definition 25.4.5. (Intensional interpretation).
[?!]M,w = {w# ( M | [!]M,w# = [!]M,w}.
The extension of an interrogative in a world w is an intensional object, a proposi-tion. It is the proposition expressed by ! in case ! is true in w, and the proposition exp-ressed by ¬! in case ! is false in w. I.e. the extension of a yes/no-interrogative is theproposition expressed by a complete and precise answer to the question posed by theinterrogative. We can identify the intension of ?! in a model M, the question expressedby ?! in M, with the set of its possible extensions in M: [?!]M = {[?!]M,w | w ( M}.The propositions in the set are mutually exclusive, and exhaust the logical space con-sisting of all possible worlds in M. In other words, we have arrived at Hamblin’spicture of the notion of a question as a partition of logical space: a bipartition in thecase of (non-tautological) yes/no-interrogatives.
This analysis is both materially and formally adequate, as the following observa-tions show. Entailment and logical equivalence between interrogatives, can be definedin the standard way:
Definition 25.4.6. (Entailment and equivalence).
(i) ?! |=?" iff "M, "w ( M : [?!]M,w ) [?"]M.w.
(ii) ?! %?" iff "M, "w ( M : [?!]M,w = [?"]M,w.
Two interrogatives are equivalent iff they always partition the logical space in thesame way. An interrogative ?! entails an interrogative ?" iff every block in the parti-tion made by ?! is always included in a block of the partition made by ?" . It cannothold of two different bipartitions of the same logical space that every block in the oneis part of some block in the other. Hence, only equivalent contingent interrogatives

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1092 — #34
1092 Handbook of Logic and Language
entail each other. And any interrogative entails the tautological interrogative, whichcorresponds to a partition which always has only one element, a single block consist-ing of the logical space as a whole.
The relation of answerhood between indicatives and interrogatives is defined asfollows:
Definition 25.4.7. (Answerhood). ! |=?" iff "M*w ( M : [!]M ) [?"]M,w.
In terms of the partition ?" makes on M, this expresses that ! is an answer to ?"iff the proposition expressed by ! in M is always a (possibly empty) part of one of theblocks in the partition made by ?" .
The facts observed above in working out the extensional interpretation, concerningthe relations between answerhood, entailment and equivalence remain in force, andwill not be repeated. This illustrates once more that what we gain in the intensionalapproach is not material, but only formal adequacy. However, at the same time wehope that it also shows that formal adequacy enhances conceptual clarity.
25.4.4.6 Remark on Coordination
An additional criterion of adequacy that can be imposed on a semantic analysis ofinterrogatives is that it can deal with coordination of interrogatives. Material ade-quacy requires that answerhood and entailment relations are appropriately accountedfor. Formal adequacy requires that conjunction and disjunction of interrogatives areanalyzed in the standard way in terms of intersection and union.34
How does the semantics presented above fare if we add coordinated interrogativesto the language? Conjunction of interrogatives (“Will John be there? And will Mary bethere?”) can be interpreted in a standard way: the pairwise intersection of the blocks intwo partitions results in another partition. By simply conjoining the possible answersto two interrogatives, we obtain the propositions that answer their conjunction. Theextension of a conjunction of two interrogatives can be defined standardly in termsof the intersection of the extensions of the conjuncts. The notions of entailment andanswerhood as they were defined above give the appropriate results. For example, aconjunction of two interrogatives will entail each of its conjuncts. And an indicativeis an answer to a conjunction of two interrogatives iff it is an answer to each of itsconjuncts.
Disjunction of interrogatives (“Will John be there? Or Mary?”) however, is anothermatter. To see why, it suffices to observe that taking the pairwise union of the blocksin two partitions, will usually not result in a new partition. We cannot identify theextension of the disjunction of two interrogatives with the union of the extensionsof its disjuncts. It would make the wrong predictions with respect to entailment andanswerhood relations.
34 See Groenendijk and Stokhof (1984a,b) for a more detailed discussion.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1093 — #35
Questions 1093
This corresponds to the fact observed above that disjunctions of interrogatives arepeculiar: they violate the Unique Answer Assumption, and it has been argued35 that adisjunction of interrogatives, unlike a conjunction, does not express a single question.More on this below.
25.4.4.7 Remark on Natural Language
In natural language, “negative” yes/no-interrogatives do not behave precisely the sameas the interrogatives of the form ?¬! in our logical language. Compare the followingsequence: “Is John at home? Yes (he is)./No (he isn’t)”, with: “Is John not at home?Yes, (of course) he IS./No (he isn’t)”. Whereas whenever ?! has a “positive” value?¬! has a “negative” value, the English interrogatives in both sequences receive thesame negative answer, and the same positive answer, except for the fact that as a replyto the negative interrogative, a positive answer is marked.
The pair of logical interrogatives and the pair of English interrogatives do have incommon that they express the same question. However, by using the negative inter-rogative in the second sequence the questioner also expresses that she is afraid to get anegative answer to the question whether John is at home. That explains why a positiveanswer is marked by emphatic elements.
So, the negative linguistic element in the second sequence does not play its usuallogical role of negation, but rather has a pragmatic function. One could bring forwardthat it is precisely the fact that from a logical semantic point of view ?! and ?¬!
express the same question, that creates the possibility for this process of pragmaticrecycling of the element of negation.
25.4.5 The Predicate Logical Case
In the previous section we only considered interrogatives which can be answered bya simple “yes” or “no”. Another basic type of interrogatives are constituent interroga-tives such as “Which students passed the test?”, which is typically answered by listingthe students that actually passed the test. One can look upon such interrogatives asasking for a characterization of the actual denotation of a particular property in caseof one-constituent interrogatives, and of a relation in the case of multiple constituentinterrogatives such as “Who plays with whom?”.
Besides the possibility that constituent interrogatives ask for an exhaustive charac-terization of a property or relation, there is also the option that they ask to mention justone or some other number of instance(s). Here, we will only consider the mention-allinterpretation, but we will return to the mention-some interpretation later on.
Properties and relations (between ordinary first order objects) is what predicatelogic is all about, and it makes sense to consider the possibility of extending the lan-guage of predicate logic with interrogatives which inquire after which objects havecertain properties and stand in certain relations.
35 See, e.g., Belnap (1982), Groenendijk and Stokhof (1984a).

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1094 — #36
1094 Handbook of Logic and Language
To be able to formulate such interrogatives, it suffices to add the following rule tothe syntax of predicate logic:36
Definition 25.4.8. (Syntax). Let ! be a formula in which all and only the variablesx1, . . . , xn (n + 0) have one or more free occurrences, then ?x1 · · · xn! is an interrog-ative formula.
As was the case in the propositional language, and for similar reasons, weleave complex interrogatives, including quantification into interrogatives, out ofconsideration.37
Since the rule allows for zero variables to be “queried over”, yes/no-interrogativesare just a special case. Thus we obtain interrogatives such as ?*x(Px ' Qx), askingwhether or not there is some object that has both the property P and the property Q.As in the case of propositional logic, there are only two possibilities to be discerned.
With the aid of the same rule, we can also form interrogatives such as ?x(Px ' Qx),which is be interpreted as asking for a characterization of the extension of the complexproperty of being both P and Q, i.e. as asking for a complete specification of thoseobjects which have both properties. In this case the number of possibilities equals thatof the number of sets of objects that can be the value of the conjunctive predicate.
Notice that whenever the question posed by ?x(Px ' Qx) is answered, the questionput by ?*x(Px ' Qx) is answered, too. That there are no objects that have both prop-erties is one possible answer to the first question, which at the same time provides anegative answer to the second question. Any other possible answer to the first ques-tion, specifying some non-empty set of objects as having both properties, would atthe same time imply a positive answer to the yes/no-question.38 This means that anadequate semantics should account for the fact that ?x(Px ' Qx) entails ?*x(Px ' Qx).
Notice furthermore that an indicative like (Pa ' Qa) ' (Pb ' Qb) does not countas a (complete) possible answer to ?x(Px ' Qx). The proposition expressed by that
36 For ease of presentation, we don’t allow for vacuously “querying over” a variable, and neither do weallow that interrogative formulae contain occurrences of free variables. Notice also that variables arequeried over in one fell swoop, rather than one by one. The latter construction would require a syntacticrule which turns interrogatives into interrogatives. Going about the way we do here, is not a matter ofprinciple, but of convenience.
37 This means that, as compared to natural language, the language under consideration has limited meansof expressing questions, even with respect to the particular domain it is suited for. Not only coordinationof interrogatives occurs in natural language, but an interrogative sentence like “Which student did eachprofessor recommend?” has an interpretation where it asks to specify for each professor which student(s)he recommended. This reading, under which the sentence can be paraphrased as “Which professorrecommended which student?”, seems to correspond to universal quantification into an interrogative.(But see the discussion of such cases below, Section 25.6.4.2.) In another sense, however, it is guaranteedthat any question concerning (simple and complex) relations between objects that can be formulated inthe indicative part of the logical language is expressible. The paraphrase we gave of the example thatseems to involve quantification into interrogatives is a case in point.
38 So, interrogatives of the form ?x! are not interpreted as having an existential presupposition. That noobjects exist that satisfy ! is taken to be one possible answer among the others.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1095 — #37
Questions 1095
sentence only informs us that at least the objects denoted by a and by b have bothproperties, and thereby still leaves open many different possibilities for the extensionof the conjunction of both properties. A question like “Which students passed thetest?” can typically be answered by “Alfred and Bill (passed the test)”, but such ananswer equally typically conveys the information that only the students Alfred and Billpassed the test. Hence, a better candidate for a complete answer is "x((Px ' Qx) ,(x = a&x = b)), which specifies the extension of the conjunction of the two propertiesto consist only of the objects denoted by a and b. However, this will still only informus about which objects have both properties to the extent that we already know whichobjects are denoted by a and b.
The question which object is denoted by a particular constant is posed by an inter-rogative like ?x(x = a). It asks the question who a is.39 Again, an indicative like*x("y(Py , x = y)' x = a), “a is the object which has property P”, will only informus about the identity of a to the extent that we are informed about which is the uniqueobject that has the property P.
As a final example consider the interrogative ?xyRxy. It asks for a specification ofthe extension of the relation R, i.e. it is answered by a specification of a set of pairs ofobjects which stand in the relation R. Obviously, whenever ?xyRxy is answered, ?yxRxyis answered also, and vice versa. Knowing who loves whom and knowing whom isloved by whom amount to the same thing. This means that an adequate semanticsshould account for the logical equivalence of these two interrogatives.
25.4.5.1 Intensional Interpretation
If only because yes/no-interrogatives are part of the language under consideration, theargument against an extensional interpretation of interrogatives given above remainsin force. As in the propositional case, it also holds for the predicate logical languagethat we can provide an extensional interpretation, and define notions of answerhood,entailment and equivalence which do give appropriate results, but only fail to meetthe formal criterion that equivalence be defined in terms of identity, and entailment interms of inclusion of semantic values. We will not pursue this line, but immediatelypresent the formally adequate intensional interpretation.
As before, a model M will be identified with a set of worlds, but now, a world w isidentified with an ordinary first order model, consisting of a domain and an interpre-tation function, assigning values to the non-logical constants of the language, relativeto the domain.40 For the indicative part of the language, the extension [!]M,w,g of aformula ! with respect to a model M, a world w, and an assignment g is defined in theusual way.
39 This is one of the meanings that natural language interrogatives of the form “Who is A?” may have. See,e.g., Hintikka and Hintikka (1989), Boër and Lycan (1985) for discussion.
40 One can look upon these models as possible information states of an agent. Each possible world in amodel is a way the world could be according to the information of the agent.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1096 — #38
1096 Handbook of Logic and Language
Interrogatives are interpreted as asking for a specification of the actual extensionof a particular relation. Relative to a world and an assignment, the extension of therelation an interrogative ?x1 · · · xn! asks to specify, is defined as follows:41
Definition 25.4.9. (Relational interpretation).
-?x1 · · · xn!.M,w,g = {-g#(x1), . . . , g#(xn). | [!]M,w,g# = 1,
where g#(x) = g(x), for all x /= x1 · · · xn}.
Note that in case n = 0, which is the case of yes/no-interrogatives; -?!.M,w,g =[!]M,w,g. Hence, the intensional interpretation of yes/no-interrogatives as given abovenow amounts to
[?!]M,w,g =!w# ( M | [!]M,w#,g = [!]M,w,g
".
The same schema gives appropriate results also for n > 0, collecting all the worldsin the model where the extension of the relation the interrogative asks to specify isthe same as in the actual world w. Hence, using ?! as a meta-variable ranging overall the interrogatives of the predicate logical language, the intensional interpretation isgiven by:
Definition 25.4.10. (Intensional interpretation).
[?!]M,w,g = {w# ( M | -?!.M,w#,g = -?!.M,w,g}.
For example, the extension of ?xPx in a world w will be the set of all worlds inwhich the same objects belong to the extension of the predicate P. This set of worldscorresponds to the proposition which exhaustively characterizes the positive extensionof the property P in world w. The intension [?xPx]M of ?xPx is then identified by theset of mutually exclusive propositions, each of which characterizes a possible exten-sion of the predicate P relative to the model M. Their union exhausts the logical space,the set of all worlds in the model. Hence, the question expressed by ?xPx fits the Ham-blin picture: it is a partition of logical space. There are as many blocks in the partitionas there are possible extensions of the predicate P within in the model.
In general, the partition induced by an interrogative ?x1 · · · xn! will consist of asmany blocks as there are possible extensions of the underlying n-place relation. Andeach block corresponds to a proposition which characterizes a possible extension ofthat relation.
41 This relational interpretation can be taken as the extensional interpretation of interrogatives in a predicatelogical language. If we do so, and use analogs of the definitions of answerhood, entailment, and equiv-alence as they were defined with respect to the extensional interpretation of the propositional language,then we arrive at a materially adequate analysis, which only fails to meet the formal criteria concerningthe notions of entailment and equivalence.

“29-ch25-1059-1132-9780444537263” — 2010/11/30 — 0:04 — page 1097 — #39
Questions 1097
not-
Figure 25.1 Partition made by ?!.
everybody Px
a1 and a2 are the ones that Px
a2 is the one that Px
a1 is the one that Px
nobody Px
Figure 25.2 Partition made by ?xPx.
Partitions can be visualized in diagrams. Figure 25.1 illustrates the bipartition madeby a yes/no-interrogative; Figure 25.2 is an example of a partition made by a one-constituent interrogative.
25.4.5.2 Entailment and Equivalence
The definition of entailment can remain “literally” the same as in the propositionalcase, but we formulate it in a more general way:
Definition 25.4.11. (Entailment).
(i) ?!1, . . . , ?!n |=M?" iff !w " M : [?!1]M,w # · · · # [?!n]M,w $ [?"]M,w.(ii) ?!1, . . . , ?!n |=?" iff !M : ?!1, . . . , ?!n |=M?".
The interrogatives ?!1 · · ·?!n entail the interrogative ?" in a model M iff anyproposition which completely answers all of ?!1 · · ·?!n in M, also completely answers?" in M. Logical entailment amounts to entailment in all models. Equivalence can bedefined as mutual entailment between two interrogatives.
Consider the following facts, which are related to observations made above:
Fact 25.4.6.
(i) ?xPx |=?%xPx.(ii) ?xPx |=M?Pa, if |=M?x(x = a).
(iii) ?xPx, ?x(x = a) |=?Pa.(iv) ?xPx |=M?x¬Px, if |=M?x(x = x).

“29-ch25-1059-1132-9780444537263” — 2010/11/30 — 0:04 — page 1098 — #40
1098 Handbook of Logic and Language
(v) ?xPx, ?x(x = x) |=?x¬Px.(vi) ?xyRxy !?yxRxy.
As is indicated by (i), in any model, a complete answer to the question who willbe at the party cannot fail to provide a (positive or negative) answer to the questionwhether there will be someone at the party. As (ii) indicates, however, it does nothold quite generally that any complete answer to the question who will be at the partyalways provides an answer to the question whether Alfred will be at the party, too.The entailment only obtains when we restrict ourselves to a proper subset of the setof all possible models, those models in which the question who Alfred is, is alreadysettled. Knowing who will be at the party does not imply knowing whether Alfred willbe there, unless we know the answer to the question who Alfred is. Another way ofsaying this, as (iii) indicates, is that whenever both the question who will be at theparty and the question who Alfred is are answered, the question whether Alfred willbe at the party is answered, too.
Similarly, as (iv) and (v) tell us, knowing who will be at the party is not the sameas knowing who will not be there, unless we know which particular set of objects weare talking about. The latter question, of what there is, is expressed by ?x(x = x).Note that whereas ?"x(x = x) expresses a tautological question (i.e. |=?"x(x = x)),?x(x = x) does not. It only does so if we restrict ourselves to models which consist ofworlds with the same domain.
On the relational interpretation of interrogatives, the standard notion of entailmentin terms of (set) inclusion would not enable us to account for these entailments andequivalences. In general, entailments and equivalences between interrogatives whichask for the specification of relations with different numbers of arguments can not beaccounted for. The (restricted) entailment between ?xPx and ?Pa is a case in point.And even with respect to two relations with the same number of arguments, onewould arrive at the wrong results. We know this already from the case of yes/no-interrogatives, but the equivalence of ?xyRxy and ?yxRxy, stated in (vi), is equallytelling. And yet another case is the equivalence of ?xPx and ?x¬Px, restricted to amodel in which the worlds have the same domain. Finally, for a case like ?x(Px # Qx)and ?xPx we would predict wrongly that the first entails the second.
25.4.5.3 Answerhood
Answerhood is defined in essentially the same way as in the propositional case, exceptthat we explicitly define a notion of answerhood restricted to a particular model, andin terms of that the more general notion of “logical” answerhood:42
42 If we view a model as an information state, then ! |=M?" can be read as: in the information state M$
which results from updating M with !, the question ?" is settled. A logical answer is such that it answersthe question with respect to any information state. Similar remarks can be made about entailment andequivalence.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1099 — #41
Questions 1099
Definition 25.4.12. (Answerhood).
(i) ! |=M?" iff *w ( M : [!]M ) [?"]M,w.(ii) ! |=?" iff "M : ! |=M?".
Consider the following facts, related to the examples discussed above:
Fact 25.4.7.
(i) ¬*xPx |=?xPx.(ii) "xPx |=M?xPx, if |=M?x(x = x).
(iii) "x(Px , x = a) |=M?xPx, if |=M?x(x = a).
(iv) "x(Px , Qx) |=M?xPx, if |=M?xQx.(v) "x(Px , x = a) |=M?x(x = a), if |=M?xPx.
These facts indicate that, unlike yes/no-interrogatives, constituent interrogatives donot always have expressible answers. We need expressions (or non-linguistic means)that identify (sets of) objects in order to be able to “really” specify the extensions ofproperties and relations. For example, the fact that "x(Px , x = a), “only a has theproperty P”, is a complete answer to ?xPx in a model in which the question ?x(x = a)
is already settled, reflects that it provides us with a nominal answer, and not with areal answer, unless we know already who a is.43
But observe that, even in case one has no idea who a is, the answer "x(Px , x = a)
does provide information which is relevant to the question posed by ?xPx. It tells usthat there is an object which has the property P, that there is only one such object, andthat it bears the name a. Thus, it excludes many possible answers, and it creates a newlink between the questions posed by ?xPx and ?x(x = a): if the one gets answered, theother is answered also. Similarly, it can be observed that in case "xPx or "x(Px , Qx)does not provide a complete answer to ?xPx, it may still provide a useful partial answerby excluding many possibilities.
25.4.5.4 Comparing Answers
Instead of defining a notion of partial answerhood as such, in terms of exclud-ing certain possibilities, we concentrate on a notion which compares indicatives asto how completely and precisely they answer a certain question. First we definean auxiliary comparative notion of informativeness, which leaves precision out ofconsideration.
43 The distinction between real and nominal answers goes back to (at least) Belnap and Steel (1976), whereone can also find the observation that in many situations a nominal answer is all that is called for. Notethat being provided with a real answer to the question expressed by an interrogative like ?xPx does notrequire that names for the objects in question be available, or that we be able to draw up a (finite) “list”of such objects. A characterization in terms of a simple or complex predicate can provide a real answeras long as it rigidly specifies a certain set of objects.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1100 — #42
1100 Handbook of Logic and Language
Definition 25.4.13. (Informativeness).
(i) ! gives a partial true answer to ?" in w in M iff [!]M 0 [?"]M,w /= 1.(ii) ! is a more informative answer to ?" in M than !# iff "w ( M : if ! gives a partial true
answer to ?" in M in w, then !# does, too.
The auxiliary notion of giving a partial true answer is a very weak one: ! gives apartial true answer in w in M iff ! overlaps with the block in the partition in whichw is situated. In particular, it is not required that ! itself be true in w, only that itbe compatible with the actual true answer. Neither is it required that ! exclude anypossible answers. Thus, even the tautology counts as a partial true answer.
Notice that the comparative notion of being a more informative answer does favorindicatives which exclude more possible answers. The contradiction then turns out tobe the most informative answer to any question. Disregarding that, the most informa-tive answers to ?" are complete answers, i.e. those ! such that ! |=?" . If ! and !#
imply the same possible answer to ?" , they count as equally informative relative tothe question. In terms of the absolute notion of informativeness, i.e. entailment, theone may be more informative than the other, or the one may imply the negation of theother, or they may be uncomparable. If ! and !# imply different possible answers to?" , they are unrelated with respect to their informativeness relative to ?" .
Partial true answerhood and relative informativeness are put to use in the followingdefinition, which also takes the precision of answers into consideration (the obviousrelativization to a model M and a world w is omitted).
Definition 25.4.14. (Comparing answers). Let ! and !# give a true partial answerto ?" . Then ! is a better answer to ?" than !# iff
(i) ! is a more informative answer to ?" than !#; or(ii) ! and !# are equally informative answers to ?" and ! is properly entailed by !#.
According to the first clause, among the true partial answers the more informativeones, which exclude more possible answers, are preferred. The second clause favorsweaker answers among equally informative ones. The sum effect is that the answer thatequals that block in the partition which contains the actual world is the most preferredone. Next are those answers which are inside that block, but do not fill it completely.This means that such answers contain additional information that the interrogativedoes not ask for. This lack of precision is not as harmless as it may seem. An answerwhich gives a complete (or partial) true answer need not express a true propositionitself. The precise true and complete answer which fills the whole block is guaranteedto do so. Stronger, and hence over-informative answers, can express false propositionsthemselves. I.e. although with respect to the question posed by the interrogative theyprovide correct information, at the same time they may provide incorrect informationwith respect to some other question. This is precisely why the comparison of answersfavors weaker propositions among the ones that give the same answer.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1101 — #43
Questions 1101
Of course, the available information may simply not support such a completeanswer, in which case a partial answer is all that can be offered. The effect of the com-parison is that among the answers supported by the information, those are selected thatare incompatible with all possible answers incompatible with the information. Thereagain, even though the available information may support stronger propositions, thecomparison prefers the unique partial answer that completely fills the union of theblocks corresponding to the possible answers compatible with the information. Again,there is a good reason for this. The information as a whole may be incorrect at somepoints. But still, it may support a true partial (or complete) answer to some questions.Providing more information than an interrogative asks for, means answering otherquestions at the same time. But the answer given to those might very well be false.The comparison cautiously tries to prevent this.
Besides partiality of information there is another reason why proper complete (orpartial) answers may not be available: it might be that they are not expressible in thelanguage. (Or not expressible relative to the information. In discussing the notion ofanswerhood, we have seen that in the predicate logical case this can easily occur.) Inthese cases, too, we have to make do with partial or over-informative answers whichare expressible, among which a choice needs to be made. In particular, to be able toprovide proper answers, expressions are needed that (with respect to the informationavailable to the questioner) rigidly identify (sets of) objects. If such expressions arelacking, a comparison among the available answers is called for. Hence, such a com-parison is a necessary ingredient of any theory of questions and answers.44
25.4.5.5 Remark on Natural Language
It should be noted that, unlike in natural language, in this predicate logical systemquerying over variables is unrestricted. In natural language, however, this is almostnever the case. A wh-phrase is usually of the form which cn, and even for those phraseswhich lack an overt cn, such as who, what, it can be argued that they are in factrestricted.
Taking our lead from quantification in standard predicate logic, we might thinkthat restricted querying can be expressed by means of conjunction: “Which P are Q?”would be turned into ?x(Px ' Qx). In most cases this representation is adequate, butthere is a snag here. Consider the following pair of sentences:45 “Which men arebachelors?”, “Which bachelors are bachelors?”. Clearly, the first sentence poses a non-trivial question, which is adequately represented by ?x(Mx'Bx). The second sentenceis trivial: it asks the tautological question. However, its representation, ?x(Bx ' Bx), isequivalent to ?xBx, which is not trivial at all: it asks who the bachelors are. Clearly, areal extension of the syntax of the representation language is called for, if we are to beable to deal with these cases.
44 See Groenendijk and Stokhof (1984a) for some more discussion of this issue.45 The example is due to Stanley Peters.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1102 — #44
1102 Handbook of Logic and Language
Up to this point we have been concerned mainly with developing an argumentthat purports to show that a semantic analysis of interrogatives is a viable subject.The outlines of one particular approach, based on the three Hamblin postulates, havebeen sketched, using two simple formal languages as pedagogical devices. But otherapproaches have been developed in the literature. In the remainder of this chapterwe will discuss them under two headings: logical and computational theories, andlinguistic theories.
25.5 Logical and Computational Theories
Although related, logical and computational theories are discussed separately, since,as we shall see, their focus is somewhat different.
25.5.1 Logical Theories
Historically,46 the study of interrogatives started out on logical premises. This is notsurprising: the enterprise of a systematic formal semantics for natural language is offairly recent date, and with the development of modern formal logic at the beginningof the twentieth century, it was only natural that some would want to try to extendits scope to include non-indicative expressions, among which interrogatives occupy aprominent position. Not that it was a subject which instantly drew massive attention.Except for a few isolated attempts, it was only in the fifties47 that regular logicaltheorizing about interrogatives started to come off the ground, with the work of Priorand Prior (1955). Of particular importance has been the work of Hamblin, Harrah,Åqvist, Hintikka, and Belnap.48
Although often inspired by observations concerning natural language, logical the-ories were occupied with different concerns. The main objective of the work done inthis tradition is to provide a set of formal tools, adequate for a formalization and sub-sequent analysis of the concepts of question and answer, and the relationships betweenthem. Quite often, the analysis is set against the background of possible applications,in the sphere of question-answering, or information retrieval. Thus from the outset theconcept of a “data-base” plays a role: a typical picture is that of a questioner formulat-ing a query, and a questionee “looking up” the answer in a data-base and formulatingit in an adequate response, which effectively answers the questioner’s query.49 It is
46 See Egli and Schleichert (1976) for an extensive bibliography which runs up to 1975.47 Which also saw the rise of the computer, electronic data storage, etc. As will become clear, this was one
important reason for the new interest in a logic of questions.48 Later work of the latter two authors witnessed an increasing interest in natural language structures. This
change of focus occurred in the Seventies, when formal approaches to natural language semantics, suchas Montague grammar, started to develop. It was in that framework that the first attempts at giving asystematic semantics of natural language interrogatives were made, first by Hamblin (1973), followed byKarttunen (1977), and later by Belnap (1982), and others.
49 See Harrah (1984, p. 725) where this perspective is introduced and discussed explicitly.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1103 — #45
Questions 1103
remarkable to note that many issues that form the core of important current develop-ments in semantics and cognitive science, such as the dynamics of meaning, updateand revision of belief, are already present in these early analyses, albeit not in the formin which they shape the debate today.
This picture sets the agenda of much of the logical research. It is concerned withexpressibility and effectivity, i.e. with the development of a formal language in whichvarious types of queries and the different kinds of answers they call for, can be exp-ressed and communicated in an effective way. The starting point in most cases issome familiar first order language, to which interrogative expressions are added andin which answers can be expressed. This language is then provided with a seman-tics, thus providing formal counterparts of the pre-theoretic notions to be analyzed.Remarkably, proof theoretic aspects are by and large ignored.50
Most logical approaches start from assumptions quite similar, and sometimes iden-tical, to the Hamblin postulates which were taken as a starting point above (see Sec-tion 25.4.1).51 Thus, questions are closely associated with answers. But in someapproaches the link is not that tight. This holds especially for the analyses in theepistemic-imperative paradigm, such as those of Hintikka and Åqvist, which, as wasobserved earlier (see Section 25.3), are more in the line of the pragmatic approach.Here, one might say, questions are tied to the (desired) effect: they describe the epis-temic situation that results after the questioner has seen updated with the answer. Thisis quite clear from the logical structure that is assigned to questions: e.g., “Does Johncome to the party” is analyzed as “Bring it about that I know whether John comes tothe party”, which can be further reduced to “Bring it about that either I know that Johncomes to the party or that I know that John does not come to the party”.52
50 Thus Belnap and Steel (1976, p. 1):
What is the logic of questions and answers? [. . .] Absolutely the wrong thing is to thinkit is a logic in the sense of a deductive system, since one would thus be driven to the pointlesstask of inventing an inferential scheme in which questions, or interrogatives, could serve aspremises and conclusions. This is to say that what one wants erotetic logic to imitate of therest of logic is not its proof theory but rather its other two grand parts, grammar (syntax)and semantics.
This is remarkable since, as was stressed above, entailment relations between interrogatives do exist,and need to be accounted for in an adequate semantics. This being the case, there seems to be no reasonto exclude a priori the possibility of a (partial) syntactic characterization of both entailment betweeninterrogatives, and the answerhood relation.Also, it should be noted that many logical analyses are involved in syntactic issues, in this sense that thedesign of an adequate language, and the definition of various logical forms, is one of their main concerns.
51 According to Belnap and Steel (1976, p. 35):
As for questions, we rely on Hamblin’s dictum (1958): “Knowing what counts as ananswer is equivalent to knowing the question.” On this insight rests the whole of our eroteticlogic.
Cf., also Harrah (1984, p. 719).52 Again, the parallel with the current concern with dynamic interpretation is striking. In effect, Hintikka’s
work on game-theoretical semantics (see, e.g., Hintikka, 1983b, cf., also Chapter 12) is one of the prede-cessors of this development. See also below, Section 25.6.5.2.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1104 — #46
1104 Handbook of Logic and Language
As we remarked, an important issue that arises from the logical point of viewconcerns expressive power: Can all questions be expressed in the language? Canall answers to a question be formulated? These issues sometimes are discussed withrespect to a particular type of data-structure. In that case they are primarily designfeatures. On a more abstract level results such as the following are obtained. Usingthe familiar diagonalization technique, a simple argument shows that if questionsare identified with sets of formulae, being their answers, then, given some plausibleassumptions concerning the number of formulae, there are more questions than can beexpressed in the language.53
Classification, of both questions and answers, is another major concern. How dotypes of questions differ? What kinds of answers does a question allow? And then therelationships between these various (sub)notions have to be characterized. As for theclassification of questions, here logical properties typically take priority over linguis-tic issues. A primary concern is always to isolate those types of questions which canbe formalized, i.e. to characterize “clear” questions which ask for some definite pieceof information, and which have an answer that can be calculated, at least in principle.Again, this may differ with the kind of domain that one has in mind. Thus from a log-ical point of view, such interrogatives as “Who is that man living next door?” stand inneed of further analysis, because it is unclear what particular type of characterizationone is asking for. With regard to answers, the distinction that is most commonly made,is that between complete and precise answers, which provide precisely the informa-tion an interrogative asks for, and partial and over-complete ones. A second distinctionis that between nominal and real answers, where the former provide merely a verbalcharacterization, whereas the latter present a real identification of objects as a reply toa constituent question. Usually, the same distinction is made with respect to questionsas such, explicitly distinguishing (in logical form) between a request for the one orthe other type of answer. As far as the distinction is implemented in the syntax of theformal language, this is another example of a logical distinction which is not linguis-tically motivated: a natural language such as English does not distinguish between thetwo by providing distinct syntactic structures to represent them. From the linguisticpoint of view, it seems more natural to account for the difference either semantically,by assigning two distinct readings, or pragmatically, explaining it in terms of differentgoals and intentions.
Presuppositions of questions also receive a surprising amount of attention inerotetic logic, surprising, because as far as indicatives are concerned, logical analysesof presupposition are mainly inspired by empirical linguistic phenomena, and not bypurely logical considerations. In the analysis of Belnap and Steel (1976) the meaningof an interrogative is more or less identified with its presuppositions, and also in theanalysis developed by Hintikka (1976, 1983a) they are essential ingredients. Roughly
53 See Harrah (1984) for a representative example of such argumentation. Notice that a similar kind ofargument can be given in an intensional setting (in which it applies to propositions conceived of as setsof possible worlds). As for answers, we have seen above that already in the case of a simple predicatelogical system not all answers need be expressible.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1105 — #47
Questions 1105
speaking, the presupposition of a question is the assumption that one of its possibleanswers is true. For questions expressed by alternative interrogatives, such as “Do youwant coffee or do you want tea?”, this amounts to the requirement that the propositionexpressing the exclusive disjunction of the two alternatives is true. And for questionsexpressed by constituent interrogatives of the form “Which A is/are B?” this comesdown to the requirement that there is at least (or precisely) one object among the A’sthat is a B. From an empirical, linguistic point of view, there is indeed much to say fora presuppositional analysis of alternative questions and wh-phrases. But from a purelylogical point of view one would rather expect the reaction that, although pragmati-cally marked, a reply like “None.” (or “There are several.”) is just as good an answeras any other. At least in comparable indicative cases (definite descriptions being acase in point) this is what one gets. In the end, of course, there is a “logical” reasonfor reducing the meaning of an interrogative to its presupposition: the latter are of apropositional nature. In this way standard truth conditional logic and semantics can bemade to apply to interrogatives.54
Another issue that arises has to do with effectiveness: here one is concerned firstof all with the problem whether it is effectively decidable whether, and if so to whatextent, a certain expression is an answer to a certain question. Again, one way to goabout this is to design a “normal form” for answers, which is often derived from thelogical form of the corresponding interrogatives. As regards effectiveness of ques-tions, one may investigate what is the most efficient way to formulate certain queries.A simple example illustrating the latter problem is the following. Suppose we are inte-rested in the question which objects have both the property A and the property B, i.e.which objects form the intersection of the extensions of the two. The queries “WhichA’s are B’s?” and “Which B’s are A’s?” both formulate this question. But the “searchroutines” they invoke are different, and that may be a reason for preferring one overthe other. If A is a predicate with a much larger extension than B, it is, other thingsbeing equal, more efficient to search among the B’s to find the A’s, than the other wayaround.55 Considerations such as these may also lead to the introduction of particu-lar syntactic constructions to be used in formulating queries in the formal language,which do not have obvious counterparts in natural language interrogatives. An exam-ple is provided by the explicit specification of a selection size within the query, whichindicates how many instances one would be satisfied with.56
Although perhaps not a very fashionable subject in current philosophical logic,the logical way of doing things has provided us with a wealth of insights, concepts,
54 But notice that the problems which we noticed with strictly reductionistic approaches above (see Sec-tion 25.3.6), seem to arise in this context, too.
55 There is an interesting connection with generalized quantifier theory here (see Chapter 19). It seems that,in general, knowing which A’s are B’s is not the same as knowing which B’s are A’s. But somethinglike conservativity does hold: knowing which A’s are B’s is the same as knowing which A’s are A’s thatare B’s.
56 In natural language, it seems that the “extremes”, viz., mention-one and mention-all (see below), aretypically formulated in the interrogative form, whereas a selection specification such as “an odd numberbetween 8 and 24” would rather be incorporated in an imperative structure.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1106 — #48
1106 Handbook of Logic and Language
and, most important, with a fruitful perspective: questions and answers set against thebackground of exchange of information concerning some data set. Not all elements ofthis picture have received the same amount of attention in the work that has been donein this tradition. In particular, the dynamic aspects of the perspective that are evidentlythere, have been relatively ignored.
Formal semantic theories of natural language interrogatives were largely inspiredby logical work (cf., above, footnote 48), but witnessed a shift in focus, which, at leastinitially, led to a less encompassing picture: the information exchange perspective byand large dropped from view. But with the advent of a more dynamic perspective oninterpretation this is again beginning to change. Both within formal semantics as wellas in cognitive science this perspective is gaining ground, and it is to be expected thatsome of the logical work will turn out to be quite relevant.
25.5.2 Computational Theories
As was already noticed above, one of the striking features of logical theories of ques-tions and answers is their often quite explicitly practical motivation. Many of theproblems that are dealt with have a distinct “computational” flavor, and return in acomputational setting. Within computer science, research in the area of questions andanswers is closely linked to data base theory and the development of query languages.More indirectly, there is also a link with the theory of declarative programming lan-guages, such as Prolog. A discussion of the growing literature is beyond the scope ofthis chapter. The reader is referred to Kanellakis (1990) for an overview.
The main issues that are dealt with bear a striking resemblance to the topics men-tioned above, although the perspective is somewhat different. The picture is that of acertain amount of data, structured in a database in such a way that it lends itself to effi-cient storage and manipulation. The problems center around the question what is themost efficient way to extract information from the database. Obviously, the require-ments imposed by the goals of efficient storage and manipulation, can, and often are, atodds with this. We typically request information from a database using concepts whichare different from those used in storing it. Thus, the design of an efficient query lan-guage often involves a translation of one mode of representation into another. Manyof the theoretical questions that are asked are related to this issue. A typical prob-lem is that of the definability of new queries in terms of old ones, and, of paramountimportance in this setting, an investigation of the complexity of this task.57 The sim-plest operators defining new queries are those of relational algebras (suitably formu-lated). This stays within first-order logic. But also, one typically wants to computequeries which involve transitive closures of predicates, or other inductively definedconstructions. This requires query languages which extend first-order logic with fixed
57 A typical result regarding the latter is the following. It is known that a first order query in a fixed, finitemodel can be resolved in polynomial time. In 1974, Fagin (see Fagin, 1974) proved that the reverse holds,almost: any polynomially resolvable query in a finite model can be expressed in a first order language towhich a limited resource of second order concepts is added.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1107 — #49
Questions 1107
point operators. Finally, given the nature of the task, questions of expressive powerand computation are usually studied over finite data bases. This gives this accountof questions the special flavor of “finite model theory”, which blends general seman-tic argumentation with combinatorial arguments over finite structures. Interestingly, arestriction to finite models has also been proposed independently in natural languagesemantics, e.g., in the theory of generalized quantifiers (see Chapter 19). The problemof giving an inductive definition of a certain set of semantic objects, too, reappears innatural language semantics, e.g., in the context of quantification over properties andfunctions, where on the one hand we do not want quantification to run over all objectsof that type, but we also do not want to restrict it to, say, the set of objects which arelexicalized. Rather, one wants the domain to consist of the set of those functions whichcan be defined in terms of certain closure operations over the lexicalized ones.58
Quite similar questions arise in the context of declarative programming languages.Such languages can also be considered as “query” languages: a typical Prolog pro-gram resolves a question concerning some data structure. One of the relevant issueshere concerns, again, definability: Which definitions are “save”, i.e. lead to computa-tionally tractable formalisms? Also other aspects are studied, such as that of findingan “informative” formulation of the answer that the execution of a program provides.
It is interesting to note, finally, that some of the mathematical tools that are used inthis research, viz., those of relational algebra, are also used in another setting in whichinformation exchange is the topic, viz., that of dynamic logic (see Chapter 12). On theother hand, it is a moot point whether iteration and recursion occur in natural languagethe way they do in computation. Examples would be not so much explicit expressionsdenoting recursive procedures but, rather, higher computational mechanisms, such asare involved in domain selection, anaphora resolution, or maintenance of discoursescheduling.
The research in these computational settings, although akin in spirit to the earlierlogical work, has rapidly grown into a subject of its own. One subject area needs tobe mentioned, in which logical, linguistic, and computational questions come togetheragain. This area is devoted to the design of natural language query systems, in which“translation” plays a role at several points.59 First of all, a natural language interroga-tive has to be mapped onto an expression in some query language, which then has tobe matched against a database. Then the reverse problem has to be solved. Given theinformation extracted from the database, a formal expression has to be defined whichanswers the query. And this expression in its turn has to be translated in some naturallanguage expression which serves as an answer to the original interrogative. If, further-more, the fact that the questioner already has information at her disposal is taken intoaccount, this task displays almost all aspects of questions and answers that are studiedin logical, computational, and linguistic frameworks. Thus, despite the differences inoutlook and techniques, it seems that to a large extent the undertaking is a common
58 See Groenendijk and Stokhof (1983, Section 25.4) for a concrete example of a discussion revolvingaround this issue in a linguistic setting, viz., that of an account of so-called “functional” readings.
59 A good, although not very recent example is the system described in Scha (1983).

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1108 — #50
1108 Handbook of Logic and Language
one, i.e. one in which in the end each party involved may benefit from the results ofthe others.
25.6 Linguistic Theories
In this section we first provide a brief overview of the main semantic approaches inthe linguistic literature. As will become apparent, such theories share certain features,but differ at other points to such an extent that they become real alternatives. Next, wesketch some empirical data that play a key role in the shaping of these alternatives,and outline how they lead to certain choices. As it will turn out, there may be goodreasons for wanting to take a liberal point of view, and not succumb to the temptationto declare one of the alternatives as the only right theory. An outline of how such amore flexible approach can be incorporated in a grammar, is given. Then we completeour survey with a sketch of some other empirical issues, and with a brief outline ofrecent developments.
25.6.1 Overview
Most linguistic theories focus on the analysis of interrogative structures as such, andthe analysis of answers comes into play only in the light of that. Consequently, hardlyany attention is paid to matters which we saw are of paramount importance to logi-cal and computational theories, such as expressibility of queries and of answers. Thefunction of interrogatives and answers in information exchange is acknowledged, butmost of the time it is deferred to pragmatics and does not influence the semantic ana-lysis as such. Of prime importance for these linguistic approaches is “to get the factsright”, and that is taken to consist in giving an account of typical ambiguities thatinterrogatives display, their presuppositions, their behavior under embedding verbs,and so on. And it is primarily in terms of their predictions on these matters that theyare compared.
All semantic linguistic theories share a basic conviction, viz., that the semanticobject that an interrogative expresses has to provide an account of the answers that theinterrogative allows. That is, they all accept the third of Hamblin’s postulates givenabove (Section 25.4.1). But they diverge as to their acceptance of the other two pos-tulates. Thus, according to some, answers are of all kinds of linguistic categories, andhence they reject Hamblin’s first postulate, which says that answers have a sentential,or propositional, character. Others accept it, but hold that interrogatives admit of morethan one true answer, which means that they reject the second postulate, which statesthat answers are exhaustive and mutually exclusive. And then there are theories whichaccept all three.
25.6.1.1 Partition Theories
Let us start with the latter, since they fit in with the kind of account we sketched aboveas the “Hamblin picture”. As we saw above, the Hamblin picture gives us a clean and

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1109 — #51
Questions 1109
coherent view of questions and answerhood. It presents us with a uniform and formallyappealing notion of a question as a partition of a logical space of possibilities. It tiesquestions in a natural fashion to answers, the latter being the blocks of the partition.And it is able to account for equivalence of interrogatives and entailments betweenthem in a standard way, i.e. without appealing to definitions of these notions whichare specific for this kind of expressions. And to some extent, it is able to account forcoordination of interrogatives in a likewise general fashion.
Partition theories have been developed by Higginbotham and May (1981),Higginbotham (1995), and Groenendijk and Stokhof (1982, 1983). The Higginbothamand May approach starts from the basic point of view expounded above, that a questioncorresponds to “a partition of the possible states of nature”, such a partition represent-ing “the suspension of judgment among a set of mutually exclusive and jointly exhaus-tive alternatives” (Higginbotham and May, 1981, p. 42). Their analysis concentrateson the derivation of interrogatives with more than one occurrence of a wh-phrase, suchas “Which man saw which woman?” and “Which people bought which books?”. Thedetails of their analysis are rather complicated, since they want to take into accountwhat they consider to be semantic presuppositions of wh-phrases, in particular theuniqueness presupposition of singular wh-phrases. A straightforward implementationthereof wrongly predicts that “John saw Mary and Bill saw Sue” violates the pre-suppositions of “Which man saw which woman?”. In fact, Higginbotham and Mayargue, the uniqueness presupposition for such structures amounts to the requirementthat there be a bijection between two subsets of the domains of the wh-phrases.60 Thederivation of such bijective interpretations, it is claimed, cannot proceed in a step-by-step fashion, introducing and interpreting one wh-phrase at a time, i.e. considering itas an ordinary unary quantifier. Given the uniqueness presupposition associated with asingular wh-phrase such a procedure would result in a reading of, for example, “Whichman saw which woman?” in which it would presuppose that only one man saw onlyone woman. For single, i.e. one constituent, wh-interrogatives this is the right reading,and for some multiple wh-interrogatives it may also be the only reading available (cf.,footnote 60). But in general this “singular” interpretation is too strict. Derivation ofthe bijective interpretation, Higginbotham and May claim, requires the introduction ofa binary (generally, n-ary) WH-operator, of which arbitrary arguments may be markedfor uniqueness. This operator is of the following general form:
WHKn (x1 · · · xn)
where K is a set of integers k such that k 2 n. When applied to a sentence of the form!(x1 · · · xn) the result is a partition with each argument xk with k ( K being interpreteduniquely. Arguments not so marked correspond to occurrences of plural wh-phrases,
60 According to Higginbotham and May, there are structures in which this reading is not available, viz.,those in which the domains of the two wh-phrases are not disjoint. An example would be “Which numberdivides which number?”, asked of a single list of numbers.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1110 — #52
1110 Handbook of Logic and Language
which lack the uniqueness presupposition. Thus, the representation of “Which mansaw which woman?” on the bijective reading would be the following:
#WH{1,2}
2 x, y : man(x) ' woman(y)$x saw y.
A representation of “Which man saw which women?”, with a plural second argument,would have WH{1}
2 x, y instead. One interesting thing about this analysis is that thisway of deriving multiple wh-interrogatives seems an instance of a general quantifica-tional mechanism, viz., that of polyadic quantification (see Van Benthem, 1989a; andChapter 19; cf., also Section 25.4.5). In fact, in the original paper, Higginbotham andMay argue that similar mechanisms provide an account of the phenomenon of crossingcoreference (as in Bach-Peters sentences such as “Every pilot who shot at it hit a Migthat chased him”). This is just one case which shows that there are interesting parallelsbetween the analysis of wh-interrogatives and that of other quantifying expressions,which one would want a general theory of quantification to account for.
The partition approach of Groenendijk and Stokhof differs from that of Higgin-botham and May in that it does not incorporate uniqueness presuppositions into thesemantics of wh-phrases. They derive interrogatives from what are called “abstracts”,which express n-place relations. The semantic rule reads as follows:61
#w#w#%#x1 · · · xn%!(w#, x1, . . . , xn)
&= #x1 · · · xn
%!(w, x1, . . . , xn)
&&.
This rule defines a partition based on an n-place relation by grouping together thoseworlds in which the relation has the same extension.62 In other words, it defines anequivalence relation on the set of worlds, which holds between two worlds iff theextension of the relation in question is the same in those worlds. An ordinary indicativesentence is taken to express a 0-place relation, i.e. a proposition. Hence this rule alsoderives questions expressed by sentential interrogatives, viz., bipartitions.
Both approaches make (roughly) the same predictions with respect to answerhood.In particular, they are committed to what is called “strong exhaustiveness”. This aspectwill be discussed more extensively below.
25.6.1.2 Sets of Propositions Theories
According to the partition view an interrogative denotes its true and complete answer.In other words, its denotation is a proposition, and its sense a function from worldsto such propositions. Hence, the meaning of an interrogative is an entity of type-s, -s, t...63 Other approaches take a different view: they hold that the denotation of aninterrogative is a set of propositions, and its sense a function from worlds to such sets.
61 In what follows we use two-sorted type theory as a representation language. Two sorted-type theory islike the familiar intensional type theory of Montague (see Chapter 1), but allows explicit reference to andquantification over worlds.
62 Cf., Definition 25.4.9 above.63 Where s is the type of possible worlds, t that of truth values. See Chapter 1 for more details.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1111 — #53
Questions 1111
Thus, they assign a different type of object to an interrogative as its meaning, viz., oneof type -s, --s, t., t...
Not all theories that assign this type of object to an interrogative interpret it inthe same way, and hence they differ in what objects they actually associate with agiven interrogative. For example, according to Hamblin (1973), the set of propositionsdenoted by an interrogative consists of its possible answers, whereas Karttunen (1977)lets it consist of its true answers. Thus a simple interrogative of the form “Who will becoming to dinner tonight?” on the Karttunen analysis will denote in a world w the setconsisting of those propositions which are true in w and which state of some personthat (s)he is coming to dinner tonight:64
#p%*x
%p = #w
%come-to-dinner(w)(x)
&&' p(w)
&.
The propositions which make up this set each state of some individual which actu-ally is coming to dinner that he/she is coming to dinner. On Hamblin’s analysis therestriction to individuals that are actually coming to dinner is dropped.65 Notice that inboth cases the propositions are mutually compatible, which marks a principled differ-ence with the partition theories.66 Exactly how the individual propositions are relatedto answers is not entirely clear. Hamblin describes them as “those propositions thatcount as answers” (Hamblin, 1973, p. 46), and Karttunen looks upon them as proposi-tions which “jointly constitute a true and complete answer” (Karttunen, 1977, p. 20).In connection with this, it is important to note that in Karttunen’s analysis the vari-ous denotations of an interrogative are also mutually compatible. This means that ifwe interpret the Karttunen sets as Karttunen himself suggests, the answers which hisanalysis defines for an interrogative are mutually compatible, too. This marks a dif-ference from partition theories. Whereas the latter subscribe to strong exhaustiveness,Karttunen only acknowledges weak exhaustiveness. More on this below.
The main difference between Hamblin’s and Karttunen’s approach, which is prob-ably the most influential analysis in the semantics literature to date, is that the formerconcentrates on stand alone interrogatives, whereas the latter is concerned mainly withembedded interrogatives. It is from their behavior in various embedding contexts thatKarttunen derives arguments in favor of his modification of Hamblin’s original pro-posal (although he adds that he considers none of them as a “knock-down argument”Karttunen, 1977, p. 10). For example, Karttunen observes that in a sentence such as“Who is elected depends on who is running” it are the true answers (in various worlds)to the respective interrogatives that are involved, not their possible ones.
64 Application (p(w)) of a propositional expression (p) to a world denoting expression (w) expresses thatthe propositional expression is true in that world.
65 The Hamblin set of propositions can be regained from the Karttunen interpretation simply by collectingall denotations. Likewise, a Karttunen set can be distinguished within the Hamblin set by selecting thoseelements which are true in a particular possible world. In this respect the difference between the two isnot very essential.
66 So Hamblin’s analysis should not be confused with the Hamblin-picture!

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1112 — #54
1112 Handbook of Logic and Language
Similarly to the Higginbotham and May approach, interrogatives on Karttunen’sanalysis are the result of what basically is a quantificational process. Roughly, Kart-tunen defines a base level of what he calls “proto-questions”, derived from indicatives!, which are of the form:67
#p(p = #w(!) ' p(w)).
Wh-phrases are regarded as existentially quantified terms. A quantificational processlike that of Montague’s quantifying-in then derives interrogatives from indicativescontaining a free pronoun, using their proto-question interpretation. Multiple con-stituent interrogatives are derived in a step-by-step fashion.
Two things need to be noticed. First of all, unlike Higginbotham and May, but likeGroenendijk and Stokhof, Karttunen does not build any existential and/or uniquenesspresuppositions into the semantics of interrogatives. Secondly, his use of a quantifi-cational analysis in combination with the level of proto-questions results in what arecalled “de re” readings of constituent interrogatives. Cf.:
#p%*x
%student(w)(x) ' p = #w
%pass-the-exam(w)(x)
&&' p(w)
&.
This is Karttunen’s translation of “Which student passed the exam?”. Notice that therestrictor cn of the wh-phrase is outside the scope of the proposition. Thus such aproposition claims of a student that he/she comes, but not (also) that he/she is a stu-dent. More on this below.
Interestingly, the Hamblin and Karttunen analyses are not the only ones in whichan interrogative is taken to denote a set of propositions. On the analysis developedby Belnap (1982) and Bennett (1979) interrogatives are assigned the same type ofsemantic object, but with a radically different interpretation: each proposition in theset is assumed to express a complete true answer. Hence, unlike in the Karttunen andHamblin interpretation, the elements of the denotation of an interrogative are mutuallyexclusive. Accordingly, an interrogative such as “Which student passed the exam?”will denote a singleton set. Why, then, introduce the complication of assigning themsets of propositions? In this way Bennett and Belnap aim to account for interrogativeswhich have more than one complete true answer. Examples of such interrogatives willbe discussed below.
We end with noting the following characteristics of these sets of propositions theo-ries regarding entailment and coordination. Let us start with the Karttunen analysis.68
The standard definition of entailment in terms of inclusion predicts no entailment of “IsBill coming to dinner? by “Who is coming to dinner?”. As an immediate consequencewe note that “John knows who is coming to dinner” does not imply “John knows
67 In two-sorted type theory every context-dependent expression has an occurrence of a variable w, rangingover worlds.
68 The following applies, mutatis mutandis, also to the Hamblin analysis.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1113 — #55
Questions 1113
whether Bill is coming to dinner”.69 This is related to the matter of exhaustiveness,to which we return shortly. As for coordination, it is easy to see that a standard con-junction rule, which amounts to taking the intersection of two denotations, does notmake adequate predictions in certain cases. For example, given that John and Maryare different individuals, the intersection of
#p%*x
%p = #w love(w)(j, x)
&' p(w)
&
which is the denotation of “Whom does John love?”, with:
#p%*x
%p = #w love(w)(m, x)
&' p(w)
&
which is denoted by “Whom does Mary love?, is empty, predicting that ‘Whom doJohn and Mary love?” (on the conjunctive reading) does not have an answer.
As for the Bennett and Belnap approach, similar observations can be made. It, too,does not do well with regard to entailment and conjunction. It does, however, makethe right predictions concerning disjunction. We return to this shortly.
25.6.1.3 Categorial Theories
A final landmark in the landscape of semantic approaches is provided by so-called“categorial theories”. Examples of categorial approaches can be found in work ofHausser and Zaefferer, Tichy, and Scha (see Hausser, 1983; Hausser and Zaefferer,1978; Scha, 1983; Tichy, 1978).
Categorial theories do analyze interrogatives in terms of answers, but do not startfrom the assumption that the latter represent a uniform type of object. Rather, it isnoted that answers are not always sentences, but may be of all kinds of categories.Also, it is observed that different kinds of interrogatives require different kinds of non-sentential answers, also called “constituent answers”. Categorial theories focus on therelation between interrogatives and constituent answers. The existence of a categorialmatch between interrogatives and their characteristic constituent answers is taken todetermine their category. The categorial definition of interrogatives is chosen in sucha way that in combination with the category of its constituent answers, the category ofindicative sentences results. Again, there is some leeway here. Hausser, for example,takes an interrogative to be of a functional category, viz., that function which takes thecategory of its characteristic answers into the category of sentences. Tichy prefers toidentify the category of an interrogative with that of its characteristic answers.
As a result, different kinds of interrogatives are of distinct categories and semantictypes. One of the consequences of this lack of a uniform interpretation of interrog-atives is that entailment relations between interrogatives of different categories can-not be accounted for by means of the standard notion of entailment, since the latter
69 Given that Karttunen requires the subject to know every proposition in the denotation of the embeddedinterrogative (or, in case the denotation is empty, the proposition that it is empty). See Heim (1994) fordiscussion and an alternative that is meant to remedy the shortcoming noted in the text.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1114 — #56
1114 Handbook of Logic and Language
requires such interrogatives to be of the same type. More generally, since catego-rial theories focus on the linguistic answerhood relation, constituted by categorial fit,a semantic notion of answerhood as a relation between propositions and questionsremains outside their scope.
25.6.2 Key Data
Up to now we have given short characterizations of various kinds of semantic theories,without going into the details of their motivation. But, surely, it must be possible togive reasons for preferring one type of approach over another? In what follows wewant to discuss this matter a little further, by discussing some crucial empirical datathat can be, and sometimes have been, adduced in favor of certain theories. But wemust warn the reader at the outset: we are not presenting the motivations as the variousproponents have given them, but discuss the matter in a systematic fashion. We knowthat in doing so we distort history, but we hope that the picture of the field that emergesis clear.
The starting point of our discussion will be the Hamblin-picture, i.e. that view onthe semantics of interrogatives that subscribes to each of Hamblin’s three postulates.As we shall see, corresponding to each of these three postulates empirical data can beadduced that provide some reason to question it. But before turning to three of them,we must point out a phenomenon that seems to lie beyond the reach of the Hamblin-approach as such.
25.6.2.1 Open Questions
It is clear that the Hamblin-picture makes certain choices with regard to, and henceimposes certain restrictions on, its subject matter. A major one is the following. Thenotion of a question that the Hamblin-picture accounts for is one where the possibleanswers are pre-set, so to speak. The alternatives are “already given”. In other words,giving an answer to a question is regarded as making a choice from a set of alterna-tives which are determined by the question itself. (In this respect there is an interestingresemblance with multiple-choice questionnaires.) This follows more or less straight-forwardly from the third postulate, viz., that to know the meaning of a question is toknow what counts as an answer to it. Questions such as these may be called “informa-tive questions”. However, if one takes informative questions as a point of departure,the picture one arrives at does not seem to apply, at least not in a straightforwardway, to so-called “open questions”, which are not requests for a particular piece ofinformation. The question addressed in this chapter, viz., the one expressed by theinterrogative “What are questions?”, is probably a good example. It seems reasonableto assume that both the authors and the reader understand this question, i.e. are able tograsp the meaning of the interrogative, without there being a number of pre-set possi-ble answers which are determined by the question itself. In this respect open questionsdiffer from those expressed by such interrogatives as “Who will be coming to din-ner tonight?”, where, depending on the domain, the set of possible answers is clearin advance (“Harry, Jane and Bill.”; “Just Bill and Suzy.”; “Nobody.”; and so on).

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1115 — #57
Questions 1115
Answering an open question is a creative process, one might say, where we make upthe answers as we go along, and do not simply choose from a pre-established set.Notice that another distinctive feature of open questions seems to be that with themit often seems to make little sense to ask whether or not a particular answer to such aquestion is true or false. Rather, answers are qualified as good or bad, as more or lesscomprehensive, or helpful, and so on. Thus, it seems that open questions do not satisfytwo assumptions which, as was observed above, are inherent features of the Hamblin-picture, viz., the Existence and Uniqueness Assumptions concerning answers. Onemight say that in the case of open questions answers do not already exist, but haveto be created, and that there is no unique answer to be created, but that there is anunlimited amount of not necessarily mutually inconsistent answers that can be given.So open questions do not fit the picture. Or rather, the picture does not fit them.
It seems fair to conclude that Hamblin’s picture (which, to be sure, was presentedby Hamblin as a proposal for a certain methodology) is restricted to one, albeit animportant, type of questions, viz., informative questions. Whether or not this method-ology is a sound one depends on whether or not open questions really are conceptuallydifferent from informative ones, a matter which has not been really settled in the liter-ature to date. As a matter of fact, we may observe that almost all analyses are limitedin that they confine themselves to informative questions.
The considerations concerning the distinction between “open” and “informative”questions point towards an “external” limitation of the Hamblin-picture, suggestingthat, if the observations made above are correct, it needs to be supplemented by ananalysis of a different kind of questions. Other considerations, however, aim at theheart of the picture itself, purporting to show that it fails to do justice to the propertiesof the kind of questions it was designed to deal with, viz., informative ones. Thus itcan be argued that the Hamblin-picture rests on assumptions concerning answerhoodwhich are empirically inadequate. One assumption in particular has been attacked, fora variety of reasons, and that is the Unique Answer Assumption, i.e. the assumptionthat in a situation an interrogative has a unique true and complete answer.70 In effect,many of the alternative theories that have been proposed can be understood (system-atically, that is, not historically) as attempts to do without this assumption.
25.6.2.2 Exhaustiveness
Before turning to a brief discussion of some phenomena that can be adduced to arguethat the Unique Answer Assumption is not warranted, we first mention briefly someobservations that seem to support it. These observations concern certain equivalences
70 Note that the assumption itself can be misunderstood in a variety of ways. Although questions in theHamblin-picture have a unique true and complete answer (if their presuppositions are fulfilled), there arestill many ways in which they can be answered (truly). The notions of complete and partial answerhooddiscussed above illustrate this fact. Furthermore, if we take the pragmatics of question-answering intoaccount, the range of potential answers that the theory allows for is virtually unlimited (see Groenendijkand Stokhof, 1984a,b, for some discussion). At the same time it brings order in this chaos by making itpossible to define clearly which propositions, given particular circumstances concerning the informationof the speech participants, count as optimal answers.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1116 — #58
1116 Handbook of Logic and Language
between interrogatives that seem to be needed to get an account of the validity ofcertain arguments.71 Thus, it seems that from “John knows who is coming to dinnertonight” it follows that “John knows whether Mary is coming to dinner tonight”. Also,it seems that, assuming that the domain is fixed over John’s epistemic alternatives,i.e. that it is known to John of which individuals the domain consists, it follows from“John knows who is coming to dinner tonight” that “John knows who is not coming todinner tonight”. To account for the validity of this type of inference, it seems we needthe equivalence, under the assumption stated, of course, of interrogatives of the form?xPx and ?x¬Px, and also the entailment between ?xPx and ?Pa.72 Hamblin’s picturedelivers these goods.
This feature is often discussed under the heading of “exhaustiveness”. Usually, adistinction is made between “weak” and “strong” exhaustiveness. By the former weunderstand the requirement that a complete answer specify all true single “instances”,i.e. that it exhaustively specify the range of true partial answers. Strong exhaustivenessrequires in addition a closure condition: that the answer not only in fact give such anexhaustive specification, but also in addition state that it is exhaustive. Thus, a weaklyexhaustive answer provides a complete list, a strongly exhaustive answer contains inaddition the closure condition stating “and that’s all, folks”. Strong exhaustiveness,thus, should not be confused with the requirement that an answer specify both thepositive and the negative extension of a relation.73 Partition theories as such are com-mitted to strong exhaustiveness in the proper sense, but not to the latter requirement.In fact, as we saw above, the latter requirement is empirically unjustified: the equiva-lence of interrogatives of the form ?xPx and ?x¬Px holds only if we assume that thedomain from which the instances are drawn is fixed.74 A phenomenon that has beensuggested to constitute a counterexample to strong exhaustiveness is that of “quantifi-cational variability”, involving adverbs of quantification, such as “mostly”, “rarely”.See below, Section 25.6.4.3.
It is of some interest to note that the phenomenon of exhaustive interpretation isnot restricted to interrogatives and answers. Within the semantics of plural nps, some(e.g., see Hendriks, 1988) have suggested that we need a “minimal”, i.e. exhaustive,interpretation of the generalized quantifiers such nps express. Also, in the theory oftopic and focus, exhaustiveness plays an important role. See, for example, Bonomi andCasalengo (1993). In fact, as many authors have suggested, there may be an intimaterelationship between questions and answers, and topic and focus. See Van Kuppevelt(1991) for systematic discussion. Rooth (1992) provides a detailed account of therelationship between Karttunen’s analysis of questions and his theory of focus, whichis based on “alternative semantics”.
71 Cf. Groenendijk and Stokhof (1982) for more elaborate discussion.72 Another observation which supports this requirement is the following. We are discussing which of our
friends are coming to dinner tonight. Suppose that Mary and Suzy are in fact coming to dinner tonight,but John erroneously believes that Mary, Suzy, and Bill will come. Then it seems wrong to attribute toJohn knowledge of who is coming to dinner.
73 This misinterpretation has caused a lot of confusion in the literature. For discussion of these issues seeGroenendijk and Stokhof (1993).
74 Cf. also Fact 4.18, (iv), in Section 24.5.6.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1117 — #59
Questions 1117
Moreover, the idea of exhaustiveness seems natural, not just from a strictly lin-guistic point of view, but also in a wider cognitive setting. In various kinds of theo-ries which deal with information exchange and with reasoning on the basis of partialinformation, we can trace the idea that informational “moves”, as a rule, are to beinterpreted exhaustively. That is, information is treated in a non-monotone way, i.e.it is interpreted as giving all information (concerning the topic in question), unlessstated otherwise.75 This ties in with the natural assumption that information exchangeis structured by an “underlying” pattern of questions and answers (cf., the relation-ship with topic and focus structure referred to above; see also Mayer, 1990). In effect,many specific features of discourse structure (both monological and dialogical) seemto depend on this.
But let us now turn to some observations that can be adduced to argue against theUnique Answer Assumption, also in order to get a better grip on the various semantictheories that have been proposed in the literature.
25.6.2.3 Mention-Some Interpretation
The following observation constitutes an internal criticism of the Hamblin-picture. Itseems that in some situations, obviously informative interrogatives do have several,mutually compatible and equally adequate answers. Consider the following example:A tourist stops you on the street and asks “Where can I buy an Italian newspaper?”.Clearly, she does not want you to provide her with a complete specification of all theplaces where Italian newspapers are sold. All she wants is that you mention somesuch place. Thus, both “At the Central Railway Station.” and “At the Athenaeumbookstore.” (and a host of others) each are in and of themselves complete answers,and they are mutually compatible.
Such an interpretation is often called the “mention-some” interpretation of an inter-rogative, since the answers mention some object that satisfies the condition expressedby the interrogative. Per contrast, the interpretation that the Hamblin-picture accountsfor is referred to as the “mention-all” interpretation, since its answers specify all suchobjects. Notice that, although the subject matter of the example we gave strongly sug-gests a mention-some interpretation, it does not exclude a mention-all interpretation.Thus we may imagine that the interrogative is used by someone who is interested insetting up a distribution network for foreign newspapers. Clearly, such a person woulduse the interrogative on its mention-all interpretation, since he would regard only a listof all stores selling Italian newspapers as a complete answer.76
The important question that needs to be settled in order to be able to evaluate therelevance of mention-some interpretations for the Hamblin-picture is whether they
75 See Chapter 8, and Van Benthem (1989b).76 There is, again, an interesting parallel with other instances of quantification, this time concerning “donkey
sentences”. Here, too, there are cases of structures for which a “universal” interpretation seems to bepreferred (“If Pedro owns a donkey, he beats it” seems to entail that Pedro beats all the donkeys he owns),whereas other instances which exhibit the same pattern, superficially at least, prefer an “existential”reading (“If I have a dime, I put it in the parking meter” does not require me to put all my dimes in themeter).

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1118 — #60
1118 Handbook of Logic and Language
constitute a distinct reading of interrogatives, or can be accounted for along otherlines. To start with the latter option, one might be tempted to think that the distinctionis of a pragmatic nature: circumstantial facts (concerning intentions and interests ofthe questioner, for example) determine whether she is satisfied with something “less”than the complete answer that is determined semantically by the interrogative. This ineffect comes down to the view that, semantically speaking, mention-some answers arenot complete answers, but function so only from a pragmatic point of view. Seman-tically, such answers are partial, rather than complete answers: they exclude somepossibilities, but do not provide an exhaustive specification. This line of reasoning,however, is difficult to maintain for the following reason. Partial answers as definedby the mention-all interpretation may also be “negative”. For example, “Not at theBijenkorf.” is a partial answer to our example interrogative on its mention-all inter-pretation, since it excludes certain possible answers. However, such “negative” partialanswers are no good when we take the interrogative on its mention-some interpreta-tion, since it does not mention some positive instance, which is what, on the mention-some interpretation, is what is required.
This suggests that mention-some interpretations really are a distinct semantic read-ing. If we accept this conclusion, we face the following question: does the distinctionbetween mention-all and mention-some interpretations constitute a genuine ambiguityof interrogatives? Or can the mention-all interpretation be derived from the mention-some interpretation? Or is there an underlying semantic object from which both areto be derived? Various answers can be found in the literature. Hintikka, for example,analyzes mention-all and mention-some interpretations in terms of an ambiguity ofwh-phrases (see Hintikka, 1976, 1983a). Groenendijk and Stokhof (with some hesita-tion, see Groenendijk and Stokhof, 1984a) turn it into a structural ambiguity. Accord-ing to Belnap’s analysis in Belnap (1981), mention-some interpretations are on a parwith so-called choice interpretations, to be discussed below.77 Various analyses in theline of Karttunen (see Karttunen, 1977) can be regarded as presenting the second kindof solution. To the third option we return below.
As we saw above, on the Karttunen approach the meaning of an interrogative is afunction from worlds to sets of propositions. So, whereas a partition in the Hamblin-picture determines a single proposition, the Karttunen interpretation delivers a set ofpropositions as the denotation of an interrogative in a particular world. Both analysesrelate questions to answers, but in a different way, and we may interpret this as a dif-ference in what basic answers are.78 According to the third postulate of the Hamblin-picture answers are mutually exclusive and together exhaustive. In other words, in
77 This identification cannot be maintained, however, for reasons discussed in Groenendijk and Stokhof(1984a), where an alternative analysis is given.
78 Notice that we refer to “the Karttunen approach”, and not to “Karttunen”. We do so deliberately. Thepoint we want to make is a systematic one, and it is not intended as a reconstruction of Karttunen’sactual motivation. In fact, given that Karttunen himself described the set of propositions denoted by aninterrogative as “jointly constituting a true and complete answer” we may as well take him to present themention-all interpretation, weakly exhausted.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1119 — #61
Questions 1119
each world a question has exactly one true answer. On this interpretation of the Kart-tunen approach, answers are mutually compatible: there may be many propositions ina given world that are a true answer. Thus, whereas the Hamblin-picture seems emi-nently suited to deal with mention-all interpretations, the Karttunen approach mightseem to provide a good basis for dealing with mention-some interpretations. For, thepropositions which make up the denotation of an interrogative in a world, each men-tion some object which satisfies the condition from which the interrogative was built.
The idea that suggests itself then is to regard the Karttunen semantics as the basicone, i.e. to assume that mention-some interpretations are fundamental, and to try toobtain the mention-all interpretations from it, by defining the partition in terms of theequivalence relation of having the same set of answers. However, for various reasonsthis strategy does not work.
First of all, it can be observed that the phenomenon of mention-some interpretationsis a particular instance of something more general: mention-n interpretation. Thus, aninterrogative such as “Where do two unicorns live?” has as one of its interpretationsthe one in which it asks for a specification of two distinct places where one (or more)unicorns can be found. Such an interpretation can be derived from the set of proposi-tions that the Karttunen analysis provides, by introducing an operation that tells howmany of the propositions will make up an answer.79 But that means that it is not theKarttunen set that is the denotation of an interrogative, but a more basic semanticentity.
Secondly, as Heim has argued (see Heim, 1994) it does not seem possible to actu-ally derive the right partition interpretation from the Karttunen set. The reasons behindthis are complicated, and perhaps not entirely understood. One issue is that no accountof “de dicto” readings of wh-interrogatives can be obtained in this way, it seems.
Thus the resulting picture is rather complicated. And it becomes even more so ifwe look at another phenomenon that challenges the Unique Answer Assumption, viz.,that of so-called “choice” interpretations.
25.6.2.4 Choice-Interpretation
One obvious instance in which the Unique Answer Assumption fails, is with respect tointerrogatives which have a so-called “choice”-interpretation. Prominent examples areprovided by disjunctions of interrogatives, such as “Where is your father? Or whereis your mother?”. This interrogative does not ask for a specification of a place whereyour father or your mother (or, perhaps, both) can be found. Rather, its purpose is tofind out about the whereabouts of either your father or your mother. Thus, it has twomutually compatible, true and complete answers. Another example of an interrogativeexhibiting this kind of interpretation is “Where do two unicorns live?”, which, besidesthe “mention-two” interpretation referred to above, also has an interpretation where itasks to specify of two unicorns where they live. Thus they are typically answered byindicatives of the form “Bel lives in the wood, and Nap lives near the lake”.80
79 See Belnap and Steel (1976) for some relevant discussion of “completeness” of questions and answers.80 Belnap was the first to discuss these kinds of examples, and to stress their importance for the semantics
of interrogatives. See Belnap (1982) for elaborate discussion.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1120 — #62
1120 Handbook of Logic and Language
Disjunctions of interrogatives are not adequately accounted for in the Hamblin-picture, at least not by application of a generalized rule of disjunction. In the case ofpartitions, application of such a rule would amount to taking the pairwise union of theelements of two partitions, which, in general, does not result in a partition at all. TheKarttunen approach, too, fails on this score. The Bennett and Belnap analysis, onthe other hand, obviously is able to account for disjunction (but fails on conjunction).
A little reflection shows that all this may not be a coincidence. In general, applica-tion of a generalized rule of coordination to two objects of a certain type results in anew object of the same type. In the case of conjunction of questions we would indeedexpect the result to be a new question. But in the case of disjunction this is, perhaps,not so obvious. Consider again the example “Where is your father? Or where is yourmother?”. As was remarked above, this interrogative has two mutually compatible,true and complete answers. But in this case it seems that this is due to the fact that theinterrogative expresses two distinct questions, and not just one. Thus, in using suchan interrogative, the questioner in effect expresses two questions, leaving the ques-tionee the choice which of the two she wants to answer. Something similar can be saidabout the choice reading of the other example, “Where do two unicorns live?”. Theuse of this interrogative amounts to the following: pick any two unicorns – the choiceis yours – and answer for each of them the question where it lives. Thus this interroga-tive, too, does not express a single question, but two. Unlike the disjunctive example,it does not explicitly identify which two questions, but rather leaves the questionee thechoice, within certain limits it sets.
What moral can be drawn from this? First of all, it seems that choice interpretationsare no straightforward counterexample to the Unique Answer Assumption: if an inter-rogative on such an interpretation expresses more than one question, it seems we canacknowledge that it has more than one complete and true answer, while still holdingon to the assumption. And actually, if we consider a slightly different example, “Whatdo two unicorns eat?”, it seems that what we are dealing with here are two questions,each with a plausible mention-all interpretation, and thus each with a unique completeand true answer.
Secondly, the existence of this kind of interpretation, and the failure of a straightfor-ward analysis in terms of a generalized coordination rule, indicates that interrogativeshave to be analyzed at yet another level. One way to account for these interpretationsis by application of a general strategy, familiar from the semantics of quantified nps.Thus one may analyze disjunctions of interrogatives, and analogously choice interpre-tations, in terms of generalized quantifiers over questions, using standard coordinationrules in combination with rules for lifting semantic objects.81 An alternative analysisis the one developed by Belnap (1982) and Bennett (1979). They give up the UniqueAnswer Assumption (which Belnap refers to as the “Unique Answer Fallacy”) and letinterrogatives denote sets of propositions, each of which constitutes a complete andtrue answer. Their analysis accounts for choice readings and disjunctions, but runs intoproblems when dealing with interpretations on which interrogatives do have a unique
81 See Groenendijk and Stokhof (1989) for an analysis along these lines.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1121 — #63
Questions 1121
answer. Thus they fail to deal with conjunctions in a standard way, and also are unableto account for the entailments and equivalences which we saw the Hamblin-picturedelivers.
All in all, the picture that emerges is rather varied. As we saw above, the Hamblinpostulates lead to elegant and simple theories, which are capable of dealing with arange of interrogatives in a uniform way. However, such analyses also show an inher-ent bias towards a certain type of interpretation, the mention-all interpretation, andhave problems accounting for mention-some interpretations of interrogatives. Alter-native theories of the Karttunen–Hamblin type, which assign sets of propositions tointerrogatives, are evidently better suited to cope with the latter, but are not able todeal with various entailments and equivalences that seem crucial for an account of avariety of phenomena, at least not in a straightforward way. The existence of choice-interpretations complicates the picture even more. Here, one of the alternatives thatcan be found in the literature is to add another level of analysis, viz., that of genera-lized quantifiers over partitions. That, however, may not be the end of the matter. Inthe next section we will discuss a range of phenomena that point towards yet anotherlevel on which interrogatives, it seems, must be analyzed.
25.6.2.5 Constituent Answers
The starting point is the observation, already alluded to earlier on, that interrogativesmay be answered not just by full sentences, but also by subsentential expressions, theso-called “constituent answers”. Thus “Who did John invite?” can be answered by“John invited Peter and Mary”, but also by “Peter and Mary.” And a reply to “Whereare you going?” can be a full sentence, “I am going to Amherst”, but also a subsen-tential phrase: “To Amherst.” Moreover, it seems that constituent answers are moreclosely tied to interrogatives than full sentential ones. Thus, “John kissed Mary” canbe an answer both to “Whom did John kiss?” and to “Why is Bill upset?”.82 But“Mary.” answers only the first, not the second.
Observations such as these have led to the development of the “categorialapproach” on interrogatives discussed above. According to the categorial view, inter-rogatives belong to a wide range of different categories, which correspond system-atically to that of their characteristic linguistic answers. Thus, this approach is moresyntax-oriented, and takes its lead from the surface syntactic properties of interroga-tives and linguistic expressions that serve as answers. It is a theory that rejects the firstof the three Hamblin postulates, which says that answers are sentences, or statements.
In view of that, one might be tempted, at first sight, to brush this approach aside,precisely because it is too syntactically oriented, and semantically deficient. The firstHamblin-postulate, one may reason, is beyond doubt: answers express propositions, orproposition-like objects anyway, since answers convey information. This much must
82 But notice that in each case the spoken sentence will carry a different intonation contour. This providesyet another ground for believing that there is an intimate relationship between questions and answers,topic and focus, and intonation, something which has been noticed by a number of authors. See thereferences given earlier.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1122 — #64
1122 Handbook of Logic and Language
be granted, it seems, but there is one aspect of the categorial view that indicates thatit can not simply be disregarded. This has to do with the derivation of mention-allinterpretations. Consider the sentence “John invited Mary”. Assuming a mention-allinterpretation, this sentence conveys different information if it answers different inter-rogatives. As an answer to “Whom did John invite?” it states that Mary is the one (theonly one) that John invited. But when it is a reply to “Who invited Mary? it meansthat John was the one (again, the only one) who invited Mary. These are differentpropositions, which shows that in some way the proposition expressed by a sententialanswer depends on the meaning of the interrogative. One way to account for that isby taking the different constituent answers, in this case “Mary.” and “John.” respec-tively, as starting point of the derivation of this single sentential answer, thus in effecttreating it as ambiguous.83 In effect this shows that also within the confines of a propo-sitional theory the categorial viewpoint has a certain role to play, and that hence thereis yet another level at which interrogatives need to be analyzed, viz., that of n-placerelations.
25.6.3 A Flexible Approach?
Summing up, we see that various semantic theories analyze interrogative structuresat various levels: as n-place relations, as (functions from possible worlds) to sets of(true) propositions, as partitions of a space of possibilities, and also at the level ofgeneralized quantifiers over such entities. This is a confusing multitude of semanticobjects. However, for each of these theories some empirical and methodological moti-vation can be given, as the foregoing survey has shown. This suggests that perhaps thesearch for one single type of object which is to function as the semantic interpretationof interrogatives is misguided by an unwarranted urge for uniformity. It might well bethat in some contexts (linguistic or otherwise) the meaning of an interrogative must betaken to consist of one type of object, and in other contexts it should be looked uponas being of another type. What a proper semantic theory should do then is not to lookfor one type of object, but to define a multitude of types and to establish systematicrelationships between them.
In fact, this situation occurs not just with the analysis of interrogatives: it appears tobe a justified methodology in other areas of linguistic description as well. The analysisof referring expressions, names, quantified nps, descriptions, is a clear case in point.Here, too, it seems that we need to analyze such expressions at various type-levels,and to define adequate type-shifting rules which capture the connections. Thus, theapparently confusing multitude observed above turns out to be another instance of afamiliar pattern. Flexible approaches to category/type assignment, and the associatedsystems of category/type shifting rules, have been the subject of extensive study, espe-cially in the context of categorial syntax with the associated type-theoretical semantics(see Chapters 1 and 2).
83 See Groenendijk and Stokhof (1984b) for an analysis along these lines.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1123 — #65
Questions 1123
One of the rules needed in the analysis of interrogatives on this account we havealready met above. It is the rule which turns an n-place relation into a partition. A sim-ilar rule that would deliver a Karttunen style set of propositions is easy to formulateas well. (It would differ from Karttunen’s actual analysis by not proceeding in a step-by-step fashion.) Further, we need the “Montague rule”, which turns an entity of acertain type into that of a generalized quantifier over entities of that type, to accountfor disjunction and related phenomena. We also observed above that, apparently, norule can be stated which transforms a Karttunen set into a partition in the Groenendijkand Stokhof style, the reason being that the latter assign de dicto readings, whereas theformer provide de re specifications. And we may need yet other rules as well, to dealwith other phenomena.
To what extent the various rules form a “coherent” set is a relatively unexploredissue. Some initial work has been done in Groenendijk and Stokhof (1989), but manyquestions remain open. Yet, the emerging picture certainly seems attractive, sheddingas it does the rigid “one category – one type” attitude that has dominated semantics forquite some time. The “polymorphic stance” has proved useful in other areas as well.
25.6.4 Other Empirical Issues
Above we have discussed mention-all, mention-some, and choice interpretations ofinterrogatives, constituent answers, and the various “pictures” that they give rise to, insome detail. In what follows we will very briefly mention some other empirical issuesand provide pointers to relevant literature.
25.6.4.1 Functional Interpretations
Some interrogatives exhibit what is often called a “functional” interpretation. Anexample is given by the following sequence: “Whom does every Englishman admiremost?” “His mother.” Here the answer does not specify an individual, but a functionthat delivers such an individual for each entity specified by the subject term of theinterrogative. These interrogatives are also interesting because they exhibit unusualbinding patterns: thus, in “Which of his relatives does every man love?” the sub-ject term “every man” binds the variable “his” which is inside the wh-phrase “whichof his relatives”. (Functional interpretations are discussed in Chierchia, 1992–1993;Engdahl, 1986; Groenendijk and Stokhof, 1983.)
Functional interpretations are not restricted to interrogatives. For example, anindicative such as “There is a woman whom every Englishman admires” has a read-ing on which it can be continued by specifying, not an individual, as in: “The QueenMother”, but a function: “His mother”. This is a separate reading, which is also tobe distinguished from the reading in which the subject np has wide scope. (Compare“There is a woman whom no Englishman admires” with “No Englishman admires awoman”.) This provides yet another indication that quantification in indicative andinterrogative structures exhibit quite similar patterns.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1124 — #66
1124 Handbook of Logic and Language
25.6.4.2 Pair-List Interpretations
Yet another type of interpretation is the so-called “pair-list” interpretation. Consider“Which student did each professor recommend?”. This interrogative can be interpretedas asking for a specification of those students that got a recommendation of everyprofessor. On this (mention-all) interpretation it is typically answered by providing alist of individuals: “John, Mary, and Suzy”. But there is also another interpretation,on which the interrogative asks to specify for each professor which student(s) (s)herecommended. A typical answer for this reading gives a list of professor-student pairs(hence the name): “Professor Jones recommended Bill and Harry; Professor Williamsrecommended Suzy and John; . . . ”. Notice that these answers are like those of a two-constituent interrogative. In fact, it has been argued that its pair-list reading “Whichstudent did each professor recommend?” is equivalent with “Which student did whichprofessor recommend?”.84
Pair-list readings are often connected with the phenomenon of quantifying intointerrogatives. See, for example, Bennett (1979), Belnap (1982). But if the aboveobservation concerning the relation with two-constituent interrogatives is correct, apair-list reading can not be the result of quantification of the subject np into an inter-rogative. For one thing, such an analysis would not account for the “two-constituent”nature of the answers. And it would give the subject np a de re reading, whereas thetwo-constituent interrogative reads both wh-phrases de dicto. For argumentation alongthese lines, see Groenendijk and Stokhof (1984a).
An extensive discussion, also of other phenomena in which quantifiers and ques-tions interact, can be found in Chierchia (1992–1993), where the patterns exhibited bythis interaction are related to Weak Crossover, and it is argued that pair-list readingsare a special case of functional readings.85
25.6.4.3 Quantificational Variability
Another phenomenon that has been related to quantification into interrogative struc-tures is that of “quantificational variability”. An example is provided by the followingsentence: “The principal mostly found out which students cheated on the final exam”.The main importance of these structures seems to be their role in the ongoing debateon exhaustiveness. According to some (see, for example, Berman, 1991) they providea counterexample: if the quantification is over students, then the principal finds aboutthe majority of the students who cheat that they do, but she need not find out about allof them, and neither does she have to find out about all students that don’t cheat thatthey don’t.
This has been challenged (see, for example, Ginzburg, 1995b; Heim, 1994; Lahiri,1991) on various grounds. Most opponents feel that in such structures the adverb quan-tifies, not over individuals, but over events, or “cases”. Also, an attempt has been madeto show how quantificational variability can be made to accord with strong exhaustive-ness (see Groenendijk and Stokhof, 1993).
84 Barring, perhaps, differences having to do with salience.85 See also Rexach (1996) for an extensive analysis using the generalized quantifier framework.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1125 — #67
Questions 1125
25.6.4.4 Embedding Verbs
Another important set of phenomena that up to now we almost have passed over insilence concerns the classification of various types of embedding verbs. This wasalready a major topic in Karttunen’s pioneering analysis (Karttunen, 1977), and hasbeen subject of further study by several authors (e.g., see Ginzburg, 1995a; Lahiri,1991). We just mention here a few issues that have received attention.
First of all, observe that not all verbs take both indicative and interrogative com-plements: know, tell, guess, for example, take both; a verb such as believe com-bines only with indicative complements; and wonder, investigate, and the like, arerestricted to interrogative complements. Furthermore, note that verbs which take both,also take “hybrid” coordinations, as in “John knows/revealed/guessed who left earlyand that Mary was disappointed”. This suggests strongly that in both the interroga-tive and the indicative context it is one and the same relation that is at stake, whichmakes an account in terms of lexical ambiguity implausible. Another interesting phe-nomenon has to do with factivity properties of embedding verbs. Some verbs whichtake both interrogative and indicative complements are factive with respect to both:“John knows that Bill comes to dinner” implies that Bill comes to dinner, and, like-wise, “John knows whether Bill comes to dinner” implies that John knows the trueanswer to this question. Other verbs behave differently, however. Thus, whereas “Johntells whether Bill comes to dinner” does imply that John tells the true answer, itdoes not follow from “John tells that Bill comes to dinner” that Bill in fact comes todinner.
Such facts need to be explained. One way to account for the factivity phe-nomenon is to let interrogatives denote their true answer(s), and to distinguishbetween “extensional” and “intensional” verbs, i.e. verbs which operate on theextension of the interrogative complement, and verbs which take its intension.Thus, know, tell would take a (true!) proposition as their argument, viz., the onedenoted by the question, whereas wonder, investigate take the question as such. SeeGroenendijk and Stokhof (1982).
A further refinement has recently been proposed by Ginzburg (see Ginzburg,1995a), who suggests to replace the three-fold distinction just mentioned by a four-fold one: factive predicates (know), nonfactive resolutive predicates (tell), questionpredicates (wonder), and truth/falsity predicates (believe). The first category takesboth interrogative and indicative complements, and semantically operates on proposi-tions. The fourth category only combines with indicative complements, and operateson an individual type of entity, related to, but different from, propositions. This is cor-roborated by the observation that such verbs also take nominal complements (“Johnbelieves the prediction Bill made”). The third category takes only interrogative com-plements, which express questions. Finally, elements of the second category have bothindicative and interrogative complements, the latter again taken to express an individ-ual type of entity, which is different from a question, but related to it. Ginzburg’sanalysis has obvious ontological ramifications, which are spelled out by him in asituation-theoretic framework, but which presumably can also be implemented in aproperty-theoretic setting.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1126 — #68
1126 Handbook of Logic and Language
25.6.4.5 Presuppositions
The question whether and, if so, which presuppositions are associated with interrog-atives, or with wh-phrases has already been alluded to earlier on. We noticed that inthe logical analyses of Belnap and Steel (1976) and Hintikka (1976, 1983a) presup-positions are essential ingredients. They provide the means for individuating (classesof) questions. In Hintikka’s approach the presupposition of a question is involved inspelling out its desideratum. Thus, alternative questions (“Is John in London, or inParis?”) are said to presuppose the truth of (exactly) one of the alternatives. Con-stituent interrogatives (“Who is coming to dinner?”) are assumed to have existentialpresuppositions, viz., that there is at least one instance satisfying the predicate. In morelinguistically oriented analyses, the discussion tends to focus on the uniqueness pre-supposition which is supposed to distinguish between singular and plural wh-phrases.The analysis of Higginbotham and May (1981) is a case in point. In the case of inter-rogatives, presupposition failure is usually said to result in the interrogative lacking a(true) answer. Other authors, e.g., Karttunen (1977), have been more indifferent.
As is the case with presuppositions of indicatives, discussion of these issues is com-plicated by the fact that one of the most important questions, viz., whether these pre-suppositions are a semantic or rather a pragmatic phenomenon, is underdetermined byour “pre-theoretic” intuitions. Some authors distinguish negative answers from rejec-tions (“mere replies”), but one may well wonder to what extent such distinctions aretheory-loaded. Keeping this in mind, the following observations86 may still serve toplace the claim that these are straightforward semantic presuppositions in a wider per-spective.
Let us start with existential presuppositions. It seems that, at least with the wh-phrase who, clear cases are actually hard to find. Of course, an interrogative such as“Who is that?” has an existential presupposition, but it seems due to the demonstrativerather than to the wh-phrase. Next, consider a case such as “Who is coming with me?”.There may be an expectation on the part of the questioner that there is someone comingwith her, but it does not seem to be a presupposition. For it seems that “Nobody.” isa perfectly straight (albeit perhaps disappointing) answer, and not a rejection of thequestion as such.
Uniqueness presuppositions do not seem to fare much better. Consider again “Whois coming with me?”. Does this presuppose that not more than one person is com-ing along, and that hence “John and Bill.” is not an answer? It seems not. This isnot to deny that expectations of uniqueness do occur. But they seem not strictly tiedto singular wh-phrases as the following example shows. Consider the following twopairs of interrogatives: “Which members of the cabinet voted against the proposal?” –“Which members of the cabinet voted against the proposal?”; and “Which member ofthe cabinet leaked the information to the press?” – “Which members of the cabinetleaked the information to the press?”. The association of uniqueness seems oppositein both cases. In the first pair the plural seems neutral as regards the number of peopleinvolved, whereas in the second pair it is the singular that is neutral, and the plural is
86 Taken from Groenendijk and Stokhof (1983).

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1127 — #69
Questions 1127
marked. An explanation can be found, it seems, by taking into account the nature ofthe activities involved: leaking information is typically an individual activity, whereasvoting against is something one (often) does along with others. Hence, the expecta-tions concerning (non-)uniqueness which are associated with the interrogative seemto depend (primarily) on other material than the wh-phrases used.
25.6.5 Extending the Scope
The survey of theories and phenomena given in the previous sections has touched uponthe main approaches and results that can be found in the literature to date, though notupon every one of them in the same detail. Thus it has provided a survey of the mainstream of theorizing in this area. In what follows we want to indicate, again onlybriefly, what we think are two important directions for current and future research.
Whatever their differences all semantic theories considered above share certaincharacteristics, which are currently being challenged. One is that the semantics ofinterrogatives is considered from a relatively context-independent point of view. Thismust not be misunderstood: what we mean is not that the semantic objects assigned tointerrogatives are context-independent, on the contrary. Rather, what we want to drawattention to is that it is often taken for granted that the semantic objects as such canbe assigned in a relatively context-independent way. Consequently, semantic objectsassociated with interrogatives are in most cases total objects. Another feature thatcharacterizes almost all existing semantic analyses is the essentially static nature ofthe semantics they assign to interrogatives, a feature that is no doubt connected withthe frameworks in which these analyses are formulated.
Recently, semantics has witnessed a move towards more context-dependent anddynamic models of meaning. This development has occurred not just in natural lan-guage semantics, where it is connected with situation theory, discourse representationtheory, and dynamic semantics, but also in more logically and computationally ori-ented research. From these developments a new view on meaning and interpretation isemerging, in which context, in particular the epistemic context, and context change arekey notions. As such, it would seem to provide a framework that is eminently suitedfor an analysis of interrogatives.
25.6.5.1 Context-Dependency and Partiality
In a series of papers (see Ginzburg, 1995a,b) Ginzburg has developed a theory whichdiffers from mainstream semantical theories in a rather fundamental way. Ginzburg,who formulates his approach in the framework of situation theory, discusses sev-eral phenomena which he takes to indicate that the relation of answerhood (or, ashe calls it, “resolvedness”) is a partial and highly contextual one. He charges otherapproaches with taking a too absolute view on this relationship. This, he claims, is notjust descriptively incorrect, but also theoretically unsound.
The phenomena Ginzburg discusses have to do with several aspects of thequestion–answer relationship. One of them concerns fine-grainedness. This seems toplay a role in interpreting and answering such interrogatives as “Where am I?”, or in

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1128 — #70
1128 Handbook of Logic and Language
judging the truth of “John knows where he is”. It depends, Ginzburg argues, essen-tially on the context (of utterance) exactly how these expressions must be interpreted.Thus the interrogative “Where am I?” when uttered by someone stepping down froma plane at Schiphol Airport, obviously needs a different kind of answer than when itis uttered by someone stepping down from a taxi at the Dam square. For notice that,although both Schiphol Airport and the Dam square are located in Amsterdam, theanswer “In Amsterdam.” is not a good answer in the latter case, since it is not likelyto resolve a lack of knowledge of the questioner. In that situation a more fine-grainedset of answers is determined by interrogative and context.
Intentionality is another issue. It seems that the intentions of the questioner playa key role in determining what kind of answer is called for by an interrogative suchas “Who attended the lecture?”: Does it call for a specification of names, roles, oryet other aspects that “identify” individuals? Likewise, the goals and plans of thequestioner must be taken into account in answering such interrogatives as “How do Iget to Rotterdam from here?”.
According to Ginzburg the essentially context-dependent character challengesexhaustiveness, even in its weak form. These phenomena certainly constitute a majorchallenge for existing approaches. To what extent they can be modified to be able todeal with these issues remains open for the moment. Another issue is whether thesephenomena are particular to interrogatives, or rather concern interpretation in a widersense.
25.6.5.2 Dynamic Interpretation
As we observed above, all mainstream semantic analyses of interrogatives are cast ina static framework. The rise of dynamically oriented frameworks in semantics raisesthe question whether interrogatives are perhaps better analyzed in such a dynamicsetting. Several attempts have already been made to cast a semantics of interroga-tives in a dynamic mould. One early attempt is the work of Hintikka, who in devel-oping his framework of game theoretical semantics (e.g., see Hintikka, 1983b) hasalso paid attention to dynamic aspects of the meaning of interrogatives. This seemsquite natural: in the game between “I” and “Nature” questions have a clear func-tion, viz., that of steering the game by determining sets of moves.87 Hintikka hasalso used questions to implement a distinction in the epistemic setting as such, viz.,that between information which is deduced from given data, and information whichis obtained by asking questions and getting them answered. These types of infor-mation play a different role. In fact, the imperative-epistemic approach as such hasa distinct dynamic flavor, although the frameworks used, those of imperative and epis-temic logic, are not explicitly concerned with information change. More indirectly,dynamic aspects have been dealt with in work that is concerned with informationexchange in discourse structured by question–answer patterns (e.g., see Mayer, 1990).Also the work on pragmatic notions of answerhood (see Groenendijk and Stokhof,1984b) must be mentioned here. Catching on to later developments, Zeevat (1994)
87 There is also an obvious connection with dialog semantics here.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1129 — #71
Questions 1129
combined the Groenendijk and Stokhof semantics with Veltman’s update semantics(see Chapter 12).
There are several interesting empirical and methodological issues that arise here.First of all, the connection with topic–focus structures, and the relation with certainprinciples of discourse organization, have to be explored systematically. These issueshave been discussed by several authors, as we have noticed above, but not in a system-atic fashion. Another topic concerns anaphoric chains across utterances, where ques-tions seem to license more than assertions (“A man is walking in the park.” “Does hewear a black hat?”). Also, a dynamic framework, in which information exchange is thekey notion, seems to provide a natural surrounding for an account of exhaustiveness,which may be tied up with non-monotonicity of information exchange.
All in all, it seems that extending the scope of semantic theories of interroga-tives, giving due attention to their context-dependent character and analyzing themin a dynamic framework, holds much promise. For interrogatives are the structures innatural language par excellence which are concerned with information and informa-tion (ex)change. To be sure, the neat distinction between semantics and pragmaticsthat has enabled the semantics of interrogative structures to develop into a field of itsown, thereby becomes more subtle, perhaps even blurred. But that should not blind usto the reality of the intimate relationships that exist between meaning and use.
Thus, it may seem that we have come full circle, returning to where we started from,viz., the pragmatic approach. But appearances are deceiving here. For in traveling thisfar, we have indeed established the possibility of a semantics of interrogatives, as afield of its own. And extending its scope is not revoking its articles of faith.
Acknowledgments
We would like to thank Jelle Gerbrandy, and the participants of the Handbook Workshop, inparticular Jonathan Ginzburg, James Higginbotham, and Jaakko Hintikka, for their comments.We owe special thanks to Johan van Benthem for his many stimulating comments and sugges-tions, and, most of all, for his patience. Of course, thanking these people does not imply thatany of them agrees with the views expressed in this chapter, or is responsible in any way forremaining errors, oversights, inconsistencies, or other flaws that it, no doubt, still contains.
References
Åqvist, L., 1965. A New Approach to the Logical Theory of Interrogatives. Filosofiska Studies,Uppsala.
Austin, J.L., 1962. How to Do Things with Words. Oxford University Press, Oxford.Bäuerle, R., Zimmermann, T.E., 1991. Fragesätze/questions, in: von Stechow, A., Wunderlich,
D. (Eds.), Semantik/Semantics: An International Handbook of Contemporary Research. deGruyter, Berlin, pp. 333–348.
Belnap Jr., N.D., 1981. In: Bäuerle, R., Schwarze, C., von Stechow, A. (Eds.), Approaches tothe semantics of questions in natural language. Part I, Meaning, Use, and Interpretation ofLanguage. Walter de Gruyter, Pittsburgh, PA, pp. 22–29.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1130 — #72
1130 Handbook of Logic and Language
Belnap Jr., N.D., 1982. Questions and answers in Montague grammar, in: Peters, S., Saarinen,E. (Eds.), Processes, Beliefs, and Questions. Reidel, Dordrecht, pp. 165–198.
Belnap Jr., N.D., Steel Jr., T.B., 1976. The Logic of Questions and Answers. Yale UniversityPress, New Haven, CT.
Bennett, M., 1979. Questions in Montague grammar. IULC, Bloomington, IN.Berman, S., 1991. On the semantics and logical form of Wh-Clauses. PhD Dissertation, Uni-
versity of Massachusetts, Amherst, MA.Boër, S., Lycan, W., 1985. Knowing Who. MIT Press, Cambridge, MA.Bonomi, A., Casalengo, P., 1993. Only: association with focus in event semantics. Nat. Lang.
Semant. 2, 1–45.Chierchia, G., 1992–1993. Questions with quantifiers. Nat. Lang. Semant. 1, 181–234.Cresswell, M., 1973. Logics and Languages. Methuen, London.Egli, U., Schleichert, H., 1976. Bibliography of the theory of questions and answers, in: Belnap
Jr., N.D., Steel Jr., T.B. (Eds.), The Logic of Questions and Answers. Yale University Press,New Haven, CT, p. 209.
Engdahl, E., 1986. Constituent Questions. Reidel, Dordrecht.Fagin, R., 1974. Generalized first-order spectra and polynomial-time recognizable sets, in:
Karp, R.M. (Ed.), Complexity of Computation, SIAM-AMS Proceedings vol. 7. Societyof Industrial and Applied Mathematics, pp. 43–73.
Frege, G., 1918. Der Gedanke, Beiträge zur Philosophie des deutschen Idealismus vol. 1.(English translation: Geach, P., Black, M., 1960. Translations from the Philosophical Writ-ings of Gottlob Frege, Blackwell, Oxford).
Ginzburg, J., 1995a. Resolving questions I & II. Ling. Philos. 18, 459–527; 567–609.Ginzburg, J., 1995b. Interrogatives: questions, facts and dialogue, in: Lappin, S. (Ed.), Hand-
book of Contemporary Semantic Theory. Blackwell, Oxford, pp. 385–422.Groenendijk, J., Stokhof, M., 1982. Semantic analysis of Wh-complements. Ling. Philos. 5,
175–233.Groenendijk, J., Stokhof, M., 1983. Interrogative quantifiers and Skolem-functions, in: Ehlich,
K., van Riemsdijk, H. (Eds.), Connectedness in Sentence, Discourse, and Text. TilburgUniversity Press, Tilburg, pp. 71–110.
Groenendijk, J., Stokhof, M., 1984a. Studies on the semantics of questions and the pragmaticsof answers. Dissertation, University of Amsterdam, Amsterdam.
Groenendijk, J., Stokhof, M., 1984b. On the semantic of questions and the pragmatics ofanswers, in: Landman, F., Veltman, F. (Eds.), Varieties of Formal Semantics. Foris, Dor-drecht, pp. 143–170.
Groenendijk, J., Stokhof, M., 1989. Type-shifting rules and the semantics of interrogatives,in: Chierchia, G., Turner, R., Partee, B. (Eds.), Properties, Types and Meaning, vol. 2:Semantic Issues. Kluwer, Dordrecht, pp. 21–68.
Groenendijk, J., Stokhof, M., 1993. Interrogatives and adverbs of quantification, in: Bimbó,K., Máté, A. (Eds.), Proceedings of the Fourth Symposium on Logic and Language. ÁronPublishers, Budapest, pp. 1–29.
Hamblin, C.L., 1958. Questions, Australas. J. Philos. 36, 159–168.Hamblin, C.L., 1973. Questions in Montague English. Found. Lang. 10, 41–53.Harrah, D., 1984. The logic of questions, in: Gabbay, D., Guenthner, F. (Eds.), Handbook of
Philosophical Logic vol. II. Kluwer, Dordrecht, pp. 715–764.Hausser, R., 1983. The syntax and semantics of English mood, in: Kiefer, F. (Ed.), Questions
and Answers. Reidel, Dordrecht, pp. 97–158.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1131 — #73
Questions 1131
Hausser, R., Zaefferer, D., 1978. Questions and answers in a context-dependent Montague gram-mar, in: Guenthner, F., Schmidt, S.J. (Eds.), Formal Semantics and Pragmatics for NaturalLanguages. Reidel, Dordrecht, pp. 339–358.
Heim, I., 1994. Interrogative complements of know, IATL1, in: Buchalla, R., Mittwoch, A.(Eds.), Proceedings of the Ninth Annual Conference and the Workshop on Discourse ofthe Israel Association for Theoretical Linguistics. Academon, Jerusalem, pp. 128–144.
Hendriks, H., 1988. Generalized Generalized Quantifiers in Natural Natural Language. ILLC,Amsterdam.
Higginbotham, J., 1995. The semantics of questions, in: Lappin, S. (Ed.), Handbook of Con-temporary Semantic Theory. Blackwell, Oxford, pp. 361–384.
Higginbotham, J., May, R., 1981. Questions, quantifiers, and crossing. Ling. Rev. 1, 41–79.Hintikka, J., 1976. The semantics of questions and the questions of semantics. Acta. Philos.
Fennica 28, (4).Hintikka, J., 1983a. New foundations for a theory of questions and answers, in: Kiefer, F. (Ed.),
Questions and Answers. Reidel, Dordrecht, pp. 159–190.Hintikka, J., 1983b. The Game of Language. Reidel, Dordrecht.Hintikka, J., Hintikka, M., 1989. The Logic of Epistemology and the Epistemology of Logic.
Kluwer, Dordrecht.Kanellakis, P., 1990. Elements of relational database theory, in: van Leeuwen, J. (Ed.), Hand-
book of Theoretical Computer Science. Elsevier, Amsterdam, pp. 1073–1156.Karttunen, L., 1977. Syntax and semantics of questions. Ling. Philos. 1, 3–44.Karttunen, L., Peters, S., 1980. Interrogative quantifiers, in: Rohrer, C. (Ed.), Time, Tense, and
Quantifiers. Niemeyer Verlag, Tübingen, pp. 181–206.Lahiri, U., 1991. Embedded Interrogatives and the Predicates That Embed Them. Dissertation,
MIT Press, Cambridge, MA.Lewis, D., 1970. General semantics. Synthese 22, 18–67.Mayer, R., 1990. The release of information in discourse: compactness, compression, and rele-
vance. J. Semant. 7, 175–219.Prior, M., Prior, A., 1955. Erotetic logic. Philos. Rev. 64, 43–59.Rexach, J.G., 1996. Semantic properties of interrogative generalized quantifiers, in: Dekker, P.,
Stokhof, M. (Eds.), Proceedings of the Tenth Amsterdam Colloquium. ILLC, Amsterdam,pp. 319–338.
Rooth, M., 1992. A theory of focus interpretation. Nat. Lang. Semant. 1, 75–116.Scha, R., 1983. Logical Foundations for Question Answering. Dissertation, University of
Groningen, the Netherlands.Searle, J., 1969. Speech Acts. Cambridge University Press, Cambridge, MA.Stenius, E., 1967. Mood and language game. Synthese 17, 254–274.Tichy, P., 1978. Questions, answers, and logic. Amer. Philos. Q. 15, 275–284.Van Benthem, J., 1989a. Polyadic quantification. Ling. Philos. 12, 437–464.Van Benthem, J., 1989b. Semantic parallels in natural language and computation, in:
Ebbinghaus, H.D. et al. (Eds.), Logic Colloquium. Granada 1987. North-Holland, Ams-terdam, pp. 331–375.
Van Kuppevelt, J., 1991. Topic en comment. Dissertation, University of Nijmegen, the Nether-lands.
Vanderveken, D., 1990. Meaning and Speech Acts, 2 vols. Cambridge University Press, Cam-bridge, MA.
Zeevat, H., 1994. Applying an exhaustivity operator in update semantics, in: Kamp, H.(Ed.), Ellipsis, Tense, and Questions. ILLC (Dyana-deliverable R2.2.B), Amsterdam,pp. 233–269.

“29-ch25-1059-1132-9780444537263” — 2010/11/29 — 21:09 — page 1132 — #74
This page intentionally left blank

“30-ch26-1133-1146-9780444537263” — 2010/11/30 — 3:44 — page 1133 — #1
26 Questions: Logic andInteractions(Update of Chapter 25)Jonathan Ginzburg!
UFR d’Etudes Anglophones, Université Paris-Diderot, 10 rue Charles V,750004 Paris, France, E-mail: [email protected]
26.1 Overview
The early years of the twenty-first century have seen an increased interest in questions.This is partly due to the rise of interest in interaction, where questions play a key role.As components of context, they are significant actors in grammatical phenomena suchas ellipsis and focus. They are of fundamental importance in explicating inquiry andof course in question answering.
This update to Jeroen Groenendijk and Martin Stokhof’s Chapter 25 focuses on thetwo main areas of recent logico-linguistic research on questions: first, the logic andontology of questions—what are questions and how do they relate to other seman-tic entities? Second, questions in interaction—issues such as how questions affectcontext, why questions get asked, what range of responses—not just answers—doquestions give rise to. The boundaries between these two areas is somewhat artificialand, therefore, not easy to demarcate, particularly in an era where meanings are oftenexplicated in terms of context change. A brief indication of other research in the areais provided before the concluding remarks.
26.2 The Ontology and Logic of Questions
Over the last decade work on the ontology and logic of questions can be groupedinto roughly three groups, though there is considerable variation in approach andassumptions even within the groups. The first group bases itself on the continueddevelopment of erotetic logic, a logic in which both questions and propositions canfigure in premises and conclusions of inference rules. The second approach, takingthe partition view of questions (Groenendijk and Stokhof, 1997) as its inspiration,attempts to integrate questions and propositions in a logic which is minimally
! I am grateful for comments received from Johan van Benthem, Jeroen Groenendijk, Alice ter Meulen, andAndrzej Wiśniewski. Alice and Johan’s patience and encouragement has been of significant help.
Handbook of Logic and Language. DOI: 10.1016/B978-0-444-53726-3.00026-8c" 2011 Elsevier B.V. All rights reserved.

“30-ch26-1133-1146-9780444537263” — 2010/11/30 — 0:10 — page 1134 — #2
1134 Handbook of Logic and Language
distinct from “standard” logics, primarily (a modalized) propositional logic. The thirdapproach associates interrogativity with the semantic operation of !-abstraction.
26.2.1 Erotetic Logic
Work in erotetic logic stretches back to the Priors and Kubiński in the 1950s. In recentyears it has been developed, particularly in works oriented towards applications in thephilosophy of science and inquiry, by Hintikka and his associates (see for examplepapers collected in Hintikka, 1999) and works by Wiśniewski and his associates (seefor example Wiśniewski, 2001; Wiśniewski, 2003), which have similar applicationsbut also a somewhat more linguistic bent. For this reason I focus on the latter here.
The starting point of Inferential Erotetic Logic (IEL) is the mundane but typicallyneglected observation that questions figure both as premises and as conclusions ininference:
(1) a. Who should we invite to the conference? Clearly someone with an interesting researchagenda. But that raises the thorny issue of where we can find such a person.
b. Where should we go on holiday? Ideally somewhere closeby with a lot of sunshine.Which raises the issue of whether there is such a place at all.
An erotetic inference, then, takes place when a question is concluded from premisesof declarative sentences and/or a question, and the task of IEL is to characterize (theconcept of) validity of such inferences. Basic notions the theory explicates are evoca-tion of questions by sets of declaratives and implication of questions by sets of declar-atives and questions. The logic distinguishes declaratives (d-wffs) and interrogatives(e-wffs). In general, it adopts a non-reductionist view of questions, remains open tovarious implementations thereof, as well as maintaining semantic flexibility, as long astruth is definable for d-wffs. On the syntactic level, the formal language assigns to aninterrogative Q a set of sentences dQ which are its direct answers. A key componentof the analysis is the use of m(ultiple)-c(onclusion) entailment (Shoesmith and Smiley,1978)—the truth of a set X of premises guarantees the truth of at least one conclusion.MC-entailment helps define evocation and erotetic implication:
(2) X evokes a question Q iff X mc-entails dQ, the set of sentences which are thedirect answers of Q, but for no A ! dQ, X |= A
Erotetic implication involves each direct answer to the implied question togetherwith the premises mc-entailing a proper subset of the answers to the implying ques-tion. So an implied question is potentially cognitively useful relative to the implyingquestion:
(3) A question Q implies a question Q1 on the basis of a set of d-wffs X iff
! for each A ! dQ: X " {A}mc # entailsdQ1! for each B ! dQ1 there exists a non-empty proper subset Y of dQ such that X " {B}mc#
entailsY
This leads on to the notion of erotetic search scenario (Wiśniewski, 2003)—a clus-ter of interrelated inference chains each of which starts with the same issue, proceeds

“30-ch26-1133-1146-9780444537263” — 2010/11/29 — 21:09 — page 1135 — #3
Questions: Logic and Interactions 1135
via a mix of classical deductive and erotetic inferences, and terminates with an answer.The notions provided by IEL have applications that include the characterization ofinquiry, the semantics of why questions, the characterization of query responses in dia-logue, and proof theory (see for example Leszczyńska-Jasion, 2009; Urbanski, 2001;Wiśniewski et al., 2005).
26.2.2 Interrogativizing Propositional Logic
Over the last decade there have been a number of approaches that strive to integratequestions in ways that require ‘minimal’ extensions to standard logics. Questions, onthese approaches, are of a similar semantic type to propositions, a strategy that bringswith it some clear advantages—as well as some risks.
Nelken and Francez (2002) develop an extensional (or as they later suggest quasi-extensional) approach to interrogatives using a five-valued logic. This is achievedby interpreting the meaning of questions as elements of type t, and re-interpretingthe domain of type t as a bilattice (Fitting, 1991; Ginsberg, 1990). The bilattice hasfive truth values: in addition to the standard True and False, construed epistemically,and the reasonably well known Unknown, it has two interrogatively-oriented values:Resolved and Unresolved. Valuations can now be extended to epistemic and interrog-ative operators L! and ?! as follows:
(4) a. v(L!) = t if v(!) = T; v(L!) = f if v(!) ! {F, uk}b. v(?!) = r if v(!) ! {T, F}; v(?!) = ur if v(!) = uk
Answerhood, construed exhaustively, can be defined straightforwardly:
(5) p answers q if whenever p is assigned t, q is assigned r.
One potential pay-off for such an approach is that by extending the standard truthtables it can provide a relatively simple—without for example the complex type rais-ing of Groenendijk and Stokhof (1989)—account of Boolean operators that appliesuniformly to declaratives and interrogatives:
(6) a. The machine is broken or does it just need fuel?b. If Millie didn’t break the vase, then who did?
Of course, with respect to natural language, such an account raises various issues—for instance, why is there no negation of interrogatives or why does a hybrid as in(7b), predicted to be interrogative, resist embedding by ‘wonder’? With respect to theformer, Nelken and Francez offer an interesting pragmatic explanation.
(7) a. #It is not the case whether Millie left.b. # Mo wonders that Bo left but who arrived in his place.
This general approach has been refined and extended in Nelken and Shan (2006).Here the setting is first-order modal epistemic logic (with the spirit of Hintikkaand Åqvist hovering in the background). Questions are identified with (the knowl-edge of) their exhaustive answerhood conditions, as in (8); though by appropriate

“30-ch26-1133-1146-9780444537263” — 2010/11/29 — 21:09 — page 1136 — #4
1136 Handbook of Logic and Language
type raising the knowledge modality is abstracted over to allow questions to occurembedded.
(8) a. ?p = def !p " !¬pb. ?x.p(x) = def #x!p(x) " !¬p(x)
Nelken and Shan’s account extends the account of Nelken and Francez (2002),without certain arguably problematic assumptions the latter require. Nelken and Shanpropose an interesting notion of question acceptability, building on Groenendijk’snotion of licensing (see discussion in section 26.3) to predict what question meaningsare available in natural language:
(9) A question is acceptable in natural language only if it licenses a non-trivial answer.That is, Q licenses ?A, where A is neither tautologically true nor tautologicallyfalse.
This offers inter alia a novel explanation for the limited acceptability of disjoinedinterrogatives (relating to earlier ideas of Grice (1989) and Simmons (2002)). An addi-tional approach, which falls under the rubric of interrogativizing propositional logic,is Inquisitive Semantics, which is discussed in section 26.3.
26.2.3 Questions as Propositional Abstracts
The view of questions as "-abstracts (see for example Hull, 1975; Scha, 1983), a viewthat fell out of the mainstream of linguistic semantics with the rise of the higher-orderview of questions, has been revived and generalized by Ginzburg and Sag (2000) andby Krifka (2001).
One of the traditional attractions of identifying questions with abstracts has beenthat they provide the requisite semantic apparatus for short answer resolution (Wholeft? Bo; Did Bo leave? Yes, etc). However, therein also lies danger because this sug-gests that, for example, unary wh-questions have the same semantic type as properties,which seems counterintuitive given data such as (10):
(10) a. Some man is happy. So we know that happiness and manfulness are not incompat-ible. # So we know that the question of who is happy and who is a man are notincompatible.
b. A: What was Bill yesterday? B: Happy. B: #The question of who is happy.
Ginzburg and Sag (2000) develop their account within the situation theoretic-motivated approach to ontology developed in Seligman and Moss (1997). Thestructure they axiomatize, a Situational Universe with Abstract Entities (SU+AE),involves propositions and other abstract semantic entities (e.g. outcomes—the deno-tata of imperatives, facts—the denotata of exclamatives) being constructed in termsof ‘concrete’ entities of the ontology such as situations and situation types. Anadditional assumption made is that the semantic universe is closed under simulta-neous abstraction, a semantic operation akin to "-abstraction with one significant

“30-ch26-1133-1146-9780444537263” — 2010/11/29 — 21:09 — page 1137 — #5
Questions: Logic and Interactions 1137
extension: abstraction is over sets of elements, including the empty set. Moreover,abstraction (including over the empty set) is potent—the body out of which abstractionoccurs is distinct from the abstract. Within such a setting propositions and situationtypes are naturally distinguished and hence propositional abstracts—questions—arenot conflated with situation type abstracts—properties—and can be assigned a uniformtype. Polar questions are 0-ary abstracts, whereas wh-questions are n-ary abstracts forn $ 1. The fact that questions involve abstraction over propositions receives empiri-cal support from evidence concerning the distribution of in situ wh-phrases in English,where proposition-denoting clauses are the sole environment out of which wh-phrasesallow (non-reprise) meanings to emerge.
In subsequent work, the reliance on the situation theoretic notion of abstraction hasbeen eliminated. Ginzburg (2005) shows how to formulate a theory of questions aspropositional abstracts in Type Theory with Records (TTR), a model theoretic offshootof Constructive Type Theory (Cooper, 2005), while using the standard TTR notion ofabstraction.
Ginzburg (1995) argued that exhaustiveness is an agent-specific notion and, con-sequently, cannot serve as the semantic underpinning of questions. And yet, inter-locuters can share intuitions about the coherence of responses to queries. Ginzburgand Sag (2000) show how within an SU+AE propositional abstracts can be usedto characterize a wide range of notions of answerhood from strong exhaustivenessthrough resolvedness—which underwrites the semantics of resolutive predicates—toaboutness, needed to characterize intuitions concerning the coherence of responses toqueries. Thus, questions serve to underspecify answerhood.
The fact that propositions are constructed from situations and situation types hasa consequence that, in contrast to approaches where questions are characterized interms of exhaustive answerhood conditions, positive and negative polar interrogativesare assigned distinct denotations. This means that the ontology can explicate the dis-tinct presuppositional backgrounds associated with positive and negative polar inter-rogatives (Hoepelmann, 1983) and can be linked to factuality conditions of negativesituation types (Cooper, 1998). These contextual differences gives rise in some lan-guages, including French and Georgian, to distinct words to affirm a positive polarquestion (oui, xo) and a negative polar question (si, diax). Nonetheless, given the def-initions of answerhood available in this system, positive and negative interrogativesspecify identical answerhood relations.
Krifka (2001) develops an account of questions as propositional abstracts within astructured meanings framework (Krifka, 1992). Krifka proposes question contents arepairs < B, R >, with B a propositional abstract and R a domain for B, with ID andNEG in (11b) denoting the identity and negation functions, respectively:
(11) a. Who did Mary see %& < "x[see(x)(M)], PERSON >
b. Did Mary see Bo %& < "f [ f (see(B)(M))], {ID, NEG} >
The structured meanings framework analyzes the content of declaratives in an anal-ogous fashion, contents having the form < B, F >, with B(ackground) a propositional

“30-ch26-1133-1146-9780444537263” — 2010/11/29 — 21:09 — page 1138 — #6
1138 Handbook of Logic and Language
abstract and F(ocus) an entity appropriate as an argument for B. A criterion forquestion-answer congruence as manifested in English by pitch accent placement canthen be formulated straightforwardly:
(12) A proposition < B', F > is congruent with a question < B, R > iff B = B' andF ! R
Krifka shows that this criterion enables a wide variety of tricky cases of focal pitchassignment to be handled. Such cases of over and under-focussing are difficult for themore coarse grained approaches within the classical Hamblin picture. Krifka furtherillustrates the need for the fine grain supplied by propositional abstracts to distinguishthe contents of certain classes of alternative and polar questions. He also argues thatcertain readings of multiple wh-interrogatives involve the specification of functions—where functions are conceived in terms familiar from constructive type theory. Build-ing up such functions, he suggests, requires access to the question constituents and thebackground of the sentence, as provided by structured meanings.
26.3 Questions in Interaction
The lion’s share of work on questions in the late twentieth century was driven byphenomena centering around embedded interrogatives, due primarily to worries thatthe unembedded variety are tainted by pragmatic complexity. Recent work, however,driven by the need to tackle dialog, has moved to offer formal accounts of semantic andpragmatic aspects relating to query uses. Sloganistically, one might adapt Hamblin’sfamous dictum as follows: to know the meaning of a query is to understand whatcounts as a relevant response to that query. Here ‘relevant’ can be understood in anumber of senses, including ‘optimal’ and ‘coherent’.
The approaches surveyed below differ, in part, by their methodology: on the onehand, approaches for which the starting point is a logic (or family thereof) and forwhich an important constraint is to develop a framework that can accommodate phe-nomena while deviating minimally from the starting point. An alternative perspec-tive is more driven by empirical conversational phenomena and the need to provide afairly detailed linguistic analysis—developing a theory of context the metamathemat-ical bounds of which are more open ended.
26.3.1 QUD-Oriented Approaches
One approach to explicating the effect of queries on context has been developed withinthe KoS framework (Fernández, 2006; Ginzburg, 1994, 2010; Ginzburg and Cooper,2004; Ginzburg and Fernández, 2010; Larsson, 2002; Purver, 2006 and, indepen-dently, by Roberts, 1996). Common to these approaches is viewing a dynamic andpartially ordered repository of questions—Questions Under Discussion (QUD)—as akey component of context.
Work in the KoS framework aims to provide a theory of relevance, here in the‘coherence’ sense, that can explain the coherence and interpretability of responses

“30-ch26-1133-1146-9780444537263” — 2010/11/29 — 21:09 — page 1139 — #7
Questions: Logic and Interactions 1139
to a query, exemplified in (13). Relevance has a number of aspects that go beyond‘semantic answerhood’, including metacommunicative (13b), metadiscursive (13c),and genre-based (13d) aspects:
(13) Carla: Are you voting for Tory?a. Denise: I might.b. Denise: Who do you mean ‘Tory’?c. Denise: I don’t know.d. Denise: What voting system is in use?
Pretheoretically, relevance relates an utterance u to an agent’s information state Ijust in case there is a way to successfully update I with u. Thus, defining relevanceinvolves interplay between semantic ontology, grammar and interaction conventions.This requires a theory that allows such relationships to be formulated. For this purposeType Theory with Records is employed. This enables simultaneous reference to bothutterances and utterance types, a key desideratum for modelling metacommunicativeinteraction. The formalism can, consequently, be used to build a semantic ontology,and to write conversational interaction and grammar rules.
The main emphasis in this domain has been on explicating two main classes ofentities: (a) the dialogue gameboard (DGB), an entity associated with each convers-ing agent, corresponding in essence to that agent’s record of the publicized aspectsof interaction. The DGB is modeled as a record type with fields tracking inter aliaturn ownership, shared assumptions, moves, and QUD; and (b) conversational rules,the regularities that describe how conversational interaction changes dialogue game-boards.
A general constraint (Q(uestion)-SPEC(ificity)) characterizes the contextualbackground of reactive queries and assertions. The rule states that if q is the maxi-mal element of QUD, then either participant may make a q-specific move—an utter-ance that is a partial answer to or sub-question of q. Disagreement is accommodatedsince asserting p makes p?, the maximal element in QUD, and p?–specific utterancesinclude disagreements. Self-answering is directly accommodated by QSPEC given thatit licenses utterances specific to the maximal element in QUD regardless of who thespeaker of the most recent Move is. Moreover, the accounts of querying and assertionscale up to multilogue: conversations involving more than two participants. Given A’squery q, QSPEC and the ordering on QUD ensures that q-specific utterances can begiven by multiple participants as long as q remains under discussion. As far as asser-tion goes, the default possibility that emerges is communal acceptance—acceptanceby one conversationalist can count as acceptance by all other addressees of an asser-tion, a possibility whose robustness is supported by corpus evidence.
Trying to operationalize genre-based relevance presupposes that we can classifyconversations into various genres, a term we use following Bakhtin (1986) to denotea particular type of interactional domain (e.g. interaction at a train station, at a bak-ery, ‘casual chat’, etc.). There are at present remarkably few such taxonomies (thoughsee Allwood (1999) for an informal one). What one can do within KoS is to developclassifications of conversations into genres. One way is by providing a description ofan information state of an agent who has successfully completed such a conversation.

“30-ch26-1133-1146-9780444537263” — 2010/11/29 — 21:09 — page 1140 — #8
1140 Handbook of Logic and Language
Final states of a conversation can be provided in terms of shared assumptions, moves,and an additional field Questions No (longer) Under Discussion (QNUD)—a list ofissues characteristic of the genre which will have been resolved in interaction. This,in turn, allows one to offer a characterization of the contextual background of initi-ating moves, moves that occur during conversation initially and periodically duringextended interactions. Roughly, one can make an initiating move m0 if one believesthat the current conversation updated with m0 can be anticipated to conclude as finalstate dgb1, which is a conversation of type G0.
Probably the main innovation of KoS is the integration of illocutionary and meta-communicative interaction. This is explicated in terms of the dynamics of the locu-tionary proposition pu, an Austinian proposition (Barwise and Etchemendy, 1987)defined by the utterance and Tu, a grammatical type for classifying u that emergesduring the process of parsing u. In the immediate aftermath of a speech event u,the DGB gets updated with pu. In case pu is true—Tu completely classifies u—pubecomes the LatestMove of the DGB and relevance possibilities discussed in the pre-vious paragraph come into operation. The other contextual branch involves clarifica-tion interaction. The coherence of clarification requests such as (13c) can be specifiedby means of a uniform class of conversational rules, dubbed Clarification ContextUpdate Rules (CCURs) in Ginzburg (2010). Each CCUR specifies a question thatgets accommodated as the maximal element of QUD built up from a sub-utteranceu1 of the target utterance and from its corresponding utterance type (e.g. ‘What didspeaker mean by u1’). Common to all CCURs is a license to make an utterance whichis co-propositional with the maximal element of QUD. CoPropositionality for twoquestions means that, modulo their domain, the questions involve similar answers.
26.3.2 Question-Integrating Logics
There is an alternative strategy for explicating the effect of questions on context interms of operations on information states conceived in standard possible worlds terms.Groenendijk (2006) defines the game of interrogation—a logical idealization ofthe process of cooperative information exchange. Groenendijk uses a simple query-language, the language from (Groenendijk and Stokhof, 1997)—first-order predicatelogic enriched with simplex interrogatives with the corresponding partition semantics.As a means of combining the data emanating from declaratives and the partition rep-resenting the issues, a context C is taken to be a symmetric and transitive relation onthe set of possible worlds W. Context change potentials can be assigned uniformly toindicatives and interrogatives, but they have different effects on context:
(14) a. An indicative !! is informative iff it eliminates a pair of worlds from the context assoon as !! is false in one of the worlds of the pair.
b. An interrogative !? is inquisitive iff it eliminates a pair of worlds (or disconnectstwo worlds) if they belong to different alternatives, i.e., if the two worlds differ insuch a way that the question would receive a different answer in them.
This set-up allows notions of consistency and entailment to be defined that applyindiscriminately to propositions and questions, notions that enable the formulation of

“30-ch26-1133-1146-9780444537263” — 2010/11/29 — 21:09 — page 1141 — #9
Questions: Logic and Interactions 1141
Quality and Quantity requirements for the cooperative exchange of information. Themain novelty is the notion of licensing, a notion of strict relevance: a sentence ! is con-textually licensed if whenever it causes a world to be eliminated from the data, it doesso also to all worlds related to it. This means that ! only addresses the currently liveissues. Licensing gives rise to notions of answerhood that are significantly more inclu-sive than given by partitions. For instance, non-exhaustified quantified propositions(e.g. (xPx and #xPx) are licensed as answers to ?xPx. Groenendijk (2006) shows howto apply these notions in ambiguity resolution based on the assumption that an inter-pretation is chosen in such a way that the emergent discourse is pertinent—a notionthat encapsulates consistency, non-redundancy, and licensing. For a related approachsee Dekker (2006) who, on the basis of a synthesis of dynamic semantics, Griceanpragmatics, and relevance theory, shows how to characterize the optimality of adiscourse.
This general strategy is taken a step further in Inquisitive Semantics (Groenendijk,2009; Groenendijk and Roelofsen, 2009). Syntactically no distinction is made betweendeclaratives and interrogatives—standard propositional logic syntax is employed.Sentences are associated with sets of alternative possibilities. Sentences are infor-mative if they contain at least one possibility and also exclude at least one possi-bility. Sentences are inquisitive if they contain at least two possibilities. The semanticsis set up in particular to ensure that sentences of the form ¬! are not inquisitive,whereas sentences of the form ! " # typically are. Thus, the polar question p? isidentified with the disjunction p " ¬p. In this approach a single uniform interpreta-tion of implication is provided that deals both with conditional questions and condi-tional assertions. Moreover, problems that beset Hamblin picture accounts concerningthe distinction between alternative and polar questions (see the earlier discussionof structured meanings) can be resolved straightforwardly. A related approach, castwithin (an extension of) Dynamic Epistemic Logic, has been developed by vanBenthem and Minicǎ (2009). They develop a logic which makes explicit the askingof questions—allowing one to track the dynamics of issues as they get introduced andare potentially resolved. Two particularly interesting features of this approach are:(a) it enables the modeling of multi-agent scenarios; and (b) its development of tem-poral protocols that allow one to encode constraints on allowable sequences of inter-rogations (cf. our earlier discussion of genres).
A number of works have refined the partition theory to enable it to accommodatethe agent-relative context dependence that has been argued to affect exhaustiveness.Aloni (2005) achieves this by defining partitions using individual concepts rather thanrigidly designating variables. van Rooy (2003a) links up semantic theory with decisiontheory (following the lead of Parikh (1992)) in developing an account of why queriesarise. van Rooy adopts the assumption that it is context dependent whether a propo-sition completely answers a question or not. He maintains the strategy that a questionis to be identified with its set of resolving answers, but assumes that the interpreta-tion of a wh-interrogative is underspecified by its conventional meaning. Crucially, heoffers a very explicit proposal as to how the underspecification is to be resolved—proposing that it be viewed as a decision problem in the sense of Decision Theory(e.g. Savage, 1954). Decision problems are conceived of via the notion of the

“30-ch26-1133-1146-9780444537263” — 2010/11/29 — 21:09 — page 1142 — #10
1142 Handbook of Logic and Language
expected utility of an action a. This allows the characterization of various keynotions:
! The utility of proposition C, UV(C): calculated as the difference between the expectedutility of the action which has maximal expected utility in case one may choose after onelearns that C is true, and correspondingly before one learns that C is true.
! The expected utility of a question: calculated as the average expected utility of the answerthat will be given.
! Information C resolves a decision problem: if after learning C, one of the actions dom-inates all other actions, i.e. if in each resulting world no action has a higher utility thanthis one.
Using decision theoretic notions allows one also to formulate a solution to prob-lems such as the required exhaustiveness of an answer and determining the domain ofquantification of a question. This is done by maximizing the relevance of a question—the expected utility value of the resulting question, i.e., partition, should be as high aspossible. This has the result that all individuals that could be relevant for the agent’sdecision should be in the domain.
26.3.3 Questions in SDRT
In a series of works Asher and Lascarides (1998, 2003) scale up Segmented Dis-course Representation Theory (SDRT), a theory originally intended to explicate thecoherence of text to provide a theory of coherence of questions in dialogue. Agentsconstruct a discourse structure (an SDRS) incrementally, as a conversation unfolds.Asher and Lascarides argue that two logics are involved in NL inference: a decidableglue logic for constructing SDRSs and a rich logic of information content. Rhetoricalrelations link pairs of speech acts—each relation corresponds to a speech act type,with the second relatum the appropriate background context. For instance, variousanswer-classifying relations relate a proposition with a prior query. This extendsspeech act theory intersententially (see discussion in Groenendijk and Stokhof,1997, pp. 1064–1073). Rhetorical relations are posited only if they have concretecontext change potential effects, for instance imposing constraints on antecedents onanaphora. The current utterance is coherent for a given agent if the agent can computea rhetorical relation that connects it to her SDRS and also a rhetorical relationintended by the speaker. In this framework a detailed theory of query/responsecoherence, able to deduce various implicatures, is developed, by formulating axiomsthat explicate various rhetorical relations. These range from an essentially semanticQuestionAnswerPair (QAP) that relates a true direct answer to a query, throughIndirectQuestionAnswerPair (IQAP) that relates a proposition that entails a truedirect answer relative to an agent’s SDRS, to (Not Enough Information) NEI,which characterizes pragmatically unsatisfactory responses. By making reference toagents’ plans, a precise and detailed characterization of query responses exemplifiedby (15a) can be provided. This is based on the axiom on the rhetorical relationQ(uery)-Elab(oration) informally summarized in (15b):

“30-ch26-1133-1146-9780444537263” — 2010/11/29 — 21:09 — page 1143 — #11
Questions: Logic and Interactions 1143
(15) a. A: When shall we meet? B: Are you free on the 18th?b. If Q-Elab($, %) holds between an utterance $ uttered by A, where g is a goal asso-
ciated by convention with utterances of the type $, and the question % uttered by B,then any answer to % must elaborate a plan to achieve g.
26.4 Other Question-Related Work
There has been much additional work on question-related issues over the last decade.This includes:
! Work on the knowing that v. knowing how distinction: the paper (Stanley and Williamson,2001) stimulated many reactions collected in Bengson and Moffett (2010).
! Negative Polarity Items in questions: van Rooy, 2003b; Guerzoni and Sharvit, 2007.! Echo/Reprise questions: Noh, 1998; Ginzburg and Sag, 2000.! ‘how’-questions: Asher and Lascarides, 1998; Jaworski, 2009.! Predicates that select for interrogatives: Ginzburg and Sag, 2000; Lahiri, 2002; Beck and
Sharvit, 2002—the latter two references address the quantificational variability effect.! polar questions: Romero and Han, 2004; Asher and Reese, 2005.
26.5 Conclusions
As this chapter has indicated, there is still vigorous discussion concerning the issueof what questions are and how best to characterize them. Nonetheless, there seemsto be an emerging consensus about the need for adopting a dialogical perspectivewithin which such characterization should take place. This entails the need to providea detailed account of the response space of a query, though the empirical range ofthis is still far from generally agreed. Queries provided as responses are an area onwhich there is much emerging and distinctive research, from all types of frameworkssurveyed here.
Another area where there has been renewed engagement and progress concernsBoolean operations on questions and propositions, including mixed cases. Detailedempirical work is still needed in combination with formal accounts, as the new possi-bilities that have emerged also lead to overgeneration unless suitably constrained.
As is common in semantics, the tension between achieving empirical v. cognitivev. logical adequacy is continually apparent. The extent to which all three can be com-bined remains an open question one hopes will be resolved positively.
References
Allwood, J., 1999. The Swedish spoken language corpus at Göteborg University. Proceedings ofFonetik 99, Gothenburg Papers in Theoretical Linguistics, vol. 81. University of Göteborg,Sweden, pp. 5–9.
Aloni, M., 2005. A formal treatment of the pragmatics of questions and attitudes. Ling. Philos.28, 505–539.

“30-ch26-1133-1146-9780444537263” — 2010/11/29 — 21:09 — page 1144 — #12
1144 Handbook of Logic and Language
Asher, N., Lascarides, A., 1998. Questions in dialogue. Ling. Philos. 21, 237–309.Asher, N., Lascarides, A., 2003. Logics of Conversation. Cambridge University Press,
Cambridge, MA, UK.Asher, N., Reese, B., 2005. Negative bias in polar questions, in: Maier, E., Bary, C., Huitink, J.
(Eds.), Proceedings of SuB9, NCS, Nijmegen, the Netherlands, pp. 30–43.Bakhtin, M., 1986. Speech Genres and Other Late Essays. University of Texas Press, Austin,
Texas, TX.Barwise, J., Etchemendy, J., 1987. The Liar. Oxford University Press, New York.Beck, S., Sharvit, Y., 2002. Pluralities of questions. J. Semant. 19 (2), 105.Bengson, J., Moffett, M. (Eds.), 2010. Knowing How: Essays on Knowledge, Mind, and Action.
Oxford University Press, Oxford.Cooper, R., 1998. Austinian propositions, Davidsonian events and perception complements, in:
Ginzburg, J., Khasidashvili, Z., Levy, J.J., Vallduvi, E., Vogel, C. (Eds.), The Tbilisi Sym-posium on Logic, Language, and Computation: Selected Papers, Foundations of Logic,Language, and Information. CSLI Publications, Stanford, CA, pp. 19–34.
Cooper, R., 2005. Austinian truth, attitudes and type theory. Res. Lang. Comput. vol. 3, 4,333–362.
Dekker, P., 2006. Optimal inquisitive discourse, in: Aloni, M., Butler, A., Dekker, P. (Eds.),Questions in Dynamic Semantics, Current Research in the Semantics/Pragmatics Interface,vol. 17. Elsevier, Amsterdam, pp. 83–102.
Fernández, R., 2006. Non-Sentential Utterances in Dialogue: Classification, Resolution andUse. PhD thesis, King’s College, London.
Fitting, M., 1991. Bilattices and the semantics of logic programming. J. Logic Program. 11,91–116.
Ginsberg, M., 1990. Bilattices and modal operators. J. Logic Comput. 1 (1), 41–69.Ginzburg, J., 1994. An update semantics for dialogue, in: Bunt, H. (Ed.), Proceedings of the 1st
International Workshop on Computational Semantics. ITK, Tilburg University, Tilburg,pp. 111–120.
Ginzburg, J., 1995. Resolving questions, i. Ling. Philos. 18, 459–527.Ginzburg, J., 2005. Abstraction and ontology: questions as propositional abstracts in construc-
tive type theory. J. Logic Comput. Oxford University Press, 15 (2), 113–130.Ginzburg, J., 2010. The Interactive Stance: Meaning for Conversation. Draft available from
www.dcs.kcl.ac.uk/staff/ginzburg/tis1.pdf. To appear in 2011, Oxford University Press,Oxford.
Ginzburg, J., Cooper, R., 2004. Clarification, ellipsis, and the nature of contextual updates. Ling.Philos. 27 (3), 297–366.
Ginzburg, J., Fernández, R., 2010. Dialogue, in: Clark, A., Fox, C., Lappin, S. (Eds.), Handbookof Computational Linguistics and Natural Language. Blackwell, Oxford, pp. 429–481.
Ginzburg, J., Sag, I.A., 2000. Interrogative Investigations: The Form, Meaning and Use ofEnglish Interrogatives, No. 123 in CSLI Lecture Notes. CSLI Publications, Stanford, CA.
Grice, H.P., 1989. Studies in the Ways of Words. Harvard University Press, Cambridge, MA,Reprinted from a 1957 article.
Groenendijk, J., 2006. The logic of interrogation, in: Aloni, M., Butler, A., Dekker, P. (Eds.),Questions in Dynamic Semantics, Current Research in the Semantics/Pragmatics Inter-face, vol. 17. Elsevier, Amsterdam, pp. 43–62. An earlier version appeared in 1999in the Proceedings of SALT 9 under the title ‘The Logic of Interrogation. Classicalversion’.

“30-ch26-1133-1146-9780444537263” — 2010/11/29 — 21:09 — page 1145 — #13
Questions: Logic and Interactions 1145
Groenendijk, J., 2009. Inquisitive semantics: two possibilities for disjunction, in: Bosch, P.,Gabelaia, D., Lang, J. (Eds.), Proceedings of The Tbilisi Symposium on Logic, Lan-guage, and Computation 2007, Lecture Notes in Artificial Intelligence. Springer, Berlin,pp. 80–94.
Groenendijk, J., Roelofsen, F., 2009. Inquisitive semantics and pragmatics, in: Larrazabel, J.M.,Zubeldia, L. (Eds.), Meaning, Content, and Argument: Proceedings of the ILCLI Inter-national Workshop on Semantics, Pragmatics, and Rhetoric. www.illc.uva.nl/inquisitive-semantics.
Groenendijk, J., Stokhof, M., 1989. Type shifting and the semantics of interrogatives, in: Chier-chia, G., Turner, R., Partee, B. (Eds.), Properties, Types, and Meaning. Studies in Linguis-tics and Philosophy, vol. 2. Kluwer, Dordrecht, pp. 21–68.
Groenendijk, J., Stokhof, M., 1997. Questions, in: van Benthem, J., ter Meulen, A., (Eds.),Handbook of Logic and Linguistics. Elsevier, North Holland, Amsterdam, pp. 1057–1126.
Guerzoni, E., Sharvit, Y., 2007. A question of strength: on NPIs in interrogative clauses. Ling.Philos. 30 (3), 361–391.
Hintikka, J., 1999. Inquiry as Inquiry: A Logic of Scientific Discovery. Kluwer, Dordrecht.Hoepelmann, J., 1983. On questions, in: Kiefer, F. (Ed.), Questions and Answers. Riedel,
Dordrecht, pp. 191–227.Hull, R., 1975. A semantics for superficial and embedded questions in natural language, in:
Keenan, E. (Ed.), Formal Semantics of Natural Language. Cambridge University Press,Cambridge, MA, pp. 35–45.
Jaworski, W., 2009. The logic of how-questions. Synthese 166 (1), 133–155.Krifka, M., 1992. A compositional semantics for multiple focus constructions, in: Jacobs, J.
(Ed.), Informationsstruktur und Grammatik. Westdeutscher Verlag, Opladen, pp. 17–53.Krifka, M., 2001. For a structured meaning account of questions and answers. Audiatur Vox
Sapientia. A Festschrift for Arnim von Stechow 52, 287–319.Lahiri, U., 2002. Questions and Answers in Embedded Contexts. Oxford University Press,
Oxford.Larsson, S., 2002. Issue Based Dialogue Management. PhD thesis, Gothenburg University,
Sweden.Leszczyńska-Jasion, D., 2009. A loop-free decision procedure for modal propositional logics
K4, S4 and S5. J. Philos. Logic 38 (2), 151–177.Nelken, R., Francez, N., 2002. Bilattices and the semantics of natural language questions. Ling.
Philos. 25, 37–64.Nelken, R., Shan, C.-C., 2006. A modal interpretation of the logic of interrogation. J. Logic,
Lang. Inf. 15, 251–271.Noh, E.-J., 1998. Echo questions. Ling. Philos. 21, 603–628.Parikh, P., 1992. A game-theoretic account of implicature. Proceedings of the 4th Conference on
Theoretical Aspects of Reasoning About Knowledge. Morgan Kaufmann Publishers Inc.,San Francisco, CA, USA, pp. 85–94.
Purver, M., 2006. Clarie: handling clarification requests in a dialogue system. Res. Lang. Com-put. 4 (2), 259–288.
Roberts, C., 1996. Information structure in discourse: towards an integrated formal theory ofpragmatics, in: Yvon, J.H., Kathol, A. (Eds.), Working Papers in Linguistics-Ohio StateUniversity Department of Linguistics, Columbus, OH, pp. 91–136.
Romero, M., Han, C., 2004. On negative yes/no questions. Ling. Philos. 27 (5), 609–658.Savage, C., 1954. The Foundation of Statistics. Wiley, New York.

“30-ch26-1133-1146-9780444537263” — 2010/11/29 — 21:09 — page 1146 — #14
1146 Handbook of Logic and Language
Scha, R., 1983. Logical Foundations for Question Answering. PhD thesis, Rijks universitet,Groningen.
Seligman, J., Moss, L., 1997. Situation theory, in: van Benthem, J., ter Meulen, A. (Eds.), Hand-book of Logic and Language. MIT Press, Cambridge, MA, pp. 239–309.
Shoesmith, D., Smiley, T., 1978. Multiple-Conclusion Logic. Cambridge University Press,Cambridge, MA.
Simmons, M., 2002. Disjunction and alternatives. Ling. Philos. 25.Stanley, J., Williamson, T., 2001. Knowing how. J. Philos. 98 (8), 411–444.Urbanski, M., 2001. Synthetic tableaux and erotetic search scenarios: extension and extraction.
Logique et Analyse 44, 173–175.van Benthem, J., Minica, S., 2009. Toward a dynamic logic of questions, in: He, X., Horty, J.,
Pacuit, E. (Eds.), Proceedings of Logic, Rationality and Interaction (LORI-II), Springer-Verlag, Deutschland, pp. 27–41.
van Rooy, R., 2003a. Asking to solve decision problems. Ling. Philos. 26 (6), 727–763.van Rooy, R., 2003b. Negative polarity items in questions: strength as relevance. J. Semant. 20
(3), 239–273.Wiśniewski, A., 2001. Questions and inferences. Logique et Analyse 173, 5–43.Wiśniewski, A., 2003. Erotetic search scenarios. Synthese 134, 389–427.Wiśniewski, A., Vanackere, G., Leszczyńska, D., 2005. Socratic proofs and paraconsistency: a
case study. Studia Logica 80 (2), 431–466.





























