Embed Size (px)
Citation preview

Journal of Advances in Information Technology ISSN 1798-2340 Volume 4, Number 2, May 2013 Contents Special Issue: Applications of Artificial Neural Networks
Guest Editors: Sumit Goyal
EDITORIAL A.C.M. Fong
59
Guest Editorial Sumit Goyal
60
SPECIAL ISSUE PAPERS An Artificial Neural Network Based Power Control strategy of Low-Speed Induction Machine Flywheel Energy Storage System Mohamed I. Daoud, Ayman S. Abdel-Khalik, A. Elserougi, A. Massoud, S. Ahmed, and Nabil H. Abbasy A Comparative Study of RBF and MLP Neural Model for Seven Element Dynamic Phased Array Smart Antenna Rahul Shrivastava, Abhishek Rawat, and Yogendra Kumar Jain Application of Radial Basis Function Network for the Modeling and Simulation of Turbogenerator Mohsen Hayati, Abbas Rezaei, and Leila Noori Cascade Artificial Neural Network Models for Predicting Shelf Life of Processed Cheese Gyanendra Kumar Goyal and Sumit Goyal
61
69
76
80
REGULAR PAPERS 28 Nanometers FPGAs Support for High Throughput and Low Power Cryptographic Applications Yaser Jararweh, Lo'ai Tawalbeh, Hala Tawalbeh, and Abidalrahman Moh'd An Intelligent Water Droplet-based Evaluation of Health Oriented Distance Learning Koffka Khan, Zulaika Ali, Nisa Philip, Gail Deane, and Ashok Sahai Tracking Livestock Movements to Figure out Potentially Infected Farms Paolino Di Felice and Americo Falcone
84
91
101


Editorial
It is not without sadness that I finally step down as Editor-in-Chief of JAIT, a journal that was established with the support of Academy Publisher. JAIT was envisaged to be a source that disseminates high quality research in advances in IT that lead the way toward solving some of the complex problems faced by humanity in the 21st century. Many of these problems require concerted efforts from the international research community that spans a spectrum of skills and expertise. Its primary aim has been to promote interdisciplinary research in the broad field of IT. To date, JAIT has attracted submissions from across the world and the current acceptance rate stands at ~30%. The journal also publishes special issues that are managed by domain experts and address specific themes that are topical in nature.
Today, JAIT is a quality journal and I am confident that it will only get better as Prof. Yongsheng Gao takes over the Editor-in-Chief role. Many dedicated people also contribute to the continued success of JAIT. In particular, Dr. George Sun and his team at Academy Publisher, JAIT Editorial Board members, guest editors of special issues, and the anonymous reviewers all deserve recognition. As I depart from JAIT, it is reassuring that the journal is in good hands. I wish them all the best.
Outgoing Founding Editor Prof. A.C.M. Fong
JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013 59
© 2013 ACADEMY PUBLISHERdoi:10.4304/jait.4.2.59

Special Issue on Applications of Artificial Neural Networks
Guest Editorial
Artificial Neural Networks (ANN) are inspired by the functioning of biological neural networks. ANNs have rich features as well as high processing speeds and the capability to learn the answer to a problem from a set of examples. ANN structure consists of three layers. The first layer is the input layer through which data is fed; second layer contains hidden units where calculation is done according to the function provided; the final layer is the output layer, which gives output. ANNs have been implemented in almost every field of science and technology, viz., speech synthesis and recognition, pattern classification, adaptive interfaces between humans and complex physical systems, clustering, function approximation, image data compression, nonlinear system modeling, associative memory, combinatorial optimization, control and several others, as they have proved valuable tools for obtaining the required output. ANN provides an exciting alternative method for solving a variety of problems in different areas of science and engineering.
The aim of this special issue is to discover the recent advances in the applications of ANN and provide an overview of the field, where the ANNs are used and discuss the critical role that ANNs play in different fields.
This special issue consists of four papers that highlight the application of ANN in different areas. As a guest editor, I received many papers for this special issue; but after critically review; I have selected the following four best papers for publication:
In paper one, authors introduce a power control strategy of a flywheel energy storage system based on an ANN as a current decoupling network to charge/discharge the flywheel for grid connected applications such as grid frequency support/control, power conditioning and UPS applications.
Second paper highlights the applicability of radial basis function network (RBF) for the modeling and simulation of turbogenerators. RBF model is compared with Multi Layer Perceptron (MLP) model, which is another important architecture of ANN. The results obtained showed that the proposed RBF model is more accurate and reliable than MLP model.
Third paper discusses the ANN modeling techniques for dynamic phased array smart antenna. Authors have optimized the seven element dynamic phased array smart antenna using RBF and MLP ANN. The beam ship prediction of seven elements has been done up to 60 degree scan angle and results of RBF and MLP have been compared to find out the better ANN approach for smart antenna optimization.
Fourth paper reports the use of Cascade ANN models for predicting the shelf life of processed cheese. Body & texture, aroma & flavour, moisture and free fatty acids were taken as input parameters, and sensory score as output parameter for developing the models. Cascade ANN models very well predicted the shelf life of processed cheese.
At last, I would like to express my gratitude to all the reviewers for their help and their contribution to the success of this special issue, and to the Editor-in-Chief of JAIT, Professor A.C.M. Fong for his professional assistance, which was very valuable in achieving this special issue in the present form.
Guest Editor Sumit Goyal (Email:[email protected]) Member, Indian Dairy Association, New Delhi, India Sumit Goyal is Bachelor of Information Technology and Master of Computer Applications from the central
university of Government of India. He has published many research papers, written book chapters, review articles, technical papers and instructional manuals. He is holding positions in the editorial board of many esteemed international journals. His research interests include Artificial Neural Network.
60 JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013
© 2013 ACADEMY PUBLISHERdoi:10.4304/jait.4.2.60

An Artificial Neural Network Based Power Control strategy of Low-Speed Induction
Machine Flywheel Energy Storage System
Mohamed I. Daoud1, Ayman S. Abdel-Khalik2, A. Elserougi2, A. Massoud1, S. Ahmed3, Nabil H. Abbasy2 1Qatar University, Qatar, [email protected]
2Alexandria University, Egypt 3Texas A&M University at Qatar, Qatar
Abstract—This study introduces a power control strategy of a flywheel energy storage system (FESS) based on an artificial neural network (ANN) as a current decoupling network to charge/discharge the flywheel for grid connected applications such as grid frequency support/control, power conditioning and UPS applications. The proposed system is a large-capacity low-speed FESS based on a field oriented controlled (FOC) squirrel cage induction machine. The controller is designed to avoid machine overloading while the flywheel is charged/discharged. Additionally, it avoids using the required outer power loop or a hysteresis power controller, hence, simplifies the overall control algorithm. The validity of the developed control system is investigated via computer simulations using MATLAB/Simulink as well as experimental results. The proposed system is also compared with conventional power control strategy with an additional outer power control loop to highlight their equivalence. Index Terms—Flywheel energy storage, artificial neural network, instantaneous power control, indirect field orientation.
I. INTRODUCTION
Due to the proliferation of non-linear loads, the utility becomes more vulnerable to disturbances such as voltage sags, unbalanced power flow and frequency fluctuations. Therefore, energy storage systems have become an essential part of electrical power utilities as they provide a higher level of power quality and stability. Flywheels as energy storage devices exhibit high performance with grid connected applications such as power conditioning, frequency regulation and voltage sag compensation due to their capability of storing energy in form of kinetic energy depending on the rotating speed and their moment of inertia according to (1);
)(2
1 2min
2max ωω −= JE (1),
where E is the amount of storage energy, J is the flywheel moment of inertia and ωmax and ωmin are the maximum and minimum rotating speeds [1].
For instance, when there is an excess or lack in the generated power, the system frequency will be increased or decreased; meanwhile when a fault occurs on the network or a sudden pulsed load is connected, voltage sag will take place [2]-[3]. Therefore, when there is an excess in the generated power compared to demanded power, the difference is stored in the flywheel energy storage system (FESS) through the electric machine which utilizes as a motor. Conversely, when there is an unbalance in the power system, the process is reversed and the flywheel discharges its energy and the machine utilizes as a generator [4] supporting the grid.
FESSs have several advantages over other energy storage systems including simple structure with very high efficiency, higher power and energy density with high dynamics and fast response, and longer lifetime with low maintenance requirements [5]-[6]. FESS merely consists of a flywheel, electric machine, power conversion system and bearings [7]-[8] as shown in Fig. 1. The flywheel is the mass in which the kinetic energy is stored and driven via the electric machine; it works as a motor while charging and works as a generator while discharging. Permanent magnet machines are normally employed with high speed flywheels [9]-[10] but induction machines are better economical alternatives for low speed flywheels [11]-[15]. A power conversion system matches the grid with the FESS and it mainly consists of power electronics devices (back-to-back converter). Bearings are used to hold the flywheel (rotor) free to rotate in a certain balanced position. There are two types of bearing, conventional mechanical bearings and magnetic bearings, and the usage of each depends mainly on the desired operating speed and the cost. In case of low speed flywheels, conventional bearings can be used while in case of high speed flywheels, magnetic bearings should be used to reduce friction and losses but their cost is much higher than conventional bearings [16].
This work was supported by a National Priorities Research Program (NPRP) grant from the Qatar National Research Fund (QNRF). M. I. Daoud (e-mail: [email protected]), A. Massoud are with Qatar University at Qatar, Doha, Qatar (e-mail: [email protected]). A. S. Abdel-Khalik is with the Department of Electrical Engineering, Faculty of Engineering, Alexandria University, Alexandria 21544, Egypt (e-mail: [email protected]). S. Ahmed is with Texas A&M University at Qatar, Doha, Qatar (e-mail:[email protected]).
JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013 61
© 2013 ACADEMY PUBLISHERdoi:10.4304/jait.4.2.61-68

gL
Fig. 1. Basic scheme of FESS
Controlling the power flow between the FESS and the
grid is the main concern of this paper. There are two main power control strategies of the FESS based on the field orientation of the induction machines; the conventional instantaneous power control (IPC) and the direct power control (DPC). The instantaneous power control using a double-closed-loop approach depends on using an outer proportional integral (PI) power controller in cascade with the synchronous frame PI current regulators [17]. This strategy is simple, but the tuning of PI controllers depends on small signal analysis based on the non-linear relation between power and stator current. This leads to a complicated overall control design over the flywheel wide speed range while being charged/discharged. The direct torque/power control approach is supposed to solve this problem [18]-[19]. However, there are always significant torque/power ripples. Increasing the switching frequency reduces the ripple magnitude but with a corresponding increase in inverter losses, which is not appropriate for large power applications. In addition, the converter switching frequency depends on the operating conditions; thus the controller performance may deteriorate during the machine starting and low-speed operation [20].
In this paper, a power control strategy based on artificial neural networks (ANN) is proposed to provide a simple power control strategy which avoids tuning and switching problems. The ANN is employed to develop the reference stator current component based on the grid power level and the flywheel rotating speed. This strategy is compared to the conventional power control strategy. Therefore a simulation study on a 2.2 kW induction machine using MATLAB/Simulink is presented and experimental results are obtained for further investigation.
II. FESS CONTROL STRATEGIES
The main concept of the control strategy depends on charging the IM (flywheel) when there is an excess grid power and discharging it when a certain power is demanded. A back-to-back converter is used, as shown in Fig. 1, to match the power from/to the flywheel with the grid allowing bi-directional power flow.
It is required to control the total injected power into the grid and charged to the flywheel for a certain period which depends on the maximum and minimum permissible speeds of the flywheel as stated in (1) and its inertia. The main concern is estimating the stator quadrature current reference component that represents the desired stator power. The three phase currents are referred to the d-q frame; iqs
* and ids
* are the quadrature and direct current reference values related to torque and flux commands.
The value of ids* can be calculated based on the relation
[21]:
e
dsmm
ViL
ωλ ≈= (2),
where λm is the magnetizing flux, Lm is the magnetizing inductance, V is the rated phase voltage and ωe is the stator angular frequency. These values are compared to the actual fed back current values iqs and ids and the error signals are applied to current regulators as shown in Fig. 2. Two different strategies based on induction field orientation will be applied on the IM studying the behavior and response of each. There are two types of field oriented control, direct FOC and indirect FOC. The indirect FOC depends on measuring the rotor position while direct FOC depends on estimating the rotor position via flux measurement [17], [22]-[25]. The proposed control strategy based on indirect FOC system supplemented by an ANN-based current decoupling network used to develop the required stator current components based on the required grid power level and flywheel instantaneous speed. This strategy is compared with the conventional instantaneous power control strategy where quadature stator current component is derived based on the instantaneous power error through a PI controller.
The machine is controlled via maintaining the flux command ids
* constant while the reference iqs*
is used to control the machine torque and hence the output power.
III. INSTANTANEOUS POWER CONTROL (IPC)
The conventional instantaneous power control strategy will be applied to the machine side converter based on the IFOC. The instantaneous stator active power is measured, via measuring the machine voltages and currents according to (3) [21], then compared to the desired value supposed to be supplied by the flywheel which depend on the state of the grid, and the errors in both powers will be applied to power regulators; then the outputs represents the current commands which are applied to the current regulators.
mmqrrdsqssqsqsdsdss TiriirivivP ω+++=+= 222
23
)(23
)(23 (3)
This technique will add an external power control loop outside the current regulation loop applied in the indirect field oriented control which increases the stability of the system and its robustness to external disturbances. This strategy has more accurate response as the control is performed on the instantaneous power values but it increases the controller effort and tuning problems, therefore a proposed control strategy based on ANNs will be compared to the IPC performance. The general block diagram for the current decoupling network is depicted in Fig. 3.
IV. PROPOSED POWER CONTROLLER VIA ANN
The power control via ANN aims to estimate the stator quadrature current without extra control loops.
62 JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013
© 2013 ACADEMY PUBLISHER

A current decoupling network based on ANN is proposed to generate the quadrature stator current component based on (3). A multilayer feed forward ANN [26]-[27] is employed as a nonlinear function approximator to generate this value based on the flywheel rotational speed and the required grid power level which is limited by charging and discharging power limits. These limits are mainly dependent on the instantaneous flywheel speed. A 2-20-1 ANN controller is used where the number of neurons in the hidden layer is chosen by trial and error method. Hyperbolic tan (tan-sigmoid) and linear activation functions are used in the hidden and output layers respectively.
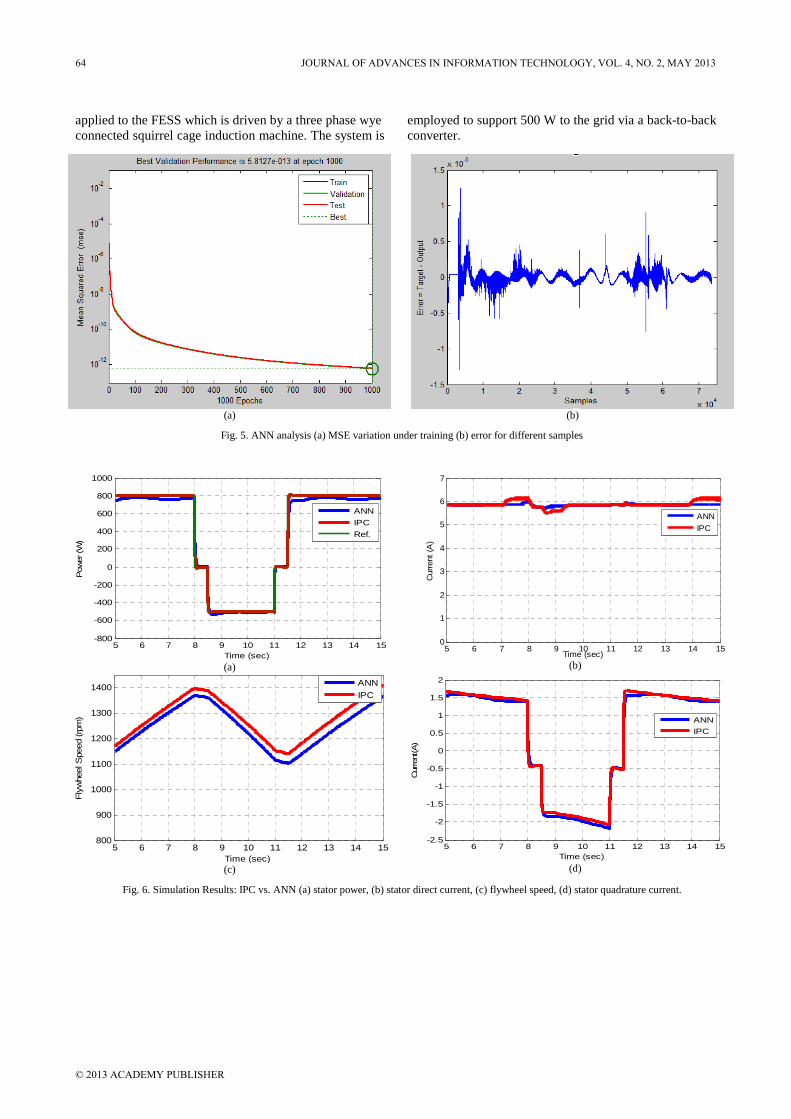
The steady state equation given in (3) is used to generate the training data for the ANN for certain ranges of machine speed and grid power. A 73731 input/output pattern is obtained, where 51611 samples are used to train the proposed ANN and 11060 samples for validating and testing the ANN. The training is performed off-line with the ANN toolbox under MATLAB using the Levenberg–Marquardt training algorithm. The training stops when the mean squared error (MSE) between targets and network outputs decays to a satisfactory level of 5.8 × 10-13, as shown in Fig. 5a. Also, the difference between the target and the ANN output for different samples is shown in Fig. 5c; it is clear that the error corresponding to all
samples is within accepted limits ±1 × 10-5. ANNs give a fast execution speed due to their parallel
processing feature; in addition they will decrease the number of controllers, hence reducing the controller effort and the tuning problems.
To deliver the grid power, the grid side converter is controlled via controlling the DC link voltage to be constant. The grid voltages and currents are transformed into the d-q frame. The desired DC link voltage is compared to its actual value and the error is applied to voltage regulators providing the active power reference. The grid reactive power is set to zero for a unity power factor operation. The grid angle is measured via phase locked loop (PLL).
A block diagram for the proposed control system is shown in Fig. 4.
V. SIMULATION RESULTS
In this section, a simulation case study of FESS control strategies is proposed. The simulation results of both control strategies are presented using MATLAB/Simulink; the results are shown in Fig. 6. The applied IM ratings and parameters are available in the appendix. A three phase grid which is emulated by a three phase supply of 400 V and a DC link of 600 V which are
dsi
qsi
*dsi
*qsi
dse
qse
rθ
sθφ3−si
dtdrω
sdqi
dsv
qsv
sθ
sabcv
φ3−gi
gdqi
qgi*qgi
dgi
0* =dgi
*dcV
dcV
}
dcV
dcV
gL
dqabc ←
abcdq ←
rr rL /
slipωp
1sθ
sdqi
eω
gabcv
φ3−gvgθ
gθ
abcdq→gθ
qgedge
dgvqgv
Fig. 2. Indirect field oriented control
*qsi*
sPsP
sdqi
sdqvsP
*dsisQ
Fig. 3. Power control via ANN
*dsi
*qsi
*sP
mω
Fig. 4. Instantaneous power control
JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013 63
© 2013 ACADEMY PUBLISHER
applied to the FESS which is driven by a three phase wye connected squirrel cage induction machine. The system is
employed to support 500 W to the grid via a back-to-back converter.
(a)
(b)
Fig. 5. ANN analysis (a) MSE variation under training (b) error for different samples
5 6 7 8 9 10 11 12 13 14 15-800
-600
-400
-200
0
200
400
600
800
1000
Time (sec)
Pow
er (W
)
ANN
IPC
Ref.
(a)
5 6 7 8 9 10 11 12 13 14 150
1
2
3
4
5
6
7
Time (sec)
Cur
rent
(A
)
ANN
IPC
(b)
5 6 7 8 9 10 11 12 13 14 15800
900
1000
1100
1200
1300
1400
Time (sec)
Fly
whe
el S
peed
(rp
m)
ANN
IPC
(c)
5 6 7 8 9 10 11 12 13 14 15-2.5
-2
-1.5
-1
-0.5
0
0.5
1
1.5
2
Time (sec)
Cur
rent
(A)
ANN
IPC
(d)
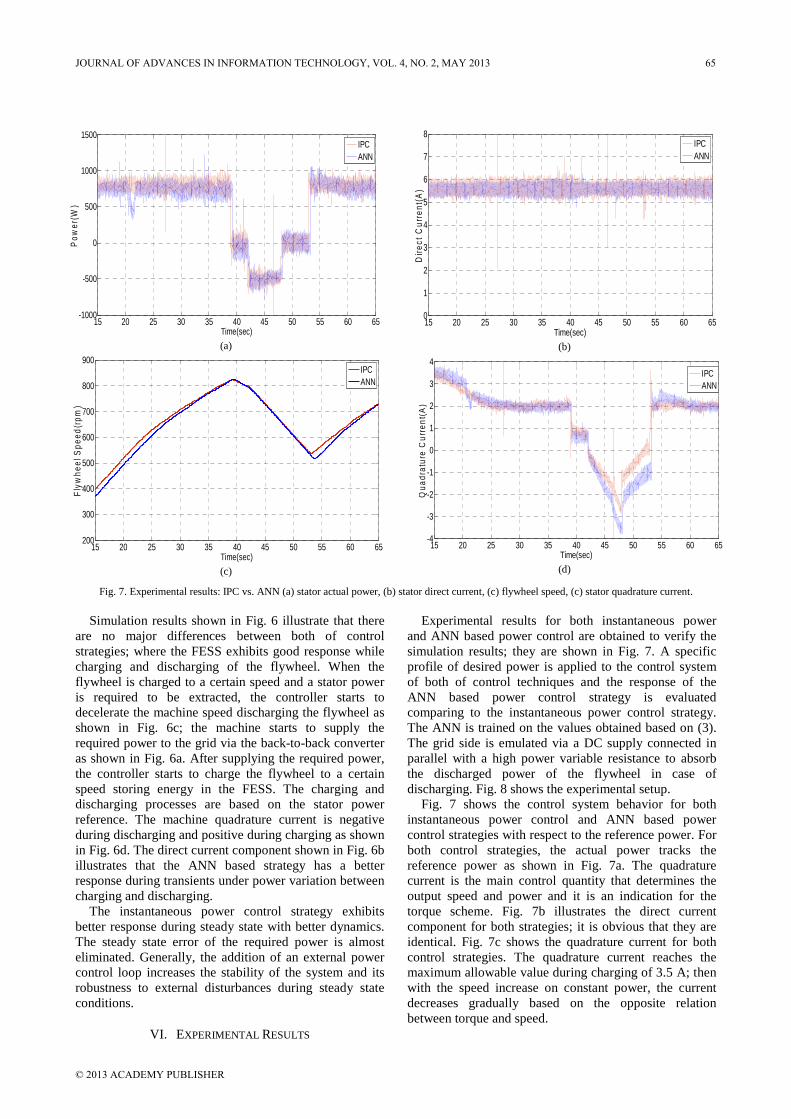
Fig. 6. Simulation Results: IPC vs. ANN (a) stator power, (b) stator direct current, (c) flywheel speed, (d) stator quadrature current.
64 JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013
© 2013 ACADEMY PUBLISHER
15 20 25 30 35 40 45 50 55 60 65-1000
-500
0
500
1000
1500
Time(sec)
Pow
er(W
)
IPCANN
(a)
15 20 25 30 35 40 45 50 55 60 650
1
2
3
4
5
6
7
8
Dire
ct C
urre
nt(A
)
Time(sec)
IPCANN
(b)
15 20 25 30 35 40 45 50 55 60 65
200
300
400
500
600
700
800
900
Time(sec)
Fly
whe
el S
peed
(rpm
)
IPCANN
(c)
15 20 25 30 35 40 45 50 55 60 65
-4
-3
-2
-1
0
1
2
3
4
Time(sec)
Qua
drat
ure
Cur
rent
(A)
IPCANN
(d)
Fig. 7. Experimental results: IPC vs. ANN (a) stator actual power, (b) stator direct current, (c) flywheel speed, (c) stator quadrature current. Simulation results shown in Fig. 6 illustrate that there
are no major differences between both of control strategies; where the FESS exhibits good response while charging and discharging of the flywheel. When the flywheel is charged to a certain speed and a stator power is required to be extracted, the controller starts to decelerate the machine speed discharging the flywheel as shown in Fig. 6c; the machine starts to supply the required power to the grid via the back-to-back converter as shown in Fig. 6a. After supplying the required power, the controller starts to charge the flywheel to a certain speed storing energy in the FESS. The charging and discharging processes are based on the stator power reference. The machine quadrature current is negative during discharging and positive during charging as shown in Fig. 6d. The direct current component shown in Fig. 6b illustrates that the ANN based strategy has a better response during transients under power variation between charging and discharging.
The instantaneous power control strategy exhibits better response during steady state with better dynamics. The steady state error of the required power is almost eliminated. Generally, the addition of an external power control loop increases the stability of the system and its robustness to external disturbances during steady state conditions.
VI. EXPERIMENTAL RESULTS
Experimental results for both instantaneous power
and ANN based power control are obtained to verify the simulation results; they are shown in Fig. 7. A specific profile of desired power is applied to the control system of both of control techniques and the response of the ANN based power control strategy is evaluated comparing to the instantaneous power control strategy. The ANN is trained on the values obtained based on (3). The grid side is emulated via a DC supply connected in parallel with a high power variable resistance to absorb the discharged power of the flywheel in case of discharging. Fig. 8 shows the experimental setup.
Fig. 7 shows the control system behavior for both instantaneous power control and ANN based power control strategies with respect to the reference power. For both control strategies, the actual power tracks the reference power as shown in Fig. 7a. The quadrature current is the main control quantity that determines the output speed and power and it is an indication for the torque scheme. Fig. 7b illustrates the direct current component for both strategies; it is obvious that they are identical. Fig. 7c shows the quadrature current for both control strategies. The quadrature current reaches the maximum allowable value during charging of 3.5 A; then with the speed increase on constant power, the current decreases gradually based on the opposite relation between torque and speed.
JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013 65
© 2013 ACADEMY PUBLISHER

Fig. 8. Experimental setup
When the power reference turns to zero, the quadrature current is ideally supposed to be zero and the speed is supposed to be kept constant, but there are machine losses (friction and core) which appear experimentally. When the power is discharged, the direction of the quadrature current is reversed to apply negative torque. The dips appear in the charging power and quadrature current in the ANN strategy at the 22nd second shown in Fig. 7a and Fig. 7c are caused due to an improper calculation at this moment of the ANN which gives a stray value of the output quadrature current which affects consequently on the output power. Fig. 7d depicts the flywheel speed profile during charging and discharging periods. It is obvious that the speed increases with positive power and decreases with negative power. During the zero power periods, the speed continues the deceleration instead of being constant to overcome the friction and core losses. Thus, there are some verifications can be extracted based on the experimental results; the ANN based system gives the same performance of the instantaneous power control strategy with the advantages that it reduces the controller effort due to the elimination of the outer loop controller and hence eliminating the tuning problems of the outer loops.
VII. CONCLUSION
A developed power control strategy using artificial neural networks (ANNs) for flywheel energy storage system is proposed and compared to the conventional power control strategy. A simulation case study is presented for both control strategies. The simulation results illustrate the competitive performance of the developed ANN based power control strategy. Then it is verified experimentally that the ANN based power control strategy provides high accurate response as well as the response obtained from the instantaneous power control strategy. Therefore the ANN based control strategy can be considered competitive to the instantaneous power
control strategy for flywheel energy storage applications due to its simplicity and less tuning problems and controller effort.
APPENDIX MACHINE RATINGS AND PARAMETERS
TABLE I IM RATINGS
Rated phase voltage (V) 230 Rated power (KW) 2
Rated frequency (Hz) 50 Full-load current (A) 4.7 Rated speed (rpm) 1410
TABLE II
IM PARAMETERS
Stator resistance 3.335 Stator leakage reactance 2.48 Rotor referred resistance 6.395 Rotor referred reactance 2.48 Magnetizing reactance 55.6
No. of poles 4 Inertia constant H (sec) 3.08
Flywheel inertia J (kg.m2) 3.93
ACKNOWLEDGMENT
This publication was made possible by NPRP grant 09-1001-2-391 from the Qatar National Research Fund (a member of Qatar Foundation). The statements made herein are solely the responsibility of the authors.
REFERENCES
[1] Ribeiro, P.F.; Johnson, B.K.; Crow, M.L.; Arsoy, A.; Liu, Y.; "Energy storage systems for advanced power applications," Proceedings of the IEEE, vol.89, no.12, pp.1744-1756, Dec 2001.H. Simpson, Dumb Robots, 3rd ed., Springfield: UOS Press, 2004, pp.6-9.
[2] Zhang Jiancheng; Huang Lipei; Chen Zhiye; Wu Su; "Research on flywheel energy storage system for power quality," Power System Technology, 2002. Proceedings. PowerCon 2002. International Conference on, vol.1, no., pp. 496- 499 vol.1, 13-17 Oct 2002.
[3] Hak-in Lee; Ki-hyun Ji; Eun-Ju Yoo; Young-Woo Park; Noh, M.D.; , "Design of a micro flywheel energy storage system including power converter," TENCON 2009 - 2009 IEEE Region 10 Conference , vol., no., pp.1-6, 23-26 Jan. 2009.
[4] Lazarewicz, M.L.; Rojas, A.; "Grid frequency regulation
by recycling electrical energy in flywheels," Power Engineering Society General Meeting, 2004. IEEE, vol., no., pp.2038-2042 Vol.2, 10-10 June 2004.
[5] Zhongwei Chen; Xudong Zou; Shanxu Duan; Huarong Wei; , "Power conditioning system of Flywheel Energy Storage," Power Electronics and ECCE Asia (ICPE & ECCE), 2011 IEEE 8th International Conference on , vol., no., pp.2763-2768, May 30 2011-June 3 2011.
[6] Meng, Y.M.; Li, T.C.; Wang, L.; "Simulation of controlling methods to flywheel energy storage on charge section," Electric Utility Deregulation and Restructuring and Power Technologies, 2008. DRPT 2008. Third International Conference on , vol., no., pp.2598-2602, 6-9 April 2008.
Induction Machine
eZdsp F28335
DC Link Capacitor
High Power Variable
Resistance
Flywheel
Speed Sensor
CAN Device
Host PC
Current Sensors
Gate Drives &
VSI
High Frequency Filter Capacitor
Flexible Coupling
66 JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013
© 2013 ACADEMY PUBLISHER

[7] Jiancheng Zhang; , "Research on Flywheel Energy Storage System Using in Power Network," Power Electronics and Drives Systems, 2005. PEDS 2005. International Conference on , vol.2, no., pp. 1344- 1347, 28-01 Nov. 2005.
[8] Sough, M.L.; Depernet, D.; Dubas, F.; Boualem, B.; Espanet, C.; "PMSM and inverter sizing compromise applied to flywheel for railway application," Vehicle Power and Propulsion Conference (VPPC), 2010 IEEE, vol., no., pp.1-5, 1-3 Sept. 2010.
[9] R. Okou, A. Sebitosi, M. Khan, P. Barendse, P. Pillay, Design and analysis of an electromechanical battery for rural electrification in sub-Saharan Africa, IEEE Transactions on Energy Conversion 26 (December (4)) (2011) 1198–1209.
[10] T. Nguyen, K. Tseng, S. Zhang, H. Nguyen, A novel axial flux permanent-magnet machine for flywheel energy storage system: design and analysis, IEEE Transactions on Industrial Electronics 58 (September (9)) (2011) 3784–3794.
[11] S. Hahn, W. Kim, J. Kim, C. Koh, S. Hahn, Low speed FES with induction motor and generator, IEEE Transactions on Applied Superconductivity 12 (1) (2002) 746–749.
[12] D. Eisenhaure, J. Kirtley Jr., L. Lesster, Uninterruptible power supply system using a slip-ring, wound-rotor-type induction machine and a method for flywheel energy storage, U.S. Patent 7,071,581 (2002).
[13] H. Akagi, H. Sato, Control and performance of a flywheel energy storage system based on a doubly-fed induction generator-motor for power conditioning, in: Conf. PESC 99, vol. 1, 1999, pp. 32–39.
[14] H. Akagi, H. Sato, Control and performance of a doubly fed induction machine intended for a flywheel energy storage system, IEEE Transactions on Power Electronics 17 (January (1)) (2002) 109–116.
[15] L. Wang, J. Yu, Y. Chen, Dynamic stability improvement of an integrated offshore wind and marine-current farm using a flywheel energy-storage system, IET Renewable Power Generation 5 (September (5)) (2011) 387–396.
[16] Jiancheng Zhang; Zhiye Chen; Lijun Cai; Yuhua Zhao; , "Flywheel energy storage system design for distribution network," Power Engineering Society Winter Meeting, 2000. IEEE , vol.4, no., pp.2619-2623 vol.4, 2000.
[17] Cimuca, G.; Breban, S.; Radulescu, M.M.; Saudemont, C.; Robyns, B.; "Design and Control Strategies of an Induction-Machine-Based Flywheel Energy Storage System Associated to a Variable-Speed Wind Generator,"Energy Conversion, IEEE Transactions on , vol.25, no.2, pp.526-534, June 2010.
[18] E. Tremblay, S. Atayde, A. Chandra, Comparative study of control strategies for the doubly fed induction generator in wind energy conversion systems: a DSPbased implementation approach, IEEE Transactions on Sustainable Energy 2 (July (3)) (2011) 288–299.
[19] H. Nian, Y. Song, P. Zhou, Y. He, Improved direct power control of a wind turbine driven doubly fed induction generator during transient grid voltage unbalance, IEEE Transactions on Energy Conversion 26 (September (3)) (2011) 976–986.
[20] M. Mohseni, S.M. Islam, M.A.S. Masoum, Enhanced hysteresis-based current regulators in vector control of DFIG wind turbines, IEEE Transactions on Power Electronics 26 (January (1)) (2011) 223–234.
[21] Novotny, D. W. and T. A. Lipo (1996). Vector Control and Dynamics of Ac Drives, Clarendon Press.
[22] Samineni, S.; Johnson, B.K.; Hess, H.L.; Law, J.D.; , "Modeling and analysis of a flywheel energy storage system for Voltage sag correction," Industry Applications, IEEE Transactions on , vol.42, no.1, pp. 42- 52, Jan.-Feb. 2006.
[23] Satish Samineni, Brian K Johnson, Herbert L Hess and Joseph D Law "Modeling and Analysis of a Flywheel Energy Storage System with a Power Converter Interface", International Conference on Power Systems Transients-IPST 2003 in New Orleans, USA.
[24] Cardenas, R.; Pena, R.; Asher, G.; Clare, J.; , "Control strategies for energy recovery from a flywheel using a vector controlled induction machine," Power Electronics Specialists Conference, 2000. PESC 00. 2000 IEEE 31st Annual , vol.1, no., pp.454-459 vol.1, 2000.
[25] Cardenas, R.; Pena, R.; Asher, G.M.; Clare, J.; Blasco-Gimenez, R.; , "Control strategies for power smoothing using a flywheel driven by a sensorless vector-controlled induction machine operating in a wide speed range,"Industrial Electronics, IEEE Transactions on , vol.51, no.3, pp. 603- 614, June 2004.
[26] Abdel-Khalik, A.S.; Elserougi, A.; Massoud, A.; Ahmed, S.; ''Control of Doubly-Fed Induction Machine Storage System for Constant Charging/Discharging Grid Power Using Artificial Neural Network'', in a conference PEMD 2012, Power Electronics, Machines and Drives Conference.
[27] P. Vas, Artificial-Intelligence-Based Electrical Machines and Drives— Application of Fuzzy, Neural, Fuzzy-Neural and Genetic Algorithm Based Techniques, Oxford University Press, New York, 1999.
BIOGRAPHIES
Mohamed I. Daoud was born in Alexandria-Egypt in November 1987. He received his B.Sc, degree in Electrical Engineering from Alexandria University, Egypt in 2009. His research interests are solid-state power conversion, electric machines, electric machine simulation and energy storage systems.
Ayman S. Abdel-Khalik was born in Alexandria-Egypt in July 1979. He received his B.Sc, and M.Sc. degrees in Electrical Engineering from Alexandria University, Egypt in 2001 and 2004 respectively. He received his Ph.D degree in May 2009 under a dual channel program between Alexandria University and Strathclyde University, Glasgow, UK. His research interests are electrical machine design, electric machine simulation, mathematical modeling and electric drives. Ahmed A. Elserougi received the B.Sc. , M.Sc. and Ph.D. degrees in electrical engineering from the Faculty of Engineering, Alexandria University, Egypt, in 2004, 2006 and 2011, respectively. He is currently a lecturer at the Electrical Department, Faculty of Engineering, Alexandria University, Egypt. His research interests include Power Quality, HVDC and FACTS, Renewable Energy and Electric power utility.
Ahmed Massoud received the B.Sc. (first-class honors) and M.Sc. degrees from The Faculty of Engineering, Alexandria University, Alexandria, Egypt, in 1997 and 2000, respectively, and the Ph.D. degree in electrical engineering from the Department of Computing and Electrical Engineering, Heriot–Watt University, Edinburgh, U.K., in 2004. His research interests include power quality, active power filtering, distributed generation, and multilevel converters.
JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013 67
© 2013 ACADEMY PUBLISHER

Shehab Ahmed was born in Kuwait City, Kuwait in July 1976. He received the B.Sc. degree in Electrical Engineering from Alexandria University, Alexandria, Egypt, in 1999; the M.Sc. and Ph.D. degrees from the Department of Electrical & Computer Engineering, Texas A&M University, College Station, TX in 2000 and 2007, respectively. His research interests include mechatronics, solid-state power conversion, electric machines, and drives. Nabil H. Abbasy was born 1956. He received the B.Sc. (Hons.) and M.Sc. degrees from the University of Alexandria, Alexandria, Egypt, in 1979 and 1983, respectively, and the Ph.D. degree from Illinois Institute of Technology, Chicago, in 1988. . His research interests include power systems operation, dynamics, and transients.
68 JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013
© 2013 ACADEMY PUBLISHER

A Comfor
Abstract—In techniques fonetworks areare used to overy much suoptimizing thantenna usin(RBFNN) an(MLPNN). This done up to are compareapproach for Index Termsphased arrayperceptron (M
Wireless cthe inventiogrowth in nutriggered an but also hicoverage. Nudeployed to provide bettepast which system uses dynamically requirements
Smart anttechnologies networks byco-channel inbased intelligelements in t
The signalto form a modirection of antenna smadegradation adoption of
mparatSeven
this paper wr dynamic pha
e mathematicaoptimize the smuitable for reahe seven elemeng Radial bnd Multilayehe beam ship 60 deg scan an
ed to find osmart antenna
— neural nety, radial basMLP), neural m
I. INT
communication of the wir
umber of wireenormous dem
igh quality oumber of new
make good er services. Uused fixed asmart antennable to adop
s. tennas [1] arthat will ena
y effectively rnterference [2gent antennasthe form of anls from these ovable beam pthe desired u
art and minimfactors like
smart antenn
tive Stn Elem
Samra
AbSamraEmail
we present theased array smaal and compumart antenna
al time applicaent dynamic pbasis functionr Perceptronprediction of s
ngle and resultout the bettea optimization
twork, smart is function (Rmodelling.
RODUCTION
on has come reless concep
eless users in pmand, not onlof service a
w technologiesuse of limit
Unlike wireleantenna systemnas or adaptivpt as per the
re one of theable higher careducing the 2],[3] These as that use a fin array as show
antenna elempattern that causer. This feamizes the vari
noise, intera techniques
tudy ofment Dy
ARa
at Ashok TechEmail: pragy
hishek Rawaat Ashok Techl: arawat@sat
e neural Modeart antenna. Ntation modelssystem, which
ations. Here wphased array sn neural netn neural netseven element ts of RBF and r neural net
n.
antenna, dynRBF), multi
a long way pts; the extenpast few yearly for the cap
and good ens are exploredted resourcesess systems inms, SDMA bve arrays thae changing tr
e most promapacity in wir
multipath faare the technofix set of radiwn in Fig. 1.
ments are comban be steered tature of makeous signal qurference etc. in future wir
f RBF ynamic
Antenn
ahul Shrivasthnological Insgyaputra.rahul@
at and Yogenhnological Instiengg.org, ykj
elling Neural s that h are
we are smart twork twork DPA MLP
twork
namic layer
since nsive
rs has pacity nough d and s and n the based at are raffic
mising reless ading, ology iating
bined to the es the uality
The reless
systeefficof eof seacro
Tefficthe uSmaanteformTheantevariascanplacthe mof racarefor urepo
Aperfis goin thbasi
1)
and Mc Phas
na tava titute, [email protected]
ndra Kumar Jtitute, Vidishajain_p@yahoo
ems is expectcient use of thestablishing neervice quality
oss multi techn
The use of smcient use of tuseful receiveart antenna sennas, dynamming, adaptive
phased arrayenna elementsable phase or
n a beam to gice of fix apertumultiplicity oadiation pattereful pattern shausing array is ositioned (scanAs the goal of formance and ood amount ohis area, in thecally three typ) Switched
MLP Nsed Arr
a, India
Jain a, India o.co.in
ted to have ahe spectrum, thew wireless n, and realizatinology wireles
mart antennas he [4] powerd power as weystem techno
mic phased are antenna sysy antenna conss, which arer time delay cven angle in sure antennas (of elements alrn, thus resultaping [14] . Hto produce a
nned) electronsmart antenngive better co
of research ande same procespes of Smart Ad Lobe Smart
Neural Mray Sm
a significant ihe minimizatinetworks, theion of transparss networks [1
will lead to r and spectrum
well as reducinologies includrray (DPA), stems [5], [13sists of multip
e fed coherencontrol at eacspace. Array c(reflectors, lenllows more prting in lower s
However the prdirective bea
nically. na is to improvoverage to thd developmen
ss of developmAntennas. antenna (SLS
Model mart
impact on theon of the cost optimizationrent operation1].
a much morem, increasingg interferencede intelligentdigital beam
3] and others.ple stationaryntly and usech element tocan be used innses), becauserecise controlside band andrimary reasonm that can be
ve the systemhe users, therent is going onment there are
SA)
e t n n
e g e. t
m .
y e o n e l d n e
m e n e
JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013 69
© 2013 ACADEMY PUBLISHERdoi:10.4304/jait.4.2.69-75

2) Ada3) DPA
A. SwitchedThe SLS
deployed at communicationly switchantennas or arrangement terms of recvarious elemwhich has thdirectivity cgain is achiein existing cadaptive arraquality of rec
B. AdaptiveAn Adap
elements thain their envidynamically taking into adaptive arraaccount othepaths as show
The Interfthe signal redirection andcan be utilizsignal paths,from multiplto noise powdevice. Eachweight that particular dircorrespondinnull in that p
In other wreception patchannel nois
aptive Array SA Smart Antend Lobe Smart
SA are convbase stations ion systems ahing functionpredefined bethat gives th
ceived power,ments are samhe best recepticompared to eved. Such an cell structureays, but it giveceived signals
e Array Smartptive Antennaat can adapt thironment. Anphased arrayaccount a g
ay adapts to er interferingwn in Fig. 3. fering deviceseceived fromd increasing itzed by formi, meaning a cle beams. Thiwer ratio givih antenna of is adaptively
rection is maxng to interferinlace.
words, they chttern dynamic
se and interfe
Smart Antennanna Antenna (SLS
ventional direof a cell in m
as shown in Fn between seams of an a
he best perfor is chosen. T
mpled periodion beam. Beca conventionantenna is ea
es than the mes a limited ims [6].
t Antenna a Array is aheir antenna p
n adaptive arry however it igreater numbeits environme
g devices and
s can be ‘blocm the antennat in others. Muing beams in combined signs provides a ming better comthe array is
y updated so ximized, whileng signals is b
hange their ancally to adjuserence, in ord
a
SA): ectional antemobile or wirFig. 2. They separate direantenna array.rmance, usualThe outputs oically to ascecause of the hinal antenna, sasier to implemore sophisticmprovement i
a set of antpattern to charay is similar is more inteller of factorsent by takingd multiple s
cked’ by redua elements inultiple signal p
the directionnal can be formuch better smmunication associated wthat its gain
e that in a direblocked by pu
ntenna radiatiot the variation
der to improve
ennas reless have
ective . The lly in
of the ertain igher some
ement cated in the
tenna anges
to a ligent . An
g into signal
ucing n that paths ns of rmed
signal to a
with a in a
ection utting
on or ns in e the
SNRadapConof adiveextedive
C.T
whilup tIn direcas sincrenulls
Inalgorangintrawithof thrececomanteits appl
D. CW
systeperfbasisectiand
S. No
R of a desired ptive beam nventional moantenna diverersity). Adaptended diversiersity branches
DPA Smart AThe DPA smale the interfero certain extethis appro
ctionally by fshown in Figeased gain in s or very smal
n DPA smart orithm tracks tge of the beama cell handofh an optimal ghe switched loeived power
mpares these thennas have thecounterpart alied to mobile
Comparison beWe discussed
ems; let us coformance, typec types of smions discussedswitched lobe
COMPARISON
SWITCHEDLOBE
A finite numof fipredefined patterns combining strategies (sectors) This kind antenna wileasier implement existing
signal. This pforming or
bile systems rsity (e.g. spative antennasity scheme, s.
Antenna art antenna [7rence is not sent where its each smart forming speci.. 4. They dithe direction ll side lobe in
antenna, a dthe user’s sign
m that is trackiff occurs, thegain. It can be obe and adaptiis maximized
hree types of se following aadaptive arrayor wireless ap
etween all thrall three ba
ompare all of e of setup andmart antennad in detail aboe smart antenn
TABLEBETWEEN BASIC T
D DYNAMPHASED
mber ixed,
or
It hanumberwhich electronsteered particuldirectio
of ll be
to in
cell
Easy electronthis creceivedmaximi
procedure is adigital bea
usually emplace, polarizats can be reg
having mor
7] achieves osuppressed coeffect is almo
antennas ific antenna birect their maof the user, andirections of
direction of anal as he roam
king him. So ee user’s signa
viewed as a give array concd. The Tablesmart antennaadvantages as ay and adaptpplications.
ree Smart Anteasic types off them on the d the pattern. Ias are shown,out the DPA, anas here is the
E I THREE SMART AN
MICALLY D ARRAY
AA
as fixed r of array
can be nically
in a lar on.
Anp(bai
to move nically. In case, the d power is ized.
Cntia
also known asam forming.loy some sorttion or anglegarded as anre than two
optimum gainompletely butost negligible.communicate
beam patternsain lobe withnd they directinterference.
arrival (DOA)ms within the
even when theal is receivedgeneralizationcept where thee I [8], [12]as. DPA smart
compared totive array as
ennas f the antennabasis of their
In Fig. 5 three, as previousadaptive arraye comparison.
NTENNAS.
ADAPTIVE ARRAY
An infinite number of patterns (scenario-based) that are adjusted in real time Complex in nature at the time of installment and best
s . t e n o
n t . e s h t
) e e d n e ] t o s
a r e s y
70 JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013
© 2013 ACADEMY PUBLISHER

structuthe sophisadaptivwhich means
The strengtdegradduringswitch
DPA smcompletely band therefore
1. DPAof radiation significant le
2. Lessystem.
3. Predshape.
This papephased arramodelling. Dand multi lathe approximantenna. Thphased arrayparticular dirfor 0 to 60 de
II. RBFN
Radial banetworks arephased arraygeneral purpmappings sinnonlinear nawhich can beproblem, RBnetworks as ahigh-dimensi
ures than more
ticated ve arrays,
also low cost.
signal th can de rapidly g the beam hing.
It int
art antennasbut reduce intee design is lesA smart antenpattern as w
evel. s complex sy
dict feeding
er presents ay smart anDevelopment ayer perceptromate beamwidhis new appry [9] can detecrection. The eg.
NN USED FOR AN
asis functione commonly uys. RBFNN’s pose methodnce the DOA pature. Unlike e viewed as an
BFNN can be a curve fittingional space.
does not null thterference.
can’t supperference up ts complex and
nna can improwell as reject
stem in comp
details for
the optimizantenna using
of radial bason based algodth of dynamiroach shows ct and estimapresent work
DYNAMIC PHNTENNAS
n and Hopfused in vario[10] are a me
d for approxiproblem and Bthe back propn application considered as
g (or interpolaRadial basis
performanin the thtypes smart antennas.
he Excellent performanin interferenc
press interferto significant d cheaper. ove shape andinterference u
parison of ada
particular pa
ation of dynneural netw
sis neural networithm to comcally phased that dynami
te beamwidthis restricted
HASED ARRAY
field type nus application
ember of a claimating nonlBeamformingpagation netwof an optimizs designing nation) problems function (R
nce hree
of
nce
ce.
rence level
d size up to
aptive
attern
namic twork twork mpute array ically h in a
only
neural ns of ass of linear
g is of works zation neural m in a RBF)
neurtune
Aneurrespinpudistacentare epatteradiaand
Aof thto pfor provoutpinpuwithof thclusnearnodestantransequiweigalgooutp
Olayearchcontin wof slayeinterabilinetwused
ral networks ed. An RBF networal network w
ponses are theut of each funance betweenter (location). excellent candern recognitioal basis neuratrained it.
A typical RBF he dimension
locally tunednon-linear, l
vides the respput y is obtainut x to an n-dimh the mth hiddhe input spacter similar inr the center oe will be actdard linear sformation ofivalent to a lghts are usuorithm rather tput layer may,
III. MLPNN U
One of the mer perceptronhitecture of Mtain two or mo
which the numelected specif
er which determediate layeity of MLPNN
work trained d to locate the
consist of n
ork can be rewith a single lae outputs of rnction of a Rn the input v
Since the raddidates for selon problems, wl network in s
network [3] Fof training pa
d neurons cenlocal mappin
ponse of the nned by calculamensional paren unit. Recepe where inpu
nput vectors. Iof a receptivetivated. The o
neurons af the hidden nlinear output ally solved trained for usor may not, c
USED FOR DYNANTEN
most common n neural nMLPNN [3] aore layers. Inp
mbers of neurofic features. Trmines the de
er collected hN for nonlinein the back p fault element
neurons which
egarded as a ayer of hiddenradial basis fuRBF neural nvector (activaadial basis neulecting relevawe are using seven element
Fig. 6 is havinatterns, hiddenntered over reng and outpunetwork. Eachating the “closrameter vectoptive fields ce
ut vectors lie, If an input v
e field (), thenoutput layer and performnode outputs.
layer in a Mfor using a
sing back propcontain biases
NAMIC PHASEDNNA
neural netwnetwork (MLas shown in put layers are ons are equal tThe output laydesired outputhidden layer ear system. Apropagation mts in an anten
h are locally
feed forwardn units, whoseunctions. Theetwork is the
ation) and itsural networksant features in
modelling oft phased array
ng input layern Layer of upceptive fieldsut layer thath hidden unitseness” of ther n associatedenter on areas
and serve tovector (x) liesn that hiddenis a layer of
ms a linearThis layer is
MLP, but theleast square
pagation. The.
D ARRAY
orks is multiLPNN). The
Fig.. 7 maythe first layer
to the numberyer is the lastt classes. Theincreases the
A MLP neuralmode can bena array from
y
d e e e s s n f y
r p s t t e d s o s n f r s e e e
i e y r r t e e l e
m
JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013 71
© 2013 ACADEMY PUBLISHER

its distorted rarrival.
Here the matrices, W outputs (alsononlinear fun
fˆ : Rn →Rm .
The weighthe gradient The activatiogiven by the
The outpuproducts betthe hidden lMLPN requtraining, the its weightsbackpropagaconsists of athrough the to update the
IV. ANT
Array facdesign [5] mfor designingto (5) calculaif the array fdimensional symmetrical and require aof the array e
Let an arraaxis having e
The array
radiation patte
neurons arand V. The M
o called input-nction.
.
hts of the MLdescent bas
on function fofollowing sig∅ ut layer neurtween the nolayer and the uires no offMLPN starts
s, and thation algorithma forward pasnetwork layer
e weights by th
TENNA SYNTH
tor is actuallmethod is ideng the FIR digitating the invefactor is the bequally spacewith respect
a slight reductelements. ay of N elemeelement spacinfactor will be
ern, and to est
re interconneMLPN transfo-output mappi
LPN are adjued backpropa
or neurons in tgmoid function11 exprons are formnlinear regreoutput weigh
fline trainings with randomhen computm at each timss propagatingr by layer, anhe gradient de
HESIS BY FOUR
ly a function ntical to the stal filters in Derse discrete Fbase of this aped arrays are u
to the origintion in the cas
ents at locationg d.
e:
timate directio
ected by worms n inputs ing) through s
usted/trained uagation algorithe hidden layn.
med by the ission vector ht matrix, V.. During on
m initial valuees a oneme step k, wg the input vd a backward
escent rule.
RIER METHOD
of Fourier ssame method
DSP. In equatioFourier transfpproach. The usually consid
n of the arrayes of even num
on Xm along th
on of
weight to m
some
using ithm. yer is
inner from The
n-line es for -pass
which vector d pass
series used
on (1) forms
one-dered
y axis umber
he X-
T
GnumOnlyserieis kn
Fwindnowresp
Fweig
Sleng
Tconvexacsevecorr
A-9-8-7-6-5-4-3-2-1-505112233445
Then the corres
Generally, desmber of coeffiy using finitees introducesnown as Gibbor minimizingdow with the
w the Fourier ponse, say Ad(φor example Nghts by e
o, the final wegth-N window
The only poivenient only wctly. The detaen dipole leg aespondent fee
DETAILS O
Angle 90 80 70 60 50 40 30 20 10 5 0 5 0 5 0 5 0 5 0
sponding inve
sired array facients and reqe number of undesired ripps Phenomenong these ripplesexpense of wseries may beφ), pick an odN= 2M+1, aevaluating t
eights are obtaw(m):
int to rememwhen the requails for desirare given in theding detail ar
TABLEF DESIRED AND I
P-5-5-5-5-5-5-5-5-50 0 0 -5-5-5-5-5-5-5-5-5
erse function w
factors requirquire exact recoefficient in
pples in the ren. s we can use a
wider transitioe summarized
dd or even winand calculate the inverse
ained by wind
mber in thisuired integralred interferenhe Table II anre given in Tab
E II. INTERFERENCE SI
Power(dB) 50 50 50 50 50 50 50 50 50 50 50 50 50 50 50 50 50 50
will be:
e an infiniteepresentation.n the Fouriersponse which
an appropriateon regions. Sod as a desiredndow length
the N ideal transform.
dowing with a
s method isl can be done
nce signal fornd the relativeble III.
IGNAL
e . r h
e o d
l .
a
s e r e
72 JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013
© 2013 ACADEMY PUBLISHER
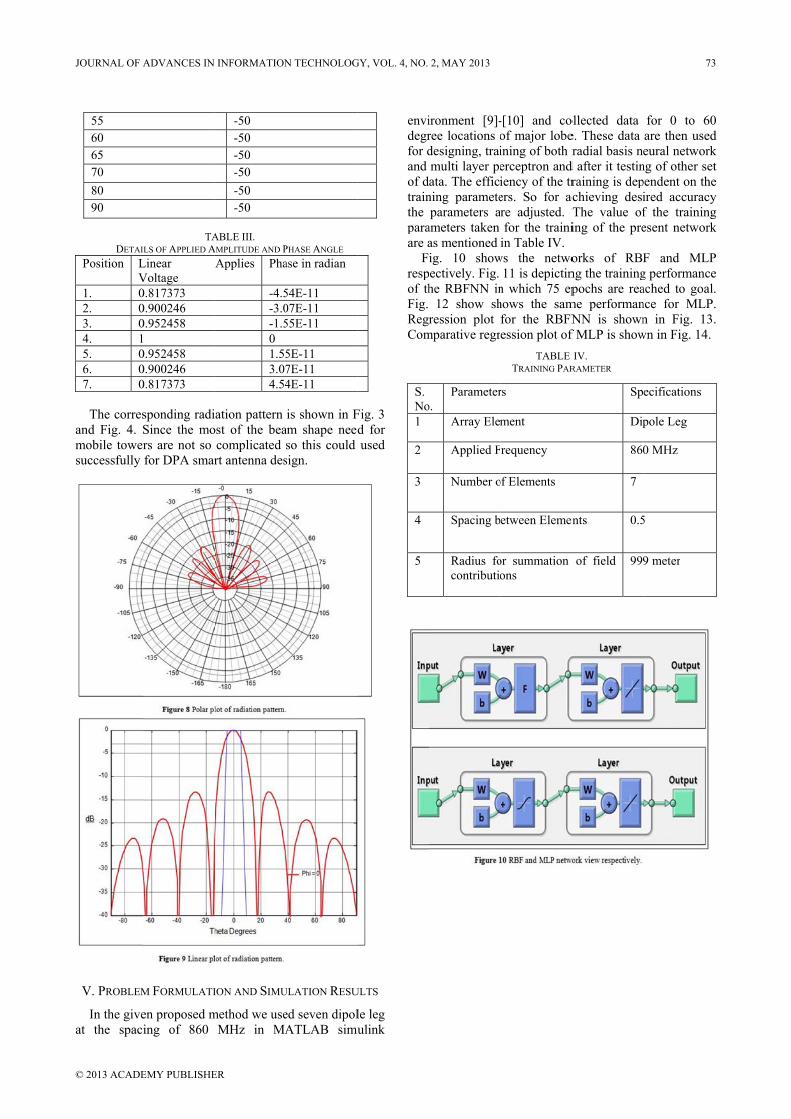
55 60 65 70 80 90
DETAI
Position LV
1. 02. 03. 04. 15. 06. 07. 0
The corres
and Fig. 4. Smobile towersuccessfully
V. PROBLEM
In the giveat the spac
TAILS OF APPLIED ALinear Voltage 0.817373 0.900246 0.952458 1 0.952458 0.900246 0.817373
sponding radiSince the mors are not so for DPA smar
M FORMULATI
en proposed ming of 860
-50 -50 -50 -50 -50 -50
ABLE III.
AMPLITUDE AND PApplies Pha
-4.5-3.0-1.50 1.553.074.54
iation pattern ost of the bea
complicated rt antenna des
ION AND SIMU
method we useMHz in MA
PHASE ANGLE ase in radian
54E-11 07E-11 55E-11
5E-11 7E-11 4E-11
is shown in Fam shape needso this could sign.
ULATION RESU
ed seven dipolATLAB simu
Fig. 3 d for used
ULTS
le leg mulink
envidegrfor dand of dtrainthe paraare a
Frespof thFig.RegCom
S. No1
2
3
4
5
ironment [9]-ree locations odesigning, traimulti layer peata. The effici
ning parameteparameters a
ameters taken as mentioned ig. 10 show
pectively. Fig. he RBFNN in
12 show shression plot
mparative regr
o.Parameter
Array Elem
Applied F
Number o
Spacing b
Radius focontributio
-[10] and coof major lobeining of both rerceptron andiency of the trers. So for acre adjusted. Tfor the traini
in Table IV. ws the netwo
11 is depictinn which 75 ephows the samfor the RBFNession plot of
TABLE TRAINING PAR
rs
ment
requency
of Elements
etween Elemen
or summation ons
ollected data e. These data radial basis n
d after it testinraining is dep
achieving desiThe value ofing of the pre
orks of RBFng the trainingpochs are rea
me performanNN is shown
f MLP is showIV.
RAMETER
Sp
Dip
860
7
ents 0.5
of field 999
for 0 to 60are then usedeural network
ng of other setpendent on theired accuracyf the trainingesent network
F and MLPg performanceached to goal.nce for MLP.n in Fig. 13.
wn in Fig. 14.
ecifications
pole Leg
0 MHz
5
9 meter
0 d k t e y g k
P e . . .
JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013 73
© 2013 ACADEMY PUBLISHER
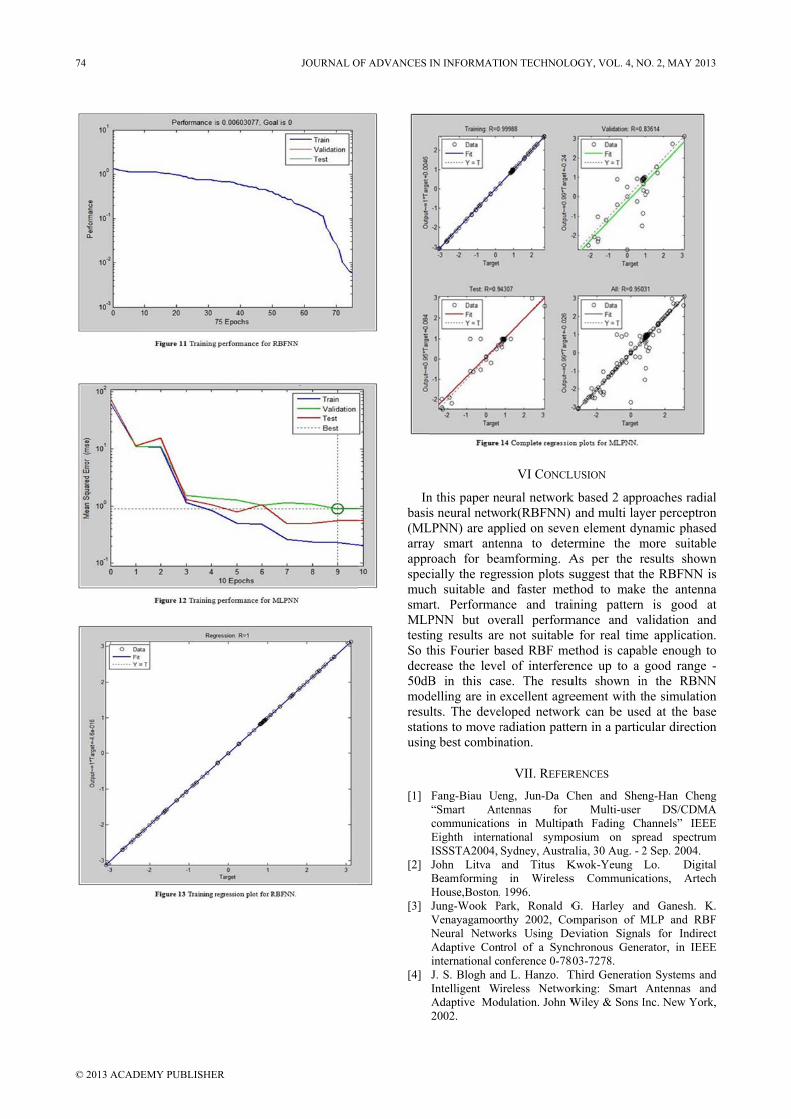
Inbasi(MLarrayapprspecmucsmarMLPtestiSo tdecr50dBmodresustatiusin
[1]
[2]
[3]
[4]
n this paper nes neural netw
LPNN) are appy smart anteroach for beacially the regrch suitable anrt. PerformanPNN but oving results arethis Fourier brease the leveB in this cadelling are in ults. The deveions to move rng best combin
Fang-Biau Ue“Smart AncommunicationEighth internISSSTA2004, John Litva Beamforming House,Boston,Jung-Wook PVenayagamoorNeural NetwoAdaptive Coninternational coJ. S. Blogh anIntelligent WAdaptive Mod2002.
VI CONCL
eural networkork(RBFNN) plied on sevenenna to deteamforming. Aression plots snd faster metnce and traierall performe not suitableased RBF me
el of interferese. The resuexcellent agre
eloped networradiation pattenation.
VII. REFER
eng, Jun-Da Cntennas for ns in Multipaational sympoSydney, Austraand Titus K
in Wireless 1996.
Park, Ronald Grthy 2002, Co
orks Using Detrol of a Synconference 0-780d L. Hanzo. Tireless Networdulation. John W
LUSION
k based 2 apprand multi lay
en element dynermine the mAs per the rsuggest that ththod to makeining pattern
mance and vae for real timethod is capabence up to a ults shown ineement with trk can be useern in a partic
RENCES Chen and Shen
Multi-user ath Fading Chosium on spralia, 30 Aug. - 2Kwok-Yeung s Communica
G. Harley anomparison of Meviation Signalchronous Gene03-7278.
Third Generatiorking: Smart Wiley & Sons I
roaches radialyer perceptronnamic phased
more suitableresults shownhe RBFNN ise the antenna
is good atalidation ande application.ble enough togood range -
n the RBNNthe simulationed at the basecular direction
ng-Han ChengDS/CDMA
hannels” IEEEread spectrum2 Sep. 2004. Lo. Digital
ations, Artech
d Ganesh. K.MLP and RBFls for Indirect
erator, in IEEE
on Systems andAntennas and
Inc. New York,
l n d e n s a t d .
o -
N n e n
g A E m
l h
. F t
E
d d ,
74 JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013
© 2013 ACADEMY PUBLISHER

[5] A. RawaDynamic Series MAntenna page(s):1
[6] M. ChryPropagatiJun. 2000
[7] Jian-Wu Antenna Systems”Technolo
[8] A. Rawaanalysis schemes of CompVol. 8, N
[9] Robert JArtech H
[10] Ahmed HMichael Function with AntTransactiNov. 199
[11] A. PaulraTime Wi2003.
[12] A. RawatapplicatioInternatio(AEÜ, EMarch 20
[13] AbhishekModelingAntenna”ComputinTechnoloPage(s):4
[14] Alexiou, future wCommunPage(s):9
[15] ChryssomPropagatiPage(s):1
[16] Lal, C. GCommunfeasibilityIEEE, Vo
[17] Mark Hu“Neural N
at, R.N. Yada phased Array
Method”, InternaAnd Propag
3-16 February yssomallis, “Sion Magazine, I0. Zhang “The ASystem in Fu
” IEEE Internogy, Singapore, at, R.N. Yadavof smart anteand algorithms
puter Science aNo. 2, May 2010J. Mailloux “P
House, 2006. H. El ZooghbyGeorgiopoulosNetworks for
tenna Arrays” ions on Volume97. aj, R. Nabar, anreless Commun
t, R.N. Yadav, ons in smaronal Journal oflsevier) in pres
012. k Rawat, R.N.g of 15 Eleme” Internationalng, Controogies, India. 45 – 48 21 dec 2
A., Haardt, Mwireless systemnications Mag90 - 97 Sept. 20mallis, M.” sion Magazine
129 – 136 June Godara. Applicanications, Part y, and System ol. 85, No. 7, Juudson Beale, MaNetwork: Toolb
av, S,C, Shrivy Smart Ante
ational Journal gation (IReCA2011.
Smarty AntennIEEE Vol. 42, N
Adaptive Algoruture Mobile national Workpp. 347-350, 2
v, S,C, Shrivanna array, bas
s : A Review”, Iand Information0 Phased array
y, Christos G. s,” Performancr Direction of Antennas and
e 45, Issue 11 P
nd D. Gore, “Innications”, Cam
S,C, Shrivastart antenna arf Electronics anss. Doi:10.1016
Yadav, S.C.Sent Dynamic Pl Conference l, and DOI 10.1109
2009. M. “Smart antenms: trends andgazine, Volum04.
smarty antenne, IEEE Volu2000. ations of Anten
I: PerformaConsiderations
uly 1997. artin T. Hagan box™” user’s G
vastava “Desigenna Using Foon Communica
AP) Vol.1 N
nas” AntennasNo. 3, pp. 129 –
rithms of the STelecommunic
kshop on An2005. astava “Comparsis of beamforInternational Jon Security (IJC
antenna handb
Christodoulouce of Radial
Arrival EstimPropagation,
Page(s):1611 -
ntroduction to Smbridge Univ. P
ava “Neural netrrays: A revnd Communica6/j.aeue.2012.0
Shrivastava ”NPhased Array S
on AdvanceTelecommunic
9/ACT.2009.Vo
nna technologied challenges “me 42, Issue
as” Antennas ume 42, Issu
nna Arrays to mance, Improve. Proceedings o
Howard, B. DeGuide 2012.
gn of ourier ations
N. 1,
s and – 136,
Smart cation ntenna
arative rming ournal CSIS),
book”
u, and Basis
mation IEEE 1617,
Space-Press,
twork view” ations
03.012
Neural Smart es in cation ol 1
es for “IEEE e 9,
and ue 3,
mobile ement, of the
emuth
Clouconte
preseTechAnteelect2007TechauthoConf
incluSecuresea
ud Computing. ent and learning
ently working hnological Instenna array synthtromagnetic. H7 by the Mahnology, Bhopaored about 1ferences.
udes Image purity, Mobile arch papers in r
Rahul Shridegree in CGandhi PBhopal 201Samrat AshVidisha,Computer Research Network so
He is e-learningg management
Abhishek Degree CommunicaM.Tech. in R.G.P.V. aInstitute of 2001 and 2Maulana ATechnology
as assistant itute, Vidisha, hesis and desige is also receivadhya Pradeshal. He is life As0 papers in
Yogendra (Hons) degrin 1991 anInstrumenta(MP), IndiaGandhi Bhopal (MPof Dept. CoSATI, V
processing, ImCommunicationeputed journals
ivastava receivComputer scienProdyogiki 10 and M.techshok Technolo2012 speciascience andinterest inc
oft commuting Eng and moodle e
systems.
Rawat receiin Electr
ation EnginMicrowave En
and Maulana Af Technology, B2006 respectiveAzad Nationay, Bhopal, Indiaprofessor in India. His m
gn, optimizationved young scieh Council of ssociate Memb
International
Kumar Jain ree in E.I. from
nd ME (Hons.)ation from SGa in 1999. Ph.Technological
P). Presently womputer Scienc
Vidisha. Resemage Compress
n. Published s and conferenc
ved B.E. (Hons.nce from RagivVishvidhyalay,
h (Hons.) fromgical Institute,
alization withd engineering.ludes NeuralE-learning, andexpert; develop
ved his B.E.ronics andneering andngineering fromAzad National
Bhopal, India inely. Ph.D. froml Institute ofa in 2012. He isSamrat Ashok
main interest isn techniques inentist award in
Science ander of IETE and
Journals and
received B.E.m SATI Vidisha) in Digital &GSITS, Indore.D. from Rajiv
University,orking as Headce & Engg. Atarch Interestsion, Networkmore than 40
ces.
.) v ,
m , h . l d p
. d d
m l n
m f s k s n n d d d
. a
& e v ,
d t t k 0
JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013 75
© 2013 ACADEMY PUBLISHER

Application of Radial Basis Function Network for the Modeling and Simulation of Turbogenerator
Mohsen Hayati 1,2,4,*
1Electrical Engineering Department, Faculty of Engineering, Razi University, Kermanshah-67149, Iran *Corresponding author: [email protected]
2Computational Intelligence Research Centre, Faculty of Engineering, Razi University, Kermanshah-67149, Iran
Abbas Rezaei3,4 and Leila Noori4 3Electrical Engineering Department, Kermanshah University of technology, Kermanshah, Iran
4Department of biomedical Engineering, Faculty of medicine, Kermanshah University of medical sciences , Kermanshah, Iran
[email protected], [email protected] Abstract—In this paper, the applicability of Radial Basis Function (RBF) network for the modeling and simulation of turbogenerators is presented. It is expensive and time- consuming to do experimental work to predict the behaviour of Turbogenerators with changing all variables. The RBF network is developed with speed and excitation current as inputs and voltage, active power and reactive power as desired outputs. The proposed RBF model is developed and trained with MATLAB 7.8 software. To obtain the optimal RBF model several structures have been constructed and tested. The comparison between experimental and predicted values using the proposed RBF model shows that there is a good agreement between them. Moreover, the RBF model is compared with another model named Multi Layer Perceptron (MLP), which is another important architectures of neural networks. The results obtained show that the proposed RBF model is more accurate and reliable than MLP model.
Index Terms— Radial basis function, Modelling, neural network, Turbogenerator.
I. INTRODUCTION
A turbogenerator is a turbine directly connected to an electric generator for the generation of electric power [1]. Turbo generators are used on steam locomotives as a power source for coach lighting and heating systems [1]. Synchronous generators or alternators are synchronous machines used to convert mechanical power to AC electric power. The term synchronous refers to the fact that the electric frequency of the machine has been locked by a mechanical shaft. Generators are composed of two parts: moving parts, which are called rotor and the fixed part known as the stator. In [2] an artificial neural network (ANN) generalised inversion control strategy for a turbo-generator governor is proposed. The ANN generalised inversion, which can approach the dynamic inversion of the original controlled system, is composed of a single static ANN and several linear components. In [3] the characteristic of neural network to model bulb turbogenerators is presented. The results obtained from
the nonlinear simulation demonstrate the adaptability and robustness of the control system based on the neural network. In [4] a novel algorithm called particle swarm optimization (PSO-BP) is proposed for ANN learning based on PSO to overcome the flaws of the traditional BP learning algorithm of its low convergence. The modeling and simulation of induction machines using vector computing technique in matlab/simulink is presented in [5], which provides an efficient approach for further research on wind generation system integration and control. A new wind turbine generator system is introduced, and its mathematical model, blade pitch control scheme, and nonlinear simulation software for the performance predication are presented [6]. A variable-speed induction generator, aimed at supplying an autonomous power system is presented [7]. The design of a fuzzy logic supervisor for the control of active and reactive power, which is generated by fixed speed wind energy conversion systems (WECS) is presented [8]. ANN [9] is used for multi-objective optimal reactive compensation of a power system with wind generators and after a training phase, the ANN model has the capacity to provide a good estimation of the voltages, the reactive productions and the losses for actual curves of the load and the wind speed, in real time. However, with regard to complexity and volume of calculations governing generator, the simulation of such a machine is time consuming. In this paper, radial basis function (RBF) network is used for modeling and simulation of turbogenerators. The schematic of the proposed RBF model is shown in Fig.1 where the RBF model is developed with speed and excitation current as inputs and voltage, active power and reactive power as desired outputs.
76 JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013
© 2013 ACADEMY PUBLISHERdoi:10.4304/jait.4.2.76-79
Figure 1. A simplified overview of RBF model.
II. RADIAL BASIS FUNCTION
A RBF network is an ANN that uses RBFs as activation functions. RBFs can fit erratic data [10, 11]. They are used in function approximation, time series prediction, and control due to their good approximation capabilities, faster learning algorithms and simpler network structures. The RBF has a feed forward structure and typically has three layers: an input layer, a hidden layer with a non-linear RBF activation function and a linear output layer as shown in Fig. 2. Hidden unit implements a radial activated function. The input layer is made up of source nodes that connect the network to its environment. The hidden layer consists of a set basis function unit that carry out a nonlinear transformation from the input space to the hidden space. The transformation from input to hidden layer is nonlinear and from hidden to output layer is linear. The output from jth neurons of the hidden layer is given by:
(1) k 1,2,..,=j2 ⎟⎟
⎠
⎞
⎜⎜
⎝
⎛ −=
j
jj
xKZ
σ
μ
where K is a strictly positive radially symmetric
function (kernel) with a unique maximum at its center ( jμ ), which drops off rapidly to zero away from the center. The number of neurons in the hidden layer is k, and jσ is the width of the receptive field in the input
space from unit j. This indirectly indicate that jz has a
desired value only when the distance jx μ− is smaller
than the jσ .
Figure 2. RBF structure.
The output of the mth neuron in the output layer is given by:
(2) M1,2,..,=m)()(1∑=
=k
jjjmm xzwxy
where jmw is the weighting factor.
III. RESULT AND DISCUSSION
For developing the proposed RBF model about 440 data were used. Total data are divided into two sets: training and testing. About 70% of the data were selected for training and 30% for testing the proposed RBF model. The best RBF network is obtained with 452 neurons in hidden layer. The comparisons between experimental and predicted values using the proposed RBF model are shown in Figs. 3-6. These figures compare the predicted values (RBF) and experimental values of voltage, active power and reactive power. From these figures, it is clear that the predicted values using the proposed RBF model are in good agreement with experimental data with least error. Also we have compared the proposed RBF model with MLP model [12] as shown in Table 1, where the mean relative error percentage ( MRE% ) is evaluated as:
Where N is the number of data and ‘XExp’ and ‘XPred’ stand for experimental and predicted values, respectively. It is observed from Figs. 3-6 and Table I that there is a good agreement between experimental and predicted values using RBF network and also the proposed RBF model is more accuracy in comparison with the MLP model [12].
Figure 3 Comparisons between the experimental and the RBF model
results for testing data.
( )310011
Pred ×⎟⎟
⎠
⎞
⎜⎜
⎝
⎛ −= ∑
= i
N
i Exp
Exp
XXX
NMRE%
JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013 77
© 2013 ACADEMY PUBLISHER
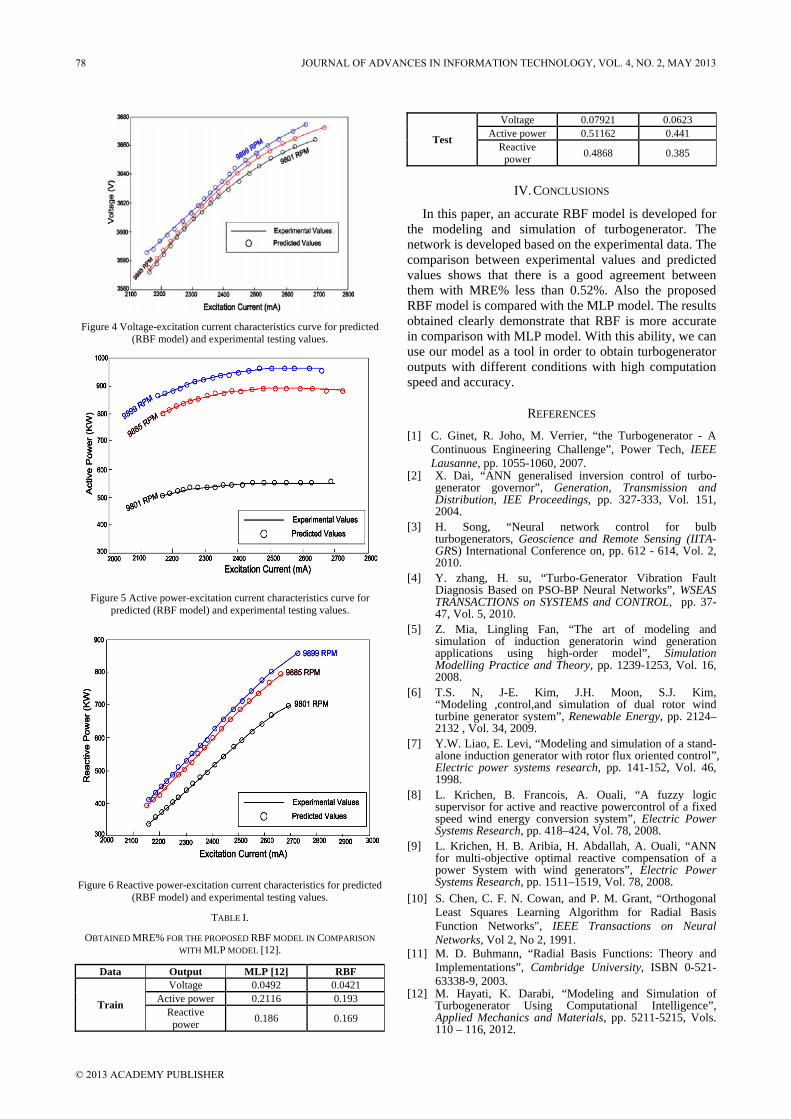
Figure 4 Voltage-excitation current characteristics curve for predicted
(RBF model) and experimental testing values.
Figure 5 Active power-excitation current characteristics curve for predicted (RBF model) and experimental testing values.
Figure 6 Reactive power-excitation current characteristics for predicted (RBF model) and experimental testing values.
TABLE I.
OBTAINED MRE% FOR THE PROPOSED RBF MODEL IN COMPARISON WITH MLP MODEL [12].
Data Output MLP [12] RBF
Train
Voltage 0.0492 0.0421 Active power 0.2116 0.193
Reactive power 0.186 0.169
Test
Voltage 0.07921 0.0623 Active power 0.51162 0.441
Reactive power 0.4868 0.385
IV. CONCLUSIONS
In this paper, an accurate RBF model is developed for the modeling and simulation of turbogenerator. The network is developed based on the experimental data. The comparison between experimental values and predicted values shows that there is a good agreement between them with MRE% less than 0.52%. Also the proposed RBF model is compared with the MLP model. The results obtained clearly demonstrate that RBF is more accurate in comparison with MLP model. With this ability, we can use our model as a tool in order to obtain turbogenerator outputs with different conditions with high computation speed and accuracy.
REFERENCES
[1] C. Ginet, R. Joho, M. Verrier, “the Turbogenerator - A Continuous Engineering Challenge”, Power Tech, IEEE Lausanne, pp. 1055-1060, 2007.
[2] X. Dai, “ANN generalised inversion control of turbo-generator governor”, Generation, Transmission and Distribution, IEE Proceedings, pp. 327-333, Vol. 151, 2004.
[3] H. Song, “Neural network control for bulb turbogenerators, Geoscience and Remote Sensing (IITA-GRS) International Conference on, pp. 612 - 614, Vol. 2, 2010.
[4] Y. zhang, H. su, “Turbo-Generator Vibration Fault Diagnosis Based on PSO-BP Neural Networks”, WSEAS TRANSACTIONS on SYSTEMS and CONTROL, pp. 37-47, Vol. 5, 2010.
[5] Z. Mia, Lingling Fan, “The art of modeling and simulation of induction generatorin wind generation applications using high-order model”, Simulation Modelling Practice and Theory, pp. 1239-1253, Vol. 16, 2008.
[6] T.S. N, J-E. Kim, J.H. Moon, S.J. Kim, “Modeling ,control,and simulation of dual rotor wind turbine generator system”, Renewable Energy, pp. 2124–2132 , Vol. 34, 2009.
[7] Y.W. Liao, E. Levi, “Modeling and simulation of a stand-alone induction generator with rotor flux oriented control”, Electric power systems research, pp. 141-152, Vol. 46, 1998.
[8] L. Krichen, B. Francois, A. Ouali, “A fuzzy logic supervisor for active and reactive powercontrol of a fixed speed wind energy conversion system”, Electric Power Systems Research, pp. 418–424, Vol. 78, 2008.
[9] L. Krichen, H. B. Aribia, H. Abdallah, A. Ouali, “ANN for multi-objective optimal reactive compensation of a power System with wind generators”, Electric Power Systems Research, pp. 1511–1519, Vol. 78, 2008.
[10] S. Chen, C. F. N. Cowan, and P. M. Grant, “Orthogonal Least Squares Learning Algorithm for Radial Basis Function Networks", IEEE Transactions on Neural Networks, Vol 2, No 2, 1991.
[11] M. D. Buhmann, “Radial Basis Functions: Theory and Implementations”, Cambridge University, ISBN 0-521-63338-9, 2003.
[12] M. Hayati, K. Darabi, “Modeling and Simulation of Turbogenerator Using Computational Intelligence”, Applied Mechanics and Materials, pp. 5211-5215, Vols. 110 – 116, 2012.
78 JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013
© 2013 ACADEMY PUBLISHER

Mohsen Hayati received the BE in electronics and communication engineering from Nagarjuna University, India, in 1985, and the ME and PhD in electronics engineering from Delhi University, Delhi, India, in 1987 and 1992, respectively. He joined the Electrical Engineering Department, Razi University, Kermanshah, Iran, as an assistant professor in 1993. At present,
he is an associate professor with the Electrical Engineering Department, Razi University. He has published more than 110 papers in international and domestic journals and conferences. His current research interests include application of computational intelligence, artificial neural networks, fuzzy systems, neuro-fuzzy systems, and electronics circuit synthesis, modeling, and simulations and design of microwave circuits.
Abbas Rezaei received the BS and MS in electronics engineering from Razi University, Kermanshah, Iran, in 2005 and 2009, respectively. He was with the Computational Intelligence Research Center, Faculty of Engineering, Razi University during 2007 to 2009. He is currently working towards the Ph.D. degree in electrical engineering at Razi
University, Kermanshah, Iran. His current research interests include nanotechnology, QCA, artificial intelligence, neural networks, fuzzy systems and neuro-fuzzy systems.
Leila Noori received the BS and MS in electronics engineering from Razi University, Kermanshah, Iran, in 2006 and 2010, respectively. She was with the Computational Intelligence Research Center, Faculty of Engineering, Razi University during 2008 to 2010 and she is currently working towards the Ph.D degree in electrical engineering at the
Shiraz University of technology, Shiraz, Iran. Her research interest includes the low-power and low-size integrated circuit design, and Passive RF component.
JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013 79
© 2013 ACADEMY PUBLISHER

Cascade Artificial Neural Network Models for Predicting Shelf Life of Processed Cheese
Gyanendra Kumar Goyal and Sumit Goyal National Dairy Research Institute, Karnal, India
Email: [email protected], [email protected]
Abstract—The purpose of this study is to develop artificial neural network (ANN) models for predicting shelf life of processed cheese stored at 7-8ºC. Body & texture, aroma & flavour, moisture and free fatty acids were taken as input parameters, and sensory score as output parameter for developing the models. The developed Cascade single layer ANN models were compared with each other. Bayesian regularization was used for training ANN models. Network was trained with 100 epochs, and neurons in each hidden layer(s) varied from 3 to 20. Cascade ANN models very well predicted the shelf life of processed cheese. Index Terms—Artificial Intelligence, Cascade, Artificial neural networks (ANN), Processed Cheese, Shelf Life, Soft Computing
I. INTRODUCTION
Processed cheese, a protein rich food is good supplement to meat protein. Generally, it is prepared from ripened Cheddar cheese, but often some quantity of less ripened or fresh cheese is also added. Its manufacturing technique involves addition of emulsifier, salt, water and spices (optional). The mixture is heated in a1double jacketed kettle with continuous gentle stirring with a flattened ladle in order to get homogeneous paste. This variety of cheese has pleasing taste, unique body and texture, and longer shelf life. An artificial neuron is a computational model inspired in the natural neurons. Natural neurons receive signals through synapses located on the dendrites or membrane of the neuron. When the signals received surpass a certain threshold, the neuron is activated and emits a signal though the axon. This signal might be sent to another synapse, and might activate other neurons. These basically consist of inputs, which are multiplied by weights (strength of the respective signals), and then computed by a mathematical function which determines the activation of the neuron. By adjusting the weights of an artificial neuron, desired output can be obtained for specific inputs. Algorithms can adjust the weights of the ANN for getting the desired output from the network, called training. The function of ANNs is to process information; and they are also used for engineering purposes, such as pattern [1]. Cascade models are similar to feedforward networks, but include a weight connection from the input to each layer
and from each layer to the successive layers. While two layer feedforward networks can potentially learn virtually any input output relationship, feedforward networks with more layers might learn complex relationships more quickly. The function newcf creates cascade forward networks [2-3]. Single layer perceptron network consists of a single layer of output nodes; the inputs are fed directly to the outputs via a series of weights. The sum of the products of the weights and the inputs is calculated in each node, and if the value is above some threshold (typically 0), the neuron fires and takes the activated value (typically 1); otherwise it takes the deactivated value (typically -1) [4]. Shelf life is the guideline of time period for which the product remains acceptable under specified conditions of distribution, storage and display. However, use prior to the expiration date does not necessarily guarantee the safety of a food, and a product is not always dangerous or ineffective after the expiration date [5]. The aim of this study is to develop cascade single hidden layer ANN models for predicting the shelf life of processed cheese stored at 7-8ºC.
II. LITERATURE REVIEW
The application of ANN for predicting the shelf life of food products in food industry is quite an effective approach [6]. ANNs are vibrant new tools to evaluate food quality, analyze shelf life and predict various properties of foodstuffs [7].
A. Milk The usefulness of ANN models for prediction of shelf-
life of milk by multivariate interpretation of gas chromatographic profiles, and flavour-related shelf-life was evaluated and compared with Principal Components Regression (PCR). The training set consisted of dynamic headspace gas chromatographic data collected during storage of pasteurized milk (input information for the ANN models used to make a decision) and its corresponding shelf-life (prediction or response). The study revealed that ANN had better predictability than PCR. A standard error of the estimate of 2 days in shelf life resulting from regression analysis of experimental versus predicted values indicated a high predictability of ANN [8].
80 JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013
© 2013 ACADEMY PUBLISHERdoi:10.4304/jait.4.2.80-83

B. Butter The seasonal variations of the fatty acids composition
of butters were investigated over three seasons during a 12-month study in the protected designation of origin Parmigiano-Reggiano cheese area. Fatty acids were analyzed by GC-FID, and then computed by ANN [9].
C. Processed Cheese The Time-delay single layer and multilayer ANN
models were suggested for predicting the shelf life of processed cheese stored at 7-8oC [10]. The input parameters of the ANN consisted of soluble nitrogen, pH; standard plate count, yeast & mould count, and spore count. The output parameter was sensory score. The results of the experiments showed excellent correlation between the training data and the validation data with a high Nash - Sutcliffe coefficient (E2) and determination coefficient (R2), suggesting that the developed models are able to analyze the non-linear multivariate data with excellent performance and shorter calculation time. From the study it was inferred that time-delay ANN models are very good for predicting the shelf life of processed cheese.
D. Kalakand The shelf life of kalakand, which is milk based
desiccated sweetened dairy product, was estimated by implementing Cascade single and double hidden layer models. The developed models were compared with each other for observing their supremacy over the other [11].
E. Burfi Radial basis (exact fit) model was suggested for
estimating the shelf life of an extremely popular milk based sweetmeat namely burfi [12]. The input variables were the lab data of the product relating to moisture, titratable acidity, free fatty acids, tyrosine, and peroxide value; and the overall acceptability score was output. Mean square error (MSE), root mean square error (RMSE), R2 and E2 were applied for comparing the prediction ability of the developed models. The observations indicated exceedingly well correlation between the actual data and the predicted values, with a high R2 and E2 establishing that the models were able to analyze non-linear multivariate data with very good performance. From the study, it was concluded that the developed model, which is very convenient, less expensive and less time consuming can be a good alternative to expensive, time consuming and cumbersome laboratory testing method for estimating the shelf life of burfi.
F. Roller Dried Goat Whole Milk Powder The possibility of using radial basis function artificial
neural network (RBF ANN) model as an alternative to
expensive, time consuming and cumbersome laboratory testing method for predicting the solubility index of roller dried goat whole milk powder has been successfully explored. The ANN models were trained with a data file composed of variables: loose bulk density, packed bulk density, wettability and dispersibility, while solubility index was the output variable. The modeling results showed that there was good agreement between the experimental data and the predicted values [13].
III. METHOD MATERIAL
Body & texture, aroma & flavour, moisture, and free fatty acids of processed cheese stored at 7-8º C were taken as input parameters, and sensory score was taken as output parameter for developing Cascade single and multilayer ANN models (Fig.1).
Figure 1. Input and output parameters of models
Data consisted of 36 observations, which were divided into two subsets, i.e., 30 for training and 6 for validation. Different combinations of internal parameters, i.e., data preprocessing, data partitioning approaches, number of hidden layers, number of neurons in each hidden layer, transfer function, error goal, etc., were explored in order to optimize the prediction ability of the cascade model. Several algorithms like Gradient Descent algorithm with adaptive learning rate, Bayesian regularization, Fletcher Reeves update conjugate gradient algorithm, Levenberg Marquardt algorithm and Powell Beale restarts conjugate gradient algorithm were tried. Bayesian regularization mechanism was finally selected for training ANN models, as it exhibited best results. The network was trained with 100 epochs, and neurons in each hidden layer varied from 3 to 20. The network was trained with single hidden layers and transfer function for hidden layer was tangent sigmoid, while for the output layer it was pure linear function. MALTAB software was used for performing the experiments.
⎥⎥
⎦
⎤
⎢⎢
⎣
⎡
⎟⎟⎠
⎞⎜⎜⎝
⎛ −= ∑
2
1 exp
exp1 Ncal
QQQ
nRMSE
(1)
Body &Texture
Aroma & Flavour
Moisture
Free fatty acids
Sensory Score
JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013 81
© 2013 ACADEMY PUBLISHER
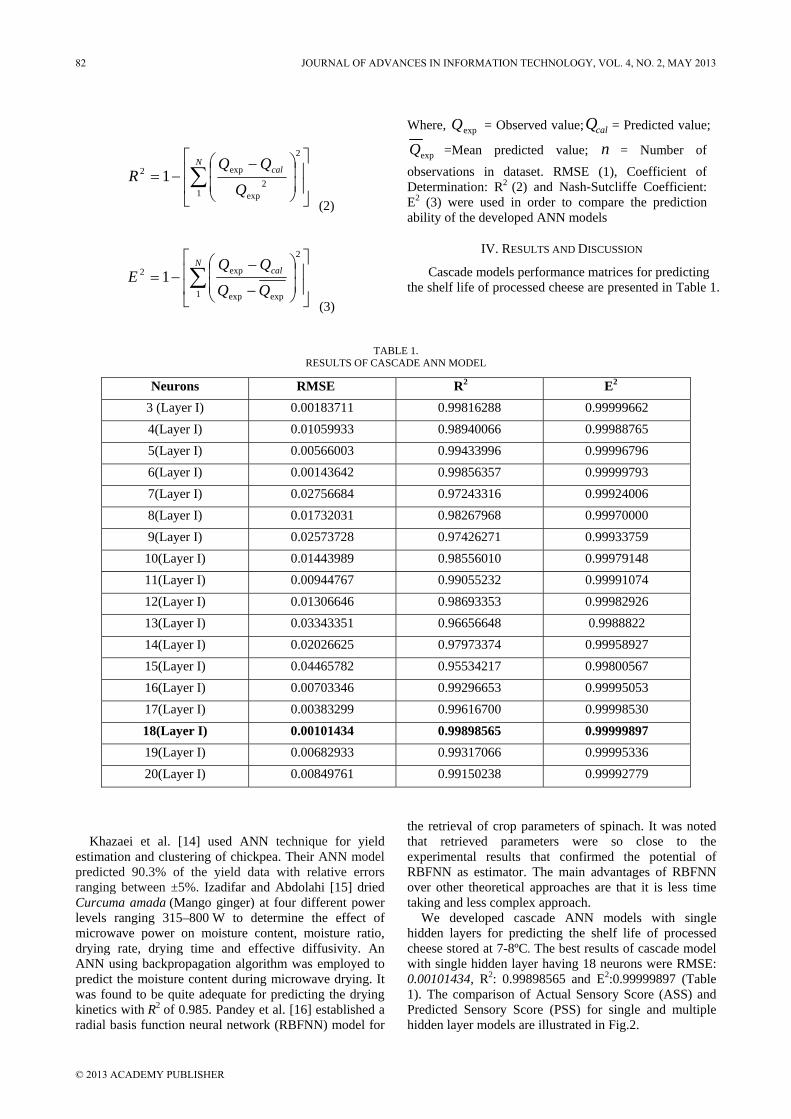
⎥⎥
⎦
⎤
⎢⎢
⎣
⎡
⎟⎟⎠
⎞⎜⎜⎝
⎛ −−= ∑
2
12
exp
exp2 1N
cal
Q
QQR
(2)
⎥⎥
⎦
⎤
⎢⎢
⎣
⎡
⎟⎟⎠
⎞⎜⎜⎝
⎛
−
−−= ∑
2
1 expexp
exp2 1N
cal
QQE
(3)
Where, expQ = Observed value; calQ = Predicted value;
expQ =Mean predicted value; n = Number of observations in dataset. RMSE (1), Coefficient of Determination: R2 (2) and Nash-Sutcliffe Coefficient: E2 (3) were used in order to compare the prediction ability of the developed ANN models
IV. RESULTS AND DISCUSSION
Cascade models performance matrices for predicting the shelf life of processed cheese are presented in Table 1.
TABLE 1.
RESULTS OF CASCADE ANN MODEL
Khazaei et al. [14] used ANN technique for yield estimation and clustering of chickpea. Their ANN model predicted 90.3% of the yield data with relative errors ranging between ±5%. Izadifar and Abdolahi [15] dried Curcuma amada (Mango ginger) at four different power levels ranging 315–800 W to determine the effect of microwave power on moisture content, moisture ratio, drying rate, drying time and effective diffusivity. An ANN using backpropagation algorithm was employed to predict the moisture content during microwave drying. It was found to be quite adequate for predicting the drying kinetics with R2 of 0.985. Pandey et al. [16] established a radial basis function neural network (RBFNN) model for
the retrieval of crop parameters of spinach. It was noted that retrieved parameters were so close to the experimental results that confirmed the potential of RBFNN as estimator. The main advantages of RBFNN over other theoretical approaches are that it is less time taking and less complex approach.
We developed cascade ANN models with single hidden layers for predicting the shelf life of processed cheese stored at 7-8ºC. The best results of cascade model with single hidden layer having 18 neurons were RMSE: 0.00101434, R2: 0.99898565 and E2:0.99999897 (Table 1). The comparison of Actual Sensory Score (ASS) and Predicted Sensory Score (PSS) for single and multiple hidden layer models are illustrated in Fig.2.
Neurons RMSE R2 E2 3 (Layer I) 0.00183711 0.99816288 0.99999662 4(Layer I) 0.01059933 0.98940066 0.99988765 5(Layer I) 0.00566003 0.99433996 0.99996796 6(Layer I) 0.00143642 0.99856357 0.99999793 7(Layer I) 0.02756684 0.97243316 0.99924006 8(Layer I) 0.01732031 0.98267968 0.99970000 9(Layer I) 0.02573728 0.97426271 0.99933759 10(Layer I) 0.01443989 0.98556010 0.99979148 11(Layer I) 0.00944767 0.99055232 0.99991074 12(Layer I) 0.01306646 0.98693353 0.99982926 13(Layer I) 0.03343351 0.96656648 0.9988822 14(Layer I) 0.02026625 0.97973374 0.99958927 15(Layer I) 0.04465782 0.95534217 0.99800567 16(Layer I) 0.00703346 0.99296653 0.99995053 17(Layer I) 0.00383299 0.99616700 0.99998530 18(Layer I) 0.00101434 0.99898565 0.99999897 19(Layer I) 0.00682933 0.99317066 0.99995336 20(Layer I) 0.00849761 0.99150238 0.99992779
82 JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013
© 2013 ACADEMY PUBLISHER

Figure 2. Comparison of ASS and PSS single layer model Several experiments were performed, as there is no
defined method to reach to a good conclusion other than hit and trial approach. Different constituents of threshold functions were used in layers, combination of TANSIG-TRAINBR-PURELIN as threshold function and Bayesian regularization as learning algorithm was finally selected. Cascade ANN model with single hidden layer having 18 neurons predicted the shelf of processed cheese very well.
V. CONCLUSION
Cascade single hidden layer ANN models were developed for predicting the shelf life of processed cheese stored at 7-8ºC. Cascade model with single hidden layer having 18 neurons gave best RMSE: 0.00101434, indicating that the cascade ANN models simulated the shelf life of processed cheese very efficiently. Based on these results, it is concluded that cascade models are excellent tool for predicting the shelf life of processed cheese.
REFERENCES
[1] http://arxiv.org/ftp/cs/papers/0308/0308031.pdf (accessed on 29.7.2011).
[2] H. Demuth, M. Beale and M. Hagan. “Neural Network Toolbox User’s Guide”. The MathWorks, Inc., Natrick, USA. 2009
[3] R.A. Chayjan, Modeling of sesame seed dehydration energy requirements by a soft-computing. Australian Journal of Crop Science, Vol.4 (3), 180-184, 2010.
[4] http://en.wikipedia.org/wiki/Feedforward_neural_network (accessed on 2.2.2011).
[5] http://www.answers.com/topic/shelf-life (accessed on 2.2.2011).
[6] Sumit Goyal and G. K. Goyal, Artificial neural networks for dairy industry: A review. Journal of Advanced Computer Science and Technology, Vol. 1(3), 101-115, 2012.
[7] Sumit Goyal and G. K. Goyal, Artificial neural networks in foodstuffs: a critical review. Scientific Journal of Review, Vol. 1(4) 147-155, 2012.
[8] B. Vallejo-Cordoba, G. E. Arteaga and S. Nakai, Predicting milk shelf-life based on artificial neural networks and headspace gas chromatographic data. Journal of Food Science, Vol. 60, 885-888, 1995.
[9] A. Gori, C. Chiara, M. Selenia, M. Nocetti, A. Fabbri, M. F. Caboni and G. Losi, Prediction of seasonal variation of butters by computing the fatty acids composition with artificial neural networks. European Journal of Lipid Science and Technology, Vol.113 (11), 1412–1419, 2011.
[10] Sumit Goyal and G. K. Goyal, Shelf life estimation of processed cheese by artificial neural network expert systems. Journal of Advanced Computer Science and Technology, Vol.1 (1), 32-41, 2012.
[11] Sumit Goyal and G. K. Goyal, Advanced computing research on cascade single and double hidden layers for detecting shelf life of kalakand: An artificial neural network approach. International Journal of Computer Science and Emerging Technologies, Vol.2 (5), 292-295, 2011.
[12] Sumit Goyal and G. K. Goyal, Radial basis (exact fit) artificial neural network technique for estimating shelf life of burfi. Advances in Computer Science and its Applications, Vol.1 (2), 93-96, 2012.
[13] Sumit Goyal and G. K. Goyal, Radial basis artificial neural network models for predicting solubility index of roller dried goat whole milk powder. In: 17th edition of the World Conference on Soft Computing in Industrial Applications, December 10-21, 2012, hosted by the VSB - Technical University of Ostrava, Czech Republic.
[14] J. Khazaei, M. R. Naghavi, M. R. Jahansouz and G. Salimi-Khorshidi, Yield estimation and clustering of chickpea genotypes using soft computing techniques. Agronomy Journal, Vol.100 (4), 1077-1087, 2008.
[15] M. Izadifar and F. Abdolahi, Comparison between neural network and mathematical modeling of supercritical CO< sub> 2</sub> extraction of black pepper essential oil. The Journal of Supercritical Fluids, Vol.38 (1), 37-43, 2006.
[16] A. Pandey, S.K. Jha and R. Prasad, Retrieval of crop parameters of spinach by radial basis neural network approach using X-band scatterometer data1. Russian Agrícultural Science, Vol. 36 (4), 312-315, 2010.
024681012141618
0 5 10
Sensory Score
Validation Data
ASS
PSS
JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013 83
© 2013 ACADEMY PUBLISHER

28 Nanometers FPGAs Support for High Throughput and Low Power Cryptographic Applications
Yaser Jararweh, Lo'ai Tawalbeh, Hala Tawalbeh
Cryptographic Hardware and information Security lab (CHiS) Jordan University of Science and Technology, Irbid, Jordan
Email: {yijararweh, Tawalbeh}@just.edu.jo, [email protected]
Abidalrahman Moh’d Engineering Mathematics and Internetworking
Dalhousie University, Halifax, Canada Email: [email protected]
Abstract—The current unprecedented advancements of communication systems and high performance computing urged for a high throughput applications with power consumption within a predefined budget. These advancements were accompanied with a crucial need for securing such systems and users critical data. Current cryptographic applications suffer from the limitations of their low throughput and extensive power consumption that severely impact the available power budget. Creating new algorithms to handle these issues will be a time consuming process. One viable solution is to use the new 28 Nanometers (nm) FPGAs devices that promise to provide less power consumption with a very competitive throughput and throughput to area ratio comparing to the older technologies. In this paper, we evaluate the 28 nm FPGAs technology and its impact in eight of the major cryptographic algorithms available today such as SHA2, SHA3, and AES. Our results revealed that using the 28 nm FPGAs reduced the power consumption to more than 50% and increase the throughput up to 100% compared to the older FPGs technologies. On the other hand, throughputs to area ratio results show about 71% improvement over other technologies. Index Terms—Hardware Evaluation, Power, Throughput, FPGA, 28 nm technology, AES, SHA.
I. INTRODUCTION
During the previous decades, engineers and scientists kept trying to have as much as possible of transistors on a chip until computers became faster, more powerful, and very useful. Consequently computers became an important part of almost every single person on this earth and that’s why all computer systems, applications, and networks must be secure, trusted, and safe in order to protect all data and information specially the sensitive ones from being accessed, stolen, or even shown to those who must not do so. Therefore it is very necessary and important to have methods that assure high level of security for the transmission of data and the communication between network's parties. The science of cryptography and its four services (confidentiality, integrity, authentication and non-repudiation) are both
available for the purpose of assuring security over the different types of communications.
Cryptographic encryption algorithms and secure hash algorithm (SHA) functions are very important for many security applications, especially for the authentication related applications, such as message authentication codes, password protection and digital signature. Data integrity verification is another field in which cryptographic hashing takes place. It is used to make sure that the data transmitted within a message is not being accessed or modified [2].
In general, cryptographic systems and applications are slow and power consuming systems when implemented with software solutions. The viable alternative is using FPGAs hardware implementations of such critical systems. However, current FPGAs hardware devices also show some limitations in their throughput and power consumption. So what we are going to provide in this paper is an evaluation for the support provided by one of the newest FPGAs technologies for raising the amount of data encrypted in specific amount of time (throughput) and for reducing the consumed power. This technology is the 28 nm technology with its Xilinx 7 series FPGAs that includes Artix™-7, Kintex™-7, and Virtex-7 devices.
II. RELATED WORK
For SHA-1, and SHA-2, many works in literature focused on how to optimize speed and throughput such as in [11] [12] [13] [14] and many other works focused on improving the different implementations of SHA-2 like the one proposed in [12] and [15].
For the under development SHA-3 and its five final candidates (Blake, Grostl, JH, Keccak, and Skein), there are many works that studied each one of them and its implementation individually or compared them together under a certain criteria. The authors in [16] shows different architectures for each algorithm of the candidates which resulted in many tradeoffs between speed and area, and provides a ranking for the 5 candidates based on their performance and other features that differentiate each algorithm from the others.
84 JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013
© 2013 ACADEMY PUBLISHERdoi:10.4304/jait.4.2.84-90

Researchers in [6] provided a comparative study for the five finalists and SHA2-256 using different FPGA families (Virtex-4, Virtex-5, Virtex-6 and Spartan-3). [1] and [2] provided a comparative study for the five finalists and SHA2-256 using different FPGA families (Virtex-5, Virtex-6 and Virtex-7).
For the Advanced Encryption Standard (AES), there are several hardware implementations that can be found in literature. These implementations were done for the original standard AES (not more than 256 bits key size), such as the work presented in [17] [18]. Before choosing Rijindael to be the AES in November of 2001, many related implementations were proposed to how much the structure of the proposed candidates for the AES competition is suitable for hardware implementation [19]. They provide a multiple architecture options for AES finalist candidates with an implementation analysis for each architecture based on both area and speed optimization with a detailed comparison of the FPGA hardware performance of the AES candidates. Many other implementations that target the Field Programmable Devices (FPD) for Rijndael with a comparison with Xilinx FPGA implementation are also available. The authors in [19] presented a new variation of the AES algorithm (called AES-512) with its hardware architecture. The goal of the AES-512 to be used when higher levels of security and throughput are required. The need for low power consumption systems such as in sensors networks [20] is continuously increasing, and this is our main motivation in this paper.
III. 28 NM TECHNOLOGY
Nanometer is a measure unit just like feet, inches and miles, but it is used to measure small things just like atoms. A meter is a billion (1000000000) of nanometers. So nanometer is a very small unit and things that are nanometers in size cannot be seen without using powerful microscopes. [3]
Inside someone's computer, thousands of tiny switches of 100 nanometers wide can be found. These stacked and packed tiny switches are manufactured by what is called nanometer technology or nanotechnology by which machines in factories can be used to take, move and mix ingredients that are nanometers big and turn them into materials that can be used to manufacture functional devices used in a wide range of complete and high performance applications and products just like electronics. Nm technology in computers refers to an individual transistor's size or the distance between the centers of two adjacent transistors on a chip. The smaller it could be made, the less energy it will use, and the more performance will be reached as more of them can be packed in a given space. [3]
Nanometer technology or the technology node selection for FPGA is passed through different stages and evolved from a version to another. Every newer version is specialized by its smaller size of transistor. The technology of node selection is started with transistors of thousands nanometers in size and kept evolving to be 150 nm by 2000, 130 nm by 2002, 90 nm by 2004, 65 nm by
2006, 45 nm by 2008 and 28 nm by 2010. In our research we are going to concentrate our efforts on the newest node selection technology that is the 28 nm technology as it is designed to efficiently and effectively manage both dynamic and static power and to raise the fundamental performance in a reasonable cost. [1]
What specializes the 28 nm technology's FPGAs is the optimized transistor mix of high threshold voltage transistors, low threshold voltage transistors, and regular threshold voltage transistors, with separate performance and leakage for each transistor in the mix. This optimized transistor mix is first introduced in Virtex-6 FPGA. Two voltages 1V and 0.9V at which 28 nm technology FPGAs operate are offered by Xilinx and this is what is called the voltage scaling option which result a 30% of static power reduction. [7]
The 7 series FPGAs of the 28 nm technology offered by Xilinx are created using the stacked silicon interconnect technology to avoid the problems caused by the different leakage components for each transistor specially for those large devices that contain billion of transistors. This technology creates large devices by using multiple dies with a recognized reduction in the static power and in the I/O interconnects power. [7]
High end, power sensitive and bandwidth sensitive applications need a very well suited nm technology. Low power process, high performance, and the different choices for cost effective mass production make the 28nm technology very appropriate and efficient for these applications.
Moreover, efficient management of current tunneling effects, which is a goal for all the process designers, utilizes 28nm technologies with the new gate dielectric material added by Xilinx such as super low-power (SLP) technology and high performance (HP) technology. These technologies are designed for applications such as graphics, wired networking and wireless mobile applications.
28nm node is a good choice for different projects since its performance variation will solve a many reliability challenges and problems by developing advanced processes and affordable techniques by which designers can detect correct reliability issues early in the custom and semi custom design phases. Furthermore, since the 28nm gate oxide is too thin, tunneling effect has to be addressed by a new gate material by making trade-offs in the overall transistor design. For this purpose a new gate with high dielectric constant for the dielectric material, called hafnium dioxide has been adopted by Xilinx. This material offers an increasing in the gate thickness, so the transistor will be more immune to the tunneling current effects [10]. Choosing the 28 nm HKMG (high-k metal gate) high performance and low-power process technology is performed by Xilinx after evaluating the 28 nm technology options including LP and HP variants [10].
After all the mentioned advantages of 28nm technology, Xilinx decided to merge the high performance and the low-power process technology in a new unified ASMBL (Advanced Silicon Modular Block)
JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013 85
© 2013 ACADEMY PUBLISHER

in order to create a new FPGAs with lower power and higher performance.
In general, the 28nm technology and FPGAs products focus on 3 main goals, reducing the static and dynamic power, so we can have the total power reduced by half at the minimum, increasing the performance by the half too, and increasing the capacity.
A. Vitrex-7 In our research we are going to focus on one of Xilinx
7 series FPAG devices, this device is Virtex-7 as it is the World’s Highest Capacity FPGA since it delivers greater than 2 x the capacity and bandwidth offered by other devices and integrates 2 million logic cells and 6.8 transistors. Virtez-7 is considered as Industry's Highest System Performance too since its FPGAs are optimized for advanced systems requiring the highest performance and highest bandwidth connectivity and delivers 2 x higher system performances at 50% lower power than previous generation FPGAs. [4]
IV. CRYPTOGRAPHIC ALGORITHMS
A. Advanced Encryption Standard (AES) The Advanced Encryption Standard algorithm AES is the FIPS-197 stander that been in use since 2001 since it provides high level of security and can be implemented easily [17]. The AES is a symmetric cipher algorithm with block size of 128-bit supports key sizes of 128, 192, and 256 bits with 10, 12, or 14 iteration rounds, respectively. Four major operations are performed during each round: byte substitution, shifting rows, mixing columns, and finally adding the round key. AES 128-bit key is considered secure compared to the other existing symmetric cipher algorithms. It is widely used in many applications where the security is very important. Many new variations of AES algorithm were proposed to provide even more security and throughput. In AES, more security comes from using larger key size, and more throughputs come from using four times larger block size than the block size used in the original AES. The only disadvantage of larger block size AES is the need for more design area and power consumption which is the core of this paper. The top level architecture of the AES-128 and its variant AES-512 bits are similar to a certain extent. The plaintext and the key size are 128 or 512-bits respectively, each (organized in bytes). The same size will be for its output ciphertext.
AES operations are going through four steps, we summarized them as follow [17] [19].
a. .Byte Substitution The input plaintext is organized in a set of arrays of
fixed size of bytes and then substituted by values obtained from Substitution boxes (S-boxes). This is done to achieve more security according to diffusion-confusion Shannon's principles for cryptographic algorithms design.
b. Shift Row After the original block data is substituted with values
from the S-boxes, the rows of the resulting matrix are
shifted in a process called ShiftRow transformation. The bytes in each row in the input data matrix will be rotated left.
c. Mix Colomn The MixColumn transformation multiplies the
columns of the data matrix by a pre-defined matrix over GF (28).
d. AddRound Key To make the relationship between the key and the
ciphertext more complicated and to satisfy the confusion principle, the AddRound Key operation is performed. This addition step takes the resulting data matrix from the previous step and performs on it a bitwise XOR operation with the sub key of that specific round (addition operation in GF (2n)).
B. Secure Hashing Algorithms SHA Secure hashing algorithms SHA take data as block
(messages) and return a string of fixed and smaller size bits (hash value), so changes on data lead to changes on the hash value (digest). However the requirements for the cryptographic hash functions differ but at the same time there are common characteristics for all functions with messages as inputs. The following are some of these characteristics:
• Secure hash functions are very simple and easy. Therefore their hardware and software implementations are always efficient.
• Hashing functions are one way functions which means that it is impossible to generate a message from its digest.
• For a specific message m it is infeasible to find another specific message n such that H(m) = H(n). This is called weak collision resistance.
• It is infeasible too to find two different messages m and n such that H(m) = H(n). In other words two different messages do not lead to the same hash digest. This is called strong collision resistance.
Cryptographic hash functions are very important for many security applications, especially for the authentication related applications such as message authentication codes and digital signatures, message and file integrity secure login, and figureprints of keys.
Most of Secure Hash Algorithms (SHA) have common components which are: Permutation or the process of swapping data (input), Substitution or the process of nonlinear transformation of data using substitution-box or S-box, Logical functions just like AND, OR, NOT and the most desired XOR and the Modular arithmetic function (mod).
SHA is a group of hash functions published by NIST (stands for the National Institute of Standards and Technologies) and developed by National Security Agency NSA [6].
SHA0: 160-bit secure hash function published in 1993. Due to an undisclosed significant flaw, SHA0 was withdrawn shortly after its publication and replaced directly by SHA1.
86 JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013
© 2013 ACADEMY PUBLISHER

SHA1: 160-bit secure hash function which is nearly similar to the MD5 but much more moderate. SHA1 was designed, developed, and published by the NSA. And among the SHA families, SHA1 is the most widely used one.
SHA2: consists of two hash functions with 4 different size blocks for the output, 224, 256, 384, and 512 bits. SHA-224 and the SHA-256 are truncated versions of the SHA-384 and SHA-512. Same as SHA1, all SHA2 families were designed, developed, and published the NSA.
SHA3: The upcoming hash function which is still under development and supposed to be published by March 2012 through a public competition held by NIST, in order to choose the best algorithm among all the candidates. The five candidates are Blake, Grostl, JH, Keccak, and Skein.
V. EVALUATION METRICS
As we are studying the 28 nm FPGAs support for high throughput and low power cryptographic applications, we are going to evaluate the new technology's effect in term of power and throughput.
Throughput: is an important metric, which means the amount of processed data by a design within a fixed amount of time. The importance of throughput is coming from being a number that weights: the block size which is a characteristic for the algorithm used in an application, the frequency which is a characteristic for the hardware design performance and the latency which is a characteristic for the hardware design architecture [5] [6].
Power: Power consumption is one of the most important factors that can be used for the FPGA selection, and that's why Xilinx tries always to reduce it, starting from Virtex-4 FPGAs, until the development of Xilinx 28 nm 7 series FPGAs that includes Artix-7, Kintex-7, and Virtex-7 devices, which all have been evaluated according to their impact on static power, dynamic power, and I/O power [7]. The power of any design is presented as a summation of dynamic power and static power, and the power of any design we are going to present in this research is calculated using Xilinx Xpower estimator tool.
VI. RESULTS AND EVALUATION
In this section a detailed description about all experiments that have been done will be presented. Our Experiments depend on the hardware implementation for SHA3 candidates. We have got these implementations from George Mason University (GMU) website and synthesized them on FPGAs for different families. [8]
A. Framework We have used VHDL implementation from the GMU
for the 5 candidates since they are all described in this language, where if different languages are used to describe different candidates may lead to unneeded bias. So the VHDL is a perfect choice for the implementations and comparisons of the candidates.
For FPGA devices, we decided to concentrate on those from Xilinx, so we have chosen 3 families of Xilinx FPGA devices optimized for high performance, Virtex-5 (xc5vlx20t-2ff323), Virtex-6 (xc6vcx75t-2ff484), and the 28 nm technology's Virtex-7 (xc7v285t-2ffg1157).
For throughput results we have used the Xilinx ISE synthesizer and design suit (version 13.1). For power results evaluation, XPower estimator was used. XPower estimator is a spreadsheet estimation tools that is used after applying the XPower analyzer tool of Xilinx ISE design software for more accurate estimations and power analysis, by mapping the results of the analyzer to the sheets [9]. We calculate throughput firstly by finding T, which stands for the period that is the length of time taken by one cycle. The formula for T is: T 1/frequency
Then, the throughput will be calculated using: TP blocksize/ latency ∗ T The block size is a fixed amount of data that the
algorithm will process at a time. The latency is the number of cycles that are needed to hash a message and we have got the values for the latency ready from the GMU website. [8]
So throughput equations will be as follow: • For Blake algorithm: 512/ 21 ∗ . • For Groestle algorithm: 512/ 21 ∗ . • For JH algorithm: 512/ 36 ∗ . • For Keccak algorithm: 1088/ 24 ∗ . • For Skein algorithm: 512/ 19 ∗ . • For SHA2 algorithm: 512/ 65 ∗ .
Then, we use the XPower analyzer tool from Xilinx ISE to generate the thermal and power summery for each algorithm. Also, we have a mapping between the XPower analyzer and the XPower estimator to work on the power experiments after extracting the map reports of the analyzer using the estimator.
B. Throughput results for different FPGAs devices Table 1 shows two things, the first point is that the use
of Virtex-7 provides a higher operating frequency compared with Virtex-5 and Virtex-6. JH and KECCAK algorithms show a higher frequency than SHA-3 candidates, SHA-2, AES-128 and AES-512. In contrast, BLAKE and SKEIN results show lower frequency when compared to SHA2 and AES-128 and AES-512. The second point is that using Virtex-7 has a little impact on the throughput compared with Virtex-5 and Virtex-6 except for KECCAK algorithm. JH and KECCAK algorithms show higher throughput than other SHA-3 and SHA-2 algorithms. KECCAK algorithm shows the best results in terms of throughput and AES-128 and AES-512 show the worst results in term of throughput [1]. The Throughput results that most of the algorithms gain about 100% increase in its throughput compared with other technologies. Table 2 shows the improvements achieved by implementing designs on Virtex-7 FPGA family as it is one of the 28nm technologies compared to Vertix-5 for SHA-3 candidates, SHA-2, AES-128 and AES-512 [1]. The results show that even the throughput to area ration is
JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013 87
© 2013 ACADEMY PUBLISHER
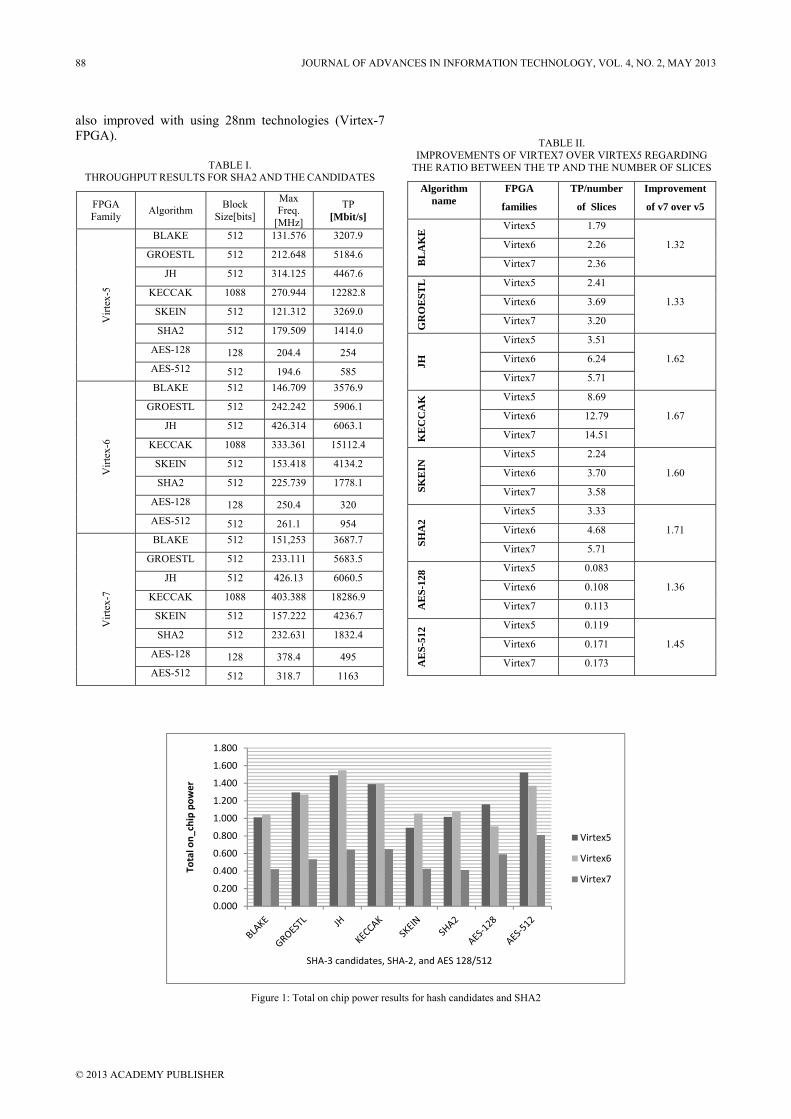
also improved with using 28nm technologies (Virtex-7 FPGA).
TABLE I. THROUGHPUT RESULTS FOR SHA2 AND THE CANDIDATES
FPGA Family Algorithm Block
Size[bits]
Max Freq.
[MHz]
TP [Mbit/s]
Virt
ex-5
BLAKE 512 131.576 3207.9
GROESTL 512 212.648 5184.6
JH 512 314.125 4467.6
KECCAK 1088 270.944 12282.8
SKEIN 512 121.312 3269.0
SHA2 512 179.509 1414.0
AES-128 128 204.4 254 AES-512 512 194.6 585
Virt
ex-6
BLAKE 512 146.709 3576.9
GROESTL 512 242.242 5906.1
JH 512 426.314 6063.1
KECCAK 1088 333.361 15112.4
SKEIN 512 153.418 4134.2
SHA2 512 225.739 1778.1
AES-128 128 250.4 320 AES-512 512 261.1 954
Virt
ex-7
BLAKE 512 151,253 3687.7
GROESTL 512 233.111 5683.5
JH 512 426.13 6060.5
KECCAK 1088 403.388 18286.9
SKEIN 512 157.222 4236.7
SHA2 512 232.631 1832.4
AES-128 128 378.4 495 AES-512 512 318.7 1163
TABLE II. IMPROVEMENTS OF VIRTEX7 OVER VIRTEX5 REGARDING
THE RATIO BETWEEN THE TP AND THE NUMBER OF SLICES
Algorithm name
FPGA
families
TP/number
of Slices
Improvement
of v7 over v5
BL
AK
E Virtex5 1.79
1.32 Virtex6 2.26
Virtex7 2.36
GR
OE
STL
Virtex5 2.41
1.33 Virtex6 3.69
Virtex7 3.20
JH
Virtex5 3.51
1.62 Virtex6 6.24
Virtex7 5.71
KE
CC
AK
Virtex5 8.69
1.67 Virtex6 12.79
Virtex7 14.51 SK
EIN
Virtex5 2.24
1.60 Virtex6 3.70
Virtex7 3.58
SHA
2
Virtex5 3.33
1.71 Virtex6 4.68
Virtex7 5.71
AE
S-12
8
Virtex5 0.083
1.36 Virtex6 0.108
Virtex7 0.113
AE
S-51
2
Virtex5 0.119
1.45 Virtex6 0.171
Virtex7 0.173
Figure 1: Total on chip power results for hash candidates and SHA2
0.000
0.200
0.400
0.600
0.800
1.000
1.200
1.400
1.600
1.800
Tota
l on_
chip
pow
er
SHA-3 candidates, SHA-2, and AES 128/512
Virtex5
Virtex6
Virtex7
88 JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013
© 2013 ACADEMY PUBLISHER

C. FPGA ResFPGA res
analyzed anestimator for(VC6VCX75FFG1157).Fiup to 50% oon Virtex-7 c3 candidatesThese promia viable alteWireless sen
The demcommunicatiThis fact is in applicatioCurrent secufrom their applications. devices succhallenges tosystems. Inadvancementtransistor dapplications consumption28 nm devicenm, the 28 nmfold increasewith 50% ppromising aapplications network, and
The authothe ScientificHigh EducatAlso, we woResearch Grotheir valuable
[1] H. TawalCandidateScience a
[2] Y. Jararw"HardwaAlgorithmpp. 69-76
[3] http://wwOnline A
[4] http://ww[5] R. McEv
"Differenand CouInformati317–332,
sults for Powesults for powd evaluated r Virtex-5 (X5T-FF484), igure 1 show
of power savincompared to Vs, SHA-2, AEsing power reernative in p
nsor networks
VII. C
mands on ions systems accompanied ons throughpurity algorithmlimitations in Furthermore,
ch mobile po adopting thn this paper, t in FPGAs d
design technthroughputs
n. Based on oues with older m FPGAs tec
e in throughpupower saving and can be
such as cloud smart mobile
ACKNO
ors would likec Research Sution in Jordanould to thank oup (CERG) ae supports and
REF
lbeh," Hardwaree Algorithms,"
and Technologyweh, L. Tawalare Performancms," Journal of6, 2012.
ww.nanooze.orgAccess [August 2ww.xilinx.com/pvoy, M. Tunstantial Power Anauntermeasures,"ion Security A, 2007.
er wer is going in this sectio
XC5VLX20T-and Virtex-7
ws remarkableng when impVirtex-6 and VES-128 and
esults made uspower limited(WSN).
ONCLUSION
securing i are increasby the unpre
put and powms e.g. AESn supporting , limited pow
phones and hem in curren
we evaluatedesign technoology promi
while decreur comparativetechnologies hnology devicut and through
gain. Theseexploited in
ud computinge devices.
OWLEDGMENT
e to thank theiupport Fund n for supportthe Cryptogr
at George Mad providing th
FERENCES
e Performance Master thesis,
y, June 2012. lbeh, H. Tawalce Evaluation of Information S
g/english/pdfs/n2012] products/technoall, C. Murphyalysis of HMA" Proceedings
Applications-WI
to be preseon using XP-FF323), Virt7 (XC7VX4 power efficilementing deVirtex-5 for SAES-512 [1]
sing 28 nm FPd devices suc
information ing continuo
ecedented incrwer requiremS and SHA s
high througer budget of mWSN add mnt communic
e the current ology. The 28ises to increase their pe evaluation oe.g. 45 nm ances achieved ahput to area re results are
many emerg, high throug
ir Universitiesat the Ministrting this reseaphic Engine
ason Universithe HDL resour
Evaluation Of SJordan Univers
lbeh, and Mohof SHA-3 CandSecurity (JIS), v
nanoozeissue01.
ology/dsp/ y, and W. MarAC based on SH
of WorkshopISA. Vol. 4867
ented, Power rtex-6 485T-iency signs
SHA-] [2]. PGAs ch as
and ously. rease
ments. suffer ghput many more
cation new
8 nm rease
power of the nd 65 a one ration
very rging ghput
s and try of earch. ering ty for rces.
Sha-3 sity of
h’d A. didate vol. 3,
.pdf.
rnane. HA-2, p on 7, Pp.
[6]
[7]
[8][9][10]
[11]
[12]
[13]
[14]
[15]
[16]
[17]
[18]
[19]
[20]
and slab a
S. Huang. "HaMaster ThesisState UniversitHussein J, Klewith Xilinx 7 SGeorge MasonXilinx. "XPowX. Wu, P. Gop28 nm FPGA TR. Lien, T. Grunrolled archit512," In Proce2004. R. Chaves, G"ImprovingProceeding of Syst. (CHES),L. Dadda, M.for a high spee256," ProceediVLSI 2004. BoN. Sklavos anSHA-2 Hash Fof Supercompu
] NIST, FIBS-August http://csrc.nist
] E. HomsirikamHardware Perusing MultipAltera FPGAsTallinn Estoni J. Daemen anAES Proposal,H. Kuo and I.for a 1.82-GbRijndael AlgEmbedded SyComputer ScGermany, pp. 5A. Moh'd, Y.Advanced Enevaluation. IASI.F. Akyildiz, Wireless sensoVolume 38, Iss
systems securitat JUST.
ardware Evaluas, Virginia Tecty. 2011. in M, and Hart Series FPGAs. Fn University: httwer Estimator Upalan, and G. LTechnology Ovrembowski, andtecture of hasheedings of CT-R
. Kuzmanov, LSHA-2 ha
Workshop Cry pp. 298-310, 2Macchetti, and
ed implementatiings of the ACMoston, MA, USAnd O. KoufopavFamily Standarduting, vol. 31, p-PUB 180-2.
t.gov/publicatiomol, M. Rogawrformance of Rle Hardware As," Proceedingsia; May 19-20 2nd V. Rijmen, ” Proc. 1st AES Verbauwhede
bits/sec VLSI gorithm” Cryystems (CHESience 2162, S53-67, 2001. Jararweh, L.
ncryption StanS, pp. 292-297W. Su, Y. Sankor networks: a sue 4, 15 March
Yaser Jaraelectrical from the August 20assistance pat Jordan Technologydifferent recomputing,
y. He is the co-
uation of SHA-ch Polytechnic
M. Lowering PFebruary 24, 20tp://www.gmu.
User Guide," MaLara, "Xilinx Nverview," Marchd K. Gaj. "A 1 h functions SHRSA, vol. 2964
L. Sousa, and ardware impyptograph. Har2006. d J. Owen. "Anion of the hash M Great Lakes A, pp. 421–425
avlou. "Implemd Using FPGApp. 227–248, 20
"Secure Hash
ons/fips/fips180wski, and K. GaRound 3 SHAArchitectures
s of Ecrypt II H2011. “The Rijndael S Candidate Co
e, “ArchitecturaImplementatio
yptographic HS 2001), LectSpringer-Verlag
Tawalbeh: AEndard algorithm7, 2011. nkarasubramania
survey, Comph 2002, Pages 3
rarweh receiveand computeUniversity o
010. He is professor of coUniversity of
y (JUST). He esearch areas , high performa-director of the
-3 Candidates,"c Institute and
Power at 28 nm011. edu/ arch 2011.
Next Generationh 2011. Gbit/s partiallyA-1 and SHA-4, pp. 324–338,
S. Vassiliadis.plementations,"rdw. Embedded
n ASIC designfunction SHA-Symposium on
5, 2004. entation of thes," The Journal005. h Standardm,"
2012.0-2/. aj. "Comparing
A-3 Candidatesin Xilinx and
Hash workshop,
Block Cipher:onf., 1998; al Optimizationn of the AES
Hardware andture Notes ing, Heidelberg,
ES-512: 512-bitm design and
am, E. Cayirci,uter Networks,
393-422.
ed his Ph.D. iner engineeringof Arizona in
currently anmputer sciencef Science andis working insuch as cloud
ance computing CHiS research
" d
m
n
y -,
. " d
n -n
e l
" .
g s d ,
:
n S d n ,
t d
, ,
n g n n e d n d g, h
JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013 89
© 2013 ACADEMY PUBLISHER

Amman's camHe got his BS2000, and his Oregon State respectively, uGPA 4.0/4.0. many refereeresearch interecryptography cryptographic forensics. Dr.editorial boardin the area of see his website
Applied Scien
Lo’ai the InformJordanTechnassistaengineand pInstitu
mpus, and DePauSc. in electrical
Masters and PUniversity (O
under the super Dr. Tawalbeh
ed internationaests includes: i
and dedicaapplications,
Tawalbeh is ds of many intethe informatione: www.just.edu
Hala compuUnive(JUSTCryptInformShe tolab acof EE
nces, Germany.
A. TawalbeCryptographic
mation Securitn University nology (JUST)ant professor eering departmpart time profeute of Tecul’s University.and computer
PhD in computOSU) , USA rvision of Dr.
h has many reseal Journals aninformation sec
ated arithmetiintrusion deteca reviewer an
ernational journn security. For u.jo/~tawalbeh
Tawalbeh isuter science deersity of ScienT), and a ographic
mation Securityook part in the ctivities as a testE and CS at Mu. Ms Tawalbeh
h is the Directc Hardware ty (CHiS) la
of Science . He is a full
at the coment at JUST, Joessor at Newchnology (NY.-Amman since eng. form (JUSter engineering in 2002 and Cetin K. Koc ,
earch publicatiod conferences.curity, hardwaric algorithms ction and comd a member onals and confermore details, p
s a lecturer aepartment at J
nce and Technmember of
Hardware y (CHiS) lab at J
IT security rester at the depart
uenster Universh received a B
tor of and
ab at and
time mputer ordan, York
YIT)-e 2005. ST) in
from 2004
, with ons in . His re for
for mputer of the rences please
at the Jordan nology
the and
JUST. search rtment sity of
BSc in
compan Mreseacloudbusin
archiboth fromFebr
puter informatiM.S. in compuarch interests ad computing, ness processes.
itectures such his B.Sc. and
m Jordan Univeruary, 2006 and
on systems frouter science froare in informati
trusted comp
AbidalrahmPh.D caMathematicDepartmenCanada, unWilliam J.Aslam. Hisdevelop protocols afor energy
as wireless sed M.Sc. Degrersity of SciencJuly, 2007 resp
om JUST, Jordaom JUST too ion security an
puting, and m
man Moh'd andidate in cs & I
nt at Dalhousnder the supe. Phillips ands main researchenergy effic
and cryptograpy efficient anensor networksees in Computce and Technolpectively.
an in 2010 andin 2012. Her
nd cryptograph,management of
is currently aEngineering
nternetworkingsie University,rvision of Dr.
d Dr. Naumanh concern is tocient securityphic algorithmsnd low-powers. He receiveder Engineeringlogy (JUST) in
d r , f
a g g , .
n o y s r d g n
90 JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013
© 2013 ACADEMY PUBLISHER

An Intelligent Water Droplet-based Evaluation of Health Oriented Distance Learning
Koffka Khan
The University of the West Indies, Department of Computing and Information Technology, St. Augustine Campus @ TRINIDAD
Email: [email protected]
Zulaika Ali, Nisa Philip, Gail Deane and Ashok Sahai The University of the West Indies, School of Medicine and Dentistry, St. Augustine Campus @ TRINIDAD
Email: { [email protected], [email protected], [email protected], [email protected]}
Abstract— An intelligent water droplet-based evaluation of health oriented distance learning of health oriented distance learning (HODL) systems integrating e-learning, e-health and usability aspects of Personal Health Record (PHR) systems is proposed. It supports HODL information processing towards a more comprehensive goal. For measuring HODL usability a checklist is used. Usability dimensions and checklist items are selected using an intelligent water droplet-based computational intelligence model. The main advantage of the methodology is the selection of most critical usability dimensions and items and thus supporting user-oriented design of HODL systems. Index Terms— health, e-learning, e-health, usability, information systems, evaluation and design, intelligent water droplets
I. INTRODUCTION
Three factors are converging to motivate a more patient-centered approach to health information. Near universal penetration of information technology in homes and work places, strong demands by some patients to have access to their own health information to participate with health care professionals in health care decision making and management, a trend toward an even larger group of consumers and patients to be active participants in decisions about their health and health care and spiraling health care costs are driving development of Personal Health Record (PHR) systems. PHRs generally include information and communication resources specific to an individual’s health and health care. PHRs are gaining widespread attention as they take electronic form and potentially link to medical health records. The complexity of health concepts and terminology and the large number and variety of health conditions makes using PHRs challenging for consumers and, especially so, for those with little computer skill and who have health conditions that limit electronic interactions. As PHRs [2] are disseminated more widely, characteristics of the PHRs themselves may propel consumers and patients toward those that are more user-oriented. The adoption
and effectiveness of PHRs will depend as much on systems and user interfaces as on the data in the records.
Usability is crucial to adoption and effective use of all types of information technology innovations, especially in Internet-based applications where help is not available and where many alternatives are a click away. This project aimed to develop an evidence-based framework for usability guidelines. The focus was on grounding the guideline framework in consumer needs assessments and in adding to the usability evidence for the important function of viewing and understanding information displayed in a PHR. The following takes a look at the dimensions of E-learning, E-health and Usability in order to create a check list that can be use assess health oriented distance learning CD courses in an effort to develop better PHRs for patient-centered usage.
Ad hoc design based on intuition and limited experience is not enough to insure the usability of a software application [15]. The literature offers many principles for good interface design. These principles can be helpful guidelines for designers. However, even if every designer in a software development organization was well versed in these design principles, this would not be enough to ensure good interface design. Many of the available design principles are based on experts’ intuitions, rather than on hard data.
Usually for any given design problem, they will come in direct conflict with each other, and there am no algorithms for making the tradeoffs. Design principles only bring the designer’s attention to the issues which should be considered. There is no “cookbook” approach to applying these principles to ensure good interface design.
User interface design is a matter of compromise ad tradeoff. We want powerful functionality, but a simple, clear interface. We want ease of use but also ease of learning. We want a system that is flexible but also one that provides good error handling. We strive for consistency across all aspects of the interface, but also to optimize individual operations. We want an “intelligent” and sophisticated interface, but also good performance and low cost. The interface designer finds him or herself
JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013 91
© 2013 ACADEMY PUBLISHERdoi:10.4304/jait.4.2.91-100

constantly confronted with these kinds of conflicting goals.
Software designers and developers need an overall process to help them effectively structure the design of the user interface, and make good design decisions for a given product with its particular set of end users. The cost effectiveness of applying usability techniques is well documented [34]. The purpose of this tutorial is to present and discuss such a process within the overall context of a typical modem software development life cycle. Practice - rather than theory - is the main focus of this tutorial. Topics presented include requirements analysis, design and testing techniques which can be applied at different points in the development process, as well as organizational medical ad managerial strategies. Specific topics include: - User Profile - Contextual Task Analysis - Usability Goal Setting - Platform Capabilities/Constraints - General Design Principles - Workflow Reengineering - Conceptual Model Design - Conceptual Model Mockups - Iterative Conceptual Model Testing - Screen Design Standards - Screen Design Standards Prototyping - Iterative Screen Design Standards Testing - Style Guide - Detailed User Interface Design - Iterative Detailed User Interface Design Testing - User Feedback
Detailed instructions on how to carry out each of the usability engineering techniques presented are not offend (most techniques could be the sole topic of a l-3 day tutorial), although brief overviews of each are provided during the tutorial, and supporting materials for many ate included in the Appendix to the tutorial notes. Instead the tutorial describes what techniques are available, and when and why to apply them in the context of the overall software engineering lifecycle. The main focus is on traditional software development, but how to adapt each technique to Web design is also addressed [35].
A. E-learning E – Learning [4], [5], [16], [18], [20], [21] can be
defined as the use of information technologies to enhance knowledge and performance. E-learning is also called Web-based learning, online learning, distributed learning, computer-assisted instruction, or Internet-based learning. Historically, there have been two common e-learning modes: distance learning and computer-assisted instruction. Distance learning uses information technologies to deliver instruction to learners who are at remote locations from a central site. Computer-assisted instruction (also called computer-based learning and computer-based training) uses computers to aid in the delivery of stand-alone multimedia packages for learning and teaching. These two modes are subsumed under e-
learning as the Internet becomes the integrating technology.
Research [4], [27], [32] suggests that an eventual information technology success will depend both on its adoption and subsequent continued usage. The following are some critical dimensions that have define e-learning. The critical dimensions of e-learning: • Quality of Courses: This covers information quality,
whether information provided is accurate, up to date and relevant to the overall theme of the course. System quality, which is concern with whether there are any bugs in the system, the consistency of the user interface, ease of use, response rates in interactive systems, quality documentation. An increasingly important component is service quality, which is derive from the comparison between what the customer feel should be offered and what actually provided.
• Relevancy of content: Content comprises all instructional material, which can range in complexity from discrete items to larger instructional modules. A digital learning object is defined as any grouping of digital materials structured in a meaningful way and tied to an educational objective. Learning objects represent discrete, self-contained units of instructional material assembled and reassembled around specific learning objectives, which are used to build larger educational materials such as lessons, modules, or complete courses to meet the requirements of a specified curriculum. Each unit must relate to the course.
• Comfort level with technology: technology literacy of the user.
• Availability of technical support: • Usability: the extent to which a product or service
can be used by specified users to achieve specified goals with effectiveness, efficiency and satisfaction in a specified context.
• Standards: standards are increasingly playing an important role in the creation of new e-learning material. Such standards are accepted principles that promote compatibility and usability of products accross many computer systems to facilitate a wide spread use of e-learning material.
B. E-health E-health [19], [13], [10], [17] is an emerging field in
the intersection of medical informatics, public health and business, referring to health services and information delivered or enhanced through the Internet and related technologies. In a broader sense, the term characterizes not only a technical development, but also a state-of-mind, a way of thinking, an attitude, and a commitment for networked, global thinking, to improve health care locally, regionally, and worldwide by using information and communication technology.
With reference to diverse medical education contexts, e-learning appears to be at least as effective as traditional instructor-led methods such as lectures. Health care providers do not see e-learning as replacing traditional
92 JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013
© 2013 ACADEMY PUBLISHER

instructor-led training but as a complement to it, forming part of a blended-learning strategy. A developing infrastructure to support e-learning within medical education includes repositories, or digital libraries, to manage access to e-learning materials, consensus on technical standardization, and methods for peer review of these resources. E-learning presents numerous research opportunities for faculty, along with continuing challenges for documenting scholarship. Innovations in e-learning technologies point toward a revolution in education, allowing learning to be individualized (adaptive learning), enhancing learners' interactions with others (collaborative learning), and transforming the role of the teacher. The integration of e-learning into medical education can catalyze the shift toward applying adult learning theory, where educators will no longer serve mainly as the distributors of content, but will become more involved as facilitators of learning and assessors of competency. Key dimension of E health are: • Relevant content: The content must be applicable to
the users. Content will therefore comprise of all instructional material which can range in complexity. Each unit having specific learning objective that adds to the overall requirements of a specified curriculum.
• Availability: the ability to access repositories of information.
• Delivery: Content delivery can either be real time where all learners receive information simultaneously and communicate directly with other learners. (Teleconferencing internet chat IM. Also delivery can be asynchronous where the learners are responsible for pacing their own self instruction and learning. ( cds, online bulletin boards, web blogs).
• Quality: information quality as it relates to timeliness, relevance, and accuracy of information, documentation.
• Content usability: The ability to use, apply or translate what is learnt into the persons every day functions.
• Demonstration of learning: changes in learner knowledge, skills or attitudes.
• Peer- review: an examination, verification and validation of content and process by peers.
• Continuing intention: The desire, drive for continuing medical education.
• Standards: Universal accepted principles that promote compatibility and usability of products across many computer systems to facilitate a wide spread use of e-learning material.
C. Usability Usability [9] can be defined as the extent to which an
application is learnable and allows the user to accomplish specified goals efficiently, effectively and with a high degree of satisfaction. In healthcare, clinicians manage sensitive and complex information while working in a highly agile work environment. A critical prerequisite for computer systems to be successfully implemented in such settings is that their interactive user interfaces are streamlined to the working practices of their users and are
highly usable [11]. To verify and optimize system usability, a variety of analytical and empirical methods from the area of usability engineering and human-computer-interaction have been adapted to and applied in healthcare system evaluation studies [26], [2].
It is argued that applying these methodologies to healthcare information systems design and evaluation will lead to an understanding of clinicians’ reasoning and processing of health care concepts crucial in system re-design efforts [19]. The diversity in usability methods and type of health care system to which these methodologies have been applied has made it difficult to gain a clear overview on what insights on healthcare systems development have been acquired and where challenges for future usability studies remain. A detailed investigation of published usability studies may reveal the benefits and trade-offs of usability methods applied in the healthcare environment and give insight into how information needs of targeted health care users may or may not be reached. An additional component that should be added to this definition is usefulness: that is a highly usable application will not be embraced by users if it fails to contain certain content that is relevant and meaning full. Some usability dimensions are: Learnability: In the informing environment. The
delivery system creates clients learning in a short amount of time leading to easily accomplished task.
Memorability: The delivery system causes the learner to remember how to use the system without reiterating the learning cycle.
Operability: the learner is able to operate/ navigate and control the delivery system with ease.
Flexibility: The delivery system is fully adaptable to variation and changes in tasks within the informing environment. It allows the learner to become accustomed to changes that are given in various tasks.
Understandability: The learner easily understands the aptness of the delivery system in accomplishing a given task within the informing environment.
Reliability: The delivery system is reliable and dependent enough for the client to accomplish tasks.
Attractiveness: is the ability of the delivery system to attract and draw client attention within the informing environment. It also addresses the aesthetic satisfaction that the delivery system provides the client within the informing environment
Effectiveness: The delivery system is effective is if the learner completely accomplishes a given task with accuracy and precision within the informing environment
Efficiency: the learner becomes efficient in using the delivery system if he or she has gained adequate skills and ability to perform a given task within the informing environment.
Attitude & Satisfaction: A & S attributes refer to the degree of the client approval. Pleasure, happiness, fulfillment, contentment agreement. Liking, comfort, appreciation, and enjoyment of /with the delivery system within the informing environment.
JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013 93
© 2013 ACADEMY PUBLISHER

II. INTELLIGENT WATER DROPLETS METHOF FOR HEALTH ORIENTED DISTANCE LEARNING
A. Methodology A methodology for HODL system evaluation and
usability redesign is developed (cf. Figure 1). It includes a checklist (cf. section D) and a model (cf. Figure 1) for HODL system assessment. At steps 1 and 2 the checklist dimensions and items are determined [33]. At step 3 data is gathered by interviews, observations and measurements. At step 4, HODL system is evaluated and a quantitative HODL index is determined using the data gathered. Based on evaluation relevant corrective measures for improving HODL systems (step 5 & 6) are proposed and implemented (step 7 & 8).
Figure 1: WD-NN-based method for HODL usability evaluation and
design
B. Artificial Neural Networks Artificial Neural Networks (ANN) (cf. Figure 2)
consist of a parallel collection of simple processing units (neurons/nodes) arranged and interconnected in a network topology [31], [22], [30]. ANN inspired by biological nervous system, are known as parallel
distributed processing (PDP) systems. ANN consists of a set of interconnected processing units (node, neurons or cells). Each node has activation functions. The activation signal sent (output) by each node to other nodes travel through weighted connection and each of these nodes accumulates the inputs it receives, producing an output according to an internal activation function. ANN is closely related to its architecture and weights. Multilayer architecture of network can be used to solve both classification and function approximation problems. There are two types of learning networks which are supervised learning and unsupervised or self-organizing. Supervised learning is when the input and desired output are provided while for unsupervised learning, only input data is provided to the network.
The most popular supervised learning technique in ANN is the back propagation (BP) algorithm. Its learning consists of the following steps: 1. An input vector is presented at the input layer. 2. A set of desired output is presented at the output
layer. 3. After a forward pass is done, the errors between the
desired and actual output are compared. 4. The comparison results are used to determine weight
changes (backwards) according to the learning rules.
Figure 2: Artificial Neural Network (ANN)
In order to get the desired output from ANN, the output from the network is compared to actual desired output. During training, the network tries to match the outputs with the desired target values. Network need to review the connection weight to get the best output. The idea of the BP is to reduce this error, until the ANN learns the training data. The training begins with random weights, and the goal is to adjust them so that the learning error will be at minimal. ANN nodes in BP algorithm are organized in layers, send their signals forward and then the learning error (difference between actual and expected results) is calculated and propagated backwards until met satisfactory learning error.
C. Intelligent Water Droplets (IWD) Intelligent Water Drops algorithm (IWD) [24] is a swarm-
based nature-inspired optimization algorithm, which has been inspired from natural rivers and how they find almost optimal path to their destination. A natural river often finds good paths among lots of possible paths in its ways from the
94 JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013
© 2013 ACADEMY PUBLISHER

source to destination. These near optimal or optimal paths follow from actions and reactions occurring among the water drops and the water drops with their riverbeds. In the IWD algorithm, several artificial water drops cooperate to change their environment in such a way that the optimal path is revealed as the one with the lowest soil on its links. The solutions are incrementally constructed by the IWD algorithm. Consequently, the IWD algorithm is generally a constructive population-based optimization algorithm. The Intelligent Water Drop, IWD for short, flows in its environment has two important properties:
1. The amount of the soil it carries now, Soil (IWD). 2. The velocity that it is moving now, Velocity (IWD).
This environment depends on the problem at hand. In an environment, there are usually lots of paths from a given source to a desired destination, which the position of the destination may be known or unknown. If we know the position of the destination, the goal is to find the best (often the shortest) path from the source to the destination. In some cases, in which the destination is unknown, the goal is to find the optimum destination in terms of cost or any suitable measure for the problem.
We consider an IWD moving in discrete finite-length steps. From its current location to its next location, the IWD velocity is increased by the amount nonlinearly proportional to the inverse of the soil between the two locations. Moreover, the IWDs soil is increased by removing some soil of the path joining the two locations. The amount of soil added to the IWD is inversely (and nonlinearly) proportional to the time needed for the IWD to pass from its current location to the next location. This duration of time is calculated by the simple laws of physics for linear motion.
Figure 3: Flowchart of the IWD algorithm
Thus, the time taken is proportional to the velocity of the IWD and inversely proportional to the distance between the two locations. Another mechanism that exists in the behavior of an IWD is that it prefers the paths with low soils on its
beds to the paths with higher soils on its beds. To implement this behavior of path choosing, we use a uniform random distribution among the soils of the available paths such that the probability of the next path to choose is inversely proportional to the soils of the available paths. The lower the soil of the path, the more chance it has for being selected by the IWD.The IWD algorithm gets a representation of the problem in the form of a graph (N, E) with the node set N and edge set E. Then, each IWD begins constructing its solution gradually by traveling on the nodes of the graph along the edges of the graph until the IWD finally completes its solution. One iteration of the algorithm is complete when all IWDs have completed their solutions. After each iteration, the iterationbest solution TIB is found and it is used to update the totalbest solution TTB. The amount of soil on the edges of the iteration-best solution TIB is reduced based on the goodness (quality) of the solution. Then, the algorithm begins iteration with new IWDs but with the same soils on the paths of the graph and the whole process is repeated. The algorithm stops when it reaches the maximum number of iterations itermax or the total-best solution TTB reaches the expected quality. The IWD algorithm has two kinds of parameters. One kind is those that remain constant during the lifetime of the algorithm and they are called ‘static parameters’. The other kind is those parameters of the algorithm, which are dynamic and they are reinitialized after each iteration of the algorithm.
The algorithm of IWD is specified in the following steps, cf. Figure 3. Note that IWD is used as the neural network backpropagation training and learning algorithm hence the terminology used in the diagram is BPNN, backpropagation neural network. For further information on the algorithm readers are referred to [24].
D. Health Oriented Distance Learning Checklist There are both unique and overlapping segments in the
fields of HODL Usability, and HODL Quality. Figure 4 presents the areas that are of primary concern to this paper (12, 123 and 23).
Figure 4: Overlapping field segments
For defining HODL e-learning, e-health and usability dimensions many scales were investigated and pertinent ones selected. Their dimensions and questions were compared and contrasted to produce HODL scales covering the three fields. The new HODL usability scale consists of ten dimensions as presented in Figure 3 and was constructed on the basis of analyses of the data from three studies done with different checklists. It is
JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013 95
© 2013 ACADEMY PUBLISHER

implemented as a new checklist with eleven HODL dimensions and 53 respective questions measured as the extent to which participants agreed with statements on five-point Likert scales, ranging from “Strongly Disagree” to “Strongly Agree.”
The initial selection of items from these checklists was based on factor loadings, relevance according to a group of experts in oncology, and the distribution of answers. Items with excessively skewed distributions were excluded. This yielded a 53-item list.
Dimension 1 – Accessibility
• I found that the lesson was free from technical problems (link errors, problems viewing sections etc.).
• I found that the lesson appeared quickly on the screen.
Dimension 2 - Feedback • I found that the feedback to my incorrect answers
was useful. Dimension 3 – Navigation
• I found that links actually lead to the content they promised.
• I always knew where I was in the lesson. Dimension 4 – Relevancy
• I found that the information was up to date. • The information presented was relevant to what I
was supposed to learn. Dimension 5 – Perspicacity
• Using the lesson improved my learning performance. • The lesson simplified my learning process.
Dimension 6 – Learning style • When a concept was taught or illustrated in more
than one way, it helped me understand it. • I quickly recognized the key points presented
throughout the lesson. Dimension 7 – Learnability
• The material was at an appropriate level for me. • I found that the information was easy to understand.
Dimension 8 – Content • Abstract concepts (principles, formulas, rules, etc.)
that were illustrated with concrete, specific examples helped improve my understanding.
• I found that the information was concise and right to the point.
Dimension 9 – Appropriate learner control • I felt in control throughout the lesson.
Dimension 10 – Motivation to learn • The lesson was enjoyable and interesting. • The lesson provided me with frequent and varied
learning activities that increased my learning success.
In HODL WD-NN usability evaluation model the entire construct of usability is represented by a single dependent variable. Two different quantitative indices are calculated for the usability evaluation of HODL systems, as shown in Figure 5.
Figure 5: HODL WD-NN usability evaluation model The usability index was calculated using the efficiency,
effectiveness and satisfaction dimensions. Both objective and subjective measures of HODL usability are gathered. The objective data (efficiency and effectiveness) are measured as follows. For each task, HODL efficiency was measured using [9]:
1. Time taken to perform a task: 2. Number of errors made while performing the
task For each task, HODL effectiveness is measured using
the percentage of the task solved. Satisfaction was measured by customer’s subjective response to a question.
The weights of the dimensions of usability index efficiency, effectiveness and satisfaction are determined by principal component analysis.
The integrated index uses ten e-learning, e-health and usability dimensions. The most critical usability dimensions / checklist items are adaptively determined by the weights of neural network. Depending on the problems that these dimensions/questions indicate relevant design improvements of HODL system are proposed.
III. CASE STUDY
For experimental implementation and study of WD-NN method a HIV e-learning tool was used. 150 medical health students and workers at the University of the West Indies participated in the study. Students were divided into two groups. Year four and five students were the largest test group and this was useful for testing purposes, because they represented the most inexperienced computer users. The students read the course material and answered an online survey with questions pertaining to what they had read. The following were the instructions given to the groups.
96 JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013
© 2013 ACADEMY PUBLISHER

TABLE 1.
TASK LIST FOR HODL GROUP ONE
Group 1
Load CD-ROM in computer
Play CD-ROM
Go to Module 2
Perform the follow tasks in Module 2:
1. Read pages 1 – 16 2. Navigate to all hyperlinks
– Pop-ups – Glossary
– PDFs 3. Take quiz 4. Enter quiz score on questionnaire 5. Return to main menu 6. Quit CD‐ROM
TABLE 2.
TASK LIST FOR HODL GROUP TWO
Group 2
Load CD-ROM in computer Play CD-ROM
Go to Module 4 Perform the follow tasks in Module 4:
1. Read pages 1 – 16 2. Navigate to all hyperlinks
– Pop‐ups – Glossary – PDFs
3. Take quiz 4. Enter quiz score on questionnaire 5. Return to main menu 6. Quit CD‐ROM
The following screenshots shows parts of a HODL course module (cf. Figure 6, 7, 8).
Figure 6: HODL homepage
Figure 7: HODL understanding HIV module
Figure 8: HODL understanding HIV module content page
For each of these three questions is recorded the time,
number of errors for performing the task and the percentage of tasks solved. The time taken to complete the tasks and checklist was on average 70-90 minutes per student. By principal component analysis the weights of the dimensions of usability index efficiency, effectiveness and satisfaction were found as 0.26, 0.34 and 0.40 respectively.
We ran a neural network (WD-NN) of two layers with 10 neurons at hidden layer using MATLAB software.
Figure 9: WD-NN training performance for (N=12) data set
JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013 97
© 2013 ACADEMY PUBLISHER
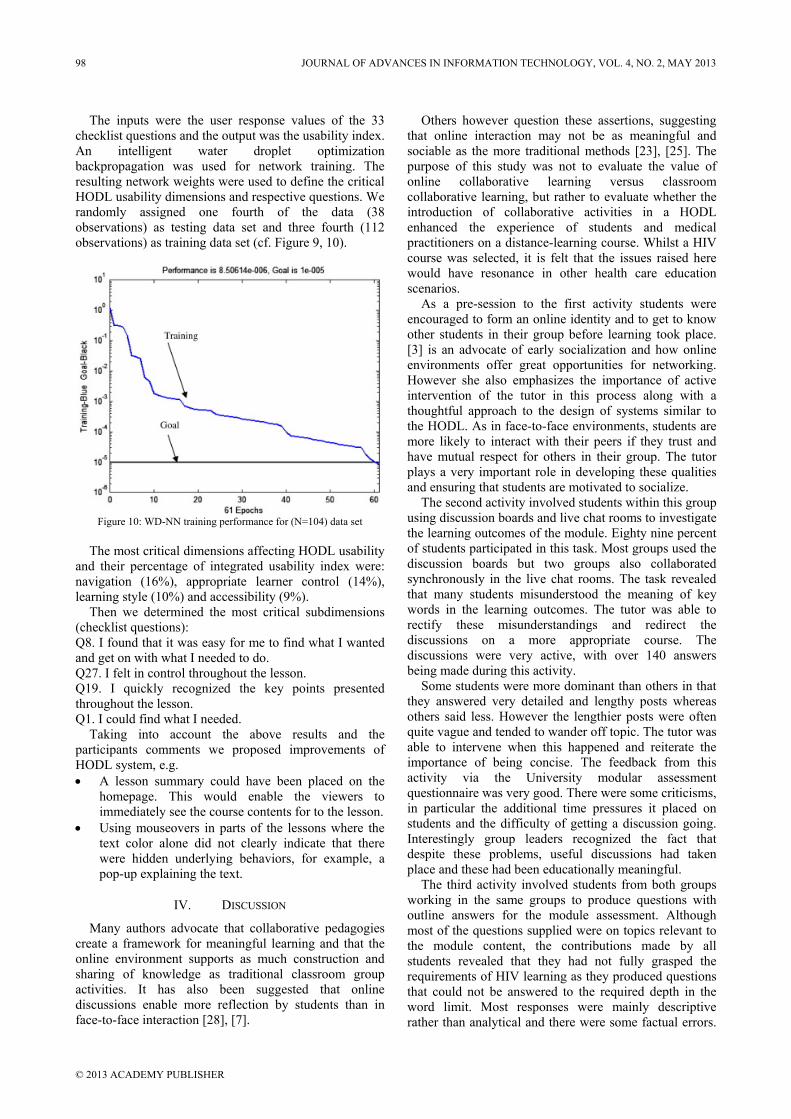
The inputs were the user response values of the 33 checklist questions and the output was the usability index. An intelligent water droplet optimization backpropagation was used for network training. The resulting network weights were used to define the critical HODL usability dimensions and respective questions. We randomly assigned one fourth of the data (38 observations) as testing data set and three fourth (112 observations) as training data set (cf. Figure 9, 10).
Figure 10: WD-NN training performance for (N=104) data set
The most critical dimensions affecting HODL usability
and their percentage of integrated usability index were: navigation (16%), appropriate learner control (14%), learning style (10%) and accessibility (9%).
Then we determined the most critical subdimensions (checklist questions): Q8. I found that it was easy for me to find what I wanted and get on with what I needed to do. Q27. I felt in control throughout the lesson. Q19. I quickly recognized the key points presented throughout the lesson. Q1. I could find what I needed.
Taking into account the above results and the participants comments we proposed improvements of HODL system, e.g. • A lesson summary could have been placed on the
homepage. This would enable the viewers to immediately see the course contents for to the lesson.
• Using mouseovers in parts of the lessons where the text color alone did not clearly indicate that there were hidden underlying behaviors, for example, a pop-up explaining the text.
IV. DISCUSSION
Many authors advocate that collaborative pedagogies create a framework for meaningful learning and that the online environment supports as much construction and sharing of knowledge as traditional classroom group activities. It has also been suggested that online discussions enable more reflection by students than in face-to-face interaction [28], [7].
Others however question these assertions, suggesting that online interaction may not be as meaningful and sociable as the more traditional methods [23], [25]. The purpose of this study was not to evaluate the value of online collaborative learning versus classroom collaborative learning, but rather to evaluate whether the introduction of collaborative activities in a HODL enhanced the experience of students and medical practitioners on a distance-learning course. Whilst a HIV course was selected, it is felt that the issues raised here would have resonance in other health care education scenarios.
As a pre-session to the first activity students were encouraged to form an online identity and to get to know other students in their group before learning took place. [3] is an advocate of early socialization and how online environments offer great opportunities for networking. However she also emphasizes the importance of active intervention of the tutor in this process along with a thoughtful approach to the design of systems similar to the HODL. As in face-to-face environments, students are more likely to interact with their peers if they trust and have mutual respect for others in their group. The tutor plays a very important role in developing these qualities and ensuring that students are motivated to socialize.
The second activity involved students within this group using discussion boards and live chat rooms to investigate the learning outcomes of the module. Eighty nine percent of students participated in this task. Most groups used the discussion boards but two groups also collaborated synchronously in the live chat rooms. The task revealed that many students misunderstood the meaning of key words in the learning outcomes. The tutor was able to rectify these misunderstandings and redirect the discussions on a more appropriate course. The discussions were very active, with over 140 answers being made during this activity.
Some students were more dominant than others in that they answered very detailed and lengthy posts whereas others said less. However the lengthier posts were often quite vague and tended to wander off topic. The tutor was able to intervene when this happened and reiterate the importance of being concise. The feedback from this activity via the University modular assessment questionnaire was very good. There were some criticisms, in particular the additional time pressures it placed on students and the difficulty of getting a discussion going. Interestingly group leaders recognized the fact that despite these problems, useful discussions had taken place and these had been educationally meaningful.
The third activity involved students from both groups working in the same groups to produce questions with outline answers for the module assessment. Although most of the questions supplied were on topics relevant to the module content, the contributions made by all students revealed that they had not fully grasped the requirements of HIV learning as they produced questions that could not be answered to the required depth in the word limit. Most responses were mainly descriptive rather than analytical and there were some factual errors.
98 JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013
© 2013 ACADEMY PUBLISHER

However this activity provided the tutor with an opportunity to formatively feedback to students at an early stage enabling them to address these shortcomings in time for a final worksheet.
It was evident that some students recognized the wide variety of experience and expertise within their group. They appreciated that this experience may be different from their own and that group discussion, particularly around the selection of questions and outline answers, could inform their own learning in a positive way. [29] contends that group diversity in terms of knowledge and experience contributes positively to the learning process. Collaborative learning strategies particularly improve problem solving because the students are confronted with different interpretations of the problem [6]. One group was particularly active in critical analysis of their group’s contributions. The tutor encouraged this by asking these students to give reasons for their comments and reflect upon the criteria used in making these judgments. Generally, peer critiquing worked well in this group with one student commenting that the ability to admit that the outline answer he submitted was flawed helped him reassess his understanding of the module content.
V. CONCLUSIONS
A method for adaptive usability evaluation of HODL systems WD-NN was proposed. It includes a checklist and a neural networks-based model for evaluation of HODL usability. A case study confirmed WD-NN applicability for measuring and allocation of usability problems. The advantages of the approach are: (1) measuring by WD-NN checklist of e-learning, e-health and usability of HODL systems; (2) adaptive selection of most significant usability dimensions and items and thus significant reduction of the time for usability evaluation and design.
The implementation of three online collaborative initiatives into the delivery of the Scientific Principles of HIV module has enhanced student socialization and has enabled students to work together to understand the learning outcomes and to learn from each other in the development of an assessment. In addition the University Modular assessment questionnaire showed that students valued these activities and improved their experience of distance learning. However some students commented on the time taken to complete these tasks and felt that they detracted from rather than added to their learning. This indicates that the tasks may need to be modified in future so that they take less time to complete without affecting their educational value.
The implementation of similar online collaborative activities may therefore be justified in other learning environments, both distance and blended. There is a huge variety in the types of tasks that could be used in the online collaborative environment including those with theoretical, clinical and educational foci. Health care educationalists should therefore consider this pedagogy [14]. However there are some important considerations. Tutors involved in e-learning must be supported and provided with training. For example, the tutor spent a
significant amount of time moderating discussions and providing feedback and this could have been done in a more efficient way. [29] stresses that different types of collaborative exercises warrant a different approach to moderation and feedback. Tutors need a different skill set to more traditional teaching methods and therefore specific training with support from e-learning experts is usually required [1]. In addition the unconstrained nature of e-learning where there may be no clear start and finish times can pose time management problems. Tutors must ensure that this is anticipated and planned for.
There is great scope for further research in this area. Issues such as group composition and size, differences in collaborative learning styles associated with ethnicity and gender and the optimum strategies for managing and moderating online collaborative activities all merit further investigation.
REFERENCES
[1] Aad, G., et al. "Observation of a New [subscript χb] State in Radiative Transitions to Υ (1S) and Υ (2S) at ATLAS." (2012).
[2] Ash J, Coiera A, Berg M. Some unintended consequences of information technology in healthcare: the nature of patient care information systems. J Am Med Inform Assoc
[3] Benson, Robyn, and Gayani Samarawickrema. "Teaching in context: Some implications for e-learning design." ICT: providing choices for learners and learning. ASCILITE, 2012.
[4] De Villiers Ruth. Usability of an E-Learning Tutorial: Criteria, Questions and Case Stud. AICSIT; 75, 2004.
[5] Ehlers, Ulf-D. "Quality in e-learning from a learner's perspective." Learning, 2012.
[6] Ellingson, J. M., et al. "Disentangling the relationships between maternal smoking during pregnancy and co-occurring risk factors." Psychological medicine 42(7): 1547, 2012.
[7] Gallivan, Michael J. "THE VALUE OF SOCIAL MEDIA FUNCTIONALITY IN “DESIRE2LEARN”." 2012.
[8] Grandon, T,G. & Cohen, E. (eds), 5: 113-134, 2003. [9] ISO 9241-11, Guidance on usability, 1998. [10] Kennedy, Catriona M., et al. "Active Assistance
Technology for Health-Related Behavior Change: An Interdisciplinary Review." Journal of Medical Internet Research 14(3): 2012.
[11] Koohang, A. Expanding the concept of usability. Foundations of informing science: 1999-2008
[12] Kushniruk AW, Triola MM, Borycki EM, Stein B, Kannry JL. Technology induced error and usability: The relationship between usability problems and prescription errors when using a handheld application. Int J Med Inform
[13] Mair, Frances S., et al. "Factors that promote or inhibit the implementation of e-health systems: an explanatory systematic review." Bulletin of the World Health Organization 90(5): 357-364, 2012.
[14] Marra, Fabio, et al. "Amikacin Reverse Iontophoresis: Optimization of in Vitro Extraction." International Journal of Pharmaceutics, 2012.
[15] Mayhew, Deborah J.. Principles and Guidelines in [16] Michael J.M. Usability in E-learning, website file:
Learning circuits, http://www.neiu.edu/~sdundis/textresources/Usability/Usability%20in%20E-Learning.pdf, 2005.
JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013 99
© 2013 ACADEMY PUBLISHER

[17] Morrison, Leanne G., et al. "What design features are used in effective e-health interventions? A review using techniques from critical interpretive synthesis." Telemedicine and e-Health 18(2): 137-144, 2012.
[18] Nawaz, Allah. "Metaphorical Interpretation of eLearning in Higher Education Institutions." Journal of Advances in Information Technology 3(1): 1-9, 2012.
[19] Patel, L.V., Kuskniruk, W.A. Interface design for health care environments: the role of cognitive science, Proc. AMIA Symp (1998), 29-37.
[20] Peterson D. What makes a good learning Website? The concept and measurement of usability in e-learning. http://www.tim-brosnan.net
[21] Raitman, Ruth S. Collaboration in the online e-learning environment. No. Ph. D.. Deakin University, 2012.
[22] Rassam, Murad Abdo, and Mohd Aizaini Maarof. "Artificial Immune Network Clustering approach for Anomaly Intrusion Detection." Journal of Advances in Information Technology 3(3): 147-154, 2012.
[23] Ravenscroft, Adrian C., and Stephen J. Kleshinski. "Removeable embolus blood clot filter and filter delivery unit." U.S. Patent No. 8,133,251. 13 Mar. 2012.
[24] Rayapudi, R.S. An Intelligent Water Drop Algorithm for Solving Economic Load Dispatch Problem, International Journal of Electrical and Electronics Engineering 5:1, 2011.
Software User Interface Design, Prentice-Hall, 1992 [25] Stacey, Elizabeth. "Learning links online: Establishing
constructivist and collaborative learning environments." Proceedings of the International Education & Technology Conference: Untangling the web-establishing learning links. ASET, 2012.
[26] Tang C.P., Patel, V.L. Major issues in user interface design for health professional workstations: summary and recommendations, Int J Biomed Comput 34(1994), 139-48
[27] Thakurta, P. K., et al. "A New Approach on Cluster based Call Scheduling for Mobile Networks." Journal of Advances in Information Technology 3(3): 184-190, 2012.
[28] Westbrook, Catherine. "Imaging (MRI), Faculty Health, Social Care and Education Department of Allied Health and Medicine, Anglia Ruskin University, United Kingdom."
[29] White, Laura M., et al. "Appraisal of Critical Thinking Skills in Animal Science Undergraduates who Participated on a Nationally Competitive Collegiate Judging Team." NACTA Journal, 2012.
[30] Winters, R. Michael, and Ichiro Fujinaga. "Artificial Neural Networks." 2012.
[31] Yao, X., Evolutionary artificial neural networks. International journal of neural systems, Vol.4, No.3, 1993, 203–222.
[32] Yu, Xiu-qing. "Research on Learning Effect based on Outer P-set." Journal of Advances in Information Technology 3(1): 21-23, 2012.
[33] Zaharias P. Developing a Usability Evaluation Method for E-Learning Applications: From Functional Usability to Motivation to Learn.http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.130.4304.
[34] Bias, Randolph G. and Mayhew, Deborah J., Eds., Cost-Justifying Usability, Academic Press, 1994
[35] Forsythe, Chris, Grose, Eric and Ratner. Julie, Human Factors and Web Development, Lawrence Erlbaum Associates, 1998
Koffka Khan was born in San
Fernando, Trinidad and Tobago in 1978. He received the B.Sc. and M.Sc. degrees from University of the West Indies, in 2002 and 2008, respectively. He was awarded by the University of the West Indies for his contributions made in postgraduate work in 2009 as a research assistant.
He is working presently at The University of The West Indies; St. Augustine Campus (TRINIDAD & TOBAGO) as a Tutor in Computer Science in the Department of Computing and Information Technology (Faculty of Science & Agriculture) since September 2006. Mr. Khan started his teaching-n-research career as a Demonstrator in Computer Science at the University of The West Indies at the Department of Mathematics and Computer Science. He has up-to-date, published ten research and co-authored four papers in journals of international repute & in the proceedings of international conferences.
Ashok Sahai is working presently at The University of The West Indies; St. Augustine Campus (TRINIDAD & TOBAGO) as a Professor of Statistics in the Department of Mathematics & Statistics (Faculty of Science & Agriculture) since February 2006. Dr. Sahai started his teaching-n-research career as a Lecturer in Statistics Department at Lucknow University
(INDIA) in July 1966, and continued thereat till April 1980. He has, up-to-date, published more than one hundred research papers in peer-reviewed journals of international repute & in the peer-reviewed proceedings of international conferences.
He worked as Reader in Statistics and as Professor of Statistics in the Department of Mathematics at University of Roorkee (Now IIT Roorkee) during the period: April 1980- July 1995. Prof. Sahai had also worked as an Assoc. Professor of Statistics at University of Dar-Es-Salaam; TANZANIA (East Africa) during the period: July 1982- June 1984, and as a Professor of Statistics at University of Swaziland (Southern Africa) during the period: July 1993- June 2003. He worked as a Guest Scholar @ PharmacoEconomic Research Centre; University of Arizona, TUCSON during the period from July 2003 to October 2003 and as Visiting Professor @ Hyderabad; INDIA during December 2003 to January 2006 in ICFAI Tech. University, Medchel Rd.; in Aurora School of Management at Chikkadpally; and in St. Ann’s P.G. (Management) College For Women at Mallapur.
100 JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013
© 2013 ACADEMY PUBLISHER

Tracking Livestock Movements
to Figure out Potentially Infected Farms
Paolino Di Felice Dipartimento di Ingegneria Industriale, Informazione ed Economia, Università di L'Aquila, L’Aquila, Italy
Email: [email protected]
Americo Falcone Dipartimento di Ingegneria Industriale, Informazione ed Economia, Università di L'Aquila, L’Aquila, Italy
Email: [email protected]
Abstract—The concern stems from the public health and
food safety aspects of animal health, but also from the
economic costs that animal disease outbreaks can trigger.
Very recently it has been proposed a method ([4]) devoted
to discover the farms that may have been infected by an
outbreak of a highly infectious disease of livestock
subjected to long trips with intermediary stops. Having a
reliable list of farms that may be infected is relevant to
feed existing farms culling strategies (e.g., [1]). The
present paper reports on an effective way to implement
the method introduced in [4] based on an emerging
software technology.
Index Terms—livestock movements, moving points
databases, SQL, animal health, prevention
I. INTRODUCTION
A primary concern of national and international
institutions for animal health (the World Organization
for Animal Health is probably the most known
institution among the many - http://www.oie.int/en/), is
to keep the animal health under control to prevent
epidemics of infectious diseases at geographic scale
whose negative effects are the need of culling entire
livestock farming, with massive economic costs to the
farmers, as well as the risk that the disease transmits to
the human beings, too (zoonosis).
The issue of controlling the diffusion of highly
infectious livestock epidemics is relevant and topical
also from the scientific community, as witnessed by the
continuous flow of papers that are published. One of
the most recent and important contribution among the
many is [1], where the authors propose a method of
epidemic investigation (called risk based culling) that
represents an evolution of the so far mostly adopted
ring culling.
An input data of the risk based culling strategy is the
list of infected farms. Unfortunately, in the cases where
the animal batches moved in time periods close to the
detection of the disease, with intermediary stops in the
so-called “parking areas” (a scenario made frequent by
the globe scale livestock market), it is utopian to
pretend to know all the farms which are infected and,
consequently, to think of being able to know exactly
the geographical areas affected by the outbreaks of the
contagion. This state of affairs reduces tremendously
the output reliability of any potential software tool
based on [1], simply because the correctness of its
prediction is subordinated to the degree of adherence to
the reality of its input data.
Ref. [4] proposes a method helpful, downstream of
the outbreak of cases of livestock disease, to set up a
list of farms that could have been infected by sick head
of cattle which moved in a period of time “close to”
that when the alarm of a sanitary hazard was issued.
The method is made up of an algorithm (CHECK) and
a database (about farm, livestock, health checks, trips,
and parking areas). Our paper is a continuation and, to
a large extent, the completion of the research described
in [4]. In a nutshell, aim of the present paper is to give
substance to the claim that to manage software
applications about the control of the diffusion of the
animal diseases more easily, effectively and efficiently
than the case where a DataBase Management System
of the current generation is adopted, it is necessary
making recourse to the body of knowledge about
moving objects databases, [7].
The paper is structured as follows. Sec. II reports a
minimum nucleus of information, taken from [4],
necessary to comprehend our contribution. In detail, we
sketch out the application context our study refers to
and mention the causes that could trigger livestock
contagion within the parking areas. Then, it is recalled
the algorithm CHECK suitable to detect potentially
infected batch of animals and, hence, the (potentially)
infected farms. The structure of a relational database
suitable to model the reference application context ends
the section. Sec. III and Sec. IV concern, in sequence,
what in [4] was left as “Further work”, that is: a) the
loading of the designed database with an example
dataset; and b) the implementation of the algorithm
CHECK in terms of SQL queries. As DBMS we use
SECONDO [8]. Sec. V ends the paper.
II. THE APPLICATION CONTEXT. ITS
MODELLING
JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013 101
© 2013 ACADEMY PUBLISHERdoi:10.4304/jait.4.2.101-110

A. Terminology
Hereafter, we use the following terminology mainly
inspired by regulations in force within the EU:
– meeting point: either the livestock aggregation
place during a cattle fair or the terminal where it
takes place the loading (unloading) of live animals
from a transportation means (truck, ship, and so
on).
– Control post: a place devoted to the animal
nutrition and rest during long trips.
– Farm: the place where animals grow up.
– Parking area: either a meeting point, a control post,
or a farm.
– Batch: a certain number of animals of the same
species that move together and that, together, rest in
the same parking area.
– Sick batch: a batch of animals where at least one
head of cattle has been found sick after a veterinary
visit. We call potentially infected batch one
containing some head of cattle that might have got
the disease from a sick batch.
– Infected farm: the farm to which a sick batch
belongs. We call potentially infected farm one
where there is at least a potentially infected batch. Ref. [6] reports of 157 approved control posts within
12 countries at the beginning of 2010. About meeting
points and farms it is not easy to get exact numbers,
however they can be estimated of the order of
thousands.
Parking areas may be conceptualized as structures
either fixed (as in the case of farms) or semi-mobile (as
in the case of meeting points) composed of a certain
number of pens (Fig. 1).
Figure 1. The organization of a parking area made up of 5 pens.
B. Causes Triggering the Contagion. Types of
Contagion
Ref. [6] reports that about 365 million farm animals
per year are transported within Europe and a large part
of them pass through parking areas where they are
unloaded and loaded many times before reaching the
final destination. The long stops, inside those areas, of
the livestock contribute considerably to the diffusion of
the epidemics in a short time interval and over large
geographical areas.
The causes that could spark off the disease are to be
re-conducted to either the “co-presence” in the same
parking area of healthy livestock batches and sick ones,
or to their “temporal contiguity” (that is when a healthy
batch enters a parking area that previously had hosted a
sick batch and where, therefore, could have been left
few pathogen agents in the environment.). Such two
“dimensions” set up the necessary condition because
the transmission of the disease among the livestock can
take place. Accordingly, two types of contagion have
to be taken into account in such an application context:
one due to the co-presence (hereafter called contagion
by co-presence) and the other due to the temporal
contiguity (hereafter called contagion by temporal
contiguity). [4] discusses in some depth both types of
contagion.
C. An Investigation Algorithm
Ref. [4] proposes an algorithm (CHECK) that,
downstream of the identification of an infected batch,
traces back to all the potentially infected batches of
animals, then it recognizes all the farms that are to be
considered either infected or potentially so. This latter
step is fundamental because its output allows to feed
the existing methods for the analysis of the diffusion of
the disease among farms such as, for instance, the
already mentioned risk based culling method. The
CHECK algorithm follows.
-------------------------------------------------------------------
Algorithm CHECK
-------------------------------------------------------------------
Input: data about the farms, the animal batches, the
veterinary visits, the animal trips over the territory,
and the involved parking areas.
Output: the (potentially) infected farms
Method:
Let <SickBatch, VisitTimestamp, LastVisit Farm> be, respectively, the identifier of the sick batch,
the time stamp when the disease was diagnosed, and
the farm where the visit took place.
1. Starting from LastVisitFarm and travelling back
in time:
– reconstruct the movements of the sick batch
until the farm where it was previously visited (PreviousVisitFarm) resulting in healthy is
reached. Both the PreviousVisitFarm and
the LastVisitFarm are assumed to be
infected.
Let {PreviousVisitFarm, PA1, PA2, …, PAk, LastVisitFarm} be the result of this
investigation step, where PAi (with
i=1,2,3,…,k) denotes the generic parking area
that had put the sick batch up. – For each PAi, compute the duration of the stop
of the SickBatch in it and the departure time
from it 2. for each PAi, the issue is to identify the animal
batches that might have been infected by the SickBatch;
3. for each those batches, identify (when possible) the
farms they belong to, these latter to be classified as
potentially infected too.
-------------------------------------------------------------------
Notice that when the CHECK algorithm is started,
not necessarily it happens that all the batches returned
by Step “2.” have reached the destination farm. Some
of them, in fact, could be still (away) on the trip
towards the final destination. This is the meaning of the
words “when possible”. For each animal batch
potentially infected by a SickBatch that falls in such
102 JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013
© 2013 ACADEMY PUBLISHER

a situation, Step “3.” returns the last parking area
occupied by the livestock.
D. A SECONDO database
Di Felice and Falcone ([4]) complete their proposal
by designing a SECONDO relational database about
farm, livestock, health checks, trips, and different types
of parking areas as an essential step towards an
effective and efficient implementation of the CHECK
algorithm. Their database is composed of the following
five tables:
animalBatch (BatchId: string,
Species: string, HeadNumber: int);
parkingArea (PAID: string, Name:
string, City: string, Type:
string, FarmerId: string,
Position: point, Layout: region);
farmer (FarmerId: string,
Name: string);
visit (BatchId: string, VisitDate:
instant, Result: string,
Diagnosis: string, PAID: string);
trip (BatchId: string, TripData:
mpoint, From: string, To: string);
The APPENDIX collects the SECONDO SQL-like
definition of those tables.
Figure 2. The map of the parking areas of the example dataset
This database models the movement of an animal
batch (from a parking area to another one) as an atomic
value of the attribute TripData of type mpoint, [7].
The organization of the database in terms of moving
points (briefly m-points) acknowledges the recent
recommendations of the EU ([2] Annex I, Chp.VI,
Point 4 – Navigation System) which hope a prompt
activation of a fully electronic procedure about the
traceability of the movements of live animals (see, for
instance, the “Identification and Tracing” section of the
Animal Health Strategy of the European Union - 2007-
2013, [5]).
III. AN EXAMPLE DATASET
We have loaded the database of Sec. IID with an
example dataset small but still sufficiently
comprehensive to cover the cases of contagion between
lots of cattle recalled in Sec IIB. The dataset consists of
20 animal batches and 20 parking areas (located in the
centre of Italy – Fig. 2) broken down as follows: 11
farms (the violet triangles), 5 control posts (the blue
circles) and 4 meeting points (the green squares).
The APPENDIX collects a summary of the SQL-
like scripts about the loading of the tuples into the
SECONDO database.
The map shown in Fig. 2 is the combined output of
the processing of the following three queries:
SELECT *
FROM parkingArea
WHERE type = "Meeting point"
SELECT *
FROM parkingArea
WHERE type = "Control post"
SELECT *
FROM parkingArea
WHERE type = "Farm"
JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013 103
© 2013 ACADEMY PUBLISHER

by defining for each query a different visualization
display of the spatial objects (i.e., of each geometric attribute of the relation parkingArea).
Figure 3. The graph of the movements of the animal batches being part of the example dataset
The database contains also the data of 37
trajectories corresponding to as many trips of the
batches between pairs of parking areas. The
movements of the animals have been generated by a
Java program which receives as input the parking area
of departure and arrival, the date and start time of the
trip and returns a text file that describes the journey.
These movements are conceptualized by the graph of
Fig. 3, where each node is labeled with the code of a
parking area (namely, a string ranging from AS01 to
AS20), while the arcs are labeled with the code of the
batch that moved between the extreme nodes. As we
can see, different batches have gone through the same
intermediate parking areas before reaching the final
destination, a circumstance very common in the reality.
The (red) arcs labeled L03 in Fig. 3 refer to the
animal batch L03 that, as the result of a transaction,
moved from farm AS14 to farm AS07. Before
departure, the livestock was subjected to a veterinary
check at the farm of origin (AS14) with negative
outcome. Reached the destination (AS07), on
11/07/2011 the batch was visited again by resulting
sick (see Sec. IIA for the definition of “sick batch”) of
a disease highly infectious. By construction, L03 is the
only one sick batch in our small example dataset.
Going through the steps of the algorithm CHECK
for the example dataset, and taking into account the
arrival and departure time of the livestock from the
parking areas, we get the situation depicted in Fig. 4
and summarized in Table 1.
IV. IMPLEMENTATION OF THE ALGORITHM
CHECK
This section reports on the implementation of the
algorithm CHECK. The solution is valid independently
of the number of sick batches. CHECK has been
realized in terms of eight “basic” queries. Table 2
shows the correspondence that exists between them and
the steps of the algorithm. It is trivial to reduce the
number of queries simply by "merging" the basic
queries of the same level at the expense, however, of a
greater difficulty of understanding the resulting
queries.
In the following, the term query is overloaded in the
sense that it denotes both what we want to compute and
the SQL formulation to reach the goal.
The syntax of the eight queries most adhere to
standard SQL. The few variations will be explained as
we met them.
104 JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013
© 2013 ACADEMY PUBLISHER
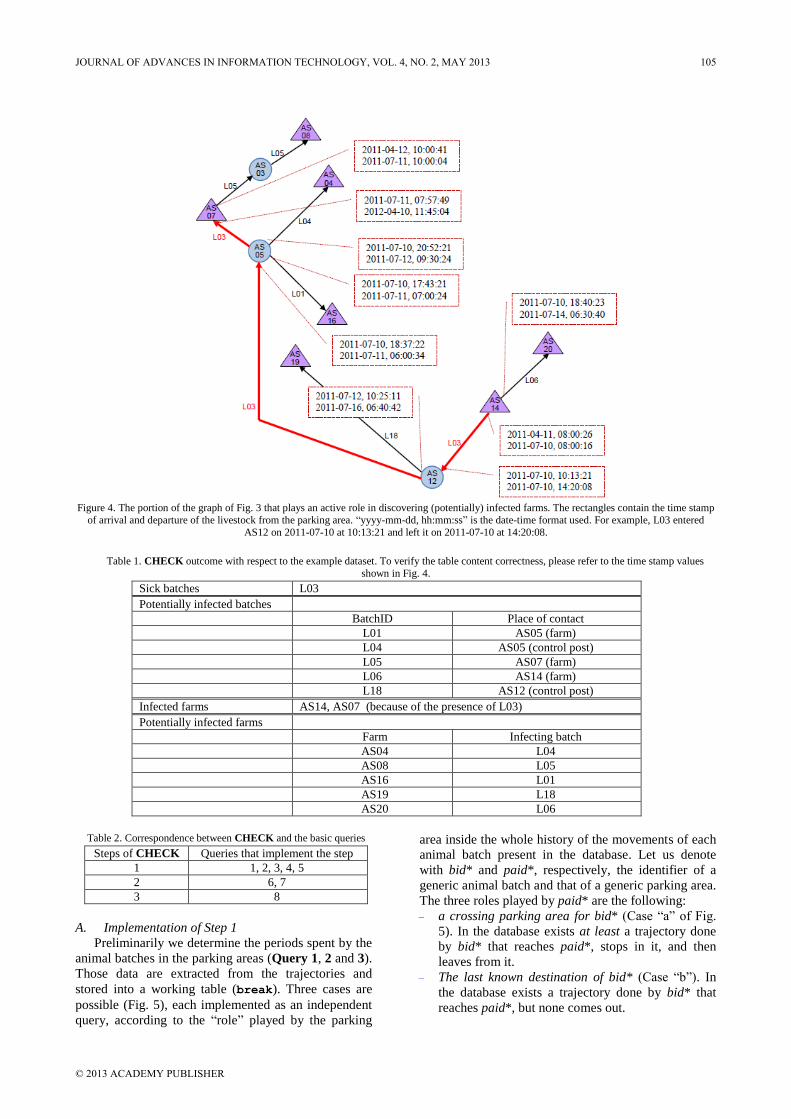
Figure 4. The portion of the graph of Fig. 3 that plays an active role in discovering (potentially) infected farms. The rectangles contain the time stamp
of arrival and departure of the livestock from the parking area. “yyyy-mm-dd, hh:mm:ss” is the date-time format used. For example, L03 entered
AS12 on 2011-07-10 at 10:13:21 and left it on 2011-07-10 at 14:20:08.
Table 1. CHECK outcome with respect to the example dataset. To verify the table content correctness, please refer to the time stamp values
shown in Fig. 4.
Sick batches L03
Potentially infected batches
BatchID Place of contact
L01 AS05 (farm)
L04 AS05 (control post)
L05 AS07 (farm)
L06 AS14 (farm)
L18 AS12 (control post)
Infected farms AS14, AS07 (because of the presence of L03)
Potentially infected farms
Farm Infecting batch
AS04 L04
AS08 L05 AS16 L01 AS19 L18 AS20 L06
Table 2. Correspondence between CHECK and the basic queries
Steps of CHECK Queries that implement the step
1 1, 2, 3, 4, 5
2 6, 7
3 8
A. Implementation of Step 1
Preliminarily we determine the periods spent by the
animal batches in the parking areas (Query 1, 2 and 3).
Those data are extracted from the trajectories and
stored into a working table (break). Three cases are
possible (Fig. 5), each implemented as an independent
query, according to the “role” played by the parking
area inside the whole history of the movements of each
animal batch present in the database. Let us denote
with bid* and paid*, respectively, the identifier of a
generic animal batch and that of a generic parking area.
The three roles played by paid* are the following:
– a crossing parking area for bid* (Case “a” of Fig.
5). In the database exists at least a trajectory done
by bid* that reaches paid*, stops in it, and then
leaves from it.
– The last known destination of bid* (Case “b”). In
the database exists a trajectory done by bid* that
reaches paid*, but none comes out.
JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013 105
© 2013 ACADEMY PUBLISHER

– The origin parking area for bid* (Case “c”). In the
database exists a trajectory done by bid* that comes
out from paid*, but none enters it. Think, for
example, to paid* as the farm of birth of bid*.
Figure 5. The roles played by a parking area in the history of
movements of an animal batch
# Query 1: Rest periods of the batches inside crossing
parking areas
let break =
SELECT [entry:BatchId AS BatchNumber,
entry:To AS ParkingAreas,
inst (final (entry:TripData))
AS StartStaging,
inst (initial (exit:TripData))
AS EndStaging]
FROM [trip AS entry, trip AS exit]
WHERE [entry:BatchId = exit:BatchId,
entry:To = exit:From]
The (SECONDO) let command builds the table
break, which stores the query result. entry:BatchId replaces the entry.BatchId standard notation.
The beginning instant of the rest in a parking area
coincides with the last instant of the incoming
trajectory in such an area, while the end of the rest is
the initial instant of the trajectory of output from the
same area. “inst(final(entry: tripData))” and
“inst(initial(exit: tripData))” return,
respectively, those time stamps (entry and exit are
two aliases of the trip table).
# Query 2: Rest periods of the batches inside the
parking area of their last known destination
INSERT into break
SELECT [entry:BatchId AS BatchNumber,
entry:To AS ParkingAreas,
inst (final (entry:TripData))
AS StartStaging,
now AS EndStaging]
FROM [trip AS entry]
WHERE [entry:to NOT IN
(SELECT t:From
FROM [trip AS t]
WHERE entry:BatchId =
t:BatchId )]
The stay period in the “last known destination”
returned by Query 2 ranges from the time of the last
timestamp of the input trajectory in the parking area
and the time of execution of query itself (in
SECONDO, the date and current time are returned by
the operator now).
# Query 3: Stay periods of the batches inside their
origin parking area
INSERT into break
SELECT [exit:BatchId AS BatchNumber,
exit:From AS ParkingAreas,
inst (initial(exit:TripData )) –
[const, duration, value,
[90,0]] AS StartStaging,
inst (initial(exit:TripData ))
AS EndStaging]
FROM [trip AS exit]
WHERE [exit:From NOT IN
(SELECT t:To
FROM [trip AS t]
WHERE exit:BatchId =
t:BatchId )]
The parameter “[const, duration, value,
[90,0]]” sets the temporal extension of the stay
period (90 days) in an “origin parking area” returned
by Query 3. Such a value can be modified according to
the needs.
# Query 4: Migration of the break’s content into table
stops and addition, to this latter, of attribute
rangeTime that stores the stay time interval
let stops = break feed
extend[rangeTime: theRange
(.StartStaging,
.EndStaging, true, true)]
sortby[BatchNumber, StartStaging]
consume;
The feed operator reads relation break from disk
and puts its tuples into a stream; while the extend
operator adds the attribute rangeTime to the query
result; lastly, the consume operation collects a tuple
stream into a persistent relation. .StartStaging
stands for break.StartStaging.
Fig. 6 shows a portion of the instance of the relation
stops computed with respect to the example dataset of
Sec. III.
# Query 5: Infected farms
SELECT [t:BatchId AS SickBatches,
site:PAID AS InfectedFarms]
FROM [ParkingArea AS site,
trip AS t, visit AS v ]
WHERE [v:result ="Sick",
t:BatchId = v:BatchId,
t:TripData passes site:Layout,
site:Type ="Farm"]
Query 5 analyzes the trips of each sick batch, to
assess whether they crossed the area that borders some
of the farms in the database (predicate: “t:TripData
passes site:Layout”). Fig. 7 shows the output of
Query 5. The result coincides with the expectation (see
Table 1).
106 JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013
© 2013 ACADEMY PUBLISHER

Figure 6. Stay intervals of the animal batches inside the parking areas (i.e., meeting points, control posts, and farms). Giving a glance at the rows of the table, it is possible to have a confirmation, for instance, of the trips of the batch L03 together with the relative time stamps, previously seen in
Fig.4.
B. Implementation of Step 2 (Search potentially
infected batches)
Query 6 uses the data in the stops table to
determine the batches potentially infected by the co-
presence with batches found sick.
# Query 6: Potentially infected batches by co-presence
SELECT [stay1:BatchNumber AS
SickAnimalBatches,
stay2:BatchNumber AS
PotentiallyInfectedBatches,
stay2:ParkingAreas AS
SitesOfInfection]
FROM [stops AS stay1, stops AS stay2,
visit AS v]
WHERE [tay1:BatchNumber #
stay2:BatchNumber,
stay1:ParkingAreas =
stay2:ParkingAreas,
stay1:rangeTime intersects
stay2:rangeTime,
stay1:BatchNumber = v:BatchId,
v:result = "Sick"]
ORDERBY [SickAnimalBatches,
SitesOfInfection,
PotentiallyInfectedBatches]
The tables listed in Query 6 are stops and visit
The predicate “stay1:BatchNumber =
v:BatchId, v:result=”Sick”” identify all the sick
batches in the database. Then, are selected all the
animal batches who have made stops in the same
parking area (predicate: “stay1:ParkingAreas =
stay2:ParkingAreas”) by ignoring the tuples that
refer to the same batch (predicate:
“stay1:BatchNumber # stay2:BatchNumber”).
Lastly, the function intersects verifies the temporal
overlapping of their periods of stay. The SELECT
clause lists the columns to be displayed, namely: the ID
of the sick batch, the infected batches, the parking area
where the infection could be occurred, the range of co-
presence.
The formulation of Query 6 is valid regardless of
the number of sick batches in the database. This thanks
to the condition “v:result = "Sick"” which takes
into account all the sick batches. In the example dataset
there is only one sick batch (L03).
With a similar procedure, it is possible to determine
the batches infected by temporal contiguity and the
places where such a contamination may have occurred
(Query 7).
Figure 7. The farms infected by the batch L03
JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013 107
© 2013 ACADEMY PUBLISHER

Figure 8. Batches potentially infected by batch L03 either by co-presence or temporal contiguity
# Query 7: Potentially infected batches by temporal
contiguity
SELECT [stay1:BatchNumber AS
SickAnimalBatches,
stay2:BatchNumber AS
PotentiallyInfectedBatches,
stay2:ParkingAreas AS
SitesOfInfection]
FROM [stops AS stay1, stops AS stay2,
visit AS v]
WHERE [stay1:BatchNumber #
stay2:BatchNumber,
stay1:ParkingAreas =
stay2:ParkingAreas,
stay1:BatchNumber = v:BatchId,
v:result ="Sick",
stay2:StartStaging >
stay1:EndStaging,
stay2:StartStaging <
stay1:EndStaging +
[const, duration, value, [2,0]]]
Because it exists temporal contiguity, the beginning
of the rest of a batch must start after the end of the stay
of the sick one (predicate: “stay2:StartStaging >
stay1:End Staging”). In Query 7, the parameter
“[const, duration, value, [2,0]]” sets the
“temporal distance” between these two events in two
days. The value of such a parameter have to be
changed according to the characteristics of the
epidemic at hand.
Query 6 and Query 7 can be merged in a single
query by using the or operator in the WHERE clause.
The combined effect of these two queries is shown in
Fig. 8.
C. Implementation of Step 3 (Search potentially
infected farms)
Query 8 returns the potentially infected farms, that
is the farms which host at least one of the batches
potentially infected (either by co-presence or temporal
contiguity) by the sick batches inside some of the
parking areas. The screen of Fig. 9 shows the result.
#Query 8: Potentially infected farms
SELECT [stay1:BatchNumber AS
SickBatches,
stay2:BatchNumber AS
PotentiallyInfectedBatches,
lastTrip:to AS
PotentiallyInfectedFarms]
FROM [stops AS stay1, stops AS stay2,
trip AS lastTrip, visit AS v ]
WHERE [stay1:BatchNumber #
stay2:BatchNumber,
stay1:ParkingAreas =
stay2:ParkingAreas,
stay1:BatchNumber = v:BatchId,
v:result ="Sick”,
(stay1:rangeTime intersects
stay2:rangeTime )
or
(stay2:StartStaging <
stay1:EndStaging +
[const, duration, value, [2,0]]
and
stay2:StartStaging >
stay1:EndStaging ),
lastTrip:BatchId =
stay2:BatchNumber,
lastTrip:to
NOT IN
(SELECT [journey:From]
FROM [trip AS journey]
WHERE [stay2:BatchNumber =
journey:BatchId ])]
ORDERBY[SickBatches,
PotentiallyInfectedFarms]
Fig. 10 summarizes the outcome of the analysis
(output of Query 5 and Query 8) on a geographic map,
that is the infected farms (red crosses) and those
potentially infected (triangles with an embedded
exclamation mark).
V. CONCLUSIONS
The paper reports about the implementation of a
method (the algorithm CHECK) that takes advantage
of the data collected in a “quasi real-time” database
about the trips of the livestock from a parking area to
another one and the sanitary controls of the livestock
itself, in order to derive which farms are infected and
which one could be so. The availability of this latter
information allows to feed the existing methods for the
analysis of the diffusion of the disease among farms
such as, for instance, the risk based culling. The
proposed solution cuts the number of head of cattle on
which has to be launched the campaign of visits, that
108 JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013
© 2013 ACADEMY PUBLISHER

otherwise should be extended to all the livestock which
has undergone movements in the period of time
elapsed from the visit of the head turned out to be sick
and the previous visit, in which the same animal was
healthy.
Figure 9. The potentially infected farms
Figure 10. The outcome of the CHECK algorithm against the example dataset
The happy notes learned through the experience
The implementation in SECONDO of the algorithm
CHECK has been accomplished in terms of eight SQL
queries of low difficulty. The realization effort has to
be considered, therefore, within the reach of anyone
who wants to repeat of his own a solution such as that
reported in this paper. Incomparably bigger is the entity
of the effort if one decides to adopt as enabling
technology one of the RDBMS today available on the
marketplace (e.g.: IBM-DB2/SE, Oracle Spatial, or
PostgreSQL/PostGIS) and this for the lack in those
software of a native data type suitable to model moving
points and, consequently, of operators that operate on
those complex objects ([3] discusses this issue in
detail).
Without such a native support, the implementation
of the algorithm CHECK binds us to develop, in
advance, ad hoc operators (such as, for example, passes
used in Query 5) with a global effort definitely higher,
besides the risk of producing a software of lower
reliability.
The painful notes learned through the experience
So far, SECONDO cannot be considered a stable
technology to put into practice in real contexts. This
system, to the authors' own admission, it is now
recommended especially in the scientific context
mainly for testing new methods and algorithms.
To reach a satisfactory command in the use of
SECONDO, it requires a period of start-up absent if
one remains with the relational DBMSs today largely
part of most corporate assets.
REFERENCES
[1] D. E. te Beest, T. J. Hagenaars, A. J. Stegeman, M. PG
Koopmans, and M. van Boven, “Risk based Culling for
highly Infectious Diseases of Livestock,” Veterinary
Research 2011, 42:81.
JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013 109
© 2013 ACADEMY PUBLISHER

[2] Council Regulation (EC) No 1255/97 of 25 June 1997
“On Community Criteria for Staging Points and
Amending the Route Plan Referred to in the Annex to
Directives 91/628/EEC,” Official Journal of the
European Union series L, n. 174/1, 2.07.1997.
(http://europa.eu/documentation/legislation/index_en.ht
m - item: Search by Official Journal reference, June
2012)
[3] P. Di Felice. A Short Term Solution to Implement
Applications about Moving Points on top of Existing
DBMSs. Int. Journal of Computer Applications (0975 –
8887) Volume 50 – No.10, July 2012. DOI:
10.5120/7804-0934.
[4] P. Di Felice, A. Falcone. “An Algorithm and a Database:
two Conceptual Tools to Control the Diffusion of
Animal Diseases,” Journal of Advances in Information
Technology. (To appear)
[5] European Commission, The new Animal Health
Strategy for the European Union (2007-2013):
“Prevention is better than Cure,” Communication from
the Commission to the Council, the European
Parliament, the European Economic and Social
Committee and the Committee of the Regions - COM
539 (2007). European Communities, 2007. ISBN 978-
92-79-06722-8. (http://ec.europa.eu/food/animal/
diseases/strategy/index_en.htm, June 2012)
[6] G. Gebresenbet, W. Baltussen, P. Sterrenburg, K. De
Roest, K. E. Nielsen, “Evaluation of the Feasibility of a
Certification Scheme for high Quality Control Posts,”
Sanco/d5/2005/SI2.548887, 2010. European
Commission Funded Project Directorate-General for
Health and Consumers.
[7] R. H. Güting, M. Schneider, Moving Objects Databases,
Morgan Kaufmann Publishers, 2005.
[8] R. H. Güting, T. Behr, and C. Düntgen, “SECONDO: A
Platform for Moving Objects Database Research and for
Publishing and Integrating Research Implementations,”
IEEE Data Engineering Bulletin, 2010, 33:2, 56-63.
APPENDIX
This section collects a summary of the SECONDO
scripts devoted to create the database, its tables and
load them with the example dataset.
# DB creation and opening
create database MODAT;
# Moving Objects Database for Animal Traceability
open database MODAT;
# Tables creation
sql CREATE TABLE animalBatch COLUMNS [BatchID: string,
Species: string, HeadNumber: int ]
sql CREATE TABLE parkingArea COLUMNS [PAID: string, Name:
string, City: string, Type: string, FarmerID: string, Position:
point, Layout: region ]
sql CREATE TABLE farmer COLUMNS [FarmerID: string, Name:
string ]
sql CREATE TABLE visit COLUMNS [BatchID: string, VisitDate:
instant, Result: string, Diagnosis: string, PAID: string]
# Tables loading (partial)
# Animal batch (1 of 20)
sql insert into animalBatch values ["L01", “Bovina chianina”, 30]
# Parking area
sql insert into parkingArea values [“AS01”, “Cerullo s. r. l.”,
”Montoro Superiore”, ”Meeting point”, ”ALL02”,
[const, point, value, [14.7949, 40.8512]],
[const, region, value, [[[
[14.79435 , 40.85105], [14.79505, 40.85090],
[14.79590 , 40.85100], [14.79590, 40.85150],
[14.79545 , 40.85195], [14.79480, 40.85165],
[14.79435 , 40.85165]]]]] ]
# Farmer (1 of 8)
sql insert into farmer values [“ALL01”, “Mario Bramieri”] # Visit (1 of 11)
sql insert into visit values [”L01”, theInstant (2011,07,2,11,00),
”Regolare”, ” Healthy”, ”AS15”]
# Trip creation and loading The creation and the loading of the table trip require
several steps. The reader interested to know the details
may refer to the Appendix in [3].
110 JOURNAL OF ADVANCES IN INFORMATION TECHNOLOGY, VOL. 4, NO. 2, MAY 2013
© 2013 ACADEMY PUBLISHER

Call for Papers and Special Issues
Aims and Scope JAIT is intended to reflect new directions of research and report latest advances. It is a platform for rapid dissemination of high quality research /
application / work-in-progress articles on IT solutions for managing challenges and problems within the highlighted scope. JAIT encourages a multidisciplinary approach towards solving problems by harnessing the power of IT in the following areas:
• Healthcare and Biomedicine - advances in healthcare and biomedicine e.g. for fighting impending dangerous diseases - using IT to model transmission patterns and effective management of patients’ records; expert systems to help diagnosis, etc.
• Environmental Management - climate change management, environmental impacts of events such as rapid urbanization and mass migration, air and water pollution (e.g. flow patterns of water or airborne pollutants), deforestation (e.g. processing and management of satellite imagery), depletion of natural resources, exploration of resources (e.g. using geographic information system analysis).
• Popularization of Ubiquitous Computing - foraging for computing / communication resources on the move (e.g. vehicular technology), smart / ‘aware’ environments, security and privacy in these contexts; human-centric computing; possible legal and social implications.
• Commercial, Industrial and Governmental Applications - how to use knowledge discovery to help improve productivity, resource management, day-to-day operations, decision support, deployment of human expertise, etc. Best practices in e-commerce, e-commerce, e-government, IT in construction/large project management, IT in agriculture (to improve crop yields and supply chain management), IT in business administration and enterprise computing, etc. with potential for cross-fertilization.
• Social and Demographic Changes - provide IT solutions that can help policy makers plan and manage issues such as rapid urbanization, mass internal migration (from rural to urban environments), graying populations, etc.
• IT in Education and Entertainment - complete end-to-end IT solutions for students of different abilities to learn better; best practices in e-learning; personalized tutoring systems. IT solutions for storage, indexing, retrieval and distribution of multimedia data for the film and music industry; virtual / augmented reality for entertainment purposes; restoration and management of old film/music archives.
• Law and Order - using IT to coordinate different law enforcement agencies’ efforts so as to give them an edge over criminals and terrorists; effective and secure sharing of intelligence across national and international agencies; using IT to combat corrupt practices and commercial crimes such as frauds, rogue/unauthorized trading activities and accounting irregularities; traffic flow management and crowd control.
The main focus of the journal is on technical aspects (e.g. data mining, parallel computing, artificial intelligence, image processing (e.g. satellite imagery), video sequence analysis (e.g. surveillance video), predictive models, etc.), although a small element of social implications/issues could be allowed to put the technical aspects into perspective. In particular, we encourage a multidisciplinary / convergent approach based on the following broadly based branches of computer science for the application areas highlighted above:
Special Issue Guidelines Special issues feature specifically aimed and targeted topics of interest contributed by authors responding to a particular Call for Papers or by
invitation, edited by guest editor(s). We encourage you to submit proposals for creating special issues in areas that are of interest to the Journal. Preference will be given to proposals that cover some unique aspect of the technology and ones that include subjects that are timely and useful to the readers of the Journal. A Special Issue is typically made of 10 to 15 papers, with each paper 8 to 12 pages of length.
The following information should be included as part of the proposal: • Proposed title for the Special Issue • Description of the topic area to be focused upon and justification • Review process for the selection and rejection of papers. • Name, contact, position, affiliation, and biography of the Guest Editor(s) • List of potential reviewers • Potential authors to the issue • Tentative time-table for the call for papers and reviews If a proposal is accepted, the guest editor will be responsible for: • Preparing the “Call for Papers” to be included on the Journal’s Web site. • Distribution of the Call for Papers broadly to various mailing lists and sites. • Getting submissions, arranging review process, making decisions, and carrying out all correspondence with the authors. Authors should be
informed the Instructions for Authors. • Providing us the completed and approved final versions of the papers formatted in the Journal’s style, together with all authors’ contact
information. • Writing a one- or two-page introductory editorial to be published in the Special Issue.
Special Issue for a Conference/Workshop A special issue for a Conference/Workshop is usually released in association with the committee members of the Conference/Workshop like general
chairs and/or program chairs who are appointed as the Guest Editors of the Special Issue. Special Issue for a Conference/Workshop is typically made of 10 to 15 papers, with each paper 8 to 12 pages of length.
Guest Editors are involved in the following steps in guest-editing a Special Issue based on a Conference/Workshop: • Selecting a Title for the Special Issue, e.g. “Special Issue: Selected Best Papers of XYZ Conference”. • Sending us a formal “Letter of Intent” for the Special Issue. • Creating a “Call for Papers” for the Special Issue, posting it on the conference web site, and publicizing it to the conference attendees.
Information about the Journal and Academy Publisher can be included in the Call for Papers. • Establishing criteria for paper selection/rejections. The papers can be nominated based on multiple criteria, e.g. rank in review process plus the
evaluation from the Session Chairs and the feedback from the Conference attendees. • Selecting and inviting submissions, arranging review process, making decisions, and carrying out all correspondence with the authors. Authors
should be informed the Author Instructions. Usually, the Proceedings manuscripts should be expanded and enhanced. • Providing us the completed and approved final versions of the papers formatted in the Journal’s style, together with all authors’ contact
information. • Writing a one- or two-page introductory editorial to be published in the Special Issue.
More information is available on the web site at http://www.academypublisher.com/jait/.

(Contents Continued from Back Cover)
An Intelligent Water Droplet-based Evaluation of Health Oriented Distance Learning Koffka Khan, Zulaika Ali, Nisa Philip, Gail Deane, and Ashok Sahai Tracking Livestock Movements to Figure out Potentially Infected Farms Paolino Di Felice and Americo Falcone
91
101





























