Embed Size (px)
Citation preview

Dosen pembimbing: Dr. Muhammad Subianto, M.Si
Laporan Tugas III Data MiningOleh: Ahmad Ariful Amri |
1108107010054

http://www.liataja.com/http://asalasah.blogspot.com/
http://asalasah.net/
Tugas 3 Data MiningTugas 3 kali ini berkaitan dengan klasifikasi. Klasifikasimerupakan memetakan (mengklasifikasikan) data ke dalam satuatau beberapa kelas yang sudah didefinisikan sebelumnya.
K-Nearest Neighbor (K-NN) adalah suatu metode yang menggunakanalgoritma supervised dimana hasil dari sampel uji yang barudiklasifikasikan berdasarkan mayoritas dari kategori pada K-NN. Tujuan dari algoritma ini adalah mengklasifikasi objekbaru berdasakan atribut dan sampel latih. pengklasifikasiantidak menggunakan model apapun untuk dicocokkan dan hanyaberdasarkan pada memori. Diberikan titik uji, akan ditemukansejumlah K objek (titik training) yang paling dekat dengantitik uji. Klasifikasi menggunakan voting terbanyak di antaraklasifikasi dari K objek. Algoritma K-NN menggunakanklasifikasi ketetanggaan sebagai nilai prediksi dari sampleuji yang baru. Dekat atau jauhnya tetangga biasanya dihitungberdasarkan jarak Eucledian.
Ada 2 file dari tugas 2 yang akan dilanjutkan. Dataset WSDLmemiliki total 569 sampel dan dataset Abalone memiliki total4177 sampel. Pada Tugas 3 ini, anda diminta untuk memecahkanfile ARFF dari dataset WDBC menjadi 2 file (WDBC-training.arffdan WDBC-testing.arff). Jumlah sampel yang harus ada dalamfile WDBC-training.arff adalah sebanyak 75% sd 80% dari totalsampel yang dipilih secara acak, sedangkan jumlah sampel yangharus ada dalam file WDBC-testing.arff adalah berkisar antara20% sd 25% dari total sampel. Lakukan hal yang sama untukdataset Abalone. Dataset ini juga harus dipecah menjadi 2 file(Abalone-training.arff dan Abalone-testing.arff). Jumlahsampel yang harus ada dalam file Abalone-training.arff adalahsebanyak 75% sd 80% dari total sampel yang juga dipilih secaraacak, sedangkan jumlah sampel yang harus ada dalam fileAbalone-testing.arff adalah sebanyak kurang lebih 20% sd 25%.
~ 2 ~

Lakukan proses klasifikasi menggunakan Classifier IBk(Lazy/KNN) yang tersedia dalam perangkat lunak WEKA.Set parameter k=3, k=5, k=7, k=9, dan k=11. Gunakan filetesting dari masing-masing dataset untuk menguji keakuratanhasil klasifikasi. Akurasi dilihat darinilai Precision, Recall dan F-Measure. Bandingkan nilaiakurasi untuk setiap k dengan parameter distanceWeighting = nodistance weighting dan nilai parameterdistanceWeighting =Weight by 1/distance. Lakukan juga pengujian (testing)menggunakan cross-validation dengan parameter folds=10.
Data training dibagi menjadi k buah subset (subhimpunan).Dimana k adalah nilai dari fold. Selanjutnya, untuk tiap darisubset, akan dijadikan data tes dari hasil klasifikasi yangdihasilkan dari k-1 subset lainnya.
1. Pemisahan Dataa. Data AbaloneSebelum mengacak barisan data yang ada di dalam fileabalone.arff, terlebih dahulu dilakukan pembersihanatribut-atribut kolom headernya, selain itu juga dilakukanbackup, untuk mengembalikan atribut headernya serta agardapat dikembalikan jika trjadi kesalahan. Setelah selesaibarulah dilakukan langkah-langkah pemisahan data abalone.Adapun langkah yang dilakukan sebagai berikut:
1. Cara mengacak data yang ada didalam file abalone.arff,
setelah diacak, akan dibuatkan file baru bernamaabalone_shuffle.arff yang diletakkan dalam folder yangsama.
~ 3 ~
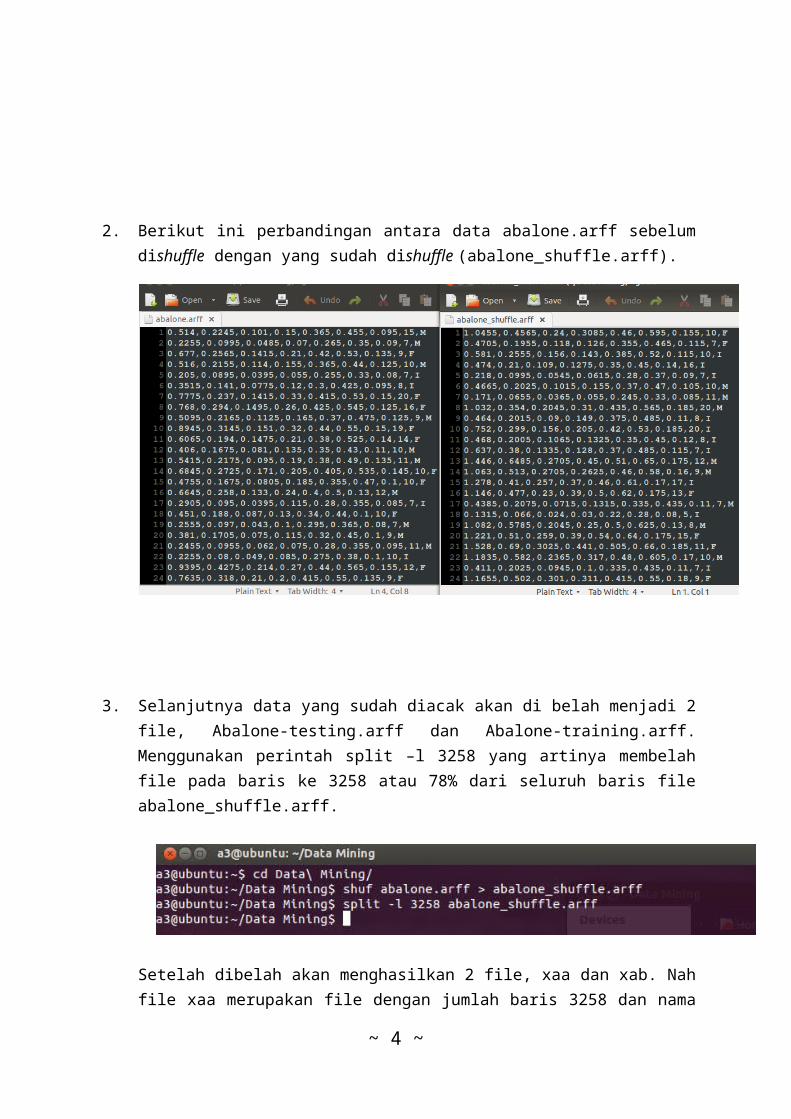
2. Berikut ini perbandingan antara data abalone.arff sebelumdishuffle dengan yang sudah dishuffle (abalone_shuffle.arff).
3. Selanjutnya data yang sudah diacak akan di belah menjadi 2file, Abalone-testing.arff dan Abalone-training.arff.Menggunakan perintah split –l 3258 yang artinya membelahfile pada baris ke 3258 atau 78% dari seluruh baris fileabalone_shuffle.arff.
Setelah dibelah akan menghasilkan 2 file, xaa dan xab. Nahfile xaa merupakan file dengan jumlah baris 3258 dan nama
~ 4 ~
file tersebut dirubah menjadi Abalone-training.arff .Sedangkan yang satunya lagi xab, yang berjumlah 22% darifile abalone_suffle.arff disimpan menjadi Abalone-training.arff
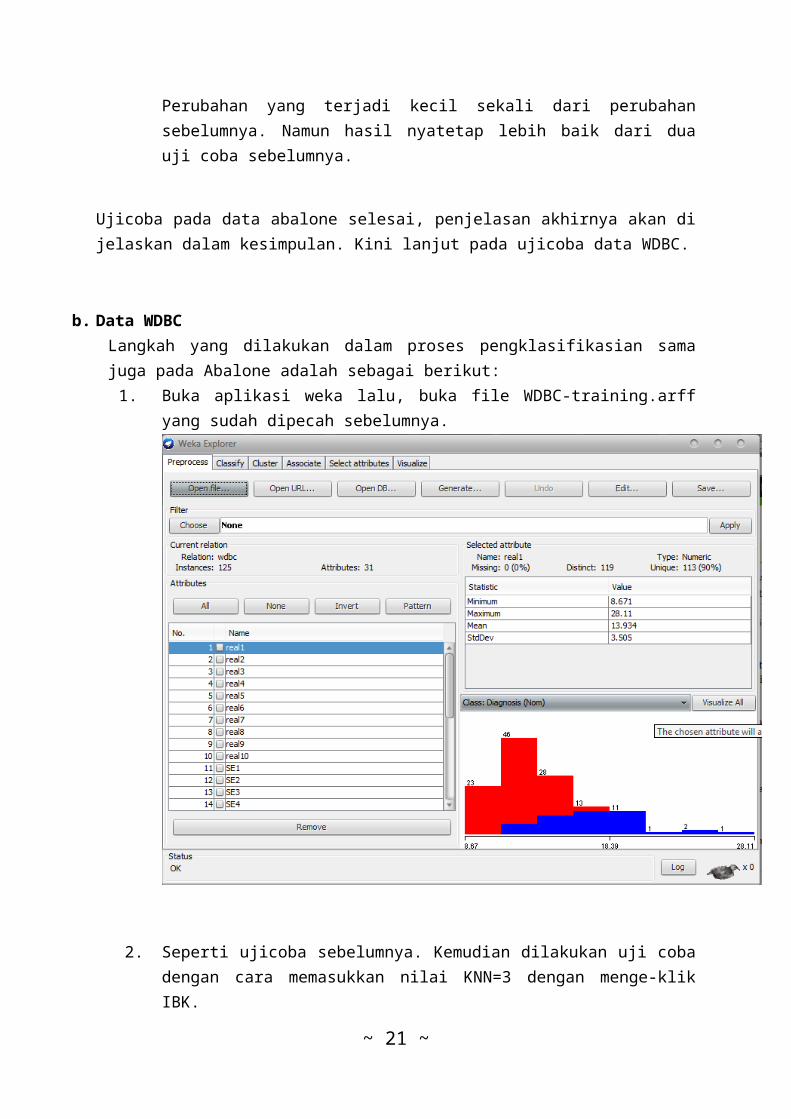
b. Data WDBCSama persis seperti yang dilakukan pada file abalone.arff.Sebelum mengacak barisan data yang ada di dalam filewsdl.arff, terlebih dahulu dilakukan pembersihan atribut-atribut kolom headernya, selain itu juga dilakukan backup..Setelah selesai barulah dilakukan langkah-langkah pemisahandata abalone. Adapun langkah yang dilakukan sebagaiberikut:
1. Cara mengacak data yang ada didalam file wsdl.arff,setelah diacak, akan dibuatkan file baru bernamawsdl_shuffle.arff yang diletakkan dalam folder yang sama.
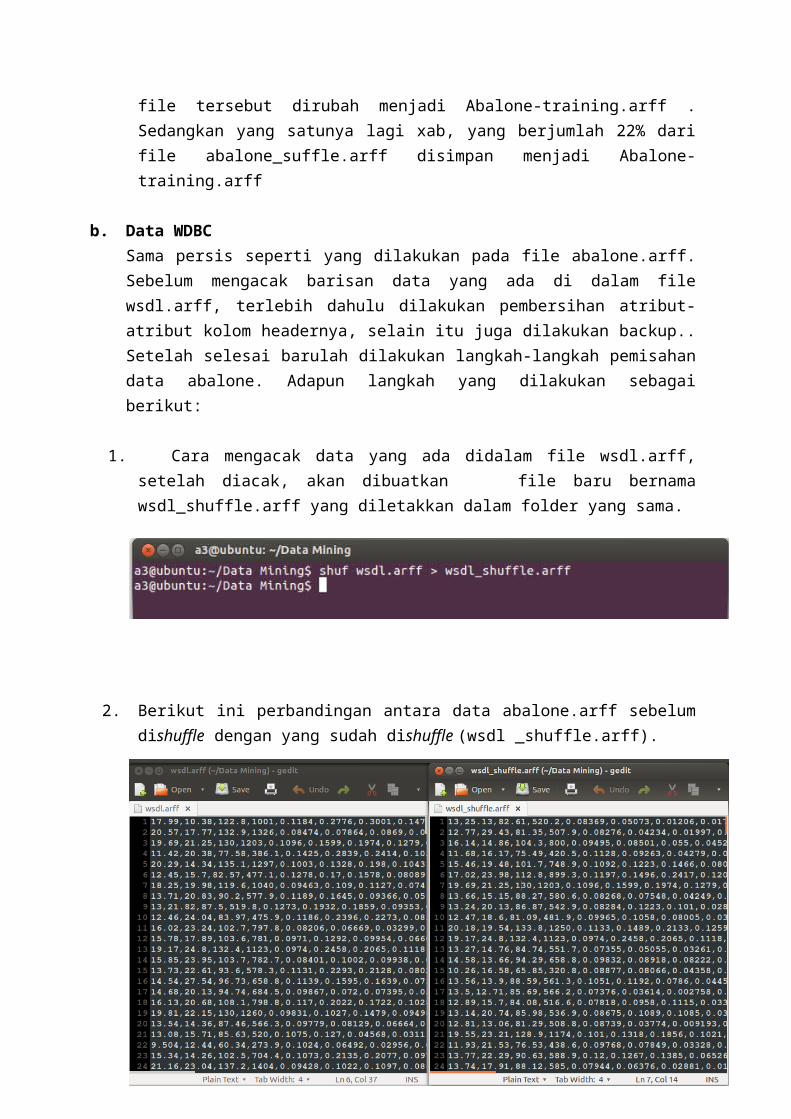
2. Berikut ini perbandingan antara data abalone.arff sebelumdishuffle dengan yang sudah dishuffle (wsdl _shuffle.arff).
~ 5 ~

3. Selanjutnya data yang sudah diacak akan di belah menjadi 2file, WDBC-testing.arff dan WDBC -training.arff.Menggunakan perintah split –l 444 yang artinya membelahfile pada baris ke 444 atau 78% dari seluruh baris filewsdl_shuffle.arff.
Setelah dibelah akan menghasilkan 2 file, xaa dan xab. Nahfile xaa merupakan file dengan jumlah baris 3258 dan namafile tersebut dirubah menjadi Abalone-training.arff .Sedangkan yang satunya lagi xab, yang berjumlah 22% darifile abalone_suffle.arff disimpan menjadi Abalone-training.arff
2. Melakukan KlasifikasiDisini akan dilakukan pengklasifikasian terhadap fileAbalone dan WDBC. Beberapa pengujian yang dilakukan misalnyamerubah aadatribut N, weight dll
a. Data AbaloneLangkah yang dilakukan dalam proses pengklasifikasian adalahsebagai berikut:1. Buka aplikasi weka lalu, buka file Abalone-
training.arff yang sudah dipecah sebelumnya.
~ 6 ~
2. Selanjutnya pilih tab ‘classify’ lalu pilih lazyselanjutnya pilih IBK.
~ 7 ~
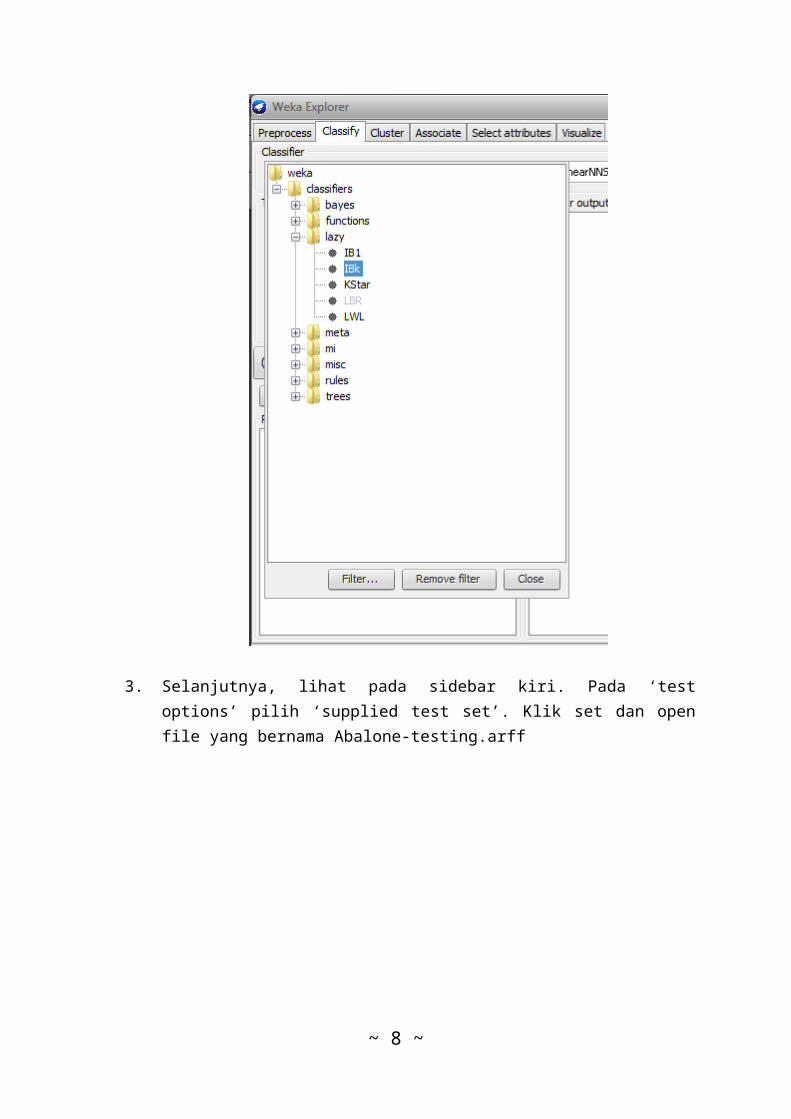
3. Selanjutnya, lihat pada sidebar kiri. Pada ‘testoptions’ pilih ‘supplied test set’. Klik set dan openfile yang bernama Abalone-testing.arff
~ 8 ~
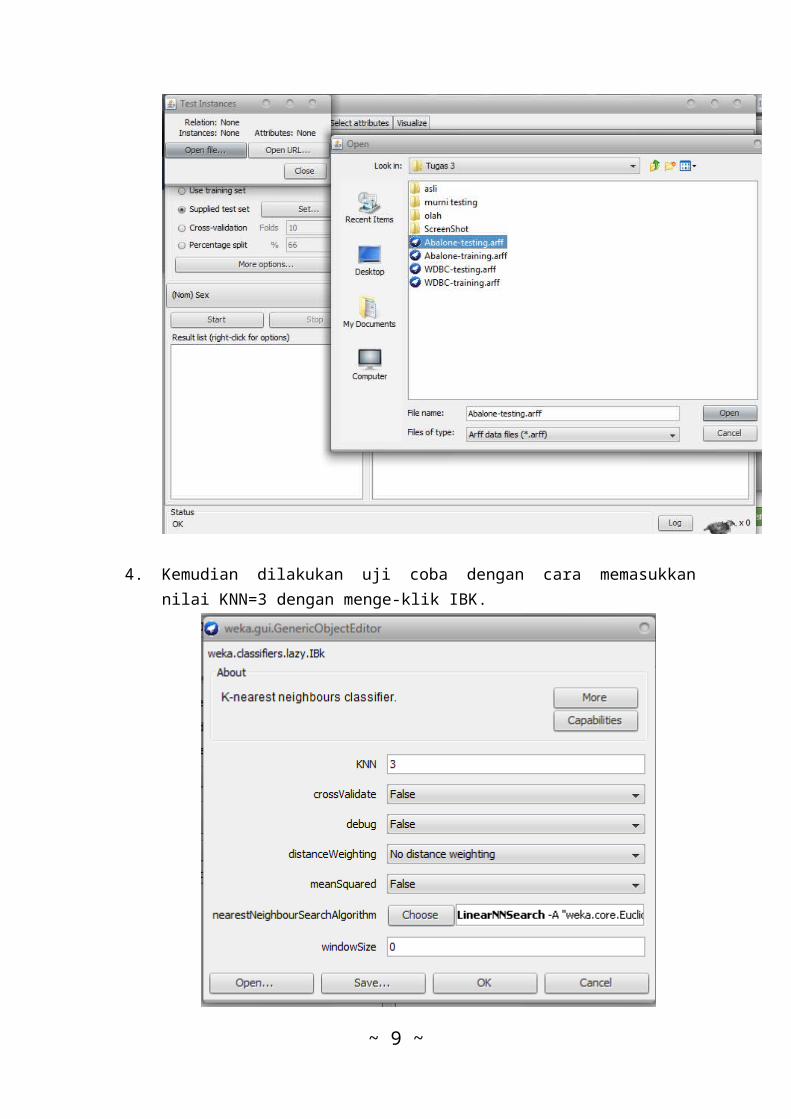
4. Kemudian dilakukan uji coba dengan cara memasukkannilai KNN=3 dengan menge-klik IBK.
~ 9 ~
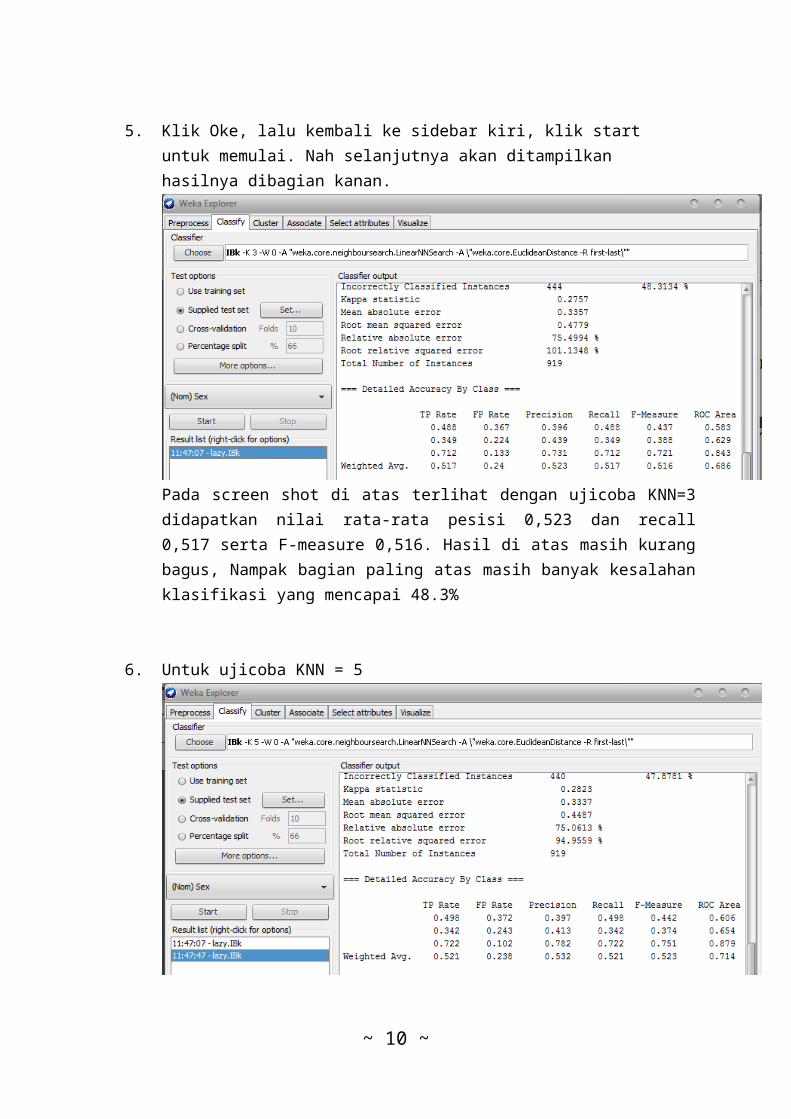
5. Klik Oke, lalu kembali ke sidebar kiri, klik start untuk memulai. Nah selanjutnya akan ditampilkan hasilnya dibagian kanan.
Pada screen shot di atas terlihat dengan ujicoba KNN=3didapatkan nilai rata-rata pesisi 0,523 dan recall0,517 serta F-measure 0,516. Hasil di atas masih kurangbagus, Nampak bagian paling atas masih banyak kesalahanklasifikasi yang mencapai 48.3%
6. Untuk ujicoba KNN = 5
~ 10 ~
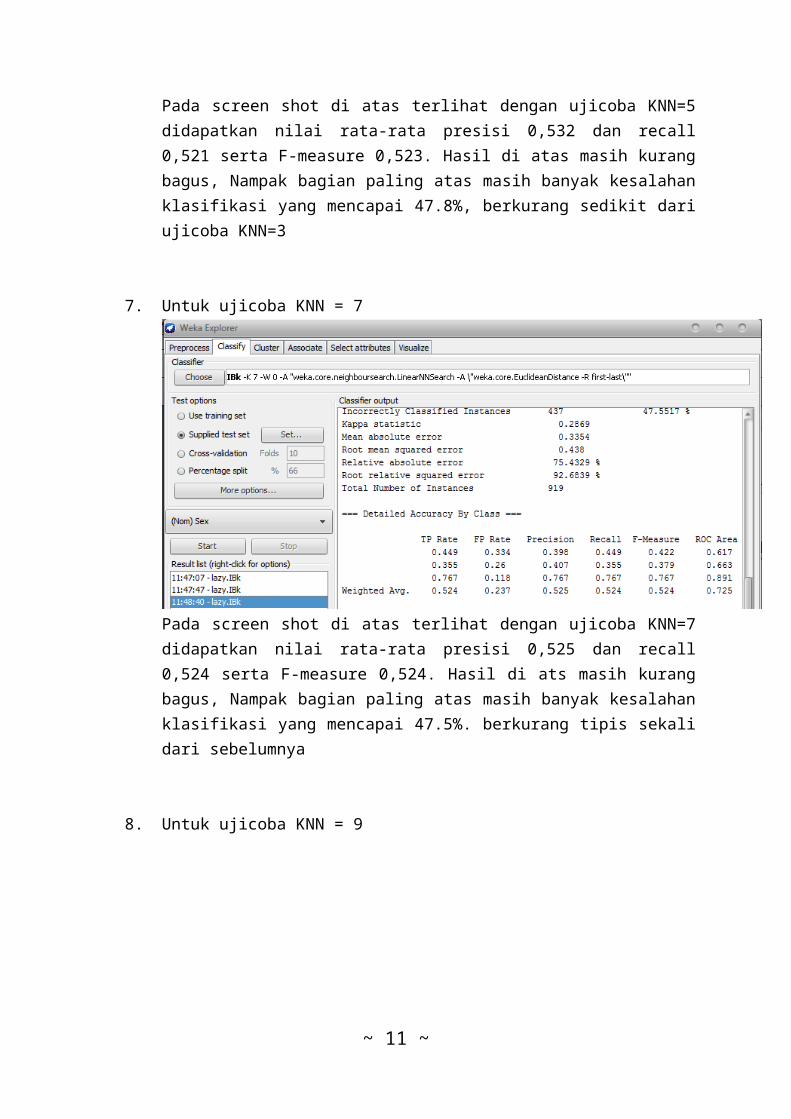
Pada screen shot di atas terlihat dengan ujicoba KNN=5didapatkan nilai rata-rata presisi 0,532 dan recall0,521 serta F-measure 0,523. Hasil di atas masih kurangbagus, Nampak bagian paling atas masih banyak kesalahanklasifikasi yang mencapai 47.8%, berkurang sedikit dariujicoba KNN=3
7. Untuk ujicoba KNN = 7
Pada screen shot di atas terlihat dengan ujicoba KNN=7didapatkan nilai rata-rata presisi 0,525 dan recall0,524 serta F-measure 0,524. Hasil di ats masih kurangbagus, Nampak bagian paling atas masih banyak kesalahanklasifikasi yang mencapai 47.5%. berkurang tipis sekalidari sebelumnya
8. Untuk ujicoba KNN = 9
~ 11 ~
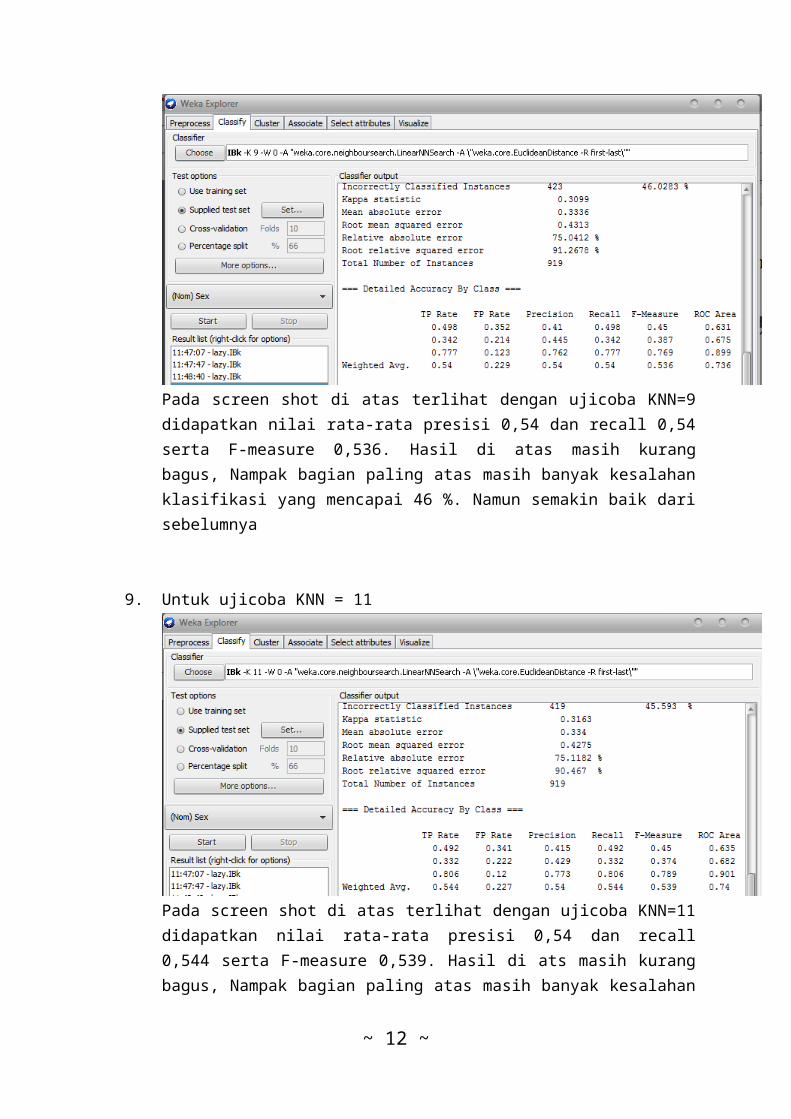
Pada screen shot di atas terlihat dengan ujicoba KNN=9didapatkan nilai rata-rata presisi 0,54 dan recall 0,54serta F-measure 0,536. Hasil di atas masih kurangbagus, Nampak bagian paling atas masih banyak kesalahanklasifikasi yang mencapai 46 %. Namun semakin baik darisebelumnya
9. Untuk ujicoba KNN = 11
Pada screen shot di atas terlihat dengan ujicoba KNN=11didapatkan nilai rata-rata presisi 0,54 dan recall0,544 serta F-measure 0,539. Hasil di ats masih kurangbagus, Nampak bagian paling atas masih banyak kesalahan
~ 12 ~
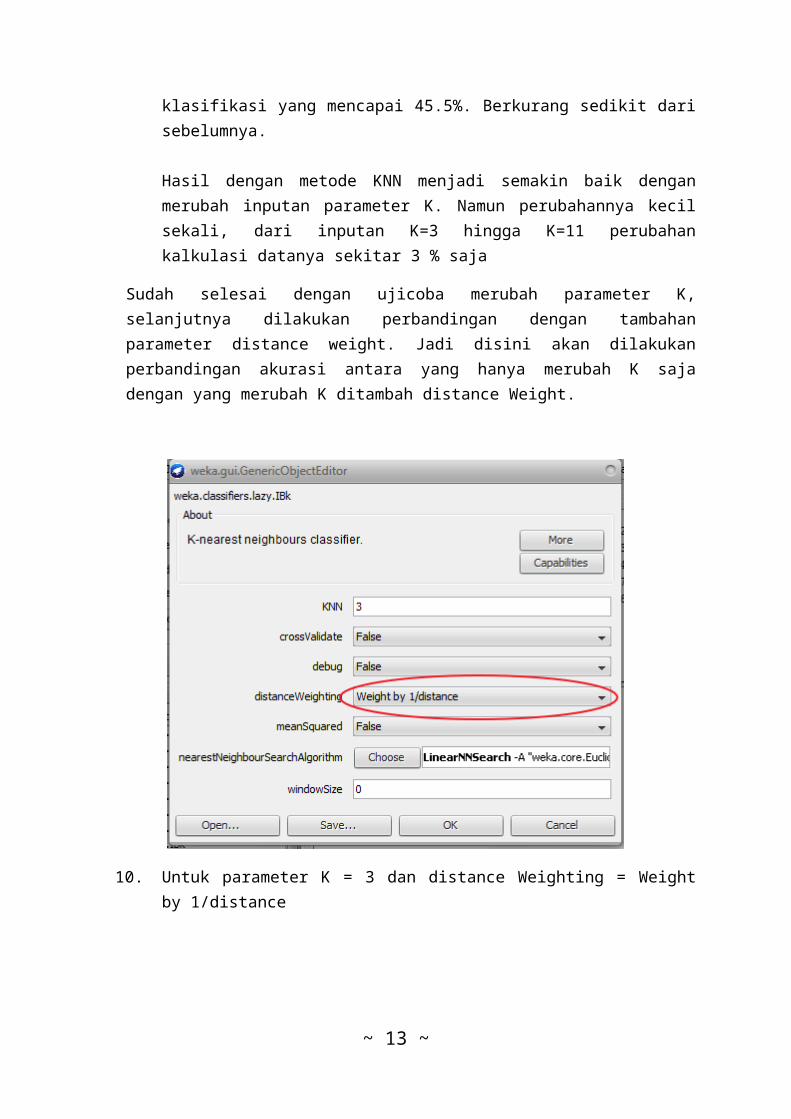
klasifikasi yang mencapai 45.5%. Berkurang sedikit darisebelumnya.
Hasil dengan metode KNN menjadi semakin baik denganmerubah inputan parameter K. Namun perubahannya kecilsekali, dari inputan K=3 hingga K=11 perubahankalkulasi datanya sekitar 3 % saja
Sudah selesai dengan ujicoba merubah parameter K,selanjutnya dilakukan perbandingan dengan tambahanparameter distance weight. Jadi disini akan dilakukanperbandingan akurasi antara yang hanya merubah K sajadengan yang merubah K ditambah distance Weight.
10. Untuk parameter K = 3 dan distance Weighting = Weightby 1/distance
~ 13 ~
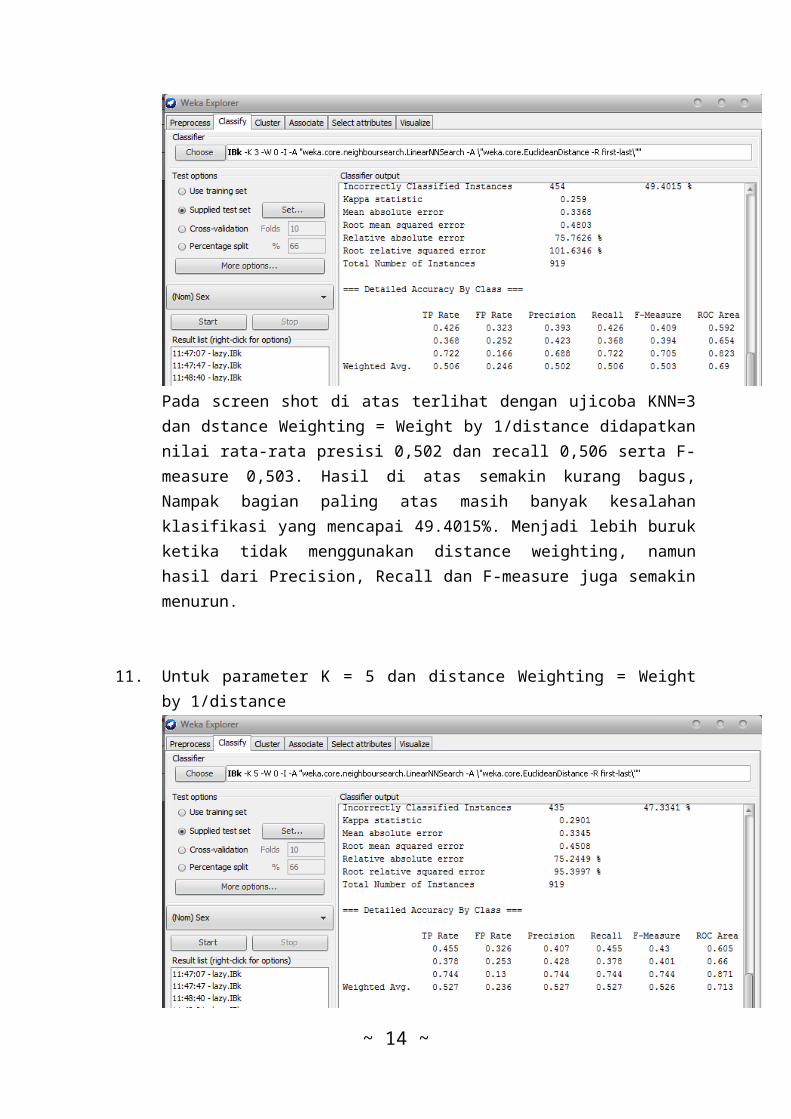
Pada screen shot di atas terlihat dengan ujicoba KNN=3dan dstance Weighting = Weight by 1/distance didapatkannilai rata-rata presisi 0,502 dan recall 0,506 serta F-measure 0,503. Hasil di atas semakin kurang bagus,Nampak bagian paling atas masih banyak kesalahanklasifikasi yang mencapai 49.4015%. Menjadi lebih burukketika tidak menggunakan distance weighting, namunhasil dari Precision, Recall dan F-measure juga semakinmenurun.
11. Untuk parameter K = 5 dan distance Weighting = Weightby 1/distance
~ 14 ~
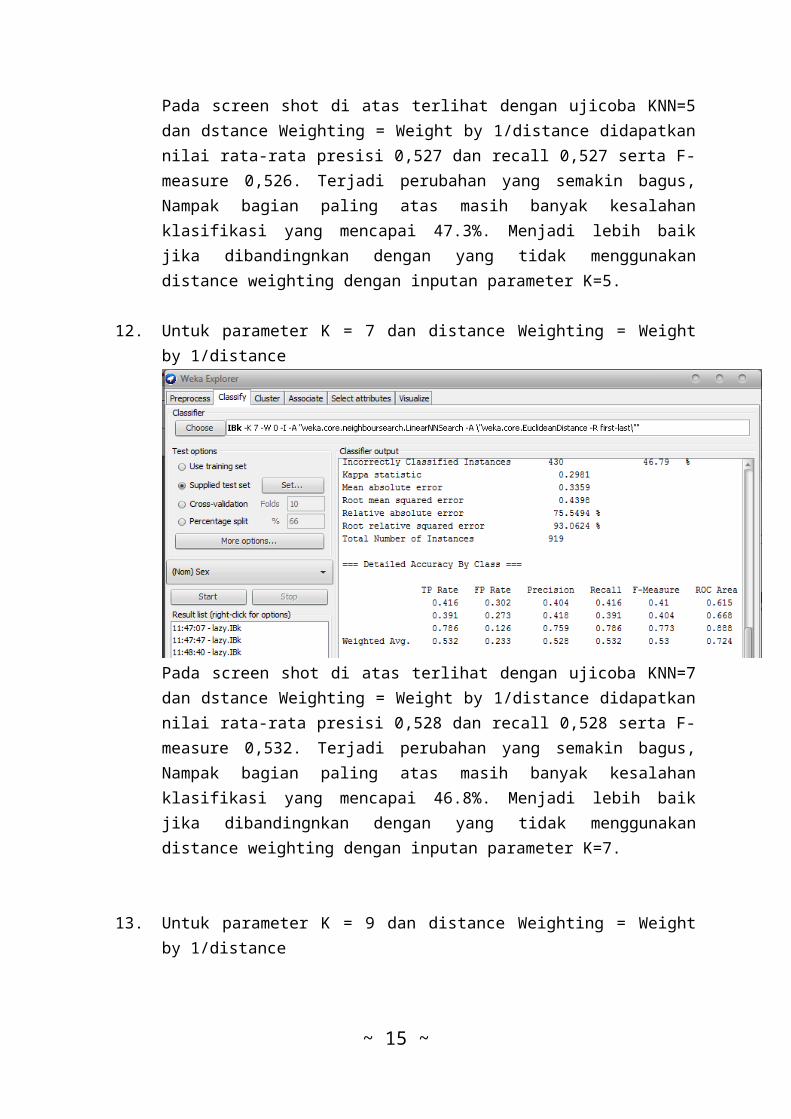
Pada screen shot di atas terlihat dengan ujicoba KNN=5dan dstance Weighting = Weight by 1/distance didapatkannilai rata-rata presisi 0,527 dan recall 0,527 serta F-measure 0,526. Terjadi perubahan yang semakin bagus,Nampak bagian paling atas masih banyak kesalahanklasifikasi yang mencapai 47.3%. Menjadi lebih baikjika dibandingnkan dengan yang tidak menggunakandistance weighting dengan inputan parameter K=5.
12. Untuk parameter K = 7 dan distance Weighting = Weightby 1/distance
Pada screen shot di atas terlihat dengan ujicoba KNN=7dan dstance Weighting = Weight by 1/distance didapatkannilai rata-rata presisi 0,528 dan recall 0,528 serta F-measure 0,532. Terjadi perubahan yang semakin bagus,Nampak bagian paling atas masih banyak kesalahanklasifikasi yang mencapai 46.8%. Menjadi lebih baikjika dibandingnkan dengan yang tidak menggunakandistance weighting dengan inputan parameter K=7.
13. Untuk parameter K = 9 dan distance Weighting = Weightby 1/distance
~ 15 ~
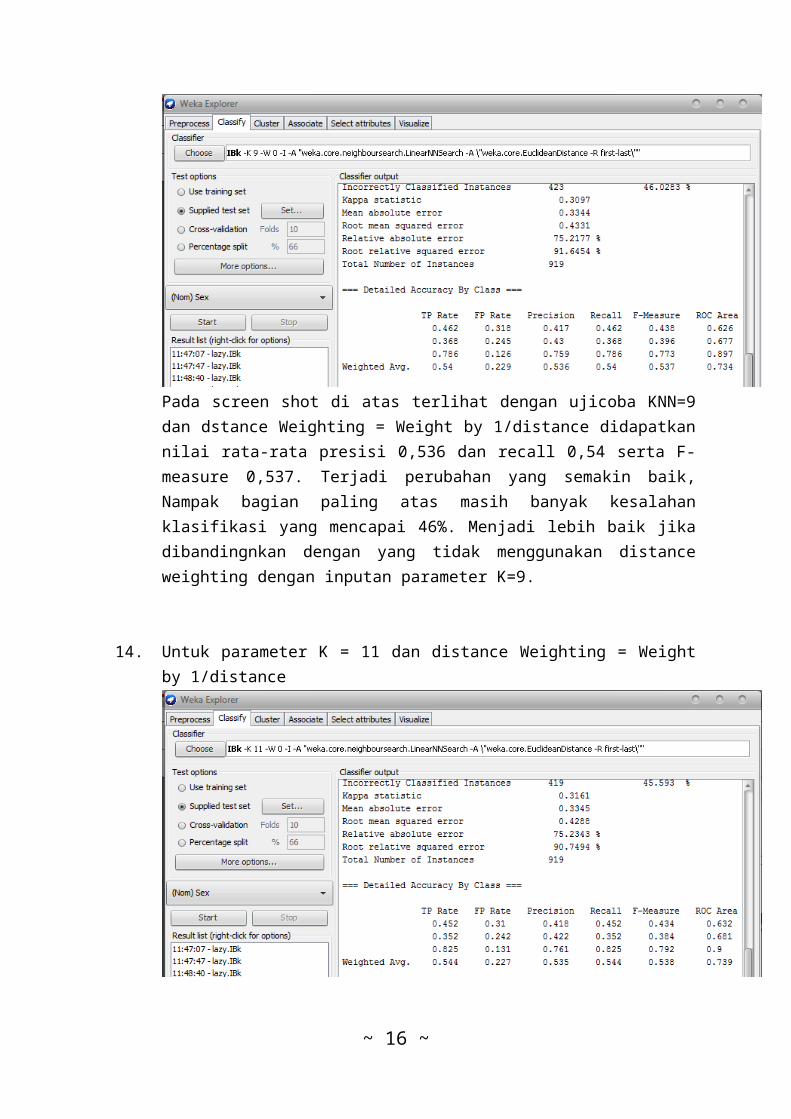
Pada screen shot di atas terlihat dengan ujicoba KNN=9dan dstance Weighting = Weight by 1/distance didapatkannilai rata-rata presisi 0,536 dan recall 0,54 serta F-measure 0,537. Terjadi perubahan yang semakin baik,Nampak bagian paling atas masih banyak kesalahanklasifikasi yang mencapai 46%. Menjadi lebih baik jikadibandingnkan dengan yang tidak menggunakan distanceweighting dengan inputan parameter K=9.
14. Untuk parameter K = 11 dan distance Weighting = Weightby 1/distance
~ 16 ~
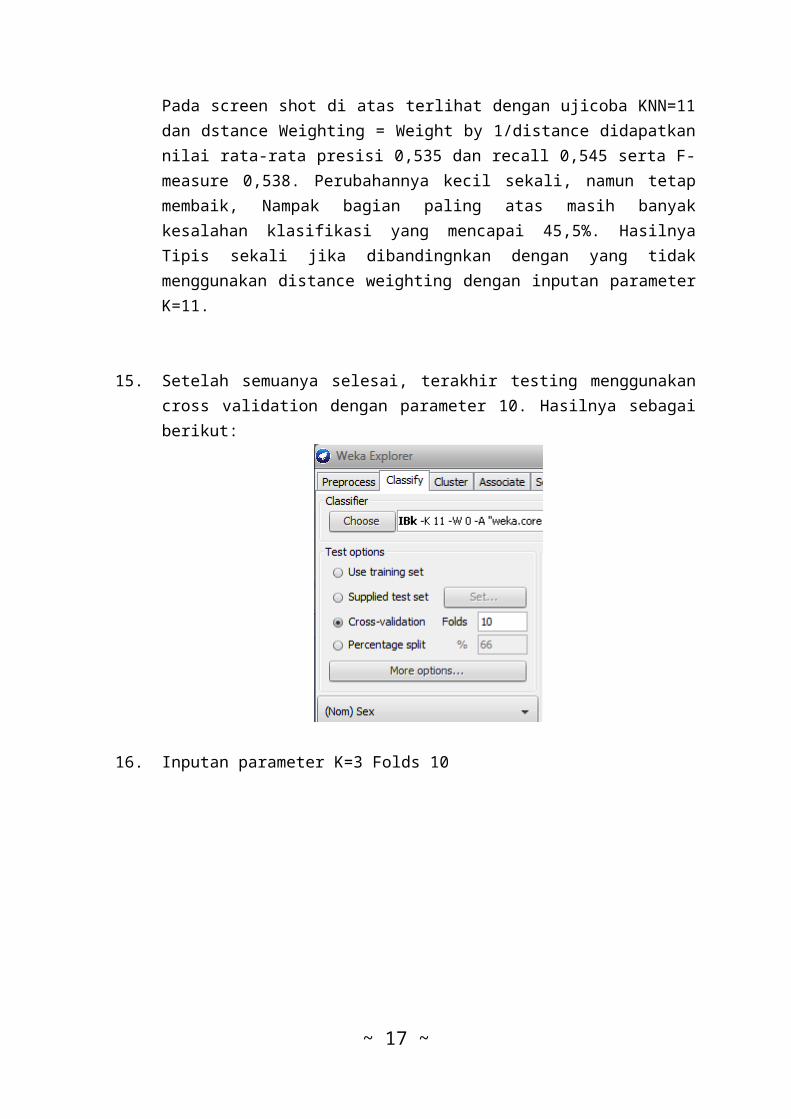
Pada screen shot di atas terlihat dengan ujicoba KNN=11dan dstance Weighting = Weight by 1/distance didapatkannilai rata-rata presisi 0,535 dan recall 0,545 serta F-measure 0,538. Perubahannya kecil sekali, namun tetapmembaik, Nampak bagian paling atas masih banyakkesalahan klasifikasi yang mencapai 45,5%. HasilnyaTipis sekali jika dibandingnkan dengan yang tidakmenggunakan distance weighting dengan inputan parameterK=11.
15. Setelah semuanya selesai, terakhir testing menggunakancross validation dengan parameter 10. Hasilnya sebagaiberikut:
16. Inputan parameter K=3 Folds 10
~ 17 ~
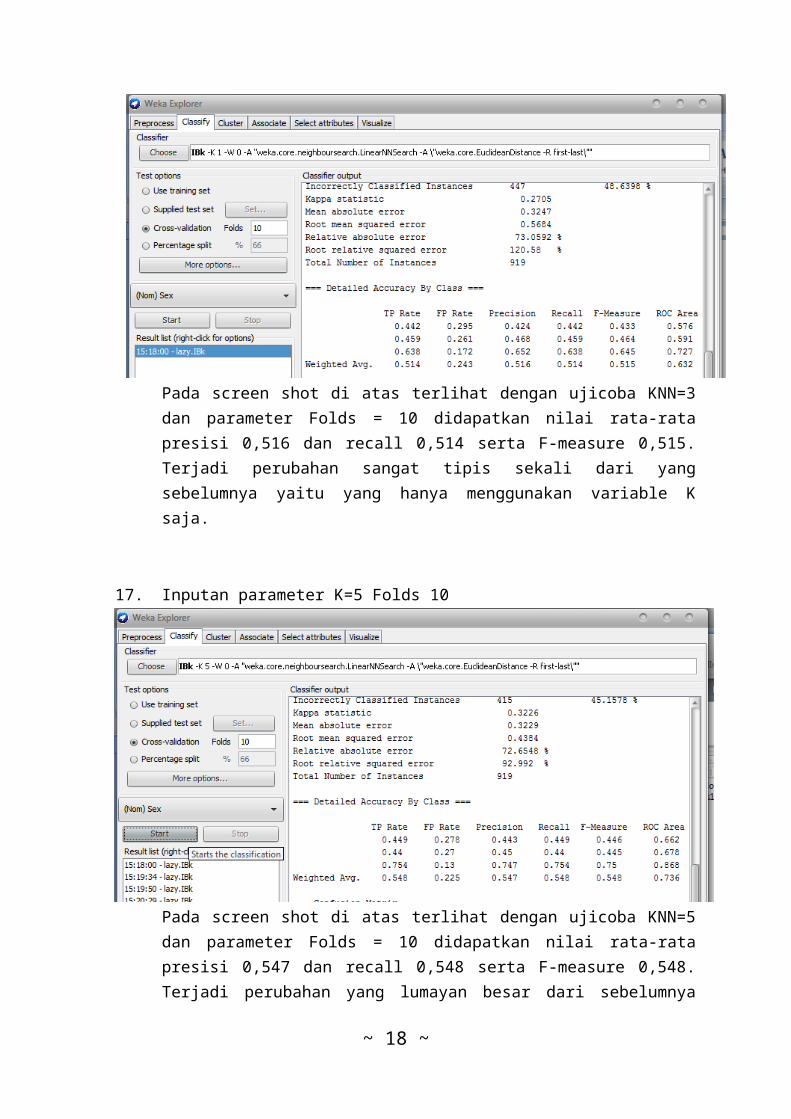
Pada screen shot di atas terlihat dengan ujicoba KNN=3dan parameter Folds = 10 didapatkan nilai rata-ratapresisi 0,516 dan recall 0,514 serta F-measure 0,515.Terjadi perubahan sangat tipis sekali dari yangsebelumnya yaitu yang hanya menggunakan variable Ksaja.
17. Inputan parameter K=5 Folds 10
Pada screen shot di atas terlihat dengan ujicoba KNN=5dan parameter Folds = 10 didapatkan nilai rata-ratapresisi 0,547 dan recall 0,548 serta F-measure 0,548.Terjadi perubahan yang lumayan besar dari sebelumnya
~ 18 ~
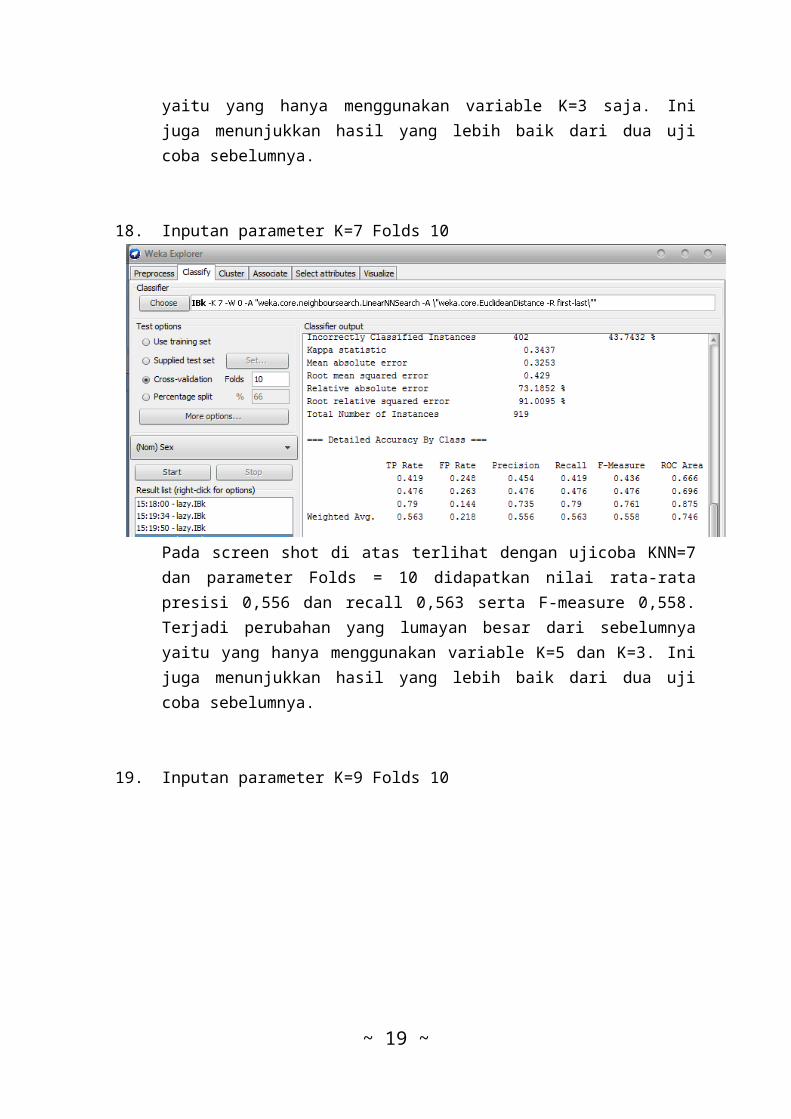
yaitu yang hanya menggunakan variable K=3 saja. Inijuga menunjukkan hasil yang lebih baik dari dua ujicoba sebelumnya.
18. Inputan parameter K=7 Folds 10
Pada screen shot di atas terlihat dengan ujicoba KNN=7dan parameter Folds = 10 didapatkan nilai rata-ratapresisi 0,556 dan recall 0,563 serta F-measure 0,558.Terjadi perubahan yang lumayan besar dari sebelumnyayaitu yang hanya menggunakan variable K=5 dan K=3. Inijuga menunjukkan hasil yang lebih baik dari dua ujicoba sebelumnya.
19. Inputan parameter K=9 Folds 10
~ 19 ~
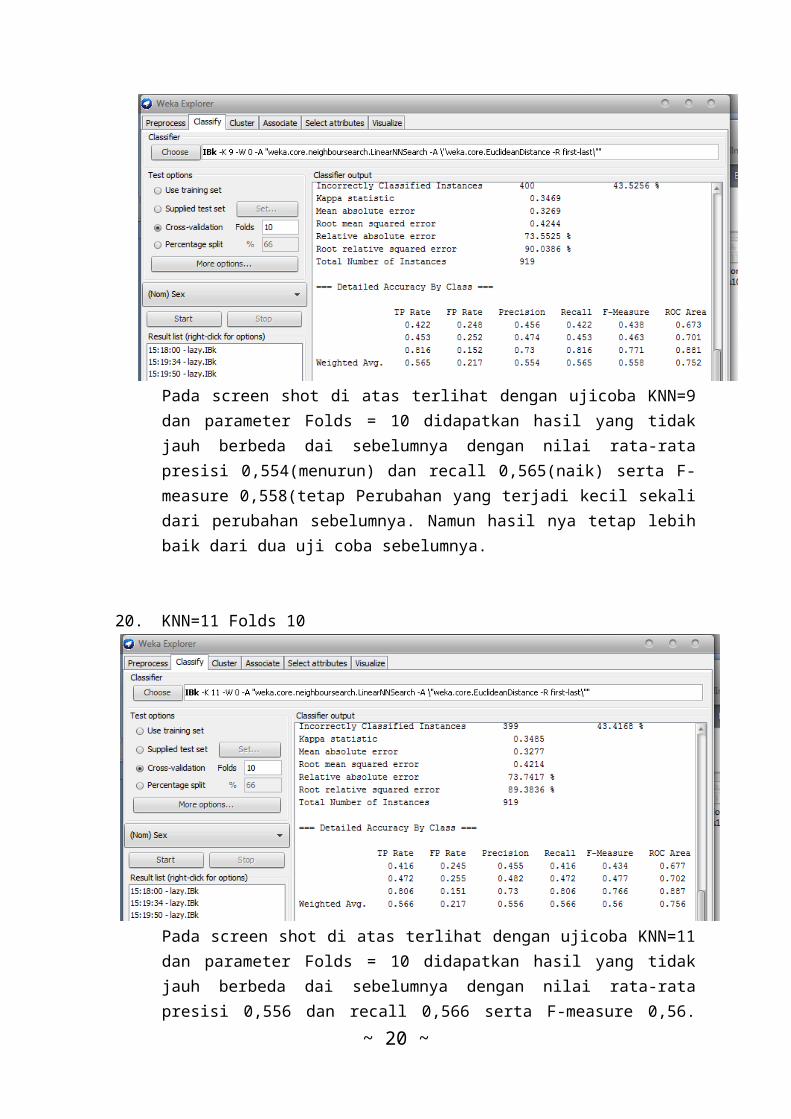
Pada screen shot di atas terlihat dengan ujicoba KNN=9dan parameter Folds = 10 didapatkan hasil yang tidakjauh berbeda dai sebelumnya dengan nilai rata-ratapresisi 0,554(menurun) dan recall 0,565(naik) serta F-measure 0,558(tetap Perubahan yang terjadi kecil sekalidari perubahan sebelumnya. Namun hasil nya tetap lebihbaik dari dua uji coba sebelumnya.
20. KNN=11 Folds 10
Pada screen shot di atas terlihat dengan ujicoba KNN=11dan parameter Folds = 10 didapatkan hasil yang tidakjauh berbeda dai sebelumnya dengan nilai rata-ratapresisi 0,556 dan recall 0,566 serta F-measure 0,56.
~ 20 ~
Perubahan yang terjadi kecil sekali dari perubahansebelumnya. Namun hasil nyatetap lebih baik dari duauji coba sebelumnya.
Ujicoba pada data abalone selesai, penjelasan akhirnya akan dijelaskan dalam kesimpulan. Kini lanjut pada ujicoba data WDBC.
b. Data WDBCLangkah yang dilakukan dalam proses pengklasifikasian samajuga pada Abalone adalah sebagai berikut:1. Buka aplikasi weka lalu, buka file WDBC-training.arff
yang sudah dipecah sebelumnya.
2. Seperti ujicoba sebelumnya. Kemudian dilakukan uji cobadengan cara memasukkan nilai KNN=3 dengan menge-klikIBK.
~ 21 ~
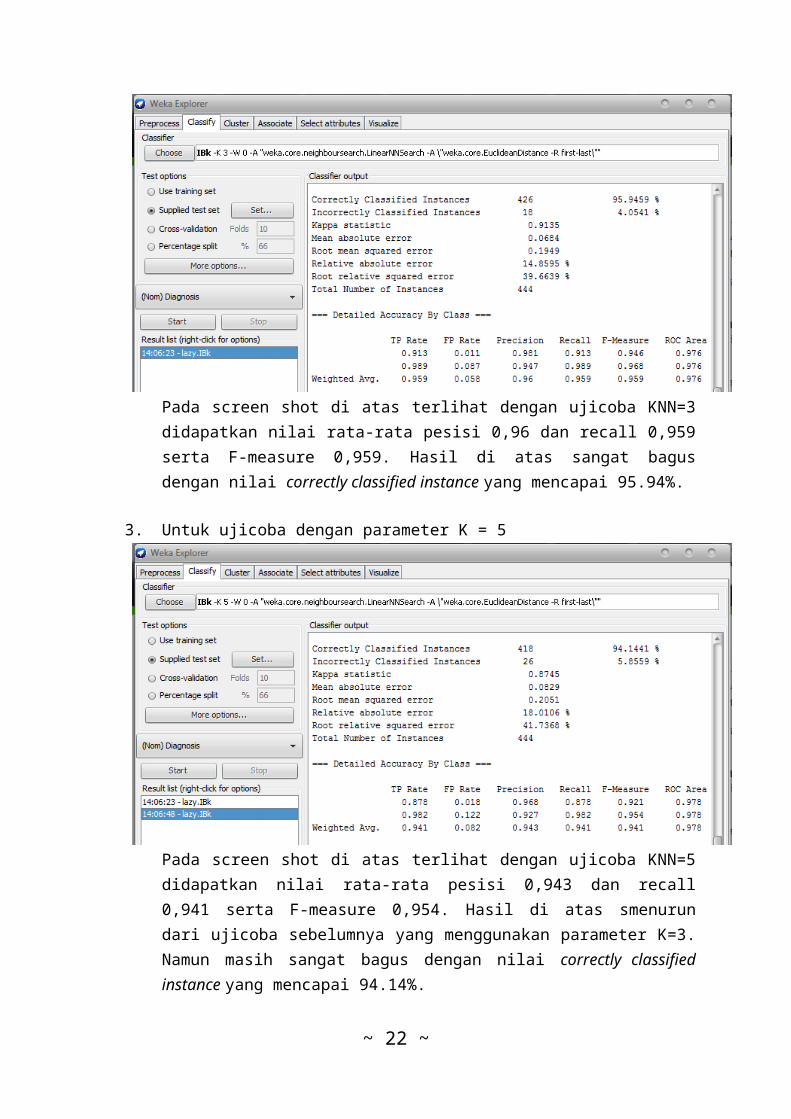
Pada screen shot di atas terlihat dengan ujicoba KNN=3didapatkan nilai rata-rata pesisi 0,96 dan recall 0,959serta F-measure 0,959. Hasil di atas sangat bagusdengan nilai correctly classified instance yang mencapai 95.94%.
3. Untuk ujicoba dengan parameter K = 5
Pada screen shot di atas terlihat dengan ujicoba KNN=5didapatkan nilai rata-rata pesisi 0,943 dan recall0,941 serta F-measure 0,954. Hasil di atas smenurundari ujicoba sebelumnya yang menggunakan parameter K=3.Namun masih sangat bagus dengan nilai correctly classifiedinstance yang mencapai 94.14%.
~ 22 ~
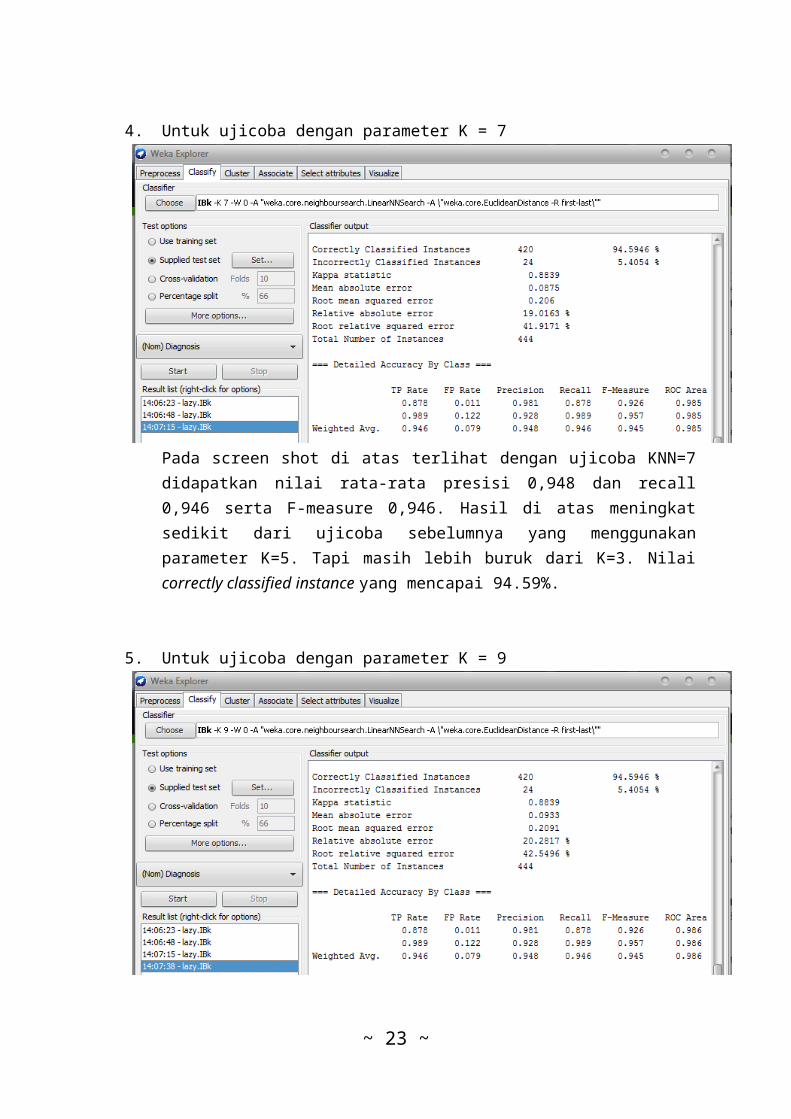
4. Untuk ujicoba dengan parameter K = 7
Pada screen shot di atas terlihat dengan ujicoba KNN=7didapatkan nilai rata-rata presisi 0,948 dan recall0,946 serta F-measure 0,946. Hasil di atas meningkatsedikit dari ujicoba sebelumnya yang menggunakanparameter K=5. Tapi masih lebih buruk dari K=3. Nilaicorrectly classified instance yang mencapai 94.59%.
5. Untuk ujicoba dengan parameter K = 9
~ 23 ~
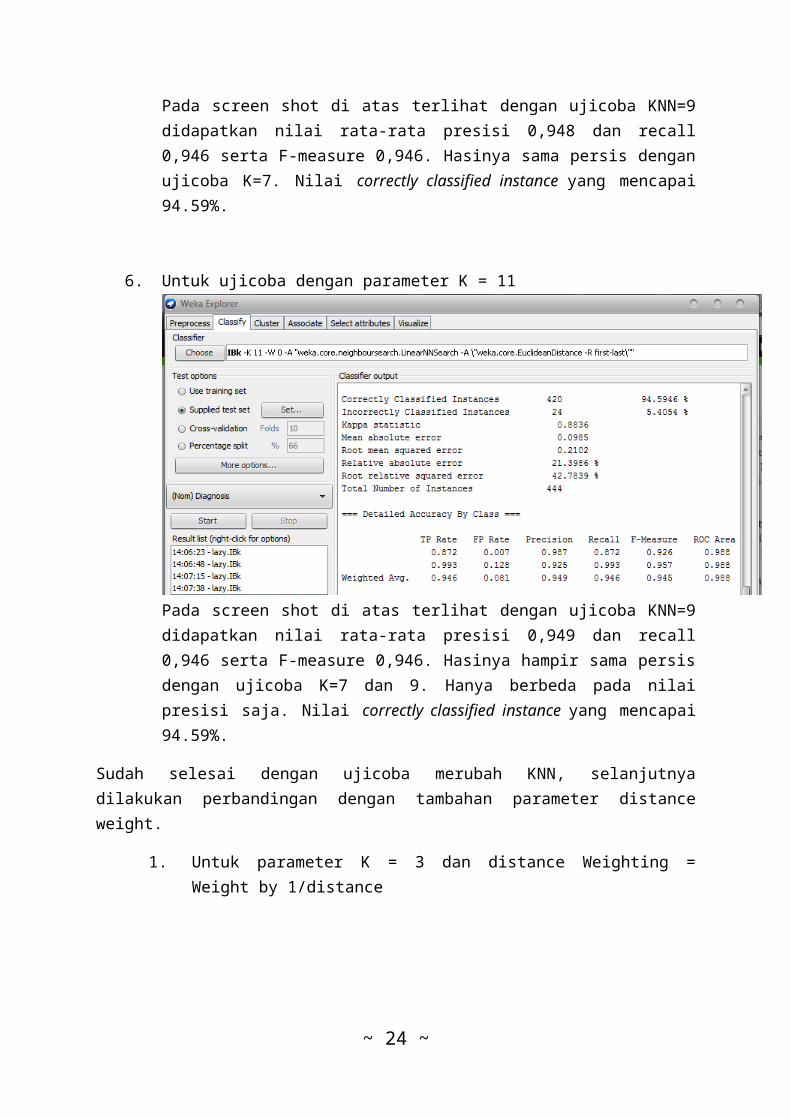
Pada screen shot di atas terlihat dengan ujicoba KNN=9didapatkan nilai rata-rata presisi 0,948 dan recall0,946 serta F-measure 0,946. Hasinya sama persis denganujicoba K=7. Nilai correctly classified instance yang mencapai94.59%.
6. Untuk ujicoba dengan parameter K = 11
Pada screen shot di atas terlihat dengan ujicoba KNN=9didapatkan nilai rata-rata presisi 0,949 dan recall0,946 serta F-measure 0,946. Hasinya hampir sama persisdengan ujicoba K=7 dan 9. Hanya berbeda pada nilaipresisi saja. Nilai correctly classified instance yang mencapai94.59%.
Sudah selesai dengan ujicoba merubah KNN, selanjutnyadilakukan perbandingan dengan tambahan parameter distanceweight.
1. Untuk parameter K = 3 dan distance Weighting =Weight by 1/distance
~ 24 ~
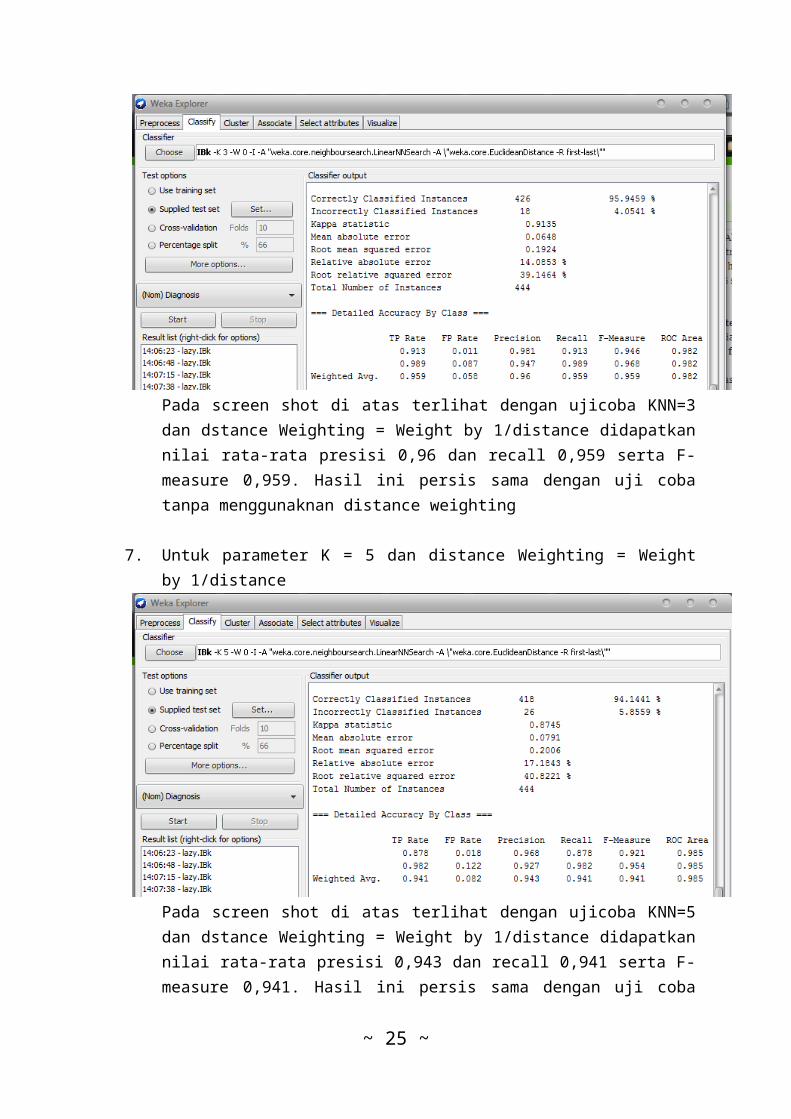
Pada screen shot di atas terlihat dengan ujicoba KNN=3dan dstance Weighting = Weight by 1/distance didapatkannilai rata-rata presisi 0,96 dan recall 0,959 serta F-measure 0,959. Hasil ini persis sama dengan uji cobatanpa menggunaknan distance weighting
7. Untuk parameter K = 5 dan distance Weighting = Weightby 1/distance
Pada screen shot di atas terlihat dengan ujicoba KNN=5dan dstance Weighting = Weight by 1/distance didapatkannilai rata-rata presisi 0,943 dan recall 0,941 serta F-measure 0,941. Hasil ini persis sama dengan uji coba
~ 25 ~
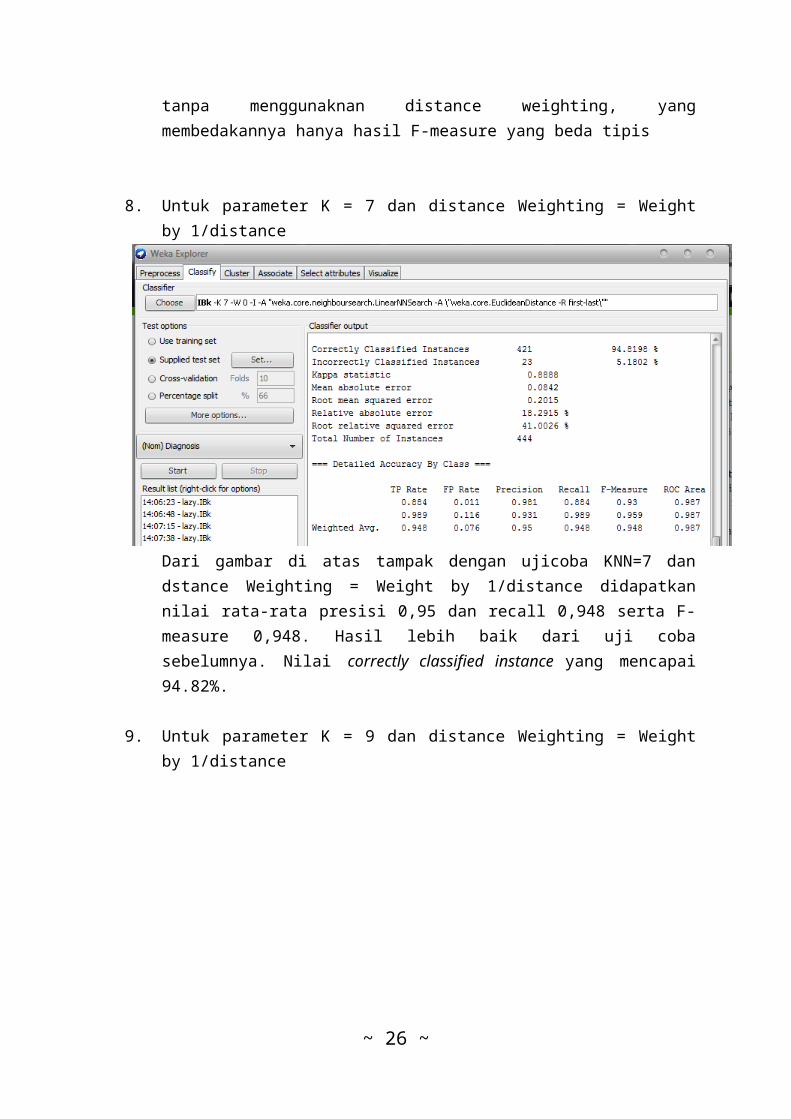
tanpa menggunaknan distance weighting, yangmembedakannya hanya hasil F-measure yang beda tipis
8. Untuk parameter K = 7 dan distance Weighting = Weightby 1/distance
Dari gambar di atas tampak dengan ujicoba KNN=7 dandstance Weighting = Weight by 1/distance didapatkannilai rata-rata presisi 0,95 dan recall 0,948 serta F-measure 0,948. Hasil lebih baik dari uji cobasebelumnya. Nilai correctly classified instance yang mencapai94.82%.
9. Untuk parameter K = 9 dan distance Weighting = Weightby 1/distance
~ 26 ~
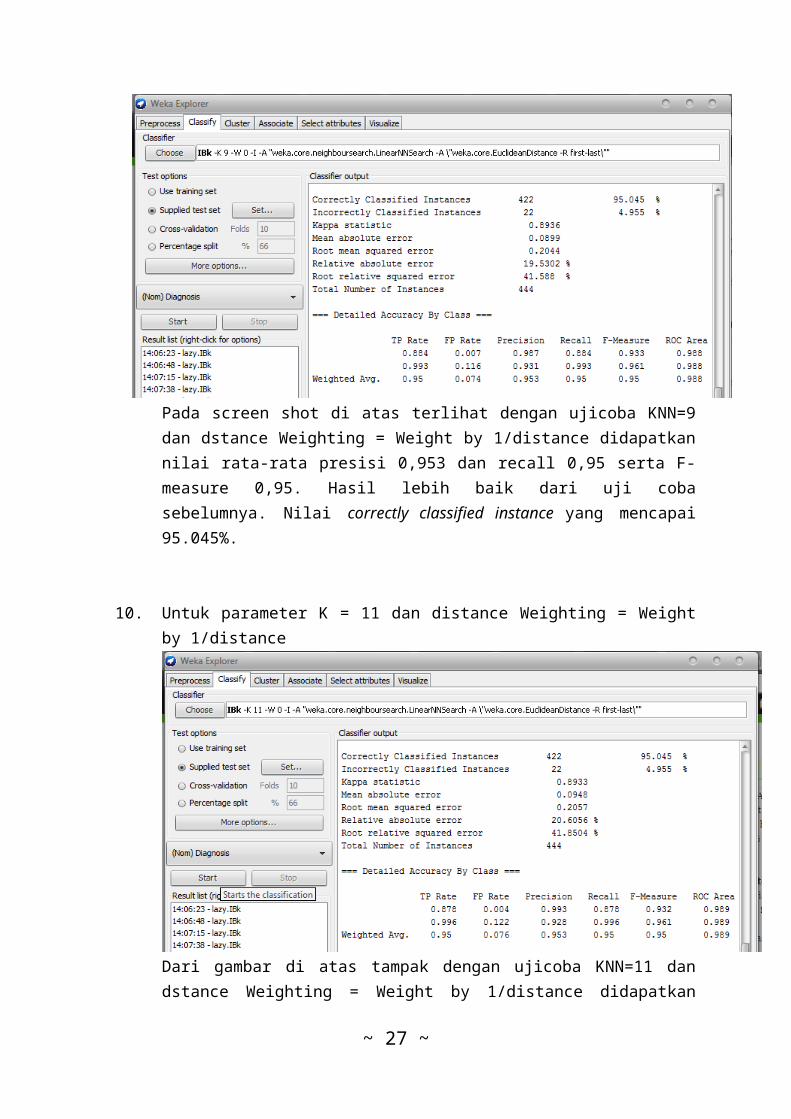
Pada screen shot di atas terlihat dengan ujicoba KNN=9dan dstance Weighting = Weight by 1/distance didapatkannilai rata-rata presisi 0,953 dan recall 0,95 serta F-measure 0,95. Hasil lebih baik dari uji cobasebelumnya. Nilai correctly classified instance yang mencapai95.045%.
10. Untuk parameter K = 11 dan distance Weighting = Weightby 1/distance
Dari gambar di atas tampak dengan ujicoba KNN=11 dandstance Weighting = Weight by 1/distance didapatkan
~ 27 ~
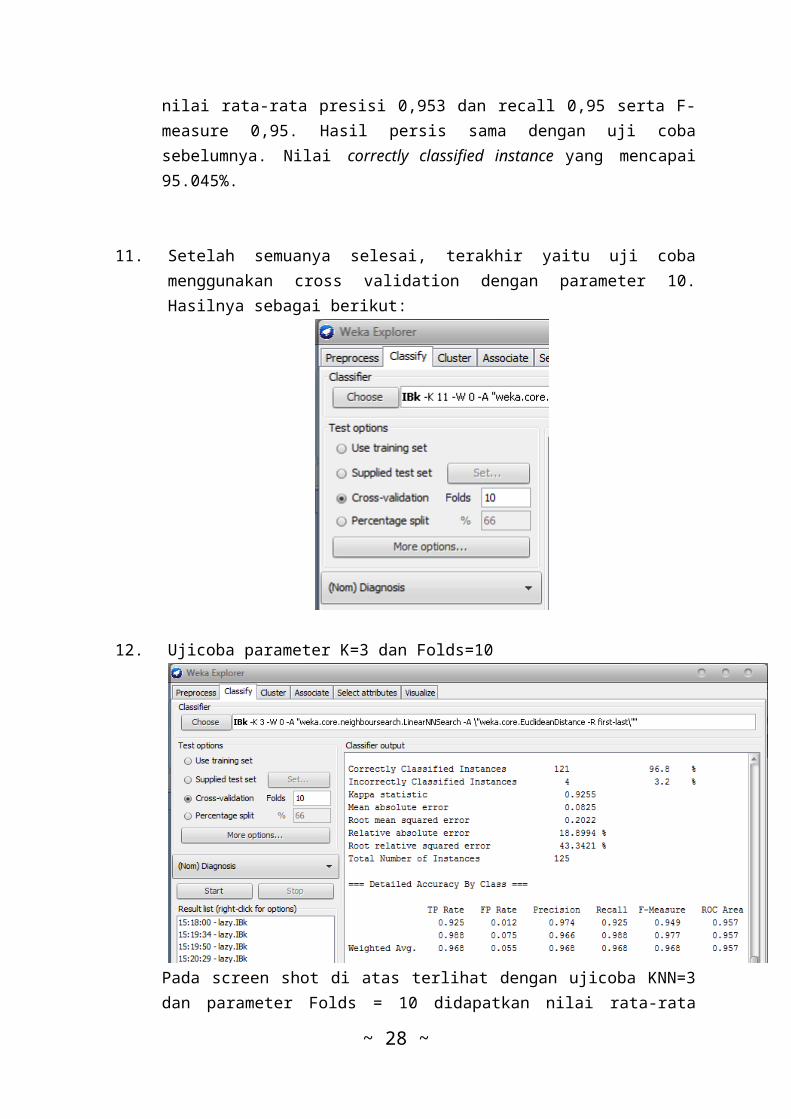
nilai rata-rata presisi 0,953 dan recall 0,95 serta F-measure 0,95. Hasil persis sama dengan uji cobasebelumnya. Nilai correctly classified instance yang mencapai95.045%.
11. Setelah semuanya selesai, terakhir yaitu uji cobamenggunakan cross validation dengan parameter 10.Hasilnya sebagai berikut:
12. Ujicoba parameter K=3 dan Folds=10
Pada screen shot di atas terlihat dengan ujicoba KNN=3dan parameter Folds = 10 didapatkan nilai rata-rata
~ 28 ~
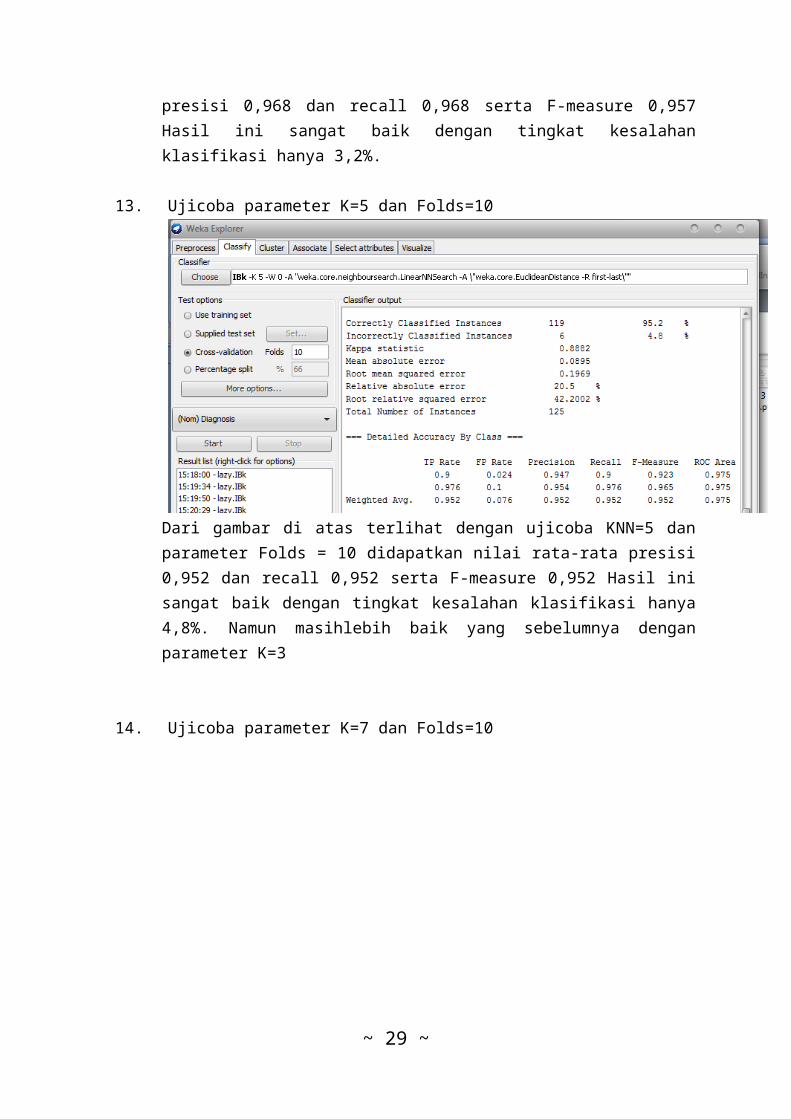
presisi 0,968 dan recall 0,968 serta F-measure 0,957Hasil ini sangat baik dengan tingkat kesalahanklasifikasi hanya 3,2%.
13. Ujicoba parameter K=5 dan Folds=10
Dari gambar di atas terlihat dengan ujicoba KNN=5 danparameter Folds = 10 didapatkan nilai rata-rata presisi0,952 dan recall 0,952 serta F-measure 0,952 Hasil inisangat baik dengan tingkat kesalahan klasifikasi hanya4,8%. Namun masihlebih baik yang sebelumnya denganparameter K=3
14. Ujicoba parameter K=7 dan Folds=10
~ 29 ~
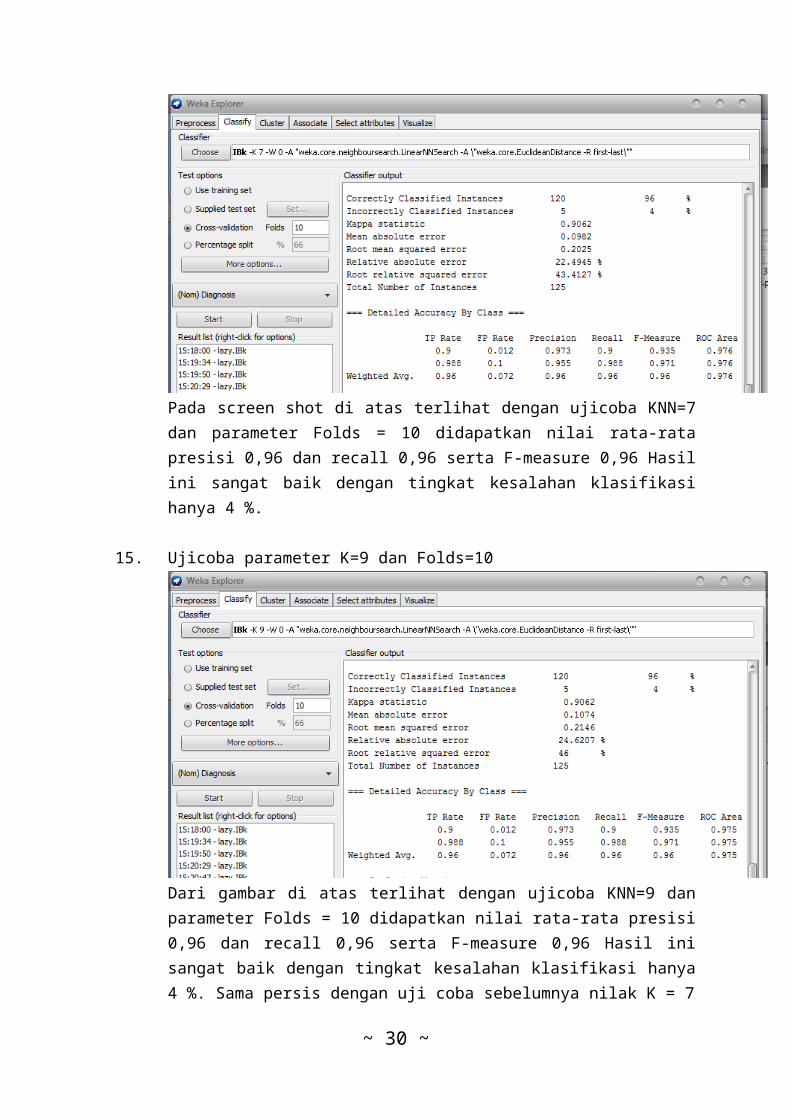
Pada screen shot di atas terlihat dengan ujicoba KNN=7dan parameter Folds = 10 didapatkan nilai rata-ratapresisi 0,96 dan recall 0,96 serta F-measure 0,96 Hasilini sangat baik dengan tingkat kesalahan klasifikasihanya 4 %.
15. Ujicoba parameter K=9 dan Folds=10
Dari gambar di atas terlihat dengan ujicoba KNN=9 danparameter Folds = 10 didapatkan nilai rata-rata presisi0,96 dan recall 0,96 serta F-measure 0,96 Hasil inisangat baik dengan tingkat kesalahan klasifikasi hanya4 %. Sama persis dengan uji coba sebelumnya nilak K = 7
~ 30 ~
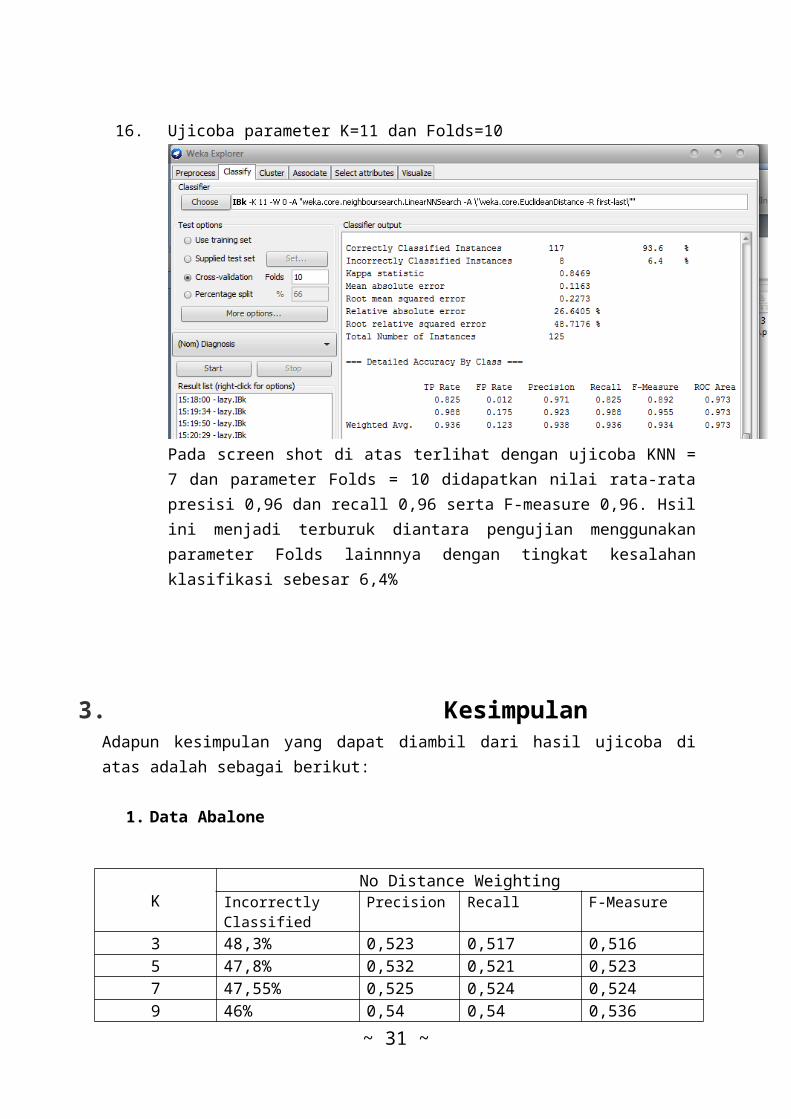
16. Ujicoba parameter K=11 dan Folds=10
Pada screen shot di atas terlihat dengan ujicoba KNN =7 dan parameter Folds = 10 didapatkan nilai rata-ratapresisi 0,96 dan recall 0,96 serta F-measure 0,96. Hsilini menjadi terburuk diantara pengujian menggunakanparameter Folds lainnnya dengan tingkat kesalahanklasifikasi sebesar 6,4%
3. KesimpulanAdapun kesimpulan yang dapat diambil dari hasil ujicoba diatas adalah sebagai berikut:
1. Data Abalone
KNo Distance Weighting
IncorrectlyClassified
Precision Recall F-Measure
3 48,3% 0,523 0,517 0,5165 47,8% 0,532 0,521 0,5237 47,55% 0,525 0,524 0,5249 46% 0,54 0,54 0,536
~ 31 ~
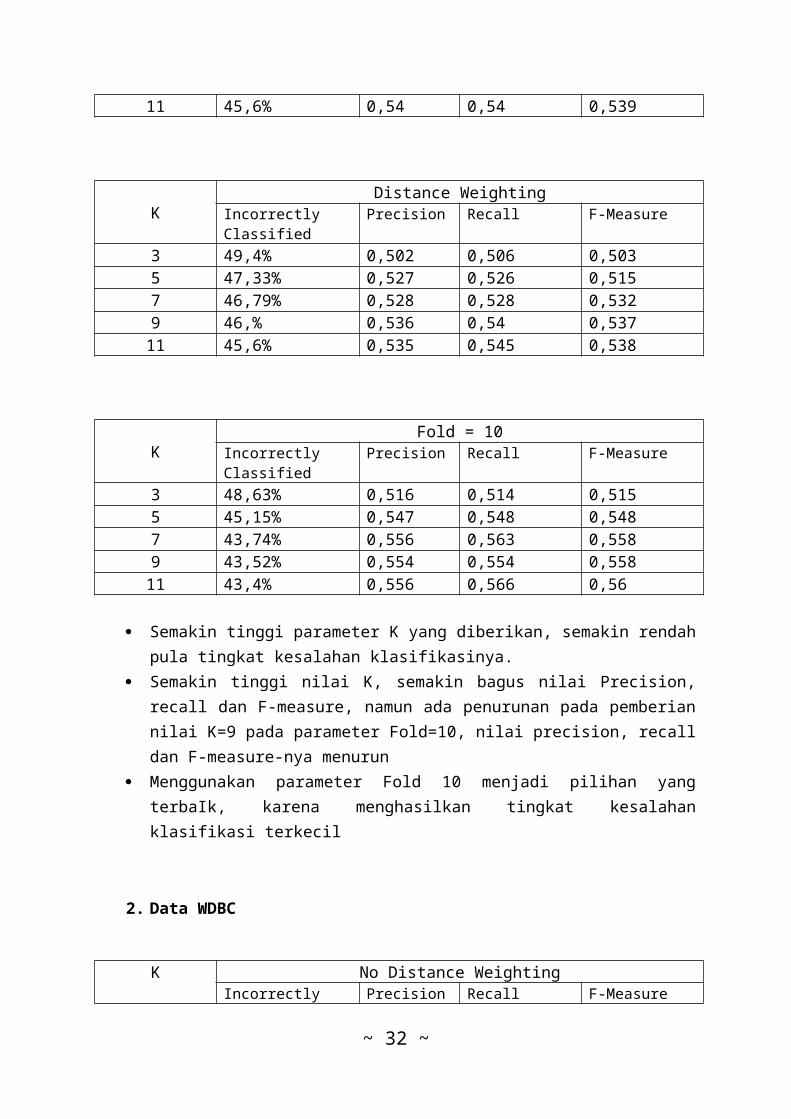
11 45,6% 0,54 0,54 0,539
KDistance Weighting
IncorrectlyClassified
Precision Recall F-Measure
3 49,4% 0,502 0,506 0,5035 47,33% 0,527 0,526 0,5157 46,79% 0,528 0,528 0,5329 46,% 0,536 0,54 0,53711 45,6% 0,535 0,545 0,538
KFold = 10
IncorrectlyClassified
Precision Recall F-Measure
3 48,63% 0,516 0,514 0,5155 45,15% 0,547 0,548 0,5487 43,74% 0,556 0,563 0,5589 43,52% 0,554 0,554 0,55811 43,4% 0,556 0,566 0,56
Semakin tinggi parameter K yang diberikan, semakin rendahpula tingkat kesalahan klasifikasinya.
Semakin tinggi nilai K, semakin bagus nilai Precision,recall dan F-measure, namun ada penurunan pada pemberiannilai K=9 pada parameter Fold=10, nilai precision, recalldan F-measure-nya menurun
Menggunakan parameter Fold 10 menjadi pilihan yangterbaIk, karena menghasilkan tingkat kesalahanklasifikasi terkecil
2. Data WDBC
K No Distance WeightingIncorrectly Precision Recall F-Measure
~ 32 ~
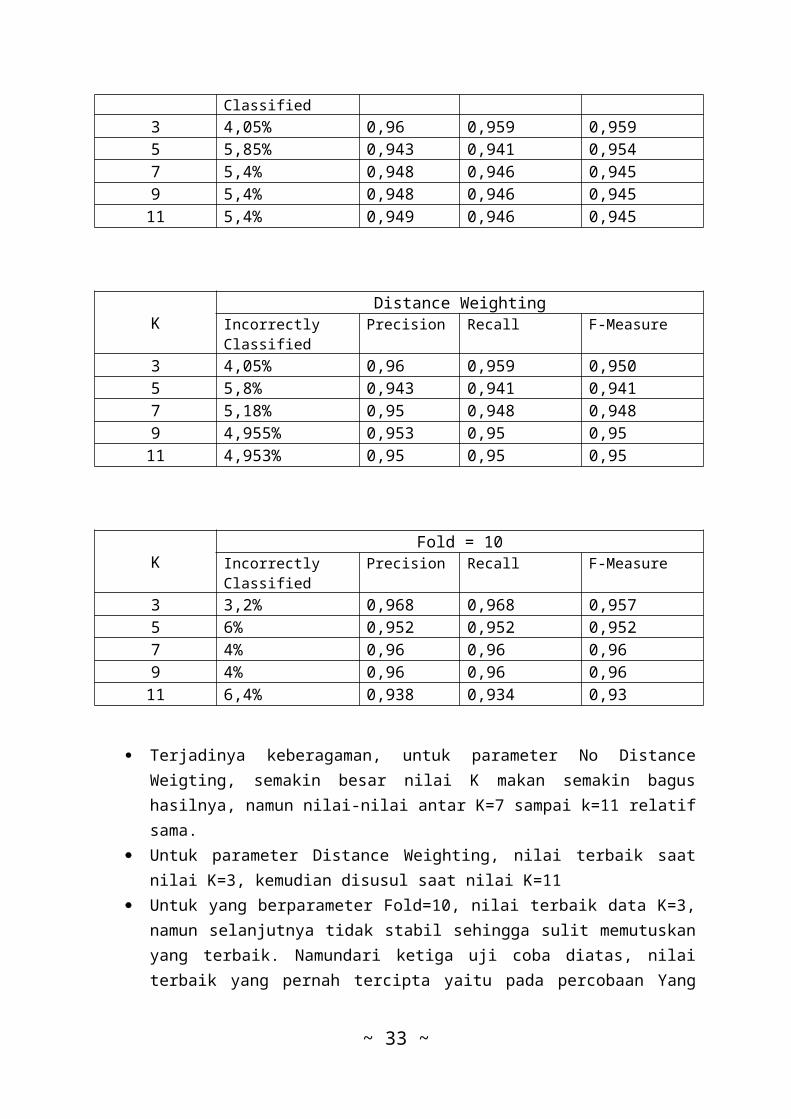
Classified3 4,05% 0,96 0,959 0,9595 5,85% 0,943 0,941 0,9547 5,4% 0,948 0,946 0,9459 5,4% 0,948 0,946 0,94511 5,4% 0,949 0,946 0,945
KDistance Weighting
IncorrectlyClassified
Precision Recall F-Measure
3 4,05% 0,96 0,959 0,9505 5,8% 0,943 0,941 0,9417 5,18% 0,95 0,948 0,9489 4,955% 0,953 0,95 0,9511 4,953% 0,95 0,95 0,95
KFold = 10
IncorrectlyClassified
Precision Recall F-Measure
3 3,2% 0,968 0,968 0,9575 6% 0,952 0,952 0,9527 4% 0,96 0,96 0,969 4% 0,96 0,96 0,9611 6,4% 0,938 0,934 0,93
Terjadinya keberagaman, untuk parameter No DistanceWeigting, semakin besar nilai K makan semakin bagushasilnya, namun nilai-nilai antar K=7 sampai k=11 relatifsama.
Untuk parameter Distance Weighting, nilai terbaik saatnilai K=3, kemudian disusul saat nilai K=11
Untuk yang berparameter Fold=10, nilai terbaik data K=3,namun selanjutnya tidak stabil sehingga sulit memutuskanyang terbaik. Namundari ketiga uji coba diatas, nilaiterbaik yang pernah tercipta yaitu pada percobaan Yang
~ 33 ~
berparameter Fold 10 dengan nilai K=3. Menghasilkantingkat kesalahan paling kecil 3,2%
http://asalasah.blogspot.com/2014/01/di-chechnya-namai-anak-muhammad-dapat-12-juta.html
~ 34 ~





























