Embed Size (px)
Citation preview

Measuring MPLS overhead
A. Pescapè+*, S. P. Romano+, M. Esposito+*, S. Avallone+, G. Ventre+*
*ITEM - Laboratorio Nazionale CINI per l’ Informatica e la Telematica Multimediali Via Diocleziano, 328
80125 – Napoli ITALY
+DIS, Dipartimento di Informatica e Sistemistica
Università degli Studi Federico II di Napoli Via Claudio, 21 80125 – Napoli
ITALY
{ pescape,spromano,mesposit,[email protected]} , [email protected]
Abstract
In this work we present a study of the MPLS overhead on Linux platform measuring the RTT (Round Trip Time). We compare the performance between two scenarios: the IP network and MPLS network. In this paper we show the results in three situations: connection oriented transport protocol (TCP), connectionless transport protocol (UDP) and network protocol (ICMP). We analyze the difference between IP and MPLS and for each protocol we study two type of network connection: back-to-back and shared connection. Finally we evaluate the overhead of the Label Stacking in the case of UDP.
1.0 Introduction
MultiProtocol Label Switching (MPLS) is a technology that has received a great deal of attention in recent years. The IETF alone has produced over 300 Internet Drafts and numerous RFCs related to MPLS and continues its work on refining the standards. MPLS is a promising effort to provide the kind of traff ic management and connection-oriented Quality of Service (QoS) support found in Asynchronous Transfer Mode (ATM) networks, to speed up the IP packet-forwarding process, and to retain the flexibility of an IP-based networking approach. MPLS has a strong role to play. MPLS reduces the amount of per-packet processing required at each router in an IP-based network, enhancing router performance even more. More significantly, MPLS provides significant new capabil ities in four areas that have ensured its popularity: QoS support, traff ic engineering, Virtual Private Networks (VPNs), and multiprotocol support [1]. There are several studies on the MPLS architecture and various works on the MPLS performance. These works are based on commercial equipments and regard the benefits of the use of MPLS to realize traff ic engineering and other interesting topics like VPNs and QoS support. The work in this paper is based on freeware project (MPLS for Linux) to implement a MPLS stack for the Linux kernel. We’d like to use MPLS for Linux in order to realize a QoS aware architecture studying the problem concerning the interoperability between DiffServ and MPLS and other MPLS features. Therefore before to study the performance of the implemented solutions we’ve analyzed

the overhead introduced in the MPLS encapsulation. This approach gives us the possibility to evaluate the performance of MPLS for Linux and use these results when we compare the values obtained from other simulations in a MPLS network. The first step in our work with MPLS for Linux is to compare the performance between two scenarios: the IP network and MPLS network. When we used MPLS for Linux the first time we didn’ t know the overhead introduced: in this work we present the experimental results that give an idea regarding the increase of the encapsulation delay when we decide to use MPLS for Linux in order to realize our MPLS network. We have studied the overhead of the MPLS label encapsulation in three different cases: UDP, TCP, ICMP. When a label is added to a packet a 4 bytes "shim" header is added to the packet. This shim is added between the layer 3 and layer 2 headers. Therefore an IP packet on Ethernet would add the shim before the IP header but after the Ethernet header. MPLS forwarding is currently defined for the following layer 2 implementations: Ethernet, packet over SONET, ATM, frame-relay. MPLS has also been defined for any medium that PPP runs on top of. On most of these layer 2 implementations a label consists of a 20 bits number. The shim that is added to the packet contains more than just a label. The MPLS label is used to determine how a packet will be switched. The next 3 bits are called the EXP bits. They are currently reserved for experimental purposes (although DiffServ over MPLS has claimed these 3 bits for its use). The next bit is referred to as the "bottom of stack bit" (S bit). Due to the fact that MPLS adds a shim to the packet a LSR needs to know if what follows this top shim is the layer 3 header or another shim: multiple shims are called a label stack. The S bit signifies that what follows this shim is the layer 3 header. For typical single shim MPLS forwarding the S bit is on. Finally the shim contains the Time To Live (TTL) counter. This is used to allow current layer 3 functions to occur even though an LSR cannot use the layer 3 header. Some examples of these are traceroute, loop detection, and multicast domains [2], [3], [4], [5]. In the next sections we show the experimental results obtained comparing RTT (Round Trip Time) in the “IP plain” network and in the MPLS network. Comparing these values we can obtain the “costs” of the MPLS Linux implementation. In order to calculate the RTT we have realized a client-server application that evaluate the Round Trip Time and storage it in a log file. The measuring method is the following: the client sends a packet to the server and waits for it to reply; after that it sends the next packet. Total number of sent packets is 100 and this operation is repeated 10 times. There are 4 different packet lengths: 10, 100, 1000 and 1500 bytes. We used two types of network configuration. In the first case (back-to-back) the client and the server are connected with another router that implements IP forwarding. The intermediate router is used in order to sniff the traff ic too. In the second case (shared) the three machines (client, server and sniff machine) are on the same hub. These scenarios are shown in the next figures.
Figure 1: Shared configuration (Shared)
192.168.0.2/24
192.168.0.3/24
192.168.0.4/24
Traffic AnalyzerClient Server
192.168.0.2/24
192.168.0.3/24
192.168.0.4/24
Traffic AnalyzerClient Server

Figure 2: Back to Back configuration (BB) 2.0 UDP and TCP values
UDP and TCP sit on top of the IP at the transport layer. Both UDP and TCP use port numbers to de-multiplex data sent to a host. A port number is specific to the application. Each UDP packet and TCP segment has a source and a destination port number. A host that waits for incoming connections is referred to as the server, and the host that initiates the connection is referred to as the client. Servers "listen" on well -known port numbers for common applications such as FTP (File Transfer Protocol), SMTP and HTTP. Clients generally choose a random source port number and connect to a server at a well-known port. UDP provides ‘best effort’ delivery of data with an optional checksum to preserve data integrity. UDP packets have the same reliabili ty issues as IP; packets are not guaranteed delivered in the same order at the remote host. TCP provides a reliable stream of data by using sequencing and acknowledgement numbers to recover lost data, detect out of order segments, and resolve transmission errors. TCP is connection-oriented, while UDP is connectionless. This implies that to send an UDP packet, a client addresses a packet to a remote host and sends it without any preliminary contact to determine whether the host is ready for data reception. UDP has no throttling mechanism so packets can be sent at full speed - as fast as the underlying physical device can send them. On slow processors, UDP’s lack of overhead can make a large difference in the throughput when compared to TCP. The lack of end-to-end connection makes it suitable for broadcasting many-to-many type messages. TCP provides a connection-oriented, reliable stream of data. Before sending data to a remote host, a TCP connection must be established. TCP offers a reliable data stream at the cost of more processing overhead and reduced throughput. Figure 3 and Figure 4 show, respectively, the experimental results for UDP and TCP, both in the back-to-back configuration and shared configuration. In this case the measuring method is the following: the client sends 100 packets and this operation is repeated 10 times. There are 4 different packet lengths: 10, 100, 1000 and 1500 bytes. In the TCP scenario the client opens the TCP connection and sends all the packets to the server and waits for its replies; after that it closes the connection. Both in UDP and TCP the RTT value consists of three contributions (tqueue, tproc and ttx):
txprocqueue tttRTT ++= (1)
where tqueue is equal to zero since the client waits for the server to reply before to send another packet, whereas tproc represents the processing time (protocol dependent) and ttx the transmission time. As you can notice looking at the figures 3 and 4 the relative difference between IP and MPLS times decreases with the increasing of packets length. This behaviour can be explained considering that the ttx time increases while the tproc (protocol dependent) is the same increasing the packet size, thus the protocol dependent component is less and less important.
192.168.0.2/24192.168.0.3/24 192.168.1.2/24
192.168.1.3/24
Router and
Traffic AnalyzerClient Server
192.168.0.2/24192.168.0.3/24 192.168.1.2/24
192.168.1.3/24
Router and
Traffic AnalyzerClient Server

Figure 3: UDP values
Figure 4: TCP values
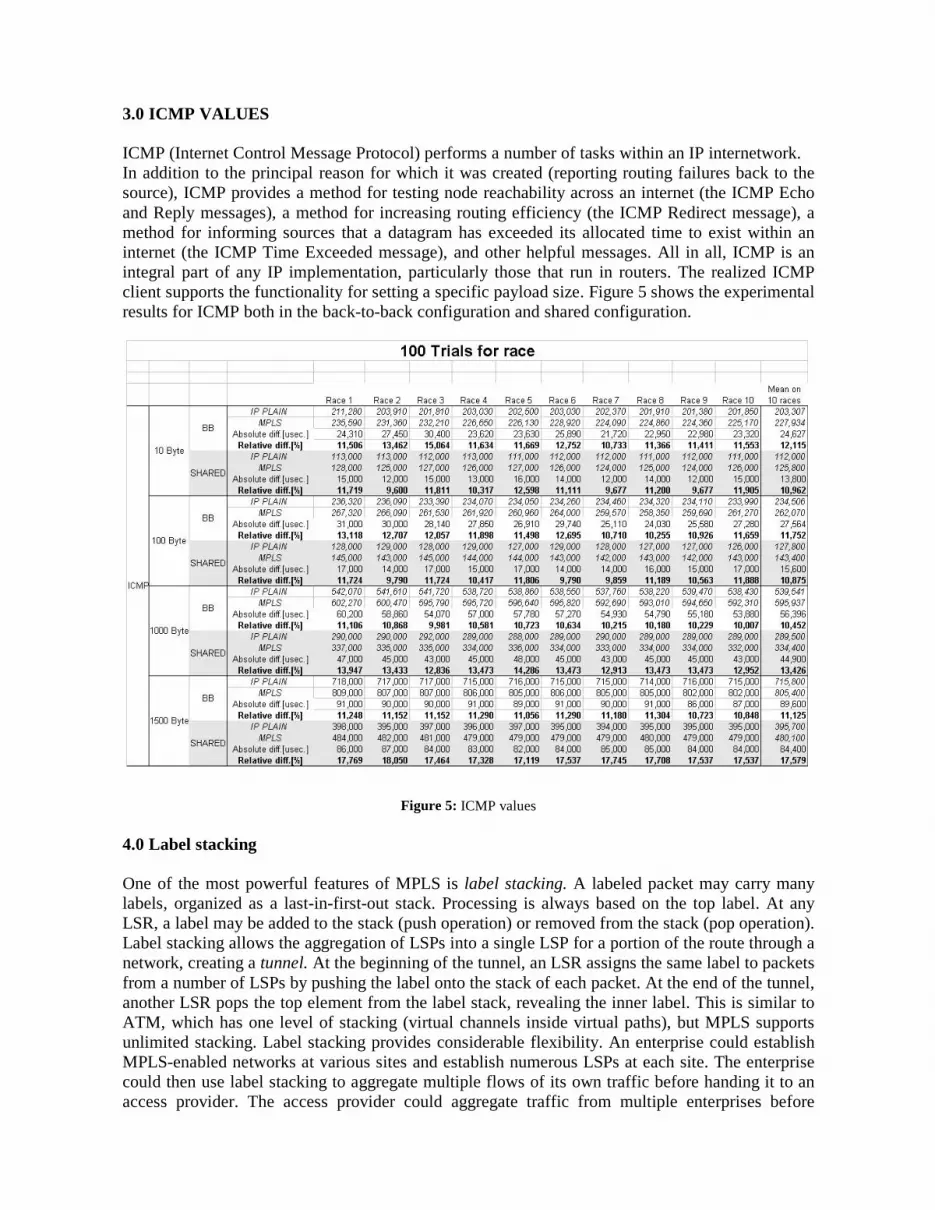
3.0 ICMP VALUES
ICMP (Internet Control Message Protocol) performs a number of tasks within an IP internetwork. In addition to the principal reason for which it was created (reporting routing failures back to the source), ICMP provides a method for testing node reachability across an internet (the ICMP Echo and Reply messages), a method for increasing routing efficiency (the ICMP Redirect message), a method for informing sources that a datagram has exceeded its allocated time to exist within an internet (the ICMP Time Exceeded message), and other helpful messages. All in all, ICMP is an integral part of any IP implementation, particularly those that run in routers. The realized ICMP client supports the functionality for setting a specific payload size. Figure 5 shows the experimental results for ICMP both in the back-to-back configuration and shared configuration.
Figure 5: ICMP values 4.0 Label stacking
One of the most powerful features of MPLS is label stacking. A labeled packet may carry many labels, organized as a last-in-first-out stack. Processing is always based on the top label. At any LSR, a label may be added to the stack (push operation) or removed from the stack (pop operation). Label stacking allows the aggregation of LSPs into a single LSP for a portion of the route through a network, creating a tunnel. At the beginning of the tunnel, an LSR assigns the same label to packets from a number of LSPs by pushing the label onto the stack of each packet. At the end of the tunnel, another LSR pops the top element from the label stack, revealing the inner label. This is similar to ATM, which has one level of stacking (virtual channels inside virtual paths), but MPLS supports unlimited stacking. Label stacking provides considerable flexibility. An enterprise could establish MPLS-enabled networks at various sites and establish numerous LSPs at each site. The enterprise could then use label stacking to aggregate multiple flows of its own traffic before handing it to an access provider. The access provider could aggregate traffic from multiple enterprises before

handing it to a larger service provider. Service providers could aggregate many LSPs into a relatively small number of tunnels between points of presence. Fewer tunnels means smaller tables, making it easier for a provider to scale the network core. In the following figures we show results regarding multiple encapsulations in order to analyze the increase of the time when a MPLS switch/router realizes label stacking. In order to study label stacking we have used UDP protocol and the same packets size used in the previous tests. Starting from 1 label we arrive until 80 labels.
Figure 6: 1 – 10 labels

Figure 7: 20 – 43 labels
Figure 8: 55 – 80 labels

In the next figures we show the graphics regarding the values related to the increase of time when multiple labels are added to a packet.
UDP MPLS LABEL STACKING - BB
0
500
1000
1500
2000
2500
3000
3500
4000
4500
1 5 9 13 17 21 25 29 33 37 41 45 49 53 57 61 65 69 73 77
Number of Labels
RTT [usec]
10 Byte
100 Byte
1000 byte
1500 Byte
Fig. 9: Label stacking in the back to back configuration
UDP MPLS LABEL STACKING - SHARED
0
1000
2000
3000
4000
5000
1 5 9 13 17 21 25 29 33 37 41 45 49 53 57 61 65 69 73 77
Number of Labels
RTT [usec]
10 Byte
100 Byte
1000 byte
1500 Byte
Fig. 10: Label stacking in the shared configuration 6.0 Acknowledgements
This work has been performed for the “Labnet II ” project at the “ITEM (Informatica e Telematica Multimediali )” Lab - CINI (Consorzio Interuniversitario Nazionale per l’I nformatica)” , in Naples and is supported by the MURST in the “Progetti Cluster, Cluster 16 Multimedialità” activity. 7.0 Conclusion
This work represents the first step in our study on the MPLS technology. The work in this paper is based on freeware project (MPLS for Linux) to implement a MPLS stack for the Linux kernel. We’d like to use MPLS for Linux [7] in order to realize a QoS aware architecture studying the problem concerning the interoperabili ty between DiffServ and MPLS [6] and other MPLS features. Therefore before to study the performance of the implemented solutions we’ve analyzed the

overhead introduced in the MPLS encapsulation. This approach gives us the possibility to evaluate the performance of MPLS for Linux and use these results when we compare the value object of the simulations in a MPLS network and it is useful when a network administrator wants to estimate the overhead of MPLS infrastructure on the Linux platform.
References [1] Black, U., MPLS and Label Switching Networks, ISBN 0130158232, Prentice Hall, 2001. [2] Rosen, E. et al., Multiprotocol Label Switching Architecture, RFC 3031, January 2001. [3] Rosen, E. et al., MPLS Label Stack Encoding, RFC 3032, January 2001. [4] Viswanathan, A. et al., Evolution of Multiprotocol Label Switching, IEEE Communications Magazine, Vol. 36, No.
5, pp. 165-173, May 1998. [5] W. Stallings, MPLS, The Internet Protocol Journal, Volume 4 no 3, pp. 165-173, September 2001. [6] C. Horney, Quality of Service and Multi-Protocol Label Switching, White Paper, November 2000 [7] James R. Leu, MPLS for Linux project on http://sourceforge.net/projects/mpls-linux/





























