Embed Size (px)
Citation preview

Pre-print: The paper is currently under review for proceedings of Practical Applications of Corpus Linguistics 2015.
Please contact the author before citing.
Victoria Kamasa
The Faculty of Modern Languages and Literatures
Adam Mickiewicz University in Poznań
Corpus Linguistics for Critical Discourse Analysis.
What can we do better?
1 Introduction
Critical Discourse Analysis (henceforth CDA) has lately celebrated its 20th birthday with
a seminar in Amsterdam. During these 20 years both theoretical reflection and empirical
studies have flourished within the field. Different approaches, such as the Discourse
Historical Approach (Reisigl & Wodak 2001) or the sociocognitive approach (Dijk, Teun A.
van 2008), have been proposed, adopted for a vast range of topics and overviewed in
publications such as Wodak & Meyer (2009) or Duszak & Fairclough (2008). But CDA has
not only been developed and practiced. It has also been criticized, most remarkably by
Widdowson (1995; 1998) and Breeze (2011) who offer an extensive overview of
controversies surrounding CDA. Some critical remarks in the context of educational research
have also been summarized by Rogers et al. (2005), while more particular comments are
scattered through various publications (O'Halloran 2009; Orpin 2005; Prentice 2010; Stubbs
1997).
This critique contributed to the application of some techniques of corpus linguistics
(henceforth CL) in CDA . First attempts of employing such an approach came from the late

Pre-print: The paper is currently under review for proceedings of Practical Applications of Corpus Linguistics 2015.
Please contact the author before citing. 1990‟s (e.g. Beaugrande 2008; Flowerdew 1997; Hardt-Mautner 1995; Krishnamurthy 1996)
and were followed by the seminal work of Baker (2006), in which he describes basic corpus
techniques useful for discourse analysis and illustrates them with examples of his own
research. The discussion on the benefits of corpus techniques for CDA continues in a wide
array of research papers using these techniques (e.g. Baker et al. 2008; Degano 2007;
Subtirelu 2013).
The idea of corpus assisted CDA led to the proliferation of studies in which corpus
techniques were used to reveal and describe discourses of interest for critical analysts. The
popularity of this approach is visible both in the variety of techniques used and the diversity
of subjects analyzed. The techniques range from straightforward analyses of concordances
(Albakry 2004) to quite sophisticated research on lexical bundles (Herbel-Eisenmann &
Wagner 2010) or automatically tagged semantic categories (Prentice 2010). The vast range of
subjects includes, among others, national identity issues in Ireland (Prentice 2010), Malaysia
(Don et al. 2010) or Quebec (Freake et al. 2010), different social problems such as sexism
(Yasin, Mohamad Subakir Mohd et al. 2012) or eating-disorders (Lukac 2011), and social
construction of businesswomen (Koller 2004) or economic crisis (Lischinsky 2011). Also, the
sheer number of publications using corpus techniques demonstrates the growing interest:
according to the Scopus database, the total number of publications combining CDA and CL in
1990‟s was 3, in 2000‟s it amounted to 29, and since 2010 it has already reached 471. This
tendency is also visible in the leading conferences in the field: the 2014 Critical Approaches
to Discourse Analysis Among Disciplines (CADAAD) conference featured talks by almost 40
authors who used some form of corpus analysis in their studies.
1
Presented numbers result from search term: “KEY ("critical discourse analysis" ) AND TITLE-ABS-
KEY (corpus OR corpora OR "corpus linguistics")” (Scopus, 2014).

Pre-print: The paper is currently under review for proceedings of Practical Applications of Corpus Linguistics 2015.
Please contact the author before citing. Such interest gave rise to some critical considerations concerning the usage of corpus
techniques in CDA. For instance, Mautner (2009b) suggests that the contextual nature of
CDA and the lack of context in corpus research may produce some tensions. She also points
to semiotic impoverishment and oversensitivity to frequency as possible drawbacks of the CL
approach. Gabrielatos (2009) and Gabrielatos & Duguid (2014), on the other hand, offer a
more detailed discussion concerning the techniques chosen (such as keywords), statistical
measures used to perform them and the way these measures are interpreted in empirical
studies. Nevertheless, until now the steadily growing body of corpus-supported CDA studies
has not been critically reviewed in order to identify the most vulnerable points of the research
practice and suggest some improvements.
We will attempt to fill this gap in the presented paper. As a way of organizing our
reflections, we will use the criticism voiced about CDA and the ways the corpus approach has
been expected to address it. We will therefore strive to answer the question whether the way
corpus techniques are used in research practice fulfills the hopes vested in them and, if not,
what are the major problems we should address.
The starting point is the critical one; therefore, we will concentrate on such research
practices that from our point of view need to be improved in order to take full advantage of
the CL approach. We will focus on weaknesses and practices which may raise doubts,
withholding from presenting all the excellent practices both in the field and in the studies we
base our overview on. We will focus our considerations on the body of research papers
published between 2002 and 2013 in which the authors both declare a commitment to some
form of CDA and use at least one of corpus techniques (such as the analysis of concordances,
collocations, keywords or lexical bundles). The presented overview is not claimed to be
exhaustive, but is hoped to provide some useful insights into how the use of corpus techniques
in CDA might be improved.

Pre-print: The paper is currently under review for proceedings of Practical Applications of Corpus Linguistics 2015.
Please contact the author before citing. The following sections will briefly present the main points of criticism of CDA and the
ways the corpus approach was expected to address them. Then we will demonstrate some
examples from research practice in which, despite using corpus techniques, the problems
pointed out by CDA critics remained unsolved. Finally, we will suggest some good practice
that should help to avoid such problems and consider issues that seem to remain unresolved
even with the use of advanced CL techniques.
2 CL as answer for criticism of CDA
In its 20 years CDA has been discussed from different perspectives and criticized for
various shortcomings. The key points of critique relate to the analyzed material
(decontextualization of analyzed texts and fragmentary character of the analyses), scholarly
discipline (bias and cherry-picking and pivotal role of the researcher's intuition) and lack of a
coherent theory of audience response. Introduction of CL techniques into CDA was believed
to address all these problems.
2.1 Decontextualisation of analyzed texts
One of CDA's weaknesses CL should help to overcome is the decontextualization of the
analyzed texts. This lack of context relates to production, consumption, distribution, or
reproduction of texts (Breeze 2011; Rogers et al. 2005), but can also be seen more broadly as
ignoring the interactional frame (Rogers et al. 2005). While the CL approach alone does not
allow for more context embedded analyses, working with large volumes of data (Mautner
2009a) might balance out the omission of context in the analyses. Consequently, researchers

Pre-print: The paper is currently under review for proceedings of Practical Applications of Corpus Linguistics 2015.
Please contact the author before citing. using the CL approach still miss the context of a particular text, but they see such a large
amount of texts that they encounter the studied phenomenon in multiple instances. Therefore,
it might suffice to obtain reliable results, even though no context is taken into account. In this
case, CL, rather than offering a simple answer to the decontextualization problem, offers the
researchers a possibility to ignore the context without detriment to the validity of the results.
2.2 Fragmentary character of analyses
Another point of criticism directed at CDA to which CL seems to offer answers is the
fragmentary character of the analyses, observed both on the levels of sampling and analytic
procedures. With respect to the former, the critics question the representativeness of the
studied texts (Stubbs 1997) and point to their exemplificatory character (Fowler 1996). With
respect to the latter, doubts arise concerning the legitimacy of conclusions about ideology
based on focusing on particular lexical items or certain grammatical features (Breeze 2011).
CL presents an obvious solution for both aspects of this problem: the representativeness of the
data is achieved through sophisticated sampling procedures and, above all, through large
sample size (Degano 2007). Moreover, CL also enables a more exhaustive analysis by
“highlighting lexical and grammatical regularities” (Lischinsky 2011: 155) and a
comprehensive, rather than selective, description of syntactic and semantic properties of
lexical items (Hardt-Mautner 1995). Therefore, the problem of the fragmentary character of
the analysis can be solved by the use of corpora and corpus tools, both on the level of
sampling and analytic procedures.
2.3 Bias
CL is also believed to reduce the bias often indicated as another weakness of CDA. This
bias has been associated with the political commitment of CDA that in some cases leads

Pre-print: The paper is currently under review for proceedings of Practical Applications of Corpus Linguistics 2015.
Please contact the author before citing. researchers to act on personal grounds, rather than a scholarly principle (Breeze 2011). The
critics of CDA also pointed out that some analyses are conducted in such a way as to confirm
the researcher‟s preconceptions (Widdowson 1995) and that “political and social ideologies
are read into the data” (Rogers et al. 2005: 372). As mentioned above, CL offers the
researchers a heuristic tool (Hardt-Mautner 1995) and a more focused approach to the texts
(Lischinsky 2011), both being helpful in reducing bias. Moreover, Subtirelu (2013: 43)
mentions that using CL techniques in CDA provides “results that are not idiosyncratic to a
specific analyst”, while Baker (2011: 24) sees the bias-reducing potential of CL in the fact
that it forces the researcher to “account for any larger-scale or salient patterns”, i.e. also those
that do not conform to her or his political or social ideologies. Hence, it is believed that focus
on frequency and regularities provided by CL helps (at least partially) to overcome the
problem of bias.
2.4 Cherry-picking
It is also hoped that using the CL approach will address the cherry-picking problem
voiced, for example, by Breeze (2011), Verschueren (2001) or Mautner (2009b). This
problem is described as a tendency to choose such sets of texts or sets of examples that fit
either the interpretative framework (Verschueren 2001) or the presumptions of the researcher
(Rogers et al. 2005), which may skew the results and diminish their social credibility. As an
answer to this, CL offers a clear and precise criterion for choosing what should be analyzed,
namely frequency. As Degano (2007: 363) puts it: “the quantitative approach forces [sic] to a
closer observation of data, with a view to the frequency with which a certain characteristic
occurs, so that uses which can be identified as recurring are considered as more relevant than
isolated examples”. As a result, such approach helps to shift the researcher's attention from

Pre-print: The paper is currently under review for proceedings of Practical Applications of Corpus Linguistics 2015.
Please contact the author before citing. what seems to be interesting and might confirm (unconscious) presumptions to what is
demonstrably frequent, regular and forms some kind of a pattern.
2.5 Pivotal role of researcher’s intuition
Additionally, the CL approach may be able to deal with the pivotal role of the
researcher‟s intuition noted by Breeze (2011), Widdowson (1998) or Prentice (2010). On a
general level, such a role of the researcher demonstrates itself in the crucial significance of
her or his interpretive and explanatory skills for the obtained results (Breeze 2011) and the
subjectivity of the reading which leads to many possible interpretations of the same text
(Breeze 2011). On a more detailed level, this intuition also plays a central role in all analyses
that involve some kind of categorization, as they are based on a subjective application of a
coding system (Prentice 2010). Here again, the focus on frequency and patterns characteristic
for CL can be helpful in dealing with this issue. “The concordancer produces „results‟ in its
own right” (Hardt-Mautner 1995: 24), so there is no need for the researcher to use her or his
intuition to decide which lexical items or patterns of co-occurrence should be analyzed. The
involvement of the intuition in the analysis is also lowered by the heuristic function of the
corpus software, which draws the researcher's attention to phenomena that should be
investigated more closely (Hardt-Mautner 1995). Finally, some level of intersubjectivity,
being a consequence of reducing the intuition‟s role in the studies, has also been confirmed
experimentally (Marchi & Taylor 2009).
2.6 Lack of coherent theory of audience effects and audience response
The problem of the lack of a coherent theory of audience effects and audience response
can also be partially tackled by using the CL approach. As Rogers et al. (2005: 386) put it:
CDA authors “failed to represent the relationship between the grammatical resources and the

Pre-print: The paper is currently under review for proceedings of Practical Applications of Corpus Linguistics 2015.
Please contact the author before citing. social practices”, whereas Breeze (2011) points to the great complexity of reader-text
relations (involving readers‟ exposure to many different discourses and subtlety of ideological
meanings‟ transfer) and advises caution in drawing conclusions about thought from language.
Once again, focusing on high frequency items and patterns in texts contributes to the solution
of this problem, as it might be suspected that persistent recurrence is related to cognitive
visibility (Baker 2011; Gabrielatos & Baker 2008).
As demonstrated above, CL presents itself as a remedy for numerous issues voiced by the
critics of CDA. For some problems the solutions offered by CL are obvious and quite
comprehensive, as in the case of the fragmentary character of the analyses or cherry-picking.
For others, it is rather indirect and more of a hint or direction to be followed and developed
than a clear answer, as in the case of the decontextualization of analyzed texts or the lack of
audience effects theory. The problems and their respective solutions are summarized in the
Figure 1.
“@@ Insert Figure1 here”
Decontextualisation of analyzed texts
Large material as balance for the lack of context
Fragmentary character of analyses Representativeness (large corpora)
Exhaustive analysis (software)
Cherry-picking Choice of analysied items on the
basis of statistics
Pivotal role to the researcher’s intuition
Statistical significance instead of intuition
Bias Intersubjective methods
Focus on patterns and regularities
Lack of a coherent theory of audience effects and audience
response
Frequency as main factor effecting the audience

Pre-print: The paper is currently under review for proceedings of Practical Applications of Corpus Linguistics 2015.
Please contact the author before citing. Figure 1 – CDA critique and CL answers
3 CL answers and research practice
With such an optimistic view of the possibilities opened for CDA by the use of CL, the
question arises if the research practice lives up to these expectations. There is a number of
problems which recur in numerous studies that might weaken the belief in CL as a solution
for most issues that CDA is facing.
3.1 Decontextualisation of analyzed texts
3.1.1 We do not pay enough attention to the numbers
As shown above, the potential of CL for solving the decontextualization problem lies in
balancing the lack of context with the great amount of data. In research practice, however, we
sometimes tend to focus on items whose frequency does not justify that interest and therefore
we limit that potential. This might be the case for Lukac‟s study (2011) on the pro-eating
disorder discourse. She analyses the corpus of 19 blogs of pro-ana community members
consisting of 222 464 tokens. Although she starts with most frequent expressions used for
eating disorders (with frequencies up to 422), at some point she bases one of her conclusions
on the co-occurrences of words which appear in the corpus as seldom as 25 times: “Goal (…)
premodifies the noun weight in 25 occurrences. Goal weight is one of the terms specific for
the pro-eating disorder vocabulary” (Lukac 2011: 204). Mulderrig (2011) presents an even
looser approach to numbers. In her analysis of “change in the discursive construction of social
identity in UK education policy” (Mulderrig 2011: 563) based on 17 policy consultation

Pre-print: The paper is currently under review for proceedings of Practical Applications of Corpus Linguistics 2015.
Please contact the author before citing. documents, she hardly gives any numbers (including the size of corpus), justifying her
conclusions with descriptions such as “more frequently” or “comparatively infrequently”.
These examples show that using CL techniques does not always lead to focusing on what is
frequent and pervasive.
Such research practice may lead to two dilemmas. Firstly, one can question the validity of
the “specific for the pro-eating disorder vocabulary” label for a term occurring only 25 times
in a corpus of more than two hundred thousand words. Moreover, limiting the comparisons
between items to vague description rather than quoting specific numbers supplies only weak
support for the conclusions based on such comparisons. But besides these small (in
comparison to the results of the described studies as a whole) doubts, an important question
can be posed: how frequent must an item be in order to state that the many contexts in which
we see it balance the decontextualization of the analyzed texts it occurs in. It seems to be
quite legitimate to claim that an analysis of 16 000 occurrences of the word refugees
(Gabrielatos & Baker 2008) allows to see it in so many different contexts that detailed
discussion of production or consumption of texts it appears in can be neglected. But the same
logic probably does not apply to 25 or even 10 instances of a word in a corpus. It is doubtful
whether any particular number of occurrences or definite frequency per thousand words can
be defined. Nevertheless, if we wish for CL to solve the decontextualization problem, we need
to pay closer attention to the numbers we base our conclusions on.
3.1.2 We do not use statistical possibilities fully
The insufficient attention paid to the numbers we obtain from our corpora is also visible
in the underuse of statistical measures in some of our research. This underuse has two
dimensions: the first involves basing our interpretations on a difference in numbers for which
the statistical significance was not checked, while the second concerns the replacement of

Pre-print: The paper is currently under review for proceedings of Practical Applications of Corpus Linguistics 2015.
Please contact the author before citing. statistical measures with raw frequencies. The first dimension may be noticed in Marling‟s
(2010) study of feminism‟s representation in Estonian print media. Describing the changes of
this representation in time, Marling points to the alterations in the number of articles
containing the word feminism in different thematic sections of the analyzed newspaper. These
alterations (specifically the increase of articles concerning domestic news) are interpreted as a
signal of the domestication of feminism in Estonia. However, the statistical significance of the
difference is not examined2 and the raw difference (2,5 per year as opposed to 3 per year)
seems to be rather small.
As for the second dimension – replacing statistical measures with raw frequencies – it
may be the case for Edwards (2012), who determines the node words in British National Party
discourse by identifying “words which stood out for their clear quantitative variation between
texts” (Edwards 2012: 247). Searching for keywords instead of concentrating on raw
frequencies would probably be more informative, keywords being a statistically based corpus
technique for comparing two sets of texts in search for words with relatively high frequencies
(Scott 2013). Such approach would grant the certainty that the differences in frequencies are
significant enough to be taken into account. Also, the study by Freake et al. (2010) on the
construction of nationhood and belonging in Quebec would presumably benefit from using
statistical measures for collocates as a replacement for raw frequencies of co-occurrence.
Such measures ensure to some extent that the co-occurrences are both frequent and unique
enough to call them collocates and base interpretations on them.
Basing conclusions on raw frequencies can be misleading and, no less importantly, it
neglects the potential of corpus supported discourse analysis to deal with the problem of
2
Chi-squared test for the numbers provided in the cited paper showed no statistical significance
(chi=0,26, p=0,39).

Pre-print: The paper is currently under review for proceedings of Practical Applications of Corpus Linguistics 2015.
Please contact the author before citing. decontextualization through balancing the lack of context with the high number of examples
taken into careful consideration.
3.2 Fragmentary character of analyses
3.2.1 Our corpus design is not always clear
Large size of corpora and sophisticated sampling methods used in corpus-supported CDA
contribute substantially to solving the problem of the fragmentary character of analyses. In
order to ensure this contribution, every step of corpus design must be carefully considered and
fully justified. Nevertheless, not all corpora we base our analyses on seem to comply with
these requirements: some claims regarding the representatives of the analyzed material,
relevance of the chosen texts to the subject in question or coverage of the studied topics can
be challenged. The problem with representativeness is exemplified by Almeida‟s (2011)
research on U.S. newspapers‟ construction of the Israeli-Palestinian conflict. Her corpus
contains 3 randomly chosen newspaper stories per week for 4 months (April through July) in
a span of 6 years (2002–2006). As a result, she grounds her findings in a corpus of 250 press
articles which she claims are representative of media coverage. Nevertheless, it is rather
doubtful if the structure of the population (all press articles concerning the Israeli-Palestinian
conflict) and the sample are similar. Such similarity is one of the most commonly described
requirements for representativeness of a sample (e.g. Babbie 2013), therefore the lack of
compliance with this requirement may suggest that the analysis remains fragmentary rather
than exhaustive.
The next problem – relevance of material – may be noticed in Subtirelu‟s (2013) research
concerning the language ideologies and nationalisms present in the U.S. Congress. Unlike
Almeida, he studies the whole population rather than a sample. He decides to work with

Pre-print: The paper is currently under review for proceedings of Practical Applications of Corpus Linguistics 2015.
Please contact the author before citing. “transcriptions of legislative events related to S203
3” (Subtirelu 2013: 44). Such approach
should ensure the exhaustive character of the analysis, especially as considerable effort has
been taken to encompass all relevant documents in the first outline of the corpus. However,
then the author decides to manually categorize the documents according to the role of
multilingual voting materials and to further analyze only those sections of the documents
which he believes to be relevant to the subject. Such approach is justified by the need to
"ensure that keywords identified in the later analysis pertained only to S203" (Subtirelu 2013:
44). However, as the specific criteria used to distinguish the relevant sections from those
considered irrelevant are not listed, the criticism related to the fragmentary character of the
analysis may still hold.
3.3 Bias
3.3.1 We do not follow our own rules
Bias in the studies should be minimized by the use of intersubjectively replicable methods
supplied by CL. Nevertheless, in some cases we tend to overstep the methods we described.
This can both provide a more detailed and sophisticated view of the discussed problems and
reintroduce bias into our studies. This double nature of not exactly following one‟s own
methods is visible, for example, in Weninger‟s (2010) study of representations of social actors
at the lexico-grammatical level in the US urban redevelopment discourse. At some point, she
complements her planned study of colligations with “a closer look at the lexis” (Weninger
2010: 604) which, on the one hand, supports her claims and provides a more comprehensive
picture of the discussed problem. On the other hand, paying closer attention to facts which
confirm a point of view may be seen as biased. In a similar manner, Albakry (2004) bases his
conclusions about text attitudinal or ideological positions expressed and negotiated in US and
3
A portion of the Voting Rights Act mandating multilingual ballots for language minorities.

Pre-print: The paper is currently under review for proceedings of Practical Applications of Corpus Linguistics 2015.
Please contact the author before citing. Canadian reports investigating the Kandahar „friendly fire‟ on the comparative analysis of the
“use of salient terms of representation, anonymity, agency terms, passivization, and use of
modals and expression of stance” (Albakry 2004: 165). But then he strengthens these
conclusions with detailed analysis of selected lexical items such as friendly or fratricide. And
again, such practice has an ambiguous character: it offers broader and deeper perspective on
the examined data, but at the same time it is selective and thus may confirm the researcher‟s
preconceptions.
3.3.2 We do not pay enough attention to the numbers
Another research practice which reintroduces bias into corpus-supported CDA is the
above-described lack of sufficient attention paid to word frequencies. Focusing on items that
are thought-provoking or supportive of our conclusions regardless of their frequencies may
undermine the bias-reducing power of corpus techniques. Resigning from considering high
frequency of an item as the only factor determining its inclusion in the analysis most likely
raises the influence of the researcher‟s convictions on the presented results.
Baker (2012) offers an exhaustive discussion of the problems related to the numbers
generated by corpus research and bias that is brought into research by interpreting them. He
suggest that every interpretation of frequencies derived from a corpus carries some level of
bias which cannot be omitted due to the critical commitment of CDA. Nevertheless, not
incorporating frequency into analysis seems to strongly increase the level of bias and reduce
the potential of corpus techniques to ensure the credibility of CDA through “analytical tools
and methods that are rigorous and grounded in scientific principles such as representativeness,
falsification, data-driven approaches, using statistical approaches to test hypotheses and a
desire to provide a full picture of representation” (Baker 2012: 255).

Pre-print: The paper is currently under review for proceedings of Practical Applications of Corpus Linguistics 2015.
Please contact the author before citing. 3.4 Cherry-picking
3.4.1 We choose examples
Research practice shows that focus on frequency only partially solves the cherry-picking
problem described in the literature. Although we use big corpora and statistical methods to
generate lists of words or phrases we wish to analyze, we sometimes still tend to narrow our
further analyses only to selected items. For example, Bachmann (2011) concentrates on
keyword analysis in order to reconstruct discursive constructions of same-sex relationships in
the debates of the British Parliament concerning the Civil Partnership Bill. He devotes
considerable effort to generate a keyword list which will be both manageable for study and
subject accurate (using different reference corpora and different significance levels). But, after
finally acquiring such lists, he uses less than a half of the keywords for further analysis
without taking into consideration either frequency or keyness of these words. Therefore, he
selected some items from those with marked frequency in the studied texts and bases his
conclusions on an in-depth analysis of these items. Similarly, Freake et al. (2010), describing
the construction of nationhood and belonging in Quebec, include only some of the
collocations they got from their corpus in their interpretations. Likewise, Salama (2011), in
his attempt to characterize discourses about Wahhabi-Saudi Islam post-9/11, discusses in
detail 33 concordances out of 435 occurrences of the word in question in the analyzed texts
without providing a description of the way those concordances were chosen.
As the above mentioned studies show, researchers who use corpus techniques in their
analysis sometimes chose the items on which they base their conclusions. The problem might
be moved to another level, as in the case of keywords and collocates: the choice concerns
words (or combination of words) which are statistically more frequent than randomly or
intuitively chosen words. But the problem of (unconsciously) picking examples that confirm

Pre-print: The paper is currently under review for proceedings of Practical Applications of Corpus Linguistics 2015.
Please contact the author before citing. the researcher‟s presumptions remains at least partially unsolved, even if the picking pool is
justified better than in the case of traditional qualitative studies.
3.5 Pivotal role of researcher’s intuition
3.5.1 We categorize on the basis of intuition
Even though corpus software draws researchers‟ attention to phenomena that call for a
closer investigation (Hardt-Mautner 1995) and, therefore, should lower the role of intuition in
the analysis, many examples from research practice show that this role continues to be
prominent. This is especially visible in studies that involve some form of categorization of the
analyzed items. The first form of such categorization is related to the determination of the
semantic prosody of a given word which is based on categorizing every collocate of this word
as positive, negative or neutral. These judgments about the evaluative load of the words seem
purely intuitive as no procedure leading to the presented result is described. They are part of
many studies such as Mautner‟s (2007) reconstruction of the ageing discourses or the author‟s
research on in vitro fertilization discourses (Kamasa 2012). A similar role of the researcher‟s
intuition may be observed in studies including the analysis of semantic preference, only the
subject of assessment shifts from emotional load to semantic field a word belongs to (eg.
(Lischinsky 2011; Salama 2011; Weninger 2010). In both cases, the researcher‟s intuition is
to some extent supported by corpus software as it provides frequency-based lists of items
which ought to be judged on their emotional load or semantic field. Nevertheless, the
judgment itself depends fully on the skills of the researcher.
Also other types of intuition-based categorization are present in the research practice.
Chen (2012) considers the changes in the usage of different evaluation types4 in the articles
from China Daily due to the political developments in China and provides information about
4
The evaluation types are based on the work of Labov (1972)

Pre-print: The paper is currently under review for proceedings of Practical Applications of Corpus Linguistics 2015.
Please contact the author before citing. statistically significant diachronic differences in the occurrences of these evaluation types.
The statistics are nevertheless performed on intuitively chosen and categorized examples.
Similarly, Edwards (2012) uses corpus tools to generate a list of all uses of the word our in his
corpus. However, then he divides these instances manually and without any specific criteria
into three types in order to base some of his conclusions on the differences in the number of
occurrences of particular types through time. As a result of such practices, the role of the
researcher‟s intuition remains pivotal to the results.
3.6 Lack of a coherent theory of audience effects and audience response
3.6.1 We try to read in minds
The caution in drawing conclusions about thought from language (as advised by Breeze
2011) is not always fully exercised in some of our analyses. Even though corpus tools allow
us to determine the frequencies of words or their co-occurrences and therefore to include
these frequencies as the main factor influencing the audience‟s response, we sometimes tend
to neglect them and build conclusions about audience‟s reception leaving them aside. This
might be the case O'Halloran‟s (2009) investigation of the pre-UE-expansion discourses about
immigrants in the UK: she investigates a 26-thousand-word corpus of newspaper articles but
her suggestion that “regular readers have been positioned into making negative contrast with
information on Eastern European immigration” (O'Halloran 2009: 38) is only based on 36
examples of specific usage of the word “but”5. The role of frequency (as a main factor
justifying the conclusions about audience response) for such an interpretation could be
questioned and thereby the potential of corpus techniques to address the lack a coherent
theory of audience effects is partially limited.
5
Specifically, she refers to Wodak‟s (1999) strategies realized via the usage of word “but”.

Pre-print: The paper is currently under review for proceedings of Practical Applications of Corpus Linguistics 2015.
Please contact the author before citing. A comparable problem concerns inferences about the intentions of the text‟s author. On
the basis of the texts‟ analysis we form claims about the state of mind or will of the sender
without grounding them in psycholinguistic knowledge about relations between
communicative intention and the form of the utterance. For example, Forchtner & Kolvraa
(2012) in their paper about representations of Europe‟s past, present and future in speeches
given by major political figures sometimes comment on the mental states of these political
figures rather than on the texts delivered by them as in “Prodi aims to6 unify the continent”,
„Merkel (2007), for example, apparently sees no contradiction between Europe‟s dark history
and an emerging ambition to make a distinctly European contribution to the running of the
world beyond Europe” or “Prodi can again avoid differentiating between perpetrators and
victims” (Forchtner & Kolvraa 2012: 388-393). Therefore, the question arises if for such
interpretation the claim that CL offers a more data-based approach to discourse analysis can
be fully sustained.
Even though CL helps to address almost every point mentioned by CDA's critics, some
shortcomings in our research practice might reintroduce all these problems back into our
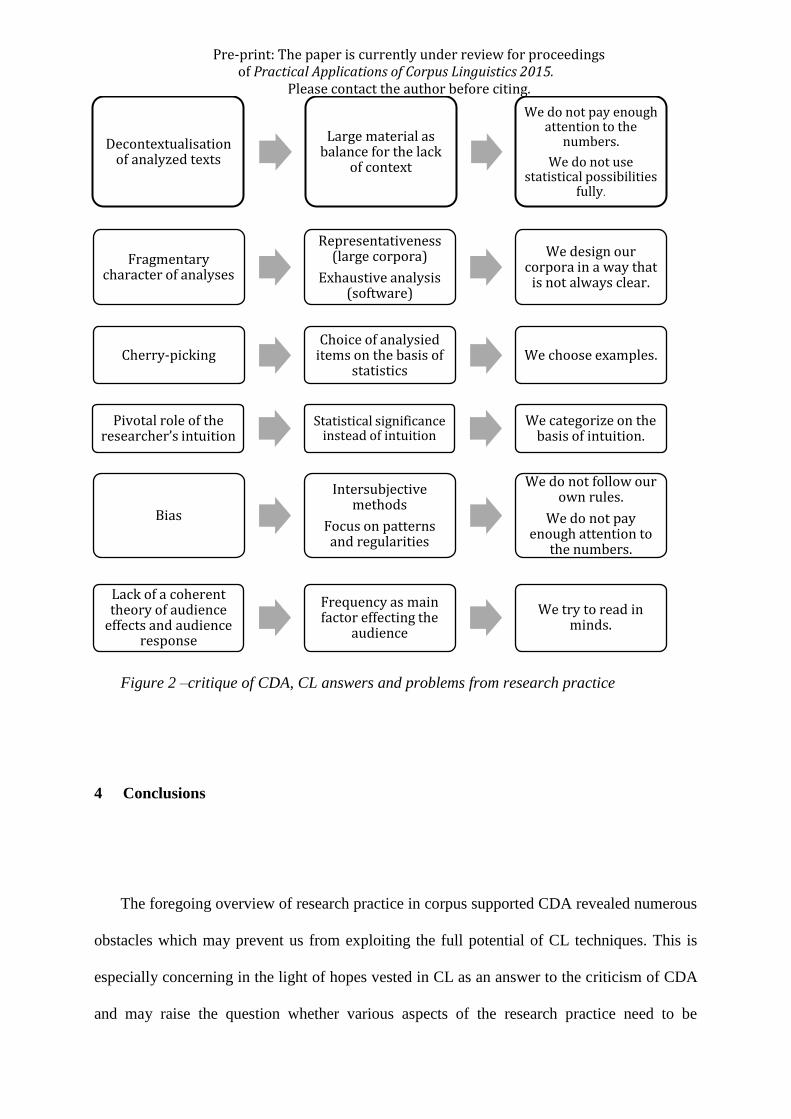
studies. Figure 2 illustrates the relation between the main points of the criticism of CDA,
solutions offered by CL and problems emerging from our research practice.
“@@ Insert Figure 2 here”
6
Emphasizes from the author of the paper.
Pre-print: The paper is currently under review for proceedings of Practical Applications of Corpus Linguistics 2015.
Please contact the author before citing.
Figure 2 –critique of CDA, CL answers and problems from research practice
4 Conclusions
The foregoing overview of research practice in corpus supported CDA revealed numerous
obstacles which may prevent us from exploiting the full potential of CL techniques. This is
especially concerning in the light of hopes vested in CL as an answer to the criticism of CDA
and may raise the question whether various aspects of the research practice need to be
Decontextualisation of analyzed texts
Large material as balance for the lack
of context
We do not pay enough attention to the
numbers.
We do not use statistical possibilities
fully.
Fragmentary character of analyses
Representativeness (large corpora)
Exhaustive analysis (software)
We design our corpora in a way that
is not always clear.
Cherry-picking Choice of analysied
items on the basis of statistics
We choose examples.
Pivotal role of the researcher’s intuition
Statistical significance instead of intuition
We categorize on the basis of intuition.
Bias
Intersubjective methods
Focus on patterns and regularities
We do not follow our own rules.
We do not pay enough attention to
the numbers.
Lack of a coherent theory of audience
effects and audience response
Frequency as main factor effecting the
audience
We try to read in minds.

Pre-print: The paper is currently under review for proceedings of Practical Applications of Corpus Linguistics 2015.
Please contact the author before citing. improved or if these hopes were simply too high considering the present state of affairs. For
the above listed issues, both seem to be valid to some extent.
A few of these problems can probably be tackled by paying more attention to the research
design and analysis itself. If we increase the number of statistical techniques used in our
studies and base every comparison only on differences that are statistically significant, we
will contribute to addressing the decontextualization problem. Avoiding any intuitive and not
intersubjective steps in our corpus design will prevent our studies from being fragmentary
rather than comprehensive. Through usage of frequency and statistical scores as the only
criterion for the selection of items we base our conclusions on, we will lessen the bias in our
studies and avoid cherry picking. Finally, we can mitigate the lack of a coherent audience
response theory by limiting conclusions about mental states of text‟s recipients by thorough
inspection of frequency and restraining ourselves from conclusions about mental states of
texts' authors.
Nevertheless, answers to other problems still remain far from clear and call for a more
through consideration. With bias being one of the main points of the criticism of CDA on the
one hand, and the need for exhaustive and in-depth analyses on the other, we probably ought
to consider to what (if to any) extent is it justified to supplement our analyses and conclusions
with observations that do not result from the application of our originally planned methods. If
we wish corpus methods to solve the problem of the pivotal role of the researcher‟s intuition,
we still need to address the question of categorization. How (if not on the basis of intuition)
should we decide whether an item is positively or negatively loaded? What (if not intuition) is
the best basis for deciding to which semantic field a word belongs? Some answers for that
problem may be found in the field of computational linguistics such as sentiment analysis
(Thelwall et al. 2010) or automated semantic tagging (Prentice 2010). However, the suitability

Pre-print: The paper is currently under review for proceedings of Practical Applications of Corpus Linguistics 2015.
Please contact the author before citing. of these solutions for an essentially interpretative perspective such as CDA could be
challenged.
Self-criticism is one of the important features of CDA advised for example by Fairclough
(2001). We hope therefore that the presented critical overview, although not extensive and
biased by the author‟s personal views, will draw our attention to some crucial points in the
design and analysis of corpus data for CDA purposes and inspire further debates. We also
hope that these remarks will be in some way useful not only for CDA practitioners but also
for all who wish to reconstruct some form of social meaning on the basis of text corpora.

Pre-print: The paper is currently under review for proceedings of Practical Applications of Corpus Linguistics 2015.
Please contact the author before citing. References
Albakry, M. 2004. U.S. “Friendly Fire” Bombing of Canadian Troops: Analysis of the
Investigative Reports. Critical Inquiry in Language Studies 1:3: 163–178.
Almeida, E. P. 2011. Palestinian and Israeli Voices in Five Years of U.S. Newspaper
Discourse. International Journal of Communication 5: 1586–1605.
Babbie, E. R. 2013. The practice of social research. Belmont, CA: Wadsworth Cengage
Learning.
Bachmann, I. 2011. Civil partnership – “gay marriage in all but name”: a corpus-driven
analysis of discourses of same-sex relationships in the UK Parliament. Corpora Vol. 6 (1):
77–105.
Baker, P. 2006. Using corpora in discourse analysis. London, New York: Continuum.
Baker, P. 2011. Social involvement in corpus studies: Interview with Paul Baker. In Viana,
V., S. Zyngier & G. Barnbrook (eds.), Perspectives on corpus linguistics, 17–28.
Amsterdam, Philadelphia: J. Benjamins Pub.
Baker, P. 2012. Acceptable bias? Using corpus linguistics methods with critical discourse
analysis. Critical Discourse Studies 9:3: 247–256.
Baker, P., C. Gabrielatos, M. KhosraviNik, M. Krzyzanowski, T. McEnery & R. Wodak.
2008. A useful methodological synergy? Combining critical discourse analysis and corpus
linguistics to examine discourses of refugees and asylum seekers in the UK press.
Discourse & Society 19:3: 273–306.
Beaugrande, R. de. 2008. Krytyczna analiza dyskursu a znaczenie „demokracji” w wielkim
korpusie. In Duszak, A. & N. Fairclough (eds.) 2008. Krytyczna analiza dyskursu:

Pre-print: The paper is currently under review for proceedings of Practical Applications of Corpus Linguistics 2015.
Please contact the author before citing. Interdyscyplinarne podejście do komunikacji społecznej, 103–119. Kraków: Towarzystwo
Autorów i Wydawców Prac Naukowych „Universitas”.
Breeze, R. 2011. Critical Discourse Analysis and Its Critics. Pragmatics 21:4: 493–525.
Chen, L. 2012. Reporting news in China: Evaluation as an indicator of change in the China
Daily. China Information 26:3: 303–329.
Degano, C. 2007. Dissociation and Presupposition in Discourse: A Corpus Study.
Argumentation 21:4: 361–378.
Dijk, Teun A. van. 2008. Discourse and context: A socio-cognitive approach. Cambridge,
New York: Cambridge university press.
Don, Z. M., Gerry Knowles & Choong K. Fatt. 2010. Nationhood and Malaysian identity: a
corpus-based approach. Text & Talk - An Interdisciplinary Journal of Language,
Discourse & Communication Studies 30:3: 267–287.
Duszak, A. & N. Fairclough (eds.) 2008. Krytyczna analiza dyskursu: Interdyscyplinarne
podejście do komunikacji społecznej. Kraków: Towarzystwo Autorów i Wydawców Prac
Naukowych „Universitas”.
Edwards, G. O. 2012. A comparative discourse analysis of the construction of „in-groups‟ in
the 2005 and 2010 manifestos of the British National Party. Discourse & Society 23:3:
245–258.
Flowerdew, J. 1997. The Discourse of Colonial Withdrawal: A Case Study in the Creation of
Mythic Discourse. Discourse & Society 8:4: 453–477.
Forchtner, B. & C. Kolvraa. 2012. Narrating a „new Europe‟: From „bitter past‟ to self-
righteousness? Discourse & Society 23:4: 377–400.
Fowler, R. 1996. On critical linguistics. In Caldas-Coulthard, C. R. & M. Coulthard (eds.),
Texts and practices: Readings in critical discourse analysis, 3–14. London, New York:
Routledge.

Pre-print: The paper is currently under review for proceedings of Practical Applications of Corpus Linguistics 2015.
Please contact the author before citing. Freake, R., G. Gentil & J. Sheyholislami. 2010. A bilingual corpus-assisted discourse study of
the construction of nationhood and belonging in Quebec. Discourse & Society 22:1: 21–
47.
Gabrielatos, C. 2009. Corpus-based methodology and critical discourse studies. Context,
content, computation. (= Siena English Language and Linguistics Seminars (SELLS).)
Siena.
Gabrielatos, C. & P. Baker. 2008. Fleeing, Sneaking, Flooding: A Corpus Analysis of
Discursive Constructions of Refugees and Asylum Seekers in the UK Press, 1996-2005.
Journal of English Linguistics 36:1: 5–38.
Gabrielatos, C. & Alison Duguid. 2014. Corpus Linguistics and CDA. A critical look at
synergy. (= CDA20+ Symposium.) Amsterdam.
Hardt-Mautner, G. 1995. ‘Only Connect.’: Critical Discourse Analysis and Corpus
Linguistics, Accessed September 10, 2012.
Herbel-Eisenmann, B. & David Wagner. 2010. Appraising lexical bundles in mathematics
classroom discourse: obligation and choice. Educational Studies in Mathematics 75:1: 43–
63.
Kamasa, V. 2012. Naming “In Vitro Fertilization”: Critical Discourse Analysis of the Polish
Catholic Church‟s Official Documents. Procedia - Social and Behavioral Sciences 95:
154-159.
Koller, V. 2004. Businesswomen and war metaphors: „Possessive, jealous and pugnacious‟?
Journal of Sociolinguistics 8/1, 2004: 3^22 8/1: 3–22.
Krishnamurthy, R. 1996. Ethnic, Racial and Tribal: The Language of Racism? In Caldas-
Coulthard, C. R. & M. Coulthard (eds.), Texts and practices: Readings in critical
discourse analysis, 129–149. London: Routledge.

Pre-print: The paper is currently under review for proceedings of Practical Applications of Corpus Linguistics 2015.
Please contact the author before citing. Lischinsky, A. 2011. In times of crisis: a corpus approach to the construction of the global
financial crisis in annual reports. Critical Discourse Studies 8:3: 153–168.
Lukac, M. 2011. Down to the bone: A corpus-based critical discourse analysis of pro-eating
disorder blogs. Jezikoslovlje 12.2: 187–209.
Marchi, A. & Charlotte Taylor. 2009. If on a Winter‟s Night Two Researchers… A Challenge
to Assumptions of Soundness of Interpretation. Critical Approaches to Discourse Analysis
across Disciplines Vol 3 (1): 1–20.
Marling, R. 2010. The Intimidating Other: Feminist Critical Discourse Analysis of the
Representation of Feminism in Estonian Print Media. NORA - Nordic Journal of Feminist
and Gender Research 18:1: 7–19.
Mautner, G. 2007. Mining large corpora for social information: The case of elderly. Language
in Society 36:01.
Mautner, G. 2009a. Checks and balances: how corpus linguistics can contribute to CDA. In
Wodak, R. & M. Meyer (eds.) 2009. Methods of critical discourse analysis, 122–144.
London: SAGE.
Mautner, G. 2009b. Corpora and Critical Discourse Analysis. In Baker, P. (ed.),
Contemporary corpus linguistics, 32-46. London, New York: Continuum.
Mulderrig, J. 2011. Manufacturing Consent: A corpus-based critical discourse analysis of
New Labour‟s educational governance. Educational Philosophy and Theory Vol. 43, No.
6: 562–578.
O‟Halloran, K. 2009. Inferencing and cultural reproduction: a corpus-based critical discourse
analysis. Text & Talk - An Interdisciplinary Journal of Language, Discourse
Communication Studies 29:1: 21–51.
Orpin, D. 2005. Corpus Linguistics and Critical Discourse Analysis: Examining the ideology
of sleaze. International Journal of Corpus Linguistics 10:1: 37–61.

Pre-print: The paper is currently under review for proceedings of Practical Applications of Corpus Linguistics 2015.
Please contact the author before citing. Prentice, S. 2010. Using automated semantic tagging in Critical Discourse Analysis: A case
study on Scottish independence from a Scottish nationalist perspective. Discourse &
Society 21:4: 405–437.
Reisigl, M. & Ruth Wodak. 2001. Discourse and discrimination: Rhetorics of racism and
antisemitism. London, New York: Routledge.
Rogers, R., E. Malancharuvil-Berkes, M. Mosley, D. Hui & G. O. Joseph. 2005. Critical
Discourse Analysis in Education: A Review of the Literature. Review of Educational
Research 75:3: 365–416.
Salama, A. H. Y. 2011. Ideological collocation and the recontexualization of Wahhabi-Saudi
Islam post-9/11: A synergy of corpus linguistics and critical discourse analysis. Discourse
& Society 22:3: 315–342.
Scott, M. 2013. WordSmith Tools Help., Accessed September 7, 2013.
Stubbs, M. 1997. Whorf‟s Children: Critical comments on Critical Discourse Analysis
(CDA). In Ryan, A. & A. Wray (eds.), Evolving models of language: Papers from the
Annual meeting of the British association for applied linguistic held at the University of
Wales, Swansea, September 1996, 110–116. Clevedon: British association for applied
linguistic.
Subtirelu, N. C. 2013. „English… it‟s part of our blood‟:: Ideologies of language and nation in
United States Congressional discourse. Journal of Sociolinguistics 37–65 17/1: 37–65.
Thelwall, M., Kevan Buckley, Georgios Paltoglou & Di Cai. 2010. Sentiment strength
detection in short informal text. Journal of the American Society for Information Science
and Technology 61:12: 2544–2558.
Verschueren, J. 2001. Predicaments of Criticism. Critique of Anthropology 21:1: 59–81.

Pre-print: The paper is currently under review for proceedings of Practical Applications of Corpus Linguistics 2015.
Please contact the author before citing. Weninger, C. 2010. The lexico-grammar of partnerships: corpus patterns of facilitated agency.
Text & Talk - An Interdisciplinary Journal of Language, Discourse & Communication
Studies 30:5: 591–613.
Widdowson, H. G. 1995. Discourse analysis: a critical view. Language and Literature 4:3:
157–172.
Widdowson, H. G. 1998. The Theory and Practice of Critical Discourse Analysis. Applied
Linguistics 19/1: 136–151.
Wodak, R. & M. Meyer (eds.) 2009. Methods of critical discourse analysis. London: SAGE.
Yasin, Mohamad Subakir Mohd, Bahiyah A. Hamid, Yuen C. Keong, Zarina Othman &
Azhar Jaludin. 2012. Linguistic Sexism In Qatari Primary Mathematics Textbooks. GEMA
Online™ Journal of Language Studies Volume 12(1): 53–68.





























