Embed Size (px)
Citation preview

ACTA UNIVERSITATIS UPSALIENSIS Studia Linguistica Upsaliensia
16


Morphosyntactic Corpora and Tools for Persian
Mojgan Seraji

Dissertation presented at Uppsala University to be publicly examined in Universitetshuset /IX, Uppsala, Wednesday, 27 May 2015 at 10:15 for the degree of Doctor of Philosophy. Theexamination will be conducted in English. Faculty examiner: Professor of ComputationalLinguistics Jan Hajic (Charles University in Prague).
AbstractSeraji, M. 2015. Morphosyntactic Corpora and Tools for Persian. Studia LinguisticaUpsaliensia 16. 191 pp. Uppsala: Acta Universitatis Upsaliensis. ISBN 978-91-554-9229-8.
This thesis presents open source resources in the form of annotated corpora and modules forautomatic morphosyntactic processing and analysis of Persian texts. More specifically, theresources consist of an improved part-of-speech tagged corpus and a dependency treebank,as well as tools for text normalization, sentence segmentation, tokenization, part-of-speechtagging, and dependency parsing for Persian.
In developing these resources and tools, two key requirements are observed: compatibilityand reuse. The compatibility requirement encompasses two parts. First, the tools in the pipelineshould be compatible with each other in such a way that the output of one tool is compatible withthe input requirements of the next. Second, the tools should be compatible with the annotatedcorpora and deliver the same analysis that is found in these. The reuse requirement means thatall the components in the pipeline are developed by reusing resources, standard methods, andopen source state-of-the-art tools. This is necessary to make the project feasible.
Given these requirements, the thesis investigates two main research questions. The first is howcan we develop morphologically and syntactically annotated corpora and tools while satisfyingthe requirements of compatibility and reuse? The approach taken is to accept the tokenizationvariations in the corpora to achieve robustness. The tokenization variations in Persian texts arerelated to the orthographic variations of writing fixed expressions, as well as various types ofaffixes and clitics. Since these variations are inherent properties of Persian texts, it is importantthat the tools in the pipeline can handle them. Therefore, they should not be trained on idealizeddata.
The second question concerns how accurately we can perform morphological and syntacticanalysis for Persian by adapting and applying existing tools to the annotated corpora. Theexperimental evaluation of the tools shows that the sentence segmenter and tokenizer achievean F-score close to 100%, the tagger has an accuracy of nearly 97.5%, and the parser achievesa best labeled accuracy of over 82% (with unlabeled accuracy close to 87%).
Keywords: Persian, language technology, corpus, treebank, preprocessing, segmentation, part-of-speech tagging, dependency parsing
Mojgan Seraji, Department of Linguistics and Philology, Box 635, Uppsala University,SE-75126 Uppsala, Sweden.
© Mojgan Seraji 2015
ISSN 1652-1366ISBN 978-91-554-9229-8urn:nbn:se:uu:diva-248780 (http://urn.kb.se/resolve?urn=urn:nbn:se:uu:diva-248780)

SammandragDenna avhandling presenterar resurser i form av annoterade korpusar och moduler för au-tomatisk morfosyntaktisk bearbetning och analys av persiska texter. Mera specifikt bestårdessa resurser av en förbättrad ordklasstaggad korpus och en dependensträdbank samt verk-tyg för textnormalisering, meningssegmentering, tokenisering, ordklasstaggning och depen-densparsning för persiska.
Vid utvecklingen av dessa resurser och verktyg har två viktiga krav antagits: kompatibilitetoch återanvändning. Kompatibilitetskravet omfattar två delar. För det första bör verktygen ikedjan vara kompatibla med varandra, på ett sådant sätt att utdatan från ett verktyg är kom-patibel med indatan i nästa. För det andra bör verktygen vara kompatibla med de annoteradekorpusarna och leverera samma analys som finns i dessa. Återanvändningskravet innebär attalla komponenter i kedjan utvecklas genom återanvändning av resurser, standardmetoder ochverktyg med öppen källkod, vilket är nödvändigt för att göra projektet genomförbart.
Mot bakgrund av de ställda kraven undersöker avhandlingen två huvudsakliga forskningsfrå-gor. Den första frågan är hur vi kan utveckla morfologiskt och syntaktiskt annoterade korpusaroch verktyg och samtidigt uppfylla kraven på kompatibilitet och återanvändning. Den strategisom tillämpas är att acceptera variation i tokenisering för att uppnå robusthet. Variationen itokenisering i persiska texter är relaterad till ortografiska varianter av flerordsuttryck samt olikatyper av affix och klitiska partiklar. Eftersom denna variation är en inneboende egenskap ipersiska texter, är det viktigt att verktygen i kedjan kan hantera dem. Därför bör de inte varatränade på tillrättalagda data.
Den andra frågan är med vilken korrekthet vi kan utföra morfologisk och syntaktiskanalys för persiska genom att anpassa och tillämpa befintliga verktyg på de annoteradekorpusarna? Den experimentella utvärderingen av verktygen visar att meningssegmenterarenoch tokenieraren uppnår en korrekthet nära 100%, taggaren har en korrekthet på nästan 97,5%,och parsern uppnår som bäst en korrekthet på över 82% med dependensrelationer (och nära87% utan relationer).
Nyckelord: Persiska, språkteknologi, korpus, trädbank, normalisering, segmentering, ord-klasstaggning, dependensparsning


To:my sons Babak and Hooman
my parents Asiyeh and Bahrammy sister Shohreh
my husband Mansour
Words cannot express how much I love you all.


Contents
1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 231.1 Goals and Research Questions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 241.2 Research Methodology . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 251.3 Outline of the Thesis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 261.4 Previous Publications . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
2 Background . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 292.1 Corpora . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
2.1.1 Morphological Annotation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 312.1.2 Syntactic Annotation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
2.2 Tools . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 382.2.1 Preprocessing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 382.2.2 Sentence Segmentation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 392.2.3 Tokenization . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 392.2.4 Part-of-Speech Tagging . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 402.2.5 Parsing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
2.3 Persian . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 452.3.1 Persian Orthography . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 462.3.2 Persian Morphology . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 522.3.3 Persian Syntax . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
2.4 Existing Corpora and Tools for Persian . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 612.4.1 Morphologically Annotated Corpora . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 612.4.2 Syntactically Annotated Corpora . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 642.4.3 Sentence Segmenentation and Tokenization . . . . . . . . . . . . . . . . . . 652.4.4 Part-of-Speech Taggers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 652.4.5 Parsers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
3 Uppsala Persian Corpus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 683.1 The Bijankhan Corpus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 683.2 Uppsala Persian Corpus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
3.2.1 Character Encodings . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 703.2.2 Sentence Segmentation and Tokenization . . . . . . . . . . . . . . . . . . . . . . 713.2.3 Morphological Annotation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
4 Normalization, Segmentation and Morphological Analysis for Persian 824.1 Preprocessing, Sentence Segmentation and Tokenization . . . . . . . . . . . 82
4.1.1 The Preprocessor: PrePer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83

4.1.2 The Sentence Segmenter and Tokenizer: SeTPer . . . . . . . . . . 884.1.3 The Evaluation of PrePer and SeTPer . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
4.2 The Statistical Part-of-Speech Tagger: TagPer . . . . . . . . . . . . . . . . . . . . . . . . . . . . 914.2.1 The Evaluation of TagPer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
5 Uppsala Persian Dependency Treebank . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 995.1 Corpus Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 995.2 Treebank Development . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1005.3 Annotation Scheme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1015.4 Basic Relations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102
5.4.1 Relations from Stanford Dependencies . . . . . . . . . . . . . . . . . . . . . . . . 1025.4.2 New Relations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1185.4.3 An Example Sentence Annotated with STD . . . . . . . . . . . . . . . 128
5.5 Complex Relations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1295.6 Unused Relations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1305.7 Comparison with Other Treebanks for Persian . . . . . . . . . . . . . . . . . . . . . . . . . . 131
5.7.1 Data and Format . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1315.7.2 Tokenization . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1325.7.3 Annotation Schemes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1345.7.4 Sample Analyses . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 140
6 Dependency Parsing for Persian . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1476.1 Preliminaries . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 148
6.1.1 Data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1486.1.2 Evaluation Metrics . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1486.1.3 Parsers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 149
6.2 Experiments with Different Parsing Representations . . . . . . . . . . . . . . . . 1516.2.1 Baseline: Full Treebank Annotation . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1516.2.2 Coarse-Grained Part-of-Speech Tags . . . . . . . . . . . . . . . . . . . . . . . . . . . 1546.2.3 Coarse-Grained LVC Relations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1586.2.4 No Complex Relations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1626.2.5 Best Parsing Representation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 166
6.3 Experiments with Different Parsers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1676.4 Dependency Parser for Persian: ParsPer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 168
6.4.1 The Evaluation of ParsPer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 169
7 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 173
References . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 177
Appendix A: UPDT Dependency Labels . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 189

List of Tables
Table 2.1: An example of the English sentence Economic news hadlittle effect on financial markets., taken from the Penn Treebank (Marcuset al., 1993), annotated with the Google universal part-of-speech tags(Petrov et al., 2012) and the STD presented in CoNLL format. . . . . . . . . . . . . . . . . . . . 37
Table 2.2: Dual-joining Persian characters. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
Table 2.3: Right-joining Persian characters. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
Table 2.4: Examples of Persian homographs disambiguated bydiacritics, N_SING = Noun Singular, V_PA = Past. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
Table 2.5: Persian homophonic letters. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
Table 2.6: Diverse spellings of certain homophonic Persian words. . . . . . . . . 48
Table 2.7: 12 different ways of writing the plural and definite form ofthe compound word øAë é
KA
gH. A
�J» (the libraries of). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
Table 2.8: Different forms of hamze. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
Table 2.9: Different forms of Persian and Arabic characters. . . . . . . . . . . . . . . . . . . 51
Table 2.10: Digital characters for Persian (Extended Arabic-IndicDigits), Arabic (Arabic-Indic Digits) and Western. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
Table 2.11: Examples of words derived from the present stem à@X /dan/
(to know) combined with various types of other stems and nouns as wellas derivational affixes. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
Table 2.12: Present indicative of the verb �P /raftan/ (to go). . . . . . . . . . . . . . . . . . 53
Table 2.13: Syntactic patterns in Persian. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
Table 2.14: Personal endings in past tense (personal endings in presenttense are illustrated in Section 2.3.2.) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
Table 2.15: Pronominal clitics. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
Table 2.16: Pronominal clitics accompanied by the word PA¿ /kar/(work). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
Table 2.17: Syntactic relations in the Persian Dependency Treebank. . . . . . . 66
Table 3.1: Part-of-speech tags in the Bijankhan Corpus. . . . . . . . . . . . . . . . . . . . . . . . . . . 69

Table 3.2: Part-of-speech tags in the UPC and the corresponding tags inthe Bijankhan Corpus (BC in the table). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
Table 3.3: A sample sentence taken from the Bijankhan Corpus and thecorresponding sentence modified in the UPC. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
Table 4.1: Personal endings in past tense. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
Table 4.2: Copula clitics. * The third singular è� /-h/ in formal usage is
consistently used along with the verb �I�@ /ast/ (is). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
Table 4.3: Verbal stems in the formation of compound words. . . . . . . . . . . . . . . . . 86
Table 4.4: Adjectival and nominal suffixes. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
Table 4.5: List of token separators. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
Table 4.6: Words not treated by segmentation tools. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90
Table 4.7: Comparison of different models for tag transitions and wordemissions. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
Table 4.8: Comparison of different models for unseen words. . . . . . . . . . . . . . . . . . 92
Table 4.9: Recall, precision, and F-score for different part-of-speechtags when TagPer was evaluated on a subset of UPC. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93
Table 4.10: Recall, precision, and F-score for different part-of-speechtags when TagPer was evaluated on 100 automatically tokenized sentences(2778 tokens) taken from the web-based journal Hamshahri. . . . . . . . . . . . . . . . . . . . . . . 94
Table 4.11: Recall, precision, and F-score for different part-of-speechtags when TagPer was evaluated on 100 manually tokenized sentences(2788 tokens) taken from the web-based journal Hamshahri. . . . . . . . . . . . . . . . . . . . . . . 95
Table 5.1: A statistical overview of the UPDT. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 99
Table 5.2: Syntactic relations in UPDT with new relations in italics. . . . 126
Table 6.1: Labeled recall and precision on the development set for the20 most frequent dependency types in the UPDT, when MaltParser istrained on the full treebank annotation (automatically generatedpart-of-speech tags). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152
Table 6.2: Labeled recall and precision on the development set for the20 most frequent dependency types in the UPDT, when MaltParser istrained on the full treebank annotation (gold standard part-of-speechtags). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 153
Table 6.3: Labeled and unlabeled attachment scores and labelaccuracy on the development set when MaltParser was trained on UPDTwith a fine-grained annotated treebank. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 154

Table 6.4: Labeled recall and precision on the development set for the20 most frequent dependency types in the UPDT, when MaltParser istrained on the UPDT with coarse-grained auto part-of-speech tags. . . . . . . . . . . 155
Table 6.5: Labeled recall and precision on the development set for the20 most frequent dependency types in the UPDT, when MaltParser istrained on the UPDT with coarse-grained gold part-of-speech tags. . . . . . . . . . 156
Table 6.6: Labeled and unlabeled attachment scores and labelaccuracy on the development set when MaltParser was trained on theUPDT with coarse-grained part-of-speech tags. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 158
Table 6.7: Labeled recall and precision on the development set for the20 most frequent dependency types in the UPDT, when MaltParser istrained on the treebank with fine-grained auto part-of-speech tags andonly one light verb construction. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 159
Table 6.8: Labeled recall and precision on the development set for the20 most frequent dependency types in the UPDT, when MaltParser istrained on the treebank with fine-grained gold part-of-speech tags andonly one light verb construction. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 160
Table 6.9: Recall and precision for LVC relations with fine-grainedauto and gold part-of-speech tags in experiments 1 and 3. . . . . . . . . . . . . . . . . . . . . . . . . . 161
Table 6.10: Labeled and unlabeled attachment scores and labelaccuracy on the development set when MaltParser was trained on UPDTwith fine-grained part-of-speech tags and only one dependency relationfor light verb construction. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 162
Table 6.11: Labeled recall and precision on the development set for the20 most frequent dependency types in the UPDT, when MaltParser istrained on the treebank with fine-grained auto part-of-speech tags andonly basic dependency relations. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 163
Table 6.12: Labeled recall and precision on the development set for the20 most frequent dependency types in the UPDT, when MaltParser istrained on the treebank with fine-grained gold part-of-speech tags andonly basic dependency relations. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 164
Table 6.13: Labeled and unlabeled attachment scores and label accuracyon the development set when MaltParser was trained on UPDT withfine-grained part-of-speech tags and merely basic dependency relations. . 165
Table 6.14: Labeled and unlabeled attachment scores, and labelaccuracy on the development set resulting from 8 empirical studieswhere MaltParser was trained on UPDT with different simplifications ofannotation schemes in part-of-speech tagset and dependency relations.Baseline = Experiment with a fine-grained annotated treebank, CPOS =

Experiment with coarser-grained part-of-speech tags and fine-graineddependency relations, 1LVC = Experiment with fine-grainedpart-of-speech tags and dependency relations free from distinctivefeatures in light verb construction, and Basic DepRel = Experiment withfine-grained part-of-speech tags and merely basic dependency relations. . 166
Table 6.15: Best results given by different parsers when trained onUPDT with auto part-of-speech tags, 1LVC, CompRel in the modelassessment. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 169
Table 6.16: The evaluation of the ParsPer when tested on 100 randomlyselected sentences from the web-based journal Hamshahri. LR =Labeled Recall, LP = Labeled Precision, UR = Unlabeled Recall, UP =Unlabeled Precision, AS = Automatically Segmented, AT =Automatically Tagged, AP = Automatically Parsed, MS = ManuallySegmented, and MT = Manually Tagged. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 171
Table 6.17: Precision and recall of binned head direction obtained whenParsPer was evaluated on 100 manually tokenized and automaticallytagged sentences taken from the web-based journal Hamshahri. . . . . . . . . . . . . . . . 172
Table 6.18: Precision and recall of binned head distance obtained whenParsPer was evaluated on 100 manually tokenized and automaticallytagged sentences taken from the web-based journal Hamshahri. . . . . . . . . . . . . . . . 172

List of Figures
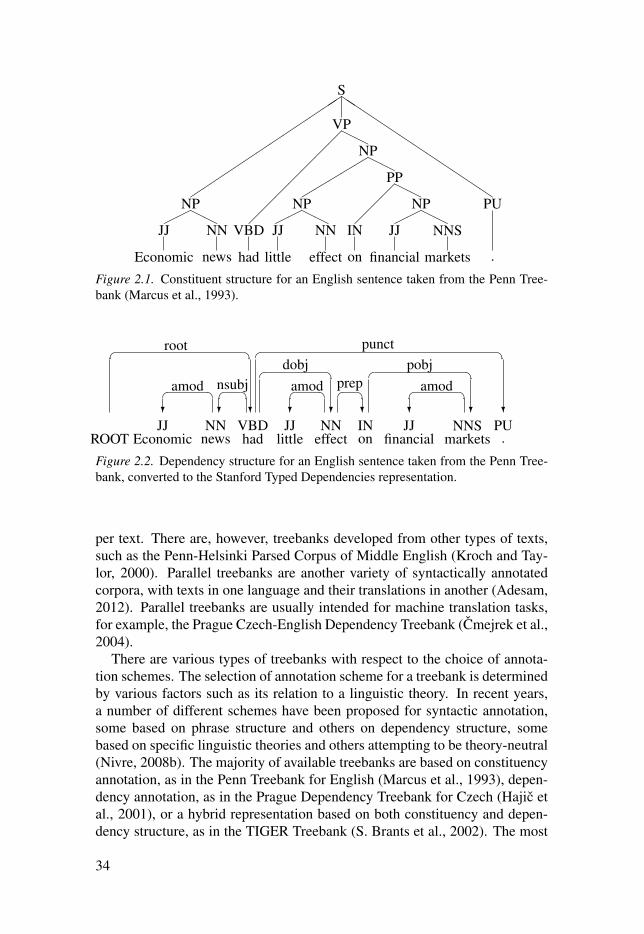
Figure 2.1: Constituent structure for an English sentence taken from thePenn Treebank (Marcus et al., 1993). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34Figure 2.2: Dependency structure for an English sentence taken from thePenn Treebank, converted to the Stanford Typed Dependenciesrepresentation. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34Figure 2.3: Constituency annotation in the IBM Paris Treebank. . . . . . . . . . . . . . . 35Figure 4.1: Persian natural language processing pipeline. . . . . . . . . . . . . . . . . . . . . . . . . . 83Figure 5.1: Data selection of the UPDT. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100Figure 5.2: Syntactic annotation of a Persian sentence. Gloss: she/hebook ra delivery-ez book.house give.past.3sg. Translation: She/hedelivered the book to the library. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121Figure 5.3: Syntactic annotation for a Persian sentence with Englishgloss. To make the figure more readable, glosses have been simplified asfollows: humans = human-pl, animals-e = animal-pl-ez, facts = fact-pl,take = cont-take.pres-3pl, features-e = feature-pl-ez, specific-e =specific-ez, own = self, have = have.pres-3pl, look-a = look-indef,kind-are = kind-be.pres-3pl. Gloss: human-pl and animal-pl-ez Bornalthough from fact-pl effect cont-take.pres-3pl, feature-pl-ez specific-ezself ra have.pres-3pl and in look-indef general all of onekind-be.pres.3pl. Translation: Although (Adolf) Born’s humans andanimals are affected by realities, they have their own specialcharacteristics and in (a) general (look) all are of the same kind. . . . . . . . . . . . . . . 127Figure 5.4: Syntactic annotation of a Persian sentence taken from thePerDT. To make the figure more readable, glosses have been simplified asfollows: they = this-pl, became = become.past-3pl, are = be.pres.3pl. Thesentence is illustrated based on two different annotation schemes: PerDTannotation and UPDT annotation. Gloss: from time-indef that they witheach.other familiar become.past-3pl happy be.pres-3pl. Translation:Since the time they became familiar with each other they are happy. . . . . . . . . 141Figure 5.5: Syntactic annotation of a Persian sentence taken from thePerDT. To make the figure more readable, glosses have been simplifiedas follows: want = cont-want.pres-3pl, do = sub-do.pres-3pl. Thesentence is illustrated based on two different annotation schemes: PerDTannotation and UPDT annotation. Gloss: if even cont-want.pres-3pl mera execution sub-do.pres-3pl, sub-do.pres-3pl. Translation: Even if theywant to execute me, let them do it. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 144


AcknowledgementsDuring my doctoral research, I have received lots of guidance, encouragement,and support from a number of people. First and foremost, I would like toexpress my special gratitude to my main supervisor Joakim Nivre and myco-supervisor Carina Jahani. I am extremely thankful to Joakim Nivre forhis continuous guidance and advice throughout the entire project as well asthe writing phase of this thesis. Joakim’s rich knowledge of ComputationalLinguistics, clear guidance, and valuable suggestions have been a great assetin my research studies. He has always been an endless source of inspirationin my work and someone whom I could count on to answer my questions. Iam deeply indebted to Carina Jahani for her expertise in Persian linguistics.Carina’s wealth of knowledge and reflection about Persian grammar and theguidance she has provided have been a significant advantage throughout myresearch process. As a PhD student with one foot in Computational Linguisticsand the other in the Persian language (as a native speaker) I feel immenselylucky to have had this opportunity to receive full support and deep scholarlyguidance from two experts in these two fields. Their expertise was a perfectmatch to my research area.
I would also like to thank Anna Sågvall Hein, my first main supervisor, foraccepting me as her PhD student. Although I did not have the chance to workclosely with her, as she retired soon after I started my work, I am grateful forthe opportunity I was given to enter into this research field.
This research would not have been possible to complete without the help Ireceived from staff and colleagues at the Department of Linguistics and Philol-ogy, as well as other researchers from elsewhere. At our department, I amimmensely thankful to Jörg Tiedemann for his guidance and help with the Up-lug tokenizer when I was adapting the software to Persian. Even though Icame by his office unexpectedly, knocking at the door as an unexpected vis-itor, he kindly answered my questions and helped me. Thank you! Lookingback, I realize that I should have booked a time. I will do that next time! Iam thoroughly thankful to Per Starbäck for his technical support. He has al-ways been very helpful and promptly resolved technical problems that arose,as well as answering my questions related to Uppsala University’s thesis tem-plate and coming up with new solutions that saved me much time. I would alsolike to thank Bengt Dahlqvist for acquainting me with the Ruby programminglanguage and answering related questions when I began developing the Per-sian normalizer in Ruby, and also for technical support once Per Starbäck wasnot available. I am deeply thankful to Forogh Hashabeiky, Mahmoud Hassan-abadi, and Esmat Esmaeili at the Persian language department for their fruitfuldiscussions, valuable advice, and suggestions regarding Persian orthography,morphology, and syntax. Even though we did not always agree on differentissues in Persian grammar, the discussions always opened my mind to thinkdifferently and see things from other points of view.
17

I would like to express my special thanks to other (former or present) col-leagues and friends at the department for their support, scholarly interaction,kind messages, company during coffee breaks or Fridays after work, or sim-ple chats in the pantry: Aynur Abish (my former officemate), Jakob Anders-son, Ali Basirat, Miguel Ballesteros, Mats Dahllöf, Marie Dubremetz, Megh-dad Farahmand, Christian Hardmeier, Eva Martinez Garcia, Daisy GurdeepKaur, Birsel Karakoç, Mattias Nilsson (my former college classmate and of-ficemate), Alexander Nilsson, Padideh Pakpour, Eva Pettersson, Yan Shao,Guiti Shokri, Aron Smith, Sara Stymne, Heinz Werner Wessler, and Vera Wil-helmsen. I am also thankful to Beáta Megyesi for her feedback and commentson some of my published articles.
I am enormously indepted to Yvonne Adesam, from Gothenburg Univer-sity, for her valuable comments and feedback when she acted as opponent atmy mock defense. I am especially thankful to Mahmood Bijankhan, fromTehran University, for kindly answering my e-mails related to the BijankhanCorpus, as well as to Hamid Hassani from the Academy of Persian Languageand Literature in Tehran, for his replies regarding the Persian linguistics. Iwould like to extend my very special thanks to Jon Dehdari, from Ohio StateUniversity, for patiently answering my questions related to the Persian LinkedGrammar Parser and cordially sharing his annotation scheme and a numberof selected annotated sentences that I used as a starting point for my workwith the treebank creation. I am extremely thankful to Jan Štepánek and Mar-tin Kruliš from Charles University in Prague, and Petr Pajas from Google inZürich (former member of the TrEd development team), for kindly followingup bugs I encountered when working with TrEd and also for their efforts toreconfigure the Tk library so that TrEd could work smoothly for Persian ona Mac! I am deeply grateful to Bernd Bohnet, from Google in London, forhis kindness and generous collaboration, running multiple experiments withdifferent Mate Parsers during the time I was tuning parameters within the tree-bank. I am particularly thankful to Recorded Future Inc. for their financialsupport in developing the treebank.
I am very grateful to Sara and her husband Pezhman for their many yearsof friendship. In particular, I am thankful to Sara for all those girls’-nights-outand the laughs we shared together. Thanks for all the fun stories we suspi-ciously made up about people who crossed our path on our way back to thecar after watching horror movies. You always made me forget about the hardwork I was doing and I enjoyed the moments to the full, like in my teenageyears. Thank you for all the wonderful memories!
Finally, I would like to express my deepest appreciation and respect to mydear parents for their lifelong support and unconditional love and encour-agement. Special thanks go to my sister for her love, care and friendshipthroughout my life, and also for designing and creating that beautiful imageof the tree with Persian sentences for foliage, resembling the shape of Iranon the map, that I used as a symbol in my work on the treebank. Last but
18

certainly not least, I am endlessly grateful to my dear family who enduredthe great amount of time I was away from them working on this thesis. I amwholeheartedly thankful to my sons, Babak and Hooman, the joys of my life,for collaborating with their mom in being more independent and doing theireveryday chores excellently. One final special thank you goes to my husbandfor his love and support and for taking on more responsibility at home so thatI could concentrate on my research.
Uppsala, April 2015Mojgan Seraji
19


Glossing Abbreviations
cl classifier
cont continuous
ez ezafe construction
fut future
gl glide
indef indefinite
inf infinitive
neg negation
past past
pc pronominal clitic
pl plural
pp past participle
pres present
sg singular
sub subjunctive mood
voc vocative
21


1. Introduction
Can computers overtake human beings when it comes to the ability to pro-duce and understand language? We live in an era characterized by real-timecommunication in which searching for, exchanging, and sharing informationhappen instantaneously, and we can therefore make use of machines that canunderstand and process human language. Machines should also be able toprovide support when we face language barriers. Over the past decades, var-ious techniques have been applied to develop tools for automatic processingof human language at different levels. Although computers are still far frombeing able to match human ability, modern breakthroughs in computationallinguistics have resulted in innovative applications in such areas as informa-tion retrieval, information extraction, machine translation, speech technology,and human-machine communication.
Techniques in computational linguistics are to some extent language in-dependent but are always dependent on the availability of language-specificresources. In particular, most approaches today rely on statistical machinelearning techniques. Systems based on supervised machine learning have theadvantage of being readily adapted to any specific domain or language, givendata sets annotated with linguistic information of that language. However,machine learning techniques require large data sets, and preferably annotatedones, for the induction of linguistic structure. In addition, they require toolsfor processing language specific data.
Thus, every language needs standardized and publicly available resourcessuch as dictionaries, lexicons, general and specialized corpora, as well as toolsfor processing data. The notion of a Basic Language Resource Kit (BLARK)has been coined for the resources and tools needed to develop language tech-nology applications for a given language. In order to be maximally useful, aBLARK should be reusable and freely available. Reusability and open accessof language specific resources and tools enable researchers and developers toeasily enlarge and modify the source materials. This may improve the qualityof data analysis results and at the same time reduce the cost and time for de-velopment. Otherwise, there is a risk that each developer will have to recreateresources and tools for more advanced language processing tasks.
Languages vary greatly in terms of the number of resources and tools thatare available. Most languages still lack basic resources and tools for languageprocessing. Persian is one of the languages with a sizable number of nativespeakers in the world. Yet, it still belongs to the group of languages with rela-tively few annotated data sets and tools. Importantly, most of those resources
23

and tools that do exist are not freely available. Although a certain amountof resources and tools have been developed recently in Persian computationallinguistics, there is still a great need to develop new ones. The aim of myresearch is to contribute to this effort.
Developing language resources and tools for Persian can additionally ben-efit computational linguistics in general. A language like Persian offers partlydifferent challenges compared to languages that have received more attention,in particular English. The lack of standardization in Persian orthography poseschallenges for tokenization that further impact the quality of morphologicaland syntactic analysis. Persian syntactic structure exhibits special character-istics, in particular the prevalence of complex predicates in the form of so-called light verb constructions. There are thus a variety of challenges in Per-sian on various levels, from orthography to syntactic structure. Hopefully, themethods and solutions put forward in this thesis can ease the way for otherlanguages with similar linguistic and orthographic characteristics to developlanguage resources and tools.
1.1 Goals and Research QuestionsThe major research motivation behind this doctoral thesis is to develop opensource language resources and tools for Persian. The goal is to make the lan-guage technology infrastructure richer and hopefully move it a step closer to afull-fledged BLARK for this language. More specifically, I want to improve apart-of-speech tagged corpus and build a dependency-based treebank for Per-sian. In addition, I want to develop a normalizer, a sentence segmenter andtokenizer, a part-of-speech tagger, and a parser for Persian text processing.
In pursuing this goal I observe two important requirements. The first isthe compatibility requirement, which has two parts. On the one hand, toolsare meant to be run in a pipeline, where the output of one tool must be com-patible with the input requirements of the next. For example the output of apart-of-speech tagger must match the input requirements of a syntactic parser.Accordingly, the pipeline will take raw text as input and provide syntacticallyanalyzed text as output. On the other hand, I want the tools to deliver the sameanalysis that is found in the annotated corpora. Otherwise, it is impossible touse the annotated corpora to train new tools that can be applied to the outputof the pipeline.
The second requirement is one of necessity. To be able to develop theseresources and tools within the scope of a thesis project the development mustbe based on reuse of existing resources and tools. Thus, the corpus resourcesdeveloped will be based on the only freely available tagged corpus of Persian,the Bijankhan Corpus (Bijankhan, 2004), and tools for morphological andsyntactic analysis will be created by adapting existing tools to Persian.
24

The goals and requirements together raise the following research questions:
Q-1 How can we develop morphologically and syntactically annotatedcorpora and tools while satisfying the requirements of compatibility andreuse?
Q-2 How accurately can we perform morphological and syntactic analysis forPersian by adapting and applying existing tools to the annotated corpora?
The first question addresses the interaction between different linguistic lev-els with respect to segmentation and annotation when modifying the exist-ing annotation scheme in the Bijankhan Corpus for higher linguistic analysis.Adding a syntactic annotation layer imposes new requirements on lower lay-ers, and the question is how I can best satisfy these requirements without re-segmenting and reannotating all the data from scratch. The situation is furthercomplicated by inconsistencies in Persian orthography with respect to syn-tactically significant elements such as clitics. The modifications are basicallyimprovements made on tokenization and part-of-speech tagging to make thecorpus more appropriate for syntactic analysis. In other words, the corpus isto be used as the basis for a dependency-based treebank for Persian.
The second question will be addressed by adapting and evaluating standardtools built on resources in question 1. For this, I make use of standard methodsand state-of-the-art tools. Among the tools I have selected are the sentencesegmentation and tokenization tools in Uplug (Tiedemann, 2003), the part-of-speech tagger HunPoS (Halácsy et al., 2007), and the data-driven parsergenerator MaltParser (Nivre et al., 2006). Adapting these tools and evaluatingthem on the morphologically and syntactically annotated corpora will providebenchmarks for morphosyntactic analysis of Persian.
1.2 Research MethodologyComputational linguistics is a multidisciplinary field, which uses methodsfrom several different sciences. Developing resources and tools can be seenas part of design science, where the notion of utility is of prime importance.Annotating corpora is a form of linguistic analysis which draws upon a longtradition of descriptive and theoretical linguistics. Evaluating tools is a kindof experimental science, based on principles for experimental design and sta-tistical inference for hypothesis testing.
Resources and tools for a specific language must be designed to match cer-tain characteristics of that language. In developing the annotated resources, Itherefore take advantage of the Persian grammatical tradition. However, theresources and tools must also serve the needs of practical language technol-ogy, which means that I will need to adapt the traditional descriptions to fit
25

the needs of automatic processing and make sure that the requirements forcompatibility can be met.
In developing the pipeline I take advantage of both rule-based and statisticaltechniques. More specifically, the development of the normalizer, the sentencesegmenter, and the tokenizer follow a rule-based approach and the creationof the part-of-speech tagger and the dependency parser are oriented towardsstatistical language modeling. For the treebank development I further employstatistical bootstrapping.
To address the first research question I will systematically study the linguis-tic properties of Persian and try to come up with suitable methods given the re-quirements of compatibility. For automatic modeling of the Persian languageI employ statistical methods, which are to some extent language independent,while the methods used for data representation are to a great extent dependenton the linguistic properties of words, phrases, and sentences (morphologicaland syntactic structure) in Persian.
To address the second research question I will rely on the established ex-perimental methodology for evaluation in computational linguistics. By mea-suring the accuracy of a tool on a sample of data that has not been used indeveloping the tool, we can use statistical inference to estimate the generalaccuracy of the tool or to test hypotheses about the relative merits of differenttools.
In the rest of the thesis, methods for research and development will not bediscussed in separate subsections. Instead this discussion will be integratedinto the discussion of tools and resources, so that different methodologicalchoices can be justified in the proper context.
1.3 Outline of the ThesisAfter introducing the goals and research questions in this introductory chapter,I organize the remainder of the thesis into the following chapters:
Chapter 2 provides background on morphosyntactically annotated corporaand tools. In addition, it gives a brief description of Persian and itsmain characteristics, as well as a discussion of challenges that arisein processing Persian text. The chapter ends with an overview ofexisting morphosyntactic corpora and tools for Persian.
Chapter 3 introduces the Uppsala Persian Corpus, a part-of-speech taggedcorpus developed by improving the tokenization and part-of-speechtagging of the Bijankhan Corpus.
Chapter 4 presents tools for automatic analysis of Persian developed byreusing and modifying existing tools such as the sentence segmen-tation and tokenization tools in Uplug and the part-of-speech taggerHunPoS, all compatible with the Uppsala Persian Corpus. The chap-
26

ter ends with empirical evaluations of the sentence segmentation andtokenization tools, as well as the part-of-speech tagger, including adetailed error analysis.
Chapter 5 presents the Uppsala Persian Dependency Treebank, adependency-based treebank with an annotation scheme basedon Stanford Typed Dependencies. This chapter additionally pro-vides a comparison with an existing dependency-based treebank forPersian.
Chapter 6 presents extensive parsing experiments using MaltParser, explor-ing the impact on parsing accuracy of different label sets for bothpart-of-speech tags and dependency relations. Moreover, it presentsevaluations of different dependency parsers such as MSTParser, Tur-boParser, and MateParsers on the best selected treebank representa-tion. The chapter ends by introducing and evaluating a parsing toolfor Persian, developed by training the graph-based MateParser onthe Uppsala Persian Dependency Treebank.
Chapter 7 summarizes the main contributions of the thesis and ends withsuggestions for future research.
1.4 Previous PublicationsThis thesis is to a large extent based on the following publications:
Mojgan Seraji (2011). A Statistical Part-of-Speech Tagger for Persian. InProceedings of the 18th Nordic Conference of Computational Linguis-tics NODALIDA, pages 340–343, Riga, Latvia.
Mojgan Seraji, Beáta Megyesi, and Joakim Nivre (2012b). Bootstrapping aPersian Dependency Treebank. Linguistic Issues in Language Technol-ogy 7 (18), pages 1–10.
Mojgan Seraji, Beáta Megyesi, and Joakim Nivre (2012a). A Basic LanguageResource Kit for Persian. In Proceedings of the 8th International Con-ference on Language Resources and Evaluation (LREC), pages 2245–2252, Istanbul, Turkey.
Mojgan Seraji, Beáta Megyesi, and Joakim Nivre (2012c). DependencyParsers for Persian. In Proceedings of 10th Workshop on Asian Lan-guage Resources, 24th International Conference on Computational Lin-guistics (COLING), pages 35–44, Mumbai, India.
Mojgan Seraji, Carina Jahani, Beáta Megyesi, and Joakim Nivre (2013). Up-psala Persian Dependency Treebank: Annotation Guidelines. Depart-ment of Linguistics and Philology, Uppsala University.
Mojgan Seraji, Carina Jahani, Beáta Megyesi, and Joakim Nivre (2014). APersian Treebank with Stanford Typed Dependencies. In Proceedings of
27

the 9th International Conference on Language Resources and Evalua-tion (LREC), pages 796–801, Reykjavik, Iceland.
Mojgan Seraji (2013). PrePer: A Pre-processor for Persian. Presented at the5th International Conference on Iranian Linguistics (ICIL5), Bamberg,Germany. [Not published.]
Mojgan Seraji, Bernd Bohnet, and Joakim Nivre (2015). ParsPer: ADependency Parser for Persian. In Proceedings of the InternationalConference on Dependency Linguistics (DepLing 2015), Uppsala,Sweden. [Submitted.]
28

2. Background
This chapter provides background on morphosyntactically annotated corporaand tools for morphosyntactic analysis. More specifically, it discusses anno-tation schemes used in part-of-speech tagging and syntactic analysis of mono-lingual corpora, as well as standard methods for preprocessing, sentence seg-mentation and tokenization, data-driven part-of-speech tagging and parsing. Itfurther gives a brief description of Persian and its main orthographic, morpho-logical, and syntactic features, while discussing interdependent text processingissues. The chapter ends by presenting the existing morphosyntactic corporaand tools for morphosyntactic analysis of Persian.
2.1 CorporaCorpora are compiled collections of linguistic data, either in the form of writ-ten or spoken material, or transcriptions of recorded speech. The usefulnessof corpora for different purposes has grown over the past 50 years, as varioustypes of corpora have been developed and often enriched with linguistic in-formation. Nowadays, corpora with different types of linguistic informationhave become essential training resources for developing computational toolsby means of machine learning. Even systems that are based on hand-craftedrules need to be evaluated with annotated corpora. Corpora are further used asresources in linguistic research and for teaching and learning.
Most created corpora are monolingual. The classic Brown Corpus (Kuceraand Nelson, 1967) and the British National Corpus (BNC) (Aston andBurnard, 1998) are typical monolingual corpora for English. However, therealso exist multilingual parallel corpora containing texts in one language withtranslations in another. The Hansard Corpus (Roukos et al., 1995) based onrecords of proceedings in the Canadian Parliament in both English and French,and the European Parliament (EUROPARL) parallel corpus (Koehn, 2002),based on European languages, are typical multilingual parallel corpora.
General corpora exist that are designed to represent a wide variety of genresand domains. These corpora are used as standard references for a given lan-guage and contain samples from regional and national newspapers, technicaljournals, academic books, fiction, political statements, etc. General corporavary in size. Some are large, consisting of more than 100 million words,such as the BNC for modern British English, or the English Gigaword ver-sion 5 (Parker et al., 2011) with a total of more than 4 billion words (currently
29

the largest corpus of English). The latter corpus consists of 10 million docu-ments taken from different news outlets. Others are much smaller and contain1 million words, such as the Stockholm Umeå Corpus (SUC) (Capková andHartmann, 2006) for Swedish. There are also specialized corpora that are de-veloped merely to be a domain-specific. The Guangzhou Petroleum EnglishCorpus (Q.-b. Zhu, 1989), for instance, consists of 411,612 words of writ-ten English from the petrochemical domain. The Computer Science corpusof the Hong Kong University of Science and Technology (HKUST) (James etal., 1994) is a further example of a domain-specific corpus, and contains onemillion words of written English taken from textbooks in computer science.Monitor (or open-ended) corpora are another variety. These are constantlybeing updated with language changes in order to track the advent and life cy-cle of neologisms. The Corpus of Contemporary American English (COCA)(Davies, 2010), an example of this kind, was started in 1990 as the first elec-tronic archive monitor corpus. With its 450 million words (1990–2012), it isthe largest freely-available corpus of American English.
Corpora may contain metadata, namely information associated with a textsuch as title, author, date of publication, etc. Metadata related to different cor-pora is represented differently. For instance, metadata in early corpora suchas the Brown Corpus was provided in a separate reference manual (a large A4volume of typescript). However, nowadays, metadata is usually representedin an integrated form together with the corpus by a particular text encoding.There are various types of text encoding standards for corpora such as Text En-coding Initiative1 (TEI), Corpus Encoding Standard (CES) (Ide et al., 1996),and the XML version of CES (XCES) (Ide et al., 2000). Different corporamay additionally possess different character encodings such as ASCII, ISO-8859-1, etc. Unicode has a unique representation for every possible characterincluding alphabets, syllabaries, and logographic systems.
At present, many corpora are annotated at different linguistic levels. Theseannotation layers are generally accomplished sequentially from lower to upperlayers of linguistic information, i.e., first morphology, then syntax, and finallysemantics (Taulé et al., 2008). Each annotation process is performed manu-ally, semi-automatically, or fully automatically. The two most common layersof linguistic description are morphological and syntactic annotations. In thefollowing sections, we will review the structure and design of morphologicaland syntactic annotation schemes. Other types of annotation such as seman-tic annotation and discourse annotation will not be covered in this thesis. Itis worth noting that the terms morphological annotation and morphosyntacticannotation are sometimes used as synonyms and sometimes not. For clarity,in this thesis I have decided to use the term morphological annotation for an-notation at the word level, syntactic annotation for annotation at the sentencelevel, and morphosyntactic annotation as a term covering both.
1http://www.tei-c.org/index.xml
30

2.1.1 Morphological AnnotationCorpora annotated with morphological information are one of the fundamen-tal language resources and are a prerequisite for creating and evaluating lan-guage analysis modules such as morphological analyzers, taggers, chunkers,and parsers. Morphological annotation encodes different aspects of lexical in-formation such as part of speech (PoS), morphological features, and lemma.For example, the morphological analysis of the word cats could be: POS =NOUN, NUMBER = PLURAL, and LEMMA = cat. Lemma involves assigningeach word its basic form while morphological annotation involves assigningpart-of-speech tags to different tokens using a fixed list of tags called a tagset.Since I have not treated lemmas and have limited my work to part-of-speechand morphological features, I will not discuss lemmatization further.
There are various types of morphological information in different languagesthat require different kinds of markup. For example, some languages con-tain information about gender and some have case systems. Tagsets thereforevary from language to language depending on the linguistic characteristics andstructure of a particular language. Tagsets can also differ within a language.Depending on what a corpus is developed for, a tagset may contain more orless fine-grained distinctions. For instance, the noun category can be assigneddifferent fine-grained classifications, such as common noun for a word likebook and proper noun for a word like John. A fine-grained tagset can be rep-resented either with atomic tags that store and combine a part-of-speech tagwith its morphological features or with complex tags that are composed ofatomic tags and additional features. An example of a fine-grained tagset us-ing atomic tags is the Penn Treebank. Each tag represents a base categorytogether with specific atomic values, such as NN is a singular or mass com-mon noun, NNP is a singular proper noun, and NNS is a plural common noun.An example of a fine-grained tagset using complex tags is SUC (Capková andHartmann, 2006). In this tagset, each part-of-speech tag is followed by oneor more feature values, such as NN UTR PLU IND NOM, where NN denotesthe base part-of-speech tag noun, followed by the features UTR (specifies gen-der as common), PLU (defines number as plural), IND (marks indefiniteness),and NOM (represents nominative case). The number of tags in a tagset de-pends on how many morphological features exist in a language. There are, forexample, differences between the basic tagset for a morphologically ambigu-ous inflective language like Czech, with 1171 part-of-speech features, and apoorly inflected language like English, with 48 tags in Penn Treebank (Hladkáand Ribarov, 1998).
Various tagset systems in different annotated corpora often share a num-ber of major part-of-speech categories such as adjective, adverb, article, con-junction, determiner, interjection, noun, numeral, pre/postposition, pronoun,verb, and in many cases punctuations (van Halteren, 1999). These main cat-egories can easily be further analyzed according to morphological features of
31

the word, giving a more fine-grained annotation. Miscellaneous categoriesthat may not fit into other tagsets, such as symbols, abbreviations, foreign ex-pressions, and so forth can be defined as special tags. Special tags can furtherbe combined with the major part-of-speech categories in a special tag systemfor specific texts and specific languages.
As languages differ greatly with regard to morphological complexity, itseems to be difficult to include all varieties of languages within one standard-ized annotation scheme. However, because the sharing, merging, and compar-ison of language resources is increasingly common in language technology,the use of common standards and interoperability between resources are to alarge extent taken into consideration.
So far, certain fundamental principles for morphological annotation havebeen adopted and many attempts have been made to create different standardsfor different languages. In natural language processing, different approacheshave been suggested to facilitate future research and to standardize best-practices. An elementary morphological annotation set based on language-independent recommendations, the EAGLES tagset, proposed in Leech andWilson (1994) was an early attempt in this area. Morphological labels wereinitially provided for English and Italian. Leech and Wilson (1994) proposedthat any morphological tagset should be at a level that can easily be mappedonto an intermediate tagset. The aim was to demonstrate what is commonbetween different languages and what options are available for extension oromission. The basic idea underlying this statement is to represent a set ofcommon morphological categories that exist across languages and are oftenrealized as universals. Multext-East (Erjavec and Ide, 1998), for instance, wasa project that used the same formal EAGLES-based morphological tagset formultiple languages, namely, Bulgarian, Czech, English, Estonian, Hungarian,Romanian, and Slovene. The project resulted in an annotated multilingual cor-pus (Erjavec and Ide, 1998) containing a speech corpus, a comparable corpusand a parallel corpus, lexical resources (Tufis et al., 1998), and tool resourcesfor the seven languages (Erjavec et al., 2003). The specifications were laterextended to cover nine languages five of which are Slavic: Bulgarian, Croat-ian, Czech, Serbian, and Slovene. Interset (Zeman, 2008) is a further exampleof an interlingual morphological tagset. It contains a universal set of partsof speech as well as morphological features such as gender, number, tense,etc. Through the Interset, any morphological tagset of any language can beconverted into any other tagset using the Interset representation as an interlin-gua. In other words, Interset is used to encode language specific tagsets in ajoint and uniform representation. Some features of the source tags may be lostduring conversion however. This may, to a great extent, be dependent on thefeatures that the target tagset can take in. More recently, Petrov et al. (2012)proposed a tagset containing twelve universal part-of-speech categories thatcover the most frequent word classes in different languages. A mapping fromfine-grained part-of-speech tags for 25 different treebanks is additionally in-
32

cluded into this universal set. When the original treebank data is included, theuniversal tagset and mapping produce a data set containing common part-of-speech tags for 22 different languages.
As we have seen, different approaches to multilingual morphological speci-fication have been presented as leading towards one standard analysis to makeit easier to add new languages. Yet, it is still far from simple to adopt a groupof inflectional tags or select what kinds of attributes and values to use as onesingle universal tagset. In other words, there is still no unified standardizedmorphological annotation scheme.
Developing morphologically annotated corpora is highly time-consuming.Therefore different techniques are usually applied in their creation with an in-terplay between automatic analysis and manual linguistic revision in order toreduce costs while preserving quality. A bootstrapping procedure is thereforeusually employed in order to increase the size of an annotated corpus. The pro-cess starts by training a part-of-speech tagger on a seed data set of manuallyannotated and validated data and then using the induced model to tag a subsetof raw texts. The tagged corpus is corrected and then added to the trainingset. The tagger is retrained with the new extended training data to tag addi-tional raw texts. This process is iterated as the size of the corpus grows andthe quality of the tagger improves because more training data ensures betterperformance.
As morphological specifications are based on the notion of words, they arenot sufficient for the structure of linguistic analysis at sentence level. There-fore, an additional layer of syntactic analysis is required, as will be describedin the next subsection.
2.1.2 Syntactic AnnotationOver the past decades there has been increasing interest in developing differ-ent syntactically annotated corpora, treebanks, for many languages, focusingon grammatical representations beyond the morphological analysis level. Insyntactically annotated corpora, each sentence is annotated with its syntacticstructure. Treebanks are often built on an already annotated corpus that haspart-of-speech tags and sometimes is enhanced with semantic information.Treebanks are typically much smaller in size than the part-of-speech taggedcorpora they are built on, usually containing between 50,000 and 1,000,000tokens.
Selecting a subset of corpus material to include as treebank data is a crucialconsideration, as it is for any annotated corpus. Since treebanks are usuallybased on previously established corpora, they inherit the genres of the originalcorpus (Nivre, 2008b). For instance, the SUSANNE Corpus (Sampson, 1995)is based on a subset of the Brown Corpus (Kucera and Nelson, 1967). Thegenre on which most available treebanks are based is contemporary newspa-
33
JJ
Economic
��
NN
news
HH
������������
NP
VBD
had
�������VP
S
JJ
little
��
NN
effect
HH
"""""
HH
NP
NP
IN
on
���
HH
PP
JJ
financial
��
NNS
markets
HH
HH
NP PU
.
QQQ
QQQQQ
Figure 2.1. Constituent structure for an English sentence taken from the Penn Tree-bank (Marcus et al., 1993).
ROOTJJ
Economic
� �?
amod
NNnews
� �?
nsubj
VBDhad
� �?
root
JJlittle
� �?
amod
NNeffect
� �?
dobj
INon
� �?
prep
JJfinancial
� �?
amod
NNSmarkets
� �?
pobj
PU.
?
� �punct
Figure 2.2. Dependency structure for an English sentence taken from the Penn Tree-bank, converted to the Stanford Typed Dependencies representation.
per text. There are, however, treebanks developed from other types of texts,such as the Penn-Helsinki Parsed Corpus of Middle English (Kroch and Tay-lor, 2000). Parallel treebanks are another variety of syntactically annotatedcorpora, with texts in one language and their translations in another (Adesam,2012). Parallel treebanks are usually intended for machine translation tasks,for example, the Prague Czech-English Dependency Treebank (Cmejrek et al.,2004).
There are various types of treebanks with respect to the choice of annota-tion schemes. The selection of annotation scheme for a treebank is determinedby various factors such as its relation to a linguistic theory. In recent years,a number of different schemes have been proposed for syntactic annotation,some based on phrase structure and others on dependency structure, somebased on specific linguistic theories and others attempting to be theory-neutral(Nivre, 2008b). The majority of available treebanks are based on constituencyannotation, as in the Penn Treebank for English (Marcus et al., 1993), depen-dency annotation, as in the Prague Dependency Treebank for Czech (Hajic etal., 2001), or a hybrid representation based on both constituency and depen-dency structure, as in the TIGER Treebank (S. Brants et al., 2002). The most
34

widely used representations are constituency and dependency. Figure 2.1 andFigure 2.2 show an English sentence annotated with constituency and depen-dency structure.
Constituency structure (also referred to as phrase structure) is defined withphrases that are built of smaller phrases. In other words, each sentence is de-composed into its constituent parts. As pointed out by Hladká and Ribarov(1998), the Penn treebank for English has been very influential for the devel-opment of similar treebanks such as Penn Arabic Treebank (ATB) (Maamouriet al., 2004), Penn Chinese Treebank (Xue et al., 2005) and so forth.
Syntactic bracketing is a constituency-based representation format that wasused in early large-scale project such as the Lancaster Parsed Corpus (Garsideet al., 1992) and the original Penn treebank (Marcus et al., 1993). The an-notation contains part-of-speech tagging for tokens and syntactic relations forphrase categories. An example from the IBM Paris Treebank, using a variantof the Lancaster annotation, taken from Nivre (2008b), is shown in Figure 2.3.
[N Vous_PPSA5MS N][V accedez_VINIP5
[P a_PREPA[N cette_DDEMFS session_NCOFS N]
P][Pv a_PREP31 partir_PREP32 de_PREP33
[N la_DARDFS fenetre_NCOFS[A Gestionnaire_AJQFS
[P de_PREPD[N taches_NCOFP N]
P]A]
N]Pv]
V]
Figure 2.3. Constituency annotation in the IBM Paris Treebank.
In dependency-based representations, on the other hand, syntactic structureis viewed as a set of linked asymmetric and binary head-dependent relationsrather than as a set of nested constituents. Every word in a dependency rep-resentation normally has at most one head governing it, and each head anddependent relation is marked and annotated with functional categories indi-cating the grammatical function (such as subject and object) of the dependentto the head. Dependency structure has become increasingly common in re-cent years, particularly for languages with flexible word order. The PragueDependency Treebank for Czech (Hajic et al., 2001) has been very influentialin this development, and dependency-based treebanks now exist for Arabic
35

(Hajic et al., 2004), Basque (Aduriz et al., 2003), Danish (Kromann, 2003),Greek (Prokopidis et al., 2005), Russian (Boguslavsky et al., 2000), Slovene(Džeroski et al., 2006), Turkish (Oflazer et al., 2003), Chinese (Chang et al.,2009), and Finnish (Haverinen et al., 2013), among other languages.
The Stanford Typed Dependencies (STD) Representation (de Marneffe andManning, 2008) is a dependency-based annotation scheme that was originallydeveloped as an automatic procedure for converting a constituency-based rep-resentation into a dependency-based one. STD has been designed to be cross-linguistically valid, and the scheme has become a de facto standard for En-glish. So far, it has been successfully adapted to different types of languagessuch as Chinese (Chang et al., 2009), Finnish (Haverinen et al., 2010), andModern Hebrew (Tsarfaty, 2013). In the basic version of STD, the depen-dency annotation of a sentence always forms a tree that contains all tokensof the sentence (including punctuation) and is rooted at an artificial root nodeprefixed to the sentence. There is also a collapsed version of STD as opposedto the basic version, where some tokens may not correspond to nodes in thedependency structure and a single node may have more than one incomingarc. A more detailed description of STD and the grammatical relations (de-pendency labels) will be given in Chapter 5, where I present the constructionof the Uppsala Persian Dependency Treebank, which is based on Stanforddependencies.
Moreover, de Marneffe et al. (2014) propose the Universal Stanford Depen-dencies, which is an improved taxonomy of STD to better cover grammaticalrelations across many languages. The proposed universal taxonomy can eas-ily be mapped onto the existing dependency schemes described in Chang etal. (2009), Bosco et al. (2013), Haverinen et al. (2013), Seraji et al. (2013),Tsarfaty (2013), and Mcdonald et al. (2013), which are drawn from STD (deMarneffe et al., 2014). Since the scheme was introduced after I released theUppsala Persian Dependency Treebank I have not yet applied it to the tree-bank. However, some relations in the Universal Stanford Dependencies areinfluenced by the relations introduced in Seraji et al. (2013), as will be dis-cussed in Section 5.3.
In addition to purely constituency- and dependency-based schemes, thereare schemes that combine elements of both. SUSANNE (Sampson, 1995), forinstance, was developed by extending the original constituency-based schemeto include a scheme of grammatical functions. Additional cases that make useof two independent annotation layers, one for constituency- and one for de-pendency structure, are the TIGER annotation scheme for German (S. Brantset al., 2002), and the VISL (Visual Interactive Syntax Learning) scheme for22 languages developed on a small scale and subsequently used in develop-ing treebanks for Portuguese (Afonso et al., 2002) and Danish (Bick, 2003).The Prague Dependency Treebank (Hajic et al., 2001), the Turin UniversityTreebank (Bosco and Lombardo, 2004), and the Sinica treebank (Huang et al.,2000) are further examples of treebanks combined with semantic annotation
36
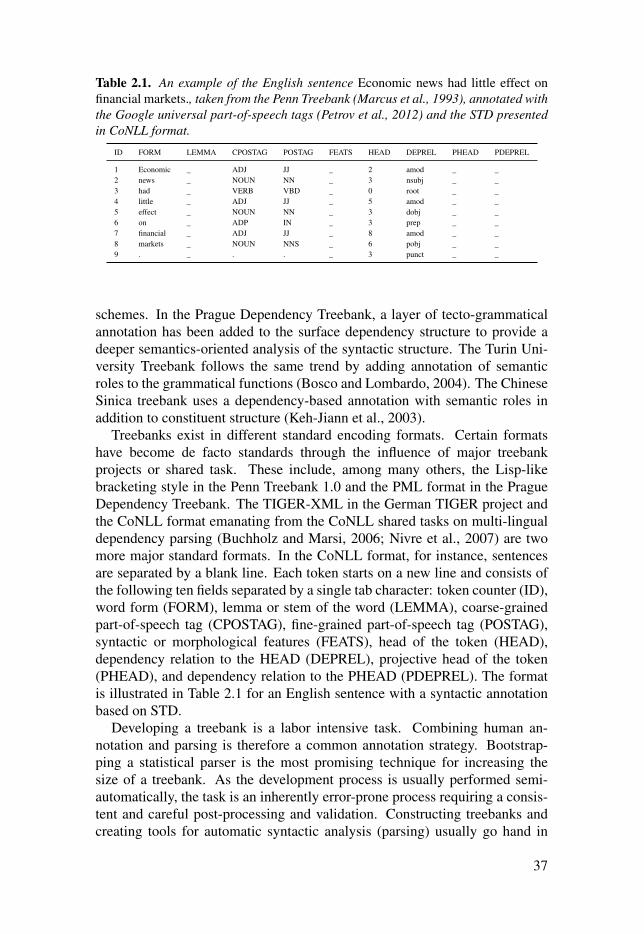
Table 2.1. An example of the English sentence Economic news had little effect onfinancial markets., taken from the Penn Treebank (Marcus et al., 1993), annotated withthe Google universal part-of-speech tags (Petrov et al., 2012) and the STD presentedin CoNLL format.
ID FORM LEMMA CPOSTAG POSTAG FEATS HEAD DEPREL PHEAD PDEPREL
1 Economic _ ADJ JJ _ 2 amod _ _2 news _ NOUN NN _ 3 nsubj _ _3 had _ VERB VBD _ 0 root _ _4 little _ ADJ JJ _ 5 amod _ _5 effect _ NOUN NN _ 3 dobj _ _6 on _ ADP IN _ 3 prep _ _7 financial _ ADJ JJ _ 8 amod _ _8 markets _ NOUN NNS _ 6 pobj _ _9 . _ . . _ 3 punct _ _
schemes. In the Prague Dependency Treebank, a layer of tecto-grammaticalannotation has been added to the surface dependency structure to provide adeeper semantics-oriented analysis of the syntactic structure. The Turin Uni-versity Treebank follows the same trend by adding annotation of semanticroles to the grammatical functions (Bosco and Lombardo, 2004). The ChineseSinica treebank uses a dependency-based annotation with semantic roles inaddition to constituent structure (Keh-Jiann et al., 2003).
Treebanks exist in different standard encoding formats. Certain formatshave become de facto standards through the influence of major treebankprojects or shared task. These include, among many others, the Lisp-likebracketing style in the Penn Treebank 1.0 and the PML format in the PragueDependency Treebank. The TIGER-XML in the German TIGER project andthe CoNLL format emanating from the CoNLL shared tasks on multi-lingualdependency parsing (Buchholz and Marsi, 2006; Nivre et al., 2007) are twomore major standard formats. In the CoNLL format, for instance, sentencesare separated by a blank line. Each token starts on a new line and consists ofthe following ten fields separated by a single tab character: token counter (ID),word form (FORM), lemma or stem of the word (LEMMA), coarse-grainedpart-of-speech tag (CPOSTAG), fine-grained part-of-speech tag (POSTAG),syntactic or morphological features (FEATS), head of the token (HEAD),dependency relation to the HEAD (DEPREL), projective head of the token(PHEAD), and dependency relation to the PHEAD (PDEPREL). The formatis illustrated in Table 2.1 for an English sentence with a syntactic annotationbased on STD.
Developing a treebank is a labor intensive task. Combining human an-notation and parsing is therefore a common annotation strategy. Bootstrap-ping a statistical parser is the most promising technique for increasing thesize of a treebank. As the development process is usually performed semi-automatically, the task is an inherently error-prone process requiring a consis-tent and careful post-processing and validation. Constructing treebanks andcreating tools for automatic syntactic analysis (parsing) usually go hand in
37

hand, as there is a symbiotic relation between designing resources and evolv-ing data-driven tools. The advantage of the method is that when errors arecorrected in the treebank, the parser, when retrained on the corrected data,provides a more correct analysis of new input sentences.
2.2 ToolsLanguage technology tools are programs for the generation and analysis oflanguage. Among the most basic and important automatic tools are tools forpreprocessing, sentence segmentation and tokenization, part-of-speech tag-ging, and parsing. Various types of language technology tools perform anal-ysis at different levels, as there are hierarchical inter-dependencies betweenthe tools. Considering the hierarchical relations, some syntactic parsers, forinstance, rely strongly on words that have already been morphologically an-alyzed and tagged with parts of speech. Similarly, part-of-speech tagging re-quires texts to be segmented into sentences and further for words to be tok-enized and distinguished from each other in order to perform analysis at theword level. There is a close connection between tools and annotation, as dis-cussed in the previous section, because annotated data is used for training andevaluation. In general, we want the two to be compatible.
2.2.1 PreprocessingText preprocessing (normalization) is the process of converting a non-standardtextual representation into a canonical form. This process is typically consid-ered the first task for any NLP system, and it is language-dependent. Prepro-cessing data is counted as an essential step in counteracting the effect of theprinciple garbage in, garbage out. When noisy data is sent in, bad results arereturned in the output data, which diminishes the accuracy of the languageanalysis.
Huge quantities of textual data are constantly being uploaded to the Internet.The data often includes non-standard token types such as words written in spe-cific digit sequences, mixed case words (WinNT, SunOS), misspelled words,acronyms, abbreviations, mixed writing styles of multi-word expressions, uni-versal resource locators (URLs) and e-mail addresses, roman numerals, andso forth. Preprocessing may additionally involve the elimination or conver-sion of typical noise such as extra line breaks, extra punctuation marks beforeor after words, lack of space as well as extra spaces between words, etc.. Apreprocessor basically rewrites texts in a standard form. Text normalizationis traditionally performed by an in-house tool and is treated in a more or lessad hoc fashion, often by using rules or machine learning methods at differentlevels (C. Zhu et al., 2007).
38

2.2.2 Sentence SegmentationSentence segmentation, commonly considered the second process in a pipelineof natural language processing, deals with splitting a text into single sentencesby recognizing the sentence boundaries. Automatic recognition of sentenceboundaries via a computer program is a straightforward process when a lan-guage has an explicit sentence termination using punctuation. However, thetask can be complex for languages lacking clearly defined punctuation marksas sentence boundaries. Thai, for instance, does not use any punctuation marksto define sentence boundaries. Aroonmanakun (2007) in an experiment showsthat Thai sentence segmentation performed by different persons can be dif-ferent. The same may also hold for languages with clearly defined sentenceboundaries, because adherence to a set of rules for sentence and clause bound-aries may vary dramatically depending on author and type of text. For in-stance, it may be unclear whether a title is a sentence or not.
Punctuation marks are clue symbols indicating the structure of a writtentext, in terms of where intonation, pauses, and emphasis are to be observed.The concept of what constitutes a sentence is to some extent arbitrary anddepends largely on an author’s adherence to conventions. Delimiters such asfull stop, question mark, and exclamation mark are usually used as sentenceboundaries in most NLP applications (Palmer, 2000). However, the punctu-ation mark used to mark a full stop (.) in English and other European lan-guages is also used in abbreviations, as a decimal point, and to mark suspenseor ellipses (...), etc. This can obstruct correct sentence segmentation becausethe full stop may not terminate the sentence. Thus, identifying such casesis another essential sub-task for sentence segmentation. Errors and inconsis-tencies of punctuation in a text can further expand the scope of the sentencesegmentation problem, which in turn makes recognizing sentence boundariesvery difficult. State-of-the-art sentence segmentation tools make use of var-ious morphological and syntactic features, and the best feature set can varyfor different languages or genres (Fung et al., 2007). Unfortunately, sentencesegmentation is an underestimated task that rarely undergoes evaluation.
2.2.3 TokenizationTokenization is the process of segmenting a sentence into separate tokens, i.e.,a sequence of characters forming a single unit. It is usually combined withsentence segmentation into a single tool. In computational linguistics, a tokenis an element similar to a word and other linguistic elements such as numbers,abbreviations, and punctuations.
Automatic identification of token boundaries can be a complex task due tothe fact that various languages have different word boundary markers. There-fore, there exist different approaches for identifying where one word ends andanother starts. For languages that mark words in a text with regular white
39

space, defined as space-delimited languages in Palmer (2000), automatic to-kenization is partly performed by identifying white space and punctuation.On the other hand, languages like Chinese, Japanese, and Thai, which do notsystematically mark words in a text (Jurafsky and Martin, 2008) and are de-fined as unsegmented languages in Palmer (2000), have a more challengingtokenization process.
In space-delimited languages, tokenization is still complicated when itcomes to multi-word expressions, such as compound words, or multi-wordtechnical terms that signify a single concept, e.g., ice cream, Artificial Intel-ligence, etc. The compound ice cream for instance, consists of two words,while mentally it corresponds to a single concept. In such cases, it is not al-ways feasible to determine word boundaries with white space. On the otherhand, it is not always possible to define word boundaries with a concept-basedcriterion either (Aroonmanakun, 2007). Therefore, compound terms are oftentreated as multiple tokens in the tokenization process and are then analyzed asmulti-word expressions in further steps of language analysis such as parsing.
2.2.4 Part-of-Speech TaggingPart-of-speech (PoS) taggers are tools for assigning part-of-speech categoriesto the words of a sentence. More specifically, a part-of-speech tagger assignsmorphological categories to tokens in a text in order to disambiguate them. Apart-of-speech tagger usually receives a tokenized text as input and delivers anoutput text tagged with part-of-speech tags with or without separate morpho-logical features (for terminology, see 2.1.1). Assigning a part-of-speech tag toeach token is non-trivial for machines due to the existence of ambiguity.
Disambiguating ambiguous words is a challenging task for taggers. Giventhat many words have more than one morphological category, a tagger needs toselect the appropriate part-of-speech category. For example, having the wordfly in a context requires different part-of-speech tags since the word involvesdifferent notions; as a noun it refers to a small insect and as a verb it refers totravelling through the air. The disambiguation process is often performed bylooking at information that the tagger receives from the tag sequences (syn-tagmatic information). Handling unknown words is another challenging taskfor taggers, and normally the accuracy of different taggers is mainly deter-mined by the proportion of unknown words. This task is frequently performedby guessing algorithms (also called smarts by Manning and Schütze (1999)),which allow taggers to guess the part-of-speech of unknown words. Smartsmake use of the morphological properties of the word, such as that words end-ing in –ed are likely to be past tense or past participle. Other cues are alsoemployed. For example, information about surrounding words or the part-of-speech of surrounding words are used to make inferences about a word’spart-of-speech tag. In general, the preceding word is sometimes the most use-
40

ful clue for determining part-of-speech. In some languages where word orderis flexible, the surrounding words contribute much less information about part-of-speech. On the other hand, the rich inflections of such a word might providemore information about part-of-speech (cf. Manning and Schütze 1999).
Most tagging algorithms are usually placed into one of the following cate-gories: rule-based taggers or stochastic taggers. Rule-based algorithms use alarge database of hand-written rules for disambiguating parts of speech. Anexample is EngCG, which is based on the Constraint Grammar architectureof Karlsson et al. (1995). On the other hand, stochastic algorithms apply ma-chine learning techniques and a training corpus to estimate the probability ofa given word having a given tag in a given context. Hidden Markov Model(HMM) taggers are examples of this. There is also transformation-based tag-ging (Brill, 1995), which shares features of both rule-based and stochasticarchitectures. Such a tagger is rule-based when disambiguating a word in con-text and stochastic when the rules are automatically induced from a previouslytagged training corpus (Jurafsky and Martin, 2008).
Modern part-of-speech taggers are generally data-driven applications thatare capable of being retrained for a new language given a tagged corpus of thatlanguage. Data-driven techniques for part-of-speech tagging have attractedgreat attention from many researchers in the computational linguistics com-munity, especially in the early 1990s and 2000s. Moreover, the techniquehas resulted in some successful data-driven part-of-speech taggers such asMX-POST (Ratnaparkhi, 1996) based on the maximum entropy framework,MBT (Daelemans et al., 1997) based on memory-based learning, Trigram ’n’Tags (TnT) (T. Brants, 2000) and HunPoS (Halácsy et al., 2007) based onHidden Markov Models (HMM). The tagger HunPoS is the one that will beused in my research, and it is introduced in Chapter 4. More recent workon data-driven taggers includes conditional random fields and support vectormachines (Toutanova et al., 2003; Giménez and Màrquez, 2004; Kumar andSingh, 2010).
Part-of-speech taggers are frequently evaluated in terms of tagging accu-racy. The state-of-the-art for part-of-speech tagging for English is 97–98%accuracy per word (Toutanova et al., 2003; Shen et al., 2007; Giesbrecht andEvert, 2009) which is close to the level of human annotators. However, this op-timal accuracy only holds when taggers are trained and evaluated on newspa-per texts, fiction, art, and user-generated texts, and does not apply to all typesof texts or genres such as spoken language, informal writing, or Web pages(Giesbrecht and Evert, 2009). The performance of data-driven approaches canbe affected by different factors such as the size of training data and the sizeof tagset. In general, larger training data sets improve tagging performanceand the error rate decreases when the size of the tagset is reduced. There-fore, if a larger tagset (for specification of more linguistic features) and highperformance are both desired, a larger training data set is needed.
41

Since most taggers accept segmented text as their input, it is crucial to makesure that the segmentation applied to preprocess texts exactly matches thatused for training data in the part-of-speech tagging process. Due to interac-tion between different linguistic levels, when it comes to segmentation andannotation, differences in segmentation during training and tagging degradethe results of a part-of-speech tagger. Therefore, as mentioned in Chapter 1,I have added the important constraint that all tools should be compatible andthe output of one tool must match the input requirements of the next.
2.2.5 ParsingParsers are tools for performing syntactic analysis of natural language. Morespecifically, the automatic analysis indicates how words compose together toform a sentence by denoting their syntactic relations to each other. The analy-sis may further include other aspects of linguistic description such as semanticinformation. A syntactic parser usually receives a morphologically annotatedsentence as input and returns a syntactically analyzed sentence as its output.In syntactic analysis, a sentence may map to a number of grammatical parsetrees due to the pervasive ambiguity of natural language. Selecting the mostplausible analysis among many alternatives is one of the major bottlenecks ofsyntactic parsing. Therefore, from tagging to full parsing, all algorithms needto be carefully selected to handle such ambiguity (Sarkar, 2011).
In parsing, as for treebanks, (see Section 2.1.2), there are two main ap-proaches to syntactic analysis: phrase-based and dependency-based. Phrase-based parsers usually rely on parsing algorithms for context-free grammar(CFG), which is built on a set of recursive rules describing a context-free lan-guage. The three most widely used of these parsing algorithms are the Cocke-Kasami-Younger algorithm (CKY) (Kasami, 1965; Younger, 1967), the Earleyalgorithm (Earley, 1970), and the chart parsing algorithm (Kay, 1982; Ka-plan, 1973). The three approaches combine insights from the two searchingstrategies underlying most parsers, namely, bottom-up and top-down search,with dynamic programming for efficient handling of complex cases (Jurafskyand Martin, 2008). However, writing a set of rules for syntactic analysis interms of CFG is not an easy task, considering the complexity of natural lan-guage. Phrase structure analysis sometimes provides additional informationabout long-distance dependencies and cases where the word order is less flex-ible (Sarkar, 2011). On the other hand, dependency analysis typically benefitslanguages with flexible word order. Since I have not applied the phrase-basedsyntactic analysis approach in my thesis, I will not further discuss models,algorithms, and frameworks pertaining to this technique.
In dependency-based parsing, syntactic structure is represented by a de-pendency graph (Nivre, 2008a). The CoNLL 2007 shared task on dependency
42

parsing (Nivre et al., 2007) defines dependency graph as follows:
In dependency-based syntactic parsing, the task is to derive asyntactic structure for an input sentence by identifying the syntactichead of each word in the sentence. This defines a dependencygraph, where the nodes are the words of the input sentence andthe arcs are the binary relations from head to dependent. Often,but not always, it is assumed that all words except one have asyntactic head, which means that the graph will be a tree withthe single independent node as the root. In labeled dependencyparsing, we additionally require the parser to assign a specific type(or label) to each dependency relation holding between head wordand dependent word.
The main philosophy behind the concept of dependency graphs is to con-nect a word, the head of a phrase, with its dependents through labeleddirected arcs. This head-dependent relation can be either head-modifieror head-complement. In the head-modifier relation, the modifier functionsas a fully independent component in relation to its head. Although themodifier always carries certain traits of its head, it can be omitted withoutaffecting the core meaning of the phrase or the syntactic structure. Bycontrast, in the head-complement relation, the complement functions as afully dependent component of its head. Here, the head contains certaintraits of its complement and hence the complement cannot normally be leftout. Furthermore, Nivre (2008a) defines the distinction between these typesof head-dependent relations as endocentric (head-modifier) and exocentric(head-complement). An endocentric construction is dominated by a head thatis the sole obligatory element and carries a large amount of semantic content.An example is the relation holding between the noun planets and the adjectivenew in the following sentence where the head noun can replace the wholewithout disrupting the syntactic structure.
• Astronomers have discovered [new] planets orbiting around Gliese–667C.
By contrast, an exocentric construction is dominated by a group of syntacti-cally related words where the head cannot provide the semantic content of thewhole, such as the relation holding between the preposition around and thenoun Gliese–667C in the following example where the head around cannotreplace the whole.
• Astronomers have discovered new planets orbiting around [Gliese–667C].
43

The distinctive element in determining complements and modifiers is oftenspecified in terms of valency, which is the core concept in the theoreticaltradition of dependency grammar (Nivre, 2008a). Aside from the fact thatdependency-based representations seem better suited for languages with freeword order than phrase structure representations, the method has been shownto be useful in language technology applications, such as machine translationand information extraction, for detecting the underlying syntactic pattern of asentence, because of its transparent encoding of predicate-argument structure(Kübler et al., 2009).
While the performance of data-driven dependency parsers is continuouslybeing improved, two approaches to dependency parsing have still remained atthe center of the spotlight (Bohnet and Kuhn, 2012), namely, the transition-based (Yamada and Matsumoto, 2003; Nivre, 2003) and the graph-based ap-proach (Eisner, 1996; McDonald et al., 2005a). Two popular data-driven andopen source dependency parsers, MaltParser (Nivre et al., 2006) and MST-Parser (McDonald et al., 2005b), are based on these two approaches. The twoparsers were the top scoring systems in the CoNLL 2006 shared task for mul-tilingual dependency parsing (Buchholz and Marsi, 2006) and have since thenbeen applied to a wide range of languages. The parsers will be presented inmore detail in Chapter 6.
Transition-based dependency parsing was pioneered by Yamada and Mat-sumoto (2003). A transition system consists of a set of states and transitionsbetween the states when deriving dependency trees using treebank-inducedclassifiers to predict the next transition (Nivre, 2008a). Recent research hasfurther shown that the accuracy of transition-based systems can be improvedusing a beam-search framework in combination with optimizing different fea-ture models during parsing (Yue Zhang and Clark, 2008; Bohnet and Nivre,2012).
On the other hand, the graph-based approach is based on global learning al-gorithms. In this approach, global optimization algorithms discover the high-est scoring tree with locally weighted models (McDonald et al., 2005a; Mc-Donald and Pereira, 2006; Koo and Collins, 2010).
Furthermore, Bohnet and Kuhn (2012) present a parsing model based on theconcept of combining the advantages of transition-based and graph-based ap-proaches. Their parser shows a substantial improvement in parsing accuracywhen applied to English, Chinese, Czech, and German. Additional experi-ments have been done with combining different kinds of statistical parsers thatare trained on treebanks, such as those explained in Sagae and Lavie (2006),Martins et al. (2008), and McDonald and Nivre (2011). Combining rule-basedand statistical parsers has also been investigated in Aranzabe et al. (2012).
Having discussed language technology tools in this section, I will, now,briefly describe Persian and its main linguistic features related to orthography,morphology and syntax, at the same time, I will discuss language technologychallenges in processing Persian text.
44

Table 2.2. Dual-joining Persian characters.
Isolated Final Medial Initial Names
H. H. K. K. be
H� H� K� K� pe�
H�
H�K
�K te
�H
�H
�K
�K se
h. h. k. k. jim
h� h� k� k� ce
h h k k he-ye jimi (literally jim-like he)
p p
k
k khe
� � � � sin�
��
��
��
� shin
� � � � s.ad
�
�
�
�¨zad
t.a
z. a
¨ © ª « ‘eyn
¨
©ª
« qeyn
¬
¬
¯
¯ fe
��
��
�¯
�¯ qaf
¸ ¸ » » kaf
À À Ã Ã gaf
È È Ë Ë lam
Ð Ð Ó Ó mimà
à
K
K nun
è é� ê ë he-ye do-cešm (literally two-eyed he)
ø ø K K ye
2.3 PersianPersian belongs to the Indo-Iranian branch of the Indo-European family. Thereare three variants of the language: Western Persian, referred to as Parsi orFarsi and spoken in Iran; Eastern Persian, referred to as Dari and spoken inAfghanistan; and Tajiki, spoken in Tajikistan and Uzbekistan. Persian has alsohad a strong influence on neighboring languages such as Turkish, Armenian,Azerbaijanian, Urdu, Pashto, and Punjabi.
45

2.3.1 Persian OrthographyThe Persian2 writing system is based on the Arabic alphabet with 28 lettersand four additional letters:3 H� , h� , �P , À, which represent the sounds /p/, /Ù/,
/Z/, /g/. The additional letters still follow the Arabic writing system. Theseletters were created by adding extra dots to the existing letters H. , h. , P , ¸,
representing the sounds /b/, /j/, /z/, and /k/. In the case of À, /g/, dots turned
into a line above the existing letter ¸, representing /k/.In Persian, characters have different forms depending on their position in
the word. Thus, characters can be divided into two groups on the basis ofhow they connect to other characters: dual-joining and right-joining. Dual-joining characters accept connections from both their right and left hand side.In this group, characters have two distinct shapes depending on their positionin the word: initial or medial, and final or isolated respectively. However, threecharacters in this group, namely ¨ /’eyn/,
¨ /qeyn/, and è /he/ (he-ye do-cešm),
appear in four distinct shapes. There are also two characters in this group,
/t.a/ and /z. a/, which have only one shape irrespective of their position in the
word. Table 2.2 displays the initial, medial, final, and isolated forms of thecharacters in the dual-joining group.
The right-joining characters do not accept any connection to their left handside and have only one shape without any distinctive initial, medial, final, orisolated forms. These characters are illustrated in Table 2.3.
Vowels and DiacriticsModern Persian has six vowels: a, a, i, e, u, o, of which three are long andthree are short. Long vowels (a, i, u) are usually conveyed by alphabet letterswhereas short vowels (a, e, o) are represented by so-called diacritics. Lexicalambiguity can occur in Persian when short vowels are left out of tokens suchthat a string of consonants, sometimes together with long vowels, is what isrepresented in the script. Table 2.4 displays examples of homographs sharingthe same letters with distinction in pronunciation, stressed syllables, meaning,
2Henceforth, by Persian I mean to contemporary Persian as spoken in Iran.3According to the Academy of Persian Language and Literature, Persian has 33 letters. Al-though the Academy of Persian Language and Literature includes hamze as one of the Persianletters, it is normally not used in words of Persian origin. Hamze is mainly used in words bor-rowed from Arabic and as a hiatus-filler. Even in Arabic, hamze has its own specific use since itexclusively appears on other host letters as a phonetic sign (see Section 2.3.1). Hamze only oc-curs as a separate letter when it is isolated at the end of a word. Since hamze is a root consonantin the Arabic consonantal root system, which characterizes the Semitic languages, it is definedas a letter in Arabic. I believe that the inclusion of hamze as a letter in the Persian alphabetneeds to be further discussed and considered by the Academy, because, as an Indo-Europeanlanguage, Persian does not follow the Arabic consonantal root system.
46
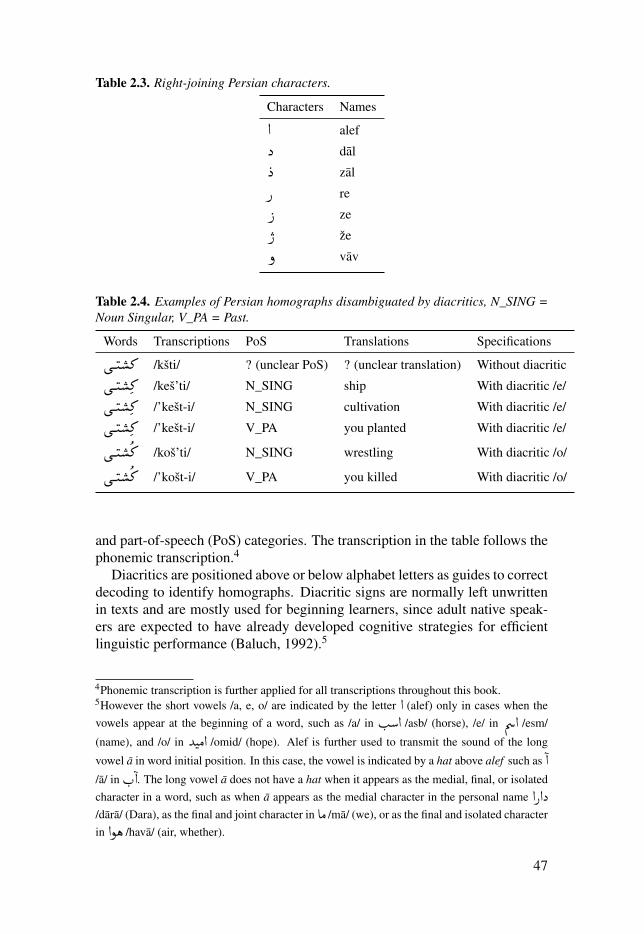
Table 2.3. Right-joining Persian characters.
Characters Names
@ alef
X dalX zal
P reP ze�P že
ð vav
Table 2.4. Examples of Persian homographs disambiguated by diacritics, N_SING =Noun Singular, V_PA = Past.
Words Transcriptions PoS Translations Specifications
ù��J
��» /kšti/ ? (unclear PoS) ? (unclear translation) Without diacritic
ù��J
��»� /keš’ti/ N_SING ship With diacritic /e/
ù��J
��»� /’kešt-i/ N_SING cultivation With diacritic /e/
ù��J
��»� /’kešt-i/ V_PA you planted With diacritic /e/
ù��J
��
�» /koš’ti/ N_SING wrestling With diacritic /o/
ù��J
��
�» /’košt-i/ V_PA you killed With diacritic /o/
and part-of-speech (PoS) categories. The transcription in the table follows thephonemic transcription.4
Diacritics are positioned above or below alphabet letters as guides to correctdecoding to identify homographs. Diacritic signs are normally left unwrittenin texts and are mostly used for beginning learners, since adult native speak-ers are expected to have already developed cognitive strategies for efficientlinguistic performance (Baluch, 1992).5
4Phonemic transcription is further applied for all transcriptions throughout this book.5However the short vowels /a, e, o/ are indicated by the letter @ (alef) only in cases when thevowels appear at the beginning of a word, such as /a/ in I. �@ /asb/ (horse), /e/ in Õæ� @ /esm/
(name), and /o/ in YJÓ@ /omid/ (hope). Alef is further used to transmit the sound of the long
vowel a in word initial position. In this case, the vowel is indicated by a hat above alef such as�@
/a/ in H.
�@. The long vowel a does not have a hat when it appears as the medial, final, or isolated
character in a word, such as when a appears as the medial character in the personal name @P@X
/dara/ (Dara), as the final and joint character in AÓ /ma/ (we), or as the final and isolated characterin @ñë /hava/ (air, whether).
47

Table 2.5. Persian homophonic letters.
/t/ /h/ /s/ /z/�
H h�
HX
è � P
�
�
Table 2.6. Diverse spellings of certain homophonic Persian words.
Common Less Common Transcriptions Affected phonemes Translations�
�A�K @
��A£@ /otaq/ /t/ room
ñ�K@ ñ£@ /otu/ /t/ iron
Pñ�K@Q��Ó@ Pñ£@Q��Ó@ /emperatur/ /t/ emperor
ém��
'AJ�
�K ém�
�'AJ�£ /tapance/ /t/ pistol
PBA�K PBA£ /talar/ /t/ forum
à@Qî
�E
à@Qê£ /Tehran/ /t/ Tehran
�IJÊK. ¡JÊK. /belit/ /t/ ticketàYJ��
�K
àYJJ�£ /tapidan/ /t/ beat, pulse
àYJ
�JÊ
«
àYJ¢Ê
« /qaltidan/ /t/ roll
úÍYJ� úÍY
J� /sandali/ /s/ chair
P@ Q�AJ�� P@Y�AJ�� /sepasgozar/ /z/ grateful
Phoneme DiversityIn Persian, a phoneme may be represented by different letters, which can causedisparities in letter substitution, especially in the case of transliterating for-eign words and deciding on a proper grapheme for a desired phoneme. Thephoneme /t/ is represented by the two letters, �
H and , the phoneme /h/ by
h and è, /s/ by the three letters �H, �, and �, and finally the phoneme /z/
by the four letters X, P,
�, and . Table 2.5 shows diverse letters for one
and the same phoneme. However, in Arabic all these letters represent distinctphonemes.
With respect to writing variations in Persian, words containing ho-mophonous letters can be spelled with different letters representing the samephoneme. Note that the writing variations of diverse letters usually occur withthe phoneme /t/. Table 2.6 shows some examples of this category. Spellingsthat have been categorized as less common in Table 2.6 are actually uncom-mon. Nowadays, for instance, Tehran is hardly ever spelled with the lesscommon form. However, the only available source is the texts themselves.Furthermore, in Persian encyclopedias such as Dehkhoda and Mo‘in, entriesfor less common spellings simply refer to the common ones.
48

Table 2.7. 12 different ways of writing the plural and definite form of the compoundword øAë é
KA
gH. A
�J» (the libraries of).
ø Aë éKA
gH. A
�J» øAë é
KA
gH. A
�J»
øAë éKA
gH. A
�J» øAë é
KA
g H. A
�J»
øAë éKA
m�'
. A�J» ø Aë é
KA
g H. A
�J»
ø Aë éKA
m�'
. A�J» ø Aë é
KA
g H. A
�J»
ø Aë éKA
m�'
. A�J» ø Aë é
KA
gH. A
�J»
øAë éKA
m�'
. A�J» øAë é
KA
g H. A
�J»
Word Boundaries and Different Space CharactersWhen representing text digitally, there are different sizes and styles ofspaces with different Unicode characters, such as no-break space (U+00A0),zero-width non-joiner (U+200B), word-joiner (U+2060), ideographic space(U+3000), zero-width no-break space (U+FEFF), and so forth. The use ofvarious space characters of specific widths depends on the language charac-teristics. In Persian white space designates word boundaries, as it does inmany languages. However, there is also another space in Persian so-calledzero-width non-joiner (ZWNJ, known as pseudo-space, zero-space, or virtualspace) as a boundary inside a word. The ZWNJ is a non-printing character incomputerized typesetting of some script, placed between two characters to beprinted with one final and one initial form unjoined next to each other. TheZWNJ keeps the word forms intact and close together without their being at-tached to each other.
Considering the wide variety of typing styles and the optionality of shiftingbetween white space and ZWNJ, one word may be written in various ways ina text. Compound words and inflectional affixes are strongly affected by thisand can be typed either as attached to their adjacent word (when ignoring bothspaces, thereby losing the internal word boundaries, such as the attached formof the word øAë é
KA
m�'
. A�J», /ketab.xane-ha-ye/ (gloss: book.house-pl-ez6, trans-
lation: the libraries)), or detached from it (when using white space instead ofZWNJ, such as the detached form of the word ø Aë é
KA
g H. A
�J», /ketab xane ha
ye/), which in both cases raises issues in text processing. Inflectional suffixesmay follow compound words; for instance the word é
KA
gH. A
�J» /ketab.xane/
(gloss: book.house, translation: library) followed by the plural suffix Aë-/-ha/ together with the ezafe (-ez) particle ø- /-ye/ might appear in 12 formsas shown in Table 2.7.
6The abbreviation -ez is used to mark ezafe construction in the gloss throughout this book. Anezafe (-ez) is an unstressed clitic particle that links the elements within a noun phrase, adjectivephrase or prepositional phrase, indicating the semantic relation between the joined elements. Itis represented by the short vowel /e/ after consonants or /ye/ after vowels. For more descriptionof the ezafe construction, see Section 2.3.3.
49

Table 2.8. Different forms of hamze.
Different types of Hamze Positions Transcriptions
Z always isolated at the glottal /@/end of a word
@ / @
hamze above/below alef glottal /@/initial, medial, or final
ð' hamze above vav glottal /U/
medial or final K' hamze above a tooth glottal /@/
initial or medial
Multi-word expressions usually consist of words representing separate lexi-cal categories. When white space is used instead of ZWNJ, words are treatedas separate tokens, which causes problems in tokenizing texts. For exam-ple, Pñ
¢
JÓ éK. /be.manzur-e/ (gloss: to.intention-ez, translation: for the sake
of) may appear either by joining the preposition éK. /be/ (to) to the nounPñ
¢
JÓ /manzur/ (intention) and building a single token (attached form), Pñ
¢
JÖß.
/be.manzur-e/ or as two single tokens delimited either with a space Pñ
¢JÓ éK.
/be manzur-e/ or with ZWNJ Pñ
¢JÓ éK. /be.manzur-e/. The optionality of writ-
ing multi-word expressions as attached single word, detached single words(delimited with space), or as one distinct word (delimited with ZWNJ) in thePersian writing system raises issues in text processing, since a single word thatshould be treated in the same way will be treated in different ways.
Hamze in PersianOne of the most ambiguous letters imported from Arabic to Persian ishamze(h) (Arabic hamza). Hamze is not normally used in words of Persianorigin. It is mainly employed in words borrowed from Arabic, normally asone of the root consonants. It represents the glottal stop and has its own be-havior. The unique characteristic of hamze is that it is mostly written with acarrier; i.e., hamze is normally written above or below the letter @ (alef), abovethe letters ð (vav), and above the so-called a tooth
K', which makes it distinctfrom the rest of the Arabic letters. Different forms of hamze are shown inTable 2.8. Although not the preferred spelling today, hamze may be used inwords of Persian origin. For instance the word Q�KAK� /paiz/ (autumn) is a Persianword, but it might be written with hamze as in Q�
KAK� /pa‘iz/.
Mapping Unicode CharactersAlthough apart from the four extra letters in Persian, Persian and Arabic sharealmost the same character encodings, there are a few stylistic disparities inthe two letters ø (ye) and ¸ (kaf), which have different Unicode characters
50

Table 2.9. Different forms of Persian and Arabic characters.
Persian Arabic Name of letters
¸ ¼ kafø ø
ye
�H
�è te
Table 2.10. Digital characters for Persian (Extended Arabic-Indic Digits), Arabic(Arabic-Indic Digits) and Western.
Persian Arabic Western
0 0 01 1 12 2 23 3 3R 4 4S 5 5T 6 67 7 78 8 89 9 9
for Persian and Arabic. These letters can be represented by U064A for ø andU06A9 for ¸ in the Persian Unicode encoding and U0649 for ø
(Arabic ye
has two dots beneath) and U0643 for ¼ in Arabic Unicode encoding. Table 2.9shows different shapes of these two letters for Persian and Arabic.
The Unicode Standard has characters for Persian letters including a sepa-rate set of ten characters for digits called Extended Arabic-Indic Digits (Es-fahbod, 2004), since three of the ten digits in Persian (4, 5, and 6) differ fromtheir Arabic counterparts. Digital characters for Persian, Arabic, and West-ern languages are presented in Table 2.10. Despite the existence of Unicodecharacters for Persian, there are still software applications that choose to setup Arabic Unicode characters for Persian letters and digits, or Arabic Unicodecharacters for Persian letters in combination with Western digits. As a conse-quence, a mixture of various encodings is found in a huge number of Persiantexts on the Web, which needs to be considered in Persian text analysis. Asan example, Ettelaat.com, one of the oldest newspaper in Iran, with 90 yearsof continuous publication, still has mixed character encoding of Arabic lettersand English digits combined with the extra Persian characters.
51

Table 2.11. Examples of words derived from the present stem à@X /dan/ (to know)
combined with various types of other stems and nouns as well as derivational affixes.
Components Transcriptions PoS Translationsà@X /dan/ Verbal stem to know
�� +
à@X /dan-eš/ Noun knowledgeñk. + �
� + à@X /dan-eš-ju/ Noun student
YJÓ + �
� + à@X /dan-eš-mand/ Noun scientist
èAÇ + �� +
à@X /dan-eš-gah/ Noun universityø + èAÇ + �
� + à@X /dan-eš-gah-i/ Adjective academic
à@ + ø + èAÇ + �
� + à@X /dan-eš-gah-i-an/ Noun academics
ø + èAÇ + �� +
à@X + Ñë /ham-dan-eš-gah-i/ Noun university-mateèY» + �
� + à@X /dan-eš-kadeh/ Noun faculty
@ + à@X /dan-a/ Adjective wise
ø + ø + @ + à@X /dan-a-y-i/ Noun wisdom
èYK +
à@X /dan-andeh/ Noun knowerà@X + A
K /na-dan/ Adjective ignorant
ø + à@X + A
K /na-dan-i/ Noun ignorance
2.3.2 Persian MorphologyPersian is dominated by an affixal system and is sometimes described as apredominantly agglutinative language (Jeremiás, 2003; Hashabeiky, 2005).Words are formed by attaching affixes with various grammatical or semanticfeatures to head words. The language is highly productive in word formationand it frequently uses derivational agglutination by combining affixes, verbstems, nouns, and adjectives to derive new words. However, the agglutinationprocess is not as extreme as in, for example, Turkish. New words are alsoformed by combining two existing words into a new one (compounding).
AffixationAffixes are bound elements that cannot stand on their own and are used forinflection and derivation. Affixes are of different kinds for different parts ofspeech. Noun affixes are always attached to nouns and verb affixes are alwaysattached to verbs. In Persian, affixes appear in the form of both prefixes andsuffixes. Table 2.11 shows different words derived from the present stem
à@X
/dan/ (to know) combined with various types of derivational affixes.
Nominal MorphologyPersian nouns have no grammatical gender. There is no definite article in theformal language. A single noun can signify a definite entity, for example:
.�
I�@ ©¢�¯ á
®Ê
�K
52

Table 2.12. Present indicative of the verb �P /raftan/ (to go).
Personal Endings Transcriptions Verb Conjugations Translations
Ð- /-am/ ÐðPú× I goø- /-i/ øðPú× you go (singular)X- /-ad/ XðPú× she/he goesÕç'- /-im/ Õç'ðPú× we goYK- /-id/ YKðPú× you go (plural)Y
K- /-and/ Y
KðPú× they go
telefonphone
qat.‘disconnection
astbe.pres.3sg
.
.The phone is disconnected.
Indefiniteness, on the other hand, is indicated by either the clitic particle ø /-i/joined to a noun, as in úG
.A�J» /ketab-i/ (gloss: book-indef, translation: a book),
or the numeral ¹K /yek/ (a, one) preceding the noun, as in H. A�J» ¹K /yek
ketab/ (one book), and sometimes by a combination of both, as in úG.A�J» ¹K
/yek ketab-i/ (gloss: one book-indef, translation: a book). The indefinite par-ticle can further be attached to plural nouns, as in úG
AëH. A
�J» /ketab-ha-y-i/7
(gloss: book-pl-gl-indef, translation: some books). There are several pluralmarkers, -ha, -an (with variants -gan and -yan), and the Arabic plural mark-ers -at, -in, -un. The plural markers -in and -un are attached only to Arabicloanwords. Arabic broken plurals also exist in Persian. They follow Arabictemplate morphology and are directly inherited together with nouns borrowedfrom Arabic.
Verbal MorphologyVerbs in Persian follow a conjugation pattern that is very regular and straight-forward. Verbs always carry information on tense, aspect and mood (TAM).They use personal endings and normally agree in person and number withthe subject. Table 2.12 shows the inflection of the verb á�
�P /raft-an/ (gloss:
go.past-inf, gloss: to go) in the present indicative TAM form.
Adjectives and AdverbsAdjectives and adverbs take the suffixes Q
�K- /-tar/ and áKQ
�K- /-tarin/ for the
comparative and superlative forms respectively.
7The glide ye /-y-/ is inserted between the two long vowels /a-/ and /-i/
53

Table 2.13. Syntactic patterns in Persian.
Head-final Head-initial
Object–Verb Preposition–ObjectDemonstrative/Adjective–Noun Noun–GenitiveNumeral–Noun Noun–AdjectiveAdverb–Adjective Noun–Relative Clause
2.3.3 Persian SyntaxPersian is a verb-final language, but does not rigidly adhere to a fixed wordorder. The sentential constituents can easily change place without affecting thecore meaning. Apart from a marker to indicate the accusative (object marker),there are no apparent markers in the language to highlight, for example, theboundary of a noun phrase, an adjective phrase, or a prepositional phrase.
Word OrderBasic word order in Persian is SOV. However, the language branching direc-tion8 indicates a position between head-final (left-branching) and head-initial(right-branching) structure. Therefore the syntactic pattern has a mixed ty-pology. The language represents a hybridization of two opposite syntacticpatterns belonging to a group of typically VO languages (as in Arabic) anda group of typically OV languages (as in Turkish) (Stilo, 2004). Table 2.13shows a set of interrelated syntactic features in Persian.
Sentences typically consist of an optional subject and an optional object,followed by a compulsory verb, i.e., (S) (O) V. Subjects can however beplaced anywhere in a sentence. The use and order of the optional constituentsare relatively arbitrary, and this scrambling characteristic (Karimi, 2003)makes Persian word order highly flexible. Person and number are inflectedon the verb using personal endings. Table 2.14 shows the different personalendings in the past tense. As already mentioned, verbs normally agree inperson and number with their subject. Nevertheless, in the following casesthe verb does not agree in person with its subject:
• To make a humble reference to oneself, the speaker may replace thefirst person singular pronoun (the subject) with the noun èY
JK. /bande/
(servant) while the personal ending of the verb is still first personsingular.
• In polite usage, a singular subject is frequently followed by a verb in thethird person plural.
8Branching direction means the position of the head word and its complement in a phrase,clause, or sentence.
54

Table 2.14. Personal endings in past tense (personal endings in present tense areillustrated in Section 2.3.2.)
Personal Endings Transcriptions Translations
Ð- /-am/ Iø- /-i/ you-∅ /-∅/ she/heÕç'- /-im/ weYK- /-id/ youY
K- /-and/ they
• If a plural subject is inanimate the verb is usually inflected in singularform. However, the agreement restriction of inanimate entities doesnot always hold since there are no clear rules concerning how one maybreak this constraint (Hashabeiky, 2007).
• In the case of non-canonical subjects,9 the verb always stays in thirdsingular regardless of the number and person implied by the subject.
Main Grammatical FunctionsThe function of subject is accomplished in Persian by a noun, an infinitive, anumeral or other expression of quantity, or a pronoun. The subject may alsoappear only as a personal ending on the verb.
Direct objects are characterized by the postposition @P (ra), which is thesingle case marker in the language. The accusative marker, however, is notobligatory unless topicalization is involved (Windfuhr, 2009). In Persian, acomplement other than the direct object is introduced by a prepositional phrase(Lazard, 1992). Hence, the sentential structure can shift between (S) (O ± ra)V and (S) (PP) V.10
Adjectives and adverbs are rarely distinct, as a large number of adjec-tives may be used as adverbs. Prepositions function as heads of preposi-tional phrases and sometimes are incorporated into multi-word expressions.There are inherited prepositions consisting of simple prepositions such as P @
(from/of), éK. (to), etc. There are compound prepositions formed of an ad-jective, or an adverb accompanied by a simple preposition such as P @ h. PA
g
9In Persian, non-canonical subjects appear in dative-subject constructions (Jahani et al., 2012).An example is given in Section 2.3.3, Light Verb Constructions.
10In colloquial Persian, adverbs of location can omit the preposition and follow the verb. Forexample:
.à@Qî
�E ÐðPú×
mi-rav-amcont-go.pres-1sg
TehranTehran
.
.
I go Tehran. (Instead of I go to Tehran.)
55

/xarej az/ (gloss: outside of, translation: outside). Furthermore, there areezafe prepositions consisting of nouns that have partially been deprived oftheir semantic content, such as P@ñKX
�I
���� /pošt-e divar/ (gloss: back-ez wall,
translation: behind the wall) and Q�Ó øðP /ru-ye miz/ (gloss: face-ez table,translation: on the table) (Lazard, 1992). Ezafe prepositions may be pre-ceded by simple prepositions as well, such as in P@ñKX
�I
���� PX /dar pošt-e
divar/ (gloss: in back-ez wall, translation: behind the wall) and Q�Ó øðP QK.
/bar ru-ye miz/ (gloss: on face-ez table, translation: on the table). Prepo-sitions can further be represented together with their object, such as in �
� P@
/az-aš/ (gloss: of-her/him, translation: of her/him) and ��îE. /beh-aš/ (gloss:
to-her/him, translation: to her/him).Modifiers may precede or follow the word they modify. There are a num-
ber of modifiers, such as adverbial clause modifiers, adverbial modifiers, ad-jectival modifiers, appositional modifiers, comparative modifiers, negationmodifiers, noun compound modifiers, nominal phrase as adverbial modifiers,possession modifiers, prepositional modifiers, prepositional modifiers in lightverb constructions, quantifier phrase modifiers, relative clause modifiers, andtemporal modifiers. A more detailed description of various modifiers is givenin Chapter 5.
Pronominal CliticsClitics are attached to different parts of speech without being related to thewords they attach to. In Persian, clitics only appear in the form of enclitics;proclitics do not exist in Persian.
Pronouns often appear as pronominal clitics (Ð- /-am/ 1sg, �H- /-at/ 2sg, �
�-/-aš/ 3sg,
àAÓ- /-eman/ 1pl, àA
�K- /-etan/ 2pl,
àA�
�- /-ešan/ 3pl) which are boundpronoun forms. The clitics are shown in Table 2.15. Pronominal clitics canbe attached to nouns, adjectives, adverbs, prepositions, and verbs. Table 2.16presents different pronominal clitics accompanied by the word PA¿ /kar/ (work).The following example shows the third person singular pronominal clitic �
�-/-aš/ (pc-3sg) to denote the direct object attached to the verb Y
KYKX /did-and/
(see.past-3pl). The subject is absent, but the information is given by the verbthrough the attached personal ending Y
K- /-and/ (3pl).
.�
�YKYKX
did-and-ašsee.past-3pl-pc.3sg
.
.They saw her/him.
In addition, pronominal clitics function as possessive genitive ���. A
�J» /ketab-aš/
(gloss: book-pc3sg, translation: her/his book), object of a preposition �� P@ /az-
aš/ (gloss: of-pc.3sg, translation: of her/him), partitive genitive ��A
�Ki.
JK� /panj-
56

Table 2.15. Pronominal clitics.
Pronominal Clitics Transcriptions Translations
Ð- /-am/ my�
H- /-at/ your�
�- /-aš/ her/his
àAÓ- /-eman/ our
àA�K- /-etan/ yours
àA
��- /-ešan/ their
Table 2.16. Pronominal clitics accompanied by the word PA¿ /kar/ (work).
Components Transcriptions Translations
ÐPA¿ /kar-am/ my work�
HPA¿ /kar-at/ your (sg) work�
�PA¿ /kar-aš/ her/his workàAÓPA¿ /kar-eman/ our workàA
�KPA¿ /kar-etan/ your (pl) work
àA
��PA¿ /kar-ešan/ their work
ta-aš/ (gloss: five-cl-pc.3sg, translation: five of it), non-canonical subjectYK
�@ú×
��YK. /bad-aš mi-ay-ad/ (gloss: bad-pc.3sg cont-come.pres-3sg, trans-
lation: she/he dislikes). Possession is expressed by the clitic ezafe and a nounor a pronoun, or by the pronominal clitics.
Complex SentencesA complex sentence may contain multiple clauses such as independent clausesor dependent clauses. An independent or coordinate clause is a clause that isnot syntactically dependent on another clause, and can stand independentlyas a sentence, while a dependent or subordinate clause is a clause that makesno sense by itself and is therefore dependent on another clause. Coordinateclauses are generally sentences that are coordinated by different types of con-junctions, for example, the house is big and the area is calm. Subordinateclauses, on the other hand, may consist of an adverbial clause, a clausal com-plement, a relative clause, or a combination thereof. In Persian, an adverbialclause is introduced by markers (as single words or as multi-word expressions)such as é» ú
�æ
�¯ð /vaqti ke/ (gloss: when that, translation: when), é» úÍAg PX
/dar hal-i ke/ (gloss: in state-indef that, translation: while), QÃ @ /agar/ (if), etc.,that modify the main clause. A clausal complement, often introduced by thecomplementizer é» /ke/ (that), is a dependent clause with an internal subject,functioning as an object to the main clause. A relative clause modifier is al-
57

ways introduced by the relative marker é» /ke/11 (that, which, who, whom)modifying a nominal constituent. The relativizer /ke/ does not vary dependingon animacy or function of the head noun as it does in English, for instance.
Light Verb ConstructionsPersian makes extensive use of so-called complex predicates or light verb con-structions (LVC), which consist of preverbal parts of speech such as a noun,adjective, adverb, or preposition forming a complex lexical predicate togetherwith the light verbs. Light verbs are verbs with weak semantic contents oftheir own. Some of the frequent light verbs in Persian are
àXQ» /kard-an/(gloss: do.past-inf, translation: to do) in
àXQ» Qº¯ /fekr kard-an/ (gloss: think
do.past-inf, translation: to think), àX@X /dad-an/ (gloss: give.past-inf, transla-
tion: to give) in àX@X
��ñà /guš dad-an/ (gloss: ear give.past-inf, translation:
to listen), àX P /zad-an/ (gloss: hit.past-inf, translation: to hit) in
àX P
©Jk. /jiq
zad-an/ (gloss: scream hit.past-inf, translation: to scream), �Qà /gereft-an/
(gloss: take.past-inf, translation: to take) in á��QÃ
��ðX /duš gereft-an/ (gloss:
shower take.past-inf, translation: to shower/take a shower), �
��@X /dašt-an/
(gloss: have.past-inf, translation: to have) in �
��@X
�I�ðX /dust dašt-an/
(gloss: friend have.past-inf, translation: to love), and àXA
�J¯ @ /oftad-an/ (gloss:
fall.past-inf, translation: to fall) in àXA
�J¯ @
��A
®�K @ /ettefaq oftad-an/ (gloss: event
fall.past-inf, translation: to happen). Main verbs may further function as lightverbs in a very abstract semantic interpretation, for instance the verb
àXPñ
k
/xord-an/ (gloss: eat.past-inf, translation: to eat) in the complex predicatesàXPñ
k
á�ÓP /zamin xord-an/ (gloss: ground eat.past-inf, translation: to fall
down). The light verb element in the complex predicate carries the TAM in-flection, tense, aspect, and mood, while the other component (noun, adjective,adverb, or preposition) carries most of the semantic content of the complexpredicate.
In non-canonical subject constructions, as previously mentioned regardingsubject-verb agreement, the verb does not inflect for number and person withthe dative subject, always staying in third person singular instead. In this case,preverbal elements carry the dative subject. The following example showsthe adjective �
�ñ
k /xoš/ (good) that functions as the adjectival complementof the complex predicate (adjectival complement in light verb construction)àYÓ
�@
��ñ
k /xoš amad-an/ (gloss: good come.past-inf, translation: to like). In
addition, ��ñ
k /xoš/ (good) carries the dative subject of the sentence in the
form of a pronominal clitic, namely, the first singular Ð- /-am/.
11In subordinate constructions, é» /ke/ marks complement clauses, relative clauses, and varioustypes of adverbial clauses.
58

. YK
�@ú× Õæ
��ñ
k
�� P@
az-ašof-pc.3sg
xoš-amgood-pc.1sg
mi-ay-adcont-come.pres-3sg
.
.I like her/him.
Persian has various types of light verb constructions depending on thevarious preverbal elements. Different varieties of light verb construc-tions are presented below with brief descriptions. More detailed descriptionsof the different light verb constructions, with examples, are given in Chapter 5.
• Adjectival complement in a light verb construction: An adjectivalcomplement in a light verb construction is a preverbal adjective thatcombines with a light verb to form a lexical unit. In the followingexample the adjective clean and the light verb do together build anadjectival complement in light verb construction.
. YJ»ú× ¸AK� @P èAJ� é
�Jm�
�' ð@
ushe/he
taxteboard
siyahblack
rara
pakclean
mi-kon-adcont-do.pres-3sg
.
.She/he cleans/wipes the blackboard.
• Direct object in a light verb construction: A direct object in a lightverb construction is a preverbal direct object that combines with a lightverb to form a lexical unit.12 In the below example, the word touchand the light verb do create a direct object in a light verb construction.Note that, there is also another direct object, sweets, followed by theaccusative marker ra in this sentence.
. YJ»ú× �ÖÏ @P Aëú
æK
Q��
� @P@X
DaraDara
širini-hasweet-pl
rara
lamstouch
mi-kon-adcont-do.pres-3sg
.
.Dara touches the sweets.
• Nominal subject in a light verb construction: A nominal subject in alight verb construction is a preverbal nominal subject that combines witha light verb to form a lexical unit (normally with a passive meaning). Inthe example below, the noun implementation and the light verb becometogether make a nominal subject in a light verb construction. There isalso a sentence level subject, ceremony, in this sentence.
12Note that this unit may in turn take a direct object. Hence the need to distinguish the light verbobject from an ordinary direct object.
59

. Y�
� @Qk. @ Õæ� @QÓ
marasemceremony
ejraimplementation
šodbecome.past.3sg
.
.The ceremony was implemented.
• Prepositional modifier in a light verb construction: A prepositionalmodifier in a light verb construction is a preverbal prepositional phrasethat combines with a light verb to form a lexical unit. In the followingexample the preposition to and its object cry, together with the verb fall,build a prepositional modifier in a light verb construction.
. XA�J¯ @ éKQÃ éK. ð@
ushe/he
beto
geryecry
oftadfall.past.3sg
.
.She/he fell into cries (she/he burst into tears).
Preverbal ParticlesPreverbal particles, or preverbs, are elements that immediately precede mainverbs. Preverbs are normally prepositions or adverbs whose meaning is mod-ified by the main verb (Lazard, 1992). Examples of preverbs are PX /dar/ (in),QK. /bar/ (on), ��� /pas/ (back, again), PAK. /baz/ (again), @Q
¯ /fara/ (above), ðQ
¯
/foru/ (down), and so forth. These particles load main verbs with new mean-ings. In other words, they interact closely with the main verbs; examples arePX /dar/ (in) in
àYÓ�@ PX /dar amad-an/ (gloss: in come.past-inf, translation: to
eventuate, to result) and ��� /pas/ (back) in �Qà ��� /pas gereft-an/ (gloss:
back take.past-inf, translation: take back, regain). The construction of verbswith preverbs is very similar to that of LVC. However, preverbal elements inLVC often co-occur with semantically bleached or light verbs to build pred-icates or new verbs in Persian, whereas preverbs co-occur with full lexicalverbs to modify the content of the verbs. The particles directly precede mainverbs; however if the future auxiliary or the negative morpheme -
K /-ne/ (not)is present then they will intervene between the particle and the main verb.
The Ezafe ConstructionThe ezafe construction is a distinct characteristic of Persian syntactic structurethat plays a significant role in phrasal categories. The literal meaning of ezafeis addition, and it describes the dependency between a head and its modifiers.This dependency is usually charaterized by the interplay of phonology, mor-phology and syntax (Bögel et al., 2008) which is easily noticeable in speechsince it is pronounced as /e/ or /ye/. Karimi (1989) in regard to this claimsthat “ezafe is not a case assigner, but it does transfer the case of the head noun
60

to its complement”. Moreover, this unstressed clitic particle is orthographi-cally unwritten when it appears after consonants, which may raise difficultiesin syntactic text analysis. The orthographic realization of ezafe occurs only inspecial cases where the word ends in the long vowels /a/, and /u:/, as well aswhere the word ends in the silent “h”.13 In this case, ezafe is represented bythe suffix ø /-ye/.
As ezafe indicates the semantic relations of phrasal constituents, it ties themodifier to the head word. In other words, ezafe links a modifier (adjectival oradverbial) to a noun as well as a genitive attribute (complement) to its noun.The last element in the phrase never carries any ezafe clitic. This fact can indi-cate the end of a phrasal category. In the following example, áÓ ú
¯@Q
ªk. H. A
�J»
/ketab-e joqrafi-e man/ (gloss: book-ez geography-ez I, translation: my geog-raphy book) the first word, book, is the head word of the noun phrase that car-ries an ezafe to link the next word, geography, to itself. The second word, ge-ography, is further the head word of its dependent, my, which is linked by an-other ezafe clitic. Finally, the noun phrase ends with the third word, my, whichdoes not carry any ezafe clitic. Ezafe additionally functions to mark nominaldetermination (Lazard, 1992), for example øPAKY
J®�@ ÈAJ
K @X øA
�¯�@ /aqa-ye14
Danial-e Esfandiari/ (gloss: Mr.-ez Danial-ez Esfandiari, translation: Mr. Da-nial Esfandiari).
2.4 Existing Corpora and Tools for PersianHaving examined the Persian language and the challenges it poses for auto-matic text analysis, we will now look at existing resources and tools for Per-sian. Since the scope of this thesis is confined to the morphosyntactic domain,I will only present resources and tools in this area.
2.4.1 Morphologically Annotated CorporaBelow are morphosyntactically annotated resources in the form of corpora forPersian.
• Bijankhan Corpus (Bijankhan, 2004):The first linguistically annotated Persian corpus was the BijankhanCorpus (Bijankhan, 2004) released in 2004. The corpus was createdfrom on-line material consisting of texts with different genres andtopics such as newspaper articles, fiction, technical descriptions, andtexts about culture and art. The corpus contains 2,597,939 tokens and
13The silent h is employed to represent a terminal -e. Accordingly, the ezafe appears as ø /-ye/,as in é
KA
g /xane/ (house) and ø é
KA
g /xane–ye/, otherwise it is unwritten.
14Since A�¯�@ /aqa/ (Mr.) ends in the long vowel /a/, ezafe is visible and appears as ø /-ye/.
61

is annotated with morphosyntactic and partly semantic features. TheBijankhan Corpus is freely available in a plain text document and willbe presented in more detail in Chapter 3.
• The Persian Linguistic Data Base (PLDB) (Assi, 2005):The Persian Linguistic Data Base contains information about pronun-ciation and grammatical annotation with a morphosyntactic tagset of44 tags. The database consists of more than 56 million words fromcontemporary texts. The corpus is not freely available.
• The Persian 1984 corpus (QasemiZadeh and Rahimi, 2006):The Persian 1984 corpus comprises a translation of the novel 1984by George Orwell annotated in the MULTEXT-East framework. Thecorpus consists of 6,604 sentences, and about 100,000 words annotatedwith parts of speech. The corpus is part of the MULTEXT-East parallelcorpus (Erjavec et al., 2003).
• Tanzil Quran Corpus (ZarrabiZadeh, 2007):Tanzil is an international Quranic project that was launched in early2007 with the aim of providing a highly-verified and accurate Qurantext. In addition, the project has provided a detailed digital versionof texts, over 100 translations of the Quran into over 40 languages,including 11 translations into Farsi. Related data and the translationsare offered in various formats on the project Web site, and can be usedfor research purposes.
• Hamshahri Collection (AleAhmad et al., 2009):The Hamshahri Collection is a corpus containing 318,000 documentsrelating to the years 1996 to 2007. All documents in the corpus havethe label Cat indicating the category of each document (economic,political, etc.). The data has been created by the research group ofTehran University with support from Iran Telecommunication ResearchCenter. The corpus is intended to be used for studying different featuresof information-retrieval algorithms like indexers and retrieval models aswell as Persian clustering and classification, stemming and so forth.
• Comparative Persian-English Corpus (Hashemi et al., 2010):University of Tehran’s Persian-English Comparative Corpus (UTPECC)has been created from two distinct news sources, Persian News fromHamshahri news agency and English News from the BBC news agency.To align documents in two different languages, in addition to datingnews, additional documents and similar contents have also been consid-ered. The corpus has been produced at the Intelligent Systems Research
62

Laboratory of Tehran University.
• Peykare (Bijankhan et al., 2011):Peykare is a large corpus containing circa 110 million words of writtenand spoken contemporary Persian. Bijankhan et al. (2011) define con-temporary Persian as the modern Persian spoken as the formal languageof Iran since the beginning of the latest era (1847). Thus, the corpushas been prepared from various types of texts dating from 1847 untilthe present. In total, 35,058 text files have been extracted from books,magazines, newspapers, web pages, unpublished texts, and manuscripts,and have been organized chronologically and into different linguisticvarieties. These varieties are based on different political milestones15
which have been used as distinctive boundaries, since the lexical itemsused by native speakers, in particular media, have been strongly affectedby political events in different eras. A small portion of Peykare to beused as a training data set, was collected randomly from different topicsin order to cover varieties of lexical and grammatical structures. Thetraining set, initially consisting of 10,612,187 tokens, was reduced to9,781,809 tokens after taking some multi-word expressions as a singleword in the tokenization process. The training set is annotated with anEAGLES-based part-of-speech tagset. Neither Peykare nor the trainingset are freely available.
• Furqan Quran Corpus (Astiri et al., 2013):The underlying text of Furqan Corpus is based on the Quran that hasbeen designed and implemented at Ferdowsi Web Technology Lab,Mashhad University. The corpus has more than 587 megabytes of data,including all information about text and translated verses of the Quranin Persian and English, morphological and syntactic analysis of theverses in Arabic, Persian and English, stemming, and many other itemsin the RDF format.
• Mizan English-Persian Parallel Corpus (Mizan, 2013):The corpus contains more than one million English sentences (often inclassic literature) and their translations into Farsi that have been pro-vided by the Supreme Council of Information and Communication Tech-
15The milestones are taken from (Bijankhan et al., 2011, p. 146) and are presented below:• 1847–1906: AD before the period of ‘Mashroutiyat’ (Constitutionality),• 1906–1925: from Constitutionality until the first king of the Pahlavi dynasty,• 1925–1941: from the first king of the Pahlavi dynasty to the second king,• 1941–1978: from the second king of the Pahlavi dynasty to the Islamic revolution,• 1978–1988: from the Islamic revolution to the end of the war with Iraq,• 1988–2006: from the end of the war until 2006 when the designing of Peykare ended,• 2006–Present: from 2006 until now, when text collecting for Peykare resumed.
63

nology in Iran. The corpus can be used in various applications, espe-cially machine translation and natural language processing.
2.4.2 Syntactically Annotated CorporaRecently, we have witnessed the emergence of three treebanks, namely, theHPSG-based PerTreeBank (Ghayoomi, 2012), the Uppsala Persian Depen-dency Treebank (Seraji et al., 2012b), and the Persian Dependency Treebank(Rasooli et al., 2013). The development of the Uppsala Persian DependencyTreebank and the HPSG-based treebank began almost simultaneously indifferent places and with different annotation schemes. Shortly after, thePersian Dependency Treebank was developed in Iran with an annotationscheme based on traditional Persian grammar. Below follows a brief descrip-tion of the HPSG-based treebank (PerTree–Bank) (Ghayoomi, 2012) and thePersian Dependency Treebank (Rasooli et al., 2013). The Uppsala PersianDependency Treebank (Seraji et al., 2012b) will be presented in detail inChapter 5.
• The Persian Treebank (PerTreeBank) (Ghayoomi, 2012): PerTreeBankconsists of 1012 sentences and 27,659 tokens taken from the BijankhanCorpus (Bijankhan, 2004). The treebank structure is defined based onan HPSG scheme, where the constituent structure is encoded for phrasecategories with the concepts of head-subject, head-complement, head-adjunct, and head-filler representing sub-categorization requirements(Ghayoomi, 2012). The original part-of-speech tags in the BijankhanCorpus, with three-level of length (e.g., N,COM,SING), were convertedinto the MulText-East framework to encode the morphosyntacticand semantic information as atomic tags (e.g., Ncs). Unfortunately,the treebank lacks annotation guidelines to separately describe eachsyntactic relation used in the treebank. The treebank development wasdiscontinued when it was at a size of 1012 sentences. PerTreeBankhas recently been automatically converted into a dependency structurenamed DepPerTreeBank.
• The Persian Dependency Treebank (PerDT) (Rasooli et al., 2013): ThePersian Dependency Treebank (PerDT) consists of circa 30,000 inde-pendent sentences and 498,081 tokens derived from several sources in-cluding Web URLs, stories, and lectures. Instead of achieving a bal-anced corpus in terms of different genres, the data source consists of iso-lated sentences taken from the Web, and these are specifically selectedbased on different verb types. To include all types of verbs, includingrare verbs, a syntactic valency lexicon of Persian verbs (Rasooli et al.,2013) is used. The morphosyntactic features are annotated using the
64

part-of-speech tagger Maximum Likelihood Estimation (MLE) and themorphological analyzer Virastyar.16 The treebank has been developedsemi-automatically through a bootstrapping procedure using MSTParser(McDonald and Pereira, 2006). The treebank annotation scheme followsthe traditional Persian linguistic grammar, and consists of 43 syntacticrelations listed in Table 2.17.
2.4.3 Sentence Segmenentation and TokenizationThere are no open source tools for performing sentence segmentation and to-kenization for Persian. However, a tool called Standard Text Preparation forPersian Language (STeP-1) (Shamsfard et al., 2010) has been designed to em-ploy a multi-task operation, including pre-processing, tokenizing, morpholog-ical analyzing, and spell checking. The software is not open source.
2.4.4 Part-of-Speech TaggersThere is no open source part-of-speech tagger for Persian. However, therehave been some experiments reporting quite good results on the performanceof several part-of-speech tagging methods such as TnT, memory-based tagger(MBT) and Maximum Likelihood Estimation (MLE) (Raja et al., 2007). Thecorpus used in these experiments was the Bijankhan Corpus. Training and testsets were created by randomly dividing the corpus into two parts with an 85%to 15% ratio, and each experiment was repeated five times to avoid accidentalresults. The overall accuracies reported for the three taggers in are 96.6%,96.6%, and 95.9% respectively.
2.4.5 ParsersTo my knowledge there is only one freely available parser for Persian, namelythe link grammar parser (Dehdari and Lonsdale, 2008). The modules of theparser have been constructed based on open source technologies such as two-level morphology (Koskenniemi, 1983) and the dependency-like link grammar(Sleator and Temperley, 1993). The parser takes a sentence as input and de-composes all inflectional morphemes through a lexicon-based morphologicalanalyzer. Subsequently, when the morphological analysis is concluded, theresults are transferred to the parser for syntactic analysis. The parser links as-sociated word pairs such as subject + verb, object + verb, preposition + object,adverbial modifier + adjective, and auxiliary + main verb. Each link possessesa label that represents a syntactic relation. However, the links are representedin such a way that every node involved in a link cannot be uniquely tied to a
16http://www.virastyar.ir/
65

Table 2.17. Syntactic relations in the Persian Dependency Treebank.
Category Description
ACL complement clause of adjectiveADV adverbADVC adverbial complement of verbAJCONJ conjunction of adjectiveAJPP prepositional complement of adjectiveAJUCL adjunct clauseAPOSTMOD adjective post-modifierAPP appositionAPREMOD adjective pre-modifierAVCONJ conjunction of adverbCOMPPP comparative prepositionENC enclitic non-verbal elementLVP light verb particleMESU measureMOS mosnadMOZ ezafe dependentNADV adverb of nounNCL clause of nounNCONJ conjunction of nounNE non-verbal element of infinitiveNEZ ezafe complement of adjectiveNPOSTMOD post-modifier of nounNPP preposition of nounNPREMOD pre-modifier of nounNPRT particle of infinitiveNVE non-verbal elementOBJ objectOBJ2 second objectPARCL participle clausePART interrogative particlePCONJ conjunction of prepositionPOSDEP post-dependentPRD predicatePREDEP pre-dependentPROG progressive auxiliaryPUNC punctuation markROOT rootSBJ subjectTAM tamizVCL complement clause of verbVCONJ conjunction of verbVPP prepositional complement of verbVPRT verb particle
66

token position in the sentence. The parser provides no explicit way to extractthe head of the sentence (Seraji et al., 2012a).
67

3. Uppsala Persian Corpus
This chapter presents the development of the Uppsala Persian Corpus1 (UPC)(Seraji et al., 2012a) which is based on the Bijankhan Corpus (Bijankhan,2004). As my goal was to develop a treebank for Persian, and the BijankhanCorpus was the only freely available annotated corpus of Persian, I used thecorpus as the starting point of my work. However, the corpus was not createdfor language technology purposes. Therefore, I developed a modified versionof the corpus and called it the Uppsala Persian Corpus. In the UPC someproperties are inherited from the Bijankhan Corpus and some I have createdthrough adjustments and improvements to make the corpus more suitable forsyntactic analysis. The chapter presents the principal modifications made tothe character encoding, segmentation, and annotation scheme in the BijankhanCorpus.
3.1 The Bijankhan CorpusThe Bijankhan Corpus was released in 2004 as the first manually annotatedPersian (Farsi) corpus. It was created from on-line material containing textsof different genres and topics such as newspaper articles, fiction, technicaldescriptions, and texts about culture and art. The corpus consists of nearly 2.6million tokens and is annotated for parts of speech.
The corpus’s original tagset contains 550 tags. A tag name starts with thename of the most general tag and continues with the names of the subcate-gories until it reaches the name of the leaf tag. An example of a three-level tagis N_PL_LOC, where N represents noun, PL defines number as plural, and LOCspecifies the tag as locative. In Oroumchian et al. (2006), the tagset has beendefined as a hierarchical tree structure, but the tag system is in fact atomic.This size of tagset is used to achieve a more fine-grained morphological anal-ysis. Later on, the number of tags was reduced to 40 in an attempt to facilitatemachine learning (Oroumchian et al., 2006). All tags with three or more levelswere accordingly reduced to two-level tags. In other words, the above exam-ple was reduced to N_PL. Some two-level tags were also reduced to one-leveltags, for example conjunctions, prepositions, and pronouns (Oroumchian etal., 2006). This version of the Bijankhan Corpus is in Unicode text format.The tagset is shown in Table 3.1.
1http://stp.lingfil.uu.se/∼mojgan/UPC.html
68
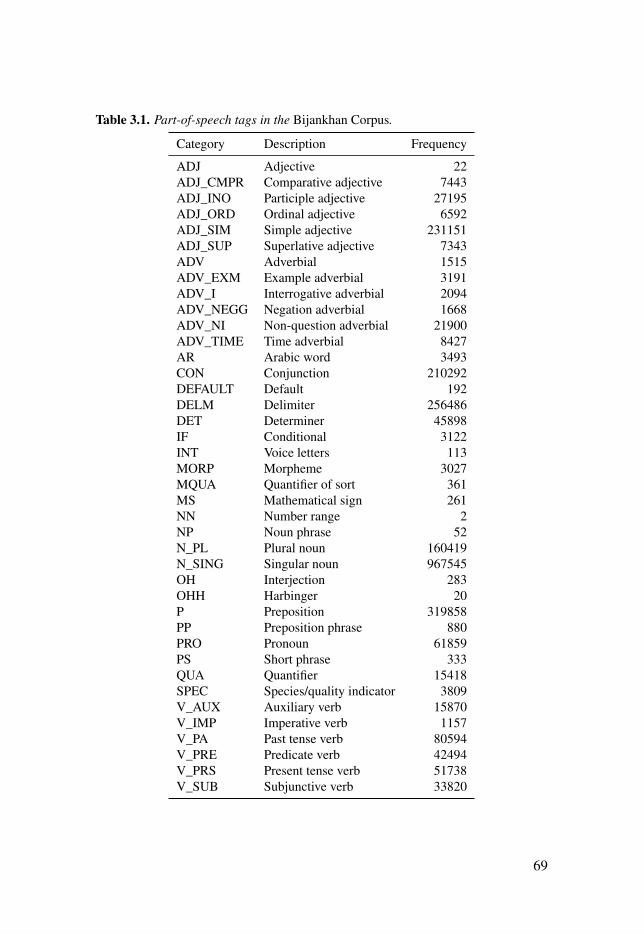
Table 3.1. Part-of-speech tags in the Bijankhan Corpus.
Category Description Frequency
ADJ Adjective 22ADJ_CMPR Comparative adjective 7443ADJ_INO Participle adjective 27195ADJ_ORD Ordinal adjective 6592ADJ_SIM Simple adjective 231151ADJ_SUP Superlative adjective 7343ADV Adverbial 1515ADV_EXM Example adverbial 3191ADV_I Interrogative adverbial 2094ADV_NEGG Negation adverbial 1668ADV_NI Non-question adverbial 21900ADV_TIME Time adverbial 8427AR Arabic word 3493CON Conjunction 210292DEFAULT Default 192DELM Delimiter 256486DET Determiner 45898IF Conditional 3122INT Voice letters 113MORP Morpheme 3027MQUA Quantifier of sort 361MS Mathematical sign 261NN Number range 2NP Noun phrase 52N_PL Plural noun 160419N_SING Singular noun 967545OH Interjection 283OHH Harbinger 20P Preposition 319858PP Preposition phrase 880PRO Pronoun 61859PS Short phrase 333QUA Quantifier 15418SPEC Species/quality indicator 3809V_AUX Auxiliary verb 15870V_IMP Imperative verb 1157V_PA Past tense verb 80594V_PRE Predicate verb 42494V_PRS Present tense verb 51738V_SUB Subjunctive verb 33820
69

The corpus further comes with statistical software for corpus processing. Thisincludes the calculation and extraction of language features such as condi-tional distribution probability and word frequency. It also includes recognitionof homonyms and synonyms, and construction of concordances and lexicons.
The Bijankhan Corpus is a pioneering effort for the Persian language and avaluable resource for my work. However, because the corpus was not intendedfor natural language processing, it has certain characteristics that make it lesssuitable for automatic processing. In order to use the corpus as the basis for atreebank, I therefore had to make certain adaptations and improvements whichwill be described in the rest of the chapter. The resulting corpus was releasedas the Uppsala Persian Corpus.
The available version of the Bijankhan Corpus as of 2006,2 which has beenused in this thesis project, lacks sentence segmentation and is unevenly nor-malized. The corpus contains different texts with a wide range of inconsis-tencies in tokenization and orthography, and is encoded in various types ofcharacter sets. The corpus additionally contains annotation errors as well asvariations in the annotation, such as inconsistent application of part-of-speechtags across the corpus. These types of inconsistencies can lead to low qualityof morphological and syntactic analysis provided by taggers and parsers.
3.2 Uppsala Persian CorpusThe Uppsala Persian Corpus is the modified version of the Bijankhan Corpuswith additional sentence segmentation and consistent tokenization. The corpusis currently the largest freely available, linguistically annotated and manuallyvalidated corpus for Persian. Due to the modifications in segmentation andpart-of-speech tagging, the UPC contains more tokens and fewer tags. Thecorpus consists of 2,704,893 tokens and is annotated with a tagset of 31 tagswith morphological information. Next, I will describe the different steps increating the UPC. The corpus is freely available in plain text and open sourceunder a GNU General Public License.
3.2.1 Character EncodingsAs mentioned in Chapter 2, Persian shares 28 of its 32 letters with Arabic, therest having been specifically invented for Persian. Stylistically, however, the28 shared letters are not exactly the same (see Table 2.9). For example, two ofthe characters, ø (ye) and ¸ (kaf), differ in shape and therefore have differentUnicode encodings. Persian and Arabic also share the same digits, althoughthey have different styles for the numbers 4, 5, and 6, each with differentUnicode characters.
2This version of the Bijankhan Corpus is available at http://ece.ut.ac.ir/dbrg/bijankhan
70

In the Bijankhan Corpus, texts are encoded with various types of charac-ter sets. Letters have a mixture of both Persian and Arabic styles. In termsof digits, the variation is even larger, and the digital characters appear in Per-sian, Arabic, and Western styles (see Section 2.3.1). Thus, in normalizing theBijankhan Corpus, all letters in Arabic style with Arabic Unicode characterswere converted to Persian style and Persian Unicode encoding. Arabic andWestern digits were all converted to Persian digits. Normalization of the char-acter encodings was performed by employing the tool PrePer, which will beintroduced in Section 4.1.1.
3.2.2 Sentence Segmentation and TokenizationAs noted earlier, the Bijankhan Corpus was not designed for NLP applications.For instance, it did not have sentence segmentation or consistent tokenization,which are important features for a part-of-speech tagger and a syntactic parser.In the UPC, I have added a sentence segmentation, with sentences separated byone of the punctuation marks ‘.’, ‘!’, ‘?’, or combinations thereof. In addition,the punctuation mark ‘:’ has been treated as a sentence separator when usedto introduce a list of alternatives.
Tokenization has been made more consistent than in the original corpus,and better adapted for automatic processing so that it can be reproduced onnew text. The basic rule for tokenization is that white space and punctuationmarks define token boundaries. However, in order to improve the quality oftokenization, two preprocessing steps were carried out before applying themain rule.
• White space is converted to ZWNJ to ensure no boundary:Word-internal white space was converted to ZWNJ in order to con-form to standard conventions. Standard conventions are stylistic andorthographic rules introduced by the Academy of Persian Language andLiterature (APLL).3 Accordingly, white space inside compound words,as well as inside words incorporating clitics and affixes, was convertedto ZWNJ to make sure that tokens in the treebank never contain internalwhite space. This has been done only if such cases could be identifieddeterministically.
• ZWNJ/no space is converted to white space in cases where preverbalparticles are joined to main verbs or other elements:White space was added between preverbal particles and their hosts to en-able them to be separated in tokenization. This phase was necessary formy further analysis on the syntax level. As mentioned in Section 2.3.3,preverbs are elements that immediately precede main verbs, except in
3http://www.persianacademy.ir/fa/das.aspx
71

negative forms and future tense contexts. Thus, preverbs are not boundelements, like prefixes to the main verbs. They are in fact separate el-ements, like prepositions and adverbs, that can stand on their own andchange position in a sentence when they are not behaving as verb parti-cles.
In the Bijankhan Corpus, preverbs were accompanied with the futureauxiliary verb either by ZWNJ or no space (without being attached to theauxiliary verb, due to the existence of right-joining characters at the endof the preverbs), for example PX /dar/ (in) in YÓ
�@ Yë@ñ
kPX /dar xah-ad
amad/ (gloss: in-will.fut.3sg come.past, translation: will become) andQK. /bar/ (on) in �
I�A
g Yë@ñ
kQK. /bar xah-ad xast/ (gloss: on-will.fut.3sgget.past, translation: will get up). Moreover, the particles, in associa-tion with the main verbs, were treated inconsistently in the corpus. Theywere sometimes joined to the main verbs in a single token and some-times separated from the main verbs and treated as distinct tokens. Thusin UPC, the preverbal particles were split from the main verbs and the fu-ture auxiliary verb and received the part-of-speech tag PREV (preverb).Note again that the modifications were performed only when the casescould be identified deterministically.
My reason for not joining the preverbs to the main verbs with ZWNJ(or no space) as I did for clitics and affixes are that: (1) preverbs aredistinct items that can stand independently in a string, whereas cliticsand affixes are bound units that cannot stand on their own; and (2)another element such as the negative morpheme and the future auxiliaryverb can easily separate them from the main verb, which does nothappen with clitics or affixes.
After performing the two preprocessing steps, white space was treated as a to-ken boundary. Fixed expressions separated with white space in the BijankhanCorpus such as é» úG
Am.�
'�@ P@ /az anja-i ke/ (gloss: from that.place-indef that,
translation: since, where), é» áK@ Ñ«P éK. /be raqm-e in ke/ (gloss: to despite-
ez this that, translation: despite), ðP áK@ P@ /az in ru/ (gloss: from this face,
translation: hence), �Iêk.
à
�@ P@ /az an jahat/ (gloss: from that direction, trans-
lation: thence) were treated inconsistently, sometimes as one single token withone tag (without considering the fact that the tokens were separated by whitespace) and sometimes as multiple tokens with multiple tags. For a more con-sistent analysis, and as a consequence of the main tokenization rule, thesefixed expressions were split into their distinct tokens.
Unfortunately, this does not mean that each and every case in the UPC hasbeen treated accordingly. There are further cases, such as when fixed expres-sions are attached to one another. Such expressions have not been separatedfrom each other. There are additionally instances where clitics and affixes are
72

attached to their head words without white space. Such instances have notbeen separated from their heads either. Plenty of similar types exist in thecorpus which have not been treated in the UPC due to the fact that they couldnot be identified deterministically and unambiguously. For instance, the word�
I�AÓ /mast/ could be a compound word containing the personal pronoun AÓ
/ma/ (we) and the clitic form of the copula verb �I� /st/ (is) and referring
to we are, or it could simply be a singular noun meaning yoghurt. With re-spect to the corpus size and the available research time it was impossible to gothrough the corpus and fix all cases manually one by one. On the other hand, Icould not handle such cases automatically, since this could lead to many incor-rect conversions by affecting other orthographically similar words with totallydifferent morphological categories and senses. Therefore, I had one option,namely to fix only those cases that could be fixed automatically and unam-biguously and accept the remaining cases as the consequences of that option.Hence, I left them as they are, but analyzed them at the syntactic level insteadby giving them special analysis. Moreover, since there may be cases in thenew data that cannot be handled by the automatic tokenizer, it is beneficialthat such cases exist as samples in the training data.
3.2.3 Morphological AnnotationIn normalizing the morphological annotation within the Bijankhan Corpus, Ihave made two types of changes. First I have modified the tagset by adding,removing, and merging categories. Secondly, I have corrected errors and in-consistencies in the annotation.
The morphological annotation in UPC consists of atomic part-of-speechtags that encode a subset of the features found in the original BijankhanCorpus. The tagset is listed with explanations in Table 3.2. New tags areshown in italics. More detailed changes are presented below.
1. Added and replaced tagsFor the improvement of corpus annotation, I introduce 11 new part-of-speech tags. Apart from one added tag (PREV), the rest of the new tags areintroduced as replacements for the former ones. The new labels in the UPCtagset represent a more thorough treatment of the morphological structurethan the Bijankhan tagset, with respect to traditional Persian grammar.
a) ADJ_VOCThe tag OH that had been used for the word A
��ñ
k /xoš-a/ (gloss:
good-voc, translation: good for, blessed) was replaced by the tagADJ_VOC. The interjection @- /-a/ (long vowel) is attached at the endof the word �
�ñ
k /xoš/ (good) to indicate a vocative case.
73
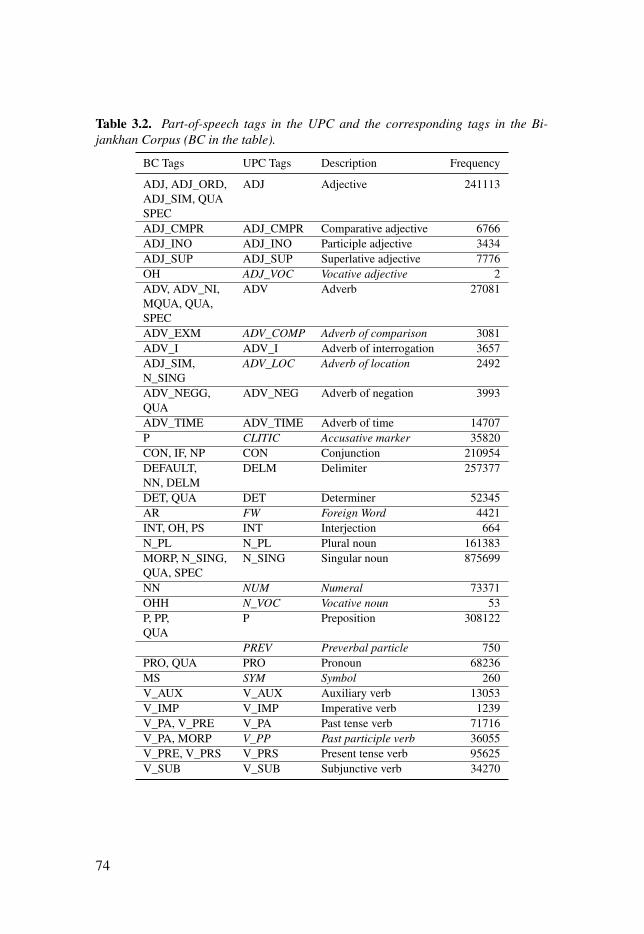
Table 3.2. Part-of-speech tags in the UPC and the corresponding tags in the Bi-jankhan Corpus (BC in the table).
BC Tags UPC Tags Description Frequency
ADJ, ADJ_ORD, ADJ Adjective 241113ADJ_SIM, QUASPECADJ_CMPR ADJ_CMPR Comparative adjective 6766ADJ_INO ADJ_INO Participle adjective 3434ADJ_SUP ADJ_SUP Superlative adjective 7776OH ADJ_VOC Vocative adjective 2ADV, ADV_NI, ADV Adverb 27081MQUA, QUA,SPECADV_EXM ADV_COMP Adverb of comparison 3081ADV_I ADV_I Adverb of interrogation 3657ADJ_SIM, ADV_LOC Adverb of location 2492N_SINGADV_NEGG, ADV_NEG Adverb of negation 3993QUAADV_TIME ADV_TIME Adverb of time 14707P CLITIC Accusative marker 35820CON, IF, NP CON Conjunction 210954DEFAULT, DELM Delimiter 257377NN, DELMDET, QUA DET Determiner 52345AR FW Foreign Word 4421INT, OH, PS INT Interjection 664N_PL N_PL Plural noun 161383MORP, N_SING, N_SING Singular noun 875699QUA, SPECNN NUM Numeral 73371OHH N_VOC Vocative noun 53P, PP, P Preposition 308122QUA
PREV Preverbal particle 750PRO, QUA PRO Pronoun 68236MS SYM Symbol 260V_AUX V_AUX Auxiliary verb 13053V_IMP V_IMP Imperative verb 1239V_PA, V_PRE V_PA Past tense verb 71716V_PA, MORP V_PP Past participle verb 36055V_PRE, V_PRS V_PRS Present tense verb 95625V_SUB V_SUB Subjunctive verb 34270
74

b) ADV_COMPThe tag ADV_EXM that had been used for descriptive adverbs withcomparative senses such as Y
JK AÓ /manand/ (as, like), É
�JÓ /mesl/
(as, such as, for example) was replaced by ADV_COMP (adverb ofcomparison).
c) ADV_LOCIn the Bijankhan Corpus a number of adverbs such as BAK. /bala/ (up),á�KAK� /payin/ (down), ñÊg. /jolo/ (forward),
àðQ�K. /birun/ (out), hadbeen tagged irregularly with different labels such as ADJ_SIM (simpleadjective) and N_SING (singular noun), even when the words weremodifying different verbs. Such cases were all replaced by the tagADV_LOC.
d) CLITICIn the Bijankhan Corpus, the accusative marker @P (ra) had beenannotated as a preposition P. In the UPC, I modified the annotationlabel to CLITIC. Since the accusative marker ra always follows theobject in Persian, it can be considered as a postposition or a clitic casemarker rather than a preposition.
e) FWAll Arabic words in the Bijankhan Corpus had received the tag AR,while other foreign words had received the tag N_SING. Hence, alltypes of foreign words, when they were discovered, were homoge-neously tagged with the label FW.
f) NUMNumerals in the Bijankhan Corpus had been labeled by N_SING.Numerals were systematically searched for throughout the corpus andgiven the tag NUM.
g) N_VOCNominal forms such as @PAÇXPðQK� /parvardegar-a/ (gloss: Lord-voc,translation: Lord), AK @Y
g /xoda-ya/ (gloss: God-voc, translation:
God) that are used in calling out to attract attention had been taggedby the label OHH which was replaced by N_VOC.
h) PREV: Preverbal particles accompanied (either with no space orintervening ZWNJ) by verbs and the future auxiliary verb á�
��@ñ
k4
/xast-an/ (gloss: will.past-inf, translation: to will) were split from
4 á���@ñ
k (to will, to want) is the base form of the future auxiliary verb which changes form in
future tense and is inflected by person.
75

their head and given the part-of-speech tag PREV (preverbal particle)as described in Section 3.2.2.
i) SYMIn the Bijankhan Corpus different mathematical signs as well asvarious types of units of measure that had been marked by the tagMS received the label SYM instead, as the concept symbol is morerepresentative of such cases.
j) V_PPAll past participle verbs with the tag V_PA (past tense verb) weremodified to V_PP (past participle verb).
2. Removed tagsSome part-of-speech tags such as QUA, MQUA, SPEC, MORP, andDEFAULT had not been applied in accordance with the traditional Persiangrammatical description and were unevenly distributed in the BijankhanCorpus. The tags were used for words belonging to different parts-of-speech. These were reconsidered and removed. Affected words receivedtheir relevant morphological labels instead to be more consistent. The tagsare presented as follows.
a) QUAThe tag QUA was used for words belonging to different parts ofspeech. The tag was applied to singular nouns, different types ofdeterminers, pronouns, various forms of adverbs, adjectives, andprepositions. The tag was modified to N_SING (singular noun) forwords such as �
IKQ��» @ /aksariyyat/ (majority), �
IJÊ�¯@ /aqaliyyat/ (mi-
nority), DET (determiner) for words such as ÐAÖ�ß /tamam/ (all), Që /har/
(each), PRO (pronoun) for words such as úæ�ªK. /ba‘zi/ (some), ú
kQK.
/barxi/ (some), ADV_NEG (adverb of negation) for word such as i� Jë
/hic/ (no, never), ADV (adverb) for words such as ùÒ» /kam-i/ (gloss:little-indef, translation: slightly), úÎJ
k /xeyli/ (very), ADJ (adjective)
for words such as Q��
���K. /bištar/ (more, major), Q�
�» @ /aksar/ (most), andP (preposition) for the word such as
àAJÓ /miyan/ (between).
b) MQUAThe tag MQUA, which had been used for the compound wordsÉ
�¯@Yg /haddeaqal/ (at least) and Q�
�» @Yg /haddeaksar/ (at most), wasconverted to ADV. The two compound words were tagged irregularlyin the corpus, alternating between QUA, MQUA, CON, N_SING, and
76

ADV.
c) SPECThe tag SPEC was used for different words associated with differentparts of speech. The tag was converted to N_SING for words suchas A
�K /ta/ (fold, piece), as a noun of measure, �
I�
�Ó /mošt/ (handful),éKñà /gune/ (species), ¨ñ
K /no‘/ (type, sort), é
KñÖ
ß /nemune/ (sample),
ADV for words such as á�Jk� /cenin/ (such),
àAJk� /cenan/ (so), á�
Jj� Òë
/hamcenin/ (also), and ADJ for words such as XðYªÓ /ma‘dud/ (few),áKY
Jk� /candin/ (several, multiple), èYÔ« /omde/ (major).
d) MORPThe tag MORP was used for some passive forms such as èY
�� /šod-e/
(gloss: become.past-pp, translation: become), é�JP /raft-e/ (gloss:
go.past-pp, translation: gone), for the adjective éËA� /sale/ (years, forinstance in the expression: years-old), and for some nouns such asQ
®
K /nafar/ (person). The tag was replaced by the word’s associated
part-of-speech tags such as V_PP (past participle verb), ADJ, andN_SING respectively.
e) NNThe tag NN was applied only to two cases in the Bijankhan Corpus,indicating dates such as 79/3/1. The tag was removed during tok-enization since this sequence of numbers and slashes were split intoseparate tokens and received associated tags. The numbers and theslashes were then marked by NUM and DELM respectively.
f) V_PREIn the Bijankhan Corpus, the copula verb was handled differentlyin different tenses. Copula verbs in present tense as well as wordsaccompanied by copula clitics were annotated as V_PRE (verbpredicate), in present continuous tense as V_PRS (verb present),and in past tense as V_PA. In the UPC the tag V_PRE was replacedby V_PRS to represent the copula verb in present tense and to beconsistent with other copula verbs in terms of being marked by tenses.
g) DEFAULTDelimiters in the Bijankhan Corpus were marked by the tag DELM.However, the tag DEFAULT had also been used irregularly for de-limiters. The tag was completely replaced by DELM to be consistentwith the rest of the delimiters.
77

3. Merged tagsSome tags in the UPC represent major part-of-speech categories only,while some also represent morphological features. In the UPC, I havesometimes merged tags that were specified with morphological featuresinto their main or related categories. These were tags that could easilybe merged with their main or other related categories and still be wellrepresentative. The idea was to reduce the size of the tagset. This approachwas applied to a number of part-of-speech tags with no particular reasonfor variations in granularity or informativeness. Thus the tags ADJ_ORDand ADJ_SIM were merged with ADJ. In addition, the tag ADV_NI wasmerged with ADV, as well as the following tags: IF to CON, OH to INT,NP to CON, PP to P, and PS to INT.
4. Errors and inconsistenciesPersian has a huge number of homographs with multiple senses. The word
¬Q
£ /zarf/, for instance, is used as a singular noun meaning dish and as a
preposition meaning within. Depending on its role in a sentence the wordreceives different part-of-speech tags. In the Bijankhan Corpus, the wordwas annotated as a preposition even when it referred to the notion of dish.The corpus contained many such cases of erroneous part-of-speech tags,and these were corrected when detected. Once an annotation error wasdiscovered, it was often the case that the same type of error could be foundelsewhere in the corpus. By browsing the corpus systematically, errors ofthe same type were traced and corrected.
Table 3.3 shows a sample sentence taken from the Bijankhan Corpus and themodified version of the sentence in the UPC. To facilitate a comparative de-scription of the changes in the UPC, words in the table are marked with IDnumber and treated words are highlighted in red. However, words in the Bi-jankhan Corpus and UPC do not appear with ID numbers.
The expression �
Iêk.à
�@ P@ /az an jahat ke/ (gloss: of that direction that,
translation: since), with ID 6 in the Bijankhan Corpus was treated as a singletoken and annotated with the tag CON. However, this fixed expression thatcontained four elements were not even merged into a single token but sepa-rated with white spaces. Given my tokenization scheme, which assumes thattokens do not contain spaces, I basically had two options: either to mergefixed expressions into a single element or to split them into independent ele-ments. As such expressions were treated inconsistently in the Bijankhan Cor-pus, sometimes as a single token annotated autonomously, despite the whitespaces, and sometimes as multiple units with different tags, I split such fixedexpressions into their components and treated them as multiple distinct tokensspecified with associated part-of-speech information. My justification for notmerging multi-word expressions into a single token is that it is impossible to
78
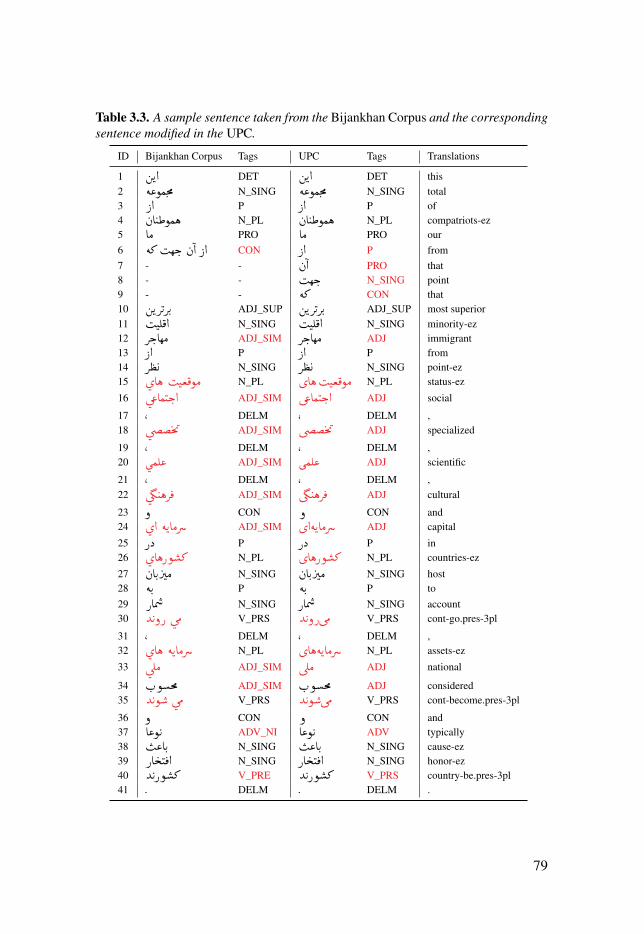
Table 3.3. A sample sentence taken from the Bijankhan Corpus and the correspondingsentence modified in the UPC.
ID Bijankhan Corpus Tags UPC Tags Translations
1 áK @ DET áK @ DET this2 é«ñÒm.
× N_SING é«ñÒm.× N_SING total
3 P @ P P @ P of4
àAJ£ñÒë N_PL
àAJ£ñÒë N_PL compatriots-ez
5 AÓ PRO AÓ PRO our6 é»
�Iêk.
à
�@ P@ CON P @ P from
7 - - à
�@ PRO that
8 - - �Iêk. N_SING point
9 - - é» CON that10 áKQ
�KQK. ADJ_SUP áKQ
�KQK. ADJ_SUP most superior
11 �IJÊ
�¯@ N_SING �
IJÊ�¯@ N_SING minority-ez
12 Qk. AêÓ ADJ_SIM Qk. AêÓ ADJ immigrant13 P @ P P @ P from14 Q
¢
� N_SING Q
¢
� N_SING point-ez
15 ø
Aë�
IJª�¯ñÓ N_PL øAë
�IJª
�¯ñÓ N_PL status-ez
16 ú«AÒ
�Jk. @ ADJ_SIM ú«AÒ
�Jk. @ ADJ social
17 , DELM , DELM ,18 ú
�
m�
�' ADJ_SIM úæ��
m�
�' ADJ specialized
19 , DELM , DELM ,20 ù
ÒÊ« ADJ_SIM ùÒÊ« ADJ scientific
21 , DELM , DELM ,22 ú
Æ
JëQ
¯ ADJ_SIM úÆ
JëQ
¯ ADJ cultural
23 ð CON ð CON and24 ø
@ éKAÓQå� ADJ_SIM ø@ éKAÓQå� ADJ capital
25 PX P PX P in26 ø
AëPñ
��» N_PL øAëPñ
��» N_PL countries-ez
27 àAK.
Q�Ó N_SING àAK.
Q�Ó N_SING host28 éK. P éK. P to29 PAÖÞ
�� N_SING PAÖÞ
�� N_SING account
30 YKðP ú
× V_PRS Y
KðPú× V_PRS cont-go.pres-3pl
31 , DELM , DELM ,32 ø
Aë éKAÓQå� N_PL øAë éKAÓQå� N_PL assets-ez
33 úÎÓ ADJ_SIM úÎÓ ADJ national
34 H. ñ�m× ADJ_SIM H. ñ�m× ADJ considered35 Y
Kñ
�� ú
× V_PRS Y
Kñ
��ú× V_PRS cont-become.pres-3pl
36 ð CON ð CON and37 A«ñ
K ADV_NI A«ñ
K ADV typically
38 �I«AK. N_SING �
I«AK. N_SING cause-ez39 PA
j
�J¯ @ N_SING PA
j
�J¯ @ N_SING honor-ez
40 YKPñ
��» V_PRE Y
KPñ
��» V_PRS country-be.pres-3pl
41 . DELM . DELM .
79

merge these expressions in new data because of ambiguities. Hence, theirstatus as multi-word expressions will be recognized in the syntactic analysisinstead.
In the Bijankhan Corpus, affixes such as plural suffixes and verb prefixes,as well as clitics that were separated from their head words by white space,were separated with ZWNJ in UPC, for example ø
Aë
�IJª
�¯ñÓ /moqeiyat -
ha-ye/ (gloss: status -pl-ez, translation: status), ø
@ éKAÓQå� /sarmaye -i/ (cap-
ital), YKðP ú
× /mi- rav-and/ (gloss: cont-go.pres-3pl, translation: they go),
ø
Aë éKAÓQå� /sarmaye -ha-ye/ (gloss: asset -pl-ez, translation: assets), and
YKñ
�� ú
× /mi- šav-and/ (gloss: cont- become.pres-3pl, translation: they be-
come) with IDs 15, 24, 30, 32, and 35 respectively.
The tag ADJ_SIM in the Bijankhan Corpus was merged with ADJ in UPC.The tag is used for words with ID numbers 12, 16, 18, 20, 22, 24, 33, and34. The tag ADV_NI was also merged with ADV in the UPC, for example theword with the ID 37.
In the Bijankhan Corpus words accompanied by the copula clitics wereannotated as V_PRE, for example Y
KPñ
��» /kešvar-and/ (gloss: country-
be.pres.3pl, translation: are country) with ID number 40. The tag V_PREwas modified to V_PRS in the UPC.
The character ø
(ye) in Arabic style (with two dots beneath) in the
Bijankhan Corpus was converted to Persian ø (ye) in the UPC, withoutany dots and with Persian Unicode encoding. Affected words in the tableareø
Aë
�IJª
�¯ñÓ /moqeiyat -ha-ye/ (gloss: status -pl-ez, translation: status),
ú«AÒ
�Jk. @ /ejtema‘i/ (social), ú
�
m�
�' /taxassosi/ (specialized), ù
ÒÊ« /elmi/ (sci-
entific), úÆ
JëQ
¯ /farhangi/ (cultural), ø
@ éKAÓQå� /sarmaye -i/ (capital), ø
AëPñ
��»
/kešvar-ha-ye/ (gloss: country-pl-ez, translation: countries), YKðP ú
× /mi- rav-
and/ (gloss: cont-go.pres-3pl, translation: they go), ø
Aë éKAÓQå� /sarmaye -
ha-ye/ (gloss: asset -pl-ez, translation: assets), úÎÓ /melli/ (national), and
YKñ
�� ú
× /mi- šav-and/ (gloss: cont- become.pres-3pl, translation: they be-
come) with IDs 15, 16, 18, 20, 22, 24, 26, 30, 32, 33, and 35. The modifica-tion was further applied to other characters in Arabic style as well as digits inArabic and Western styles (see 3.2.1).
As most NLP applications rely on normalized, white space tokenized, andconsistently annotated data, normalizing the Bijankhan Corpus at different lev-els was the fundamental procedure in developing the Uppsala Persian Corpusas a prerequisite for building a treebank. By making sure that tokens do not
80

need to be composed or decomposed for subsequent processing in the UPC, Iensured that such words will be identified as distinct units to be processed inthe syntactic analysis. I aimed to make changes consistent with linguistic unitsas long as these units are reproducible with an automatic tokenizer on new text.When this was not possible I fell back on white space tokenization and addedthe linguistic information to the syntactic annotation. In this way I guaranteedthat the linguistic units in the annotated corpus would be comparable with newtokenized text.
The main improvements were systematically accomplished by automatic orsemi-automatic processing. Automatic processing was used for specific caseswhen there was no risk of affecting words with multiple parts of speech. Forexample, the accusative marker ra with the part-of-speech tag P was auto-matically modified to CLITIC. Automatic processing was further applied tocorrect misspellings. Semi-automatic processing, on the other hand, was usedfor cases containing multiple part-of-speech categories. Although detectingand correcting the part-of-speech annotation of such words is usually carriedout by bigram or trigram searching, the method is not applicable in certaincases. Semi-automatic processing was therefore applied manually, back andforth, by browsing the corpus systematically and tracing the errors. For in-stance YªK. /ba‘d/ (next, later, dimension) is a word with multiple notions andpart-of-speech information. The word can be used simply as an adjective,as an adverb or, with totally different pronunciation (which is unimportant intexts), as a noun. In the Bijankhan Corpus, the word was sometimes annotatedas a noun, a conjunction, or a determiner when it was serving as an adjec-tive or adverb. The errors were sometimes traced through bigram or trigramsearching and corrected. However, cases such as where the word was used as anoun in the corpus and was given wrong tag were undetectable by this method,as the tag N_SING was also applied for the word in adjectival and adverbialstate. Thus, the correction was carried out manually when the errors werediscovered. In this way, UPC, as a re-tokenized version of the Bijankhan Cor-pus with additional sentence segmentation and more consistent morphologicalannotation, can serve as a normalized and balanced corpus of contemporaryPersian for language technology purposes.
81

4. Normalization, Segmentation andMorphological Analysis for Persian
As mentioned in Chapter 1, one of the goals of this thesis is to build adependency-based treebank for Persian by first improving a part-of-speechanalyzed corpus to serve as the treebank data. Furthermore, I aim to developtools for automatic text processing and analysis of Persian, such as tools forsentence segmentation and tokenization, part-of-speech tagging, and parsing.
In addition to reusing existing resources and tools, which is a practical ne-cessity, I impose a compatibility requirement on my resources and tools. Tosatisfy this requirement, I first of all want to be able to run the tools in apipeline, where the output of one tool is compatible with the input require-ments of the next. Moreover, I want the tools to render the same analysis thatis found in the annotated corpora, so that they can be used with additionaltools derived from these corpora. Thus, for each and every step of process-ing, from normalization to syntactic parsing, I have developed a tool that iscompatible with my annotated corpora. In building these tools, I have madeuse of standard methods and state-of-the-art tools, in particular, the sentencesegmentation and tokenization tools in Uplug (Tiedemann, 2003), the part-of-speech tagger HunPoS (Halácsy et al., 2007), and the data-driven parsergenerator MaltParser (Nivre et al., 2006). Figure 4 shows the pipeline of toolsfor automatic processing and analysis of Persian. In this chapter I describe thetools that go with UPC, that is, tools for preprocessing, sentence segmentationand tokenization, and part-of-speech tagging. The tools for syntactic parsingwill be described after presenting the Uppsala Persian Dependency Treebankin Chapter 5.
4.1 Preprocessing, Sentence Segmentation andTokenization
In this section I present the first two tools in the pipeline, namely PrePer andSeTPer. The section ends with a joint evaluation of the tools. PrePer1 andSeTPer2 are both freely available tools for the normalization and segmentationof Persian texts. They are open source under a GNU General Public License.
1http://stp.lingfil.uu.se/∼mojgan/preper.html2http://stp.lingfil.uu.se/∼mojgan/setper.html
82

BLARK Pipeline for PersianPreprocessorPrePer
Sentence Segmenter & Tokenizer: SeTPer
PoS Tagger:TagPer
Parser:ParsPer
Treebank:
UPDT
PoS tagged Corpus: UPC
Figure 4.1. Persian natural language processing pipeline.
4.1.1 The Preprocessor: PrePerAs mentioned earlier, one of the major bottlenecks in automatic processingof Persian is the lack of standardization in Persian orthography in terms ofdifferent writing styles, spacing and font encoding. Persian orthography is notconsistent. A word may be spelled in various forms and with different Unicodecharacters in a text. Compound words and inflectional affixes are highly prob-lematic in this regard, and can be spelled either as attached to or detached fromtheir adjacent word (see Section 2.3). These inconsistencies can easily impactthe tokenization process, which in turn affects the quality of morphologicaland syntactic analysis. Therefore, prior to any morphosyntactic analysis theinput text needs to pass through a preprocessor module. For that reason, in mypipeline I have inserted a preprocessor for Persian, called PrePer, to take careof various encodings and typing styles in different genres.
PrePer (Seraji et al., 2012a) is an open source tool, developed in the pro-gramming language Ruby, for editing and cleaning up Persian texts to solveinconsistency issues. The program uses the Virastar module (Bargi, 2011)for some formatting tasks. It handles miscellaneous cases and normalizestexts into computational standard script. PrePer, via Virastar, takes care ofthe occurrences of mixed character encodings. When normalizing texts, allletters in Arabic style with Arabic character encoding are converted to Persianstyle with mappings to Persian character encoding. Furthermore, Arabic andWestern digits are all converted to Persian digits. PrePer furthermore treatscases that Virastar does not treat, such as the following cases where white
83

space can unambiguously be identified as token-internal. In this case, whitespace will instead be replaced by ZWNJ to create a single token.
1. Nouns and plural suffixes Aë- /-ha/ , à@- /-an/,
àAK- /-yan/, àAÇ- /-gan/, �
H@-/-at/ , and áK- /-in/, e.g.:
Aë H. A�J» ................................ AëH. A
�J»
(/ketab/ + /-ha/ ....................... books)
à@ Q�
�
gX ................................. à@Q
��
gX
(/doxtar/ + /-an/ ...................... girls)
àAK ñj.
��
� @X ...........................
àAKñj.�
�� @X
(/danešju/ + /-yan/ .................. students)
àAÇ PA
�J� ................................
àAÇPA�J�
(/setare/ + /-gan/ ................... stars)
�H@ QëA
¢
�� ............................... �
H@QëA
¢��
(/tazahor/ + /-at/ ............... demonstrations)
áK Q¯A�Ó ................................ áKQ
¯A�Ó
(/mosafer/ + /-in/ .................. passengers)
2. Any noun that ends in silent h and the indefinite clitic ø@- /-i/, e.g.:
ø@ éKA
g .................................. ø@ é
KA
g
(/xane/ + /-i/ .......................... a house)
3. Any noun indicating trade names and the abstract suffix ø- /-ye/ or úG- /-i/,
e.g.:
ø QÃP P ................................... øQÃP P
(/zargar/ + /-i/ ...................... goldsmith’s trade)
úG
@ñKA
K .................................... úG
@ñ
KA
K
(/nanva/ + /-i/ .......................... bakery)
4. Any noun and the abstract suffix ø- /-ye/ forming adjectives, e.g.:
ø Q���» A
g ................................ øQ�
��» A
g
(xakestar + /-i/ ........................ gray)
84

Table 4.1. Personal endings in past tense.
Personal Endings Transcriptions Translations
Ð- /-am/ Iø- /-i/ you∅ ∅ she/heÕç'- /-im/ weYK- /-id/ youY
K- /-and/ they
Table 4.2. Copula clitics. * The third singular è� /-h/ in formal usage is consistentlyused along with the verb �
I�@ /ast/ (is).
Copula Clitics Transcriptions Translations
Ð@- /-am/ Iø@- /-i/ youè- * /-h/ she/heÕç' @- /-im/ weYK@- /-id/ youY
K@- /-and/ they
5. Any adjective and the abstract suffix ø- /-ye/ forming nouns, e.g.:
ø QÓQ�¯ ...................................... ø QÓQ
�¯
(/qermez/ + /-i/ ....................... redness)
6. Nouns and different pronominal clitics, e.g.:
àA
�K Q�
�¯X .....................................
àA�KQ
��¯X
(/daftar/ + /-etan/ ....................... your office)
7. Any preceding word and personal endings shown in Table 4.1 as well ascopula clitics shown in Table 4.2 e.g.:
YK@ èYÓ
�@ ................................... Y
K@ èYÓ
�@
(/amad-e/ + /-and/ .............. they have come)
8. Nouns and verbal stems in compound forms. Verbal stems shown inTable 4.3 are usually used as the second element of a compound word andserve as derivational suffixes.
85
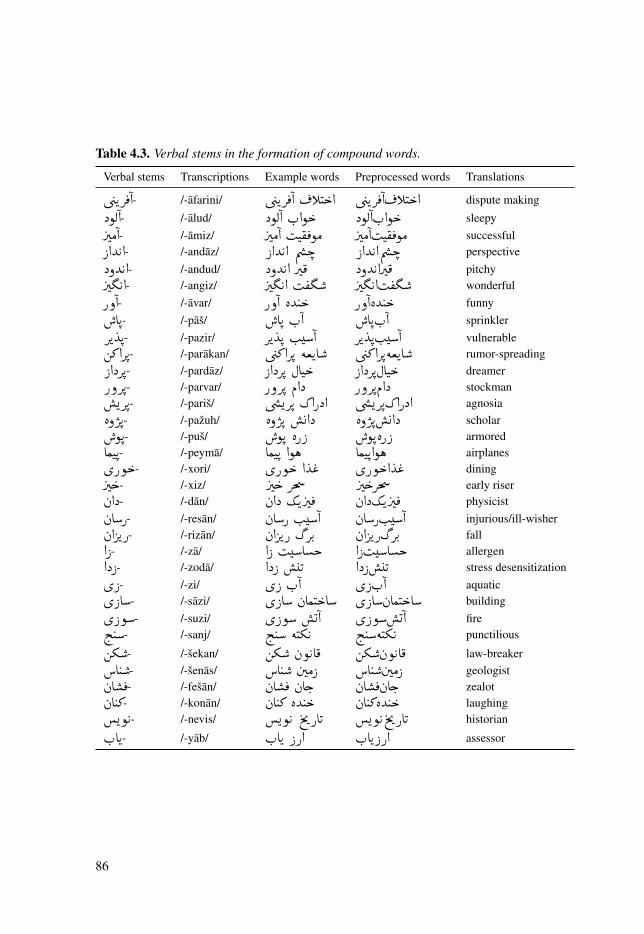
Table 4.3. Verbal stems in the formation of compound words.
Verbal stems Transcriptions Example words Preprocessed words Translations
ú
æKQ¯�@- /-afarini/ ú
æKQ
¯�@
¬C
�J
k@ ú
æKQ
¯�@
¬C
�J
k@ dispute making
XñË�@- /-alud/ XñË
�@ H. @ñ
k XñË
�@H. @ñ
k sleepy
Q�Ó�@- /-amiz/ Q�Ó
�@
�IJ
�®
¯ñÓ
Q�Ó�@
�IJ
�®
¯ñÓ successful
P @YK @- /-andaz/ P @Y
K @ Õæ
��k�
P@YK @Õæ
��k� perspective
XðYK @- /-andud/ XðY
K @ Q�
�¯ XðY
K @Q�
�¯ pitchy
Q�ÂK @- /-angiz/ Q�Â
K @
�I
®Â
��
Q�ÂK @
�I
®Â
�� wonderful
Pð�@- /-avar/ Pð
�@ èY
J
k Pð
�@ èY
J
k funny
��AK�- /-paš/ �
�AK� H.
�@
��AK�H.
�@ sprinkler
QKYK�- /-pazir/ QK
YK� I. ��
�@ QK
YK�I. ��
�@ vulnerable
á» @QK�- /-parakan/ ú
æ» @QK� éªKA�
� ú
æ» @QK� éªKA�
� rumor-spreadingP @XQK�- /-pardaz/ P @XQK� ÈAJ
k P@XQK�ÈAJ
k dreamer
PðQK�- /-parvar/ PðQK� Ð@X PðQK�Ð@X stockman�
��QK�- /-pariš/ úæ���QK� ¸@PX@ úæ
���QK�¸@PX@ agnosia
èð �QK�- /-pažuh/ èð �QK��
��@X èð �QK�
��
�@X scholar
��ñK�- /-puš/ �
�ñK� èP P�
�ñK� èP P armoredAÒJK�- /-peyma/ AÒJK� @ñë AÒJK� @ñë airplanesøPñ
k- /-xori/ øPñ
k @
Y
« øPñ
k@
Y
« dining
Q�
g- /-xiz/ Q�
g Qm�� Q�
gQm�� early riserà@X- /-dan/
à@X ¹KQ�
¯
à@X¹K
Q�¯ physicist
àA�P- /-resan/
àA�P I. ���@
àA�PI. ��
�@ injurious/ill-wisher
à@ QKP- /-rizan/
à@ QKP ÀQK.à@ QKPÀQK. fall
@ P- /-za/ @ P�
I��A�k @ P�
I��A�k allergen@X P- /-zoda/ @X P
��
��K @X P
��
��K stress desensitization
ø P- /-zi/ ø P H.
�@ ø PH.
�@ aquatic
ø PA�- /-sazi/ ø PA�àAÒ
�J
kA� ø PA�
àAÒ
�J
kA� building
ø Pñ�- /-suzi/ ø Pñ��
����@ ø Pñ�
��
���@ fire
i.J�- /-sanj/ i.
J� é
�Jº
K i.
J� é
�Jº
K punctilious
�
�- /-šekan/ áº�
�
àñKA
�¯ áº
��
àñ
KA
�¯ law-breaker
�AJ
��- /-šenas/ �A
J
��
á�ÓP �A
J
��
á�ÓP geologist
àA
��
¯- /-fešan/
àA�
�¯
àAg.
àA
��
¯
àAg. zealot
àA
J»- /-konan/
àAJ» èY
J
k
àA
JȏY
J
k laughing
��ñK- /-nevis/ ��ñ
K t�'PA
�K ��ñ
Kt�'PA
�K historian
H. AK- /-yab/ H. AKPP@ H. AK
PP@ assessor
86

9. Suffixes shown in Table 4.4 and their adjacent words forming adjective-adverbs and adjective-nouns.3
Table 4.4. Adjectival and nominal suffixes.
Suffixes Transcriptions Example words Processed words Translations
PA�- /-sar/ PA� ÐQå�� PA�ÐQå
�� ashamed
¸- /-ak/ ¸ Qå��� Qå��� little boyéKAÇ- /-gane/ é
KAÇ ém�
�'. é
K AÇém�
�'. childish
QÃ- /-gar/ Qà Õ�æ� QÃÕ
�æ� tyrant
úÃ- /-gi/ úà XQå�¯ @ úÃXQå�
¯ @ depression
á�Ã- /-gin/ á�à Õæ��
k
á�ÃÕæ��
k angry
YJÓ- /-mand/ Y
JÓ
�HðQ
�K Y
JÓ
�HðQ
�K rich
¸AK- /-nak/ ¸A
K
�I
��kð ¸A
K
�I
��kð terrible
P@ð- /-var/ P@ð YJÓ@ P@ðYJÓ@ hopefulPð- /-var/ Pð á
m�� Pð á
m�� eloquent
YKð- /-vand/ Y
Kð QîD
�� Y
KðQîD
�� citizen
�IK- /-yat/ �
IKQ�
�» @�
IKQ��» @ majority
10. Nouns and the indefinite suffix ø- /-ye/ forming indefinite nouns, e.g.:
ø Qå��� ....................................... øQå���
(/pesar/ + /-i/ .......................... a boy)
11. Verbal stems and the suffix ¸@- /-ak/ forming nouns, e.g.:
¸@ Pñ
k ..................................... ¸@Pñ
k
(/xor/ + /-ak/ ............................... food)
12. Verbal past stems and the suffix P@- /-ar/ forming nouns, e.g.:
P@ YKQ
k ...................................... P@YKQ
k
(/xarid/ + /-ar/ ............................ buyer)
13. Verbal present stems and the suffix PAÇ- /-gar/ forming nouns, e.g.:
3In Persian, adjectives rather frequently play different grammatical roles in a sentence and caneasily be exchanged for nouns and adverbs (Lazard, 1992). For instance
à@ñk. (young) is anadjective but can simply fill the role of a noun in the following sentence:
.�
I�@ XP@ð è PA�K
à@ñk.
áK@
inthis
javanyoung
taze-varednew-entered
astbe.pres.3sg
.
.This young woman/man is a newcomer.
87

PAÇ PñÓ�@ ...................................... PAÇ PñÓ
�@
(/amuz/ + /-gar/ ..................... instructor )
14. Nouns and the suffix éK @- /-aneh/ forming adverbs, e.g.:
éK @ XQÓ .......................................... é
K @XQÓ
(/mard/ + /-ane/ .......................... manly)
15. The negative prefix - AK /na-/ (im-, in-, un-, -less) and adjectives or verbal
stems, as well as the negative prefix -úG.
/bi-/ (im-, in-, un-, -less) andadjectives, e.g.:
a) the negative prefix - AK /na-/ and adjectives, e.g.:
�I�PX A
K .............................. �
I�PXAK
(/na-/ + /dorost/ ................... incorrect)
b) the negative prefix - AK /na-/ and verbal stems, e.g.:
�AJ
�� A
K ................................ �A
J
��A
K
(/na-/ + /šenas/ ..................... unknown)
c) the negative prefix -úG./bi-/ and adjectives, e.g.:
�I
��¯X úG
................................... �
I��¯XúG
.(/bi-/ + /deqqat/ ..................... careless)
4.1.2 The Sentence Segmenter and Tokenizer: SeTPerThe sentence segmenter and tokenizer SeTPer (Seraji et al., 2012a) was devel-oped for segmenting texts based on Persian sentence boundaries, which com-prise full stop, exclamation mark, and question mark, and tokenizing a ZWNJnormalized text. SeTPer was created by reusing and modifying the sentencesegmenter and tokenizer tools in the modular software platform Uplug, a sys-tem designed for the integration of text processing tools (Tiedemann, 2003).The Uplug sentence segmenter and tokenizer is a rule-based program that canbe adapted to various languages by using regular expressions for matchingcommon word and sentence boundaries. SeTPer treats the full stop, the ques-tion mark, and the exclamation mark as sentence boundaries.
Table 4.5 shows tokens that are handled as token separators by SeTPer. Thetokenizer also handles numerical expressions, web URLs, abbreviations, andtitles. Acronyms are rarely used in Persian but might exist in text messagingand social media platforms, and they are therefore also handled. To fulfill
88

Table 4.5. List of token separators.
apostrophe “ and ”parentheses ( and )brackets [ and ]colon :semicolon ;
dash -exclamation mark !question mark ?
at sign @slash /backslash \percent %asterisk *tilde ∼
the compatibility requirement mentioned earlier, the output of the sentencesegmentation and tokenization tool must match the input requirements of thenext tool in the pipeline, namely, the part-of-speech tagger.
4.1.3 The Evaluation of PrePer and SeTPerTo evaluate the normalization and segmentation tools I carried out an exper-iment on the performance of the normalizer, PrePer, and the sentence seg-menter and tokenizer, SeTPer. For the experiment, I used texts from the web-based journal www.hamshahri.com. I downloaded multiple texts from differ-ent genres and then randomly picked 100 sentences containing 2778 tokens todevelop a test set. As my experiment involved some manual work, I opted fora small-sized sample to make the evaluation task more feasible. I then createda gold set by manually normalizing the internal word boundaries and charactersets and then segmenting the text into sentence and token levels. I normalizedthe test set with PrePer and then segmented it with SeTPer. The evaluationshowed that all 100 sentences were correctly segmented at sentence level withan accuracy of 100%. The evaluation of normalization and tokenization oftokens furthermore resulted in 99.25% recall, 99.59% precision, and 99.42%F-score. The experiment showed that some cases were not handled by thenormalizer and the tokenizer. Examples were bigram words that were mis-takenly typed without any space. Further cases were words that were typedtogether with digits without white space. Thus, the automated segmented filecontains 10 fewer words than the gold file. Table 4.6 shows all words that thenormalizer and tokenizer were not able to handle.
Normally, PrePer correctly converts Western quotation marks to Persianstyle, which is angle quotes « ». However, when several quotation marks are
89

Table 4.6. Words not treated by segmentation tools.
Words/Symbols Expected spellings Glosses Translations
P @PñK.QÓ P@ PñK.
QÓ aforementionedof aforementioned ofAK.1382 AK. 1382 1382with 1382 withéK.10TS3 éK. 10TS3 10653to 10653 toðQ�� ð Q�� browsingand browsing andXñ
k éJ.
K Aj. ºK Xñ
k éJ.
K Aj. ºK unilateralself unilateral self
Q®
K10 Q
®
K 10 10people 10 people
PñîD��ÓQÃQKñ�
�� PñîD
��Ó QÃQKñ�
�� illustratorfamous famous illustrator
áKCK�@øQîD
��Òë áKC
K�@ øQîD
��Òë Hamshahrionline Hamshahri online
« » “ “» « ” ”292 X@Yª
�K 292 X@Yª
�K number292 number 292
�I�@ é
�JQÃ
�I�@ é
�JQÃ takenis is taken
included in a sentence, PrePer cannot fully succeed in the conversion. Anexample is given below:
". Õç'Q�Ãú× á
��k. @P " @YÊK I.
��\ éËA� Që AÓ\ : Y
J�J®Ã Aë
à
�@
an-hathis-pl
goft-andsay.past-3pl
::
““
mawe
harevery
saleyear
““
šab-enight-ez
YaldaMithra
””
rara
jašncelebration
mi-gir-imcont-take.pres-1pl
.
.””
They said: “We celebrate “the night of Mithra” every year.”
The second opening angle quote was instead converted to a closing anglequote and the first closing angle quote became an opening angle quote. For aneasy follow up, the example below is only shown in gloss, along with Persianquotation marks.
The expected conversion:They said: «we every year «night-ez Mithra» ra celebration cont-take.pres-1pl.»
The rendered conversion:They said: «we every year »night-ez Mithra« ra celebration cont-take.pres-1pl.»
90

4.2 The Statistical Part-of-Speech Tagger: TagPerMy goal in creating a tagger for Persian was to develop a robust, data-drivenpart-of-speech tagger to disambiguate ambiguous words (words with morethan one tag) and annotate unknown words (not in the training data). Thepart-of-speech tagger TagPer (Seraji et al., 2012a) was developed for Persianusing the statistical part-of-speech tagger HunPoS (Halácsy et al., 2007), anopen source reimplementation of TnT (T. Brants, 2000). TagPer4 is releasedas a freely available tool for part-of-speech tagging of Persian and is opensource under a GNU General Public License.
HunPoS is based on Hidden Markov Models with trigram language mod-els which allow the user to tune the tagger by applying different feature set-tings. The tagger is similar to TnT with the difference that it (optionally)estimates emission/lexical probabilities based on current and previous tags.One additional difference to TnT lies in the fact that the tagger is open sourcewhereas TnT is not. The strong side of TnT, namely its suffix-based guess-ing algorithm, which is used for handling unseen words, is also implementedin HunPoS. Moreover, HunPoS can use a morphological analyzer to narrowdown the list of alternatives (possible tags) that the algorithm needs to dealwith, which not only speeds up searching but also significantly improves pre-cision. In other words, the morphological analyzer generates the possible tags,to which weights are assigned by a suffix-based guessing algorithm (Halácsyet al., 2007).
The tagger has various options for training, and I made use of this flexibilityby testing several parameters. To optimize HunPoS for Persian, I ran a num-ber of experiments on the development set5 of the UPC with different featuresettings and feature combinations. I experimented with the order of the tagtransition probability by setting the option -t to either bigram tagging or thedefault trigram tagging, in order to estimate the probability of a tag based onthe previous tags. I also examined the order of the emission probability -e forestimating the probability of a token based on the tag of the token itself as wellas the previous tags. The results of training the tagger with a combination ofdifferent feature settings showed that, as could be predicted, by applying thetrigram models I achieved a higher accuracy than with the bigram models. Ta-ble 4.7 shows a comparison of different models for tag transitions and wordemissions.
For tag distributions of unseen words based on tag distributions of rarewords (words seen less than N times in the training corpus) I used the option-f with the default value 10. I tested the -s parameter, which sets the length
4http://stp.lingfil.uu.se/∼mojgan/tagper.html5In all UPC experiments the first 10% of the UPC is the development set, the second 10% is thetest set, and the remaining 80% is the training data. For model selection the experiments havebeen run on the development set and for model assessment the experiments have been run onthe test set.
91

Table 4.7. Comparison of different models for tag transitions and word emissions.
Tag Transitions Word Emissions Accuracy (%)
bigram unigram 96.42bigram bigram 96.53trigram unigram 96.61trigram bigram 96.81
Table 4.8. Comparison of different models for unseen words.
Max Suffix Length Max Frequency Accuracy (%)
10 10 96.818 10 96.804 10 96.70
of the longest suffix to be considered by the algorithm when estimating anunseen word’s tag distribution, at the default value 10. It is worth mentioningthat the most desirable possible value of this parameter (-s) may depend on themorphology and orthography of the language involved (Halácsy et al., 2007).To examine the tagger performance for unseen words, I varied the length ofthe suffixes. I tested suffixes of length 10 (the default value), 8 and 4. Lookingat the results in Table 4.8, I can infer a decrease in accuracy when reducingthe length of the suffixes. Thus, for Persian, setting suffix length to 10 yieldsthe best results.
TagPer was developed when HunPoS was trained on UPC containing 31atomic part-of-speech tags with encoded morphological information. Thereare 15 main part-of-speech categories consisting of adjective, adverb, clitic,conjunction, delimiter, determiner, foreign word, interjection, symbol, noun,numeral, preposition, preverbal particle, pronoun, and verb. In addition, cat-egories such as adjective, adverb, noun, and verb are annotated for morpho-logical and some semantic features. The tagset is listed with explanations inTable 3.2.
4.2.1 The Evaluation of TagPerThere are various possibilities for estimating tagging accuracy. Hence, I se-lected three different ways to evaluate TagPer. I first carried out a tagging es-timation (model assessment) where HunPoS was trained on 90% of the UPCand evaluated on the remaining 10%. The tagger achieved an overall accu-racy of 97.46% (Seraji et al., 2014). With respect to the performance of otherdata-driven part-of-speech taggers, such as TnT, memory-based tagger, andMaximum Likelihood Estimation, HunPoS is a good alternative for part-of-speech tagging of Persian. The result reported here is the best published resultfor Persian so far, though the scores may not be directly comparable with
92
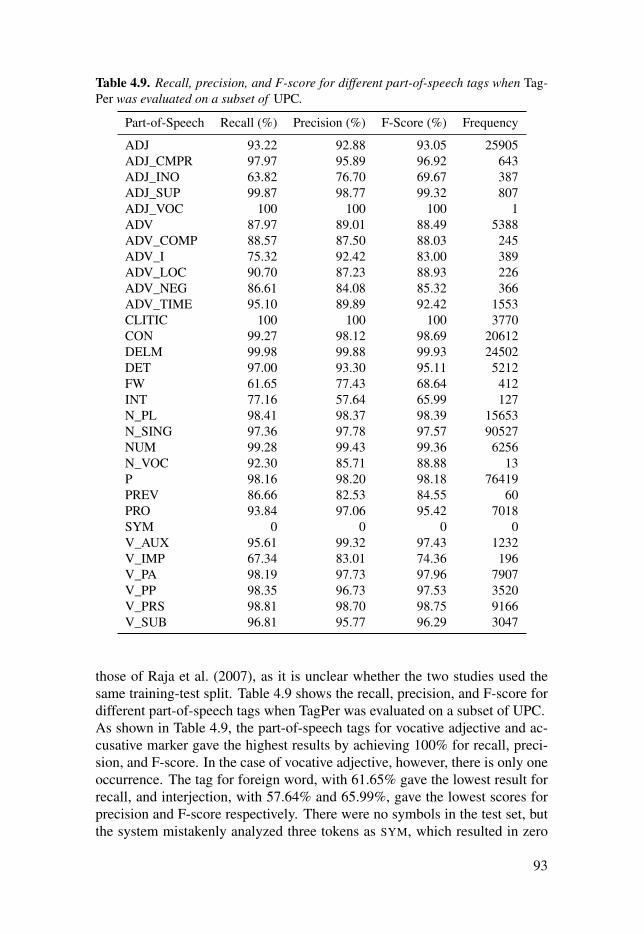
Table 4.9. Recall, precision, and F-score for different part-of-speech tags when Tag-Per was evaluated on a subset of UPC.
Part-of-Speech Recall (%) Precision (%) F-Score (%) Frequency
ADJ 93.22 92.88 93.05 25905ADJ_CMPR 97.97 95.89 96.92 643ADJ_INO 63.82 76.70 69.67 387ADJ_SUP 99.87 98.77 99.32 807ADJ_VOC 100 100 100 1ADV 87.97 89.01 88.49 5388ADV_COMP 88.57 87.50 88.03 245ADV_I 75.32 92.42 83.00 389ADV_LOC 90.70 87.23 88.93 226ADV_NEG 86.61 84.08 85.32 366ADV_TIME 95.10 89.89 92.42 1553CLITIC 100 100 100 3770CON 99.27 98.12 98.69 20612DELM 99.98 99.88 99.93 24502DET 97.00 93.30 95.11 5212FW 61.65 77.43 68.64 412INT 77.16 57.64 65.99 127N_PL 98.41 98.37 98.39 15653N_SING 97.36 97.78 97.57 90527NUM 99.28 99.43 99.36 6256N_VOC 92.30 85.71 88.88 13P 98.16 98.20 98.18 76419PREV 86.66 82.53 84.55 60PRO 93.84 97.06 95.42 7018SYM 0 0 0 0V_AUX 95.61 99.32 97.43 1232V_IMP 67.34 83.01 74.36 196V_PA 98.19 97.73 97.96 7907V_PP 98.35 96.73 97.53 3520V_PRS 98.81 98.70 98.75 9166V_SUB 96.81 95.77 96.29 3047
those of Raja et al. (2007), as it is unclear whether the two studies used thesame training-test split. Table 4.9 shows the recall, precision, and F-score fordifferent part-of-speech tags when TagPer was evaluated on a subset of UPC.As shown in Table 4.9, the part-of-speech tags for vocative adjective and ac-cusative marker gave the highest results by achieving 100% for recall, preci-sion, and F-score. In the case of vocative adjective, however, there is only oneoccurrence. The tag for foreign word, with 61.65% gave the lowest result forrecall, and interjection, with 57.64% and 65.99%, gave the lowest scores forprecision and F-score respectively. There were no symbols in the test set, butthe system mistakenly analyzed three tokens as SYM, which resulted in zero
93
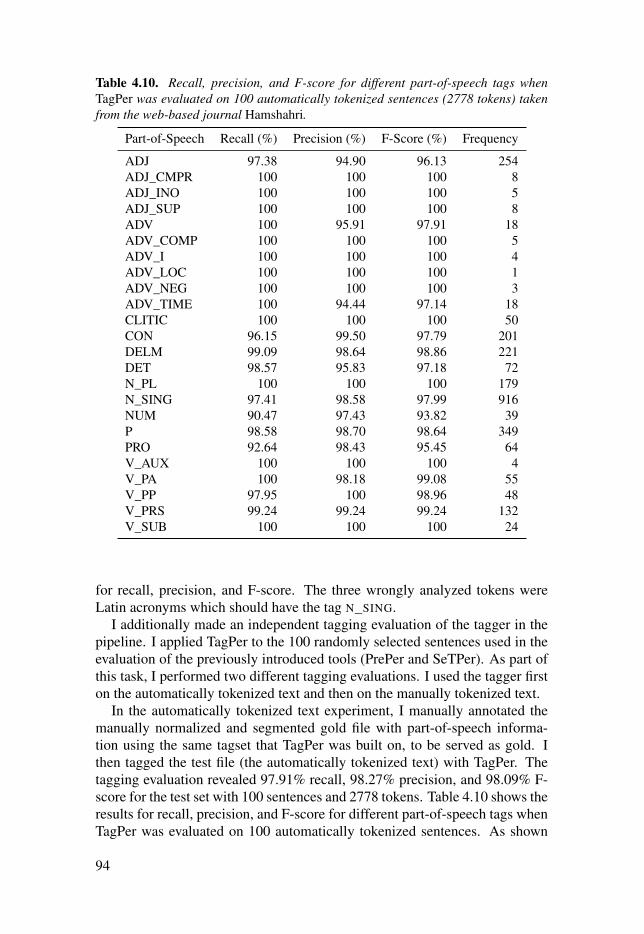
Table 4.10. Recall, precision, and F-score for different part-of-speech tags whenTagPer was evaluated on 100 automatically tokenized sentences (2778 tokens) takenfrom the web-based journal Hamshahri.
Part-of-Speech Recall (%) Precision (%) F-Score (%) Frequency
ADJ 97.38 94.90 96.13 254ADJ_CMPR 100 100 100 8ADJ_INO 100 100 100 5ADJ_SUP 100 100 100 8ADV 100 95.91 97.91 18ADV_COMP 100 100 100 5ADV_I 100 100 100 4ADV_LOC 100 100 100 1ADV_NEG 100 100 100 3ADV_TIME 100 94.44 97.14 18CLITIC 100 100 100 50CON 96.15 99.50 97.79 201DELM 99.09 98.64 98.86 221DET 98.57 95.83 97.18 72N_PL 100 100 100 179N_SING 97.41 98.58 97.99 916NUM 90.47 97.43 93.82 39P 98.58 98.70 98.64 349PRO 92.64 98.43 95.45 64V_AUX 100 100 100 4V_PA 100 98.18 99.08 55V_PP 97.95 100 98.96 48V_PRS 99.24 99.24 99.24 132V_SUB 100 100 100 24
for recall, precision, and F-score. The three wrongly analyzed tokens wereLatin acronyms which should have the tag N_SING.
I additionally made an independent tagging evaluation of the tagger in thepipeline. I applied TagPer to the 100 randomly selected sentences used in theevaluation of the previously introduced tools (PrePer and SeTPer). As part ofthis task, I performed two different tagging evaluations. I used the tagger firston the automatically tokenized text and then on the manually tokenized text.
In the automatically tokenized text experiment, I manually annotated themanually normalized and segmented gold file with part-of-speech informa-tion using the same tagset that TagPer was built on, to be served as gold. Ithen tagged the test file (the automatically tokenized text) with TagPer. Thetagging evaluation revealed 97.91% recall, 98.27% precision, and 98.09% F-score for the test set with 100 sentences and 2778 tokens. Table 4.10 shows theresults for recall, precision, and F-score for different part-of-speech tags whenTagPer was evaluated on 100 automatically tokenized sentences. As shown
94
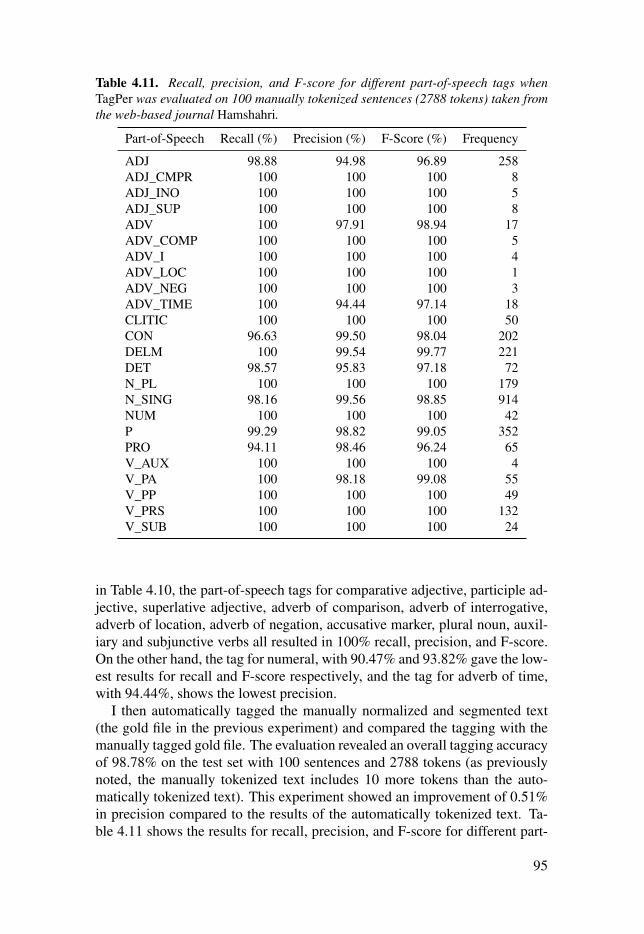
Table 4.11. Recall, precision, and F-score for different part-of-speech tags whenTagPer was evaluated on 100 manually tokenized sentences (2788 tokens) taken fromthe web-based journal Hamshahri.
Part-of-Speech Recall (%) Precision (%) F-Score (%) Frequency
ADJ 98.88 94.98 96.89 258ADJ_CMPR 100 100 100 8ADJ_INO 100 100 100 5ADJ_SUP 100 100 100 8ADV 100 97.91 98.94 17ADV_COMP 100 100 100 5ADV_I 100 100 100 4ADV_LOC 100 100 100 1ADV_NEG 100 100 100 3ADV_TIME 100 94.44 97.14 18CLITIC 100 100 100 50CON 96.63 99.50 98.04 202DELM 100 99.54 99.77 221DET 98.57 95.83 97.18 72N_PL 100 100 100 179N_SING 98.16 99.56 98.85 914NUM 100 100 100 42P 99.29 98.82 99.05 352PRO 94.11 98.46 96.24 65V_AUX 100 100 100 4V_PA 100 98.18 99.08 55V_PP 100 100 100 49V_PRS 100 100 100 132V_SUB 100 100 100 24
in Table 4.10, the part-of-speech tags for comparative adjective, participle ad-jective, superlative adjective, adverb of comparison, adverb of interrogative,adverb of location, adverb of negation, accusative marker, plural noun, auxil-iary and subjunctive verbs all resulted in 100% recall, precision, and F-score.On the other hand, the tag for numeral, with 90.47% and 93.82% gave the low-est results for recall and F-score respectively, and the tag for adverb of time,with 94.44%, shows the lowest precision.
I then automatically tagged the manually normalized and segmented text(the gold file in the previous experiment) and compared the tagging with themanually tagged gold file. The evaluation revealed an overall tagging accuracyof 98.78% on the test set with 100 sentences and 2788 tokens (as previouslynoted, the manually tokenized text includes 10 more tokens than the auto-matically tokenized text). This experiment showed an improvement of 0.51%in precision compared to the results of the automatically tokenized text. Ta-ble 4.11 shows the results for recall, precision, and F-score for different part-
95

of-speech tags when TagPer was evaluated on 100 manually tokenized sen-tences.
As shown in Table 4.11, the part-of-speech tags for comparative adjective,participle adjective, superlative adjective, adverb of comparison, adverb ofinterrogative, adverb of location, adverb of negation, accusative marker, pluralnoun, numeral, auxiliary verb, past participle verb, present tense verb, andsubjunctive verb all attain 100% recall, precision, and F-score, whereas thetag for pronoun, with 94.11% and 96.24%, gave the lowest results for recalland F-score respectively. The tag for adverb of time, with 94.44%, deliversthe lowest precision.
The evaluation measures of tagging performance in the presented exper-iments are very good. The results show that TagPer is the best automatic-learning part-of-speech tagger for Persian so far, since it outperforms otherpart-of-speech taggers developed for Persian. Thus, the achieved scores canbe considered as the state-of-the-art results.
96

© Mojgan Seraji


5. Uppsala Persian Dependency Treebank
This chapter presents the Uppsala Persian Dependency Treebank (UPDT)1
with a syntactic annotation scheme based on Stanford Typed Dependencies.The chapter describes the principles of data selection and the overall ap-proach to syntactic annotation. It further gives a comparative analysis of theUPDT and another dependency treebank developed in parallel with the UPDT,namely, the Persian Dependency Treebank (PerDT) (Rasooli et al., 2013).
5.1 Corpus OverviewThe Uppsala Persian Dependency Treebank (Seraji et al., 2012b; Seraji et al.,2013; Seraji et al., 2014) is a syntactically annotated corpus of contemporaryPersian based on dependency grammar. The treebank consists of 6,000 anno-tated and validated sentences, 151,671 word tokens, and 15,692 word types.Table 5.1 presents statistical information about the treebank. The average sen-tence length in the treebank is 25 words, ranging from a few words to over150 words. The treebank data is from different genres, including newspaperarticles and fiction, as well as technical descriptions and texts about cultureand art taken from the open source, validated UPC (see Section 3.2).
Table 5.1. A statistical overview of the UPDT.
Categories Number
Sentences 6,000Tokens 151,671Types 15,692PoS tags 31Dependency labels 96
To select sentences for the treebank, I extracted the first 6,000 sentences ofthe UPC. I decided not to randomly choose the data from various parts of theUPC, as this could impact text cohesion (discourse). In other words, it couldinterrupt the continuity of multiple syntactic characteristics such as presup-positions, implications, anaphoric elements, and the natural tense structure,which consequently could impact the frequency distribution. As shown in
1http://stp.lingfil.uu.se/∼mojgan/UPDT.html
99

Figure 5.1, this means that the data overlaps with the development set of theUPC that was used for various part-of-speech tagging experiments in Chap-ter 4.2 as well as in the parsing experiments described in Seraji et al. (2012c).In Seraji et al. (2012c) I trained two parsers (MaltParser and MSTParser) onthe UPDT by using different part-of-speech tag sets, once with gold standardpart-of-speech tags taken from UPC and once with tags automatically gener-ated during training and testing. For automatic generation of part-of-speechfeatures I used TagPer. However, I excluded the treebank data from UPC andretrained TagPer to avoid overlap. Moreover, in future experiments I want toavoid overlap between the treebank data and the training or test set of the UPC.Selecting the first 6,000 sentences was thus the best compromise I could find.
UPC
TrainTestDev
UPDT
Figure 5.1. Data selection of the UPDT.
The treebank is freely available in CoNLL-format2 and is open source un-der a Creative Commons Attribution 3.0 Unported License (CC BY 3.0). Acomprehensive description of the extended version of Stanford Typed Depen-dencies for Persian and the morphosyntactic features can be found in Serajiet al. (2013).
5.2 Treebank DevelopmentTo annotate the sentences in the treebank, I used MaltParser (Nivre et al.,2006) in a bootstrapping scenario. I started by training MaltParser on a seeddata set of 215 manually validated sentences and used the induced model toparse the rest of the treebank corpus. I then selected a subset of these sentencesfor manual correction, added them to the training set, retrained the parser,and reparsed the remaining corpus. This process was iterated as the size ofthe treebank grew and the quality of the parser improved. The selection ofsentences for human validation could have been done using active learning(Hwa, 2004; Sassano and Kurohashi, 2010). However, since the treebank was
2http://ilk.uvt.nl/conll/#dataformat
100

relatively small I did not do that, opting instead for a simple approach andproceeding sequentially.
In order to annotate and correct the syntactic annotation in the tree structureI used the free tree-editing software TrEd.3 TrEd (Hajic et al., 2001) is a fullyprogrammable and customizable graphical user interface for tree-like struc-tures, and was the main annotation tool used for the Prague Dependency Tree-bank. From TrEd I exported annotations in the PML format4 to the CoNLL-Xformat (Buchholz and Marsi, 2006), which is the official distribution formatof UPDT.
5.3 Annotation SchemeI use a syntactic annotation scheme based on dependency structure, whereeach dependency relation is annotated with a functional category, indicatingthe grammatical function of the dependent to the head. The annotation schemeis based on Stanford Typed Dependencies (STD) (de Marneffe et al., 2006),which has become a de facto standard for English. As mentioned earlier inSection 2.1.2, there is additionally a revised version of Stanford dependen-cies, namely, the Universal Stanford Dependencies (de Marneffe et al., 2014).In developing the UPDT I could not use the universal grammatical relationsdescribed in de Marneffe et al. (2014) since the treebank was released muchearlier than when the scheme was introduced. However, some relations thatare referred to as universal grammatical relations in the Universal StanfordDependencies are taken from the relations that are introduced as added rela-tions to the STD for Persian described in Seraji et al. (2013). The dependencyrelations are designated by the labels fw for foreign words, dep-top for topicdependent, and dep-voc for vocative dependent in UPDT. These relations aregeneralized in the Universal Stanford Dependencies to foreign, dislocated, andvocative respectively.
The extended version of STD for Persian has a total of 96 dependency re-lations of which 48 (including 10 new additions) are used for indicating basicrelations. The remaining 48 labels are complex, and are used to assign syntac-tic relations to words containing unsegmented clitics. In the following sectionsI will describe the basic relations from STD, including the new relations in theUPDT and the complex relations. Moreover, there are relations in the originalSTD that are excluded in the UPDT due to the fact that these are not relevant inPersian. These relations are introduced as unused relations which will furtherbe described.
3TrEd is licensed under a GNU General Public License and is available athttp://ufal.mff.cuni.cz/∼pajas/.4Prague Markup Language (PML) is a generic data format used for the storing and interchangeof linguistic annotations. The PML format is based on XML.
101

5.4 Basic RelationsIn the STD representation, the dependency annotation of a sentence alwaysforms a tree representing all tokens of the sentence (including punctuationmarks) and rooted at an artificial root node prefixed to the sentence. Thus,I adopt the so-called basic version of STD (with punctuation retained), asopposed to the collapsed version, where some tokens may not correspond tonodes in the dependency structure and a single node may have more than oneincoming arc. In general, every token in a sentence is assigned a syntactichead and one dependency label.
5.4.1 Relations from Stanford DependenciesI have used 38 grammatical relations from the 50 relations in the originalSTD.5 These are defined below in alphabetical order according to the abbrevi-ated name of the dependency labels that appear in the parser output. For eachrelation, I give examples taken from UPDT. I then discuss in Section 5.4.2 thenew relations that I have found necessary to introduce for the annotation ofPersian.
acomp: Adjectival ComplementAn adjectival complement of a verb is an adjectival phrase that functions asthe complement (like an object of the verb).
. Y�Pú× áºÜØAK Q
¢
� éK. èYJ
�®« áK@
inthis
aqideidea
beto
nazarthought
na-momkenneg-possible
mi-res-adcont-reach.pres-3sg
.
.This idea seems to be impossible.
acomp(Y�Pú× , áºÜØAK)
acomp(cont-reach.pres-3sg, neg-possible)
advcl: Adverbial Clause ModifierAn adverbial clause modifier is a clause modifying the verb (temporal clause,conditional clause, etc.).
YK@ñ
�Kú× Aë
à
�@ øAë é
�J¯AK , Y
J
��AK. èX P �Yg
�I�PX
à@QÂ
��ëð �QK�
áK@ ém��
'A
Jk�
. XQ�à P@Q�¯ PñK.
QÓ ø èPAJ��
�J�¯X
�IÓA
m�
� ð Ñm.
k �J
j�
��� ø@QK.
5I have considered the relations in the Stanford Typed Dependencies manual from 2008. Therelations were revised and changed for the Stanford Parser v.3.3 in December 2013, about sixmonths after I released the treebank. Some of the applied relations have been removed inthe new version of the manual. These relations are the dependency labels for complementizer(complm), relative clause modifier (rcmod), and relative (rel).
102

cenanceif
inthis
pažuhešgar-anresearcher-pl
dorostcorrect
hadsguess
zad-ehit.past-pp
baš-andsub.be.pres-3pl
,,
yafte-ha-yefinding-pl-ez
an-hathis-pl
mi-tavan-adcont-can.pres-3sg
bara-yefor-ez
tašxis-ediagnosis-ez
hajmvolume
vaand
zexamat-ethickness-ez
daqiq-eexact-ez
sayare-yeplanet-ez
mazburaforementioned
qararplace
gir-adsub.take.pres-3sg
.
.If these researchers made a correct guess, their findings/results can determinethe exact volume and thickness of the aforementioned planet.
advcl(XQ�à , èX P)advcl(sub.take.pres-3sg, hit.past-pp)
advmod: Adverbial ModifierAn adverbial modifier of a word is a (non-clausal) adverb or adverbial phrasethat serves to modify the meaning of the word.
. YJ�P H� Ag� éK.�
HAKQ�� PX l .
�'PY�JK.
àPñK. PA
�K�@
asar-ework.pl-ez
BornBorn
be.tadrijto.gradualness
darin
našriy-atmagazine-pl
beto
cappublication
residreach.past.3sg
.
.Born’s artworks were published gradually in magazines.
advmod(YJ�P , l .�'PY
�JK.)
advmod(reach.past.3sg, to.gradualness)
. XñK. èXAÓ�@ é
���Òë ð@
ushe/he
hamišealways
amadeready
budbe.past.3sg
.
.She/he was always ready.
advmod( èXAÓ�@ , é
���Òë)
advmod(ready, always)
amod: Adjectival ModifierAn adjectival modifier of a nominal is any adjectival phrase that serves tomodify the meaning of the nominal.
.�
I�@ AêÓX�@ øP@Qº
�K úÃY
K P PX Q
�Kú
GY
KAÓ úG
AJ
KX ÈAJ.
KX éK. ð@
103

ushe/he
beto
donbal-eafter-ez
donya-iworld-indef
mandani-tarlasting-more
darin
zendegi-elife-ez
tekrari-erepetitive-ez
adam-hapeople-pl
astbe.pres.3sg
.
.She/he is after a more lasting world in people’s repetitive life.
amod(úGAJ
KX ,Q
�Kú
GY
KAÓ)
amod(world-indef, lasting-more)
amod(úÃYK P , øP@Qº
�K)
amod(life-ez, repetitive)
appos: Appositional ModifierAn appositional modifier of a nominal is another nominal that serves tomodify the first. It includes parenthesized examples.
. XQ»�
HA�¯CÓ , é�
� @Q
¯ ék. PA
g PñÓ@ QK
Pð , Q �
��ñ» XPA
KQK. AK. XAK.
�@ÐC�@ PX ð@
ushe/he
darin
EslamabadIslamabad
bawith
BernardBernard
KušnerKouchner
,,
vazir-eminister-ez
omur-eaffair.pl-ez
xareje-yeforeign-ez
faranseFrance
,,
molaqatmeeting
karddo.past.3sg
.
.She/he met Bernard Kouchner, French foreign mininster, in Islamabad.
appos(XPAKQK. ,QK
Pð)appos(Bernard, minister)
aux: AuxiliaryAn auxiliary of a clause is a non-main verb of the clause, e.g. modal auxiliary,àXñK. (be), and á�
��
�@X (have) in a composed tense.
.�
I�@ é�J
��@Y
K Xñk. ð CJ.
�¯ é» X PA��. @P ø
Q�g� Yë@ñ
kú× ð@
ushe/he
mi-xah-adcont-want.pres-3sg
ciz-ithing-indef
rara
be-saz-adsub-build.pres-3sg
kethat
qablanbefore
vojudexist
na-dašt-eneg-have.past-pp
astbe.pres.3sg
.
.She/he wants to create something that did not exist before.
aux(X PA��. , Yë@ñ
kú×)aux(sub-build.pres-3sg, cont-want.pres-3sg)
aux( é�J
��@Y
K ,
�I�@)
aux(neg-have.past-pp, be.pres.3sg)
104

auxpass: Passive AuxiliaryA passive auxiliary of a clause is a non-main verb of the clause which containsthe passive information.
. Y�
� èYKX úæ�ÖÞ�� éÓñ
¢
JÓ P@ h. PA
g èPAJ�
á�Ëð@
avalinfirst
sayyareplanet
xarejoutside
azof
manzume-yesystem-ez
šamsisolar
did-esee.past-pp
šodbecome.past.3sg
.
.The first planet outside the solar system was sighted.
auxpass( èYKX , Y�
�)auxpass(see.past-pp, become.past.3sg)
cc: CoordinationA coordination is the relation between an element of a conjunct and the co-ordinating conjunction word of the conjunct. One conjunct of a conjunction,normally the first, is taken as the head of the conjunction.
. YK Pú× Y
KñJK� AKðP ð ÉJ
m�
�' AK. @P
�IJª
�¯@ð øAJ
KX
àPñK.
ËX
�@
AdolfAdolf
BornBorn
donya-yeworld-ez
vaqeiyatreality
rara
bawith
taxayolimagination
vaand
royadream
peyvandlink
mi-zan-adcont-hit.pres-3sg
.
.Adolf Born links the world of reality with imagination and dream.
cc(ÉJm�
�' , ð)
cc(imagination, and)
èXQºK hQ¢Ó @P ú
�æ�@ñ
kPX
á�Jk�
àñ
J» A
�K
àA
�J�» AK�
�IËðX AÓ@ Xð Q
¯ @ ð@
.�
I�@
ushe/he
afzudadd.past.3sg
ammabut
dolat-egovernment-ez
PakestanPakistan
ta.konununtil.now
ceninsuch
darxast-irequest-indef
rara
matrahraise
na-kard-eneg-do.past-pp
astbe.pres.3sg
.
.She/he added: but the goverment of Pakistan has not yet proposed such arequest.
cc( èXQºK , AÓ@)
cc(neg-do.past-pp, but)
105

ccomp: Clausal ComplementA clausal complement of a verb or adjective is a dependent clause with aninternal subject which functions like an object of the verb, or adjective.
P @ Q�KBAK. ñJ»ñ
�K QîD
�� PX Aë é
JK
Qëá�Â
KAJÓ é» YëXú×
àA
��
� Aëúæ�PQK.
.�
I�@ PñKñJK
barresi-hastudy-pl
nešanindication
mi-dah-adcont-give.pres-3sg
kethat
miyangin-eaverage-ez
hazine-hacost-pl
darin
šahr-ecity-ez
TokioTokyo
bala-tarhigh-more
azthan
Niu-YorkNew-York
astbe.pres.3sg
.
.Studies show that average costs in Tokyo city are higher than in New York.
ccomp(YëXú× ,Q�KBAK.)
ccomp(cont-give.pres-3sg, high-more)
.�
I�
�@X éÓ@X@ Aë�
H�YÓ A
�K
��ðA¿ áK@ é» YëXú×
àA
��
� Aëúæ�PQK.
barresi-hastudy-pl
nešanindication
mi-dah-adcont-give.pres-3sg
kethat
inthis
kavošsearch
tauntil
moddat-hatime-pl
edamecontinuation
dašthave.past.3sg
.
.Studies show that this search continued for a long time.
ccomp(YëXú× ,�
I�
�@X)ccomp(cont-give.pres-3sg, have.past.3sg)
complm: ComplementizerA complementizer of a clausal complement (ccomp) is the word introducingit. It will be the subordinating conjunction é» (that).
P @ Q�KBAK. ñJ»ñ
�K QîD
�� PX Aë é
JK
Qëá�Â
KAJÓ é» YëXú×
àA
��
� Aëúæ�PQK.
.�
I�@ PñKñJK
barresi-hastudy-pl
nešanindication
mi-dah-adcont-give.pres-3sg
kethat
miyangin-eaverage-ez
hazine-hacost-pl
darin
šahr-ecity-ez
TokioTokyo
bala-tarhigh-more
azthan
Niu-YorkNew-York
astbe.pres.3sg
.
.Studies show that average costs in Tokyo city are higher than in New York.
complm(Q�KBAK. , é»)
complm(high-more, that)
.�
I�
�@X éÓ@X@ Aë�
H�YÓ A
�K
��ðA¿ áK@ é» YëXú×
àA
��
� Aëúæ�PQK.
106

barresi-hastudy-pl
nešanindication
mi-dah-adcont-give.pres-3sg
kethat
inthis
kavošsearch
tauntil
moddat-hatime-pl
edamecontinuation
dašthave.past.3sg
.
.Studies show that this search continued for a long time.
complm( �I
��@X , é»)
complm(have.past.3sg, that)
conj: ConjunctA conjunct is a relation between two elements connected by a coordinatingconjunction, such as ð (and), AK (or), etc. Conjunctions are treated asymmet-rically. The head of the relation is the first conjunct, and other conjunctionsdepend on it via the conj relation.
. YK Pú× Y
KñJK� AKðP ð ÉJ
m�
�' AK. @P
�IJª
�¯@ð øAJ
KX
àPñK.
ËX
�@
AdolfAdolf
BornBorn
donya-yeworld-ez
vaqeiyatreality
rara
bawith
taxayolimagination
vaand
royadream
peyvandlink
mi-zan-adcont-hit.pres-3sg
.
.Adolf Born links the world of reality with imagination and dream.
conj(ÉJm�
�' , AKðP)
conj(imagination, dream)
cop: CopulaA copula is the relation between the complement of a copula verb and thecopula itself. The copula verb is taken as a dependent of its complement,except when the complement is a prepositional phrase (second examplebelow).
.�
I�@ YJÓQ
�ë ¹K
àPñK.
BornBorn
yekan
honarmandartist
astbe.pres.3sg
.
.Born is an artist.
cop(YJÓQ
�ë ,
�I�@)
cop(artist, be.pres.3sg)
. ÐXñK. AJ.�KP@ PX
�HPñ
��Ó ø@QK. AÖ
ß @X Ñë éºJ.
��
àB
ñ�Ó AK.
áK@ XPñÓ PX
107

darin
mored-ecase-ez
inthis
bawith
mas‘ul-an-eofficial-pl-ez
šabakenetwork
hamlikewise
daemanconstantly
bara-yefor-ez
mašveratconsultation
darin
ertebatcontact
bud-ambe.past-1sg
.
.In this case I was constantly in contact with network officials for consultationtoo.
root(ROOT, ÐXñK.)root(ROOT, be.past-1sg)prep(ÐXñK. , PX)prep(be.past-1sg, in)
dep: DependentThe dependent relation is used when it is impossible to determine a moreprecise dependency relation between two words, or when the dependency re-lation is deemed to rare or insignificant to merit its own label. In the followingexample, the past participle verb é
�JQÃ (taken) is placed in circumposition6 to
emphasize the preposition P @ (from) as a point of departure.
, qÊ�K øQKðA�
�� A
�K é
�JQÃ Aë ém�
�'. ø@QK.
�
��ËX ð èXA� øAëø PA�QKñ�
�� P@ . . .
. AêË A�ÃP QK. ø@QK. èYJj� �K� ð PñÓQÓ
...
...azfrom
tasvir.sazi-ha-yeimage.making-pl-ez
sadesimple
vaand
delnešinpleasant
bara-yefor-ez
bace-hachild-pl
gereft-etake.past-pp
tato
tasavir-iimage.pl-indef
talxbitter
,,
marmuzmysterious
vaand
picidecomplex
bara-yefor-ez
bozorgsal-haadult-pl
.
.... from simple and pleasant illustration for children to bitter, mysterious andcomplex images for adults.
dep( P @ , é�JQÃ)
dep(from, take.past-pp)
det: DeterminerA determiner is the relation between a nominal head and its determiner.
. . . YJ
��AK. èX P �Yg
�I�PX
à@QÂ
��ëð �QK�
áK@ ém��
'A
Jk�
cenanceif
inthis
pažuhešgar-anresearcher-pl
dorostcorrect
hadsguess
zad-ehit.past-pp
baš-andsub.be.pres-3pl
...
...
6Circumposition implies a position where a prepositional phrase is surrounded by prepositions,more specifically, it has a preposition and a postposition.
108

If these researchers made a correct guess ...
det( à@QÂ
��ëð �QK� , áK@)
det(researcher-pl, this)
dobj: Direct ObjectThe direct object of a verb is the nominal which is the (accusative) object ofthe verb.
. YK Pú× Y
KñJK� AKðP ð ÉJ
m�
�' AK. @P
�IJª
�¯@ð ø AJ
KX
àPñK.
ËX
�@
AdolfAdolf
BornBorn
donya-yeworld-ez
vaqeiyatreality
rara
bawith
taxayolimagination
vaand
royadream
peyvandlink
mi-zan-adcont-hit.pres-3sg
.
.Adolf Born links the world of reality with imagination and dream.
dobj(YK Pú× , AJ
KX)
dobj(cont-hit.pres-3sg, world)
mark: MarkerA marker of an adverbial clause modifier (advcl) is the word introducingit. It will be a subordinating conjunction different from é» (that), e.g., themulti-word expressions é» ú
�æ
�¯ð /vaqti ke/ (gloss: when that, translation:
when), é» úÍAg PX /dar hal-i ke/ (gloss: in state-indef that, translation:while), é» QÃ @ /agar ke/ (gloss: if that, translation: if), etc.
. . . èYJ�. �k� @P XñÒm× é�®K é» úÍAg PX YÔg@
AhmadAhmad
darin
hal-istate-indef
kethat
yaqe-yecollar-ez
MahmudMahmoud
rara
casbid-eattach.past-pp
...
...While Ahmad attached Mahmoud’s collar ...
mark( èYJ�. �k� ,[ é» úÍAg]PX)mark(attach.past-pp, in [state-indef that])
. . . YJ
��AK. èX P �Yg
�I�PX
à@QÂ
��ëð �QK�
áK@ ém��
'A
Jk�
cenanceif
inthis
pažuhešgar-anresearcher-pl
dorostcorrect
hadsguess
zad-ehit.past-pp
baš-andsub.be.pres-3pl
...
...If these researchers made a correct guess ...
mark( èX P , ém��
'A
Jk�)
mark(hit.past-pp, if)
109

mwe: Multi-Word ExpressionThe multi-word expression (modifier) relation is used for certain multi-wordexpressions that behave like a single function word, in particular conjunctionsand prepositions. Examples include: é» áK@ Xñk. ð AK. /ba vojud-e in ke/ (gloss:with existence-ez this that, translation: despite), é» áK@ éK. ék. ñ
�K AK. /ba
tavajjoh be in ke/ (gloss: with attention to this that, translation: with respectto), é» áK@ QK. èðC« /alave bar in ke/ (gloss: addition to this that, translation:in addition to), á�
Jj� Òë ð /va hamcenin/ (gloss: and also, translation: and
also), é» áK@ øAg. éK. /be ja-ye in ke/ (gloss: to place-ez this that, translation:instead of), é» áK@ Q£A
g éK. /be xater-e in ke/ (gloss: to sake-ez this that,
translation: because of), ÉJJ.�¯ P@ /az qabil-e/ (gloss: of type-ez, translation:
such as), AÓ@ ð /va amma/ (gloss: and but, translation: but), ÉJËX éK. /bedalil-e/ (gloss: to reason-ez, translation: because of), �
IÊ« éK. /be ellat-e/(gloss: to cause-ez, translation: because of), Q£A
g éK. /be xater-e/ (gloss: to
sake-ez, translation: for the sake of), é» áK@ A�K /ta in ke/ (gloss: than this that,
translation: rather than). The first token of a multi-word expression is treatedas the head of the expression, and subsequent elements are attached in a chainwith each word being dependent on the immediately preceding one by themwe relation.
èXñK. P@YÓ PX ø@ èPAJ� éK.XAg.
�IÊ« éK.
�� PQË áK@ é» Xñ
��ú× Pñ�
��
á�Jk�
.�
I�@
ceninso
tasavvorthought
mi-šav-adcont-become.pres-3sg
kethat
inthis
larzešvibration
beto
ellat-ereason-ez
jazebe-yegravity-ez
sayyare-iplanet-indef
darin
madarorbit
bud-ebe.past-pp
astbe.pres.3sg
.
.It is thought that this vibration has been due to the gravity of a planet in orbit/itis thought that this vibration has been caused by the gravity of a planet in orbit.
mwe( éK. ,�
IÊ«)mwe(to, reason)
neg: Negation ModifierThe negation modifier is the relation between a negation word and the word itmodifies.
. èXñK. úÆJëQ
¯ éºÊK. ú«AÒ
�Jk. @
�HC
�ªÓ é
K
��J
�®m�
�' hQ£
tarh-eproject-ez
tahqiqresearch
nano
mo‘zal-at-eissue-pl-ez
ejtema‘isocial
balkebut
farhangicultural
bud-ebe.past-pp
.
.
110

The research project has not been a social issue but a cultural problem.
neg( �HC
�ªÓ , é
K)
neg(issue-pl, no)
nn: Noun Compound ModifierA noun compound modifier of a nominal is any noun that serves to modifythe head noun. In UPDT, this relation is also used for compound names, withthe first name as the head.
. XQ»�
HA�¯CÓ , é�
� @Q
¯ ék. PA
g PñÓ@ QK
Pð , Q �
��ñ» XPA
KQK. AK. XAK.
�@ÐC�@ PX ð@
ushe/he
darin
EslamabadIslamabad
bawith
BernardBernard
KušnerKouchner
,,
vazir-eminister-ez
omur-eaffair.pl-ez
xareje-yeforeign-ez
faranseFrance
,,
molaqatmeeting
karddo.past.3sg
.
.She/he met Bernard Kouchner, French foreign mininster, in Islamabad.
nn(XPAKQK. ,Q
�
��ñ»)
nn(Bernard, Kouchner)
npadvmod: NP as Adverbial ModifierThis relation captures various location where something that is syntacticallya noun phrase is used as an adverbial modifier in a sentence. These usagesinclude: (i) a measure phrase, which is the relation between an adjective,adjective/adverb/prepositional modifier and the head of a measure phrasemodifying it; (ii) extent phrases, which modify verbs but are not objects;(iii) financial constructions involving an adverbial noun phrase (iv) floatingreflexives; and (v) certain other absolute noun phrase constructions. Atemporal modifier (tmod) is a subclass of npadvmod that is distinguished as aseparate relation.
. . . YëXú× ø �PQK @
àYK. éK.
�I�AÓ
àA¾
�J�@ ¹K
P@ Q��
���K. øQËA¿ 20 . . .
...
...2020
kaloricalory
bištarmore
azthan
yeka
estekancup
mastyogurt
beto
badanbody
eneržienergy
mi-dah-adcont-give.pres-3sg
...
...... gives 20 more calories of energy to the body than a cup of yogurt ...
npadvmod(Q��
���K. , øQËA¿)
npadvmod(more, calory)
111

nsubj: Nominal SubjectA nominal subject is a noun phrase that is the syntactic subject of a clause.The governor of this relation might not always be a verb; when the verb is acopula, the root of the clause is the complement of the copula verb, which canbe an adjective or noun. (When the complement is a prepositional phrase, thecopula is taken as the root of the clause.)
. . . YJ
��AK. èX P �Yg
�I�PX
à@QÂ
��ëð �QK�
áK@ ém��
'A
Jk�
cenanceif
inthis
pažuhešgar-anresearcher-pl
dorostcorrect
hadsguess
zad-ehit.past-pp
baš-andsub.be.pres-3pl
...
...If these researchers made a correct guess ...
nsubj( èX P ,à@QÂ
��ëð �QK�)
nsubj(hit.past-pp, researcher-pl)
nsubjpass: Passive Nominal SubjectA passive nominal subject is a noun phrase that is the syntactic subject of apassive clause.
. Y�
� èYKX úæ�ÖÞ�� éÓñ
¢
JÓ P@ h. PA
g èPAJ�
á�Ëð@
avvalinfirst
sayyareplanet
xarejoutside
azof
manzume-yesystem-ez
šamsisolar
did-esee.past-pp
šodbecome.past.3sg
.
.The first planet outside the solar system was sighted.
nsubjpass( èYKX , èPAJ�)nsubjpass(see.past-pp, planet)
num: Numerical StructureA numeric modifier of a noun is any number phrase that serves to modify themeaning of the noun.
. XPñ
kú× YJ®�ñà 3 ÐA�
SamSam
33
gusfandsheep
mi-xor-adcont-eat.pres-3sg
.
.Sam eats 3 sheep.
num(YJ®�ñà ,3)
num(sheep, 3)
112

number: Element of Compound NumberAn element of a compound number is a part of a number phrase or currencyamount.
. YJ»
�I
k@XQK�
�IÓ@Q
« PBX
àñJÊJÓ 466 YKAK. ð@
ushe/he
bayadshould
466466
miliunmillion
dolardollar
qaramatcompensation
pardaxtpay
kon-adsub.do.pres-3sg
.
.She/he should pay $ 466 million in compensation.
number(PBX ,àñJÊJÓ)
number(dollar, million)
parataxis: ParataxisThe parataxis relation (from Greek for ‘place side by side’) is a relationbetween the main verb of a clause and other sentential elements, such as asentential parenthetical, or a clause after colon (:) or semicolon (;).
. Y�
� QKX�
H@ é�PYÓ : PXAÓ
madarmother
::
madrese-atschool-pc.2sg
dirlate
šodbecome.past.3sg
.
.Mother: you are late for school.
parataxis(PXAÓ ,QKX)parataxis(mother, late)
pobj: Object of a PrepositionThe object of a preposition is the head of a noun phrase following thepreposition. (The preposition may in turn be modifying a noun, verb, etc.)
. . . YJ»ú× úÃY
K P éJ»Q
�K PX ð@
ushe/he
darin
TorkiyeTurkey
zendegilife
mi-kon-adcont-do.pres-3sg
...
...She/he lives in Turkey.
pobj(PX , éJ»Q�K)
pobj(in, Turkey)
poss: Possession ModifierThe possession modifier relation holds between a noun and its possessivedeterminer, or a genitive complement. In Persian a noun is usually followedby a modifier or a genitive complement with ezafe marking on the head noun.The relation poss is used when the modifier is a noun, pronoun or infinitive,
113

except in the case of compound names, where the nn relation is used instead.(For adjectival and participial modifiers in ezafe constructions, the amodrelation is used.) In the case of lexicalized units without ezafe the relation isdefined as mwe.7
ém��'
.�
I�X
dast-ehand-ez
baccechild
child’s hand
poss( �I�X , ém�
�'.)
poss(hand-ez, child)
preconj: PreconjunctA preconjunct is the relation between the head of a coordinated phrase and aword that appears at the beginning bracketing a conjunction (such as either,both, neither in English).
. XP@X ��m�
�' Ðñm.
�' øAJ
KX PX ék� ð úæ
�AKP øAJ
KX PX ék� ð@ . . .
...
...ushe/he
cealso
darin
donya-yeworld-ez
riyazimathematics
vaand
cealso
darin
donya-yeworld-ez
nojumastronomy
taxassosexpertise
dar-adhave.pres-3sg
.
.... She/he has expertise in the worlds of both mathematics and astronomy.
preconj(PX , ék�)preconj(in, also)
predet: PredeterminerA predeterminer is the relation between a noun and a word that precedes andmodifies the meaning of its determiner.
. . . AëÈA� áK@ ÐAÖ�ß
tamam-eall-ez
inthis
sal-hayear-pl
...
...All of these years ...
7Poss is an unfortunate choice of name, since this relation covers much more than the narrowpossessive relation. However, for the sake of conformance with STD for English, the label isretained rather than being renamed to genitive modifier (genmod), or even nominal modifier(nmod), which would be more appropriate.
114

predet( AëÈA� , ÐAÖ�ß)
predet(year-pl, all)
prep: Prepositional ModifierA prepositional modifier of a verb, adjective, or noun is any prepositionalphrase that serves to modify the meaning of the verb, adjective, noun, or evenanother preposition.
. . . YJ»ú× úÃY
K P éJ»Q
�K PX ð@
ushe/he
darin
TorkiyeTurkey
zendegilife
mi-kon-adcont-do.pres-3sg
...
...She/he lives in Turkey.
prep(YJ»ú× ,PX)
prep(cont-do.pres-3sg, in)
prt: Phrasal Verb ParticleThe verb particle relation holds between the verb and its particle.
. YÓ�@ Yë@ñ
k PX
�HPñ� ék� éK.
beto
cewhat
suratshape
darin
xah-adwill.fut-3sg
amadcome.past
.
.How will it be.
prt(YÓ�@ ,PX)
prt(come.past, in)
punct: PunctuationThis relation is used for any piece of punctuation in a clause.
. Y�
� èYKX úæ�ÖÞ�� éÓñ
¢
JÓ P@ h. PA
g èPAJ�
á�Ëð@
avvalinfirst
sayyareplanet
xarejoutside
azof
manzume-yesystem-ez
šamsisolar
did-esee.past-pp
šodbecome.past.3sg
.
.The first planet outside the solar system was sighted.
punct( èYKX , .)punct(see.past-pp, .)
115

quantmod: Quantifier Phrase ModifierA quantifier modifier is an element modifying the head of a quantifier phrase.(These are modifiers in complex numeric quantifiers, not other types of‘quantification’.)
. YëXú×àA
��
� @P Á
K P éK. é
�®J
�¯X èX XðYg
�I«A�
sa‘atclock
hodud-eabout-ez
dahten
daqiqeminute
beto
zangbell
rara
nešanshow
mi-dah-adcont-do.pres-3sg
.
.The clock shows about ten minutes before the break.
quantmod( èX , XðYg)quantmod(ten, about-ez)
rcmod: Relative Clause ModifierA relative clause modifier of a noun is a relative clause modifying the noun.The relation points from the noun to the head of the relative clause, normallya verb.
. Y�
�»ú× QKñ��� éK.
�I�@ øPAg. ð@ ÉJ
m�
�' é¢Jk PX ¡
�®
¯ é» @P úG
Aë
Q�g� ð@
ushe/he
ciz-ha-ithing-pl-indef
rara
kethat
faqatonly
darin
hite-yescope-ez
taxayol-eimagination-ez
ushe/he
jarirunning
astbe.pres.3sg
beto
tasvirillustration
mi-keš-adcont-draw.pres-3sg
.
.She/he only portrays things that lie within the scope of her/his imagination.
rcmod(úGAë
Q�g� , øPAg. )
rcmod(thing-pl-indef, running)
rel: RelativeA relative of a relative clause is the relative marker “ é»” /ke/ that introduces it(and which cannot be analyzed as a relative pronoun).
. Y�
�»ú× QKñ��� éK.
�I�@ øPAg. ð@ ÉJ
m�
�' é¢Jk PX ¡
�®
¯ é» @P úG
Aë
Q�g� ð@
ushe/he
ciz-ha-ithing-pl-indef
rara
kethat
faqatonly
darin
hite-yescope-ez
taxayol-eimagination-ez
ushe/he
jarirunning
astbe.pres.3sg
beto
tasvirillustration
mi-keš-adcont-draw.pres-3sg
.
.She/he only portrays things that lie within the scope of her/his imagination.
rel(øPAg. , é»)rel(running, that)
116

root: RootThe grammatical relation root points to the root of the sentence. A fake node‘ROOT’ is used as the governor. The ROOT node is indexed with ‘0’, sincethe indexing of real words in the sentence starts at 1. The root of the sentenceis normally a verb but in the case of copula constructions can be a noun,pronoun, adjective or adverb. The copula is taken as the root of the sentenceonly when its complement is a prepositional phrase (analyzed as prep).
.�
I�@ �A
g ú¾J.��
�ËA
g �
I�@ é�J
��@Y
K A«X@ èAÆj� Jë
àPñK.
BornBorn
hic-gahnever-time
eddeaclaim
na-dašt-eneg-have.past-pp
astbe.pres.3sg
kethat
xaleq-ecreator-ez
sabk-istyle-indef
xasparticular
astbe.pres.3sg
.
.Born never claimed to be the creator of a particular style.
root(ROOT, é�J
��@Y
K)
root(ROOT, neg-have.past-pp)
.�
I�@ YJÓQ
�ë ¹K ð@
ushe/he
yekan
honarmandartist
astbe.pres.3sg
.
.She/he is an artist.
root(ROOT, YJÓQ
�ë)
root(ROOT, artist)
.�
I�@ èXAªË@�
�ñ¯ ð@ PA¿
kar-eWork-ez
ushe/he
foqoladeoutstanding
astbe.pres.3sg
.
.Her/his work is outstanding.
root(ROOT, èXAªË@�
�ñ¯)
root(ROOT, outstanding)
.�
I�@ Xñ
k AK.àXQ»
�IJ. m
�� ÈAg PX éJK
�@ øñÊg. Ð@YÓ , Èð@ øAë
�IÒ�
�¯ PX
darin
qesmat-ha-yepart-pl-ez
avvalfirst
,,
modamconstantly
jolo-yefront-ez
ainemirror
darin
hal-eposition-ez
sohbattalk
kardandoing
bawith
xodself
astbe.pres.3sg
.
.
117

In the first parts, she/he is constantly talking to herself/himself in front of amirror.
root(ROOT, �I�@)
root(ROOT, be.pres.3sg)
tmod: Temporal ModifierA temporal modifier of a verb, noun or adjective is a bare noun constituentthat serves to modify the meaning of the constituent by specifying a time.(Other temporal modifiers are prepositional phrases, which are introduced asprep.)
. Y�
� é�J
��» øY
JJ�Ëð@P PX é
�J
��
YÃ éJ.
�
��j.
JK� ñ
�KñK. Õç
' A
g
xanom-emadam-ez
ButoBhutto
panjšanbeThursday
gozaštelast
darin
RavalpendiRawalpindi
košt-ekill.past-pp
šodbecome.past.3sg
.
.Mrs. Bhutto was killed last Thursday in Rawalpindi.
tmod( é�J
��» , éJ.
�
��j.
JK�)
tmod(kill.past-pp, Thursday)
xcomp: Open Clause ComplementAn open clause complement (xcomp) of a verb or adjective is a clausecomplement without its own subject, whose reference is determined by anexternal subject. These complements are always non-finite.
.á��P ø èXAÓ
�@ Y
�J��@ú×
mi-ist-adcont-stand.pres-3sg
amade-yeready-ez
raft-ango.past-inf
.
.She/he stands ready to go.
xcomp( èXAÓ�@ ,
�P)
xcomp(ready-ez, go.past-inf)
5.4.2 New RelationsWhile I have tried to keep the labels and construction set as close as possibleto the original STD scheme, I have extended the scheme in order to include allsyntactic relations that could not be covered by the primary scheme developedfor English. Altogether I have added 10 new relations to describe variousrelations in light verb constructions (LVC), such as adjectival complement
118

in LVC acomp-lvc, direct object in LVC dobj-lvc, nominal subject in LVCnsubj-lvc, prepositional modifier in LVC prep-lvc; the accusative marker raacc; object of comparative cpobj; comparative modifier cprep; topic depen-dent dep-top; vocative dependent dep-voc; and foreign words fw. Table 5.2lists all atomic labels used in the syntactic annotation of UPDT, with newrelations in italics. The new relations are explained and discussed below.
1. Light Verb Constructions (LVC)The light verb construction in Persian is a pervasive phenomenon and, asnoted in Section 2.3.3, different preverbal parts of speech, such as nouns,adjectives, adverbs, or prepositions, can form complex predicates togetherwith light verbs. However, the internal complements of light verb con-structions do not represent the same syntactic structures as ordinary com-plements do. When analyzing these constructions, two extreme positionscan be adopted. We can treat them as either opaque lexicalized units oras entirely transparent syntactic constructions. Neither of these options isquite adequate. We cannot treat LVCs as completely lexicalized units, forinstance by using the mwe relation for multi-word expressions, since theyare different from other multi-word expressions such as compound prepo-sitions and conjunctions. In particular, other words such as modifiers maybe placed between the LVC-elements and the verb. Hence, the structurewithin LVCs is not completely fixed and solid, like the fixed structure in themulti-word expressions.
On the other hand, we cannot treat LVCs as transparent syntactic con-structions either, due to the fact that as soon as preverbal parts of speechget semantically involved with light verbs (or with a certain types of mainverbs that operate as light verbs in abstract semantic relations) they losetheir internal structures. The complex predicate
àXPñ
k Õæ��k� /cešm xord-
an/ (gloss: eye eat.past-inf, translation: losing fortune8 or to be put un-der a spell) in the meaning XPñ
k Õæ
��k� ÐA� /Sam cešm xord/ (gloss: Sam
eat.past.3sg eyes, translation: Sam lost fortune) is a typical LVC that cannever be treated as syntactically transparent since the sentence will lose itsconceptual content. The word Õæ
��k� /cešm/ (eye) can never be treated as
the (direct) object of the sentence since the word has already lost its lex-ical sense and its internal structure in combination with the verb
àXPñ
k9
8The expression refers to traditional belief in many parts of the world including Iran, and isused of a person who has lost her/his fortune or been put under a spell based on negative energygenerated by envy or the evil eye. To prevent receiving such energy people usually knock onwood.9The occurrence of the main verb
àXPñ
k /xord-an/ (gloss: eat.past-inf, translation: to eat) aslight verb in Persian is quite common. More examples of similar cases are:
àXPñ
ká�Ó
P /zaminxord-an/ (gloss: ground eat.past-inf, translation: to fall down),
àXPñ
k�
I�º�
� /šekast xord-an/ (gloss: defeat eat.past-inf, translation: to lose, to fail),
àXPñ
k é�
�« /qosse xord-an/ (gloss:
119

/xord-an/ (gloss: eat.past-inf, translation: to eat) when building the com-plex predicate in the sense of losing fortune.
An additional argument against treating LVCs as syntactically transpar-ent is that LVCs consisting of a verb and an object can themselves takedirect objects, and certain elements cannot move elsewhere in the sentencebut need to stand right before the verb. For instance the complex predi-cate
àX@X ÉKñm��' /tahvil dad-an/ (gloss: delivery give.past-inf, translation:
to deliver) in X@X ÉKñm��' @P H. A
�J» ð@ /u ketab ra tahvil dad/ (gloss: she/he
book ra delivery give.past.3sg, translation: She/he delivered the book) isan example of a LVC (dobj-lvc) placed in the vicinity of the direct objectbook.
The object delivery, which is in a light verb construction relation tothe verb X@X /dad/ (gave), cannot move around or be placed elsewhere inthe sentence. Only modifiers may be placed between the dobj-lvc and theverb. For example the word library may be used in the sentence withoutinvolving any preposition but instead being linked to the dobj-lvc by anezafe construction, as in:
. X @X éK A
m�'
. A�J» ÉKñm�
�' @P H. A
�J» ð@
ushe/he
ketabbook
rara
tahvil-edelivery-ez
ketab.xanebook.house
dadgive.past.3sg
.
.She/he delivered the book to the library.
As shown in Figure 5.2 the word library is placed as a dependent to therelation dobj-lvc and not to the light verb X@X /dad/ (gave). Therefore, Ichose a middle ground that indicates both the internal structure of the LVCand its special status as a complex predicate. In other words, I handledLVCs as a separate category in the treebank by specifying four differentrelations in light verb constructions, which are presented below.
a) acomp-lvc: Adjectival Complement in LVCAn adjectival complement in a light verb construction is an adjective
sorrow eat.past-inf, translation: to sorrow), àXPñ
k Õæ�
�¯ /qasam xord-an/ (gloss: swear/oath
eat.past-inf, translation: to swear/oath), àXPñ
k Èñà /gul xord-an/ (gloss: deception eat.past-
inf, translation: to be deceived). Moreover, the verb àXPñ
k /xord-an/ (to eat) in the case of
àXPñ
k Õæ
��k� /cešm xord-an/ (gloss: eye eat.past-inf, translation: losing fortune),
àXPñ
k ÈñÃ
/gul xord-an/ (gloss: deception eat.past-inf, translation: to be deceived), and àXPñ
k
�I�º
��
/šekast xord-an/ (gloss: defeat eat.past-inf, translation: to lose, to fail) are intransitive con-structions and as soon as the concepts turn into transitive constructions, the light verbs
àX P
/zad-an/ (to hit) and àX@X /dad-an/ (to give) will be used, as in
àX P Õæ��k� /cešm zad-an/ (gloss:
eye hit.past-inf, translation: to give somebody the evil eye) and àX P Èñà /gul zad-an/ (gloss:
deception hit.past-inf, translation: to deceive), and àX@X
�I�º
�� /šekast dad-an/ (gloss: defeat
give.past-inf, translation: to beat).
120

booknsubj dobj
delivery-e
داد
root
.
را
gave
او تحویل کتاب.
S/he
acc
کتابخانهlibraryposs
dobj-lvc punct
rā
. را او دادکتابخانه تحویل کتاب
Figure 5.2. Syntactic annotation of a Persian sentence. Gloss: she/he book ra delivery-ez book.house give.past.3sg. Translation: She/he delivered the book to the library.
that forms a complex lexical predicate together with the verb. Forinstance, the adjective Õæ�m.
× /mojasam/ (incarnate) in the followingexample functions as the adjectival complement of the complexpredicate
àXQ» Õæ�m.× /mojasam kard-an/ (gloss: incarnate do.past-inf,
translation: to visualize).
. YJ»ú× Õæ�m.
× Xñ
k áëX PX @P ð@ Pñ
�k
hozur-epresence-ez
ushe/he
rara
darin
zehn-emind-ez
xodown
mojasamincarnate
mi-kon-adcont-do.pres-3sg
.
.She/he visualizes her/his presence in her/his mind.
acomp-lvc(YJ»ú×, Õæ�m.
×)acomp-lvc(cont-do.pres-3sg, incarnate)
b) dobj-lvc: Direct Object in LVCA direct object in a light verb construction is a noun that forms a com-plex lexical predicate together with the verb. Thus, dobj-lvc denotes adirect object functioning as the nominal part of the complex predicate.In the following example, the complex predicate Y
KXQ»
��
m�'
� /paxš
121

kard-and/ (gloss: broadcast do.past-3pl, translation: they broadcast)consists of the light verb Y
KXQ» /kard-and/ (gloss: do.past-3pl, transla-
tion: did) and the nominal part ��
m�'
� /paxš/ (broadcast).
. YKXQ»
��
m�'
� @P éÓAKQK.
barnameprogram
rara
paxšbroadcast
kard-anddo.past-3pl
.
.They broadcast the program.
dobj-lvc(YKXQ», �
�m�'
�)dobj-lvc(do.past-3pl, broadcast)
c) nsubj-lvc: Nominal Subject in LVCA nominal subject in a light verb construction is a noun that forms acomplex lexical predicate together with the verb. The nsubj-lvc anddobj-lvc are similar and at the same time different, depending on theverb. Intransitive verbs take nsubj-lvc whereas transitive verbs takedobj-lvc. In the following example Broadcast functions as the nominalsubject of the intransitive verb
àY�
� /šod-an/ (gloss: become.past-inf,translation: to become). Y
��
��
m�'
� /paxš šod-an/ (gloss: broadcastbecome.past-3sg, translation: was broadcast) is the intransitive formof the verb
àXQ»�
�m�'
� /paxš kard-an/ (gloss: broadcast do.past-inf,translation: to broadcast).
. Y�
��
�m�'
� éÓAKQK.
barnaneprogram
paxšbroadcast
šodbecome.past.3sg
.
.The program was broadcast.
nsubj-lvc(Y�
�, ��
m�'
�)nsubj-lvc(become.past.3sg, broadcast)
d) prep-lvc: Prepositional Modifier in LVCA prepositional modifier in a light verb construction is a prepo-sition/prepositional phrase that forms a complex lexical predicatetogether with the verb. In the following example the preposition éK.
/be/ (to) with its object �I�X /dast/ (hand) functions as the prepo-
sitional modifier to the verb àXPð
�@ /avard-an/ (gloss: bring.past-inf,
translation: to bring) and forms the complex predicate àXPð
�@
�I�X éK.
/be dast avard-an/ (gloss: to hand bring.past-inf, translation: toachieve/to gain).
122

. XPð�@
�I�X éK. I. KQ
m�
�' AK. @P Xñ
k ø PðQ�K� ð@
ushe/he
piruzi-yevictory-ez
xodself
rara
bawith
taxribdestroying
beto
dasthand
avardbring.past.3sg
.
.She/he achieved her/his victory by destroying.
prep-lvc(XPð�@, éK.)
prep-lvc(bring.past.3sg, to)
2. Dislocated ElementsLike many other languages, Persian uses a number of dislocated con-stituents. These can be of either the pre- or post-dislocation type.Pre-dislocated elements are those which are preposed topics and post-dislocated elements are those which are postposed topics.
dep-top: Topic DependentThe topic dependent relation is used for a fronted (pre-dislocated) elementthat introduces the topic of a sentence. It is often anaphorically related tothe subject or object of the main clause. In the following example peoplefunctions as a topic dependent in the sentence implicating to the nominalsubject their mentality.
.�
I�@ èXQ» Q�Jª
�K
àA
��
�ë
X ÐXQÓ
mardompeople
zehn-ešanmentality-pc.3pl
taqyirchange
kard-edo.past-pp
astbe.pres.3sg
.
.People, their mentality has changed.
dep-top( èXQ», ÐXQÓ)dep-top(do.past-pp, people)
3. VocativeVocative is used to directly address a listener. Vocative utterances are mostfrequently used in Persian with proper nouns at the beginning or end of asentence.
dep-voc: Vocative DependentThe vocative dependent relation is used for a vocative element, usuallya proper name or pronoun. Vocative dependent in Persian can be placedeither as preposed or postponed topics. In the following example, sirfunctions as the vocative dependent of the sentence.
. ÕæK
�@ùÖ
ß AÓ A
�¯�@
123

aqasir
mawe
ne-mi-ay-imneg-cont-come.pres-1pl
.
.Sir we are not coming.
dep-voc(ÕæK
�@ùÖ
ß, A
�¯�@)
dep-voc(neg-cont-come.pres-1pl, sir)
Sir may be positioned at the end of the sentence, as in we are not comingsir.
4. Comparative ConstructionsPersian has a number of preposition-like elements, such as É
�JÓ /mesl/, Y
JK AÓ
/manand/, àñk� /cun/,
àñj� Òë /hamcun/, and Q�
¢� /nazir/, all meaning like,
as, or similar to, that appear in similes. A simile is employed to make acomparison or to describe a metaphor. Lazard (1992) calls these elementssimilitudes and remarks that similes are used in adverbial expressions andare introduced by prepositions. However, similitudes cannot function en-tirely as prepositions or adverbs. Different similitudes may independentlyrepresent different categories; for instance É
�JÓ /mesl/ (like) can be treated
as a preposition, YJK AÓ /manand/,
àñk� /cun/, or àñj� Òë /hamcun/ (similar,
like) as an adjective, and Q�
¢� /nazir/ (match, like) as a noun. Hence, these
elements are analyzed in the UPC as ADV_COMP (adverb of comparison)and are further distinguished in the UPDT to describe simile constructions.The constructions are defined as follows.
a) cprep: Comparative ModifierThe comparative modifier relation is used for comparative con-structions that resemble prepositional phrases but are introduced byconjunctions or adverbs and can be analyzed as elliptical comparativeclauses (see English like a child in he cries like a child).
. YJ»ú× éKQÃ ém�
�'. ¹K É
�JÓ ð@
ushe/he
mesl-elike-ez
yekone
baccechild
geryecry
mi-kon-adcont-do.pres-3sg
.
.She/he cries like a child.
cprep(YJ»ú×, É
�JÓ)
cprep(cont-do.pres-3sg, like)
b) cpobj: Object of ComparativeThe object of a comparative is the complement of a preposition-likeconjunction or adverb introducing a comparative modifier (see English
124

a child in he cries like a child).
. YJ»ú× éKQÃ ém�
�'. ¹K É
�JÓ ð@
ushe/he
mesl-elike-ez
yekone
baccechild
geryecry
mi-kon-adcont-do.pres-3sg
.
.She/he cries like a child.
cpobj(É�JÓ, ém�
�'. ,)
cpobj(like, child)
5. Foreign WordsComplete phrases or sentences quoted in another language than Persianare not given an internal syntactic analysis. Instead all the words areconnected in a chain with the first word as the head and all relationsare marked as fw. The incoming arc to the head of the chain however isassigned a regular syntactic relation reflecting its role in the larger sentence.
. . . ÐAÒªË @ ù
�®�
���� éêk. ñK. :
�I
®Ã ð@
ushe/he
goftsay.past.3sg
::
bevejheface
yastasqipraying
alqemamclouds
...
...She/he requested: rain from clouds with the blessings of his face ...
fw( éêk. ñK. , ù
�®�
����)
fw(face, praying)
6. Accusative MarkerAn accusative marker is a clitic highlighting the direct object. When thedirect object is definite, it is always followed by ra. On the other hand,when the direct object is indefinite but individuated, it may or may notbe followed by ra depending on certain conditions (Lazard, 1992). Theaccusative marker ra is analyzed with the relation acc and is found inFigure 5.3 when marking the direct object �
HAJ�ñ�
k /xosusiy-at-e/ (gloss:feature-pl-ez, translation: characteristics).
. . . ð YKP@X @P Xñ
k �A
g
�HAJ�ñ�
k . . .
...
...xosusiy-at-efeature-pl-ez
xas-especific-ez
xodself
rara
dar-andhave.pres-3pl
vaand
...
...... they have their own special characteristics and ...
acc( �HAJ�ñ�
k, @P)
acc(features-pl, ra)
125
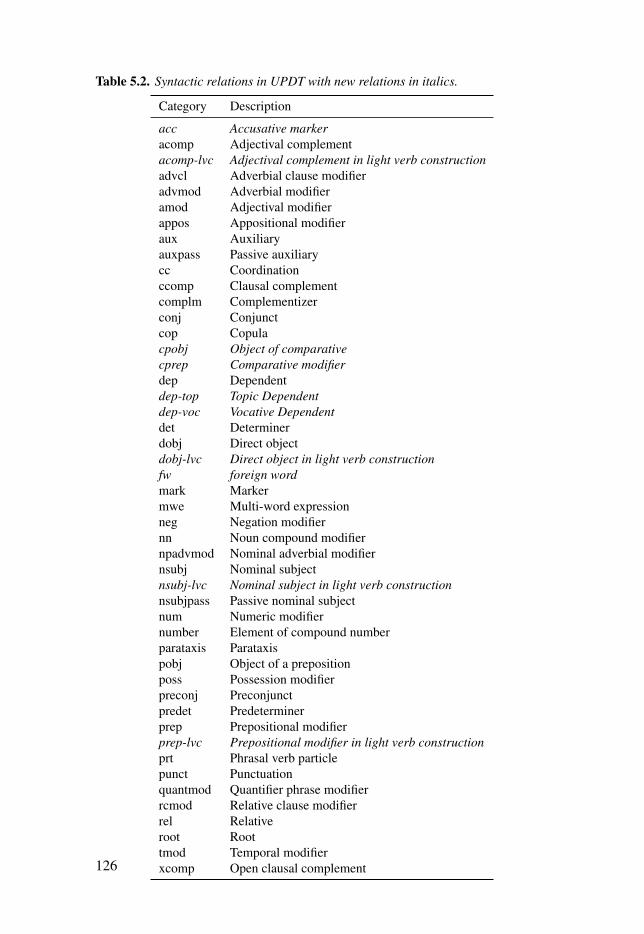
Table 5.2. Syntactic relations in UPDT with new relations in italics.
Category Description
acc Accusative markeracomp Adjectival complementacomp-lvc Adjectival complement in light verb constructionadvcl Adverbial clause modifieradvmod Adverbial modifieramod Adjectival modifierappos Appositional modifieraux Auxiliaryauxpass Passive auxiliarycc Coordinationccomp Clausal complementcomplm Complementizerconj Conjunctcop Copulacpobj Object of comparativecprep Comparative modifierdep Dependentdep-top Topic Dependentdep-voc Vocative Dependentdet Determinerdobj Direct objectdobj-lvc Direct object in light verb constructionfw foreign wordmark Markermwe Multi-word expressionneg Negation modifiernn Noun compound modifiernpadvmod Nominal adverbial modifiernsubj Nominal subjectnsubj-lvc Nominal subject in light verb constructionnsubjpass Passive nominal subjectnum Numeric modifiernumber Element of compound numberparataxis Parataxispobj Object of a prepositionposs Possession modifierpreconj Preconjunctpredet Predeterminerprep Prepositional modifierprep-lvc Prepositional modifier in light verb constructionprt Phrasal verb particlepunct Punctuationquantmod Quantifier phrase modifierrcmod Relative clause modifierrel Relativeroot Roottmod Temporal modifierxcomp Open clausal complement126
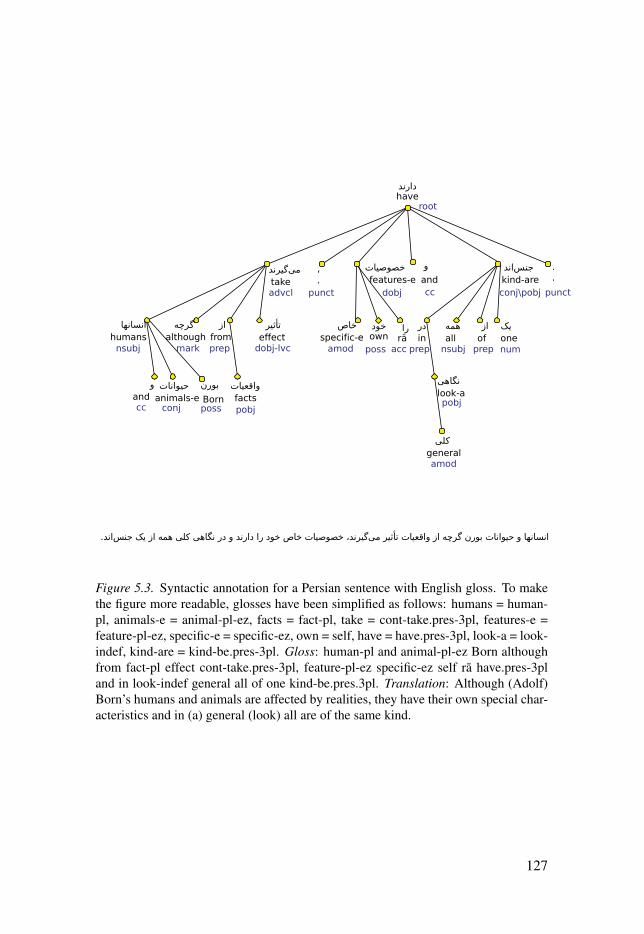
انسانها
nsubj
andcc
animals-econj
بورن
poss
markfromprep
factspobj
effectdobj-lvc
takeadvcl
،
punctfeatures-e
dobj
specific-eamod
ownposs
rāacc
دارند
root
andcc
inprep
look-apobj
generalamod
allnsubj
ofprep
onenum
kind-areconj\pobj
.
punct
و
humans
have
حیوانات
Born
althoughگرچه از
واقعیات
تأثیر
میگیرند,
خصوصیات
خاص خود را
و
در
نگاهی
کلی
همه از یک
جنساند.
. جنساند یک از همه کلی نگاهی در و دارند را خود خاص خصوصیات میگیرند، تأثیر واقعیات از گرچه بورن حیوانات و انسانها
Figure 5.3. Syntactic annotation for a Persian sentence with English gloss. To makethe figure more readable, glosses have been simplified as follows: humans = human-pl, animals-e = animal-pl-ez, facts = fact-pl, take = cont-take.pres-3pl, features-e =feature-pl-ez, specific-e = specific-ez, own = self, have = have.pres-3pl, look-a = look-indef, kind-are = kind-be.pres-3pl. Gloss: human-pl and animal-pl-ez Born althoughfrom fact-pl effect cont-take.pres-3pl, feature-pl-ez specific-ez self ra have.pres-3pland in look-indef general all of one kind-be.pres.3pl. Translation: Although (Adolf)Born’s humans and animals are affected by realities, they have their own special char-acteristics and in (a) general (look) all are of the same kind.
127

5.4.3 An Example Sentence Annotated with STDFigure 5.3 shows the dependency annotation for a sentence from UPDT aboutthe Czech artist Adolf Born, with English glosses. The sentence consists ofthe following subordinate clause:
YKQ�Ãú× Q�
�K A�K
�HAJª
�¯@ð P@ ék� QÃ
àPñK.
�HA
K @ñJk ð Aî
EA�
� @
ensan-hahuman-pl
vaand
heyvan-at-eanimal-pl-ez
BornBorn
garcealthough
azfrom
vaqeiy-atfact-pl
ta‘sireffect
mi-gir-andcont-take.pres-3plAlthough Born’s humans and animals are affected by realities
and the main clause:
. YK @�
�k. ¹K
P@ éÒë úο ùëAÆK PX ð Y
KP@X @P Xñ
k �A
g
�HAJ�ñ�
k
xosusiy-at-efeature-pl-ez
xas-especific-ez
xodself
rara
dar-andhave.pres-3pl
vaand
darin
negah-ilook-indef
kolligeneral
hameall
azof
yekone
jens-andkind-be.pres.3pl
.
.they have their own special characteristics and in (a) general (look) all are ofthe same kind.
The subordinate clause is an adverbial clause with the head cont-take.pres-3plmarked by the label advcl and governing the nominal subject human-pl andanimal-pl-ez Born, the subordinating conjunction although, the prepositionalmodifier from followed by the prepositional object fact-pl, and the preverbalnoun effect in light verb construction with cont-take.pres-3pl. The nominalsubjects human-pl and animal-pl-ez are coordinated and linked with an ezafeconstruction to their possessive modifier Born. The main clause is rooted atthe verb have.pres-3pl which governs an implied subject,10 the direct objectfeature-pl-ez specific-ez self ra, the coordinating conjunction and, and the co-ordinated verb phrase in look-indef general all of one kind-be.pres.3pl. Thedirect object is headed by feature-pl-ez, which is linked by an ezafe construc-tion to its adjectival modifier specific-ez and further to its genitive complementself. The direct object further contains the accusative marker ra. The coordi-nated verb phrase kind-be.pres.3pl governs the prepositional modifier in look-indef general, the nominal subject all, and the second prepositional modifierof. The first prepositional modifier is rooted at the preposition in linked to itsobject look-indef which is modified by the adjectival modifier general. The
10The subject is absent (pro-drop) but the information is given by the verb through the attachedpersonal ending Y
K- /-and/ (3pl).
128

second prepositional modifier, of, has its object, kind, in the form of a com-plex element with the attached copula clitic Y
K@- /-and/ (be.pres.3pl) modified
by the numeric modifier num. Thus the coordinated verb kind-be.pres.3pl hasreceived the complex label conj\pobj. In other words, the conj (conjunct) isitself a clitic on a pobj (prepositional object) element. Since I gave priorityto the verb as the most important part in the syntactic structure, and the verbis attached to the prepositional object, the prepositional object, which shouldactually be under the prep, ends up higher in the structure.
5.5 Complex RelationsAs noted in Section 3.2.2, in developing the UPC, I made a special decisionconcerning the handling of different types of clitics (pronominal and copulaclitics), as they were written in various forms in the corpus. They were some-times segmented and sometimes unsegmented from the head words. To manu-ally separate clitics from the head words consistently in a large corpus suchas the Bijankhan Corpus was impossible, with respect to the project time.On the other hand, automatically handling such cases was also impossiblesince such a process could result in many incorrect conversions by impact-ing orthographically similar words/endings with different part-of-speech cat-egories. For example, the word �
I�AKP may refer to the word /riasat/ (presi-dency or generalship) or to the compound word /ria-st/ (with a small variationin pronunciation that is unmarked in texts, as short vowels are not transcribed)(gloss: duplicity/hypocrisy-be.pres.3sg, translation: is hypocrisy). Thus, au-tomatically segmenting the copula clitic �
I� /-st/ (is) from the word AKP /ria/(duplicity/hypocrisy) in the corpus could undoubtedly affect the homographnoun �
I�AKP /riasat/ (presidency or generalship).Furthermore, automatic conversion could impact words that are not exact
homographs but share the same endings. For instance, segmenting the copulaclitic (for a list of copula clitics see Table 4.2) ø@- /-i/ (be-2sg) in words suchas ø@ é
�J�
k /xaste-i/ (gloss: tired-be.pres.2sg, translation: you are tired or are
you tired) may further affect other words with similar endings, since /-i/ canalso serve as a suffix to form adjectives, as in ø@ é
�J�ë /haste-i/ (gloss: core-
i/nucleus-i, translation: nuclear). Hence, to avoid introducing such errors intothe corpus, I decided not to separate clitics from the head words, and to analyzethem with special labels at the syntactic level instead.
In the treatment of complex unsegmented word forms, I use complex labelswhere the first label indicates the main syntactic function, and subsequent la-bels mark other functions carried by elements incorporated into the word form.The additional functions are listed in the order in which they occur and are pre-fixed with a backslash (\) if they precede the segment carrying the main func-tion and a forward slash (/) if they follow it. Thus, the label poss/pc is assignedto a word that has the main function poss and an additional (clitic) pc element.
129

By contrast, the label ccomp\poss is used for (the head of) a clausal com-plement, which is itself a clitic on a poss element. Figure 5.3 shows the un-segmented copula clitic Y
K@- /-and/ (be.pres.3pl) together with the word �
�k.
/jens/ (material) in YK@�
�k. /jens-and/ (gloss: kind-be.pres.3pl, translation:
are kind) analyzed as conj\pobj (for annotation key, see Section 5.4.3). InTable 5.2, I only list atomic labels. A complete list of all simple and complexlabels with frequency information can be found in Appendix A.
5.6 Unused RelationsSome dependency relations in the original STD scheme have been excludedfrom the Persian STD since the corresponding relations either do not exist orare not applicable to Persian. For instance, I have not found any instancesof the dependency relations indirect object (iobj), agent (agent), and preposi-tional complement (pcomp). Indirect objects, agent, and prepositional com-plements are always realized as prepositional phrases in Persian, so the re-lations prepositional modifier (prep) and prepositional object (pobj) are suffi-cient. Furthermore, I have not found any instances of the dependency relationsabbreviation modifier (abbrev), as the relation is defined by the appositionalmodifier (appos) instead; attributive (attr), since the complement of the copulaverb is defined as the head; purpose clause modifier (purpcl), as the relationcan be defined by the adverbial clause modifier (advcl); clausal subject (csubj)and clausal passive subject (csubjpass), since Persian has no clausal subjector clausal passive subject, and instead uses a construction with a noun or pro-noun plus a relative clause for which the relations rel and rcmod can readilybe used. As there is no genitive modifier in Persian and the ezafe construc-tion is constantly used in the language, I did not use the relation possessivemodifier (possessive) either. Other relations that do not exist in Persian andare excluded from the extended version of Persian STD are expletive (expl),infinitival modifier (infmod), and participial modifier (partmod).11 The twolatter relations are found as the relations prepositional modifier (prep) andprepositional object (pobj) or ezafe construction in Persian.
11As noted earlier, I have considered the relations based on the Stanford Typed Dependenciesmanual from 2008. The relations were revised and changed in 2013. Therefore some of theexcluded relations are not found in the new version of the manual. These are abbreviationmodifier (abbrev), attributive (attr), infinitival modifier (infmod), participial modifier (partmod),and purpose clause modifier (purpcl).
130

5.7 Comparison with Other Treebanks for PersianThere are currently three treebanks available for Persian: the HPSG-basedPerTreeBank12 (Ghayoomi, 2012), the UPDT (Seraji et al., 2012b), and thePerDT (Rasooli et al., 2013). The first two treebanks contain texts from thesame domain; in other words, they both share the same corpus data, namelythe Bijankhan Corpus. However, the treebanks differ in size and annotationstyles. The development of PerTreeBank ended with 1012 sentences (see2.4.2). Thus, the treebank is considerably smaller in size than other treebanksand it lacks annotation guidelines. In the following subsections I compareUPDT only with PerDT, because PerDT is the largest treebank and providesbetter-documented guidelines for each syntactic relation than the other tree-bank.
5.7.1 Data and FormatUPDT and PerDT are two syntactically annotated corpora of contemporaryPersian based on dependency structure. UPDT consists of 6,000 sentences and151,671 tokens while PerDT is larger, containing nearly 30,000 sentences and498,081 tokens. UPDT uses 31 tags for encoding the parts of speech and pro-vides no lemma information, while PerDT includes 32 part-of-speech tags andinformation about lemmas. The number of dependency relations also variesbetween the two treebanks. UPDT comprises in total 96 dependency labels (ofwhich 48 are basic and the remaining 48 are complex), while PerDT has a totalof 43 relations. The data in UPDT is taken from the Bijankhan Corpus with alarge variety of genres (see 3.1) while the data in PerDT is specifically pickedbased on different verb types (see 2.4.2). In other words, data in PerDT con-tains only isolated sentences from the Web. The selection of sentences is basedon different verb types, and in order to cover different types of Persian verbs, avalency lexicon is employed. Although PerDT’s special data selection methodgives good coverage of different verb types, the sentences do not appear in acoherent discursive order, as sentences normally should do in a text. This canimpact the unbroken syntactic features that normally are found in a regulartext, such as anaphoric elements, implications, presuppositions, and the natu-ral tense structure. Moreover, since the number of occurrences of rare verbsis lower than that of frequent ones, there is an uneven distribution of differentverb types in the treebank. Simply put, the PerDT, has prioritized includingalmost all Persian verbs in the data over including different variations of genre,whereas, the UPDT has aimed to cover a wide range of domains and genres toachieve robustness. Statistical systems that are trained on annotated data withlimited genre (domain-specific) often suffer performance drops when applied
12The treebank has recently been automatically converted to dependency structure (Ghayoomiand Kuhn, 2014).
131

to texts containing domain variations (Hogan et al., 2008; Yi Zhang and Wang,2009).
The treebanks do not contain the same character encodings. Charactersand digits in the UPDT consistently use Persian style and Persian Unicodeencodings due to the conversion of the Bijankhan Corpus into the UPC (c.f.3.2.1). However, in the PerDT, characters shift from Persian to Arabic styleand digits vary between Persian and Western Unicode characters.
5.7.2 TokenizationThe treebank data further differs in some aspects of tokenization. For instance,in the UPDT, various types of clitics (such as pronominal clitics, copula cli-tics, and personal endings) are all treated consistently and are not separatedfrom the head words, whilst clitics in the PerDT are treated differently de-pending on the type of clitic. Personal endings are not separated from headwords but are written with a space. However, pronominal clitics and cop-ula clitics are separated from head words and processed as separate tokens.This means that in order to apply the PerDT to new text, the text needs toundergo the same segmentation as the PerDT, to be compatible and match thetreebank data, otherwise there is no guarantee that the same tokens, but withdifferent segmentation, will receive the correct arcs. On the other hand, re-producing similar segmentation in new text requires a powerful tokenizationtool that can identify homograph tokens with various senses (and pronunci-ations) such as ÐXQÓ /mard-am/ with the pronominal clitic /-am/ meaning myhusband, ÐXQÓ /mard-am/ with the copula clitic /-am/ meaning I am a/the man,ÐXQÓ /mord-am/13 with the personal ending /-am/ meaning I died, and finallyÐXQÓ /mardom/ without any clitics or personal endings, meaning people. To thebest of my knowledge, no such tokenization tool is available. As mentioned inSection 2.3.1, clitics are written differently in different texts due to the lack ofstandardization in Persian orthography. Hence, we need a normalizer that cantake care of these inconsistencies and automatically identify orthographicallysimilar instances (homograph tokens) with various morphological categoriesand notions without giving incorrect conversions. This is a difficult task con-sidering the morphological ambiguities in the language. At the same time Iknew that no such normalizer was (or is) available able to perform all thesetasks successfully. Therefore, in order to avoid having to face these issueswhen analyzing new text, I decided not to separate clitics from head words.Instead I made sure that the normalizer PrePer merges clitics with their hostsin cases where they have been separated by whitespace, so that all clitics aretreated consistently. That was the best compromise I could make, as such el-
13Note that short vowels are not written in Persian. Hence, the short vowel /a/ in /mard/ or /o/ in/mord/ are not marked in text and the words are typed similarly as /mrd/.
132

ements (unseparated clitics from the head words) are easily reproducible witha simple automatic tokenizer.
Moreover in the UPDT, all types of auxiliaries such as YKAK. /bayad/ (must),á���@ñ
k /xastan/ (will), and á�
��� @ñ
�K /tavanestan/ (can), as well as copula verbs
(both when used as auxiliaries and when connecting a predicate to its subject),are treated consistently as distinct tokens, whereas in the PerDT these verbsare handled differently. The auxiliary verbs YKAK. /bayad/ (must), and á�
��� @ñ
�K
/tavanestan/ (can), as well as copula verbs in the form of predicates in thePerDT, similar to the UPDT, are treated as separate items, whereas the aux-iliary verb á�
��@ñ
k /xastan/ (will) and copula verbs, when used as auxiliariestogether with main verbs, are treated as single verbs separated by a space char-acter. It is noteworthy that the copula is often used as an auxiliary together withpast participle verbs. However, when past participles function as adjectives (asmany adjectives are derived from verbs), the copula does not function as anauxiliary but as a link to connect a predicate to its subject. Thus, in Persianthese cases are generally treated as distinct units and are normally typed, if notmisspelled, with intervening space character. This also means that in order toapply the PerDT to new text, the text needs to be adapted based on the samesegmentation as the analysis for the PerDT. As mentioned in the previous para-graph, a tokenization tool is needed to distinguish, for instance, whether thecopula functions as an auxiliary to past participle verbs or as a link connect-ing the past participle verbs (that function as adjectives) to their head. Onceagain, to my knowledge no such tool is available. Therefore, in order to avoidthis problem in the UPDT, I have treated such tokens separately to make themconsistent with the ordinary style of writing these tokens, as well as becausethe elements are easily reproducible by an automatic tokenizer on new text.
The present/past continuous prefix -ú× /mi-/ in the PerDT is also handleddifferently than in the UPDT. The prefix is accompanied with main verbs,sometimes with a space and sometimes with no space (without being attachedto the main verb, due to the existence of right-joining characters at the begin-ning of the main verbs). This means that the PerDT is not in valid CoNLLformat, as space characters are not allowed inside tokens in CoNLL. However,this orthographic issue has already been solved in the UPDT due to the con-version of the Bijankhan Corpus to the UPC, when the normalizer PrePer wasused (see 4.1.1).
Acronyms are further treated differently in the treebanks. In Persian texts,acronyms may appear as transcriptions with Persian letters, either with in-serted dots such as ñJÊK. X.Ð@.úG
./bi.em.dabelyu/ (B.M.W), inserted space such
as ñJÊK. X Ð@ úG.
/bi em dabelyu/ (B M W), or a combination of inserted dots
and space as ñJÊK. X .Ð@ .úG.
/bi. em. dabelyu/ (B. M. W). They may addition-ally appear with Western letters, often without any inserted dots or space. Inthe UPDT, acronyms are either treated as single tokens without any internal
133

dots or space, in terms of the above example as BMW, or they are dividedinto separate units as B, M, and W but linked together with the syntactic la-bel mwe. The reason why acronyms are handled in two different ways in theUPDT is that they were typed dissimilarly in Bijankhan Corpus, sometimeswith internal space, sometimes with a combination of internal dots and space,and sometimes as single tokens with neither dots nor space. When I convertedthe Bijankhan Corpus into the UPC, I left untouched all those acronyms thatwere typed as single tokens (without internal dots or space). Since the spacecharacter in the tokenizer is considered a token separator, the acronyms witha combination of inserted dots and space were split and treated as separatetokens in the UPC, but marked as mwe at syntax level. Thus in the UPDTacronyms are represented in various forms as samples in the training data. Itis worth noting that I could retain acronyms with inserted dots if they existedin the corpus; the tokenizer SeTPer can easily take care of acronyms with in-serted dots, because internal dots are not defined as sentence segmenters aslong as there is no space character after them. On the other hand, in the PerDTacronyms appear with dots and are treated as single tokens. Accordingly, theacronym ñJÊK. X.Ð@.úG
.(B.M.W) is defined as a single token in the PerDT. It is
unclear whether they have standardized the acronyms in this way or if theacronyms appeared with this style in their corpus.
Dates and measurements are additionally presented differently in the twotreebanks. In Persian, dates are indicated by specifying year-month-day sep-arated by slashes, e.g., 1917/2/11. Thus, any sequence of digits and slashesin UPDT is decomposed and each element is separately defined as a token.Since slash is considered a separator character in the tokenizer SeTPer, I splitthis ordered list into numbers and slashes during the conversion of the Bi-jankhan Corpus into the UPC. However, in the PerDT, dates are presented asa sequence of year-month-day together with slashes defined as single tokenssuch as 1917/2/11. For measurements, numbers are also accompanied withslash, as in 0/01 millimeter.
As a general overview of tokenization differences between the two tree-banks, I can conclude that the PerDT has cleaned up the treebank by followinga specific template but may have problems with new text. The UPDT, on theother hand, has preserved the variations inherent in Persian texts that normallyappear in the general standard texts to support robust processing.
5.7.3 Annotation SchemesSome relations in both treebanks function the same under different names, forinstance the relation subject is treated as dependent, under the names SBJ inthe PerDT and nsubj in the UPDT. In addition, noun dependents in the PerDTare annotated either as NPREMOD (pre-modifier for noun) marking superla-tive adjectives (in Persian superlative adjectives always precede nouns) and
134

demonstrative pronouns, or as NPOSTMOD (post-modifier of noun) labelingadjectives. The same relation structures appear in the UPDT when treating thenoun as the head node and the noun dependents as dependents to the head.The dependent relation marking different types of adjectives in the UPDT iscalled amod (adjectival modifier) and for demonstrative pronouns is called det(determinative). The two treebanks also share the same structure for the re-lation apposition when it serves to define an NP. The relation is called APP(apposition) in the PerDT and appos (appositional modifier) in the UPDT.Furthermore, the ezafe construction is treated more or less the same in thetwo treebanks. As noted in Section 2.3.3, ezafe is a particle in Persian thatindicates the semantic relation between joint elements within a noun phrase,adjective phrase, or prepositional phrase. In the PerDT these relations are clas-sified as MOZ (ezafe dependent), NPOSTMOD (post-modifier of noun), andNEZ (ezafe complement of adjective). The relation MOZ defines the depen-dency between two nouns, NPOSTMOD defines the dependency between anoun and an adjective, and NEZ defines the dependency between an adjectiveand its nominal complement. In the UPDT, ezafe construction is also classi-fied by specific dependency labels such as poss (possession modifier), amod(adjectival modifier), and nn (noun compound modifier). The relation MOZin the PerDT functions similarly as the relations poss and nn, NPOSTMOD asamod, and NEZ as poss in the UPDT.
However, despite the fact that both treebanks are based on dependencystructure, they vary highly in terms of annotation scheme (for the syntac-tic relations in the PerDT, see Table 2.17). One systematic structural di-vergence of the UPDT compared to the PerDT concerns when words withheavier semantic content are chosen to be the head of a relation based on se-mantic principles. Thus, the UPDT mainly chooses content words as headsin the dependency relations. However, there are two exceptions where theUPDT chooses function words as heads: prepositions in prepositional phrases,and copula verbs that have a prepositional phrase as their complement. Inthe example �
I�@Q�Ó øðP YJÊ¿ /kelid ru-ye miz ast/ (gloss: key on-ez table
be.pres.3sg, translation: the key is on the table), the copula verb �I�@ /ast/
(gloss: be.pres.3sg, translation: is) is the root of the sentence since the com-plement is a prepositional phrase, and a preposition cannot occupy the rootposition in a sentence. The reason that the UPDT generally preserves the rela-tions between content words is that it is simple and transparent to have directlinks between content words and predicates. Moreover, STD is more orientedtowards deep syntax (or semantics) than towards surface syntax, where func-tion words to a larger extent are treated as heads. On the other hand, the PerDTdoes not follow the same principle as the UPDT in terms of head relations. Inthe PerDT the head relations easily shift between content and function words.Thus, in the PerDT auxiliaries can appear in the head position whereas in the
135

UPDT, labels such as auxiliaries and complementizers always serve as depen-dents.
Subordinate constructions in Persian are often introduced by é» /ke/ (that)which marks both complement clauses and relative clauses (see Section 2.3.3).To distinguish these constructs in the UPDT, /ke/ is marked as complm (com-plementizer) when signifying a complementizer and as rel (relative) whendenoting a relativizer. Since complementizers and relativizers are functionwords, /ke/ stands as a dependent to the head nodes in both cases. The headnodes of such subordinate constructions are always content words marked asccomp (clause complement) and rcmod (relative clause modifier). In otherwords, the relations clause complement (ccomp) and relative clause modifier(rcmod) are always defined with a verb or a predicative complement. In thePerDT, on the other hand, the grammatical functions of /ke/ are categorizeddifferently. When /ke/ functions as a complementizer it is marked by the re-lations VCL (complement clause of verb), AJUCL (adjunct clause), or ACL(complement clause of adjective), and when /ke/ functions as a relativizer, it ismarked as NCL (clause of noun). In all cases /ke/ heads the subordinate clausewhile the verb of the clause follows as a dependent to /ke/. The verb of theclause is marked in all cases by the relation PRD (predicate).
Direct objects are usually preceded by the direct accusative marker ra (di-rect objects can also appear without the ra marker). In the UPDT this relationis always marked as the head node (content word) and is introduced by dobj,which is the accusative object of the verb. In any case whether or not the directaccusative marker is present, the ra marker is always positioned as a dependentto the direct object since the accusative marker, like the complementizer andthe relativizer /ke/, is considered a function word. However, in the PerDT therelation OBJ is inconsistently marked and shifts between a function word anda content word. In other words, the relation OBJ constantly shifts between thedirect accusative marker ra and the direct object itself.Thus, when ra is absentin the sentence, the label OBJ denotes the content word and the direct objectis marked as the head node. Otherwise the relation OBJ refers to the functionword and the direct object marker ra is treated as the head.
An adverbial clause complement (advcl) is normally introduced in theUPDT by a subordinating conjunction that is labeled as the relation mark(marker), which is a dependent of the subordinate clause, since the label isused for function words, and function words in the UPDT never (apart fromthe two exceptions described at the beginning of this section) stand as parentnodes in dependency relations. However, in the PerDT the relation is intro-duced as AJCONJ (conjunction of adjective) and is placed as superior in thehierarchy.
Apart from the structural differences between the UPDT and the PerDT,the treebanks additionally differ in specificity. Different labels are chosen onvarious specific levels; in other words, sometimes the UPDT is more specificand sometimes the PerDT is. For instance, in the UPDT all the dependency
136

relations for prepositions are annotated as prep (prepositional modifier), butin the PerDT the relation is specified by a number of labels such as AJPP(prepositional complement of adjective), NPP (preposition of noun), PCONJ(conjunction of preposition), and VPP (prepositional complement of verb).The distinctions are described in more detail below:
• AJPP is used for a preposition that is the complement of an adjectivesuch as the preposition AK. /ba/ (with) in úæ�A¾« AK. A
J
��
�@ /ašena ba akkasi/
(familiar with photography). Thus, the preposition with is annotatedwith the relation AJPP as a dependent of the adjective familiar. In theUPDT the preposition with is also treated as a dependent of the adjectivefamiliar, but is analyzed with the label prep.
• NPP is used for a preposition that is the complement of a noun suchas the preposition PX /dar/ (in) in ú»ñ�A
�K PX È@Yg. /jedal dar Tasuki/
(battle in Tasooki). The preposition in is annotated with the relationNPP as a dependent of the noun battle. In the UPDT, the preposition in,just as in the PerDT, is treated as a dependent of the noun battle, but isanalyzed with the label prep.
• PCONJ is used for a coordinating conjunction that is the complementof a preposition such as ð /va/ (and) in AÓ AK. ð
à@Qî
�E PX /dar Tehran
va ba ma/ (in Tehran and with us). The coordination and is annotatedas the dependent of the preposition in, but governs the prepositionwith. The prepositions in and with are analyzed as ADV (adverb) andPOSDEP (post-dependent) respectively. In the UPDT, the coordinatingconjunction, as in to the PerDT, is annotated as the dependent of thepreposition in (the first conjunct) but does not govern the prepositionwith. The coordination and as well as the preposition with (the secondconjunct) are both governed by the first conjunct, namely the prepo-sition in. Moreover, in the UPDT, the relations for the first conjunctin, the coordination and, and the second conjunct with are annotatedby the labels prep (preposition), cc (coordination), and conj (conjunct)respectively.
• VPP is used for a preposition that is the complement of a verb suchas the preposition éK. /be/ (to) in Õ
�æ
P é�PYÓ éK.
áÓ /man be madreseraft-am/ (gloss: I to school go.past-1sg, translation: I went to school).The preposition to is annotated with the relation VPP as a dependentof the verb went. In the UPDT, the preposition to, as in the PerDT, istreated as a dependent of the verb but analyzed with the label prep.
137

A light verb construction is defined in the UPDT as the relations acomp-lvc,dobj-lvc, nsubj-lvc, and prep-lvc, and is placed in a subordinate relation tothe verb. This relation is divided in the PerDT into different classificationgrounds, namely, clitic non-verbal element (ENC), light verb particle (LVP),non-verbal element (NVE), non-verbal element of infinitive (NE), and secondobject (OBJ2). This categorization is described in more detail below:
• ENC is used for the non-verbal element of a light verb constructioncontaining a pronominal clitic such as the preverbal Õæ
��ñ
k /xoš-am/14
(gloss: good-pc.1sg, translation: I like) in YÓ�@ Õæ
��ñ
k @
Y
« P@ /az qaza
xoš-am amad/ (gloss: of food good-pc.1sg come.past.3sg, translation:I liked the food). The preverbal good-am is annotated with the relationENC as a dependent of the verb came. This relation is also treated inthe UPDT as a dependent of the verb, but is analyzed as an adjectivalcomplement to the light verb came with the label acomp-lvc/pc.
• LVP is used for the non-verbal element @YJK� /peyda/ (visible) of thecompound verb
àXQ» @YJK� /peyda kard-an/ (gloss: find do.past-inf,translation: to find) when the compound verb is used in to form newcompound verbs in three words (three-word compound verbs). Thus,the compound verb can appear with other elements (normally nouns)and form a three-word complex predicate in passive form, such asin XQ» @YJK�
Q�Jª
�K éÓA
KQK. /barname taqyir peyda kard/ (gloss: program
change find do.past.3sg, translation: the program was changed/theprogram found a change). In this analysis, Q�J
ª
�K /taqyir/ (change) is
taken to be part of the compound verb àXQ» @YJK� /peyda kard-an/ (gloss:
find do.past-inf, translation: to find). In other words, the elementschange and find are dependents of the light verb do and are annotatedas two different LVCs in this compound: change as NVE (as describedbelow) and find as LVP. In the UPDT, on the other hand, only find isincluded in the LVC, and it is analyzed as acomp-lvc. The noun changeis analyzed in a more syntactically transparent way with the label dobj.As in the PerDT, both elements are headed by the light verb do. I believethat counting a compound verb as a three-word or two-word expressionis completely dependent on our interpretation of the sentence. Forinstance, in the above example, we can interpret the sentence simply asthe program was changed or as the program found a change withoutaffecting the sense, as the sentence works with both interpretations. Thesame fact further applies to similar combinations of other words withthis compound verb such as in XQ» @YJK�
���@ Q
¯ @ 2% Aë
�IÒJ
�¯ /qeymat-ha
14-am is used as the first singular form of the pronominal clitics, defined as pc.1sg in the gloss(see Section 2.3.3).
138

2% afzayeš peyda kard/ (gloss: price-pl 2% increase find do.past.3sg).Here we can interpret the sentence with a three-word compound verb asprices were increased by 2% or in a more syntactically transparent wayas prices found an increase of 2%.
• NVE is used for the non-verbal element of a compound verb, which isa noun, adjective, or similar, such as the noun �
IJ. m�� /sohbat/ (talking)
in àXQ»
�IJ. m
�� /sohbat kard-an/ (gloss: talking do.past-inf, translation:to talk). In UPDT, the corresponding relations are acomp-lvc, dobj-lvc,nsubj-lvc, or prep-lvc depending on the function of the preverbalelements.
• NE is used for the non-verbal element of a compound verb whenthe verbal element is in infinitive form, for example the non-verbalelement h. @Q
k@ /exraj/ in
àXQ» h. @Q
k@ /exraj kard-an/ (gloss: exclusiondo.past-inf, translation: to fire). In the UPDT this relation completelydepends on the function of the non-verbal element. This means thatthe corresponding relation can be a acomp-lvc, dobj-lvc, nsubj-lvc, orprep-lvc.
• OBJ2 is used for the second object of a sentence that can nevertake the accusative marker ra, such as the object éKYë /hadiye/(gift) in X@X éKYë áÓ éK. @P úG
.A�J» ð@ /u ketab-i ra be man hadiye dad/
(gloss: she/he book-indef ra to me gift give.past.3sg, translation: she/hegave me a book as a gift). In the UPDT the relation is analyzed asdobj-lvc.
A coordination relation is defined in the UPDT by the relation conj (conjunct)between two elements linked by a coordinating conjunction, such as and, or,etc, and is treated asymmetrically. In other words, the head node is alwaysthe first conjunct and other conjuncts are in a subordinate relation to theirhead. In the PerDT, on the other hand, there are a number of conjunction re-lations specifying constraints on different elements depending on the lexicalcategories. These relations include AJCONJ (conjunction of adjective), AV-CONJ (conjunction of adverb), NCONJ (conjunction of noun), PCONJ (con-junction of preposition), and VCONJ (conjunction of verb). The first elementin the conjunct is the head node and the second conjunct is the dependent ofthe coordinating conjunction. However, the analysis for conjunction of verb(VCONJ) differs from that for the other types of the conjunction relation. Inother words, the verb that appears last is the head, and the first verb is thedependent of the coordinating conjunction.
This comparative analysis describes some structural differences regardingheadedness and dependency relations between the PerDT and the UPDT. It
139

also shows that some relations in the two treebanks are very general, and thatsome relations are more specific in one treebank and less specific in the other.
5.7.4 Sample AnalysesIn order to illustrate the comparison, we review two annotated sentences takenfrom the PerDT. I have analyzed the sentences based on the UPDT scheme toprovide a better understanding of how the two schemes differ. Figure 5.4 and5.5 illustrate the structural varieties in the PerDT and the UPDT. A discussionsection follows at the end of the sample analysis of each figure.
Figure 5.4: PerDT AnnotationFigure 5.4 shows an analysis based on the PerDT. The sentence is rooted inthe copula verb Y
J���ë /hast-and/ (gloss: be.pres-3pl, translation: are) with
the relation ROOT and consists of two parts, the following subordinate clause,which is analyzed as an adverbial ADV:
YKY
�� A
J
��
�@ Ñë AK. Aî
E�@ é» ú
GAÓ P P@
azfrom
zaman-itime-indef
kethat
an-hathis-pl
bawith
hameach.other
ašenafamiliar
šod-andbecome.past-3pl
Since the time they became familiar with each other
and the adjective happy, labeled as MOS (Mosnad) which is a property of aname whose main verb is a copula verb:
. YJ���ë
�I
j�.
��ñ
k
xošbaxthappy
hast-andbe.pres-3pl
.
.They are happy.
The preposition from, labeled as ADV, consists of the child node time-indefanalyzed as POSDEP (post-dependent) defining the object of the prepositionfrom. Further, that is annotated as NCL (clause of noun) functioning as depen-dent on its nominal head time-indef. The complementizer that with the relationNCL governs the relative clause they with each.other familiar become.past-3pl, which is headed by the predicate become.past-3pl analyzed as PRD.
The relative clause starts with the subject they, analyzed as SBJ, and fol-lowed by the adjective familiar with the relation MOS. The mosnad (MOS)familiar is modified by the sub-tree with each.other. This sub-tree consists ofthe preposition with annotated as NPP, which takes the dependent each.other,labeled as POSDEP (post-dependent) and functions as the object of the prepo-
140
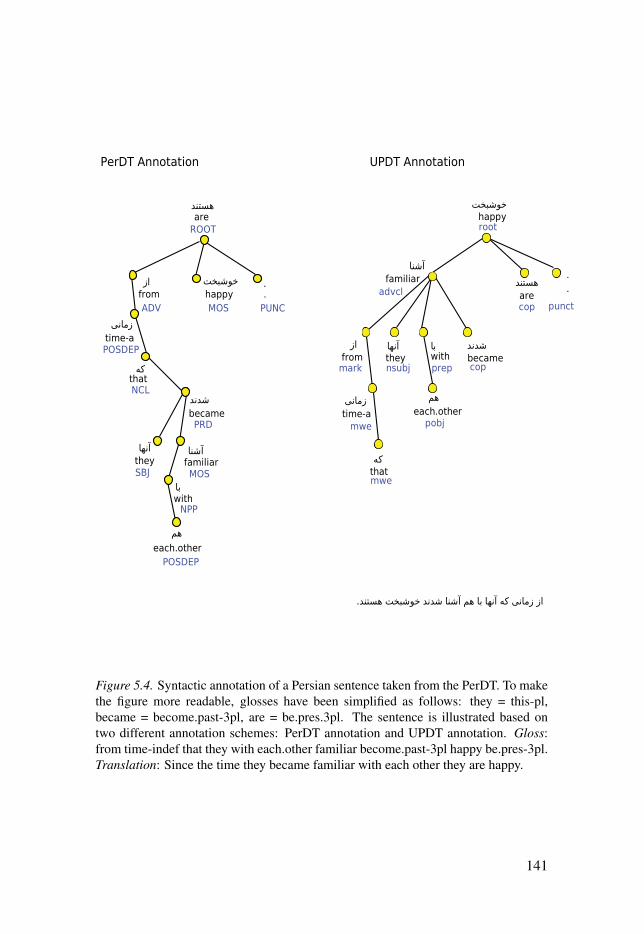
fromADV
time-aPOSDEP
thatNCL
theySBJ
withNPP
each.otherPOSDEP
familiarMOS
becamePRD
happyMOS
areROOT
.
PUNC
از زمانی که آنها با هم آشنا شدند خوشبخت هستند.
هستند
زمانی
که
آنها
شدند
آشنا
با
هم
خوشبخت.
از
از
mark
time-amwe
thatmwe
theynsubj
withprep
each.otherpobj
آشنا
advcl
becamecop
happyroot
arecop
.
punct
UPDT Annotation
familiar
from
زمانی
که
آنها با
هم
شدند
هستند.
خوشبخت
PerDT Annotation
Figure 5.4. Syntactic annotation of a Persian sentence taken from the PerDT. To makethe figure more readable, glosses have been simplified as follows: they = this-pl,became = become.past-3pl, are = be.pres.3pl. The sentence is illustrated based ontwo different annotation schemes: PerDT annotation and UPDT annotation. Gloss:from time-indef that they with each.other familiar become.past-3pl happy be.pres-3pl.Translation: Since the time they became familiar with each other they are happy.
141

sition with. Finally the punctuation PUNC has the root of the sentence as itshead.
Figure 5.4: UPDT AnnotationThe UPDT annotated sentence also starts with the subordinate clause fromtime-indef that they with each.other familiar become.past-3pl and ends withthe main clause happy be.pres-3pl. However, as shown in Figure 5.4, theUPDT annotation style offers a different analysis of each clause.
The subordinate clause is an adverbial clause modifier with the head nodefamiliar marked by the relation advcl governing the subordinating conjunctionfrom time-indef that, the nominal subject they, the prepositional modifier witheach.other, and the copula verb become.past-3pl. Since the adverbial clauseincludes a copula construction, the predicative complement familiar (whichin this case is an adjective) takes the position as head. Taking a closer lookat the complex sub-trees in this adverbial clause we see that the subordinateconjunction from time-indef that (since the time) is composed of three words.The first word, from, is labeled as mark and placed as the head node. Therest of the words are linked together in a chain, and annotated as a multi-wordexpression with the label mwe. In the UPDT I distinguish different subor-dinate conjunctions that appear in the form of multi-word expressions, suchas é» ú
�æ
�¯ð /vaqti ke/ (gloss: when that, translation: when), é» úÍAg PX /dar
hal-i ke/ (gloss: in state-indef that, translation: while), and é» QÃ @ /agar ke/(gloss: if that, translation: if), from the complementizer é» /ke/ (that). Thesubordinate conjunctions in the UPDT are always labeled as mark (marker) tointroduce adverbial clauses. The nominal subject sub-tree has they as its nsubj.The prepositional modifier sub-tree starts with the preposition with followedby its prepositional object each.other as its dependent. The adverbial clause isterminated with the copula verb become.past-3pl as its last sub-tree.
The main clause, happy be.pres-3pl, is also a copula construction consist-ing of the predicative happy, an adjective functioning as the root of the tree,governing the adverbial clause and the copula verb be.pres-3pl. Finally thepunctuation punct has the root of the sentence as its head.
Figure 5.4: AnalysisSince in the UPDT content words occupy the head position, a copula verbcannot be selected as the root or head word of a sentence unless the sentencedoes not contain a predicate. However, in the PerDT the copula verb can beplaced as the root of a sentence, as illustrated in Figure 5.4.
Fixed expressions such as é» úGAÓ P P@ /az zaman-i ke/ (gloss: from time-
indef that, translation: from the time, since), áK @ Xñk. ð AK. /ba vojud-e in/(gloss: with existence-ez this, translation: however), and ék� QÃ @ (gloss: ifwhat, translation: although) have been grammaticalized in Persian as clauselinkers used to link an adverbial clause to a main clause. Fixed expressions
142

are treated in the UPDT as mwe while in the PerDT each element in the ex-pression is treated separately. In the PerDT that, in from time-indef that, istreated as a complementizer introducing the clause they with each.other fa-miliar become.past-3pl to define time-indef. In the PerDT, the complemen-tizer links the relative clause to the main clause by attaching to the noun be-ing modified while in the UPDT, the complementizer attaches to the head ofthe subordinate clause. In this case, it attaches to become.past-3pl instead oftime-indef. As mentioned earlier, the copula become.past-3pl, according tothe UPDT, could not be the head of the relative clause as long as there exists apredicate such as familiar.
In the PerDT the prepositional phrase with each.other is placed as a childnode of the predicate familiar and not of the head word become.past-3pl. Inthe UPDT the preposition phrase also attaches to the predicate familiar, butthe predicate stands as the head of the clause rather than as the dependent.The subject they is set in the same state in both analyses.
Figure 5.5: PerDT AnnotationFigure 5.5 shows a sentence containing the following subordinate clause:
, YJJºK. Ð@Y«@ @P áÓ Y
Jë@ñ
kú× Ñë QÃ @
agarif
hameven
mi-xah-andcont-want.pres-3pl
manme
rara
e‘damexecution
be-kon-andsub-do.pres-3pl
,,
Even if they want to execute me,
starting with if, which is analyzed as AJUCL (adjunct clause), the headnode of the clause, modified by the sub-tree even cont-want.pres-3pl me raexecution sub-do.pres-3pl,. The sentence ends with the following main clause:
. YJJºK.
be-kon-andsub-do.pres-3pl
.
.let them do that.
More specifically, the sub-tree if even cont-want.pres-3pl is rooted in if gov-erning the child node cont-want.pres-3pl labeled as PRD (predicate), and fur-ther the adverb even analyzed as ADV. The sub-tree heads another sub-tree,namely, me ra execution sub-do.pres-3pl, rooted in sub-do.pres-3pl with thelabel VCL (complement clause of verb). The sub-tree is a complement clauseto the verb cont-want.pres-3pl. In this sub-tree, the subject is absent but isindicated in the form of a personal ending with the verb. The object me isdefined as the child node of the accusative marker ra. However, the accusativemarker is labeled as the object OBJ and the object me is analyzed as PRE-DEP (pre-dependent). The word execution, which builds a complex predicate
143
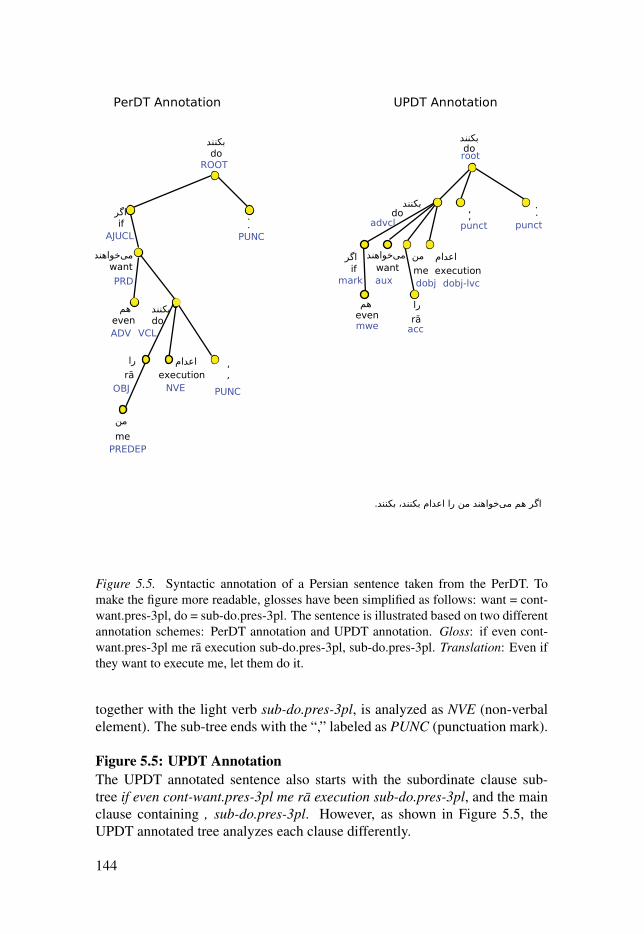
بکنند
PRD
هم
PREDEP
میوخواهند
ADV
من
NVE
را
VCL
اگر
AJUCL
اعدام
OBJ
doROOT
PUNC
.
PUNC
اگر هم میوخواهند من را اعدام بکنند، بکنند.
،
if
even
want
me
rā execution ,
do
بکنند
.
ifmark
evenmwe
wantaux
medobj
rāacc
doadvcl
executiondobj-lvc
doroot
punct
.
punct
،
بکنند
اگر
هم
میوخواهند من
را
اعدام
بکنند, .
UPDT Annotation PerDT Annotation
Figure 5.5. Syntactic annotation of a Persian sentence taken from the PerDT. Tomake the figure more readable, glosses have been simplified as follows: want = cont-want.pres-3pl, do = sub-do.pres-3pl. The sentence is illustrated based on two differentannotation schemes: PerDT annotation and UPDT annotation. Gloss: if even cont-want.pres-3pl me ra execution sub-do.pres-3pl, sub-do.pres-3pl. Translation: Even ifthey want to execute me, let them do it.
together with the light verb sub-do.pres-3pl, is analyzed as NVE (non-verbalelement). The sub-tree ends with the “,” labeled as PUNC (punctuation mark).
Figure 5.5: UPDT AnnotationThe UPDT annotated sentence also starts with the subordinate clause sub-tree if even cont-want.pres-3pl me ra execution sub-do.pres-3pl, and the mainclause containing , sub-do.pres-3pl. However, as shown in Figure 5.5, theUPDT annotated tree analyzes each clause differently.
144

The subordinate clause is an adverbial clause modifier with the head nodesub-do.pres-3pl marked as advcl dominating the subordinate conjunction ifeven, the auxiliary verb cont-want.pres-3pl, the direct object me, and the di-rect object in light verb construction execution. The subordinate conjunctionif even (even if, even though) is a multi-word expression (fixed-expression).Hence, the leading word in the expression is analyzed by the relation markand the latter word as a multi-word expression. The subject is absent, butthe information about it is given by related personal ending on the verb sub-do.pres-3pl. The direct object me is marked by the relation dobj followed bythe accusative marker ra labeled acc. The adverbial clause sub-tree ends withthe word execution, which creates a direct object in light verb construction incombination with the light verb sub-do.pres-3pl.
The sentence terminates with the main clause containing sub-do.pres-3pl,rooted in sub-do.pres-3pl governing the entire sentence.
Figure 5.5: AnalysisAs noted earlier, because content words in the UPDT are usually selected ashead nodes in the dependency relations, auxiliaries and complementizers areconsistently treated as dependents. The reasons behind this principle are thatit is more transparent to have direct links between content words and that STDis designed for deep-syntactic analysis (semantic analysis) more than for sur-face analysis. Therefore, as illustrated in the UPDT sample tree (Figure 5.5),unlike the PerDT, the auxiliary cont-want.pres-3pl is treated as a dependent.However, function words in the PerDT are treated as head nodes. Even whenlooking back at the previous sample trees shown in Figure 5.4 the complemen-tizer that with the relation NCL in PerDT and mwe is treated differently.
Another striking difference revealed in Figure 5.5 is how subordinate con-junctions, which are usually expressed with fixed expressions in Persian, aretreated in the treebanks. For instance the relation between the words if andeven in the expression if even is marked in the UPDT as a multi-word expres-sion and the entire term is considered as a subordinate conjunction introduc-ing the adverbial clause cont-want.pres-3pl me ra execution sub-do.pres-3pl.However, in the PerDT this relation is completely broken and the words arehandled discretely.
Moreover, the accusative marker ra is treated as a function word in theUPDT and is therefore placed as a dependent of the direct object with thelabel acc, whereas this relation is treated as a superior in the hierarchy in thePerDT and is placed as a head node to the direct object and is marked by thelabel OBJ.
Despite the fact that both the UPDT and the PerDT are based on a depen-dency structure, they differ greatly concerning both head-dependent relationsand functional labels. Moreover, the data in the UPDT and the PerDT aretaken from different sources and contain different character encodings. The
145

treebanks further provide different tokenization and annotation schemes, aswas described in this chapter.
146

6. Dependency Parsing for Persian
The previous chapter provided a detailed description of the UPDT. In thischapter I describe how I use the treebank in developing a state-of-the-art syn-tactic parser for Persian. The construction of the parser and the treebank infact went hand in hand, and the processes were accomplished simultaneouslyin a bootstrapping procedure. As noted earlier, in Section 5.2, I employedMaltParser (Nivre et al., 2006) for the treebank development and the qualityof the parser was enhanced as the size of the training data grew.
Fine-grained annotated data in treebanks normally provides a morecomplete grammatical analysis, which in turn enhances the quality of parsingresults. However, complex annotation may not always be beneficial and canimpair automatic analysis. In this chapter, I present different empirical studieswhere I systematically simplify the annotation schemes for part-of-speechtags and dependency relations. More precisely, I perform experiments underfour different conditions. I first experiment with all the features and labelsthat already exist in the treebank. The results achieved by this experimentwill be used as the baseline results. I then experiment with different relationsets by removing or merging various feature distinctions in the part-of-speechtagset and the syntactic annotation scheme. More specifically, I will performthe following experiments:
1. Experiment with full treebank annotation (baseline).
2. Experiment with coarse-grained part-of-speech tags.
3. Experiment with merged dependency relations for light verb constructions.
4. Experiment with no complex dependency relations.
In Experiment 2, I remove all morphological features and only keep the part-of-speech tags. For instance, I merge all distinctions for adjectives, such asADJ-CMPR, ADJ-INO, ADJ-SUP, and ADJ-VOC, into ADJ. In Experiment3, I do a similar study by converting different occurrences of lvc, such asacomp-lvc, dobj-lvc, nsubj-lvc, and prep-lvc, into only lvc. In Experiment4, I investigate the usefulness of complex syntactic labels by removing allinformation about clitics. The experiments are designed to serve as indicatorsof whether the conversions help or do not help the parser. In order to geta realistic picture of the parser performance, all these experiments will be
147

performed using automatically generated part-of-speech tags. However, forcomparison, I will also run the experiments with gold standard part-of-speechtags.
All the above experiments will be carried out using MaltParser. After dis-covering the best label set for both part-of-speech tags and dependency rela-tions, I will experiment with other parsers such as MSTParser (McDonald etal., 2005b), MateParser (Bohnet and Kuhn, 2012), and TurboParser (Martinset al., 2010) to find a state-of-the-art parser for Persian. I evaluate the parsersby experimenting with various feature settings when optional parameter set-tings for optimization are available. However, only results for final settingsare presented.
The selected state-of-the-art parser for Persian will then be used as a mod-ule in the pipeline of tools for automatic processing and analysis of Persian.The parsing module will be called ParsPer. For evaluation of ParsPer I firstperform a parsing experiment on the treebank data. I then make an indepen-dent parsing evaluation as I did for the other tools in the pipeline. I apply theparser to the 100 randomly selected sentences used in the evaluation of thetools previously introduced in Chapter 4 and present the final results.
6.1 Preliminaries6.1.1 DataThe treebank is sequentially split into 10 parts, of which segments 1–8 areused for training (80%), segment 9 for development (10%), and 10 for testing(10%). In my basic experiments with MaltParser, the first phase, I train theparser on the training set and test it on the development set. In the experimentswith other parsers, the second phase, I train the parser on the joint training anddevelopment sets (90%) and test it on the test set.
6.1.2 Evaluation MetricsFor the evaluation of the experiments, I use the standard and most commonlyapplied evaluation metrics for dependency parsers: the labeled attachmentscore (LAS), unlabeled attachment score (UAS), and label accuracy (LA).The labeled attachment score measures the percentage of tokens with correcthead and correct label. The unlabeled attachment score measures the percent-age of tokens with correct head. The label accuracy measures the percentageof tokens with correct dependency label. For my basic experiments with Malt-Parser I will further report labeled recall and precision for the 20 most frequentdependency relations in the treebank in order to get a more fine-grained pictureof the impact of the representation.
148

6.1.3 ParsersIn this chapter I make use of different freely available dependency parsers thatuntil now have been successfully used for different languages, namely Malt-Parser (Nivre et al., 2006), MSTParser (McDonald et al., 2005b), MateParsers(Bohnet, 2010; Bohnet and Nivre, 2012; Bohnet and Kuhn, 2012), and Tur-boParser (Martins et al., 2010). The parsers are briefly described below.
MaltParserMaltParser (Nivre et al., 2006) is an open source data-driven parser genera-tor for dependency parsing that has been applied to a large number of lan-guages. The parser is characterized as transition-based and can be used todevelop a parser for a new language given a dependency treebank represent-ing the syntactic relations of that language. The system allows the user tochoose different parsing algorithms, and to define optional feature modelsindicating lexical features, part-of-speech features and dependency type fea-tures. The main parsing algorithms available in MaltParser are Nivre’s algo-rithms, including the arc-eager and arc-standard versions described in Nivre(2003) and Nivre (2004), Covington’s algorithms, containing the projectiveand non-projective versions described by Covington (2001), and Stack algo-rithms, including the projective and non-projective versions of the algorithmdescribed in Nivre (2009) and Nivre et al. (2009). Covington’s algorithmsand the Stack algorithms can handle non-projective trees, whereas Nivre’salgorithms cannot (Ballesteros and Nivre, 2012). An optimization tool forMaltParser, MaltOptimizer (Ballesteros and Nivre, 2012) has been developedspecifically to optimize MaltParser for new data sets with respect to parsingalgorithm and feature selection.
MSTParserMSTParser (McDonald et al., 2005b; McDonald et al., 2005a) is an opensource system that has also been applied to a wide range of languages, similarto MaltParser. The parser is based on the graph-based approach to dependencyparsing using global learning and exact (or nearly exact) inference algorithms.A graph-based parser extracts the highest scoring spanning tree from a com-plete graph containing all possible dependency arcs, using a scoring modelthat decomposes into scores for smaller subgraphs of a tree (McDonald et al.,2005b; Koo and Collins, 2010). MSTParser implements first- and second-order models, where subgraphs are single arcs and pairs of arcs, respectively,and provides different algorithms for projective and non-projective trees.
MateParsersMateParsers are open source statistical dependency parsers in the NLP toolkitMate Tools (Bohnet, 2010). The pipeline contains a lemmatizer, part-of-speech tagger, morphological tagger, dependency parsers (Bohnet, 2010;
149

Bohnet and Nivre, 2012; Bohnet and Kuhn, 2012), and a semantic role labeler(Björkelund et al., 2010). The dependency parsers in the pipeline include agraph-based parser, a transition-based parser, and a joint tagger-parser derivedfrom the transition-based parser.
The basis of the graph-based parser is the second-order maximum span-ning tree dependency parsing algorithm of Carreras (2007) combined withthe passive-aggressive perceptron described in Crammer et al. (2006) and Mc-Donald et al. (2005a) and a hash kernel. This method improves the mapping offeature values, which in turn has led to higher attachment scores for languagessuch as Czech, English, German, and Spanish (Bohnet, 2010). In addition tohigh accuracy, Bohnet (2010) reports a substantial increase in parsing speed:3.5 times faster on a single CPU core than the baseline parser that has an ar-chitecture for a maximum spanning tree parser.1
The transition-based parser is a system that combines part-of-speech tag-ging and labeled dependency parsing with non-projective trees. However,when one only desires to run the transition-based parser, the tagger can beswitched off. Thus, the tagger is an option that can easily be switched onand off. The parser employs beam search in combination with structured per-ceptron learning. The system has exhibited steady improvements in accuracyfor tagging and parsing when evaluated on Chinese, Czech, English, and Ger-man, compared to the results achieved by the graph-based system in the Matepipeline (Bohnet and Nivre, 2012).
TurboParserTurboParser (Martins et al., 2010; Martins et al., 2013) is another open sourcemultilingual dependency parser. The system is based on a second-order non-projective parser with features for arcs, consecutive siblings and grandparents,using the AD3 algorithm as a decoder. In order to reduce the number of can-didate arcs and increase the parsing speed, the system trains a probabilisticmodel for unlabeled arc-factored pruning.
The parser presented in Martins et al. (2013) uses the AD3 algorithm, whichis an accelerated dual decomposition algorithm proposed by Martins et al.(2011). The new version is considerably faster than that of Martins et al.(2011). The parser further handles large components, such as specialized headautomata for the third-order features, and a sequence model for head bigrams.The scores presented in Martins et al. (2013) show state-of-the-art results forlarge data sets of languages with most non-projective dependencies, such asEnglish, Czech, German, and Dutch.
1According to the last shared tasks, the transition-based parsers have similar run times as max-imum spanning tree parsers (Bohnet, 2010).
150

6.2 Experiments with Different Parsing RepresentationsIn this section I describe a number of basic experiments performed for dif-ferent purposes with MaltParser. To evaluate the overall performance of theparser, I tune parameters to achieve the best possible results. Thus, I exper-iment with different algorithms and feature settings to optimize MaltParser.To accomplish the optimization process, I apply MaltOptimizer (Ballesterosand Nivre, 2012). Parser accuracy is evaluated on automatically generatedpart-of-speech tags as well as gold standard tags.
In order to generate automatic part-of-speech tags, I used the Persianpart-of-speech tagger, TagPer. However, for the treebank experiments Iretrained the tagger to exclude the treebank data to avoid data overlap. Thetagging evaluation performed by the new TagPer revealed an overall accuracyof 97.17% when HunPoS was trained on 90% of the UPC and evaluated onthe remaining 10%. The four different experiments include (1) an overallparsing evaluation on full treebank annotation, (2) an experiment withoutmorphological features in the part-of-speech tagset, (3) an experiment withoutfine-grained LVC labels, and (4) an experiment without complex labels, asdescribed in the introduction.
6.2.1 Baseline: Full Treebank AnnotationIn this parsing evaluation I trained MaltParser on the UPDT with automaticallygenerated part-of-speech tags. I used the treebank with full part-of-speech tagsand all existing dependency relations. The experiment resulted in a labeledattachment score of 78.84% and an unlabeled attachment score of 83.07%.These results will be used as a baseline for subsequent experiments. Labeledrecall and precision for the 20 most frequent dependency relations (with aminimum frequency of 2022) are presented in Table 6.1. As can be seen, theresults vary greatly across the relation types, with recall ranging from 53.75%for direct object (dobj) to 97.12% for object of a preposition (pobj), and preci-sion varying between 55.37% for clausal complement (ccomp) to 95.57% forobject of a preposition (pobj). Recall and precision for a number of relations,such as object of a preposition (pobj), adjectival modifier (amod), direct objectin light verb construction (dobj-lvc), determiner (det), numeric modifier (num)with similar recall and precision, and auxiliary (aux), are all over 90%. In ad-dition to the direct object (dobj), the most erroneous2 relations are nominalsubject (nsubj), conjunct (conj), copula (cop), adverbial modifier (advmod),clausal complement (ccomp), noun compound modifier (nn), and accusativemarker (acc). However, their recall and precision figures vary somewhat.
As indicated in Table 6.1 the results for core arguments such as nominalsubject (nsubj) and direct object (dobj) are slightly low. This can be explained
2I define most erroneous relations as relations with scores lower than 70%.
151
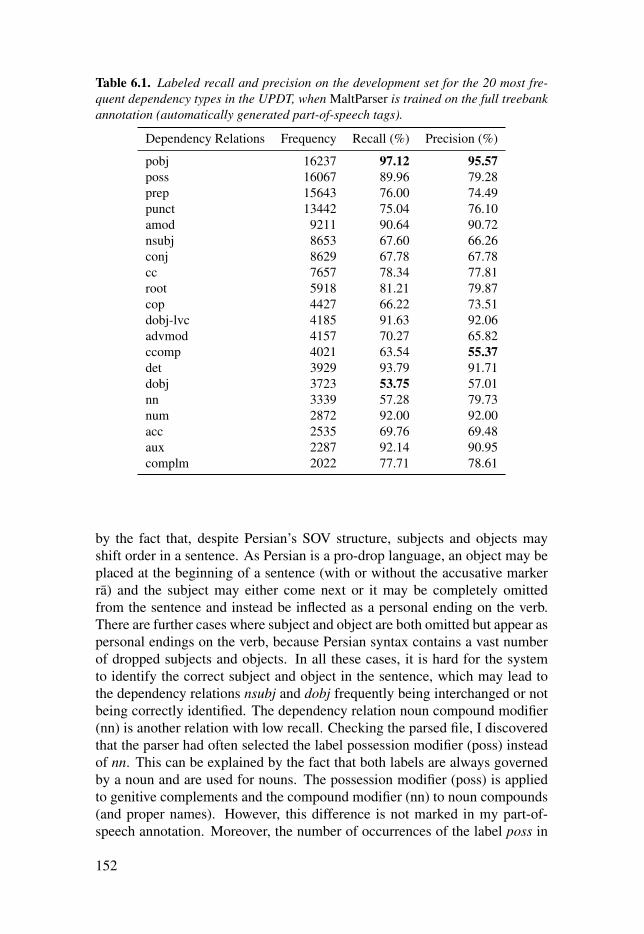
Table 6.1. Labeled recall and precision on the development set for the 20 most fre-quent dependency types in the UPDT, when MaltParser is trained on the full treebankannotation (automatically generated part-of-speech tags).
Dependency Relations Frequency Recall (%) Precision (%)
pobj 16237 97.12 95.57poss 16067 89.96 79.28prep 15643 76.00 74.49punct 13442 75.04 76.10amod 9211 90.64 90.72nsubj 8653 67.60 66.26conj 8629 67.78 67.78cc 7657 78.34 77.81root 5918 81.21 79.87cop 4427 66.22 73.51dobj-lvc 4185 91.63 92.06advmod 4157 70.27 65.82ccomp 4021 63.54 55.37det 3929 93.79 91.71dobj 3723 53.75 57.01nn 3339 57.28 79.73num 2872 92.00 92.00acc 2535 69.76 69.48aux 2287 92.14 90.95complm 2022 77.71 78.61
by the fact that, despite Persian’s SOV structure, subjects and objects mayshift order in a sentence. As Persian is a pro-drop language, an object may beplaced at the beginning of a sentence (with or without the accusative markerra) and the subject may either come next or it may be completely omittedfrom the sentence and instead be inflected as a personal ending on the verb.There are further cases where subject and object are both omitted but appear aspersonal endings on the verb, because Persian syntax contains a vast numberof dropped subjects and objects. In all these cases, it is hard for the systemto identify the correct subject and object in the sentence, which may lead tothe dependency relations nsubj and dobj frequently being interchanged or notbeing correctly identified. The dependency relation noun compound modifier(nn) is another relation with low recall. Checking the parsed file, I discoveredthat the parser had often selected the label possession modifier (poss) insteadof nn. This can be explained by the fact that both labels are always governedby a noun and are used for nouns. The possession modifier (poss) is appliedto genitive complements and the compound modifier (nn) to noun compounds(and proper names). However, this difference is not marked in my part-of-speech annotation. Moreover, the number of occurrences of the label poss in
152
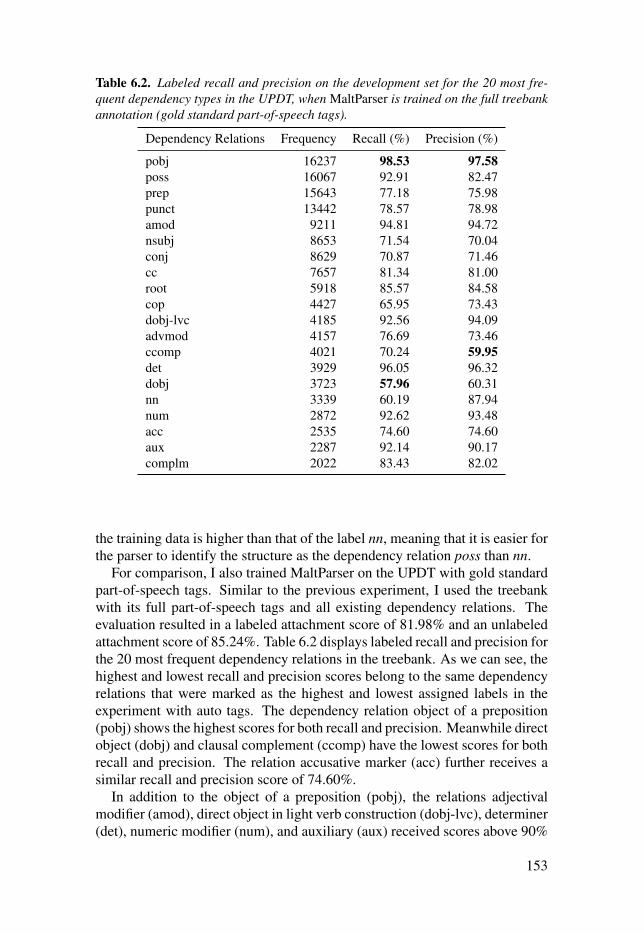
Table 6.2. Labeled recall and precision on the development set for the 20 most fre-quent dependency types in the UPDT, when MaltParser is trained on the full treebankannotation (gold standard part-of-speech tags).
Dependency Relations Frequency Recall (%) Precision (%)
pobj 16237 98.53 97.58poss 16067 92.91 82.47prep 15643 77.18 75.98punct 13442 78.57 78.98amod 9211 94.81 94.72nsubj 8653 71.54 70.04conj 8629 70.87 71.46cc 7657 81.34 81.00root 5918 85.57 84.58cop 4427 65.95 73.43dobj-lvc 4185 92.56 94.09advmod 4157 76.69 73.46ccomp 4021 70.24 59.95det 3929 96.05 96.32dobj 3723 57.96 60.31nn 3339 60.19 87.94num 2872 92.62 93.48acc 2535 74.60 74.60aux 2287 92.14 90.17complm 2022 83.43 82.02
the training data is higher than that of the label nn, meaning that it is easier forthe parser to identify the structure as the dependency relation poss than nn.
For comparison, I also trained MaltParser on the UPDT with gold standardpart-of-speech tags. Similar to the previous experiment, I used the treebankwith its full part-of-speech tags and all existing dependency relations. Theevaluation resulted in a labeled attachment score of 81.98% and an unlabeledattachment score of 85.24%. Table 6.2 displays labeled recall and precision forthe 20 most frequent dependency relations in the treebank. As we can see, thehighest and lowest recall and precision scores belong to the same dependencyrelations that were marked as the highest and lowest assigned labels in theexperiment with auto tags. The dependency relation object of a preposition(pobj) shows the highest scores for both recall and precision. Meanwhile directobject (dobj) and clausal complement (ccomp) have the lowest scores for bothrecall and precision. The relation accusative marker (acc) further receives asimilar recall and precision score of 74.60%.
In addition to the object of a preposition (pobj), the relations adjectivalmodifier (amod), direct object in light verb construction (dobj-lvc), determiner(det), numeric modifier (num), and auxiliary (aux) received scores above 90%
153
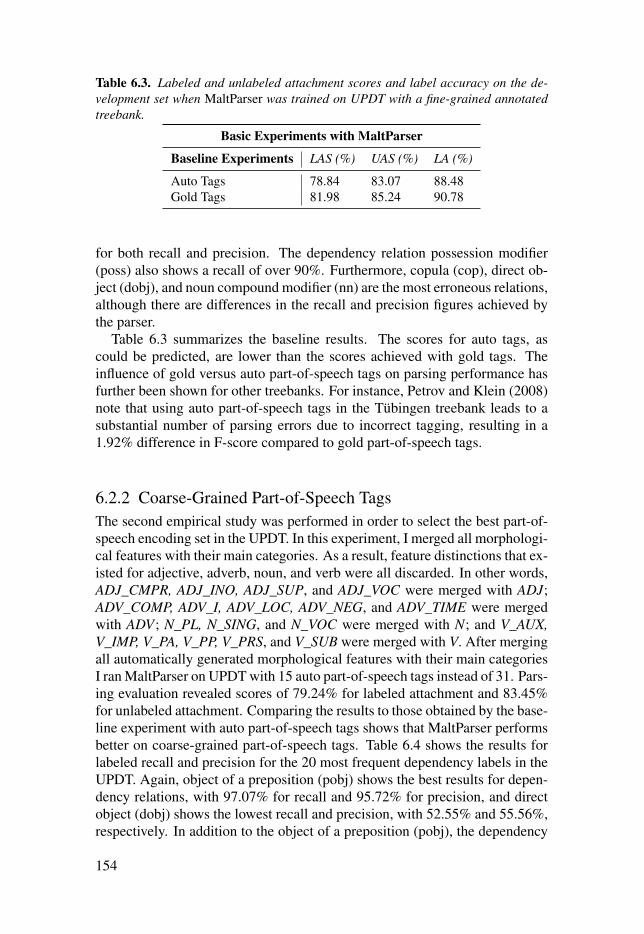
Table 6.3. Labeled and unlabeled attachment scores and label accuracy on the de-velopment set when MaltParser was trained on UPDT with a fine-grained annotatedtreebank.
Basic Experiments with MaltParser
Baseline Experiments LAS (%) UAS (%) LA (%)
Auto Tags 78.84 83.07 88.48Gold Tags 81.98 85.24 90.78
for both recall and precision. The dependency relation possession modifier(poss) also shows a recall of over 90%. Furthermore, copula (cop), direct ob-ject (dobj), and noun compound modifier (nn) are the most erroneous relations,although there are differences in the recall and precision figures achieved bythe parser.
Table 6.3 summarizes the baseline results. The scores for auto tags, ascould be predicted, are lower than the scores achieved with gold tags. Theinfluence of gold versus auto part-of-speech tags on parsing performance hasfurther been shown for other treebanks. For instance, Petrov and Klein (2008)note that using auto part-of-speech tags in the Tübingen treebank leads to asubstantial number of parsing errors due to incorrect tagging, resulting in a1.92% difference in F-score compared to gold part-of-speech tags.
6.2.2 Coarse-Grained Part-of-Speech TagsThe second empirical study was performed in order to select the best part-of-speech encoding set in the UPDT. In this experiment, I merged all morphologi-cal features with their main categories. As a result, feature distinctions that ex-isted for adjective, adverb, noun, and verb were all discarded. In other words,ADJ_CMPR, ADJ_INO, ADJ_SUP, and ADJ_VOC were merged with ADJ;ADV_COMP, ADV_I, ADV_LOC, ADV_NEG, and ADV_TIME were mergedwith ADV; N_PL, N_SING, and N_VOC were merged with N; and V_AUX,V_IMP, V_PA, V_PP, V_PRS, and V_SUB were merged with V. After mergingall automatically generated morphological features with their main categoriesI ran MaltParser on UPDT with 15 auto part-of-speech tags instead of 31. Pars-ing evaluation revealed scores of 79.24% for labeled attachment and 83.45%for unlabeled attachment. Comparing the results to those obtained by the base-line experiment with auto part-of-speech tags shows that MaltParser performsbetter on coarse-grained part-of-speech tags. Table 6.4 shows the results forlabeled recall and precision for the 20 most frequent dependency labels in theUPDT. Again, object of a preposition (pobj) shows the best results for depen-dency relations, with 97.07% for recall and 95.72% for precision, and directobject (dobj) shows the lowest recall and precision, with 52.55% and 55.56%,respectively. In addition to the object of a preposition (pobj), the dependency
154
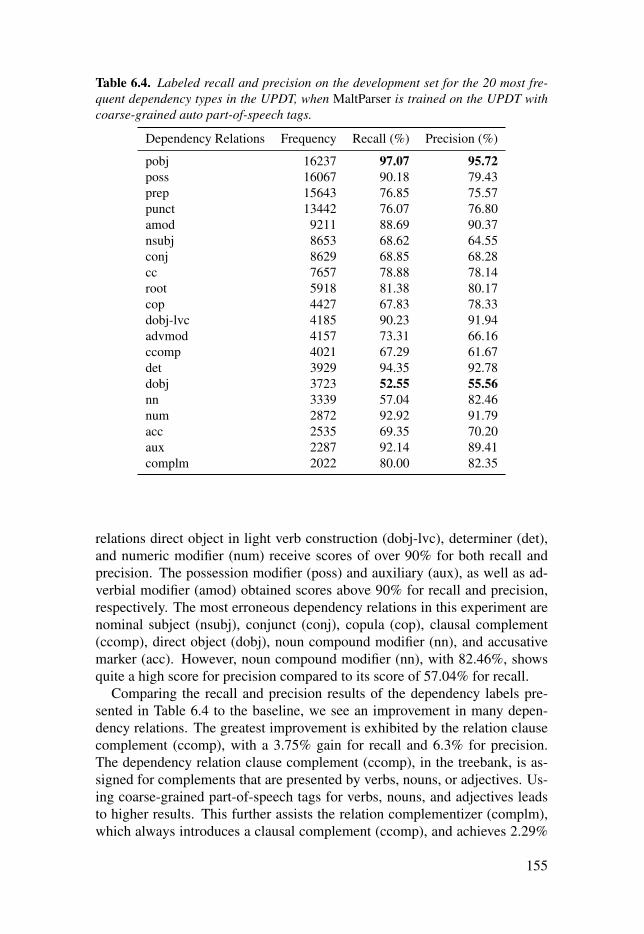
Table 6.4. Labeled recall and precision on the development set for the 20 most fre-quent dependency types in the UPDT, when MaltParser is trained on the UPDT withcoarse-grained auto part-of-speech tags.
Dependency Relations Frequency Recall (%) Precision (%)
pobj 16237 97.07 95.72poss 16067 90.18 79.43prep 15643 76.85 75.57punct 13442 76.07 76.80amod 9211 88.69 90.37nsubj 8653 68.62 64.55conj 8629 68.85 68.28cc 7657 78.88 78.14root 5918 81.38 80.17cop 4427 67.83 78.33dobj-lvc 4185 90.23 91.94advmod 4157 73.31 66.16ccomp 4021 67.29 61.67det 3929 94.35 92.78dobj 3723 52.55 55.56nn 3339 57.04 82.46num 2872 92.92 91.79acc 2535 69.35 70.20aux 2287 92.14 89.41complm 2022 80.00 82.35
relations direct object in light verb construction (dobj-lvc), determiner (det),and numeric modifier (num) receive scores of over 90% for both recall andprecision. The possession modifier (poss) and auxiliary (aux), as well as ad-verbial modifier (amod) obtained scores above 90% for recall and precision,respectively. The most erroneous dependency relations in this experiment arenominal subject (nsubj), conjunct (conj), copula (cop), clausal complement(ccomp), direct object (dobj), noun compound modifier (nn), and accusativemarker (acc). However, noun compound modifier (nn), with 82.46%, showsquite a high score for precision compared to its score of 57.04% for recall.
Comparing the recall and precision results of the dependency labels pre-sented in Table 6.4 to the baseline, we see an improvement in many depen-dency relations. The greatest improvement is exhibited by the relation clausecomplement (ccomp), with a 3.75% gain for recall and 6.3% for precision.The dependency relation clause complement (ccomp), in the treebank, is as-signed for complements that are presented by verbs, nouns, or adjectives. Us-ing coarse-grained part-of-speech tags for verbs, nouns, and adjectives leadsto higher results. This further assists the relation complementizer (complm),which always introduces a clausal complement (ccomp), and achieves 2.29%
155
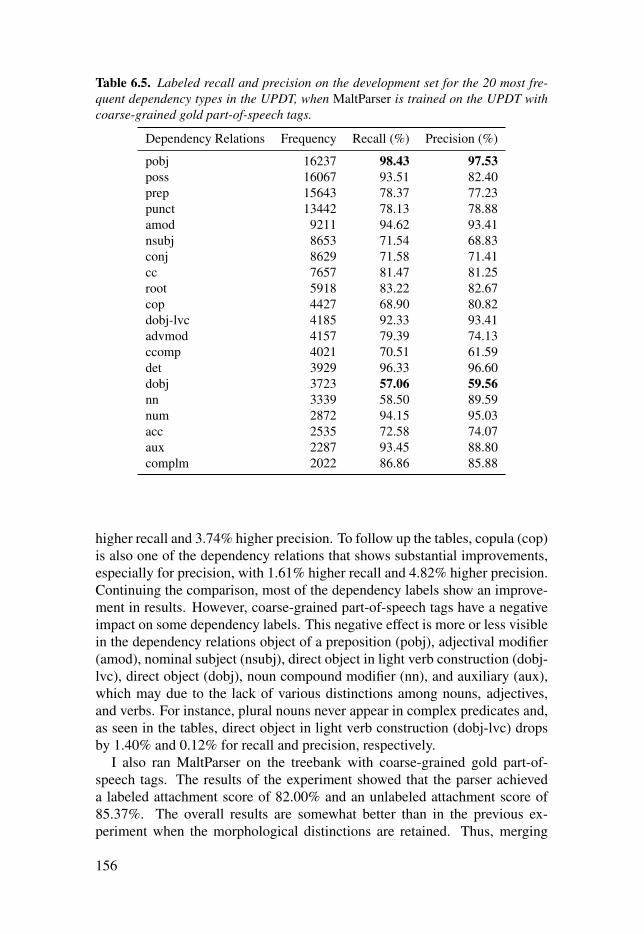
Table 6.5. Labeled recall and precision on the development set for the 20 most fre-quent dependency types in the UPDT, when MaltParser is trained on the UPDT withcoarse-grained gold part-of-speech tags.
Dependency Relations Frequency Recall (%) Precision (%)
pobj 16237 98.43 97.53poss 16067 93.51 82.40prep 15643 78.37 77.23punct 13442 78.13 78.88amod 9211 94.62 93.41nsubj 8653 71.54 68.83conj 8629 71.58 71.41cc 7657 81.47 81.25root 5918 83.22 82.67cop 4427 68.90 80.82dobj-lvc 4185 92.33 93.41advmod 4157 79.39 74.13ccomp 4021 70.51 61.59det 3929 96.33 96.60dobj 3723 57.06 59.56nn 3339 58.50 89.59num 2872 94.15 95.03acc 2535 72.58 74.07aux 2287 93.45 88.80complm 2022 86.86 85.88
higher recall and 3.74% higher precision. To follow up the tables, copula (cop)is also one of the dependency relations that shows substantial improvements,especially for precision, with 1.61% higher recall and 4.82% higher precision.Continuing the comparison, most of the dependency labels show an improve-ment in results. However, coarse-grained part-of-speech tags have a negativeimpact on some dependency labels. This negative effect is more or less visiblein the dependency relations object of a preposition (pobj), adjectival modifier(amod), nominal subject (nsubj), direct object in light verb construction (dobj-lvc), direct object (dobj), noun compound modifier (nn), and auxiliary (aux),which may due to the lack of various distinctions among nouns, adjectives,and verbs. For instance, plural nouns never appear in complex predicates and,as seen in the tables, direct object in light verb construction (dobj-lvc) dropsby 1.40% and 0.12% for recall and precision, respectively.
I also ran MaltParser on the treebank with coarse-grained gold part-of-speech tags. The results of the experiment showed that the parser achieveda labeled attachment score of 82.00% and an unlabeled attachment score of85.37%. The overall results are somewhat better than in the previous ex-periment when the morphological distinctions are retained. Thus, merging
156

the morphological features in the treebank is useful as it improves the pars-ing performance. Note that parsing performance follows the same trend as inthe experiment where coarse-grained auto part-of-speech tags were used. Ta-ble 6.5 presents labeled recall and precision scores for the 20 most frequentdependency relations in the UPDT. Once again, object of a preposition (pobj),with 98.43% and 97.53%, receives the highest recall and precision scores. Onthe other hand, the lowest recall and precision was shown by direct object(dobj) with 57.06% and 59.56%, respectively. Preposition modifier (prep),coordination (cc), copula (cop), adverbial modifier (advmod), clause comple-ment (ccomp), determiner (det), numeric modifier (num), and complementizer(complm) get higher recall and precision scores than in the baseline experi-ment. Additionally, possession modifier (poss) conjunct (conj), and auxiliary(aux) score higher for recall, and noun compound modifier (nn) has higher pre-cision. The relation nominal subject (nsubj) shows no difference in recall butits precision has decreased. Apart from the aforementioned dependency rela-tions, the rest of the relations receive lower recall and precision scores. The de-pendency relations object of a preposition (pobj), adjectival modifier (amod),direct object in light verb construction (dobj-lvc), determiner (det), and nu-meric modifier (num) obtain scores of over 90% for both recall and precision.The relations possession modifier (poss) and auxiliary (aux) show scores ofover 90% for recall. Moreover, nominal subject (nsubj), copula (cop), clausalcomplement (ccomp), direct object (dobj), and noun compound modifier (nn)all belong to the most erroneous dependency relations even if there are differ-ences in the recall and precision figures obtained by the parser.
As when the same experiment was run with auto part-of-speech tags, thestudy shows an improvement in overall parsing results. However, the improve-ment is slightly less than the results for auto tags. The greatest improvement isobserved for the relation copula (cop) with a 2.95% gain for recall and 7.39%for precision. Comparing the results to the baseline, although using coarse-grained gold part-of-speech tags improves the results for a number of depen-dency relations, it affects some other dependency relations negatively. Theserelations are object of a preposition (pobj), possession modifier (poss), punc-tuation (punct), adjectival modifier (amod), nominal subject (nsubj), conjunct(conj), root, direct object in light verb construction (dobj-lvc), direct object(dobj), noun compound modifier (nn), accusative marker (acc), and auxiliary(aux), though with differences in recall and precision scores. The reason forthis reduction may be that various distinctions between nouns, adjectives, andverbs are not clear to the parser. These may also be dependent on the surround-ing words and their specific characteristics in the context. For instance, propernouns are always given the tag N_SING, and the lack of feature distinctionsfor nouns in the tag set makes it harder for the parser to achieve a high recallscore for the relation noun compound modifier (nn). The dependency relationshows a decrease of 1.69% for recall. However, the score increases by 1.65%
157
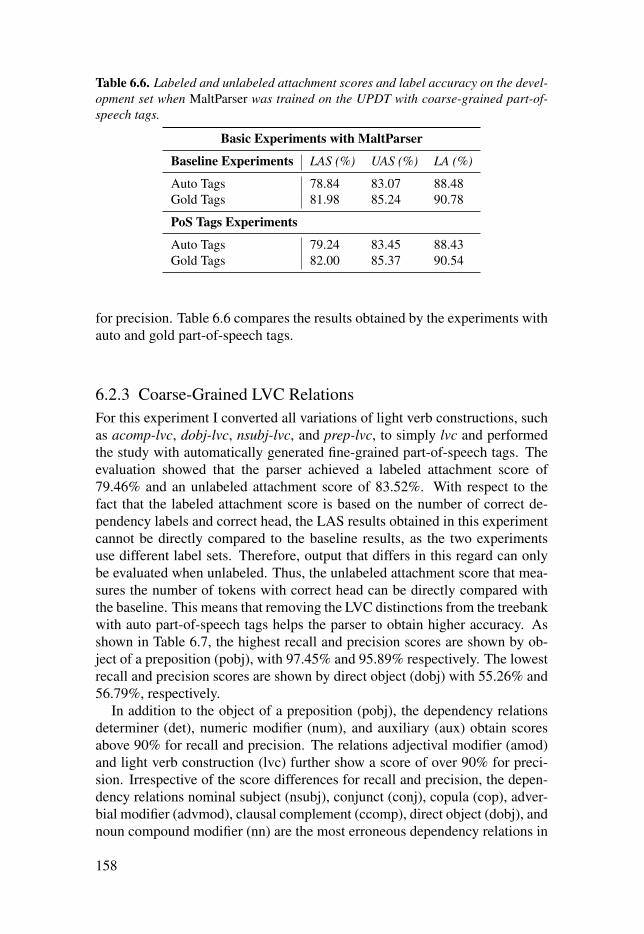
Table 6.6. Labeled and unlabeled attachment scores and label accuracy on the devel-opment set when MaltParser was trained on the UPDT with coarse-grained part-of-speech tags.
Basic Experiments with MaltParser
Baseline Experiments LAS (%) UAS (%) LA (%)
Auto Tags 78.84 83.07 88.48Gold Tags 81.98 85.24 90.78
PoS Tags Experiments
Auto Tags 79.24 83.45 88.43Gold Tags 82.00 85.37 90.54
for precision. Table 6.6 compares the results obtained by the experiments withauto and gold part-of-speech tags.
6.2.3 Coarse-Grained LVC RelationsFor this experiment I converted all variations of light verb constructions, suchas acomp-lvc, dobj-lvc, nsubj-lvc, and prep-lvc, to simply lvc and performedthe study with automatically generated fine-grained part-of-speech tags. Theevaluation showed that the parser achieved a labeled attachment score of79.46% and an unlabeled attachment score of 83.52%. With respect to thefact that the labeled attachment score is based on the number of correct de-pendency labels and correct head, the LAS results obtained in this experimentcannot be directly compared to the baseline results, as the two experimentsuse different label sets. Therefore, output that differs in this regard can onlybe evaluated when unlabeled. Thus, the unlabeled attachment score that mea-sures the number of tokens with correct head can be directly compared withthe baseline. This means that removing the LVC distinctions from the treebankwith auto part-of-speech tags helps the parser to obtain higher accuracy. Asshown in Table 6.7, the highest recall and precision scores are shown by ob-ject of a preposition (pobj), with 97.45% and 95.89% respectively. The lowestrecall and precision scores are shown by direct object (dobj) with 55.26% and56.79%, respectively.
In addition to the object of a preposition (pobj), the dependency relationsdeterminer (det), numeric modifier (num), and auxiliary (aux) obtain scoresabove 90% for recall and precision. The relations adjectival modifier (amod)and light verb construction (lvc) further show a score of over 90% for preci-sion. Irrespective of the score differences for recall and precision, the depen-dency relations nominal subject (nsubj), conjunct (conj), copula (cop), adver-bial modifier (advmod), clausal complement (ccomp), direct object (dobj), andnoun compound modifier (nn) are the most erroneous dependency relations in
158
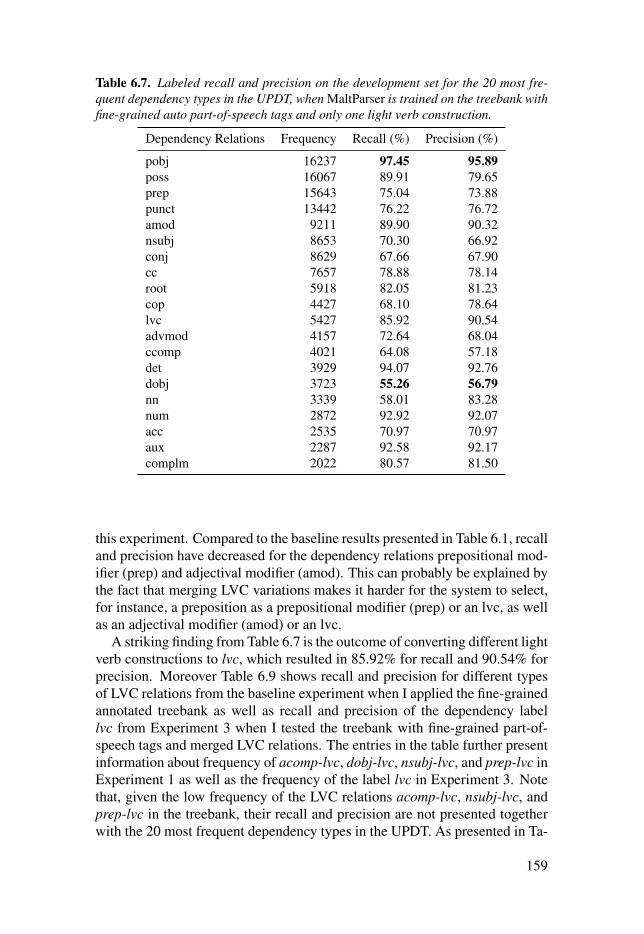
Table 6.7. Labeled recall and precision on the development set for the 20 most fre-quent dependency types in the UPDT, when MaltParser is trained on the treebank withfine-grained auto part-of-speech tags and only one light verb construction.
Dependency Relations Frequency Recall (%) Precision (%)
pobj 16237 97.45 95.89poss 16067 89.91 79.65prep 15643 75.04 73.88punct 13442 76.22 76.72amod 9211 89.90 90.32nsubj 8653 70.30 66.92conj 8629 67.66 67.90cc 7657 78.88 78.14root 5918 82.05 81.23cop 4427 68.10 78.64lvc 5427 85.92 90.54advmod 4157 72.64 68.04ccomp 4021 64.08 57.18det 3929 94.07 92.76dobj 3723 55.26 56.79nn 3339 58.01 83.28num 2872 92.92 92.07acc 2535 70.97 70.97aux 2287 92.58 92.17complm 2022 80.57 81.50
this experiment. Compared to the baseline results presented in Table 6.1, recalland precision have decreased for the dependency relations prepositional mod-ifier (prep) and adjectival modifier (amod). This can probably be explained bythe fact that merging LVC variations makes it harder for the system to select,for instance, a preposition as a prepositional modifier (prep) or an lvc, as wellas an adjectival modifier (amod) or an lvc.
A striking finding from Table 6.7 is the outcome of converting different lightverb constructions to lvc, which resulted in 85.92% for recall and 90.54% forprecision. Moreover Table 6.9 shows recall and precision for different typesof LVC relations from the baseline experiment when I applied the fine-grainedannotated treebank as well as recall and precision of the dependency labellvc from Experiment 3 when I tested the treebank with fine-grained part-of-speech tags and merged LVC relations. The entries in the table further presentinformation about frequency of acomp-lvc, dobj-lvc, nsubj-lvc, and prep-lvc inExperiment 1 as well as the frequency of the label lvc in Experiment 3. Notethat, given the low frequency of the LVC relations acomp-lvc, nsubj-lvc, andprep-lvc in the treebank, their recall and precision are not presented togetherwith the 20 most frequent dependency types in the UPDT. As presented in Ta-
159
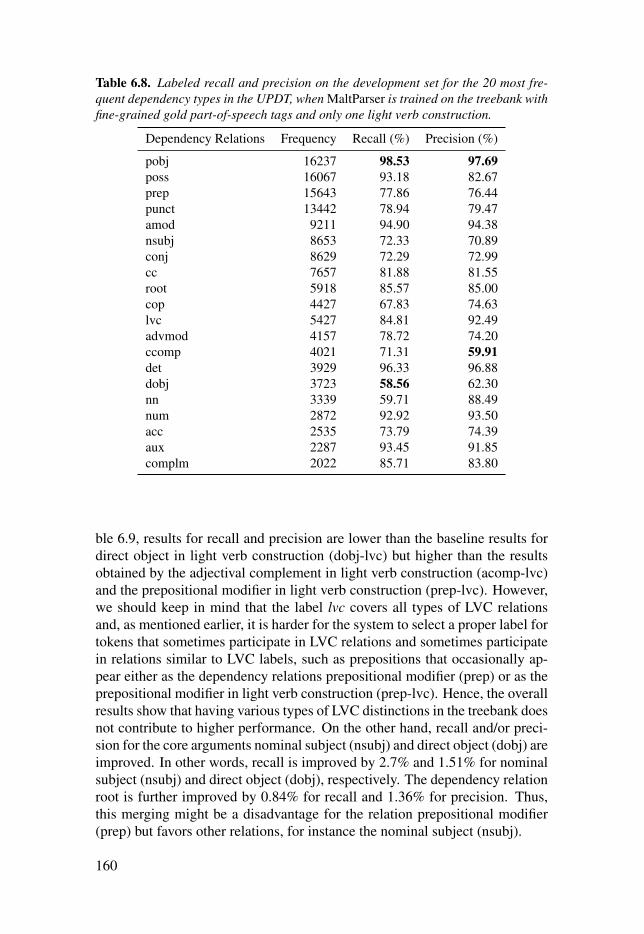
Table 6.8. Labeled recall and precision on the development set for the 20 most fre-quent dependency types in the UPDT, when MaltParser is trained on the treebank withfine-grained gold part-of-speech tags and only one light verb construction.
Dependency Relations Frequency Recall (%) Precision (%)
pobj 16237 98.53 97.69poss 16067 93.18 82.67prep 15643 77.86 76.44punct 13442 78.94 79.47amod 9211 94.90 94.38nsubj 8653 72.33 70.89conj 8629 72.29 72.99cc 7657 81.88 81.55root 5918 85.57 85.00cop 4427 67.83 74.63lvc 5427 84.81 92.49advmod 4157 78.72 74.20ccomp 4021 71.31 59.91det 3929 96.33 96.88dobj 3723 58.56 62.30nn 3339 59.71 88.49num 2872 92.92 93.50acc 2535 73.79 74.39aux 2287 93.45 91.85complm 2022 85.71 83.80
ble 6.9, results for recall and precision are lower than the baseline results fordirect object in light verb construction (dobj-lvc) but higher than the resultsobtained by the adjectival complement in light verb construction (acomp-lvc)and the prepositional modifier in light verb construction (prep-lvc). However,we should keep in mind that the label lvc covers all types of LVC relationsand, as mentioned earlier, it is harder for the system to select a proper label fortokens that sometimes participate in LVC relations and sometimes participatein relations similar to LVC labels, such as prepositions that occasionally ap-pear either as the dependency relations prepositional modifier (prep) or as theprepositional modifier in light verb construction (prep-lvc). Hence, the overallresults show that having various types of LVC distinctions in the treebank doesnot contribute to higher performance. On the other hand, recall and/or preci-sion for the core arguments nominal subject (nsubj) and direct object (dobj) areimproved. In other words, recall is improved by 2.7% and 1.51% for nominalsubject (nsubj) and direct object (dobj), respectively. The dependency relationroot is further improved by 0.84% for recall and 1.36% for precision. Thus,this merging might be a disadvantage for the relation prepositional modifier(prep) but favors other relations, for instance the nominal subject (nsubj).
160
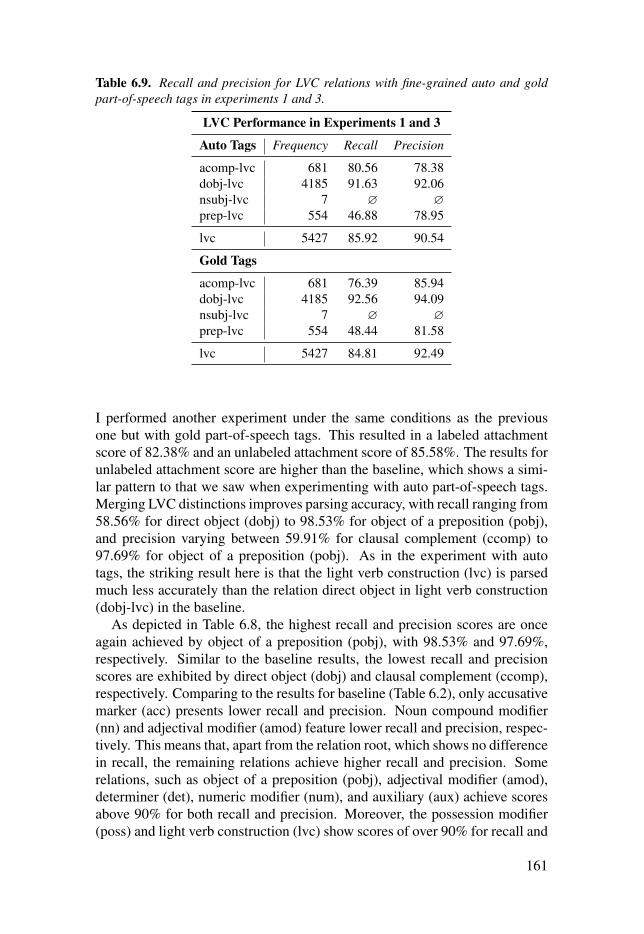
Table 6.9. Recall and precision for LVC relations with fine-grained auto and goldpart-of-speech tags in experiments 1 and 3.
LVC Performance in Experiments 1 and 3
Auto Tags Frequency Recall Precision
acomp-lvc 681 80.56 78.38dobj-lvc 4185 91.63 92.06nsubj-lvc 7 ∅ ∅prep-lvc 554 46.88 78.95
lvc 5427 85.92 90.54
Gold Tags
acomp-lvc 681 76.39 85.94dobj-lvc 4185 92.56 94.09nsubj-lvc 7 ∅ ∅prep-lvc 554 48.44 81.58
lvc 5427 84.81 92.49
I performed another experiment under the same conditions as the previousone but with gold part-of-speech tags. This resulted in a labeled attachmentscore of 82.38% and an unlabeled attachment score of 85.58%. The results forunlabeled attachment score are higher than the baseline, which shows a simi-lar pattern to that we saw when experimenting with auto part-of-speech tags.Merging LVC distinctions improves parsing accuracy, with recall ranging from58.56% for direct object (dobj) to 98.53% for object of a preposition (pobj),and precision varying between 59.91% for clausal complement (ccomp) to97.69% for object of a preposition (pobj). As in the experiment with autotags, the striking result here is that the light verb construction (lvc) is parsedmuch less accurately than the relation direct object in light verb construction(dobj-lvc) in the baseline.
As depicted in Table 6.8, the highest recall and precision scores are onceagain achieved by object of a preposition (pobj), with 98.53% and 97.69%,respectively. Similar to the baseline results, the lowest recall and precisionscores are exhibited by direct object (dobj) and clausal complement (ccomp),respectively. Comparing to the results for baseline (Table 6.2), only accusativemarker (acc) presents lower recall and precision. Noun compound modifier(nn) and adjectival modifier (amod) feature lower recall and precision, respec-tively. This means that, apart from the relation root, which shows no differencein recall, the remaining relations achieve higher recall and precision. Somerelations, such as object of a preposition (pobj), adjectival modifier (amod),determiner (det), numeric modifier (num), and auxiliary (aux) achieve scoresabove 90% for both recall and precision. Moreover, the possession modifier(poss) and light verb construction (lvc) show scores of over 90% for recall and
161
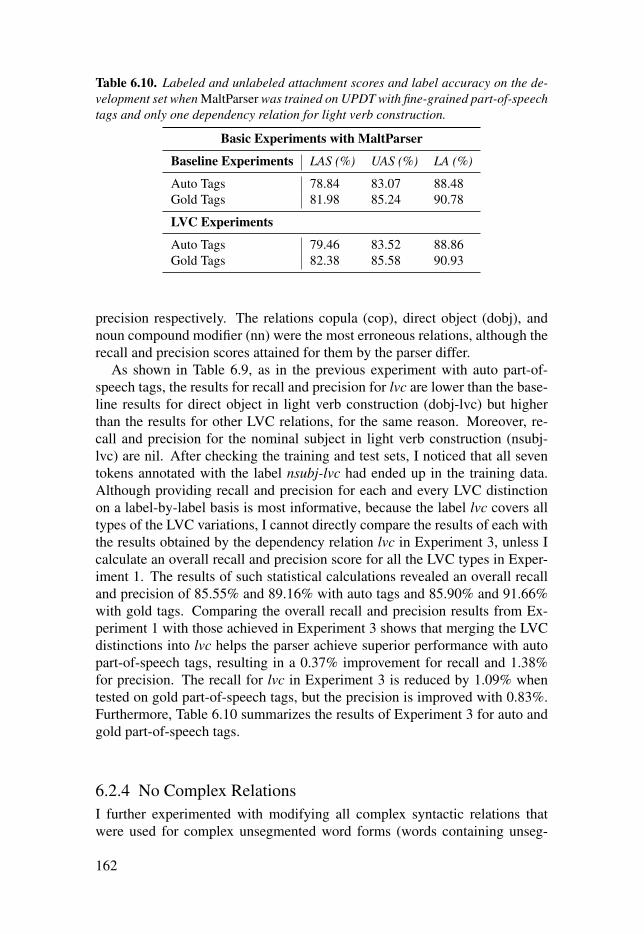
Table 6.10. Labeled and unlabeled attachment scores and label accuracy on the de-velopment set when MaltParser was trained on UPDT with fine-grained part-of-speechtags and only one dependency relation for light verb construction.
Basic Experiments with MaltParser
Baseline Experiments LAS (%) UAS (%) LA (%)
Auto Tags 78.84 83.07 88.48Gold Tags 81.98 85.24 90.78
LVC Experiments
Auto Tags 79.46 83.52 88.86Gold Tags 82.38 85.58 90.93
precision respectively. The relations copula (cop), direct object (dobj), andnoun compound modifier (nn) were the most erroneous relations, although therecall and precision scores attained for them by the parser differ.
As shown in Table 6.9, as in the previous experiment with auto part-of-speech tags, the results for recall and precision for lvc are lower than the base-line results for direct object in light verb construction (dobj-lvc) but higherthan the results for other LVC relations, for the same reason. Moreover, re-call and precision for the nominal subject in light verb construction (nsubj-lvc) are nil. After checking the training and test sets, I noticed that all seventokens annotated with the label nsubj-lvc had ended up in the training data.Although providing recall and precision for each and every LVC distinctionon a label-by-label basis is most informative, because the label lvc covers alltypes of the LVC variations, I cannot directly compare the results of each withthe results obtained by the dependency relation lvc in Experiment 3, unless Icalculate an overall recall and precision score for all the LVC types in Exper-iment 1. The results of such statistical calculations revealed an overall recalland precision of 85.55% and 89.16% with auto tags and 85.90% and 91.66%with gold tags. Comparing the overall recall and precision results from Ex-periment 1 with those achieved in Experiment 3 shows that merging the LVCdistinctions into lvc helps the parser achieve superior performance with autopart-of-speech tags, resulting in a 0.37% improvement for recall and 1.38%for precision. The recall for lvc in Experiment 3 is reduced by 1.09% whentested on gold part-of-speech tags, but the precision is improved with 0.83%.Furthermore, Table 6.10 summarizes the results of Experiment 3 for auto andgold part-of-speech tags.
6.2.4 No Complex RelationsI further experimented with modifying all complex syntactic relations thatwere used for complex unsegmented word forms (words containing unseg-
162
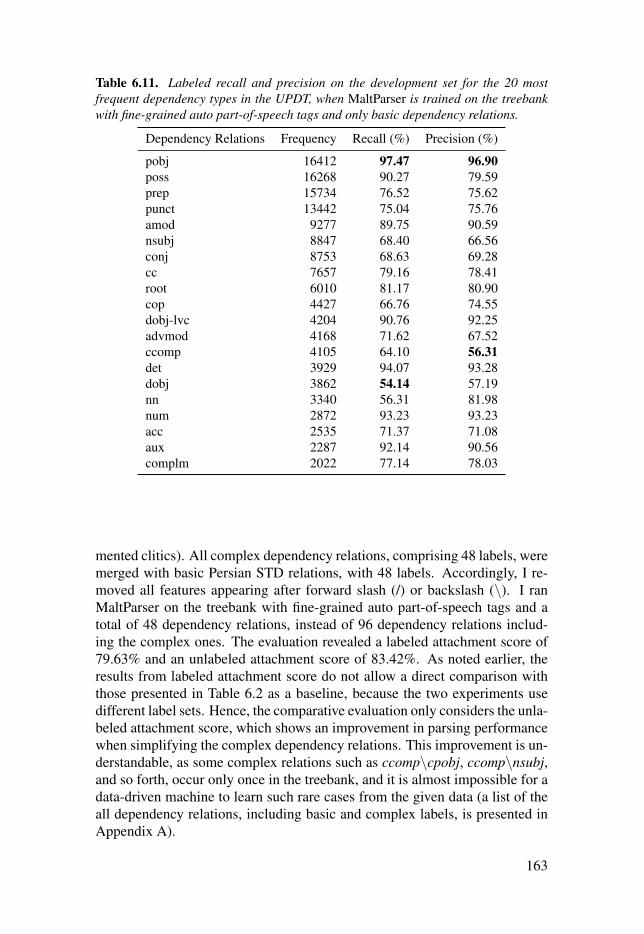
Table 6.11. Labeled recall and precision on the development set for the 20 mostfrequent dependency types in the UPDT, when MaltParser is trained on the treebankwith fine-grained auto part-of-speech tags and only basic dependency relations.
Dependency Relations Frequency Recall (%) Precision (%)
pobj 16412 97.47 96.90poss 16268 90.27 79.59prep 15734 76.52 75.62punct 13442 75.04 75.76amod 9277 89.75 90.59nsubj 8847 68.40 66.56conj 8753 68.63 69.28cc 7657 79.16 78.41root 6010 81.17 80.90cop 4427 66.76 74.55dobj-lvc 4204 90.76 92.25advmod 4168 71.62 67.52ccomp 4105 64.10 56.31det 3929 94.07 93.28dobj 3862 54.14 57.19nn 3340 56.31 81.98num 2872 93.23 93.23acc 2535 71.37 71.08aux 2287 92.14 90.56complm 2022 77.14 78.03
mented clitics). All complex dependency relations, comprising 48 labels, weremerged with basic Persian STD relations, with 48 labels. Accordingly, I re-moved all features appearing after forward slash (/) or backslash (\). I ranMaltParser on the treebank with fine-grained auto part-of-speech tags and atotal of 48 dependency relations, instead of 96 dependency relations includ-ing the complex ones. The evaluation revealed a labeled attachment score of79.63% and an unlabeled attachment score of 83.42%. As noted earlier, theresults from labeled attachment score do not allow a direct comparison withthose presented in Table 6.2 as a baseline, because the two experiments usedifferent label sets. Hence, the comparative evaluation only considers the unla-beled attachment score, which shows an improvement in parsing performancewhen simplifying the complex dependency relations. This improvement is un-derstandable, as some complex relations such as ccomp\cpobj, ccomp\nsubj,and so forth, occur only once in the treebank, and it is almost impossible for adata-driven machine to learn such rare cases from the given data (a list of theall dependency relations, including basic and complex labels, is presented inAppendix A).
163
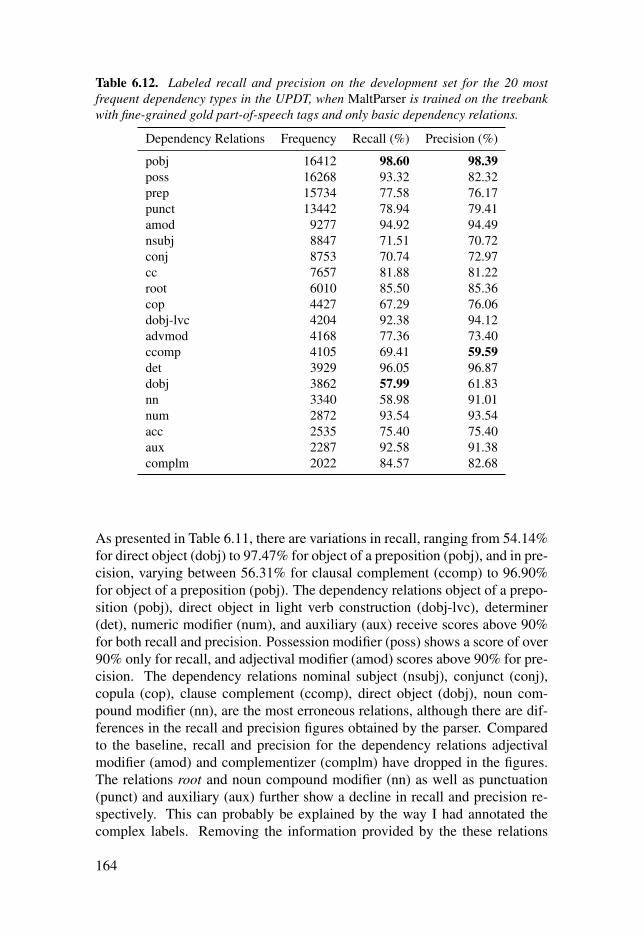
Table 6.12. Labeled recall and precision on the development set for the 20 mostfrequent dependency types in the UPDT, when MaltParser is trained on the treebankwith fine-grained gold part-of-speech tags and only basic dependency relations.
Dependency Relations Frequency Recall (%) Precision (%)
pobj 16412 98.60 98.39poss 16268 93.32 82.32prep 15734 77.58 76.17punct 13442 78.94 79.41amod 9277 94.92 94.49nsubj 8847 71.51 70.72conj 8753 70.74 72.97cc 7657 81.88 81.22root 6010 85.50 85.36cop 4427 67.29 76.06dobj-lvc 4204 92.38 94.12advmod 4168 77.36 73.40ccomp 4105 69.41 59.59det 3929 96.05 96.87dobj 3862 57.99 61.83nn 3340 58.98 91.01num 2872 93.54 93.54acc 2535 75.40 75.40aux 2287 92.58 91.38complm 2022 84.57 82.68
As presented in Table 6.11, there are variations in recall, ranging from 54.14%for direct object (dobj) to 97.47% for object of a preposition (pobj), and in pre-cision, varying between 56.31% for clausal complement (ccomp) to 96.90%for object of a preposition (pobj). The dependency relations object of a prepo-sition (pobj), direct object in light verb construction (dobj-lvc), determiner(det), numeric modifier (num), and auxiliary (aux) receive scores above 90%for both recall and precision. Possession modifier (poss) shows a score of over90% only for recall, and adjectival modifier (amod) scores above 90% for pre-cision. The dependency relations nominal subject (nsubj), conjunct (conj),copula (cop), clause complement (ccomp), direct object (dobj), noun com-pound modifier (nn), are the most erroneous relations, although there are dif-ferences in the recall and precision figures obtained by the parser. Comparedto the baseline, recall and precision for the dependency relations adjectivalmodifier (amod) and complementizer (complm) have dropped in the figures.The relations root and noun compound modifier (nn) as well as punctuation(punct) and auxiliary (aux) further show a decline in recall and precision re-spectively. This can probably be explained by the way I had annotated thecomplex labels. Removing the information provided by the these relations
164
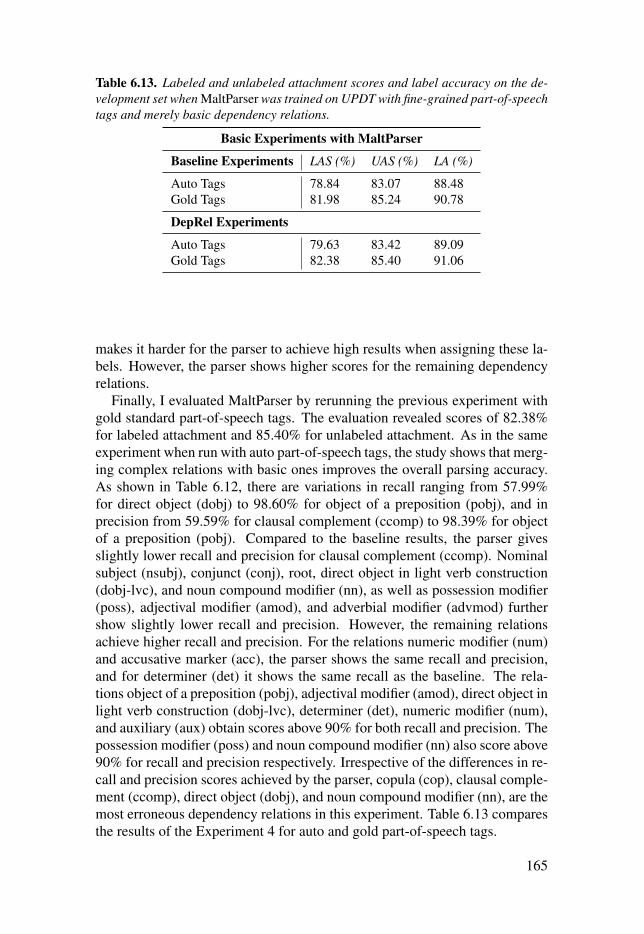
Table 6.13. Labeled and unlabeled attachment scores and label accuracy on the de-velopment set when MaltParser was trained on UPDT with fine-grained part-of-speechtags and merely basic dependency relations.
Basic Experiments with MaltParser
Baseline Experiments LAS (%) UAS (%) LA (%)
Auto Tags 78.84 83.07 88.48Gold Tags 81.98 85.24 90.78
DepRel Experiments
Auto Tags 79.63 83.42 89.09Gold Tags 82.38 85.40 91.06
makes it harder for the parser to achieve high results when assigning these la-bels. However, the parser shows higher scores for the remaining dependencyrelations.
Finally, I evaluated MaltParser by rerunning the previous experiment withgold standard part-of-speech tags. The evaluation revealed scores of 82.38%for labeled attachment and 85.40% for unlabeled attachment. As in the sameexperiment when run with auto part-of-speech tags, the study shows that merg-ing complex relations with basic ones improves the overall parsing accuracy.As shown in Table 6.12, there are variations in recall ranging from 57.99%for direct object (dobj) to 98.60% for object of a preposition (pobj), and inprecision from 59.59% for clausal complement (ccomp) to 98.39% for objectof a preposition (pobj). Compared to the baseline results, the parser givesslightly lower recall and precision for clausal complement (ccomp). Nominalsubject (nsubj), conjunct (conj), root, direct object in light verb construction(dobj-lvc), and noun compound modifier (nn), as well as possession modifier(poss), adjectival modifier (amod), and adverbial modifier (advmod) furthershow slightly lower recall and precision. However, the remaining relationsachieve higher recall and precision. For the relations numeric modifier (num)and accusative marker (acc), the parser shows the same recall and precision,and for determiner (det) it shows the same recall as the baseline. The rela-tions object of a preposition (pobj), adjectival modifier (amod), direct object inlight verb construction (dobj-lvc), determiner (det), numeric modifier (num),and auxiliary (aux) obtain scores above 90% for both recall and precision. Thepossession modifier (poss) and noun compound modifier (nn) also score above90% for recall and precision respectively. Irrespective of the differences in re-call and precision scores achieved by the parser, copula (cop), clausal comple-ment (ccomp), direct object (dobj), and noun compound modifier (nn), are themost erroneous dependency relations in this experiment. Table 6.13 comparesthe results of the Experiment 4 for auto and gold part-of-speech tags.
165
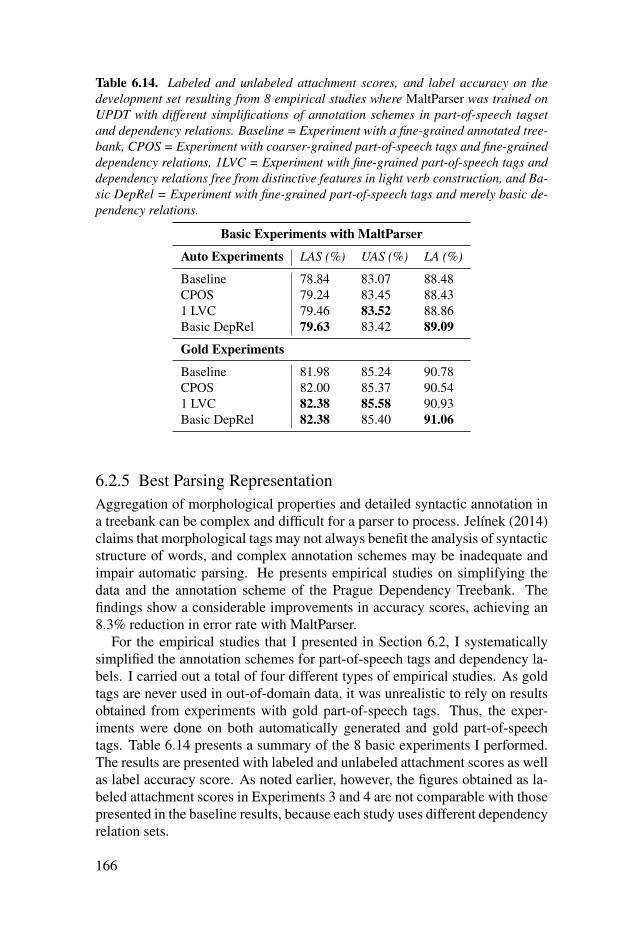
Table 6.14. Labeled and unlabeled attachment scores, and label accuracy on thedevelopment set resulting from 8 empirical studies where MaltParser was trained onUPDT with different simplifications of annotation schemes in part-of-speech tagsetand dependency relations. Baseline = Experiment with a fine-grained annotated tree-bank, CPOS = Experiment with coarser-grained part-of-speech tags and fine-graineddependency relations, 1LVC = Experiment with fine-grained part-of-speech tags anddependency relations free from distinctive features in light verb construction, and Ba-sic DepRel = Experiment with fine-grained part-of-speech tags and merely basic de-pendency relations.
Basic Experiments with MaltParser
Auto Experiments LAS (%) UAS (%) LA (%)
Baseline 78.84 83.07 88.48CPOS 79.24 83.45 88.431 LVC 79.46 83.52 88.86Basic DepRel 79.63 83.42 89.09
Gold Experiments
Baseline 81.98 85.24 90.78CPOS 82.00 85.37 90.541 LVC 82.38 85.58 90.93Basic DepRel 82.38 85.40 91.06
6.2.5 Best Parsing RepresentationAggregation of morphological properties and detailed syntactic annotation ina treebank can be complex and difficult for a parser to process. Jelínek (2014)claims that morphological tags may not always benefit the analysis of syntacticstructure of words, and complex annotation schemes may be inadequate andimpair automatic parsing. He presents empirical studies on simplifying thedata and the annotation scheme of the Prague Dependency Treebank. Thefindings show a considerable improvements in accuracy scores, achieving an8.3% reduction in error rate with MaltParser.
For the empirical studies that I presented in Section 6.2, I systematicallysimplified the annotation schemes for part-of-speech tags and dependency la-bels. I carried out a total of four different types of empirical studies. As goldtags are never used in out-of-domain data, it was unrealistic to rely on resultsobtained from experiments with gold part-of-speech tags. Thus, the exper-iments were done on both automatically generated and gold part-of-speechtags. Table 6.14 presents a summary of the 8 basic experiments I performed.The results are presented with labeled and unlabeled attachment scores as wellas label accuracy score. As noted earlier, however, the figures obtained as la-beled attachment scores in Experiments 3 and 4 are not comparable with thosepresented in the baseline results, because each study uses different dependencyrelation sets.
166

To sum up the four experiments I can conclude that:
1. Using coarse-grained part-of-speech tags in the dependency representationimproves parsing performance without losing any information. By usingthe part-of-speech tagger TagPer I can recreate and restore this informationat the end once the parsing is done. Thus, fined-grained part-of-speechtags can still be in the output. Considering the part-of-speech tags in theUPC, it is worth noting that I had already simplified these properties tosome extent, as described in Section 3.2.3, when improving the tagsetof the Bijankhan Corpus. Although I have not done any parsing studyusing the entire original Bijankhan tagset and with detailed morphologicalinformation, I believe that tags with complex morphological information interms of number and specification impact parsing accuracy negatively, andthe above experiments can support this idea, because further simplificationswere beneficial for automatic parsing.
2. The studies further show that simplifying the representation of light verbconstructions helps the parser to perform better without loss of importantinformation. In other words, by using coarse LVC, the results become lessspecific and less informative only with respect to the LVC construction, andyield better parsing performance overall. Furthermore, the lvc specificationat the end can mostly be recovered from the part-of-speech tags in theoutput.
3. Using only basic relations might provide a marginal improvement, but thisis not a sufficient justification to remove them, because by eliminating thecomplex labels I lose essential information that cannot be recovered by thetagger, which affects the quality of parsing analysis. Using the treebankwith complex relations provides a richer grammatical analysis that booststhe quality of parsing results.
These results provided us with a valuable insight about how different mor-phosyntactic parameters in data influence the parsing analysis. The studiesalso have brought us to the point where I shall select the best configurationfor further experiments. Specifically, I will use a representation with coarse-grained part-of-speech tags, single LVC representation, and fine-grained de-pendency relations containing both basic and complex labels (96 labels).
6.3 Experiments with Different ParsersThe experiments described in this section are designed to estimate the per-formance of different parsers on the best performing data representations se-lected by MaltParser in the baseline experiments. Hence, I set up the data with
167

the best achieved parameters, which use the automatically generated coarse-grained part-of-speech tags with a single LVC label and the fine-grained de-pendency relations consisting of 96 basic and complex labels. The treebank isfurther organized with a different split than in the basic experiments. In otherwords, I train the parser on the joint training and development sets (90%)and test on the test set (10%). I will experiment with MaltParser (Nivre etal., 2006), MSTParser (McDonald et al., 2005b), MateParsers (Bohnet, 2010;Bohnet and Nivre, 2012), and TurboParser (Martins et al., 2010).
For evaluating MaltParser, I used Nivre’s algorithms, as these were foundto be the best parsing algorithms by MaltOptimizer during my previous exper-iments. The parser resulted in scores of 79.40% and 83.47% for labeled andunlabeled attachment, respectively.
In evaluating MSTParser, I used the second-order model with projectiveparsing, as this setting had yielded the highest results in my earlier parametertuning experiments. The parser achieved results of 77.79% for labeled and83.45% for unlabeled attachment scores.
For experimenting with MateParsers, I trained the graph-based andtransition-based parsers on the UPDT with the best parameters selected. Theresults of Mate experiments showed that the graph-based parser outperformedthe transition-based parser, resulting in 82.58% for labeled and 86.69% forunlabeled attachment scores.
For experimenting with TurboParser, I trained the second-order non-projective parser with features for arcs, consecutive siblings and grandparents,using the AD3 algorithm as a decoder. I adopted the full setting, as it hadperformed best with my earlier parameter-tuning experiments. The full settingenables arc-factored, consecutive sibling, grandparent, arbitrary sibling, headbigram, grand-sibling (third-order), and tri-sibling (third-order) parts. Theparser achieved results of 80.57% for labeled and 85.32% for unlabeled at-tachment scores.
As shown in Table 6.15 the graph-based parser in the Mate Tools achievesthe highest results for Persian. The parser thus developed will be treated as thestate-of-the-art parser for the language and will be called ParsPer. The parserwill undergo further evaluation which will be presented more in detail in thenext section.
6.4 Dependency Parser for Persian: ParsPerThe goal of developing a state-of-the-art syntactic parser for Persian is to ap-ply the parser to new text that has already been automatically segmented andtagged by my tools in the pipeline, namely, SetPer and TagPer (see Chapter 4).
As the results of the previous experiments showed, the graph-basedMateParser outperformed MaltParser, MSTParser, and TurboParser, obtain-ing scores of 82.58% and 86.69% for labeled and unlabeled attachment. This
168

Table 6.15. Best results given by different parsers when trained on UPDT with autopart-of-speech tags, 1LVC, CompRel in the model assessment.
Final Results
Evaluations LAS (%) UAS (%) LA (%)
MaltParser 79.40 83.47 88.72MSTParser 77.79 83.45 87.11Mate graph-based 82.58 86.69 90.55Mate transition-based 81.72 85.94 89.87TurboParser 80.57 85.32 88.93
means that this time, I need to train the graph-based MateParser on the entireUPDT with the selected configuration. The parser developed will be includedin the pipeline of tools for automatic processing and analysis of Persian, andwill be called ParsPer.3 ParsPer has been released as a freely available tool forparsing of Persian and is open source under a GNU General Public License.The parser will be further evaluated in the next subsection.
6.4.1 The Evaluation of ParsPerIn order to assess the performance of ParsPer I conducted an independent pars-ing evaluation as I had done for my earlier tools. I applied ParsPer to the 100randomly selected sentences with an average sentence length of 28 tokens usedin the evaluation of tools previously introduced in the pipeline (PrePer, SeT-Per, and TagPer). For this task I performed three different parsing evaluations.First I ran the parser on the automatically normalized, tokenized and taggedtext. In other words, I parsed the text (containing 100 randomly selected sen-tences) that had already passed through the pipeline and been processed by allthe developed tools. This is the main experiment in the ParsPer evaluation,and also indicates the performance of other tools in the pipeline and how eachprocess is affected by previous processes, when the output of one tool is theinput of the next tool. Next, I performed two more experiments with the 100randomly selected sentences in order to analyze the results in a more nuancedway, by experimenting on the sentences when they are manually normalizedand tokenized but automatically tagged and then, when they are manually nor-malized, tokenized, and tagged.
In the automatically tokenized and tagged text experiment, I manually an-notated the manually normalized, tokenized, and tagged gold file that was usedin the evaluation of TagPer (see Section 4.1.3) with dependency informationusing the same dependency scheme on which ParsPer was built, to served as agold standard. I then parsed the automatically tokenized and tagged text with
3http://stp.lingfil.uu.se/∼mojgan/parsper-mate.html
169

ParsPer. As the automatically tokenized text contained 10 fewer4 tokens thanthe gold file (the number of tokens in the gold file was 2788 and in the automat-ically processed file was 2778) I cannot directly present labeled and unlabeledattachment scores. Instead, however, I present scores for labeled recall andprecision, as well as unlabeled recall and precision. The parsing evaluationrevealed labeled recall and precision scores of 73.52% and 73.79%, and un-labeled recall and precision scores of 81.99% and 82.28%, respectively. Ascould be expected, the results for labeled recall and precision are low. This isdue to the fact that in addition to there being incorrect tokens in the automat-ically tokenized file, incorrect part-of-speech tags have had a negative impacton the results.
I then automatically parsed the manually normalized, tokenized, but au-tomatically tagged text and compared the parsing results with the manuallyparsed gold text. By this experiment, I wanted to isolate the impact of taggingerrors. The evaluation resulted in labeled and unlabeled attachment scores of78.50% and 86.27% on the test set with 100 sentences and 2788 tokens. Asthe results indicate, the unlabeled attachment score is close to the unlabeledattachment score obtained by the parser when evaluated on in-domain text.Furthermore, the unlabeled attachment score is 7.77% higher than the labeledattachment score. This may partly be due to fact that the structural variationfor the head nodes is lower than the variation for labels. Moreover, I have afirm structure for the head nodes in the syntactic annotation when invariablychoosing content words as head position. The solidity of this structure in turnmakes it easier for the parser to learn the structure after repeatedly seeing it.Hence, the parser assigns the head nodes more accurately than the combina-tions of head and label. This does not mean that I do not follow a consistentstructure for the dependency relations. What I mean is that the number of oc-currences of certain cases for dependency relations may not be the same asthe number of repeated cases for head structures. This might be perceived asa sparseness on the part of the parser, which can directly affect the labeled at-tachment score. Moreover, the syntactic (non)complexity of the data can havea direct impact on parser performance.
Finally, I automatically parsed the manually normalized, tokenized, andtagged text (the gold file in the tagging evaluation) and compared the parsingwith the manually parsed gold file. The evaluation resulted in straightforwardlabeled and unlabeled attachment scores of 78.76% and 86.12% for the testset with 100 sentences and 2788 tokens. The same kind of pattern as in theprevious experiment was also found here. In other words, we see a nearlyidentical gap of 7.36% between the labeled and unlabeled attachment scores.Table 6.16 shows results from different evaluations of the ParsPer.
4In addition to the 10 fewer tokens, two more tokens had not been successfully normalized byPrePer in the normalization process and looked different (see Section 4.1.3). Hence, differencein number was 12.
170
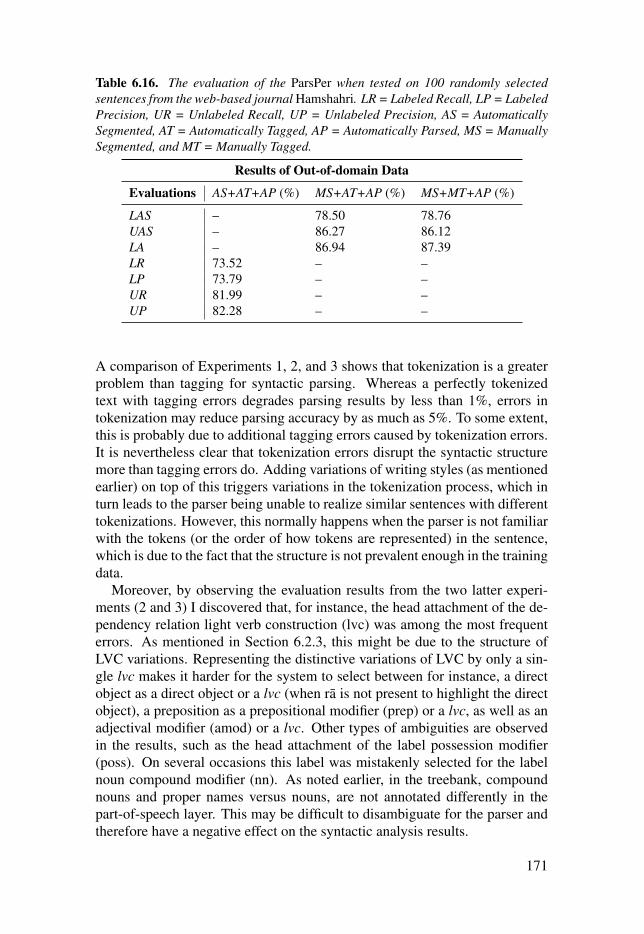
Table 6.16. The evaluation of the ParsPer when tested on 100 randomly selectedsentences from the web-based journal Hamshahri. LR = Labeled Recall, LP = LabeledPrecision, UR = Unlabeled Recall, UP = Unlabeled Precision, AS = AutomaticallySegmented, AT = Automatically Tagged, AP = Automatically Parsed, MS = ManuallySegmented, and MT = Manually Tagged.
Results of Out-of-domain Data
Evaluations AS+AT+AP (%) MS+AT+AP (%) MS+MT+AP (%)
LAS – 78.50 78.76UAS – 86.27 86.12LA – 86.94 87.39LR 73.52 – –LP 73.79 – –UR 81.99 – –UP 82.28 – –
A comparison of Experiments 1, 2, and 3 shows that tokenization is a greaterproblem than tagging for syntactic parsing. Whereas a perfectly tokenizedtext with tagging errors degrades parsing results by less than 1%, errors intokenization may reduce parsing accuracy by as much as 5%. To some extent,this is probably due to additional tagging errors caused by tokenization errors.It is nevertheless clear that tokenization errors disrupt the syntactic structuremore than tagging errors do. Adding variations of writing styles (as mentionedearlier) on top of this triggers variations in the tokenization process, which inturn leads to the parser being unable to realize similar sentences with differenttokenizations. However, this normally happens when the parser is not familiarwith the tokens (or the order of how tokens are represented) in the sentence,which is due to the fact that the structure is not prevalent enough in the trainingdata.
Moreover, by observing the evaluation results from the two latter experi-ments (2 and 3) I discovered that, for instance, the head attachment of the de-pendency relation light verb construction (lvc) was among the most frequenterrors. As mentioned in Section 6.2.3, this might be due to the structure ofLVC variations. Representing the distinctive variations of LVC by only a sin-gle lvc makes it harder for the system to select between for instance, a directobject as a direct object or a lvc (when ra is not present to highlight the directobject), a preposition as a prepositional modifier (prep) or a lvc, as well as anadjectival modifier (amod) or a lvc. Other types of ambiguities are observedin the results, such as the head attachment of the label possession modifier(poss). On several occasions this label was mistakenly selected for the labelnoun compound modifier (nn). As noted earlier, in the treebank, compoundnouns and proper names versus nouns, are not annotated differently in thepart-of-speech layer. This may be difficult to disambiguate for the parser andtherefore have a negative effect on the syntactic analysis results.
171
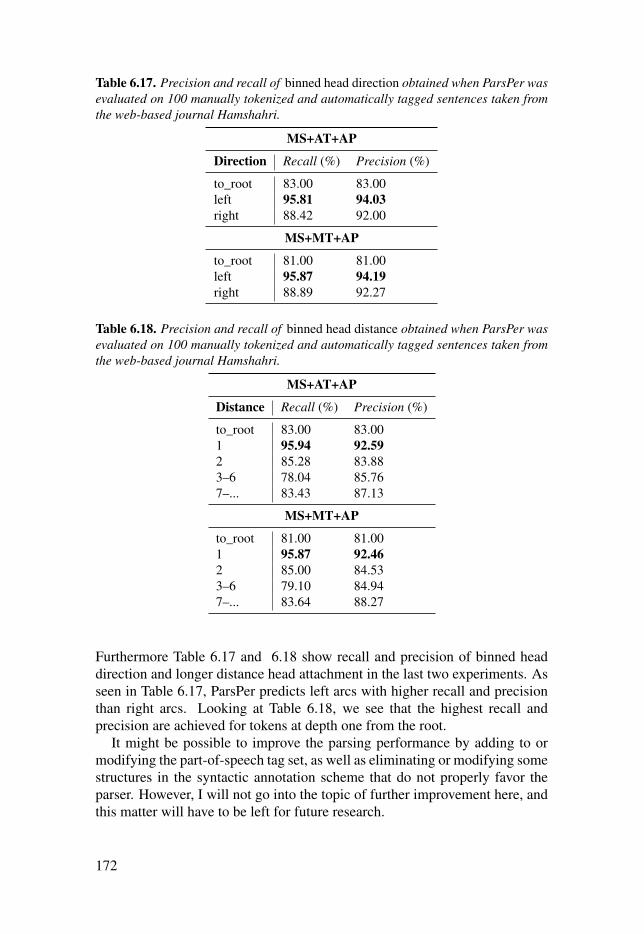
Table 6.17. Precision and recall of binned head direction obtained when ParsPer wasevaluated on 100 manually tokenized and automatically tagged sentences taken fromthe web-based journal Hamshahri.
MS+AT+AP
Direction Recall (%) Precision (%)
to_root 83.00 83.00left 95.81 94.03right 88.42 92.00
MS+MT+AP
to_root 81.00 81.00left 95.87 94.19right 88.89 92.27
Table 6.18. Precision and recall of binned head distance obtained when ParsPer wasevaluated on 100 manually tokenized and automatically tagged sentences taken fromthe web-based journal Hamshahri.
MS+AT+AP
Distance Recall (%) Precision (%)
to_root 83.00 83.001 95.94 92.592 85.28 83.883–6 78.04 85.767–... 83.43 87.13
MS+MT+AP
to_root 81.00 81.001 95.87 92.462 85.00 84.533–6 79.10 84.947–... 83.64 88.27
Furthermore Table 6.17 and 6.18 show recall and precision of binned headdirection and longer distance head attachment in the last two experiments. Asseen in Table 6.17, ParsPer predicts left arcs with higher recall and precisionthan right arcs. Looking at Table 6.18, we see that the highest recall andprecision are achieved for tokens at depth one from the root.
It might be possible to improve the parsing performance by adding to ormodifying the part-of-speech tag set, as well as eliminating or modifying somestructures in the syntactic annotation scheme that do not properly favor theparser. However, I will not go into the topic of further improvement here, andthis matter will have to be left for future research.
172

7. Conclusion
The goal of this thesis project was to develop open source morphosyntacticcorpora and tools for natural language processing of Persian. To achieve mygoal, I adopted two key requirements: compatibility and reuse. The compat-ibility requirement stipulates that (1) the tools should be run in a pipelinewhere the output of one tool is compatible with the input requirements ofthe next and (2) the tools have to deliver the same analysis as is found in theannotated corpora. The reuse requirement was primarily chosen as a practicalnecessity. Two research questions were formulated and have been discussedthroughout this thesis. In this chapter they will be revisited and brieflydiscussed to highlight the contributions made by this work. The questionswere:
Q-1 How can we develop morphologically and syntactically annotatedcorpora and tools while satisfying the requirements of compatibility andreuse?
Q-2 How accurately can we perform morphological and syntactic analysis forPersian by adapting and applying existing tools to the annotated corpora?
In response to question Q-1, Chapter 3 provides a detailed description of howI have handled challenges related to tokenization with respect to the lack ofstandardization in Persian orthography. Modifying the Bijankhan Corpus forhigher linguistic analysis was the basic procedure of my thesis, as a subset ofthe corpus was employed in developing a dependency treebank for Persian.With respect to the interaction between different linguistic levels, which in-troduces challenges for segmentation and annotation, I had to make decisionsconcerning issues ranging from tokenizing to syntactic analysis. The mostchallenging cases concerned the handling of fixed expressions and differenttypes of clitics such as pronominal and copula clitics, as they are normallywritten in various forms in Persian texts. They are sometimes segmented andsometimes unsegmented from the head words. Manually merging (or sepa-rating the attached form of) fixed expressions and separating clitics from thehead words in a consistent way in such a large corpus as the Bijankhan Cor-pus was impossible, with respect to the time available. On the other hand,automatically handling such cases was also impossible, because this couldresult in many incorrect conversions by impacting orthographically similarwords/endings with different part-of-speech categories. Moreover, automatic
173

conversion could impact words that are not exactly homographs but share thesame endings. Therefore, to avoid introducing such errors into the corpus I de-cided to handle fixed expressions as distinct tokens and not to separate cliticsfrom the head words, but rather to analyze them with special labels at the syn-tactic level instead. In other words, as described in Chapter 5, in the syntacticannotation, I analyzed fixed expressions as multi-word expressions and treatedclitics as complex unsegmented word forms by annotating them with complexdependency labels. Hence, in the treebank, apart from 48 dependency labelsfor basic relations, I have 48 complex dependency labels to cover the syntacticrelations for words containing unsegmented clitics. The complex labels areindicated by two or more labels separated by either a backslash or a forwardslash, depending on the function of the clitics (see Section 5.5). Thus, by im-proving the segmentation and annotation of the Bijankhan Corpus, and addinga syntactic annotation layer, I made sure that I best satisfied my requirementsof compatibility and reuse without resegmenting and reannotating the entirecorpus from scratch. The approach used was to accept the tokenization (ororthographic) variations in the input data in order to achieve robustness. Manyevaluations to date have been done on cleaned-up data, hiding tokenizationvariations from the system, which gives unrealistic performance estimates.Typical variations that normally exist in out-of-domain data, in particular theorthographic variations in Persian texts, can directly impact tokenization andrequire different adjustments for morphosyntactic analysis.
Question Q-2 is addressed thoroughly in Chapters 4 and 6 where I presenta pipeline containing tools for morphosyntactic processing and analysis ofPersian. In these chapters I describe how various standard tools are developedon resources presented in Chapters 3 and Chapter 5. In other words, for alltools developed in the pipeline I have made use of standard methods and state-of-the-art tools, in particular, the sentence segmentation and tokenization toolsin Uplug (Tiedemann, 2003), the part-of-speech tagger HunPoS (Halácsyet al., 2007), and the graph-based parser in Mate Tools (Bohnet, 2010). Inaddition, MaltParser was also used as the main tool for bootstrapping thecorpus data during the treebank development. In reusing existing tools, whichwas a practical necessity for my project, I also made sure that the developmentsatisfied my requirement of compatibility. To achieve this, all tools developedare compatible and run in a pipeline where the output of one tool matchesthe input requirements of the next. Furthermore, since there is a directconnection between tools and annotation, the annotated data that are used fortraining and evaluation are also compatible with the tools. More precisely,the tools render the same analysis that is found in the annotated corpora.Therefore, having domain variations in the annotated corpora, in terms ofdifferent genres and tokenization variations related to orthographic variations,was one of my highest priorities to achieve efficiency and robustness whenapplying the tools to out-of-domain texts. For each and every process, fromnormalization to syntactic parsing, I have developed a tool that is compatible
174

with my annotated corpora. In my pipeline of tools for automatic processingand analysis of Persian, I introduced the tools PrePer for normalization,SeTPer for sentence segmentation and tokenization, TagPer for part-of-speechtagging, and ParsPer for syntactic parsing. Detailed descriptions of PrePer,SeTPer, and TagPer are given in Chapter 4 and the creation of ParsPer ispresented in Chapter 6. Each tool developed for the pipeline was evaluatedon out-of-domain context containing 100 randomly selected sentences takenfrom the web-based journal Hamshahri, in addition to evaluations I madeon in-domain text. In this chapter I only report the results achieved by thetools when tested on the out-of-domain text. The evaluation of the SeTPershowed an accuracy of 100% for the sentence segmenter as well as 99.25%and 99.59% recall and precision for the tokenization tool when tested on atext already normalized by PrePer. For tagging evaluation, TagPer resultedin an F-score of 98.09%. Finally, parsing performance evaluation revealed alabeled recall and precision of 73.52% and 73.79%, and an unlabeled recalland precision of 81.99% and 82.28%, respectively. The resources and toolsdeveloped in this project are open source and freely available (see descriptionsin the relevant chapter). To sum up, the main contributions of this thesis interms of resources and tools are:
1. Resources:1. The Uppsala Persian Corpus (UPC)2. The Uppsala Persian Dependency Treebank (UPDT)
2. Tools:1. Preprocessor for Persian (PrePer)2. Sentence Segmenter and Tokenizer for Persian (SeTPer)3. Part-of-Speech Tagger for Persian (TagPer)4. Dependency Parser for Persian (ParsPer)
My research attempts to contribute to the field of natural language process-ing by discussing various important issues and challenges in the automaticmorphosyntactic processing and analysis of Persian. I further explore differ-ent methods for handling noisy data to address challenges relating to Persianorthography, morphology, and syntax. The methodologies described in thisthesis, from decisions about handling tokenization issues to the innovativeanalysis used in developing the Persian dependency treebank, which are allempirically evaluated, bring new insights and ideas to the field. These meth-ods, with their emphasis on handling variations in tokenization, may deviatefrom the abstract linguistic conventions used in the literature, but are able tocope with common difficulties in user-generated texts due to the lack of acommon standard for Persian orthography. Based on these ideas, I developeda pipeline of resources and tools for Persian that can easily be employed onout-of-domain texts.
175

In my future work, I intend to bring the Uppsala Persian Corpus and the Up-psala Persian Dependency Treebank to a higher level by converting them intothe framework of the Universal Dependencies. Given that Persian is a pro-drop language with a large number of dropped/null subjects and objects, verbendings are of great importance in carrying information about subjects as wellas objects. Therefore, in future annotation schemes I plan to handle verb end-ings differently than in the current schemes in the UPC and UPDT. Since theencoding labels in the corpora will be changed, the results of the data-driventools will accordingly be changed and hopefully improved. This means thata new tagger and parser will be developed for Persian, and I hope that withthe new TagPer and ParsPer I will be able to cover a wider set of structuralvariations for the head and dependency labels in out-of-domain data. Further-more, I hope that the new ParsPer, in particular, will more easily distinguishthe sentence subjects from objects.
It is important to continuously improve the resources and tools that havebeen created. This is an advantage of the reusability and compatibility require-ments that I imposed on the tools in my pipeline. Easily being able to reuseand modify data is a crucial feature for achieving high quality tools based onthese resources. It further facilitates adaptation for different needs. Hopefully,the approaches I chose and the different solutions I found for Persian in thisthesis can benefit the work with other languages with similar linguistic andorthographic characteristics.
176

References
Adesam, Yvonne (2012). “The Multilingual Forest, Investigating High–quality Paral-lel Corpus Development”. PhD thesis. Stockholm University.
Aduriz, I., M. J. Aranzabe, J. M. Arriola, A. Atutxa, A. Díaz de Ilarraza, A. Garmen-dia, and M. Oronoz (2003). “Construction of a Basque Dependency Treebank”.In: Proceedings of the 2nd Workshop on Treebanks and Linguistic Theories (TLT),pp. 201–204.
Afonso, Susana, Eckhard Bick, Renato Haber, and Diana Santos (2002). “FlorestaSintáctica: A Treebank for Portuguese”. In: Proceedings of the Third InternationalConference on Language Resources and Evaluation, pp. 1698–1703.
AleAhmad, Abolfazl, Hadi Amiri, Ehsan Darrudi, Masoud Rahgozar, and FarhadOroumchian (2009). “Hamshahri: A Standard Persian Text Collection”. Journalof Knowledge-Based Systems 22.5, pp. 382–387.
Aranzabe, María Jesús, Arantza Díaz de Ilarraza, Nerea Ezeiza, Kepa Bengoetxea,Iakes Goenaga, and Koldo Gojenola (2012). “Combining Rule-Based and Statis-tical Syntactic Analyzers”. In: Proceedings of the ACL 2012 Joint Workshop onStatistical Parsing and Semantic Processing of Morphologically Rich Languages,pp. 48–54.
Aroonmanakun, Wirote (2007). “Thoughts on Word and Sentence Segmentation inThai”. In: Proceedings of the SNLP2007–Symposium on Natural Language Pro-cessing, pp. 85–90.
Assi, Mostafa S. (2005). PLDB Persian Linguistics Database Pažuhešgaran (Re-searchers). Technical Report. Institute for Humanities and Cultural Studies.
Astiri, Ahmad, Mohsen Kahani, and Hadi Qaemi (2013). Furqan Quran Corpus.Technical Report. Web Technology Laboratory, University of Mashhad.
Aston, Guy and Lou Burnard (1998). Exploring the British National Corpus withSARA. Cambridge University Press.
Ballesteros, Miguel and Joakim Nivre (2012). “MaltOptimizer: A System for Malt-Parser Optimization”. In: Proceedings of the 8th International Conference on Lan-guage Resources and Evaluation (LREC), pp. 833–841.
Baluch, Bahman (1992). “Reading with and without Vowels: What Are the Psycho-logical Consequences?” Journal of Social and Evolutionary Systems 15, pp. 95–104.
Bargi, Alan Aziz (2011). Virastar. URL: https://github.com/aziz/virastar.Bick, Eckhard (2003). “Arboretum, a Hybrid Treebank for Danish”. In: Proceedings
of the Second Workshop on Treebanks and Linguistic Theories, pp. 9–20.Bijankhan, Mahmood (2004). “The Role of the Corpus in Writing a Grammar: An
Introduction to a Software”. Iranian Journal of Linguistics 19, pp. 38–67.Bijankhan, Mahmood, Javad Sheykhzadegan, Mohammad Bahrani, and Masood
Ghayoomi (2011). “Lessons from building a Persian written corpus: Peykare”. Lan-guage Resources and Evaluation 45.2, pp. 143–164.
177

Björkelund, Anders, Bernd Bohnet, Hafdell Love, and Nugues Pierre (2010). “AHigh-Performance Syntactic and Semantic Dependency Parser”. In: Proceedingsof the 23rd International Conference on Computational Linguistics: Demonstra-tions (COLING ’10), pp. 33–36.
Bögel, Tina, Miriam Butt, and Sebastian Sulger (2008). “Urdu Exafe and theMorphology-Syntax Interface”. In: Proceedings of the LFG08 Conference, MiriamButt and Tracy Holloway King (Editors), pp. 129–149.
Boguslavsky, Igor, Svetlana Grigorieva, Nikolai Grigoriev, Leonid Kreidlin, andNadezhda Frid (2000). “Dependency Treebank for Russian: Concept, Tools, Typesof Information”. In: Proceedings of the 18th International Conference on Compu-tational Linguistics (COLING), pp. 987–991.
Bohnet, Bernd (2010). “Top Accuracy and Fast Dependency Parsing is not a Contra-diction”. In: Proceedings of the 23rd International Conference on ComputationalLinguistics (Coling 2010), pp. 89–97.
Bohnet, Bernd and Jonas Kuhn (2012). “The Best of Both Worlds: A Graph-basedCompletion Model for Transition-based Parsers”. In: Proceedings of the 13th Con-ference of the European Chapter of the Association for Computational Linguistics(EACL ’12), pp. 77–87.
Bohnet, Bernd and Joakim Nivre (2012). “A Transition-Based System for Joint Part-of-Speech Tagging and Labeled Non-Projective Dependency Parsing”. In: Pro-ceedings of the 2012 Joint Conference on Empirical Methods in Natural LanguageProcessing and Computational Natural Language Learning (EMNLP-CoNLL ’12),pp. 1455–1465.
Bosco, Cristina and Vincenzo Lombardo (2004). “Dependency and Relational Struc-ture in Treebank Annotation”. In: Proceedings of the Workshop Recent Advancesin Dependency Grammar, pp. 9–16.
Bosco, Cristina, Simonetta Montemagni, and Maria Simi (2013). “Converting ItalianTreebanks: Towards an Italian Stanford Dependency Treebank”. In: Proceedingsof the 7th Linguistic Annotation Workshop and Interoperability with Discourse,pp. 61–69.
Brants, Sabine, Stefanie Dipper, Silvia Hansen, Wolfgang Lezius, and George Smith(2002). “The TIGER Treebank”. In: Proceedings of the First Workshop on Tree-banks and Linguistic Theories (TLT), pp. 24–42.
Brants, Thorsten (2000). “TnT a Statistical Part-of-Speech Tagger”. In: Proceedingsof the 6th Applied Natural Language Processing Conference (ANLP), pp. 224–231.
Brill, Eric (1995). “Transformation-Based Error-Driven Learning and Natural Lan-guage Processing: A Case Study in Part-of-Speech Tagging”. Journal of Computa-tional Linguistics 21.4, pp. 543–565.
Buchholz, Sabine and Erwin Marsi (2006). “CoNLL-X Shared Task on MultilingualDependency Parsing”. In: Proceedings of the Tenth Conference on ComputationalNatural Language Learning (CoNLL), pp. 149–164.
Capková, Sofia Gustafson and Britt Hartmann (2006). Manual of the Stockholm UmeåCorpus Version 2.0. URL: http : / / spraakbanken . gu . se / parole / Docs / SUC2 . 0 -manual.pdf.
Carreras, Xavier (2007). “Experiments with a higher-order projective dependencyparser”. In: Proceedings of the Joint Conference on Empirical Methods in Natural
178

Language Processing and Computational Natural Language Learning, pp. 957–961.
Chang, Pi-Chuan, Huihsin Tseng, Dan Jurafsky, and Christopher D. Manning (2009).“Discriminative reordering with Chinese grammatical relations features”. In: Pro-ceedings of the Third Workshop on Syntax and Structure in Statistical Translation(SSST-3) at NAACL HLT 2009, pp. 51–59.
Cmejrek, Martin, Jan Curin, Jiri Havelka, Jan Hajic, and Vladislav Kubon (2004).“Prague Czech-English Dependency Treebank: Syntactically Annotated Resourcesfor MachineTranslation”. In: Proceedings of the IV International Conference onLanguage Resources and Evaluation, pp. 1597–1600.
Covington, Michael A. (2001). “A Fundamental Algorithm for Dependency Parsing”.In: Proceedings of the 39th Annual ACM Southeast Conference, pp. 95–102.
Crammer, Koby, Ofer Dekel, Joseph Keshet, Shai Shalev-Shwartz, and Yoram Singer(2006). “Online Passive-Aggressive Algorithms”. Journal of Machine LearningResearch 7, pp. 551–585.
Daelemans, Walter, Jakob Zavrel, Peter Berck, and Steven Gillis (1997). “A Memory-Based Part-of-Speech Tagger Generator”. In: Proceedings of the Fourth Workshopon Very Large Corpora, pp. 14–27.
Davies, Mark (2010). “The Corpus of Contemporary American English as the first reli-able monitor corpus of English”. Literary and Linguistic Computing 25.4, pp. 447–464.
de Marneffe, Marie-Catherine, Timothy Dozat, Natalia Silveira, Katri Haverinen, FilipGinter, Joakim Nivre, and Christopher D. Manning (2014). “Universal StanfordDependencies: A cross-linguistic typology”. In: Proceedings of the 9th Interna-tional Conference on Language Resources and Evaluation (LREC 2014), pp. 4585–4592.
de Marneffe, Marie-Catherine, Bill MacCartney, and Christopher D. Manning (2006).“Generating Typed Dependency Parses from Phrase Structure Parses”. In: Proceed-ings of the 5th International Conference on Language Resources and Evaluation(LREC), pp. 449–454.
de Marneffe, Marie-Catherine and Christopher D. Manning (2008). “The StanfordTyped Dependencies Representation”. In: Proceedings of the COLING’08 Work-shop on Cross-Framework and Cross-Domain Parser Evaluation, pp. 1–8.
Dehdari, Jon and Deryle Lonsdale (2008). “A Link Grammar Parser for Persian”. In:Aspects of Iranian Linguistics. Cambridge Scholars Press, pp. 19–34.
Džeroski, Sašo, Tomaž Erjavec, Nina Ledinek, Petr Pajas, Zdenek Žabokrtsky, andAndreja Žele (2006). “Towards a Slovene Dependency Treebank”. In: Proceed-ings of the Fifth International Conference on Language Resources and Evaluation(LREC), pp. 1388–1391.
Earley, Jay (1970). “An Efficient Context-Free Parsing Algorithm”. Journal of Com-munications of the ACM 13.2, pp. 94–102.
Eisner, Jason (1996). “Three New Probabilistic Models for Dependency Parsing: AnExploration”. In: Proceedings of the 16th International Conference on Computa-tional Linguistics (COLING), pp. 340–345.
Erjavec, Tomaž and Nancy Ide (1998). “The MULTEXT-East Corpus”. In: Proceed-ings of The First International Conference on Language Resources and Evaluation(LREC), pp. 971–974.
179

Erjavec, Tomaž, Cvetana Krstev, Vladimír Petkevic, Kiril Simov, Marko Tadic, andDuško Vitas (2003). “The MULTEXT-East Morphosyntactic Specifications ForSlavic Languages”. In: Proceedings of The EACL 2003 Workshop on the Morpho-logical Processing of Slavic Languages, pp. 25–32.
Esfahbod, Behdad (2004). Persian Computing with Unicode. URL: http : / / www .farsiweb.info.
Fung, James G, Dilek Hakkani-Tür, Mathew Magimai Doss, Liz Shriberg, SebastienCuendet, and Nikki Mirghafori (2007). “Cross-Linguistic Analysis of ProsodicFeatures for Sentence Segmentation”. INTERSPEECH 2007, 8th Annual Confer-ence of the International Speech Communication Association, Antwerp, Belgium(ISCA), pp. 2585–2588.
Garside, Roger, Geoffrey Leech, and Tamás Váradi (1992). The Lancaster ParsedCorpus. A machine-readable Syntactically Analyzed Corpus of 144,000 Words.Available for Distribution Through ICAME. Technical Report. Bergen: The Nor-wegian Computing Centre for the Humanities.
Ghayoomi, Masood (2012). “Bootstrapping the Development of an HPSG-based Tree-bank for Persian”. Journal of Linguistic Issues in Language Technology 7, pp. 105–114.
Ghayoomi, Masood and Jonas Kuhn (2014). “Converting an HPSG Treebank into itsParallel Dependency Treebank”. In: Proceedings of the 9th International Confer-ence on Language Resources and Evaluation (LREC), pp. 2245–2252.
Giesbrecht, Eugenie and Stefan Evert (2009). “Is Part-of-Speech Tagging a SolvedTask? An Evaluation of POS Taggers for the German Web as Corpus”. In: Pro-ceedings of the 5th Web as Corpus Workshop WAC5, pp. 27–35.
Giménez, Jesus and Lluís Màrquez (2004). “SVMTool: A general POS tagger gener-ator based on Support Vector Machines”. In: Proceedings of the 4th InternationalConference on Language Resources and Evaluation (LREC), pp. 43–46.
Hajic, Jan, Barbora Vidová Hladká, and Petr Pajas (2001). “Prague Dependency Tree-bank: Annotation Structure and Support”. In: Proceeding of the IRCS Workshop onLinguistic Databases, Philadelphia, pp. 105–114.
Hajic, Jan, Otakar Smrž, Petr Zemánek, Petr Pajas, Jan Šnaidauf, Emanuel Beška,Jakub Krácmar, and Kamila Hassanová (2004). “Prague Arabic Dependency Tree-bank: Development in data and tools”. In: Proceedings of the NEMLAR Interna-tional Conference on Arabic Language Resources and Tools, pp. 110–117.
Halácsy, Péter, András Kornai, and Csaba Oravecz (2007). “HunPos: an Open SourceTrigram Tagger”. In: Proceedings of the 45th Annual Meeting of the Association forComputational Linguistics Interactive Poster and Demonstration Sessions (ACL),pp. 209–212.
Hashabeiky, Forogh (2005). “Persian Orthography, Modification or Changeover(1850–2000)”. PhD Thesis. Studia Iranica Upsaliensia 7.
Hashabeiky, Forogh (2007). “The Usage of Singular Verbs for Inanimate Plural Sub-jects in Persian”. Orientalia Suecana, Journal of Indological, Iranian, Semitic andTurkic Studies LVI, pp. 77–101.
Hashemi, Homa B., Azadeh Shakery, and Heshaam Faili (2010). “Creating a Persian-English Comparable Corpus”. In: Proceedings of the International Conference onMultilingual and Multimodal Information Access Evaluation (CLEF), pp. 27–39.
180

Haverinen, Katri, Jenna Nyblom, Timo Viljanen, Veronika Laippala, Samuel Koho-nen, Anna Missilä, Stina Ojala, Tapio Salakoski, and Filip Ginter (2013). “Buildingthe Essential Resources for Finnish: The Turku Dependency Treebank”. Journal ofLanguage Resources and Evaluation, pp. 493–531.
Haverinen, Katri, Timo Viljanen, Veronika Laippala, Samuel Kohonen, Filip Ginter,and Tapio Salakoski (2010). “Treebanking Finnish”. In: Proceedings of the NinthInternational Workshop on Treebanks and Linguistic Theories (TLT), pp. 79–90.
Hladká, Barbora and Kiril Ribarov (1998). “Part of Speech Tags for Automatic Tag-ging and Syntactic Structures”. Issues of Valency and Meaning - Studies in honourof Jarmila Panevova, pp. 226–237.
Hogan, Deirdre, Jennifer Foster, Joachim Wagner, and Josef Van Genabith (2008).“Parser-Based Retraining for Domain Adaptation of Probabilistic Generators”. In:Proceedings of the Fifth International Natural Language Generation Conference,pp. 165–168.
Huang, Chu-Ren, Feng-Yi Chen, Keh-Jiann Chen, Zhao-ming Gao, and Kuang-YuChen (2000). “Sinica Treebank: design criteria, annotation guidelines, and on-lineinterface”. In: Proceedings of the second workshop on Chinese language process-ing: held in conjunction with the 38th Annual Meeting of the Association for Com-putational Linguistics, pp. 29–37.
Hwa, Rebecca (2004). “Sample Selection for Statistical Parsing”. Computational Lin-guistics 30, pp. 253–276.
Ide, Nancy, Patrice Bonhomme, and Laurent Romary (2000). “XCES: An XML-basedEncoding Standard for Linguistic Corpora”. In: Proceedings of the Second Inter-national Language Resources and Evaluation Conference, pp. 825–30.
Ide, Nancy, Greg Priest-Dorman, and Jean Véronis (1996). Corpus Encoding Stan-dard (CES). Technical Report. Department of Computer Science, Vassar College,Poughkeepsie, New York.
Jahani, Carina, Behrooz Barjasteh Delforooz, and Maryam Nourzaei (2012). “Non-canonical Subjects in Balochi”. In: Iranian Languages and Culture. Mazda Pub-lishers, pp. 196–218.
James, Gregory, Robert Davison, Amos C. Heung-yeung, and Scott Deerwester(1994). English in Computer Science: A corpus-based lexical analysis. The HongKong University of Science and Technology.
Jelínek, Tomáš (2014). “Improvements to Dependency Parsing Using Automatic Sim-plification of Data”. In: Proceedings of the Ninth International Conference on Lan-guage Resources and Evaluation (LREC’14), pp. 73–77.
Jeremiás, Éva M. (2003). “New Persian”. In: The Encyclopaedia of Islam. Ed. bySupplement. Brill Publishers, pp. 426–448.
Jurafsky, Daniel and James H. Martin (2008). Speech and Language Processing:An Introduction to Natural Language Processing, Computational Linguistics, andSpeech Recognition, 2nd Edition. Prentice Hall.
Kaplan, Ronald M. (1973). “A General Syntactic Processor”. In: Rustin R. (Ed.), Nat-ural Language Processing, pp. 193–241.
Karimi, Simin (1989). “Aspects of Persian Syntax, Specificity and the Theory ofGrammar”. PhD Thesis. University of Washington.
Karimi, Simin (2003). Word Order and Scrambling. Wiley-Blackwell.
181

Karlsson, Fred, Atro Voutilainen, Juha Heikkilä, and Arto Anttila (1995). ConstraintGrammar: A Language-Independent System for Parsing Unrestricted Text. Walterde Gruyter.
Kasami, Tadao (1965). An Efficient Recognition and Syntax-Analysis Algorithm forContext-Free Languages. Technical Report. University of Illinois Coordinated Sci-ence Lab., Amsterdam.
Kay, Martin (1982). “Algorithm Schemata and Data Structures in Syntactic Process-ing”. In: Readings in Natural Language Processing. Ed. by Barbara J. Grosz, KarenSparck Jones, and Bonnie Lynn Webber. Morgan Kaufmann, pp. 35–70.
Keh-Jiann, Chen, Chu-Ren Huang, Feng-Yi Chen, Chi-Ching Luo, Ming-ChungChang, Chao-Jan Chen, and Zhao-Ming Gao (2003). “Sinica Treebank: DesignCriteria, Representational Issues and Implementation”. In: Treebanks: Building andUsing Parsed Corpus. Ed. by Anne Abeillé. KLUWER, Dordrecht, pp. 231–248.
Koehn, Philipp (2002). Europarl: A Multilingual Corpus for Evaluation of MachineTranslation. Technical Report. Information Sciences Institute.
Koo, Terry and Michael Collins (2010). “Efficient Third-order Dependency Parsers”.In: Proceedings of 48th Meeting of the Association for Computional Linguistics(ACL’10), pp. 1–11.
Koskenniemi, Kimmo (1983). “Two-Level Model for Morphological Analysis”. In:Proceedings of the 8th International Joint Conference on Artificial Intelligence,pp. 683–685.
Kroch, Anthony and Ann Taylor (2000). The Penn-Helsinki Parsed Corpus of MiddleEnglish (PPCME2). URL: http://www.ling.upenn.edu/hist-corpora.
Kromann, Matthias T. (2003). “The Danish Dependency Treebank and the DTAGTreebank Tool”. In: Proceedings of the Second Workshop on Treebanks and Lin-guistic Theories (TLT 2003), pp. 217–220.
Kübler, Sandra, Ryan McDonald, and Joakim Nivre (2009). Dependency Parsing.Morgan and Claypool.
Kucera, Henry and Francis W. Nelson (1967). Computational Analysis of Present-dayAmerican English. Brown University Press, 1st Edition.
Kumar, Dinesh and Josan Gurpreet Singh (2010). “Part of Speech Tagger for Morpho-logically Rich Indian Languages: A Survey”. International Journal of ComputerApplications (IJCA) 6.5, pp. 1–9.
Lazard, Gilbert (1992). A Grammar of Contemporary Persian. Tanslated into Englishby Shirley A. Lyon. Mazda Publishers.
Leech, Geoffrey and Andrew Wilson (1994). EAGLES Morphosyntactic Annotation.Technical Report. Pisa: Istituto di Linguistica Computazionale.
Maamouri, Mohamed, Ann Bies, Tim Buckwalter, and Wigdan Mekki (2004). “ThePenn Arabic Treebank: Building a Large-Scale Annotated Arabic Corpus”. In:NEMLAR, International Conference on Arabic Language Resources and Tools,pp. 102–109.
Manning, Christopher D. and Hinrich Schütze (1999). Foundations of Statistical Nat-ural Language Processing. The MIT Press.
Marcus, Mitchell P., Beatrice Santorini, and Mary Ann Marcinkiewicz (1993). “Build-ing a Large Annotated Corpus of English: The Penn Treebank”. ComputationalLinguistics 19, pp. 313–330.
182

Martins, André F. T., Miguel B. Almeida, and Noah A. Smith (2013). “Turning onthe Turbo: Fast Third-Order Non-Projective Turbo Parsers”. In: Proceedings of the51st Annual Meeting of the Association for Computational Linguistics: Volume 2,pp. 617–622.
Martins, André F. T., Dipanjan Das, Noah A. Smith, and Eric P. Xing (2008). “Stack-ing Dependency Parsing”. In: Proceedings of the Conference on Empirical Methodsin Natural Language Processing, EMNLP ’08, pp. 157–166.
Martins, André F. T., Noah A. Smith, Pedro M. Q. Aguiar, and Mário A. T. Figueiredo(2011). “Dual Decomposition with Many Overlapping Components”. In: Proceed-ings of the Conference on Empirical Methods for Natural Language Processing(EMNLP ’11), pp. 238–249.
Martins, André F. T., Noah A. Smith, Eric P. Xing, Pedro M. Q. Aguiar, and MárioA. T. Figueiredo (2010). “Turbo Parsers: Dependency Parsing by ApproximateVariational Inference”. In: Proceedings of the 2010 Conference on Empirical Meth-ods in Natural Language Processing (EMNLP ’10), pp. 34–44.
McDonald, Ryan, Koby Crammaer, and Fernando Pereira (2005a). “Online Large-Margin Training of Dependency Parsers”. In: Proceedings of the 43rd AnnualMeeting of the Association for Computational Linguistics (ACL), pp. 91–98.
McDonald, Ryan and Joakim Nivre (2011). “Analyzing and Integrating DependencyParsers”. Computational Linguistics 37.1, pp. 197–230.
McDonald, Ryan and Fernando Pereira (2006). “Online Learning of ApproximateDependency Parsing Algorithms”. In: Proceedings of the Eleventh Conference ofthe European Chapter of the Association for Computational Linguistics (EACL),pp. 81–88.
McDonald, Ryan, Fernando Pereira, Kiril Ribarov, and Jan Hajic (2005b). “Non-Projective Dependency Parsing Using Spanning Tree Algorithms”. In: Proceed-ings of the Conference on Human Language Technology and Empirical Methods inNatural Language Processing (HLT/EMNLP), pp. 523–530.
Mcdonald, Ryan et al. (2013). “Universal Dependency Annotation for MultilingualParsing”. In: Proceeding of the 51st Annual Meeting of the Association for Com-putational Linguistics (Volume 2: Short Papers, pp. 92–97.
Mizan, Corpus (2013). Mizan English-Persian Parallel Corpus. Technical Report.Supreme Council of Information and Communication Technology, (http://dadegan.ir/catalog/mizan).
Nivre, Joakim (2003). “An Efficient Algorithm for Projective Dependency Pars-ing”. In: Proceedings of the 8th International Workshop on Parsing Technologies(IWPT), pp. 149–160.
Nivre, Joakim (2004). “Incrementality in Deterministic Dependency Parsing”. In: Pro-ceedings of the Workshop on Incremental Parsing: Bringing Engineering and Cog-nition Together (ACL), pp. 50–57.
Nivre, Joakim (2008a). “Algorithms for Deterministic Incremental Dependency Pars-ing”. Journal of Computational Linguistics 34.4, pp. 513–553.
Nivre, Joakim (2008b). “Treebanks”. In: Corpus Linguistics: An International Hand-book. Vol. 1. Walter de Gruyter, pp. 225–241.
Nivre, Joakim (2009). “Non-Projective Dependency Parsing in Expected LinearTime”. In: Proceedings of the Joint Conference of the 47th Annual Meeting of ACL
183

and the 4th International Joint Conference on Natural Language Processing of theAFNLP (ACL-IJCNLP), pp. 351–359.
Nivre, Joakim, Johan Hall, Sandra Kübler, Ryan McDonald, Jens Nilsson, SebastianRiedel, and Deniz Yuret (2007). “The CoNLL 2007 Shared Task on DependencyParsing”. In: Proceedings of the CoNLL Shared Task Session of EMNLP-CoNLL,pp. 915–932.
Nivre, Joakim, Johan Hall, and Jens Nilsson (2006). “MaltParser: A Data-DrivenParser-Generator for Dependency Parsing”. In: Proceedings of the 5th Interna-tional Conference on Language Resources and Evaluation (LREC), pp. 2216–2219.
Nivre, Joakim, Marco Kuhlmann, and Johan Hall (2009). “An Improved Oracle forDependency Parsing with Online Reordering”. In: Proceedings of the 11th Inter-national Conference on Parsing Technologies (IWPT’09), pp. 73–76.
Oflazer, Kemal, Bilge Say, Dilek Zeynep Hakkani-Tür, and Gökhan Tür (2003).“Building A Turkish Treebank”. In: Treebanks: Building and Using Parsed Cor-pus. Ed. by Anne Abeillé. KLUWER, Dordrecht, pp. 261–277.
Oroumchian, Farhad, Samira Tasharofi, Hadi Amiri, Hossein Hojjat, and FahimehRaja (2006). Creating a Feasible Corpus for Persian POS Tagging. Technical Re-port. UAE Institution.
Palmer, David D. (2000). “Tokenization and Sentence Segmentation, Handbook ofNatural Language Processing”. In: Handbook of Natural Language Processing.Marcel Dekker, pp. 11–35.
Parker, Robert, David Graff, Junbo Kong, Ke Chen, and Kazuaki Maeda (2011). En-glish Gigaword Fifth Edition, Linguistic Data Consortium. Technical Report. Lin-guistic Data Consortium, Philadelphia.
Petrov, Slav, Dipanjan Das, and Ryan McDonald (2012). “A Universal Part-of-SpeechTagset”. In: Proceedings of the Eight International Conference on Language Re-sources and Evaluation (LREC ’12), pp. 2089–2096.
Petrov, Slav and Dan Klein (2008). “Parsing German with Latent Variable Grammars”.In: Proceedings of the ACL–08: HLT Workshop on Parsing German (PaGe-08),pp. 33–39.
Prokopidis, Prokopis, Elina Desipri, Maria Koutsombogera, Harris Papageorgiou, andStelios Piperidis (2005). “Theoretical and Practical Issues in the Construction of aGreek Dependency Treebank”. In: Proceedings of the Fourth Workshop on Tree-banks and Linguistic Theories (TLT), pp. 149–160.
QasemiZadeh, Behrang and Saeed Rahimi (2006). “Persian in MULTEXT-EastFramework”. In: Proceedings of the Advances in Natural Language Processing,5th International Conference on NLP, FinTAL, pp. 541–551.
Raja, Fahimeh, Hadi Amiri, Samira Tasharofi, Hossein Hojjat, and Farhad Oroum-chian (2007). “Evaluation of Part-of-Speech Tagging on Persian Text”. In:2nd Workshop on Computational Approaches to Arabic Script-based Languages(CAASL2), pp. 120–127.
Rasooli, Mohammad Sadegh, Manouchehr Kouhestani, and Amirsaeid Moloodi(2013). “Development of a Persian Syntactic Dependency Treebank”. In: Proceed-ings of North American Chapter of the Association for Computational Linguistics:Human Language Technologies (NAACL-HLT), pp. 306–314.
184

Ratnaparkhi, Adwait (1996). “A Maximum Entropy Model for Part-of-Speech Tag-ging”. In: Proceedings of the Conference on Empirical Methods in Natural Lan-guage Processing (EMNLP), pp. 133–142.
Roukos, Salim, David Graff, and Dan Melamed (1995). Hansard French/English Cor-pus. Technical Report. Linguistic Data Consortium, Philadelphia.
Sagae, Kenji and Alon Lavie (2006). “Parser Combination by Reparsing”. In: Pro-ceedings of the Human Language Technology Conference of the North American,pp. 129–132.
Sampson, Geoffrey (1995). English for the Computer. The SUSANNE Corpus andAnalytic Scheme. Oxford University Press.
Sarkar, Anoop (2011). “Syntax and Parsing”. In: Multilingual Natural Language Pro-cessing Applications: From Theory to Practice. Ed. by Daniel M. Bikel and ImedZitouni. Prentice Hall, pp. 1–51.
Sassano, Manabu and Sadao Kurohashi (2010). “Using Smaller Constituents RatherThan Sentences in Active Learning for Japanese Dependency Parsing”. In: Pro-ceedings of the 48th Annual Meeting of the Association for Computational Lin-guistics, pp. 356–365.
Seraji, Mojgan, Carina Jahani, Beáta Megyesi, and Joakim Nivre (2013). The UppsalaPersian Dependency Treebank Annotation Guidelines. Technical Report. Depart-ment of Linguistics and Philology, Uppsala University.
Seraji, Mojgan, Carina Jahani, Beáta Megyesi, and Joakim Nivre (2014). “A PersianTreebank with Stanford Typed Dependencies”. In: Proceedings of the 9th Inter-national Conference on Language Resources and Evaluation (LREC), pp. 2245–2252.
Seraji, Mojgan, Beáta Megyesi, and Joakim Nivre (2012a). “A Basic Language Re-source Kit for Persian”. In: Proceedings of the 8th International Conference onLanguage Resources and Evaluation (LREC), pp. 2245–2252.
Seraji, Mojgan, Beáta Megyesi, and Joakim Nivre (2012b). “Bootstrapping a PersianDependency Treebank”. Linguistic Issues in Language Technology 7.18, pp. 1–10.
Seraji, Mojgan, Beáta Megyesi, and Joakim Nivre (2012c). “Dependency Parsers forPersian”. In: Proceedings of 10th Workshop on Asian Language Resources, COL-ING 2012, 24th International Conference on Computational Linguistics, pp. 35–44.
Shamsfard, Mehrnoush, Hoda Sadat Jafari, and Mahdi Ilbeygi (2010). “STeP-1: ASet of Fundamental Tools for Persian Text Processing”. In: Proceedings of the Sev-enth Conference on International Language Resources and Evaluation (LREC’10),pp. 859–865.
Shen, Libin, Giorgio Satta, and Aravind Joshi (2007). “Guided Learning for Bidirec-tional Sequence Classification”. In: Proceedings of the 45th Annual Meeting of theAssociation of Computational Linguistics, pp. 760–767.
Sleator, Daniel and Davy Temperley (1993). “Parsing English with a Link Gram-mar”. In: Proceedings of the Third International Workshop on Parsing Technolo-gies, pp. 277–292.
Stilo, Donald (2004). “Iranian as Buffer Zone Between the Universal Typologies ofTurkic and Semitic”. In: Linguistic Convergence and Areal Diffusion: Case StudiesFrom Iranian, Semitic, and Turkic. Routledge, pp. 35–63.
185

Taulé, Mariona, Maria Antònia Martí, and Marta Recasens (2008). “AnCora: Multi-level Annotated Corpora for Catalan and Spanish”. In: Proceedings of the Interna-tional Conference on Language Resources and Evaluation (LREC), pp. 96–101.
Tiedemann, Jörg (2003). “Recycling Translation - Extraction of Lexical Data fromParallel Corpora and their Application in Natural Language Processing”. PhD The-sis. Studia Linguistica Upsaliensia 1.
Toutanova, Kristina, Dan Klein, Christopher D. Manning, and Yoram Singer (2003).“Feature-rich Part-of-Speech Tagging with a Cyclic Dependency Network”. In:Proceedings of the 2003 Conference of the North American Chapter of the Asso-ciation for Computational Linguistics on Human Language Technology, pp. 173–180.
Tsarfaty, Reut (2013). “A Unified Morpho-Syntactic Scheme of Stanford Dependen-cies”. In: Proceedings of the 51st Annual Meeting of the Association for Computa-tional Linguistics (ACL), pp. 578–584.
Tufis, Dan, Nancy Ide, Tomaž Erjavec, and Romanian Academy (1998). “StandardizedSpecifications, Development and Assessment of Large Morpho-Lexical Resourcesfor Six Central and Eastern European Languages”. In: Proceedings of The First In-ternational Conference on Language Resources and Evaluation (LREC), pp. 233–240.
van Halteren, Hans (1999). Syntactic Word Class Tagging. Kluwer Academic Publish-ers.
Windfuhr, Gernot L. (2009). “Persian”. In: The World’s Major Languages. Routledge,pp. 532–546.
Xue, Nianwen, Fei Xia, Fu-Dong Chiou, and Martha Palmer (2005). “The Penn Chi-nese TreeBank: Phrase Structure Annotation of a Large Corpus”. Natural Lan-guage Engineering, 11.2, pp. 207–238.
Yamada, Hiroyasu and Yuji Matsumoto (2003). “Statistical Dependency Analysis withSupport Vector Machines”. In: Proceedings of the Eighth International Workshopon Parsing Technologies (IWPT), pp. 195–206.
Younger, Daniel H. (1967). “Recognition and Parsing of Context-Free Languages inTime n3”. Journal of Information and Control 10, pp. 189–208.
ZarrabiZadeh, Hamid (2007). Tanzil Project. URL: http : / / tanzil . net / wiki / Tanzil _Project.
Zeman, Daniel (2008). “Reusable Tagset Conversion Using Tagset Drivers”. In: Pro-ceedings of the Sixth International Conference on Language Resources and Evalu-ation (LREC’08), pp. 213–218.
Zhang, Yi and Rui Wang (2009). “Cross-Domain Dependency Parsing Using a DeepLinguistic Grammar”. In: Proceedings of the 47th Annual Meeting of the ACL andthe 4th IJCNLP of the AFNLP, pp. 378–386.
Zhang, Yue and Stephen Clark (2008). “A Tale of Two Parsers: investigating and com-bining graph-based and transition-based dependency parsing using beam-search”.In: Proceedings of the Conference on Empirical Methods in Natural Language Pro-cessing, pp. 562–571.
Zhu, Qi-bo (1989). “A Quantitative Look at the Guangzhou Petroleum English Cor-pus”. International Computer Archive of Modern English (ICAME Journal) 13,pp. 28–38.
186

Zhu, Conghui, Jie Tang, Hang Li, Hwee Tou Ng, and Tiejun Zhao (2007). “A Uni-fied Tagging Approach to Text Normalization”. In: Proceedings of the 45th AnnualMeeting of the Association of Computational Linguistics (ACL), pp. 688–695.
187


Appendix A.UPDT Dependency Labels
60002535 acc360 acomp681 acomp-lvc
3 acomp-lvc/pc2 acomp/pc
655 advcl8 advcl/cop2 advcl/pc
4157 advmod11 advmod/pc
9211 amod4 amod/cop
62 amod/pc583 appos
3 appos/pc2287 aux217 auxpass
7657 cc4021 ccomp
55 ccomp/cop1 ccomp\cpobj1 ccomp\nsubj
12 ccomp/pc1 ccomp/pc/cop6 ccomp\pobj8 ccomp\poss
2022 complm8629 conj
34 conj/cop85 conj/pc2 conj\pobj3 conj\poss
4427 cop185 cpobj
189

2 cpobj/pc187 cprep376 dep
3 dep/pc68 dep-top63 dep-voc
3929 det3723 dobj
16 dobj/acc4185 dobj-lvc
19 dobj-lvc/pc123 dobj/pc168 fw733 mark
1773 mwe1 mwe/pc
105 neg3339 nn
1 nn/cop490 npadvmod
8653 nsubj7 nsubj-lvc
146 nsubjpass1 nsubjpass/pc
194 nsubj/pc2872 num313 number194 parataxis
6 parataxis/cop4 parataxis/pc
16237 pobj13 pobj/cop
162 pobj/pc16067 poss
6 poss/acc44 poss/cop
151 poss/pc49 preconj51 predet
15643 prep41 prep/det
554 prep-lvc49 prep/pc1 prep/pobj
190

102 prt13442 punct
75 quantmod1408 rcmod
2 rcmod\amod9 rcmod/cop2 rcmod/pc2 rcmod\pobj2 rcmod\poss
1410 rel5918 root
1 root\conj65 root/cop6 root/pc
13 root\pobj7 root\poss
382 tmod133 xcomp
191


ACTA UNIVERSITATIS UPSALIENSIS Studia Linguistica Upsaliensia
Editors: Joakim Nivre and Åke Viberg 1. Jörg Tiedemann, Recycling translations. Extraction of lexical data from parallel
corpora and their application in natural language processing. 2003. 2. Agnes Edling, Abstraction and authority in textbooks. The textual paths towards
specialized language. 2006. 3. Åsa af Geijerstam, Att skriva i naturorienterande ämnen i skolan. 2006. 4. Gustav Öquist, Evaluating Readability on Mobile Devices. 2006. 5. Jenny Wiksten Folkeryd, Writing with an Attitude. Appraisal and student texts
in the school subject of Swedish. 2006. 6. Ingrid Björk, Relativizing linguistic relativity. Investigating underlying assump-
tions about language in the neo-Whorfian literature. 2008. 7. Joakim Nivre, Mats Dahllöf and Beáta Megyesi, Resourceful Language Tech-
nology. Festschrift in Honor of Anna Sågvall Hein. 2008. 8. Anju Saxena & Åke Viberg, Multilingualism. Proceedings of the 23rd Scandinavi-
an Conference of Linguistics. 2009. 9. Markus Saers, Translation as Linear Transduction. Models and Algorithms for
Efficient Learning in Statistical Machine Translation. 2011. 10. Ulrika Serrander, Bilingual lexical processing in single word production. Swedish
learners of Spanish and the effects of L2 immersion. 2011. 11. Mattias Nilsson, Computational Models of Eye Movements in Reading : A Data-
Driven Approach to the Eye-Mind Link. 2012. 12. Luying Wang, Second Language Acquisition of Mandarin Aspect Markers by
Native Swedish Adults. 2012. 13. Farideh Okati, The Vowel Systems of Five Iranian Balochi Dialects. 2012. 14. Oscar Täckström, Predicting Linguistic Structure with Incomplete and Cross-
Lingual Supervision. 2013. 15. Christian Hardmeier, Discourse in Statistical Machine Translation. 2014. 16. Mojgan Seraji, Morphosyntactic Corpora and Tools for Persian. 2015.






























