Embed Size (px)
Citation preview

1 Introduction
Parallel Delaunaytriangulation in E3:make it simple
Josef Kohout,Ivana Kolingerova
Centre of Computer Graphics and Data Visualization,Department of Computer Science and Engineering,University of West Bohemia, Univerzitnı 8, 306 14Plzen, Czech RepublicE-mail: [email protected]
Published online: 29 October 2003c© Springer-Verlag 2003
The randomized incremental insertion algo-rithm of Delaunay triangulation in E3 is verypopular due to its simplicity and stability.This paper describes a new parallel algo-rithm based on this approach. The goals ofthe proposed parallel solution are not onlyto make it efficient but also to make it sim-ple. The algorithm is intended for computerarchitectures with several processors andshared memory. Several versions of the pro-posed method were tested on workstationswith up to eight processors and on datasets ofup to 200 000 points with favorable results.
Key words: Delaunay triangulation – Par-alellization – Incremental insertion – Tetra-hedronization
Triangulation in E3, or in other words constructionof tetrahedral meshes, is an important task not onlyin numerical computation but also in problems re-lated to computer graphics such as isosurface gen-eration or surface reconstruction. The most popularmethod is Delaunay triangulation. There exist manyalgorithms for its computation. Although for smalldatasets runtimes are acceptable on nearly any com-puter, input size in today’s applications can be over-whelming. Therefore, parallelism can be one way toincrease the speed of computation. The importanceof a good parallel solution for Delaunay triangula-tion in E3 has already been recognized, and some al-gorithms exist. Most of them were made with specialarchitectures with hundreds or thousands of proces-sors in mind and they put stress on good efficiencyfor a high degree of parallelism.As Delaunay triangulation is difficult to break downinto independent subproblems, parallel algorithmsare usually quite complicated in comparison withtheir serial counterparts and, therefore, difficultto understand and implement. For most applica-tions, a less scalable but easy-to-implement and sta-ble algorithm is preferred to a more scalable butcomplex one. The current situation on the hard-ware market supports this tendency – workstationswith up to eight processors are available; two-processor workstations are especially widespread.At present, there is a lack of algorithms suitablefor this computer category. Such algorithms shoulduse simple means of parallelization to be imple-mentable by the computer science community, butthey should be effective enough to be an attrac-tive choice among competing long-existing serialalgorithms.This paper describes the newly proposed, practicallyoriented parallel algorithm for Delaunay triangula-tion in E3 suitable for multiprocessor workstations.This algorithm was developed with the aim of easyimplementation and debugging as well as good effi-ciency. It is based on a randomized incremental in-sertion algorithm parallelized with the use of sharedmemory and threads. The algorithm was developedas the next step toward the parallel planar Delaunaytriangulation algorithm described in [18].The paper is organized as follows. Section 2 pro-vides a definition and properties of Delaunay tri-angulation in E3. Section 3 surveys previous workon its parallelization. Section 4 describes a random-ized incremental insertion algorithm, and Sects. 5and 6 explain the suggested parallel approach. Sec-
The Visual Computer (2003) 19:532–548Digital Object Identifier (DOI) 10.1007/s00371-003-0219-x

J. Kohout, I. Kolingerova: Parallel Delaunay triangulation in E3: make it simple 533
tion 7 presents experiments and results. Section 8concludes the paper.
2 Delaunay triangulation
Given a point set P in Ed, a k-simplex, k ≤ d, isa convex combination of k +1 affinely independentpoints in P, called vertices of the simplex.A triangulation T(P) of a set of points P in the Eu-clidean space Ed is the set of d-simplices such that
1. a point p in Ed is a vertex of a simplex in T(P) ifp ∈ P;
2. the intersection of two d-simplices in T(P) is ei-ther empty or a common (maximally d −1) sim-plex;
3. the set T(P) is maximal, i.e., it is not possible toadd any simplex without violating the previousrules.
A triangulation T(P) in E3 is a Delaunay triangula-tion if the circumsphere of each d-simplex does notcontain any other point of the set P.As in this paper we will concentrate only on d = 3,we will call a 3-simplex a tetrahedron, a 2-simplexa face or a triangle, a 1-simplex an edge, and a 0-simplex a vertex. A triangulation in E3 will bemostly abbreviated as only a “triangulation”.Delaunay triangulation for the set of n input pointscan be constructed in O(n2) time in the worst case,using O(n2) memory because, in the worst case,O(n2) tetrahedra may appear [1, 9, 22], although formost data only O(n) tetrahedra are necessary. Thussubquadratic time as well as memory requirementscan be expected for most cases.Delaunay tetrahedra have quite good shape proper-ties, although it has been proven that there exist alsosome tetrahedra of bad quality, the so-called sliv-ers, in this triangulation and need to be eliminatedby a mesh modification, usually as a postprocess-ing [8, 24]. Delaunay triangulation minimizes thelargest containment radius of the tetrahedra, that is,the radius of the smallest sphere containing a tetrahe-dron [1, 21].Serial algorithms for the Delaunay triangulation arein most cases based on incremental insertion [10,13, 15, 16, 27] or incremental construction [7, 11].Divide-and-conquer (D&C)-based [7] and higher-dimensional embedding-based methods also exist.Some of the effective approaches from E2, such assweeping or flipping, are rather complicated in E3 or
they do not ensure a convergent algorithm. A surveyof serial E3 algorithms can be found in [19].
3 Previous work in parallel DelaunayE3 triangulation
Parallelizing Delaunay triangulation in any dimen-sion is not easy as any input point influences all thesimplices in whose circumspheres it lies. Therefore,no simple division into subproblems solved indepen-dently by particular processing elements (PEs) canbe done. Thus each parallel algorithm for this prob-lem has to face either an expensive synchronizationor some overhead in multiple construction of thesame simplices and in replicated input data.Most of the existing algorithms are oriented to theplanar case. A survey can be found in [18]. In thispaper, we will concentrate only on the E3 case.Cignoni [6] provides two parallel algorithms. Theformer parallelizes a serial divide-and-conquer(D&C)-based algorithm called DeWall, and the latteris based on the incremental construction algorithmcalled InCoDe. Both solutions were aimed at a dis-tributed computing environment – coarse-grain PEs.DeWall applies D&C in an unusual way. A splittingplane divides the space into two half-spaces and theintended triangulation into three parts: the tetrahedrathat are intersected by the plane, those completelyto the left of the splitting plane, and those to theright. First, the intersected part of the triangulation isconstructed, and then, recursively, the left and rightparts are solved. Thanks to this solution, PEs donot need to wait for one another to merge subsolu-tions because the “merging part” of the triangulation,the one intersected by the plane, has already beenfinished. The disadvantage is that each PE has to ex-ecute all recursive calls in the path from the tree rootto the root of its own subtree, which causes computa-tional overhead. Triangulation on the lowest level ofthe tree is made by an incremental construction. Tospeed up the triangulation, a regular, nonhierarchi-cal 3D grid is used. DeWall was tried on an nCube2system model 6410. The results fell short of the au-thors’ expectations, e.g., for 8000 points the speedupwas 1.7 on 2 PEs, 2.46 on 4 PEs, 3.05 on 8 PEs, and3.35 on 16 PEs. This shows bad scalability, but dueto its simplicity it can be a good solution for the cat-egory of multiprocessor workstations addressed inthis paper.

534 J. Kohout, I. Kolingerova: Parallel Delaunay triangulation in E3: make it simple
InCoDe divides the input points into cells of the samesize, each computed by one PE. Each PE knows allthe input needed to construct tetrahedra correctly onthe boundary between cells. Each PE computes allthe tetrahedra at least partially contained in the cell;this means that computation of the boundary tetrahe-dra is replicated. Despite this overhead, this methodprovides better results than DeWall; for example,for 1000 points, the speedup is from 1.74 for 2 PEsto 19.20 for 64 PEs. The decrease in efficiency iscaused by a growing number of duplicated tetrahedrawith growing input size and by nonequal load of PEs– cells contain various numbers of points for nonuni-form data. Hardwick [14] found that for nonuniformdata, runtimes are as much as ten times worse. Theadvantage of the algorithm is its simplicity, and formostly regular data it might be a viable solution.Teng [26] is based on a similar strategy with a list offaces shared by all PEs. Then, no tetrahedra are com-puted twice, but some synchronization has to be in-corporated. Speedup on Connection Machines CM-2and CM-5 is, for 16 000 uniformly distributed points,3.43 for 128 PEs and 6.08 for 256 PEs, where thespeedup is computed against 32 PEs.Chrisochoides [4] parallelizes the well-knownBowyer–Watson algorithm (incremental insertionwith cavity retriangulation) [27]. Stress is givenrather to mesh refinement than to the triangulation it-self. First, a sequential Delaunay triangulation is run.The resulting tetrahedra are divided into k continu-ous parts for k PEs. Each element inserts the pointsinto its part. When a new point is to be inserted, allthe tetrahedra that have the new point in their circum-sphere are removed. If the whole resulting cavity is inthe area of one PE, retriangulation can be done with-out any synchronization. If not, synchronization withthe other PEs is necessary. Boundaries between areasare formed by faces of tetrahedra and may changeduring triangulation. A heuristic for boundary selec-tion to balance the load of processors and minimizethe length of the boundary is used in [4]. The speedupis shown to be nearly linear in [5], but there is neitherproof nor experimental evidence for this statement.
4 Randomized incremental insertion
Let us review now the sequential algorithm of De-launay triangulation by randomized incremental in-sertion. This algorithm is probably the most popu-lar way of performing the serial E3 Delaunay con-
struction because it is easy to understand, simple toimplement, relatively robust, and online. Althoughincremental insertion algorithms are not among thefastest, their efficiency can be improved by the intro-duction of a data structure that speeds up a location inthe mesh. There are two versions of the incrementalinsertion Delaunay triangulation. The first one is thealready mentioned Bowyer–Watson algorithm [27],which removes all tetrahedra influenced by the in-serted point and retriangulates the resulting cavity.The second one [15, 16] restores Delaunay triangu-lation by a sequence of local swaps of faces. Thesecond version is preferred because of its simplic-ity, better robustness to numerical errors (see, e.g.,Golias [12]), and slightly higher speed. The last ar-gument for our decision was our own positive expe-rience with the local swap version in E2.Our exposition of the algorithm is based onGuibas [13], deBerg [2], and Joe [15, 16]. Let usassume an input set of n points P. Points will beprocessed in random order. We may start in twoways – either with a convex hull of the points orwith an auxiliary tetrahedron, which is a large tetra-hedron containing all input points. The vertices ofthis tetrahedron are temporarily added to P. At eachstep, one point is inserted into the triangulation asfollows. First, the tetrahedron containing the newlyinserted point has to be found. Then this tetrahedronis subdivided into four new tetrahedra (Fig. 1a). Ifthe new point lies on a face, both tetrahedra shar-ing this face have to be subdivided (Fig. 1b). If thepoint lies on an edge, all tetrahedra sharing this edgehave to be divided (Fig. 1c). After this insertion, newtetrahedra have to be checked with their neighborson empty circumsphere property, or “legalized”. Ifa tetrahedron does not satisfy this property, it has tobe swapped with its neighbors. These checks con-tinue recursively from the newly inserted point outover the opposite faces until no change in the givendirection is made. If the checked tetrahedron is cor-rect, i.e., “legal”, the check in this direction stops.Unlike E2, the swap operation in E3 is not com-pletely straightforward. It involves two to four tetra-hedra in four kinds of swaps [15]. Let us assumetwo tetrahedra abcd, abce sharing a nonlegal faceabc. If the line segment de intersects the face abcin an inner point, then the tetrahedra abcd, abceare replaced by the tetrahedra abde, bcde, acde,(Fig. 2a). If de does not intersect the face abc andif de is an edge of another tetrahedron (bcde inFig. 2b), these three tetrahedra can be replaced

J. Kohout, I. Kolingerova: Parallel Delaunay triangulation in E3: make it simple 535
1a 1b 1c
2a Swap S23 2b Swap S32
2c Swap S22 or S44
Fig. 1. Point insertion. a Point inside a tetrahedron. b Pointon a face. c Point on an edge (for readability, only twotetrahedra sharing the edge are shown)Fig. 2. Swap operations
by a pair of tetrahedra abde and acde (Fig. 2b).These two kinds of swaps – S23 and S32 – pre-vail. Other types of swaps – S22 and S44 – areused if de intersects abc on one of its edges (e.g.,bc in Fig. 2c), which would mean that one ofthe tetrahedra resulting from the S23 swap wouldhave zero volume, which is undesirable. Therefore,abcd, abce are swapped for abde, acde (Fig. 2c),making a swap S22 if bcd and bce are convex hullfaces and a swap S44 if they are shared by two othertetrahedra that must also be changed to keep meshconsistency.
This insertion is repeated for all input points. If westarted with the convex hull, we are finished. If westarted with the auxiliary tetrahedron, the added ver-tices and all tetrahedra containing them have to beremoved, leaving a tetrahedrized convex hull of theoriginal points (Fig. 3).Speedup of the point location is ensured by vari-ous data structures allowing logarithmic search. Weuse here a traditional solution with DAG (directedacyclic graph) – a data structure whereby the historyof a triangulation is retained (each node correspondsto one tetrahedron and has sons corresponding to the

536 J. Kohout, I. Kolingerova: Parallel Delaunay triangulation in E3: make it simple
Fig. 3. Two examples of E3 triangulations
new tetrahedra created from the parent tetrahedronby insertion or swap). The DAG for this algorithmclosely resembles a tree with the auxiliary tetrahe-dron in a root and the current triangulation in theleaves. The difference between it and a tree is thatthe nodes created by the swaps have more than oneparent. During triangulation, the tree is not kept bal-anced; instead, input points are randomized. Ran-domization decreases the probability of degradationinto a list-like data structure with O(n) time per loca-tion; thus the O(log n) amortized time per location isachieved.The step of the algorithm yet to be described is theproper choice of the auxiliary tetrahedron. Its ver-tices should be taken “far enough” to embed all thepoints and not to influence the empty circumspheretests but not “too far” to cause problems with poorlyconditioned determinants in geometrical predicates.We use vertices as follows: (m, 0, 0), (0, m, 0),(0, 0, m), (−m,−m,−m), where m is equal to 200times the size of the minmax box. Our experience hasshown that no choice of m can prevent the problemscaused by the inaccurate floating point arithmetic,which does not satisfy the theoretical presumption ofunlimited accuracy. Thus decisions based on the re-sults of such tests might be incorrect. After a long
struggle with these problems, we incorporated theadaptive technique of reliable computation of geo-metric predicates according to Shewchuk [19, 23],which made our implementation reliable with thepenalty of a slowdown. However, we should pointout that the results presented for both parallel and se-rial algorithms in this paper were measured withoutthis technique in order not to distort the results.
5 Parallelization
The choice of an online type of algorithm for paral-lelization looks strange because it is a typical serialmethod. However, in our opinion, there is an inher-ent parallelism – more points can be inserted simul-taneously into a triangulation residing in a sharedmemory if a nonconsistent modification of tetrahe-dra is somehow prevented. The bigger the mesh, thelarger that part of it that stays idle when the swapsafter point insertions are made. Some mechanism isneeded to recognize which tetrahedra cannot be in-fluenced by the insertion of the point. Then, basedon the architecture with shared memory and morePEs, we can let each PE insert its subset of pointsinto the shared triangulation. If the sets of modified

J. Kohout, I. Kolingerova: Parallel Delaunay triangulation in E3: make it simple 537
Fig. 4. Runtime needed for the main parts of the se-rial incremental algorithm for uniform data
tetrahedra of these PEs are mutually disjoint, syn-chronization is not necessary, and vice versa. Witha higher number of tetrahedra, the probability of col-lision of more PEs on the same tetrahedra decreases.Computation will be partitioned among threads.1One thread usually runs on one PE. It is possible torun more threads on one PE, but it does not bringa substantial improvement. Before we address thequestion of thread synchronization, let us analyze thebehavior of the sequential algorithm. The runtime ofthis algorithm consists of four parts (see Fig. 4):
1. Location of the tetrahedron that contains the in-serted point: The DAG is traversed but no modifi-cation is performed.
2. Subdivision of the tetrahedron; new tetrahedraare created: The DAG is modified.
3. Legalization of the triangulation: The DAG ismodified.
4. Other operations, such as randomization, creatingan auxiliary tetrahedron, destruction of the DAGstructure, etc. These operations are not effectivefor parallelization.
The legalization takes 67% to 82% of the total run-time, the location 15% to 30%, subdivision almost2%, and other operations about 2%. It can be seenthat any parallelization must take into account above
1 When an application is run, it is loaded into memory readyfor execution. At this point it becomes a process containing oneor more threads that contain the data, code, and other systemresources for the program. A thread executes one part of an ap-plication and is allocated CPU time by the operating system.All threads of a process share the same address space and canaccess the process’s global variables [3].
all legalization, which consumes the largest part ofthe time. Parallelizing only locations where no mod-ification is made to DAG can be easy but not ef-fective enough. Nonparallelizable “other operations”are negligible.There are three possible synchronization methods:1. Batch method: This method contains two dif-
ferent algorithms, one for reading and anotherfor the DAG modifications. There exist severalthreads locating the tetrahedron that contains theinserted point. The subdivision and legalizationare done by one specialized thread that receivesthe point and the containing tetrahedron from thesearching thread. Communication between thespecialized thread and the searching threads is en-sured by a queue in the shared memory. If thisqueue is empty, the specialized thread must wait;if it is full, the searching threads must wait. Thequestion is how long the queue must be to pre-vent the threads from waiting. The batch methodwould be effective if location took much moretime than subdivision and legalization. If not, ina short time the queue would be full and theperformance would go down. However, the loca-tion in the serial algorithm occupies at most 30%of the total time, and so we consider the batchmethod inefficient for our problem and did notimplement it.
2. Pessimistic method: In this case, all threads dothe same work. While several threads can read theDAG simultaneously, only one thread can modifyit at a time. To achieve this, a location is dividedinto two parts. Tetrahedra on the leaf level canbe read or modified, and therefore access to them

538 J. Kohout, I. Kolingerova: Parallel Delaunay triangulation in E3: make it simple
Master thread:Input: A set P = {pi, i = 0, 1, ..., n −1} of n points in E3
Output: A Delaunay triangulation of P DT(P)
1. begin2. Initialize the auxiliary tetrahedron;3. Compute a random permutation of p0, p1, ..., pn−1 of P;4. Subdivide P into m subsets
where m is the number of threads;5. Start all worker threads and wait inactively until finished;6. Remove all tetrahedra containing vertices
of the auxiliary tetrahedron;7. end
Worker thread:
Input: A set Pt = {pi, i = 0, 1, ..., nm −1} of nm points in E3,Pt ⊂ P
Output: Modifies the shared DT(P)
1. begin2. for r := 0 to nm −1 do3. begin // insert pr into DT(P)4. Locate the tetrahedron containing pr on the level
of the parents of the leaves;5. if any thread working with the leaves exists, then wait;6. Enter the critical section;
//start of work with leaves7. Finish location on the leaf level and find
the tetrahedron containing pr ;8. Subdivide and check the new tetrahedra;9. Leave the critical section; //end of work with leaves10. end;11. end
Fig. 5. Pessimistic method
must be synchronized. Tetrahedra in inner nodescannot be modified by any other thread. Thus itis possible for a thread to locate the last nonleaftetrahedron that contains the input point (reading)without any synchronization. The decision aboutwhether the thread is on the leaf level can be madesimply by adding a flag to the DAG structure. Thethread then enters a critical section, finishes thelocation on the leaf level, subdivides and legalizes(writing), and finally leaves the critical section.The pessimistic method contains two partial al-gorithms, one for the main thread and one forthe working threads (Fig. 5). The main (master)
thread initializes the computation and starts therequired number of working threads. Each work-ing thread gets its own subset of input points. Theproblem of how to distribute the points amongthe threads will be discussed later. After startingthe working threads’ execution, the master threadwaits inactively (i.e., no CPU time is consumed)until all the working threads are finished.The pessimistic method is simple, but critical sec-tions can be expected to limit its speedup. Also,it does not respect the information from Fig. 4– only the location part is parallelized. However,we tried to implement this method, and the re-

J. Kohout, I. Kolingerova: Parallel Delaunay triangulation in E3: make it simple 539
Worker thread:
Input: A set {Pt = pi, i = 0, 1, ..., nm −1} of nm points in E3,Pt ⊂ P
Output: Modifies the shared DT(P)
1. begin2. for r := 0 to nm −1 do begin // insert pr into DT(P)3. Locate in DAG the tetrahedron containing pr;4. while the subdivided tetrahedron or its neighbors
are locked by other threads do wait;5. Lock the tetrahedron and all its neighbors;6. Subdivide the tetrahedron and lock new sons
of this DAG node;7. while the new tetrahedra or their neighbours
are locked by some other thread do wait;8. Lock the new tetrahedra and their neighbors;9. Legalization;10. Unlock all tetrahedra locked by this thread;11. Wake up all threads waiting for this thread;12. end;13. end
Fig. 6. Optimistic method with deadlock detection
sults are given in Sect. 7. The results of the planarversion of the pessimistic method can be foundin [17, 18].
3. Optimistic method: Although legalization maychange the whole triangulation, swaps are ob-viously made locally. This means that a threaddoes not process all DAG leaves, and thereforeit is not necessary to “lock” all leaves only forone thread if we ensure synchronization of thethreads. The location is the same as the loca-tion in the pessimistic method (which means itis not protected). Then the worker thread locksall the accessed tetrahedra, and only after thenew point has been inserted are the locked tetra-hedra unlocked. If another thread has alreadylocked the tetrahedron, the thread must waituntil the blocking thread finishes its work andunlocks this tetrahedron. To retain the lockinginformation about tetrahedra, a flag specifyingwhich thread had locked the tetrahedron is addedinto DAG nodes. The simplified algorithm forworking threads is to be found in Fig. 6. Themaster thread is the same as in the pessimisticmethod.
There exists the possibility of deadlock caused bymutual waiting of threads. Before a thread startswaiting, it tests whether the waiting will not causea deadlock. This detection requires a short criticalsection. If the result is positive, then the thread re-turns to the location part and gives up insertion forthe moment. We call this approach the optimisticmethod with deadlock detection.This problem can also be solved by priorities ofthreads and by deadlock prevention. In such a case,the thread is not allowed to wait for a thread witha higher priority. If another thread with a higher pri-ority locks the accessed tetrahedron, then the threadwith a lower priority has to give up insertion, returnsto the location, and increases its priority. Of course,this approach causes more cases of giving up thanthe method with deadlock detection, but it does notrequire a critical section. We call this solution the op-timistic method with deadlock prevention.Both versions of the optimistic method lead to theuse of transactions that limit the speedup. However,the number of deadlocks divided by the number ofpoints decreases with the growing input size. Thus,in most cases, the transactions are a “luxury”, which

540 J. Kohout, I. Kolingerova: Parallel Delaunay triangulation in E3: make it simple
is why we developed the third version, the optimisticburglary method (or the burglary method for short).This method eliminates transactions in the penaltyof some non-Delaunay tetrahedra in the triangulationcaused by a collision of threads. Because we knowwhich tetrahedra the collision appeared on, we alsoknow which tetrahedra may be potentially problem-atic and can check them in an additional sequentialphase.The burglary method works as follows. Whilea thread in the optimistic method owns just one keyduring the entire process (referred to as the “private”key) to lock, access, and unlock nodes, a thread inthe burglary method owns a key ring with the privatekey and several “picklocks” (hence the name bur-glary method). The thread uses picklocks to accessnodes locked by other threads. At the beginning of it-eration, the key ring contains just the private key. Thethread receives a picklock when it detects a dead-lock; thus instead of performing rollback, it breaksinto the requested tetrahedra that were locked by itscounterpart. As the victim must wait until the at-tacker (burglar) unlocks its nodes, this violent actiondoes not lead to run sharing.When the owner of the tetrahedra that were at-tacked is “woken up”, it has to check whether itis allowed to change this part of the mesh becausethe burglar could have modified it. If the threadis not able to continue, the counter of potentialproblems is increased and suspicious tetrahedra aremarked to be checked sequentially in the postpro-cessing. As the optimistic burglary method is im-plemented without transactions, it may be faster. Onthe other hand, it needs some extra time for trian-gle checks. As we detected only a small number ofwrong tetrahedra experimentally, we ceased to checkthem, thus accepting a small number of errors in thetriangulation.To conclude our description of the optimistic meth-ods, we would like to stress that locking and unlock-ing of tetrahedra must be performed as an atomicoperation. It may be performed in a critical section;however, entering and leaving a critical section slowdown the computation if we use standard means forthe synchronization provided by the operating sys-tem such as the semaphores, etc. Fortunately, it isnot necessary to use them because low-level atomicinstructions are usually available, e.g., Intel x86 pro-vides atomic instructions such as XADD, CMPX-CHG, lock INC, or lock DEC that are satisfactory forour purposes.
We implemented all three versions of the optimisticmethod; the results are given in Sect. 7.
6 Distribution of input pointsamong the threads
There are two main principles involved in subdivid-ing the input set of n points into m subsets that are aninput for the particular worker threads:
1. Static: Each thread receives a part of the input setat the beginning. The last thread gets less than theother; however, the difference is small in compar-ison with the size of the tasks.
2. Dynamic: Each thread inserts the first point notyet inserted that is indicated by an atomically in-creased global pointer.
As was already mentioned, it is reasonable to ran-domize the order of insertion for the serial algorithm.However, is this enough for the parallel version?Common sense suggests that if the areas of insertedpoints for particular threads are separated, fewer col-lisions should appear. To test this, we also subdividedthe randomized input points into vertical or horizon-tal strips with boundaries derived from a median.A natural extension is to divide the input set accord-ing to two or three coordinates. In this way, the spaceis divided into several blocks.This concludes our explanation of the proposed par-allel solution. In the following section, we give someinformation about the implementation, experiments,and results achieved.
7 Experiments and results
Parallel solution of Delaunay triangulation was im-plemented in Microsoft Visual C++ v. 6.0 (later inMicrosoft Visual Studio.NET 7.0) using serial in-cremental algorithm implemented in Delphi 5. Basictests were run on a computer with two Intel Celeronchips at 533 MHz, 512 MB RAM with MicrosoftWindows 2000 operating system and on a Dell Pre-cision 410 (2x Pentium III, 500 MHz, 1 GB RAM)with Microsoft Windows NT 4.0. The main testswere done on a 64-bit Dell Power Edge 7150 (4xIntel Itanium, cache 4 MB, 800 MHz, 2 GB RAM)with Microsoft Windows XP Advanced Server andon Unisys ES5000 (8x Intel Pentium III Xeon, cache

J. Kohout, I. Kolingerova: Parallel Delaunay triangulation in E3: make it simple 541
7
8
Fig. 7. Examples of 1000 points in some of the tested distributions in the projection into the yz-planeFig. 8. Number of required local transformations, tested on a Dell Precision 410
2 MB, 700 MHz, 2 GB RAM) with Microsoft Win-dows 2000 DataCenter operating system. The pre-sented speedup was calculated as the total sequen-tial time divided by the total parallel time. Naturally,time for I/O operations is excluded. The efficiency iscomputed as speedup divided by the number of PEs.We tested several ways of subdividing the inputpoints among particular processors, as describedin Sect. 6. To our surprise, “sophisticated” ways,e.g., the use of the median, strips or blocks ofdata, had no substantial influence. The achievedspeedup was about 5% against the static distribu-tion of randomized points with no geometric sub-division. Part of the speedup was lost in mediancomputation. Therefore, we chose the simplest way,i.e., no space subdivision. Thus all the presentedresults will be for randomized points statically al-lotted to threads without any geometrically basedsubdivision.In the experiments, we used two groups of testingdata. The first group consists of artificially gener-ated points with various distributions – uniform,normal, the so-called cluster, grid, and sphere, withcoordinates in the range [0,1]. Cluster distribu-tion is formed by several groups of normally dis-tributed points. Points for grid distribution lie ina regular orthogonal grid. Sphere distribution pro-
vides points on the surface of a sphere. The gridand sphere were especially useful in testing the ro-bustness of both serial and parallel implementationbecause these data contain many cases that are sin-gular for Delaunay triangulation (five or more pointson a sphere). Examples of distributions are shownin Fig. 7. The second group of testing datasets isthe so-called real data – points from some popu-lar surface models. They are: cos (n = 961), mon-trose (n = 9918), casual_man (n = 15 145), baby-sumo (n = 19 074), whale (n = 52 635), CTMayo(n = 98 869), and bell (n = 213 373). Most of thesemodels were obtained from the Stanford scanningrepository [25]. This type of real data correspondsto one of our intended applications for surfacereconstruction.The distribution influences the types of swaps andthe linearity and growth of the number of requiredlocal transformations (Fig. 8), i.e., it affects thetotal time needed by a sequential version of ouralgorithm. The different number of local transfor-mations for various types of data also means dif-ferent numbers of nodes in DAG. If we plot thedependence of the total runtime on the size of theDAG structure, the rate of growth of these func-tions is almost identical (Fig. 9a). Thus we expectthat our parallel implementation could achieve al-

542 J. Kohout, I. Kolingerova: Parallel Delaunay triangulation in E3: make it simple
a Serial algorithm, measured on Dell Precision 410
b Parallel algorithm – optimistic method with deadlockdetection, measured on 2x Intel Celeron
Fig. 9. Runtime as a function of number of nodes in DAG
most the same speedup for all data distributions.The graph in Fig. 9b attempts to acknowledge that.The graph reveals that the grid distribution slightlydiffers. It is because S22 and S44 need to lockmore nodes for their typical swaps than S23 orS32. According to our experiments, S22 and S44are rare for distributions other than the grid dis-
tribution, where they have on average about 20%of all swaps. Also, while in the uniform datasetsthe probability that a point will be on an edge isvery low, for the grid datasets it is not an neg-ligible percentage. However, the grid points arenot a typical input; if the user prefers a structuredmesh, he will probably not use Delaunay triangu-

J. Kohout, I. Kolingerova: Parallel Delaunay triangulation in E3: make it simple 543
10a Uniform datasets
10b Real datasets
11
Fig. 10. The speedup for the pessimistic method mea-sured on a Dell Power Edge 7150Fig. 11. The comparison of the speedup for the pes-simistic method for uniform and grid distribution, mea-sured on 2x Intel Celeron
lation. Therefore, for final experiments on comput-ers with more processors (to which we have onlylimited access) we chose uniform and real data asrepresentative.Figure 10 shows the speedup obtained with the pes-simistic method. The results acknowledge our expec-tation that parallelizing only the location part of thealgorithm is not enough. It seems that this method isuseless for more than two processors. On the otherhand, the speedup 1.25–1.57 for uniform data (i.e.,
efficiency of 63% to 79%) and 1.31–1.72 for realdata (efficiency of 66% to 86%) for two PEs showsthat this simple method may be a reasonable can-didate for two-processor workstations. What is cer-tain is the fact that a low speedup is achieved fordatasets smaller than 10 000 points and the speedupincreases with input size. The speedup for uniformdata is comparable with that for the other data dis-tributions with the exception of grid data, where bet-ter results were achieved (Fig. 11). This behavior is
544 J. Kohout, I. Kolingerova: Parallel Delaunay triangulation in E3: make it simple
12a Uniform datasets
12b Real datasets
13
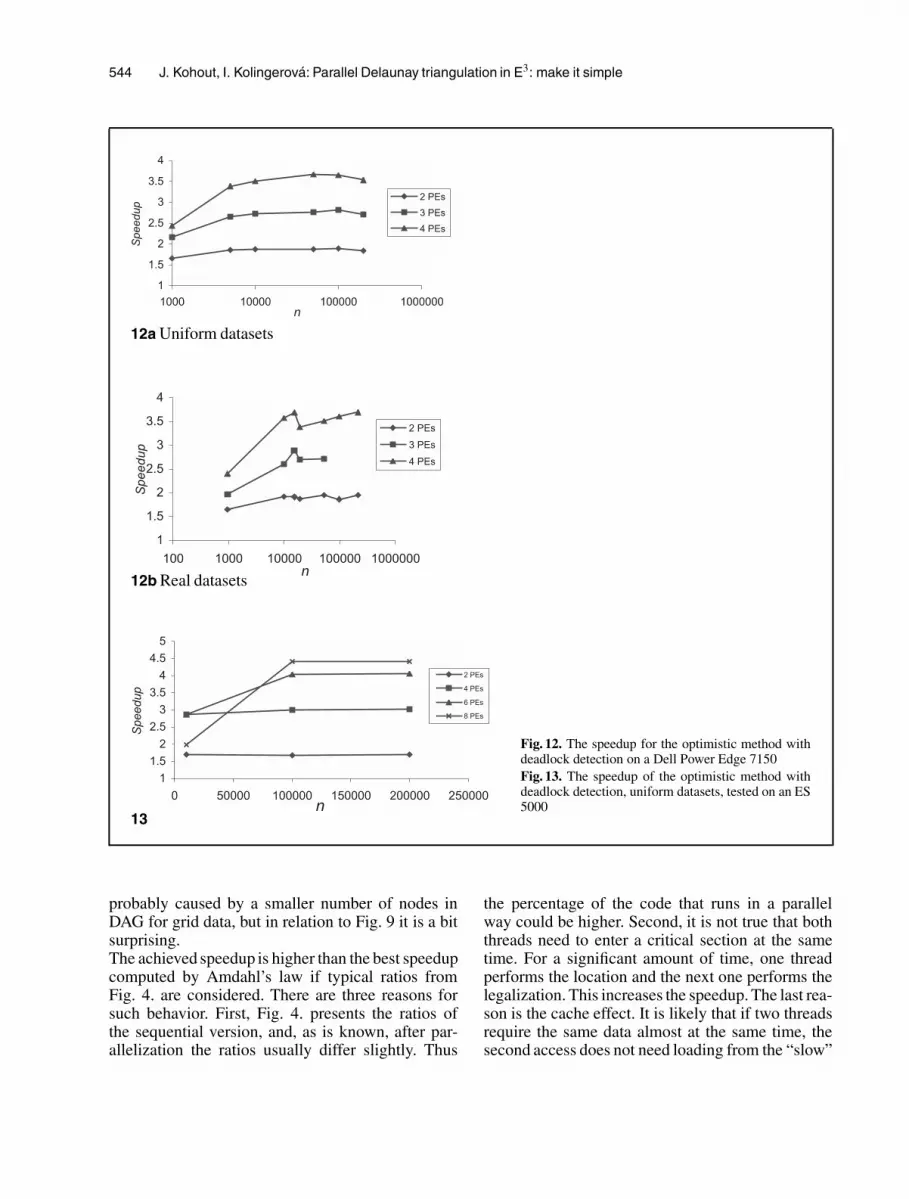
Fig. 12. The speedup for the optimistic method withdeadlock detection on a Dell Power Edge 7150Fig. 13. The speedup of the optimistic method withdeadlock detection, uniform datasets, tested on an ES5000
probably caused by a smaller number of nodes inDAG for grid data, but in relation to Fig. 9 it is a bitsurprising.The achieved speedup is higher than the best speedupcomputed by Amdahl’s law if typical ratios fromFig. 4. are considered. There are three reasons forsuch behavior. First, Fig. 4. presents the ratios ofthe sequential version, and, as is known, after par-allelization the ratios usually differ slightly. Thus
the percentage of the code that runs in a parallelway could be higher. Second, it is not true that boththreads need to enter a critical section at the sametime. For a significant amount of time, one threadperforms the location and the next one performs thelegalization. This increases the speedup. The last rea-son is the cache effect. It is likely that if two threadsrequire the same data almost at the same time, thesecond access does not need loading from the “slow”

J. Kohout, I. Kolingerova: Parallel Delaunay triangulation in E3: make it simple 545
14
15a Uniform datasets
15b Real datasets
Fig. 14. Number of deadlocks, uniform datasets, DellPower Edge 7150 (2, 3, and 4 PEs) and ES5000 (6and 8 PEs)Fig. 15. The comparison of the speedup achieved bythe burglary method (BG) and the optimistic methodwith deadlock detection (OPT), Dell Power Edge7150
memory into the “fast” cache, i.e., the second threadruns faster.We now present results for the optimistic method.There was virtually no difference between dead-
lock detection and prevention. The detection ver-sion is slightly better and also simpler. The achievedspeedup for the optimistic method with deadlock de-tection is shown in Fig. 12. For two PEs and uniform
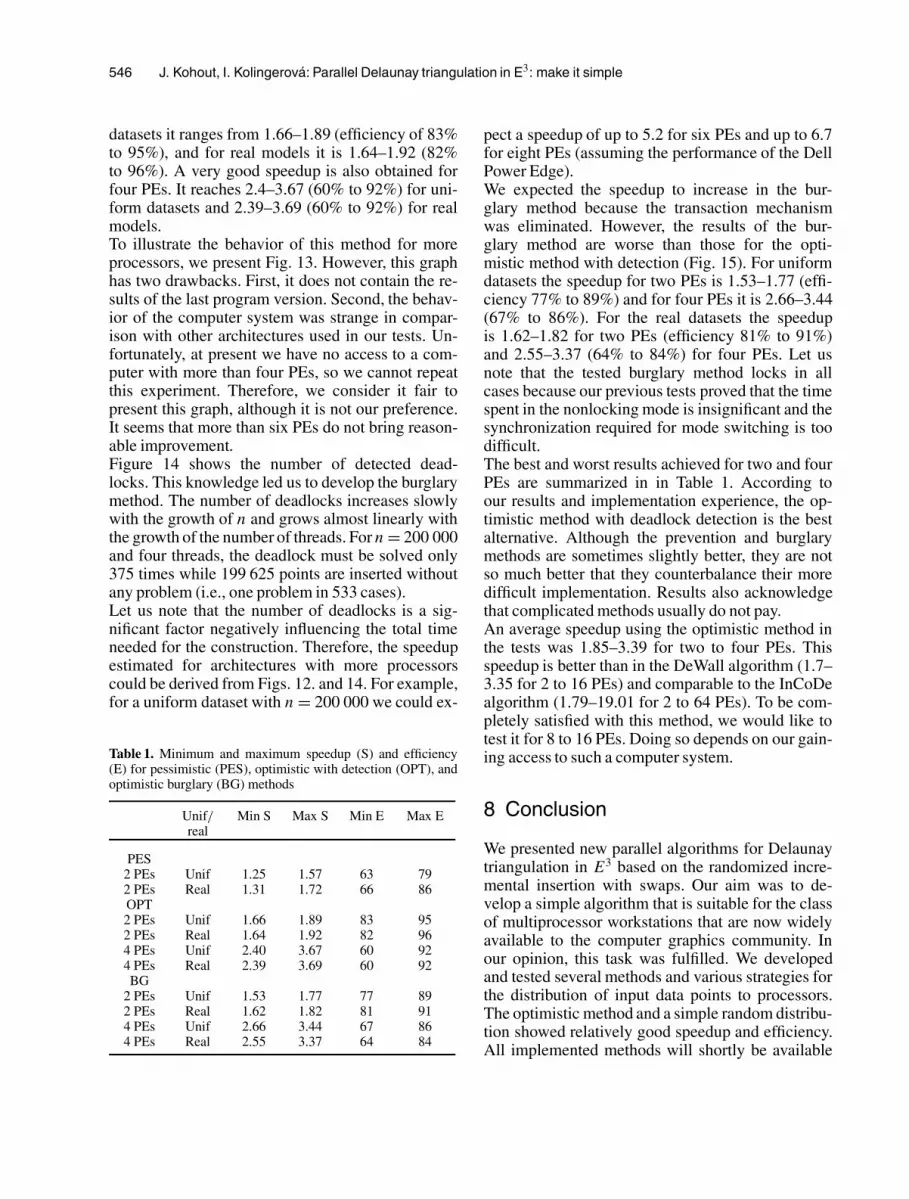
546 J. Kohout, I. Kolingerova: Parallel Delaunay triangulation in E3: make it simple
datasets it ranges from 1.66–1.89 (efficiency of 83%to 95%), and for real models it is 1.64–1.92 (82%to 96%). A very good speedup is also obtained forfour PEs. It reaches 2.4–3.67 (60% to 92%) for uni-form datasets and 2.39–3.69 (60% to 92%) for realmodels.To illustrate the behavior of this method for moreprocessors, we present Fig. 13. However, this graphhas two drawbacks. First, it does not contain the re-sults of the last program version. Second, the behav-ior of the computer system was strange in compar-ison with other architectures used in our tests. Un-fortunately, at present we have no access to a com-puter with more than four PEs, so we cannot repeatthis experiment. Therefore, we consider it fair topresent this graph, although it is not our preference.It seems that more than six PEs do not bring reason-able improvement.Figure 14 shows the number of detected dead-locks. This knowledge led us to develop the burglarymethod. The number of deadlocks increases slowlywith the growth of n and grows almost linearly withthe growth of the number of threads. For n = 200 000and four threads, the deadlock must be solved only375 times while 199 625 points are inserted withoutany problem (i.e., one problem in 533 cases).Let us note that the number of deadlocks is a sig-nificant factor negatively influencing the total timeneeded for the construction. Therefore, the speedupestimated for architectures with more processorscould be derived from Figs. 12. and 14. For example,for a uniform dataset with n = 200 000 we could ex-
Table 1. Minimum and maximum speedup (S) and efficiency(E) for pessimistic (PES), optimistic with detection (OPT), andoptimistic burglary (BG) methods
Unif/ Min S Max S Min E Max Ereal
PES2 PEs Unif 1.25 1.57 63 792 PEs Real 1.31 1.72 66 86OPT2 PEs Unif 1.66 1.89 83 952 PEs Real 1.64 1.92 82 964 PEs Unif 2.40 3.67 60 924 PEs Real 2.39 3.69 60 92BG
2 PEs Unif 1.53 1.77 77 892 PEs Real 1.62 1.82 81 914 PEs Unif 2.66 3.44 67 864 PEs Real 2.55 3.37 64 84
pect a speedup of up to 5.2 for six PEs and up to 6.7for eight PEs (assuming the performance of the DellPower Edge).We expected the speedup to increase in the bur-glary method because the transaction mechanismwas eliminated. However, the results of the bur-glary method are worse than those for the opti-mistic method with detection (Fig. 15). For uniformdatasets the speedup for two PEs is 1.53–1.77 (effi-ciency 77% to 89%) and for four PEs it is 2.66–3.44(67% to 86%). For the real datasets the speedupis 1.62–1.82 for two PEs (efficiency 81% to 91%)and 2.55–3.37 (64% to 84%) for four PEs. Let usnote that the tested burglary method locks in allcases because our previous tests proved that the timespent in the nonlocking mode is insignificant and thesynchronization required for mode switching is toodifficult.The best and worst results achieved for two and fourPEs are summarized in in Table 1. According toour results and implementation experience, the op-timistic method with deadlock detection is the bestalternative. Although the prevention and burglarymethods are sometimes slightly better, they are notso much better that they counterbalance their moredifficult implementation. Results also acknowledgethat complicated methods usually do not pay.An average speedup using the optimistic method inthe tests was 1.85–3.39 for two to four PEs. Thisspeedup is better than in the DeWall algorithm (1.7–3.35 for 2 to 16 PEs) and comparable to the InCoDealgorithm (1.79–19.01 for 2 to 64 PEs). To be com-pletely satisfied with this method, we would like totest it for 8 to 16 PEs. Doing so depends on our gain-ing access to such a computer system.
8 Conclusion
We presented new parallel algorithms for Delaunaytriangulation in E3 based on the randomized incre-mental insertion with swaps. Our aim was to de-velop a simple algorithm that is suitable for the classof multiprocessor workstations that are now widelyavailable to the computer graphics community. Inour opinion, this task was fulfilled. We developedand tested several methods and various strategies forthe distribution of input data points to processors.The optimistic method and a simple random distribu-tion showed relatively good speedup and efficiency.All implemented methods will shortly be available

J. Kohout, I. Kolingerova: Parallel Delaunay triangulation in E3: make it simple 547
under the Modular Visualization Environment [20],a software package developed at our institute.
Acknowledgements. We would like to thank Dell computer, CzechRepublic and UniSys Praha, Czech Republic for allowing us to experi-ment on their computers.
References
1. Aurenhammer F (1991) Voronoi diagrams: a survey ofa fundamental geometric data structure. ACM Comput Surv23(3):345–405
2. De Berg M, van Kreveld M, Overmars M, SchwarzkopfO (1997) Computational geometry: algorithms and applica-tions. Springer, Berlin Heidelberg New York
3. Borland Delphi v. 5.0 (1999) Online help4. Chrisochoides N, Sukup F (1996) Task parallel implemen-
tation of the Bowyer–Watson algorithm. In: Proceedingsof the 5th international conference on numerical grid gen-eration in computational fluid dynamic and related fields,Mississippi State University, Mississippi State, MS, April1996
5. Chrisochoides N, Nave D (1999) Simultaneous mesh gener-ation and partitioning for Delaunay meshes. In: Proceedingsof the 8th international meshing roundtable, South LakeTahoe, CA, October 1999, pp 55–66
6. Cignoni P, Montani C, Perego R, Scopigno R (1993) Par-allel 3D Delaunay triangulation. Computer Graphics Forum12(3), NCC Blackwell, 1993, pp C129–C142
7. Cignoni P, Montani C, Scopigno R (1998) DeWall: a fast di-vide and conquer Delaunay triangulation algorithm in Ed .Comput Aided Des 30(5):333–341
8. Edelsbrunner H, Guoy D (2001) Sink insertion for meshimprovement. In: Proceedings of the 17th annual ACMsymposium on computational geometry, Tufts University,Medford, MA, 3–5 July 2001, pp 115–123
9. Erickson J (2001) Nice point sets can have nasty Delau-nay triangulations. In: Proceedings of the 17th annual ACMsymposium on computational geometry, Tufts University,Medford, MA, 3–5 July 2001, pp 96–105
10. Facello MA (1995) Implementation of a randomized al-gorithm for Delaunay and regular triangulations in threedimensions. Comput Aided Geom Des 12:349–370
11. Fang TP, Piegl LA (1995) Delaunay triangulation in threedimensions. IEEE Comput Graph Appl 9:62–69
12. Golias NA, Dutton RW (1997) Delaunay triangulationand 3D adaptive mesh generation. Finite Elem Anal Des25:331–341
13. Guibas LJ, Knuth DE, Sharir M (1992) Randomized in-cremental construction of Delaunay and Voronoi diagrams.Algorithmica 7:381–413
14. Hardwick JC (1997) Implementation and Evaluation OfAn Efficient parallel Delaunay triangulation algorithm. In:Proceedings of the 9th annual symposium on parallel al-gorithms and architectures, Newport, RI, 22–25 June 1997,pp 22–25
15. Joe B (1991a) Construction of three-dimensional Delaunaytriangulations using local transformations. Comput AidedGeom Des 8:123–142
16. Joe B (1991b) Delaunay versus max-min solid angle trian-gulations for 3D mesh generation. Int J Numer Meth Eng31:987–997
17. Kolingerova I, Kohout J (2000) Pessimistic threaded Delau-nay triangulation by randomized incremental insertion. In:Proceedings of Graphicon 2000, Moscow, pp 76–83
18. Kolingerova I, Kohout J (2002) Optimistic parallel Delau-nay triangulation. Vis Comput 18:511–529
19. Maur P (2002) Delaunay triangulation in 3D. TechnicalReport, Departmen.of Computer Science and Engineering,University of West Bohemia, Pilsen, Czech Republic
20. MVE – Modular Visualization Environment.Available at: http://herakles.zcu.cz/research/mveruntime/index.php
21. Rajan VT (1994) Optimality of the Delaunay triangulationin Rd , Discrete Comput Geom 12:189–202
22. Shewchuk JR (2000) Stabbing Delaunay tetrahedraliza-tions.Available at: http://www.cs.berkeley.edu/∼jrs/stab.html
23. Shewchuk JR (1996) Robust adaptive floating-point geo-metric predicates In: Proceedings of the 12th annual sympo-sium on computational geometry, Philadelphia, 24–26 May1996, pp 141–150
24. Siu-Wing C, Dey TK, Edelsbrunner H, Facello MA, Shang-Hua T (1999) Sliver excudation. In: Proceedings of the15th annual symposium on computational geometry, MiamiBeach, FL, 13–16 June 1999, pp 1–13
25. http://www.graphics.stanford.edu/data/3Dscanrep/26. Teng YA, Sullivan F, Beichl I, Puppo E (1993) A data-
parallel algorithm for three-dimensional Delaunay triangu-lation and its implementation. In: Proceedings of the 1993ACM/IEEE conference on Supercomputing, Portland, OR,pp 112–121
27. Watson DF (1981) Computing the n-dimensional Delaunaytesselation with application to Voronoi polytopes. Comput J24(2):167–172
Photographs of the authors and their biographies are given onthe next page.

548 J. Kohout, I. Kolingerova: Parallel Delaunay triangulation in E3: make it simple
JOSEF KOHOUT graduatedwith a degree in computer sci-ence in 2002 from the Univer-sity of West Bohemia in Pilsen,Czech Republic and is nowa Ph.D. student in computer sci-ence. He specializes in computergraphics, and his research in-terests include parallel compu-tation, Web programming, anddatabase system development.
IVANA KOLINGEROVA grad-uated with a degree in com-puter science in 1987, receivedher Ph.D. in informatics andcomputer science in 1994, andbecame associate professor in2000. She works as an associateprofessor in the Department ofComputer Science and Engineer-ing at the University of WestBohemia in Pilsen, Czech Re-public. Her research interestsinclude computer graphics andcomputational geometry, espe-cially the application of nontra-
ditional mathematical methods. She has been a visiting scholarin Denmark, the United States, Slovenia, and Austria.




























