Embed Size (px)
Citation preview

adfa, p. 1, 2012.© Springer-Verlag Berlin Heidelberg 2012
Performance Comparison of Some Hybrid DeadlineBased Scheduling Algorithms for Computational Grid
Haruna Ahmed Abba, Nordin B. Zakaria, and Anindya. J. Pal
High Performance Computing Service Center (HPCC),Universiti Teknologi PETRONAS, Seri Iskandar, 31750 Tronoh, Perak, Malaysia
[email protected], [email protected], [email protected], [email protected]
Abstract.
Grid computing is a form of distributed computing that involves collection of independentcomputers coordinating and sharing computing, application, data storage or network resourceswith high speed across dynamic and geographically distributed environment. Grid scheduling isa vital component of a Computational Grid infrastructure. Typical scheduling challenges tendto be NP-hard problems where there is no optimal solution. In this paper, we evaluate our pro-posed Grid scheduling algorithm ( Least Slack Time Round Robin Based Scheduling Algo-rithm) using real workload traces, taken from leading computational centers. An extensiveperformance comparison is presented using real workload traces to evaluate the efficiency ofscheduling algorithms. Moreover, experimental results, based on performance metrics, demon-strate that the performances of our grid scheduling algorithms give good results. Our proposedschedule algorithms also support true scalability, that is, they maintain an efficient approachwhen increasing the number of CPUs. This paper also includes a statistical analysis of work-load traces to present the nature and behavior of jobs.
Keywords: Grid computing, Grid scheduling, Cluster, Parallel Processing and Deadline.
1 Introduction
The word “Grid” was ideal to describe this environment over centuries from the electric energypower grid that's a significantly pervasive, easily available resource that enables multiple differentproducts, systems and conditions at distributed sites. Furthermore, grid computing originates earlyin the 1990’s like a mark to make computing resources easily accessible computer researcher IanPromote [1] was promoting a program to consider shared computing to some global level. Just likethe internet which is a tool for mass communication, grids are a tool that provides computerresources and space for storage. However, to facilitate job scheduling as well as resourcemanagement in grid, a resource scheduler or a meta-scheduler has to be used. A scheduler isessential in any large-scale grid environment. The task of the grid resource scheduler is todynamically identify as well as characterize the accessible resources, and also to pick the rightresource for submitting jobs. Grid scheduling is a vital component of a Computational Grid infrastructure.In recent years, lots of research have been offered in different types of approaches fordynamic job scheduling in different nations. However, in this paper two essential issues wereconsidered in the performance evaluation of new grid scheduling algorithms. Firstly, representativeworkload traces were required to produce dependable results. Secondly, a good testing environmentwas set up, as is most commonly used is simulations [2]. Grid scheduling presents severalchallenges that make the implementation of practical systems challenging. However, we developedgrid scheduling algorithm that makes efficient utilization of resources and possess a high degree ofscalability. This paper evaluates the performance and efficiency of our proposed schedulingalgorithm.
The rest of this paper is organized as follows. Section 2 gives an overview on previous s

researches in grid scheduling. Section 3 Baseline Approaches, Section 4 discusses the systemdesign and implementation details of our grid resource scheduling respectively. Section 5 describesexperimental results and section 6 concludes the paper.
2 Related ResearchA brief overview of some previous researches based on different type of approaches being used ingrid scheduling. In recent years, many researchers have offered different types of methods as well asdifferent types of algorithms for dynamic job scheduling in different notion.
A work by [3], proposed a meta-heuristic algorithm based on genetic algorithm to solve theworkflow scheduling problem with the objective of minimizing the time and cost of the execution.Similarly in [4], a distributed scheduler of workflows with deadlines in a P2P computing platformhas been presented. It’s completely decentralized model which has been validated using simulationsthat have shown good response times and low overhead in a system with one million nodes. Bigworkflows with highly concurrent tasks can be easily scheduled with low overhead and a goodspeedup.
In another work by [5], proposed a new algorithm for fair scheduling. [5], used a Max-Min fairsharing approach for providing fair access to users. When there is no shortage of resources, itassigns to each task enough computational power for it to finish within its deadline. When there iscongestion, the main idea is to fairly reduce the CPU rates assigned to the tasks, so that the share ofresources that each user gets is proportional to the user’s weight. The weight of a user may bedefined as the users’ contribution to the infrastructure or the price he is willing to pay for services orany other socioeconomic consideration.
[6], presented a fault-tolerant scheduling framework through DIOGENES (”DIstributed OptimalGenetic algorithm with respect to grid application Scheduling”), of which is mapped to the actualarchitecture of MedioGRID, a real-time satellite image processing system operating within a Gridenvironment. The proposed solution provides a fault tolerant mechanism of mapping the imageprocessing applications, on the available resources in MedioGRID clusters and uniform access.
[7], improved particle swarm optimization (PSO) algorithm with discrete coding rules for gridscheduling with regard to the optimization of grid task scheduling problems, as well as optimizingthe grid resources allocation.
[8], approach reduces processing time frame and utilize grid resource adequately. The primarygoal is to maximize the resource utilization and reduce the processing time frame of jobs. The gridresource selection approach is based on Max Heap Tree (MHT) of which best suits regarding thelarge scale application and the root node of MHT are selected for job submission.
In another work, [9] applied a technique which fills earliest existing gaps in the schedule withnewly arriving jobs. If no gap for a coming job is available EG-EDF rule uses Earliest DeadlineFirst (EDF) strategy for including new job into the existing schedule. Scheduling choices are takento meet the Quality of Service (QoS) requested by the submitted jobs, and to optimize the usage ofhardware resources.
While in the work of [10], shows that combining redundant scheduling with deadline-basedscheduling could lead to a fundamental tradeoff between throughput and fairness. However [10],came up with a new scheduling algorithm called Limited Resource Earliest Deadline (LRED) thatcouples redundant scheduling with deadline driven scheduling in a flexible way by using a simpletunable parameter to exploit this tradeoff.
The majority of the scheduling algorithms; highlighted in the literature has not been evaluatedusing real grid workload traces. However, the aim of this paper is to evaluate the performance andscalability of our proposed hybrid grid scheduling algorithm and compare it with other well knownscheduling algorithms which were hybrid as well. The followings are our scheduling performance

metrics: average turnaround, average waiting time, time and Maximum tardiness.
3 Baseline Approaches
Here, we described and simulate other well known scheduling algorithms such as: First-Come-First-Served Scheduling Algorithm (FCFS) and Earliest Deadline First Round Robin Based SchedulingAlgorithm (EDFRR) and Shortest Processing Time First Round Robin Based Scheduling Algorithm(SPTFRR) as a baseline to compare and evaluate the performance of (LSTRR).
A. Earliest Deadline First Round Robin Based Scheduling Algorithm (EDFRR) Schedulingalgorithm is the simplest scheduling and a famous algorithm that the earlier the deadline is, thehigher the priority is; Processes are dispatched based on minimum deadline on the readyqueue. Processes being executed is preempted based on a time quantum, which is a systemdefined variable. When a process has completed its task, i.e. Before the expiry of the timequantum, it terminates and is deleted from the system. The next process is then dispatchedfrom the head of the ready queue. When a process has completed its task it will be terminatedand then the next job with a minimum deadline will be dispatched from the ready queue.
B. First-Come-First-Served Scheduling algorithm (FCFS): is the simplest scheduling. Processesare dispatched based on their arrival time on the ready queue. Being a non-preemptive disci-pline, once a process has a CPU, it runs to completion. When a process has completed its taskit will be terminated and then the next process will be dispatched from the ready queue. FCFSis not efficient, because long jobs make short jobs wait and unimportant jobs make importantjobs await.
C. Shortest Processing Time First Round Robin Based Scheduling Algorithm (SPTFRR): in thisprospective ready queue is maintained and dispatched based on minimum processing timefirst on the ready queue queue. The algorithm dispatches processes from the head of the readyqueue for execution by the CPU. Processes being executed is preempted based on a timequantum, which is a system defined variable. A preempted process’s PCB is linked to the tailof the ready queue. When a process has completed its task, i.e. Before the expiry of the timequantum, it terminates and is deleted from the system. The next process with minimum proc-essing time first is then dispatched from the head of the ready queue, till the pool is empty.
In this paper we used master slave architecture for implementation of scheduling algorithms asshown in Fig. 1. This involves the use of an actual cluster. The master takes process as the input anddistributes the processes on the cluster processors using the round robin allocation strategy (i.e. 1, 2,3…. n, 1, 2, 3) for parallel computation. Moreover, it should be clear that a real workload trace,Grid5000 [11], is used as input. The same scheduling algorithm either Hybrid Scheduling or someother scheduling algorithm is used on each slave processor for computation.

Fig.1. Master/Slave Architecture
4 Proposed Job Scheduling Algorithm
Least Slack Time Round Robin Based Scheduling Algorithm (LSTRR) : This algorithm executes theprocess with the minimum time delay (Slack Time) in the cyclic manner using a dynamic timequantum. Based on our algorithm the allocation is carried out is based on a master slavearchitecture. LSTRR employs a round robin allocation strategy for jobs distribution among slaveprocessors; and used on each slave processor for computation. Once a computation is done atslave processor, then the results are sent to the master processor.
Basic definition of the aforementioned criteria:
Let us assume Ji : ith Job;n: the number of jobs;TQi : time quantum of job i;Ti : arrival time of job i;di: deadline of job i;αi: burst time of job i;Ci: Job completion time of job i;TTRi: turnaround time of job i;TWTi: waiting time of job i;TTDi: time delay of job i;TTRDi: tardiness of job i;TMax_TRD: maximum tardiness;S-list: Sorted list;
I. Earliest deadline: Referred to the time difference between burst time and deadline time.
Time delay, TTDi: di - αi................................................................................. (1)
II. Time quantum TQi: referred to a fixed time for each job to be executed in cyclic mannermeaning when a process has completed its task, i.e. Before the expiry of the time quantum,it terminates and is deleted from the system. The next process is then dispatched from thehead of the ready queue. TQi .........................................................................(2)
III. Turnaround time: Referred to the total time taken between the submission of job forexecution and the return of the completed result.Turnaround time TTRi = Ci - Ti ......................................................................(3)
Master
Slaves Slaves Slaves

Average turnaround time,
n
TT
n
iTRi
TRAvg
1
_ ..................................................................................(4)
IV. Waiting time: Referred to the total waiting time of job before its final execution.Waiting time TWTi = TTRi - αi.......................................................................(5).Average waiting time,
n
TT
n
iTWi
WTAvg
1
_ ................................................................................(6)
V. Maximum tardiness: Referred to the maximum time delay between turnaround time anddeadline time.
Tardiness, TTRDi = di - TTRi ........................................................(7)Therefore,Maximum Tardiness TMax_TRD = Max (TTRD1, TTRD2,......TTRDn)…….......(8)
The algorithm takes the input from users, where as each job is described by its process ID, arrivaltime, burst time and deadline. It assigns fixed time quantum, and and then compute the value of timedelay for each job by sorting out the jobs on the basis of time delay in ascending order, thenselecting the jobs with minimum time delay for execution. If multiple jobs have same earliestdeadline value then, it will break the tie by selecting a job from job set on the basis of FCFS,The algorithm dispatches processes from the head of the ready queue for execution by the CPU.Processes being executed are preempted based on a time quantum. A preempted process’s processcontrol block (PCB) is linked to the tail of the ready queue. When a process has completed its task,i.e. before the expiry of the time quantum, it terminates and is deleted from the system. The nextprocess is then dispatched from the head of the ready queue till the pool is empty. The value ofturnaround time waiting time and tardiness for each job are computed. The algorithm computes theaverage turnaround time each user's job, average waiting time each user's job and finally computethe maximum tardiness value for jobs to identify the maximum time delay of jobs execution.The compact algorithm is presented below:Algorithm EDFRR:
Input: pool of jobs with processID, arrival time, CPU time and deadlineBegin
For all jobs in the poolCompute time quantum TQ (2)Earliest deadline of all processes using (1)Arrange the job list in ascending order based on earliest deadline (S-list)
if (TTDi = TTDj)Arrange Ji, Jj based on FCFS
Endif

while (S-list is not empty)Begin
Execute the job at CPU level based on demandCompute the value of Turnaround Time using (3)Compute the value of Turnaround Time using (5)Compute the value of Tardiness using (7)
if (αi > 0)Begin
αi -TQEndif
EndwhileCompute average turnaround time using (4)Compute average waiting time using (6)Compute the value of Maximum tardiness using (8)
End
5 Results and DiscussionOur The experiments made use of HPC facility at high performance computing center at
Universiti Teknologi PETRONAS using SGI Altixs 4700. Moreover, we made use of anumber of CPUs and real workload traces (Grid5000) for evaluation of the schedulingalgorithms. The simulations of the algorithms have generated useful data that has been analyzed.However, to check the performance of the proposed algorithms, i.e. LSTRR, SPTFRR, EDFRR andFCFS scheduling algorithm. We incorporate scalability test of scheduling algorithms under anincreasing real workload. We formed four data sets by using 20%, 40%, 60%, 80% and 90% of theGrid5000 workload, 10000, 20000, 30000, 40000, 50000 and 60000 processes, respectively.Moreover, we performed our experiment by varying the number of CPUs from 32 to 64showing the heterogeneous demands of the user’s jobs, each with different characteristics. Eachprocess set has been given a time quantum for simulation. Each process is specified by its CPUburst length, arrival time and priority number. However, performance metrics for the CPUscheduling algorithms are based on the following factors - Average Turnaround Time, AverageWaiting Time and Maximum tardiness.
Below is the graph derived from LSTRR, SPTF, EDFRR, and FCFS Scheduling algorithmfollowed by a discussion. Fig.2 and Fig.3 shows graphs of the Average Turnaround Times, Fig.4and Fig.5 Average Waiting Times, and Fig.6 and Fig.8 Maximum tardiness, respectively.
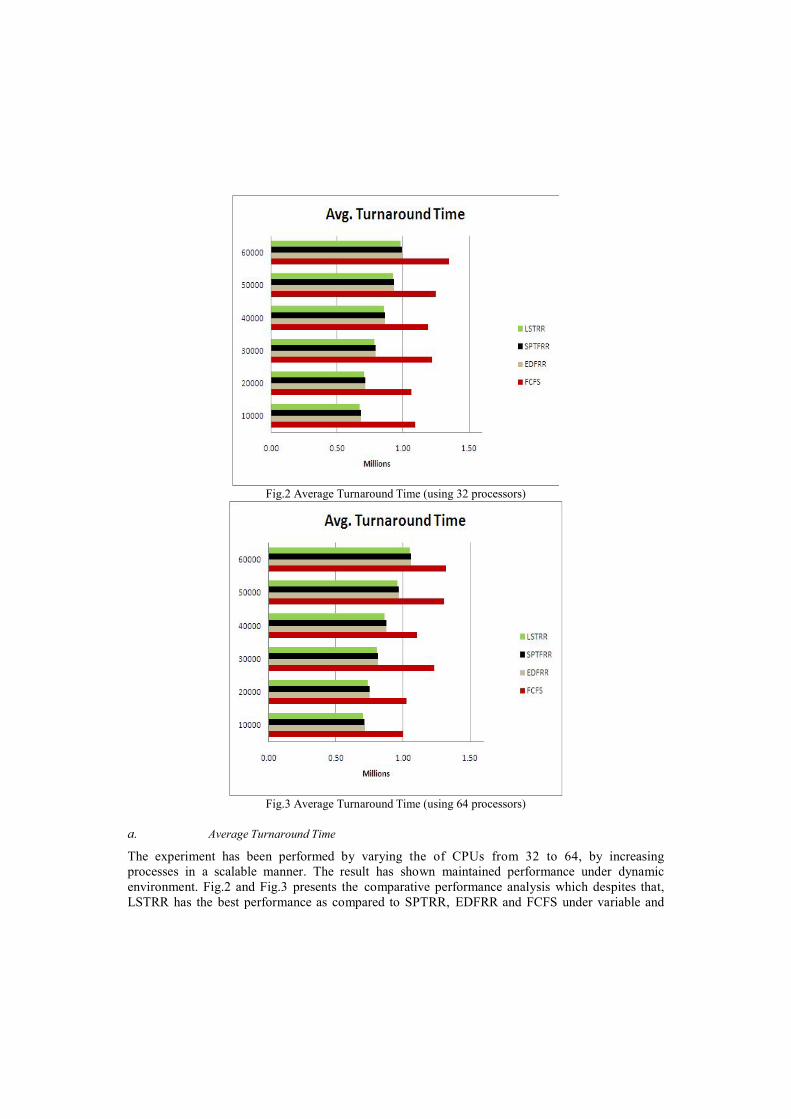
Fig.2 Average Turnaround Time (using 32 processors)
Fig.3 Average Turnaround Time (using 64 processors)
a. Average Turnaround Time
The experiment has been performed by varying the of CPUs from 32 to 64, by increasingprocesses in a scalable manner. The result has shown maintained performance under dynamicenvironment. Fig.2 and Fig.3 presents the comparative performance analysis which despites that,LSTRR has the best performance as compared to SPTRR, EDFRR and FCFS under variable and

scalable workload. Moreover, all scheduling algorithms show that the average turnaround time isindependent of the workload size and the number of CPUs used for computation.
Fig.4 Average waiting Time (using 32 processors)
Fig.5 Average waiting Time (using 64 processors)
b. Average waiting Time
Fig.4 and Fig.5 shows that, LSTRR has the best performance as compared to SPTRR, EDFRR andFCFS under variable and scalable workload. Moreover, all scheduling algorithms show that the

average waiting time is independent of the workload size and the number of CPUs used forcomputation.
Fig.6 Maximum Tardiness (using 32 processors)
Fig.7 Maximum Tardiness (using 64 processors)
c. Maximum Tardiness
The result has shown maintained performance under dynamic environment. However, Fig.6 and

Fig.7 shows that maximum tardiness is not fixed it varies on the workload. Moreover, LSTRR hasthe best performance in terms Average Turnaround Time, Average Waiting Time of SPTRR,EDFRR and FCFS under variable and scalable workload.
6 Conclusions and Future WorkIn this paper, a scheduling algorithm for executing jobs on grid systems is proposed. we have
evaluated our proposed Grid scheduling algorithms on a simulator running on a Cluster using theGrid5000 workload trace. We compare the efficiency of our scheduling algorithms with fourother hybrid scheduling algorithms( LSTRR, SPTFRR, EDFRR and FCFS scheduling algorithm).The result has shown maintained performance under dynamic environment. Based on thecomparative performance analysis we conclude that LSTRR works well from a systemperspective. However, this has been input simply by extensive experimentation. Various possibleinput patterns were experimented with all the CPU scheduling algorithms. We can say thatLSTRR is a scheduling policy from the system point of view; it satisfies the system requirements(i.e. Short Average Waiting Time and short Turnaround Time) and also support scalability underheavy workload.
In the future, we will enhance and evaluate the proposed hybrid scheduling algorithms as farthe results shown. Furthermore, we will perform detailed comparative performance analysis withother scheduling approaches.
AcknowledgementsWe want to express our gratitude to Dr. Nordin B Zakaria and all HPCC members from UniversitiTeknology PETRONAS for their help during the research. Furthermore, we also thank theGrid'5000 team (special thanks to Dr. Franck Cappello and to Dr. Olivier Richard), the owners ofthe Grid'5000 system, and by the OAR team (special thanks to Nicolas Capit), the developers ofthe Grid'5000 resource management infrastructure and the Grid Workloads Archive for theircontribution in making the data publicly available.
References
1. Foster, I. and Kesselman C. (eds.). The Grid: Blueprint for a New Computing Infrastructure.Morgan Kaufmann, 1999.
2. Hui Li, Rajkumar Buyya, 2007, Model-Driven Simulation of Grid Scheduling Strategies, ThirdIEEE International Conference on e-Science and Grid Computing.
3. Golnar Gharooni-fared, Fahime Moein-darbari, Hossein Deldari, Anahita Morvaridi,”Schedulingof scientific workflows using a chaos-genetic algorithm” International Conference on Computa-tional Science, ICCS 2010.
4. Javier Celaya and Unai Arronateui “Distributed Scheduler of Workflows with Deadlines in a P2PDesktop Grid” Parallel, Distributed and Network-Based Processing (PDP), 2010 18th EuromicroInternational Conference on page(s): 69 – 73.
5. Nikolaos D. Doulamis, Member, IEEE, Anastasios D. Doulamis, Member, IEEE, Emmanouel A.Varvarigos, and Theodora A. Varvarigou, Member, IEEE, “Fair Scheduling Algorithms in GridsEEE Transactions On Parallel And Distributed Systems, VOL. 18, NO. 11, NOVEMBER 2007.
6. BU Yan-ping, ZHOU Wei and YU Jin-shou”An Improved PSO Algorithm and ItsApplication to Grid cheduling Problem” 2008 International Symposium on Computer Scienceand Computational Technology, 978-0-7695-3498-5/08 © 2008 IEEE
7. Mr. P.Mathiyalagan, U.R.Dhepthie and Dr. S.N.Sivanandam” Grid scheduling using EnhancedPSO algorithm” P.Mathiyalagan et al. / (IJCSE) International Journal on Computer Science andEngineering ,Vol. 02, No. 02, 2010, 140-145

8. Raksha Sharma, Vishnu Kant Soni, Manoj Kumar Mishra, Prachet Bhuyan and Utpal ChandraDey” An Agent Based Dynamic Resource Scheduling Model with FCFS-Job Grouping Strategyin Grid Computing” World Academy of Science, Engineering and Tech
9. Vasumathi Sundaram, Abhishek Chandra, and Jon Weissman,”Exploring the Throughput-FairnessTradeoff of Deadline Scheduling in Heterogeneous Computing Environments”, ProceedingSIGMETRICS '08 Proceedings of the 2008 ACM SIGMETRICS international conference onMeasurement and modeling of computer systems Pages 463-464 ACM New York, NY, USA2008.
10. Dalibor Klusacek and Hana Rudova,” Comparison Of Multi-Criteria Scheduling Techniques”, InCoreGRID Integration Workshop 2008. Integrated Research in Grid Computing. Heraklion-Crete,2008.
11. Dr. Franck Cappello and to Dr. Olivier Richard, The Grid5000 trace is kindly provided by theGrid5000 team.





























