Embed Size (px)
Citation preview

ISS
N 0
249-
6399
ap por t de r ech er ch e
THÈME 1
INSTITUT NATIONAL DE RECHERCHE EN INFORMATIQUE ET EN AUTOMATIQUE
Putting Polyhedral Loop Transformations to Work
Cédric Bastoul — Albert Cohen — Sylvain Girbal — Saurabh Sharma — Olivier Temam
N° ????
Juillet 2003


Unité de recherche INRIA RocquencourtDomaine de Voluceau, Rocquencourt, BP 105, 78153 Le ChesnayCedex (France)
Téléphone : +33 1 39 63 55 11 — Télécopie : +33 1 39 63 53 30
Putting Polyhedral Loop Transformations to WorkCédri Bastoul∗† , Albert Cohen∗ , Sylvain Girbal‡∗§ , Saurabh Sharma∗ ,Olivier Temam‡Thème 1 � Réseaux et systèmesProjet A3Rapport de re her he n° ???? � Juillet 2003 � 26 pagesAbstra t: We seek to extend the s ope and e� ien y of iterative ompilation te h-niques by sear hing not only for the most appropriate program transformation pa-rameters but for the most appropriate transformations themselves, or even for om-positions of transformations. For that purpose, we need to �nd a generi way toexpress program transformations and ompositions of transformations. In this arti- le, we introdu e a framework for the polyhedral representation of a wide range ofprogram transformations in a uni�ed and generi way. We also show that it is pos-sible to generate e� ient ode after the appli ation of polyhedral program transfor-mations. Finally, we demonstrate an implementation of the program transformationframework and the ode generation te hniques in the Open64/ORC ompiler.Key-words: Automati parallelization, optimization, loop nests, polyhedral trans-formations, ode generation
∗ A3 group, INRIA Ro quen ourt† PRiSM, University of Versailles‡ LRI, Paris South University§ LIST, CEA Sa lay

Mise en Pratique des Transformation Polyédriques deBou lesRésumé : Nous her hons à étendre l'appli abilité et l'e� a ité des te hniques de ompilation itératives, en her hant non seulement les paramètres de transformationles plus appropriés, mais aussi les meilleures transformations elles mêmes, voire les ompositions de transformations. Pour ela, nous avons besoin d'une é riture gé-nérique pour exprimer des transformations et des ompositions de transformations.Dans et arti le, nous introduisons un adre général pour la représentation poly-édrique d'une large lasse de transformations, de manière uni�ée et générique. Nousmontrons également qu'il est possible de générer du ode e� a e après appli ationdes transformations de programmes. En�n, nous dé rivons une implémentation de e adre général et de ses te hniques de génération de ode dans le ompilateurOpen64/ORC.Mots- lés : Parallélisation automatique, optimisation, nids de bou les, transfor-mations polyédriques, génération de ode

Putting Polyhedral Loop Transformations to Work 31 Introdu tionOptimizing and parallelizing ompilers fa e a tough hallenge. Due to their impa ton produ tivity and portability, programmers of high-performan e appli ations want ompilers to automati ally produ e quality ode on a wide range of ar hite tures.Simultaneously, Moore's law indire tly urges the ar hite ts to build omplex ar hi-te tures with deeper pipelines and (non uniform) memory hierar hies, wider general-purpose and embedded ores with lustered units and spe ulative stru tures. Ag-gressive program transformations targeting parallelism and memory hierar hies havematured sin e the �rst manual te hniques, but the stati ost models implemented in ompilers have a hard time oping with rapidly in reasing ar hite ture omplexity.Re ent resear h works on iterative and feedba k-dire ted optimizations [1℄ suggestthat pra ti al approa hes based on dynami , i.e., exe ution-time, information anbetter harness omplex ar hite tures.Current approa hes to iterative optimizations usually hoose a rather small setof program transformations, e.g., a he tiling and array padding, and fo us on �nd-ing the best possible transformation parameters, e.g., tile size and padding size [2℄using parameter sear h spa e te hniques. However, a re ent omparative study ofmodel-based vs. empiri al optimizations [3℄ stresses that many motivations for it-erative, feedba k-dire ted or dynami optimizations are irrelevant when the propertransformations are not available.Within our resear h group, we want to extend the s ope and e� ien y of iterative ompilation te hniques by making the program transformation itself one of the pa-rameters, so that sear hing the parameter spa e means both �nding the appropriateprogram transformation and the appropriate program transformation parameters.Moreover, we want to sear h for omposition of program transformations and notonly single program transformations. For that purpose, we need to have a generi method for expressing program transformations and omposition of those, and thismethod should be amenable to parameter sear h spa e te hniques.This arti le introdu es a uni�ed framework for implementing program transfor-mations, and omposition of program transformations in a generi way. This frame-work relies on a polyhedral representation of loops and loop transformations. Byseparating the iteration domains from the statement and iteration s hedules, andby enabling per-statement transformations, this representation avoids many of thelimitations of iteration-based program transformations, widens the set of possibleprogram transformations and provides a parameterized expression of program trans-formations. Although a few invariants onstrain the sear h spa e, we beleive thisRR n° 0123456789

4 Bastoul, Cohen, Girbal, Sharma & Temamgeneri expression of program transformations is appropriate for systemati sear hspa e te hniques.The orresponding sear h te hniques are out of the s ope of this work and will beinvestigated in a follow-up arti le. This work presents the prin iples of our uni�edframework and the �rst part of its implementation. Also, sin e polyhedral transfor-mation te hniques an better a ommodate omplex ontrol stru tures than tradi-tional loop-based transformations, we start with an empiri al study of ontrol stru -tures within a set of ben hmarks. The four key aspe ts of our resear h work are: (1)empiri ally evaluating the s ope of polyhedral program transformations, (2) de�ninga pra ti al transformation environment based on a polyhedral representation, (3)showing that it is possible to generate e� ient ode from a polyhedral transforma-tion, (4) implementing the polyhedral representation and ode generation te hniquein a real ompiler, Open64/ORC [4℄.Eventually, our framework operates at an abstra t semanti al level to hide thedetails of the ontrol stru tures, rather than on a syntax tree. This eases the de-sign and implementation of omplex program transformations, su h as ombineds hedule and data-layout reordering [5℄. We also de�ne useful extensions of exist-ing te hniques, su h as per-statement and versatile transformations that make fewassumptions about ontrol stru tures and loop bounds. Consequently, while ourframework is initially geared toward iterative optimization te hniques, it an alsofa ilitate the implementation of stati ally driven program transformations in a tra-ditional optimizing ompiler.The paper is organized as follows. We present the empiri al analysis of stati on-trol stru tures in Se tion 2 and dis uss their signi� an e in typi al ben hmarks. Theuni�ed transformation model is des ribed in Se tion 3, followed by the ompositionof polyhedral transformations in Se tion 4. Se tion 5 presents the ode generationte hniques used after polyhedral transformations. Finally, the implementation ofthese di�erent te hniques in Open64/ORC is des ribed in Se tion 6.2 Stati Control PartsLet us start with some related works. Sin e we did not dire tly ontribute to thedriving of optimizations and parallelization te hniques, we will not ompare with thevast literature in the �eld of model-based and empiri al optimization.Well-known loop restru turing ompilers proposed uni�ed models and intermedi-ate representations for loop transformations, but none of them addressed the general omposition and parameterization problem of polyhedral te hniques. ParaS ope [6℄INRIA

Putting Polyhedral Loop Transformations to Work 5is both a dependen e-based framework and an intera tive sour e-to-sour e ompilerfor Fortran; it implements lassi al loop transformations. SUIF [7℄ was designedas an intermediate representation and framework for automati loop restru turing;it qui kly be ame a standard platform for implementing virtually any optimizationprototype, with multiple front-ends, ma hine-dependent ba k-ends and variants. Po-laris [8℄ is an automati parallelizing ompiler for Fortran; it features a ri h sequen eof analyzes and loop transformations appli able to real ben hmarks. These threeproje ts are based on a syntax-tree representation, ad-ho dependen e models andimplement polynomial algorithms. PIPS [9℄ is probably the most omplete looprestru turing ompiler, implementing polyhedral analyses and transformations (in- luding a�ne s hedulng) and interpro edural analyses (array regions, alias). PIPSuses an expressive intermediate representation, a syntax-tree with polyhedral anno-tations.Within the Omega proje t [10℄, the Petit dependen e analyzer and loop restru -turing tool [11℄ is loser to our work: it provides a uni�ed polyhedral framework foriteration reordering only, and it shares our emphasis on per-statement transforma-tions. It is intended as a resear h tool for ompute-intensive kernels.Two odesign tools share a lot of motivations and te hnology with our semi-automati optimization proje t. MMAlpha [12℄ is a domain-spe i� single assign-ment language for systoli array omputations, a polyhedral transformation frame-work, and a high-level ir uit synthesis tool. The intera tive and semi-automati approa h to polyhedral transformations were introdu ed by MMAlpha. The PICOproje t [13℄ is a more pragmati approa h to odesign, restri ting the appli ationdomain to loop nests with uniform dependen es and aiming at the sele tion and oordination of existing fun tional units to generate an appli ation-spe i� VLIWpro essor. Both tools target ompute-intensive kernels only.2.1 De omposition into Stati Control PartsIn the following, loops are normalized and split in two ategories:� loops from 0 to some bound expression with an integer stride, alled do loops;� other kinds of loops, referred to as while loops.In our implementation, early phases of the Open64 ompiler perform most of thisnormalization, along with losed form substitution of indu tion variables. Noti esome Fortran and C while loops may be normalized to do loops when bound andstride an be dis overed stati ally.RR n° 0123456789

6 Bastoul, Cohen, Girbal, Sharma & TemamThe following de�nition is a slight extension of stati ontrol nests [14℄. Withina fun tion body, a stati ontrol part (SCoP) is a maximal set of onse utive state-ments without while loops, where loop bounds and onditionals may only dependon invariants within this set of statements. These invariants in lude symboli on-stants, formal fun tion parameters and surrounding loop ounters: they are alledthe global parameters of the SCoP, as well as any invariant appearing in some ar-ray subs ript within the SCoP. A stati ontrol part is alled ri h when it holds atleast one non-empty loop; ri h SCoPs are the natural andidates for polyhedral looptransformations. An example is shown in Figure 1. We will only onsider ri h SCoPsint he following. SCoP de ompositiondo i=1, 3....................................................................S1 SCoP 1, one statement, non ri h....................................................................do j=1, i*i....................................................................S2 SCoP 2, three statements, ri hdo k=0, j parameters: i,jif (j .ge. 2) then iterators: kS3S4....................................................................do p = 0, 6 SCoP 3, two statements, ri hS5 iterators: pS6Figure 1: Example of de omposition into stati ontrol partsAs su h, a SCoP may hold arbitrary memory a esses and fun tion alls; a SCoPis thus larger than a stati ontrol loop nest [14℄. Interpro edural alias and arrayregion analysis would be useful for pre ise dependen e analysis. Nevertheless, oursemi-automati framework opes with rude dependen e information in authorizingthe expert user to override stati analysis when applying transformations. Moreover,extensions to �sparsely-irregular� odes (with a few unpredi table onditionals andwhile loops) are possible [15, 16℄, although a �fully� polyhedral representation isnot possible anymore. Unifying hybrid stati -dynami optimization [17℄ with thepolyhedral model would also be interesting.2.2 Automati Dis overy of SCoPsINRIA

Putting Polyhedral Loop Transformations to Work 7SCoP extra tion is greatly simpli�ed when implemented within a modern ompilerinfrastru ture su h as Open64/ORC. Previous phases in lude fun tion inlining, on-stant propagation, loop normalization, integer omparison normalization, dead- odeand goto elimination, and indu tion variable substitution, along with language-spe i� prepro essing: pointer arithmeti is repla ed with indexed arrays, pointeranalysis information is available (but not yet used in our tool), et .The algorithm for SCoP extra tion pro eeds through the following steps:Gather useful information: traverse the syntax tree of a given fun tion (afterinlining) and store do loop ounters, bounds and strides, onditional predi ates,array referen es, and parameters involved in these expressions.Re ognize a�ne information:� among do loops, sele t the stati ontrol ones by he king the boundexpressions and the invarian e of the loop ounter and parameters withinthe loop body;� sele t the stati ontrol onditionals whose predi ate is an a�ne expressionof parameters and loop ounters;� restri t previous stati ontrol loops to those en losing stati ontrol loopsand stati ontrol onditionals;� sele t the array referen es whose subs ript is an a�ne expression of pa-rameters and loop ounters.Build stati ontrol parts: traverse the syntax tree, starting with the reation ofa new SCoP. Let N be the �rst operational or ontrol node in the loop body:� if N is a stati ontrol loop, add this loop and its en losed statements tothe SCoP;� if N is a stati ontrol onditional, add this onditional with its bran hesto the SCoP;� if N is not a onditional or loop node, add it to the SCoP;� otherwise, lose the urrent SCoP and reate a new one;� drop the SCoP if it does not ontain at least one loop.Then, set N to the next node and ontinue the traversal.Identify the global parameters: for ea h SCoP, iterate over the loop bounds, onditional expressions and array subs ripts to gather the global parameters.RR n° 0123456789

8 Bastoul, Cohen, Girbal, Sharma & TemamThis algorithm outputs a list of SCoPs asso iated with any fun tion in the syntaxtree. Our implementation in Open64 is dis ussed in Se tion 6.2.3 Signi� an e Within Real Appli ationsThanks to an implementation of the previous algorithm into Open64, we studied theappli ability of our polyhedral framework to several ben hmarks.Figure 2 summarizes the results for the Spe FP 2000 and Perfe tClub ben hmarkshandled by our tool (single-�le programs only, at the time being). All odes arewritten in Fortran77, ex ept for art and quake in C, and lu as in Fortran90. The �rst olumn shows the number of fun tions, outlining that ode modularity does not seemto impa t the appli ability of polyhedral transformations (inlining was not appliedin these experiments). The next two olumns ount the number of SCoPs withat least one global parameter and en losing at least one onditional, respe tively;the �rst one advo ates for parametri analysis and transformation te hniques; these ond one shows the need for te hniques that handle stati - ontrol onditionals.The next two olumns in the �Statements� se tion shows that SCoPs hold a largemajority of statements whi h reinfor es the overage of stati ontrol parts, and alsoillustrates the omputationally intensive nature of the ben hmarks (many statementsare en losed in loops). The last two olumns in the �Array Referen es� se tion arevery promising for dependen e analysis: most subs ripts are a�ne ex ept for lu asand mg3d; moreover, the rate is over 99% in 7 ben hmarks, but approximate arraydependen e analyses will be required for an good overage of the 5 other ben hmarks.In a ordan e with earlier results using Polaris [18℄, the overage of regular loopnests is strongly in�uen ed by the quality of the onstant propagation, loop normal-ization and indu tion variable dete tion.Our tool also gathers detailed statisti s about the number of parameters andstatements per SCoP, and about statement depth (within a SCoP, not ounting non-stati en losing loops). Figure 3 shows that almost all SCoPs are smaller than 100statements, with a few ex eptions, and that loop depth is rarely greater than 3.Moreover, deep loops also tend to be very small, ex ept for applu, adm and mg3dwhi h ontain depth-3 loop nests with tenths of statements. This means that mostpolyhedral analysis and transformations will su eed and require only a reasonableamount of time and resour es. It also gives an estimate of the s alability requiredfor worst- ase exponential algorithms, like the ode generation phase to onvert thepolyhedral representation ba k to sour e ode.INRIA

Putting Polyhedral Loop Transformations to Work 9SCoPs Statements Array Referen esFun tions All Parametri A�ne ifs All in SCoPs All A�neapplu 16 19 15 1 757 633 1245 100%apsi 97 80 80 25 2192 1839 977 78%art 26 28 27 4 499 343 52 100%lu as 4 4 4 2 2070 2050 411 40%mgrid 12 12 12 2 369 369 176 99%quake 27 20 14 4 639 489 218 100%swim 6 6 6 1 123 123 192 100%adm 97 80 80 25 2260 1899 147 95%dyfesm 78 75 70 3 1497 1280 507 99%mdg 16 17 17 5 530 464 355 84%mg3d 28 39 39 6 1442 1242 1274 19%q d 35 30 23 6 819 641 943 100%Figure 2: Coverage of stati ontrol parts in high-performan e appli ations
Figure 3: Distribution of statement depths and SCoP size3 Uni�ed Polyhedral RepresentationIn this se tion, we de�ne the prin iples of polyhedral program transformations. Theterm polyhedron will be used in a broad sense to denote a onvex set of points in alatti e (also alled Z-polyhedron or latti e-polyhedron), i.e., a set of points in a Zve tor spa e bounded by a�ne inequalities [19℄.RR n° 0123456789

10 Bastoul, Cohen, Girbal, Sharma & TemamLet us now introdu e the representation of a SCoP and its elementary transfor-mations. A stati ontrol part within the syntax tree is a pair (S, igp), where S isthe set of onse utive statements � in their polyhedral representation � and igpis the ve tor of global parameters of the SCoP. Ve tor igp is onstant for the SCoPbut stati ally unknown; yet its value is known at runtime, when entering the SCoP.dgp = dim(igp) denotes the number of global parameters.We will use a few spe i� linear algebra notations:� matri es are always denoted by apital letters, ve tors and fun tions in ve torspa es are not;� pfx(v, n) returns a length-n pre�x of v, i.e., the ve tor built from the n �rst omponents of v;� u ⊑ w is equivalent to u being a pre�x of v;� 1k denotes the k-th unit ve tor in a referen e base (11, . . . , 1d) of a d-dimensionalspa e, i.e., (0, . . . , 0, 1, 0, . . . , 0); likewise, 1i,j denotes the matrix �lled with ze-ros but element (i, j) set to 1.A SCoP may also be de orated with stati properties related with the polyhedralrepresentation, su h as array dependen es [14℄ or regions [20℄, but this work does notaddress stati analysis.3.1 Domains, S hedules and A ess Fun tionsThe depth dS of a statement S is the number of nested loops en losing S in theSCoP. A statement S ∈ S is a quadruple (DS ,LS ,RS , θS), where DS is the dS-dimensional iteration domain of S, LS and RS are sets of polyhedral representationsof array referen es, and θS is the a�ne s hedule of S, de�ning the sequential exe utionordering of iterations of S. To represent arbitrary latti e polyhedra, ea h statementis provided with a number dSlp of lo al parameters to implement integer division andmodulo operations via a�ne proje tion: e.g., the set of even values of i is des ribedby means of a lo al parameter p � existentially quanti�ed � and equation i = 2p.Let us des ribe these on epts in more detail and give some examples.� DS is a onvex polyhedron de�ned by matrix ΛS ∈ Mn,dS+dSlp+dgp+1(Z) su hthat
i ∈ DS ⇐⇒ ∃ilp,ΛS
i
ilpigp1
≥ 0.
INRIA

Putting Polyhedral Loop Transformations to Work 11Noti e the last matrix olumn is always multiplied by the onstant 1; it orre-sponds to the homogeneous oordinate en oding of a�ne inequalities into linearform. The number n of onstraints in ΛS is not limited. Program statementsguarded by non- onvex onditionals � su h as 0 ≤ i ≤ 3 ∨ i ≥ 8 � are splitinto separate statements with onvex domains in the polyhedral representation.Example.The Figure 4 show an example that illustrates these de�nitions.Running exampledo i = 1, NA(i) = 0 (S1)do j=1, MA(i) = A(i) + B(i, 2*i+j-N-1) (S2)D[0℄ = 1 (S3)do k = 3, N, 2D(k) = 2*D(k-2) (S4)E(k) = -A(k); (S5)Figure 4: Running exampleThe domains of the �ve statements are:DS1 = {i | 1 ≤ i ≤ N}DS2 = {(i, j) | 1 ≤ i ≤ N, 1 ≤ j ≤M}DS3 = {()} (the zero-dimensional ve tor)DS4 = DS5 = {k | 3 ≤ k ≤ N ∧ ∃p, k = 3 + 2p}So, the Λ-matrix for those statements are:ΛS1 =
[
1 0 0 −1−1 1 0 0
] with ∣
∣
∣
∣
∣
∣
i = (i)ilp = ()igp = (N, M)
ΛS2 =
1 0 0 0 −1−1 0 1 0 00 1 0 0 −10 −1 0 1 0
with ∣
∣
∣
∣
∣
∣
i = (i, j)ilp = ()igp = (N, M)
ΛS3 = [] with ∣
∣
∣
∣
∣
∣
i = ()ilp = ()igp = (N, M)
ΛS4 = ΛS5 =
1 0 0 0 −3−1 0 1 0 01 −2 0 0 −3−1 2 0 0 3
with ∣
∣
∣
∣
∣
∣
i = (k)ilp = (p)igp = (N, M)
RR n° 0123456789

12 Bastoul, Cohen, Girbal, Sharma & Temam� LS and RS des ribe array referen es written by S (left-hand side) or read byS (right-hand side), respe tively; it is a set of pairs (A, f) where A is an arrayvariable and f is the a ess fun tion mapping iterations in DS to lo ations inA. The a ess fun tion f is de�ned by a matrix F ∈ Mdim(A),dS+dSlp+dgp+1(Z)su h that
f(i) = ∃ilp,F
i
ilpigp1
.Example.Consider statement S2 of previous example:LS2 =
{(A, (i))} RS2 ={
(A, (i)), (B, ( i
2 ∗ i + j −N − 1
))}and they are stored as:LS2 =
{(A, [ 1 0 0 0 0])}
RS2 ={(A, [ 1 0 0 0 0
])
,(B, [ 1 0 0 0 0
2 1 −1 0 −1
])}with∣
∣
∣
∣
∣
∣
i = (i, j)ilp = ()igp = (N, M)� θS is the a�ne s hedule of S; it maps iterations in DS to time-stamps (i.e.,logi al exe ution dates) in 2dS + 1-dimensional time [21℄. Multidimensionaltime-stamps are ompared through the lexi ographi ordering over ve tors, de-noted by ≪: iteration i of S is exe uted before iteration i
′ of S′ if and only ifθS(i)≪ θS(i′).To fa ilitate ode generation and to s hedule independently iterations andstatements, we need 2dS + 1 time dimensions instead of dS (the minimum foran a�ne sequential s hedule). This en oding was �rst proposed by Feautrier[21℄ and used extensively by Kelly and Pugh [11℄: dimension 2k en odes therelative ordering of statements at depth k and dimension 2k − 1 en odes theordering of iterations in loops at depth k. INRIA

Putting Polyhedral Loop Transformations to Work 13Eventually, θS is de�ned by a matrix ΘS ∈M2dS+1,dS+dgp+1(Z) su h thatθS(i) = ΘS
i
igp1
.Noti e ΘS does not involve lo al parameters, sin e latti e polyhedra do notin rease the expressivity of sequential s hedules.Example.The Θ-matri es from the previous example are:θS1(i) =
0i
0
stored as ΘS1 =
0 0 0 01 0 0 00 0 0 0
with ∣
∣
∣
∣
∣
∣
i = (i)ilp = ()igp = (N, M)
θS2(i) =
0i
1j
0
stored as ΘS2 =
0 0 0 0 01 0 0 0 00 0 0 0 10 1 0 0 00 0 0 0 0
with ∣
∣
∣
∣
∣
∣
i = (i, j)ilp = ()igp = (N, M)
θS3(i) =(
1) stored as ΘS3 =
[
0 0 1] with ∣
∣
∣
∣
∣
∣
i = ()ilp = ()igp = (N, M)
θS4 =
2k
0
stored as ΘS4 =
0 0 0 21 0 0 00 0 0 0
with ∣
∣
∣
∣
∣
∣
i = (k)ilp = ()igp = (N, M)
θS5 =
2k
1
stored as ΘS5 =
0 0 0 21 0 0 00 0 0 1
with ∣
∣
∣
∣
∣
∣
i = (k)ilp = ()igp = (N, M)3.2 InvariantsWe will now present an important ontribution of this work: our representationmakes a lear separation between the semanti ally meaningful transformations ex-pressible on the polyhedral representation from the semanti ally safe transformationssatisfying the stati ally he kable properties. The goal is of ourse to relax as many onstraints on the sour e ode as possible to widen the range of meaningful trans-formations without relying on the a ura y of a stati analyzer. For example, manyloop transformations are hampered by the la k of information about the bounds orthe limitation to whole-blo k operations: in most ases, a polyhedral representationRR n° 0123456789

14 Bastoul, Cohen, Girbal, Sharma & Temamhides these di� ulties in separating the domains from the s hedules and by autho-rizing transparent statementwise operations. To rea h this goal, and also to a hievea high degree of transformation ompositionality, the polyhedral representation en-for es a few invariants on the domains and s hedules.There is only one domain invariant. To avoid integer over�ows (in the transfor-mation and ode generation phases), the oe� ients in a row of ΛS must be relativelyprime:∀1 ≤ i ≤ dS , gcd(Λi,1, . . . ,Λi,dgp+1) = 1. (1)This restri tion has no e�e t on the expressible domains.The �rst s hedule invariant is that the s hedule matrix must �t into a de om-position more amenable to expert-driven transformation and ode generation. Itseparates the square iteration reordering matrix AS ∈ MdS ,dS(Z) operating on it-eration ve tors, from the parameterized matrix ΓS ∈ MdS ,dgp+1(Z) and from thestatement-s attering ve tor βS ∈ N
dS+1:ΘS =
0 · · · 0 0 · · · 0 βS0
AS1,1 · · · AS
1,dS ΓS1,1 · · · ΓS
1,dgp ΓS1,dgp+1
0 · · · 0 0 · · · 0 βS1
AS2,1 · · · AS
2,dS ΓS2,1 · · · ΓS
2,dgp ΓS2,dgp+1... . . . ... 0
. . . 0...
ASdS ,1
· · · ASdS ,dS ΓS
dS ,1· · · ΓS
dS ,dgp ΓSdS ,dgp+1
0 · · · 0 0 · · · 0 βSdS
. (2)Dimensions asso iated with statement s attering may not depend on loop ountersor parameters, hen e the zeroes in �even dimensions�. We will show in Se tion 3.4how most primitive transformations operate on AS , βS or ΓS separately. Noti e βsubs ripts range from 0 to dS .Ba k to the running example, matrix ΘS2 splits intoΘS2 =
0 0 0 0 01 0 0 0 00 0 0 0 10 1 0 0 00 0 0 0 0
−→ AS2 =
[
1 00 1
]
∧ ΓS2 =
[
0 0 00 0 0
]
∧ βS2 =
010
The se ond s hedule invariant is the sequentiality one: two distin t statementiterations may not have the same time-stamp:S 6= S′ ∨ i 6= i
′ ⇒ θS(i) 6= θS′
(i′). (3)INRIA

Putting Polyhedral Loop Transformations to Work 15Whether the iterations belong to the domain of S and S′ does not matter in (3): wewish to be able to transform iteration domains without bothering with the sequen-tiality of the s hedule. Be ause this invariant is hard to enfor e dire tly, we introdu etwo additional invariants with no impa t on s hedule expressivity and stronger than(3):|det(AS)| = 1, i.e., AS is unimodular, (4)
S 6= S′ ⇒ βS 6= βS′
. (5)Finally, we add a density invariant to avoid integer over�ow and ease s hed-ule omparison. The �odd dimensions� of the image of ΘS form a dS-dimensionalsub-spa e of the multidimensional time, sin e AS is unimodular, but an additionalrequirement is needed to enfor e that �even dimensions� satisfy some form of denseen oding:βS
k > 0⇒ ∃S′ ∈ S,pfx(βS , k) = pfx(βS′
, k) ∧ βS′
k = βSk − 1, (6)i.e., for a given pre�x, the next dimension of the statement-s attering ve tors spanan interval of non-negative integers.3.3 Constru torsWe de�ne some elementary fun tions on SCoPs, alled onstru tors. Many matrix op-erations onsist in adding or removing a row or olumn. Given a ve tor v and matrix
M with dim(v) olumns and at least i rows, AddRow(M, i, v) inserts a new row at po-sition i in M and �lls it with the value of ve tor v, whereas RemRow(M, i) does the op-posite transformation. Analogous onstru tors exist for olumns, AddCol(M, j, v) in-serts a new olumn at position j in M and �lls it with ve tor v, whereas RemCol(M, j)undoes the insertion. AddRow and RemRow are extended to operate on ve tors.Displa ement of a statement S is also a ommon operation. It only impa tsthe statement-s attering ve tor βS′ of some statements S′ sharing some ommonproperty with S. Indeed, forward or ba kward movement of S at depth ℓ triggers thesame movement on every subsequent statement S′ at depth ℓ su h that pfx(βS′, ℓ) =
pfx(βS , ℓ). Although rather intuitive, the following de�nition with pre�xed blo ks ofstatements is rather te hni al. Consider a SCoP S, a statement-s attering pre�x Pde�ning the depth at whi h statements should be displa ed, a statement-s atteringpre�x Q � pre�xed by P � making the initial time-stamp of statements to bedispla ed, and a displa ement distan e o; o is the value to be added/subtra ted tothe omponent at depth dim(P ) of any statement-s attering ve tor βS pre�xed by PRR n° 0123456789

16 Bastoul, Cohen, Girbal, Sharma & Temamand following Q. The displa ement onstru tor Move leave all statements un hangedex ept those satisfying the following onditions:Move(P,Q, o) : ∀S ∈ S, P ⊑ βS ∧ (Q≪ βS ∨Q ⊑ βS) : βSdim(P ) ← βS
dim(P ) +o (7)Noti e these onstru tors make no assumption about the representation invariantsand may violate them.3.4 PrimitivesFrom the earlier onstru tors, we will now de�ne transformation primitives that en-for e the invariants and serve as building blo ks for higher level, semanti ally soundtransformations. Most primitives orrespond to simple polyhedral operations, buttheir formal de�nition is rather te hni al and will be des ribed more extensively ina further paper. Figure 5 lists the main primitives a�e ting the polyhedral rep-resentation of a statement.1 U denotes a unimodular matrix; M implements theparameterized shift (or translation) of the a�ne s hedule of a statement; ℓ denotesthe depth of a statement insertion, iteration domain extension or restri tion; and cis a ve tor implementing an additional domain onstraint.The last two primitives � fusion and split (or distribution) � show the bene�t ofdesigning loop transformations at the abstra t semanti al level of polyhedra. First ofall, loop bounds are not an issue sin e the ode generator will handle any overlappingof iteration domains. Next, these primitives do not dire tly operate on loops, but onsider pre�xes P of statement-s attering ve tors. As a result, they may virtuallybe omposed with any possible transformation. For the split primitive, ve tor (P, o)pre�xes all statements on erned by the split; and parameter b indi ates the positionwhere statement delaying should o ur. For the fusion primitive, ve tor (P, o + 1)pre�xes all statements that should be interleaved with statements pre�xed by (P, o).Eventually, noti e that fusion followed by split (with the appropriate value of b)leaves the SCoP un hanged.This table is not omplete: privatization, array ontra tion and opy-propagationrequire primitives operating on the a ess fun tions of individual array referen es.This will be the purpose of another paper.Finally, embedding stati analysis in the primitives raises no fundamental prob-lem; but updating the analyzes' meta-information a ross transformations is still un-der investigation.1As a osmeti improvement, many of these primitives an be extended to work on blo ks ofstatements sharing a ommon statement-s attering pre�x (along the lines of the fusion and splittingprimitives). INRIA

Putting Polyhedral Loop Transformations to Work 17Syntax & Name Prerequisites E�e tLeftU(S,U) S ∈ S ∧ U ∈ MdS,dS (Z) AS ← U.ASUnimodular ∧|det(U)| = 1RightU(S,U) S ∈ S ∧ U ∈ MdS,dS (Z) AS ← AS .UUnimodular ∧|det(U)| = 1Shift(S, M) S ∈ S ∧M ∈MdS ,dgp+1(Z) ΓS ← ΓS + MShiftInsert(S, ℓ) ℓ ≤ dS ∧ βSℓ+1 = · · · = βS
dS= 0 P = pfx(βS , ℓ)Insertion ∧(∃S′ ∈ S,pfx(βS , ℓ + 1) ⊑ βS′
S ← Move(P, (P, βSℓ), 1) ∪ S
∨ (pfx(βS , ℓ), βSℓ− 1) ⊑ βS′
)Delete(S) S ∈ S P = pfx(βS , dS)Deletion S ← Move(P, (P, βSdS
),−1) \ SExtend(S, ℓ) S ∈ S dS ← dS + 1;ΛS ← AddCol(ΛS , ℓ, 0);Extension AS ← AddRow(AddCol(AS , ℓ, 0), ℓ, 1ℓ);βS ← AddRow(βS , ℓ, 0); ΓS ← AddRow(ΓS , ℓ, 0);∀(A,F) ∈ LS ∪RS ,F← AddRow(F, ℓ, 0)Restri t(S, ℓ) S ∈ S dS ← dS − 1;ΛS ← RemCol(ΛS , ℓ);Restri tion AS ← RemRow(RemCol(AS , ℓ), ℓ);βS ← RemRow(βS , ℓ); ΓS ← RemRow(ΓS , ℓ);∀(A,F) ∈ LS ∪RS ,F← RemRow(F, ℓ)CutDomain(S, c) S ∈ S ΛS ← AddRow(ΛS , 0,Cut Domain ∧dim(c) = dS + dSlp + dgp + 1 c/ gcd(c1, . . . , c
dS+dSlp+dgp+1))AddLP(S) S ∈ S dSlp ← dSlp + 1;Add Lo al ΛS ← AddCol(ΛS , dS + 1, 0);Parameter ∀(A,F) ∈ LS ∪RS ,F← AddCol(F, dS + 1, 0)Fuse(P, o) b = max{βSdim(P )+1
| (P, o) ⊑ βS}+ 1;Fusion Move((P, o + 1), (P, o + 1), b);Move(P, (P, o + 1),−1)Split(P, o, b) Move(P, (P, o, b), 1);Move((P, o + 1), (P, o + 1),−b)Split Figure 5: Main transformation primitives4 Transformation CompositionWe will illustrate the omposition of primitives on a typi al example: two-dimensionaltiling. To de�ne su h a omposed transformation, we �rst build the strip-mining andinter hange transformations from the primitives, as shown in Figure 6.Inter hange(S, o) swaps the roles of io and io+1 in the s hedule of S; it is a per-statement extension of the lassi al inter hange of io and io+1. StripMine(S, o, k)� where k is a known integer � prepends a new iterator to virtually k-times unrollthe s hedule and iteration domain of S at depth o. Finally, Tile(S, o, k) tiles theloops at depth o and o + 1 with k × k blo ks.This tiling transformation is a �rst step towards a higher-level ombined trans-formation, integrating strip-mining and inter hange with privatization, array opyRR n° 0123456789
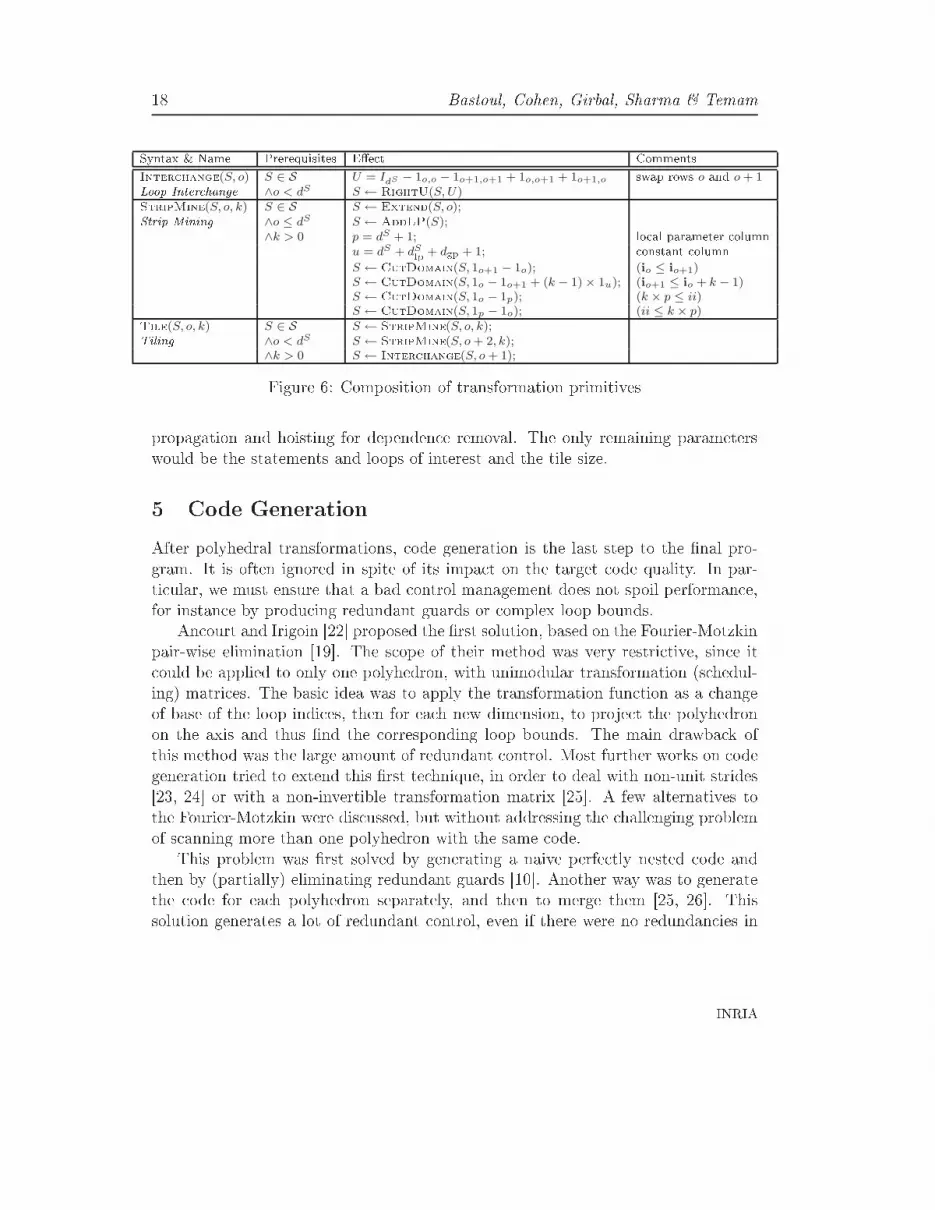
18 Bastoul, Cohen, Girbal, Sharma & TemamSyntax & Name Prerequisites E�e t CommentsInter hange(S, o) S ∈ S U = IdS − 1o,o − 1o+1,o+1 + 1o,o+1 + 1o+1,o swap rows o and o + 1Loop Inter hange ∧o < dS S ← RightU(S, U)StripMine(S, o, k) S ∈ S S ← Extend(S, o);Strip Mining ∧o ≤ dS S ← AddLP(S);∧k > 0 p = dS + 1; lo al parameter olumn
u = dS + dSlp + dgp + 1; onstant olumnS ← CutDomain(S, 1o+1 − 1o); (io ≤ io+1)S ← CutDomain(S, 1o − 1o+1 + (k − 1)× 1u); (io+1 ≤ io + k − 1)S ← CutDomain(S, 1o − 1p); (k × p ≤ ii)S ← CutDomain(S, 1p − 1o); (ii ≤ k × p)Tile(S, o, k) S ∈ S S ← StripMine(S, o, k);Tiling ∧o < dS S ← StripMine(S, o + 2, k);
∧k > 0 S ← Inter hange(S, o + 1);Figure 6: Composition of transformation primitivespropagation and hoisting for dependen e removal. The only remaining parameterswould be the statements and loops of interest and the tile size.5 Code GenerationAfter polyhedral transformations, ode generation is the last step to the �nal pro-gram. It is often ignored in spite of its impa t on the target ode quality. In par-ti ular, we must ensure that a bad ontrol management does not spoil performan e,for instan e by produ ing redundant guards or omplex loop bounds.An ourt and Irigoin [22℄ proposed the �rst solution, based on the Fourier-Motzkinpair-wise elimination [19℄. The s ope of their method was very restri tive, sin e it ould be applied to only one polyhedron, with unimodular transformation (s hedul-ing) matri es. The basi idea was to apply the transformation fun tion as a hangeof base of the loop indi es, then for ea h new dimension, to proje t the polyhedronon the axis and thus �nd the orresponding loop bounds. The main drawba k ofthis method was the large amount of redundant ontrol. Most further works on odegeneration tried to extend this �rst te hnique, in order to deal with non-unit strides[23, 24℄ or with a non-invertible transformation matrix [25℄. A few alternatives tothe Fourier-Motzkin were dis ussed, but without addressing the hallenging problemof s anning more than one polyhedron with the same ode.This problem was �rst solved by generating a naive perfe tly nested ode andthen by (partially) eliminating redundant guards [10℄. Another way was to generatethe ode for ea h polyhedron separately, and then to merge them [25, 26℄. Thissolution generates a lot of redundant ontrol, even if there were no redundan ies inINRIA

Putting Polyhedral Loop Transformations to Work 19the separated ode. Quilleré et al. proposed to re ursively generate a set of loopnests s anning several unions of polyhedra by separating them into subsets of disjointpolyhedra and generating the orresponding loop nests from the outermost to theinnermost levels [27℄. This later approa h provides at present the best solutionssin e it guarantees that there is no redundant ontrol. However, it su�ers fromsome limitations, e.g. high omplexity, ode generation with unit strides only, andan arbitrary partial order on the polyhedra. Some improvements are presented inthe next se tion.This se tion presents the ode generation problem, its resolution with a modernpolyhedral-s anning te hnique, and its implementation.5.1 The Code Generation ProblemIn the polyhedral model, ode generation amounts to a polyhedron s anning problem.We onsider this problem as a two-part spe i� ation for ea h statement:� A onvex polyhedron, de�ned by a set of parameterized inequalities in the n-dimensional spa e:DS =
{
i ∈ ZdS
| ∃ilp,ΛSi i + ΛSlpilp + ΛSgpigp + λS ≥ 0}
,this is the same de�nition as in Se tion 3.1 but Λ is split a ording to the fourparts of the homogeneous oordinate ve tor.� A s heduling fun tion, an a�ne fun tion spe ifying a s anning order for theintegral points belonging to the union of iteration domains:θS(i) = ΘSi i + ΘSgpigp + βS ,again, ΘS is split into three parts a ording to the homogeneous oordinateve tor. Depending on the ontext, the s anning fun tion may have severalinterpretations: to distribute the iterations a ross di�erent pro essors, to orderthem in time, or both (by omposition), et .The problem boils down to �nding a set of nested loops visiting ea h integralpoint, following the s anning order. The generated ode quality an be assessed byusing two valuations: the most important is the amount of dupli ated ontrol in the�nal ode; se ond, the ode size, sin e a large ode may pollute the instru tion a he.We hoose the re ent Quilleré et al. method [27℄ with some additional improvements,whi h guarantee a ode generation without any dupli ated ontrol. The outline ofthe modi�ed algorithm is presented in Se tion 5.2 and some useful optimization aredis ussed in Se tion 5.3.RR n° 0123456789

20 Bastoul, Cohen, Girbal, Sharma & Temam5.2 Outline of the Code Generation AlgorithmOur ode generation pro ess is divided in two main steps. First, we take the s hedul-ing fun tions into a ount by modifying ea h polyhedron's lexi ographi order. Next,we use an improved Quilleré et al. algorithm to perform the a tual ode generation.When no s hedule is spe i�ed, the s anning order is the plain lexi ographi order.Applying a new s anning order to a polyhedron amounts to adding new dimensionsin leading positions. Thus, from ea h polyhedron DS and s heduling fun tion θS, webuild another polyhedron with the desired lexi ographi order:T S =
t
i
∣
∣
∣
∣
∣
∃ilp, Id −ΘSi0 ΛSi
t
i
+
0
ΛSlp
ilp +
−ΘSgpΛSgp
igp +
−βS
λS
=
≥0
.By de�nition, (t, i) ∈ T S if and only if t = θS(i).The main part of the algorithm is a re ursive generation of the s anning ode,maintaining a list of polyhedra from the outermost to the innermost loops. At ea hstep, it:1. interse ts ea h polyhedron of the list with the ontext of the urrent loop (torestri t the s anning ode to this loop);2. proje ts the resulting polyhedra onto the outermost dimensions, then separatethe proje tions into disjoint polyhedra;3. sorts the resulting polyhedra su h that a polyhedron is before another one ifits s anning ode has to pre ede the other to respe t the lexi ographi order;4. merges su essive polyhedra having at least another loop level to generate anew list and re ursively generate the loops that s an this list;5. omputes the strides that the urrent dimension imposes to the outer dimen-sions.This algorithm is slightly di�erent from the one presented by Quilleré et al. in [27℄; ourtwo main ontributions are the following: the support for non-unit strides (Step 5)and the exploitation of degrees of freedom (i.e., when some operations do not havea s hedule) to produ e a more e�e tive ode (Step 4).Let us des ribe this algorithm with a non-trivial example. We propose to s anthe two polyhedral domains presented in Figure 7(a). Both statements have iterationve tor (i, j), lo al parameter ve tor (k) and global parameter ve tor (n). We �rstINRIA

Putting Polyhedral Loop Transformations to Work 21 ompute the interse tions with the ontext (i.e., at this point, the onstraints on theglobal parameters, supposed to be n ≥ 6). We proje t the polyhedra onto the �rstdimension, i, then we separate them into disjoint polyhedra. This means that we ompute the domains where there are points to s an for T S1 alone, both T S1 andT S2 , and T S2 alone (as shown in Figure 7(b), this last domain is empty). Here,we noti e there is a lo al parameter implying a non-unit stride; we an determinethis stride and update the lower bound. We �nally generate the s anning ode forthis �rst dimension. We now re urse on the next dimension, repeating the pro essfor ea h polyhedron list (in this example, there are now two lists: one inside ea hgenerated outer loop). We interse t ea h polyhedra with the new ontext, now theouter loop iteration domains; then we proje t the resulting polyhedra on the outerdimensions, and �nally we separate these proje tions into disjoint polyhedra Thislast pro essing is trivial for the se ond list but yields two domains for the �rst list,as shown in Figure 7( ). Eventually, we generate the ode asso iated with the newdimension, and sin e this is the last one, the s anning ode is fully generated.
.
.
.
.
.
.
21
j
i6. . . 7 . . . n
1
2
6
7
Operation of S2
Operation of S1
n
.
.
.
.
.
.
21
j
i6. . . 7 . . . n
1
2
6
7
Operation of S2
Operation of S1
nS1 and S2 S1
.
.
.
.
.
.
21
j
i6. . . 7 . . . n
1
2
6
7
Operation of S2
Operation of S1
n
T S1
1 (n) :
8
<
:
1 ≤ i ≤ ni = 2k + 11 ≤ j ≤ n
T S2
1 (n) :
8
<
:
1 ≤ i ≤ 6i = 2k + 11 ≤ j ≤ i
do i = 1, 6, 2T S1
1,1 (n) : {1 ≤ j ≤ n}
T S2
1,1 (n) : {1 ≤ j ≤ i}do i = 7, n, 2T S1
1,2 (n) : {1 ≤ j ≤ n}
do i = 1, 6, 2do j = 1, iS1S2do j = i+1, nS1do i = 7, n, 2do j = 1, nS1(a) Initial domains to s an (b) Proje tion and separation onthe �rst dimension ( ) Re ursion on next dimensionsFigure 7: Step by step ode generation exampleRR n° 0123456789

22 Bastoul, Cohen, Girbal, Sharma & Temam5.3 Complexity IssuesThe main omputing kernel in the ode generation pro ess is the separation intodisjoint polyhedra. Given a list of n polyhedra, we have to ompute T S1 − T S2 (S1alone), T S1 ∩ T S2 (both S1 and S2) and T S2 − T S1 (S2 alone), then do the samefor ea h resulting polyhedra with S3, and so on. Thus, the worst- ase omplexityis O(3n) polyhedral operations (exponential themselves). In addition, the memoryusage is very high sin e we have to allo ate memory for ea h separated domain. Forboth issues, we propose a partial solution.� We use pattern mat hing to redu e the number of polyhedral omputations: ata given depth, the domains are often the same (this is a property of the input odes), or disjoint (this is a property of the statement-s attering ve tors of thes heduling matri es). We thus he k these properties before any polyhedraloperation and signi� antly improve performan e.� To avoid a memory allo ation explosion, when we dete t a high memory on-sumption, we ontinue the ode generation pro ess for the remaining re ursionswith a more naive algorithm, leading to a less e� ient ode but using far lessmemory.Our implementation of this algorithm is alled CLooG (Chunky Loop Genera-tor) and was originally designed for a lo ality-improvement algorithm and software(Chunky) [5℄. CLooG ould regenerate ode for all 12 ben hmarks in Figure 2. Itprodu ed optimal ontrol for all but two SCoPs in apsi and adm (the same loop nest,the two ben hmarks being quasi-identi al). These two SCoPs have less than 50 state-ments, but 16 parameters; sin e the urrent version of WRaP-IT does not analysethe linear relations vetween variables, the variability of parameter intera tions leadsto an exponential growth of the generated ode. Noti e the ode generation for thelarge SCoP with more than 1700 statements in lu as took 22 minutes and 1GB ofmemory on a Itanium 800MHz pro essor. Complexity improvements and studies ofthe generated ode quality are under investigation.6 WRaP-IT: an Open64 Plug-In for Polyhedral Trans-formationsOur main goal is to streamline the extra tion of stati ontrol parts and the odegeneration, to ease the integration of polyhedral te hniques into optimizing and par-allelizing ompilers. This interfa e tool is built on Open64/ORC. It onverts theINRIA

Putting Polyhedral Loop Transformations to Work 23WHIRL � the ompiler's hierar hi al intermediate representation � to an aug-mented polyhedral representation, maintaining a orresponden e between matri esin SCoP des riptions with the symbol table and syntax tree. This representation is alled the WRaP: WHIRL Represented as Polyhedra. It is the basis for any poly-hedral analysis or transformation. Then, the se ond part of the tool is a modi�edversion of CLooG, to regenerate a WHIRL syntax tree from the WRaP. The wholeInterfa e Tool is alled WRaP-IT. Sin e its input and output are binary en oding ofthe WHIRL (Open64 .B or .N �le), WRaP-IT may be used in a normal ompilation�ow as well as in a sour e-to-sour e framework. This versatile behaviour is bestunderstood on the following example:1. run Open64/ORC and suspend the ompilation �ow after loop normalization,indu tion variable substitution, and s alar optimizations;2. re ognize stati ontrol parts;� a�ne loop bounds, onditionals and array subs ripts;� build polyhedral domains, sequential s hedules and array a esses;� gra eful degradation when all onditions are not met;3. apply WRaP analyses and transformations;4. polyhedral ode generation, modifying CLooG to output WHIRL;� generate new loops, onditionals and variables;� move/dupli ate the original statement nodes;� optimize onditionals;5. resume the ompilation �ow, redoing s alar optimizations, or regenerate sour e ode with Open64 tools (whirl2 or whirl2f).Although WRaP-IT is still a prototype, it proved to be very robust and thewhole sour e-to-polyhedra-to-sour e transformation was su essfully applied to all 12ben hmarks in Figure 2. All the tools are free software, and further do umentationand information an be found on http://www-ro q.inria.fr/a3/wrap-it.7 Con lusionWe des ribed a theoreti al framework to streamline the design of polyhedral trans-formations, based on a uni�ed polyhedral representation and a set of transformationRR n° 0123456789

24 Bastoul, Cohen, Girbal, Sharma & Temamprimitives. It de ouples the transformation from the stati analyses. It is intendedas a formal tool for semi-automati optimization, where program transformations �with the asso iated stati analyses for semanti -preservation � are separated fromthe optimization or parallelization algorithm whi h drives the transformations andsele t their parameters.We also des ribed WRaP-IT, a robust tool to onvert ba k and forth betweenFortran or C sour e and the polyhedral representation. This tool is implemented inOpen64/ORC. The omplexity of the ode generation phase, when onverting ba kto sour e ode, has long been a deterrent for using polyhedral representations in opti-mizing or parallelizing ompilers. However, our ode generator (CLooG) an handleloops with more than 1700 statements. Moreover, the whole sour e-to-polyhedra-to-sour e transformation was su essfully applied to the 12 ben hmarks. This is astrong point in favor of polyhedral te hniques, even in the ontext of real odes.Current and future work in lude the design and implementation of a polyhedraltransformation library, an iterative ompilation s heme with a ma hine-learning al-gorithm and/or an empiri al optimization methodology, and the optimization of the ode generator to keep produ ing optimal ode on larger odes.Referen es[1℄ T. Kisuki, P. Knijnenburg, M. O'Boyle, and H. Wijsho�. Iterative ompilationin program optimization. In Pro . CPC'10 (Compilers for Parallel Computers),pages 35�44, 2000.[2℄ M. O'Boyle, P. Knijnenburg, and G. Fursin. Feedba k assisted iterative om-piplation. In Parallel Ar hite tures and Compilation Te hniques (PACT'01).IEEE Computer So iety Press, O tober 2001.[3℄ K. Yotov, X. Li, G. Ren, M. Cibulskis, G. DeJong, M. Garzaran, D. Padua,K. Pingali, P. Stodghill, and P. Wu. A omparison of empiri al and model-driven optimization. In ACM Symp. on Programming Language Design andImplementation (PLDI'03), San Diego, California, USA, June 2003.[4℄ Open resear h ompiler. http://ipf-or .sour eforge.net.[5℄ C. Bastoul and P. Feautrier. Improving data lo ality by hunking. In CC'12International Conferen e on Compiler Constru tion, LNCS 2622, pages 320�335, Warsaw, Poland, april 2003.INRIA

Putting Polyhedral Loop Transformations to Work 25[6℄ Keith D. Cooper, Mary W. Hall, Robert T. Hood, Ken Kennedy, Kathryn S.M Kinley, John M. Mellor-Crummey, Linda Tor zon, and S ott K. Warren.The ParaS ope parallel programming environment. Pro eedings of the IEEE,81(2):244�263, 1993.[7℄ M. Hall et al. Maximizing multipro essor performan e with the SUIF ompiler.IEEE Computer, 29(12):84�89, De ember 1996.[8℄ W. Blume, R. Eigenmann, K. Faigin, J. Grout, J. Hoe�inger, D. Padua, P. Pe-tersen, W. Pottenger, L. Rau hwerger, P. Tu, and S. Weatherford. Parallelprogramming with Polaris. IEEE Computer, 29(12):78�82, De ember 1996.[9℄ F. Irigoin, P. Jouvelot, and R. Triolet. Semanti al interpro edural paralleliza-tion: An overview of the pips proje t. In ACM Int. Conf. on Super omputing(ICS'2), Cologne, Germany, June 1991.[10℄ W. Kelly, W. Pugh, and E. Rosser. Code generation for multiple mappings.In Frontiers'95 Symposium on the frontiers of massively parallel omputation,M Lean, 1995.[11℄ W. Kelly. Optimization within a uni�ed transformation framework. Te hni alReport CS-TR-3725, University of Maryland, 1996.[12℄ A.-C. Guillou, F. Quilleré, P. Quinton, S. Rajopadhye, and T. Risset. Hard-ware design methodology with the alpha language. In FDL'01, Lyon, Fran e,September 2001.[13℄ R. S hreiber, S. Aditya, B. Rau, V. Kathail, S. Mahlke, S. Abraham, andG. Snider. High-level synthesis of nonprogrammable hardware a elerators.Te hni al report, Hewlett-Pa kard, May 2000.[14℄ P. Feautrier. Data�ow analysis of s alar and array referen es. Int. Journal ofParallel Programming, 20(1):23�53, February 1991.[15℄ J.-F. Collard, D. Barthou, and P. Feautrier. Fuzzy array data�ow analysis. InACM Symp. on Prin iples and Pra ti e of Parallel Programming, pages 92�102,Santa Barbara, California, USA, July 1995.[16℄ D. Wonna ott and W. Pugh. Nonlinear array dependen e analysis. In Pro .Third Workshop on Languages, Compilers and Run-Time Systems for S alableComputers, 1995. Troy, New York, USA.RR n° 0123456789

26 Bastoul, Cohen, Girbal, Sharma & Temam[17℄ L. Rau hwerger and D. Padua. The lrpd test: Spe ulative run�time paralleliza-tion of loops with privatization and redu tion parallelization. IEEE Transa tionson Parallel and Distributed Systems, Spe ial Issue on Compilers and Languagesfor Parallel and Distributed Computers, 10(2):160�180, 1999.[18℄ R. Eigenmann, J. Hoe�inger, and D. Padua. On the automati parallelizationof the perfe t ben hmarks. IEEE Trans. on Parallel and Distributed Systems,9(1):5�23, January 1998.[19℄ A. S hrijver. Theory of Linear and Integer Programming. John Wiley and Sons,Chi hester, UK, 1986.[20℄ B. Creusillet and F. Irigoin. Interpro edural array region analyses. Int. Journalof Parallel Programming, 24(6):513�546, De ember 1996.[21℄ P. Feautrier. Some e� ient solution to the a�ne s heduling problem, part II,multidimensional time. Int. Journal of Parallel Programming, 21(6):389�420,De ember 1992. See also Part I, One Dimensional Time, 21(5):315�348.[22℄ C. An ourt and F. Irigoin. S anning polyhedra with DO loops. In 3rd ACM SIG-PLAN Symposium on Prin iples and Pra ti e of Parallel Programming, pages39�50, june 1991.[23℄ W. Li and K. Pingali. A singular loop transformation framework based on non-singular matri es. International Journal of Parallel Programming, 22(2):183�205, April 1994.[24℄ J. Xue. Automating non-unimodular loop transformations for massive paral-lelism. Parallel Computing, 20(5):711�728, 1994.[25℄ M. Griebl, C. Lengauer, and S. Wetzel. Code generation in the polytope model.In PACT'98 International Conferen e on Parallel Ar hite tures and CompilationTe hniques, pages 106�111, 1998.[26℄ P. Boulet, A. Darte, G-A. Silber, and F. Vivien. Loop parallelization algorithms:From parallelism extra tion to ode generation. Parallel Computing, 24(3):421�444, 1998.[27℄ F. Quilleré, S. Rajopadhye, and D. Wilde. Generation of e� ient nested loopsfrom polyhedra. International Journal of Parallel Programming, 28(5):469�498,o tober 2000.INRIA

Unité de recherche INRIA RocquencourtDomaine de Voluceau - Rocquencourt - BP 105 - 78153 Le ChesnayCedex (France)
Unité de recherche INRIA Futurs : Domaine de Voluceau - Rocquencourt - BP 105 - 78153 Le Chesnay Cedex (France)Unité de recherche INRIA Lorraine : LORIA, Technopôle de Nancy-Brabois - Campus scientifique
615, rue du Jardin Botanique - BP 101 - 54602 Villers-lès-Nancy Cedex (France)Unité de recherche INRIA Rennes : IRISA, Campus universitaire de Beaulieu - 35042 Rennes Cedex (France)Unité de recherche INRIA Rhône-Alpes : 655, avenue de l’Europe - 38330 Montbonnot-St-Martin (France)
Unité de recherche INRIA Sophia Antipolis : 2004, route des Lucioles - BP 93 - 06902 Sophia Antipolis Cedex (France)
ÉditeurINRIA - Domaine de Voluceau - Rocquencourt, BP 105 - 78153 Le Chesnay Cedex (France)http://www.inria.fr
ISSN 0249-6399





























