Embed Size (px)
Citation preview

Centro Federal de Educação Tecnológica Celso Suckow Da
Fonseca – CEFET/RJ
Diretoria de Pesquisa e Pós-Graduação - DIPPG
Coordenadoria de Pesquisa e Estudos Tecnológicos - COPET
RELATÓRIO FINAL DE INICIAÇÃO CIENTÍFICA
PROJETO DE ESTIMAÇÃO DA DIREÇÃO DE CHEGADA (DoA)
Aluno(a):
Priscila Vieira Gameiro (Engenharia de Controle e
Automação/ 5º período) Bolsista CEFET/RJ
Orientador:
Amaro Lima e Thiago Prego

Rio de Janeiro, RJ – Brasil
Agosto/ 2014
RESUMO:
Este artigo tem como objetivo estimar a direção de chegada do
sinal de voz. Para isso foi analisado primeiramente o
processamento de sinal acústico e a construção e utilização de
filtros, sejam estes digitais ou espaciais, em sinais de voz.
Foram analisados principalmente os filtros digitais FIR e IIR.
Foram analisadas as características da reamostragem de sinal e
identificamos as mudanças que o sinal sofre ao ser reamostrado
em diferentes taxas de amostragens. Mediante a isso construímos
dois filtros LPC, onde exploramos a filtragem com sobreposição e
sem sobreposição. Por ultimo exploramos o beamformer, que é
utilizado para estimar a direção de chegada de um sinal, entre
outras características, contudo não houve tempo hábil para que
pudéssemos analisar com melhor clareza esse processo, por isso
há apenas um exemplo restrito onde pudemos verificar a sua
atuação, porém não houve um aprofundamento. Todos os exemplos e
análises feitas nesse projeto foram efetuados com o auxilio do
programa MATLAB e os códigos utilizados estão disponíveis em
anexo
Palavras-chave: Filtro; LPC; Beamformer; FIR

ÍNDICE:
1- Processamento de sinal acústico
4
1.1- Introdução 4
1.2- Filtros 5
1.2.1- Filtros digitais
6
1.3- Janelamento 8
1.3.1- Janela Retangular
9
1.3.2- Janela de Hanning
9
2- Filtragem de sinais de voz
10
3- Filtro LPC 17
4- Beamformer 24
4.1- Beamformer utilizando Delay-and-Sum
25
5-Conclusão 26
Referências Bibliográficas
27
ANEXOS
ANEXO A - Reamostragem de um sinal de voz utilizando o filtro FIRPM 29
ANEXO B – Filtro LPC sem sobreposição
30
ANEXO C – Filtro LPC com sobreposição
31
ANEXO D – Exemplo de um Beamformer 33


1. PROCESSAMENTO DE SINAL ACÚSTICO:
1.1 INTRODUÇÃO
O processamento de sinais é considerado a parte básica do
reconhecimento de voz, pois ele compreende grande parte das
etapas da qual o reconhecimento necessita. O processamento é
responsável por extrair do sinal de voz os dados relevantes do
sinal e menosprezar a informação redundante, com a finalidade de
repassar a informação de interesse à fase de comparação dos
padrões.
Vários passos compõem a etapa de processamento de sinais:
inicia-se com a aquisição do sinal de voz, que pode ser
percebida ao falarmos em um microfone, pois através dele a voz é
convertida em um sinal analógico que alimenta (excita) a placa
de som do computador. Então é utilizado um conversor analógico-
digital, para que o software possa interpretar a voz como dados
digitais, esse conversor filtra o sinal analógico resultante
através de um filtro passa-baixa, chamado também de filtro anti-
aliasing. Este faz uso da transformada discreta de Fourier para
decodificar o sinal [11]. Depois desse passo a diversas formas das
quais os sons digitalizados serão processados, o que varia de
acordo com a aplicação que o programa foi preparado. Em geral
todos os programas utilizam dois componentes primários: modelo
acústico e linguístico.
A filtragem ocorrida no sinal tem o intuito de suprimir as
componentes de frequência superiores à metade da frequência de
amostragem. Critério esse conhecido como critério de Nyquist[12,13]. De todos estes sinais digitais capturados muitos dados são
considerados como ruído e informações desnecessárias para a
caracterização do sinal utilizada. O método para delimitar o

início e o fim de uma amostra é a detecção dos seus endpoints, ou
seja, pontos extremos de uma locução. No reconhecimento de
palavras discretas, parte-se do princípio de que a locução é
precedida e seguida por um período de ruído de fundo ou
silêncio, fazendo-se necessária esta detecção a fim de filtrar o
sinal bruto adquirido.
Uma vez realizada a detecção dos endpoints, o sinal obtido
necessita ser dividido em janelas, as quais representam termos
curtos do sinal, onde se considera que o mesmo seja invariante.
A literatura cita que os intervalos de 10 a 40 ms atendem a este
requisito.
É importante ressaltar que na etapa de utilização do filtro
passa-baixa ocorre também a escolha da taxa de amostragem e a
escolha da precisão de gravação do sinal, a partir do número de
níveis que esse sinal poderá assumir, após ser amostrado. Esses
níveis são representados por uma cadeia de bits e deve ser
escolhido de forma a conseguir uma boa precisão. Quanto maior o
número de níveis maior será a precisão. Uma cadeia de 16 bits
por amostra, o que equivale a 65536 níveis, já é suficiente para
sinais de voz.
Abaixo na figura 1, demonstramos de forma simplificada como
ocorre o processo de codificação do sinal de voz:

Figura 1 - Demonstração da transformação, do processamento do sinal acústico mecânico, em digital.
1.2 FILTROS:
Os filtros são classificados de acordo com a função de
resposta em frequência, ou seja, de acordo com as frequências em
que se tem uma resposta para se recusar ou aceitar faixas de
frequências. Podem ser classificados da seguinte forma:
- Passa-baixas;
- Passa-altas:
- Passa-faixa;
- Rejeita-faixa;
O gráfico de resposta em frequência possui características
próprias para cada filtro, no entanto, existem pontos
importantes que se pode determinar como, frequência de corte,
frequência de corte inferior e superior, banda de passagem,
banda de rejeição e outros. Dependendo do filtro em estudo, ele
pode ter uma frequência central fo e outras duas frequências, uma
frequência de corte inferior, situada a um valor abaixo da
central, e uma outra situada acima da central, denominada de

frequência de corte superior. Essas frequências de corte são
determinadas nos pontos onde o sinal está com metade da potência
da frequência fo[14]. As frequências que estiverem fora dessa
faixa, ou seja, que possuírem menos da metade da energia da
frequência f0, são consideradas não-passantes ou na banda de
rejeição. Outro ponto que podemos citar é a existência da função
transferência dos filtros, muito utilizado nos cálculos e
determinamos por ele, por exemplo, se o filtro que será
projetado é um filtro estável, ou seja, em primeiro lugar num
projeto, devemos definir o tipo de filtro, em segundo analisar
sua função transferência para determinarmos a ordem do filtro,
determinar os polos e zeros, e assim, calcular os valores de
resistores, capacitores e indutores. De acordo com a resposta em
frequência os filtros podem ser classificados como passa-baixa,
passa-alta, passa-faixa e rejeita-faixa, como já citado
anteriormente.
Notemos as principais características desses filtros:
Filtro passa-altas:
Os filtros passa-alta comportam-se de maneira oposta à dos
filtros passa-baixa, permitindo a passagem dos sinais de
frequência superior á de corte. Os sinais de frequência menor
são atenuados.
Filtro passa-faixa:
Os filtros passa-faixa exibem duas frequências de corte uma
superior e outra inferior. Esses filtros permitem a passagem
de uma banda intermediária de frequências e atenuam as
frequências fora dessa banda.
Filtro corta-faixa:

Os filtros corta-faixa exibem duas frequências de corte,
uma inferior e outra superior. Porém ao contrário dos filtros
passa-faixa, os filtros corta-faixa produzem atenuação máxima
para os sinais cujas frequências estejam dentro da faixa de
rejeição, que esta localizada entre as duas frequências de
corte.
Filtro passa-baixas:
O filtro pode ser caracterizado como um circuito eletrônico
que permite a passagem de baixas frequências sem dificuldades.
Ele também atenua (ou reduz) a amplitude das frequências maiores
que a frequência de corte. A quantidade de atenuação pode variar
de acordo com o filtro.
1.2.1 FILTROS DIGITAIS:O processo de filtragem de sinais pode ser realizado também
digitalmente, como esquematizado a baixo:
O bloco conversor A/D converte o sinal de tempo contínuo
x(t) em uma sequência x[n]. O filtro digital processa a
sequência x[n], resultando em outra sequência y[n], que
representa o sinal filtrado na forma digital. Este sinal y[n] é
então convertido para um sinal de tempo contínuo por um
conversor D/A e reconstruído através de um filtro passa-baixas,
cuja saída é o sinal y(t), que representará a versão filtrada do
sinal x(t)[3].
Quando aplicamos um sinal tipo impulso na entrada do bloco,
obtemos uma sequência y[n] e de acordo com a sua duração podemos
X(t)t)
Y[n]t)A / D
Filtro
Digitalal
D/A Passa Baixa
X[n]t)
Y(t)
caracterizar os filtros em duração finita (FIR – Finite Impulse
Response) ou duração infinita (IIR – Infinite Impulse Response)
[3].
FIR:
Possuem a seguinte equação:
an=0,comn≥1,então:
y [k ]=∑n=0
Nbnx[k−n ]
E são utilizados, pois possuem as seguintes características:
memória finita, portanto qualquer transitório tem duração
limitada; são sempre BIBO estáveis; podem implementar uma
resposta em módulo desejada com resposta em fase linear.
IIR:
Possuem a seguinte equação:
y [k ]=∑n=0
Nbnx[k−n]−∑
n=1
Nany [k−n]
Nesse tipo de filtro observamos: uma operação de forma
recursiva; um bom desempenho em relação ao seu comprimento;
uma maior rapidez se comparado aos filtros FIR; podem se
tornar instáveis. Também pode ser observado que as suas
características de entrada e saída são geradas por equações
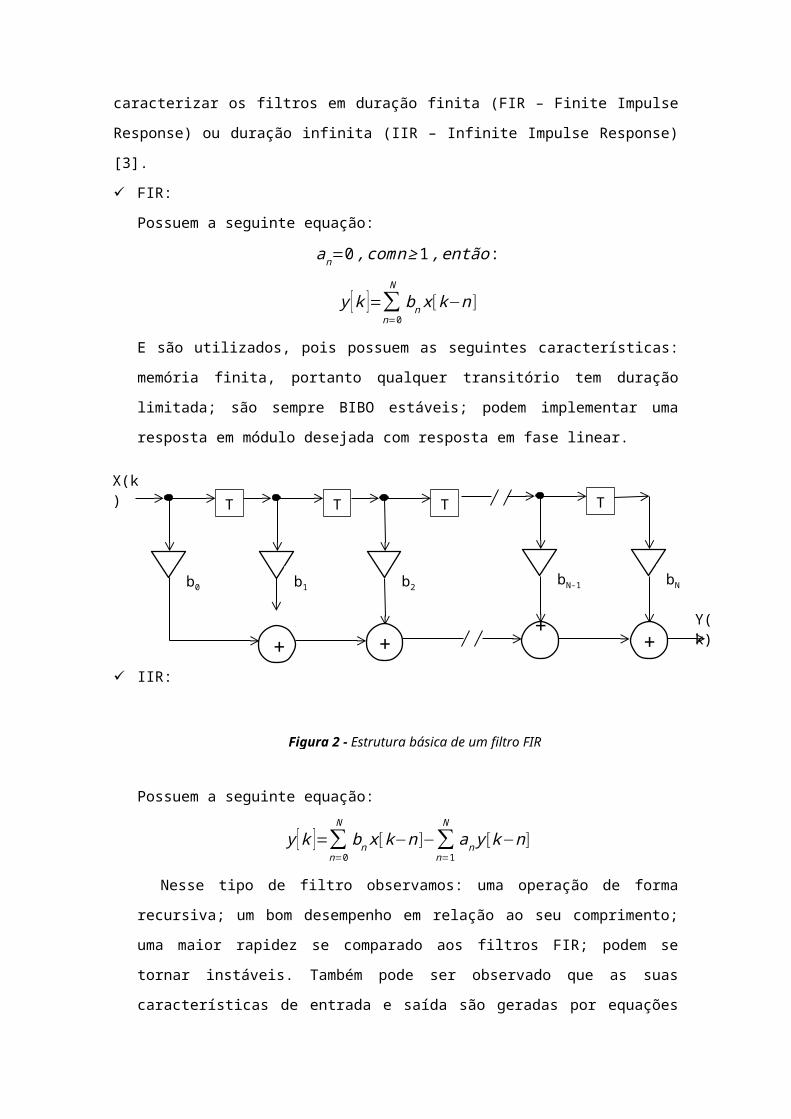
Figura 2 - Estrutura básica de um filtro FIR
X(k) T
b0
T
b1
T
b2
++
T
bN-1
++
bN
++Y(k)+
lineares de diferenças com coeficientes constantes de
natureza recursiva, conforme pode se observar na figura a
seguir:
.
1.3 JANELAMEN
TO:
É um recurso essencial para o processamento de sinais, que
consiste em segmentar o sinal, para que ele possa ser
processado e modelado de acordo com o desejado. Contudo ao
efetuar essa segmentação no âmbito da fala, causamos
distorções nos domínios da frequência e do tempo, por isso
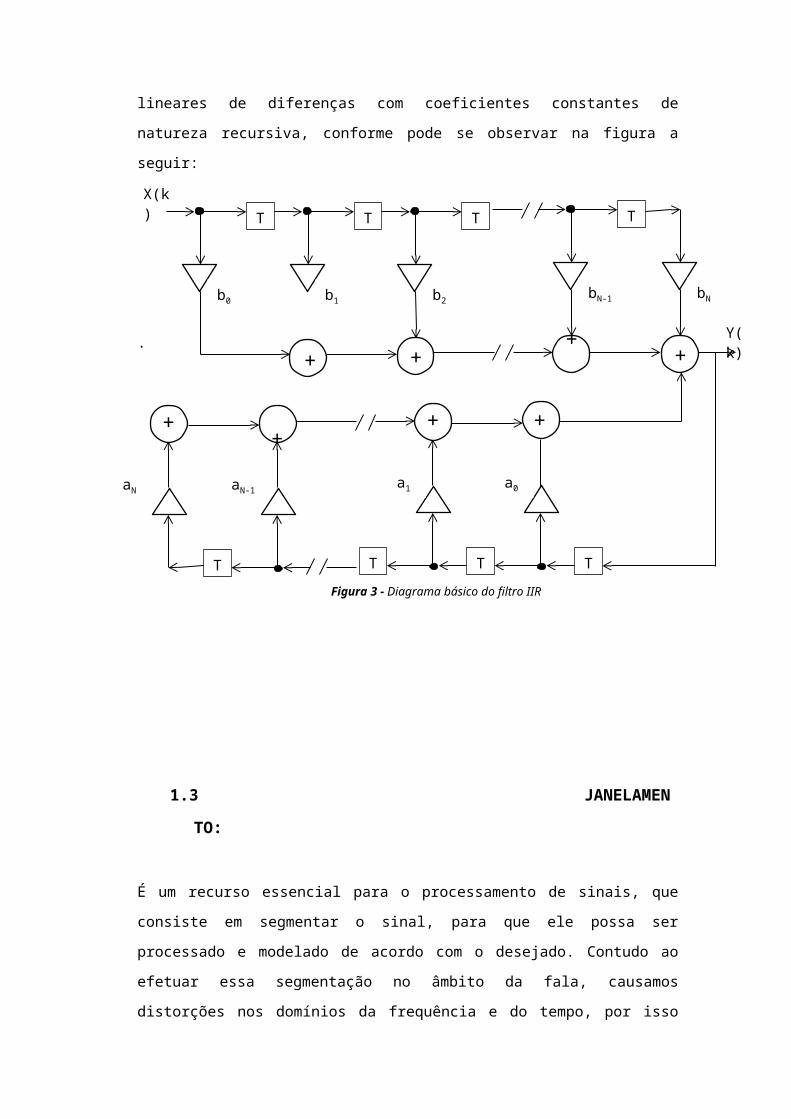
X(k) T
b0
T
b1
T
b2
++
T
bN-1
++
bN
++Y(k)+
TT
a0
T
a1
++
T
aN-1
++
aN
++ +
Figura 3 - Diagrama básico do filtro IIR

foram criados diversos tipos de janelas a fim de reduzir ao
máximo essas distorções.
De uma forma geral: a janela retangular não distorce o sinal
no domínio do tempo, entretanto no domínio da frequência é a
que mais apresenta distorções; Na janela de Kaiser [4] a
distorção é minimizada no âmbito da frequência, porém há uma
maior distorção no domínio do tempo. Com isso as janelas mais
utilizadas são as de Hamming e Hanning, pois são as que
possuem um melhor equilíbrio entre as distorções no domínio
do tempo e da frequência. Em análises de voz o tamanho da
janela pode variar entre 10ms e 30ms.
1.3.1 JANELA RETANGULAR:
A janela retangular possui o valor igual a 1 sobre todo o seu
intervalo de tempo. Matematicamente, uma janela de tamanho N
pode ser definida através da equação:
w [n]=1,n=0,1,2,...,N−1
Aplicar uma janela retangular é equivalente a não utilizar
qualquer janela. A janela retangular possui o maior volume de
perda espectral.
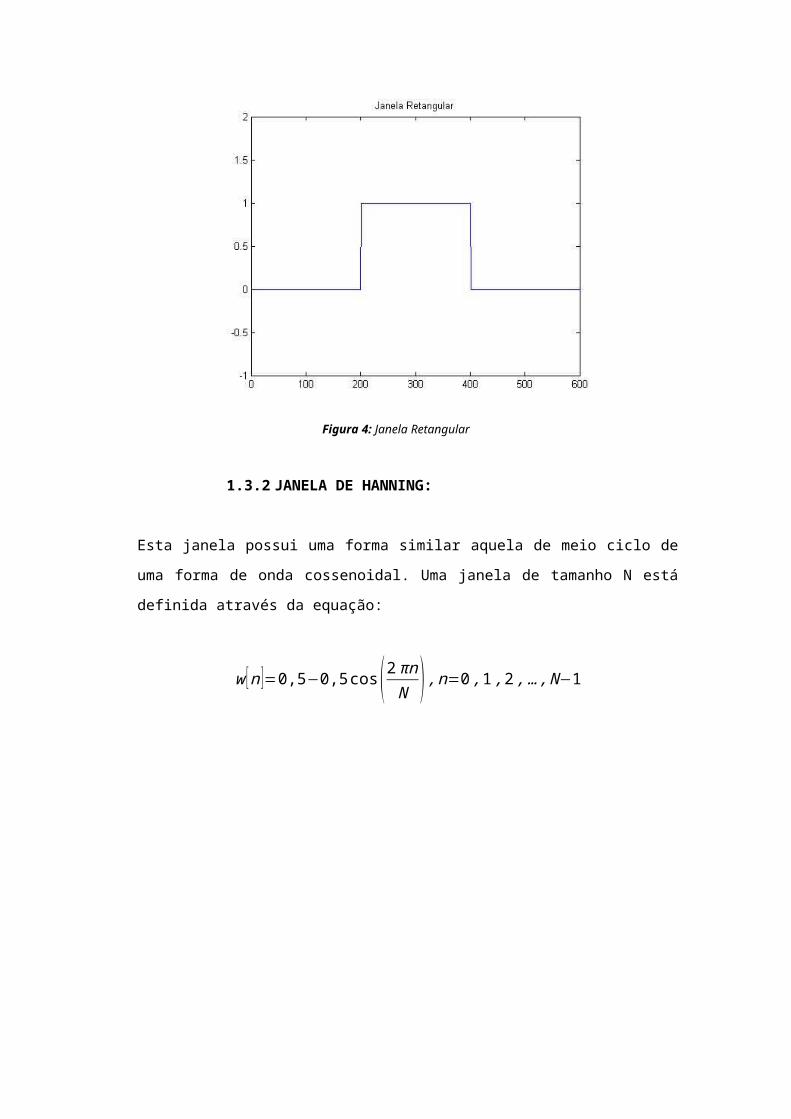
Figura 4: Janela Retangular
1.3.2 JANELA DE HANNING:
Esta janela possui uma forma similar aquela de meio ciclo de
uma forma de onda cossenoidal. Uma janela de tamanho N está
definida através da equação:
w [n ]=0,5−0,5cos(2πnN ),n=0,1,2,…,N−1
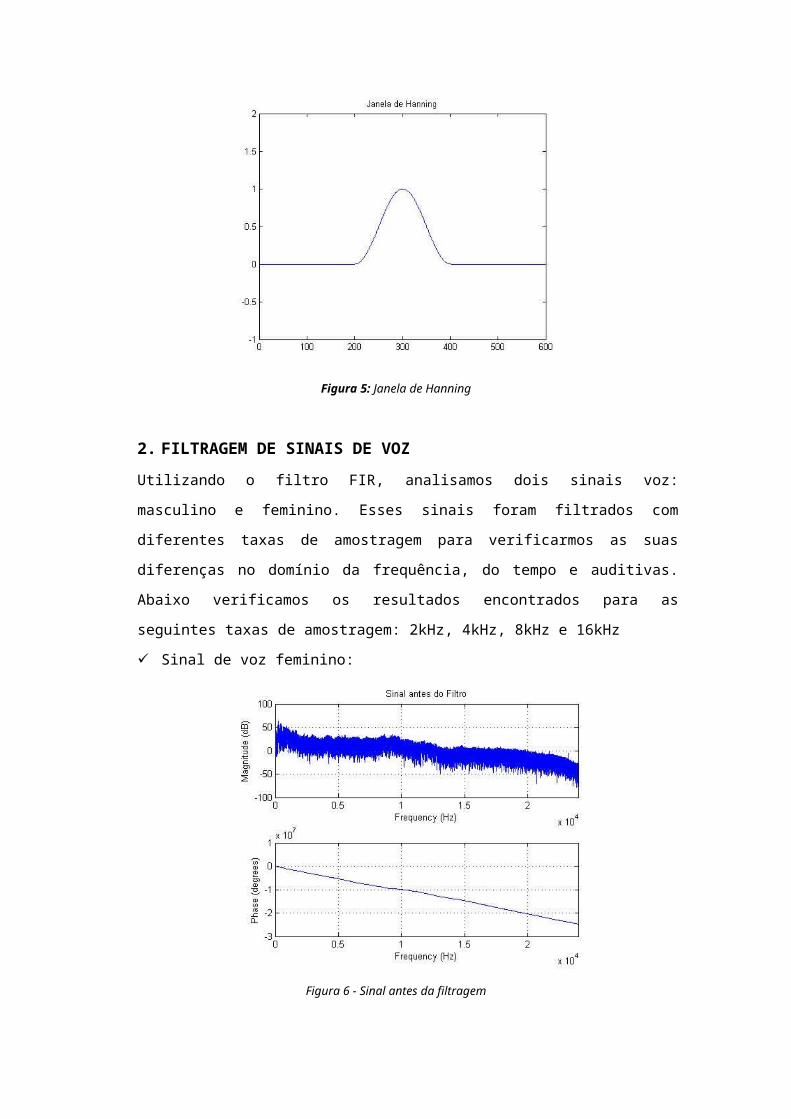
Figura 5: Janela de Hanning
2. FILTRAGEM DE SINAIS DE VOZUtilizando o filtro FIR, analisamos dois sinais voz:
masculino e feminino. Esses sinais foram filtrados com
diferentes taxas de amostragem para verificarmos as suas
diferenças no domínio da frequência, do tempo e auditivas.
Abaixo verificamos os resultados encontrados para as
seguintes taxas de amostragem: 2kHz, 4kHz, 8kHz e 16kHz
Sinal de voz feminino:
Figura 6 - Sinal antes da filtragem
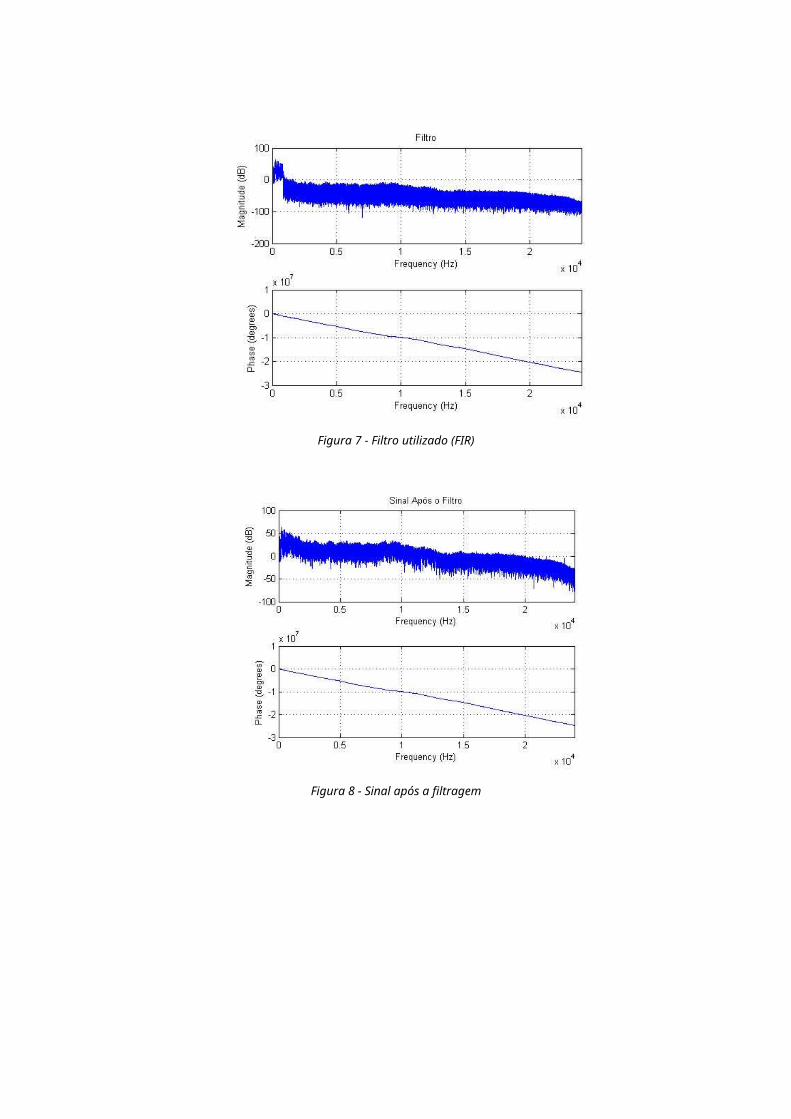
Figura 7 - Filtro utilizado (FIR)
Figura 8 - Sinal após a filtragem
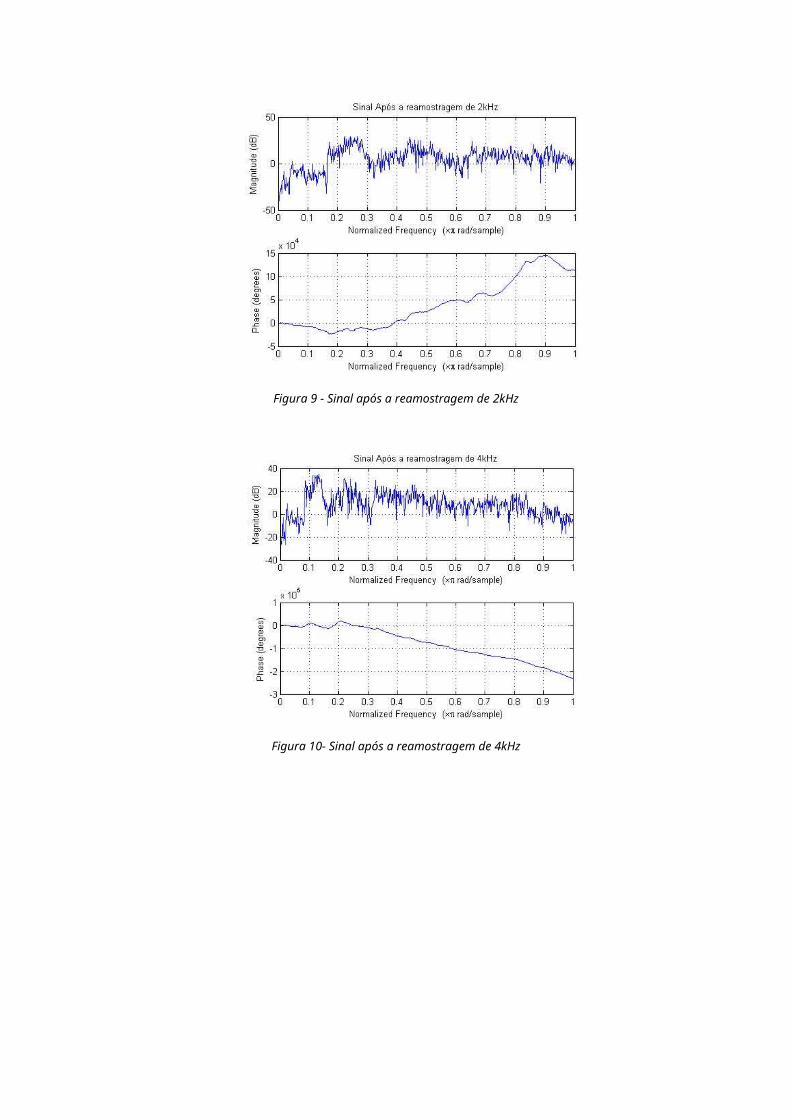
Figura 9 - Sinal após a reamostragem de 2kHz
Figura 10- Sinal após a reamostragem de 4kHz
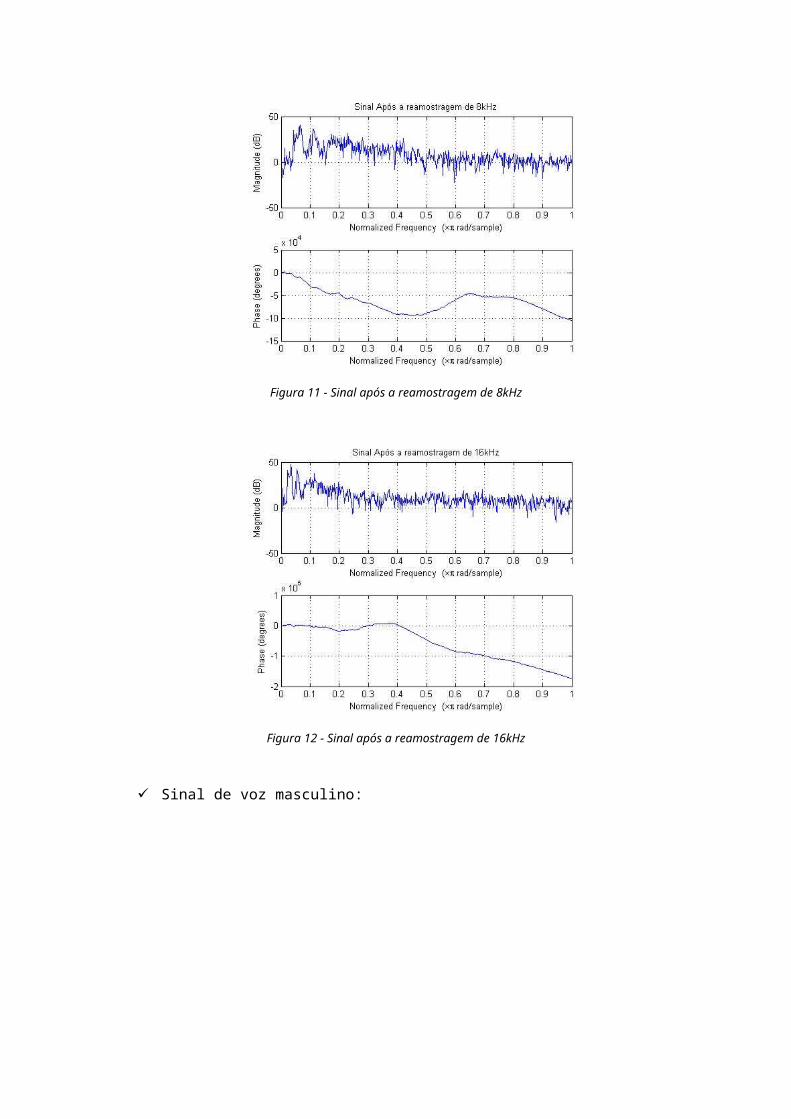
Figura 11 - Sinal após a reamostragem de 8kHz
Figura 12 - Sinal após a reamostragem de 16kHz
Sinal de voz masculino:
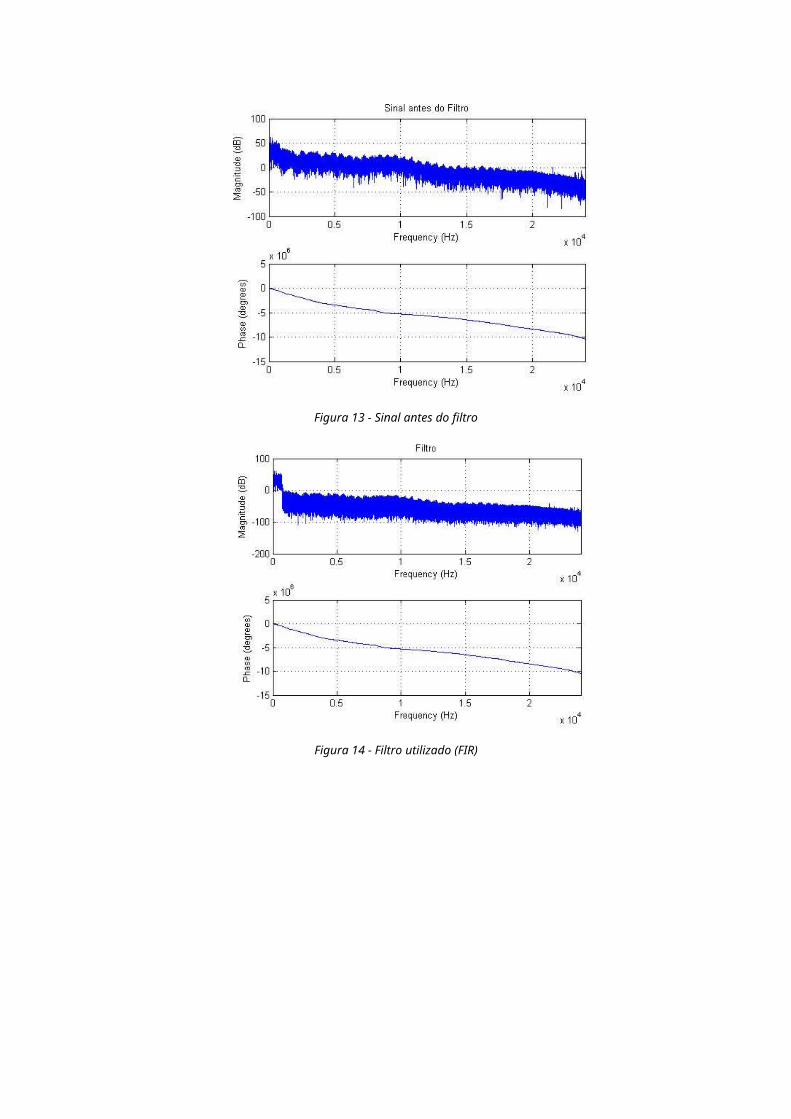
Figura 13 - Sinal antes do filtro
Figura 14 - Filtro utilizado (FIR)
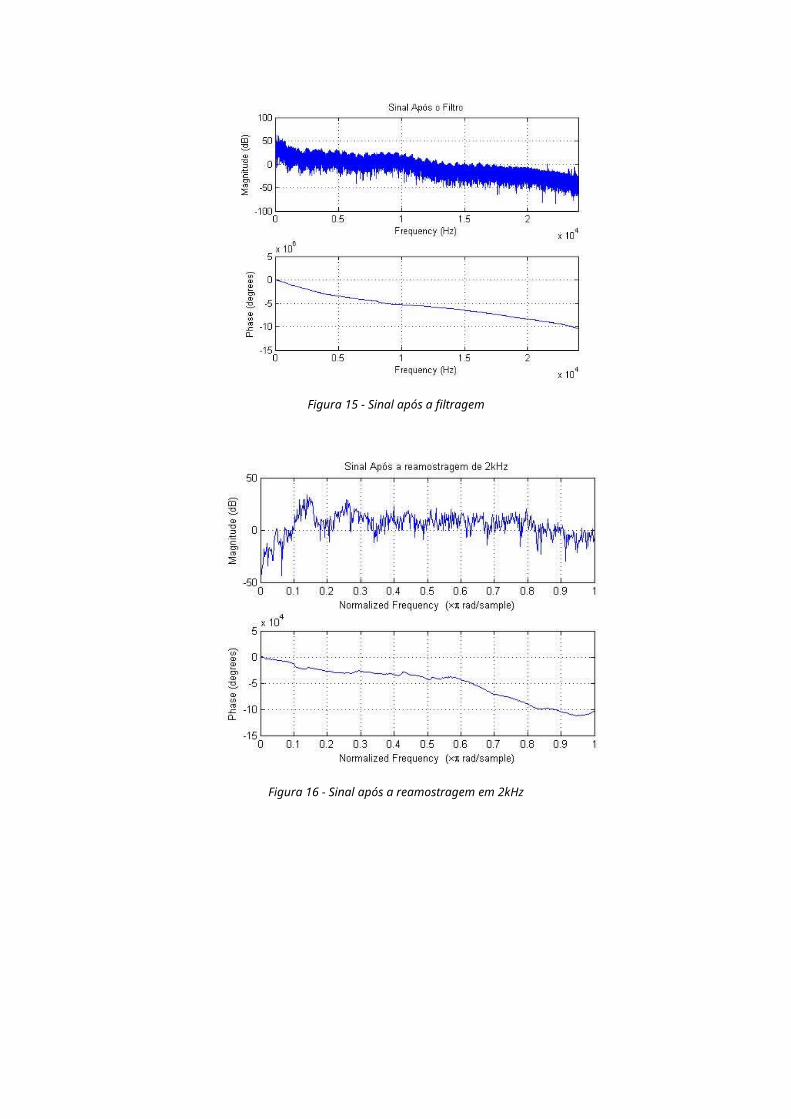
Figura 15 - Sinal após a filtragem
Figura 16 - Sinal após a reamostragem em 2kHz
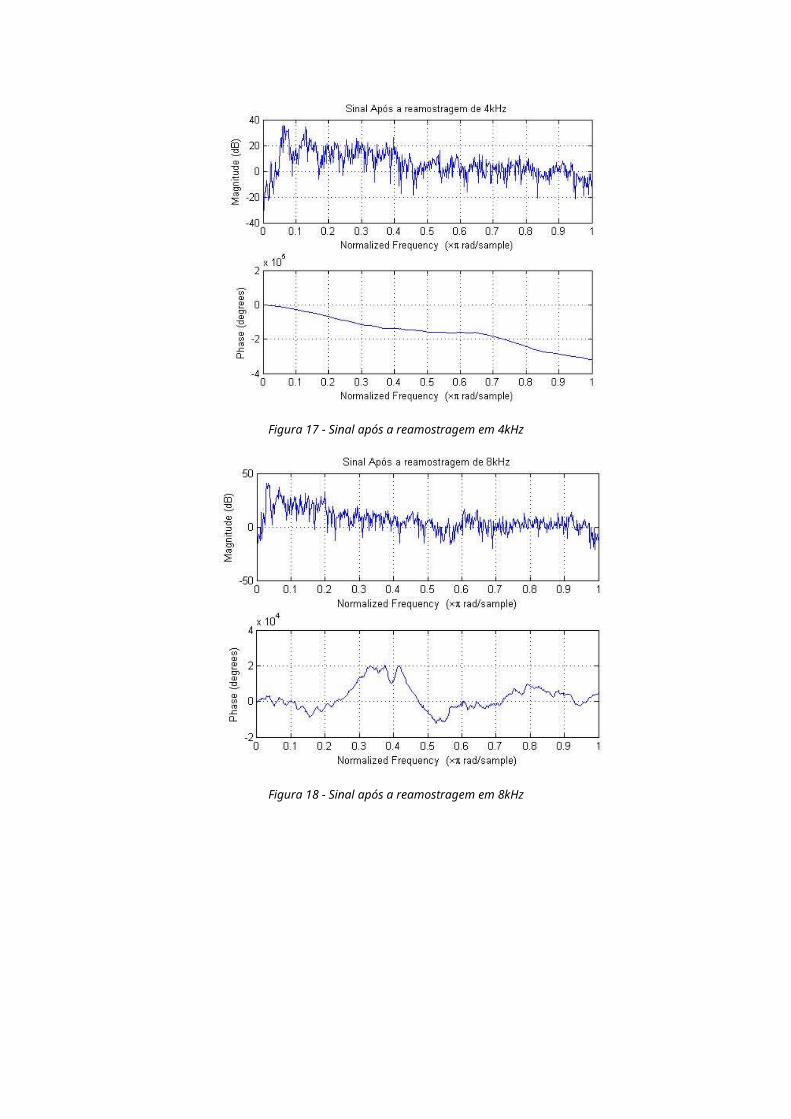
Figura 17 - Sinal após a reamostragem em 4kHz
Figura 18 - Sinal após a reamostragem em 8kHz
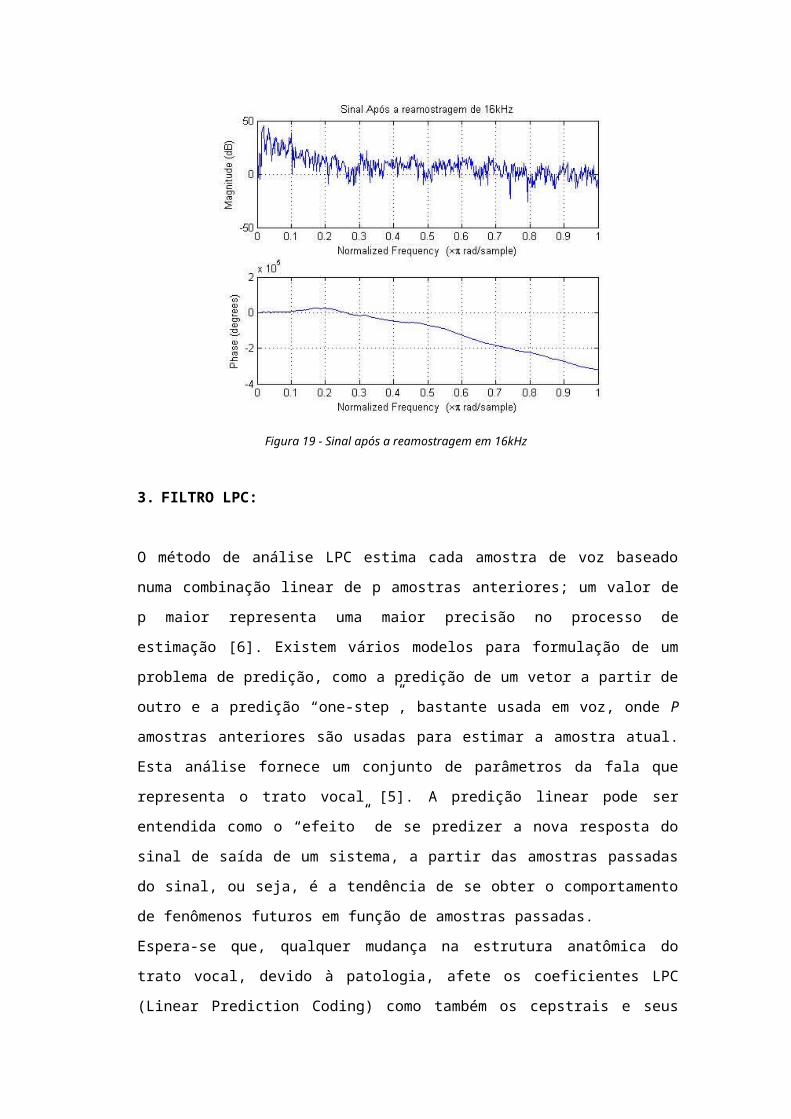
Figura 19 - Sinal após a reamostragem em 16kHz
3. FILTRO LPC:
O método de análise LPC estima cada amostra de voz baseado
numa combinação linear de p amostras anteriores; um valor de
p maior representa uma maior precisão no processo de
estimação [6]. Existem vários modelos para formulação de um
problema de predição, como a predição de um vetor a partir de
outro e a predição “one-step”, bastante usada em voz, onde P
amostras anteriores são usadas para estimar a amostra atual.
Esta análise fornece um conjunto de parâmetros da fala que
representa o trato vocal [5]. A predição linear pode ser
entendida como o “efeito” de se predizer a nova resposta do
sinal de saída de um sistema, a partir das amostras passadas
do sinal, ou seja, é a tendência de se obter o comportamento
de fenômenos futuros em função de amostras passadas.
Espera-se que, qualquer mudança na estrutura anatômica do
trato vocal, devido à patologia, afete os coeficientes LPC
(Linear Prediction Coding) como também os cepstrais e seus

derivados. Um preditor linear com coeficientes de predição,
α(k), é definido como um sistema cuja saída é dada pela
equação:
s (n )=∑k=1
pa (k )s(n−k)
Onde α(k) são os coeficientes de predição, s(n−k) são as
amostras passadas e p é a ordem do preditor. O método de
autocorrelação e o da covariância são dois métodos padrões
para o cálculo dos coeficientes do preditor.
Para garantir que o erro de predição seja minimizado,
precisamos escolher corretamente os seus coeficientes e para
isso utilizamos o critério de mínimos quadrados, para gerar
esses coeficientes. Para se projetar um preditor, deve-se
dispor inicialmente de um conjunto de amostras do sinal que
se quer prever, para que possam ser calculadas estatísticas
deste sinal, onde o que buscaremos é um preditor que tenha o
menor erro possível. Mais uma vez, ao invés de minimizar a
soma do erro (o que permitiria que erros positivos se
cancelassem com erros negativos), minimiza-se o erro
quadrático médio (EQM), após isso basta derivar o EQM e
igualar a relação a zero para determinar o valor mínimo.
Para o caso de um preditor de ordem M, considera-se
inicialmente sp(n) como uma sequência de amostras preditas por
um preditor linear de M-ésima ordem, da forma:
sp (n )=−∑k=1
Maks(n−k) (3.1)
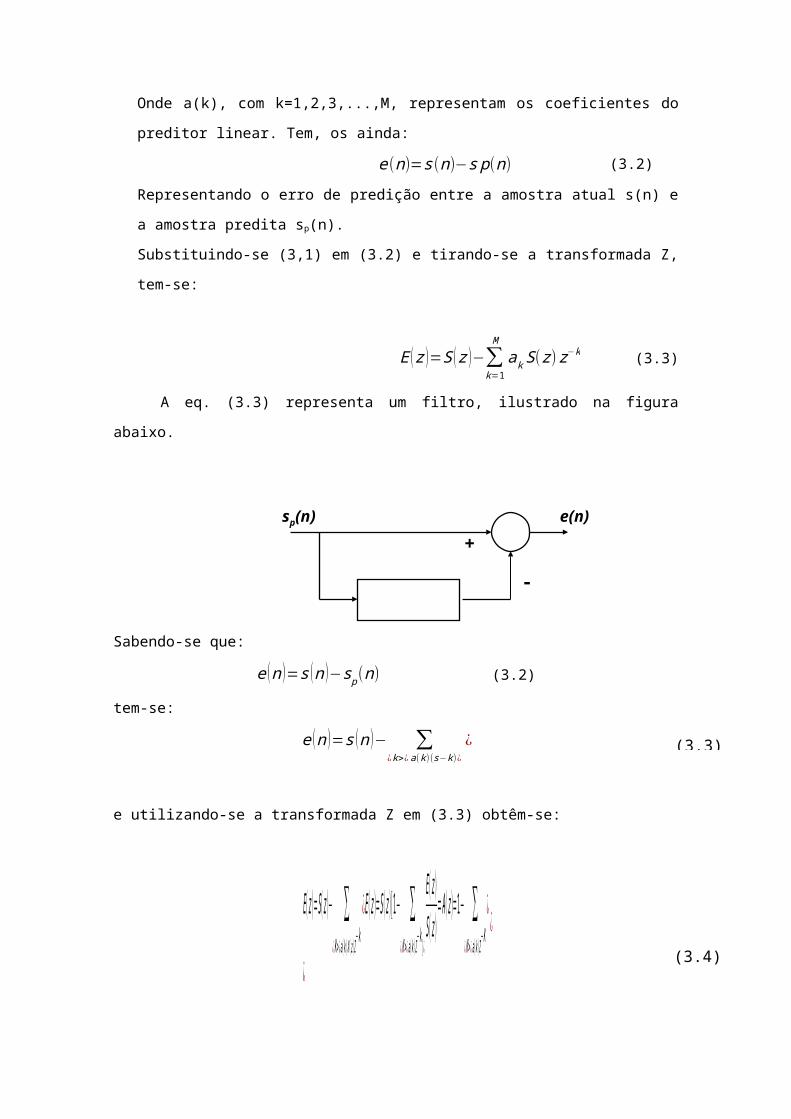
Onde a(k), com k=1,2,3,...,M, representam os coeficientes do
preditor linear. Tem, os ainda:
e(n)=s(n)−sp(n) (3.2)
Representando o erro de predição entre a amostra atual s(n) e
a amostra predita sp(n).
Substituindo-se (3,1) em (3.2) e tirando-se a transformada Z,
tem-se:
E (z )=S (z )−∑k=1
MakS(z)z−k (3.3)
A eq. (3.3) representa um filtro, ilustrado na figura
abaixo.
Sabendo-se que:
e (n )=s (n )−sp(n) (3.2)
tem-se:
e (n )=s (n )− ∑¿k>¿ a(k)(s−k)¿
¿
e utilizando-se a transformada Z em (3.3) obtêm-se:
E(z )=S(z )− ∑¿ K>¿a(k )X (z)Z−k
¿E (z )=S (z )[1− ∑¿K>¿a(k )Z−k] ¿
E(z )S(z )
=A(z)=1− ∑¿K>¿a(k )Z−K
¿
¿
¿(3.4)
(3.3)
+
-
e(n)sp(n)

sendo , a equação (3.4) pode ser representada por:
onde A(z) é denominado de Filtro Preditor Inverso, sendo
ilustrado na figura abaixo.
A equação (3.5) pode ainda ser representada por:
(3.6)
Deve-se observar que o primeiro coeficiente do preditor, a(0), é
sempre igual a 1. Considerando-se o erro de predição e(n) dado
por:
A obtenção dos coeficientes do preditor é feita através da
minimização do erro quadrático da função e(n), ou seja:
Em
=∑ne2(n)=∑
n¿¿¿¿
Agora os coeficientes do preditor, a(k), serão aqueles que
irão minimizar o erro quadrático. Assim, após derivarmos
obtemos:
Soma do Erro de Predição instantâneoErro Quadrático
(3.5
(3.7)
(3.8
Figura 20: Modelo de Filtro Preditor Inverso
A(z) e(n)
E(z)
s(n)
S(z)

∂Em∂a(k)
=∂∂a(k)
∑n (s(n)−∑
K=1
pa(k )s(n−k))
2
∂Em∂a(k)
=2∑n
¿¿
¿
¿
obtendo-se:
onde
A equação (3.11) representa o mínimo erro quadrático de
saída de um sinal:
∑−∞
∞
s(n).s(n−k)=∑K=1
pa (k).∑
−∞
∞
s(n−k ).s(n−j)
e é conhecida como “equação normal” ou equação “Yule-Walker".
O valor das n amostras em (3.11) seria ilimitado (- < n
< ), onde a “equação normal” para o cálculo dos coeficientes do
preditor, é obtida pela equação (3.12)
(3.12)
onde,
e
(3.13)
são funções simétricas.
No primeiro termo da equação (3.12), tem-se a representação
da função de autocorrelação. Porém, quando o valor médio do
sinal é nulo (sem nível DC) a autocorrelação coincide com a
covariância. O segundo termo é representado por p coeficientes
a(k) que multiplicam a função autocorrelação deslocada, R(k-j).
(3.10)
(3.9
(3.11 j p
(1 j p)
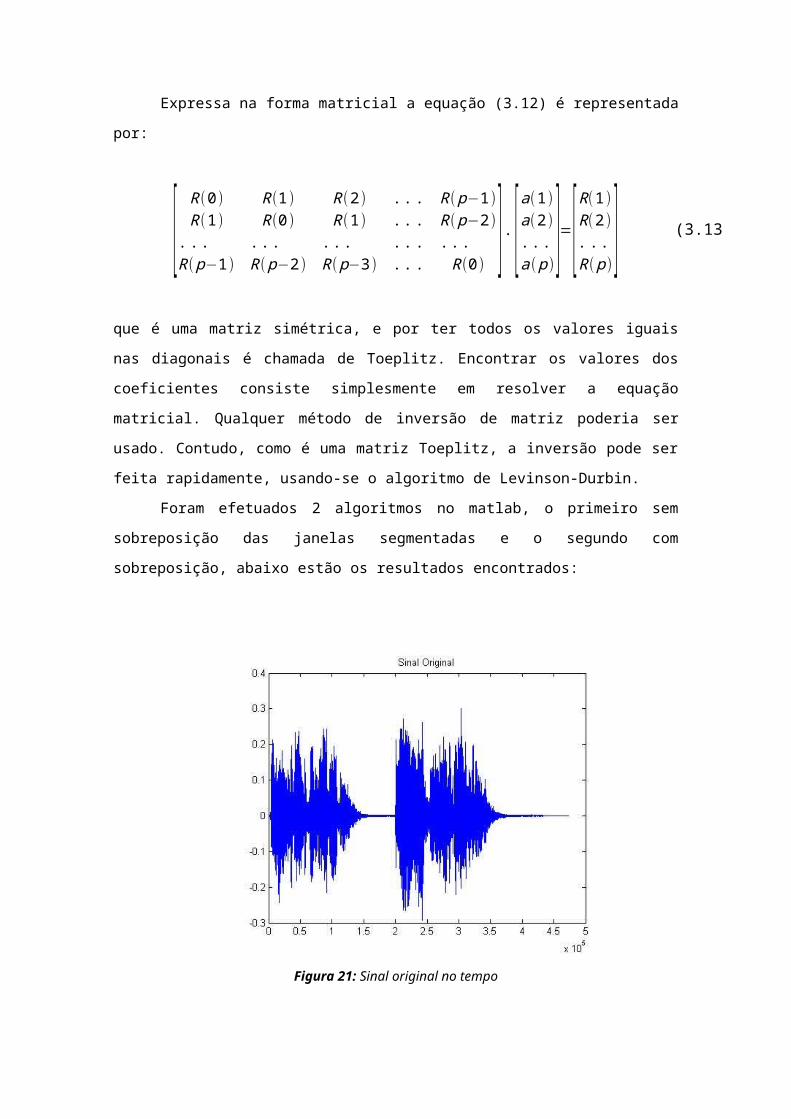
Expressa na forma matricial a equação (3.12) é representada
por:
[ R(0) R(1) R(2) ... R(p−1)R(1) R(0) R(1) ... R(p−2)
... ... ... ... ...R(p−1) R(p−2) R(p−3) ... R(0)
]. [a(1)a(2)...a(p)
]=[R(1)R(2)...R(p)
]que é uma matriz simétrica, e por ter todos os valores iguais
nas diagonais é chamada de Toeplitz. Encontrar os valores dos
coeficientes consiste simplesmente em resolver a equação
matricial. Qualquer método de inversão de matriz poderia ser
usado. Contudo, como é uma matriz Toeplitz, a inversão pode ser
feita rapidamente, usando-se o algoritmo de Levinson-Durbin.
Foram efetuados 2 algoritmos no matlab, o primeiro sem
sobreposição das janelas segmentadas e o segundo com
sobreposição, abaixo estão os resultados encontrados:
Figura 21: Sinal original no tempo
(3.13)
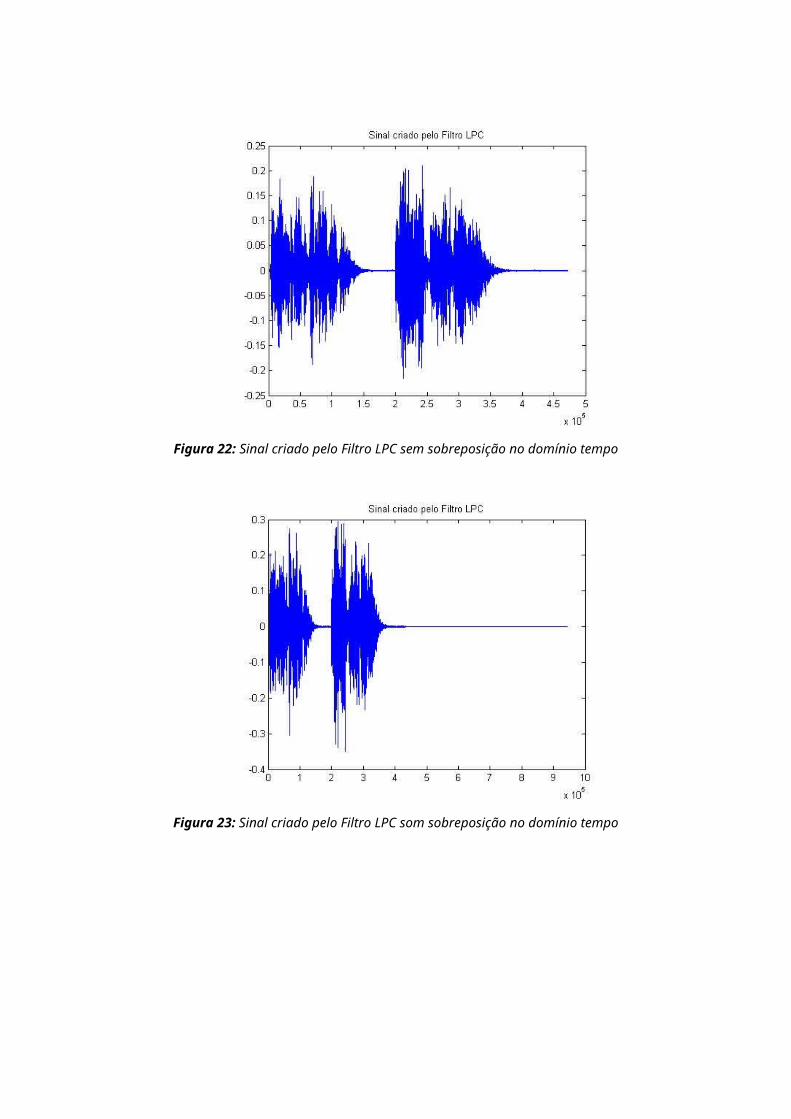
Figura 22: Sinal criado pelo Filtro LPC sem sobreposição no domínio tempo
Figura 23: Sinal criado pelo Filtro LPC som sobreposição no domínio tempo
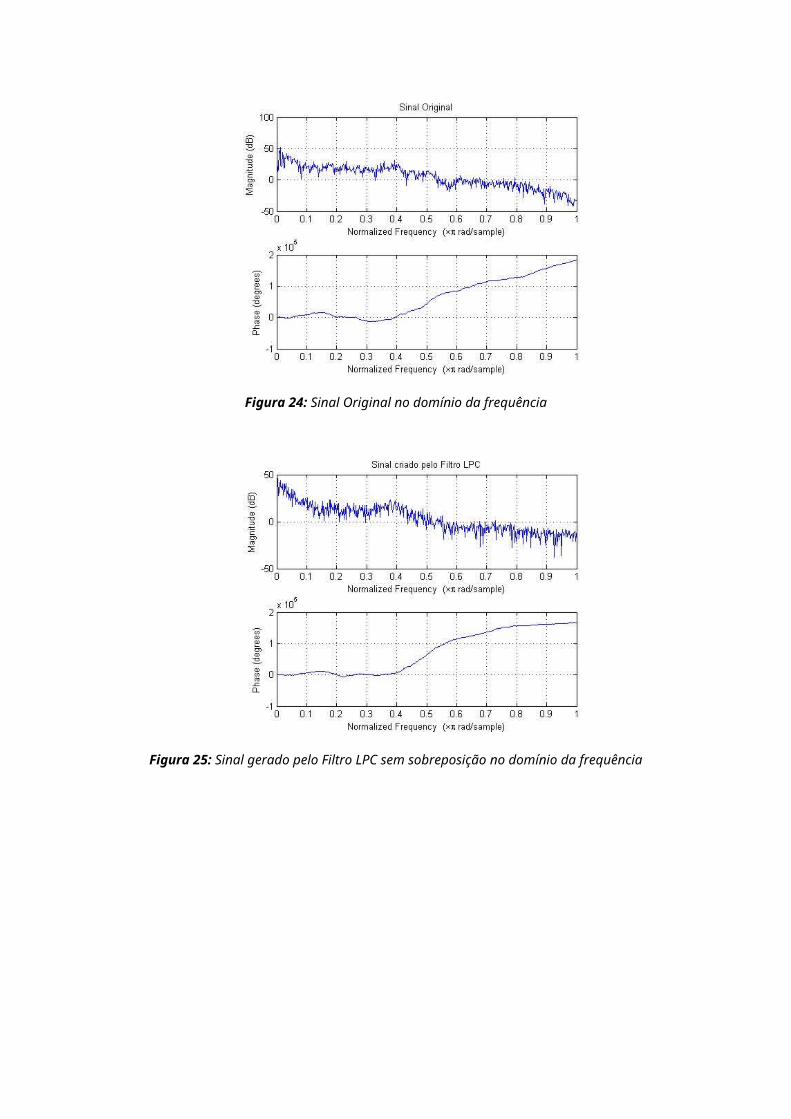
Figura 24: Sinal Original no domínio da frequência
Figura 25: Sinal gerado pelo Filtro LPC sem sobreposição no domínio da frequência
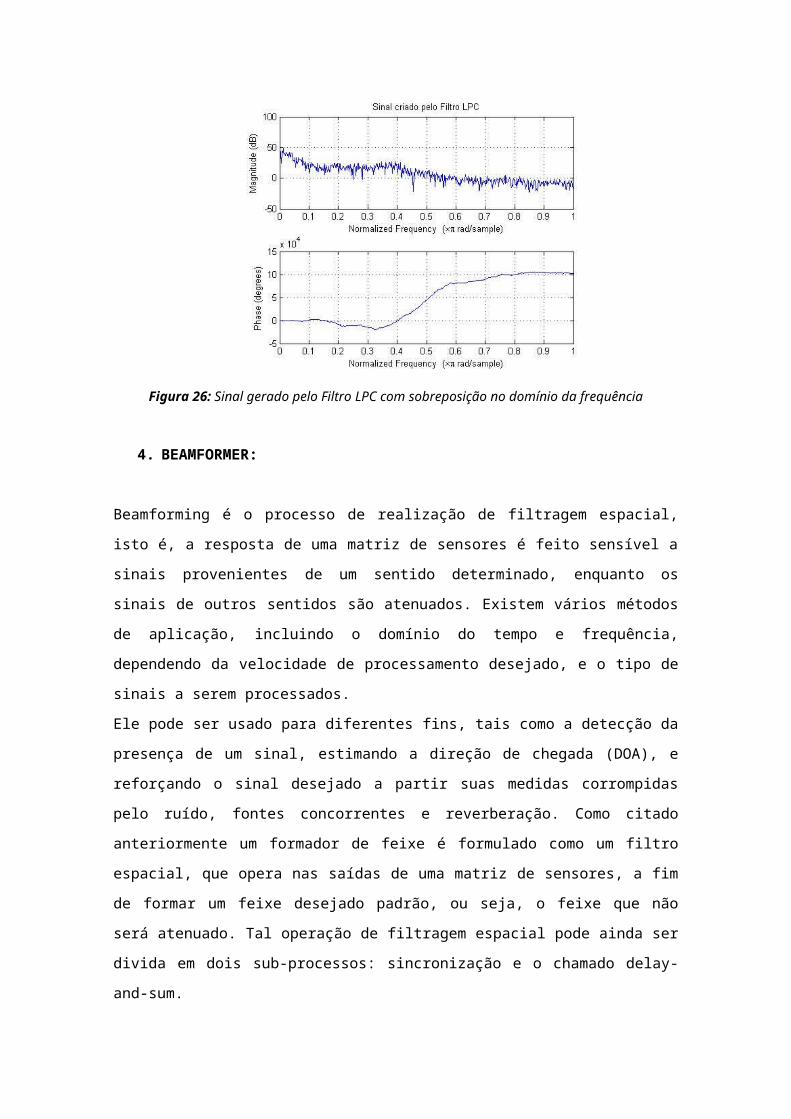
Figura 26: Sinal gerado pelo Filtro LPC com sobreposição no domínio da frequência
4. BEAMFORMER:
Beamforming é o processo de realização de filtragem espacial,
isto é, a resposta de uma matriz de sensores é feito sensível a
sinais provenientes de um sentido determinado, enquanto os
sinais de outros sentidos são atenuados. Existem vários métodos
de aplicação, incluindo o domínio do tempo e frequência,
dependendo da velocidade de processamento desejado, e o tipo de
sinais a serem processados.
Ele pode ser usado para diferentes fins, tais como a detecção da
presença de um sinal, estimando a direção de chegada (DOA), e
reforçando o sinal desejado a partir suas medidas corrompidas
pelo ruído, fontes concorrentes e reverberação. Como citado
anteriormente um formador de feixe é formulado como um filtro
espacial, que opera nas saídas de uma matriz de sensores, a fim
de formar um feixe desejado padrão, ou seja, o feixe que não
será atenuado. Tal operação de filtragem espacial pode ainda ser
divida em dois sub-processos: sincronização e o chamado delay-
and-sum.

O processo de sincronização consiste em atrasar ou antecipar
cada saída do sensor por uma quantidade adequada de tempo de
modo que os componentes de sinal provenientes de uma direção
pretendida estejam sincronizados. As informações necessárias
nesta etapa é a diferença de tempo de chegada (TDOA), o qual, se
não for conhecida, a priori, pode ser estimada a partir das
medições de matriz usando técnicas de estimativa do tempo de
atraso.
O delay-and-sum é o atraso dos sinais alinhados e, em seguida,
adicionar todos os resultados, de modo a formar uma única saída.
Embora ambos os processos desempenhem um papel importante em
controlar o padrão de feixe array (a parte de sincronização
controla o sentido de direção e do processo de delay-and-sum
controla a largura do feixe do lóbulo principal e as
características dos lóbulos laterais). Em muitas aplicações, os
coeficientes de ponderação podem ser determinados com base em um
padrão de feixe conjunto pré-especificado, mas geralmente é mais
vantajoso estimar os coeficientes de um modo adaptativo com base
no sinal e ruído característico.
4.1 BEAMFORMIN
G UTILIZANDO DELAY-AND-SUM:
Têm-se uma matriz de microfones e com isso podemos medir o tempo
de atraso a partir do momento o som atinge o primeiro microfone
até que se atinja o segundo. Se assumirmos onda é originalmente
ente longe que pode tratar da borda da sua propagação como um
avião, em seguida, os atrasos são simples de modelar com a
trigonometria, como mostrado na figura abaixo:
M1 M2 M3 M4 MN
X3(k)θ
Plane wave
X2(k))
X1(k)
X4(k)
XN(k)
d

Suponha que temos uma matriz linear de microfones M1 até Mn, cada
um espaçados d metros distante. Então Ddelay, a distância a mais
que o som tem que viajar para cada microfone sucessiva, é dada
por:
Ddelay=d.cos (θ)
Ao nível do mar, a velocidade do som é 340,29 m/s, o que
significa que o tempo de atraso é:
Tdelay=d
340,29.cos (θ)
Invertendo esse atraso de cada microfone e somando as entradas,
podemos recuperar o sinal original. Se um sinal vem de uma
direção diferente, os atrasos serão diferentes e, como
resultado, os sinais individuais não vão alinhar e tenderão a
anular-se mutuamente quando adicionado. Isto essencialmente cria
um filtro espacial que podemos apontar em qualquer direção,
alterando os atrasos [10].
Para determinar a direção de um sinal veio, podemos varrer nosso
raio ao redor da sala, e registrar a potência total do sinal
Figura 27: Plano de onda para uma array linear de microfones

recebido por cada feixe. A fonte veio da direção com o sinal de
maior poder [10].
5. CONCLUSÃO:
Através das técnicas de processamento do sinal descritas, visa-
se obter informações relevantes para que seja possível obter uma
maior precisão do feixe padrão de voz e retirar deles ruídos
indesejados. Para isso foi necessário entender como é o
funcionamento de filtros digitais, sua segmentação e
características, para depois utilizarmos o beamformer. Contudo
não houve tempo hábil para que fossem estudadas todas as
características desse processamento e as aplicações dele.

REFERÊNCIAS BIBLIOGRÁFICAS:
[1] Rabiner, L. R., Schafer, R.W. Digital processing of
speech signals. Prentice Hall, 1978;
[2] Proakis, J. G., Manolakis, D. G. Digital Signal
Processing: principles, algorithms, and applications. New
Jersey: Prentice Hall, 1996, 968 p;
[3] NETTO, Sergio Lima, Codificação de Voz para Sistemas
de Telecomunicações, Rio de Janeiro.
[4] A. Antoniou, Digital Filters: Analysis, Design, and
Applciations, McGraw-Hill, New York:NW, 2nd, edition, 1992.
[5] RABINER, L. R. and SCHAFER, R. W. Digital Processing
of Speech Signals. New Jersey: Prentice-Hall, 1978.
[6] MONTEIRO, Nathália A. Brunet; VIEIRA, Raissa Tavares;
LUCIENE, Silvana; CORREIA, Suzete. TÉCNICAS DE
PROCESSAMENTO DIGITAL DE SINAIS DE VOZ PARA DETECÇÃO DE
PARALISIA NAS DOBRAS VOCAIS. João Pessoa, Paraíba.
[7] Schafer R. W. and Rabiner L. R., "A digital signal processing
approach to Interpolation", Proceedings of the IEEE, vol. 61,
June 1973.
[8] Shannon C., "Communication in the presence of noise",
Proceedings of the IRE, vol. 37, pp. 10-21, January 1949.
[9] Sotelo J., "Matrix Circuit Descriptions and Test Information",
Interphase Technologies, 1201 Shaffer Road, Santa Cruz,

California, 95060, October 1991.The MathWorks Inc., PRO-
MATLAB. Available at (http://www.mathworks.com ).
[10] BELL, Steven; WEST, Nathan. “Acoustic Beamforming
System Theory and Requirements. Article students IEEE.
[11] Rabiner, L. R., Schafer, R.W. Digital processing of
speech signals. Prentice Hall, 1978;
[12] Proakis, J. G., Manolakis, D. G. Digital Signal
Processing: principles, algorithms, and applications. New
Jersey: Prentice Hall, 1996, 968 p;
[13]Oppenhein, A. V., Schafer, R. W. Discrete Time Signal
Processing, 2.ed. New York: Prentice Hall, 2002;
[14] Chou, W., Juang, B.H. Pattern recognition in speech
and language processing. CRC Press, 2003;

ANEXO A – Reamostragem de um sinal de voz utilizando o filtro FIRPM
clfclear all [y, Fs] = wavread('C:\Users\Priscila\Documents\Cefet\IC\Sons Matlab\Som 1 - Feminino\Som 1.wav');Fs;v = fft(y);t = (0:length (y) - 1)/Fs; figure freqz(y, 1, length(y), 48000);title ('Sinal antes do Filtro') %exemplo de utilização % frequencia de corte = %amplitude = [1 0] [n,fo,ao,w] = firpmord([ 800 850 ],[ 1 0 ],[ 0.1 0.01 ], 48000);b = firpm(n,fo,ao,w); Y = filter(b, 1,y);figure freqz(Y, 1, length (Y), 48000)title ('Filtro') %O sinal após o filtrofigure freqz(y,1,length(y),48000);title ('Sinal Após o Filtro'); wavplay(Y, Fs); % Reamostragem em 2 kHzF4 = 2000;y4 = resample (y,F4,Fs);t4 = (0:length (y) - 1)/F4;wavplay (y4, F4)figure freqz(y4)title ('Sinal Após a reamostragem de 2kHz'); % Reamostragem em 4 kHz

F3 = 4000;y3 = resample (y,F3,Fs);t3 = (0:length (y) - 1)/F3;wavplay (y3, F3)figure freqz(y3)title ('Sinal Após a reamostragem de 4kHz'); % Reamostragem em 8 kHzF2 = 8000;y2 = resample (y,F2,Fs);t2 = (0:length (y) - 1)/F2;wavplay (y2, F2)figure freqz(y2)title ('Sinal Após a reamostragem de 8kHz'); % Reamostragem em 16 kHzF1 = 16000;y1 = resample (y,F1,Fs);t1 = (0:length (y) - 1)/F1;wavplay (y1, F1)figure freqz(y1)title ('Sinal Após a reamostragem de 16kHz');
ANEXO B – Filtro LPC sem sobreposição
clfclear all [sinaloriginal, Fs] = wavread('C:\Users\Priscila\Documents\Cefet\IC\Sons Matlab\Som 1 - Feminino\Som 1.wav');Fs;%Janela de Hanningx = 0.03*Fs; %tamanho da janelas de Hanningn = length(sinaloriginal); %tamanho do vetorNseg = floor(n/x); %Numero de segmentos sem sobreposiçãoM = zeros( x, Nseg); %Matriz inicial pro armazenamentosinal = zeros(x,Nseg);wHan = hanning(x); j=1; %SEM SOBREPOSIÇÃO for k=1:Nseg z = k*x; M(:,k) = sinaloriginal((k-1)*x+1:z).* wHan;

end % Obtendo o sinal de voz for k=1:Nseg r = randn (length (M(:,k)),1); %Ruído BrancoC =lpc(M(:,k),10); %Coeficientes LPC[sinal(:,k),f] = filter (1, C, r); %sinal após o filtro ser excitado com ruido branco% size(sinal) end %Normalizando a potênciafor k=1:Nseg P0 = sum(M(:,k).^2);P1= (sum(sinal(:,k).^2)); P(k) = sqrt(P0/P1);end for k=1:Nseg sinal(:,k) = sinal(:,k)*P(k); end %reproduzindo o som sem saturação soundsc(sinal(:),Fs); %tripona da matriz sinal %Comparando os gráficos antes x depois%Antesplot(sinaloriginal)title ('Sinal Original')figurefreqz(sinaloriginal)title ('Sinal Original')figure %Depoisplot (sinal(:))title ('Sinal criado pelo Filtro LPC')figure

freqz (sinal (:))title ('Sinal criado pelo Filtro LPC')figure
ANEXO C – Filtro LPC com sobreposição
clfclear all [sinaloriginal, Fs] = wavread('C:\Users\Priscila\Documents\Cefet\IC\Sons Matlab\Som 1 - Feminino\Som 1.wav');Fs;%v = fft(sinaloriginal);%t = (0:length () - 1)/Fs;%wavplay (y, Fs)%figure %plot (t, y)%length (t); %Janela de Hanningx = 0.03*Fs; %tamanho da janelas de Hanningx1 = round(x/2);n = length(sinaloriginal); %tamanho do vetorNseg = floor((n-x)/(x/2) + 1); %Numero de segmentos sem sobreposiçãoseg = zeros( Nseg*x, 1); %Vetor inicial pro armazenamentoM = zeros( x, Nseg); %Matriz inicial pro armazenamentosinal = zeros(x,Nseg);wHan = hanning(x); j=1;% COM SOBREPOSIÇÃO DE 50%%Tamanho da janela
for k= 1:Nseg inicial = 1+(k-1)*(x1); final = k*x1+(x1); M(:,k) = sinaloriginal(inicial:final).*wHan; % seg(inicial:final,1) = M(inicial:final, 1) + seg; end % Obtendo o sinal de voz

for k=1:Nseg r = randn (length (M(:,k)),1); %Ruído BrancoC =lpc(M(:,k),10); %Coeficientes LPC[sinal(:,k),f] = filter (1, C, r); %sinal após o filtro ser excitado com ruido branco% size(sinal) end %Normalizando a potênciafor k=1:Nseg P0 = sum(M(:,k).^2);P1= (sum(sinal(:,k).^2)); P(k) = sqrt(P0/P1);end for k=1:Nseg sinal(:,k) = sinal(:,k)*P(k); end %reproduzindo o som sem saturação for k=1:Nseg inicial = 1+(k-1)*(x1); final = k*x1+(x1); seg(inicial:final,1) = sinal(:, k) + seg(inicial:final,1); end soundsc(seg(:),Fs); %tripona da matriz sinal %Comparando os gráficos antes x depois%plot(sinaloriginal)%figurefigureplot (seg(:))title ('Sinal criado pelo Filtro LPC')figurefreqz (seg(:))title ('Sinal criado pelo Filtro LPC')

ANEXO D – Exemplo de um Beamformer
close allclear all%%hmic = phased.OmnidirectionalMicrophoneElement;ha = phased.ULA(10,0.05,'Element',hmic); %d=0,05, Numero de microfones: 10c = 340,29; % sound speed, in m/s %% Simulate the Received Signals% Next, we simulate the multi-channel signals received by the microphone% array. We first load two recorded speech signals: speech1 and speech2. We% also load a laughter audio segment to use as interference. The laughter% is truncated to have the same length as the speech signals. The sampling% frequency of the speech signals is 8.192 kHz. load('twospeeches','speech1','speech2');load('laughter','y'); % The laughter is stored in variable yy = 2*y(1:length(speech1)); % Amplify and truncatefs = 8192; % in Hz %angulos de incidencia ang1 = [-30; 0];ang2 = [60; 10];angInt = [20; 0];%%% Now we can use a wideband collector to simulate the multi-channel signal% received by the array. Note each input single-channel signal is assumed% to be received at the origin of the array by a single microphone. Atthe% output, the received signal is stored in a 39922x10 matrix. Each column% of the matrix represents the signal collected by one microphone. hCollector = phased.WidebandCollector('Sensor',ha,'PropagationSpeed',c,... 'SampleRate',fs,'ModulatedInput', false);sigSource = step(hCollector,[speech1 speech2 y],[ang1 ang2 angInt]); %gera o sinal

%%% We generate a white noise signal with a power of 1e-4 Watts to% represent the thermal noise for each sensor. We create a local random% number stream for reproducible results. rs = RandStream.create('mt19937ar','Seed',2008);noisePwr = 1e-4; % noise powersigNoise = sqrt(noisePwr)*randn(rs,size(sigSource)); %%% Now we combine the signal and the noise.sigArray = sigSource + sigNoise; % Plot channel 3figureplot(sigArray(:,3));xlabel('Time (sec)'); ylabel ('Amplitude (V)');title('Signal Received at Channel 3'); ylim([-3 3]);





























