Embed Size (px)
Citation preview

Descubrimiento de Conocimiento en Big Data:
Estudio de Mapeo Sistémico Luis F. Tabares, Jhonatan F. Hernández
Estudiantes Maestría en Ingeniería de Software, Universidad de San Buenaventura
Cali, Colombia
Abstract— El constante uso de las tecnologías ha traído consigo
un crecimiento explosivo en la cantidad, velocidad y diversidad
de los datos, conocido como Big Data. A partir de este
crecimiento, se da la necesidad de generar conocimiento de forma
rápida y eficiente, para lo cual, el tradicional KDD ha tenido que
evolucionar en busca de rendimiento y escalabilidad. Sin
embargo, Big Data en combinación con KDD es un tópico nuevo
que se plantea como un término comercial, una tecnología o,
simplemente, una caracterización relacionada con datos. El
presente artículo busca obtener una clasificación general de la
combinación de estos términos para conciliar estas diferencias y
descubrir algunos retos y tendencias importantes. Para esto se
llevó a cabo un estudio de mapeo sistémico, que partió desde unas
preguntas de investigación hasta llegar a la búsqueda, selección y
clasificación de 106 estudios. El análisis realizado permitió
concluir que es un tópico multidisciplinar relativamente nuevo y
en aumento, año tras año, en cuanto a investigaciones, en su
mayoría, de tipo propositivas.
Palabras Clave: KDD, Big Data, Analytics, Mapeo Sistémico
I. INTRODUCCIÓN
El constante avance de las tecnologías de información, ha permitido un crecimiento “explosivo” en la cantidad de datos generados desde diferentes fuentes, tales como, redes sociales, dispositivos móviles, sensores, máquinas de rayos x, telescopios, sondas espaciales, log de aplicativos, sistemas de predicción del clima, sistemas de geo-posicionamiento, entre otros, caracterizados por tratarse de datos, en su mayoría, sin estructura [1].
A este crecimiento explosivo o revolución de datos se le ha atribuido el famoso término “Big Data”, que según [1] y [2], hace referencia –principalmente- a las 3 Vs: Volumen, Velocidad y Variedad. Tal como sucedió con los problemas convencionales, surgió la necesidad de extraer, de manera eficiente, patrones, tendencias y/o conocimiento que permitan apoyar la toma de decisiones a partir de Big Data, para lo cual, los métodos tradicionales de procesamiento de datos han tenido que evolucionar rápidamente, buscando escalabilidad y rendimiento principalmente, con el fin de suministrar respuestas en tiempo real, al menor costo posible.
En este contexto, a los patrones, tendencias y/o conocimiento generado a partir de estos datos se le conoce como la cuarta V (Valor) y las técnicas que lo respaldan se encuentran enmarcadas dentro de alguno de los procesos de KDD (Knowledge Discovery in Databases) [3]. Existe un amplio espectro de investigaciones relacionadas con estos dos tópicos (KDD + Big Data), las cuales se encuentran tipificadas
de numerosas maneras y presentan diversos resultados, siendo Big Data el tópico más reciente, mientras que KDD (o sus tópicos derivados) data de mucho tiempo atrás (década de los 70 y 80).
Aún y si se estudian KDD y Big Data de forma combinada, las investigaciones que debieran revisarse son bastante extensas en número y variedad. Por lo anterior, se hace necesario llevar a cabo un estudio de mapeo sistémico [4], el cual cuenta con unas líneas guía para llevarlo a cabo de una forma estandarizada, por procesos, cuyo resultado final es la clasificación y estructuración del tópico de interés.
En este reporte se presentan los resultados de la aplicación de un estudio de mapeo sistémico sobre los tópicos de interés, los cuales son KDD y Big Data, es decir, Big Data Analytics, con el fin de clasificar adecuadamente la información que evidencia la combinación de estos tópicos y, de esta manera, aplicarla en investigaciones futuras. El reporte se divide en las siguientes secciones: Metodología de Investigación (Sección II), donde se describe el alcance de los procesos que fueron llevados a cabo durante el estudio. Resultados (Sección III), que corresponde a la sección principal del reporte y presenta los resultados obtenidos en la aplicación del estudio. Finalmente, se presenta una discusión final (Sección IV), las conclusiones (Sección V) a las que condujo el estudio y el trabajo futuro (Sección VI ).
II. METODOLOGÍA DE INVESTIGACIÓN
Según [4], un estudio de mapeo sistémico es un estudio secundario que tiene como objetivo construir un esquema de clasificación y estructurar un campo de interés de la ingeniería de software. Esta metodología de investigación es la más adecuada para llevar a cabo el estudio requerido ya que se cuenta con tópicos de ingeniería de software con un espectro bastante amplio. Estos tópicos requieren ser estudiados de forma combinada con el fin de evidenciar, primordialmente, su uso y los posibles trabajos futuros que puedan emerger de los mismos.
Para llevar a cabo un estudio de este tipo, se debe definir un objetivo principal, el cual será transformado en las preguntas de investigación, que conducirán las siguientes fases del estudio hasta llegar a un esquema de clasificación bien definido, con el cual puedan abordarse otro tipo de estudios como la Revisión Sistemática de Literatura, descrita en [5] por el profesor Cochrane, la cual, a diferencia del estudio de mapeo sistémico, es utilizada para trabajar con áreas o tópicos más específicos. En este orden de ideas, se puede deducir que uno de los insumos principales de la revisión sistemática de

literatura por abordar en el futuro, será precisamente este estudio.
En el presente estudio, se utilizaron las líneas guía propuestas en [5], las cuales corresponden a la ejecución de cinco procesos: (1) Definición de las Preguntas de Investigación, (2) Selección de Fuentes, (3) Conducción de la
Búsqueda, (4) Selección de Estudios y (5) Extracción y Síntesis de Datos. Estos procesos pertenecen a unas fases conocidas como Planeación (Protocolo y Preguntas), Conducción (Fuentes, Búsqueda y Selección) y Resultados (Extracción y Síntesis). De igual forma, cada proceso presenta unas entradas (que vienen de su predecesor) y unas salidas (que son insumo de su sucesor), tal como se muestra en la Figura 1.
Figura 1. Procesos del Estudio de Mapeo Sistémico. Tomado de [4]
Es importante mencionar la importancia que tiene la
elaboración del protocolo, el cual evitará cualquier sesgo que pueda presentarse durante la aplicación del estudio. El protocolo corresponde al plan del estudio y, en este caso, fue definido en términos de alcance y tiempo, donde el alcance básicamente corresponde al objetivo principal y las preguntas de investigación. El abordaje de cada proceso del estudio de mapeo sistémico llevado a cabo se describe con mayor detalle a continuación. Después de la descripción de estos procesos, se muestra el cronograma elaborado para la planeación del tiempo del estudio.
A. Preguntas de Investigación
Se parte de que los tópicos de interés son Big Data y KDD, haciendo referencia a este último como cualquiera de sus procesos o, en un ámbito más general, todo lo que se conoce como Inteligencia de Negocios o el término “Analytics” comúnmente acuñado a éste. Lo que se busca con estos tópicos básicamente es la aplicación de los procesos o técnicas de KDD en entornos caracterizados como Big Data y, en términos generales, hablando de Big Data más como un paradigma que como una tecnología emergente.
Según lo anterior, la pregunta principal que se plantea es: ¿Qué evidencia existe sobre la implementación de procesos KDD en entornos caracterizados como Big Data? Esta pregunta busca obtener la mayor evidencia posible sobre la implementación o aplicación de cualquiera de los procesos de ingeniería de software relacionada con alguno de los procesos KDD (ETL, Minería, Visualización/Interpretación) en entornos que previamente fueron categorizados como Big Data. La idea con esta evidencia es encontrar, inicialmente, las principales tendencias, retos, tipos de abordaje de los estudios y su distribución, en términos de año, tipo de publicación, dominio de aplicación y enfoque principal.
Esta pregunta principal fue descompuesta en siete secundarias, dentro las cuales, cinco de ellas son auxiliares, puesto que apuntan a la distribución de los estudios. Estas preguntas están representadas en la Tabla 1.
Tabla 1. Preguntas de Investigación
Id. Pregunta de Investigación Explicación
RQ1
¿Qué tendencias existen sobre
la implementación de KDD en
entornos Big Data? ¿Qué proceso KDD se aborda
principalmente?
Busca obtener las principales
tendencias que se marcan en las
implementaciones de los procesos de KDD en entornos de Big Data
y cuáles son los procesos del KDD
a los que apuntan estas tendencias.
RQ2
¿Cuáles son los principales
retos relacionados con la implementación de KDD en
entornos de Big Data? ¿Qué
proceso KDD se aborda principalmente?
Busca abordar los principales
retos, amenazas y trade-offs con los que pueden encontrarse los
practicantes durante la
implementación de algún proceso KDD en entornos de Big Data y
cuáles son los procesos del KDD a
los que apuntan estos retos.
RQ3
¿En qué tipos de publicación y en qué años tienen mayor foco
las investigaciones?
Busca evidenciar la distribución de los estudios seleccionados y
analizados, desde el punto de vista
de los tipos (i.e. journals, conferences) y años de
publicación de los mismos.
RQ4
¿Cuáles son los dominios o
áreas de aplicación a los que
más apuntan las investigaciones?
Busca evidenciar la distribución
de los estudios seleccionados y
analizados, desde el punto de vista del contexto, área de aplicación o
dominio (i.e. Health, Retail, Telco,
Social Computing).
RQ5
¿Cuáles son los tipos de
investigación más abordados?
Busca evidenciar la distribución
de los estudios seleccionados y analizados, desde el punto de vista
de los tipos de investigación bajo
los cuales fueron abordados.
RQ6
¿Cuáles son los tipos de
resultado más comunes?
Busca evidenciar la distribución
de los estudios seleccionados y analizados, desde el punto de vista
de los tipos de resultados que
fueron presentados en las
Systematic Mapping Studies in Software Engineering
main one being the considerable effort required. In software engineering the systematic reviews
have focused on quantitative and empirical studies, but a large set of methods for synthesizing
qualitative research results exists (Dixon-Woods et al. 2005).
Systematic mapping is a methodology that is frequently used in medical research, but that have
largely been neglected in SE. To the best of our knowledge there is only one clear example of
a systematic mapping study within SE (Bailey et al. 2007). This may be due to that systematic
maps have not yet been discovered as a method for aggregating software engineering research.
A systematic mapping study provides a structure of the type of research reports and results that
have been published by categorizing them. It often gives a visual summary, the map, of its results.
It requires less effort while providing a more coarse-grained overview. Previously, systematic
mapping studies in software engineering have been recommended mostly for research areas
where there is a lack of relevant, high-quality primary studies (Kitchenham & Charters 2007).
In this paper we analyze the differences between systematic review and systematic mapping
studies and argue for a broader set of situations where the latter is appropriate. In Section
2 we describe a detailed process for systematic maps. Section 3 summarizes the existing SE
systematic reviews and contrasts them with systematic maps. Section 4 then discusses additional
guidelines for systematic maps before we conclude in Section 5.
2. THE SYSTEMATIC MAPPING PROCESS
We have adapted and applied systematic mapping to software engineering in a study focusing on
software product line variability (Mujtaba et al. 2008). In the following, we detail the process we
used. We also discuss some of the choices in the systematic map by (Bailey et al. 2007).
Definition of
Research Quesiton
Review Scope
Conduct Search
All Papers
Screening of Papers
Relevant Papers
Keywording using
Abstracts
Classification
Scheme
Data Extraction and
Mapping Process
Systematic Map
Process Steps
Outcomes
FIGURE 1: The Systematic Mapping Process
The essential process steps of our systematic mapping study are definition of research questions,
conducting the search for relevant papers, screening of papers, keywording of abstracts and data
extraction and mapping (see Figure 1). Each process steps has an outcome, the final outcome of
the process being the systematic map.
2.1. Definition of Research Questions (Research Scope)
The main goal of a systematic mapping studies is to provide an overview of a research area,
and identify the quantity and type of research and results available within it. Often one wants to
map the frequencies of publication over time to see trends. A secondary goal can be to identify
the forums in which research in the area has been published. These goals are reflected in both
papers’ research questions (RQs) which are similar, as shown in Table 1.
TABLE 1: Research Questions for Systematic Maps
Object Oriented Design Map (Bailey et al. 2007) Software Product Line Variability Map (Mujtaba et al.
2008)
RQ1: Which journals include papers on software design?
RQ2: What are the most investigated object oriented
design topics and how have these changed over time?
RQ3: What are the most frequently applied research
methods, and in what study context?
RQ1: What areas in software product line variability are
addressed and how many articles cover the different
areas?
RQ2: What types of papers are published in the area and
in particular what type of evaluation and novelty do they
constitute?
2

investigaciones.
RQ7
¿Cuáles son las técnicas de
validación más utilizadas?
Busca evidenciar la distribución
de los estudios seleccionados y
analizados, desde el punto de vista de las técnicas de validación que
fueron utilizadas en las
investigaciones (i.e. Analysis, Experience, Example, Persuation,
Evaluation).
Para la formulación de las preguntas de investigación se
revisó y aplicó la técnica PICO, de la siguiente forma:
Population: Estudios publicados sobre entornos caracterizados como Big Data
Intervention: Implementación de procesos KDD
Control: Criterios de inclusión y exclusión de estudios. Previo conocimiento de la temática, logrado a partir de la construcción de un estado del arte en el año 2014 [6]
Outcome: Listado de evidencias concretas sobre la implementación de procesos KDD sobre Big Data. Estas evidencias pueden ser: modelos, frameworks, taxonomías, estados del arte, ontologías, arquitecturas, soluciones específicas de software, casos de estudio, técnicas, tendencias y retos
Contexto: Cualquier dominio o área de aplicación
B. Selección de Fuentes
Las fuentes utilizadas en el estudio fueron las siguientes bibliotecas digitales: Compendex, Scopus, IEEE Xplore y ACM. Los criterios de selección utilizados en este caso fueron básicamente la disponibilidad de estas bibliotecas y el hecho de ser referentes en ingeniería de software. Con respecto a la disponibilidad, la universidad San Buenaventura tiene un convenio con Compendex y Scopus para el acceso de sus estudiantes, mientras que IEEE Xplore y ACM son de libre acceso para su búsqueda y revisión de abstracts.
Compendex y Scopus son las que tienen una mayor cantidad de estudios y presentan una interfaz de búsqueda más completa y flexible, comparadas con las otras dos. Sin embargo, dado que IEEE Xplore y ACM representan las bibliotecas digitales de mayor referencia en el campo de la ingeniería de software, fueron utilizadas como complemento a las búsquedas realizadas en las dos primeras, para evitar perder estudios importantes. En la Tabla 2 se muestra el resumen de las fuentes seleccionadas.
C. Estrategia de Búsqueda
Para la búsqueda de los estudios en las fuentes definidas se utilizó la guía propuesta en [4]. Se aplicaron los pasos representados en la Figura 2 y descritos a continuación:
1) Palabras Clave Se obtuvieron las palabras clave a través de la
descomposición de las preguntas de investigación y la pregunta principal. Las palabras claves que se dedujeron fueron Big Data y KDD.
2) Sinónimos Se buscaron y generaron sinónimos para las palabras clave.
En este caso, se acudió al diccionario de IEEE y a los estudios realizados previamente sobre los tópicos para identificar los términos con los que son referidas normalmente las palabras clave. Los sinónimos generados se encuentran representados en la Tabla 3.
3) Cadena de Búsqueda Se organizó la cadena de búsqueda con las palabras clave
utilizando los operadores OR para sinónimos o alternativas, AND para combinar las palabras clave y NOT para exclusiones o negaciones. En este caso, no se encontraron negaciones por incluir. Inicialmente, se formuló la siguiente cadena de búsqueda:
SQ = (SQBDA OR (SQBD AND SQA)), donde SQBDA corresponde a términos con combinaciones típicas entre Big Data y KDD, SQBD corresponde a los términos relacionados con Big Data y SQA corresponde a los términos utilizados para KDD (o Analytics). De esta formulación, se generó la siguiente cadena de búsqueda:
SQ = (("big data analytics" OR "big data warehousing" OR "big data mining" OR "big data bussiness intelligence" OR "big data BI" OR "big data knowledge discovery" OR "big data KDD" OR "big data OLAP" OR "big data analysis") OR ((“big data” OR bigdata) AND (analytics OR "data warehousing" OR "data mining" OR "bussiness intelligence" OR BI OR "knowledge discovery" OR KDD OR OLAP OR analysis)))
En un posterior refinamiento, motivado por consultas previas en las fuentes seleccionadas más grandes, se optó por únicamente incluir las combinaciones puntuales entre Big Data y KDD (variable SQBDA en la fórmula descrita anteriormente), quedando la cadena de búsqueda reducida a:
SQ = "big data analytics" OR "big data warehousing" OR "big data mining" OR "big data bussiness intelligence" OR "big data BI" OR "big data knowledge discovery" OR "big data KDD" OR "big data OLAP" OR "big data analysis"
4) Generación de la búsqueda en las fuentes
seleccionadas La cadena de búsqueda generada fue ajustada según el
formato de cada fuente para su posterior aplicación en las mismas. Cabe resaltar que en este punto se aplicaron los siguientes criterios de inclusión: Años [2010,2015]; Tipos de publicación {Journals, Conference Proceedings}; Idioma {Inglés}; Acceso a Abstract y Keywords {Sí}. En la Tabla 4 se muestran las búsquedas ajustadas y realizadas en cada fuente, las cuales arrojaron 2.258 estudios inicialmente.
5) Filtrado Automático de duplicados Se unieron las búsquedas y, a través de una solución
informática basada en la búsqueda por distancia en las cadenas de los títulos, se removieron los títulos similares a otros en por lo menos un 80%. Con este filtrado se llegó a 1.112 estudios.
6) Filtrado Manual de duplicados Utilizando la misma solución informática del punto
anterior, se generó un listado de los títulos con al menos un 70% de similitud. Este listado de sugerencias fue revisado de forma manual, removiendo los estudios que ya eran abordados en otros. Con este filtrado se llegó a 1.100 estudios.

Tabla 2. Fuentes seleccionadas para el estudio de mapeo sistémico
Fuente URL Cantidad Estudios Fuentes que Indexa
Compendex
http://www.engineeringvillage.com/
>17M
IEEE, ACM
Scopus http://www.scopus.com/ >55M SpringerVerLag, IEEE,
ACM
IEEE http://ieeexplore.ieee.org/Xplore/home.jsp >3M IEEE
ACM http://dl.acm.org/ >2M
ACM
Definición de Palabras Clave
Definición de Alternativas y
Sinónimos
Definición de la Cadena de Búsqueda
Búsqueda en Fuentes
Filtro DuplicadosAutomático
Filtro DuplicadosManual
Palabras ClaveSinónimos y
Operadores AND/OR
Cadena de Búsqueda
2.258 estudios
1.112 estudios 1.100 estudios
CompendexCompendex ScopusScopus
IEEEIEEE ACMACM
Figura 2. Proceso establecido para la Búsqueda
Tabla 3. Palabras Clave y sus alternativas
Palabra Clave Alternativas
Big Data
Ninguna
KDD analytics, data warehousing, data mining, bussiness intelligence, BI,
knowledge discovery, OLAP, analysis
Tabla 4. Búsquedas realizadas en las fuentes seleccionadas
Fuente Cadena de Búsqueda Cantidad
Compendex
((((((("big data analytics" OR "big data warehousing" OR "big data mining" OR "big data
bussiness intelligence" OR "big data BI" OR "big data knowledge discovery" OR "big data KDD" OR "big data OLAP" OR "big data analysis")) WN KY)) AND ({english} WN LA)) AND ((2015
OR 2014 OR 2013 OR 2012 OR 2011 OR 2010) WN YR)) AND (({ca} OR {ja}) WN DT))
636
Scopus TITLE-ABS-KEY("big data analytics" OR "big data warehousing" OR "big data mining" OR "big
data bussiness intelligence" OR "big data BI" OR "big data knowledge discovery" OR "big data
KDD" OR "big data OLAP" OR "big data analysis") AND PUBYEAR>2009 AND (EXCLUDE(DOCTYPE,"no") OR EXCLUDE(DOCTYPE,"bk") OR EXCLUDE(DOCTYPE,"ch"
) ) AND ( LIMIT-TO(LANGUAGE,"English" ) ) AND ( LIMIT-TO(SRCTYPE,"p" ) OR LIMIT-TO(SRCTYPE,"j" ) ) AND ( EXCLUDE(DOCTYPE,"re" ) OR EXCLUDE(DOCTYPE,"ed" ) OR
EXCLUDE(DOCTYPE,"sh" ) )
700
IEEE (("big data analytics" OR "big data warehousing" OR "big data mining" OR "big data bussiness
intelligence" OR "big data BI" OR "big data knowledge discovery" OR "big data KDD" OR "big
data OLAP" OR "big data analysis"))
529
ACM (Title:("big data analytics" OR "big data warehousing" OR "big data mining" OR "big data bussiness intelligence" OR "big data BI" OR "big data knowledge discovery" OR "big data KDD"
OR "big data OLAP" OR "big data analysis") OR Abstract:("big data analytics" OR "big data
393

warehousing" OR "big data mining" OR "big data bussiness intelligence" OR "big data BI" OR
"big data knowledge discovery" OR "big data KDD" OR "big data OLAP" OR "big data analysis") OR Keywords:("big data analytics" OR "big data warehousing" OR "big data mining" OR "big
data bussiness intelligence" OR "big data BI" OR "big data knowledge discovery" OR "big data
KDD" OR "big data OLAP" OR "big data analysis") AND (PublishedAs:journal) AND (AbstractFlag:yes))
Total: 2.258
D. Selección de Fuentes
Para la selección final de los estudios, se definieron los criterios de inclusión y exclusión que se muestran en la Tabla 5, con los cuales se excluyeron estudios no relevantes o que no respondieron a alguna de las preguntas de investigación.
Tabla 5. Criterios de Inclusión/Exclusión
Tipo Criterio
Inclusión
Artículos publicados entre los años 2010 y
2015
Artículos publicados en Journals y
Conference Proceedings
Artículos escritos en idioma inglés
Artículos que tengan acceso a la revisión de
abstract y keywords mínimo
Artículos que aborden alguno de los procesos
de KDD, aplicándolo(s) estrictamente en
entornos Big Data
Artículos de aplicación general o en un área
específica
Artículos relacionados específicamente con
ingeniería de software
Artículos que permitan evidenciar el método
de validación utilizado
Exclusión
Si se requiere un artículo completo y éste no
es accesible por medio de la universidad o
directamente con el autor, será excluido
Artículos que aborden uno de los tópicos pero
sin relación o con una relación no muy clara
Artículos que no presenten una
implementación o aplicación por medio de los
procesos de la Ingeniería de Software
Artículos relacionados con Hardware o
Telecomunicaciones (solo se incluirá
Software)
Artículos que no presenten un objetivo
claramente identificable
Artículos que no indiquen la consecución y
validación de resultados
Artículos que no involucren ninguna
característica de este tipo de
implementaciones (arquitecturas, modelos,
técnicas, herramientas)
Teniendo estos criterios definidos, este proceso se llevó a cabo en tres fases representadas en la Figura 3, los cuales se describen a continuación:
1.100 estudios
Revisión en TítulosRevisión en Abstracts y Keywords
428 estudios 106 estudios
Figura 3. Proceso establecido para la Selección de estudios
1) Selección por revisión en Títulos Se revisaron los títulos de los artículos utilizando como
criterio principal de inclusión/exclusión, el hecho de encontrar los tópicos de interés -o alguna alusión a ellos- en el título. También se descartaron artículos utilizando la relevancia que fue asignada por las fuentes seleccionadas. Con esta selección se pasó de 1.100 a 428 estudios.
2) Selección por revisión en Abstracts y Keywords Posteriormente, se revisaron los abstracts y palabras clave
de los artículos, utilizando el resto de criterios de inclusión/exclusión. Se utilizó también la relevancia de las fuentes para llevar a cabo algunas exclusiones. Con esta selección se pasó de 428 a 106 estudios.
Finalmente, se pasó al proceso de extracción de datos y clasificación de la información con 106 estudios seleccionados. Estos estudios corresponden a las siguientes referencias: [7]–[111].
E. Extracción de Datos y Síntesis
Con el fin de obtener toda la información relevante, según las preguntas de investigación planteadas, se llevó a cabo la elaboración de un esquema de clasificación y, posteriormente, éste fue aplicado a cada uno de los estudios. Para el esquema de clasificación, se aplicó la técnica de descomposición de las preguntas de investigación en facetas o categorías. Mediante esta técnica se generaron ocho, las cuales pueden ser vistas en la Figura 4 y se describen a continuación.

Figura 4. Facetas/Categorías para la clasificación de los estudios
1) Year Año de publicación del estudio [2010, 2011, 2012, 2013,
2014, 2015]. Intenta responder a la pregunta RQ3.
2) Publication Type Tipo o canal de Publicación del estudio [Journal paper,
Conference paper/proceeding]. Intenta responder a la pregunta RQ3.
3) Domain Dominio, Contexto o Área de Aplicación del estudio
[Scientific discipline, Social and personal computing, Business, Government, Health Care, Telco and Utilities, Manufacture, IT, IT Security, Transport and Logistic, Education, General, Other]. Estas áreas de aplicación fueron generadas durante la lectura de los mismos artículos, tomando como base [6]. Se incluyeron las categorías General y Other dado que varios estudios no corresponden a aplicaciones específicas. Intenta responder a la pregunta RQ4.
4) Research Type Tipo de Investigación [Validation Research, Evaluation
Research, Solution Proposal, Philosophical Papers, Opinion Papers, Experience Papers, Other]. Estos tipos de investigación fueron tomados de [4]. Intenta responder a la pregunta RQ5.
5) Result Type Tipo de Resultado [Procedure or technique, Qualitative or
descriptive model, Empirical model, Analytic model, Notation or tool, Specific solution, Answer or judgment, Report]. Estos tipos de resultado fueron tomados de [4]. Intenta responder a la pregunta RQ6.
6) Validation Type Tipo de Investigación [Analysis, Experience, Example,
Persuasion, Evaluation]. Estos tipos de validación fueron tomados de [4]. Intenta responder a la pregunta RQ7.
7) Trends and/or Challenges Tendencias y/o Retos relacionados con Big Data Analytics
[Data capture and storage, Data transmission, Data security,
Architecture, Data analysis, Data visualization, Enterprise, Computing Platform]. Para generar estas categorías, se consultaron en [6] los puntos principales a los que se direccionan las tendencias y retos/amenazas. Se consideró de gran relevancia conocer sobre cual de estas categoría se abordó principalmente el estudio. Intenta responder a las preguntas RQ1 y RQ2.
8) KDD Process Proceso o Subproceso de KDD abordado [ETL, Data
mining, Visualization, All]. Se agrupó la extracción, transformación y carga en ETL. Con estas categorías se busca identificar sobre qué proceso de KDD se enfocaron los estudios. Se considera de gran relevancia determinar la relación que existe entre esta categoría y las demás. Intenta apoyar la respuesta a las preguntas RQ1 y RQ2.
Estas categorías fueron identificadas para cada uno de los 106 estudios, permitiendo llegar fácilmente a los resultados. En la Tabla 6 se puede evidenciar un ejemplo de las clasificaciones asignadas para un estudio.
Tabla 6. Ejemplo de Clasificación de un estudio
Paper ID: 1
Paper Title: OCEANRT: REAL-TIME ANALYTICS OVER
LARGE TEMPORAL DATA
Autors: Zhang, S.; Yang, Y.; Fan, W.; Lan, L.; Yuan, M.
Published in: SIGMOD '14 Proceedings of the 2014 ACM SIGMOD
international conference on Management of data
Abstract: We demonstrate OceanRT, a novel cloud-based
infrastructure that performs online analytics in real time, over large-
scale temporal data such as call logs from a telecommunication
company. Apart from proprietary systems for which few details have
been revealed, most existing big-data analytics systems are built on
top of an offline, MapReduce-style infrastructure, which inherently
limits their efficiency. In contrast, OceanRT employs a novel
computing architecture consisting of interconnected Access Query
Engines (AQEs), as well as a new storage scheme that ensures data
locality and fast access for temporal data. Our preliminary evaluation
shows that OceanRT can be up to 10x faster than Impala [10], 12x
faster than Shark [5], and 200x faster than Hive [13]. The demo will
show how OceanRT manages a real call log dataset (around 5TB per
day) from a large mobile network operator in China. Besides
presenting the processing of a few preset queries, we also allow the
audience to issue ad hoc HiveQL [13] queries, watch how OceanRT
answers them, and compare the speed of OceanRT with its
competitors.
Category Assigned Value
TYPE OF PUBLICATION Conference Paper
YEAR 2014
DOMAIN Telco and Utilities
RESEARCH TYPE Solution Proposal
RESULT TYPE Specific solution
Big
Dat
a K
DD
- F
acet
s Publication Type - RQ3
Year - RQ3
Domain - RQ4
Research Type - RQ5
Result Type - RQ6
Validation Type - RQ7
Challenges/Trends - RQ1 y RQ2
KDD Process - RQ1 y RQ2

VALIDATION TYPE Example
TREND / CHALLENGE Architecture
KDD PROCESS Data mining
Teniendo clasificados todos los estudios, se realizó un proceso de recolección y agregación de información, el cual corresponde básicamente a la generación de dos tipos de resultados:
1) Frecuencia por categoría individual Corresponde a la obtención de las frecuencias (conteo de
estudios) para cada categoría o faceta, de forma individual.
2) Frecuencia por correlación de categorías Corresponde a la obtención de las frecuencias de las
correlaciones más importantes entre categorías o facetas. Las correlaciones definidas fueron:
Año vs Tipo de Publicación: Tiene como objetivo determinar cuáles son los años en los que más se publicaron artículos de determinado tipo.
Año vs Dominio: Tiene como objetivo determinar cuáles son los años en los que más se publicaron artículos de determinados dominios, o cuáles son los dominios que presentaron mayor auge en algún año en particular.
Año vs Reto/Tendencia: Tiene como objetivo determinar cuáles son los años en los que más se publicaron artículos relacionados con algún reto o tendencia en particular, o cuáles son los retos/tendencias relacionados con Big Data Analytics que presentaron mayor foco en algún año en particular.
Tipo de Publicación vs Dominio: Tiene como objetivo determinar cuáles son los tipos de publicación en los que se encuentra la mayor frecuencia de artículos de determinados dominios, o cuáles son los dominios que presentaron mayor publicación de un tipo particular.
Tipo de Investigación vs Tipo de Resultado vs Tipo de Validación: Tiene como objetivo identificar cuál es el plan más común para el abordaje de las investigaciones revisadas.
Dominio vs Retos/Tendencias vs Proceso KDD: Tiene como objetivo identificar los escenarios más comunes de implementación de Big Data Analytics, según las investigaciones revisadas.
Finalmente, se generaron las tablas de frecuencias con sus correspondientes gráficos con el fin de evidenciar los resultados visualmente. Estos son presentados con su respectiva reflexión en la Sección III.
F. Cronograma de Actividades
El presente mapeo sistémico fue ejecutado siguiendo el protocolo previamente definido. Este protocolo se definió en términos de alcance y tiempo. El alcance fue construido siguiendo la guía descrita en [4], mientras que en cuanto al tiempo, se construyó un cronograma de actividades, teniendo en cuenta cada proceso del mapeo sistémico. Este cronograma puede ser visto en la Tabla 7.
III. RESULTADOS
A continuación se presentarán los resultados del mapeo sistémico, los cuales fueron enfocados a brindar una primera aproximación, basados en las preguntas de investigación elaboradas para dar un entendimiento general al tema de interés.
A. RQ1 y RQ2: ¿Qué tendencias existen sobre la
implementación de KDD en entornos Big Data? ¿Cuáles
son los principales retos relacionados con la
implementación de KDD en entornos de Big Data? ¿Qué
proceso KDD se aborda principalmente?
En la Figura 5 se puede observar que, de 106 los artículos clasificados, un 56.6% se enfocan o hacen referencia al análisis de datos “Data Analysis” como el principal reto y/o tendencia que se presenta para las implementaciones de KDD en ambientes Big Data, lo que refleja que el interés primordial es extraer “Valor” de los datos. También se evidencia que existe preocupación por las arquitecturas y/o plataformas computacionales utilizadas, ya que de éstas y sus atributos de calidad depende, en gran parte, que el “Data Analysis” arroje resultados que generen dicho valor deseado.
Figura 5. Frecuencia para Categoría Tendencias/Retos
Con respecto a la línea de tiempo, según la Figura 6, en relación con los principales retos y/o tendencias, se encuentra que los años 2013 y 2014 son los de mayor número de publicaciones. También se evidencia una tendencia hacia el crecimiento en el abordaje del “Data Analysis” como principal reto y/o tendencia en los estudios realizados. Sin embargo, se debe tener en cuenta que, en el momento en el que fue realizado este mapeo sistémico (entre mayo y junio de 2015), aún no se habían publicado todos los estudios del año 2015 y, por consiguiente, no se puede evidenciar si el número de artículos relacionados continúa en aumento o si, por el contrario, se puede observar una disminución.
2
2
2
3
7
13
17
60
0 20 40 60 80
Data security
Enterprise
Data transmission
Data capture and storage
Data visualization
Computing Platform
Architecture
Data analysis
Challenges / Trends
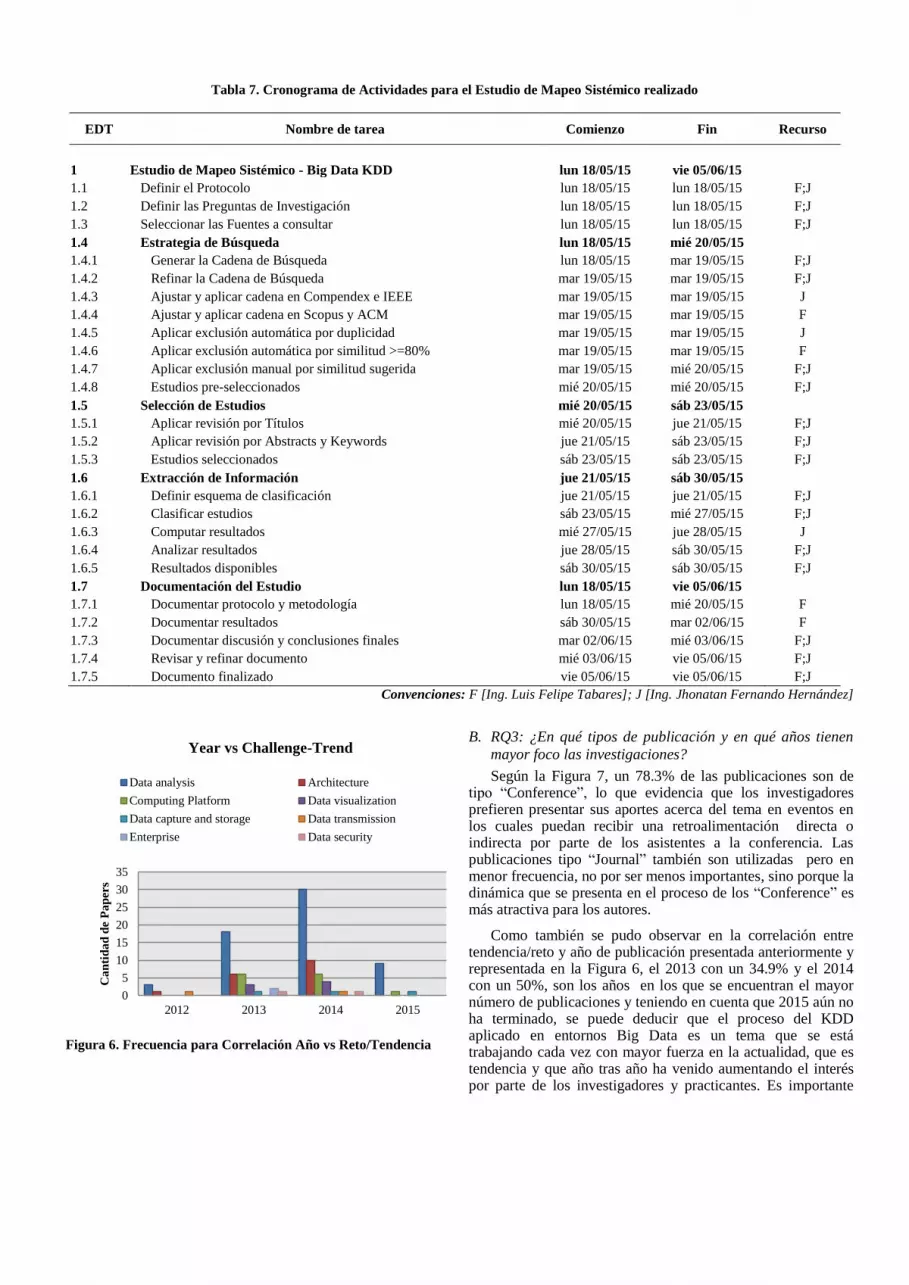
Tabla 7. Cronograma de Actividades para el Estudio de Mapeo Sistémico realizado
EDT Nombre de tarea Comienzo Fin Recurso
1
Estudio de Mapeo Sistémico - Big Data KDD
lun 18/05/15
vie 05/06/15
1.1 Definir el Protocolo lun 18/05/15 lun 18/05/15 F;J
1.2 Definir las Preguntas de Investigación lun 18/05/15 lun 18/05/15 F;J
1.3 Seleccionar las Fuentes a consultar lun 18/05/15 lun 18/05/15 F;J
1.4 Estrategia de Búsqueda lun 18/05/15 mié 20/05/15
1.4.1 Generar la Cadena de Búsqueda lun 18/05/15 mar 19/05/15 F;J
1.4.2 Refinar la Cadena de Búsqueda mar 19/05/15 mar 19/05/15 F;J
1.4.3 Ajustar y aplicar cadena en Compendex e IEEE mar 19/05/15 mar 19/05/15 J
1.4.4 Ajustar y aplicar cadena en Scopus y ACM mar 19/05/15 mar 19/05/15 F
1.4.5 Aplicar exclusión automática por duplicidad mar 19/05/15 mar 19/05/15 J
1.4.6 Aplicar exclusión automática por similitud >=80% mar 19/05/15 mar 19/05/15 F
1.4.7 Aplicar exclusión manual por similitud sugerida mar 19/05/15 mié 20/05/15 F;J
1.4.8 Estudios pre-seleccionados mié 20/05/15 mié 20/05/15 F;J
1.5 Selección de Estudios mié 20/05/15 sáb 23/05/15
1.5.1 Aplicar revisión por Títulos mié 20/05/15 jue 21/05/15 F;J
1.5.2 Aplicar revisión por Abstracts y Keywords jue 21/05/15 sáb 23/05/15 F;J
1.5.3 Estudios seleccionados sáb 23/05/15 sáb 23/05/15 F;J
1.6 Extracción de Información jue 21/05/15 sáb 30/05/15
1.6.1 Definir esquema de clasificación jue 21/05/15 jue 21/05/15 F;J
1.6.2 Clasificar estudios sáb 23/05/15 mié 27/05/15 F;J
1.6.3 Computar resultados mié 27/05/15 jue 28/05/15 J
1.6.4 Analizar resultados jue 28/05/15 sáb 30/05/15 F;J
1.6.5 Resultados disponibles sáb 30/05/15 sáb 30/05/15 F;J
1.7 Documentación del Estudio lun 18/05/15 vie 05/06/15
1.7.1 Documentar protocolo y metodología lun 18/05/15 mié 20/05/15 F
1.7.2 Documentar resultados sáb 30/05/15 mar 02/06/15 F
1.7.3 Documentar discusión y conclusiones finales mar 02/06/15 mié 03/06/15 F;J
1.7.4 Revisar y refinar documento mié 03/06/15 vie 05/06/15 F;J
1.7.5 Documento finalizado vie 05/06/15 vie 05/06/15 F;J
Convenciones: F [Ing. Luis Felipe Tabares]; J [Ing. Jhonatan Fernando Hernández]
Figura 6. Frecuencia para Correlación Año vs Reto/Tendencia
B. RQ3: ¿En qué tipos de publicación y en qué años tienen
mayor foco las investigaciones?
Según la Figura 7, un 78.3% de las publicaciones son de tipo “Conference”, lo que evidencia que los investigadores prefieren presentar sus aportes acerca del tema en eventos en los cuales puedan recibir una retroalimentación directa o indirecta por parte de los asistentes a la conferencia. Las publicaciones tipo “Journal” también son utilizadas pero en menor frecuencia, no por ser menos importantes, sino porque la dinámica que se presenta en el proceso de los “Conference” es más atractiva para los autores.
Como también se pudo observar en la correlación entre tendencia/reto y año de publicación presentada anteriormente y representada en la Figura 6, el 2013 con un 34.9% y el 2014 con un 50%, son los años en los que se encuentran el mayor número de publicaciones y teniendo en cuenta que 2015 aún no ha terminado, se puede deducir que el proceso del KDD aplicado en entornos Big Data es un tema que se está trabajando cada vez con mayor fuerza en la actualidad, que es tendencia y que año tras año ha venido aumentando el interés por parte de los investigadores y practicantes. Es importante
0
5
10
15
20
25
30
35
2012 2013 2014 2015
Ca
nti
da
d d
e P
ap
ers
Year vs Challenge-Trend
Data analysis Architecture
Computing Platform Data visualization
Data capture and storage Data transmission
Enterprise Data security

tener en cuenta que aunque el rango de años para la búsqueda y selección de artículos fue de 2010 a 2015, solo hasta 2012 se comenzó a tratar este tema con formalidad, lo que lo convierte en un “Hot Topic”, el cual trae consigo una curva de crecimiento a través de los años y se espera que en 2015 ésta continúe marcando tendencia al alza. Esto puede evidenciarse con la frecuencia simple mostrada en la Figura 8.
Figura 7. Frecuencia para Categoría Tipo de Publicación
Figura 8. Frecuencia para Categoría Año de Publicación
Al cruzar las facetas tipo y año de publicación, se encuentra que, a través de los años, los artículos de tipo “Conference” siempre han sido superiores en cantidad a los de tipo “Journal”, reflejando así que el medio preferido para abordar este tópico se encuentra en los eventos. La frecuencia de esta correlación se puede observar en la Figura 9.
Figura 9. Frecuencia para Correlación Año vs Tipo de
Publicación
C. RQ4: ¿Cuáles son los dominios o áreas de aplicación a los
que más apuntan las investigaciones?
Según la Figura 10, con un 35%, el dominio de aplicación “General” es el más abordado, seguido de “Social and personal computing” con un 13%, “Business” con un 10% y “Health Care” con un 9 % del total de publicaciones. Basados en lo anterior, se evidencia que las investigaciones están siendo aplicadas en diferentes dominios, lo que convierte al KDD sobre Big Data en un proceso transversal y multidisciplinario que se puede aplicar en cualquier campo donde se garanticen las características para necesarias para su implementación (alguna de las 3 Vs).
Lo anterior también demuestra que estas condiciones se están dando en los diferentes dominios de aplicación y que la tecnología está apoyando mediante la creación de paradigmas –como Big Data-, los cuales intentan abordar la complejidad impuesta por estos entornos de una forma diferente a los que aportan los paradigmas, técnicas y métodos convencionales. De una u otra manera, esto está funcionando y comienza a ser aplicado en otros dominios cada vez con mayor fuerza y resultados positivos.
Figura 10. Frecuencia para Categoría Dominio de Aplicación
En la Figura 11 se puede observar cómo el número de publicaciones por dominio de aplicación ha venido creciendo a través de los años, reafirmando que Big Data KDD es un tema reciente y que su aplicación es multidisciplinaria y toma cada vez mayor fuerza. En la Figura 12 se puede observar también que el tipo de publicación más utilizado en los diferentes dominios se ratifica y corresponde al “Conference”.
Esto confirma que no existe un dominio que presente diferencias substanciales con respecto a los otros en cuanto a las tendencias de tipo y año de publicación.
Conference Paper Journal Paper
Total 83 23
0
20
40
60
80
100
Ca
nti
da
d d
e P
ap
ers
Publication Type
2012 2013 2014 2015
Total 5 37 53 11
0
10
20
30
40
50
60
Ca
nti
da
d d
e P
ap
ers
Publication Year
2012 2013 2014 2015
Conference Paper 4 27 41 11
Journal Paper 1 10 12
0
10
20
30
40
50
Ca
nti
da
d d
e P
ap
ers
Year vs Publication Type
IT Security
2% Transport
and Logistic
2%
Other
3%
Education
3% IT General
4%
Government
6%
Scientific
discipline
6%
Telco and
Utilities
7%
Health Care
9% Business
10%
Social and
personal
computing 13%
General
35%
Application Domain

Figura 11. Frecuencia para Correlación Año vs Dominio de Aplicación
Figura 12. Frecuencia para Correlación Tipo de Publicación vs Dominio
0
2
4
6
8
10
12
14
16
18
2012 2013 2014 2015
Ca
nti
da
d d
e P
ap
ers
Year vs Application Domain
General Social and personal computing Business Health Care
Telco and Utilities Scientific discipline Government IT General
Education Other Transport and Logistic IT Security
General
Social
andpersonal
computin
g
BusinessHealth
Care
Telco and
Utilities
Scientific
discipline
Governm
ent
IT
General
Educatio
nOther
Transport
andLogistic
IT
Security
Conference Paper 28 11 9 9 6 4 4 4 2 3 1 2
Journal Paper 9 3 2 1 1 3 2 1 1
0
5
10
15
20
25
30
Ca
nti
da
d d
e P
ap
ers
Publication Type vs Application Domain
Conference Paper Journal Paper

Figura 13. Frecuencia para Correlación Proceso KDD vs Reto/Tendencia vs Dominio de Aplicación
Ya analizando una correlación más compleja, como lo es Dominio de Aplicación vs Reto-tendencia vs Proceso KDD (representada en la Figura 13), se puede observar que, independientemente del dominio de aplicación, cuando las publicaciones fueron enfocadas al proceso especifico de “Data Mining”, el principal reto/tendencia fue “Data Analysis” mientras que, cuando se incluía todo el proceso KDD, los retos/tendencias más abordados fueron “Architecture” y “Computing Platform”, evidenciando que la arquitectura y la plataforma computacional juegan un papel fundamental en el éxito de estas implementaciones y que varios estudios se han preocupado por dar solución a estos tópicos, mediante la propuesta de algún diseño, framework, técnica o metodología.
D. RQ5: ¿Cuáles son los tipos de investigación más
abordados?
Si bien existen muchos tipos de investigación en el tema, cada uno de ellos con su respectiva importancia, los resultados del estudio permiten sostener que “Solution Proposal”, con un 63.2%, es el principal aporte de los autores en cuanto a tipo de investigación o abordaje. Esto puede justificarse por el hecho de que el tema y su campo de acción se prestan para suministrar, a los practicantes, propuestas de solución que
puedan ser aplicadas a nivel general o en algún dominio especifico.
Figura 14. Frecuencia para Categoría Tipo de Investigación
Según la Figura 14, otros tipos de investigaciones, como los de opinión, experiencia y evaluación son importantes y útiles para cubrir este tópico. Esta evidencia proporciona una orientación precisa sobre el tipo de abordajes que deben ser
0
1
2
3
4
5
6
7
8
9
Dat
a an
alysi
s
Co
mputi
ng P
latf
orm
Arc
hit
ectu
re
Dat
a se
curi
ty
Ente
rpri
se
Dat
a ca
ptu
re a
nd
sto
rage
Dat
a an
alysi
s
Arc
hit
ectu
re
Co
mputi
ng P
latf
orm
Dat
a vis
ual
izat
ion
Dat
a tr
ansm
issi
on
Ente
rpri
se
Dat
a se
curi
ty
Dat
a ca
ptu
re a
nd
sto
rage
Dat
a vis
ual
izat
ion
Arc
hit
ectu
re
Dat
a tr
ansm
issi
on
Dat
a ca
ptu
re a
nd
sto
rage
Data mining
All
VisualizationETL
Application Domain vs Challenges-Trends vs KDD Process
General Social and personal computing Business Health Care
Telco and Utilities Scientific discipline Government IT General
Education Other Transport and Logistic IT Security
Evaluatio
nResearch
Experien
ce Papers
Opinion
Papers
Philosoph
icalPapers
Solution
Proposal
Total 10 12 12 5 67
0
10
20
30
40
50
60
70
80
Ca
nti
da
d d
e P
ap
ers
Research Type

utilizados en trabajos futuros ya que son éstos los que están siendo utilizados en la industria y la academia para predicar estos temas de interés. Es probable que un tipo de investigación como lo es el “paper filosófico” no sea tan adecuado para presentar avances en estos tópicos.
E. RQ6: ¿Cuáles son los tipos de resultado más comunes?
Como se puede evidenciar en la Figura 15, “Qualitative or descriptive model” (frameworks, modelos, taxonomías), “Specific solution” y “Procedure or technique” (técnicas, algoritmos), con el 37%, 22% y 10% de participación, respectivamente, son los tipos de resultados que más se presentan en los estudios seleccionados. Dichos resultados son coherentes con los presentados para la RQ5 ya que éstos se encaminan hacia suministrar propuestas de solución a problemas y/u oportunidades que se presentan en los tópicos, en forma de Arquitecturas, Frameworks, Taxonomías, Algoritmos, Metodologías o la implementación de algún software.
Es importante resaltar que, aunque no se mencionó anteriormente, el tipo de resultado “Answer or judgment” abarca un 23% de las publicaciones, las cuales están relacionadas con los otros tipos de investigación -no menos importantes pero que no son tan abordados-, como lo son “Evaluation Research”, “Experience Papers” y “Opinion Papers”.
Figura 15. Frecuencia para Categoría Tipo de Resultado
F. RQ7: ¿Cuáles son las técnicas de validación más
utilizadas?
Como se puede apreciar en la Figura 16, “Experience” con un 40.5% y “Analysis” con un 28.3% son las técnicas mas utilizadas para validar diferentes tipos de resultados arrojados en las investigaciones. Dicho comportamiento puede obedecer a que el tema se presta para realizar validaciones en escenarios simulados o pseudo-reales en los cuales una prueba con una muestra representativa permite visualizar como sería el comportamiento del proceso en escenarios reales.
Figura 16. Frecuencia para Categoría Tipo de Validación
Al analizar correlaciones más complejas como la representada en la Figura 17, se puede abstraer una serie de relaciones entre los tipos de investigación, resultado y validación. Por ejemplo, “Analysis” es la forma más utilizada para validar propuestas de solución encaminadas a brindar un modelo descriptivo o cualitativo, así como “Experience” es muy frecuente cuando se trata de validar una respuesta o juicio resultante de un “Experience Paper”.
El análisis anterior permite deducir posibles rutas comunes de abordaje en las investigaciones reseñadas, las cuales pueden ser utilizadas en un trabajo de investigación futuro. Algunos ejemplos de las rutas deducidas a partir de la se muestran en la Tabla 8.
Tabla 8. Ejemplos de Planes de Investigación Comunes
Tipo de
Investigación
Tipo de
Resultado
Tipo de
Validación Solution Proposal
Qualitative or
descriptive model
Analysis/Experience
Solution Proposal
Specific Solution
Experience/Example
Experience Paper
Answer or judgement
Experience
Opinion Paper
Answer or judgement
Persuasion
Evaluation Research
Answer or judgement
Experience/Evaluation
IV. DISCUSIÓN
El fenómemo conocido como la “revolución de los datos”, que fue causado por el frecuente uso de dispositivos móviles, redes sociales y sensores, ha traido consigo nuevas tecnologías y paradigmas encerrados en un término conocido como “Big Data”. En principio, Big Data resuelve retos relacionados con la captura, transmisión, almacenamiento y presentación de los datos. Sin embargo, éstos datos por si solos no representan la promesa de valor de Big Data, la cual apunta a proporcionar un entendimiento sobre estos datos, atendiendo algunas condiciones que imponen los dominios por estos tiempos, como por ejemplo, el Time-to-Market y el aumento del tamaño de las muestras utilizadas en la Inteligencia de negocios.
Notation or
tool
1%
Analytic
model
3%
Report
4% Procedure or
technique
10%
Specific
solution
22% Answer or
judgment
23%
Qualitative or
descriptive
model 37%
Result Type
AnalysisEvaluatio
nExample
Experien
ce
Persuasio
n
Total 30 6 14 43 13
0
10
20
30
40
50
Ca
nti
da
d d
e P
ap
ers
Validation Type

Figura 17. Frecuencia para Correlación Tipo de Investigación vs Tipo de Resultado vs Tipo de Validación
En términos más prácticos, lo anterior no es otra cosa que
transformar estos datos en información útil en un determinado contexto con unas determinadas características, lo que se traduce en los objetivos del proceso de KDD. De lo anterior se puede deducir que las necesidades de los diferentes dominios de aplicación han evolucionado a la par de las tecnologías, generando entornos cada vez más complejos que requieren ser tratados de una forma diferente y esto es lo que muestran los estudios analizados. KDD y Big Data han comenzado a ser investigados de forma combinada con mayor fuerza desde el año 2011 (asumiendo que los estudios publicados en 2012 datan de dicho año), lo que indica que se trata de un tema de interés bastante nuevo y con una tendencia al crecimiento lineal. Lo que también muestran los estudios analizados es que, al ser un tema relativamente nuevo, las investigaciones requieren retroalimentación, por lo que se percibe una preferencia a presentarlas en eventos relacionados bien sea con Big Data directamente o con algún dominio de aplicación (por ejemplo, Health Care).
Existen diversos dominios de aplicación interesados en este tema. Algunos de estos dominios, como la computación social y la salud, están cobrando más fuerza dada la naturaleza de sus datos. Por ejemplo, el hecho de poner la computación social y personal al servicio de la salud pública implica generar valor a partir de un conjunto de datos que cumple con algunas de las Vs que son caracterizadas en Big Data. El uso de Big Data Analytics también puede verse impulsado por la implementación de otras tecnologías de vanguardia que buscan
otro tipo de soluciones. Por ejemplo, implementar la interoperabilidad y acceso a los registros clínicos a través de la nube, genera la oportunidad de analizarlos en busca de apoyar el diagnóstico médico en tiempo real y con una precisión adecuada. Existen diversos ejemplos que muestran que la aplicación de Big Data Analytics es bastante amplia y de pertinencia mundial.
El presente estudio confirmó la relación que existe entre el proceso KDD y los retos y tendencias que se enmarcan en Big Data Analytics, los cuales, cuando el proceso está principalmente orientado a la minería de datos, se enfocan en algoritmos, técnicas y demás soluciones orientadas al análisis y a la conversión de las entradas de los algoritmos tradicionales de la minería de datos a entradas de tipo Map Reduce. Se puede deducir que el primer intento de los investigadores corresponde a utilizar técnicas y herramientas existentes orquestadas para trabajar en entornos Big Data, como lo es el caso de “Machine Learning”, algoritmos de Data Mining, “Support Vector Machine” y demás derivados principalmente de la Inteligencia Artificial. Por otro lado, cuando el estudio se enfoca hacia el ETL, los retos y tendencias que más se enmarcan tienen qué ver con captura, transmisión y almacenamiento de los datos. Finalmente, cuando el estudio pasa por todo el proceso KDD, existe una mayor preocupación por la arquitectura y la plataforma de cómputo, lo que muestra la importancia de la Arquitectura de Software en este tipo de implementaciones.
0
5
10
15A
nal
ysi
s
Exper
ien
ce
Exam
ple
Per
suas
ion
Eval
uat
ion
Exper
ien
ce
Anal
ysi
s
Per
suas
ion
Exper
ien
ce
Anal
ysi
s
Exper
ien
ce
Eval
uat
ion
Anal
ysi
s
Per
suas
ion
Anal
ysi
s
Solution ProposalExperience
Papers Opinion Papers
Evaluation ResearchPhilosophical
Papers
Research Type vs Result Type vs Validation Type
Qualitative or descriptive model Answer or judgment Specific solution Procedure or technique
Report Analytic model Notation or tool

El presente estudio de mapeo sistémico también permitió deducir algunos posibles planes de abordaje a investigaciones futuras sobre los tópicos. Por ejemplo, en los resultados se evidencia que para las propuestas de solución es apropiado generar resultados como la generación de un modelo cualitativo o descriptivo, o una solución específica, que puede ser un sistema o alguno de sus entregables en términos de ingeniería de software y, que a su vez, las posibles validaciones a estos resultados se encuentran entre el análisis, la experiencia o la demostración mediante un ejemplo.
Finalmente, se puede deducir que Big Data Analytics es una propuesta relativamente nueva o recientemente explorada que se encuentra aún muy joven en algunos dominios de aplicación y que aún no cuenta con la madurez suficiente como para permear a la industria con la fuerza que ésta lo requiere. Gran parte de esta falta de madurez puede deberse a que Big Data está siendo tomado como un término comercial y no se ha comprendido su verdadero potencial y los retos que acarrea su implementación. Otra parte de esta falta de madurez es que en varios sectores solo se ve como una tecnología de apoyo y no como un paradigma o una forma de pensar. Esta serie de controversias generan la oportunidad de explorar estos tópicos, de manera combinada, con mayor profundidad.
V. CONCLUSIONES
Este artículo proporciona una visión general sobre el estudio e implementación de los procesos del KDD aplicados a entornos caracterizados como Big Data en términos del cumplimiento de algunas de las 3 Vs. Para proporcionar esta visión global se realizó un estudio de mapeo sistémico, en el cual se logró una clasificación general basada en las preguntas de investigación que los autores se propusieron a responder. Esta clasificación proporcionó datos importantes acerca de la distribución de los estudios analizados y también aproximaciones con las cuales se trabajan estos tópicos desde la investigación hasta su aplicación como tal.
La conclusión que puede obtenerse a partir de los resultados y la discusión que se generó alrededor de los mismos, es que Big Data Analytics es un tema jóven, prometedor, multidisciplinar y de alta pertinencia, que debe ser estudiado y encaminado a permear en las organizaciones, saliendose del término comercial y entrando a su verdadera caracterización. Sobre estos estudios se puede afirmar también que la combinación con la Ingeniería de Software es necesaria para abordar las soluciones de Big Data Analytics de forma integral para generar mayor impacto en el contexto que lo requiera.
VI. TRABAJO FUTURO
El trabajo futuro corresponde a la elaboración de una propuesta de investigación aplicada enmarcada en los tópicos analizados y con un enfoque ya dirigido al sector salud. Posteriormente, se llevará a cabo una revisión sistemática de literatura con el fin de proporcionar una clasificación más detallada de los aportes presentados para responder a la pregunta de investigación que será planteada. Esta revisión sistemática de literatura permitirá deducir, justificar y conducir la propuesta de solución que sea generada posteriormente.
REFERENCIAS
[1] C. L. Philip Chen and C. Y. Zhang, “Data-intensive
applications, challenges, techniques and technologies: A survey on Big Data,” Inf. Sci. (Ny)., pp. 1–34, Jan. 2014.
[2] K. Krishnan, Data Warehousing in the Age of Big Data. 2013.
[3] P.-N. Tan, M. Steinbach, and V. Kumar, “Introduction to Data Mining,” J. Sch. Psychol., vol. 19, pp. 51–56, 2005.
[4] K. Petersen, R. Feldt, S. Mujtaba, and M. Mattsson,
“Systematic mapping studies in software engineering,” in
EASE’08 Proceedings of the 12th international conference
on Evaluation and Assessment in Software Engineering, 2008, pp. 68–77.
[5] B. A. Kitchenham, S. L. Pfleeger, L. M. Pickard, P. W.
Jones, D. C. Hoaglin, K. El Emam, and J. Rosenberg,
“Preliminary guidelines for empirical research in software
engineering,” IEEE Trans. Softw. Eng., vol. 28, no. 8, pp. 721–734, 2002.
[6] L. F. Tabares and J. F. Hernández, “Big Data Analytics : Oportunidades , Retos y Tendencias,” Cali, Colombia, 2014.
[7] H. Alshammari, H. Bajwa, and J. Lee, “Hadoop based
enhanced cloud architecture for bioinformatic algorithms,”
in Systems, Applications and Technology Conference (LISAT), 2014 IEEE Long Island, 2014, pp. 1–5.
[8] X. Amatriain, “Big & Personal: Data and Models
Behind Netflix Recommendations,” in Proceedings of the
2Nd International Workshop on Big Data, Streams and
Heterogeneous Source Mining: Algorithms, Systems,
Programming Models and Applications, 2013, pp. 1–6.
[9] J. A. Amorim, S. F. Andler, P. M. Gustavsson, and O. L.
Agostinho, “Big Data Analytics in the Public Sector:
Improving the Strategic Planning in World Class
Universities,” in 2013 International Conference on Cyber-
Enabled Distributed Computing and Knowledge Discovery, 2013, pp. 155–162.
[10] M. Anjaria and R. M. R. Guddeti, “Influence factor based
opinion mining of Twitter data using supervised learning,”
in 2014 Sixth International Conference on Communication Systems and Networks (COMSNETS), 2014, pp. 1–8.
[11] E. Baralis, L. Cagliero, T. Cerquitelli, S. Chiusano, P. Garza,
L. Grimaudo, and F. Pulvirenti, “NEMICO: Mining
Network Data through Cloud-Based Data Mining
Techniques,” in 2014 IEEE/ACM 7th International
Conference on Utility and Cloud Computing, 2014, pp. 503–
504.
[12] J.-P. Belaud, S. Negny, F. Dupros, D. Michéa, and B.
Vautrin, “Collaborative simulation and scientific big data
analysis: Illustration for sustainability in natural hazards

management and chemical process engineering,” Comput. Ind., vol. 65, no. 3, pp. 521–535, Apr. 2014.
[13] J. Bian, U. Topaloglu, and F. Yu, “Towards large-scale
twitter mining for drug-related adverse events,” in
Proceedings of the 2012 international workshop on Smart health and wellbeing - SHB ’12, 2012, p. 25.
[14] A. Bindra, S. Pokuri, K. Uppala, and A. Teredesai,
“Distributed Big Advertiser Data Mining,” in 2012 IEEE
12th International Conference on Data Mining Workshops,
2012, pp. 914–914.
[15] L. M. Bruce, “Game theory applied to big data analytics in
geosciences and remote sensing,” in 2013 IEEE
International Geoscience and Remote Sensing Symposium - IGARSS, 2013, pp. 4094–4097.
[16] M. R. Brule, “Big data in EP: Real-time adaptive analytics
and data-flow architecture,” in Society of Petroleum
Engineers - SPE Digital Energy Conference and Exhibition 2013, 2013, pp. 305–311.
[17] J. P. Buerck, S. P. Mudigonda, S. E. Mooshegian, K.
Collins, N. Grimm, K. Bonney, and H. Kombrink,
“Predicting Non-traditional Student Learning Outcomes
Using Data Analytics - a Pilot Research Study,” J. Comput.
Sci. Coll., vol. 28, no. 5, pp. 260–265, May 2013.
[18] A. Candelieri and F. Archetti, “Smart water in urban
distribution networks: limited financial capacity and Big
Data analytics,” in WIT Transactions on the Built Environment, 2014, vol. 139, pp. 63–73.
[19] L. Cao and J. She, “Can Your Friends Predict Where You
Will Be?,” in 2014 IEEE International Conference on
Internet of Things(iThings), and IEEE Green Computing and
Communications (GreenCom) and IEEE Cyber, Physical and Social Computing (CPSCom), 2014, pp. 450–455.
[20] P. Chandarana and M. Vijayalakshmi, “Big Data analytics
frameworks,” in 2014 International Conference on Circuits,
Systems, Communication and Information Technology Applications (CSCITA), 2014, pp. 430–434.
[21] V. Chandola, S. R. Sukumar, and J. C. Schryver,
“Knowledge Discovery from Massive Healthcare Claims
Data,” in Proceedings of the 19th ACM SIGKDD
International Conference on Knowledge Discovery and Data
Mining, 2013, pp. 1312–1320.
[22] A. M. Chandramohan, D. Mylaraswamy, B. Xu, and P.
Dietrich, “Big data infrastructure for aviation data
analytics,” in 2014 IEEE International Conference on Cloud Computing in Emerging Markets, CCEM 2014, 2015.
[23] A. Cheptsov and B. Koller, “A service-oriented approach to
facilitate big data analytics on the web,” in Civil-Comp
Proceedings, 2013, vol. 102.
[24] W. Cho, Y. Lim, H. Lee, M. K. Varma, M. Lee, and E. Choi,
“Big Data Analysis with Interactive Visualization Using R
Packages,” in Proceedings of the 2014 International
Conference on Big Data Science and Computing, 2014, pp. 18:1–18:6.
[25] A. Clarke and H. Margetts, “Governments and Citizens
Getting to Know Each Other? Open, Closed, and Big Data in
Public Management Reform,” Policy & Internet, vol. 6, no.
4, pp. 393–417, Dec. 2014.
[26] J. Cohen and S. Acharya, “Towards a more secure Apache
Hadoop HDFS infrastructure: Anatomy of a targeted
advanced persistent threat against HDFS and analysis of
trusted computing based countermeasures,” in Lecture Notes
in Computer Science (including subseries Lecture Notes in
Artificial Intelligence and Lecture Notes in Bioinformatics), 2013, vol. 7873 LNCS, pp. 735–741.
[27] J. Conejero, B. Caminero, and C. Carrion, “Analysing
Hadoop performance in a multi-user IaaS Cloud,” in 2014
International Conference on High Performance Computing
& Simulation (HPCS), 2014, pp. 399–406.
[28] A. Cuzzocrea, “Analytics over Big Data: Exploring the
Convergence of DataWarehousing, OLAP and Data-
Intensive Cloud Infrastructures,” in Computer Software and
Applications Conference (COMPSAC), 2013 IEEE 37th Annual, 2013, pp. 481–483.
[29] A. Das and H. S. Ranganath, “Effective Interpretation of
Bucket Testing Results through Big Data Analytics,” in
2013 IEEE International Congress on Big Data, 2013, pp. 439–440.
[30] Y. Demchenko, C. de Laat, and P. Membrey, “Defining
architecture components of the Big Data Ecosystem,” in
2014 International Conference on Collaboration Technologies and Systems (CTS), 2014, pp. 104–112.
[31] C. Deng, L. Qian, M. Xu, Y. Du, Z. Luo, and S. Sun,
“Federated cloud-based big data platform in
telecommunications,” in Proceedings of the 2012 workshop
on Cloud services, federation, and the 8th open cirrus
summit - FederatedClouds ’12, 2012, p. 44.
[32] C. Esposito, M. Ficco, F. Palmieri, and A. Castiglione, “A
knowledge-based platform for Big Data analytics based on
publish/subscribe services and stream processing,” Knowledge-Based Syst., May 2014.
[33] S. Fiore, A. D’Anca, C. Palazzo, I. Foster, D. N. Williams,
and G. Aloisio, “Ophidia: Toward Big Data Analytics for
eScience,” Procedia Comput. Sci., vol. 18, pp. 2376–2385, 2013.
[34] S. Fiore, M. Mancini, D. Elia, P. Nassisi, F. V. Brasileiro,
and I. Blanquer, “Big Data Analytics for Climate Change
and Biodiversity in the EUBrazilCC Federated Cloud
Infrastructure,” in Proceedings of the 12th ACM

International Conference on Computing Frontiers, 2015, pp. 52:1–52:8.
[35] J. Fiosina, M. Fiosins, and J. P. Müller, “Big data processing
and mining for next generation intelligent transportation
systems,” J. Teknol. (Sciences Eng., vol. 63, no. 3, pp. 23–38, 2013.
[36] G. Fotaki, M. Spruit, S. Brinkkemper, and D. Meijer,
“Exploring Big Data Opportunities for Online Customer
Segmentation,” Int. J. Bus. Intell. Res., vol. 5, no. 3, pp. 58–
75, 2014.
[37] S. Fuicu, M. Marcu, A. Avramescu, D. Lascu, and R.
Padurariu, “Real Time E-health System for Continuous
Care,” in Proceedings of the 8th International Conference
on Pervasive Computing Technologies for Healthcare, 2014,
pp. 436–439.
[38] A. Gattiker, F. H. Gebara, H. P. Hofstee, J. D. Hayes, and A.
Hylick, “Big Data text-oriented benchmark creation for
Hadoop,” IBM J. Res. Dev., vol. 57, no. 3/4, pp. 10:1–10:6, May 2013.
[39] A. K. Ghose, E. Morrison, and Y. Gou, “A Novel Use of Big
Data Analytics for Service Innovation Harvesting,” in 2013
Fifth International Conference on Service Science and
Innovation, 2013, pp. 208–214.
[40] S. Gole and B. Tidke, “Frequent itemset mining for Big Data
in social media using ClustBigFIM algorithm,” in Pervasive
Computing (ICPC), 2015 International Conference on, 2015, pp. 1–6.
[41] A. Gupta, “Big Data analysis using Computational
Intelligence and Hadoop: A study,” in Computing for
Sustainable Global Development (INDIACom), 2015 2nd International Conference on, 2015, pp. 1397–1401.
[42] T. Hassan, R. Peixoto, C. Cruz, A. Bertaux, and N. Silva,
“Semantic HMC for big data analysis,” in 2014 IEEE
International Conference on Big Data (Big Data), 2014, pp.
26–28.
[43] O. Hazzan and C. A. Shaffer, “Big Data in Computer
Science Education Research,” in Proceedings of the 46th
ACM Technical Symposium on Computer Science Education, 2015, pp. 591–592.
[44] S. Hipgrave, “Smarter fraud investigations with big data analytics,” Netw. Secur., vol. 2013, no. 12, pp. 7–9, 2013.
[45] K. Horikawa, Y. Kitayama, S. Oda, H. Kumazaki, J. Han, H.
Makino, M. Ishii, K. Aoya, M. Luo, and S. Uchikawa,
“Jubatus in action: Report on realtime big data analysis by jubatus,” NTT Tech. Rev., vol. 10, no. 12, 2012.
[46] W. Hurst, M. Merabti, and P. Fergus, “Big Data Analysis
Techniques for Cyber-threat Detection in Critical
Infrastructures,” in 2014 28th International Conference on
Advanced Information Networking and Applications Workshops, 2014, pp. 916–921.
[47] L. Ismail, M. M. Masud, and L. Khan, “FSBD: A
Framework for Scheduling of Big Data Mining in Cloud
Computing,” in 2014 IEEE International Congress on Big Data, 2014, pp. 514–521.
[48] H. Ituski, H. Matsubara, K. Arita, and K. Omi, “Effective
Clusterization of Political Tweets Using Kurtosis and
Community Duration,” in 2013 International Conference on
Social Computing, 2013, pp. 928–931.
[49] M. D. Kakhki, R. Singh, and K. W. Loyd, “Developing
health analytics design artifact for improved patient
activation: An on-going case study,” in Advances in
Intelligent Systems and Computing, 2015, vol. 353, pp. 733–
739.
[50] I. A. Karatepe and E. Zeydan, “Anomaly detection in
cellular network data using big data analytics,” in 20th European Wireless Conference, EW 2014, 2014, pp. 81–85.
[51] S. Khalifa and P. Martin, “Smart Big Data Analytics As a
Service Framework: A Proposal,” in Proceedings of 24th
Annual International Conference on Computer Science and Software Engineering, 2014, pp. 327–330.
[52] Z. Khan, A. Anjum, and S. L. Kiani, “Cloud Based Big Data
Analytics for Smart Future Cities,” in 2013 IEEE/ACM 6th
International Conference on Utility and Cloud Computing, 2013, pp. 381–386.
[53] J. Kobielus, “Going cloud with your big data: A structured approach,” IBM Data Manag. Mag., no. 4, 2013.
[54] P. M. Kogge and D. A. Bayliss, “Comparative performance
analysis of a Big Data NORA problem on a variety of
architectures,” in 2013 International Conference on
Collaboration Technologies and Systems (CTS), 2013, pp. 22–34.
[55] B. Kotiyal, A. Kumar, B. Pant, and R. H. Goudar, “Big data:
Mining of log file through hadoop,” in 2013 International
Conference on Human Computer Interactions (ICHCI),
2013, pp. 1–7.
[56] R. Krishnamurthy and K. C. Desouza, “Big data analytics:
The case of the social security administration,” Inf. Polity, vol. 19, no. 3–4, pp. 165–178, 2014.
[57] J. Krumeich, S. Jacobi, D. Werth, and P. Loos, “Big Data
Analytics for Predictive Manufacturing Control - A Case
Study from Process Industry,” in 2014 IEEE International Congress on Big Data, 2014, pp. 530–537.
[58] C. Lee, S. Chaisiri, B. Zoebir, C. Chen, and B.-S. Lee, “A
Demo Paper: An Analytic Workflow Framework for Green
Campus,” in Parallel and Distributed Systems (ICPADS),

2012 IEEE 18th International Conference on, 2012, pp. 851–855.
[59] J. Leveling, M. Edelbrock, and B. Otto, “Big data analytics
for supply chain management,” in Industrial Engineering
and Engineering Management (IEEM), 2014 IEEE International Conference on, 2014, pp. 918–922.
[60] P. Leyshock, D. Maier, and K. Tufte, “Minimizing data
movement through query transformation,” in 2014 IEEE
International Conference on Big Data (Big Data), 2014, pp.
311–316.
[61] S. Li, L. Song, and H. Zhao, “A Discriminant Framework
for Detecting Similar Scientific Research Projects Based on
Big Data Mining,” in 2014 IEEE International Congress on Big Data, 2014, pp. 478–481.
[62] Q. Liu, A. H. Sung, B. Ribeiro, and D. Suryakumar,
“Mining the Big Data: The Critical Feature Dimension
Problem,” in Advanced Applied Informatics (IIAIAAI), 2014 IIAI 3rd International Conference on, 2014, pp. 499–504.
[63] S. Liu, W. Cui, Y. Wu, and M. Liu, “A survey on
information visualization: recent advances and challenges,” Vis. Comput., vol. 30, no. 12, pp. 1373–1393, Jan. 2014.
[64] D. Lopez, M. Gunasekaran, B. S. Murugan, H. Kaur, and K.
M. Abbas, “Spatial big data analytics of influenza epidemic
in Vellore, India,” in Proceedings - 2014 IEEE International
Conference on Big Data, IEEE Big Data 2014, 2015, pp. 19–24.
[65] R. D. A. Ludena and A. Ahrary, “Big Data approach in an
ICT Agriculture project,” in 2013 International Joint
Conference on Awareness Science and Technology & Ubi-
Media Computing (iCAST 2013 & UMEDIA 2013), 2013, pp. 261–265.
[66] T. Luo, Y. Liao, G. Chen, and Y. Zhang, “P-DOT: A model
of computation for big data,” in 2013 IEEE International Conference on Big Data, 2013, pp. 31–37.
[67] T. Luo, W. Yuan, P. Deng, Y. Zhang, and G. Chen, “A
hybrid system of Hadoop and DBMS for earthquake
precursor application,” Int. Rev. Comput. Softw., vol. 8, no. 2, pp. 463–467, 2013.
[68] A. Mandloi, “Big Data analytics with case study on financial
organization,” in IT in Business, Industry and Government (CSIBIG), 2014 Conference on, 2014, p. 1.
[69] R. Miller, “Big Data Curation,” in Proceedings of the 20th
International Conference on Management of Data, 2014, p. 4.
[70] T. Nam, K. Choi, C. Ok, and K. Yeom, “Service
Composition Framework for Big Data Service,” in 2014
International Conference on Future Internet of Things and Cloud, 2014, pp. 328–333.
[71] R. Nambiar, R. Bhardwaj, A. Sethi, and R. Vargheese, “A
look at challenges and opportunities of Big Data analytics in
healthcare,” in 2013 IEEE International Conference on Big
Data, 2013, pp. 17–22.
[72] J. Nandimath, E. Banerjee, A. Patil, P. Kakade, S. Vaidya,
and D. Chaturvedi, “Big data analysis using Apache
Hadoop,” in 2013 IEEE 14th International Conference on Information Reuse & Integration (IRI), 2013, pp. 700–703.
[73] A. Nasridinov and Y.-H. Park, “Visual Analytics for Big
Data Using R,” in Cloud and Green Computing (CGC), 2013 Third International Conference on, 2013, pp. 564–565.
[74] A. Ochian, G. Suciu, O. Fratu, C. Voicu, and V. Suciu, “An
overview of cloud middleware services for interconnection
of healthcare platforms,” in 2014 10th International Conference on Communications (COMM), 2014, pp. 1–4.
[75] J. Park, Y. M. Baek, and M. Cha, “Cross-Cultural
Comparison of Nonverbal Cues in Emoticons on Twitter:
Evidence from Big Data Analysis,” J. Commun., vol. 64, no. 2, pp. 333–354, Apr. 2014.
[76] A. Parkavi and N. Vetrivelan, “A smart citizen information
system using Hadoop: A case study,” in 2013 IEEE
International Conference on Computational Intelligence and
Computing Research, 2013, pp. 1–3.
[77] S. Patil, R. Argiddi, and S. Apte, “Financial forecasting by
improved fragmentation algorithm of Granular Fragment
based mining,” in Pervasive Computing (ICPC), 2015 International Conference on, 2015, pp. 1–6.
[78] L. Peipeng and R. T. T. Sim, “Research Experience of Big
Data Analytics: The Tools for Government: a Case Using
Social Network in Mining Preferences of Tourists,” in
Proceedings of the 8th International Conference on Theory and Practice of Electronic Governance, 2014, pp. 312–315.
[79] B. R. Prasad and S. Agarwal, “Handling big data stream
analytics using SAMOA framework - a practical
experience,” Int. J. Database Theory Appl., vol. 7, no. 4, pp. 197–208, 2014.
[80] S. Prom-on, S. N. Ranong, P. Jenviriyakul, T. Wongkaew,
N. Saetiew, and T. Achalakul, “DOM: A big data analytics
framework for mining Thai public opinions,” in 2014
International Conference on Computer, Control, Informatics
and Its Applications (IC3INA), 2014, pp. 1–6.
[81] Y. B. Qin, J. Housell, and I. Rodero, “Cloud-Based Data
Analytics Framework for Autonomic Smart Grid
Management,” in 2014 International Conference on Cloud and Autonomic Computing, 2014, pp. 97–100.
[82] P. Rad, V. Lindberg, J. Prevost, W. Zhang, and M. Jamshidi,
“ZeroVM: secure distributed processing for big data
analytics,” in World Automation Congress (WAC), 2014, 2014, pp. 1–6.

[83] R. Ramasamy, “Towards Big Data Analytics Framework:
ICT Professionals Salary Profile Compilation Perspective,”
in Proceedings of the 8th International Conference on
Theory and Practice of Electronic Governance, 2014, pp. 450–451.
[84] A. Sahni, D. Marwah, and R. Chadha, “Real time
monitoring and analysis of available bandwidth in cellular
network-using big data analytics,” in Computing for
Sustainable Global Development (INDIACom), 2015 2nd International Conference on, 2015, pp. 1743–1747.
[85] M. Saravanan, D. Sundar, and V. S. Kumaresh, “Probing of
geospatial stream data to report disorientation,” in 2013
IEEE Recent Advances in Intelligent Computational Systems (RAICS), 2013, pp. 227–232.
[86] V. Scherer and B. Kaponig, “EMC Hadoop as a service
solution for use cases in the automotive industry,” in 2013
International Conference on Connected Vehicles and Expo (ICCVE), 2013, pp. 488–493.
[87] J. Schildgen, T. Jorg, M. Hoffmann, and S. Dessloch,
“Marimba: A Framework for Making MapReduce Jobs
Incremental,” in Big Data (BigData Congress), 2014 IEEE International Congress on, 2014, pp. 128–135.
[88] F. Schnizler, T. Liebig, S. Marmor, G. Souto, S. Bothe, and
H. Stange, “Heterogeneous stream processing for disaster
detection and alarming,” in 2014 IEEE International Conference on Big Data (Big Data), 2014, pp. 914–923.
[89] D. Shin, T. Sahama, and R. Gajanayake, “Secured e-health
data retrieval in DaaS and Big Data,” in e-Health
Networking, Applications Services (Healthcom), 2013 IEEE 15th International Conference on, 2013, pp. 255–259.
[90] C. A. Steed, D. M. Ricciuto, G. Shipman, B. Smith, P. E.
Thornton, D. Wang, X. Shi, and D. N. Williams, “Big data
visual analytics for exploratory earth system simulation
analysis,” Comput. Geosci., vol. 61, pp. 71–82, Dec. 2013.
[91] W. Tan, M. B. Blake, I. Saleh, and S. Dustdar, “Social-
Network-Sourced Big Data Analytics,” IEEE Internet Comput., vol. 17, no. 5, pp. 62–69, Sep. 2013.
[92] P. Tin, T. T. Zin, H. Hama, and T. Toriu, “A data-driven key
information search system in big data analytics,” ICIC Express Lett. Part B Appl., vol. 5, no. 2, pp. 365–370, 2014.
[93] P. Tin, T. T. Zin, T. Toriu, and H. Hama, “An Integrated
Framework for Disaster Event Analysis in Big Data
Environments,” in 2013 Ninth International Conference on
Intelligent Information Hiding and Multimedia Signal Processing, 2013, pp. 255–258.
[94] D. Van Hieu, S. Smanchat, and P. Meesad, “MapReduce
join strategies for key-value storage,” in 2014 11th
International Joint Conference on Computer Science and Software Engineering (JCSSE), 2014, pp. 164–169.
[95] J. Wang, Z.-Q. Zhao, X. Hu, Y.-M. Cheung, H. Hu, and F.
Gu, “Online Learning Towards Big Data Analysis in Health
Informatics,” in Proceedings of the International
Conference on Brain and Health Informatics - Volume 8211, 2013, pp. 516–523.
[96] Y. Wang and V. J. Wiebe, “Big Data Analyses for
Collective Opinion Elicitation in Social Networks,” in 2014
IEEE 13th International Conference on Trust, Security and
Privacy in Computing and Communications, 2014, pp. 630–637.
[97] Z. Wang, Q. Ding, F. Gao, D. Shen, and G. Yu, “iHDFS: A
distributed file system supporting incremental computing,”
in IFIP Advances in Information and Communication Technology, 2015, vol. 503, pp. 151–158.
[98] P. C. Wong, Z. Huang, Y. Chen, P. MacKey, and S. Jin,
“Visual analytics for power grid contingency analysis,” IEEE Comput. Graph. Appl., vol. 34, no. 1, pp. 42–51, 2014.
[99] P. Woźniak, R. Valton, and M. Fjeld, “Volvo Single View of
Vehicle: Building a Big Data Service from Scratch in the
Automotive Industry,” in Proceedings of the 33rd Annual
ACM Conference Extended Abstracts on Human Factors in Computing Systems, 2015, pp. 671–678.
[100] W.-C. Wu and S.-H. Hung, “DroidDolphin: A Dynamic
Android Malware Detection Framework Using Big Data and
Machine Learning,” in Proceedings of the 2014 Conference
on Research in Adaptive and Convergent Systems, 2014, pp.
247–252.
[101] J. Xiang, M. Westerlund, D. Sovilj, and G. Pulkkis, “Using
Extreme Learning Machine for Intrusion Detection in a Big
Data Environment,” in Proceedings of the 2014 Workshop
on Artificial Intelligent and Security Workshop, 2014, pp.
73–82.
[102] Q. Xu, Z. X. Zhao, and W. Wang, “Volume-based data
representation of big data analysis,” in Advanced Materials Research, 2013, vol. 798, pp. 680–684.
[103] S. W. Xu and Z. Y. Xia, “Hot news recommendation system
across heterogonous websites using hadoop,” in Advanced Materials Research, 2014, vol. 989–994, pp. 4704–4707.
[104] F. Ye, Z.-J. Wang, F.-C. Zhou, Y.-P. Wang, and Y.-C. Zhou,
“Cloud-Based Big Data Mining & Analyzing Services
Platform Integrating R,” in 2013 International Conference on Advanced Cloud and Big Data, 2013, pp. 147–151.
[105] S.-H. Yoon, J.-S. Park, and M.-S. Kim, “Behavior signature
for big data traffic identification,” in 2014 International
Conference on Big Data and Smart Computing
(BIGCOMP), 2014, pp. 261–266.
[106] D. ZHANG, “GRANULARITIES AND
INCONSISTENCIES IN BIG DATA ANALYSIS,” Int. J.

Softw. Eng. Knowl. Eng., vol. 23, no. 06, pp. 887–893, Aug. 2013.
[107] G. L. Zhang, J. Sun, L. Chitkushev, and V. Brusic, “Big data
analytics in immunology: a knowledge-based approach.,”
Biomed Res. Int., vol. 2014, p. 437987, Jan. 2014.
[108] S. Zhang, Y. Yang, W. Fan, L. Lan, and M. Yuan,
“OceanRT,” in Proceedings of the 2014 ACM SIGMOD
international conference on Management of data - SIGMOD ’14, 2014, pp. 1099–1102.
[109] Y. Zhang, M. Chen, S. Mao, L. Hu, and V. Leung, “CAP:
community activity prediction based on big data analysis,”
IEEE Netw., vol. 28, no. 4, pp. 52–57, Jul. 2014.
[110] H. Zhao and X. Ye, “A multidimensional OLAP engine
implementation in key-value database systems,” in Lecture
Notes in Computer Science (including subseries Lecture
Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), 2014, vol. 8585, pp. 155–170.
[111] F. Zulkernine, P. Martin, Y. Zou, M. Bauer, F. Gwadry-
Sridhar, and A. Aboulnaga, “Towards Cloud-Based
Analytics-as-a-Service (CLAaaS) for Big Data Analytics in
the Cloud,” in 2013 IEEE International Congress on Big Data, 2013, pp. 62–69.





























