Embed Size (px)
Citation preview

WEB USAGE MINING USING APRIORI ALGORITHM: UUM LEARNING CARE
PORTAL CASEAzizul Azhar bin Ramli
Information System DepartmentFaculty of Information Technology and Multimedia,
Kolej Universiti Teknologi Tun Hussein Onn (KUiTTHO)86400 Parit Raja, Batu Pahat, Johor D/T
Tel: +607-4538000 ext. 8056, Fax: +607-4532119Email: [email protected]
Abstract
The enormous content of information on the World Wide Web makes it obvious
candidate for data mining research. Application of data mining techniques to the World
Wide Web referred as Web mining where this term has been used in three distinct ways;
Web Content Mining, Web Structure Mining and Web Usage Mining. E Learning is one of
the Web based application where it will facing with large amount of data. In order to
produce the university E Learning (UUM Educare) portal usage patterns and user
behaviors, this paper implements the high level process of Web Usage Mining using
basic Association Rules algorithm call Apriori Algorithm. Web Usage Mining consists of
three main phases, namely Data Preprocessing, Pattern Discovering and Pattern
Analysis. Server log files become a set of raw data where it’s must go through with all
the Web Usage Mining phases to producing the final results. Here, Web Usage Mining,
approach has been combining with the basic Association Rules, Apriori Algorithm to
optimize the content of the university E Learning portal. Finally, this paper will present
an overview of results analysis and Web administrator can use the findings for the
suitable valuable actions.
1

KEY WORDS: server log file, data mining, Web mining, Web Usage
Mining, Association Rules, Apriori algorithm.
1.0 PROJECT OVERVIEW
Data mining is a technique used to deduce useful and
relevant information to guide professional decisions and other
scientific research (Chen, Han and Yu, 1996). It is a cost-
effective way of analyzing large amounts of data, especially when
a human could not analyze such datasets.
Massification of the use the internet has made automatic
knowledge extraction from Web log files a necessity. Information
provided are interested in techniques that could learn Web users’
information needs and preferences. This can improve the
effectiveness of their Web sites by adapting the information
structure of the sites to the users’ behavior.
Recently, the advent of data mining techniques for
discovering usage pattern from Web data (Web Usage Mining)
indicates that these techniques can be a viable alternative to
traditional decision making tools (Srivastava et al., 2000). Web
Usage Mining is the process of applying data mining techniques to
the discovery of usage patterns from Web data and is targeted
2

towards applications (Srivastava et al., 2000). Web Usage Mining
mines the secondary data (Web server access logs, browser logs,
user profiles, registration data, user sessions or transactions,
cookies, user queries, mouse clicks and any other data as the
result of interaction with the Web) derived from the interactions
of the users during certain period of Web sessions.
This paper explores the use of Web Usage Mining techniques
to analyze Web log records collected from E-Learning portal (UUM
Educare). Using commercial data Web mining tools (WebLog Expert Lite
3.5 and Sawmill 7) and ARunner 1.0 (prototype of GUI Christian Borgelt
Apriori tool by Shamrie Sainin, FTM, UUM), it have identified
several Web access pattern by applying well known data mining
techniques (Apriori Algorithm) to the access logs of this
educational portal. This includes descriptive statistic and
Association Rules for the portal including support and confidence
to represent the Web usage and user behavior for UUM Educare. The
results and findings for this experimental analysis can be use by
the Web administration and may be upper level in the UUM
community in order to plan the upgrading and enhancement to the
portal presentation.
Objective and Scopes of Project
3

Generally, the main objective of this project is to perform
Web Usage Mining process, specifically:
i. To preprocess UUM Educare server logs files from the
university E-Learning Web servers for determining and
discovering the user access pattern.
ii. To apply the basic Association Rules – Apriori algorithm
for implementation of Web Usage Mining process to
producing usage pattern by determine the most user
interest based on the options that being provided by the
university E-Learning portal.
iii. To analyze the outputs usage patterns and user behaviors
for UUM Educare from the Web Usage Mining implementation
process.
The scopes of this project are:
i. Research Organization: University E-Learning portal (UUM
Educare)
ii. Focus of Project: Extract the server log file from
university E-Learning server on certain of weeks within a
semester, preprocessing the set of raw data, select the
data that contribute for pattern analysis, implement the
pattern mining using basic Association Rule, Apriori
algorithm, in order to produce the final results (rules).
4

2.0 LITERATURE REVIEW
Data Mining, Web Mining and Web Usage Mining
Data mining (DM) is a step from Knowledge Discovery in
Database (KDD) process, which is defined as a “nontrivial process
of identifying valid, novel, potentially useful and ultimately
understandable pattern in data” (Fayyad et al., 1996). The term
pattern here refers some abstract representation of a subset data
of the data, that is, an expression in some language describing a
data subset or a data subset or a model applicable to that
subset.
Data mining efforts associated with the Web, called Web
mining, can be broadly categorized into three areas of interest
based on which part of the Web to mine; Web Content mining, Web
Structure mining, and Web Usage Mining (Kosala and Blockeel,
2000). In Web mining, data can be collected at the server-side,
client-side, proxy servers or a consolidated Web/business
database (Srivastava et al., 2000). The information provided by the
data sources described above can be used to construct several
5
data abstractions, namely users, page-views, click-streams and
server sessions.
Web Usage Mining is defined as the process of applying data
mining techniques to the discovery of usage patterns from Web
logs data which to identify Web user’s behavior (Srivastava et al.,
2000). Web Usage Mining is the type of Web mining activity that
involves an automatic discovery of user access patterns from one
or more Web servers.
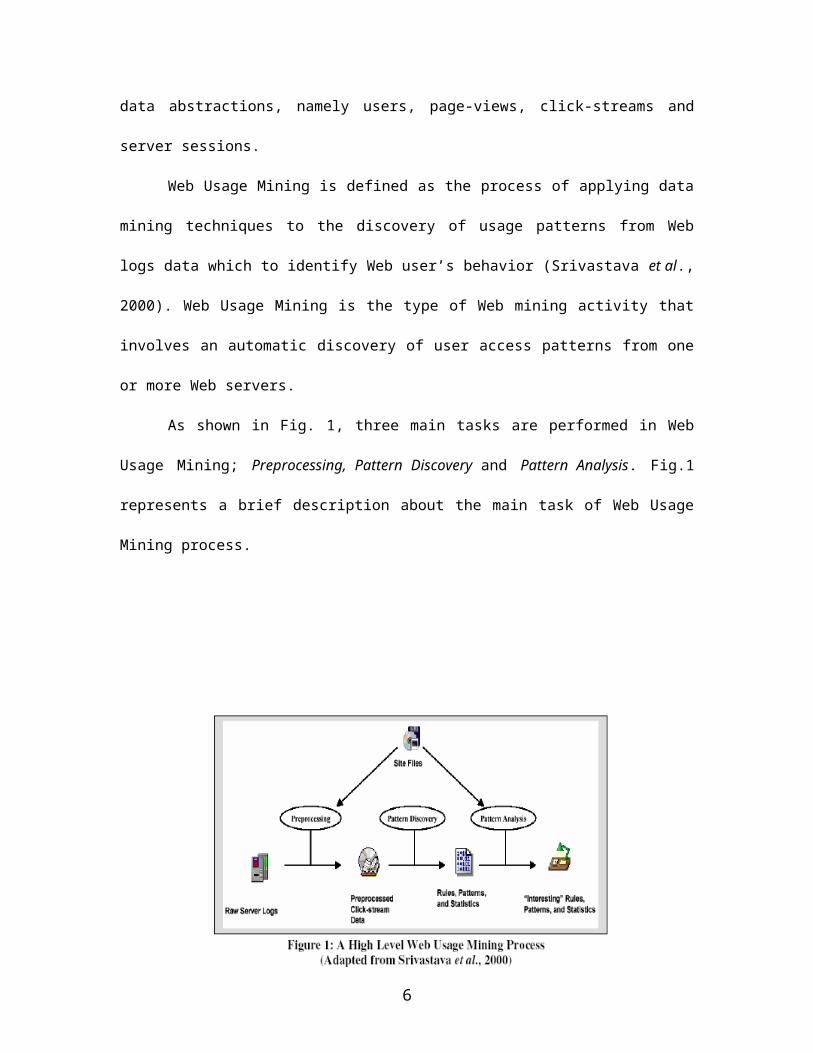
As shown in Fig. 1, three main tasks are performed in Web
Usage Mining; Preprocessing, Pattern Discovery and Pattern Analysis. Fig.1
represents a brief description about the main task of Web Usage
Mining process.
6

Association Rules and Apriori Algorithm
The problem of deriving Association Rules from data was
first formulated in (Agrawal, Imielinski and Swami, 1993) and is
called the “market-basket problem”. The problem is that we are
given a set of items and a large collection of transactions which
are sets (baskets) of items. The task is to find relationships
between the containments of various items within those baskets.
Apart from the supermarket scenario there are many other
examples where Association Rules have been used, for example
users’ visits of WWW pages which the structure and its content
can be optimized. Xue et al., (2001) have used re-ranking method
and generalized Association Rules to extract access patterns of
the Web sites pattern usage. Mannila et al., (1999) use page
accesses from a Web server log as events for discovering frequent
episodes. Chen et al., (1996) introduce the concept of using the
maximal forward references in order to break down user sessions into
transactions for the mining of traversal patterns. Batista and
Silva, (2001) perform mining process for online newspaper Web
access logs by using Apriori algorithm.
7

The task in Association Rules mining involves finding all
rules that satisfy user defined constraints on minimum support
and confidence with respect to a given dataset. Most commonly
used Association Rule discovery algorithm that utilizes the
frequent itemset strategy is exemplified by the Apriori algorithm
(Agrawal et al., 1993).
Apriori was the first scalable algorithm designed for
association-rule mining algorithm. Apriori is an improvement over
the AIS and SETM algorithms (Agrawal and Srikant, 1994). The
Apriori algorithm searches for large itemsets during its initial
database pass and uses its result as the seed for discovering
other large datasets during subsequent passes. Rules having a
support level above the minimum are called large or frequent
itemsets and those below are called small itemsets (Chen et al.,
1996). The algorithm is based on the large itemset property which
states: Any subset of a large itemset is large and if an itemset is not large and then
none of its supersets are large (Agrawal and Srikant, 1994).
Web Usage Mining in Educational Field
In a Web-based learning environment, where both the tutors
and learners are separated spatially and physically, student
modeling is one of the biggest challenges. Traditional student
modeling techniques are inapplicable in these systems when tutors
8

are overwhelmed by the huge volumes of sequential data generated
as learners browse through the Web pages (Agrawal and Srikant,
1995). Web mining techniques, including clustering and
Association Rules mining can be applied to extract hidden and
interesting knowledge to facilitate instructional planning and
student diagnosis. Web mining in education is not new. It has
been applied to mine aggregate paths for learners engaged in a
distance education environment (Ha, Bae and Park, 2000); relevant
words to students based on text mining from their browsed
documents (Ochi et al., 1998); e-articles for students based on
key-word-driven text mining (Tang et al., 2000), and to analyze
learners’ learning behaviors (Zaiane and Luo, 2001). The previous
research proposed the beyond usage mining to consider the content
of the pages that have been visited. In the E-learning system,
both learners’ browsing behaviors and course content are
important to derive learners’ learning levels, intentions, goals,
interests or abilities. Incorporating course content can aid in
an understanding of learners’ browsing habits. In particular,
understanding the learners’ browsing behaviors can facilitate,
the course contain personalization.
The existing system called Artificial intelligence in
Education (AIED), employs a knowledge base, a student model and
9

instructional plans. For a Web based AIED system, Web mining
becomes part of student modeling. The system can relate its mined
knowledge of page contents and student navigation patterns to
students’ level of understanding to decide upon appropriate
feedback to them (Tang et al., 2001).
3.0 PROJECT METHODOLOGY AND IMPLIMENTATION
The Web Usage Mining process proposed by (Srivastava et al.,
2000) becomes a major guide line upon project implementation.
Fig.3 shows the general flow of the project methodology.
Server Log File
The server log file dated from 19 February 2004 until 13
March 2004 has been selected for further analysis. The server log
files are retrieved from the UUM Educare server, www.e-
web.uum.edu.my . The total amount of the server log file between
10

that duration is about 650 MB and the large amount of data
becomes the most challenging problem to handle during the Data
Preprocessing phase. The server log file consists of nine
attributes in the single line of record as shown in Fig 4.
In the data selection phase, log files started on 19
February 2004 until the end of semester (13 March 2004) have been
selected. The selection of the server log files must be done
carefully because of the UUM Educare is part of the GroupWeb
facilities where beside the Educare (My Desktop) as an E Learning,
there are several facilities such as My Portfolio and Resources.
Because of the UUM Educare facilities that provided by the
GroupWeb is mixed with another facilities or options, the server
log file also includes the mix of log file for every transaction
between the facilities in the GroupWeb portal.
Data Preprocessing
Data Preprocessing phase is one of the most challenging
phase in this study. The major task in this phase are includes
11

handling missing values, identifying outliers, smooth out noisy
data and correct inconsistent data (Han and Kamber, 2001). Data
Preprocessing consists of all the actions taken before the actual
Pattern Analysis phase process starts.
The Data Preprocessing phase is being done by using
available software in the market. On early stage of this phase,
Macro tool in Microsoft Access have been selected to assist the
preprocessing tasks and for the following data preprocessing
task, filter tool in Microsoft Excel becomes the selected tool.
The selection of this period is because of the universities
academic calendar shows the selected dates are nearly to the end
of second semester of 2003/2004 session where 13 March 2004 the
last day for final examination. Fig. 5 shows the data after
preprocessing phase is done.
Pattern Analysis
During the Pattern Analysis phase, the descriptive method is
being used analyze the data such as general summary of the Web
12

usage and customer behaviors. This general summary includes the
most active users using the portal either from Malaysia or other
country. If the users came from Malaysia, it’s also shows the
locality of the users either accessing the UUM Educare portal
from the UUM Local Area Network (LAN) or outside of UUM campus.
The analysis also tries to find out the top visitors for
each facility or option that being provided by the UUM Educare
portal. There are several facilities or option that being placed
in UUM Educare portal such as dms, profile, resources, announcement,
assessment, calendar, pnotes, assignment and forum. The dms as one of the
options in UUM Educare can be analyzed to know the most requested
documents in UUM Educare portal. Beside the dms option analysis,
the sever log files also trace the information of documents that
was downloaded.
Pattern Discovery – Association Rules
Given a server log files that represent UUM Educare portal
activities, the main purpose of Association Rules is to generate
all Association Rules that have support and confidence greater
than the user specified minimum support (called min_sup) and
minimum confidence (called min_conf) respectively. An algorithm
for finding all Association Rules, henceforth, referred to as the
Apriori algorithm (Agrawal and Srikant, 1994).
13

The selected of Apriori algorithm is because of the
performance where it able to run the mining process in short
period. Currently, Apriori algorithm is commonly used for
generating the Association Rules for Web Usage Mining and this
experimental study focus on exploratory of Web Usage Mining in
university E-Learning portal (UUM Educare).
Results
As stated above, this study will focus on Web Usage Mining
of UUM Educare portal. The results of this study are divided into
two sections where the first section will discuss about the
general descriptions of the access pattern and users behaviors of
UUM Educare portal (descriptive statistic). Another section will
display the supports and confidences of the different level in
UUM Educare portal. All the results will display using certain
chart for such as pie and bar chart to make it easier understand.
4.0 FINDINGS AND RESULTS
The Web Usage Mining for Universiti Utara Malaysia E
Learning (UUM Educare) portal where the main URL, www.e-
web.uum.edu.my are divided into two main stages or section. Each
stages having their own phases with certain sub activities. The
first stages are including log data retrieving from the UUM
14

Educare server where the Data Selection and Data Preprocessing
phases are directly involves. The second stages are the mining
stages where its will involving Pattern Discovery by applying
Association Rules and Pattern Analysis phases in order to
discovered the UUM Educare portal usage pattern.
General Pattern Analysis Results (access pattern and users behaviors –
descriptive statistic)
The UUM Educare portal has several options (dms, resources,
announcement, assessment, calendar and forum) that can be chooses by the
users. Based on the Universal Resource Locator (URL) stem, the
users only accessed the UUM Educare options in host of www.e-
web.uum.edu.my without navigating other sub options provided by
UUM Educare portal are shows on the figure below.
15
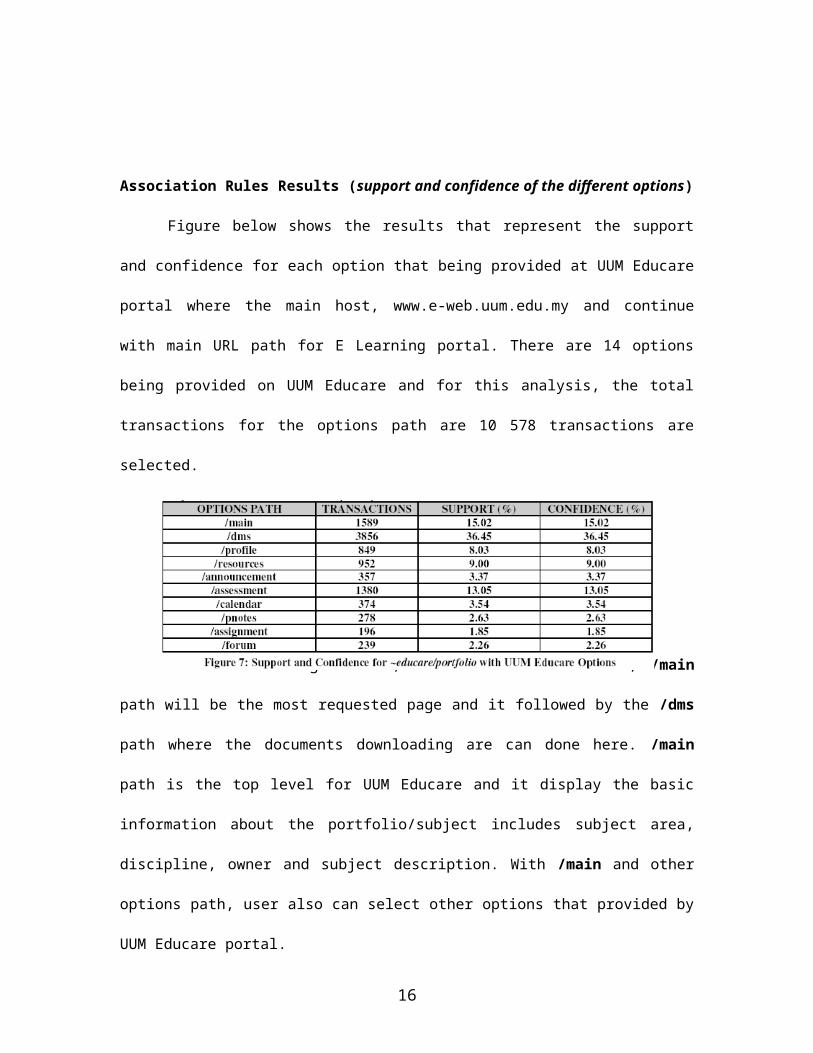
Association Rules Results (support and confidence of the different options)
Figure below shows the results that represent the support
and confidence for each option that being provided at UUM Educare
portal where the main host, www.e-web.uum.edu.my and continue
with main URL path for E Learning portal. There are 14 options
being provided on UUM Educare and for this analysis, the total
transactions for the options path are 10 578 transactions are
selected.
Based on the Fig.6 above, it can be conclude that, /main
path will be the most requested page and it followed by the /dms
path where the documents downloading are can done here. /main
path is the top level for UUM Educare and it display the basic
information about the portfolio/subject includes subject area,
discipline, owner and subject description. With /main and other
options path, user also can select other options that provided by
UUM Educare portal.
16

Fig. 7 shows that support and confidence for each
directories and the /dms option path with 36.45% percentage of
support and confidence where it is a highest percentage for
support and also for the confidence level. It’s followed by /main
and /assessment option path where the support and confidence is
15.02% and 13.05%.
Association Rules induction is the extraction of rules in
the form of X => Y (if X then Y) quantified with a confidence
(proportion of occurrences that verifies Y among occurrences that
verifies X) and a support (proportion of occurrences that
verifies X and Y among all occurrences).
A next result shows the Association Rules, including support
and confidence by applying Apriori algorithm for identifying the
patterns, defining a threshold of 15% for the minimum support and
a threshold of 70% for the minimum confidence. Fig. 8 shows the
pages that related to each other where the most frequent options
that being selected during the certain options is selected.
17
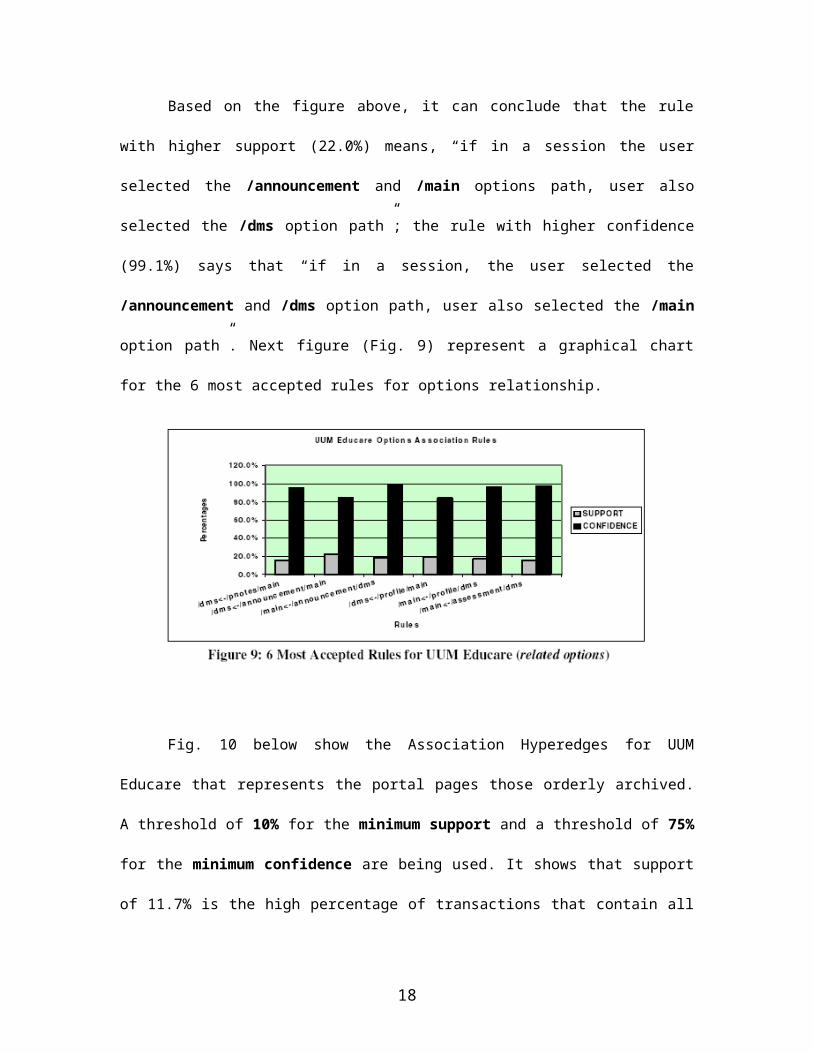
Based on the figure above, it can conclude that the rule
with higher support (22.0%) means, “if in a session the user
selected the /announcement and /main options path, user also
selected the /dms option path”; the rule with higher confidence
(99.1%) says that “if in a session, the user selected the
/announcement and /dms option path, user also selected the /main
option path”. Next figure (Fig. 9) represent a graphical chart
for the 6 most accepted rules for options relationship.
Fig. 10 below show the Association Hyperedges for UUM
Educare that represents the portal pages those orderly archived.
A threshold of 10% for the minimum support and a threshold of 75%
for the minimum confidence are being used. It shows that support
of 11.7% is the high percentage of transactions that contain all
18

items appearing in the hyperadge, that is in the /assignment
/announcement /main with the percentages of confidence is 78.1%.
The confidence of 92.2% with 10.6% of support is on
/assignment /announcement /assessment /main is represent the
highest of average confidence of all rules that can be formed
using the items in the hyperedge with all items appearing in the
rule (average confidence of the rules including /main <-
/assessment /announcement /assignment, /assessment <- /main
/announcement /assignment, /announcement <- /main /assessment
/assignment and /assignment <- /main /assessment /announcement.
The following figure (Fig. 11) shows 6 most accepted
Association Rules Hyperedge for UUM Educare server log files
during selected period of time.
19

5.0 PROJECT SIGNFICANCE
Generally, this project will produce the useful finding for
analyzing the Web usage pattern for UUM ELearning, www.e-
web.uum.edu.my and more specific:
i. This study will become the first step for the analyzing
university E-Learning portal by applying Web usage mining
approach with basic Association Rules – Apriori algorithm.
ii. The outcomes from this study can be used by the Web
administrator in order to plan necessary improvement,
20

enhancement and valuable actions to the university E-
Learning portal.
iii. The implementation of Web usage mining process for
university E-Learning portal may becomes the guide line for
the system development purposes.
6.0 CONCLUSION AND RECOMMENDATION
Web Usage Mining is an active field for research and it will
generate new hopes in internet based business. Web Usage Mining
applications are being used in some famous Websites and this
paper totally focuses on education field. This paper presents a
brief introduction of Web mining technique, apart of the data
mining technologies and also the implementation of the Web Usage
Mining in E-Learning portal. Server log files of UUM E-Learning
(UUM Educare) in server host, www.e-web.uum.edu.my have been
selected for this project. In order to perform the Web Usage
Mining, the methodology that being introduce by (Srivastava et al.,
2000) becomes major guide where it includes three main phases;
Data Preprocessing, Pattern Analysis and Pattern Discovery. All the particular
phases were done carefully to produce quality results. Data
Processing phase for the Web Usage Mining is a challenging task
and basic Association Rules algorithm, Apriori algorithm was
21

selected as a technique to produce the support and confidence of
the different levels in Web usage mining of UUM Eduacare portal.
The selection of the Apriori algorithm for performing Web
usage mining on UUM Educare portal is because of Apriori algorithm
is a common data mining technique for association based analysis.
By applying this algorithm to the Web log file, the relationship
between the accessed pages can be mined. The Web usage patterns
and user behavior on UUM Educare portal also can analyze by using
this algorithm where the descriptive statistic approach can’t
perform this analysis. The results and findings for this analysis
are more reliable but less of accuracy because of the Apriori
algorithm properties where the same selected itemsets are always
counted. The results or findings from this experimental analysis
are surely useful for Web administrator in order to improve Web
services and performance through the improvement of Web sites,
including their contents, structure, presentation and delivery.
The valuable actions may contain of performing the Web pages
value added modification.
As a recommendation, in order to enhance and continue this
project, the suggested methodology can be implemented for system
development purposes. The system may perform and implement the
Web usage mining phase including data selection, data
22

preprocessing, pattern discovery and analysis. Apriori algorithm
may be a part of the pattern discovery sub function.
Beside that, there are certain important recommendation may
propose for improving the results during project implementation.
As discussed in chapter V, Findings and Results, there is placed
there the Association Rules with percentages support and
confidence for 10 most requested options in UUM Educare portal
and also represent the Association Rules for /dms option. The
figures for each support and confidence in particular results are
same because the step calculation for Apriori algorithm. According
to Boon Lay et., al (1999), the percentages of support for
Association Rules can be improve by finding all sets items
(attribute=value) that have transactions support above minimum
support. Itemsets with minimum support are called large itemsets
and the large itemsets are used to generate the desired rules.
Lastly, for future work, the another method for analyzing
sparse data can be used in the study of E-Learning Web log
access, use of different similarity Association Rules and
conclude about the most suitable alternatives for knowledge
extraction from Web log data.
REFERENCES
23

Abd. Wahab, M. H, Siraj, F and Yusoff, N. (2004). Log Mining Using
Generalize Association Rules. In Proceedings of Master Final
Project 2004 Presentation, UUM, Malaysia.
Agrawal, R., Imielinski, T. and Swami, A. (1993). Mining Association
Rules between Sets of Items in Large Databases. In Proceedings of the
International ACM SIGMOD Conference, Washington DC, USA,
pages 207–216.
Agrawal, R. and Srikant, R. (1994). Fast Algorithm for Mining Association
Rules. Proc. of the 20th VLDB Conference. Pp 487-499.
Agrawal, R., and Srikant, R. (1995). Mining Sequential Patterns. In
Proc. of the Eleventh International Conference on Data
Engineering (ICDE), Taiwan. Pp 3-14.
Batista, P and Silva, M (2001). Prospeccao dos Dados de Acesso a um
Servidor de Noticias na Web, 2nd Coferencia sobre Redes de
Computadores, Evora, Portogal.
Boon Lay, C, Khalid, M and Yusof, R. (!999). Intelligent Database
by Neural Network and Data Mining. In Proc. of Artificial
24

Intelligent Applications in Industry, Kuala Lumpur. Pp 201-
219.
Borgelt, C. (2004). Apriori: Finding Association Rules/Hyperedges with the
Apriori Algorithm. School of Computer Science, University of
Magdeburg.
Chen, M.-S., Jan, J., Yu, P.S. (1996). Data Mining: An Overview from a
Database Perspective. IEEE Transactions on Knowledge and Data
Engineering, (8:6). Pp 866.883.
Fayyad, U., Piatetsky-Shapiro, G., and Smyth, R. (1996). The KDD
Process for Extracting Useful Knowledge from Volumes of Data.
Communications of the ACM, (39:11). Pp 27-34.
Han, J., Kamber, M. (2001). Data Mining: Concepts and Techniques. Morgan-
Kaufmann Academic Press, San Francisco.
Jiang, Q. (2003). Web Usage Mining: Process and Application. Presentation
for CSE 8331.
25

Kosala, R., Blockeel, H. (2000). Web Mining Research: A Survey. ACM
SIGKDD (Special Interest Group on Knowledge Discovery and
Data Mining) Explorations. June, (2:1). Pp 1-10.
Mannila, H., Toivonen, H. and Verkamo, A. I. (1994). Efficient
Algorithms for Discovering Association Rules. In AAAIWorkshop on
Knowledge and Discovery in Databases, Seattle, Washington,
USA, Pp 181–192.
Srivasta, J., Cooley, R., Deshpande, M., and Tan P. N. (2000).
Web Usage Mining: Discovery and Application of Web Usage Pattern from Web
Data. Department of Computer Science and Engineering,
University of Minnesota.
Tang, C.; Lau, R.W.H.; Li, Q.; Yin, H.; Li, T.; and Kilis, D.
(2000). Personalized Courseware Construction Based on Web Data Mining.
In Proc. of the First International Conference on Web
Information Systems Engineering (WISE 2000) vol.2, Pp. 204-
211.
26

Tang, Y. T. and McCalla, G. (2001). Student modeling for a Web based
Learning Environment: a Data Mining Approach. Department of Computer
Science, University of Saskatchewan, Canada.
Xue, G. R., Zeng, H. J., Ma, W. Y and Lu, C. J. (2002). Log Mining
to Improve the Performance of the Methods from statistic, Neural Nets, Machine
Learning and Experts System. Morgan Kaufman.
Zaiane, O. and Luo, J. (2001). Towards Evaluating Learners’ Behavior in a
Web-based Distance Learning Environment. In Proc. of IEEE
International Conference on Advanced Learning Technologies,
Pp 357-360, Madison, WI.
27





























