Embed Size (px)
Citation preview

BAB 2
LANDASAN TEORI
2.1 Teori Umum
2.1.1 Definisi Transportasi Umum
Definisi transportasi umum terdiri dari :
a. Kendaraan umum (Keputusan Menteri Perhubungan No.35 Tahun 2003)
adalah setiap kendaraan bermotor yang disediakan untuk dipergunakan
oleh umum dengan dipungut bayaran baik langsung maupun tidak
langsung.
b. Bus besar (Keputusan Menteri Perhubungan No.35 Tahun 2003) adalah
kendaraan bermotor dengan kapasitas lebih dari 28 dengan ukuran dan
jarak antar tempat duduk normal tidak termasuk tempat duduk pengemudi
dengan panjang kendaraan lebih dari 9 meter.
c. Bus sedang (Keputusan Menteri Perhubungan No.35 Tahun 2003) adalah
kendaraan bermotor dengan kapasitas 16 s/d 28 dengan ukuran jarak
tempat antar tempat duduk normal tidak termasuk tempat duduk pengemudi
dengan panjang kendaraan lebih dari 6,5 sampai dengan 9 meter.
d. Trayek (Keputusan Menteri Perhubungan No.35 Tahun 2003) adalah
lintasan kendaraan umum untuk pelayanan jasa angkutan orang dengan
mobil bus, yang mempunyai asal dan tujuan perjalanan tetap, lintasan tetap
dan jadwal tetap maupun tidak berjadwal.
e. Terminal (Keputusan Menteri Perhubungan No.35 Tahun 2003) adalah
prasarana transportasi jalan untuk keperluan memuat dan menurunkan
orang dan/atau barang serta mengatur kedatangan dan pemberangkatan
kendaraan umum, yang merupakan salah satu wujud simpul jaringan
transportasi.
9

2.1.2 Definisi Data, Informasi, Pengetahuan, dan Kebijakan
Berikut adalah beberapa definisi dari data,informasi,pengetahuan,dan
kebijakan :
a. Data (Bali, Wickramasinghe, & Lehaney, 2009) adalah serangkaian
kejadian diskrit, observasi, pengukuran, atau fakta yang dapat berbentuk
angka, kata, suara, dan/atau gambar.
b. Informasi (Bali, Wickramasinghe, & Lehaney, 2009) adalah data yang
sudah disusun sedemikian rupa menjadi pola yang memiliki arti dan
memiliki bentuk yang dikenali. Contohnya adalah data yang sudah
diciptakan dengan relevansi dan tujuan.
c. Pengetahuan/knowledge (Davenport & Pruzak, 1998, p.5 dalam Bali,
Wickramasinghe, & Lehaney, 2009) adalah campuran dengan cara yang
tidak baku (fluid) dari pengalaman dalam konteks tertentu, nilai, informasi
yang kontekstual, dan kapasitas dari seseorang/sekelompok ahli untuk
mendapatkan pemahaman dari seseorang/sesuatu (expert insight) yang
menyediakan dan mengkorporasikan pengalaman dengan informasi baru.
Pengetahuan berasal dan diaplikasikan di dalam pikiran seseorang yang
memiliki pengetahuan tersebut.
Terdapat 3 jenis pengetahuan (Popper, 1972, 1978, 1994, 1999, Popper
and Eckles, 1977 di dalam Firestone & McElroy, 2005), yaitu:
1. Teruji, terevaluasi, dan struktur informasi yang masih ada
(surviving) di dalam sistem fisik yang memungkinkan mereka untuk
beradaptasi terhadap lingkungannya (biological knowledge).
2. Teruji, terevaluasi, dan kepercayaan yang masih ada (surviving
beliefs) di dalam pikiran tentang dunia (yang bersifat subjektif, atau
tidak dapat dibagikan, mental knowledge).
3. Teruji, terevaluasi, masih ada (surviving) dan dapat dibagikan
(karena bersifat objektif), formulasi linguistik tentang dunia (seperti
klaim dan meta-claims yang berbasis perkataan (speech) maupun
artifak, atau cultural knowledge). Pengetahuan ini diekspresikan di
dalam bentuk fakta, nilai dan tindakan (Firestone & McElroy,
2005).

11
d. Kebijakan/wisdom (Wickramasinghe & Von Lubitz, 2007 dalam Bali,
Wickramasinghe, & Lehaney, 2009) adalah proses yang memungkinkan
kita untuk menyadari dan menginterpretasikan (discern) atau menghakimi
(judge) antara baik dan buruknya sesuatu secara esensial. Kebijakan
mengandung ekspresi implisit (embodied) pemahaman prinsip
fundamental yang terkandung di dalam pengetahuan orang tersebut.
Akan tetapi Jarche (2013) mengatakan bahwa mendapatkan pengetahuan
dan kebijakan/wisdom bukanlah sebuah proses yang linear, karena mendapatkan
pengetahuan jauh lebih rumit (messier) dari itu. Menjadi tahu (knowledgeable)
dapat dibayangkan sebagai sebuah pengetahuan yang dibagikan secara sebagian
dan dialami dari waktu ke waktu. Hal ini membutuhkan usaha dan waktu
(laborious), dan karena hal ini pula seorang ahli (master) selama bertahun – tahun
hanya dapat memiliki jumlah murid yang terbatas. Ketika melakukan mentoring
dengan seorang ahli atau membaca sebuah buku, pengetahuan tidak berpindah
(transferred) begitu saja, namun dengan observasi bersama (shared observations)
dan informasi dapat membantu mereka yang memiliki keinginan untuk belajar
untuk memahami hal tersebut.
2.1.3 Definisi Mobile Website dan perbedaannya dengan Mobile Application
Berikut adalah definisi perbedaan mobile website dan mobile application :
a. Mobile Website adalah website yang bertujuan untuk dilihat dengan
menggunakan browser mobile dengan variasi ukuran layar dari
smartphone, tablet, dan perangkat mobile lainnya. Secara tipikal, mobile
website adalah simplifikasi dari website standar yang memberikan user
experience yang lebih baik melalui usability yang lebih dikembangkan,
page load yang lebih cepat, dan terkadang reorganisasi konten untuk
memberikan fitur spesifik mobile di dalam penggunaan (Klein, 2012).
b. Mobile Application adalah aplikasi software yang berjalan secara spesifik
di operating system mobile tertentu, dan diunduh ke dalam peralatan mobile
untuk melakukan seperangkat fungsi secara spesifik. Aplikasi juga bersifat
device-specific seperti aplikasi Ipad dan Iphone (Klein, 2012).

Tabel berikut menunjukkan perbedaan antara Mobile Website dan Mobile
Application :
Tabel 2.1 Perbedaan Mobile Website dan Mobile Application.
(Klein,2012)
2.2 Teori Khusus
2.2.1 Definisi Tacit Knowledge
Definisi tacit knowledge terdiri dari :
a. Tacit Knowledge (Polanyi, 1966 dalam Bali, Wickramasinghe, &
Lehaney, 2009) adalah pengetahuan yang implisit dan tidak
terdokumentasi. Pengetahuan tacit berfokus pada pengetahuan
personal yang berasal dari pengalaman seeseorang yang melibatkan

13
kepercayaan (belief), perspektif dan nilai (value) dari individu
tersebut.
b. Karakteristik dari pengetahuan tacit (Kane et al. 2006, dalam Bali,
Wickramasinghe, & Lehaney, 2009) adalah:
1. Keahlian
2. Know-How
3. Dimanifestasikan melalui tindakan
4. Didapatkan hanya melalui tindakan sehari – hari (practice)
5. Sulit untuk dipindahkan (transfer)
6. Tidak dapat dipisahkan dari individu
7. Kepercayaan yang dianut
8. Nilai yang dimiliki
9. Kapasitas dari individu untuk mendapatkan sebuah pamahaman
10. Perasaan individu
11. Ide yang dimiliki di dalam pikiran individu.
2.2.2 Definisi Explicit Knowledge
Definisi explicit knowledge terdiri dari :
a. Explicit Knowledge (Skyrme & Amidon, 1997 dalam Bali,
Wickramasinghe, & Lehaney, 2009) adalah pengetahuan yang
formal, sistematis dan objektif, yang merupakan sebuah entitas yang
secara umum terkodifikasi di dalam angka dan kata.
b. Karakteristik dari pengetahuan explicit (Kane et al. 2006 dalam Bali,
Wickramasinghe, & Lehaney, 2009) adalah:
1. Rasionalisasi
2. Informasi
3. Dapat disimpan dan ditransmisikan
4. Dapat diartikulasikan
5. Faktual
6. Direpresentasikan dalam bentuk dokumen, desain, bahasa
formal, objektif, dan pengetahuan yang rasional.

2.2.3 Perbedaan Antara Informasi dan Pengetahuan
Berikut adalah perbedaan antara informasi dan pengetahuan:
Tabel 2.2 Perbedaan antara informasi dan pengetahuan
(Tiwana,2007)
Informasi Pengetahuan
Data yang sudah diproses. Informasi yang dapat dilakukan (actionable).
Hanya memberikan fakta. Dapat melakukan prediksi, asosiasi kasual, keputusan prediktif.
Jelas, singkat, padat, terstruktur, sederhana. Tidak seluruhnya terstruktur dan teracak.
Mudah diekspresikan di dalam bentuk tulisan. Intuitif, sulit untuk dikomunikasikan dalam kata dan iterasi.
Didapatkan dari kondensasi, koreksi,
kontekstualisasi, dan kalkulasi data*.
Terdapat dalam koneksi, percakapan antar orang, intuisi
berdasarkan pengalaman kemampuan seseorang untuk
membandingkan situasi, masalah beserta solusinya.
Tidak terikat (devoid) oleh ketergantungan pemilik. Bergantung pada sang pemilik pengetahuan.
Dikendalikan dengan baik oleh system informasi. Membutuhkan saluran informal.
Merupakan sumber daya kunci dalam
pemahaman (making sense) data dengan
volume besar.
Merupakan sumber daya kunci dalam pengambilan keputusan
yang cerdas, prediksi, desain, perencanaan, diagnosa,
dan judging secara intuitif.
Berevolusi dari data, formalisasi dari basis data,
buku, manual dan dokumen.
Terbentuk dan dibagikan di dalam pemikiran kolektif, berevolusi
dengan pengalaman, kesuksesan, kegagalan,
dan pembelajaran terus menerus.
Sudah diformalisasi, ditangkap, dianalisa serta
dikembangkan secara detil dengan
ide dan prinsip (explicated).Terbentuk di dalam pemikiran masing – masing orang
melalui pengalaman yang dimiliki oleh orang tersebut.Dapat dibentuk dalam bentuk
yang dapat digunakan kembali (reuseable).

15
a. Berikut adalah penjelasan dari istilah – istilah tersebut:
1. Kondensasi Data: Data dirangkum di dalam bentuk yang lebih
ringkas, dengan menghilangkan kedalaman/rincian yang tidak
dibutuhkan.
2. Kontekstualisasi Data: Kita mengetahui bagaimana data tersebut
diambil.
3. Kalkulasi Data: Analisa data, mirip dengan kondensasi data.
Perbedaannya adalah kalkulasi data menggunakan perhitungan
matematis.
4. Kategorisasi Data: Setiap unit dari analisa sudah diketahui.
5. Koreksi Data: Kesalahan yang terjadi sudah dihilangkan, data yang
tidak lengkap sudah dilengkapi.
2.2.4 Komponen – Komponen Pengetahuan
Berikut adalah komponen – komponen dari pengetahuan (Tiwana, 2007):
a. Kebenaran (truth), yang berupa penemuan (discovery), perekaman
(recording), dan pemeliharaan (maintenance) dari asumsi dan
kemampuan untuk melakukan what-if analysis. Namun,
permasalahannya adalah seringkali terdapat asumsi, dan asumsi
tersebut terkandung secara tersirat (embedded).
b. Pengambilan keputusan (judgement), yaitu informasi dengan
komponen penghakiman yang terkait. Informasi yang tidak dapat
dilakukan (inactionable) bukanlah pengetahuan. Pengambilan
keputusan menyebabkan pengetahuan untuk melebihi sebuah opini
ketika memeriksa kembali (re-examines) dirinya sendiri dan
memperkuat (refines) dirinya sendiri setiapkali pengambilan keputusan
diaplikasikan dan dilakukan.
c. Pengalaman (experience), yaitu pengetahuan diambil dari pengalaman
dan memiliki perspektif historis. Kemampuan untuk
memindahkan/memberikan pengetahuan mengimplikasikan bahwa
bagian dari pengetahuan yang berdasarkan pengalaman juga
dipindahkan/diberilan kepada resipien. Orang yang berpengalaman
biasanya lebih dihargai karena memiliki sudut pandang historis yang

memberikan mereka kemampuan untuk melihat situasi saat ini dan
membuat koneksi dengan masa lalu yang berhubungan – sesuatu yang
tidak dimiliki oleh orang baru.
d. Asumsi: Proses bisnis didasari oleh seperangkat asumsi yang sulit
dihilangkan (ingrained) tetapi tidak diartikulasikan dan tidak
berhubungan di dalam sebuah konteks (oblivious). Seorang spesialis
teknik (engineer) dapat berasumsi bahwa sebuah benda yang
beroperasi secara tidak normal pasti memiliki hal yang rasional.
e. Kepercayaan (belief) dan Nilai (value): Perusahaan biasanya dibentuk
oleh beberapa tokoh yang bekerja disana, seperti:
1. Bersenang – senang di dalam lingkungan kerja, yang dilakukan
oleh Starbucks.
2. Membuat produk yang sangat hebat oleh Apple.
3. Dominasi pasar yang sulit dihilangkan oleh Microsoft.
4. Nilai, asumsi, dan kepercayaan tersebut adalah komponen
yang penting (integral) dari pengetahuan. Mengetahui,
mendapatkan dan membagikan komponen dari pengetahuan
yang dapat membuat perbedaan antara pengetahuan yang
lengkap dengan informasi yang tidak lengkap dan tidak dapat
diaplikasikan.
Tidak seluruh kepercayaan dapat diperoleh secara eksplisit.
Karena alasan ini, penekanan dilakukan pada penyediaan
sistem yang mengindikasikan figur untuk orang – orang yang
memiliki komponen tersebut.
f. Kecerdasan (intelligence): Ketika pengetahuan diaplikasikan pada saat
dan tempat yang diperlukan, kemudian menjadi pertimbangan
pengambilan keputusan di masa kini (sekarang) pengetahuan dapat
membawa orang tersebut menuju performa dan hasil yang lebih baik
dimana pengetahuan dikualifikasikan menjadi kecerdasan yang
dimiliki orang tersebut.

17
2.2.5 Definisi Knowledge Management
Berikut adalah definisi knowledge management :
a. Knowledge Management (Dalkir, 2011) adalah koordinasi yang
sistematis dan dipertimbangkan (deliberate) oleh manusia, struktur,
proses, dan teknologi dari organisasi untuk memberikan nilai melalui
inovasi dan penggunaan ulang. Hal ini dapat dicapai melalui promosi
untuk menciptakan, membagikan, dan mengaplikasikan pengetahuan
serta melalui pemberian (feeding) pengalaman dari kesalahan (lesson
learned) yang berharga serta best practice ke dalam memori
korporasi dalam melakukan pembelajaran organisasi secara
berkelanjutan.
2.2.6 Definisi Knowledge Management Cycle dan Knowledge Management
Model
Berikut adalah Definisi Knowledge Management Cycle dan Knowledge
Management Model :
a. Knowledge Management Cycle (Dalkir, 2011) melingkupi
(encompassing) pencatatan (capture), penciptaan (creation),
kodifikasi, pembagian (sharing), dapat menggunakan pengetahuan
(accessing), mengaplikasikan, dan menggunakan kembali (reuse)
pengetahuan di dalam dan diantara organisasi.
b. Knowledge Management Model (Dalkir, 2011) adalah rangka kerja
konseptual yang beroperasi bersamaan dengan Knowledge
Management Cycle.
2.2.6.1 McElroy Knowledge Life Cycle KM Cycle
Knowledge Life Cycle adalah sebuah gambaran dari knowledge processing dan
hubungannya dengan operational business processing (Firestone & McElroy,
2005) yang dikembangkan oleh komunitas knowledge management yaitu sebuah
model tiga tahap untuk knowledge management generasi kedua (McElroy, 1999).
Knowledge Management Generasi Pertama (McElroy, 1999) adalah skema yang
teknologi sentris… yang hanya didevosikan untuk meningkatkan knowledge
operations dengan mempertimbangkan performa dari day-to-day business (untuk)

memberikan informasi yang tepat untuk orang yang tepat di saat yang tepat.
Knowledge Operations adalah peranan pengetahuan di dalam mendukung proses
bisnis.
Knowledge Management Generasi Kedua (McElroy, 1999) adalah skema
yang menekankan produksi pengetahuan (demand-side thinking) tanpa
mengurangi pentingnya kodifikasi dan sharing (supply-side thinking) dari
knowledge management generasi pertama. Secara kontras dengan KM Generasi
Pertama, KM Generasi Kedua lebih menekankan pada produksi pengetahuan
secara organisasi, dan menggunakan perspektif knowledge process (akan
dijelaskan kemudian). Setelah pengetahuan tersebut didefinisikan, klaim tersebut
dapat ditingkatkan untuk validasi formal dan informal (knowledge validation).
Single Loop Learning (Argyris, 1991 di dalam McElroy, 1999) dapat
dipikirkan sebagai bagian dari sebuah proses yang berjalan ketika berusaha untuk
berfungsi secara sukses di dalam dunia nyata. Ketika seseorang menemui sebuah
kondisi yang diskrit, atau kejadian, selama pengalaman normal berlangsung,
aturan yang dikelola secara pribadi (internally-maintained rules) akan
dipanggil/dilakukan (invoked) sebagai respon. Aturan, di dalam konteks ini,
adalah pengetahuan. Single Loop Learning juga dapat dikatakan enhanced day-to-
day operation.
Double Loop Learning (McElroy, 1999) secara kontras, tidak
mereferensikan pada aturan itu sendiri, namun mempertanyakan (challenges)
secara konstruktif refleks dari single loop learning untuk melakukan respon
(dalam berupa aturan) tersebut.
Argyris, 1991 di dalam McElroy, 1999 menjelaskan kedua hal tersebut
dengan sebuah analogi: sebuah termostat yang secara otomatis akan menyalakan
penghangat ketika temperature di dalam ruangan turun dibawah 68 derajat
(Fahrenheit) adalah contoh yang baik dari Single Loop Learning. Termostat
tersebut dapat bertanya, “Mengapa saya diatur di 68 derajat?” dan kemudian
mengeksplorasi apakah terdapat (derajat) temperatur lain yang dapat mencapai
tujuan untuk menghangatkan ruangan secara lebih ekonomis. Hal tersebut dapat
dikatakan Double Loop Learning.

19
McElroy, 1999 mengatakan bahwa di dalam pikiran manusia, pemikiran
double loop seperti ini dapat menyebabkan konstruksi aktif dari skenario alternatif
dimana orang yang belajar dapat mensimulasikan (play out) hasil yang
kemungkinan besar terjadi dengan cara memprediksi (in a lookahead fashion). Ide
yang menjanjikan kemudian dapat diuji coba, dimana pembelajar tersebut dapat
mengganti respon yang seharusnya dilakukan (respon dari single loop learning)
dan secara sementara menggantikan respon tersebut dengan hal yang baru.
Tergantung dari bagaimana respon baru tersebut bekerja, respon yang lama dapat
digunakan kembali atau digantikan.
Dua fundamental Knowledge Management Generasi Kedua menurut McElroy,
1999 adalah:
a. Knowledge Structures, yaitu ekspresi yang terkodifikasi di dalam
pengetahuan organisasi. Proses bisnis, Contohnya, adalah kodifikasi
pengetahuan dari procedural knowledge (know-how).
Know-How (Bali, Wickramasinghe, & Lehaney, 2009) adalah
pengetahuan bagaimana untuk menyelesaikan sesuatu. Kebanyakan dari
pengetahuan ini adalah tacit.
b. Knowledge Processes (McElroy, 1999) adalah organisasi secara literal
menciptakan pengetahuan baru melalui proses interaksi nonlinear antara
grup dan individu, dimana didalamnya terdapat knowledge claims yang
terbentuk (knowledge productions). Secara kontras dengan Knowledge
Management Generasi Pertama, inisiatif generasi pertama cenderung
untuk berkonsentrasi hanya pada knowledge sharing dan knowledge
transfer … dan tidak memperdulikan knowledge creation pada tingkat
organisasi.
Tiga prinsip Knowledge Management Generasi Kedua menurut McElroy, 1999
adalah:
a. Pengetahuan organisasi dapat ditemukan di berbagai struktur pengetahuan
di dalam sebuah organisasi. Berbagai aturan yang tercermin dalam
tindakan (embedded) di dalam sebuah struktur (contohnya praktik dalam

pengetahuan) seharusnya dapat dikonversikan ke dalam bentuk tulisan
(deciphered) dan kemudian dikelola.
b. Organizational Knowledge adalah produk dari natural knowledge learning
processes di dalam seluruh organisasi manusia. Proses tersebut seharusnya
diformalisasikan dan kemudian dikelola.
c. Ketahui apa yang kita ketahui dan mengapa kita mengetahui hal tersebut.
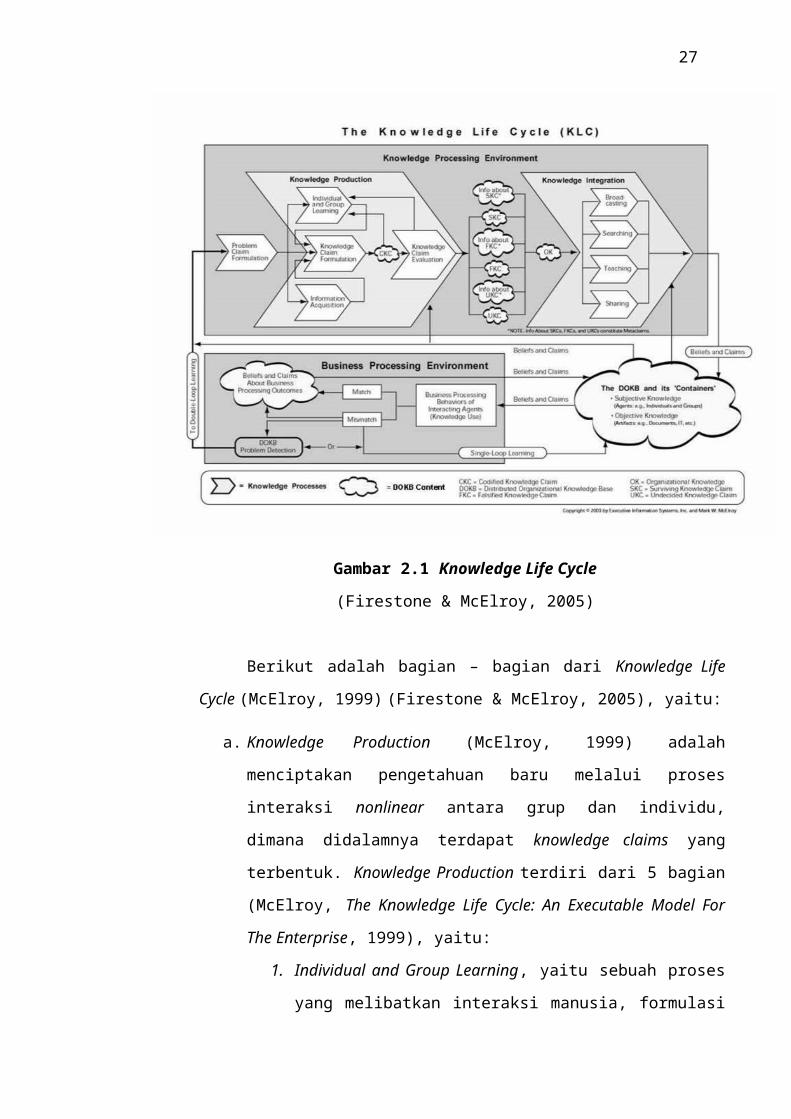
Gambar 2.1 Knowledge Life Cycle
(Firestone & McElroy, 2005)
Berikut adalah bagian – bagian dari Knowledge Life Cycle (McElroy,
1999) (Firestone & McElroy, 2005), yaitu:
a. Knowledge Production (McElroy, 1999) adalah menciptakan pengetahuan
baru melalui proses interaksi nonlinear antara grup dan individu, dimana
didalamnya terdapat knowledge claims yang terbentuk. Knowledge
Production terdiri dari 5 bagian (McElroy, The Knowledge Life Cycle: An
Executable Model For The Enterprise, 1999), yaitu:

21
1. Individual and Group Learning, yaitu sebuah proses yang
melibatkan interaksi manusia, formulasi knowledge claim, dan
validasi dimana pengetahuan individual/grup baru tercipta.
2. Knowledge Claim Formulation, yaitu sebuah proses yang
melibatkan interaksi manusia dimana organizational knowledge
claim diformulasikan. Dengan kata lain, kodifikasi dari knowledge
claims pada tingkat organisasi.
3. Information Acquisition, yaitu sebuah proses dimana sebuah
organisasi baik secara disengaja (deliberately) atau tidak terduga
(serendipitously) mendapatkan knowledge claims atau informasi
yang diproduksi pihak eksternal organisasi.
4. Codified Knowledge Claim, yaitu informasi yang sudah
dikodifikasi, namun belum menjadi subjek dari organizational
validation.
5. Knowledge Validation/Knowledge Claim Evaluation, yaitu sebuah
proses dimana knowledge claims adalah subjek dari kriteria
organisasi untuk menentukan nilai (value) dan akurasinya
(veracity).
b. Knowledge Integration (McElroy, 1999) adalah mengintegrasikan
pengetahuan organisasi kedalam kegiatan operasional sehari – hari dari
organisasi. Hal ini termasuk mengoperasionalkan (operationalizing)
pengetahuan baru, lengkap dengan kodifikasi dan indexing dari KM
Generasi Pertama.
Proses dari knowledge intergration terdiri dari empat subprocess
tambahan (Firestone & McElroy, 2005) yaitu:
1. Knowledge and Information Broadcasting
2. Searching/Retrieving
3. Knowledge Sharing (Presentasi peer-to-peer dari pengetahuan
yang sudah diproduksi sebelumnya)
4. Teaching (Presentasi hierarkis dari pengetahuan yang sudah
diproduksi sebelumnya).

c. DOKB (Distributed Organizational Knowledge Base) (Firestone &
McElroy, 2005) adalah landasan dari informasi dan pengetahuan untuk
seluruh processing environments. DOKB dapat berupa pengetahuan
subjektif dan pengetahuan objektif (lihat gambar 2.2). Pengetahuan dapat
berbentuk artifak (A) atau mental/pikiran (M) seperti yang digambarkan
pada gambar berikut:
Gambar 2.2 Distributed Organizational Knowledge Base
(Firestone & McElroy, 2005)
2.2.6.2 Boisot Information Space KM Model
Sebagai rangka kerja konseptual, Information Space dibangun dengan
premise intuitif yang simple, aliran pengetahuan yang terstruktur lebih siap dan
ekstensif dibandingkan dengan pengetahuan yang tidak terstruktur. Ketika
pengetahuan yang penting dan bersifat sangat tacit dan situasional oleh seorang
zen master contohnya, pengetahuan tersebut hanya dapat diakses oleh sedikit
murid melalui interaksi tatap muka dan abstraksi secara terus – menerus dalam

23
waktu yang lama. Pengetahuan manusia dibangun melalui proses ganda
diskriminasi dan asosiasi (Thelen dan Smith, 1994 dalam Boisot, Canals, &
Macmillan, 2004), sehingga dengan melakukan framing dari hal tersebut sebagai
proses informasi, Information Space menjadikan strukturisasi informasi sebagai
hal yang dapat dicapai melalui dua aktivitas kognitif: kodifikasi dan abstraksi.
Kodifikasi mengartikulasikan dan membantu membedakan pengetahuan
satu dengan yang lainnya ke dalam kategori yang kita gunakan untuk memahami
(making sense) dunia kita. Secara umum, semakin kompleks atau semakin buram
sebuah fenomena atau kategori yang kita buat untuk memahami hal tersebut
(seperti kodifikasi yang sedikit), semakin besar pula usaha pemrosesan data yang
harus kita lakukan.
Abstraksi berarti memperlakukan sesuatu yang berbeda seakan-akan
seluruhnya sama (Dretske, 1981, dalam Boisot, Canals, & Macmillan, 2004),
dengan mengurangi jumlah kategori yang perlu kita buat dalam memahami
sebuah fenomena. Ketika dua kategori memiliki asosiasi yang tinggi (keduanya
memiliki relasi yang sangat erat), satu kategori dapat bertumpang tindih dengan
yang lainnya. Semakin sedikit kategori yang perlu kita buat untuk memahami
sebuah fenomena, semakin abstrak pengalaman kita terhadap fenomena tersebut.
Kodifikasi dan abstraksi bekerja secara berpasangan. Kodifikasi
memfasilitasi asosiasi yang dibutuhkan untuk mendapatkan abstraksi, dan
abstraksi membatasi jumlah kategori yang dibutuhkan seminimal mungkin,
mengurangi pemrosesan data yang diasosiasikan dengan tindakan kategorisasi.
Secara bersamaan, keduanya bergabung untun membentuk strategi kognitif untuk
melakukan pemrosesan data secara ekonomis. Hasilnya adalah data yang lebih
terstruktur. Data yang lebih terstruktur, dengan mengurangi usaha kodifikasi,
transmisi, dan de-kodifikasi, memfasilitasi dan mempercepat difusi pengetahuan
di dalam populasi agen dengan sumber daya komunikatif yang lebih ekonomis.
Hubungan antara kodifikasi, abstraksi dan difusi pengetahuan
digambarkan dalam bentuk kurva difusi (gambar 2.3). Kurva tersebut
menjelaskan semakin terkodifikasi dan abstrak sebuah pengetahuan, semakin
besar populasi dari agen pemrosesan data yang dapat didifusikan di dalam sebuah
waktu. Agen tersebut dapat berupa individu, namun dapat pula beragregasi ke

dalam sebuah kelompok kecil, departemen, atau organisasi seperti firma.
Seluruhnya dibutuhkan untuk membangun baru (establish) kandidat dari agen
dengan kemampuan untuk menerima, memproses dan mentransmisikan data
kepada agen lain di dalam populasi, sekaligus kapasitas dari unified agency.
Gambar 2.3 Information Space Diffusion Curve
(Boisot, Canals, & Macmillan, 2004)
Kodifikasi, abstraksi dan difusi hanya membangun satu bagian dari social
learning process. Pengetahuan yang disebarkan di dalam populasi target juga
harus diserap oleh populasi tersebut dan kemudian diaplikasikan dalam situasi
yang spesifik. Ketika diaplikasikan, pengetahuan tersebut mungkin tidak cocok
sepenuhnya oleh skema yang ada dan dapat memulai (trigger) pencarian untuk
penyesuaian dan adaptasi – apa yang dideskripsikan oleh Piaget sebagai proses
asimilasi dan akomodasi (Piaget, 1967 dalam Boisot, Canals, & Macmillan,
2004). Siklus pembelajaran sosial yang kita miliki ini adalah bentuk deskripsi di
dalam siklus information space – Social Learning Cycle atau SLC, yang terdiri
dari enam langkah: scanning, kodifikasi, abstraksi, difusi, absorbtion, dan
impacting. Berbagai bentuk siklus dimungkinkan di dalam information space,
direfleksikan ke dalam halangan dan insentif dalam proses pembelajaran. Ketika
pembelajaran menjadi pembangunan sebuah pengetahuan baru, kita berhipotesa
bahwa siklus akan berubah menuju arah yang diindikasikan dalam gambar 2.4.

25
Gambar 2.4 Social Learning Cycle Information Space
(Boisot, Canals, & Macmillan, 2004)
Social Learning Cycle dijelaskan secara lebih rinci di dalam matriks berikut.
Tabel 2.3 Social Life Cycle
(Boisot, Canals, & Macmillan, 2004)
Social Learning Cycle
Scanning
Mengidentifikasi ancaman dan kesempatan yang secara umum tersedia namun
seringkali dalam bentuk fuzzy data (seperti sinyal yang lemah). Pola scanning
seperti data menjadi unik kemudian menjadi milik dari individu atau kelompok
kecil. Scanning mungkin terjadi secara sangat cepat ketika data terkodifikasi dan
terabstrak dengan baik, dan mungkin sangat lambat dan acak ketika data tidak
terkodifikasi dan spesifik pada konteks.
Problem
Solving/
Kodifikasi
Proses pemberian struktur dan koherensi pada insight (kapasitas seseorang untuk
memahami sesuatu) seperti mengkodifikasi sesuatu. Di dalam tahapan ini, insight
tersebut diberikan bentuk definit dan banyak asosiasi awal yang tidak pasti
dieliminasi. Problem solving diinisiasikan di dalam region dari information space
yang belum dikodifikasi dan seringkali menuai konflik.
Abstraksi Generalisasi dari pengaplikasian insight yang baru saja dikodifikasi kedalam
situasi yang lebih luas. Hal ini termasuk mengurangi insight tersebut menjadi fitur
yang paling esensial (dikonseptualisasikan). Problem solving dan abstraksi

bekerja secara berdampingan.
Diffusion
Membagikan insight yang baru saja dibuat di dalam populasi target. Penyebaran
dari data yang terkodifikasi dan terabstraksi dengan baik ke dalam populasi yang
lebih besar akan lebih mudah secara teknis dibandingkan dengan data yang tidak
terkodifikasi dan spesifik secara konteks. Hanya membagikan konteks melalui
pengirim dan penerima dapat mempercepat difusi dari data yang tidak
terkodifikasi; probabilitas dari konteks yang dibagikan berbanding terbalik
(inverse) dengan pencapaian secara proporsional di dalam populasi.
Absorbtion
Mengaplikasikan (menerapkan) insight yang baru saja dikodifikasi pada situasi
yang berbeda dengan cara “learning by doing” atau “learning by using”. Seiring
berjalannya waktu, insight tersebut akan mencapai penumbra dari pengetahuan
yang tidak terkodifikasi yang membantu untuk mengarahkan pengaplikasian
pengetahuan mereka di dalam kondisi tertentu.
Impacting
Terdapat embedding dari pengetahuan abstrak di dalam tindakan konkrit.
Embedding dapat berupa artifak, teknis atau peranan dalam organisasi, atau dalam
tindakan sehari – hari. Absorbtion dan impacting bekerja secara berdampingan.
Dalam SLC, setiaDalam SLC setiap agen memiliki resiko dan biaya
karena tidak terdapat jaminan bahwa siklus tersebut akan selesai. Lalu, bagaimana
cara menentukan bahwa seorang agen sudah mengambil cukup nilai dari proses
pembelajaran untuk mengkompensasi usaha dan resiko yang terjadi? Apabila kita
mengartikan nilai dalam konteks ekonomi, maka pasti terdapat campuran antara
utilitas dan kelangkaan (Walras, 1874 di dalam Boisot, Canals, & Macmillan,
2004).
Di dalam information space, utilitas (utility) dicapai dengan
menggerakkan informasi ke arah atas, yang menggambarkan kodifikasi dan
abstraksi dengan tingkat yang lebih tinggi. Kodifikasi dan abstraksi secara
bersama – sama menjadikan sumber daya pemrosesan dan transmisi data menjadi
lebih ekonomis ketika meningkatkan keandalan (reliability) dan generalizability
dari informasi yang tercipta. Kelangkaan (scarcity), secara kontras, tercapai
27
dengan menjaga aset pengetahuan yang terbentuk berada di posisi kiri dari
diffusion curve – lebih jelasnya, kelangkaan dari informasi akan berbanding
terbalik dengan orang yang memiliki pengetahuan tersebut.
Gambar 2.5 Maximum Value Menurut Information Space
(Boisot, Canals, & Macmillan, 2004)
Seperti yang terlihat pada gambar 2.5, nilai maksimal (maximum value)
didapatkan pada titik MV dalam information space, yaitu pada titik dimana
kodifikasi dan abstraksi berada pada titik maksimum dan diffusion berada pada
titik minimal. Ini adalah titik yang sama pada diffusion curve (gambar 2.1) yang
terletak pada puncak lengkung kurva, dimana tekanan dari diffusion berada pada
titik maksimal. Titik ini juga tidak stabil, dan terdapat biaya yang harus
dikeluarkan untuk mencegah diffusion terjadi, seperti dengan menggunakan hak
paten dan kerahasiaan/secrecy (Boisot, Canals, & Macmillan, 2004).
Utilitas dan kelangkaan memiliki relasi invers (berbanding terbalik).
Semakin tinggi utilitas yang dicapai, semakin sulit untuk menjaga kelangkaan
untuk mengekstraksi nilai (value) dari pengetahuan secara penuh. Paradoks dari
nilai informasi ini, dalam hal information good dapat diatasi dengan dua cara,
yaitu:
a. Dengan menimbun (hoarding) – strategi ini dibangun karena dinamika
dari diffusion yang terlihat pada gambar 2.3. Hal ini diasumsikan bahwa
seluruh potential economic returns ditawarkan oleh aset pengetahuan yang
diberikan dan diatas accounting rate of return (seperti sewa ekonomis)
normal akan habis seiring berjalannya waktu pengetahuan tersebut

terdifusi di dalam populasi. Strategi ini menghalangi atau memperlambat
difusi untuk menjaga nilai sewa ekonomis tetap pada nilai positif. Karena
strategi ini didorong oleh pemikiran equilibrium yang diasosiasikan
dengan ekonomi neoklasik, maka strategi ini dinamakan pembelajaran
neoklasik atau strategi n-learning (Boisot, 1998 dalam Boisot, Canals, &
Macmillan, 2004).
b. Dengan berbagi (sharing) – strategi ini dibangun dari dinamika
pembelajaran yang diperlihatkan pada gambar 2.3. Hal ini diasumsikan
bahwa aset pengetahuan baru – dan nilai yang baru – dibangun pada tahap
absorbtion, impacting dan scanning pada social learning cycle, dimana
kreasi dari aset pengetahuan baru tersebut dalam beberapa hal berbeda
dengan aset pengetahuan yang saat ini sedang berdifusi, dan nilai dari
pengetahuan yang baru tersebut akan lebih besar dibandingkan dengan
nilai yang hilang karena erosi kelangkaan yang disebabkan oleh diffusion
dari aset pengetahuan sekarang. Strategi terdiri dari pergerakan di sekitar
social learning cycle yang lebih cepat dibandingkan pesaing untuk
mengamankan first-mover advantage dalam kreasi pengetahuan baru dan
menghancurkan pengetahuan yang sekarang sudah ada. Strategi ini diberi
nama Schumpeterian Learning atau strategi S-Learning (Boisot, 1998
dalam Boisot, Canals, & Macmillan, 2004).
Sangat jelas terlihat bahwa strategi N-Learning berfokus pada menjaga
pengetahuan yang ada, sedangkan S-Learning berfokus pada menghancurkan
pengetahuan yang sudah ada melalui kreasi pengetahuan baru, seperti inovasi
(Nelson dan Winter, 1982 dalam Boisot, Canals, & Macmillan, 2004).
2.2.7 Task Analysis and Modelling
Task Analysis mempelajari apa yang harus dilakukan oleh knowledge
worker untuk tindakan tertentu yang harus diambil dengan proses kognitif yang
harus dipanggil (called) untuk menyelesaikan sebuah tugas/task (Preece et al.
1994 dalam Dalkir, 2011). Metode yang paling sering digunakan adalah task
decomposition, dimana task dengan tingkat yang lebih tinggi dipecah menjadi
subtask dan operation. Tingkatan yang lebih rendah (yang merupakan hasil dari

29
task decomposition) ini dapat digunakan untuk membuat task flow diagram,
decision flowcharts, atau bahkan screen layout untuk mengilustrasikan secara
lebih baik tahap demi tahap proses yang harus dilakukan untuk menyelesaikan
sebuah tugas hingga sukses. Untuk melakukan breakdown sebuah task,
pertanyaan yang harus ditanyakan adalah “bagaimana cara menyelesaikan
task/tugas ini?” Apabila sebuah subtask teridentifikasi pada tingkatan yang lebih
rendah, maka hal tersebut memungkinkan untuk membangun struktur (dari task
analysis) dengan bertanya, “mengapa hal ini harus dilakukan?” (Dalkir, 2011)
Gambar 2.6 Contoh Task Analysis
(Dalkir, 2011)
2.2.8 Knowledge Taxonomy
Knowledge Taxonomy adalah sistem klasifikasi dasar yang memungkinkan
kita untuk mendeskripsikan konsep dan dependensi mereka – secara tipikal
hierarkis. Semakin tinggi letak dari konsep tersebut, semakin umum dan generik

pula konsep itu. Semakin rendah letak dari konsep tersebut, semakin spesifik
instansi tersebut dari kategori yang lebih tinggi. Konsep penting yang terdapat
dalam taxonomy adalah notion of inheritance. Setiap node (bagian) adalah
subgroup dari node diatasnya, yang berarti seluruh properti dari node yang lebih
tinggi secara otomatis dipindahkan (transferred) dari “parent” (node bagian atas)
menuju “child” (node bagian bawah). Seperti yang ditunjukkan pada gambar 2.6,
apabila node bagian atas adalah houseplant (tumbuhan rumah) dan node bagian
bawah adalah foliage (semak) dan flowering plants (bunga), kedua subgroup
tersebut memiliki seluruh karakteristik dari houseplant.
Knowledge Taxonomy memungkinkan pengetahuan untuk
direpresentasikan secara grafis untuk merefleksikan organisasi konsep diantara
bidang keahlian tertentu atau organisasi secara keseluruhan. Sebuah kamus
pengetahuan adalah cara yang baik untuk tetap pada konsep kunci dan ketentuan
(terms) yang digunakan. Hal ini dapat dibangun (compiled) selagi mendapatkan
dan mengkodifikasi pengetahuan (Dalkir, 2011).
Gambar 2.7 Knowledge Taxonomy
(Dalkir, 2011)

31
2.2.9 Definisi Personal Knowledge Management
Definisi Personal Knowledge Management terdiri dari :
a. Personal Knowledge Management (Martin, 2008 dalam
Kusumawardhani, 2012) adalah mengetahui pengetahuan apa saja yang
kita punya dan bagaimana cara kita mengelolanya, memobilisasi dan
menggunakannya untuk mencapai target yang kita inginkan dan
bagaimana cara kita untuk menciptakan pengetahuan secara terus –
menerus.
b. Personal Knowledge Management bukanlah sebuah sistem individu,
tetapi adalah seperangkat alat dan dan sistem (seperti blog, discussion
forum, social networking systems, dll) yang digunakan untuk mengelola
pengetahuan dan/atau hubungan personal/profesional. Karakteristik dari
sistem tersebut faktanya adalah terbuka dan didesain untuk mengundang
kolaborasi dan memfasilitasi interaksi sosial. Eksternalisasi dari
pengetahuan personal dapat dilakukan secara self-initiated/sendiri
(seperti blog dan wiki) atau dengan permintaan orang lain (seperti Yahoo!
Answers dan LinkedIn Answers) (Razmerita, Kirchner, & Sudzina, 2009).
c. Harold Jarche (Jarche, 2013) mengatakan bahwa instruksi formal yang
terhitung (accounts) hanya kurang dari 10% dari pembelajaran di tempat
kerja. Menangkap dan mengkodifikasikan 10% ini esensial, terutama
untuk karyawan baru. Struktur tim terlalu lambat dan hierarkis untuk
berguna di dalam era jaringan (network). Organisasi yang terstuktur
disekitar hierarki yang lebih lepas dan jaringan yang lebih kuat jauh lebih
efektif untuk pekerjaan yang semakin lama semakin kompleks.
2.2.10 Tacit Knowledge Capture Beserta Relasinya dengan Personal Knowledge
Management
Manajemen tacit knowledge adalah proses dari melakukan capture dari
pengalaman dan keahlian dari individu di sebuah organisasi dan membuatnya
tersedia untuk setiap orang yang membutuhkannya. Proses capture dari explicit
knowledge adalah pendekatan sistematis dari capturing, organizing dan refining
information dengan cara yang membuat informasi mudah untuk ditemukan, dan

memfasilitasi pembelajaran dan problem solving. Pengetahuan biasanya (often)
tetap berbentuk (remains) tacit hingga seseorang menanyakan pertanyaan
langsung. Pada titik tersebut, tacit dapat menjadi explicit, tetapi apabila informasi
tersebut tidak di-capture untuk orang lain untuk digunakan lagi di lain waktu,
maka pembelajaran, produktivitas, dan inovasi akan terhenti.
Ketika pengetahuan berbentuk explicit, pengetahuan tersebut seharusnya
diorganisasikan di dalam dokumen terstruktur penggunaan multifungsi
(multipurpose use). KM tools terbaik menciptakan pengetahuan kemudian
meningkatkannya antar jalur (multiple channel), termasuk telepon, e-mail, forum
diskusi, internet telephony, dan berbagai channel baru lainnya yang menjadi
online. Di dalam KM, penciptaan atau peng-capture-an pengetahuan ini dapat
dilakukan oleh individu yang bekerja untuk organisasi atau kelompok di dalam
organisasi tersebut, oleh seluruh Community of Practice (CoP) atau oleh individu
CoP yang berdedikasi. Hal ini juga dilakukan pada tingkatan personal, karena
hampir seluruh orang melakukan beberapa aktivitas knowledge creation, capture,
dan codification dalam melakukan tugas mereka, yang disebut sebagai personal
knowledge management (Cope, 2000 dalam Dalkir, 2011).
Pendekatan yang digunakan untuk melakukan capture, describe, dan
mengkodifikasi pengetahuan setelahnya (subsequently) bergantung pada tipe
pengetahuan. Explicit knowledge sudah dideskripsikan dengan baik, namun kita
perlu mengabstraksikan atau merangkum isi dari pengetahuan tersebut. Di sisi
lain, Tacit knowledge mungkin membutuhkan analisis yang lebih signifikan dan
organisasi sebelum dapat dideskripsikan dan direpresentasikan. Procedural
Knowledge adalah pengetahuan tentang bagaimana untuk melakukan sesuatu,
bagaimana untuk mengambil keputusan, bagaimana untuk melakukan diagnosa,
dan bagaimana cara untuk memberitahukan kepada orang lain (prescribed). Tipe
pengetahuan yang lain, declarative knowledge, menyatakan (denotes) descriptive
knowledge atau mengetahui “apa” (what) dibandingkan dengan (as opposed to)
mengetahui “bagaimana” (how) (Dalkir, 2011).

33
2.2.11 Definisi Blog Beserta Relasinya dengan Personal Knowledge Management
Weblog, atau secara singkat Blog, adalah sebuah tipe web page yang
memiliki informasi yang singkat dan disusun secara kronologis (Shiau & Chau,
2012). Menurut Herring et al. (2004) dalam Razmerita, Kirchner & Sudzina
(2009), terdapat tiga jenis blog: jurnal personal, “filter” (karena mereka memilih
informasi dan menyediakan komentar dari website lain) dan “knowledge logs”.
Akan tetapi, mayoritas dari blog (70 persen) adalah tipe online diary (jurnal
personal).
Terdapat 10 hal yang mendefinisikan sebuah blog (Ives & Watlington, 2005), yaitu:
a. Menyediakan web page yang simple dan mendukung update secara
berkala. Tidak seperti web page formal yang membutuhkan coding, blog
menggunakan template yang simple, memungkinkan percakapan yang
informal, sedang berlangsung (ongoing), dan easy-to-engage.
b. Membutuhkan sedikit, bahkan tidak sama sekali coding, serta tidak mahal
untuk melakukan set-up. Hal ini secara virtual menghilangkan penghalang
awal (entry barrier) untuk memiliki web presence. Apabila seseorang
memiliki komputer dan akses ke web, tidak ada lagi yang diperlukan
selain waktu dan imajinasi.
c. Menyediakan setiap entri dengan alamat internet unik. Search engine
dapat mengambil (spider) dan melakukan index terhadap post setiap
individu, dan penulis atau pembaca blog lain dapat membagikan (pass on)
link untuk setiap post individu untuk memperluas pembacaan (expanding
readership).
d. Membuat hubungan (linking) menuju post atau situs lain menjadi mudah.
Hal ini memfasilitasi kreasi komunitas online dari minat yang sejenis dan
memudahkan pembaca untuk menemukan informasi yang relevan. Karena
banyak informasi sekarang disimpan di dalam lokasi yang dapat diakses
oleh web, sebuah blog post menyediakan cara untuk menambahkan
konteks pada link konten, memfasilitasi terbentuknya Personal Knowledge
Management.
e. Mengakomodasi comments. Hal ini menambahkan dimensi interaksi yang
membangun koneksi dan pembagian ide (sharing ideas).

f. Disusun di dalam urutan kronologis terbalik. Hal ini menempatkan konten
yang paling baru di bagian halaman paling atas.
g. Menempatkan konten di dalam arsip yang dapat dicari yang dapat
mendukung navigasi melalui kategori untuk kemudahan browsing.
Beberapa blog menambahkan search engine sebagai tambahan dari
kategori.
h. Menggunakan RSS, ATOM atau XML feeds, yang memungkinkan
pembaca untuk melakukan subscribe pada update. Pengguna dapat
melakukan subscribe pada konten blog dan secara mudah membaca blog
tersebut. RSS (Really Simple Syndication, sebuah format XML ringan
yang didesain untuk membagikan headlines dan konten lain) adalah salah
satu breakthrough terbesar, yang menghilangkan kebutuhan untuk mencari
sebuah situs.
i. Biasanya ditulis dalam perspektif personal. Ini adalah sebuah gaya yang
berevolusi dan diharapkan (expected) dari blog. Untuk bisnis, blog
menyediakan kontak yang lebih personal dan informal dengan customer
yang komplemen dengan website formal.
j. Mempromosikan transparansi melalui aksesibilitas. Blog
mengkombinasikan arsip yang dapat dicari (searchable) dari sebuah
sistem KM dengan aksesibilitas terbuka dari website.
Melalui perspektif individu, blog menyediakan (Ives & Watlington, 2005) :
a. Creation: Konten yang dipublikasi dengan suara personal.
b. Collection: Mengelola konten personal di dalam arsip yang dapat dicari.
c. Context: Memberikan komentar kepada konten yang ingin dikelola oleh
individu.
Melalui perspektif networking, blog menyediakan (Ives & Watlington, 2005) :
a. Connection: Menemukan orang lain dengan minat yang sejenis.
b. Conversation: Terlibat (engaging) dalam dialog dalam organisasi atau
basis global.
c. Community: Membangun network di sekitar tema yang dibagikan (shared
themes).
d. Collaboration: Menemukan business partner baru.

35
Terdapat 2 jenis fungsi dari blog (Ives & Watlington, 2005), yaitu outward
facing (untuk eksternal) dan inward facing (untuk internal). Outward facing dapat
berupa expanding market exposure, establish a thought, introduce new product
and series, enhance customer relations, dan provide another direct sales channel
and new revenue streams. Internal facing dapat berupa internal communication
and team collaboration, project management, learning channel dan personal
knowledge management. Tools produktivitas yang di desain untuk membuat hidup
lebih mudah biasanya memiliki efek yang terbalik. Seperti yang didiskusikan,
blog menawarkan penciptaan arsip personal yang memiliki konteks
(contextualized personal archive). Banyak blogger mengandalkan blog mereka
sebagai back-up dari otak mereka. Ketika seseorang menulis sebuah buku, belajar
tentang sebuah teknologi baru atau bekerja di dalam era terhubung secara digital,
hal ini menghasilkan informasi yang tidak berhubungan (disconnected
information) dengan volume yang sangat besar. Seluruh informasi ini dapat
dikodifikasikan di dalam personal blog. Dengan blog, hal ini memungkinkan
untuk memasukkan komentar dan konteks dari setiap bagian dari informasi yang
diambil.
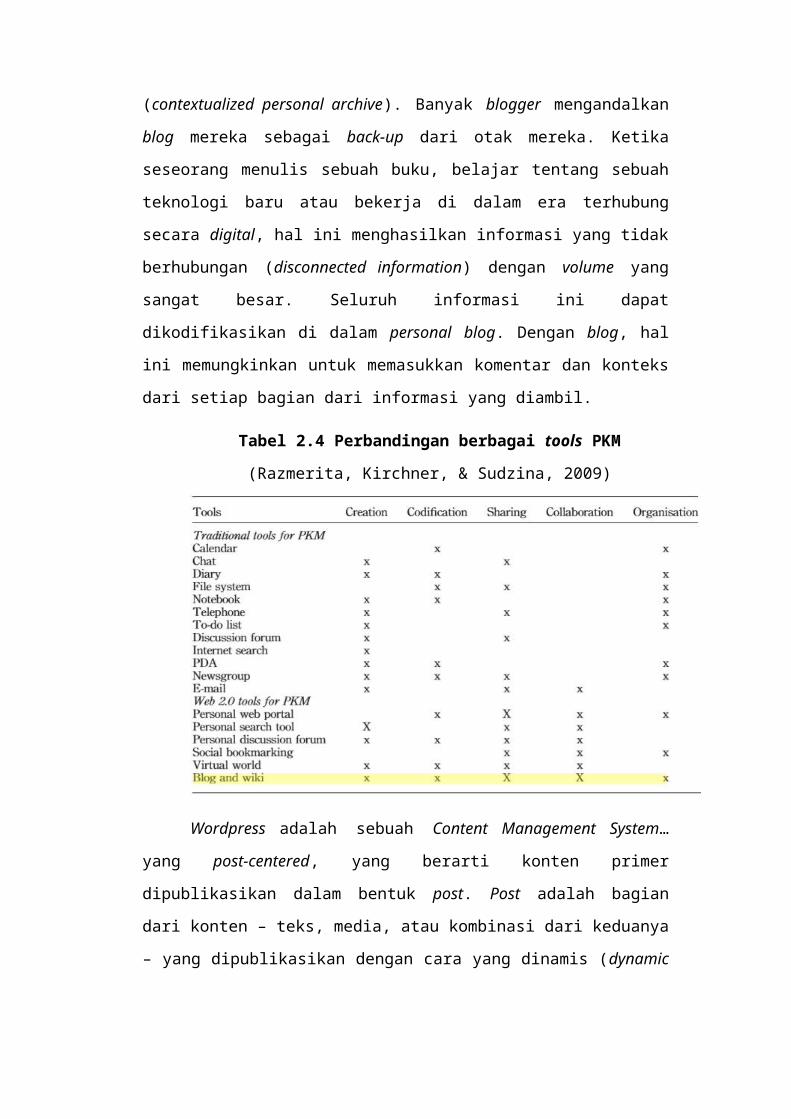
Tabel 2.4 Perbandingan berbagai tools PKM
(Razmerita, Kirchner, & Sudzina, 2009)
Wordpress adalah sebuah Content Management System… yang post-
centered, yang berarti konten primer dipublikasikan dalam bentuk post. Post
adalah bagian dari konten – teks, media, atau kombinasi dari keduanya – yang

dipublikasikan dengan cara yang dinamis (dynamic manners) (Jones &
Farrington, 2011). Wordpress dibangun dengan menggunakan bahasa
pemrograman PHP.
2.2.12 Data Flow Diagram
Data Flow Diagram menggunakan simbol untuk merepresentasikan
entitas, proses, alur data (data flow), dan penyimpanan data (data stores) yang
dapat diterapkan (pertain) ke dalam sistem. DFD digunakan untuk
merepresentasikan sistem pada tingkatan detail yang berbeda dari sangat umum
hingga sangat spesifik. Entitas di dalam DFD adalah objek eksternal pada batasan
sistem yang dijadikan permodelan. Mereka merepresentasikan sumber dan dan
tujuan dari data. Entitas mungkin sistem atau fungsi lain yang berinteraksi dengan
sistem ini, atau merupakan eksternal dari organisasi. Entitas seharusnya selalu
diberikan label sebagai kata benda di dalam DFD, seperti customer atau supplier.
Data Store merepresentasikan catatan accounting yang digunakan pada setiap
proses, dan diberikan panah yang diberikan label (labeled arrows)
merepresentasikan aliran data dari setiap proses, data store, dan entitas.
Proses di dalam DFD seharusnya diberikan label kata kerja deskriptif
seperti mengirimkan barang (ship goods), memperbaharui catatan (update
records), atau menerima customer order (receive customer order). Objek proses
seharusnya tidak direpresentasikan di dalam kata benda seperti gudang
(warehouse), departemen AR dan departemen sales. Panah yang diberikan label
(labeled arrows) menghubungkan objek proses merepresentasikan aliran data
seperti Sales Order, Invoice, atau Shipping Notice. Setiap label dari data flow
harus unik – label yang sama seharusnya tidak dipasangkan (attached) pada dua
garis alur (flow lines) dalam satu ERD yang sama. Ketika data mengalir menuju
proses dan keluar kembali menuju proses lain, data tersebut (dengan sebuah cara
tertentu) sudah berubah. Hal ini berlaku (true) bahkan ketika data tersebut tidak
berubah secara fisik. Contohnya, ketika Sales Order diperiksa untuk kelengkapan
sebelum diproses lebih lanjut. Sales Order ini mengalir di dalam proses sebagai
Sales Order dan keluar sebagai Approved Sales Order.
System Analyst menggunakan DFD secara ekstensif untuk
merepresentasikan elemen logical di dalam sistem. Namun, teknik ini tidak

37
menggambarkan fisik dari sistem. Dengan kata lain, DFD menunjukkan logical
task yang diselesaikan, namun tidak bagaimana task tersebut diselesaikan atau
siapa yang melakukan task tersebut. Contohnya, DFD tidak menunjukkan apakah
proses penyetujuan sales dilakukan secara terpisah secara fisik dari proses billing
untuk mematuhi (compliance) tujuan (objectives) dari internal control. (Hall,
2011)
Gambar 2.8 Data Flow Diagram
(Hall, 2011)
2.2.13 Entity Relationship Diagram
Entity Relationship Diagram adalah teknik dokumentasi yang digunakan
untuk merepresentasikan hubungan antar entitas. Entitas adalah sumber daya fisik
(mobil, cash, atau inventori), event (ordering inventory, penerimaan cash,

pengiriman barang), atau agent (salesperson, customer, atau vendor) tentang
bagaimana organisasi ingin melakukan capture data. Salah satu penggunaan
umum ERD adalah melakukan permodelan dari database organisasi.
Simbol kotak merepresentasikan entitas di dalam sistem. Garis
penghubung berlabel (Labeled connecting line) merepresentasikan nature dari
relationship antara dua entitas. Tingkatan dari relationship, disebut cardinality,
adalah pemetaan numerik antara instansi entitas. Sebuah relationship dapat berupa
one to one (1:1), one to many (1:M) atau many to many (M:M). Apabila kita
berpikir entitas di dalam ERD sebagai file dari record, cardinality adalah jumlah
maksimal dari record di dalam sebuah file yang memiliki relasi pada sebuah
record di dalam file lain dan sebaliknya.
Cardinality merefleksikan aturan bisnis normal dan juga organizational
policy. Contohnya, cardinality 1:1 memberitahukan (suggests) setiap salesperson
di dalam organisasi ditugaskan pada satu mobil. Apabila organization policy
mengatur satu mobil kepada satu atau lebih salesperson yang saling berbagi
(share), policy ini direfleksikan oleh relationship 1:M. Begitu juga dengan
relationship antara vendor dan inventory yang mengimplikasikan bahwa
organisasi membeli produk dengan tipe yang sama dari satu atau lebih vendor.
Policy dari perusahaan untuk membeli barang tersebut dari satu vendor
direfleksikan oleh cardinality 1:M.
System designer mengidentifikasikan entitas dan menyiapkan model untuk
entitas tersebut. Data model adalah blueprint dari apa yang akan menjadi
database fisik. Membangun sebuah data model yang realistik adalah topik
lanjutan yang melibatkan pemahaman dan pengaplikasian teknik dan aturan
tertentu (Hall, 2011).

39
Gambar 2.9 Entity Relationship Diagram
(Hall, 2011)
2.2.14 Hubungan Antara Entity Relationship Diagram dan Data Flow
Diagram
Sebuah DFD adalah model dari sebuah proses sistem, dan ERD adalah
model dari data yang digunakan atau terpengaruh (affected) oleh sistem. Kedua
diagram memiliki hubungan melalui data; setiap data store di dalam DFD
merepresentasikan data yang berhubungan dari data entity dalam ERD. Data
model berikut merepresentasikan ERD dari DFD sebelumnya (Hall, 2011).
Gambar 2.10 Data Model
(Hall, 2011)

2.2.15 Web Development Life Cycle
Web Development Life Cycle adalah gabungan dari dua metodologi
sebelumnya yang dikenal sebagai System Development Life Cycle dan Prototyping
(French, 2011). WDLC menggunakan komponen dari setiap metodologi,
mengkombinasikannya menjadi sebuah pendekatan baru yang akan mengurangi
waktu pengembangan, menambah struktur untuk masalah yang tidak terstruktur,
dan tetap melibatkan pengguna dalam keseluruhan Development Life Cycle
(French, 2011).
Gambar 2.10 Web Development Life Cycle
(French, 2011)
a. Information Gathering (Graphical)
Tahapan pertama dari WDLC adalah tahap pengambilan informasi untuk
melakukan desain pada website. Desain pada website sangat penting
(extremely important) karena apabila tidak menarik (appealing) untuk
customer dan mudah untuk dinavigasikan, maka mereka akan cenderung
tidak kembali (less likely to return) dan membeli produk atau

41
menggunakan jasa yang ditawarkan. Analis diharuskan (required)
mengumpulkan informasi yang akan membantu desainer grafis dalam
menciptakan sebuah layout yang efektif untuk website dan menentukan
berbagai halaman yang akan dimasukkan (included). Bagaimana informasi
akan disusun (arranged) dan dinavigasikan melalui informasi ini juga
harus didiskusikan di dalam tahapan WDLC ini
b. Analysis (Graphical)
Tahapan selanjutnya melibatkan analisa dari informasi yang dibutuhkan
dan mendokumentasikan kebutuhan dari desain website. Dokumentasi ini
termasuk skema warna yang akan digunakan bersamaan dengan logo dan
gambar lain yang berhubungan (incorporated) di dalam website. Analis
juga diharuskan untuk membuat outline situs yang akan menentukan
(entailing) bagaimana pengguna akan melakukan navigasi di dalam
website. Menghubungkan (incorporating) elemen dari navigasi,
mekanisme pencarian, dan site map dari website akan meningkatkan
kemampuan pengguna untuk mencari informasi yang mereka inginkan
(Malak et al. 2010, dalam French, 2011). Ini juga penting untuk
skalabilitas karena akan memungkinkan (allow) programmer untuk
menciptakan template dan mengimplementasikan CSS (Cascading Style
Sheet) ke dalam situs yang memungkinkan update dan maintenance di
masa depan. Desainer grafis menggunakan informasi yang dibutuhkan
untuk menciptakan image dari bagaimana website akan tampil untuk
kepentingan (use) para Developer. Ini adalah representasi grafis, atau
Prototype, dari website yang akan digunakan oleh programmer untuk
mengembangkan template. Desainer grafis secara tipikal akan bekerja
langsung (work closely) dengan pengguna (marketing, merchandising, dan
lain – lain) yang berkepentingan (in charge) untuk memimpin usaha
pengembangan dalam website (leading the efforts for development of the
website). Image dari website juga akan dimasukkan ke dalam
dokumentasi.

c. Graphical Design
Tahap design grafis di dalam WDLC adalah dimana pengembang
menggunakan dokumentasi yang diberikan (provided) oleh analis dan
desainer grafis untuk menciptakan prototype dari website. Satu – satunya
fungsional yang terdapat di dalam tahap WDLC ini adalah kemampuan
untuk melakukan navigasi dalam website. Ini adalah dimana programmer
menciptakan template dan navigasi untuk website. Setelah prototype
diselesaikan dan diuji, model yang bekerja dan dipilih (working model)
akan digunakan di dalam sistem yang sebenarnya.
d. Information Gathering (Functional)
Tahap 2 melibatkan pengembangan fungsional di dalam website. Selama
tahap information gathering untuk pengembangan fungsional, system
analyst bertemu dengan pengguna untuk mencari kebutuhan (gathering
requirements) untuk fungsionalitas website. Mereka mengidentifikasi
tujuan dari website, fungsionalitas apa yang dibutuhkan, dan komponen
yang berbeda di setiap seksi dari website.
e. Analysis (Functional)
Tahap Functional Analysis dari WDLC adalah dimana analis menciptakan
Entity Relationship Diagram (ERD) dan Data Flow Diagram (DFD) yang
dibutuhkan untuk fungsionalitas website. Mereka kemudian akan
melakukan breakdown pada komponen yang berbeda dari website menjadi
bagian yang lebih kecil. Contohnya, apabila mengembangkan website e-
commerce, pengembang akan menciptakan komponen yang berbeda
seperti shopping cart, product page, contact page, information page dan
frequently asked question page. Kemudian setiap komponen akan didesain
dan dikembangkan seperti mereka adalah program individu. Setelah
fungsional website didesain dan komponen berbeda telah dikembangkan,
pengembang akan mulai menciptakan prototype fisik.

43
f. Functional Design
Tahapan Functional Design dari WDLC adalah dimana pengembang
mulai menciptakan prototype dari setiap komponen website. Ini adalah
dimana fungsionalitas dari website dikembangkan. Web developer bekerja
dengan pengguna untuk mengidentifikasikan komponen dari website yang
dibutuhkan dalam implementasi. Setelah mengidentifikasi komponen
penting, mereka mulai mengembangkan prototype dari komponen
tersebut. Pengguna harus terlibat secara aktif dengan pengembang selama
setiap komponen diciptakan. Seringkali pengguna tahu apa yang mereka
inginkan namun tidak mengerti bagaimana cara membuatnya di dalam
pengembangan web. Untuk itu, web developer harus mengarahkan
pengguna dan melibatkannya di dalam proses pengembangan. Seraya
fungsionalitas ditambahkan di dalam website, pengguna harus menguji
setiap komponen dan memberikan umpan balik kepada web developer.
Setelah seluruh perubahan yang dibutuhkan (necessary changes)
dilakukan pada komponen, web developer akan mulai mengembangkan
komponen selanjutnya dan mengulangi proses ini. Setiap komponen dapat
diimplementasikan setelah selesai pembuatan dan testing. Ini menciptakan
proses iteratif dari tahapan fungsional dalam WDLC dan meningkatkan
kecepatan dari pengembangan website dengan bekerja dalam modul.
g. Implementation
Tahapan WDLC ini mirip dengan implementasi biasa di dalam SDLC.
Prototype secara tipikal dikembangkan dalam test server atau development
server. Ini memungkinkan pengguna untuk bekerja sama dengan web
developer hingga prototype selesai. Setelah komponen yang
dikembangkan selesai, file database dan web page akan dipindahkan ke
production server untuk implementasi.
h. Maintenance
Maintenance (Pemeliharaan) adalah tahapan yang tidak pernah selesai di
dalam WDLC. Maintenance mungkin termasuk modifikasi dari program
yang sedang berjalan, meng-update style sheet untuk memberikan website

tampilan yang berbeda, atau apapun yang perlu diperbaiki di dalam
website setelah diimplementasikan.
WDLC adalah proses yang iteratif, terutama (particularly) selama tahapan
fungsional dalam pengembangan. Setelah website didesain, hanya sedikit
kebutuhan untuk melakukan fase grafis di dalam WDLC sampai proses
desain ulang website dibutuhkan. Untuk setiap aplikasi dan komponen
baru yang ditambahkan ke dalam website setelah di desain, system analyst
dapat memulai tahap kedua dari WDLC. Untuk desain ulang website,
hanya tahapan pertama yang perlu diselesaikan karena desain ulang akan
mengganti layout dan tampilan website namun tidak mengubah
fungsionalitas dari website itu sendiri.
Satu limitasi dari hasil penelitian ini adalah kurangnya bukti empiris untuk
membuktikan sukses dari WDLC. WDLC adalah sebuah model teoritis
berdasarkan literatur dengan komunitas sistem informasi yang dibimbing
(guided) oleh pengalaman penulis. Penelitian di masa depan seharusnya
mengevaluasi sukses dari model ini dengan lingkungan praktek. Kesulitan
untuk menguji model ini adalah mendapatkan sampel yang cukup besar
untuk melakukan analisa statistik untuk menunjukkan signifikasi. Banyak
perusahaan memiliki departemen pengembangan kecil dengan sedikit web
developer untuk mengambil sampel tersebut. Untuk mengatasi limitasi ini,
penelitian di masa depan mungkin menggunakan metode tersebut di dalam
kelompok pengembangan web untuk melakukan studi kasus bersamaan
dengan analisis kuantitatif untuk mendapatkan perspektif dari business
professional yang sudah setuju untuk menggunakan model ini.
2.2.16 Aplikasi Konsep Personal Knowledge Management dengan Social Web
Terdapat tujuh keterampilan PKM (Dorsey, 2000 dalam Kusumawardhani, 2012),
yaitu:
a. Pengambilan informasi - merupakan keterampilan yang digunakan untuk
mengelola proses pencarian individu (contoh: pelebaran atau penyimpanan
pencarian, Boolean logic dan aplikasi pengulangan pencarian).

45
b. Pengevaluasian informasi - dengan tujuan untuk menemukan informasi
yang berharga dan relevan, maka PKM mengehendaki evaluasi dari
informasi yang tersedia secara luas, yang tidak disaring ataupun di-sensor.
c. Pengaturan informasi - pengaturan dari informasi (contoh: kronologikal,
fungsional, role-based) memfasilitasi KM dengan cara menghubungkan
informasi baru dan lama.
d. Analisis informasi - membangun keterampilan organisasi informasi dalam
menganalisis dapat membantu pengguna untuk mengubah informasi
menjadi pengetahuan.
e. Penyajian informasi - keterampilan PKM melibatkan penyajian informasi
kepada pihak lain, melalui desain yang efektif dan komunikasi.
f. Pengamanan informasi - dengan adanya pertumbuhan resiko dan
kesempatan yang terasosiasi dengan information sharing, para knowledge
worker harus dapat menjamin keamanannya.
g. Pengkolaborasian di sekitar informasi - keterampilan PKM yang
memungkinkan para knowledge worker untuk berpartisipasi dalam
aktifitas yang bernilai tinggi (high-value activities) di dalam suatu proses
kolaborasi di sekitar informasi.
Tujuan utama dari PKM adalah untuk menyediakan kerangka kerja bagi
para knowledge worker agar dapat mengelola informasi baru,
mengintegrasikannya dan memperkaya basis data pengetahuan pada masing-
masing individu secara efektif. Jika hal ini berhasil dilakukan, dapat
memberdayakan setiap individu untuk menerapkan pengetahuan personal milik
mereka (Kusumawardhani, 2012).
Situs jejaring sosial (Boyd & Ellison, 2007 dalam Kusumawardhani, 2012) adalah
layanan berbasis web yang memperbolehkan para individu untuk:
a. Membangun sebuah profil publik dan semi-publik dalam suatu sistem
yang memiliki batasan – batasan.
b. Memiliki suatu daftar yang berisikan pengguna-pengguna lain yang
tersambung dengan individu tersebut.
c. Dapat melihat dan melintasi daftar koneksi-koneksi yang terhubung dari
para individu lainnya dalam sistem tersebut. Keunikan dari situs ini bukan

pada kemampuan yang memperbolehkan para individu untuk bertemu
dengan individu lain yang tidak dikenalnya dalam dunia nyata, namun
pada kemampuan untuk mengartikulasikan dan membuat situs pribadi
mereka dapat dilihat oleh individu lain.
Dari definisi tersebut diatas dapat disimpulkan bahwa, berbagai macam
jejaring sosial online (LinkedIn, Myspace dan Facebook), blogs dan
microblogging (Blogger, Twitter), video atau photo sharing (Youtube, Flickr),
instant messaging dan masih banyak lainnya, dapat dikategorikan sebagai jejaring
sosial. Hal ini dikarenakan, keseluruhan situs tersebut memiliki tiga kemampuan
yang dipaparkan oleh Boyd dan Ellison (2007).
Dalam konteks PKM, para individu memiliki keahlian yang berbeda-beda.
Sehingga, mereka membutuhkan tools yang bermacam-macam. Pemanfaatan
tools yang optimal sangatlah bergantung pada performa para knowledge worker
dan pengguna lainnya dalam mengasimilasi keahlian PKM dan teknologi ke
dalam perilaku KM. Para knowledge worker diharapkan untuk membuat
keputusan dan melakukan pekerjaan yang berasosiasi pada pengetahuan, yang
berdampak positif terhadap kinerja perusahaan serta terhadap diri mereka sendiri.
Oleh karena itu, tools dari PKM harus sejajar dengan keahlian khusus serta PKM
yang dipilihnya. Hal ini untuk membantu para pengguna dalam melakukan
berbagai knowledge activities (Agnihotri & Troutt, 2008 dalam Kusumawardhani,
2012).
2.2.17 Sampling dan Sampling Design Process
Sampling adalah tindakan untuk mengambil subgroup dari elemen sebuah
populasi yang terpilih untuk berpartisipasi di dalam studi (Malhotra, 2010).
Sebuah sampel mungkin dipreferensikan apabila di dalam hasil proses
pengukuran terdapat kontaminasi dari elemen yang disampel. Contohnya, hasil
pengujian pengunaan produk di dalam konsumsi dari produk itu sendiri.
Pertimbangan pragmatis lain untuk menggunakan teknik sampling adalah
kebutuhan untuk menjaga kerahasiaan dari studi tersebut. Desain sampling
dimulai dengan menspesifikasikan populasi target. Populasi target adalah koleksi
dari elemen atau objek yang memiliki informasi yang dicari oleh peneliti dan
inferensi (relasi kepada sesuatu) apa yang akan dibuat. Populasi target harus

47
didefinisikan dengan presisi. Definisi populasi target yang tidak presisi akan
menghasilkan riset yang tidak efektif, atau yang lebih parah lagi, menyesatkan
(misleading). Pendefinisian dari populasi target melibatkan pengubahan
(translating) definisi masalah menjadi statement presisi tentang siapa yang
harus/tidak boleh dilibatkan di dalam sampel (Malhotra, 2010).
Populasi target harus didefinisikan di dalam bentuk elemen, unit sampel,
extent, dan waktu. Sebuah elemen adalah objek tentang sesuatu yang memiliki
informasi yang diinginkan. Unit sampel adalah sebuah elemen yang tersedia di
dalam tahapan tertentu untuk proses sampling. Extent berarti batasan geografis
dari sampling, dan waktu adalah lamanya waktu sampling. Contoh dari populasi
target adalah:
Tabel 2.5 Contoh Target Populasi
(Malhotra, 2010)
Populasi Target
Elemen
Pria atau wanita yang menjadi kepala dari rumah tangga
yang bertanggung jawab untuk sebagian besar tindakan
perbelanjaan.
Unit Sampel Rumah Tangga
Extent Metropolitan Atlanta
Waktu 2009
Sampling frame adalah representasi dari elemen dari populasi target.
Sampling frame terdiri dari urutan atau seperangkat arahan untuk
mengidentifikasikan populasi target. Contoh dari sampling frame adalah buku
telepon, asosiasi direktori tentang urutan firma dari industri, mailing list yang
sudah dibeli dari sebuah organisasi komersial, direktori kota, atau sebuah peta.
Apabila sebuah daftar (list) tidak dapat dikompilasikan, maka setidaknya terdapat
arahan untuk mengidentifikasi populasi target apa yang harus dispesifikasikan,
contohnya seperti prosedur random digit dialing dalam survei telepon. Dalam

instansi tertentu, discrepancy (kurangnya kesamaan antara dua atau lebih fakta)
antara populasi (agregat dari seluruh elemen yang membagikan beberapa
kesamaan seperangkat karakteristik) dan sampling frame yang ada kecil, sehingga
bisa diabaikan. Akan tetapi, di kebanyakan kasus, peneliti seharusnya menyadari
dan melakukan treatment terhadap sampling frame error, yang dapat dilakukan
dengan tiga cara yaitu:
a. Melakukan redefinisi pada sampling frame. Pendekatan ini simplistik,
namun mencegah peneliti untuk salah arah (misled) dari populasi aktual
yang sedang diinvestigasi.
b. Melakukan screening (seleksi) responden di dalam tahapan data
collection. Responden dapat di screening terhadap demografi
karakteristik, familiarity, pengunaan produk, dan karakteristik lain untuk
memastikan bahwa mereka memenuhi kriteria dari populasi target.
Screening dapat menghilangkan elemen yang tidak pantas di dalam
sampling frame, namun tidak dapat menghitung (account) elemen yang
sudah dimasukkan (omitted).
c. Memberikan skema bobot untuk mengimbangi kesalahan pada sampling
frame.
Penting untuk mengenali kesalahan pada sampling frame yang ada, sehingga
inferensi (konklusi yang berdasar dari fakta atau pemikiran/reasoning) dari
populasi yang tidak pantas dapat dihindari.
2.2.18 Teknik Sampling Nonprobabilitas dan Convenience Sampling
Teknik sampling dapat diklasifikasikan menjadi probabilitas dan
nonprobabilitas. Sampling nonprobabilitas mengandalkan keputusan personal
(personal judgement) dari peneliti dibandingkan dengan kesempatan untuk
memilih elemen sampel. Peneliti dapat menentukan secara arbiter (dengan
menggunakan pihak ketiga) atau secara sadar elemen apa yang akan dimasukkan
kedalam sampel. Sampel nonprobabilitas dapat mengestimasi secara baik
karakteristik populasi, namun tidak memungkinkan evaluasi yang objektif dari
presisi hasil sampel. Hal ini dikarenakan ketiadaan cara untuk menentukan
probabilitas dari setiap elemen yang terpilih di dalam sampel, estimasi yang
didapatkan juga tidak dapat diproyeksikan secara statistik ke dalam populasi.

49
Convenience Sampling adalah sebuah teknik sampling non-probabilitas
yang berusaha untuk mendapatkan sampel dari elemen yang nyaman (mudah
untuk didapatkan). Seleksi dari unit sampel sepenuhnya diputuskan (left
primarily) oleh orang yang melakukan interview. Seringkali, responden dipilih
karena berada di tempat yang tepat dan waktu yang tepat. Contoh dari
pengambilan sampel adalah:
a. Penggunaan murid, grup keagamaan, dan anggota dari organisasi sosial
sebagai sampel,
b. Interview yang dilakukan dengan cara bertanya langsung dengan
pengunjung mall yang sedang berada disekitar kita tanpa
mengkualifikasi terlebih dahulu responden tersebut,
c. Department store yang menggunakan charge account list,
d. Kuesioner yang dapat disobek yang terdapat pada majalah,
e. Interview yang dilakukan dengan orang - orang yang ditemui di jalan
raya (people on the street).
Convenience Sampling adalah metode yang paling murah dan paling tidak
memakan waktu dari seluruh teknik sampling lainnya. Seluruh unit sampel dapat
diakses, mudah untuk diukur, dan koperatif. Terlepas dari keuntungan ini, bentuk
dari sampling ini memiliki keterbatasan yang serius. Banyak sumber potensial
dari seleksi yang bias terdapat disini, termasuk responden yang memilih dirinya
sendiri. Sampel convenience tidak representatif untuk seluruh populasi yang dapat
didefinisikan. Sebagai konsekuensinya (hence), hal ini secara teoritis tidak berarti
untuk menggeneralisasi populasi apapun dari sampel, dan sampel convenience
tidak pantas untuk proyek riset marketing yang melibatkan inferensi sampel.
Sampel convenience tidak direkomendasikan untuk riset deskriptif atau kausal,
namun dapat digunakan sebagai riset exploratory (investigasi) untuk membangun
ide, insights, dan hipotesis. Sampel convenience dapat digunakan untuk focus
group, pre-tes kuesioner, atau pilot studies. Bahkan di dalam kasus tersebut,
diperlukan kehati – hatian (caution) dalam menginterpretasikan hasil dari
sampling tersebut. Namun (nevertheless), teknik ini terkadang digunakan bahkan
di dalam survei besar (Malhotra, 2010).
2.2.19 Kuesioner dan Questionnaire Design Process
Kuesioner adalah seperangkat pertanyaan yang sudah diformalisasikan
untuk mendapatkan informasi dari responden. Secara tipikal, sebuah kuesioner
hanya salah satu elemen dari paket data-collection yang mungkin didalamnya
terdapat:
a. Prosedur Kerja Lapangan, seperti instruksi untuk memilih, pendekatan,
dan mempertanyakan (questioning) responden,
b. Hadiah, atau kompensasi lain yang ditawarkan kepada responden,
c. Pembantu komunikasi (communication aids), seperti peta, gambar, iklan,
dan produk (seperti didalam interview pribadi) dan mengembalikan
amplop (di dalam survei melalui surat).
Terlepas (regardless) dari bentuk form administrasi, sebuah kuesioner memiliki
karakter dari beberapa objektif spesifik. Tiga objektif spesifik dari setiap
kuesioner adalah:
a. Harus mengubah (must translate) informasi yang dibutuhkan menjadi
seperangkat pertanyaan yang spesifik, dimana pertanyaan tersebut akan
dan dapat dijawab oleh responden.
b. Sebuah kuesioner harus mengangkat, memotivasi, dan encourage
responden untuk dapat terlibat di dalam interview, untuk bekerjasama, dan
menyelesaikan interview.
c. Sebuah kuesioner harus meminimalisir response error. Response error
adalah kesalahan yang terjadi ketika responden memberikan jawaban yang
tidak akurat, kesalahan perekaman atau kesalahan analisa.
Sebuah kuesioner dapat menjadi sumber utama dari response error.
Menekan kesalahan ini adalah objektif yang penting dari desain kuesioner …
Mengembangkan pertanyaan yang dapat dijawab, akan dijawab dan memberikan
(yield) informasi yang diinginkan adalah hal yang sulit. … Dalam merancang
kuesioner, peneliti seharusnya berusaha (strive) untuk meminimalisir kelelahan,
kebosanan, ketidaklengkapan, dan ketiadaan respon (nonresponse) dari
responden. Kuesioner yang didesain dengan baik dapat memotivasi responden dan
meningkatkan response rate (Malhotra, 2010).

51
Questionnaire Design Process adalah sebuah guideline yang berguna
untuk mendesain kuesioner yang terdapat pada buku The Art of Asking Questions
yang dipublikasikan oleh Stanley Payne pada tahun 1951. Akan tetapi, tidak ada
prinsip saintifik yang menjamin kuesioner yang ideal dan optimal. Hal ini
(kuesioner) lebih kepada sebuah seni dibandingkan sebuah ilmu pengetahuan.
Meskipun aturan ini dapat membantu untuk menghindari kesalahan major,
kuesioner yang baik datang dari kreativitas peneliti yang terlatih (Malhotra,
2010).
Gambar 2.11 Questionnaire Design Process
(Malhotra, 2010)

Berikut adalah penjelasan dari tahapan dari Questionnaire Design Process:
a. Specify the information needed (spesifikasikan informasi yang
dibutuhkan)
Tahap pertama dari desain kuesioner adalah menspesifikasikan
informasi yang dibutuhkan. Seiring dengan berjalannya progress riset,
informasi yang dibutuhkan menjadi semakin lama semakin jelas
didefinisikan. Hal ini membantu untuk mereview komponen dari
masalah dan pendekatan yang digunakan, terutama pertanyaan riset,
hipotesis, dan informasi yang dibutuhkan.
Hal penting lainnya adalah memiliki ide yang jelas tentang target
populasi. Karakteristik dari grup responden memiliki pengaruh yang
besar dalam desain kuesioner. Pertanyaan yang pantas untuk mahasiswa
mungkin tidak pantas untuk ibu rumah tangga. Pemahaman ini
berhubungan dengan karakteristik sosio-ekonomi yang dimiliki oleh
masing – masing grup responden. Lebih dari itu, pemahaman yang
buruk diasosiasikan dengan tingkat insiden yang tinggi untuk respon
yang tidak pasti dan/atau tanpa respon opini (no-opinion). Semakin
terdiversifikasi grup responden, semakin sulit untuk mendesain sebuah
kuesioner tunggal yang pantas untuk seluruh grup yang terlibat di dalam
penelitian.
b. Specify the type of interviewing method (spesifikasikan metode interview
yang digunakan)
Sebuah apresiasi tentang bagaimana tipe dari metode interview
mempengaruhi desain kuesioner, yang dapat didapatkan dengan
mempertimbangkan bagaimana kuesioner akan dikelola dengan metode
tertentu. Di dalam personal interview, responden dapat melihat
kuesioner dan berinteraksi tatap muka dengan interviewer. Selain itu,
pertanyaan yang panjang, kompleks, dan bervariasi dapat ditanyakan.

53
c. Determine the content of individual question (tentukan konten dari setiap
pertanyaan individu)
Setiap pertanyaan di dalam kuesioner seharusnya berkontribusi kepada
informasi yang diperlukan atau memiliki tujuan spesifik tertentu.
Apabila tidak terdapat kegunaan dari data yang mencukupi (satisfactory)
dari data yang dihasilkan dari sebuah pertanyaan, pertanyaan tersebut
harus dieliminasi. Di dalam situasi tertentu, pertanyaan mungkin
ditanyakan meskipun tidak memiliki relasi langsung dengan informasi
yang dibutuhkan. Hal ini berguna untuk menanyakan beberapa
pertanyaan netral di awal dari kuesioner untuk membangun (establish)
keterlibatan (involvement) dan rapport (hubungan harmonis dimana
seseorang atau sekelompok orang mengerti perasaan atau ide satu sama
lain dan dapat berkomunikasi secara baik), terlebih (particularly) ketika
topik dari kuesioner adalah sensitif dan kontroversial. Terkadang
pertanyaan pengisi (filler questions) ditanyakan untuk menyembunyikan
(disguise) tujuan atau sponsorship dari sebuah project. Dibandingkan
(rather) dengan membatasi pertanyaan kepada sebuah merk (brand)
yang diminati, pertanyaan tentang merk yang saling bersaing (competing
brands) juga dapat dimasukkan untuk menyembunyikan sponsorship.
Setelah menentukan (ascertained) bahwa pertanyaan tersebut
dibutuhkan, peril dipastikan bahwa pertanyaan tersebut cukup untuk
memenuhi informasi yang diinginkan. Terkadang, beberapa pertanyaan
dibutuhkan untuk mendapatkan informasi yang dibutuhkan dengan cara
yang tidak ambigu (unambiguous manner). Contoh dari pertanyaan jenis
ini adalah “Apakah Coca-Cola adalah softdrink yang enak dan
menyegarkan?” Jawaban “ya” adalah jawaban yang jelas, tetapi
bagaimana jika jawabannya “tidak”? Apakah ini berarti responden
berpikir bahwa Coca-Cola tidak enak, tidak menyegarkan, atau
keduanya? Pertanyaan seperti ini disebut dengan Double-Barreled
Question, karena terdapat dua atau lebih pertanyaan yang digabung
menjadi satu. Untuk mendapatkan informasi yang dibutuhkan tanpa
ambigu, dua pertanyaan terpisah seharusnya ditanyakan, “Apakah Coca-

Cola adalah softdrink yang enak?” dan “Apakah Coca-Cola adalah
softdrink yang menyegarkan?”.
Contoh dari pertanyaan Double-Barelled Question lainnya adalah
pertanyaan mengapa (why), di dalam konteks penelitian (study)
department store: “Mengapa anda berbelanja di Nike Town?”
Kemungkinan jawaban yang mungkin terjadi termasuk “untuk membeli
sepatu atletik”, “lokasinya lebih mudah dan nyaman untuk dicapai”, dan
“toko ini direkomendasikan oleh teman baik saya”. Setiap jawaban
memiliki relasi dengan pertanyaan berbeda yang tergabung (embedded)
di dalam pertanyaan mengapa (why). Jawaban pertama memberitahukan
mengapa responden berbelanja di toko merchandise atletik, jawaban
kedua memberitahukan apa yang responden sukai tentang Nike Town
dibandingkan dengan toko lain, dan jawaban ketiga memberitahukan apa
yang responden pelajari tentang Nike Town. Ketiga jawaban ini tidak
dapat dibandingkan satu sama lain dan tidak satupun dari jawaban
tersebut memenuhi kebutuhan informasi yang dicari. Informasi yang
lengkap mungkin dapat didapatkan dengan menanyakan dua pertanyaan
yang terpisah, yaitu: “Apa yang anda sukai dari Nike Town dibandingkan
dengan toko lain?” dan “Bagaimana anda pertama kali berbelanja di
Nike Town?” Kebanyakan pertanyaan mengapa (why) tentang
penggunaan produk, atau pilihan alternatif melibatkan dua aspek: atribut
dari produk dan pengaruh yang membawa (leading) pengetahuan dari
produk tersebut.
d. Design the question to overcome the respondent’s inability and
unwillingness to answer (rancang pertanyaan untuk mengatasi
ketidakmampuan dan ketidakinginan responden untuk menjawab
pertanyaan)
Peneliti seharusnya tidak berasumsi bahwa responden dapat memberikan
jawaban yang akurat atau logis untuk seluruh pertanyaan. Peneliti harus
mencoba (attempt) untuk mengatasi ketidakmampuan responden untuk
menjawab. Beberapa faktor membatasi kemampuan responden untuk
menyediakan informasi yang dibutuhkan. Responden mungkin tidak

55
diberitahukan (informed), tidak mampu mengingat, atau tidak mampu
untuk mengartikulasikan jenis respon tertentu.
Responden sering ditanyakan tentang topik dimana mereka tidak
diberitahukan sebelumnya. Contohnya adalah seorang suami yang
mungkin tidak diberitahukan tentang pengeluaran bulanan untuk
membeli bahan makanan apabila seorang istri yang melakukan hal
tersebut, dan sebaliknya. Di dalam situasi dimana tidak seluruh
responden diberitahukan sebelumnya tentang sebuah topic of interest,
filter question yang mengukur familiarity, pengunaan produk, dan
pengalaman sebelumnya seharusnya ditanyakan sebelum pertanyaan
tentang topik itu sendiri. Filter question adalah sebuah pertanyaan awal
di dalam kuesioner yang melihat responden potensial untuk meyakinkan
bahwa mereka memenuhi kebutuhan untuk menjadi seorang sampel.
Seorang peneliti mungkin memberi ekspektasi tentang banyak hal yang
seharusnya seluruh orang ketahui hanya diingat oleh sedikit orang.
Beberapa contoh dari pertanyaan tersebut adalah:
1. Apa nama dari merk baju yang anda gunakan dua minggu lalu?
2. Dimana anda makan siang minggu lalu?
3. Apa yang anda lakukan bulan lalu di sore hari?
4. Berapa banyak gallon softdrink yang anda konsumsi selama
empat minggu terakhir?
Pertanyaan – pertanyaan ini tidak tepat karena mereka melebihi
kemampuan dari responden untuk mengingat. Ketidakmampuan
untuk mengingat menyebabkan (leading to) kesalahan dalam
omission, telescoping, dan creation. Omission adalah
ketidakmampuan untuk mengingat sebuah kejadian yang secara
aktual terjadi. Telescoping adalah fenomena psikologis yang terjadi
ketika seseorang mengkompresi waktu dengan cara mengingat sebuah
kejadian yang terjadi seakan – akan memiliki rentang waktu lebih
dekat (more recently) dengan waktu yang sebenarnya terjadi.
Kesalahan creation terjadi ketika sebuah responden “mengingat”
sebuah kejadian yang sebenarnya tidak terjadi. Maka dari itu, (dari

pertanyaan diatas) untuk mengetahui konsumsi softdrink seseorang
mungkin akan didapatkan secara lebih baik dengan bertanya:
“Seberapa sering anda mengkonsumsi softdrink dalam
seminggu?”
1. Kurang dari seminggu sekali
2. 1 – 3 kali dalam seminggu
3. 4 – 6 kali dalam seminggu
4. 7 kali atau lebih dalam seminggu
Responden mungkin tidak dapat mengartikulasikan beberapa jenis respon
tertentu. Contohnya, apabila ditanya untuk mendeskripsikan atmosfir dari
department store, kebanyakan responden mungkin tidak mampu untuk
merangkai kalimat untuk menjawab pertanyaan tersebut. Di sisi lain,
apabila responden diberikan deskripsi alternatif dari atmosfir toko, mereka
akan mampu untuk mengindikasikan salah satu dari respon yang mereka
sukai. Apabila responden tidak dapat mengartikulasikan respon mereka
untuk pertanyaan tersebut, mereka akan mengacuhkan pertanyaan tersebut
dan menolak untuk merespon kuesioner lainnya. Responden seharusnya
diberikan bantuan, seperti gambar, peta, dan deskripsi, untuk membantu
mereka mengartikulasikan respon mereka.
Bahkan ketika responden mampu untuk menjawab sebuah pertanyaan,
mereka mungkin tidak ingin untuk melakukan hal tersebut. Hal ini
sebabkan antara terlalu banyak usaha (effort) yang dibutuhkan, situasi atau
konteks tidak pantas untuk dipublikasikan, peneliti tidak memiliki tujuan
yang sah (legitimate) ataupun informasi yang dibutuhkan adalah sensitif.
Kebanyakan responden tidak menginginkan untuk memberi usaha (effort)
yang sangat besar untuk menyediakan informasi. Maka dari itu, peneliti
harus meminimalisir usaha yang dibutuhkan oleh responden. Contoh dari
pertanyaan yang membutuhkan usaha yang besar adalah:
“Tolong urutkan seluruh department dimana anda membeli merchandise
saat terakhir kali anda berbelanja di department store.”
Pertanyaan yang seharusnya ditanyakan adalah,

57
“Dalam list (urutan) dibawah ini, pilih seluruh departemen dimana anda
membeli merchandise saat terakhir kali anda berbelanja di department
store.”
1. Pakaian Wanita _____
2. Pakaian Pria _____
3. Pakaian Anak – Anak _____
4. Kosmetik _____
Selain usaha, hal lain yang perlu diperhatikan adalah konteks. Beberapa
pertanyaan mungkin pantas untuk ditanyakan di dalam konteks tertentu
tetapi tidak untuk yang lainnya. Contohnya, pertanyaan tentang kebiasaan
kebersihan diri mungkin pantas ketika survei tersebut dilakukan oleh
American Medical Association, tetapi tidak pantas apabila ditanyakan oleh
restoran cepat saji. Responden juga tidak ingin untuk memberikan
informasi yang sensitif (divulge) ketika responden tidak melihat tujuan
yang sah (legitimate). Mengapa sebuah lembaga marketing sereal ingin
mengetahui umur, pendapatan, dan pekerjaan dari responden? Selain itu,
responden juga tidak menginginkan untuk memberitahukan (disclose),
minimal secara akurat, informasi sensitif karena dapat menyebabkan aib
(embarrassment) dan mengancam prestige dan image dirinya. Topik
sensitif menyangkut uang, kehidupan keluarga, politik, agama,
kepercayaan, dan keterlibatan di dalam kecelakaan dan/atau kriminalitas.
e. Decide on the question structure (tentukan struktur pertanyaan)
Terdapat dua jenis struktur pertanyaan, yaitu pertanyaan tidak terstruktur
dan pertanyaan terstruktur. Pertanyaan tidak terstruktur adalah pertanyaan
terbuka dimana responden harus menjawab dengan kata – kata mereka
sendiri. Pertanyaan terstruktur adalah pertanyaan dengan seperangkat
respon alternatif yang terspesifikasi sebelumnya (prespecify) dan format
dari respon tersebut. Salah satu bentuk dari pertanyaan terstruktur adalah
scale (skala). Scale adalah pembangunan (generation) dari sebuah
continuum (sekuensial yang berurutan dimana elemen selanjutnya tidak
begitu berbeda dengan yang lainnya, meskipun pada setiap ujungnya
sangat berbeda) dimana setiap objek yang diukur berada. Scaling dapat

dikatakan sebagai perpanjangan dari pengukuran. Sebagai ilustrasi,
pertimbangkan (consider) sebuah scale dari 1 sampai 100 untuk
menemukan (locating) konsumen berdasarkan karakteristik “tingkah laku
terhadap department store”. Setiap responden diberikan angka dari 1
sampai 100 yang mengindikasikan tingkatan dari unfavorableness, dengan
1 = sangat unfavorable, dan 100 = sangat favorable. Pengukuran adalah
pekerjaan aktual dari angka 1 hingga 100 dari seluruh responden. Scaling
adalah sebuah proses untuk menempatkan responden ke dalam continuum
dengan memperhatikan tingkah laku mereka terhadap department store.
Terdapat 4 karakteristik di dalam scale, yaitu description, order, distance,
dan origin. Description berarti label unik atau penjelasan yang digunakan
untuk membedakan (designate) setiap nilai dari scale. Contoh dari
description adalah 1 = sangat tidak setuju, 2 = tidak setuju, 3 = netral, 4 =
setuju, dan 5 = sangat setuju.
Order adalah ukuran relatif atau posisi dari description. Order dinotasikan
oleh penjelasan lebih dari, kurang dari, atau sama dengan. Contohnya,
preferensi responden untuk tiga brand dari sepatu atletik dinyatakan di
dalam sebuah order, dengan brand yang paling dipreferensikan diurutkan
pertama dan yang paling tidak dipreferensikan diurutkan ketiga (Nike,
Reebok, Adidas). Untuk responden ini, preferensi Nike lebih tinggi
dibandingkan preferensi Reebok, preferensi Adidas lebih rendah dari Nike
dan Reebok.
Distance adalah perbedaan absolut antar scale description yang diketahui
dan dapat diekspresikan dalam unit. Contoh dari distance adalah jumlah
orang yang tinggal di dalam rumah responden. Perlu diperhatikan bahwa
scale yang memiliki distance juga memiliki order, dimana 5 orang yang
tinggal di dalam rumah seorang responden lebih besar dibandingkan
dengan 4 orang yang tinggal di dalam rumah seorang responden.
Origin adalah karakteristik yang menjelaskan bahwa skala memiliki
awalan yang unik, atau “true zero point”. Apabila terdapat scale seperti 1
= sangat tidak setuju, 2 = tidak setuju, 3 = netral, 4 = setuju, dan 5 =

59
sangat setuju seperti diatas, maka 1 adalah origin dari scale tersebut.
Origin dapat bernilai negatif, seperti -1 dan -2.
Interval Scale (skala interval) adalah sebuah scale dimana angka
digunakan untuk menilai objek yang secara numerik memiliki jarak yang
sama pada scale yang mempresentasikan jarak pada karakteristik yang
sedang diukur.
Likert Scale adalah sebuah skala (scale) pengukuran dengan lima respon
kategori, yang dimulai dari “sangat tidak setuju” hingga “sangat setuju”
dimana memerlukan responden untuk mendindikasikan hingga tingkatan
(degree) persetujuan atau ketidaksetujuan dari setiap seri dari pernyataan
(statement) yang berhubungan dengan objek stimulus. Nama Likert
berasal dari pencipta dari skala ini, Rensis Likert.
Data secara tipikal diperlakukan sebagai interval. Likert Scale memiliki
karakteristik description, order dan distance. Untuk memulai analisis,
setiap pernyataan diberikan skor numerik, yang berkisar dari -2 sampai
dengan +2 atau 1 sampai 5. Analisis dapat dimulai (conducted) dengan
basis item-by-item, atau jumlah total skor dapat dikalkulasikan untuk
setiap responden dengan menambahkan skor dari setiap item. Pendekatan
yang paling sering digunakan dengan Likert Scale adalah summated scale,
dimana pendekatan ini digunakan untuk menentukan skor total dari setiap
responden. Hal yang penting untuk dilakukan adalah untuk menggunakan
prosedur penilaian yang konsisten, sehingga tinggi atau rendahnya skor
secara konsisten merefleksikan respon yang diinginkan.
Likert Scale memiliki beberapa keuntungan. Skala ini mudah untuk
dibangun dan dikelola (administer). Responden sudah mengerti bagaimana
cara untuk menggunakan skala ini, sehingga cocok untuk interview
melalui surat, telepon, personal atau elektronik. Kerugian utama dari skala
ini adalah memerlukan waktu yang lebih lama untuk menyelesaikan skala
ini (bagi responden) karena responden harus membaca masing – masing
statement. Terkadang, sulit untuk menginterpretasikan respon dari sebuah
item Likert, terlebih ketika pernyataan tersebut tidak menguntungkan
(unfavorable).

f. Determine the question’s wording (tentukan kata – kata yang akan
digunakan di dalam pertanyaan)
Menentukan kata yang digunakan mungkin adalah tugas yang paling kritis
dan sulit di dalam mengembangkan sebuah kuesioner. Apabila sebuah
pertanyaan menggunakan kata dengan tidak tepat (poorly), responden
mungkin menolah untuk menjawab pertanyaan tersebut, atau dijawab
secara tidak tepat. Kondisi pertama, yang dikenal dengan item
nonresponse, dapat meningkatkan kompleksitas dari analisis data. Kondisi
kedua menyebabkan kesalahan respon (response error). Terlepas dari
responden dan peneliti yang memberikan arti yang sama persis di dalam
sebuah pertanyaan, hasil yang didapat akan sangat bias. Untuk mengatasi
masalah itu, digunakanlah guideline ini:
1. Define the issue (definisikan isu)
Sebuah pertanyaan seharusnya mendefinisikan secara jelas isu yang
sedang dituju (addressed). Jurnalis pemula akan memulai untuk
mendefinisikan isu dengan menggunakan 6w (who, what, when,
where, why, and which). Hal ini dapat berguna sebagai guideline
untuk mendefinisikan isu dari sebuah pertanyaan. Pertimbangkan
pertanyaan tersebut:
“Merk shampoo apa yang anda gunakan?” (which)
Dari permukaan, hal ini mungkin pertanyaan yang didefinisikan
dengan baik, namun orang dapat mengambil konklusi yang berbeda
ketika kita menganalisa kembali dari sudut pandang siapa (who), apa
(what), kapan (when), dan dimana (where). Siapa (who) di dalam
pertanyaan ini menunjuk pada responden, yang tidak jelas kepada
siapa peneliti menunjuk apakah merk itu digunakan oleh responden
tersebut atau oleh seluruh penghuni rumah (household). Apa (what)
menunjuk pada merk dari shampoo. Akan tetapi, bagaimana cara
responden tersebut menjawab apabila terdapat lebih dari satu brand
shampoo yang digunakan? Apakah responden menyebut brand yang
paling disukai, paling sering digunakan, digunakan akhir – akhir ini,
atau merk yang paling pertama terlintas di dalam pikiran? Kapan

61
(when) juga tidak jelas – apakah peneliti bermaksud terakhir kali
digunakan, minggu terakhir, bulan terakhir, setahun terakhir, atau
kapan? Untuk dimana (where), mengimplikasikan bahwa shampoo
tersebut digunakan dirumah, namun tidak disampaikan secara jelas.
Pengunaan kata yang benar untuk pertanyaan ini adalah:
“Merk shampoo apa yang anda gunakan secara pribadi dirumah
sebulan terakhir ini? Apabila terdapat lebih dari satu brand,
urutkan merk yang anda gunakan.
2. Use ordinary words (gunakan kata – kata yang biasa digunakan)
Kata – kata yang biasa (ordinary words) seharusnya digunakan di
dalam kuesioner dan cocok dengan tingkatan kata yang digunakan
(vocabulary) oleh responden. Ketika memilih kata – kata, perlu
diingat bahwa rata – rata orang di Amerika (dan Indonesia) memiliki
edukasi tingkat sekolah, bukan universitas. Untuk beberapa grup
responden, tingkatan edukasi berada jauh lebih rendah dari itu.
Jargon yang bersifat teknis juga seharusnya dihindari. Contoh dari
pertanyaan ini adalah:
“Apakah distribusi dari soft drink sudah memadai?”
Seharusnya adalah,
“Apakah softdrink tersedia ketika anda ingin membelinya?”
3. Use unambiguous words (gunakan kata – kata yang tidak ambigu)
Kata – kata yang digunakan dalam kuesioner seharusnya memiliki
satu arti yang diketahui oleh responden. Beberapa kata yang terlihat
tidak ambigu memiliki arti yang berbeda untuk orang yang berbeda,
contohnya adalah biasanya (usually/regularly), normal-nya
(normally), akhir – akhir ini (frequently), sering (often), terkadang
(occasionally/sometimes). Contoh dari pertanyaan tersebut adalah:

“Bulan ini, seberapa sering anda berbelanja di department
store?”
____ Tidak pernah
____ Terkadang
____ Sering
Jawaban dari pertanyaan ini memiliki respon yang bias, karena kata
yang digunakan untuk mendeskripsikan label kategori memiliki arti
yang berbeda untuk responden yang berbeda. Penggunaan kata yang
lebih baik untuk pertanyaan ini adalah:
“Bulan ini, seberapa sering anda berbelanja di department
store?”
___ Kurang dari sekali
___ 1 – 2 kali
___ 3 – 4 kali
___ Lebih dari 4 kali
Sebagai tambahan, kata – kata yang “seluruhnya atau tidak sama
sekali” (all-inclusive or all-exclusive words) dapat dipahami secara
berbeda dengan responden yang berbeda. Beberapa contoh dari kata
ini adalah seluruhnya (all), selalu (always), salah satu (any), siapa
saja (anybody), selamanya (ever), dan setiap (every). Kata – kata ini
seharusnya dihindari. Untuk memilih pilihan kata, peneliti seharusnya
menggunakan kamus dan thesaurus dan menanyakan pertanyaan
berikut untuk setiap kata yang ditambahkan:
i. Apakah kata ini mengartikan apa yang ingin kita artikan
(intended)?
ii. Apakah kata ini memiliki arti yang lain?
iii. Apabila ya, apakah konteks yang digunakan memberikan
pengartian yang jelas?
iv. Apakah kata ini memiliki lebih dari satu pengucapan?

63
v. Apakah ada kata lain dengan pengucapan yang mirip dan
dapat tertukar satu sama lain?
vi. Apakah terdapat kata atau kalimat yang lebih mudah?
4. Avoid leading questions (hindari pertanyaan yang cenderung untuk
memanipulasi jawaban ke arah tertentu)
Leading question adalah pertanyaan yang memberi responden
petunjuk (clue) apa yang harus dijawab oleh responden menjadi
jawaban yang diinginkan atau mempengaruhi responden untuk
menjawab dengan cara tertentu. Salah satunya adalah acquiescence
bias, yaitu bias yang merupakan hasil dari beberapa tendensi
responden untuk menjawab pertanyaan dari leading questions.
Contoh dari pertanyaan ini adalah:
“Menurut anda, apakah orang Amerika yang patriotik seharusnya
membeli mobil impor yang akan membuat buruh Amerika
kehilangan pekerjaan?”
___ Ya
___ Tidak
___ Tidak tahu
Pertanyaan ini akan membawa responden pada jawaban “tidak”.
Maka dari itu, pertanyaan ini tidak membantu untuk menentukan
preferensi orang Amerika terhadap mobil impor melawan mobil
domestik. Pertanyaan yang lebih baik adalah:
“Apakah orang Amerika harus membeli mobil impor?”
___ Ya
___ Tidak
___ Tidak tahu

Contoh lain dari pertanyaan yang bias adalah “Apakah Colgate
adalah pasta gigi favorit anda?” dan “Apakah anda setuju dengan
American Dental Association bahwa Colgate efektif dalam mencegah
karang gigi?” Kedua pertanyaan ini membuat responden cenderung
untuk bias kepada Colgate.
5. Avoid implicit alternative (hindari alternatif respon yang tidak
tertulis)
Alternatif yang tidak tertulis adalah implicit alternative. Membuat
sebuah implicit alternative dapat meningkatkan persentasi orang
dalam memilih alternatif tersebut. Contoh dari pertanyaan ini adalah:
“Apakah anda menyukai penerbangan (dengan pesawat terbang)
untuk melakukan perjalanan jarak dekat?”
Pertanyaan ini memberikan preferensi yang lebih tinggi untuk
melakukan penerbangan dibandingkan opsi lain yang tidak
disebutkan. Penggunaan kata yang lebih baik adalah:
“Apakah anda menyukai penerbangan (dengan pesawat terbang)
untuk melakukan perjalanan jarak dekat, atau anda lebih baik
menyetir dengan menggunakan kendaraan darat pribadi?”
6. Avoid implicit assumptions (hindari asumsi yang tidak tertulis)
Implicit assumptions adalah asumsi yang tidak dituliskan di dalam
pertanyaan. Contoh dari pertanyaan ini adalah:
“Apakah anda mendukung balanced budget?”
Pertanyaan yang seharusnya adalah,
“Apakah anda mendukung balanced budget apabila hal itu
menghasilkan kenaikan dari pajak pribadi?”
Pertanyaan pertama gagal untuk memberikan asumsinya secara
eksplisit, sehingga dapat menghasilkan estimasi yang berlebihan dari
dukungan responden untuk balanced budget.

65
7. Avoid generalization and estimates (hindari generalisasi dan estimasi)
Pertanyaan seharusnya spesifik, bukan secara umum (general).
Terlebih lagi, pertanyaan seharusnya dibentuk sehingga responden
tidak perlu membuat generalisasi atau menghitung estimasi. Apabila
kita menanyakan responden sebagai berikut:
“Berapa pengeluaran per capita tahunan untuk kebutuhan pokok
keluarga anda?”
Responden pertama kali harus menentukan pengeluaran pertahun
dengan perhitungan terlebih dahulu. Cara yang lebih baik untuk
mendapatkan informasi yang dibutuhkan adalah dengan menanyakan
responden dua pertanyaan mudah, yaitu:
“Berapa pengeluaran perbulan keluarga anda untuk kebutuhan
pokok?”
“Berapa banyak orang yang ada di dalam keluarga anda?”
Peneliti kemudian dapat melakukan perhitungan yang dibutuhkan
untuk mendapatkan hasil yang diinginkan.
8. Use positive and negative statement (gunakan pernyataan positif dan
negatif).
Banyak pertanyaan, terutama yang mengukur perilaku dan gaya
hidup, dibentuk menjadi pernyataan yang mengindikasikan tingkatan
(degree) persetujuan atau ketidaksetujuan mereka, bukti
menunjukkan bahwa respon yang didapatkan dipengaruhi oleh arah
dari pernyataan tersebut, apakah pernyataan tersebut dibentuk secara
positif atau negatif. Dua jenis kuesioner dapat disiapkan, dimana
keduanya memiliki setengah pernyataan positif dan setengah
pernyataan negatif. Arah/kecenderungan dari pernyataan ini dapat
dibalik pada kuesioner yang lain. Penggunaan positive and negative
statement dapat digunakan pada Likert Scale.

g. Arrange the questions in proper order (Urutkan pertanyaan pada urutan
yang tepat)
Pertanyaan pembukaan dapat menjadi krusial di dalam mendapatkan
keyakinan dan koperasi dari responden. Pertanyaan pembuka harus
menarik, mudah, dan tidak mengancam. Pertanyaan yang menanyakan
responden tentang opini mereka dapat menjadi pertanyaan pembuka yang
baik, karena kebanyakan orang senang untuk mengekspresikan opininya.
Terkadang pertanyaan tersebut ditanyakan meskipun tidak ada relasi
dengan permasalahan riset dan respon mereka tidak dianalisa. Terdapat
beberapa hal yang harus diperhatikan di dalam opening question, yaitu:
1. Type of Information (Tipe Informasi)
Tipe informasi yang didapatkan dari kuesioner dapat diklasifikasikan
menjadi tiga bagian, yaitu basic information, classification
information, dan identification information. Basic information
berhubungan langsung dengan masalah riset. Classification
information berisi karakteristik sosioekonomi dan demografi, yang
digunakan untuk mengklasifikasi responden dan memahami hasil
kuesioner. Identification information terdiri dari nama, kodepos,
alamat email, dan nomor telepon. Identification information dapat
didapatkan untuk berbagai kepentingan tertentu, seperti untuk
kepentingan verifikasi dan list responden yang sudah di-interview.
Sebagai guideline, basic information didapatkan terlebih dahulu,
dilanjutkan dengan classification information dan terakhir
identification information. Basic information adalah kepentingan
utama untuk proyek riset dan harus didapatkan pertama, sebelum kita
mengambil resiko untuk mengalienasi responden dengan menanyakan
rangkaian pertanyaan pribadi.
2. Difficult Question (Pertanyaan Sulit)
Pertanyaan sulit atau pertanyaan yang sensitif, memalukan, kompleks,
atau kurang penting (dull) harus ditaruh di bagian akhir, setelah
membangun rapport (hubungan harmonis dimana seseorang atau
sekelompok orang mengerti perasaan atau ide satu sama lain dan

67
dapat berkomunikasi secara baik) dan responden dilibatkan. Contoh
dari pertanyaan sulit adalah tagihan kartu kredit dan nomor telepon.
3. Effect of subsequent questions (efek dari pertanyaan sebelumnya)
Pertanyaan yang ditanyakan lebih dahulu dapat mempengaruhi respon
dari pertanyaan sebelumnya. Sebagai rule of thumb, pertanyaan yang
lebih umum harus mendahului pertanyaan yang lebih spesifik. Hal ini
mencegah pertanyaan spesifik memiliki respon yang bias
dibandingkan pertanyaan umum. Contoh dari pertanyaan ini adalah:
“Pertimbangan apa yang penting untuk anda untuk memilih
department store?”
“Dalam memilih department store, seberapa penting kemudahan
dalam akses (convenience of location)?”
Strategi ini disebut funnel approach. Funnel approach adalah strategi
pengurutan pertanyaan di dalam kuesioner dimana urutan diawali
oleh pertanyaan umum dan diikuti secara progresif pertanyaan
spesifik, untuk menghindari pertanyaan spesifik menjadi bias kepada
pertanyaan umum.
4. Logical Order (urutan logis)
Pertanyaan seharusnya ditanyakan dengan urutan yang logis. Seluruh
pertanyaan yang menyangkut topik yang sedang dibahas seharusnya
ditanyakan sebelum topik baru dimulai. Ketika mengganti topik,
diperlukan kalimat transisi yang seharusnya membantu responden
untuk mengganti alur pikiran mereka. Untuk melakukan hal ini, dapat
dilakukan branching questions. Branching questions adalah
pertanyaan yang digunakan untuk memandu interviewer dalam
melakukan survei dengan mengarahkan interviewer pada titik berbeda
di dalam kuesioner tergantung pada jawaban yang diberikan.

h. Identify the form and layout (Identifikasi form dan layout)
Praktik yang baik untuk membagi kuesioner membagi beberapa bagian.
Beberapa bagian mungkin dibutuhkan untuk mendapatkan basic information.
Pertanyaan dari setiap bagian harus diberi nomor, terlebih apabila branching
question digunakan. Penomoran pertanyaan juga membuat kodifikasi respon
lebih mudah. Kuesioner seharusnya dikodifikasi lebih awal, dengan cara
melakukan precoding. Precoding adalah pemberian kode untuk setiap respon
yang mungkin diberikan sebelum dimulainya pengambilan data. Secara
tipikal, kode mengidentifikasikan baris angka dan kolom angka dimana respon
tersebut akan di-input.
Kuesioner seharusnya juga diberikan nomor secara serial. Hal ini
memfasilitasi kontrol dari kuesioner di lapangan dan juga sebagai coding dan
analysis. Penomoran (numbering) juga membuat mudah untuk perhitungan
kuesioner dan untuk menentukan apabila terdapat kuesioner yang hilang.
i. Reproduce the questionnaire (reproduksi kuesioner)
Bagaimana kuesioner direproduksi dapat mempengaruhi hasil. Contohnya,
apabila kuesioner direproduksikan pada kertas yang memiliki kualitas rendah
atau memiliki penampilan yang kurang menarik, responden akan berpikir
proyek yang sedang dilakukan tidak penting dan kualitas respon yang
dihasilkan akan terpengaruh. Maka dari itu, kuesioner harus direproduksi pada
kertas dengan kualitas baik dan penampilan yang profesional.
Apabila kuesioner yang di-print memiliki beberapa halaman, seharusnya
memiliki bentuk booklet dibandingkan dengan nomor dari jumlah sheet yang
di-stapled bersamaan. Arahan atau instruksi untuk pertanyaan individu
seharusnya ditaruh sedekat mungkin dari pertanyaan. Instruksi yang terkait
kepada bagaimana menjawab sebuah pertanyaan seharusnya ditulis sebelum
pertanyaan tersebut. Meskipun warna tidak mempengaruhi respon dari
kuesioner, kodifikasi warna penting untuk melakukan branching question.
Kuesioner seharusnya direporduksikan dengan cara yang mudah untuk dibaca
dan dijawab.

69
j. Pretesting (Testing awal)
Pretesting adalah percobaan kuesioner pada sampel responden kecil untuk
kepentingan memperbaiki kuesioner dan mengidentifikasi dan mengeliminasi
masalah yang potensial. Sebagai aturan umum, kuesioner seharusnya tidak
dilakukan pada survei lapangan tanpa pretesting yang baik. Pretest seharusnya
ekstensif, seluruh aspek dari kuesioner seharusnya diuji, termasuk konten
pertanyaan, wording (pembentukan kalimat), urutan, form dan layout, tingkat
kesulitan pertanyaan dan instruksi. Responden di dalam pretest seharusnya
sejenis dengan responden yang akan dimasukkan ke dalam survei sebenarnya
dalam hal background karakteristik, familiarity pada topik, tingkah laku dan
tanggapan responden dari topik tersebut.
2.3 Kerangka Pikir
Latar Belakang:
Keengganan masyarakat untuk beralih ke transportasi umum.
“Anomali” masyarakat untuk terus membeli transportasi pribadi, padahal kemacetan semakin menjadi di Kota Jakarta. Hal ini juga didukung oleh adanya “mobil murah” atau LCGC.
Sebuah usaha untuk membagikan pengetahuan tentang penggunaan transportasi umum di Kota Jakarta.
(Kementerian Pekerjaan Umum, 2009) (The Jakarta Post, 2012) (Katadata, 2013) (Liputan 6, 2013) (Tempo, 2013) (The Jakarta Post, 2013)
Penerapan Boisot Information Space
(Boisot, Canals, & Macmillan, 2004)
Penerapan McElroy Knowledge Lifecycle
(McElroy, 1999)
(Firestone & McElroy, 2005)

70
Gambar 2.12 Kerangka Pikir
Problem Claim Formulation
Scanning Problem Solving
Knowledge Production
Individual and Group Learning
Knowledge Claim Formulation
Information Acquisition
Abstraction
Knowledge Production
Codified Knowledge Claim
Knowledge Claim Evaluation
Task Analysis and Modelling (Dalkir, 2011).
Distributed Organizational Knowledge Base (Pembangunan
BinusRaya)
Jurnal Utama:
(French, 2011)
Jurnal Pendukung:
(Ives & Watlington, 2005)
(Razmerita, Kirchner, & Sudzina, 2009)
(Kusumawardhani, 2012)
(Jarche, 2013)
Knowledge Integration
DiffusionAbsorbingImpacting
Knowledge Use
Pengumpulan data dengan menggunakan kuesioner
(Malhotra, 2010)
Scanning

71
2.4 Tahapan Penelitian
Mulai
Pem
bang
unan
B
inus
Ray
a
(Fre
nch,
201
1)
Peng
ambi
lan
info
rmas
i
(McE
lroy,
199
9)
(Boi
sot,
Can
als,
&
Mac
mill
an, 2
004)
(Fire
ston
e &
M
cElro
y, 2
005)
Info
rmat
ion
Gat
heri
ng
(Gra
phic
al)
Men
gam
bil
info
rmas
i des
ain
graf
is B
inus
Ray
a
Anal
ysis
(G
raph
ical
)
Ana
lisa
dan
doku
men
tasi
ke
butu
han
desa
in
Gra
phic
al D
esig
n
Pera
ncan
gan
tem
plat
e da
n na
viga
si
Info
rmat
ion
Gat
heri
ng
(Fun
ctio
nal)
Peng
emba
ngan
fu
ngsi
onal
, den
gan
benc
hmar
king
se
rta m
ener
apka
n:
(Raz
mer
ita,
Kirc
hner
, &
Sudz
ina,
200
9)
dan
(Kus
umaw
ardh
ani
, 201
2)
Obs
erva
si
lang
sung
Stud
i Pus
taka
Task
Ana
lysi
s an
d M
odel
ling
Kod
ifika
si
Peng
etah
uan

72
Gambar 2.13 Tahapan Penelitian
Anal
ysis
(F
unct
iona
l)
Pem
bang
unan
D
FD, E
RD
, dan
fit
ur B
inus
Ray
a
Func
tiona
l Des
ign
& Im
plem
enta
tion
Pem
bang
unan
B
inus
Ray
a
Mai
nten
ance
Perb
aika
n fit
ur
dan
kont
en
Bin
usR
aya
Pem
buat
an K
uesi
oner
(Mal
hotra
, 201
0)
Pene
rapa
n B
inus
Ray
a ke
pada
resp
onde
n ku
esio
ner b
eser
ta d
okum
enta
si b
erup
a vi
deo
dan
foto
Rek
apitu
lasi
K
uesi
oner
Selesai

73





























