Embed Size (px)
DESCRIPTION
superscalar
Citation preview

A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
Superscalar Processors• Superscalar Execution
– How it can help– Issues:
• Maintaining Sequential Semantics• Scheduling
– Scoreboard– Superscalar vs. Pipelining
• Example: Alpha 21164 and 21064

A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
Sequential Semantics - Review• Instructions appear as if they executed:
– In the order they appear in the program– One after the other
• Pipelining: Partial Overlap of Instructions– Initiate one instruction per cycle– Subsequent instructions overlap partially– Commit one instruction per cycle

A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
Superscalar - In-order • Two or more consecutive instructions in
the original program order can execute in parallel– This is the dynamic execution order
• N-way Superscalar– Can issue up to N instructions per cycle– 2-way, 3-way, …
A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
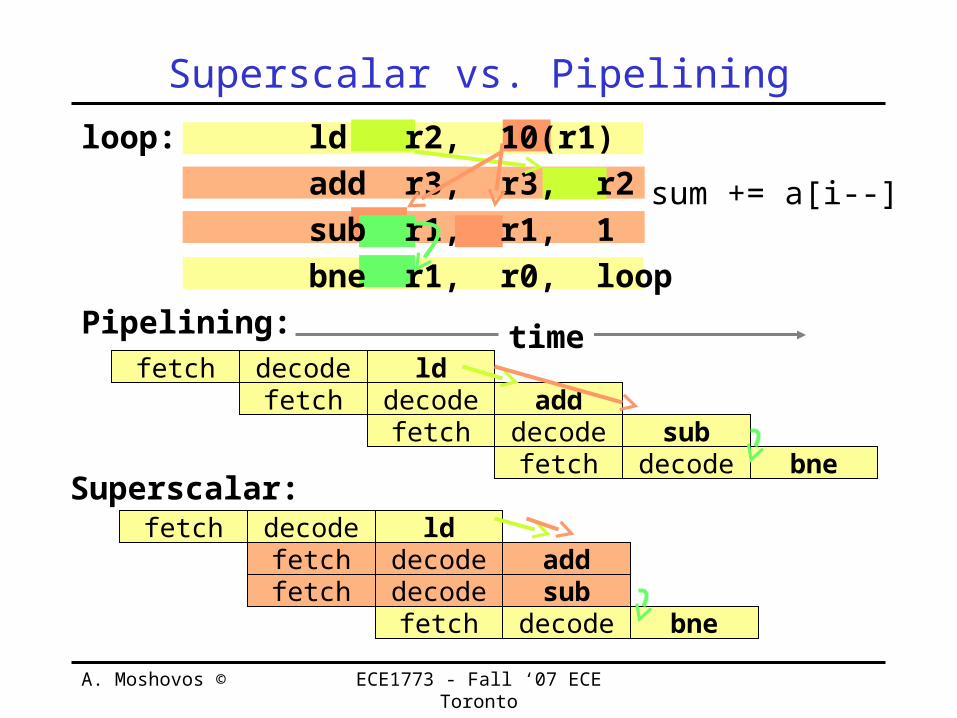
Superscalar vs. Pipeliningloop: ld r2, 10(r1)
add r3, r3, r2sub r1, r1, 1bne r1, r0, loop
Pipelining:
sum += a[i--]
fetch decode ldfetch decode add
fetch decode subfetch decode bne
time
Superscalar:fetch decode ld
fetch decode addfetch decode sub
fetch decode bne
A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
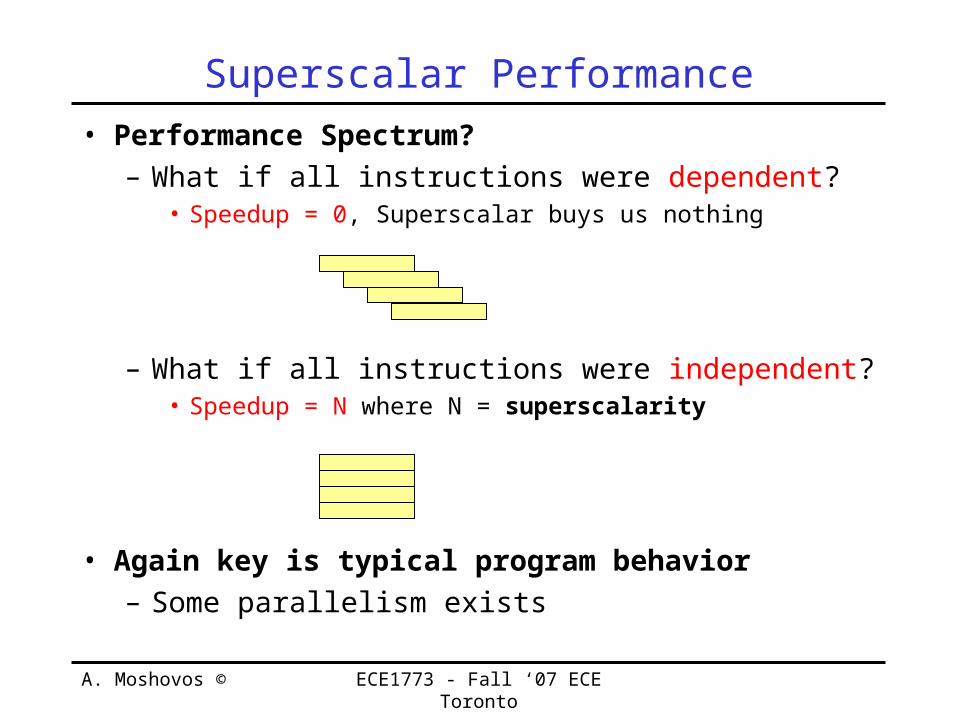
• Performance Spectrum?– What if all instructions were dependent?
• Speedup = 0, Superscalar buys us nothing
– What if all instructions were independent?• Speedup = N where N = superscalarity
• Again key is typical program behavior– Some parallelism exists
Superscalar Performance
A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
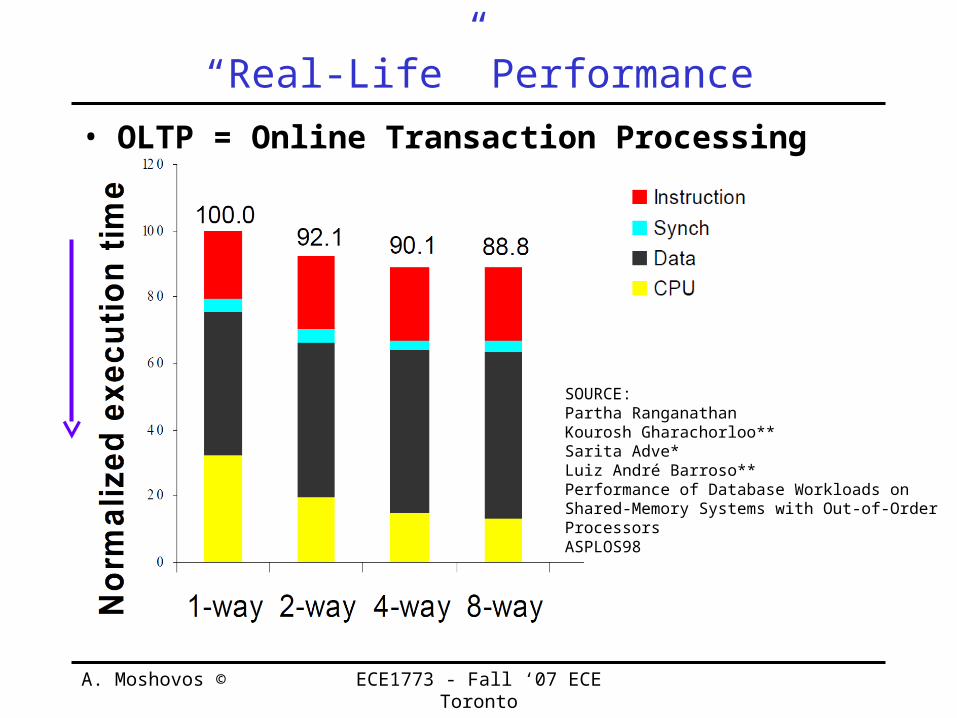
“Real-Life” Performance• OLTP = Online Transaction Processing
SOURCE:Partha RanganathanKourosh Gharachorloo**Sarita Adve*Luiz André Barroso**Performance of Database Workloads onShared-Memory Systems with Out-of-OrderProcessorsASPLOS98
A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
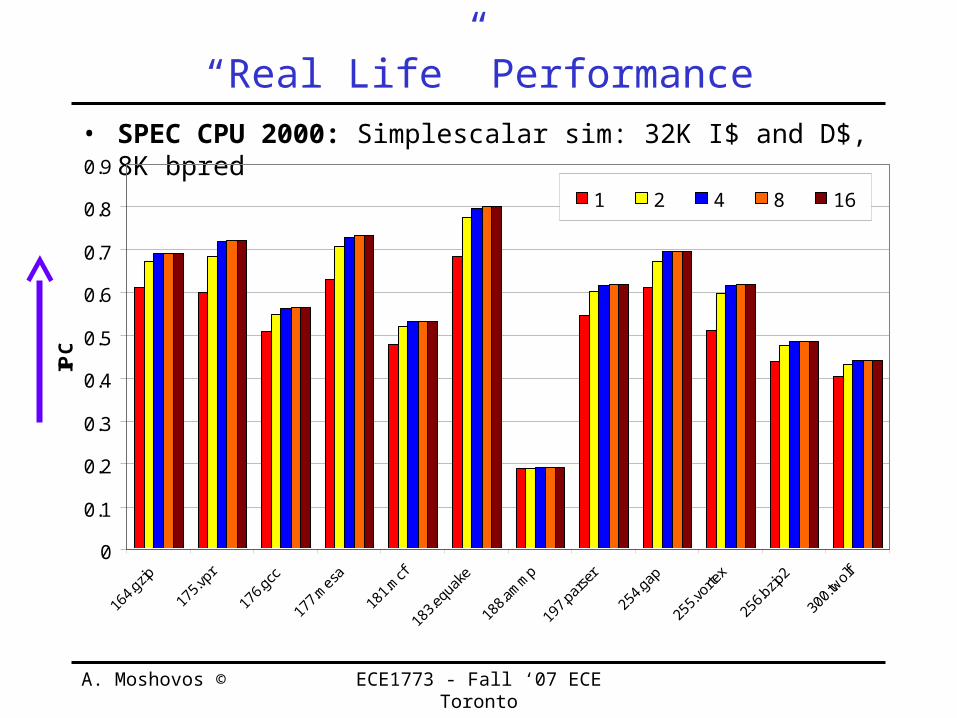
“Real Life” Performance• SPEC CPU 2000: Simplescalar sim: 32K I$ and D$, 8K
bpred
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
164.g
zip
175.v
pr
176.g
cc
177.m
esa
181.m
cf
183.e
quak
e
188.a
mmp
197.p
arse
r
254.g
ap
255.v
ortex
256.b
zip2
300.t
wolf
IPC
1 2 4 8 16

A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
Superscalar Issue• An instruction at decode can execute if:
– Dependences• RAW
– Input operand availability• WAR and WAW
• Must check against Instructions:• Simultaneously Decoded• In-progress in the pipeline (i.e., previously issued)
– Recall the register vector from pipelining
• Increasingly Complex with degree of superscalarity– 2-way, 3-way, …, n-way

A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
Issue Rules• Stall at decode if:
– RAW dependence and no data available• Source registers against previous targets
– WAR or WAW dependence• Target register against previous targets + sources
– No resource available• This check is done in program order
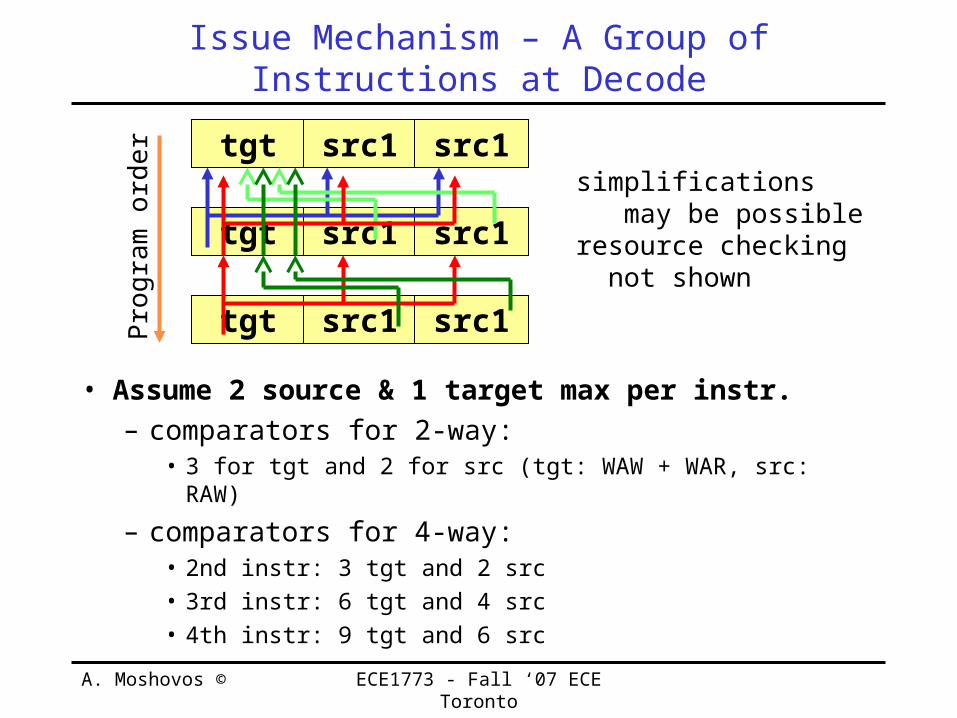
A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
Issue Mechanism – A Group of Instructions at Decode
• Assume 2 source & 1 target max per instr.– comparators for 2-way:
• 3 for tgt and 2 for src (tgt: WAW + WAR, src: RAW)– comparators for 4-way:
• 2nd instr: 3 tgt and 2 src• 3rd instr: 6 tgt and 4 src• 4th instr: 9 tgt and 6 src
tgt src1 src1
tgt src1 src1
tgt src1 src1
� simplifications may be possible� resource checking not shown
Pro
gram
ord
er

A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
Issue – Checking for Dependences with In-Flight instructions
• Naïve Implementation:– Compare registers with all outstanding
registers– RAW, WAR and WAW– How many comparators we need?
• Stages x Superscalarity x Ops per Instructruction– Priority enforcers?– But we need some of this for bypassing
• RAW

A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
Issue – Checking for Dependences with In-Flight instructions
• Scoreboard:– Pending Write per register, one bit
• Set at decode / Reset at writeback– Pending Read?
• Not needed if all reads are done in order • WAR and WAW not possible
• Can handle structural hazards– Busy indicators per resource
• Can handle bypass– Where a register value is produced– R0 busy, in ALU0, at time +3

A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
Implications• Need to multiport some structures
– Register File• Multiple Reads and Writes per cycle
– Register Availability Vector (scoreboard)• Multiple Reads and Writes per cycle
– From Decode and Commit– Also need to worry about WAR and WAW
• Resource tracking– Additional issue conditions
• Many Superscalars had additional restrictions– E.g., execute one integer and one floating point op– one branch, or one store/load

A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
Preserving Sequential Semantics• In principle not much different than pipelining• Program order is preserved in the pipeline• Some instructions proceed in parallel
– But order is clearly defined• Defer interrupts to commit stage (i.e.,
writeback)– Flush all subsequent instructions
• may include instructions committing simultaneously– Allow all preceding instructions to commit
• Recall comparisons are done in program order• Must have sufficient time in clock cycle to
handle these
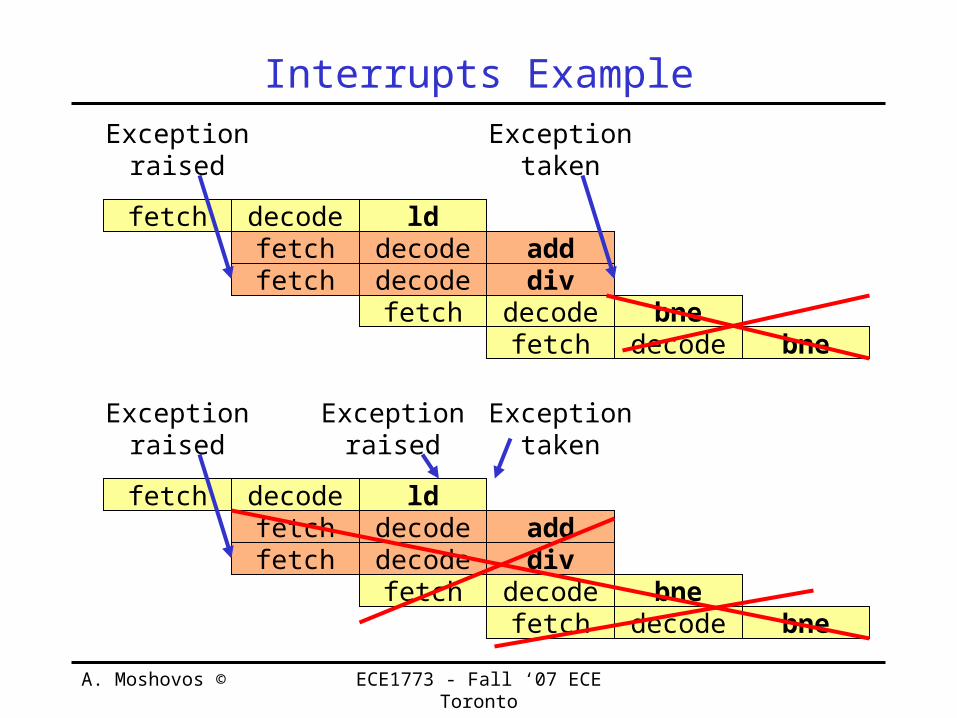
A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
Interrupts Example
fetch decode ldfetch decode addfetch decode div
fetch decode bne
Exceptionraised
Exceptiontaken
fetch decode bne
fetch decode ldfetch decode addfetch decode div
fetch decode bne
Exceptionraised
Exceptiontaken
fetch decode bne
Exceptionraised

A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
Superscalar and Pipelining• In principle they are orthogonal
– Superscalar non-pipelined machine– Pipelined non-superscalar– Superscalar and Pipelined (common)
• Additional functionality needed by Superscalar:– Another bound on clock cycle– At some point it limits the number of
pipeline stages

A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
Superscalar vs. Superpipelining• Superpipelining:
– Vaguely defined as deep pipelining, i.e., lots of stages• Superscalar issue complexity: limits super-pipelining• How do they compare?
– 2-way Superscalar vs. Twice the stages– Not much difference.
fetch decode instfetch decode inst
fetch decode instfetch decode inst
F1 D1D1
F1 D1D1
D2D2
D2D2
F2F1 F2
F2F1 F2
E1 E2E1 E2
E1 E2E1 E2
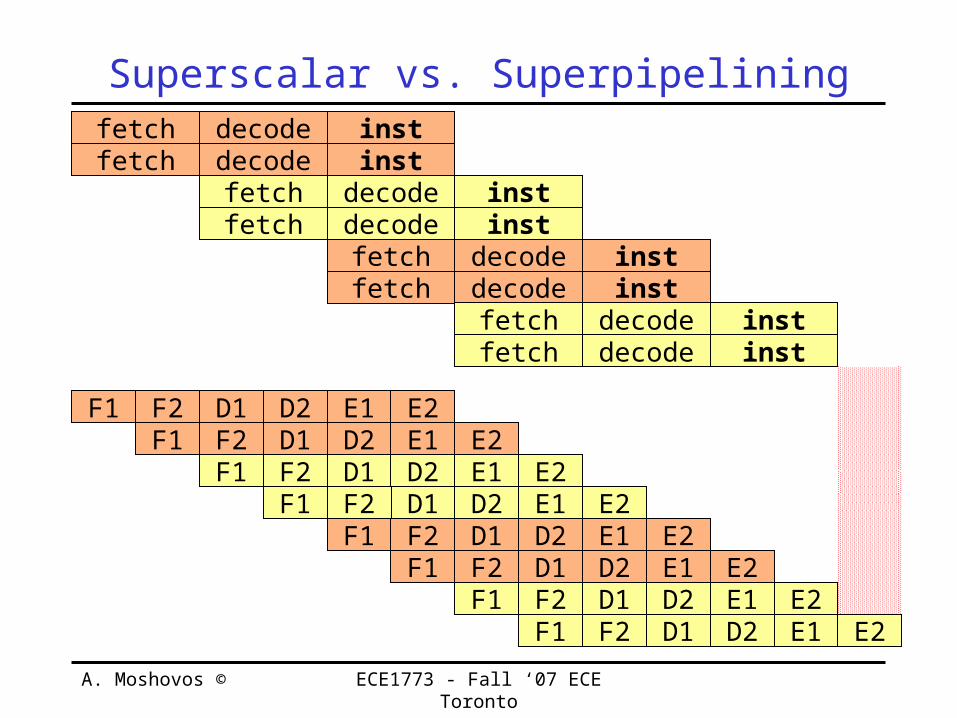
A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
Superscalar vs. Superpipeliningfetch decode instfetch decode inst
fetch decode instfetch decode inst
F1 D1D1
F1 D1D1
D2D2
D2D2
F2F1 F2
F2F1 F2
E1 E2E1 E2
E1 E2E1 E2
fetch decode instfetch decode inst
fetch decode instfetch decode inst
F1 D1D1D2
D2F2F1 F2
E1 E2E1 E2
F1 D1D1D2
D2F2F1 F2
E1 E2E1 E2

A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
Superscalar vs. Superpipelining
fetch decode instfetch decode inst
fetch decode instfetch decode inst
F1 D1 instD1 inst
F1 D1 instD2 inst
D2D2 D2
D1 D2
F2F1 F2
F2F1 F2 F2
fetch decode inst
D2 instF1 F1 D1
RAW
RAW
decode
fetch
D1 D2F2 D1F1 D1 instD2F2
fetch decode instfetch decode inst
F1 D1 instD2D1D2F2
F2D1F2
WANT 2X PERFORMANCE:
A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
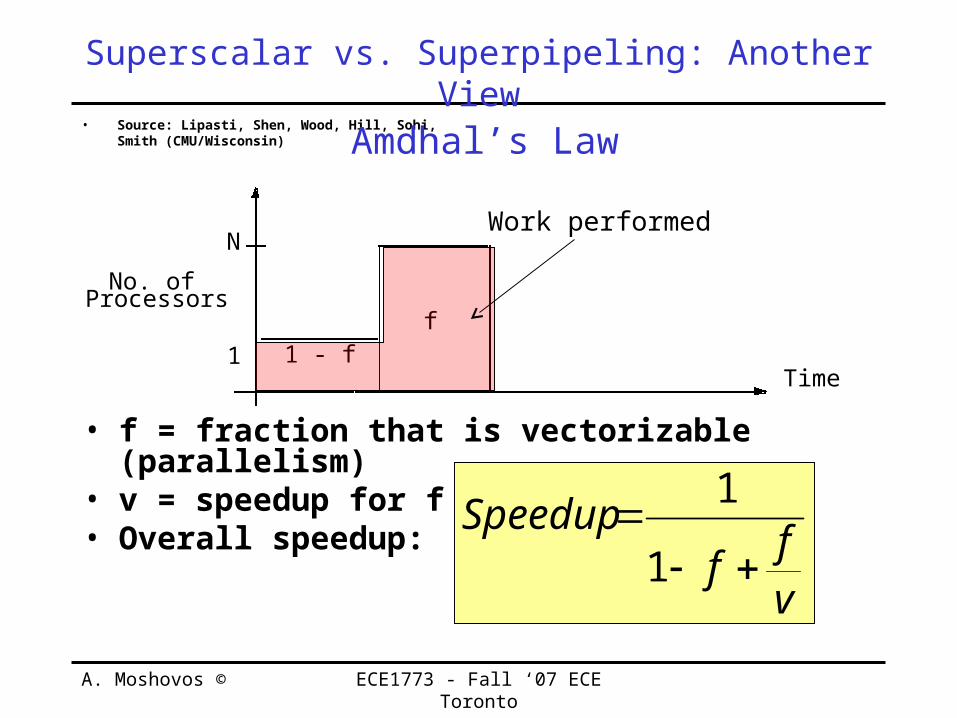
Superscalar vs. Superpipeling: Another View• Source: Lipasti, Shen, Wood, Hill, Sohi, Smith
(CMU/Wisconsin)
• f = fraction that is vectorizable (parallelism)
• v = speedup for f• Overall speedup:
No. ofProcessors
N
Time1 1 - f
f
Amdhal’s Law
Work performed
vff
Speedup
1
1
A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
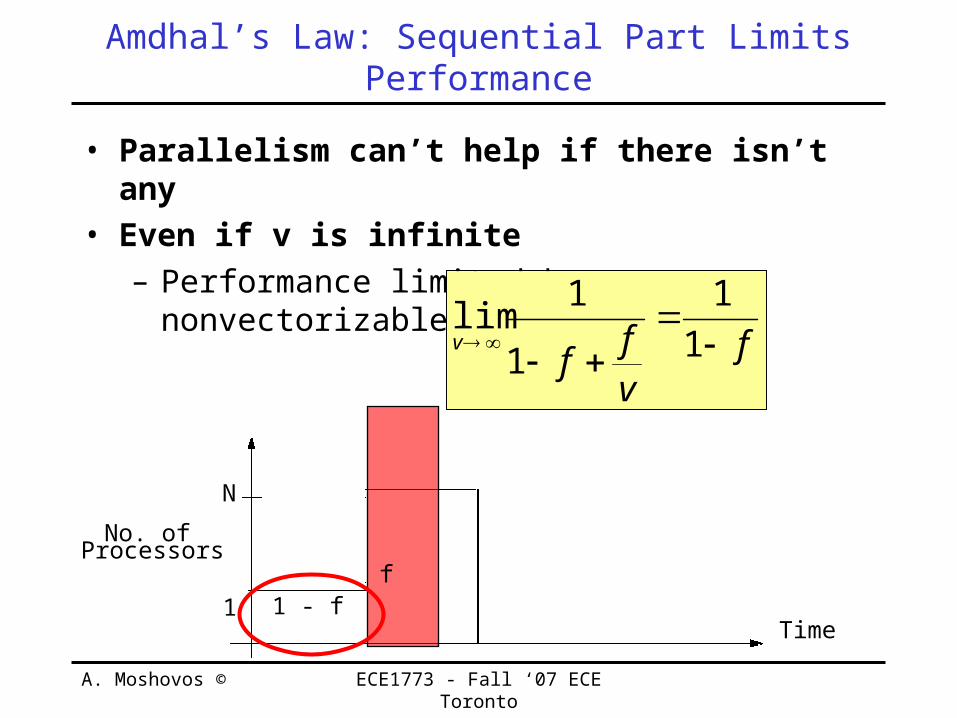
Amdhal’s Law: Sequential Part Limits Performance
• Parallelism can’t help if there isn’t any• Even if v is infinite
– Performance limited by nonvectorizable portion (1-f)
fvff
v
1
1
1
1lim
No. ofProcessors
N
Time1 1 - f
f
A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
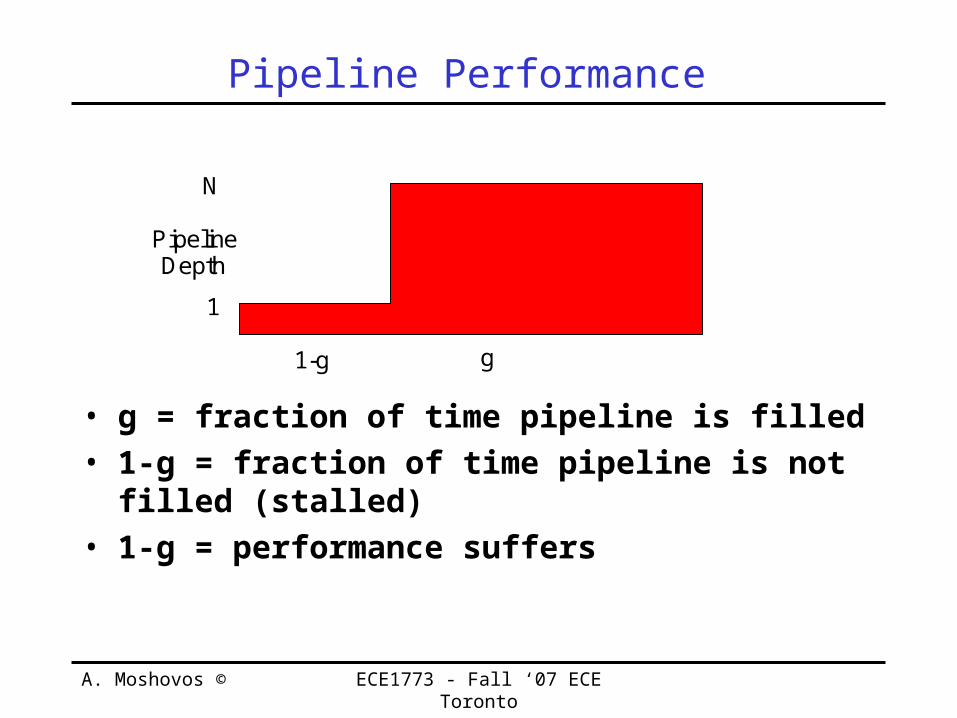
Pipeline Performance
• g = fraction of time pipeline is filled• 1-g = fraction of time pipeline is not
filled (stalled)• 1-g = performance suffers
1-g g
PipelineDepth
N
1
A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
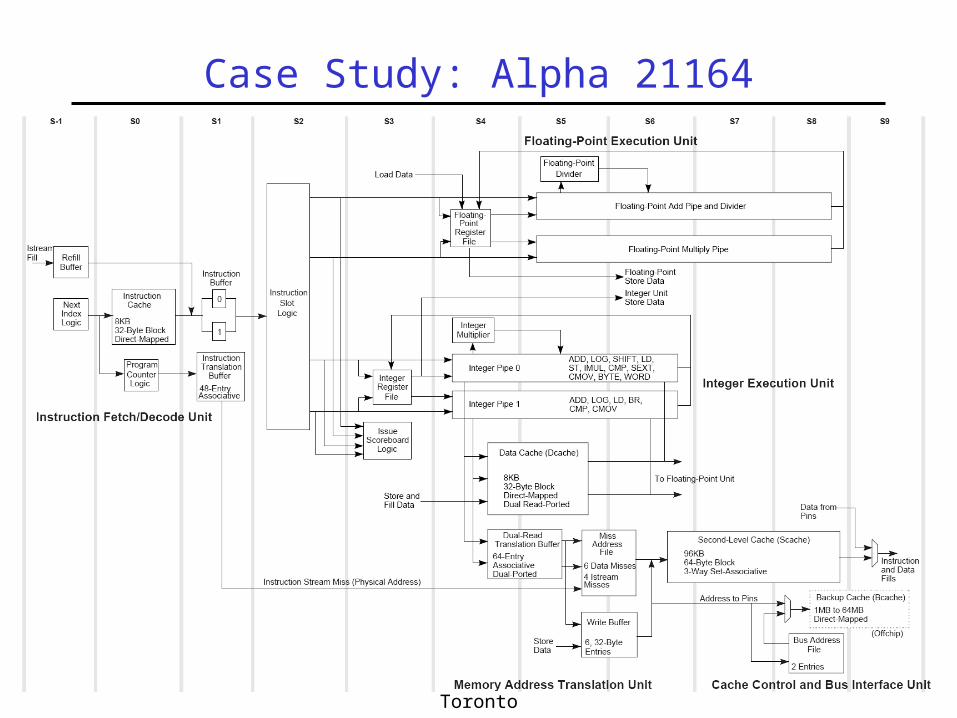
Case Study: Alpha 21164
A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
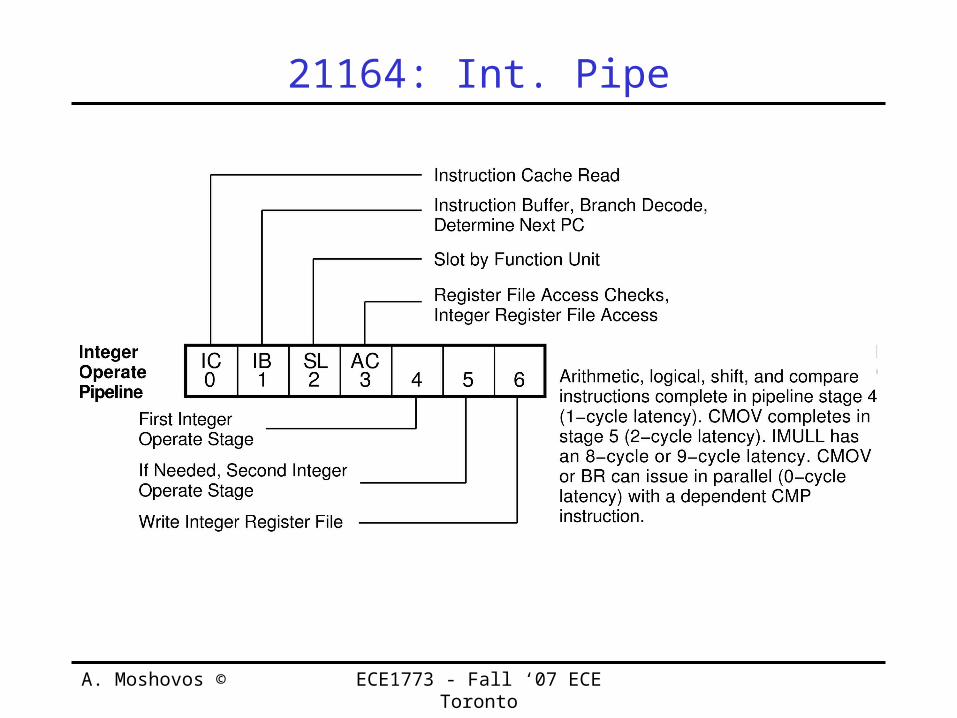
21164: Int. Pipe
A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
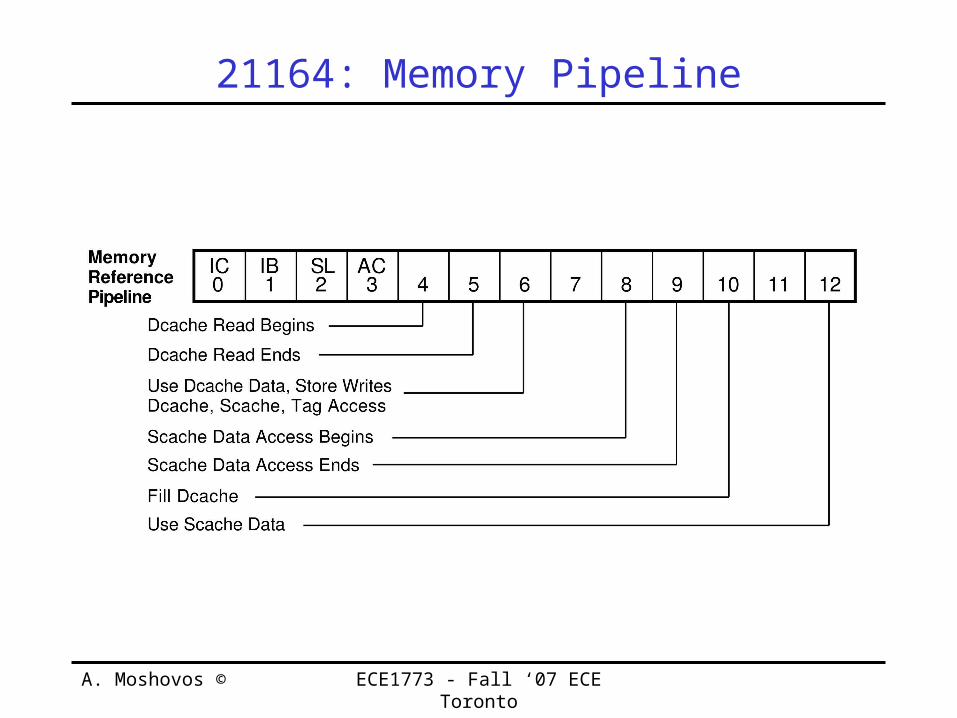
21164: Memory Pipeline

A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
21164: Floating-Point Pipe
A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
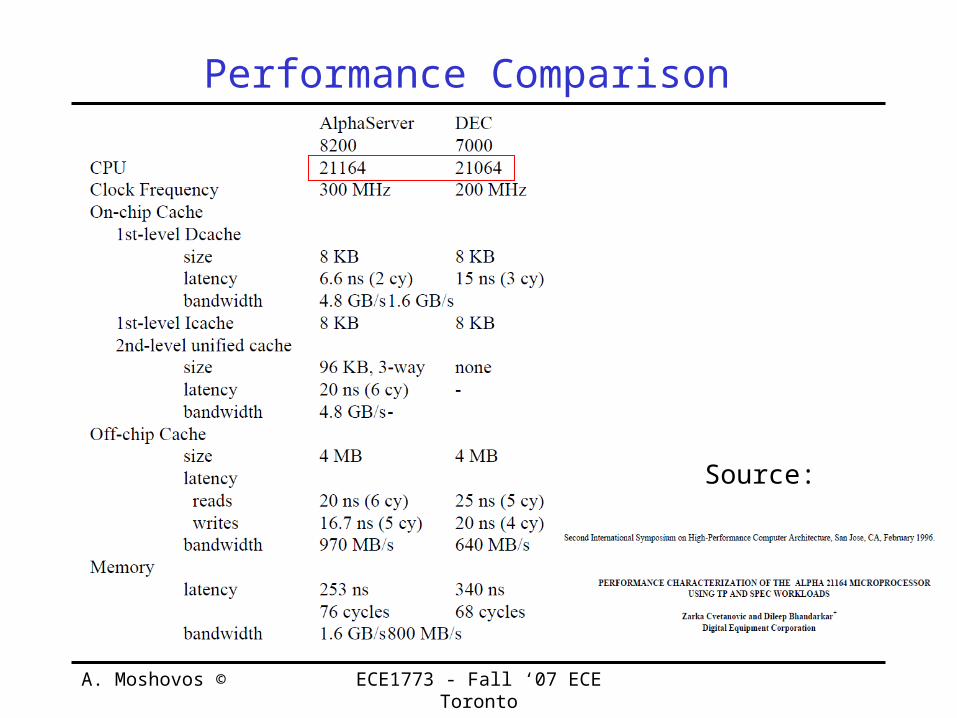
Performance Comparison
Source:
A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
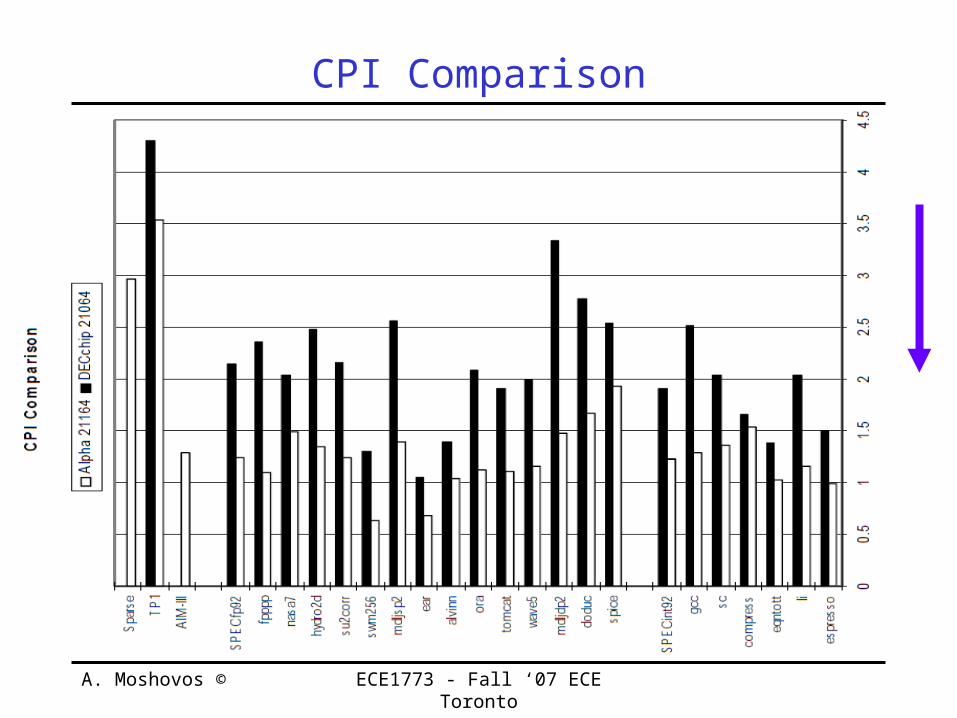
CPI Comparison
A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
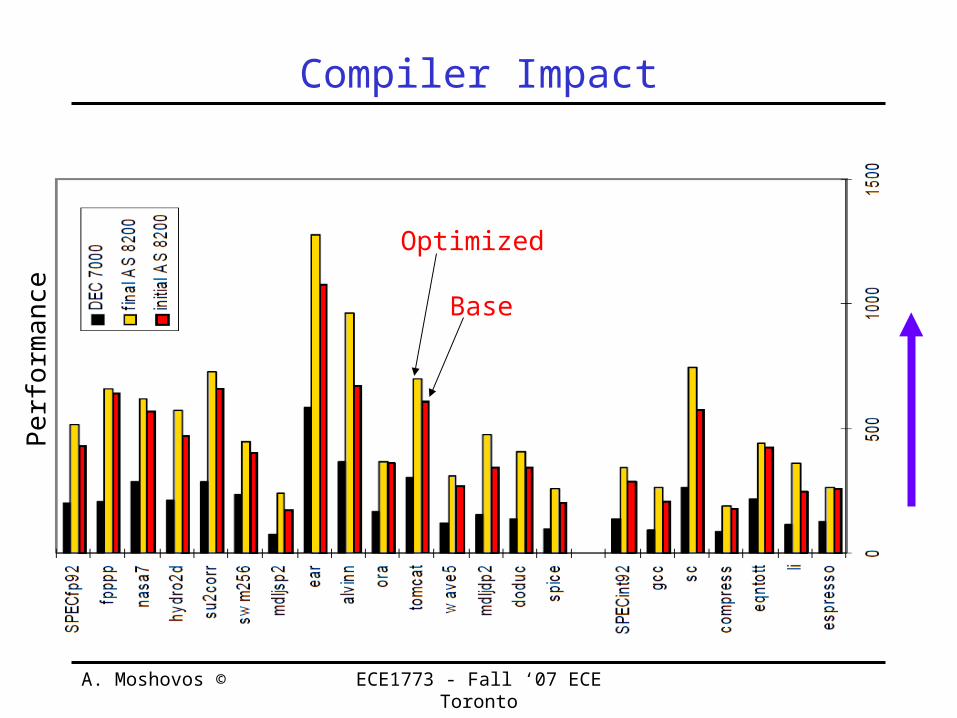
Compiler Impact
Optimized
Base
Perf
orm
ance
A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
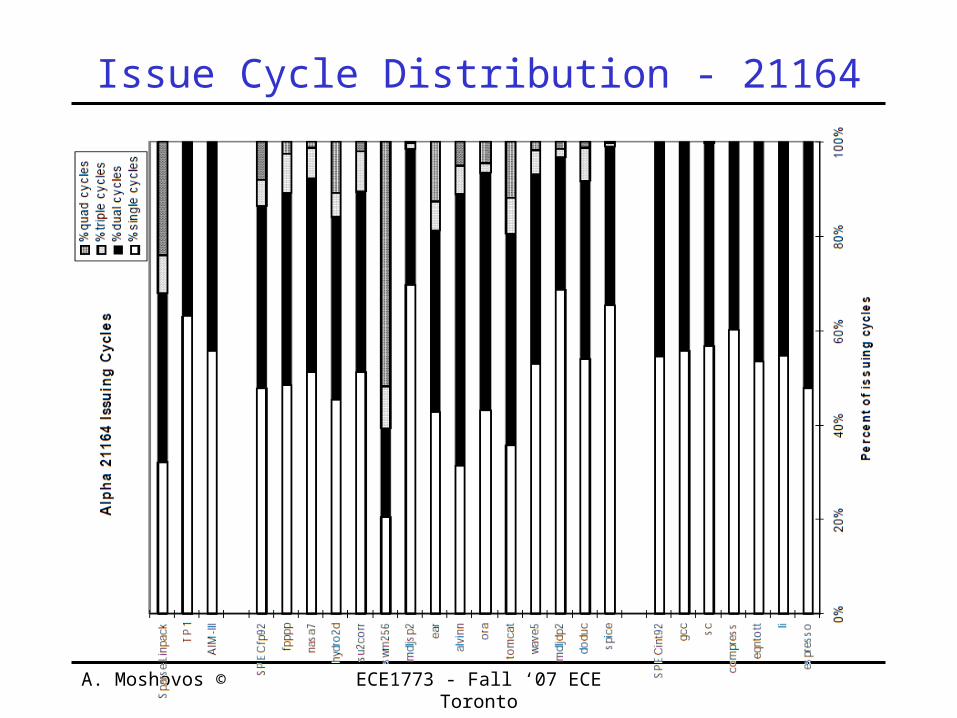
Issue Cycle Distribution - 21164
A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
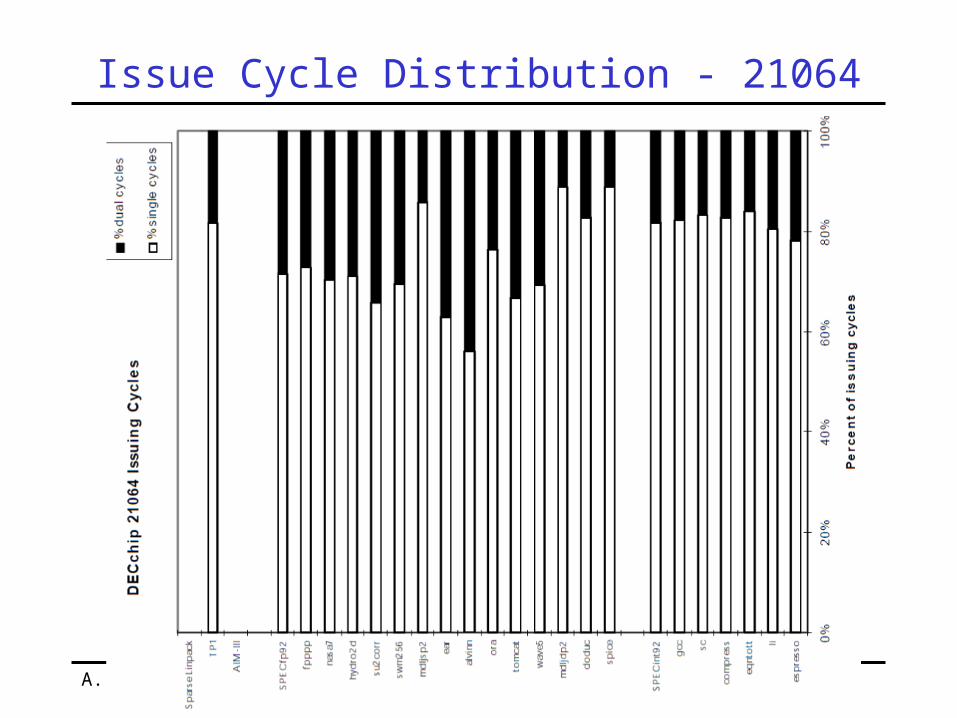
Issue Cycle Distribution - 21064
A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
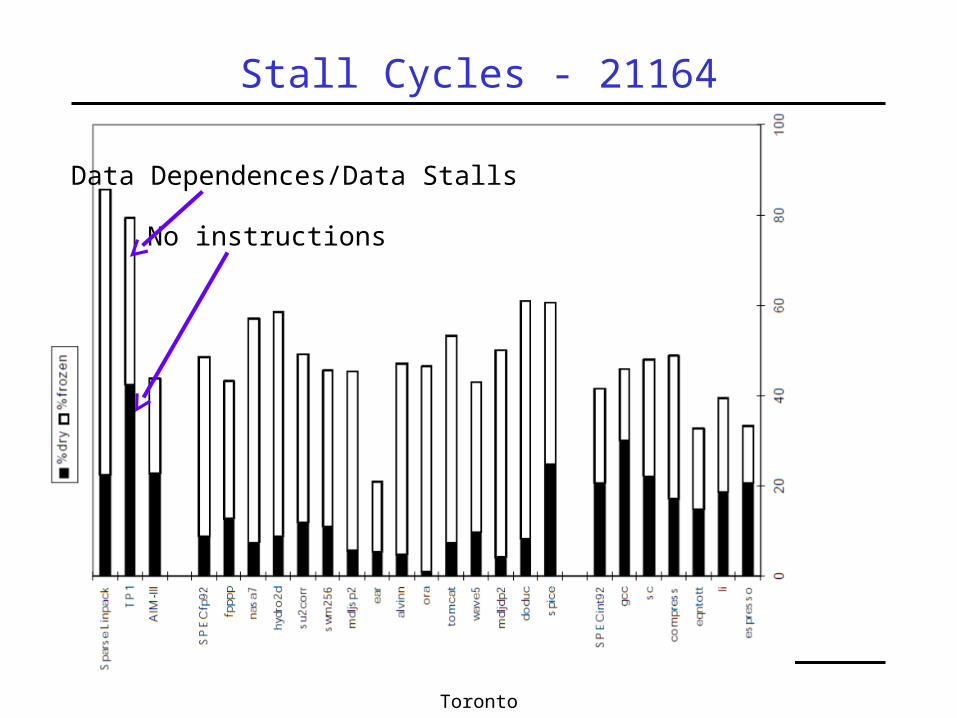
Stall Cycles - 21164
No instructions
Data Dependences/Data Stalls

A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
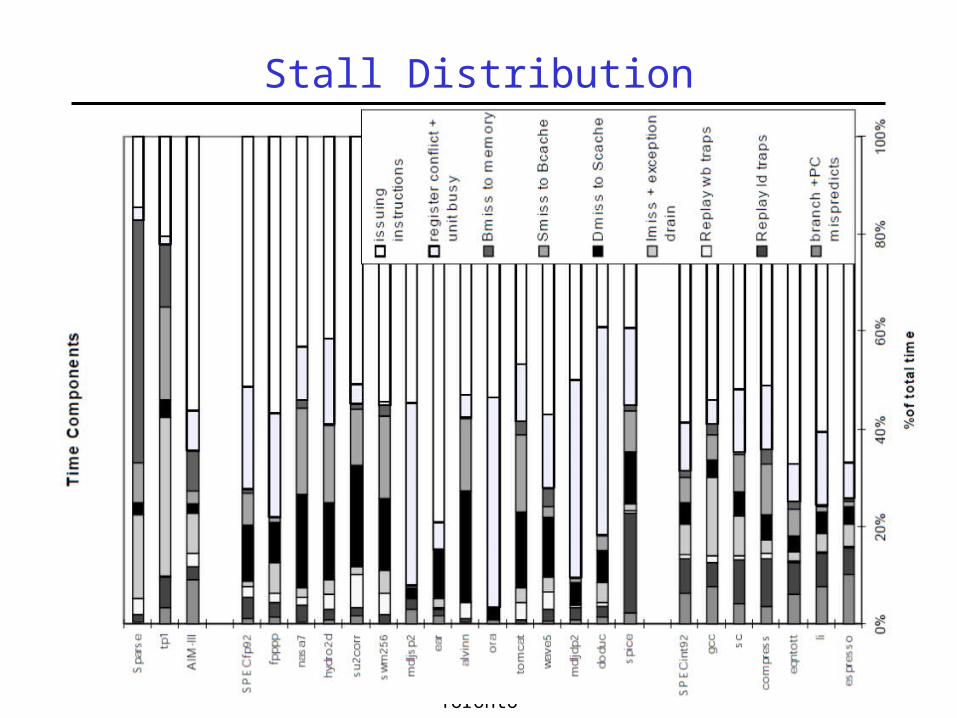
Stall Cycles Distrubution• Model:
When no instruction is committingDoes not capture overlapping factors:
Stall due to dependence while committingStall due to cache miss while committing

A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
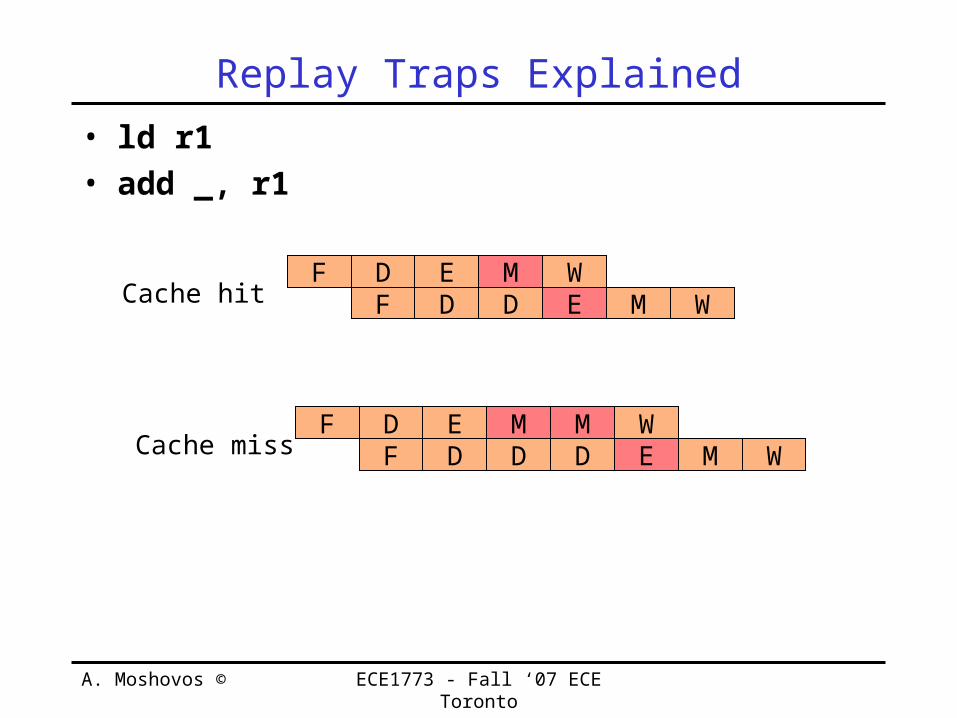
Replay Traps• Tried to do something and couldn’t
– Store and write-buffer is full• Can’t complete instruction
– Load and miss-address-file full• Can’t complete instruction
– Assumed Cache hit and was miss• Dependent instructions executed• Must re-execute dependent instructions
• Re-execute the instruction and everything that follows
A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
Replay Traps Explained• ld r1• add _, r1
F E MD WF E MD WCache hit D
F E MD WF E MD WCache miss D
MD
A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
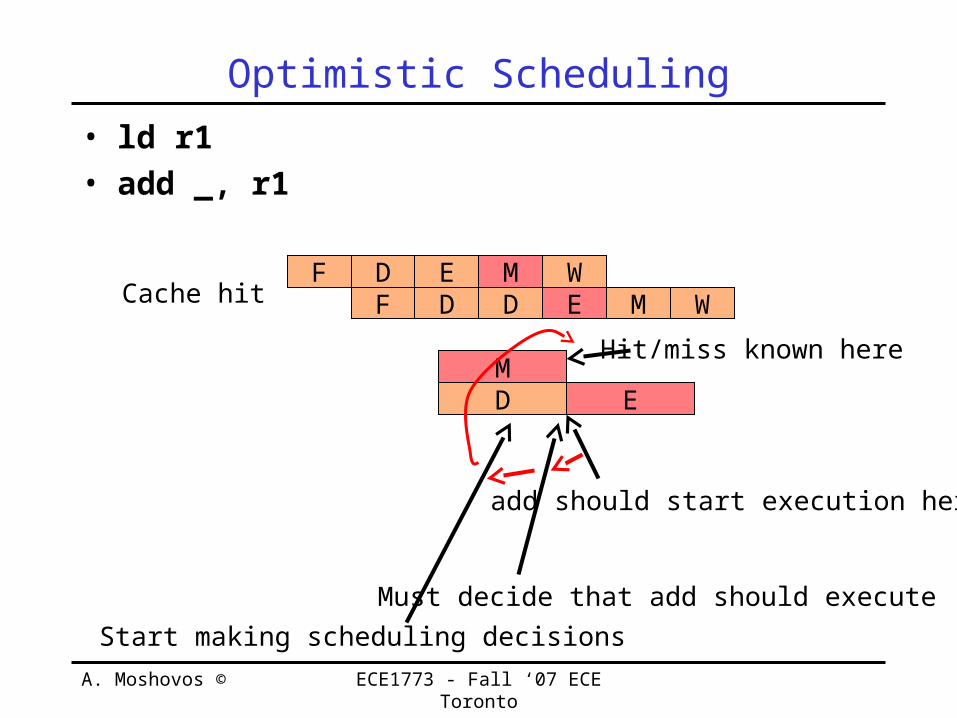
Optimistic Scheduling• ld r1• add _, r1
F E MD WF E MD WCache hit D
MED
add should start execution here
Must decide that add should executeStart making scheduling decisions
Hit/miss known here
A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
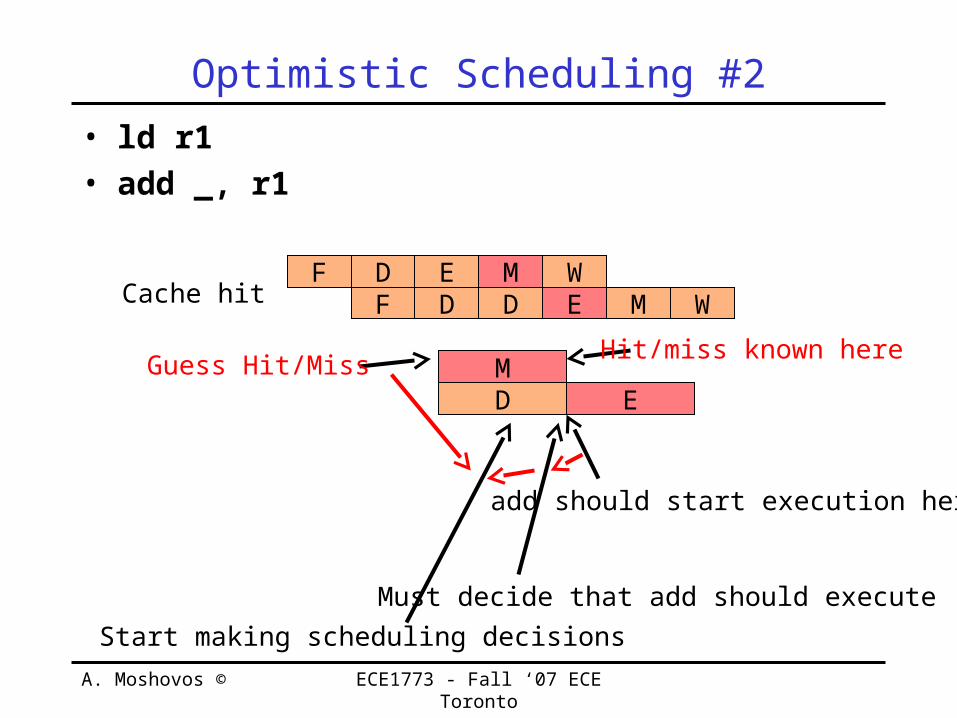
Optimistic Scheduling #2• ld r1• add _, r1
F E MD WF E MD WCache hit D
MED
add should start execution here
Must decide that add should executeStart making scheduling decisions
Hit/miss known hereGuess Hit/Miss
A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
Stall Distribution

A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
21164 Microarchitecture• Instruction Fetch/Decode + Branch Units• Integer Execution Unit• Floating-Point Execution Unit• Memory Address Translation Unit• Cache Control and Bus Interface• Data Cache• Instruction Cache• Second-Level Cache

A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
Instruction Decode/Issue • Up to four insts/cycle• Naturally aligned groups
– Must start at 16 byte boundary (INT16)– Simplifies Fetch path (in a second)
• All of group must issue before next group gets in
• Simplifies Scheduling – No need for reshuffling

A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
Instruction Decode/Issue • Up to four insts/cycle• Naturally aligned groups
– Must start at 16 byte boundary (INT16)– Simplifies Fetch path
CPU needs:
I-Cache:Where instructions come from?
A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
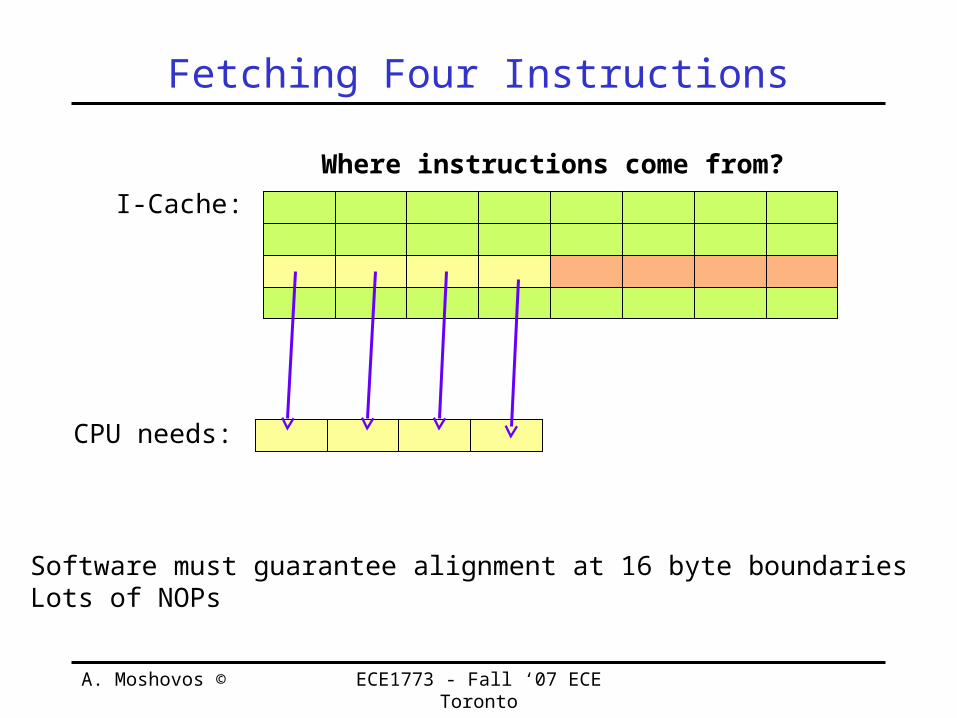
Fetching Four Instructions
CPU needs:
I-Cache:Where instructions come from?
Software must guarantee alignment at 16 byte boundariesLots of NOPs

A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
Instruction Buffer and Prefetch• I-buffer feeding issue• 4-entry, 8-instruction prefetch buffer• Check I-Cache and PB in parallel• PB hit: Fill Cache, Feed pipeline• PB miss: Prefetch four lines

A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
Branch Execution• One cycle delay Calc. target PC
– Naïve implementation: • Can fetch every other cycle
• Branch Prediction to avoid the delay• Up to four pending branches in stage 2
– Assignment to Functional Units• One at stage 3
– Instruction Scheduling/Issue• One at stage 4
– Instruction Execution• Full and execute from right PC

A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
Return Address Stack• Returns Target Address Changes• Conventional Branch Prediction can’t
handle • Predictable change
– Return address = Call site return point• Detect Calls
– Push return address onto hardware stack– Return pops address– Speculative– 12-entry “stack”
• Circular queue overflow/underflow messes it up

A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
Instruction Translation Buffer• Translate Virtual Addresses to Physical• 48-entry fully-associative• Pages 8KB to 4MB• Not-last-used/Not-MRU replacement• 128 Address space identifiers

A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
Integer Execution Unit• Two of:
– Adder– Logic
• One of:– Barrel shifter– Byte-manipulation– Multiply
• Asymmetric Unit Configurations are common– Tradeoff between;
• Flexibility/Performance• Area/Cost/Complexity
• How to decide? Common application behavior

A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
Integer Register File• 32+8 registers
– 8 are legacy DEC• Four read ports, two write ports
– Support for up to two integer ops

A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
Floating-Point Unit• FPU ADD• FPU Multiply• 2 ops per cycle• Divides take multiple cycles• 32 registers, five reads, four writes
– Four reads and two writes for FP pipe– One read for stores (handled by integer
pipe)– One write for loads (handled by integer
pipe)

A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
Memory Unit• Up to two accesses• Data translation buffer
– 512-entries, not-MRU– Loads access in parallel with D-cache
• Miss Address File– Pending misses– Six data loads– Four instruction reads– Merges loads to same block
A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
Store/Load Conflicts• Load immediately after a store
– Can’t see the data– Detect and replay
• Flush pipe and re-execute• Compiler can help
– Schedule load three cycles after store– Two cycles stalls the load at issue/address
generation

A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
Write Buffer• Six 32-byte entries• Defer stores until there is a port
available• Loads can read from Writebuffer

A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
Pipeline Processing Front-End

A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
Integer Add

A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
Floating-Point Add

A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
Load Hit

A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
Load Miss
A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
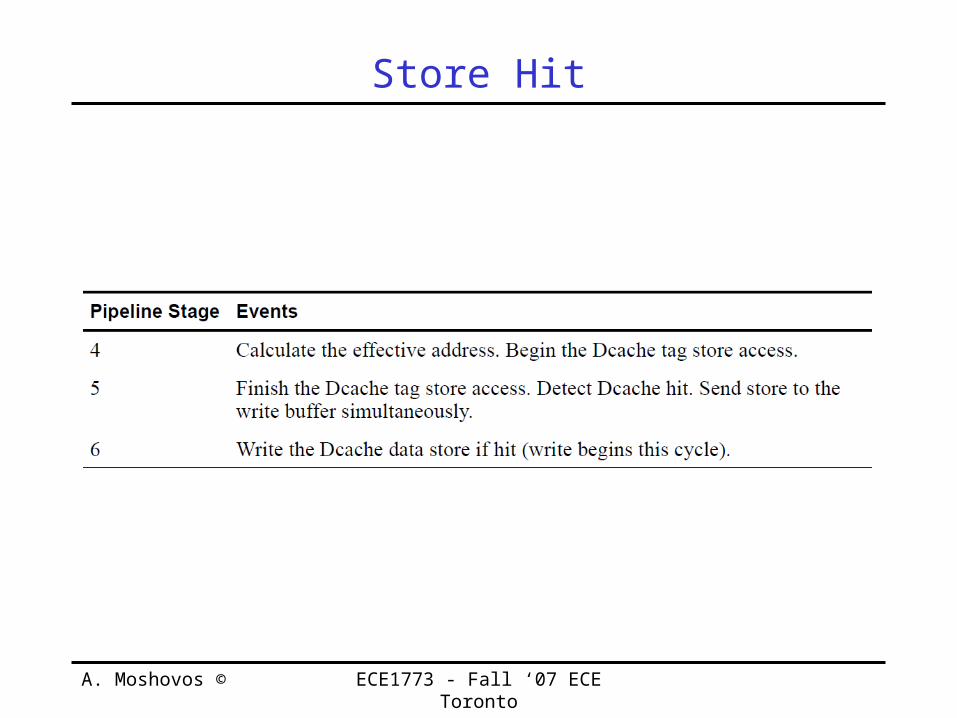
Store Hit

A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
80486 Pipeline• Fetch
– Load 16-bytes from into prefetch buffer• Decode 1
– Determine instruction length and type• Decode 2
– Compute memory address– Generate immediate operands
• Execute– Register Read– ALU– Memory read/write
• Write-back– Update register file
• (source: CS740 CMU, ’97, all slides on 486)

A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
80486 Pipeline detail• Fetch
– Moves 16 bytes of instruction stream into code queue– Not required every time– About 5 instructions fetched at once (avg. length 2.5
bytes)– Only useful if don’t branch– Avoids need for separate instruction cache
• D1– Determine total instruction length– Signals code queue aligner where next instruction
begins– May require two cycles
• When multiple operands must be decoded• About 6% of “typical” DOS program

A. Moshovos © ECE1773 - Fall ‘07 ECE Toronto
80486 Pipeline• D2
– Extract memory displacements and immediate operands
– Compute memory addresses– Add base register, and possibly scaled index register– May require two cycles
• If index register involved, or both address & immediate operand
• Approx. 5% of executed instructions• EX
– Read register operands– Compute ALU function– Read or write memory (data cache)
• WB– Update register result





























