Embed Size (px)
Citation preview

1
CS 430: Information Discovery
Lecture 1
Overview of Information Discovery

2
Course Administration
Web site: http://www.cs.cornell.edu/courses/cs430/2001fa
Instructor: William Arms, Upson 5159
Teaching assistants:
Assistant: Rosemary Adessa, Upson 5147
Sign-up sheet: Include your NetID

3
Course Administration
Text book.
William B. Frakes and Ricardo Baeza-Yates, Information Retrieval Data Structures and Algorithms. Prentice Hall, 1992

4
Discussion Classes
Format of Wednesday evening classes:
• Topic announced on web site with chapter or article to read
• Allow several hours to prepare for class by reading the materials
• Class has discussion format
• One third of grade is class participation
Class time is 7:30 to 8:30

5
Code of Conduct
• Computing is a collaborative activity. You are encouraged to work together, but ...
• Some tasks may require individual work.
• Always give credit to your sources and collaborators.
To make use of the expertise of others and to build on previous work, with proper attribution is good professional practice.
To use the efforts of others without attribution is unethical and academic cheating.
http://www.cs.cornell.edu/courses/cs430/2001fa/code.html

6
Information Discovery
People have many reasons to look for information:
• Known item Where will I find the wording of the US Copyright Act?
• Facts What is the capital of Barbados?
• Introduction or overview How do diesel engines work?
• Related information Is there a review of this article?
• Comprehensive search What is known of the effects of global warming on
hurricanes?

7
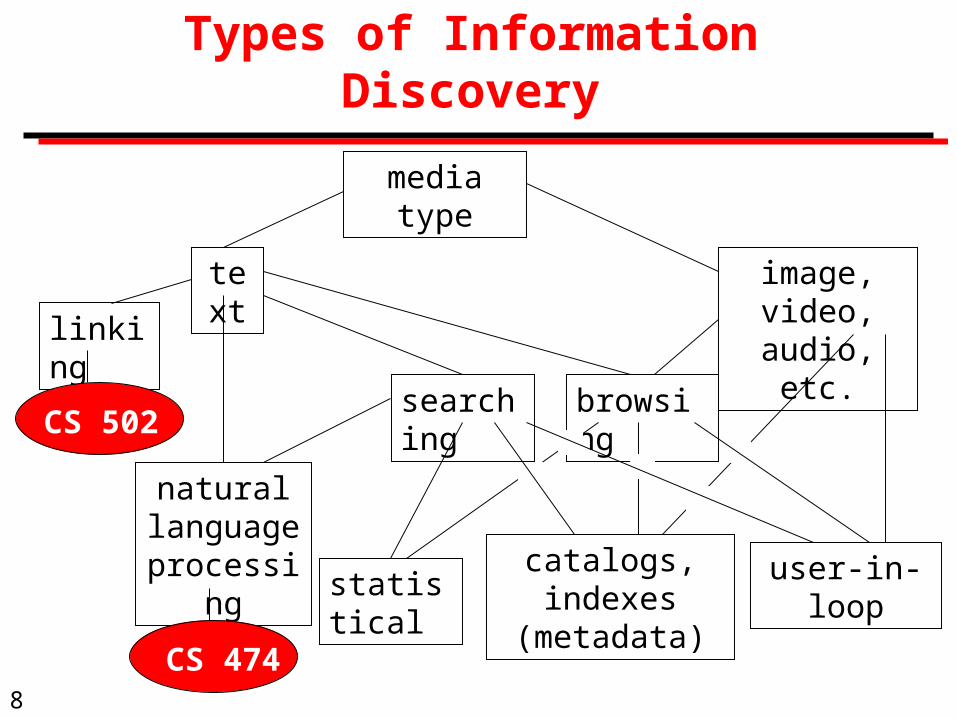
Definitions
Information retrieval: subfield of computer science that deals with automated retrieval of documents.
Searching: seeking for specific information within a body of information. The result of a search is a set of hits.
Browsing: unstructured exploration of a body of information.
Linking: Moving from one item to another following links, such as citations, references, etc.
8
Types of Information Discovery
media type
text image, video, audio, etc.
searching browsing
linking
statistical user-in-loopcatalogs, indexes (metadata)
CS 502
natural language
processing
CS 474
9
Classical Information Retrieval
media type
text image, video, audio, etc.
searching browsing
linking
statistical user-in-loopcatalogs, indexes (metadata)
CS 502
natural language
processing
CS 474

10
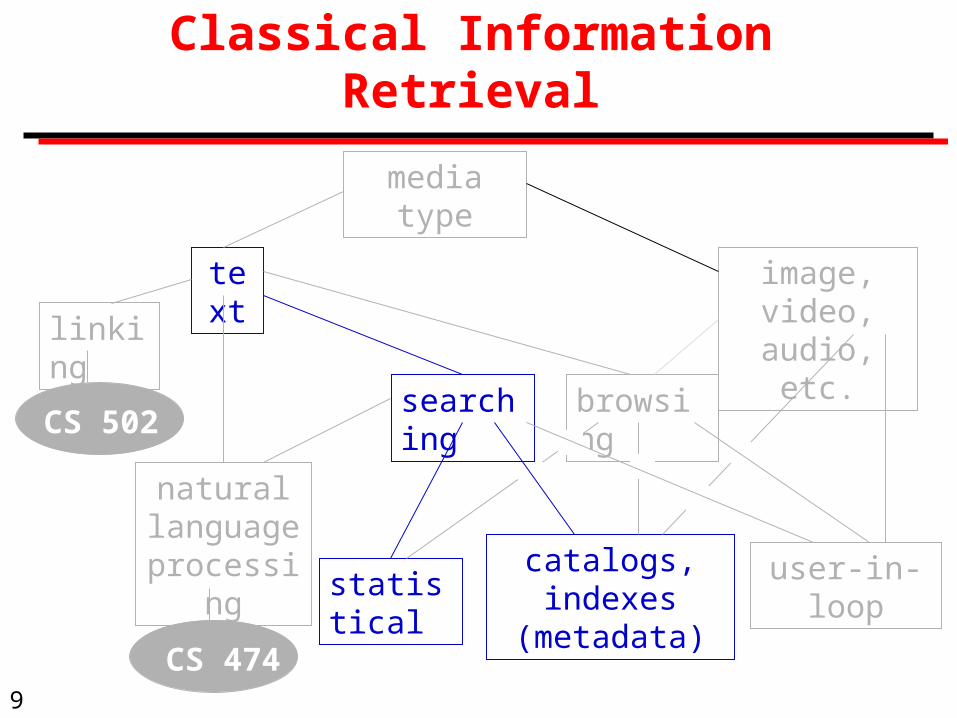
The Basics of Information Retrieval
Query: A string of text, describing the information that the user is seeking. Each word of the query is called a search term.
A query can be a single search term, a string of terms, a phrase in natural language, or a stylized expression using special symbols.
Full text searching: Methods that compare the query with every word in the text, without distinguishing the function of the various words.
Fielded searching: Methods that search on specific bibliographic or structural fields, such as author or heading.

11
Descriptive metadata
Some methods of information discovery search descriptive metadata about the objects.
Metadata typically consists of a catalog or indexing record, or an abstract, one record for each object. The record acts as a surrogate for the object.
• Usually stored separately from the objects that it describes, but sometimes is embedded in the objects.
• Usually the metadata is a set of text fields.
Textual metadata can be used to describe non-textual objects, e.g., software, images, music

12
Descriptive metadata
Catalog: metadata records that have a consistent structure, organized according to systematic rules.
Abstract: a free text record that summarizes a longer document.
Indexing record: less formal than a catalog record, but more structure than a simple abstract.
13
Documents and Surrogates
The sea is calm to-night.
The tide is full, the moon lies fair
Upon the straits;--on the French coast the light
Gleams and is gone; the cliffs of England stand,
Glimmering and vast, out in the tranquil bay.
Come to the window, sweet is the night-air!
Only, from the long line of spray
Where the sea meets the moon-blanch'd land,
Listen! you hear the grating roar
Of pebbles which the waves draw back, and fling,
At their return, up the high strand,
Begin, and cease, and then again begin,
With tremulous cadence slow, and bring
The eternal note of sadness in.
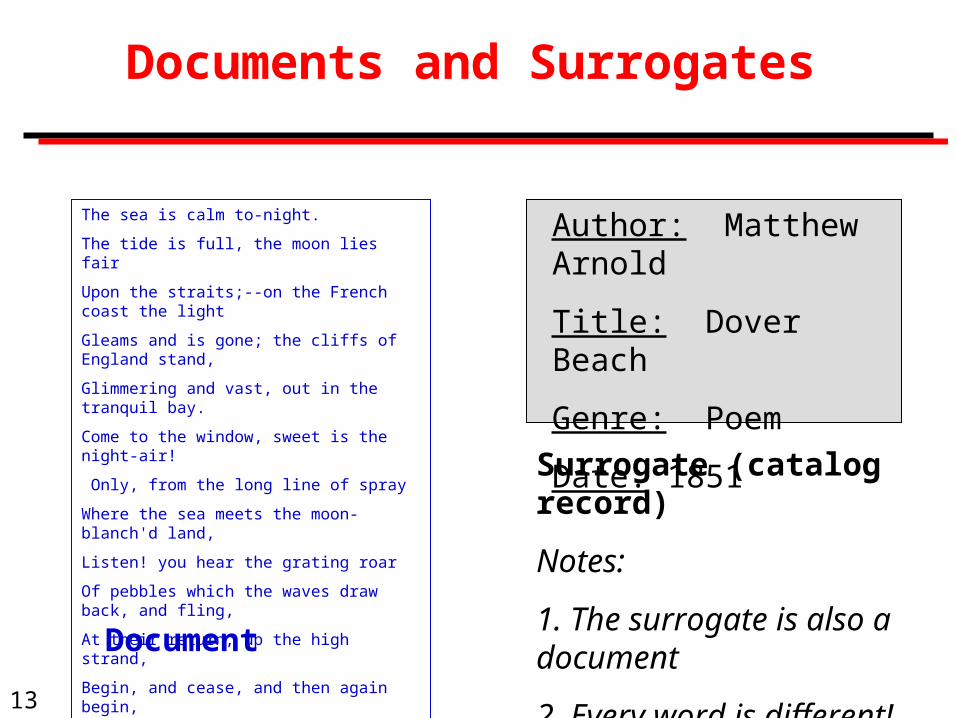
Author: Matthew Arnold
Title: Dover Beach
Genre: Poem
Date: 1851
Document
Surrogate (catalog record)
Notes:
1. The surrogate is also a document
2. Every word is different!

14
Lexicon and thesaurus
Lexicon contains information about words, their morphological variants, and their grammatical usage.
Thesaurus relates words by meaning:
ship, vessel, sail; craft, navy, marine, fleet, flotilla
book, writing, work, volume, tome, tract, codex
search, discovery, detection, find, revelation
(From Roget's Thesaurus, 1911)

15
Surrogates for non-textual materials
Textual catalog record about a non-textual item (photograph)
Surrogate
Text based methods of information retrieval can search a surrogate for a photograph

16
Library of Congress catalog record
CREATED/PUBLISHED: [between 1925 and 1930?]
SUMMARY: U. S. President Calvin Coolidge sits at a desk and signs a photograph, probably in Denver, Colorado. A group of unidentified men look on.
NOTES: Title supplied by cataloger. Source: Morey Engle.
SUBJECTS: Coolidge, Calvin,--1872-1933. Presidents--United States--1920-1930. Autographing--Colorado--Denver--1920-1930. Denver (Colo.)--1920-1930. Photographic prints.
MEDIUM: 1 photoprint ; 21 x 26 cm. (8 x 10 in.)

17
Automatic indexing
Creating catalog records manually is labor intensive and hence expensive.
The aim of automatic indexing is to build indexes and retrieve information without human intervention.
History
Much of the fundamental research in automatic indexing was carried out by Gerald Salton, Professor of Computer Science at Cornell, and his graduate students.

18
Recall and Precision
If information retrieval were perfect ...
Every hit would be relevant to the original query, and every relevant item in the body of information would be found.
Precision: percentage of the hits that are relevant, the extent to which the set of hits retrieved by a query satisfies the requirement that generated the query.
Recall: percentage of the relevant items that are found by the query, the extent to which the query found all the
items that satisfy the requirement.

19
Recall and Precision: Example
• Collection of 10,000 documents, 50 on a specific topic
• Ideal search finds these 50 documents and reject others
• Actual search identifies 25 documents; 20 are relevant but 5 were on other topics
• Precision: 20/ 25 = 0.8
• Recall: 20/50 = 0.4

20
Measuring Precision and Recall
Precision is easy to measure:
• A knowledgeable person looks at each document that is identified and decides whether it is relevant.
• In the example, only the 25 documents that are found need to be examined.
Recall is difficult to measure:
• To know all relevant items, a knowledgeable person must go through the entire collection, looking at every object to decide if it fits the criteria.
• In the example, all 10,000 documents must be examined.

21
History
Much of the work on evaluation of information retrieval derives from the ASLIB Cranfied projects led by Cyril Cleverdon, which began in 1957.





























