Embed Size (px)
Citation preview

1
Unsupervised and Knowledge-Free Natural Language
Processing in the Structure Discovery Paradigm
Chris BiemannUniversity of Leipzig, Germany
Talk at University of Wolverhampton
September 7, 2007

2
OutlineReview of traditional approaches• Knowledge-intensive vs. knowledge-free• Degrees of Supervision
A new approach• The Structure Discovery Paradigm
Graph-based SD procedures• Graph models for language processing• Chinese Whispers Graph Clustering
Structure Discovery Processes• Language Separation• Unsupervised POS tagging• Word Sense Induction

3
Knowledge-Intensive vs. Knowledge-Free
In traditional automated language processing, knowledge is involved in all cases where humans manually tell machines
• How to process language by explicit knowledge
• How a task should be solved by implicit knowledge
Knowledge can be provided by the means of:
• Dictionaries, e.g. thesaurus, WordNet, ontologies, …
• (grammar) rules
• Annotation

4
Degrees of Supervision
Supervision is providing positive and negative training examples to Machine Learning algorithms, which use this as a basis for building a model that reproduces the classification on unseen data
Degrees:• Fully supervised (Classification): Learning is only carried out on
fully labeled training set• Semi-supervised: Unlabeled examples are also used for building
a data model• Weakly-supervised (Bootstrapping): A small set of labeled
examples is grown and classifications are used for re-training• Unsupervised (Clustering): No labeled examples are provided

5
Structure Discovery Paradigm SD:• Analyze raw data and identify regularities• Statistical methods, clustering• Knowledge-free, unsupervised• Structures: as many as can be discovered• Language-independent, domain-independent, encoding-independent• Goal: Discover structure in language data and mark it in the data

6
Example: Discovered Structures
• Annotation on various levels
• Similar labels denote similar properties as found by the SD algorithms
• Similar structures in corpus are annotated in a similar way
„ Increased interest rates lead to investments in banks .“
<sentence lang=12, subj=34.11> <chunk id=c25> <word POS=p3 m=0.0 s=s14>In=creas-ed</word> <MWU POS=p1 s=s33> <word POS=p1 m=5.1 s=s44>interest</word> <word POS=p1 m=2.12 s=s106>rate-s</word> </MWU> </chunk> <chunk id=c13> <MWU POS=p2> <word POS=p2 m=17.3 s=74>lead</word> <word POS=p117 m=11.98>to</word> </MWU> </chunk> <chunk id=c31> <word POS=p1 m=1.3 s=33>investment-s</word> <word POS=p118 m=11.36>in</word> <word POS=p1 m=1.12 s=33>bank-s</word> </chunk> <word> POS=298> . </word></sentence>

7
Consequences of Working in SD• Only input allowed is raw text data• Machines are told how to algorithmically discover structure• Self-annotation process by marking regularities in the data• Structure Discovery process is iterated
Text Data
SD algorithm
Find regularities by analysis
Annotate data with regularitiesSD algorithm
SD algorithmSD algorithms

8
Pros and Cons of Structure Discovery
Advantages:
• Cheap: only raw data needed• Alleviation of acquisition bottleneck• Language and domain independent• No data-resource mismatch (all resources leak)
Disadvantages:
• No control over self-annotation labels• Congruence to linguistic concepts not guaranteed• Much computing time needed

9
What is it good for? How do I know?
• Many structural regularities can be thought of, some are interesting, some are not.
• Structures discovered by SD algorithms will not necessarily match the concepts of linguists
• Working in the SD paradigm means to over-generate structure acquisition methods and to check, whether these are helpful
Methods for telling helpful from useless SD procedures:• „Look at my nice clusters“-approach: Examine data by hand. While
good in the initial phase of testing, this is inconclusive: choice of clusters, coverage…
• Task-based evaluation: Use the labels obtained as features in a Machine Learning scenario and measure the contribution of each label type. Involves supervision, is indirect

10
Graph models for SD procedures
Motivation for graph representation• Graphs are an intuitive and natural way to encode
language units as nodes and their similarities as edges - but also other representations are possible
• Graph clustering can efficiently perform abstraction by grouping units into homogeneous sets with Chinese Whispers
Some graphs on basic units• Word co-occurrence (neighbour/sentence), significance,
higher orders• Word context similarity based on global context vectors• Sentence/document similarity on common words

11
Graph Clustering• Find groups of nodes in undirected, weighted graphs• Hierarchical Clustering vs. Flat Partitioning
3 3 3
3 4 4 3

12
? Desired outcomes ?
• Colors symbolise partitions
3 3 3
3 4 4 3

13
Chinese Whispers Algorithm
• Nodes have a class and communicate it to their adjacent nodes
• A node adopts one of the the majority class in its neighbourhood
• Nodes are processed in random order for some iterations
Algorithm:
initialize:forall vi in V: class(vi)=i;
while changes:
forall v in V, randomized order:
class(v)=highest ranked class in neighborhood of v;
AL1
DL2
EL3
BL4
CL3
58
63
deg=1deg=2
deg=3deg=5
deg=4

14
Properties of CWPRO:• Efficiency: CW is time-linear in the number of edges. This is bound by
n² with n= number of nodes, but in real world data, graphs are much sparser
• Parameter-free: this includes number of clusters
CON:• Non-deterministic: due to random order processing and possible ties
w.r.t. the majority.• Does not converge: See tie example:• Formally hard to analyse
However, the CONs are not severe for real world data...

15
Application: Language Separation
• Cluster the co-occurrence graph of a multilingual corpus
• Use words of the same class in a language identifier as lexicon
• Almost perfect performance
Precision, Recall and F-value for 7-lingual corpora
0,96
0,97
0,98
0,99
1
100 1000 10000 100000
# of sentences per language
P/R
/F
Precision Recall F-value

16
“Look at my nice languages!” Cleaning CUCWeb
Latin:In expeditionibus tessellata et sectilia pauimenta circumferebat.Britanniam petiuit spe margaritarum: earum amplitudinem conferebat et interdum sua manu
exigebat ..
Scripting:@echo @cd $(TLSFDIR);$(CC) $(RTLFLAGS) $(RTL_LWIPFLAGS) -c $(TLSFSRC) …@echo @cd $(TOOLSDIR);$(CC) $(RTLFLAGS) $(RTL_LWIPFLAGS) -c $(TOOLSSRC) ..
Hungarian:A külügyminiszter a diplomáciai és konzuli képviseletek címjegyzékét és konzuli …Köztestületek, jogi személyiséggel és helyi jogalkotási jogkörrel.
Esperanto:Por vidi ghin kun internacia kodigho kaj kun kelkaj bildoj kliku tie chi ) La Hispana.. Ne nur pro tio, ke ghi perdigis la vivon de kelk-centmil hispanoj, sed ankau pro ghia efiko..
Human Genome:1 atgacgatga gtacaaacaa ctgcgagagc atgacctcgt acttcaccaa ctcgtacatg 61 ggggcggaca
tgcatcatgg gcactacccg ggcaacgggg tcaccgacct ggacgcccag 121 cagatgcacc …
Isoko (Nigeria):(1) Ko Ileleikristi a re rowo ino Oghene yo Esanerovo?(5) Ko Jesu o whu evao uruwhere?

17
Unsupervised POS taggingGiven:
Unstructured monolingual text corpus
Goal: Induction of POS tags for all words.
Motivation: • POS information is a processing step in a variety of NLP
applications such as parsing, IE, indexing• POS taggers need a considerable amount of hand-tagged
training data which is expensive and only available for major languages
• Even for major languages, POS taggers are suited for well-formed texts and do not cope well with domain-dependent issues as being found e.g. in email or spoken corpora

18
Steps in unsupervised POS tagging... , sagte der Sprecher bei der Sitzung .... , rief der Vorsitzende in der Sitzung .
... , warf in die Tasche aus der Ecke .
17
C1: sagte, warf, riefC2: Sprecher, Vorsitzende, TascheC3: inC4: der, die
... , sagte|C1 der|C4 Sprecher|C2 bei der|C4 Sitzung .... , rief|C1 der|C4 Vorsitzende|C2 in|C3 der|C4 Sitzung .
... , warf|C1 in|C3 die|C4 Tasche|C2 aus der|C4 Ecke .
)24,|3( CCwordCP
... , sagte|C1 der|C4 Sprecher|C2 bei|C3 der|C4 Sitzung|C2 .... , rief|C1 der|C4 Vorsitzende|C2 in|C3 der|C4 Sitzung|C2 .
... , warf|C1 in|C3 die|C4 Tasche|C2 aus|C3 der|C4 Ecke|C2 .
Unlabelled Text
Distributional Vectors NB-cooccurrences
high frequency words medium frequency words
Graph 1 Graph 2
Partitio
nin
g1
Maxtag Lexicon
Partially Labelled Text
Fully Labelled Text
Trigram Viterbi Tagger
Chinese Whispers Graph Clustering
Partitio
nin
g2

19
Partitioning 1 Example• Collect global contexts
for top 10K words
• Cosine between vectors = similarity- matrix not sparse!
• Construct graph, cluster with Chinese Whispers– no predefined number of
clusters– efficient– parameter: threshold on sim.
Value– excludes singletons
... _KOM_ sagte der Sprecher bei der Sitzung _ESENT_
... _KOM_ rief der Vorsitzende in der Sitzung _ESENT_
... _KOM_ warf in die Tasche aus der Ecke _ESENT_Features: der(1), die(2), bei(3), in(4), _ESENT_(5), _KOM_(6)
Word
1 2 3 4 5 6 1 2 3 4 5 6 1 2 3 4 5 6 1 2 3 4 5 6
sagte
1 1
rief
1 1
warf
1 1 1
Sprecher
1 1 1
Vorsitzende
1 1 1
Tasche
1 1 1
-2 -1 +1 +2
Cos(x,y) sagte rief warf Sprecher Vorsitzende Tasche
sagte 1
rief 1 1
warf 0.408 0.408 1
Sprecher 0 0 0 1
Vorsitzende 0 0 0.333 0.666 1
Tasche 0 0 0 0.408 0.333 1

20
Partitioning 2 Example• Clustering more than 10K words based on context vectors
is not viable (time-quadratic). Vectors tend to get sparser for lower frequency words
• Use neigbouring cooccurrences to compute similarity between medium- and low frequency words (without top 2000):
• Clustering with CW: Medium and low frequency words are arranged in POS-motivated clusters

21
unsuPOS: Ambiguity Example
Word cluster ID cluster members (size)
I 166 I (1)
saw 2 past tense verbs (3818)
the 73 a, an, the (3)
man 1 nouns (17418)
with 13 prepositions (143)
a 73 a, an, the (3)
saw 1 nouns (17418)
. 116 . ! ? (3)

22
unsuPOS: Medline tagset1 (13721) recombinogenic, chemoprophylaxis, stereoscopic, MMP2, NIPPV, Lp, biosensor, bradykinin, issue, S-100beta,
iopromide, expenditures, dwelling, emissions, implementation, detoxification, amperometric, appliance, rotation, diagonal, 2(1687) self-reporting, hematology, age-adjusted, perioperative, gynaecology, antitrust, instructional, beta-thalassemia, interrater,
postoperatively, verbal, up-to-date, multicultural, nonsurgical, vowel, narcissistic, offender, interrelated, 3(1383) proven, supplied, engineered, distinguished, constrained, omitted, counted, declared, reanalysed, coexpressed, wait, 4(957) mediates, relieves, longest, favor, address, complicate, substituting, ensures, advise, share, employ, separating, allowing, 5(1207) peritubular, maxillary, lumbar, abductor, gray, rhabdoid, tympanic, malar, adrenal, low-pressure, mediastinal, 6(653) trophoblasts, paws, perfusions, cerebrum, pons, somites, supernatant, Kingdom, extra-embryonic, Britain, endocardium, 7(1282) acyl-CoAs, conformations, isoenzymes, STSs, autacoids, surfaces, crystallins, sweeteners, TREs, biocides, pyrethroids, 8(1613) colds, apnea, aspergilloma, ACS, breathlessness, perforations, hemangiomas, lesions, psychoses, coinfection, terminals,
headache, hepatolithiasis, hypercholesterolemia, leiomyosarcomas, hypercoagulability, xerostomia, granulomata, pericarditis, 9(674) dysregulated, nearest, longest, satisfying, unplanned, unrealistic, fair, appreciable, separable, enigmatic, striking, i10(509) differentiative, ARV, pleiotropic, endothermic, tolerogenic, teratogenic, oxidizing, intraovarian, anaesthetic, laxative, 13(177) ewe, nymphs, dams, fetuses, marmosets, bats, triplets, camels, SHR, husband, siblings, seedlings, ponies, foxes,
neighbor, sisters, mosquitoes, hamsters, hypertensives, neonates, proband, anthers, brother, broilers, woman, eggs, 14(103) considers, comprises, secretes, possesses, sees, undergoes, outlines, reviews, span, uncovered, defines, shares, s15(87) feline, chimpanzee, pigeon, quail, guinea-pig, chicken, grower, mammal, toad, simian, rat, human-derived, piglet, ovum, 16(589) dually, rarely, spectrally, circumferentially, satisfactorily, dramatically, chronically, therapeutically, beneficially, already, 18(124) 1-min, two-week, 4-min, 8-week, 6-hour, 2-day, 3-minute, 20-year, 15-minute, 5-h, 24-h, 8-h, ten-year, overnight, 120-21(12) July, January, May, February, December, October, April, September, June, August, March, November23(13) acetic, retinoic, uric, oleic, arachidonic, nucleic, sialic, linoleic, lactic, glutamic, fatty, ascorbic, folic25(28) route, angle, phase, rim, state, region, arm, site, branch, dimension, configuration, area, Clinic, zone, atom, isoform, 247(6) P<0.001, P<0.01, p<0.001, p<0.01, P<.001, P<0.0001391(119) alcohol, ethanol, heparin, cocaine, morphine, cisplatin, dexamethasone, estradiol, melatonin, nicotine, fibronectin,

23
Task-based unsuPOS evaluationUnsuPOS tags are used as features, performance is
compared to no POS and supervised POS. Tagger was induced in one-CPU-day from BNC
• Kernel-based WSD: better than noPOS, equal to suPOS• POS-tagging: better than noPOS• Named Entity Recognition: no significant differences• Chunking: better than noPOS, worse than suPOS

24
Application: Word Sense Induction
• Co-occurrence graphs of ambiguous words can be partitioned: Leave out focus word
• Clusters contain context words for disambiguation

25
hip

26
hip

27
hip

28
hip

29
Future work
• Grammar induction: Use unsupervised POS labels and sequences for inducing tree-like structures
• Word Sense Induction and Disambiguation with hierarchical sense models, evaluation in SEMEVAL framework
• Structure Discovery Machine: putting many SD procedures together, including morphology induction, multiword expression identification, relation finding etc.
• Semisupervised SD: Framework for connecting SD processes to application-based settings

30
Summary• Structure Discovery Paradigm contrasted to
traditional approaches:– no manual annotation, no resources (cheaper)– language- and domain-independent– iteratively enriching structural information by finding and
annotating regularities
• Graph-based SD procedures– Chinese Whispers for Language Separation,
unsupervised POS tagging and Word Sense Induction

31
Questions?
THANKS FOR YOUR ATTENTION!

32
Emergent Language Generation Models
From SD to NLG• Structure Discovery allows us to process yet undescribed
languages• Generation models only capture certain aspects of real natural
language• SD processes can identify what is common and what is different
between generated and real language• Generation models can be improved according to meet the
criteria of SD processes
Understanding the emergence of natural language is a third way of approaching the understanding of natural language structure (besides classical linguistics and bottum-up NLP)
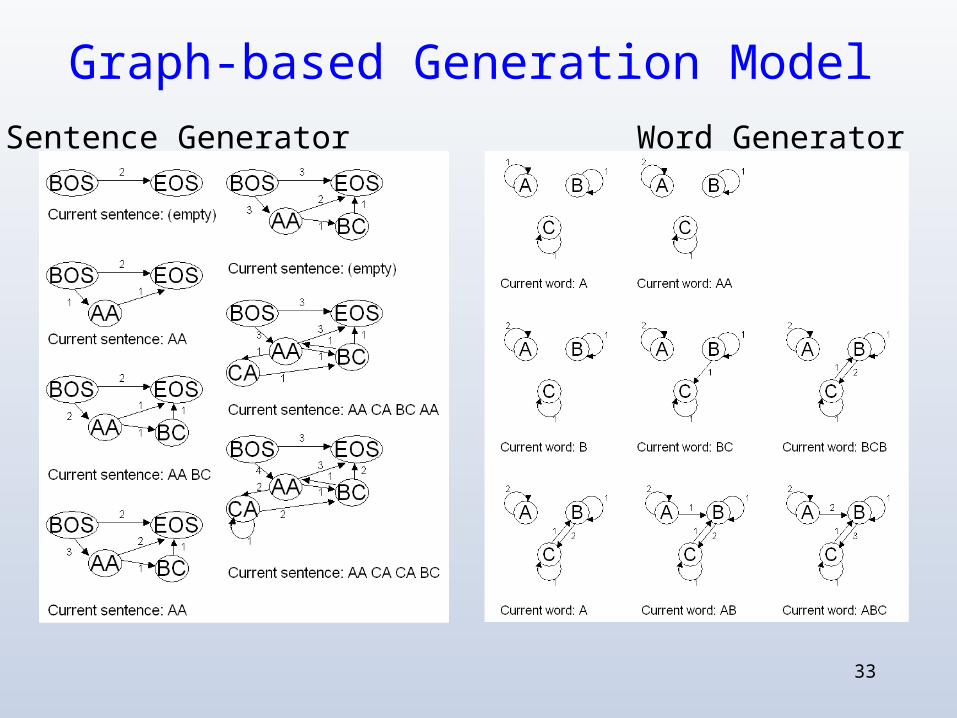
33
Graph-based Generation ModelWord GeneratorSentence Generator

34
Comparison: Generated and Real
1
10
100
1000
10000
1 10 100 1000 10000
fre
qu
en
cy
rank
rank-frequency
sentence generatorEnglish
power law z=1.5
1
10
100
1000
10000
100000
1 10
fre
qu
en
cy
length in letters
word length
sentence generatorEnglish
gamma distribution
1
10
100
1000
10000
1 10 100
num
ber
of s
ente
nces
length in words
sentence length
sentence generatorEnglish
0.001
0.01
0.1
1
10
100
1000
10000
1 10 100 1000
nr o
f ver
tices
degree interval
degree distribution
sentence generatorEnglish
word generatorpower law z=2

35
Computational Linguistics and Statistical NLP
CL:• Implementing linguistic theories with computers• Rule-based approaches• Rules found by introspection, not data-driven• Explicit knowledge• Goal: understanding language itself
Statistical NLP:• Building systems that perform language processing tasks• Machine Learning approaches• Models are built by training on annotated dataset• Implicit knowledge• Goal: Build robust systems with high performance
There is a continuum rather than a sharp cutting edge

36
Building Blocks in SD
Hierarchical levels of basic units in text data:• Letters• Words• Sentences• DocumentsThese are assumed to be recognizable in the remainder.
SD allows for • arbitrary numbers of intermediate levels • grouping of basic into complex units, but these have to be found by SD procedures.

37
Similarity and Homogeneity
For determining which units share structure, a similarity measure for units is needed. Two kinds of features are possible:
• Internal features: compare units based on the lower level units they contain
• Context features: compare units based on other units of same or other level that surround them
A clustering based on unit similarity yields sets of units that are homogeneous w.r.t. structure
This is an abstraction process: Units are subsumed under the same label.





























