Embed Size (px)
Citation preview

111
From Big Data to Little Knowledge
Electrical and Computer Engineering
Vladimir Cherkassky University of Minnesota
[email protected] at CodeFreeze, Jan 16, 2014

222
Motivation: What is Big Data?• Traditional IT infrastructure
Data storage, access, connectivity etc.
• Making sense / acting on this dataData Knowledge Decision makingalways predictive by nature
• Objectives of my talk- Hype vs. Reality- Methodological aspects of data-analytic knowledge discovery

333
Scientific Discovery• Combines ideas/models and facts/data• First-principle knowledge:
hypothesis experiment theory ~ deterministic, causal, intelligible models
• Modern data-driven discovery:
s/w program + DATA knowledge~ statistical, complex systems
• Two different philosophies

444
History of Scientific Knowledge• Ancient Greece:
Logic+deductive_reasoning• Middle Ages: Deductive (scholacticism)• Renaissance, Enlightment:
(1) First-Principles (Laws of Nature)
(2) Experimental science (empirical data)
Combining (1) + (2) problem of induction• Digital Age: the problem of induction attains
practical importance in many fields
5
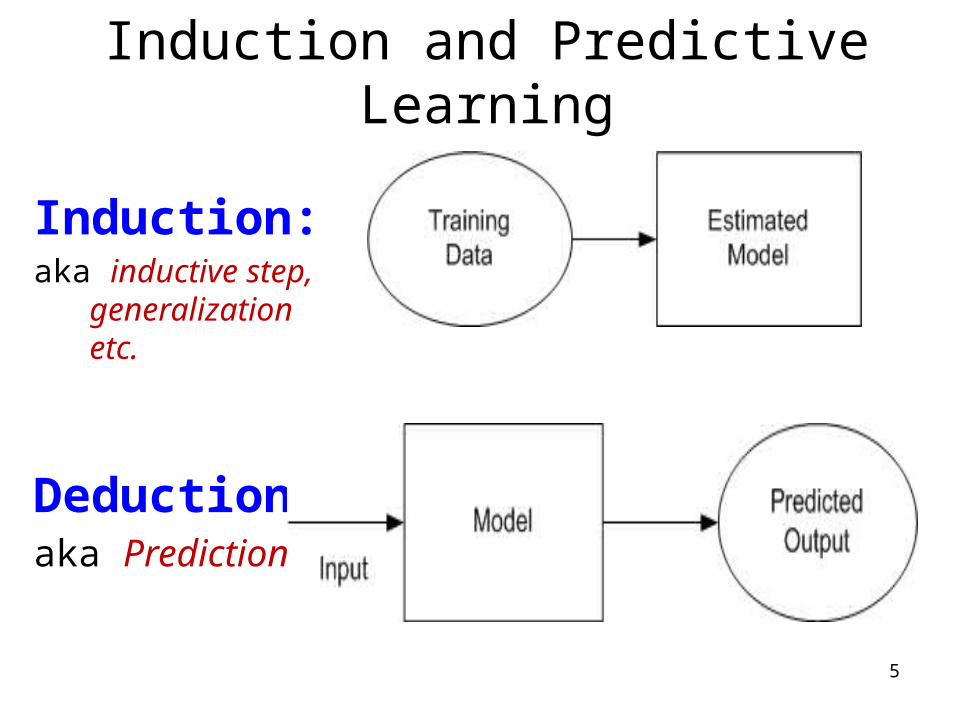
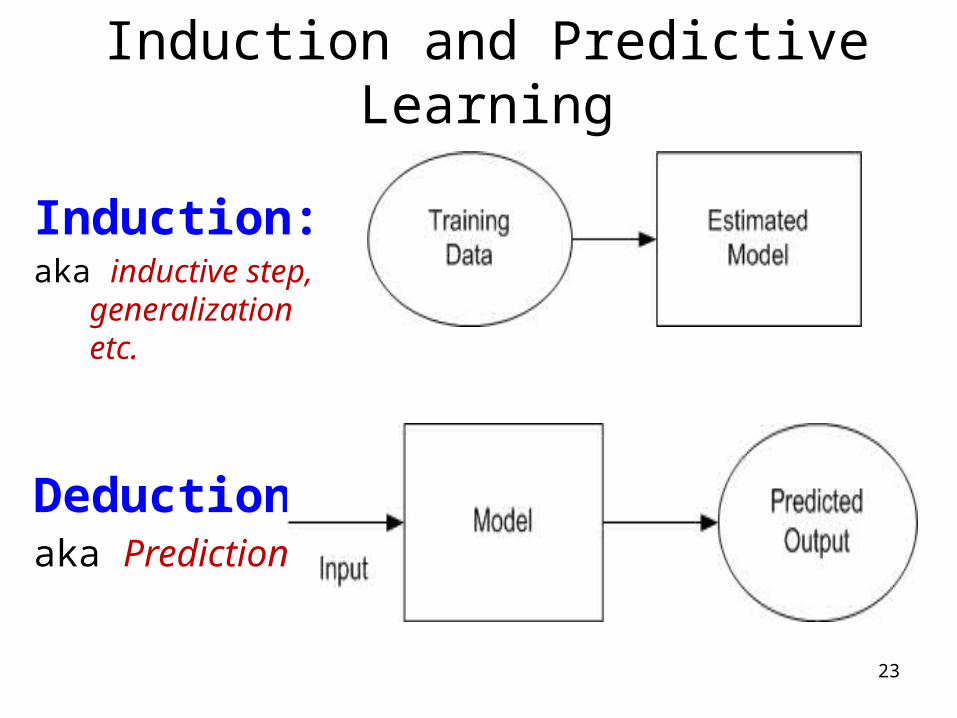
Induction and Predictive Learning
Induction:
aka inductive step, generalization etc.
Deduction:aka Prediction

666
Problem of Induction in Philosophy• Francis Bacon: advocated empirical
knowledge (inductive) vs scholastic• David Hume: What right do we have to
assume that the future will be like the past?• Philosophy of Science tries to resolve this
dilemma/contradiction between deterministic logic and uncertain nature of empirical data.
• Digital Age: growth of empirical data, and this dilemma becomes important in practice.

7
Cultural and Psychological Aspects• All men by nature desire knowledge• Man has an intense desire for assured
knowledge• Assured Knowledge ~ belief in
- religion (much of human history)
- reason (causal determinism)
- science / pseudoscience
- data-analytic models (~ Big Data)
- genetic risk factors …

888
Gods, Prophets and Shamans

999
Uncertainty and Risk in Science• Math, Logic and Science are about
certainty ~ deterministic rules• Probability and empirical data: involves
uncertainty ~ inferior knowledge
Causal Determinism dominates modern science• True Scientific knowledge consists of
deterministic Laws of Nature• There is a single (true, causal) model that
explains natural phenomenon

10
Knowledge Discovery in Digital Age• Most information in the form of digital data• Can we get assured knowledge from data?• Big Data ~ technological nirvana
data + connectivity more knowledge
Wired Magazine, 16/07: We can stop looking for (scientific) models. We can analyze the data without hypotheses about what it might show. We can throw the numbers into the biggest computing clusters the world has ever seen and let statistical algorithms find patterns where science cannot.

111111
REALITY• Many studies have questionable value
- statistical correlation vs causation • Some border nonsense
- US scientists at SUNY discovered Adultery Gene !!! (based on a sample of 181 volunteers interviewed about their sex life)
• Economic forecasting, i.e. ‘predicting’-unemployment rate, monthly job gain/loss...

121212
More examples …• Duke biologists discovered an unusual link btwn
the popular singer and a new species of fern, i.e.- bisexual reproductive stage of the ferns;- the team found the sequence GAGA when analyzing the fern’s DNA base pairs

13
Real Data Mining: Kepler’s Laws• How planets move among the stars?
- Ptolemaic system (geocentric)- Copernican system (heliocentric)
• Tycho Brahe (16 century)- measured positions of the planets in the sky- use experimental data to support one’s view (hypothesis)
• Johannes Kepler- used volumes of Tycho’s data to discover three remarkably simple laws
14
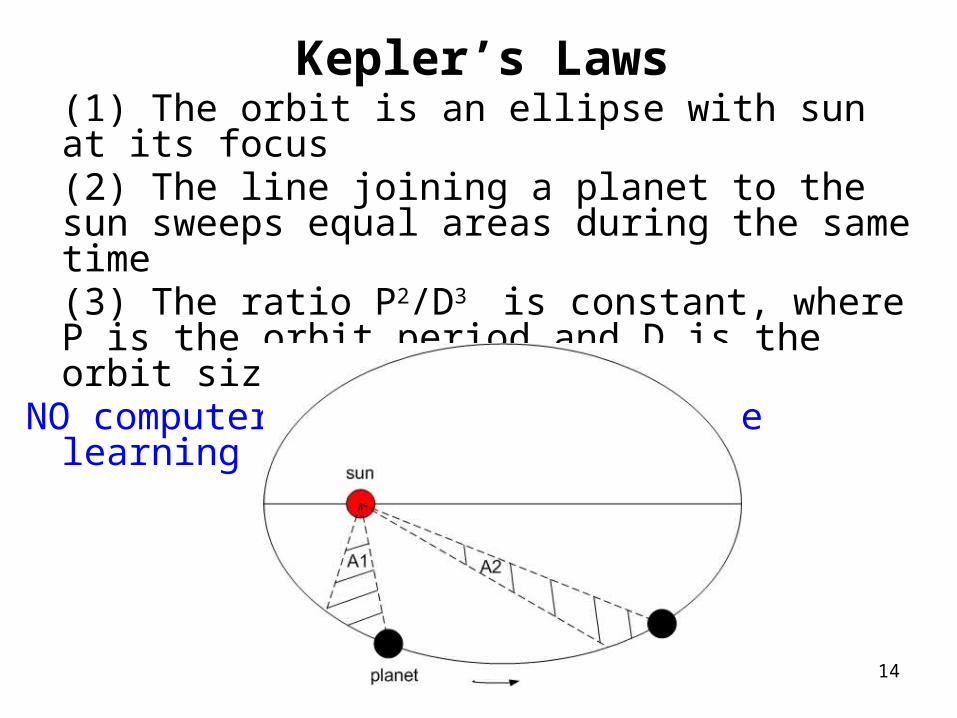
Kepler’s Laws(1) The orbit is an ellipse with sun at its focus(2) The line joining a planet to the sun sweeps equal areas during the same time(3) The ratio P2/D3 is constant, where P is the orbit period and D is the orbit size.
NO computers, statistics, machine learning or Big Data

151515
Kepler’s Laws vs. ‘Lady Gaga’ knowledge• Both search for assured knowledge• Kepler’s Laws
- well-defined hypothesis stated a priori- prediction capability- human intelligence
• Lady Gaga knowledge- no hypothesis stated a priori- no prediction capability- computer intelligence (software program)- popular appeal (to widest audience)

1616
Lessons from Natural Sciences• Prediction capability
Prediction is hard. Especially about the future.
• Empirical validation/repeatable events• Limitations (of scientific knowledge)• Important to ask the right question
-Science starts from problems, and not from observations (K. Popper)
-What we observe is not nature itself, but nature exposed to our method of questioning (W.Heisenberg)

1717
Limitations of Scientific MethodWhen the number of factors coming into play in a phenomenological complex is too large, scientific method in most cases fails us.
We are going to be shifting the mix of our tools as we try to land the ship in a smooth way onto the aircraft carrier.
Recall: the Ancient Greeks scorned ‘predictability’

1818
Important DifferencesAlbert Einstein: • It might appear that there are no methodological
differences between astronomy and economics: scientists in both fields attempt to discover general laws for a group of phenomena. But in reality such differences do exist.
• The discovery of general laws in economics is difficult because observed economic phenomena are often affected by many factors that are very hard to evaluate separately.
• The experience which has accumulated during the civilized period of human history has been largely influenced by causes which are not economic in nature.
191919
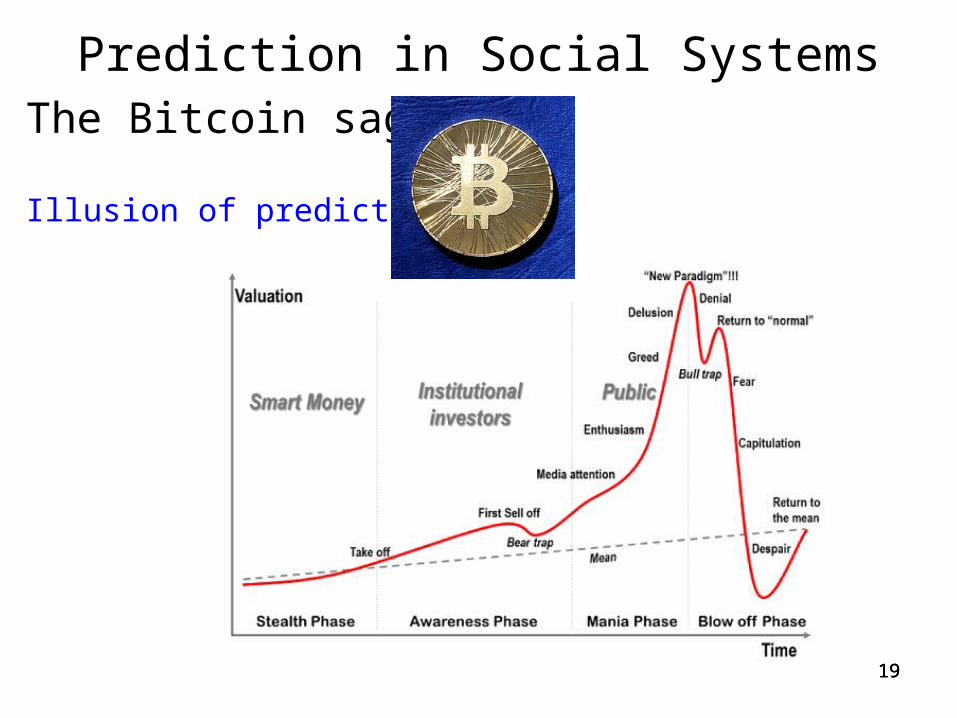
Prediction in Social SystemsThe Bitcoin saga
Illusion of predictability:

202020
Methodological Aspects ofData-Driven Knowledge Discovery
• Empirical Knowledge vs. First-Principles
• Method of Questioning:- Two Data-Analytic Methodologies- Statistical Modeling Assumptions
• Example: Market Timing of Mutual Funds
• Interpretation of Predictive Models
212121
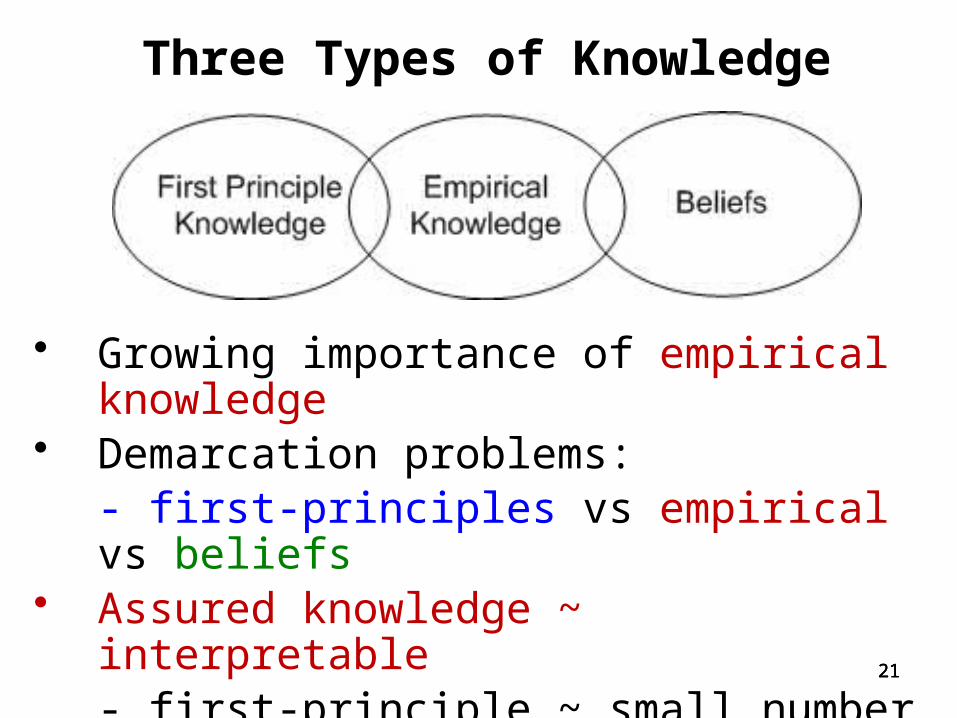
Three Types of Knowledge
• Growing importance of empirical knowledge• Demarcation problems:
- first-principles vs empirical vs beliefs• Assured knowledge ~ interpretable
- first-principle ~ small number of concepts- empirical knowledge ???

2222
Empirical Knowledge
These methodological/philosophical issues need to be properly addressed
• Can it be obtained from data alone? • How is it different from ‘beliefs’ ?• Role of a priori knowledge vs. data ?• What is ‘the method of questioning’ ?
23
Induction and Predictive Learning
Induction:
aka inductive step, generalization etc.
Deduction:aka Prediction

242424
Inductive Inference Step• Inductive inference step:
Data model ~ ‘uncertain inference’
• Is it possible to make uncertain inferences mathematically rigorous? (Fisher 1935)
• Many types of ‘uncertain inferences’- hypothesis testing- maximum likelihood- risk minimization ….
each comes with its own methodology/assumptions

252525
Two Data-Analytic Methodologies• Many existing data-analytic methods but
lack of methodological assumptions
• Two theoretical developments- classical statistics ~ mid 20-th century- Vapnik-Chervonenkis (VC) theory ~ 1970’s
• Two related technological advances- applied statistics (R. Fisher)- machine learning, neural nets, data mining etc.

26
Binary Classification ProblemGiven: training data (x,y) ~ i.i.d. samples from
unknown distribution P(x,y)
Estimate: a model or function f(x) that:
- explains this data
- can predict future data
Classification problem:
Learning ~ function estimation

27
Classical StatisticsGoal of data modeling /Asking the right question
- estimate unknown distribution P(x,y)• Classical statistics approach (R. Fisher)
- specify a parametric model for P(x,y)
- estimate its parameters from training data
Observed_Data ~ Model + Noise
more data better (more accurate) model• Assumed parametric form of P(x,y) is based
on first-principle knowledge, so it is true.

282828
Critique of Statistical Approach (Leo Breiman)
• The Belief that a statistician can invent a reasonably good parametric class of models for a complex mechanism devised by nature
• Then parameters are estimated and conclusions are drawn
• But conclusions are about - the model’s mechanism- not about nature’s mechanism
• Many modern data-analytic sciences (economics, life sciences) have similar flaws

292929
Risk Minimization ApproachGoal of data modeling /Asking the right question
~estimate a model that will predict well• Predictive Approach:
estimate only properties of P(x, y) that are useful for predicting y
Note: no need to estimate P(x, y)
• Requires specification of:- a set of possible models f(x,w)- loss function to measure prediction performance- proper formalization of the learning problem

303030
Standard Modeling Assumptions• Future is similar to Past
- training and test data from the same distribution- i.i.d. training data- large test set
• Prediction accuracy ~ given loss function- misclassification costs (classification problems)- squared loss (regression problems) - etc.
• Proper formalization (for an application)e.g., classification is used in many applications

313131
Predictive Methodology (VC-theory)
• Method of questioning is- the learning problem setting(inductive step)- driven by application requirements
• Standard inductive learning commonly used (may not be the best choice)
• Good generalization depends on two factors- (small) training error- small VC-dimension ~ large ‘falsifiability’

323232
Timing of International Funds• International mutual funds
- priced at 4 pm EST (New York time)
- reflect price of foreign securities traded at European/ Asian markets
- Foreign markets close earlier than US market Possibility of inefficient pricing.
Market timing exploits this inefficiency.• Scandals in the mutual fund industry ~2002• Solution adopted: restrictions on trading
333333
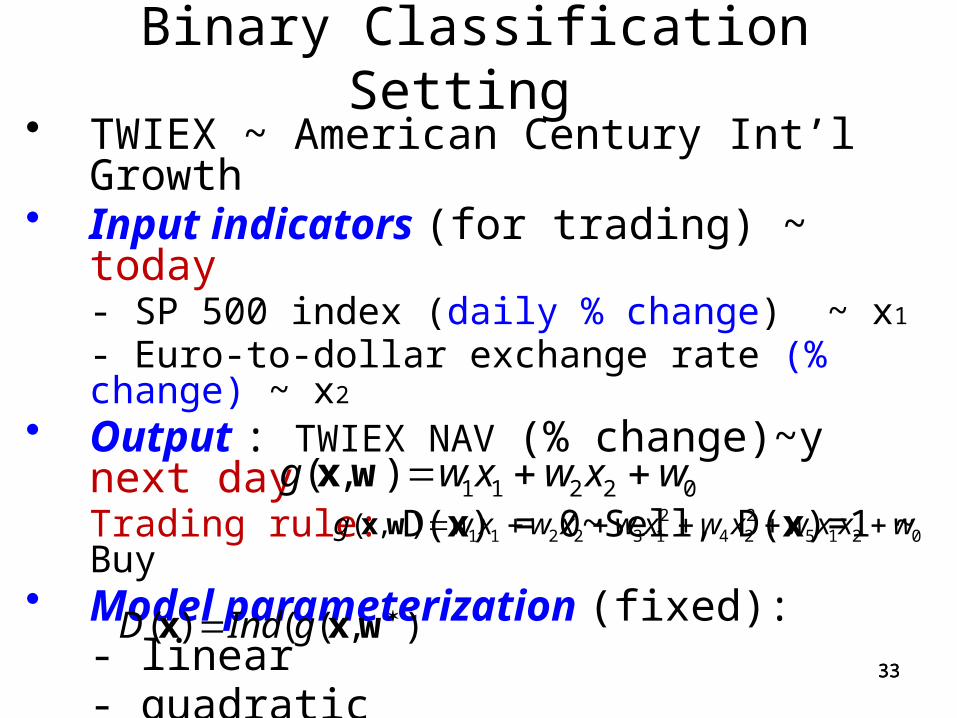
Binary Classification Setting • TWIEX ~ American Century Int’l Growth• Input indicators (for trading) ~ today
- SP 500 index (daily % change) ~ x1
- Euro-to-dollar exchange rate (% change) ~ x2
• Output : TWIEX NAV (% change)~y next dayTrading rule: D(x) = 0~Sell, D(x)=1 ~ Buy
• Model parameterization (fixed):- linear- quadratic
• Decision rule (estimated from training data): Buy /Sell decision (+1 /
0)
1 1 2 2 0( , )g w x w x w x w2 2
1 1 2 2 3 1 4 2 5 1 2 0( , )g w x w x w x w x w x x w x w
)),(()( wxx gIndD

343434
Methodological Assumptions• When a trained model can predict well?(1) Future/test data is similar to training data
i.e., use 2004 period for training, and 2005 for testing
(2) Estimated model is ‘simple’ and provides good performance during training period
i.e., the trading strategy is consistently better than buy-and-hold during training period
• Loss function (to measure performance):
whereyDyL )(),( xx )),(()( wxx gIndD
353535
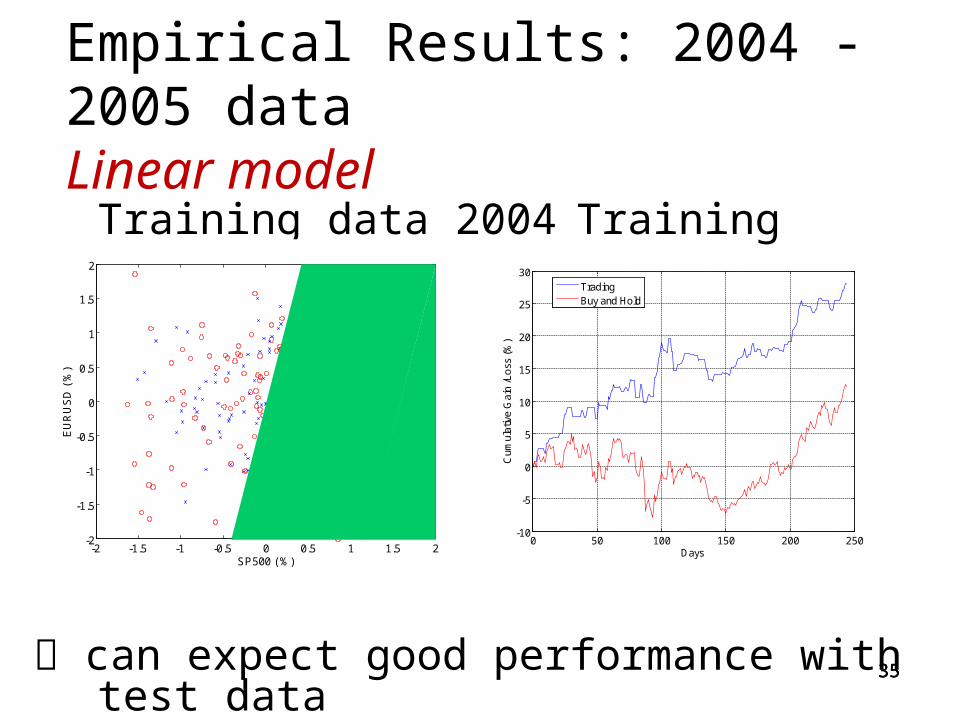
Empirical Results: 2004 -2005 data Linear model
Training data 2004 Training period 2004
can expect good performance with test data
0 50 100 150 200 250-10
-5
0
5
10
15
20
25
30
Days
Cu
mu
lativ
e G
ain
/Lo
ss (
%)
TradingBuy and Hold
-2 -1.5 -1 -0.5 0 0.5 1 1.5 2-2
-1.5
-1
-0.5
0
0.5
1
1.5
2
SP500 ( %)
EU
RU
SD
( %
)
363636
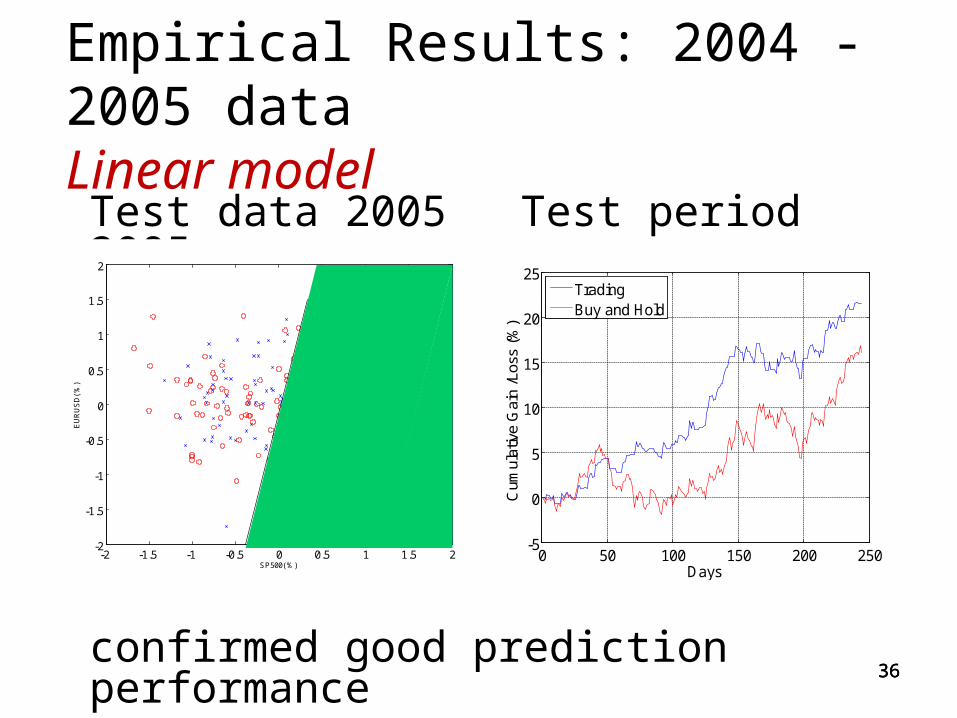
Empirical Results: 2004 -2005 data Linear model
Test data 2005 Test period 2005
confirmed good prediction performance
0 50 100 150 200 250-5
0
5
10
15
20
25
Days
Cum
ulat
ive
Gai
n /L
oss
(%)
TradingBuy and Hold
-2 -1.5 -1 -0.5 0 0.5 1 1.5 2-2
-1.5
-1
-0.5
0
0.5
1
1.5
2
SP500( %)
EU
RU
SD
( %
)
373737
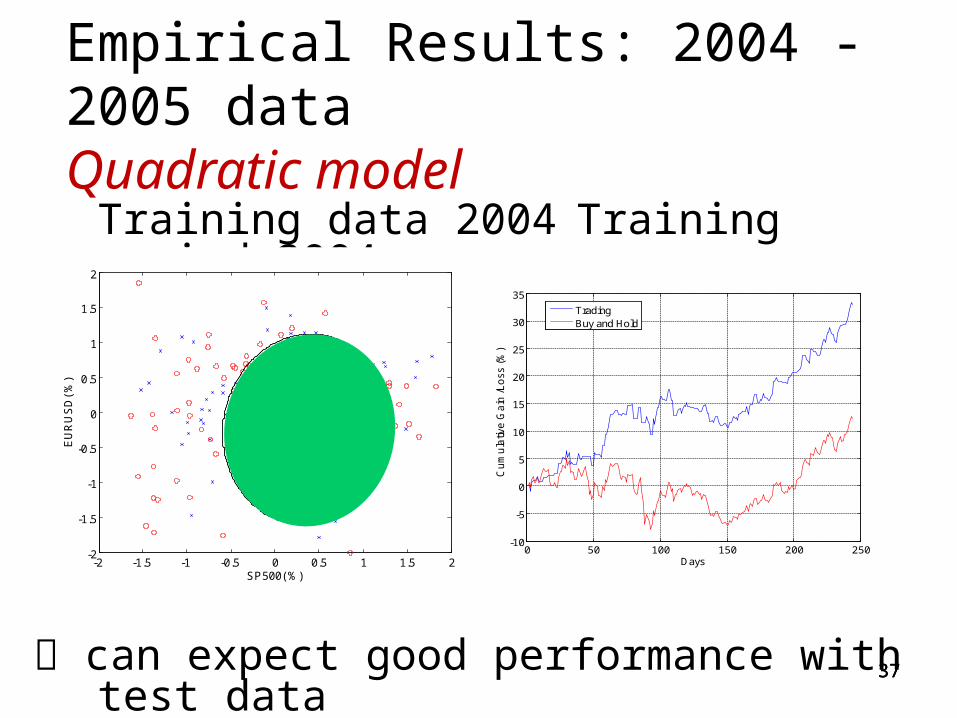
Empirical Results: 2004 -2005 data Quadratic model
Training data 2004 Training period 2004
can expect good performance with test data
-2 -1.5 -1 -0.5 0 0.5 1 1.5 2-2
-1.5
-1
-0.5
0
0.5
1
1.5
2
SP500( %)
EU
RU
SD
( %
)
0 50 100 150 200 250-10
-5
0
5
10
15
20
25
30
35
Days
Cu
mu
lativ
e G
ain
/L
oss (
%)
TradingBuy and Hold
383838
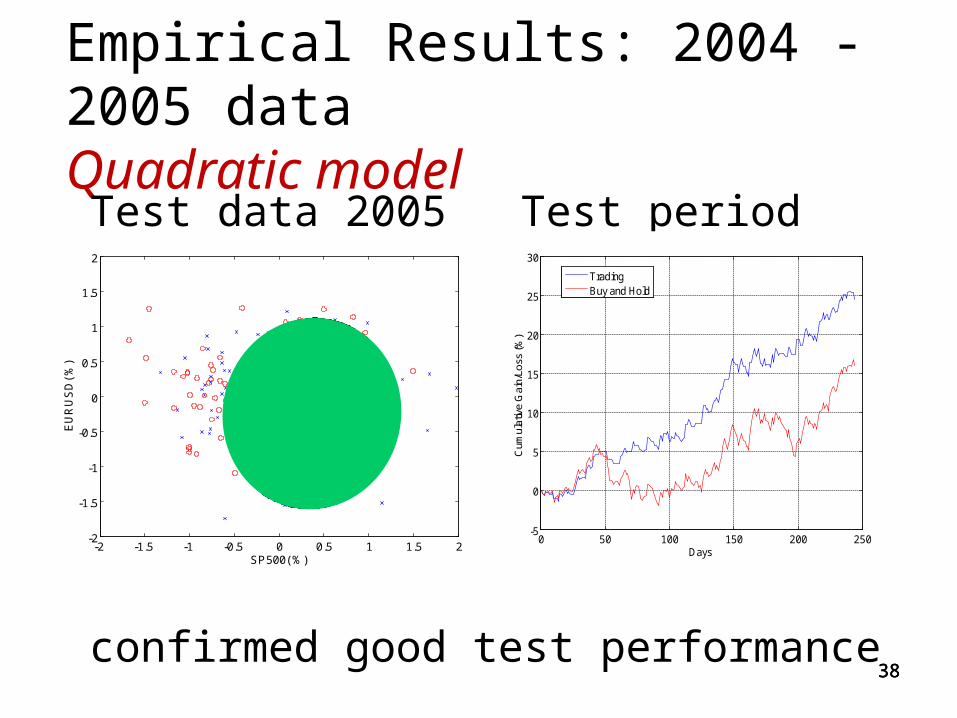
Empirical Results: 2004 -2005 data Quadratic model
Test data 2005 Test period 2005
confirmed good test performance
-2 -1.5 -1 -0.5 0 0.5 1 1.5 2-2
-1.5
-1
-0.5
0
0.5
1
1.5
2
SP500( %)
EU
RU
SD
( %
)
0 50 100 150 200 250-5
0
5
10
15
20
25
30
Days
Cum
ulat
ive
Gai
n/Lo
ss (%
)
TradingBuy and Hold
393939
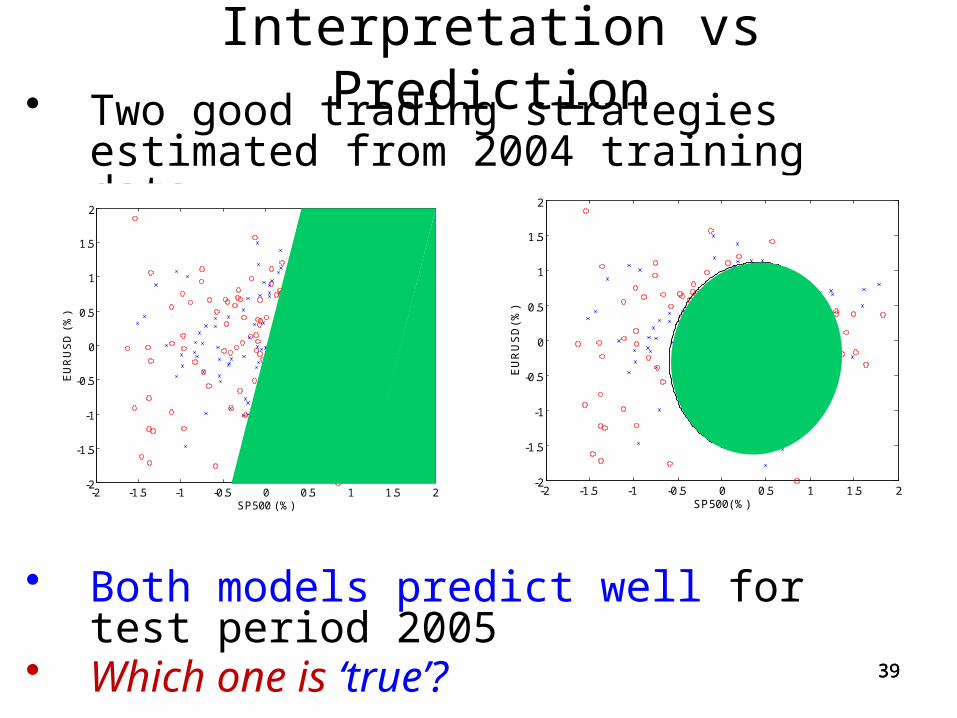
Interpretation vs Prediction• Two good trading strategies estimated from
2004 training data
• Both models predict well for test period 2005• Which one is ‘true’?
-2 -1.5 -1 -0.5 0 0.5 1 1.5 2-2
-1.5
-1
-0.5
0
0.5
1
1.5
2
SP500 ( %)
EU
RU
SD
( %
)
-2 -1.5 -1 -0.5 0 0.5 1 1.5 2-2
-1.5
-1
-0.5
0
0.5
1
1.5
2
SP500( %)E
UR
US
D(
%)

404040
DISCUSSION• Can this trading strategy be used now ?
- NO, this market timing strategy becomes ineffective since ~ year 2008. The reason is changing statistical characteristics of the market- YES, it can be used occasionally.
• Hypocrisy of the mutual fund industry Story 1: markets are very efficient, so individual investors cannot trade successfully and outperform the market indices (such as SP500) Story 2: market timing is harmful for mutual funds, so such abusive trading activity should be bannedStory 3: restrictions also apply to domestic funds
414141
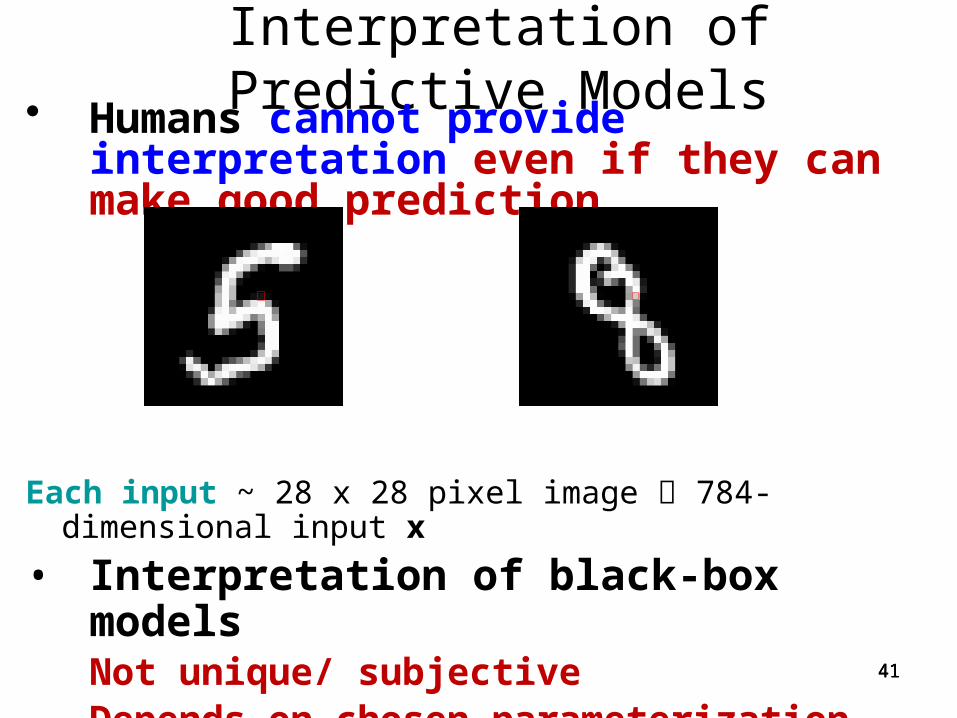
Interpretation of Predictive Models• Humans cannot provide interpretation
even if they can make good prediction
Each input ~ 28 x 28 pixel image 784-dimensional input x
• Interpretation of black-box modelsNot unique/ subjective Depends on chosen parameterization (method)
424242
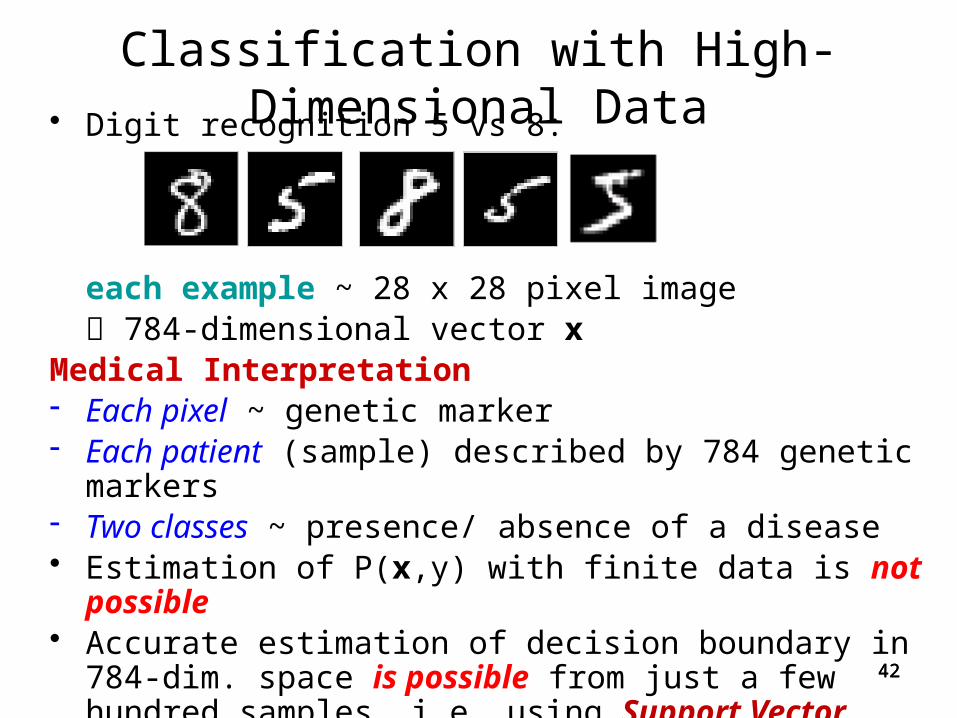
Classification with High-Dimensional Data• Digit recognition 5 vs 8:
each example ~ 28 x 28 pixel image 784-dimensional vector x
Medical Interpretation- Each pixel ~ genetic marker- Each patient (sample) described by 784 genetic markers - Two classes ~ presence/ absence of a disease• Estimation of P(x,y) with finite data is not possible• Accurate estimation of decision boundary in 784-dim.
space is possible from just a few hundred samples, i.e. using Support Vector Machine (SVM) classifiers

434343
Interpretation of SVM models
How to interpret high-dimensional models?(say, SVM model)
Strategy 1: dimensionality reduction/feature selection prediction accuracy usually suffers
Strategy 2: approximate SVM model via a set of rules (using rule induction, decision tree etc.)
does not scale well for high-dim. models

444444
Dimensionality Reduction(1) Reduce dimensionality (small # features)
(a) 10 top ranked pixels using Fisher’s criterion(b) extract 3 principal components (via PCA)
(2) Estimate RBF SVM model
Generalization performance degrades:
Method Test Error (%) Training Error (%)
SVM 1.08 0
FISHER+SVM 7.28 4.93
PCA+SVM 6.22 6.18

454545
Rule Induction (via ALBA method)
(1) Estimate SVM model using all 784 pixels(2) Interpret this SVM model via ALBA method
(Active Learning Based Algorithm: Martens et al 2009)
Generalization performance degrades:
METHODSRBF Polynomial (d=3)
SVM ALBA SVM ALBA
Training Error (%) 0 0 0 0
Test Error (%) 1.23 6.48 1.98 8.47

464646
SUMMARY (A)• Predictive Data-Analytic Modeling:
usually on the boundary btwn trivial and impossible
• Asking the right question ~ problem setting- depends on modeler’s creativity/ intelligence- requires application domain knowledge- cannot be formalized
• Modeling Assumptions (not just algorithm)
• Interpretation of black-box models- very difficult (requires domain knowledge) - multiplicity of ‘good’ models

474747
SUMMARY (B)• Common misconception:
data-driven models are intrinsically objective• Explanation bias (favors
simplicity+causality)psychological + cultural reasons
• Cognitive bias (favor only positive findings)• When all these human biases are
incorporated into data-analytic modeling:- many ‘interesting’ discoveries - little objective value- no real predictive value

484848
SUMMARY (C)• Predictive learning methodology is useful for
safeguarding against these biases• It clearly differentiates between
(1) The learning problem setting (~ creation of human mind, intelligent speculation - cannot be logically justified or derived from data) (2) The learning algorithm /software ~ particular implementation of (1)(3) Predictive data-analytic model~ estimated from data; provides the only objective evaluation of the original intelligent speculation (1). Model (3) makes sense only in the context of (1).

49
V. CherkasskyPredictive Learning, 2013
www.VCtextbook.com
Available on Amazon.com
This book presents a very good introduction to machine learning for undergraduate students and practitioners. It differs from other textbooks in its original coverage of the philosophical aspects of inference and their relationship to machine learning theory. This will allow readers to develop a better understanding of generalization problems and learning algorithms. - V. Vapnik, Columbia University

50
References• V. Vapnik, Estimation of Dependencies Based on Empirical
Data. Empirical Inference Science: Afterword of 2006 Springer
• L. Breiman, Statistical Modeling: the Two Cultures, Statistical Science, vol. 16(3), pp. 199-231, 2001
• A. Einstein, Ideas and Opinions, Bonanza Books, NY 1954
• V. Cherkassky and F. Mulier, Learning from Data, second edition, Wiley, 2007
• V. Cherkassky and S. Dhar, Market timing of international mutual funds: a decade after the scandal, Proc. CIFEr 2012



















![Организационные изменения, только хардкор [CodeFreeze 2013]](https://img.pdfslide.net/doc/110x75/557f0a35d8b42ac0728b4e15/-codefreeze-2013-55848d597b86c.jpg)




