Embed Size (px)
Citation preview

BBR 23303 -Asas Pengurusan Data
Nota ni kau edar2 kan ekk ngan yang lain.. Baca bab 1 baca dan faham tentang jenis-jenis data dan cuba buat carta2 palang, pai, histogram, poligon seperti contoh yang aku bagi tu... then bab 2 cuba buat contoh latihan tentang purata (min) untuk data berkelompok dan tidak berkelompok.... yang lain baca je....beri penekanan pada yang aku sebut tadi hehe.... Untuk PCK nanti aku send nota lagi ....
1
Asas Data
1.1 Jenis –jenis Data
Terdapat 2 jenis data yang perlu diketahui oleh pelajar. Data ini sering
digunakan dalam proses kajian dalam menentukan permasalahan atau mengenal pasti
sesuatu perkara. Data tersebut adalah :
1. Data Kualitatif
2. Data Kuantitatif
1.1.1 Data Kualitatif
Data kualitatif diperoleh melalui cerapan data kajian melalui pendekatan
kualitatif. Pendekatan kualitatif ialah prosedur penyelidikan yang menghasilkan data
gambaran yang boleh diamati (Lexy, 2007), tradisi tertentu dalam ilmu pengetahuan
sosial yang secara fundamental bergantung kepada pengamatan manusia dalam
kawasannya sendiri dan berkait dengan orang-orang tersebut dalam bahasa dan
peristilahannya (Kirk & Miller, 1986). Pendekatan kualitatif dalam penyelidikan ini
adalah kajian kes, adalah suatu penyelidikan yang dilakukan terhadap suatu kesatuan
sistem, sama ada yang berbentuk program mahupun kejadian yang terikat oleh tempat,
waktu atau ikatan tertentu (Nana, 2005).
Kajian kes dilaksanakan untuk menghimpun data, memperoleh makna, dan
memperoleh pemahaman daripada suatu kes. Proses pengumpulan data berdasarkan
Cresswell (1998) iaitu mengenalpasti tapak atau individu, mendapatkan akses dan
membina rekod, persampelan bertujuan, mengumpul data, merekod maklumat,
menyelesaikan isu-isu lapangan dan menyimpan data.
Data Kualitatif merupakan data bukan angka (nonnumerical data) dan tidak
boleh diukur melalui skala nombor. Nilai yang dinyatakan adalah melambangkan
kategori dan bukanya mewakili nilai angka sebenar.

BBR 23303 -Asas Pengurusan Data
Contoh data kualitatif adalah:-
Nominal
Data yang boleh dikategorikan, mempunyai nama atau label tertentu seperti
jantina, respon pelajar terhadap satu kajian: ya, tidak atau tidak pasti. Contoh :-
a. Saiz baju - 1-Small, 2-Medium, 3-Large.
b. Jantina - 1-Lelaki, 2-Perempuan
c. Jenama telefon - 1-Nokia, 2-Samsung, 3-Cokia, 4-Sony Erickson.
Ordinal
Data yang boleh disusun mengikut tertib tetapi perbezaan nilai data tidak dapat
ditafsirkan atau ditentukan. Sebagai contoh, pengetahuan komputer pelajar dikelaskan
kepada cemerlang, baik, sederhana atau lemah. Contoh:-
a. Pendapat - 1 - Sangat Setuju,
2 - Setuju,
3 - Kurang Setuju,
4 - Tidak setuju,
5 - Sangat Setuju.
b. Tahap kebersihan - 1 - Sangat Bersih,
2 - Bersih,
3 - Tidak Bersih,
4 - Sangat Tidak Bersih
Data di atas menunjukkan nilai yang tidak melambangkan sesuatu ukuran. Ia
hanya mewakili kepada sesuatu kategori seperti nilai 1 mewakili kepada pelajar lelaki
dan 2 pula mewakili pelajar perempuan. Tujuannya adalah memudahkan kelompokan
dan pentadbiran data.
1.1.2 Data Kuantitatif
Data kuantitatif diperoleh melalui cerapan data kajian melalui pendekatan
kuantitatif. Pendekatan kuantitatif ialah penyelidikan yang menekankan kepada
fenomena-fenomena objektif dan dikawal melalui pengumpulan dan analisis data
(Nana, 2005; Chua, 2006; Fraenkel, 2007). Suatu penyelidikan yang melibatkan
pengukuran pemboleh ubah kajian dengan menggunakan alatan saintifik dan
eksperimen. Penggunaan ujian statistik terhadap sesuatu kajian adalah sebagai usaha
untuk menerangkan, menjelaskan atau mencari perhubungan antara pemboleh ubah-
pemboleh ubah dalam suatu penyelidikan.

BBR 23303 -Asas Pengurusan Data
Data kuantitatif adalah merupakan data berbentuk bilangan atau ukuran
berangka (numerical data) dan boleh diukur serta wujud dalam skala nombor. Data
yang terhasil boleh dalam bentuk :-
Deskrit
Data Deskrit merupakan data dengan nilai yang tepat dan boleh nyatakan
dengan nombor yang negatif. Contoh :-
Bilangan anak dalam sesebuah keluarga – 5 orang.
Bilangan tandan kelapa sawit – 3 tandan.
Jumlah kelahiran bayi dalam tahun 2011 – 1200 orang
Selanjar.
Data selanjar pula mempunyai sukatan data berterusan dan boleh mengambil nilai-nilai
dalam satu selang. Contoh :-
Berat pelajar – 55 kg, atau boleh dinyatakan sebagai,
Berat pelajar adalah di antara 45 kg – 60 kg.
Tinggi Pelajar – 160 cm – 170 cm.
Halaju Kenderaan – 110 km/j – 120km/
2.1 Persembahan Data
Data akan lebih mudah difahami apabila ia dianalisis dan dipersembahkan
dengan baik dan berkesan. Salah satu kaedah persembahan data adalah dengan
menggunakan jadual, carta dan graf. Salah satu daripada mekanisma yang paling
berkesan di dalam mempersembahkan data di dalam bentuk yang bermakna untuk
pembuat keputusan ialah di dalam bentuk geraf. Melalui geraf dan carta, pembuat
keputusan biasanya memperolehi gambaran keseluruhan bagi data dan mencapai
beberapa rumusan yang amat berguna dengan hanya mengkaji carta atau geraf.
Menukarkan data kepada geraf merupakan aktiviti yang kreatif dan berseni. Salah satu
daripada penggunaan penting geraf di dalam statistik adalah untuk membantu
penyelidik menentukan bentuk taburan. Lima bentuk geraf yang akan dibincangkan
disini: (1) histogram, (2) poligon kekerapan, (3) orgif (4) carta pai dan (4) lakaran
batang dan daun.
BBR 23303 -Asas Pengurusan Data
Histogram
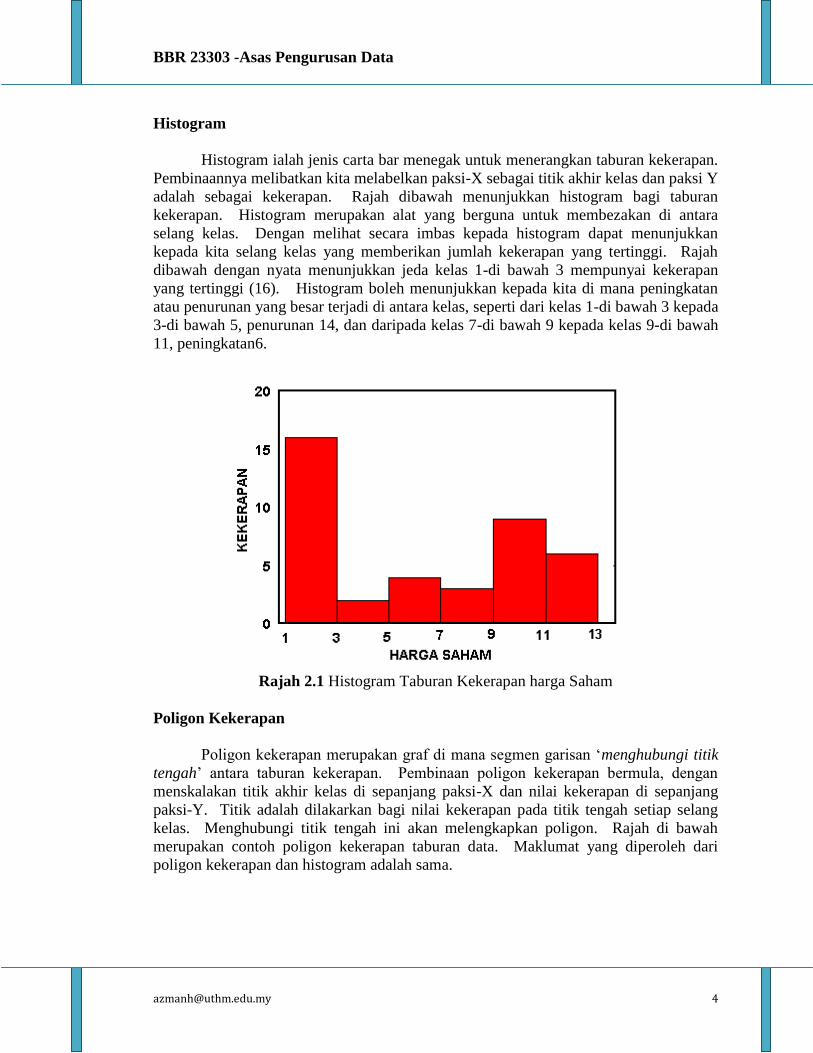
Histogram ialah jenis carta bar menegak untuk menerangkan taburan kekerapan.
Pembinaannya melibatkan kita melabelkan paksi-X sebagai titik akhir kelas dan paksi Y
adalah sebagai kekerapan. Rajah dibawah menunjukkan histogram bagi taburan
kekerapan. Histogram merupakan alat yang berguna untuk membezakan di antara
selang kelas. Dengan melihat secara imbas kepada histogram dapat menunjukkan
kepada kita selang kelas yang memberikan jumlah kekerapan yang tertinggi. Rajah
dibawah dengan nyata menunjukkan jeda kelas 1-di bawah 3 mempunyai kekerapan
yang tertinggi (16). Histogram boleh menunjukkan kepada kita di mana peningkatan
atau penurunan yang besar terjadi di antara kelas, seperti dari kelas 1-di bawah 3 kepada
3-di bawah 5, penurunan 14, dan daripada kelas 7-di bawah 9 kepada kelas 9-di bawah
11, peningkatan6.
Rajah 2.1 Histogram Taburan Kekerapan harga Saham
Poligon Kekerapan
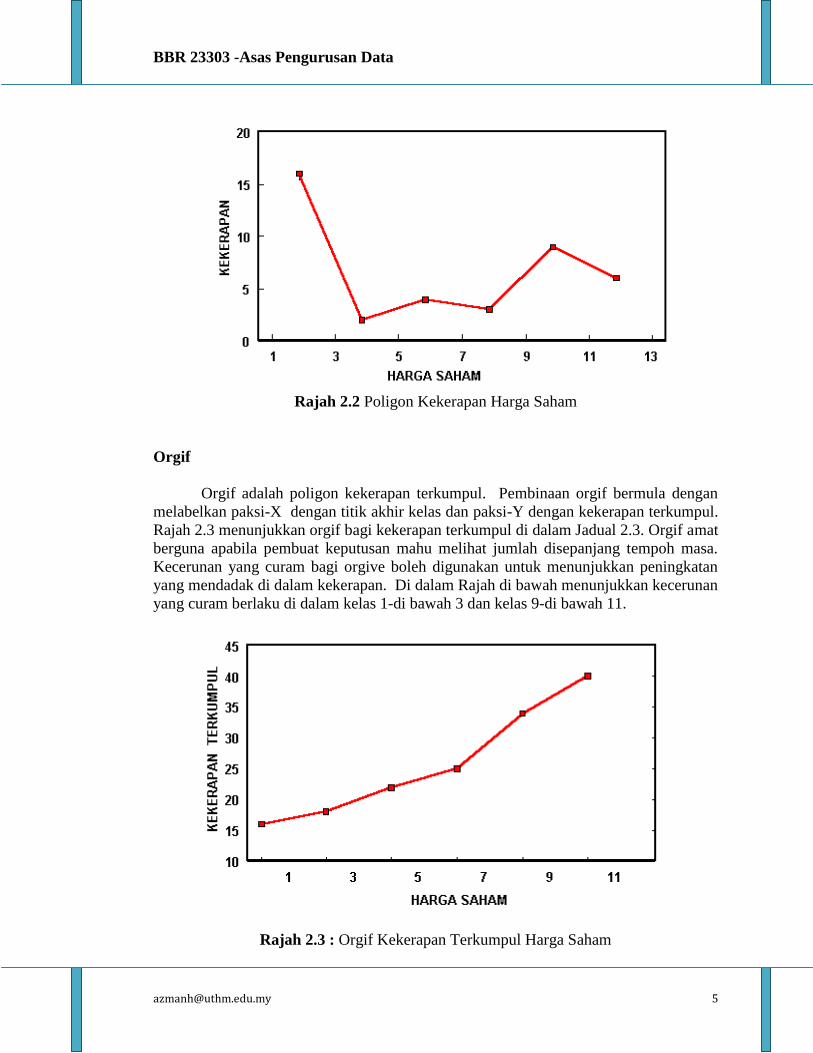
Poligon kekerapan merupakan graf di mana segmen garisan „menghubungi titik
tengah‟ antara taburan kekerapan. Pembinaan poligon kekerapan bermula, dengan
menskalakan titik akhir kelas di sepanjang paksi-X dan nilai kekerapan di sepanjang
paksi-Y. Titik adalah dilakarkan bagi nilai kekerapan pada titik tengah setiap selang
kelas. Menghubungi titik tengah ini akan melengkapkan poligon. Rajah di bawah
merupakan contoh poligon kekerapan taburan data. Maklumat yang diperoleh dari
poligon kekerapan dan histogram adalah sama.
BBR 23303 -Asas Pengurusan Data
Rajah 2.2 Poligon Kekerapan Harga Saham
Orgif
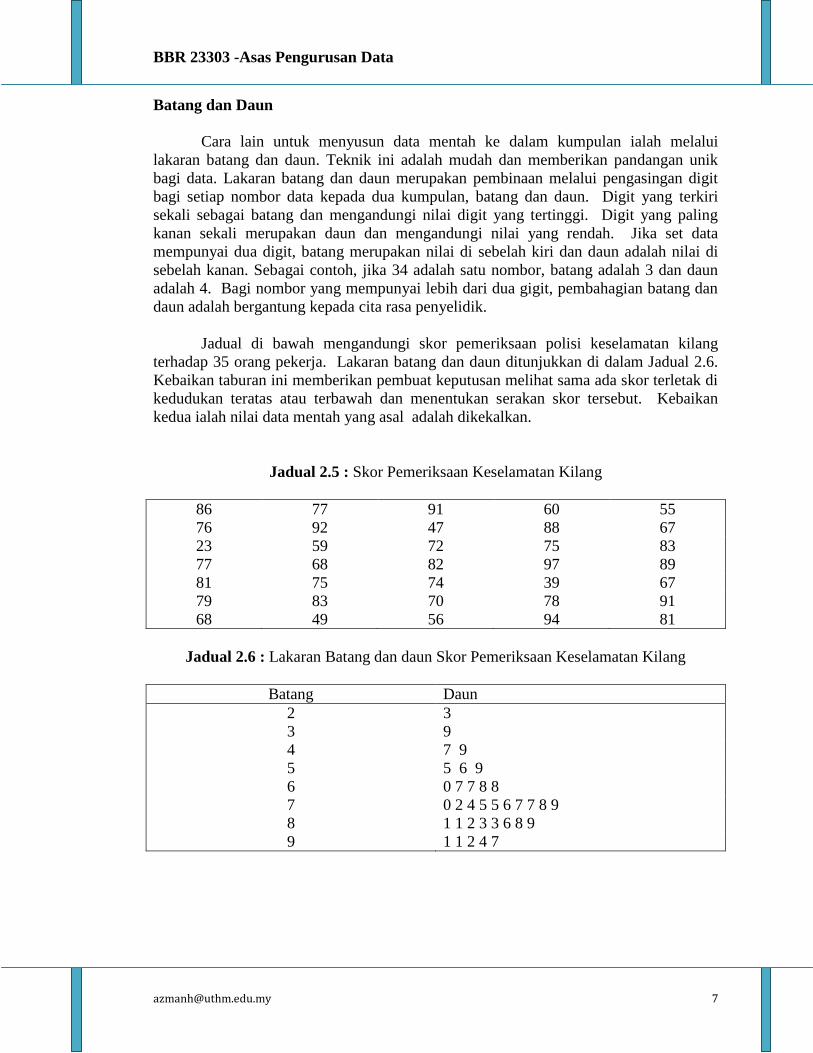
Orgif adalah poligon kekerapan terkumpul. Pembinaan orgif bermula dengan
melabelkan paksi-X dengan titik akhir kelas dan paksi-Y dengan kekerapan terkumpul.
Rajah 2.3 menunjukkan orgif bagi kekerapan terkumpul di dalam Jadual 2.3. Orgif amat
berguna apabila pembuat keputusan mahu melihat jumlah disepanjang tempoh masa.
Kecerunan yang curam bagi orgive boleh digunakan untuk menunjukkan peningkatan
yang mendadak di dalam kekerapan. Di dalam Rajah di bawah menunjukkan kecerunan
yang curam berlaku di dalam kelas 1-di bawah 3 dan kelas 9-di bawah 11.
Rajah 2.3 : Orgif Kekerapan Terkumpul Harga Saham

BBR 23303 -Asas Pengurusan Data
Carta Pie
Carta pie merupakan bahagian data di mana kawasan keseluruhan pie mewakili
100% daripada data yang dikaji dan kepingan pie merupakan peratus pecahan sub-level.
Sebagai contohnya, ia digunakan untuk mempersembahkan data perniagaan,
terutamanya untuk menggambarkan beberapa perkara seperti kategori belanjawan,
bahagian pasaran, dan pengagihan masa dan sumber. Jadual di bawah menunjukkan
jumlah aduan yang diterima oleh perkhidmatan kereta api dan Rajah berikutnya
menunjukkan cara pie yang dibentuk.
Jadual 2.4: Aduan oleh Pelanggan Keretapi
Komplen Bilangan Bahagian Darjah
Stesyen 28,000 0.40 144.0
Keupayaan Keretapi 14,700 0.21 75.6
Peralatan 10,500 0.15 50.4
Personel 9,800 0.14 50.6
Penjadualan 7,000 0.10 36.0
Jumlah 70,000 1.00 360.00
Rajah 2.4 : Carta Pie Komplen Pelanggan Keretapi
Stesyen
40.0%
Keupayaan Keretapi
21.0%
Peralatan
15.0%
Personel
14.0%
Penjadualan
10.0%
BBR 23303 -Asas Pengurusan Data
Batang dan Daun
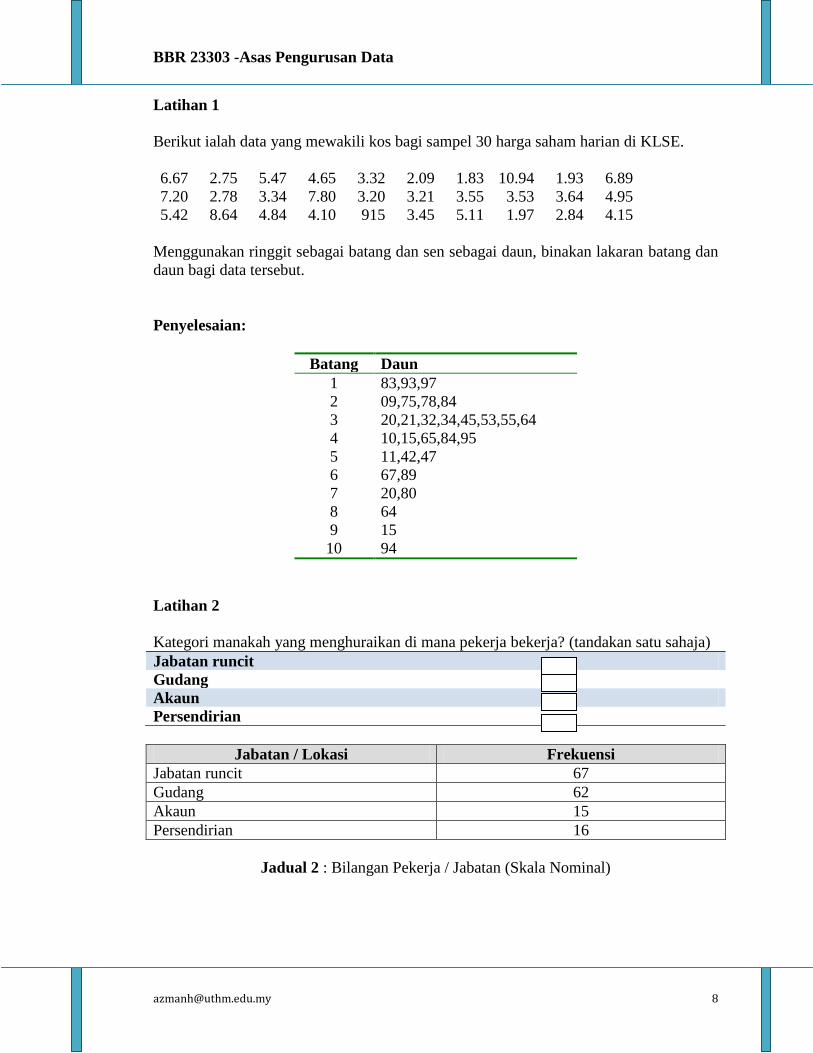
Cara lain untuk menyusun data mentah ke dalam kumpulan ialah melalui
lakaran batang dan daun. Teknik ini adalah mudah dan memberikan pandangan unik
bagi data. Lakaran batang dan daun merupakan pembinaan melalui pengasingan digit
bagi setiap nombor data kepada dua kumpulan, batang dan daun. Digit yang terkiri
sekali sebagai batang dan mengandungi nilai digit yang tertinggi. Digit yang paling
kanan sekali merupakan daun dan mengandungi nilai yang rendah. Jika set data
mempunyai dua digit, batang merupakan nilai di sebelah kiri dan daun adalah nilai di
sebelah kanan. Sebagai contoh, jika 34 adalah satu nombor, batang adalah 3 dan daun
adalah 4. Bagi nombor yang mempunyai lebih dari dua gigit, pembahagian batang dan
daun adalah bergantung kepada cita rasa penyelidik.
Jadual di bawah mengandungi skor pemeriksaan polisi keselamatan kilang
terhadap 35 orang pekerja. Lakaran batang dan daun ditunjukkan di dalam Jadual 2.6.
Kebaikan taburan ini memberikan pembuat keputusan melihat sama ada skor terletak di
kedudukan teratas atau terbawah dan menentukan serakan skor tersebut. Kebaikan
kedua ialah nilai data mentah yang asal adalah dikekalkan.
Jadual 2.5 : Skor Pemeriksaan Keselamatan Kilang
86 77 91 60 55
76 92 47 88 67
23 59 72 75 83
77 68 82 97 89
81 75 74 39 67
79 83 70 78 91
68 49 56 94 81
Jadual 2.6 : Lakaran Batang dan daun Skor Pemeriksaan Keselamatan Kilang
Batang Daun
2 3
3 9
4 7 9
5 5 6 9
6 0 7 7 8 8
7 0 2 4 5 5 6 7 7 8 9
8 1 1 2 3 3 6 8 9
9 1 1 2 4 7
BBR 23303 -Asas Pengurusan Data
Latihan 1
Berikut ialah data yang mewakili kos bagi sampel 30 harga saham harian di KLSE.
6.67 2.75 5.47 4.65 3.32 2.09 1.83 10.94 1.93 6.89
7.20 2.78 3.34 7.80 3.20 3.21 3.55 3.53 3.64 4.95
5.42 8.64 4.84 4.10 915 3.45 5.11 1.97 2.84 4.15
Menggunakan ringgit sebagai batang dan sen sebagai daun, binakan lakaran batang dan
daun bagi data tersebut.
Penyelesaian:
Batang Daun
1 83,93,97
2 09,75,78,84
3 20,21,32,34,45,53,55,64
4 10,15,65,84,95
5 11,42,47
6 67,89
7 20,80
8 64
9 15
10 94
Latihan 2
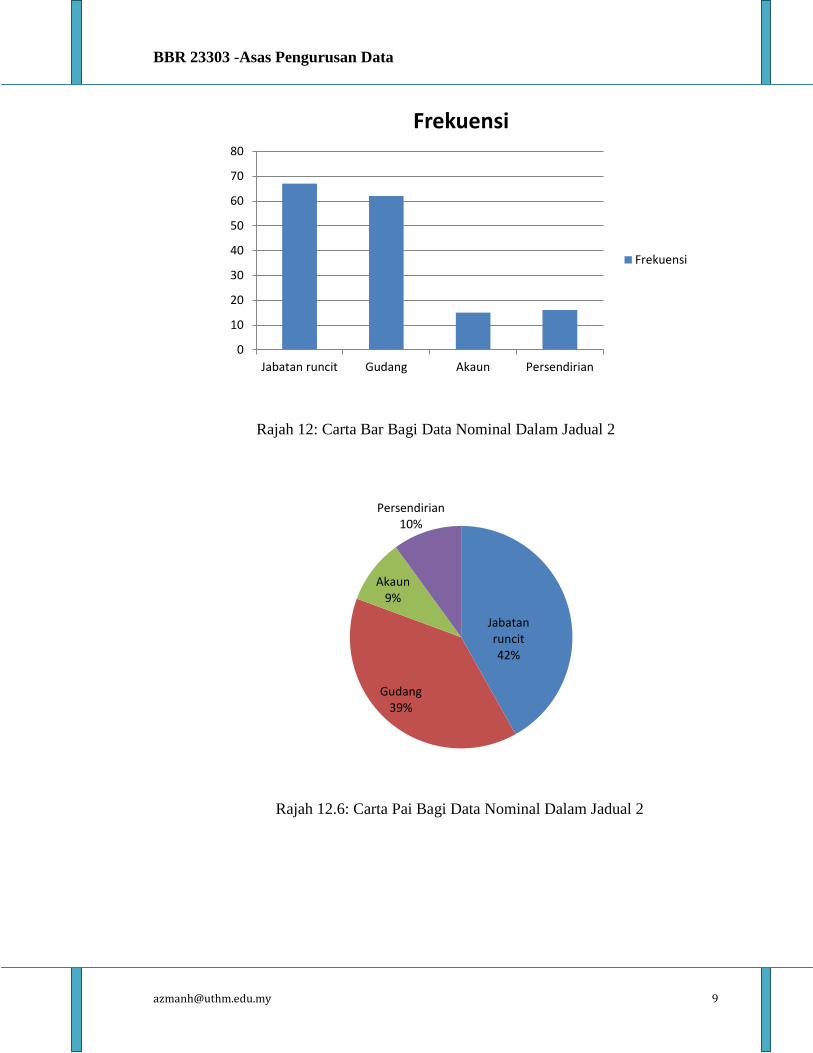
Kategori manakah yang menghuraikan di mana pekerja bekerja? (tandakan satu sahaja)
Jabatan runcit
Gudang
Akaun
Persendirian
Jabatan / Lokasi Frekuensi
Jabatan runcit 67
Gudang 62
Akaun 15
Persendirian 16
Jadual 2 : Bilangan Pekerja / Jabatan (Skala Nominal)
BBR 23303 -Asas Pengurusan Data
Rajah 12: Carta Bar Bagi Data Nominal Dalam Jadual 2
Rajah 12.6: Carta Pai Bagi Data Nominal Dalam Jadual 2
0
10
20
30
40
50
60
70
80
Jabatan runcit Gudang Akaun Persendirian
Frekuensi
Frekuensi
Jabatan runcit 42%
Gudang 39%
Akaun 9%
Persendirian 10%

BBR 23303 -Asas Pengurusan Data
2
Statistik Perihalan
2.1 Ukuran Kecenderungan Memusat
Satu jenis pengukuran yang digunakan untuk memerihalkan set data adalah
ukuran kecenderungan memusat. Pengukuran kecenderungan memusat menghasilkan
maklumat berkaitan dengan titik tengah pada satu kumpulan nombor.
2.1.1 Data Tidak Berkumpul
Ditunjukkan di dalam Jadual 3.1 adalah harga tawaran saham bagi 20 syarikat
yang akan disenaraikan di Bursa Saham Kuala Lumpur pada tahun 2000. Bagai data
ini, ukuran kecenderungan memusat boleh menghasilkan maklumat berkaitan dengan
purata harga tawaran, titik tengah harga tawaran dan juga harga tawaran yang paling
kerap ditawarkan. Ukuran kecenderungan memusat tidak menumpukan ke atas
pengembangan set data atau berapa jauh nilai daripada titik tengah. Ukuran
kecenderungan memusat bagi data yang tidak berkumpul adalah min, mod, median,
peratusan dan quartile.
Jadual 3.1: Harga Saham bagi 20 Kaunter KLSE (RM)
14.25 19.00 11.00 28.00
24.00 23.00 43.25 19.00
27.00 25.00 15.00 7.00
34.22 15.50 15.00 22.00
19.00 19.00 27.00 21.00
Mod
Mod adalah nilai yang paling kerap wujud di dalam set data. Bagi data yang
ditunjukkan di dalam Jadual 3.1, mod ialah RM19.00 kerana harga tawaran berlaku

BBR 23303 -Asas Pengurusan Data
sebanyak 4 kali. Menyusun data di dalam susunan yang menaik (menyusun dari
nombor terkecil hingga terbesar) membantu kita menentukan mod. Berikut adalah
susunan nilai daripada Jadual 3.1.
7.00 11.00 14.25 15.00 15.00 15.50 19.00 19.00 19.00 19.00
21.00 22.00 23.00 24.00 25.00 27.00 27.00 28.00 34.22 43.25
Penyusunan ini membuatkan kita dengan mudah untuk melihat RM19.00 adalah
harga yang kerap berlaku. Jika terdapat dua kumpulan angka yang kerap wujud di
dalam set data, ia mempunyai dua mod. Di dalam kes seperti ini, ia dikatakan bi-model.
Jika set data tidak sebenarnya bi-model, tetapi mengandungi dua nilai di mana lebih
dominan daripada yang lain, sesetengah penyelidik mempunyai kebebasan dengan
menunjukkan set data sebagai bi-model walaupun ia sebenarnya tidak terikat kepada
mod. Data set dengan lebih daripada dua mod dipanggil sebagai berbilang-model.
Di dalam dunia perniagaan, konsep mod biasanya digunakan di dalam
menentukan saiz. Sebagai contoh, pengilang baju mengeluarkan baju di dalam empat
saiz, S, M, L, dan XL. Setiap saiz adalah berpadanan dengan model badan manusia.
Dengan pengurangan bilangan kepada beberapa model saiz, syarikat boleh
mengurangkan jumlah kos pengeluaran dengan menghadkan kos penyediaan mesin dan
bahan.
Mod adalah ukuran kecenderungan memusat sesuai bagi data nominal. Mod
boleh digunakan untuk menentukan manakah kategori yang kerap terjadi.
Median
Median ialah titik tengah sesuatu kumpulan nombor yang disusun secara
menaik. Jika bilangan data tersebut adalah ganjil, median ialah nombor yang di tengah.
Jika bilangan data adalah genap, median ialah purata dua nombor yang terletak di
tengah-tengah. Langkah berikut adalah digunakan untuk menentukan median.
Langkah 1: Susun data di dalam susunan menaik.
Langkah 2: Jika bilangan data adalah ganjil, carikan sebutan di tengah-tengah di
dalam susunan tersebut. Ia adalah median.
Langkah 3: Jika bilangan data adalah genap, kirakan purata dua angka di tengah-
tengah susunan tersebut. Purata ini adalah median.

BBR 23303 -Asas Pengurusan Data
Katakan ahli statistik hendak mencari median bagi kumpulan data berikut:
15 11 14 3 21 17 22 16 19 16 5 7 19 8 9 20 4
Susunan nombor di dalam sebutan menaik:
3 4 5 7 8 9 11 14 15 16 16 17 19 19 20 21 22
Terdapat 17 sebutan (bilangan ganjil), oleh itu median terletak di tengah-tengah susunan
tersebut, iaitu 15. Jika nombor 22 dikeluarkan daripada senarai, terdapat hanya 16
sebutan (bilangan genap):
3 4 5 7 8 9 11 14 15 16 16 17 19 19 20 21
Sekarang kita mempunyai bilangan sebutan genap, median ditentukan dengan
mengira purata dua nombor yang terletak di tengah-tengah susunan tersebut, 14 dan 15.
Ini menghasilkan nilai median iaitu 14.5. Satu cara lain untuk menentukan median ialah
mencari sebutan 2
1n di dalam susunan yang menaik. Sebagai contoh, jika set data
mempunyai 77 sebutan, median adalah terletak pada sebutan yang ke 39, iaitu:
39 2
1 77
2
1 n
Formula ini amat berguna apabila melibatkan bilangan data yang besar. Median
tidak dipengaruhi oleh magnitud nilai ekstrem. Ciri-ciri ini merupakan kelebihan
disebabkan nilai terbesar atau terkecil tidak mempengaruhi median. Oleh sebab itu,
median merupakan ukuran lokasi yang terbaik untuk digunakan di dalam analisis
pembolehubah seperti kos rumah, pendapatan dan usia. Sebagai contoh, broker
perumahan mahu menentukan median, harga jualan 10 buah rumah yang disenaraikan
seperti berikut:
67,000 91,000 95,000 105,000 116,000
122,000 148,000 167,000 189,000 5,250,000
Median harga rumah tersebut adalah purata dua sebutan di tengah-tengah,
116,000 dan 122,000 atau 119,000. Harga ini adalah munasabah mewakili harga
kesemua rumah. Perhatikan harga rumah 5,250,000 tidak termasuk di dalam analisis
melainkan diambil kira sebagai satu daripada 10 rumah. Jika harga rumah yang ke 10
adalah 200,000, keputusannya masih lagi sama. Walau bagaimanapun, jika semua
harga rumah dipuratakan, menghasilkan harga purata 10 rumah adalah RM635,000 dan
lebih tinggi daripada harga 9 rumah yang pertama.

BBR 23303 -Asas Pengurusan Data
Kelemahan median ialah tidak semua maklumat daripada data digunakan. Iaitu,
maklumat berkaitan dengan harga rumah termahal tidak diambil kira di dalam
pengiraan median. Paras pengeluaran data mestilah sekurang-kurangnya ordinal untuk
median lebih bermakna.
Min
Min aritmetik adalah susunan sinonim dengan purata kumpulan nombor dan ia
dikira dengan menjumlahkan semua nombor dan membahagikannya dengan bilangan
nombor tersebut. Disebabkan min aritmetik digunakan dengan meluas, kebanyakan ahli
statistik hanya menggunakan istilah min sahaja.
Min populasi ditandakan dengan huruf Greek mu (). Min sampel pula
ditandakan dengan huruf Roman ( X ). Formula bagi mengira min bagi populasi dan
min sampel adalah sebagaimana berikut:
Min populasi: N
X ........... X X X
N
X N321
Min sampel: n
X ........... X X X
n
X X n321
Huruf Greek sigma () biasanya digunakan oleh ahli matematik untuk
menunjukkan jumlah semua nombor-nombor di dalam kumpulan data. Di samping itu,
N adalah bilangan nombor di dalam populasi dan n adalah bilangan nombor di dalam
sampel. Algoritma untuk mengira min adalah dengan menjumlahkan nombor-nombor
di dalam populasi atau sampel dan kemudiannya membahagikannya dengan bilangan
populasi atau sampel.
Secara amnya, definisi min adalah:
N
X
N
1i
i
Walau bagaimanapun, untuk tujuan rujukan ini
XMenandakan
N
1i
iX

BBR 23303 -Asas Pengurusan Data
Min adalah sesuai digunakan untuk menganalisis data sekurang-kurangnya data
bertaraf interval di dalam pengukuran.
Contoh 1.1
Katakan syarikat mempunyai lima jabatan dengan bilangan pekerja 24, 13, 19, 26 dan
11 masing-masingnya. Min populasi adalah:
X = 24 + 13 + 19 +26 + 11
= 93
18.6 5
93
N
X
Pengiraan min sampel adalah menggunakan algoritma yang sama bagi min
populasi. Walau bagaimanapun adalah tidak sesuai untuk mengira min sampel untuk
populasi atau min populasi untuk sampel. Oleh kerana kedua-dua min populasi dan
sampel adalah penting di dalam statistik, simbol yang berasingan adalah perlu untuk
membezakan min populasi dan sampel.
Min adalah dipengaruhi oleh setiap nilai di dalam data, yang merupakan
kelebihannya. Ia juga merupakan kelemahannya, disebabkan nilai ekstrem yang
terbesar atau terkecil boleh menyebabkan nilai min tertarik ke arah nilai ekstrem.
Min amat biasa digunakan di dalam mengukur lokasi disebabkan ia
menggunakan setiap data dalam pengiraannya dan ia mempunyai kandungan matematik
yang membuatkannya menarik untuk digunakan di dalam analisis statistik pentadbiran.
Peratusan
Peratusan adalah ukuran kecenderungan memusat yang membahagikan
kumpulan data kepada 100 bahagian. Terdapat 99 peratusan, disebabkan ia mengambil
99 pembahagi untuk memisahkan data kepada 99 bahagian. Peratusan ke-n adalah nilai
dimana sekurang-kurangnya n peratus data terletak di bawah nilai tersebut dan selebih-
lebihnya (100 – n) peratus adalah di atas nilai tersebut. Khususnya, 87 peratusan adalah
nilai dimana sekurang-kurangnya 87% daripada data di bawah nilai tersebut dan tidak
lebih daripada 13% di atas nilai. Peratusan adalah nilai “anak-tangga”, sebagaimana
ditunjukkan di dalam Rajah 3.1, disebabkan 87 peratusan dan 88 peratusan tetapi tiada
peratusan di antaranya. Jika operator kilang mengambil ujian keselamatan 87.6%
sebagai skor ujian keselamatan adalah di bawah skor pekerja, ia masih lagi mempunyai
skor hanya pada 87 peratusan, walaupun lebih daripada 87% skor tersebut adalah
terendah.

BBR 23303 -Asas Pengurusan Data
Rajah 3.1
Peraturan Anak Tangga
Berikut adalah langkah-langkah di dalam menentukan kedudukan peratusan:
Langkah 1: Susun nombor di dalam kedudukan menaik.
Langkah 2: Kirakan kedudukan peratusan i dengan:
(n) 100
P i
Di mana;
P = peratusan yang dikehendaki
i = kedudukan peratusan
N = bilangan nombor di dalam set data.
Langkah 3: Tentukan lokasi samada melalui (a) atau (b)
a. Jika i adalah nombor bulat, P peratusan adalah purata nilai pada kedudukan ke i
dan nilai pada kedudukan (i + 1)
b. Jika i bukan nombor bulat, nilai P peratusan adalah bahagian nombor bulat (i +
1)
Contoh 3.2.
Katakan kita hendak menentukan 80 peratusan daripada 1240 nombor.
P = 80, n = 1240
1. Kedudukan 80 peratusan
992 (1240) 100
80 i
88 peratusan
87
peratusan 86 peratusan

BBR 23303 -Asas Pengurusan Data
2. Disebabkan oleh I = 992 dan nombor bulat, ikut langkan 3(a). 80 peratusan adalah
purata nombor 992 dan 993.
2
993nombor 992nombor P80
= 992.5
Contoh 3.3
Tentukan 30 peratusan bagi 8 nombor berikut:
14 12 19 23 5 13 28 17
Penyelesaian:
1. Susun dalam keadaan susunan menaik
5 12 13 14 17 19 23 28
2. Kirakan kedudukan peratusan dengan P = 30 dan n = 8.
2.4 (8) 100
30 i
3. Disebabkan i bukan nombor bulat, langkah 3(b) digunakan. Nilai i + 1 = 2.4 + 1 =
3.4. Nombor bulat 3.4 ialah 3. Oleh itu 30 peratusan adalah di kedudukan pada nilai
ke 3, dan nilai ketiga ialah 13. Oleh itu 13 adalah 30 peratusan. Perhatikan bahawa
peratusan mungkin atau mungkin tidak satu daripada nilai data.
Sukuan
Sukuan adalah ukuran kecenderungan memusat yang membahagikan kumpulan
data kepada empat sub-kumpulan atau bahagian. Terdapat tiga sukuan, ditandakan
sebagai Q1, Q2 dan Q3. Sukuan pertama, memisahkan pertama, atau terendah, satu per
empat daripada tiga suku teratas adalah sama dengan 25 peratus. Quartil kedua, Q2,
memisahkan suku kedua data daripada suku ketiga. Q2 adalah terletak pada 50
peratusan, dan sama dengan media bagi data. Sukuan ketiga, Q3, membahagikan tiga
suku pertama daripada sukuan terakhir dan adalah sama dengan nilai 75 peratusan.
Tiga sukuan ini ditunjukkan di dalam Rajah 3.2.

BBR 23303 -Asas Pengurusan Data
Katakan kita hendak menentukan nilai Q1, Q2 dan Q3 dari nombor berikut:
106 109 114 116 121 122 125 129
Nilai Q1 adalah diperolehi pada 25 peratusan, P25;
Bagi n = 8; I = 100
25(8) = 2.
Disebabkan I adalah nombor bulat, P25, adalah ditemui dengan mempuratakan
sebutan kedua dan ketiga.
P25 = 2
114 109 = 111.5
Nilai Q1 adalah P25 = 111.5. Perhatikan satu per empat, atau dua, bagi nilai (106
dan 109) adalah kurang daripada 111.5.
Nilai Q2 adalah sama dengan median. Oleh kerana bilangan yang genap, median
adalah purata dua sebutan ditengah:
Q2 = median = 2
121 116 = 118.5
Perhatikan bahawa sebenarnya separuh daripada sebutan adalah kurang daripada
Q2 dan separuh lagi lebih besar daripada Q2.
Nilai Q3 ditentukan oleh P75, sebagaimana berikut:
I = 100
75(8) = 8
Disebabkan i adalah angka bulat, maka P75 adalah purata kedudukan ke 6 dan 7.
P75 = 2
125 122 = 123.5
Nilai Q3 adalah P75 = 123.5. Perhatikan bahawa tiga suku atau 6 sebutan,
daripada nilai adalah lebih kecil daripada 123.5 dan dua daripada nilai lebih besar
daripada 123.5.

BBR 23303 -Asas Pengurusan Data
Data Berkumpulan
Tiga ukuran kecenderungan memusat akan dibincangkan bagi data berkumpulan
iaitu min, median dan mod.
Min
Bagi data yang tidak terkumpul, min adalah dikira dengan menjumlahkan nilai di dalam
set data dan kemudiannya membahagikannya dengan bilangan data tersebut. Tetapi
bagi data yang telah terkumpul, nilai yang khusus tidak diketahui. Apakah yang boleh
digunakan untuk mewakili nilai data? Titik tengah bagi setiap jeda kelas adalah
digunakan untuk mewakili semua nilai di dalam jeda kelas tersebut. Titik tengah ini
akan diwajarkan dengan kekerapan nilai di dalam jeda kelas tersebut. Min bagi data
terkumpul kemudiannya dikira dengan menjumlahkan hasil dharab titik tengah kelas
dengan kekerapan kelas dan membahagiman jumlah tersebut dengan bilangan
kekerapan. Formulanya adalah sebagaimana berikut:
i21
ii2211
i
ii
kumpulanf ... f f
m.........f mf mf
f
mf
Di mana;
i = bilangan jeda
f = kekerapan kelas
M = titik tengah kelas
N = jumlah kekarap.
Contoh 3.4:
Jeda Kelas Kekerapan (fi) Titik Tengah
(Mi)
fiMi
1 – 3 16 2 32
3 – 5 2 4 8
5 – 7 4 6 24
7 – 9 3 8 24
9 – 11 9 10 90
11 - 13 6 12 72
f = N = 40 fM = 250
6.25 40
250
f
Mf
ii
i

BBR 23303 -Asas Pengurusan Data
Min bagi data yang terkumpul adalah 6.25. Perlu diingat bahawa setiap jeda
kelas diwakili oleh nilai titik tengah kelas tersebut bukannya nilai sebenar. Oleh sebab
itu, nilai min tersebut hanyalah nilai penghampiran sahaja.
Median
Nilai median bagi data tidak terkumpul adalah nilai yang terletak di tengah-tengah
apabila data tersebut disusun secara menaik. Bagi data yang terkumpul, pengiraan
median agak rumit dan menggunakan formula berikut:
W f
cf - L Median
med
p2N
Di mana
L = had bawah jeda kelas median
cfp = jumlah terkumpul kekerapan sehingga kelas tersebut, tetapi tidak
melibatkan kekerapan median kelas
Fmed = kekerapan median
W = keluasan jeda kelas median (had atas kelas – had bawah kelas)
N = jumlah bilangan kekerapan
Contoh 3.5:
1. Kirakan nilai 2N yang merupakan kedudukan sebutan di tengah-tengah. 20
240
2N .
Oleh itu median terletak di kedudukan ke 20. Persoalannya di kelas manakah
sebutan ke 20?
2. Kirakan kekerapan terkumpul bagi setiap kelas.
Jeda Kelas Kekerapan (fi) Titik Tengah
(Mi)
1 – 3 16 2
3 – 5 2 4
5 – 7 4 6
7 – 9 3 8
9 – 11 9 10
11 - 13 6 12
f = N = 40

BBR 23303 -Asas Pengurusan Data
Berdasarkan kepada kekerapan terkumpul, sebutan ke 20 terletak di dalam kelas ke
tiga kerana terdapat hanya 18 nilai sahaja dalam dua kelas pertama. Oleh itu nilai
median terletak di mana-mana di antara 5 – 7 (kelas ke tiga). Jeda kelas yang
mengandungi nilai median dirujukkan sebagai jeda kelas median.
3. Oleh kerana nilai ke 20 adalah di antara 5 dengan 7, nilai median adalah sekurang-
kurangnya 5. Tetapi apakah nilai tersebut? Perbezaan di antara kedudukan nilai
median, 2N = 20, dan kekerapan terkumpul sehingga itu, tetapi tidak termasuk jeda
kelas median, cfp = 18, memberitahu berapa banyak nilai sehingga jeda kelas
median bagi nilai median terletak. Ini boleh ditentukan dengan menyelesaikan 2N –
cfp = 20 – 18 = 2. Nilai median terletak dia nilai ke dalam jeda kelas median.
Walau bagaimanapun, terdapat empat nilai di dalam jeda kelas median (fmed). Nilai
median adalah 42 jauh ke dalam jeda, iaitu
2
1
4
2
4
18 - 20
f
cf -
med
p2N
4. Oleh itu, nilai median sekurang-kurangnya 5 – nilai L – dan separuh jauhnya
daripada jeda median. Berapa jauhkah secara geometri di sepanjang jeda median?
Setiap jeda kelas adalah dua unit luas (W). Separuh daripada jarak ini memberitahu
kita berapa jauh nilai median ke dalam jeda kelas.
1 (2) 2
1 (2)
4
2 (2)
4
18 - (W)
f
cf - 240
med
p2N
5. Menambahkan jarak ini dengan had bawah jeda kelas median menghasilkan nilai
median.
6 1 5 (2) 2
1 5 (2)
4
18 - 5 W
f
cf - L Median 2
20
med
p2N
Perlu diingat bahawa nilai median ini juga merupakan nilai penghampiran.
Andaian yang dibuat di dalam pengiraan ini adalah nilai sebenar adalah jatuh secara
seragam di sepanjang jeda kelas median.
BBR 23303 -Asas Pengurusan Data
Mod
Mod bagi data terkumpul adalah titik tengah kelas mod. Kelas kod adalah jeda kelas
yang mempunyai kekerapan yang tertinggi. Di dalam contoh di atas, kelas mod adalah
di antara 1 – 3 dengan bilangan kekerapan 16. Oleh itu titik tengah kelas mod ialah 2
dan mod ialah 2.
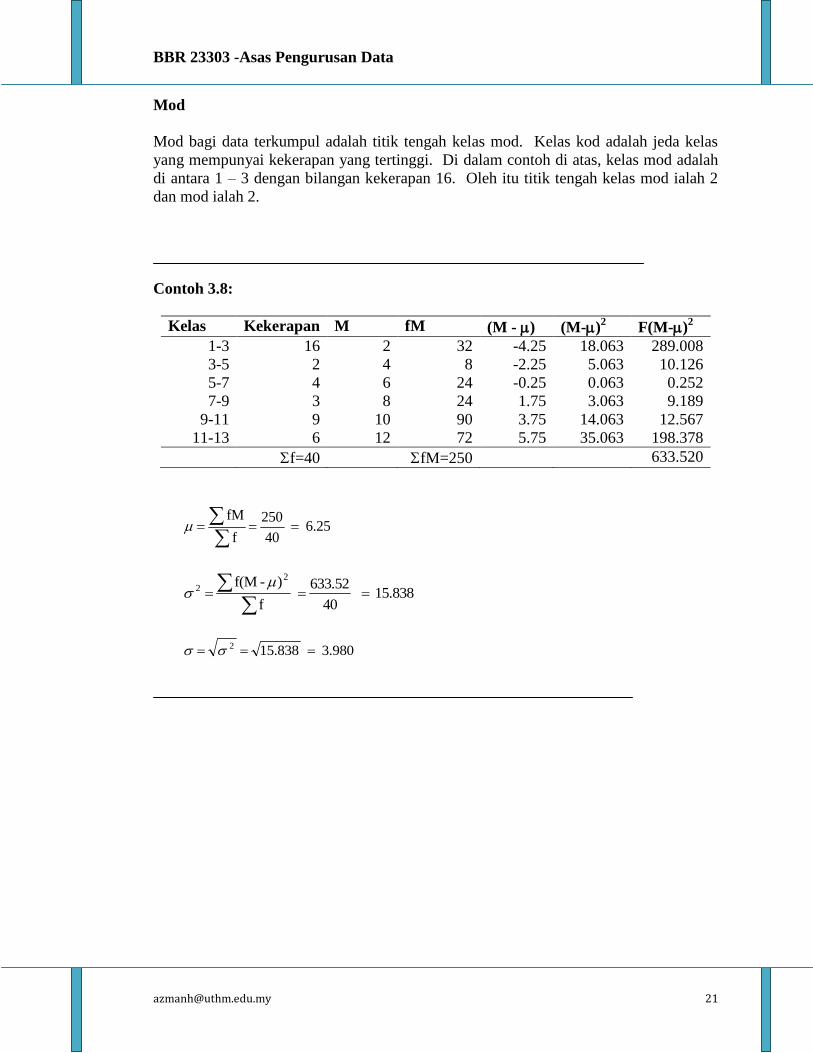
Contoh 3.8:
Kelas Kekerapan M fM (M - ) (M-)2 F(M-)
2
1-3 16 2 32 -4.25 18.063 289.008
3-5 2 4 8 -2.25 5.063 10.126
5-7 4 6 24 -0.25 0.063 0.252
7-9 3 8 24 1.75 3.063 9.189
9-11 9 10 90 3.75 14.063 12.567
11-13 6 12 72 5.75 35.063 198.378
f=40 fM=250 633.520
6.25 40
250
f
fM
15.838 40
633.52
f
) - f(M
2
2
3.980 15.838 2





























