Embed Size (px)
Citation preview

Journal o f Psycholinguistic Research, Vol. 23, No. 6, 1994
A Corpus-Based Analysis of Verb Continuation Frequencies for Syntactic Processing
Paola Mer lo t,2
In the experimental study o f how much verb guidance occurs in parsing syntactic am- biguity, the preference o f an ambiguously subcategorized verb for its continuations is a relevant factor in the choice o f the stimuli and in the interpretation of the results. Many methods have been used to measure this bias, ranging from experimenter's intuitions to sentence completion studies. In this paper, I assume that an acceptable definition o f frequency is the count o f the occurrences in a corpus, and I provide some cooccurrence counts calculated on a set o f verbs and their syntactic siblings in a subset o f the Penn Treebank (Marcus, Santorini, & Marcinkiewicz, 1993). Second, I perform some corre- lations with sentence completion and sentence production studies, which show that the two data collection methods are not strongly correlated with the corpus counts. Finally, I analyze the stimuli o f some experiments which have shown evidence both in favor o f tl, e garden path theory o f sentence processing and the lexical guidance theory. I argue that all the stimuli were balanced, and that a minimal attachment effect is not a con- sequence of the overall NP-bias o f the stimuli. Moreover, evidence from the relation bet~veen processing times and verb conwletions with declarative and interrogative com- plemet,tizers is used to argue that the parser is sensitive to the lexical content o f the complementizers.
I N T R O D U C T I O N
In the study of sentence processing a frequently debated issue is the amount and specificity of the syntactic information that the parser uses in building
The corpus on wh ich the ana lys i s was done has been provided by the A C L Data Col- lect ion Initiative. Th i s work has benef i ted f rom d i s cus s i ons wi th Susan A r m s t r o n g , Uli Fraucnfe lder , Paul Gorrell , Noel N g u y e n , and Phil ip Resnik . T h a n k s also to Mart ine M o r n a c c h i for help wi th the Perl scr ipts , to Doro thee J o a n n o u and Nathal ie Niederberger for coun t ing verbs wi th me , and to S usan Garnsey for g iv ing me access to her unpub - l i shed resul ts . Al l r e m a i n i n g errors are m y own. i Univers i ty o f Geneva , Geneva , Switzer land. 2 A d d r e s s all co r r e spondence to Paola Merlo , Labora tory for Psycho l ingu i s t i c s , Un ive r s i ty
o f Geneva , 9 route de Drize, 1227 C a r o u g e - G e n ~ v e Suisse .
435
0090-6905/94/I 100-043557.00/0 �9 1994 Plenum Publishing Corporation

436 M e r l o
a representation of the sentence. Consider, for instance, the following sen- tences [adapted from Frazier & Rayner (1982)]:
1. a. Sherlock Holmes didn't suspect the very beautiful young countess. b. Sherlock Holmes didn't suspect the very beautiful young countess was
a fraud.
The verb suspect subcategorizes both for an NP and a clausal comple- ment; thus an NP following the verb is locally ambiguous as a potential object of the verb, as in the first sentence, or as the subject of a following clause, in the second sentence.
This kind of local ambiguity has been studied in several experiments. Contradictory results have been found. Some results support a model of sentence processing which is driven by the phrase structure rules of the grammar, and, therefore, does not use word-specific lexical information, but only syntactic information, while other results support a model which as- sumes that texical information is used as soon as possible and that parsing is driven by lexical expectation.
These two positions make different predictions about the use of sub- categorization information. The phrase-structure-driven model predicts that lexical information is used only to filter incorrect analyses, in a second stage of parsing, while the first representation of the sentence is assembled using only phrase structure rules and general strategies for parsing. It predicts, therefore, a general tendency to assemble an NP following a verb as its direct object, as this is the simplest representation, independently of the lexical preference of the verb (minimal attachment). Because this model does not use subcategorization information, it is going to be often in error (led down the garden path), and in need of subsequent reanalysis. 3 This position has been dubbed the garden path model (Ferreira & Clifton, 1986; Ferreira & Henderson, 1990; Frazier & Rayner, 1982; Mitchell, 1987; Rayner & Frazier, 1987).
The other position supports a view where both syntactic class and word- specific lexical information is used, so that particular preference for a given
J H o w frequently the parser is in error can be calculated, based on the frequency of the dispreferred interpretation. For example, in the NP/clause ambiguity, we found that the number of continuations for NP was 48% of all the cases, while the number of clause continuations without a complement izer was 6%. By choosing a preferred-NP strategy, the parser makes 6% of errors on the total of occurrences. (The remaining 52% of cases are not ambiguous , so they do not pose any problem.) If one considers only the am- biguous cases, then the preferred-NP strategy is incorrect 11% of the time. Hindle and Rooth (1993) calculated that a minimal at tachment strategy will make 65% errors for PP attachment, as it favors at tachment to the verb, which occurs approximately 35% of
the time.

Analys i s o f Verb Continuat ion Frequencies 437
continuation depends on the verb usage. This model, which has been called the lexical guidance model (Ford, Bresnan, & Kaplan, 1982; Holmes, Stowe, & Cupples, 1989; Mitchell & Holmes, 1985; Trueswell, Tanenhaus, & Kel- low, 1993), predicts a tendency to assemble an NP following a verb only if the verb itself is biased for an NP continuation, with consequent need for reanalysis, if the sentence being parsed is in fact a sentence with a reduced clausal complement, as sentence lb above. On the other hand, if the verb is biased for a clausal continuation, the analysis of sentences such as lb should not show any disruption.
In either model, the verb's preference is the variable to manipulate or control in the experimental setting. For the lexical guidance model to be tested directly, the bias of the verbs used in the experiments is directly manipulated. When testing the garden path theory, the biases of the stimuli are not manipulated, but they need to be controlled. If the stimuli prefer overall an NP continuation, one could interpret the increased reading times that have been found for sentences such as lb above as an effect of fre- quency, instead of a general parsing strategy. Since the preference of an ambiguously subcategorized verb for its continuations is a relevant factor in the choice of the stimuli and in the interpretation of the results, one must address the question of how to measure the bias of a verb for a given continuation. To this date, many methods have been used to measure this bias, ranging from experimenter's intuitions to sentence completion studies: Corpus analysis suggests itself as a method to collect this information, given the recent availability of large amounts of text.
In this paper, I assume that an acceptable definition of bias is a verb tendency to cooccur most frequently with a given continuation, and I define frequency as the number of occurrences in a corpus. In the second section, I describe the method and some of the results of a partially automatic count performed on a corpus extracted from the Penn Treebank (Marcus et al., 1993). In the third section, I then investigate the relation of the corpus counts to other data collection methods, namely, sentence completion and sentence production. In the fourth section, I use the corpus counts to analyse the stimuli of some experiments, and to explore whether the discrepancy of the results is due to properties of the stimuli. I reject the hypothesis that the stimuli in the experiments supporting the garden path theory showed an
4 To give some examples, Ferreira and Henderson (1990) used norms in Connine, Fer- rcira, Jones, Clifton, & Frazier (1984). Trueswell et al. (1993) performed a pretest of the stimuli by doing a sentence completion study on 14 subjects. Mitchell (1987) relied on the Concise Oxford Dictionary (dictionaries are mostly written using the lexicogra- pher's intuitions). Ford et al. (1982) used subcategorization preferences according to a sentence completion task. Frazier and Rayner (1982) relied on the experimenters' in- tuitions.

438 M e r l o
overa l l NP bias. Ev idence f rom the re la t ion be tween p rocess ing t imes and verb comple t i ons is used to argue that the parser is sens i t ive to the lexical content of the complemen t i ze r .
E S T A B L I S H I N G T H E C O R P U S - B A S E D N O R M S
Materials
The l ist o f ve rbs to be inves t iga ted was cons t ruc ted by co l l ec t ing the verbs in the s t imul i for on- l ine expe r imen t s repor ted in Fraz ie r and R a y n e r (1982) and Trueswe l l et al. (1993), and also f rom a p roduc t ion s tudy, which co l lec ted subca tegor i za t ion f requenc ies for 105 verbs (Connine et al., 1984). A l l the verbs used in these s tudies are subca t ego r i zed ambiguous ly , and therefore g ive r ise to local amb igu i ty in pars ing , as shown in sen tence 1. In wha t fo l lows , verbs that, based on f requency counts , prefer to be f o l l o w e d by an ob jec t are ca l led NP-biased verbs, whi le those that p re fe r to be fol- l owed by a c lause are ca l led S-biased verbs.
The corpus on wh ich the search was pe r fo rmed is a subse t o f the Penn T r e e b a n k (Marcus et al., 1993), the files con ta ined in the d i rec tor ies DJ, M A R l , and A T I S , respec t ive ly , ar t ic les f rom the Wall Street Journal, t ran- scr ipts f rom radio broadcas t s , and spon taneous sen tences co l lec ted as t rain- ing mate r ia l by the D A R P A A i r Trave l In fo rmat ion S y s t e m p rogram, for a total of app rox ima te ly 340,000 words o f t e x t :
Method
The occur rence o f each verb was c lass i f ied au tomat ica l ly , a cco rd ing to
the syntac t ic ca tegory of the v e r b ' s cont inuat ion . So each occur rence was c lass i f ied accord ing to whe the r the verb was fo l l owed by a direct ob jec t (NP), an inf ini t ive (S), a sentence c o m p l e m e n t wi th the c o m p l e m e n t i z e r
( SBAR) , a sentence c o m p l e m e n t wi thout the c o m p l e m e n t i z e r ( S B A R 0 ) , a PP, or others (which also conta ins occur rences o f the in t rans i t ive use o f the verb) . Here followed means immediately followed linearly in the bracketed text. Given the encod ing o f s t ructural re la t ions used in the da tabase , the
ca tegory mus t be a s is ter o f the verb, in a tree r e p r e s e n t a t i o n :
5 Although larger corpora are available, the choice of this corpus was dictated by practical restrictions. We did not include the MUC corpus counts, which are also freely available, as they are too skewed. This is of crucial concern for reliability of the correlation with sentence production studies, as such studies are usually not constrained by domain. If they are, as in the Connine et al. (1984) study, the domains are quite varied. The script contains a certain number of special cases, conceived to circumvent brack- eting and labeling errors in the database. Not all errors in the database could be detected in this way.

Analys i s of Verb Continuat ion Frequencies 439
The verb biases were calculated in steps. First, counts were produced
automatical ly. Second, for a subset of 44 verbs, these counts were corrected manual ly . Final ly, the counts for all the verbs were adjusted by a l inear
regression, where the abscissa axis was consti tuted by the automatic counts, and the ordinate axis by the manual ly corrected values. 504 data points over 768 total were fitted this way. 7 The results are reported in the appendix. The
automatic count is not perfect, but it is highly correlated to the manual count (r = .983). The overall accuracy is 95%. 8 In no case did the manua l cor-
rection change the preference of the verb, i.e., the mode of cont inuat ion, so this fitting step might not be necessary, if all that is needed is the verb bias.
C O M P A R I S O N S T O O T H E R S T U D I E S
The corpus-based results were compared to four sentence product ion
and comple t ion studies (Connine et al., 1984; Garnsey, 1994; Holmes et al.,
1989; Trueswel l et al., 1993) to assess the hypothesis that corpora can be useful in de te rmin ing verb frequencies and preferences of exper imental stim-
uli. Two measures of similari ty were calculated: the correlat ion coefficient
and Cohen ' s K [Cohen (1960), cited in Klauer (1987, p. 53)], which is a measure of inter judge agreement for quali tative data, where a cont ingency
table is used as a model. My reasoning for having this second measure was
that the corpus and the exper imental counts might not be highly correlated numerical ly , but they might still assign the cont inuat ion preferences in a
s imilar w a y ? In a con t ingency table, such as the one in Table I, the diagonal values
are the number of t imes in which two counts assign the cont inuat ion to the
same class. All the off-diagonal numbers represent the instances in which
the two counts differ. For example, the [NP, clause] cell gives the number of t imes in which a cont inuat ion was counted as NP in the corpus, and
clause by Trueswel l et al. (1993).
7 The counts for the verbs in Trueswell et al. (1993) were done diferently because all the verbs were corrected manually, but no record of the automatic count was kept. Thus, they were not included in the regression.
0 Accuracy is calculated as the ratio between the number of correct assignments and the total number of occurrences. Given a two-dimensional contingency table, where the two counts are each on one dimension, the number of correct assignments is given by the sum of the diagonal cells and the total number of occurrences is the total sum of all the cells.
9A X 2 test cannot be used in this instance, because one cannot assume that the two variables are independent, as the same set of verbs is used in both cases.

440 Merlo
Table I. Comparison of the Classifications Based on the Corpus Counts and the Sentence Completion Study in Trueswell et al. (1993)
Trucswell Corpus et al. (1993) NP Clause Others Total
NP 12 (8) 3 (2) 2 (2) 17 (12) Clause 1 (1) 5 (3) 3 (2) 9 (6) Others 0 (0) 5 (4) 5 (4) 10 (8) Total 13 (9) 13 (9) 10 (8) 36 (26)
Sentence Complet ion Studies
Table II reports the compar i sons be tween corpus counts wi th three sen- tence comple t ion s tudies (Garnsey , 1994; H o l m e s et al., 1989; T rueswe l l et al., 1993), ind ica ted in the first co lumn of the table, as TTK93 , HSC89 , and G A R 9 4 , respec t ive ly . The sentence comple t i on task usua l ly consis ts in pre- sent ing subjec ts wi th a sentence f ragment , e.g., John insisted, asking the subject to comple t e the sentence with the first con t inua t ion that comes to mind. The second co lumn of the table indica tes the number o f subjects on which the sentence comple t i on s tudy was pe r fo rmed . The third co lumn in- dicates the number of verbs used in the s tudy which were found in the corpus, or, in o ther words , the size of the s amp le on which the cor re la t ion was computed . The three r igh tmost co lumns p rov ide the quant i ta t ive and qual i ta t ive measures of corre la t ion . The numbers in paren thes i s b e l o w T I ' K 9 3 indicate the va lue o f K ca lcu la ted only on the 26 verbs for which more than 14 occur rences were found in the corpus. The actual f igures are repor ted in Tab le I, wh ich compares the corpus counts to T rueswe l l et a l . ' s (1993) counts. Number s in paren theses refer to those verbs for which more
than 14 occur rences were found in the co rpus? ~
Connine et al . (1984)
Connine et al. (1984) pe r fo rmed a large sentence p roduc t ion s tudy, in
which 108 subjec t s were tested. This task di f fered f rom sen tence comple t ion , because subjec ts were asked to p roduce a sentence con ta in ing a cer tain word . In some cases they were g iven a domain , in some others a s i tuat ion. Subjec t s
had no t ime or space constraints .
lo I considered this subset separately, because Trueswell et al. (1993)'s study was on 14 subjects. To support the validity of their sentence completion study, they cited the unpublished study by Garnsey on 107 subjects, which has a very high correlation to theirs (for NP r = .935; for S r = .916; for that r = .767).

Analysis of Verb Continuation Frequencies 441
0 .,.~
8 6
c -
o
e-
o L)
Y
0
N
r..)
tf~
o
CO G~ tf~
II II II
V V
II II II
o II
o
"E
E
II
L~
v
"G
II

442 Mer lo
Table III. Correlations Between the Corpus Counts and Connine et al. (1984)
r
NP S PP SBAR Others K
Group 1 < 50 .598 .751 .134 .291 .475
Group 2 > 50 .784 .835 .880 .371 .557 .694
F(1, 24)(Group 2) 38.362 55.258 82.304 3.820 10.805 p (Group 2) < .0001 < .0001 < .0001 .0624 .0031 .0001
As some of the counts in the corpus are very low, in comparing the corpus counts to those of Connine et al. (1984), I divided the verbs in two groups around the mean of occurrence (50) in the corpus. Sixty verbs were below the mean and 25 were above. 11 The data were reaggregated, both in the corpus and Connine et al. 's (1984) count, into five categories: NP, PP, S, SBAR, and others. Table III shows the correlation coefficients for each continuation class. 12
General Discussion
Several conclusions can be drawn from these data. First, the pattern of correlations between the corpus and the experimental counts is inconsistent, if one looks either at different experimental methods or at different cate- gories within the same correlation. Thus, in comparing the corpus analysis and the sentence completion studies, the NP continuation shows a better correlation than the clause continuation. The correlation between the corpus and the sentence production study seems good overall, with the exception of the clause continuation, which does not reach significance. The global qualitative measure of agreement reaches a satisfactory level only with the sentence production study, while the values of K in Table II show that the corpus and the sentence completion method are not strongly correlated.
Second, the size of the sample seems to play a role in the correlation. The correlation with Trueswell et al. (1993) increases in taking into account a group of verbs, which, although smaller, consists of verbs with higher occurrences. The correlations of Group 2 with Connine et al. (1984) are
11 AS Connine et al. (1984) partitioned the continuat ions into many more classes than I did, a reaggregat ion of their data was necessary, as fol lows (numbers correspond to those used in their paper for different continuations): NP = 9-14; PP = 2; S = 3,4,7,8; SBAR = 5,6; others = 1,15.
12 One notices that in no case, in either of the reaggregations, is the SBAR continuation the preferred one. Thus, in reality, the adjudication is to four categories. I discuss the possible consequences of this below.

Analys i s of Verb Cont inuat ion Frequencies 443
consistently better than Group 1. For PPs the increase is striking, probably due to the fact that this syntactic category includes all types of PPs following the verb, selected by the verb but also not selected, such as temporal, in- strumental or locative PPs. We expect more fluctuation in this category than in the others. This conjecture is also confirmed by some global comparisons of the corpus counts to the sentence production percentages in Connine et al. (1984), which do not show any relevant difference for any category, except PPs (corpus: 47; sentence production: 17). As PPs are often optional parts of the sentence, one might hypothesize that, in sentence production norms, subjects tend to drop (or not produce) optional parts of the sentence. It is unlikely that this discrepancy affects studies of verb subcategorization preference, unless one of the frames studied starts with a PP.
Other global counts, which compare corpus and sentence completion average percentages of occurrence, are presented in Table IV. They show that, while the clausal continuations are comparable, the sentence completion task has more NP continuations. It appears that sentence completion does not underestimate clause continuations, compared to edited text.
Moreover, in Connine et al. (1984), the fact that in the qualitative com- parison no verb preferred the clause as the continuation should lead to re- flection on the use of preference data in general. Holmes et al. (1989) also noticed that some of the verbs that they classified either as NP or as S-bias had in fact a different preference, i.e., a mode of continuation in some other category. In experimental research that has manipulated verb preference, the verb bias was calculated by looking only at the categories that were relevant for the experiment. This practice implicitly assumes that the parser is sen- sitive to the ranking of preferences, and that if the most-preferred continu- ation is absent, the nextmost preferred continuation will act as the bias. In fact, this is an interesting assumption that needs to be tested. It is not im- possible to envisage a different scenario, where, for example, the parsing device is exclusively sensitive to bias, and incapable of making further dis- tinctions. Consider the case in which the pattern of preference is actually S, indicating an infinitival clause, NP and SBAR, in this order of preference, but where the experimental testing is done only for NP and SBAR. Exper- imentation up to the present has assumed that in this case the parser prefers
Table IV. GlobaI Counts on Average Percentage of Occurrence
Corpus TTK93 ~ Corpus Garnsey
NP 28 42 31 39
Clause 33 32 30 33
"TTK93 = Trueswell et al. (1993).

444 M e r l o
the NP. Thus, it assumes a direct relation to the ranking of preference. But, in fact, in this instance, a parser which is only sensitive to the distinction bias~else, would rank both NP and SBAR at the same level as, simply, equally nonpreferred? 3
Finally, one can remark that there is an unexplained difference between subjective and objective norms. The fact that subjective and objective norms can vary greatly is relevant in light of Shapiro, Nagel, & Levin 's (1993) results, which showed that processing complexity correlates with individual verb preferences (for each subject) even when no such correlation is found with average verb preference (across subjects). This finding might lead one to think that subjective norms are the only relevant norms to be used in experimentation. On the other hand, norms collected from corpora have been successfully used for a long time in the study of isolated words. In the area of lexical access, for instance, Segui, Mehler, Frauenfelder, & Morton (1982) found that lexical access for both closed-class and open-class words shows frequency effects, where frequency was taken from objective norms (Goug- enheim, Michlea, Rivenc, & Sauvageot 1956). With respect to syntax, for example, MacDonald, Pearlmutter, & Seidenberg (1994) showed that fre- quencies for isolated words, according to either the Brown Corpus or the Wall Street Journal, correlate (negatively) to syntactic complexity in the main verb/reduced relative clause type of ambiguity. In Juliano and Tanen- haus (1994), and later in this paper, one finds that corpus-based frequencies of verbs are indeed predictors of the complementizer effect.
It is probably more appropriate to keep using corpus counts when needed and to continue exploring the possible sources of difference. I present some work in this direction in the next section.
ANALYSIS OF S T I M U L I
Under the assumption that corpus-based counts are actually relevant for psycholinguistics, I performed an analysis of some of the experimental stim- uli found in the literature.
This revisitation of the stimuli is particularly interesting for those ex- periments that have found evidence in favor of the garden path theory of processing (Ferreira & Henderson, 1990; Frazier & Rayner, 1982; Rayner & Frazier, 1987). If the stimuli show a global preference in favor of an NP
13 It shou ld not be difficult to de te rmine w h i c h is the case, e i ther by tes t ing direct ly or by ana lyz ing in re t rospect the i t em-by - i t em resul ts o f ex is t ing exper imen t s . If the cur- rent pract ice is correct, then there shou ld be no d i f fe rence be tween " f a k e " and " r e a l " bias, as for ins tance predic tors o f d i f fe rences in react ion t imes.

Analysis of Verb Continuation Frequencies 445
continuation, then it could be that the tendency to attach an NP fol lowing a verb as the direct object is an effect of the frequency of the construction, rather than the consequence of a more general parsing strategy. If, on the other hand, the stimuli are balanced between the two possible continuations being studied, then the preference for the NP attachments cannot be due to a lexical preference.
In all cases the stimuli were analyzed according to a measure of strength of the bias, shown in equation 2 below, which results in a positive value if the bias is for NP, a negative value if the bias is for clause, and zero for equibiased stimuli:
NNp Nclausc 1 1
2. - - ~ N P , - clause/ + ~ ]~ N P j - clausej 2NNp i=1 2Nclausc j=l
NNp indicates the number of NP-biased verbs, while Nr .... is the number of the clause-biased verbs. NPI and clausei indicate the percentage of NP and clause continuations for verb i. This difference is a rough measure o f the strength of the bias of a verb (see also Juliano & Tanenhaus, 1994, who used a similar measure). The second summat ion is always negative; thus equation 2 is a weighted difference of means. The two means are weighted by the size of the respective group, because often not all the verbs in the stimuli were found in the corpus. Not weight ing the sums would introduce a bias due to the corpus counts and not due to the stimuli.
Results
The global results o f the analysis described above are shown in Table V. The first column shows how many of the verbs used in the experiments are included in the analysis. Verbs were eliminated because of null or low counts or because they were equibiased, and therefore could not affect the balance o f the stimuli. The second and third columns show how many verbs preferred an NP continuation and how many preferred a clause continuation, respectively. For the late closure experiment (FR82LC), the third column reports the counts of verbs with an intransitive preference? 4 The fourth col- umn (W diff) reports the total weighted difference between NP and clause bias. The fifth column (Mean diff) reports the mean difference, while the fol lowing two columns show the significance of these numbers as given by
1~ The ambiguity studied in late closure is not directly available in our counts, so a reinspection of the continuation contained in PP and in others was necessary. The measure adopted was conservative: only those verbs that were clearly intransitives were included. (For example, middles were not counted as intransitives.) For the PP cases, clearly phrasal constructions were excluded.

446 Merlo
Table V. Global Analysis of Experimental Stimuli
NP- S- W Mean Comp Experiment ~ Verbs bias bias Diff Diff t p %
FR82LC 10/i6 8 2 5.9375 .594 .376 .7155 - -
FR82MA 14/16 7 7 -10.6428 -.760 -.793 .4423 59 FH90 24/40 10 14 4.8340 .201 .466 .6458 60
RF87 17/20 11 6 1.7650 .104 .166 .8702 56 TTK93 20/20 11 9 3.5050 .175 .386 .7037 63
IlSC89 21/32 14 7 2.1785 .104 .206 .8391 68
HKM87 19/23 12 7 5.9100 .311 .604 .5535 61
FR82LC = Frazier and Rayner (1982), late cIosure; FR82MA = Frazicr an Rayner (1982), min- imal attachment; FH90 = Fcrreira and Henderson (1990); RF87 = Rayner and Frazier (1987); TTK93 = Trueswell et al. (1993); HSC89 = Holmes ct al. (1989); ItKM87 = Holmes el al. (1987); W diff = weighted difference; glean diff = mean difference; Comp = complementizer.
a t-test. The r ightmost co lumn shows the percentage of use of that as overt
compIement ize r for the S-biased verbs.
T h e G a r d e n Path M o d e l
Description
Three exper iments that have supported the garden path theory of sen- tence process ing have been analyzed (Ferreira & Henderson , 1990; Frazier
& Rayner, 1982; Rayner & Frazier, 1987). The exper iments were des igned
to test the hypothesis that the human sentence processor adopts general parsing strategies, based on economy of syntact ic representat ion. More pre-
cisely, the parser at tempts to bui ld the representat ion with the smal ler num-
ber of nodes (minimal attachment). W h e n possible al ternat ives have the same number of nodes, an overr iding strategy of late closure operates, s ince
the parser has the tendency to incorporate i ncoming material into exis t ing
nodes. These two hypotheses can be tested in two cases of syntact ic ambigui ty .
In one case, when a verb presents the t ransi t ive/ intransi t ive ambigui ty , late
closure predicts that the parser prefers the transi t ive interpretat ion. This am- biguity is shown in sentences 3a and 3b, with predicted preference for 3a [adapted from Frazier & Rayner (1982)]:
3. a. Since Jay always jogs a mile that seems like a short distance to him.
b. Since Jay always jogs a mile seems like a short distance to him.

Analys i s of Verb Continuat ion Frequencies 447
In the second case, when a verb presents an NP/clause ambiguity, such as those studied in the third section above, minimal attachment predicts that the parser will prefer the direct object, i.e. NP attachment, exemplified in sentence 4a:
4. a. It appears that Sherlock Holmes didn't suspect the very beautiful young countess.
b. It appears that Sherlock Holmes didn't suspect the very beautiful young countess was a fraud.
Frazier and Rayner (1982) presented two reading experiments, where eye movements of the subjects were recorded, one to test late closure and one to test minimal attachment. They found increased reading times at the disambiguation region for the reduced clauses (examples 3a and 4a above), which they interpreted as evidence of a complexity effect, caused by the garden path in the conditions where the ambiguous NP is not the object.
Ferreira and Henderson (1990) presented three experiments, where they studied the NP/clause ambiguity. Although they explicitly controlled for the bias of the verbs, following the norms of Connine et al. (1984), they still found evidence in favor of a garden path model of parsing, namely, no interaction with verb type.
Rayner and Frazier (1987) tested a corollary of minimal attachment: If the increased reading times are an effect of reanalysis at the disambiguating region, then the clausal complement with an overt complementizer should be parsed faster since it is not ambiguous, as also Holmes, Kennedy, and Murray (1987) noted. They found a difference in reading times, with the unambiguous sentence being parsed faster.
As can be seen, the predictions of the garden path theory are empirically indistinguishable, in these experiments, from a general preference for direct object attachment of an NP following a verb. This preference for object attachment has been generalized to a parsing strategy which seeks to mini- mize representation (Frazier, 1978). However, it could also be that this gen- eral preference for object attachment is an effect of the frequency of this construction after the verbs used in the stimuli.
Discussion
For the late closure experiment (FR82LC), Table V shows that the stimuli of this experiment are the most strongly biased in favor of an NP continuation. Many fewer clause-biased verbs were found than NP-biased verbs. If the verbs that were found are a representative sample, then the fact that only two verbs showed a clause bias confirms the conclusion that the stimuli could have favored a direct object interpretation.

448 M e r l o
The minimal attachment experiment (FR82MA in Table V) is rather strongly biased in the opposite direction from NP attachment. Nonetheless, garden path effects were reported. Here a balanced sample of verbs was found, which constitutes a good percentage of the total. This result supports a structural theory of parsing, and argues against a frequency account. How- ever, a confounding factor could have occurred in this case, as discussed at length by TrueswetI et aI. (1993). Namely, the increased reading times might not be a complexity effect, but rather an effect of "surpr i se . " If the verbs that were used have the tendency to be used with the complementizer, which, on the contrary, was omitted in the stimuli, the increased reading times in the verb region might simply be due to an effect generated by an unexpected structure. Fifty-nine percent of the occurrences of the stimuli in the corpus used in the minimal attachment experiment were with the complementizer. Trueswell et al. 's (1993) stimuli had a preference of 63% for overt that. They found a strong correlation (r = .734, in their count) between the per- centage of clausal completions with a that and the complementizer effect (measured as a difference in naming latency between sentences without a that and with a that). Thus one could think that 59% ef preference for the use of the overt complementizer is sufficient to trigger a surprise effect.
The stimuli in Ferreira and Henderson (1990) were balanced, but the garden path effects could have been affected by the use of verbs strongly preferring the use of the overt complementizer (among the clause-bias verbs, 4 of 14 preferred to use that at least 80% of the time).
The stimuli in Rayner and Frazier (1987) were also balanced. Since this experiment focused on the comparison between sentences with an overt complementizer and sentences with a null one, the percentage of the com- plementizer was crucial here. (See Table IV, rightmost column, for per- centage of complementizer used.) Rayner and Frazier (1987) had the lowest complementizer percentage of all the experiments. In particular it was lower than the percentage in Holmes et al. (1987), in which results that contra- dicted Rayner and Frazier (1987) were found. Increased reading times for both the reduced clause (without the complementizer) and the unambiguous clause were found, starting from the beginning of the embedded clause. Holmes et al. (1987) interpreted this result as showing that increased reading times are not the effect of reanalysis, but rather of the complexity of a new clause. If the increased reading times are due to a complementizer effect, one would have expected to find a bigger percentage of complementizer usage for Rayner and Frazier (1987), since they found a difference between the reduced clause and the unambiguous clause. Such a difference could have been explained by a stronger complementizer effect than what was triggered by Holmes et al . 's (1987) stimuli. The corpus percentages instead

Analysis of Verb Continuation Frequencies 449
suggest that the expectation for the complementizer is in the opposite direc- tion.
T h e Lex ica l G u i d a n c e M o d e l
Two experiments were analyzed that found an interaction between verb type and processing time (Trueswell et al., 1993; Holmes et al., 1989). These experiments found an increase in processing times only for NP-bias verbs, but not for S-bias verbs, thus suggesting that the parser uses lexicat infor- mation immediately.
Description
Trueswell et al. (1993) described three experiments where they con- trolled for the bias of the verbs used in the stimuli, according to the pref- erence counts discussed in the third section above. The experiments confirmed the hypothesis that subcategorisation becomes available right after the verb is recognized, and that individual lexical biases of verbs influence structural attachments.
Holmes et al. (1989) reported on three experiments to study lexical expectation in parsing, using a word-by-word reading task. They confirmed the hypothesis that lexical expectation is used early in parsing, as they found a complexity effect after NP-bias verbs, but not after S-bias verbs.
Discussion
In both these experiments the biases of the verbs were prejudged through a sentence completion task, as described in the third section above. The corpus counts show that, in agreement with the sentence completion task, the stimuli of the experiments were balanced.
Trueswell et al. (1993) argued that the increase in processing time in the disambiguating region of the S-biased verbs can be explained as a sur- prise effect, since the verbs used as stimuli are more often used with the complementizer, while in the experiment they appeared in a reduced com- plement clause. They supported this claim by showing that the size of the complementizer effect is strongly correlated with the percentage of usage of that clauses. They also argued that no residual effect remains, as the re- gression line has a negative intercept.
Table VI shows correlations between the complementizer effect and the percentages of use of that, collected by corpus analysis or by other sentence completion studies. The fifth and the sixth columns present percentages of usage of sentences with the complementizer, both declarative and interrog-

450 Merlo
Table VI. Percentages of Completions with Declarative and All Embedded Sentences in Different Studies, Compared to the Increase in Reading Times for Reduced Sentential
Complements*
Corpus TI'K93 GAR94 Corpus GAR94 Comp Verb that % that % that % Comp % Comp % effect
boast 100 100 87 100 87 90 decide 60 0 64 90 67 2 hint 20 100 81 20 81 90 hope 41 29 39 41 39 4 imply 75 91 85 75 86 31 insist 65 70 77 65 77 15 realize 50 62 60 50 62 43 r .117 .805 .620 -.079 .599 - - p ns .02 ns ns ns - -
*TFK93 = Trueswcll et al. (1993); GAR94 = Garnsey (1994); Comp = complementizer.
ative, and their correlat ion with the complement ize r effect. I discuss these compar isons in turn.
As far as the correlat ion be tween the percentage of that usage and the complement ize r effect is concerned, one notices that it nei ther holds for the
corpus analysis, nor does it extend to other sentence comple t ion studies. As one can see in the second and third co lumns of Table VI, the percentage of
that usage in the corpus and Trueswel l et al. (1993) has a s imilar profile for most verbs, with the exception of the verbs hint and decide. Because of
these two verbs, there is no correlat ion be tween the corpus percentages and the complement ize r effect ( r = .117, slope .181, intercept 28.5). 15
One can notice that the difference be tween the corpus and the sentence
comple t ion percentages cannot be entirely due to the method, as shown by
the percentages found in Garnsey (1994), which are listed in the fourth co lumn of Table VI. Garnsey found a percentage of that usage which was
closer to the corpus results for the verb decide, but closer to Trueswel l et
al . 's (1993) result for hint. Moreover, there is no correlat ion be tween Garn- sey ' s (1994) percentages and the complement ize r effect. Thus, the correla-
tion found by Trueswel l et al. (1993) does not seem to carry across different
collect ions of data, even if obtained by the same task. Instead, a better predictor of the complement ize r effect is perhaps verb
frequency, as noticed by Jul iano and Tanenhaus (1994). This measure gives
1~ If one excludes the verbs hint and decide, the correlation betv,,een the corpus propor- tions and the complementizer effect has a coefficient of .814. The intercept, as in Trueswell et at. (1993), is also negative (slope 1.18, intercept --41.5). But, in this case, the correlation is not significant.

Analys i s of Verb Continuat ion Frequencies 451
good results with frequency counts extracted from the corpus, as presented
in the appendix. The correlation be tween the logto of the frequency and the
complement izer effect is r = - . 8 2 1 , p = .02. In Trueswel l et al. (1993), only declarative sentences which use the
complement izer t ha t were included in the percentages; thus the effect cannot, strictly speaking, be called a c o m p l e m e n t i z e r effect. It is in fact an interesting quest ion to see if the correlation found for t ha t holds for all complement iz -
ers. The classification labeled SBAR in the corpus includes all types of
complement izers , declarative and interrogative, since from the l inguist ic
point of v iew these sentences have similar structures. If one considers all
types of complement izers , the pattern of percentage of usage is marginal ly different from the pattern seen above for the declarative complement izer
t h a t (see co lumn C O M P % in Table VI), and the correlation is not higher. The same can be said for the correlation be tween the complement izer effect and the percentages obtained by Garnsey. t6
One can conclude that, on one hand, these results show that more work
needs to be done to explore the relations between experimental data and the types of complement izers , and, on the other hand, results obtained for the
declarative complement ize r and the sentence complet ion task do not gen-
eralize very well. On the other hand, this result supports the claim in Trueswel l et al.
(1993) that the parser is sensit ive to patterns of lexical cooccurrence, as the
different correlations between reaction times and only declarative or all com- plement izers provides evidence in this direction. They say that " these cor-
r e l a t i o n s . . , demonstrate that the processing system is sensit ive t o . . . subtle
patterns of lexical co -occur rence" (p. 536). Their experiments did not show this directly, in fact. To show that the parser is sensit ive to l e x i c a l cooc-
currence, one needs to look at more than one type of complement izer , and
~ In performing these correlations, I noticed that the use of wh completions is lower in the sentence completion task than in the corpus counts. Actually, in the corpus counts, wq, sentences are the preferred continuations after the verb decide (15/20), while in Garnsey (1994) only one occurrence was found. The actual distribution of the SBAR complements for decide, in the corpus, is two null complementizer clauses, three that complement clause, and fifteen wh complementizer clauses (eight whether, four what, two how, and one which N complements). I explored the relationship between the corpus and sentence completion with respect to indirect questions, by comparing the wh completions provided to me by Garnsey to the wh completions found in a fragment of the IVall Street Journal corpus of about 1.6 million words, for a small sample of 14 verbs. I indeed found that there is no correlation (r = .381, p = .2672) between the two. At the moment, I can only speculate on the cause of this difference. Perhaps the sentence completion task induces simpler continuations, and thus wh completions are disfavored, or the particular corpus used is biased toward interrogatives.

452 Merlo
then show that for different types of complementizers one finds different effects. This is what one finds. The parser is indeed sensitive to effects of " lexical cooccurrence," as the reaction times correlate with the declarative complementizer, at least in their study, but not with a comprehensive count that includes all complementizers, thus showing that this effect is not ex- plicable simply at the syntactic level, but requires the parser to look at the lexical level, or at least at more specific classes than "complemen t i ze r . "
General Discussion
According to the corpus counts all experiments were rather well bal- anced, with the possible exception of the late closure experiment in Frazier and Rayner (1982). However, even in cases in which the stimuli were strongly biased against a minimal attachment continuation, complexity ef- fects were found. Thus the frequency hypothesis is not tenable in its simplest form, as it would not explain the findings of the garden path experiments, especially the one which tested the use of the minimal attachment strategy. Trueswell et al. 's (1993) explanation of increased processing times in terms of a surprise effect has been shown to be in need of refinement. It is not confirmed either by the corpus data or by the data collected by sentence completion in Garnsey (1994). The fact that one finds different patterns of correlation with different complementizers seems to support a model in which word-specific information is relevant in building the structure.
C O N C L U S I O N S
In this paper I have explored the use of corpora counts in the study of psycholinguistic stimuli and the results of experiments. The first result, that corpus-based counts of structures, although in part correlated, still differ in important ways from sentence completion and production counts, is of in- terest to clarify the relationship between spontaneous and elicited produc- tion. By exploring in more detail the partial counts and classifications of the different methods, one can shed light on the properties of these counts. For example, it seems that the production of declarative and interrogative com- plements varies substantially in the different methods.
I have used corpus-based counts to investigate the influence of fre- quency-based verb preference on experimental results. On the somewhat limited evidence provided by a few experiments, I have found that studies which have reported results in favor of the garden path theory of sentence processing are as balanced as those studies which have found evidence for lexical guidance, thus rendering a parsing model based simply on frequency

Analys i s of Verb Cont inuat ion Frequencies 453
effects untenable. On the other hand, the comparison of reading times to the lexical expectation related to different types of complementizers has shown that the parser is sensitive to the lexical content of the complementizer, and thus it makes use of word-specific frequency information.
A P P E N D I X
Verbs corrected manually
Verb NP PP S SBAR SBAR0 Others Total
accept 31 4 0 1 0 2 38 admit 3 2 0 3 8 3 19 advise 11 2 0 0 0 4 17 agree 1 32 96 16 4 20 169 argue 3 3 0 36 3 17 62 assert 1 0 0 7 0 2 10 believe 4 5 10 27 60 10 116 boast 2 4 0 2 0 0 8 claim 3 1 3 11 9 6 33 confirm 17 3 0 7 2 5 34 decide 5 5 25 19 2 9 65 deny 29 1 0 2 7 1 40 dispute 9 2 0 0 0 0 11 feel 8 5 0 8 13 22 56 figure 0 0 1 1 11 3 16 forget 3 1 0 2 0 2 8 guess 2 0 0 2 1 2 7 hint 0 4 0 1 4 2 11 hope 1 5 32 12 17 4 71 imply 2 2 0 3 1 1 9 insist 1 7 0 11 6 5 30 learn 7 6 5 9 1 4 32 maintain 18 1 0 9 5 5 38 mention 9 4 0 1 0 3 17 observe 1 0 0 1 0 7 11 predict 18 1 0 13 17 5 54 promise 5 2 5 0 1 4 17 prompt 21 1 0 0 0 0 22 realize 12 1 0 6 6 4 29 recall 7 3 0 2 0 9 21 remember 10 0 1 1 3 6 21

454 M e r l o
Verbs corrected manually
Verb NP PP S SBAR SBAR0 Others Total
reveal 6 0 0 4 0 0 10 speculate 1 3 0 5 1 1 11 suppose 0 0 17 0 1 1 19 teach 7 1 0 0 0 0 6 think 2 22 7 10 85 16 117
Other Verbs
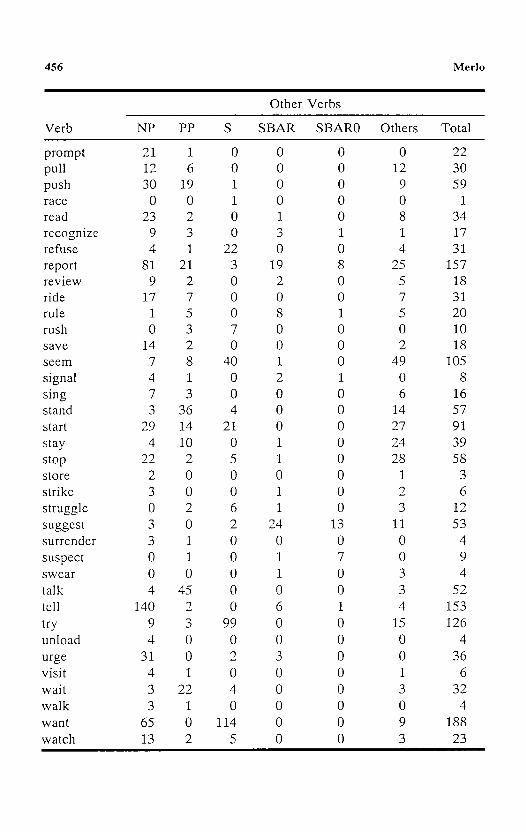
Verb NP PP S SBAR SBAR0 Others Total
allow 94 2 18 1 0 3 118 announce 55 11 0 12 7 26 104 answer 9 1 0 0 0 1 11 approve 41 18 0 2 0 9 70 ask 44 12 17 16 0 18 105 attack 2 2 0 1 0 1 6 attempt 1 1 16 0 0 0 18 block 20 0 0 0 0 1 21 buy 213 14 0 0 0 18 245 call 135 43 1 7 0 10 196 carry 48 2 0 0 0 8 58 chase 1 0 0 0 0 0 1 cheat 1 0 0 0 0 0 1 check 4 0 0 1 0 1 6 choose 10 3 9 0 0 1 23 comfort 0 1 0 0 0 0 1 continue 22 19 110 0 0 49 200 criticize 9 3 0 0 0 0 12 debate 1 1 0 0 0 0 2 describe 30 10 0 1 0 2 43 disappear 0 1 0 0 0 6 7 discuss 19 2 0 0 0 2 23 drink 2 1 0 0 0 5 8 drive 15 5 0 0 0 13 33 encourage 29 2 1 0 0 1 33 escape 5 4 0 0 0 0 9 expect 121 7 161 9 5 35 338 fail 1 3 44 0 0 10 58 fight 15 5 0 0 0 4 24

Analys i s of Verb Cont inuat ion Frequencies
Other Verbs
455
Verb NP PP S SBAR SBAR0 Others Total
fly 14 23 0 0 0 14 51 follow 94 18 0 0 1 9 122 gore 1 0 0 0 0 0 1 guard 3 2 0 0 0 0 5 happen 6 20 3 1 0 28 58 hear 20 4 1 4 0 4 33 help 60 4 33 1 0 43 141 hesitate 0 0 1 0 0 0 1 hire 15 2 1 0 0 3 21 hit 36 5 0 0 0 13 54 include 291 7 7 0 0 9 314 investigate 9 1 0 2 0 1 13 invite 5 2 2 0 0 2 11 judge 1 4 0 0 0 1 6 jump 18 8 1 0 0 6 33 keep 80 8 2 0 0 22 112 kick 0 0 0 0 0 3 3 kill 21 4 0 0 0 8 33 know 40 41 4 41 21 38 185 leave 91 85 4 0 0 25 205 lecture 2 0 0 0 0 0 2 load 0 1 0 0 0 0 1 lose 71 8 0 1 0 9 89 move 30 32 4 0 0 43 109 notice 1 1 0 0 0 0 2 object 0 4 0 0 0 1 5 order 7 4 1 1 0 0 13 paint 3 0 0 0 0 1 4 pass 15 12 0 0 0 7 34 pay 122 49 0 2 0 49 222 perform 7 2 0 0 0 4 13 permit 17 1 0 0 0 2 20 persuade 10 0 0 0 0 1 11 phone 1 0 0 0 0 0 1 play 35 8 1 0 0 12 56 point 0 12 0 0 0 17 29 position 1 0 1 0 0 0 2 praise 2 0 0 0 0 0 2
456 Merlo
Other Verbs
Verb NP PP S SBAR SBAR0 Others Total
prompt 21 1 0 0 0 0 22 pull 12 6 0 0 0 12 30 push 30 19 1 0 0 9 59 race 0 0 1 0 0 0 1 read 23 2 0 1 0 8 34 recognize 9 3 0 3 1 1 17 refuse 4 1 22 0 0 4 31 report 81 21 3 19 8 25 157 review 9 2 0 2 0 5 18 ride 17 7 0 0 0 7 31 rule 1 5 0 8 1 5 20 rush 0 3 7 0 0 0 10 save 14 2 0 0 0 2 18 seem 7 8 40 1 0 49 105 signal 4 1 0 2 1 0 8 sing 7 3 0 0 0 6 16 stand 3 36 4 0 0 14 57 start 29 14 21 0 0 27 91 stay 4 10 0 1 0 24 39 stop 22 2 5 1 0 28 58 store 2 0 0 0 0 1 3 strike 3 0 0 1 0 2 6 struggle 0 2 6 1 0 3 12 suggest 3 0 2 24 13 11 53 surrender 3 1 0 0 0 0 4 suspect 0 1 0 1 7 0 9 swear 0 0 0 1 0 3 4 talk 4 45 0 0 0 3 52 tell 140 2 0 6 1 4 153 try 9 3 99 0 0 15 126 unload 4 0 0 0 0 0 4 urge 31 0 2 3 0 0 36 visit 4 1 0 0 0 1 6 wait 3 22 4 0 0 3 32 walk 3 1 0 0 0 0 4 want 65 0 114 0 0 9 188 watch 13 2 5 0 0 3 23

Analys i s of Verb Continuat ion Frequencies 457
R E F E R E N C E S
Cohen, J. (1960). A coefficient of agreement for nominal scales. Educational and Psy- chological Measurement, 20, 37--46.
Connine, C. M., Fcrrcira, F., Jones, C., Clifton, C., & Frazicr, L. (1984). Verb framc prefercnccs: Descriptive norms. Journal of Psycholinguistics Research, 13, 307-319.
Ferreira, F., & Clifton, C. (1986). The independence of syntactic processing. Journal of l~lcmory and Language, 25, 348-368.
Fcrrcira, F., &Hcndcrson, J. M. (1990). The use of verb information in syntactic parsing: A comparison of evidence from eye-movements and word-by-;vord self-paced reading. Journal of Experimental Psychology: Learning, Memory and Cognition, 16, 555-568.
Ford, M., Bresnan, J., & Kaplan, R. (1982). A competence-based theory of syntactic closure. In J. Brcsnan (Ed.), The mental representation of grammatical relations (pp. 727-796). Cambridge, MA: MIT Press.
Frazicr, L. (1978). On cor~wrehending sentences: Syntactic parsing strategies. Unpub- lished doctoral dissertation, University of Connecticut.
Frazicr, L., & Rayner, K. (1982). Making and correcting errors during sentence compre- hension: Eye movements in the analysis of structurally ambiguous sentences. Cog- nitive Psycl, ology, 14, 178-210.
Garnsey, S. (1994). [Percentages of completions in a sentcnce completion task on 107 subjects]. Unpublished data.
Gougcnheim, G., Michlca, R., Rivenc, P., & Sauvagcot, A. (1956). L'~laboration du Franfais ~l~mentaire et d'une grammaire de base. Paris: Didier.
Klauer, K. J. (1987). Kriteriumsorientierte Tests. G6ttingen: Verlag ftir Psychologic. Hindle, D., & Rooth, M. (1993). Structural ambiguity and lexical relations. Computa-
tional Linguistics, 19, 103-120. Holmes, V. M., Kennedy, A., & Murray, W. S. (1987). Syntactic structure and the garden
path. The Quarterly Journal of Experimental Psychology, 39/1, 277-293. Holmes, V. M., Stowe, L., & Cupples, L. (1989). Lexical expectations in parsing com-
plement-verb sentences. Journal of Memory and Language, 28, 668--689. Juliano, C., & Tancnhaus, M. (1994). A constraint-based lexicalist account of subject/
object attachment ambiguity. Journal of Psycholinguistics Research, 23, 459-471. MacDonald, M. C., Pcarlmutter, N. J., & Scidenberg, M. (in press). The lexical nature
of syntactic ambiguity resolution. Psychological Review. Marcus, M., Santorini, B., & Marcinkicwicz, M. A. (1993). Building a large annotated
corpus of English: the Penn Trcebank. Computational Linguistics, 19, 313-330. Mitchell, D. (1987). Lcxical guidance in human parsing: Locus and processing charac-
teristics. In M. Colthcart (Ed.), Attention and Performance XII: The psychology of reading, pp. 601-618). Hillsdale, N J: Erlbaum.
Mitchcli, D., & Holmes, V. (1985). The role of specific information about the vcrb in parsing sentenccs with local structural ambiguity. Journal of 3lemory and Language, 24, 542-559.
Rayncr, K., & Frazicr, L. (1987). Parsing temporarily ambiguous complemcnts. The Quarterly Journal of Experimental Psychology, 39A, 657--673.
Segui, J., Mehlcr, J., Frauenfeldcr, U., & Morton, J. (1982). The word frequency effect and lexical access. Neuropsychologia, 20, 615---627.
Shapiro, L., Nagel, P., & Levin, B. (1993). Preferences for a verb ' s complements and their use in sentence processing. Journal of Memory and Language, 32, 96-115.
Trueswell, J., Tanenhaus, M., & Kello, C. (1993). Verb specific constraints in sentence processing: Separating effects of lexical preference from garden-paths. Journal of Experimental Psychology: Learning, Memory and Cognition, 19, 528-553.

![arXiv:1504.04097v2 [cond-mat.str-el] 2 Feb 2016 · analytic continuation of the data to real frequencies is essential3, which is a mathematically ill-posed problem. ... (MIPT). In](https://img.pdfslide.net/doc/110x75/5ad25fd67f8b9a92258d0e37/arxiv150404097v2-cond-matstr-el-2-feb-2016-continuation-of-the-data-to-real.jpg)



























