Embed Size (px)
Citation preview

A PARALLEL COMPILER FOR SequenceL
by
PER ANDERSEN, B.E., M.S.
A DISSERTATION
IN
COMPUTER SCIENCE
Submitted to the Graduate Faculty of Texas Tech University in
Partial Fulfillment of the Requirements for
die Degree of
DOCTOR OF PHILOSOPHY
Approved
Chairperson of the Committee
Accepted
Dean of the Graduate School
August, 2002

Copyright 2002, Per Andersen

ACKNOWUEDGEMENTS
I could not have completed this dissertation without the support and encouragement
of a number of people who I wish to acknowledge here.
Foremost, in this group of people is Dr. Daniel Cooke. Dr. Cooke has been a
dedicated advisor, a judicious mentor, and a good friend. Dr. Cooke introduced me to
compiler theory and SequenceL and during a three-year process he provided constant
guidance to my academic work and research projects. He stood by me at times of
difficulty, encouraging me and showing his confidence in me. This dissertation work
would not be in the current form without his insightful input and constmctive criticism.
I am very grateful to Dr. Noe Lopez-Benitez, Dr. Milton Smith, and Dr. Richard
Watson, who served on my dissertation committee. I appreciate their intellectual
perspectives and general encouragement over the process of this dissertation work.
I would like to thank my family for putting up with the time I have spent away
from them during this process. At times I may have been near them physically but
mentally I was a thousand miles away. Even so my wife Sue has always given me her full
support and encouragement. Without this support this dissertation would not have taken
place.

TABLE OF CONTENTS
ACKNOWLEDGEMENTS ii
ABSTRACT vii
UST OF TABLES viii
USTOFHGURES ix
CHAPTER
L INTRODUCTION 1
1.1 An Introduction to SequenceL 4
1.1.1 Regular Constmct 7
1.1.2 Irregular Constmct 7
1.1.3 Generative Constmct 8
1.1.4 Consume-Simplify-Produce 8
1.2 Imphed Parallelisms in SequenceL 12
1.2.1 Singleton Computations 13
1.2.2 Parallelisms Involving Indexing 13
1.2.3 Control Flow Parallelisms 15
1.3 Document Overview 16
n. CURRENT STATE OF PARALLEL PROGRAMMING 17
2.1 Message Passing Interface 18
2.1.1 MPI Programming Example 20
2.2 0penMP 25
111

2.2.1 OpenMP Programming Example 26
2.3 POSIX Threads 28
2.4 Parallel Programming Languages 29
2.4.1 NESL 31
2.4.1.1 VCODE 32
2.5 Automated Parallel Language Tools 37
2.5.1 PARAMAT 38
2.5.2 PAP 40
2.6 Parallel Architectures 42
m. METHODOLOGY 44
3.1 Lexical Analysis and Syntax Analysis 45
3.1.1 Eliminating Left Recursion 47
3.1.2 Eliminating Common Prefixes 48
3.1.3 Selection Set Generation 49
3.2 Semantic Analysis 55
3.3 Intermediate Code 59
3.3.1 Quadruples and Triples 59
3.4 Code Generation 60
3.4.1 Parallel C Code 62
3.5 Scheduling 65
rv. RESULTS 67
4.1 Proof of Concept 68
IV

4.1.1 General Approach to Mapping SequenceL Constmcts 70
4.1.1.1 Regular Constmcts 70
4.1.1.2 Irregular Constmcts 75
4.1.1.3 Generative Constmcts 78
4.1.2 Proof of Concept Through Testing 78
4.2 Intermediate Language 83
4.2.1 Initial Intermediate Language 84
4.2.2 SequenceL Intermediate Language 89
4.2.2.1 SequenceL IC Operations 91
4.2.2.2 Multi-Operand Operations 93
4.2.2.3 Conditional Operation 98
4.2.2.4 Generative Operation 99
4.3 SequenceL Thread Model 100
4.3.1 Dynamic Thread Function Creation 104
4.3.2 Dynamic Thread Functions for Conditional Expression.. .111
4.4 Optimization and Scheduling Issues 116
4.4.1 Granularity 116
4.4.2 Code Restmcturing 121
4.4.3 Data Distribution 122
4.4.4 IC Collect Operation 123
4.5 Data Representation 124
4.5.1 Circular Linked List Sequence Representation 124

4.5.2 Sequence Stmcture Representation 126
V. CONCLUSIONS AND FUTURE RESEARCH 129
5.1 Conclusions 129
5.2 Future Research 132
5.2.1 Preprocessor 132
5.2.2 Optimization 133
5.2.3 Parallel Models 133
5.2.4 Granularity 134
REFERENCES 136
APPENDIX
A. SEQUENCEL GRAMMAR 140
B. AN IMPLMENTATION GUIDE TO A SEQUENCEL COMPILER 142
VI

ABSTRACT
Procedural languages like C and FORTRAN have historically been the languages
of choice for implementing programs for high performance parallel computers. This
dissertation is an investigation of a high-level nested programming language, SequenceL,
and whether a SequenceL compiler that compiles to parallel code can be developed for a
parallel system. This dissertation has achieved the following results.
• Established a proof of concept that there exists a SequenceL compiler that can
create executable programs that embody the inherent parallelisms and other
implied controls stmctures in SequenceL,
• Developed a new intermediate language capable of representing the meaning of a
SequenceL source program,
• Developed the techniques for spawning threads to dynamically create parallelisms
using a threaded approach, and discovered that the SequenceL language implies a
parallel execution model,
• Identified a number of optimization and performance enhancement opportunities,
• Identified a new SequenceL language requirement for defining nesting and
cardinality typing information for SequenceL data stmctures.
Vll

LIST OF TABLES
3.1 Selection Sets 51
3.2 Triples 60
3.3 Quadmples 60
4.1 Thread Execution Times 108
B. 1 SequenceL Selection Sets 150
Vlll

LIST OF HGURES
2.1 Parallel Multiplications by Associative Rule 36
2.2 Syntax Tree 39
2.3 Derivation Tree for PAP 41
3.1 Syntax Checking 54
4.1 Mapping SequenceL Constmcts 70
4.2 Mapping Regular Constmcts 74
4.3 Interpreter Identified Parallelisms 79
4.4 Matrix Multiply Execution Trace 80
4.5 Gaussian Parallehsms 81
4.6 Quicksort Execution Trace 82
4.7 Object Code Flow Chart 106
4.8 Object Code Flow Chart with Cache Locality 112
4.9 Tree Diagram of a Sequence 116
4.10 Granularity Study 118
4.11 Repeatability of Execution Times 120
4.12 Linked List Sequence 125
B.l Matrix Multiple 180
IX

CHAPTER I
INTRODUCTION
This report presents the research in developing a compiler for SequenceL, a
nested high-level language that exploits the full extent of parallelisms inherent in a
problem solution. The specific results of the research are as follows.
• Established a proof of concept that there exists a SequenceL compiler that can
create executable programs that embody the inherent parallelisms and other
implied controls stmctures in SequenceL,
• Developed a new intermediate language capable of representing the meaning of a
SequenceL source program,
• Developed the techniques for spawning threads to dynamically create parallelisms
using a threaded approach, and discovered that the SequenceL language implies a
parallel execution model,
• Identified a number of optimization and performance enhancement opportunities,
• Identified a new SequenceL language requirement for defining nesting and
cardinality typing information for SequenceL data stmctures.
Why should developers consider this high level parallel language when so many
other high level parallel languages have not been particularly successful? The problem
with high level parallel programming languages is that they ultimately force the
developer into coding the data decomposition [CooOO]. This is also the nature of
procedural languages and the motivation for seeking improvements in programming from

high level parallel languages. The hard part of programming is making the implied data
product appear in the programmer's mind when reading or writing the explicit control
stmctures that produce or process the data product. Something as simple as multiplying
two matrices together can quickly get lost in the coding that is required in a procedural
language like C.
for (i=0;i<=m.rows;i++) for (j=0;j<=m.columns;j++)
{s = 0; for (k=0;k<=m.length-l;k++)
{s+=mU][k]*m[k][i];} mr[i]|j] = s;}
High-level functional languages like NESL [Ble96] and Sisal [Feo] attempt to
redefine the way data stmctures are realized. The following is an example of matrix
multiplication in NESL.
function matrix_multiply(A,B) = {{sum({x*y: x inrowA; yincolumnB}) : columnB in transpose(B)}
: rowA in A}
Note the nesting of the data stmctures, nesting levels are delineated by curly
brackets. A programmer decides where to locate the curly brackets based on the
parallelisms they wish to exploit. Even for so simple a numerical operation as matrix
multiply the distribution of the data stmcture across the control stmcture is explicitly
defined by the programmer.
Sisal requires programmers to explicitly express loops. The following matrix
multiplication example is written in Sisal, note the explicit use of the "for" looping
constmcts.

function dot_product( x, y : array [ real ] returns real) for a in x dot b in y returns value of sum a * b end for
end function type One_Dim_R = array [ real ]; type Two_Dim_R = array [ One_Dim_R J; function matrix_mult( x, y_transposed : Two_Dim_R
returns Two_Dim_R) for x_row in x % for all rows of x cross y_col in y_transposed % & all columns of y (rows of
y_transposed) returns array of dot_product(x_row, y_col) end for
end function % matrix mult
Like NESL, Sisal puts the responsibility for data decomposition onto the
developer tiirough the need to explicitiy express the computational loops upon which
concurrent or parallel opportunities are exploited.
For the same numerical method in SequenceL the programmer declares the
matrices and defines the calculation as a row multiplied by a column and the control
stmcture and parallelisms are implied.
{{matmul(s_l(n,*),s_2(*,m)),where next = {([+([*(s_l(i,*),s_2(*,j))])])} taking [i,j] from cartesian_product([gen([l,...,n]),gen([l,...,m])])} matmul, s_l}
Given the level of complexity in as simple a numerical method as matrix
multiplication, the development of a procedural language algorithm for parallel execution
is just that much harder. (A description of SequenceL matrix multiply is presented in
Appendix B.) It has been estimated that the development of parallel code costs on
average $800 per line of code [Pan]. Even the migration of existing serial code to

parallel execution, a problem of critical interest in many enterprises, may cost anywhere
from $50 to $500 per line of code.
The goal of the SequenceL language [Coo96] is to provide an environment where
the problem solution can be stated at a high level of abstraction - where one can describe
the data product explicitly and have the iterative and parallel program stmctures that
produce and process the data product generated automatically. In other words, the desire
is for a language that is based upon high-level constmcts that permits one to declare data
products directly. In such an environment, the abstraction should be easier for the
problem solver - the problem solver no longer has the difficult task of envisioning the
elusive and implied data product. Rather than having to write the explicit algorithm that
implies the data product, the problem solver explicitly declares the data product.
1.1 An Introduction to SequenceL
The definition of the SequenceL language began in 1991. In 1995 the proof of
Turing-completeness was published [Fri]. The current version of the language was
completed in 1998. Parallelisms implied by the language statements were discovered in
early 1999. Papers introducing the language include [Coo96, Coo98, CooOO]. In this
section these papers are summarized in order to provide an overview of the language
constmcts.
SequenceL is a high-level nested language whose fundamental data type is the
sequence. Sequences are collections of integers, reals, strings, identifiers, functions and

computations delineated by square brackets. Reals and integers can be mixed, but string
sequences can only appear in sequences with strings.
[1,2,3]
Sequence
[3]
Singleton
A sequence of one element is called a singleton. The simple sequence listed above
contains three singletons. Sequences can contain sequences. These types of sequences are
called multi-dimensional or nested sequences.
[[1,2,3],[4,5,6],[7,8,9]]
Sequences can contain references to identifiers and functions. The following
sequence contains references to the functions eigen, matmul and max and the input
variables s_l and s_2.
[eigen,matmul,s_l ,max,s_2]
Although not necessary, a language convention adopted for this dissertation is to
begin input variables with s_. Input variables are always constant sequences. Sequences
can also be unbalanced. The following is an example of an unbalanced sequence.
[[1,2,3],[4,5],6]
Unbalanced sequences are normalized before operations are preformed on them.
Therefore, normalization by default is performed for every sequence operation when
necessary. For example the following expression does not undergo normalization before
addition.

+([[1,2,3],[4,5,6]])
The result produced by this expression is;
[5,7,8]
This next expression does undergo normalization before the addition.
+([[1,2,3],[4,5],6])
Normalization before the addition results in;
+([[I,2,3],[4,5,4],[6,6,6])
The result produced by this expression is;
[11,13,13]
Computations can also appear in sequences. In the language definition the
functions and operators operate only on sequences and produce as results only sequences.
This expression contains a computation and a constant sequence.
[+([s_2]),[l,2]]
The expression is evaluated in place resulting. If s_2 has the following value;
s_2=[[l,2,3],[4,5],6]
Then the result produced by the expression is;
[[11,13,13],[1,2]]
SequenceL provides the following operators +,-,*,/ in support of addition, subtraction,
multiplication and division.
The fact that function references and computations can appear in a sequence is a
powerful feature of SequenceL and supports the consume-simplify-produce philosophy
of the language. Details on this philosophy will be presented later in this section.

SequenceL has three basic constmcts for processing sequences: regular, irregular
and generative constmcts [Coo96].
1.1.1 Regular Constmct
A regular constmct applies an operation in a uniform manner to a normalized
non-scalar operand or sequence. For example given the sequence.
s_l=[l,2,3,4,5]
The following SequenceL addition expression:
+([s_l])
Is applied to all the elements of the sequence s_l in a uniform manner. The result of this
expression is a summation of all five singletons.
[15]
1.1.2 Irregular Constmct
An irregular constmct applies an operation selectively to a non-scalar operand
based on a conditional expression. Conditional expressions are expressed with the
"when" clause which has a relational operation component and a tme and false
expression component. For example the following SequenceL expression uses the not
equal relational operator <>.
/([s_l(i),x(i)]) when <>([x(i),[0]) else [ ]
The tme expression is;
/([s_l(i),x(i)])

The false expression is the null or empty sequence.
[ ]
In this example only elements in x that are not equal to zero are divided into the
corresponding sub-sequence of s_l which are selected by index i. Additional relational
operators include <, >, =, <=, >= which provide for less, greater, equal less than or equal,
and greater than or equal.
1.1.3 Generative Constmct
While the regular and irregular reduce their inputs in terms of size and dimension,
tiie generative operation is an expansion operation. The following expression is a
generative expression.
gen([[l],...,[5]])
This generative expression results in the sequence.
[[1],[2],[3],[4],[5]]
1 • 1.4 Consume-Simplify-Produce
The SequenceL tableau can best be described as a shared memory area that
contains a complete problem solution in SequenceL. This includes all functions,
operations and sequences. Within the tableau SequenceL expressions are processed using
a consume-simplify-produce strategy. When SequenceL expressions or functions are
referenced they proceed to consume input arguments and undergo a simplification
process before they are evaluated. When no more simplifications can take place the

simplified expressions are evaluated and a result is produced. The result produced will
normally be a sequence. Some functions can produce as a result, another function.
SequenceL expressions and function references are also placeholders in the tableau.
Therefore the result produced will replace the evaluated SequenceL expression or
function in the tableau. The examples in this paper use small data sets, memory is the
only limitation on the maximum size of an input data set.
A simple example of this consume-simplify-produce philosophy is illustrated in
the following example. Assume the following sequence appears in a function.
[eigen,matmul,max,s_2,s_l]
Assume that eigen and max are SequenceL functions and each accepts one input
argument. Matmul is also a SequenceL function, but it accepts two input arguments. In
the evaluation of this sequence, s_2 would be consumed by max. Max would then
simplify its expressions working towards producing a result that would replace max in
the sequence. The function matmul would then consume the result that max produced and
the sequence s_l. Matmul would then simplify its terms producing a result. The function
eigen would finally be referenced and it consumes the sequence produced by matmul,
eigen then simplifies its terms and produces a result. Note that this consume-simplify-
produce process continues until no more functions or operators appear in the tableau. In
this example all function references and input variables have been consumed, the only
expression left is the sequence produced by eigen. This consume-simplify-produce
philosophy is also the case for sequences containing nested computations. For example
the multiply/add operation in matrix multiply is carried out by.

[+([*(s_I(i,*),s_2(*,j))])] taking [i,j] from [[I,1],[I,2],[2,1],[2,2]]
In this example the multiply operation consumes the sequences s_l and s_2 and
simplifies the nested expression, which becomes,
[ [ +([*([s_l(l,*),s_2(*,l)])])
+([*([s_I(l,*),s_2(*,2)])]) ] [ +([*([s_l(2,*),s_2(M)])])
+([*([s_l(2,*),s_2(*,2)])]) ] ]
If we set, s_l and s_2: s_l = [1,2] s_2=[[5,6],[7,8]]
The above set of terms are simplified further to:
[ [ +([*([[1],[5,7]])])
+([*([[1],[6,8]])]) ] [ +([*([[2],[5,7]])])
+([*([[2],[6,8]])]) ] ]
Because the two sequences that are to be multiplied and added together are not the same
dimension, normalization will take place.
[ [ +([*([[1,1],[5,7]])])
+([*([[1,1],[6,8]])]) ] [ +([*([[2,2],[5,7]])])
+([*([[2,2],[6,8]])]) ] ]
The terms are now ready for evaluation, and a result is produced.
In the above example, the identifiers / and j are indexes used by the index operation
to select sub-sequences of s_l and s_2. The index constmct s_l(i,*) also contains the
wildcard operator * which says select all. The wildcard is useful in selecting larger parts
of a nested or multi-dimensional sequence. For example given.
10

s_l = [[l,2],[3,4],[5,6]]
The expression s_l(l,*) means "select all elements of sub-sequence 1". Which results in:
[1,2]
The expression s_l(*,l) means "select only element 1 of all sub-sequences." Which
results in:
[1,3,5]
In the nested computation example / and 7 are assigned values by the taking
expression:
taking [i,j] from [[1,1],[1,2],[2,1],[2,2]]
The taking expression is the only assignment statement in SequenceL. It processes the
sequence specified after "from," in the above expression that sequence is;
[[1,1],[1,2],[2,1],[2,2]]
We will call this sequence the "taking sequence." Taking will assign parts of the taking
sequence to identifiers specified after "taking." In this example there are two identifiers
after "taking." The determination of how to assign parts of the taking sequence to the
identifiers is dependent on the number of identifiers specified. For the above expression
since there are two identifiers two assignments need to be made for each sub-sequence
taken from the taking sequence. The first sub-sequence processed will be [1,1], therefore
identifiers i and; are set to 1 and 1 respectively. If there had been only one identifier,
such as:
taking [i] from [[1,1],[1,2],[2,1],[2,2]]
11

Then taking would assign / [ 1,1]. The next sub-sequence from the taking sequence is
[1,2]. This process of taking sub-sequences from the taking sequence and assigning
values to identifiers continues until the taking sequence has no more sub-sequences left to
process. The process of assigning values to taking identifiers and then using those
identifiers as indexes in an index operation is at the heart of one of the implied
parallelisms that is inherent to SequenceL.
SequenceL is a Turing-complete language [Fri], a more complete description of the
language can be found in [Coo96, Coo98, CooOO]. A listing of the language grammar can
be found in Appendix A.
1.2 ImpUed Parallelisms in SequenceL
It is the mixing of SequenceL's regular, irregular and generative constmcts that the
programmer is provided with the tools needed to specify problem solutions. In
SequenceL these problem solutions are specified by their data stmctures, in a procedural
language the same problem solution is specified by an interaction between data and
control stmctures. It is the combination of these constmcts as well as the execution
strategy of SequenceL that supports the languages ability to imply parallelisms. Implied
parallelisms involve one of three SequenceL operations,
a. Computations on singletons,
b. Computations involving indexing, and
c. Control Flow Parallelisms.
12

1.2.1 Singleton Computations
The implied parallelisms associated with singleton computations come from the
fact that a constant sequence, consists of singletons. For example the following sequence
contains six singletons.
[[1,2,3],[4,5,6]]
When this type of sequence is referenced in an operation such as addition.
+([[1,2,3],[4,5,6]])
Simplification would produce the following singleton additions:
[l]+[4] [2]+[5] [3]+[6]
These three additions are data independent and therefore there is no reason why these
three computations cannot take place in parallel. Any SequenceL operation on a set of
sequences can take advantage of parallelism involving singletons. This includes
operations like arithmetic operations and relational operations.
1.2.2 Parallelisms Involving Indexing
The next type of parallelism is similar to the previous example of parallelism,
except in this case we move up to a higher level of sequence computation. The taking
clause is the mechanism through which parallel operations on sequences are implied. By
distributing indexes to the index operation computations that selected sequences can
imply parallelisms. The following is an example of a taking expression.
taking [i] from gen([[l],...,[5]])
13

In this example the gen expression is evaluated first and results in the sequence.
[[1],[2],[3],[4],[5]]
This sequence becomes the source of values for i, which is assigned by the taking
expression. Note, this is the closest SequenceL comes to an actual assignment statement.
Typically, the different i values are passed by the taking expression to an index operation
which provides sequences for a computation. Consider the following example
+([s_l(i)]) taking i from gen([[l],...n])
For this example s_I is defined as.
s_l=[[[I],[2]],[[3],[4]],[[5],[6]]]
The identifier n contains the length of s_l, which equals 3. SequenceL evaluates the
example as follows.
+([s_l{i)]) taking i from [[1],[2],[3]]
This simplifies to:
This simplifies to:
+([s_l(l)]) +([s_l(2)]) +([s_l(3)])
+([[1],[2]]) +([[3],[4]]) +([[5],[6]])
This is evaluated to produce the result:
[3,7,11]
14

In this example there is no reason why the simplification stages cannot occur in parallel
and that is exactly what happens in the SequenceL execution strategy for implied
parallelisms.
1.2.3 Control Flow Parallelisms
The final source of parallel execution is control flow parallelisms. An earlier
consume-simplify-produce example was given.
[eigen,matmul,s_l ,max,s_2]
In this example each function is dependent on a result from the function to its right.
Matmul is dependent on the result produced by max and eigen is dependent on the result
produced by matmul. Therefore, matmul cannot be evaluated until max has been
evaluated and eigen cannot be evaluated until matmul has been evaluated. Given a
situation where there are no dependencies between SequenceL expressions or functions,
parallel execution becomes possible. For example consider the following sequence.
[quick,less,s_l[l],s_l,s_l[l],quick,great,s_l[l],s_l]
Quick is a SequenceL function that accepts one input argument, less and greater are
SequenceL functions that accept two input arguments. SequenceL evaluates sequences
from right to left. A control flow analysis of this sequence reveals that the result of the
quick in the middle of the sequence is not needed by any of the functions to its left.
quick,great,s_l[l],s_l
Therefore the above expression can execute at the same time expression shown below.
quick,less,s_l[l],s_l
15

The term control flow parallelism is used here to describe this parallel evaluation process.
The actual parallelisms associated with this type of expression are defined by the
language semantics.
1.3 Document Overview
The research on SequenceL from 1991 to 1998 has focused on the language
definition. Then around 1999 it was discovered that problem solutions implemented in
SequenceL exhibited implied parallelism, this led to the development of a SequenceL
interpreter capable of identifying implied parallelisms. The next phase of this research is
presented in tiiis dissertation. This phase of the SequenceL research is to do a proof of
concept for a SequenceL compiler. This compiler will be capable of producing
executable parallel code from SequenceL source code.
The rest of the dissertation is presented as follows. Chapter n will explore briefly
aspects of the current parallel programming domain. Chapter IH lays out the
methodology behind the development of the compiler. Chapter IV will report on the
results of the compiler implementation and Chapter V will provide conclusions.
Appendix B is an implementation guide that lays out the mechanics behind the
development of the compiler. It also provides some background information on some
issues, such as cache locality, that needed to be addressed during compiler development.
16

CHAPTER n
CURRENT STATE OF PARALLEL PROGRAMMING
A number of different areas of parallel programming have been reviewed in order
to establish some sense of the current state of Parallel Programming in the High
Performance Computing field. There are three areas or approaches to parallel
programming that will be reviewed, explicit parallel languages, high-level languages that
are compiled into a parallel form and the automatic transformation of serial code into
parallel code [DiM96b]. Examples from each of these areas will be presented as
background material. Hardware, although not a primary focus of this research is of some
importance, therefore a brief review of the current state of parallel hardware systems will
also be included. The specific class of parallel machine the SequenceL compiler is
designed for is a shared memory multi-processor that supports POSIX threads.
There seem to be as many different strategies for achieving effective parallel
programming, as there are parallel computers. These programming strategies typically
center on the procedural language paradigm since procedural languages like C and
FORTRAN are the most widely used for scientific programming and are available for
most systems [All]. It can be speculated that the resultant large investment in the existing
pool of procedural code, and programmers is also a motivation for focusing on procedural
languages. Examples of this approach is the Message Passing Interface (MPI) and
OpenMP, both which attempt to equip programmers with the tools they need to develop
parallel applications using procedural languages like C and FORTRAN.
17

2.1 Message Passing Interface
MPI is a Message Passing Interface standardized by a consortium of vendors,
implementers, and users [MPI]. Typically, MPI consists of a parallel library and some
server code. The server code is designed to manage multiple cooperating processes or
tasks executing on a distributed memory system. Since MPI developers are responsible
for coding all parallel operations, MPI can be described as an explicit approach to parallel
programming. MPI codes can mn on either shared memory or distributed memory
parallel architecture, making it very popular with experienced parallel programmers. It
scales very well on most architectures [Leu], provided the level of inter-process
communication is reasonable. Like any parallel application, if the communication level
donunates the overall efficiency of the system becomes poor [Kum].
Efficiency, E is defined by the following formula.
£ _ Execution time using one processor
Total Parallel Execution time * number of processors
Total Parallel Execution time = time to compute + time to communicate.
We can see from the above equation that as communication time increases the
total parallel execution time for the multiprocessor increases and therefore the efficiency
drops. Ideally we would like to have the parallel execution time, on the multiprocessor, to
be as close as possible to the sequential time divided by the number of processors. The
expectation is that if one processor executes a program in x seconds then a multiprocessor
with y processors would execute in x/y seconds. For example if a program executes on a
18

single processor system in 20 seconds, then ideally a parallel version would execute on a
4-processor system in 5 seconds.
The efficiency for this ideal condition would be:
Efficiency = 20/(5*4) = 1.
As communication overhead increases on the multiprocessor system the parallel
execution time increases. If for example the parallel execution time for our 4-processor
system increases to 10 seconds, then efficiency drops to .5. It is easy to see that efficiency
is one way of measuring how much time a parallel system is spending on computations.
The MPI model is primitive from a programmer's viewpoint. There is no implicit
data sharing, MPI provides a set of communication library routines that allows a
programmer to setup a process to send a message from one task to another. The message
typically contains some data that the two parallel tasks are sharing. Therefore, the
developer must explicitly program every single point in a parallel application in which
data sharing occurs. The tasks themselves are UNIX processes that can be generated from
the same binary image or from different binary images. Typically, the Single Program
Multiple Data or SPMD model is used to program MPI based applications. This means
that MPI uses one binary image to spawn a UNIX process for each processor in a
multiprocessor system. When there is a single task for each processor, the parallel model
is called a coarse-grain parallel execution model [Nar]. When a SPMD parallel
programming model is used every processor executes the same binary image, what
differentiates each program is a task identification number assigned by MPI. SPMD
19

programs should be designed to use this identification number in conditional expressions
so that each task processes a different part of a data stmcture.
The strength of MPI is also its weakness. MPI, through the use of low level
communication calls, gives the developer complete control over the parallel environment
this puts all the onus on the developer to create an efficient and reliable parallel
application. It has been documented that MPI program development is both costly and
time consuming [Cha]. The scheduling of tasks or threads of computation within a
parallel application can be a complex task but is not a technical problem with MPI since
MPI gives the developer complete control over all of a task's parallelisms through MPI's
low level message passing calls.
Some manufacturers of shared memory computers, such as Silicon Graphics Inc.
have extended the use of MPI to shared memory systems by bundling MPI on their
shared memory computers.
2.1.1 MPI Programming Example
The following simple but meaningless code will be used to demonstrate the
process behind the development of parallel code using MPI.
#include <stdio.h>
#define SIZE 10 /* must be even number *l
int mainO {
intinputs[SIZE],i,j; intresult[SIZE/2];
20

}
int total=0;
for(i=0; i < SIZE; i-i-+){ inputs[i]=i;
}
j=0; for(i=0; i < SIZE; i=i+2){
result[j]=inputs[i] * inputs[i+l]; total= total + resultlj];
} printfC'total = %d\n",total);
This code take the values 0,1,...8,9 and multiples each pair and then sums the
products. Therefore the following computation takes place.
0*1+2*3+4*5+6*7+8*9=140
Before an MPI programmer attempts to code this simple algorithm a number of
decisions need to be made. First, how many tasks should be executing in parallel? Data
decomposition is always the most difficult step, decomposition has a major impact on
efficiency, and for more complex data stmctures finding an optimal data decomposition
can be a hard problem. Ignoring granularity issues the data decomposition for this
example is simple enough. Since the problem is uniform in nature, 5 processes could be
created with each process getting two array variables to multiply. The next decision the
MPI developer needs to make is how should the 5 tasks be initialized? Should one
process initialize an array and then distribute it to the other four tasks or should each task
do its own initialization? In this case the static nature of the initial data makes the second
choice a good one. Since communication costs are lowered and the four other processes
21

would probably be idle during initialization anyway. In some cases a broadcast of
initialization data might be a better choice. For this example broadcasting will be
demonstrated. The final step, before displaying the result, is communicating all the
products back to one process. We will assume that summation is a serial operation. One
process is selected to sum the results and display the result. The MPI code is as follows.
#include <stdio.h> #include <mpi.h>
#define SIZE 10
int main(int argc, char **argv) {
int myrank, nsize, x, inputs[SIZE], result, total;
MPI_Init(&argc, &argv); MPI_Comm_size(MPI_COMM_WORLD, &nsize); MPI_Comm_rank(MPI_COMM_WORLD, &myrank);
if(nsize != SIZE/2)retum(l);
MPI_Bcast(inputs, SIZE, MPI_INT, 0, MPI_COMM_WORLD);
x=myrank*2; result=inputs[x] * inputs[x+l];
MPI_Reduce(&result, &total, 1, MPI_INT, MPI_SUM, 0, MPI_COMM_WORLD);
if(!myrank){ printfC'total = %d\n",total);
}
MPI_Finalize();
return (0);
22

This MPI program is fairly painless since it makes use of the MPI broadcast and
reduce library calls. The MPI broadcast library call, MPI_Bcast, is used to send a
message from one MPI task to a collection of MPI tasks. Since all the MPI tasks are
executing the same binary image, they all execute the MPI_Bcast function call. One MPI
task is selected in the MPI_Bcast argument list to broadcast, by default the rest of the
tasks listen. In this example task 0 is selected to broadcast. Even though each task needs
only part of the array, task 0 broadcasts the entire array to every task. Each task uses its
task identification number (myrank) to determine which part of the array it's responsible
for processing. Upon completing the computation all the tasks call MPI_Reduce. Again
one task is selected through the argument list to listen and sum the data, by default all the
other tasks send their results. Task 0 is selected to reduce all the products to one
summation value. Task 0 then prints the result.
For more complex data sharing or to optimize data sharing, explicit sends and
receives between tasks can be coded. For example the above program can be redone
using the MPI send and receive library calls.
#include <stdio.h> #include <mpi.h>
#define SIZE 10
int main(int argc, char **argv)
int myrank, nsize, x, inputs[SIZE], result, total; int myresults, myinputs[2];
MPI_Init(&argc, &argv); MPI_Comm_size(MPI_COMM_WORLD, /* total */
&nsize); /* cluster size */
23

MPI_Comm_rank(MPI_COMM_WORLD, /* group of everybody */ &myrank); /* 0 thm N-1 */
if(nsize != SIZE/2)retum(l);
i=0; if(!myrank){
for(I=l;I<nsize;I++) MPI_Send(&inputs[myrank*i], 2, MPI_INT i
MPI_COMM_WORLD); } else
MPI_Recv(myinput[0], 2, MPI_INT, 0, MPI_COMM_WORLD);
myresult=myinputs[0] * myinputs[l];
if(!myrank){
for(I=l; I < nsize; I++) MPI_Recv(&results[i], 1, MPI_INT, i, MPI_COMM_WORLD);
else MPI_Send(&myresult, 1, MPI_INT, 0, MPI_COMM_WORLD);
if( .'myrank) { total=0; for(i=0; i < nsize; i++)
total= total + results [i]; printfC'total = %d\n",total);
}
MPI_Finalize(); retum(O);
}
In this code, task 0 uses the MPI_Send library routine to explicitly send each task
the part of the array its been assigned to do computations on. The rest of the tasks use
MPI_Recv to receive the array data in a message sent from task 0. The task id (myrank)
is again used, this time in a conditional statement to control the send/receive operations
between task 0 and the rest of the tasks. When results are available task 0 uses
24

MPLRecev to get the results and the rest of the tasks use MPI_Send to send their results.
Since the reduce call was not used task 0 must explicitly sum the results. For even such a
simple algorithm it is evident, from the example that the level of complexity can increase
rapidly with MPI. Given the difficulties programmers face when using MPI, OpenMP has
become an attractive altemative.
2.2 OpenMP
OpenMP has been described as a shared memory or distributed shared memory
parallel programming tool [Cha]. Its implementation is at a higher level of abstraction
than MPI although it would be wrong to describe it as a high level language. Silicon
Graphics Inc. pioneered the development of OpenMP in collaboration with other parallel
computer vendors. The OpenMP specification can be found at www.openmp.org, until
recentiy this specification makes up the bulk of the information available on OpenMP.
OpenMP can best be described as a thread model for shared memory processor systems
(SMP) implemented through the use of compiler directives. Therefore, OpenMP is not
really a language. On the Silicon Graphic Origin2000 multiprocessor system parallel
program developers can utilize OpenMP in one of two ways. Sequential programs can be
submitted to the OpenMP compiler, which can be requested to automatically add
OpenMP compiler directives to the code or a developer can manually place the directives
in the code. A typical approach is to have the compiler add the parallel directives. The
developer can then go back through the resultant source code and remove the directives
associated with code sections that would not be efficient to execute in parallel [SGI]. This
25

methodology forces the difficult task of explicitly specifying parallelisms back on to the
developer. OpenMP directives are designed to take advantage of fine-grained
parallelisms in loops. Coarse-grained parallel programming is also available through the
use of parallel regions and work sharing constmcts [Cha]. The advantage of OpenMP is
that the parallelisms are left up to a compiler; if a compiler doesn't support OpenMP the
directives are ignored. The disadvantage is that the compiler directives isolate the
developer from the actual thread implementation, the lack of thread tuning at a low level
means tiie developer cannot easily explicitiy specify how shared data will be distributed
and accessed. Being unable to explicitly specify data sharing has led to scaling problems
with some algorithms implemented using OpenMP [Leu].
2.2.1 OpenMP Programming Example
OpenMP compiler directives are typically placed around loops that operate on
large data sets or arrays. For example the following code illustrates the OpenMP directive
to parallelize a "for" loop.
#include <stdio.h>
#define SIZE 10 /* must be even number */
int main() {
int inputs [SIZE], i,j; intresult[SIZE/2]; int total=0;
for(i=0; i < SIZE; i++){ inputs[i]=i;
}
26

J=0;
#pragma omp parallel for shared(inputs,result) private(i,j) reduction(+:total) for(i=0; i < SIZE; i=i+2){
result[j]=inputs[i] * inputs[i+I]; total= total+ result[j]; j++;
} printfC'total = %d\n",total);
}
In this example the arrays "inputs" and "results" are shared amongst all the
threads created by the OpenMP directive. The variable / and; are private or unique to
each thread created by the OpenMP directive. The reduction directive instmcts the
compiler to setup a mechanism in the code to gather all the individual product results
from each thread and sum them together. The sum is stored in "total". Private data is
kept in each processors local memory; any shared data located on a processor's local
memory can be accessed remotely over the interconnection network by all other
processors. It is this remote memory access to shared data that leads to bottlenecks and
scaling problems on shared memory systems.
This example illustrates both the power and the weaknesses of OpenMP. The
advantage is obvious; any programmer of average ability can quickly identify loops
within their code that are candidates for parallelization. The developer can then place the
directives in the appropriate location so as to direct the compiler to parallelize the loop.
The disadvantage is the fact that the developer must still work hard at specifying data
sharing at a low level in order to avoid the scaling problems encountered with the
automatic placement of the directives, by the OpenMP compiler [Leu].
27

2.3 POSIX Threads
Threads such as POSIX threads are another tool available to developers for
parallelizing codes for SMP systems. POSIX threads or Pthreads are available for all
mainstream UNIX platforms as well as for Microsoft NT. The advantages of Pthreads
are; they are light-weight since they carry only part of a task stmcture, the UNIX process
that generated the threads manages the rest of the stmcture. Pthreads provide the
developer with low-level control over execution; they are universally accepted and
implemented in a standard way and therefore portable; they execute on single processor
systems as well as SMP systems without change. OpenMP will do the same except
parallel programs must be recompiled to eliminate the effect of the thread directives. MPI
requires the installation of the underiying MPI server environment before MPI programs
can mn on a single processor system.
On Solaris and IRIX systems Pthreads execute on light-weight processes (LWP).
A LWP can be described as a virtual processor upon which code can execute [Lew].
LWPs are capable of executing from one to many threads per LWP. The developer can
control the number of LWPs created per process and the number of threads executing on
each LWP but the operating system kernel is responsible for scheduling LWPs on
processors.
A classic approach to writing Pthread parallel programs has been to use a coarse
grain thread model where one thread is created for each processor [Nar]. A fine-grained
thread model has been found to have a number of advantages over coarse-grained
models. A fine-grained model has many threads per processor. This makes the fine-
28

grained thread-programming model more adaptable to changes in the number of available
processor. It can handle irregular parallelisms more effectively and is more effective at
load balancing a system [Nar]. The reason the fine-grained model is better at handling
irregular parallelisms and load balancing can be explained with the following example.
Assume that 10 fine-grained threads accomplish the computations done by a single
coarse-grained thread. When the coarse grained thread is executing on a processor at
some point in time it will be forced to yield the processor. While the coarse grained
thread waits to get the processor back it is in a suspended state. The same is tme for fine
grained threads except when one fine-grained thread is suspended the other nine threads
could still be executing on other processors that potentially could have been idle
otherwise.
A disadvantage of the fine-grained model is the increased number of threads
created and the associated thread creation overhead and subsequent load on operating
system kernel resources.
2.4 Parallel Prograrmning Languages
Parallel language development has also been a factor in parallel programming,
although parallel languages have not achieved the level of interest and use that MPI and
OpenMP have achieved they still have their advocates. The problem parallel language
developers face in gaining the acceptance of parallel programmers is the pressure placed
on developers to stay with FORTRAN or C owing to the huge amount of code already
written in C and FORTRAN [Dow]. Unless the language is easy to use, reduces time
29

spent programming and executes efficientiy, parallel program developers will tend to
ignore it. Therefore the most significant language work done has been in extending
FORTRAN and C [Dow]. Examples of this type of work are FORTRAN 90 and High
Performance FORTRAN (HPF). These two languages are not high-level parallel
programming languages and FORTRAN 90 is not a Parallel language but is the core of
HPF.
FORTRAN 90 brings new extensions to FORTRAN 77, such as.
Array constmcts
Dynamic memory allocation and automatic variables
Pointers
New data types, stmctures
New intrinsic functions, including many that operate on vectors and matrices
New control stmctures, such as a WHERE statement which uses a logical
expression to control array assignments without indexing.
• Enhanced procedure interfaces.
After reviewing these features it becomes apparent that FORTRAN 90 is an
attempt to bring FORTRAN 77 up to date with some of the features found in C. The
problem facing FORTRAN 90 is that in an attempt to become more like C it begins to
encounter the same optimization difficulties encounter in C code [Dow]. The use of
pointers and dynamic data stmctures can effect optimization since they introduce data
stmctures that are not clearly identified until mntime. One of FORTRAN'S strengths over
languages like C is that it is easier to optimize at compile time [Dow]. The development
30

of FORTRAN 90 led to the development of HPF. HPF like OpenMP uses directives to
guide the compiler in parallelizing the code. Therefore a FORTRAN 90 program mn
through an HPF compiler will produce the same results as mnning the same program
through a FORTRAN 90 compiler. It is the addition of the HPF directives to the
FORTRAN 90 code, which identify parallel opportunities in the code, that differentiate
FORTRAN 90 from HPF code. What makes HPF different then from OpenMP? The
design of HPF is based on a message-passing model, while OpenMP is based on a shared
memory model. Therefore HPF can take advantage of distributed memory systems such
as the IBM SP. HPF compilers are designed to optimize parallel execution by minimizing
communication between processors, developers must be aware of this and decompose
and align the data stmctures with this mind.
2.4.1 NESL
NESL is a high-level parallel programming language that comes closest to
SequenceL in terms of the features and objectives for the language. Therefore, it will be
examined in a little more detail. NESL is based on constmcts, which manipulate
sequences or ordered sets. NESL is described by its authors; as "a strongly typed,
applicative, data-parallel language" [Ble96]. NESL is a language that uses nested
constmcts to achieve parallel execution. In order to encourage programming of parallel
applications NESL does not provide for any looping. Although it is pointed out that
looping can be implemented through recursion.
31

The goals set out for the NESL language by the developers is four fold;
1. Support parallelism by means of data-parallel constmcts, which operate on
sequences or vectors of numbers.
2. Support nested parallelism, any user defined function can be applied over
a nested sequence in parallel.
3. Support a variety of different parallel architectures.
4. To easily implement parallelisms through the simple use of its constmcts.
Each of these goals have been met in some fashion by the language developers
except for, perhaps 3. NESL is actually an interface to another language called VCODE
[Ble96]. VCODE is a portable intermediate language that has been implemented on Cray
Y-MP, IBM SP, Intel Paragon and Connection CM-2 machines, or any serial machine
with a C-compiler. VCODE seems to have restricted NESL to a small set of parallel
computers. A prototype compiler was developed which converted NESL to VCODE and
then the resultant VCODE to Java [Har]. This effort was an attempt to investigate the
possibility of making NESL more portable by using Java since Java is a more widely
used language for parallel computing systems than NESL. The speed of the resultant
NESIWCODE/Java code using a JDK interpreter was as much as 10 times slower than
native VCODE [Har].
2.4.1.1 VCODE
Since NESL is dependent on VCODE, what is VCODE? The language developers
describe VCODE as a data-parallel intermediate language [Ble94]. VCODE is based on a
32

stack heap model. It has a small set of about 50 instmctions, which are divided into two
categories of instmctions, vector instmctions and memory/control instmctions. There are
four vector types in VCODE, Boolean vectors, integer vectors, floating-point vectors and
segment descriptor vectors. The segment descriptor vector is used to partition one or
more data vectors into segments. The vector instmctions pull vectors off the top of a
stack and return results to the top of the stack. Here is a partial list of VCODE
instmctions [Ble94].
Memory Control Instmctions Memory Instmctions copy, pop, load, store, const
Control Instmctions if-then-else, call, ret
Vector Instmctions Elementwise
negate, +, *, =, >, and, not, select Permute Instmctions
permute, spermute, bpermute, dist Scan Instmctions
+-scan, max-scan, or-scan Segment Descriptor Manipulation Instmctions
length, segdes
VCODE was never meant to be a development language; its goal was to provide
compiler designers with a portable intermediate language for the development of high-
level parallel programming languages, like NESL. For example VCODE understands and
supports nested-parallelisms, which is the concept that makes NESL a high-level parallel
programming language. VCODE implements nested parallelisms indirectly through the
use of the segment descriptor vector and segment instmctions. A technique called
flattened nested parallelism is used by VCODE to support nested parallelisms for high-
33

level languages like NESL [Ble94]. Flattened nested parallelism can be implemented in
VCODE because segments are designed to operate independently, and in parallel. By
placing each nested parallel call in it's own segment, parallel execution of the nested calls
can take place.
NESL implements its parallelisms by performing operations on sequences, an
example of a sequence would be
[1,-3,2,4]
All elements in a sequence must be of the same type in NESL. Parallelism are
implemented in one of two ways on sequences, either by applying a function or operator
across a sequence in parallel or though the use of built-in parallel functions which apply
parallelisms across a sequence.
The NESL examples shown are taken directly from the NESL interpreter. A
simple NESL example that implements parallelisms;
{negate(a): a in [3, -4, -9, 5]};
=^ [-3,4, 9, -5] : [int]
The above statement is read as " for each a in the sequence [3, -4, -9, 5], negate,
in parallel, each a". The result is returned after the symbol ^ . The [int] is the type of tiie
result: a sequence of integers. The parentheses { } delineate the operation that is to be
implemented in parallel. Multiple sequences can also be handled;
{a + b : a in [3, -4, -9, 5]; b in [1, 2, 3, 4]};
^ [4, -2, -6, 9] : [int]
34

For the above example to work the two sequences must be of the same length.
Normalization in SequenceL allows for sequences of different length to be handled. The
above constmct is referred to as an apply-to-each constmct in the NESL documentation.
This capability is also available to NESL functions; the following factorial example is
given in the NESL documentation.
function factorial(i) = i f ( i== l ) then l else i*factorial(i-l);
The function constmct is defined as;
function name(arguments) = body;
If not declared, int is implied by the compiler as the type to be retumed by a function. To
use the factorial function in an apply-to-each constmct;
{factorial(x): x in [3, 1, 7]};
=> [6, 1, 5040] : [int]
In this example the factorial function is applied to 3,1 and 7, in parallel. What is
surprising about this example is the use of serial recursion in the function, which defeats
the parallelism that is pursued in the language. What would make more sense is if NESL
expanded 3, 1 and 7 and then did the multiplication. For example;
{prod(x): x in [1,2,3,4,5,6,7,8]};
^ [40320] : int
This would then produce the factorial of 8 in parallel. This is accomplished through the
associative mle for multiplication which is known to NESL [Ble96]. Using the
35

associative mle for multiplication parallel execution of multiplication can be
implemented on a parallel machine in logarithmic time using a tree.
40320 t
24*1680 / \
2*12 30*56
^ \ / \
1*2 3*4 5*6 7*8
Figure 2.1 Parallel Multiplications by Associative Rule
Time to do this computation is t*log2 8 = 3t where t is the time for one computation. To
do this kind of parallel computation associative mles for all operators must be known to
NESL. NESL also supports multiple levels of parallelism, for example;
{sum(v):v in [[2,1], [7,3,0], [1,2,3]]};
=> [19] : [int]
In this example NESL performs each sub-sequence addition first in parallel and then
sums the three results in parallel. Again the associative mle, this time for summation, is
implemented on a parallel machine in logarithmic time using a tree.
The last constmct to be examined is the nested constmct; this is the heart of what
makes NESL tick as a parallel programming language. A simple example of a nested
constmct might be
{{x*y:xin A }:yinB};
Note the nesting of the constmcts through the use of the curiy brackets {{ } }; it is this
stmcture that defines a NESL nested constmct. For the above nested constmct, assume
36

sequence A consists of [1,2] and sequence B consists of [3,4] the analysis of this nested
constmct is as follows;
1) read sequence [3,4] in parallel
2) read sequence [ 1,2] in parallel and apply to 3 and 4 in parallel.
The result of nesting tiie constmcts is the parallel multiplication of all the elements in
both sequences; a two-processor system would be required for this concurrent
multiplication. This pattem of nesting NESL constmcts is followed in the development of
the NESL programs. Understanding how to layout the data stmctures, along the lines of
the computation, into a series of NESL nested constmcts is how parallehsms are achieved
in NESL.
2.5 Automated Parallel Language Tools
The third approach to parallel programming is the use of automatic transformation
tools. One example is Algorithm Recognition. The work of KePler and DiMartino is
presented as examples of this type approach to parallel programming. One of the goals of
this approach is to translate, in an effective way, serial codes into parallel codes. With the
billions of lines of procedural code already in use automatic conversion tools have the
potential to save millions of dollars and man-hours, while at the same time preserving the
investment in the original codes. So why has not this approach gained more wide spread
use and acceptance? Keller points out that for some serial algorithms determining how to
distribute the serial data stmctures in parallel for a parallel algorithm is an NP-complete
problem. In addition there are problems dealing with, syntactic variation, algorithmic
37

variation, delocalization (pattem is spread throughout the code) and overiapping
implementations. Also sorting out mntime issues like caching, network contention etc...
propagated by the original serial algorithm is very difficult for an automatic parallelizing
compiler.
2.5.1 PARAMAT
Kepler's PARAMAT tool works by processing a syntax tree of the original source
code. Before generating the syntax tree the program is preprocessed in order to make it as
explicit as possible by; in lining all functions, which means replacing all function calls
witii the associated function code; forward propagation of constant expressions, which
means removing all constant assignment statements, for example given c=3+pi, if pi is a
constant then c is also a constant; recognition and replacement of induction variables i.e.
integer variables indexing arrays that are not a loop variable of a surrounding loop [KeP];
and eliminating dead code, which is code that has become isolated and is never executed.
[DiM]. The idea with PARAMAT is to annotate as many nodes as possible in an abstract
syntax tree with a pattem instance. The abstract syntax tree is traversed from left to right
in post-order. An example of a syntax tree for matrix multiply is as follows.
for(i=l;i<=n;i++) { for(j=l;j<=m;j++)
SI: c[i][j]=0.0; for(j=l;j<=m;j++)
for(k=l;k<=r;k++) S2: c[i][j]=c[i]|j]+a[i][k]*b[k]|j];
Leaf nodes are trivial to pattem match since they are typically variables or
;onstants. The inner nodes are tested by a pattem matching algorithm that accounts for
38

the effect of child nodes on a given parent node whose pattem is currently being tested.
The testing will result in the assignment of a pattem instance to the node. For example
the statement at SI is recognized as a scalar assignment statement and assigned the
pattem instance SINIT. The recognizer then moves up the tree to the "forj" loop around
SI, this combination is recognized as an array assignment pattem and the SESflT and the
"forj" loop statement is replaced with VINIT, the vector assignment pattem instance.
The syntax tree is;
fori
c[i]U]
t assign
^ \ ] 0.0
forj
t fork
t assign
/ \
c[i]U] +
!
/ \ a[i][k] b[k][j]
The code now looks like;
Figure 2.2 Syntax Tree
for(i=l;i<=n;i++) VINrr(c[i][l:m],0.0)
for(j=l;j<=m;j++) for(k=l;k<=r;k++)
39

S2: c[i][j] = c[i]Ij]+a[i][k]*b[k][i];
The process then moves over to the multiply statement and recognizes it as such, it then
moves up to the addition and recognized that the child pattem for multiply can be rolled
into the add as an add/multiply pattem instance. The next pattem is dot product and so on
up the syntax tree. This process continues until finally the matrix multiply pattem has
been recognized. The matrix multiply pattem is then replaced with a template of matrix
multiply (function call), which is designed to execute in parallel.
PARAMAT can recognize 91 nontrivial patterns and has 150 nontrivial templates.
PARAMAT does a reasonable job of recognizing pattems but is limited to certain types
of problem domains involving numerical methods. As new domains are explored new
pattems can be added.
2.5.2 PAP
DiMartino's PAP tool is more general in its algorithm recognition and for that
reason is more general purpose in terms of handling a problem domain. It therefore does
not have the performance of PARAMAT in recognizing code. PAP uses the idea of
concept recognition rales that recognize concept instances. For example a concept might
be a do or an assign statement at the lowest level, a scalar product at some intermediate
level and matrix multiplication at the highest level. PAP uses the Vienna Fortran
Compilation System (VFCS) as a front-end. PAP gets from the VFCS a data dependency
graph, a control flow graph, a syntax tree and a symbol table. With this information PAP
uses a Prolog based inference engine and database to build the Base Internal
40

Representation of the program and it stores this in a Concept Instance Database. This
representation is die Program Dependency Graph (PDG) where nodes are statements and
edges are control and data dependencies. While the PDG is being build the HPDG is
being created from concepts that reflex what was recognized in the PDG. Figure 2.3 is
the derivation tree for matrix multiply and directly corresponds to a HPDG for matrix
multiply.
Matrix-matrix-multiply
Matrix-vector-multiply
Scalar-product Count-loop
Scalar-shift-incr-product Count-loop do
Scalar-shift
assign
Count-loop
do
do
Figure 2.3 Derivation Tree for PAP
The PAP recognizer uses a concept database and backtracking methods to
generate the HPDG. Unlike PARAMAT, which tries to develop one concept instance,
like matrix multiply, PAP maintains a pattem that contains all the sub-concept such as the
add/multiple concept [DiM]. Implementation of PAP has been limited to parallel systems
utilizing the Vienna Fortran Compilation System. PAP itself is written in Prolog and
takes advantage of Prolog's inference engine in carrying out its concept recognition. The
41

final output of PAP is the HPDG, the next phase of the PAP research is to automatically
generate parallel code from the concept tree.
2.6 Parallel Architectures
From a hardware standpoint, many of the more recent successful parallel
architectures have been either shared memory systems (SMS) like that found in the
Silicon Graphics Inc's Origin2000 which is a NUMA cache coherent system [Lau], or
distributed memory systems (DMS) such as IBM's SP and Beowulf clusters. A quick
review of the TOP 500 supercomputer list reveals that 396 are either, IBM SPs (DMS),
SGI Origins (SMS), Sun HPCs (DMS), Compaq Alphas (DMS) or self made clusters
(DMS). Ideally any new parallel languages and compilers would be developed with one
of these types of system in mind. Typically, distributed memory architectures are more
difficult to program since they are message-passing architectures. Also they have fewer
sophisticated development tools such as good parallel debuggers. Shared memory
architecture, like the Origin2000, are shipped with vendor supplied integrated
development tools and compilers that can take advantage of all processors using standard
program development techniques. In addition systems like the Origin2000 can also be
programmed using message passing if necessary.
A third architecture that is not a parallel architecture but is of importance to the
success of any new language and its acceptance is the desktop workstation. A language
that can take advantage of parallel supercomputers and single processor desktop systems
42

without requiring the rewriting of the code has a better chance for acceptance than a
language that does not meet this requirement.
Most of the parallel programming tools reviewed in this chapter require the
developer to explicitly code or specify the parallelisms. The automated tools like
PARAMAT convert serial code to parallel, and therefore do little in reducing the
programming effort associated with coding new applications in parallel since a serial
program is required first. Therefore, tools like PARAMAT target legacy code. High-level
programming languages like SequenceL target new application development.
43

CHAPTER m
METHODOLOGY
This chapter describes the methodologies that guided the development and
implementation of the SequenceL compiler. Traditional compiler design involves the
following steps [Aho],
• Lexical Analysis
• Syntax Analysis
• Intermediate Code Generation (Semantic Analysis)
• Optimization
• Code Generation
Each steps has its corollary for this compiler implementation as well as some additional
steps.
• Lexical Analysis
• Syntax Analysis
• Intermediate Code Generation
• Scheduling Analysis (Optimization)
• Conversion to C (Code generation)
• Compile to Parallel C
• Runtime Environment
44

3.1 Lexical Analysis and Syntax Analysis
Rather than using a compiler-compiler to generate the lexical and syntax analyzer,
the conciseness of the SequenceL grammar and experience with LL(1) compilation
motivated the choice to write an LL(1) parser from scratch. An LL(1) parser is a grammar
driven approach that processes a source program as a string from left to right (that's the
first L) using leftmost derivations (the second L) and has a one token look ahead buffer.
The lexical analyzer performs a character by character scan of the input to identify the
language vocabulary, analysis involves identifying tokens and determining if the tokens
are legal members of the language. A token is a sequence of characters having a
collective meaning [Aho].
As tokens are read they are placed in a symbol table, each token has at least two
attributes, type and a pointer value into the symbol table. Syntax analysis checks the
token pattems in the source code to insure that the code meets the language specification
as set down by the language grammar. Before proceeding with the design of the syntax
analyzer the language grammar must be made compliant with the requirements of an
LL(1) parser.
Definition: "A context-free grammar is a formal system that describes a language by
specifying how any legal text can be derived from a distinguished symbol called the
axiom, or sentence symbol. It consists of a set of productions, each of which states that a
given symbol can be replaced by a given sequence of symbols" [Onl].
Definition: A selection set is a set of tokens that define what are the first legal tokens for
a given production. If a production has an epsilon option or empty option the selection set
45

for the epsilon option will be the first token of the productions that can legally follow the
production that has the epsilon option.
Definition: A context free grammar is an LL(1) grammar if and only if any two
productions with the same left-hand sides have different selection sets. This means that
the grammar must be first context free and that all productions must be uniquely
identifiable.
Aho and Ullman in "Principles of Compiler Design," also affectionately known as
the "Dragon Book," present techniques for placing a grammar in a form that is suitable
for LL(1) parsing, without losing the meaning of the original grammar. These steps are:
1. Elimination of Left Recursion; and
2. Elimination of common prefixes; and
3. Selection set determination.
A simple grammar will be introduced in order to provide examples of the methods
used to develop the compiler.
E=>E + E | E * E | ( E ) | i d
This grammar is ambiguous, what this means is that more than one parse tree can be
generated from the same expression [Aho]. For example the expression id + id * id
generates two different parse trees. This is because the grammar gives no indication of
operator precedence, as a result a derivation of id + id * id can start with either the + or *
resulting in the two different parse trees. This problem can be eliminating by associating
precedence with the operators. Aho and Ullman provide a methodology for eliminating
46

ambiguity. The first step is to set up a production for the elements. An element is a single
identifier or a parenthesized expression.
F ^ (E) I id
The next step is to give multiplication a higher precedence than addition. Therefore a
term for the multiplication operator must be set up.
T = > T * F | F
The final step is to set up the production for the addition, which links terms through the +
operator. E=>E + T | T
The final unambiguous grammar is:
E=>E + T | T T ^ T * F | F F =^ (E) I id
3.1.1 Eliminate Left Recursion
Both direct and indirect left recursion must be eliminated. The definitions of direct
and indirect left recursion are taken from [Coo02].
Direct left recursion exists if and only if:
Ap :=> Ap'
Indirectiy left recursive exists if and only if it is not directly left recursive but can satisfy
the derivation:
AP i^ AP'
The following algorithm is used to eliminate left recursion [Coo02].
47

Input: Left Recursive Syntax Rule in a form wherein left recursive options precede non-
left recursive options:
B ::= Bai | Ba2 |... | Bom | a^+i ] am+2 I- I "m+n ;
Output: Two rales, which are not directly left recursive but are equivalent to the input
rale.
Procedure: Replace B with two productions:
B ::= ttm+iBl | 0^+261 |... | Om+nBl
B l : : = a i B l | a 2 B l | . . . | a m B l | 6
The symbol e signifies the epsilon option or empty production.
Returning to the simple grammar the elimination of left recursion produces
E =>TE' E' ^ +TE I 8 T ^ F T ' T' => *FT' I e F ^ (E) I id
3.1.2 Eliminate Common Prefixes
Common prefix elimination or left-factoring, as Aho and Ullman describes it, is
necessary since LL(1) parsers have a one token look ahead buffer. This means that the
parser makes decisions on where it is to go next in the parse tree based on looking ahead
only one token. If a production has two sentences with the same first token the parser is
unable to reliably choose the next production to syntax check. The result is the potential
false reporting of a syntax error. For example given;
A => aPi I aP2
48

If the parser has a in its look ahead buffer and chooses option api as the current
production but encounters a P2 after consuming the a, a syntax error occurs. The
following algorithm eliminates the common prefix problem [Coo02].
Input: Common prefix mle:
B ::= aPi | a|32 |... | a P ^ I Xm+1 I Xm+2 I- I Xm+n ;
Output: Two rales which have no common prefixes.
Procedure:
Replace B with two productions:
B::= cxBl|Xm+llXm+2l-IXm+n
Bl : :=P l l P 2 I - I Pm
Eliminating common prefixes from the example yields:
A=>aA' A ' ^ P, I P2
In effect the A' production introduces a branch in the A production. Now after accepting
the a token the parser moves to the A' production and checks for either a Pi or a P2
returning a trae when it encounters a Pi or P2.
For the example grammar there are no common prefixes.
3.1.3 Selection Set Generation
Once left recursion and common prefixes are eliminated the resultant grammar
must be inspected for e options. If an s options appears in the grammar selection sets
49

must be generated. The following steps must be carried out in order to establish the
selection sets [Coo02].
1. Determine the FIRST set. This is a set that contains all the initial grammar
symbols in a production.
2. Determine the FOLLOW set. There are three steps in generating the FOLLOW
sets.
A. Set the FOLLOW set of the start symbol to {$}.
B. For each RHS aAp, add non-e elements of FIRST(P) to FOLLOW(A).
C. repeat for each rale B::= aAp, where P ,add FOLLOW(B) to
FOLLOW (A) until no more changes occur.
3. Determine the SELECTION sets. The SELECTION set of a non-epsilon RHS
options is the option's FIRST set. The SELECTION set of an epsilon option is
the rale's FOLLOW set:
The following is the SELECTION set table for the simple grammar introduced earlier in
the chapter. Because this grammar has epsilon options, SELECTION sets must be
generated so that the syntax analyzer can determine what tokens legally follow a
production with an epsilon option. $ is used to indicate end of sentence. Once the
SELECTION sets are generated the full specification for the LL(1) parser exists. The
source code for the syntax analyzer can be taken directly from the SELECTION set table.
50

Table 3.1 Selection Sets
Production
E=i>TE'
E' => +TE'
=>E
T=>FT'
T' ^ *FT'
=^s
F=>(E)
=>id
First
(id
+
(id
*
(
id
Follow
$ )
$ )
+ $)
+ $ )
* + $ )
Selection
(id
+
$ )
(id
*
+ $)
(
id
int e() { ift(){
ife'O retum trae;
else retum false
} else retum false
inte'OI if(token == '+')
token=get_token() ift(){ ife'O retum trae;
else retum false;
51

}
intt(){
} else
retum false; } else{
if(token == $ || token == ')' ) retum trae;
else retum false;
}
iff(){ ift'O retum trae
else retum false
} else
false }
intt'Oi
}
intfO
if(token == '*') token=get_token()
iff(){ ift'O retum trae;
else retum false;
} else
retum false; } else{
if(token == '+' || token == $ || token == ')' ) retum trae;
else retum false;
1
52

if( token =='('){ token = get_token() ifeO{
if(token == ')') retum trae
else retum false
} else
retum false; } else{
if(token == id) retum trae
else retum false;
} }
This pseudo-code is generated directly from the productions, and their
SELECTION sets. Note that tokens are only consumed when a token is matched.
The following is the call sequence for the syntax analysis of the expression
A * B .
Using the syntax analyzer for the example grammar.
1. e() is called.
2. eO calls to
3. to calls f(),
4. f() determines the token is an id, gets next token and retums tme
5. to calls t'().
6. t'O determines that token is a *, gets next token and calls f()
7. f() determines that token is is, gets next token retums tme
8. t'O calls t'O
53
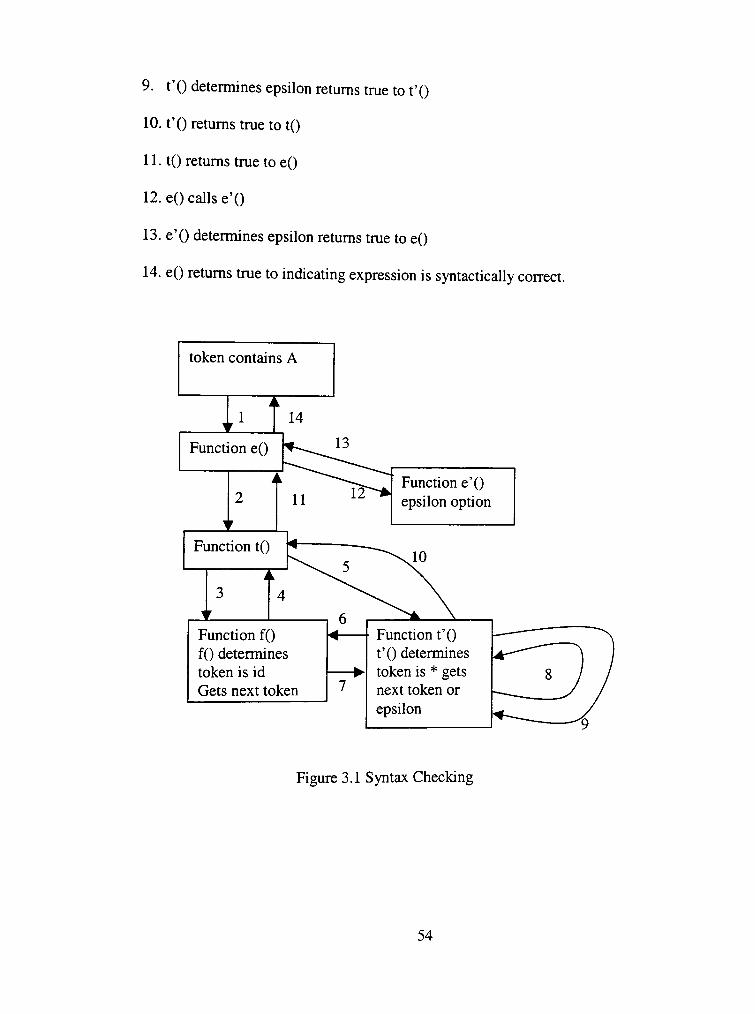
9. t'O determines epsilon retums trae to t'()
10. t'O retums trae to t()
11.1() retums trae to e()
12. eO calls e'O
13. e'O determines epsilon retums trae to e()
14. e() retums trae to indicating expression is syntactically correct.
token contains A
Function e'() epsilon option
Function f() f() determines token is id Gets next token
Function t'() t'O determines token is * gets next token or epsilon
Figure 3.1 Syntax Checking
54

3.2 Semantic Analysis
Semantic analysis is typically integrated into the syntax analyzer, to create what is
known as a one-pass compiler. This means that the source code file is parsed and
analyzed for lexical errors, syntax errors, and semantic errors on one pass through the
source code. Additionally, the semantic analyzer may generate intermediate code via
what are know as semantic actions. The triggers for initiating a semantic action must be
placed at appropriate points in the productions.
The semantics of a program are typically captured in a machine-independent
code. This code is machine independent because there is no management of memory or
register usage defined. One example of a machine independent intermediate code is
quadruples [Aho]. Quadraples consist of four fields an operation, two operands, and a
result field. During intermediate code generation the fields are assigned addresses, which
are locations in the symbol table. Not every quadraple generated has all its fields'
assigned addresses. Unary operators like x = -y use only one of the operand fields. Jumps
put the target in the result field [Aho].
For the following expression:
A + B
Semantic analysis will generate the following quadraple or quad for this expression.
OP ArgI Arg2 Result
+ A B Ti
In order to accomplish the task of generating a quad for an expression the
semantic analyzer must be able to recall information about the expression when the
55

semantic action is invoked. A Semantic Analysis Stack (SAS) is utilized for this purpose.
In the syntax analyzer a "push token instraction" is placed whenever a token needs to be
placed on the SAS. For example operands are typically pushed onto the SAS, therefore a
"push token instraction" is placed in the syntax analyzer whenever an operand is detected
by syntax analysis and needs to be pushed onto the SAS. As semantic actions are
triggered in the granunar, the semantic action will pop tokens off the SAS and use'd them
to generate the appropriate quads. For the above expression the SAS will contain A and B
when the semantic action is triggered for the addition expression. The semantic action
routine will pop the two operands off of the SAS and generate the quadraple or quad for
addition at that point. Semantic action generates the temporary Ti which is used to store
the result of the addition expression. Ti is pushed back onto the SAS making it available
for a semantic action rale associated with whatever expression might use the result of A +
B as an operand. Using the example grammar, the semantic action for the addition
expression will be.
B :=pop(SAS) A := pop(SAS) Ti := generate temporary genquad(+, B, A, TO push(Ti,SAS)
The following is the syntax code with the semantic actions placed in the locations
that allow for the generation of the appropriate quads for multiplication and addition.
int e() { iftOi
ife'O retum trae;
else
56

retum false } else retum false
}
inte'Of if(token == '+')
token=get_token() iftO{
op2=pop(SAS) opl=pop(SAS) result=genquad("+",op 1 ,op2) push(S AS .result)
ife'0{ retum trae;
} else retum false;
} else
retum false; } else{
if(token == $ || token == ') ' ) retum trae;
else retum false;
1 }
inttOi iffOi ift'O retum trae
else retum false
} else
false 1
intt'Of if (token =='* ')
57

}
intfO
token=get_token() iffO{
op2=pop(SAS) opl=pop(SAS) result=genquad("*",opl,op2) push(S AS,result) ift'Oi retum trae;
} else
retum false; } else
retum false; } else{
if(token == '+' || token == $ || token == ') ' ) retum trae;
else retum false;
}
if( token == '('){ token = get_token() ifeOI if(token == ')') retum trae
else retum false
} else
retum false; } else{ if(token == id)( push(token, SAS); retum trae
else retum false;
}
58

Note how each time an identifier is correctly identified in f() it is pushed onto the SAS.
When the second identifier has been correctly identified either e'O's semantic action will
generate the quads for addition or t'()'s semantic action will generate the quads for
multiplication. Therefore, the semantic action occurs at the following locations in the
grammar.
E =>TE' E' => +T(semantic action)E' | e T ^ F T ' T' => *F(semantic action)T' | 8 F => (E) I id
3.3 Intermediate Code
In many compilers source code is translated into an intermediate representation
(IR) or intermediate code (IC) before compiling to the final object code. In the
NESL/Java implementation the intermediate code is VCODE. One of four kinds of IR
codes is often used in compilers [Aho], postfix notation, syntax trees, quadraples and
triples. The advantage of going to an IC as opposed to going directiy to machine code is
that optimization on the IC is generally easier to perform than on machine code.
3.3.1 Quadraples and Triples
Triples or three address codes are made up of expressions involving an operator
and two operands. Quadraples are similar to triples except they have an additional
address specified for the result. The address tables for A = X + Y * Z for triples and
quadraples are as follows.
59
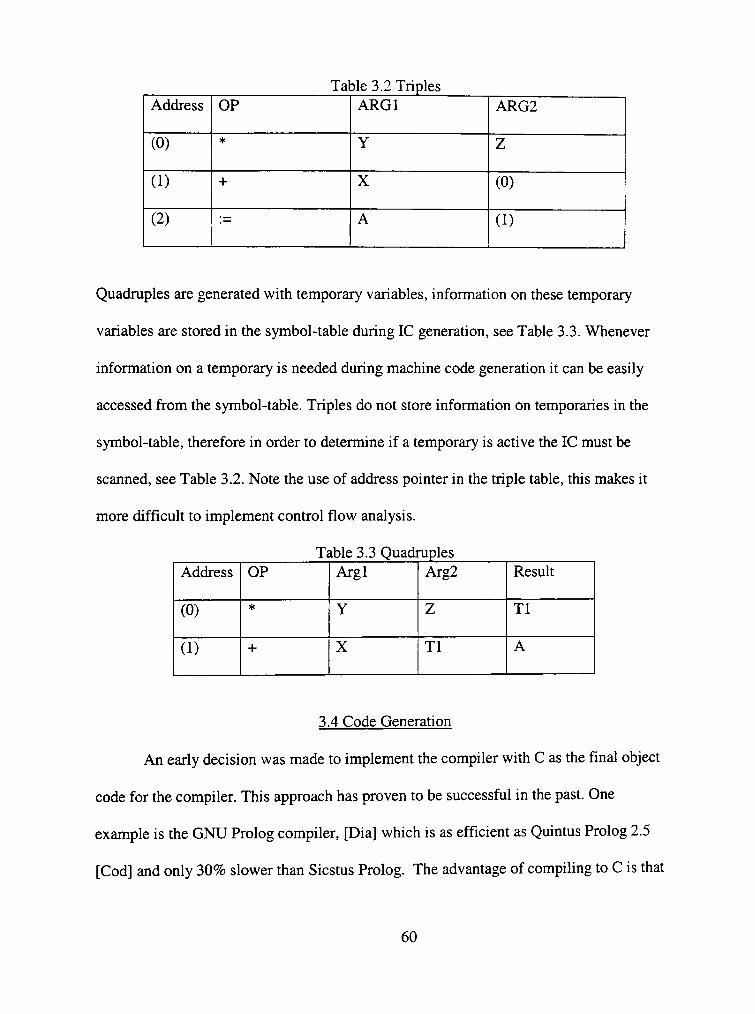
Address
(0)
(1)
(2)
Table 3.2 Triples OP
*
+
:=
ARGI
Y
X
A
ARG2
Z
(0)
(1)
Quadraples are generated with temporary variables, information on these temporary
variables are stored in the symbol-table during IC generation, see Table 3.3. Whenever
information on a temporary is needed during machine code generation it can be easily
accessed from the symbol-table. Triples do not store information on temporaries in the
symbol-table, therefore in order to determine if a temporary is active the IC must be
scanned, see Table 3.2. Note the use of address pointer in the triple table, this makes it
more difficult to implement control flow analysis.
Table 3.3 Quadraples Address
(0)
(1)
OP
*
+
Argl
Y
X
Arg2
Z
TI
Result
TI
A
3.4 Code Generation
An early decision was made to implement the compiler with C as the final object
code for the compiler. This approach has proven to be successful in the past. One
example is the GNU Prolog compiler, [Dia] which is as efficient as Quintus Prolog 2.5
[Cod] and only 30% slower than Sicstus Prolog. The advantage of compiling to C is that
60

it reduces the complexity of the compiler; optimization will not be implemented in this
compiler. The SequenceL compiler will rely on the C compiler's optimization capabilities
to handle optimization. Another advantage of using C is the availability of monitoring
and debugging tools for C programs, there are no tools designed for monitoring and
debugging SequenceL code. Finally, since many parallel programmers code in C they
may find it more acceptable to work with a language that generates parallel C code.
During the proposal phase the question was asked why not use FORTRAN as the
object language? Parallel programmers have often chosen FORT AN over C because
automatic parallelization of C has always been difficult due to pointer arithmetic,
irregular control flow and complicated data aggregation [Dow, Ken]. Availability of
FORTRAN compilers is the primary reason not to select it. Typically, if there is only one
compiler on a computer system it is probably a C compiler. It is also easier to implement
threaded programs in C rather than in FORTRAN [Cha].
Normally code generation involves the process of taking optimized intermediate
code and converting it to assembly or machine language code [Pys]. Some of the
difficulties associated with code generation to assembly or machine code include;
deciding what machine language code to generate, deciding on the order of the
computations and deciding which registers to use [Aho]. When code generating to C code
a new set of issues must be dealt with; such as what C code should be generated,
generating the correct control flow, use of global variables, variable and function naming
conventions, memory allocation, dynamic creation of functions and data stmctures.
61

3.4.1 Parallel C Code
A pilot research effort was carried out in order to investigate and compare a series
of algorithms implemented in SequenceL versus a parallel implementation in a
procedural language [CooOO]. Matrix Multiplication, Gaussian Elimination and Quicksort
were chosen as the algorithms to be implemented. Each of these algorithms presents a
different challenge. Matrix Multiply and the Gaussian Elimination are examples of
problems for which static a-priori schedules can be generated. The difference between
the Matrix Multiply and Gaussian Elimination is the need for Gaussian Elimination to
provide intermediate data to the various parallel paths setting up a communication
requirement. The paths of execution can be determined based upon the dimensions of the
matrix, in the Matrix Multiply, and the number of equations, in Gaussian Elimination.
Quicksort, requires dynamic scheduling and provided insights into SequenceL's ability to
imply parallelisms under dynamic scheduling conditions. Although the pilot research
smdy focused on SequenceL it also provided insight into the implementation of the
algorithms using procedural languages while reflecting on the SequenceL
implementations. C/MPI and Java threaded codes were experimented with. Java was
never considered for code generation, but experiments with Java's thread model did help
in making a decision on how to implement the parallelisms in SequenceL using C.
Given the decision to use C and a shared memory architecture the choices for the
underlying C based parallel development tool where narrowed down to three choices.
62

1. Multi-threading (Pthreads)
2. Message Passing Interface (MPI)
3. OpenMP
MPI is normally thought of as a distributed memory programming model but it
has also been implemented on many distributed shared memory systems such as the SGI
Origin2000. MPI uses a UNIX process model for its parallel tasks. This means a UNIX
process is spawned for every task that executes in parallel. Data sharing with MPI is
complex and requires message passing. The problems with portability and the difficult
programming model associated with MPI coupled with the lack of adequate monitoring
and debugging tools eliminated MPI from consideration for this first SequenceL
compiler.
OpenMP is a very attractive choice for the underlying parallel environment.
OpenMP has a standard interface and therefore should port well between OpenMP
systems. OpenMP is based on a thread model and is capable of data sharing between
threads executing on different processors. OpenMP can support fine-grained parallelisms
through loop parallelisms and coarse-grain parallelisms using parallel regions and work
sharing constmcts. Finally, OpenMP has good tools for monitoring and debugging tools.
The basic problem with OpenMP is that it requires an OpenMP compiler and a system
that supports OpenMP. This makes it impossible to port OpenMP programs to a shared
memory system that does not support OpenMP. OpenMP codes can be recompiled for
single processor systems, but in reality the OpenMP directives are just ignored and the
resultant program is a serial program.
63

The final decision was to select Pthreads. Pthreads have the following advantages.
Pthreads are standardized and widely implemented. Pthreads use a lightweight process
model. Pthreads are lightweight because they do not require a complete task stmcture.
Instead Pthreads inherit the task stmcture from their parent UNIX process. Second
Pthreads can take advantage of shared memory accesses, different threads can access the
same memory locations. Pthread programs have the advantage of mnning on either a
single processor system or a multi-processor system as a multi-threaded program. Some
disadvantages of Pthreads are, Pthreads require more of a programming effort from a
developer. This should not be a problem since the SequenceL compiler will be generating
the thread code. Pthreads functions restrict thread functions to just one user defined
argument and no user definable retum values. A pointer to a C stmcture containing the
input arguments and retum variable is the recommended method for getting around this
problem [Lew]. Pthread functions must also be synchronized with the calling routine so
that results from the threaded function are not used before the threaded function
completes. Pthreads provide two methods for synchronizing the data returning from a
thread function, the semaphore and the thread join. The semaphore works by having the
thread function set a semaphore just before it exits. The code that needs the thread result
will wait for the semaphore to be set at a location just before the results produced by the
thread are needed. The thread join works in a sinular fashion, except in this case the
thread must completely exit before a result can be used.
64

3.5 Scheduling
Task scheduling for parallel systems must be addressed and considered in the
design an implementation of the SequenceL compiler. Factors such as task granularity,
task allocation and task synchronization are scheduling issues that must be considered.
Granularity is defined as the ratio between computation and communication [Kum] or
how much computation should or will take place before there is communication between
tasks. A fine-grained parallelism has very few computational instmctions between
communication cycles while a coarse grained parallelism has many computational
instmctions between communication cycles. For example a coarse grained parallelism
involving 1000 calculations might involve only 10 threads with 100 computations on
each while a fine-grained parallelism might involve 1000 threads of execution for the
1000 calculations. The amount of communication overhead must also be considered. For
example if each thread, whether it is coarse-grained or fine-grained, requires one
communication cycle, the coarse grain example will have 10 communication cycles and
the fine grain model 1000 communication cycles.
The difficult with granularity is that, communication overhead differs between
parallel systems. Therefore it can be very difficult to establish a grain size for complex
computations from one parallel system to another.
The scheduling methodology for the SequenceL compiler will include the
development of simple grain size controls.
The operating system scheduler will handle task or thread allocation. Numerical
methods typically have minimal thread scheduling issues, since there are usually not a lot
65

of independent threads executing in a numerical program. A debugger is an example of a
program that does execute independent threads, threads to ran and monitor a program,
threads to keep the GUI alive, performance monitor threads, etc. This type of program
would require a time-slicing thread scheduler in order to give all the threads adequate
CPU cycles. The typical approach for scheduling threads associated with numerical
methods is to schedule them without any difference in priority as they are generated
[Lew].
Task or thread synchronization is a key element in using threads. Semaphores are
the preferred method for synchronizing threads but they suffer from race conditions in
recursive stmctures. Therefore the thread join will be used for thread synchronization.
The methodologies discussed in this chapter are used to build the SequenceL compiler.
The mechanics of implementing these methods are documented in Appendix B.
66

CHAPTER TV
RESULTS
There are number of differences between designing a SequenceL compiler and
designing a compiler for a procedural language. Typically, the lack of static stmctures
has made high-level functional languages more likely to be interpreted. Procedural
languages have more static properties and therefore are more likely to have compilers
[Lou]. Therefore it is not hard to believe that many of the tools and instmments used to
build compilers have been developed for procedural languages. The primary difference
between implementing the SequenceL compiler and a procedural language compiler is;
the source code is in SequenceL, a high-level nested language; the development of a new
intermediate language, an enhanced symbol-table, C as the target object code and the
compiler is built to generate parallel code.
This dissertation has achieved the following results!
• Established a proof of concept that there exists a SequenceL compiler that can
create executable programs that embody the inherent parallelisms and other
implied controls stmctures in SequenceL,
• Developed a new intermediate language capable of representing the meaning of a
SequenceL source program,
• Developed the techniques for spawning threads to dynamically create parallelisms
using a threaded approach, and discovered that the SequenceL language implies a
parallel execution model.
67

• Identified a number of optimization and performance enhancement opportunities,
• Identified a new SequenceL language requirement for defining nesting and
cardinality typing information for SequenceL data stmctures.
This chapter outiines how these five results were achieved. The most basic question this
research needed to answer is can a compiler be built that exploited the inherent
parallelisms in the SequenceL language? The answer to this question is yes. What follows
in the next few sections are the results of this implementation and a report on the issues
that the SequenceL compiler had to address and overcome before it could translate
SequenceL source code to parallel procedural code.
4.1 Proof of Concept
To date the language has been implemented as an interpreter in Prolog [CooOO].
Although the SequenceL interpreter can identify implied parallelisms it cannot actually
execute in parallel. The next phase of the SequenceL language development was to build
a proof of concept compiler. The goal of the SequenceL compiler is to take SequenceL
source code and generate parallel executable code. Chapter HI describes the formal
methods behind the development of the compiler. Chapter IV will describe the results of
that development process. Specific details on the mechanics of building the compiler are
presented in the Appendix B. Appendix B describes the translation of the grammar to an
1.1.(1) grammar, the implementation of the syntax analyzer, symbol table stmcture,
semantic analyzer, intermediate language generation, code generation and the mntime
libraries.
68

The SequenceL compiler implementation dealt with a number of research issues
related to the translation of high-level nested SequenceL code to procedural code. Some
of the basic constmcts of a procedural language include:
a. type statements,
b. assignment statements,
c. iterative constmcts,
d. jump statements, and
e. computational statements.
The procedural programming model forces developers to focus more on how to get things
done as opposed to what needs to get done [Mac]. SequenceL has no type statement,
jump statement, and iterative constmcts. SequenceL has one kind of assignment
statement, the taking expression. Unlike procedural languages SequenceL is designed so
that developers can focus on what needs to be done rather than on how to do it.
The only data stmcture in SequenceL is the sequence. As described in chapter I a
sequence can contain constant sequences, operations, and functions, sequences can also
be nested. The SequenceL compiler has been designed to deal with sequence stmctures
and will generate object code that faithfully preserves the meaning of the original source
code.
The SequenceL compiler uses the SequenceL language semantics and seeks out
opportunities for parallel execution and exploits them. It does so by examining the data
dependencies between intermediate code (IC) statements in the IC table and by
monitoring attribute information stored in the symbol tables. Together the symbol table
69

and the IC are key elements in the compiler's ability to generate the C object code that
includes the implied parallelisms. The IC statements and the attribute information in the
symbol table are taken directly from the SequenceL language constmcts during semantic
analysis, and it is therefore the SequenceL language constmcts that provide the necessary
information about the location of the implied parallelisms in a SequenceL program.
4.1.1 General Approach to Mapping SequenceL Constmcts
The proof of concept for the SequenceL compiler ultimately led to the definition
of a formal method to map SequenceL constmcts to Multi-threaded constracts. This
mapping takes place through the intermediate code and symbol table. There are three
SequenceL constracts; regular, irregular and generative which need to be defined in terms
of this mapping. The mapping can be expressed as follows.
SequenceL-v r Symbol Table >. r Multithreaded
r • i ^ r—• i Constmct J L Intermediate Code J L code
Figure 4.1 Mapping SequenceL Constracts
4.1.1.1 Regular Constract
The SequenceL regular constract was described in chapter I as a constmct that
applies an operation in a uniform manner to a set of singletons.
(t)(S)
Where ([) is a SequenceL built-in operator (+,-,*,...).
S is a sequence.
The operator (|) can be applied to linear sequences and nested sequences.
70

A linear sequence is a collection of singletons.
S={Si,S2,S3,...,Sn}
A nested sequence is a collection of sequences.
Given this definition of a sequence the regular constract for SequenceL is defined as.
Multithreaded code implements (<t),S) in a way that takes advantage of array stmctures it
uses to represent sequences. Therefore the multithreaded code uses the following
approach for implementing a regular constract.
The first level of nesting is defined as follows;
r if S={si,S2,S3,...,Sn} and V Si 6 S
Si(l)S2(t),...,Sn(|) ((t),S) \ else
V t 6 Si X S2 x,„Sn : fork((t),t)
• The singletons [a] and [b] are first level sequences of sequence [a,b]
• [[a,b],[c,d]] and [[e,fl,[g,h]] are first level sequences of [[[a,b],[c,d]], [[e,f],[g,h]]]
Object code implements (l)[[[a,b],[c,d]], [[e,f],[g,h]]] as an operation between arrays of
first level singletons.
For [[[a,b],[c,d]], [[e,f],[g,h]]] the singleton arrays are ai=a,b,c,d and a2=e,f,g,h.
Where afSfa.2 = a<{)e,b(t)f,c(t)g,d(t)h
(t)[[[a,b],[c,d]], [[e,f],[g,h]]] = gather(ai(t)a2)
Where "gather" maps the resultant array to the cardinality and nesting of a first level
sequence. Therefore the regular constract in object code is defined as;
gather(Ai 0 A2 (t) A3,..., An )
71

where each array Ai contains a set of singletons {ai,a2,...am}
Ai is a first level sequence array.
rj = { aji(t)aji,...,aji} where j = {l,...,m} andi={I,...,n}
rj is the result of each set of singleton operations.
For every singleton in the first array, Ai, a thread is forked. For every thread forked there
is a result rj. This result TJ in each thread is updated by (]) for a given singleton in each
subsequent array, .i.e. TJ 0 aj. This continues until all first level sequence arrays have been
processed.
((t),S)
V t 6 ai X a2 x,„ain : fork((t),t,aj) V Ai e {Ai X A2X„An} 3 {ai, a2,„an,} : rj< rj (]) aj gather(ri,r2„,rm)
The following applies to both definitions of (^,S).
Define;
S'= { Si, S2, S3,..., Sn }
Where S' is a set of sequences that contains Si, S2, S3,.. .,Sn.
The taking expression generates a set of index values that is used to index a sequence;
taking i from S
S(i)={Si,S2,S3,...,Sn}
Therefore
S(i)=S'
72

A regular constract with index variables is defined as;
[(1)(S')]
or
[(t)(S,),(l)(S2),(l)(S3),...,(t)(Sn)]
The implied parallelism for a regular constract involving indexed sequences can be
defined semantically as the Cartesian product of an operation 0 and a set of sequences.
During intermediate code generation a symbol for S is placed in the symbol-table.
V S 6 ST where ST=symbol table
The following is the IC for the SequenceL expressions listed after the semicolon.
from S i ; taking i from S _M S i to ;S(i) (t) to t l ;(J)(S(i))
S is defined as a sequence, intermediate code has no knowledge of what S might in terms
of dimension. S could be a singleton, sequence or nested sequence. This information is
not available until mntime. tO and tl are temporary sequences that are generated by
intermediate code generation to store the results. tO is defined in the symbol table as a
being produced by an index operation. Therefore tl will also be defined in the symbol
table as being produced indirectly by an index operation.
Object code generation will generate the multithreaded constmcts when it detects
the index attribute in the symbol-table. When the IC code is read during object code
generation the index attribute triggers code generation to build an iterative thread
constract to process the set.
73
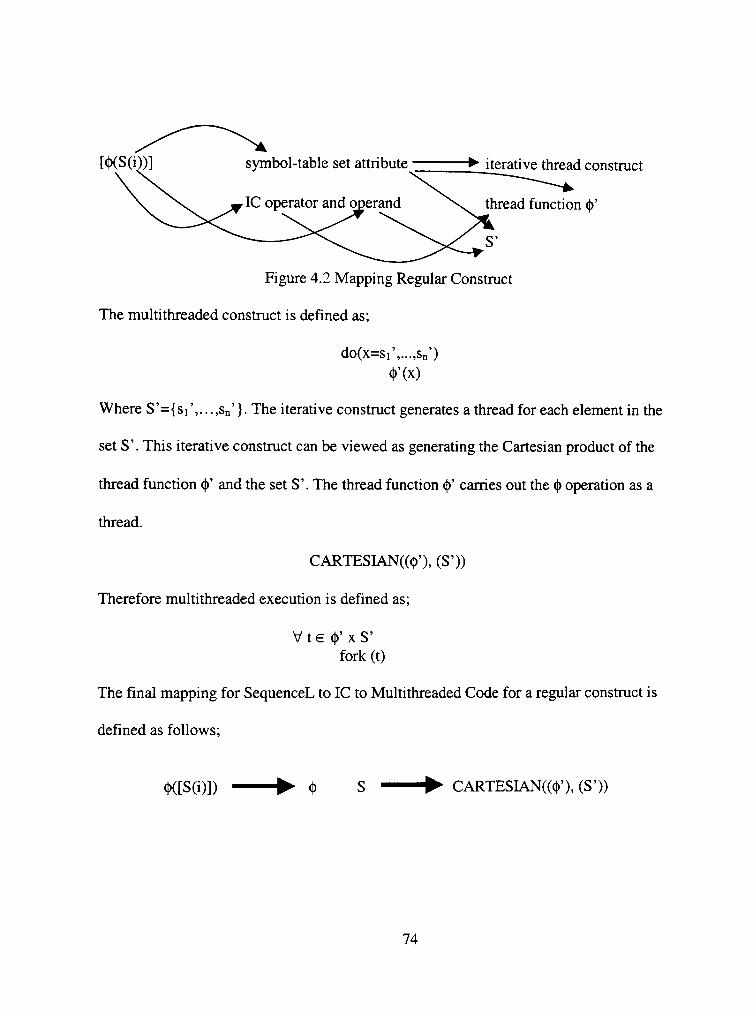
[<t)(S(i))] symbol-table set attribute • - • iterative thread constract
thread function (|)'
S'
Figure 4.2 Mapping Regular Constract
The multithreaded constract is defined as;
do(x=sr,...,Sn') (t)'(x)
Where S'={si',.. .,Sn'}. The iterative constract generates a thread for each element in the
set S'. This iterative constract can be viewed as generating the Cartesian product of the
thread function (j)' and the set S'. The thread function ((>' carries out the (j) operation as a
thread.
CARTESIAN(((t)'), (S'))
Therefore multithreaded execution is defined as;
V t e (t)'xS' fork (t)
The final mapping for SequenceL to IC to Multithreaded Code for a regular constract is
defined as follows;
0([S(i)]) CARTESL\N(((1)'), (S'))
74

4.1.1.2 Irregular Constract
The irregular constract mapping follows the same pattem as the regular with some
added complexity. The irregular constract can be defines as follows;
[(t)i(Si)] when P(S2) else [(1)3(S3)]
Vpe {>,<,>=,<=,<>}.
P tests the sequence Si. If S2 is not an indexed sequence then;
S2={S}
Where s is a single sequence.
Either the trae or false expressions will execute depending on the outcome of (t)(s). The
trae and false expressions are regular constracts. The mapping of this conditional
expression to multithreaded code is;
[(t)i(Si)] when P(s) else [([) (S3)]
I P s then 01 Si else (t)2 S2
i ifP(s)
CARTESL\N(((t)r),(S,')) else
CARTESL\N(((t)3'), (S3'))
75

What of the case where S2 is an indexed sequence? When this occurs an implied
parallelism is associated with the relational operation. The following statement is tme of
all SequenceL conditional expressions.
Given :
|S2'| = m : m > I
then|Sr,...,S3'| = mor I
If S2> 1 the relational expression is placed in its own thread function P'.
The input variables to P' is the set of index variables:
Si'=(sli,...,slm); S2'=(s2i,...,s2n,);.... S3'=(sni,...,snni);
The thread function P' contains the conditional expression.
ifP(X2)
then
else
The multithreaded call to P' would be via an iterative loop:
do(Xi=Sli,...,Slm; X2=s2i,...,s2m;... Xn=s3i,...,s3ni)
P ' (Xi,X2,...,Xn)
Therefore a conditional operation with implied parallelisms can be defined as m sets of
function P' and n sequences.
S"=(p', sli, s2i,...,sni),( P', SI2, s22,...,sn2),...,( P', sl^, s2m,...,snm)
or
V t e S" forkt
76

The number of sets goes from 1 to n since n relational, trae and false expressions can be
linked together.
[01 (S,)] when p (S2) else [US3)] ...else [(t)„(S„)]
i P S2 then 01 Si else 03 S3
else 0n Sn
i V t e S"
forkt
There are two assumptions made about this mapping. The first assumption is that
the sequences in the set of sequences Si,S2,...,Sn are the index variables required by the
thread function P'. In the multithreaded object code, the input arguments to the thread
function P' are the variables required to resolve these index variables. Therefore, when
index variable s_l(l) is required by P', s_l and 1 are passed to the thread function and
the actual index variable is resolved in the thread function.
77

The second assumption has to do with the use of a non-indexed variable in a
conditional expression. For example, for the following expression;
s_l(i) when >([s_I(i),[I]]) else [ ]
If / has values from 1 to n then this simplifies to;
s_l(l) when >([s_I(I),[l]]) else [ ] s_I(2) when >([s_I(2),[I]]) else [ ] s_l(3) when >([s_l(3),[l]]) else [ ]
s_l(n) when >([s_l(n),[l]]) else [ ]
The assumption is that there are n [ ], one for each conditional expression.
4.1.1.3 Generative Constract
The mapping of the generative constract from SequenceL to IC to multithreaded
code is as follows;
gen(a,...b) ^ gen a b tO ^ gen(S)
S is a set containing three elements, a, b and tO.
These three formal methods were developed as a result of the insights gained
during intermediate code development and reinforced by results from object code
generation and testing of the thread model.
4.1.2 Proof of Concept through Testing
A number of SequenceL problem solutions have been compiled and executed to
verify the compiler has met its objectives. Of specific interest are the algorithms that
78

were used in [CooOO], Matrix Multiply, Gaussian Elimination and Quicksort. These three
algorithms were identified in [CooOO] as having certain parallel properties that would
present a challenge to a parallel programming language. Both Matrix Multiply and
Gaussian Elimination provide a compiler with apriori knowledge of the parallel execution
opportunities, while Quicksort has dynamic properties associated with parallel execution
that are known only during mntime. The difference between the Matrix Multiply and
Gaussian Elimination is the need of the latter to communicate intermediate values during
execution. The SequenceL interpreter identified the following implied parallelisms for
Matrix Multiply, shown in Figure 4.3. The first version of the SequenceL compiler
generated the same trace as the interpreter. The current version of the SequenceL
compiler includes some scheduling capabilities. The SequenceL execution trace in Figure
4.4 reflects this.
mm
H e * * * * * * * * * * * * * * * * * * * * * * * * * *
Number of processors 1
27
Figure 4.3 Interpreter Identified Parallelisms [CooOO]
79

mm Number of processors 1
Figure 4.4 Matrix Multiply Execution Trace
Initially, the Gaussian Elimination program failed on a logic error, when
executed. This was caused by a semantic inconsistence between the interpreter and the
compiler. The following generative constmct generates a descending set of sequences.
gen([5,...,l])
For this expression using the compiler semantics gen produces;
[5,4,3,2,1]
The interpreter produces;
[1]
After making an adjustment to the compiler semantics the execution trace in
Figure 4.5, this matches the interpreter's trace. The Quicksort algorithm provides the most
interesting test for the SequenceL compiler. Quicksort involves parallel execution and
recursion mixed together. The SequenceL compiler generated program duplicated the
findings of the SequenceL interpreter.
80
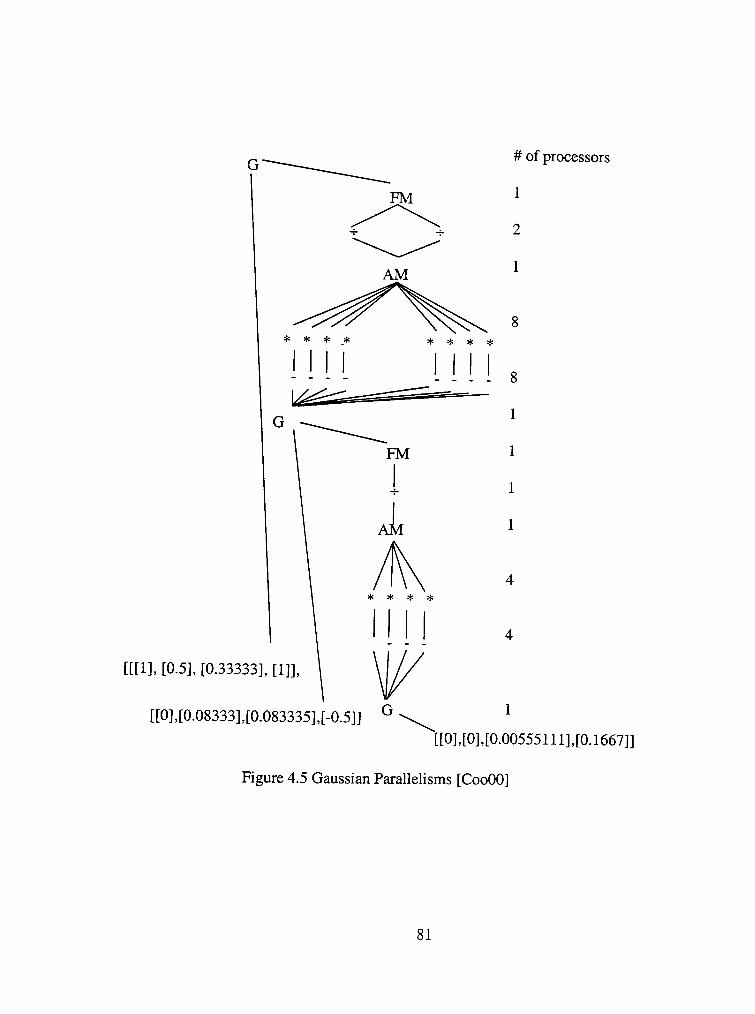
FM
AM
* * * * * * * *
FM
^M
# of processors
I
2
1
8
8
1
1
1
1
t" 'K "F 5t*
[[[1], [0.5], [0.33333], [1]],
[[0],[0.08333],[0.083335],[-0.5]] ° \ ^ ^
[[0],[0],[0.00555111],[0.1667]]
Figure 4.5 Gaussian Parallelisms [CooOO]
81

# of processors 1
2
2
4
4
4
4
Figure 4.6 Quicksort Execution Trace
In the execution trace Q is the quick function, L is the less function and G is the
great function. For this example the quick function has 10 recursive calls, and the less
and great have 4 each.
These results have led to the conclusion that the SequenceL compiler achieved its
goal of generating executable parallel code that exploits the inherent implied parallelisms
found in SequenceL. (Future research will include extending the set of algorithms that
have been parallelized by the SequenceL compiler.) The following sections describe how
this proof of concept result was achieved as well as new insights and research issues
identified for the SequenceL language.
82

4.2 Intermediate Language
The development of the SequenceL intermediate language was a major step in the
compiler's development. While the concept used is not new the implementation is. What
makes the implementation different is that a typical intermediate language is designed to
preserve the semantics of a language with some target machine code in mind. SequenceL
expressions and functions can be evaluates without side effects because they have no
dependent control stmctures. The SequenceL intermediate language is designed to
preserve the advantages of this independent function evaluation model that SequenceL
employs, while at the same time providing a bridge to the C object code. The independent
function evaluation model means that SequenceL functions and expressions can be
evaluated with no side effects associated with implied control stmctures. An example of a
side effect in a procedural language is a global variable assignment. In C if multiple
functions update the same variable, with no synchronization mechanisms, data could be
lost causing unpredictable results.
A significant difference in the SequenceL IC is that it has no conditional jump
statements or assignment statements, two features fundamental to implementing iterative
stmctures. For example, the following code fragment is a "for" loop from the C
programming language.
for(i=0; i < 10; i++) a[i]=0;
This simple statement consists of three assignment statements and a conditional jump.
The intermediate language representation might be something like the following.
83

loopl: := 1
< i jfalse t5 := a[i] + i jump
10
1
0 t5 exit 0 i loopl
4.2.1 Initial Intermediate Language
This section describes the initial intermediate language design, which was later
abandoned. The description is given here because its development led to some key
insights about the SequenceL language constracts. All of the examples of IC given in
this section are based on this initial intermediate language. The following section will
introduce and describe the current SequenceL intermediate language.
Initially, the intermediate language for the SequenceL compiler was specified
with support for conditional jumps and assignment statements. To generate object code
that contains iterative stmctures without the benefit of conditional jump statements and
assignment statements in the intermediate language was initially perceived as an
unreasonable condition to place on object code generation. This turned out to be untrae.
This initial design led to certain insights about the SequenceL language that will be
explained in this section, as well as the development of the current intermediate language.
The reason iterative stmctures were placed in the initial intermediate language
specification is that they are a very important language feature for procedural languages
and particularly important for parallel procedural languages. Parallel numerical methods
are of particular interest to many parallel program developers, and many numerical
methods employ iterative stmctures. Matrix multiply is one example.
84

for (i=0;i<=m.rows;i++) for (j=0;j<=m.columns;j++)
{s = 0; for (k=0;k<=m.length-l;k++)
{s+=m|j][k]*m[k][i];} mr[i][j] = s;}
Many parallel languages such as OpenMP, identify iterative constracts in
procedural code and mark them for parallelization. Parallelizing iterative stmctures that
have no dependencies is what languages like OpenMP exploits when parallelizing
procedural code. An iterative stmcture with no dependencies means that one iteration
does not depend on the result of any other iteration. If these conditions exist, then the
iteration can be partitioned and distributed to multiple tasks and executed in parallel. The
SequenceL compiler implementation must do the same, but in this case it must translate
the SequenceL code, which has no iterative constmcts to a parallel procedural
programming model based on threads that does have iterative constmcts.
If there are no iterative constmcts in SequenceL, how are iterative stmctures
generated in this initial intermediate language?
The taking expression in SequenceL is the source of some of the iterative
constracts in the object code. The "taking" expression is SequenceL's only assigninent
statement. It assigns values to identifiers. Therefore in the following expression i is
assigned the value [1].
taking i from [1]
85

The taking expression has capabilities beyond assigning one value to /, it can assign
many values to i. For example, the following expression assigns the values [1] through
[5] to /.
taking i from [1,2,3,4,5]
This is not unlike assigning / values in a C expression using a "for" statement.
for(i=l; i <=5; i++)
There are a number of semantic differences between the two statements. The first
difference is that the "taking" expression does not assign integer values to /, it assigns
sequences to i. Therefore the i identifier in the taking expression is actually assigned the
singleton values:
[1],[2],[3],[4],[5]
This difference is significant, for example the following taking expression assigns i the
values [1,2], [3,4] and [5,6].
taking i from [[1,2],[3,4],[5,6]]
The second difference is that SequenceL treats the assignment of values to i as a
distribution of i values among copies of the function the taking expression modifies. The
C expression assigns i a value after each iteration of the "for" loop. Therefore, the taking
expression is not just a method of implementing an iterative constract in SequenceL, it is
also a distribution point. The copies of the functions that reference i are a result of this
distribution and they execute concurrently. This makes the taking expression a source of
implied parallelisms. With these facts in mind it seems obvious to generate the iterative
86

constracts in the intermediate language using the taking expression as a starting point.
Therefore the following SequenceL code:
*([s_l(i),s_2(i)]) taking i from [1,2,3,4,5]
Translates to the following initial intermediate code (IC)
:= i 1 loopl: <= i 5 t5
jfalse exit * s_I[i] s_2[i] tO[i] + i 1 i jump loopl
This results in the following C object code.
for(i=l;i<=5;i++) _tO(i)=mult(s_I(i), s_2(i));
The function mult handles sequence multiplications. Parallelization of this "for" loop
would involve partitioning the iterations into threads of execution. Although this
approach appeared promising, closer analysis revealed problems.
SequenceL expressions are typically nested expressions; a one-pass compiler
parsing expressions from left to right evaluates these expressions and generates
intermediate code in that order. For example, the following SequenceL expression has
two computational expressions, highlighted by bold.
[+([s_l(i),s_2(i)]), +([s_3(i),s_4(i)])] taking i from [1,2,3,4,5]
The compiler will generate the initial intermediate code for the first expression followed
by the second.
loopl: := i <= i jfalse
1 5 t5
exit
87

+ s_l[i] s_2[i] tO[i] + s_3[i] s_4[i] tl[i] + i 1 i jump t5 loopl
The C object code might be something like the following:
for(i=l; i<= 5; i++){ _t0(i)=add(s_l(i),s_2(i)); _tl(i)=add(s_3(i), s_4(i));
}
This constract can be parallelized by partitioning the loop. The next example
extends the nesting a little further and places a function reference and its input argument
between the two expressions.
[+([s_l(i),s_2(i)]),function2,s_l, +([s_3(i),s_4(i)])] taking i from [1,2,3,4,5]
The IC code for this expression would be:
:= i 1 loopl: <= i 5 t5
jfalse exit + s_l[i] s_2[i] tO[i] call function2 s_l tl + s_3[i] s_4[i] t2[i] + i 1 i jump loopl
The object C code would be:
for(i=l;i<=5;i++){ _tO(i)=add(s_l(i), s_2(i)); _tl=function2(s_l); _t2(i)=add(s_3(i), s_4(i));
}
88

This is an inefficient situation since function2 is called multiple times when only one call
is required. If code relocation were an option then a more acceptable intermediate code
might be as follows:
:= i 1 call function2 s_I tl
loopl: <= i 5 t5 jfalse exit + s_l[i] s_2[i] tO[i] + s_3[i] s_4[i] t2[i] + i 1 i jump loopl
The resultant object C code would be:
_tl=function2(s_l); for(i=l; i<=5;i++){
_tO(i)=add(s_l(i), s_2(i)); _t2(i)=add(s_3(i), s_4(i));
}
An early decision was made to not develop code relocation capabilities for this version of
the compiler. Code relocation involves complex analysis of intermediate code [Aho] and
was deemed beyond the scope of this research. Therefore a better intermediate language
design was needed.
4.2.2 SequenceL Intermediate Language
Certain key insights resulted from the first version of a SequenceL intermediate
language representation. On closer examination of the intermediate code it became
evident that the individual expressions were independent of each other until a result was
needed. This characteristic of SequenceL is also typical of functional programming
languages. It has long been known that pure functional programming languages can
89

execute in parallel [Ham]. This is because there are no implicit control dependencies
between expressions in a functional language. Functional programming is a style of
programming that emphasizes the evaluation of functional expressions, rather than
execution of commands. Expressions are formed in functional languages by using
functions to combine basic values. A functional programming language only has
identifiers bound to values, no variables, no assignment statements and no iterative
constracts [Fin]. This description applies to SequenceL. The semantics of functional
languages is called reduction semantics. This simply means that expressions in functional
languages are created from functions that are evaluated or reduced in place with out side
effects. This is similar to the consume-simplify-produce execution strategy SequenceL
employs, the difference being the SequenceL simplification process typically expands an
expression as it simplifies it until the expression can be evaluated. When a SequenceL
expression is being evaluated, there are no implied control dependencies that affect other
expressions. This revelation led to a re-examination of the possibilities for an
intermediate language design that did not include conditional jumps and assignment
statements. If SequenceL expressions could be treated in an independent manner, then the
parallelisms associated with these expressions could also be treated in an independent
manner. The intermediate language design grew from this premise.
Given this premise, what are the design requirements for an intermediate language
that must bridge a gap between SequenceL and C object code? The typical approach for
developing an intermediate language is to specify it with a target machine language in
mind [Aho]. The approach taken for the SequenceL intermediate code was to develop it
90

from the SequenceL perspective and move towards the object code. First and foremost,
the SequenceL expressions and their meanings needed to be preserved in some form.
Second, there must be a mechanism to identify IC statements that potentially can be
parallelized. In addition, SequenceL has a conditional statement that needs to be
considered.
s_l when >([s_l,[l]) else [ ]
Does this force a conditional jump operation back into the SequenceL intermediate
language? SequenceL also imposes certain conditions on the intermediate language with
respect to the way SequenceL passes resultant sequences between expressions. The
following sections present classes of intermediate language operations. These
classifications are based on an aspect of the operations behavior. For example operations
that accept multiple operands are called multi-operand intermediate operations. For the
general approach to mapping these classes of IC operation to SequenceL constmcts see
section 4.1.1.
4.2.2.1 SequenceL IC Operations
The first requirement, preserving the meaning of the SequenceL expressions,
resulted in the creation of the first class of intermediate language operators. We can call
these operators the SequenceL IC operators. When we examine the earlier examples for
an intermediate language, we can see that the multiplication expression can be executed
independent of any other expressions, other than the need for the index and input
variables.
91

:= i 1 loopl: <= i 5 t5
jfalse exit * s_l[i] s_2[i] tO[i] + i 1 i jump loopl
This code corresponds to a SequenceL regular constmct see section 4.1.1.1. We can
define a simple class of IC operators based on the SequenceL operations that exhibit this
behavior. These operations include the arithmetic operators +,*,-,/ the relational operators
<, >, <=, >=, <>, the logic operators, "and", "or" and "not" and the SequenceL functions
abs, cos, sin etc.... These operators accept a single sequence operand and produce a
single result.
Languages like C allow multiple operands and produce a single result, for
example the following expression is a legal C statement.
t=a+b+c+d+e;
In SequenceL the expression to sum sequences a,b,c,d, and e would be:
+([a,b,c,d,e])
SequenceL expresses the sequences a,b,c,d and e within a sequence before addition is
applied. This means, from the prospective of the intermediate language, that there is an
additional operation that takes place with this type of SequenceL expression, which we
shall call the intermediate language's collective sequence operation. The SequenceL
intermediate language has been given an operator called the "collect sequences" operator.
Therefore, the intermediate code for this SequenceL expression would be:
_seq a b c d tO + to tl
92

Note that the collect sequences statement in the first line has more than one
operand. Because machine code is implemented with only two operands, intermediate
languages typically have only two operands [Aho]. Since the compiler was not compiling
to machine code it was decided that more than two operands would be allowed. An
operand stack was chosen as the method for handling more than two operands. The
operand stack was implemented with no fixed upper limit on the number of operands it
could handle. This IC language design implies that the C object code must also be
designed to deal with any number of operands. There are significant implications
associated with the collect sequences operation with respect to the C object code's
intemal data representation and performance. These issues will be addressed in section
4.4.
4.2.2.2 Multi-Operand Operations
Five operations fall into this class of IC operations, which are called "multi-
operand" operations. The collective sequence operation, the taking operation, the index
operation or index variable operation, the function call operation and the function begin
operation. The collective sequence operator has already been described. The function call
operation and the function begin operations are related. The function call operation
references a function and passes input arguments. While the function begin operation
specifies a function and its formal parameter list. Functions can only accept sequences
and retum one sequence. A function can have any number of arguments, which are
treated as operands by IC.
93

The SequenceL taking expression can also have more than two operands. In the
examples so far only one identifier has been used in a taking expression, more can be
specified. For example the following taking expression has three identifiers i,j and k.
taking [i,j,k] from s_l
The SequenceL IC for this expression would be:
from s_l i j k
The following is an index operation. This statement makes use of the taking expression
identifiers as index values.
s_l(i,j,k)
The SequenceL IC for this expression would be:
_M s_l [i j k] to
The variable index operation has a result field, which it uses to indicate where the result
of the index variable will be stored. Square brackets are shown only to improve
readability.
It is the combination of the taking expression and variable index expression that
makes the taking expression a distribution point for parallelisms. By specifying a variable
index operation as an operand in a computational expression, the index will produce all
the indexed variables concurrentiy for the simplified expression. For example;
+([s_l(i)]) taking i from [1,2,3]
Simplifies to; +([s_l(l)]) +([s_l(2)])
94

+([s_I(3)])
Ifs_l = [[l,2],[3,4],[5,6]]
The simplification process continues and generates;
+([1,2]) +([3,4]) +([5,6])
These three computations can be evaluated in parallel producing the result.
[3,7,11]
The following SequenceL expression will be translated to IC statements.
*([s_l(i),s_2(i)]) taking i from [1,2,3,4,5]
This code fragment results in the following IC.
from _M _M _seq *
[1,2,3,4,5] i s_l i s_2 i tl t2 t3
tl t2 t3 t4
Notice that there is no indication of possible iterative operations, and no indication of
parallelisms. At first glance it appears to be a set of operations on scalars. To identify the
implied parallelisms the semantic analyzer will mark the identifier i as being an index
variable, by setting an attribute for / in the symbol table. Any operation that has an index
variable, as an operand will produce a result that also has an attribute set in the symbol
table identifying it as the result of an operation, which uses an index variable. Therefore
in this example t l , t2, t3 and t4 have this attribute set. The result is the C object code
95

generator treats the multiply operation as multiple operations and will therefore generate
an iterative constract for this SequenceL expression. The trigger for iterative constracts in
the object code in the first intermediate language design was the taking operation in this
current version it is the taking identifier. Another way of describing this is that
parallelism has shifted from being driven by control flow to data driven. The IC code
from above translates to the following object code. TO is a queue of sequences containing
the index variables associated with s_l(i) and s_2(i). This queue is processed from its
beginning or head until the tail is detected.
11 =select_sequences(s_l ,i) t2=select_sequences(s_2,i) t3=collect_sequence(t 1 ,t2); t3->element=t3->head; while(t3->element !=NULL){
mult(t3 ->element]) tO->element=tO->element->next;
}
In the above object code the multiplication function mult is not execution as a thread, to
execute the mult function as a thread requires it to be invoked by pthread_create.
11=select_sequences(s_l ,i) t2=select_sequences(s_2,i) t3=collect_sequence(s_l(i),s_2(i)); t3 ->element=t3 ->head; while(t3->element !=NULL){
pthread_create(&thr_id[j], NULL,(void *) mult, (void *)t3->element)); t3->element=t3->element->next;
}
The following expression:
[+([s_l(i),s_2(i)]),function2,s_l, +([s_3(i),s_4(i)])] taking i from [1,2,3,4,5]
96

Now results in the following IC code.
from _M _M _seq + _call _M _M _seq + _seq
1,2,3,4,5 i s_l i s_2 i t l t 2 t3 function2 s_l s_l i s_2 i t6 t7 t8 t4 t5 t9
tl t2 t3 t4 t5 t6 t7 t8 t9 tlO
All the operands are in stacks. The stack elements are shown here in order to give the IC
statements a little more meaning for the reader. The C object code for this set of IC
statements would be.
tl=select_sequences(s_l ,i) t2=select_sequences(s_2,i) t3=collect_sequence(tl ,t2); t3->element=t3->head; while(t3->element != NULL){
pthread_create(&thr_id[j], NULL,(void *) add, (void *)t3->element)); t3->element=t3->element->next;
} t4=t3; t5=function2(s_l); t6=select_sequences(s_l ,i) t7=select_sequences(s_2,i) t8=collect_sequence(t6,t7); t8->element=t 1 ->head; while(t8->element != NULL){
pthread_create(&thr_id[j], NULL,(void *) add, (void *)t8->element)); t8->element=t8->element->next;
} t9=t8;
110=collect_queues("qsq",t4,t5 ,t9);
There are now two loops one for the multiply and one for the addition with the function
call in between. This might not appear to be a big improvement and certainly combining
97

the two loops would be better, but it does reduce the number of calls to function2. Simple
code movement where the first and second loops are combined would reduce the number
of loop iteration by half
t5=function2(s_l); 11=select_sequences(s_ 1 ,i) t2=select_sequences(s_2,i) t3=collect_sequence(tl ,t2); t3->element=t3->head; t6=select_sequences(s_l ,i) t7=select_sequences(s_2,i) t8=collect_sequence(t6,t7); t8->element=t 1 ->head;
while(t3->element != NULL){ pthread_create(&thr_id[j], NULL,(void *) add, (void *)t3->element)); t3 ->element=t3 ->element->next; pthread_create(&thr_id[j], NULL,(void *) add, (void *)t8->element)); t8->element=t8->element->next;
} t4=t3; t9=t8; tl0=collect_queues("qsq",t4,t5,t9);
Notice the use of the queue length t3 to also used to control the thread generation for t8.
Queues that are generated from the same taking expression identifier, / in this case, will
be the same length. The object code for the taking expression is not shown in this
example, an example of it cab be found in section 4.3.
4.2.2.3 Conditional Operation
The next class of SequenceL IC operations is a class of operations that require a
temporary to be used twice as a result. The conditional operation is this type of operation.
98

One of the features of the SequenceL conditional is that it cannot be nested. The
following is an example of a SequenceL conditional expression.
+([s_l,s_2]) when >([s_l,s_2) else -([s_l,s_2]) when =([s_l,s_2]) else [ ] It reads as follows,
if s_l > s_2 execute s_l+s_2 else
if s_l == s_2 execute s_l-s_2
else
[]
SequenceL allows SequenceL expression to produce one result for each
expression and conditional expressions are no exception. Once a condition is trae, or the
last else expression is reached a single result is produced. For example, in the above
SequenceL conditional expression, if s_l > s_2 is tme the result of the conditional
expression is produced by s_l+s_2 but if s_l > s_2 is false and s_l==s_2 is tme, the
result of the conditional expression would be produced by s_l-s_2. The result for either
of these expressions are assigned to the same temporary. The conditional operation is the
only statement where a temporary is used multiply times in an assignment statement in
the object code.
4.2.2.4 Generative Operation
The final IC operation is the generative operation. The simple generative
operation requires two operands and generates one result. The following SequenceL
expression:
gen([n,...,m])
99

Results in the following generative IC statements.
gen n m tO
The generative statement is a very good example of an expression that can be evaluated
without producing side effects. It uses two bound identifiers, n and m, and produces a
single result.
The SequenceL research leading up to this research had clearly shown that
SequenceL has inherent implied parallelisms [CooOO]. In this research, the development
of the SequenceL intermediate language supports the contention, that SequenceL
expressions inherentiy support their own evaluation in parallel. Even though SequenceL
is not purely functional, it does exhibit certain characteristics of a functional
programming language, the most important being that SequenceL expressions can be
evaluated independently. The thread model covered in the next section will reinforce this
result.
4.3 SequenceL Thread Model
The SequenceL compiler's parallel execution model is based on a thread model,
specifically Pthreads. The reasons for choosing a thread model for the SequenceL
compiler were given in Chapter m. In addition to these reasons, the intermediate
language research has revealed that the SequenceL language is a natural fit for the thread
programming model. This is because of the independence of a SequenceL statement.
There are no implied control stmctures defined in the SequenceL language that effect
100

functions or expressions being evaluated. Therefore, for the following SequenceL
expression;
( ([S])
0 is a SequenceL operation or function that has no implied control stmctures that effect
its evaluation, S is a sequence input argument. Under these conditions 0 can be
implemented as a function 0' in object code with S as an input argument. If 0 ([S])
exhibit implied parallelisms then the object code thread function 0' can be created.
Thread function can be invoked by the POSIX thread's pthread_create library routine,
which creates threads as a result. This process of generating object code thread functions
from SequenceL expressions is the SequenceL thread model.
For example the following SequenceL code has two multiply operations or
expressions that can be evaluated independently of each other. Only when the results are
needed by the addition operation is there any relationship. Once the results are available
to the addition operation it too can be evaluated in place without consideration of any
other SequenceL expressions.
+([*([s_l,s_2]),*([s_3,s_4])])
Since each of the multiply operations are independent and can be evaluated
without effecting any other code, they can be treated as independent functions. This point
becomes more significant when implied parallelisms are involved. For example, if the
multiply operations involves the taking and index operation, multiple multiply and
addition operations will occur. This can be illustrated using the following example.
+([*([s_l(i),s_2(i)]),*([s_3(i),s_4(i)])]) taking i from [1,2,3,4,5]
101

from _M _M _seq *
_M _M _seq *
_seq +
to s_l s_2 tl t2 t3 s_l s_2 t6 t8 t4 tlO
i i i
i i t7
t9
tl t2 t3 t4 t6 t7 t8 t9 tlO t i l
The SequenceL compiler's thread model will set up the two multiply functions so that
they are invoked for each sequence produced by the index operation. In this example
there would be 10 multiply operations, 5 for each, this would be followed by 5 additions.
Each set of arithmetic operations can be executed in C object code using an iterative
constract, changing values of / would control iterations. For each loop iteration a thread is
generated. The compiler will place blocks for the multiply threads just before the iterative
addition where the results from the multiply operations are needed.
t0=sequence_atos("[l,2,3,4,5]");
/* taking expression */ i=(taking_data*)malloc(sizeof(taking_data)); i->from=tO; i->var=l; i->num_var=l; take_thri=(pthread_t*)malloc(sizeof(pthread_t)); pthread_create(take_thri, NULL, (void *)taking, (void*)i); pthreadJoin(*take_thri, NULL);
/* first multiply operation */ tl=select_sequences(s_l,i->result); t2=select_sequences(s_2, i->result); t3=collect_sequence(tl ,t2); t3 ->element=t3 ->head; thread=0;
102

while(t3->element != NULL){ pthread_create(&thr_id_t4[thread++], NULL,(void *) mult, (void *)t3-
>element)); t3->element=t3->element->next;
} t4=t3;
/* second nested multiply operation */ t6=select_sequences(s_ 1, i ->result); t7=select_sequences(s_2, i->result); t8=collect_sequence(t6,t7); t8->element=t8->head; thread=0; while(t8->element != NULL){
pthread_create(&thr_id_t8[thread++], NULL,(void *) mult, (void *)t8->element));
t8->element=t8->element->next; } t9=t8;
/* result t4 is needed for addition, therefore a join is required */ thread=0; t4->element=t4->head; while(_t4->element) {
pthreadJoin(thr_id_t4[thread++],NULL); t4->element=t4->element->next;
}
/* result t9 is needed for addition, therefore a join is required */ thread=0; t9->element=t9->head; while(_t9->element) {
pthreadJoin(thr_id_t9[thread++],NULL); t9->element=t9->element->next;
}
/* addition operation */ tl0=collect_queues("qq",t4,t9); 110->element=t 10->head; thread=0; while(tlO->element != NULL){
pthread_create(&thr_id_tll[thread++], NULL,(void *) add, (void *)tlO->element));
110->element=t 10->element->next;
103

}
The implementation of the SequenceL IC operators as thread functions was fairly
straight forward, since they required only one input argument. The pthread_create library
routine then uses these thread functions to create the threads. Thread functions that are
setup for pthread_create can have only one input argument and no retum value. At first
this might seem to be a problem, but recall that SequenceL uses a consume-simplify-
produce execution strategy, this means that a SequenceL expression consumes its input
arguments and produces a result in its place. Therefore, functions that are to be invoked
by pthread_create can also retum their result in the input argument. With this design
approach the SequenceL IC operations were implemented in C object code as mntime
library functions. The thread joins (pthreadjoin) are placed in the object code using an
as-needed strategy. Therefore a join will not be set up until a result associated with a
thread is needed.
4.3.1 Dynamic Thread Function Creation
In the first version of the SequenceL compiler every expression that was
associated with an implied parallelism was executed in object code as a thread. This
model works well for an ideal parallel system where memory access is uniform; however
it does not work as well in the real worid. Not every function in SequenceL should have
its own thread function. For example given the following expression;
+([*([s_l(i),s_2(i)])])
The first compiler generated the following C object code fragment.
104

1. tO=sequence_atosC'[ 1,2,3,4,5]"); 2. /* taking expression */ 3. i=(taking_data*)malloc(sizeof(taking_data)); 4. i->from=tO; 5. i->yar=l; 6. i->num_var=l; 7. take_thri=(pthread_t*)malloc(sizeof(pthread_t)); 8. pthread_create(take_thri, NULL, (void *)taking, (void*)i); 9. pthreadJoin(*take_thri, NULL); 10. /* first multiply operation */ 11. tl=select_sequences(s_l,i->result); 12. t2=select_sequences(s_2, i->result); 13. t3=collect_sequence(tl,t2); 14. t3->element=t3->head; 15. thread=0; 16. while(t3->element != NULL){ 17. pthread_create(&thr_id_t4[thread++], NULL,(yoid *) mult, (void
*)t3->element)); 18. t3->element=t3->element->next; 19.} 20. t4=t3; 21. /* result t4 is needed for addition, therefore a join is required */ 22. thread=0; 23. t4->element=t4->head; 24. while(_t4->element){ 25. pthreadJoin(thr_id_t4[thread++],NULL); 26. t4->element=t4->element->next; 27. } 28. /* addition operation */ 29. t5->element=t4->head; 30. thread=0; 31. while(t5->element != NULL){ 32. pthread_create(&thr_id_t5[thread++], NUUL,(void *) add, (void
*)t5->element)); 33. t5->element=t5->element->next; }
105

Generate values for i using a thread (lines 2-9)
Setup input arguments for thread function (lines 11-14)
false While (!last queue element) (Line 16)
I trae Generate a thread using mult Line 17
Get next queue element (line 18)
false
While (!last queue element) (Line 24)
^ tme
Pthreadjoin (line 25)
Get next queue element (line 26)
^ While (!last queue element) (Line 31)
4r trae
Generate a thread using add Line 32
continue Get next queue element (line 33)
Figure 4.7 Object Code Flow Chart
Element is a pointer into a queue containing sequences. The while loop processes each
106

queue element and passes a sequence to pthread_create, which passes the sequence to the
function mult, which executes as a thread. If the / values are [1], [2], [3], [4] and [5] the
queue t3 contains the following sequences.
[s_l(l),s_2(l)] [s_l(2),s_2(2)] [s_l(3),s_2(3)] [s_l(4),s_2(4)] [s_l(5),s_2(5)]
When the thread model was chosen for this compiler these were the type of
parallelisms that seemed to fit so well with the model. The arithmetic functions mult and
add are mntime library functions that accept one input argument and retum a result in
that argument.
Research into cache locality and its effects on parallel system performance led to
a realization that this simple thread model was not going to be adequate. Philbin et al in
their research discovered that thread scheduling associated with cache locality effects
program performance by as much as 50% [Phi]. A study to confirm this was done on the
Origin2000. Two series of tests were mn. Both tests executed the following nested
computation.
+([*([s_l(i),s_2(i)])])
The first test used the same C object code loop stmcture as the multiply/add example just
presented in this section. The code generates all of the multiply threads and then waits for
the threads to complete before it generates the addition threads for the addition operation.
This execution strategy makes no effort to place threads that need results from other
threads on the same processor. Therefore a thread associated with an addition operation,
107

that needs a result from one of the threads that generates a multiply result, must access
that result from main memory. This thread relationship is called Parent-Parent [Phi]. The
second test generates the threads for the addition operation first. Within each addition
thread a thread for the multiply operation is generated. This creates a Parent-Child
relationship between threads where the multiply thread is a child of the addition thread.
Upon creating the child thread, the parent blocks until the child completes its multiply
operation. The parent then unblocks and uses the result from the child to complete its
addition operation. Philbin et al. showed that this parent-child execution strategy, coupled
with a FIFO based thread scheduler in the operating system, greatly increases the chances
that the result from the multiply will be in cache memory where the parent thread can
access it.
Table 4.1 Thread Parent Parent (sees)
33.36 34.12 33.7
33.76 33.32 33.85 33.52 32.41 33.82 32.17
Average 33.403
Execution Times Parent-Child (sees)
24.08 23.6 24.22 24.05 23.7
23.87 23.51 23.71 23.23 21.84
Average 23.581
Table 4.1 lists the results form the Origin2000 tests. These results clearly show the
performance improvements Philbin et al. reported. The table lists execution times for the
108

same amount of work for parent-parent and parent-child thread execution. These results
led to a change in the design of the thread model. To setup a parent-child relationship
between nested operations would require code restmcturing, this was beyond the scope of
this research. Therefore, it was decided that the nested expressions would be placed in the
same thread function. This change required the compiler to create a thread function for
any nested expressions found in a SequenceL function. This process is called dynamic
thread function creation. The dynamic thread function creation process for SequenceL
code was simplified by the knowledge gained from the IC development, which indicate
that SequenceL expressions are inherently independent. To implement the dynamic
thread creation a dependency analysis between results and operands is needed to
determine whether a set of computations in the IC table are nested and can be placed in
the same thread function. Examining temporaries in the IC table to see if a given
statement generates an operand for the next statement is how the dependency analysis
works. For example:
+(*(s_l))
Generates the IC statements;
* s_l to + to tl
These two IC statements have a dependency, the temporary tO. The ability to dynamically
generate thread functions for combinations of SequenceL expressions is a new result for
the thread model.The following code illustrates the code generated using dynamic thread
function creation:
109

+([*([s_l(i),s_2(i)])]) taking i from [1,2,3,4,5]
1. tO=sequence_atosC'[l,2,3,4,5]");
2. /* taking expression */ 3 4 5 6 7 8
i=(taking_data*)malloc(sizeof(taking_data)); i->from=tO; i->var=l; i->num_var=l; take_thri=(pthread_t*)malloc(sizeof(pthread_t)); pthread_create(take_thri, NULL, (void *)taking, (void*)i); pthreadJoin(*take_thri, NULL);
10. /* multiply/add operation */ 11. tl=select_sequences(s_l,i->result); 12. t2=select_sequences(s_2, i->result); 13. t3=collect_sequence(tl,t2); 14. t3->element=t3->head; 15. thread=0; 16. while(t3->element != NULL){ 17. pthread_create(&thr_id_t5[thread++], NULL,(yoid *) _t5agg,
(void *)t3->element)); 18. t3->element=t3->element->next; 19.} 20. t5=t3;
21. /* join required before result of multi/add can be used */ 22. thread=0; 23. t5->element=t5->head; 24. while(_t5->element){ 25. pthread J oin(thr_id_t5 [thread++] ,NULL); 26. t5->element=t5->element->next; 27. }
28. /* the following is the thread function _t5agg */ 29. void * _t5agg(sequence *input){ 30. mult(input); 31. add(input); 32. }
110

The compiler dynamically creates _t5agg so that the multiply/add operations can take
place in the same thread. The thread function accepts one sequence as an input argument
and retums a result in the input argument. The data flow is illustrated in Figure 4.8. The
first while loop generates all the threads for _t5agg and the second loop waits uses a join
to detect when all the threads have exited. Once all the threads have joined the results are
available. The difference between Figure 4.8 and Figure 4.7 is that Figure 4.7 has two
thread loops one for multiply and one for add. Figure 4.8 has one thread loop for the
thread function _t5agg that contains the multiply/add. The code continues with whatever
expression (not shown) uses the result of the multiply/add operation.
4.3.2 Dynamic Thread Functions for Conditional Expressions
Parallelizing conditional expressions also involves dynamic thread function
creation but with some added complexities. The following production is the Sequence
conditional production.
B => T^ I T* when R else B
R is the relational expression. T" is one or more terms. The following expression is an
example of a conditional expression.
[s_2] when >([s_l,[l]]) else []
In the expression when s_l is greater than [1] the relational is trae and s_2 is produced,
when the relational is false the null or empty sequence is produced. This particular
conditional example has no indexed variables. Therefore it has no implied parallelisms.
HI
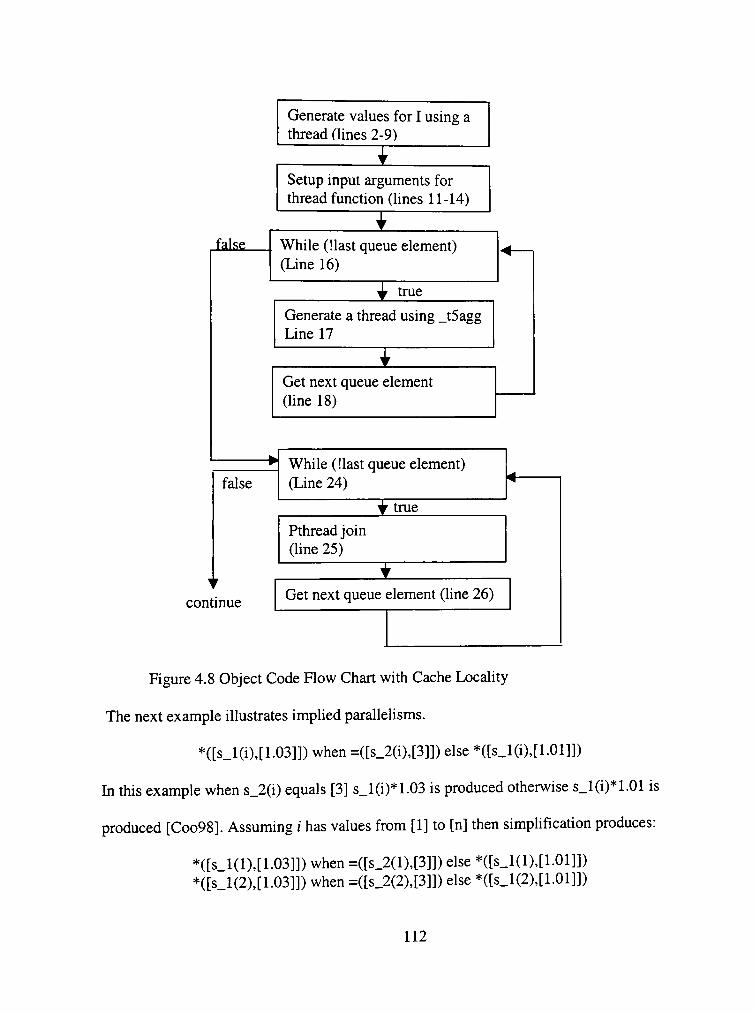
false
false
continue
Generate values for I using a thread (lines 2-9)
Setup input arguments for thread function (lines 11-14)
While (!last queue element) (Line 16)
T trae Generate a thread using _t5agg Line 17
Get next queue element (line 18)
While (!last queue element) (Line 24)
^ trae
Pthreadjoin (line 25)
Get next queue element (line 26)
Figure 4.8 Object Code Flow Chart with Cache Locality
The next example illustrates implied parallelisms.
*([s_l(i),[1.03]]) when =([s_2(i),[3]]) else *([s_l(i),[1.01]])
In this example when s_2(i) equals [3] s_l(i)*1.03 is produced otherwise s_l(i)*1.01 is
produced [Coo98]. Assuming i has values from [1] to [n] then simplification produces:
*([s_l(l),[1.03]]) when =([s_2(l),[3]]) else *([s_l(l),[1.01]]) *([s_l(2),[1.03]]) when =([s_2(2),[3]]) else *([s_l(2),[1.01]])
112

*([s_l(3),[1.03]]) when =([s_2(3),[3]]) else *([s_l(3),[1.01]])
*([s_l(n),[1.03]]) when =([s_2(n),[3]]) else *([s_l(n),[1.01]])
In this example, some value s_l, is increased by 3% if some associate corresponding
value s_2, equals 3, otherwise the initial s_I value is increased by 1%. This conditional
expression has indexed variables in the trae false and relational parts of the conditional
expression therefore it exhibits implied parallelisms. The difficulty the thread model has
to deal with is that the dynamically created thread function must contain the code to do a
complete conditional statement such as;
*([s_l(l),[1.03]]) when =([s_2(l),[3]]) else *([s_l(l),[1.01]])
This statement contains the relational operation as well as the trae and false expressions.
The code to implement this expression must be placed in a thread function. Each time the
index variables are to be tested, by the conditional expression, these index variables are
passed to the thread function. For this example the conditional thread function would
contain the pseudo object code:
if(condition(EQUAL, [s_2,3]))
result=mult([s_l,[1.03]]); else
result=mult([s_l,[1.01]]);
The variables s_l and s_2 are sequences passed to the thread function by the calling
routine that invokes the thread. Each time the thread function is invoked by the calling
routing a thread is created. For each thread created the calling routine passes one index
variable for s_l and one index variable for s_2. Therefore the first pair of index variables
113

passed to the first thread function would be s_l(I),s_2(l), the next pair would be
s_l(2),s_2(2) and so on, until all n index variable pairs have been tested in the
conditional thread function.
Conditional thread functions are not required for every conditional expression that
exhibits implied parallelisms. For example, here is the same expression without the index
variable in the relational expression.
*([s_l(i),[1.03]]) when =([s_2,[3]]) else *([s_l(i),1.01]]
In this example no conditional thread function is created. If the expression is trae then the
following trae expression is executed as a parallel expression.
*([s_l(i),[1.03]])
If the expression is false then the following false expression is executed in parallel.
*([s_l(i),[1.01]]).
The thread model must also handle conditional expressions that are linked
together through the false expressions. The examples shown involve only expressions of
the following stmcture.
Tl when Rl else T2
The following stracture is also valid:
Tl when Rl else T2 when R2 else T3
There is no limit on the number of conditional expressions that can be linked together.
The thread model uses the following rale to initiate dynamic thread creation for
conditionals, the first relational expression encountered that uses indexed variable, forces
the rest of the expression into a conditional thread function. Therefore given
114

Tl when Rl else T2 when R2 else T3
If Tl uses an indexed variable and Rl does not then something like the following
stracture will appear in object code.
if(Rl) while
OPl
Where OPl is a thread function that contains Tl. Each time a thread is created using OPl
an indexed variable value is passed to OPl for the Tl term. If T2, R2 and T3 use indexed
variables then R2 is the first relational expression that uses an index variable and
therefore it triggers the creation of a thread function. This thread function would contain
a stracture something like:
if(R2) T2
else T3
If CONDI is the name given to this thread function, then in the object code it is placed in
a thread creation loop.
if(Rl) while
OPl else
while CONDI
Each time a thread is created using CONDI the index variables that R2, T2 and T3 need
are passed to the thread.
115

Even when mixing expressions in a conditional expression, where some
expressions use index variables (implied parallelisms) and other expression do not (non-
parallel) the thread function creation process allows for the parallelisms to be exploited in
a straightforward manner. A complete example of conditional operations involving
parallelisms can be found in the Quicksort listings at the end of Appendix B.
4.4 Optimization and Scheduling Issues
This section discusses a number of scheduling and optimization issues that were
identified during compiler development.
4.4.1 Granularity
The primary design objective of the SequenceL compiler was to exploit all
SequenceL implied parallelisms. This included exploiting computational parallelisms at
the singleton level. If a sequence is described using a tree stmcture, singletons are the leaf
nodes, see Figure 4.9. The following sequence has eight singletons with four singletons in
two sub-sequences.
[[1,2,3,4],[5,6,7,8]]
[]
[] ^^^-^W^^-^
[1] [2] [3] [4] [5] [6] [7] [8]
Figure 4.9 Tree Diagram of a Sequence
116

The following expression is the addition expression for this sequence.
+([[I,2,3,4],[5,6,7,8]])
+(I,5),+(2,6),+(3,7),+(4,8)
[6,8,10,12]
Each singleton addition, is independent of the other additions, therefore, the four
additions can be done in parallel. Four threads of execution can be created with each
thread executing one addition. The problem with executing one singleton computation in
parallel is tiiat multi-processor systems have overhead issues that need to be addressed.
Thread creation time is one such overhead that must be accounted for. The advantage of
doing the computations in parallel is speedup, ideally if the time to execute a single
addition takes x seconds then doing n additions on an n processor system will still take
only X seconds. This is an idealized view of a multi-processor system. Parallel threads of
execution typically have overhead associated with them. For example, if thread creation
time is Ax seconds then the total time for the n additions in parallel would be Anx+ x
seconds assuming one addition per thread. Two additions would take 9x seconds, eight
additions would take 33x seconds. The problem with this example is that due to the
thread creation times, the parallel execution times for two and eight additions are greater
than the serial execution times. This is not unusual. Tests were conducted on the Texas
Tech University Origin2000 and indicated that as many as 50,000 multiplications can be
executed in the time it takes to create a thread. The graph in Figure 4.10 shows the results
of this test.
117

Granularity Experiment
0.06
-•—no thread
- •—1 thread
2 thread
-i^—4 thread
HK—8 thread
100000 200000 300000 400000 500000 600000 700000 800000 900000 1E+06 1E+06 1E+06
Number of Computations
Figure 4.10 Granularity Study
At around 150,000 computations generating threads to share the computations
begins to improve execution times over serial execution times. Retuming to the example,
if eight additions are divided between two threads the total execution time would be
8;c+4x, or 12x seconds. 12x is better than the 33x seconds for eight threads but still worse
than the Sx seconds it takes to do the eight computations in series. If the number of
additions are increased to thirty-two, then execution time for thirty-two threads with one
addition per thread would be 129x seconds; for two threads it would be 24x seconds and
for serial execution 32x seconds. There are now enough additions to justify two threads
of computation. Before creating a single thread a decision needs to be made by the
compiler about how many computations per thread are required to offset the cost of
thread creation overhead. This is an optimization issue that requires future research.
118

Granularity Experiment
0.06
0.05
8 0.04
0)
E c g
0.03
0.02
0.01
- •— no thread
-•— 1 thread
2 thread
-^<—4 thread
Hte- 8 thread
100000 200000 300000 400000 500000 600000 700000 800000 900000 1E+06 1E+06 1E+06
Number of Computations
Figure 4.10 Granularity Study
At around 150,000 computations generating threads to share the computations
begins to improve execution times over serial execution times. Retuming to the example,
if eight additions are divided between two threads the total execution time would be
8JC+4JC, or I2.v seconds. 12A is better than the 33JC seconds for eight threads but still worse
than the 8JC seconds it takes to do the eight computations in series. If the number of
additions are increased to thirty-two, then execution time for thirty-two threads with one
addition per thread would be 129JC seconds; for two threads it would be 24x seconds and
for serial execution 32.v seconds. There are now enough additions to justify two threads
of computation. Before creating a single thread a decision needs to be made by the
compiler about how many computations per thread are required to offset the cost of
thread creation overhead. This is an optimization issue that requires future research.
118

This problem also extends upward from singletons to sequences. In an earlier
example the following parallel computation was presented.
+(s_l(l),s_2(l)) +(s_l(2),s_2(2)) +(s_l(3),s_2(3)) +(s_l(4),s_2(4)) +(s_l(5),s_2(5)) +(s_l(6),s_2(6))
It is trae in any case that these can be done in parallel - the question is "Is it worthwhile
to do them or should they be done?" It is possible that executing these sequence additions
in parallel is inefficient. Like the singleton example just shown there may not be enough
work in these additions to justify thread creation. It could be that a number of sequence
additions need to be group together before creating threads for parallel execution is
justified.
For this SequenceL compiler, sequence operations are always executed in parallel.
At the singleton level, singletons are executed in series until a certain threshold level is
reached. The compiler user can set this level. When the threshold is reached the singleton
operations are divided up into groups for parallel threads of execution.
Creating a thread for every sequence operation makes the parallel code generated
by this compiler fine-grained. A fine-grained parallel model is defined as having many
threads per processor. A coarse-grained model typically has one thread of execution per
processor. The advantages of a fine-grained model are that irregular parallelisms and load
balancing issues are easier to deal with [Nar]. The following graph was generated from
data collected from the Origin2000.
119
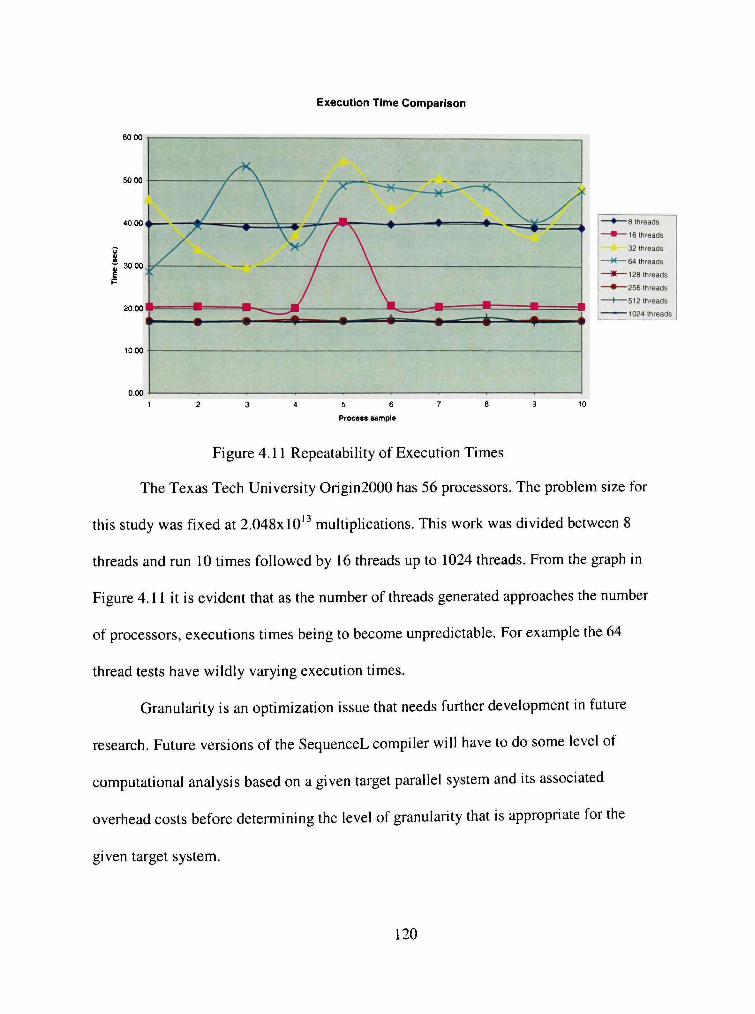
Execution Time Comparison
60 00
•8 threads
16 threads
32 threads
64 threads
•256 threads
•512 threads
Process sample
Figure 4.11 Repeatability of Execution Times
The Texas Tech University Origin2000 has 56 processors. The problem size for
this study was fixed at 2.048xl0'^ multiplications. This work was divided between 8
threads and run 10 times followed by 16 threads up to 1024 threads. From the graph in
Figure 4.11 it is evident that as the number of threads generated approaches the number
of processors, executions times being to become unpredictable. For example the 64
thread tests have wildly varying execution times.
Granularity is an optimization issue that needs further development in future
research. Future versions of the SequenceL compiler will have to do some level of
computational analysis based on a given target parallel system and its associated
overhead costs before determining the level of granularity that is appropriate for the
given target system.
120

4.4.2 Code Restmcturing
Another area identified for performance enhancements is the issue of code
restmcturing. The following expression from section 4.3,
[+([s_l(i),s_2(i)]),function2,s_l, +([s_3(i),s_4(i)])] taking i from [1,2,3,4,5]
Resulted in the following C object code.
for(i=l;i<=5;i++){ _tO(i)=add(s_l(i), s_2(i));
}
_tl=function2(s_l);
for(i=l;i<=5;i++){ _t2(i)=add(s_3(i), s_4(i));
}
There are two iterative thread creation loops associated with this code, one for each for
loop. It is obvious that the two for loops can be combined into one, but this would require
code movement. Any future optimization component of the compiler will have to be
designed to deal with code restmcturing. In this example ideally the following code
would be generated as a result of code movement.
_tl=function2(s_l); for(i=l;i<=5;i++){
_tO(i)=add(s_l(i), s_2(i)); _t2(i)=add(s_3(i), s_4(i));
}
121

4.4.3 Data Distribution
Data distribution is another area for optimization. From section 1.1 the following
matrix multiple example was presented.
([+([*(s_l(i,*),s_2(*,j))])]) taking [i,j] from [[1,1],[1,2],[2,1],[2,2]]
In this example the multiply operation consumes the sequences s_l and s_2 and
simplifies to;
[ [ +([''([s_l(l,*),s_2(*,l)])])
+([*([s_l(l,*),s_2(*,2)])]) ] [ +([*([s_l(2,*),s_2(*,l)])])
+([*([s_l(2,*),s_2(*,2)])]) ] ]
If
s_l = [[l,2],[3,4]]s_2 = [[5,6],[7,8]]
Then the next simplification produces;
[ [ +([*([[1,2],[5,7]])])
+([*([[1,2],[6,8]])]) ] [ +([*([[3,4],[5,7]])])
+([*([[3,4],[6,8]])]) ] ]
Note the repetition of rows and columns in the data stracture. Problem domains with
large data sets, using this kind of data distribution approach can quickly consume all of
memory. In this example twice as much memory is consumed than is necessary. The
question is should the repetition be allowed to occur? The basic problem with conserving
space is that it works against speed. Time and Space trade-offs are an important area of
research on parallel systems [Ble]. For this matrix multiply algorithm, if space is
conserved by having only one copy of each row and column in memory, then all
122

computations that use a given row or columns will have to access the same memory
location. As the problem size increases memory locations can become a point of
contention. This problem is described as a memory bottleneck problem in the literature
on studies of scaling problems on shared memory multiprocessor systems [Leu]. Any
future SequenceL compilers will have to address this issue.
4.4.4 IC Collect Operation.
The collect sequence operation was described in section 4.2 as an object code
requirement. The collect sequence operation creates a single sequence before any
operation can take place on that sequence. Since thread functions can only accept one
sequence, these two conditions work together in making the thread model easier to
implement for the SequenceL compiler. For example the following expression produces a
single sequence in object code:
*([s_l])
The next expression also produces a single sequence in object code.
*([s_2])
When these two expressions are nested in another expressions such as:
+([*([s_l]),*([s_2])])
Each result produced in object code is collected into a single sequence, which is then
passed to the addition operation. The problem with this "object code collect sequences
operation" is that it creates overhead. It takes time to collect the sequences together. The
problem with not collecting sequences together is that all of the thread functions that
123

carry out computations on sequences will have to be designed to handle an unknown
number of arguments, which may be unknown until mntime. For the current compiler,
the collective operation is in use. For future compilers it should be reconsidered.
4.5 Data Representation
The strength of SequenceL is the use of sequences in conjunction with the
language constmcts to specify an algorithm. This is at the heart of the programming
philosophy of describing "what" to do as opposed to "how" to do it. Therefore the design
of this SequenceL compiler preserves the sequence data stracture in the object code.
4.5.1 Circular Linked List Sequence Representation
The first attempt at defining a C object code representation of a sequence was a
circular linked list approach. The circular linked list approach was very attractive since it
was relatively easy to normalize sequences without requiring additional memory
allocations. For example the following sequence is not normalized.
[[1,2,3],[4,5]]
Normalized this sequence becomes
[[1,2,3],[4,5,4]]
Note that the normalized sequence is larger than the non-normalized sequence. After
normalization a sequence will always be increased in size. The only time a sequence will
not increase in size due to normalization is if it is already normalized.
124
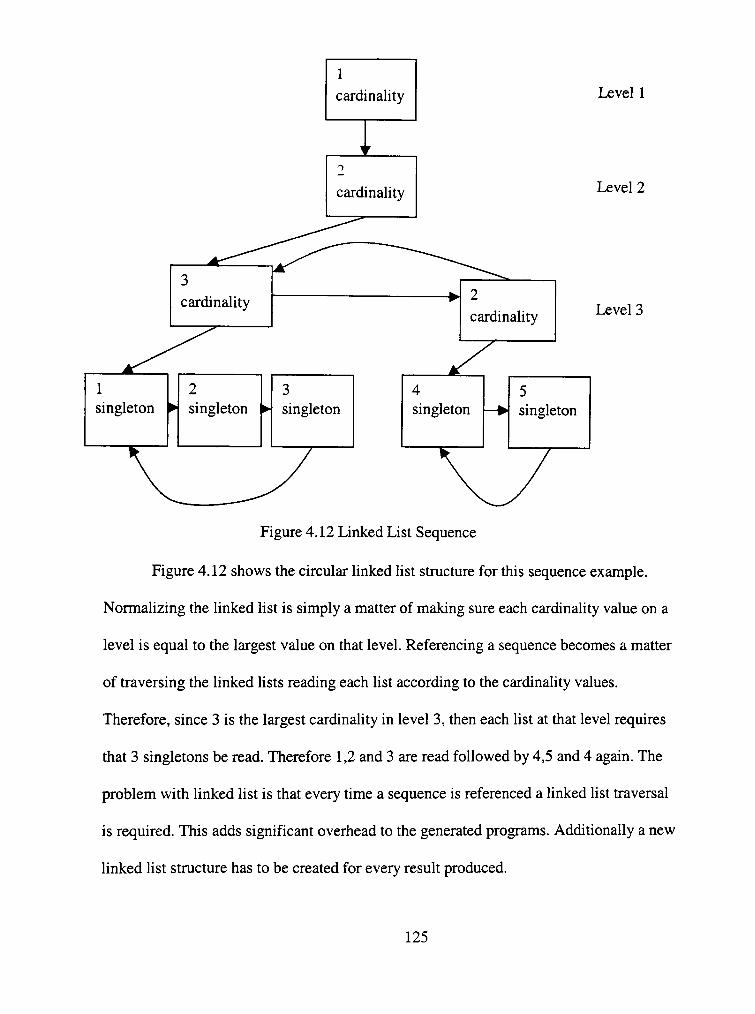
cardinality
1 cardinality
I cardinality
cardinality
Level 1
Level 2
Level 3
1 singleton W singleton ^ singleton
4 singleton singleton
Figure 4.12 Linked List Sequence
Figure 4.12 shows the circular linked list stracture for this sequence example.
Normalizing the linked list is simply a matter of making sure each cardinality value on a
level is equal to the largest value on that level. Referencing a sequence becomes a matter
of traversing the linked lists reading each list according to the cardinality values.
Therefore, since 3 is the largest cardinality in level 3, then each list at that level requires
that 3 singletons be read. Therefore 1,2 and 3 are read followed by 4,5 and 4 again. The
problem with linked list is that every time a sequence is referenced a linked list traversal
is required. This adds significant overhead to the generated programs. Additionally a new
linked list stracture has to be created for every result produced.
125

4.5.2 Sequence Stracture Representation
The second approach was driven by the objective of reducing the overhead
associated with the linked list approach and making computations on sequences
equivalent to processing arrays. Arrays and array processing is a key element in many
numerical and non-numerical application [Kum]. The matrix multiply example in chapter
I is typical of the type of array processing that takes place in numerical methods.
The current mntime sequence data stracture is as follows.
typedef union { int *i; double *f; char **s;
}numerics;
typedef stract{ numerics data; char *string; int *card; int *nest; int *start; int *end; int *empty; int length; int dimlength; char type; /* i for int, r for real and s for string */
} sequence;
The data or singleton information is stored in an array the "numerics data" points to. This
array is allocated as a contiguous memory array. This array can be of type string, real or
integer. The char *string points to a string representation of the sequence, which is used
by normalization. Int card and nest are used to determine if a sequence needs to be
126

normalized. The int start and end arrays track sub-sequence positions within the string
representation, this is used for extracting sub-sequences of a sequence. Int empty is an
array that indicates whether there is a null sequence present and its location in the
sequence. Int dimlength stores the size of the nest, card, start, end and empty arrays. Int
length stores the size of the data array. Char type indicates whether the sequence
singletons are real, integer or string in type. The advantage of this design is that
normalization can be quickly checked. Therefore, if a sequence is normalized then a
computation becomes a simple contiguous memory traversal of the data array.
The problem with this representation is that it is space inefficient. Too much
information is being carried in order to fully describe the sequence. Another problem
with this representation is that normalization involves the dynamic allocation of
additional memory during rantime. Additionally, the lifetime of the normalized stracture
lasts only the time it takes to execute the computation that triggered normalization. It is
possible that an input argument to a function could be referenced by numerous
SequenceL statements within a function resulting in repeated normalizations for the input
argument within the function. Therefore, this finding is only an improvement over the
linked list approach if sequences do not require normalization.
Both the current sequence representation and the circular linked list representation
share a common problem; sequences are allocated memory at mntime. This is due to the
fact that typing information associated with cardinality and nesting is not available for
input arguments until rantime. This causes an unacceptable rantime overhead. What the
compiler needs to improve this situation is dimension and typing information for input
127

arguments at compile time. The compiler could then do a data flow analysis to determine
the dimension and typing of all subsequent sequences. Additionally, given knowledge of
the sequences at compile time, the data representation for a sequence could be simplified.
Conditional expressions will pose a problem for this data flow analysis approach
since the control flow path is non-deterministic. Functions that have conditional
expressions can produce a result from either the trae or false expressions within the
conditional. The dimension and typing of any sequence produced by a conditional's trae
expression may be different than the dimension and typing of the false expression. The
result is that functions with conditional expressions can produce sequences of different
dimension and type depending on the outcome of a conditional expression at rantime.
Therefore, under these conditions it is difficult for data flow analysis to figure out the
dimension and type of the placeholder for a function. Data flow analysis has been left as
a future research issue.
There are no specific recommendations on the definition of the sequence
representation for future SequenceL compilers. There is a requirement that nesting and
cardinality information be provided at compile time for all input arguments.
128

CHAPTER V
CONCLUSIONS AND FUTURE RESEARCH
This chapter presents conclusions on the results of this research. Future research
opportunities are presented as well. The initial goal of this research was to develop the
first SequenceL compiler that exploits the inherent parallelisms in SequenceL. The result
of this development process has gone beyond that goal with the development of a general
approach to mapping SequenceL constracts to multi-threaded code. This result is
important since it provides an approach to implementing the inherent parallelisms found
in SequenceL, for all future SequenceL compilers.
5.1 Conclusions
The result of this research is the first SequenceL compiler. This SequenceL
compiler can create executable programs that embody the inherent parallelisms and other
implied controls stmctures in SequenceL. A number of algorithms have been tested using
the compiler in order to exercise the full range of SequenceL constracts and implied
parallelisms. Three types of parallelisms are detected and exploited by the SequenceL
compiler: (a) Parallelisms involving singleton operations, (b) Parallelisms involving
indexed sequences, and (c) Control Flow Parallelisms.
The compiler development process has identified a number of insights into the
SequenceL language. A key finding is that SequenceL expressions inherentiy support
their own evaluation in parallel. A formal definition of implied parallelisms for regular.
129

irregular and generative constracts has been developed. The key to uncovering this
insight was the process of developing the SequenceL intermediate language. The
intermediate language along with the symbol table definition provides a complete
representation of the SequenceL constracts and parallelisms. Although parallel object
code was generated based on a thread model, the intermediate code has no specific
support for the thread model. Therefore, future research projects should consider the
intermediate code as transferable to message-passing parallel programming models as
well as other shared memory parallel programming models.
The thread model was found to be flexible at meeting all the requirements for
implementing the parallel constracts necessary for executing the SequenceL parallelisms.
The function based model that Pthreads uses for implementing the threads allowed for the
development of a dynamic thread function capability. This capability allowed the
compiler to take advantage of the inherent independency found in SequenceL expressions
and functions. This result also supported the conclusion that SequenceL expressions
inherently support their own evaluation in parallel.
During development, the compiler was moved back and forth between two
different single processor systems and a multiprocessor system. The single processor
systems include a Linux Intel system and a Solaris Sparc system. Both the GNU C
compiler and the IRIX C compiler where used to compile the compiler components and
the SequenceL compiler generated object code. The only issue encountered was the IRIX
compiler's strict adherence to the POSIX thread interface standard. After this was
130

addressed, no further changes were required in the compiler code due to the underlying
system and its compiler.
A number of optimization and performance enhancements have been identified.
Some such as cache locality and granularity have been partially addressed. Others, such
as code restmcturing and optimizing the collect sequence operation, have not. Before any
of these issues are pursued in future research the question of the SequenceL data
representation in object code needs to be addressed.
The way in which SequenceL data stmctures are represented in object code
should be redefined. Neither of the two approaches developed was satisfactory. Any data
representation developed will have to compete with procedural codes, which typically use
arrays. Although no specific data stracture is being recommended, any data stmcture that
is developed will need to meet the following requirement. The new SequenceL data
representation must, preserve the nesting capability of sequence stmctures, minimize
overhead, allow for normalization, and allow for compile time memory allocation. By
providing dimension and type information on input variables it might possible to do a
data flow analysis on the SequenceL code to determine the memory allocation
requirement at compiles time. One impediment to this methodology has already been
documented in this report. Conditional statements make it difficult to do data flow
analysis since they can retum sequence from either a trae expression or a false
expression. These sequences may not be of the same type or dimension. This problem
creates a fork and two paths different paths for data flow analysis. This problem will have
to be solved in any future SequenceL research.
131

5.2 Future Research
A number of possible future research opportunities were raised in this document.
These will be summarized in this section.
5.2.1 Preprocessor
A preprocessor was never developed for this compiler. The SequenceL source
code that was used to test the compiler was specified as if a preprocessor generated it.
The preprocessor has two roles the first role is to restracture some of the SequenceL
expressions before they go through semantic analysis. The function clause is a good
example. The grammar production that defines the function clause is:
F =^ V(V*) where next = {B} C
The C and {B} will be reversed by the preprocessor, that way semantic analysis will have
information in the symbol table on the identifiers defined in the C part of the function
clause. The C grammar production is:
C => [ ] I taking [V^] from T
It is the identifiers defined by V" that are required by semantic analysis before {B} is
processed.
The second role of the preprocessor is to allow programmers to use a little more
readable SequenceL programming style. For example the following sequence,
[1,2,3,4,5]
is coded this way by the programmer. The preprocessor will read this and convert the
sequence to;
132

[[1],[2],[3],[4],[5]].
This first representation defines a singleton in a sequence of singletons without square
brackets this potentially creates a new data type for SequenceL called a singleton. The
second representation defines a singleton as a sequence of one element.
5.2.2 Optimization
An optimization capability has always been deemed beyond the scope of this
research. It was anticipated that this research would uncover a number of issues that
would have to be addressed before the development of an optimization component could
be considered. For example, the problem with the object code's sequence representation
needs to be resolved before optimization can be considered. The current representation
causes a number of problems for the compiler, the most significant being mntime
overhead. A representation that provides compile time information on dimension and
type will allow for example, the process of optimization of memory allocation to take
place.
5.2.3 Parallel Models
The thread model was picked for this first compiler because it had the advantages
listed in Chapter HI. These include light-weight tasks, portability, a standard interface,
low-level control over parallel execution and data sharing. Ultimately, the compiler
should be developed using the MPI model. The advantages of the MPI model is that it
can execute parallel codes on distributed memory systems, as well as shared memory
133

systems. OpenMP/MLP parallel programming model is of particular interest [Taf]. The
advantage of pursuing the OpenMP/MLP parallel programming model is that it would
exposure SequenceL to many research issues being pursued by NASA. This would
provide SequenceL with "real" hard problems that would test SequenceL's capabilities
and limits.
5.2.4 Granularity
The SequenceL compiler manages granularity using threshold levels set in the
rantime library thread functions. These thread functions include the arithmetic and
relational functions. Dealing with granularity can be a difficult problem. Both compile
time and rantime analysis for granularity has been researched. Runtime analysis can
create an overhead problem in itself. This leads to a tradeoff between doing a good job of
estimating granularity and the length of time it takes to do the estimate [Ham94].
Compile time analysis suffers from a lack of knowledge about rantime issues such as
contention for resources. One compile time approach is to set up certain strategies to
manage granularity, such as clustering. Clustering is the arranging of parallel tasks to
operate on related sub-collections of data [Loi]. Scheduling associated with granularity
will be an ongoing research effort for every SequenceL compiler developed.
A number of algorithms have been tested on the compiler. This includes the three
algorithms described in this document. Matrix Multiply, Gaussian Elimination and
Quicksort. More algorithms involving parallelisms need to be tested, these include
134

algorithms such as sparse matrix multiplication and search algorithms such as branch and
bound [Kum].
The success of this compiler has added to the development of the SequenceL
language. The continued success of the language will be built on this work. It is hoped
that in the near future that the compiler can be released to the parallel programming
community. This release would provide the community with a new and effective
language for solving many difficult parallel programming problems.
135

REFERENCES
[Aho] Aho, A. V. and Ullman, J. D. Principles of Compiler Design, Reading, MA: Addison-Wesley Publishing Co., 1979.
[All] Allan, R.J., Heggarty, J., Goodman, M. and Ward, R.R., Parallel Application Software on High Performance Computers. Survey of Parallel Perfonruxnce Tools and Debuggers, Darebury Warrington, England: Computational Science and Engineering Department CLRC Daresbury Laboratory, June 16 1999, Retrieved from http://www.cse.clrc.ac.uk/Activitv/HPCI.
[Ban] Banks, J., Carson, J. S. n and Ngo Sy, J. Getting Started with GPSS/H, Annandale VA: Wolverrine Software Corp., 1989.
[Ble94] Blelloch, G.E, Chatteijee, S., Sipelstein, J. andZagha, M, VCODE Reference Manual 2.0, Retrieved from http://www-.cs.cmu.edu/afs/cs.cmu.edu/proiect/scandal/public/papers/vcode-ref.html 1994.
[Ble95] Blelloch, G. E. NESL: A Nested Data-Parallel Language, Version 3.1, CMU-CS-95-170, Pittsburgh PA: School of Computer Science, Camegie Mellon University, Sept. 19, 1995.
[Ble96] Blelloch, G. E. and Greiner, J. A Provable Time and Space Efficient Implementation of NESL. Proceedings of International Conference on Functional Programming, Philadelphia, Pennsylvania, May 1996, pp. 213-225.
[Cha] Chandra, R. Dagum, L., Kohr, D., Maydan, D., McDonald, J., and Menon, R. Parallel Programming in OpenMP, San Diego CA: Morgan Kaufmann Publishers, 2001.
[Cod] Codognet P and Diaz D. wamcc: Compiling Prolog to C, I2th International Conference on Logic Programming, Tokyo, Japan: The MIT Press, 1995.
[Coo96] Cooke, D.E. An Introduction to SEQUENCEL: A Language to Experiment with Nonscalar Constracts, Software Practice and Experience, Vol. 26, No. 11, November 1996, pp. 1205-1246.
[Coo98] Cooke, D.E. "SequenceL Provides a Different Way to View Programming," Computer Languages, 1998, pp. 1-32.
[CooOO] Cooke, D.E. and Andersen, P. Automatic Parallel Control Stmctures in SequenceL, Software Practice and Experience, Volume 30, Issue 14, November 2000, pp.1541-1570.
136

[CooOl] Cooke, D. E., and Andersen P. Specification of a Parallelizing SequenceL Compiler, Proceeding of the Monterey Formal Methods Workshop, Monterey, CA. June 19, 2001, pp. 37-48.
[Coo02] Cooke, D.E., A Concise Introduction to Computer Language: Design, Experimentation and Paradigms, Pacific Grove, CA: Brooks/Cole Publishers, 2002.
[Dia] Diaz, D. and Codognet, P., GNU Prolog: Beyond compiling Prolog to C, Practical Aspects of Declarative Languages, Boston: 2000.
[DiM96] Di Martino, B. and KePler C. W., Program Comprehension Engines for Automatic Parallelization: A Comparative Study, Proc. of 1st Int. Workshop on Software Engineering for Parallel and Distributed Systems, Berlin, Germany: Chapman & Hall, March 25-26, 1996.
[DiM96b] Di Martino, B. and lannello, G. PAP: Recoginzer: A Tool for Automatic Recognition of Parallelizable Pattems, 4''' Workshop on program Comprehem Technische Universitat Berlin, Berlin, Germany March 30-31 1996.
[Dow] Dowd, K. and Severance, C. High Performance Computing, Sebastopol, CA: O'Reilly & Associates Inc., 1998.
[Feo] John T. Feo, David C. Cann, and Rodney R. Oldehoeft. A Report on the Sisal Language Project. Journal of Parallel and Distributed Computing, 10(4), pp. 349-366, December 1990.
[Fin] Finkel, R., Advanced Programming Language Design, Reading MA: Addison-Wesley Pub Co., December 1995.
[Fri] Friesen, B., The Universality ofBagL, Master's Thesis, University of Texas at El Paso, May, 1995.
[Ham] Hammond, K and Michaelson, G, Research Directions in Parallel Functional Programming, London: Springer-Verlag, 1999.
[Ham94] Hammond, K., Mattson Jr., J.S. and Peyton Jones, S.L. Conference on Algorithms and Hardware for Parallel Processing, Linz, Austria: Springer Veriag, September 6-8 1994.
[IBM] IBM White Paper: Power2 Floating-Point Unit: Architecture and Implementation, retrieved from http://www-l.ibm.com/servers/eserver/pseries/hardware/whitepapers/power/fpu.html, 2002
137

[Jon] Jones Telecommunications, Software: History and Development, retrieved from http://www.digitalcenturv.com/encyclo/update/software.html June 2002.
[KeP] Kepier, C. W. Pattern-driven Automatic Parallelization. Scientific Programming 5, pp 251-274,1996.
[Ken] Kennell, R.L. and Eigenmann, R. Automatic Parallelization of C by Means of Language Transcription, Proceedings of the II''' International Workshop on Languages and Compilers for Parallel Computing (LCPC-98), Chapel Hill, NC, August 1998.
[Kum] Kumar, V., Grams, A., Gupta, A., Karypis, G. Introduction to Parallel Computing, Redwood City, CA: Benjamin/Cummings PubUshing Co., 1994
[Lam] Lam/MPI Parallel Computing, retrieved from <http://www.mpi.nd.edu/lam/> 2000.
[Lau] Laudon, J. and Lenoski, D., "The SGI Origin: A ccNUMA Highly Scalable Server," Silicon Graphics, Inc. Mountain View, CA., retrieved from <http://www.sgi.com/>, 1999.
[Lew] Lewis, B. and Berg, D. J., Multithreaded Programming With Pthreads, Upper Saddle River, NJ: Prentice Hall PTR/Sun Microsystems Press, 1997.
[Loi] Loidl, H., Trinder, P.W., and Butz . Tuning Task Granularity and Data Locality of Data Parallel GpH Programs, HLPP'OI International Workshop on High-level Parallel Programming and Applications, Orieans, France, 26-27 March, 2001.
[Lue] Luecke, G. R. and Lin W. Scalability and Performance of OpenMP and MPI on a 128-Processor SGI Origin 2000, Iowa State University, August 16 2000.
[Mac] Maclennan, B. Principles of Programming Languages, (third edition). New York : Oxford University Press, 1999.
[MPI] The Message Passing Interface (MPI) Standard, retrieved from http://www-unix.mcs.anl.gov/mpi/ May 2002.
[Muc] Muchnick, S.S. Advanced Compiler Design & Implementation, San Francisco, CA: Morgran Kaufmann, 1997.
[Nar] Narlikar, G. J. and Blelloch, G. E. Pthreads for Dynamic and Irregular Parallelism, Proceedings ofSC98: High Performance Networking and Computing, Nov 1998.
138

[Onl] Online Documents, retrieved from http://www.cs.colorado.edU/~eliuser/elionline4.3/syntax 1 .html. June 2002.
[Pag] Pagh, R. and Pagter, J. Optimal Time-Space Trade-Offs for Non-Comparison-Based Sorting, Proceedings of the 13th Annual ACM-SIAM Symposium on Discrete Algorithms (SODA 2002), New York: ACM Press, 2002, pp. 9-18.
[Pan] Pancake C. M., " Those who live by the flop may die by the flop," Keynote Address, 41" International Cray User Group Conf, Minneapolis, MN, 24-28 May 1999.
[Phi] Philbin, J., Edler, J., Anshus, O.J., Douglas, C.C. and Li, K. Thread Scheduling for Cache Locality, Proceedings of the Seventh ACM Conference on Architectural Support for Programming Languages and Operating Systems, Cambridge, MA: ACM, 1996, pp. 60 - 73
[Piz] Pizzi J, A SequenceL Compiler, Master's Thesis, Texas Tech University, 2001.
[SGI] Discussion with Instractor at SGI Global Education, Developer Training for Origin2000, April 20 2000.
[Taf] Taft, J. MLP Parallelisms and current results on NASA's 512 CPU Origin System, Japan HPC Forum Presentations, Sept 20-27 2000, retrieve June 13 2000 from www.cc.uec.ac.jp/SGI3000.doc/docs/developer_news/hpc_forum/pdf/jim_taft.pdf
[Tor] Torrellas, J., Tucker, A., and Gupta, A., Evaluating the Performance of Cache-Affinity Scheduling in Shared-Memory Multiprocessors, Journal of Parallel and Distributed Computing, vol. 24, no. 2, Feb. 1995, pp. 139—151.
[Tri] Trinder, P.W., Hammond, K., Mattson, Jr. J.S., Partridge, A.S. and Peyton Jones, S.L. GUM: a portable implementation of Haskell, Proceedings of Programming Language Design and Implementation, Philadelphia, PA, May 1996.
[Whi] White, S. A Brief History of Computing, retrieved June 10 2002 from http://www.ox.compsoc.net/~swhite/historv/timeline-LANG.html.
139

APPENDIX A
SEQUENCEL GRAMMAR
140

SequenceL Grammar
A => integer | real | string L ^ A,L I E,[L] I A E ^ [ ] I [L] I s(integer)
V =? id O => + I -1 / I * I abs I sqrt | cos | sin | tan | log | mod | reverse | transpose |
rotateright | rotateleft | cartesianproduct M => *,M I T,M I * I T T => E I [T*] I V I 0(T) I gen([T,...,T]) | T(M) | T | V(map(M)) | $ RO => < I > I = I >= I <= I <> I integer | real | var | operator R => RO(T) I and(R^) | or(R*) | not(R*) B => T^ IT* when R else B C ^ [] I taking [V*] from T F ^ V(V^) where next = {B} C U ^ V ,U IE, U I V IE p ^ { { r } u }
P is a program U is initial tableau F* in P is a hst of callable functions One to many C ) and zero to many ( ) has implied delimiters when necessary, usually commas
141

APPENDIX B
AN IMPLEMENTATION GUIDE TO A SEQUENCEL COMPILER
142

This document is a guide for anyone who wishes to implement a compiler for
SequenceL. The methodologies used to build this compiler are detailed in Chapter m of
the dissertation report and will not be repeated here. A brief overview of some of the
components will be detailed in this document. Issues associated with the generation of
parallel object code will also be detailed. Examples of the intermediate code and C object
code will be presented. The source code files referenced in this document are available on
the CDROM.
In addition to the goal of converting SequenceL source code to parallel C object
code, the compiler had the following objectives;
Extensibility - a framework methodology has been implemented for achieving
extensibility. A modular approach with clear interface definitions is the framework
methodology followed. This approach makes it relatively easy to add or replace modules.
Portability - The implementation of all the SequenceL compiler components in C
provides the compiler with the advantage of having one of the most widely used
programming languages in the world as the only requirement for installing and using the
compiler. To ran SequenceL executables POSIX threads must also be available.
Efficiency - The SequenceL scheduling mechanism and the C compiler's optimization
will provide the SequenceL compiler with its optimization phase.
The components of the SequenceL compiler provide for the usual compilation
functions: lexical analysis, syntax analysis, intermediate language generation, and code
generation. Also provided is a rantime library. The interfaces between compiler
143

components are generally implemented as function calls. The one exception is the
standard interface between the semantic analysis and code generation, in this instance the
interface is the intermediate language and symbol table.
An early decision was made to keep the compiler dependencies on multiple
languages and tools to a minimum. Experience with other compilers and their associated
installation difficulties was the motivating factor in restricting the compiler
implementation to one language. To force users to install multiple support tools and
packages before the compiler can be installed would probably discourage a number of
potential compiler users. Therefore, this compiler has been completely implemented with
C.
The following terms used in this document are defined here. Function files are
files that contain C source code derived from a SequenceL function and generated by the
SequenceL compiler. Include files are C source code files containing declarations for the
function file and are also generated by the compiler. A SequenceL file contains
SequenceL source code. An input file contains a text string of a SequenceL sequence.
The compiler is designed to create function and include files from a SequenceL
file. The function and include files can then be compiled and linked by a C compiler. The
SequenceL compiler is designed to compile each SequenceL function, appearing in a
SequenceL file, to its own function file. Developers will have the opportunity to analyze
and modify these function files before actually compiling the files to executable code. If
any modifications are made to the function files additional C libraries can be linked in if
144

required. It is possible that SequenceL developers might want to add additional code for
monitoring purposes in order to obtain intermediate results for a program.
The implementation details described in this paper will follow the design
chronology of the compiler development.
B.l Lexical and Syntax Analyzer Implementation
B.1.1 Lexical Analyzer
The Lexical analyzer reads text strings from a SequenceL source code file. As the
Lexical analyzer reads these strings it identifies tokens, in the strings, by matching
characters using an if-then-else stracture that tests for valid tokens. The following code is
a fragment taken from of the lexical analyzer code for this SequenceL compiler.
token_ptr = token; /* remove white spaces */
if(whitespace(**ptr)){ while(whitespace(**ptr))
(*ptr) ++; retum WH;
}
/* check for comment line */ c_ptr = *ptr; c_ptr++; if(**ptr == V && *c_ptr == '*')
retum CM;
if(delimit(**ptr)) { /* nested if-then-else stracture starts here */
/* check for two character relational operator */
if(**ptr == '<' && (*c_ptr == '=' II *c_ptr == '>')) { *token_ptr = **ptr; (*ptr) ++; token_ptr++;
145

*token_ptr= **ptr; *token_ptr = ^0'; retum DL;
}
The lexical analyzer is designed to eliminate all white spaces and comment lines. Once
the lexical analyzer recognizes a valid token it enters it into the symbol table. The rest of
the lexical analyzer code can be found in seq.c on the CDROM.
B.1.2 Syntax Analyzer
The initial SequenceL grammar can be found in Appendix A of the dissertation
report. This grammar completely describes SequenceL. Having chosen to implement
syntax analysis using an LL(1) parser the grammar in Appendix A needs to be put in
LL(1) format. For example there are common prefixes in the following productions, L, E
M, B, U and indirectly in T that must be eliminated. There is also left recursion in the T
production that must also be eliminated.
Additionally, there are implied commas in some productions these must be made
explicit. For example the P production can include one or many F productions.
P ^ {{F^}U}
If more than one function appears in a P expression then comma separators are
required between the functions. For example if Fl and F2 are SequenceL functions then
the expression based on the P production is as follows.
P ^ {{F1,F2}U}
146

In addition to the issues listed above the initial grammar did not allow for the
nesting of constants with expressions and functions. This was a mistake and was
discovered and corrected. There were some additional changes made to the grammar to
assist the semantic analyzer, which the preprocessor will manage. The preprocessor was
not built for this SequenceL compiler. The syntax analyzer component of the
preprocessor has been built and tested, but the rest of the preprocessor will be left for
future development. The following changes were made;
B => TO^ ITO^ when R else B
Is changed to
B => TO^ I R then TO* else B
This creates a conditional expression corresponding to a procedural approach. The
original SequenceL production is read as "execute TO"*" when R is trae else execute B",
the new production is read as "when R is trae execute TO" else execute B".
F => V(V*) where next = {B} C
Is changed to
F => V(S*) where next(V*) = C {B}
The key change in the above production is reversing C and {B}. This was done because
the identifier information specified in C is used in B and therefore needs to be in the
symbol table before the semantic analysis of B. Also (V*) was added after "where next".
(V*) provides output formatting information for results produced by SequenceL
functions. The complete grammar with the above changes is listed below.
147

A => integer | real | string L => A,L I TO,L I A I TO E => [ ] I [L] I s(integer) V ^ id S => V|V(M) O => + I -1 /1 * I abs I sqrt j cos | sin | tan j log j mod j reverse (transpose |
rotateright j rotateleft | cartesianproduct M => all,M I TO,M j all | TO T => E I V I 0(TO) I gen([TO,...,TO]) | $ TO => T I T(M) I T(map(M)) RO => < I > I = I >= I <= I <> I integer | real j var | operator R => RO(TO) I and(R*) j or(R*) | not(R*) j trae j false B ^ TO* I R then TO* else B C => [ ] I from TO taking [V*] F ^ V(S*) where next(V*) = C {B} U => V ,U IE, U I V IE P=>{{F*}U}
P is a program, U is initial tableau One to many (*) and zero to many ( ) has implied delimiters when necessary, usually commas.
With these grammar changes in place the process of placing the grammar into
LL(1) format can begin. Left recursion was already eliminated with the creation of TO,
but there are still a number of common prefixes that need to be eliminated. The grammar
after eliminating the common prefixes is listed below. Note, the wildcard operator has
been changed from * to "all" this change eliminates the need to do overload processing
on the multiplication operator.
p Fl F2 F U Ul V
=>
=>
=>
^>
=>
=>
=>
{{FF1}U} F2F118 ,F V(SS2) where next(V3) = C{B} VUl 1 EUl , U | s id
148

VI => V2V1|8 V2 => ,V V3 =^ VVl I e s ^ VSl 51 => (M)\e 52 => S3S2 53 => ,S B => TOTl IR then TOTl else B Tl => T2T1 18 T2 => ,T0 C => [ ] I from TO taking [VVl] E ^ [ El I s(integer) El ^ L] I ] L => AAl I TOAl A => integer | real | string Al => ,L 18 M => allMl I TOMl Ml => ,M 18 T ^ E|V|0(TO)|gen([TO,...,TO])|$ TO => TT3 T3 => cr418 T4 => map(M)) | M) O => + I - I / I * I abs I sqrt j cos j sin | tan | log j mod | reverse j transpose j rotateright | rotateleft | cartesianproduct R => RO(TO) I and(RRl) j or(RRl) | not(RRl) Rl => RR1|8 RO => < I > I = I >= I <= I o I integer | real | var | operator
The above grammar is not an LL(1) grammar yet. The epsilon options appearing
in the grammar must be dealt with. This means selection sets must be generated for the
grammar. The selection set methodology described in chapter DI was used to generate the
following table of selection sets for SequenceL.
149
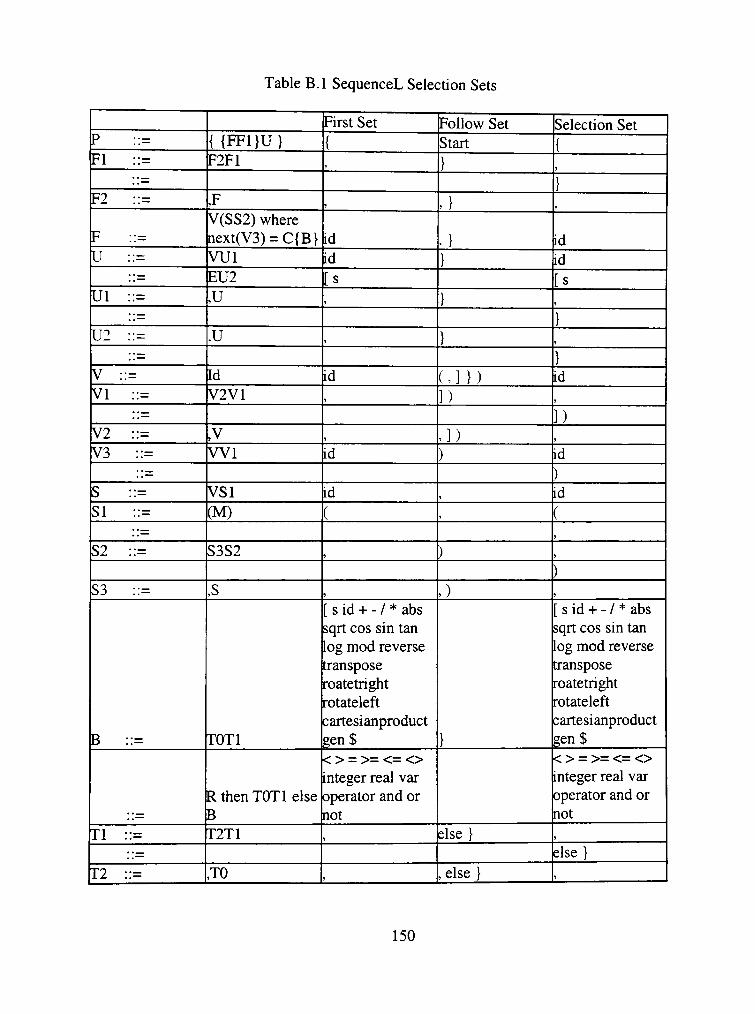
Table B.l SequenceL Selection Sets
p Fl
F2 :
:=
:= :=
:=
F ::= U ::=
::= Ul ::=
::= U2 ::=
::= V ::= VI
:
V2 : V3
:= :z=
:=
••= S ::= SI ::=
::= S2 ::=
S3 ::=
B ::=
Tl ::= ::=
T2 ::=
{{FF1}U} F2FI
,F V(SS2) where next(V3) = C{B} VUl EU2 ,U
,U
Id V2V1
,v VVl
VSl (M)
S3S2
,S
TOTl
R then TOTl else B T2T1
,T0
First Set { J
f
id id [s f
t
id )
?
id
id
(
1
[ s id + - / * abs sqrt cos sin tan log mod reverse transpose roatetright rotateleft cartesianproduct gen$ < > = > = < = < > integer real var operator and or not )
J
Follow Set Start
}
,}
,} }
}
}
( , ] } ) ])
, ] ) )
J
)
, )
}
else }
, else }
Selection Set { •>
} »
id id [s )
} 1
} id
]) ) id \ id ( y
1
) ?
[ s id + - / * abs sqrt cos sin tan log mod reverse transpose roatetright rotateleft cartesianproduct gen$ < > = >=<=<> integer real var operator and or not ) else } )
150
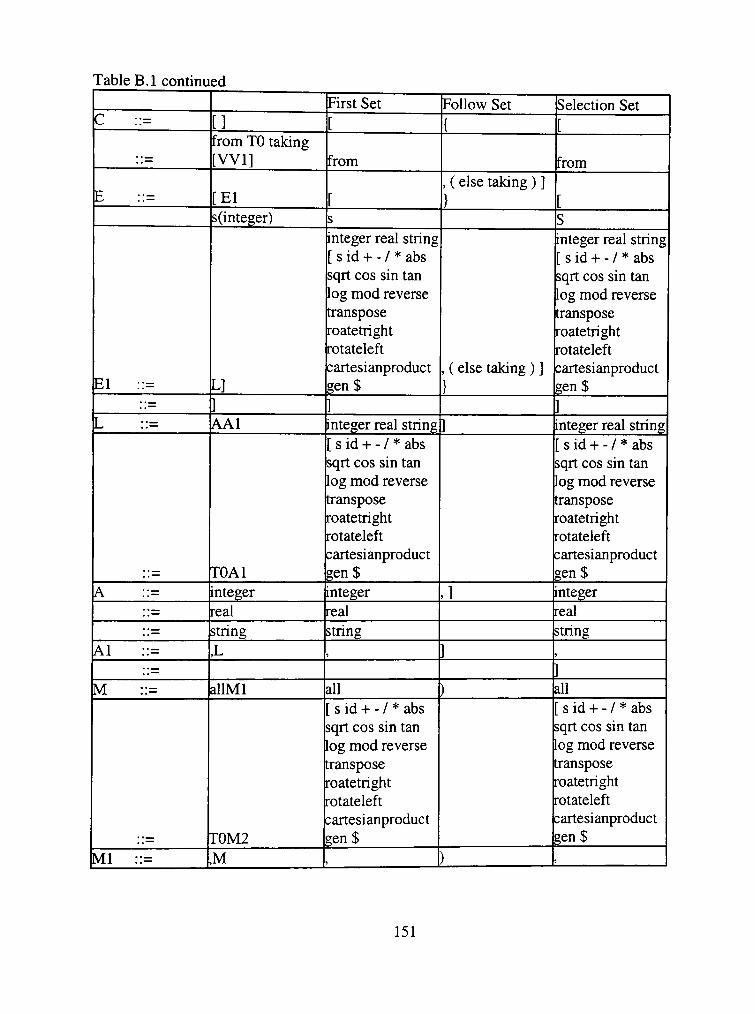
Table B.l continued
C ::=
• •"
E ::=
El ::=
L ::=
A ::=
::= Al ::=
::= M ::=
Ml ::=
[] from TO taking [VVl]
[E l s(integer)
L] ] AAl
TOAl integer real string ,L
allMl
T0M2 M
First Set [
from
[ s integer real string [ s id + - / * abs sqrt cos sin tan log mod reverse transpose roatetright rotateleft cartesianproduct gen$
] integer real string [ s id + - / * abs sqrt cos sin tan log mod reverse transpose roatetright rotateleft cartesianproduct gen$ integer real string ?
all [ s id + - / * abs sqrt cos sin tan log mod reverse transpose roatetright rotateleft cartesianproduct gen$ •>
Follow Set {
, ( else taking) ] }
, (else taking) ] }
]
,]
]
)
)
Selection Set [
from
[ S integer real string [ s id + - / * abs sqrt cos sin tan log mod reverse transpose roatetright rotateleft cartesianproduct gen$
] integer real string [ s id + - / * abs sqrt cos sin tan log mod reverse transpose roatetright rotateleft cartesianproduct gen$ integer real string )
] all ; s id + - / * abs sqrt cos sin tan og mod reverse transpose roatetright rotateleft cartesianproduct gen$
151
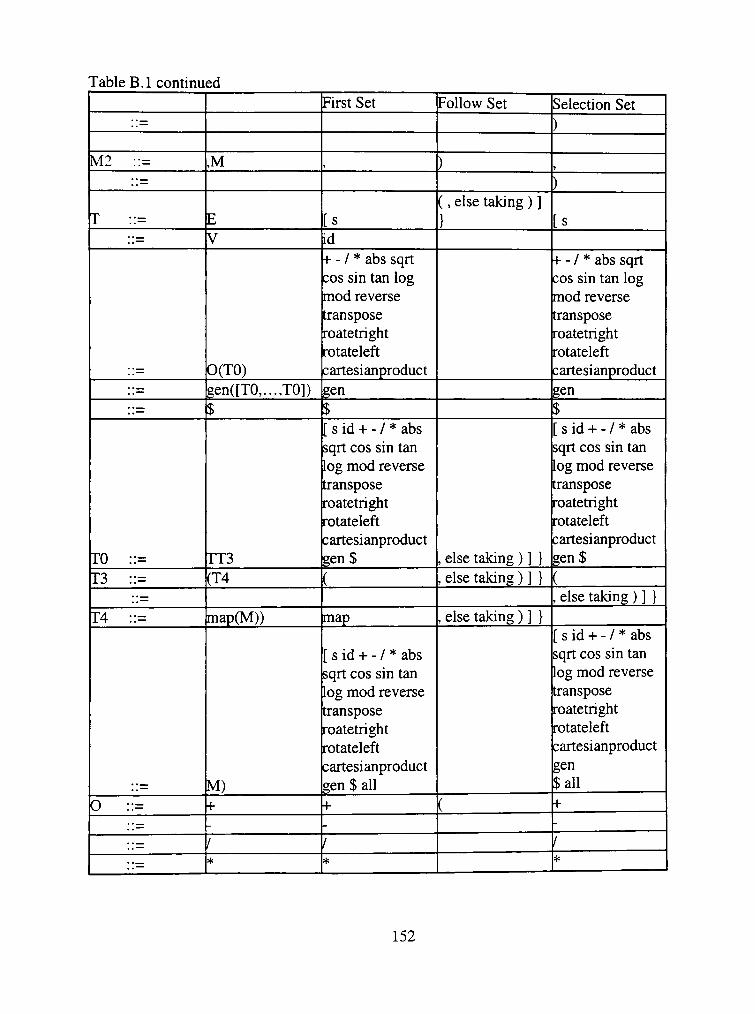
Table B.l continued
::=
M2 ::= ::=
T ::=
::=
TO ::= T3 ::=
::= T4 ::=
0 ::= : :—
::=
,M
E V
0(TO) gen([TO,...,TO]) $
TT3 (T4
mapCM))
M) +
/ *
First Set
[s id + - / * abs sqrt cos sin tan log mod reverse transpose roatetright rotateleft cartesianproduct gen $ [ s id + - / * abs sqrt cos sin tan log mod reverse transpose roatetright rotateleft cartesianproduct gen$
(
map
[ s id + - / * abs sqrt cos sin tan log mod reverse transpose roatetright rotateleft cartesianproduct gen $ all +
/ *
Follow Set
)
(, else taking) ] }
, else taking ) ] } , else taking ) ] }
, else taking ) ] }
(
Selection Set )
9
)
[s
+ - / * abs sqrt cos sin tan log mod reverse transpose roatetright rotateleft cartesianproduct gen $ [ s id + - / * abs sqrt cos sin tan log mod reverse transpose roatetright rotateleft cartesianproduct gen$
( , else taking ) ] }
[ s id + - / * abs sqrt cos sin tan log mod reverse transpose roatetright rotateleft cartesianproduct gen $all + -
/ *
152

Table B.l continued
= —
=
=
=
= =
R ::=
Rl
RO ::=
;;=
;;=
::= ::—
;;=
::=
::=
abs sqrt cos sin tan log mod reverse transpose rotateright rotateleft cartesianproduct
RO(TO) and(RRl) or(RRl) not(RRl)
RRl
<
>
= >=
<=
<>
integer real var operator
First Set abs sqrt cos sin tan log mod reverse transpose rotateright rotateleft cartesianproduct
< > = > = < = < > integer real var operator and or not < > = > = < = < > integer real var operator and or not
<
>
>=
<=
<>
integer real var operator
Follow Set
then <> = >=<= o integer real var operator and or not)
)
(
Selection Set abs sqrt cos sin tan log mod reverse transpose rotateright rotateleft cartesianproduct
< > = >=<=<> integer real var operator and or not <> = >=<= o integer real var operator and or not ) <
>
= >=
<=
o integer real var operator
The syntax analyzer is written directly from the selection set table using the
methods described in Chapter m. The following code is the syntax code for the L
production.
153

L=> A,L I TO,L I A I TO
int 10 {
if(a()){ if(al()){
retum trae; } else
retum false; } else
if(tO()){ if(al()){ retum trae;
} retum false;
} else
retum false;
The complete syntax analyzer code is in syntax.c on the CDROM.
B. 1.2.1 Syntax Error Checking
Error reporting by the syntax analyzer occurs whenever a syntax error is detected.
A classic approach with some compilers is to report the syntax error and do some sort of
error recovery, this allows the compiler to continue processing the source code file [Aho].
A number of strategies are available for error recovery, the simplest method being panic
mode. This method will discard symbols until a designated synchronizing token has been
found, in C this might be the semicolon used to terminate statements. A SequenceL
program is an expression of a complete problem solution using nested constmcts. This
makes the panic mode method not as effective as it has been found to be in a procedural
154

language like C. It is possible to introduce terminating symbols into SequenceL but this
idea was rejected. Instead the compiler is designed to stop immediately and generate an
error message when it detects a syntax error. It will then dump to the display system the
SequenceL file up to the point at which the error was detected. This implementation has
worked reasonable well.
B.2 Symbol Table
All symbols including, identifiers, reserve words and temporaries have an entry in
a symbol table. Through a symbol's type information meaning is given to the symbol.
This compiler creates multiple symbol tables. There is a symbol table for each SequenceL
function encountered in a SequenceL file as well as a global symbol table. The global
symbol table contains reserve words, SequenceL function symbols and any SequenceL
program input variables. Every symbol table entry, except reserve words and SequenceL
function names, are local in scope. By creating a symbol table for each SequenceL
function, local scope of all function identifiers is automatically provided. Function
symbols can appear in both the function symbol tables and the global symbol table. When
a function g is reference in a function/the function g's symbol is placed in function/s
symbol table. A symbol table update program rans before object code generation (OCG)
to make sure the attributes of the symbol for function g, in function/s symbol table,
matches g's symbol attributes in the global symbol table.
Symbol tables for this compiler are implemented using hash tables with a
maximum table size of 499; each hashed entry in the symbol table has a linked list
155

capability. If a symbol hashes to an entry already in use the new entry will be linked to
the existing symbol table entry. If a symbol table location is not in use a new entry is
created for that location. This design makes the symbol table size dynamic. Memory is
allocated for symbol table entries only as symbols are added.
Initially the symbol attributes consisted of only a name and type but has since
grown to include additional attribute information. The current symbol attributes are listed
in the following C stracture taken from the compiler source code.
stract entry { char* name; /* symbol name */ int type; /* symbol type information */ int constype; /* symbol is a constant */ int gen; /* identifier is gen result */ int taking; /* symbol is a taking identifier */ int queue; /* symbol is a queue */ int numarg; /* number of function arguments */ int formal; /* symbol is a formal parameter */ int if_result; /* symbol is retum value for if-then-else constract */ stract entry next; /* pointer to next symbol in chain */
};
The name attribute contains a pointer to a character string, which contains the
symbol's name. For example the name for reserve word "taking" is "taking". Type is a
numerical value arbitrarily assigned to each symbol. The "taking" symbol has been
assigned the type value 15. Constants will have their constype attribute set by semantic
analysis, this gives the compiler an opportunity to do some compile time memory
allocation for constants during OCG. Taking expression identifiers are associated with
one type of implied parallelisms. Therefore, the symbols for these identifiers will have
their taking attribute set by semantic analysis. For example in the following expression
the taking identifier is /.
156

taking i from gen([l,...,4])
The queue attribute is set when an identifier has been identified by semantic
analysis as a queue. Any expression that uses a taking identifier in an operation will have
the result it produces defined as a queue. Any expression that has a queue as one of its
operands will have the result it produces defined as a queue. The numarg stores
information on the number of input arguments a SequenceL function can accept. The
formal attribute is set for input arguments to a SequenceL function. In the generated C
code the conditional expressions can retum a result from either its trae or false
expressions, the temporary that retums a result from a conditional expression has its if-
result attribute set. The symbol table is critical to code generation. Without the attribute
information it would be very difficult to identify implied parallelisms.
B.3 Semantic Analyzer
Semantic analysis (SA) converts the SequenceL code to SequenceL intermediate
code (IC) statements. Semantic analysis generates the SequenceL IC statements through a
set of semantic action rales. The decision on where to place the semantic action rales
depends on when a given production is recognized by syntax analysis. The S production
is used here as an example of the semantic analysis code.
S=^ VSl
The following code is the S production code from syntax.c
int s() {
stract entry *p; if(v()){
157

}
p=lookup(last,prevtoken); create_arg(p); if(sl()){
retum trae; } else
retum false; } else
retum false;
The create_arg(p) is the semantic action for function input arguments. The semantic
function create_arg is listed below.
void create_arg(stmct entry *p) {
stract entry *pl; symtbl_stack_TOP *operand_top;
operand_top=(symtbl_stack_TOP*)malloc(sizeof(symtbl_stack_ELEMENT)); *operand_top=NULL; push_sym(p,operand_top); p->formal=l; p 1 =pop_sym(&sas_top); gen_quad(lookup(last,"_arg"),operand_top,NULL,0); argcount++;
}
The code first sets up the operand stack using the pointer operand_top. The input
argument is on the SAS when this function is called. Therefore the input argument is
popped off the SAS and placed in the operand stack. Next the input argument has its
formal attribute set. The function gen_quad is passed the operator "_arg", the operand
stack and a NULL for the result. The variable argcount is used to update the symbol
attribute numargs for the function whose input arguments are being processed. PI is
158

getting a marker off the SAS that was used at one time but is not used now. The rest of
the semantic analyzer implementation follows this pattem. The semantic action functions
can be found in quads.c on the CDROM.
B.4 Intermediate Code Representation
The IC statements are a key interface point in the compiler between
lexical/syntax/semantic analysis and object code generation. Complete details on the
development of the SequenceL intermediate language can be found in Chapter FV.
The following sections will describe the intermediate code by example. As each
example is reviewed a description of each step will be provided.
B.4.1 Evaluation of IC for Matrix Multiply
The following is a listing of the IC statements generated by the compiler for the
SequenceL Matrix Multiple;
/* matrix multiply */ {{ matmul(s_l(n,all),s_2(all,m)) where next(n,m) = from cartesianproduct([gen([[l],...,n]),gen([[l],...,m])]) taking [i,j] {+([*([s_l(i,all),s_2(all,j)])])}} matmul, s_l, s_2 }
1. _beginfunc:: matmul s_l s_2 2. 3. 4. 5. 6. 7. 8. 9.
_arg:: _arg:: next:: _seq :: gen:: _seq :: gen:: _seq ::
s_l s_2 n 1 ::
_to 1 ::
_t2 _tl
n all m
_to n ::
_t2 m :: _t3 ::
all m
_tl
_t3 _t4
159

10. cartesianproduct: 11. from :: 12. _M:: 13. _M:: 14. _seq :: 15.*: : 16. + ::
_t5 s_l s_2 _t6
_t8 :: _t9 ::
17. _endfunc :: ::
:
i i
all _t7
_t9 _tio _tio
_t4 :: j J
all : j :
_t5
: _t6 _t7
_t8
18. _call:: matmul s_l s_2
The lines are numbered for reference purposes. Two colons are used as delimiters
between operator, operands and results and are added by the compiler's IC dump to
display feature. To make the IC listing more readable the operand field includes all the
operands in the operand stack. Therefore on line 15 the operator is * the operand is _t8
and the result is stored in _t9. Note the use of temporaries. All temporaries generated by
semantic analysis begin with _t followed by a numerical value.
Before an IC statement can be generated by the semantic analyzer three things are
required, a pointer to the symbol table entry for the operator, a pointer to the operand
stack and a pointer to the symbol table entry for the result. The elements in the operand
stack are pointers to the symbol table entries for the operands. An IC statement that has
no operands or result will have the operand stack address or result address set to NULL in
the IC table. For example _endfunc in line 17 has no operand stack.
The semantic actions coupled with the SAS effectively pull apart all the
SequenceL nested operations and lay them out in serial order as IC statements. An
examination of the IC statements for data dependencies is the only way to tell that the IC
statements were generated from a nested stmcture. For example the nested computation
in matrix multiply is;
160

+([*([s_I(i,*),s_2(*,j)])])
Semantic analysis generates the following IC statements for the multiply and add parts of
this expression.
* _t8 _t9 + _t9 _tl0
_t9 is the result produced by multiplication, _t9 is also an operand for the addition. This
data dependency means the IC statements were generated for a nested SequenceL
expression.
A complete description of the matrix multiply IC listing is presented below along
with a description of each IC statement and what part of SequenceLMatrix Multiply
program the IC maps back to.
1) _beginfunc:: matmul s_l s_2 Indicates the beginning of a function called matmul which accepts two input arguments, s_l and s_2. Generated by SA from matmul(s_l(n,*),s_2(*,m))
2) _arg:: s_l n all Set n to the number of columns in s_l, generated by SA from s_l(n,*)
3) _arg:: s_2 all m Set m to the number of rows in s_2, generated by SA from s_2(*,m)
4) next:: n m Set the output format based on n and m, generated by SA from next(n,m)
5) _seq:: 1 :: _tO Setup a constant sequence, generated by SA from [1]
6) gen:: _tO n :: _tl Generate a sequence ranging from _tO to n and store the resultant sequence in _tl, generated by SA from gen([[l],...,n])
7) _seq:: 1 :: _t2 Setup a constant sequence, generated by SA from [1]
161

8) gen:: _t2 m :: _t3 Generate a sequence ranging from _t2 to m and store the resultant sequence in _t3, generated by SA from gen([l,...,m])
9) _seq:: _tl _t3 :: _t4 Collect the two generated sequences together, generated by SA from [_tl, _t3 ] _tl and _t3 are the results associated with the two gen IC statements in lines 6 and 8.
10) cartesianproduct:: _t4 :: _t5 Generate the Cartesian product of _t4 and store in _t5, generated by SA from cartesian_product([_t4 ]) _t4 is the result associated with the collect sequences IC in line 9.
11) from:: _t5 i j Generate / and; values from _t5, generated by SA from taking [i,j] from _t5, _t5 is the result associated with the Cartesian product IC in line 10.
12) _M:: s_l i all :: _t6 Select column sequences from s_l based on / and store resultant sequence in _t6, generated by SA from s_l(i,*)
13) _M:: s_2 all j :: _t7 Select row sequences from s_2 based on j and store resultant sequence in _t7, generated by SA from s_2(*,j)
14)_seq:: _t6 _t7 :: _t8 Collect the column and rows together in _t8, generated by SA from [_t6, _t7] _t6 and _t7 are the results associated with the index IC statements in lines 12 and 13.
15) * :: _t8 :: _t9 Multiply the columns and rows and store the resultant sequence in _t9, generated by SA from *([_t8])
16) + :: _t9 :: _tlO Add the sequence in _t9 and store the resultant sequence in _tlO, generated by SA from +([_t9])
17)_endfunc:: :: _tlO retum _tlO to the referencing function, generated by SA from the } at the end of a function.
18)_call:: matmul s_l s_2
162

This IC specifies the initial call to matmul, the result of matmul is retumed here. Generated by SA from matmul, s_l, s_2}.
This example will be continued in the section on object code generation.
B.5 Object Code Generation
Every SequenceL program passed to the SequenceL compiler results in the
compiler creating a number of function files and their associated include files. For
example given the following SequenceL code fragment, and assuming that function2
contains an implied parallelism that retums a result in the temporary identifier _t30;
{{
functionl(s_l(n)) where next(n)... },
function2(s_l,s_2(n)) where next(n) ... },
function3(s_l,s_2(n)) where next(n)... }} function1,s_l }
The following file open and close cycles occur during OCG.
163

Open main.c main.h and initialize
Close main.c and main.h and open functionl.c functionl.h
Close function l.c functionl.h open main.c and main.h
Close main.c and main.h and open function2.c function2.h
Open _t30agg.c _t30agg.h
Close _t30agg.c _t30agg.h
Close function2.c function2.h open main.c and main.h
Close main.c and main.h and open function3.c function3.h
Close function3.c function3.h open main.c and main.h
Complete update of main.c and main.h and close
Figure 4
Between each file's open and close statement the function file is being updated with C
code by OCG. Note that function2.c and function2.h remains open when _t30agg.c and
_t30agg.h are open, this is because _t30agg.c and _t30agg.h are being created
dynamically as a result of control flow analysis detecting the implied parallelism. The C
functions created in _t30agg.c will be a thread function that will be invoked by the
pthread_create library call from within function2.c. When main.c and main.h are initially
opened the first part of main.c is written to main.c. If the file open and write fails the
compiler reports an error and exits. The file open and close trace is the result of using
164

only one file pointer for function files and one file pointer for include files. The current
setting of the two file pointers is controlled by OCG's current location in the IC table.
Only when an implied parallelism has been detected are more than two files open at the
same time.
The initial code written to main.c is as follows.
#include <stdio.h> #include <pthread.h> #include <math.h> #include <semaphore.h> #include <rantimel.h>
int main(){ #include "main.h"
The very first IC read from the IC table by OCG will always be a _beginfunc.
This IC causes the OCG to close main.c and main.h and open a new C function file and
include file. As OCG reads IC statements it generates C code and writes it to the function
file, C code declarations for identifiers are written to the function's include file. When
OCG reads the _endfunc IC this IC causes OCG to generate the function's retum
statement and close the function file and it's include file, reopening main.c and main.h.
The very last IC in the IC table will always be derived from the SequenceL initial
tableau expression that SequenceL uses to begin the consume-simplify-produce execution
process. In the matrix multiply IC table listing this IC is;
_call:: matmul s_l s_2
This IC causes OCG to write the following C code for matrix multiply to main.c.
s_l=get_input("s_l"); s_2=get_input("s_2");
165

result=matmul(s_l,s_2); printf("result = %s\n",result->string); }
The declarations for s_l, s_2, result and the function prototype for matmul are written to
the file main.h
sequence *s_l; sequence *s_2; sequence* result; sequence * matmul (sequence *, sequence *);
Since the queue flags are not set for s_l, s_2 and result they are sequences.
Additionally since the s_l and s_2 are not function names and do not appear within a
SequenceL function they are input arguments for the SequenceL program. All inputs to a
SequenceL program are read from input files that must have the same name as the input
arguments. The stracture of an input file is a string sequence. Therefore if a sequence
representing a 3x3 matrix is to be loaded into the input variable s_l, the following string
would be placed in a text file called s_l.
[[[1],[2],[3]],[[4],[5],[6]],[[1],[1],[1]]]
Code generation by example is presented in section B.5.2. The compiler code for
code generation is in codgen.c on the CDROM.
B.5.1 Parallel Code Generation
The queue is the fundamental data stracture for supporting parallel execution in
the generated C object code. The inspiration for developing the queue for the object code
166

was tiie SequenceL execution strategy. For example in matrix multiply the following
stracture is created in the tableau for a 3x3 matrix multiplication [CooOO].
T = [
]
[ 2:+([*([[2,4,6],[2,3,l]])]) 2+([*([[2,4,6],[4,5,l]])]) 2:+([*([[2,4,6],[6,7,l]])]) 2:+([*([[3,5,7],[2,3,l]])]) 2:+([*([[3,5,7],[4,5,l]])]) 2+([*([[3,5,7],[6,7,l]])]) 2:+([*([[l,l,l],[2,3,l]])]) 2:+([*([[l,l,l],[4,5,l]])]) 2:+([*([[l,l,l],[6,7,l]])])
It is not difficult to see that this stracture can be envisioned as a queue, or at least the data
can be easily processed into a queue.
[[2,4,6],[2,3,1] [[2,4,6],[4,5,1] [[2,4,6],[6,7,1] [[3,5,7],[2,3,1] [[3,5,7],[4,5,1] [[3,5,7],[6,7,1] [[1,1,1],[2,3,1] [[1,1,1],[4,5,1] [[1,1,1],[6,7,1]
The queue length can be anywhere from zero to whatever system memory will
allow.
The above queue listing reveals a problem that can occur with some parallel
execution strategies. Note that there are only three columns and three rows in a 3x3
matrix multiply yet the queue has nine columns and nine rows stored in it. Each column
and row is repeated three times. It's easy enough to setup a queue using pointers.
167

Therefore instead of storing three copies of each column and row in a queue the queue
has three pointers to each column and row. That way only one copy of a column or row is
actually stored in memory. This implementation has its problems as well. It leads to
memory bottlenecks on shared memory system. For example if a 1000 threads needed
access to that one column a potential memory bottleneck is created. Further more on a
distributed shared memory system such as the SGI Origin2000 chances are that the
matrix will be stored in contiguous memory. Therefore all the columns and rows will be
together in the same area of memory, this makes the bottleneck condition even worse.
Optimization for space versus time is beyond the scope of this research. For now time
gets priority over space for this compiler.
The queues created in the C generated code begin with the taking identifiers. The
taking expression is a known point of distribution for one class of implied parallelisms.
For example the following taking expression,
taking i from gen([l,...5])
Results in a queue in object code. The queue / will contain the elements;
[1] [2] [3] [4] [5]
When an expression is evaluated that references i the expression produces a result that is
also a queue. For example given;
s_l = [[[1],[2]],[[3],[4]],[[5],[6]],[[7],[8]],[[9],[10]]]
The expression s_l(i) produces the following result in a queue.
168

[[1],[2]] [[3],[4]] [[5],[6]] [[7],[8]] [[9],[10]]
If the expression s_l(i) appears in a computation such as +([s_l(i)]) then the result
produced is also a queue.
[3] [7] [11] [15]
[19]
A the end of a function the output formatting information associated with the
"next(V*) expression will determine the format the queue must be placed in before a
sequence is retumed. For this queue example assume the result is linear.
[[3],[7],[11],[15],19]]
Any operation that utilizes a queue is a potential opportunity for parallelism. The
key to processing the queues in parallel is to setup a loop to pass the queue elements one
at a time to a thread function. Thread functions are invoked by the POSIX thread library
routine pthread_create. Thread functions that are invoked by pthread_create are non-
blocking. Therefore before the result of a thread function can be used a block must be
setup that unblocks when the thread function exits. Pthreadjoin is the POSIX thread
library routine that provides the block for thread functions. Pthread joins are placed in
object using an as-needed strategy. Therefore, a pthreadjoin is not placed in object code
until a result is needed from a thread function. This strategy leads to another type of
parallelism.
169

In a nested SequenceL stracture, if there is more than one computation at the
same level of nesting these computations can execute in parallel. For example the
following is a SequenceL example of two multiply expressions at the same level of
nesting in the nested expression.
+([*([s_l(i),s_2(i)]),*([s_3(i),s_4(i)])])
The results from the two multiply operations is required by the addition operation.
The following pseudo code for this expression will be utilized to explain how the object
code handles nested stmctures executing in parallel.
for(i=0; i < size; i++) /* loop 1 */ _t0(i)=*(s_l(i),s_2(i))/* threaded execution */
for(i=0; i < size; i++) /*loop 2 */ _tl(i)=*(s_3(i),s_4(i))/* threaded execution */
block here for loop 1 block here for loop 2
for(i=0; i < size; i++) /* loop 3 */
_t2(i)=+(_t0(i),_tl(i));/* threaded execution */
Since the results from loop 1 and 2 are needed in loop 3 a block is placed just
before loop 3. This block will unblock when all the threads generated in loop 1 and 2
have exited. This works very well for balanced nested expressions but mns into problems
with unbalanced nested expressions. The following expression is unbalanced, the first
addition is nested one level below the second addition.
*([*([+([s_l(i),s_2(i)])]),+([s_3(i),s_4(i)])])
The pseudo procedural code from the above expression is;
for(i=0; i < SIZE; i++) /* loop 1 */ _tl(i)=+(s_l(i),s_2(i))/* first addition */
170

block here for loop 1
for(i=0; i<SIZE; i++) /* loop 2 */ -t3(i)=*(_tl(i)) /* inner or second multiply */
for(i=0; i < SIZE; i++) /* loop 3 */ _t2(i)=+(s_3(i),s_4(i))/* second addition */
block here for loop 2 and 3
for(i=0; i<SIZE; i++) /* loop 4 */
_t4(i)=*(_t3(i),_t2(i)) /* outer or first multiply */
Even tiiough loopl and loop3 can be executed in parallel the block on loop 1 just before
loop 2 keeps loop 3 from executing until all of loop I's threads have exited. The block is
there because loop 2 uses the results from loop 1. The result is a reduction in parallel
execution. A side effect of optimizing the compiler for cache locality has been to reduce
the effects of this problem for simple unbalanced nested expressions. Cache locality is
detailed in a B.6.2.1. Cache locality is improved by combining data dependent
computations into the same thread function. Therefore the above code would be
restractured so that the first addition and inner multiply share the same thread function.
The procedural code then becomes.
for(i=0; i < SIZE; i++){ /* loop 1 */ _tl(i)=+(s_l(i),s_2(i))/* first addition */ _t3(i)=*(_tl(i)) /* inner or second multiply */
}
for(i=0; i < SIZE; i++) /* loop 2 */ _t2(i)=+(s_3(i),s_4(i))/* second addition */
block here for loop 1 block here for loop 2
for(i=0; i<SIZE; i++) /* loop 3 */
171

_t4(i)=*(_t3(i),_t2(i)) /* outer or first multiply */
This implementation strategy works well for both balanced and simple unbalanced nested
computations. More complex unbalanced nested computations could require code
restmcturing.
The final type of parallelism that code generation must deal with is control flow
parallelisms associated with function calls, or references. For example, given two
functions, function 1 and function2 were each receives one argument and each retums one
argument and given the following SequenceL expression that references function 1 and
function2.
[function2,s_l,function 1 ,s_l ]
The IC statements generated from this SequenceL expression will be;
_call function 1 s_l _tO
_call function2 s_l _tl
In this example there are no dependencies between the functions. When control flow
analysis detects this kind of IC arrangement it creates two thread functions. OCG then
places the calls to function 1 in one thread function and the call to function2 in the other
thread function. The result is the two thread functions execute in parallel.
B.5.2 Code Generation by Example
Two examples of code generation will be presented in this section. Together the
two examples demonstrate the code generated for all the SequenceL grammar
productions except "and", "or" and "not. The two examples demonstrate all the classes of
172

implied parallelisms. The first example will be matrix multiple and the second will be
quicksort. In each example an IC statement is presented first followed by the OCG
generated object code. The appropriate variable and function declarations are placed in
the function include files as OCG generates the object code.
B.5.2.1 Matrix Multiply
The first IC statement encountered will be the _beginfunc statement. This
statement causes OCG to set up the function prototype and formal arguments for the
SequenceL function matmul.
_beginfunc:: matmul s_l s_2
OCG generates the following code in function file matmul.c
#include <stdio.h> #include <pthread.h> #include <math.h> #include <semaphore.h> #include <rantimel.h>
sequence *matmul(sequence *s_l,sequence *s_2) { #include "matmul.h"
This next IC instmcts OCG to setup object code that assigns a value to n.
_arg:: s_l n all
OCG generates;
n=Msizeof(s_l,l,2);
173

Msizeof is a rantime library routine. It accepts sequence and integer information that
helps it to retum a size value associated with the sequence it is passed. The two integer
values indicate how many indexes are involved in the size specification and which index
is of interest. Msizeof will assign to n size information associated with s_l. The 1 in the
argument list indicate that n, is the first of two identifiers in the original SequenceL
expression, therefore column information is required. The 2 in the argument list indicate
that there are two identifiers in the original SequenceL index expression.
This next IC instmcts OCG to setup object code that assigns a value to m.
_arg:: s_2 all m
OCG generates;
m=Msizeof(s_2,2,2);
In this case Msizeof is informed that m is the second identifier of two. Therefore row information is being requested.
next:: n m
Code generation does no generate anything for the next IC. It will be scanned for when
the _endfunc IC is encountered.
This IC statement sets a temporary to a constant.
_seq:: 1 :: _tO
OCG generates; _tO=sequence_atos(" [ 1 ]");
Sequence_atos is a string-to-sequence conversion routine. Constants like "[1]" can be
allocated memory at compile time or at mntime. Here it is allocated at mntime.
174

This next IC statement is a generative statement.
gen:: _tO n :: _tl
OCG generates the following statements;
_tl gen. start=_tO; _tlgen.end=n; gen_thr_t 1=(pthread_t*)malloc(sizeof (pthread_t));
pthread_create(gen_thr_tl, NULL, (void *)gen, (void*)&_tlgen);
All generative constracts are implemented as threads. The argument stracture for gen is
predefined. The stracture includes a start sequence, an end sequence and a sequence to
store the result of the gen. The result name in the IC is used as part of the name of all
variables associated with the gen. This includes the name of the stmcture (_tlgen) as well
as the thread id (gen_thr_tl). This strategy of using a result name for variables guarantees
that the names are unique since a result name can be used as a result only once in an IC
table. The rantime library routine gen is setup as a thread function.
A constant;
_seq:: 1 :: _t2
OCG sets up a constant;
_t2=sequence_atos(" [ 1 ]");
Another generative constract.
gen:: _t2 m :: _t3 generates _t3gen.start=_t2;
_t3gen.end=m; gen_thr_t3=(pthread_t*)malloc(sizeof(pthread_t)); pthread_create(gen_thr_t3, NULL, (void *)gen, (yoid*)&_t3gen);
This IC collects _tl and _t3 together in a new sequence _t4.
175

_seq:: _tl _t3 :: _t4
OCG generates these statements;
pthreadJoin(*gen_thr_tl,NULL); _tl=_tlgen.seq; pthreadJoin(*gen_thr_t3,NULL); _t3=_t3gen.seq; _t4=collect_sequences("ss",_tl,_t3);
_tl has it's gen flag set therefore a gen operation was involved in creating the contents of
_tl. Therefore a pthreadjoin is required for _tl. This also holds for _t3. _tl and _t3 are
collected together by the collect_sequences mntime library call.
This IC is a Cartesian product statement;
cartesianproduct:: _t4 :: _t5
OCG generates;
_t5=cartesian(_t4);
Except for the multiply, add, subtract and divide functions all of the SequenceL functions
such as cartesian, abs, cos, sin etc... are implemented as non-threaded functions in the
rantime library. They accept one sequence and retum one sequence.
This IC is a taking statement;
from:: _t5 i j
OCB generates the following statementsl
i=(taking_data*)malloc(sizeof(taking_data)); i->from=_t5; i->yar=l; i->num_var=2; take_thri=(pthread_t*)malloc(sizeof(pthread_t)); pthread_create(take_thri, NULL, (void *)taking, (yoid*)i);
176

j=(taking_data*)malloc(sizeof(taking_data)); j->from=_t5; j->yar=2; j->num_var=2; take_thrj=(pthread_t*)malloc(sizeof(pthread_t)); pthread_create(take_thrj, NULL, (void *)taking, (void*)j); pthreadJoin(*take_thri,NULL); pthreadJoin(*take_thrj,NULL);
A thread is generated for each identifier in the taking clause. In this example / and; are
the taking identifiers. A stracture has been pre-defined for the input argument for the
taking rantime library function. The taking stracture requires the following information,
the sequence the taking is to be done from; how many identifiers there are; and which
identifier the call is being made for. The joins are placed after the last taking identifier's
thread is created.
This IC is an index statement
_M:: s_l i all :: _t6
OCG generates; _t6=selection_queue("sq*",s_l,i->result,all);
The rantime library function selection_queue can take any number of arguments. In this
example sq* defines the number of arguments and their types. The s in sq* means the
first argument, s_l is a sequence, the q in sq* means the second argument, i->result is a
queue and the * in sq* means the last argument is a wildcard. The call retums a queue in
_t6, in this matrix multiply example all of the columns in s_l are stored in _t6.
An IC index statement;
_M:: s_2 all j :: _t7
177

OCG generates;
_t7=selection_queue("s*q",s_2,all,j->result);
Again selection_queue is called except this time the second argument is the wildcard, the
result of this call is that all of the rows in s_2 are stored in _t7.
The collect queue IC statement;
_seq:: _t6 _t7 :: _t8
OCG generates; _t8=collect_queues("qq",_t6,_t7);
The rantime library function collect_queues places all the column and row sequences in
the queues _t6 and _t7 into a new queue, _t8.
The two arithmetic IC statements will be reviewed together.
*:: _t8 :: _t9 + :: _t9 :: _tlO
OCG generates; _tlO=_t8;
_tlO_element= _tlO->head; size=queue_size(_t 10);
thr_tlO=(pthread_t*)malloc(sizeof(pthread_t)*size); while(_tlO_element !=NULL){
pthread_create(&thr_tlO[_tlO_thread], NULL, (void *)_tlOagg, (void*)_tlO_element->p);
_t 10_element=_t 10_element->next; _tlO_thread++;
}
Control flow analysis seeks out opportunities to improve cache locality. Tests
were carried out on the Origin2000 that revealed that cache locality can reduce execution
times by as much as 50%, this figure is supported by the literature [Phi]. Control flow
178

analysis detects the data dependency between these two IC statements and dynamically
creates a thread function to place both in. Additionally OCG must dynamically generate a
stracture for all the input arguments this new thread function will need. Since _tlO will
eventually contain the results of this multiply/add function, _tlO is setup as the control
for tiie loop. _tlO initially points at the input queue _t8. Size is assigned the number of
threads tiiat will be created. The variable _tlO_element is setup to point at the first
column/row sequence in the input queue. Each time the while loop cycles the pointer
_tlO_element is moved so that it points at the next column/row sequence. The
column/row sequence is passed to the thread function, which retums a result in this same
sequence.
The dynamically created thread function _tlOagg is listed below.
void* _tlOagg(void *arg) { #include "_tlOagg.h"
_t8=(sequence*)arg; multiply(_t8); _t9=_t8; add(_t9); _t8=_t9;
}
The end function IC statement;
endfunc :: :: _tlO
OCG generates; do{
_tlO_thread-; pthread J oin(thr_t 10 [_t 10_thread] ,NULL);
}while(_tlO_thread > 0); retum queue_reduc("qii",_tlO,n,m);
179

}
The queue flag for _tlO has been set therefore a join is needed before the results stored in
_tlO can be used. When all of the threads have joined the results will be stored in the
queue _tlO. Once all of the results are available they must be placed back in a sequence
format. The IC statement specifies the format;
next:: n m
The queue_reduc rantime library function, is passed this format information and
restractures the queue into a sequence.
Finally the initial tableau IC is processed and main.c and main.h are updated with the call
to matmul.
The execution trace for the C generated parallel code is shown below.
mm Number of processors
1
Figure B.l Matrix Multiply
B.5.2.2 Quicksort
The SequenceL quicksort code is as follows.
{{ quick(s_l(n)) where next(n) = [ ] { =([[ ],s_l]) then [ ] else >([n,[l]]) then [$,quick,less,s_l([l]),s_l,s_l([l]),$,quick,great,s_l([l]),s_l] else [s_l] },
less(s_l,s_2(n)) where next(n) = from gen([[l],...,n]) taking [i]
180

{ <([s_2(i),s_l]) then [s_2(i)] else [ ] },
great(s_I,s_2(n)) where next(n) = from gen([[l],...,n]) taking [i] { >([s_2(i),s_l]) then [s_2(i)] else [ ] }} quick, s_l }
Quicksort in SequenceL clearly illustrates the high-level nature of the SequenceL
language, not including includes and the contents of the include files, 184 lines of C
code were required to execute quicksort in C code. The Quicksort IC statements and
generated code are listed at the end of this document.
Of interest in quicksort is the code generation associated with the relational
operations. In the quick function there are two relational expressions, in the less function
and the great function there is one in each. There is also a sequence containing multiple
function references, which includes two recursive calls to quick.
The quick function IC statements for the relational operations are on lines 7 and 14
in the IC table listing.
= :: _tl :: _t2 >:: _t5 :: _t6
An examination of the operands _tl and _t5 reveals that these two identifiers do not have
their symbol queue attribute set therefore they are sequences. This means OCG will
generate non-parallel code for these two relational expressions. For the first IC the code
generated is,
if(convert_logic(condition(EQUAL,_tl)))
Which is in line 13 in the quick.c file listing. The rantime library routine condition
accepts a flag indicating what relational operation is being invoked, equality in this case.
181

and the sequence upon which the operation is taking place on, _tl. The condition routine
retums a trath sequence of trae or false singletons. Convertjogic is a rantime library
routine that translates the trath sequence, retumed by condition, into something that a C if
statement can understand. The second IC causes the generation of
if(conyert_logic(condition(GREATER,_t5)))
Note that the result of the relational operations are stored in _t2 and _t6, these two
identifiers are tracked by OCG so that the result of either a tme or false will be retumed
in them. Since _t2 was the result of the first relational and the second relational only
executes if the first is false then ultimately the result of _t6 is passed to _t2. The IC at line
32 performs this function.
_seq:: _t6 :: _t2
Note the tracking of _t2 and _t6 by the conditional operators at lines, 8, 11, 15, 28,
31 and 33 in the IC table.
Quick also provides an opportunity to demonstrate the compiler's ability to
generate parallel code for implied control flow parallelism. The following SequenceL
expression contains function references that generate the code for this type of parallelism.
[$,quick,less,s_l([l]),s_l,s_l([l]),$,quick,great,s_l([l]),s_l]
The ICs generated from this expression are listed below.
_seq:: 1 :: _t7 _M:: s_l _t7 :: _t8 _seq:: 1 :: _t9 _M:: s_l _t9 :: _tlO _seq:: 1 :: - tH _M:: s_l _tl l :: _tl2 _call:: great _tl2 s_l :: _t29 _call:: quick _t29 :: _t30
182

_call:: less _t8 s_l :: _t31 _call:: quick _t31 :: _t32 _seq:: $ _t32 _tlO $ _t30 :: _tl3
Of particular interest are the _call IC statements. When control flow analysis
encounters the _call operator it checks the next IC for a data dependency. Upon
discovering a data dependency control flow will place both of these function calls into
one thread function, it then continues and discovers the same opportunity with the next
two _call IC statements and repeats the process. Finally when control flow reaches the
_seq IC it recognizes that the results of the calls are needed here. Therefore pthreadjoins
are generated for the two thread functions. The code generated for the _call IC staements
is as follows.
_t30args=(_t30call_stract*)malloc(sizeof(_t30call_stract)); _t30args->_tl2=_tl2; _t30args->s_l=s_l; pthread_create(&thr_t30, NULL, (void *)_t30agg,(void*)_t30args); _t32args=(_t32call_stract*)malloc(sizeof(_t32call_stract)); _t32args->_t8=_t8; _t32args->s_l=s_l; pthread_create(&thr_t32, NULL, (void *)_t32agg,(void*)_t32args);
The contents of the two thread functions will be the code that would normally be
generated for a _call IC, plus the code associated with the passing of arguments to a
thread function.
_t30args=(_t30call_stract*)arg; _tl2=_t30args->_tl2; s_l=_t30args->s_l; _t29=great(_tl2,s_l); _t30=quick(_t29); _t30args->result=_t30;
183

The complete listing for _t30agg and _t32agg is in the object code listing.
Unlike the relational operations in quick the relational operations in less and great
do present an opportunity for parallel execution since the queue attribute is set for _tl8
and _t25. A thread function needs to be created that will do the comparisons on each of
the elements in the queues. The IC statements for the relational operations in less and
great are listed below.
<:: _tl8 :: _tl9 and
>:: _t25 :: _t26
These two IC statements along with the fact that the queue attribute is set for the
operands cause OCG to setup two loop stmctures, one in less.c and one in great.c. These
loops will generate the threads and pass each thread a sequence to compare. The code
generated for the first IC statement is as follows.
while(_tl8_element !=NULL){ _tl9args=(cond_arguments*)malloc(sizeof(cond_arguments)); _tl9args->s_2=s_2; _tl9args->n=n; _tl9args->s_l=s_l; _tl9args->result=(sequence*)malloc(sizeof(sequence)); push_queue(_t 19args->result,_t 19queue); _t 19args->parameter=_t 18_element->p; _t 19args->i=i_element->p; i_element=i_element->next; pthread_create(&thr_id[_tl9_thread], NULL, (void *)_tl9cond, (yoid*)_tl9args); _t 18_element=_t 18_element->next; _tl9_thread++; }
The actual relational expressions that execute as a result of either a tme or false
are in the new thread functions.
184

_t 19args=(cond_arguments*)arg; i=_tl9args->i; s_2=_tl9args->s_2; n=_tl9args->n; s_l=_tl9args->s_l;
if(convert_logic(condition(LESS,_tl9args->parameter)))
_t20=selection_seq("ss",s_2,i); copy_seq(_t 19args->result,_t20);
} else{
t21=sequence_atos("[ ]"); copy_seq(_t 19args->result,_t21);
} }
All input variables used by these dynamically created thread functions are passed
in a dynamically created input variable stracture. The copy_seq is a way of updating a
previously allocated sequence with another sequence.
B.6 Runtime Setup
B.6.1 Sequence Representation
This topic is covered in Chapter IV.
B.6.2 Scheduling
Scheduling issues have been addressed with respect to control flow parallelisms
in the OCG section. Cache locality issues will be reviewed in the next section.
185

B.6.2.1 Cache Locality
Cache locality is a problem that occurs on multi-processor systems, which thread
scheduling can address [Phi]. A thread that executes on a processor will store its data in
the processor's cache memory. Any subsequent thread requiring access to the data should
be scheduled to execute on the same processor so it can take advantage of the data
already in cache. It is a complex task to explicitly schedule threads on processors through
an analysis of data dependency and control flow [Phi].
An operating system's thread scheduler typically uses a FIFO protocol to
schedule threads[ Lew]. The first thread created executes first, followed by the second
and so on. When a thread yields a processor the next thread on the FIFO queue will be
loaded onto the vacated processor for execution [Nar]. It is possible to setup a thread
creation strategy so that threads can share data with each other using the same cache
memory. When an initial thread is created, if that thread immediately creates a child
thread that child thread will be placed next to the parent in the FIFO queue. The result is
that when the parent yields a processor the child thread will get the vacated processor and
when the child yields the processor back, the parent thread will be retumed the same
processor. Given a multiply/add senario, where one thread does the multiply operation
and a second does the addition. Then the following strategy would result in data sharing
via the same cache. The first thread created will do the addition operation, but before it
does so it creates the multiply thread and then waits for the multiply to complete before
the addition takes place. The result is a data sharing through the same cache. For this
compiler, instead of creating two threads the multiply/add are placed in the same thread
186

and execute serial there. This saves overhead in thread creation and has no ill effects on
parallelisms since the two operations are serial anyway.
B.6.3 Runtime Library
The rantime library thread functions were initially designed to use a semaphore to
synchronize threads. Some developers recommend semaphores over thread joins [Lew]
since the blocked routine does not have to wait for the thread function to exit before it
can use a result. The problem with semaphores is that they are subject to race. For
example, assume that the function function 1 created a thread from the thread function
threadl and that function2 also created a thread from thread function threadl. After
creating the threads function 1 and function2 block on a semaphore waiting for threadl to
set the semaphore. If the thread created by function 1 completes first function2 may detect
the semaphore before function 1 and assume that it was its thread that completed first.
This condition occurs in the quicksort program. One solution to this problem is to have
every function dynamically create a unique semaphore and pass it to the thread function.
Another solution is to create threads with a unique thread id and use the pthreadjoin to
wait on the thread. This second method was implemented since it removed all traces of
the thread model from the rantime library making the ran time library a little more
general purpose. In its final configuration, granularity capabilities were added to a
number of the rantime library routines, this change reintroduced the thread model to the
rantime library.
187

The following is a list of all the mntime library routines. Some of the routines are
for intemal library use others appear in the generated C code. These functions are
important to the development of the compiler in that they provide much of the
functionality expressed by SequenceL constmcts, such as the taking expression. The code
for these routines is in rantimel.c on the CDROM.
These are the sequence normalization functions.
char* norm(sequence*, int, int*); /* retum a normalized character string */ int do_normalize(sequence*); /* check for normalization requirement */ void normalize(sequence*); /* normalize a sequence */
int* cardinality(sequence*); /* retum an array containing a sequence's cardinality */
These are the arithmetic, relational and logic mntime routines.
void* multipIy(void*); /* threadable multiply function */ void* add(void*); /* threadable add function */ void* subtract(void*); /* threadable subtract function */ void* divide(void*); /* threadable divide function */ sequence* compute_seq(sequence*,int); /* arithmetic function */ sequence* condition(int, sequence*); /* relational function */ int convert_logic(sequence*); /* convert relational result to something C understands */ sequence* logic(int, sequence*); /* logical operation function */
These are the sequence rantime routines. These routines typically generate sequences,
measure sequences or retum parts of a sequence.
sequence* sequence_atos(char*); /* convert a string to a sequence */ sequence* collect_sequences(char*,...); /* collect sequences */ sequence* get_sequence(sequence*, sequence*, int); /* get a sequence */ sequence* selection_seq(char*,...); /* sequence selection function */ sequence* get_row(sequence*, int); /* get a sequence row */ sequence* get_col(sequence*, int); /* get a sequence column */ sequence* Msizeof(sequence*,int,int); /* get a sequence size */ sequence* remove_null(sequence*); /* remove empty sequences fr-om sequence / sequence* sequence_ntos(int,int*,double*,sequence*); /* convert data to sequence /
These are the queue rantime routines.
188

sequence* queue_reduc(char*,...); /* reduce queue to a sequence */ sequence* pop_queue(stract queue*); /* pop a sequence from queue */ void push_queue(sequence*,stract queue*); /* push sequence onto queue */ int isempty_queue(stract queue*); /* is queue empty */ stract queue* selection_queue(char*,...); /* queue selection function */ stract queue* collect_queues(char*,...); /* collect queues */ stract queue* copy_queue(stract queue*); /* copy queue to queue */ int queue_size(stract queue*); /* retum queue size */
The generative and taking routines.
void* taking(taking_data*); /* taking function */ void* gen(gen_args*); /* generative function */
Functions such as abs, sqrt, cos, sin, tan, log, mod are the computational functions that
apply some kind of mathematical operation on a sequence and retum a result. Functions
that manipulate or modify sequences or generate new sequences are reverse, transpose,
rotateright, rotateleft, cartesianproduct. Only cartesianproduct and transpose have been
implemented, the rest will be added as needed.
sequence* cartesian(sequence*); /* Cartesian product function */ sequence* transpose(sequence*); /* transpose function */
This routine reads in sequences from input files.
sequence* getjnput(char*); /* get sequence from file */
These are miscellaneous rantime routines that support the routines listed above.
int** create_2d(int, int); /* create a two dimensional integer array */ void stringcpy(char**, char*); /* copy to a string, expanding original string size */ void stringncpy(char**, char*, int); /* copy n char to a string expanding original */ void stringcat(char**, char*); /* cat a string to a string expanding original */ void stringncat(char**, char*, int); /* cat n char to a string expanding original */
These routines support stack manipulation, which is used by routines that use stacks.
int popJnt(TOP_INT*); /* pop integer off stack */ void pushJnt(int,TOP_INT*); /* push an integer onto stack */ int pull_int(TOP_INT*); /* pop integer from bottom of stack */
189

int isempty_int(TOP_INT); /* is stack empty */
B.6.4 Linking a SequenceL Program
Once a sequenceL program has been compiled it can be linked, assuming the
rantime library file is in the parent directory of the current directory the command to link
the function files is the following command.
cc -I., -o main *.c ../rantimel.c -Ipthread
The result is the SequenceL executable file main.
190

Quicksort IC Statements
1. _beginfunc :: 2. _arg:: 3. next:: 4. null:: 5. _seq :: 6. _seq :: 7. =:: 8. then :: :: 9. _seq :: 10. _seq :: 11. else:: :: 12. _seq :: 13. _seq :: 14. >:: 15. then :: :: 16. _seq :: 17. _M :: 18. _seq :: 19. _M:: 20. _seq :: 21. _M:: 22. _call:: 23. _call:: 24._call:: 25. _caU :: 26. _seq :: 27. _seq :: 28. else :: :: 29. _seq :: 30. _seq :: 31._endif:: 32. _seq :: 33._endif:: 34. _endfunc
s_l n
null null : _to
J l :: _t2
null : _t3 :
_t2 1 :: n
_t5 :: _t6
1 :: s_l
1 :: s_I
I :: s_l great quick less
quick $
_tl3 : _t6
s_l : _tl4 :
_t6 ~. ;;
35. _beginfunc :: 36. _arg:: 37. _arg :: 38. next:: 39. _seq :: 40. gen :: 41. from :: 42. M::
s_l s_2 n 1 ::
_tl5 _tl6
s_2
quick n
: _tO s_l ::
_t2
_t3 _t2
_t4 _t4 :: _t6
_t7 _t7 ::
_t9 _t9 ::
_t l l _t l l ::
_tl2 _t29 :: _t8 _t31 ::
_t32 : _t6
tl4 : _t6 t6
_t2 t2
_t2 less s
n
_tl5 n ::
i i ::
s_l
_tl
_t5
_t8
_tio
_tl2 s_l ::
_t30 s_l ::
_t32 _tio
_1 s_
_tl6
_tl7
_t29
.t31
t30 :: tl3
191

43. _seq :: _tl7 44. <:: _tl8 :: 45. then :: :: _tl9 46. _M:: s_2 47. _seq :: _t20 :: 48. else:: :: _tl9 49. _seq :: null :: 50. _seq :: _t21 ::
s_I :: _tl9
i :: _tl9
_t21 _tl9
51._endif:: :: _tl9 52. _endfunc :: :: _tl9 53. _beginfunc:: great s 54. _arg :: s_l 55._arg:: s_2 56. next:: n 57. _seq:: 1 :: 58. gen :: _t22 59. from :: _t23 60. _M:: s_2 61._seq:: _t24 62. >:: _t25 :: 63. then:: :: _t26 64. _M:: s_2 65. _seq:: _t27 :: 66. else :: :: _t26 67. _seq :: nufl :: 68. _seq :: _t28 ::
n
_t22 n ::
i i " s_l ::
_t26
i " _t26
_t28 _t26
69._endif:: :: _t26 70. _endfunc :: :: 71. _call :: quick
_t26 s_l
_tl8
_t20
_1
_t23
_t24 _t25
_t27
s 2
The code generated for quicksort consists of 8 functions and are listed below.
/* main.c */ #include <stdio.h> #include <pthread.h> #include <math.h> #include <semaphore.h> #include <rantimel.h>
int main(){
192

#include "main.h'
s_l=getjnput("s_l"); result=quick(s_l); result=remove_nulls(result); printf("result = %s\n",result->string);
1. /* quick.c*/ 2. #include <stdio.h> 3. #include <pthread.h> 4. #include <math.h> 5. #include <semaphore.h> 6. #include <rantimel.h>
7. sequence *quick(sequence *s_l) 8. { 9. #include "quick.h" 10. n=Msizeof(s_l,l,l); 11. _tO=sequence_atos("[ ]"); 12. _tl=collect_sequences("ss",_tO,s_l); 13.if(convert_logic(condition(EQUAL,_tl))) 14. { 15. _t3=sequence_atos("[ ]"); 16. _t2=_t3; 17.} 18. else{ 19. _t4=sequence_atos("[l]"); 20. _t5=collect_sequences("ss",n,_t4); 21. if (con vertJogic(condition(GREATER,_t5))) 22. { 23. _t7=sequence_atos("[l]"); 24. _t8=selection_seq("ss",s_l,_t7); 25. _t9=sequence_atos("[l]"); 26. _tlO=selection_seq("ss",s_l,_t9); 27. _tll=sequence_atos("[l]"); 28. _tl2=selection_seq("ss",s_l,_tll); 29.
_t30args=(_t30call_stract*)malloc(sizeof(_t30call_stmct)); 30. _t30args->_tl2=_tl2; 31. _t30args->s_l=s_l; 32. pthread_create(thr_t30, NULL, (void *)_t30agg,
(void*)_t30args);
193

P,- -t32args=(_t32call_stract*)malloc(sizeof(_t32call_stract)); 34. _t32args->_t8=_t8; 35. _t32args->s_l=s_l; 3^- pthread_create(thr_t32, NULL, (void *)_t32agg
(void*)_t32args); 37. pthreadJoin(*thr_t30,NULL); 38. pthreadJoin(*thr_t32,NULL); 39. _t32=_t32args->result; 40. _t30=_t30args->result; " 1 • -tl3=collect_sequences("$ss$s",NULL,_t32,_tlO,NULL,_t30); 42. _t6=_tl3; 43. } 44. else{ 45. _t 14=sequence_atos(s_ 1 ->string); 46. _t6=_tl4; 47. } 48. _t2=_t6; 49. } 50. retum _t2; 51.}
1. /* less.c */ 2. #include <stdio.h> 3. #include <pthread.h> 4. #include <math.h> 5. #include <semaphore.h> 6. #include <rantimel.h>
7. sequence *less(sequence *s_l,sequence *s_2) 8. { 9. #include "less.h" 10. n=Msizeof(s_2,l,l); 11. _tl5=sequence_atos("[l]"); 12. _tl6gen.start=_tl5; 13. _tl6gen.end=n; 14. gen_thr_t 16=(pthread_t*)malloc(sizeof(pthread_t)); 15. pthread_create(gen_thr_tl6, NULL, (void *)gen, (void*)&_tl6gen); 16. pthreadJoin(*gen_thr_tl6,NULL); 17. _tl6=_tl6gen.seq; 18. i=(taking_data*)malloc(sizeof(taking_data)); 19. i->from=_tl6; 20. i->vai^l; 21. i->num_yar=l; 22. take_thri=(pthread_t*)malIoc(sizeof(pthread_t));
194

23. pthread_create(take_thri, NULL, (void *)taking, (void*)i); 24. pthreadJoin(*take_thri,NUUL); 25._tl7=selection_queue("sq",s_2,i->result); 26. _tl8=collect_queues("qs",_tl7,s_l); 27. i_element=i->result->head; 28. _tl9queue=(stract queue*)malloc(sizeof(stmct queue)); 29. _tl9queue->head=NULL; 30. _tl9queue->tail=NULL; 31. _tl8_element=_tl8->head; 32. size=queue_size(_tl8); 33. thr_id=(pthread_t*)malloc(sizeof(pthread_t)*size); 34. while(_tl8_element != NULL){ 35. _tl9args=(cond_arguments*)malloc(sizeof(cond_arguments)); 36. _tl9args->s_2=s_2; 37. _tl9args->n=n; 38. _tl9args->s_l=s_l; 39. _tl9args->result=(sequence*)malloc(sizeof(sequence)); 40. push_queue(_t 19args->result,_t 19queue); 41. _tl9args->parameter=_tl8_element->p; 42. _tl9args->i=i_element->p; 43. i_element=i_element->next; 44. pthread_create(&thrjd[_tl9_thread], NULL, (void *)_tl9cond, (void*)_tl9args); 45. _t 18_element=_t 18_element->next; 46. _tI9_thread++; 47.} 48. while(_tl9_thread-) 49. pthreadJoin(thr_id[_tl9_thread],NULL); 50. _t 19=queue_reduc("q",_t 19queue); 51. retum _tl9; 52.}
1. /*great.c*/ 2. #include <stdio.h> 3. #include <pthread.h> 4. #include <math.h> 5. #include <semaphore.h> 6. #include <rantimel.h>
7. sequence *great(sequence *s_l,sequence *s_2)
8. { 9. #include "great.h" 10. n=Msizeof(s_2,l,l); 11. _t22=sequence_atos("[l]"); 12. _t23gen.start=_t22;
195

13. _t23gen.end=n;
14.gen_thr_t23=(pthread_t*)malloc(sizeof(pthread_t)); 15. pthread_create(gen_thr_t23, NULL, (void *)gen, (yoid*)&_t23gen); 16. pthreadJoin(*gen_thr_t23,NULL); 17. _t23=_t23gen.seq; 18. i=(taking_data*)malloc(sizeof(taking_data)); 19. i->from=_t23; 20. i->va:^l; 21. i->num_var=l; 22. take_thri=(pthread_t*)malloc(sizeof(pthread_t)); 23. pthread_create(take_thri, NULL, (void *)taking, (void*)i); 24. pthreadJoin(*take_thri,NULL); 25._t24=selection_queue("sq",s_2,i->result); 26. _t25=collect_queues("qs",_t24,s_l); 27. i_element=i->result->head; 28. _t26queue=(stmct queue*)malloc(sizeof(stract queue)); 29. _t26queue->head=NULL; 30. _t26queue->tail=NULL; 31. _t25_element=_t25->head; 32. size=queue_size(_t25); 33. thrJd=(pthread_t*)malloc(sizeof(pthread_t)*size); 34. while(_t25_element !=NULL){ 35._t26args=(cond_arguments*)malloc(sizeof(cond_arguments)); 36. _t26args->s_2=s_2; 37. _t26args->n=n; 38. _t26args->s_I=s_l; 39. _t26args->result=(sequence*)malloc(sizeof(sequence)); 40. push_queue(_t26args->result,_t26queue); 41. _t26args->parameter=_t25_element->p; 42. _t26args->i=i_element->p; 43. i_element=i_element->next; 44. pthread_create(&thr_id[_t26_thread], NULL, (void *)_t26cond, (void*)_t26args); 45. _t25_element=_t25_element->next; 46. _t26_thread++; 47.} 48. while(_t26_thread-) 49. pthreadJoin(thrJd[_t26_thread],NULL); 50. _t26=queue_reduc("q",_t26queue); 51. retum _t26; 52.}
1. /* _tl9cond.c */ 2. #include <stdio.h> 3. #include <pthread.h>
196

4. #include <math.h> 5. #include <semaphore.h> 6. #include<rantimel.h>
7. void* _tI9cond(void *arg) 8. { 9. #include "_tl9cond.h"
10. _tl9args=(cond_arguments*)arg; 11. i=_tl9args->i; 12. s_2=_tl9args->s_2; 13. n=_tl9args->n; 14. s_l=_tl9args->s_l; 15. if(convert_logic(condition(LESS,_tl9args->parameter))) 16. { 17. _t20=selection_seq("ss",s_2,i); 18. copy_seq(_tl9args->result,_t20); 19.} 20. else{ 21. _ t21=sequence_atos("[ ]"); 22. copy_seq(_tl9args->result,_t21); 23. } 24.}
1. /* _t26cond.c */ 2. #include <stdio.h> 3. #include <pthread.h> 4. #include <math.h> 5. #include <semaphore.h> 6. #include <rantime 1 .h>
7. void* _t26cond(yoid *arg) 8. { 9. #include "_t26cond.h"
10. _t26args=(cond_arguments*)arg; ll.i=_t26args->i; 12. s_2=_t26args->s_2; 13. n=_t26args->n; 14. s_l=_t26args->s_l; 15.if(convertJogic(condition(GREATER,_t26args->parameter)))
16. { 17. _t27=selection_seq("ss",s_2,i); 18. copy_seq(_t26args->result,_t27);
197

19.} 20. else{
21. _t28=sequence_atos("[ ]"); 22. copy_seq(_t26args->result, t28); 23. } 24.}
1. /* _t30agg.c */ 2. #include <stdio.h> 3. #include <pthread.h> 4. #include <math.h> 5. #include <semaphore.h> 6. #include<rantimel.h>
7. void* _t30agg(void *arg) 8. { 9. #include "_t30agg.h"
10. _t30args=(_t30call_stract*)arg; Il._tl2=_t30args->_tl2; 12. s_l=_t30args->s_l; 13. _t29=great(_tl2,s_l); 14. _t30=quick(_t29); 15. _t30args->result=_t30; 16.}
1. /* _t32agg.c */ 2. #include <stdio.h> 3. #include <pthread.h> 4. #include <math.h> 5. #include <semaphore.h> 6. #include <rantimel.h>
7. void* _t32agg(void *arg) 8. { 9. #include "_t32agg.h"
10. _t32args=(_t32call_stract*)arg; Il._t8=_t32args->_t8; 12. s_l=_t32args->s_l; 13._t31=less(_t8,s_l); 14._t32=quick(_t31); 15. _t32args->result=_t32;
198

16.}
199





























