Embed Size (px)
Citation preview

A
Real-Time Anomaly Detection Framework for Many-Core Routerthrough Machine Learning Techniques
Amey Kulkarni, University of Maryland Baltimore CountyYoungok Pino, University of Southern California, Information Sciences InstituteMatthew French, University of Southern California, Information Sciences InstituteTinoosh Mohsenin, University of Maryland Baltimore County
In this paper, we propose a real-time anomaly detection framework for an NoC-based many-core architec-ture. We assume that, processing cores and memories are safe and anomaly is included through communica-tion medium i.e router. The paper targets three different attacks namely traffic diversion, route looping andcore address spoofing attacks. The attacks are detected by using Machine Learning techniques. Comprehen-sive analysis on machine learning algorithms suggests that, Support Vector Machine (SVM) and K-NearestNeighbor (K-NN) have better attack detection efficiency. It has been observed that both algorithms haveaccuracy in the range of 94% to 97%. Additional hardware complexity analysis advocates SVM to be im-plemented on hardware. To test the framework, we implement condition-based attack insertion module,attacks are performed intra and inter-cluster. The proposed real-time anomaly detection framework is fullyplaced and routed on Xilinx Virtex-7 FPGA. Post place and route implementation results show that SVMhas 12% to 2% area overhead and 3% to 1% power overhead for the Quad-core and Sixteen-core implemen-tation, respectively. It is also observed that it takes 25% to 18% of the total execution time to detect anomalyin transferred packet for Quad-core and Sixteen-core, respectively. The proposed framework achieves 65%reduction in area overhead and is 3 times faster compared to previous published work.
Categories and Subject Descriptors: C.2.0 [Computer-Communication Networks]: Security and protec-tion
General Terms: Design, Algorithms, Performance
Additional Key Words and Phrases: Hardware Security; Anomaly Detection; Many-Core; NoC; MachineLearning
ACM Reference Format:Amey Kulkarni, Youngok Pino, Matthew French, and Tinoosh Mohsenin, 2015. Real-Time Anomaly De-tection Framework for Many-Core Router through Machine Learning Techniques. ACM J. Emerg. Technol.Comput. Syst. V, N, Article A (January YYYY), 23 pages.DOI:http://dx.doi.org/10.1145/0000000.0000000
Author’s addresses(Current address):A. Kulkarni and T. Mohsenin are with Computer Science and Electrical Engineering Department, Universityof Maryland, Baltimore County, Baltimore, MD 21250 USA (e-mail:[email protected];[email protected]).Y. Pino and M. French are with University of Southern California, Information Sciences Institute, Arling-ton, VA 22203 USA (e-mail:[email protected]; [email protected]).Permission to make digital or hard copies of all or part of this work for personal or classroom use is grantedwithout fee provided that copies are not made or distributed for profit or commercial advantage and thatcopies bear this notice and the full citation on the first page. Copyrights for components of this work ownedby others than ACM must be honored. Abstracting with credit is permitted. To copy otherwise, or republish,to post on servers or to redistribute to lists, requires prior specific permission and/or a fee. Request per-missions from [email protected]. Copyright 2015 1550-4832/2015/MonthOfPublication - ArticleNumber$15.00Permission to make digital or hard copies of part or all of this work for personal or classroom use is grantedwithout fee provided that copies are not made or distributed for profit or commercial advantage and thatcopies show this notice on the first page or initial screen of a display along with the full citation. Copyrightsfor components of this work owned by others than ACM must be honored. Abstracting with credit is per-mitted. To copy otherwise, to republish, to post on servers, to redistribute to lists, or to use any componentof this work in other works requires prior specific permission and/or a fee. Permissions may be requestedfrom Publications Dept., ACM, Inc., 2 Penn Plaza, Suite 701, New York, NY 10121-0701 USA, fax +1 (212)869-0481, or [email protected]© YYYY ACM 1550-4832/YYYY/01-ARTA $15.00DOI:http://dx.doi.org/10.1145/0000000.0000000
ACM Journal on Emerging Technologies in Computing Systems, Vol. V, No. N, Article A, Pub. date: January YYYY.

A:2 A.Kulkarni et al.
1. INTRODUCTIONIn last decade, there has been a significant research on hardware security. The systemcan be secured by two means i.e. software and hardware. Software security layer suchas anti-virus scanners, can be easily bypassed by hardware anomaly [Karri et al. 2010]whereas detecting an anomaly in hardware is very complex considering increasingtransistor count and system complexity. Furthermore in a given system, hardwareis more vulnerable to the attacks and gives more flexibility to the attacker. Increasein attacker’s skills and resources, hardware oriented attacks concern researchers tobuild robust hardware against new security threats [Potlapally 2011]. To fix hardwareanomalies before production, many researchers have proposed Security DevelopmentLife-cycle (SDL) [Khattri et al. 2012], [Potlapally 2011], but with increasing productcomplexity, it is extremely difficult to detect all the hardware vulnerabilities usingSDL.
The anomaly inclusion can be classified based on five important aspects: Phase inIC design life cycle effected, Hardware abstraction level effected, trojan activationscheme, effect on performance and physical location of trojan inclusion [Rajendranet al. 2010]. Whereas trojan detection can be performed at either test-time, or run-time. In this work, we assume that anomaly is inserted at design or fabrication phaseby untrusted third party. Therefore, the attack insertion hardware cannot get modified.The attack insertion module is very small circuit that does not change functionality orarea or power characteristics of the design. Also, the attack insertion module activatesan attack only if certain conditions are met. Most of the researchers consider detectionof trojan at test-time, however trojans that are activated based on a particular eventcan bypass the test-time trojan detection phase. Run-time trojan detection considersescaped trojans at test-time. Therefore, run-time hardware trojan detection is veryimportant.
Unfortunately hardware trojan activation is a very rare event and their size is rel-atively small compared to the original design. Therefore trojan detection is very chal-lenging. The goal of this paper is to detect attacks by using an effective method suchthat it has minimal hardware overhead and implementation complexity with a veryhigh accuracy of detection.
We propose a real-time anomaly detection framework and test for a custom many-core router architecture as a case study that considers different features to detectmalicious inclusions while transferring packet from one core to the other. To our bestknowledge, this is the first time that an implementation of security in hardware isapproached using Machine Learning algorithm, particularly SVM method for anomalydetection in core to core communication. This technique can be utilized as additionalsecurity along with the secured procedure. The main contributions to the researchinclude:
— A novel real-time hardware trojan detection based on Machine Leaning techniques.— Feature Data set generation based on hardware behavior and feature optimization
based on correlation analysis and hardware implementation feasibility.— Anomaly detection analysis on most of the commonly used Supervised and Un-
Supervised machine learning algorithms.— Best Machine learning algorithm selection based on anomaly detection accuracy and
hardware complexity analysis.— Efficient hardware implementation of SVM algorithm and its integration with cus-
tom many-core router architecture that can target both FPGA and ASIC.— Fully placed and routed implementation of the proposed framework on Xilinx Virtex-
7 FPGA
ACM Journal on Emerging Technologies in Computing Systems, Vol. V, No. N, Article A, Pub. date: January YYYY.

A:3
— Test our proposed real-time security framework for trojan detection by emulatingreal traffic loads on the many-core hardware while randomly injecting anomaly onthe routers.
The rest of the paper is organized as follows: Section 2 presents a survey of relatedwork. Commonly used Supervised learning algorithms and their complexity analysisare discussed in Section 3. Section 4 describes our proposed architecture includingthe many-core router design, Machine Learning algorithm selection and attack sce-narios. Finally, Section 5 explains the proposed hardware implementation results onXilinx Virtex-7 FPGA and its evaluation.
2. BACKGROUNDIt has been discussed [Rostami et al. 2014], [Rostami et al. 2013], that trojan detectiontechniques can be classified based on their stage in IC design life cycle: 1. Design-time2. Test-time, and 3. Run-time. Design for Trust (DFT) is a design-time detection tech-nique. In this technique, existing design is modified to facilitate anomaly detection[Salmani et al. 2012], [Shekarian et al. 2013]. Functional tests and side channel anal-ysis are the most popular test-time trojan detection techniques. The trojan activationis a rare event, therefore trojan detection through functional tests is exhaustive andimpractical. Most of the anomaly detection techniques are proposed focusing on sidechannel effect analysis to detect malicious activity [Yier and Makris 2008a], [Zhanget al. 2012], [Hu et al. 2013]. However, side-channel analysis based techniques workwell for small circuits, but not for complex circuits such as Network on Chips (NoC)[Adamov et al. 2009]. The design-time and test-time techniques are performed beforeICs are deployed, but run-time approaches monitor abnormal behavior of circuit oper-ation to detect Trojans in post-deployment.
Firewall architecture is built to secure NoC architecture at run-time [Fiorin et al.2008]. Memory accesses are handled on the basis of look up table which contains theaccess rights. For protection mechanism, the paper considers data / control packetformat and transactions between initiator and target. The Data Protection Unit (DPU)is implemented by look up table, while the protocol conversion and the DPU accessare performed in parallel. Therefore, design has less execution time, but the use ofTernary Content Address Memory increases the area. The paper assumes that all thedata within the same block have same permission rights. Also, it considers memoriesand other IP cores are safe and attack is only through the communication medium.
[Cotret et al. 2012a] proposes bus-based MPSoc security through communicationprotection. The paper aims reduction in latency overhead while protecting externalmemory units. The threat model is covered using timestamps and read/write memoryaccesses. This paper mainly addresses spoofing and relocation attacks. [Fiorin et al.2009] presents, security of NoC architecture by monitoring system behavior at run-time. The paper monitors throughput, time stamps and occurrences of an event. Thispaper targets reduction in area for monitoring hazards / malicious events. The monitor-ing system considered for this paper consists of probe network interfaces and run-timemanager. It has been observed that probes impact monitoring traffic.
An asynchronous security framework based on 4 phase handshake signaling fora GALS NoC design is proposed in [M. Mirza-Aghatabar 2014]. Advantage of asyn-chronous circuits is taken to reduce hardware overhead. Though asynchronous circuitsprovide various advantages such as eliminating clock skew, quick adaption to new tech-nologies and reduce dynamic power overhead, they are complex in design and henceit increases area over head. The framework secures NoCs, through packet deadlockattacks recovery.
ACM Journal on Emerging Technologies in Computing Systems, Vol. V, No. N, Article A, Pub. date: January YYYY.
A:4 A.Kulkarni et al.
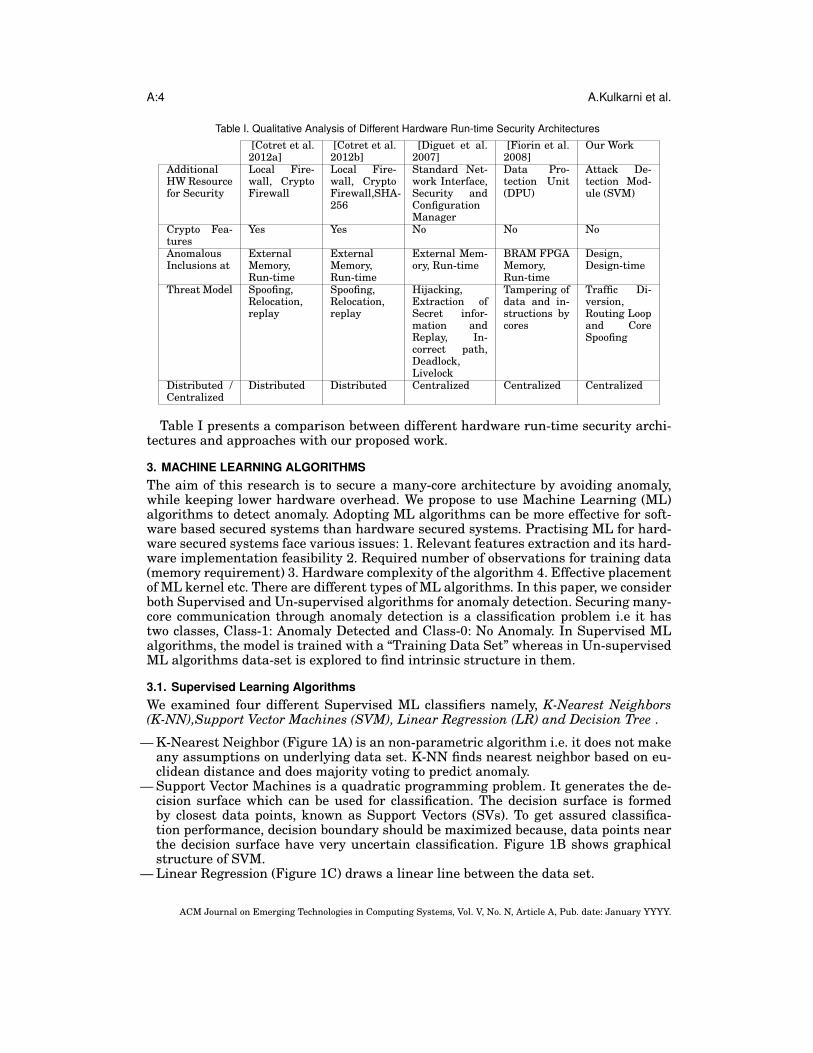
Table I. Qualitative Analysis of Different Hardware Run-time Security Architectures
[Cotret et al.2012a]
[Cotret et al.2012b]
[Diguet et al.2007]
[Fiorin et al.2008]
Our Work
AdditionalHW Resourcefor Security
Local Fire-wall, CryptoFirewall
Local Fire-wall, CryptoFirewall,SHA-256
Standard Net-work Interface,Security andConfigurationManager
Data Pro-tection Unit(DPU)
Attack De-tection Mod-ule (SVM)
Crypto Fea-tures
Yes Yes No No No
AnomalousInclusions at
ExternalMemory,Run-time
ExternalMemory,Run-time
External Mem-ory, Run-time
BRAM FPGAMemory,Run-time
Design,Design-time
Threat Model Spoofing,Relocation,replay
Spoofing,Relocation,replay
Hijacking,Extraction ofSecret infor-mation andReplay, In-correct path,Deadlock,Livelock
Tampering ofdata and in-structions bycores
Traffic Di-version,Routing Loopand CoreSpoofing
Distributed /Centralized
Distributed Distributed Centralized Centralized Centralized
Table I presents a comparison between different hardware run-time security archi-tectures and approaches with our proposed work.
3. MACHINE LEARNING ALGORITHMSThe aim of this research is to secure a many-core architecture by avoiding anomaly,while keeping lower hardware overhead. We propose to use Machine Learning (ML)algorithms to detect anomaly. Adopting ML algorithms can be more effective for soft-ware based secured systems than hardware secured systems. Practising ML for hard-ware secured systems face various issues: 1. Relevant features extraction and its hard-ware implementation feasibility 2. Required number of observations for training data(memory requirement) 3. Hardware complexity of the algorithm 4. Effective placementof ML kernel etc. There are different types of ML algorithms. In this paper, we considerboth Supervised and Un-supervised algorithms for anomaly detection. Securing many-core communication through anomaly detection is a classification problem i.e it hastwo classes, Class-1: Anomaly Detected and Class-0: No Anomaly. In Supervised MLalgorithms, the model is trained with a “Training Data Set” whereas in Un-supervisedML algorithms data-set is explored to find intrinsic structure in them.
3.1. Supervised Learning AlgorithmsWe examined four different Supervised ML classifiers namely, K-Nearest Neighbors(K-NN),Support Vector Machines (SVM), Linear Regression (LR) and Decision Tree .
— K-Nearest Neighbor (Figure 1A) is an non-parametric algorithm i.e. it does not makeany assumptions on underlying data set. K-NN finds nearest neighbor based on eu-clidean distance and does majority voting to predict anomaly.
— Support Vector Machines is a quadratic programming problem. It generates the de-cision surface which can be used for classification. The decision surface is formedby closest data points, known as Support Vectors (SVs). To get assured classifica-tion performance, decision boundary should be maximized because, data points nearthe decision surface have very uncertain classification. Figure 1B shows graphicalstructure of SVM.
— Linear Regression (Figure 1C) draws a linear line between the data set.
ACM Journal on Emerging Technologies in Computing Systems, Vol. V, No. N, Article A, Pub. date: January YYYY.

A:5
Fig. 1. Basic Supervised ML Algorithms (A) K-Nearest Neighbor (B) Support Vector Machine (C) LinearRegression (D) Decision Tree
— Decision Tree (Figure 1D) classifier constructs a tree based on features from the traindata set.
Accuracy analysis of Supervised algorithms is briefly discussed in section 4.4.1whereas their hardware complexity is discussed in section 4.4.3.
3.2. Un-Supervised Learning AlgorithmsTraining of Supervised learning techniques is more complex than evaluating predic-tions based on weight vector/trained model. Un-supervised learning does not requiretraining, hence most of the Un-supervised learning algorithms have less complexity.In this paper, we perform analysis of four Un-supervised machine learning algorithmsnamely Simple K-means, Farthest first, Estimation Maximization and Hierarchicalclustering. These algorithms are based on clustering. As name suggests, clustering al-gorithms group together similar observations in a cluster. Simple K-means algorithmrandomly chooses K cluster centers. Cluster is formed by finding nearest distance be-tween the features. Simple K-means algorithm has less time-complexity, but choiceof randomly chosen initial points have large influence on anomaly detection (predic-tions). In Farthest First algorithm, the first cluster center is picked randomly whereasother cluster centers are chosen furthest from each other. Estimation maximizationis an iterative algorithm, which finds maximum likelihood estimates of parameters.However, in hierarchical clustering algorithm, hierarchy is built in a greedy manner.Though Un-supervised learning algorithms are less complex, in section 4.4.2 we willshow that they are inefficient for hardware anomaly detection in terms of time com-plexity and accuracy.
4. PROPOSED WORKIn this paper, we propose a run-time anomaly detection technique for a custom many-core by using machine learning techniques. The proposed architecture is applicationand network independent and we use the many-core router as a case study. We assumethat IP cores, processing cores and memories are secured, similar to [Fiorin et al.2008]. Therefore, the many-core is attacked only through communication network.
4.1. Many-Core Router and Packet GenerationA custom many-core router is designed as a 4-ary tree architecture (with hierarchicalrouter), as shown in Figure 2. Each router hop forms cluster of four cores and has fiveports. Each port communicates with processing cores except, the fifth port that com-municates with the upper level router. Figure 3 shows the router architecture consists
ACM Journal on Emerging Technologies in Computing Systems, Vol. V, No. N, Article A, Pub. date: January YYYY.
A:6 A.Kulkarni et al.
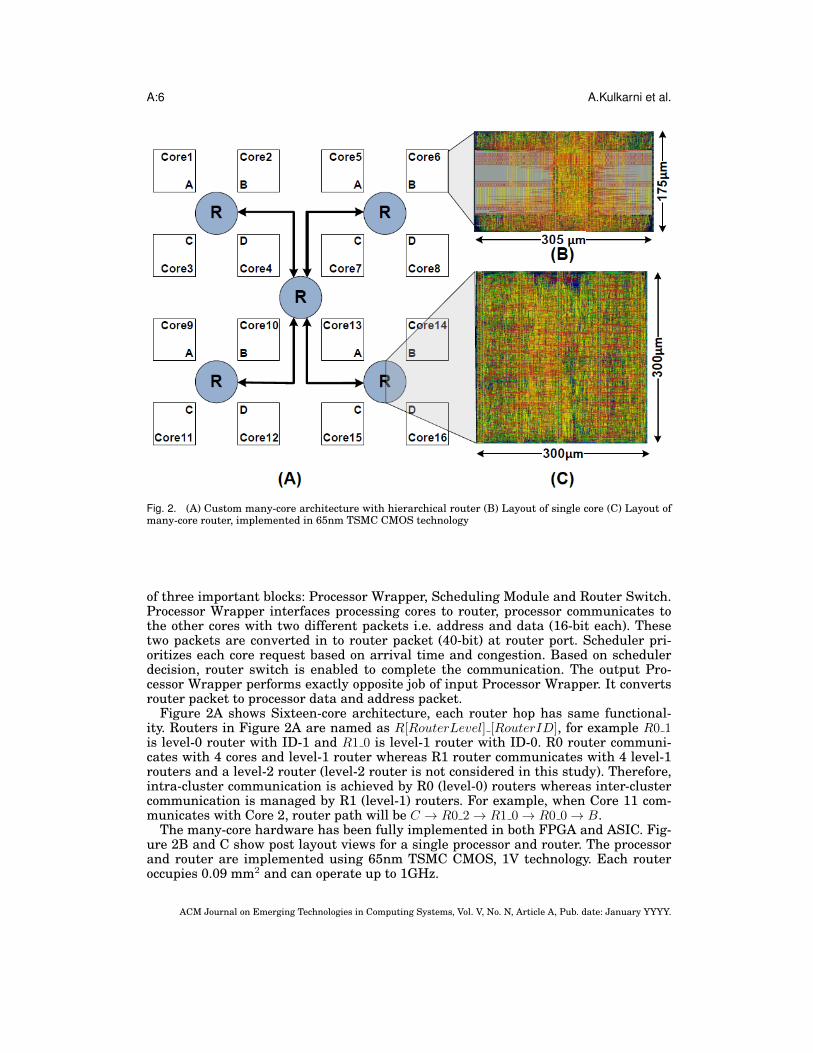
Fig. 2. (A) Custom many-core architecture with hierarchical router (B) Layout of single core (C) Layout ofmany-core router, implemented in 65nm TSMC CMOS technology
of three important blocks: Processor Wrapper, Scheduling Module and Router Switch.Processor Wrapper interfaces processing cores to router, processor communicates tothe other cores with two different packets i.e. address and data (16-bit each). Thesetwo packets are converted in to router packet (40-bit) at router port. Scheduler pri-oritizes each core request based on arrival time and congestion. Based on schedulerdecision, router switch is enabled to complete the communication. The output Pro-cessor Wrapper performs exactly opposite job of input Processor Wrapper. It convertsrouter packet to processor data and address packet.
Figure 2A shows Sixteen-core architecture, each router hop has same functional-ity. Routers in Figure 2A are named as R[RouterLevel] [RouterID], for example R0 1is level-0 router with ID-1 and R1 0 is level-1 router with ID-0. R0 router communi-cates with 4 cores and level-1 router whereas R1 router communicates with 4 level-1routers and a level-2 router (level-2 router is not considered in this study). Therefore,intra-cluster communication is achieved by R0 (level-0) routers whereas inter-clustercommunication is managed by R1 (level-1) routers. For example, when Core 11 com-municates with Core 2, router path will be C → R0 2→ R1 0→ R0 0→ B.
The many-core hardware has been fully implemented in both FPGA and ASIC. Fig-ure 2B and C show post layout views for a single processor and router. The processorand router are implemented using 65nm TSMC CMOS, 1V technology. Each routeroccupies 0.09 mm2 and can operate up to 1GHz.
ACM Journal on Emerging Technologies in Computing Systems, Vol. V, No. N, Article A, Pub. date: January YYYY.

A:7
Processor WrapperProcessor Wrapper
R1_0
Core1
A
Core2
B
C
Core3
D
Core4
R0_0
Core5
A
Core6
B
C
Core7
D
Core8
R0_1
Core9
A
Core10
B
C
Core11
D
Core12
R0_2
Core13
A
Core14
B
C
Core15
D
Core16
R0_3
305 µm
17
5µm
30
0µm
300µm
Router
Switch
Scheduling
ModuleRequests
Router
I/P Port
1
Router
I/P Port
2
Router
I/P Port
3
Router
I/P Port
4
Processor
2
Interface
Processor
3
Interface
Processor
0
Interface
Proc RequestFIFO EmptyRouter ACK
Processor
1
Interface
Proc RequestFIFO EmptyRouter ACK
Proc RequestFIFO EmptyRouter ACK
Router
O/P Port
1
Router
O/P Port
2
Router
O/P Port
3
Router
O/P Port
4
Proc RequestFIFO EmptyRouter ACK
Proc RequestFIFO EmptyRouter ACK
Processor
0
Interface
Proc RequestFIFO EmptyRouter ACK
Processor
1
Interface
Proc RequestFIFO EmptyRouter ACK
Processor
2
Interface
Proc RequestFIFO EmptyRouter ACK
Processor
3
Interface
DATA ADDR
DATA ADDR
DATA ADDR
DATA ADDR
DATA ADDR
DATA ADDR
DATA ADDR
DATA ADDR
Router Packet
Router Packet
Router Packet
Router Packet
Router Packet
Router Packet
Router Packet
Router Packet
Router
O/P Port
0
Router
I/P Port
0
Router Packet Router Packet
(A)
(B)
(C)
Fig. 3. Quad-Core Router Architecture
4.2. Attack ScenarioIn this paper, we first review the anomaly based on five features proposed in [Rajen-dran et al. 2010], to understand anomaly characteristics and implement efficient detec-tion technique. The paper implements different attack scenarios for testing anomalydetection of the custom many-core router. The trojan is implemented at Design-phaseand activated internally. There are two different ways trojans can be activated inter-nally: Always-on and Condition-based. As the name suggests, always-on trojans arealways active and can include malicious activity at any-time whereas condition-basedtrojans are activated under specific conditions. In this paper, condition-based trojan ac-tivation is implemented on internal logic state after particular number of core-to-coretransfers or clock cycles.
Attacks on many-core router can affect network packet transfer rate, net-work/processing core availability and interruption in core communication [Gebaliet al. 2009]. The router (communication network) can be attacked externally, throughmemory architecture interface, specialized core interface or internally by corruptingrouting table to include Traffic diversions, Routing loops, Core spoofing attacks. Allthree attacks are also called as Denial-of-Service (DoS) attack, where in a specific coreunder attack is made unavailable.
— Traffic Diversion Attack : It is a very common attack in many-core router architec-ture. Under this attack, the router selects a random core to transfer the data. Thisattack affects the deadline for the other cores, which are dependent on the attackedtransfer packet. For example, when traffic diversion attack is triggered and core 11is transferring to core 2, it alters the path to C → R0 2→ R1 0→ R0 1→ B (Figure5). Therefore, router transfers data to core 6 instead of transferring it to core 2.
— Routing loop attack: Under this attack, the packets are routed back to the sendingcore. The Sending core is made unavailable to other communicating cores, therebycausing latency in other core transfers. Figure 6 shows that when routing loop attackis triggered and core 11 is transferring data to core 2, router path is modified toC → R0 2 → R1 0 → R0 2 → C i.e data packets are transferred back to sourcedestination.
ACM Journal on Emerging Technologies in Computing Systems, Vol. V, No. N, Article A, Pub. date: January YYYY.

A:8 A.Kulkarni et al.
— Core Spoofing Attack: This attack transfers all packets to randomly chosen (address)destination. The attack saturates the core, and makes it unavailable for other cores.
The attacker changes a single bit at the router hop (any level) to change the destina-tion core address. Moreover, attacker can also do physical attacks by varying externalenvironmental conditions such as clock frequency and voltage supply etc. To securerouter from above mentioned attacks, we use different features. The feature valuesare formulated based on hardware functionality to form an observation. The super-vised model is trained based on these observations to detect an attack in real-time.
4.3. Feature Extraction and OptimizationCollecting relevant data based on hardware behavior analysis is the first and mostimportant step in this research. Based on hardware behavior analysis, we initiallyconsider following features for trojan detection and then optimize the number of fea-tures:
— Source Core : Source Core Number— Destination Core : Destination Core Number— Packet Transfer Path : Packet transfer between the two cores has a unique path.
Packet transfer path is altered in case of trojan. In this paper, we experiment on a4×4 NoC i.e Sixteen-core router architecture, with two level router hop and thereforehighest number of hops to be traveled by packet can be 3 for inter-cluster communi-cation.
— Distance : At each router hop, distance vector is incremented by 1. For example, whencore 11 is transferring packet to core 2, distance vector is incremented at R0 2 (Dis-tance=1), R1 0 (Distance=2), R0 0 (Distance=3). Since there will be four vertices (3router hops and 1 processing core) and three edges, highest distance is 4.
— Dynamic Power Range : This feature will show local (intra-cluster) and global (inter-cluster) dynamic power range to predict an attack. In case of route looping attacklocal dynamic power will be higher as compared to global.
— Execution Time Range : The many-core router runs at 1GHz (known variable), intra-cluster communication takes 8 cycles whereas inter-cluster communication needs 32cycles to complete the packet transfer. Considering different traffic patterns, we de-fine a packet transfer time range between two cores. This feature is used to keeptrack of allowed execution time for the packet to reach the destination from sourcebased on the distance.
— Clock Frequency : This feature defines the maximum clock frequency at which many-core is running. This feature is used to avoid Physical (Fault Induction) attack.
— Supply Voltage : This feature defines the least supply voltage required to run many-core. This feature is used to reduce Physical (Fault Induction) attack. 1
Table II gives an example of expected test packets received from router in case ofanomaly (Class “0”) and without anomaly (Class “1”) when packet is transferred fromcore 11 to core 2. Observation 3 shows routing loop attack whereas observation 4 and 5show core spoofing attack. In a good ML data-set, each feature must contribute to theclass i.e better correlation between feature and the class, but not among the features.Therefore, for feature extraction we first do feature correlation analysis for relevantattribute selection. Relevant attribute selection will aid both increasing accuracy oftrojan detection and hardware implementation. Removing irrelevant features will re-duce data-set thereby decreasing resource utilization and memory usage. Processingof feature and reduction in memory transfers will reduce overall latency of operations.
1Physical attacks are performed when attacker has access to the hardware.
ACM Journal on Emerging Technologies in Computing Systems, Vol. V, No. N, Article A, Pub. date: January YYYY.

A:9
Fig. 4. Feature Extraction: Correlation between Features and Corresponding to the Class
Table II. Example Observations from “Golden Data Set” for Real-time Anomaly Detection
Features Source Dest. Route Route Route Route Route Distance Class Attack/Obs Core Core 0 1 2 3 4 Type
1 11 2 C R0 2 R1 0 R0 0 B 4 Secured -2 11 2 C R0 2 R1 0 R0 1 B 4 Anomaly Traffic
Diversion3 11 2 C R0 2 0 0 C 2 Anomaly Route
Looping4 11 2 C R0 2 R1 0 R0 3 D 4 Anomaly Core
AddressSpoofing
5 11 2 C R0 2 0 0 A 2 Anomaly CoreAddressSpoofing
Figure 4 shows the correlation between various features of the feature set. It can beobserved that distance feature is highly correlated with dynamic power and executiontime required for the packet transfer between the cores. Also, calculation of dynamicpower consumption in real-time is complex. Therefore, dynamic power and executiontime features are not considered. Instead we use Source Core, Destination Core, PacketTransfer Path and Distance features only for hardware implementation and accuracyanalysis in this paper.
4.4. Algorithm SelectionWe examine commonly used Supervised and Un-supervised ML algorithms for thesecured many-core analysis. Matlab statistics toolbox is used for implementation andaccuracy analysis. The training data set consists of 216 different observations with 8attributes and a binary class whereas, test data set consists of 203 observations. Samedata set is used for accuracy, recall and precision analysis of different ML algorithms.Accuracy is calculated as number of correctly labelled observations in total labelledobservations.
For machine learning algorithms, accuracy is not the only measure to comment onefficiency of an algorithm. Some observations may be frequently misclassified without
ACM Journal on Emerging Technologies in Computing Systems, Vol. V, No. N, Article A, Pub. date: January YYYY.

A:10 A.Kulkarni et al.
A1
Core1
A
Core2
B
C
Core3
D
Core4
1
Core5
A
Core6
B
C
Core7
D
Core8
2
Core9
A
Core10
B
C
Core11
D
Core12
3
Core13
A
Core14
B
C
Core15
D
Core16
4
R1_0
Core1
A
Core2
B
C
Core3
D
Core4
R0_0
Core5
A
Core6
B
C
Core7
D
Core8
R0_1
Core9
A
Core10
B
C
Core11
D
Core12
R0_2
Core13
A
Core14
B
C
Core15
D
Core16
R0_3
Traffic Diversion
Attack
Desired Path- Packet Transfer
from Core 11 to Core 2
Traffic Diversion Attack
Attacked
Router
Routing Loop Attack
R1_0
Core1
A
Core2
B
C
Core3
D
Core4
R0_0
Core5
A
Core6
B
C
Core7
D
Core8
R0_1
Core9
A
Core10
B
C
Core11
D
Core12
R0_2
Core13
A
Core14
B
C
Core15
D
Core16
R0_3
Desired Path- Packet Transfer
from Core 11 to Core 2
Traffic Diversion Attack
Attacked
Router
Fig. 5. Router Behavior whenExposed to Traffic Diver-sion Attack, Original FeatureData= [11,2,C,R0 2,R1 0,R0 0,B,4]After Attack FeatureData= [11,2,C,R0 2,R1 0,R0 1,B,4]
A1
Core1
A
Core2
B
C
Core3
D
Core4
1
Core5
A
Core6
B
C
Core7
D
Core8
2
Core9
A
Core10
B
C
Core11
D
Core12
3
Core13
A
Core14
B
C
Core15
D
Core16
4
R1_0
Core1
A
Core2
B
C
Core3
D
Core4
R0_0
Core5
A
Core6
B
C
Core7
D
Core8
R0_1
Core9
A
Core10
B
C
Core11
D
Core12
R0_2
Core13
A
Core14
B
C
Core15
D
Core16
R0_3
Traffic Diversion
Attack
Desired Path- Packet Transfer
from Core 11 to Core 2
Traffic Diversion Attack
Attacked
Router
Routing Loop Attack
R1_0
Core1
A
Core2
B
C
Core3
D
Core4
R0_0
Core5
A
Core6
B
C
Core7
D
Core8
R0_1
Core9
A
Core10
B
C
Core11
D
Core12
R0_2
Core13
A
Core14
B
C
Core15
D
Core16
R0_3
Desired Path- Packet Transfer
from Core 11 to Core 2
Traffic Diversion Attack
Attacked
Router
Fig. 6. Router Behavior whenExposed to Routing LoopAttack, Original FeatureData= [11,2,C,R0 2,R1 0,R0 0,B,4]After Attack FeatureData= [11,2,C,R0 2,0,0,C,2]
much impact on accuracy. Therefore, we evaluate precision and recall. Precision andrecall are calculated based on true negatives (i.e test observation incorrectly labelledas belonging to the positive class) and false positives (i.e. test observation incorrectlylabelled as belonging to the negative class). These two measures are very importantfor algorithm selection. Precision calculates number of relevant test observations fromretrieved observations whereas Recall calculates number of retrieved test observa-tions from relevant test observations. Precision value of “1” suggests that all relevanttest observations are retrieved from test whereas Recall value of “1” suggests that allretrieved test observations are relevant. We chose ML algorithm based on softwareand hardware-complexity analysis. We perform accuracy, precision and recall analysisof both Supervised and Un-Supervised learning algorithm on software (using matlabtools). Based on software analysis, we calculate hardware complexity of the chosen al-gorithms. Finally the most accurate and less hardware complex algorithm is selected.
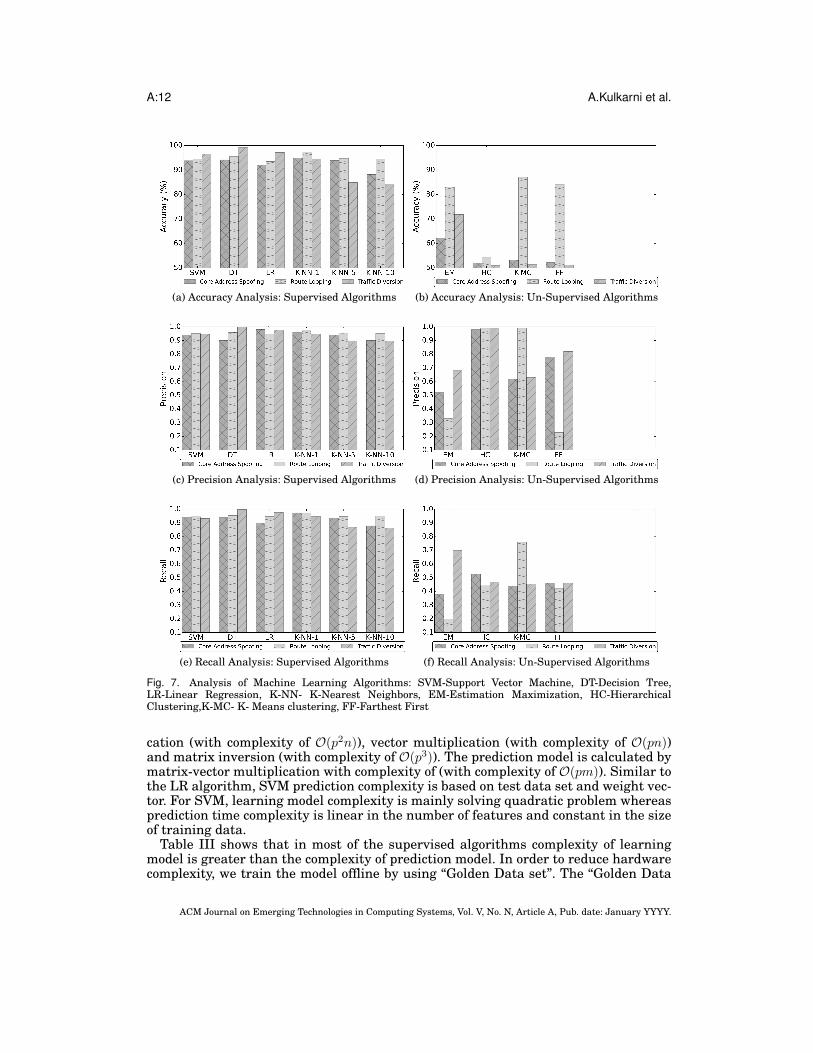
4.4.1. Analysis of Supervised Learning Algorithms. Figure 7 shows accuracy, recall and pre-cision analysis on supervised algorithms. The analysis is performed for each attackseparately. Decision tree has better detection accuracy among all Supervised learningalgorithms for traffic diversion attacks. However, decision tree performs worst for coreaddress spoofing attacks. Linear regression algorithm detects 97% of traffic diversionattacks, but it performs better than only K-NN-10 algorithm for core address spoof-ing attack detection. K-Nearest Neighbor (K-NN) is very flexible algorithm and it hasdata-adaptive approach. Usually different values of k are tried to find the best pre-diction algorithm. For example, in Figure 1A, with three neighbors (inner circle), thetest will be predicted with anomaly label while with eleven neighbors (outer circle) thetest prediction will be non-anomalous label. However, accuracy of Linear Regressionand Support Vector Machines rely on underlying data patterns. As shown in Figure1C, linear regression uses a simple dividing line based on least square function. HenceK-NN can adapt to islands of train data therefore, it gives better accuracy as comparedto Linear Regression. We experimented K-Nearest Neighbor algorithm with differentK (neighbors). It can be observed that K-NN-1 has better performance among all other
ACM Journal on Emerging Technologies in Computing Systems, Vol. V, No. N, Article A, Pub. date: January YYYY.

A:11
K-NN variations. Also, it can be observed that as we increase the k distance detectionaccuracy of core spoofing attack decreases. Decision tree algorithm performs betterthan Linear regression irrespective type of attack. It has been also observed that av-erage accuracy of the Decision Tree algorithm performs better than SVM. One of thereasons behind is that the decision tree recursively partitions training data set onwhich a test is made. Also, Decision Trees does entropy based ordering of features,where entropy is the impurity of training data set.
Though SVM rely on underlying data pattern, it works better than K-NN and LinearRegression. Since it is an optimization problem and weighs support vectors (are train-ing vectors which fall in largest margin formed by hyper-plane) instead of all featuresunlike Linear Regression. Thus SVM usually works better even in case of non-lineartraining data set. Furthermore in SVM accuracy is mainly based on feature selection.The correlation analysis performed in Figure 4 helped us getting better accuracy forSVM. Therefore, SVM performs better than K-NN and Linear Regression algorithms.It can be noticed that SVM has detection accuracy in range of 94% to 97% i.e it per-forms better irrespective of the type of attack. Also, average precision and recall is inrange of 0.9 to 1.0, which is comparatively better than other classifiers. Therefore theanalysis suggests that SVM and K-NN perform better than other algorithms.
4.4.2. Analysis of Un-Supervised Learning Algorithm. As discussed earlier in section 3.2, inSupervised Learning algorithms, training data with class label is provided, whereas inUn-Supervised learning training model is not provided with class label. Un-Supervisedlearning usually does the clustering based on statistical properties of the data only,whereas in Supervised learning algorithm analyzes the labelled training data andproduces inferred function, which is used for mapping new tests. Therefore, in Un-Supervised learning algorithms, accuracy depends on compactness and separation ofclustering. Hence supervised learning algorithms are usually more accurate than un-supervised algorithm. In this study, we consider four different un-supervised learningalgorithm. It has been observed that route looping attack can be efficiently detectedby using estimation maximization, K-means clustering and farthest first algorithms.However, none of the un-supervised algorithms could detect core spoofing attack ef-ficiently. Though Hierarchical clustering algorithm performs worst irrespective of at-tacks, precision is highest for all three attacks.
K-means clustering is the only algorithm, which performs better than K-NN-10. Ac-curacy of detection is in range of 50% to 88% for un-supervised learning. Also, for mostof the algorithms, precision and recall values all in the range of 0 to 0.6 range. There-fore, we consider supervised learning algorithms for hardware implementation.
4.4.3. Hardware Complexity Analysis. In this section, we perform complexity analysis ofSupervised learning algorithms. Classification of a test observation, in Supervised MLalgorithm involves two steps. First kernel is to form a supervised model using trainingdata set, whereas second kernel involves predicting a test observation based on trainedsupervised model.
Assuming n training data, m test data and p features, K-Nearest Neighbor (K-NN)algorithm has complexity O(p) to compute distance to one observation, therefore itneeds O(np) and O(knp) to find k nearest observations. Therefore, K-NN algorithmis very expensive for large training data. However, for Decision Tree classifier (DTC),training model is formed by ID3 or equivalent tree search algorithm. In a simple sce-nario, construction of binary tree isO(np log(n)) and query time isO(log(n)). Therefore,considering n nodes, decision tree’s learning complexity is O(pn2 log(n)) and predictioncomplexity is independent of training data set. For Linear Regression, learning modelgives weight vector formed by training data set whereas prediction complexity is basedon test data set and weight vector. The learning model is formed by matrix multipli-
ACM Journal on Emerging Technologies in Computing Systems, Vol. V, No. N, Article A, Pub. date: January YYYY.
A:12 A.Kulkarni et al.
(a) Accuracy Analysis: Supervised Algorithms (b) Accuracy Analysis: Un-Supervised Algorithms
(c) Precision Analysis: Supervised Algorithms (d) Precision Analysis: Un-Supervised Algorithms
(e) Recall Analysis: Supervised Algorithms (f) Recall Analysis: Un-Supervised Algorithms
Fig. 7. Analysis of Machine Learning Algorithms: SVM-Support Vector Machine, DT-Decision Tree,LR-Linear Regression, K-NN- K-Nearest Neighbors, EM-Estimation Maximization, HC-HierarchicalClustering,K-MC- K- Means clustering, FF-Farthest First
cation (with complexity of O(p2n)), vector multiplication (with complexity of O(pn))and matrix inversion (with complexity of O(p3)). The prediction model is calculated bymatrix-vector multiplication with complexity of (with complexity of O(pm)). Similar tothe LR algorithm, SVM prediction complexity is based on test data set and weight vec-tor. For SVM, learning model complexity is mainly solving quadratic problem whereasprediction time complexity is linear in the number of features and constant in the sizeof training data.
Table III shows that in most of the supervised algorithms complexity of learningmodel is greater than the complexity of prediction model. In order to reduce hardwarecomplexity, we train the model offline by using “Golden Data set”. The “Golden Data
ACM Journal on Emerging Technologies in Computing Systems, Vol. V, No. N, Article A, Pub. date: January YYYY.

A:13
Table III. Time Complexity Analysis of Supervised ML algorithms, Wheren size of training data, m size of test data and p features
Algorithm Complexity of Complexity ofLearning Model Prediction Model
K-NN - O(knp)Decision Tree O(pn2 log(n)) O(m)
Linear Regression O(p2n) O(pm)Support Vector Machine O(pn3) O(pm)
Table IV. Hardware Complexity Analysis of Supervised ML algorithms when Trained off-line, Where n size oftraining data, m size of test data and p features
Algorithm Multiplications Subtractions Additions Comparisons MemoryRequirement
K-NN p× n×m p× n×m (p− 1)× n×m log2n n× pDecision p× n - n× 2p+1 − 1 - p
TreeLinear p2 × n+ p3/3 - p2(n− 1) - n× p
Regression −p2/2 + p/6 +(p3/3− p/3)Support Vector p×m - m× (p− 1) p
Machine
set” is created by emulating real traffic loads on many-core hardware while randomlyinjecting anomaly on the routers and obtaining feature data for each communication,based on the three types of attacks as discussed in Section 4.2. We increased the train-ing data set size to examine the performance of the algorithm to a point that it reachesstability. The Golden Data Set consists of 60% - Feature data without anomaly (Class-1) and 40% - Feature data with anomaly (Class-0). We consider 216 training observa-tions and 203 testing observations for matlab accuracy, precision and recall analysis(Figure. 7) and hardware implementation. Golden Data (training) set is built to detectthe three attacks (as mentioned in Section 4.2) efficiently.
Table IV shows the hardware complexity of the supervised algorithms when train-ing is performed off-line. For K-NN algorithm, though training cannot be performedoffline, computation requirements are almost equal to Decision tree algorithm. LR andSVM have same computational and memory requirements as both algorithms giveweight vectors after training. The obtained weight vector is used to predict the testclass. Training ML algorithm offline reduces two overheads i.e resource utilizationand execution time. Based on the complexity and detection accuracy analysis, SVM isthe best option among these algorithms.
4.5. Hardware Implementation of Support Vector MachineImplementing hardware architecture for ML algorithms faces several challenges suchas pre-processing of features, computational model implementation, managing mem-ory transfers etc. Usually, SVM is trained offline [Kim et al. 2012], [Anguita et al.2007] i.e. the Support Vectors are found offline and test vectors are predicted based onSupport Vectors on-line. In this study, SVM is trained by using “Golden Data Set”. Toavoid over-fitting and Bias/Variance trade-off, the “Golden Data Set” is built based onthe results obtained in section 4.4.1. The offline training is performed by using Matlabtoolbox and SVM Linear Library (liblinear-1.94). The SVM linear library outputs Sup-port Vectors and its coefficients. These outputs are used to obtain Weight Vector forthe algorithm. The weight vector is converted to the appropriate format (fixed point orinteger), such that binary point equivalent is closer to their equivalent floating pointformat. The floating point arithmetic is complex and requires more area, thereforeuse of fixed point arithmetic will avoid complex multipliers. Since the SVM is trainedoffline using “Golden Data Set”, it already knows the patterns of communication with
ACM Journal on Emerging Technologies in Computing Systems, Vol. V, No. N, Article A, Pub. date: January YYYY.

A:14 A.Kulkarni et al.
Fig. 8. Architecture for (A) Support Vector Machine Kernel (B) Example of Dot Product when feature dataConsists of 4 Features
and without anomaly. The SVM uses “Golden Data Set” to formulate function (in termsof weight vector and bias), the test feature is then mapped onto function to detect ananomaly.
AnomalyDetection = W ∗ featuredata+BiasV ector (1)We consider Source Core, Destination Core, Packet Transfer Path (router hop), and
Distance features for anomaly detection. 216 observations are used to build “Golden(Training) Data Set”. The weight vector is, 6×1 for Quad-core router whereas in caseof Sixteen-core router it is 8×1 and each vector is 6-bit. The 6-bit Bias is obtained fromtraining data set. The SVM predicts an attack on router by using equation 1. For largeNoCs, size of all features will remain same except Packet Transfer Path. The PacketTransfer Path increases based on number of router hops data packet is passing. Thusfeature data used for anomaly classification in SVM Kernel will increase and thereforeweight vector. For example, in case of Quad-Core, we have 6 features whereas in caseof Sixteen-Cores 8 features. Similarly, in case of 64-Cores, 10 features are required.Also, in terms of memory usage, it only needs to store larger feature data sizes. Thememory usage and computational complexity is shown in Table IV which depends on“p” (# features). Further implementation results in Section 5, indicate that overheaddue to the SVM kernel reduces as the network size increases.
If the feature data is scaled as described above and the SVM kernel is trained withthe new “Golden Data Set” containing scaled feature data, the accuracy remains thesame.The SVM architecture consists of three main blocks: Test Feature Extraction,SVM Computation and Post Processing, as shown in Figure 8. These three blocks areinterdependent, and designed in pipeline to reduce execution cycles. The input to SVMis feature data, which is formed by router architecture. The Quad-core router featuredata is 16-bit, whereas Sixteen-core feature data is 27-bit. In Test feature data Ex-traction Module, the feature data is separated to form each feature vector. This featurevector is then padded with zero to match with the weight vector. The SVM Computa-tion block consists of Dot Product and Bias Vector Addition blocks. The predicted classis calculated by using equation 1. Finally, Post Processing block converts calculatedpredicted class to the binary class i.e. feature data with anomaly or without anomaly.
5. IMPLEMENTATION RESULTS5.1. Efficient Security vs. Hardware OverheadPlacing an attack detection module precisely will reduce hardware overhead and yieldto other system constraints. The security kernel is always considered as an overhead,
ACM Journal on Emerging Technologies in Computing Systems, Vol. V, No. N, Article A, Pub. date: January YYYY.

A:15
Fig. 9. Test Setup of Quad-Core, Trigger signal is used to attack router
therefore in this study we reduce the overhead by examining security kernel behaviorand overall hardware overhead, at different hops in many-core router. First, we imple-ment security kernel at “Level-0 (R0)” router hop. Since Sixteen-core router will have4 different “Level-0” hops (i.e Quad-Cores) it will increase hardware overhead. Plac-ing attack detection module at each hop increases the area and power consumptionof the whole system but it reduces detection time and overall dynamic power. Section5.2.1 discusses brief summary of Quad-Core security kernel implementation. We thenimplement an attack detection module at higher level hop (level-1 R1). It not only re-duces hardware overhead but also increases the efficiency of traffic diversion attacks.However, it has been observed that there exist a trade-off between efficient securityand hardware overhead.
5.2. Hardware Test Setup5.2.1. Quad-Core Setup. Figure 9 shows the Quad-Core test setup implemented on Xil-
inx Virtex-7 FPGA. The test setup consists of four important modules : 1. Traffic Gen-eration Module, 2. Router Architecture, 3. Attack Detection Module and 4. Attack In-sertion Module.
Traffic Generation Module generates intra-cluster traffic patterns. It generatessource and destination core address at every state. At each state, there will be onlyone source and destination core. For each core to core communication, Router Packet isgenerated which has data to be transferred and also address of the destination core.Feature Data is updated at each communication hop and it contains features discussedin Section 4.3. At the source core, Feature Data is updated with two features i.e. sourcecore, destination core, and other feature vectors are initialized as zeros. At each routerhop, Feature Data updates other features i.e path and distance. Finally at destina-tion router i.e before the destination core, Feature Data is transferred to the AttackDetection Module which is designed based on ML algorithm as discussed in Section4.5.
ACM Journal on Emerging Technologies in Computing Systems, Vol. V, No. N, Article A, Pub. date: January YYYY.
A:16 A.Kulkarni et al.
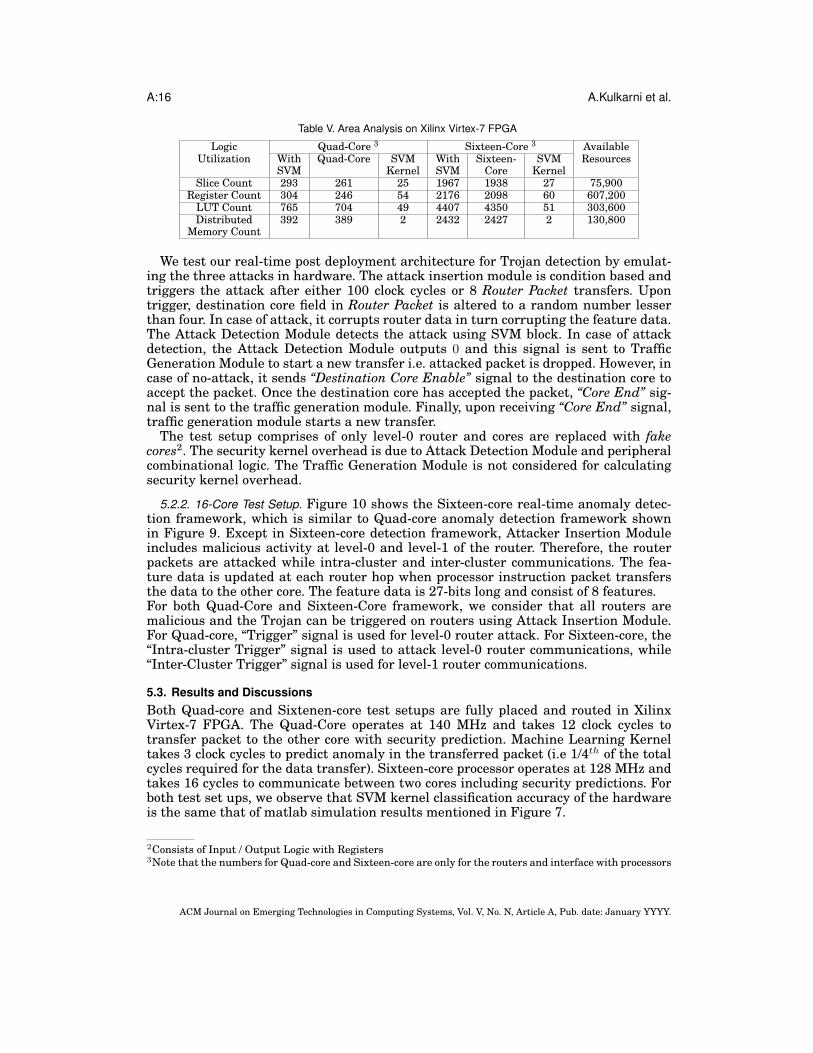
Table V. Area Analysis on Xilinx Virtex-7 FPGA
Logic Quad-Core 3 Sixteen-Core 3 AvailableUtilization With Quad-Core SVM With Sixteen- SVM Resources
SVM Kernel SVM Core KernelSlice Count 293 261 25 1967 1938 27 75,900
Register Count 304 246 54 2176 2098 60 607,200LUT Count 765 704 49 4407 4350 51 303,600Distributed 392 389 2 2432 2427 2 130,800
Memory Count
We test our real-time post deployment architecture for Trojan detection by emulat-ing the three attacks in hardware. The attack insertion module is condition based andtriggers the attack after either 100 clock cycles or 8 Router Packet transfers. Upontrigger, destination core field in Router Packet is altered to a random number lesserthan four. In case of attack, it corrupts router data in turn corrupting the feature data.The Attack Detection Module detects the attack using SVM block. In case of attackdetection, the Attack Detection Module outputs 0 and this signal is sent to TrafficGeneration Module to start a new transfer i.e. attacked packet is dropped. However, incase of no-attack, it sends “Destination Core Enable” signal to the destination core toaccept the packet. Once the destination core has accepted the packet, “Core End” sig-nal is sent to the traffic generation module. Finally, upon receiving “Core End” signal,traffic generation module starts a new transfer.
The test setup comprises of only level-0 router and cores are replaced with fakecores2. The security kernel overhead is due to Attack Detection Module and peripheralcombinational logic. The Traffic Generation Module is not considered for calculatingsecurity kernel overhead.
5.2.2. 16-Core Test Setup. Figure 10 shows the Sixteen-core real-time anomaly detec-tion framework, which is similar to Quad-core anomaly detection framework shownin Figure 9. Except in Sixteen-core detection framework, Attacker Insertion Moduleincludes malicious activity at level-0 and level-1 of the router. Therefore, the routerpackets are attacked while intra-cluster and inter-cluster communications. The fea-ture data is updated at each router hop when processor instruction packet transfersthe data to the other core. The feature data is 27-bits long and consist of 8 features.For both Quad-Core and Sixteen-Core framework, we consider that all routers aremalicious and the Trojan can be triggered on routers using Attack Insertion Module.For Quad-core, “Trigger” signal is used for level-0 router attack. For Sixteen-core, the“Intra-cluster Trigger” signal is used to attack level-0 router communications, while“Inter-Cluster Trigger” signal is used for level-1 router communications.
5.3. Results and DiscussionsBoth Quad-core and Sixtenen-core test setups are fully placed and routed in XilinxVirtex-7 FPGA. The Quad-Core operates at 140 MHz and takes 12 clock cycles totransfer packet to the other core with security prediction. Machine Learning Kerneltakes 3 clock cycles to predict anomaly in the transferred packet (i.e 1/4th of the totalcycles required for the data transfer). Sixteen-core processor operates at 128 MHz andtakes 16 cycles to communicate between two cores including security predictions. Forboth test set ups, we observe that SVM kernel classification accuracy of the hardwareis the same that of matlab simulation results mentioned in Figure 7.
2Consists of Input / Output Logic with Registers3Note that the numbers for Quad-core and Sixteen-core are only for the routers and interface with processors
ACM Journal on Emerging Technologies in Computing Systems, Vol. V, No. N, Article A, Pub. date: January YYYY.

A:17
Fig. 10. Test Setup of 16-Core, Intra-Cluster trigger is used to attack all Level-0 (R0 0,. . .,R0 3) routersand Inter-Cluster trigger is used to attack Level-1 (R1 0) routers
Table VI. Dynamic Power Analysis on Xilinx Virtex-7 FPGA at 100 MHZ Op-erating frequency with the static power for all three designs is 0.207 Watt
Quad-Core 3 (mW ) Sixteen-Core 3(mW )With Quad-Core SVM With Sixteen- SVMSVM Kernel SVM Core Kernel
Clocks 6.96 6.42 0.6 26.4 26.1 0.6Logic 1.48 1.42 0.08 4.22 4.19 0.13
Wires/Nets 10.92 10.92 0.17 10.12 10.08 0.17IOs 0.36 0.35 0.03 0.71 0.71 0.03
Table V consists of area analysis for SVM Kernel, which is Support Vector Ma-chine algorithm implemented in the Attack Detection Module and also Quad-Coreand Sixteen-Core routers with and without SVM kernel to show the security over-head. Quad-Core and Sixteen-Core with SVM kernel consists of routers and interfacewith processors, including Attack Insertion Module, SVM Kernel (Attack DetectionModule) and other interfaces consisting of Multiplexers and De-multiplexers (ShownFigure 9 and 10). The table also shows different types of resources and their availablecount for Xilinx Virtex-7 (7VX485T) FPGA. Memory requirement for SVM kernel is# features×# Bits as described in Table IV, where feature size for Sixteen-Core is 8and Bit Size is 8 i.e 64-bit stored in LUTs. The Distributed Memory used for SVMkernel is shift register, whereas for routers it’s a dual-port memory registers used forInput/Output buffers. For the design we are not using Block RAMs in routers or SVMkernel.
The feature packet contains information which is updated at each router hop (Forexample as shown in Table II, Figure 5 and 6). The feature data is transferred throughseparate bus from each hop to another hop and then to SVM kernel. The overheadanalysis includes the additional bus for feature data. Therefore feature data will in-
ACM Journal on Emerging Technologies in Computing Systems, Vol. V, No. N, Article A, Pub. date: January YYYY.
A:18 A.Kulkarni et al.
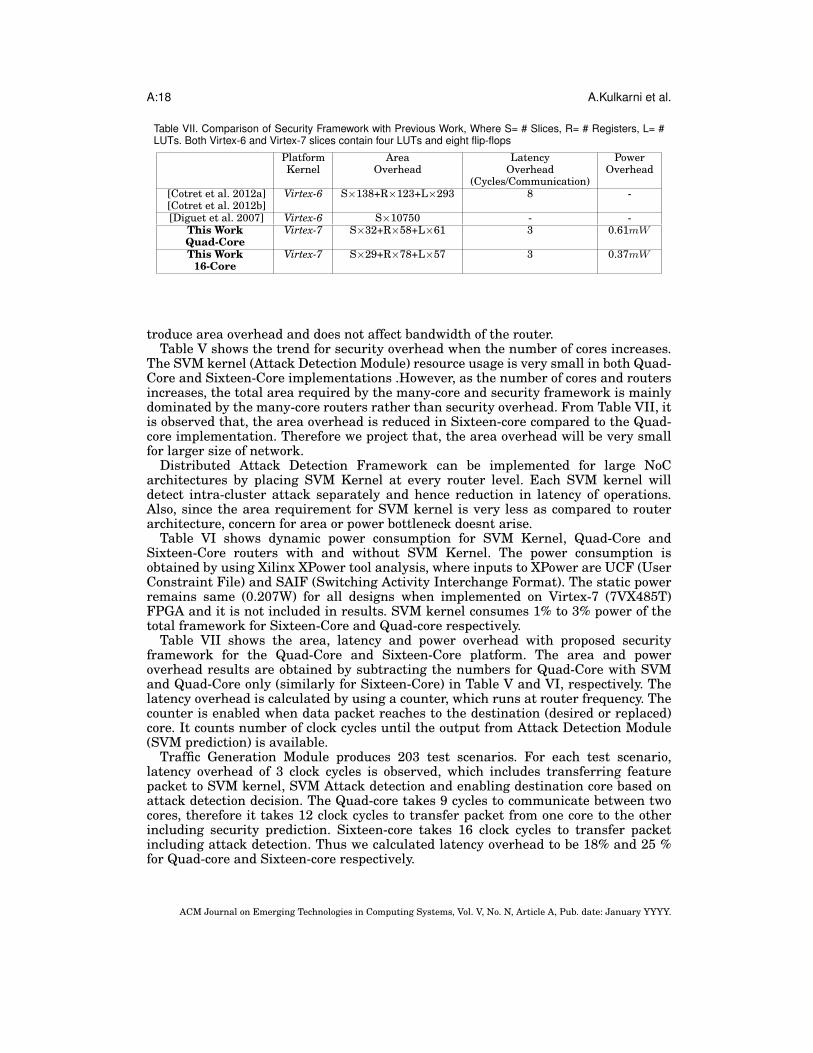
Table VII. Comparison of Security Framework with Previous Work, Where S= # Slices, R= # Registers, L= #LUTs. Both Virtex-6 and Virtex-7 slices contain four LUTs and eight flip-flops
Platform Area Latency PowerKernel Overhead Overhead Overhead
(Cycles/Communication)[Cotret et al. 2012a] Virtex-6 S×138+R×123+L×293 8 -[Cotret et al. 2012b][Diguet et al. 2007] Virtex-6 S×10750 - -
This Work Virtex-7 S×32+R×58+L×61 3 0.61mWQuad-CoreThis Work Virtex-7 S×29+R×78+L×57 3 0.37mW
16-Core
troduce area overhead and does not affect bandwidth of the router.Table V shows the trend for security overhead when the number of cores increases.
The SVM kernel (Attack Detection Module) resource usage is very small in both Quad-Core and Sixteen-Core implementations .However, as the number of cores and routersincreases, the total area required by the many-core and security framework is mainlydominated by the many-core routers rather than security overhead. From Table VII, itis observed that, the area overhead is reduced in Sixteen-core compared to the Quad-core implementation. Therefore we project that, the area overhead will be very smallfor larger size of network.
Distributed Attack Detection Framework can be implemented for large NoCarchitectures by placing SVM Kernel at every router level. Each SVM kernel willdetect intra-cluster attack separately and hence reduction in latency of operations.Also, since the area requirement for SVM kernel is very less as compared to routerarchitecture, concern for area or power bottleneck doesnt arise.
Table VI shows dynamic power consumption for SVM Kernel, Quad-Core andSixteen-Core routers with and without SVM Kernel. The power consumption isobtained by using Xilinx XPower tool analysis, where inputs to XPower are UCF (UserConstraint File) and SAIF (Switching Activity Interchange Format). The static powerremains same (0.207W) for all designs when implemented on Virtex-7 (7VX485T)FPGA and it is not included in results. SVM kernel consumes 1% to 3% power of thetotal framework for Sixteen-Core and Quad-core respectively.
Table VII shows the area, latency and power overhead with proposed securityframework for the Quad-Core and Sixteen-Core platform. The area and poweroverhead results are obtained by subtracting the numbers for Quad-Core with SVMand Quad-Core only (similarly for Sixteen-Core) in Table V and VI, respectively. Thelatency overhead is calculated by using a counter, which runs at router frequency. Thecounter is enabled when data packet reaches to the destination (desired or replaced)core. It counts number of clock cycles until the output from Attack Detection Module(SVM prediction) is available.
Traffic Generation Module produces 203 test scenarios. For each test scenario,latency overhead of 3 clock cycles is observed, which includes transferring featurepacket to SVM kernel, SVM Attack detection and enabling destination core based onattack detection decision. The Quad-core takes 9 cycles to communicate between twocores, therefore it takes 12 clock cycles to transfer packet from one core to the otherincluding security prediction. Sixteen-core takes 16 clock cycles to transfer packetincluding attack detection. Thus we calculated latency overhead to be 18% and 25 %for Quad-core and Sixteen-core respectively.
ACM Journal on Emerging Technologies in Computing Systems, Vol. V, No. N, Article A, Pub. date: January YYYY.

A:19
5.4. Comparison with Previous WorkTable VII compares the FPGA resource (in terms of slices, registers and LUTs) uti-lization and latency overhead of this work with previous work. [Cotret et al. 2012a]proposed a run-time security solution for interfaces between IPs. Whereas [Cotretet al. 2012b] propose a security solution for both boot and run-time protection. Botharchitectures target three main attacks namely Spoofing, Relocation and Replay at-tacks. In [Cotret et al. 2012b], The boot protection is implemented by SHA-256 cryptocore and [Cotret et al. 2012a] [Cotret et al. 2012b] run-time protection is implementedby two important kernels i.e. Local Firewalls (LF) and Crypto Firewalls (CF). All theresources (IPs, Processors, and internal memories) are connected to a bus based onthe AXI communication standard. Each resource is connected to a LF whereas exter-nal memory is connected through CF. Each firewall consists of Security Builder (SB)and Firewall Interface, where SB manages security policies. Also, each firewall has itsown Block RAM and reconfiguration port to redefine security policies. In our proposeddesign, we do not consider to protect the system through external communications.Therefore, we compare our architecture with only LF.
[Diguet et al. 2007] presents an architecture based on simple network interfacesimplementing distributed security rule checking and separation between security andapplication channels. The aim of the design is to reconfigure system for secure com-munications. It considers Hijacking, Extraction of Secret information and Denial ofService (Replay, Incorrect path, Deadlock, Livelock) attacks. It proposes three differ-ent configurations such as Standard Network Interface (SNI), SNI: IP configurationand SNI: SCM(Security and Configuration Manager) configuration. SNI is based on asingle channel with end to end flow controls based on credit exchanges between IPs.This configuration is closely matched with our proposed architecture, thus we compareour proposed architecture with this configuration. While looking at comparisons, oneshould also consider that [Diguet et al. 2007] performs experiments with 4×3 2D meshrouter consists of 12 router hops, whereas the proposed architecture has hierarchicalrouters. Therefore, it consists of only one router hop for Quad-Core and 5 router hopsfor Sixteen-Core processor. Also, both Virtex-6 and Virtex-7 slices contain four LUTsand eight flip-flops.
Compared to [Cotret et al. 2012a] the area overhead of this work is approximately3.7 times smaller. For [Diguet et al. 2007] and comparing only the slice overhead, ourwork is 300 times smaller. [Fiorin et al. 2008] does not report a related overhead resultin terms of area, power and latency and we didnt include in the comparison table. Theproposed architecture takes only 3 extra cycles to detect an anomaly in communica-tion between two cores (on-chip), whereas previous work [Cotret et al. 2012a] takes 8extra cycles. [Cotret et al. 2012a], [Diguet et al. 2007], [Cotret et al. 2012b], commenton security overhead for benchmark applications in terms of area, power and latency,but they have limited information on accuracy of the framework. Our proposed workachieves 95% to 97% anomaly detection accuracy.
6. CONCLUSIONIn this paper, we present a low-overhead security framework for a custom many-corerouter by using Machine Learning techniques. We assume that processing cores andmemories are safe, and anomaly is included only through router. The attack corruptsthe router packet by changing the destination address. It can be traffic diversion, routelooping, or core spoofing attack. We built “Golden Data Set” based on hardware featureanalysis and anomaly insertion effects. In this study, we experimented commonly usedSupervised and Un-supervised Machine Learning techniques. It has been observedthat most of the Supervised techniques have anomaly detection accuracy more than
ACM Journal on Emerging Technologies in Computing Systems, Vol. V, No. N, Article A, Pub. date: January YYYY.

A:20 A.Kulkarni et al.
90% however, Un-supervised techniques fails to efficiently detect trojans. We choseSupport Vector Machine (SVM) to be implemented on hardware based on Accuracy,recall and precision analysis on Matlab and Hardware Complexity analysis. To testour framework, Attack Insertion Module is implemented to insert condition basedattack. The frame is fully placed and routed on Xilinx Virtex-7 FPGA. The SVMimplementation on hardware has low power and area overhead. In Sixteen-core routerframework, SVM consumes only 0.37mW (1%) of the total power and utilizes less than1% of overall FPGA resources. For Quad-core router framework, it takes 18% of thetotal execution time to detect an anomaly and it has 3% power and 9% area overhead.Compared to previous anomaly detection frameworks, the proposed frameworkachieves 65% reduction in area overhead and is 3 times faster. The proposed securityframework has detection accuracy of up to 97% for three expected attacks, howeverin future, the proposed framework can be modified to learn unexpected attacks usingonline learning techniques.
7. ACKNOWLEDGEMENTSThis research was developed with funding from the Defense Advanced ResearchProjects Agency (DARPA). The views, opinions, and/or findings contained in this ar-ticle are those of the authors and should not be interpreted as representing the officialviews or policies of the Department of Defense or the U.S. Government. DistributionStatement “A” (Approved for Public Release, Distribution Unlimited).
ACM Journal on Emerging Technologies in Computing Systems, Vol. V, No. N, Article A, Pub. date: January YYYY.

A:21
REFERENCES
M. Abramovici and P. Bradley. 2009. Integrated circuit security: new threats and solutions.In Cyber Security and Information Intelligence Research, 2009 5th Annual Workshop on.DOI:http://dx.doi.org/10.1145/1558607.1558671
A. Adamov, A. Saprykin, D. Melnik, and O. Lukashenko. 2009. The problem of Hardware Trojans detec-tion in System-on-Chip. In CAD Systems in Microelectronics, 2009. CADSM 2009. 10th InternationalConference - The Experience of Designing and Application of. 178–179.
D. Agrawal and others. 2007. Trojan Detection using IC Fingerprinting. In Security and Privacy, 2007 IEEESymposium on. 296–310. DOI:http://dx.doi.org/10.1109/SP.2007.36
A Almalawi, Z. Tari, A Fahad, and I Khalil. 2013. A Framework for Improving the Accuracy ofUnsupervised Intrusion Detection for SCADA Systems. In Trust, Security and Privacy in Com-puting and Communications (TrustCom), 2013 12th IEEE International Conference on. 292–301.DOI:http://dx.doi.org/10.1109/TrustCom.2013.40
D. Anguita, A. Ghio, S. Pischiutta, and S. Ridella. 2007. A Hardware-friendly Support Vector Machine forEmbedded Automotive Applications. In Neural Networks, 2007. IJCNN 2007. International Joint Con-ference on. 1360–1364. DOI:http://dx.doi.org/10.1109/IJCNN.2007.4371156
G. Becker, F. Regazzoni, C. Paar, and W. Burleson. 2013. Stealthy dopant-level hardware trojans. In Cryp-tographic Hardware and Embedded Systems (CHES), 2013 15th International Workshop on. 197–214.DOI:http://dx.doi.org/10.1007/978-3-642-40349-1 12
S. Bhunia, M. Abramovici, D. Agrawal, P. Bradley, M.S. Hsiao, J. Plusquellic, and M. Tehranipoor. 2013.Protection Against Hardware Trojan Attacks: Towards a Comprehensive Solution. Design Test, IEEE30, 3 (June 2013), 6–17. DOI:http://dx.doi.org/10.1109/MDT.2012.2196252
J. Bisasky, H. Homayoun, F. Yazdani, and T. Mohsenin. 2013. A 64-core platform for biomedical signalprocessing. In Quality Electronic Design (ISQED), 2013 14th International Symposium on. 368–372.DOI:http://dx.doi.org/10.1109/ISQED.2013.6523637
D. Cao, J. Han, X. Zeng, and S. Lu. 2008. A core-based multi-function security processor with GALS Wrapper.In Solid-State and Integrated-Circuit Technology, 2008. ICSICT 2008. 9th International Conference on.1839–1842. DOI:http://dx.doi.org/10.1109/ICSICT.2008.4734938
R. Chakraborty, F. Wolff, S. Paul, C. Papachristou, and S. Bhunia. 2009. MERO: A Statistical Ap-proach for Hardware Trojan Detection. In Proceedings of the 11th International Workshop on Cryp-tographic Hardware and Embedded Systems (CHES ’09). Springer-Verlag, Berlin, Heidelberg, 396–410.DOI:http://dx.doi.org/10.1007/978-3-642-04138-9 28
P. Cotret, J. Crenne, G. Gogniat, and J-P Diguet. 2012a. Bus-based MPSoC Security throughCommunication Protection: A Latency-efficient Alternative. In Field-Programmable Custom Com-puting Machines (FCCM), 2012 IEEE 20th Annual International Symposium on. 200–207.DOI:http://dx.doi.org/10.1109/FCCM.2012.42
P. Cotret, F. Devic, G. Gogniat, B. Badrignans, and L. Torres. 2012b. Security enhancements for FPGA-based MPSoCs: A boot-to-runtime protection flow for an embedded Linux-based system. In Reconfig-urable Communication-centric Systems-on-Chip (ReCoSoC), 2012 7th International Workshop on. 1–8.DOI:http://dx.doi.org/10.1109/ReCoSoC.2012.6322896
J.-P. Diguet, S. Evain, R. Vaslin, G. Gogniat, and E. Juin. 2007. NOC-centric Security of Reconfig-urable SoC. In Networks-on-Chip, 2007. NOCS 2007. First International Symposium on. 223–232.DOI:http://dx.doi.org/10.1109/NOCS.2007.32
L. Fiorin, S. Lukovic, and G. Palermo. 2008. Implementation of a reconfigurable data protection modulefor NoC-based MPSoCs. In Parallel and Distributed Processing, 2008. IPDPS 2008. IEEE InternationalSymposium on. 1–8. DOI:http://dx.doi.org/10.1109/IPDPS.2008.4536514
L. Fiorin, G. Palermo, and C. Silvano. 2009. MPSoCs run-time monitoring through Networks-on-Chip. In Design, Automation Test in Europe Conference Exhibition, 2009. DATE ’09. 558–561.DOI:http://dx.doi.org/10.1109/DATE.2009.5090726
D. Forte, Chongxi Bao, and A. Srivastava. 2013. Temperature tracking: An innovative run-time approachfor hardware Trojan detection. In Computer-Aided Design (ICCAD), 2013 IEEE/ACM InternationalConference on. 532–539. DOI:http://dx.doi.org/10.1109/ICCAD.2013.6691167
F. Gebali, H. Elmiligi, and M El-Kharashi. 2009. Networks-on-Chips: Theory and Practice (1st ed.). CRCPress, Inc., Boca Raton, FL, USA.
ACM Journal on Emerging Technologies in Computing Systems, Vol. V, No. N, Article A, Pub. date: January YYYY.

A:22 A.Kulkarni et al.
M. Hicks and others. 2010. Overcoming an Untrusted Computing Base: Detecting and Removing Ma-licious Hardware Automatically. In Security and Privacy, 2009 IEEE Symposium on. 159–172.DOI:http://dx.doi.org/10.1109/SP.2010.18
K Hu, A. N. Nowroz, S. Reda, and F. Koushanfar. 2013. High-sensitivity hardware Trojan detection us-ing multimodal characterization. In Design, Automation Test in Europe Conference Exhibition (DATE),2013. 1271–1276.
R. Karri, J. Rajendran, K. Rosenfeld, and M. Tehranipoor. 2010. Trustworthy Hardware:Identifying and Classifying Hardware Trojans. Computer 43, 10 (Oct 2010), 39–46.DOI:http://dx.doi.org/10.1109/MC.2010.299
H. Khattri, N.K.V. Mangipudi, and S. Mandujano. 2012. HSDL: A Security Development Lifecycle for hard-ware technologies. In Hardware-Oriented Security and Trust (HOST), 2012 IEEE International Sympo-sium on. 116–121. DOI:http://dx.doi.org/10.1109/HST.2012.6224330
M. Khavari, A. Kulkarni, A. Rahimi, T. Mohsenin, and H. Homayoun. 2014. Energy-efficient Mapping ofBiomedical Applications on Domain-specific Accelerator Under Process Variation. In Proceedings of the2014 International Symposium on Low Power Electronics and Design (ISLPED ’14). ACM, New York,NY, USA, 275–278. DOI:http://dx.doi.org/10.1145/2627369.2627654
S. Kim, S. Lee, and K. Cho. 2012. Design of high-speed support vector machine circuit fordriver assistance system. In SoC Design Conference (ISOCC), 2012 International. 45–48.DOI:http://dx.doi.org/10.1109/ISOCC.2012.6406921
A. Kulkarni, H. Homayoun, and T. Mohsenin. 2014. A Parallel and Reconfigurable Architecturefor Efficient OMP Compressive Sensing Reconstruction. In Proceedings of the 24th Edition ofthe Great Lakes Symposium on VLSI (GLSVLSI ’14). ACM, New York, NY, USA, 299–304.DOI:http://dx.doi.org/10.1145/2591513.2591598
A. Kulkarni and T. Mohsenin. 2014. Parallel Heterogeneous Architectures for Efficient OMP CompressiveSensing Reconstruction. International SPIE Conference on Defense, Security, and Sensing (May 2014).
A. Kulkarni and T. Mohsenin. 2015. Accelerating compressive sensing reconstruction OMP algorithm withCPU, GPU, FPGA and domain specific many-core. In Circuits and Systems (ISCAS), 2015 IEEE Inter-national Symposium on. 970–973. DOI:http://dx.doi.org/10.1109/ISCAS.2015.7168797
K.H. Lee, Z. Wang, and N. Verma. 2013. Hardware specialization of machine-learning kernels: Possibilitiesfor applications and possibilities for the platform design space (Invited). In Signal Processing Systems(SiPS), 2013 IEEE Workshop on. 330–335. DOI:http://dx.doi.org/10.1109/SiPS.2013.6674528
A. Sadeghi M. Mirza-Aghatabar. 2014. An Asynchronous, Low Power and Secure Framework for Network-On-Chips. In IJCSNS International Journal of Computer Science and Network Security (Vol. 8 No. 7).214–223. http://paper.ijcsns.org/07 book/200807/20080732.pdf
S. Narasimhan and others. 2012. Improving IC Security Against Trojan Attacks Through Inte-gration of Security Monitors. IEEE Design and Test of Computers 29 (2012), 37–46. Issue 5.DOI:http://dx.doi.org/10.1109/MDT.2012.2210183
A. Page, C. Sagedy, E. Smith, N. Attaran, T. Oates, and T. Mohsenin. 2015. A Flexible Multichannel EEGFeature Extractor and Classifier for Seizure Detection. Circuits and Systems II: Express Briefs, IEEETransactions on 62, 2 (Feb 2015), 109–113. DOI:http://dx.doi.org/10.1109/TCSII.2014.2385211
N. Potlapally. 2011. Hardware security in practice: Challenges and opportunities. In Hardware-Oriented Security and Trust (HOST), 2011 IEEE International Symposium on. 93–98.DOI:http://dx.doi.org/10.1109/HST.2011.5955003
J. Rajendran, E. Gavas, J. Jimenez, V. Padman, and R. Karri. 2010. Towards a comprehensive and system-atic classification of hardware Trojans. In Circuits and Systems (ISCAS), Proceedings of 2010 IEEEInternational Symposium on. 1871–1874. DOI:http://dx.doi.org/10.1109/ISCAS.2010.5537869
M. Rostami, F. Koushanfar, and R. Karri. 2014. A Primer on Hardware Security: Models, Methods, andMetrics. Proc. IEEE 102, 8 (Aug 2014), 1283–1295. DOI:http://dx.doi.org/10.1109/JPROC.2014.2335155
M. Rostami, F. Koushanfar, J. Rajendran, and R. Karri. 2013. Hardware Security: Threat Models and Met-rics. In Proceedings of the International Conference on Computer-Aided Design (ICCAD ’13). IEEE Press,Piscataway, NJ, USA, 819–823. http://dl.acm.org/citation.cfm?id=2561828.2561985
H. Salmani, M. Tehranipoor, and J. Plusquellic. 2012. A Novel Technique for Improving Hardware TrojanDetection and Reducing Trojan Activation Time. Very Large Scale Integration (VLSI) Systems, IEEETransactions on 20, 1 (Jan 2012), 112–125. DOI:http://dx.doi.org/10.1109/TVLSI.2010.2093547
S.M.H. Shekarian, M.S. Zamani, and S. Alami. 2013. Neutralizing a design-for-hardware-trust technique.In Computer Architecture and Digital Systems (CADS), 2013 17th CSI International Symposium on.73–78. DOI:http://dx.doi.org/10.1109/CADS.2013.6714240
M. Tehranipoor and F. Koushanfar. 2010. A survey of hardware trojan taxonomy and detection. IEEE Designand Test of Computers 27 (2010), 10–25. Issue 1. DOI:http://dx.doi.org/10.1109/MDT.2010.7
ACM Journal on Emerging Technologies in Computing Systems, Vol. V, No. N, Article A, Pub. date: January YYYY.

A:23
S. Viseh, M. Ghovanloo, and T. Mohsenin. 2015. Toward an Ultralow-Power Onboard Processor for TongueDrive System. Circuits and Systems II: Express Briefs, IEEE Transactions on 62, 2 (Feb 2015), 174–178.DOI:http://dx.doi.org/10.1109/TCSII.2014.2387683
A. Waksman and S. Sethumadhavan. 2011. Stealthy dopant-level hardware trojans. In Security and Privacy,2011 IEEE Symposium on. 49–63. DOI:http://dx.doi.org/10.1109/SP.2011.27
J. Yier and Y. Makris. 2008a. Hardware Trojan detection using path delay fingerprint. In Hardware-Oriented Security and Trust, 2008. HOST 2008. IEEE International Workshop on. 51–57.DOI:http://dx.doi.org/10.1109/HST.2008.4559049
J. Yier and Y. Makris. 2008b. Hardware Trojan detection using path delay fingerprint. InHardware-Oriented Security and Trust (HOST), 2008 IEEE International Workshop on. 51–57.DOI:http://dx.doi.org/10.1109/HST.2008.4559049
J. Zhang, H. Yu, and Q. Xu. 2012. HTOutlier: Hardware Trojan detection with side-channel signature outlieridentification. In Hardware-Oriented Security and Trust (HOST), 2012 IEEE International Symposiumon. 55–58. DOI:http://dx.doi.org/10.1109/HST.2012.6224319
J. Zhang, Feng Yuan, and Qiang Xu. 2014. DeTrust: Defeating Hardware Trust Verification withStealthy Implicitly-Triggered Hardware Trojans. In Proceedings of the 2014 ACM SIGSAC Confer-ence on Computer and Communications Security (CCS ’14). ACM, New York, NY, USA, 153–166.DOI:http://dx.doi.org/10.1145/2660267.2660289
ACM Journal on Emerging Technologies in Computing Systems, Vol. V, No. N, Article A, Pub. date: January YYYY.













![Anomaly Detection: Principles, Benchmarking, Explanation ...web.engr.oregonstate.edu/~tgd/...anomaly-detection... · Towards a Theory of Anomaly Detection [Siddiqui, et al.; UAI 2016]](https://img.pdfslide.net/doc/110x75/5fd8992320a65f059c333c6d/anomaly-detection-principles-benchmarking-explanation-webengr-tgdanomaly-detection.jpg)















