Embed Size (px)
Citation preview

A SEMI-AUTOMATED WORKFLOW FOR PRODUCING TIME-ALIGNED INTERMEDIATE TONAL REPRESENTATIONS LAURA MCPHERSON AND EMILY GRABOWSKI (DARTMOUTH COLLEGE)
ICLDC 9, March 2, 2017
1

Introduction 2

The problem
¨ Tone is notoriously difficult ¤ Inherently relative
¨ Early transcriptions unreliable ¤ How many contrastive levels? ¤ Are contours phonetic or phonological?
¨ Researchers are not always trained in tone ¤ Community members ¤ Linguists too
3

Annotations
¨ “Phonetic” annotations can be unsystematic and difficult to digitize: ¤ [ ¯ – ] [– _ ] [ _ / ] etc.
4
Annotation of Numèè by Jean-Claude Rivierre (1973:134)

Annotations 5
¨ Phonological analyses often abstract, obscuring phonetic underpinnings
q No guarantee the researcher’s analysis is correct

The proposal
¨ We need a tool to help produce objective, replicable tone annotations from Day 1
¨ Desiderata: ¤ Based on acoustic data (f0) ¤ User friendly ¤ Easily interpretable annotations ¤ Interface with existing software and technology
6

The proposal 7
We want to go from this (f0, messy, hard to interpret):
To this (discrete levels, able to be digitized and included in annotations): mo3 ba1 mo3 tsEn4 kO2rO2

ATLAS
¨ ATLAS: Automated Tone Level Annotation System ¨ Annotates recordings for phonetic tone level based on
normalized f0 ¤ Output is time-stamped ¤ Can be imported into ELAN as a tonal tier
¨ NB: Does not replace the need for phonological analysis, but can appear alongside
¨ Analytical upshots: ¤ Produces a searchable corpus of tone tied to other
grammatical information ¤ Annotations can be used to study phonetics or intonational
realizations of tone
8

Today’s talk 9
¨ Existing technologies for tone ¨ Overview of ATLAS ¨ Research applications ¨ Conclusions/future work

Existing technologies for tone 10

Existing technologies 11
¨ Tone is relatively underserved technologically, but a few tools have been developed
¨ Focus on analysis of lexical/phonological tone, not surface/phonetic representation
¨ Two broad categories: ¤ Hidden Markov models (language specific) ¤ Clustering (language independent)

Hidden Markov Models 12
¨ Hidden Markov Models ¤ Mandarin Chinese (Wu, Zahorian, and Hu 2013, Yang
et al 1984) ¤ Cantonese (Tan Lee et al. 1995) ¤ Thai (Cooper-Leavitt 2016)
¨ Tone requires more context than most HMMs utilize (Bird 1994)
¨ Tools are limited to a handful of well-studied languages ¤ All of which are East Asian contour-based tone systems

Clustering 13
¨ Not many computational tools for unstudied tone systems
¨ Toney (Bird and Lee, 2014) ¤ Displays F0 contour on a canvas and allows the user to
group similar contours together ¤ Does not appear to be in active development

ATLAS: How it works 14

Three basic steps 15
Input: Praat TextGrid and .wav file
Analysis: Python Script
Output: ELAN and Excel-
compatible .txt files

Three basic steps 16
Input: Praat TextGrid and .wav file
Analysis: Python Script
Output: ELAN and Excel-
compatible .txt files

Python script: a closer look 17
Call Praat Import Data
Clean Data • Missing Data • Praat Errors
Normalize Pitches
“Bin” Normalized
Data
Write Output

Input 18
¨ Semi-automated version requires a .wav file and Praat .TextGrid annotations as input ¤ Annotate each TBU

Python script: a semi-automated tool 19
¨ Prompts the user to input arguments ¨ Currently command line tool
¤ Initial arguments are input via a form
¨ Does not require the user to interface directly with Python

Python Script: Cleaning the Data 20
Error Cause(s) How we deal with it
Undefined: Praat pitch-tracking not obtaining a signal
• Noisy/poor quality recording • TextGrid capturing part of a
consonant
1. Remove all tokens with errors, or,
2. Smooth tokens with errors on boundaries, remove the rest
The Octave Problem (Doubling/Halving)
• Praat’s algorithm thinks that the pitch is either an octave higher or lower
• More often found with speakers with larger-than-average ranges
1. Automatically remove flagged tokens, or,
2. Manually confirm doubling/halving
Outliers: Other • Praat picked up data from outside the speaker
• Speaker had one really high or low token
After correcting for the above two categories of errors, fit to a normal distribution (within 3 SDs) to find the speaker’s probable range.

Python script: normalization 21
¨ Normalization allows for better comparison between speakers
¨ Hertz à semitones ¤ cf. Baken 1987, Hart et al. 1990, Liberman and
Pierrehumbert 1984, Ross et al. 1986, Xu 2004, etc. ¤ A measure of frequency based on number of ‘half-steps’ (in
the Western musical tradition) from a reference tone ¤ Reference tone is the speaker’s mean pitch in Hertz (after
outlier correction) ¤ Equation:

Python script: creating bins 22
¨ Start with speaker’s overall range (corrected for outliers)
¨ Range is divided up into equal parts (equal bins) ¨ User can specify the number of bins that they wish
to use ¤ More bins = more phonetic detail ¤ We have found 8 to be a good number so far

Python script: assigning tokens to bins 23
¨ Take samples throughout the TBU ¨ Two extremes:
¤ Could take as much as every 1/100th second throughout the TBU n Could be time-normalized for analysis n Can be overwhelming amount of detail
¤ Could also do average for the overall token n Loses contour tone/phonetic detail
¨ Compromise: Measure at 20%/80% ¤ Avoids consonant effects ¤ Preserves contours and most important phonetic details

Output 24
¨ Desired output can be selected at the beginning: ¨ Main types
1. ELAN-compatible (minimalist: time stamp + bins) 2. Detail-rich spreadsheets
n Two points (20%/80%) per syllable n Every 1/100s per syllable
3. Metadata

Output: .txt files 25

Output: tonal tier in ELAN 26

ATLAS: Research applications 27

Phonetic realization of tone 28
¨ With finer grain settings, phonetic realization can be visualized
¨ Case study: Tommo So (Dogon, Mali) ¤ Two phonemic tones (H, L), plus surface
underspecification (0)
¨ Controlled elicitation data from three speakers ¤ 2 male, 1 female
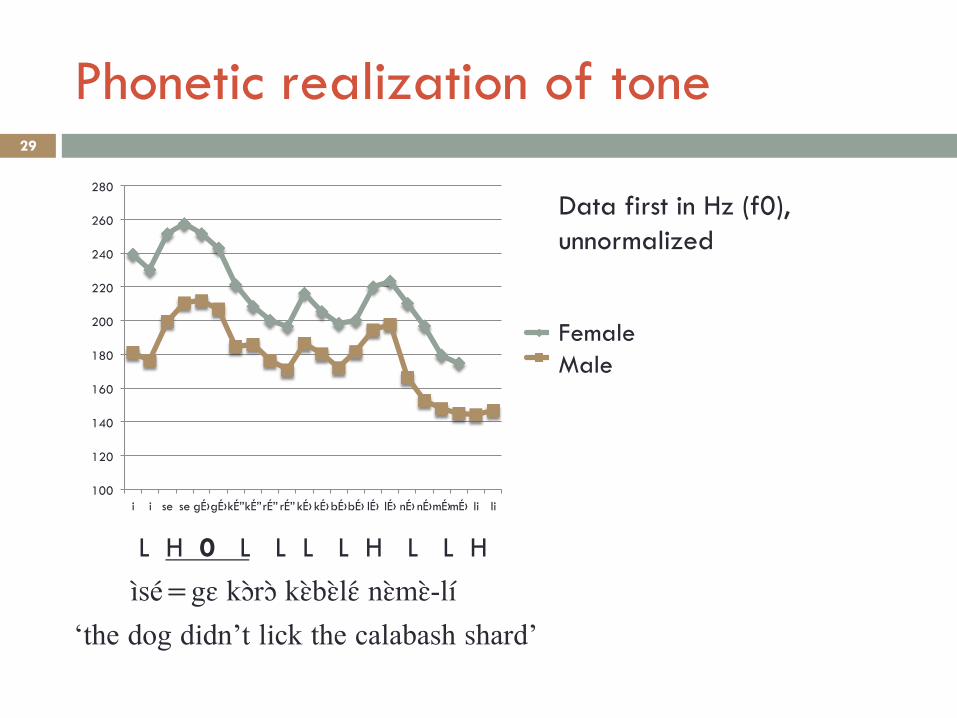
Phonetic realization of tone 29
L H 0 L L L L H L L H
ìsé=gɛ kɔ̀rɔ̀ kɛ̀bɛ̀lɛ́ nɛ̀mɛ̀-lí‘the dog didn’t lick the calabash shard’
Data first in Hz (f0), unnormalized
100
120
140
160
180
200
220
240
260
280
i i se se gÉ› gÉ› kÉ” kÉ” rÉ” rÉ” kÉ› kÉ› bÉ› bÉ› lÉ› lÉ› nÉ› nÉ› mÉ› mÉ› li li
Series1
Series2
Female Male
0
1
2
3
4
5
6
7
8
9
10
i i se se gÉ› gÉ› kÉ” kÉ” rÉ” rÉ” kÉ› kÉ› bÉ› bÉ› lÉ› lÉ› nÉ› nÉ› mÉ› mÉ› li li
Series1
Series2
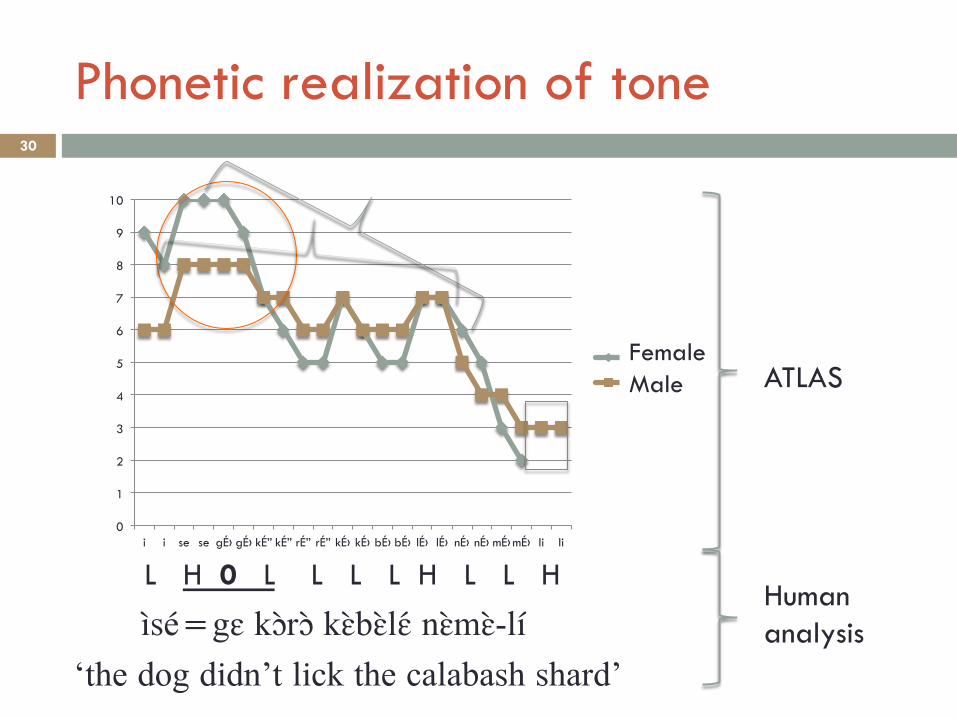
Phonetic realization of tone 30
L H 0 L L L L H L L H
ìsé=gɛ kɔ̀rɔ̀ kɛ̀bɛ̀lɛ́ nɛ̀mɛ̀-lí‘the dog didn’t lick the calabash shard’
Female Male
ATLAS
Human analysis

Confirming the literature 31
¨ Can be used in early stages of work to confirm descriptions in the literature
¨ Case study: Kwényï and Numèè (New Caledonia) ¨ Both languages are (probably) tonal, but neither
tone system well understood ¨ Rivierre (1973) reports Numèè and Kwényï are
mutually intelligible, but with opposite tone systems ¤ Numèè overall falling melodies ¤ Kwényï overall ascending (“plaintive”) melodies

Confirming the literature 32
¨ Created TextGrids for a Kwényï narrative recorded in 2016 and a recording of Numèè from the LACITO archives ¤ Both versions of a classic Melanesian “rat and the
octopus” story
¨ Ran ATLAS with 10 bins

Confirming the literature 33
Kwényï
Numèè

Confirming the literature 34
¨ Average beginning and end levels for intonational units confirms the literature
¨ Though Numèè typically rises before it falls ¨ Also an example of including tonal annotations for
Kwényï before tonal analysis is complete
Average sentence beginning level
Average sentence ending level
Numèè 3.9 2
Kwényï 2.7 5.7

Conclusions 35

Summary of ATLAS 36
¨ Semi-automated tool to produce broad phonetic tone transcriptions
¨ User-friendly, requiring no programming knowledge and no prior experience with tone
¨ Transcriptions can be imported into ELAN

Summary of ATLAS 37
¨ ATLAS is not meant to: ¤ Automate phonological analysis ¤ Replace the need for phonological analysis and
subsequent marking of tone
¨ Phonetic tonal annotations promote transparency and replicability ¤ Whether alongside phonological analysis or on their
own

Future development 38
¨ Fully automate, creating web and desktop versions ¤ Forced alignment (e.g. FAVE, Rosenfelder et al. 2011) ¤ Better interface with ELAN
¨ Optimization and development ¤ Outliers ¤ Doubling/halving ¤ Maintaining speaker databases across recordings
To download the beta version… 39
¨ Go to dartmouth.edu/~mcpherson and follow the link on the home page.

Acknowledgments 40
¨ We would like to thank the Dartmouth College Neukom Institute and Office of Undergraduate Advising and Research for financial support. Many thanks to our colleagues, particularly Jim Stanford, for helpful discussions and feedback in the development of this prototype.

References 41
Baken, Ronald. J. (1987). Clinical measurement of speech and voice. Boston: College Hill Press. Bird, Steven. 1994. Bird, S. (1994). Automated tone transcription. Retrieved from http://arxiv.org/
abs/cmp-lg/9410022 Bird, Steven and Haejoong Lee. 2014. Computational support for early elicitation and
classification of tone. LDC 8: 453-461. Cooper-Leavitt, J. E. (2016). A computational classification of Thai lexical tones. The Journal of the
Acoustical Society of America, 139(4), 2216–2216. Cruz, E., & Woodbury, A. C. (2014). Finding a way into a family of tone languages: The story and
methods of the Chatino language documentation project. Language Documentation & Conservation (Vol. 8).
Hart, Johan T., Collier, René, & Cohen, Antonie. (1990). A perceptual study of intonation: An experimental approach to speech melody. Cambridge: Cambridge University Press.
Liberman, M. and J. Pierrehumbert (1984) Intonational Invariance under Changes in Pitch Range and Length , in M. Aronoff and R. Oehrle, eds, Language Sound Structure, MIT Press, Cambridge MA. 157-233.
McPherson, Laura. 2011. Tonal underspecification and interpolation in Tommo So. MA Thesis, UCLA McPherson, Laura. 2013. A Grammar of Tommo So. Berlin: De Gruyter Mouton.

References 42
Rivierre, Jean-Claude. 1973. Phonologie comparée des dialectes de l’extrême-sud de la Nouvelle Calédonie. Paris: SELAF.
Rosenfelder, Ingrid, Josef Fruehwald, Keelan Evanini, and Jiahong Yuan. 2011. FAVE (Forced Alignment and Vowel Extraction) program suite. Software.
Ross, Elliott D., Edmondson, Jerold A., & Seibert, G. Burton. (1986). The effect of affect on various acoustic measures of prosody in tone and non-tone languages: A comparison based on computer analysis of voice. Journal of Phonetics 14(2):283–302.
Tan Lee, Ching, P. C., Chan, L. W., Cheng, Y. H., & Mak, B. (1995). Tone recognition of isolated Cantonese syllables. IEEE Transactions on Speech and Audio Processing, 3(3), 204–209.
Wu, Jiang, Zahorian, Stephen A., & Hu, Hongbing. (2013). Tone Recognition for Continuous Accented Mandarin Chinese. 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, 2013, pp. 7180-7183.
Xu, Yi (2004). Understanding tone from the perspective of production and perception. Language and Linguistics 5:757-97.
Yang, W.-J., Lee, J.-C., Chang, Y.-C., & Wang, H.-C. (1988). Hidden Markov model for Mandarin lexical tone recognition. IEEE Transactions on Acoustics, Speech, and Signal Processing, 36(7), 988–992.

Data Organization 43
¨ Calls Praat script from Python (uses praatIO module developed by Tim Mahrt)
¨ Automatically imports the results ¨ TokenList:
¤ Info (speaker id, etc.) ¤ Token1
n Info (e.g. # undefined tokens) n [Pitchentry1, Pitchentry2…]
¤ Token2 n Info n [Pitchentry1, Pitchentry2...]





























