Embed Size (px)
Citation preview

A Survey of Rollback-Recovery Protocols inMessage-Passing Systems
E. N. (MOOTAZ) ELNOZAHY
IBM Research
LORENZO ALVISI
The University of Texas at Austin
YI-MIN WANG
Microsoft Research
AND
DAVID B. JOHNSON
Rice University
This survey covers rollback-recovery techniques that do not require special languageconstructs. In the first part of the survey we classify rollback-recovery protocols intocheckpoint-based and log-based. Checkpoint-based protocols rely solely on checkpointingfor system state restoration. Checkpointing can be coordinated, uncoordinated, orcommunication-induced. Log-based protocols combine checkpointing with logging ofnondeterministic events, encoded in tuples called determinants. Depending on howdeterminants are logged, log-based protocols can be pessimistic, optimistic, or causal.Throughout the survey, we highlight the research issues that are at the core ofrollback-recovery and present the solutions that currently address them. We alsocompare the performance of different rollback-recovery protocols with respect to aseries of desirable properties and discuss the issues that arise in the practicalimplementations of these protocols.
Categories and Subject Descriptors: D.4.5 [Operating Systems]: Reliability—Checkpoint/restart; fault-tolerance; D.4.7 [Operating Systems]: Organization andDesign—Distributed systems; D.2.8 [Software]: Metrics—Performance measures;
General Terms: Design, Reliability, Performance
Additional Key Words and Phrases: message logging, rollback-recovery
Mootaz Elnozahy started this work while at Carnegie Mellon University, where he was supported in part bythe National Science Foundation through a Research Initiation Award under contract CCR 9410116 and aCAREER Award under contract CCR 9502933. Lorenzo Alvisi was supported in part by an NSF CAREERaward (CCR-9734185), an Alfred P. Sloan Fellowship, an IBM Faculty Partnership award, DARPA/SPAWARgrant N66001-98-8911, and a grant of the Texas Advanced Research Program.Authors’ addresses: E. N. (Mootaz) Elnozahy, IBM Austin Research Lab., M/S 904-6C-020, 11501 Burnet Rd.,Austin, TX 78578; email: [email protected]; Lorenzo Alvisi, Department of Computer Sciences, Taylor Hall2.124 The University of Texas at Austin, Austin, TX 78712-1188; email: [email protected]; Yi-Min Wang,Microsoft Corporation, One Microsoft Way, Redmond, WA 98052; email: [email protected]; David B.Johnson, Rice University, Department of Computer Science, 6100 Main St., MS 132, Houston, TX 77005-1892; email: [email protected] to make digital/hard copy of part or all of this work for personal or classroom use is grantedwithout fee provided that the copies are not made or distributed for profit or commercial advantage, thecopyright notice, the title of the publication, and its date appear, and notice is given that copying is bypermission of the ACM, Inc. To copy otherwise, to republish, to post on servers, or to redistribute to lists,requires prior specific permission and/or a fee.c©2002 ACM 0360-0300/02/0900-0375 $5.00
ACM Computing Surveys, Vol. 34, No. 3, September 2002, pp. 375–408.

376 Elnozahy et al.
1. INTRODUCTION
Distributed systems today are ubiqui-tous and enable many applications, in-cluding client-server systems, transactionprocessing, World Wide Web, and scien-tific computing, among many others. Thevast computing potential of these systemsis often hampered by their susceptibilityto failures. Therefore, many techniqueshave been developed to add reliabilityand high availability to distributed sys-tems. These techniques include transac-tions, group communication, and rollback-recovery, and have different tradeoffs andfocuses. For example, transactions focuson data-oriented applications, while groupcommunication offers an abstraction ofan ideal communication system that sim-plifies the development of reliable appli-cations. This survey covers transparentrollback-recovery, which focuses on long-running applications such as scientificcomputing and telecommunication appli-cations [Huang and Kintala 1993; Plank1993].
Rollback-recovery treats a distributedsystem as a collection of application pro-cesses that communicate through a net-work. The processes have access to a stablestorage device that survives all toleratedfailures. Processes achieve fault toleranceby using this device to save recovery in-formation periodically during failure-freeexecution. Upon a failure, a failed pro-cess uses the saved information to restartthe computation from an intermediatestate, thereby reducing the amount oflost computation. The recovery informa-tion includes, at a minimum, the statesof the participating processes, calledcheckpoints. Other recovery protocols mayrequire additional information, such aslogs of the interactions with input and out-put devices, events that occur to each pro-cess, and messages exchanged among theprocesses.
Rollback-recovery has many flavors. Forexample, a system may rely on the ap-plication to decide when and what tosave on stable storage. Or, it may providethe application programmer with linguis-tic constructs to structure the application
[Randell 1975]. We focus in this survey ontransparent techniques, which do not re-quire any intervention on the part of theapplication or the programmer. The sys-tem automatically takes checkpoints ac-cording to some specified policy, and re-covers automatically from failures if theyoccur. This approach has the advantagesof relieving the application programmersfrom the complex and error-prone choresof implementing fault tolerance and of of-fering fault tolerance to existing applica-tions written without consideration to re-liability concerns.
Rollback-recovery has been studiedin various forms and in connection withmany fields of research. Thus, it is per-haps impossible to provide an extensivecoverage of all the issues related torollback-recovery within the scope ofone article. This survey concentrateson the definitions, fundamental con-cepts, and implementation issues ofrollback-recovery protocols in distributedsystems. The coverage excludes the use ofrollback-recovery in many related fieldssuch as hardware-level instruction retry,distributed shared memory [Morin andPuaut 1997], real-time systems, and de-bugging [Mellor-Crummey and LeBlanc1989]. The coverage also excludes theissues of using rollback-recovery whenfailures could include Byzantine modes orare not restricted to the fail-stop model[Schlichting and Schneider 1983]. Alsoexcluded are rollback-recovery techniquesthat rely on special language constructssuch as recovery blocks [Randell 1975] andtransactions. Finally, the section on imple-mentation exposes many relevant issuesrelated to implementing checkpointing onuniprocessors, although the coverage isby no means an exhaustive one becauseof the large number of issues involved.
Message-passing systems complicaterollback-recovery because messages in-duce inter-process dependencies duringfailure-free operation. Upon a failureof one or more processes in a system,these dependencies may force some ofthe processes that did not fail to rollback, creating what is commonly calledrollback propagation. To see why rollback
ACM Computing Surveys, Vol. 34, No. 3, September 2002.

Rollback-Recovery Protocols in Message-Passing Systems 377
propagation occurs, consider the situationwhere a sender of a message m rolls backto a state that precedes the sending of m.The receiver of m must also roll back to astate that precedes m’s receipt; otherwise,the states of the two processes would beinconsistent because they would showthat message m was received withoutbeing sent, which is impossible in anycorrect failure-free execution. Undersome scenarios, rollback propagation mayextend back to the initial state of the com-putation, losing all the work performedbefore a failure. This situation is knownas the domino effect [Randell 1975].
The domino effect may occur ifeach process takes its checkpointsindependently—an approach known asindependent or uncoordinated checkpoint-ing. It is obviously desirable to avoidthe domino effect and therefore severaltechniques have been developed to pre-vent it. One such technique is to performcoordinated checkpointing in which pro-cesses coordinate their checkpoints inorder to save a system-wide consistentstate [Chandy and Lamport 1985]. Thisconsistent set of checkpoints can then beused to bound rollback propagation. Alter-natively, communication-induced check-pointing forces each process to takecheckpoints based on information pig-gybacked on the application messagesreceived from other processes [Russell1980]. Checkpoints are taken such thata system-wide consistent state alwaysexists on stable storage, thereby avoidingthe domino effect.
The approaches discussed so far imple-ment checkpoint-based rollback-recovery,which relies only on checkpoints toachieve fault-tolerance. In contrast, log-based rollback-recovery combines check-pointing with logging of nondeterministicevents.1 Log-based rollback-recovery re-lies on the piecewise deterministic (PWD)
1 Earlier papers in this area have assumed a modelin which the occurrence of a nondeterministic eventis modeled as a message receipt. In this model, non-deterministic event logging reduces to message log-ging. In this paper, we use the terms event loggingand message logging interchangeably.
assumption [Strom and Yemini 1985],which postulates that all nondeterminis-tic events that a process executes can beidentified and that the information neces-sary to replay each event during recoverycan be logged in the event’s determinant[Alvisi 1996; Alvisi and Marzullo 1998]. Bylogging and replaying the nondeterminis-tic events in their exact original order, aprocess can deterministically recreate itspre-failure state even if this state has notbeen checkpointed. Log-based rollback-recovery in general enables a system torecover beyond the most recent set of con-sistent checkpoints. It is therefore partic-ularly attractive for applications that fre-quently interact with the outside world,which consists of all input and outputdevices that cannot roll back. Log-basedrollback-recovery has three flavors, de-pending on how the determinants arelogged to stable storage. In pessimistic log-ging, the application has to block waitingfor the determinant of each nondetermin-istic event to be stored on stable storagebefore the effects of that event can beseen by other processes or the outsideworld. Pessimistic logging simplifies re-covery but hurts failure-free performance.In optimistic logging, the application doesnot block, and determinants are spooled tostable storage asynchronously. Optimisticlogging reduces the failure-free over-head, but complicates recovery. Finally, incausal logging, low failure-free overheadand simpler recovery are combined bystriking a balance between optimistic andpessimistic logging. The three flavors alsodiffer in their requirements for garbagecollection and their interactions with theoutside world, as will be explained later.
The outline of the rest of the survey isas follows:
r Section 2: System model, terminologyand generic issues in rollback-recovery.r Section 3: Checkpoint-based rollback-recovery protocols.r Section 4: Log-based rollback-recoveryprotocols.r Section 5: Implementation issues.r Section 6: Conclusions.
ACM Computing Surveys, Vol. 34, No. 3, September 2002.

378 Elnozahy et al.
Fig. 1 . An example of a message-passing systemwith three processes.
2. BACKGROUND AND DEFINITIONS
2.1. System Model
A message-passing system consists of afixed number of processes that communi-cate only through messages. Throughoutthis survey, we use N to denote the to-tal number of processes in a system. Pro-cesses cooperate to execute a distributedapplication program and interact with theoutside world by receiving and sendinginput and output messages, respectively.Figure 1 shows a sample system consist-ing of three processes, where horizontallines extending toward the right-hand siderepresent the execution of each process,and arrows between processes representmessages.
Rollback-recovery protocols generallyassume that the communication networkis immune to partitioning but differ inthe assumptions they make about net-work reliability. Some protocols assumethat the communication subsystem de-livers messages reliably, in first-in-first-out (FIFO) order [Chandy and Lamport1985], while other protocols assume thatthe communication subsystem can lose,duplicate, or reorder messages [Johnson1989]. The choice between these two as-sumptions usually affects the complexityof recovery and its implementation in dif-ferent ways. Generally, assuming a reli-able network simplifies the design of therecovery protocol but introduces imple-mentation complexities that will be de-scribed in Sections 2.3, 2.4 and 5.4.2.
A process execution is a sequence ofstate intervals, each started by a nonde-terministic event. Execution during eachstate interval is deterministic, such that ifa process starts from the same state and
is subjected to the same nondeterministicevents at the same locations within the ex-ecution, it will always yield the same out-put. A concept related to the state intervalis the piecewise deterministic assumption(PWD). This assumption states that thesystem can detect and capture sufficientinformation about the nondeterministicevents that initiate the state intervals.
A process may fail, in which case it losesits volatile state and stops execution ac-cording to the fail-stop model [Schlichtingand Schneider 1983]. Processes have ac-cess to a stable storage device that sur-vives failures, such that state informationsaved on this device during failure-free ex-ecution can be used for recovery. The num-ber of tolerated process failures may varyfrom 1 to N , and the recovery protocolneeds to be designed accordingly. Further-more, some protocols may not tolerate fail-ures that occur during recovery.
A generic correctness condition forrollback-recovery can be defined as fol-lows: “A system recovers correctly ifits internal state is consistent with theobservable behavior of the system beforethe failure” [Strom and Yemini 1985].Rollback-recovery protocols thereforemust maintain information about the in-ternal interactions among processes andalso the external interactions with the out-side world. A description of the notion ofconsistency and the interactions with theoutside world follows.
2.2. Consistent System States
A global state of a message-passing systemis a collection of the individual states of allparticipating processes and of the states ofthe communication channels. Intuitively,a consistent global state is one that mayoccur during a failure-free, correct execu-tion of a distributed computation. Moreprecisely, a consistent system state is onein which, if the state of a process reflectsa message receipt, then the state of thecorresponding sender reflects sendingthat message [Chandy and Lamport1985]. For example, Figure 2 shows twoexamples of global states—a consistentstate in Figure 2(a), and an inconsistent
ACM Computing Surveys, Vol. 34, No. 3, September 2002.

Rollback-Recovery Protocols in Message-Passing Systems 379
Fig. 2 . An example of a consistent and inconsistentstate.
state in Figure 2(b). Note that the consis-tent state in Figure 2(a) shows messagem1 to have been sent but not yet received.This state is consistent, because it repre-sents a situation in which the message hasleft the sender and is still traveling acrossthe network. On the other hand, the statein Figure 2(b) is inconsistent becauseprocess P2 is shown to have received m2but the state of process P1 does not reflectsending it. Such a state is impossible inany failure-free, correct computation. In-consistent states occur because of failures.For example, the situation shown in part(b) of Figure 2 may occur if process P1 failsafter sending message m2 to P2 and thenrestarts at the state shown in the figure.
A fundamental goal of any rollback-recovery protocol is to bring the systeminto a consistent state when inconsisten-cies occur because of a failure. The recon-structed consistent state is not necessarilyone that has occurred before the failure. Itis sufficient that the reconstructed statebe one that could have occurred before thefailure in a failure-free, correct execution,provided that it be consistent with the in-teractions that the system had with theoutside world. We describe these interac-tions next.
2.3. Interactions with the Outside World
A message-passing system often interactswith the outside world to receive inputdata or show the outcome of a computa-tion. If a failure occurs, the outside worldcannot be relied on to roll back [Pausch1988]. For example, a printer cannot rollback the effects of printing a character,and an automatic teller machine cannotrecover the money that it dispensed to acustomer. To simplify the presentation of
how rollback-recovery protocols interactwith the outside world, we model the latteras a special process that interacts with therest of the system through message pass-ing. This special process cannot fail, and itcannot maintain state or participate in therecovery protocol. Furthermore, since thisspecial process models irreversible effectsin the outside world, it cannot roll back.We call this special process the “outsideworld process” (OWP).
It is necessary that the outside worldperceive a consistent behavior of the sys-tem despite failures. Thus, before send-ing a message (output) to OWP, the sys-tem must ensure that the state from whichthe message is sent will be recovered de-spite any future failure. This is commonlycalled the output commit problem [Stromand Yemini 1985]. Similarly, input mes-sages that a system receives from the out-side world may not be reproducible duringrecovery, because it may not be possiblefor OWP to regenerate them. Thus, recov-ery protocols must arrange to save theseinput messages so that they can be re-trieved when needed for execution replayafter a failure. A common approach is tosave each input message on stable storagebefore allowing the application program toprocess it.
Rollback-recovery protocols, therefore,must provide special treatment for inter-actions with the outside world. There aretwo metrics that express the impact of thisspecial treatment, namely the latency ofinput/output and the resulting slowdownof system’s execution during input/output.The first metric represents the time ittakes for an output message to be releasedto OWP after it has been issued by the sys-tem, or the time it takes a process to con-sume an input message after it has beensent from OWP. The second metric repre-sents the overhead that the system incursto ensure that its state will remain con-sistent with the messages exchanged withthe OWP despite future failures.
2.4. In-Transit Messages
In Figure 2(a), the global state showsthat message m1 has been sent but not
ACM Computing Surveys, Vol. 34, No. 3, September 2002.

380 Elnozahy et al.
Fig. 3 . Implementation of rollback-recovery (a) ontop of a reliable communication protocol; (b) directlyon top of unreliable communication channels.
yet received. We call such a message anin-transit message. When in-transit mes-sages are part of a global system state,they do not cause any inconsistency. How-ever, depending on whether the systemmodel assumes reliable communicationchannels, rollback-recovery protocols mayhave to guarantee the delivery of in-transit messages when failures occur. Forexample, the rollback-recovery protocol inFigure 3(a) assumes reliable communi-cations, and therefore it must be imple-mented on top of a reliable communicationprotocol layer. In contrast, the rollback-recovery protocol in Figure 3(b) does notassume reliable communications.
Reliable communication protocols en-sure the reliability of message deliveryduring failure-free executions. Theycannot, however, ensure by themselves,the reliability of message delivery in thepresence of process failures. For instance,if an in-transit message is lost because theintended receiver has failed, conventionalcommunication protocols will generatea timeout and inform the sender thatthe message cannot be delivered. In arollback-recovery system, however, the re-ceiver will eventually recover. Therefore,the system must mask the timeout fromthe application program at the sender pro-cess and must make in-transit messagesavailable to the intended receiver processafter it recovers, in order to ensure aconsistent view of the reliable system. Onthe other hand, if a system model assumesunreliable communication channels, asin Figure 3(b), then the recovery protocolneed not handle in-transit messages
in any special way. Indeed, in-transitmessages lost because of process failurescannot be distinguished from those lost be-cause of communication failures in an un-reliable communication channel. There-fore, the loss of in-transit messages due toeither communication or process failure isan event that can occur in any failure-free,correct execution of the system.
2.5. Logging Protocols
Log-based rollback-recovery uses check-pointing and logging to enable processesto replay their execution after a failure be-yond the most recent checkpoint. This isuseful when interactions with the outsideworld are frequent, since it enables a pro-cess to repeat its execution and be consis-tent with messages sent to OWP withouthaving to take expensive checkpoints be-fore sending such messages. Additionally,log-based recovery generally is not suscep-tible to the domino effect, thereby allow-ing processes to use uncoordinated check-pointing if desired.
Log-based recovery relies on the piece-wise deterministic (PWD) assumption[Strom and Yemini 1985]. Under thisassumption, the rollback-recovery proto-col can identify all the nondeterminis-tic events executed by each process, andfor each such event, logs a determinantthat contains all information necessary toreplay the event should it be necessaryduring recovery. If the PWD assumptionholds, log-based rollback-recovery proto-cols can recover a failed process and re-play its execution as it occurred before thefailure.
Examples of nondeterministic events in-clude receiving messages, receiving in-put from the outside world, or undergoingan internal state transfer within a pro-cess based on some nondeterministic ac-tion such as the receipt of an interrupt.Rollback-recovery implementations differin the range of actual nondeterministicevents that are covered under this model.For instance, a particular implementa-tion may only cover message receipts fromother processes under the PWD assump-tion. Such an implementation cannot
ACM Computing Surveys, Vol. 34, No. 3, September 2002.

Rollback-Recovery Protocols in Message-Passing Systems 381
Fig. 4 . Message logging for deterministic replay.
replay an execution that is subjected toother forms of nondeterministic eventssuch as asynchronous interrupts. Therange of events covered under the PWD as-sumption is an implementation issue andis covered in Section 5.7.
A state interval is recoverable if thereis sufficient information to replay the ex-ecution up to that state interval despiteany future failures in the system. Also, astate interval is stable if the determinantof the nondeterministic event that startedit is logged on stable storage [Johnson andZwaenepoel 1990]. A recoverable state in-terval is always stable, but the opposite isnot always true [Johnson 1989].
Figure 4 shows an execution in whichthe only nondeterministic events are mes-sage deliveries. Suppose that processes P1and P2 fail before logging the determi-nants corresponding to the deliveries ofm6 and m5, respectively, while all otherdeterminants survive the failure. Messagem7 becomes an orphan message becauseprocess P2 cannot guarantee the regen-eration of the same m6 during recovery,and P1 cannot guarantee the regenerationof the same m7 without the original m6.As a result, the surviving process P0 be-comes an orphan process and is forced toroll back as well. States X , Y and Z formthe maximum recoverable state [Johnson1989], that is, the most recent recover-able consistent system state. Processes P0and P2 roll back to checkpoints A and C,respectively, and replay the deliveries ofmessages m4 and m2, respectively, to reachstates X and Z . Process P1 rolls back tocheckpoint B and replays the deliveries ofm1 and m3 in their original order to reachstate Y .
During recovery, log-based rollback-recovery protocols force the execution ofthe system to be identical to the one thatoccurred before the failure, up to the maxi-mum recoverable state. Therefore, the sys-tem always recovers to a state that isconsistent with the input and output inter-actions that occurred up to the maximumrecoverable state.
2.6. Stable Storage
Rollback-recovery uses stable storage tosave checkpoints, event logs, and otherrecovery-related information. Stable stor-age in rollback-recovery is only an abstrac-tion, although it is often confused with thedisk storage used to implement it. Sta-ble storage must ensure that the recoverydata persist through the tolerated failuresand their corresponding recoveries. Thisrequirement can lead to different imple-mentation styles of stable storage:
r In a system that tolerates only a singlefailure, stable storage may consist of thevolatile memory of another process [Borget al. 1989; Johnson and Zwaenepoel1987].r In a system that wishes to tolerate an ar-bitrary number of transient failures, sta-ble storage may consist of a local disk ineach host.r In a system that tolerates non-transientfailures, stable storage must consist of apersistent medium outside the host onwhich a process is running. A replicatedfile system is a possible implementationin such systems [Lampson and Sturgis1979].
2.7. Garbage Collection
Checkpoints and event logs consume stor-age resources. As the application pro-gresses and more recovery informationis collected, a subset of the stored in-formation may become useless for recov-ery. Garbage collection is the deletion ofsuch useless recovery information. A com-mon approach to garbage collection is toidentify the most recent consistent set ofcheckpoints, which is called the recovery
ACM Computing Surveys, Vol. 34, No. 3, September 2002.

382 Elnozahy et al.
line [Randell 1975], and discard all infor-mation relating to events that occurredbefore that line. For example, processesthat coordinate their checkpoints to formconsistent states will always restart fromthe most recent checkpoint of each pro-cess, and so all previous checkpoints canbe discarded. While it has received lit-tle attention in the literature, garbagecollection is an important pragmatic is-sue in rollback-recovery protocols, becauserunning a special algorithm to discarduseless information incurs overhead. Fur-thermore, recovery-protocols differ in theamount and nature of the recovery infor-mation they need to store on stable stor-age, and therefore differ in the complexityand invocation frequency of their garbagecollection algorithms.
3. CHECKPOINT-BASED ROLLBACKRECOVERY
Upon a failure, checkpoint-based rollback-recovery restores the system state to themost recent consistent set of checkpoints,that is the recovery line [Randell 1975].It does not rely on the PWD assump-tion, and so does not need to detect,log, or replay nondeterministic events.Checkpoint-based protocols are thereforeless restrictive and simpler to imple-ment than log-based rollback-recovery.But checkpoint-based rollback-recoverydoes not guarantee that pre-failure execu-tion can be deterministically regeneratedafter a rollback. Therefore, checkpoint-based rollback-recovery is ill suited for ap-plications that require frequent interac-tions with the outside world, since suchinteractions require that the observablebehavior of the system through failuresand recoveries be the same as during afailure-free execution. Checkpoint-basedrollback-recovery techniques can be clas-sified into three categories: uncoordinatedcheckpointing, coordinated checkpointing,and communication-induced checkpoint-ing. We examine each category in detail.
3.1. Uncoordinated Checkpointing
3.1.1. Overview. Uncoordinated check-pointing allows each process the maxi-
Fig. 5 . Checkpoint index and checkpoint interval.
mum autonomy in deciding when to takecheckpoints. The main advantage of thisautonomy is that each process may takea checkpoint when it is most convenient.For example, a process may reduce theoverhead by taking checkpoints when theamount of state information to be saved issmall [Wang 1993]. But there are severaldisadvantages. First, there is the possibil-ity of the domino effect, which may causethe loss of a large amount of useful work,possibly all the way back to the beginningof the computation. Second, a process maytake a useless checkpoint that will neverbe part of a global consistent state. Use-less checkpoints are undesirable becausethey incur overhead and do not contributeto advancing the recovery line. Third, un-coordinated checkpointing forces each pro-cess to maintain multiple checkpoints, andto periodically invoke a garbage collectionalgorithm to reclaim the checkpoints thatare no longer useful. Fourth, it is not suit-able for applications with frequent out-put commits because these require globalcoordination to compute the recoveryline, negating much of the advantage ofautonomy.
In order to determine a consistentglobal checkpoint during recovery, the pro-cesses record the dependencies amongtheir checkpoints during failure-free op-eration using the following technique[Bhargava and Lian 1988]. Let ci,xbe the xthe checkpoint of process Pi. We call x thecheckpoint index. Let Ii,xdenote the check-point interval or simply interval betweencheckpoints ci,x−1 and ci,x . As illustrated inFigure 5, if process Pi at interval Ii,xsendsa message m to Pj , it will piggyback thepair (i, x) on m. When Pj receives m dur-ing interval I j , y , it records the dependencyfrom Ii,xto I j , y , which is later saved onto
ACM Computing Surveys, Vol. 34, No. 3, September 2002.

Rollback-Recovery Protocols in Message-Passing Systems 383
Fig. 6 . (a) Example execution; (b) rollback-dependency graph; (c) check-point graph.
stable storage when Pj takes checkpointc j , y .
If a failure occurs, the recovering pro-cess initiates rollback by broadcasting adependency request message to collect allthe dependency information maintainedby each process. When a process receivesthis message, it stops its execution andreplies with the dependency informationsaved on stable storage as well as with thedependency information, if any, that is as-sociated with its current state. The initia-tor then calculates the recovery line basedon the global dependency information andbroadcasts a rollback request message con-taining the recovery line. Upon receiv-ing this message, a process whose currentstate belongs to the recovery line simplyresumes execution; otherwise it rolls backto an earlier checkpoint as indicated by therecovery line.
3.1.2. Dependency Graphs and RecoveryLine Calculation. There are two approachesproposed in the literature to determinethe recovery line in checkpoint-based re-covery. The first approach is based on arollback-dependency graph [Bhargava andLian 1988] in which each node representsa checkpoint and a directed edge is drawnfrom ci,x to c j , y if either:
(1) i 6= j , and a message m is sent from Ii,xand received in I j , y , or
(2) i= j and y = x+ 1.
The name “rollback-dependency graph”comes from the observation that if thereis an edge from ci,x to c j , y and a failureforces Ii,x to be rolled back, then I j , y mustalso be rolled back.
Figure 6(b) shows the rollback de-pendency graph for the execution inFigure 6(a). The algorithm used to com-pute the recovery line first marks thegraph nodes corresponding to the statesof processes P0 and P1 at the failure point(shown in figure in dark ellipses). It thenuses reachability analysis [Bhargava andLian 1988] to mark all reachable nodesfrom any of the initially marked nodes.The union of the last unmarked nodesover the entire system forms the recoveryline, as shown in Figure 6(b).
The second approach is based on thecheckpoint graph [Wang 1993]. Check-point graphs are similar to rollback-dependency graphs except that, when amessage is sent from Ii,xand received inI j , y , a directed edge is drawn from ci,x−1to c j , y (instead of ci,x to c j , y ), as shown inFigure 6(c). The recovery line can be cal-culated by first removing both the nodes
ACM Computing Surveys, Vol. 34, No. 3, September 2002.

384 Elnozahy et al.
Fig. 7 . Rollback propagation, recovery line and thedomino effect.
corresponding to the states of the failedprocesses at the point of failures and theedges incident on them, and then applyingthe rollback propagation algorithm [Wang1993] on the checkpoint graph. Both therollback-dependency graph and the check-point graph approaches are equivalent, inthat they always produce the same recov-ery line (as indeed they do in the exam-ple). These methods form the basis for per-forming garbage collection in independentcheckpointing, by determining the mostadvanced recovery line and removing thecheckpoints that precede it [Wang 1993].Additionally, some checkpoints taken in-dependently by a process may never bepart of a consistent state and therefore willbe useless for recovery purposes. Thesecheckpoints also can be removed using thealgorithm described by Wang [1993]. Fi-nally, it can be shown under independentcheckpointing that the maximum numberof useful checkpoints that must be kept onstable storage cannot exceed (N (N+1)/2)[Wang et al. 1995a].
3.1.3. The Domino Effect. While sim-ple to implement, uncoordinated check-pointing can lead to the domino effect[Randell 1975]. For example, Figure 7shows an execution in which processestake their checkpoints—represented byblack bars—without coordinating witheach other. Each process starts its execu-tion with an initial checkpoint. Supposeprocess P2 fails and rolls back to check-point C. The rollback “invalidates” thesending of message m6, and so P1 must rollback to checkpoint B to “invalidate” thereceipt of that message. Thus, the invali-dation of message m6 propagates the roll-
back of process P2 to process P1, which inturn “invalidates” message m7 and forcesP0 to roll back as well.
This cascaded rollback may continueand eventually may lead to the domino ef-fect, which causes the system to roll backto the beginning of the computation, inspite of all the saved checkpoints. In theexample shown in Figure 7, cascading roll-backs due to the single failure of processP2 forces the system to restart from theinitial set of checkpoints, effectively caus-ing the loss of all the work done by allprocesses.
3.2. Coordinated Checkpointing
3.2.1. Overview. Coordinated check-pointing requires processes to orchestratetheir checkpoints in order to form aconsistent global state. Coordinatedcheckpointing simplifies recovery and isnot susceptible to the domino effect, sinceevery process always restarts from itsmost recent checkpoint. Also, coordinatedcheckpointing requires each process tomaintain only one permanent check-point on stable storage, reducing storageoverhead and eliminating the need forgarbage collection. Its main disadvantage,however, is the large latency involvedin committing output, since a globalcheckpoint is needed before messages canbe sent to OWP.
A straightforward approach to coordi-nated checkpointing is to block communi-cations while the checkpointing protocolexecutes [Tamir and Sequin 1984]. A coor-dinator takes a checkpoint and broadcastsa request message to all processes, askingthem to take a checkpoint. When a processreceives this message, it stops its execu-tion, flushes all the communication chan-nels, takes a tentative checkpoint, andsends an acknowledgment message backto the coordinator. After the coordinatorreceives acknowledgments from all pro-cesses, it broadcasts a commit messagethat completes the two-phase checkpoint-ing protocol. After receiving the commitmessage, each process removes the old per-manent checkpoint and atomically makesthe tentative checkpoint permanent. The
ACM Computing Surveys, Vol. 34, No. 3, September 2002.

Rollback-Recovery Protocols in Message-Passing Systems 385
Fig. 8 . Non-blocking coordinated checkpointing: (a) checkpoint inconsis-tency; (b) with FIFO channels; (c) non-FIFO channels (short dashed line rep-resents piggybacked checkpoint request).
process is then free to resume execu-tion and exchange messages with otherprocesses. This straightforward approach,however, can result in large overhead,and therefore non-blocking checkpointingschemes are preferable [Elnozahy et al.1992].
3.2.2. Non-blocking Checkpoint Coordination.A fundamental problem in coordinatedcheckpointing is to prevent a process fromreceiving application messages that couldmake the checkpoint inconsistent. Con-sider the example in Figure 8(a), in whichmessage m is sent by P0 after receiv-ing a checkpoint request from the check-point coordinator. Now, assume that mreaches P1 before the checkpoint request.This situation results in an inconsistentcheckpoint since checkpoint c1,x shows thereceipt of message m from P0, while check-point c0,x does not show it being sent fromP0. If channels are FIFO, this problemcan be avoided by preceding the first post-checkpoint message on each channel bya checkpoint request, and forcing eachprocess to take a checkpoint upon receiv-ing the first checkpoint-request message,as illustrated in Figure 8(b). An exam-ple of a non-blocking checkpoint coordi-nation protocol using this idea is the dis-tributed snapshot [Chandy and Lamport1985], in which markers play the role ofthe checkpoint-request messages. In thisprotocol, the initiator takes a checkpointand broadcasts a marker (a checkpointrequest) to all processes. Each processtakes a checkpoint upon receiving the firstmarker and rebroadcasts the marker to all
processes before sending any applicationmessage. The protocol works assuming thechannels are reliable and FIFO. If thechannels are non-FIFO, the marker canbe piggybacked on every post-checkpointmessage as in Figure 8(c) [Lai and Yang1987]. Alternatively, checkpoint indicescan serve the same role as markers, wherea checkpoint is triggered when the re-ceiver’s local checkpoint index is lowerthan the piggybacked checkpoint index[Elnozahy, et al. 1992; Silva 1997].
3.2.3. Checkpointing with SynchronizedClocks. Loosely synchronized clockscan facilitate checkpoint coordination[Cristian and Jahanian 1991; Tong etal. 1992]. More specifically, loosely syn-chronized clocks can trigger the localcheckpointing actions of all participatingprocesses at approximately the same timewithout a checkpoint initiator [Cristianand Jahanian 1991]. A process takes acheckpoint and waits for a period thatequals the sum of the maximum deviationbetween clocks and the maximum timeto detect a failure in another process inthe system. The process can be assuredthat all checkpoints belonging to thesame coordination session have beentaken without the need of exchanging anymessages. If a failure occurs, it is detectedwithin the specified time and the protocolis aborted.
3.2.4. Checkpointing and CommunicationReliability. Depending on the assumptionof reliability of the communication chan-nel (Section 2.4), the protocol may require
ACM Computing Surveys, Vol. 34, No. 3, September 2002.

386 Elnozahy et al.
some messages to be saved as part ofthe checkpoint. Consider the case wherereliable channels are assumed. Supposeprocess p sends a message m beforetaking a checkpoint, and that messagem arrives at the intended destination atprocess q after q has taken its checkpoint.In this case, the recorded state of p wouldshow message m to have been sent, whileq′s state would show that the messagehas not been received. If a failure were toforce p and q to roll back to thesecheckpoints, it would be impossible toguarantee the reliable delivery of m afterrecovery. To avoid this problem, the pro-tocol requires that all in-transit messagesbe saved by their intended destinationsas part of their recorded state. However,if reliable channels are not assumed, thenin-transit messages need not be saved, asthe recorded state in this case would stillbe consistent with the assumption of thecommunication channels (in this case, theloss of message m if the system fails andrestarts would be equivalent to its lossdue to a communication failure in a legalexecution).
3.2.5. Minimal Checkpoint Coordination.Coordinated checkpointing requiresall processes to participate in everycheckpoint. This requirement generatesvalid concerns about its scalability. Itis desirable to reduce the number ofprocesses involved in a coordinatedcheckpointing session. This can be donesince the processes that need to takenew checkpoints are only those thathave communicated with the checkpointinitiator either directly or indirectly sincethe last checkpoint [Koo and Toueg 1987].
The following two-phase protocolachieves minimal checkpoint coordi-nation [Koo and Toueg 1987]. Duringthe first phase, the checkpoint initiatoridentifies all processes with which it hascommunicated since the last checkpointand sends them a request. Upon receivingthe request, each process in turn iden-tifies all processes it has communicatedwith since the last checkpoints and sendsthem a request, and so on, until no more
Fig. 9 . Z-paths Z cycles.
processes can be identified. During thesecond phase, all processes identified inthe first phase take a checkpoint. Theresult is a consistent checkpoint thatinvolves only the participating processes.In this protocol, after a process takes acheckpoint, it cannot send any messageuntil the second phase terminates suc-cessfully, although receiving a messageafter the checkpoint has been taken isallowed.
3.3. Communication-induced Checkpointing
3.3.1. Overview. Communication-induced checkpointing (CIC) protocolsavoid the domino effect without requiringall checkpoints to be coordinated. Inthese protocols, processes take two kindsof checkpoints, local and forced. Localcheckpoints can be taken independently,while forced checkpoint must be taken toguarantee the eventual progress of therecovery line. In particular, CIC protocolstake forced checkpoints to prevent thecreation of useless checkpoints, that ischeckpoints (such as c2,2 in Figure 9) thatwill never be part of a consistent globalstate. Useless checkpoints are not desir-able because they do not contribute tothe recovery of the system from failures,but they consume resources and causeperformance overhead.
As opposed to coordinated checkpoint-ing, CIC protocols do not exchange anyspecial coordination messages to deter-mine when forced checkpoints should betaken: instead, they piggyback protocol-specific information on each applicationmessage; the receiver then uses this in-formation to decide if it should take aforced checkpoint. Informally, this deci-sion is based on the receiver determin-ing if past communication and checkpoint
ACM Computing Surveys, Vol. 34, No. 3, September 2002.

Rollback-Recovery Protocols in Message-Passing Systems 387
patterns can lead to the creation of uselesscheckpoints: a forced checkpoint is thentaken to break these patterns. This intu-ition has been formalized in an eleganttheory based on the notions of Z-path andZ-cycle.
A Z-path (zigzag path) is a special se-quence of messages that connects twocheckpoints [Netzer and Xu 1995]. Let 7→denote Lamport’s happen-before relation[Lamport 1978]. Let ci,x denote the xth
checkpoint of process Pi. Also, define theexecution portion between two consecu-tive checkpoints on the same process to bethe checkpoint interval starting with theearlier checkpoint. Given two checkpointsci,x and c j , y , a Z-path exists between ci,xand c j , y if and only if one of the followingtwo conditions holds:
1. x< y and i= j ; or2. There exists a sequence of messages
[m0, m1, . . . , mn], nµ 0, such that:r ci,x 7→ sendi(m0);r ∀l <n, either deliverk(ml ) andsendk(ml+1) are in the same check-point interval, or deliverk(ml ) 7→sendk(ml+1); andr deliver j (mn) 7→ c j , y
where sendi and deliveri are communi-cation events executed by process Pi. InFigure 9, [m1, m2] and [m3, m4] are exam-ples of Z-paths between checkpoints c0,1and c2,2.
A Z-cycle is a Z-path that beginsand ends with the same checkpoint. InFigure 9, the Z-path [m5, m3, m4] is aZ-cycle that starts and ends at checkpointc2,2. Z-cycles are interesting in the contextof CIC protocols because it can be provedthat a checkpoint is useless if and only if itis part of a Z-cycle [Netzer and Xu 1995].Hence, one way to avoid useless check-points is to make sure that no Z-path everbecomes a Z-cycle.
Traditionally, CIC protocols have beenclassified in one of two types. Model-basedcheckpointing protocols maintain check-point and communication structures thatprevent useless checkpoints or achievesome even stronger properties [Wang1997]. Index-based coordination protocols
assign timestamps to local and forcedcheckpoints such that checkpoints withthe same timestamp at all processes forma consistent state. Recently, it has beenproved that the two types are fundamen-tally equivalent [Helary et al. 1997a],although in practice, there may be someevidence that index-based coordination re-sults in fewer forced checkpoints [Alvisiet al. 1999].
3.3.2. Model-based Protocols. Model-based checkpointing relies on preventingpatterns of communications and check-points that could result in Z-cycles anduseless checkpoints. A model is set up todetect the possibility that such patternscould be forming within the system, ac-cording to some heuristic. A checkpoint isusually forced to prevent the undesirablepatterns from occurring. The decision toforce a checkpoint is done locally using theinformation piggybacked on applicationmessages. Therefore, under this style ofcheckpointing it is possible that multipleprocesses detect the potential for inconsis-tent checkpoints and independently forcelocal checkpoints to prevent the formationof undesirable patterns that may neveractually materialize or that could beprevented by a single forced checkpoint.Thus, model-based checkpointing alwayserrs on the conservative side by takingmore forced checkpoints than is proba-bly necessary, because without explicitcoordination, no process has completeinformation about the global system state.
The literature contains several domino-effect-free checkpoint and communica-tion models. The MRS model [Russell1980] avoids the domino effect by ensur-ing that within every checkpoint inter-val all message-receiving events precedeall message-sending events. This modelcan be maintained by taking an addi-tional checkpoint before every message-receiving event that is not separated fromits previous message-sending event bya checkpoint [Wang 1997]. Another wayto prevent the domino effect is to avoidrollback propagation completely by tak-ing a checkpoint immediately before every
ACM Computing Surveys, Vol. 34, No. 3, September 2002.

388 Elnozahy et al.
message-sending event [Bartlett 1981].Recent work has focused on ensuring thatevery checkpoint can belong to a consis-tent global checkpoint and therefore is notuseless [Baldoni et al. 1998; Helary et al.1997a; Helary et al. 1997b; Netzer and Xu1995].
3.3.3. Index-based Protocols. Index-based CIC protocols guarantee, throughforced checkpoints if necessary, that (1)if there are two checkpoints ci,m andc j ,n such that ci,m 7→ c j ,n, then ts(c j ,n)≥ts(ci,m), where ts(c) is the timestampassociated with checkpoint c; and (2)consecutive local checkpoints of a pro-cess have increasing timestamps. Thetimestamps are piggybacked on applica-tion messages to help receivers decidewhen they should force a checkpoint. Forinstance, the protocol by Briatico et al.forces a process to take a checkpoint uponreceiving a message with a piggybackedindex greater than the local index, andguarantees that the checkpoints havingthe same index at different processes,form a consistent state [Briatico et al.1984]. Helary et al. instead rely on theobservation that if checkpoints’ times-tamps always increase along a Z-path(as opposed to simply non-decreasing, asrequired by rule (1) above), then no Z-cycle can ever form [Helary et al. 1997b].More sophisticated protocols piggybackmore information on top of applicationmessages to minimize the number offorced checkpoints [Helary et al. 1997b].
CIC protocols can potentially have sev-eral performance advantages over otherstyles of checkpointing. Because CIC al-lows considerable autonomy in decidingwhen to take checkpoints, processes cantake local checkpoints when their state issmall and saving it incurs a small over-head [Li and Fuchs 1990; Plank et al.1995b]. CIC protocols may also, in theory,scale up well in systems with a large num-ber of processes, since they do not requireprocesses to participate in a globally coor-dinated checkpoint. We discuss the degreeto which these advantages materialize inpractice in Section 5.
4. LOG-BASED ROLLBACK-RECOVERY
As opposed to checkpoint-based rollback-recovery, log-based rollback-recoverymakes explicit use of the fact that aprocess execution can be modeled as asequence of deterministic state inter-vals, each starting with the executionof a nondeterministic event [Strom andYemini 1985]. Such an event can be thereceipt of a message from another pro-cess or an event internal to the process.Sending a message, however, is not anondeterministic event. For example, inFigure 7, the execution of process P0 is asequence of four deterministic intervals.The first one starts with the creation ofthe process, while the remaining threestart with the receipt of messages m0, m3,and m7, respectively. Sending message m2is uniquely determined by the initial stateof P0 and by the receipt of message m0,and is therefore not a nondeterministicevent.
Log-based rollback-recovery assumesthat all nondeterministic events can beidentified and their corresponding deter-minants can be logged to stable storage.During failure-free operation, each pro-cess logs the determinants of all the non-deterministic events that it observes ontostable storage. Additionally, each processalso takes checkpoints to reduce the ex-tent of rollback during recovery. Aftera failure occurs, the failed processes re-cover by using the checkpoints and loggeddeterminants to replay the correspond-ing nondeterministic events precisely asthey occurred during the pre-failure exe-cution. Because execution within each de-terministic interval depends only on thesequence of nondeterministic events thatpreceded the interval’s beginning, the pre-failure execution of a failed process canbe reconstructed during recovery up to thefirst nondeterministic event whose deter-minant is not logged.
Log-based rollback-recovery protocolshave been traditionally called “messagelogging protocols.” The association of non-deterministic events with messages isrooted in the earliest systems that pro-posed and implemented this style of
ACM Computing Surveys, Vol. 34, No. 3, September 2002.

Rollback-Recovery Protocols in Message-Passing Systems 389
recovery [Bartlett 1981; Borg, et al. 1989;Strom and Yemini 1985]. These systemstranslated nondeterministic events intodeterministic message-receipt events.
Log-based rollback-recovery protocolsguarantee that upon recovery of all failedprocesses, the system does not contain anyorphan process, that is, a process whosestate depends on a nondeterministic eventthat cannot be reproduced during recov-ery. The way in which a specific protocolimplements this condition affects the pro-tocol’s failure-free performance overhead,latency of output commit, and simplicityof recovery and garbage collection, as wellas its potential for rolling back correct pro-cesses. There are three flavors of theseprotocols:r Pessimistic log-based rollback-recovery
protocols guarantee that orphans arenever created due to a failure. These pro-tocols simplify recovery, garbage collec-tion and output commit, at the expenseof higher failure-free performance over-head.r Optimistic log-based rollback-recoveryprotocols reduce the failure-free perfor-mance overhead, but allow orphans to becreated due to failures. The possibilityof having orphans complicates recovery,garbage collection and output commit.r Causal log-based rollback-recovery pro-tocols attempt to combine the advan-tages of low performance overhead andfast output commit, but they may re-quire complex recovery and garbagecollection.
We present log-based rollback-recoveryprotocols by first specifying a propertythat guarantees that no orphans are cre-ated during an execution, and then by dis-cussing how the three major classes oflog-based rollback-recovery protocols im-plement this consistency condition.
4.1. The No-Orphans Consistency Condition
Let e be a nondeterministic event that oc-curs at process p, we define:r Depend(e), the set of processes that are
affected by a nondeterministic event e.
This set consists of p, and any processwhose state depends on the event e ac-cording to Lamport’s happened before re-lation [Lamport 1978].r Log(e), the set of processes that havelogged a copy of e’s determinant in theirvolatile memory.r Stable(e), a predicate that is true if e’sdeterminant is logged on stable storage.
A process p becomes an orphan when p it-self does not fail and p’s state depends onthe execution of a nondeterministic evente whose determinant cannot be recoveredfrom stable storage or from the volatilememory of a surviving process. Formally[Alvisi 1996]:
∀e : ¬Stable(e)⇒ Depend(e) ⊆ Log(e)
We call this property the always-no-orphans condition. It stipulates that if anysurviving process depends on an event e,then either the event is logged on stablestorage, or the process has a copy of thedeterminant of event e. If neither condi-tion is true, then the process is an orphanbecause it depends on an event e that can-not be generated during recovery since itsdeterminant has been lost.
4.2. Pessimistic Logging
4.2.1. Overview. Pessimistic loggingprotocols are designed under the assump-tion that a failure can occur after anynondeterministic event in the computa-tion. This assumption is “pessimistic”since in reality, failures are rare. In theirmost straightforward form, pessimisticprotocols log to stable storage, the deter-minant of each nondeterministic eventbefore the event is allowed to affect thecomputation. These pessimistic proto-cols implement the following property,often referred to as synchronous log-ging, which is a strengthening of thealways-no-orphans condition:
∀e : ¬Stable(e)⇒ |Depend(e)| = 0
This property stipulates that if an eventhas not been logged on stable storage, thenno process can depend on it.
ACM Computing Surveys, Vol. 34, No. 3, September 2002.

390 Elnozahy et al.
In addition to logging determinants,processes also take periodic checkpointsto limit the amount of work that has tobe repeated in execution replay during re-covery. Should a failure occur, the appli-cation program is restarted from the mostrecent checkpoint and the logged determi-nants are used during recovery to recreatethe pre-failure execution.
Consider the example in Figure 10.During failure-free operation the logsof processes P0, P1 and P2 contain thedeterminants needed to replay messages[m0, m4, m7], [m1, m3, m6] and [m2, m5],respectively. Suppose processes P1 and P2fail as shown, restart from checkpointsB and C, and roll forward using their de-terminant logs to again deliver the samesequence of messages as in the pre-failureexecution. This guarantees that P1 andP2 will exactly repeat their pre-failureexecution and re-send the same messages.Hence, once recovery is complete, bothprocesses will be consistent with the stateof P0 that includes the receipt of messagem7 from P1.
In a pessimistic logging system, the ob-servable state of each process is always re-coverable. This property has four advan-tages:
1. Processes can send messages to the out-side world without running a specialprotocol.
2. Processes restart from their most re-cent checkpoint upon a failure, there-fore limiting the extent of executionthat has to be replayed. Thus, thefrequency of checkpoints can be de-termined by trading off the desiredruntime performance with the desiredprotection of the ongoing execution.
3. Recovery is simplified because the ef-fects of a failure are confined only tothe processes that fail. Functioning pro-cesses continue to operate and never be-come orphans because a process alwaysrecovers to the state that included itsmost recent interaction with any otherprocess including OWP. This is highlydesirable in practical systems [Huangand Wang 1995].
4. Garbage collection is simple. Oldercheckpoints and determinants of non-deterministic events that occurredbefore the most recent checkpoint canbe reclaimed because they will never beneeded for recovery.
The price to be paid for these advantagesis a performance penalty incurred by syn-chronous logging. Implementations of pes-simistic logging must therefore resort tospecial techniques to reduce the effectsof synchronous logging on performance.Some protocols rely on special hardwareto facilitate logging [Borg, et al. 1989],while others may limit the number of tol-erated failures to improve performance[Johnson and Zwaenepoel 1987; Juangand Venkatesan 1991].
4.2.2. Techniques for Reducing PerformanceOverhead. Synchronous logging can po-tentially result in a high performanceoverhead. This overhead can be low-ered using special hardware. For example,fast non-volatile semiconductor memorycan be used to implement stable storage[Banatre et al. 1988]. Synchronous log-ging in such an implementation is ordersof magnitude cheaper than with a tradi-tional implementation of stable storagethat uses magnetic disk devices. Anotherform of hardware support uses a specialbus to guarantee atomic logging of allmessages exchanged in the system [Borg,et al. 1989]. Such hardware support en-sures that the log of one machine is auto-matically stored on a designated backupwithout blocking the execution of the ap-plication program. This scheme, however,requires that all nondeterministic eventsbe converted into external messages[Bartlett 1981; Borg, et al. 1989].
Some pessimistic logging systems re-duce the overhead of synchronous log-ging without relying on hardware. Forexample, the Sender-Based Message Log-ging (SBML) protocol keeps the determi-nants corresponding to the delivery of eachmessage m in the volatile memory of itssender [Johnson and Zwaenepoel 1987].The determinant of m, which consists ofits content and the order in which it was
ACM Computing Surveys, Vol. 34, No. 3, September 2002.

Rollback-Recovery Protocols in Message-Passing Systems 391
Fig. 10 . Pessimistic logging.
delivered, is logged in two steps. First, be-fore sending m, the sender logs its contentin volatile memory. Then, when the re-ceiver of m responds with an acknowledg-ment that includes the order in which themessage was delivered, the sender addsthe ordering information to the determi-nant. SBML avoids the overhead of access-ing stable storage but tolerates only onefailure and cannot handle nondeterminis-tic events internal to a process. Extensionsto this technique can tolerate more thanone failure in special network topologies[Juang and Venkatesan 1991].
4.2.3. Relaxing Logging Atomicity. Theperformance overhead of pessimisticlogging can be reduced by delivering amessage or an event and deferring itslogging until the receiver communicateswith any other process, including OWP[Johnson and Zwaenepoel 1987]. In theexample of Figure 10, process P0 maydefer the logging of messages m4 andm7 until it communicates with anotherprocess or the outside world. ProcessP0 implements the following weakerproperty, which still guarantees thealways-no-orphans condition:
∀e : ¬Stable(e)⇒ |Depend(e)| ≤ 1
This property relaxes the condition of pes-simistic logging by allowing a single pro-cess to be affected by an event that hasyet to be logged, provided that the pro-
cess does not externalize the effect of thisdependency to other processes includingOWP. Thus, messages m4and m7 are al-lowed to affect process P0, but this effectis local—no other process, or the outsideworld can see it until the messages arelogged.
The observed behavior of each process isthe same as with an implementation thatlogs events before delivering them to ap-plications. Event logging and delivery arenot performed in one atomic operation inthis variation of pessimistic logging. Thisscheme reduces overhead because severalevents can be logged in one operation, re-ducing the frequency of synchronous ac-cess to stable storage. Latency of interpro-cess communication and output commit,are not reduced since a logging opera-tion may often be needed before sending amessage.
Systems that separate logging of anevent from its delivery may lose thelast messages delivered before a failure.This may be a problem for applicationsthat assume that processes communicatethrough reliable channels. Consider oneof these applications going through theexecution shown in Figure 10, and as-sume that process P0 fails after deliver-ing messages m4 and m7 but before thecorresponding determinants—containingthe content and order of receipt of themessages—are logged. Protocols in whichthe receiver logs the message content can-not guarantee that the recovered P0 willever deliver m4 and m7, violating the
ACM Computing Surveys, Vol. 34, No. 3, September 2002.

392 Elnozahy et al.
Fig. 11 . Optimistic logging.
assumption about reliable channels. Thisproblem does not arise in protocols thatlog messages at the sender or do notassume reliable communication channels[Elnozahy 1993; Johnson 1989; Johnsonand Zwaenepoel 1987].
4.3. Optimistic Logging
4.3.1. Overview. In optimistic loggingprotocols, processes log determinantsasynchronously to stable storage [Stromand Yemini 1985]. These protocols makethe optimistic assumption that loggingwill complete before a failure occurs. De-terminants are kept in a volatile log, whichis periodically flushed to stable storage.Thus, optimistic logging does not requirethe application to block waiting for thedeterminants to be actually written tostable storage, and therefore incurs lit-tle overhead during failure-free execution.However, this advantage comes at the ex-pense of more complicated recovery andgarbage collection, and slower output com-mit, than in pessimistic logging. If a pro-cess fails, the determinants in its volatilelog will be lost, and the state intervalsthat were started by the nondeterminis-tic events corresponding to these determi-nants cannot be recovered. Furthermore,if the failed process sent a message dur-ing any of the state intervals that cannotbe recovered, the receiver of the messagebecomes an orphan process and must rollback to undo the effects of receiving the
message. Optimistic protocols do not im-plement the always-no-orphans condition,and therefore permit the temporary cre-ation of orphan processes. However, theyrequire that the property holds by the timerecovery is complete. This is achieved dur-ing recovery by rolling back orphan pro-cesses until their states do not depend onany message whose determinant has beenlost. For example, suppose process P2 inFigure 11 fails before the determinant form5 is logged to stable storage. Process P1then becomes an orphan process and mustroll back to undo the effects of receivingthe orphan message m6. The rollback ofP1 further forces P0 to roll back to undothe effects of receiving message m7.
To perform these rollbacks correctly, op-timistic logging protocols track causal de-pendencies during failure-free execution.Upon a failure, the dependency informa-tion is used to calculate and recover thelatest global state of the pre-failure execu-tion in which no process is in an orphan.
The above example also illustrates whyoptimistic logging protocols require anontrivial garbage collection algorithm.While pessimistic protocols need onlykeep the most recent checkpoint of eachprocess, optimistic protocols may need tokeep multiple checkpoints. In the exam-ple, the failure of P2 forces P1 to restartfrom checkpoint B instead of its mostrecent checkpoint D.
Finally, since determinants are loggedasynchronously, output commit in opti-mistic logging protocols generally requires
ACM Computing Surveys, Vol. 34, No. 3, September 2002.

Rollback-Recovery Protocols in Message-Passing Systems 393
multi-host coordination to ensure that nofailure scenario can revoke the output. Forexample, if process P0 needs to commitoutput at state X , it must log messagesm4 and m7 to stable storage and ask P2 tolog m2 and m5.
4.3.2. Synchronous vs. Asynchronous Re-covery. Recovery in optimistic loggingprotocols can be either synchronous orasynchronous. In synchronous recovery[Johnson 1989; Sistla and Welch 1989],all processes run a recovery protocol tocompute the maximum recoverable sys-tem state based on dependency and loggedinformation, and then perform the actualrollbacks. During failure-free execution,each process increments a state intervalindex at the beginning of each state in-terval. Dependency tracking can be eitherdirect or transitive.
In direct dependency tracking [John-son 1989; Sistla and Welch 1989], thestate interval index of the sender is piggy-backed on each outgoing message to allowthe receiver to record the dependency di-rectly caused by the message. These directdependencies can then be assembled atrecovery time to obtain complete depen-dency information. Alternatively, tran-sitive dependency tracking [Sistla andWelch 1989; Strom and Yemini 1985] canbe used: each process Pi maintains a size-N vector TDi, where TDi[i] is Pi ’s currentstate interval index, and TDi[ j ], j 6= i,records the highest index of any state in-terval of Pj on which Pi depends. Transi-tive dependency tracking generally incursa higher failure-free overhead for piggy-backing and maintaining the dependencyvectors, but allows faster output commitand recovery.
In asynchronous recovery, a failed pro-cess restarts by sending a rollback an-nouncement broadcast or a recovery mes-sage broadcast to start a new incarnation[Strom and Yemini 1985]. Upon receiv-ing a rollback announcement, a processrolls back if it detects that it has becomean orphan with respect to that announce-ment, and then broadcasts its own roll-back announcement. Since rollback an-
Fig. 12 . Exponential rollbacks.
nouncements from multiple incarnationsof the same process may coexist in thesystem, each process in general needs totrack the dependency of its state on ev-ery incarnation of all processes to correctlydetect orphaned states. A way to limitdependency tracking to only one incarna-tion of each process is to force a processto delay its delivery of certain messages.That is, before a process Pi can deliver anymessage carrying a dependency on an un-known incarnation of process Pj , Pi mustfirst receive rollback announcements fromPj to verify that Pi ’s current state does notdepend on any invalid state of Pj ’s pre-vious incarnations. Piggybacking all roll-back announcements known to a processon every outgoing message can eliminateblocking, and the amount of piggybackedinformation can be further reduced to aprovable minimum [Smith and Johnson1996].
Another issue in asynchronous recoveryprotocols is the possibility of exponentialrollbacks. This phenomenon occurs if a sin-gle failure causes a process to roll back anexponential number of times [Sistla andWelch 1989]. Figure 12 gives an example,where each integer pair (i, x) representsthe xth state interval of the ith incarna-tion of a process. Suppose P0 fails andloses its interval (1,2). When P0’s rollbackannouncement r0 reaches P1, the latterrolls back to interval (2,3) and broadcastsanother rollback announcement r1. If r1reaches P2 before r0 does, P2 will first rollback to (4,5) in response to r1, and laterroll back again to (4,4) upon receiving r0.By generalizing this example, we can con-struct scenarios in which process Pi, i >0, rolls back 2i−1 times in response to P0’sfailure.
ACM Computing Surveys, Vol. 34, No. 3, September 2002.

394 Elnozahy et al.
Several approaches have been proposedto ensure that any process will roll back atmost once in response to a single failure.Exponential rollbacks can be eliminatedby distinguishing failure announcementsfrom rollback announcements and bybroadcasting only the former [Sistla andWelch 1989]. Another possibility is topiggyback the original rollback announce-ment from the failed process on everysubsequent rollback announcement thatit triggers. For example, in Figure 12, pro-cess P1 piggybacks r0 on r1. Exponentialrollbacks can be avoided by piggybackingall rollback announcements on everyapplication message [Smith and Johnson1996].
4.4. Causal Logging
4.4.1. Overview. Causal logging has thefailure-free performance advantages ofoptimistic logging while retaining mostof the advantages of pessimistic logging[Alvisi 1996; Elnozahy 1993]. Like opti-mistic logging, it avoids synchronous ac-cess to stable storage except during out-put commit. Like pessimistic logging, itallows each process to commit output in-dependently and never creates orphans,thereby isolating each process from the ef-fects of failures that occur in other pro-cesses. Furthermore, causal logging lim-its the rollback of any failed process to themost recent checkpoint on stable storage.This reduces the storage overhead and theamount of work at risk. These advantagescome at the expense of a more complex re-covery protocol.
Causal logging protocols ensure thealways-no-orphans property by ensuringthat the determinant of each nondeter-ministic event that causally precedes thestate of a process is either stable or it isavailable locally to that process. Considerthe example in Figure 13(a). While mes-sages m5 and m6 may be lost upon the fail-ure, process P0 at state X will have loggedthe determinants of the nondeterministicevents that causally precede its state ac-cording to Lamport’s happened-before re-lation [Lamport 1978]. These events con-sist of the delivery of messages m0, m1,
m2, m3 and m4. The determinant of eachof these nondeterministic events is eitherlogged on stable storage or is available inthe volatile log of process P0. The determi-nant of each of these events contains theorder in which its original receiver deliv-ered the corresponding message. The mes-sage sender, as in sender-based messagelogging, logs the message content. Thus,process P0 will be able to “guide” the re-covery of P1 and P2 since it knows the or-der in which P1 should replay messages m1and m3 to reach the state from which P1sends message m4. Similarly, P0 has theorder in which P2 should replay messagem2 to be consistent with both P0 and P1.The content of these messages is obtainedfrom the sender log of P0 or regenerateddeterministically during the recovery of P1and P2. Notice that information about m5and m6 is not available anywhere. Thesemessages may be replayed after recoveryin a different order, if at all. However, sincethey had no effect on a surviving processor the outside world, the resulting stateis consistent. The determinant log keptby each process acts as an insurance toprotect it from the failures that occur inother processes. It also allows the processto make its state recoverable by simplylogging the information available locally.Thus, a process does not need to run amulti-host protocol to commit output.
4.4.2. Tracking Causality. Causal loggingprotocols implement the always-no-orphans condition by having processespiggyback the non-stable determinantsin their volatile log on the messages theysend to other processes. On receivinga message, a process first adds anypiggybacked determinant to its volatiledeterminant log and then delivers themessage to the application.
The Manetho system propagates thecausal information in an antecedencegraph [Elnozahy 1993]. The antecedencegraph provides every process in the sys-tem with a complete history of the nonde-terministic events that have causal effectson its state. The graph has a node repre-senting each nondeterministic event that
ACM Computing Surveys, Vol. 34, No. 3, September 2002.

Rollback-Recovery Protocols in Message-Passing Systems 395
Fig. 13 . Causal logging (a) Maximum recoverablestates, and (b) antecedence graph of P0 at state X .
precedes the state of a process, and theedges correspond to the happened-beforerelation [Lamport 1978]. Figure 13(b)shows the antecedence graph of process P0of Figure 13(a) at state X . During failure-free operation, each process piggybackson each application message, the determi-nants that contain the receipt orders of itsdirect and transitive antecedents, — its lo-cal antecedence graph. The receiver of themessage records these receipt orders in itsvolatile log.
In practice, carrying the entire graph oneach application message may lead to anunacceptable overhead. Fortunately, eachmessage carries a graph that is a super-set of the one piggybacked on the pre-vious message sent from the same host.This fact can be used in practical imple-mentations to reduce the amount of infor-mation carried on application messages.Thus, any message between processes pand q carries only the difference betweenthe graphs piggybacked on that messageand the previous message exchanged be-tween these two hosts. Furthermore, if phas recently received a message from q,it can exclude the graph portions thathave been piggybacked on that message.Process q already has the information inthese excluded portions, therefore trans-mitting them serves no purpose. Other op-timizations are also possible but dependon the semantics of the communication
protocol. An implementation of this tech-nique shows that it has very low overheadin practice [Elnozahy 1993].
Further reduction of the overhead ispossible if the system is willing to toler-ate a number of failures that is less thanthe total number of processes in the sys-tem. This observation is the basis of Fam-ily Based Logging protocols (FBL) thatare parameterized by the number of tol-erated failures [Alvisi 1996]. The basis ofthese protocols is that, to tolerate f pro-cess failures, it is sufficient to log each non-deterministic event in the volatile storeof f + 1 different hosts. Hence, the predi-cate Stable(e) holds as soon as |Log(e)|> f .Sender-based logging is used to supportmessage replay during recovery and de-terminants are piggybacked on applica-tion messages. However, unlike Manetho,propagation of information about an eventstops when it has been recorded inf + 1 processes. For f <N , FBL proto-cols do not access stable storage exceptfor checkpointing. Reducing access to sta-ble storage in turn reduces performanceoverhead and implementation complexity.Applications pay only the overhead thatcorresponds to the number of failures theyare willing to tolerate. An implementationfor the protocol with f = 1 confirms thatthe performance overhead is very small[Alvisi 1996]. The Manetho protocol is anFBL protocol corresponding to the case off =N .
4.5. Comparison
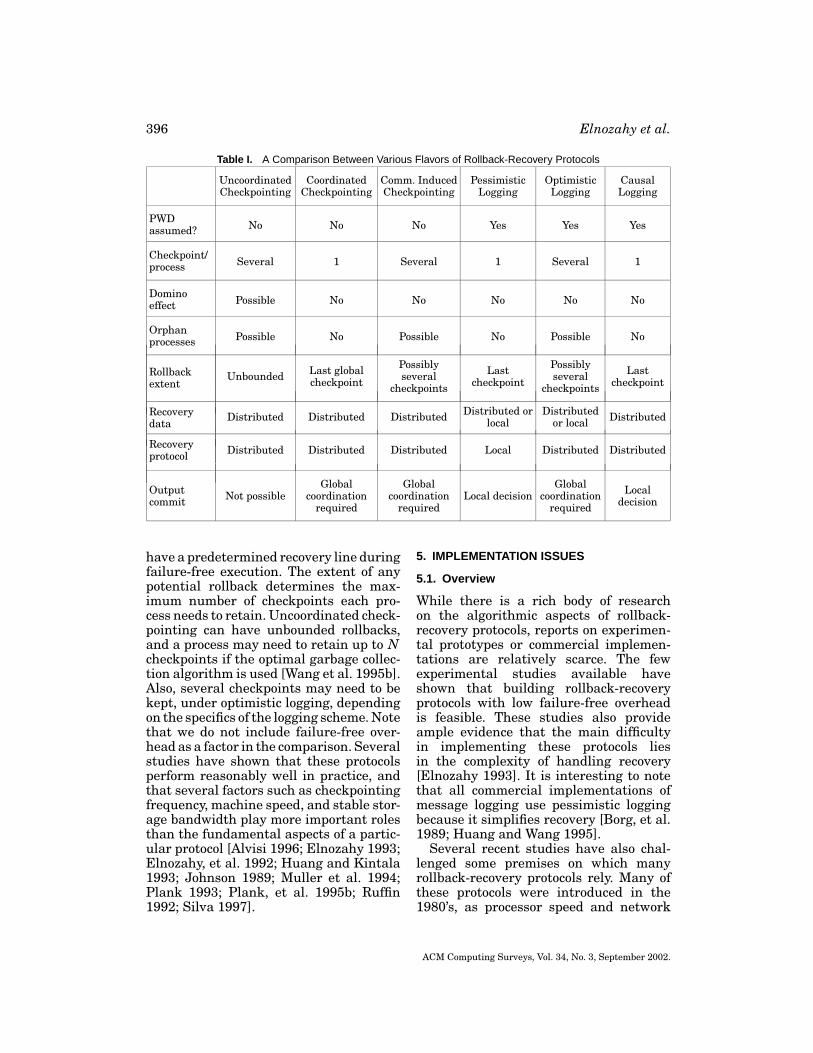
Different rollback-recovery protocolsoffer different tradeoffs with respect toperformance overhead, latency of outputcommit, storage overhead, ease of garbagecollection, simplicity of recovery, freedomfrom domino effect, freedom from orphanprocesses, and the extent of rollback.Table I summarizes a comparison amongthe different variations of rollback-recovery protocols.
Since garbage collection and recoveryboth involve calculating a recovery line,they can be performed by simple pro-cedures under coordinated checkpointingand pessimistic logging, both of which
ACM Computing Surveys, Vol. 34, No. 3, September 2002.
396 Elnozahy et al.
Table I. A Comparison Between Various Flavors of Rollback-Recovery Protocols
UncoordinatedCheckpointing
CoordinatedCheckpointing
Comm. InducedCheckpointing
PessimisticLogging
OptimisticLogging
CausalLogging
PWDassumed? No No No Yes Yes Yes
Checkpoint/process Several 1 Several 1 Several 1
Dominoeffect Possible No No No No No
Orphanprocesses Possible No Possible No Possible No
Rollbackextent
Unbounded Last globalcheckpoint
Possiblyseveral
checkpoints
Lastcheckpoint
Possiblyseveral
checkpoints
Lastcheckpoint
Recoverydata
Distributed Distributed Distributed Distributed orlocal
Distributedor local Distributed
Recoveryprotocol Distributed Distributed Distributed Local Distributed Distributed
Outputcommit Not possible
Globalcoordination
required
Globalcoordination
requiredLocal decision
Globalcoordination
required
Localdecision
have a predetermined recovery line duringfailure-free execution. The extent of anypotential rollback determines the max-imum number of checkpoints each pro-cess needs to retain. Uncoordinated check-pointing can have unbounded rollbacks,and a process may need to retain up to Ncheckpoints if the optimal garbage collec-tion algorithm is used [Wang et al. 1995b].Also, several checkpoints may need to bekept, under optimistic logging, dependingon the specifics of the logging scheme. Notethat we do not include failure-free over-head as a factor in the comparison. Severalstudies have shown that these protocolsperform reasonably well in practice, andthat several factors such as checkpointingfrequency, machine speed, and stable stor-age bandwidth play more important rolesthan the fundamental aspects of a partic-ular protocol [Alvisi 1996; Elnozahy 1993;Elnozahy, et al. 1992; Huang and Kintala1993; Johnson 1989; Muller et al. 1994;Plank 1993; Plank, et al. 1995b; Ruffin1992; Silva 1997].
5. IMPLEMENTATION ISSUES
5.1. Overview
While there is a rich body of researchon the algorithmic aspects of rollback-recovery protocols, reports on experimen-tal prototypes or commercial implemen-tations are relatively scarce. The fewexperimental studies available haveshown that building rollback-recoveryprotocols with low failure-free overheadis feasible. These studies also provideample evidence that the main difficultyin implementing these protocols liesin the complexity of handling recovery[Elnozahy 1993]. It is interesting to notethat all commercial implementations ofmessage logging use pessimistic loggingbecause it simplifies recovery [Borg, et al.1989; Huang and Wang 1995].
Several recent studies have also chal-lenged some premises on which manyrollback-recovery protocols rely. Many ofthese protocols were introduced in the1980’s, as processor speed and network
ACM Computing Surveys, Vol. 34, No. 3, September 2002.

Rollback-Recovery Protocols in Message-Passing Systems 397
bandwidth were such that communica-tion overhead was deemed too high, es-pecially as compared to the cost of sta-ble storage access [Bhargava et al. 1990].In such platforms, multi-host coordina-tion incurs a large overhead because ofthe necessary control messages. A pro-tocol that does not require a large com-munication overhead at the expense ofmore stable storage accesses performs bet-ter in such platforms. Recently, processorspeed and network bandwidth have in-creased dramatically, while the speed ofstable storage access has remained rela-tively the same.2 This change in the equa-tion suggests a fresh look at the premisesof many rollback-recovery protocols. Re-cent results [Alvisi 1996; Elnozahy 1993;Johnson 1989; Muller, et al. 1994; Plank1993; Silva 1997; Slye and Elnozahy 1998]have shown that:r Stable storage access is now the ma-
jor source of overhead in checkpoint-ing or message logging systems. Com-munication overhead is much lower incomparison. Such changes favor coordi-nated checkpointing schemes over mes-sage logging or uncoordinated check-pointing systems, as they require lessaccess to stable storage and are simplerto implement.r The case for message logging hasbecome the ability to interact withthe outside world, instead of reduc-ing the overhead of multi-process co-ordination [Elnozahy and Zwaenepoel1994]. Message logging systems canimplement efficient protocols for com-mitting output and logging input thatare not possible in checkpoint-onlysystems.r Recent advances have shown that arbi-trary forms of nondeterminism can besupported at a very low overhead inlogging systems. Nondeterminism was
2 While semiconductor-based stable storage is becom-ing more widely available, the size-cost ratio is toolow compared to disk-based stable storage. It appearsthat for some time to come, disk-based systems willcontinue to be the medium of choice for storing thelarge files that are needed in checkpointing and log-ging systems.
deemed one of the complexities inherentin message logging systems.
In the remainder of this section, we ad-dress these and other issues in somedetail.
5.2. Checkpointing Implementation
All available studies have shown thatwriting the state of a process to stable stor-age is the largest contributor to the per-formance overhead [Plank 1993]. The sim-plest way to save the state of a process is tosuspend execution, save the process’s ad-dress space on stable storage, and then re-sume execution [Tamir and Sequin 1984].This scheme can be costly for programswith large address spaces if stable storageis implemented using magnetic disks, asit is the custom. Several techniques existto reduce this overhead.
5.2.1. Concurrent Checkpointing. Allavailable studies show that concurrentcheckpointing greatly reduces the over-head of saving the state of a process[Goldberg et al. 1990; Plank 1993].Concurrent checkpointing relies on thememory protection hardware availablein modern computer architectures tocontinue the execution of the processwhile its checkpoint is being saved onstable storage. The address space isprotected from further modification atthe start of a checkpoint and the memorypages are saved to disk concurrently withthe program execution. If the programattempts to modify a page, it incurs aprotection violation. The checkpointingsystem copies the page into a separatebuffer from which it is saved on stablestorage. The original page is unprotectedand the application program is allowedto resume. Implementations that do notincorporate concurrent checkpointingmay pay a heavy performance overheadunless the checkpointing interval is setto a large value, which in turn wouldincrease the time for rollback.
5.2.2. Incremental Checkpointing. Addingincremental checkpointing [Feldman and
ACM Computing Surveys, Vol. 34, No. 3, September 2002.

398 Elnozahy et al.
Brown 1989] to concurrent checkpoint-ing can further reduce the overhead[Elnozahy, et al. 1992]. Incremental check-pointing avoids rewriting portions of theprocess states that do not change betweenconsecutive checkpoints. It can be imple-mented by using the dirty-bit of the mem-ory protection hardware or by emulatinga dirty-bit in software [Babaoglu and Joy1981]. A public domain package imple-menting this technique along with con-current checkpointing is available [Plank,et al. 1995b].
Incremental checkpointing can also beextended over several processes. In thistechnique, the system saves the computedparity or some function of the memorypages that are modified across several pro-cesses [Plank and Li 1994]. This techniqueis very similar to parity computation inRAID disk systems. The parity pages canbe saved in volatile memory of some otherprocesses thereby avoiding the need to ac-cess stable storage. The storage overheadof this method is very low, and it can beadjusted depending on how many failuresthe system is willing to tolerate.
Another technique for implementingincremental checkpointing is to directlycompare the program’s state with the pre-vious checkpoint in software, and writingthe difference in a new checkpoint [Planket al. 1995a]. The required storage andcomputation overhead to perform such acomparison may waste the benefit of in-cremental checkpointing. Another varia-tion on this technique is to use proba-bilistic checkpointing [Nam et al. 1997].The unit of checkpointing in this schemeis a memory block that is typically muchsmaller than a memory page. Changes toa memory block are detected by comput-ing a signature and comparing it to thecorresponding signature in the previouscheckpoint. Probabilistic checkpointing isportable, and has lower storage and com-putation requirements than required bycomparing the checkpoints directly. On thedownside, computing a signature to detectchanges opens the door for aliasing. Thisproblem occurs when the computed signa-ture does not differ from the correspond-ing one in the previous checkpoint, even
though the associated memory block haschanged. In such a situation, the mem-ory block is excluded from the new check-point, which therefore becomes erroneous.A probabilistic analysis has shown thatthe likelihood of aliasing in practice isnegligible, but an experimental evaluationhas shown that probabilistic checkpoint-ing could be unsafe in practice [Elnozahy1998].
5.2.3. System-level versus User-level Imple-mentations. Support for checkpointing canbe implemented in the kernel [Bartlett1981; Borg, et al. 1989; Elnozahy 1993;Johnson 1989], or it can be implementedby a library linked with the user pro-gram [Alvisi 1996; Goldberg, et al. 1990;Huang and Kintala 1993; Plank, et al.1995b]. Kernel-level implementations aremore powerful because they can also cap-ture kernel data structures that supportthe user process. However, these imple-mentations are necessarily not portable.
Checkpointing can also be implementedin user level. System calls that manip-ulate memory protection such as mpro-tect of UNIX can emulate concurrent andincremental checkpointing. The fork sys-tem call of UNIX can implement concur-rent checkpointing if the operating systemimplements fork using copy-on-write pro-tection [Goldberg, et al. 1990]. User-levelimplementations, however, cannot accesskernel’s data structures that belong to theprocess, such as open file descriptors andmessage buffers, but these data structurescan be emulated at user level [Huang andKintala 1993].
5.2.4. Compiler Support. A compiler canbe instrumented to generate code thatsupports checkpointing [Li and Fuchs1990]. The compiled program containscode that decides when and what to check-point. The advantage of this techniqueis that the compiler can decide on thevariables that must be saved, thereforeavoiding unnecessary data. For example,dead variables within a program are notsaved in a checkpoint though they havebeen modified. Furthermore, the compiler
ACM Computing Surveys, Vol. 34, No. 3, September 2002.

Rollback-Recovery Protocols in Message-Passing Systems 399
may decide the points during programexecution where the amount of state to besaved is small.
Despite these promising advantages,there are difficulties with this approach.It is generally undecidable to find thepoint in program execution most suitableto take a checkpoint. There are, however,several heuristics that can be used. Theprogrammer can provide hints to the com-piler about where checkpoints should beinserted or what data variables shouldbe stored [Beguelin et al. 1997; Plank,et al. 1995b]. The compiler may also betrained by running the application in aniterative manner and by observing its be-havior [Li and Fuchs 1990]. The observedbehavior could help decide the executionpoints where it would be appropriate to in-sert checkpoints. Compiler support couldalso be simplified in languages that sup-port automatic garbage collection [Appel1989]. The execution point after each ma-jor garbage collection provides a conve-nient place to take a checkpoint at a min-imum cost.
5.2.5. Checkpoint Placement. A largeamount of work has been devoted toanalyzing and deriving the optimalcheckpointing frequency and placement[Chandy and Ramamoorthy 1972]. Theproblem is usually formulated as an opti-mization problem subject to constraints.For instance, a system may attempt toreduce the number of taken checkpointssubject to a certain limit on the amount ofexpected rollback. Generally, it has beenobserved in practice that the overheadof checkpointing is usually negligibleunless the checkpointing interval is rel-atively small, therefore the optimality ofcheckpoint placement is rarely an issuein practical systems [Elnozahy, et al.1992].
5.3. Checkpointing Protocols in Comparison
Many checkpointing protocols were intro-duced at a time when the communica-tion overhead far exceeded the overheadof accessing stable storage. Furthermore,
the memory available to run processestended to be small. These tradeoffs nat-urally favored uncoordinated checkpoint-ing schemes over coordinated ones. Cur-rent technological trends however havereversed this tradeoff.
In modern systems, the overhead of co-ordinating checkpoints is negligible com-pared to the overhead of saving the states[Alvisi 1996; Elnozahy 1993; Johnson1989; Muller, et al. 1994; Plank 1993; Silva1997]. Using concurrent and incrementalcheckpointing, the overhead of either co-ordinated or uncoordinated checkpointingis essentially the same. Therefore, uncoor-dinated checkpointing is not likely to bean attractive technique in practice giventhe negligible performance gains. Thesegains do not justify the complexities offinding a consistent recovery line after thefailure, the susceptibility to the dominoeffect, the high storage overhead of sav-ing multiple checkpoints of each process,and the overhead of garbage collection.It follows that coordinated checkpointingis superior to uncoordinated checkpoint-ing when all aspects are considered onbalance.
A recent study has also shed somelight on the behavior of communication-induced checkpointing [Alvisi, et al. 1999].It presents an analysis of these proto-cols based on a prototype implementa-tion and validated simulations, showingthat communication-induced checkpoint-ing does not scale well as the numberof processes increases. The occurrenceof forced checkpoints at random pointswithin the execution due to communi-cation messages makes it very difficultto predict the required amount of sta-ble storage for a particular applicationrun. Also, this unpredictability affects thepolicy for placing local checkpoints andmakes communication-induced protocolscumbersome to use in practice. Further-more, the study shows that the benefit ofautonomy in allowing processes to take lo-cal checkpoints at their convenience doesnot seem to hold. In all experiments,a process takes at least twice as manyforced checkpoints as local, autonomousones.
ACM Computing Surveys, Vol. 34, No. 3, September 2002.

400 Elnozahy et al.
5.4. Communication Protocols
Rollback-recovery complicates the imple-mentation of protocols used for inter-process communications. Some protocolsoffer the abstraction of reliable communi-cation channels such as connection-basedprotocols (e.g. TCP, RPC). Alternatively,other protocols offer the abstraction of anunreliable datagram service (e.g. UDP).Each type of abstraction requires addi-tional support to operate properly acrossfailures and recoveries.
5.4.1. Location-Independent Identities andRedirection. For all communication pro-tocols, a rollback-recovery system mustmask the actual identity and location ofprocesses or remote ports from the ap-plication program. This masking is nec-essary to prevent any application pro-gram from acquiring a dependency on thelocation of a certain process, making it im-possible to restart the process on a differ-ent machine after a failure. A solution tothis problem is to assign a logical, location-independent identifier to each process inthe system. This scheme also allows thesystem to appropriately redirect commu-nication to a restarting process after afailure [Elnozahy 1993].
5.4.2. Reliable Channel Protocols. After afailure, identity masking and commu-nication redirection are sufficient forcommunication protocols that offer theabstraction of an unreliable channel. Pro-tocols that offer the abstraction of reli-able channels require additional support.These protocols usually generate a time-out upcall to the application program if theprocess at the other end of the channel hasfailed. These timeouts should be maskedsince the failed program will soon restartand resume computation. If such upcallsare allowed to affect the application, thenthe abstraction of a reliable system is nolonger upheld. The application will haveto encode the necessary support to com-municate with the failed process after itrecovers.
Masking timeouts should also be cou-pled with the ability of the protocol im-
plementation to reestablish the connec-tion with the restarting process (possiblyrestarting on a different machine). Thissupport includes the ability to clean upthe old connection in an orderly manner,and to establish a new connection with therestarting host. Furthermore, messagesretransmitted as part of the execution re-play of the remote host must be identi-fied and, if necessary, suppressed. Thisrequires the protocol implementation toinclude a form of sequence number thatis only used for this purpose.
Recovering in-transit messages that arelost because of a failure is another prob-lem for reliable communication protocols.In TCP/IP communication style, for in-stance, a message is considered deliveredonce an acknowledgment is received fromthe remote host. The message itself maylinger in the kernel’s buffer for a while be-fore the receiving process consumes it. Ifthis process fails, the in-transit messagesmust be resent to preserve the seman-tics of the reliable communication chan-nel. Messages must be saved at the senderside for possible retransmission during re-covery. This step can be combined in asystem that performs sender-based mes-sage logging as part of the log mainte-nance. In other systems that do not logmessages or log messages at the receiver,the copying of each message at the senderside introduces overhead and complexity.The complexity is due to the need for exe-cuting some garbage collection algorithmwith other sites to reclaim the volatilestorage.
5.5. Log-based Recovery
5.5.1. Message Logging Overhead. Mes-sage logging introduces three sources ofoverhead. First, each message must ingeneral be copied to the local memory ofthe process. Second, the volatile log is reg-ularly flushed to stable storage to freeup space. Third, message logging nearlydoubles the communication bandwidth re-quired to run the application for sys-tems that implement stable storage viaa highly available file system accessiblethrough the network. The first source of
ACM Computing Surveys, Vol. 34, No. 3, September 2002.

Rollback-Recovery Protocols in Message-Passing Systems 401
overhead may directly affect communica-tion throughput and latency. This is es-pecially true if the copying occurs in thecritical path of the inter-process commu-nication protocol. In this respect, sender-based logging is considered more efficientthan receiver-based logging because thecopying can take place after sending themessage over the network. Additionally,the system may combine the logging ofmessages with the implementation of thecommunication protocol and share themessage log with the transmission buffers.This scheme avoids the extra copying ofthe message. Logging at the receiver ismore expensive because it is in the criti-cal path of the communication protocol.
Another optimization for sender-basedlogging systems is to use copy-on-writeto avoid making extra-copying [Elnozahyand Zwaenepoel 1994]. This scheme workswell in systems where broadcast messagesare implemented using several point-to-point messages. In this case, copy-on-writewill allow the system to have one copyfor identical messages and thus reducethe storage and performance overheadof logging. No similar optimization canbe performed in receiver-based systems[Elnozahy and Zwaenepoel 1994].
5.5.2. Combining Log-Based Recovery withCoordinated Checkpointing. Log-based re-covery has been traditionally presentedas a mechanism to allow the use of unco-ordinated checkpointing with no dominoeffect. But a system may also combineevent logging with coordinated check-pointing, yielding several benefits withrespect to performance and simplicity[Elnozahy and Zwaenepoel 1994]. Thesebenefits include those of coordinatedcheckpointing—such as the simplicityof recovery and garbage collection—andthose of log-based recovery—such as fastoutput commit. Most prominently, thiscombination obviates the need for flushingthe volatile message logs to stable storagein a sender-based logging implementa-tion. Thus, there is no need for main-taining large logs on stable storage, re-sulting in lower performance overhead
and simpler implementations. The combi-nation of coordinated checkpointing andmessage logging has been shown to out-perform one with uncoordinated check-pointing and message logging [Elnozahyand Zwaenepoel 1994]. Therefore, the pur-pose of logging should no longer be to al-low uncoordinated checkpointing. Rather,it should be the desire for enabling fastoutput commit for those applications thatneed this feature.
5.6. Stable Storage
Magnetic disks have been the mediumof choice for implementing stable storage[Lampson and Sturgis 1979]. Althoughthey are slow, their storage capacity andlow cost combination cannot be matchedby other alternatives. An implementationof a stable storage abstraction on top ofa conventional file system may not bethe best choice, however. Such an imple-mentation will not generally give the per-formance or reliability needed to imple-ment stable storage [Banatre, et al. 1988;Elnozahy 1993; Ruffin 1992]. Modern filesystems tend to be optimized for the pat-tern of access expected in workstation orpersonal computing environments. Fur-thermore, these file systems are often ac-cessed through a network via a protocolthat is optimized for small file accessesand not for the large file accesses thatare more common in checkpointing andlogging.
An implementation of stable storageshould bypass the file system layer andaccess the disk directly. One such imple-mentation is the KitLog package, whichoffers a log abstraction that can sup-port checkpointing and message logging[Ruffin 1992]. The package runs in con-ventional UNIX systems and bypasses thefile system by accessing the disk in rawmode. There have also been several at-tempts at implementing stable storage us-ing non-volatile semiconductor memory[Banatre, et al. 1988]. Such implementa-tions do not have the performance prob-lems associated with disks, but the priceand the small storage capacity remain twoproblems that limit their wide acceptance.
ACM Computing Surveys, Vol. 34, No. 3, September 2002.

402 Elnozahy et al.
5.7. Support for Nondeterminism
Nondeterminism occurs when the applica-tion program interacts with the operatingsystem through system calls and upcalls(asynchronous events). In log-based recov-ery, these nondeterministic events mustbe logged on stable storage so that they canbe replayed during recovery. Log-based re-covery systems differ in the range of actualevents that can be covered.
5.7.1. System Calls. System calls ingeneral can be classified into threetypes [Borg, et al. 1989; Elnozahy 1993;Goldberg, et al. 1990]. Idempotent systemcalls are those that return deterministicvalues whenever executed. Examples in-clude calls that return the user identifierof the process owner. These calls do notneed to be logged. A second class of callsconsists of those that must be logged dur-ing failure-free operation but should notbe re-executed during execution replay.The results from these calls should simplybe replayed to the application program.These calls include those that inquireabout the environment, such as gettingthe current time of day. Re-executingthese calls during recovery might returna different value that is inconsistentwith the pre-failure execution. The lasttype of system calls includes those thatmust be logged during failure-free oper-ation and re-executed during executionreplay. These calls generally modify theenvironment and therefore they must bere-executed to re-establish the environ-ment changes. Examples include callsthat allocate memory or create processes.Ensuring that these calls return thesame values and generate the same effectduring re-execution can be very complex.
5.7.2. Asynchronous Signals. Nonde-terminism results from asynchronoussignals available in the form of soft-ware interrupts under various operatingsystems. Such signals must be appliedat the same execution points duringreplay to reproduce the same result.Log-based rollback-recovery can coverthis form of nondeterminism by taking a
checkpoint after the occurrence of eachsignal, but this can be very expensive[Bartlett 1981]. Alternatively, the systemmay convert these asynchronous signalsto synchronous messages such as inTargon/32 [Borg, et al. 1989], or it mayqueue the signals until the applicationpolls for them. Both alternatives convertasynchronous event notifications into syn-chronous ones, which may not be suitableor efficient for many applications. Suchsolutions also may require substantialmodifications to the operating system orthe application program.
Another example of nondeterminismthat is difficult to track is shared memorymanipulation in multithreaded applica-tions. Reconstructing the same executionduring replay requires the same interleav-ing of shared memory accesses by the vari-ous threads as in the pre-failure execution.Systems that support this form of nonde-terminism supply their own sets of lockingprimitives, and require applications to usethem for protecting access to shared mem-ory [Goldberg, et al. 1990]. The primitivesare instrumented to insert an entry in thelog identifying the calling thread and thenature of the synchronization operation.However, this technique has several prob-lems. It makes shared memory access ex-pensive, and may generate a large volumeof data in the log. Furthermore, if the ap-plication does not adhere to the synchro-nization model (because of a programmer’serror, for instance), execution replay maynot be possible.
A technique for tracking nondetermin-ism due to asynchronous signals andinterleaved memory access on single pro-cessor systems is to use instruction coun-ters [Bressoud and Schneider 1995]. Aninstruction counter is a register thatdecrements by one upon the execution ofeach instruction, leading the hardware togenerate an exception when the registercontents become 0. An instruction countercan thus be used in two modes. In onemode, the register is loaded with the num-ber of instructions to be executed beforea breakpoint occurs. After the CPU exe-cutes the specified number of instructions,the counter reaches 0 and the hardware
ACM Computing Surveys, Vol. 34, No. 3, September 2002.

Rollback-Recovery Protocols in Message-Passing Systems 403
generates an exception. The operating sys-tem fields the exception and executes apre-specified handler. This mode is use-ful in setting breakpoints efficiently, suchas during debugging. In the second mode,the instruction counter is loaded with themaximum value it can hold. Executionproceeds until an event of interest oc-curs, at which time the content of thecounter is sampled, and the number ofinstructions executed since the time thecounter was set is computed and logged.The use of instruction counters has beensuggested for debugging shared memoryparallel programs [Mellor-Crummey andLeBlanc 1989].
Instruction counters can be used inrollback-recovery to track the numberof instructions that occur between asyn-chronous interrupts [Slye and Elnozahy1998]. These instruction counts are loggedas part of the log that describes the non-deterministic events. During recovery, thesystem recovers the instruction countsfrom the log and uses them to regener-ate the software interrupts at the sameexecution points within the application asbefore the failure. The application there-fore goes through the same set of asyn-chronous events precisely as it did beforethe failure, and therefore it can recon-struct its execution.
An instruction counter can be imple-mented in hardware, as in the PA-RISCprecision architecture where it has beenused to augment the hypervisor of avirtual-machine manager and coordinatea primary virtual machine with its backup[Bressoud and Schneider 1995]. It also canbe emulated in software [Mellor-Crummeyand LeBlanc 1989]. An implementationstudy shows that the overhead of programinstrumentation and tracking nondeter-minism is less than 6% for a variety of userprograms and synthetic benchmarks [Slyeand Elnozahy 1998].
5.8. Dependency Tracking
Rollback-recovery protocols vary in theways they track inter-process dependen-cies. Some protocols require tagging onlyan index or a sequence number on ev-
ery application message [Briatico, et al.1984], while some require the propaga-tion of a vector of timestamps [Strom andYemini 1985]. At an extreme, some pro-tocols require the propagation of a graphdescribing the history of the computation[Elnozahy 1993], or matrices containingbit or timestamp vectors [Baldoni, et al.1998].
Tagging a message with an index or asequence number on an application mes-sage is simple and does not cause anymeasurable overhead. When dependencytracking, however, requires more complexstructures, there are techniques for reduc-ing the amount of actual data that needto be transferred on top of each message.All these techniques revolve around twothemes. First, only incremental changesneed to be sent. If some elements of avector or a graph haven’t changed sinceprocess p last sent a message to processq, then p need only include those ele-ments that have changed. Implementa-tion of this optimization is straightforwardin systems that assume FIFO communi-cation channels. When lossy channels areassumed, this optimization is still possi-ble, but at the expense of more processingoverhead [Elnozahy 1993].
The other technique for reducing theoverhead of dependency tracking exploitsthe semantics of the applications and thecommunication patterns [Elnozahy 1993].For instance, if it can be inferred fromthe dependency information available toprocess p that process q already knowsparts of the information that is to be pig-gybacked on a message outgoing to q, thenprocess p can exclude this information.Surprisingly, implementing this optimiza-tion is simple and yields good performance[Elnozahy 1993]. Regardless of the partic-ular method used to track inter-process de-pendencies, various prototype implemen-tations have shown that the overheadresulting from dependency tracking isnegligible compared to the overhead ofcheckpointing or logging [Alvisi 1996;Alvisi, et al. 1999; Bhargava and Lian1988; Borg, et al. 1989; Elnozahy 1993;Goldberg, et al. 1990; Johnson 1989; Silva1997].
ACM Computing Surveys, Vol. 34, No. 3, September 2002.

404 Elnozahy et al.
5.9. Recovery
Handling execution restart and replay is adifficult part of implementing a rollback-recovery system [Borg, et al. 1989]. Themajor challenge is reintegrating the re-covered process in a computation environ-ment that may or may not be the same asthe one in which the process was executingbefore failure.
5.9.1. Reinstating a Process in its Environ-ment. Implanting a process in a differentenvironment during recovery can createdifficulties if its state depends on the pre-failure environment. For example, the pro-cess may need to access files that exist onthe local disk of the machine. The simplestsolution to this problem is to attempt torestart the program on the same host. Ifthis is not feasible, then the system mustinsulate the process from environment-specific variables [Elnozahy 1993]. Thiscan be done for instance by intercept-ing system calls that return environment-specific results and replacing them withabstract values under the control of therecovery system. Also, file access couldbe made highly available by placingall files in network-wide highly avail-able file servers or by using dual-porteddisks.
Another problem in implementing re-covery is the need to reconstruct the auxil-iary state within the operating system ker-nel that supports the recovering process[Elnozahy 1993; Huang and Kintala 1993;Johnson 1989; Plank 1993]. This state isusually outside of the recovery protocol’scontrol during failure-free operation, un-less the protocol is implemented insidethe operating system. For protocols im-plemented outside the operating system,the rollback-recovery system must emu-late these data structures and log suffi-cient information to be able to recreatethem during recovery. For example, the re-covery system may create a data structureto shadow the open file table of a particu-lar process by intercepting all file manip-ulation calls from the process itself. Then,the recovery system records some informa-tion that would enable it to issue requests
to the operating system during recoveryin order to force the operating system torecreate these data structures indirectly.Obviously, not all states within the oper-ating system kernel can be emulated thisway, and therefore, out-of-kernel imple-mentations should have stricter coverageof the system’s state that must be emu-lated. Since most of the applications thatbenefit from rollback-recovery seem to bein the realm of scientific computing whereno sophisticated state is maintained bythe kernel on behalf of the processes, thisproblem does not seem to be severe in thatparticular context [Plank, et al. 1995b].
5.9.2. Behavior During Recovery. Previousstudies have outlined several character-istics of rollback-recovery systems duringrecovery [Elnozahy 1993; Rao et al. 1998].For example, it has been observed that forlog-based recovery systems, the messagesand determinants available in the logs arereplayed at a considerably higher speedduring recovery than during normal exe-cution. This is because during normal exe-cution, a process may have to block waitingfor messages or synchronization events,while during recovery these messages orevents can be immediately replayed.
Also, it has been observed that sender-based logging protocols typically slowdown recovery if there are multiple fail-ures, because of the need to re-executesome of the processes under control to re-generate the messages. Moreover, some ofthese protocols may require sympatheticrollbacks [Strom and Yemini 1985], whichincrease the overhead of synchronizingthe processes during recovery. This ex-perimental evidence seems to confirm thetradeoff between protocols that performwell during failure-free executions, suchas causal and optimistic logging, and pro-tocols that perform well during recovery,such as pessimistic logging [Rao, et al.1998]. It is possible to address this tradeoffby performing logging both at the senderand receivers [Strom and Yemini 1985],such that the sender log is volatile andis kept only until the receiver flushes itsvolatile logs to stable storage.
ACM Computing Surveys, Vol. 34, No. 3, September 2002.

Rollback-Recovery Protocols in Message-Passing Systems 405
5.10. Checkpointing and Mobility
Several studies have examined the issuesof checkpointing, logging, and rollback-recovery in mobile computing [Prakashand Singhal 1996]. The fundamental con-cepts of distributed checkpointing, consis-tency, and rollback are identical to those intraditional distributed systems, but spe-cial considerations must be made for is-sues inherent to mobile computing, suchas energy constraints, intermittent com-munications, and low-performance pro-cessors. These issues favor checkpointingprotocols that allow maximum autonomyto participating processes, require lowoverhead in resources, and can functionwith the minimum possible number ofmessage exchanges. Therefore, indepen-dent checkpointing and communication-induced checkpointing tend to be moreappropriate for these environments thancoordinated checkpointing. Also, log-basedrecovery protocols that allow a high de-gree of autonomy during recovery suchas receiver-based optimistic or pessimisticlogging tend to be more appropriate forthese environments than those protocolsthat require global communication dur-ing recovery. Nevertheless, checkpoint-ing and rollback-recovery have yet toprove useful for mobile hosts. The ap-plications in the mobile domain tendto be structured as client-server inter-actions for which transaction processingon the server is most appropriate. Also,it is often the case for these applica-tions that high availability is more im-portant than fault tolerance or recover-ability, favoring some form of replicatedserver that can continue to function de-spite a failure of some of its replicas.Finally, there is an emerging generation ofhandheld devices that are meant to serveas enhanced input-output devices forremote computations, with little process-ing or storage capacity to support check-pointing or recovery. Whether this situ-ation changes, will depend on whetherrollback-recovery proves to be useful out-side the scientific and engineering com-puting domain in which it has proved verysuccessful.
5.11. Rollback-Recovery in Practice
Despite the wealth of research in the areaof rollback-recovery in distributed sys-tems, very few commercial systems actu-ally have adopted it. Difficulties in imple-menting recovery perhaps are the mainreason why these protocols have not beenwidely adopted. Additionally, the rangeof applications that benefit from theseprotocols tend to be in the realm of long-running, scientific programs, which arerelatively few. Many of these, in fact,are written to run on supercomputerswhere some facility exists for checkpoint-ing the entire system’s state. For the fewthat run in a distributed system, public do-main libraries that implement checkpoint-ing have proved adequate [Plank, et al.1995b].
Log-based recovery seemed to have lesssuccess than checkpoint-only systems. Acommercial implementation of pessimisticlogging did not fare well, although the rea-sons are not clear [Borg, et al. 1989]. Onecould conjecture that the complex modifi-cations made to the operating system andthe special-purpose hardware that wasused to mitigate performance overheadmade the machine expensive. Some otherusage of log-based recovery has been re-ported in telecommunication applications[Huang and Kintala 1993], although thereare no reports on how they fared. Interest-ingly, both commercial implementationsused pessimistic logging, and were usedfor applications where the performanceoverhead of this form of logging could betolerated. We are unaware, however, ofany use of optimistic or causal loggingrollback-recovery protocols in commercialsystems.
6. CONCLUDING REMARKS
We have reviewed and compared differ-ent approaches to rollback-recovery withrespect to a set of properties includingthe assumption of piecewise determinism,performance overhead, storage overhead,ease of output commit, ease of garbagecollection, ease of recovery, freedom fromdomino effect, freedom from orphan
ACM Computing Surveys, Vol. 34, No. 3, September 2002.

406 Elnozahy et al.
processes, and the extent of rollback.These approaches fall into two broad cat-egories: checkpointing protocols and log-based recovery protocols.
Checkpointing protocols require theprocesses to take periodic checkpointswith varying degrees of coordination.At one end of the spectrum, coordi-nated checkpointing requires the pro-cesses to coordinate their checkpoints toform global consistent system states. Co-ordinated checkpointing generally simpli-fies recovery and garbage collection, andyields good performance in practice. Atthe other end of the spectrum, uncoordi-nated checkpointing does not require theprocesses to coordinate their checkpoints,but it suffers from potential domino effect,complicates recovery, and still requirescoordination to perform output commitor garbage collection. Between these twoends are communication-induced check-pointing schemes that depend on the com-munication patterns of the applicationsto trigger checkpoints. These schemes donot suffer from the domino effect and donot require coordination. Recent studies,however, have shown that the nondeter-ministic nature of these protocols compli-cates garbage collection and degrades per-formance.
Log-based rollback-recovery is often anatural choice for applications that fre-quently interact with the outside world.It allows efficient output commit, andhas three flavors, pessimistic, optimistic,and causal. The simplicity of pessimisticlogging makes it attractive for practicalapplications where a high failure-freeoverhead is tolerable. This form of loggingsimplifies recovery, output commit, andprotects surviving processes from havingto roll back. These advantages have madepessimistic logging attractive in commer-cial environments where simplicity androbustness are necessary. Causal loggingreduces the overhead while still preserv-ing the properties of fast output commitand orphan-free recovery. Alternatively,optimistic logging reduces the overheadfurther at the expense of complicating re-covery and increasing the extent of roll-back upon a failure.
ACKNOWLEDGMENTS
The authors wish to express their sincere thanks toPi-Yu Chung, Om Damani, W. Kent Fuchs, YennunHuang, Chandra Kintala, Andy Lowry, KeithMarzullo, James Plank, Fred Schneider and PauloVerissimo for valuable discussions, encouragementand comments.
REFERENCES
ALVISI, L. 1996. Understanding the Message Log-ging Paradigm for Masking Process Crashes.Ph.D. Thesis, Cornell University, Department ofComputer Science.
ALVISI, L. AND MARZULLO, K. 1998. Message log-ging: pessimistic, optimistic, causal and optimal.IEEE Trans. Softw. Eng. 24, 2, 149–159.
ALVISI, L., ELNOZAHY, E. N., RAO, S., HUSAIN,S. A., and MEL, A. D. 1999. An analysis ofcommunication-induced checkpointing. In Di-gest of Papers, FTCS-29, The Twenty NinethAnnual International Symposium on Fault-Tolerant Computing (Madison, Wisconsin), 242–249.
APPEL, A. W. 1989. A runtime system. TechnicalReport CS-TR220-89, Department of ComputerScience, Princeton University.
BABAOGLU, O. AND JOY, W. 1981. Converting a swap-based system to do paging in an architecturelacking page-reference bits. In Proceedings of theEighth ACM Symposium on Operating SystemsPrinciples, 78–86.
BALDONI, R., QUAGLIA, F., AND CICIANI, B. 1998. AVP-accordant checkpointing protocol prevent-ing useless checkpoints. In Proceedings, Sev-enteenth Symposium on Reliable DistributedSystems, 61–67.
BANATRE, J. P., BANATRE, M., AND MULLER, G. 1988.Ensuring data security and integrity with a faststable storage. In Proceedings of The Fourth Con-ference on Data Engineering, 285–293.
BARTLETT, J. F. 1981. A Non Stop Kernel. In Pro-ceedings of the Eighth ACM Symposium on Op-erating Systems Principles, 22–29.
BEGUELIN, A., SELIGMAN, E., AND STEPHAN, P. 1997.Application-level fault tolerance in heteroge-neous networks of workstations. J. Parallel andDistributed Comput. 43, 2, 147–155.
BHARGAVA, B. AND LIAN, S. R. 1988. Indepen-dent checkpointing and concurrent rollbackfor recovery—An optimistic approach. In Pro-ceedings, Seventh Symposium on Reliable Dis-tributed Systems, 3–12.
BHARGAVA, B., LIAN, S. R., AND LEU, P. J. 1990. Ex-perimental evaluation of concurrent checkpoint-ing and rollback-recovery algorithms. In Pro-ceedings of the Sixth International Conference onData Engineering, 182–189.
BORG, A., BLAU, W., GRAETSCH, W., HERMANN,F., AND OBERLE, W. 1989. Fault tolerance
ACM Computing Surveys, Vol. 34, No. 3, September 2002.

Rollback-Recovery Protocols in Message-Passing Systems 407
under UNIX. ACM Trans. Comput. Syst. 7, 1,1–24.
BRESSOUD, T. C. AND SCHNEIDER, F. B. 1995.Hypervisor-based fault tolerance. In Proceedingsof the Fifteenth ACM Symposium on OperatingSystems Principles, 1–11.
BRIATICO, D., CIUFFOLETTI, A., AND SIMONCINI, L. 1984.A distributed domino-effect free recovery algo-rithm. In IEEE International Symposium on Re-liability, Distributed Software, and Databases,207–215.
CHANDY, M. AND RAMAMOORTHY, C. V. 1972. Rollbackand recovery strategies for computer programs.IEEE Trans. Comput. 21, 6, 546–556.
CHANDY, M. AND LAMPORT, L. 1985. Distributedsnapshots: Determining global states of dis-tributed systems. ACM Trans. Comput. Syst. 31,1, 63–75.
CRISTIAN, F. AND JAHANIAN, F. 1991. A timestamp-based checkpointing protocol for long-lived dis-tributed computations. In Proceedings, TenthSymposium on Reliable Distributed Systems,12–20.
ELNOZAHY, E. N. 1993. Manetho: Fault Tolerancein Distributed Systems using Rollback-Recoveryand Process Replication. Ph.D. Thesis, Rice Uni-versity, Department of Computer Science.
ELNOZAHY, E. N. 1998. How safe is probabilisticcheckpointing? In Digest of Papers, FTCS-28, theTwenty Eight Annual International Symposiumon Fault-Tolerant Computing, 358–363.
ELNOZAHY, E. N. AND ZWAENEPOEL, W. 1994. On theuse and implementing of message logging. InDigest of Papers, FTCS-24, The Twenty FourthInternational Symposium on Fault-TolerantComputing, 298–307.
ELNOZAHY, E. N., JOHNSON, D. B., AND ZWAENEPOEL, W.1992. The performance of consistent check-pointing. In Proceedings, Eleventh Symposiumon Reliable Distributed Systems, 39–47.
FELDMAN, S. I. AND BROWN, C. B. 1989. Igor: A sys-tem for program debugging via reversible execu-tion. ACM SIGPLAN Notices, Workshop on Par-allel and Distributed Debugging 24, 1, 112–123.
GOLDBERG, A., GOPAL, A., LI, K., STROM, R., AND BACON,D. 1990. Transparent recovery of Mach appli-cations. In Usenix Mach Workshop Proceedings,169–184.
HELARY, J. M., MOSTEFAOUI, A., AND RAYNAL, M. 1997a.Virtual precedence in asynchronous systems:concepts and applications. In Proceedings ofthe 11th Workshop on Distributed Algorithms,WDAG’97.
HELARY, J. M., MOSTEFAOUI, A., NETZER, R. H., AND
RAYNAL, M. 1997b. Preventing useless check-points in distributed computations. In Proceed-ings, Sixteenth Symposium on Reliable Dis-tributed Systems, 183–190.
HUANG, Y. AND KINTALA, C. 1993. Software imple-mented fault tolerance: Technologies and ex-perience. In Digest of Papers, FTCS-23, the
Twenty Third Annual International Symposiumon Fault-Tolerant Computing, 2–9.
HUANG, Y. AND WANG, Y.-M. 1995. Why optimisticmessage logging has not been used in telecom-munication systems. In Digest of Papers, FTCS-25, the Twenty Fifth Annual InternationalSymposium on Fault-Tolerant Computing, 459–463.
JOHNSON, D. B. 1989. Distributed System FaultTolerance Using Message Logging and Check-pointing. Ph.D. Thesis, Rice University, Depart-ment of Computer Science.
JOHNSON, D. B. AND ZWAENEPOEL, W. 1987. Sender-based message logging. In Digest of Papers,FTCS-17, The Seventeenth Annual InternationalSymposium on Fault-Tolerant Computing, 14–19.
JOHNSON, D. B. AND ZWAENEPOEL, W. 1990. Recoveryin distributed systems using optimistic messagelogging and checkpointing. J. Algorithms 11, 3,462–491.
JUANG, T. T.-Y. AND VENKATESAN, S. 1991. Crash re-covery with little overhead. In Proceedings, The11th International Conference on DistributedComputing Systems, 454–461.
KOO, R. AND TOUEG, S. 1987. Checkpointing androllback-recovery for distributed systems. IEEETrans. Softw. Engin. 13, 1, 23–31.
LAI, T. H. AND YANG, T. H. 1987. On distributedsnapshots. Information Processing Letters 25,153–158.
LAMPORT, L. 1978. Time, clocks, and the ordering ofevents in a distributed system. Commun. ACM21, 7, 588–565.
LAMPSON, B. W. AND STURGIS, H. E. 1979. Crash re-covery in a distributed data storage system. Tech-nical Report, Xerox Palo Alto Research Center.
LI, C. C. AND FUCHS, W. K. 1990. CATCH: Compiler-assisted techniques for checkpointing. In Di-gest of Papers, FTCS-20, The Twentieth AnnualInternational Symposium on Fault-TolerantComputing, 74–81.
MELLOR-CRUMMEY, J. AND LEBLANC, T. 1989. A soft-ware instruction counter. In Proceedings of theThird International Conference on ArchitecturalSupport for Programming Languages and Oper-ating Systems, 78–86.
MORIN, C. AND PUAUT, T. 1997. A survey of recover-able distributed shared memory systems. IEEETrans. Parallel and Distributed Syst. 8, 9, 959–969.
MULLER, G., HUE, M., AND PEYROUZ, N. 1994. Per-formance of consistent checkpointing in a mod-ular operating system: Results of the FTM ex-periment. In Lecture Notes in Computer Science:Dependable Computing, EDDC-1, 491–508.
NAM, H.-C., KIM, J., HONG, S. J., AND LEE, S. 1997.Probabilistic checkpointing. In Digest of Papers,FTCS-27, The Twenty Seventh Annual Interna-tional Symposium on Fault-Tolerant Computing,48–57.
ACM Computing Surveys, Vol. 34, No. 3, September 2002.

408 Elnozahy et al.
NETZER, R. H. AND XU, J. 1995. Necessary and suffi-cient conditions for consistent global snapshots.IEEE Trans. Parallel and Distributed Syst. 6, 2,165–169.
PAUSCH, R. 1988. Adding Input and Output to theTransactional Model. Ph.D. Thesis, CarnegieMellon University, Department of ComputerScience.
PLANK, J. S. 1993. Efficient Checkpointing onMIMD Architectures. Ph.D. Thesis, PrincetonUniversity, Department of Computer Science.
PLANK, J. S. AND LI, K. 1994. Faster checkpointingwith N + 1 parity. In Digest of Papers, FTCS-24, The Twenty Fourth Annual InternationalSymposium on Fault-Tolerant Computing, 288–297.
PLANK, J. S., XU, J., AND NETZER, R. H. 1995a. Com-pressed differences: An algorithm for fast incre-mental checkpointing. Technical Report CS-95-302, University of Tennessee at Knoxville.
PLANK, J. S., BECK, M., KINGSLEY, G., AND LI,K. 1995b. Libckpt: Transparent checkpoint-ing under UNIX. In Proceedings of the USENIXWinter 1995 Technical Conference, 213–223.
PRAKASH, R. AND SINGHAL, M. 1996. Low-cost check-pointing and failure recovery in mobile com-puting systems. IEEE Trans. Parallel and Dis-tributed Syst. 7, 10, 1035–1048.
RANDELL, B. 1975. System structure for softwarefault tolerance. IEEE Trans. Softw. Engin. 1, 2,220–232.
RAO, S., ALVISI, L., AND VIN, H. M. 1998. The cost ofrecovery in message logging protocols. In Pro-ceedings, Seventeenth Symposium on ReliableDistributed Systems, 10–18.
RUFFIN, M. 1992. KITLOG: A generic logging ser-vice. In Proceedings, Eleventh Symposium onReliable Distributed Systems, 139–148.
RUSSELL, D. L. 1980. State restoration in systemsof communicating processes. IEEE Trans. Softw.Engin. 6, 2, 183–194.
SCHLICHTING, R. D. AND SCHNEIDER, F. B. 1983.Fail-stop processors: An approach to designingfault-tolerant computing systems. ACM Trans.Comput. Syst. 1, 3, 222–238.
SILVA, L. M. 1997. Checkpointing Mechanisms forScientific Parallel Applications. Ph.D. Thesis,University of Coimbra, Department of ComputerScience.
SISTLA, A. AND WELCH, J. 1989. Efficient dis-tributed recovery using message logging. In Pro-ceedings of the 8th Annual ACM Symposiumon Principles of Distributed Computing (PODC),223–238.
SLYE, J. H. AND ELNOZAHY, E. N. 1998. Supportfor software interrupts in log-based rollback-recovery. IEEE Trans. Comput. 47, 10, 1113–1123.
SMITH, S. W. AND JOHNSON, D. B. 1996. Minimizingtimestamp size for completely asynchronous op-timistic recovery with minimal rollback. In Pro-ceedings, the Fifteenth Symposium on ReliableDistributed Systems, 66–75.
STROM, R. AND YEMINI, S. 1985. Optimistic recov-ery in distributed systems. ACM Trans. Comput.Syst. 3, 3, 204–226.
TAMIR, Y. AND SEQUIN, C. H. 1984. Error recoveryin multicomputers using global checkpoints. InProceedings of the International Conference onParallel Processing, 32–41.
TONG, Z., KAIN, R. Y., AND TSAI, W. T. 1992.Rollback-recovery in distributed systems usingloosely synchronized clocks. IEEE Trans. Paral-lel and Distributed Syst. 3, 2, 246–251.
WANG, Y.-M. 1993. Space Reclamation for Un-coordinated Checkpointing in Message-PassingSystems. Ph.D. Thesis, University of Illinois,Department of Computer Science.
WANG, Y.-M. 1997. Consistent global checkpointsthat contain a set of local checkpoints. IEEETrans. Comput. 46, 4, 456–468.
WANG, Y.-M., CHUNG, P. Y., AND FUCHS, W. K. 1995a.Tight upper bound on useful distributed sys-tem checkpoints. Technical Report, University ofIllinois.
WANG, Y.-M., CHUNG, P. Y., LIN, I. J., AND FUCHS, W. K.1995b. Checkpoint space reclamation for un-coordinated checkpointing in message-passingsystems. IEEE Trans. Parallel and DistributedSyst. 6, 5, 546–554.
Received October 1996; revised June 1997, June 1999, February 2001; accepted April 2002
ACM Computing Surveys, Vol. 34, No. 3, September 2002.

Rollback-Recovery Protocols in Message-Passing Systems
BIBLIOGRAPHY
ACHARYA, A. AND BADRINATH, B. R. 1992. Recordingdistributed snapshots based on causal order ofmessage delivery. Information Processing Letters44, 6.
ACHARYA, A. AND BADRINATH, B. R. 1994. Check-pointing distributed applications on mobile com-puters. In Proceedings of the Third InternationalConference on Parallel and Distributed Informa-tion Systems.
AHAMAD, M. AND LIN, L. 1989. Using checkpointsto localize the effects of faults in distributedsystems. In Proceedings, Eighth Symposium onReliable Distributed Systems, 2–11.
AHUJA, M. 1989. Repeated global snapshots inasynchronous distributed systems. Technical Re-port OSU-CISRC-8/89 TR40, The Ohio StateUniversity.
ALGUDADY, M. S. AND DAS, C. R. 1991. A cache-based checkpointing scheme for MIN-basedmultiprocessors. In Proceedings of the Inter-national Conference on Parallel Processing,497–500.
ALVISI, L. AND MARZULLO, K. 1995. Message log-ging: Pessimistic, optimistic and causal. In Pro-ceedings of the IEEE International Conferenceon Distributed Computing Systems (Vancouver,Canada).
ALVISI, L. AND MARZULLO, K. 1995. Deriving op-timal checkpointing protocols for distributedshared memory architectures. In Proceedingsof the 1995 ACM SIGACT-SIGOPS Symposiumon Principles of Distributed Computing (PODC)(Ottawa, Canada).
ALVISI, L. AND MARZULLO, K. 1996. Tradeoffs in im-plementing causal message logging protocols. InProceedings of the 1996 ACM SIGACT-SIGOPSSymposium on Principles of Distributed Com-puting (PODC), 58–67.
ALVISI, L., HOPPE, B., AND MARZULLO, K. 1993. Non-blocking and orphan-free message logging pro-tocols. In Digest of Papers, FTCS-23, The TwentyThird Annual International Symposium onFault-Tolerant Computing (Toulouse, France),145–154.
ALVISI, L., RAO, S., AND VIN, H. M. 1998. Low-overhead protocols for fault-tolerant file sharing.In Proceedings of the IEEE 18th InternationalConference on Distributed Computing Systems,452–461.
ALVISI, L., BHATIA, K., AND MARZULLO, K. 2000.Tracking causality in causal message loggingprotocols. Technical Report, The University ofTexas at Austin.
ALVISI, L., BRESSOUD, T. C., EL-KHASHAB, A., MARZULLO,K., AND ZAGORODNOV, D. 2001. Wrapping
server-side TCP to mask connection failures. InInfoComm.
ANYANWU, J. A. 1985. A reliable stable storage sys-tem for UNIX. Software–Practice and Experience15, 10, 973–900.
ARTSY, Y. AND FINKEL, R. 1989. Designing a pro-cess migration facility: The Charlotte experi-ence. IEEE Computer, 47–56.
ATTIG, N. AND SANDER, V. 1993. Automatic check-pointing of NQS batch jobs on CRAY UNICOS.In Proceedings of the Cray User Group Meeting.
BABAOGLU, O. 1990. Fault-tolerant computingbased on Mach. In Proceedings of the USENIXMach Symposium, 186–199.
BABAOGLU, O. AND MARZULLO, K. 1993. Consistentglobal states of distributed systems: Fundamen-tal concepts and mechanisms. In Mullender, S.ed. Distributed Systems, Addison-Wesley,55–96.
BACON, D. 1991. Transparent recovery in dis-tributed systems. Operating Systems Review,91–94.
BACON, D. 1991. File system measurements andtheir application to the design of efficient oper-ation logging algorithms. In Proceedings, TenthSymposium on Reliable Distributed Systems,21–30.
BALDONI, R., QUAGLIA, F., AND FORNARA, P. 1997.An index-based checkpointing algorithm for au-tonomous distributed systems. In Proceedings,Sixteenth Symposium on Reliable DistributedSystems, 27–34.
BALDONI, R., HELARY, J.-M., MOSTEFAOUI, A., AND
RAYNAL, M. 1997. A communication-inducedcheckpointing protocol that ensures rollback-dependency trackability. In Digest of Papers,(FTCS-27), The Twenty Seventh Annual Interna-tional Symposium on Fault-Tolerant Computing(Seattle), 68–77.
BALDONI, R., HELARY, J.-M., MOSTEFAOUI, A., AND RAY-NAL, M. 1997. Adaptive checkpointing in mes-sage passing distributed systems. InternationalJournal of Systems Science 28, 11, 1145–1161.
BALDONI, R., HELARY, J.-M., MOSTEFAOUI, A., AND
RAYNAL, M. 1997. Adaptive checkpointing inmessage passing distributed systems. Interna-tional Journal of Systems Science 28, 11, 1145–1161.
BANATRE, J. P., BANATRE, M., AND MULLER, G. 1989.Architecture of fault-tolerant multiprocessorworkstations. In Proceedings of the Workshop onWorkstation Operating Systems, 20–24.
BANATRE, M., HENG, P., MULLER, G., AND ROCHARD,B. 1991. How to design reliable servers us-ing fault-tolerant micro-kernel mechanisms.
ACM Computing Surveys, Vol. 34, No. 3, September 2002, pp. 1–10.

2 Elnozahy et al.
In Proceedings of the USENIX Mach Sympo-sium, 223–231.
BANATRE, M., GEFFLAUT, A., JOUBERT, P., LEE, P.,AND MORIN, C. 1993. An architecture for tol-erating processor failures in shared-memorymultiprocessors. Technical Report No. 707–93,IRISA.
BARIGAZZI, G. AND STRIGINI, L. 1983. Application-transparent setting of recovery points. In Di-gest of Papers, FTCS-13, The Thirteenth AnnualInternational Symposium on Fault-TolerantComputing, 48–55.
BECK, M., PLANK, J. S., AND KINGSLEY, G. 1994.Compiler-assisted checkpointing. TechnicalReport CS-94-269, University of Tennessee atKnoxville, Department of Computer Science.
BEEDUBAIL, G., KARMARKAR, A., GURIJALA, A., MARTI,W., AND POOCH, U. 1995. An algorithm forsupporting fault-tolerant objects in distributedobject oriented operating systems. In Proceed-ings of the Fourth International Workshopon Object-Orientation in Operating Systems(IWOOOS’95), 142–148.
BHATIA, K., MARZULLO, K., AND ALVISI, L. 1998. Therelative overhead of piggybacking in causalmessage logging protocols. In Proceedings, Sev-enteenth Symposium on Reliable DistributedSystems, 348–353.
BIEKER, B., DEONINCK, G., MAEHLE, E., AND VOUNCKX,J. 1994. Reconfiguration and checkpointingin massively parallel systems. In Proceedings ofthe 1st European Dependant Computing Confer-ence (EDCC-1), 353–370.
BORG, A., BAUMBACH, J., AND GLAZER, S. 1983.A message system supporting fault tolerance. InProceedings of the 9th ACM Symposium on Op-erating System Principles, 90–99.
BOWEN, N. S., AND PRADHAN, D. K. 1991. Surveyof checkpoint and rollback-recovery techniques.Technical Report TR-91-CSE-17, Department ofElectrical and Computer Engineering, Univ. ofMass.
BOWEN, N. S. AND PRADHAN, D. K. 1992. Vir-tual checkpoints: Architecture and performance.IEEE Transactions on Computers 41, 5, 516–525.
BOWEN, N. S. AND PRADHAN, D. K. 1993. Processor-and memory-based checkpoint and rollback-recovery. IEEE Computer 26, 2, 22–32.
CABILLIC, G., MULLER, G., AND PUAUT, I. 1995. Theperformance of consistent checkpointing indistributed shared memory systems. In Proceed-ings, Fourteenth Symposium on Reliable Dis-tributed Systems.
CAMPOS, A. E. AND CASTILLO, M. A. 1996. Check-pointing through garbage collection. TechnicalReport, Escuela de Ingenierıa Pontificia Univer-sidad Catolica de Chile, Departamento de Cien-cia de la Computacion.
CAO, J. 1991. On correctness of distributedrollback-recovery. In Proceedings of the 14th
Australia Computer Science Conference, 39.31–39.10.
CAO, J. 1992. Efficient synchronous checkpointingin distributed systems. In Proceedings of the 15thAustralia Computer Science Conference, 165–179.
CAO, J. AND WANG, K. C. 1991. Efficient syn-chronous checkpointing in distributed systems.Technical Report 91/6, James Cook Universityof North Queensland, Department of ComputerScience.
CAO, J. AND WANG, K. C. 1992. An abstract model ofrollback-recovery control in distributed systems.Operating Systems Review, 62–76.
CAO, G. AND SINGHAL, M. 1998. On the impossibil-ity of min-process non-blocking checkpointingand an efficient checkpointing algorithm for mo-bile computing systems. In Proceedings.1998 In-ternational Conference on Parallel Processing,37–44.
CAO, G. AND SINGHAL, M. 1998. Low-cost check-pointing with mutable checkpoints in mobilecomputing systems. In Proceedings of the 18thInternational Conference on Distributed Com-puting, 464–471.
CARGILL, T. AND LOCANTHI, B. 1987. Cheap hard-ware support for software debugging and pro-filing. In Proceedings of the 2nd Symposiumon Architectural Support for Programming Lan-guages and Operating Systems, 82–83.
CARTER, J. B., COX, A., DWARKADAS, S., ELNOZAHY,E. N., JOHNSON, D. B., KELEHER, P., RODRIGUES,S., YU, W., AND ZWAENEPOEL, W. 1993. Networkmulticomputing using recoverable distributedshared memory. In Proceedings of COMP-CON’93.
CASAS, J., CLARK, D., GALBIATI, P., AND KONURU, R.1995. MIST: PVM with transparent migrationand checkpointing. Technical Report, OregonGraduate Institute of Science and Technology,Department of Computer Science.
CHEN, R. AND NG, T. P. 1990. Building a fault-tolerant system based on Mach. In Proceedingsof the USENIX Mach Workshop, 157–168.
CHEN, R. AND NG, T. P. 1992. Microkernel supportfor checkpointing. In Open Forum.
CHIU, G.-M. AND YOUNG, C.-R. 1996. Efficientrollback-recovery technique in distributed com-puting systems. IEEE Transactions on Paralleland Distributed Systems 7, 6.
CHIUEH, T. 1992. Polar: A storage architecture forfast checkpointing. In Proceedings of the 1992International Conference on Parallel and Dis-tributed Systems, 251–258.
CHIUEH, T.-C. AND DENG, P. 1996. Evaluation ofcheckpoint mechanisms for massively parallelmachines. In Digest of Papers, FTCS-26, TheTwenty-Sixth Annual International Symposiumon Fault-Tolerant Computing, 370–379.
CHOY, M., LEONG, H., AND WONG, M. H. 1995. Ondistributed object checkpointing and recovery.
ACM Computing Surveys, Vol. 34, No. 3, September 2002.

Bibliography 3
In Proceedings of the 1995 ACM SIGACT-SIGOPS Symposium on Principles of Dis-tributed Computing (PODC).
CHUNG, K.-S., KIM, K.-B., HWANG, C.-S., SHON, J. G.,AND YU, H.-C. 1997. Hybrid checkpointingprotocol based on selective sender-based mes-sage logging. In Proceedings of the 1997 Inter-national Conference on Parallel and DistributedSystems, 788–793.
CLEMATIS, A. 1994. Fault-tolerant programmingfor network based parallel computing. Micropro-cessing and Microprogramming 40, 765–768.
CLEMATIS, A., DODERO, G., AND GIANUZZI, V. 1992.Process checkpointing primitives for fault toler-ance: Definitions and examples. Microprocessorsand Microsystems 16, 1, 15–23.
CUMMINGS, D. AND ALKALAJ, L. 1994. Check-point/rollback in a distributed system usingcoarse-grained dataflow. In Digest of Pa-pers, FTCS-24, The Twenty Fourth AnnualInternational Symposium on Fault-TolerantComputing, 424–433.
DAMANI, O. P. AND GARG, V. K. 1996. How to recoverefficiently and asynchronously when optimismfails. In Proceedings of the 16th InternationalConference on Distributed Computing, 108–115.
DECONINCK, G. AND LAUWEREINS, R. 1997. User-triggered checkpointing: system-independentand scalable application recovery. In Proceed-ings Second IEEE Symposium on Computer andCommunications, 418–423.
DECONINCK, G., VOUNCKX, J., LAUWEREINS, R., AND
PEPERSTRAETE, J. A. 1993. Survey of backwarderror recovery techniques for multicomputersbased on checkpointing and rollback. In IASTEDInternational Conference on Modeling and Sim-ulation, 262–265.
DECONINCK, G., VOUNCKX, J., LAUWEREINS, R., AND
PEPERSTRAETE, J. 1998. Survey of backwarderror recovery techniques for multicomputersbased on checkpointing and rollback. Interna-tional Journal of Modeling and Simulation 18,1, 66–71.
DI, Z. 1987. Eliminating domino effect in back-ward error recovery in distributed systems. InProceedings of the 2nd International Conferenceon Computers and Applications, 243–248.
DIETER, W. AND LUMPP JR., J. 1999. A user-levelcheckpointing library for POSIX threads pro-grams. In Digest of Papers, FTCS-29, TheTwenty Ninth Annual International Sym-posium on Fault-Tolerant Computing, 224–227.
DUDA, A. 1983. The effects of checkpointing onprogram execution time. Information ProcessingLetters 16, 221–229.
ECUYER, P. L. AND MALEFANT, J. 1988. Computingoptimal checkpointing strategies for rollbackand recovery systems. IEEE Transactions onComputers 37, 491–496.
ELLENBERGER, E. L. 1995. Transparent processrollback-recovery: Some new techniques anda portable implementation. Technical Report,Texas A&M University, Department of Com-puter Science.
ELLIS, B. 1985. A stable storage package. In Pro-ceedings of the USENIX Summer Technical Con-ference, 209–212.
ELNOZAHY, E. N. 1990. Efficient fault-tolerancesupport for interactive distributed applications.Technical Report TR90-120, Rice University, De-partment of Computer Science.
ELNOZAHY, E. N. 1994. Fault tolerance for clustersof workstations. In Banatre, M. AND Lee, P. eds.Hardware and software architectures for faulttolerance, Springer Verlag.
ELNOZAHY, E. N. 1995. On the relevance of commu-nication costs of rollback-recovery protocols. InProceedings of the 1995 ACM SIGACT-SIGOPSSymposium on Principles of Distributed Com-puting (PODC).
ELNOZAHY, E. N. AND ZWAENEPOEL, W. 1992.Manetho, transparent rollback-recovery withlow overhead, limited rollback and fast outputcommit. IEEE Transactions on Computers,Special Issue on Fault-Tolerant Computing 41,5, 526–531.
ELNOZAHY, E. N. AND ZWAENEPOEL, W. 1992. Repli-cated distributed processes in Manetho.In Digest of Papers, FTCS-22, The TwentySecond Annual International Sympo-sium on Fault-Tolerant Computing, 18–27.
ELNOZAHY, E. N. AND ZWAENEPOEL, W. 1992. An in-tegrated approach to fault tolerance. In Proceed-ings of the Second Workshop on Management ofReplicated Data, 82–85.
FIDGE, C. J. 1988. Timestamps in message-passingsystems that preserve the partial ordering. InProceedings of the 11th Australian ComputerScience Conference, 55–66.
FISCHER, M. J., GRIFFETH, N. D., AND LYNCH, N. A.1982. Global states of a distributed system.IEEE Transactions on Software Engineering SE-8, 3, 198–202.
FRAZIER, T. M. AND TAMIR, Y. 1989. Application-transparent error-recovery techniques for mul-ticomputers. In Proceedings of The Fourth Con-ferences on Hypercubes, Concurrent computers,and Applications, 103–108.
GAIT, J. 1990. A checkpointing page store for write-once optical disk. IEEE Transactions on Com-puters 39, 1, 2–9.
GARG, S. AND WONG, K. F. 1993. Improving thespeed of a distributed checkpointing algorithm.In Proceedings of the 6th International Con-ference on Parallel and Distributed ComputingSystems.
GELENBE, E. 1979. On the optimum checkpoint-ing interval. Journal of the ACM 2, 259–270.
ACM Computing Surveys, Vol. 34, No. 3, September 2002.

4 Elnozahy et al.
GELENBE, E. AND DEROCHETTE, D. 1978. Perfor-mance of rollback-recovery systems under inter-mittent failures. Communications of the ACM21, 6, 493–499.
GOLDING III, R. AND SINGHAL, M. 1993. Using log-ging and asynchronous checkpointing to imple-ment recoverable distributed shared memory.In Proceedings, Twelfth Symposium on ReliableDistributed Systems, 58–67.
GREGORY, S. T. AND KNIGHT, J. C. 1989. On the pro-vision of backward error recovery in productionprogramming languages. In Digest of Papers,FTCS-19, The Nineteenth Annual InternationalSymposium on Fault-Tolerant Computing, 506–511.
GROSELJ, B. 1993. Bounded and minimum globalsnapshots. IEEE Parallel and Distributed Tech-nology 1, 4.
HADZILACOS, V. 1982. An algorithm for minimizingrollback cost. In Proceedings of the ACM SIG-MOD Symposium on Principles of Database Sys-tems, 93–97.
HELARY, J. M. 1989. Observing global states ofasynchronous distributed applications. LectureNotes in Computer Science 392, 124–135.
HELARY, J. M., MOSTEFAOUI, A., AND RAYNAL, M.1998. Communication-induced determinationof consistent snapshots. In Digest of Papers,FTCS-28, The Twenty Eighth Annual Interna-tional Symposium on Fault-Tolerant Computing,208–217.
HELARY, J. M., MOSTEFAOUI, A., AND RAYNAL, M. 1999.Communication-induced determination of con-sistent snapshots. IEEE Transactions on Paral-lel and Distributed Systems 10, 9, 865–877.
HEWITT, C. E. 1980. Checkpoint and recovery inACTOR systems. Technical Report, MIT, Artifi-cial Intelligence Laboratory.
HIGAKI, H. AND TAKIZAWA, M. 1998. Checkpoint-recovery protocol for reliable mobile systems.In Proceedings, Seventeenth Symposium on Re-liable Distributed Systems, 93–99.
HIGAKI, H., SHIMA, K., TACHIKAWA, T., AND TAKIZAWA,M. 1997. Checkpoint and rollback in asyn-chronous distributed systems. In ProceedingsIEEE INFOCOM ’97. Sixteenth Annual JointConference of the IEEE Computer and Commu-nications Societies, 998–1005.
ISRAEL, S. AND MORRIS, D. 1989. A non-intrusivecheckpointing protocol. In Proceedings of thePhoenix Conference on Communications andComputers, 413–421.
JALOTE, P. 1989. Fault-tolerant processes. Dis-tributed Computing 3, 187–195.
JANAKIRAMAN, G. AND TAMIR, Y. 1994. Coordinatedcheckpointing-rollback error recovery for dis-tributed shared memory multicomputers. InProceedings, Thirteenth Symposium on ReliableDistributed Systems, 42–51.
JANSSENS, B. AND FUCHS, W. K. 1993. Relaxingconsistency in recoverable distributed shared
memory. In Digest of Papers, FTCS-23, TheTwenty Third Annual International Symposiumon Fault-Tolerant Computing, 155–163.
JANSSENS, B. AND FUCHS, W. K. 1994. Reducinginterprocessor dependence in recoverable dis-tributed shared memory. In Proceedings, Thir-teenth Symposium on Reliable Distributed Sys-tems, 34–41.
JASPER, D. P. 1969. A discussion of checkpointrestart. Software Age.
JEONG, K. AND SHASHA, D. 1994. Plinda 2.0: A trans-actional/checkpoint approach to fault-tolerantLinda. In Proceedings, Thirteenth Symposium onReliable Distributed Systems, 96–105.
JOHNSON, D. B. 1993. Efficient transparent opti-mistic rollback-recovery for distributed applica-tion programs. In Proceedings, Twelfth Sympo-sium on Reliable Distributed Systems, 86–95.
JOHNSON, D. B. AND ZWAENEPOEL, W. 1988. Recoveryin distributed systems using optimistic messagelogging and checkpointing. In Proceedings of theSixth Annual ACM Symposium on Principles ofDistributed Computing (PODC-88), 171–181.
JOHNSON, D. B. AND ZWAENEPOEL, W. 1990. Output-driven distributed optimistic message loggingand checkpointing. Technical Report TR90-118, Rice University, Department of ComputerScience.
JOHNSON, D. B., AND ZWAENEPOEL, W. 1991. Trans-parent optimistic rollback-recovery. OperatingSystems Review, 99–102.
KAASHOEK, M. F., MICHIELS, R., BAL, H. E., AND
TANENBAUM, A. S. 1992. Transparent fault-tolerance in parallel Orca programs. In Proceed-ings of the Symposium on Experiences with Dis-tributed and Multiprocessor Systems III, 297–312.
KAMBHALTA, S. AND WALPOLE, J. 1990. Recoverywith limited replay: Fault-tolerant processes inLinda. In Proceedings of the 2nd IEEE Sym-posium on Parallel and Distributed Processing,715–718.
KANT, K. 1978. A model for error recovery withglobal checkpointing. Information Sciences 30,58–68.
KANTHADAI, S. AND WELCH, J. L. 1996. Implementa-tion of recoverable distributed shared memoryby logging writes. In Proceedings of the 16th In-ternational Conference on Distributed Comput-ing Systems (ICDCS-16), 27–30.
KERMARREK, A. M., CABILLIC, G., GEFFLAUT, A.,MORIN, C., AND PUAUT, I. 1995. A recoverabledistributed shared memory integrating coher-ence and recoverability. In Digest of Papers,FTCS-25, The Twenty Fifth Annual Interna-tional Symposium on Fault-Tolerant Computing,289–298.
KIM, K. H. 1982. Approaches to mechanizationof the conversation scheme based on monitors.IEEE Transactions on Software Engineering SE-8, 3, 189–197.
ACM Computing Surveys, Vol. 34, No. 3, September 2002.

Bibliography 5
KIM, K. H. 1988. Programmer-transparent coordi-nation of recovering concurrent processes: Phi-losophy and rules for efficient implementation.IEEE Transactions on Software Engineering SE-14, 6, 189–197.
KIM, K. H. AND YOU, J. H. 1990. A highly decentral-ized implementation model for the Programmer-Transparent Coordination (PTC) scheme forcooperative recovery. In Digest of Papers, FTCS-20, The Twentieth Annual International Sympo-sium on Fault-Tolerant Computing, 282–289.
KIM, J. L. AND PARK, T. 1993. An efficient proto-col for checkpointing recovery in distributed sys-tems. IEEE Transactions on Parallel and Dis-tributed Systems 4, 8, 955–960.
KIM, K. H., YOU, J. H., AND ABOUELNAGA, A. 1986.A scheme for coordinated execution of inde-pendently designed recoverable distributed pro-cesses. In Digest of Papers, FTCS-16, TheSixteenth Annual International Symposium onFault-Tolerant Computing, 130–135.
KIM, Y., PLANK, J. S., AND DONGARRA, J. J. 1996.Fault-tolerant matrix operations using check-sum and reverse computation. In Proceedingsof 6th Symposium on the Frontiers of MassivelyParallel Computation.
KIM, Y., PLANK, J. S., AND DONGARRA, J. J. 1997.Fault-tolerant matrix operations for network ofworkstations using multiple checkpointing. InProceedings of HPC Asia’97, High PerformanceComputing in the Information Superhighway,460–465.
KINGSBURY, B. A. AND KLINE, J. T. 1989. Job and pro-cess recovery in a UNIX-based operating sys-tem. In Usenix Association Winter ConferenceProceedings, 355–364.
KLAIBER, A. C. AND LEVY, H. M. 1993. Crash re-covery for scientific applications. In Proceedingsof the International Conference on Parallel andDistributed Systems.
KRISHNA, P., VAIDYA, N. T., AND PRADHAN, D. K. Recoveryin distributed mobile environments. In Proceed-ings of the IEEE Workshop on Advances in Par-allel and Distributed Systems (Princeton, NewJersey), 83–88.
KRISHNA, C. M., KANG, G., AND LEE, Y. 1984. Op-timization criteria for checkpoint placement.Communications of the ACM 27, 10, 1008–1012.
KRISHNA, P., VAIDYA, N. T., AND PRADHAN, D. K. 1994.Recovery in multicomputers with finite errordetection latency. In Proceedings of the 23rd In-ternational Conference on Parallel Processing.
LAI, T. H. AND YANG, T. H. 1987. On distributedsnapshots. Information Processing Letters 25,153–158.
LAMPORT, L. 1984. Using time instead of time-out for fault-tolerant distributed systems. ACMTransactions on Programming Languages andSystems 6, 2, 254–280.
LANDAU, C. R. 1992. The checkpoint mechanism inKeyKOS. In Proceedings of the 2nd International
Workshop on Object Orientation in OperatingSystems.
LEE, B., PARK, T., YEOM, H., AND CHO, Y. 1998.An efficient algorithm for causal message log-ging. In Proceedings, Seventeenth Symposium onReliable Distributed Systems, 19–25.
LEON, J., FICHER, A. L., AND STEENKISTE, P. 1993.Fail-safe PVM: A portable package for dis-tributed programming with transparentrecovery. Technical Report CMU-CS-93-124,Carnegie Mellon University, School of ComputerScience.
LEONG, H. V. AND AGRAWAL, D. 1994. Using messagesemantics to reduce rollback in optimistic mes-sage logging recovery schemes. In Proceedings ofthe 13th IEEE International Conference on Dis-tributed Computing Systems (ICDCS-13), 227–234.
LEU, P.-J. AND BHARGAVA, B. 1988. Concurrent ro-bust checkpointing and recovery in distributedsystems. In Proceedings of the InternationalConference on Data Engineering, 154–163.
LI, W.-J. AND TSAY, J.-J. 1997. Checkpointingmessage-passing interface (MPI) parallel pro-grams. In Proceedings of the Pacific Rim Inter-national Symposium on Fault-Tolerant Systems,147–152.
LI, K., NAUGHTON, J. F., AND PLANK, J. S. 1990. Real-time concurrent checkpoint for parallel pro-grams. In Proceedings of the 1990 Conference onthe Principles and Practice of Parallel Program-ming, 79–88.
LI, K., NAUGHTON, J. F., AND PLANK, J. S. 1991.Checkpointing multicomputer applications. InProceedings, Tenth Symposium on Reliable Dis-tributed Systems, 1–10.
LI, K., NAUGHTON, J. F., AND PLANK, J. S. 1992. Anefficient checkpointing method for multicomput-ers with wormhole routing. International Jour-nal of Parallel Programming 20, 3, 159–180.
LIN, L. AND AHAMAD, M. 1990. Checkpointing androllback-recovery in distributed object based sys-tems. In Digest of Papers, FTCS-20, The Twenti-eth Annual International Symposium on Fault-Tolerant Computing, 97–104.
LIN, T.-H. AND SHIN, K. G. 1998. Damage assess-ment for optimal rollback-recovery. IEEE Trans-actions on Computers 47, 5, 603–613.
LITZKOW, M. AND SOLOMON, M. 1992. Supportingcheckpointing and process migration outside theUNIX kernel. In Usenix Winter 1992 TechnicalConference, 283–290.
LONG, J., FUCHS, W. K., AND ABRAHAM, J. A. 1990.Forward recovery using checkpointing in par-allel systems. In Proceedings of the 19th In-ternational Conference on Parallel Processing,272–275.
LONG, J., FUCHS, W. K., AND ABRAHAM, J. A. 1991.Implementing forward recovery using check-pointing in distributed systems. In Proceedingsof the International Conference on Dependable
ACM Computing Surveys, Vol. 34, No. 3, September 2002.

6 Elnozahy et al.
Computing for Critical Applications (DCCA),20–27.
LONG, J., FUCHS, W. K., AND ABRAHAM, J. A. 1992.Compiler-assisted static checkpoint insertion.In Digest of Papers, FTCS-22, The Twenty Sec-ond Annual International Symposium on Fault-Tolerant Computing, 58–65.
LOWRY, A., RUSSELL, J. R., AND GOLDBERG, A. P.1991. Optimistic failure recovery for very largenetworks. In Proceedings, Tenth Symposium onReliable Distributed Systems, 66–75.
MANDELBERG, K. I. AND SUNDERAM, V. S. 1988.Process migration in UNIX networks. InProceedings of the Usenix Winter Technical Con-ference, 357–364.
MANIVANNAN, D. AND SINGHAL, M. 1996. A low-overhead recovery technique using synchronouscheckpointing. In Proceedings of the 16th Inter-national Conference on Distributed ComputingSystems (ICDCS-16), 100–107.
MANIVANNAN, D., NETZER, R. H., AND SINGHAL, M.1997. Finding consistent global checkpointsin a distributed computation. IEEE Transac-tions on Parallel & Distributed Systems 8, 6,623–627.
MATTERN, F. 1988. Virtual time and global states ofdistributed systems. In Proceedings of the Work-shop on Parallel and Distributed Algorithms,215–226.
MCDERMID, J. A. 1982. Checkpointing and error re-covery in distributed systems. In Proceedings ofthe 2nd International Conference on DistributedComputing Systems, 271–282.
MERLIN, P. M. AND RANDELL, B. 1978. State restora-tion in distributed systems. In Digest of Pa-pers, FTCS-8, The Eighth Annual InternationalSymposium on Fault-Tolerant Computing, 129–134.
MITCHELL, J. R. AND GARG, V. K. 1998. A non-blocking recovery algorithm for causal messagelogging. In Proceedings, Seventeenth Symposiumon Reliable Distributed Systems, 3–9.
MOSTEFAOUI, A. AND RAYNAL, M. 1996. Efficientmessage logging for uncoordinated checkpoint-ing protocols. In Dependable Computing-EDCC-2, the Second European Dependable ComputingConference Proceedings, 353–364.
MULLER, G., BANATRE, M., PEYROUZ, N., AND ROCHAT,B. 1996. Lessons from FTM: an experiment indesign and implementation of a low-cost fault-tolerant system. IEEE Transactions on Reliabil-ity 45, 2, 332–340.
NETT, E., KROGER, R., AND KAISER, J. 1986. Imple-menting a general error recovery mechanismin a distributed operating system. In Digest ofPapers, FTCS-16, The Sixteenth Annual Interna-tional Symposium on Fault-Tolerant Computing,124–129.
NETZER, R. B. AND MILLER, B. P. 1992. Optimal trac-ing and replay for debugging message-passingparallel programs. In Proceedings of Supercom-puting’92, 502–511.
NETZER, R. B. AND XU, J. 1993. Adaptive mes-sage logging for incremental program replay.IEEE Parallel and Distributed Technology 1, 4,32–39.
NETZER, R. B. AND WEAVER, M. H. 1994. Optimaltracing and incremental reexecution for Debug-ging Long-Running Programs. In SIGPLAN ’94:Conference on Programming Language Designand Implementation (PLDI), 313–325.
NETZER, R. B. AND XU, J. 1997. Replaying dis-tributed programs without message log-ging. In Proceedings of the Sixth IEEEInternational Symposium on High Perfor-mance Distributed Computing (HPDC), 137–147.
NEVES, N. AND FUCHS, W. K. 1996. Using time toimprove the performance of coordinated check-pointing. In Proceedings of the IEEE Interna-tional Computer Performance and DependabilitySymposium, IPDS’96, 282–291.
NEVES, N. AND FUCHS, W. K. 1997. Adaptive recov-ery for mobile environments. Communications ofACM 40, 1, 68–74.
NEVES, N. AND FUCHS, W. K. 1998. RENEW: A toolfor fast and efficient implementation of check-point protocols. In Digest of Papers, FTCS-28,The Twenty Eighth Annual International Sym-posium on Fault-Tolerant Computing.
NEVES, N. AND FUCHS, W. K. 1998. Coordinatedcheckpointing without direct coordination. InProceedings of the IEEE International Com-puter Performance and Dependability Sympo-sium (IPDS’98), 23–31.
NEVES, N., CASTRO, M., AND GUEDES, P. 1994.A checkpoint protocol for an entry consis-tent shared memory system. In Proceedingsof the 1994 ACM SIGACT-SIGOPS Sympo-sium on Principles of Distributed Computing(PODC).
NICOLA, V. 1995. Checkpointing and the modelingof program execution time. In Lyu, M. ed. Soft-ware Fault Tolerance.
PARK, T. AND YEOM, H. Y. 2000. An asynchronousrecovery scheme based on optimistic messagelogging for mobile computing systems. In Pro-ceedings of the 20th International Conferenceon Distributed Computing Systems (ICDCS-20),436–443.
PETERSON, S. L. AND KEARNS, P. 1993. Rollbackbased on vector time. In Proceedings, TwelfthSymposium on Reliable Distributed Systems,68–77.
PETERSON, L. L., BUCHHOLZ, N. C., AND SCHLICHTING,R. D. 1989. Preserving and using context in-formation in interprocess communication. ACMTransaction on Computing Systems 7, 3, 217–246.
PLANK, J. S. 1996. Improving the performance ofcoordinated checkpointers on networks of work-stations using RAID techniques. In Proceedings,Fifteenth Symposium on Reliable DistributedSystems, 76–85.
ACM Computing Surveys, Vol. 34, No. 3, September 2002.

Bibliography 7
PLANK, J. S. AND ELWASIF, W. R. 1998. Experimen-tal assessment of workstation failures and theirimpact on checkpointing systems. In Digest ofPapers, FTCS-28, The Twenty Eighth Annual In-ternational Symposium on Fault-Tolerant Com-puting, 48–57.
PLANK, J. S., BECK, M., AND KINGSLEY, G. 1995.Compiler-assisted memory exclusion for fastcheckpointing. IEEE Technical Committee onOperating Systems Newsletter, 62–67.
PLANK, J. S., KIM, Y., AND DONGARRA, J. J. 1995.Algorithm-based diskless checkpointing forfault-tolerant matrix computations. In Digestof Papers, FTCS-25, The Twenty Fifth AnnualInternational Symposium on Fault-TolerantComputing, 351–360.
PLANK, J. S., YOUNGBAE, K., AND DONGARA, J. J. 1997.Fault-tolerant matrix operations for networks ofworkstations using diskless checkpointing. Jour-nal of Parallel & Distributed Computing 43, 2,125–138.
PLANK, J. S., LI, K., AND PUENING, M. A. 1998. Disk-less checkpointing. IEEE Transactions on Paral-lel & Distributed Systems 9, 10, 972–986.
PLANK, J. S., CHEN, Y., LI, K., BECK, M., AND KINGS-LEY, G. 1996. Memory exclusion: Optimizingthe performance of checkpointing systems. Tech-nical Report UT-CS-96-335, University of Ten-nessee at Knoxville, Department of ComputerScience.
POWELL, M. AND PRESOTTO, D. 1993. Publishing: Areliable broadcast communication mechanism.In Proceedings of the 9th ACM Symposium onOperating System Principles, 100–109.
PRADHAN, D. K. AND VAIDYA, N. 1992. Roll-forwardcheckpointing scheme: Concurrent retry withnon-dedicated spares. In Proceedings of theIEEE Workshop on Fault-Tolerant Parallel andDistributed Systems, 166–174.
PRADHAN, D. K. AND VAIDYA, N. 1994. Roll-forwardand rollback-recovery: Performance-reliabilitytrade-off. In Digest of Papers, FTCS-24, TheTwenty Fourth Annual International Sym-posium on Fault-Tolerant Computing, 186–195.
RAMAMURTHY, B., UPADHYAYA, S., AND IYER, R. K.1997. An object-oriented testbed for the eval-uation of checkpointing and recovery systems.In Digest of Papers, FTCS-27, The Twenty Sev-enth Annual International Symposium on Fault-Tolerant Computing, 194–203.
RAMAMURTHY, B., UPADHYAYA, S., AND BHARGAVA, J.1998. Design and analysis of a hardware-assisted checkpointing and recovery scheme fordistributed applications. In Proceedings, Sev-enteenth Symposium on Reliable DistributedSystems, 84–90.
RAMANATHAN, P. AND SHIN, K. G. 1988. Checkpoint-ing and rollback-recovery in a distributed sys-tem using common time base. In Proceedings,Seventh Symposium on Reliable Distributed Sys-tems (SRDS-7), 13–21.
RAMANATHAN, P. AND SHIN, K. G. 1993. Use of com-mon time base for checkpointing and rollback-recovery in a distributed system. IEEE Trans-actions on Software Engineering SE-19, 6,571–583.
RAMKUMAR, B. AND STRUMPEN, V. 1997. Portablecheckpointing for heterogeneous architectures.In Digest of Papers, FTCS-22, The Twenty Sec-ond Annual International Symposium on Fault-Tolerant Computing, 58–67.
RANGARAJAN, S., GARG, S., AND HUANG, Y. 1998.Checkpoints-on-demand with active replication.In Proceedings, Seventeenth Symposium on Re-liable Distributed Systems, 75–83.
RAO, S., ALVISI, L., AND VIN, H. 1999. Egida: Anextensible toolkit for low-overhead fault tol-erance. In Digest of Papers, FTCS-29, TheTwenty Ninth Annual International Symposiumon Fault-Tolerant Computing.
RUSSINOVICH, M. AND COGSWELL, B. 1996. Replayfor concurrent non-deterministic shared mem-ory applications. In Proceedings of the 1996 ACMSIGPLAN Conference on Programming Lan-guage Design and Implementation, 258–266.
RUSSINOVICH, M., SEGALL, Z., AND SIEWIOREK, D.P. 1993. Application transparent fault man-agement in fault-tolerant Mach. In Digest ofPapers, FTCS-23, The Twenty Third Annual In-ternational Symposium on Fault-Tolerant Com-puting, 10–19.
SCHWARZ, R. AND MATTERN, F. 1994. Detectingcausal relationships in distributed computa-tions: in search of the Holy Grail. DistributedComputing 7, 149–174.
SELIGMAN, E. AND BEGUELIN, A. 1994. High-levelfault tolerance in distributed programs. Tech-nical Report CMU-CS-94-223, Carnegie MellonUniversity, School of Computer Science.SHARMA, D. D. AND PRADHAN, D. K. 1994. Anefficient coordinated checkpointing scheme formulticomputers. In Proceedings of the IEEEWorkshop on Fault-Tolerant Parallel and Dis-tributed Systems.
SILVA, L. M. AND SILVA, J. G. 1992. Global check-pointing for distributed programs. In Proceed-ings, Eleventh Symposium on Reliable Dis-tributed Systems, 155–162.
SILVA, L. M. AND SILVA, J. G. 1994. Integrating acheckpointing and rollback-recovery algorithmwith a causal order protocol. In Proceedings ofthe 12th Brazilian Symposium on Computer Net-works, 523–540.
SILVA, L. M. AND SILVA, J. G. 1994. Checkpointingpipeline applications. In Proceedings of the 1994World Transputer Congress, 497–512.
SILVA, L. M. AND SILVA, J. G. 1994. On the optimumrecovery of distributed programs. In Proceedingsof the 20th EUROMICRO Conference, 704–711.
SILVA, L. M. AND SILVA, J. G. 1996. A checkpointingfacility for a heterogeneous DSM system. In Pro-ceedings of the 9th Conference on Parallel andDistributed Computing Systems, 554–559.
ACM Computing Surveys, Vol. 34, No. 3, September 2002.

8 Elnozahy et al.
SILVA, L. M. AND SILVA, J. G. 1998. Avoiding check-point contamination in parallel system. In Di-gest of Papers, FTCS-28, The Twenty EighthAnnual International Symposium on Fault-Tolerant Computing, 364–369.
SILVA, L. M. AND SILVA, J. G. 1998. An experimen-tal study about diskless checkpointing. In Pro-ceedings of the 24th EUROMICRO Conference,395–402.
SILVA, L. M. AND SILVA, J. G. 1998. System-levelversus user-defined checkpointing. In Proceed-ings, Seventeenth Symposium on Reliable Dis-tributed Systems, 68–74.
SILVA, L. M., VEER, B., AND SILVA, J. G. 1994. Check-pointing SPMD applications on transputernetworks. In Proceedings of the Scalable High-Performance Computing Conference, SHPCC94,694–701.
SILVA, L. M., SILVA, J. G., AND CHAPPLE, S. 1996.Portable transparent checkpointing for dis-tributed shared memory. In Proceedings of theFifth IEEE International Symposium on HighPerformance Distributed Computing, HPDC-5,422–431.
SILVA, L. M., TAVORA, V. N., AND SILVA, J. G. 1996.Mechanisms of file-checkpointing for UNIX ap-plications. In Proceedings of the 14th IASTEDConference on Applied Informatics, 358–361.
SILVA, L. M., SILVA, J. G., CHAPPLE, S., AND CLARKE,L. 1995. Portable checkpointing and recovery.In Proceedings of the 4th International Sympo-sium on High-Performance Distributed Comput-ing, HPDC-4, 188–195.
SINHA, A., DAS, P. K., AND CHAUDHURI, A. 1992.Checkpointing and recovery in a pipeline oftransputers. In Proceedings of Euromicro’92,141–148.
SLYE, J. H. 1996. Adding support for software in-terrupts in log-based rollback-recovery proto-cols. Master Thesis, Carnegie Mellon University,Department of Computer Science.
SLYE, J. H. AND ELNOZAHY, E. N. 1996. Support-ing nondeterministic execution in fault-tolerantsystems. In Digest of Papers, FTCS-26, TheTwenty-Sixth Annual International Symposiumon Fault-Tolerant Computing.
SMITH, J. M. AND IOANNIDIS, J. 1989. Implement-ing remote fork() with checkpoint/restart. IEEETechnical Committee on Operating SystemsNewsletter, 12–16.
SOLIMAN, H. M. AND ELMAGHRABY, A. S. 1998. An an-alytical model for hybrid checkpointing in timewarp distributed simulation. IEEE Transactionson Parallel & Distributed Systems 9, 10, 947–951.
SPEZIALETTI, M. AND KEARNS, P. 1986. Efficient dis-tributed snapshots. In Proceedings of the Inter-national Conference on Distributed ComputingSystems, 382–388.
SSU, K.-F. AND FUCHS, W. K. 1998. PREACHES-portable recovery and checkpointing in het-
erogeneous systems. In Digest of Papers,FTCS-28, The Twenty Eighth Annual Interna-tional Symposium on Fault-Tolerant Computing,38–47.
STAINOV, R. 1991. An asynchronous checkpoint-ing service. Microprocessing and Microprogram-ming 31, 117–120.
STAKNIS, M. 1989. Sheaved memory: Architecturalsupport for state saving and restoration in pagedsystems. In Proceedings of the 3rd Symposiumon Architectural Support for Programming Lan-guages and Operating Systems, 96–102.
STELLNER, G. 1994. Consistent checkpoints ofPVM applications. In Proceedings of the FirstEuropean PVM User Group Meeting.
STELLNER, G. 1996. CoCheck: Checkpointing andprocess migration for MPI. In Proceedingsof the 10th International Parallel ProcessingSymposium.
STROM, R. E., BACON, D. F., AND YEMINI, S. A. 1988.Volatile logging in n-fault-tolerant distributedsystems. In Digest of Papers, FTCS-18, TheEighteenth Annual International Symposium onFault-Tolerant Computing, 44–49.
STROM, R. E., YEMINI, S. A., AND BACON, D. F. 1988.A recoverable object store. In Proceedings ofthe Hawaii International Conference on SystemSciences, II-215–II221.
SURI, G., JANSSENS, B., AND FUCHS, W. K. 1995. Re-duced overhead logging for rollback-recovery indistributed shared memory. In Digest of Pa-pers, FTCS-25, The Twenty Fifth Annual Inter-national Symposium on Fault-Tolerant Comput-ing, 279–288.
SURI, G., HUANG, Y., WANG, Y. M., FUCHS, W. K., AND
KINTALA, C. 1995. An implementation andperformance measurement of the progressiveretry technique. In Proceedings of the IEEE In-ternational Computer Performance and Depend-ability Symposium, 41–48.
TAM, V.-O. AND HSU, M. 1990. Fast recovery in dis-tributed shared virtual memory systems. In Pro-ceedings of the 10th International Conference onDistributed Computing Systems, 38–45.
TAMIR, Y. AND GAFNI, E. 1987. A software-basedhardware fault tolerance scheme for multicom-puters. In Proceedings of the International Con-ference on Parallel Processing, 117–120.
TAMIR, Y. AND FRAZIER, T. M. 1989. Application-transparent process-level error recovery for mul-ticomputers. In Proceedings of the Hawaii In-ternational Conferences on System Sciences-22,296–305.
TAMIR, Y. AND FRAZIER, T. M. 1991. Error-recoveryin multicomputers using asynchronous coordi-nated checkpointing. Technical Report CSD-010066, University of California.
TANAKA, K. AND TAKIZAWA, M. 1996. Distributedcheckpointing based on influential messages. InProceedings of the 1996 International Conferenceon Parallel and Distributed Systems, 440–447.
ACM Computing Surveys, Vol. 34, No. 3, September 2002.

Bibliography 9
TANAKA, K., HIGAKI, H., AND TAKIZAWA, M. 1998.Object-based checkpoints in distributed sys-tems. Computer Systems Science & Engineering13, 3, 179–185.
TAYLOR, D. J. AND WRIGHT, M. L. 1986. Backwarderror recovery in a UNIX environment. In Digestof Papers, FTCS-16, The Sixteenth Annual Inter-national Symposium on Fault-Tolerant Comput-ing, 118–123.
THANAWASTIAN, S., PAMULA, R. S., AND VAROL, Y. L.1986. Evaluation of global checkpoint rollbackstrategies for error recovery in concurrent pro-cessing systems. In Digest of Papers, FTCS-16,The Sixteenth Annual International Symposiumon Fault-Tolerant Computing, 246–251.
TONG, Z., KAIN, R. Y., AND TSAI, W. T. 1989. A loweroverhead checkpointing and rollback-recoveryscheme for distributed systems. In Proceed-ings, Eighth Symposium on Reliable DistributedSystems, 12–20.
TSAI, J., KUO, S. Y., AND WANG, Y.-M. 1998. Theoret-ical analysis for communication-induced check-pointing protocols with rollback-dependencytrackability. IEEE Transactions on Parallel &Distributed Systems 9, 10, 963–971.
TSURUOKA, K., KANEKO, A., AND NISHIHARA, Y. 1981.Dynamic recovery schemes for distributed pro-cesses. In Proceedings of the IEEE 2nd Symp.on Reliability in Distributed Software andDatabase Systems, 124–130.
TULLMANN, P., LEPREAU, J., FORD, B., AND HIBLER, M.1996. User-level checkpointing through ex-portable kernel state. In Proceedings of the FifthInternational Workshop on Object-Orientation inOperating Systems, 85–88.
VAIDYA, N. H. 1993. Dynamic cluster-based recov-ery: Pessimistic and optimistic schemes. Techni-cal Report 93-027, Texas A&M University, De-partment of Computer Science.
VAIDYA, N. H. 1995. A case of two-level distributedrecovery schemes. In Proceedings of the Inter-national Conference on Measurement and Mod-eling of Computer Systems (SIGMETRICS’95),64–73.
VAIDYA, N. H. 1996. On staggered checkpointing.In Proceedings of the Eighth IEEE Symposiumon Parallel and Distributed Processing, 572–580.
VENKATESAN, S. 1989. Message-optimal incremen-tal snapshots. In Proceedings of the Interna-tional Conference on Distributed ComputingSystems, 53–60.
VENKATESAN, S. 1997. Optimistic crash recoverywithout changing application messages. IEEETransactions on Parallel and Distributed Sys-tems 8, 3, 263–271.
VENKATESH, K., RADAKRISHNAN, T., AND LI, H. L. 1987.Optimal checkpointing and local recording fordomino-free rollback-recovery. Information Pro-cessing Letters 25, 295–303.
WANG, Y. M. 1993. Reducing message logging over-head for log-based recovery. In Proceedings of the
IEEE International Symposium on Circuits andSystems, 1925–1928.
WANG, Y. M. 1995. The maximum and minimumconsistent global checkpoints and their applica-tions. In Proceedings, Fourteenth Symposium onReliable Distributed Systems.
WANG, Y.-M. AND FUCHS, W. K. 1992. Optimisticmessage logging for independent checkpointingin message passing systems. In Proceedings,Eleventh Symposium on Reliable DistributedSystems, 147–154.
WANG, Y. M. AND FUCHS, K. 1992. Scheduling mes-sage processing for reducing rollback propaga-tion. In Digest of Papers, FTCS-22, The TwentySecond Annual International Symposium onFault-Tolerant Computing, 204–211.
WANG, Y. M. AND FUCHS, K. 1993. Lazy checkpointcoordination for bounding rollback propagation.In Proceedings, Twelfth Symposium on ReliableDistributed Systems, 78–85.
WANG, Y. M. AND FUCHS, W. K. 1994. Optimal mes-sage log reclamation for uncoordinated check-pointing. In Proceedings of the IEEE Work-shop on Fault-Tolerant Parallel and DistributedSystems.
WANG, Y. M., HUANG, Y., AND FUCHS, W. K. 1993.Progressive retry for software error recovery indistributed systems. In Digest of Papers, FTCS-23, The Twenty Third Annual InternationalSymposium on Fault-Tolerant Computing Sys-tems, 138–144.
WANG, Y. M., LOWRY, A., AND FUCHS, W. K. 1994.Consistent global checkpoints based on directdependency tracking. Information ProcessingLetters 50, 4, 223–230.
WANG, Y. M., HUANG, Y., AND KINTALA, C. 1997. Pro-gressive retry for software failure recovery inmessage passing applications. IEEE Transac-tions on Computers 46, 10, 1137–1141.
WANG, Y. M., DAMANI, O. P., AND GARG, V. K. 1997.Distributed recovery with K-optimistic logging.In Proceedings of the 17th International Confer-ence on Distributed Computing Systems, 60–67.
WANG, Y. M., CHUNG, E., HUANG, Y., AND ELNOZAHY, E. N.1997. Integrating checkpointing with transac-tion processing. In Digest of Papers, FTCS-27,The Twenty Seventh Annual International Sym-posium on Fault-Tolerant Computing, 304–308.
WANG, Y. M., HUANG, Y., VO, K. P., CHUNG, P. Y., AND
KINTALA, C. 1995. Checkpointing and its ap-plications. In Digest of Papers, FTCS-25, TheTwenty Fifth Annual International Symposiumon Fault-Tolerant Computing, 22–31.
WEI, X. AND JU, J. 1998. A consistent checkpointingalgorithm with shorter freezing time. OperatingSystems Reviews 32, 4, 70–76.
WOJCIK, Z. AND WOJCIK, B. E. 1990. Fault-tolerantdistributed computing using atomic send receivecheckpoints. In Proceedings of the 2nd IEEESymposium on Parallel and Distributed Process-ing, 215–222.
ACM Computing Surveys, Vol. 34, No. 3, September 2002.

10 Elnozahy et al.
WONG, K. F. AND FRANKLIN, M. 1996. Checkpoint-ing in distributed computing systems. Jour-nal of Parallel & Distributed Computing, 67–75.
WOOD, W. G. 1981. A decentralized recovery con-trol protocol. In Digest of Papers, FTCS-11, The Eleventh Annual International Sym-posium on Fault-Tolerant Computing, 159–164.
WOOD, W. G. 1995. Recovery control of communi-cating processes in a distributed system. In Shri-vastava, S. K. ed. Reliable Computing Systems,Springer Verlag.
WU, K. L. AND FUCHS, W. K. 1990. Recoverable dis-tributed shared virtual memory. IEEE Transac-tions on Computers 39, 4, 460–469.
WYNER, D. S. 1972. A technique for optimizing theperformance of a checkpoint restart system. InProceedings of the Canadian Computer Confer-ence (Montreal), 201–212.
XU, J. AND NETZER, R. H. B. 1993. Adaptive in-dependent checkpointing for reducing rollbackpropagation. In Proceedings of the 5th IEEE
Symposium on Parallel and Distributed Process-ing, 754–761.
XU, J., NETZER, R. B., AND MACKEY, M. 1995. Sender-based message logging for reducing rollbackpropagation. In Proceedings of the Seventh IEEESymposium on Parallel and Distributed Process-ing, 602–609.
YOUNG, J. W. 1974. A first order approximation tothe optimum checkpoint interval. Communica-tions of the ACM 17, 9.
ZAMBONELLI, F. 1998. Distributed checkpoint algo-rithms to avoid rollback propagation. In Proceed-ings of the 24th EUROMICRO Conference, 403–410.
ZIV, A. AND BRUCK, J. 1994. Efficient checkpointingover local area networks. In Proceedings of theIEEE Workshop on Fault-Tolerant Parallel andDistributed Systems, 30–35.
ZIV, A. AND BRUCK, J. 1997. An on-line algorithmfor checkpoint placement. IEEE Transactions onComputers 46, 9, 976–985.
ZWEIACKER, M. 1997. Fault-tolerant CORBA usingcheckpointing and recovery. Comtec 75, 8, 20–25.
ACM Computing Surveys, Vol. 34, No. 3, September 2002.








![A Survey of Rollback-Recovery Protocols › courses › cs614 › 2004sp › papers › EAWJ02.pdf · esses [Russell 1980]. Checkpoints are taken such that a system-wide consistent](https://img.pdfslide.net/doc/110x75/5f2067e59455e9750f4725d7/a-survey-of-rollback-recovery-a-courses-a-cs614-a-2004sp-a-papers-a-eawj02pdf.jpg)




















